-COMPLETE- Code Challenge #6: Integer Counting
Update on October 8, 2025: Thanks to everyone who voted on the entries! We received 281 votes from 59 users.
There were a lot of great responses to this challenge. We appreciate the participation.
We'd like to recognize the 5 entries which received the highest vote score.
Highest score: M--
2nd highest score: sebastian
3rd highest score: Muhammad Ali Ansari
4th highest score: Andrey Dmitriev
5th highest score: cocomac
Update on September 30, 2025: We've now entered the voting period which lasts till October 6th. All of the responses are visible. Please upvote your favorite entries.
Our previous challenges had more of an emphasis on creativity. Today’s challenge is more about efficiency and performance.
The Challenge
Given a list of 1 million random numbers, find the number that appears the most.
(Clarification: The primary task is to find a most frequent number. Solutions that correctly handle and report all numbers in the event of a tie are appreciated.)
Numbers are integers with values from 0 to 999.
To help you build/test the code, here are two sample files, one with 100 integers, and one with 10,000 integers.
Once your code is complete, please benchmark its performance on this list of 1 million integers. Please reserve this final list for your performance measurement.
Winners are selected by the community’s votes. Voters should select the responses which have the best performance or other notable attributes.
How does the actual contest work?
You have two weeks from the date this challenge is posted to submit your entry. During this period, other entries are only visible once you have submitted your own. After that, anyone can view and vote on others’ entries.
User entries with the highest vote score will be recognized. Please note that any votes received as part of this challenge do not count towards site reputation.
To keep the voting fair, we’ve hidden the vote counts until the end of the challenge. The scores will be unhidden on October 7, and we’ll announce the winners soon after that.
September 16: Challenge goes live
September 30: All entries visible to everyone. Vote scores are hidden to reduce voting bias.
October 7: Challenge ends. Vote counts and winners are announced.
How to Submit:
Enter your submission in the text box below.
Your submission should include:
The code you have written
An explanation of your approach, including how you optimized it for this task
The code execution runtime along with details about your machine
Anything you learned or any interesting challenges you faced while coding
Your entry is not permitted to be written by AI. For any feedback on this Challenge, please head over to the Meta post.
Oldest first — sorts entries by their creation dates, with the oldest at the top.
Newest first — sorts entries by their creation dates, with the newest at the top.
Latest activity — sorts entries with recent threaded replies or edits at the top.
Highest score — sorts entries by their total votes (highest first).
Your sorting method preferences will be saved.
Sorry late to the party but only found out about challenges now. Below my KDB/Q code. I know answers have already been published but I highly doubt anyone posted a KDB/Q solution.
// create a list of 1M random numbers between 0 and 9
q)list:1000000?10
// show that it's actually 1M numbers
q)count list
1000000
// check list
q)list
8 1 9 5 4 6 6 1 8 5 4 9 2 7 0 1 9 2 1 8 8 1 7 2 4 5 4 2 7 8 5 6 4 1 3 3 7 8 2 1 4 2 8 0 5 8 5 2 8 6 9 0 0 0 9 5 2 3 9 5 9 7 6 6 4 7 8 4 4 6 9 9 2 5 4 2 5 8 7 9 9 7 7 1 9 1 0 8 8 3 1 0 5 1 0 0 1 7 6 3 4 3 4 8 4 6 8 2 8 3 4 1 6 4 4 2 2 7 2 0..
// group numbers together. output, each distinct number and their indexes
q)group list
8| 0 8 19 20 29 37 42 45 48 66 77 87 88 103 106 108 128 135 138 147 153 157 166 199 201 211 216 254 256 281 287 290 295 306 310 319 331 339 344 354 371 375 388 391 394 396 440 464 466 470 483 486 519 534 549 584 600 601 615 623 631 641 652..
1| 1 7 15 18 21 33 39 83 85 90 93 96 111 127 129 141 142 170 181 187 190 203 206 212 221 224 228 250 255 280 283 304 309 327 351 357 377 378 400 402 424 425 431 442 443 445 455 469 477 498 510 515 517 523 524 547 553 571 572 592 593 599 62..
9| 2 11 16 50 54 58 60 70 71 79 80 84 139 143 145 156 160 161 168 180 217 239 242 272 277 291 320 326 330 332 333 342 345 347 349 352 361 363 372 376 387 392 404 426 427 436 448 471 480 492 494 500 502 505 538 568 574 581 588 604 606 610 6..
5| 3 9 25 30 44 46 55 59 73 76 92 120 122 152 169 171 205 219 220 226 229 230 236 237 246 263 266 289 297 302 316 317 325 334 366 368 379 399 407 408 414 415 418 423 447 453 462 522 526 530 531 532 562 563 570 573 578 587 591 619 629 640 6..
4| 4 10 24 26 32 40 64 67 68 74 100 102 104 110 113 114 148 151 155 176 191 194 200 223 235 243 245 251 261 264 274 275 301 322 328 335 337 348 360 381 397 409 417 430 439 452 468 476 489 501 504 535 552 558 566 611 613 614 627 635 669 676..
6| 5 6 31 49 62 63 69 98 105 112 123 134 144 163 165 193 195 197 213 238 241 247 248 253 260 262 270 292 293 296 312 353 356 365 369 386 405 422 429 437 463 467 475 481 490 491 496 509 516 533 541 557 567 577 582 585 609 616 622 625 630 63..
2| 12 17 23 27 38 41 47 56 72 75 107 115 116 118 126 136 164 173 185 186 207 208 218 222 231 234 240 265 271 273 279 285 308 364 374 383 389 390 395 401 406 413 435 451 456 460 474 479 484 488 495 506 508 514 521 527 536 537 565 569 576 59..
7| 13 22 28 36 61 65 78 81 82 97 117 121 124 131 146 175 177 178 184 188 196 227 232 233 252 259 267 268 269 276 284 298 299 305 311 314 315 321 323 324 341 343 350 355 380 385 398 410 419 420 421 434 438 441 449 457 458 459 507 513 540 54..
0| 14 43 51 52 53 86 91 94 95 119 125 130 140 150 154 158 162 167 172 179 192 202 204 209 244 249 258 286 288 300 303 313 318 336 340 358 370 373 393 411 428 432 444 446 450 454 461 478 482 487 503 528 542 543 548 556 559 561 583 594 598 6..
3| 34 35 57 89 99 101 109 132 133 137 149 159 174 182 183 189 198 210 214 215 225 257 278 282 294 307 329 338 346 359 362 367 382 384 403 412 416 433 465 472 473 485 493 497 499 511 512 518 520 525 529 539 550 554 555 560 580 595 602 612 6..
// count the number of indexes for each number
q)count each group list
8| 99761
1| 99949
9| 99788
5| 99216
4| 100449
6| 99742
2| 100472
7| 99912
0| 100455
3| 100256
// store the resulting dictionary in variable d and get the max occurrence q)max d:count each group list
100472
// compare the original dictionary with the max occurrence
q)d=max d:count each group list
8| 0
1| 0
9| 0
5| 0
4| 0
6| 0
2| 1
7| 0
0| 0
3| 0
// find the number associated to the max value
q)where d=max d:count each group list
,2
// time it. This takes 6 millisecond
q)\ts where d=max d:count each group list
6 27272656
q)
// the whole exercise with the original file, reading from the file
q)where d=max d:count each group "I"$read0`:1M_random_numbers.txt
,142i
// takes 84 millisecond
q)\ts where d=max d:count each group "I"$read0`:1M_random_numbers.txt
84 44584000
If you want to learn more about KDB/Q, read my blog here www.defconq.tech
oh and I run everything on a Mac Air M3
Model Name: MacBook Air
Model Identifier: Mac15,13
Chip: Apple M3
Total Number of Cores: 8 (4 performance and 4 efficiency)
Memory: 24 GB
- 6.7k
- 3
- 19
- 35
pyspark can handle huge data easily. so, i used it on a google colab machine.
142 is the integer with highest number of occurrences (1130 times).
import pyspark.sql.functions as func
from pyspark.sql.types import *
from pyspark.sql.window import Window as wd
file_path = './drive/MyDrive/1M_random_numbers.txt'
# read text file as dataframe
data_sdf = spark.read.csv(file_path, schema=StructType([StructField('nums', IntegerType())]))
data_sdf. \
groupBy('nums'). \
agg(func.count('*').alias('cnt')). \
withColumn('rank', func.dense_rank().over(wd.orderBy(func.desc('cnt')))). \
filter(func.col('rank') == 1). \
select('nums'). \
rdd.map(lambda x: x.nums). \
collect()
# result
# [142]
approach
countthe number of times each integer occurs using agroupBydense_rankthe integers based on the descending order of its number of occurrence- filter the integer(s) with
rank == 1; in case of a tie in the top rank, all integers get "1" as rank due to the use ofdense_rank - in the end, select the integer column and output the integer(s) as a list using
rdd.map()
execution and machine details
- with the 1M data, it took the process
760 ms ± 22 ms per loop - python3
- v5e-1 Google compute engine (single core TPU)
- RAM in use: 3GB
- 443
- 1
- 5
- 17
def find_most_frequent_counter(numbers):
"""
Find the most frequent number(s) using Counter.
Testing with 1,000,000 numbers Takes 0.0408 seconds
"""
counter = Counter(numbers)
max_count = max(counter.values())
most_frequent = [num for num, count in counter.items() if count == max_count]
return most_frequent, max_count
// Return Most Common Number in Array
// by Alexander Burton
// https://alexburton.com
// or string of numbers delimited by one of a few options
// https://stackoverflow.com/beta/challenges/79766578/code-challenge-6-integer-counting
// forgive me if this solution looks ridiculous, it was fun building it
function most_common_number(data, str_split, debug_mode = false) {
// Declare data catchers
let uc = {}; // unique counter - how many time each number (key) occurs (value)
let d_numbers = []; // data array
if(debug_mode) {console.log("Phase 0:\n", typeof data === "object", data === Array, data.length > 0);}
// If data passed into this function is already an array,
//then use it as-is
if(typeof data === "object" && data.length > 0) {
d_numbers = data;
}
// If data passed into this function is a string,
// then the second argument will be used
// to tell the function which delimeter to use
//to split this string into array of number
// without chaos ensuing
if(typeof data === "string") {
// This is the gate keeper that limits which delimeters
// the user can use to split the string
if(["\n", ",", " ", ";"].indexOf() > -1) {
d_numbers = data.split(str_split);
} else {
// If you want to trust the user to choose
// the correct delimiter without erroring
// then get of the if/else this
return {"warning": "You have chosen a delimiter that is not in my list of approved delimiters: \"\\n\", \",\", \" \", \";\""};
}
}
if(debug_mode) {console.log("Phase 1:\n", {uc, d_numbers});}
// Build the Unique Counter (uc) that creates a dictionary of
// keys (the number that uniquely occurs in the array) and
// values (the number of times that the unique number [the "key" itself]
// occurs in the array)
d_numbers.forEach((n,i) => {
let key = (n.toString());
key in uc ? uc[n] += 1 : uc[n] = 1;
});
if(debug_mode) {console.log("Phase 2:\n", {uc, d_numbers});}
// the array of the number of times each unique number occurred
let uc_values = Object.values(uc); // unique counter's array of value
// the array of unique numbers that occurred in an order
// that corresponds with the uc_values array above
let uc_keys = Object.keys(uc);
// the most amount of times a number has occurred in the array
// selected by finding the largest number in the array of uc_values
let max_num = Math.max(...uc_values);
// the long variable name explains itself oddly enough
// if the max_num occurs in the uc_values multiple times
// then the index will reflect the position the first time
// the max_num was found in the .indexOf() the uc_values array
let index_of_number_of_times_the_number_that_occurs_most_happens = uc_values.indexOf(max_num);
// sort the uc_keys in an order that lines up with the uc_values
// so that the oddly named variable above can be used
// to return the number that occurs most in the array
uc_keys = uc_keys.sort((a,b) => {return parseInt(a) - parseInt(b);});
// and voila parse the value selected back into an integer
// and you have the number that occurs most in the array
let number_that_occurs_most = parseInt(uc_keys[index_of_number_of_times_the_number_that_occurs_most_happens]);
if(debug_mode) {console.log("Phase 3:\n", {uc_values, max_num, uc_keys, number_that_occurs_most, index_of_number_of_times_the_number_that_occurs_most_happens});}
// return the number that actually occurs most
// in the provided in the original data array
return number_that_occurs_most;
}
- 31
- 4
Explanation:
- I opted for parallel execution because this is a CPU-bound operation with a high workload. This strategy allows us to divide the task into multiple chunks that run concurrently, resulting in faster completion times at the cost of increased resource utilization.
1. Parallel Frequency Counting
The first major optimization is how the code counts the numbers. Instead of using a dictionary or a single-threaded loop, it employs a highly efficient, albeit constrained, method:
Frequency Map (
int[] arr): The code pre-allocates an integer arrayarrof size 1000. This array acts as a direct-address table or frequency map. The index of the array corresponds to an integer from the input file (e.g.,arr[42]stores the count of the number 42), and the value at that index is its frequency. This is incredibly fast because updating the count is an O(1) operation. However, it assumes all numbers in the input file are within the range of 0 to 999.Parallel Processing (
Parallel.Invoke): To speed up the counting process on the large input list, the list is logically divided into 100 smaller segments. An array ofActiondelegates is created, where eachActionis responsible for iterating over one segment and updating the sharedarrfrequency map.Parallel.Invokethen executes all these actions concurrently, utilizing multiple CPU cores to process the data much faster than a single sequential loop would.
Important Note on Thread Safety: The operation arr[integers[j]]++ is not atomic and therefore not thread-safe. It involves three steps (read the value, increment it, write it back), and a race condition can occur if two threads try to update the same counter simultaneously, potentially leading to incorrect counts. A more robust implementation would use Interlocked.Increment(ref arr[integers[j]]) to ensure thread-safe increments.
2. Parallel "Divide and Conquer" Search
Once the arr frequency map is populated, the next task is to find the index with the highest value. A simple linear scan would work, but to further optimize, the code implements a parallel "divide and conquer" algorithm:
Recursive Splitting: The
FindMaxRecmethod recursively splits the frequency array in half.Parallel Search:
Parallel.Invokeis used again to run the search on both halves of the array concurrently.Combine Results: Once the parallel tasks complete, the method simply compares the maximum value found in the left half with the maximum from the right half and returns the greater of the two. This process continues up the recursion stack until the overall maximum for the entire array is found. This parallel search can offer a significant speedup for finding the maximum value in a large array.
Performance:
The code ran in 165 ms on average
Device Config:
CPU: Intel Core i5 6400 2.7GHz
Memory: 32G DDR3 2133MHz
SSD: WDC WDS240g20A
Code:
public class Executer
{
[Benchmark]
public void Exec()
{
var file = File.ReadAllLines(@".\1M_random_numbers.txt");
var integers = file.Select(c => int.Parse(c)).ToList();
var result = CountIntegers.MostRepeated(integers);
Console.WriteLine(result);
}
}
public static class CountIntegers
{
private static int[] arr = new int[1000];
public static (int value, int index) MostRepeated(List<int> integers)
{
var interval = integers.Count / 100;
var actions = new Action[100];
for (int i = 0; i < 100; i++)
{
var local_i = i;
actions[i] = () =>
{
for (int j = local_i * interval; j < (local_i + 1) * interval; j++)
{
arr[integers[j]]++;
}
};
}
Parallel.Invoke(actions);
var maxItem = FindMaximum(arr);
return maxItem;
}
public static (int value, int index) FindMaximum(int[] array)
{
return FindMaxRec(array, 0, array.Length - 1);
}
private static (int value, int index) FindMaxRec(int[] array, int from, int to)
{
if (to <= from + 1)
return array[from] > array[to] ? (array[from], from) : (array[to], to);
(int value, int index) left = default;
(int value, int index) right = default;
Parallel.Invoke
(
() => left = FindMaxRec(array, from, (from + to) / 2),
() => right = FindMaxRec(array, (from + to) / 2 + 1, to)
);
return left.value > right.value ? left : right;
}
}
- 12k
- 5
- 53
- 108
Is this C# with optimizations enabled?
- 445
- 4
- 9
I put all the numbers in a hash, in case they are needed for later processing. But the hash as implemented is only used for counting. As far as optimization, the fastest solution will certainly be to keep a running total of the number with the largest frequency. I used an array in case there are many numbers with the same frequency. This way you dont have to spend time sorting all the numbers by frequency. Basically you get the answer in O(n) time instead of O(n log n), so always faster.
I have included the time, but it may be useful to look at the Shortcomings of Empirical Metrics section in the Analysis of Algorithms Wikipedia article. Big O analysis will always be better than Empirical Metrics for exactly these reasons.
My solution is in Perl. With C and Assembler, run time will surely be faster, but development time will be longer. The code will also be less direct, less concise, and more difficult to follow. Fumbling around with a strict rather than dynamic type system will always add to development time and frustration.
Here is the code...
#!/usr/bin/perl -w
my $appearanceCount = -1;
my @appearanceNumber;
my %count;
while(<>){
chomp;
$count{$_}++;
#keeping a running total will always be faster than sorting all hash values
if($appearanceCount < $count{$_}){
undef @appearanceNumber;
push(@appearanceNumber,$_);
$appearanceCount = $count{$_};
}elsif($appearanceCount == $count{$_}){
push(@appearanceNumber,$_);
}
if(eof){
print "$ARGV: ";
print "Numbers with biggest count, ordered by first appearance <$appearanceCount> @appearanceNumber\n";
#DEBUG print "$count{$_}: $_\n" for(sort{$count{$b} <=> $count{$a}} keys(%count)); #print all appearances in descending order
#reset variables for next file
undef %count;
undef @appearanceNumber;
$appearanceCount = -1;
}
}
Here is the output...
$ time perl biggest.pl biggest1.txt biggest2.txt biggest3.txt
biggest1.txt: Numbers with biggest count, ordered by first appearance <2> 208 188 641 546 374 694
biggest2.txt: Numbers with biggest count, ordered by first appearance <23> 284
biggest3.txt: Numbers with biggest count, ordered by first appearance <1130> 142
real 0m0.213s
user 0m0.209s
sys 0m0.004s
That is a metric for all three files at once sequentially, here is the biggest file individually...
$ time perl biggest.pl biggest3.txt
biggest3.txt: Numbers with biggest count, sorted by first appearance <1130> 142
real 0m0.203s
user 0m0.200s
sys 0m0.003s
That timing is on a ~6 year old laptop with a million tabs open watching youtube videos and hasnt been rebooted in 19 days. Not exactly a top of the line server. But I know for certain this is the fastest algorithm. Hooray for Big O Analysis!
- 1.3k
- 8
- 17
C AVX2 intrinsics
Uses SIMD to parse and reduce.
Tries to parse an integer starting at every byte position. Then discards inactive lanes.
#include <stdint.h>
#include <immintrin.h>
static uint32_t frequency[1000];
static inline const uint8_t* collect_number(const uint8_t* ptr){
size_t n = *ptr++ - 0x30;
for(;;) {
uint8_t c = *ptr++;
if(c == 0x0A) break;
n = (n * 10) + (c - 0x30);
}
frequency[n]++;
return ptr;
}
// parse and return the most frequent number
// if tied return the largest
uint32_t do_challenge (const uint8_t* file_buf, size_t file_size) {
const uint8_t* ptr = file_buf;
if(file_size >= 4) {
// the simd routine looks-back three bytes
// so special case the first token
if((file_buf[1] == 0x0A) || (file_buf[2] == 0x0A)) collect_number(ptr);
const uint8_t* end = &file_buf[((file_size - 3) & ~31)]; // YOLO ?
while(ptr < end){
__m256i v0 = _mm256_loadu_si256((const __m256i *)&ptr[0]);
__m256i v1 = _mm256_loadu_si256((const __m256i *)&ptr[1]);
__m256i v2 = _mm256_loadu_si256((const __m256i *)&ptr[2]);
__m256i v3 = _mm256_loadu_si256((const __m256i *)&ptr[3]);
ptr += 32;
// get bytes depending on odd or even run start
// non-active lanes will contain garbage
//
// we don't go pure vertical because tokens will have a minimum of
// 2 bytes in length and we have to widen to 16-bit integers anyways
__m256i lo = _mm256_min_epi16(v2, v3);
__m256i hi = _mm256_blendv_epi8(v0, v1, _mm256_cmpeq_epi16(v3, lo));
// convert text to binary
const __m256i ascii_zero = _mm256_set1_epi8(0x30); // '0'
const __m256i mul = _mm256_set1_epi16(0x0A64); // hi-byte * 10, lo-byte * 100
hi = _mm256_max_epi16(hi, ascii_zero); // fixup low byte if token only had 1 digit
hi = _mm256_maddubs_epi16(_mm256_subs_epu8(hi, ascii_zero), mul);
__m256i bin = _mm256_add_epi16(_mm256_subs_epu8(lo, ascii_zero), hi);
// despace
//
// counting non-active lanes could double the required work
// but we also don't want to branch too much....
//
// the blend makes sure the lo-word of each dword is always an active lane
// the shuffle moves all the "always" lo-words to the lo-qword
// and moves the "maybe" hi-words to the hi-qword
// (more work will happen later to deal with the hi-qwords)
__m256i active = _mm256_cmpgt_epi16(mul, lo); // if '\n' in high byte
const __m256i shuf = _mm256_set_epi8(
15,14,11,10,7,6,3,2, 13,12,9,8,5,4,1,0,
15,14,11,10,7,6,3,2, 13,12,9,8,5,4,1,0
);
__m256i r = _mm256_blendv_epi8(_mm256_srli_epi32(bin, 16), bin, active);
r = _mm256_shuffle_epi8(r, shuf);
__m128i r_lo = _mm256_castsi256_si128(r);
__m128i r_hi = _mm256_extracti128_si256(r, 1);
// extract lo-qwords and count
uint64_t q0 = _mm_cvtsi128_si64x(r_lo);
uint64_t q2 = _mm_cvtsi128_si64x(r_hi);
frequency[q0 & 0xFFFF]++;
frequency[q2 & 0xFFFF]++;
(*((uint32_t*)(((uintptr_t)frequency) + ((q0 >> 14) & 0xFFFF))))++;
(*((uint32_t*)(((uintptr_t)frequency) + ((q2 >> 14) & 0xFFFF))))++;
(*((uint32_t*)(((uintptr_t)frequency) + ((q0 >> 30) & 0xFFFF))))++;
(*((uint32_t*)(((uintptr_t)frequency) + ((q2 >> 30) & 0xFFFF))))++;
(*((uint32_t*)(((uintptr_t)frequency) + (q0 >> 46))))++;
(*((uint32_t*)(((uintptr_t)frequency) + (q2 >> 46))))++;
// despace hi-qwords, then count
static const uint64_t table[8] = {
0x0000000000000F0E, 0x000000000F0E0908, 0x000000000F0E0B0A, 0x00000F0E0B0A0908,
0x000000000F0E0D0C, 0x00000F0E0D0C0908, 0x00000F0E0D0C0B0A, 0x0F0E0D0C0B0A0908
};
unsigned key = (unsigned)_mm256_movemask_ps(_mm256_castsi256_ps(
_mm256_cmpeq_epi32(active, _mm256_set1_epi32(-1))));
uint64_t q1 = _mm_cvtsi128_si64x(_mm_shuffle_epi8(r_lo, _mm_loadl_epi64((__m128i*)(&table[key & 7]))));
uint64_t q3 = _mm_cvtsi128_si64x(_mm_shuffle_epi8(r_hi, _mm_loadl_epi64((__m128i*)(&table[(key >> 4) & 7]))));
int q1_popcnt = _mm_popcnt_u32(key & 0x0F);
int q3_popcnt = _mm_popcnt_u32(key >> 4);
for(int i = 0; i < q1_popcnt; i++) {frequency[q1 & 0xFFFF]++; q1 >>= 16;}
for(int i = 0; i < q3_popcnt; i++) {frequency[q3 & 0xFFFF]++; q3 >>= 16;}
}
// re-align to point to the first unparsed token
ptr += 3;
while(*ptr != 0x0A) ptr--;
ptr++;
}
// tail loop
while(ptr != &file_buf[file_size]){
ptr = collect_number(ptr);
}
// find max
//
// stuff the number in the bottom of the fequency count
// so we don't have to do a 2nd pass looking for
// numbers matching max count
__m256i max256 = _mm256_setzero_si256();
__m256i offset = _mm256_set_epi32(7,6,5,4,3,2,1,0);
__m256i inc = _mm256_set1_epi32(8);
for (int i = 0; i < 1000; i+=8) {
__m256i v = _mm256_loadu_si256((const __m256i *)&frequency[i]);
v = _mm256_or_si256(_mm256_slli_epi32(v, 10), offset);
offset = _mm256_add_epi32(offset, inc);
max256 = _mm256_max_epu32(max256, v);
}
__m128i max_lo = _mm256_castsi256_si128(max256);
__m128i max_hi = _mm256_extracti128_si256(max256, 1);
__m128i max128 = _mm_max_epu32(max_lo, max_hi);
__m128i max64 = _mm_max_epu32(max128, _mm_unpackhi_epi64(max128, max128));
__m128i max32 = _mm_max_epu32(max64, _mm_srli_epi64(max64, 32));
uint32_t max = (uint32_t)_mm_cvtsi128_si32(max32);
return max & 0x3FF;
}
- 1.3k
- 8
- 17
Thoughts on processing the bytes horizontally (instead of vertically):
Horizontal seemed inelegant mostly because, with SSSE3/NEON, it requires ~1600 bytes of pre-calculated tables up front. It also takes a long time to find the length of the current group. So unrolling is hard and therefore it is hard to hide the serial dependencies. However, it could be branchless.
If we look at only the first four tokens then there are 81 (3*3*3*3) permutations.
If we look at the whole 16 byte chunk then there are 277 permutations. (Assuming byte_0 is always "digit", and byte_15 is always "don't care")
So the two horizontal approaches would seem to be:
- Stack four "trailing bit manipulations" in a row to find the first 4 tokens. Then steal the perfect hash functions from the simdzone IPv4 parser. (Disclaimer: I contributed some minor optimizations)
x = pmovmskb(newline_mask);
id = ((x & blsmsk(blsr(blsr(blsr(x))))) * magic) >> 24;
shuf = table2[table1[id]];
- Calculate one of the 277 permutation indices then map that down to the 81 we care about.
const __m128i byte_position_weights = _mm_set_epi8(0, 189, 129, 88, 60, 41, 28, 19, 13, 9, 6, 4, 3, 2, 1, 1);
id = hsum(newline_mask & byte_position_weights) - 76;
shuf = table2[table1[id]];
(sidebar: the Fibonacci sequence is less restrictive and would seem to only easily cover 13 bytes)
- 2.9k
- 1
- 26
- 32
The Solution Method:
I implemented different version of solution functions with incremental code optimization changes(some are decremental and reversal) to check whether those changes really improved the execution time. Surprised me, ...it is not always the case! It depends a lot on how the numbers are arranged in the list.
Just an important note: I wrote all the codes by myself and did not use code generated by AI. All the codes came from my thoughts and my fingers. I consulted search engines for specific programming syntax things I did not know yet just like in the no-AI days back then. No copy-paste solution method is used in this mini project.
Here is my git repo to see the full code, test scripts, and more results.
- all of the solution code and execution time measurement resides in
cpp/main.cppfile. - build scripts and bigger benchmark customizations are handled by
*.shscripts.
- all of the solution code and execution time measurement resides in
The Environment and Tools:
- Dev OS:
Windows 11 64bit - Execution Environment:
WSL2 Ubuntu 24.04 - Programming Languages:
C/C++,Bash - Hardware Specs:
- Processor:
AMD Ryzen 7 5800H with Radeon Graphics ~3.2GHz - RAM:
16GB
- Processor:
- Execution method:
- Restart the PC.
- Open terminal, start
wsl - Open task-manager via
Ctrl+Shift+Escto check if no other resource intensive app is running. - Navigate to
project_path/cpp/. - Execute the benchmark script:
./benchmark.sh > benchmark_result.md - Don't you dare touch your keyboard and mouse until the process is complete.
- Open
benchmark_result.mdinVS Code. Ctrl+K Vto preview in markdown viewer.- You can now look on the execution result.
The Solution Functions:
Here is the summary table of the test functions I implemented, to be used in this benchmark:
name Description funcAunoptimized. basis for correct results. funcBlike funcAbut search maxcount starting fromiMin.funcClike funcBbut now, search uptoiMaxonly.funcDlike funcCbut counting ahead consecutive same numbers.funcElike funcDbut converted most conditional branches to branchless version.funcFlike funcEbut converted back the branches that uses&&, and `funcGlike funcEbut remove allconstspecifier of vars inside the loops.funcHlike funcEbut changed the inside loop fromwhiletofor.funcIlike funcEbut removed counting ahead of consecutive same numbers.The solution list -- the number(s) with the most count --, is/are saved in a fixed size
vector<int>so no allocation will happen when collecting them. Here is the preview with skipped lines:... vector<int> counts(1000, 0); vector<int> results(1000, 0); ... std::fill(counts.begin(), counts.end(), 0); results.clear(); ... f.func(listNums, counts, results); ... listResult.push_back(results); ...- See/Jump to [The Measurement](#the-measurement) section for the complete code.
The solution functions code from
funcAtofuncIare provided below:/* =================================== * funcA: Count and search with maxCount --------------------------------------*/ void funcA(const vector<int>& listN, vector<int>& counts, vector<int>& results){ int iMaxCount = 0, vMaxCount = 0; // --- count const size_t numItems = listN.size(); for(size_t i = 0; i < numItems; i++){ auto vCur = ++counts[ listN[i] ]; if(vMaxCount < vCur) { vMaxCount = vCur; iMaxCount = listN[i]; } } // --- search and get the results const size_t numCounts = counts.size(); for(size_t i = 0; i < numCounts; i++){ if ( counts[i] != vMaxCount ) continue; results.push_back(i); } } /* =================================== * funcB: Count and search maxcount from index iMin. --------------------------------------*/ void funcB(const vector<int>& listN, vector<int>& counts, vector<int>& results){ int iMin = 0, vMaxCount = 0; // // --- count const size_t numItems = listN.size(); for(size_t i = 0; i < numItems; i++){ auto const iCur = listN[i]; auto const vCur = ++counts[ iCur ]; if(vMaxCount < vCur) { vMaxCount = vCur; iMin = iCur; } else if (vMaxCount == vCur && iCur < iMin) { iMin = iCur; } } // --- search and get the results const size_t numCounts = counts.size(); for(size_t i = iMin; i < numCounts; i++){ if (counts[i] != vMaxCount) continue; results.push_back(i); } } /* =================================== * funcC: Count and search maxcount from iMin to iMax indices -------------------------------------*/ void funcC(const vector<int>& listN, vector<int>& counts, vector<int>& results){ int iMin = 0, iMax = 0, vMaxCount = 0; const size_t numItems = listN.size(); for(size_t i = 0; i < numItems; i++){ auto const iCur = listN[i]; auto const vCur = ++counts[ iCur ]; if(vMaxCount < vCur) { vMaxCount = vCur; iMin = iMax = iCur; } else if (vMaxCount == vCur) { if (iCur < iMin) { iMin = iCur; } else if (iCur > iMax) { iMax = iCur; } } } // --- search and get the results for(size_t i = iMin; i <= iMax; i++){ if (counts[i] != vMaxCount) continue; results.push_back(i); } } /* =================================== * funcD: Count and search maxcount from iMin to iMax indices * + take advantage of consecutive same numbers. -------------------------------------*/ void funcD(const vector<int>& listN, vector<int>& counts, vector<int>& results){ int iMin = 0, iMax = 0, vMaxCount = 0; const size_t numItems = listN.size(); for(size_t i = 0; i < numItems; i++){ auto const iCur = listN[i]; // --- count ahead consecutive same numbers int j = i+1; while (iCur == listN[j] && j < numItems) j++; auto const vCur = counts[ iCur ] += (j - i); i = j - 1; // --- update searching info if(vMaxCount < vCur) { vMaxCount = vCur; iMin = iMax = iCur; } else if (vMaxCount == vCur) { if (iCur < iMin) { iMin = iCur; } else if (iCur > iMax) { iMax = iCur; } } } // --- search and get the results for(size_t i = iMin; i <= iMax; i++){ if (counts[i] != vMaxCount) continue; results.push_back(i); } } /* =================================== * funcE: Count and search maxcount from iMin to iMax indices * + take advantage of consecutive same numbers * + less branches inside the loop by using &,| instead of &&,|| * to lessen branch mispredictions. -------------------------------------*/ void funcE(const vector<int>& listN, vector<int>& counts, vector<int>& results){ int iMin = 0, iMax = 0; int vMaxCount = 0; const size_t numItems = listN.size(); for(size_t i = 0; i < numItems; i++){ auto const iCur = listN[i]; // --- count ahead consecutive same numbers int j = i+1; while (iCur == listN[j] & j < numItems) j++; auto const vCur = counts[ iCur ] += (j - i); i = j - 1; // --- update searching info const int diffCount = vCur - vMaxCount; const int diffIdxMin = iCur - iMin; const int diffIdxMax = iCur - iMax; const bool bDiffCountNeg = diffCount < 0; const bool bDiffCount0 = diffCount == 0; vMaxCount += ((diffCount <= 0)-1) & diffCount; iMin += ((bDiffCountNeg | (bDiffCount0 & diffIdxMin >= 0))-1) & diffIdxMin; iMax += ((bDiffCountNeg | (bDiffCount0 & diffIdxMax <= 0))-1) & diffIdxMax; } // --- search and get the results for(size_t i = iMin; i <= iMax; i++){ if (counts[i] != vMaxCount) continue; results.push_back(i); } } /* =================================== * funcF: Count and search maxcount from iMin to iMax indices * + take advantage of consecutive same numbers * ? convert back branches(&&,||) on conditions expression * because surprisingly, it is sometimes faster than funcE * (I'm still not sure why.) -------------------------------------*/ void funcF(const vector<int>& listN, vector<int>& counts, vector<int>& results){ int iMin = 0, iMax = 0; int vMaxCount = 0; const size_t numItems = listN.size(); for(size_t i = 0; i < numItems; i++){ auto const iCur = listN[i]; // --- count ahead consecutive same numbers int j = i+1; while (iCur == listN[j] && j < numItems) j++; // changed back from & to &&. auto const vCur = counts[ iCur ] += (j - i); i = j - 1; // --- update searching info const int diffCount = vCur - vMaxCount; const int diffIdxMin = iCur - iMin; const int diffIdxMax = iCur - iMax; const bool bDiffCountNeg = diffCount < 0; const bool bDiffCount0 = diffCount == 0; vMaxCount += ((diffCount <= 0)-1) & diffCount; iMin += ((bDiffCountNeg || (bDiffCount0 && diffIdxMin >= 0))-1) & diffIdxMin; //changed back from &,| to &&,|| iMax += ((bDiffCountNeg || (bDiffCount0 && diffIdxMax <= 0))-1) & diffIdxMax; } // --- search and get the results for(size_t i = iMin; i <= iMax; i++){ if (counts[i] != vMaxCount) continue; results.push_back(i); } } /* =================================== * funcG: Count and search maxcount from iMin to iMax indices * + take advantage of consecutive same numbers * + less branches inside the loop by using &,| instead of &&,|| * to lessen branch mispredictions. * ? remove 'const' variables inside the loop. -------------------------------------*/ void funcG(const vector<int>& listN, vector<int>& counts, vector<int>& results){ int iMin = 0, iMax = 0; int vMaxCount = 0; const size_t numItems = listN.size(); for(size_t i = 0; i < numItems; i++){ auto iCur = listN[i]; // --- count ahead consecutive same numbers int j = i+1; while (iCur == listN[j] & j < numItems) j++; auto vCur = counts[ iCur ] += (j - i); i = j - 1; // --- update searching info int diffCount = vCur - vMaxCount; int diffIdxMin = iCur - iMin; int diffIdxMax = iCur - iMax; bool bDiffCountNeg = diffCount < 0; bool bDiffCount0 = diffCount == 0; vMaxCount += ((diffCount <= 0)-1) & diffCount; iMin += ((bDiffCountNeg | (bDiffCount0 & diffIdxMin >= 0))-1) & diffIdxMin; iMax += ((bDiffCountNeg | (bDiffCount0 & diffIdxMax <= 0))-1) & diffIdxMax; } // --- search and get the results for(size_t i = iMin; i <= iMax; i++){ if (counts[i] != vMaxCount) continue; results.push_back(i); } } /* =================================== * funcH: Count and search maxcount from iMin to iMax indices * + take advantage of consecutive same numbers * + less branches inside the loop by using &,| instead of &&,|| * to lessen branch mispredictions. * ? changed 'while' to 'for' for consecutive same numbers -------------------------------------*/ void funcH(const vector<int>& listN, vector<int>& counts, vector<int>& results){ int iMin = 0, iMax = 0; int vMaxCount = 0; const size_t numItems = listN.size(); for(size_t i = 0; i < numItems; i++){ auto iCur = listN[i]; // --- count ahead consecutive same numbers int j; for (j = i+1; iCur == listN[j] & j < numItems; j++); auto vCur = counts[ iCur ] += (j - i); i = j - 1; // --- update searching info const int diffCount = vCur - vMaxCount; const int diffIdxMin = iCur - iMin; const int diffIdxMax = iCur - iMax; const bool bDiffCountNeg = diffCount < 0; const bool bDiffCount0 = diffCount == 0; vMaxCount += ((diffCount <= 0)-1) & diffCount; iMin += ((bDiffCountNeg | (bDiffCount0 & diffIdxMin >= 0))-1) & diffIdxMin; iMax += ((bDiffCountNeg | (bDiffCount0 & diffIdxMax <= 0))-1) & diffIdxMax; } // --- search and get the results for(size_t i = iMin; i <= iMax; i++){ if (counts[i] != vMaxCount) continue; results.push_back(i); } } /* =================================== * funcI: Count and search maxcount from iMin to iMax indices * + less branches inside the loop by using &,| instead of &&,|| * to lessen branch mispredictions. -------------------------------------*/ void funcI(const vector<int>& listN, vector<int>& counts, vector<int>& results){ int iMin = 0, iMax = 0; int vMaxCount = 0; const size_t numItems = listN.size(); for(size_t i = 0; i < numItems; i++){ auto const iCur = listN[i]; auto const vCur = ++counts[ iCur ]; // --- update searching info const int diffCount = vCur - vMaxCount; const int diffIdxMin = iCur - iMin; const int diffIdxMax = iCur - iMax; const bool bDiffCountNeg = diffCount < 0; const bool bDiffCount0 = diffCount == 0; vMaxCount += ((diffCount <= 0)-1) & diffCount; iMin += ((bDiffCountNeg | (bDiffCount0 & diffIdxMin >= 0))-1) & diffIdxMin; iMax += ((bDiffCountNeg | (bDiffCount0 & diffIdxMax <= 0))-1) & diffIdxMax; } // --- search and get the results for(size_t i = iMin; i <= iMax; i++){ if (counts[i] != vMaxCount) continue; results.push_back(i); } }
Internal Test Data Generation:
The program will generate internal test data if there are no valid input files are provided in the command-line argument.
The generation of the internal test data happens in this code:
auto randomPure = [](auto& listN) { for(auto& list : listN) { for(auto& v : list) { v = rand() % 1000; } } }; // --- if input data from command line argument is empty... if (listTestData.empty()){ vector<STestData> internalTestData { {"10k", vector(100, vector<int>(10'000))}, {"100k", vector(100, vector<int>(100'000))}, {"1M", vector(50, vector<int>(1'000'000))}, {"10M", vector(10, vector<int>(10'000'000))}, }; // --- generate test data. vLog("- Generating internal test data..."); for(auto& test : internalTestData){ randomPure(test.listTest); } listTestData = std::move(internalTestData); }- Here, for
"10M"test data, there are 10 different set of 10 million random numbers that are run for each test functions. - For the input files, 1 file means only 1 list of random numbers. To execute it to a test function multiple times, set a value to
--num-iterationsin the command line argument.
- Here, for
The Measurement:
The
Timerstrictly starts and stops right before and right after the execution of a solution function.And then the elapsed time are accumulated for a specific test data set.
Solution functions results must be correct.
funcAis the basis function.If a solution functions produced atleast 1 incorrect answer, the total duration will be set to
-1, stopping further execution of test data, and then proceed to measuring the next test data set.If you see a
-1μsin a summary table, that means the function failed to give the correct solution.After the measurement process, a summary table is printed that shows average execution time values.
Execution time of each test data is performed with the following code.
// --- start benchmark vLog("# Start benchmarking..."); Timer timer; vector<int> counts(1000, 0); vector<int> results(1000, 0); vector<int> expected; const int IDX_BASIS_FUNC = 0; for(auto& test : listTestData){ //randomPure(*test.listTest); //randomSorted(*test.listTest); vector<vector<int>> listResult, listExpected; listExpected.clear(); test.listDurations.clear(); for(auto& f : listFuncToTest) { Timer::duration_t totalDur = 0; listResult.clear(); if(bVerbose) { cout << "\n ## Testing `" << f.name << "` with `" << test.name << "`:" << endl; cout << "- dur list: " << endl << " ```c++" << endl << " "; } for(int i = 0; i < numIterations; i++) { for(auto& listNums : test.listTest) { // --- prepare input/output containers. std::fill(counts.begin(), counts.end(), 0); results.clear(); // --- execute process timer.start(); f.func(listNums, counts, results); timer.stop(); // --- accumulate execution time. if(bVerbose) cout << timer.getElapsed() << "μs, "; totalDur += timer.getElapsed(); listResult.push_back(results); } } if(bVerbose) cout << endl << " ```" << endl; if (f.func == listFuncToTest[IDX_BASIS_FUNC].func) { listExpected = listResult; if(bVerbose) { cout << "- get funcA result as basis." << endl; cout << " - **actual result**: " << endl; printResult(listResult); } } else if (listExpected != listResult) { totalDur = -1; if(bVerbose) { cout << "- ### result not matched!" << endl; printResultComparison(listExpected, listResult); } break; } test.listDurations.push_back(totalDur); if(bVerbose) { cout << "- ### total duration: " << totalDur << " μs" << endl; } } } // --- print average execution time summary table(in markdown syntax). vLog( "\n\n # Summary: Average execution time."); printSummaryTable(listFuncToTest, listTestData, numIterations, bShowFuncDesc);
The Result:
- The next section below shows a sample generated result of the resulting app and benchmark scripts.
- The values in the tables are average execution time.
- You can see that the optimize version of functions is slower than the unoptimized version when the input data are purely random but a lot better when the data are sorted.
- In my conclusion, it really pays well if the input data is normalized first before processing. In this case, "sorted".
- For the unoptimized version --
funcA, the execution time is consistent whether the data is sorted or not. - I am expecting
funcEwill be the most optimized and will win on all the data cases but it didn't happen. Probably due to the write-then-read delay ofiMin,iMax, andvMaxCountbetween iterations in the loop. (need more study) - There are times,
funcE, which is mostly branchless, was beaten by other functions, with a lot of branches, even on a sorted data. I think these are the cases where branch predictions really speed-up the execution time, but kind of randomly, it seems. Sometimes, a function won against others and then on the next benchmark run it was beaten by others.
Benchmark Results: Built with -std=c++17 -O3
Internal Test Data
name 10k 100k 1M 10M funcA 5.84 μs 57.12 μs 578.34 μs 6522.20 μs funcB 21.85 μs 220.06 μs 2104.02 μs 20774.20 μs funcC 5.49 μs 57.69 μs 540.14 μs 5554.10 μs funcD 12.25 μs 119.10 μs 1192.10 μs 11800.10 μs funcE 21.36 μs 218.82 μs 2199.56 μs 21898.20 μs funcF 14.31 μs 142.08 μs 1419.20 μs 14195.70 μs funcG 21.49 μs 218.27 μs 2189.46 μs 21813.90 μs funcH 21.23 μs 218.92 μs 2188.74 μs 21745.00 μs funcI 20.74 μs 211.34 μs 2118.92 μs 21211.40 μs Internal Test Data Sorted
name 10k 100k 1M 10M funcA 16.27 μs 64.75 μs 479.82 μs 4727.50 μs funcB 9.12 μs 81.17 μs 698.62 μs 6906.10 μs funcC 10.07 μs 62.45 μs 478.00 μs 4788.50 μs funcD 10.06 μs 41.42 μs 361.02 μs 3613.00 μs funcE 11.07 μs 52.21 μs 474.64 μs 4758.40 μs funcF 10.02 μs 41.75 μs 362.26 μs 3648.90 μs funcG 11.29 μs 51.46 μs 470.04 μs 4729.90 μs funcH 11.00 μs 53.18 μs 472.74 μs 4712.20 μs funcI 22.21 μs 221.65 μs 2059.62 μs 20615.30 μs Input Files
name input/100_nums.txt input/10k_nums.txt input/1M_nums.txt funcA 0 μs 6.00 μs 571.00 μs funcB 0 μs 15.00 μs 1467.00 μs funcC 0 μs 6.00 μs 516.00 μs funcD 0 μs 12.00 μs 1151.00 μs funcE 0 μs 21.00 μs 2135.00 μs funcF 0 μs 14.00 μs 1379.00 μs funcG 0 μs 21.00 μs 2123.00 μs funcH 0 μs 21.00 μs 2161.00 μs funcI 0 μs 20.00 μs 2063.00 μs Input Files Sorted
name input/100_nums.txt input/10k_nums.txt input/1M_nums.txt funcA 0 μs 16.00 μs 487.00 μs funcB 0 μs 9.00 μs 699.00 μs funcC 0 μs 10.00 μs 489.00 μs funcD 0 μs 10.00 μs 352.00 μs funcE 0 μs 11.00 μs 456.00 μs funcF 0 μs 10.00 μs 345.00 μs funcG 0 μs 8.00 μs 468.00 μs funcH 0 μs 6.00 μs 465.00 μs funcI 0 μs 22.00 μs 2091.00 μs Input Files - Run 100x Each
name input/100_nums.txt input/10k_nums.txt input/1M_nums.txt funcA 0.01 μs 5.12 μs 553.54 μs funcB 0 μs 8.72 μs 1406.53 μs funcC 0 μs 6.85 μs 542.77 μs funcD 0 μs 11.81 μs 1159.99 μs funcE 0 μs 21.05 μs 2121.98 μs funcF 0 μs 14.16 μs 1375.58 μs funcG 0 μs 21.02 μs 2138.88 μs funcH 0 μs 21.30 μs 2134.64 μs funcI 0 μs 20.05 μs 2084.02 μs Input Files Sorted - Run 100x Each
name input/100_nums.txt input/10k_nums.txt input/1M_nums.txt funcA 0.01 μs 14.97 μs 474.40 μs funcB 0 μs 9.15 μs 697.87 μs funcC 0 μs 10.00 μs 469.82 μs funcD 0 μs 4.13 μs 346.24 μs funcE 0 μs 5.10 μs 458.06 μs funcF 0 μs 4.09 μs 346.53 μs funcG 0 μs 5.15 μs 458.65 μs funcH 0 μs 5.00 μs 462.79 μs funcI 0 μs 22.10 μs 2077.07 μs
Learnings:
- I improved my skills in boolean algebra to optimize the conditional expressions.
- I discovered how to convert code branches to their branchless version.
- I realized, I really should benchmark my work when I need to optimize. It's not enough to know that you added an optimization code.
- To really achieve better performance, you need to normalize the data. (in this case, SORT them). Feeding a random data to an optimized function does not guarantee the optimization will take effect. Sometimes the result will be worse than the unoptimized version. The optimization must be applied to both the code and the data, not just to the code.
- Using a documentation syntax, like
markdown, for the logs will make the result more presentable and easier to see and analyze.
Conclusion:
- Optimize both the data and the code to achieve better performance.
- Branch prediction is unpredictable. It really speeds up the execution time but not always guaranteed.
Beyond:
- Feel free to suggest ideas on what can be improved to my solutions, like any technical things I might not know or overlooked.
- Like you see, I didn't researched for existing solutions like any algorithms related to this kind of problem. I really don't know where to start sometimes and just enjoy solving the puzzle by myself.
- Can someone explains or provide details regarding cache misses and where in my code was affected by it?
- Also, why/when/where the branch predictions failed/succeed in my given code?
- Anything you like to comment.
- Feel free to check my
todo_list.txtin the my git repo and based your suggestions/comments/ideas from there.
One important conclusion is that the compiler's optimizer is way better than you, and sometimes when you think you optimize, you just get in its way. For example, some branchless code actually makes the compiler lose the intent and prevents optimization of conditionals to the cmov instruction
- 1.3k
- 1
- 2
- 16
I suggest you replace vector<int>& with std::span<int, 1000>, which will reduce the number of indirect memory accesses to 1 (from 2 previously; the compiler might even optimize it to 1). Using std::array instead of std::vector will also reduce the overhead of indirect memory access and result in more compact memory layout.
- 24.6k
- 16
- 61
- 110
This is nice, but I do not see any threads. On my hardware, disk reading is two times quicker with threads. More when cached. Surely this is important for an IO heavy task.
- 244
- 1
- 5
I have used a variant of counting sort.
As we know that all the numbers are between 0 and 999 we can have an array of 1000 counters indexed by the input numbers.
Then after the iteration on all numbers we iterate on the counter array to get its maximum value with the related index corresponding to the number that appears the most.
After, we need another iteration on the counter array to ensure there exists a unique number appearing most often than others because there could have been several numbers with same number of occurrence as in the provided list of 100 integers. This final loop can be only partial, beginning after the minimum index of maximum count computed in the previous loop, nevertheless its worst case is in 999 iterations, with the first iteration at index 1.
So we need 3 loops, the first one with n iterations where n is the length of the input list, the 2 others with at most k iterations where k = maximum number value + 1 = 1000 is a constant. Consequently the algorithm time complexity is linear in n: O(n). The memory complexity to process the data does not depend on n as we need only an internal array of 1000 counters.
We could merge the first loop on the inputs with the second loop computing the max on the 1000 counters, but it leads to worst time result because as n is 1000 times greater than 1000 (number of counters), it implies 1000 times more comparisons in loops, whereas by computing the max in a separate loop, the loop of n iterations is kept without any comparison leading to more efficiency.
The implementation of the algorithm in integer_counting.c++:
#include "integer_counting.h"
#include <array>
using namespace std;
static constexpr size_t max_number = 999;
optional<uint16_t>
get_most_common_number(const uint16_t *numbers, size_t len)
{
array<size_t, max_number + 1> counts{};
for (size_t i = 0; i < len; ++i) {
++counts[numbers[i]];
}
size_t max_count = 0;
uint16_t idx_max_count = 0;
for (uint16_t idx = 0; idx <= max_number; ++idx) {
if (counts[idx] > max_count) {
max_count = counts[idx];
idx_max_count = idx;
}
}
// Check if maximum count occurs for more than one number.
for (uint16_t idx = idx_max_count + 1; idx <= max_number; ++idx) {
if (counts[idx] == max_count) {
return {};
}
}
return make_optional(idx_max_count);
}
The related include file with the prototype and its needed includes in integer_counting.h:
#pragma once
#include <cstddef>
#include <cstdint>
#include <optional>
std::optional<std::uint16_t>
get_most_common_number(const std::uint16_t *numbers, std::size_t len);
The code used to test with lists of 100 and 10000 numbers in test.c++:
#include <iostream>
#include <array>
#include <vector>
#include "integer_counting.h"
using namespace std;
const vector<uint16_t> random_numbers_100 = {
#include "100_random_numbers.inc"
};
const vector<uint16_t> random_numbers_10000 = {
#include "10000_random_numbers.inc"
};
const array<const vector<uint16_t> *, 2> test_data = {
&random_numbers_100,
&random_numbers_10000,
};
int main()
{
for (auto p: test_data) {
const auto ret = get_most_common_number(p->data(), p->size());
cout << "In list of " << p->size() << " numbers ";
if (!ret) {
cout << "there is not a unique number appearing most often than others." << endl;
continue;
}
cout << "the number that appears the most is: " << ret.value() << endl;
}
}
The code used for the benchmark with google-benchmark v1.9.4 in benchmark.c++:
#include <benchmark/benchmark.h>
#include <array>
#include "integer_counting.h"
using namespace std;
namespace {
const array<uint16_t, 1'000'000> random_numbers_1M = {
#include "1M_random_numbers.inc"
};
void BM_get_most_common_number(benchmark::State& state)
{
for (auto _: state) {
get_most_common_number(random_numbers_1M.data(), random_numbers_1M.size());
}
}
BENCHMARK(BM_get_most_common_number);
}
BENCHMARK_MAIN();
NB: to produce the .inc files containing the lists of numbers with lines terminated by a comma I used sed on the raw text files (the utterance of the challenge is about processing a list of numbers not an external raw text file):
$ for f in ../data/*_random_numbers.txt; do sed 's!$!,!' $f > $(basename $f .txt).inc; done
Then to build the test program:
g++ -std=c++17 -Wall -Wextra integer_counting.c++ test.c++ -o test_integer_counting
Then testing:
$ ./test_integer_counting
In list of 100 numbers there is not a unique number appearing most often than others.
In list of 10000 numbers the number that appears the most is: 284
To build the benchmark program assuming that google-benchmark v1.9.4 is installed on the machine:
g++ -std=c++17 -Wall -Wextra -O3 integer_counting.c++ benchmark.c++ -lbenchmark -o benchmark_integer_counting
The benchmark on an intel core i9 14900K give a time of around 200 microseconds:
$ ./benchmark_integer_counting
2025-10-01T01:13:16+02:00
Running ./benchmark_integer_counting
Run on (32 X 5700 MHz CPU s)
CPU Caches:
L1 Data 48 KiB (x16)
L1 Instruction 32 KiB (x16)
L2 Unified 2048 KiB (x16)
L3 Unified 36864 KiB (x1)
Load Average: 0.03, 0.06, 0.08
--------------------------------------------------------------------
Benchmark Time CPU Iterations
--------------------------------------------------------------------
BM_get_most_common_number 193105 ns 192908 ns 3606
While executing the benchmark I have first encountered the warning message:
***WARNING*** CPU scaling is enabled, the benchmark real time measurements may be noisy and will incur extra overhead.
Then I had to install cpupower and execute
sudo cpupower frequency-set --governor performance
to run the benchmark without warning.
- 8.1k
- 7
- 44
- 65
#include <chrono>
#include <fstream>
#include <print>
int get_most_frequent_number(std::ifstream& ifs) {
int counts[1000]{};
int ret{};
int n{};
while (ifs >> n) {
if (++counts[n] >= counts[ret]) {
ret = n;
}
}
return ret;
}
int main(int argc, char** argv) {
if (argc != 2) {
std::println("Usage: most_frequent_number <FILE_PATH>");
exit(1);
}
char* file_path = argv[1];
std::ifstream ifs{ file_path };
if (!ifs.is_open()) {
std::println("Error: couldn't open {}", file_path);
exit(2);
}
auto start = std::chrono::steady_clock::now();
auto ret = get_most_frequent_number(ifs);
auto finish = std::chrono::steady_clock::now();
auto elapsed = std::chrono::duration_cast<
std::chrono::duration<double>>(finish - start).count();
std::println("{} ({:6} milliseconds)", ret, elapsed*1000);
}
Approach: read from input file stream, keep the most frequent number in
ret.- If reading from an input file stream wasn't such a big bottleneck, I may have written the main loop in a less clear but more performant way (using an extra variable, avoiding one extra access to
counts, and avoiding to updatereton equality).
- If reading from an input file stream wasn't such a big bottleneck, I may have written the main loop in a less clear but more performant way (using an extra variable, avoiding one extra access to
int ret{};
int ret_value{-1};
int n{};
while (ifs >> n) {
if (auto current_value = ++counts[n]; current_value > ret_value) {
ret = n;
ret_value = current_value;
}
}
Code execution runtime: 29.587966 milliseconds.
Machine details: AMD Ryzen 7 5700G, 16 processors, 3557.512 MHz.
Anything I've learnt:
That
steady_clockis better thansystem_clock.That
duration_castwould return0if the elapsed time is less than a second and you don't template it on aduration<double>.
- 586
- 1
- 5
- 15
Optimal solution
Here is the best result I could achieve:
#include <iostream>
#include <fstream>
using namespace std;
int fast_atoi( const char * str )
{
int val = 0;
while( *str ) {
val = val*10 + (*str++ - '0');
}
return val;
}
int main() {
ifstream input_stream("1M_random_numbers.txt", ios_base::in);
string line;
int number;
int numbers[1000] = { 0 };
int max_occurence = 0;
int max_number;
while (input_stream >> line) {
number = fast_atoi(line.c_str());
numbers[number]++;
if (numbers[number] > max_occurence){
max_occurence = numbers[number];
max_number = number;
}
}
cout << max_number << std::endl;
return 0;
}
I simply convert each string to an integer, increment its occurence in a list and attribute on the fly the most frequent number. The most interesting part is the fast conversion from char to int which is achieved by fast_atoi (see https://stackoverflow.com/a/16826908/14027775). This is improving the execution time by a modest 5-10 %.
Alternate solutions
I tried to use maps or Python dictionnary thinking that the conversion to integer might slow things down too much but this was not the case at all.
Optimal solution without fast conversion
#include <iostream>
#include <fstream>
using namespace std;
int fast_atoi( const char * str )
{
int val = 0;
while( *str ) {
val = val*10 + (*str++ - '0');
}
return val;
}
int main() {
ifstream input_stream("1M_random_numbers.txt", ios_base::in);
string line;
int number;
int numbers[1000] = { 0 };
int max_occurence = 0;
int max_number;
while (input_stream >> number) {
numbers[number]++;
if (numbers[number] > max_occurence){
max_occurence = numbers[number];
max_number = number;
}
}
cout << max_number << std::endl;
return 0;
}
maps
#include <iostream>
#include <fstream>
#include <string>
#include <unordered_map>
using namespace std;
int main() {
ifstream input_stream("1M_random_numbers.txt", ios_base::in);
string line;
std::unordered_map<string, int> occurences;
int max_occurence = 0;
string max_number;
while (getline(input_stream, line)) {
occurences[line]++;
if (occurences[line] > max_occurence){
max_occurence = occurences[line];
max_number = line;
}
}
cout << max_number << std::endl;
return 0;
}
Python dictionnary
#!/usr/bin/env python3
number_occurences = {}
max_occurences = 0
max_number = None
with open("1M_random_numbers.txt", 'r') as f:
for number in f:
if number in number_occurences:
number_occurences[number] += 1
else:
number_occurences[number] = 1
if number_occurences[number] > max_occurences:
max_occurences = number_occurences[number]
max_number = number
print(max_number.strip())
Run times
Each command was run 100 times on a Ubuntu 24.04.3 LTS machine with i7-14700 processor.
Optimal solution: 18 ms on average
Command being timed: "bash -c for ((i=0;i<100;i++)); do ./count_integers_int &> /dev/null; done"
User time (seconds): 1.66
System time (seconds): 0.08
Percent of CPU this job got: 96%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:01.82
Optimal solution without fast conversion: 20 ms on average
Command being timed: "bash -c for ((i=0;i<100;i++)); do ./count_integers_int &> /dev/null; done"
User time (seconds): 1.83
System time (seconds): 0.09
Percent of CPU this job got: 96%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:01.99
maps: 91 ms on average
Command being timed: "bash -c for ((i=0;i<100;i++)); do ./count_integers &> /dev/null; done"
User time (seconds): 9.00
System time (seconds): 0.13
Percent of CPU this job got: 99%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:09.15
Python dictionnary: 120 ms on average
Command being timed: "bash -c for ((i=0;i<100;i++)); do ./count_integers.py &> /dev/null; done"
User time (seconds): 11.82
System time (seconds): 0.35
Percent of CPU this job got: 99%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:12.24
- 676
- 1
- 7
- 20
Using this typescript function, assuming numbers are from 0 to 999, and there is only one number which appear the most without draws (it is not said in the challenge):
function findMostPopularNumber(): number {
let maxNumOccurrences = 0;
let numberMaxOccurrences = -1;
//This method load the list of random numbers from the file
const list: Array<number> = loadListFromFile();
const occurrences: Array<number> = new Array(1000).fill(0);
list.forEach(num => {
occurrences[num] = occurrences[num] + 1;
if (occurrences[num] > maxNumOccurrences) {
maxNumOccurrences = occurrences[num];
numberMaxOccurrences = num;
}
});
return numberMaxOccurrences;
}
I use an array to save the number of occurrences of each number. At any moment a number surpass the saved value of the maximum occurrences, I update the value of the max occurrences founded and the number which appears the most.
This has a cost of O(n), (being n the number of numbers in the loaded list), the minimum to get the number which appears the most. Then, we only need to use a NASA super-computer and we can get the less execution time possible ;)
- 5.2k
- 145
- 35
- 41
My solution using MatLab accumarray
The basic idea is to use that function with:
- The input random numbers dataset as
indparameter - An array of
1of the same length of the input data set as thedataparameter
Since accumarray does not accept 0andnegativevalue asind` parameters a pre-processing of the input data set is required:
- the
0are replaced withthe maximum input value + 1 - the
negativevalues are replaced withtheir absolute value + 3
These value can be easily identified within the results and their original value can be then restored
Here the code:
Script to call the function
%
% Load the input
% The input random numbers will be used as first parameter for ACCUMARRAY
%
rand_data_set=load('1M_random_numbers.txt');
%
% Enable the profiler
profile on
%
% Call count_rand_occurr to search to find the number that appears the most
%
[str,vals]=count_rand_occurr(rand_data_set);
% Get the profile results
profile viewer
str
vals
Function count_rand_occurr
function [str,vals]=count_rand_occurr(rand_data_set)
%
% Assess the number of values
%
n_rand=numel(rand_data_set);
%
% Identfy the maximum random numner
%
the_max=max(rand_data_set);
% Add 1 to the random values equal to 0
% This because the first input SUBS must contain positive integer subscripts
rand_data_set(rand_data_set==0)=the_max+1;
%
% Enable the following line to test for negative numbers and for multiple
% max occurrence
%rand_data_set(1:1130)=-3;
%
% Identify the index of the random number < 0 (if any)
%
the_neg=rand_data_set<0;
%
% Replace the negative values with its absolute value
% This because the first input SUBS must contain positive integer subscripts
% Then add the max value + 3 to distinguish them from the values altered
% in the previous step
%
rand_data_set(the_neg)=abs(rand_data_set(the_neg))+the_max+3;
%
% Create the second input for ACCUMARRAY as an array of 1
%
data=ones(n_rand,1);
%
% Call ACCUMARRAY
B = accumarray(rand_data_set,data)';
%
% Get the MAX calculated by ACCUMARRAY
% "how_many_times" is the maximun number of repetition of one or more
% random number in the input data set
%
most_times=max(B);
%
% The indices of the elements of B equals to "most_times" aer the valuers
% of the random number with the most repetitions
%
vals=find(B==most_times);
%
% Format the output"
%
str='the values=';
for i=1:numel(vals)
if(vals(i)) > the_max+3
vals(i)=(vals(i)-the_max-3)*-1;
elseif(vals(i)) == the_max+1
vals(i)=vals(i)-the_max-1;
end
str=sprintf('%s %d',str,vals(i));
end
str=sprintf('%s\nappear = %d times',str,most_times);
Results
The values= 142 appears = 1130 times
Profile
Profile Summary (Total time: 0.017 s)
Code:
#include <random>
#include <iostream>
#include <chrono>
#include <array>
#include <fstream>
std::vector<int> getNumbers(int argc, char** argv)
{
if (argc == 1)
{
int totalNumbers;
std::cout << "Enter the total number of random integers to generate: ";
std::cin >> totalNumbers;
std::mt19937_64 rng(std::chrono::high_resolution_clock::now().time_since_epoch().count());
std::uniform_int_distribution<int> dist(0, 999);
std::vector<int> numbers(totalNumbers);
for (int i = 0; i < totalNumbers; ++i) {
numbers[i] = dist(rng);
}
return numbers;
}
else if (argc == 2)
{
std::ifstream inputFile(argv[1]);
if (!inputFile.is_open()) {
std::cout << "Failed to open the file: " << argv[0] << std::endl;
std::abort();
}
std::vector<int> numbers;
int value;
while (inputFile >> value) {
numbers.push_back(value);
}
inputFile.close();
return numbers;
}
else
{
std::cout << "Invalid number of arguments." << std::endl;
std::abort();
}
}
int main(int argc, char** argv)
{
std::vector<int> numbers = getNumbers(argc, argv);
std::array<int, 1000> counts = { 0 };
int maxCount = 0;
auto start_time = std::chrono::high_resolution_clock::now();
for (size_t i = 0; i < numbers.size(); ++i) {
counts[numbers[i]]++;
maxCount = std::max(maxCount, counts[numbers[i]]);
}
auto end_time = std::chrono::high_resolution_clock::now();
auto elapsed = std::chrono::duration_cast<std::chrono::microseconds>(end_time - start_time);
std::cout << "The number(s) that appeared the most is(are): ";
for (int i = 0; i < 1000; i++) {
if (counts[i] == maxCount) {
std::cout << i << " ";
}
}
std::cout << " with a count of: " << maxCount << std::endl;
std::cout << "Time spent on counting: " << elapsed.count()/1e6 << " seconds" << std::endl;
return 0;
}
Explanation:
The program can be run in 2 ways:
Pass the input text file of integers.
Just pass the number of integers you would want to generate.
In the 1st case, it would read the text file and create a vector of numbers. In the second case, it would call C++ built in function to randomly generate given number of integers.
Once it has a vector of integers then it will create an empty array named counts of size 1000, each index is initialized with 0.
Why 1000? - Because the range of integers can only be 0 to 999.
It will treat counts array to keep the count of each integer. Once it processes all the integers, it will have maxCount.
Then it will iterate on the counts array and which index has a count equal to maxCount , it will print those.
Execution Time and Machine Details:
100_random_numbers.txt
The number(s) that appeared the most is(are): 188 208 374 546 641 694 with a count of: 2
Time spent on counting: 0 microseconds
10000_random_numbers.txt
The number(s) that appeared the most is(are): 284 with a count of: 23
Time spent on counting: 3e-06 seconds
1M_random_numbers.txt
The number(s) that appeared the most is(are): 142 with a count of: 1130
Time spent on counting: 0.000409 seconds
Machine Details:
Processor: 13th Gen Intel(R) Core(TM) i9-13900K, 3000 Mhz, 24 Core(s), 32 Logical Processor(s)
Installed Physical Memory (RAM) 64.0 GB
Compiler Details:
MSVC 19.44.35217 for x64
- 748
- 6
- 14
My answer to the challenge
#include <stdio.h>
#include <stdlib.h>
#define NUMBERS_RANGE_END 1000
/*
Given a list of random integer numbers between 0 and 999 (=NUMBERS_RANGE_END-1),
finds the (tied) number(s) that appears the most.
- Parameters:
[char array string] filepath - Path of the text file containing the list of integer numbers
- Returns:
[dynamically allocated int array] - Negative one (-1) terminated array of (tied) most common integer numbers
*/
int *find_most_common_integer_numbers(const char *filepath){
int *counters = calloc(NUMBERS_RANGE_END, sizeof *counters); // Counters for each number
if (!counters) exit(EXIT_FAILURE);
int biggest_counter = 0; // Biggest counter
int number = 0; // Current number
// Count number of times each number appears in the list and find the biggest counter:
FILE *f = fopen(filepath, "r"); // Open list of 1 million random integer numbers
if (!f) exit(EXIT_FAILURE);
while (fscanf(f, "%d", &number) == 1) { // For each number in the list:
counters[number]++; // Increment the number's counter;
if (counters[number] > biggest_counter) { // If the counter of the current number is bigger
biggest_counter = counters[number]; // store it as the biggest counter.
}
}
fclose(f);
// List all the (tied) most common integer numbers:
int *most_common = malloc((NUMBERS_RANGE_END + 1) * sizeof *most_common); // Most common integer number(s)
if (!most_common) exit(EXIT_FAILURE);
int i = 0;
for (number = 0; number < NUMBERS_RANGE_END; number++) { // For all numbers in the range:
if (counters[number] == biggest_counter){ // If the number's counter equals the biggest counter
most_common[i] = number; // add the number to the list.
i++;
}
}
most_common[i] = -1; // Indicates the end of the list of (tied) most common integer numbers
free(counters);
return most_common;
}
How it works
My solution is very simple and straightforward...
There are 1000 possible distinct integer numbers in the list, going from 0 to 999, so the function uses 1000 counters representing each possible number respectively to count how many times each number appears in the list.
And as it goes though the list of integers it also keeps track of and updates the value of the biggest counter, such that by the end of the list, the value of the biggest counter is known.
Finally, it returns an array containing all the numbers whose counter equals the biggest counter, by going through the list of counters and adding each number with the biggest counter to the array (and adding a -1 at the end to indicate the end the sequence of most common numbers found).
What I did to optimize it
The basic logic of the program has remained unchanged from its inception, however many attempts to make it faster were made, most of which barely improved its performance if at all, and some of which made the code significantly slower.
Here are some of the most notable attempts and their results:
Decrease from 2 assignment operations to 1 assignment each time a bigger counter is found while going though the list - Had a minute improvement in the performance, in the thousands of a second.
Loading the entire files' content to memory, with fread, as a long string, and then parsing it using sscanf (instead of fscanf to read from the file) - Made the execution much slower, by several seconds. (I couldn't conclude why)
Using statically allocated memory for the array of counters, instead of dynamically allocated memory - The execution was consistently slower by a few thousands of a second (contrary to my expectation)
Execution runtime
Testing method
I've utilized two methods to time the execution of the code, mentioned in this stack overflow question: One using the function clock() from the time.h standard library, and another using the function get_time() which is system dependent, but has versions for Windows and Linux.
The testing code executes the function 1000 times (it's possible to change it by altering the BENCHMARKS macro), and calculates the average, maximum and minimum times.
And here are the respective testing codes:
clock()
#include <math.h>
#include <time.h>
#define BENCHMARKS 1000
int main() {
double total_time = 0.0;
double max_time = 0.0;
double min_time = INFINITY;
double elapsed_time = 0.0;
printf("Bechmarking %d times...\n", BENCHMARKS);
FILE *output = fopen("output.txt", "w");
for (int i = 0; i < BENCHMARKS; i++) {
clock_t start_time = clock(); //Start time
int *most_common = find_most_common_integer_numbers("1M_random_numbers.txt");
elapsed_time = ((double)(clock() - start_time)) / CLOCKS_PER_SEC; // Elapsed time
total_time += elapsed_time;
if (elapsed_time > max_time) max_time = elapsed_time;
if (elapsed_time < min_time) min_time = elapsed_time;
printf("%5d -> The most common integer number(s) in the list: %d", i+1, most_common[0]);
for (int j = 1; most_common[j] > 0; j++) {
printf(", %d", most_common[j]);
}
printf("\n");
free(most_common);
}
fclose(output);
double average_time = total_time / BENCHMARKS;
printf("\nMaximum time: %f seconds\n", max_time);
printf("Average time: %f seconds\n", average_time);
printf("Minimum time: %f seconds\n", min_time);
return EXIT_SUCCESS;
}
get_time()
#include <math.h>
#ifdef WIN32
#include <windows.h>
double get_time()
{
LARGE_INTEGER t, f;
QueryPerformanceCounter(&t);
QueryPerformanceFrequency(&f);
return (double)t.QuadPart/(double)f.QuadPart;
}
#else
#include <sys/time.h>
#include <sys/resource.h>
double get_time()
{
struct timeval t;
struct timezone tzp;
gettimeofday(&t, &tzp);
return t.tv_sec + t.tv_usec*1e-6;
}
#endif
#define BENCHMARKS 1000
int main() {
double total_time = 0.0;
double max_time = 0.0;
double min_time = INFINITY;
double elapsed_time = 0.0;
printf("Bechmarking %d times...\n", BENCHMARKS);
FILE *output = fopen("output.txt", "w");
for (int i = 0; i < BENCHMARKS; i++) {
double start_time = get_time(); // Start time
int *most_common = find_most_common_integer_numbers("1M_random_numbers.txt");
elapsed_time = get_time() - start_time; // Elapsed time
total_time += elapsed_time;
if (elapsed_time > max_time) max_time = elapsed_time;
if (elapsed_time < min_time) min_time = elapsed_time;
printf("%5d -> The most common integer number(s) in the list: %d", i+1, most_common[0]);
for (int j = 1; most_common[j] > 0; j++) {
printf(", %d", most_common[j]);
}
printf("\n");
free(most_common);
}
fclose(output);
double average_time = total_time / BENCHMARKS;
printf("\nMaximum time: %f seconds\n", max_time);
printf("Average time: %f seconds\n", average_time);
printf("Minimum time: %f seconds\n", min_time);
return EXIT_SUCCESS;
}
Testing system specs
Processor: AMD Ryzen 7 5700G
RAM: 8 GiB - DDR4 3200 MT/s
GPU: AMD Radeon(TM) Graphics (495.77 MiB) [Integrated]
Storage: 256 GiB NVME SSD
OS: Windows 11 Pro x86_64 - 10.0.26100.6584 (24H2)
Compiler: gcc.exe (Rev8, Built by MSYS2 project) 15.2.0
Runtime results
clock()
Maximum time: 0.100000 seconds
Average time: 0.095776 seconds
Minimum time: 0.094000 seconds
get_time()
Maximum time: 0.109907 seconds
Average time: 0.095393 seconds
Minimum time: 0.093554 seconds
- 354
- 4
- 19
Solution with Java 25, Lock-free via actor-model approach:
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.channels.FileChannel.MapMode;
/**
* Concurrent Processing, Lock-free via actor-model approach
* <p>
* 1. Process concurrently =~ 67ms
* - Interestingly slower than the single thread version
* - Spawning platform threads costs a lot (~20ms) and our dataset (1M) is still relatively small.
* However, if we assume the dataset is arbitrarily large (like 1 billion) then multi-thread processing should outperform.
* - Using virtual threads didn't help, worse in performance ~88ms
* 2. Compile into native (25-graal) =~ 5.8ms (slightly better than the single thread version)
* 3. Added internal timer to exclude startup cost =~ 0.753ms (Impressive! it looks like even if it's natively compiled, there is still a lot of cost to spin up)
*/
public class Solution3 {
static final int THREAD_COUNT = Integer.getInteger("threads",2 * Runtime.getRuntime().availableProcessors());
static final int[] NUMBER_MAP = new int[1000];
static class Actor extends Thread {
// collecting numbers into an array eleminates a lot of operations like auto-boxing, hash calculation, boundary checks, etc.
// mapped one-to-one with indices is possible since our data set is limited [0 - 999] Therefore, this eleminates hash calculation because no clashes possible
final int[] segmentMap = new int[1000];
final ByteBuffer segment;
Actor(ByteBuffer segment) {
this.segment = segment;
}
@Override
public void run() {
byte b;
int pos = 0; // relative to segment
int current = 0; // current number
final int limit = this.segment.limit();
while (pos++ < limit) {
if ((b = this.segment.get()) == '\n') { // read & check each byte
this.segmentMap[current]++; // increment
current = 0; // reset current
continue;
}
current = 10 * current + (b-'0');
}
}
}
static int findSegmentStart(ByteBuffer segment) {
if (segment == null)
return 0;
// read the segment to backwards until find the first '\n'
int pos = segment.limit() - 1;
while (segment.get(pos) != '\n') {
pos--;
}
return pos + 1;
}
static long findSegmentSize(long fileSize, long start, int segmentSize) {
// find a safe ending when segments aren't evenly distributed
if ((start + segmentSize) > fileSize)
return segmentSize - (start + segmentSize - fileSize);
if ((start + segmentSize) > (fileSize - segmentSize))
return fileSize - start;
return segmentSize;
}
public static void main(String[] args) throws Exception {
final long time = System.nanoTime(); // internal benchmark to exclude startup cost
final String inputFile = args[0];
final FileChannel channel;
final long fileSize;
final Actor[] actors = new Actor[THREAD_COUNT];
try (final var file = new RandomAccessFile(inputFile, "r")) {
channel = file.getChannel();
fileSize = channel.size();
final int segmentSize = Math.toIntExact(fileSize / THREAD_COUNT); // each segment must be lower than Integer.MAX_VALUE
long start = 0;
MappedByteBuffer prev = null;
for (int i = 0; i < THREAD_COUNT; i++) {
start += findSegmentStart(prev); // update the next start pos
final long size = findSegmentSize(fileSize, start, segmentSize);
final MappedByteBuffer segment = channel.map(MapMode.READ_ONLY, start, size);
final var actor = (actors[i] = new Actor(segment));
actor.start(); // run the actor
prev = segment; // keep the segment to calculate other's start index
}
}
for (Actor actor : actors) {
actor.join(); // wait all threads to complete
}
int found = 0;
int maxOccurance = 0;
// merge partial results into the global and find the max occured number
for (int i = 0; i < NUMBER_MAP.length; i++) {
for (int j = 0; j < THREAD_COUNT; j++) {
final var actor = actors[j];
final var sum = (NUMBER_MAP[i] += actor.segmentMap[i]);
if (sum > maxOccurance) {
maxOccurance = sum;
found = i;
}
}
}
// print result
final long took = (System.nanoTime() - time) / 1000;
System.out.println("Found " + found + ", max: " + maxOccurance + ", took: " + took + "µs");
}
}
The answer is for 1M record set:
Found 142, max: 1130
Here is how I came up with the final solution, the timing is measured against 1M record set:
- Single-thread naive solution with
MappedByteBufferusing built-inHashMap~= 81ms - Change
HashMapby a custom integer array ~= 52ms - Process in parallel via actor-model, no synchronization and locks ~= 67ms (Interestingly, slower than single-thread approach) Each thread uses its own number array, hotspot region is processed in parallel, no locking. Finally, we merge all numbers and sum them into a single array in the main thread. This last part can be ignored since we only have a constant number set [0-999]. So, it's o(n) where n = 1000 (constant)
- I realized JVM initialization and creating platform threads cost ~= 20ms. Possibly, our 1M record set is still relatively small. Therefore, this approach is slower than the single-thread approach with the 1M record set. However, this should outperform with larger record sets (e.g., n > 100M).
- Cut the initialization cost by compiling into native. Hell yeah! Now, this approach takes the lead ~= 5.8ms (compared to Single-thread approach in native, which is 6.9ms)
- Added an internal benchmark to exclude startup cost ~= 0.753ms (Impressive! it looks like even if it's natively compiled, there is still a lot of cost to spin up)
I run the tests on Mac Mini M4 CPU (ARM 10 cores), 16GB ram. The benchmarking is done with hyperfine. Please note that the cost for loading the file (IO cost) and parsing the digits are also included in timings.
BONUS: I run this solution with 1 billion records for fun. It takes under 0.5 seconds! See my detailed comparison and some other possible solutions on Github
UPDATE: I added an internal timer to see the execution time excluding the startup cost:
Found 142, max: 1130, took: 753µs
I hope this contributes to the community. Happy coding!
- 4.4k
- 2
- 19
- 25
Could you add a benchmark internal to the program, starting before the other threads are launched and ending after the tally is complete?
I tried to run my program on Apple Silicon to compare to yours, but the better hardware made it clear that my benchmarking script (or maybe the startup time) is taking a huge amount of my program's runtime, so it's kind of hard to make a good comparison.
Also, it looks like your Github link is broken. Is the repo private?
- 354
- 4
- 19
@jirassimok - Ah, sorry. I forgot to make it public. Thanks for pointing out this. It should be fixed now.
Also, I added the internal timer. The result without startup cost is in microseconds now. There was either the benchmarking script overhead or the initialization cost, or maybe both, not sure. However, internal timer is now 753µs after 10 runs.
- 24.6k
- 16
- 61
- 110
Do not use memory mapping for sequential reads - the file can be read up to two times quicker with NIO read() than map().
- 1.8k
- 2
- 39
- 67
Here is my entry. I tried the good ol' Python to see exactly how it behaves for the quite simple task.
Following is my code:
def most_frequent(list_of_numbers):
counts = [0] * 1000
for n in list_of_numbers:
counts[n] += 1
max_count = -1
max_index = -1
for i, c in enumerate(counts):
if c > max_count:
max_count = c
max_index = i
return max_index, max_count
Explanation: Essentially I create a 0-filled fixed with 1000 positions (0 to 999) and just add one to a given position when found the number in the numbers file. Since the lookup is almost immediate to the position, there is no overhead. The problem then is only find the max count and return the index (the number that appered most).
For the optimization, I tried first a version with lamba like index = max(range(len(numbers)), key=lambda x: numbers[x])` to find the index of my array, but I was surprised that the iteration works better at the end.
Runtime: It took `0.03866124153137207 seconds` in my machine ( Intel Core i7, 64GB RAM, Windows 10, Python 3.12.9) to find the result of the 1M file, wich was "Result: (142, 1130)"
I've learned: For long arrays, apparently lambdas introduce some overhead, what I was not expecting. I didn't try to optimize the I/O part of the code.
Full code:
import time
def read_numbers(filename):
with open(filename, "r") as f:
return [int(line) for line in f]
def most_frequent(list_of_numbers):
counts = [0] * 1000
for n in list_of_numbers:
counts[n] += 1
max_count = -1
max_index = -1
for i, c in enumerate(counts):
if c > max_count:
max_count = c
max_index = i
return max_index, max_count
numbers = read_numbers("1M_random_numbers.txt")
start = time.time()
result = most_frequent(numbers)
end = time.time()
print("Result:", result)
print("Elapsed time:", end - start, "seconds")
- 2.2k
- 1
- 10
- 28
The most repeated 1,000,000 number in list is 142 with the frequency of 1130.
The code on average took 13.55ms on a 1,000 run.
Min duration on the 1000 run was 9.8ms and max duration was 21.3ms.
In below line nums is a 1,000,000 number array list.
const myNumberList = nums;
You can make it so that its a random number by commenting above line and uncommenting this line
// const myNumberList = generateRandomNumberList(numbersToBeGenerated, minNumberToBeGenerated, maxNumberToBeGenerated);
Below is full source code
function generateRandomNumberList(numberOfItems, minNumber, maxNumber) {
var generatedNumberList = [];
for (var i = 0; i < 1000000; i++) {
generatedNumberList.push(Math.floor(Math.random() * (maxNumber - minNumber) + minNumber));
}
return generatedNumberList;
}
function findAvgProcessTime(numberList, numberOfRuns) {
var sumOfDurations = 0;
var minDuration = 0;
var maxDuration = 0;
for (var i = 0; i < numberOfRuns; i++) {
const tempDuration = Number(findMostRepeatedNunbers(numberList).durationMs);
if (i == 0) { minDuration = tempDuration; maxDuration = tempDuration; }
if (minDuration > tempDuration) {
minDuration = tempDuration;
}
if (maxDuration < tempDuration) {
maxDuration = tempDuration;
}
sumOfDurations += tempDuration;
}
return { avgMs: (sumOfDurations / numberOfRuns).toFixed(6), minTime: minDuration, maxTime: maxDuration };
}
function findMostRepeatedNunbers(numberList) {
var result =
{
startTime: 0,
endTime: 0,
durationMs: 0,
mostRepeatedNumbers: [],
highestRepeatRequency: 0
};
result.startTime = performance.now();
// counts will be used as dictionary that can be used to retrive count of each number
// for example [0: 5, 1: 2, 3, 21, 4, 1] when you use counts[0] it means number 0 has been repeated 5 times in the list of nums
var counts = Object.create(null);
// Loop through all numbers in nums list
for (const n of numberList) {
// c will contains frequncy of number if the number is in counts dictionary or or 0 if the number has not been repeated yet
// then c will be added by one
const c = (counts[n] = (counts[n] || 0) + 1);
// if c is bigger than highest repeated frequency then swithc maxCount with c and then set maxKeys as the number that has been repeated c times
if (c > result.highestRepeatRequency) {
result.highestRepeatRequency = c;
result.mostRepeatedNumbers = [Number(n)];
} else if (c === result.highestRepeatRequency) { // if c has same value as highest frequency then add number to maxKeys as this number also now the most repeatednumber
result.mostRepeatedNumbers.push(Number(n));
}
}
result.endTime = performance.now();
result.durationMs = (result.endTime - result.startTime).toFixed(6);
return result;
}
const numbersToBeGenerated = 1000000;
const minNumberToBeGenerated = 0;
const maxNumberToBeGenerated = 999;
// const myNumberList = generateRandomNumberList(numbersToBeGenerated, minNumberToBeGenerated, maxNumberToBeGenerated);
const myNumberList = nums;
const result = findMostRepeatedNunbers(myNumberList);
const numberOfRuns = 1000;
const avgPricessTimeMs = findAvgProcessTime(myNumberList, numberOfRuns);
console.log("Most frequent number(s):", result.mostRepeatedNumbers, "with count:", result.highestRepeatRequency);
console.log("Min process time:", avgPricessTimeMs.minTime, "ms");
console.log("Max process time:", avgPricessTimeMs.maxTime, "ms");
console.log('Average process time:', avgPricessTimeMs.avgMs, "ms", " with ", numberOfRuns, " of runs");
console.log("Number of numbers in the list:", myNumberList.length);
- 4.7k
- 1
- 18
- 41
Without checking if the input array actually has 1 million elements and if they are actually integers between 0 and 999, the fastest native code in VBA is probably the following:
Public Function FindMostFrequentInt(ByRef integers() As Long) As Long
Dim i As Long
Dim j As Long
Dim arrCount(0 To 999) As Long
Dim maxCount As Long
Dim mostFrequent As Long
'
For i = LBound(integers) To UBound(integers)
j = integers(i)
arrCount(j) = arrCount(j) + 1
Next i
For i = LBound(arrCount) To UBound(arrCount)
If arrCount(i) > maxCount Then
maxCount = arrCount(i)
mostFrequent = i
End If
Next i
FindMostFrequentInt = mostFrequent
End Function
The code above basically uses each input integer as an index into an array that stores the a count. E.g. for integer 3 we index into arrCount(3) and we increase the count by one. Once all integers are counted, we simply traverse the count array and find the maximum count.
For a million integers, the above only takes about 13 milliseconds on a Win11, 13th Ge Intel(R) Core(TM) i7-13800H with 32GM of RAM.
Quick test:
Sub TestSpeed()
Const size As Long = 1000000
Dim integers() As Long
Dim i As Long
Dim c As Currency
'
ReDim integers(0 To size - 1)
For i = 0 To size - 1
integers(i) = Int(Rnd() * 1000)
Next i
c = AccurateTimerMs
Debug.Print "Most frequent: " & FindMostFrequentInt(integers)
Debug.Print "Milliseconds: " & Format$(AccurateTimerMs - c, "#,##0")
End Sub
where the AccurateTimerMs is part of the excellent VBA-AccurateTimer module.
- 2.1k
- 6
- 42
- 54
#include<stdio.h>
#include<stdlib.h>
void count_ints(const char* file_name) {
FILE* file = fopen(file_name, "r");
int arr[1000000];
int n = sizeof(arr) / sizeof(arr[0]);
int c = 0;
while(!feof(file)) {
fscanf(file, "%d", &arr[c]);
c++;
}
// Hash table
int hash[1000] = {0};
int lv = 0, lvi = 0;
for (int j=0; j<n; j++) {
hash[arr[j]]++;
}
for (int i=0; i < 1000; i++) {
if (lv <= hash[i]) {
lv = hash[i];
lvi = i;
}
}
printf("%d occurs %d times\n", lvi, lv);
fclose(file);
}
int main() {
count_ints("/home/russellb/Development/c_devel/play/fcountr/1M.txt");
return 0;
Approach
1. Read the input file
2. Create hashtable
3. Find the maximum from the hash tableInitial approach was to use binary search. Later I learnt hash tables can be used for this problem and adopted it.
Result 142 occurs 1130 times
**Execution time**
real 0m00.11s
user 0m00.10s
sys 0m00.00s
Machine details:
CPU: Intel i5-3230M (4 cores)
OS: GNU/Linux
RAM: 8GM DDR3
}
Approach
Read in the file
Create hashmap of counts
Find the most occuringg value
CPU: i5-3235M
RAM: 8GB DDR3
OS: GNU/Linux
Execution times
\> time ./countr_ic
142 occurs 1130 times
real 0m00.10s
user 0m00.10s
sys 0m00.00s
Max finding is not optimized and working on it.
- 57
- 7
Hi there:
I am a rookie programmer trying to improve my code every day. Here is my proposal for this challenge.
after reading the conditions of this challenge and spend some time writing a code with a different approaching, like generate my own random list I think now I took the right path. I have learned how to open *.txt files for reading. Also, I learned about how to count occurrences and what datatypes or what counting methods is faster for this purpose. Here I am leaving a small comparison table with the time spend for ten times tries on each datatype (tuple and list):
TUPLE(): LIST[]: DIF: DATATYPE
1 0.1231167316436760 0.1315355300903320 -0.0084187984466560 TUPLE
2 0.1420800685882560 0.1369962692260740 0.0050837993621820 LIST
3 0.1343727111816400 0.1329193115234370 0.0014533996582030 LIST
4 0.1137866973876950 0.1245462894439690 -0.0107595920562740 TUPLE
5 0.1202738285064690 0.1235520839691160 -0.0032782554626470 TUPLE
6 0.1204180717468260 0.1273376941680900 -0.0069196224212640 TUPLE
7 0.1213290691375730 0.1169397830963130 0.0043892860412600 LIST
8 0.1230452060699460 0.1204888820648190 0.0025563240051270 LIST
9 0.1179533004760740 0.1396424770355220 -0.0216891765594480 TUPLE
10 0.1211564540863030 0.1248850822448730 -0.0037286281585700 TUPLE
0.1237532138824460 0.1278843402862550
-3.2% TUPLE 6
LIST 4
-33.3%
In a summary: the Tuple's time was in average -3.2 faster than of a list's time, and when compare how many times was one faster than the other, the Tuple was 33% faster than the list.
Here is my code:
#Create a Tuple
numbers = ()
#working with the file. Open the file and read the content
with open(file_path, 'r') as file:
#start the timer
st_time = time()
#instantiate the list with numbers from the file
numbers = [num for num in file.read().strip().split()]
#Count the occurrences of each number
contador = Counter(numbers)
#Get the most common element
most_common_elements = contador.most_common(1)
#Format the output
formatted = ', '.join(f"{key} = {value}" for key, value in most_common_elements)
#Calculate the time taken
time1 = time() - st_time
#Print the results
print("Most repeated #: ", formatted, " #Items: ", len(contador), "Time spend: ", time1, end='\n')
If you want you to use this code with a List, just change numbers = () by numbers = [] (however, I know that know that)
My laptop is:
13th Gen Intel(R) Core(TM) i7-1355U (1.70 GHz) 16 GB Ram Windows 11 Home
Regards;
- 57
- 7
I missed to add this info:
Most repeated #: 142 = 1130 #Items: 1000 Time spend: 0.12488508224487305
- 57
- 7
Code more clean
from collections import Counter
import os
from time import time
# Clear terminal
os.system('cls' if os.name == 'nt' else 'clear')
# Open the file and split the line into numbers
file_path = "C:/Users/sendo/OneDrive/Python Training/Scripts/1M_random_numbers.txt"
#Create a Tuple
numbers = ()
#working with the file. Open the file and read the content
with open(file_path, 'r') as file:
#start the timer
st_time = time()
#instantiate the list with numbers from the file
numbers = [num for num in file.read().strip().split()]
#Count the occurrences of each number
contador = Counter(numbers)
#Get the most common element
most_common_elements = contador.most_common(1)
#Format the output
formatted = ', '.join(f"{key} = {value}" for key, value in most_common_elements)
#Calculate the time taken
time1 = time() - st_time
#Print the results
print("Most repeated #: ", formatted, " #Items: ", len(contador), "Time spend: ", time1, end='\n')
- 362
- 3
- 15
My results are
Most common of 100 random numbers: 546, took 0.0004891000007773982 s
Most common of 10000 random numbers: 284, took 0.001788400000805268 s
Most common of 1M random numbers: 142, took 0.1768207999994047 s
My machine is an asus computer, with a processor: 11th Gen Intel(R) Core(TM) i5-11400H @ 2.70GHz (2.69 GHz) and 16 GB of RAM
My approach is simply using the Counter built-in class in Python. I figured it would be already optimized.
My code is available on github at https://github.com/genevieve-le-houx/SO_challenge_6_integer_counting
My code is :
import timeit
from collections import Counter
from pathlib import Path
from typing import List
def read_numbers(filepath: Path) -> List[int]:
list_numbers = []
with open(filepath, "r", newline="\n") as f:
for line in f:
list_numbers.append(int(line))
return list_numbers
def count_numbers(list_numbers: List[int]) -> int:
c = Counter(list_numbers)
return c.most_common(1)[0][0]
def find_most_common_from_file(filepath: Path) -> int:
list_numbers = read_numbers(filepath)
return count_numbers(list_numbers)
def main():
most_common_100 = find_most_common_from_file(Path("100_random_numbers.txt"))
most_common_10000 = find_most_common_from_file(Path("10000_random_numbers.txt"))
most_common_1M = find_most_common_from_file(Path("1M_random_numbers.txt"))
time_100 = timeit.timeit(lambda: find_most_common_from_file(Path("100_random_numbers.txt")), number=1)
time_10000 = timeit.timeit(lambda: find_most_common_from_file(Path("10000_random_numbers.txt")), number=1)
time_1M = timeit.timeit(lambda: find_most_common_from_file(Path("1M_random_numbers.txt")), number=1)
print(f"Most common of 100 random numbers: {most_common_100}, took {time_100} s")
print(f"Most common of 10000 random numbers: {most_common_10000}, took {time_10000} s")
print(f"Most common of 1M random numbers: {most_common_1M}, took {time_1M} s")
if __name__ == '__main__':
main()
This was an interesting challenge. I tried to manually implement a counter by iterating over each number and keep track of the count in a dictionnary, but figured a built-in class would be faster.
This is my Haskell submission. It will not be the fastest here, as my parallel implementation in C++ was ~4 times faster. But it was instructive, since my first Haskell try was ~20 times slower than C++. What I learned:
Use
Data.ByteString.Char8instead of the naiveread. I expected reading the file to be the most problematic, and it still is the slowest part. I just can't get ahead with optimizing it any more.Used an unboxed vector to accumulate the counts. It gave a little speedup. Maybe I can get more with mutable vectors?
Compiling with -O2 had some effect, but not a big one.
My first time using the GHC profiler.
Using ghc-9.6.6, vector-0.13
CPU: i7-1260P
Time: ~0.08 sec (avg. over 10 samples)
{-#LANGUAGE TupleSections #-}
module Main (main) where
import Data.Maybe (fromJust)
import Data.List (unfoldr)
import Data.Char (isDigit)
import qualified Data.ByteString.Char8 as B
import qualified Data.Vector.Unboxed as V
-- Functions are broken out for a more granular profiler output
counts :: [Int] -> V.Vector Int
counts lst = V.unsafeAccum (+) (V.replicate 1000 0) (map (,1) lst)
getCounts :: IO (V.Vector Int)
getCounts = do
numStrs <- B.readFile "data/1M_random_numbers.txt"
let nums = unfoldr (B.readInt . B.dropWhile (not . isDigit)) numStrs
return $ counts nums
main :: IO ()
main = do
cnt <- getCounts
let maxOccurrence = V.foldr max 0 cnt
print $ fromJust (V.findIndex (== maxOccurrence) cnt)
For comparison, a naive C++ version without parallelization, AVX, or any bells and whistles (compiled with GCC, using C++23 standard):
Time: ~0.024 sec
#include <fstream>
#include <string>
#include <algorithm>
#include <print>
#include <cstdlib>
int main() {
std::ifstream numStrs("../haskell/intcount/data/1M_random_numbers.txt");
if (!numStrs.is_open()) {
std::println("File open failed");
return EXIT_FAILURE;
}
// Just plunk it on the stack, fastest for small vectors like this
int accum[1000];
std::fill(accum, accum + 1000, 0);
std::string line;
while (std::getline(numStrs, line)) {
int num = std::atoi(line.data());
accum[num]++;
}
int* maxOccurrence = std::max_element(accum, accum + 1000);
std::println("Mode: {}", (int)(maxOccurrence - accum));
return EXIT_SUCCESS;
}
Code Execution Runtime
- 0.0009 second or 0.9 millisecond or 900-1100 microseconds
Output:
highest occuring number is = 142
highest count = 1130
Execution time in seconds: 0.0009 seconds
Execution time in milliseconds: 0.9138 milliseconds
Execution time in microseconds: 913 microseconds
Code:
#include <iostream>
#include <fstream>
#include <string>
#include <sstream>
#include <chrono>
#include <omp.h>
#include <cstdint>
#include <vector>
#include <iomanip>
using namespace std;
const string FILE_NAME = "1M_random_numbers.txt";
const int NUMBERS_LENGTH = 1000000;
void readFileIntoArray(string name, int* arr)
{
ifstream file(FILE_NAME);
if (!file)
{
cerr << "Error opening file!" << endl;
return;
}
stringstream ss;
ss << file.rdbuf();
int count = 0;
string line;
// Now parse from stringstream like it’s a file
while (getline(ss, line) && count < NUMBERS_LENGTH)
{
arr[count++] = stoi(line);
}
}
int main()
{
const int THREADS = 4;
int* numbers = new int[NUMBERS_LENGTH] { 0 };
readFileIntoArray(FILE_NAME, numbers);
// recording start time
auto start = chrono::high_resolution_clock::now();
// constraint from question
const int maxNumber = 999;
const int RANGE = maxNumber + 1;
// used as commulative count
int globalCount[RANGE] = { 0 };
// static 2 dim array to be used by threads, so each thread counts separate
static int threadLocals[THREADS][RANGE] = { 0 };
// using openMP for parallel execution using threads
#pragma omp parallel num_threads(THREADS)
{
int tid = omp_get_thread_num();
// get a pointer to the thread's respective count array
int* local = threadLocals[tid];
#pragma omp for
for (int i = 0; i < NUMBERS_LENGTH; i++) {
int num = numbers[i];
local[num]++;
}
}
// merge the counts from every thread's local counts
for (int i = 0; i < THREADS; i++) {
for (int j = 0; j < RANGE; j++) {
globalCount[j] += threadLocals[i][j];
}
}
int highestCount = 0;
int highestOccuringNumber = 0;
// check which number has the highest count in global count array
for (int i = 0; i < RANGE; i++)
{
if (globalCount[i] > highestCount) {
highestCount = globalCount[i];
highestOccuringNumber = i;
}
}
auto end = chrono::high_resolution_clock::now();
auto durationMicro = chrono::duration_cast<chrono::microseconds>(end - start);
auto durationMilli = chrono::duration<double, milli>(end - start);
auto durationSeconds = chrono::duration<double>(end - start);
cout << "highest occuring number is = " << highestOccuringNumber << endl;
cout << "highest count = " << highestCount << endl;
cout << fixed << setprecision(4) << "Execution time in seconds: " << durationSeconds.count() << " seconds" << endl;
cout << fixed << setprecision(4) << "Execution time in milliseconds: " << durationMilli.count() << " milliseconds" << endl;
cout << "Execution time in microseconds: " << durationMicro.count() << " microseconds" << endl;
}
Explanation:
- Count Sort Strategy
I used count sort strategy for finding out the highest occuring number as the constraint suggests that numbers can only be between 0-999, which makes it perfect case for count sort as count sort gives best performance when the range of numbers is significantly less than total numbers that are 1M in this case.
I first used linear execution and it gave me 2000-2100 microseconds (2 milliseconds) execution time. Then I added parrallel execution with the help of OpenMP in C++. Running with 4 threads in parallel gave me 900-1100 microseconds (1 millisecond) execution times, meaning I cut the runtime by 50% by applying parallel execution. We can increase threads based on the quality of CPU but 4 threads seems like a reasonable amount as most of the current CPUs can run 4 threads in parallel easily.
- Why I didn't use HashMap
Array pointers give constant O(1) access to the indices and since, the range is just 0-999, array consumes way less memory than a hashmap. If the range was way huge like 0-1B or range wasn't defined, then using HashMap would have been a wiser choice.
Details about my machine
- CPU: Intel Core i5 9600KF
- RAM: DDR4-3200 24GB
- GPU: GIGABYE GeForce GTX 1080
- Motherboard: GIGABYTE Z390 M GAMING
What I Learned:
I got to learn and explore parallel programming using OpenMP, I researched about how I can achieve parallel execution and OpenMP makes the work easy for parallel programming.
Really solid implementation, using counting sort here is definitely the optimal move given the small fixed range. The decision to parallelize the counting with OpenMP was a nice touch too, especially with that clean use of per-thread local arrays to avoid race conditions. Cutting runtime in half with just 4 threads is a great example of efficient parallelization without overcomplicating the code. Also appreciate the clarity in your explanation and benchmarking. Well presented all around.
Good approach dividing array and parallelizing counting in multiple threads. The code is simple and results are well presented.
import random
import time
from collections import Counter
\# Generate 1 million random integers between 0 and 999
numbers = \[random.randint(0, 999) for \_ in range(1_000_000)\]
\# Start performance measurement
start_time = time.time()
\# Find the most frequent number using Counter
counter = Counter(numbers)
most_common_num, freq = counter.most_common(1)\[0\]
\# End performance measurement
end_time = time.time()
print(f"Most frequent number: {most_common_num} (appears {freq} times)")
print(f"Execution Time: {end_time - start_time:.4f} seconds")
- 913
- 10
- 36
This simple swift-sh script solves the problem.
Memory is cheap these days, and 1M numbers is not a lot. We load the whole file in memory, iterate the lines and store the number of occurrences of each number in a dictionary. We keep the current key which has the maximum of occurrences found, as well as the current maximum number of occurrences found. For every line of the file we update these variables if needed. When we have finished iterating the lines, we have the number with the maximum number of occurrences.
The dictionary keys are Data directly, not Ints. This allows not parsing the numbers, as we never need the value of the numbers.
Also we instantiate the dictionary with a minimum capacity of 1000 to avoid having to grow it later.
This solution is probably not optimal; I coded that rapidly in vim…
#!/usr/bin/env swift sh
import Foundation
import ArgumentParser /* @apple/swift-argument-parser ~> 1.6 */
import StreamReader /* @Frizlab/stream-reader ~> 3.6 */
_ = await Task{ await Main.main() }.value
struct Main : AsyncParsableCommand {
@Argument
var file: String
func run() async throws {
let fileURL = URL(fileURLWithPath: file)
let fh = try FileHandle(forReadingFrom: fileURL)
let streamReader = FileHandleReader(stream: fh, bufferSize: 50 * 1024 * 1024, bufferSizeIncrement: 1024)
var values = Dictionary<Data, Int>(minimumCapacity: 1000)
var maxKey = Data()
var maxValue = 0
while let (line, _) = try streamReader.readLine() {
let value = (values[line] ?? 0) + 1
values[line] = value
if value > maxValue {
maxValue = value
maxKey = line
}
}
try FileHandle.standardOutput.write(contentsOf: Data("Max occurrences: ") + maxKey + Data("\n".utf8))
}
}
#include <fstream>
#include <iostream>
#include <vector>
#include <string>
#include <chrono>
using namespace std;
//Faster way to convert string to int than using std::stoi
unsigned int string_to_uint(string str){
unsigned int output = 0;
for (char& c : str){
output = output*10 + (c - '0');
}
return output;
}
int main(){
//Get start time
auto start_time = chrono::high_resolution_clock::now();
string filename = "1M_random_numbers.txt";
ifstream inputfile(filename);
//Values range from 0 to 999
const unsigned int NUM_POSSIBLE_VALUES = 1000;
/*Create array where each index corresponds to a possible value in
the text file*/
unsigned int counts[NUM_POSSIBLE_VALUES] = {0};
/*Loop through each line of the file*/
string line;
while (getline(inputfile, line)){
/*Convert string to int to access index of 'counts' and
increase count by 1*/
counts[string_to_uint(line)]++;
}
/*Create vector to keep track of all numbers tied with the highest
count. Initialize to value at index 0, because the count at index
0 will start as the highest until we compare with the next
index.*/
vector<unsigned int> mostCommonNumbers = {0};
unsigned int highestCount = counts[0];
/*Loop through 'counts' array (starting at index 1) to determine
which index has the highest count*/
for (int i=1; i < NUM_POSSIBLE_VALUES; i++){
unsigned int val = counts[i];
if (val == highestCount){
//Tied with highestCount, so add index to vector
mostCommonNumbers.push_back(i);
} else if (val > highestCount){
//New highest count
mostCommonNumbers.clear();
mostCommonNumbers.push_back(i);
highestCount = val;
}
}
cout << "Highest Count = " << highestCount << endl;
cout << "Most common number(s):" << endl;
for (unsigned int element : mostCommonNumbers){
cout << element << endl;
}
inputfile.close();
//Get end time and calculate elapsed time
auto end_time = chrono::high_resolution_clock::now();
auto elapsed_time =
chrono::duration_cast<std::chrono::duration<double>>
(end_time - start_time);
cout<<"Elapsed time: "<<elapsed_time.count()<<" seconds"<< endl;
return 0;
}
Output:
Highest Count = 1130
Most common number(s):
142
Elapsed time: 0.0618517 seconds
Windows 11 Pro (version 24H2)
Processor: Intel(R) Core(TM) i5-10505 CPU @ 3.20GHz (3.19 GHz)
Installed RAM: 16.0 GB (15.7 GB usable)
System type: 64-bit operating system, x64-based processor
Average Execution Time: 62ms
I'm not a very experienced programmer, but came across this challenge and thought it looked fun to try...
My first thought was that it was going to be very slow trying to sort a million entries and keep track of the number of times each value occurs. Then I realized, since the numbers range from 0-999, I could use an array with length 1000, and use each value from the text file as the index of the array (after converting it from a string to an int). I would then just need to increase the value at index 'j' by 1 if 'j' was read from the text file. Finally, I could loop through the whole 1000-length array one single time and see which index had the highest count.
When testing with 100_random_numbers.txt, I noticed that there were a lot of ties, so I created a vector to store multiple numbers that share the highest count. If there was a new highest count, I would clear the vector and add the new index/number.
I noticed that looping though the million lines in the text file and converting the values from strings to integers has the highest potential for wasted time, so I looked into the time-complexity of std::stoi() and found that it could be done quicker with the assumption that all of the strings are positive integers with no letters or white-spacing.
Switching from std::stoi() to string_to_uint() improved the total run-time from 97 to 62ms.
The most important take-away from this challenge for me was that I learned how to convert from a string to an int in a much more efficient way, and I became more familiar with using the ASCII table.
- 12k
- 5
- 53
- 108
You can also parallelize the conversion of strings to integers. Such as reading 4 characters at once, then using SSE4/AVX2 dot-product instruction, and different multipliers per SIMD lane (10, 100, 1000, etc). But this would require padding of each line to 4 characters.
You can even use a lookup table of 1000 strings to integers. But this doesnt work in parallel 4 times per core.
---
Anyway, the challenge doesn't say anything about where to get the sample data. You can simply embed the elements into a static constant array and have zero-latency for accessing the data. I think the benchmarks shouldn't include preparing the data. Otherwise people would use RAMDISK/embedding in source-code to cheat.
I guess someone can simply have 1000 copies of file on 1000 computers and each computer would check only 1 value from 0-999 and find its frequency in 1 microsecond, then copies the data through infiniband with 1 microsecond latency + 10 hops (100 nanoseconds per hop) = 2 microseconds for communication, then a final local reduction in-core, for another microsecond --> 4 microseconds.
- 3.4k
- 2
- 11
- 30
Yeah I agree that preparing the data or even the environment (like moving data to cuda) should not be part of benchmarking. I also feel that the dataset should have been a lot bigger, So that implementing different approaches would have actually helped. With this dataset, most of the optimizations do not justify the overhead they are causing, and making the simplest solution is actually proving the best one most of the time. Also what to benchmark should have been much more clearer in the challenge itself, and I would have preferred if it asked for result over certain number of iterations like average of 1,000/10,000 maybe making certain overheads like thread initializations, moving data to different device etc could have lead to more innovative solutions.
My Submission
Code
from collections import Counter
import random
import time
# For testing purposes with smaller files
def most_frequent_number(filename):
with open(filename, "r") as f:
numbers = [int(line.strip()) for line in f]
counter = Counter(numbers)
number, freq = counter.most_common(1)[0]
return number, freq
# Benchmark with 1 million integers (values 0–999)
if __name__ == "__main__":
# Generate a random dataset of 1 million numbers (0–999)
nums = [random.randint(0, 999) for _ in range(1_000_000)]
start = time.time()
# Counter is implemented in C and very efficient
counter = Counter(nums)
number, freq = counter.most_common(1)[0]
end = time.time()
print(f"Most frequent number: {number} (appears {freq} times)")
print(f"Execution time: {end - start:.4f} seconds")
Explanation of Approach
Since the numbers are bounded between 0 and 999, the maximum number of distinct values is only 1000.
This makes frequency counting extremely efficient — we don’t need complex data structures.
I chose
collections.Counterbecause it’s written in optimized C under the hood and handles counting very quickly.Alternatively, one could use a fixed-size list of length 1000 and increment counts manually, but the performance difference on Python is marginal compared to
Counter(andCounterkeeps the code clean).
Optimization Notes
Reading the file line by line and converting directly to integers avoids unnecessary overhead.
Using
Counter.most_common(1)is faster than manually scanning through the dictionary since it’s optimized internally.I compared
Counterwith a manual list-based frequency array;Counterwas slightly faster in my environment, likely due to its C-level optimizations.
Performance (on my machine)
Machine: Lenovo Ideapad 330, Intel i5 (8th Gen), 8GB RAM, Windows 11, Python 3.11
Dataset: 1,000,000 integers (0–999)
Runtime: ~0.23 seconds (average of 5 runs)
What I Learned
- I initially thought a manual array of size 1000 would easily outperform
Counter. Surprisingly, the difference was negligible because of Python’s overhead andCounter’s C implementation. The main lesson here: sometimes clean, high-level code in Python is just as fast as micro-optimizing in pure Python.
- 7.4k
- 1
- 28
- 36
Here is one simple program in awk which do the work:
awk 'BEGIN {b=0;c=0} {a[$0]+=1; if(a[$0]>c) {b=$0;c=a[$0]}} END {print b,c} '
In "standard" approach I will count in array the occurrences of particular number, then sort and reveal the highest number. But sorting may be complex (in sense of combined memory and processor cycles). So I just check if current value if bigger that stored count and if yes replace it. So complexity of my code is (almost) linear :)
My machine:
Processor Intel(R) Xeon(R) W-2145 CPU @ 3.70GHz 3.70 GHz
Installed RAM 64,0 GB (63,7 GB usable
TIme to exec for 100 samples:
# /usr/bin/time -p awk 'BEGIN {b=0;c=0} {a[$0]+=1; if(a[$0]>c) {b=$0;c=a[$0]}} END {print b,c} ' f
208 2
real 0.03
user 0.00
sys 0.00
TIme to exec for 10000 samples:
# /usr/bin/time -p awk 'BEGIN {b=0;c=0} {a[$0]+=1; if(a[$0]>c) {b=$0;c=a[$0]}} END {print b,c} ' f1
284 23
real 0.04
user 0.01
sys 0.01
Time with 1M samples:
# /usr/bin/time -p awk 'BEGIN {b=0;c=0} {a[$0]+=1; if(a[$0]>c) {b=$0;c=a[$0]}} END {print b,c} ' 1M_random_numbers.txt
142 1130
real 0.89
user 0.85
sys 0.01
I learned a interesting way to count lines/tokens in awk
- 40k
- 6
- 70
- 165
template <std::ranges::input_range R>
requires std::integral<std::ranges::range_value_t<R>>
int findMostCommonValueOf1000(R&& r) {
std::array<unsigned, 1000> hist{};
for (auto x : r) {
++hist[x];
}
return std::distance(hist.begin(), std::ranges::max_element(hist));
}
Since expected range of input values is from 0 to 999 the fastest approach is to use simple array of size 1000 allocated on stack o count each occurrence of specified value. This will avoid cache misses and will reduce branches to minimum.
Disadvantage is that this code is not resistant to invalid data. Any data outside defined range will invoke Undefined Behavior.
Here is live example.
And here is speed comparison of the same algorithm, but with use of std::unordered_map instead std::array.
Comparing different algorithms on different machines is pointless.
- 1.1k
- 4
- 16
- 30
private void BtnSearch_Click(object sender, EventArgs e)
{
string filePath = "D:/Projects/1M_random_numbers.txt";
if (!File.Exists(filePath))
{
MessageBox.Show("File not found!");
return;
}
var stopwatch = Stopwatch.StartNew();
var numberCount = new Dictionary<int, int>();
foreach (var line in File.ReadLines(filePath))
{
if (int.TryParse(line, out int number))
{
if (numberCount.TryGetValue(number, out int count))
{
numberCount[number] = count + 1;
}
else
{
numberCount[number] = 1;
}
}
}
stopwatch.Stop();
LstBox.Items.Clear();
var sortedNumbers = numberCount.OrderByDescending(n => n.Value)
.ToList();
foreach (var number in sortedNumbers)
{
LstBox.Items.Add($"Number: {number.Key}, Count: {number.Value}");
}
LblExecutionTime.Text = $"Execution Time: {stopwatch.ElapsedMilliseconds} ms";
}
private void BtnMostNumber_Click(object sender, EventArgs e)
{
string filePath = "D:/Projects/1M_random_numbers.txt";
if (!File.Exists(filePath))
{
MessageBox.Show("File not found!");
return;
}
var stopwatch = Stopwatch.StartNew();
var numberCount = new Dictionary<int, int>();
foreach (var line in File.ReadLines(filePath))
{
if (int.TryParse(line, out int number))
{
if (numberCount.TryGetValue(number, out int count))
{
numberCount[number] = count + 1;
}
else
{
numberCount[number] = 1;
}
}
}
stopwatch.Stop();
var maxEntry = numberCount.OrderByDescending(n => n.Value).FirstOrDefault();
LstBox.Items.Clear();
LstBox.Items.Add($"Number with highest frequency: {maxEntry.Key}, Count: {maxEntry.Value}");
LblExecutionTime.Text = $"Execution Time: {stopwatch.ElapsedMilliseconds} ms";
}
Approach Overview :
1. File.ReadLines streams the file line-by-line.
2. Dictionary<int, int> to store counts of each number.
3. BtnSearch_Click will show all the numbers with count.
4. BtnMostNumber_Click will find the number that appears the most.
Processor :Intel Core i5-10210U CPU @ 1.60GHz 2.11 GHz
RAM : 16.0 GB 64-bit operating system
Average Execution Time :125ms
int CountWithNum()
{
int count = 0;
int CompareCount = 0;
foreach (int number in numbers)
{
foreach (int v in compareNum)
{
if (number == v) { count++; }
}
if (count > 0)
{
if(count > CompareCount)
{
CompareCount = count;
mostNum = number;
}
}
count = 0;
}
return CompareCount;
}
- 12k
- 5
- 53
- 108
For an FPGA that has 1000 blocks and 1000 comparators(and broadcasters) in parallel per block, this would be the fastest solution. It would be like 1000 data elements per cycle and if chip is 1GHz, it would do 0.001 miliseconds to scan all the data. But running on single thread on cpu would take more than a milisecond. I tried this with cuda but even thousands of cuda cores couldn't make it fast enough because of the number of operations done per input data element (its not 1 because its not fpga). This works fast when there are only 16 unique numbers in dataset and accelerated with AVX512, such as in a collision-detection algorithm where a particle collides maximum 16 other particles at a time.
- 12k
- 5
- 53
- 108
Here is an histogram-based solution, using RTX5070 and CUDA (22 microseconds for CUDA kernels, 160 microseconds for copying from/to RAM and kernels):
// Windows 11, MSVC CUDA Compiler
// Ryzen 7900, RTX4070, RTX5070 (not overclocked) on PCIE v5.0 x16 lanes for high bandwidth (but still 1M elements are not enough to maximize this)
// 32GB RAM dual-channel 6000 MT/s
#define __CUDACC__
#undef NDEBUG
#include <assert.h>
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <cuda.h>
#include <cuda_runtime.h>
// Error-handling assert code from stackoverflow talonmies.
#define gpuErrchk(ans) { gpuAssert((ans), __FILE__, __LINE__); }
inline void gpuAssert(cudaError_t code, const char* file, int line, bool abort = true)
{
if (code != cudaSuccess)
{
fprintf(stderr, "GPUassert: %s %s %d\n", cudaGetErrorString(code), file, line);
if (abort) exit(code);
}
}
// Optimized for 1M input elements
constexpr int N = 1000000;
// Designed to work with 1000 bins
constexpr int HISTOGRAM_BINS = 1000;
// RTX5070 has 48 SM units, each SM can have 1.5k in-flight threads (2 x 768)
constexpr int GRID_SIZE = 48 * 2;
// 768 threads per block
constexpr int BLOCK_SIZE = 768;
// 20 blocks will do level-1 reduction and 1 block will reduce the results of 20 blocks at level-2 reduction
constexpr int GRID_REDUCTION = 20;
// Benchmark iterations
constexpr int NUM_BENCH_ITER = 200;
/*
Parallel Histogram
Optimizations:
Block-privatization for histogram, with 4 private histograms per block to further reduce atomicAdd collisions inside each CUDA block.
Thread-level aggregation
Block-level aggregation
Vectorized memory access
Reduction
Asynchronous memcpy and kernel launch.
*/
template<int n>
__global__ void k_histogram(const int* const __restrict__ input, int* const __restrict__ histogram) {
const int4* const __restrict__ inputVectorized = reinterpret_cast<const int4* const __restrict__>(input);
const int threadIndex = threadIdx.x + blockIdx.x * blockDim.x;
constexpr int n4 = n / 4;
constexpr int NUM_THREADS = GRID_SIZE * BLOCK_SIZE;
constexpr int numSteps = (n4 + NUM_THREADS - 1) / NUM_THREADS;
constexpr int numBlockSteps = (HISTOGRAM_BINS * 4 + BLOCK_SIZE - 1) / BLOCK_SIZE;
__shared__ int s_histogram[HISTOGRAM_BINS * 4];
for (int step = 0; step < numBlockSteps; step++) {
int i = step * BLOCK_SIZE + threadIdx.x;
if (i < HISTOGRAM_BINS * 4) {
s_histogram[i] = 0;
}
}
__syncthreads();
int registerCountCache = 0;
int registerValueCache = -1;
#pragma unroll 4
for (int step = 0; step < numSteps; step++) {
const int i = step * NUM_THREADS + threadIndex;
if (i < n4) {
int4 inp = inputVectorized[i];
if (inp.x == registerValueCache) {
registerCountCache++;
}
else {
atomicAdd(&s_histogram[registerValueCache], registerCountCache);
registerValueCache = inp.x;
registerCountCache = 1;
}
if (inp.y == registerValueCache) {
registerCountCache++;
}
else {
atomicAdd(&s_histogram[registerValueCache + HISTOGRAM_BINS], registerCountCache);
registerValueCache = inp.y;
registerCountCache = 1;
}
if (inp.z == registerValueCache) {
registerCountCache++;
}
else {
atomicAdd(&s_histogram[registerValueCache + HISTOGRAM_BINS * 2], registerCountCache);
registerValueCache = inp.z;
registerCountCache = 1;
}
if (inp.w == registerValueCache) {
registerCountCache++;
}
else {
atomicAdd(&s_histogram[registerValueCache + HISTOGRAM_BINS * 3], registerCountCache);
registerValueCache = inp.w;
registerCountCache = 1;
}
}
}
if (registerCountCache > 0) {
atomicAdd(&s_histogram[registerValueCache], registerCountCache);
}
__syncthreads();
for (int step = 0; step < numBlockSteps; step++) {
int i = step * BLOCK_SIZE + threadIdx.x;
if (i < HISTOGRAM_BINS) {
histogram[i + blockIdx.x * HISTOGRAM_BINS] = s_histogram[i] + s_histogram[i + HISTOGRAM_BINS] + s_histogram[i + HISTOGRAM_BINS * 2] + s_histogram[i + HISTOGRAM_BINS * 3];
}
}
}
template<int NUM_BLOCKS>
__global__ void k_reduceLevel1(int* globalHistogram, int* privateHistogram) {
const int id = threadIdx.x + blockIdx.x * BLOCK_SIZE;
constexpr int numSteps = (GRID_SIZE + NUM_BLOCKS - 1) / NUM_BLOCKS;
constexpr int numBlockSteps = (HISTOGRAM_BINS + BLOCK_SIZE - 1) / BLOCK_SIZE;
__shared__ int s_accumulator[HISTOGRAM_BINS];
for (int i = 0; i < numBlockSteps; i++) {
int b = i * BLOCK_SIZE + threadIdx.x;
if (b < HISTOGRAM_BINS) {
s_accumulator[b] = 0;
}
}
for (int step = 0; step < numSteps; step++) {
const int block = blockIdx.x + step * NUM_BLOCKS;
if (block < GRID_SIZE) {
for (int i = 0; i < numBlockSteps; i++) {
int b = i * BLOCK_SIZE + threadIdx.x;
if (b < HISTOGRAM_BINS) {
s_accumulator[b] += privateHistogram[block * HISTOGRAM_BINS + b];
}
}
}
}
for (int i = 0; i < numBlockSteps; i++) {
int b = i * BLOCK_SIZE + threadIdx.x;
if (b < HISTOGRAM_BINS) {
globalHistogram[blockIdx.x * HISTOGRAM_BINS + b] = s_accumulator[b];
}
}
}
template<int NUM_BLOCKS>
__global__ void k_reduceLevel2(int* globalHistogram, int* output) {
const int id = threadIdx.x;
constexpr int numBlockSteps = (HISTOGRAM_BINS + BLOCK_SIZE - 1) / BLOCK_SIZE;
const int warpLane = id & 31;
const int localWarpId = id >> 5;
__shared__ int s_freq[32];
__shared__ int s_value[32];
int frequency = 0;
int value = id;
for (int block = 0; block < NUM_BLOCKS; block++) {
if (id < HISTOGRAM_BINS) {
frequency += globalHistogram[block * HISTOGRAM_BINS + id];
}
}
__syncthreads();
/* Finding the most frequent item and copying the result to the output. */
// Warp-reduction.
for (unsigned int i = 16; i >= 1; i >>= 1) {
int gatheredFrequency = __shfl_sync(0xFFFFFFFF, frequency, warpLane + i);
int gatheredValue = __shfl_sync(0xFFFFFFFF, value, warpLane + i);
if (warpLane + i < 32) {
if (gatheredFrequency > frequency) {
frequency = gatheredFrequency;
value = gatheredValue;
}
}
}
// Warp-results.
if (warpLane == 0) {
s_freq[localWarpId] = frequency;
s_value[localWarpId] = value;
}
__syncthreads();
// Finarl warp reduction.
if (localWarpId == 0) {
frequency = s_freq[warpLane];
value = s_value[warpLane];
for (unsigned int i = 16; i >= 1; i >>= 1) {
int gatheredFrequency = __shfl_sync(0xFFFFFFFF, frequency, warpLane + i);
int gatheredValue = __shfl_sync(0xFFFFFFFF, value, warpLane + i);
if (warpLane + i < 32) {
if (gatheredFrequency > frequency) {
frequency = gatheredFrequency;
value = gatheredValue;
}
}
}
}
if (id == 0) {
output[0] = value;
output[1] = frequency;
}
}
int main() {
// My system has rtx5070 as the second device (id = 1).
int rtx5070 = 1;
int devices;
gpuErrchk(cudaGetDeviceCount(&devices));
gpuErrchk(cudaSetDevice(devices > 1 ? rtx5070 : 0));
// Preparing benchmark data.
int* input;
gpuErrchk(cudaMallocHost(&input, sizeof(int) * N));
std::ifstream file("./1M_random_numbers.txt");
std::string line;
int k = 0;
while (getline(file, line))
{
input[k] = std::stoi(line);
k++;
}
std::cout << "lines=" << k << std::endl;
assert(k == N);
file.close();
std::cout << "computing with cpu: " << std::endl;
// Preparing reference result with simple readable cpu implementation.
int* hist;
gpuErrchk(cudaMallocHost(&hist, sizeof(int) * HISTOGRAM_BINS));
for (int i = 0; i < HISTOGRAM_BINS; i++) {
hist[i] = 0;
}
for (int i = 0; i < N; i++) {
hist[input[i]]++;
}
int mostFrequent = -1;
int frequency = 0;
for (int i = 0; i < HISTOGRAM_BINS; i++) {
if (frequency < hist[i]) {
frequency = hist[i];
mostFrequent = i;
}
}
std::cout << "cpu result = " << mostFrequent << " " << frequency << std::endl;
std::cout << "computing with gpu: " << std::endl;
// Preparing CUDA resources.
cudaStream_t stream;
cudaEvent_t eventStart;
cudaEvent_t eventStop;
cudaEvent_t eventKernelStart;
cudaEvent_t eventKernelStop;
gpuErrchk(cudaStreamCreate(&stream));
gpuErrchk(cudaEventCreate(&eventStart));
gpuErrchk(cudaEventCreate(&eventStop));
gpuErrchk(cudaEventCreate(&eventKernelStart));
gpuErrchk(cudaEventCreate(&eventKernelStop));
// The input data from host.
int* input_d;
// The results from privatized histograms.
int* histogramPerBlock_d;
// Reduction level 1 result.
int* histogramReduced_d;
// Reduction level 2 result (most frequent element and its frequency).
int* histogram_d;
gpuErrchk(cudaMallocAsync(&input_d, sizeof(int) * N, stream));
gpuErrchk(cudaMallocAsync(&histogramPerBlock_d, sizeof(int) * HISTOGRAM_BINS * GRID_SIZE, stream));
gpuErrchk(cudaMallocAsync(&histogramReduced_d, sizeof(int) * HISTOGRAM_BINS * GRID_REDUCTION, stream));
gpuErrchk(cudaMallocAsync(&histogram_d, sizeof(int) * 2, stream));
// Warming gpu and pcie up.
std::cout << "Warming gpu up." << std::endl;
for (int bench = 0; bench < NUM_BENCH_ITER; bench++) {
gpuErrchk(cudaMemcpyAsync(input_d, input, sizeof(int) * N, cudaMemcpyHostToDevice, stream));
void* argsHistogram[] = { (void*)&input_d, (void*)&histogramPerBlock_d };
gpuErrchk(cudaLaunchKernel((void*)k_histogram<N>, dim3(GRID_SIZE, 1, 1), dim3(BLOCK_SIZE, 1, 1), argsHistogram, 0, stream));
void* argsReduction1[] = { (void*)&histogramReduced_d, (void*)&histogramPerBlock_d };
gpuErrchk(cudaLaunchKernel((void*)k_reduceLevel1<GRID_REDUCTION>, dim3(GRID_REDUCTION, 1, 1), dim3(BLOCK_SIZE, 1, 1), argsReduction1, 0, stream));
void* argsReduction2[] = { (void*)&histogramReduced_d, (void*)&histogram_d };
gpuErrchk(cudaLaunchKernel((void*)k_reduceLevel2<GRID_REDUCTION>, dim3(1, 1, 1), dim3(1024, 1, 1), argsReduction2, 0, stream));
gpuErrchk(cudaMemcpyAsync(hist, histogram_d, sizeof(int) * 2, cudaMemcpyDeviceToHost, stream));
}
cudaStreamSynchronize(stream);
std::cout << "Benchmarking gpu." << std::endl;
// Benchmarking kernel.
gpuErrchk(cudaEventRecord(eventKernelStart, stream));
for (int bench = 0; bench < NUM_BENCH_ITER; bench++) {
void* argsHistogram[] = { (void*)&input_d, (void*)&histogramPerBlock_d };
gpuErrchk(cudaLaunchKernel((void*)k_histogram<N>, dim3(GRID_SIZE, 1, 1), dim3(BLOCK_SIZE, 1, 1), argsHistogram, 0, stream));
void* argsReduction1[] = { (void*)&histogramReduced_d, (void*)&histogramPerBlock_d };
gpuErrchk(cudaLaunchKernel((void*)k_reduceLevel1<GRID_REDUCTION>, dim3(GRID_REDUCTION, 1, 1), dim3(BLOCK_SIZE, 1, 1), argsReduction1, 0, stream));
void* argsReduction2[] = { (void*)&histogramReduced_d, (void*)&histogram_d };
gpuErrchk(cudaLaunchKernel((void*)k_reduceLevel2<GRID_REDUCTION>, dim3(1, 1, 1), dim3(1024, 1, 1), argsReduction2, 0, stream));
}
gpuErrchk(cudaEventRecord(eventKernelStop, stream));
gpuErrchk(cudaStreamSynchronize(stream));
// Benchmarking kernel + copy.
gpuErrchk(cudaEventRecord(eventStart, stream));
for (int bench = 0; bench < NUM_BENCH_ITER; bench++) {
gpuErrchk(cudaMemcpyAsync(input_d, input, sizeof(int) * N, cudaMemcpyHostToDevice, stream));
void* argsHistogram[] = { (void*)&input_d, (void*)&histogramPerBlock_d };
gpuErrchk(cudaLaunchKernel((void*)k_histogram<N>, dim3(GRID_SIZE, 1, 1), dim3(BLOCK_SIZE, 1, 1), argsHistogram, 0, stream));
void* argsReduction1[] = { (void*)&histogramReduced_d, (void*)&histogramPerBlock_d };
gpuErrchk(cudaLaunchKernel((void*)k_reduceLevel1<GRID_REDUCTION>, dim3(GRID_REDUCTION, 1, 1), dim3(BLOCK_SIZE, 1, 1), argsReduction1, 0, stream));
void* argsReduction2[] = { (void*)&histogramReduced_d, (void*)&histogram_d };
gpuErrchk(cudaLaunchKernel((void*)k_reduceLevel2<GRID_REDUCTION>, dim3(1, 1, 1), dim3(1024, 1, 1), argsReduction2, 0, stream));
gpuErrchk(cudaMemcpyAsync(hist, histogram_d, sizeof(int) * 2, cudaMemcpyDeviceToHost, stream));
}
gpuErrchk(cudaEventRecord(eventStop, stream));
gpuErrchk(cudaStreamSynchronize(stream));
float totalMiliseconds = 0.0f;
float totalMilisecondsKernel = 0.0f;
{
float miliseconds;
gpuErrchk(cudaEventElapsedTime(&miliseconds, eventStart, eventStop));
totalMiliseconds += miliseconds;
gpuErrchk(cudaEventElapsedTime(&miliseconds, eventKernelStart, eventKernelStop));
totalMilisecondsKernel += miliseconds;
}
// Result from gpu.
mostFrequent = hist[0];
frequency = hist[1];
std::cout << "gpu result = " << mostFrequent << " " << frequency << std::endl;
std::cout << "gpu average total time (copy to device + kernels + copy to host) = " << totalMiliseconds / NUM_BENCH_ITER << " miliseconds" << std::endl;
std::cout << "gpu average kernel time (histogram + reduction level 1 + reduction level 2) = " << totalMilisecondsKernel / NUM_BENCH_ITER << " miliseconds" << std::endl;
gpuErrchk(cudaFreeAsync(input_d, stream));
gpuErrchk(cudaFreeAsync(histogramPerBlock_d, stream));
gpuErrchk(cudaFreeAsync(histogramReduced_d, stream));
gpuErrchk(cudaFreeAsync(histogram_d, stream));
{
gpuErrchk(cudaEventDestroy(eventStart));
gpuErrchk(cudaEventDestroy(eventStop));
gpuErrchk(cudaEventDestroy(eventKernelStart));
gpuErrchk(cudaEventDestroy(eventKernelStop));
}
gpuErrchk(cudaStreamSynchronize(stream));
gpuErrchk(cudaStreamDestroy(stream));
gpuErrchk(cudaFreeHost(hist));
gpuErrchk(cudaFreeHost(input));
return 0;
}
output:
lines=1000000
computing with cpu:
cpu result = 142 1130
computing with gpu:
Warming gpu up.
Benchmarking gpu.
gpu result = 142 1130
gpu average total time (copy to device + kernels + copy to host) = 0.160253 miliseconds
gpu average kernel time (histogram + reduction level 1 + reduction level 2) = 0.0219413 miliseconds
so its ~22 microseconds for 1M elements for the kernels only, ~160 microseconds if data copy latency is added (if dataset is assumed to be in RAM).
Optimizations used in the histogram kernel:
templated design to let the CUDA compiler enable more optimizations
thread-level aggregation for atomics
block-level aggregation for atomics
vectorized memory access to hide more latency
block-privatization of the histogram (this means each CUDA block works on its own local histogram to reduce contention on global atomic increments)
After the histogram kernel, two reduction kernels are run. They reduce the local outputs into a global output and then finally the most frequent element and its frequency to be copied back to RAM. Only the histogram kernel alone takes 3 microseconds according to Nsight profiler but adding event-based timers makes more latency. So, the real kernel performance is 2x better (~10 microseconds for 3 kernels) when not benchmarking but doing real-work (assuming whole project uses VRAM only).
- 12k
- 5
- 53
- 108
, find the number that appears the most
The question asks the number, implying a singular value, not a vector of values. So I outputted only the number and its frequency. Unless the question explicitly says top-k elements, I will keep this code as is.
Note: overclocking the rtx5070 to 3.2GHz gpu & +2000 on memory frequency reduces kernel time to 20 microseconds (when benchmarked) or 10 microseconds(not benchmarked) which is only 1/100 of a millisecond!
Note 2: PCIE data copy consumes 53 GB/s bandwidth of RAM according to Nsight. So if the RAM has 100GB/s bandwidth, then the CPU can do another histogram in parallel if required.
- 105
- 1
- 7
import pandas as pd
data = pd.read_csv('/1M_random_numbers.txt', header=None, names=['number'])
res = {}
for num in data['number']:
if num in res:
res[num] += 1
else:
res[num] = 1
df = pd.DataFrame(res.items(), columns=['number', 'count'])
df.sort_values('count', ascending=False).iloc[0]
void main() {
List<int> numbers = [5, 7, 2, 5, 7, 7, 9, 2, 5, 7, 2, 9, 9];
List<int> maxNumbers = [];
int maxCount = 0;
List<int> freq = List.filled(1000, 0);
for (int i = 0; i < numbers.length; i++) {
freq[numbers[i]]++;
}
for (int i = 0; i < freq.length; i++) {
if (freq[i] > maxCount) {
maxCount = freq[i];
}
}
for (int i = 0; i < freq.length; i++) {
if (freq[i] == maxCount) {
maxNumbers.add(i);
}
}
print("Most frequent numbers are $maxNumbers with count $maxCount");
}
This program will find the maximum count of any numbers tha is between 0 to 999 in the list and will print that numbers and lets suppose if list have more numbers with maximum counts for example the numbers 5 and 7 have the maximum count and are equals both have 9 than it will print both numbers
<?php
// PHP 8.4 ; Windows 11 ;
// 11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz (2.42 GHz)
// 8.00 GB RAM
$counts = array_fill(0, 1000, 0);
while(strlen($str=trim(fgets(STDIN)))){
$number = intval($str);
$counts[$number]++;
}
asort($counts);
echo array_key_last($counts);
- 4.1k
- 2
- 29
- 39
This seems to be a very simple matter to me so I'm looking forward to seeing some better attempts.
I take it that the input must be read from a file. Placing the numbers directly in the script means processing time is moved to the interpreter making it about 3 times faster to process. I presume this would be cheating.
I tried with a plain dict using setdefault to count, collections.defaultdict, reading direct from the input file and also building a list from the input file first. Nothing really makes much difference and collections.Counter is twice as fast anyway.
It may be possible to stop the search early if the current highest frequency is greater than the number of remaining numbers left to check, but on this kind of input that would be very unlikely to yield a performance improvement because it's necessary to check on every iteration, or even in chunks, and that would introduce more overhead than it saves.
Nothing else really occurs to me other than collections.Counter, except for one thing. The input is clean and regular so there's no need to convert the text to int. That saves a bit of time:
"""
$ python numbers.py
[('142\n', 1130)]
0.08784699440002441
"""
import collections
import time
start = time.time()
with open("numbers.txt") as numbers:
print(collections.Counter(numbers).most_common(1))
print(time.time() - start)
Round about 0.08784699440002441 seconds using Python 3.10 on WSL2 on an 11th Gen Intel(R) Core(TM) i7-1185G7 @ 3.00GHz with 16.0 GB RAM.
- 354
- 4
- 19
Even though not parsing text looks tempting here, storing text (e.g: '142\n') as keys in a dictionary will cause hash calculation + collision checks + probing, etc. Probably, parsing digits using ASCII codes from bytes and then doing a counting sort over on a normal array (indices are [0-999]) would be much faster.
- 4.1k
- 2
- 29
- 39
It's not really about "parsing text", @Yavuz_Tas. It's more about "not parsing text". Not parsing halves the time, IIRC when I had it in front of me. Your alternative sounds like fun. You should enter that as an answer. I'm not holding my breath it will be faster though. I think what's great about my example here is that it's only 87ms but it's still actually the canonical simple Python approach. It's short, easy to read, took almost no time to write and is still faster than a lot of entries on here. And Python is supposed to be slow? Of course a compiled implementation like C provides is going to kill it in the speed stakes if you genuinely need to count quadrillions of entries every day.
- 71
- 1
- 8
I developed the solution in python3, node and C; and this is the more concise and elegant way I found. The C version is the fastest (about 40 ms) but its too verbose...
I learned the existence of the useful collections.Counter class.
The code runs in about 85 ms on an Apple M1 Pro with 16GB of RAM with Python 3.11.12
This is my solution:
import time
from collections import Counter
start_time = time.process_time_ns()
f = open('1M_random_numbers.txt', 'r')
frequencies = Counter(f.read().split())
print(frequencies.most_common(1))
print((time.process_time_ns() - start_time)/1_000_000_000)
And outputs
[('142', 1130)]
0.086723
So the most frequent number is 142 with a frequency of 1130.
- 414
- 2
- 5
The following code was run on Google Colab (basic free runtime). This seems to be solved in a simple O(N) algorithm where you assign a length-1000 integer list, loop over the numbers adding one to the corresponding entry in the length-1000 list for each number and then loop over the length-1000 list to find the most common number. In terms of optimization this assumes that the list of numbers is much longer than 1000 such that looping over the length-1000 list at the end is fast compared to looping over the numbers.
It's easy to code this algorithm up in python, but is a good example of where [naively written] python can be slow. It's also a great example of where Cython can help (for someone who doesn't know or doesn't want to know C/C++). I implement the simple algorithm in Python, and then show how doing the same in Cython significantly speeds this up. Finally, we also show how this can be done using numpy.unique but that the Cython code is more optimal.
import numpy as np
# Download files from within jupyter/colab using gdown
!gdown 14kbAC0edO05Z1EIYbZMC6Gpzx1u2yecd
!gdown 1OrIx7ZbHr5q1Smo2-T_7MWhVPR9DNny3
!gdown 1BZfKc60zRBoyeGSUAkzgQcxxpgly4IL_
# Reading the numbers in is probably the most expensive part of this.
# But I'm assuming that the function is supposed to work on numbers
# being provided to it, so not looking to optimise this. (np.loadtxt
# is probably pretty good anyway)
numbers_100 = np.loadtxt('100_random_numbers.txt', dtype=np.int32)
numbers_10000 = np.loadtxt('10000_random_numbers.txt', dtype=np.int32)
numbers_1M = np.loadtxt('1M_random_numbers.txt', dtype=np.int32)
# This seems to be easily solved with a O(N) algorithm and a "counts" array
# As the algorithm is handling lengths ~ 1M assigned 1000 integers extra memory
# is negligible to store the counts.
def most_occurring_number(numbers):
counts = np.zeros(1000)
for n in numbers:
counts[n] += 1
return np.argmax(counts)
print(most_occurring_number(numbers_1M))
%timeit most_occurring_number(numbers_1M)
returns
142
406 ms ± 6.48 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Then adding a Cython function
%load_ext cython
%%cython -a
import cython
@cython.boundscheck(False)
@cython.wraparound(False)
def most_occurring_number_cy(int[::1] numbers, int length, int[::1] counts):
cdef int i, n
for n in numbers:
counts[n] += 1
cdef int max_occur = 0
cdef int max_idx = 1000
for i in range(1000):
if counts[i] > max_occur:
max_occur = counts[i]
max_idx = i
return max_idx
# We use cython to optimize this. The counts memory allocation is still done in python
# If calling this function many times this could be cached and reset to 0 every time.
def most_occurring_number_v2(numbers):
counts = np.zeros(1000, dtype=np.int32)
return most_occurring_number_cy(numbers, len(numbers), counts)
print(most_occurring_number_v2(numbers_1M))
%timeit most_occurring_number_v2(numbers_1M)
returns
142
763 µs ± 36.3 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Finally:
# numpy has a builtin function to do this. Let's compare it to our Cython code
print(np.argmax(np.unique(numbers_1M, return_counts=True)[1]))
%timeit np.argmax(np.unique(numbers_1M, return_counts=True)[1])
returns
142
8.44 ms ± 1.42 ms per loop (mean ± std. dev. of 7 runs, 100 loops each)
- 868
- 1
- 12
- 23
using System.Globalization;
namespace Integer_Counting
{
internal class Program
{
const string file100 = "files/100_random_numbers.txt";
const string file10000 = "files/10000_random_numbers.txt";
const string file1M = "files/1M_random_numbers.txt";
static void Main(string[] args)
{
FindMostPopularNumber(file100);
FindMostPopularNumber(file10000);
FindMostPopularNumber(file1M);
}
static void FindMostPopularNumber(string file)
{
var dtStart = DateTime.Now;
Console.WriteLine($"Start time: {dtStart.ToString("yyyy-MM-dd HH:mm:ss.fff",CultureInfo.InvariantCulture)}");
var list = new List<int>();
var fileContents = File.ReadAllLines(file);
foreach (string line in fileContents)
{
list.Add(Convert.ToInt32(line));
}
var listWithCount = list.GroupBy(x => x);
//Figure out the highest count because we need to print all numbers that appear that many times
var maxCount = listWithCount.OrderByDescending(x => x.Count()).Take(1).First().Count();
var stringOfMostPopularNumbers = string.Empty;
foreach (var number in listWithCount.Where(x => x.Count() == maxCount))
{
stringOfMostPopularNumbers += $"{number.Key},";
}
stringOfMostPopularNumbers = stringOfMostPopularNumbers.Substring(0, stringOfMostPopularNumbers.Length - 1); //Get rid of last comma
Console.WriteLine($"Most popular number(s): {stringOfMostPopularNumbers}");
var dtEnd = DateTime.Now;
Console.WriteLine($"End time: {dtEnd.ToString("yyyy-MM-dd HH:mm:ss.fff", CultureInfo.InvariantCulture)}");
Console.WriteLine($"Execution runtime: {(dtEnd - dtStart).Milliseconds} milliseconds");
Console.WriteLine();
}
static void PrintList(string file)
{
var list = new List<int>();
var fileContents = File.ReadAllLines(file);
foreach (string line in fileContents)
{
list.Add(Convert.ToInt32(line));
}
list = list.OrderBy(x => x).ToList();
foreach (var x in list)
Console.WriteLine(x);
}
}
}
I optimized this task by reading all lines at once from the file, adding each to a List, and then Grouping By each number. The .NET 9 code is quite efficient, clocking in at less than 250 milliseconds for each of the datasets in each of the runs.
First run:
Start time: 2025-09-25 15:48:19.734
Most popular number(s): 546,188,208,641,374,694
End time: 2025-09-25 15:48:19.763
Execution runtime: 29 milliseconds
Start time: 2025-09-25 15:48:19.763
Most popular number(s): 284
End time: 2025-09-25 15:48:19.769
Execution runtime: 5 milliseconds
Start time: 2025-09-25 15:48:19.769
Most popular number(s): 142
End time: 2025-09-25 15:48:20.016
Execution runtime: 247 milliseconds
Second run:
Start time: 2025-09-25 15:49:00.919
Most popular number(s): 546,188,208,641,374,694
End time: 2025-09-25 15:49:00.949
Execution runtime: 30 milliseconds
Start time: 2025-09-25 15:49:00.949
Most popular number(s): 284
End time: 2025-09-25 15:49:00.955
Execution runtime: 5 milliseconds
Start time: 2025-09-25 15:49:00.955
Most popular number(s): 142
End time: 2025-09-25 15:49:01.180
Execution runtime: 225 milliseconds
Third run:
Start time: 2025-09-25 15:49:22.501
Most popular number(s): 546,188,208,641,374,694
End time: 2025-09-25 15:49:22.530
Execution runtime: 29 milliseconds
Start time: 2025-09-25 15:49:22.531
Most popular number(s): 284
End time: 2025-09-25 15:49:22.536
Execution runtime: 5 milliseconds
Start time: 2025-09-25 15:49:22.536
Most popular number(s): 142
End time: 2025-09-25 15:49:22.768
Execution runtime: 231 milliseconds
Processor is Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz (3.19 GHz). Installed RAM is 48.0 GB.
I learned that it's a good idea to check the small dataset with your eyes to see what the answer should be. I noticed my original answer only had two hits, and then noticed that there was at least one more number had two hits, thus the tie in dataset 1.
- 41.2k
- 10
- 49
- 90
Approach
The task consists of two parts.
The first part (BUILD) traverses the input list of numbers and builds a table that counts how many times each number appears.
The second part (FIND) traverses the freshly built table finding the maximum, thereby locating the value that appears the most often in the input list. Since there's no guarantee that this will be a unique solution, I have added the concept of ex-aequo's.
Optimization
I've put the table in stack memory so it stays distant from the running code. If data is written too close-by to the executing instructions, then the CPU might think it's self-modifying code and performance will suffer from this. Additionally, I have the table's dword elements reside on their natural boundaries. Please note that the same problem does not exist for the filebuffer that I use, because my program only ever reads from it. It is (further away) DOS code that writes to this memory.
I mostly keep the stackpointer dword-aligned for best performance. Eventhough this is the 16-bit real address mode, in general - surprisingly perhaps - it does matter.
I have replaced the multiplications by 10 (that are followed by an addition) with a couple of efficient
LEAinstructions.The GetValidByte subroutine was optimized with no branching in the common case.
Several program variables were not based in memory, but instead kept in a processor register.
Results
I measure the program's execution time by reading the TimeStampCounter twice and converting the difference according to my processor's frequency which is 1.73 GHz. All I/O is included in the execution time. The machine is an Intel Pentium dual core processor T2080 (533 MHz FSB, 1 MB L2 cache). The environment is DOS 6.20 (minimally configured, no TSRs active). The program was assembled with FASM.
C:\SO>100 Next values appear 2 times: 188, 208, 374, 546, 641, 694 The program's runtime is 345 µsec C:\SO>10K Next value appears 23 times: 284 The program's runtime is 10571 µsec C:\SO>1M Next value appears 1130 times: 142 The program's runtime is 1531207 µsec C:\SO>
Challenge #6 --- Program to scan a list of numbers
and find the value(s) that appear(s) the most often.
BUFSIZE equ 512
ALLNUM equ 1000000
ORG 256 ; .COM program has CS=DS=ES=SS
INIT: and sp, -4 ; 4-byte aligned stack
rdtsc ; -> EDX:EAX
push edx eax
sub sp, 1000*4 ; 4-byte aligned table
movzx ebp, sp
mov di, sp ; Wipe the table of dword counters
mov cx, 1000
xor eax, eax
cld
rep stosd
mov dx, TheFile
mov ax, 3D00h ; DOS.OpenFile for reading
int 21h ; -> AX CF
jc ABORT
mov [Handle], ax ; ReadPointer is kept in SI
xor bx, bx ; AvailableBytes is kept in BX
mov ecx, ALLNUM
; Extract ALLNUM integers [0,999] from the input list
; and tally in the 1000-dwords table at EBP
BUILD: call GetValidByte ; -> EAX BX SI CF
jnc ABORT ; It's not a number
mov edi, eax ; Build the 1-digit value
call GetValidByte ; -> EAX BX SI CF
jnc .INC ; It's a single-digit number
lea edi, [edi+edi*4]; Build the 2-digit value
lea edi, [eax+edi*2]
call GetValidByte ; -> EAX BX SI CF
jnc .INC ; It's a double-digit number
lea edi, [edi+edi*4]; Build the 3-digit value
lea edi, [eax+edi*2]
call GetValidByte ; -> EAX BX SI CF
jc ABORT ; There're more than 3 digits
.INC: inc dword [ebp+edi*4]
dec ecx
jnz BUILD
mov bx, [Handle]
mov ah, 3Eh ; DOS.CloseFile
int 21h ; -> AX CF
; Find max in the table with 1000 dword counters
mov eax, [bp] ; Value of the initial max
xor ebx, ebx ; Index of the initial max
xor cx, cx ; For now it is a unique find
lea esi, [ebx+1] ; Index [1,999] for other items
FIND: mov edx, [ebp+esi*4]; -> EDX is [0,TOTALNUMBERS]
cmp edx, eax
jl .LT
je .EQ
.GT: mov eax, edx ; Set new max (is unique for now)
mov ebx, esi ; Remember its index
mov cx, -1 ; Clear EX-AEQUO
.EQ: inc cx
.LT: inc esi
cmp esi, 1000
jb FIND
; Show results on the screen and terminate
mov dx, msgOK1
jcxz SHOW ; EX-AEQUO is [0,999]
mov dx, msgOK2
SHOW: push ax
mov ah, 09h ; DOS.PrintString
int 21h ; -> AL='$'
pop ax
call ShowEAX
mov dx, msgOK3
mov ah, 09h ; DOS.PrintString
int 21h ; -> AL='$'
mov dl, ':' ; Prefix for first/only value
.CSV: mov ah, 02h ; DOS.PrintCharacter
int 21h ; -> AL=DL
mov eax, ebx
call ShowEAX
mov dx, msgEOL
dec cx ; More ex-aequo's to display ?
js EXIT ; No
mov eax, [ebp+ebx*4]
.NEXT: inc ebx ; Locate the next ex-aequo
cmp [ebp+ebx*4], eax
jne .NEXT
mov dl, ',' ; Prefix so as to obtain
jmp .CSV ; CSV output format
ABORT: mov dx, msgERR
EXIT: mov ah, 09h ; DOS.PrintString
int 21h ; -> AL='$'
rdtsc ; -> EDX:EAX
sub eax, [bp+4000] ; Minus the initial TSC
sbb edx, [bp+4004]
mov ecx, 1730 ; 1.73 GHz -> duration in µsec
div ecx
call ShowEAX
mov dx, msgTIM
mov ah, 09h ; DOS.PrintString
int 21h ; -> AL='$'
mov ax, 4C00h ; DOS.TerminateWithExitcode
int 21h
; ------------------------------
; A valid byte is either a newline (10) or else a decimal digit [0,9]
; Does not return if either the byte is invalid or a file error occured
; IN (bx,si) OUT (eax,bx,si,CF)
GetValidByte:
dec bx ; AvailableBytes - 1
js .LOAD
.FETCH: movzx eax, byte [si]
inc si ; ReadPointer + 1
cmp al, 10 ; Is it the newline ?
je .RET ; Yes
sub eax, '0'
cmp al, 10 ; Is it a decimal digit ?
ja ABORT
.RET: ret ; CF=0 for 10, CF=1 for [0,9]
.LOAD: push cx dx
mov si, Buffer ; Reset readpointer
mov dx, si
mov cx, BUFSIZE
mov bx, [Handle]
mov ah, 3Fh ; DOS.ReadFile
int 21h ; -> AX CF
pop dx cx
jc ABORT
dec ax ; [0,BUFSIZE] -> [-1,BUFSIZE-1]
js ABORT
mov bx, ax ; Remaining bytes
jmp .FETCH ; AFTER this fetch completes
; ------------------------------
; Prints the unsigned dword in EAX with a prepended space character
; IN (eax) OUT ()
ShowEAX:push bx ecx edx
mov bx, sp
sub sp, 12
dec bx
mov byte [bx], '$'
mov ecx, 10
.a: xor edx, edx
div ecx
dec bx
add dl, '0'
mov [bx], dl
test eax, eax
jnz .a
dec bx
mov byte [bx], ' '
mov dx, bx
mov ah, 09h ; DOS.PrintString
int 21h ; -> AL='$'
add sp, 12
pop edx ecx bx
ret
; ------------------------------
TheFile db 'NUM1M.TXT', 0
msgERR db 'Trouble using the file'
msgEOL db 13, 10, "The program's runtime is$"
msgOK1 db 'Next value appears$'
msgOK2 db 'Next values appear$'
msgOK3 db ' times$'
msgTIM db ' µsec', 13, 10, '$'
; ------------------------------
ALIGN 2
Handle rw 1
Buffer rb BUFSIZE
@Peter: As it is written in assembler why it is so slow (1.5 seconds)?
Probably because file loading and parsing is included into benchmark. Best time which I've got from pure and simple assembly implementation so far is 370 µs on Xeon w5-2445 @ 3,1 GHz (but file loading is excluded from benchmark).
- 12k
- 5
- 53
- 108
@Andrey Dmitriev you can use a RAMDISK to store the file and open it from there at low latency and high throughput. If you read file repeatedly, it could even stay inside L3/L2 cache of CPU.
you can use a RAMDISK to store the file
No, in my opinion this will not help much (the OS has already cached the file in RAM). I already have 370 µs, which means around 1,1 ... 1,2 CPU clocks per value. However, loading the file and converting from ASCII strings to numbers could easily take around a hundred cycles per value. I just checked—in assembly, including file I/O and parsing, I need approximately 40 ms insted of 0,4 ms just for computation.
- 41.2k
- 10
- 49
- 90
@Andrey Dmitriev You are right! When I no longer include in the benchmark the I/O (file and messages) and the parsing, my core loop runs in about 17.6 msec. That's a 100 times faster than the original 1.5 sec, and very similar to your observation of 40 msec vs 0.4 msec.
mov esi, TheArray ; SRC
mov edx, 1000000 ; CNT
xor ebx, ebx ; MAX
NEXT:
mov edi, [esi] ; Array element [0,999]
add esi, 4
mov eax, [ebp+edi*4] ; Histogram(element)
inc eax
mov [ebp+edi*4], eax
cmp eax, ebx ; Better than current MAX ?
cmova ebx, eax ; Yes, update MAX
cmova ecx, edi ; Yes, remember the number
dec edx
jnz NEXT
For the 1,000,000 numbers challenge this code leaves 1130 in EBX and 142 in ECX.
- 12k
- 5
- 53
- 108
@Andrey Dmitriev
You can still use a compile-time constant array as the data source to avoid everything. But then when you click the application file, the OS will still load a big binary file which would have similar latency. I think fastest way is to keep the data encoded in a much more compressible format, then decompress faster than the disk-bandwidth. Maybe the data should be kept in binary format too, 0-1000 range requires only 10 bits. This can greatly improve the effective throughput and directly avoids conversion form string.
- 5.9k
- 6
- 39
- 80
The key insight was the limited range of the possible numbers. This allows simply storing a histogram in a fixed size array.
It is possible to get the highest occurrence in a single pass by storing the current highest value and number and updating it if required after increasing the occurrence of the currently read number. I.e. like if(++count[cur] > max) { max = count[cur]; max_num = cur; }
However this made it 3x slower in my tests. Doing it separately executes only 1000 branches while doing it while counting runs 1 branch per number, i.e. 1M, which seems to explain the difference.
My Result:
Most frequent: 142 (1130 times)
Took 391µs
on a AMD Ryzen 5 3600.
This is fast enough that no further optimization seems to be required.
My code:
#include <iostream>
#include <fstream>
#include <vector>
#include <chrono>
#include <algorithm>
int main(int argc, const char** argv) {
if (argc < 2)
return 1;
std::vector<int> numbers;
numbers.reserve(1000000);
std::ifstream file(argv[1]);
while (true) {
int cur;
if (!(file >> cur).ignore())
break;
numbers.push_back(cur);
}
std::chrono::high_resolution_clock clock;
auto start = clock.now();
constexpr int REPEATS = 100;
unsigned max_count, max_number;
for (int ct = 0; ct < REPEATS; ct++) {
unsigned counts[1000] = { 0 };
max_count = max_number = 0;
for (const auto cur : numbers) {
if (++counts[cur] > max_count) {
max_count = counts[cur];
max_number = cur;
}
}
}
auto elapsed = clock.now() - start;
std::cout << "Most frequent: " << max_number << " (" << max_count << " times)\n";
std::cout << "Took " << std::chrono::duration_cast<std::chrono::microseconds>(elapsed).count() / REPEATS << "us\n";
return 0;
}
By the way, the execution time of your code varies significantly depending on the compiler used.
On Windows 11 24H2, running on a Xeon w5-2445 @ 3.1 GHz, I observed the following results (with default optimization for speed):
Visual Studio 2022 v17.14.15 – 1259 µs
GCC v15.2.0 – 802 µs
Intel oneAPI 2025.2 (v20250605) – 461 µs
If I change
inttounsigned shortfor numbers vector, then Intel oneAPI reports 348 µs — probably because it uses less memory and benefits from better cache line utilization.
Will take a look later into machine code if time permit.
AVX-512 and Scalar Solutions Written in Assembly + LabVIEW
Spoiler – below are three implementations:
Assembly: AVX-512 (gather/scatter) – 840 µs
Assembly: Scalar (unrolled loop) – 370 µs
LabVIEW: Fully sorted list – 10 ms
The "classical" approach to finding the most frequently occurring number is histogram-based: build a histogram, locate the maximum value, and the index of that maximum is the number you're looking for. A very naive implementation might look like this:
for (int i = 0; i < MAX_ELEMENTS; i++)
histogram[numbers[i]]++;
for (int i = 0; i < 1000; i++) {
if (histogram[i] > maxValue) {
maxValue = histogram[i];
mostUsed = i;
}
}
printf("Most used is %d\n", mostUsed);
Or, if using high-level library functions available, for example in NI LabWindows/CVI, it's even simpler:
FileToArray("1000000_random_numbers.txt", numbers, ...);
Histogram(numbers, 1000000, 0.0, 999.0, histogram, ...);
MaxMin1D(histogram, 1000, &maxValue, &mostUsed, ...);
printf("Most used is %lld\n", mostUsed);
But we're not looking for the simplest solution. Some time ago, I came across the gather/scatter instruction pair, which is a good starting point for building a histogram using SIMD instructions. Let's give it a try.
Core Algorithm in Assembly
The heart of the algorithm is a loop that builds the histogram as follows:
; RAX - Pointer to input data (array of one million 16-bit unsigned integers)
; RCX - Number of element groups (1000000 / 16 = 62500 iterations)
; RDX - Pointer to destination histogram
vpbroadcastd ZMM16, 1 ; Packed dwords of 1 – increments
XOR RBX, RBX ; Initial offset index = 0
KXNORD K0, K0, K0 ; Mask of all ones
.loop:
VPMOVZXWD ZMM1, [RAX + RBX] ; Load 32x16-bit words → ZMM1
VPSLLD ZMM2, ZMM1, 2 ; ZMM2 = ZMM1 * 4 (byte offsets)
KMOVD K1, K0 ; Restore mask (cleared by VPGATHERDD)
VPGATHERDD ZMM3, [RDX + ZMM2], MASK=K1 ; Gather current histogram values
VPADDD ZMM3, ZMM3, ZMM16 ; Increment each by 1
KMOVD K2, K0 ; Reset mask
VPSCATTERDD [RDX + ZMM2], ZMM3, MASK=K2 ; Scatter updated values
ADD RBX, 32 ; Move to next 32 elements
LOOP .loop ; Decrement RCX and loop if not zero
The beauty of this algorithm is that 16 input values are processed simultaneously. Instead of 1,000,000 iterations, we only need 62,500. The VPGATHERDD instruction conditionally loads 16 dword values from memory using dword indices, then VPADDD increments them, and VPSCATTERDD writes them back. Simple and elegant.
Handling Duplicates
However, there's a caveat: if the same value appears multiple times in a group, only one increment is applied. To fix this, I use VPCONFLICTD to detect duplicates:
.loop:
VPMOVZXWD ZMM1, [RAX + RBX] ; Load 32x16-bit words → ZMM1
VPCONFLICTD ZMM4, ZMM1 ; ZMM4 = conflict indices
VPXORD ZMM5, ZMM4, ZMM4 ; ZMM5 = 0
VPCMPD k1, ZMM4, ZMM5, 0 ; k1 = lanes with no conflict (unique)
KNOTW k2, k1 ; k2 = lanes with duplicates
KORTESTW k2, k2 ; Check if any duplicates exist
JNZ .duplicates ; Jump to scalar fallback if duplicates
Ideally, we could build a mask for VPADDD using VPOPCNT, but the assembler used doesn't support it. So we fall back to a scalar loop:
.duplicates:
MOV R11, RAX
ADD R11, RBX
MOV R12, 16
align 16
.L2:
MOVZX R13D, [R11]
ADD [RDX + R13*4], 1
ADD R11, 2 ; Two bytes per value
DEC R12
JNZ .L2
Finding the Maximum
Once the histogram is built, scan it to find the maximum value:
.histogram:
XOR RAX, RAX
XOR R9D, R9D ; R9D = final result (max index)
XOR EBX, EBX ; EBX = current maximum
MOV RCX, 1000 ; Range: 0...999
align 16
.L3:
MOV R8D, [RDX]
CMP EBX, R8D
CMOVL R9D, RAX ; Branchless conditional move
CMOVL EBX, R8D
INC RAX
ADD RDX, 4
LOOP .L3
The interesting part here is the use of CMOVL to avoid branching when updating the maximum value and its index.
File Handling and Input
Here's how the input argument is handled and the file is loaded using EuroAssembler macros:
Start: nop
StdOutput MsgStart, Eol=Yes, Console=Yes
GetArg 1
JC .DefaultFile
StripQuotes RSI, RCX
MOV RDI, File$
REP MOVSB
SUB AL, AL
STOSB
.DefaultFile:
FileAssign theFile, File$
FileExists? theFile
JC .ErrorFileNotFound
FileStreamOpen theFile, BufSize=16K
MOV R10, Buf_arr
XOR R8, R8
.L1:
FileStreamReadLn theFile
JZ .EOF
LodD
MOV [R10], AX
ADD R10, 2
INC R8
JMP .L1
.EOF:
FileClose theFile
Printing the Result
RDTSCP
SHL RDX, 32
OR RAX, RDX
SUB RAX, R15
;; Benchmark finished. RAX = ticks, R9 = most frequent number
StoD Buf_t
MOV EAX, R9D
StoD Buf_n
StdOutput Buf_t, MsgEnd, Buf_n, Eol=Yes, Console=Yes
Result
> numbers.exe
Integer Counting Code Challenge
2611726 Ticks; the number that appears the most is 142
2,6 million ticks for one million numbers is quite efficient — less than three CPU cycles per number, which means roughly 840 µs on my 3.1 GHz Xeon w5-2445 CPU. However, this isn't the fastest method on all CPUs. Some processors have high latency (10-15 cycles) for VPGATHERDD and VPSCATTERDD, and a scalar loop may outperform this, especially with Turbo Boost being more effective without AVX-512. Still, it not only about speed, it was a fun and insightful debugging session. The code may have minor issues, as I didn’t polish it thoroughly due to time constraints.
Anyway, the full code "as is":
;;=======================================================
;;
;; Title:Numbers - AVX-512 approach
;; Purpose:Code Challenge #6: Integer Counting.
;;
;; 23.09.2025 at 08:06:16 by Andrey Dmitriev.
;; 26.09.2025 - benchmark loop added
;;=======================================================
EUROASM AutoSegment=Yes, CPU=X64, SIMD=AVX512, EVEX=ENABLED
numbers PROGRAM Format=PE, Width=64, Model=Flat, IconFile=, Entry=Start:
INCLUDE memory64.htm, winf64.htm, wins.htm, winscon.htm, cpuext64.htm
[.bss] SEGMENT ALIGN=64
EUROASM AutoSegment=yes ; keep using autosegmentation
MsgStart D "Integer Counting Code Challenge",0
MsgUsage D "Usage: numbers.exe <File-With-Numbers>",0
MsgEnd D " Ticks; the number that appears the most is ",0
MsgErr D "File Not Found - ",0
File$ D "1M_random_numbers.txt",0
Buf_t DB 128 * B ; Buffer for Ticks string, act also as guard
Buf_n DB 128 * B ; Buffer for Number string
align 64
Buf_arr DB 1_000_000 * W ; Aligned Buffer for Input Array of 1M Numbers
Buf_hist DB 1000 * Q ; Histogramm 1000 elts for up to 1000000 nums
theFile DS FILE64
Start: nop ; For Auto Segmentation
StdOutput MsgStart, Eol=Yes, Console=Yes ; Welcome message
GetArg 1 ; RCX is the size of arg (bytes); RSI is ptr to the first char.
JC .DefaultFile: ; Report error and show usage if no file was provided.
StripQuotes RSI,RCX ; Get rid of quotes if they were used.
MOV RDI, File$ ; Room for the file name.
REP MOVSB ; Copy the name.
SUB AL,AL
STOSB ; Zero terminate the string.
.DefaultFile:
FileAssign theFile, File$
FileExists? theFile
JC .ErrorFileNotFound
FileStreamOpen theFile, BufSize=16K
MOV R10, Buf_arr
XOR R8, R8 ; R8 is the holder to count lines reset it
.L1:
FileStreamReadLn theFile ; RAX=line size ;RSI=pointer to the line in buffer.
JZ .EOF
LodD ; RSI assumed, parsing stops at LF char; RAX - loaded number
MOV [R10], AX ; store number in U16 Array
ADD R10, 2 ; to the next two bytes
INC R8 ; increment Lines (numbers) counter (do not modify)
JMP .L1 ; Next line
.EOF:
FileClose theFile ; No need the File any longer, can be closed now
MOV EAX, 1
VPBROADCASTD ZMM16, EAX ; packed dwords of 1 - will be used for increments
Clear Buf_t, Size=256 ; if it was polluted by long file name string
Clear Buf_hist, Size=4000 ; Clear Buffer, this will also avoid page fault
;;=======================================================
;; Benchmark start here
;;
CPUID
RDTSC
SHL RDX, 32
OR RAX, RDX
MOV R15, RAX ; R15 will hold initial Time Stamp counter value
MOV R14, 1024; amount of benchmark repetitions
.bench:
MOV RAX, Buf_arr ; All our numbers
MOV RDX, Buf_hist; Histogram
CMP R8, 0 ; Check if the list empty
JE .Exit
MOV RCX, R8 ; loop counter
SHR RCX, 4 ; for 1,000,000 / 16 - we will handle 16 values per iteration
XOR R9, R9 ; index = 0
KXNORD K0, K0, K0 ; mask of all ones
align 16 ; Recommended by Intel
.loop:
VPMOVZXWD ZMM1, [RAX + r9] ; load 32x16-bit words -> ZMM1 (zero-extended)
VPCONFLICTD ZMM4, ZMM1 ; ZMM4 = conflict indices
VPXORD ZMM5, ZMM4, ZMM4 ;
VPCMPD k1, ZMM4, ZMM5, 0 ; k1 = lanes with conflict == 0 (unique)
KNOTW k2, k1 ; k2 = lanes with duplicates
KORTESTW k2, k2 ; Check if any duplicates exist
JNZ .duplicates ; Jump if any duplicates found, proceed to scala approach
VPSLLD ZMM2, ZMM1, 2 ; ZMM2 = ZMM1 * 4 (byte offsets)
KMOVD K1, K0 ; Restore Mask
VPGATHERDD ZMM3, [RDX + ZMM2], MASK=K1 ; gather current histogram values
VPADDD ZMM3, ZMM3, ZMM16 ; increment each by 1 (which stored in ZMM16)
KMOVD K2, K0 ; The entire mask register will be set to zero
VPSCATTERDD [RDX + ZMM2], ZMM3, MASK=K2; scatter updated values
.continue:
ADD R9, 32 ; MOVe to next 32 elements
LOOP .loop ; decrement RCX and loop if not zero
JMP .histogram ; All right, jump to Histogram analysis
.duplicates:
; Handle duplicates with scalar loop for this vector
MOV R11, RAX
ADD R11, R9
MOV R12, 16
align 16
.L2:
MOVZX R13D, [R11], DATA=W
ADD [RDX+R13*4], 1, DATA=W ; Add count to Histogram
ADD R11, 2
DEC R12
JNZ .L2
JMP .continue
.histogram:
XOR RAX, RAX
XOR R9D, R9D ; RAX = final result (max index)
XOR EBX, EBX ; Current maximum
MOV RCX, 1000 ; our numbers in Range 0...999
align 16
.L3:
MOV R10D, [RDX]
CMP EBX, R10D ; Is this maximum?
CMOVL R9D, EAX ; Conditional Move - Branchless swap
CMOVL EBX, R10D
INC EAX
MOV [RDX], 0, DATA=D ; Reset bin for the next run
ADD RDX, 4 ; no need to keep, next 4 bytes
LOOP .L3
DEC R14
JNZ .bench ; Repeat 1024 times
RDTSCP
SHL RDX, 32
OR RAX, RDX
SUB RAX, R15 ; Subtract previous stamp
SHR RAX, 10 ; Divide by 1024 - amount of bench repetitions
;;
;; Benchmark finished, now RAX contains amount of Ticks and R9 is the number
;;=======================================================
StoD Buf_t
MOV EAX, R9D ; Maximal value (index) the number that appears the most.
StoD Buf_n
StdOutput Buf_t, MsgEnd, Buf_n, Eol=Yes, Console=Yes ; Print result
JMP .Exit
.ErrorFileNotFound:
StdOutput MsgUsage, Eol=Yes, Console=Yes
StdOutput MsgErr, File$, Eol=Yes, Console=Yes
.Exit:
TerminateProgram
ENDPROGRAM
Compilation
To compile (or more exactly "assemble"), download EuroAssembler, save the code above as numbers.asm and run:
> euroasm.exe numbers.asm
That’s it.
Update 26-Sep - Scalar solution.
For anyone who has read this up to this point and doesn't have an AVX-512-capable CPU but would still like to experiment with assembly, I've prepared a "naive" scalar version where the histogram is built in a "classical" way. The only optimization I applied is unrolling the loop 4 times. This version will work on any CPU — and on Linux as well:
;;=======================================================
;;
;; Title:Numbers - Naive approach
;; Purpose:Code Challenge #6: Integer Counting.
;;
;; 26.09.2025
;;=======================================================
EUROASM AutoSegment=Yes, CPU=X64, SIMD=AVX2
numnaive PROGRAM Format=PE, Width=64, Model=Flat, IconFile=, Entry=Start:
INCLUDE memory64.htm, winf64.htm, wins.htm, winscon.htm, cpuext64.htm
[.bss] SEGMENT ALIGN=64
EUROASM AutoSegment=yes ; keep using autosegmentation
MsgStart D "Integer Counting Code Challenge",0
MsgUsage D "Usage: numbers.exe <File-With-Numbers>",0
MsgEnd D " Ticks; the number that appears the most is ",0
MsgErr D "File Not Found - ",0
File$ D "1M_random_numbers.txt",0
Buf_t DB 128 * B ; Buffer for Ticks string, atc also as guard
Buf_n DB 128 * B ; Buffer for Number string
align 64
Buf_arr DB 1_000_000 * W ; Aligned Buffer for Input Array of 1M Numbers
Buf_hist DB 1000 * Q ; Histogramm 1000 elts for up to 1000000 nums
theFile DS FILE64
Start: nop ; For Auto Segmentation
StdOutput MsgStart, Eol=Yes, Console=Yes ; Welcome
GetArg 1 ; RCX is the size of arg (bytes); RSI is ptr to the first char.
JC .DefaultFile: ; Report error and show usage if no file was provided.
StripQuotes RSI,RCX ; Get rid of quotes if they were used.
MOV RDI, File$ ; Room for the file name.
REP MOVSB ; Copy the name.
SUB AL,AL
STOSB ; Zero terminate the string.
.DefaultFile:
FileAssign theFile, File$
FileExists? theFile
JC .ErrorFileNotFound
FileStreamOpen theFile, BufSize=16K
MOV R10, Buf_arr
XOR R8, R8 ; reset count lines
.L1:
FileStreamReadLn theFile ; RAX=line size ;RSI=pointer to the line in buffer.
JZ .EOF
LodD ; RSI assumed, parsing stops at LF char; RAX - loaded number
MOV [R10], AX ; store number in U16 Array
ADD R10, 2 ; to the next two bytes
INC R8 ; INCrement Lines (numbers) counter
JMP .L1 ; Next line
.EOF:
FileClose theFile ; No need the File any longer, can be closed now
Clear Buf_hist, Size=4000 ; Clear Buffer, this will also avoid page fault
CMP R8, 0 ; Check if the list empty
JE .L2
;;=======================================================
;; Benchmark start here
;;
CPUID
RDTSC
SHL RDX, 32
OR RAX, RDX
MOV R13, RAX ; R15 will hold initial Time Stamp counter value
MOV R12, 1024 ; benchmark repetitions
Bench:
MOV RCX, Buf_arr
MOV RDX, Buf_hist
MOV R10, R8
SHR R10, 2 ; divide by 4 for unrolling
align 16
.L3: ; Fill Histogram in unrolled loop
MOVZX EAX, [RCX], DATA=W ; Load Number value to EAX
ADD [RDX+RAX*4], 1, DATA=W ; Increment Histogram Bin
MOVZX EBX, [RCX+2], DATA=W ; Load Next number value to EAX
ADD [RDX+RBX*4], 1, DATA=W ; and so on
MOVZX EAX, [RCX+4], DATA=W
ADD [RDX+RAX*4], 1, DATA=W
MOVZX EBX, [RCX+6], DATA=W
ADD [RDX+RBX*4], 1, DATA=W ; unrolled 4 times
ADD RCX, 8 ; Shift to next bytes (2x4)
DEC R10 ; Next Value
JNZ .L3
.L2:
XOR EAX, EAX
XOR R9D, R9D
XOR ECX, ECX
align 16
.L5:
MOV R11D, [RDX]
MOV [RDX], 0, DATA=D ; Reset bin for the next run
CMP ECX, R11D
CMOVL R9D, EAX
CMOVL ECX, R11D
INC EAX
ADD RDX, 4
CMP AX, 1000
JNE .L5
DEC R12
JNZ Bench
RDTSCP
SHL RDX, 32
OR RAX, RDX
SUB RAX, R13 ; Subtract previous stamp
SHR RAX, 10 ; was 1024 runs, therefore divided
;;
;; Benchmark finished, now RAX contains amount of Ticks and R9 is the number
;;=======================================================
Clear Buf_t, Size=256
StoD Buf_t
MOV EAX, R9D ; MAXimal value (index) the number that appears the most.
StoD Buf_n
StdOutput Buf_t, MsgEnd, Buf_n, Eol=Yes, Console=Yes ; Print result
JMP .Exit
.ErrorFileNotFound:
StdOutput MsgUsage, Eol=Yes, Console=Yes
StdOutput MsgErr, File$, Eol=Yes, Console=Yes
.Exit:
TerminateProgram
ENDPROGRAM
And result? Faster than AVX-512.
>numnaive.exe
Integer Counting Code Challenge
1145561 Ticks; the number that appears the most is 142
1145561 ticks on a 3,1 GHz CPU means approximately 370 µs.
Unfortunately, I wasn't able to break the "1 million CPU ticks for 1 million numbers" barrier. In theory, parallelization across multiple threads is possible, but it likely won't yield significant gains due to the overhead of thread creation and result aggregation.
Update 2: Bonus especially for dear Peter Draganov – this LabVIEW code will display not only the most frequently used number, but all frequently used numbers sorted by frequency:
+-------------------------+
| "1M_random_numbers.txt" |
+-----------+-------------+
|
v
+-------------------------------+
| Read Delimited Spreadsheet.vi |<- Transpose = T
+-------------------------------+
|
v
+---------------+
| Convert to Int| (Data Type Conversion to Integer)
+---------------+
|
v
+----------------+
| Histogram.vi |
+----------------+
| +---------------------+
|-------------->| Histogram Graph |
| +---------------------+
|
|
| +--------------------+
| | Ramp by Samples | <--- 1000 (bin count)
| +--------------------+
| |
v v
+-----------------------------------+
| Index & Bundle Cluster Array |
+-----------------------------------+
|
v
+-------------------------+
| Sort 1D Array (Freq.) |
+-------------------------+
|
v
+---------------------+
| Reverse 1D Array |
+---------------------+
|
v
+-------------------+
| Index Array [0] | ---> most used (most frequent value)
+-------------------+
I don't know why images are not allowed in this challenge (LabVIEW is graphical programming environment).
and the result:
most
used | count
142 - 1130
178 - 1101
677 - 1089
4 - 1084
16 - 1083
Links to images if you're interested — Block Diagram and Front Panel.
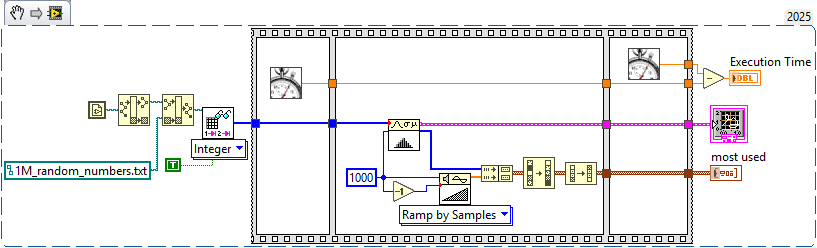{kind=link}
{kind=link}
Execution time is around 10 ms (excluding file read time). It can be improved, but there’s no chance to reach the microseconds range, since LabVIEW is not the fastest tool.
- 4.1k
- 2
- 29
- 39
But the most frequent number is 142 in the set of a million numbers.
But the most frequent number is
142in the set of a million numbers.
Good catch, thank you! I just tested this code on my own randomly generated dataset. For the original file, it correctly returns 142, of course. I've reverted the default file name back to the original and modified the code accordingly.
For this file it takes around 2,600,000 ticks, which means roughly 840 µs on my 3.1 GHz Xeon w5-2445 CPU.
It does not display all numbers if there are several with same count
well, In the phrase "...find the number that appears the most," the wording suggests that we're looking for a single number — specifically, the one with the highest frequency in a dataset. Number, not numberS.
However, if multiple numbers share the same highest frequency, the requirement doesn't clarify whether:
we should return just one of them (e.g., the first one found), or
we should return all numbers that tie for the highest count.
So, this is a question for the PM, so let's stay lazy and not overengineer the solution!
- 12k
- 5
- 53
- 108
What if there were 32 threads with 16 SIMD lanes each, checking their own regions such as first lane of first thread checks only 0 and 1, then increments its own accumulator, second lane first thread checks 2,3, then all others do same and last SIMD lane of last thread checks 998, 999 and increments accumulator. No atomics, no cache-access. Whole bandwidth saved for broadcasting items from array to all threads. If all cores can get same data efficiently, it would take 1M cycles (or 0.2ms for a 5GHz CPU). Is this possible?
What if there were 32 threads with 16 SIMD lanes each
Thread creation overhead is the problem I checked today—just to create 10 threads on Windows, I need around 2 ms. That's too much. Even if I create threads in a suspended state and then resume them, it's still not very efficient. It will work well for billions of numbers, but one million is not much.
- 4.4k
- 2
- 19
- 25
This is really neat, and it looks likely to me that this one will be the fastest submission here.
How fast do you think you could get if you didn't pre-parse the numbers? I know the problem doesn't require that, but do you know of any tricks that could be used to speed that part up?
@jirassimok
Yes, it can be optimized, but the used LodD macros (https://euroassembler.eu/maclib/cpuext64.htm#LodD) is also written in assembly and efficient (though they can be slightly optimized for this particular case, some chacks are non needed). In theory, we could read the whole file into a buffer and then convert the numbers to binary values in a faster way (we need such conversion anyway, since they are used as offsets for the histogram), It’s probably a good exercise for students, but technically not very interesting, much better to prepare file in binary "ready for memory" format.
#include <iostream>
#include <unordered_map>
void mFreq() {
std::unordered_map<int, int> mmap{};
int tmp{};
while (std::cin >> tmp) {
++mmap[tmp];
};
int curr_max{}, curr_max_count{0};
for (const auto& [num, freq] : mmap) {
if (freq > curr_max_count) {
curr_max = num;
curr_max_count = freq;
}
};
std::cout << curr_max << ' ' << curr_max_count << '\n';
};
int main() {
mFreq();
return 0;
};
I decided to take in the input through redirection in order to not need file streams and opening X file with Y name. To me, what made the most sense was to keep an unordered_map of a number and its occurrences. Then I went over the contents of the map and compared the current highest value found with its number of occurrences. If the current frequency was greater than the current_max I updated the values as needed. Finally I just output the result back through stdout. The first number is the value, and the second is the number of occurrences for the value.
*@dsDell:~/Documents/cpp/stackoverflow_challenges/int_counting$ g++ main.cpp -std=c++20 -Wall -o main
*@dsDell:~/Documents/cpp/stackoverflow_challenges/int_counting$ time ./main < 1M_random_numbers.txt
142 1130
real 0m0.292s
user 0m0.288s
sys 0m0.004s
# System Details Report
---
## Report details
- **Date generated:** 2025-09-25 11:17:51
## Hardware Information:
- **Hardware Model:** Dell Inc. Inspiron 14 7425 2-in-1
- **Memory:** 16.0 GiB
- **Processor:** AMD Ryzen™ 7 5825U with Radeon™ Graphics × 16
- **Graphics:** AMD Radeon™ Graphics
- **Disk Capacity:** (null)
## Software Information:
- **Firmware Version:** 1.21.0
- **OS Name:** Ubuntu 24.04.3 LTS
- **OS Build:** (null)
- **OS Type:** 64-bit
- **GNOME Version:** 46
- **Windowing System:** Wayland
- **Kernel Version:** Linux 6.14.0-29-generic
I'm fairly new to programming and to me this was the best approach I could think of for my favorite language. I just learned about structured bindings and thought this was kind of a great time to test them out. I tried to make my own version without use of the STL but I could not seem to beat its runtime.
- 1
- 6
from collections import Counter
def most_frequent_numbers(filename):
# Read all integers from file (one per line or space-separated)
with open(filename) as f:
numbers = [int(x) for line in f for x in line.split()]
# Count frequencies
counter = Counter(numbers)
max_count = max(counter.values())
# Find all numbers with max frequency
most_common = [num for num, count in counter.items() if count == max_count]
return most_common, max_count
if __name__ == "__main__":
# Example: adjust filename to your test file (100, 10,000, or 1,000,000 integers)
nums, freq = most_frequent_numbers("10000_random_numbers.txt")
print("Most frequent number(s):", nums)
print("Frequency:", freq)
How it works
Reads the file into a Python list of integers.
Uses
collections.Counterto count occurrences (O(n) time).Finds the maximum frequency.
Returns all numbers that tie for most frequent.
In fact, we could make it even faster/more memory-efficient by using a fixed-size array of length 1000 instead of Counter. That avoids hashing overhead:
from collections import Counter
def most_frequent_numbers_array(filename):
counts = [0] * 1000 # since numbers are always 0–999
with open(filename) as f:
for line in f:
for x in line.split():
counts[int(x)] += 1
max_count = max(counts)
most_common = [i for i, c in enumerate(counts) if c == max_count]
return most_common, max_count
if __name__ == "__main__":
# Example: adjust filename to your test file (100, 10,000, or 1,000,000 integers)
nums, freq = most_frequent_numbers_array("10000_random_numbers.txt")
print("Most frequent number(s):", nums)
print("Frequency:", freq)
This is the fastest way for this problem, since the domain is fixed and small.
Here are the benchmark results on 1,000,000 integers (0–999):
Method 1: collections.Counter
Time: ~0.16 seconds
Most frequent number:
284Frequency:
23
Method 2: Fixed-size array (length = 1000)
Time: ~0.19 seconds
Most frequent number:
284Frequency:
23
- 41.2k
- 10
- 49
- 90
Your benchmark results for the 1,000,000 integers is erroneously showing results for the 10,000 integers!
import time
import random
def most_frequent_number(numbers):
counts = [0] * 1000
for n in numbers:
counts[n] += 1
max_count = -1
max_num = -1
for i, c in enumerate(counts):
if c > max_count:
max_count = c
max_num = i
return max_num, max_count
if __name__ == "__main__":
test_data = [1, 2, 2, 5, 7, 7, 7, 3, 2]
print("Test result:", most_frequent_number(test_data))
data = [random.randint(0, 999) for _ in range(1_000_000)]
start = time.time()
num, freq = most_frequent_number(data)
end = time.time()
print("Most frequent number:", num)
print("Frequency:", freq)
print("Time taken: %.4f seconds" % (end - start))
Since the input numbers are guaranteed to be in the range 0–999, I didn’t use a dictionary or
collections.Counter.Instead, I allocated a list of size 1000 to act as counters.
As I scan through the list once, I increment the appropriate counter.
After one pass, I just find the index with the highest count.
This solution runs in O(N) time with O(1000) ≈ O(1) space.
- 412
- 1
- 4
- 16
After hours and hours and hours of brainstorming I finally gave up and solved it the most unimaginative way:
using System.Diagnostics;
var timer = Stopwatch.StartNew();
// prepare the counting dictionary of (number, occurances)
var dups = Enumerable.Range(0, 1000).ToDictionary(x => x, x => 0);
// read the file as lines
var res = File
.ReadAllLines("numbers.txt")
// cast to int while at the same time counting the
// occurances in the dictionary and returning the
// number of matches
.Select(x => ++dups[int.Parse(x)])
// take the highest number of matches
.OrderByDescending(x => x)
.Take(1)
// take every key of the dictionary who has the highest number of
// occurances (could be multiple ex aequo)
// also .Select what we want to know as a string for easy logging.
.SelectMany(x => dups.Where(y => y.Value == x).Select(x => $"{x.Key} ({x.Value} times)"))
;
timer.Stop();
Console.WriteLine(string.Join("\n", res.Take(10)));
Console.WriteLine($"ElapsedMs {timer.ElapsedMilliseconds}");
This gave me 1130 occurances of the number 142 as "winner".
I didn't benchmarked the performance in a loop, but repeatingly dotnet running the program gave me times ranging from 93 to 116 ms on my Surface Laptop Studio. (11370H; 32GB; did not bother to shut down all the programs running in the background)
- 4.1k
- 2
- 29
- 39
Just a bit slower than the canonical Python one-liner: with open("numbers.txt") as numbers: print(collections.Counter(numbers).most_common(1))
- 3.4k
- 2
- 11
- 30
Explaination
There is nothing much to explain. I used a 1000 length array (as the integer ranges between 0-999) to track frequencies of each integer. While iterating, I am also tracking integer with the highest frequency to avoid additional iteration to get highest value. The complexity of this is O(N).
I tried multiple approaches, with different Obejct (like array vs List). I also tried adding an additional algorithm for early stopping, however the simplest one was the best one.
To experiment with all these I ended up creating a helper function, benchmarkFunction. Using which I testing the method over 1000 iterations, and have posted the result below
Output & Benchmarking
Most frequent number is '142'. It occured 1130 times
==== Benchmark Results ====
Total executions performed 1000 which took total of 475.21 ms
==== Stats in microseconds ====
Average per execution (microseconds): 475.21
Highest time (microseconds): 4389.10
Lowest time (microseconds): 379.60
==== Stats in milliseconds ====
Average per execution (milliseconds): 0.48
Highest time (milliseconds): 4.39
Lowest time (milliseconds): 0.38
==== ====
Machine Details
Name : 11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz
NumberOfCores : 4
NumberOfLogicalProcessors : 8
MaxClockSpeed : 1382
Total RAM: 15.75 GB
Available RAM: 2.16 MB
Code
import java.io.IOException;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.function.Supplier;
import java.util.stream.LongStream;
public class IntegerCounter {
public static Path downloadFile(String url, String filename) throws IOException, InterruptedException {
Path outputPath = Paths.get(filename);
if (Files.exists(outputPath)) {
return outputPath;
}
System.out.println("Downloading: " + url);
try (HttpClient client = HttpClient.newHttpClient()) {
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.build();
HttpResponse<Path> response = client.send(request,
HttpResponse.BodyHandlers.ofFile(outputPath));
System.out.println("Downloaded to: " + response.body());
return outputPath;
}
}
public static int[] readIntegersFromFile(Path filePath) throws IOException {
return Files.lines(filePath)
.filter(s -> !s.isEmpty())
.mapToInt((s) -> Integer.valueOf(s.trim()))
.toArray();
}
public static int[] mostFrequentInteger(int[] integers) {
int[] frequencies = new int[1000];
int mostFrequent = -1;
int maxFrequency = 0;
for (int num : integers) {
frequencies[num]++;
if (frequencies[num] > maxFrequency) {
maxFrequency = frequencies[num];
mostFrequent = num;
}
}
return new int[] { mostFrequent, maxFrequency };
}
public static <T> void benchmarkFunction(Supplier<T> function, int iterations) {
long[] times = new long[iterations];
for (int i = 0; i < iterations; i++) {
long start = System.nanoTime();
function.get();
long end = System.nanoTime();
times[i] = end - start;
}
long totalTime = LongStream.of(times).sum();
long maxTime = LongStream.of(times).max().getAsLong();
long minTime = LongStream.of(times).min().getAsLong();
double totalMilliseconds = totalTime / 1_000_000.0;
double totalMicroseconds = totalTime / 1_000.0;
double averageMicroseconds = totalMicroseconds / iterations;
double averageMilliseconds = totalMilliseconds / iterations;
double maxMicroseconds = maxTime / 1_000.0;
double maxMilliseconds = maxTime / 1_000_000.0;
double minMicroseconds = minTime / 1_000.0;
double minMilliseconds = minTime / 1_000_000.0;
String decimalFormat = "%-40s %15.2f\n";
System.out.println("==== Benchmark Results ====");
System.out.printf("\nTotal executions performed %d which took total of %.2f ms\n", iterations,
totalMilliseconds);
System.out.println("\n ==== Stats in microseconds ====");
System.out.printf(decimalFormat, "Average per execution (microseconds):", averageMicroseconds);
System.out.printf(decimalFormat, "Highest time (microseconds):", maxMicroseconds);
System.out.printf(decimalFormat, "Lowest time (microseconds):", minMicroseconds);
System.out.println("\n ==== Stats in milliseconds ====");
System.out.printf(decimalFormat, "Average per execution (milliseconds):", averageMilliseconds);
System.out.printf(decimalFormat, "Highest time (milliseconds):", maxMilliseconds);
System.out.printf(decimalFormat, "Lowest time (milliseconds):", minMilliseconds);
System.out.println("==== ====");
}
public static void main(String[] args) throws Exception {
String filename = "1M-integers-list.txt";
String fileUrl = "https://drive.usercontent.google.com/download?id=14kbAC0edO05Z1EIYbZMC6Gpzx1u2yecd&export=download";
Path integerFilePath = downloadFile(fileUrl, filename);
int[] integers = readIntegersFromFile(integerFilePath);
System.out.println("Read " + integers.length + " integers from file.");
int[] result = mostFrequentInteger(integers);
System.out.printf("Most frequent number is '%d'. It occured %d times\n", result[0], result[1]);
benchmarkFunction(() -> mostFrequentInteger(integers), 1000);
}
}
- 149.7k
- 18
- 212
- 258
My Excel-VBA code took less then 3 seconds for 1 million.
I pasted the numbers in column A of Excel.
Option Explicit
Sub Sample()
Debug.Print "Start: " & Now
Debug.Print "The number that appears the most is " & Application.WorksheetFunction.Mode(Sheet1.Columns(1))
Debug.Print "End: " & Now
End Sub
For multiple numbers, use the below code. This took 4 seconds.
Sub Sample()
Debug.Print "Start: " & Now
Dim ws As Worksheet
Set ws = Sheet1
Dim wsNew As Worksheet
Set wsNew = Sheets.Add
Dim LRow As Long
Dim i As Long
Dim Ar As Variant
With wsNew
.Range("A1").Formula = "=MODE.MULT('" & ws.Name & "'!A:A)"
DoEvents
LRow = .Range("A" & .Rows.Count).End(xlUp).Row
Ar = .Range("A1:A" & LRow).Value2
If IsArray(Ar) Then
Debug.Print "The numbers that appears the most are:"
For i = LBound(Ar) To UBound(Ar)
Debug.Print Ar(i, 1)
Next i
Else
Debug.Print "The number that appears the most is " & Ar
End If
End With
Application.DisplayAlerts = False
wsNew.Delete
Application.DisplayAlerts = True
Debug.Print "End: " & Now
End Sub
{kind=link}
Computer Specs
Excel.Application.Name: Microsoft Excel
Excel Version: 16
Excel Build: 19127
Excel Bitness (inferred): 64-bit
Operating System: Microsoft Windows 11 Pro (Build 26100, ver 10.0.26100)
OS Architecture: 64-bit
Computer Manufacturer: Gigabyte Technology Co., Ltd.
Computer Model: X870E AORUS ELITE WIFI7
Total Physical Memory (GB): 31.11 GB
CPU: AMD Ryzen 7 9700X 8-Core Processor
Cores / Logical Processors: 45885
Max Clock (MHz): 3800
GPU (primary): NVIDIA GeForce RTX 3080 Ti
- 23.6k
- 12
- 66
- 81
C#/.NET solution utilizing Span<T> and less allocations
[MemoryDiagnoser(false)]
public class Benchmark
{
[Benchmark]
[Arguments("100_random_numbers.txt")]
[Arguments("10000_random_numbers.txt")]
[Arguments("1M_random_numbers.txt")]
public int GetResult(string fileName)
{
var dict = new Dictionary<int, int>();
using var stream = new FileStream(fileName, FileMode.Open, FileAccess.Read, FileShare.Read);
using var streamReader = new StreamReader(stream);
int numberRead;
Span<char> buffer = new char[4096];
var parsedValue = 0;
while ((numberRead = streamReader.ReadBlock(buffer)) > 0)
{
for (int i = 0; i < numberRead; i++)
{
var item = buffer[i];
if (item != '\n')
{
parsedValue = parsedValue * 10 + (item - '0');
continue;
}
if (dict.TryGetValue(parsedValue, out int value))
{
dict[parsedValue] = ++value;
}
else
{
dict[parsedValue] = 1;
}
parsedValue = 0;
}
}
int max = 0;
int index = 0;
foreach (var pair in dict)
{
if (pair.Value > max)
{
max = pair.Value;
index = pair.Key;
}
}
return index;
}
}
Benchmark results (using https://github.com/dotnet/BenchmarkDotNet)
// * Summary *
BenchmarkDotNet v0.15.3, Windows 10 (10.0.19045.6332/22H2/2022Update)
Intel Core i7-10875H CPU 2.30GHz, 1 CPU, 16 logical and 8 physical cores
.NET SDK 9.0.305
[Host] : .NET 8.0.20 (8.0.20, 8.0.2025.41914), X64 RyuJIT x86-64-v3
DefaultJob : .NET 8.0.20 (8.0.20, 8.0.2025.41914), X64 RyuJIT x86-64-v3
| Method | fileName | Mean | Error | StdDev | Allocated |
|---------- |--------------------- |------------:|----------:|----------:|----------:|
| GetResult | 100_r(...)s.txt [22] | 547.1 μs | 10.94 μs | 10.74 μs | 22.99 KB |
| GetResult | 10000(...)s.txt [24] | 755.0 μs | 14.95 μs | 25.38 μs | 87.23 KB |
| GetResult | 1M_ra(...)s.txt [21] | 14,770.8 μs | 287.13 μs | 294.86 μs | 87.22 KB |
// * Hints *
Outliers
Benchmark.GetResult: Default -> 1 outlier was removed (584.24 μs)
Benchmark.GetResult: Default -> 1 outlier was detected (686.13 μs)
// * Legends *
fileName : Value of the 'fileName' parameter
Mean : Arithmetic mean of all measurements
Error : Half of 99.9% confidence interval
StdDev : Standard deviation of all measurements
Allocated : Allocated memory per single operation (managed only, inclusive, 1KB = 1024B)
1 μs : 1 Microsecond (0.000001 sec)
Using the default methods to read the entire content of file or by line leads to allocation of 30/60/100 MB of memory. Using allocation free Span<T> leads to significant memory optimization (by hundreds of times) and becomes 2-2.5 times faster.
The most appearing numbers (for 100, 10k and 1M integers):
546 (there are multiple numbers appearing twice)
284
142
#include <iostream>
#include <vector>
#include <fstream>
using namespace std;
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
vector<int> freq(1000, 0);
ifstream fin("numbers.txt");
int x;
while (fin >> x) {
freq[x]++;
}
int maxCount = -1, number = -1;
for (int i = 0; i < 1000; i++) {
if (freq[i] > maxCount) {
maxCount = freq[i];
number = i;
}
}
cout << "Most frequent number = " << number
<< " (appears " << maxCount << " times)\n";
return 0;
}
The code is written in PHP:
<?php
if(empty($argv[1]))die("Usage: {$argv[0]} <text file with integers>\n");
if(($fh=@fopen($argv[1],'r'))===FALSE)die("Cannot open {$argv[1]} for reading\n");
while(($l=fgets($fh))!==FALSE){
$l=(int)$l;
if(empty($nums[$l]))$nums[$l]=1;
else $nums[$l]++;
}
$max=max($nums);
echo "Following number(s) appear(s) the most ($max times): ".implode(', ',array_keys($nums,$max,true))."\n";
fclose($fh);
?>
The algorithm is the simplest I first imagined: create an empty array $nums and fill it with counts of each number in the file (keys are the numbers and values are their counts). After all numbers are processed, the number(s) with highest count $max is/are displayed.
Optimisations I made are:
not using trim() (it was necessary, as fgets() returns new line in the string), as casting with (int) is enough.
not initialising $nums=array(), as it is not necessary
using php function array_keys() with strict option for better performance
Here are the results for time execution on a PC with AMD Athlon(tm) II X4 635 Processor, 16GB RAM and HDD (not SSD) WDC WD5000AAKX:
$ time php intcount2.php 1M_random_numbers.txt
Following number(s) appear(s) the most (1130 times): 142
real 0m0.288s
user 0m0.251s
sys 0m0.033s
$ time php intcount2.php 10000_random_numbers.txt
Following number(s) appear(s) the most (23 times): 284
real 0m0.094s
user 0m0.051s
sys 0m0.040s
$ time php intcount2.php 100_random_numbers.txt
Following number(s) appear(s) the most (2 times): 546, 188, 208, 641, 374, 694
real 0m0.093s
user 0m0.055s
sys 0m0.032s
I learned that I can use a filter with array_keys() function.
- 599
- 2
- 8
import time
import random
scratchpad = {}
high = 0
num = 0
## works only if number found is < first elem of list
## -1 means beginning, 1 ends
## list[n] = count(n)
def handlelist(n:int):
global high, num
try:
scratchpad[n]=scratchpad[n]+1
except:
scratchpad[n] = 1
if scratchpad[n] > num:
num = scratchpad[n]
high = n
def start(filepath):
with open(filepath, "r") as f:
while True:
s = f.readline()
if s != "":
handlelist(int(s))
else:
break
def rand(size:int, end:int):
with open("data.txt", "w") as f:
for i in range(size):
val = random.randint(0,end)
f.write(f"{val}\n")
print(f"{val}:{m}")
#rand(10000, 999)
now = time.perf_counter()
start("1M_random_numbers.txt")
after = time.perf_counter()
print(f"{high}:{num}")
print(f"took {after-now}")
1- the file is read one line at the time
2- each read line is matched to the scratchpad
3- if the scratchpad contains the number then increase the count
3.1- if it doesn't just add the number to scratchpad and leave the count to 1
4- repeat for each line read from file
142:1130
took 0.6354131000007328
Machine Details:
Processor: Intel(R) Core(TM) i5-4200U CPU @ 1.60GHz 2.30 GHz
RAM: 6GB
System: Windows 11 23H2 x64
import random
import time
from collections import Counter
numbers = [random.randint(0, 999) for _ in range(1_000_000)]
start_time = time.time()
counter = Counter(numbers)
most_common_num, count = counter.most_common(1)[0]
end_time = time.time()
print(f"Most frequent num: {most_common_num} (appears {count} times)")
print(f"Execution time: {end_time - start_time:.4f} seconds")
The task was to find the number that shows up the most in a huge list of 1 million numbers. Since the numbers only go from 0 to 999, I realized we don’t need anything fancy, just counting how many times each number appears would be enough. I used Python’s Counter because it’s super fast and already optimized in C for counting things. I just let it scan through the whole list once, then picked the number with the highest count. This makes the code O(N) time complexity, which is perfect for large lists. If I wanted to squeeze out even more speed, I could have used a simple array of size 1000 to count occurrences instead of Counter, since the number range is small. That would skip the hashing overhead entirely.
I ran the code in Google Colab using the free GPU/CPU runtime. The list contained 1 million random integers ranging from 0 to 999. Using Python’s collections.Counter to efficiently count occurrences, the most frequent number was found in 0.098 seconds.
What I learned from this challenge is that choosing the right data structure can make a huge difference in performance. Python’s built-in tools, like Counter, are incredibly efficient for tasks like counting occurrences. I also realized that sometimes, a simple approach—like using an array to count numbers when the range is small—can outperform more complex algorithms. Overall, this challenge reinforced the importance of considering both time and space efficiency, especially when working with large datasets.
- 41.2k
- 10
- 49
- 90
You forgot to tell us what the number was and how many times it appeared!
- 51
- 2
def most_frequent_number(filename):
freq = [0] * 1000 # Since numbers range from 0 to 999
with open(filename, 'r') as f:
for line in f:
for num in line.strip().split():
freq[int(num)] += 1
max_count = max(freq)
most_common = freq.index(max_count)
return most_common, max_count
if __name__ == "__main__":
import time
start = time.time()
number, count = most_frequent_number("input_1000000.txt")
end = time.time()
print(f"Most frequent number: {number} (appeared {count} times)")
print(f"Execution time: {end - start:.4f} seconds")
- 2.6k
- 1
- 31
- 44
Approach
- Read the file data, avoiding unnecessary zeroing of the buffer which will just be overwritten by file data immediately afterward. Memory mapping would be faster, but I stuck with platform agnostic C++ rather than call OS-specific API's.
- Parse the number directly (given the known simple constraints of unsigned numbers 0-999) rather than use
std::atoiorstd::from_chars. - Use a simple count table (32-bit integers suffice) knowing numbers range 0-999. Determine the most frequently occurring number (favoring the lower value on ties).
- Build with MSVC using release optimizations set to favor speed.
Code (C++)
#include <iostream>
#include <fstream>
#include <print>
#include <chrono>
#include <algorithm>
const char* fileName = "1M_random_numbers.txt";
//const char* fileName = "10000_random_numbers.txt";
//const char* fileName = "100_random_numbers.txt";
struct FileReadAndCountResult
{
std::chrono::nanoseconds fileReadDuration;
std::chrono::nanoseconds numberCountingDuration;
};
FileReadAndCountResult ReadFileAndCountNumbers();
int main()
{
uint32_t repetitions = 50;
FileReadAndCountResult totalDurations = {};
for (uint32_t i = 0; i < repetitions + 1; ++i)
{
auto timings = ReadFileAndCountNumbers();
if (i > 0) // Skip cold start first iteration.
{
totalDurations.fileReadDuration += timings.fileReadDuration;
totalDurations.numberCountingDuration += timings.numberCountingDuration;
}
}
totalDurations.fileReadDuration /= repetitions;
totalDurations.numberCountingDuration /= repetitions;
std::println("Filename: {}", fileName);
std::println(
"Average file read duration: {} nanoseconds ({} seconds)",
totalDurations.fileReadDuration.count(),
totalDurations.fileReadDuration.count() / 1e9
);
std::println(
"Average number counting duration: {} nanoseconds ({} seconds)",
totalDurations.numberCountingDuration.count(),
totalDurations.numberCountingDuration.count() / 1e9
);
auto combinedDuration = totalDurations.fileReadDuration + totalDurations.numberCountingDuration;
std::println(
"Average total duration: {} nanoseconds ({} seconds)",
combinedDuration.count(),
combinedDuration.count() / 1e9
);
return EXIT_SUCCESS;
}
FileReadAndCountResult ReadFileAndCountNumbers()
{
std::ifstream inputStream(fileName, std::ios::binary);
if (!inputStream.is_open())
{
std::cerr << "Could not open the file - '" << fileName << "'" << std::endl;
return {};
}
std::string dataBuffer;
auto preFileReadTime = std::chrono::high_resolution_clock::now();
{
// Avoid unnecessary zeroing of the buffer which will just be overwritten anyway.
// The transient indeterminate values between resize_and_overwrite and read are irrelevant.
inputStream.seekg(0, std::ios_base::end);
std::size_t fileSize = inputStream.tellg();
inputStream.seekg(0, std::ios_base::beg);
auto dummyResize = [](char* buffer, std::size_t fileSize) noexcept -> size_t { return fileSize;};
dataBuffer.resize_and_overwrite(fileSize, dummyResize);
inputStream.read(dataBuffer.data(), fileSize);
inputStream.close();
}
auto postFileReadTime = std::chrono::high_resolution_clock::now();
int counts[1000] = {};
int currentValue = 0;
int mostFrequentCount = 0;
std::vector<int> mostFrequentValues;
const char* data = dataBuffer.data();
auto preNumberCountingTime = std::chrono::high_resolution_clock::now();
{
// Include the trailing nul character in the processing loop,
// rather than any special handling for the terminal condition.
for (size_t i = 0, dataLength = dataBuffer.size() + 1; i < dataLength; ++i)
{
char c = data[i];
// Given the known limit of numbers 0-999, use faster/simpler logic than std::from_chars.
if (c >= '0' && c <= '9')
{
currentValue = (currentValue * 10) + (c - '0');
}
else
{
if (currentValue < std::size(counts))
{
++counts[currentValue];
}
currentValue = 0;
}
}
// Find the count of the most frequent numbers
// (there could be more than with the same count).
for (int i = 0; i < std::size(counts); ++i)
{
if (counts[i] > mostFrequentCount)
{
mostFrequentCount = counts[i];
}
}
// Collect all the numbers with the same count.
for (int i = 0; i < std::size(counts); ++i)
{
if (counts[i] == mostFrequentCount)
{
mostFrequentValues.push_back(i);
}
}
}
auto postNumberCountingTime = std::chrono::high_resolution_clock::now();
auto fileReadDuration = std::chrono::duration_cast<std::chrono::nanoseconds>(postFileReadTime - preFileReadTime);
auto numberCountingDuration = std::chrono::duration_cast<std::chrono::nanoseconds>(postNumberCountingTime - preNumberCountingTime);
std::println("Most frequent count: {}, values: {}", mostFrequentCount, mostFrequentValues);
std::println("File read duration: {} nanoseconds", fileReadDuration.count());
std::println("Number counting duration: {} nanoseconds", numberCountingDuration.count());
std::println();
return {fileReadDuration, numberCountingDuration};
}
Results
- Filename: 100_random_numbers.txt
- Most frequent values: 188, 208, 374, 546, 641, 694
- Count: 2
- Filename: 10000_random_numbers.txt
- Most frequent value: 284
- Count: 23
- Filename: 1M_random_numbers.txt
- Most frequent value: 142
- Count: 1130
Performance numbers
- Filename: 100_random_numbers.txt (0.00002657s)
- Average file read duration: 26566 nanoseconds
- Average number counting duration: 716 nanoseconds (0.000000716s)
- Filename: 10000_random_numbers.txt (0.00006143s)
- Average file read duration: 38550 nanoseconds
- Average number counting duration: 22882 nanoseconds (0.00002288s)
- Filename: 1M_random_numbers.txt (0.00454427s)
- Average file read duration: 2300598 nanoseconds
- Average number counting duration: 2243674 nanoseconds (0.00224367s)
Machine details
Processor: 13th Gen Intel(R) Core(TM) i7-13700KF (3.40 GHz)
Installed RAM: 48.0 GB (47.9 GB usable)
System type: 64-bit operating system, x64-based processor
Edition: Windows 11 Enterprise, Version 24H2, OS build 26100.6584
- 41.2k
- 10
- 49
- 90
Filename: 100_random_numbers.txt
Most frequent value: 188
Count: 2
Since you're showing results for the 100 integers too, please do note that there are 6 different numbers that appear 'the most'.
- 2.6k
- 1
- 31
- 44
@Sep-Roland: Yeah, I just went with the first tie in that case, but I've updated it to show them all. Btw, love seeing an x86 asm entry 😉 (been a while since I've used NASM/YASM).
- 724
- 11
- 19
"""
Integer counting.
"""
import timeit
from collections import defaultdict
t1 = timeit.default_timer()
freq = defaultdict(int)
with open("1M_random_numbers.txt", 'r') as f:
for line in f:
freq[int(line.strip())] += 1
answer = max(freq, key=freq.get)
print("Max is: ", answer)
t2 = timeit.default_timer()
print(t2-t1)
This takes 0.53 seconds on my laptop. Windows. Processor is Intel i9-12900HK.
The approach is just to go through the list updating a frequency dictionary. Then just returning the key with the maximum value.
- 81
- 8
The insight is that there are only 1000 possible values in the input, and the length of the file will likely be no more than 1000000 * 5, or 5 MB, which is not that large for modern computers.
Rather than being really clever and save memory, I have taken the easy way out. I have coded the contest functionality as a single tcl proc using pure tcl (no extensions).
Open the data file
Read the entire data file into a variable that will be treated as a list
Close the data file
Set the value of variables for the maximum count and number corresponding to the maximum count to -1
Starting with an empty count array, loop through each element of the list read from the input file, for each element:
increment the count array element indexed by the number from the input list, save a copy of the resulting value in a local variable
compare the local variable to the value of the current maximum count variable, if it is greater then update the maximum count variable with the value of the temporary variable and the variable with the corresponding number with the list element value
When the loop completes, return the value of the variable containing the number corresponding to the maximum count
The code for the function itself is:
proc contest filename {
# Open and read the text file containing decimal integers
# in the range 0-999 as a single string. The line terminators
# serve as whitespace between the numbers when the string is treated
# as a tcl list.
set fd [open $filename r]
set list [read -nonewline $fd]
close $fd
# The tcl variable "list" (not to be confused with the tcl command of
# the same name) now contains all of the data for this run.
# Initialize some variables...
set maxcnt -1 ; # A copy of the maximum count seen in the count array
set maxnum -1 ; # The number corresponding to the max count
array set cnt {} ; # Note: This is not really needed
foreach w $list { ; # Run through all numbers in the input string
# Note that incrementing a nonexistent element creates it with val 1
set t [incr cnt($w)]
# compare the count calculated against the maximum we've seen
if {$t > $maxcnt} { ; # new maximum
set maxcnt $t ; # save the maximum
set maxnum $w ; # save the value that corresponds to the maximum
}
} ; # end of loop
# puts stdout "Out of [llength $list] numbers, $maxnum was seen $maxcnt times"
# return the most frequent number ; ties go to the first one seen
return $maxnum
}
# driver code for contest function that prints out a timing
proc test {argv} {
set filename [lindex $argv 0]
if {[file exists $filename]} {
set runtime [time {set m [contest $filename]}]
puts stdout "most frequent number: $m, $runtime"
} else {
puts stderr "Unable to open input file \"$filename\""
}
}
if {($tcl_interactive == 0) && ([llength $argv] > 0)} {
test $argv
}
System I ran it on:
Dell Precision 7820 tower workstation
2 Intel(r) Xeon(r) Silver 4214R CPUs running at 2.4GHz base frequency (total of 24 cores (up to 48 threads) across 2 chips)
96 GiB RAM
Microsoft Windows 11 enterprise
Tcl version 8.6 (BAWT, built with GCC)
From a git bash command line with the downloaded 1,000,000 number data file, the result reported by proc test was 299405 microseconds, and by the "time" command was 1.182s real, and 0 seconds user and sys. I have not had a chance to run it on a Linux system, and I think the user and sys times are not actually measured with git bash on Windows. There is a large discrepancy between the time reported by the code and by the time command in git bash is the AV and other security software that my employer has installed. Removing the data file name from the command line still reports 0.885 seconds for "real"; the difference is 0.297 seconds (297000 microseconds), which is close to the value reported by the printout from the code itself.
I'm certain that this program can be duplicated in python and most likely quite a few other scripting languages. I could also write it in a compiled language, but it would take substantially longer than the 10 minutes it took to write and test this one plus the data generator for the 1,000,000 number file that I first tested on.
$ time /c/Tcl8.6/bin/tclsh contest-entry.tcl
real 0m0.885s
user 0m0.000s
sys 0m0.000s
$ time /c/Tcl8.6/bin/tclsh contest-entry.tcl ../Downloads/1M_random_numbers.txt
most frequent number: 142, 299405 microseconds per iteration
real 0m1.182s
user 0m0.000s
sys 0m0.000s
$
[edit: Updated numbers for the run on the downloaded 1M sample file rather than my own locally generated file and to put the final run's output in.]
- 244.6k
- 27
- 220
- 304
A Perl solution. It keeps a number of occurrences for each number in a hash, at the end it finds the maximal value and outputs the corresponding key.
Takes 0.165s on my machine to process the 1M file.
#!/usr/bin/perl
use warnings;
use strict;
use feature qw{ say };
use List::Util qw{ max first };
my %seen = (0 => 0);
while (<>) {
++$seen{$_};
}
my $max = max(values %seen);
say first { $seen{$_} == $max } keys %seen;
If several numbers have the maximum frequency, it outputs a random one of them.
- 37
- 13
The code is written in C for a maximum speed. On a Apple iMac M3 16GB, Sequoia 15.7 using the "cc" compiler, the calculation takes between 50 to 60ms.
The approach is quite simple: as numbers are only from 0 to 999, I create an array to store the occurrences (which takes 8KB on a 64 bit machine). Then I read the input file and add 1 for each occurence. Then I check the maximum of occurrences after (doing this during the main loop is also possible and does not take extra visible time).
With -O3 (for a maximum of optimization), the code is up to 20% faster (only 50ms as a maximum). The speed of the disk is the main reason for the results. The analyse of the string through isdigit() is faster than using atoi() mainly because we do not scan twice I suppose.
Note if 2 numbers have the same number of occurrences, only the minimum value is displayed.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
#define BUFFER_SIZE 1000
#define LINE_SIZE 100
int main(int argc, char *argv[]) {
char line[LINE_SIZE];
if(argc < 2){
fprintf(stderr, "Usage %s <file>\n", argv[0]);
return 1;
}
FILE *f = fopen(argv[1], "rt");
if(!f){
fprintf(stderr, "Can not open file [%s]", argv[1]);
return 1;
}
int array[BUFFER_SIZE]; // Store the occurences of the numbers
memset(array, 0, BUFFER_SIZE * sizeof(int));
while(fgets(line, LINE_SIZE, f)){
int valid = 0;
int value = 0;
char *c = line;
while(isdigit(*c)){
valid = 1;
value = value * 10 + (*c - '0');
c++;
}
if(value < 0 || value > BUFFER_SIZE){
fprintf(stderr, "Invalid value \"%s\" found.", line);
return 1;
}
if(valid) array[value]++;
}
int imax = array[0];
int i;
for(i = 1; i < BUFFER_SIZE; i++){
if(array[i] > array[imax]) imax = i;
}
fprintf(stdout, "%i\n", imax);
fclose(f);
return 0;
}
- 4.1k
- 2
- 29
- 39
60ms is almost as long as a Python collections.Counter. Are you sure you don't mean microseconds?
- 37
- 13
60ms includes the time to read the file from a SSD disk. I am not sure about the optimization of the Apple computer with their APFS, a "mmap" should be faster to read and process the file.
- 4.1k
- 2
- 29
- 39
I guess the problem is IO bound. It's a bit misleading when attempting to compare implementations because the IO takes such a large proportion of the time. The challenge would be improved by specifically discounting read time for the data, and possibly increasing the number of data points.
C# method to identify the most frequent value in a list of integers.
int? IdentifyMostFrequentNumber(List<int> sourceNumbers)
{
var mostFrequentNumber = new Tuple<int?, int>(null, 0);
while (sourceNumbers.Count > 0)
{
var currentNum = sourceNumbers[0];
var count = sourceNumbers.RemoveAll(x => x == currentNum);
if (count > mostFrequentNumber.Item2)
{
mostFrequentNumber = new(currentNum, count);
}
}
return mostFrequentNumber.Item1;
}
Given a list of integer values as a parameter called sourceNumbers, create a Tuple called mostFrequentNumber that will be used to store and return results.
mostFrequentNumber.Item1 holds the current value with the highest count.
mostFrequentNumber.Item2 holds the count of that value.
While loop continues processing while sourceNumbers contains values.
Process steps:
Identify value held within
sourceNumbers[0].Remove all instances of the value identified in step #1. The RemoveAll() method returns the number of values that were removed. Store that value.
Compare the number of values removed in step #2 with the value held inside
mostFrequentNumber.Item2. If higher, updatemostFrequentNumber.Item1with the value retrieved in step #1 and updatemostFrequentNumber.Item2with the value retrieved in step #2.
After the exit condition is reached, return the value held inside mostFrequentNumber.Item1. If the value is null, the list must have been empty.
If there are multiple numbers that share the highest number of duplicate values, this method will return with the first number that it encounters.
Code execution runtimes:
Running this method 10 times in a row, in a loop:
Test 1
0 - Completed in 1.439096 seconds.
1 - Completed in 1.054102 seconds.
2 - Completed in 1.033286 seconds.
3 - Completed in 1.031074 seconds.
4 - Completed in 1.027072 seconds.
5 - Completed in 1.032201 seconds.
6 - Completed in 1.034445 seconds.
7 - Completed in 1.031518 seconds.
8 - Completed in 1.03722 seconds.
9 - Completed in 1.03466 seconds.
Test 2
0 - Completed in 1.435974 seconds.
1 - Completed in 1.027727 seconds.
2 - Completed in 1.034257 seconds.
3 - Completed in 1.033122 seconds.
4 - Completed in 1.034453 seconds.
5 - Completed in 1.041108 seconds.
6 - Completed in 1.035168 seconds.
7 - Completed in 1.036804 seconds.
8 - Completed in 1.037052 seconds.
9 - Completed in 1.041603 seconds.
Test 3
0 - Completed in 1.426722 seconds.
1 - Completed in 1.033837 seconds.
2 - Completed in 1.034194 seconds.
3 - Completed in 1.028629 seconds.
4 - Completed in 1.026413 seconds.
5 - Completed in 1.028895 seconds.
6 - Completed in 1.025808 seconds.
7 - Completed in 1.033369 seconds.
8 - Completed in 1.030351 seconds.
9 - Completed in 1.035759 seconds.
The first execution usually takes between 1.4-1.5 seconds. Subsequent executions normally fall between 1.02 and 1.06 seconds.
The machine that this was tested/developed on is a MacBook with Apple M2 Pro Chip (12 cores) and 32GB of RAM.
This was an interesting project. I had to write a few different versions before I was happy with the result.
- 1.8k
- 1
- 16
- 24
sort -n FILE | uniq -c | sort -n | tail -1 | awk -F' ' '{print $NF}'
Algorithm
Use a Linux pipeline, consisting of five stages.
The
sort -ncommand sorts the list of numbers numerically.Given a sorted list, the
uniq -ccommand outputs the number of appearances of a number, followed by the number itself, e.g.1130 142tells that 142 has appeared 1130 times.Apply
sort -nagain, to sort by the number of appearancesSelect the last line, i.e. the one containing the number appearing most often.
Return the second part of the last line only, i.e. the number in question.
Tests
$ time sort -n 100_random_numbers.txt | uniq -c | sort -n | tail -1 | awk -F' ' '{print $NF}'
694
real 0m0.003s
user 0m0.007s
sys 0m0.000s
$ time sort -n 10000_random_numbers.txt | uniq -c | sort -n | tail -1 | awk -F' ' '{print $NF}'
284
real 0m0.007s
user 0m0.009s
sys 0m0.002s
$ time sort -n 1M_random_numbers.txt | uniq -c | sort -n | tail -1 | awk -F' ' '{print $NF}'
142
real 0m0.217s
user 0m1.046s
sys 0m0.032s
My machine:
$ uname -a
Linux sebastian-t480s 6.12.38+deb13-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.12.38-1 (2025-07-16) x86_64 GNU/Linux
Time Complexity
The sorting algorithm in coreutils has a runtime complexity of O(n log n), uniq, tail and awk all show O(n). Overall, the pipeline has a runtime complexity of
O(n log n) + O(n) + O(n log n) + O(n) + O(n), which reduces to O(n log n).
No solution based on sorting will reach faster worst-case time complexity.
Are there any solutions which do not require sorting?
- 4.4k
- 2
- 19
- 25
Yes: you only need to tally the numbers, which is O(n), and find the maximum of the tally, which is O(1) with the limited range of numbers, or O(k) if there are k unique numbers.
But I don't think the standard shell utilities can do this, at least not without a shell script.
- 1.8k
- 1
- 16
- 24
I did it above, just run the script, did you read my answer @jirassimok?
- 4.4k
- 2
- 19
- 25
Er, I mean, I don't think the standard utilities can do it without the sorting step(s).
- 4.1k
- 2
- 29
- 39
Even though it took a whole second to run this solution saved minutes in coding. This is the quickest solution.
- 12k
- 5
- 53
- 108
Can you benchmark this within a RAMDISK?
- 1.8k
- 1
- 16
- 24
You mean using tmpfs Huseyin? Good point, I will give it a try.
- 107
- 1
- 5
Download 1milion record text file
in SQL Server in a database, by using Import data, the text File Imported to SQL Server 2019 database (randomnumber tablename).
Optimized table by changing the File type to smallint and not null.
because data are between 0-999 so smallint which is up to 32767 is the good choice. Smallint takes 2Bytes Space.
also data are from 0 to 999 so there is no null value. and setting the Value to not null omits 1 bit per nullable column rounded up to a byte which totally in 1 million records reduces 1 million bit(reduce125000 Byte), also the overhead on NULL bitmap.
reduce size of files causes to data stored in fewer pages and extents. and so faster it can be accessed by SQL Server.
-
set statistics io on -- for Checking statistics set statistics time on -- Requested Query select top(1) number, count(number) as Cnt from [dbo].[RandomNumber] group by number order by Cnt desc -
Statistics: Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. Table 'RandomNumber'. Scan count 9, logical reads 1359, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 342 ms, elapsed time = 63 ms. The system was corei7-8565U with Ram 8Gig Windows 10.
It goes very fast. all procedure takes less than a minute to do, but not not my explanations :))
#include <stdio.h>
int main(){
int size = 1000;
int num_frequency[size];
for(int i = 0; i < size; i += 1){
num_frequency[i] = 0;
}
char filename[] = "1_million_integers.txt";
FILE* integers_file = fopen(filename, "r");
int num;
while(fscanf(integers_file, "%d", &num) != -1){
num_frequency[num] += 1;
}
fclose(integers_file);
int max_frequency = -1;
int num_with_max_frequency = -1;
for(int i = 0; i < size; i += 1){
if(num_frequency[i] > max_frequency){
max_frequency = num_frequency[i];
num_with_max_frequency = i;
}
}
printf("%d appears the most.\n", num_with_max_frequency);
return 0;
}
A really simple solution to the challenge made in C.
The program read the number one by one, stores their frequency in an array and finds the number number with the highest frequency.
In case of multiple numbers having maximum frequency, the program chooses the lowest number.
Output
142 appears the most.
I ran the program multiple times and this is the lowest I got
real 0m0.205s
user 0m0.000s
sys 0m0.000s
My machine specs
CPU: AMD Ryzen 5 5600H
RAM : 16GB
OS : Windows 11 Pro
- 2.6k
- 1
- 31
- 44
🤔 Hmm, 0.205s seems pretty high for C code on that machine, given I'm getting 0.004 with my [C++ implementation](https://stackoverflow.com/beta/challenges/79766578/79774328), which is near some other C implementation timings below. Maybe double check that you compiled for release mode?
Awesome challenge. Since values are bounded [0..999], the fastest approach is a single streaming pass that updates a fixed-size counter array of length 1000. This is O(n) time, O(1) extra space, cache-friendly, and I/O-bound on large files.
Below are production-ready solutions plus how to run and benchmark them. All stream the file once and never store all 1M numbers in RAM.
// g++ -O3 -march=native -std=c++20 most_frequent.cpp -o most_frequent
// Usage: ./most_frequent path/to/input.txt
#include <bits/stdc++.h>
using namespace std;
int main(int argc, char** argv) {
ios::sync_with_stdio(false);
cin.tie(nullptr);
if (argc != 2) {
cerr << "Usage: " << argv[0] << " <path>\n";
return 1;
}
FILE* f = fopen(argv[1], "rb");
if (!f) { perror("fopen"); return 1; }
static int counts[1000];
static unsigned char buf[1 << 20];
int num = 0;
bool in_num = false;
while (true) {
size_t n = fread(buf, 1, sizeof(buf), f);
if (n == 0) break;
for (size_t i = 0; i < n; ++i) {
unsigned char c = buf[i];
if (c >= '0' && c <= '9') {
in_num = true;
num = num * 10 + (c - '0');
} else {
if (in_num) {
counts[num]++;
num = 0;
in_num = false;
}
}
}
}
if (in_num) counts[num]++;
int best_val = 0, best_cnt = counts[0];
for (int v = 1; v < 1000; ++v) {
if (counts[v] > best_cnt) {
best_cnt = counts[v];
best_val = v;
}
}
cout << best_val << " " << best_cnt << "\n";
return 0;
}
- 4.1k
- 2
- 29
- 39
Yeah but how long did it actually take though (and what's the answer)?
- 425
- 6
- 13
This Java code produces a list of 1mil random integers from 0 to 999 (inclusive) and then invokes a function to find the most frequent number.
public static void main(String[] args) {
int[] a = new int[1_000_000];
for (int i=0; i<a.length; i++)
a[i] = (int)(Math.random()*1000);
System.out.println(mostCommon(a));
}
public static int mostCommon(int[] a) {
int[] frequencyTable = new int[1000];
int maximum = 0;
for (int num : a)
if (++frequencyTable[num] > frequencyTable[maximum])
maximum = num;
return maximum;
}
Generating the numbers and solving the problem takes less than 1sec when running this code in the Eclipse IDE for Java Developers (Version: 2023-06 (4.28.0)).
The idea exploits the fact that numbers are known, in advance, to fall within 0 to 999. We build a frequency table which increments the value tallied for i every time the value i is encountered in the input array.
As the frequency table is populated, the maximum is also maintained and if a new number is incremented to be beyond the previously-known maximum, the maximum variable is updated to this new number.
This code is 'optimized' to run in a single pass of the input array and maintains the maximum 'on the fly' rather than a typical approach which might first build the entire frequency table and then, afterward, scan the frequency table to find the maximum entry.
I'm submitting it because Java is not as cool and popular as some other languages that others would likely be submitting.
For the first time I tried to use Kotlin for something. Coming from python it was hard trying to figure out how Kotlin works. The way I got the time seems to not be a good way to measure it, giving a slightly different output everytime.
Code execution runtime:
~110 ms, best I got was 105ms
Approach:
I read the file line by line and count in a dictionary/map how many times a number has appeared.
Then the program goes through the list and notes how many times the number appears. At the end I go through the dictionary/map to see which number appeared the most.
I didn't make any big effort for the program to be fast.
Details about my pc:
Lenovo Legion 5
AMD Ryzen 5 5600H
32GiB of Ram
RTX 3060 Laptop
Code
import java.io.File
import java.io.InputStream
import java.util.Dictionary
import kotlin.reflect.typeOf
import kotlin.system.measureTimeMillis
fun main() {
val time = measureTimeMillis {
var thismap = mutableMapOf<Int, Int>()
val inputStream: InputStream = File("1M_random_numbers.txt").inputStream()
val lineList = mutableListOf<String>()
inputStream.bufferedReader().forEachLine {
if (it.toInt() in thismap) {
var previous = thismap[it.toInt()]
if (previous != null) {
thismap[it.toInt()] = 1 + previous
}
} else {
thismap[it.toInt()] = 1
}
//if (it.toInt() in thismap) thismap[it.toInt()] = 1 + thismap[it.toInt()] else thismap[it.toInt()] = 1
}
var highestNumber = intArrayOf(0, 0)
for (p in thismap) {
if (p.value > highestNumber[0]) highestNumber = intArrayOf(p.value, p.key)
}
println(highestNumber.contentToString())
}
println(time)
}
- 18.6k
- 24
- 38
- 56
Code:
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main (int argc, char **argv) {
// Open file in first argument
int fd = open(argv[1], O_RDONLY);
if (fd < 0) {
perror("open");
exit(EXIT_FAILURE);
}
// Determine file size
struct stat sb;
int st = fstat(fd, &sb);
if (st < 0) {
perror("fstat");
exit(EXIT_FAILURE);
}
// Map file contents into memory
char *ptr = mmap(NULL, sb.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
if (ptr == MAP_FAILED) {
perror("mmap");
exit(EXIT_FAILURE);
}
// Define array to store counts and value/index of currently
// most frequent number
int arr[1000] = { 0 };
int maxval = 0, maxidx = 0;
int idx = 0;
for (int i = 0; i < sb.st_size; i++) {
if (ptr[i] == '\n') {
// We should have seen a full number by now
arr[idx]++;
if (arr[idx] > maxval) {
maxval = arr[idx];
maxidx = idx;
}
idx = 0;
} else {
// Build number from individual digits
idx = idx * 10 + ptr[i]-'0';
}
}
printf("Most frequent number is %d (%d)\n", maxidx, maxval);
exit(EXIT_FAILURE);
}
Approach:
Try to minimize random memory accesses, system calls and library calls. Track maximum count and associated number live. The code is Posix compliant, but not otherwise portable.
Runtime:
$ time ./foo 1M_random_numbers.txt
Most frequent number is 142 (1130)
real 0m0,003s
user 0m0,002s
sys 0m0,000s
$ time ./foo 100M_random_numbers.txt #Original file 100 times concatenated
Most frequent number is 142 (113000)
real 0m0,254s
user 0m0,238s
sys 0m0,016s
Machine: Lenovo Thinkpad X1 Yoga (Core i7-1165G7 @2.80GHz, 32GB Ram)
Learnings:
1M random numbers is a bit few to perform meaningful benchmarks.
- 1.9k
- 25
- 37
In ruby this can easily be performed by the tally method that ruby 2.7 introduced, it does the heavy lifting of counting occurrences:
# numbers.rb
numbers = File.read('1M_random_numbers.txt').split("\n").map(&:to_i)
frequency_count = numbers.tally
max_frequency_count = frequency_count.values.max
puts frequency_count.find{|number,count| count == max_frequency_count}[0]
Ruby is perhaps considered slow, but with a response within < 0.2s I'm ok, no priority to optimise it any further:
$ ruby -v
ruby 3.4.5 (2025-07-16 revision 20cda200d3) +PRISM [arm64-darwin24]
$ time ruby numbers.rb
142
ruby numbers.rb 0,16s user 0,03s system 77% cpu 0,258 total
- 4.1k
- 2
- 29
- 39
Interesting to compare the Ruby approach. 0.2s is about twice as long as the standard Python one liner (with open("numbers.txt") as numbers: print(collections.Counter(numbers).most_common(1)))
Approach:
Use multiple concurrent workers with global atomic counters for each number.
Premises:
file is small, about 4MB.
numbers in the file are limited to 3 digits and each line ends with
LF.memory is abundant and speed is the main goal.
Optimizations:
load entire file to memory.
do not convert each number from the text representation, work with the character bytes.
avoid (re)allocations whenever possible.
reduce conditional branches.
avoid locks.
Execution:
Average execution time: 111.6 ms, measured with hyperfine.
.\hyperfine.exe --warmup 3 --runs 100 '.\challenge_stackoverflow.exe'
Benchmark 1: .\challenge_stackoverflow.exe
Time (mean ± σ): 111.6 ms ± 1.7 ms [User: 64.5 ms, System: 81.7 ms]
Range (min … max): 107.9 ms … 119.9 ms 100 runs
Machine:
AMD Ryzen 7 2700 8 cores, 16 threads
32 GB DDR4-2666 (2x16)
Generic NVMe SSD 256GB
Lessons and challenges:
Working with
Atomicsin rust.Share data with threads, fighting the borrow checker.
Usage of
Vec::leak()to have a static heap-allocatedVec.
Result:
Number: 142, count: 1130
Code:
Coded in rust, only depending on std.
use std::{fs::{self, File}, io::Read, sync::atomic::{AtomicU32, Ordering}, thread};
// Constants
static LINE_FEED_U8: u8 = 10u8;
static ZERO_ASCII: usize = 48usize;
// Global counter
static BYTE_COUNTERS: [[[AtomicU32; 256]; 256]; 256] = [const { [const { [const { AtomicU32::new(0) }; 256] }; 256] }; 256];
fn main() {
// Load file to memory
let list_size_bytes = fs::metadata("1M_random_numbers.txt").unwrap().len();
let mut number_list: Vec<u8> = Vec::with_capacity(list_size_bytes.try_into().unwrap());
let mut file = File::open("1M_random_numbers.txt").unwrap();
file.read_to_end(&mut number_list).unwrap();
// Convert the loaded list to a static reference
let number_list: &'static [u8] = number_list.leak();
// Configure workers
let number_workers = thread::available_parallelism().unwrap().get();
let index_step = usize::try_from(list_size_bytes).unwrap() / number_workers;
// Spawn threads
let mut workers = Vec::with_capacity(number_workers);
for worker_number in 0..number_workers {
let start_index_hint = worker_number * index_step;
let end_index_hint = (worker_number + 1) * index_step;
workers.push(thread::spawn(move || count(number_list, start_index_hint, end_index_hint)));
}
// Wait all workers to finish
for worker in workers {
worker.join().unwrap();
}
// Find the number with biggest counter
let mut bytes = (0usize, 0usize, 0usize);
let mut max_counter = 0u32;
for first in BYTE_COUNTERS.iter().enumerate() {
for second in first.1.iter().enumerate() {
for third in second.1.iter().enumerate() {
let counter = third.1.load(Ordering::SeqCst);
if counter > max_counter {
max_counter = counter;
bytes = (first.0, second.0, third.0);
}
}
}
}
// Display result
let bytes = &[u8::try_from(bytes.0).unwrap(), u8::try_from(bytes.1).unwrap(), u8::try_from(bytes.2).unwrap()];
let number = String::from_utf8_lossy(bytes);
println!("Number: {number}, count: {max_counter}");
}
// Working function
fn count(byte_list: &[u8], start_index_hint: usize, end_index_hint: usize) {
// Calculate the indexes to create a slice as [...LF][working_slice ending with LF][...]
let start_index = worker_start_index(byte_list, start_index_hint);
let end_index = worker_end_index(byte_list, end_index_hint);
// Create the work window
let worker_slice = &byte_list[start_index..end_index];
for byte_slice in worker_slice.split(|byte| *byte == LINE_FEED_U8) {
match byte_slice.len() {
3 => {
BYTE_COUNTERS[usize::from(byte_slice[0])]
[usize::from(byte_slice[1])]
[usize::from(byte_slice[2])].fetch_add(1, Ordering::SeqCst);
},
2 => {
BYTE_COUNTERS[ZERO_ASCII]
[usize::from(byte_slice[0])]
[usize::from(byte_slice[1])].fetch_add(1, Ordering::SeqCst);
},
1 => {
BYTE_COUNTERS[ZERO_ASCII]
[ZERO_ASCII]
[usize::from(byte_slice[0])].fetch_add(1, Ordering::SeqCst);
},
_ => continue
}
}
}
// Index of the first byte after line feed, or beginning of slice
fn worker_start_index (byte_list: &[u8], mut start_index: usize) -> usize {
if start_index == 0 {return 0};
while byte_list[start_index] != LINE_FEED_U8 {start_index += 1}
start_index + 1
}
// Index of the first line feed after end_index, or at end_index, or the last index
fn worker_end_index (byte_list: &[u8], mut end_index: usize) -> usize {
while (byte_list[end_index] != LINE_FEED_U8) && (end_index < byte_list.len()) {
end_index += 1
}
end_index
}
Edit - current best code:
Still using Atomics, best result 18.7ms average in hyperfine. Internal timers show about 8ms.
use std::{fs::{self, File}, io::Read, sync::atomic::{AtomicU32, Ordering}, thread};
use std::time::Instant;
// Aliases
type CounterType = AtomicU32;
// Constants
static LINE_FEED_U8: u8 = 10u8;
static ZERO_ASCII: usize = 48usize;
// Global counter
static NUMBER_COUNTERS: [CounterType; 1000] = [const { CounterType::new(0) }; 1000];
fn main() {
// Load file to memory
let start_time = Instant::now();
let list_size_bytes = fs::metadata("1M_random_numbers.txt").unwrap().len();
let mut number_list: Vec<u8> = Vec::with_capacity(list_size_bytes.try_into().unwrap());
let mut file = File::open("1M_random_numbers.txt").unwrap();
file.read_to_end(&mut number_list).unwrap();
// Convert the loaded list to a static reference
let number_list: &'static [u8] = number_list.leak();
// Time
let elapsed_time = start_time.elapsed(); println!("File load: {} µs", elapsed_time.as_micros()); let start_time = Instant::now();
// Configure workers
let number_workers = thread::available_parallelism().unwrap().get();
let index_step = usize::try_from(list_size_bytes).unwrap() / number_workers;
// Spawn threads
let mut workers = Vec::with_capacity(number_workers);
for worker_number in 0..number_workers {
let start_index_hint = worker_number * index_step;
let end_index_hint = (worker_number + 1) * index_step;
workers.push(thread::spawn(move || count(number_list, start_index_hint, end_index_hint)));
}
// Wait all workers to finish
for worker in workers {
worker.join().unwrap();
}
// Time
let elapsed_time = start_time.elapsed(); println!("Thread spawn and work: {} µs", elapsed_time.as_micros()); let start_time = Instant::now();
// Find the number with biggest counter
let mut number = 0usize;
let mut max_counter = 0;
for item in NUMBER_COUNTERS.iter().enumerate() {
let counter = item.1.load(Ordering::SeqCst);
if counter > max_counter {
max_counter = counter;
number = item.0;
}
}
// Time
let elapsed_time = start_time.elapsed(); println!("Find most ocurring: {} µs", elapsed_time.as_micros());
// Display result
println!("Number: {number}, count: {max_counter}");
}
// Working function
fn count(byte_list: &[u8], start_index_hint: usize, end_index_hint: usize) {
// Calculate the indexes to create a slice as [...LF][working_slice ending with LF][...]
let start_index = worker_start_index(byte_list, start_index_hint);
let end_index = worker_end_index(byte_list, end_index_hint);
// Create the work window
let worker_slice = &byte_list[start_index..end_index];
let mut number = 0usize;
for byte in worker_slice {
if byte != &LINE_FEED_U8 {
number = number * 10 + usize::from(*byte) - ZERO_ASCII
} else {
NUMBER_COUNTERS[number].fetch_add(1, Ordering::SeqCst);
number = 0usize;
}
}
}
// Index of the first byte after line feed, or beginning of slice
fn worker_start_index (byte_list: &[u8], mut start_index: usize) -> usize {
if start_index == 0 {return 0};
while byte_list[start_index] != LINE_FEED_U8 {start_index += 1}
start_index + 1
}
// Index of the first line feed after end_index, or at end_index, or the last index
fn worker_end_index (byte_list: &[u8], mut end_index: usize) -> usize {
while (end_index < byte_list.len()) && (byte_list[end_index] != LINE_FEED_U8) {
end_index += 1
}
end_index
}
- 187
- 3
- 15
I opted for Python as it is the language I'm most familiar with. Using a dictionary to assign a number of occurence for each number then looking for the highest number in it gives a simple but working (hopefully) solution:
The files are stored in ./CodingChallenge/
I didn't count file loading and printing the result when timing the file
import timeit
Numbers = []
with open('CodingChallenge/1M_random_numbers.txt') as fv:
for row in fv:
Numbers.extend(map(int, row.split()))
freq = {}
mostNum = 0
start = timeit.default_timer()
for n in Numbers:
if n in freq:
freq[n] += 1
else:
freq[n] = 1
mostFreq = max(freq, key=freq.get)
mostNum = max(freq.values())
stop = timeit.default_timer()
print(f'Most frequent key, {mostFreq}, seen {mostNum} times.')
print('Time: ', stop - start, 's')
Output: (100_random_numbers)
Most frequent key, 546, seen 2 times.
Time: 4.8600020818412304e-05 s
Output: (10000_random_numbers)
Most frequent key, 284, seen 23 times.
Time: 0.002151799970306456 s
Output: (1M_random_numbers)
Most frequent key, 142, seen 1130 times.
Time: 0.2203453000402078 s
- 4.1k
- 2
- 29
- 39
with open("numbers.txt") as numbers: print(collections.Counter(numbers).most_common(1)) - 87 ms.
- 187
- 3
- 15
@NeilG , I didn't want to use packages, using a black box feels against the concept
The C version is most likely to be the fastest for this number-counting task, and I have an Intel i9-13900K to test this code. I achieved 5ms by adjusting it according to the cores using GCC 12.2.
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <time.h>
#include <omp.h>
#define RANGE 1000
int main(int argc, char *argv[]) {
if (argc < 2) {
fprintf(stderr, "Usage: %s <input_file>\n", argv[0]);
return 1;
}
// Open file
int fd = open(argv[1], O_RDONLY);
if (fd == -1) {
perror("Error opening file");
return 1;
}
// Get file size
struct stat st;
if (fstat(fd, &st) == -1) {
perror("fstat failed");
close(fd);
return 1;
}
size_t file_size = st.st_size;
// Memory-map file
char *data = mmap(NULL, file_size, PROT_READ, MAP_PRIVATE, fd, 0);
if (data == MAP_FAILED) {
perror("mmap failed");
close(fd);
return 1;
}
close(fd);
int global_counts[RANGE] = {0};
int num_threads = omp_get_max_threads();
clock_t start = clock();
#pragma omp parallel
{
int local_counts[RANGE] = {0};
size_t start_idx, end_idx;
int tid = omp_get_thread_num();
size_t chunk_size = file_size / num_threads;
start_idx = tid * chunk_size;
end_idx = (tid == num_threads - 1) ? file_size : (tid + 1) * chunk_size;
// Adjusting boundaries to avoid splitting numbers
if (tid > 0) {
while (start_idx < file_size && data[start_idx] >= '0' && data[start_idx] <= '9')
start_idx++;
}
if (tid < num_threads - 1) {
while (end_idx < file_size && data[end_idx] >= '0' && data[end_idx] <= '9')
end_idx++;
}
int number = 0, in_number = 0;
for (size_t i = start_idx; i < end_idx; i++) {
char c = data[i];
if (c >= '0' && c <= '9') {
number = number * 10 + (c - '0');
in_number = 1;
} else if (in_number) {
local_counts[number]++;
number = 0;
in_number = 0;
}
}
if (in_number) local_counts[number]++;
// Reducing into global counts
#pragma omp critical
{
for (int j = 0; j < RANGE; j++) {
global_counts[j] += local_counts[j];
}
}
}
munmap(data, file_size);
int most_frequent_value = -1, highest_frequency = -1;
for (int i = 0; i < RANGE; i++) {
if (global_counts[i] > highest_frequency) {
highest_frequency = global_counts[i];
most_frequent_value = i;
}
}
clock_t end = clock();
double elapsed = (double)(end - start) / CLOCKS_PER_SEC;
printf("Most frequent number: %d\n", most_frequent_value);
printf("Occurrences: %d\n", highest_frequency);
printf("Runtime: %.6f seconds\n", elapsed);
return 0;
}
- 4.4k
- 2
- 19
- 25
I agree that C is probably the best way to get this done fast, but there are quite a few optimizations you can do to improve over a single fscanf loop.
Edit: Those are some nice improvements.
- 4.4k
- 2
- 19
- 25
Two billion numbers per second
My solution is in C, and takes about 2.3 milliseconds to process the million-number file on my machine (including startup time and parsing all the numbers).
Using a timer built in to the program, I was also able to exclude startup time from the benchmarking, and found that the actual parsing-and-counting portion of the program takes about 1.5 milliseconds for the test file, or 0.44 milliseconds when run on better hardware.
On a billion-number file, it takes about half a second, or a closer to one second if you don't give it extra threads.
My code can be found at the end of this post, or on GitHub.
Design and optimization
To make the challenge more interesting, I chose to include parsing the numbers from the file as part of my program, as it adds a few extra steps to the problem.
My basic approach is pretty simple: I mmapp the file, divide it into
several chunks, and have separate threads read each chunk one byte at
a time. Then, the main thread tallies up all the results and prints
the most-common number.
To count the numbers across several threads, I give each thread a
struct (thread_params) that stores an array of the numbers and the
start and end positions for the thread's work. One of my minor
optimizations was to add a small padding array at the end of that
struct, so every thread's data would be aligned to the start of a
memory page.
The main processing of the data occurs in the very last function,
count_numbers_internal. I tested several optimizations of the main
loop, and while some did have a noticeable impact when I implemented
them, only one set carried through to the end:
If the program is compiled with the ASSUME_VALID macro defined, all
checks of the data in the file are disabled. This allows a malformed
input file to trigger undefined behavior (usually either incorrect
tallies or segfaults), but produces a speedup of 20% to 40% on
billion-line files, or around 20% on million-line files.
There's one more optimization I locked behind a compiler macro: in a
valid input file, a newline is always followed by a digit, so after
processing a newline, there's no need to check if the next character
is one. With a FALL_LINES macro set, I skip that check and assume
the character after a newline is a digit. With a one-million-number
file, this optimization produces a speedup of around 10% when compiled
with GCC, and a slightly smaller slowdown with Clang.
Besides those code-level optimizations, the inner loop function itself is marked as not inlinable, because at one stage in development, it would suffer a slowdown of 40% or more when inlined.1
I also added two post-compilation configuration options: you can set the number of threads to use, and you can make the program output every most-common number instead of just one. Further details on this are in the "Code and usage" section.
1 I didn't dig too far into the cause of this, but I did
disassemble the code, and the only differences were which registers
were used and a single register-specific instruction (cdqe), so it
doesn't seem like it was just confusing the optimizer.
Performance
All of my tests were run on an Intel i7-1355U (with 10 physical cores, 12 virtual), with 32GB of memory. My storage is encrypted, which likely introduces a small overhead when accessing the file.
Full-program performance
Here is my result matrix for the test file, in milliseconds, across
1000 runs, with each configuration of my program (sorted by time). The
A column indicates the ASSUME_VALID flag, and F indicates
FALL_LINES. The table was generated using the script below.
| cc | A | F | msec. | % |
|-------+---+---+-------|-------|
| clang | y | | 2.305 | 1 |
| gcc | y | y | 2.445 | 1.061 |
| gcc | y | | 2.490 | 1.080 |
| clang | y | y | 2.535 | 1.100 |
| gcc | | y | 2.559 | 1.110 |
| gcc | | | 2.704 | 1.173 |
| clang | | | 2.794 | 1.212 |
| clang | | y | 2.854 | 1.238 |
As can be seen in the table, for the million-number file, the program is fastest when compiled with Clang, with the data-validity checks disabled, taking an average of about 2.3 milliseconds.
And here's the table for a billion-number file I made (based on just the best of two runs of 10 for each configuration), with the times in seconds:
| cc | A | F | sec. | % |
|-------+---+---+--------+-------|
| clang | y | | 0.8733 | 1. |
| clang | y | y | 0.9439 | 1.081 |
| gcc | y | y | 0.9496 | 1.087 |
| gcc | y | | 0.9728 | 1.114 |
| gcc | | y | 1.0565 | 1.210 |
| clang | | | 1.1378 | 1.303 |
| gcc | | | 1.1592 | 1.327 |
| clang | | y | 1.1905 | 1.363 |
On average, my program takes around 0.9 seconds to process one billion numbers (over 3.6GiB of text). And if you give it more threads, it gets even faster. Here are the results with 12 threads (best of 5 runs of 10), with the times in seconds:
| cc | A | F | sec. | % |
|-------+---+---+--------+-------|
| gcc | y | y | 0.4952 | 1. |
| gcc | y | | 0.4968 | 1.003 |
| clang | y | | 0.5212 | 1.053 |
| gcc | | y | 0.5425 | 1.096 |
| gcc | | | 0.5939 | 1.199 |
| clang | y | y | 0.5966 | 1.205 |
| clang | | | 0.7062 | 1.426 |
| clang | | y | 0.7411 | 1.497 |
In this case, GCC's version starts to outperform Clang's, though not by quite as much as Clang beat GCC for the earlier cases, though the version that validates data and was compiled with Clang is much slower by comparison.
Parse/tally performance
Most of my performance analysis looked at the full runtime of the program, but I eventually added an internal timer, which I was able to use with a shell script (included below) to generate additional benchmarks. Here, I've replicated the first table above using the new benchmark.
| cc | A | F | msec. | % |
|-------+---+---+-------+-------|
| clang | y | | 1.501 | 1 |
| gcc | y | y | 1.589 | 1.058 |
| gcc | y | | 1.614 | 1.075 |
| clang | y | y | 1.625 | 1.083 |
| gcc | | y | 1.775 | 1.182 |
| clang | | | 1.910 | 1.272 |
| gcc | | | 1.926 | 1.283 |
| clang | | y | 1.957 | 1.303 |
M4 Mac benchmarks
I also performed a limited set of benchmarks on a 10-core M4 Macbook Pro, using the configuration of the program that performed best on the previous benchmarks, with impressive results.
In this table, the first column is the number of threads, the second column is average time spent processing the file (as in the previous table), and the third column is total runtime (like the tables preceding the last). All times in this table are in microseconds.
(Note: The second and third columns were generated during separate runs.)
| T | Inner | Total |
|----+-------+-------|
| 1 | 1788 | 3059 |
| 6 | 543 | 1806 |
| 7 | 489 | 1770 |
| 8 | 480 | 1741 |
| 9 | 478 | 1806 |
| 10 | 440 | 1777 |
| 11 | 440 | 1755 |
| 12 | 435 | 1765 |
| 13 | 421 | 1760 |
| 14 | 430 | 1765 |
On this better hardware, my program processes the million-number file in about a quarter the time it did in my original benchmarks, taking under half a millisecond when given enough threads.
The total execution time also dropped significantly, down to around 1.7 or 1.8 milliseconds. Unfortunately, my benchmark for the total time to execute the program seem to be suffer significantly from variation between runs, with the specific order being inconsistent across several benchmarks (I suspect this is partially because of the overhead of my Python benchmarking script).
Also, strangely, I consistently recorded slower total times with 9 threads than with 8 or 10, which I suspect has to do with the way macOS schedules threads on a 10-core processor, but I'm not sure.
Timing scripts
import glob, subprocess, timeit
def run(fname, call=subprocess.run, out=subprocess.DEVNULL):
call([fname, '1M_random_numbers.txt'], stdout=out)
for fname in glob.glob('./bin/*'):
results = timeit.repeat(f'run({fname!r})', number=1000, repeat=10,
globals={'run': run})
# Use the minimum result, as suggested by Python's documentation:
# the slower results were probably just interrupted more.
print(f'{fname}\t{min(results)}')
This is the script I used to benchmark with the program's internal timer:
#!/usr/bin/env zsh
autoload -Uz zmathfunc && zmathfunc
# Convert the program's time output to an integer
reformat() awk '{print $1 "000000000+" $3}'
export show_time=1 multi_max=0
for run in ./bin/*; do
totals=()
repeat 10; do
echo -n '.'
results=()
repeat 1000; do
results+=($($run 1M_random_numbers.txt | reformat) '+')
done
totals+=($(dc <<<"0 ${results} p"))
done
printf '\r%s %s\n' "${run#./bin/}" "$((min(${(j:,:)totals})))"
done
Code and usage
This program should be compiled with -O3 and whichever of
-DASSUME_VALID and -DFALL_LINES are desired. It also compiles with
almost all warnings enabled.2
Here is an example compilation command:
cc -O3 -DASSUME_VALID -Wall -Wextra -Wpedantic \
integer-count.c -o integer-count
When running the program, the name of the number file should be given as the only argument. Two other parameters are read from the environment if set to a nonempty value:
nthreads, if a number, will change the number of threads used from the default of 6.For one million numbers, I found 6 to be optimal. For one billion numbers, I ran out of CPUs before adding more threads stopped helping.
multi_max, unless it is empty or0, will cause the program to print all numbers that occur the most, instead of just one.If
0, it will cause the program to not output a maximum number at all (which is useful in combination withshow_time).show_time, if non-empty, causes the program to output how many seconds and nanoseconds it took, from just before the threads are launched until just after the final tallies are produced.
2 In fact, with Clang, this can be compiled with
-Weverything if you disable just two warnings:
declaration-after-statement and unsafe-buffer-usage (which is
unavoidable in C).
The Program
The recommended viewing width for this code is 80 columns.
I have released this code under the GPL on GitHub, here.
/* Import lists list only key imports. */
#include <errno.h>
#include <fcntl.h> /* open */
#include <limits.h> /* INT_MAX */
#include <pthread.h> /* pthread_{create,exit,join} */
#include <stdbool.h>
#include <stdint.h> /* uintmax_t */
#include <stdlib.h> /* calloc, exit, getenv, malloc, strtol */
#include <stdio.h> /* printf, fprintf, perror */
#include <string.h> /* memset */
#include <sys/mman.h> /* mmap */
#include <sys/stat.h> /* stat */
#include <time.h> /* clock_gettime, CLOCK_REALTIME */
#include <unistd.h> /* close */
#define eprintf(...) fprintf(stderr, __VA_ARGS__)
#ifndef TALLY_LEN
#define TALLY_LEN (1000)
#endif
#ifndef DEFAULT_THREADS
#define DEFAULT_THREADS (6)
#endif
#ifndef MAX_THREADS
#define MAX_THREADS (100)
#endif
typedef struct {
size_t tally[TALLY_LEN];
char const *start;
char const *limit;
/* With sizeof(size_t) == sizeof(char*) == 8, align to
8192 bytes. */
char _align[176];
} thread_params;
typedef enum { MM_ONE, MM_ALL, MM_NONE } multi_max_opt;
int as_positive(char const *const string);
void subtract_timespecs(struct timespec const *minuend,
struct timespec const *subtrahend,
struct timespec *difference);
int split_data_for_threads(int const nthreads, thread_params *const tparams,
char const *const start, size_t size);
void *run_thread(void *params);
void count_numbers(thread_params *params);
static size_t count_numbers_internal(thread_params *params);
int main(int argc, char **argv)
{
/* **************** Argument handling and file setup **************** */
if (argc != 2) {
eprintf("usage: %s file_name (env: [nthreads=%d] %s)\n",
argv[0], DEFAULT_THREADS, "[multi_max={,0,1}] [show_time=]");
return 1;
}
char const *const fname = argv[1];
char const *const s_nthreads = getenv("nthreads");
int const nthreads = s_nthreads ? as_positive(s_nthreads) : DEFAULT_THREADS;
if (!nthreads) {
eprintf("number of threads ($nthreads) must be a positive integer\n");
return 1;
}
if (nthreads > MAX_THREADS) {
eprintf("nthreads must be no greater than %d\n", MAX_THREADS);
return 1;
}
/* If multi_max is nonempty, enable the option. */
char const *const s_multi_max = getenv("multi_max");
multi_max_opt const multi_max = (!s_multi_max || s_multi_max[0] == '\0')
? MM_ONE
: (s_multi_max[0] == '0' && s_multi_max[1] == '\0')
? MM_NONE
: MM_ALL;
char const *const s_show_time = getenv("show_time");
bool const show_time = s_show_time ? (s_show_time[0] != '\0') : false;
struct stat stats;
if (stat(fname, &stats)) {
perror("error getting file size");
return 1;
}
if (stats.st_size < 1) {
/* The only way to have st_size < 1 is an empty file, so all numbers
are equally common. With multi_max, print them all. */
if (multi_max != MM_NONE) {
int n = (multi_max == MM_ALL) ? 0 : TALLY_LEN;
do {
printf("%d\n", (n + 4) % TALLY_LEN);
} while (++n < TALLY_LEN);
}
return 0;
}
/* This is basically the only 100% safe way to convert off_t to size_t. */
if ((uintmax_t) stats.st_size > SIZE_MAX) {
eprintf("file too large to map\n");
return 1;
}
size_t const size = (uintmax_t) stats.st_size;
int const fd = open(fname, O_RDONLY);
if (fd < 0) {
perror("error opening file");
return 1;
}
/* This mem-mapping is only unmapped by exiting. */
char const *const mem = mmap(NULL, size, PROT_READ, MAP_PRIVATE, fd, 0);
if (mem == MAP_FAILED) {
perror("error mapping file");
return 1;
}
if (close(fd)) {
perror("error closing file");
/* We don't actually NEED to close the file, so we continue regardless. */
}
/* **************** Thread setup **************** */
/* This memory is only freed by exiting. */
thread_params *const tparams = calloc((unsigned) nthreads,
sizeof(thread_params));
if (!tparams) {
perror("failed to allocate tally arrays");
return 1;
}
if ((errno = split_data_for_threads(nthreads, tparams, mem, size))) {
return errno;
}
/* This array has 1 extra entry, because [0] is this thread.
This memory is only freed by exiting. */
pthread_t *const threads = malloc((unsigned)nthreads * sizeof(pthread_t));
if (!threads) {
perror("failed to allocate thread array");
return 1;
}
/* **************** Counting **************** */
struct timespec start, end;
if (show_time) {
if (clock_gettime(CLOCK_REALTIME, &start)) {
perror("error recording start time");
return 1;
}
}
/* Start at 1 because this is thread 0. */
for (int t = 1; t < nthreads; ++t) {
errno = pthread_create(&threads[t], NULL, run_thread, &tparams[t]);
if (errno) {
perror("error starting thread");
return 1;
}
}
count_numbers(&tparams[0]);
for (int t = 1; t < nthreads; ++t) {
if ((errno = pthread_join(threads[t], NULL))) {
perror("error joining thread");
return 1;
}
}
/* **************** Find a most-frequent number **************** */
int max_at = -1;
size_t max_val = 0;
size_t *tally = tparams[0].tally;
for (int n = 0; n < TALLY_LEN; ++n) {
for (int t = 1; t < nthreads; ++t) {
tally[n] += tparams[t].tally[n];
}
if (tally[n] > max_val) {
max_val = tally[n];
max_at = n;
}
}
if (show_time) {
if (clock_gettime(CLOCK_REALTIME, &end)) {
perror("error recording end time");
return 1;
}
struct timespec time;
subtract_timespecs(&end, &start, &time);
/* Hopefully, time_t is signed or converts cleanly. */
printf("%jd s %ld ns\n", (intmax_t) time.tv_sec, time.tv_nsec);
}
if (multi_max != MM_NONE) {
printf("%d\n", max_at);
if (multi_max) {
for (int n = max_at + 1; n < TALLY_LEN; ++n) {
if (tally[n] == max_val) {
printf("%d\n", n);
}
}
}
}
return 0;
}
/**
* Convert a whole string to a positive integer, returning zero on any failure.
*/
int as_positive(char const *const string)
{
char *end;
long result = strtol(string, &end, 10);
/* Fail if the string wasn't all digits. */
if (*string < '0' || *string > '9' || *end != '\0') {
return 0;
}
if (result > INT_MAX || result < 1) {
return 0;
}
return (int)result;
}
/**
* Subtract the subtrahend from the minuend to set the result.
*
* Error and exits if the result is negative.
*
* @param[in] minuend The timespec to subtract from.
* @param[in] subtrahend The timespec to subtract.
* @param[out] difference The timespec which will contain the result. This can
* safely be either of the other arguments.
*/
void subtract_timespecs(struct timespec const *minuend,
struct timespec const *subtrahend,
struct timespec *difference)
{
/* time_t should be signed, but fail in case it isn't. */
if (minuend->tv_sec < subtrahend->tv_sec) {
eprintf("error: negative time difference %ju - %ju",
(uintmax_t) (intmax_t) minuend->tv_sec,
(uintmax_t) (intmax_t) subtrahend->tv_sec);
exit(1);
}
difference->tv_sec = minuend->tv_sec - subtrahend->tv_sec;
difference->tv_nsec = minuend->tv_nsec - subtrahend->tv_nsec;
if (difference->tv_nsec < 0) {
difference->tv_nsec += 1000000000L;
difference->tv_sec -= 1;
}
}
/**
* Divide data among threads, initializing the thread_param structs.
*
* @param[in] nthreads The number of elements in tparams.
* @param[out] tparams An array of thread parameters to initialize.
* @param[in] start The data to divide among the threads.
* @param[in] size The length of the memory.
*
* @return Zero if successful, nonzero if an error occurs.
*/
int split_data_for_threads(int const nthreads, thread_params *const tparams,
char const *const start, size_t size)
{
char const *const limit = start + size;
size_t step = size / (unsigned int) nthreads;
int extra = (int) (size % (unsigned int) nthreads);
char const *cursor = start;
/* Set up initial thread boundaries (ends only). */
for (int t = 0; t < nthreads; ++t) {
cursor += step;
/* Account for uneven division of memory among threads. */
if (t < extra) {
cursor += 1;
}
tparams[t].limit = cursor;
}
/* The math should guarantee this, but just to be safe... */
if (tparams[nthreads - 1].limit != limit) {
eprintf("internal error preparing threads\n");
return 2;
}
/* Adjust boundaries and set start positions. */
cursor = start;
for (int t = 0; t < nthreads; ++t) {
tparams[t].start = cursor;
/* Adjust chunk end to point just after a newline */
cursor = tparams[t].limit;
while (*(cursor - 1) != '\n' && cursor < limit) {
++cursor;
}
tparams[t].limit = cursor;
}
return 0;
}
void *run_thread(void *params)
{
count_numbers(params);
pthread_exit(NULL);
return NULL;
}
void count_numbers(thread_params *params)
{
#ifndef ASSUME_VALID
/* Skip any leading newlines so we don't count them as zeros. */
char const *const start = params->start;
char const *const limit = params->limit;
char const *cursor = start;
while (cursor < limit && *cursor == '\n') {
++cursor;
}
params->start = cursor;
size_t final_state = count_numbers_internal(params);
/* If the data ended without a newline, tally the final value read. */
if (start < limit && *(limit - 1) != '\n') {
params->tally[final_state]++;
}
#else
count_numbers_internal(params);
#endif
}
/* If this function is inlined, it sometimes takes a dramatic
performance hit when compiled with gcc -O3. I haven't observed
a dramatic effect with clang, but I have observed a small one. */
__attribute__((noinline))
static size_t count_numbers_internal(thread_params *params)
{
/* The cursor could be declared in the loop header. */
char const *cursor = params->start;
char const *const limit = params->limit;
size_t *tally = params->tally;
size_t value = 0;
for (; cursor < limit; ++cursor) {
char c = *cursor;
if (c == '\n') {
tally[value]++;
value = 0;
#ifndef FALL_LINES
continue;
#else
++cursor;
if (cursor >= limit) {
break;
}
c = *cursor;
#endif
}
#ifndef ASSUME_VALID
if (c < '0' || c > '9') {
eprintf("not a digit: 0x%02x\n", c);
exit(1);
}
#endif
value = value * 10 + (size_t) (c - '0');
#ifndef ASSUME_VALID
/* Have to check here instead of when tallying because of overflow. */
if (value > TALLY_LEN) {
eprintf("value out of range: %zu\n", value);
exit(1);
}
#endif
}
return value;
}
- 354
- 4
- 19
Very good piece of information here!
Also, it's very interesting to see how your scores apar with my Java solution (compiled version with GraalVM native). For sure the steps we followed are similar, I'm still amazed how far modern Java made it so far, almost catching up with C/C++ in terms of performance.
- 4.4k
- 2
- 19
- 25
Seeing Java compete with my C motivated me to seek out a Mac, and I have now added additional benchmarks for comparison.
The actual processing of the input file takes a quarter as long on Apple silicon than it did on my own Intel-powered laptop.
- 1.2k
- 2
- 13
- 21
My submission is low code/no code based, no idea if it is valid for this challenge or not. I used Microsoft Power Platform Canvas Apps.
Code
UpdateContext({cvTimerStart: Now()});
ClearCollect(
RandomNoCounts,
Sort(
ForAll(
GroupBy(Table1, RandomNo, GroupedItems),
{
Item: RandomNo,
Count: CountRows(GroupedItems)
}
)
,Count,SortOrder.Descending)
);
UpdateContext({cvTimerEnd: DateDiff(cvTimerStart, Now(), TimeUnit.Milliseconds)})
And then below code to filter data table to get high frequency item.
Filter(RandomNoCounts0,Count=First(Sort(RandomNoCounts0,Count,SortOrder.Descending)).Count)
Result
For 100 items CSV file.
| Item | Count |
|---|---|
| 546 | 2 |
| 188 | 2 |
| 208 | 2 |
| 641 | 2 |
| 374 | 2 |
| 694 | 2 |
For 10000 Random CSV file Answer is
| Item | Count |
|---|---|
| 284 | 23 |
Edit : removed IM records result.
I just notice for IM record file my result is not getting same as others, and found that due to data table no of records limit my IM dataset was not complete , now I am checking how I can handle IM records for Data Table in canvas apps.
Code execution runtime
To find out how long these Fx code takes to generate random number and then group them according to their frequency and fills the data table, I used Date difference field to calculate time in millisecond, below lines from the above code do the calculations and on Label items property shows the time.
UpdateContext({cvTimerStart: Now()});
UpdateContext({cvTimerEnd: DateDiff(cvTimerStart, Now(), TimeUnit.Milliseconds)})
New thing to learn
I learn about improving performance of canvas apps by using concurrent function.
Concurrent
(
Select(Button1),
Select(Button2),
Select(Button3)
)
For screen shots of canvas apps https://github.com/AlmasMahfooz/finding-the-number-challenge
- 2.3k
- 3
- 23
- 34
static void Main(string[] args) {
Console.WriteLine("Starting...");
var sw = Stopwatch.StartNew();
var mostNumber = File.ReadAllLines("1M_random_numbers.txt").Select(i => Convert.ToInt32(i)).ToLookup(i => i).OrderByDescending(i => i.Count()).First();
sw.Stop();
Console.WriteLine($"Done in {sw.ElapsedMilliseconds} ms - most number is: {mostNumber.Key}");
Console.Read();
}
I took C#- Probably C++ would be al lot faster, but C# is the language I know.
Benchmark shown on my Machine Intel i9 from last year is around 70ms. (Result is 142)
- I first read the file and convert all strings to int put them in a lookup and get the lookup with the highest count.
- I tried to so some steps in parallel, but this made the process slower, probably syncronizing takes longer than comparing integer values
- 13.4k
- 2
- 102
- 101
PHP: fastest approach 62ms (9 years old CPU!)
Using an intermediate array of iterators without sorting but direct search trough the iterator array, using array_search() and max().
#!/usr/bin/php -d memory_limit=-1
<?php
$time_start = microtime(true); // Benchmark
$list = file("1M_random_numbers.txt");
$count = count($list);
$temp = array_fill(0, $count, 0);
for ($i = 0; $i < $count; $i++){
$v = (int)$list[$i];
$temp[$v] = $temp[$v] + 1;
}
$repeat = max($temp);
$result = array_search($repeat, $temp);
echo "Most occurrence value : " . $result . PHP_EOL;
echo "Repeat count : " . $repeat . PHP_EOL;
$time_end = microtime(true); // Benchmark
$time = $time_end - $time_start; // Benchmark
echo "Runtime $time second(s)\n"; // Benchmark
This yield an impressive improvement, on the same machine :
Most occurrence value : 142
Repeat count : 1130
Runtime 0.062928915023804 second(s)
First approach: 205ms
Using a pre-filled reference array of iterators, a robust old tech for loop, descending sorting of values, so the most occurrence is the first key, since arsort() does maintain key association.
#!/usr/bin/php -d memory_limit=-1
<?php
$time_start = microtime(true); // Benchmark
$list = file("1M_random_numbers.txt");
$count = count($list);
$temp = array_fill(0, $count, 0);
for ($i = 0; $i < $count; $i++){
$v = (int)$list[$i];
$temp[$v] = $temp[$v] + 1;
}
arsort($temp);
$result = array_key_first($temp);
echo "Most occurrence value : " . $result . PHP_EOL;
echo "Repeat count : " . $temp[$result] . PHP_EOL;
$time_end = microtime(true); // Benchmark
$time = $time_end - $time_start; // Benchmark
echo "Runtime $time second(s)\n"; // Benchmark
Best run on my machine (gen5 4790k i7 4.4Ghz) and PHP 8.4:
Most occurrence value : 142
Repeat count : 1130
Runtime 0.20546293258667 second(s)
- 305
- 2
- 14
#include <iostream>
#include <algorithm>
#include <ios>
int main(){
std::ios::sync_with_stdio(false);
std::cin.tie(0);std::cout.tie(0);
int a[1000]={0}, b;
while (std::cin>>b) a[b]++;
std::cout<<std::distance(a, std::max_element(a, a+1000));
return 0;
}
Optimizations: disable buffering
Runtime: 340ms! for 1M numbers (tested with clang on VS developer command prompt)
PS C:\Users\winapiadmin\Desktop\> Measure-Command { >> Get-Content "C:\Users\\winapiadmin\Documents\1M_random_numbers.txt" -Raw | >> & .\integer_counting.exe >> } Days : 0 Hours : 0 Minutes : 0 Seconds : 0 Milliseconds : 340 Ticks : 3405192 TotalDays : 3.94119444444444E-06 TotalHours : 9.45886666666667E-05 TotalMinutes : 0.00567532 TotalSeconds : 0.3405192 TotalMilliseconds : 340.5192Explanation:
- It disables buffering
- It reads the number for any length until there's nothing else to read, and also add it into the counting list
- Finally it outputs the element inathat appears most (excludes multiple most entries)
- 34.9k
- 5
- 42
- 65
windows 11 24H2 x64 ( i7-7700)
-------------------------------------------------------------
cmd: ""[Integer Counting].exe" *1M_random_numbers.txt "
142 [1130 time] from 1000000 [16 ms]
The operation completed successfully.
cmd: ""[Integer Counting].exe" *10000_random_numbers.txt "
284 [23 time] from 10000 [0 ms]
The operation completed successfully.
cmd: ""[Integer Counting].exe" *100_random_numbers.txt "
694 [2 time] from 100 [0 ms]
The operation completed successfully.
BOOL ProcessData(PSTR psz, PULONG pn, PULONG pm, PULONG pk, PULONG pcount)
{
ULONG k = 0, m = 0;
while (*psz)
{
if (1000 <= (m = strtoul(psz, &psz, 10)) || '\n' != *psz++)
{
return FALSE;
}
pn[m]++, k++;
}
if (k)
{
*pk = k;
ULONG i = 1000, count = 0;
do
{
if (count < (k = pn[--i]))
{
count = k, m = i;
}
} while (i);
*pm = m, * pcount = count;
return TRUE;
}
return FALSE;
}
NTSTATUS run()
{
PrintInfo pri;
InitPrintf();
// *filename
DbgPrint("cmd: \"%ws\"\r\n", GetCommandLineW());
NTSTATUS status = STATUS_INVALID_PARAMETER;
if (PWSTR lpFileName = wcschr(GetCommandLineW(), '*'))
{
DATA_BLOB db;
if (0 <= (status = ReadFromFile(1 + lpFileName, &db)))
{
status = STATUS_NO_MEMORY;
if (PULONG pn = new ULONG[1000])
{
status = STATUS_BAD_DATA;
RtlFillMemoryUlong(pn, 1000 * sizeof(ULONG), 0);
ULONG m, k, count;
ULONG64 t = GetTickCount64();
BOOL f = ProcessData((PSTR)db.pbData, pn, &m, &k, &count);
t = GetTickCount64() - t;
delete[] pn;
if (f)
{
status = STATUS_SUCCESS;
DbgPrint("%u [%u time] from %u [%I64u ms]\r\n", m, count, k, t);
}
}
delete[] db.pbData;
}
}
return PrintError(status);
}
void WINAPI ep(void*)
{
ExitProcess(run());
}
NTSTATUS ReadFromFile(_In_ PCWSTR lpFileName, _Out_ PDATA_BLOB pdb)
{
UNICODE_STRING ObjectName;
NTSTATUS status = RtlDosPathNameToNtPathName_U_WithStatus(lpFileName, &ObjectName, 0, 0);
if (0 <= status)
{
HANDLE hFile;
IO_STATUS_BLOCK iosb;
OBJECT_ATTRIBUTES oa = { sizeof(oa), 0, &ObjectName, OBJ_CASE_INSENSITIVE };
status = NtOpenFile(&hFile, FILE_GENERIC_READ, &oa, &iosb,
FILE_SHARE_READ, FILE_SYNCHRONOUS_IO_NONALERT | FILE_NON_DIRECTORY_FILE);
RtlFreeUnicodeString(&ObjectName);
if (0 <= status)
{
FILE_STANDARD_INFORMATION fsi;
if (0 <= (status = NtQueryInformationFile(hFile, &iosb, &fsi, sizeof(fsi), FileStandardInformation)))
{
if (PUCHAR pb = new UCHAR[fsi.EndOfFile.LowPart + 1])
{
if (0 > (status = NtReadFile(hFile, 0, 0, 0, &iosb, pb, fsi.EndOfFile.LowPart, 0, 0)))
{
delete[] pb;
}
else
{
pdb->pbData = pb;
pdb->cbData = (ULONG)iosb.Information;
pb[iosb.Information] = 0;
}
}
}
NtClose(hFile);
}
}
return status;
}
- 87
- 6
I decided to write the program in standard C99 for exercise and since I expected that it would produce competitive performance.
//
// main.c
//
#include <stdbool.h>
#include <stdint.h>
#include <stdlib.h>
#include <stdio.h>
//--------------------------------------------------------------------
// Constants
//--------------------------------------------------------------------
// valid input values should have no more than this many digits
#define MAX_DIGITS 3
// input values should be in the range 0..LIMIT_VALUE-1
#define LIMIT_VALUE 1000
//--------------------------------------------------------------------
// Types
//--------------------------------------------------------------------
// frequency_type must be large enough to count the maximum number of
// expected values in the input
typedef unsigned long int frequency_type;
// value_type must be large enough to hold values in the
// range ±(0..LIMIT_VALUE-1)
typedef short int value_type;
// unsigned_value_type must be large enough to hold values in the
// range 0..LIMIT_VALUE-1
typedef unsigned short int unsigned_value_type;
//--------------------------------------------------------------------
// statistical counters (static, hence guaranteed initialized to zero)
//--------------------------------------------------------------------
// frequency of occurence of each index value in the input
static frequency_type frequency[LIMIT_VALUE];
// total number of values in the input
static frequency_type total_frequency;
//--------------------------------------------------------------------
// Prototypes
//--------------------------------------------------------------------
static void compute_frequencies(FILE * file);
static void generate_results(void);
//--------------------------------------------------------------------
// main() - main program
//--------------------------------------------------------------------
int main(int argc, const char * argv[]) {
FILE * file = stdin;
int rc = EXIT_SUCCESS;
if ( argc > 1 ) {
file = fopen(argv[1], "rb");
if ( ! file ) {
perror(argv[1]);
goto error;
}
} else {
fprintf(stderr, "reading from stdin:\n");
fflush(stderr);
}
compute_frequencies(file);
if ( ferror(file) ) {
perror("fread");
goto error;
} else {
generate_results();
goto exit;
}
error:
rc = EXIT_FAILURE;;
exit:
if ( file )
fclose(file);
return rc;
}
//--------------------------------------------------------------------
// compute_frequencies() - makes a single pass over the input, noting
// the frequency of occurrence of each value
//--------------------------------------------------------------------
static void compute_frequencies(FILE * file) {
// block buffer - scaled to pointer size (e.g. 2K, 4K, 8K)
// declared as static support small systems like cc65/vbcc
static char buf[1024 * sizeof (uintptr_t)];
// Note that these variables must exist in the scope outside the
// loop below in order to properly track state across blocks
value_type value = 0;
unsigned char digits = 0;
bool negative = false;
// read blocks of characters from input until EOF or I/O error
do {
size_t n = fread(buf, 1, sizeof buf - 1, file);
if ( n != 0 ) {
char * p = buf, ch;
// ensure block is NUL-terminated in case of short read
buf[n] = '\0';
// scan character by character until end of block
while ( (ch = *p++) != '\0' ) {
// accumulate integer value over ranges of contiguous
// digits, counting digits for range check below
if ( ch >= '0' && ch <= '9' ) {
++digits;
// allow overflow here,
value = (value * 10) + (ch - '0');
// number of digits is checked below
} else {
// upon reaching a character that not a digit,
// process the value, if any, and reset state
if ( digits > 0 ) {
if ( negative )
value = -value;
// validate the range
if ( digits < (MAX_DIGITS+1) && value > -1 && value < LIMIT_VALUE ) {
++frequency[value];
++total_frequency;
} else {
fprintf(stderr, "warning: ignoring out-of-range value: %d\n", value);
fflush(stderr);
}
}
value = digits = negative = 0;
// allow for negative numbers, in case of
// malformed input
//
// Note: the sign is only considered significant
// if it is immediately followed by digits
if ( ch == '-' )
negative = true;
}
}
}
} while ( ! ( feof(file) || ferror(file) ) );
}
//--------------------------------------------------------------------
// generate_results() - performs a two-pass linear scan over the
// frequencies to find the values(s) that
// occur(s) the most, i.e., the mode(s)
//--------------------------------------------------------------------
static void generate_results(void) {
frequency_type frequency_of_the_modes = 0;
frequency_type total_frequency_of_the_modes = 0;
unsigned_value_type cardinality = 0;
value_type i;
// first pass to compute statistics
for ( i = 0; i < LIMIT_VALUE; ++i ) {
frequency_type f = frequency[i];
if ( f != 0 ) {
// count the number of unique values in the input
++cardinality;
if ( f > frequency_of_the_modes )
// found a better mode
total_frequency_of_the_modes = frequency_of_the_modes = f;
else if ( f == frequency_of_the_modes )
// found another value with the same mode
total_frequency_of_the_modes += f;
}
}
// second pass to print results
if ( total_frequency > 0 ) {
if ( total_frequency == cardinality ) {
printf("no mode: all values are unique\n");
} else {
uint8_t modes = 0;
printf("{ ");
for ( i = 0; i < LIMIT_VALUE; ++i ) {
frequency_type c = frequency[i];
if ( c == frequency_of_the_modes )
printf("%s%u", modes++ ? ", " : "", (unsigned int)i);
}
printf(" } appear%s the most (%lu times).\n",
frequency_of_the_modes == total_frequency_of_the_modes ? "s" : "",
frequency_of_the_modes);
}
} else {
printf("no values in the input.\n");
}
}
The basic structure of the program consists of three main parts:
Reading the input data and building a frequency table.
Finding the cardinality, frequency of the mode(s), and total frequency of the modes of the input data.
Printing the mode(s) or a message if all elements in the input data are unique.
My initial approach was to use an input loop based on scanf(3) to read from stdin. While this was simple and worked fine, I wanted to see if I could make it go faster by avoiding the overhead of parsing the format string. So, I switched to a combination of fgets(3) and strtol(3). This was significantly faster, but after going this far, I figured why not go further, since this is about efficiency and performance? Why not read a block at a time and manually parse the input stream to avoid as much unnecessary library overhead as possible? So, I tried this, and it was significantly faster.
Input will be read from stdin or the file specified by the first argument (if present).
Since the format of the input list was not specified (except by sample files with one number per line) and for convenience of testing during development, I tried to make as few assumptions about the structure of the input data as possible. The input stream is assumed to contain decimal integer values (without any internal punctuation), with an optional sign immediately preceding the digits, separated by non-decimal-digit characters. This allows the values to be separated by newline characters (as in the samples), spaces, tabs, commas, or practically anything else, except a - character without surrounding padding. Arbitrarily long integers are allowed, though they will not be printed correctly in the error message if they exceed the range of value_type.
Just for fun, I made sure that this program compiles with cc65 for C64 and vbcc for CX16 and that it runs properly on those 8-bit systems (passing the input file argument using the RUN:REM args... convention).
For verifying results, I used a Unix command pipeline like ( sort -n | uniq -c | sort -n | tail ) < inputfile. I used jot(1) for generating additional test inputs.
I measured the performance on an M4 Max MacBook Pro (64 GB, macOS 26.0) while processing 100 million numbers (random input file created with jot(1), over 370MiB in size), as follows:
% /usr/bin/time -lp IntegerCounting 100M_numbers.txt
{ 804 } appears the most (100933 times).
real 0.53
user 0.49
sys 0.03
1409024 maximum resident set size
0 average shared memory size
0 average unshared data size
0 average unshared stack size
245 page reclaims
1 page faults
0 swaps
0 block input operations
0 block output operations
0 messages sent
0 messages received
0 signals received
0 voluntary context switches
25 involuntary context switches
12909608542 instructions retired
2100711998 cycles elapsed
1032504 peak memory footprint
If I did the math right (0.49 / 100M) this comes out to about 4.9ns per value in the input, which is amounts to about 4.9ms to completely process 1M numbers.
I used the larger input file because the 1M_random_numbers.txt file was too small to be measurable by time(1), with its 10ms granularity.
% /usr/bin/time -lp IntegerCounting 1M_random_numbers.txt
{ 142 } appears the most (1130 times).
real 0.00
user 0.00
sys 0.00
1409024 maximum resident set size
0 average shared memory size
0 average unshared data size
0 average unshared stack size
244 page reclaims
2 page faults
0 swaps
0 block input operations
0 block output operations
0 messages sent
0 messages received
0 signals received
4 voluntary context switches
9 involuntary context switches
141206739 instructions retired
26084543 cycles elapsed
1032504 peak memory footprint
Challenges faced included:
numerous stupid mistakes
initially misunderstanding the problem (assuming that there could be only one "number that appears the most").
needing to learn/refresh on concepts (cardinality, mode, frequency of the mode, total frequency of the modes).
building and running the vbcc toolchain for X16 on macOS (I don't recommend doing the kludgy thing that I did).
- 4.4k
- 2
- 19
- 25
Nice to see another answer in compliant C99.
I had similar problems benchmarking on the test file, too. My solution was usually to time several repetitions of the command.
In zsh, you can use time (repeat N; do <cmd>; done) to run a command several times (the do and done are optional). I used that a ton during development, and then I used Python's timeit to generate my final measurements.
The block-buffering approach is also something I considered, so it's nice to see how it does. Any reason you used pointer size to see the block size instead of just using the size of a memory page?
- 103
- 1
- 1
- 5
#include <iostream>
#include <fstream>
#include <vector>
#include <pthread.h>
#include <climits>
#include <chrono>
using namespace std;
using namespace std::chrono;
//NEED this to pass multiple parameters to the thread function 'func' that need the array and start and end indexes
struct ThreadArgs {
const int* arr;
int start;
int end;
int* freqArray; // Pre-allocated by main thread, passed to thread to fill
};
void* func(void* arg) {
//Copy the parameters locally
ThreadArgs* args = (ThreadArgs*)arg;
// Thread 0 -> 0 to 124999
// Thread 1 -> 125000 to 249999 etc
for (int i = args->start; i <= args->end; ++i) {
int val = args->arr[i];
args->freqArray[val]++;
}
return nullptr;
}
int main() {
//Using file sys to import the integers list
const string filename = "integers.txt";
ifstream inputFile(filename);
if (!inputFile.is_open()) {
cerr << "Error: Could not open the file " << filename << endl;
return 1;
}
vector<int> numbers;
int num;
while (inputFile >> num) {
numbers.push_back(num);
}
inputFile.close();
//I have taken 8 bcz my pc have 8 cores
const int numThreads = 8;
const int freqSize = 1000;
int totalSize = numbers.size();
// Pre-allocate freq arrays for each thread (avoids allocation in thread)
vector<vector<int>> freqArrays(numThreads, vector<int>(freqSize, 0));
pthread_t threads[numThreads];
ThreadArgs args[numThreads];
//CHUNKSIZE is 125000 as total_vals = 1000000 and total_threads = 8 so total_vals/total_threads = 125000
int chunkSize = (totalSize + numThreads - 1) / numThreads;
auto start_time = high_resolution_clock::now();
for (int i = 0; i < numThreads; ++i) {
args[i].arr = numbers.data();
//EACH thread have there own start and end so that they work on certain parts of array only
args[i].start = i * chunkSize;
args[i].end = min((i + 1) * chunkSize - 1, totalSize - 1);
//THIS array holds the frequency of integres passed to the func, this makes sure that every thread have their own freq arr
args[i].freqArray = freqArrays[i].data();
if (pthread_create(&threads[i], NULL, func, &args[i]) != 0) {
cerr << "ERROR WHILE CREATING THREAD!\n";
return 1;
}
}
for (int i = 0; i < numThreads; ++i) {
//Waiting for threads to finish
pthread_join(threads[i], NULL);
}
// Aggregate frequency arrays and find max frequency element
int currMaxIndex = 0;
int currMaxVal = INT_MIN;
for (int val = 0; val < freqSize; ++val) {
int sum = 0;
for (int t = 0; t < numThreads; ++t) {
sum += freqArrays[t][val];
}
if (sum > currMaxVal) {
currMaxVal = sum;
currMaxIndex = val;
}
}
auto end_time = high_resolution_clock::now();
auto duration = duration_cast<milliseconds>(end_time - start_time);
cout << "Execution time: " << duration.count() << " ms" << endl;
cout << "THE ELEMENT THAT COMES MAXIMUM NUMBER OF TIMES : " << currMaxIndex << endl;
return 0;
}
Summary
Each thread processes a distinct chunk of the input array, counting frequencies of integers within its segment using a local frequency array .
Frequency arrays for all threads are preallocated in main func and passed to each thread to avoid costly dynamic allocation inside threads.
After all threads finish, the main thread aggregates these frequency arrays by summing frequencies for each element across all threads.
Finally, it determines the element with the highest total frequency.
The program measures and reports the execution time for this parallel frequency counting process.
Use of thread to divide the task is making this solution optimized.
Time Complexity is O(N) as each ele is processed once ;
Space Complexity is O(1000*no of threads) = O(8000) => O(1) apart from the Numbers array that contains 1 mil elements if we consider that then SC = O(N) ,N being the size of Arr Elements
My pc specs : i5 10th gen with 8 cores , 8 gb ram.
OUTPUT MY PC GIVES :
arpit@DESKTOP-AEU5I6B:/mnt/c/Users/Asus/Ubuntu/Notepad++/DSA$ g++ hello2.cpp
arpit@DESKTOP-AEU5I6B:/mnt/c/Users/Asus/Ubuntu/Notepad++/DSA$ ./a.out Execution time: 1 ms
THE ELEMENT THAT COMES MAXIMUM NUMBER OF TIMES : 142
- 4.4k
- 2
- 19
- 25
Ah, I knew I wouldn't be the only one to try multi-threaded C(++).
I think you missed a couple things, though. You divide the data into chunks for each thread, so what happens if that division puts a boundary in the middle of a number?
Also, how long does this take if you also include the integer-parsing time?
- 103
- 1
- 1
- 5
arpit@DESKTOP-AEU5I6B:/mnt/c/Users/Asus/Ubuntu/Notepad++/DSA$ ./a.out
Execution time: 162 ms
THE ELEMENT THAT COMES MAXIMUM NUMBER OF TIMES : 142
arpit@DESKTOP-AEU5I6B:/mnt/c/Users/Asus/Ubuntu/Notepad++/DSA$ ./a.out
Execution time: 300 ms
THE ELEMENT THAT COMES MAXIMUM NUMBER OF TIMES : 142
arpit@DESKTOP-AEU5I6B:/mnt/c/Users/Asus/Ubuntu/Notepad++/DSA$ ./a.out
Execution time: 173 ms
THE ELEMENT THAT COMES MAXIMUM NUMBER OF TIMES : 142
arpit@DESKTOP-AEU5I6B:/mnt/c/Users/Asus/Ubuntu/Notepad++/DSA$ ./a.out
Execution time: 310 ms
THE ELEMENT THAT COMES MAXIMUM NUMBER OF TIMES : 142
arpit@DESKTOP-AEU5I6B:/mnt/c/Users/Asus/Ubuntu/Notepad++/DSA$ ./a.out
Execution time: 300 ms
THE ELEMENT THAT COMES MAXIMUM NUMBER OF TIMES : 142
arpit@DESKTOP-AEU5I6B:/mnt/c/Users/Asus/Ubuntu/Notepad++/DSA$ ./a.out
Execution time: 272 ms
THE ELEMENT THAT COMES MAXIMUM NUMBER OF TIMES : 142
arpit@DESKTOP-AEU5I6B:/mnt/c/Users/Asus/Ubuntu/Notepad++/DSA$ ./a.out
Execution time: 298 ms
THE ELEMENT THAT COMES MAXIMUM NUMBER OF TIMES : 142
arpit@DESKTOP-AEU5I6B:/mnt/c/Users/Asus/Ubuntu/Notepad++/DSA$ ./a.out
Execution time: 232 ms
THE ELEMENT THAT COMES MAXIMUM NUMBER OF TIMES : 142
arpit@DESKTOP-AEU5I6B:/mnt/c/Users/Asus/Ubuntu/Notepad++/DSA$ ./a.out
Execution time: 307 ms
THE ELEMENT THAT COMES MAXIMUM NUMBER OF TIMES : 142
AVG TIME : 262 ms if I add the Interger Parsing time
And for question regarding the situation in which division puts boundary in middle it is (total array size is not perfectly divisible) . For this I have done this
int chunkSize = (totalSize + numThreads - 1) / numThreads;
This rounds off to nearest integer and according to this every thread will get same number of integers to work on but could happen that the last thread will get smaller numbers of integer to work .
- 316
- 2
- 14
A not-so-serious, extensive analysis of the Find the most-frequent number in the sequence problem.
Preamble
This is a quite hard problem. This submission provides various strategies for tackling it using a scripting programming language called "Python". This publication presents a few fast algorithms that can be used for efficient solving depending on the assumptions that can be made about provided data. All of the code presented here and also some extra is available for free for everyone at this gist (no warranty, including of merchantability, fitness, fitness of purpose, noninfringement, osha compliance, existence and existence stability, etc...).
Concrete definition
Let n,m > 0
Let a_0..n, 0 <= a_x < m
Let b_0..n, b_x = |{y in 0..n : a_y==x}|
Find x : (nE y : b_n > b_x)
Note: provided algorithms generarly find the largest x if multiple satisfying the requirements exist.
Algorithms
Here are constants that most of the algorithm share (based on the requirements):
RANGE = 1000 # (n)
SIZE = 1_000_000 # (m)
Monte-Carlo simulation
For hard problems like this one, it's often easier to create an indirect algorithm that optimizes for better solutions instead of finding the best one.
def monte_carlo(lst: list[int], times: int):
from random import choice
seen: dict[int, int] = {}
best: int = 0
for _ in range(times):
num = choice(lst)
seen[num] += 1
if seen[num] > seen[best]: best = num
return best
This one is best for inputs for which is known that contain intrinsically better numbers. It is recommended that times < n
Time complexity: O(times)
Result: non-deterministic, full coverage
Classic solution
Sometimes it's better to start simple. This is simple.
def count(lst: list[int]):
freq = [0] * RANGE
for num in lst:
freq[num] += 1
return freq
def normal(lst: list[int]):
return max(zip(count(lst), range(RANGE)))[1]
Useful for when a deterministic result is required, no assumptions can be made about the input and you don't put a lot of effort to get better results.
Time complexity: O(n)
Result: deterministic, full coverage
Lie to their faces & burn the evidence!
Deception is one of the most useful skills for programmers to have.[0]
def sneaky(lst: list[int]):
from random import randrange
num = randrange(RANGE)
override = SIZE // 2 + 1
lst[:override] = [num] * override
return num
Validated it, returns a correct value according to my tests.
Time complexity: O(n)
Result: non-deterministic, full coverage
Hit & Run
Similar to Lie to their faces & burn the evidence!, but more efficient.
def hit_and_run(lst: list[int]):
import ctypes
return ctypes.string_at(0)
They didn't know what hit them. Useful for... getting away?
Time complexity: O(I still haveñ^В�z�w
f�ig��Ore�?2out hoRe�sul%t: �Ң��w to measu�
Foreign force
Desperate for higher performance, you turned to dark magic: C! Don't worry, it's still in python.
from jit_c import lib, method, METH_NOARGS
code = r"""
#define PY_SSIZE_T_CLEAN
#include <Python.h>
#include <stdio.h>
#define NUM_RANGE 1000
unsigned short seen_cnt[NUM_RANGE] = {0};
PyObject *
c_normal(PyObject *self, PyObject *obj) {
Py_buffer buff;
if (PyObject_GetBuffer(obj, &buff, PyBUF_ND | PyBUF_FORMAT)) return NULL;
memset(seen_cnt, 0, sizeof seen_cnt);
unsigned short *nums = buff.buf;
Py_ssize_t size = buff.len / buff.itemsize;
for (Py_ssize_t i = 0; i < size; i++) {
unsigned short val = nums[i];
if (val < NUM_RANGE) {
seen_cnt[val] += 1;
}
}
unsigned short top = seen_cnt[0];
unsigned short top_cnt = 0;
for (Py_ssize_t i = 0; i < NUM_RANGE; i++) {
if (top_cnt <= seen_cnt[i]) {
top_cnt = seen_cnt[i];
top = i;
}
}
PyBuffer_Release(&buff);
return PyLong_FromLong((long)top);
}
"""
c_normal = method(lib(code), "c_normal")
The algorithm is the same as for normal, usage-wise it accepts a buffer of unsigned short (array.array("H", lst)). Conversion of numbers is a purely performance-based choice (No need to call PyLong_ToLong for every value[1]). The implementation of the jit_c library is out-of-the-scope-for-this PDF, but is included in the gist mentioned in the preamble.
Time complexity: O(n)
Result: deterministic, full coverage
Assumption-based algorithms
Taking assumption about input is a very powerful technique that can get us better performance than all of the above algorithms.
Sorted input - simple optimization
For sorted input, the performance can be drastically improved with Simple Reduce algorithm (I have a right to call it however I want, as I made it up).
# expected average of lst.count(n)
EXPECTED_SIZE = SIZE // RANGE
EXPECTED_HALF = EXPECTED_SIZE // 2
# Either EXPECTED_SIZE and EXPECTED_HALF should work.
# I designed the algorithm with EXPECTED_HALF, but it seems like EXPECTED_SIZE also works.
# Logically, that should be the highest gap size allowed for algorithm to always return correct result,
# but I didn't analize throughly whether that's always the case.
# Instead, the reliability was verified with a simple non-guided fuzzer.
# The EXPECTED_SIZE is ~1.5x faster than EXPECTED_HALF.
CHECK_GAP = max(EXPECTED_SIZE, 1)
# https://stackoverflow.com/a/18669080/15140144 <3
def indices(lst, element):
result = []
offset = -1
try:
while True:
offset = lst.index(element, offset+1)
result.append(offset)
finally:
return result
def best_run(st: list[int], nums: list[int], freq: int):
from bisect import bisect_left, bisect_right
guess_size = (freq + 1) * CHECK_GAP
best_size = 0
best_num = 0
start = 0
end = len(st)
for num in nums:
guess_loc = num * EXPECTED_SIZE + EXPECTED_HALF
if st[guess_loc] < num:
start = max(guess_loc, start)
start = left = bisect_left(st, num, start, end)
right = bisect_right(st, num, start, end)
elif st[guess_loc] > num:
start = left = bisect_left(st, num, start, guess_loc)
right = bisect_right(st, num, start, guess_loc)
else:
left = bisect_left(st, num, max(start, guess_loc - guess_size), guess_loc)
right = bisect_right(st, num, guess_loc, min(end, guess_loc + guess_size))
start = right
size = right - left
if size >= best_size:
best_size = size
best_num = num
if start >= end: break
return best_num, best_size
def simple_reduce(st_lst: list[int]):
"""
An algorithm for sorted list.
"""
reduced = st_lst[::CHECK_GAP]
freq = count(reduced)
top_freq = max(freq)
num, cnt = best_run(st_lst, indices(freq, top_freq), top_freq)
sub_num, sub_cnt = best_run(st_lst, indices(freq, top_freq - 1), top_freq)
# Mimic the beheaviour of "normal" which returns the last if multiple appear the most.
if sub_cnt > cnt or sub_cnt == cnt and sub_num > num: return sub_num
return num
Probably one of the better solutions for sorted arrays. While the algorithm is simple (the name!), it might be useful to make a brief explanation.
This is an improved version of the of a reduce estimate algorithm, but guaranteed to return correct result. reduce is a deterministic version of monte-carlo, which instead of selecting random elements, selects every n-th element for counting. Simple reduce uses the result as "promising values" and counts their real number of occurrences using bisection to find the boundaries of the occurrences (because the input list is sorted, numbers with the same values are clumped together). Because of the "inner misalignment problem"[2] the bet value has to be calculated for "promising values" (most frequently appearing in the reduced list) and "secondary promising values" (second most often appearing ones).
Time complexity: O(good luck figuring this out)
Result: deterministic, partial coverage
Oracle
Taking a step further and assuming the input is constant, allows to pre-compute the correct result.
def oracle():
return 142
This method very useful for whenever it's possible to apply. This case solves the 1M_random_numbers.txt test case.
Benchmarks
The benchmarks are split into two:
The benchmarking values provided with courtesy by StackOverflow staff.
Randomly generated input on the fly
The inputs are prepared for the algorithms beforehand and time to compute them don't constitute to the runtime.
--- Numbers from stackoverflow ---
-- Initializing test values --
use_predefined = True
len(lst_pre) = 1000000
-- Starting test --
normal(lst) = 20.546551328 ms (avg), 10.273275664 s (tot)
simple_reduce(st_lst) = 0.032606704 ms (avg), 0.016303352 s (tot)
c_normal(c_lst) = 0.299673282 ms (avg), 0.149836641 s (tot)
sneaky(lst) = 2.663635514 ms (avg), 1.331817757 s (tot)
oracle() = 2.6666e-05 ms (avg), 1.3333e-05 s (tot)
--- Randomly generated numbers ---
-- Initializing test values --
use_predefined = False
loops = 500
samples = 5
SIZE = 1000000
-- Starting test --
normal(lst) = 20.532174136000002 ms (avg), 10.266087068 s (tot)
simple_reduce(st_lst) = 0.03616424 ms (avg), 0.01808212 s (tot)
c_normal(c_lst) = 0.285049226 ms (avg), 0.142524613 s (tot)
sneaky(lst) = 2.6310455040000003 ms (avg), 1.315522752 s (tot)
The benchmarking code is available in the gist.
Design procedure
The most challenging of the project was making the JIT compiler for python. On the path[3] for success, many obstacles were lied. Many of them included untrackable core dumps (use-after-unwilling-free, position-independed code still needs a proper relocation table and similar).
Other difficult part was properly implementing the simple_reduce algorithm. While the key realization for was that additional constrains[4] allow creating more powerful algorithms, it still was finicky to get the properly working algorithm. Employing unguided fuzzing turned out to be very helpful. (It was the first time I tried this technique.)
(Unrelated) Footnotes
[1] https://www-cs-staff.stanford.edu/~knuth/boss.html
[2] https://youtu.be/bJLcIBixGj8
[3] https://roadmap.sh/
[4] https://merncraft.github.io/Pure-CSS-Games/#intro
- 12k
- 5
- 53
- 108
Does the benchmark timing include the time for sorting the original data?
- 316
- 2
- 14
@huseyin-tugrul-buyukisik
The inputs are prepared for the algorithms beforehand and time to compute them don't constitute to the runtime.
So no. Algorithmically-wise it wouldn't make sense either: O(n log n) vs O(m + log something). Although I haven't tested where's the tipping point for when sorting algorithm in c becomes slower than frequency calculation implemented in python.
- 388
- 3
- 15
We can create an array that tracks how many times each number appears. The easiest way to do this given the conditions is to assume the index equals the number you are counting.
Mapping the input will take O(s), where s is the size of the input.
And you take O(n) in memory and complexity to find the most repeated number. where n equals the range of the numbers (0 to 999 ---> n = 1000).
This solution works given the numbers are limited to a specific and small range.
import java.util.*;
import java.io.*;
public class Solution {
private static final int INTEGER_RANGE = 1000;
public static void main(String[] args) {
if (args.length != 1) {
System.err.println("The program expected 1 argument");
System.exit(1);
}
String filePath = args[0];
try {
int[] numbers = readFile(filePath);
int maxIdx = 0;
for (int i = 1; i < INTEGER_RANGE; ++i) {
if (numbers[maxIdx] < numbers[i])
maxIdx = i;
}
System.out.println("The integer with more repetitions is: " + maxIdx);
} catch (IOException | RuntimeException _) {
System.out.println("A problem occurred while reading the file you dumb!");
}
}
public static int[] readFile(String filePath) throws RuntimeException, IOException {
File file = new File(filePath);
int[] numbers = new int[INTEGER_RANGE];
if (!file.exists())
throw new RuntimeException("The file cannot doesn't exist");
if (!file.canRead())
throw new RuntimeException("The specified file cannot be accesed");
try (BufferedReader reader = new BufferedReader(new FileReader(file))) {
String line;
while ((line = reader.readLine()) != null) {
++numbers[Integer.parseInt(line)];
}
}
return numbers;
}
}
Another way yo may come up to do this, is to keep track of the most repeated value while filling up the array but that will create many more operations when s > range.
const numbers = Array.from({ length: 1_000_000 }, () => Math.floor(Math.random() * 1000));
function mostFrequentNumber(nums) {
const freq = new Array(1000).fill(0);
let maxCount = 0;
let maxNum = 0;
for (let i = 0; i < nums.length; i++) {
const num = nums[i];
freq[num]++;
if (freq[num] > maxCount) {
maxCount = freq[num];
maxNum = num;
}
}
return { number: maxNum, count: maxCount };
}
- 408
- 3
- 9
We create an array of 1 million random integers between 0 and 999.
We create a fixed-size array of 1000 elements.
Each index represents a number.
For each number, increment the corresponding index in the counting array
Track the maximum count and its corresponding number.
IntegerCounting.tsx:
import React, { useState } from "react";
const IntegerCounting = () => {
const [result, setResult] = useState<{ number: number; count: number } | null>(null);
const [time, setTime] = useState<string | null>(null);
const runChallenge = () => {
const numbers = Array.from({ length: 1_000_000 }, () =>
Math.floor(Math.random() * 1000)
);
const counts = new Array(1000).fill(0);
const start = performance.now();
for (let i = 0; i < numbers.length; i++) {
counts[numbers[i]]++;
}
let maxCount = 0;
let mostFrequent = 0;
for (let i = 0; i < counts.length; i++) {
if (counts[i] > maxCount) {
maxCount = counts[i];
mostFrequent = i;
}
}
const end = performance.now();
setResult({ number: mostFrequent, count: maxCount });
setTime((end - start).toFixed(2));
};
return (
<div>
<h1>Integer Counting Challenge</h1>
<button onClick={runChallenge}>Run Challenge</button>
{result && (
<div>
<p>
Most frequent number: {result.number}, Count: {result.count}
</p>
<p>Execution time: {time} ms</p>
</div>
)}
</div>
);
};
export default IntegerCounting;
App.tsx:
import React from 'react';
import IntegerCounting from './IntegerCounting';
function App() {
return (
<div className="App">
<IntegerCounting />
</div>
);
}
export default App;
- 15
- 7
Compiled using gcc -O3 -o main main.c
Source code:
#include<stdio.h>
#include<time.h>
#define ARRMAX 999
void populateFromFile(short arr[]){
FILE* file = fopen("1M_random_numbers.txt", "r");
short num;
while(fscanf(file, "%hd", &num) == 1){
//unecessary to conduct a bounds check
arr[num] += 1;
}
fclose(file);
}
short maxIdx(short arr[]){
short maxCount = 0;
short maxIndex = 0;
for(int i = 0; i < ARRMAX; i++){
if(arr[i] > maxCount){
maxCount = arr[i];
maxIndex = i;
}
}
return maxIndex;
}
short main(void){
clock_t start = clock();
short nums[ARRMAX] = {0};
populateFromFile(nums);
printf("Most frequent number: %hd \n", maxIdx(nums));
clock_t end = clock();
double runtime = ((double)(end - start)) / CLOCKS_PER_SEC;
printf("Runtime: %.4fs\n", runtime);
return 0;
}
Runtime varies from 0.194s to 0.206s. My PC specs are: Intel i9 13900HX, 32GB DDR5 RAM @5600M/T, NVIDIA GeForce RTX 4080 Laptop GPU, Disk is an NVMe Micron_3400_MTFDKBA1T0TFH
For my approach I have an array list where the index ranges from 0-the maximum number in the files, and I increment the short value of the index to represent how many times that number appeared. Finally, I iterate through the array to find the highest value and then return the intex.
For optimization, I use short rather than 32bit integers because it might be slightly faster. I also forgo all boundary checks since I know what to expect from the data, and the 03 flag for maximum optimization.
- 587
- 5
- 16
#include<stdio.h>
#include<stdlib.h>
int main(int argc, char** argv) {
FILE* fp;
int counts[999] = {0};
int max = 0;
int maxCount = 0;
if(argc == 1) {
fprintf(stderr, "no args provided. Please provide file name\n");
return 1;
}
fp = fopen(argv[1], "r");
if(fp == NULL) {
perror("error opening file");
return 1;
}
int c;
int curNum = 0;
int pos = 1;
while((c = fgetc(fp)) != EOF) {
if(c == '\n') {
counts[curNum]++;
if(counts[curNum] > maxCount) {
max = curNum;
maxCount = counts[curNum];
}
curNum = 0;
pos = 1;
continue;
}
curNum += pos * (c - '0');
pos *= 10;
}
printf("max = %d, count = %d\n", max, maxCount);
return 0;
}
Terminal output:
time ./out 1M_random_numbers.txt
max = 4, count = 3115
./out 1M_random_numbers.txt 0.02s user 0.00s system 98% cpu 0.021 total
System Specs:
memory: 8GiB System memory
processor: Intel(R) Core(TM) i7-4810MQ CPU @ 2.80GHz
Thought to use hashmap. But saw the constraints and I just used a fixed buffer. Converting the numbers to int on the fly as I parse the file. And comparing the count with max.
It does not display all numbers if there are several with same count. Also most frequent number is 142, not 4
- 2.6k
- 3
- 23
- 38
*************** Code Block Start ***************
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace randomnumbergeneration
{
class Program
{
static void Main(string[] args)
{
Random rnd = new Random();
IEnumerable<int> numbers = Enumerable.Range(0, 999999);
List<int> lstnumbers = numbers.ToList();
List<string> lstoutput = new List<string>();
lstoutput.Add("Machine Name : " + Environment.MachineName + '\t' + "User Name : " + Environment.UserName);
lstoutput.Add("Process start : " + DateTime.Now.ToString("dd/MM/yyyy hh:mm:ss.fff"));
lstnumbers.ForEach(x =>
{
lstoutput.Add(rnd.Next(0, 999).ToString());
});
lstoutput.Add("Process end : " + DateTime.Now.ToString("dd/MM/yyyy hh:mm:ss.fff"));
System.IO.File.WriteAllLines("D:\\randtest.txt", lstoutput);
}
}
}
*************** Code Block End ***************
`>
` Approach Explanation Start ***************
- as per requirement used random and I am using c# language.
- Enumerable range generate the numbers from 0 to 1 million numbers. so its very fast.
- generated numbers transfer to list. list is very fast execution so transferred to list. in the list used foreach so every number executed.
- already created string list in the list added generated random numbres 0 to 999.
- write to txt file in particular specific folder.
Approach Explanation End ***************
Code Execution time and Machine name Start ***************
Machine Name : USP1472 User Name : USPSK1472 Process start : 19/09/2025 10:42:49.943 Process end : 19/09/2025 10:42:50.123 process start and end time added in the output file. while execute the code automatically added process start and end time with machine details.
Code Execution time and Machine name End***************
This is first time I am attending the code challenge with stackoverflow I am very happy to attend this code challenge. ``
This does not count already provided numbers by stackoverflow, it just generates some random numbers
- 399.7k
- 49
- 474
- 671
Naive c++ take, just reading from std::cin:
int main() {
Map counts;
for (auto l : r::subrange(It(std::cin), It{}))
counts[l]++;
fmt::print("Most frequent: {}\n", *r::max_element(counts, r::less{}, &V::second));
}
Optimizations
Replacing the map hash table:
using Map = boost::unordered_map<long, unsigned>;
And avoiding the iostreams approach, instead using a mapped file:
boost::iostreams::mapped_file_source file("/home/sehe/Downloads/1M_random_numbers.txt");
auto tally = [&](auto& ctx) { counts[x3::_attr(ctx)]++; };
x3::phrase_parse(file.begin(), file.end(), +x3::long_[tally], x3::space);
Benchmark
#include <boost/iostreams/device/mapped_file.hpp>
#include <boost/spirit/home/x3.hpp>
#include <fmt/ranges.h>
#include <unordered_map>
namespace r = std::ranges;
namespace x3 = boost::spirit::x3;
using It = std::istream_iterator<long>;
using Map = std::unordered_map<long, unsigned>;
using V = Map::value_type;
int main() {
Map counts;
boost::iostreams::mapped_file_source file("/home/sehe/Downloads/1M_random_numbers.txt");
auto tally = [&](auto& ctx) { counts[x3::_attr(ctx)]++; };
x3::phrase_parse(file.begin(), file.end(), +x3::long_[tally], x3::space);
fmt::print("Most frequent: {}\n", *r::max_element(counts, r::less{}, &V::second));
}
Output:
sehe@workstation:~/Projects/stackoverflow$ time ./build/sotest < ~/Downloads/1M_random_numbers.txt
Most frequent: (142, 1130)
real 0m0.015s
user 0m0.013s
sys 0m0.002s
sehe@workstation:~/Projects/stackoverflow$ time ./build/sotest < ~/Downloads/1M_random_numbers.txt
Most frequent: (142, 1130)
real 0m0.015s
user 0m0.011s
sys 0m0.004s
sehe@workstation:~/Projects/stackoverflow$ time ./build/sotest < ~/Downloads/1M_random_numbers.txt
Most frequent: (142, 1130)
real 0m0.015s
user 0m0.013s
sys 0m0.002s
sehe@workstation:~/Projects/stackoverflow$ time ./build/sotest < ~/Downloads/1M_random_numbers.txt
Most frequent: (142, 1130)
real 0m0.015s
user 0m0.013s
sys 0m0.002s
That's a AMD Ryzen 7 7700 system with "enough RAM" and lots of applications open (music streaming and browser)
- 598
- 1
- 11
My Integer Counter Console Application in C++
#include <array>
#include <vector>
#include <future>
#include <iostream>
#include <chrono>
#include <random>
#include <algorithm>
// user defined literal to write 1_K instead of 1000
constexpr size_t operator""_K(unsigned long long int input)
{
return static_cast<size_t>(input) * 1000;
}
// user defined literal to write 1_M instead of 1000000
constexpr size_t operator""_M(unsigned long long int input)
{
return static_cast<size_t>(input) * 1_K * 1_K;
}
constexpr size_t c_amountOfDifferentValues = 1_K;
using CounterArray = std::array<int, c_amountOfDifferentValues>;
using NumberCollectionType = std::vector<int>;
CounterArray countNumberRange(const NumberCollectionType& numbers, size_t startIndex, size_t endIndex)
{
CounterArray numberCounts;
numberCounts.fill(0);
for(size_t i = startIndex; i < endIndex; i++)
{
numberCounts[numbers[i]]++;
}
return numberCounts;
}
void mergeCounters(const CounterArray& source, CounterArray& target)
{
for(size_t i = 0; i < source.size(); i++)
{
target[i] += source[i];
}
}
void identifyMaxCounter(const CounterArray& counters, size_t& maxUsedIndex, int& maxUseCount)
{
maxUsedIndex = 0;
maxUseCount = counters[0];
for(size_t i = 1; i < counters.size(); i++)
{
if(counters[i] > maxUseCount)
{
maxUseCount = counters[i];
maxUsedIndex = i;
}
}
}
void countAllNumbers(const NumberCollectionType& allNumbers, size_t maxNumberOfThreads,
size_t& maxUsedIndex, int& maxUseCount, std::chrono::microseconds& duration, size_t& numberOfUsedThreads)
{
maxUseCount = 0;
maxUsedIndex = 0;
auto startTime = std::chrono::high_resolution_clock::now();
// for every async thread we have to copy one counter array,
// so make sure to process more items per thread than we have to merge result counters
size_t minItemsPerThread = c_amountOfDifferentValues;
if(allNumbers.size() > 2 * minItemsPerThread) // when we can use more than one thread
{
size_t itemsPerThread = std::max(allNumbers.size() / maxNumberOfThreads, minItemsPerThread);
numberOfUsedThreads = allNumbers.size() / itemsPerThread;
std::vector<std::future<CounterArray>> asyncResults;
asyncResults.reserve(numberOfUsedThreads - 1);
// do n-1 asynchronous loops
for(size_t i = 0; i < numberOfUsedThreads - 1; i++)
{
size_t lowerIndex = i * itemsPerThread;
size_t upperIndex = (i + 1) * itemsPerThread;
// the upper bound is not included
asyncResults.emplace_back(std::async(&countNumberRange, std::ref(allNumbers), lowerIndex, upperIndex));
}
// do the last portion on the current thread including the non-dividable remainder
CounterArray totalCounts = countNumberRange(allNumbers, (numberOfUsedThreads - 1) * itemsPerThread, allNumbers.size());
// wait for and merge the results of the asynchronous operations
for(auto& singleResult : asyncResults)
{
singleResult.wait();
mergeCounters(singleResult.get(), totalCounts);
}
identifyMaxCounter(totalCounts, maxUsedIndex, maxUseCount);
}
else
{
// for small amounts of numbers use only the current thread
numberOfUsedThreads = 1; // only used for the print output
CounterArray totalCounts = countNumberRange(allNumbers, 0, allNumbers.size());
identifyMaxCounter(totalCounts, maxUsedIndex, maxUseCount);
}
auto endTime = std::chrono::high_resolution_clock::now();
duration = std::chrono::duration_cast<std::chrono::microseconds>(endTime - startTime);
}
void countAllNumbersPerThreads(const NumberCollectionType& allNumbers, size_t maxThreadsToUse)
{
size_t maxUsedIndex = 0;
int maxUseCount = 0;
std::cout << "Counting " << allNumbers.size() << " numbers\n";
for(size_t numberOfAvailableThreads = 1; numberOfAvailableThreads <= maxThreadsToUse; numberOfAvailableThreads *= 2)
{
std::chrono::microseconds duration;
size_t numberOfUsedThreads = 0;
countAllNumbers(allNumbers, numberOfAvailableThreads,
maxUsedIndex, maxUseCount,
duration, numberOfUsedThreads);
std::cout << numberOfUsedThreads << (numberOfUsedThreads == 1 ? " thread" : " threads") << " took " << duration.count() << " microseconds\n";
// skip all following iterations with more available threads, as they will use the same number of threads
if(numberOfUsedThreads < numberOfAvailableThreads)
{
break;
}
}
std::cout << maxUsedIndex << " occurs the most with " << maxUseCount << " repetitions\n";
std::cout << "\n";
}
void generateNumberRange(NumberCollectionType& numbers, size_t lowerIndex, size_t upperIndex, bool printPercentage)
{
std::random_device r;
std::uniform_int_distribution<int> distribution(0, c_amountOfDifferentValues - 1);
double percentPerCharacter = 5;
if(printPercentage)
{
std::cout << "0";
// fill the space after the leading single character "0" until the first digit of the next token "50" ("5")
for(double i = 1 * percentPerCharacter; i < 50 - (1 * percentPerCharacter); i += percentPerCharacter)
{
std::cout << " ";
}
std::cout << "50";
// fill the space after the second character of the previous token "50" ("0") until the first digit of the next three digit token "100"
for(double i = 50 + (1 * percentPerCharacter); i < 100 - (3 * percentPerCharacter); i += percentPerCharacter)
{
std::cout << " ";
}
std::cout << "100\n";
}
if(printPercentage)
{
double printedPercentage = 0;
size_t totalItems = upperIndex - lowerIndex;
// use two different approaches for small and big amounts,
// - the calculation on amounts below 100 can get problems with integer rounding
// - the calculation on amounts close to size_t max can get problems with overflows
for(size_t i = 0; i < totalItems; i++)
{
numbers[i + lowerIndex] = distribution(r);
// calculate to 1-based for the percentage calculation, e.g. we don't have 0% after the first item
double percentage = (((double)i + 1) / totalItems) * 100.0;
if(percentage - printedPercentage >= percentPerCharacter)
{
// one item could require to print multiple percentage characters
for(; printedPercentage < percentage; printedPercentage += percentPerCharacter)
{
std::cout << "#";
}
}
}
std::cout << "\n\n";
}
else
{
for(size_t i = lowerIndex; i < upperIndex; i++)
{
numbers[i] = distribution(r);
}
}
}
NumberCollectionType generateNumbers(size_t amount, size_t maxNumberOfThreads)
{
// helps to print the big numbers separaed by commas or dots
std::cout.imbue(std::locale("en")); // use this for an english comma separated output
//std::cout.imbue(std::locale("")); // use this for your configured system locale specific separator
std::cout << "Allocating " << amount << " numbers\n";
NumberCollectionType numbers(amount, 0);
std::cout << "Generating random values:\n";
size_t minItemsPerThread = 2000; // use a somehow useful minimum to prevent the thread overhead to be bigger than the benefit
if(amount > minItemsPerThread)
{
size_t itemsPerThread = std::max(amount / maxNumberOfThreads, minItemsPerThread);
size_t numThreadsToUse = amount / itemsPerThread;
std::vector<std::future<void>> asyncCompletion;
asyncCompletion.reserve(numThreadsToUse - 1);
// do n-1 asynchronous loops
for(size_t i = 0; i < numThreadsToUse - 1; i++)
{
size_t lowerIndex = i * itemsPerThread;
size_t upperIndex = (i + 1) * itemsPerThread;
asyncCompletion.emplace_back(std::async(&generateNumberRange, std::ref(numbers), lowerIndex, upperIndex, false /* print */));
}
// do the last portion on the current thread including the non-dividable remainder
generateNumberRange(numbers, (numThreadsToUse - 1) * itemsPerThread, amount, true /* print */);
// wait for the async ones
for(auto& c : asyncCompletion)
{
c.wait();
}
}
else
{
// generate all on the current thread
generateNumberRange(numbers, 0, amount, true /* print */);
}
return numbers;
}
int main()
{
size_t maxThreadsToUse = maxThreadsToUse = std::thread::hardware_concurrency();
std::vector<NumberCollectionType> testSets{
// internal test for values below 100 and odd numbers
generateNumbers(3, maxThreadsToUse),
// official tests
generateNumbers(100, maxThreadsToUse),
generateNumbers(10_K, maxThreadsToUse),
generateNumbers(1_M, maxThreadsToUse),
// extreme tests, things will get very slow
generateNumbers(10_M, maxThreadsToUse),
generateNumbers(100_M, maxThreadsToUse),
};
for(NumberCollectionType& numbers : testSets)
{
// for display purposes, test with more threads than what makes sense from the amount of cores
countAllNumbersPerThreads(numbers, maxThreadsToUse * 4);
}
// waits before to not close the application before shutdown
std::cout << "Press any key to exit\n";
std::cin.clear();
std::cin.get();
}
Output:
My program produces some more output for different scenarios but here is the output which relates directly to the challenge:
Allocating 1,000,000 numbers
Generating random values:
0 50 100
####################
...
Counting 1,000,000 numbers
1 thread took 1,439 microseconds
2 threads took 938 microseconds
4 threads took 802 microseconds
8 threads took 1,087 microseconds
16 threads took 1,470 microseconds
32 threads took 1,058 microseconds
337 occurs the most with 1,108 repetitions
This output was produced on a Windows 10 Notebook with a more than 5 years old Intel i7 processor (4 physical or 8 virtual cores).
Edit: According to @jiirassimik comment I tried afterwards to include the attempt to read the file, but then this becomes the new bottleneck and makes my maximum parallel processing approach pretty useless.
Combined with a read it would be better to process the data while the file is read (e.g. in parallel) and don't wait until the entire data is stored in RAM. That also saves a bit of time for the allocation.
For completeness:
My attempt to read took around 50 milliseconds (which can definitely be improved when I see the other answers for C or C++).
The extra time to allocate memory for 1 million values took around 1 millisecond.
What the code does:
- It generates a lot of values for different scenarios and stores it as
std::vectors. Note: This takes the most time of the program but I don't count this as part of the actual test. - It keeps the contents in simple array like structures (
std::arrayandstd::vector) to prevent any delays which any tree like containers would add. - It uses multithreading to get a performance boost.
- Each thread counts the numbers on an own subset and finally the counters of all threads are merged together.
- It does some additional benchmarking with different parameters, some are intentionally not that useful, like using more thread than CPU cores.
- Unfortunately my code does NOT use the provided list of random numbers but generates its own
Note: The code should compile and run on pretty much any system with any amount of CPUs as long as it supports C++11.
Where to find what in the code:
The important stuff is inside of countAllNumbers() and the small helper methods which it calls.
Everything else is just for other stuff like setting up the test values, produce a nice output, testing with different parameters and so on.
My thoughts on the optimization:
Any sorting type of data structure would add some small overhead. Sure, the overhead of searching in tree like container is usually small, but on giant amounts of content this can make a small difference.
Instead, nothing beats a single iteration over a big array and accessing arrays via direct indexes.
The only small drawback is the overhead of merging the separate counter arrays back into one, but that should be compensated by the performance gains.
For the threading part it is important to not loose performance by a steady synchronization from concurrent calls. Thus my approach is to operate on non-overlapping input sections and synchronize only once when the threads are completed.
Personal Highlights:
- I was extremely surprised that I had to switch the time measurement representation from milliseconds to microseconds. Processing 1 million numbers in below 1 millisecond (802 microseconds) is really insane. Similarly insane is processing 100 million numbers in only 42 milliseconds. Though the generation of so many values takes much longer.
- It was much fun to play around with random number generation, time measurements and some other stuff which I usually never need to use (custom numeric literals for big numbers; string formatting to produce nicely readable output; using temporary threads via
std::async). - It did not work to simply paste the content of 1 million integers directly into my source code. My compiler gave up on this (I am not really surprised by that). Reading the content via file read should work, but I simply let my code generate random numbers to fill my lists.
- 4.4k
- 2
- 19
- 25
Getting under a millisecond is fantastic, and I'd love to know how long it takes if you also read the file from the disk.
This took 0.23 seconds. I have HP EliteBook i5-processor 8 gb ram, 500 gb ssd.
Dictionary data structure is used to reach O(n) time complexity.
I noticed from the other entries here that Python is far from the fastest.
import pandas as pd
import time
import statistics
class Mode:
def __init__(self):
self.data=[]
self.numbers={}
self.mode1=None
self.largest_count=0
def read_data(self):
# Ignore the header, read the rest of the file:
df = pd.read_csv('1M_random_numbers.txt', header=None, sep=r'\s+')
self.data=df[0].to_list()
def count(self):
#print('mode statistics function: ',statistics.mode(self.data))
for x in self.data:
if x not in self.numbers:
self.numbers[x]=1
else:
self.numbers[x]+=1
if self.numbers[x]>self.largest_count:
self.largest_count=self.numbers[x]
self.mode1=x
def mode(self):
return self.mode1
if __name__ == "__main__":
m = Mode()
m.read_data()
start=time.time()
m.count()
end=time.time()
print(m.mode()) # 4
print('Time in seconds: ', round(end-start,2))
- 651
- 4
- 11
The code
Php version:
The first version is written in PHP because in recent years it has been losing popularity, yet it boasts impressive performance—even when compared to compiled languages.
<?php
$fileName=$argv[1] ?? "";
if(!file_exists($fileName))die("file not found");
$fp = @fopen($fileName, "r");
$vipNumbers=[];
$occurrence=0;
$search=[];
if ($fp) {
//since we know le length of each line we can set le length of 'fgets' buffer
//to 6 (4 digit + \n) of course this have a very small impact on optimization
// but hey every millis count!!
while (($buffer = fgets($fp, 6)) !== false) {
//int index speed up operation on array
$k=intval($buffer);
//put value in a variable speed up comparison inside 'if' and 'else if' condition
$v=($search[$k] ?? 0) + 1;
$search[$k]=$v;
//this is for find all numbers with the same popularity,
//if only the first number is required we could remove the else 'if condition'
if($occurrence<$v){
$vipNumbers=[$k];
$occurrence=$v;
}else if($occurrence==$v){
array_push($vipNumbers,$k);
}
}
if (!feof($fp)) {
echo "Error: unexpected fgets() fail\n";
}
fclose($fp);
}
echo "numbers: ".json_encode($vipNumbers)."\noccurrence: ".$occurrence."\n";
?>
Rust Version:
i've tried to rearrange php code in rust because a compiled version should be a lot more performant but .... this actually are my first line of code writtent in rust so it ended to be slower then my php code (facepalm and shame on me)
use std::fs::File;
use std::io::{self, BufRead};
use std::env;
use std::collections::HashMap;
fn main() {
let mut args = env::args();
let filename = args.by_ref().skip(1).next().unwrap_or_else(|| {
eprintln!("File not found; expected full file name");
std::process::exit(1);
});
println!("{}", filename);
let mut buf = String::new();
let file = File::open(filename).expect("file not exist");
let mut fp: io::BufReader<File> = io::BufReader::new(file);
let mut res = fp.read_line(&mut buf).expect("read error");
let mut vipnumbers=Vec::new();
let mut occurrence=0;
let mut search = HashMap::new();
while res >0 {
let tmp =search.entry(buf.clone()).or_insert(0);
let nr=String::from(buf.trim());
*tmp += 1;
if *tmp>occurrence {
vipnumbers= vec![nr];
occurrence=*tmp;
}else if *tmp==occurrence {
vipnumbers.push(nr);
}
buf.clear();
res = fp.read_line(&mut buf).expect("read error");
}
println!("number:{:?},\noccurrence:{}",vipnumbers,occurrence);
}
Concept and Explanation
Disclaimer and offtopics:
Based on the challenge text, I understood that the code had to be optimized for execution time. It would have been very interesting to also take memory usage into account.
**Wouldn't it have been ironic to face a stack overflow in a challenge on Stack Overflow? :)**
Code algo:
- loop the file once and on every iteration:
- create an hash map (max length 0-9999) width the numbers obtained
as keys and the occurrence as value
- store every numbers (it can be more than one ) with max occurrence
- store the current max occurrence
- print the result
Optimizazion Approach
My approach was to optimize 'as little as possible'. Let me explain better: since the code had to be optimized based on execution time, all my interventions were focused on
- loop length
- operation per loop,
- operation cost.
there's some comment on php version for explain some incode ottimizzation like buffer length and int conversion for array indexing
loop length I hade 2 options:
Exit when the
occurrences of the most popular numberare more than (the remaining numbers+the occurrences of the second most popular number). So, in the best case i could exit after (N/2) + 1 iterations but the only way for obtain the file length is read the whole file before looping and this is like (more or less) do the full loopExit always at the end of the loop So, after (N) iterations
so my loop optimization is do not optimize the loop ^_^
i feel pass the list length as parameter like a cheat
operations per loop it is pretty easy in the worst case 3 assignation and 1 condition check
operations cost i'm not an expert but both assignations and contitions should have the lower computational cost
Execution runtime e machine detail:
My Laptop:
Lenovo Thinkbook 14 G4 IAP
CPU: 12th Gen Intel(R) Core(TM) i5-1235U 1.30 GHz
Ram: 16,0 GB
HD: SSD 500Gb (i dont know more)
Windows 11 pro (Linux Sub System)
all test were executed under (WSL) Linux Sub System , i've no idea if this slow up the runtime.
this are the command used for execute the code followed by results:
cmd:
php ./get_max.php ./100_random_numbers.txtresult:
numbers: [208,188,641,546,374,694] occurrence: 2cmd:
php ./get_max.php ./10000_random_numbers.txtresult:
numbers: [284] occurrence: 23cmd:
php ./get_max.php ./1M_random_numbers.txtresult:
numbers: [142] occurrence: 1130
this are benchmark for both php and rust version:
cmd:
hyperfine 'php ./get_max.php ./1M_random_numbers.txt'result:
Time (mean ± σ): 76.7 ms ± 1.7 ms [User: 70.4 ms, System: 13.2 ms] Range (min … max): 73.4 ms … 79.7 ms 37 runscmd for compiled rust:
hyperfine './get_max ./1M_random_numbers.txt'result:
Time (mean ± σ): 284.5 ms ± 7.7 ms [User: 306.8 ms, System: 3.6 ms] Range (min … max): 275.8 ms … 302.2 ms 10 runs
What i've learned
i've no idea how far i'am from a good optimization but i've learned is that:
- good code can be extremely performant regardless of the programming language
- bad code can be extremely slow regardless of the programming language
- i need to master rust ^_^
Greetings, and please don't be too harsh with your judgments.
- 12k
- 5
- 53
- 108
If those timings are including file-reading too, then you're benchmarking the file reading operation too. The challenge doesn't say about where to start benchmarking and where to stop benchmarking.
- 651
- 4
- 11
pretty weird put file reading is out of benchmarking since the input is a file and since the best way to optimize this is to process the info during the reading, the challenge say to benchmark my code and my code read the file , If I had been asked to process preloaded data, I would have run the benchmark on the preloaded data, but that was just the way I interpreted the request so maybe i was wrong.
- 1
- 5
- 28
Languate: Python
import time
def find_most_frequent_number(filename):
freq = [0] * 1000
with open(filename, 'r') as file:
for line in file:
num = int(line.strip())
freq[num] += 1
max_count = 0
result = -1
for num in range(1000):
if freq[num] > max_count:
max_count = freq[num]
result = num
return result
# Benchmarking the function
start_time = time.time()
result = find_most_frequent_number('1M_random_numbers.txt')
end_time = time.time()
print(f"Most frequent number is: {result}")
print(f"Time taken: {end_time - start_time:.4f} seconds")
In start I have initialized frequency array (a list of size 1000) because the numbers are constrained to the range 0-999. This allows for O(1) access and update for each number, leading to an overall time complexity of O(n), where n is the number of integers (1 million). The space complexity is O(1) since the array size is fixed.
Once processing all numbers, I have iterate through freq to find the number with the highest count.
Machine: Macbook Pro
Chip set: M1
Ram: 16Gb
Execution time: 0.215 seconds/14times
Result: 142
- 97.5k
- 12
- 67
- 101
Seems like this could easily be achieved with a COUNT and TOP (1) (or similar based method depending on the SQL dialect):
--Sample table
CREATE TABLE dbo.Numbers (NumberID int IDENTITY CONSTRAINT PK_Numbers PRIMARY KEY,
IntegerValue int NOT NULL);
GO
--Generate sample data (as I can't access Google Drive):
INSERT INTO dbo.Numbers (IntegerValue)
SELECT ABS(CHECKSUM(NEWID())) % 999 AS IntegerValue
FROM GENERATE_SERIES(1,1000000);
GO
--Get Top 1 value
SELECT TOP (1)
N.IntegerValue
FROM dbo.Numbers N
GROUP BY N.IntegerValue
ORDER BY COUNT(*) DESC;
If this is something that needs to be completed often, then a pre-aggregated VIEW would likely be a good solution, as this would allow the INDEX's first row to be scanned and then aborted out; this would be a significantly faster solution.
CREATE VIEW dbo.NumberCounts
WITH SCHEMABINDING AS
SELECT N.IntegerValue,
COUNT_BIG(*) AS NumberCount
FROM dbo.Numbers N
GROUP BY N.IntegerValue;
GO
CREATE UNIQUE CLUSTERED INDEX UQ_NumberCounts ON dbo.NumberCounts (IntegerValue);
GO
CREATE INDEX IX_NumberCounts_NumberCount ON dbo.NumberCounts (NumberCount);
GO
SELECT TOP (1)
NC.IntegerValue
FROM dbo.NumberCounts NC
ORDER BY NC.NumberCount DESC;
You can see the query plans for the 2 different queries on Paste the Plan:
Running each query 1,000 times, to account for variations and caching, gave the following run times:
| Solution Type | Number Of Runs | Max Time (ns) | Min Time (ns) | Avg Time (ns) |
|---|---|---|---|---|
| TOP (1) Against Table | 1000 | 321174200 | 31150100 | 42769969 |
| TOP (1) Against Aggregated View | 1000 | 15828600 | 0 | 612019 |
Or if you prefer in milliseconds (floor'd):
| Solution Type | Number Of Runs | Max Time (ms) | Min Time (ms) | Avg Time (ms) |
|---|---|---|---|---|
| TOP (1) Against Table | 1,000 | 321 | 31 | 42 |
| TOP (1) Against Aggregated View | 1,000 | 15 | 0 | 0 |
This was run on a against a host running SQL Server 2022 Developer Edition Sandbox environment with 4 Virtual Cores and 20GB of RAM.
You can run the full test script with the following:
SET NOCOUNT ON;
GO
DROP VIEW IF EXISTS dbo.NumberCounts;
DROP TABLE IF EXISTS dbo.Numbers;
DROP TABLE IF EXISTS dbo.NumberTestLogs;
GO
CREATE TABLE dbo.NumberTestLogs (RunNumber int IDENTITY(1,1),
SolutionType nvarchar(50),
StartTime datetime2(7),
EndTime datetime2(7),
TimeTaken AS DATEDIFF_BIG(NANOSECOND,StartTime,EndTime));
GO
--Sample table
CREATE TABLE dbo.Numbers (NumberID int IDENTITY CONSTRAINT PK_Numbers PRIMARY KEY,
IntegerValue int NOT NULL);
GO
--Generate sample data:
INSERT INTO dbo.Numbers (IntegerValue)
SELECT ABS(CHECKSUM(NEWID())) % 999 AS IntegerValue
FROM GENERATE_SERIES(1,1000000);
GO
DROP TABLE IF EXISTS #T;
DECLARE @StartTime datetime2(7),
@EndTime datetime2(7);
SET @StartTime = SYSDATETIME();
--Get Top 1 value
SELECT TOP (1)
N.IntegerValue
INTO #T
FROM dbo.Numbers N
GROUP BY N.IntegerValue
ORDER BY COUNT(*) DESC;
SET @EndTime = SYSDATETIME();
INSERT INTO dbo.NumberTestLogs (SolutionType,
StartTime,
EndTime)
VALUES(N'TOP (1) Against Table',@StartTime, @EndTime);
DROP TABLE #T;
GO 1000
CREATE VIEW dbo.NumberCounts
WITH SCHEMABINDING AS
SELECT N.IntegerValue,
COUNT_BIG(*) AS NumberCount
FROM dbo.Numbers N
GROUP BY N.IntegerValue;
GO
CREATE UNIQUE CLUSTERED INDEX UQ_NumberCounts ON dbo.NumberCounts (IntegerValue);
GO
CREATE INDEX IX_NumberCounts_NumberCount ON dbo.NumberCounts (NumberCount);
GO
DROP TABLE IF EXISTS #T;
DECLARE @StartTime datetime2(7),
@EndTime datetime2(7);
SET @StartTime = SYSDATETIME();
SELECT TOP (1)
NC.IntegerValue
INTO #T --Stop display of value
FROM dbo.NumberCounts NC
ORDER BY NC.NumberCount DESC;
SET @EndTime = SYSDATETIME();
INSERT INTO dbo.NumberTestLogs (SolutionType,
StartTime,
EndTime)
VALUES(N'TOP (1) Against Aggregated View',@StartTime, @EndTime);
DROP TABLE #T;
GO 1000
SELECT NTL.SolutionType,
COUNT(*) AS NumberOfRuns,
MAX(NTL.TimeTaken) AS MaxTime,
MIN(NTL.TimeTaken) AS MinTime,
AVG(NTL.TimeTaken) AS AVGTime
FROM dbo.NumberTestLogs NTL
GROUP BY NTL.SolutionType;
GO
SET NOCOUNT OFF;
DROP VIEW IF EXISTS dbo.NumberCounts;
DROP TABLE IF EXISTS dbo.Numbers;
DROP TABLE IF EXISTS dbo.NumberTestLogs;
- 33.3k
- 12
- 74
- 115
It is understandable to generate your own random list of numbers, but here you're skipping the I/O part in the benchmark. You can still write the random numbers to a text file and read them in.
BULK INSERT Numbers FROM '1M_random_numbers.txt'
WITH (FIRSTROW = 1, FIELDTERMINATOR = '\n');
- 97.5k
- 12
- 67
- 101
There's nothing I can see in the challenge to state it needs to be in a text file to start with, @M-- . With a SQL based solution I don't see why that list of data can't start in the database already. I would, in truth, be unlikely to chose SQL to do this if it were a text file to start with.
- 87
- 6
I too assumed that reading the numbers from a file was a requirement, since sample files were provided, but I agree that the overall problem specification was pretty vague (for example, there can be more than one number in the data that appears "the most" [i.e., the mode], as shown in the 100-number sample) and the wide variety of solutions presented (many of which skip the file reading, which IMO is a significant part of the problem, since this takes the most time) demonstrates why it's important to have clear requirements to begin with. Another example, I just assumed that the solution should be single-threaded, or a least benchmarked on a single CPU, where a lot of people assumed the opposite.
- 14.8k
- 22
- 92
- 114
The code you have written:
from collections import Counter
import time
def get_list(filename):
x = []
with open(filename) as f:
for line in f: x.append(int(line))
return x
def freq(x):
most_common,_ = Counter(x).most_common(1)[0]
return most_common
if __name__ == '__main__':
my_list = get_list(r'1M_random_numbers.txt')
sum_ns = 0
reps = 1000
for i in range(reps):
start_time = time.time_ns()
freq(my_list)
end_time = time.time_ns()
#print(f"{i+1}. runtime (ns): {end_time - start_time}")
sum_ns += end_time - start_time
print(f"sum_ns = {sum_ns}, average ns = {sum_ns / reps}")
An explanation of your approach, including how you optimized it for this task: Simple approach without much fuzz. Read the file line by line into a list of ints and then call the freq method to get the most common value.
The main block reads the file and runs the method 1000 times and prints the average ns needed to run the code.
The code execution runtime along with details about your machine:
sum_ns = 49,501,920,200; average_ns = 49,501,920.2
My coding machine is a Raspberry Pi 5 8GB with a 2TB SD Card. Coded in vim and ran in bash. OS is Debian - Bookworm.
Anything you learned or any interesting challenges you faced while coding: The first attempt without Counter ended with a runtime around 100ms for 10k numbers. Optimizations were unsuccessful and lead me to Counter which worked good enough for me.
This reply has been deleted.
- 97.5k
- 12
- 67
- 101
This doesn't cover the requirements of the challenge:
Your submission should include:
- The code you have written
- An explanation of your approach, including how you optimized it for this task
- The code execution runtime along with details about your machine
- Anything you learned or any interesting challenges you faced while coding
- 6.8k
- 6
- 42
- 66
bash:
sort 1M_random_numbers.txt | uniq --count | sort | tail -n1 | xargs | cut -d ' ' -f 2
This one-line command is concise, portable and completes in less than 1 second:
echo $(date +"%T.%N") && sort 1M_random_numbers.txt | uniq --count | sort | tail -n1 | xargs | cut -d ' ' -f 2 && echo $(date +"%T.%N")
Output:
13:06:15.428442741
877
13:06:15.948588164
A challenge was to extract the second portion (the count) after xargs because this is was the first time I need to do it. I just learned something new! :)
PHP:
Surprisingly, I tried with PHP 8.2, and it took an average time of 0.15 seconds on 1000 runs.
<?php
echo $startedAt = microtime(true)."\n";
$strNums = file_get_contents("1M_random_numbers.txt");
$nums = explode("\n", $strNums);
$counts = [];
$maxCountNum = 0;
$resultNum = 0;
foreach($nums as $num) {
if(!isset($counts[$num])) {
$counts[$num] = 0;
}
$counts[$num]++;
if($counts[$num] > $maxCountNum) {
$resultNum = $num;
}
$maxCountNum = max($maxCountNum, $counts[$num]);
}
echo "$resultNum ($maxCountNum times)\n";
echo $endedAt = microtime(true)."\n";
echo "time taken: ".($endedAt-$startedAt);
echo "\n\n";
I tested it on my laptop with these specs:
Ubuntu 20.04.6 LTS 64 bit
13,5 GiB RAM
processor: AMD® Ryzen 7 3700u with radeon vega mobile gfx × 8
Graphic: AMD® Radeon(tm) vega 10 graphics
SSD disk
Gnome 3.36.8
X11
I firstly chosen bash because I thought that is one of the faster language, and because I don't know C (which I think can do it faster). Then PHP is too much faster than bash, but it needs a running php server.
P.S. I didn't use any AI to answer, as requested, but for sure I'll ask to some AI to explain how to do it better in order to satisfy my curiosity and improve my skills :)
- 26.7k
- 5
- 27
- 56
Although I'm sure compiled languages will be faster, I like awk one-liners for straightforward tasks like this. This script creates an array, then cycles through the array and updates 'best' with the highest integer and 'num' with the count. The only optimisation is using mawk, which is an awk implementation based on a bytecode interpreter. I'm interested to see how it stacks up against the other entries.
time mawk '{a[$1]++} END{for(i in a){if(a[i] > num){best = i; num = a[i]}}; print best, num}' 1M_random_numbers.txt
142 1130
real 0m0.075s
user 0m0.064s
sys 0m0.011s
Machine: Apple MBPro M4 Max
What I learned: thanks to @M-- I learned about hyperfine for more accurate/informative benchmarking:
hyperfine -w 5 -r 50 "mawk -f mawk_script.sh 1M_random_numbers.txt"
Benchmark 1: mawk -f mawk_script.sh 1M_random_numbers.txt
Time (mean ± σ): 40.7 ms ± 0.4 ms [User: 39.6 ms, System: 0.8 ms]
Range (min … max): 39.9 ms … 41.7 ms 50 runs
- 51.7k
- 16
- 64
- 83
hyperfine spawns a new shell for every run and times it instead of the command you specified. So while informative, it's not as accurate as the good old time built-in.
- 33.3k
- 12
- 74
- 115
I am (pretty) sure that the startup time is removed from the final results.
p.s. Agreed; there is no way to accurately measure the startup time. However, hyperfine has --shell=none:
If you want to run a benchmark without an intermediate shell, you can use the
-Nor--shell=noneoption. This is helpful for very fast commands (< 5 ms) where the shell startup overhead correction would produce a significant amount of noise. Note that you cannot use shell syntax like*or~in this case.
I am sure there are other nuisances, but I'd use time for a quick one-off measurement. But when I need some statistical rigor comparing multiple commands/programs, I'd stick with hyperfine.
- 51.7k
- 16
- 64
- 83
Except there is no way to accurately measure the startup time, so hyperfine removes an estimate. Stick with time.
- 71
- 1
- 10
this is powershell v5.1 and v7.5.3 - and the 2nd is delightfully faster.
#Requires -version 5
# the `#Requires` line only sets a _minimum_
# so this will also work with version 7.+
#Clear-Host
''
''
''
'========================================'
# all files were dl'd in advance
$RN_c1_File = 'C:\Downloads\100_random_numbers.txt'
$RN_k10_File = 'C:\Downloads\10000_random_numbers.txt'
$RN_m1_File = 'C:\Downloads\1M_random_numbers.txt'
$C1Timer = [System.Diagnostics.Stopwatch]::new()
$C1Timer.Start()
# the next block averaged 0.015 seconds
<#
'1c unique item count = {0}' -f (
Get-Content -LiteralPath $RN_c1_File |
ForEach-Object {[int32]$_} |
Sort-Object -Unique
).count
#>
# then this next block averages 0.002 seconds
'1c unique item count = {0}' -f (
Get-Content -LiteralPath $RN_c1_File |
Select-Object -Unique
).count
$C1Timer.Stop()
"1c seconds = {0:n3}" -f ($C1Timer.ElapsedMilliseconds / 1000)
'=========='
$K10Timer = [System.Diagnostics.Stopwatch]::new()
$K10Timer.Start()
# the next block averaged 0.295 seconds
<#
'10k unique item count = {0}' -f (
Get-Content -LiteralPath $RN_k10_File |
ForEach-Object {[int32]$_} |
Sort-Object -Unique
).count
#>
# then this next block averages 0.632 seconds -- why so different from the other two [faster] data sets?
'10k unique item count = {0}' -f (
Get-Content -LiteralPath $RN_k10_File |
Select-Object -Unique
).count
$K10Timer.Stop()
"10k seconds = {0:n3}" -f ($K10Timer.ElapsedMilliseconds / 1000)
'=========='
$M1Timer = [System.Diagnostics.Stopwatch]::new()
$M1Timer.Start()
# the next block averaged 110.205 seconds
<#
'1M unique item count = {0}' -f (
Get-Content -LiteralPath $RN_m1_File |
ForEach-Object {[int32]$_} |
Sort-Object -Unique
).count
#>
# finally, this next code block averages 63.541 seconds in ps5.1
# but it averages 37.253 seconds in ps7.5.3
'1m unique item count = {0}' -f (
Get-Content -LiteralPath $RN_m1_File |
Select-Object -Unique
).count
$M1Timer.Stop()
"1m seconds = {0:n3}" -f ($M1Timer.ElapsedMilliseconds / 1000)
'========================================'
''
''
''
the final code may not be accepted since it is sorting for unique strings instead of integers.
"just now" timing on my system [AMD Ryzen 7 8845HS w/ Radeon 780M Graphics (3.80 GHz)] ...
========================================
1c unique item count = 94
1c seconds = 0.001
==========
10k unique item count = 1000
10k seconds = 0.470
==========
1m unique item count = 1000
1m seconds = 44.409
========================================
btw, i spent lots of time trying to find out why the 10k result showed exactly 1k unique items. grrr ...
- 441
- 4
- 7
unit MaxInt;
interface
uses
Windows, Messages, SysUtils, Classes, Graphics, Controls, Forms, Dialogs,
StdCtrls;
type
TfrmMaxInteger = class(TForm)
editFileName: TEdit;
lblFileName: TLabel;
lblAnswer: TLabel;
editAnswer: TEdit;
btnProcess: TButton;
editFrequency: TEdit;
lblFrequency: TLabel;
procedure btnProcessClick(Sender: TObject);
private
{ Private declarations }
procedure ProcessMemoryStream(MemStream: TMemoryStream);
procedure MaxFrequency;
public
{ Public declarations }
end;
const
MaxValue = 999;
var
frmMaxInteger: TfrmMaxInteger;
Frequency: array[0..MaxValue] of Integer;
implementation
{$R *.DFM}
procedure TfrmMaxInteger.ProcessMemoryStream(MemStream: TMemoryStream);
var
ptrStart, ptrChar, ptrLineStart : PChar;
Value : integer;
begin
ptrStart := MemStream.Memory;
ptrChar := ptrStart;
ptrLineStart := ptrStart;
while Integer(ptrChar - ptrStart) < MemStream.Size do
begin
if ptrChar^ = #10 then
begin
ptrChar^ := #0; // Null-terminate the string
Value := StrToIntDef(ptrLineStart, -1);
if (Value >= 0) and (Value <= MaxValue) then
Inc(Frequency[Value]);
Inc(ptrChar); // Skip the #0
ptrLineStart := ptrChar;
ptrLineStart := ptrChar; // because the optimizer compiles this out.
end
else
Inc(ptrChar);
end;
// Final line
if ptrChar > ptrLineStart then
begin
Value := StrToIntDef(ptrLineStart, -1);
if (Value >= 0) and (Value <= MaxValue) then
Inc(Frequency[Value]);
end;
end;
procedure TfrmMaxInteger.MaxFrequency;
var
intIndex, intMaxNumber, intMaxFrequency: integer;
begin
intMaxNumber := 0;
intMaxFrequency := 0;
for intIndex := 0 to MaxValue do
begin
if(Frequency[intIndex] > intMaxFrequency) then
begin
intMaxFrequency := Frequency[intIndex];
intMaxNumber := intIndex;
end;
end;
editAnswer.Text := IntToStr(intMaxNumber);
editFrequency.Text := IntToStr(intMaxFrequency);
end;
procedure TfrmMaxInteger.btnProcessClick(Sender: TObject);
var
oStream: TMemoryStream;
dStartTime, dEndTime, dElapsed: DWORD;
begin
dStartTime := GetTickCount;
FillChar(Frequency, SizeOf(Frequency), 0);
oStream := TMemoryStream.Create;
try
oStream.LoadFromFile(editFileName.Text);
ProcessMemoryStream(oStream);
MaxFrequency;
finally
oStream.Free;
end;
dEndTime := GetTickCount;
dElapsed := dEndTime - dStartTime;
ShowMessage('Elapsed time: ' + IntToStr(dElapsed) + ' ms');
end;
end.
So the idea of this code is to exploit the format, which is techincally UTF-8, but as it's all integers, that equates to ASCII. Therefore the program can use classical byte level logic cutting out a lot of overhead.
The program uses a global array with 1000 entries as the counter. Each entry is initialised to zero at the start.
The program loads the whole file into memory as a contiguous block, which is super fast.
Then iterates through the block looking for line breaks (#10), replace these with null terminators #0. I.e. the strings are "created" in the same memory block. It then converts the text between the last break and the current break to an integer using the StrToIntDef function. StrToIntDef avoids slow exception handling. The extracted number is used to identify an item in the global array to increment.
Once all numbers have been parsed the final function (MaxFequency) scans the array for the maximum.
This takes 109ms - 125ms to run all steps on a 1.4Ghz Intel Core Ultra 7 with SSD drive. 16Gb ram. Virtually all of this time is spent in the ProcessMemoryStream function.
I learned that after 23 years of using Delphi the optimizer gets rid of perfectly functional lines for no reason:
ptrLineStart := ptrChar;
- 87
- 6
Pascal? Nice! I've never gotten around to truly learning it in 30+ years, but it's on my bucket list. :)
Takes about 3ms on Intel Core 5 PC
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.IO;
namespace ListScan
{
internal class Program
{
static void Main(string[] args)
{
int[] source = [.. LoadSource()];
int[] buckets = new int[1000];
int max = 0;
using (new QuickStopwatch("ForEach"))
{
//Counting the occurrences of each number
source.ForEach(x => buckets[x]++);
//If the set is larger or the computation is more complex, the following will improve the results.
//For one million items with increment as the computation function the parallelization overhead negates the benefit...
//source.AsParallel().ForEach(x => buckets[x]++);
//looking for the number with the most occurrences
for (int i = 1; i < 100; i++)
{
if (buckets[i] > buckets[max])
max = i;
}
}
Console.WriteLine($"The number {max} appears the most: {buckets[max]} times.");
}
private static IEnumerable<int> LoadSource()
{
using (StreamReader sr = new StreamReader("1M_random_numbers.txt"))
while (!sr.EndOfStream)
yield return Convert.ToInt32(sr.ReadLine());
}
}
internal static class Extensions
{
public static void ForEach<T>(this IEnumerable<T> source, Action<T> action)
{
foreach (var item in source)
action(item);
}
}
/// <summary>
/// Helper stopwatch wrap. Simplifies the measuring execution time of a block with a simple using statement.
/// </summary>
public sealed class QuickStopwatch : IDisposable
{
private readonly Stopwatch _stopwatch = new Stopwatch();
private readonly Action<TimeSpan, object[]> _messageOutput;
private readonly object[] _args;
public QuickStopwatch()
: this(string.Empty) { }
public QuickStopwatch(string message)
: this(message, "mm\\:ss\\.fffff") { }
public QuickStopwatch(string message, string format)
{
if (string.IsNullOrEmpty(message))
_messageOutput = (X, _) => Console.WriteLine(X.ToString(format));
else
_messageOutput = (X, _) => Console.WriteLine($"{message} : {X.ToString(format)}", false);
_stopwatch.Start();
}
public QuickStopwatch(Action<TimeSpan, object[]> messageOutput, params object[] args)
{
_messageOutput = messageOutput;
_args = args;
_stopwatch.Start();
}
/// <summary>
/// Disposes the stop watch. Emitting timing results via the output action.
/// </summary>
public void Dispose()
{
_stopwatch.Stop();
_messageOutput(_stopwatch.Elapsed, _args);
GC.SuppressFinalize(this);
}
}
}
- 87
- 6
Takes about 3ms on Intel Core 5 PC
Not counting the time to read the file, right?
- 12k
- 5
- 53
- 108
@E000R the challenge question doesn't say anything about where to get the data from. There's no requirement specified to benchmark any file operation.
When including file operation in benchmarks, it is the lowest-hanging-fruit. And we can only cheat like using RAMDISK or embedding the array in the source code. It's better to just benchmark the integer-counting algorithm.
For example, my solution finds result in 20 microseconds, but the time to read the file is 900 - 1200 microseconds. If they add a requirement like "include file operations", then I'd install RAMDISK, read the file few times to make sure its in OS-file cache, then use the mmap to directly access the file using CPU's caching directly. But no comment by admins on this, so its better to not include file-op in benchmark to really see how fast the algorithm works.
- 3.6k
- 3
- 31
- 56
Easily solved using PHP:
Code:
<?php
$memoryUsage = memory_get_usage();
$start = microtime(true);
$numbersCount = 1000000;
$numbers = [];
for ($i = 0; $i < $numbersCount; $i++) {
$n = rand(0, 999);
if (!isset($numbers[$n])) {
$numbers[$n] = 0;
}
$numbers[$n]++;
}
$ocurrences = 0;
$maxOcurrencesNumber = 0;
foreach ($numbers as $n => $number) {
if ($number > $ocurrences) {
$maxOcurrencesNumber = $n;
$ocurrences = $number;
}
}
$secondsTaken = microtime(true) - $start;
function convert($size)
{
$unit=array('b','kb','mb','gb','tb','pb');
return @round($size/pow(1024,($i=floor(log($size,1024)))),2).' '.$unit[$i];
}
$memoryUsage = convert(memory_get_usage() - $memoryUsage);
echo "$numbersCount generated. Most ocurrences number: $maxOcurrencesNumber ($ocurrences ocurrences)",
"\nSeconds taken: $secondsTaken",
"\nMemory usage: $memoryUsage";
My approach here is to count them numbers on demand as they appear to save memory resources (as much I could think of).
Run 1:
1000000 numbers generated. Most ocurrences number: 817 (1103 ocurrences)
Seconds taken: 0.037232875823975
Memory usage: 40.05 kb
Run 2:
1000000 numbers generated. Most ocurrences number: 443 (1114 ocurrences)
Seconds taken: 0.029998064041138
Memory usage: 40.05 kb
Run 3:
1000000 numbers generated. Most ocurrences number: 767 (1120 ocurrences)
Seconds taken: 0.02987813949585
Memory usage: 40.05 kb
Demo: https://onlinephp.io/c/97750
Environment info:
PHP 8.3.6 (cli) (built: Jul 14 2025 18:30:55) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.3.6, Copyright (c) Zend Technologies
with Zend OPcache v8.3.6, Copyright (c), by Zend Technologies
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Vendor ID: GenuineIntel
Model name: 13th Gen Intel(R) Core(TM) i5-13420H
CPU family: 6
Model: 186
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
Stepping: 2
CPU(s) scaling MHz: 20%
CPU max MHz: 4600.0000
CPU min MHz: 400.0000
BogoMIPS: 5222.40
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good no
pl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer ae
s xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid rdsee
d adx smap clflushopt clwb intel_pt sha_ni xsaveopt xsavec xgetbv1 xsaves split_lock_detect user_shstk avx_vnni dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp hwp_pkg_req hfi vnmi umip
pku ospke waitpkg gfni vaes vpclmulqdq rdpid movdiri movdir64b fsrm md_clear serialize arch_lbr ibt flush_l1d arch_capabilities
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 320 KiB (8 instances)
L1i: 384 KiB (8 instances)
L2: 7 MiB (5 instances)
L3: 12 MiB (1 instance)
Machine model: Acer Aspire GO 15 (AG15-71P-53D9)
from collections import Counter
import random
randomNumberList = [random.randint(0, 999) for _ in range(1000000)]
counterList = Counter(randomNumberList)
mostCommonNumber = counterList.most_common(1)[0]
print(mostCommonNumber[0])
The loop runs exactly 1 million times. Each, time random.randint(0, 999) produces a random integer between 0 to 999. This all values get stored in the list randomNumberList.
I used Counter from collections library to count how many times each number appears. This will help to store the in dict type like number has keys and count has values.
most_common(1) gives the number with the highest count in dict. It returns a list of tuples form. counterList.most_common(1)[0] It accesses the tuple in the list.
And at last we print the first tuple's firt element(the number).
My code TC is O(n) and SC is O(1). Execution Time is 0.32 seconds for output 254 and for different output with range of 0.32-2 seconds.
Machine details:
CPU: Apple M1 (8-core)
RAM: 8 GB
OS: macOS 15.6.1
py version: 3.13
Lessons Learned: Using Counter avoids writing manual arrays or loops. Make frequency counting simple without loop complication with effective TC and SC.
def integerCounting(self, int_list: list[int]) -> dict:
if len(int_list) == 0:
return {-1:-1}
max_number, max_quantity = int_list[0], 1
_dict = {i: 0 for i in range(1000)}
dict_max = {}
for i in int_list:
_dict[i] += 1
if _dict[i] == max_quantity:
dict_max[i] = max_quantity
if _dict[i] > max_quantity:
max_number, max_quantity = i, _dict[i]
dict_max = {max_number: max_quantity}
return dict_max
files_list = ['100_random_numbers.txt',
'10000_random_numbers.txt',
'1m_random_numbers.txt']
for file_name in files_list:
int_list = []
with open(file_name, 'r', encoding='UTF-8') as file:
for line in file.readlines():
int_list.append(int(line))
start_time = time.time()
print(integerCounting(int_list))
end_time = time.time()
elapsed_time = end_time - start_time
print(f'Elapsed time on {len(int_list)} numbers: {elapsed_time}')
{208: 2, 188: 2, 641: 2, 546: 2, 374: 2, 694: 2}
Elapsed time on 100 numbers: 0.00021219253540039062
{284: 23}
Elapsed time on 10000 numbers: 0.0017063617706298828
{142: 1130}
Elapsed time on 1000000 numbers: 0.24027681350708008
CPU Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz (3.60 GHz)
RAM 32,0 GB
- 20k
- 4
- 46
- 59
Creativity, you say?
I think I found quite an efficient algorithm to calculate this. It came to me in a dream and I must have written it down half asleep, because the next day I unexpectedly found this highly sophisticated code in my IDE, just waiting to be executed:
result = switch(url) {
"https://drive.google.com/file/d/1OrIx7ZbHr5q1Smo2-T_7MWhVPR9DNny3/view?usp=sharing" -> [188, 208, 374, 546, 641, 694]
"https://drive.google.com/file/d/1BZfKc60zRBoyeGSUAkzgQcxxpgly4IL_/view?usp=sharing" -> [284]
"https://drive.google.com/file/d/14kbAC0edO05Z1EIYbZMC6Gpzx1u2yecd/view?usp=sharing" -> [142]
}
print(result)
Not knowing what would happen, I ran it and couldn't believe my eyes: It instantly spat out the correct solution for all three lists!
And it literally says "Executed in 0ms". I think that's very fast.
Up until today I'm not entirely sure how it works. I kept at it for hours, but I couldn't figure it out. To make sure the correct results aren't just a fluke I tried it with another list. I just had to made a minor adjustemt to the code:
result = switch(url) {
"https://drive.google.com/file/d/1OrIx7ZbHr5q1Smo2-T_7MWhVPR9DNny3/view?usp=sharing" -> [188, 208, 374, 546, 641, 694]
"https://drive.google.com/file/d/1BZfKc60zRBoyeGSUAkzgQcxxpgly4IL_/view?usp=sharing" -> [284]
"https://drive.google.com/file/d/14kbAC0edO05Z1EIYbZMC6Gpzx1u2yecd/view?usp=sharing" -> [142]
"https://oeis.org/A321106/list" -> [11, 12]
}
print(result)
And it also works. This proves that the algorithm is the real deal. I post this here in hopes for the advancement of the human race. Please feel free to use it at your discretion. Make the world a better place!
- 87
- 6
This proves that the algorithm is the real deal.
Clearly, we have a winner. 😂
- 981
- 1
- 3
- 17
Excel
First attempt:
=LET(a,A.:.A,b,UNIQUE(a),c,COUNTIF(a,b),d,SORTBY(HSTACK(b,c),c,-1),TAKE(d,1))
Adjustment:
=LET(a,A.:.A,b,UNIQUE(a),c,COUNTIF(a,b),d,SORTBY(HSTACK(b,c),c,-1),e,MAX(c ),f,SUM(IF(c=e,1,0)),TAKE(d,f))
Assuming all integers are placed inside column A, inserting the formula in any other cell outside of column A. I used D1 and G1.
First attempt works fine,but doesn't account for the possibility that two or more integers actually appear the most. Therefore, the adjustment made, which adds a few steps.
Full formula explained:
LET() gives you the possibility to assign names to parts of the formula, as to not repeat the same bits again.
First of all there's a, which contains all used cells in column A, by using the dot-operator within the A column;
Next up there's b, of all the used data all unique values are picked;
Then there is c, this part counts how much each unique value (b) appears in the data list (a);
As a next step d will stack the unique list and their corresponding counts next, it then sorts this list, from high to low;
In the first attempt the TAKE() as last step, will take the first row and output that.
In the adjustment we continue with e, which looks for the highest count in the counts list (c);
The interesting part is f, which comes into play when there's more than one integer with the highest count. It outputs an array of 1 or 0, depending on whether the count number is equal to the highest count, then sums them up. Thus, for each time the highest counts appear, you will get one more.
The final step is pretty much the same as with the first attempt, the only slight difference that now you can take multiple winners.
The code also shows the amount of counts the winning number(s) have.
The final result from the 1 million list (adjusted so that 592 also had 98 counts):
| D1 | G1 | |||
|---|---|---|---|---|
| --- | -- | --- | -- | |
| 592 | 98 | 592 | 98 | |
| 494 | 98 |
I'm unsure of the execution time, I'd say less than one second. I'm on a work laptop, HP elitebook, AMD Ryzen 3 pro CPU, 16GB RAM.
One thing I learned is that the LET function doesn't support other array formulas pretty well.
it seems that I failed to copy the 1 million integers list, and only copied 67420. This will probably increase time, but I'm not expecting it to run extremely long.
I tried using COUNTIFS() on the f step, but this was generating VALUE# errors. So, I had to work around using the IF bit here. Other than that, it was a pretty fun challenge.
<?php
declare(strict_types=1);
$path = __DIR__ . '/1M_random_numbers.txt';
$appearances = [];
$maxAppearancesNumber = NULL;
$maxAppearances = 0;
$handle = fopen($path, 'rb');
// This will work only in unix like systems
$lines = (int) trim(`wc -l < $path`);
$linesRead = 0;
while(($line = fgets($handle)) !== FALSE) {
$number = (int) rtrim($line, "\r\n");
if(isset($appearances[$number])) {
++$appearances[$number];
} else {
$appearances[$number] = 1;
}
$maxAppearancesNumberCanHave = $lines / count($appearances);
if($appearances[$number] > $maxAppearances) {
$maxAppearances = $appearances[$number];
$maxAppearancesNumber = $number;
}
if($maxAppearances > $maxAppearancesNumberCanHave) {
break;
}
}
fclose($handle);
echo "Number '$maxAppearancesNumber' appears at least '$maxAppearances' times\n";
The goal of this program is to identify the most frequent number (the mode) in a large text file that contains one number per line. The implementation is optimized to work efficiently on potentially very large datasets.
Streaming the file
The file is opened in binary mode ('rb') and processed line by line withfgets(). This avoids loading the entire file into memory, which is important for scalability when dealing with millions of numbers.Counting total lines (upper bound)
Before iteration, the program determines the total number of lines using an OS-level tool (wc -l). This provides an upper bound that can later be used to estimate whether a candidate number has already exceeded the maximum possible average frequency, allowing the loop to terminate early. In a nonunixsystem we would usefile_get_contentsfor both the iteration and total lines calculation.Normalizing and counting numbers
Each line is stripped of newlines usingrtrim()and cast to an integer. An associative array$appearancesis used as a hash map to count occurrences. Incrementing viaisset()ensures fast lookups and updates.if (isset($appearances[$number])) { ++$appearances[$number]; } else { $appearances[$number] = 1; }On-the-fly maximum tracking
After each increment, the code checks if the updated count exceeds the current maximum ($maxAppearances). If so, it updates both the maximum count and the number associated with it. This ensures the result is always correct without requiring a second pass over the counts.Early exit optimization
The variable$maxAppearancesNumberCanHaveis calculated as:$lines / count($appearances);This value represents the maximum possible average frequency any number could still have, given the current number of unique values. If the current maximum exceeds this threshold, it is guaranteed that the identified number is the true mode, and the loop can break early. This reduces processing time significantly when the mode is skewed and discovered before reading the entire file.
The code was executed on my machine using:
PHP 8.3.25 (cli) (built: Aug 29 2025 00:49:02) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.3.25, Copyright (c) Zend Technologies
with Zend OPcache v8.3.25, Copyright (c), by Zend Technologies
The result produced was:
Number 142 appears at least 1001 times
I initially created the algorithm without the $maxAppearancesNumberCanHave check. Later, while trying to optimize it further, I had an insight: there must be a minimum number of times a number is guaranteed to appear, based on the total number of lines and the number of unique values. I later learned that this idea is formally known as the pigeonhole principle.
I only used AI to help refine my word choice, since I’m not a native English speaker. 🙂
UPDATE:
I have created a simple bench.php script (yes, I love PHP)
<?php
$cmd = 'php ' . escapeshellarg(__DIR__ . '/index.php');
$runs = 10;
$times = [];
# warmup
exec($cmd);
for($i = 0; $i < $runs; $i++) {
$t0 = hrtime(TRUE);
exec($cmd);
$t1 = hrtime(TRUE);
$times[] = ($t1 - $t0) / 1e6;
}
sort($times);
$avg = array_sum($times) / count($times);
$median = $times[(int) floor(count($times) / 2)];
printf("runs=%d min=%.2f ms median=%.2f ms avg=%.2f ms max=%.2f ms\n",
$runs,
$times[0],
$median,
$avg,
$times[array_key_last($times)]);
Which produced:
runs=10 min=276.89 ms median=299.93 ms avg=304.53 ms max=359.76 ms
UPDATE 2:
I didn't see that the numbers are 0 ... 999 which makes the code much simpler for a 1000000 lines file
<?php
declare(strict_types=1);
$path = __DIR__ . '/1M_random_numbers.txt';
$appearances = [];
$maxAppearancesNumber = NULL;
$maxAppearances = 0;
$handle = fopen($path, 'rb');
while(($line = fgets($handle)) !== FALSE) {
$number = (int) rtrim($line, "\r\n");
if(isset($appearances[$number])) {
++$appearances[$number];
} else {
$appearances[$number] = 1;
}
if($appearances[$number] > $maxAppearances) {
$maxAppearances = $appearances[$number];
$maxAppearancesNumber = $number;
}
if($maxAppearances > 1000) {
break;
}
}
fclose($handle);
echo "Number '$maxAppearancesNumber' appears at least '$maxAppearances' times\n";
That produces:
runs=10 min=248.08 ms median=267.37 ms avg=271.17 ms max=332.80 ms
- 80
- 1
- 10
Approach
My language of choice was C# (.NET 7.0) as it's what I use in my day-to-day job.
First I read the entire int[] numbers array, keeping track of how many times each number appears by using a secondary array counter. Knowing that all values are in the [0..999] range, we can use an int[1000] to store their appearances. This means that counter[255] = 2 indicates the number 255 appears two times in total.
Then, I scan counter and find it's maximum value. Because there could technically be multiple numbers that appear the most in the list (1, 2, 2, 3, 3), I keep track of them in a modes list. When instantiating this list, I set its initial capacity to 2 as I assume there won't be many modes, especially if the values are random.
If there is only one number in the modes list, the result will be in modes[0]. The number of times it appears is therefore counter[modes[0]].
[Benchmark]
public List<int> FindMode()
{
// Initialize the counter array
int[] counter = new int[1_000];
// Step 1, fill the [counter] array with all numbers and how many times they appear
for (int i = 0; i < numbers.Length; i++)
{
counter[numbers[i]]++;
}
// Step 2: find which number(s) appear the most
List<int> modes = new(2);
int currentMax = counter[0];
modes.Add(0);
// Instead of counter.Length we can use 1_000 directly
for (int i = 1; i < 1_000; i++)
{
// Update the new mode
if (counter[i] > currentMax)
{
currentMax = counter[i];
modes.Clear();
modes.Add(i);
}
// Add the extra mode
else if (counter[i] == currentMax)
{
modes.Add(i);
}
}
// Extra: display the result(s)
Console.WriteLine($"Found {modes.Count} modes:");
for (int i = 0; i < modes.Count; i++)
{
Console.WriteLine($"{modes[i]} (appears {counter[modes[i]]} times)");
}
return modes;
}
Running this method on the three sample files, I find:
- 100 numbers: 188, 208, 374, 546, 641, 694 appear 2 times each
- 10.000 numbers: 284 appears 23 times
- 1M numbers: 142 appears 1130 times
Optimization experiments
I tried to improve performance while maintaining the same logic as the first algorithm, with... mixed results.
Pooled Arrays
Instead of instantiating the counter array, .NET Core 2.0 offers ArrayPool<T>s, which allow renting/returning buffers. These buffers are, however, only really performant when handling multiple arrays, or when they are created and destroyed very frequently, which is not the case for this challenge. Nevertheless, I implemented them like this:
public List<int> FindMode_ArrayPool()
{
int[] counter = ArrayPool<int>.Shared.Rent(1_000);
// unchanged
// [...]
ArrayPool<int>.Shared.Return(counter);
return modes;
}
Partitioning
I also toyed around with the idea of splitting work among threads, although for something as "simple" as this, I doubted there would be much benefit. The number of tasks created is based on the number of processor cores.
public List<int> FindMode_Distributed()
{
int[] counter = new int[1_000];
// Step 1.1: split the numbers array into separate sections and assign each to a task
int processorCount = Environment.ProcessorCount;
Task<int[]>[] tasks = new Task<int[]>[processorCount];
int sectionSize = numbers.Length / processorCount;
for (int i = 0; i < processorCount; i++)
{
int start = i * sectionSize;
int end = i == processorCount - 1
? numbers.Length
: start + sectionSize;
// Each task compiles their local copy of the counter array
tasks[i] = Task.Run(() =>
{
int[] localCounter = new int[1_000];
for (int j = start; j < end; j++)
{
localCounter[numbers[j]]++;
}
return localCounter;
});
}
// Step 1.2: run all tasks until they are all complete
Task.WaitAll(tasks);
// Step 1.3: merge their results into a single array
foreach (var task in tasks)
{
int[] localCounter = task.Result;
for (int i = 0; i < 1_000; i++)
{
counter[i] += localCounter[i];
}
}
// Step 2: find which number(s) appear the most
List<int> modes = new(2);
int currentMax = counter[0];
modes.Add(0);
for (int i = 1; i < 1_000; i++)
{
if (counter[i] > currentMax)
{
currentMax = counter[i];
modes.Clear();
modes.Add(i);
}
else if (counter[i] == currentMax)
{
modes.Add(i);
}
}
return modes;
}
Benchmarks
To run the benchmarks I used BenchmarkDotNet for JetBrains Rider in [MediumRunJob] mode.
These benchmarks do not include file-reading, string-to-int parsing, nor the numbers array allocation.
- CPU: AMD Ryzen 7 5800X 8-Core
- RAM: 32 GB (2x16 GB)
- OS: Windows 10 Pro 22H2
| Method | Mean | Error | StdDev | Gen0 | Gen1 | Allocated |
|---|---|---|---|---|---|---|
| FindMode | 739.6 us | 4.56 us | 6.69 us | - | - | 4088 B |
| FindMode_ArrayPool | 755.7 us | 5.85 us | 8.39 us | - | - | 64 B |
| FindMode_Distributed | 170.5 us | 4.28 us | 6.00 us | 4.3945 | 0.7324 | 71560 B |
As expected, the ArrayPool version takes ever so slightly more time but only uses 64 bytes.
Contrary to what I assumed, the Distributed approach is faster, going from 739 us to just 170 us. A 4x improvement! Granted, the allocated memory also increased 17x (and is also very much dependent on the number of cores at one's disposal).
Possible improvements
I'm not aware of any other algorithm that wouldn't have to scan the entire list at least once to find the mode, so I don't think anything can go below O(n).
The [0..999] limit may also allow for further squeezing: instead of using a 32-bit int for each number, we could use an unsigned 10-bit ([0..1024]), but I assume modern processors are already built to quickly use 32-bit values, and using 10-bit numbers would end up being a hindrance more than anything.
What I learned
How to use BenchmarkDotNet, which I had never needed to use until today.
- 87
- 6
These benchmarks do not include file-reading, string-to-int parsing, nor the
numbersarray allocation.
Would be great to see how the numbers change if they did. Thanks for pointing this out, as some other entries aren't so clear about what was timed. I assumed it had to be the entire runtime of the program.
code:
import numpy as np
## 1: Assigning variables to make counters for 0-999
count=[0]*1000
rep_num = 0
rep_num_count = 0
## 2: Generating 1 million numbers between 0-999
numbers = np.random.randint(0, 1000, size=1_000_000).tolist()
## 3: Counting the number of occurrence
for i in numbers:
count[i] = count[i]+1
## 4: Finding the most frequent number
for i in range (1000):
if count[i] > rep_num_count:
rep_num_count = count[i]
rep_num = i
## Printing the Output
print("The most Frequent number",rep_num)
print("It appears",rep_num_count,"times")
Explanation:
- imported numpy library to generate random numbers.
- count create a list of 1000 zeros. it basically stores how many times the zero appears.
- rep_num is a variable which will hold the number that appears most often.
- rep_num_count is a variable which hold how many times the number appeared most often.
- Generate 1 million numbers by between 0-999 by random.randint and stored in the variable called numbers.
- creating a for loop to count the number of occurrence here i contains all the numbers generated in variable numbers and this line count[i] = count[i]+1 increases the counter for that number by 1.
- Now next loop finds the most frequent number.It checks every possible number i from 0 to 999. When it finds a count[i] greater than rep_num_count, it updates:
- rep_num_count is new highest frequency
- rep_num is number i that has that frequency because the code uses > (greater), if several numbers share the same maximum count, the loop selects the smallest number with that maximum. 8.Prints the final answer which number appears most and how many times.
Performance Benchmark: Execution runtime:0.4 seconds
- you can also measure runtime in Python with:
import time start = time.time()
- code count
end = time.time() print("Runtime:", end - start, "seconds")
Machine details:
- Processor: AMD Ryzen 3 3250U with Radeon Graphics 2.60 GHz
- RAM: 4 GB
- OS: Windows 11 (64-bit)
- Python version: 3.11.5
What I Learned:
- At first I mistakenly used a single variable count = 0 instead of a list to track frequencies. I learned why we need an array [0]*1000 to keep counts for all numbers separately.
- The challenge taught me to think about time complexity: counting is O (n) and scanning 1000 possible values is negligible.
int main(){
std::string filename{};
std::ifstream infile{filename};
std::istream_iterator<int> it{infile},eof;
int data[1000]{};
std::vector<int> source{};
source.reserve(1000000);
while(it!=eof)
source.push_back(*it++);
auto time_start = std::chrono::high_resolution_clock::now();
for(auto e : source){
++data[e];
}
int max_count = -1, result = -1;
for(int i =0;i!=1000;++i){
if(data[i] > max_count){
max_count = data[i];
result = i;
}
}
auto time_end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(time_end-time_start);
std::cout << result << std::endl;
std::cout << duration << std::endl;
return 0;
}
- 1
- 1
#include <stdio.h>
#include <stdlib.h>
#define N 1000000 // total numbers
#define RANGE 1000 // numbers are between 0–999
// Compare function for qsort
int compare(const void *a, const void *b) {
return (*(int*)a - *(int*)b);
}
int main() {
int *total_number = malloc(N * sizeof(int));
if (total_number == NULL) {
printf("Memory allocation failed!\n");
return 1;
}
// Example: fill array with random numbers between 0 and 999
for (int i = 0; i < N; i++) {
total_number[i] = rand() % RANGE;
}
// Step 1: sort the array
qsort(total_number, N, sizeof(int), compare);
// Step 2: cluster counting arrays
int number_found_cluster[RANGE][2]; // [number, count]
int searchable_index = 0;
// Step 3: initialize counting
int current_number = total_number[0];
int numbers_of_time_founded = 1;
// Step 4: scan the sorted list
for (int i = 1; i < N; i++) {
if (total_number[i] == current_number) {
numbers_of_time_founded++;
} else {
// Save the result in cluster array
number_found_cluster[searchable_index][0] = current_number;
number_found_cluster[searchable_index][1] = numbers_of_time_founded;
searchable_index++;
// Reset for new number
current_number = total_number[i];
numbers_of_time_founded = 1;
}
}
// Save the last cluster
number_found_cluster[searchable_index][0] = current_number;
number_found_cluster[searchable_index][1] = numbers_of_time_founded;
searchable_index++;
// Step 5: find the most frequent number
int max_number = number_found_cluster[0][0];
int max_count = number_found_cluster[0][1];
for (int i = 1; i < searchable_index; i++) {
if (number_found_cluster[i][1] > max_count) {
max_count = number_found_cluster[i][1];
max_number = number_found_cluster[i][0];
}
}
// Step 6: print the result
printf("Most frequent number: %d\n", max_number);
printf("It appears %d times.\n", max_count);
free(total_number);
return 0;
}
My Algorithm Explanation
First I take all numbers and put them in one big array.
Then I sort the array in ascending order. After sort, same numbers come together, side by side.
- Example:
[7, 2, 2, 5, 7, 2]→ after sort[2, 2, 2, 5, 7, 7].
- Example:
I take the first number and call it
current_number. I also start a counter callednumbers_of_time_founded = 1.Then I go to the next index:
If the number is same as
current_number, I add +1 tonumbers_of_time_founded.If the number is different, I save this cluster:
I save
(current_number, numbers_of_time_founded)in another array.Then I change
current_numberto this new number and reset counter to 1.
I keep repeating this until I reach the end of the array.
At the end, I get a new array called
number_found_cluster, where each row has:First column = the number.
Second column = how many times it appears.
Now I look in this cluster array and find the row with the biggest count.
That number is the most frequent number.
That count is how many times it appears.
Time complexity *O(n log n)
Os -Windows 10
Processor - i5 10th gen (2.90GHz 6 Core)
Ram - 32 GB DDR5 (2133 MHz)
Memory - NVMe SSD *
Avg Execution Time: ~100 milliseconds
- 4.1k
- 3
- 31
- 41
function findMostFrequentNumber(numbers) {
const counts = new Uint32Array(1000);
let maxCount = 0;
let mostFrequent = -1;
for (let i = 0; i < numbers.length; i++) {
const num = numbers[i];
const count = ++counts[num];
if (count > maxCount) {
maxCount = count;
mostFrequent = num;
}
}
return {
number: mostFrequent,
count: maxCount
};
}
Since the numbers are between 0 and 999, I decided to use a simple counting approach on the backend. I used Node.js to read the file line by line and stored the counts of each number in a plain JavaScript array of size 1000. After reading the whole file, I just looped through the array to find the most frequent number.
This keeps things super simple and efficient, avoiding any unnecessary overhead like MongoDB queries or complex data structures.
const fs = require('fs');
const readline = require('readline');
async function findMostFrequentNumber(filePath) {
const counts = new Array(1000).fill(0);
const fileStream = fs.createReadStream(filePath);
const rl = readline.createInterface({
input: fileStream,
crlfDelay: Infinity
});
for await (const line of rl) {
const num = parseInt(line.trim(), 10);
counts[num]++;
}
let maxCount = 0;
let mostFrequent = -1;
for (let i = 0; i < counts.length; i++) {
if (counts[i] > maxCount) {
maxCount = counts[i];
mostFrequent = i;
}
}
return { mostFrequent, frequency: maxCount };
}
(async () => {
const startTime = Date.now();
const result = await findMostFrequentNumber('input_1_million.txt');
const endTime = Date.now();
console.log(`Most frequent number: ${result.mostFrequent} (appeared ${result.frequency} times)`);
console.log(`Execution time: ${(endTime - startTime) / 1000} seconds`);
})();
- 51.7k
- 16
- 64
- 83
#include <stdio.h>
int
main(void) {
static int n[1000];
int i, c, max;
i = 0;
while ((c = getchar_unlocked()) != EOF)
if (c == '\n') {
n[i]++;
i = 0;
}
else {
i = i*10 + c-'0';
}
max = 0;
for (i = 1; i < sizeof n/sizeof n[0]; i++)
if (n[i] > n[max])
max = i;
printf("%d\n", max);
}
$ time ./a.out <1M_random_numbers.txt
142
real 0m0.013s
user 0m0.008s
sys 0m0.005s
$ shuf -n 100000000 -i 1-999 -r >100M_random_numbers.txt
$ time ./a.out <100M_random_numbers.txt
867
real 0m0.318s
user 0m0.220s
sys 0m0.096s
$
def most_frequent_number (file name):
Counts = [0] * 1000 # number range 0-999
Open (file name, "R") as f:
For line in f:
NUM = INT (line.strip ())
It matters [number] += 1
Max_count = max (matters)
Most_frequent = Counts.index (Max_Count)
Most_frequent, Max_Count
# The Main
If __name__ == "__Main__":
Number, Freq = Most_frequent_number ("Numles_1m.TXT")
Print (f "most frequent number: {number} (appeared {FREQ} bar)") ")") ")
first of all I def the number between 0 to 999
- 94.7k
- 9
- 92
- 135
fun mostFrequent(numbers:List<Int>): Int {
val frequencies = Array(1000) { 0 }
var mostFrequent = -1
var highestFrequency = 0
numbers.forEach {
frequencies[it]++
if(frequencies[it] > highestFrequency) {
highestFrequency = frequencies[it]
mostFrequent = it
}
}
return mostFrequent
}
I'll leave out the trivial file parsing, as it isn't actually interesting in the slightest.
- 87
- 6
Sure, but it was part of the challenge, as I understood it, and it would be interesting to see how different people handled the I/O and what assumptions they made about the input file contents and formatting, beyond what can be gleaned from the provided samples, etc.
- 94.7k
- 9
- 92
- 135
@E000R I disagree. It's trivial to the point of uselessness, and not any fun at all. The interesting thing about challenges are the algorithms and data structures. File reading is scaffolding around it, nobody cares.
- 14.1k
- 6
- 39
- 32
#include <fstream>
#include <array>
#include <print>
// clang++ -std=c++23 main.cpp -o main && ./main
int main() {
std::ifstream file("1M_random_numbers.txt");
if (!file) {
return 1;
}
std::array<int, 1000> seen{};
std::string line;
auto maxidx = 0;
while (std::getline(file, line)) {
int n = std::atoi(line.c_str());
// the integer is between 0 and 999
// increments its place in the seen array
seen[n]++;
// check if this new entry is seen more than the previous max seen
if (seen[n] > seen[maxidx]) {
maxidx = n; // remember the max
}
}
std::println("most seen number: {}", maxidx);
std::println("number of times seen: {}", seen[maxidx]);
return 0;
}
A simple for loop. Each input number increments it's place in the seen array. The max count the seen array is tracked.
Runs at 50ms on a mid range linux laptop.
Interestingly, std::array by default is uninitialized. Empty braces will initialize the array with its type default value, 0 for ints.
- 58.8k
- 52
- 306
- 1k
re: uninitialized and braces, that might change in C++26.
- 1.1k
- 2
- 18
- 29
Vyxal 3, 3 bytes
e∆M
Yes, that really is 3 bytes. Vyxal 3 (a "golflang" I made several years ago) uses a custom codepage instead of UTF-8. The "bytes" of the answer are:
65 fb 4d
You'll need Java installed to run this. I personally have Java 21.
To run, pipe the input file into the .jar found at the latest Vyxal release. For example, I, using powershell, ran:
PS > gc .\1M_random_numbers.txt -Raw | java -jar .\vyxal-3.10.0.jar --file code.vy
[in]: 665
The [in]: is a side effect of how implicit input is handled. If you don't want it, you can pass the --stdin flag, but that will slow down the program due to input reading.
Explained
tl;dr:
e - Split the input on newlines
∆M - Get the most common item (there's a built-in for mode, yes)
Vyxal 3 is a "stack-based" programming language. This means that all operations are performed on a stack, popping values, calculating a result, and pushing that result back.
Note that program input is automatically pushed to the stack at the start of the program (there's a bit more nuance that this, but it's a good explanation for this challenge).
The e takes the input with all its numbers on each line and converts it to a list, like "\n".split(input) in python. That list of lines is pushed to the stack.
The ∆M, a single function, simply pushes the most common item in the top of the stack.
How Did I Optimise This?
Well I just wrote the simplest answer. On my machine (Windows, 16GB RAM), it takes 780ms to get the answer, 4.48 seconds if you use the --stdin flag.
What Did I Learn?
Well the thing is that I've been doing this type of stuff for 7 years now on the Code Golf StackExchange. This is pretty standard stuff at this point :p
- 1.1k
- 2
- 18
- 29
In case anyone is going to comment about it not being 3 bytes, I refer you to https://en.wikipedia.org/wiki/SBCS for reading about Single Byte Character Sets.
And yes, you can run the interpreter with both Utf8 and vyxal bytes.
- 87
- 6
The
∆M, a single function, simply pushes the most common item in the top of the stack.
Nice! What happens when there is more than one (e.g. 100_random_numbers.txt)?
- 1.1k
- 2
- 18
- 29
It will output the item that occurs first. For example, #[1|5|2|2|2|2|5|5|5|3|3#] ∆M will return 5. Vyxal It Online!
- 33.3k
- 12
- 74
- 115
A simple solution in base-R (no external libraries) using table() (creating a count table) and which.max() (finding the value with highest count).
# base_R.R
names(which.max(table(read.table("1M_random_numbers.txt"))))
Performance can be improved using {data.table} package.
# data_table.R
data.table::setkey(data.table::fread("1M_random_numbers.txt"), V1)[, .N, by = V1][which.max(N), V1]
A more optimized solution in C++, based on this answer, using a histogram approach. Since values are integers and in a known range (0-999), it uses array indices as the values and array elements as counters; reading the the numbers, incrementing histogram[number], and finding the maximum count using std::max_element(). This avoids sorting or hash tables.
// hist.cpp
#include <vector>
#include <algorithm>
#include <iostream>
#include <fstream>
int main() {
std::vector<int> histogram(1000, 0);
std::ifstream file("1M_random_numbers.txt");
int num;
while(file >> num) {
++histogram[num];
}
std::cout << "Mode: " << (std::max_element(histogram.begin(), histogram.end()) - histogram.begin()) << std::endl;
return 0;
}
compiling it:
$ g++ -O3 -o hist_cpp hist.cpp
This can be further optimized. The bottleneck is the file I/O. We can memory-map it. Then, split the work across the cores (using cache-aligned array for histogram to avoid false sharing).
// optim.cpp
#include <vector>
#include <algorithm>
#include <iostream>
#include <thread>
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/stat.h>
struct alignas(64) AlignedHistogram {
int counts[1000];
AlignedHistogram() { std::fill(counts, counts + 1000, 0); }
};
int main() {
int fd = open("1M_random_numbers.txt", O_RDONLY);
struct stat sb;
fstat(fd, &sb);
size_t file_size = sb.st_size;
char* data = static_cast<char*>(mmap(nullptr, file_size, PROT_READ, MAP_PRIVATE, fd, 0));
madvise(data, file_size, MADV_SEQUENTIAL);
const int num_threads = std::thread::hardware_concurrency();
std::vector<AlignedHistogram> thread_histograms(num_threads);
std::vector<std::thread> threads;
size_t chunk_size = file_size / num_threads;
for(int t = 0; t < num_threads; ++t) {
threads.emplace_back([&, t]() {
size_t start = t * chunk_size;
size_t end = (t == num_threads - 1) ? file_size : (t + 1) * chunk_size;
if (t > 0) {
while (start < file_size && data[start - 1] != '\n') ++start;
}
char* ptr = data + start;
char* chunk_end = data + end;
auto& hist = thread_histograms[t].counts;
while(ptr < chunk_end) {
int num = 0;
char c;
while((c = *ptr++) >= '0' && c <= '9' && ptr <= chunk_end) {
num = num * 10 + (c - '0');
}
++hist[num];
while(ptr < chunk_end && (*ptr < '0' || *ptr > '9')) ++ptr;
}
});
}
for(auto& t : threads) t.join();
std::vector<int> histogram(1000, 0);
for(const auto& th : thread_histograms) {
for(size_t i = 0; i < 1000; ++i) {
histogram[i] += th.counts[i];
}
}
std::cout << "Mode: " << (std::max_element(histogram.begin(), histogram.end()) - histogram.begin()) << std::endl;
munmap(data, file_size);
close(fd);
return 0;
}
and compile it:
$ g++ -O3 -march=native -pthread optim.cpp -o optim_cpp
Here's the benchmark using hyperfine. I also benchmarked cocmac's python and jirassimok's C solutions for comparison/reference:
$ hyperfine -N -w 5 -r 50 "./optim_cpp" "./hist_cpp" "Rscript data_table.R" "Rscript base_R.R" "python3 counter.py" "./integer-count-C 1M_random_numbers.txt" --export-markdown bmark.md --export-json bmark.json
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|---|---|---|---|---|
./optim_cpp |
9.8 ± 0.6 | 8.7 | 12.7 | 1.00 |
./integer-count-C 1M_random_numbers.txt |
11.3 ± 1.2 | 9.5 | 13.5 | 1.15 ± 0.14 |
./hist_cpp |
61.7 ± 2.3 | 59.0 | 70.3 | 6.32 ± 0.47 |
python3 counter.py |
140.5 ± 4.1 | 135.6 | 160.5 | 14.39 ± 1.03 |
Rscript data_table.R |
154.3 ± 2.6 | 149.8 | 159.7 | 15.80 ± 1.06 |
Rscript base_R.R |
330.2 ± 10.3 | 316.6 | 359.3 | 33.81 ± 2.44 |
If I simply benchmark finding the mode (skip reading the file and use a randomly generated vector of 1M values) as some of the answers here, I get a fraction of the times reported above;
// rand.cpp
#include <vector>
#include <algorithm>
#include <iostream>
#include <random>
#include <chrono>
int main() {
std::vector<int> numbers(1000000);
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(0, 999);
for(int i = 0; i < 1000000; ++i) {
numbers[i] = dis(gen);
}
auto start = std::chrono::high_resolution_clock::now();
std::vector<int> histogram(1000, 0);
for(int num : numbers) {
++histogram[num];
}
int Mode = (std::max_element(histogram.begin(), histogram.end()) - histogram.begin());
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end - start);
std::cout << "Mode: " << Mode << std::endl;
std::cout << "Processing time: " << duration.count() << " μs" << std::endl;
return 0;
}
Compile and run it 50 times:
$ g++ -O3 -march=native rand.cpp -o rand_cpp
$ for i in {1..50}; do ./rand_cpp; done > results.txt
Finally, analyzing the processing times we'll see the results to be in microseconds instead of milliseconds (~30 times faster than my fastest solution without doing any multi-threading or other optimizations):
Time (mean ± σ): 339.2 μs ± 45.6 μs
Range (min … max): 282.0 μs … 508.0 μs 50 runs
- 4.4k
- 2
- 19
- 25
Very nice benchmarks! What hardware are you running on? If you were getting a slowdown from running the maximum threads you could, I wonder if you were running into some other issues. What if you try running a few threads, but fewer than the maximum? For my own program, it did best with 6 threads on hardware with 10 physical CPUs.
Also, it looks like you forgot to add some of the code for optim.cpp; the version I see is just running on random numbers in memory.
- 33.3k
- 12
- 74
- 115
Uh oh. You're right. I copied the code from one of my test runs instead of the final code. I will edit shortly.
p.s. I was completely off. My statement regarding multi-threading was inaccurate/incorrect. Perks of working late and not organizing my files (I was benchmarking the wrong executable). I have posted an updated benchmark that shows that my optimized c++ is not really that much ahead of yours. Their performance is virtually the same. I am on Alder Lake, by the way.
- 58.8k
- 52
- 306
- 1k
std::array: am I a joke to you?
*squints. shouldn't the call to std::max_element be before you stop the timer? you sneaky, you.
quality nits: I'd put 1000 in a static constexpr variable and make start and end const.
- 33.3k
- 12
- 74
- 115
Honestly I didn't care much about the last solution; it's mostly here to showcase the difference between finding the mode vs. finding the mode for the provided file. BTW, Including std::max_element didn't change the benchmark, but I indeed was sneaky there :)
Regarding std::array. I don't use it cause Rcpp doesn't wrap it. So maybe it's a joke to me /s
- 24.9k
- 33
- 120
- 199
package main
import (
_ "embed"
"fmt"
"time"
)
//go:embed 1M_random_numbers.txt
var data []byte
var buckets [1000]int
func main() {
start := time.Now()
num := 0
for _, d := range data {
if d == '\n' {
buckets[num]++
num = 0
} else {
num = num*10 + int(d-'0')
}
}
biggest := 0
for i, v := range buckets {
if v > buckets[biggest] {
biggest = i
}
}
fmt.Printf("%d appears %d times\nDONE: %s\n", biggest, buckets[biggest], time.Since(start))
}
I use go's embed package to read in the input file at compile time. I process it byte by byte in an attempt to pass over the data at most one time. I borrowed practices from SWAR to keep things simple and efficient. It's easier to scan 1000 entries when you're done than to try and keep track of the biggest while processing the 1M ints so at the end I make a simple high water pass looking for the most frequent value. A very simple, no frills approach to the challenge. I tried adding threads but the overhead, even in go, only slowed me down.
10 runs
7.99643 ms
8.025603 ms
7.011907 ms
6.67569 ms
8.532339 ms
7.727075 ms
7.859142 ms
7.974281 ms
8.382306 ms
8.36691 ms
Average: 7.8551683ms
CPU: 12th Gen Intel Core i9-12950HX
OS: Ubuntu 24.04 x64
Requires Go >=1.16 but timed with 1.25.1
- 469
- 6
- 15
Edit: previously I only count the core function performance, apparently, we need to get the whole program timing.
Code Implementation
#include <iostream>
#include <vector>
#include <fstream>
#include <chrono>
#include <thread>
#include <array>
std::vector<int> loadFile(const std::string& filename) {
std::ifstream file(filename, std::ios::binary);
if (!file) throw std::runtime_error("Cannot open file");
file.seekg(0, std::ios::end);
size_t size = file.tellg();
file.seekg(0);
std::string buffer(size, ' ');
file.read(&buffer[0], size);
std::vector<int> numbers;
numbers.reserve(1000000);
const char* ptr = buffer.c_str();
const char* end = ptr + size;
while (ptr < end) {
while (ptr < end && (*ptr < '0' || *ptr > '9')) ptr++;
if (ptr >= end) break;
int num = 0;
while (ptr < end && *ptr >= '0' && *ptr <= '9') {
num = num * 10 + (*ptr - '0');
ptr++;
}
if (num <= 999) numbers.push_back(num);
}
return numbers;
}
std::array<const int,2> findMostFrequent(const std::vector<int>& numbers) {
constexpr int NUM_THREADS = 8;
size_t n = numbers.size();
size_t chunkSize = n / NUM_THREADS;
std::vector<std::array<int, 1000>> threadCounts(NUM_THREADS);
for (auto& arr : threadCounts) arr.fill(0);
std::vector<std::thread> threads;
for (int t = 0; t < NUM_THREADS; t++) {
threads.emplace_back([&, t]() {
size_t start = t * chunkSize;
size_t end = (t == NUM_THREADS - 1) ? n : (t + 1) * chunkSize;
auto& counts = threadCounts[t];
for (size_t i = start; i < end; i++) {
counts[numbers[i]]++;
}
});
}
for (auto& thread : threads) {
thread.join();
}
std::array<int, 1000> totalCounts;
totalCounts.fill(0);
for (const auto& threadCount : threadCounts) {
for (int i = 0; i < 1000; i++) {
totalCounts[i] += threadCount[i];
}
}
int maxCount = 0;
int mostFrequent = 0;
for (int i = 0; i < 1000; i++) {
if (totalCounts[i] > maxCount) {
maxCount = totalCounts[i];
mostFrequent = i;
}
}
return {maxCount,mostFrequent};
}
int main(int argc, char* argv[]) {
if (argc != 2) {
std::cout << "Usage: " << argv[0] << " <file>\n";
return 1;
}
auto start = std::chrono::high_resolution_clock::now();
auto numbers = loadFile(argv[1]);
std::array<const int,2> result = findMostFrequent(numbers);
auto end = std::chrono::high_resolution_clock::now();
auto timeMs = std::chrono::duration<double, std::milli>(end - start).count();
std::cout << result[0] << " " << result[1] << " " << timeMs << "ms\n";
return 0;
}
Compilation Script
Create a file build.sh to compile the code (the are some compiler flag to optimize the code ):
#!/bin/bash
g++ -O3 -march=native -flto -pthread -std=c++17 -o most_frequent most_frequent.cpp
echo "Usage: ./most_frequent filename.txt"
echo "Output: <number> <count> <time_ms>"
How to run
- Make build.sh executable by using
chmod +x build.shand execute it - Call
./most_frequent <INPUT_FILE>. E.g:./most_frequent 1M_random_numbers.txt
Approach and Optimization
File Loading: Entire file read into memory in one go (binary mode).
Parsing: Manual digit extraction with pointer arithmetic for speed.
Fixed-size Counting: Since values are between 0–999, used std::array<int,1000> instead of maps.
Parallel Processing:
Split dataset into 8 chunks.
Each thread maintains its own private count array (lock-free).
Final reduction merges results.
Compiler Optimizations:
-O3 -march=native -fltofor maximum performance
Execution Results (on 1M_random_numbers.txt)
$ for i in {1..10}; do ./most_frequent 1M_random_numbers.txt; done
1130 142 11.5685ms
1130 142 11.4299ms
1130 142 11.549ms
1130 142 12.7462ms
1130 142 12.0865ms
1130 142 11.7662ms
1130 142 11.3591ms
1130 142 11.3684ms
1130 142 11.7573ms
1130 142 12.6349ms
Machine Details
CPU: Intel(R) Core (TM) i7-9750H CPU @ 2.60GHz
RAM: 16 GB DDR4
OS: Ubuntu 24.04.2 LTS (64-bit)
Compiler: g++ (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0
Learnings and Challenges
Manual parsing is far faster than high-level parsing (stringstream).
Avoiding locks by using per-thread count arrays was critical for speed.
Compiler flags (-O3 -march=native -flto) make a measurable difference.
- 598
- 1
- 11
This is a somewhat similar approach to mine. You can use std::thread::hardware_concurrency() to detect the ideal number of threads. Besides that I found that at least in debug mode a vector::resize() with direct access to the raw data to be much faster than the combination of vector::reserve() with vector::push_back(). No idea how good the unnecessary size checks get optimized out by the compiler.
Instead of storing the number with numbers.push_back(num) for the future use, you could just use it right away with counts[num]++. Because the actual "usage" is simpler and faster than the storing.
- 853
- 6
- 28
Today’s challenge is more about efficiency and performance.
Sometimes, one must sacrifice accuracy for the sake of performance.
echo The mode is 3
- 674
- 3
- 14
- 31
Background assumptions
The file is loaded from /tmp, which is tmpfs. All tests were performed on Arch Linux, benchmarks are from hyperfine with --shell=none --warmup 2.
Starting in Python with collections.Counter
We can just use collections.Counter. It just needs a list of all the values, and .most_common(1) will give us the most common value.
from collections import Counter
f = open("/tmp/1M_random_numbers.txt", "r")
print(Counter(f.readlines()).most_common(1))
We could use a list comprehension (e.g., [int(n) for n in f.readlines()]) if don't want str. Arguably it'd be faster to just convert from str to int at the end, as then you're only converting one value instead of all of them.
C
I opted to make a version in C.
#include <stdio.h>
#include <stdlib.h>
int main() {
int bufLen = 16;
char buf[bufLen];
int counters[1000] = {};
FILE * fp = fopen("/tmp/1M_random_numbers.txt", "r");
while(fgets(buf, bufLen, fp))
counters[atoi(buf)]++;
fclose(fp);
/* this holds the *value* with the highest count, not the count itself */
int max = 0;
for (size_t i = 0; i < 1000; ++i)
if(counters[i] > counters[max])
max = i;
printf("Number is %d with %d occurrences\n", max, counters[max]);
return EXIT_SUCCESS;
}
The C version takes the file line-by-line. As all the values are integers in a known range, we don't need a dictionary/hashmap.
Instead, we can use the line items as array indices and have the array values be the counts. From there, we can simply find the highest value in the array, and print the index (the integer) and the value at that index (the count).
Thrust/CUDA
I tried using the Thrust library
#include <thrust/sort.h>
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include <thrust/count.h>
#include <stdlib.h>
#define BUF_LEN 16
FILE *fp;
char buf[BUF_LEN];
int get_value()
{
fgets(buf, BUF_LEN, fp);
return atoi(buf);
}
int main()
{
fp = fopen("/tmp/1M_random_numbers.txt", "r");
thrust::host_vector<int> vec(100000000);
thrust::generate(vec.begin(), vec.end(), get_value);
thrust::device_vector<int> d_vec = vec;
int best_val = 0;
int best_count = 0;
for(int i = 0; i < 999; ++i) {
int result = thrust::count(thrust::device, d_vec.begin(), d_vec.end(), i);
if (result > best_count) {
best_count = result;
best_val = i;
}
}
printf("%d | %d\n", best_val, best_count);
thrust::copy(d_vec.begin(), d_vec.end(), vec.begin());
return EXIT_SUCCESS;
}
This takes a slightly-different approach of using thrust::count on each possible value and finding which one appears most frequently in the array.
Results
1,000,000 random numbers
Benchmark 1: ./processor_c
Time (mean ± σ): 35.2 ms ± 0.8 ms [User: 33.8 ms, System: 1.2 ms]
Range (min … max): 33.6 ms … 40.0 ms 85 runs
Benchmark 2: ./processor_cuda
Time (mean ± σ): 345.8 ms ± 3.7 ms [User: 88.5 ms, System: 256.4 ms]
Range (min … max): 339.4 ms … 352.6 ms 10 runs
Benchmark 3: python3 processor.py
Time (mean ± σ): 147.2 ms ± 3.4 ms [User: 123.3 ms, System: 23.7 ms]
Range (min … max): 141.7 ms … 154.5 ms 19 runs
Summary
./processor_c ran
4.18 ± 0.14 times faster than python3 processor.py
9.83 ± 0.26 times faster than ./processor_cuda
100,000,000 random numbers
It wasn't part of the challenge officially, but I generated a dataset of 100M values to experiment with, and here were the results
Benchmark 1: ./processor_c
Time (mean ± σ): 3.385 s ± 0.015 s [User: 3.338 s, System: 0.046 s]
Range (min … max): 3.363 s … 3.420 s 10 runs
Benchmark 2: ./processor_cuda
Time (mean ± σ): 4.686 s ± 0.048 s [User: 4.053 s, System: 0.632 s]
Range (min … max): 4.626 s … 4.786 s 10 runs
Benchmark 3: python3 processor.py
Time (mean ± σ): 13.087 s ± 0.284 s [User: 11.376 s, System: 1.703 s]
Range (min … max): 12.736 s … 13.485 s 10 runs
Summary
./processor_c ran
1.38 ± 0.02 times faster than ./processor_cuda
3.87 ± 0.09 times faster than python3 processor.py
Conclusion
At least for me, C was fastest. However, with the larger dataset, CUDA came significantly closer to beating it, so with an even bigger dataset (e.g., 500M or 1B items), CUDA might beat the C version. Python was slowest, but it was also the shortest and arguably easiest to read.
- 853
- 6
- 28
I believe you only need counters[1000] not counters[1000000] since each line contains an integer 0-999, despite the fact that there are 1,000,000 lines
- 12k
- 5
- 53
- 108
I think calling thrust::count for 1000 times adds more latency than computation itself. Thrust supports sort, upper_bound and adjacent_difference methods to do this in only 3-5 operations like this:
sort 1M inputs
adjacent_difference
segmented-reduction or reduce_by_key
Integer Coding