diff --git "a/02.\347\274\226\345\206\231\350\207\252\345\256\232\344\271\211Annotation.md" "b/02.\347\274\226\345\206\231\350\207\252\345\256\232\344\271\211Annotation.md"
index fbe3f55..06afcd1 100644
--- "a/02.\347\274\226\345\206\231\350\207\252\345\256\232\344\271\211Annotation.md"
+++ "b/02.\347\274\226\345\206\231\350\207\252\345\256\232\344\271\211Annotation.md"
@@ -18,7 +18,7 @@ public @interface TestCase { // 使用@Interface修饰这个是一个Annotation
以上就完成了一个Annotation接口的编写。接着我们写一个Test类来使用@TestCase这个注释。
```java
public class Test {
- @TestCase
+
public void m_1(){
System.out.println("This is Method with @TestCase!");
}
diff --git "a/03.\350\233\213\347\226\274\347\232\204AOP\346\246\202\345\277\265.md" "b/03.\350\233\213\347\226\274\347\232\204AOP\346\246\202\345\277\265.md"
index 94c614f..6e24207 100644
--- "a/03.\350\233\213\347\226\274\347\232\204AOP\346\246\202\345\277\265.md"
+++ "b/03.\350\233\213\347\226\274\347\232\204AOP\346\246\202\345\277\265.md"
@@ -1,6 +1,6 @@
#AOP介绍
-AOP全称Aspect Oriented Programming,面向切面编程。在事务管理,代码跟踪方面应用很广泛。教科书上的对于AOP概念的解释比较让人晕眩,下面是偶本人对AOP一些概念的理解:
+AOP全称Aspect Oriented Programming,面向切面编程。在事务管理,代码跟踪方面应用很广泛。教科书上的对于AOP概念的解释比较让人晕眩。
>**连接点(Joinpoint)**:程序流中可以用于代码植入的点,通常是某些边界,例如:类初始化前、类初始化后、方法执行前、方法执行后、方法抛异常后。
diff --git "a/05.\350\243\205\351\245\260\345\231\250\346\250\241\345\274\217.md" "b/05.\350\243\205\351\245\260\345\231\250\346\250\241\345\274\217.md"
index 4876258..78fc517 100644
--- "a/05.\350\243\205\351\245\260\345\231\250\346\250\241\345\274\217.md"
+++ "b/05.\350\243\205\351\245\260\345\231\250\346\250\241\345\274\217.md"
@@ -2,9 +2,6 @@
## 遇到的问题
- 学习的最好方法就是实践,想当年大学学《设计模式》这门课的时候,重修两次,补考还挂了两次,最后还是甩小聪明才拿到的毕业证。
-往事不多提,甚是可悲。
-
最近遇到一个问题,这里有一个controller的方法,方法里面需要获取request header的 __x-forwarded-for__ 属性的值:
```java
diff --git "a/07.\344\275\277\347\224\250socket\345\217\221\351\200\201HTTP POST\350\257\267\346\261\202.md" "b/07.\344\275\277\347\224\250socket\345\217\221\351\200\201HTTP POST\350\257\267\346\261\202.md"
index f5757b2..900f70a 100644
--- "a/07.\344\275\277\347\224\250socket\345\217\221\351\200\201HTTP POST\350\257\267\346\261\202.md"
+++ "b/07.\344\275\277\347\224\250socket\345\217\221\351\200\201HTTP POST\350\257\267\346\261\202.md"
@@ -54,16 +54,3 @@ socket.close();
```
一个HTTP POST的登陆请求就完成了。Java代码不难实现,唯一需要注意的HTTP报文的格式了。
-
-##Connection: close
-
- 细心的人,可能会发现上面的请求,控制台虽然正确地打印了服务器响应的登陆报文,但是控制台的线程是还没有断开的。
-即使客户端使用了socket.close()。
-
- 这里涉及TCP协议以及HTTP 1.1的长连接,先不详细解释。这里我们简单地使用一个Header就可以断开请求了。
-
-```java
-bw.write("Connection: close\r\n");
-```
-
- 把上面这一段代码复制到前面一段代码的Header部分即可。perfect!
diff --git "a/22.\347\274\226\347\240\201\350\247\243\347\240\201.md" "b/22.\347\274\226\347\240\201\350\247\243\347\240\201.md"
index 689d289..5281478 100644
--- "a/22.\347\274\226\347\240\201\350\247\243\347\240\201.md"
+++ "b/22.\347\274\226\347\240\201\350\247\243\347\240\201.md"
@@ -9,7 +9,7 @@
```Java
System.out.println("中国");
```
-1. 无论文件以任何编码格式载入到JVM中,"中国"二字都会以unicode码的形式存在JVM中(\u4e2d\u56fd);
+1. 无论文本以任何编码格式载入到JVM中,"中国"二字都会以unicode码的形式存在JVM中(\u4e2d\u56fd);
2. 假如IDE控制台的编码为UTF-8,当对"中国"二字进行控制台输出时,系统会将unicode码转为具体的UTF-8编码格式。(\u4e2d\u56fd -> e4b8ade59bbd)
```
@@ -77,4 +77,4 @@ public void gbk_unicode_utf8() throws DecoderException,
实际上,这里的unicode编码对应的是unicode的`UTF-16`编码。以16位定长的二进制表示一个unicode码。
-## 参考资料
\ No newline at end of file
+## 参考资料
diff --git "a/27.Java\345\212\240\345\257\206\350\247\243\345\257\206\344\271\213\345\257\271\347\247\260\345\212\240\345\257\206\347\256\227\346\263\225.md" "b/27.Java\345\212\240\345\257\206\350\247\243\345\257\206\344\271\213\345\257\271\347\247\260\345\212\240\345\257\206\347\256\227\346\263\225.md"
index 567e86e..caaaded 100644
--- "a/27.Java\345\212\240\345\257\206\350\247\243\345\257\206\344\271\213\345\257\271\347\247\260\345\212\240\345\257\206\347\256\227\346\263\225.md"
+++ "b/27.Java\345\212\240\345\257\206\350\247\243\345\257\206\344\271\213\345\257\271\347\247\260\345\212\240\345\257\206\347\256\227\346\263\225.md"
@@ -6,7 +6,7 @@
**对称加密算法的安全基于密钥的保密,所以密钥的安全与否决定了加密信息的安全!**
-虽然说**对称加密算法**不适用于安全要求较高的场合,对是对于一般应用来说,这已经足够了。与此同时,对称加密的速度远由于非对称加密,所以还是很多场景适用对称加密。
+虽然说**对称加密算法**不适用于安全要求较高的场合,对是对于一般应用来说,这已经足够了。与此同时,对称加密的速度远低于非对称加密,所以还是很多场景适用对称加密。
对称加密的速度比公钥加密快很多,在很多场合都需要对称加密。
@@ -36,7 +36,7 @@ IDEA(International Data Encryption Algorithm,国际数据加密标准)是
在加密之前,我们先要生成加密算法对应的密钥。我们之前所说的密钥长度都是基于位元为单位的。例如128位的密钥,则该密钥占用128个位元,以一个字节八位元,128密钥占用128 / 8 = 16个字节。使用byte[]数组存放,则byte[]的长度为16。
-为了方便存储和传输,我们通常使用Base64对密钥的字节组数进行编码。而ASCII编码有很多字符是不可打印的,所以不建议使用ASCII。当然你可以使用ASCII,当时很容易在存储或传输过程中丢失字节(在计算器中存储和传输没有问题,但是使用纸质就歇菜了)。当然你可以使用其他方式和编码,一般情况下都是使用Base64,约定俗成。
+为了方便存储和传输,我们通常使用Base64对密钥的字节组数进行编码。而ASCII编码有很多字符是不可打印的,所以不建议使用ASCII。当然你可以使用ASCII,但是很容易在存储或传输过程中丢失字节(在计算器中存储和传输没有问题,但是使用纸质就歇菜了)。当然你可以使用其他方式和编码,一般情况下都是使用Base64,约定俗成。
Java中使用`KeyGenerator`类来生成密钥。如下:
@@ -58,7 +58,7 @@ public void generateKey() throws NoSuchAlgorithmException {
Cipher是JCA中用于加密解密的类,它同时负责数据的加密与解密。在初始化时,需要为Cipher指定是加密或是解密模式。
-加密与加密的过程直接操作的是数据的字节数组,由于字符在JVM中是以unicode形式存在的,字符串的不同编码的字节数组序列是一样的,例如UTF-8和GBK的字节序列就不一样。所以在加密之前或加密之后需要将字符编码进行编码与解码。当然,这不是必须的,你可以使用系统默认的ASCII字符编码,只要统一即可。
+加密与加密的过程直接操作的是数据的字节数组,由于字符在JVM中是以unicode形式存在的,字符串的不同编码的字节数组序列是不一样的,例如UTF-8和GBK的字节序列就不一样。所以在加密之前或加密之后需要将字符编码进行编码与解码。当然,这不是必须的,你可以使用系统默认的ASCII字符编码,只要统一即可。
数据加密后是以字节数组存在的,跟密钥类似,为了方面存储和传输,我们将加密后的结果转为Base64表示形式。
@@ -111,4 +111,4 @@ public void decrypt() throws InvalidKeyException, NoSuchAlgorithmException, NoSu
* 密码学:http://zh.wikipedia.org/wiki/%E5%AF%86%E7%A2%BC%E5%AD%B8
* 经典密码:http://zh.wikipedia.org/wiki/%E7%B6%93%E5%85%B8%E5%AF%86%E7%A2%BC
* DES:http://zh.wikipedia.org/wiki/%E8%B3%87%E6%96%99%E5%8A%A0%E5%AF%86%E6%A8%99%E6%BA%96
-* 3DES:http://zh.wikipedia.org/wiki/3DES
\ No newline at end of file
+* 3DES:http://zh.wikipedia.org/wiki/3DES
diff --git "a/28.Java\345\212\240\345\257\206\350\247\243\345\257\206\344\271\213\351\235\236\345\257\271\347\247\260\345\212\240\345\257\206\347\256\227\346\263\225.md" "b/28.Java\345\212\240\345\257\206\350\247\243\345\257\206\344\271\213\351\235\236\345\257\271\347\247\260\345\212\240\345\257\206\347\256\227\346\263\225.md"
index 025fe05..0398372 100644
--- "a/28.Java\345\212\240\345\257\206\350\247\243\345\257\206\344\271\213\351\235\236\345\257\271\347\247\260\345\212\240\345\257\206\347\256\227\346\263\225.md"
+++ "b/28.Java\345\212\240\345\257\206\350\247\243\345\257\206\344\271\213\351\235\236\345\257\271\347\247\260\345\212\240\345\257\206\347\256\227\346\263\225.md"
@@ -10,7 +10,7 @@
###28.2.1 典型非对称加密算法:RSA
-RSA算法密钥的长度为512位至65535位之间,且必须是64的倍数。Java6默认的RSA算法的密钥长度是1014位。
+RSA算法密钥的长度为512位至65535位之间,且必须是64的倍数。Java6默认的RSA算法的密钥长度是1024位。
###28.2.2 常用非对称加密算法:EIGamal
@@ -74,4 +74,4 @@ public void t6_decrypt() throws NoSuchAlgorithmException, InvalidKeySpecExceptio
}
```
-##28.4 参考资料
\ No newline at end of file
+##28.4 参考资料
diff --git a/30.Java Runtime Data Areas.md b/30.Java Runtime Data Areas.md
new file mode 100644
index 0000000..ca4875d
--- /dev/null
+++ b/30.Java Runtime Data Areas.md
@@ -0,0 +1,76 @@
+#30.Java Runtime Data Areas.md
+
+ +
+##30.1 运行时数据区(Runtime Data Areas)
+
+Java虚拟机为程序的运行提供了各种不同的数据区,部分数据区与JVM的生命周期一致(随JVM启动而分配,JVM退出而释放),而另一部分则跟线程绑定,随着线程的启动和退出进行分配和释放。
+
+###30.1.1 程序计数器(Program Counter Rigister)
+
+Java虚拟机支持多个线程在同一时刻运行。每一个Java虚拟机线程拥有自己的程序计数器。在任意时刻,任意线程都处于一个方法中(称为当前方法(current method)),如果是该方法是**非本地方法(not native method)**,则该程序计数器记录着**Java虚拟机执行的当前指令的地址**。而如果该方法为**本地方法(native method)**,则该程序计数器为undefined。
+
+###30.1.2 Java虚拟机栈(Java Virtual Machine Stacks)
+
+每个Java虚拟机线程都拥有各自的**Java虚拟机栈**,并与线程同时被创建。Java虚拟机栈用于存储**帧(frames)**。Java虚拟机栈跟传统语言的栈相似:存储局部变量、结果,同时参与方法的调用和返回。
+Because the Java Virtual Machine stack is never manipulated directly except to push and pop frames, frames may be heap allocated. The memory for a Java Virtual Machine stack does not need to be contiguous.
+
+在第一版的Java虚拟机规范中,**Java虚拟机栈**做为**Java栈** 为人们所熟知。这个规范允许Java虚拟机栈是固定的大小或根据需要通过计算来动态地扩展和收缩。如果Java虚拟机堆的大小是固定的,(If the Java Virtual Machine stacks are of a fixed size, the size of each Java Virtual Machine stack may be chosen independently when that stack is created.)
+
+Java虚拟的实现可以提供让程序员或用户来控制Java虚拟栈初始大小,并且,可以让Java虚拟机栈在最小值和最大值的限制范围内根据实际需要动态地拓展或收缩。
+
+以下异常情况与Java虚拟栈相关:
+* 如果线程需要的Java虚拟机栈大小超过限额,则抛出**StackOverflowError**。
+* 如果Java虚拟机栈被设置为可动态拓展,当拓展时由于受限于物理内存的限制而无法实现拓展时,则抛出**OutOfMemoryError**。
+
+###30.1.2 堆(Heap)
+
+Java虚拟机具有一个由所有Java虚拟机线程共享的一个堆。堆是**分配和储存所有的实例对象和数组的运行时数据区域**。
+
+堆是在Java虚拟机启动时被创建的。堆的对象储存空间通过**自动存储管理系统(garbage collector简称gc)**进行回收,并不能像c/c++语言那样显示地进行释放。Java虚拟机没有指定限制使用的gc,这个可以由程序员和用户根据自己的情况来进行选择。堆可以是固定大小的,也可以通过计算来动态地拓展和收缩。同时,堆的内容空间地址不需要是连续的。
+
+Java虚拟机的实现可以提供让程序员和用户控制初始的堆大小,并且,可以让栈在最小值和最大值的限制范围内根据实际需要动态地拓展或收缩。
+
+以下异常情况与堆相关:
+
+* 当堆需要拓展的内存大小大于自动存储管理系统所能提供的内存大小时,抛出**OutOfMemoryError**。
+
+### 方法区(Method Area)
+
+Java虚拟机拥有一个由所有Java虚拟机线程共享的方法区。方法区类似于传统语言的用于存储编译代码的内存区域。(The method area is analogous to the storage area for compiled code of a conventional language or analogous to the "text" segment in an operating system process. )它用于存储每个类的类结构,例如**运行时常量池(Runtime Constant Pool)**,字段和方法数据,以及方法和构造方法的代码,包括类、实例和接口在初始化时使用的特殊方法。
+
+方法区也是在Java虚拟机启动时创建的。虽然方法区作为堆的一部分,但简单的Java虚拟机的实现可能不会对这部分区域进行gc操作和内存紧凑操作。Java虚拟机规范并不强制规范方法区的存储位置和管理已编译代码的策略。方法区可以是固定大小,也可以根据实际需要对方法区的大小进行拓展和紧凑操作。同时,方法区的内存不需要是连续的。
+
+Java虚拟机的实现应该提供让程序员和用户控制初始的方法区内存大小,并且,可以让方法区在最小值和最大值的限制范围内根据实际需要动态地拓展或收缩。
+
+以下异常情况与方法区相关:
+* 如果方法区不能提供满足需要分配的内存时,Java虚拟机抛出**OutOfMemoryError**。
+
+###运行时常量池(Runtime Constant Pool)
+**运行时常量池**是一个类或接口的class文件的中**constant_pool**表的运行时表示。它包含多种常量:编译期的数值型字面量,运行时的方法和字段的引用。运行时常量池提供类似于一个传统的编程语言中的符号表的功能,但它比典型的符号表包含了更广泛的范围中的数据。
+
+每个运行时常量池都是在Java虚拟机的方法区中进行分配的(也就是说运行时常量池是方法区中的一部分)。类/接口的运行时常量池在类/接口创建时被Java虚拟机构造。
+
+以下异常情况与类/接口的运行时常量池的创建相关:
+
+当创建一个类或接口时,如果运行时常量池的创建需要更多的内存,而方法区没有足够的内存可以提供时,Java虚拟机抛出**OutOfMemoryError**。
+
+###本地方法栈(Native Method Stacks)
+Java虚拟机应该使用传统的栈(通俗地将:C栈)来对**本地方法**(非Java实现的方法)进行支持。Native method stacks may also be used by the implementation of an interpreter for the Java Virtual Machine's instruction set in a language such as C. Java Virtual Machine implementations that cannot load native methods and that do not themselves rely on conventional stacks need not supply native method stacks. If supplied, native method stacks are typically allocated per thread when each thread is created.
+
+This specification permits native method stacks either to be of a fixed size or to dynamically expand and contract as required by the computation. If the native method stacks are of a fixed size, the size of each native method stack may be chosen independently when that stack is created.
+
+
+Java虚拟机的实现应当提供这样的功能:程序员和用户可以控制本地方法栈的初始化大小,并且,可以让本地方法栈在最小值和最大值的限制范围内根据实际需要动态地拓展或收缩。
+
+以下异常情况与本地方法栈相关:
+* 如果本地方法栈需要更多的内存,但无法进行分配时,Java虚拟机抛出**StackOverflowError**。
+
+
+If native method stacks can be dynamically expanded and native method stack expansion is attempted but insufficient memory can be made available, or if insufficient memory can be made available to create the initial native method stack for a new thread, the Java Virtual Machine throws an OutOfMemoryError.
+
+### 拓展阅读
+
+* 翻译自:http://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.5
+* understanding-jvm-internals: http://www.cubrid.org/blog/dev-platform/understanding-jvm-internals/
+* understanding-java-garbage-collection: http://www.cubrid.org/blog/dev-platform/understanding-java-garbage-collection/
\ No newline at end of file
diff --git a/31.Understanding Java Garbage Collection.md b/31.Understanding Java Garbage Collection.md
new file mode 100644
index 0000000..51beb95
--- /dev/null
+++ b/31.Understanding Java Garbage Collection.md
@@ -0,0 +1,120 @@
+#31.Understanding Java Garbage Collection
+
+理解GC(Garbage Collection)的工作原理对Java编程有什么益处呢?满足软件工程师的求知欲或许是一个不错的原因,但与此同时,也可以帮助你编写更加优秀的Java应用程序。
+
+这是我的个人的主观意见,但是我相信那些深谙GC的人往往更容易成为一个优秀的Java工程师。如果你对GC感兴趣,那么意味着你有不错的开发经验。如果你有过仔细选择合适的GC算法经验,这意味着你完全了解你开发应用程序的功能特点。当然,这也许只是优秀开发者的普遍衡量标准,然而我要说的是,要想成为一名优秀的开发者,理解GC是一门必修的课程。
+
+这篇文章的主要目的是以尽量简洁的方式向你讲解GC。我希望这篇文章能切切实实地对你有所帮助。回到正题,在GC中有个词汇**stop-the-word**,stop-the-word这个过程总会发生,无论你选择何种GC算法。stop-the-world意味着在**执行GC的过程中,JVM会中断所有的应用程序线程**( 除了GC需要的线程外)。被中断的线程会在GC完成后恢复。我们所关注的**GC调优就在于如何减少stop-the-world的运行时间**。
+
+## 垃圾收集器(Generational Garbage Collection)
+
+Java代码并不能显式地对内存进行分配和移除。有些人会将对象设置为null或者调用System.gc()方法来**显式**地移除内存空间。将对象设置为null没有大不了的,当调用System.gc()方法却会大大地响应系统的性能(我们并不需要这样做)。
+
+在Java中,开发者并不需要显式地在代码中释放内存,垃圾收集器会帮助我们找到不需要的对象并讲它们移除。垃圾收集器只所以被引入使用是基于以下两个假定前提:
+
+1. 大多数对象很快成为不可达状态;
+2. **老对象引用新对象**这种情况总是控制在很小的数量内。
+
+这两个假定前提被成为**弱世代假说(Weak generational hypothesis)**,基于这个假设,在HotSpot虚拟机中,内存(切确地说是Java Heap)被分为两种:**新生代(Young Generation)**与**老年代(Old Generation)**。
+
+新生代:绝大部分的新创建的对象都被分配到这里。由于大部分的对象很快会成为不可达状态,很多新创建的对象都分配到新生代,然后很快从这个区域被释放。对象从新生代被释放,我们称这个过程为**Minor GC**。
+
+老年代:当在新生代的对象没有成为不可达状态,并且从新生代存活下来后,我们会将这些对象复制到老年代。老年代的储存空间会比新生代的要大,所以在老年代发生GC的频率要远远低于在新生代的GC频率。对象从老年代被释放,我们称这个过程为**major GC**或**full GC**。
+
+我们看下以下两个图表:
+
+
+
+##30.1 运行时数据区(Runtime Data Areas)
+
+Java虚拟机为程序的运行提供了各种不同的数据区,部分数据区与JVM的生命周期一致(随JVM启动而分配,JVM退出而释放),而另一部分则跟线程绑定,随着线程的启动和退出进行分配和释放。
+
+###30.1.1 程序计数器(Program Counter Rigister)
+
+Java虚拟机支持多个线程在同一时刻运行。每一个Java虚拟机线程拥有自己的程序计数器。在任意时刻,任意线程都处于一个方法中(称为当前方法(current method)),如果是该方法是**非本地方法(not native method)**,则该程序计数器记录着**Java虚拟机执行的当前指令的地址**。而如果该方法为**本地方法(native method)**,则该程序计数器为undefined。
+
+###30.1.2 Java虚拟机栈(Java Virtual Machine Stacks)
+
+每个Java虚拟机线程都拥有各自的**Java虚拟机栈**,并与线程同时被创建。Java虚拟机栈用于存储**帧(frames)**。Java虚拟机栈跟传统语言的栈相似:存储局部变量、结果,同时参与方法的调用和返回。
+Because the Java Virtual Machine stack is never manipulated directly except to push and pop frames, frames may be heap allocated. The memory for a Java Virtual Machine stack does not need to be contiguous.
+
+在第一版的Java虚拟机规范中,**Java虚拟机栈**做为**Java栈** 为人们所熟知。这个规范允许Java虚拟机栈是固定的大小或根据需要通过计算来动态地扩展和收缩。如果Java虚拟机堆的大小是固定的,(If the Java Virtual Machine stacks are of a fixed size, the size of each Java Virtual Machine stack may be chosen independently when that stack is created.)
+
+Java虚拟的实现可以提供让程序员或用户来控制Java虚拟栈初始大小,并且,可以让Java虚拟机栈在最小值和最大值的限制范围内根据实际需要动态地拓展或收缩。
+
+以下异常情况与Java虚拟栈相关:
+* 如果线程需要的Java虚拟机栈大小超过限额,则抛出**StackOverflowError**。
+* 如果Java虚拟机栈被设置为可动态拓展,当拓展时由于受限于物理内存的限制而无法实现拓展时,则抛出**OutOfMemoryError**。
+
+###30.1.2 堆(Heap)
+
+Java虚拟机具有一个由所有Java虚拟机线程共享的一个堆。堆是**分配和储存所有的实例对象和数组的运行时数据区域**。
+
+堆是在Java虚拟机启动时被创建的。堆的对象储存空间通过**自动存储管理系统(garbage collector简称gc)**进行回收,并不能像c/c++语言那样显示地进行释放。Java虚拟机没有指定限制使用的gc,这个可以由程序员和用户根据自己的情况来进行选择。堆可以是固定大小的,也可以通过计算来动态地拓展和收缩。同时,堆的内容空间地址不需要是连续的。
+
+Java虚拟机的实现可以提供让程序员和用户控制初始的堆大小,并且,可以让栈在最小值和最大值的限制范围内根据实际需要动态地拓展或收缩。
+
+以下异常情况与堆相关:
+
+* 当堆需要拓展的内存大小大于自动存储管理系统所能提供的内存大小时,抛出**OutOfMemoryError**。
+
+### 方法区(Method Area)
+
+Java虚拟机拥有一个由所有Java虚拟机线程共享的方法区。方法区类似于传统语言的用于存储编译代码的内存区域。(The method area is analogous to the storage area for compiled code of a conventional language or analogous to the "text" segment in an operating system process. )它用于存储每个类的类结构,例如**运行时常量池(Runtime Constant Pool)**,字段和方法数据,以及方法和构造方法的代码,包括类、实例和接口在初始化时使用的特殊方法。
+
+方法区也是在Java虚拟机启动时创建的。虽然方法区作为堆的一部分,但简单的Java虚拟机的实现可能不会对这部分区域进行gc操作和内存紧凑操作。Java虚拟机规范并不强制规范方法区的存储位置和管理已编译代码的策略。方法区可以是固定大小,也可以根据实际需要对方法区的大小进行拓展和紧凑操作。同时,方法区的内存不需要是连续的。
+
+Java虚拟机的实现应该提供让程序员和用户控制初始的方法区内存大小,并且,可以让方法区在最小值和最大值的限制范围内根据实际需要动态地拓展或收缩。
+
+以下异常情况与方法区相关:
+* 如果方法区不能提供满足需要分配的内存时,Java虚拟机抛出**OutOfMemoryError**。
+
+###运行时常量池(Runtime Constant Pool)
+**运行时常量池**是一个类或接口的class文件的中**constant_pool**表的运行时表示。它包含多种常量:编译期的数值型字面量,运行时的方法和字段的引用。运行时常量池提供类似于一个传统的编程语言中的符号表的功能,但它比典型的符号表包含了更广泛的范围中的数据。
+
+每个运行时常量池都是在Java虚拟机的方法区中进行分配的(也就是说运行时常量池是方法区中的一部分)。类/接口的运行时常量池在类/接口创建时被Java虚拟机构造。
+
+以下异常情况与类/接口的运行时常量池的创建相关:
+
+当创建一个类或接口时,如果运行时常量池的创建需要更多的内存,而方法区没有足够的内存可以提供时,Java虚拟机抛出**OutOfMemoryError**。
+
+###本地方法栈(Native Method Stacks)
+Java虚拟机应该使用传统的栈(通俗地将:C栈)来对**本地方法**(非Java实现的方法)进行支持。Native method stacks may also be used by the implementation of an interpreter for the Java Virtual Machine's instruction set in a language such as C. Java Virtual Machine implementations that cannot load native methods and that do not themselves rely on conventional stacks need not supply native method stacks. If supplied, native method stacks are typically allocated per thread when each thread is created.
+
+This specification permits native method stacks either to be of a fixed size or to dynamically expand and contract as required by the computation. If the native method stacks are of a fixed size, the size of each native method stack may be chosen independently when that stack is created.
+
+
+Java虚拟机的实现应当提供这样的功能:程序员和用户可以控制本地方法栈的初始化大小,并且,可以让本地方法栈在最小值和最大值的限制范围内根据实际需要动态地拓展或收缩。
+
+以下异常情况与本地方法栈相关:
+* 如果本地方法栈需要更多的内存,但无法进行分配时,Java虚拟机抛出**StackOverflowError**。
+
+
+If native method stacks can be dynamically expanded and native method stack expansion is attempted but insufficient memory can be made available, or if insufficient memory can be made available to create the initial native method stack for a new thread, the Java Virtual Machine throws an OutOfMemoryError.
+
+### 拓展阅读
+
+* 翻译自:http://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.5
+* understanding-jvm-internals: http://www.cubrid.org/blog/dev-platform/understanding-jvm-internals/
+* understanding-java-garbage-collection: http://www.cubrid.org/blog/dev-platform/understanding-java-garbage-collection/
\ No newline at end of file
diff --git a/31.Understanding Java Garbage Collection.md b/31.Understanding Java Garbage Collection.md
new file mode 100644
index 0000000..51beb95
--- /dev/null
+++ b/31.Understanding Java Garbage Collection.md
@@ -0,0 +1,120 @@
+#31.Understanding Java Garbage Collection
+
+理解GC(Garbage Collection)的工作原理对Java编程有什么益处呢?满足软件工程师的求知欲或许是一个不错的原因,但与此同时,也可以帮助你编写更加优秀的Java应用程序。
+
+这是我的个人的主观意见,但是我相信那些深谙GC的人往往更容易成为一个优秀的Java工程师。如果你对GC感兴趣,那么意味着你有不错的开发经验。如果你有过仔细选择合适的GC算法经验,这意味着你完全了解你开发应用程序的功能特点。当然,这也许只是优秀开发者的普遍衡量标准,然而我要说的是,要想成为一名优秀的开发者,理解GC是一门必修的课程。
+
+这篇文章的主要目的是以尽量简洁的方式向你讲解GC。我希望这篇文章能切切实实地对你有所帮助。回到正题,在GC中有个词汇**stop-the-word**,stop-the-word这个过程总会发生,无论你选择何种GC算法。stop-the-world意味着在**执行GC的过程中,JVM会中断所有的应用程序线程**( 除了GC需要的线程外)。被中断的线程会在GC完成后恢复。我们所关注的**GC调优就在于如何减少stop-the-world的运行时间**。
+
+## 垃圾收集器(Generational Garbage Collection)
+
+Java代码并不能显式地对内存进行分配和移除。有些人会将对象设置为null或者调用System.gc()方法来**显式**地移除内存空间。将对象设置为null没有大不了的,当调用System.gc()方法却会大大地响应系统的性能(我们并不需要这样做)。
+
+在Java中,开发者并不需要显式地在代码中释放内存,垃圾收集器会帮助我们找到不需要的对象并讲它们移除。垃圾收集器只所以被引入使用是基于以下两个假定前提:
+
+1. 大多数对象很快成为不可达状态;
+2. **老对象引用新对象**这种情况总是控制在很小的数量内。
+
+这两个假定前提被成为**弱世代假说(Weak generational hypothesis)**,基于这个假设,在HotSpot虚拟机中,内存(切确地说是Java Heap)被分为两种:**新生代(Young Generation)**与**老年代(Old Generation)**。
+
+新生代:绝大部分的新创建的对象都被分配到这里。由于大部分的对象很快会成为不可达状态,很多新创建的对象都分配到新生代,然后很快从这个区域被释放。对象从新生代被释放,我们称这个过程为**Minor GC**。
+
+老年代:当在新生代的对象没有成为不可达状态,并且从新生代存活下来后,我们会将这些对象复制到老年代。老年代的储存空间会比新生代的要大,所以在老年代发生GC的频率要远远低于在新生代的GC频率。对象从老年代被释放,我们称这个过程为**major GC**或**full GC**。
+
+我们看下以下两个图表:
+
+ +
+以上图中**永久代(Permanent Generation)**被称为**方法区**,它用于存储class文件和运行时常量池。所以,这里的存储空间并不用于“收留”从老年代存活下来的对象。当GC可能会在这个区域发生,我们也把在这个区域发生的GC算作full GC。
+
+有些人会有疑问:当老年代的对象需要引用新生代的对象,这时候会发生什么情况?
+
+为了处理这些情况,在老年代中会有个叫做**卡表(card table)**的东西,它是一个512字节的数据块。在老年代的对象需要引用新生代的对象时,会被记录到这里。然后,当新生代的GC执行时,这个**card table**会被检查以确定对象是否应该被GC处理,这样做可以防止对老年代的所有对象进行遍历。这个卡表使用一个被称为**写屏障**的装置进行管理,它可以让minor GC的性能更加高效,虽然它本身也需要一定的开销,但是整体的开销却是减少的。
+
+
+
+以上图中**永久代(Permanent Generation)**被称为**方法区**,它用于存储class文件和运行时常量池。所以,这里的存储空间并不用于“收留”从老年代存活下来的对象。当GC可能会在这个区域发生,我们也把在这个区域发生的GC算作full GC。
+
+有些人会有疑问:当老年代的对象需要引用新生代的对象,这时候会发生什么情况?
+
+为了处理这些情况,在老年代中会有个叫做**卡表(card table)**的东西,它是一个512字节的数据块。在老年代的对象需要引用新生代的对象时,会被记录到这里。然后,当新生代的GC执行时,这个**card table**会被检查以确定对象是否应该被GC处理,这样做可以防止对老年代的所有对象进行遍历。这个卡表使用一个被称为**写屏障**的装置进行管理,它可以让minor GC的性能更加高效,虽然它本身也需要一定的开销,但是整体的开销却是减少的。
+
+ +
+## 新生代(Composition of the Young Generation)
+
+为了深入理解GC,我们来看一下新生代。新生代被划分为3个区域空间:
+
+* 一个伊甸园(One Eden Space)
+* 两个幸存区 (Two Survivor Spaces)
+
+这三个区域空间中,有两个是幸存区(Survivor Spaces)。每个区域空间的执行过程如下:
+
+1. 绝大多数新创建的对象都首先被分配到伊甸园(Eden Space)。
+2. 当伊甸园的GC执行以后,存活下来的对象会被移动到其中一个幸存区(这个幸存区存放着之前存活下来的对象)。
+3. 一旦幸存区满了以后,该幸存区存活下来的对象会移动到另外一个幸存区,然后该幸存区会重置为空状态。
+4. 在多次幸存区的GC执行后而存活下来的对象会被移动到老年代。
+
+在这个过程中,其中一个幸存区必须要保持为空状态。如果两个幸存区都是空状态或者都同时存在数据,你的系统一定出现了什么错误。
+
+数据通过minor GC并堆砌进入老年代的过程如下图所示:
+
+
+
+## 新生代(Composition of the Young Generation)
+
+为了深入理解GC,我们来看一下新生代。新生代被划分为3个区域空间:
+
+* 一个伊甸园(One Eden Space)
+* 两个幸存区 (Two Survivor Spaces)
+
+这三个区域空间中,有两个是幸存区(Survivor Spaces)。每个区域空间的执行过程如下:
+
+1. 绝大多数新创建的对象都首先被分配到伊甸园(Eden Space)。
+2. 当伊甸园的GC执行以后,存活下来的对象会被移动到其中一个幸存区(这个幸存区存放着之前存活下来的对象)。
+3. 一旦幸存区满了以后,该幸存区存活下来的对象会移动到另外一个幸存区,然后该幸存区会重置为空状态。
+4. 在多次幸存区的GC执行后而存活下来的对象会被移动到老年代。
+
+在这个过程中,其中一个幸存区必须要保持为空状态。如果两个幸存区都是空状态或者都同时存在数据,你的系统一定出现了什么错误。
+
+数据通过minor GC并堆砌进入老年代的过程如下图所示:
+
+ +
+在HotSpot虚拟机中,有两项被用于快速分配内存的技术。一种被成为**bump-the-pointer**,而另一种是所谓的线程局部缓冲器TLABs (Thread-Local Allocation Buffers)。
+
+Bump-the-pointer technique tracks the last object allocated to the Eden space. That object will be located on top of the Eden space. And if there is an object created afterwards, it checks only if the size of the object is suitable for the Eden space. If the said object seems right, it will be placed in the Eden space, and the new object goes on top. So, when new objects are created, only the lastly added object needs to be checked, which allows much faster memory allocations. However, it is a different story if we consider a multithreaded environment. To save objects used by multiple threads in the Eden space for Thread-Safe, an inevitable lock will occur and the performance will drop due to the lock-contention. TLABs is the solution to this problem in HotSpot VM. This allows each thread to have a small portion of its Eden space that corresponds to its own share. As each thread can only access to their own TLAB, even the bump-the-pointer technique will allow memory allocations without a lock.
+
+你并不需要技术以上提到的两种技术。你需要记住的是:当对象创建之后会首先分配到伊甸园空间,然后通过在幸存区的长时间存活被晋升到老年代空间。
+
+##老年代的GC(GC for the Old Generation)
+
+老年代基本在空间被沾满时才执行GC操作。GC的执行过程根据GC的类型不同而有所差异,如果你对不同的GC类型有所了解,则会明白其中的差异所在。
+
+根据JDK7,共有5中GC类型:
+
+* Serial GC
+* Parallel GC
+* Parallel Old GC (Parrallel Compacting GC)
+* Concurrent Mark & Sweep GC (or CMS)
+* Garbage First GC (G1)
+
+其中,串行GC不能使用的操作的服务器上。这种类型的GC创建时有在台式计算机上只有一个CPU核心。使用该系列GC将显著删除应用程序的性能。 使用这种将很明显地降低应用程序的性能。
+
+现在让我们来了解每种GC的类型:
+
+###串行GC( Serial GC (-XX:+UseSerialGC))
+
+(The GC in the young generation uses the type we explained in the previous paragraph. ?)
+在新生代中我们使用一种称为**标记-清除-紧凑(mark-sweep-compact)**的算法。
+
+这种算法的第一步就是对新生代的幸存对象进行标记。然后,它从堆的从前往后逐个清理不需要的对象。最后对幸存的对象进行紧凑,使它们在位于连续的内存空间。这个过程会将堆分为两部分:一部分有数据,一部分没数据。Serial GC适用于小的内存空间和少量的CPU核心的机器。
+
+###并行GC (Parallel GC (-XX:+UseParallelGC))
+
+
+
+在HotSpot虚拟机中,有两项被用于快速分配内存的技术。一种被成为**bump-the-pointer**,而另一种是所谓的线程局部缓冲器TLABs (Thread-Local Allocation Buffers)。
+
+Bump-the-pointer technique tracks the last object allocated to the Eden space. That object will be located on top of the Eden space. And if there is an object created afterwards, it checks only if the size of the object is suitable for the Eden space. If the said object seems right, it will be placed in the Eden space, and the new object goes on top. So, when new objects are created, only the lastly added object needs to be checked, which allows much faster memory allocations. However, it is a different story if we consider a multithreaded environment. To save objects used by multiple threads in the Eden space for Thread-Safe, an inevitable lock will occur and the performance will drop due to the lock-contention. TLABs is the solution to this problem in HotSpot VM. This allows each thread to have a small portion of its Eden space that corresponds to its own share. As each thread can only access to their own TLAB, even the bump-the-pointer technique will allow memory allocations without a lock.
+
+你并不需要技术以上提到的两种技术。你需要记住的是:当对象创建之后会首先分配到伊甸园空间,然后通过在幸存区的长时间存活被晋升到老年代空间。
+
+##老年代的GC(GC for the Old Generation)
+
+老年代基本在空间被沾满时才执行GC操作。GC的执行过程根据GC的类型不同而有所差异,如果你对不同的GC类型有所了解,则会明白其中的差异所在。
+
+根据JDK7,共有5中GC类型:
+
+* Serial GC
+* Parallel GC
+* Parallel Old GC (Parrallel Compacting GC)
+* Concurrent Mark & Sweep GC (or CMS)
+* Garbage First GC (G1)
+
+其中,串行GC不能使用的操作的服务器上。这种类型的GC创建时有在台式计算机上只有一个CPU核心。使用该系列GC将显著删除应用程序的性能。 使用这种将很明显地降低应用程序的性能。
+
+现在让我们来了解每种GC的类型:
+
+###串行GC( Serial GC (-XX:+UseSerialGC))
+
+(The GC in the young generation uses the type we explained in the previous paragraph. ?)
+在新生代中我们使用一种称为**标记-清除-紧凑(mark-sweep-compact)**的算法。
+
+这种算法的第一步就是对新生代的幸存对象进行标记。然后,它从堆的从前往后逐个清理不需要的对象。最后对幸存的对象进行紧凑,使它们在位于连续的内存空间。这个过程会将堆分为两部分:一部分有数据,一部分没数据。Serial GC适用于小的内存空间和少量的CPU核心的机器。
+
+###并行GC (Parallel GC (-XX:+UseParallelGC))
+
+ +
+ 看上图,你可以清楚看到Serial GC与Parallel之间的差异。Serial GC仅使用一个线程去执行GC过程,而Parallel GC会使用多个线程去执行GC过程,因此,可得到更加优秀的性能。当机器拥有很大的内存和较多的CPU核心时,Paraller GC会表现得非常不错。Parallel GC也被称为**throughput GC**。
+
+###Parallel Old GC
+
+Parallel Old GC从JDK 5 update版本开始得到支持。相比Parallel GC,唯一的区别在于:Parallel Old GC只工作于老年代。它通过三个步骤进行工作:标记-总结-紧凑。The summary step identifies the surviving objects separately for the areas that the GC have previously performed, and thus different from the sweep step of the mark-sweep-compact algorithm. It goes through a little more complicated steps.
+
+###Concurrent Mark & Sweep GC (or CMS)
+
+
+
+ 看上图,你可以清楚看到Serial GC与Parallel之间的差异。Serial GC仅使用一个线程去执行GC过程,而Parallel GC会使用多个线程去执行GC过程,因此,可得到更加优秀的性能。当机器拥有很大的内存和较多的CPU核心时,Paraller GC会表现得非常不错。Parallel GC也被称为**throughput GC**。
+
+###Parallel Old GC
+
+Parallel Old GC从JDK 5 update版本开始得到支持。相比Parallel GC,唯一的区别在于:Parallel Old GC只工作于老年代。它通过三个步骤进行工作:标记-总结-紧凑。The summary step identifies the surviving objects separately for the areas that the GC have previously performed, and thus different from the sweep step of the mark-sweep-compact algorithm. It goes through a little more complicated steps.
+
+###Concurrent Mark & Sweep GC (or CMS)
+
+ +
+ 如你上图所看的,Concurrent Mark-Sweep GC比之前介绍的几种GC都要复杂得多。早期的**初始标记阶**段很简单,它的主要功能是最接近根类加载器的对象进行标记,这个阶段的停顿时间十分短暂。在**并发标记**阶段,对刚刚幸存下来的对象的引用进行跟踪和检查,这个过程中,其他的JVM线程不会被中止(也就是没有stop-the-world)。在**重新标记**阶段,会对**并发标记**阶段新添加或停止的引用进行确认。最后,在**并发清除**阶段,对不可达对象进行清理工作(也就GC动作),这个过程,其他的JVM线程也不会被中止。由于这种GC工作方式,GC的停顿时间非常短暂。CMS GC也被称为**低延迟GC**,这对那些对响应时间有严格要求的应用程序是至关重要的。
+
+虽然这种GC垃圾收集的停顿时间非常短暂,但是他对内存大小和CPU内核数量与性能有着更高的要求。
+虽然这种GC类型具有极其短暂的停顿时间,但它也有以下缺点:
+
+* 对内存和CPU的要求更加高。
+* 不提供默认的内存紧凑步骤
+
+在使用这种GC之前,你需要仔细地review。此外,在内存紧凑阶段,如果存在大量的内存碎片,那么这种GC需要停顿时间可能会比其他的GC类型的要长。你需要仔细检查内存紧凑发生的频率和时间。
+
+###Garbage First GC (G1)
+
+最后,让我们来看下Garbage First GC(G1)
+
+
+
+ 如你上图所看的,Concurrent Mark-Sweep GC比之前介绍的几种GC都要复杂得多。早期的**初始标记阶**段很简单,它的主要功能是最接近根类加载器的对象进行标记,这个阶段的停顿时间十分短暂。在**并发标记**阶段,对刚刚幸存下来的对象的引用进行跟踪和检查,这个过程中,其他的JVM线程不会被中止(也就是没有stop-the-world)。在**重新标记**阶段,会对**并发标记**阶段新添加或停止的引用进行确认。最后,在**并发清除**阶段,对不可达对象进行清理工作(也就GC动作),这个过程,其他的JVM线程也不会被中止。由于这种GC工作方式,GC的停顿时间非常短暂。CMS GC也被称为**低延迟GC**,这对那些对响应时间有严格要求的应用程序是至关重要的。
+
+虽然这种GC垃圾收集的停顿时间非常短暂,但是他对内存大小和CPU内核数量与性能有着更高的要求。
+虽然这种GC类型具有极其短暂的停顿时间,但它也有以下缺点:
+
+* 对内存和CPU的要求更加高。
+* 不提供默认的内存紧凑步骤
+
+在使用这种GC之前,你需要仔细地review。此外,在内存紧凑阶段,如果存在大量的内存碎片,那么这种GC需要停顿时间可能会比其他的GC类型的要长。你需要仔细检查内存紧凑发生的频率和时间。
+
+###Garbage First GC (G1)
+
+最后,让我们来看下Garbage First GC(G1)
+
+ +
+如果你想要了解G1 GC,首先你要忘记关于新生代和老年代的一切知识点。Java堆(新生代&老年代)被划分为一个个大小固定的区域,对象被分派到这些区域中,如果一个区域被占满,则继续分配另外的区域,同时在后台维护一个优先列表,每次在允许的GC时间内,优先回收占用内存多的对象,这是就G1的来源。
+
+待续...
+
+## 参考文档
+* 翻译自:http://www.cubrid.org/blog/dev-platform/understanding-java-garbage-collection/
diff --git "a/32.\350\277\255\344\273\243\345\231\250\346\250\241\345\274\217.md" "b/32.\350\277\255\344\273\243\345\231\250\346\250\241\345\274\217.md"
new file mode 100644
index 0000000..2238327
--- /dev/null
+++ "b/32.\350\277\255\344\273\243\345\231\250\346\250\241\345\274\217.md"
@@ -0,0 +1,69 @@
+# 32.迭代器模式
+
+## 32.1 从Iterable接口说起
+
+ 在Java中的集合类接口有Set、List、Map、Queue,而这些接口的子类不计其数。以List接口为例,常用的实现类有:ArrayList、LinkedList、Stack、Vector。每个List子类实现的方式各不一样,ArrayList使用数组,LinkedList使用链表,Stack和Vector可以数组,甚至有些其他的集合类使用混合的数据结构。
+
+ 为了对外隐藏集合类的实现方式,保持良好的封装性,必须要统一这些集合类的迭代接口。同时调用者也无效关心集合类的底层实现方式,使用统一的接口即可对集合进行迭代。
+
+ 这不禁让人想到Java的`Iterable`接口,这也是迭代器模式在JDK中的经典实例。
+
+## 32.2 ArrayList实现Iterable接口
+
+Iterable.java 实现:
+```Java
+public interface Iterable {
+ Iterator iterator();
+}
+```
+Iterator.java 实现
+```Java
+public interface Iterator {
+ boolean hasNext();
+ E next();
+}
+```
+ArrayList.java 实现 Iterable接口
+```Java
+ @Override
+ public Iterator iterator() {
+ return new ArrayListIterator();
+ }
+```
+
+ArrayListIterator.java 实现
+```Java
+public class ArrayListIterator {
+ int cursor;
+ int lastRet = -1;
+
+ public boolean hasNext() {
+ return cursor != size;
+ }
+
+ public E next() {
+ int i = cursor;
+ if (i >= size)
+ throw new NoSuchElementException();
+ Object[] elementData = ArrayList.this.elementData;
+ cursor = i + 1;
+ return (E) elementData[lastRet = i];
+ }
+}
+```
+
+为了减少类文件和易于维护,我们通常把ArrayListIterator.java作为ArrayList的内部类,或者在ArrayList的iterator方法中世界采用匿名内部类,这里我们使用的外部类。
+
+## 32.3 迭代器模式
+
+**意图**:使用统一的方式遍历集合的各个元素,而无需暴露集合的内部结构。
+
+**使用场景**:
+
+* 为聚合类统一遍历接口;
+* 需要为聚合类提供多种遍历方式,例如二叉树的前序遍历,中序遍历,后续遍历,层次遍历;
+* 访问聚合对象的内容而无需暴露其内部结构;
+
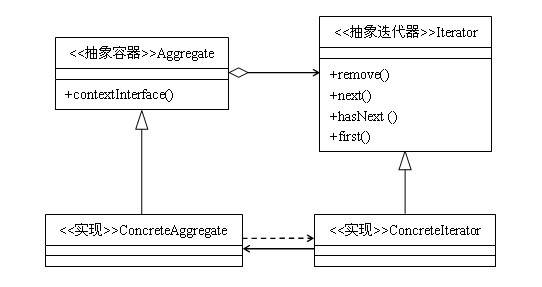
+**类图**:
+
+
+
+如果你想要了解G1 GC,首先你要忘记关于新生代和老年代的一切知识点。Java堆(新生代&老年代)被划分为一个个大小固定的区域,对象被分派到这些区域中,如果一个区域被占满,则继续分配另外的区域,同时在后台维护一个优先列表,每次在允许的GC时间内,优先回收占用内存多的对象,这是就G1的来源。
+
+待续...
+
+## 参考文档
+* 翻译自:http://www.cubrid.org/blog/dev-platform/understanding-java-garbage-collection/
diff --git "a/32.\350\277\255\344\273\243\345\231\250\346\250\241\345\274\217.md" "b/32.\350\277\255\344\273\243\345\231\250\346\250\241\345\274\217.md"
new file mode 100644
index 0000000..2238327
--- /dev/null
+++ "b/32.\350\277\255\344\273\243\345\231\250\346\250\241\345\274\217.md"
@@ -0,0 +1,69 @@
+# 32.迭代器模式
+
+## 32.1 从Iterable接口说起
+
+ 在Java中的集合类接口有Set、List、Map、Queue,而这些接口的子类不计其数。以List接口为例,常用的实现类有:ArrayList、LinkedList、Stack、Vector。每个List子类实现的方式各不一样,ArrayList使用数组,LinkedList使用链表,Stack和Vector可以数组,甚至有些其他的集合类使用混合的数据结构。
+
+ 为了对外隐藏集合类的实现方式,保持良好的封装性,必须要统一这些集合类的迭代接口。同时调用者也无效关心集合类的底层实现方式,使用统一的接口即可对集合进行迭代。
+
+ 这不禁让人想到Java的`Iterable`接口,这也是迭代器模式在JDK中的经典实例。
+
+## 32.2 ArrayList实现Iterable接口
+
+Iterable.java 实现:
+```Java
+public interface Iterable {
+ Iterator iterator();
+}
+```
+Iterator.java 实现
+```Java
+public interface Iterator {
+ boolean hasNext();
+ E next();
+}
+```
+ArrayList.java 实现 Iterable接口
+```Java
+ @Override
+ public Iterator iterator() {
+ return new ArrayListIterator();
+ }
+```
+
+ArrayListIterator.java 实现
+```Java
+public class ArrayListIterator {
+ int cursor;
+ int lastRet = -1;
+
+ public boolean hasNext() {
+ return cursor != size;
+ }
+
+ public E next() {
+ int i = cursor;
+ if (i >= size)
+ throw new NoSuchElementException();
+ Object[] elementData = ArrayList.this.elementData;
+ cursor = i + 1;
+ return (E) elementData[lastRet = i];
+ }
+}
+```
+
+为了减少类文件和易于维护,我们通常把ArrayListIterator.java作为ArrayList的内部类,或者在ArrayList的iterator方法中世界采用匿名内部类,这里我们使用的外部类。
+
+## 32.3 迭代器模式
+
+**意图**:使用统一的方式遍历集合的各个元素,而无需暴露集合的内部结构。
+
+**使用场景**:
+
+* 为聚合类统一遍历接口;
+* 需要为聚合类提供多种遍历方式,例如二叉树的前序遍历,中序遍历,后续遍历,层次遍历;
+* 访问聚合对象的内容而无需暴露其内部结构;
+
+**类图**:
+
+ diff --git "a/33.\350\243\205\351\245\260\345\231\250\346\250\241\345\274\2172.md" "b/33.\350\243\205\351\245\260\345\231\250\346\250\241\345\274\2172.md"
new file mode 100644
index 0000000..fd930a4
--- /dev/null
+++ "b/33.\350\243\205\351\245\260\345\231\250\346\250\241\345\274\2172.md"
@@ -0,0 +1 @@
+# 33.装饰器模式2
diff --git "a/Java-Concurrency-Util/01.Java\345\271\266\345\217\221\345\267\245\345\205\267\347\261\273.md" "b/Java-Concurrency-Util/01.Java\345\271\266\345\217\221\345\267\245\345\205\267\347\261\273.md"
new file mode 100644
index 0000000..191a794
--- /dev/null
+++ "b/Java-Concurrency-Util/01.Java\345\271\266\345\217\221\345\267\245\345\205\267\347\261\273.md"
@@ -0,0 +1,23 @@
+#01.Java并发工具类
+
+Java 5 added a new Java package to the Java platform, the java.util.concurrent package. This package contains a set of classes that makes it easier to develop concurrent (multithreaded) applications in Java. Before this package was added, you would have to program your utility classes yourself.
+
+In this tutorial I will take you through the new java.util.concurrent classes, one by one, so you can learn how to use them. I will use the versions in Java 6. I am not sure if there are any differences to the Java 5 versions.
+
+I will not explain the core issues of concurrency in Java - the theory behind it, that is. If you are interested in that, check out my Java Concurrency tutorial.
+
+
+##Work in Progress
+
+This tutorial is very much "work in progress", so if you spot a missing class or interface, please be patient. I will add it when I get the time to do it.
+
+
+##Table of Contents
+
+Here is a list of the topics covered in this java.util.concurrent trail. This list (menu) is also present at the top right of every page in the trail.
+
+
+##Feel Free to Contact Me
+
+If you disagree with anything I write here about the java.util.concurrent utilities, or just have comments, questions, etc, feel free to send me an email. You wouldn't be the first to do so. You can find my email address on the about page.
+
diff --git "a/Java-Concurrency-Util/02.\351\230\273\345\241\236\351\230\237\345\210\227\357\274\210BlockingQueue\357\274\211.md" "b/Java-Concurrency-Util/02.\351\230\273\345\241\236\351\230\237\345\210\227\357\274\210BlockingQueue\357\274\211.md"
new file mode 100644
index 0000000..0454d9d
--- /dev/null
+++ "b/Java-Concurrency-Util/02.\351\230\273\345\241\236\351\230\237\345\210\227\357\274\210BlockingQueue\357\274\211.md"
@@ -0,0 +1,118 @@
+#02.阻塞队列(BlockingQueue)
+
+在Java `java.util.concurrent`包中的*BlockingQueue*是一个线程安全的阻塞队列接口,在这个接口中,入列和出类的操作都是线程安全的。
+
+##BlockingQueue用法(BlockingQueue Usage)
+
+阻塞队列(BlockingQueue)通常被用于**生产消费者模式**。看下面这张图:
+
+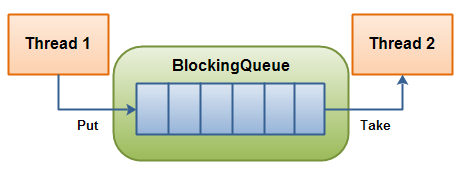
+
+**生产者线程**生产新的对象,并把对象插入到队列中,直到队列中元素达到上限。如果阻塞队列达到了上限,则尝试插入对象的生产者线程会进入阻塞状态,它们会一直阻塞直到有**消费者线程**从队列中取出对象。
+
+**消费者线程**会持续从阻塞队列中取出对象并进行相应处理。如果消费者线程试图从空的阻塞队列中取出对象,则会进入阻塞状态,直到有生产者线程向队列中插入对象。
+
+##BlockingQueue的方法(BlockingQueue Methods)
+
+*BlockingQueue*分别有四种用于**入列**和**出列**的方法。每种方法都有不同的处理行为用以处理不同的应用场景:
+
+||Throws Exception| Special Value| Blocks| Times Out
+ ------|--------------|------------|--------------|----------------
+Insert | add(o) | offer(o) | put(o) |offer(o, timeout, timeunit)
+Remove | remove(o) | poll(o)| take(o) |poll(timeout, timeunit)
+Examine | element(o) | peek(o) | |
+
+
+四种不同的行为含义:
+
+* 抛出异常(Throws Exception):
+如果尝试的操作不能立即执行则抛出异常。
+* 特殊值(Special Value):
+如果尝试的操作不能立即执行,则返回特殊值(通常为true/false)。
+* 阻塞(Blocks):
+如果尝试的操作不能立即执行,则方法进入阻塞直到能够执行。
+* 超时(Times Out):
+如果尝试的方法不能立即执行,则方法进入阻塞直到能够执行,但如果阻塞超过设置的超时时间,则返回一个特殊值指明操作是否成功执行(通常为true/false)
+
+往*BlockingQueue*中插入null是不可能的,如果你往*BlockingQueue*中插入null,则会抛出*NullPointerException*异常。
+
+获取*BlockingQueue*中任意的元素都是可以的,不仅限于队列的头部或尾部。举个例子,如果你已经将一个任务插入队列,但你现在想取消这个任务,你可以通过类似`remove(task)`的方法来删除特定的在*BlockingQueue*中的元素。然而,这些操作都并非高性能的,除非迫不得已,不要调用这些方法。
+
+##BlockingQueue的实现类(BlockingQueue Implementations)
+
+由于*BlockingQueue*只是一个接口,所以我们要用时,应该选择具体的实现类。在Java 6的*java.util.concurrent*包中包含以下*BlockingQueue*的实现类:
+
+* ArrayBlockingQueue
+* DelayQueue
+* LinkedBlockingQueue
+* PriorityBlockingQueue
+* SynchronousQueue
+
+##BlockingQueue示例(Java BlockingQueue Example)
+
+下面是一个*BlockingQueue*的例子,这个例子中使用了实现*BlockingQueue*接口的*ArrayBlockingQueue*类。
+
+首先,这个*BlockingQueueExample*类中,分别启动了一个*Producer*和一个*Consumer*线程。*Producer*线程往共享的阻塞队列中插入数据,而*Consumer*线程从阻塞队列中取出数据并进行相应处理:
+
+```Java
+public class BlockingQueueExample {
+
+ public static void main(String[] args) throws Exception {
+ BlockingQueue queue = new ArrayBlockingQueue(1024);
+
+ Producer producer = new Producer(queue);
+ Consumer consumer = new Consumer(queue);
+
+ new Thread(producer).start();
+ new Thread(consumer).start();
+
+ Thread.sleep(4000);
+ }
+}
+```
+
+下面是*Producer*类的实现。注意这里的每个`put()`方法间线程都休眠了1s。这会导致等待队列元素的*Consumer*线程阻塞。
+
+```Java
+public class Producer implements Runnable{
+ protected BlockingQueue queue = null;
+
+ public Producer(BlockingQueue queue) {
+ this.queue = queue;
+ }
+
+ public void run() {
+ try {
+ queue.put("1");
+ Thread.sleep(1000);
+ queue.put("2");
+ Thread.sleep(1000);
+ queue.put("3");
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+}
+```
+
+下面是*Consumer*类的实现,它仅仅只是连续从队列中取出三个元素并进行打印:
+
+```Java
+public class Consumer implements Runnable{
+ protected BlockingQueue queue = null;
+
+ public Consumer(BlockingQueue queue) {
+ this.queue = queue;
+ }
+
+ public void run() {
+ try {
+ System.out.println(queue.take());
+ System.out.println(queue.take());
+ System.out.println(queue.take());
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+}
+```
\ No newline at end of file
diff --git a/Java-Concurrency-Util/03.ArrayBlockingQueue.md b/Java-Concurrency-Util/03.ArrayBlockingQueue.md
new file mode 100644
index 0000000..d85e550
--- /dev/null
+++ b/Java-Concurrency-Util/03.ArrayBlockingQueue.md
@@ -0,0 +1,15 @@
+#03.ArrayBlockingQueue
+
+*ArrayBlockingQueue*类实现了*BlockingQueue*接口。*ArrayBlockingQueue*是一个有界的阻塞队列,其内部维护了一个数组用于存储元素。有界意味着*ArrayBlockingQueue*不能存储无限量的元素。在同一时间内*ArrayBlockingQueue*存储的元素有一个上限,我们可以在初始化*ArrayBlockingQueue*时设置这个上限,而在此之后无法进行修改这个上限。
+
+*ArrayBlockingQueue*存储元素时遵循FIFO(先进先出)原则。在队列头部的元素的最先入列的元素,而在队列尾部的元素则是最新入列的元素。
+
+下面的例子演示了如何初始化*ArrayBlockingQueue*类:
+
+```Java
+BlockingQueue queue = new ArrayBlockingQueue(1024);
+
+queue.put("1");
+
+String string = queue.take();
+```
\ No newline at end of file
diff --git "a/Java-Concurrency-Util/04.DelayQueue\357\274\210\345\273\266\346\227\266\351\230\237\345\210\227\357\274\211.md" "b/Java-Concurrency-Util/04.DelayQueue\357\274\210\345\273\266\346\227\266\351\230\237\345\210\227\357\274\211.md"
new file mode 100644
index 0000000..d80e353
--- /dev/null
+++ "b/Java-Concurrency-Util/04.DelayQueue\357\274\210\345\273\266\346\227\266\351\230\237\345\210\227\357\274\211.md"
@@ -0,0 +1,47 @@
+04.DelayQueue(延时队列)
+
+DelayQueue class implements the BlockingQueue interface. Read the BlockingQueue text for more information about the interface.
+
+The DelayQueue keeps the elements internally until a certain delay has expired. The elements must implement the interface java.util.concurrent.Delayed. Here is how the interface looks:
+
+```Java
+public interface Delayed extends Comparable unbounded = new LinkedBlockingQueue();
+BlockingQueue bounded = new LinkedBlockingQueue(1024);
+
+bounded.put("Value");
+
+String value = bounded.take();
+```
\ No newline at end of file
diff --git a/Java-Concurrency-Util/06.PriorityBlockingQueue.md b/Java-Concurrency-Util/06.PriorityBlockingQueue.md
new file mode 100644
index 0000000..9f3d012
--- /dev/null
+++ b/Java-Concurrency-Util/06.PriorityBlockingQueue.md
@@ -0,0 +1,22 @@
+#06.PriorityBlockingQueue
+
+The PriorityBlockingQueue class implements the BlockingQueue interface. Read the BlockingQueue text for more information about the interface.
+
+The PriorityBlockingQueue is an unbounded concurrent queue. It uses the same ordering rules as the java.util.PriorityQueue class. You cannot insert null into this queue.
+
+All elements inserted into the PriorityBlockingQueue must implement the java.lang.Comparable interface. The elements thus order themselves according to whatever priority you decide in your Comparable implementation.
+
+Notice that the PriorityBlockingQueue does not enforce any specific behaviour for elements that have equal priority (compare() == 0).
+
+Also notice, that in case you obtain an Iterator from a PriorityBlockingQueue, the Iterator does not guarantee to iterate the elements in priority order.
+
+Here is an example of how to use the PriorityBlockingQueue:
+
+```Java
+BlockingQueue queue = new PriorityBlockingQueue();
+
+//String implements java.lang.Comparable
+queue.put("Value");
+
+String value = queue.take();
+```
diff --git a/Java-Concurrency-Util/README.md b/Java-Concurrency-Util/README.md
new file mode 100644
index 0000000..d1d2694
--- /dev/null
+++ b/Java-Concurrency-Util/README.md
@@ -0,0 +1 @@
+翻译自:http://tutorials.jenkov.com/java-util-concurrent/index.html
diff --git "a/Java-Concurrency/01.Java \345\271\266\345\217\221\344\270\216\345\244\232\347\272\277\347\250\213.md" "b/Java-Concurrency/01.Java \345\271\266\345\217\221\344\270\216\345\244\232\347\272\277\347\250\213.md"
new file mode 100644
index 0000000..b024e2c
--- /dev/null
+++ "b/Java-Concurrency/01.Java \345\271\266\345\217\221\344\270\216\345\244\232\347\272\277\347\250\213.md"
@@ -0,0 +1,20 @@
+# 01.Java 并发与多线程
+
+在以前,一台计算机只有一个CPU,而且在同一时间只能执行一个应用程序。后来引入了多任务的概念,这意味着计算机能再同一时间内执行多个应用程序。虽然,这并不是真正意义上的“同时”。多个应用程序共享计算机的CPU,操作系统在极小的时间切片内对应用程序进行切换以获得CPU资源。
+
+多任务的引入对软件开发者带来的新的挑战。应用程序不再能占用所有的CPU时间和所有的内存以及其他计算机资源。同时,一个好的应用程序在退出之后应该释放所有的系统系统以供其它应用程序使用。
+
+不久之后,多线程的概念被引入,这意味着,在一个应用程序中可以拥有多个执行线程。A thread of execution can be thought of as a CPU executing the program. 当一个应用程序有多个线程执行时,它就像拥有多个CPU在执行任务。
+
+多线程比多任务带来的挑战更加巨大。多线程意味着,在一个应用程序内部,可以存在多个线程同时地对内存进行读写操作。它会出现一些在单线程中永远不会出现的错误。有些错误也许在单个CPU的计算机上也不会出现(因为在单个CPU的计算机上,两个线程永远不可能真正意义上的同时执行)。现代计算机,基本都拥有多个CPU内核,线程可以通过独占内核来实现真正意义上的并行。
+
+如果一个线程往一块内存读取数据,而同时另一个线程往同样的地址写入数据,那么第一个线程读取的值是多少?原来的值?或是被第二个线程写入的值?或是两者混合的值?再举个例子,如果有两个线程同时往一块内存地址写入数据,那么这块内存最终的值是什么?第一个线程写入的值?还是第二个线程写入的值?还是两者的混合?如果没有恰当的预防措施,所有的这些结果都是可能的。线程的执行行为不能预测,所以最终的计算结果也跟着不同。
+
+
+##Java的多线程与并发(Multithreading and Concurrency in Java)
+
+Java was one of the first languages to make multithreading easily available to developers. Java had multithreading capabilities from the very beginning. Therefore, Java developers often face the problems described above. That is the reason I am writing this trail on Java concurrency. As notes to myself, and any fellow Java developer whom may benefit from it.
+
+The trail will primarily be concerned with multithreading in Java, but some of the problems occurring in multithreading are similar to problems occurring in multitasking and in distributed systems. References to multitasking and distributed systems may therefore occur in this trail too. Hence the word "concurrency" rather than "multithreading".
+
+This trail is still work in progress. Texts will be published whenver time is available to write them. Below is a list of the current texts in this trail. The list is also repeated at the top right of every page in the trail.
\ No newline at end of file
diff --git "a/Java-Concurrency/02.\345\244\232\347\272\277\347\250\213\347\232\204\345\245\275\345\244\204.md" "b/Java-Concurrency/02.\345\244\232\347\272\277\347\250\213\347\232\204\345\245\275\345\244\204.md"
new file mode 100644
index 0000000..5389b28
--- /dev/null
+++ "b/Java-Concurrency/02.\345\244\232\347\272\277\347\250\213\347\232\204\345\245\275\345\244\204.md"
@@ -0,0 +1,66 @@
+#02.多线程的好处
+
+尽管多线程带来的一些挑战,也让先写应用程序变得复杂,但它也带来了一系列好处:
+
+* 更好的资源利用率
+* 更简单的程序设计
+* More responsive programs
+
+
+##更好的资源利用率(Better resource utilization)
+
+试想一下,一个读取和处理本地系统文件的应用程序。比方说,从磁盘读取AF文件需要5秒,处理需要2秒,处理两个文件过程如下:
+
+```
+读取文件A消耗5s
+处理文件A消耗2s
+读取文件B消耗5s
+处理文件B消耗2s
+-------------
+总共消耗时间14s
+```
+
+当从磁盘读取文件时,大部分的CPU时间都消耗在了等待磁盘读取数据,而在这段时间内,CPU大部分时间内都是空闲的,它原本可以用来做其他操作。改变操作的顺序,可以让CPU得到更高的利用率。如下所示:
+
+```
+读取文件A消耗5s
+读取文件B消耗5s + 处理文件A消耗2s
+处理文件B消耗2s
+-------------
+总共消耗时间12s
+```
+
+当CPU读取往文件A后,则紧随着读取文件B,在此同时处理文件A。需要谨记的是,在等带磁盘读取文件时,CPU大部分时间都是空闲的。
+
+一般来说,在CPU等待IO操作时可以处理其他任务。IO操作可以是磁盘IO,网络IO或者用户的输入。磁盘IO和网络IO远远慢于CPU IO和内存IO。
+
+
+##更简单的程序设计(Simpler Program Design)
+
+If you were to program the above ordering of reading and processing by hand in a singlethreaded application, you would have to keep track of both the read and processing state of each file. Instead you can start two threads that each just reads and processes a single file. Each of these threads will be blocked while waiting for the disk to read its file. While waiting, other threads can use the CPU to process the parts of the file they have already read. The result is, that the disk is kept busy at all times, reading from various files into memory. This results in a better utilization of both the disk and the CPU. It is also easier to program, since each thread only has to keep track of a single file.
+
+##更具响应性的程序(More responsive programs)
+
+把单线程应用转化为多线程应用的另一个目标就是实现更具有响应性的应用程序。试想一下,监听某个端口请求的服务器应用程序,当请求到达时,应用程序进行处理,然后返回继续监听。程序设计勾勒如下:
+
+```Java
+while(server is active){
+ listen for request
+ process request
+}
+```
+
+如果请求需要很长的处理时间,在这段期间内,应用程序不能处理后续的请求,只有当应用程序处理请求返回监听状态,才能继续接收请求。
+
+另一种设计就是监听线程接收请求,然后将请求传递给工作线程进行处理,并立即返回到监听状态。工作线程对请求进行处理,然后将结果响应给客户端。这种设计勾勒如下:
+
+ ```Java
+while(server is active){
+ listen for request
+ hand request to worker thread
+}
+```
+
+在这种方式下,服务器线程将很快回到监听状态。因此,可以响应更多的用户请求。服务器变成更具有响应性。
+
+The same is true for desktop applications. If you click a button that starts a long task, and the thread executing the task is the thread updating the windows, buttons etc., then the application will appear unresponsive while the task executes. Instead the task can be handed off to a worker thread. While the worker thread is busy with the task, the window thread is free to respond to other user requests. When the worker thread is done it signals the window thread. The window thread can then update the application windows with the result of the task. The program with the worker thread design will appear more responsive to the user.
diff --git "a/Java-Concurrency/03.\345\244\232\347\272\277\347\250\213\347\232\204\346\210\220\346\234\254.md" "b/Java-Concurrency/03.\345\244\232\347\272\277\347\250\213\347\232\204\346\210\220\346\234\254.md"
new file mode 100644
index 0000000..b83143f
--- /dev/null
+++ "b/Java-Concurrency/03.\345\244\232\347\272\277\347\250\213\347\232\204\346\210\220\346\234\254.md"
@@ -0,0 +1,21 @@
+#03.多线程的代价
+
+Going from a singlethreaded to a multithreaded application doesn't just provide benefits. It also has some costs. Don't just multithread-enable an application just because you can. You should have a good idea that the benefits gained by doing so, are larger than the costs. When in doubt, try measuring the performance or responsiveness of the application, instead of just guessing.
+
+##设计更加复杂(More complex design)
+
+Though some parts of a multithreaded applications is simpler than a singlethreaded application, other parts are more complex. Code executed by multiple threads accessing shared data need special attention. Thread interaction is far from always simple. Errors arising from incorrect thread synchronization can be very hard to detect, reproduce and fix.
+
+##上下文切换的开销(Context Switching Overhead)
+
+When a CPU switches from executing one thread to executing another, the CPU needs to save the local data, program pointer etc. of the current thread, and load the local data, program pointer etc. of the next thread to execute. This switch is called a "context switch". The CPU switches from executing in the context of one thread to executing in the context of another.
+
+Context switching isn't cheap. You don't want to switch between threads more than necessary.
+
+You can read more about context switching on Wikipedia:
+
+http://en.wikipedia.org/wiki/Context_switch
+
+##增加资源消耗(Increased Resource Consumption)
+
+A thread needs some resources from the computer in order to run. Besides CPU time a thread needs some memory to keep its local stack. It may also take up some resources inside the operating system needed to manage the thread. Try creating a program that creates 100 threads that does nothing but wait, and see how much memory the application takes when running.
\ No newline at end of file
diff --git "a/Java-Concurrency/04.\345\210\233\345\273\272\345\222\214\345\220\257\345\212\250Java\347\272\277\347\250\213.md" "b/Java-Concurrency/04.\345\210\233\345\273\272\345\222\214\345\220\257\345\212\250Java\347\272\277\347\250\213.md"
new file mode 100644
index 0000000..efcec90
--- /dev/null
+++ "b/Java-Concurrency/04.\345\210\233\345\273\272\345\222\214\345\220\257\345\212\250Java\347\272\277\347\250\213.md"
@@ -0,0 +1,161 @@
+#04.创建和启动Java线程
+
+Java线程对象与其它的对象相似。线程对象是`java.lang.Thread`的实例,或是`java.lang.Thread`的子类的实例。跟普通对象不同,线程对象可以执行代码。
+
+##创建和启动线程(Creating and Starting Threads)
+
+在Java中,可以使用以下方式创建线程:
+
+```Java
+Thread thread = new Thread();
+```
+
+调用`Thread.start()`可以启动线程:
+
+```Java
+thread.start();
+```
+
+这个例子并没有为线程指定要执行的代码,所以它会很快返回并停止。
+
+有两种方法可以为线程指定需要执行的代码。第一种方式是创建`Thread`的子类并重写`run()`方法;第二种方式是将实现`Runnable`接口的对象作为构造参数传给`Thread(Runnale r)`。
+
+##继承Thread类(Thread Subclass)
+
+第一种为线程指定执行代码的方法:**继承Thread类并重写run方法。** `run()`方法在调用`Thread.start()`后执行。例子:
+
+```Java
+public class MyThread extends Thread {
+ public void run(){
+ System.out.println("MyThread running");
+ }
+}
+```
+
+通过下面的代码创建并执行线程:
+
+```
+ MyThread myThread = new MyThread();
+ myTread.start();
+```
+
+`start()`方法的调用会立即返回,并不会等待`run()`方法的执行,就好像这段代码被其他的CPU执行一样。
+
+你还可以使用匿名子类来创建线程对象:
+
+```Java
+Thread thread = new Thread(){
+ public void run(){
+ System.out.println("Thread Running");
+ }
+}
+
+thread.start();
+```
+
+##实现Runnable接口(Runnable Interface Implemention)
+
+第二种为线程指定执行代码的方法:创建实现`java.lang.Runnable`接口的对象,然后把该对象交给Thread执行。
+
+MyRunnable类实现Runnable接口:
+
+```Java
+public class MyRunnable implements Runnable {
+ public void run(){
+ System.out.println("MyRunnable running");
+ }
+}
+```
+
+将MyRunnable的实例作为构造参数传给Thread,然后通过`thread.start()`启动线程:
+
+```Java
+Thread thread = new Thread(new MyRunnable());
+thread.start();
+```
+
+当线程启动后,它会调用MyRunnable实例的`run()` 方法而不是自身的`run()`方法。
+
+
+同样,你可以通过匿名Runnable类来实现:
+
+````Java
+Runnable myRunnable = new Runnable(){
+
+ public void run(){
+ System.out.println("Runnable running");
+ }
+}
+
+Thread thread = new Thread(myRunnable);
+thread.start();
+```
+
+##子类还是实现接口(Subclass or Runnable)?
+
+There are no rules about which of the two methods that is the best. Both methods works. Personally though, I prefer implementing Runnable, and handing an instance of the implementation to a Thread instance. When having the Runnable's executed by a thread pool it is easy to queue up the Runnable instances until a thread from the pool is idle. This is a little harder to do with Thread subclasses.
+
+Sometimes you may have to implement Runnable as well as subclass Thread. For instance, if creating a subclass of Thread that can execute more than one Runnable. This is typically the case when implementing a thread pool. ??? Thread本身已经实现Runnable接口,这段话如何理解??
+
+##常见陷阱:(Common Pitfall: Calling run() instead of start())
+
+一个常见的陷阱就是调用`run()`方法来启动线程:
+
+```Java
+Thread newThread = new Thread(MyRunnable());
+thread.run(); //should be start();
+```
+
+这段代码的`run()`会正常执行,然而,它并不是由新创建的线程执行的,而是由当前线程执行。如果要创建新的线程来执行,必须调用`start()`方法而不是`run()`方法。
+
+
+##线程名称(Thread Names)
+
+ 当创建线程时,可以对线程命名,通过对线程命名可以用来区分不同的线程。举个例子,有多个线程通过`System.out`写内容到控制台,那么可以通过名字很方便地区分不同的线程:
+
+```Java
+Thread thread = new Thread("New Thread") {
+ public void run(){
+ System.out.println("run by: " + getname());
+ }
+};
+
+thread.start();
+System.out.println(thread.getName());
+```
+字符串“New Thread”通过构造函数传给Thread,这个就是线程的名字。可以通过`getName()`获取线程的名字。使用Runnable接口时,可以通过如下方式进行命名:
+
+```Java
+MyRunnable runnable = new MyRunnable();
+Thread thread = new Thread(runnable, "New Thread");
+
+thread.start();
+System.out.println(thread.getName());
+```
+
+获取当前线程的名字,可以通过一下方式获取:
+
+```Java
+String threadName = Thread.currentThread().getName();
+```
+##Java线程示例(Java Thread Example)
+
+下面的线程例子。首先打印执行main方法线程的名字(这个线程由JVM分配)。然后启动10个线程,并递增赋予它们名字i,每个线程打印自己的名字,最后停止:
+
+```Java
+public class ThreadExample {
+
+ public static void main(String[] args){
+ System.out.println(Thread.currentThread().getName());
+ for(int i=0; i<10; i++){
+ new Thread("" + i){
+ public void run(){
+ System.out.println("Thread: " + getName() + " running");
+ }
+ }.start();
+ }
+ }
+}
+```
+
+值得注意的是,虽然线程是依次按1,2,3启动,但是它们的执行却不是顺序的,也就说第一个启动的线程,并不一定第一个打印输出。这是因为线程**原则上**是并行执行而不是顺序执行,由JVM或操作系统来决定线程的执行顺序,这个顺序并不需要与它们的启动顺序一致。
\ No newline at end of file
diff --git "a/Java-Concurrency/05.\347\253\236\346\200\201\346\235\241\344\273\266\345\222\214\344\270\264\347\225\214\345\214\272.md" "b/Java-Concurrency/05.\347\253\236\346\200\201\346\235\241\344\273\266\345\222\214\344\270\264\347\225\214\345\214\272.md"
new file mode 100644
index 0000000..3aa7154
--- /dev/null
+++ "b/Java-Concurrency/05.\347\253\236\346\200\201\346\235\241\344\273\266\345\222\214\344\270\264\347\225\214\345\214\272.md"
@@ -0,0 +1,46 @@
+
+#05.竞态条件和临界区(Race Conditions and Critical Sections)
+
+在一个应用程序中运行多个线程这本身不会导致什么问题。问题在于多个线程同时对同一资源进行存取,例如同样的内存空间(变量、数组或对象),系统资源(数据库,文件系统等等)。如果是多个线程对同一资源进行读取,则不会有任何问题。
+
+以下的代码,如果有多个线程同时执行,则会导致问题:
+
+```Java
+public class Counter {
+ protected long count = 0;
+
+ public void add(long value){
+ this.count = this.count + value;
+ }
+}
+```
+
+想象一下,有两个线程:`A`和`B`,同时执行Counter类的实例的一个`add()`方法。操作系统中的线程调度如何进行,我们是无法进行预测的。并且,这个方法的代码在JVM内部并不是作为一个单独的指令执行的,而是有如下步骤:
+
+```
+get this.count from memory into register
+add value to register
+write register to memory
+```
+
+观察下面A线程和B线程的运行过程和结果:
+
+```
+this.count = 0;
+A: reads this.count into a register (0)
+B: reads this.count into a register (0)
+B: adds value 2 to register
+B: writes register value (2) back to memory. this.count now equals 2
+A: adds value 3 to register
+A: writes register value (3) back to memory. this.count now equals 3
+ ```
+
+ 线程A和线程B分别加2和3到counter中,在正常情况下,counter的结果应该为5。然而,由于两个线程的执行是互相交织的,两个线程同时从内存中读取0值到寄存器。然后它们分别把2和3跟0相加,最后由线程A把寄存器中的值写回到内存中,所以执行的最后结果是3。在上面的例子中,最后由线程A把3写到内存中,而实际上也可能是线程B。如果没有适当的同步机制,那么我们无从知晓这两个线程间到底如何交织执行。
+
+
+
+## 竞态条件和临界点(Race Conditions & Critical Sections)
+
+当多个线程对同一个资源进行竞争,访问这个资源的顺序是非常重要的,称之为**竞态条件**(he situation where two threads compete for the same resource, where the sequence in which the resource is accessed is significant, is called race conditions)。可以引起竞态条件的代码区域,称之为**临界区**。在前面的示例中,`add()`方法就是一个临界区。竞态条件可以通过在临界区进行适当的**线程同步**来避免。
+
+
diff --git "a/Java-Concurrency/06.\347\272\277\347\250\213\345\256\211\345\205\250\344\270\216\350\265\204\346\272\220\345\205\261\344\272\253.md" "b/Java-Concurrency/06.\347\272\277\347\250\213\345\256\211\345\205\250\344\270\216\350\265\204\346\272\220\345\205\261\344\272\253.md"
new file mode 100644
index 0000000..96a66b9
--- /dev/null
+++ "b/Java-Concurrency/06.\347\272\277\347\250\213\345\256\211\345\205\250\344\270\216\350\265\204\346\272\220\345\205\261\344\272\253.md"
@@ -0,0 +1,117 @@
+#06.线程安全与资源共享(Thread Safety and Shared Resources)
+
+
+如果一段代码可以安全地由多个线程并行调用,则称这段代码是**线程安全**的。如果一段代码是线程安全的,则这段代码不会引起**竞态条件**。只有当多个线程更新共享资源时才会发生**竞态条件**问题。因此,重要是要知道程序执行过程中哪些资源是线程共享的。
+
+##局部变量(Local Variables)
+
+局部变量存储在各自线程的栈中,这意味着局部变量不是线程共享的,这同样意味着所有的局部基本类型变量都是线程安全的。如下代码代码线程安全的:
+
+```Java
+public void someMethod(){
+
+ long threadSafeInt = 0;
+
+ threadSafeInt++;
+}
+```
+
+## 局部对象引用(Local Object References)
+
+ 局部对象的引用有一些差异。引用本身是不同享的,然而,引用的对象并不是存储在线程栈中,所有的对象都存储在Java堆,如果一个对象始终不逃逸出创建它的方法作用域之外,则它是线程安全的(If an object created locally never escapes the method it was created in, it is thread safe. )。而实际上,你也可以把这个对象引用传递给其他对象或者方法,只要传递的对象没有被其他线程处理,则它也是线程安全的。
+
+下面这个例子中的局部对象是线程安全的:
+
+```Java
+public void someMethod(){
+ LocalObject localObject = new LocalObject();
+
+ localObject.callMethod();
+ method2(localObject);
+}
+
+public void method2(LocalObject localObject){
+ localObject.setValue("value");
+}
+```
+
+在这个例子中,LocalObject的实例并没有从`someMethod()`方法中返回,也没有传递给其他在`someMethod()`作用域外的对象。每个执行`someMethod()`的线程都会创建各自的LocalObject实例,然后将引用传递给localObject引用变量。因此,这里的LocalObject的使用是线程安全的,实际上,整个`someMethod()`方法都是线程安全的,即使LocalObject实例作为参数传给本身对象或其他对象的方法,它都是线程安全的。唯一意外的情况就是:当localObject传递给其他的方法,而这些方法是可以被多线程访问的,则会导致线程安全问题。
+
+
+##对象成员变量(Object Members)
+
+对象的成员变量跟随对象本身存储在Java共享堆中。因此,如果两个变量调用同一个对象的一个方法,而这个方法会对对象的成员变量进行修改,则这个方法是**线程不安全**的。如下面这个例子:
+
+
+```Java
+public class NotThreadSafe{
+ StringBuilder builder = new StringBuilder();
+
+ public add(String text){
+ this.builder.append(text);
+ }
+}
+```
+
+如果两个线程同时调用同一个NotThreadSafe实例的`add(String texty)`方法,则会导致竞态条件:
+
+```Java
+NotThreadSafe sharedInstance = new NotThreadSafe();
+
+new Thread(new MyRunnable(sharedInstance)).start();
+new Thread(new MyRunnable(sharedInstance)).start();
+
+public class MyRunnable implements Runnable{
+ NotThreadSafe instance = null;
+
+ public MyRunnable(NotThreadSafe instance){
+ this.instance = instance;
+ }
+
+ public void run(){
+ this.instance.add("some text");
+ }
+}
+```
+
+注意两个MyRunnable实例共享同一个NoThreadSafe实例。因此,当两个线程同时调用`add()` 方法时则会导致竞态条件。
+
+然而,如果两个线程同时调用不同NoThreadSafe实例的`add()`方法则不会导致竞态条件。如下面这个例子:
+
+
+```Java
+new Thread(new MyRunnable(new NotThreadSafe())).start();
+new Thread(new MyRunnable(new NotThreadSafe())).start();
+```
+
+现在两个线程都拥有各自的NoThreadSafe实例,它们调用`add()`方法时并不会互相干扰,所以并没有导致竞态条件。因此,即使一个对象不是线程安全的,它们也可以用在不会引起竞态条件的代码中。
+
+
+##The Thread Control Escape Rule(线程控制逃逸规则)
+
+如果想知道你的代码是否线程安全,可以使用以下规则:
+
+> 如果一个资源的创建和使用始终在同一个线程的控制下,并且从没有逃逸出这个线程的控制,则认为是线程安全的。
+
+
+>If a resource is created, used and disposed within the control of the same thread, and never escapes the control of this thread, the use of that resource is thread safe.
+
+Resources can be any shared resource like an object, array, file, database connection, socket etc. In Java you do not always explicitly dispose objects, so "disposed" means losing or null'ing the reference to the object.
+
+Even if the use of an object is thread safe, if that object points to a shared resource like a file or database, your application as a whole may not be thread safe. For instance, if thread 1 and thread 2 each create their own database connections, connection 1 and connection 2, the use of each connection itself is thread safe. But the use of the database the connections point to may not be thread safe. For example, if both threads execute code like this:
+
+```
+check if record X exists
+if not, insert record X
+```
+
+If two threads execute this simultanously, and the record X they are checking for happens to be the same record, there is a risk that both of the threads end up inserting it. This is how:
+
+```
+Thread 1 checks if record X exists. Result = no
+Thread 2 checks if record X exists. Result = no
+Thread 1 inserts record X
+Thread 2 inserts record X
+```
+
+This could also happen with threads operating on files or other shared resources. Therefore it is important to distinguish between whether an object controlled by a thread is the resource, or if it merely references the resource.
\ No newline at end of file
diff --git "a/Java-Concurrency/07.\347\272\277\347\250\213\345\256\211\345\205\250\345\222\214\344\270\215\345\217\230\346\200\247.md" "b/Java-Concurrency/07.\347\272\277\347\250\213\345\256\211\345\205\250\345\222\214\344\270\215\345\217\230\346\200\247.md"
new file mode 100644
index 0000000..1264207
--- /dev/null
+++ "b/Java-Concurrency/07.\347\272\277\347\250\213\345\256\211\345\205\250\345\222\214\344\270\215\345\217\230\346\200\247.md"
@@ -0,0 +1,73 @@
+#07.线程安全和不变性
+
+只有当多个线程访问共享资源,并且一个线程或多个线程对资源进行写操作时,才会发生竞态条件。如果多个线程同时只对共享资源进行读操作,则不会发生**竞态条件**。
+
+我们可以通过把共享对象设置为不可变以至于让线程不能对对象进行改动,从而保证了线程安全。如下面这个例子:
+
+```Java
+public class ImmutableValue{
+
+ private int value = 0;
+
+ public ImmutableValue(int value){
+ this.value = value;
+ }
+
+ public int getValue(){
+ return this.value;
+ }
+}
+```
+
+注意value的值是通过构造函数进行设置的,并且value没有提供setter方法,所以一旦ImmutableValue实例被创建后,value的值就不能进行更改了。可以通过`getValue()`获取value的值,但不能进行改动。
+
+
+如果想要对ImmutableValue对象进行操作,可以通过返回一个新的实例来完成。例如下面这个
+
+```Java
+public class ImmutableValue{
+
+ private int value = 0;
+
+ public ImmutableValue(int value){
+ this.value = value;
+ }
+
+ public int getValue(){
+ return this.value;
+ }
+
+ public ImmutableValue add(int valueToAdd){
+ return new ImmutableValue(this.value + valueToAdd);
+ }
+
+}
+```
+
+注意这里返回了一个新的ImmutableValue实例,而不是对value的值进行修改。
+
+##引用不是线程安全的!(The Reference is not Thread Safe!)
+
+有一点需要谨记:**即使一个对象是线程安全的不可变对象,指向这个对象的引用也可能不是线程安全的。**
+
+```Java
+public class Calculator{
+ private ImmutableValue currentValue = null;
+
+ public ImmutableValue getValue(){
+ return currentValue;
+ }
+
+ public void setValue(ImmutableValue newValue){
+ this.currentValue = newValue;
+ }
+
+ public void add(int newValue){
+ this.currentValue = this.currentValue.add(newValue);
+ }
+}
+```
+
+The Calculator class holds a reference to an ImmutableValue instance. Notice how it is possible to change that reference through both the setValue() and add() methods. Therefore, even if the Calculator class uses an immutable object internally, it is not itself immutable, and therefore not thread safe. In other words: The ImmutableValue class is thread safe, but the use of it is not. This is something to keep in mind when trying to achieve thread safety through immutability.
+
+To make the Calculator class thread safe you could have declared the getValue(), setValue(), and add() methods synchronized. That would have done the trick.
diff --git "a/Java-Concurrency/08.Java\345\220\214\346\255\245\345\235\227.md" "b/Java-Concurrency/08.Java\345\220\214\346\255\245\345\235\227.md"
new file mode 100644
index 0000000..9ab49f6
--- /dev/null
+++ "b/Java-Concurrency/08.Java\345\220\214\346\255\245\345\235\227.md"
@@ -0,0 +1,183 @@
+#08.Java同步块
+
+Java synchronized block(Java同步块)用来对方法或代码块进行标记,表明这个方法或代码块是同步的。Java同步块可以避免**竞态条件**。
+
+
+##synchronized关键字(The Java synchronized Keyword)
+
+Java中的同步块使用关键字**synchronized**进行标记**。同步块在Java中是同步在某个对象上。所有同步在一个对象上的同步块在同一时间只能被一个线程进入并执行里面的代码。**其他所有试图进入该对象同步块的线程将被阻塞,直到执行该同步块中的线程退出。
+
+**synchronized**关键字可以被用于标记以下四种不同类型的块:
+
+- 实例方法(Instance methods)
+- 静态方法(Static methods)
+- 实例方法中的代码块(Code blocks inside instance methods)
+- 静态方法中的代码块(Code blocks inside static methods)
+
+上述同步块都同步在不同对象上。实际需要那种同步块视具体情况而定。
+
+##同步实例方法(Synchronized Instance Methods)
+
+下面是一个同步的实例方法:
+
+```Java
+ public synchronized void add(int value){
+ this.count += value;
+ }
+```
+
+使用**synchronized**关键字对方法进行声明,告诉JVM这是一个同步的方法。
+
+Java中的**同步实例方法是基于这个方法所属的实例对象上进行同步的**。因此,每一个同步实例方法都是基于各自的实例对象进行同步的。同一时间,只有一个线程可以访问一个实例对象的同步实例方法。如果有多个实例存在,那么每个线程都可以同时访问各自不同实例对象的同步实例方法,一个实例对象对应一个线程。
+
+##同步静态方法(Synchronized Static Methods)
+
+静态方法的同步与实例方法一致,都是使用**synchronized**在方法放进行声明。
+
+```Java
+ public static synchronized void add(int value){
+ count += value;
+ }
+```
+
+同样的,这里的**synchronized**关键字用于告诉JVM这个静态方法是同步的。
+
+**同步静态方法是基于这个静态方法所属的类对象进行同步的**。由于在JVM中,每个类有且只有一个类对象,因此,在同一时间内,只有一个线程能够访问同一个类的同步静态方法。
+
+如果同步静态方法位于不同的类中,那么每个线程都可以访问各自对应的类的同步静态方法,一个线程对应一个类。
+
+##实例方法中的同步块(Synchronized Blocks in Instance Methods)
+
+有些时候,你并不需要同步整一个方法,而只需要同步这个方法下的一小部分代码块。你可以在方法里面使用同步代码块。
+
+下面这个例子就是在非同步方法里面使用了同步代码块:
+
+```Java
+ public void add(int value){
+
+ synchronized(this){
+ this.count += value;
+ }
+ }
+```
+
+这个例子里,用了Java的同步代码块来使代码进行同步,让这个方法像同步方法一样执行。
+
+注意在Java的同步代码块里,需要在括号里传递一个对象。这个例子中,这个对象是**this**,this指的是这个实例对象本身。在Java同步代码块括号中的对象称为**监听器对象**。意味着,这个同步块是基于这个监听器对象进行同步的。同步实例方法使用其所在实例对象作为监听器对象。
+
+**同一时间,只有一个线程能够访问基于同一个监听器对象的同步代码。**
+
+下面这个例子,两个同步代码都是基于同一个实例对象进行同步的:
+
+```Java
+ public class MyClass {
+
+ public synchronized void log1(String msg1, String msg2){
+ log.writeln(msg1);
+ log.writeln(msg2);
+ }
+
+
+ public void log2(String msg1, String msg2){
+ synchronized(this){
+ log.writeln(msg1);
+ log.writeln(msg2);
+ }
+ }
+ }
+```
+
+因此,在这个例子中,每次仅能有一个线程能够访问这两个同步代码的任意一个同步代码。
+
+如果第二个同步块是基于其他监听器对象,例如`synchronized (this.getClass()) {}`,则此时第一个和第二个同步代码的监听器对象分别为:当前实例对象和当前类对象。因此,这两个同步代码可以同时由不同的线程进行访问。
+
+##静态方法中的同步块(Synchronized Blocks in Static Methods)
+
+下面这个例子中,两个同步代码都是基于当前的类对象进行同步的:
+
+```Java
+ public class MyClass {
+
+ public static synchronized void log1(String msg1, String msg2){
+ log.writeln(msg1);
+ log.writeln(msg2);
+ }
+
+
+ public static void log2(String msg1, String msg2){
+ synchronized(MyClass.class){
+ log.writeln(msg1);
+ log.writeln(msg2);
+ }
+ }
+ }
+```
+
+同一时间,只有一个线程能够访问这两个同步代码的任意一个同步代码。
+
+如果第二个方法的监听器对象非MyClass.class对象,则两个同步代码可以同时被两个线程访问。
+
+
+##Java同步示例(Java Synchronized Example)
+
+Here is an example that starts 2 threads and have both of them call the add method on the same instance of Counter. Only one thread at a time will be able to call the add method on the same instance, because the method is synchronized on the instance it belongs to.
+
+```Java
+public class Counter{
+ long count = 0;
+
+ public synchronized void add(long value){
+ this.count += value;
+ }
+}
+public class CounterThread extends Thread{
+ protected Counter counter = null;
+
+ public CounterThread(Counter counter){
+ this.counter = counter;
+ }
+
+ public void run() {
+for(int i=0; i<10; i++){
+ counter.add(i);
+ }
+ }
+}
+public class Example {
+
+ public static void main(String[] args){
+ Counter counter = new Counter();
+ Thread threadA = new CounterThread(counter);
+ Thread threadB = new CounterThread(counter);
+
+ threadA.start();
+ threadB.start();
+ }
+}
+```
+
+Two threads are created. The same Counter instance is passed to both of them in their constructor. The Counter.add() method is synchronized on the instance, because the add method is an instance method, and marked as synchronized. Therefore only one of the threads can call the add() method at a time. The other thread will wait until the first thread leaves the add() method, before it can execute the method itself.
+
+If the two threads had referenced two separate Counter instances, there would have been no problems calling the add() methods simultaneously. The calls would have been to different objects, so the methods called would also be synchronized on different objects (the object owning the method). Therefore the calls would not block. Here is how that could look:
+
+```Java
+public class Example {
+ public static void main(String[] args){
+ Counter counterA = new Counter();
+ Counter counterB = new Counter();
+ Thread threadA = new CounterThread(counterA);
+ Thread threadB = new CounterThread(counterB);
+
+ threadA.start();
+ threadB.start();
+ }
+}
+```
+
+Notice how the two threads, threadA and threadB, no longer reference the same counter instance. The add method of counterA and counterB are synchronized on their two owning instances. Calling add() on counterA will thus not block a call to add() on counterB.
+
+##Java Concurrency Utilities
+
+`synchronized`机制是Java第一个引进的用于同步多线程资源共享的机制。然而`synchroniez`机制并不高效。这就是为什么Java 5提供了一整套的并发工具类,以帮助开发人员实现更细粒度的并发控制
+。
+Status API Training Shop Blog About © 2014 GitHub, Inc. Terms Privacy Security Contact
diff --git "a/Java-Concurrency/09.Java\347\232\204volatile\345\205\263\351\224\256\345\255\227.md" "b/Java-Concurrency/09.Java\347\232\204volatile\345\205\263\351\224\256\345\255\227.md"
new file mode 100644
index 0000000..4cf1bfb
--- /dev/null
+++ "b/Java-Concurrency/09.Java\347\232\204volatile\345\205\263\351\224\256\345\255\227.md"
@@ -0,0 +1,90 @@
+#09.Java的volatile关键字
+
+未完,有疑惑,待续!
+
+Java的**volatile**关键字用来标识让变量**像存储在主内存中一样** (The Java volatile keyword is used to mark a Java variable as "being stored in main memory". )。更准确地说,被volatile声明的变量,它们的读操作都是从**主内存**中而不是**CPU缓存**中读取,同时,以及它们的写操作,都会同时写到**主内存**和**CPU缓存**中。
+
+实际上,从Java 5开始,volatile关键字不仅仅只是保证变量从主内存中读取和写入。我会在接下来的章节进行详细讲解。
+
+##volatile保证变量可见性(Java volatile Guarantees Variable Visibility)
+
+Java的volatile关键字保证了**线程间变量的可见性**。这听起来似乎很抽象, 让我来解释一下。
+
+在多线程的应用程序中,当多个线程对没有volatile关键字声明的变量进行操作时,基于性能考虑,每个线程都会从主内存中拷贝一份变量的值到CPU缓存里。如果你的计算器拥有多个CPU,那么每个线程都有可能使用不同的CPU运行。这意味着,每个线程都有可能拷贝一份数据到各自的CPU缓存中。这种情况如下图所示:
+
+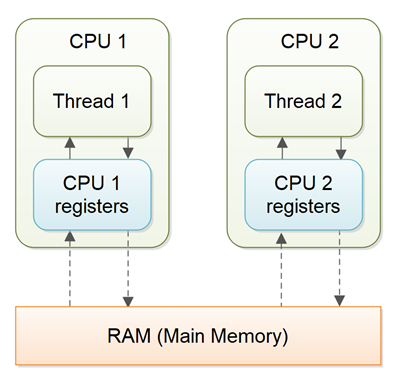
+
+没有使用volatile声明的变量,将不能保证**JVM何时从主内存中读取数据到CPU缓存,以及何时从CPU缓冲中读取数据到内存**。让我解释一下这样会发生什么状况:
+
+想象这样一个场景:多个线程访问同一个共享对象,这个对象包含一个计数器变量:
+
+```Java
+public class SharedObject {
+ public int counter = 0;
+}
+```
+
+线程1读取counter变量值0到CPU缓存,同时对该变量加1,但并不立即写回主内存。线程2同样读取主内存中的counter变量值0到自己的CPU缓存中,同样对这个值加1,也不立即写回主内存。线程1和线程2实际上并不是同步的(Thread 1 and Thread 2 are now practically out of sync. )。此时,counter的正确值应该为2,而线程1和线程2在CPU缓存的值却是1,而主内存中counter的值目前仍然是0。这种情况是十分混乱的,即使线程将CPU缓存的值写回住内存中,这个值也是错误的。
+
+如果使用**volatile**关键字声明counter变量,JVM将会保证每次读取counter的值都会从主内存中读取,每次对counter变量的修改都会立即写回到主内存。
+
+```Java
+public class SharedObject {
+ public volatile int counter = 0;
+}
+```
+
+在一些情况下,简单地用volatile声明变量,也许已经足够让多个线程每次读取的都是变量的最新值。
+
+然而,在另一些情况下,当两个线程都对变量读取和写入时,volatile并不足够。线程1读取counter的值0到CPU1的寄存器中,于此同时(或紧接着)线程2读取counter的值0到CPU2的寄存器中。两个线程都是直接从主内存中读取counter的值。然后,两个线程分别对counter的值加1,并写回主内存中。经过加1后,两个寄存器中的值都是1,并且把这个值写回主内存中。然而counter的正确值应该为2 。
+
+上述问题中,多个线程并没有读取到变量的最新值,是因为其他线程还没将寄存器的值写回主内存,这就是“** 可见性**”问题。一个线程的更新对其他线程不可见。
+
+In some cases simply declaring a variable volatile may be enough to assure that multiple threads accessing the variable see the latest written value. I will get back to which cases volatile is sufficient later.
+
+In the situation with the two threads reading and writing the same variable, simply declaring the variable volatile is not enough. Thread 1 may read the counter value 0 into a CPU register in CPU 1. At the same time (or right after) Thread 2 may read the counter value 0 into a CPU register in CPU 2. Both threads have read the value directly from main memory. Now both variables increase the value and writes the value back to main memory. They both increment their register version of counter to 1, and both write the value 1 back to main memory. The value should have been 2 after two increments.
+
+The problem with multiple threads that do not see the latest value of a variable because that value has not yet been written back to main memory by another thread, is called a "visibility" problem. The updates of one thread are not visible to other threads.
+
+##valatile的保证(The Java volatile Guarantee)
+
+从Java 5之后,volatile关键字不仅仅只是保证每次都是从主内存中读取和写入数据。实际上volatile关键字保证:
+
+> If Thread A writes to a volatile variable and Thread B subsequently reads the same volatile variable, then all variables visible to Thread A before writing the volatile variable, will also be visible to Thread B.
+
+The reading and writing instructions of volatile variables cannot be reordered by the JVM (the JVM may reorder instructions for performance reasons as long as the JVM detects no change in program behaviour from the reordering). Instructions before and after can be reordered, but the volatile read or write cannot be mixed with these instructions. Whatever instructions follow a read or write of a volatile variable are guaranteed to happen after the read or write.
+Look at this example:
+
+```Java
+Thread A:
+ sharedObject.nonVolatile = 123;
+ sharedObject.counter = sharedObject.counter + 1;
+
+Thread B:
+ int counter = sharedObject.counter;
+ int nonVolatile = sharedObject.nonVolatile;
+```
+
+Since Thread A writes the non-volatile variable sharedObject.nonVolatile before writing to the volatile sharedObject.counter, then both sharedObject.nonVolatile and sharedObject.counter are written to main memory.
+
+Since Thread B starts by reading the volatile sharedObject.counter, then both the sharedObject.counter and sharedObject.nonVolatile are read in from main memory.
+
+The reading and writing of the non-volatile variable cannot be reordered to happen before or after the reading and writing of the volatile variable.
+
+##volatile足够了吗?(When is volatile Enough?)
+
+正如前面我所提到的,当两个线程都对共享变量进行读取和写入时,使用volatile关键字是不足够的。你需要
+对变量的读取和写入进行同步,保证这些操作都是原子性的。
+
+当如果只有一个线程对变量进行读取和写入,而其它线程都只对变量进行读取,那么就可以保证读线程每次读到的都是volatile变量的最新值。如果没有volatile关键字,这些都是不可以保证的。
+
+As I have mentioned earlier, if two threads are both reading and writing to a shared variable, then using the volatile keyword for that is not enough. You need to use synchronization in that case to guarantee that the reading and writing of the variable is atomic.
+
+But in case one thread reads and writes the value of a volatile variable, and other threads only read the variable, then the reading threads are guaranteed to see the latest value written to the volatile variable. Without making the variable volatile, this would not be guaranteed.
+
+##volatile的性能考虑(Performance Considerations of volatile)
+
+volatile关键字保证变量的读取和写入都会在主内存中进行。相比从CPU缓存中读取和写入数据,在主内存中读取和写入数据是相对比较消耗性能的。volatile关键字会阻止指令重排(指令重排是很常见的用于增强性能的技术)。因此,只有当真正需要让变量强制可见时才使用volatile关键字。
+
+Reading and writing of volatile variables causes the variable to be read or written to main memory. Reading from and writing to main memory is more expensive than accessing the CPU cache. Accessing volatile variables also prevent instruction reordering which is anormal performance enhancement techqniqe. Thus, you should only use volatile variables when you really need to enforce visibility of variables.
+
diff --git "a/Java-Concurrency/10.\347\272\277\347\250\213\351\200\232\344\277\241.md" "b/Java-Concurrency/10.\347\272\277\347\250\213\351\200\232\344\277\241.md"
new file mode 100644
index 0000000..5d4878d
--- /dev/null
+++ "b/Java-Concurrency/10.\347\272\277\347\250\213\351\200\232\344\277\241.md"
@@ -0,0 +1,208 @@
+#10.线程通信
+
+线程通信的目的在于:让线程之间可以彼此发送信号。因此,线程通信也让线程等待其他线程发送的信号。举个例子,线程B等待线程A的信号,这个信号用于通知线程B数据已经准备就绪。
+
+##通过共享对象通信(Signaling via Shared Objects)
+
+线程间进行通信,一个简单的做法就是**通过共享对象存储信号值**。线程A在同步代码块中将`hasDataToProcess`的值设为`true`,然后线程B在同步代码块中读取`hasDataToProcess`的值,这就完成了一次线程通信。下面的这个示例MySignal类用于保存信号值,并提供方法获取这个信号值:
+
+```Java
+public class MySignal{
+ protected boolean hasDataToProcess = false;
+
+ public synchronized boolean hasDataToProcess(){
+ return this.hasDataToProcess;
+ }
+
+ public synchronized void setHasDataToProcess(boolean hasData){
+ this.hasDataToProcess = hasData;
+ }
+}
+```
+
+为了进行通信,线程A和线程B必须拥有共享的MySignal的实例对象的引用。如果线程A和线程B拥有的是不同的MySignal实例引用,它们将不会检测到彼此的信号。The data to be processed can be located in a shared buffer separate from the MySignal instance.
+
+##忙等待(Busy Wait)
+
+
+线程B等待数据可用,然后对数据进行处理。换言之,线程B等待线程A发送的信号量,通过检测`hasDataToProcess() `的返回值,如果返回值为true,则证明此时数据准备就绪。下面的循环用于检测信号:
+
+```Java
+protected MySignal sharedSignal = ...
+
+while(!sharedSignal.hasDataToProcess()){
+ //do nothing... busy waiting
+}
+```
+
+注意这个while循环直至`hasDataToProcess() `返回`true`才退出,这种做法称为**忙等待(Busy Waiting)**。线程在等待过程中一直处于忙碌状态。
+
+
+##wait(), notify()和notifyAll()
+
+忙等待对计算机的CPU利用率并不友好,除非平均等待时间十分短暂。更好的做法是,让等待的线程处于休眠状态或非活动状态直至它收到信号。
+
+Java内置了等待机制可以让线程处于非活动状态直至收到信号。`java.lang.Object`中定义了三个方法:**wait()**,**notify()**和**notifyAll**用来实现这个机制。
+
+在线程内部调用任意对象的`wait()`会使该线程变成暂停状态,直到其他线程调用同一个对象的`notify()`或`notifyAll()`方法。如果想要调用对象的wait()/notify()方法,线程先必须取的该对象的同步锁。换言之,**wait()和notify()方法的调用必须在同步代码内部**。上面例子的wait()/notify()版本:
+
+```Java
+public class MonitorObject{
+}
+
+public class MyWaitNotify{
+
+ MonitorObject myMonitorObject = new MonitorObject();
+
+ public void doWait(){
+ synchronized(myMonitorObject){
+ try{
+ myMonitorObject.wait();
+ } catch(InterruptedException e){...}
+ }
+ }
+
+ public void doNotify(){
+ synchronized(myMonitorObject){
+ myMonitorObject.notify();
+ }
+ }
+}
+```
+
+等待通知的线程调用`doWait()`方法,而通知线程调用`doNotify()`方法。当一个线程调用一个对象的`notify()`方法后,等待这个对象的其中一个线程就被唤醒并执行。与`notify()`方法不同的是,`notifyAll()`会唤醒所有等待这个对象的线程。
+
+正如你所看到的,`wait()`和`notify()`的调用都在同步块中。这是强制性的要求。如果线程没有拥有对象的锁,则不能调用该对象的`wait()`,`notify()`和`notifyAll()`方法,否则将会抛出`IlleageMonitorStateException` 异常。
+
+But, how is this possible? Wouldn't the waiting thread keep the lock on the monitor object (myMonitorObject) as long as it is executing inside a synchronized block? Will the waiting thread not block the notifying thread from ever entering the synchronized block in doNotify()? The answer is no. Once a thread calls wait() it releases the lock it holds on the monitor object. This allows other threads to call wait() or notify() too, since these methods must be called from inside a synchronized block.
+
+当一个等待的线程被唤醒之后并不会立即离开`wait()`方法直至调用`notify()`方法的线程退出代码块。换言之,因为`wait()`方法嵌套在同步代码块内部,所以被唤醒的线程需要重新获得模拟器对象的锁才能够离开`wait()`方法。如果有多个线程通过`notifyAll()`方法被唤醒,同一时间也只能有一个线程能够离开`wait()`方法并重新进入同步代码块,因为每一个线程都必须先获得模拟器对象的锁才能够离开`wait()`方法。
+
+##信号丢失(Missed Signals)
+
+The methods notify() and notifyAll() do not save the method calls to them in case no threads are waiting when they are called. The notify signal is then just lost. Therefore, if a thread calls notify() before the thread to signal has called wait(), the signal will be missed by the waiting thread. This may or may not be a problem, but in some cases this may result in the waiting thread waiting forever, never waking up, because the signal to wake up was missed.
+
+该方法的通知()和notifyAll()不救的方法调用它们的情况下没有线程在等待的时候,他们被称为。该通知信号然后就失去了。因此,如果一个线程调用notify()的线程之前,信号调用wait()时,信号将被等待的线程被错过。这可能会或可能不会成为问题,但在某些情况下,这可能会导致等待线程永远等待,从未苏醒,因为该信号被错过醒来。
+
+To avoid losing signals they should be stored inside the signal class. In the MyWaitNotify example the notify signal should be stored in a member variable inside the MyWaitNotify instance. Here is a modified version of MyWaitNotify that does this:
+
+```Java
+public class MyWaitNotify2{
+
+ MonitorObject myMonitorObject = new MonitorObject();
+ boolean wasSignalled = false;
+
+ public void doWait(){
+ synchronized(myMonitorObject){
+ if(!wasSignalled){
+ try{
+ myMonitorObject.wait();
+ } catch(InterruptedException e){...}
+ }
+ //clear signal and continue running.
+ wasSignalled = false;
+ }
+ }
+
+ public void doNotify(){
+ synchronized(myMonitorObject){
+ wasSignalled = true;
+ myMonitorObject.notify();
+ }
+ }
+}
+```
+
+Notice how the doNotify() method now sets the wasSignalled variable to true before calling notify(). Also, notice how the doWait() method now checks the wasSignalled variable before calling wait(). In fact it only calls wait() if no signal was received in between the previous doWait() call and this.
+
+##假唤醒(Spurious Wakeups)
+
+For inexplicable reasons it is possible for threads to wake up even if notify() and notifyAll() has not been called. This is known as spurious wakeups. Wakeups without any reason.
+
+If a spurious wakeup occurs in the MyWaitNofity2 class's doWait() method the waiting thread may continue processing without having received a proper signal to do so! This could cause serious problems in your application.
+
+To guard against spurious wakeups the signal member variable is checked inside a while loop instead of inside an if-statement. Such a while loop is also called a spin lock. The thread awakened spins around until the condition in the spin lock (while loop) becomes false. Here is a modified version of MyWaitNotify2 that shows this:
+
+```Java
+public class MyWaitNotify3{
+
+ MonitorObject myMonitorObject = new MonitorObject();
+ boolean wasSignalled = false;
+
+ public void doWait(){
+ synchronized(myMonitorObject){
+ while(!wasSignalled){
+ try{
+ myMonitorObject.wait();
+ } catch(InterruptedException e){...}
+ }
+ //clear signal and continue running.
+ wasSignalled = false;
+ }
+ }
+
+ public void doNotify(){
+ synchronized(myMonitorObject){
+ wasSignalled = true;
+ myMonitorObject.notify();
+ }
+ }
+}
+```
+
+Notice how the wait() call is now nested inside a while loop instead of an if-statement. If the waiting thread wakes up without having received a signal, the wasSignalled member will still be false, and the while loop will execute once more, causing the awakened thread to go back to waiting.
+
+##Multiple Threads Waiting for the Same Signals
+
+The while loop is also a nice solution if you have multiple threads waiting, which are all awakened using notifyAll(), but only one of them should be allowed to continue. Only one thread at a time will be able to obtain the lock on the monitor object, meaning only one thread can exit the wait() call and clear the wasSignalled flag. Once this thread then exits the synchronized block in the doWait() method, the other threads can exit the wait() call and check the wasSignalled member variable inside the while loop. However, this flag was cleared by the first thread waking up, so the rest of the awakened threads go back to waiting, until the next signal arrives.
+
+
+##Don't call wait() on constant String's or global objects
+
+An earlier version of this text had an edition of the MyWaitNotify example class which used a constant string ( "" ) as monitor object. Here is how that example looked:
+
+```Java
+public class MyWaitNotify{
+
+ String myMonitorObject = "";
+ boolean wasSignalled = false;
+
+ public void doWait(){
+ synchronized(myMonitorObject){
+ while(!wasSignalled){
+ try{
+ myMonitorObject.wait();
+ } catch(InterruptedException e){...}
+ }
+ //clear signal and continue running.
+ wasSignalled = false;
+ }
+ }
+
+ public void doNotify(){
+ synchronized(myMonitorObject){
+ wasSignalled = true;
+ myMonitorObject.notify();
+ }
+ }
+}
+```
+
+The problem with calling wait() and notify() on the empty string, or any other constant string is, that the JVM/Compiler internally translates constant strings into the same object. That means, that even if you have two different MyWaitNotify instances, they both reference the same empty string instance. This also means that threads calling doWait() on the first MyWaitNotify instance risk being awakened by doNotify() calls on the second MyWaitNotify instance.
+
+The situation is sketched in the diagram below:
+
+
+
+Calling wait()/notify() on string constants
+Remember, that even if the 4 threads call wait() and notify() on the same shared string instance, the signals from the doWait() and doNotify() calls are stored individually in the two MyWaitNotify instances. A doNotify() call on the MyWaitNotify 1 may wake threads waiting in MyWaitNotify 2, but the signal will only be stored in MyWaitNotify 1.
+
+At first this may not seem like a big problem. After all, if doNotify() is called on the second MyWaitNotify instance all that can really happen is that Thread A and B are awakened by mistake. This awakened thread (A or B) will check its signal in the while loop, and go back to waiting because doNotify() was not called on the first MyWaitNotify instance, in which they are waiting. This situation is equal to a provoked spurious wakeup. Thread A or B awakens without having been signaled. But the code can handle this, so the threads go back to waiting.
+
+The problem is, that since the doNotify() call only calls notify() and not notifyAll(), only one thread is awakened even if 4 threads are waiting on the same string instance (the empty string). So, if one of the threads A or B is awakened when really the signal was for C or D, the awakened thread (A or B) will check its signal, see that no signal was received, and go back to waiting. Neither C or D wakes up to check the signal they had actually received, so the signal is missed. This situation is equal to the missed signals problem described earlier. C and D were sent a signal but fail to respond to it.
+
+If the doNotify() method had called notifyAll() instead of notify(), all waiting threads had been awakened and checked for signals in turn. Thread A and B would have gone back to waiting, but one of either C or D would have noticed the signal and left the doWait() method call. The other of C and D would go back to waiting, because the thread discovering the signal clears it on the way out of doWait().
+
+You may be tempted then to always call notifyAll() instead notify(), but this is a bad idea performance wise. There is no reason to wake up all threads waiting when only one of them can respond to the signal.
+
+So: Don't use global objects, string constants etc. for wait() / notify() mechanisms. Use an object that is unique to the construct using it. For instance, each MyWaitNotify3 (example from earlier sections) instance has its own MonitorObject instance rather than using the empty string for wait() / notify() calls.
diff --git "a/Java-Concurrency/11.\346\255\273\351\224\201.md" "b/Java-Concurrency/11.\346\255\273\351\224\201.md"
new file mode 100644
index 0000000..6d5e624
--- /dev/null
+++ "b/Java-Concurrency/11.\346\255\273\351\224\201.md"
@@ -0,0 +1,96 @@
+#11.死锁
+
+死锁是指两个或多个线程等待其他处于死锁状态的线程所持有的锁。死锁通常发生在多个线程同时但以不同的顺序请求同一组锁的时候。
+
+例如,如果线程1持有锁A,但试图去获取锁B,而此时线程1持有锁B,却试图去获取锁A,这时死锁就发生了。线程1永远得不到锁B,线程2也永远得不到线程A,并且它们永远也不知道发生了什么事。为了获得彼此所持有的锁,它们将永远阻塞下去。这种情况就是一个死锁。
+
+这种情况描述如下:
+
+```
+Thread 1 locks A, waits for B
+Thread 2 locks B, waits for A
+```
+
+这里有一个TreeNode类的例子,它调用了不同实例的synchronized方法:
+
+```Java
+public class TreeNode {
+ TreeNode parent = null;
+ List children = new ArrayList();
+
+ public synchronized void addChild(TreeNode child){
+ if(!this.children.contains(child)) {
+ this.children.add(child);
+ child.setParentOnly(this);
+ }
+ }
+
+ public synchronized void addChildOnly(TreeNode child){
+ if(!this.children.contains(child){
+ this.children.add(child);
+ }
+ }
+
+ public synchronized void setParent(TreeNode parent){
+ this.parent = parent;
+ parent.addChildOnly(this);
+ }
+
+ public synchronized void setParentOnly(TreeNode parent){
+ this.parent = parent;
+ }
+}
+```
+
+ 如果线程1调用`parent.addChild(child)`方法,而与此同时线程2调用`child.setParent(parent)`方法,两个线程中的parent和child都是同一个对象实例,此时死锁就发生了。
+
+下面的伪代码说明了这个过程:
+
+```
+Thread 1: parent.addChild(child); //locks parent
+ --> child.setParentOnly(parent);
+
+Thread 2: child.setParent(parent); //locks child
+ --> parent.addChildOnly()
+```
+
+首先线程1调用`parent.addChild(child)`方法,由于这个方法是同步的,所以线程1锁住了parent对象以防止其他线程访问。
+
+然后线程2调用`child.setParent(parent)`方法,由于这个方法的同步的,所以线程2锁住了child对象以防止其他线程访问。
+
+现在parent对象和child对象都分别被线程1和线程2锁住了。下一步,线程1试图调用`child.setParentOnly()`方法,但child方法已经被线程2锁住,所以这个方法会阻塞。线程2也试图调用`parent.addChildOnly()`方法,但parent对象此时已被线程1锁住,所以这个方法也会阻塞。现在两个线程都试图获取对方所持有的锁而进入阻塞状态。
+
+注意:两个线程必须同时调用`parent.addChild(child)`和`child.setParent(parent)`方法,而且并需是在同一个parent和child对象上,死锁才有可能发生。上面的代码可能要运行一段时间才可能出现死锁。
+
+这两个线程必须要同时获得锁。举个例子,如果线程1稍微先与线程2获得A和B的锁,这时线程2在试图获取B的锁时就会阻塞,这时不会产生死锁。由于线程的调度不可预测,所以我们无法预测什么时候会产生死锁,仅仅是可能会发生。
+
+##更加复杂的死锁(More Complicated Deadlocks)
+
+死锁的发生可能由多于两个线程造成,在这种情况下,很难对死锁进行检测。下面的例子演示了多个线程造成的死锁:
+
+```
+Thread 1 locks A, waits for B
+Thread 2 locks B, waits for C
+Thread 3 locks C, waits for D
+Thread 4 locks D, waits for A
+```
+
+线程1等待线程2,线程2等待线程3,线程3等待线程4,而线程4等待线程1.
+Thread 1 waits for thread 2, thread 2 waits for thread 3, thread 3 waits for thread 4, and thread 4 waits for thread 1.
+
+##数据库死锁(Database Deadlocks)
+
+更加复杂的死锁场景发生在数据库中。一个数据库事务通常包含多条SQL更新请求。当一条记录被事务更新时,这条记录就会被这个事务锁住,以防止其他事务更新,直到当前事务结束。同一个事务中的多个更新语句都有可能需要锁住一些记录。
+
+当多个事务同时需要对一些相同的记录做更新操作时,就很有可能发生死锁,例如:
+
+举个例子:
+
+```
+Transaction 1, request 1, locks record 1 for update
+Transaction 2, request 1, locks record 2 for update
+Transaction 1, request 2, tries to lock record 2 for update.
+Transaction 2, request 2, tries to lock record 1 for update.
+```
+
+因为锁发生在不同的请求中,并且对于一个事务来说不可能提前知道所有它需要的锁,因此很难检测和避免数据库事务中的死锁。
diff --git "a/Java-Concurrency/12.\351\242\204\351\230\262\346\255\273\351\224\201.md" "b/Java-Concurrency/12.\351\242\204\351\230\262\346\255\273\351\224\201.md"
new file mode 100644
index 0000000..0c6b61d
--- /dev/null
+++ "b/Java-Concurrency/12.\351\242\204\351\230\262\346\255\273\351\224\201.md"
@@ -0,0 +1,91 @@
+#12.预防死锁
+
+在某些情况,死锁是可以预防的。下面介绍三种可以预防死锁的技术:
+
+* 加锁顺序
+* 加锁超时
+* 死锁检测
+
+
+##加锁顺序(Lock Ordering)
+
+当多个线程需要相同的锁,但以不同的顺序获取锁时,这时死锁就很容易发生。
+
+如果所有的锁都是按照相同的顺序获取,那么死锁是不会出现的。看下下面的例子:
+
+```
+Thread 1:
+
+ lock A
+ lock B
+---------------------
+Thread 2:
+
+ wait for A
+ lock C (when A locked)
+---------------------
+Thread 3:
+
+ wait for A
+ wait for B
+ wait for C
+```
+
+如果一个线程,例如线程3,需要一些锁,那么她必须按照一定的顺序获取锁。只有按照顺序获取前面的锁,才能够依次获取后面的锁。
+
+例如,线程2和线程3,只有当它们获得锁A后才能够去尝试获取锁C。由于线程1持有锁A,线程2和线程3都会阻塞直至锁A被线程1释放。
+
+顺序加锁是一个非常有效的用于预防死锁的机制。然而,它只有预先知道所有的加锁顺序时才能很好的地工作,它并不适用于所有情况。(However, it can only be used if you know about all locks needed ahead of taking any of the locks. This is not always the case.)
+
+
+##加锁超时(Lock Timeout)
+
+另一种预防死锁的机制就是试图获取锁时设置超时。如果线程在规定时间内没有获得锁,则会放弃,并释放自身锁持有的锁,等待一个随机时间,然后重试。在随机等待时间内,给予其他线程获取相同的锁,从而避免死锁发生。
+
+下面是两个线程尝试以不同的顺序获取两个锁,在超时回退后进行重试的例子:
+
+```
+Thread 1 locks A
+Thread 2 locks B
+
+Thread 1 attempts to lock B but is blocked
+Thread 2 attempts to lock A but is blocked
+
+Thread 1's lock attempt on B times out
+Thread 1 backs up and releases A as well
+Thread 1 waits randomly (e.g. 257 millis) before retrying.
+
+Thread 2's lock attempt on A times out
+Thread 2 backs up and releases B as well
+Thread 2 waits randomly (e.g. 43 millis) before retrying.
+```
+
+在上面的例子中,线程2比线程1早大约200ms进行重新加锁,因此很有可能可以取到全部的锁。线程1尝试获取锁A,由于2持有所有A,所以线程1进入等待状态。当线程2执行完释放所有的锁,线程1就可以持有所有的锁了。(除非有其他线程也在争夺锁A和锁B)
+
+有个问题需要注意的就是,如果出现了加锁超时,并不意味着出现了死锁。加锁超时可能是因为某个持有锁的线程需要大量的时间来执行任务。
+
+另外,如果有大量的线程去争夺相同的资源,即使有加锁超时和重试机制,也有可能会导致线程不停地重试但却无法获取所需的锁。如果只有两个线程,且重试时间在0-500ms之间,也许死锁不会发生。但如果线程在10-20之间情况则有可能不同,因为这些线程中的超时重试时间很大概率生是相同或相近的。
+
+加锁超时机制的一个缺点是:Java并不提供进入synchronized块的超时设置。你可以自定义锁或使用Java 5提供的在`java.util.concurrency`包中的工具类。自定义锁并不困难,但是超出了本文的内容。后面的教程会做详细讲解。
+
+##死锁检测(Deadlock Detection)
+
+Deadlock detection is a heavier deadlock prevention mechanism aimed at cases in which lock ordering isn't possible, and lock timeout isn't feasible.
+
+Every time a thread takes a lock it is noted in a data structure (map, graph etc.) of threads and locks. Additionally, whenever a thread requests a lock this is also noted in this data structure.
+
+When a thread requests a lock but the request is denied, the thread can traverse the lock graph to check for deadlocks. For instance, if a Thread A requests lock 7, but lock 7 is held by Thread B, then Thread A can check if Thread B has requested any of the locks Thread A holds (if any). If Thread B has requested so, a deadlock has occurred (Thread A having taken lock 1, requesting lock 7, Thread B having taken lock 7, requesting lock 1).
+
+Of course a deadlock scenario may be a lot more complicated than two threads holding each others locks. Thread A may wait for Thread B, Thread B waits for Thread C, Thread C waits for Thread D, and Thread D waits for Thread A. In order for Thread A to detect a deadlock it must transitively examine all requested locks by Thread B. From Thread B's requested locks Thread A will get to Thread C, and then to Thread D, from which it finds one of the locks Thread A itself is holding. Then it knows a deadlock has occurred.
+
+Below is a graph of locks taken and requested by 4 threads (A, B, C and D). A data structure like this that can be used to detect deadlocks.
+
+Deadlock Detection Data Structure
+
+
+
+So what do the threads do if a deadlock is detected?
+
+One possible action is to release all locks, backup, wait a random amount of time and then retry. This is similar to the simpler lock timeout mechanism except threads only backup when a deadlock has actually occurred. Not just because their lock requests timed out. However, if a lot of threads are competing for the same locks they may repeatedly end up in a deadlock even if they back up and wait.
+
+A better option is to determine or assign a priority of the threads so that only one (or a few) thread backs up. The rest of the threads continue taking the locks they need as if no deadlock had occurred. If the priority assigned to the threads is fixed, the same threads will always be given higher priority. To avoid this you may assign the priority randomly whenever a deadlock is detected.
diff --git "a/Java-Concurrency/13.\351\245\245\351\245\277\345\222\214\345\205\254\345\271\263.md" "b/Java-Concurrency/13.\351\245\245\351\245\277\345\222\214\345\205\254\345\271\263.md"
new file mode 100644
index 0000000..62c3b95
--- /dev/null
+++ "b/Java-Concurrency/13.\351\245\245\351\245\277\345\222\214\345\205\254\345\271\263.md"
@@ -0,0 +1,193 @@
+#13.饥饿和公平(Starvation and Fairness)
+
+如果一个线程由于CPU时间全部被其他线程抢占而得不到CPU时间,这就称为**饥饿(Starvation)**。这个线程因为得不到CPU机会而“饿死(starved to death)"。解决饥饿的方案称为**公平(Fairness)**--所有的线程都能公平地获得CPU时间。
+
+##Java中产生饥饿的原因
+
+在Java中,下面三种常见原因会导致饥饿:
+
+* 高优先级的线程抢占了所有的CPU时间。
+* 线程陷入无止境地等待进入同步块状态,因为其他线程总是能够在它之前获得进入同步块的机会。
+* 线程陷入无止境地等待被唤醒(调用了对象的wait()方法)状态,因为其他线程总能够持续获得唤醒机会而不是这个线程。
+
+###高优先级线程抢占了所有的CPU时间
+
+你可以为每个线程设置优先级。高优先级的线程能够获得更多的CPU时间。优先级可以设置为1-10之间。这些优先级值的解释根据操作系统的差异而有所不同。对于大部分应用程式来说,你最好不要改变其优先级值。
+
+###线程陷入无止境地等待进入同步块状态
+
+Java同步代码块是另一个能够导致饥饿的原因。Java同步代码块不能够保证进入同步块线程的顺序。这意味着,理论上存在可以陷入无限等待进入同步块的线程。线程会因为得不到任何CPU机会而饿死。
+
+### 线程陷入无止境地等待被唤醒(调用了对象的wait()方法)状态,
+
+如果多个线程都调用了同一个对象的`wait()`方法而,当一个线程调用这个对象的`notify()`方法后,并不能确定哪个调用了`wait()`方法的线程能够被唤醒。它可以是这些线程的任意一个。如果一个线程由于唤醒机会被其他线程抢占而一直无法被唤醒,这是非常危险的。
+
+##在Java中的公平性实现(Implementing Fairness in Java)
+
+虽然在Java中实现100%的公平是不可能,但是我们仍然能够通过同步结构提高线程的公平性。
+
+我们学习一下同步代码块:
+
+```Java
+public class Synchronizer{
+
+ public synchronized void doSynchronized(){
+ //do a lot of work which takes a long time
+ }
+
+}
+```
+
+如果有多个线程调用`doSynchroinized()`方法,有一个线程会进入同步代码块,而剩余的则会阻塞直到第一个线程离开同步代码块。在多个线程阻塞的时候,我们并不知道哪个线程会成为下一个进入同步代码块的线程。
+
+##使用Locks代替Synchronized块(Using Locks Instead of Synchronized Blocks)
+
+为了提高线程的公平性,我们可以使用Locks来代替Synchronized块:
+
+```Java
+public class Synchronizer{
+ Lock lock = new Lock();
+
+ public void doSynchronized() throws InterruptedException{
+ this.lock.lock();
+ //critical section, do a lot of work which takes a long time
+ this.lock.unlock();
+ }
+
+}
+```
+
+注意这里并没有使用**synchronized** 关键字声明方法。取而代之,我们使用`lock.lock()`和`lock.unlock()`来包裹临界区。
+
+下面是一个Lock类的简单实现:
+
+```Java
+public class Lock{
+ private boolean isLocked = false;
+ private Thread lockingThread = null;
+
+ public synchronized void lock() throws InterruptedException{
+ while(isLocked){
+ wait();
+ }
+ isLocked = true;
+ lockingThread = Thread.currentThread();
+ }
+
+ public synchronized void unlock(){
+ if(this.lockingThread != Thread.currentThread()){
+ throw new IllegalMonitorStateException(
+ "Calling thread has not locked this lock");
+ }
+ isLocked = false;
+ lockingThread = null;
+ notify();
+ }
+}
+```
+看下Synchronizer类和lock类,当多个线程同时调用`lock()` 方法时,只有一个线程能够进入`lock()`方法,其余的会阻塞在`lock()`方法上。然后,如果isLocked的值为true,则该线程会进入while循环内部,调用`wait()`方法并释放当前对象的锁,阻塞在同步块的其中一个线程会进入同步块。结果就是,阻塞在`lock()`方法上的线程依次进入同步块并调用`wait()`方法。
+
+再看下Synchronized类的`doSynchronized()`方法,你会发现`lock()`方法与`unlock()`方法之间的注释,这之间的代码会执行相当长的一段时间。让我们假设这段代码相比进入`lock()`方法和调用`wait()`方法会执行相当长一段时间。这意味着大部分时间用在等待进入锁和进入临界区的过程是用在wait()的等待中,而不是被阻塞在试图进入lock()方法中。
+
+(If you look back at the doSynchronized() method you will notice that the comment between lock() and unlock() states, that the code in between these two calls take a "long" time to execute. Let us further assume that this code takes long time to execute compared to entering the lock() method and calling wait() because the lock is locked. This means that the majority of the time waited to be able to lock the lock and enter the critical section is spent waiting in the wait() call inside the lock() method, not being blocked trying to enter the lock() method.)
+
+在早些时候提到过,同步块不会对等待进入的多个线程谁能获得访问做任何保障,同样当调用notify()时,wait()也不会做保障一定能唤醒线程(至于为什么,请看线程通信)。因此这个版本的Lock类和doSynchronized()那个版本就保障公平性而言,没有任何区别。
+
+(As stated earlier synchronized blocks makes no guarantees about what thread is being granted access if more than one thread is waiting to enter. Nor does wait() make any guarantees about what thread is awakened when notify() is called. So, the current version of the Lock class makes no different guarantees with respect to fairness than synchronized version of doSynchronized(). But we can change that.)
+
+但我们能改变这种情况。当前的Lock类版本调用自己的wait()方法,如果每个线程在不同的对象上调用wait(),那么只有一个线程会在该对象上调用wait(),Lock类可以决定哪个对象能对其调用notify(),因此能做到有效的选择唤醒哪个线程。
+
+(The current version of the Lock class calls its own wait() method. If instead each thread calls wait() on a separate object, so that only one thread has called wait() on each object, the Lock class can decide which of these objects to call notify() on, thereby effectively selecting exactly what thread to awaken.)
+
+##公平锁(A Fair Lock)
+
+Below is shown the previous Lock class turned into a fair lock called FairLock. You will notice that the implementation has changed a bit with respect to synchronization and wait() / notify() compared to the Lock class shown earlier.
+
+Exactly how I arrived at this design beginning from the previous Lock class is a longer story involving several incremental design steps, each fixing the problem of the previous step: Nested Monitor Lockout, Slipped Conditions, and Missed Signals. That discussion is left out of this text to keep the text short, but each of the steps are discussed in the appropriate texts on the topic ( see the links above). What is important is, that every thread calling lock() is now queued, and only the first thread in the queue is allowed to lock the FairLock instance, if it is unlocked. All other threads are parked waiting until they reach the top of the queue.
+
+如下图所示先前的锁类变成一个公平的锁叫FairLock。你会发现,实施已经改变了一下关于同步和wait()有/通知()相比前面介绍的锁类。
+
+究竟我是怎么来到这个设计从以前的锁类开始是一个较长的故事,涉及多个增量的设计步骤,每个固定的上一步的问题:嵌套监控锁定,溜条件和未接信号。这种讨论留出这段文字保存在文本短,但是每个步骤都是在这个专题的相应文本(见上面的链接)进行讨论。最重要的是,每一个线程调用lock()现在是排队的,只有在队列中的第一个线程被允许锁定FairLock举例来说,如果它被解锁。所有其他线程都停在等待,直到它们到达队列的顶部。
+
+
+```
+public class FairLock {
+ private boolean isLocked = false;
+ private Thread lockingThread = null;
+ private List waitingThreads =
+ new ArrayList();
+
+ public void lock() throws InterruptedException{
+ QueueObject queueObject = new QueueObject();
+ boolean isLockedForThisThread = true;
+ synchronized(this){
+ waitingThreads.add(queueObject);
+ }
+
+ while(isLockedForThisThread){
+ synchronized(this){
+ isLockedForThisThread =
+ isLocked || waitingThreads.get(0) != queueObject;
+ if(!isLockedForThisThread){
+ isLocked = true;
+ waitingThreads.remove(queueObject);
+ lockingThread = Thread.currentThread();
+ return;
+ }
+ }
+ try{
+ queueObject.doWait();
+ }catch(InterruptedException e){
+ synchronized(this) { waitingThreads.remove(queueObject); }
+ throw e;
+ }
+ }
+ }
+
+ public synchronized void unlock(){
+ if(this.lockingThread != Thread.currentThread()){
+ throw new IllegalMonitorStateException(
+ "Calling thread has not locked this lock");
+ }
+ isLocked = false;
+ lockingThread = null;
+ if(waitingThreads.size() > 0){
+ waitingThreads.get(0).doNotify();
+ }
+ }
+}
+public class QueueObject {
+
+ private boolean isNotified = false;
+
+ public synchronized void doWait() throws InterruptedException {
+ while(!isNotified){
+ this.wait();
+ }
+ this.isNotified = false;
+ }
+
+ public synchronized void doNotify() {
+ this.isNotified = true;
+ this.notify();
+ }
+
+ public boolean equals(Object o) {
+ return this == o;
+ }
+}
+```
+
+First you might notice that the lock() method is no longer declared synchronized. Instead only the blocks necessary to synchronize are nested inside synchronized blocks.
+
+FairLock creates a new instance of QueueObject and enqueue it for each thread calling lock(). The thread calling unlock() will take the top QueueObject in the queue and call doNotify() on it, to awaken the thread waiting on that object. This way only one waiting thread is awakened at a time, rather than all waiting threads. This part is what governs the fairness of the FairLock.
+
+Notice how the state of the lock is still tested and set within the same synchronized block to avoid slipped conditions.
+
+Also notice that the QueueObject is really a semaphore. The doWait() and doNotify() methods store the signal internally in the QueueObject. This is done to avoid missed signals caused by a thread being preempted just before calling queueObject.doWait(), by another thread which calls unlock() and thereby queueObject.doNotify(). The queueObject.doWait() call is placed outside the synchronized(this) block to avoid nested monitor lockout, so another thread can actually call unlock() when no thread is executing inside the synchronized(this) block in lock() method.
+
+Finally, notice how the queueObject.doWait() is called inside a try - catch block. In case an InterruptedException is thrown the thread leaves the lock() method, and we need to dequeue it.
+
+##性能(A Note on Performance)
+
+If you compare the Lock and FairLock classes you will notice that there is somewhat more going on inside the lock() and unlock() in the FairLock class. This extra code will cause the FairLock to be a sligtly slower synchronization mechanism than Lock. How much impact this will have on your application depends on how long time the code in the critical section guarded by the FairLock takes to execute. The longer this takes to execute, the less significant the added overhead of the synchronizer is. It does of course also depend on how often this code is called.
diff --git "a/Java-Concurrency/14.\345\265\214\345\245\227\347\256\241\347\250\213\351\224\201\346\255\273.md" "b/Java-Concurrency/14.\345\265\214\345\245\227\347\256\241\347\250\213\351\224\201\346\255\273.md"
new file mode 100644
index 0000000..8752fdd
--- /dev/null
+++ "b/Java-Concurrency/14.\345\265\214\345\245\227\347\256\241\347\250\213\351\224\201\346\255\273.md"
@@ -0,0 +1,133 @@
+#14.嵌套管程锁死(Nested Monitor Lockout)
+
+##嵌套管程锁死如何发生
+
+嵌套管程锁死类似与死锁。它发生的情况类似这样:
+Nested monitor lockout is a problem similar to deadlock. A nested monitor lockout occurs like this:
+
+```
+线程1 获得对象A的锁
+线程1 获得对象B的锁(同时持有对象A的锁)
+线程1 决定等待另一个线程的信号再继续
+线程1 调用B.wait()方法释放对象B的锁,当仍然拥有对象A的锁
+
+线程2 需要依次获得对象A和对象B的锁
+线程2 由于对象A的锁由线程1持有,线程2进入阻塞状态
+线程2 一直被阻塞,等待线程1释放对象A的锁
+
+线程1 由于需要等待线程2的信号而一直陷入等待状态,因此一直没有释放对象A的锁,而线程2需要持有对象A的锁才能给线程1发送信号...
+```
+
+这听起来像是纯理论的场景,不妨看下这个比较幼稚的Lock实现:
+
+```Java
+//lock implementation with nested monitor lockout problem
+
+public class Lock{
+ protected MonitorObject monitorObject = new MonitorObject();
+ protected boolean isLocked = false;
+
+ public void lock() throws InterruptedException{
+ synchronized(this){
+ while(isLocked){
+ synchronized(this.monitorObject){
+ this.monitorObject.wait();
+ }
+ }
+ isLocked = true;
+ }
+ }
+
+ public void unlock(){
+ synchronized(this){
+ this.isLocked = false;
+ synchronized(this.monitorObject){
+ this.monitorObject.notify();
+ }
+ }
+ }
+}
+```
+
+注意`lock()`方法中,首先获得this的锁,然后获得`monitorObject`的锁。当`isLock`为`false`时不会有什么问题,此时线程不会调用`monitorObject.wait()`方法。而当`isLock`为`true`时,线程会调用`monitorObjct.wait()`方法而陷入等待状态。
+
+问题就在于,调用`monitorObject.wait()`方法会释放monitorObject的锁,而不会释放this上的锁。换言之,线程在嵌入等待状态的同时,仍然持有this的锁。
+
+当一个线程调用`lock()`方法成功锁住后,再次调用`unlock()`方法时则会在进入this的同步块时陷入阻塞状态。它只有当陷入等待状态的线程释放this的锁才能够进入this的同步块。而嵌入等待的线程却需要嵌入阻塞的线程将isLock设置为false和调用`monitorObject.notify()` 才会释放this的锁。
+
+简而言之,调用`lock()`方法而陷入等待的线程1需要调用了`unlock()`方法的线程2正常地执行`unlock()`方法,但线程2却需要线程1释放锁才能够正确地执行下去。
+
+这导致的结果就是:任意调用`lock()`和`unlock()`的线程都会陷入无止境的阻塞和等待状态。这种线程称之为**嵌套管程锁死**。
+
+##更现实的例子(A More Realistic Example)
+
+也许你会抱怨,你永远也不会实现像上面那样的锁。也许你不会像上面一样调用**嵌套管程(内部监听器)**对象的`wait()`和`notify()`方法,当完全有可能会调用在外层的this对象上。(You may claim that you would never implement a lock like the one shown earlier. That you would not call wait() and notify() on an internal monitor object, but rather on the This is probably true. )有很多类似上面的例子。例如,如果你需要实现一个公平锁。你可能希望每个线程在它们各自的QueueObject上调用`wait()`,这样就可以每次唤醒一个线程。
+
+下面的公平锁实现:
+
+```
+//Fair Lock implementation with nested monitor lockout problem
+
+public class FairLock {
+ private boolean isLocked = false;
+ private Thread lockingThread = null;
+ private List waitingThreads =
+ new ArrayList();
+
+ public void lock() throws InterruptedException{
+ QueueObject queueObject = new QueueObject();
+
+ synchronized(this){
+ waitingThreads.add(queueObject);
+
+ while(isLocked || waitingThreads.get(0) != queueObject){
+
+ synchronized(queueObject){
+ try{
+ queueObject.wait();
+ }catch(InterruptedException e){
+ waitingThreads.remove(queueObject);
+ throw e;
+ }
+ }
+ }
+ waitingThreads.remove(queueObject);
+ isLocked = true;
+ lockingThread = Thread.currentThread();
+ }
+ }
+
+ public synchronized void unlock(){
+ if(this.lockingThread != Thread.currentThread()){
+ throw new IllegalMonitorStateException(
+ "Calling thread has not locked this lock");
+ }
+ isLocked = false;
+ lockingThread = null;
+ if(waitingThreads.size() > 0){
+ QueueObject queueObject = waitingThread.get(0);
+ synchronized(queueObject){
+ queueObject.notify();
+ }
+ }
+ }
+}
+public class QueueObject {}
+```
+
+At first glance this implementation may look fine, but notice how the lock() method calls queueObject.wait(); from inside two synchronized blocks. One synchronized on "this", and nested inside that, a block synchronized on the queueObject local variable. When a thread calls queueObject.wait()it releases the lock on the QueueObject instance, but not the lock associated with "this".
+
+Notice too, that the unlock() method is declared synchronized which equals a synchronized(this) block. This means, that if a thread is waiting inside lock() the monitor object associated with "this" will be locked by the waiting thread. All threads calling unlock() will remain blocked indefinately, waiting for the waiting thread to release the lock on "this". But this will never happen, since this only happens if a thread succeeds in sending a signal to the waiting thread, and this can only be sent by executing the unlock() method.
+
+And so, the FairLock implementation from above could lead to nested monitor lockout. A better implementation of a fair lock is described in the text Starvation and Fairness.
+
+##嵌套管程锁死 vs 死锁(Nested Monitor Lockout vs. Deadlock)
+
+The result of nested monitor lockout and deadlock are pretty much the same: The threads involved end up blocked forever waiting for each other.
+
+The two situations are not equal though. As explained in the text on Deadlock a deadlock occurs when two threads obtain locks in different order. Thread 1 locks A, waits for B. Thread 2 has locked B, and now waits for A. As explained in the text on Deadlock Prevention deadlocks can be avoided by always locking the locks in the same order (Lock Ordering). However, a nested monitor lockout occurs exactly by two threads taking the locks in the same order. Thread 1 locks A and B, then releases B and waits for a signal from Thread 2. Thread 2 needs both A and B to send Thread 1 the signal. So, one thread is waiting for a signal, and another for a lock to be released.
+
+两者的不同点如下:
+
+* 在死锁中,两个线程互相等待对方释放锁。
+* 在嵌套管程锁死中,线程1持有锁A,并等待线程2的信号,而线程2需要锁A才能够发送信号给线程1.
diff --git a/Java-Concurrency/15.Slipped Conditions.md b/Java-Concurrency/15.Slipped Conditions.md
new file mode 100644
index 0000000..1e9e919
--- /dev/null
+++ b/Java-Concurrency/15.Slipped Conditions.md
@@ -0,0 +1,229 @@
+#15.Slipped Conditions
+
+What is Slipped Conditions?
+
+Slipped conditions means, that from the time a thread has checked a certain condition until it acts upon it, the condition has been changed by another thread so that it is errornous for the first thread to act. Here is a simple example:
+
+public class Lock {
+
+ private boolean isLocked = true;
+
+ public void lock(){
+ synchronized(this){
+ while(isLocked){
+ try{
+ this.wait();
+ } catch(InterruptedException e){
+ //do nothing, keep waiting
+ }
+ }
+ }
+
+ synchronized(this){
+ isLocked = true;
+ }
+ }
+
+ public synchronized void unlock(){
+ isLocked = false;
+ this.notify();
+ }
+
+}
+Notice how the lock() method contains two synchronized blocks. The first block waits until isLocked is false. The second block sets isLocked to true, to lock the Lock instance for other threads.
+
+Imagine that isLocked is false, and two threads call lock() at the same time. If the first thread entering the first synchronized block is preempted right after the first synchronized block, this thread will have checked isLocked and noted it to be false. If the second thread is now allowed to execute, and thus enter the first synchronized block, this thread too will see isLocked as false. Now both threads have read the condition as false. Then both threads will enter the second synchronized block, set isLocked to true, and continue.
+
+This situation is an example of slipped conditions. Both threads test the condition, then exit the synchronized block, thereby allowing other threads to test the condition, before any of the two first threads change the conditions for subsequent threads. In other words, the condition has slipped from the time the condition was checked until the threads change it for subsequent threads.
+
+To avoid slipped conditions the testing and setting of the conditions must be done atomically by the thread doing it, meaning that no other thread can check the condition in between the testing and setting of the condition by the first thread.
+
+The solution in the example above is simple. Just move the line isLocked = true; up into the first synchronized block, right after the while loop. Here is how it looks:
+
+public class Lock {
+
+ private boolean isLocked = true;
+
+ public void lock(){
+ synchronized(this){
+ while(isLocked){
+ try{
+ this.wait();
+ } catch(InterruptedException e){
+ //do nothing, keep waiting
+ }
+ }
+ isLocked = true;
+ }
+ }
+
+ public synchronized void unlock(){
+ isLocked = false;
+ this.notify();
+ }
+
+}
+Now the testing and setting of the isLocked condition is done atomically from inside the same synchronized block.
+
+A More Realistic Example
+
+You may rightfully argue that you would never implement a Lock like the first implementation shown in this text, and thus claim slipped conditions to be a rather theoretical problem. But the first example was kept rather simple to better convey the notion of slipped conditions.
+
+A more realistic example would be during the implementation of a fair lock, as discussed in the text on Starvation and Fairness. If we look at the naive implementation from the text Nested Monitor Lockout, and try to remove the nested monitor lock problem it, it is easy to arrive at an implementation that suffers from slipped conditions. First I'll show the example from the nested monitor lockout text:
+
+//Fair Lock implementation with nested monitor lockout problem
+
+public class FairLock {
+ private boolean isLocked = false;
+ private Thread lockingThread = null;
+ private List waitingThreads =
+ new ArrayList();
+
+ public void lock() throws InterruptedException{
+ QueueObject queueObject = new QueueObject();
+
+ synchronized(this){
+ waitingThreads.add(queueObject);
+
+ while(isLocked || waitingThreads.get(0) != queueObject){
+
+ synchronized(queueObject){
+ try{
+ queueObject.wait();
+ }catch(InterruptedException e){
+ waitingThreads.remove(queueObject);
+ throw e;
+ }
+ }
+ }
+ waitingThreads.remove(queueObject);
+ isLocked = true;
+ lockingThread = Thread.currentThread();
+ }
+ }
+
+ public synchronized void unlock(){
+ if(this.lockingThread != Thread.currentThread()){
+ throw new IllegalMonitorStateException(
+ "Calling thread has not locked this lock");
+ }
+ isLocked = false;
+ lockingThread = null;
+ if(waitingThreads.size() > 0){
+ QueueObject queueObject = waitingThread.get(0);
+ synchronized(queueObject){
+ queueObject.notify();
+ }
+ }
+ }
+}
+public class QueueObject {}
+Notice how the synchronized(queueObject) with its queueObject.wait() call is nested inside the synchronized(this) block, resulting in the nested monitor lockout problem. To avoid this problem the synchronized(queueObject) block must be moved outside the synchronized(this) block. Here is how that could look:
+
+//Fair Lock implementation with slipped conditions problem
+
+public class FairLock {
+ private boolean isLocked = false;
+ private Thread lockingThread = null;
+ private List waitingThreads =
+ new ArrayList();
+
+ public void lock() throws InterruptedException{
+ QueueObject queueObject = new QueueObject();
+
+ synchronized(this){
+ waitingThreads.add(queueObject);
+ }
+
+ boolean mustWait = true;
+ while(mustWait){
+
+ synchronized(this){
+ mustWait = isLocked || waitingThreads.get(0) != queueObject;
+ }
+
+ synchronized(queueObject){
+ if(mustWait){
+ try{
+ queueObject.wait();
+ }catch(InterruptedException e){
+ waitingThreads.remove(queueObject);
+ throw e;
+ }
+ }
+ }
+ }
+
+ synchronized(this){
+ waitingThreads.remove(queueObject);
+ isLocked = true;
+ lockingThread = Thread.currentThread();
+ }
+ }
+}
+Note: Only the lock() method is shown, since it is the only method I have changed.
+
+Notice how the lock() method now contains 3 synchronized blocks.
+
+The first synchronized(this) block checks the condition by setting mustWait = isLocked || waitingThreads.get(0) != queueObject.
+
+The second synchronized(queueObject) block checks if the thread is to wait or not. Already at this time another thread may have unlocked the lock, but lets forget that for the time being. Let's assume that the lock was unlocked, so the thread exits the synchronized(queueObject) block right away.
+
+The third synchronized(this) block is only executed if mustWait = false. This sets the condition isLocked back to true etc. and leaves the lock() method.
+
+Imagine what will happen if two threads call lock() at the same time when the lock is unlocked. First thread 1 will check the isLocked conditition and see it false. Then thread 2 will do the same thing. Then neither of them will wait, and both will set the state isLocked to true. This is a prime example of slipped conditions.
+
+Removing the Slipped Conditions Problem
+
+To remove the slipped conditions problem from the example above, the content of the last synchronized(this) block must be moved up into the first block. The code will naturally have to be changed a little bit too, to adapt to this move. Here is how it looks:
+
+//Fair Lock implementation without nested monitor lockout problem,
+//but with missed signals problem.
+
+public class FairLock {
+ private boolean isLocked = false;
+ private Thread lockingThread = null;
+ private List waitingThreads =
+ new ArrayList();
+
+ public void lock() throws InterruptedException{
+ QueueObject queueObject = new QueueObject();
+
+ synchronized(this){
+ waitingThreads.add(queueObject);
+ }
+
+ boolean mustWait = true;
+ while(mustWait){
+
+
+ synchronized(this){
+ mustWait = isLocked || waitingThreads.get(0) != queueObject;
+ if(!mustWait){
+ waitingThreads.remove(queueObject);
+ isLocked = true;
+ lockingThread = Thread.currentThread();
+ return;
+ }
+ }
+
+ synchronized(queueObject){
+ if(mustWait){
+ try{
+ queueObject.wait();
+ }catch(InterruptedException e){
+ waitingThreads.remove(queueObject);
+ throw e;
+ }
+ }
+ }
+ }
+ }
+}
+Notice how the local variable mustWait is tested and set within the same synchronized code block now. Also notice, that even if the mustWait local variable is also checked outside the synchronized(this) code block, in the while(mustWait) clause, the value of the mustWait variable is never changed outside the synchronized(this). A thread that evaluates mustWait to false will atomically also set the internal conditions (isLocked) so that any other thread checking the condition will evaluate it to true.
+
+The return; statement in the synchronized(this) block is not necessary. It is just a small optimization. If the thread must not wait (mustWait == false), then there is no reason to enter the synchronized(queueObject) block and execute the if(mustWait) clause.
+
+The observant reader will notice that the above implementation of a fair lock still suffers from a missed signal problem. Imagine that the FairLock instance is locked when a thread calls lock(). After the first synchronized(this) block mustWait is true. Then imagine that the thread calling lock() is preempted, and the thread that locked the lock calls unlock(). If you look at the unlock() implementation shown earlier, you will notice that it calls queueObject.notify(). But, since the thread waiting in lock() has not yet called queueObject.wait(), the call to queueObject.notify() passes into oblivion. The signal is missed. When the thread calling lock() right after calls queueObject.wait() it will remain blocked until some other thread calls unlock(), which may never happen.
+
+The missed signals problems is the reason that the FairLock implementation shown in the text Starvation and Fairness has turned the QueueObject class into a semaphore with two methods: doWait() and doNotify(). These methods store and react the signal internally in the QueueObject. That way the signal is not missed, even if doNotify() is called before doWait().
diff --git "a/Java-Concurrency/16.Java\344\270\255\347\232\204\351\224\201.md" "b/Java-Concurrency/16.Java\344\270\255\347\232\204\351\224\201.md"
new file mode 100644
index 0000000..da983ec
--- /dev/null
+++ "b/Java-Concurrency/16.Java\344\270\255\347\232\204\351\224\201.md"
@@ -0,0 +1,185 @@
+#16.Java中的锁
+
+**锁**跟**synchronized**的一样,是Java中的一种同步机制,但要比synchronized复杂得多。在Java 5之前,锁(以及其它更高级的线程同步机制)是由synchronized同步块的方式实现的,我们还不能完全摆脱synchronized关键字。
+
+在Java 5的`java.util.concurrent.locks`包有多种锁的实现,因此,你并不需要自己去实现锁。当你仍然需要知道如何使用它们以及了解它们的实现原理。
+
+##一个简单的锁(A Simple Lock)
+
+让我们从一个简单的Java synchronized块开始:
+
+```Java
+public class Counter{
+ private int count = 0;
+
+ public int inc(){
+ synchronized(this){
+ return ++count;
+ }
+ }
+}
+```
+
+注意`inc()`方法中的`synchronized(this)`块,这个块每次只允许一个线程进入执行`return ++count`代码。
+
+Counter类可以用Lock类来实现同样的功能:
+
+```Java
+public class Counter{
+
+ private Lock lock = new Lock();
+ private int count = 0;
+
+ public int inc(){
+ lock.lock();
+ int newCount = ++count;
+ lock.unlock();
+ return newCount;
+ }
+}
+```
+
+`lock()`方法会对Lock对象进行加锁,其他的线程都会在这个方法上阻塞,执行`unlock()`方法被调用。
+
+下面是一个简单Lock类的实现:
+
+```Java
+public class Lock{
+ private boolean isLocked = false;
+
+ public synchronized void lock() throws InterruptedException{
+ while(isLocked){
+ wait();
+ }
+ isLocked = true;
+ }
+
+ public synchronized void unlock(){
+ isLocked = false;
+ notify();
+ }
+}
+```
+
+注意`while(isLocked)`这个循环,我们称之为**自旋锁**。自旋锁、wait方法和notify方法,我们在线程通信一文已经介绍过。当isLocked为true时,调用`lock()`方法的线程会嵌入等待状态。为了防止线程**虚假唤醒**(没调用notify()却无缘无故唤醒),将isLock作为循环的判断条件,如果线程虚假唤醒,则由于isLocked为true,则会再次调用`wait()`进入等待状态。当isLocked为false时,线程会离开while循环,将isLocked设置为true并锁住Lock对象。
+
+当线程执行玩**临界区**(lock方法和unlock方法之间的代码)的代码后
+,线程调用`unlock()`方法,将isLocked设置为`false`,同时调用`notify()`方法唤醒在`lock()`方法中陷入等待的其中一个线程。
+
+##锁的可重入性(Lock Reentrance)
+
+Java中的`synchronized`块是可重入的,意思是,当一个线程进入了一个`synchronized`块并持有该监听器对象的锁后,这个线程可以进入其他的基于这个监听器对象的`synchronized`块。例如下面这个例子:
+
+```Java
+public class Reentrant{
+ public synchronized outer(){
+ inner();
+ }
+
+ public synchronized inner(){
+ //do something
+ }
+}
+```
+
+注意`outer()` 方法和`inner()`方法都用了 **synchronized** 关键字声明(等同于synchronized(this){}同步块)。如果一个线程成功进入`outer()` 方法后,也可以顺利成章地成功进入`inner()`方法,因为两个同步方法的监听器对象都是 **this** 对象。如果一个方法持有一个监听器对象的锁,则它可以任意进入基于这个监听器对象的同步块。这称之为**重入性**。
+
+我们之前所实现的Lock类没不具有**可重入性**。如果我们将Reentrant类按照下面一样进行重构,调用`outer()`方法的线程将会陷入阻塞。
+
+```Java
+public class Reentrant2{
+ Lock lock = new Lock();
+
+ public outer(){
+ lock.lock();
+ inner();
+ lock.unlock();
+ }
+
+ public synchronized inner(){
+ lock.lock();
+ //do something
+ lock.unlock();
+ }
+}
+```
+
+调用`outer()`方法的线程首先获得Lock实例的锁,然后调用`inner()` 方法。在`inner()`方法内部会再次调用同一个Lock实例的`lock()`方法。由于此时isLocked为true,则它将进入`while(isLocked)`内部并调`this.wait()`而进入阻塞状态。
+
+让我们在看下Lock类的实现:
+
+```Java
+public class Lock{
+
+ boolean isLocked = false;
+
+ public synchronized void lock() throws InterruptedException{
+ while(isLocked){
+ wait();
+ }
+ isLocked = true;
+ }
+
+ ...
+}
+```
+
+问题在于while循环的判断,当同一个线程第一次调用`lock()`方法时,isLocked为true,当它再次调用`lock()` 方法时,则会进入while循环内部并调用wait()方法而阻塞。
+
+为了让Lock类具有可重入性的特征,我们需要对它进行小小修改:
+
+```Java
+public class Lock{
+ boolean isLocked = false;
+ Thread lockedBy = null;
+ int lockedCount = 0;
+
+ public synchronized void lock() throws InterruptedException{
+ Thread callingThread = Thread.currentThread();
+ while(isLocked && lockedBy != callingThread){
+ wait();
+ }
+ isLocked = true;
+ lockedCount++;
+ lockedBy = callingThread;
+ }
+
+ public synchronized void unlock(){
+ if(Thread.curentThread() == this.lockedBy){
+ lockedCount--;
+
+ if(lockedCount == 0){
+ isLocked = false;
+ notify();
+ }
+ }
+ }
+
+ ...
+}
+```
+
+注意现在while循环添加了**当前线程是否与持有锁的线程一样**的判断。如果isLocked为false或者当前线程与持有锁的线程一样,则会绕过while循环,因此,即使连续调用两次`lock()`方法将不会再阻塞。
+
+除此之外,我们需要统计同一个线程调用`lock()`的次数。否则,线程线程在调用一次`unlock()`方法后将会释放锁,而不管之前调用了多少次`lock()`方法。在`unlock()`调用没有达到对应`lock()`调用的次数之前,我们不希望锁被释放。
+
+现在,Lock类具有可重入性了。
+
+## 锁的公平性(Lock Fairness)
+
+Java的`synchronized`块并不保证进入同步块的线程顺序。因此,如果存在多个线程同时争用同一个同步块,那么将有某个或多个线程永远得不到进入同步块机会的危险。我们称之为**饥饿**。为了避免这种情况,我们需要保证锁的公平性。上面例子的Lock类是通过`synchronized`关键字实现的,在这里,它们并不能保证锁的公平性。
+
+##在finally块中调用unlock方法(Calling unlock() From a finally-clause)
+
+当使用锁来隔离临界区时,临界区的代码有可能抛出异常,所以把`unlock()`方法放入finally块中是非常有必要的,这样做可以保证无论发生什么`unlock()`方法总可以被调用:
+
+```Java
+lock.lock();
+try{
+ //do critical section code, which may throw exception
+} finally {
+ lock.unlock();
+}
+```
+
+这个小小的结构改变可以保证当临界区的代码抛出异常时`unlock()`总可以被调用。当临界区代码抛出异常时,如果finally块中的`unlock()`方法没有被调用,那么Lock实例将永远被锁住,调用`lock()`方法的线程将陷入无止境的阻塞状态。
diff --git "a/Java-Concurrency/17.Java\344\270\255\347\232\204\350\257\273\345\206\231\351\224\201.md" "b/Java-Concurrency/17.Java\344\270\255\347\232\204\350\257\273\345\206\231\351\224\201.md"
new file mode 100644
index 0000000..8fea652
--- /dev/null
+++ "b/Java-Concurrency/17.Java\344\270\255\347\232\204\350\257\273\345\206\231\351\224\201.md"
@@ -0,0 +1,410 @@
+#17.Java中的读/写锁
+
+Java中,读/写锁的实现比普通锁的实现更加复杂。想象一个读写资源的应用程序,读操作比写操作要频繁得多。假如两个线程同时对同一个资源进行读操作,则不会发生任何问题,因此,如果多个线程同时请求对资源进行读操作将可同时被授权并对资源进行读取。但是,如果有一个线程对资源进行写操作,则不应该存在其他写线程或读线程在执行。我们可以使用读/写锁来实现这种需求。
+
+Java 5的`java.util.concurrent`包含了读写锁。即使如此,了解读写锁的实现原理也是非常有用的。
+
+##Java中读/写锁的实现(Read / Write Lock Java Implementation)
+
+首先,我们对**读访问**和**写访问**做一个概述:
+
+```
+Read Access If no threads are writing, and no threads have requested write access.
+Write Access If no threads are reading or writing.
+```
+
+一个线程请求对资源进行读操作,如果此时没有线程对资源进行写操作和没有线程请求对资源进行写访问,则这个线程可以正常对资源进行读操作。我们假定写访问比读访问更加重要,因此具有更高的优先级。另外,如果读访问更加频繁,而如果我们不降低写访问的优先级,饥饿就会发生。请求写访问的线程会一直阻塞,直到所有的读访问的线程持有的读写锁被释放。如果新的读访问线程总是能够获得锁,写访问的线程就会陷入阻塞,从而造成饥饿。因此,只有当没有线程正在对共享对象进行写访问并且没有线程请求对共享对象进行写访问,读访问线程才能够获得共享对象的锁。
+
+当一个线程需要对资源写访问时,如果没有其他线程正在进行读操作或写操作,则这个线程可以获得授权。不管当前有多少线程请求对资源进行写访问以及它们的顺序如何,除非你想实现对写访问请求的公平锁实现。
+
+根据这个简单的需求,我们可以参照下面这样实现ReadWriteLock:
+
+```Java
+public class ReadWriteLock{
+ private int readers = 0;
+ private int writers = 0;
+ private int writeRequests = 0;
+
+ public synchronized void lockRead() throws InterruptedException{
+ while(writers > 0 || writeRequests > 0){
+ wait();
+ }
+ readers++;
+ }
+
+ public synchronized void unlockRead(){
+ readers--;
+ notifyAll();
+ }
+
+ public synchronized void lockWrite() throws InterruptedException{
+ writeRequests++;
+
+ while(readers > 0 || writers > 0){
+ wait();
+ }
+ writeRequests--;
+ writers++;
+ }
+
+ public synchronized void unlockWrite() throws InterruptedException{
+ writers--;
+ notifyAll();
+ }
+}
+```
+
+这个ReadWriteLock类有两个加锁方法以及两个释放锁方法。一个`lock()`方法和一个`unlock()`方法用于读访问,一个`lock()`方法和一个`unlock()`方法用于写访问。
+
+读访问的实现在`lockRead()`方法中。如果当前没有线程持有写访问的锁以及没有线程请求写访问,则线程请求读访问都可以授权。
+
+写访问的实现在`lockWrite()`方法中。线程请求写访问,会将`writeRequest`加1,然后检查是否可以获得写访问授权。如果当前没有线程在进行读访问以及没有线程写访问,则可以获得写访问授权。
+
+值得注意的是,`unlockRead()`方法和`unlockWrite()`方法调用的是`notifyAll()`方法而非`notify()`方法。至于原因,考虑下面的场景:
+
+假设当前有多个请求**读访问**和**写访问**的线程,当调用`notify()`方法唤醒的线程是**读访问**线程时因为此时有请求**写访问**的线程,被唤醒的线程会继续进入等待状态。然而,因为没有写访问请求的线程被唤醒,所以程序都会因此停止,线程既不能获得读访问授权,也不能获得写访问授权。而调用`notifyAll()`方法可以唤醒所有等待的线程,并检测它们自身是否可以获得锁。
+
+调用`notifyAll()`方法还有一个好处就是,假设当前有很多请求**读访问**的线程,当**写访问**的线程调用`unlockWrite()`释放锁后,所有的请求**读访问**都可以同时获得授权,而不是一个接着一个授权。
+
+(The ReadWriteLock has two lock methods and two unlock methods. One lock and unlock method for read access and one lock and unlock for write access.
+
+The rules for read access are implemented in the lockRead() method. All threads get read access unless there is a thread with write access, or one or more threads have requested write access.
+
+The rules for write access are implemented in the lockWrite() method. A thread that wants write access starts out by requesting write access (writeRequests++). Then it will check if it can actually get write access. A thread can get write access if there are no threads with read access to the resource, and no threads with write access to the resource. How many threads have requested write access doesn't matter.
+
+It is worth noting that both unlockRead() and unlockWrite() calls notifyAll() rather than notify(). To explain why that is, imagine the following situation:
+
+Inside the ReadWriteLock there are threads waiting for read access, and threads waiting for write access. If a thread awakened by notify() was a read access thread, it would be put back to waiting because there are threads waiting for write access. However, none of the threads awaiting write access are awakened, so nothing more happens. No threads gain neither read nor write access. By calling noftifyAll() all waiting threads are awakened and check if they can get the desired access.
+
+Calling notifyAll() also has another advantage. If multiple threads are waiting for read access and none for write access, and unlockWrite() is called, all threads waiting for read access are granted read access at once - not one by one.)
+
+##读/写锁的可重入性(Read / Write Lock Reentrance)
+
+上面实现的ReadWriteLock类并不具有可重入性。如果持有**写访问**锁的线程再次调用`lockWrite()` 方法,则会陷入阻塞。除此之外,考虑下这种情况:
+
+```
+线程1 授权读访问
+线程2 请求写访问,因为线程1正在读,所以线程2会进入等待状态
+线程1 再次请求读访问,因为当前已有一个写访问请求,所以线程1会进入等待状态
+```
+
+这种情况下,ReadWriteLock会被锁死(lock up)(类似于死锁)。其他的读访问和写访问请求也因此不能再获得授权。
+
+有必要对`ReadWriteLock`做一些修改让它具有**可重入性**。**读访问**和**写访问**的**可重入性**将分别进行处理。
+
+##读可重入性(Read Reentrance)
+
+为了让`ReadWriteLock`类具有**读可重入性**,我们需要建立读可重入的规则:
+
+> A thread is granted read reentrance if it can get read access (no writers or write requests), or if it already has read access (regardless of write requests).
+
+To make the ReadWriteLock reentrant for readers we will first establish the rules for read reentrance:
+
+A thread is granted read reentrance if it can get read access (no writers or write requests), or if it already has read access (regardless of write requests).
+
+
+
+To determine if a thread has read access already a reference to each thread granted read access is kept in a Map along with how many times it has acquired read lock. When determing if read access can be granted this Map will be checked for a reference to the calling thread. Here is how the lockRead() and unlockRead() methods looks after that change:
+
+```Java
+public class ReadWriteLock{
+ private Map readingThreads = new HashMap();
+
+ private int writers = 0;
+ private int writeRequests = 0;
+
+ public synchronized void lockRead() throws InterruptedException{
+ Thread callingThread = Thread.currentThread();
+ while(! canGrantReadAccess(callingThread)){
+ wait();
+ }
+
+ readingThreads.put(callingThread,(getAccessCount(callingThread) + 1));
+ }
+
+
+ public synchronized void unlockRead(){
+ Thread callingThread = Thread.currentThread();
+ int accessCount = getAccessCount(callingThread);
+ if(accessCount == 1){ readingThreads.remove(callingThread); }
+ else { readingThreads.put(callingThread, (accessCount -1)); }
+ notifyAll();
+ }
+
+
+ private boolean canGrantReadAccess(Thread callingThread){
+ if(writers > 0) return false;
+ if(isReader(callingThread) return true;
+ if(writeRequests > 0) return false;
+ return true;
+ }
+
+ private int getReadAccessCount(Thread callingThread){
+ Integer accessCount = readingThreads.get(callingThread);
+ if(accessCount == null) return 0;
+ return accessCount.intValue();
+ }
+
+ private boolean isReader(Thread callingThread){
+ return readingThreads.get(callingThread) != null;
+ }
+
+}
+```
+
+As you can see read reentrance is only granted if no threads are currently writing to the resource. Additionally, if the calling thread already has read access this takes precedence over any writeRequests.
+
+##写可重入性(Write Reentrance)
+
+Write reentrance is granted only if the thread has already write access. Here is how the lockWrite() and unlockWrite() methods look after that change:
+
+```Java
+public class ReadWriteLock{
+
+ private Map readingThreads =
+ new HashMap();
+
+ private int writeAccesses = 0;
+ private int writeRequests = 0;
+ private Thread writingThread = null;
+
+ public synchronized void lockWrite() throws InterruptedException{
+ writeRequests++;
+ Thread callingThread = Thread.currentThread();
+ while(! canGrantWriteAccess(callingThread)){
+ wait();
+ }
+ writeRequests--;
+ writeAccesses++;
+ writingThread = callingThread;
+ }
+
+ public synchronized void unlockWrite() throws InterruptedException{
+ writeAccesses--;
+ if(writeAccesses == 0){
+ writingThread = null;
+ }
+ notifyAll();
+ }
+
+ private boolean canGrantWriteAccess(Thread callingThread){
+ if(hasReaders()) return false;
+ if(writingThread == null) return true;
+ if(!isWriter(callingThread)) return false;
+ return true;
+ }
+
+ private boolean hasReaders(){
+ return readingThreads.size() > 0;
+ }
+
+ private boolean isWriter(Thread callingThread){
+ return writingThread == callingThread;
+ }
+}
+```
+
+Notice how the thread currently holding the write lock is now taken into account when determining if the calling thread can get write access.
+
+##读到写的可重入性(Read to Write Reentrance)
+
+Sometimes it is necessary for a thread that have read access to also obtain write access. For this to be allowed the thread must be the only reader. To achieve this the writeLock() method should be changed a bit. Here is what it would look like:
+
+```Java
+public class ReadWriteLock{
+
+ private Map readingThreads =
+ new HashMap();
+
+ private int writeAccesses = 0;
+ private int writeRequests = 0;
+ private Thread writingThread = null;
+
+ public synchronized void lockWrite() throws InterruptedException{
+ writeRequests++;
+ Thread callingThread = Thread.currentThread();
+ while(! canGrantWriteAccess(callingThread)){
+ wait();
+ }
+ writeRequests--;
+ writeAccesses++;
+ writingThread = callingThread;
+ }
+
+ public synchronized void unlockWrite() throws InterruptedException{
+ writeAccesses--;
+ if(writeAccesses == 0){
+ writingThread = null;
+ }
+ notifyAll();
+ }
+
+ private boolean canGrantWriteAccess(Thread callingThread){
+ if(isOnlyReader(callingThread)) return true;
+ if(hasReaders()) return false;
+ if(writingThread == null) return true;
+ if(!isWriter(callingThread)) return false;
+ return true;
+ }
+
+ private boolean hasReaders(){
+ return readingThreads.size() > 0;
+ }
+
+ private boolean isWriter(Thread callingThread){
+ return writingThread == callingThread;
+ }
+
+ private boolean isOnlyReader(Thread thread){
+ return readers == 1 && readingThreads.get(callingThread) != null;
+ }
+
+}
+```
+
+Now the ReadWriteLock class is read-to-write access reentrant.
+
+##写到读的可重入性(Write to Read Reentrance)
+
+Sometimes a thread that has write access needs read access too. A writer should always be granted read access if requested. If a thread has write access no other threads can have read nor write access, so it is not dangerous. Here is how the canGrantReadAccess() method will look with that change:
+
+```Java
+public class ReadWriteLock{
+
+ private boolean canGrantReadAccess(Thread callingThread){
+ if(isWriter(callingThread)) return true;
+ if(writingThread != null) return false;
+ if(isReader(callingThread) return true;
+ if(writeRequests > 0) return false;
+ return true;
+ }
+
+}
+````
+
+##Fully Reentrant ReadWriteLock
+
+Below is the fully reentran ReadWriteLock implementation. I have made a few refactorings to the access conditions to make them easier to read, and thereby easier to convince yourself that they are correct.
+
+```Java
+public class ReadWriteLock{
+
+ private Map readingThreads = new HashMap();
+
+ private int writeAccesses = 0;
+ private int writeRequests = 0;
+ private Thread writingThread = null;
+
+
+ public synchronized void lockRead() throws InterruptedException{
+ Thread callingThread = Thread.currentThread();
+ while(! canGrantReadAccess(callingThread)){
+ wait();
+ }
+
+ readingThreads.put(callingThread,
+ (getReadAccessCount(callingThread) + 1));
+ }
+
+ private boolean canGrantReadAccess(Thread callingThread){
+ if( isWriter(callingThread) ) return true;
+ if( hasWriter() ) return false;
+ if( isReader(callingThread) ) return true;
+ if( hasWriteRequests() ) return false;
+ return true;
+ }
+
+
+ public synchronized void unlockRead(){
+ Thread callingThread = Thread.currentThread();
+ if(!isReader(callingThread)){
+ throw new IllegalMonitorStateException("Calling Thread does not" +
+ " hold a read lock on this ReadWriteLock");
+ }
+ int accessCount = getReadAccessCount(callingThread);
+ if(accessCount == 1){ readingThreads.remove(callingThread); }
+ else { readingThreads.put(callingThread, (accessCount -1)); }
+ notifyAll();
+ }
+
+ public synchronized void lockWrite() throws InterruptedException{
+ writeRequests++;
+ Thread callingThread = Thread.currentThread();
+ while(! canGrantWriteAccess(callingThread)){
+ wait();
+ }
+ writeRequests--;
+ writeAccesses++;
+ writingThread = callingThread;
+ }
+
+ public synchronized void unlockWrite() throws InterruptedException{
+ if(!isWriter(Thread.currentThread()){
+ throw new IllegalMonitorStateException("Calling Thread does not" +
+ " hold the write lock on this ReadWriteLock");
+ }
+ writeAccesses--;
+ if(writeAccesses == 0){
+ writingThread = null;
+ }
+ notifyAll();
+ }
+
+ private boolean canGrantWriteAccess(Thread callingThread){
+ if(isOnlyReader(callingThread)) return true;
+ if(hasReaders()) return false;
+ if(writingThread == null) return true;
+ if(!isWriter(callingThread)) return false;
+ return true;
+ }
+
+
+ private int getReadAccessCount(Thread callingThread){
+ Integer accessCount = readingThreads.get(callingThread);
+ if(accessCount == null) return 0;
+ return accessCount.intValue();
+ }
+
+
+ private boolean hasReaders(){
+ return readingThreads.size() > 0;
+ }
+
+ private boolean isReader(Thread callingThread){
+ return readingThreads.get(callingThread) != null;
+ }
+
+ private boolean isOnlyReader(Thread callingThread){
+ return readingThreads.size() == 1 &&
+ readingThreads.get(callingThread) != null;
+ }
+
+ private boolean hasWriter(){
+ return writingThread != null;
+ }
+
+ private boolean isWriter(Thread callingThread){
+ return writingThread == callingThread;
+ }
+
+ private boolean hasWriteRequests(){
+ return this.writeRequests > 0;
+ }
+
+}
+```
+
+##Calling unlock() From a finally-clause
+
+When guarding a critical section with a ReadWriteLock, and the critical section may throw exceptions, it is important to call the readUnlock() and writeUnlock() methods from inside a finally-clause. Doing so makes sure that the ReadWriteLock is unlocked so other threads can lock it. Here is an example:
+
+```Java
+lock.lockWrite();
+try{
+ //do critical section code, which may throw exception
+} finally {
+ lock.unlockWrite();
+}
+```
+
+This little construct makes sure that the ReadWriteLock is unlocked in case an exception is thrown from the code in the critical section. If unlockWrite() was not called from inside a finally-clause, and an exception was thrown from the critical section, the ReadWriteLock would remain write locked forever, causing all threads calling lockRead() or lockWrite() on that ReadWriteLock instance to halt indefinately. The only thing that could unlock the ReadWriteLockagain would be if the ReadWriteLock is reentrant, and the thread that had it locked when the exception was thrown, later succeeds in locking it, executing the critical section and calling unlockWrite() again afterwards. That would unlock the ReadWriteLock again. But why wait for that to happen, if it happens? Calling unlockWrite() from a finally-clause is a much more robust solution.
diff --git "a/Java-Concurrency/18.\351\207\215\345\205\245\351\224\201\346\255\273.md" "b/Java-Concurrency/18.\351\207\215\345\205\245\351\224\201\346\255\273.md"
new file mode 100644
index 0000000..e438f20
--- /dev/null
+++ "b/Java-Concurrency/18.\351\207\215\345\205\245\351\224\201\346\255\273.md"
@@ -0,0 +1,44 @@
+#18.重入锁死
+
+Reentrance lockout is a situation similar to deadlock and nested monitor lockout. Reentrance lockout is also covered in part in the texts on Locks and Read / Write Locks.
+
+Reentrance lockout may occur if a thread reenters a Lock, ReadWriteLock or some other synchronizer that is not reentrant. Reentrant means that a thread that already holds a lock can retake it. Java's synchronized blocks are reentrant. Therefore the following code will work without problems:
+
+public class Reentrant{
+
+ public synchronized outer(){
+ inner();
+ }
+
+ public synchronized inner(){
+ //do something
+ }
+}
+Notice how both outer() and inner() are declared synchronized, which in Java is equivalent to a synchronized(this) block. If a thread calls outer() there is no problem calling inner() from inside outer(), since both methods (or blocks) are synchronized on the same monitor object ("this"). If a thread already holds the lock on a monitor object, it has access to all blocks synchronized on the same monitor object. This is called reentrance. The thread can reenter any block of code for which it already holds the lock.
+
+The following Lock implementation is not reentrant:
+
+public class Lock{
+
+ private boolean isLocked = false;
+
+ public synchronized void lock()
+ throws InterruptedException{
+ while(isLocked){
+ wait();
+ }
+ isLocked = true;
+ }
+
+ public synchronized void unlock(){
+ isLocked = false;
+ notify();
+ }
+}
+If a thread calls lock() twice without calling unlock() in between, the second call to lock() will block. A reentrance lockout has occurred.
+
+To avoid reentrance lockouts you have two options:
+
+Avoid writing code that reenters locks
+Use reentrant locks
+Which of these options suit your project best depends on your concrete situation. Reentrant locks often don't perform as well as non-reentrant locks, and they are harder to implement, but this may not necessary be a problem in your case. Whether or not your code is easier to implement with or without lock reentrance must be determined case by case.
diff --git "a/Java-Concurrency/19.\344\277\241\345\217\267\351\207\217.md" "b/Java-Concurrency/19.\344\277\241\345\217\267\351\207\217.md"
new file mode 100644
index 0000000..5fdcae9
--- /dev/null
+++ "b/Java-Concurrency/19.\344\277\241\345\217\267\351\207\217.md"
@@ -0,0 +1,162 @@
+#19.信号量
+
+信号量是一种线程同步结构,它可以用于线程间的信号通信,也可以用来像锁一样来保护临界区。Java 5在`java.util.concurrency`包中引入了信号量(Semaphores)的实现。但是,了解信号量背后的实现原来对我们也是非常有帮助的。
+
+Java 5引入了信号量的实现,因此,你不必自己去实现信号量。详细的介绍请看这里:http://tutorials.jenkov.com/java-util-concurrent/semaphore.html
+
+##简单的信号量实现(Simple Semaphore)
+
+下面是一个简单的信号量类的实现:
+
+```Java
+public class Semaphore {
+ private boolean signal = false;
+
+ public synchronized void take() {
+ this.signal = true;
+ this.notify();
+ }
+
+ public synchronized void release() throws InterruptedException{
+ while(!this.signal) {
+ wait();
+ }
+ this.signal = false;
+ }
+
+}
+```
+
+Semmaphore类的`take()`方法用于发送信号,`release()`方法用于等待信号。
+
+使用信号量可以避免信号丢失的问题。在这里,`take()`方法代替了`notify()`方法,`release()`方法代替了`wait()`方法。如果我们在调用`take()`方法之前调用了`release()`方法,`release()`方法通过判断signal变量可以判断`take()`被调用过,因此不会造成信号丢失的问题。而直接`wait()`和`notify()`则会有这个问题。
+
+在使用信号量(Semaphore )进行信号通信(Signaling)时,`take()`和`release()`方法的命名似乎有点过时。下面的示例中会使用Lock中的方法命名,使得方法命名更加**语义化**( The names origin from the use of semaphores as locks, as explained later in this text. In that case the names make more sense.)。
+
+##使用信号量通信(Using Semaphores for Signaling)
+
+下面的示例的两个线程使用信号量进行通信:
+
+```Java
+Semaphore semaphore = new Semaphore();
+
+SendingThread sender = new SendingThread(semaphore);
+ReceivingThread receiver = new ReceivingThread(semaphore);
+
+receiver.start();
+sender.start();
+
+public class SendingThread {
+ Semaphore semaphore = null;
+
+ public SendingThread(Semaphore semaphore){
+ this.semaphore = semaphore;
+ }
+
+ public void run(){
+ while(true){
+ //do something, then signal
+ this.semaphore.take();
+
+ }
+ }
+}
+
+public class RecevingThread {
+ Semaphore semaphore = null;
+
+ public ReceivingThread(Semaphore semaphore){
+ this.semaphore = semaphore;
+ }
+
+ public void run(){
+ while(true){
+ this.semaphore.release();
+ //receive signal, then do something...
+ }
+ }
+}
+```
+
+
+##计数信号量(Counting Semaphore)
+
+上面实现的Semaphore类,并没有计算通过调用`take()`方法发送的信号的次数。我们通过修改让它提供这个功能。这个称之为**计数信号量**。下面是一个简单的计数信号量的实现:
+
+```Java
+public class CountingSemaphore {
+ private int signals = 0;
+
+ public synchronized void take() {
+ this.signals++;
+ this.notify();
+ }
+
+ public synchronized void release() throws InterruptedException{
+ while(this.signals == 0) {
+ wait();
+ }
+ this.signals--;
+ }
+
+}
+```
+
+
+##有界信号量(Bounded Semaphore)
+
+CountingSemaphores只是存储了发送的信号量的个数,但是没有限定信号量的个数。我们可以按照下面这个例子让它限制信号量的上界:
+
+```Java
+public class BoundedSemaphore {
+ private int signals = 0;
+ private int bound = 0;
+
+ public BoundedSemaphore(int upperBound){
+ this.bound = upperBound;
+ }
+
+ public synchronized void take() throws InterruptedException{
+ while(this.signals == bound) {
+ wait();
+ }
+ this.signals++;
+ this.notify();
+ }
+
+ public synchronized void release() throws InterruptedException{
+ while(this.signals == 0) {
+ wait();
+ }
+ this.signals--;
+ this.notify();
+ }
+}
+```
+
+注意这里的`take()`方法,如果signals的个数达到上限则线程进入阻塞,直到有线程调用`release()`方法,当前线程才能被允许发送信号。
+
+##像锁一样使用信号量(Using Semaphores as Locks)
+
+我们可以把有**界信号量(bounded semaphore)**当成锁使用。这时候,我们将上界设置为1,用`take()`方法和`release()`方法包裹临界区。如下面这个例子:
+
+It is possible to use a bounded semaphore as a lock. To do so, set the upper bound to 1, and have the call to take() and release() guard the critical section. Here is an example:
+
+```Java
+BoundedSemaphore semaphore = new BoundedSemaphore(1);
+
+semaphore.take();
+
+try{
+ //critical section
+} finally {
+ semaphore.release();
+}
+```
+
+与发送信号不同,这里的`take()`方法和`release()`方法都是在同一个线程里面调用的。这是因为当上界为1时,一个线程调用`take()`方法后,其他调用`take()`方法的线程都会阻塞,直到这个线程调用`release()`方法。
+
+你也可以利用**有界信号量**去限制同时进入同一个临界区的线程数量。举个例子,在上面的例子中,假如将limit的值设置为5会发生什么情况呢?5个线程会被允许同时进入同一个临界区。当然,你也需要确保这5个线程间的操作不会互相干扰,否则应用程序会因此挂掉。
+
+`release()`方法在`finally`块中被调用,这样就可以确保即使临界区发生异常时,`release()`总能够被调用。
+
diff --git "a/Java-Concurrency/20.\351\230\273\345\241\236\351\230\237\345\210\227.md" "b/Java-Concurrency/20.\351\230\273\345\241\236\351\230\237\345\210\227.md"
new file mode 100644
index 0000000..660a140
--- /dev/null
+++ "b/Java-Concurrency/20.\351\230\273\345\241\236\351\230\237\345\210\227.md"
@@ -0,0 +1,52 @@
+#20.阻塞队列
+
+**阻塞队列**是这样一种队列:当队列为空时**出列(dequeue)**会阻塞,当队列满时**入队**会阻塞。当一个线程试图从一个空队列出列就会进入阻塞,直到其他线程将元素入列;当一个线程试图从一个满的队列中入列也会阻塞,直到其他线程将对队列中的元素出列或者将队列清空。
+
+下面的图展示了两个线程如何跟阻塞队列进行交互:
+
+
+
+
+Java 5的`java.util.concurrent`包中引入了阻塞队列的实现。即使如此,了解底层的实现原理也是非常有必要和有帮助的。
+
+##阻塞队列的实现(Blocking Queue Implementation)
+
+ **阻塞队列**的实现跟**有界信号量**的实现类似。下面是一个阻塞队列的实现:
+
+```Java
+public class BlockingQueue {
+
+ private List queue = new LinkedList();
+ private int limit = 10;
+
+ public BlockingQueue(int limit){
+ this.limit = limit;
+ }
+
+
+ public synchronized void enqueue(Object item) throws InterruptedException {
+ while(this.queue.size() == this.limit) {
+ wait();
+ }
+ if(this.queue.size() == 0) {
+ notifyAll();
+ }
+ this.queue.add(item);
+ }
+
+
+ public synchronized Object dequeue() throws InterruptedException{
+ while(this.queue.size() == 0){
+ wait();
+ }
+ if(this.queue.size() == this.limit){
+ notifyAll();
+ }
+
+ return this.queue.remove(0);
+ }
+
+}
+```
+
+ok,很简单,也不过多解释了!
\ No newline at end of file
diff --git "a/Java-Concurrency/21.\347\272\277\347\250\213\346\261\240.md" "b/Java-Concurrency/21.\347\272\277\347\250\213\346\261\240.md"
new file mode 100644
index 0000000..47fa13f
--- /dev/null
+++ "b/Java-Concurrency/21.\347\272\277\347\250\213\346\261\240.md"
@@ -0,0 +1,84 @@
+#21.线程池
+
+当你需要在应用程序中限制同一时间线程的数量时,线程池就显得非常有用,因为创建并启动新的线程是消耗性能的。
+
+给每个任务创建并启动单独的线程不同,你可以将任务交给线程池,当线程中有线程空闲时,线程池就会将任务非配给线程执行。在线程池内部,任务被插入到一个阻塞队列里面,空闲线程将从这个队列汇总出列(dequeue)需要执行的任务。如果队列中没有任务,线程池中的空闲线程就会进入阻塞等待新的任务。
+
+线程池经常被用于多线程处理的服务器中。每个到达服务器的连接都会被包装成一个任务然后交给线程池进行处理,线程池中的线程会并行地对这些任务进行处理。
+
+Java 5中内置了线程池的实现,所以你不必要自己去实现线程池。但是了解其中的实现原理是非常有必要和有帮助的。
+
+下面是一个线程池的简单实现:
+
+```Java
+public class ThreadPool {
+ private BlockingQueue taskQueue = null;
+ private List threads = new ArrayList();
+ private boolean isStopped = false;
+
+ public ThreadPool(int noOfThreads, int maxNoOfTasks){
+ taskQueue = new BlockingQueue(maxNoOfTasks);
+
+ for(int i=0; i readingThreads = new HashMap();
+
+ private int writeAccesses = 0;
+ private int writeRequests = 0;
+ private Thread writingThread = null;
+
+ ...
+
+ public synchronized void lockWrite() throws InterruptedException{
+ writeRequests++;
+ Thread callingThread = Thread.currentThread();
+ while(! canGrantWriteAccess(callingThread)){
+ wait();
+ }
+ writeRequests--;
+ writeAccesses++;
+ writingThread = callingThread;
+ }
+
+
+ ...
+}
+```
+
+The BoundedSemaphore class shown below has two test-and-set methods: take() and
+release(). Both methods test and sets the internal state.
+
+```Java
+public class BoundedSemaphore {
+ private int signals = 0;
+ private int bound = 0;
+
+ public BoundedSemaphore(int upperBound){
+ this.bound = upperBound;
+ }
+
+
+ public synchronized void take() throws InterruptedException{
+ while(this.signals == bound) {
+ wait();
+ }
+ this.signals++;
+ this.notify();
+ }
+
+ public synchronized void release() throws InterruptedException{
+ while(this.signals == 0) {
+ wait();
+ }
+ this.signals--;
+ this.notify();
+ }
+
+}
+```
+
+##Set Method
+
+The set method is the second type of method that synchronizers often contain. The set method just sets the internal state of the synchronizer without testing it first. A typical example of a set method is the unlock() method of a Lock class. A thread holding the lock can always unlock it without having to test if the Lock is unlocked.
+
+The program flow of a set method is usually along the lines of:
+
+Set internal state
+Notify waiting threads
+Here is an example unlock() method:
+
+```Java
+public class Lock{
+ private boolean isLocked = false;
+
+ public synchronized void unlock(){
+ isLocked = false;
+ notify();
+ }
+
+}
+```
\ No newline at end of file
diff --git a/Java-Concurrency/README.md b/Java-Concurrency/README.md
new file mode 100644
index 0000000..41cada4
--- /dev/null
+++ b/Java-Concurrency/README.md
@@ -0,0 +1 @@
+ 翻译自:http://tutorials.jenkov.com/java-concurrency/index.html
diff --git "a/Java-NIO/01.Java NIO\346\225\231\347\250\213.md" "b/Java-NIO/01.Java NIO\346\225\231\347\250\213.md"
new file mode 100644
index 0000000..8f75dd7
--- /dev/null
+++ "b/Java-NIO/01.Java NIO\346\225\231\347\250\213.md"
@@ -0,0 +1,15 @@
+#01.Java NIO教程
+
+Java NIO(New IO)是一个可以替代标准IO的IO API,这意味着,它可以替代标准IO和Java Networking API。它提供了与标准IO不同的工作方式。
+
+##通道和缓冲区(Channels and Buffers)
+
+在标准IO接口中,操作的对象是**字节流**和**字符流**。而在NIO中,操作的对象则是**通道(Channels)**和**缓冲区(Buffers)**。数据总是从通道中读取到缓冲区,或从缓冲区写入到通道。
+
+##非阻塞IO(Non-blocking IO)
+
+Java NIO提供了非阻塞IO。举个例子,线程可以让通道读取数据到缓冲区中,当通道读取数据到缓冲区时,线程可以不必等待操作的完成,就可以去处理其他操作。从缓冲区写入到通道也类似。
+
+##选择器( Selectors)
+
+Java NIO引入了**选择器(Selectors)**的概念。一个选择器可以监听多个通道的时间(例如:连接打开,数据到达)。因此,单个线程可以监听多个数据通道。
diff --git "a/Java-NIO/02.Java NIO\346\246\202\350\247\210.md" "b/Java-NIO/02.Java NIO\346\246\202\350\247\210.md"
new file mode 100644
index 0000000..27327bb
--- /dev/null
+++ "b/Java-NIO/02.Java NIO\346\246\202\350\247\210.md"
@@ -0,0 +1,50 @@
+#02.Java NIO概览
+
+Java NIO包括以下核心组件:
+
+* 通道(Channels)
+* 缓冲区(Buffers)
+* 选择器(Selectors)
+
+Java NIO包含许多类和组件,但是**通道(Channels)**,**缓冲区(Buffers)**和**选择器(Selectors)**是其中最核心的接口。其他的组件,例如**管道(Pipe)**和文件锁**(FileLock)**只是为这三个核心组件服务的工具类。
+
+##通道和缓冲区(Channels and Buffers)
+
+通常情况下,在NIO中的所有IO都起始于**通道(Channels)**。通道有点类似于**流**。来自通道的数据可以读取到缓冲区中,同样地,也可以从缓存区中写入数据到通道,如下图所示:
+
+
diff --git "a/33.\350\243\205\351\245\260\345\231\250\346\250\241\345\274\2172.md" "b/33.\350\243\205\351\245\260\345\231\250\346\250\241\345\274\2172.md"
new file mode 100644
index 0000000..fd930a4
--- /dev/null
+++ "b/33.\350\243\205\351\245\260\345\231\250\346\250\241\345\274\2172.md"
@@ -0,0 +1 @@
+# 33.装饰器模式2
diff --git "a/Java-Concurrency-Util/01.Java\345\271\266\345\217\221\345\267\245\345\205\267\347\261\273.md" "b/Java-Concurrency-Util/01.Java\345\271\266\345\217\221\345\267\245\345\205\267\347\261\273.md"
new file mode 100644
index 0000000..191a794
--- /dev/null
+++ "b/Java-Concurrency-Util/01.Java\345\271\266\345\217\221\345\267\245\345\205\267\347\261\273.md"
@@ -0,0 +1,23 @@
+#01.Java并发工具类
+
+Java 5 added a new Java package to the Java platform, the java.util.concurrent package. This package contains a set of classes that makes it easier to develop concurrent (multithreaded) applications in Java. Before this package was added, you would have to program your utility classes yourself.
+
+In this tutorial I will take you through the new java.util.concurrent classes, one by one, so you can learn how to use them. I will use the versions in Java 6. I am not sure if there are any differences to the Java 5 versions.
+
+I will not explain the core issues of concurrency in Java - the theory behind it, that is. If you are interested in that, check out my Java Concurrency tutorial.
+
+
+##Work in Progress
+
+This tutorial is very much "work in progress", so if you spot a missing class or interface, please be patient. I will add it when I get the time to do it.
+
+
+##Table of Contents
+
+Here is a list of the topics covered in this java.util.concurrent trail. This list (menu) is also present at the top right of every page in the trail.
+
+
+##Feel Free to Contact Me
+
+If you disagree with anything I write here about the java.util.concurrent utilities, or just have comments, questions, etc, feel free to send me an email. You wouldn't be the first to do so. You can find my email address on the about page.
+
diff --git "a/Java-Concurrency-Util/02.\351\230\273\345\241\236\351\230\237\345\210\227\357\274\210BlockingQueue\357\274\211.md" "b/Java-Concurrency-Util/02.\351\230\273\345\241\236\351\230\237\345\210\227\357\274\210BlockingQueue\357\274\211.md"
new file mode 100644
index 0000000..0454d9d
--- /dev/null
+++ "b/Java-Concurrency-Util/02.\351\230\273\345\241\236\351\230\237\345\210\227\357\274\210BlockingQueue\357\274\211.md"
@@ -0,0 +1,118 @@
+#02.阻塞队列(BlockingQueue)
+
+在Java `java.util.concurrent`包中的*BlockingQueue*是一个线程安全的阻塞队列接口,在这个接口中,入列和出类的操作都是线程安全的。
+
+##BlockingQueue用法(BlockingQueue Usage)
+
+阻塞队列(BlockingQueue)通常被用于**生产消费者模式**。看下面这张图:
+
+
+
+**生产者线程**生产新的对象,并把对象插入到队列中,直到队列中元素达到上限。如果阻塞队列达到了上限,则尝试插入对象的生产者线程会进入阻塞状态,它们会一直阻塞直到有**消费者线程**从队列中取出对象。
+
+**消费者线程**会持续从阻塞队列中取出对象并进行相应处理。如果消费者线程试图从空的阻塞队列中取出对象,则会进入阻塞状态,直到有生产者线程向队列中插入对象。
+
+##BlockingQueue的方法(BlockingQueue Methods)
+
+*BlockingQueue*分别有四种用于**入列**和**出列**的方法。每种方法都有不同的处理行为用以处理不同的应用场景:
+
+||Throws Exception| Special Value| Blocks| Times Out
+ ------|--------------|------------|--------------|----------------
+Insert | add(o) | offer(o) | put(o) |offer(o, timeout, timeunit)
+Remove | remove(o) | poll(o)| take(o) |poll(timeout, timeunit)
+Examine | element(o) | peek(o) | |
+
+
+四种不同的行为含义:
+
+* 抛出异常(Throws Exception):
+如果尝试的操作不能立即执行则抛出异常。
+* 特殊值(Special Value):
+如果尝试的操作不能立即执行,则返回特殊值(通常为true/false)。
+* 阻塞(Blocks):
+如果尝试的操作不能立即执行,则方法进入阻塞直到能够执行。
+* 超时(Times Out):
+如果尝试的方法不能立即执行,则方法进入阻塞直到能够执行,但如果阻塞超过设置的超时时间,则返回一个特殊值指明操作是否成功执行(通常为true/false)
+
+往*BlockingQueue*中插入null是不可能的,如果你往*BlockingQueue*中插入null,则会抛出*NullPointerException*异常。
+
+获取*BlockingQueue*中任意的元素都是可以的,不仅限于队列的头部或尾部。举个例子,如果你已经将一个任务插入队列,但你现在想取消这个任务,你可以通过类似`remove(task)`的方法来删除特定的在*BlockingQueue*中的元素。然而,这些操作都并非高性能的,除非迫不得已,不要调用这些方法。
+
+##BlockingQueue的实现类(BlockingQueue Implementations)
+
+由于*BlockingQueue*只是一个接口,所以我们要用时,应该选择具体的实现类。在Java 6的*java.util.concurrent*包中包含以下*BlockingQueue*的实现类:
+
+* ArrayBlockingQueue
+* DelayQueue
+* LinkedBlockingQueue
+* PriorityBlockingQueue
+* SynchronousQueue
+
+##BlockingQueue示例(Java BlockingQueue Example)
+
+下面是一个*BlockingQueue*的例子,这个例子中使用了实现*BlockingQueue*接口的*ArrayBlockingQueue*类。
+
+首先,这个*BlockingQueueExample*类中,分别启动了一个*Producer*和一个*Consumer*线程。*Producer*线程往共享的阻塞队列中插入数据,而*Consumer*线程从阻塞队列中取出数据并进行相应处理:
+
+```Java
+public class BlockingQueueExample {
+
+ public static void main(String[] args) throws Exception {
+ BlockingQueue queue = new ArrayBlockingQueue(1024);
+
+ Producer producer = new Producer(queue);
+ Consumer consumer = new Consumer(queue);
+
+ new Thread(producer).start();
+ new Thread(consumer).start();
+
+ Thread.sleep(4000);
+ }
+}
+```
+
+下面是*Producer*类的实现。注意这里的每个`put()`方法间线程都休眠了1s。这会导致等待队列元素的*Consumer*线程阻塞。
+
+```Java
+public class Producer implements Runnable{
+ protected BlockingQueue queue = null;
+
+ public Producer(BlockingQueue queue) {
+ this.queue = queue;
+ }
+
+ public void run() {
+ try {
+ queue.put("1");
+ Thread.sleep(1000);
+ queue.put("2");
+ Thread.sleep(1000);
+ queue.put("3");
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+}
+```
+
+下面是*Consumer*类的实现,它仅仅只是连续从队列中取出三个元素并进行打印:
+
+```Java
+public class Consumer implements Runnable{
+ protected BlockingQueue queue = null;
+
+ public Consumer(BlockingQueue queue) {
+ this.queue = queue;
+ }
+
+ public void run() {
+ try {
+ System.out.println(queue.take());
+ System.out.println(queue.take());
+ System.out.println(queue.take());
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+}
+```
\ No newline at end of file
diff --git a/Java-Concurrency-Util/03.ArrayBlockingQueue.md b/Java-Concurrency-Util/03.ArrayBlockingQueue.md
new file mode 100644
index 0000000..d85e550
--- /dev/null
+++ b/Java-Concurrency-Util/03.ArrayBlockingQueue.md
@@ -0,0 +1,15 @@
+#03.ArrayBlockingQueue
+
+*ArrayBlockingQueue*类实现了*BlockingQueue*接口。*ArrayBlockingQueue*是一个有界的阻塞队列,其内部维护了一个数组用于存储元素。有界意味着*ArrayBlockingQueue*不能存储无限量的元素。在同一时间内*ArrayBlockingQueue*存储的元素有一个上限,我们可以在初始化*ArrayBlockingQueue*时设置这个上限,而在此之后无法进行修改这个上限。
+
+*ArrayBlockingQueue*存储元素时遵循FIFO(先进先出)原则。在队列头部的元素的最先入列的元素,而在队列尾部的元素则是最新入列的元素。
+
+下面的例子演示了如何初始化*ArrayBlockingQueue*类:
+
+```Java
+BlockingQueue queue = new ArrayBlockingQueue(1024);
+
+queue.put("1");
+
+String string = queue.take();
+```
\ No newline at end of file
diff --git "a/Java-Concurrency-Util/04.DelayQueue\357\274\210\345\273\266\346\227\266\351\230\237\345\210\227\357\274\211.md" "b/Java-Concurrency-Util/04.DelayQueue\357\274\210\345\273\266\346\227\266\351\230\237\345\210\227\357\274\211.md"
new file mode 100644
index 0000000..d80e353
--- /dev/null
+++ "b/Java-Concurrency-Util/04.DelayQueue\357\274\210\345\273\266\346\227\266\351\230\237\345\210\227\357\274\211.md"
@@ -0,0 +1,47 @@
+04.DelayQueue(延时队列)
+
+DelayQueue class implements the BlockingQueue interface. Read the BlockingQueue text for more information about the interface.
+
+The DelayQueue keeps the elements internally until a certain delay has expired. The elements must implement the interface java.util.concurrent.Delayed. Here is how the interface looks:
+
+```Java
+public interface Delayed extends Comparable unbounded = new LinkedBlockingQueue();
+BlockingQueue bounded = new LinkedBlockingQueue(1024);
+
+bounded.put("Value");
+
+String value = bounded.take();
+```
\ No newline at end of file
diff --git a/Java-Concurrency-Util/06.PriorityBlockingQueue.md b/Java-Concurrency-Util/06.PriorityBlockingQueue.md
new file mode 100644
index 0000000..9f3d012
--- /dev/null
+++ b/Java-Concurrency-Util/06.PriorityBlockingQueue.md
@@ -0,0 +1,22 @@
+#06.PriorityBlockingQueue
+
+The PriorityBlockingQueue class implements the BlockingQueue interface. Read the BlockingQueue text for more information about the interface.
+
+The PriorityBlockingQueue is an unbounded concurrent queue. It uses the same ordering rules as the java.util.PriorityQueue class. You cannot insert null into this queue.
+
+All elements inserted into the PriorityBlockingQueue must implement the java.lang.Comparable interface. The elements thus order themselves according to whatever priority you decide in your Comparable implementation.
+
+Notice that the PriorityBlockingQueue does not enforce any specific behaviour for elements that have equal priority (compare() == 0).
+
+Also notice, that in case you obtain an Iterator from a PriorityBlockingQueue, the Iterator does not guarantee to iterate the elements in priority order.
+
+Here is an example of how to use the PriorityBlockingQueue:
+
+```Java
+BlockingQueue queue = new PriorityBlockingQueue();
+
+//String implements java.lang.Comparable
+queue.put("Value");
+
+String value = queue.take();
+```
diff --git a/Java-Concurrency-Util/README.md b/Java-Concurrency-Util/README.md
new file mode 100644
index 0000000..d1d2694
--- /dev/null
+++ b/Java-Concurrency-Util/README.md
@@ -0,0 +1 @@
+翻译自:http://tutorials.jenkov.com/java-util-concurrent/index.html
diff --git "a/Java-Concurrency/01.Java \345\271\266\345\217\221\344\270\216\345\244\232\347\272\277\347\250\213.md" "b/Java-Concurrency/01.Java \345\271\266\345\217\221\344\270\216\345\244\232\347\272\277\347\250\213.md"
new file mode 100644
index 0000000..b024e2c
--- /dev/null
+++ "b/Java-Concurrency/01.Java \345\271\266\345\217\221\344\270\216\345\244\232\347\272\277\347\250\213.md"
@@ -0,0 +1,20 @@
+# 01.Java 并发与多线程
+
+在以前,一台计算机只有一个CPU,而且在同一时间只能执行一个应用程序。后来引入了多任务的概念,这意味着计算机能再同一时间内执行多个应用程序。虽然,这并不是真正意义上的“同时”。多个应用程序共享计算机的CPU,操作系统在极小的时间切片内对应用程序进行切换以获得CPU资源。
+
+多任务的引入对软件开发者带来的新的挑战。应用程序不再能占用所有的CPU时间和所有的内存以及其他计算机资源。同时,一个好的应用程序在退出之后应该释放所有的系统系统以供其它应用程序使用。
+
+不久之后,多线程的概念被引入,这意味着,在一个应用程序中可以拥有多个执行线程。A thread of execution can be thought of as a CPU executing the program. 当一个应用程序有多个线程执行时,它就像拥有多个CPU在执行任务。
+
+多线程比多任务带来的挑战更加巨大。多线程意味着,在一个应用程序内部,可以存在多个线程同时地对内存进行读写操作。它会出现一些在单线程中永远不会出现的错误。有些错误也许在单个CPU的计算机上也不会出现(因为在单个CPU的计算机上,两个线程永远不可能真正意义上的同时执行)。现代计算机,基本都拥有多个CPU内核,线程可以通过独占内核来实现真正意义上的并行。
+
+如果一个线程往一块内存读取数据,而同时另一个线程往同样的地址写入数据,那么第一个线程读取的值是多少?原来的值?或是被第二个线程写入的值?或是两者混合的值?再举个例子,如果有两个线程同时往一块内存地址写入数据,那么这块内存最终的值是什么?第一个线程写入的值?还是第二个线程写入的值?还是两者的混合?如果没有恰当的预防措施,所有的这些结果都是可能的。线程的执行行为不能预测,所以最终的计算结果也跟着不同。
+
+
+##Java的多线程与并发(Multithreading and Concurrency in Java)
+
+Java was one of the first languages to make multithreading easily available to developers. Java had multithreading capabilities from the very beginning. Therefore, Java developers often face the problems described above. That is the reason I am writing this trail on Java concurrency. As notes to myself, and any fellow Java developer whom may benefit from it.
+
+The trail will primarily be concerned with multithreading in Java, but some of the problems occurring in multithreading are similar to problems occurring in multitasking and in distributed systems. References to multitasking and distributed systems may therefore occur in this trail too. Hence the word "concurrency" rather than "multithreading".
+
+This trail is still work in progress. Texts will be published whenver time is available to write them. Below is a list of the current texts in this trail. The list is also repeated at the top right of every page in the trail.
\ No newline at end of file
diff --git "a/Java-Concurrency/02.\345\244\232\347\272\277\347\250\213\347\232\204\345\245\275\345\244\204.md" "b/Java-Concurrency/02.\345\244\232\347\272\277\347\250\213\347\232\204\345\245\275\345\244\204.md"
new file mode 100644
index 0000000..5389b28
--- /dev/null
+++ "b/Java-Concurrency/02.\345\244\232\347\272\277\347\250\213\347\232\204\345\245\275\345\244\204.md"
@@ -0,0 +1,66 @@
+#02.多线程的好处
+
+尽管多线程带来的一些挑战,也让先写应用程序变得复杂,但它也带来了一系列好处:
+
+* 更好的资源利用率
+* 更简单的程序设计
+* More responsive programs
+
+
+##更好的资源利用率(Better resource utilization)
+
+试想一下,一个读取和处理本地系统文件的应用程序。比方说,从磁盘读取AF文件需要5秒,处理需要2秒,处理两个文件过程如下:
+
+```
+读取文件A消耗5s
+处理文件A消耗2s
+读取文件B消耗5s
+处理文件B消耗2s
+-------------
+总共消耗时间14s
+```
+
+当从磁盘读取文件时,大部分的CPU时间都消耗在了等待磁盘读取数据,而在这段时间内,CPU大部分时间内都是空闲的,它原本可以用来做其他操作。改变操作的顺序,可以让CPU得到更高的利用率。如下所示:
+
+```
+读取文件A消耗5s
+读取文件B消耗5s + 处理文件A消耗2s
+处理文件B消耗2s
+-------------
+总共消耗时间12s
+```
+
+当CPU读取往文件A后,则紧随着读取文件B,在此同时处理文件A。需要谨记的是,在等带磁盘读取文件时,CPU大部分时间都是空闲的。
+
+一般来说,在CPU等待IO操作时可以处理其他任务。IO操作可以是磁盘IO,网络IO或者用户的输入。磁盘IO和网络IO远远慢于CPU IO和内存IO。
+
+
+##更简单的程序设计(Simpler Program Design)
+
+If you were to program the above ordering of reading and processing by hand in a singlethreaded application, you would have to keep track of both the read and processing state of each file. Instead you can start two threads that each just reads and processes a single file. Each of these threads will be blocked while waiting for the disk to read its file. While waiting, other threads can use the CPU to process the parts of the file they have already read. The result is, that the disk is kept busy at all times, reading from various files into memory. This results in a better utilization of both the disk and the CPU. It is also easier to program, since each thread only has to keep track of a single file.
+
+##更具响应性的程序(More responsive programs)
+
+把单线程应用转化为多线程应用的另一个目标就是实现更具有响应性的应用程序。试想一下,监听某个端口请求的服务器应用程序,当请求到达时,应用程序进行处理,然后返回继续监听。程序设计勾勒如下:
+
+```Java
+while(server is active){
+ listen for request
+ process request
+}
+```
+
+如果请求需要很长的处理时间,在这段期间内,应用程序不能处理后续的请求,只有当应用程序处理请求返回监听状态,才能继续接收请求。
+
+另一种设计就是监听线程接收请求,然后将请求传递给工作线程进行处理,并立即返回到监听状态。工作线程对请求进行处理,然后将结果响应给客户端。这种设计勾勒如下:
+
+ ```Java
+while(server is active){
+ listen for request
+ hand request to worker thread
+}
+```
+
+在这种方式下,服务器线程将很快回到监听状态。因此,可以响应更多的用户请求。服务器变成更具有响应性。
+
+The same is true for desktop applications. If you click a button that starts a long task, and the thread executing the task is the thread updating the windows, buttons etc., then the application will appear unresponsive while the task executes. Instead the task can be handed off to a worker thread. While the worker thread is busy with the task, the window thread is free to respond to other user requests. When the worker thread is done it signals the window thread. The window thread can then update the application windows with the result of the task. The program with the worker thread design will appear more responsive to the user.
diff --git "a/Java-Concurrency/03.\345\244\232\347\272\277\347\250\213\347\232\204\346\210\220\346\234\254.md" "b/Java-Concurrency/03.\345\244\232\347\272\277\347\250\213\347\232\204\346\210\220\346\234\254.md"
new file mode 100644
index 0000000..b83143f
--- /dev/null
+++ "b/Java-Concurrency/03.\345\244\232\347\272\277\347\250\213\347\232\204\346\210\220\346\234\254.md"
@@ -0,0 +1,21 @@
+#03.多线程的代价
+
+Going from a singlethreaded to a multithreaded application doesn't just provide benefits. It also has some costs. Don't just multithread-enable an application just because you can. You should have a good idea that the benefits gained by doing so, are larger than the costs. When in doubt, try measuring the performance or responsiveness of the application, instead of just guessing.
+
+##设计更加复杂(More complex design)
+
+Though some parts of a multithreaded applications is simpler than a singlethreaded application, other parts are more complex. Code executed by multiple threads accessing shared data need special attention. Thread interaction is far from always simple. Errors arising from incorrect thread synchronization can be very hard to detect, reproduce and fix.
+
+##上下文切换的开销(Context Switching Overhead)
+
+When a CPU switches from executing one thread to executing another, the CPU needs to save the local data, program pointer etc. of the current thread, and load the local data, program pointer etc. of the next thread to execute. This switch is called a "context switch". The CPU switches from executing in the context of one thread to executing in the context of another.
+
+Context switching isn't cheap. You don't want to switch between threads more than necessary.
+
+You can read more about context switching on Wikipedia:
+
+http://en.wikipedia.org/wiki/Context_switch
+
+##增加资源消耗(Increased Resource Consumption)
+
+A thread needs some resources from the computer in order to run. Besides CPU time a thread needs some memory to keep its local stack. It may also take up some resources inside the operating system needed to manage the thread. Try creating a program that creates 100 threads that does nothing but wait, and see how much memory the application takes when running.
\ No newline at end of file
diff --git "a/Java-Concurrency/04.\345\210\233\345\273\272\345\222\214\345\220\257\345\212\250Java\347\272\277\347\250\213.md" "b/Java-Concurrency/04.\345\210\233\345\273\272\345\222\214\345\220\257\345\212\250Java\347\272\277\347\250\213.md"
new file mode 100644
index 0000000..efcec90
--- /dev/null
+++ "b/Java-Concurrency/04.\345\210\233\345\273\272\345\222\214\345\220\257\345\212\250Java\347\272\277\347\250\213.md"
@@ -0,0 +1,161 @@
+#04.创建和启动Java线程
+
+Java线程对象与其它的对象相似。线程对象是`java.lang.Thread`的实例,或是`java.lang.Thread`的子类的实例。跟普通对象不同,线程对象可以执行代码。
+
+##创建和启动线程(Creating and Starting Threads)
+
+在Java中,可以使用以下方式创建线程:
+
+```Java
+Thread thread = new Thread();
+```
+
+调用`Thread.start()`可以启动线程:
+
+```Java
+thread.start();
+```
+
+这个例子并没有为线程指定要执行的代码,所以它会很快返回并停止。
+
+有两种方法可以为线程指定需要执行的代码。第一种方式是创建`Thread`的子类并重写`run()`方法;第二种方式是将实现`Runnable`接口的对象作为构造参数传给`Thread(Runnale r)`。
+
+##继承Thread类(Thread Subclass)
+
+第一种为线程指定执行代码的方法:**继承Thread类并重写run方法。** `run()`方法在调用`Thread.start()`后执行。例子:
+
+```Java
+public class MyThread extends Thread {
+ public void run(){
+ System.out.println("MyThread running");
+ }
+}
+```
+
+通过下面的代码创建并执行线程:
+
+```
+ MyThread myThread = new MyThread();
+ myTread.start();
+```
+
+`start()`方法的调用会立即返回,并不会等待`run()`方法的执行,就好像这段代码被其他的CPU执行一样。
+
+你还可以使用匿名子类来创建线程对象:
+
+```Java
+Thread thread = new Thread(){
+ public void run(){
+ System.out.println("Thread Running");
+ }
+}
+
+thread.start();
+```
+
+##实现Runnable接口(Runnable Interface Implemention)
+
+第二种为线程指定执行代码的方法:创建实现`java.lang.Runnable`接口的对象,然后把该对象交给Thread执行。
+
+MyRunnable类实现Runnable接口:
+
+```Java
+public class MyRunnable implements Runnable {
+ public void run(){
+ System.out.println("MyRunnable running");
+ }
+}
+```
+
+将MyRunnable的实例作为构造参数传给Thread,然后通过`thread.start()`启动线程:
+
+```Java
+Thread thread = new Thread(new MyRunnable());
+thread.start();
+```
+
+当线程启动后,它会调用MyRunnable实例的`run()` 方法而不是自身的`run()`方法。
+
+
+同样,你可以通过匿名Runnable类来实现:
+
+````Java
+Runnable myRunnable = new Runnable(){
+
+ public void run(){
+ System.out.println("Runnable running");
+ }
+}
+
+Thread thread = new Thread(myRunnable);
+thread.start();
+```
+
+##子类还是实现接口(Subclass or Runnable)?
+
+There are no rules about which of the two methods that is the best. Both methods works. Personally though, I prefer implementing Runnable, and handing an instance of the implementation to a Thread instance. When having the Runnable's executed by a thread pool it is easy to queue up the Runnable instances until a thread from the pool is idle. This is a little harder to do with Thread subclasses.
+
+Sometimes you may have to implement Runnable as well as subclass Thread. For instance, if creating a subclass of Thread that can execute more than one Runnable. This is typically the case when implementing a thread pool. ??? Thread本身已经实现Runnable接口,这段话如何理解??
+
+##常见陷阱:(Common Pitfall: Calling run() instead of start())
+
+一个常见的陷阱就是调用`run()`方法来启动线程:
+
+```Java
+Thread newThread = new Thread(MyRunnable());
+thread.run(); //should be start();
+```
+
+这段代码的`run()`会正常执行,然而,它并不是由新创建的线程执行的,而是由当前线程执行。如果要创建新的线程来执行,必须调用`start()`方法而不是`run()`方法。
+
+
+##线程名称(Thread Names)
+
+ 当创建线程时,可以对线程命名,通过对线程命名可以用来区分不同的线程。举个例子,有多个线程通过`System.out`写内容到控制台,那么可以通过名字很方便地区分不同的线程:
+
+```Java
+Thread thread = new Thread("New Thread") {
+ public void run(){
+ System.out.println("run by: " + getname());
+ }
+};
+
+thread.start();
+System.out.println(thread.getName());
+```
+字符串“New Thread”通过构造函数传给Thread,这个就是线程的名字。可以通过`getName()`获取线程的名字。使用Runnable接口时,可以通过如下方式进行命名:
+
+```Java
+MyRunnable runnable = new MyRunnable();
+Thread thread = new Thread(runnable, "New Thread");
+
+thread.start();
+System.out.println(thread.getName());
+```
+
+获取当前线程的名字,可以通过一下方式获取:
+
+```Java
+String threadName = Thread.currentThread().getName();
+```
+##Java线程示例(Java Thread Example)
+
+下面的线程例子。首先打印执行main方法线程的名字(这个线程由JVM分配)。然后启动10个线程,并递增赋予它们名字i,每个线程打印自己的名字,最后停止:
+
+```Java
+public class ThreadExample {
+
+ public static void main(String[] args){
+ System.out.println(Thread.currentThread().getName());
+ for(int i=0; i<10; i++){
+ new Thread("" + i){
+ public void run(){
+ System.out.println("Thread: " + getName() + " running");
+ }
+ }.start();
+ }
+ }
+}
+```
+
+值得注意的是,虽然线程是依次按1,2,3启动,但是它们的执行却不是顺序的,也就说第一个启动的线程,并不一定第一个打印输出。这是因为线程**原则上**是并行执行而不是顺序执行,由JVM或操作系统来决定线程的执行顺序,这个顺序并不需要与它们的启动顺序一致。
\ No newline at end of file
diff --git "a/Java-Concurrency/05.\347\253\236\346\200\201\346\235\241\344\273\266\345\222\214\344\270\264\347\225\214\345\214\272.md" "b/Java-Concurrency/05.\347\253\236\346\200\201\346\235\241\344\273\266\345\222\214\344\270\264\347\225\214\345\214\272.md"
new file mode 100644
index 0000000..3aa7154
--- /dev/null
+++ "b/Java-Concurrency/05.\347\253\236\346\200\201\346\235\241\344\273\266\345\222\214\344\270\264\347\225\214\345\214\272.md"
@@ -0,0 +1,46 @@
+
+#05.竞态条件和临界区(Race Conditions and Critical Sections)
+
+在一个应用程序中运行多个线程这本身不会导致什么问题。问题在于多个线程同时对同一资源进行存取,例如同样的内存空间(变量、数组或对象),系统资源(数据库,文件系统等等)。如果是多个线程对同一资源进行读取,则不会有任何问题。
+
+以下的代码,如果有多个线程同时执行,则会导致问题:
+
+```Java
+public class Counter {
+ protected long count = 0;
+
+ public void add(long value){
+ this.count = this.count + value;
+ }
+}
+```
+
+想象一下,有两个线程:`A`和`B`,同时执行Counter类的实例的一个`add()`方法。操作系统中的线程调度如何进行,我们是无法进行预测的。并且,这个方法的代码在JVM内部并不是作为一个单独的指令执行的,而是有如下步骤:
+
+```
+get this.count from memory into register
+add value to register
+write register to memory
+```
+
+观察下面A线程和B线程的运行过程和结果:
+
+```
+this.count = 0;
+A: reads this.count into a register (0)
+B: reads this.count into a register (0)
+B: adds value 2 to register
+B: writes register value (2) back to memory. this.count now equals 2
+A: adds value 3 to register
+A: writes register value (3) back to memory. this.count now equals 3
+ ```
+
+ 线程A和线程B分别加2和3到counter中,在正常情况下,counter的结果应该为5。然而,由于两个线程的执行是互相交织的,两个线程同时从内存中读取0值到寄存器。然后它们分别把2和3跟0相加,最后由线程A把寄存器中的值写回到内存中,所以执行的最后结果是3。在上面的例子中,最后由线程A把3写到内存中,而实际上也可能是线程B。如果没有适当的同步机制,那么我们无从知晓这两个线程间到底如何交织执行。
+
+
+
+## 竞态条件和临界点(Race Conditions & Critical Sections)
+
+当多个线程对同一个资源进行竞争,访问这个资源的顺序是非常重要的,称之为**竞态条件**(he situation where two threads compete for the same resource, where the sequence in which the resource is accessed is significant, is called race conditions)。可以引起竞态条件的代码区域,称之为**临界区**。在前面的示例中,`add()`方法就是一个临界区。竞态条件可以通过在临界区进行适当的**线程同步**来避免。
+
+
diff --git "a/Java-Concurrency/06.\347\272\277\347\250\213\345\256\211\345\205\250\344\270\216\350\265\204\346\272\220\345\205\261\344\272\253.md" "b/Java-Concurrency/06.\347\272\277\347\250\213\345\256\211\345\205\250\344\270\216\350\265\204\346\272\220\345\205\261\344\272\253.md"
new file mode 100644
index 0000000..96a66b9
--- /dev/null
+++ "b/Java-Concurrency/06.\347\272\277\347\250\213\345\256\211\345\205\250\344\270\216\350\265\204\346\272\220\345\205\261\344\272\253.md"
@@ -0,0 +1,117 @@
+#06.线程安全与资源共享(Thread Safety and Shared Resources)
+
+
+如果一段代码可以安全地由多个线程并行调用,则称这段代码是**线程安全**的。如果一段代码是线程安全的,则这段代码不会引起**竞态条件**。只有当多个线程更新共享资源时才会发生**竞态条件**问题。因此,重要是要知道程序执行过程中哪些资源是线程共享的。
+
+##局部变量(Local Variables)
+
+局部变量存储在各自线程的栈中,这意味着局部变量不是线程共享的,这同样意味着所有的局部基本类型变量都是线程安全的。如下代码代码线程安全的:
+
+```Java
+public void someMethod(){
+
+ long threadSafeInt = 0;
+
+ threadSafeInt++;
+}
+```
+
+## 局部对象引用(Local Object References)
+
+ 局部对象的引用有一些差异。引用本身是不同享的,然而,引用的对象并不是存储在线程栈中,所有的对象都存储在Java堆,如果一个对象始终不逃逸出创建它的方法作用域之外,则它是线程安全的(If an object created locally never escapes the method it was created in, it is thread safe. )。而实际上,你也可以把这个对象引用传递给其他对象或者方法,只要传递的对象没有被其他线程处理,则它也是线程安全的。
+
+下面这个例子中的局部对象是线程安全的:
+
+```Java
+public void someMethod(){
+ LocalObject localObject = new LocalObject();
+
+ localObject.callMethod();
+ method2(localObject);
+}
+
+public void method2(LocalObject localObject){
+ localObject.setValue("value");
+}
+```
+
+在这个例子中,LocalObject的实例并没有从`someMethod()`方法中返回,也没有传递给其他在`someMethod()`作用域外的对象。每个执行`someMethod()`的线程都会创建各自的LocalObject实例,然后将引用传递给localObject引用变量。因此,这里的LocalObject的使用是线程安全的,实际上,整个`someMethod()`方法都是线程安全的,即使LocalObject实例作为参数传给本身对象或其他对象的方法,它都是线程安全的。唯一意外的情况就是:当localObject传递给其他的方法,而这些方法是可以被多线程访问的,则会导致线程安全问题。
+
+
+##对象成员变量(Object Members)
+
+对象的成员变量跟随对象本身存储在Java共享堆中。因此,如果两个变量调用同一个对象的一个方法,而这个方法会对对象的成员变量进行修改,则这个方法是**线程不安全**的。如下面这个例子:
+
+
+```Java
+public class NotThreadSafe{
+ StringBuilder builder = new StringBuilder();
+
+ public add(String text){
+ this.builder.append(text);
+ }
+}
+```
+
+如果两个线程同时调用同一个NotThreadSafe实例的`add(String texty)`方法,则会导致竞态条件:
+
+```Java
+NotThreadSafe sharedInstance = new NotThreadSafe();
+
+new Thread(new MyRunnable(sharedInstance)).start();
+new Thread(new MyRunnable(sharedInstance)).start();
+
+public class MyRunnable implements Runnable{
+ NotThreadSafe instance = null;
+
+ public MyRunnable(NotThreadSafe instance){
+ this.instance = instance;
+ }
+
+ public void run(){
+ this.instance.add("some text");
+ }
+}
+```
+
+注意两个MyRunnable实例共享同一个NoThreadSafe实例。因此,当两个线程同时调用`add()` 方法时则会导致竞态条件。
+
+然而,如果两个线程同时调用不同NoThreadSafe实例的`add()`方法则不会导致竞态条件。如下面这个例子:
+
+
+```Java
+new Thread(new MyRunnable(new NotThreadSafe())).start();
+new Thread(new MyRunnable(new NotThreadSafe())).start();
+```
+
+现在两个线程都拥有各自的NoThreadSafe实例,它们调用`add()`方法时并不会互相干扰,所以并没有导致竞态条件。因此,即使一个对象不是线程安全的,它们也可以用在不会引起竞态条件的代码中。
+
+
+##The Thread Control Escape Rule(线程控制逃逸规则)
+
+如果想知道你的代码是否线程安全,可以使用以下规则:
+
+> 如果一个资源的创建和使用始终在同一个线程的控制下,并且从没有逃逸出这个线程的控制,则认为是线程安全的。
+
+
+>If a resource is created, used and disposed within the control of the same thread, and never escapes the control of this thread, the use of that resource is thread safe.
+
+Resources can be any shared resource like an object, array, file, database connection, socket etc. In Java you do not always explicitly dispose objects, so "disposed" means losing or null'ing the reference to the object.
+
+Even if the use of an object is thread safe, if that object points to a shared resource like a file or database, your application as a whole may not be thread safe. For instance, if thread 1 and thread 2 each create their own database connections, connection 1 and connection 2, the use of each connection itself is thread safe. But the use of the database the connections point to may not be thread safe. For example, if both threads execute code like this:
+
+```
+check if record X exists
+if not, insert record X
+```
+
+If two threads execute this simultanously, and the record X they are checking for happens to be the same record, there is a risk that both of the threads end up inserting it. This is how:
+
+```
+Thread 1 checks if record X exists. Result = no
+Thread 2 checks if record X exists. Result = no
+Thread 1 inserts record X
+Thread 2 inserts record X
+```
+
+This could also happen with threads operating on files or other shared resources. Therefore it is important to distinguish between whether an object controlled by a thread is the resource, or if it merely references the resource.
\ No newline at end of file
diff --git "a/Java-Concurrency/07.\347\272\277\347\250\213\345\256\211\345\205\250\345\222\214\344\270\215\345\217\230\346\200\247.md" "b/Java-Concurrency/07.\347\272\277\347\250\213\345\256\211\345\205\250\345\222\214\344\270\215\345\217\230\346\200\247.md"
new file mode 100644
index 0000000..1264207
--- /dev/null
+++ "b/Java-Concurrency/07.\347\272\277\347\250\213\345\256\211\345\205\250\345\222\214\344\270\215\345\217\230\346\200\247.md"
@@ -0,0 +1,73 @@
+#07.线程安全和不变性
+
+只有当多个线程访问共享资源,并且一个线程或多个线程对资源进行写操作时,才会发生竞态条件。如果多个线程同时只对共享资源进行读操作,则不会发生**竞态条件**。
+
+我们可以通过把共享对象设置为不可变以至于让线程不能对对象进行改动,从而保证了线程安全。如下面这个例子:
+
+```Java
+public class ImmutableValue{
+
+ private int value = 0;
+
+ public ImmutableValue(int value){
+ this.value = value;
+ }
+
+ public int getValue(){
+ return this.value;
+ }
+}
+```
+
+注意value的值是通过构造函数进行设置的,并且value没有提供setter方法,所以一旦ImmutableValue实例被创建后,value的值就不能进行更改了。可以通过`getValue()`获取value的值,但不能进行改动。
+
+
+如果想要对ImmutableValue对象进行操作,可以通过返回一个新的实例来完成。例如下面这个
+
+```Java
+public class ImmutableValue{
+
+ private int value = 0;
+
+ public ImmutableValue(int value){
+ this.value = value;
+ }
+
+ public int getValue(){
+ return this.value;
+ }
+
+ public ImmutableValue add(int valueToAdd){
+ return new ImmutableValue(this.value + valueToAdd);
+ }
+
+}
+```
+
+注意这里返回了一个新的ImmutableValue实例,而不是对value的值进行修改。
+
+##引用不是线程安全的!(The Reference is not Thread Safe!)
+
+有一点需要谨记:**即使一个对象是线程安全的不可变对象,指向这个对象的引用也可能不是线程安全的。**
+
+```Java
+public class Calculator{
+ private ImmutableValue currentValue = null;
+
+ public ImmutableValue getValue(){
+ return currentValue;
+ }
+
+ public void setValue(ImmutableValue newValue){
+ this.currentValue = newValue;
+ }
+
+ public void add(int newValue){
+ this.currentValue = this.currentValue.add(newValue);
+ }
+}
+```
+
+The Calculator class holds a reference to an ImmutableValue instance. Notice how it is possible to change that reference through both the setValue() and add() methods. Therefore, even if the Calculator class uses an immutable object internally, it is not itself immutable, and therefore not thread safe. In other words: The ImmutableValue class is thread safe, but the use of it is not. This is something to keep in mind when trying to achieve thread safety through immutability.
+
+To make the Calculator class thread safe you could have declared the getValue(), setValue(), and add() methods synchronized. That would have done the trick.
diff --git "a/Java-Concurrency/08.Java\345\220\214\346\255\245\345\235\227.md" "b/Java-Concurrency/08.Java\345\220\214\346\255\245\345\235\227.md"
new file mode 100644
index 0000000..9ab49f6
--- /dev/null
+++ "b/Java-Concurrency/08.Java\345\220\214\346\255\245\345\235\227.md"
@@ -0,0 +1,183 @@
+#08.Java同步块
+
+Java synchronized block(Java同步块)用来对方法或代码块进行标记,表明这个方法或代码块是同步的。Java同步块可以避免**竞态条件**。
+
+
+##synchronized关键字(The Java synchronized Keyword)
+
+Java中的同步块使用关键字**synchronized**进行标记**。同步块在Java中是同步在某个对象上。所有同步在一个对象上的同步块在同一时间只能被一个线程进入并执行里面的代码。**其他所有试图进入该对象同步块的线程将被阻塞,直到执行该同步块中的线程退出。
+
+**synchronized**关键字可以被用于标记以下四种不同类型的块:
+
+- 实例方法(Instance methods)
+- 静态方法(Static methods)
+- 实例方法中的代码块(Code blocks inside instance methods)
+- 静态方法中的代码块(Code blocks inside static methods)
+
+上述同步块都同步在不同对象上。实际需要那种同步块视具体情况而定。
+
+##同步实例方法(Synchronized Instance Methods)
+
+下面是一个同步的实例方法:
+
+```Java
+ public synchronized void add(int value){
+ this.count += value;
+ }
+```
+
+使用**synchronized**关键字对方法进行声明,告诉JVM这是一个同步的方法。
+
+Java中的**同步实例方法是基于这个方法所属的实例对象上进行同步的**。因此,每一个同步实例方法都是基于各自的实例对象进行同步的。同一时间,只有一个线程可以访问一个实例对象的同步实例方法。如果有多个实例存在,那么每个线程都可以同时访问各自不同实例对象的同步实例方法,一个实例对象对应一个线程。
+
+##同步静态方法(Synchronized Static Methods)
+
+静态方法的同步与实例方法一致,都是使用**synchronized**在方法放进行声明。
+
+```Java
+ public static synchronized void add(int value){
+ count += value;
+ }
+```
+
+同样的,这里的**synchronized**关键字用于告诉JVM这个静态方法是同步的。
+
+**同步静态方法是基于这个静态方法所属的类对象进行同步的**。由于在JVM中,每个类有且只有一个类对象,因此,在同一时间内,只有一个线程能够访问同一个类的同步静态方法。
+
+如果同步静态方法位于不同的类中,那么每个线程都可以访问各自对应的类的同步静态方法,一个线程对应一个类。
+
+##实例方法中的同步块(Synchronized Blocks in Instance Methods)
+
+有些时候,你并不需要同步整一个方法,而只需要同步这个方法下的一小部分代码块。你可以在方法里面使用同步代码块。
+
+下面这个例子就是在非同步方法里面使用了同步代码块:
+
+```Java
+ public void add(int value){
+
+ synchronized(this){
+ this.count += value;
+ }
+ }
+```
+
+这个例子里,用了Java的同步代码块来使代码进行同步,让这个方法像同步方法一样执行。
+
+注意在Java的同步代码块里,需要在括号里传递一个对象。这个例子中,这个对象是**this**,this指的是这个实例对象本身。在Java同步代码块括号中的对象称为**监听器对象**。意味着,这个同步块是基于这个监听器对象进行同步的。同步实例方法使用其所在实例对象作为监听器对象。
+
+**同一时间,只有一个线程能够访问基于同一个监听器对象的同步代码。**
+
+下面这个例子,两个同步代码都是基于同一个实例对象进行同步的:
+
+```Java
+ public class MyClass {
+
+ public synchronized void log1(String msg1, String msg2){
+ log.writeln(msg1);
+ log.writeln(msg2);
+ }
+
+
+ public void log2(String msg1, String msg2){
+ synchronized(this){
+ log.writeln(msg1);
+ log.writeln(msg2);
+ }
+ }
+ }
+```
+
+因此,在这个例子中,每次仅能有一个线程能够访问这两个同步代码的任意一个同步代码。
+
+如果第二个同步块是基于其他监听器对象,例如`synchronized (this.getClass()) {}`,则此时第一个和第二个同步代码的监听器对象分别为:当前实例对象和当前类对象。因此,这两个同步代码可以同时由不同的线程进行访问。
+
+##静态方法中的同步块(Synchronized Blocks in Static Methods)
+
+下面这个例子中,两个同步代码都是基于当前的类对象进行同步的:
+
+```Java
+ public class MyClass {
+
+ public static synchronized void log1(String msg1, String msg2){
+ log.writeln(msg1);
+ log.writeln(msg2);
+ }
+
+
+ public static void log2(String msg1, String msg2){
+ synchronized(MyClass.class){
+ log.writeln(msg1);
+ log.writeln(msg2);
+ }
+ }
+ }
+```
+
+同一时间,只有一个线程能够访问这两个同步代码的任意一个同步代码。
+
+如果第二个方法的监听器对象非MyClass.class对象,则两个同步代码可以同时被两个线程访问。
+
+
+##Java同步示例(Java Synchronized Example)
+
+Here is an example that starts 2 threads and have both of them call the add method on the same instance of Counter. Only one thread at a time will be able to call the add method on the same instance, because the method is synchronized on the instance it belongs to.
+
+```Java
+public class Counter{
+ long count = 0;
+
+ public synchronized void add(long value){
+ this.count += value;
+ }
+}
+public class CounterThread extends Thread{
+ protected Counter counter = null;
+
+ public CounterThread(Counter counter){
+ this.counter = counter;
+ }
+
+ public void run() {
+for(int i=0; i<10; i++){
+ counter.add(i);
+ }
+ }
+}
+public class Example {
+
+ public static void main(String[] args){
+ Counter counter = new Counter();
+ Thread threadA = new CounterThread(counter);
+ Thread threadB = new CounterThread(counter);
+
+ threadA.start();
+ threadB.start();
+ }
+}
+```
+
+Two threads are created. The same Counter instance is passed to both of them in their constructor. The Counter.add() method is synchronized on the instance, because the add method is an instance method, and marked as synchronized. Therefore only one of the threads can call the add() method at a time. The other thread will wait until the first thread leaves the add() method, before it can execute the method itself.
+
+If the two threads had referenced two separate Counter instances, there would have been no problems calling the add() methods simultaneously. The calls would have been to different objects, so the methods called would also be synchronized on different objects (the object owning the method). Therefore the calls would not block. Here is how that could look:
+
+```Java
+public class Example {
+ public static void main(String[] args){
+ Counter counterA = new Counter();
+ Counter counterB = new Counter();
+ Thread threadA = new CounterThread(counterA);
+ Thread threadB = new CounterThread(counterB);
+
+ threadA.start();
+ threadB.start();
+ }
+}
+```
+
+Notice how the two threads, threadA and threadB, no longer reference the same counter instance. The add method of counterA and counterB are synchronized on their two owning instances. Calling add() on counterA will thus not block a call to add() on counterB.
+
+##Java Concurrency Utilities
+
+`synchronized`机制是Java第一个引进的用于同步多线程资源共享的机制。然而`synchroniez`机制并不高效。这就是为什么Java 5提供了一整套的并发工具类,以帮助开发人员实现更细粒度的并发控制
+。
+Status API Training Shop Blog About © 2014 GitHub, Inc. Terms Privacy Security Contact
diff --git "a/Java-Concurrency/09.Java\347\232\204volatile\345\205\263\351\224\256\345\255\227.md" "b/Java-Concurrency/09.Java\347\232\204volatile\345\205\263\351\224\256\345\255\227.md"
new file mode 100644
index 0000000..4cf1bfb
--- /dev/null
+++ "b/Java-Concurrency/09.Java\347\232\204volatile\345\205\263\351\224\256\345\255\227.md"
@@ -0,0 +1,90 @@
+#09.Java的volatile关键字
+
+未完,有疑惑,待续!
+
+Java的**volatile**关键字用来标识让变量**像存储在主内存中一样** (The Java volatile keyword is used to mark a Java variable as "being stored in main memory". )。更准确地说,被volatile声明的变量,它们的读操作都是从**主内存**中而不是**CPU缓存**中读取,同时,以及它们的写操作,都会同时写到**主内存**和**CPU缓存**中。
+
+实际上,从Java 5开始,volatile关键字不仅仅只是保证变量从主内存中读取和写入。我会在接下来的章节进行详细讲解。
+
+##volatile保证变量可见性(Java volatile Guarantees Variable Visibility)
+
+Java的volatile关键字保证了**线程间变量的可见性**。这听起来似乎很抽象, 让我来解释一下。
+
+在多线程的应用程序中,当多个线程对没有volatile关键字声明的变量进行操作时,基于性能考虑,每个线程都会从主内存中拷贝一份变量的值到CPU缓存里。如果你的计算器拥有多个CPU,那么每个线程都有可能使用不同的CPU运行。这意味着,每个线程都有可能拷贝一份数据到各自的CPU缓存中。这种情况如下图所示:
+
+
+
+没有使用volatile声明的变量,将不能保证**JVM何时从主内存中读取数据到CPU缓存,以及何时从CPU缓冲中读取数据到内存**。让我解释一下这样会发生什么状况:
+
+想象这样一个场景:多个线程访问同一个共享对象,这个对象包含一个计数器变量:
+
+```Java
+public class SharedObject {
+ public int counter = 0;
+}
+```
+
+线程1读取counter变量值0到CPU缓存,同时对该变量加1,但并不立即写回主内存。线程2同样读取主内存中的counter变量值0到自己的CPU缓存中,同样对这个值加1,也不立即写回主内存。线程1和线程2实际上并不是同步的(Thread 1 and Thread 2 are now practically out of sync. )。此时,counter的正确值应该为2,而线程1和线程2在CPU缓存的值却是1,而主内存中counter的值目前仍然是0。这种情况是十分混乱的,即使线程将CPU缓存的值写回住内存中,这个值也是错误的。
+
+如果使用**volatile**关键字声明counter变量,JVM将会保证每次读取counter的值都会从主内存中读取,每次对counter变量的修改都会立即写回到主内存。
+
+```Java
+public class SharedObject {
+ public volatile int counter = 0;
+}
+```
+
+在一些情况下,简单地用volatile声明变量,也许已经足够让多个线程每次读取的都是变量的最新值。
+
+然而,在另一些情况下,当两个线程都对变量读取和写入时,volatile并不足够。线程1读取counter的值0到CPU1的寄存器中,于此同时(或紧接着)线程2读取counter的值0到CPU2的寄存器中。两个线程都是直接从主内存中读取counter的值。然后,两个线程分别对counter的值加1,并写回主内存中。经过加1后,两个寄存器中的值都是1,并且把这个值写回主内存中。然而counter的正确值应该为2 。
+
+上述问题中,多个线程并没有读取到变量的最新值,是因为其他线程还没将寄存器的值写回主内存,这就是“** 可见性**”问题。一个线程的更新对其他线程不可见。
+
+In some cases simply declaring a variable volatile may be enough to assure that multiple threads accessing the variable see the latest written value. I will get back to which cases volatile is sufficient later.
+
+In the situation with the two threads reading and writing the same variable, simply declaring the variable volatile is not enough. Thread 1 may read the counter value 0 into a CPU register in CPU 1. At the same time (or right after) Thread 2 may read the counter value 0 into a CPU register in CPU 2. Both threads have read the value directly from main memory. Now both variables increase the value and writes the value back to main memory. They both increment their register version of counter to 1, and both write the value 1 back to main memory. The value should have been 2 after two increments.
+
+The problem with multiple threads that do not see the latest value of a variable because that value has not yet been written back to main memory by another thread, is called a "visibility" problem. The updates of one thread are not visible to other threads.
+
+##valatile的保证(The Java volatile Guarantee)
+
+从Java 5之后,volatile关键字不仅仅只是保证每次都是从主内存中读取和写入数据。实际上volatile关键字保证:
+
+> If Thread A writes to a volatile variable and Thread B subsequently reads the same volatile variable, then all variables visible to Thread A before writing the volatile variable, will also be visible to Thread B.
+
+The reading and writing instructions of volatile variables cannot be reordered by the JVM (the JVM may reorder instructions for performance reasons as long as the JVM detects no change in program behaviour from the reordering). Instructions before and after can be reordered, but the volatile read or write cannot be mixed with these instructions. Whatever instructions follow a read or write of a volatile variable are guaranteed to happen after the read or write.
+Look at this example:
+
+```Java
+Thread A:
+ sharedObject.nonVolatile = 123;
+ sharedObject.counter = sharedObject.counter + 1;
+
+Thread B:
+ int counter = sharedObject.counter;
+ int nonVolatile = sharedObject.nonVolatile;
+```
+
+Since Thread A writes the non-volatile variable sharedObject.nonVolatile before writing to the volatile sharedObject.counter, then both sharedObject.nonVolatile and sharedObject.counter are written to main memory.
+
+Since Thread B starts by reading the volatile sharedObject.counter, then both the sharedObject.counter and sharedObject.nonVolatile are read in from main memory.
+
+The reading and writing of the non-volatile variable cannot be reordered to happen before or after the reading and writing of the volatile variable.
+
+##volatile足够了吗?(When is volatile Enough?)
+
+正如前面我所提到的,当两个线程都对共享变量进行读取和写入时,使用volatile关键字是不足够的。你需要
+对变量的读取和写入进行同步,保证这些操作都是原子性的。
+
+当如果只有一个线程对变量进行读取和写入,而其它线程都只对变量进行读取,那么就可以保证读线程每次读到的都是volatile变量的最新值。如果没有volatile关键字,这些都是不可以保证的。
+
+As I have mentioned earlier, if two threads are both reading and writing to a shared variable, then using the volatile keyword for that is not enough. You need to use synchronization in that case to guarantee that the reading and writing of the variable is atomic.
+
+But in case one thread reads and writes the value of a volatile variable, and other threads only read the variable, then the reading threads are guaranteed to see the latest value written to the volatile variable. Without making the variable volatile, this would not be guaranteed.
+
+##volatile的性能考虑(Performance Considerations of volatile)
+
+volatile关键字保证变量的读取和写入都会在主内存中进行。相比从CPU缓存中读取和写入数据,在主内存中读取和写入数据是相对比较消耗性能的。volatile关键字会阻止指令重排(指令重排是很常见的用于增强性能的技术)。因此,只有当真正需要让变量强制可见时才使用volatile关键字。
+
+Reading and writing of volatile variables causes the variable to be read or written to main memory. Reading from and writing to main memory is more expensive than accessing the CPU cache. Accessing volatile variables also prevent instruction reordering which is anormal performance enhancement techqniqe. Thus, you should only use volatile variables when you really need to enforce visibility of variables.
+
diff --git "a/Java-Concurrency/10.\347\272\277\347\250\213\351\200\232\344\277\241.md" "b/Java-Concurrency/10.\347\272\277\347\250\213\351\200\232\344\277\241.md"
new file mode 100644
index 0000000..5d4878d
--- /dev/null
+++ "b/Java-Concurrency/10.\347\272\277\347\250\213\351\200\232\344\277\241.md"
@@ -0,0 +1,208 @@
+#10.线程通信
+
+线程通信的目的在于:让线程之间可以彼此发送信号。因此,线程通信也让线程等待其他线程发送的信号。举个例子,线程B等待线程A的信号,这个信号用于通知线程B数据已经准备就绪。
+
+##通过共享对象通信(Signaling via Shared Objects)
+
+线程间进行通信,一个简单的做法就是**通过共享对象存储信号值**。线程A在同步代码块中将`hasDataToProcess`的值设为`true`,然后线程B在同步代码块中读取`hasDataToProcess`的值,这就完成了一次线程通信。下面的这个示例MySignal类用于保存信号值,并提供方法获取这个信号值:
+
+```Java
+public class MySignal{
+ protected boolean hasDataToProcess = false;
+
+ public synchronized boolean hasDataToProcess(){
+ return this.hasDataToProcess;
+ }
+
+ public synchronized void setHasDataToProcess(boolean hasData){
+ this.hasDataToProcess = hasData;
+ }
+}
+```
+
+为了进行通信,线程A和线程B必须拥有共享的MySignal的实例对象的引用。如果线程A和线程B拥有的是不同的MySignal实例引用,它们将不会检测到彼此的信号。The data to be processed can be located in a shared buffer separate from the MySignal instance.
+
+##忙等待(Busy Wait)
+
+
+线程B等待数据可用,然后对数据进行处理。换言之,线程B等待线程A发送的信号量,通过检测`hasDataToProcess() `的返回值,如果返回值为true,则证明此时数据准备就绪。下面的循环用于检测信号:
+
+```Java
+protected MySignal sharedSignal = ...
+
+while(!sharedSignal.hasDataToProcess()){
+ //do nothing... busy waiting
+}
+```
+
+注意这个while循环直至`hasDataToProcess() `返回`true`才退出,这种做法称为**忙等待(Busy Waiting)**。线程在等待过程中一直处于忙碌状态。
+
+
+##wait(), notify()和notifyAll()
+
+忙等待对计算机的CPU利用率并不友好,除非平均等待时间十分短暂。更好的做法是,让等待的线程处于休眠状态或非活动状态直至它收到信号。
+
+Java内置了等待机制可以让线程处于非活动状态直至收到信号。`java.lang.Object`中定义了三个方法:**wait()**,**notify()**和**notifyAll**用来实现这个机制。
+
+在线程内部调用任意对象的`wait()`会使该线程变成暂停状态,直到其他线程调用同一个对象的`notify()`或`notifyAll()`方法。如果想要调用对象的wait()/notify()方法,线程先必须取的该对象的同步锁。换言之,**wait()和notify()方法的调用必须在同步代码内部**。上面例子的wait()/notify()版本:
+
+```Java
+public class MonitorObject{
+}
+
+public class MyWaitNotify{
+
+ MonitorObject myMonitorObject = new MonitorObject();
+
+ public void doWait(){
+ synchronized(myMonitorObject){
+ try{
+ myMonitorObject.wait();
+ } catch(InterruptedException e){...}
+ }
+ }
+
+ public void doNotify(){
+ synchronized(myMonitorObject){
+ myMonitorObject.notify();
+ }
+ }
+}
+```
+
+等待通知的线程调用`doWait()`方法,而通知线程调用`doNotify()`方法。当一个线程调用一个对象的`notify()`方法后,等待这个对象的其中一个线程就被唤醒并执行。与`notify()`方法不同的是,`notifyAll()`会唤醒所有等待这个对象的线程。
+
+正如你所看到的,`wait()`和`notify()`的调用都在同步块中。这是强制性的要求。如果线程没有拥有对象的锁,则不能调用该对象的`wait()`,`notify()`和`notifyAll()`方法,否则将会抛出`IlleageMonitorStateException` 异常。
+
+But, how is this possible? Wouldn't the waiting thread keep the lock on the monitor object (myMonitorObject) as long as it is executing inside a synchronized block? Will the waiting thread not block the notifying thread from ever entering the synchronized block in doNotify()? The answer is no. Once a thread calls wait() it releases the lock it holds on the monitor object. This allows other threads to call wait() or notify() too, since these methods must be called from inside a synchronized block.
+
+当一个等待的线程被唤醒之后并不会立即离开`wait()`方法直至调用`notify()`方法的线程退出代码块。换言之,因为`wait()`方法嵌套在同步代码块内部,所以被唤醒的线程需要重新获得模拟器对象的锁才能够离开`wait()`方法。如果有多个线程通过`notifyAll()`方法被唤醒,同一时间也只能有一个线程能够离开`wait()`方法并重新进入同步代码块,因为每一个线程都必须先获得模拟器对象的锁才能够离开`wait()`方法。
+
+##信号丢失(Missed Signals)
+
+The methods notify() and notifyAll() do not save the method calls to them in case no threads are waiting when they are called. The notify signal is then just lost. Therefore, if a thread calls notify() before the thread to signal has called wait(), the signal will be missed by the waiting thread. This may or may not be a problem, but in some cases this may result in the waiting thread waiting forever, never waking up, because the signal to wake up was missed.
+
+该方法的通知()和notifyAll()不救的方法调用它们的情况下没有线程在等待的时候,他们被称为。该通知信号然后就失去了。因此,如果一个线程调用notify()的线程之前,信号调用wait()时,信号将被等待的线程被错过。这可能会或可能不会成为问题,但在某些情况下,这可能会导致等待线程永远等待,从未苏醒,因为该信号被错过醒来。
+
+To avoid losing signals they should be stored inside the signal class. In the MyWaitNotify example the notify signal should be stored in a member variable inside the MyWaitNotify instance. Here is a modified version of MyWaitNotify that does this:
+
+```Java
+public class MyWaitNotify2{
+
+ MonitorObject myMonitorObject = new MonitorObject();
+ boolean wasSignalled = false;
+
+ public void doWait(){
+ synchronized(myMonitorObject){
+ if(!wasSignalled){
+ try{
+ myMonitorObject.wait();
+ } catch(InterruptedException e){...}
+ }
+ //clear signal and continue running.
+ wasSignalled = false;
+ }
+ }
+
+ public void doNotify(){
+ synchronized(myMonitorObject){
+ wasSignalled = true;
+ myMonitorObject.notify();
+ }
+ }
+}
+```
+
+Notice how the doNotify() method now sets the wasSignalled variable to true before calling notify(). Also, notice how the doWait() method now checks the wasSignalled variable before calling wait(). In fact it only calls wait() if no signal was received in between the previous doWait() call and this.
+
+##假唤醒(Spurious Wakeups)
+
+For inexplicable reasons it is possible for threads to wake up even if notify() and notifyAll() has not been called. This is known as spurious wakeups. Wakeups without any reason.
+
+If a spurious wakeup occurs in the MyWaitNofity2 class's doWait() method the waiting thread may continue processing without having received a proper signal to do so! This could cause serious problems in your application.
+
+To guard against spurious wakeups the signal member variable is checked inside a while loop instead of inside an if-statement. Such a while loop is also called a spin lock. The thread awakened spins around until the condition in the spin lock (while loop) becomes false. Here is a modified version of MyWaitNotify2 that shows this:
+
+```Java
+public class MyWaitNotify3{
+
+ MonitorObject myMonitorObject = new MonitorObject();
+ boolean wasSignalled = false;
+
+ public void doWait(){
+ synchronized(myMonitorObject){
+ while(!wasSignalled){
+ try{
+ myMonitorObject.wait();
+ } catch(InterruptedException e){...}
+ }
+ //clear signal and continue running.
+ wasSignalled = false;
+ }
+ }
+
+ public void doNotify(){
+ synchronized(myMonitorObject){
+ wasSignalled = true;
+ myMonitorObject.notify();
+ }
+ }
+}
+```
+
+Notice how the wait() call is now nested inside a while loop instead of an if-statement. If the waiting thread wakes up without having received a signal, the wasSignalled member will still be false, and the while loop will execute once more, causing the awakened thread to go back to waiting.
+
+##Multiple Threads Waiting for the Same Signals
+
+The while loop is also a nice solution if you have multiple threads waiting, which are all awakened using notifyAll(), but only one of them should be allowed to continue. Only one thread at a time will be able to obtain the lock on the monitor object, meaning only one thread can exit the wait() call and clear the wasSignalled flag. Once this thread then exits the synchronized block in the doWait() method, the other threads can exit the wait() call and check the wasSignalled member variable inside the while loop. However, this flag was cleared by the first thread waking up, so the rest of the awakened threads go back to waiting, until the next signal arrives.
+
+
+##Don't call wait() on constant String's or global objects
+
+An earlier version of this text had an edition of the MyWaitNotify example class which used a constant string ( "" ) as monitor object. Here is how that example looked:
+
+```Java
+public class MyWaitNotify{
+
+ String myMonitorObject = "";
+ boolean wasSignalled = false;
+
+ public void doWait(){
+ synchronized(myMonitorObject){
+ while(!wasSignalled){
+ try{
+ myMonitorObject.wait();
+ } catch(InterruptedException e){...}
+ }
+ //clear signal and continue running.
+ wasSignalled = false;
+ }
+ }
+
+ public void doNotify(){
+ synchronized(myMonitorObject){
+ wasSignalled = true;
+ myMonitorObject.notify();
+ }
+ }
+}
+```
+
+The problem with calling wait() and notify() on the empty string, or any other constant string is, that the JVM/Compiler internally translates constant strings into the same object. That means, that even if you have two different MyWaitNotify instances, they both reference the same empty string instance. This also means that threads calling doWait() on the first MyWaitNotify instance risk being awakened by doNotify() calls on the second MyWaitNotify instance.
+
+The situation is sketched in the diagram below:
+
+
+
+Calling wait()/notify() on string constants
+Remember, that even if the 4 threads call wait() and notify() on the same shared string instance, the signals from the doWait() and doNotify() calls are stored individually in the two MyWaitNotify instances. A doNotify() call on the MyWaitNotify 1 may wake threads waiting in MyWaitNotify 2, but the signal will only be stored in MyWaitNotify 1.
+
+At first this may not seem like a big problem. After all, if doNotify() is called on the second MyWaitNotify instance all that can really happen is that Thread A and B are awakened by mistake. This awakened thread (A or B) will check its signal in the while loop, and go back to waiting because doNotify() was not called on the first MyWaitNotify instance, in which they are waiting. This situation is equal to a provoked spurious wakeup. Thread A or B awakens without having been signaled. But the code can handle this, so the threads go back to waiting.
+
+The problem is, that since the doNotify() call only calls notify() and not notifyAll(), only one thread is awakened even if 4 threads are waiting on the same string instance (the empty string). So, if one of the threads A or B is awakened when really the signal was for C or D, the awakened thread (A or B) will check its signal, see that no signal was received, and go back to waiting. Neither C or D wakes up to check the signal they had actually received, so the signal is missed. This situation is equal to the missed signals problem described earlier. C and D were sent a signal but fail to respond to it.
+
+If the doNotify() method had called notifyAll() instead of notify(), all waiting threads had been awakened and checked for signals in turn. Thread A and B would have gone back to waiting, but one of either C or D would have noticed the signal and left the doWait() method call. The other of C and D would go back to waiting, because the thread discovering the signal clears it on the way out of doWait().
+
+You may be tempted then to always call notifyAll() instead notify(), but this is a bad idea performance wise. There is no reason to wake up all threads waiting when only one of them can respond to the signal.
+
+So: Don't use global objects, string constants etc. for wait() / notify() mechanisms. Use an object that is unique to the construct using it. For instance, each MyWaitNotify3 (example from earlier sections) instance has its own MonitorObject instance rather than using the empty string for wait() / notify() calls.
diff --git "a/Java-Concurrency/11.\346\255\273\351\224\201.md" "b/Java-Concurrency/11.\346\255\273\351\224\201.md"
new file mode 100644
index 0000000..6d5e624
--- /dev/null
+++ "b/Java-Concurrency/11.\346\255\273\351\224\201.md"
@@ -0,0 +1,96 @@
+#11.死锁
+
+死锁是指两个或多个线程等待其他处于死锁状态的线程所持有的锁。死锁通常发生在多个线程同时但以不同的顺序请求同一组锁的时候。
+
+例如,如果线程1持有锁A,但试图去获取锁B,而此时线程1持有锁B,却试图去获取锁A,这时死锁就发生了。线程1永远得不到锁B,线程2也永远得不到线程A,并且它们永远也不知道发生了什么事。为了获得彼此所持有的锁,它们将永远阻塞下去。这种情况就是一个死锁。
+
+这种情况描述如下:
+
+```
+Thread 1 locks A, waits for B
+Thread 2 locks B, waits for A
+```
+
+这里有一个TreeNode类的例子,它调用了不同实例的synchronized方法:
+
+```Java
+public class TreeNode {
+ TreeNode parent = null;
+ List children = new ArrayList();
+
+ public synchronized void addChild(TreeNode child){
+ if(!this.children.contains(child)) {
+ this.children.add(child);
+ child.setParentOnly(this);
+ }
+ }
+
+ public synchronized void addChildOnly(TreeNode child){
+ if(!this.children.contains(child){
+ this.children.add(child);
+ }
+ }
+
+ public synchronized void setParent(TreeNode parent){
+ this.parent = parent;
+ parent.addChildOnly(this);
+ }
+
+ public synchronized void setParentOnly(TreeNode parent){
+ this.parent = parent;
+ }
+}
+```
+
+ 如果线程1调用`parent.addChild(child)`方法,而与此同时线程2调用`child.setParent(parent)`方法,两个线程中的parent和child都是同一个对象实例,此时死锁就发生了。
+
+下面的伪代码说明了这个过程:
+
+```
+Thread 1: parent.addChild(child); //locks parent
+ --> child.setParentOnly(parent);
+
+Thread 2: child.setParent(parent); //locks child
+ --> parent.addChildOnly()
+```
+
+首先线程1调用`parent.addChild(child)`方法,由于这个方法是同步的,所以线程1锁住了parent对象以防止其他线程访问。
+
+然后线程2调用`child.setParent(parent)`方法,由于这个方法的同步的,所以线程2锁住了child对象以防止其他线程访问。
+
+现在parent对象和child对象都分别被线程1和线程2锁住了。下一步,线程1试图调用`child.setParentOnly()`方法,但child方法已经被线程2锁住,所以这个方法会阻塞。线程2也试图调用`parent.addChildOnly()`方法,但parent对象此时已被线程1锁住,所以这个方法也会阻塞。现在两个线程都试图获取对方所持有的锁而进入阻塞状态。
+
+注意:两个线程必须同时调用`parent.addChild(child)`和`child.setParent(parent)`方法,而且并需是在同一个parent和child对象上,死锁才有可能发生。上面的代码可能要运行一段时间才可能出现死锁。
+
+这两个线程必须要同时获得锁。举个例子,如果线程1稍微先与线程2获得A和B的锁,这时线程2在试图获取B的锁时就会阻塞,这时不会产生死锁。由于线程的调度不可预测,所以我们无法预测什么时候会产生死锁,仅仅是可能会发生。
+
+##更加复杂的死锁(More Complicated Deadlocks)
+
+死锁的发生可能由多于两个线程造成,在这种情况下,很难对死锁进行检测。下面的例子演示了多个线程造成的死锁:
+
+```
+Thread 1 locks A, waits for B
+Thread 2 locks B, waits for C
+Thread 3 locks C, waits for D
+Thread 4 locks D, waits for A
+```
+
+线程1等待线程2,线程2等待线程3,线程3等待线程4,而线程4等待线程1.
+Thread 1 waits for thread 2, thread 2 waits for thread 3, thread 3 waits for thread 4, and thread 4 waits for thread 1.
+
+##数据库死锁(Database Deadlocks)
+
+更加复杂的死锁场景发生在数据库中。一个数据库事务通常包含多条SQL更新请求。当一条记录被事务更新时,这条记录就会被这个事务锁住,以防止其他事务更新,直到当前事务结束。同一个事务中的多个更新语句都有可能需要锁住一些记录。
+
+当多个事务同时需要对一些相同的记录做更新操作时,就很有可能发生死锁,例如:
+
+举个例子:
+
+```
+Transaction 1, request 1, locks record 1 for update
+Transaction 2, request 1, locks record 2 for update
+Transaction 1, request 2, tries to lock record 2 for update.
+Transaction 2, request 2, tries to lock record 1 for update.
+```
+
+因为锁发生在不同的请求中,并且对于一个事务来说不可能提前知道所有它需要的锁,因此很难检测和避免数据库事务中的死锁。
diff --git "a/Java-Concurrency/12.\351\242\204\351\230\262\346\255\273\351\224\201.md" "b/Java-Concurrency/12.\351\242\204\351\230\262\346\255\273\351\224\201.md"
new file mode 100644
index 0000000..0c6b61d
--- /dev/null
+++ "b/Java-Concurrency/12.\351\242\204\351\230\262\346\255\273\351\224\201.md"
@@ -0,0 +1,91 @@
+#12.预防死锁
+
+在某些情况,死锁是可以预防的。下面介绍三种可以预防死锁的技术:
+
+* 加锁顺序
+* 加锁超时
+* 死锁检测
+
+
+##加锁顺序(Lock Ordering)
+
+当多个线程需要相同的锁,但以不同的顺序获取锁时,这时死锁就很容易发生。
+
+如果所有的锁都是按照相同的顺序获取,那么死锁是不会出现的。看下下面的例子:
+
+```
+Thread 1:
+
+ lock A
+ lock B
+---------------------
+Thread 2:
+
+ wait for A
+ lock C (when A locked)
+---------------------
+Thread 3:
+
+ wait for A
+ wait for B
+ wait for C
+```
+
+如果一个线程,例如线程3,需要一些锁,那么她必须按照一定的顺序获取锁。只有按照顺序获取前面的锁,才能够依次获取后面的锁。
+
+例如,线程2和线程3,只有当它们获得锁A后才能够去尝试获取锁C。由于线程1持有锁A,线程2和线程3都会阻塞直至锁A被线程1释放。
+
+顺序加锁是一个非常有效的用于预防死锁的机制。然而,它只有预先知道所有的加锁顺序时才能很好的地工作,它并不适用于所有情况。(However, it can only be used if you know about all locks needed ahead of taking any of the locks. This is not always the case.)
+
+
+##加锁超时(Lock Timeout)
+
+另一种预防死锁的机制就是试图获取锁时设置超时。如果线程在规定时间内没有获得锁,则会放弃,并释放自身锁持有的锁,等待一个随机时间,然后重试。在随机等待时间内,给予其他线程获取相同的锁,从而避免死锁发生。
+
+下面是两个线程尝试以不同的顺序获取两个锁,在超时回退后进行重试的例子:
+
+```
+Thread 1 locks A
+Thread 2 locks B
+
+Thread 1 attempts to lock B but is blocked
+Thread 2 attempts to lock A but is blocked
+
+Thread 1's lock attempt on B times out
+Thread 1 backs up and releases A as well
+Thread 1 waits randomly (e.g. 257 millis) before retrying.
+
+Thread 2's lock attempt on A times out
+Thread 2 backs up and releases B as well
+Thread 2 waits randomly (e.g. 43 millis) before retrying.
+```
+
+在上面的例子中,线程2比线程1早大约200ms进行重新加锁,因此很有可能可以取到全部的锁。线程1尝试获取锁A,由于2持有所有A,所以线程1进入等待状态。当线程2执行完释放所有的锁,线程1就可以持有所有的锁了。(除非有其他线程也在争夺锁A和锁B)
+
+有个问题需要注意的就是,如果出现了加锁超时,并不意味着出现了死锁。加锁超时可能是因为某个持有锁的线程需要大量的时间来执行任务。
+
+另外,如果有大量的线程去争夺相同的资源,即使有加锁超时和重试机制,也有可能会导致线程不停地重试但却无法获取所需的锁。如果只有两个线程,且重试时间在0-500ms之间,也许死锁不会发生。但如果线程在10-20之间情况则有可能不同,因为这些线程中的超时重试时间很大概率生是相同或相近的。
+
+加锁超时机制的一个缺点是:Java并不提供进入synchronized块的超时设置。你可以自定义锁或使用Java 5提供的在`java.util.concurrency`包中的工具类。自定义锁并不困难,但是超出了本文的内容。后面的教程会做详细讲解。
+
+##死锁检测(Deadlock Detection)
+
+Deadlock detection is a heavier deadlock prevention mechanism aimed at cases in which lock ordering isn't possible, and lock timeout isn't feasible.
+
+Every time a thread takes a lock it is noted in a data structure (map, graph etc.) of threads and locks. Additionally, whenever a thread requests a lock this is also noted in this data structure.
+
+When a thread requests a lock but the request is denied, the thread can traverse the lock graph to check for deadlocks. For instance, if a Thread A requests lock 7, but lock 7 is held by Thread B, then Thread A can check if Thread B has requested any of the locks Thread A holds (if any). If Thread B has requested so, a deadlock has occurred (Thread A having taken lock 1, requesting lock 7, Thread B having taken lock 7, requesting lock 1).
+
+Of course a deadlock scenario may be a lot more complicated than two threads holding each others locks. Thread A may wait for Thread B, Thread B waits for Thread C, Thread C waits for Thread D, and Thread D waits for Thread A. In order for Thread A to detect a deadlock it must transitively examine all requested locks by Thread B. From Thread B's requested locks Thread A will get to Thread C, and then to Thread D, from which it finds one of the locks Thread A itself is holding. Then it knows a deadlock has occurred.
+
+Below is a graph of locks taken and requested by 4 threads (A, B, C and D). A data structure like this that can be used to detect deadlocks.
+
+Deadlock Detection Data Structure
+
+
+
+So what do the threads do if a deadlock is detected?
+
+One possible action is to release all locks, backup, wait a random amount of time and then retry. This is similar to the simpler lock timeout mechanism except threads only backup when a deadlock has actually occurred. Not just because their lock requests timed out. However, if a lot of threads are competing for the same locks they may repeatedly end up in a deadlock even if they back up and wait.
+
+A better option is to determine or assign a priority of the threads so that only one (or a few) thread backs up. The rest of the threads continue taking the locks they need as if no deadlock had occurred. If the priority assigned to the threads is fixed, the same threads will always be given higher priority. To avoid this you may assign the priority randomly whenever a deadlock is detected.
diff --git "a/Java-Concurrency/13.\351\245\245\351\245\277\345\222\214\345\205\254\345\271\263.md" "b/Java-Concurrency/13.\351\245\245\351\245\277\345\222\214\345\205\254\345\271\263.md"
new file mode 100644
index 0000000..62c3b95
--- /dev/null
+++ "b/Java-Concurrency/13.\351\245\245\351\245\277\345\222\214\345\205\254\345\271\263.md"
@@ -0,0 +1,193 @@
+#13.饥饿和公平(Starvation and Fairness)
+
+如果一个线程由于CPU时间全部被其他线程抢占而得不到CPU时间,这就称为**饥饿(Starvation)**。这个线程因为得不到CPU机会而“饿死(starved to death)"。解决饥饿的方案称为**公平(Fairness)**--所有的线程都能公平地获得CPU时间。
+
+##Java中产生饥饿的原因
+
+在Java中,下面三种常见原因会导致饥饿:
+
+* 高优先级的线程抢占了所有的CPU时间。
+* 线程陷入无止境地等待进入同步块状态,因为其他线程总是能够在它之前获得进入同步块的机会。
+* 线程陷入无止境地等待被唤醒(调用了对象的wait()方法)状态,因为其他线程总能够持续获得唤醒机会而不是这个线程。
+
+###高优先级线程抢占了所有的CPU时间
+
+你可以为每个线程设置优先级。高优先级的线程能够获得更多的CPU时间。优先级可以设置为1-10之间。这些优先级值的解释根据操作系统的差异而有所不同。对于大部分应用程式来说,你最好不要改变其优先级值。
+
+###线程陷入无止境地等待进入同步块状态
+
+Java同步代码块是另一个能够导致饥饿的原因。Java同步代码块不能够保证进入同步块线程的顺序。这意味着,理论上存在可以陷入无限等待进入同步块的线程。线程会因为得不到任何CPU机会而饿死。
+
+### 线程陷入无止境地等待被唤醒(调用了对象的wait()方法)状态,
+
+如果多个线程都调用了同一个对象的`wait()`方法而,当一个线程调用这个对象的`notify()`方法后,并不能确定哪个调用了`wait()`方法的线程能够被唤醒。它可以是这些线程的任意一个。如果一个线程由于唤醒机会被其他线程抢占而一直无法被唤醒,这是非常危险的。
+
+##在Java中的公平性实现(Implementing Fairness in Java)
+
+虽然在Java中实现100%的公平是不可能,但是我们仍然能够通过同步结构提高线程的公平性。
+
+我们学习一下同步代码块:
+
+```Java
+public class Synchronizer{
+
+ public synchronized void doSynchronized(){
+ //do a lot of work which takes a long time
+ }
+
+}
+```
+
+如果有多个线程调用`doSynchroinized()`方法,有一个线程会进入同步代码块,而剩余的则会阻塞直到第一个线程离开同步代码块。在多个线程阻塞的时候,我们并不知道哪个线程会成为下一个进入同步代码块的线程。
+
+##使用Locks代替Synchronized块(Using Locks Instead of Synchronized Blocks)
+
+为了提高线程的公平性,我们可以使用Locks来代替Synchronized块:
+
+```Java
+public class Synchronizer{
+ Lock lock = new Lock();
+
+ public void doSynchronized() throws InterruptedException{
+ this.lock.lock();
+ //critical section, do a lot of work which takes a long time
+ this.lock.unlock();
+ }
+
+}
+```
+
+注意这里并没有使用**synchronized** 关键字声明方法。取而代之,我们使用`lock.lock()`和`lock.unlock()`来包裹临界区。
+
+下面是一个Lock类的简单实现:
+
+```Java
+public class Lock{
+ private boolean isLocked = false;
+ private Thread lockingThread = null;
+
+ public synchronized void lock() throws InterruptedException{
+ while(isLocked){
+ wait();
+ }
+ isLocked = true;
+ lockingThread = Thread.currentThread();
+ }
+
+ public synchronized void unlock(){
+ if(this.lockingThread != Thread.currentThread()){
+ throw new IllegalMonitorStateException(
+ "Calling thread has not locked this lock");
+ }
+ isLocked = false;
+ lockingThread = null;
+ notify();
+ }
+}
+```
+看下Synchronizer类和lock类,当多个线程同时调用`lock()` 方法时,只有一个线程能够进入`lock()`方法,其余的会阻塞在`lock()`方法上。然后,如果isLocked的值为true,则该线程会进入while循环内部,调用`wait()`方法并释放当前对象的锁,阻塞在同步块的其中一个线程会进入同步块。结果就是,阻塞在`lock()`方法上的线程依次进入同步块并调用`wait()`方法。
+
+再看下Synchronized类的`doSynchronized()`方法,你会发现`lock()`方法与`unlock()`方法之间的注释,这之间的代码会执行相当长的一段时间。让我们假设这段代码相比进入`lock()`方法和调用`wait()`方法会执行相当长一段时间。这意味着大部分时间用在等待进入锁和进入临界区的过程是用在wait()的等待中,而不是被阻塞在试图进入lock()方法中。
+
+(If you look back at the doSynchronized() method you will notice that the comment between lock() and unlock() states, that the code in between these two calls take a "long" time to execute. Let us further assume that this code takes long time to execute compared to entering the lock() method and calling wait() because the lock is locked. This means that the majority of the time waited to be able to lock the lock and enter the critical section is spent waiting in the wait() call inside the lock() method, not being blocked trying to enter the lock() method.)
+
+在早些时候提到过,同步块不会对等待进入的多个线程谁能获得访问做任何保障,同样当调用notify()时,wait()也不会做保障一定能唤醒线程(至于为什么,请看线程通信)。因此这个版本的Lock类和doSynchronized()那个版本就保障公平性而言,没有任何区别。
+
+(As stated earlier synchronized blocks makes no guarantees about what thread is being granted access if more than one thread is waiting to enter. Nor does wait() make any guarantees about what thread is awakened when notify() is called. So, the current version of the Lock class makes no different guarantees with respect to fairness than synchronized version of doSynchronized(). But we can change that.)
+
+但我们能改变这种情况。当前的Lock类版本调用自己的wait()方法,如果每个线程在不同的对象上调用wait(),那么只有一个线程会在该对象上调用wait(),Lock类可以决定哪个对象能对其调用notify(),因此能做到有效的选择唤醒哪个线程。
+
+(The current version of the Lock class calls its own wait() method. If instead each thread calls wait() on a separate object, so that only one thread has called wait() on each object, the Lock class can decide which of these objects to call notify() on, thereby effectively selecting exactly what thread to awaken.)
+
+##公平锁(A Fair Lock)
+
+Below is shown the previous Lock class turned into a fair lock called FairLock. You will notice that the implementation has changed a bit with respect to synchronization and wait() / notify() compared to the Lock class shown earlier.
+
+Exactly how I arrived at this design beginning from the previous Lock class is a longer story involving several incremental design steps, each fixing the problem of the previous step: Nested Monitor Lockout, Slipped Conditions, and Missed Signals. That discussion is left out of this text to keep the text short, but each of the steps are discussed in the appropriate texts on the topic ( see the links above). What is important is, that every thread calling lock() is now queued, and only the first thread in the queue is allowed to lock the FairLock instance, if it is unlocked. All other threads are parked waiting until they reach the top of the queue.
+
+如下图所示先前的锁类变成一个公平的锁叫FairLock。你会发现,实施已经改变了一下关于同步和wait()有/通知()相比前面介绍的锁类。
+
+究竟我是怎么来到这个设计从以前的锁类开始是一个较长的故事,涉及多个增量的设计步骤,每个固定的上一步的问题:嵌套监控锁定,溜条件和未接信号。这种讨论留出这段文字保存在文本短,但是每个步骤都是在这个专题的相应文本(见上面的链接)进行讨论。最重要的是,每一个线程调用lock()现在是排队的,只有在队列中的第一个线程被允许锁定FairLock举例来说,如果它被解锁。所有其他线程都停在等待,直到它们到达队列的顶部。
+
+
+```
+public class FairLock {
+ private boolean isLocked = false;
+ private Thread lockingThread = null;
+ private List waitingThreads =
+ new ArrayList();
+
+ public void lock() throws InterruptedException{
+ QueueObject queueObject = new QueueObject();
+ boolean isLockedForThisThread = true;
+ synchronized(this){
+ waitingThreads.add(queueObject);
+ }
+
+ while(isLockedForThisThread){
+ synchronized(this){
+ isLockedForThisThread =
+ isLocked || waitingThreads.get(0) != queueObject;
+ if(!isLockedForThisThread){
+ isLocked = true;
+ waitingThreads.remove(queueObject);
+ lockingThread = Thread.currentThread();
+ return;
+ }
+ }
+ try{
+ queueObject.doWait();
+ }catch(InterruptedException e){
+ synchronized(this) { waitingThreads.remove(queueObject); }
+ throw e;
+ }
+ }
+ }
+
+ public synchronized void unlock(){
+ if(this.lockingThread != Thread.currentThread()){
+ throw new IllegalMonitorStateException(
+ "Calling thread has not locked this lock");
+ }
+ isLocked = false;
+ lockingThread = null;
+ if(waitingThreads.size() > 0){
+ waitingThreads.get(0).doNotify();
+ }
+ }
+}
+public class QueueObject {
+
+ private boolean isNotified = false;
+
+ public synchronized void doWait() throws InterruptedException {
+ while(!isNotified){
+ this.wait();
+ }
+ this.isNotified = false;
+ }
+
+ public synchronized void doNotify() {
+ this.isNotified = true;
+ this.notify();
+ }
+
+ public boolean equals(Object o) {
+ return this == o;
+ }
+}
+```
+
+First you might notice that the lock() method is no longer declared synchronized. Instead only the blocks necessary to synchronize are nested inside synchronized blocks.
+
+FairLock creates a new instance of QueueObject and enqueue it for each thread calling lock(). The thread calling unlock() will take the top QueueObject in the queue and call doNotify() on it, to awaken the thread waiting on that object. This way only one waiting thread is awakened at a time, rather than all waiting threads. This part is what governs the fairness of the FairLock.
+
+Notice how the state of the lock is still tested and set within the same synchronized block to avoid slipped conditions.
+
+Also notice that the QueueObject is really a semaphore. The doWait() and doNotify() methods store the signal internally in the QueueObject. This is done to avoid missed signals caused by a thread being preempted just before calling queueObject.doWait(), by another thread which calls unlock() and thereby queueObject.doNotify(). The queueObject.doWait() call is placed outside the synchronized(this) block to avoid nested monitor lockout, so another thread can actually call unlock() when no thread is executing inside the synchronized(this) block in lock() method.
+
+Finally, notice how the queueObject.doWait() is called inside a try - catch block. In case an InterruptedException is thrown the thread leaves the lock() method, and we need to dequeue it.
+
+##性能(A Note on Performance)
+
+If you compare the Lock and FairLock classes you will notice that there is somewhat more going on inside the lock() and unlock() in the FairLock class. This extra code will cause the FairLock to be a sligtly slower synchronization mechanism than Lock. How much impact this will have on your application depends on how long time the code in the critical section guarded by the FairLock takes to execute. The longer this takes to execute, the less significant the added overhead of the synchronizer is. It does of course also depend on how often this code is called.
diff --git "a/Java-Concurrency/14.\345\265\214\345\245\227\347\256\241\347\250\213\351\224\201\346\255\273.md" "b/Java-Concurrency/14.\345\265\214\345\245\227\347\256\241\347\250\213\351\224\201\346\255\273.md"
new file mode 100644
index 0000000..8752fdd
--- /dev/null
+++ "b/Java-Concurrency/14.\345\265\214\345\245\227\347\256\241\347\250\213\351\224\201\346\255\273.md"
@@ -0,0 +1,133 @@
+#14.嵌套管程锁死(Nested Monitor Lockout)
+
+##嵌套管程锁死如何发生
+
+嵌套管程锁死类似与死锁。它发生的情况类似这样:
+Nested monitor lockout is a problem similar to deadlock. A nested monitor lockout occurs like this:
+
+```
+线程1 获得对象A的锁
+线程1 获得对象B的锁(同时持有对象A的锁)
+线程1 决定等待另一个线程的信号再继续
+线程1 调用B.wait()方法释放对象B的锁,当仍然拥有对象A的锁
+
+线程2 需要依次获得对象A和对象B的锁
+线程2 由于对象A的锁由线程1持有,线程2进入阻塞状态
+线程2 一直被阻塞,等待线程1释放对象A的锁
+
+线程1 由于需要等待线程2的信号而一直陷入等待状态,因此一直没有释放对象A的锁,而线程2需要持有对象A的锁才能给线程1发送信号...
+```
+
+这听起来像是纯理论的场景,不妨看下这个比较幼稚的Lock实现:
+
+```Java
+//lock implementation with nested monitor lockout problem
+
+public class Lock{
+ protected MonitorObject monitorObject = new MonitorObject();
+ protected boolean isLocked = false;
+
+ public void lock() throws InterruptedException{
+ synchronized(this){
+ while(isLocked){
+ synchronized(this.monitorObject){
+ this.monitorObject.wait();
+ }
+ }
+ isLocked = true;
+ }
+ }
+
+ public void unlock(){
+ synchronized(this){
+ this.isLocked = false;
+ synchronized(this.monitorObject){
+ this.monitorObject.notify();
+ }
+ }
+ }
+}
+```
+
+注意`lock()`方法中,首先获得this的锁,然后获得`monitorObject`的锁。当`isLock`为`false`时不会有什么问题,此时线程不会调用`monitorObject.wait()`方法。而当`isLock`为`true`时,线程会调用`monitorObjct.wait()`方法而陷入等待状态。
+
+问题就在于,调用`monitorObject.wait()`方法会释放monitorObject的锁,而不会释放this上的锁。换言之,线程在嵌入等待状态的同时,仍然持有this的锁。
+
+当一个线程调用`lock()`方法成功锁住后,再次调用`unlock()`方法时则会在进入this的同步块时陷入阻塞状态。它只有当陷入等待状态的线程释放this的锁才能够进入this的同步块。而嵌入等待的线程却需要嵌入阻塞的线程将isLock设置为false和调用`monitorObject.notify()` 才会释放this的锁。
+
+简而言之,调用`lock()`方法而陷入等待的线程1需要调用了`unlock()`方法的线程2正常地执行`unlock()`方法,但线程2却需要线程1释放锁才能够正确地执行下去。
+
+这导致的结果就是:任意调用`lock()`和`unlock()`的线程都会陷入无止境的阻塞和等待状态。这种线程称之为**嵌套管程锁死**。
+
+##更现实的例子(A More Realistic Example)
+
+也许你会抱怨,你永远也不会实现像上面那样的锁。也许你不会像上面一样调用**嵌套管程(内部监听器)**对象的`wait()`和`notify()`方法,当完全有可能会调用在外层的this对象上。(You may claim that you would never implement a lock like the one shown earlier. That you would not call wait() and notify() on an internal monitor object, but rather on the This is probably true. )有很多类似上面的例子。例如,如果你需要实现一个公平锁。你可能希望每个线程在它们各自的QueueObject上调用`wait()`,这样就可以每次唤醒一个线程。
+
+下面的公平锁实现:
+
+```
+//Fair Lock implementation with nested monitor lockout problem
+
+public class FairLock {
+ private boolean isLocked = false;
+ private Thread lockingThread = null;
+ private List waitingThreads =
+ new ArrayList();
+
+ public void lock() throws InterruptedException{
+ QueueObject queueObject = new QueueObject();
+
+ synchronized(this){
+ waitingThreads.add(queueObject);
+
+ while(isLocked || waitingThreads.get(0) != queueObject){
+
+ synchronized(queueObject){
+ try{
+ queueObject.wait();
+ }catch(InterruptedException e){
+ waitingThreads.remove(queueObject);
+ throw e;
+ }
+ }
+ }
+ waitingThreads.remove(queueObject);
+ isLocked = true;
+ lockingThread = Thread.currentThread();
+ }
+ }
+
+ public synchronized void unlock(){
+ if(this.lockingThread != Thread.currentThread()){
+ throw new IllegalMonitorStateException(
+ "Calling thread has not locked this lock");
+ }
+ isLocked = false;
+ lockingThread = null;
+ if(waitingThreads.size() > 0){
+ QueueObject queueObject = waitingThread.get(0);
+ synchronized(queueObject){
+ queueObject.notify();
+ }
+ }
+ }
+}
+public class QueueObject {}
+```
+
+At first glance this implementation may look fine, but notice how the lock() method calls queueObject.wait(); from inside two synchronized blocks. One synchronized on "this", and nested inside that, a block synchronized on the queueObject local variable. When a thread calls queueObject.wait()it releases the lock on the QueueObject instance, but not the lock associated with "this".
+
+Notice too, that the unlock() method is declared synchronized which equals a synchronized(this) block. This means, that if a thread is waiting inside lock() the monitor object associated with "this" will be locked by the waiting thread. All threads calling unlock() will remain blocked indefinately, waiting for the waiting thread to release the lock on "this". But this will never happen, since this only happens if a thread succeeds in sending a signal to the waiting thread, and this can only be sent by executing the unlock() method.
+
+And so, the FairLock implementation from above could lead to nested monitor lockout. A better implementation of a fair lock is described in the text Starvation and Fairness.
+
+##嵌套管程锁死 vs 死锁(Nested Monitor Lockout vs. Deadlock)
+
+The result of nested monitor lockout and deadlock are pretty much the same: The threads involved end up blocked forever waiting for each other.
+
+The two situations are not equal though. As explained in the text on Deadlock a deadlock occurs when two threads obtain locks in different order. Thread 1 locks A, waits for B. Thread 2 has locked B, and now waits for A. As explained in the text on Deadlock Prevention deadlocks can be avoided by always locking the locks in the same order (Lock Ordering). However, a nested monitor lockout occurs exactly by two threads taking the locks in the same order. Thread 1 locks A and B, then releases B and waits for a signal from Thread 2. Thread 2 needs both A and B to send Thread 1 the signal. So, one thread is waiting for a signal, and another for a lock to be released.
+
+两者的不同点如下:
+
+* 在死锁中,两个线程互相等待对方释放锁。
+* 在嵌套管程锁死中,线程1持有锁A,并等待线程2的信号,而线程2需要锁A才能够发送信号给线程1.
diff --git a/Java-Concurrency/15.Slipped Conditions.md b/Java-Concurrency/15.Slipped Conditions.md
new file mode 100644
index 0000000..1e9e919
--- /dev/null
+++ b/Java-Concurrency/15.Slipped Conditions.md
@@ -0,0 +1,229 @@
+#15.Slipped Conditions
+
+What is Slipped Conditions?
+
+Slipped conditions means, that from the time a thread has checked a certain condition until it acts upon it, the condition has been changed by another thread so that it is errornous for the first thread to act. Here is a simple example:
+
+public class Lock {
+
+ private boolean isLocked = true;
+
+ public void lock(){
+ synchronized(this){
+ while(isLocked){
+ try{
+ this.wait();
+ } catch(InterruptedException e){
+ //do nothing, keep waiting
+ }
+ }
+ }
+
+ synchronized(this){
+ isLocked = true;
+ }
+ }
+
+ public synchronized void unlock(){
+ isLocked = false;
+ this.notify();
+ }
+
+}
+Notice how the lock() method contains two synchronized blocks. The first block waits until isLocked is false. The second block sets isLocked to true, to lock the Lock instance for other threads.
+
+Imagine that isLocked is false, and two threads call lock() at the same time. If the first thread entering the first synchronized block is preempted right after the first synchronized block, this thread will have checked isLocked and noted it to be false. If the second thread is now allowed to execute, and thus enter the first synchronized block, this thread too will see isLocked as false. Now both threads have read the condition as false. Then both threads will enter the second synchronized block, set isLocked to true, and continue.
+
+This situation is an example of slipped conditions. Both threads test the condition, then exit the synchronized block, thereby allowing other threads to test the condition, before any of the two first threads change the conditions for subsequent threads. In other words, the condition has slipped from the time the condition was checked until the threads change it for subsequent threads.
+
+To avoid slipped conditions the testing and setting of the conditions must be done atomically by the thread doing it, meaning that no other thread can check the condition in between the testing and setting of the condition by the first thread.
+
+The solution in the example above is simple. Just move the line isLocked = true; up into the first synchronized block, right after the while loop. Here is how it looks:
+
+public class Lock {
+
+ private boolean isLocked = true;
+
+ public void lock(){
+ synchronized(this){
+ while(isLocked){
+ try{
+ this.wait();
+ } catch(InterruptedException e){
+ //do nothing, keep waiting
+ }
+ }
+ isLocked = true;
+ }
+ }
+
+ public synchronized void unlock(){
+ isLocked = false;
+ this.notify();
+ }
+
+}
+Now the testing and setting of the isLocked condition is done atomically from inside the same synchronized block.
+
+A More Realistic Example
+
+You may rightfully argue that you would never implement a Lock like the first implementation shown in this text, and thus claim slipped conditions to be a rather theoretical problem. But the first example was kept rather simple to better convey the notion of slipped conditions.
+
+A more realistic example would be during the implementation of a fair lock, as discussed in the text on Starvation and Fairness. If we look at the naive implementation from the text Nested Monitor Lockout, and try to remove the nested monitor lock problem it, it is easy to arrive at an implementation that suffers from slipped conditions. First I'll show the example from the nested monitor lockout text:
+
+//Fair Lock implementation with nested monitor lockout problem
+
+public class FairLock {
+ private boolean isLocked = false;
+ private Thread lockingThread = null;
+ private List waitingThreads =
+ new ArrayList();
+
+ public void lock() throws InterruptedException{
+ QueueObject queueObject = new QueueObject();
+
+ synchronized(this){
+ waitingThreads.add(queueObject);
+
+ while(isLocked || waitingThreads.get(0) != queueObject){
+
+ synchronized(queueObject){
+ try{
+ queueObject.wait();
+ }catch(InterruptedException e){
+ waitingThreads.remove(queueObject);
+ throw e;
+ }
+ }
+ }
+ waitingThreads.remove(queueObject);
+ isLocked = true;
+ lockingThread = Thread.currentThread();
+ }
+ }
+
+ public synchronized void unlock(){
+ if(this.lockingThread != Thread.currentThread()){
+ throw new IllegalMonitorStateException(
+ "Calling thread has not locked this lock");
+ }
+ isLocked = false;
+ lockingThread = null;
+ if(waitingThreads.size() > 0){
+ QueueObject queueObject = waitingThread.get(0);
+ synchronized(queueObject){
+ queueObject.notify();
+ }
+ }
+ }
+}
+public class QueueObject {}
+Notice how the synchronized(queueObject) with its queueObject.wait() call is nested inside the synchronized(this) block, resulting in the nested monitor lockout problem. To avoid this problem the synchronized(queueObject) block must be moved outside the synchronized(this) block. Here is how that could look:
+
+//Fair Lock implementation with slipped conditions problem
+
+public class FairLock {
+ private boolean isLocked = false;
+ private Thread lockingThread = null;
+ private List waitingThreads =
+ new ArrayList();
+
+ public void lock() throws InterruptedException{
+ QueueObject queueObject = new QueueObject();
+
+ synchronized(this){
+ waitingThreads.add(queueObject);
+ }
+
+ boolean mustWait = true;
+ while(mustWait){
+
+ synchronized(this){
+ mustWait = isLocked || waitingThreads.get(0) != queueObject;
+ }
+
+ synchronized(queueObject){
+ if(mustWait){
+ try{
+ queueObject.wait();
+ }catch(InterruptedException e){
+ waitingThreads.remove(queueObject);
+ throw e;
+ }
+ }
+ }
+ }
+
+ synchronized(this){
+ waitingThreads.remove(queueObject);
+ isLocked = true;
+ lockingThread = Thread.currentThread();
+ }
+ }
+}
+Note: Only the lock() method is shown, since it is the only method I have changed.
+
+Notice how the lock() method now contains 3 synchronized blocks.
+
+The first synchronized(this) block checks the condition by setting mustWait = isLocked || waitingThreads.get(0) != queueObject.
+
+The second synchronized(queueObject) block checks if the thread is to wait or not. Already at this time another thread may have unlocked the lock, but lets forget that for the time being. Let's assume that the lock was unlocked, so the thread exits the synchronized(queueObject) block right away.
+
+The third synchronized(this) block is only executed if mustWait = false. This sets the condition isLocked back to true etc. and leaves the lock() method.
+
+Imagine what will happen if two threads call lock() at the same time when the lock is unlocked. First thread 1 will check the isLocked conditition and see it false. Then thread 2 will do the same thing. Then neither of them will wait, and both will set the state isLocked to true. This is a prime example of slipped conditions.
+
+Removing the Slipped Conditions Problem
+
+To remove the slipped conditions problem from the example above, the content of the last synchronized(this) block must be moved up into the first block. The code will naturally have to be changed a little bit too, to adapt to this move. Here is how it looks:
+
+//Fair Lock implementation without nested monitor lockout problem,
+//but with missed signals problem.
+
+public class FairLock {
+ private boolean isLocked = false;
+ private Thread lockingThread = null;
+ private List waitingThreads =
+ new ArrayList();
+
+ public void lock() throws InterruptedException{
+ QueueObject queueObject = new QueueObject();
+
+ synchronized(this){
+ waitingThreads.add(queueObject);
+ }
+
+ boolean mustWait = true;
+ while(mustWait){
+
+
+ synchronized(this){
+ mustWait = isLocked || waitingThreads.get(0) != queueObject;
+ if(!mustWait){
+ waitingThreads.remove(queueObject);
+ isLocked = true;
+ lockingThread = Thread.currentThread();
+ return;
+ }
+ }
+
+ synchronized(queueObject){
+ if(mustWait){
+ try{
+ queueObject.wait();
+ }catch(InterruptedException e){
+ waitingThreads.remove(queueObject);
+ throw e;
+ }
+ }
+ }
+ }
+ }
+}
+Notice how the local variable mustWait is tested and set within the same synchronized code block now. Also notice, that even if the mustWait local variable is also checked outside the synchronized(this) code block, in the while(mustWait) clause, the value of the mustWait variable is never changed outside the synchronized(this). A thread that evaluates mustWait to false will atomically also set the internal conditions (isLocked) so that any other thread checking the condition will evaluate it to true.
+
+The return; statement in the synchronized(this) block is not necessary. It is just a small optimization. If the thread must not wait (mustWait == false), then there is no reason to enter the synchronized(queueObject) block and execute the if(mustWait) clause.
+
+The observant reader will notice that the above implementation of a fair lock still suffers from a missed signal problem. Imagine that the FairLock instance is locked when a thread calls lock(). After the first synchronized(this) block mustWait is true. Then imagine that the thread calling lock() is preempted, and the thread that locked the lock calls unlock(). If you look at the unlock() implementation shown earlier, you will notice that it calls queueObject.notify(). But, since the thread waiting in lock() has not yet called queueObject.wait(), the call to queueObject.notify() passes into oblivion. The signal is missed. When the thread calling lock() right after calls queueObject.wait() it will remain blocked until some other thread calls unlock(), which may never happen.
+
+The missed signals problems is the reason that the FairLock implementation shown in the text Starvation and Fairness has turned the QueueObject class into a semaphore with two methods: doWait() and doNotify(). These methods store and react the signal internally in the QueueObject. That way the signal is not missed, even if doNotify() is called before doWait().
diff --git "a/Java-Concurrency/16.Java\344\270\255\347\232\204\351\224\201.md" "b/Java-Concurrency/16.Java\344\270\255\347\232\204\351\224\201.md"
new file mode 100644
index 0000000..da983ec
--- /dev/null
+++ "b/Java-Concurrency/16.Java\344\270\255\347\232\204\351\224\201.md"
@@ -0,0 +1,185 @@
+#16.Java中的锁
+
+**锁**跟**synchronized**的一样,是Java中的一种同步机制,但要比synchronized复杂得多。在Java 5之前,锁(以及其它更高级的线程同步机制)是由synchronized同步块的方式实现的,我们还不能完全摆脱synchronized关键字。
+
+在Java 5的`java.util.concurrent.locks`包有多种锁的实现,因此,你并不需要自己去实现锁。当你仍然需要知道如何使用它们以及了解它们的实现原理。
+
+##一个简单的锁(A Simple Lock)
+
+让我们从一个简单的Java synchronized块开始:
+
+```Java
+public class Counter{
+ private int count = 0;
+
+ public int inc(){
+ synchronized(this){
+ return ++count;
+ }
+ }
+}
+```
+
+注意`inc()`方法中的`synchronized(this)`块,这个块每次只允许一个线程进入执行`return ++count`代码。
+
+Counter类可以用Lock类来实现同样的功能:
+
+```Java
+public class Counter{
+
+ private Lock lock = new Lock();
+ private int count = 0;
+
+ public int inc(){
+ lock.lock();
+ int newCount = ++count;
+ lock.unlock();
+ return newCount;
+ }
+}
+```
+
+`lock()`方法会对Lock对象进行加锁,其他的线程都会在这个方法上阻塞,执行`unlock()`方法被调用。
+
+下面是一个简单Lock类的实现:
+
+```Java
+public class Lock{
+ private boolean isLocked = false;
+
+ public synchronized void lock() throws InterruptedException{
+ while(isLocked){
+ wait();
+ }
+ isLocked = true;
+ }
+
+ public synchronized void unlock(){
+ isLocked = false;
+ notify();
+ }
+}
+```
+
+注意`while(isLocked)`这个循环,我们称之为**自旋锁**。自旋锁、wait方法和notify方法,我们在线程通信一文已经介绍过。当isLocked为true时,调用`lock()`方法的线程会嵌入等待状态。为了防止线程**虚假唤醒**(没调用notify()却无缘无故唤醒),将isLock作为循环的判断条件,如果线程虚假唤醒,则由于isLocked为true,则会再次调用`wait()`进入等待状态。当isLocked为false时,线程会离开while循环,将isLocked设置为true并锁住Lock对象。
+
+当线程执行玩**临界区**(lock方法和unlock方法之间的代码)的代码后
+,线程调用`unlock()`方法,将isLocked设置为`false`,同时调用`notify()`方法唤醒在`lock()`方法中陷入等待的其中一个线程。
+
+##锁的可重入性(Lock Reentrance)
+
+Java中的`synchronized`块是可重入的,意思是,当一个线程进入了一个`synchronized`块并持有该监听器对象的锁后,这个线程可以进入其他的基于这个监听器对象的`synchronized`块。例如下面这个例子:
+
+```Java
+public class Reentrant{
+ public synchronized outer(){
+ inner();
+ }
+
+ public synchronized inner(){
+ //do something
+ }
+}
+```
+
+注意`outer()` 方法和`inner()`方法都用了 **synchronized** 关键字声明(等同于synchronized(this){}同步块)。如果一个线程成功进入`outer()` 方法后,也可以顺利成章地成功进入`inner()`方法,因为两个同步方法的监听器对象都是 **this** 对象。如果一个方法持有一个监听器对象的锁,则它可以任意进入基于这个监听器对象的同步块。这称之为**重入性**。
+
+我们之前所实现的Lock类没不具有**可重入性**。如果我们将Reentrant类按照下面一样进行重构,调用`outer()`方法的线程将会陷入阻塞。
+
+```Java
+public class Reentrant2{
+ Lock lock = new Lock();
+
+ public outer(){
+ lock.lock();
+ inner();
+ lock.unlock();
+ }
+
+ public synchronized inner(){
+ lock.lock();
+ //do something
+ lock.unlock();
+ }
+}
+```
+
+调用`outer()`方法的线程首先获得Lock实例的锁,然后调用`inner()` 方法。在`inner()`方法内部会再次调用同一个Lock实例的`lock()`方法。由于此时isLocked为true,则它将进入`while(isLocked)`内部并调`this.wait()`而进入阻塞状态。
+
+让我们在看下Lock类的实现:
+
+```Java
+public class Lock{
+
+ boolean isLocked = false;
+
+ public synchronized void lock() throws InterruptedException{
+ while(isLocked){
+ wait();
+ }
+ isLocked = true;
+ }
+
+ ...
+}
+```
+
+问题在于while循环的判断,当同一个线程第一次调用`lock()`方法时,isLocked为true,当它再次调用`lock()` 方法时,则会进入while循环内部并调用wait()方法而阻塞。
+
+为了让Lock类具有可重入性的特征,我们需要对它进行小小修改:
+
+```Java
+public class Lock{
+ boolean isLocked = false;
+ Thread lockedBy = null;
+ int lockedCount = 0;
+
+ public synchronized void lock() throws InterruptedException{
+ Thread callingThread = Thread.currentThread();
+ while(isLocked && lockedBy != callingThread){
+ wait();
+ }
+ isLocked = true;
+ lockedCount++;
+ lockedBy = callingThread;
+ }
+
+ public synchronized void unlock(){
+ if(Thread.curentThread() == this.lockedBy){
+ lockedCount--;
+
+ if(lockedCount == 0){
+ isLocked = false;
+ notify();
+ }
+ }
+ }
+
+ ...
+}
+```
+
+注意现在while循环添加了**当前线程是否与持有锁的线程一样**的判断。如果isLocked为false或者当前线程与持有锁的线程一样,则会绕过while循环,因此,即使连续调用两次`lock()`方法将不会再阻塞。
+
+除此之外,我们需要统计同一个线程调用`lock()`的次数。否则,线程线程在调用一次`unlock()`方法后将会释放锁,而不管之前调用了多少次`lock()`方法。在`unlock()`调用没有达到对应`lock()`调用的次数之前,我们不希望锁被释放。
+
+现在,Lock类具有可重入性了。
+
+## 锁的公平性(Lock Fairness)
+
+Java的`synchronized`块并不保证进入同步块的线程顺序。因此,如果存在多个线程同时争用同一个同步块,那么将有某个或多个线程永远得不到进入同步块机会的危险。我们称之为**饥饿**。为了避免这种情况,我们需要保证锁的公平性。上面例子的Lock类是通过`synchronized`关键字实现的,在这里,它们并不能保证锁的公平性。
+
+##在finally块中调用unlock方法(Calling unlock() From a finally-clause)
+
+当使用锁来隔离临界区时,临界区的代码有可能抛出异常,所以把`unlock()`方法放入finally块中是非常有必要的,这样做可以保证无论发生什么`unlock()`方法总可以被调用:
+
+```Java
+lock.lock();
+try{
+ //do critical section code, which may throw exception
+} finally {
+ lock.unlock();
+}
+```
+
+这个小小的结构改变可以保证当临界区的代码抛出异常时`unlock()`总可以被调用。当临界区代码抛出异常时,如果finally块中的`unlock()`方法没有被调用,那么Lock实例将永远被锁住,调用`lock()`方法的线程将陷入无止境的阻塞状态。
diff --git "a/Java-Concurrency/17.Java\344\270\255\347\232\204\350\257\273\345\206\231\351\224\201.md" "b/Java-Concurrency/17.Java\344\270\255\347\232\204\350\257\273\345\206\231\351\224\201.md"
new file mode 100644
index 0000000..8fea652
--- /dev/null
+++ "b/Java-Concurrency/17.Java\344\270\255\347\232\204\350\257\273\345\206\231\351\224\201.md"
@@ -0,0 +1,410 @@
+#17.Java中的读/写锁
+
+Java中,读/写锁的实现比普通锁的实现更加复杂。想象一个读写资源的应用程序,读操作比写操作要频繁得多。假如两个线程同时对同一个资源进行读操作,则不会发生任何问题,因此,如果多个线程同时请求对资源进行读操作将可同时被授权并对资源进行读取。但是,如果有一个线程对资源进行写操作,则不应该存在其他写线程或读线程在执行。我们可以使用读/写锁来实现这种需求。
+
+Java 5的`java.util.concurrent`包含了读写锁。即使如此,了解读写锁的实现原理也是非常有用的。
+
+##Java中读/写锁的实现(Read / Write Lock Java Implementation)
+
+首先,我们对**读访问**和**写访问**做一个概述:
+
+```
+Read Access If no threads are writing, and no threads have requested write access.
+Write Access If no threads are reading or writing.
+```
+
+一个线程请求对资源进行读操作,如果此时没有线程对资源进行写操作和没有线程请求对资源进行写访问,则这个线程可以正常对资源进行读操作。我们假定写访问比读访问更加重要,因此具有更高的优先级。另外,如果读访问更加频繁,而如果我们不降低写访问的优先级,饥饿就会发生。请求写访问的线程会一直阻塞,直到所有的读访问的线程持有的读写锁被释放。如果新的读访问线程总是能够获得锁,写访问的线程就会陷入阻塞,从而造成饥饿。因此,只有当没有线程正在对共享对象进行写访问并且没有线程请求对共享对象进行写访问,读访问线程才能够获得共享对象的锁。
+
+当一个线程需要对资源写访问时,如果没有其他线程正在进行读操作或写操作,则这个线程可以获得授权。不管当前有多少线程请求对资源进行写访问以及它们的顺序如何,除非你想实现对写访问请求的公平锁实现。
+
+根据这个简单的需求,我们可以参照下面这样实现ReadWriteLock:
+
+```Java
+public class ReadWriteLock{
+ private int readers = 0;
+ private int writers = 0;
+ private int writeRequests = 0;
+
+ public synchronized void lockRead() throws InterruptedException{
+ while(writers > 0 || writeRequests > 0){
+ wait();
+ }
+ readers++;
+ }
+
+ public synchronized void unlockRead(){
+ readers--;
+ notifyAll();
+ }
+
+ public synchronized void lockWrite() throws InterruptedException{
+ writeRequests++;
+
+ while(readers > 0 || writers > 0){
+ wait();
+ }
+ writeRequests--;
+ writers++;
+ }
+
+ public synchronized void unlockWrite() throws InterruptedException{
+ writers--;
+ notifyAll();
+ }
+}
+```
+
+这个ReadWriteLock类有两个加锁方法以及两个释放锁方法。一个`lock()`方法和一个`unlock()`方法用于读访问,一个`lock()`方法和一个`unlock()`方法用于写访问。
+
+读访问的实现在`lockRead()`方法中。如果当前没有线程持有写访问的锁以及没有线程请求写访问,则线程请求读访问都可以授权。
+
+写访问的实现在`lockWrite()`方法中。线程请求写访问,会将`writeRequest`加1,然后检查是否可以获得写访问授权。如果当前没有线程在进行读访问以及没有线程写访问,则可以获得写访问授权。
+
+值得注意的是,`unlockRead()`方法和`unlockWrite()`方法调用的是`notifyAll()`方法而非`notify()`方法。至于原因,考虑下面的场景:
+
+假设当前有多个请求**读访问**和**写访问**的线程,当调用`notify()`方法唤醒的线程是**读访问**线程时因为此时有请求**写访问**的线程,被唤醒的线程会继续进入等待状态。然而,因为没有写访问请求的线程被唤醒,所以程序都会因此停止,线程既不能获得读访问授权,也不能获得写访问授权。而调用`notifyAll()`方法可以唤醒所有等待的线程,并检测它们自身是否可以获得锁。
+
+调用`notifyAll()`方法还有一个好处就是,假设当前有很多请求**读访问**的线程,当**写访问**的线程调用`unlockWrite()`释放锁后,所有的请求**读访问**都可以同时获得授权,而不是一个接着一个授权。
+
+(The ReadWriteLock has two lock methods and two unlock methods. One lock and unlock method for read access and one lock and unlock for write access.
+
+The rules for read access are implemented in the lockRead() method. All threads get read access unless there is a thread with write access, or one or more threads have requested write access.
+
+The rules for write access are implemented in the lockWrite() method. A thread that wants write access starts out by requesting write access (writeRequests++). Then it will check if it can actually get write access. A thread can get write access if there are no threads with read access to the resource, and no threads with write access to the resource. How many threads have requested write access doesn't matter.
+
+It is worth noting that both unlockRead() and unlockWrite() calls notifyAll() rather than notify(). To explain why that is, imagine the following situation:
+
+Inside the ReadWriteLock there are threads waiting for read access, and threads waiting for write access. If a thread awakened by notify() was a read access thread, it would be put back to waiting because there are threads waiting for write access. However, none of the threads awaiting write access are awakened, so nothing more happens. No threads gain neither read nor write access. By calling noftifyAll() all waiting threads are awakened and check if they can get the desired access.
+
+Calling notifyAll() also has another advantage. If multiple threads are waiting for read access and none for write access, and unlockWrite() is called, all threads waiting for read access are granted read access at once - not one by one.)
+
+##读/写锁的可重入性(Read / Write Lock Reentrance)
+
+上面实现的ReadWriteLock类并不具有可重入性。如果持有**写访问**锁的线程再次调用`lockWrite()` 方法,则会陷入阻塞。除此之外,考虑下这种情况:
+
+```
+线程1 授权读访问
+线程2 请求写访问,因为线程1正在读,所以线程2会进入等待状态
+线程1 再次请求读访问,因为当前已有一个写访问请求,所以线程1会进入等待状态
+```
+
+这种情况下,ReadWriteLock会被锁死(lock up)(类似于死锁)。其他的读访问和写访问请求也因此不能再获得授权。
+
+有必要对`ReadWriteLock`做一些修改让它具有**可重入性**。**读访问**和**写访问**的**可重入性**将分别进行处理。
+
+##读可重入性(Read Reentrance)
+
+为了让`ReadWriteLock`类具有**读可重入性**,我们需要建立读可重入的规则:
+
+> A thread is granted read reentrance if it can get read access (no writers or write requests), or if it already has read access (regardless of write requests).
+
+To make the ReadWriteLock reentrant for readers we will first establish the rules for read reentrance:
+
+A thread is granted read reentrance if it can get read access (no writers or write requests), or if it already has read access (regardless of write requests).
+
+
+
+To determine if a thread has read access already a reference to each thread granted read access is kept in a Map along with how many times it has acquired read lock. When determing if read access can be granted this Map will be checked for a reference to the calling thread. Here is how the lockRead() and unlockRead() methods looks after that change:
+
+```Java
+public class ReadWriteLock{
+ private Map readingThreads = new HashMap();
+
+ private int writers = 0;
+ private int writeRequests = 0;
+
+ public synchronized void lockRead() throws InterruptedException{
+ Thread callingThread = Thread.currentThread();
+ while(! canGrantReadAccess(callingThread)){
+ wait();
+ }
+
+ readingThreads.put(callingThread,(getAccessCount(callingThread) + 1));
+ }
+
+
+ public synchronized void unlockRead(){
+ Thread callingThread = Thread.currentThread();
+ int accessCount = getAccessCount(callingThread);
+ if(accessCount == 1){ readingThreads.remove(callingThread); }
+ else { readingThreads.put(callingThread, (accessCount -1)); }
+ notifyAll();
+ }
+
+
+ private boolean canGrantReadAccess(Thread callingThread){
+ if(writers > 0) return false;
+ if(isReader(callingThread) return true;
+ if(writeRequests > 0) return false;
+ return true;
+ }
+
+ private int getReadAccessCount(Thread callingThread){
+ Integer accessCount = readingThreads.get(callingThread);
+ if(accessCount == null) return 0;
+ return accessCount.intValue();
+ }
+
+ private boolean isReader(Thread callingThread){
+ return readingThreads.get(callingThread) != null;
+ }
+
+}
+```
+
+As you can see read reentrance is only granted if no threads are currently writing to the resource. Additionally, if the calling thread already has read access this takes precedence over any writeRequests.
+
+##写可重入性(Write Reentrance)
+
+Write reentrance is granted only if the thread has already write access. Here is how the lockWrite() and unlockWrite() methods look after that change:
+
+```Java
+public class ReadWriteLock{
+
+ private Map readingThreads =
+ new HashMap();
+
+ private int writeAccesses = 0;
+ private int writeRequests = 0;
+ private Thread writingThread = null;
+
+ public synchronized void lockWrite() throws InterruptedException{
+ writeRequests++;
+ Thread callingThread = Thread.currentThread();
+ while(! canGrantWriteAccess(callingThread)){
+ wait();
+ }
+ writeRequests--;
+ writeAccesses++;
+ writingThread = callingThread;
+ }
+
+ public synchronized void unlockWrite() throws InterruptedException{
+ writeAccesses--;
+ if(writeAccesses == 0){
+ writingThread = null;
+ }
+ notifyAll();
+ }
+
+ private boolean canGrantWriteAccess(Thread callingThread){
+ if(hasReaders()) return false;
+ if(writingThread == null) return true;
+ if(!isWriter(callingThread)) return false;
+ return true;
+ }
+
+ private boolean hasReaders(){
+ return readingThreads.size() > 0;
+ }
+
+ private boolean isWriter(Thread callingThread){
+ return writingThread == callingThread;
+ }
+}
+```
+
+Notice how the thread currently holding the write lock is now taken into account when determining if the calling thread can get write access.
+
+##读到写的可重入性(Read to Write Reentrance)
+
+Sometimes it is necessary for a thread that have read access to also obtain write access. For this to be allowed the thread must be the only reader. To achieve this the writeLock() method should be changed a bit. Here is what it would look like:
+
+```Java
+public class ReadWriteLock{
+
+ private Map readingThreads =
+ new HashMap();
+
+ private int writeAccesses = 0;
+ private int writeRequests = 0;
+ private Thread writingThread = null;
+
+ public synchronized void lockWrite() throws InterruptedException{
+ writeRequests++;
+ Thread callingThread = Thread.currentThread();
+ while(! canGrantWriteAccess(callingThread)){
+ wait();
+ }
+ writeRequests--;
+ writeAccesses++;
+ writingThread = callingThread;
+ }
+
+ public synchronized void unlockWrite() throws InterruptedException{
+ writeAccesses--;
+ if(writeAccesses == 0){
+ writingThread = null;
+ }
+ notifyAll();
+ }
+
+ private boolean canGrantWriteAccess(Thread callingThread){
+ if(isOnlyReader(callingThread)) return true;
+ if(hasReaders()) return false;
+ if(writingThread == null) return true;
+ if(!isWriter(callingThread)) return false;
+ return true;
+ }
+
+ private boolean hasReaders(){
+ return readingThreads.size() > 0;
+ }
+
+ private boolean isWriter(Thread callingThread){
+ return writingThread == callingThread;
+ }
+
+ private boolean isOnlyReader(Thread thread){
+ return readers == 1 && readingThreads.get(callingThread) != null;
+ }
+
+}
+```
+
+Now the ReadWriteLock class is read-to-write access reentrant.
+
+##写到读的可重入性(Write to Read Reentrance)
+
+Sometimes a thread that has write access needs read access too. A writer should always be granted read access if requested. If a thread has write access no other threads can have read nor write access, so it is not dangerous. Here is how the canGrantReadAccess() method will look with that change:
+
+```Java
+public class ReadWriteLock{
+
+ private boolean canGrantReadAccess(Thread callingThread){
+ if(isWriter(callingThread)) return true;
+ if(writingThread != null) return false;
+ if(isReader(callingThread) return true;
+ if(writeRequests > 0) return false;
+ return true;
+ }
+
+}
+````
+
+##Fully Reentrant ReadWriteLock
+
+Below is the fully reentran ReadWriteLock implementation. I have made a few refactorings to the access conditions to make them easier to read, and thereby easier to convince yourself that they are correct.
+
+```Java
+public class ReadWriteLock{
+
+ private Map readingThreads = new HashMap();
+
+ private int writeAccesses = 0;
+ private int writeRequests = 0;
+ private Thread writingThread = null;
+
+
+ public synchronized void lockRead() throws InterruptedException{
+ Thread callingThread = Thread.currentThread();
+ while(! canGrantReadAccess(callingThread)){
+ wait();
+ }
+
+ readingThreads.put(callingThread,
+ (getReadAccessCount(callingThread) + 1));
+ }
+
+ private boolean canGrantReadAccess(Thread callingThread){
+ if( isWriter(callingThread) ) return true;
+ if( hasWriter() ) return false;
+ if( isReader(callingThread) ) return true;
+ if( hasWriteRequests() ) return false;
+ return true;
+ }
+
+
+ public synchronized void unlockRead(){
+ Thread callingThread = Thread.currentThread();
+ if(!isReader(callingThread)){
+ throw new IllegalMonitorStateException("Calling Thread does not" +
+ " hold a read lock on this ReadWriteLock");
+ }
+ int accessCount = getReadAccessCount(callingThread);
+ if(accessCount == 1){ readingThreads.remove(callingThread); }
+ else { readingThreads.put(callingThread, (accessCount -1)); }
+ notifyAll();
+ }
+
+ public synchronized void lockWrite() throws InterruptedException{
+ writeRequests++;
+ Thread callingThread = Thread.currentThread();
+ while(! canGrantWriteAccess(callingThread)){
+ wait();
+ }
+ writeRequests--;
+ writeAccesses++;
+ writingThread = callingThread;
+ }
+
+ public synchronized void unlockWrite() throws InterruptedException{
+ if(!isWriter(Thread.currentThread()){
+ throw new IllegalMonitorStateException("Calling Thread does not" +
+ " hold the write lock on this ReadWriteLock");
+ }
+ writeAccesses--;
+ if(writeAccesses == 0){
+ writingThread = null;
+ }
+ notifyAll();
+ }
+
+ private boolean canGrantWriteAccess(Thread callingThread){
+ if(isOnlyReader(callingThread)) return true;
+ if(hasReaders()) return false;
+ if(writingThread == null) return true;
+ if(!isWriter(callingThread)) return false;
+ return true;
+ }
+
+
+ private int getReadAccessCount(Thread callingThread){
+ Integer accessCount = readingThreads.get(callingThread);
+ if(accessCount == null) return 0;
+ return accessCount.intValue();
+ }
+
+
+ private boolean hasReaders(){
+ return readingThreads.size() > 0;
+ }
+
+ private boolean isReader(Thread callingThread){
+ return readingThreads.get(callingThread) != null;
+ }
+
+ private boolean isOnlyReader(Thread callingThread){
+ return readingThreads.size() == 1 &&
+ readingThreads.get(callingThread) != null;
+ }
+
+ private boolean hasWriter(){
+ return writingThread != null;
+ }
+
+ private boolean isWriter(Thread callingThread){
+ return writingThread == callingThread;
+ }
+
+ private boolean hasWriteRequests(){
+ return this.writeRequests > 0;
+ }
+
+}
+```
+
+##Calling unlock() From a finally-clause
+
+When guarding a critical section with a ReadWriteLock, and the critical section may throw exceptions, it is important to call the readUnlock() and writeUnlock() methods from inside a finally-clause. Doing so makes sure that the ReadWriteLock is unlocked so other threads can lock it. Here is an example:
+
+```Java
+lock.lockWrite();
+try{
+ //do critical section code, which may throw exception
+} finally {
+ lock.unlockWrite();
+}
+```
+
+This little construct makes sure that the ReadWriteLock is unlocked in case an exception is thrown from the code in the critical section. If unlockWrite() was not called from inside a finally-clause, and an exception was thrown from the critical section, the ReadWriteLock would remain write locked forever, causing all threads calling lockRead() or lockWrite() on that ReadWriteLock instance to halt indefinately. The only thing that could unlock the ReadWriteLockagain would be if the ReadWriteLock is reentrant, and the thread that had it locked when the exception was thrown, later succeeds in locking it, executing the critical section and calling unlockWrite() again afterwards. That would unlock the ReadWriteLock again. But why wait for that to happen, if it happens? Calling unlockWrite() from a finally-clause is a much more robust solution.
diff --git "a/Java-Concurrency/18.\351\207\215\345\205\245\351\224\201\346\255\273.md" "b/Java-Concurrency/18.\351\207\215\345\205\245\351\224\201\346\255\273.md"
new file mode 100644
index 0000000..e438f20
--- /dev/null
+++ "b/Java-Concurrency/18.\351\207\215\345\205\245\351\224\201\346\255\273.md"
@@ -0,0 +1,44 @@
+#18.重入锁死
+
+Reentrance lockout is a situation similar to deadlock and nested monitor lockout. Reentrance lockout is also covered in part in the texts on Locks and Read / Write Locks.
+
+Reentrance lockout may occur if a thread reenters a Lock, ReadWriteLock or some other synchronizer that is not reentrant. Reentrant means that a thread that already holds a lock can retake it. Java's synchronized blocks are reentrant. Therefore the following code will work without problems:
+
+public class Reentrant{
+
+ public synchronized outer(){
+ inner();
+ }
+
+ public synchronized inner(){
+ //do something
+ }
+}
+Notice how both outer() and inner() are declared synchronized, which in Java is equivalent to a synchronized(this) block. If a thread calls outer() there is no problem calling inner() from inside outer(), since both methods (or blocks) are synchronized on the same monitor object ("this"). If a thread already holds the lock on a monitor object, it has access to all blocks synchronized on the same monitor object. This is called reentrance. The thread can reenter any block of code for which it already holds the lock.
+
+The following Lock implementation is not reentrant:
+
+public class Lock{
+
+ private boolean isLocked = false;
+
+ public synchronized void lock()
+ throws InterruptedException{
+ while(isLocked){
+ wait();
+ }
+ isLocked = true;
+ }
+
+ public synchronized void unlock(){
+ isLocked = false;
+ notify();
+ }
+}
+If a thread calls lock() twice without calling unlock() in between, the second call to lock() will block. A reentrance lockout has occurred.
+
+To avoid reentrance lockouts you have two options:
+
+Avoid writing code that reenters locks
+Use reentrant locks
+Which of these options suit your project best depends on your concrete situation. Reentrant locks often don't perform as well as non-reentrant locks, and they are harder to implement, but this may not necessary be a problem in your case. Whether or not your code is easier to implement with or without lock reentrance must be determined case by case.
diff --git "a/Java-Concurrency/19.\344\277\241\345\217\267\351\207\217.md" "b/Java-Concurrency/19.\344\277\241\345\217\267\351\207\217.md"
new file mode 100644
index 0000000..5fdcae9
--- /dev/null
+++ "b/Java-Concurrency/19.\344\277\241\345\217\267\351\207\217.md"
@@ -0,0 +1,162 @@
+#19.信号量
+
+信号量是一种线程同步结构,它可以用于线程间的信号通信,也可以用来像锁一样来保护临界区。Java 5在`java.util.concurrency`包中引入了信号量(Semaphores)的实现。但是,了解信号量背后的实现原来对我们也是非常有帮助的。
+
+Java 5引入了信号量的实现,因此,你不必自己去实现信号量。详细的介绍请看这里:http://tutorials.jenkov.com/java-util-concurrent/semaphore.html
+
+##简单的信号量实现(Simple Semaphore)
+
+下面是一个简单的信号量类的实现:
+
+```Java
+public class Semaphore {
+ private boolean signal = false;
+
+ public synchronized void take() {
+ this.signal = true;
+ this.notify();
+ }
+
+ public synchronized void release() throws InterruptedException{
+ while(!this.signal) {
+ wait();
+ }
+ this.signal = false;
+ }
+
+}
+```
+
+Semmaphore类的`take()`方法用于发送信号,`release()`方法用于等待信号。
+
+使用信号量可以避免信号丢失的问题。在这里,`take()`方法代替了`notify()`方法,`release()`方法代替了`wait()`方法。如果我们在调用`take()`方法之前调用了`release()`方法,`release()`方法通过判断signal变量可以判断`take()`被调用过,因此不会造成信号丢失的问题。而直接`wait()`和`notify()`则会有这个问题。
+
+在使用信号量(Semaphore )进行信号通信(Signaling)时,`take()`和`release()`方法的命名似乎有点过时。下面的示例中会使用Lock中的方法命名,使得方法命名更加**语义化**( The names origin from the use of semaphores as locks, as explained later in this text. In that case the names make more sense.)。
+
+##使用信号量通信(Using Semaphores for Signaling)
+
+下面的示例的两个线程使用信号量进行通信:
+
+```Java
+Semaphore semaphore = new Semaphore();
+
+SendingThread sender = new SendingThread(semaphore);
+ReceivingThread receiver = new ReceivingThread(semaphore);
+
+receiver.start();
+sender.start();
+
+public class SendingThread {
+ Semaphore semaphore = null;
+
+ public SendingThread(Semaphore semaphore){
+ this.semaphore = semaphore;
+ }
+
+ public void run(){
+ while(true){
+ //do something, then signal
+ this.semaphore.take();
+
+ }
+ }
+}
+
+public class RecevingThread {
+ Semaphore semaphore = null;
+
+ public ReceivingThread(Semaphore semaphore){
+ this.semaphore = semaphore;
+ }
+
+ public void run(){
+ while(true){
+ this.semaphore.release();
+ //receive signal, then do something...
+ }
+ }
+}
+```
+
+
+##计数信号量(Counting Semaphore)
+
+上面实现的Semaphore类,并没有计算通过调用`take()`方法发送的信号的次数。我们通过修改让它提供这个功能。这个称之为**计数信号量**。下面是一个简单的计数信号量的实现:
+
+```Java
+public class CountingSemaphore {
+ private int signals = 0;
+
+ public synchronized void take() {
+ this.signals++;
+ this.notify();
+ }
+
+ public synchronized void release() throws InterruptedException{
+ while(this.signals == 0) {
+ wait();
+ }
+ this.signals--;
+ }
+
+}
+```
+
+
+##有界信号量(Bounded Semaphore)
+
+CountingSemaphores只是存储了发送的信号量的个数,但是没有限定信号量的个数。我们可以按照下面这个例子让它限制信号量的上界:
+
+```Java
+public class BoundedSemaphore {
+ private int signals = 0;
+ private int bound = 0;
+
+ public BoundedSemaphore(int upperBound){
+ this.bound = upperBound;
+ }
+
+ public synchronized void take() throws InterruptedException{
+ while(this.signals == bound) {
+ wait();
+ }
+ this.signals++;
+ this.notify();
+ }
+
+ public synchronized void release() throws InterruptedException{
+ while(this.signals == 0) {
+ wait();
+ }
+ this.signals--;
+ this.notify();
+ }
+}
+```
+
+注意这里的`take()`方法,如果signals的个数达到上限则线程进入阻塞,直到有线程调用`release()`方法,当前线程才能被允许发送信号。
+
+##像锁一样使用信号量(Using Semaphores as Locks)
+
+我们可以把有**界信号量(bounded semaphore)**当成锁使用。这时候,我们将上界设置为1,用`take()`方法和`release()`方法包裹临界区。如下面这个例子:
+
+It is possible to use a bounded semaphore as a lock. To do so, set the upper bound to 1, and have the call to take() and release() guard the critical section. Here is an example:
+
+```Java
+BoundedSemaphore semaphore = new BoundedSemaphore(1);
+
+semaphore.take();
+
+try{
+ //critical section
+} finally {
+ semaphore.release();
+}
+```
+
+与发送信号不同,这里的`take()`方法和`release()`方法都是在同一个线程里面调用的。这是因为当上界为1时,一个线程调用`take()`方法后,其他调用`take()`方法的线程都会阻塞,直到这个线程调用`release()`方法。
+
+你也可以利用**有界信号量**去限制同时进入同一个临界区的线程数量。举个例子,在上面的例子中,假如将limit的值设置为5会发生什么情况呢?5个线程会被允许同时进入同一个临界区。当然,你也需要确保这5个线程间的操作不会互相干扰,否则应用程序会因此挂掉。
+
+`release()`方法在`finally`块中被调用,这样就可以确保即使临界区发生异常时,`release()`总能够被调用。
+
diff --git "a/Java-Concurrency/20.\351\230\273\345\241\236\351\230\237\345\210\227.md" "b/Java-Concurrency/20.\351\230\273\345\241\236\351\230\237\345\210\227.md"
new file mode 100644
index 0000000..660a140
--- /dev/null
+++ "b/Java-Concurrency/20.\351\230\273\345\241\236\351\230\237\345\210\227.md"
@@ -0,0 +1,52 @@
+#20.阻塞队列
+
+**阻塞队列**是这样一种队列:当队列为空时**出列(dequeue)**会阻塞,当队列满时**入队**会阻塞。当一个线程试图从一个空队列出列就会进入阻塞,直到其他线程将元素入列;当一个线程试图从一个满的队列中入列也会阻塞,直到其他线程将对队列中的元素出列或者将队列清空。
+
+下面的图展示了两个线程如何跟阻塞队列进行交互:
+
+
+
+
+Java 5的`java.util.concurrent`包中引入了阻塞队列的实现。即使如此,了解底层的实现原理也是非常有必要和有帮助的。
+
+##阻塞队列的实现(Blocking Queue Implementation)
+
+ **阻塞队列**的实现跟**有界信号量**的实现类似。下面是一个阻塞队列的实现:
+
+```Java
+public class BlockingQueue {
+
+ private List queue = new LinkedList();
+ private int limit = 10;
+
+ public BlockingQueue(int limit){
+ this.limit = limit;
+ }
+
+
+ public synchronized void enqueue(Object item) throws InterruptedException {
+ while(this.queue.size() == this.limit) {
+ wait();
+ }
+ if(this.queue.size() == 0) {
+ notifyAll();
+ }
+ this.queue.add(item);
+ }
+
+
+ public synchronized Object dequeue() throws InterruptedException{
+ while(this.queue.size() == 0){
+ wait();
+ }
+ if(this.queue.size() == this.limit){
+ notifyAll();
+ }
+
+ return this.queue.remove(0);
+ }
+
+}
+```
+
+ok,很简单,也不过多解释了!
\ No newline at end of file
diff --git "a/Java-Concurrency/21.\347\272\277\347\250\213\346\261\240.md" "b/Java-Concurrency/21.\347\272\277\347\250\213\346\261\240.md"
new file mode 100644
index 0000000..47fa13f
--- /dev/null
+++ "b/Java-Concurrency/21.\347\272\277\347\250\213\346\261\240.md"
@@ -0,0 +1,84 @@
+#21.线程池
+
+当你需要在应用程序中限制同一时间线程的数量时,线程池就显得非常有用,因为创建并启动新的线程是消耗性能的。
+
+给每个任务创建并启动单独的线程不同,你可以将任务交给线程池,当线程中有线程空闲时,线程池就会将任务非配给线程执行。在线程池内部,任务被插入到一个阻塞队列里面,空闲线程将从这个队列汇总出列(dequeue)需要执行的任务。如果队列中没有任务,线程池中的空闲线程就会进入阻塞等待新的任务。
+
+线程池经常被用于多线程处理的服务器中。每个到达服务器的连接都会被包装成一个任务然后交给线程池进行处理,线程池中的线程会并行地对这些任务进行处理。
+
+Java 5中内置了线程池的实现,所以你不必要自己去实现线程池。但是了解其中的实现原理是非常有必要和有帮助的。
+
+下面是一个线程池的简单实现:
+
+```Java
+public class ThreadPool {
+ private BlockingQueue taskQueue = null;
+ private List threads = new ArrayList();
+ private boolean isStopped = false;
+
+ public ThreadPool(int noOfThreads, int maxNoOfTasks){
+ taskQueue = new BlockingQueue(maxNoOfTasks);
+
+ for(int i=0; i readingThreads = new HashMap();
+
+ private int writeAccesses = 0;
+ private int writeRequests = 0;
+ private Thread writingThread = null;
+
+ ...
+
+ public synchronized void lockWrite() throws InterruptedException{
+ writeRequests++;
+ Thread callingThread = Thread.currentThread();
+ while(! canGrantWriteAccess(callingThread)){
+ wait();
+ }
+ writeRequests--;
+ writeAccesses++;
+ writingThread = callingThread;
+ }
+
+
+ ...
+}
+```
+
+The BoundedSemaphore class shown below has two test-and-set methods: take() and
+release(). Both methods test and sets the internal state.
+
+```Java
+public class BoundedSemaphore {
+ private int signals = 0;
+ private int bound = 0;
+
+ public BoundedSemaphore(int upperBound){
+ this.bound = upperBound;
+ }
+
+
+ public synchronized void take() throws InterruptedException{
+ while(this.signals == bound) {
+ wait();
+ }
+ this.signals++;
+ this.notify();
+ }
+
+ public synchronized void release() throws InterruptedException{
+ while(this.signals == 0) {
+ wait();
+ }
+ this.signals--;
+ this.notify();
+ }
+
+}
+```
+
+##Set Method
+
+The set method is the second type of method that synchronizers often contain. The set method just sets the internal state of the synchronizer without testing it first. A typical example of a set method is the unlock() method of a Lock class. A thread holding the lock can always unlock it without having to test if the Lock is unlocked.
+
+The program flow of a set method is usually along the lines of:
+
+Set internal state
+Notify waiting threads
+Here is an example unlock() method:
+
+```Java
+public class Lock{
+ private boolean isLocked = false;
+
+ public synchronized void unlock(){
+ isLocked = false;
+ notify();
+ }
+
+}
+```
\ No newline at end of file
diff --git a/Java-Concurrency/README.md b/Java-Concurrency/README.md
new file mode 100644
index 0000000..41cada4
--- /dev/null
+++ b/Java-Concurrency/README.md
@@ -0,0 +1 @@
+ 翻译自:http://tutorials.jenkov.com/java-concurrency/index.html
diff --git "a/Java-NIO/01.Java NIO\346\225\231\347\250\213.md" "b/Java-NIO/01.Java NIO\346\225\231\347\250\213.md"
new file mode 100644
index 0000000..8f75dd7
--- /dev/null
+++ "b/Java-NIO/01.Java NIO\346\225\231\347\250\213.md"
@@ -0,0 +1,15 @@
+#01.Java NIO教程
+
+Java NIO(New IO)是一个可以替代标准IO的IO API,这意味着,它可以替代标准IO和Java Networking API。它提供了与标准IO不同的工作方式。
+
+##通道和缓冲区(Channels and Buffers)
+
+在标准IO接口中,操作的对象是**字节流**和**字符流**。而在NIO中,操作的对象则是**通道(Channels)**和**缓冲区(Buffers)**。数据总是从通道中读取到缓冲区,或从缓冲区写入到通道。
+
+##非阻塞IO(Non-blocking IO)
+
+Java NIO提供了非阻塞IO。举个例子,线程可以让通道读取数据到缓冲区中,当通道读取数据到缓冲区时,线程可以不必等待操作的完成,就可以去处理其他操作。从缓冲区写入到通道也类似。
+
+##选择器( Selectors)
+
+Java NIO引入了**选择器(Selectors)**的概念。一个选择器可以监听多个通道的时间(例如:连接打开,数据到达)。因此,单个线程可以监听多个数据通道。
diff --git "a/Java-NIO/02.Java NIO\346\246\202\350\247\210.md" "b/Java-NIO/02.Java NIO\346\246\202\350\247\210.md"
new file mode 100644
index 0000000..27327bb
--- /dev/null
+++ "b/Java-NIO/02.Java NIO\346\246\202\350\247\210.md"
@@ -0,0 +1,50 @@
+#02.Java NIO概览
+
+Java NIO包括以下核心组件:
+
+* 通道(Channels)
+* 缓冲区(Buffers)
+* 选择器(Selectors)
+
+Java NIO包含许多类和组件,但是**通道(Channels)**,**缓冲区(Buffers)**和**选择器(Selectors)**是其中最核心的接口。其他的组件,例如**管道(Pipe)**和文件锁**(FileLock)**只是为这三个核心组件服务的工具类。
+
+##通道和缓冲区(Channels and Buffers)
+
+通常情况下,在NIO中的所有IO都起始于**通道(Channels)**。通道有点类似于**流**。来自通道的数据可以读取到缓冲区中,同样地,也可以从缓存区中写入数据到通道,如下图所示:
+
+ +
+Java NIO中有很多Channel和Buffer实现。以下是Java NIO中最主要的Channel的实现类;
+
+* FileChannel
+* DatagramChannel
+* SocketChannel
+* ServerSocketChannel
+
+正如你所见,这些通道覆盖了UDP、TCP和文件IO。
+
+以下是Java NIO中最主要的Buffer的实现类:
+
+* ByteBuffer
+* CharBuffer
+* ShortBuffer
+* IntBuffer
+* LongBuffer
+* FloatBuffer
+* DoubleBuffer
+
+以上的缓冲区实现类覆盖了你能通过IO发送的全部基本类型数据数据。Java NIO也提供了一个叫MappedByteBuffer的Buffer实现类,它用于跟内存映射文件交互。
+
+##选择器(Selectors)
+
+选择器允许使用一个线程来操作多个通道。这对于那些有大量网络连接但传输的数据量非常少的应用来说是非常方便有利的,例如聊天服务器。
+
+下面的示图描述了一个线程使用选择器来处理三个通道:
+
+
+
+Java NIO中有很多Channel和Buffer实现。以下是Java NIO中最主要的Channel的实现类;
+
+* FileChannel
+* DatagramChannel
+* SocketChannel
+* ServerSocketChannel
+
+正如你所见,这些通道覆盖了UDP、TCP和文件IO。
+
+以下是Java NIO中最主要的Buffer的实现类:
+
+* ByteBuffer
+* CharBuffer
+* ShortBuffer
+* IntBuffer
+* LongBuffer
+* FloatBuffer
+* DoubleBuffer
+
+以上的缓冲区实现类覆盖了你能通过IO发送的全部基本类型数据数据。Java NIO也提供了一个叫MappedByteBuffer的Buffer实现类,它用于跟内存映射文件交互。
+
+##选择器(Selectors)
+
+选择器允许使用一个线程来操作多个通道。这对于那些有大量网络连接但传输的数据量非常少的应用来说是非常方便有利的,例如聊天服务器。
+
+下面的示图描述了一个线程使用选择器来处理三个通道:
+
+ +
+当你需要使用选择器时,你需要使用它向通道进行注册(register)。然后调用选择器的`select()`方法。这个方法会阻塞直至其中一个通道的事件就绪。一旦方法返回后,线程就可以对事件进行处理。这些事件包括:网路连接,接收数据等等。
\ No newline at end of file
diff --git "a/Java-NIO/03.Java NIO\351\200\232\351\201\223.md" "b/Java-NIO/03.Java NIO\351\200\232\351\201\223.md"
new file mode 100644
index 0000000..291e3f3
--- /dev/null
+++ "b/Java-NIO/03.Java NIO\351\200\232\351\201\223.md"
@@ -0,0 +1,46 @@
+#03. Java NIO通道
+
+Java NIO的**通道(Channels)**类似与标准IO中的**流(Stream)**,它们之间的区别在于:
+
+* 你可以从管道中读取或写入数据(双向),但是流只能是读取或写入(单向)。
+* 通道可以进行异步(Asynchonously)操作。
+* 通道(Channel)总是从缓冲区(Buffers)中读取或写入数据。
+
+如上面所提到的,数据总是从管道中读取到缓冲区,后从缓冲区中写入到通道。如下图所示:
+
+
+
+ 以下是Java NIO中Chanel的最重要的实现类:
+
+* FileChannel:从文件中读取或写入数据
+* DatagramChannel:从UPD中读取或写入数据
+* SocketChannel:从TCP中读取或写入数据
+* ServerSocketChannel:用于监听TCP连接,每接收一个连接就创建一个`SocketChannel`
+
+##Channel例子(Basic Channel Example)
+
+以下的代码示例演示了从FileChannel读取数据到Buffer中:
+
+```Java
+RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw");
+FileChannel inChannel = aFile.getChannel();
+
+ByteBuffer buf = ByteBuffer.allocate(48);
+
+int bytesRead = inChannel.read(buf);
+while (bytesRead != -1) {
+
+ System.out.println("Read " + bytesRead);
+ buf.flip();
+
+ while(buf.hasRemaining()){
+ System.out.print((char) buf.get());
+ }
+
+ buf.clear();
+ bytesRead = inChannel.read(buf);
+}
+aFile.close();
+```
+
+注意`buf.flip`的调用。当你写入数据到Buffer后,需要调用这个方法,然后才能从Buffer中读取数据。
diff --git "a/Java-NIO/04.Java NIO\347\274\223\345\206\262\345\214\272.md" "b/Java-NIO/04.Java NIO\347\274\223\345\206\262\345\214\272.md"
new file mode 100644
index 0000000..3b33ef3
--- /dev/null
+++ "b/Java-NIO/04.Java NIO\347\274\223\345\206\262\345\214\272.md"
@@ -0,0 +1,196 @@
+#04.Java NIO缓冲区
+
+Java NIO中的**缓冲区(Buffers)**用于跟**通道(Channels)**交互时使用。如你所知,数据从通道中读取到缓冲区,或从缓冲区中写入到通道。
+
+缓冲区本质上是一个内存块,在这个块中,你可以进行写入和读取操作。Java NIO将这个内存块用缓存区包装起来,并提供了一系列的用于操作这个内存块的API。
+
+##缓冲区的基本用法(Basic Buffer Usage)
+
+利用缓冲区读写数据通常遵循这个小4个步骤:
+
+* 写入数据到缓冲区;
+* 调用buffer.flip()方法;
+* 从缓冲区中读取数据;
+* 调用buffer.clear()或buffer.compact()方法。
+
+当你往缓冲区写入数据的时候,缓冲区会跟踪记录你写入的数据量。当你需要缓冲区读取数据时,你需要调用`flip()`方法将缓冲区从**写模式**切换为**读模式**。在读模式中,你可以读取之前往缓冲区写入的所有数据。
+
+当你读取完数据之后,你需要清空缓冲区,以便可以写入数据。你可以通过两种方式来完成:调用`clear()`或`compact()`方法。__`clear()`方法会清空整个缓冲区的数据。而`compact()`方法只会清空已经读取过的数据,尚未读取过的数据会被移动到缓冲区的前端,以便下次继续读取。__
+
+简单示例:
+
+```Java
+RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw");
+FileChannel inChannel = aFile.getChannel();
+
+//create buffer with capacity of 48 bytes
+ByteBuffer buf = ByteBuffer.allocate(48);
+
+int bytesRead = inChannel.read(buf); //read into buffer.
+while (bytesRead != -1) {
+
+ buf.flip(); //make buffer ready for read
+
+ while(buf.hasRemaining()){
+ System.out.print((char) buf.get()); // read 1 byte at a time
+ }
+
+ buf.clear(); //make buffer ready for writing
+ bytesRead = inChannel.read(buf);
+}
+aFile.close();
+```
+
+##Capacity, Position和Limit
+
+缓冲区本质上是一个内存块,在这个块中,你可以进行写入和读取操作。Java NIO将这个内存块用缓存区包装起来,并提供了一系列的用于操作这个内存块的API。
+
+如果你想知道缓冲区是如何工作的,那么你需要理解缓冲区的三个属性,它们分别是:
+
+* 容量(Capacity)
+* 位置(Position)
+* 极限(Limit)
+
+
+**position**和**limit**在读模式/写模式中具有不同的含义。而**capacity**在任何情况都具有同一含义:**缓冲区的容量大小。**
+
+下面这个图描绘了capacity,position和limit在读模式和写模式中的含义:
+
+
+
+###Capacity
+
+做为一个内存块,缓冲区有固定的大小,称之为:**容量(capcity)**。你只能往缓冲区中写入固定大小的bytes,long,chars等类型数据。一旦缓冲区慢后,你需要清空它(读取数据或clear())才能继续写入数据。
+
+###Position
+
+当你往缓冲区写入数据时,实际上你是往缓冲区中的指定的位置写入数据。这个位置初始值为0,当往缓冲区写入数据时,position会指向下一个可写入的内存单元。postion的最大值为capacity-1。
+
+当你从缓冲区读取数据时,你同样的是从position指定的位置读取数据。当你调用`flip()`方法使缓冲区由**写模式**切换成**读模式**后,position会重置为0。当从position指定单元读数据后,postion会移至下一个可读取单元。
+
+###Limit
+
+在**写模式**中,limit指定的是能写入数据量的大小。在写模式中,limit的值等于capacity的值。
+
+当调用`flip()`方法使缓冲区切换成**读模式**后,limit会重置为你能读取的数据量的大小。因此,在调用`flip()`方法后,limit重置为position的值,而position重置为0。
+
+##Buffer Types
+
+Java NIO提供了一下缓冲区类型:
+
+* ByteBuffer
+* MappedByteBuffer
+* ShortBuffer
+* IntBuffer
+* LongBuffer
+* FloatBuffer
+* DoubleBuffer
+
+###Allocating a Buffer
+
+要获得缓冲区,你需要为它开辟空间。每一个缓冲区类都有一个`allocate()`方法用于开辟内存空间。下面这个代码示例显示了如何开辟48个字节的缓冲区。
+
+```Java
+ByteBuffer buf = ByteBuffer.allocate(48);
+```
+
+下面的代码显示了如何开辟1024个字符的内存空间:
+
+```Java
+CharBuffer buf = CharBuffer.allocate(1024);
+```
+
+###Writing Data to a Buffer
+
+你可以通过两种方式往缓冲区中写入数据:
+
+* 从通道中写入数据到缓冲区。
+* 通过缓冲区的`put()`方法直接往缓冲区写入数据。
+
+下面的代码演示了从通道中写入数据到缓冲区:
+
+```Java
+int bytesRead = inChannel.read(buf); //read into buffer.
+```
+
+下面的代码演示了通过`put()`方法直接往缓冲区写入数据:
+
+```Java
+buf.put(127);
+```
+
+有很多重载的`put`方法方便你往缓冲区写入数据。例如,将数据写入到指定位置,或者将字节数组写入缓冲区。具体的方法请查阅API。
+
+###flip()
+
+调用`flip()`方法可以将缓冲区区从写模式切换为模式,此时limit被重置为position的值,而position被重置为0。
+
+换句话说,position标识当前读的位置,而limit标识缓存区可读内容的大小。
+
+##从缓冲区读取数据(Reading Data from a Buffer)
+
+从缓冲区读取数据有两种方式:
+
+* 从缓冲区读取数据到通道中。
+* 直接调用缓冲区的`get()`方法。
+
+以下是这两种方法对应的代码:
+
+```Java
+//read from buffer into channel.
+int bytesWritten = inChannel.write(buf);
+```
+
+```Java
+byte aByte = buf.get();
+```
+
+Java API提供了多种重载的`get()`方法。详情请查阅文档。
+
+###rewind()
+
+`Buffer.rewind()`可以将**position**重置为0,这样你就可以多次读取缓冲区的数据,期间**limit**的值保持不边
+
+###clear() and compact()
+
+当从缓冲区读取完数据后,可以调用`clear()`或`compact()`将缓冲区切换为写模式。
+
+如果调用的是`clear()`方法,position重置为0,limit重置为capacity的值。换言之,缓冲区被清除了,但实际上缓冲区的数据并没被清除。
+
+如果缓冲区中还有需要读取的数据,同时你需要清除已经读取过的数据,这时你可以调用`compact()`方法。
+
+`compact()`方法会复制尚未读取的数据到缓冲区的前面,然后将position设置为未读取数据的最后一个元素的后一位,而limit重置为capacity的值。这样就可以保证未读取的数据不会丢失,同时又可以继续写入数据。
+
+
+###mark()和reset()
+
+`Buffer.mark()`可以对position的位置进行标志,在进行一系列操作后,可以调用`reset()`将position重置为`Buffer.mark()`标志的位置。例子:
+
+```Java
+buffer.mark();
+//call buffer.get() a couple of times, e.g. during parsing.
+
+buffer.reset(); //set position back to mark.
+```
+
+##equals()和compareTo()
+
+
+可以调用缓冲区的`equals()`方法和`compareTo()`方法对缓冲区进行比较。
+
+####equals()
+
+如果符合以下情况,则两个缓冲区的`equals()`返回值为true:
+
+* 缓冲区的类型相同(byte、char等等);
+* 缓冲区中有效数据的数据量相等;
+* 缓冲区中有效数据的数据一致;
+
+如上所示,如果缓冲区中的**有效数据**都相同,则`equals()`返回值为true。
+
+####compareTo()
+
+The compareTo() method compares the remaining elements (bytes, chars etc.) of the two buffers, for use in e.g. sorting routines. A buffer is considered "smaller" than another buffer if:
+
+The first element which is equal to the corresponding element in the other buffer, is smaller than that in the other buffer.
+All elements are equal, but the first buffer runs out of elements before the second buffer does (it has fewer elements).
\ No newline at end of file
diff --git a/Java-NIO/05.Java NIO Scatter, Gather.md b/Java-NIO/05.Java NIO Scatter, Gather.md
new file mode 100644
index 0000000..f984a50
--- /dev/null
+++ b/Java-NIO/05.Java NIO Scatter, Gather.md
@@ -0,0 +1,51 @@
+#05.Java NIO Scatter, Gather
+
+Java NIO开始支持scatter/gater。scatter和gather分别用于从Channel中读取数据和写入数据到Channel中。
+
+**分散(Scatter)**操作是指**将同一个通道(Channel)的数据读到多个缓冲区(Buffer)中**。
+
+**聚集(Gather)**是指**将多个缓冲区(Buffer)的数据写入到同一个通道(Channel)中**。
+
+分散/聚集(scatter/gather)操作非常适用于一些需要把数据分开几个不同的部分进行处理的场景。例如处理固定大小的header和body的数据,你可以将header和body中的数据分别用不同的缓冲区中进行处理。
+
+##分散读取(Scattering Reads)
+
+分散读取是指**将同一个通道中的数据读到不同的缓冲区中**。如下图所示:
+
+
+
+下面的代码演示了如何使用Scatterring Reads:
+
+```Java
+ByteBuffer header = ByteBuffer.allocate(128);
+ByteBuffer body = ByteBuffer.allocate(1024);
+
+ByteBuffer[] bufferArray = { header, body };
+
+channel.read(bufferArray );
+```
+
+注意首先要将buffers插入到数组中,然后在再数组作为`channel.read()`的参数。`channel.read()`方法会依次将数组的缓冲区填满,上面的例子中,先填满header缓存区,然后再填满body缓冲区。
+
+由于分散读取(Scattering Reads)在移动到下个缓冲区前,必须填满当前的缓冲区,所以分散操作并不适用于大小不固定的数据体。换言之,上面的例子中,header必须填充128个字节,否则无法正常工作。
+
+##(聚集写入)Gathering Writes
+
+**聚集(Gather)**是指**将多个缓冲区(Buffer)的数据写入到同一个通道(Channel)中**。。如下图所示:
+
+
+
+下面的代码演示了如何使用Gathering Writes:
+
+```Java
+ByteBuffer header = ByteBuffer.allocate(128);
+ByteBuffer body = ByteBuffer.allocate(1024);
+
+//write data into buffers
+
+ByteBuffer[] bufferArray = { header, body };
+
+channel.write(buffers);
+```
+
+缓冲区数组作为参数传递给`channel.write()`方法,这个方法依次从缓冲区中写入数据到通道中。缓冲区中有效数据才会写入到通道中,例如header缓冲区的容量为128字节,但实际有效数据位58字节,所以实际上header缓冲区中只有前58字节写入到了通道。因此,与分散读取操作不同,聚集写入(Gathering Writes)操作适用于大小不固定的数据块。
diff --git "a/Java-NIO/06. Java NIO\351\200\232\351\201\223\345\210\260\351\200\232\351\201\223\347\232\204\344\274\240\350\276\223.md" "b/Java-NIO/06. Java NIO\351\200\232\351\201\223\345\210\260\351\200\232\351\201\223\347\232\204\344\274\240\350\276\223.md"
new file mode 100644
index 0000000..f3b96e4
--- /dev/null
+++ "b/Java-NIO/06. Java NIO\351\200\232\351\201\223\345\210\260\351\200\232\351\201\223\347\232\204\344\274\240\350\276\223.md"
@@ -0,0 +1,48 @@
+
+##06. Java NIO通道到通道的传输
+
+在Java NIO中,如果其中一个通道是`FileChannel`,那么你可以在两个通道间直接传输数据。`FileChannel`类提供了`transferTo()`和`transferFrom()` 两个方法来在通道中进行数据传输。
+
+##transferFrom()
+
+`FileChannel.transferFrom()`方法用来将其他通道的数据传输给`FileChannel`。看下这个例子:
+
+```Java
+RandomAccessFile fromFile = new RandomAccessFile("fromFile.txt", "rw");
+FileChannel fromChannel = fromFile.getChannel();
+
+RandomAccessFile toFile = new RandomAccessFile("toFile.txt", "rw");
+FileChannel toChannel = toFile.getChannel();
+
+long position = 0;
+long count = fromChannel.size();
+
+toChannel.transferFrom(fromChannel, position, count);
+```
+
+*position* 参数和*count*参数指明目标文件从那个地方开始读取与读取的最大字节数。
+
+另外,有一些*SocketChannel*实现也许只是传输当前部分可用数据-即使在传输过程中可能会有更多可用数据,因此`SocketChannel`有可能不会将整个数据都传输给`FileChannel`。
+
+(Additionally, some SocketChannel implementations may transfer only the data the SocketChannel has ready in its internal buffer here and now - even if the SocketChannel may later have more data available. Thus, it may not transfer the entire data requested (count) from the SocketChannel into FileChannel.)
+
+##transferTo()
+
+`transferTo()`方法将*FileChannel*的数据传输给其他通道。看下这个例子:
+
+```Java
+RandomAccessFile fromFile = new RandomAccessFile("fromFile.txt", "rw");
+FileChannel fromChannel = fromFile.getChannel();
+
+RandomAccessFile toFile = new RandomAccessFile("toFile.txt", "rw");
+FileChannel toChannel = toFile.getChannel();
+
+long position = 0;
+long count = fromChannel.size();
+
+fromChannel.transferTo(position, count, toChannel);
+```
+
+这个例子跟之前的有点相似,只是*FileChannel*对象调用的方法有所不同,其他都是一样的。
+
+The issue with SocketChannel is also present with the transferTo() method. The SocketChannel implementation may only transfer bytes from the FileChannel until the send buffer is full, and then stop.
\ No newline at end of file
diff --git "a/Java-NIO/07.Java NIO\351\200\211\346\213\251\345\231\250.md" "b/Java-NIO/07.Java NIO\351\200\211\346\213\251\345\231\250.md"
new file mode 100644
index 0000000..e11a4f6
--- /dev/null
+++ "b/Java-NIO/07.Java NIO\351\200\211\346\213\251\345\231\250.md"
@@ -0,0 +1,235 @@
+#07.Java NIO选择器
+
+选择器(Selector)是Java NIO中的一个组件,它用于检测一个或多个通道,并确定哪些通道可以进行读、写。这就是为什么Java NIO中可以使用单个线程对多个通道或网络连接进行管理。
+
+
+##为何要使用选择器(Why Use a Selector?)
+
+使用选择器的优势在于:**使用单个线程就可以对多个管道进行操作,从而可以减少处理通道的线程数量**。实际上,你可以仅仅使用一个线程来处理所有的通道。在操作系统中,线程的切换是非常昂贵的,并且,每个线程需要消耗一定的系统资源(例如内存)。因此,线程使用越少越好。
+
+不过,随着操作系统软硬件的更新迭代,多线程的开销越来越小,性能也越来越优异。而事实上,如果计算机拥有多个CPU内核,这时候如果不采用多线程,反而是对CPU资源的浪费。然而,这已不属于本教程讨论的范畴。
+
+下面的图片描绘了如何使用一个选择器来处理3个通道:
+
+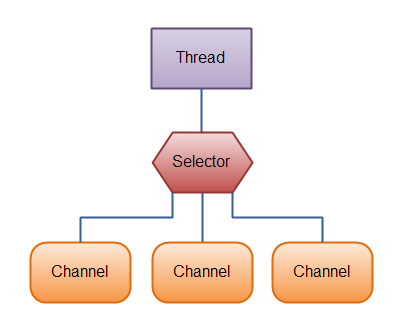
+
+##创建选择器(Creating a Selector)
+
+可以通过`Selector.open()`方法来创建选择器:
+
+```Java
+Selector selector = Selector.open();
+```
+
+#Registering Channels with the Selector
+
+为了让选择器能够处理通道,必须向选择器注册需要处理的通道,调用`SelectableChannel.register()`方法来完成注册:
+
+```
+channel.configureBlocking(false);
+
+SelectionKey key = channel.register(selector, SelectionKey.OP_READ);
+```
+
+注册的通道必须先设置为**非阻塞模式(non-blocking mode)**。由于**FileChannel**不能设置为非阻塞模式,所以FileChannel不能进行注册,而**SocketChanne**l则可以。
+
+注意`SelectableChannel.register()`方法的第二个参数。这个参数代表着**选择器需要监听通道的事件类型**。总共有四种不同的事件类型:
+
+通道**触发一个事件**,我们称之为**事件就绪**。所以,如果通道跟远程服务器建立了连接,称之为**连接就绪**;服务器socket接受客户端连接,称为**接收就绪**;通道中有数据可读,称为**读就绪**,可向通道中写数据,称为**写就绪**。
+
+以上四个事件分别由`SelectionKey`类中的四个常量来表示:
+
+```Java
+SelectionKey.OP_CONNECT
+SelectionKey.OP_ACCEPT
+SelectionKey.OP_READ
+SelectionKey.OP_WRITE
+```
+
+如果需要监听多个事件,可以使用OR操作符:
+
+```Java
+int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
+```
+由于SelectionKey中是四个常量OP\_READ、OP\_WRITE、OP\_CONNECT、OP\_ACCEPTF分别用二进制0001、0010、0100、1000表示,所以可以通过interestSet中的二进制判断监听的事件类型。
+
+##SelectionKey's
+
+上面的例子中,当调用`SelectableChannel.register()`向选择器注册通道后,该返回会返回一个`SeletionKey`对象。该`SelectionKey`对象包含以下属性:
+
+```
+The interest set(监听的事件集合)
+The ready set(就绪的事件集合)
+The Channel(通道)
+The Selector(选择器)
+An attached object (optional)
+```
+
+###Interest Set(监听的事件集合)
+
+InterestSet表示的是监听的时间集合,可以通过`SelctionKey.interestOPs()`方法获取监听的时间集合,它是一个int类型数据,由于SelectionKey中是四个常量OP\_READ、OP\_WRITE、OP\_CONNECT、OP\_ACCEPTF分别用二进制0001、0010、0100、1000表示,所以,我们可以通过**按位与**操作判断监听的事件类型:
+
+```Java
+int interestSet = selectionKey.interestOps();
+
+boolean isInterestedInAccept = interestSet & SelectionKey.OP_ACCEPT;
+boolean isInterestedInConnect = interestSet & SelectionKey.OP_CONNECT;
+boolean isInterestedInRead = interestSet & SelectionKey.OP_READ;
+boolean isInterestedInWrite = interestSet & SelectionKey.OP_WRITE;
+```
+
+###Ready Set(就绪集合)
+
+可以通过`SelectionKey.readyOps()`方法获取就绪集合。同样地,通过按位与操作判断就绪的事件类型:
+
+```Java
+int readySet = selectionKey.readyOps();
+
+selectionKey.isAcceptable();
+selectionKey.isConnectable();
+selectionKey.isReadable();
+selectionKey.isWritable();
+```
+
+
+###Channel + Selector(通道和选择器)
+
+Accessing the channel + selector from the SelectionKey is trivial. Here is how it's done:
+
+```Java
+Channel channel = selectionKey.channel();
+
+Selector selector = selectionKey.selector();
+```
+
+###附加对象(Attaching Objects)
+
+You can attach an object to a SelectionKey this is a handy way of recognizing a given channel, or attaching further information to the channel. For instance, you may attach the Buffer you are using with the channel, or an object containing more aggregate data. Here is how you attach objects:
+
+```Java
+selectionKey.attach(theObject);
+
+Object attachedObj = selectionKey.attachment();
+```
+
+You can also attach an object already while registering the Channel with the Selector, in the register() method. Here is how that looks:
+
+```Java
+SelectionKey key = channel.register(selector, SelectionKey.OP_READ, theObject);
+```
+
+##Selecting Channels via a Selector
+
+当向选择器注册一个或多个通道后,可以调用`Selector.slect(...)`方法,这个返回会当前已经就绪的通道(说明该通道有选择器监听的事件就绪)的个数。换言之,如果选择器监听了一个通道的读事件,当该通道有数据可读时,`Selector.select(...)`操作就会返回 1。
+
+有多个重载的`select()`方法:
+
+> int select()
+> int select(long timeout)
+> int selectNow()
+
+`select()`方法会阻塞直到有通道事件就绪。
+
+`select(long timeout)`方法会阻塞直到有通道事件就绪或超时。
+
+`selectNow()`方法不管有没有通道事件就绪,都会立即返回。
+
+`select()`返回值为int类型,代表从上次调用`select()`方法到这次的就绪通道数量。当你调用select返回1时,则代表上次调用select方法到这次调用之间有一个通道变成了就绪状态,然后,再次调用select方法,如果返回值为1,则说明又有一个通道变成了就绪状态。如果你没对第一个就绪通道进行处理,则此时共有两个就绪通道,虽然最后一次select的返回值为1。
+
+###selectedKeys()
+
+当你调用select()方法返回值不为0时,则说明有一个或多个通道已经就绪。你可以通过调用`selector.selectedKeys()`获取就绪的通道:
+
+```Java
+Set selectedKeys = selector.selectedKeys();
+```
+
+When you register a channel with a Selector the Channel.register() method returns a SelectionKey object. This key represents that channels registration with that selector. It is these keys you can access via the selectedKeySet() method. From the SelectionKey.
+
+You can iterate this selected key set to access the ready channels. Here is how that looks:
+
+```Java
+Set selectedKeys = selector.selectedKeys();
+
+Iterator keyIterator = selectedKeys.iterator();
+
+while(keyIterator.hasNext()) {
+
+ SelectionKey key = keyIterator.next();
+
+ if(key.isAcceptable()) {
+ // a connection was accepted by a ServerSocketChannel.
+
+ } else if (key.isConnectable()) {
+ // a connection was established with a remote server.
+
+ } else if (key.isReadable()) {
+ // a channel is ready for reading
+
+ } else if (key.isWritable()) {
+ // a channel is ready for writing
+ }
+
+ keyIterator.remove();
+}
+```
+
+This loop iterates the keys in the selected key set. For each key it tests the key to determine what the channel referenced by the key is ready for.
+
+Notice the `keyIterator.remove()` call at the end of each iteration. The Selector does not remove the SelectionKey instances from the selected key set itself. You have to do this, when you are done processing the channel. The next time the channel becomes "ready" the Selector will add it to the selected key set again.
+
+The channel returned by the SelectionKey.channel() method should be cast to the channel you need to work with, e.g a ServerSocketChannel or SocketChannel etc.
+
+###wakeUp()
+
+A thread that has called the select() method which is blocked, can be made to leave the select() method, even if no channels are yet ready. This is done by having a different thread call the Selector.wakeup() method on the Selector which the first thread has called select() on. The thread waiting inside select() will then return immediately.
+
+If a different thread calls wakeup() and no thread is currently blocked inside select(), the next thread that calls select() will "wake up" immediately.
+
+###close()
+
+When you are finished with the Selector you call its close() method. This closes the Selector and invalidates all SelectionKey instances registered with this Selector. The channels themselves are not closed.
+
+##Full Selector Example
+
+Here is a full example which opens a Selector, registers a channel with it (the channel instantiation is left out), and keeps monitoring the Selector for "readiness" of the four events (accept, connect, read, write).
+
+Selector selector = Selector.open();
+
+channel.configureBlocking(false);
+
+SelectionKey key = channel.register(selector, SelectionKey.OP_READ);
+
+```Java
+while(true) {
+
+ int readyChannels = selector.select();
+
+ if(readyChannels == 0) continue;
+
+
+ Set selectedKeys = selector.selectedKeys();
+
+ Iterator keyIterator = selectedKeys.iterator();
+
+ while(keyIterator.hasNext()) {
+
+ SelectionKey key = keyIterator.next();
+
+ if(key.isAcceptable()) {
+ // a connection was accepted by a ServerSocketChannel.
+
+ } else if (key.isConnectable()) {
+ // a connection was established with a remote server.
+
+ } else if (key.isReadable()) {
+ // a channel is ready for reading
+
+ } else if (key.isWritable()) {
+ // a channel is ready for writing
+ }
+
+ keyIterator.remove();
+ }
+}
+```
\ No newline at end of file
diff --git a/Java-NIO/08.Java NIO FileChannel.md b/Java-NIO/08.Java NIO FileChannel.md
new file mode 100644
index 0000000..19c14a8
--- /dev/null
+++ b/Java-NIO/08.Java NIO FileChannel.md
@@ -0,0 +1,101 @@
+#08.Java NIO FileChannel
+
+*FileChannel*是一个用于连接文件的通道类。使用*FileChannel*你可以读取文件的数据或往文件里写入数据。使用*FileChannel*可以代替标准的Java IO API中对文件的操作。
+
+*FileChannel*不能设置为非阻塞模式,它总是以阻塞模式运行。
+
+##打开FileChannel(Opening a FileChannel)
+
+当需要使用*FileChannel*时,你需要首先打开一个*FileChannel*,但你不能直接打开。你必须要通过*InputStream*,*OutputStream*或*RandomAccessFile*来获得一个*FileChannel*实例。如下面这个例子:
+
+```Java
+RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw");
+FileChannel inChannel = aFile.getChannel();
+```
+
+##从FileChannel中读取数据(Reading Data from a FileChannel)
+
+从*FileChannel*中读取数据,可以调用多个重载的`read()`方法。
+
+```Java
+ByteBuffer buf = ByteBuffer.allocate(48);
+
+int bytesRead = inChannel.read(buf);
+```
+
+当**缓冲区(Buffer)**分配之后,数据从*FileChannel*中读取到缓冲区。
+
+当`FileChannel.read()`被调用后,这个方法会从*FileChannel*中读取数据到缓冲区。`read()`方法会返回一个int值,这个值代表了写入缓冲区的字节数。如果返回值是-1,则没有数据被读取。
+
+##往FileChannel中写入数据(Writing Data to a FileChannel)
+
+往*FileChannel*中写数据用的是`FileChannel.write()`方法,这个方法也会带有个Buffer类型参数。
+
+```Java
+String newData = "New String to write to file..." + System.currentTimeMillis();
+
+ByteBuffer buf = ByteBuffer.allocate(48);
+buf.clear();
+buf.put(newData.getBytes());
+
+buf.flip();
+
+while(buf.hasRemaining()) {
+ channel.write(buf);
+}
+```
+
+ 注意这里的`FileChannel.write()`方法是在while循环里面进行的。我们并不知道有多少数据要写入到*FileChannel*中,因此我们需要重复地调用`write()`方法直到缓冲区中没有数据可写。
+
+##关闭FileChannel(Closing a FileChannel)
+
+当使用完FileChannel后,必须要关闭它:
+
+
+```Java
+channel.close();
+```
+
+##FileChannel Position
+
+当从*FileChannel*读取数据往其中写人数据时,我们需要要指定特定的位置。你可以通过调用`position()`方法来获得*FileChannel*当前的位置。
+
+你也可以通过`position(long pos)`方法来设置*FileChannel*的位置。
+
+```Java
+long pos channel.position();
+
+channel.position(pos +123);
+```
+
+如果你将*position*设置到文件的末尾之后,当你再对*FileChannel*进行读取时,将会返回-1,表明读取到了文件末尾。
+
+如果你将*position*设置到文件的末尾之后,让你往*FileChannel*写入数据时,文件就会自动拓展到`position`所指定的位置并写入数据。这会导致**文件空洞(File Hole)**。
+
+
+##FileChannel Size
+
+`FileChannel.size()`方法会返回通道所连接的文件的大小。
+
+```Java
+long fileSize = channel.size();
+```
+
+##FileChannel Truncate
+
+你可以通过`FileChannel.truncate()`方法对通道所关联的文件进行截取:
+
+```Java
+channel.truncate(1024);
+```
+
+
+##FileChannel Force
+
+`FileChannel.force()`方法会将所有通道中的数据刷新到磁盘中。操作系统会处于性能考虑将数据缓存到内存中,所以你不能保证写入到通道中的数据会立刻同步到磁盘,因此你可以通过`force()`方法将通道中的数据刷新到物理磁盘。
+
+`FileChannel.forece()`方法带有一个布尔类型的参数,这个参数用于指定文件的**元数据(meta data)**是否也需要刷新到物理磁盘。
+
+```Java
+channel.force(true);
+```
\ No newline at end of file
diff --git a/Java-NIO/09.Java NIO SocketChannel.md b/Java-NIO/09.Java NIO SocketChannel.md
new file mode 100644
index 0000000..9b6c223
--- /dev/null
+++ b/Java-NIO/09.Java NIO SocketChannel.md
@@ -0,0 +1,87 @@
+#09.Java NIO SocketChannel
+
+A Java NIO SocketChannel is a channel that is connected to a TCP network socket. It is Java NIO's equivalent of Java Networking's Sockets. There are two ways a SocketChannel can be created:
+
+You open a SocketChannel and connect to a server somewhere on the internet.
+A SocketChannel can be created when an incoming connection arrives at a ServerSocketChannel.
+
+
+##Opening a SocketChannel
+
+Here is how you open a SocketChannel:
+
+```Java
+SocketChannel socketChannel = SocketChannel.open();
+socketChannel.connect(new InetSocketAddress("http://jenkov.com", 80));
+```
+
+##Closing a SocketChannel
+
+You close a SocketChannel after use by calling the SocketChannel.close() method. Here is how that is done:
+
+```Java
+socketChannel.close();
+```
+
+##Reading from a SocketChannel
+
+To read data from a SocketChannel you call one of the read() methods. Here is an example:
+
+```Java
+ByteBuffer buf = ByteBuffer.allocate(48);
+
+int bytesRead = socketChannel.read(buf);
+```
+
+First a Buffer is allocated. The data read from the SocketChannel is read into the Buffer.
+
+Second the SocketChannel.read() method is called. This method reads data from the SocketChannel into the Buffer. The int returned by the read() method tells how many bytes were witten into the Buffer. If -1 is returned, the end-of-stream is reached (the connection is closed).
+
+##Writing to a SocketChannel
+
+Writing data to a SocketChannel is done using the SocketChannel.write() method, which takes a Buffer as parameter. Here is an example:
+
+```Java
+String newData = "New String to write to file..." + System.currentTimeMillis();
+
+ByteBuffer buf = ByteBuffer.allocate(48);
+buf.clear();
+buf.put(newData.getBytes());
+
+buf.flip();
+
+while(buf.hasRemaining()) {
+ channel.write(buf);
+}
+```
+
+Notice how the SocketChannel.write() method is called inside a while-loop. There is no guarantee of how many bytes the write() method writes to the SocketChannel. Therefore we repeat the write() call until the Buffer has no further bytes to write.
+
+##Non-blocking Mode
+
+You can set a SocketChannel into non-blocking mode. When you do so, you can call connect(), read() and write() in asynchronous mode.
+
+##connect()
+
+If the SocketChannel is in non-blocking mode, and you call connect(), the method may return before a connection is established. To determine whether the connection is established, you can call the finishConnect() method, like this:
+
+```Java
+socketChannel.configureBlocking(false);
+socketChannel.connect(new InetSocketAddress("http://jenkov.com", 80));
+
+while(! socketChannel.finishConnect() ){
+ //wait, or do something else...
+}
+```
+
+##write()
+
+In non-blocking mode the write() method may return without having written anything. Therefore you need to call the write() method in a loop. But, since this is already being done in the previous write examples, no need to do anything differently here.
+
+##read()
+
+In non-blocking mode the read() method may return without having read any data at all. Therefore you need to pay attention to the returned int, which tells how many bytes were read.
+
+##Non-blocking Mode with Selectors
+
+The non-blocking mode of SocketChannel's works much better with Selector's. By registering one or more SocketChannel's with a Selector, you can ask the Selector for channels that are ready for reading, writing etc. How to use Selector's with SocketChannel's is explained in more detail in a later text in this tutorial.
\ No newline at end of file
diff --git a/Java-NIO/10.Java NIO ServerSocketChannel.md b/Java-NIO/10.Java NIO ServerSocketChannel.md
new file mode 100644
index 0000000..9f1cff7
--- /dev/null
+++ b/Java-NIO/10.Java NIO ServerSocketChannel.md
@@ -0,0 +1,73 @@
+
+#10.Java NIO ServerSocketChannel
+
+A Java NIO ServerSocketChannel is a channel that can listen for incoming TCP connections, just like a ServerSocket in standard Java Networking. The ServerSocketChannel class is located in the java.nio.channels package.
+
+Here is an example:
+
+```Java
+ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
+
+serverSocketChannel.socket().bind(new InetSocketAddress(9999));
+
+while(true){
+ SocketChannel socketChannel =
+ serverSocketChannel.accept();
+
+ //do something with socketChannel...
+}
+```
+
+##Opening a ServerSocketChannel
+
+You open a ServerSocketChannel by calling the ServerSocketChannel.open() method. Here is how that looks:
+
+```Java
+ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
+```
+
+
+##Closing a ServerSocketChannel
+
+Closing a ServerSocketChannel is done by calling the ServerSocketChannel.close() method. Here is how that looks:
+
+```Java
+serverSocketChannel.close();
+```
+
+##Listening for Incoming Connections
+
+Listening for incoming connections is done by calling the ServerSocketChannel.accept() method. When the accept() method returns, it returns a SocketChannel with an incoming connection. Thus, the accept() method blocks until an incoming connection arrives.
+
+Since you are typically not interested in listening just for a single connection, you call the accept() inside a while-loop. Here is how that looks:
+
+```Java
+while(true){
+ SocketChannel socketChannel =
+ serverSocketChannel.accept();
+
+ //do something with socketChannel...
+}
+```
+
+Of course you would use some other stop-criteria than true inside the while-loop.
+
+##Non-blocking Mode
+
+A ServerSocketChannel can be set into non-blocking mode. In non-blocking mode the accept() method returns immediately, and may thus return null, if no incoming connection had arrived. Therefore you will have to check if the returned SocketChannel is null. Here is an example:
+
+```Java
+ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
+
+serverSocketChannel.socket().bind(new InetSocketAddress(9999));
+serverSocketChannel.configureBlocking(false);
+
+while(true){
+ SocketChannel socketChannel =
+ serverSocketChannel.accept();
+
+ if(socketChannel != null){
+ //do something with socketChannel...
+ }
+}
+```
diff --git a/Java-NIO/11.Java NIO DatagramChannel.md b/Java-NIO/11.Java NIO DatagramChannel.md
new file mode 100644
index 0000000..ef9ecdd
--- /dev/null
+++ b/Java-NIO/11.Java NIO DatagramChannel.md
@@ -0,0 +1,48 @@
+#11.Java NIO DatagramChannel
+
+A Java NIO DatagramChannel is a channel that can send and receive UDP packets. Since UDP is a connection-less network protocol, you cannot just by default read and write to a DatagramChannel like you do from other channels. Instead you send and receive packets of data.
+
+Opening a DatagramChannel
+
+Here is how you open a DatagramChannel:
+
+DatagramChannel channel = DatagramChannel.open();
+channel.socket().bind(new InetSocketAddress(9999));
+This example opens a DatagramChannel which can receive packets on UDP port 9999.
+
+Receiving Data
+
+You receive data from a DatagramChannel by calling its receive() method, like this:
+
+ByteBuffer buf = ByteBuffer.allocate(48);
+buf.clear();
+
+channel.receive(buf);
+The receive() method will copy the content of a received packet of data into the given Buffer. If the received packet contains more data than the Buffer can contain, the remaining data is discarded silently.
+
+Sending Data
+
+You can send data via a DatagramChannel by calling its send() method, like this:
+
+String newData = "New String to write to file..."
+ + System.currentTimeMillis();
+
+ByteBuffer buf = ByteBuffer.allocate(48);
+buf.clear();
+buf.put(newData.getBytes());
+buf.flip();
+
+int bytesSent = channel.send(buf, new InetSocketAddress("jenkov.com", 80));
+This example sends the string to the "jenkov.com" server on UDP port 80. Nothing is listening on that port though, so nothing will happen. You will not be notified of whether the send packet was received or not, since UDP does not make any guarantees about delivery of data.
+
+Connecting to a Specific Address
+
+It is possible to "connect" a DatagramChannel to a specific address on the network. Since UDP is connection-less, this way of connecting to an address does not create a real connection, like with a TCP channel. Rather, it locks your DatagramChannel so you can only send and receive data packets from one specific address.
+
+Here is an example:
+
+channel.connect(new InetSocketAddress("jenkov.com", 80));
+When connected you can also use the read() and write() method, as if you were using a traditional channel. You just don't have any guarantees about delivery of the sent data. Here are a few examples:
+
+int bytesRead = channel.read(buf);
+int bytesWritten = channel.write(buf);
\ No newline at end of file
diff --git a/Java-NIO/12.Java NIO Pipe.md b/Java-NIO/12.Java NIO Pipe.md
new file mode 100644
index 0000000..426e0b0
--- /dev/null
+++ b/Java-NIO/12.Java NIO Pipe.md
@@ -0,0 +1,44 @@
+#12.Java NIO Pipe
+
+A Java NIO Pipe is a one-way data connection between two threads. A Pipe has a source channel and a sink channel. You write data to the sink channel. This data can then be read from the source channel.
+
+Here is an illustration of the Pipe principle:
+
+Java NIO: Pipe Internals
+Java NIO: Pipe Internals
+Creating a Pipe
+
+You open a Pipe by calling the Pipe.open() method. Here is how that looks:
+
+Pipe pipe = Pipe.open();
+Writing to a Pipe
+
+To write to a Pipe you need to access the sink channel. Here is how that is done:
+
+Pipe.SinkChannel sinkChannel = pipe.sink();
+You write to a SinkChannel by calling it's write() method, like this:
+
+String newData = "New String to write to file..." + System.currentTimeMillis();
+
+ByteBuffer buf = ByteBuffer.allocate(48);
+buf.clear();
+buf.put(newData.getBytes());
+
+buf.flip();
+
+while(buf.hasRemaining()) {
+ sinkChannel.write(buf);
+}
+Reading from a Pipe
+
+To read from a Pipe you need to access the source channel. Here is how that is done:
+
+Pipe.SourceChannel sourceChannel = pipe.source();
+To read from the source channel you call its read() method like this:
+
+ByteBuffer buf = ByteBuffer.allocate(48);
+
+int bytesRead = inChannel.read(buf);
+The int returned by the read() method tells how many bytes were read into the buffer.
+
+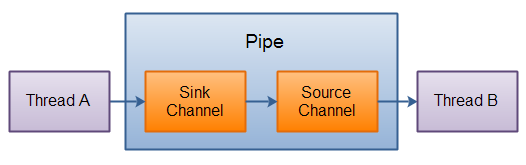
\ No newline at end of file
diff --git a/Java-NIO/13.Java NIO vs IO.md b/Java-NIO/13.Java NIO vs IO.md
new file mode 100644
index 0000000..5b1b9ef
--- /dev/null
+++ b/Java-NIO/13.Java NIO vs IO.md
@@ -0,0 +1,115 @@
+#13.Java NIO vs. IO
+
+When studying both the Java NIO and IO API's, a question quickly pops into mind:
+
+When should I use IO and when should I use NIO?
+
+In this text I will try to shed some light on the differences between Java NIO and IO, their use cases, and how they affect the design of your code.
+
+Main Differences Betwen Java NIO and IO
+
+The table below summarizes the main differences between Java NIO and IO. I will get into more detail about each difference in the sections following the table.
+
+IO NIO
+Stream oriented Buffer oriented
+Blocking IO Non blocking IO
+ Selectors
+Stream Oriented vs. Buffer Oriented
+
+The first big difference between Java NIO and IO is that IO is stream oriented, where NIO is buffer oriented. So, what does that mean?
+
+Java IO being stream oriented means that you read one or more bytes at a time, from a stream. What you do with the read bytes is up to you. They are not cached anywhere. Furthermore, you cannot move forth and back in the data in a stream. If you need to move forth and back in the data read from a stream, you will need to cache it in a buffer first.
+
+Java NIO's buffer oriented approach is slightly different. Data is read into a buffer from which it is later processed. You can move forth and back in the buffer as you need to. This gives you a bit more flexibility during processing. However, you also need to check if the buffer contains all the data you need in order to fully process it. And, you need to make sure that when reading more data into the buffer, you do not overwrite data in the buffer you have not yet processed.
+
+Blocking vs. Non-blocking IO
+
+Java IO's various streams are blocking. That means, that when a thread invokes a read() or write(), that thread is blocked until there is some data to read, or the data is fully written. The thread can do nothing else in the meantime.
+
+Java NIO's non-blocking mode enables a thread to request reading data from a channel, and only get what is currently available, or nothing at all, if no data is currently available. Rather than remain blocked until data becomes available for reading, the thread can go on with something else.
+
+The same is true for non-blocking writing. A thread can request that some data be written to a channel, but not wait for it to be fully written. The thread can then go on and do something else in the mean time.
+
+What threads spend their idle time on when not blocked in IO calls, is usually performing IO on other channels in the meantime. That is, a single thread can now manage multiple channels of input and output.
+
+Selectors
+
+Java NIO's selectors allow a single thread to monitor multiple channels of input. You can register multiple channels with a selector, then use a single thread to "select" the channels that have input available for processing, or select the channels that are ready for writing. This selector mechanism makes it easy for a single thread to manage multiple channels.
+
+How NIO and IO Influences Application Design
+
+Whether you choose NIO or IO as your IO toolkit may impact the following aspects of your application design:
+
+The API calls to the NIO or IO classes.
+The processing of data.
+The number of thread used to process the data.
+The API Calls
+
+Of course the API calls when using NIO look different than when using IO. This is no surprise. Rather than just read the data byte for byte from e.g. an InputStream, the data must first be read into a buffer, and then be processed from there.
+
+The Processing of Data
+
+The processing of the data is also affected when using a pure NIO design, vs. an IO design.
+
+In an IO design you read the data byte for byte from an InputStream or a Reader. Imagine you were processing a stream of line based textual data. For instance:
+
+Name: Anna
+Age: 25
+Email: anna@mailserver.com
+Phone: 1234567890
+This stream of text lines could be processed like this:
+
+InputStream input = ... ; // get the InputStream from the client socket
+
+BufferedReader reader = new BufferedReader(new InputStreamReader(input));
+
+String nameLine = reader.readLine();
+String ageLine = reader.readLine();
+String emailLine = reader.readLine();
+String phoneLine = reader.readLine();
+Notice how the processing state is determined by how far the program has executed. In other words, once the first reader.readLine() method returns, you know for sure that a full line of text has been read. The readLine() blocks until a full line is read, that's why. You also know that this line contains the name. Similarly, when the second readLine() call returns, you know that this line contains the age etc.
+
+As you can see, the program progresses only when there is new data to read, and for each step you know what that data is. Once the executing thread have progressed past reading a certain piece of data in the code, the thread is not going backwards in the data (mostly not). This principle is also illustrated in this diagram:
+
+Java IO: Reading data from a blocking stream.
+Java IO: Reading data from a blocking stream.
+A NIO implementation would look different. Here is a simplified example:
+
+ByteBuffer buffer = ByteBuffer.allocate(48);
+
+int bytesRead = inChannel.read(buffer);
+Notice the second line which reads bytes from the channel into the ByteBuffer. When that method call returns you don't know if all the data you need is inside the buffer. All you know is that the buffer contains some bytes. This makes processing somewhat harder.
+
+Imagine if, after the first read(buffer) call, that all what was read into the buffer was half a line. For instance, "Name: An". Can you process that data? Not really. You need to wait until at leas a full line of data has been into the buffer, before it makes sense to process any of the data at all.
+
+So how do you know if the buffer contains enough data for it to make sense to be processed? Well, you don't. The only way to find out, is to look at the data in the buffer. The result is, that you may have to inspect the data in the buffer several times before you know if all the data is inthere. This is both inefficient, and can become messy in terms of program design. For instance:
+
+ByteBuffer buffer = ByteBuffer.allocate(48);
+
+int bytesRead = inChannel.read(buffer);
+
+while(! bufferFull(bytesRead) ) {
+ bytesRead = inChannel.read(buffer);
+}
+The bufferFull() method has to keep track of how much data is read into the buffer, and return either true or false, depending on whether the buffer is full. In other words, if the buffer is ready for processing, it is considered full.
+
+The bufferFull() method scans through the buffer, but must leave the buffer in the same state as before the bufferFull() method was called. If not, the next data read into the buffer might not be read in at the correct location. This is not impossible, but it is yet another issue to watch out for.
+
+If the buffer is full, it can be processed. If it is not full, you might be able to partially process whatever data is there, if that makes sense in your particular case. In many cases it doesn't.
+
+The is-data-in-buffer-ready loop is illustrated in this diagram:
+
+Java NIO: Reading data from a channel until all needed data is in buffer.
+Java NIO: Reading data from a channel until all needed data is in buffer.
+Summary
+
+NIO allows you to manage multiple channels (network connections or files) using only a single (or few) threads, but the cost is that parsing the data might be somewhat more complicated than when reading data from a blocking stream.
+
+If you need to manage thousands of open connections simultanously, which each only send a little data, for instance a chat server, implementing the server in NIO is probably an advantage. Similarly, if you need to keep a lot of open connections to other computers, e.g. in a P2P network, using a single thread to manage all of your outbound connections might be an advantage. This one thread, multiple connections design is illustrated in this diagram:
+
+Java NIO: A single thread managing multiple connections.
+Java NIO: A single thread managing multiple connections.
+If you have fewer connections with very high bandwidth, sending a lot of data at a time, perhaps a classic IO server implementation might be the best fit. This diagram illustrates a classic IO server design:
+
+Java IO: A classic IO server design - one connection handled by one thread.
+Java IO: A classic IO server design - one connection handled by one thread.
diff --git a/Java-NIO/README.md b/Java-NIO/README.md
new file mode 100644
index 0000000..13df960
--- /dev/null
+++ b/Java-NIO/README.md
@@ -0,0 +1,3 @@
+#Java NIO
+
+翻译自:http://tutorials.jenkov.com/java-nio/index.html
diff --git a/Java-NIO/images/buffers-modes.png b/Java-NIO/images/buffers-modes.png
new file mode 100644
index 0000000..15a094a
Binary files /dev/null and b/Java-NIO/images/buffers-modes.png differ
diff --git a/Java-NIO/images/overview-channels-buffers.png b/Java-NIO/images/overview-channels-buffers.png
new file mode 100644
index 0000000..ad73809
Binary files /dev/null and b/Java-NIO/images/overview-channels-buffers.png differ
diff --git a/Java-NIO/images/overview-selectors.png b/Java-NIO/images/overview-selectors.png
new file mode 100644
index 0000000..d5c0757
Binary files /dev/null and b/Java-NIO/images/overview-selectors.png differ
diff --git "a/Java-Security/01.\351\224\201.md" "b/Java-Security/01.\351\224\201.md"
new file mode 100644
index 0000000..0b798e3
--- /dev/null
+++ "b/Java-Security/01.\351\224\201.md"
@@ -0,0 +1,138 @@
+#01.锁
+
+##不要在可重用的对象上加锁
+
+不要在可重用的对象上加锁,如果你这样做了,可能导致死锁或其他不可预测的行为。
+
+####不合规的代码(Boolean类型锁)
+
+下面的代码在Boolean类型上加锁:
+
+```Java
+private final Boolean lock= Boolean.FALSE;
+public void doSomething() {
+ synchronized (lock) {
+ // ...
+ }
+}
+```
+
+Boolean类型对象并不适合加锁,因为它只有两个值:`true`和`false`。在JVM中,Boolean类型的两个字面量值都分别都指向同一个共享对象。在这里例子中,lock指向JVM中的一个Boolean.FALSE实例,而这个实例的所有线程共享的。如果有其他的线程不注意地也使用了Boolean.FALSE进行加锁,就可能导致死锁或不可预测的行为。
+
+####有缺陷的代码示例(Integer的自动装箱)
+
+这个例子中的不合规代码在自动装箱的Integer类型上加锁:
+
+```Java
+private int = 0;
+private final Integer lock = count; // Boxed primitive lock is shared
+public void doSomething() {
+ synchronized (lock) {
+ count++;
+ // ...
+ }
+}
+```
+
+自动装箱的Integer对象,在一定范围内是共享的( 这个范围是-128到127),因此,这会导致跟Boolean常量一样的问题。JVM的常量池中缓存了Integer(-128)到Integer(127)这个范围的Integer对象,在这个范围内的自动装箱Integer对象,都是从这个常量池中共享这些对象。有一些JVM实现也允许大于这个范围的Integer常量池。所以,在自动装箱的对象上加锁是不安全的。而使用`new Integer(value)`创建的Integer实例对象是不共享的。**一般来说,在自动装箱的数据类型上加锁都是不可取和不安全的。**
+
+####解决方案(Integer)
+
+上面例子的解决方法就是在非装箱的Integer对象上加锁。如下面的代码所示:
+
+```Java
+private int count = 0;
+private final Integer lock = new Integer(count);
+
+public void doSomething() {
+ synchronized (lock) {
+ count++;
+ // ...
+ }
+}
+```
+当使用构造方法时,会创建独立的Integer对象,而不会使用常量池中共享的Intege对象。这是一个可接受的解决方法,但这会导致维护问题,开发人员会错误地认为使用自动装箱的Integer也是可以的。更好的解决方法就是`new Object()`对象,最后一个例子会详细介绍。
+
+####有缺陷的代码示例(new String("lock").intern())
+
+下面是一个不合规的代码示例:
+
+```Java
+private final String lock = new String("LOCK").intern();
+public void doSomething() {
+ synchronized (lock) {
+ // ...
+ }
+}
+```
+
+Java API对java.lang.String类的inern()方法解释如下:
+
+> 当调用`intern()`方法时,如果常量池中存在这个字符串对象,则会返回这个字符串对象,否则创建这个这个字符串对象,放置常量池并返回。
+
+因此,`new String("lock").intern()`返回的对象有可能是JVM中共享的。即使这个字符串对象已经用`private`和`final`修饰,其他的线程仍然可以从JVM的常量池中共享这个对象。使用字符串常量也同样会有这个问题。
+
+除此,恶意代码可能会利用这个漏洞进行攻击。详见:https://www.securecoding.cert.org/confluence/display/java/LCK00-J.+Use+private+final+lock+objects+to+synchronize+classes+that+may+interact+with+untrusted+code
+
+
+####有缺陷的代码(字符串字面量)
+
+下面不合规代码在字符串的字面量上加锁:
+
+```Java
+// This bug was found in jetty-6.1.3 BoundedThreadPool
+private final String lock = "lock";
+
+public void doSomething() {
+ synchronized (lock) {
+ // ...
+ }
+}
+```
+
+String字面量实际上是个常量,在内部会调用`intern()`方法。因此,这段代码会陷入上面所说的陷阱:
+
+####解决方法(String实例)
+
+This compliant solution locks on a noninterned String instance.
+
+```Java
+private final String lock = new String("LOCK");
+
+public void doSomething() {
+ synchronized (lock) {
+ // ...
+ }
+}
+```
+
+String实例不同于String字面量。String实例拥有各自独立的引用,并不会使用常量池中存在的String实例,因此拥有自己独立的锁。然而,这不是最好的解决方法。最好的解决方法是下面一个。
+
+####解决方法(private final Obejct = new Object())
+
+使用Object对象,能够轻松解决上面的问题:
+
+```Java
+private final Object lock = new Object();
+
+public void doSomething() {
+ synchronized (lock) {
+ // ...
+ }
+}
+```
+
+更多的详细信息,请看这里:https://www.securecoding.cert.org/confluence/display/java/LCK00-J.+Use+private+final+lock+objects+to+synchronize+classes+that+may+interact+with+untrusted+code
+
+在私有的不可变Object对象上加锁,可以轻松解决上面遇到的问题。
+
+####风险评估(Risk Assessment)
+
+A significant number of concurrency vulnerabilities arise from locking on the wrong kind of object. It is important to consider the properties of the lock object rather than simply scavenging for objects on which to synchronize.
+
+----------
+
+
+##另一个主题
+
+
\ No newline at end of file
diff --git a/Java-Security/README.md b/Java-Security/README.md
new file mode 100644
index 0000000..e7fe136
--- /dev/null
+++ b/Java-Security/README.md
@@ -0,0 +1,2 @@
+
+翻译自:https://www.securecoding.cert.org/confluence/display/java/The+CERT+Oracle+Secure+Coding+Standard+for+Java
diff --git "a/web\345\274\200\345\217\221\350\247\204\350\214\203/06.Eclipse\345\277\253\346\215\267\351\224\256.md" "b/web\345\274\200\345\217\221\350\247\204\350\214\203/06.Eclipse\345\277\253\346\215\267\351\224\256.md"
index c818432..050af4a 100644
--- "a/web\345\274\200\345\217\221\350\247\204\350\214\203/06.Eclipse\345\277\253\346\215\267\351\224\256.md"
+++ "b/web\345\274\200\345\217\221\350\247\204\350\214\203/06.Eclipse\345\277\253\346\215\267\351\224\256.md"
@@ -98,6 +98,10 @@ ALT + UP 可以将选择的文本向下移,ALT + DOWN 则是向上移。
ALT + LEFT 为左切换,ALT + RIGHT 为右切换
+## 2.16 删除当前行
+
+CTRL + D
+
+
+当你需要使用选择器时,你需要使用它向通道进行注册(register)。然后调用选择器的`select()`方法。这个方法会阻塞直至其中一个通道的事件就绪。一旦方法返回后,线程就可以对事件进行处理。这些事件包括:网路连接,接收数据等等。
\ No newline at end of file
diff --git "a/Java-NIO/03.Java NIO\351\200\232\351\201\223.md" "b/Java-NIO/03.Java NIO\351\200\232\351\201\223.md"
new file mode 100644
index 0000000..291e3f3
--- /dev/null
+++ "b/Java-NIO/03.Java NIO\351\200\232\351\201\223.md"
@@ -0,0 +1,46 @@
+#03. Java NIO通道
+
+Java NIO的**通道(Channels)**类似与标准IO中的**流(Stream)**,它们之间的区别在于:
+
+* 你可以从管道中读取或写入数据(双向),但是流只能是读取或写入(单向)。
+* 通道可以进行异步(Asynchonously)操作。
+* 通道(Channel)总是从缓冲区(Buffers)中读取或写入数据。
+
+如上面所提到的,数据总是从管道中读取到缓冲区,后从缓冲区中写入到通道。如下图所示:
+
+
+
+ 以下是Java NIO中Chanel的最重要的实现类:
+
+* FileChannel:从文件中读取或写入数据
+* DatagramChannel:从UPD中读取或写入数据
+* SocketChannel:从TCP中读取或写入数据
+* ServerSocketChannel:用于监听TCP连接,每接收一个连接就创建一个`SocketChannel`
+
+##Channel例子(Basic Channel Example)
+
+以下的代码示例演示了从FileChannel读取数据到Buffer中:
+
+```Java
+RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw");
+FileChannel inChannel = aFile.getChannel();
+
+ByteBuffer buf = ByteBuffer.allocate(48);
+
+int bytesRead = inChannel.read(buf);
+while (bytesRead != -1) {
+
+ System.out.println("Read " + bytesRead);
+ buf.flip();
+
+ while(buf.hasRemaining()){
+ System.out.print((char) buf.get());
+ }
+
+ buf.clear();
+ bytesRead = inChannel.read(buf);
+}
+aFile.close();
+```
+
+注意`buf.flip`的调用。当你写入数据到Buffer后,需要调用这个方法,然后才能从Buffer中读取数据。
diff --git "a/Java-NIO/04.Java NIO\347\274\223\345\206\262\345\214\272.md" "b/Java-NIO/04.Java NIO\347\274\223\345\206\262\345\214\272.md"
new file mode 100644
index 0000000..3b33ef3
--- /dev/null
+++ "b/Java-NIO/04.Java NIO\347\274\223\345\206\262\345\214\272.md"
@@ -0,0 +1,196 @@
+#04.Java NIO缓冲区
+
+Java NIO中的**缓冲区(Buffers)**用于跟**通道(Channels)**交互时使用。如你所知,数据从通道中读取到缓冲区,或从缓冲区中写入到通道。
+
+缓冲区本质上是一个内存块,在这个块中,你可以进行写入和读取操作。Java NIO将这个内存块用缓存区包装起来,并提供了一系列的用于操作这个内存块的API。
+
+##缓冲区的基本用法(Basic Buffer Usage)
+
+利用缓冲区读写数据通常遵循这个小4个步骤:
+
+* 写入数据到缓冲区;
+* 调用buffer.flip()方法;
+* 从缓冲区中读取数据;
+* 调用buffer.clear()或buffer.compact()方法。
+
+当你往缓冲区写入数据的时候,缓冲区会跟踪记录你写入的数据量。当你需要缓冲区读取数据时,你需要调用`flip()`方法将缓冲区从**写模式**切换为**读模式**。在读模式中,你可以读取之前往缓冲区写入的所有数据。
+
+当你读取完数据之后,你需要清空缓冲区,以便可以写入数据。你可以通过两种方式来完成:调用`clear()`或`compact()`方法。__`clear()`方法会清空整个缓冲区的数据。而`compact()`方法只会清空已经读取过的数据,尚未读取过的数据会被移动到缓冲区的前端,以便下次继续读取。__
+
+简单示例:
+
+```Java
+RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw");
+FileChannel inChannel = aFile.getChannel();
+
+//create buffer with capacity of 48 bytes
+ByteBuffer buf = ByteBuffer.allocate(48);
+
+int bytesRead = inChannel.read(buf); //read into buffer.
+while (bytesRead != -1) {
+
+ buf.flip(); //make buffer ready for read
+
+ while(buf.hasRemaining()){
+ System.out.print((char) buf.get()); // read 1 byte at a time
+ }
+
+ buf.clear(); //make buffer ready for writing
+ bytesRead = inChannel.read(buf);
+}
+aFile.close();
+```
+
+##Capacity, Position和Limit
+
+缓冲区本质上是一个内存块,在这个块中,你可以进行写入和读取操作。Java NIO将这个内存块用缓存区包装起来,并提供了一系列的用于操作这个内存块的API。
+
+如果你想知道缓冲区是如何工作的,那么你需要理解缓冲区的三个属性,它们分别是:
+
+* 容量(Capacity)
+* 位置(Position)
+* 极限(Limit)
+
+
+**position**和**limit**在读模式/写模式中具有不同的含义。而**capacity**在任何情况都具有同一含义:**缓冲区的容量大小。**
+
+下面这个图描绘了capacity,position和limit在读模式和写模式中的含义:
+
+
+
+###Capacity
+
+做为一个内存块,缓冲区有固定的大小,称之为:**容量(capcity)**。你只能往缓冲区中写入固定大小的bytes,long,chars等类型数据。一旦缓冲区慢后,你需要清空它(读取数据或clear())才能继续写入数据。
+
+###Position
+
+当你往缓冲区写入数据时,实际上你是往缓冲区中的指定的位置写入数据。这个位置初始值为0,当往缓冲区写入数据时,position会指向下一个可写入的内存单元。postion的最大值为capacity-1。
+
+当你从缓冲区读取数据时,你同样的是从position指定的位置读取数据。当你调用`flip()`方法使缓冲区由**写模式**切换成**读模式**后,position会重置为0。当从position指定单元读数据后,postion会移至下一个可读取单元。
+
+###Limit
+
+在**写模式**中,limit指定的是能写入数据量的大小。在写模式中,limit的值等于capacity的值。
+
+当调用`flip()`方法使缓冲区切换成**读模式**后,limit会重置为你能读取的数据量的大小。因此,在调用`flip()`方法后,limit重置为position的值,而position重置为0。
+
+##Buffer Types
+
+Java NIO提供了一下缓冲区类型:
+
+* ByteBuffer
+* MappedByteBuffer
+* ShortBuffer
+* IntBuffer
+* LongBuffer
+* FloatBuffer
+* DoubleBuffer
+
+###Allocating a Buffer
+
+要获得缓冲区,你需要为它开辟空间。每一个缓冲区类都有一个`allocate()`方法用于开辟内存空间。下面这个代码示例显示了如何开辟48个字节的缓冲区。
+
+```Java
+ByteBuffer buf = ByteBuffer.allocate(48);
+```
+
+下面的代码显示了如何开辟1024个字符的内存空间:
+
+```Java
+CharBuffer buf = CharBuffer.allocate(1024);
+```
+
+###Writing Data to a Buffer
+
+你可以通过两种方式往缓冲区中写入数据:
+
+* 从通道中写入数据到缓冲区。
+* 通过缓冲区的`put()`方法直接往缓冲区写入数据。
+
+下面的代码演示了从通道中写入数据到缓冲区:
+
+```Java
+int bytesRead = inChannel.read(buf); //read into buffer.
+```
+
+下面的代码演示了通过`put()`方法直接往缓冲区写入数据:
+
+```Java
+buf.put(127);
+```
+
+有很多重载的`put`方法方便你往缓冲区写入数据。例如,将数据写入到指定位置,或者将字节数组写入缓冲区。具体的方法请查阅API。
+
+###flip()
+
+调用`flip()`方法可以将缓冲区区从写模式切换为模式,此时limit被重置为position的值,而position被重置为0。
+
+换句话说,position标识当前读的位置,而limit标识缓存区可读内容的大小。
+
+##从缓冲区读取数据(Reading Data from a Buffer)
+
+从缓冲区读取数据有两种方式:
+
+* 从缓冲区读取数据到通道中。
+* 直接调用缓冲区的`get()`方法。
+
+以下是这两种方法对应的代码:
+
+```Java
+//read from buffer into channel.
+int bytesWritten = inChannel.write(buf);
+```
+
+```Java
+byte aByte = buf.get();
+```
+
+Java API提供了多种重载的`get()`方法。详情请查阅文档。
+
+###rewind()
+
+`Buffer.rewind()`可以将**position**重置为0,这样你就可以多次读取缓冲区的数据,期间**limit**的值保持不边
+
+###clear() and compact()
+
+当从缓冲区读取完数据后,可以调用`clear()`或`compact()`将缓冲区切换为写模式。
+
+如果调用的是`clear()`方法,position重置为0,limit重置为capacity的值。换言之,缓冲区被清除了,但实际上缓冲区的数据并没被清除。
+
+如果缓冲区中还有需要读取的数据,同时你需要清除已经读取过的数据,这时你可以调用`compact()`方法。
+
+`compact()`方法会复制尚未读取的数据到缓冲区的前面,然后将position设置为未读取数据的最后一个元素的后一位,而limit重置为capacity的值。这样就可以保证未读取的数据不会丢失,同时又可以继续写入数据。
+
+
+###mark()和reset()
+
+`Buffer.mark()`可以对position的位置进行标志,在进行一系列操作后,可以调用`reset()`将position重置为`Buffer.mark()`标志的位置。例子:
+
+```Java
+buffer.mark();
+//call buffer.get() a couple of times, e.g. during parsing.
+
+buffer.reset(); //set position back to mark.
+```
+
+##equals()和compareTo()
+
+
+可以调用缓冲区的`equals()`方法和`compareTo()`方法对缓冲区进行比较。
+
+####equals()
+
+如果符合以下情况,则两个缓冲区的`equals()`返回值为true:
+
+* 缓冲区的类型相同(byte、char等等);
+* 缓冲区中有效数据的数据量相等;
+* 缓冲区中有效数据的数据一致;
+
+如上所示,如果缓冲区中的**有效数据**都相同,则`equals()`返回值为true。
+
+####compareTo()
+
+The compareTo() method compares the remaining elements (bytes, chars etc.) of the two buffers, for use in e.g. sorting routines. A buffer is considered "smaller" than another buffer if:
+
+The first element which is equal to the corresponding element in the other buffer, is smaller than that in the other buffer.
+All elements are equal, but the first buffer runs out of elements before the second buffer does (it has fewer elements).
\ No newline at end of file
diff --git a/Java-NIO/05.Java NIO Scatter, Gather.md b/Java-NIO/05.Java NIO Scatter, Gather.md
new file mode 100644
index 0000000..f984a50
--- /dev/null
+++ b/Java-NIO/05.Java NIO Scatter, Gather.md
@@ -0,0 +1,51 @@
+#05.Java NIO Scatter, Gather
+
+Java NIO开始支持scatter/gater。scatter和gather分别用于从Channel中读取数据和写入数据到Channel中。
+
+**分散(Scatter)**操作是指**将同一个通道(Channel)的数据读到多个缓冲区(Buffer)中**。
+
+**聚集(Gather)**是指**将多个缓冲区(Buffer)的数据写入到同一个通道(Channel)中**。
+
+分散/聚集(scatter/gather)操作非常适用于一些需要把数据分开几个不同的部分进行处理的场景。例如处理固定大小的header和body的数据,你可以将header和body中的数据分别用不同的缓冲区中进行处理。
+
+##分散读取(Scattering Reads)
+
+分散读取是指**将同一个通道中的数据读到不同的缓冲区中**。如下图所示:
+
+
+
+下面的代码演示了如何使用Scatterring Reads:
+
+```Java
+ByteBuffer header = ByteBuffer.allocate(128);
+ByteBuffer body = ByteBuffer.allocate(1024);
+
+ByteBuffer[] bufferArray = { header, body };
+
+channel.read(bufferArray );
+```
+
+注意首先要将buffers插入到数组中,然后在再数组作为`channel.read()`的参数。`channel.read()`方法会依次将数组的缓冲区填满,上面的例子中,先填满header缓存区,然后再填满body缓冲区。
+
+由于分散读取(Scattering Reads)在移动到下个缓冲区前,必须填满当前的缓冲区,所以分散操作并不适用于大小不固定的数据体。换言之,上面的例子中,header必须填充128个字节,否则无法正常工作。
+
+##(聚集写入)Gathering Writes
+
+**聚集(Gather)**是指**将多个缓冲区(Buffer)的数据写入到同一个通道(Channel)中**。。如下图所示:
+
+
+
+下面的代码演示了如何使用Gathering Writes:
+
+```Java
+ByteBuffer header = ByteBuffer.allocate(128);
+ByteBuffer body = ByteBuffer.allocate(1024);
+
+//write data into buffers
+
+ByteBuffer[] bufferArray = { header, body };
+
+channel.write(buffers);
+```
+
+缓冲区数组作为参数传递给`channel.write()`方法,这个方法依次从缓冲区中写入数据到通道中。缓冲区中有效数据才会写入到通道中,例如header缓冲区的容量为128字节,但实际有效数据位58字节,所以实际上header缓冲区中只有前58字节写入到了通道。因此,与分散读取操作不同,聚集写入(Gathering Writes)操作适用于大小不固定的数据块。
diff --git "a/Java-NIO/06. Java NIO\351\200\232\351\201\223\345\210\260\351\200\232\351\201\223\347\232\204\344\274\240\350\276\223.md" "b/Java-NIO/06. Java NIO\351\200\232\351\201\223\345\210\260\351\200\232\351\201\223\347\232\204\344\274\240\350\276\223.md"
new file mode 100644
index 0000000..f3b96e4
--- /dev/null
+++ "b/Java-NIO/06. Java NIO\351\200\232\351\201\223\345\210\260\351\200\232\351\201\223\347\232\204\344\274\240\350\276\223.md"
@@ -0,0 +1,48 @@
+
+##06. Java NIO通道到通道的传输
+
+在Java NIO中,如果其中一个通道是`FileChannel`,那么你可以在两个通道间直接传输数据。`FileChannel`类提供了`transferTo()`和`transferFrom()` 两个方法来在通道中进行数据传输。
+
+##transferFrom()
+
+`FileChannel.transferFrom()`方法用来将其他通道的数据传输给`FileChannel`。看下这个例子:
+
+```Java
+RandomAccessFile fromFile = new RandomAccessFile("fromFile.txt", "rw");
+FileChannel fromChannel = fromFile.getChannel();
+
+RandomAccessFile toFile = new RandomAccessFile("toFile.txt", "rw");
+FileChannel toChannel = toFile.getChannel();
+
+long position = 0;
+long count = fromChannel.size();
+
+toChannel.transferFrom(fromChannel, position, count);
+```
+
+*position* 参数和*count*参数指明目标文件从那个地方开始读取与读取的最大字节数。
+
+另外,有一些*SocketChannel*实现也许只是传输当前部分可用数据-即使在传输过程中可能会有更多可用数据,因此`SocketChannel`有可能不会将整个数据都传输给`FileChannel`。
+
+(Additionally, some SocketChannel implementations may transfer only the data the SocketChannel has ready in its internal buffer here and now - even if the SocketChannel may later have more data available. Thus, it may not transfer the entire data requested (count) from the SocketChannel into FileChannel.)
+
+##transferTo()
+
+`transferTo()`方法将*FileChannel*的数据传输给其他通道。看下这个例子:
+
+```Java
+RandomAccessFile fromFile = new RandomAccessFile("fromFile.txt", "rw");
+FileChannel fromChannel = fromFile.getChannel();
+
+RandomAccessFile toFile = new RandomAccessFile("toFile.txt", "rw");
+FileChannel toChannel = toFile.getChannel();
+
+long position = 0;
+long count = fromChannel.size();
+
+fromChannel.transferTo(position, count, toChannel);
+```
+
+这个例子跟之前的有点相似,只是*FileChannel*对象调用的方法有所不同,其他都是一样的。
+
+The issue with SocketChannel is also present with the transferTo() method. The SocketChannel implementation may only transfer bytes from the FileChannel until the send buffer is full, and then stop.
\ No newline at end of file
diff --git "a/Java-NIO/07.Java NIO\351\200\211\346\213\251\345\231\250.md" "b/Java-NIO/07.Java NIO\351\200\211\346\213\251\345\231\250.md"
new file mode 100644
index 0000000..e11a4f6
--- /dev/null
+++ "b/Java-NIO/07.Java NIO\351\200\211\346\213\251\345\231\250.md"
@@ -0,0 +1,235 @@
+#07.Java NIO选择器
+
+选择器(Selector)是Java NIO中的一个组件,它用于检测一个或多个通道,并确定哪些通道可以进行读、写。这就是为什么Java NIO中可以使用单个线程对多个通道或网络连接进行管理。
+
+
+##为何要使用选择器(Why Use a Selector?)
+
+使用选择器的优势在于:**使用单个线程就可以对多个管道进行操作,从而可以减少处理通道的线程数量**。实际上,你可以仅仅使用一个线程来处理所有的通道。在操作系统中,线程的切换是非常昂贵的,并且,每个线程需要消耗一定的系统资源(例如内存)。因此,线程使用越少越好。
+
+不过,随着操作系统软硬件的更新迭代,多线程的开销越来越小,性能也越来越优异。而事实上,如果计算机拥有多个CPU内核,这时候如果不采用多线程,反而是对CPU资源的浪费。然而,这已不属于本教程讨论的范畴。
+
+下面的图片描绘了如何使用一个选择器来处理3个通道:
+
+
+
+##创建选择器(Creating a Selector)
+
+可以通过`Selector.open()`方法来创建选择器:
+
+```Java
+Selector selector = Selector.open();
+```
+
+#Registering Channels with the Selector
+
+为了让选择器能够处理通道,必须向选择器注册需要处理的通道,调用`SelectableChannel.register()`方法来完成注册:
+
+```
+channel.configureBlocking(false);
+
+SelectionKey key = channel.register(selector, SelectionKey.OP_READ);
+```
+
+注册的通道必须先设置为**非阻塞模式(non-blocking mode)**。由于**FileChannel**不能设置为非阻塞模式,所以FileChannel不能进行注册,而**SocketChanne**l则可以。
+
+注意`SelectableChannel.register()`方法的第二个参数。这个参数代表着**选择器需要监听通道的事件类型**。总共有四种不同的事件类型:
+
+通道**触发一个事件**,我们称之为**事件就绪**。所以,如果通道跟远程服务器建立了连接,称之为**连接就绪**;服务器socket接受客户端连接,称为**接收就绪**;通道中有数据可读,称为**读就绪**,可向通道中写数据,称为**写就绪**。
+
+以上四个事件分别由`SelectionKey`类中的四个常量来表示:
+
+```Java
+SelectionKey.OP_CONNECT
+SelectionKey.OP_ACCEPT
+SelectionKey.OP_READ
+SelectionKey.OP_WRITE
+```
+
+如果需要监听多个事件,可以使用OR操作符:
+
+```Java
+int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
+```
+由于SelectionKey中是四个常量OP\_READ、OP\_WRITE、OP\_CONNECT、OP\_ACCEPTF分别用二进制0001、0010、0100、1000表示,所以可以通过interestSet中的二进制判断监听的事件类型。
+
+##SelectionKey's
+
+上面的例子中,当调用`SelectableChannel.register()`向选择器注册通道后,该返回会返回一个`SeletionKey`对象。该`SelectionKey`对象包含以下属性:
+
+```
+The interest set(监听的事件集合)
+The ready set(就绪的事件集合)
+The Channel(通道)
+The Selector(选择器)
+An attached object (optional)
+```
+
+###Interest Set(监听的事件集合)
+
+InterestSet表示的是监听的时间集合,可以通过`SelctionKey.interestOPs()`方法获取监听的时间集合,它是一个int类型数据,由于SelectionKey中是四个常量OP\_READ、OP\_WRITE、OP\_CONNECT、OP\_ACCEPTF分别用二进制0001、0010、0100、1000表示,所以,我们可以通过**按位与**操作判断监听的事件类型:
+
+```Java
+int interestSet = selectionKey.interestOps();
+
+boolean isInterestedInAccept = interestSet & SelectionKey.OP_ACCEPT;
+boolean isInterestedInConnect = interestSet & SelectionKey.OP_CONNECT;
+boolean isInterestedInRead = interestSet & SelectionKey.OP_READ;
+boolean isInterestedInWrite = interestSet & SelectionKey.OP_WRITE;
+```
+
+###Ready Set(就绪集合)
+
+可以通过`SelectionKey.readyOps()`方法获取就绪集合。同样地,通过按位与操作判断就绪的事件类型:
+
+```Java
+int readySet = selectionKey.readyOps();
+
+selectionKey.isAcceptable();
+selectionKey.isConnectable();
+selectionKey.isReadable();
+selectionKey.isWritable();
+```
+
+
+###Channel + Selector(通道和选择器)
+
+Accessing the channel + selector from the SelectionKey is trivial. Here is how it's done:
+
+```Java
+Channel channel = selectionKey.channel();
+
+Selector selector = selectionKey.selector();
+```
+
+###附加对象(Attaching Objects)
+
+You can attach an object to a SelectionKey this is a handy way of recognizing a given channel, or attaching further information to the channel. For instance, you may attach the Buffer you are using with the channel, or an object containing more aggregate data. Here is how you attach objects:
+
+```Java
+selectionKey.attach(theObject);
+
+Object attachedObj = selectionKey.attachment();
+```
+
+You can also attach an object already while registering the Channel with the Selector, in the register() method. Here is how that looks:
+
+```Java
+SelectionKey key = channel.register(selector, SelectionKey.OP_READ, theObject);
+```
+
+##Selecting Channels via a Selector
+
+当向选择器注册一个或多个通道后,可以调用`Selector.slect(...)`方法,这个返回会当前已经就绪的通道(说明该通道有选择器监听的事件就绪)的个数。换言之,如果选择器监听了一个通道的读事件,当该通道有数据可读时,`Selector.select(...)`操作就会返回 1。
+
+有多个重载的`select()`方法:
+
+> int select()
+> int select(long timeout)
+> int selectNow()
+
+`select()`方法会阻塞直到有通道事件就绪。
+
+`select(long timeout)`方法会阻塞直到有通道事件就绪或超时。
+
+`selectNow()`方法不管有没有通道事件就绪,都会立即返回。
+
+`select()`返回值为int类型,代表从上次调用`select()`方法到这次的就绪通道数量。当你调用select返回1时,则代表上次调用select方法到这次调用之间有一个通道变成了就绪状态,然后,再次调用select方法,如果返回值为1,则说明又有一个通道变成了就绪状态。如果你没对第一个就绪通道进行处理,则此时共有两个就绪通道,虽然最后一次select的返回值为1。
+
+###selectedKeys()
+
+当你调用select()方法返回值不为0时,则说明有一个或多个通道已经就绪。你可以通过调用`selector.selectedKeys()`获取就绪的通道:
+
+```Java
+Set selectedKeys = selector.selectedKeys();
+```
+
+When you register a channel with a Selector the Channel.register() method returns a SelectionKey object. This key represents that channels registration with that selector. It is these keys you can access via the selectedKeySet() method. From the SelectionKey.
+
+You can iterate this selected key set to access the ready channels. Here is how that looks:
+
+```Java
+Set selectedKeys = selector.selectedKeys();
+
+Iterator keyIterator = selectedKeys.iterator();
+
+while(keyIterator.hasNext()) {
+
+ SelectionKey key = keyIterator.next();
+
+ if(key.isAcceptable()) {
+ // a connection was accepted by a ServerSocketChannel.
+
+ } else if (key.isConnectable()) {
+ // a connection was established with a remote server.
+
+ } else if (key.isReadable()) {
+ // a channel is ready for reading
+
+ } else if (key.isWritable()) {
+ // a channel is ready for writing
+ }
+
+ keyIterator.remove();
+}
+```
+
+This loop iterates the keys in the selected key set. For each key it tests the key to determine what the channel referenced by the key is ready for.
+
+Notice the `keyIterator.remove()` call at the end of each iteration. The Selector does not remove the SelectionKey instances from the selected key set itself. You have to do this, when you are done processing the channel. The next time the channel becomes "ready" the Selector will add it to the selected key set again.
+
+The channel returned by the SelectionKey.channel() method should be cast to the channel you need to work with, e.g a ServerSocketChannel or SocketChannel etc.
+
+###wakeUp()
+
+A thread that has called the select() method which is blocked, can be made to leave the select() method, even if no channels are yet ready. This is done by having a different thread call the Selector.wakeup() method on the Selector which the first thread has called select() on. The thread waiting inside select() will then return immediately.
+
+If a different thread calls wakeup() and no thread is currently blocked inside select(), the next thread that calls select() will "wake up" immediately.
+
+###close()
+
+When you are finished with the Selector you call its close() method. This closes the Selector and invalidates all SelectionKey instances registered with this Selector. The channels themselves are not closed.
+
+##Full Selector Example
+
+Here is a full example which opens a Selector, registers a channel with it (the channel instantiation is left out), and keeps monitoring the Selector for "readiness" of the four events (accept, connect, read, write).
+
+Selector selector = Selector.open();
+
+channel.configureBlocking(false);
+
+SelectionKey key = channel.register(selector, SelectionKey.OP_READ);
+
+```Java
+while(true) {
+
+ int readyChannels = selector.select();
+
+ if(readyChannels == 0) continue;
+
+
+ Set selectedKeys = selector.selectedKeys();
+
+ Iterator keyIterator = selectedKeys.iterator();
+
+ while(keyIterator.hasNext()) {
+
+ SelectionKey key = keyIterator.next();
+
+ if(key.isAcceptable()) {
+ // a connection was accepted by a ServerSocketChannel.
+
+ } else if (key.isConnectable()) {
+ // a connection was established with a remote server.
+
+ } else if (key.isReadable()) {
+ // a channel is ready for reading
+
+ } else if (key.isWritable()) {
+ // a channel is ready for writing
+ }
+
+ keyIterator.remove();
+ }
+}
+```
\ No newline at end of file
diff --git a/Java-NIO/08.Java NIO FileChannel.md b/Java-NIO/08.Java NIO FileChannel.md
new file mode 100644
index 0000000..19c14a8
--- /dev/null
+++ b/Java-NIO/08.Java NIO FileChannel.md
@@ -0,0 +1,101 @@
+#08.Java NIO FileChannel
+
+*FileChannel*是一个用于连接文件的通道类。使用*FileChannel*你可以读取文件的数据或往文件里写入数据。使用*FileChannel*可以代替标准的Java IO API中对文件的操作。
+
+*FileChannel*不能设置为非阻塞模式,它总是以阻塞模式运行。
+
+##打开FileChannel(Opening a FileChannel)
+
+当需要使用*FileChannel*时,你需要首先打开一个*FileChannel*,但你不能直接打开。你必须要通过*InputStream*,*OutputStream*或*RandomAccessFile*来获得一个*FileChannel*实例。如下面这个例子:
+
+```Java
+RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw");
+FileChannel inChannel = aFile.getChannel();
+```
+
+##从FileChannel中读取数据(Reading Data from a FileChannel)
+
+从*FileChannel*中读取数据,可以调用多个重载的`read()`方法。
+
+```Java
+ByteBuffer buf = ByteBuffer.allocate(48);
+
+int bytesRead = inChannel.read(buf);
+```
+
+当**缓冲区(Buffer)**分配之后,数据从*FileChannel*中读取到缓冲区。
+
+当`FileChannel.read()`被调用后,这个方法会从*FileChannel*中读取数据到缓冲区。`read()`方法会返回一个int值,这个值代表了写入缓冲区的字节数。如果返回值是-1,则没有数据被读取。
+
+##往FileChannel中写入数据(Writing Data to a FileChannel)
+
+往*FileChannel*中写数据用的是`FileChannel.write()`方法,这个方法也会带有个Buffer类型参数。
+
+```Java
+String newData = "New String to write to file..." + System.currentTimeMillis();
+
+ByteBuffer buf = ByteBuffer.allocate(48);
+buf.clear();
+buf.put(newData.getBytes());
+
+buf.flip();
+
+while(buf.hasRemaining()) {
+ channel.write(buf);
+}
+```
+
+ 注意这里的`FileChannel.write()`方法是在while循环里面进行的。我们并不知道有多少数据要写入到*FileChannel*中,因此我们需要重复地调用`write()`方法直到缓冲区中没有数据可写。
+
+##关闭FileChannel(Closing a FileChannel)
+
+当使用完FileChannel后,必须要关闭它:
+
+
+```Java
+channel.close();
+```
+
+##FileChannel Position
+
+当从*FileChannel*读取数据往其中写人数据时,我们需要要指定特定的位置。你可以通过调用`position()`方法来获得*FileChannel*当前的位置。
+
+你也可以通过`position(long pos)`方法来设置*FileChannel*的位置。
+
+```Java
+long pos channel.position();
+
+channel.position(pos +123);
+```
+
+如果你将*position*设置到文件的末尾之后,当你再对*FileChannel*进行读取时,将会返回-1,表明读取到了文件末尾。
+
+如果你将*position*设置到文件的末尾之后,让你往*FileChannel*写入数据时,文件就会自动拓展到`position`所指定的位置并写入数据。这会导致**文件空洞(File Hole)**。
+
+
+##FileChannel Size
+
+`FileChannel.size()`方法会返回通道所连接的文件的大小。
+
+```Java
+long fileSize = channel.size();
+```
+
+##FileChannel Truncate
+
+你可以通过`FileChannel.truncate()`方法对通道所关联的文件进行截取:
+
+```Java
+channel.truncate(1024);
+```
+
+
+##FileChannel Force
+
+`FileChannel.force()`方法会将所有通道中的数据刷新到磁盘中。操作系统会处于性能考虑将数据缓存到内存中,所以你不能保证写入到通道中的数据会立刻同步到磁盘,因此你可以通过`force()`方法将通道中的数据刷新到物理磁盘。
+
+`FileChannel.forece()`方法带有一个布尔类型的参数,这个参数用于指定文件的**元数据(meta data)**是否也需要刷新到物理磁盘。
+
+```Java
+channel.force(true);
+```
\ No newline at end of file
diff --git a/Java-NIO/09.Java NIO SocketChannel.md b/Java-NIO/09.Java NIO SocketChannel.md
new file mode 100644
index 0000000..9b6c223
--- /dev/null
+++ b/Java-NIO/09.Java NIO SocketChannel.md
@@ -0,0 +1,87 @@
+#09.Java NIO SocketChannel
+
+A Java NIO SocketChannel is a channel that is connected to a TCP network socket. It is Java NIO's equivalent of Java Networking's Sockets. There are two ways a SocketChannel can be created:
+
+You open a SocketChannel and connect to a server somewhere on the internet.
+A SocketChannel can be created when an incoming connection arrives at a ServerSocketChannel.
+
+
+##Opening a SocketChannel
+
+Here is how you open a SocketChannel:
+
+```Java
+SocketChannel socketChannel = SocketChannel.open();
+socketChannel.connect(new InetSocketAddress("http://jenkov.com", 80));
+```
+
+##Closing a SocketChannel
+
+You close a SocketChannel after use by calling the SocketChannel.close() method. Here is how that is done:
+
+```Java
+socketChannel.close();
+```
+
+##Reading from a SocketChannel
+
+To read data from a SocketChannel you call one of the read() methods. Here is an example:
+
+```Java
+ByteBuffer buf = ByteBuffer.allocate(48);
+
+int bytesRead = socketChannel.read(buf);
+```
+
+First a Buffer is allocated. The data read from the SocketChannel is read into the Buffer.
+
+Second the SocketChannel.read() method is called. This method reads data from the SocketChannel into the Buffer. The int returned by the read() method tells how many bytes were witten into the Buffer. If -1 is returned, the end-of-stream is reached (the connection is closed).
+
+##Writing to a SocketChannel
+
+Writing data to a SocketChannel is done using the SocketChannel.write() method, which takes a Buffer as parameter. Here is an example:
+
+```Java
+String newData = "New String to write to file..." + System.currentTimeMillis();
+
+ByteBuffer buf = ByteBuffer.allocate(48);
+buf.clear();
+buf.put(newData.getBytes());
+
+buf.flip();
+
+while(buf.hasRemaining()) {
+ channel.write(buf);
+}
+```
+
+Notice how the SocketChannel.write() method is called inside a while-loop. There is no guarantee of how many bytes the write() method writes to the SocketChannel. Therefore we repeat the write() call until the Buffer has no further bytes to write.
+
+##Non-blocking Mode
+
+You can set a SocketChannel into non-blocking mode. When you do so, you can call connect(), read() and write() in asynchronous mode.
+
+##connect()
+
+If the SocketChannel is in non-blocking mode, and you call connect(), the method may return before a connection is established. To determine whether the connection is established, you can call the finishConnect() method, like this:
+
+```Java
+socketChannel.configureBlocking(false);
+socketChannel.connect(new InetSocketAddress("http://jenkov.com", 80));
+
+while(! socketChannel.finishConnect() ){
+ //wait, or do something else...
+}
+```
+
+##write()
+
+In non-blocking mode the write() method may return without having written anything. Therefore you need to call the write() method in a loop. But, since this is already being done in the previous write examples, no need to do anything differently here.
+
+##read()
+
+In non-blocking mode the read() method may return without having read any data at all. Therefore you need to pay attention to the returned int, which tells how many bytes were read.
+
+##Non-blocking Mode with Selectors
+
+The non-blocking mode of SocketChannel's works much better with Selector's. By registering one or more SocketChannel's with a Selector, you can ask the Selector for channels that are ready for reading, writing etc. How to use Selector's with SocketChannel's is explained in more detail in a later text in this tutorial.
\ No newline at end of file
diff --git a/Java-NIO/10.Java NIO ServerSocketChannel.md b/Java-NIO/10.Java NIO ServerSocketChannel.md
new file mode 100644
index 0000000..9f1cff7
--- /dev/null
+++ b/Java-NIO/10.Java NIO ServerSocketChannel.md
@@ -0,0 +1,73 @@
+
+#10.Java NIO ServerSocketChannel
+
+A Java NIO ServerSocketChannel is a channel that can listen for incoming TCP connections, just like a ServerSocket in standard Java Networking. The ServerSocketChannel class is located in the java.nio.channels package.
+
+Here is an example:
+
+```Java
+ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
+
+serverSocketChannel.socket().bind(new InetSocketAddress(9999));
+
+while(true){
+ SocketChannel socketChannel =
+ serverSocketChannel.accept();
+
+ //do something with socketChannel...
+}
+```
+
+##Opening a ServerSocketChannel
+
+You open a ServerSocketChannel by calling the ServerSocketChannel.open() method. Here is how that looks:
+
+```Java
+ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
+```
+
+
+##Closing a ServerSocketChannel
+
+Closing a ServerSocketChannel is done by calling the ServerSocketChannel.close() method. Here is how that looks:
+
+```Java
+serverSocketChannel.close();
+```
+
+##Listening for Incoming Connections
+
+Listening for incoming connections is done by calling the ServerSocketChannel.accept() method. When the accept() method returns, it returns a SocketChannel with an incoming connection. Thus, the accept() method blocks until an incoming connection arrives.
+
+Since you are typically not interested in listening just for a single connection, you call the accept() inside a while-loop. Here is how that looks:
+
+```Java
+while(true){
+ SocketChannel socketChannel =
+ serverSocketChannel.accept();
+
+ //do something with socketChannel...
+}
+```
+
+Of course you would use some other stop-criteria than true inside the while-loop.
+
+##Non-blocking Mode
+
+A ServerSocketChannel can be set into non-blocking mode. In non-blocking mode the accept() method returns immediately, and may thus return null, if no incoming connection had arrived. Therefore you will have to check if the returned SocketChannel is null. Here is an example:
+
+```Java
+ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
+
+serverSocketChannel.socket().bind(new InetSocketAddress(9999));
+serverSocketChannel.configureBlocking(false);
+
+while(true){
+ SocketChannel socketChannel =
+ serverSocketChannel.accept();
+
+ if(socketChannel != null){
+ //do something with socketChannel...
+ }
+}
+```
diff --git a/Java-NIO/11.Java NIO DatagramChannel.md b/Java-NIO/11.Java NIO DatagramChannel.md
new file mode 100644
index 0000000..ef9ecdd
--- /dev/null
+++ b/Java-NIO/11.Java NIO DatagramChannel.md
@@ -0,0 +1,48 @@
+#11.Java NIO DatagramChannel
+
+A Java NIO DatagramChannel is a channel that can send and receive UDP packets. Since UDP is a connection-less network protocol, you cannot just by default read and write to a DatagramChannel like you do from other channels. Instead you send and receive packets of data.
+
+Opening a DatagramChannel
+
+Here is how you open a DatagramChannel:
+
+DatagramChannel channel = DatagramChannel.open();
+channel.socket().bind(new InetSocketAddress(9999));
+This example opens a DatagramChannel which can receive packets on UDP port 9999.
+
+Receiving Data
+
+You receive data from a DatagramChannel by calling its receive() method, like this:
+
+ByteBuffer buf = ByteBuffer.allocate(48);
+buf.clear();
+
+channel.receive(buf);
+The receive() method will copy the content of a received packet of data into the given Buffer. If the received packet contains more data than the Buffer can contain, the remaining data is discarded silently.
+
+Sending Data
+
+You can send data via a DatagramChannel by calling its send() method, like this:
+
+String newData = "New String to write to file..."
+ + System.currentTimeMillis();
+
+ByteBuffer buf = ByteBuffer.allocate(48);
+buf.clear();
+buf.put(newData.getBytes());
+buf.flip();
+
+int bytesSent = channel.send(buf, new InetSocketAddress("jenkov.com", 80));
+This example sends the string to the "jenkov.com" server on UDP port 80. Nothing is listening on that port though, so nothing will happen. You will not be notified of whether the send packet was received or not, since UDP does not make any guarantees about delivery of data.
+
+Connecting to a Specific Address
+
+It is possible to "connect" a DatagramChannel to a specific address on the network. Since UDP is connection-less, this way of connecting to an address does not create a real connection, like with a TCP channel. Rather, it locks your DatagramChannel so you can only send and receive data packets from one specific address.
+
+Here is an example:
+
+channel.connect(new InetSocketAddress("jenkov.com", 80));
+When connected you can also use the read() and write() method, as if you were using a traditional channel. You just don't have any guarantees about delivery of the sent data. Here are a few examples:
+
+int bytesRead = channel.read(buf);
+int bytesWritten = channel.write(buf);
\ No newline at end of file
diff --git a/Java-NIO/12.Java NIO Pipe.md b/Java-NIO/12.Java NIO Pipe.md
new file mode 100644
index 0000000..426e0b0
--- /dev/null
+++ b/Java-NIO/12.Java NIO Pipe.md
@@ -0,0 +1,44 @@
+#12.Java NIO Pipe
+
+A Java NIO Pipe is a one-way data connection between two threads. A Pipe has a source channel and a sink channel. You write data to the sink channel. This data can then be read from the source channel.
+
+Here is an illustration of the Pipe principle:
+
+Java NIO: Pipe Internals
+Java NIO: Pipe Internals
+Creating a Pipe
+
+You open a Pipe by calling the Pipe.open() method. Here is how that looks:
+
+Pipe pipe = Pipe.open();
+Writing to a Pipe
+
+To write to a Pipe you need to access the sink channel. Here is how that is done:
+
+Pipe.SinkChannel sinkChannel = pipe.sink();
+You write to a SinkChannel by calling it's write() method, like this:
+
+String newData = "New String to write to file..." + System.currentTimeMillis();
+
+ByteBuffer buf = ByteBuffer.allocate(48);
+buf.clear();
+buf.put(newData.getBytes());
+
+buf.flip();
+
+while(buf.hasRemaining()) {
+ sinkChannel.write(buf);
+}
+Reading from a Pipe
+
+To read from a Pipe you need to access the source channel. Here is how that is done:
+
+Pipe.SourceChannel sourceChannel = pipe.source();
+To read from the source channel you call its read() method like this:
+
+ByteBuffer buf = ByteBuffer.allocate(48);
+
+int bytesRead = inChannel.read(buf);
+The int returned by the read() method tells how many bytes were read into the buffer.
+
+
\ No newline at end of file
diff --git a/Java-NIO/13.Java NIO vs IO.md b/Java-NIO/13.Java NIO vs IO.md
new file mode 100644
index 0000000..5b1b9ef
--- /dev/null
+++ b/Java-NIO/13.Java NIO vs IO.md
@@ -0,0 +1,115 @@
+#13.Java NIO vs. IO
+
+When studying both the Java NIO and IO API's, a question quickly pops into mind:
+
+When should I use IO and when should I use NIO?
+
+In this text I will try to shed some light on the differences between Java NIO and IO, their use cases, and how they affect the design of your code.
+
+Main Differences Betwen Java NIO and IO
+
+The table below summarizes the main differences between Java NIO and IO. I will get into more detail about each difference in the sections following the table.
+
+IO NIO
+Stream oriented Buffer oriented
+Blocking IO Non blocking IO
+ Selectors
+Stream Oriented vs. Buffer Oriented
+
+The first big difference between Java NIO and IO is that IO is stream oriented, where NIO is buffer oriented. So, what does that mean?
+
+Java IO being stream oriented means that you read one or more bytes at a time, from a stream. What you do with the read bytes is up to you. They are not cached anywhere. Furthermore, you cannot move forth and back in the data in a stream. If you need to move forth and back in the data read from a stream, you will need to cache it in a buffer first.
+
+Java NIO's buffer oriented approach is slightly different. Data is read into a buffer from which it is later processed. You can move forth and back in the buffer as you need to. This gives you a bit more flexibility during processing. However, you also need to check if the buffer contains all the data you need in order to fully process it. And, you need to make sure that when reading more data into the buffer, you do not overwrite data in the buffer you have not yet processed.
+
+Blocking vs. Non-blocking IO
+
+Java IO's various streams are blocking. That means, that when a thread invokes a read() or write(), that thread is blocked until there is some data to read, or the data is fully written. The thread can do nothing else in the meantime.
+
+Java NIO's non-blocking mode enables a thread to request reading data from a channel, and only get what is currently available, or nothing at all, if no data is currently available. Rather than remain blocked until data becomes available for reading, the thread can go on with something else.
+
+The same is true for non-blocking writing. A thread can request that some data be written to a channel, but not wait for it to be fully written. The thread can then go on and do something else in the mean time.
+
+What threads spend their idle time on when not blocked in IO calls, is usually performing IO on other channels in the meantime. That is, a single thread can now manage multiple channels of input and output.
+
+Selectors
+
+Java NIO's selectors allow a single thread to monitor multiple channels of input. You can register multiple channels with a selector, then use a single thread to "select" the channels that have input available for processing, or select the channels that are ready for writing. This selector mechanism makes it easy for a single thread to manage multiple channels.
+
+How NIO and IO Influences Application Design
+
+Whether you choose NIO or IO as your IO toolkit may impact the following aspects of your application design:
+
+The API calls to the NIO or IO classes.
+The processing of data.
+The number of thread used to process the data.
+The API Calls
+
+Of course the API calls when using NIO look different than when using IO. This is no surprise. Rather than just read the data byte for byte from e.g. an InputStream, the data must first be read into a buffer, and then be processed from there.
+
+The Processing of Data
+
+The processing of the data is also affected when using a pure NIO design, vs. an IO design.
+
+In an IO design you read the data byte for byte from an InputStream or a Reader. Imagine you were processing a stream of line based textual data. For instance:
+
+Name: Anna
+Age: 25
+Email: anna@mailserver.com
+Phone: 1234567890
+This stream of text lines could be processed like this:
+
+InputStream input = ... ; // get the InputStream from the client socket
+
+BufferedReader reader = new BufferedReader(new InputStreamReader(input));
+
+String nameLine = reader.readLine();
+String ageLine = reader.readLine();
+String emailLine = reader.readLine();
+String phoneLine = reader.readLine();
+Notice how the processing state is determined by how far the program has executed. In other words, once the first reader.readLine() method returns, you know for sure that a full line of text has been read. The readLine() blocks until a full line is read, that's why. You also know that this line contains the name. Similarly, when the second readLine() call returns, you know that this line contains the age etc.
+
+As you can see, the program progresses only when there is new data to read, and for each step you know what that data is. Once the executing thread have progressed past reading a certain piece of data in the code, the thread is not going backwards in the data (mostly not). This principle is also illustrated in this diagram:
+
+Java IO: Reading data from a blocking stream.
+Java IO: Reading data from a blocking stream.
+A NIO implementation would look different. Here is a simplified example:
+
+ByteBuffer buffer = ByteBuffer.allocate(48);
+
+int bytesRead = inChannel.read(buffer);
+Notice the second line which reads bytes from the channel into the ByteBuffer. When that method call returns you don't know if all the data you need is inside the buffer. All you know is that the buffer contains some bytes. This makes processing somewhat harder.
+
+Imagine if, after the first read(buffer) call, that all what was read into the buffer was half a line. For instance, "Name: An". Can you process that data? Not really. You need to wait until at leas a full line of data has been into the buffer, before it makes sense to process any of the data at all.
+
+So how do you know if the buffer contains enough data for it to make sense to be processed? Well, you don't. The only way to find out, is to look at the data in the buffer. The result is, that you may have to inspect the data in the buffer several times before you know if all the data is inthere. This is both inefficient, and can become messy in terms of program design. For instance:
+
+ByteBuffer buffer = ByteBuffer.allocate(48);
+
+int bytesRead = inChannel.read(buffer);
+
+while(! bufferFull(bytesRead) ) {
+ bytesRead = inChannel.read(buffer);
+}
+The bufferFull() method has to keep track of how much data is read into the buffer, and return either true or false, depending on whether the buffer is full. In other words, if the buffer is ready for processing, it is considered full.
+
+The bufferFull() method scans through the buffer, but must leave the buffer in the same state as before the bufferFull() method was called. If not, the next data read into the buffer might not be read in at the correct location. This is not impossible, but it is yet another issue to watch out for.
+
+If the buffer is full, it can be processed. If it is not full, you might be able to partially process whatever data is there, if that makes sense in your particular case. In many cases it doesn't.
+
+The is-data-in-buffer-ready loop is illustrated in this diagram:
+
+Java NIO: Reading data from a channel until all needed data is in buffer.
+Java NIO: Reading data from a channel until all needed data is in buffer.
+Summary
+
+NIO allows you to manage multiple channels (network connections or files) using only a single (or few) threads, but the cost is that parsing the data might be somewhat more complicated than when reading data from a blocking stream.
+
+If you need to manage thousands of open connections simultanously, which each only send a little data, for instance a chat server, implementing the server in NIO is probably an advantage. Similarly, if you need to keep a lot of open connections to other computers, e.g. in a P2P network, using a single thread to manage all of your outbound connections might be an advantage. This one thread, multiple connections design is illustrated in this diagram:
+
+Java NIO: A single thread managing multiple connections.
+Java NIO: A single thread managing multiple connections.
+If you have fewer connections with very high bandwidth, sending a lot of data at a time, perhaps a classic IO server implementation might be the best fit. This diagram illustrates a classic IO server design:
+
+Java IO: A classic IO server design - one connection handled by one thread.
+Java IO: A classic IO server design - one connection handled by one thread.
diff --git a/Java-NIO/README.md b/Java-NIO/README.md
new file mode 100644
index 0000000..13df960
--- /dev/null
+++ b/Java-NIO/README.md
@@ -0,0 +1,3 @@
+#Java NIO
+
+翻译自:http://tutorials.jenkov.com/java-nio/index.html
diff --git a/Java-NIO/images/buffers-modes.png b/Java-NIO/images/buffers-modes.png
new file mode 100644
index 0000000..15a094a
Binary files /dev/null and b/Java-NIO/images/buffers-modes.png differ
diff --git a/Java-NIO/images/overview-channels-buffers.png b/Java-NIO/images/overview-channels-buffers.png
new file mode 100644
index 0000000..ad73809
Binary files /dev/null and b/Java-NIO/images/overview-channels-buffers.png differ
diff --git a/Java-NIO/images/overview-selectors.png b/Java-NIO/images/overview-selectors.png
new file mode 100644
index 0000000..d5c0757
Binary files /dev/null and b/Java-NIO/images/overview-selectors.png differ
diff --git "a/Java-Security/01.\351\224\201.md" "b/Java-Security/01.\351\224\201.md"
new file mode 100644
index 0000000..0b798e3
--- /dev/null
+++ "b/Java-Security/01.\351\224\201.md"
@@ -0,0 +1,138 @@
+#01.锁
+
+##不要在可重用的对象上加锁
+
+不要在可重用的对象上加锁,如果你这样做了,可能导致死锁或其他不可预测的行为。
+
+####不合规的代码(Boolean类型锁)
+
+下面的代码在Boolean类型上加锁:
+
+```Java
+private final Boolean lock= Boolean.FALSE;
+public void doSomething() {
+ synchronized (lock) {
+ // ...
+ }
+}
+```
+
+Boolean类型对象并不适合加锁,因为它只有两个值:`true`和`false`。在JVM中,Boolean类型的两个字面量值都分别都指向同一个共享对象。在这里例子中,lock指向JVM中的一个Boolean.FALSE实例,而这个实例的所有线程共享的。如果有其他的线程不注意地也使用了Boolean.FALSE进行加锁,就可能导致死锁或不可预测的行为。
+
+####有缺陷的代码示例(Integer的自动装箱)
+
+这个例子中的不合规代码在自动装箱的Integer类型上加锁:
+
+```Java
+private int = 0;
+private final Integer lock = count; // Boxed primitive lock is shared
+public void doSomething() {
+ synchronized (lock) {
+ count++;
+ // ...
+ }
+}
+```
+
+自动装箱的Integer对象,在一定范围内是共享的( 这个范围是-128到127),因此,这会导致跟Boolean常量一样的问题。JVM的常量池中缓存了Integer(-128)到Integer(127)这个范围的Integer对象,在这个范围内的自动装箱Integer对象,都是从这个常量池中共享这些对象。有一些JVM实现也允许大于这个范围的Integer常量池。所以,在自动装箱的对象上加锁是不安全的。而使用`new Integer(value)`创建的Integer实例对象是不共享的。**一般来说,在自动装箱的数据类型上加锁都是不可取和不安全的。**
+
+####解决方案(Integer)
+
+上面例子的解决方法就是在非装箱的Integer对象上加锁。如下面的代码所示:
+
+```Java
+private int count = 0;
+private final Integer lock = new Integer(count);
+
+public void doSomething() {
+ synchronized (lock) {
+ count++;
+ // ...
+ }
+}
+```
+当使用构造方法时,会创建独立的Integer对象,而不会使用常量池中共享的Intege对象。这是一个可接受的解决方法,但这会导致维护问题,开发人员会错误地认为使用自动装箱的Integer也是可以的。更好的解决方法就是`new Object()`对象,最后一个例子会详细介绍。
+
+####有缺陷的代码示例(new String("lock").intern())
+
+下面是一个不合规的代码示例:
+
+```Java
+private final String lock = new String("LOCK").intern();
+public void doSomething() {
+ synchronized (lock) {
+ // ...
+ }
+}
+```
+
+Java API对java.lang.String类的inern()方法解释如下:
+
+> 当调用`intern()`方法时,如果常量池中存在这个字符串对象,则会返回这个字符串对象,否则创建这个这个字符串对象,放置常量池并返回。
+
+因此,`new String("lock").intern()`返回的对象有可能是JVM中共享的。即使这个字符串对象已经用`private`和`final`修饰,其他的线程仍然可以从JVM的常量池中共享这个对象。使用字符串常量也同样会有这个问题。
+
+除此,恶意代码可能会利用这个漏洞进行攻击。详见:https://www.securecoding.cert.org/confluence/display/java/LCK00-J.+Use+private+final+lock+objects+to+synchronize+classes+that+may+interact+with+untrusted+code
+
+
+####有缺陷的代码(字符串字面量)
+
+下面不合规代码在字符串的字面量上加锁:
+
+```Java
+// This bug was found in jetty-6.1.3 BoundedThreadPool
+private final String lock = "lock";
+
+public void doSomething() {
+ synchronized (lock) {
+ // ...
+ }
+}
+```
+
+String字面量实际上是个常量,在内部会调用`intern()`方法。因此,这段代码会陷入上面所说的陷阱:
+
+####解决方法(String实例)
+
+This compliant solution locks on a noninterned String instance.
+
+```Java
+private final String lock = new String("LOCK");
+
+public void doSomething() {
+ synchronized (lock) {
+ // ...
+ }
+}
+```
+
+String实例不同于String字面量。String实例拥有各自独立的引用,并不会使用常量池中存在的String实例,因此拥有自己独立的锁。然而,这不是最好的解决方法。最好的解决方法是下面一个。
+
+####解决方法(private final Obejct = new Object())
+
+使用Object对象,能够轻松解决上面的问题:
+
+```Java
+private final Object lock = new Object();
+
+public void doSomething() {
+ synchronized (lock) {
+ // ...
+ }
+}
+```
+
+更多的详细信息,请看这里:https://www.securecoding.cert.org/confluence/display/java/LCK00-J.+Use+private+final+lock+objects+to+synchronize+classes+that+may+interact+with+untrusted+code
+
+在私有的不可变Object对象上加锁,可以轻松解决上面遇到的问题。
+
+####风险评估(Risk Assessment)
+
+A significant number of concurrency vulnerabilities arise from locking on the wrong kind of object. It is important to consider the properties of the lock object rather than simply scavenging for objects on which to synchronize.
+
+----------
+
+
+##另一个主题
+
+
\ No newline at end of file
diff --git a/Java-Security/README.md b/Java-Security/README.md
new file mode 100644
index 0000000..e7fe136
--- /dev/null
+++ b/Java-Security/README.md
@@ -0,0 +1,2 @@
+
+翻译自:https://www.securecoding.cert.org/confluence/display/java/The+CERT+Oracle+Secure+Coding+Standard+for+Java
diff --git "a/web\345\274\200\345\217\221\350\247\204\350\214\203/06.Eclipse\345\277\253\346\215\267\351\224\256.md" "b/web\345\274\200\345\217\221\350\247\204\350\214\203/06.Eclipse\345\277\253\346\215\267\351\224\256.md"
index c818432..050af4a 100644
--- "a/web\345\274\200\345\217\221\350\247\204\350\214\203/06.Eclipse\345\277\253\346\215\267\351\224\256.md"
+++ "b/web\345\274\200\345\217\221\350\247\204\350\214\203/06.Eclipse\345\277\253\346\215\267\351\224\256.md"
@@ -98,6 +98,10 @@ ALT + UP 可以将选择的文本向下移,ALT + DOWN 则是向上移。
ALT + LEFT 为左切换,ALT + RIGHT 为右切换
+## 2.16 删除当前行
+
+CTRL + D
+