 ](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)
+- 推荐在线阅读(体验更好,速度更快):[javaguide.cn](https://javaguide.cn/)
+- 面试突击版本(只保留重点,附带精美 PDF 下载):[interview.javaguide.cn](https://interview.javaguide.cn/)
](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)
+- 推荐在线阅读(体验更好,速度更快):[javaguide.cn](https://javaguide.cn/)
+- 面试突击版本(只保留重点,附带精美 PDF 下载):[interview.javaguide.cn](https://interview.javaguide.cn/)
 -
- diff --git a/README_EN.md b/README_EN.md
new file mode 100644
index 00000000000..ec1366de844
--- /dev/null
+++ b/README_EN.md
@@ -0,0 +1,452 @@
+Recommended to read through online reading platforms for better experience and faster speed! Link: [javaguide.cn](https://javaguide.cn/).
+
+
+
diff --git a/README_EN.md b/README_EN.md
new file mode 100644
index 00000000000..ec1366de844
--- /dev/null
+++ b/README_EN.md
@@ -0,0 +1,452 @@
+Recommended to read through online reading platforms for better experience and faster speed! Link: [javaguide.cn](https://javaguide.cn/).
+
+
++ 为保障正常阅读体验,本站部分内容已开启一次性验证。验证后全站解锁。 +
+ ++ 扫码/微信搜索关注 + “JavaGuide” +
+回复 “验证码”
+验证码错误,请重试
++ 为保障正常阅读体验,本站部分内容已开启一次性验证。验证后全站自动解锁。 +
+ ++ 扫码关注公众号,回复 “验证码” +
+验证码错误,请重新输入
+
-## 公众号
+## 🌐 关于网站
-最新更新会第一时间同步在公众号,推荐关注!另外,公众号上有很多干货不会同步在线阅读网站。
+JavaGuide 已经持续维护 6 年多了,累计提交了接近 **6000** commit ,共有 **570+** 多位贡献者共同参与维护和完善。真心希望能够把这个项目做好,真正能够帮助到有需要的朋友!
+
+如果觉得 JavaGuide 的内容对你有帮助的话,还请点个免费的 Star(绝不强制点 Star,觉得内容不错有收获再点赞就好),这是对我最大的鼓励,感谢各位一路同行,共勉!传送门:[GitHub](https://github.com/Snailclimb/JavaGuide) | [Gitee](https://gitee.com/SnailClimb/JavaGuide)。
-
+- [项目介绍](./javaguide/intro.md)(JavaGuide 的诞生)
+- [贡献指南](./javaguide/contribution-guideline.md)(期待你的贡献,奖励丰富)
+- [常见问题](./javaguide/faq.md)(统一回复大家的一些疑问)
diff --git a/docs/about-the-author/README.md b/docs/about-the-author/README.md
index 12f6eab7f3f..43524d2ff58 100644
--- a/docs/about-the-author/README.md
+++ b/docs/about-the-author/README.md
@@ -1,5 +1,6 @@
---
title: 个人介绍 Q&A
+description: JavaGuide作者Guide个人介绍,19年本科毕业、大学期间变现20w+实现经济独立、坚持写博客的经历与收获分享。
category: 走近作者
---
diff --git a/docs/about-the-author/deprecated-java-technologies.md b/docs/about-the-author/deprecated-java-technologies.md
new file mode 100644
index 00000000000..84dc6e720b2
--- /dev/null
+++ b/docs/about-the-author/deprecated-java-technologies.md
@@ -0,0 +1,102 @@
+---
+title: 已经淘汰的 Java 技术,不要再学了!
+description: 已淘汰的Java技术盘点,JSP、Struts、EJB、Java Applets、SOAP等过时技术不建议学习,附现代替代方案推荐。
+category: 走近作者
+tag:
+ - 杂谈
+---
+
+前几天,我在知乎上随手回答了一个问题:“Java 学到 JSP 就学不下去了,怎么办?”。
+
+出于不想让别人走弯路的心态,我回答说:已经淘汰的技术就不要学了,并顺带列举了一些在 Java 开发领域中已经被淘汰的技术。
+
+## 已经淘汰的 Java 技术
+
+我的回答原内容如下,列举了一些在 Java 开发领域中已经被淘汰的技术:
+
+**JSP**
+
+- **原因**:JSP 已经过时,无法满足现代 Web 开发需求;前后端分离成为主流。
+- **替代方案**:模板引擎(如 Thymeleaf、Freemarker)在传统全栈开发中更流行;而在前后端分离架构中,React、Vue、Angular 等现代前端框架已取代 JSP 的角色。
+- **注意**:一些国企和央企的老项目可能仍然在使用 JSP,但这种情况越来越少见。
+
+**Struts(尤其是 1.x)**
+
+- **原因**:配置繁琐、开发效率低,且存在严重的安全漏洞(如世界著名的 Apache Struts 2 漏洞)。此外,社区维护不足,生态逐渐萎缩。
+- **替代方案**:Spring MVC 和 Spring WebFlux 提供了更简洁的开发体验、更强大的功能以及完善的社区支持,完全取代了 Struts。
+
+**EJB (Enterprise JavaBeans)**
+
+- **原因**:EJB 过于复杂,开发成本高,学习曲线陡峭,在实际项目中逐步被更轻量化的框架取代。
+- **替代方案**:Spring/Spring Boot 提供了更加简洁且功能强大的企业级开发解决方案,几乎已经成为 Java 企业开发的事实标准。此外,国产的 Solon 和云原生友好的 Quarkus 等框架也非常不错。
+
+**Java Applets**
+
+- **原因**:现代浏览器(如 Chrome、Firefox、Edge)早已全面移除对 Java Applets 的支持,同时 Applets 存在严重的安全性问题。
+- **替代方案**:HTML5、WebAssembly 以及现代 JavaScript 框架(如 React、Vue)可以实现更加安全、高效的交互体验,无需插件支持。
+
+**SOAP / JAX-WS**
+
+- **原因**:SOAP 和 JAX-WS 过于复杂,数据格式冗长(XML),对开发效率和性能不友好。
+- **替代方案**:RESTful API 和 RPC 更轻量、高效,是现代微服务架构的首选。
+
+**RMI(Remote Method Invocation)**
+
+- **原因**:RMI 是一种早期的 Java 远程调用技术,但兼容性差、配置繁琐,且性能较差。
+- **替代方案**:RESTful API 和 PRC 提供了更简单、高效的远程调用解决方案,完全取代了 RMI。
+
+**Swing / JavaFX**
+
+- **原因**:桌面应用在开发领域的份额大幅减少,Web 和移动端成为主流。Swing 和 JavaFX 的生态不如现代跨平台框架丰富。
+- **替代方案**:跨平台桌面开发框架(如 Flutter Desktop、Electron)更具现代化体验。
+- **注意**:一些国企和央企的老项目可能仍然在使用 Swing / JavaFX,但这种情况越来越少见。
+
+**Ant**
+
+- **原因**:Ant 是一种基于 XML 配置的构建工具,缺乏易用性,配置繁琐。
+- **替代方案**:Maven 和 Gradle 提供了更高效的项目依赖管理和构建功能,成为现代构建工具的首选。
+
+## 杠精言论
+
+没想到,评论区果然出现了一类很常见的杠精:
+
+> “学的不是技术,是思想。那爬也是人类不需要的技术吗?为啥你一生下来得先学会爬?如果基础思想都不会就去学各种框架,到最后只能是只会 CV 的废物!”
+
+ +
+这句话表面上看似有道理,但实际上却暴露了一个人的**无知和偏执**。
+
+**知识越贫乏的人,相信的东西就越绝对**,因为他们从未认真了解过与自己观点相对立的角度,也缺乏对技术发展的全局认识。
+
+举个例子,我刚开始学习 Java 后端开发的时候,完全没什么经验,就随便买了一本书开始看。当时看的是 **《Java Web 整合开发王者归来》** 这本书(梦开始的地方)。
+
+在我上大学那会儿,这本书的很多内容其实已经过时了,比如它花了大量篇幅介绍 JSP、Struts、Hibernate、EJB 和 SVN 等技术。不过,直到现在,我依然非常感谢这本书,带我走进了 Java 后端开发的大门。
+
+
+
+这本书一共 **1010** 页,我当时可以说是废寝忘食地学,花了很长时间才把整本书完全“啃”下来。
+
+回头来看,我如果能有意识地避免学习这些已经淘汰的技术,真的可以节省大量时间去学习更加主流和实用的内容。
+
+那么,这些被淘汰的技术有用吗?说句实话,**屁用没有,纯粹浪费时间**。
+
+**既然都要花时间学习,为什么不去学那些更主流、更有实际价值的技术呢?**
+
+现在本身就很卷,不管是 Java 方向还是其他技术方向,要学习的技术都很多。
+
+想要理解所谓的“底层思想”,与其浪费时间在 JSP 这种已经不具备实际应用价值的技术上,不如深入学习一下 Servlet,研究 Spring 的 AOP 和 IoC 原理,从源码角度理解 Spring MVC 的工作机制。
+
+这些内容,不仅能帮助你掌握核心的思想,还能在实际开发中真正派上用场,这难道不比花大量时间在 JSP 上更有意义吗?
+
+## 还有公司在用的技术就要学吗?
+
+我把这篇文章的相关言论发表在我的[公众号](https://mp.weixin.qq.com/s/lf2dXHcrUSU1pn28Ercj0w)之后,又收到另外一类在我看来非常傻叉的言论:
+
+- “虽然 JSP 很老了,但还是得学学,会用就行,因为我们很多老项目还在用。”
+- “很多央企和国企的老项目还在用,肯定得学学啊!”
+
+这种观点完全是钻牛角尖!如果按这种逻辑,那你还需要去学 Struts2、SVN、JavaFX 等过时技术,因为它们也还有公司在用。我有一位大学同学毕业后去了武汉的一家国企,写了一年 JavaFX 就受不了跑了。他在之前从来没有接触过 JavaFX,招聘时也没被问过相关问题。
+
+一定不要假设自己要面对的是过时技术栈的项目。你要找工作肯定要用主流技术栈去找,还要尽量找能让自己技术有成长,干着也舒服点。真要是找不到合适的工作,去维护老项目,那都是后话,现学现卖就行了。
+
+**对于初学者来说别人劝了还非要学习淘汰的技术,多少脑子有点不够用,基本可以告别这一行了!**
diff --git a/docs/about-the-author/dog-that-copies-other-people-essay.md b/docs/about-the-author/dog-that-copies-other-people-essay.md
index 653b616eaab..2ae67150843 100644
--- a/docs/about-the-author/dog-that-copies-other-people-essay.md
+++ b/docs/about-the-author/dog-that-copies-other-people-essay.md
@@ -1,5 +1,6 @@
---
title: 抄袭狗,你冬天睡觉脚必冷!!!
+description: 原创文章被抄袭的无奈经历,知乎、CSDN多平台盗文现象吐槽,分享如何屏蔽低质量内容和维护原创权益。
category: 走近作者
tag:
- 杂谈
diff --git a/docs/about-the-author/feelings-after-one-month-of-induction-training.md b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
index ed57578a907..8ea32dd5c74 100644
--- a/docs/about-the-author/feelings-after-one-month-of-induction-training.md
+++ b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
@@ -1,5 +1,6 @@
---
title: 入职培训一个月后的感受
+description: ThoughtWorks入职培训一个月感受,从Windows切换到Mac的适应、TWU培训内容、Feedback反馈文化等新人入职体验分享。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md b/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
index cc9fe136749..d737f1a10b4 100644
--- a/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
+++ b/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
@@ -1,5 +1,6 @@
---
title: 从毕业到入职半年的感受
+description: 应届生入职半年的工作感受,CRUD业务代码的价值、技术积累靠工作之余、从学校到职场的转变心得分享。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/internet-addiction-teenager.md b/docs/about-the-author/internet-addiction-teenager.md
index 78f94e2a483..82788023c3c 100644
--- a/docs/about-the-author/internet-addiction-teenager.md
+++ b/docs/about-the-author/internet-addiction-teenager.md
@@ -1,5 +1,6 @@
---
title: 我曾经也是网瘾少年
+description: 从网瘾少年到程序员的成长经历,初中沉迷游戏、高中觉醒奋起直追、高考失眠的真实故事,分享如何克服网瘾专注学习。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/javaguide-100k-star.md b/docs/about-the-author/javaguide-100k-star.md
index e89060dbe27..da851386ee9 100644
--- a/docs/about-the-author/javaguide-100k-star.md
+++ b/docs/about-the-author/javaguide-100k-star.md
@@ -1,5 +1,6 @@
---
title: JavaGuide 开源项目 100K Star 了!
+description: JavaGuide开源项目达成100K Star里程碑,从2018年创建到突破十万星标的复盘总结,分享开源维护心得与未来规划。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md b/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
index 2fa306d2fe9..67306b969fa 100644
--- a/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
+++ b/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
@@ -1,5 +1,6 @@
---
title: 某培训机构盗我文章做成视频还上了B站热门
+description: 原创文章被培训机构盗用制作成B站视频的维权经历,揭露培训机构剽窃原创引流的套路,呼吁尊重原创内容。
category: 走近作者
tag:
- 杂谈
diff --git a/docs/about-the-author/my-college-life.md b/docs/about-the-author/my-college-life.md
index 43d96bd4186..4df47ca785d 100644
--- a/docs/about-the-author/my-college-life.md
+++ b/docs/about-the-author/my-college-life.md
@@ -1,5 +1,6 @@
---
title: 害,毕业三年了!
+description: 双非一本程序员的大学四年,从参加社团活动到办补习班赚钱、确定Java后端方向、创建JavaGuide、最终拿到ThoughtWorks offer的真实经历。
category: 走近作者
star: 1
tag:
diff --git a/docs/about-the-author/writing-technology-blog-six-years.md b/docs/about-the-author/writing-technology-blog-six-years.md
index 9e18a67d8c4..b03faf75e76 100644
--- a/docs/about-the-author/writing-technology-blog-six-years.md
+++ b/docs/about-the-author/writing-technology-blog-six-years.md
@@ -1,5 +1,6 @@
---
title: 坚持写技术博客六年了!
+description: 坚持写技术博客六年的心得分享,写博客的好处、如何坚持下去、写哪些方向的博客、实用写作技巧等经验总结。
category: 走近作者
tag:
- 杂谈
diff --git a/docs/about-the-author/zhishixingqiu-two-years.md b/docs/about-the-author/zhishixingqiu-two-years.md
index 644478b455a..f1f7885390a 100644
--- a/docs/about-the-author/zhishixingqiu-two-years.md
+++ b/docs/about-the-author/zhishixingqiu-two-years.md
@@ -1,14 +1,13 @@
---
-title: 我的知识星球 4 岁了!
+title: 我的知识星球 6 岁了!
+description: JavaGuide知识星球介绍,提供Java面试指北专栏、简历修改、一对一答疑等服务,已帮助9000+球友提升求职竞争力。
category: 知识星球
star: 2
---
-
+在 **2019 年 12 月 29 号**,经过了大概一年左右的犹豫期,我正式确定要开始做一个自己的星球,帮助学习 Java 和准备 Java 面试的同学。一转眼,已经六年了。感谢大家一路陪伴,我会信守承诺,继续认真维护这个纯粹的 Java 知识星球,不让信任我的读者失望。
-在 **2019 年 12 月 29 号**,经过了大概一年左右的犹豫期,我正式确定要开始做一个自己的星球,帮助学习 Java 和准备 Java 面试的同学。一转眼,已经四年多了。感谢大家一路陪伴,我会信守承诺,继续认真维护这个纯粹的 Java 知识星球,不让信任我的读者失望。
-
-
+
我是比较早一批做星球的技术号主,也是坚持做下来的那一少部人(大部分博主割一波韭菜就不维护星球了)。最开始的一两年,纯粹靠爱发电。当初定价非常低(一顿饭钱),加上刚工作的时候比较忙,提供的服务也没有现在这么多。
@@ -16,29 +15,58 @@ star: 2
**我有自己的原则,不割韭菜,用心做内容,真心希望帮助到他人!**
-## 什么是知识星球?
+## 我的知识星球评价如何?
+
+知识星球是一个私密、长期的知识社群,用来连接创作者和铁杆读者。相比微信群,它更适合沉淀内容、做系统化的学习和信息管理。
+
+下面是今年收到了部分好评,每一条都是真实存在的。我看到很多培训班或者机构通过虚构一些不存在的好评来欺骗他人购买高价服务(行业内非常常见),真的很难理解。
+
+
+
+在这里,不只有理论,更有具体、可落地的求职/转行指导:
+
+- 有球友入球后,在多次一对一建议下,很快就收到了美国大模型应用开发的面试并通过;
+- 有球友在指导下顺利转行,拿到满意的中厂 Offer。
+
+不少球友评价我是“良心博主”:深夜 11 点多还在帮忙改简历、给建议;对非科班、大龄转行等焦虑问题,也会耐心一一解答,做到有问必回。
+
+口碑是最好的证明!这里有连续续费三年的老球友,也有因为信任而把星球推荐给弟弟妹妹的朋友。
-简单来说,知识星球就是一个私密交流圈子,主要用途是知识创作者连接铁杆读者/粉丝。相比于微信群,知识星球内容沉淀、信息管理更高效。
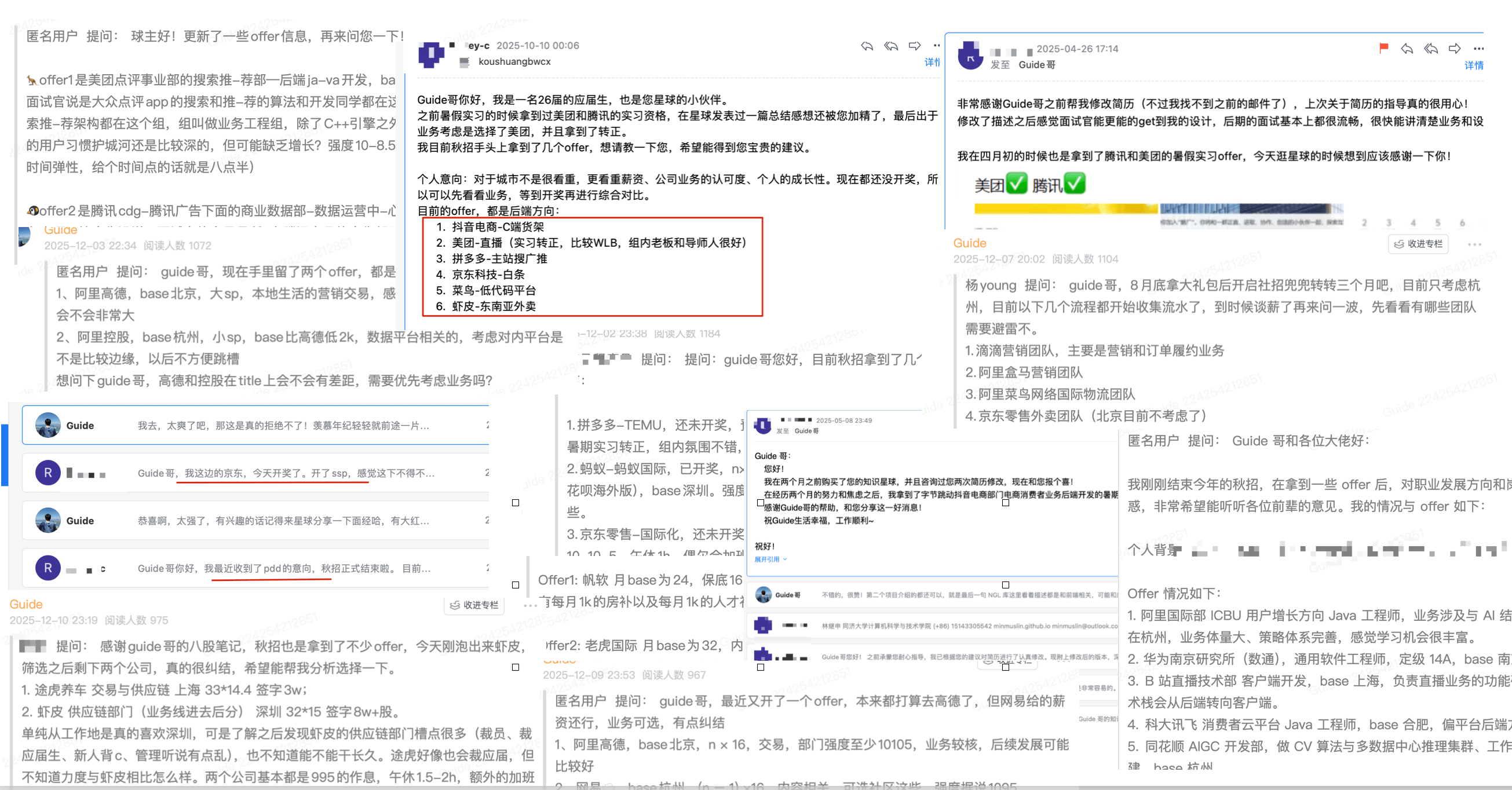
+下面是部分球友今年的求职战绩分享(只是一小部分,有校招,也有社招),同样完全真实。每年面试季之后,星球就有大量的球友询问 offer 如何选择。
-
+
## 我的知识星球能为你提供什么?
-努力做一个最优质的 Java 面试交流星球!加入到我的星球之后,你将获得:
+致力于打造最优质的 Java 面试交流星球(后端面试通用)!加入我们,你将获得远超票价的一站式成长服务:
+
+💎 **核心面试求职服务**
+
+- **简历深度精修**:提供免费的一对一简历修改服务(已累计帮助 **9000+** 位球友,好评如潮)。
+- **6 大精品专栏**:永久阅读权限,内容涵盖高频面试题、源码解析、实战项目,构建完整知识体系。
+- **独家面试手册**:多本原创 PDF 后端面试手册免费领取,全网独家。
+- **有问必答**:一对一免费提问,提供专属求职指南,拒绝焦虑。
+
+**🚀 实战项目**
+
+星球已经推出的实战项目如下:
+
+- [⭐AI 智能面试辅助平台 + RAG 知识库](https://javaguide.cn/zhuanlan/interview-guide.html):基于 Spring Boot 4.0 + Java 21 + Spring AI 2.0 开发。非常适合作为学习和简历项目,学习门槛低,帮助提升求职竞争力,是主打就业的实战项目。
+- [手写 RPC 框架](https://javaguide.cn/zhuanlan/handwritten-rpc-framework.html):从零开始基于 Netty+Kyro+Zookeeper 实现一个简易的 RPC 框架。麻雀虽小五脏俱全,项目代码注释详细,结构清晰。
+
+今年陆续还会推出更多企业级实战案例(预告一下,下一个是大家期待的:**企业智能客服**)!
+
+🔥 **氛围与福利**
-1. 6 个高质量的专栏永久阅读,内容涵盖面试,源码解析,项目实战等内容!
-2. 多本原创 PDF 版本面试手册免费领取。
-3. 免费的简历修改服务(已经累计帮助 7000+ 位球友修改简历)。
-4. 一对一免费提问交流(专属建议,走心回答)。
-5. 专属求职指南和建议,让你少走弯路,效率翻倍!
-6. 海量 Java 优质面试资源分享。
-7. 打卡活动,读书交流,学习交流,让学习不再孤单,报团取暖。
-8. 不定期福利:节日抽奖、送书送课、球友线下聚会等等。
-9. ……
+- **海量资源**:Java 优质面试资源持续更新分享。
+- **抱团成长**:打卡活动、读书交流、线下聚会,让学习之路不再孤单。
+- **惊喜福利**:不定期节日抽奖、送书送课,福利拿到手软。
-其中的任何一项服务单独拎出来价值都远超星球门票了。
+💡 **总结**:这里的任何一项服务(尤其是简历修改和面试资料),单独拎出来的价值都已远超星球门票。
-这里再送一个 **30** 元的星球专属优惠券吧,数量有限(价格即将上调。老用户续费半价 ,微信扫码即可续费)!
+目前星球正在做活动,两本书的价格,就能让你拥有上万培训班的服务!
+
+这里再提供一张 **30**元的优惠卷(**价格马上上调,老用户扫码续费半价** ):

@@ -46,14 +74,25 @@ star: 2
星球更新了 **《Java 面试指北》**、**《Java 必读源码系列》**(目前已经整理了 Dubbo 2.6.x、Netty 4.x、SpringBoot2.1 的源码)、 **《从零开始写一个 RPC 框架》**(已更新完)、**《Kafka 常见面试题/知识点总结》** 等多个优质专栏。
-
+
《Java 面试指北》内容概览:
-
+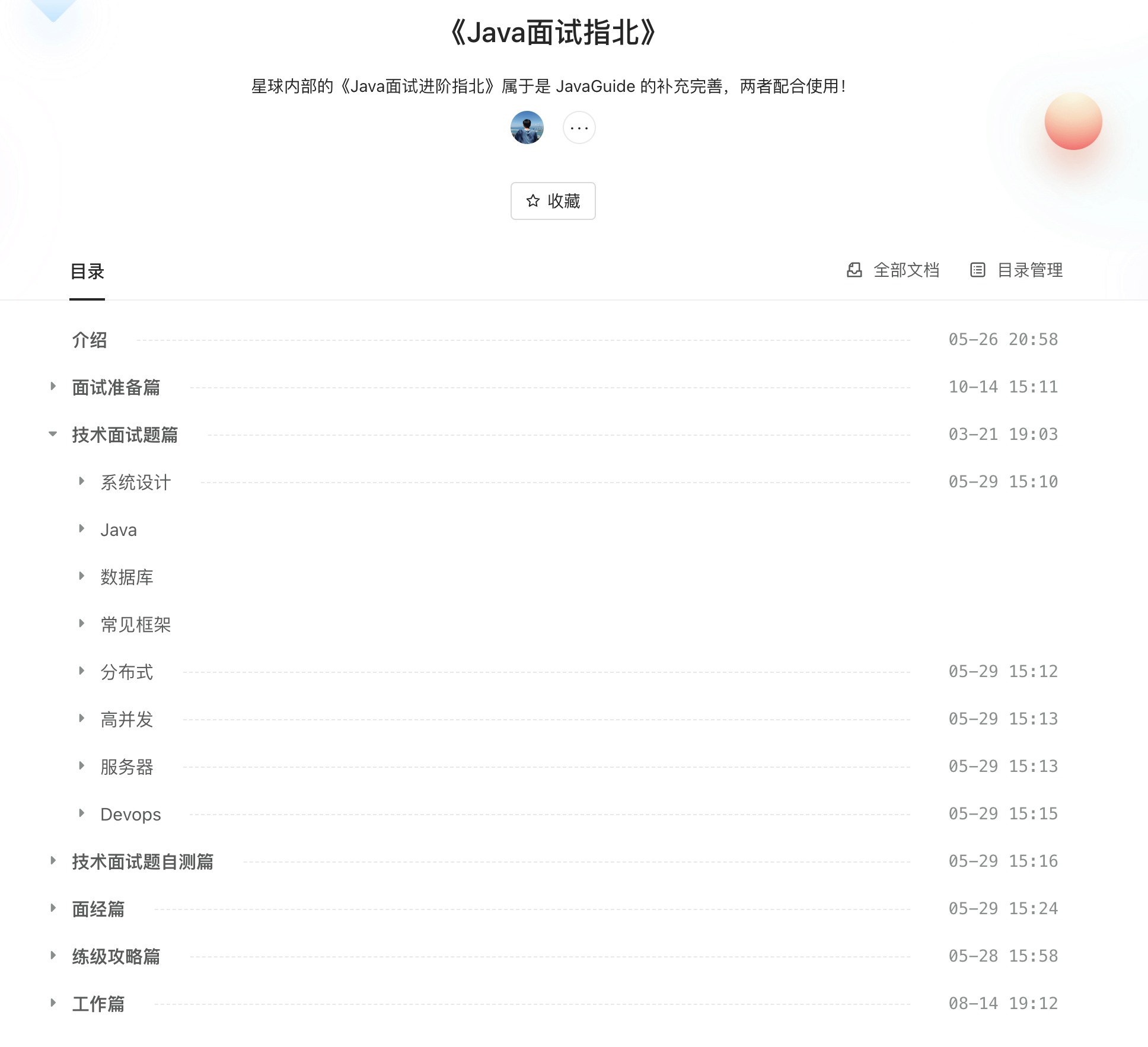
进入星球之后,这些专栏即可免费永久阅读,永久同步更新!
+### 实战项目
+
+星球已经推出的实战项目如下:
+
+- [⭐AI 智能面试辅助平台 + RAG 知识库](https://javaguide.cn/zhuanlan/interview-guide.html):基于 Spring Boot 4.0 + Java 21 + Spring AI 2.0 开发。非常适合作为学习和简历项目,学习门槛低,帮助提升求职竞争力,是主打就业的实战项目。
+- [手写 RPC 框架](https://javaguide.cn/zhuanlan/handwritten-rpc-framework.html):从零开始基于 Netty+Kyro+Zookeeper 实现一个简易的 RPC 框架。麻雀虽小五脏俱全,项目代码注释详细,结构清晰。
+
+今年陆续还会推出更多企业级实战案例!并且,星球还分享了很多高频项目经历的优化版介绍和面试准备(持续更新中)。
+
+
+
### PDF 面试手册
进入星球就免费赠送多本优质 PDF 面试手册。
@@ -82,7 +121,7 @@ JavaGuide 知识星球优质主题汇总传送门:
+
+这句话表面上看似有道理,但实际上却暴露了一个人的**无知和偏执**。
+
+**知识越贫乏的人,相信的东西就越绝对**,因为他们从未认真了解过与自己观点相对立的角度,也缺乏对技术发展的全局认识。
+
+举个例子,我刚开始学习 Java 后端开发的时候,完全没什么经验,就随便买了一本书开始看。当时看的是 **《Java Web 整合开发王者归来》** 这本书(梦开始的地方)。
+
+在我上大学那会儿,这本书的很多内容其实已经过时了,比如它花了大量篇幅介绍 JSP、Struts、Hibernate、EJB 和 SVN 等技术。不过,直到现在,我依然非常感谢这本书,带我走进了 Java 后端开发的大门。
+
+
+
+这本书一共 **1010** 页,我当时可以说是废寝忘食地学,花了很长时间才把整本书完全“啃”下来。
+
+回头来看,我如果能有意识地避免学习这些已经淘汰的技术,真的可以节省大量时间去学习更加主流和实用的内容。
+
+那么,这些被淘汰的技术有用吗?说句实话,**屁用没有,纯粹浪费时间**。
+
+**既然都要花时间学习,为什么不去学那些更主流、更有实际价值的技术呢?**
+
+现在本身就很卷,不管是 Java 方向还是其他技术方向,要学习的技术都很多。
+
+想要理解所谓的“底层思想”,与其浪费时间在 JSP 这种已经不具备实际应用价值的技术上,不如深入学习一下 Servlet,研究 Spring 的 AOP 和 IoC 原理,从源码角度理解 Spring MVC 的工作机制。
+
+这些内容,不仅能帮助你掌握核心的思想,还能在实际开发中真正派上用场,这难道不比花大量时间在 JSP 上更有意义吗?
+
+## 还有公司在用的技术就要学吗?
+
+我把这篇文章的相关言论发表在我的[公众号](https://mp.weixin.qq.com/s/lf2dXHcrUSU1pn28Ercj0w)之后,又收到另外一类在我看来非常傻叉的言论:
+
+- “虽然 JSP 很老了,但还是得学学,会用就行,因为我们很多老项目还在用。”
+- “很多央企和国企的老项目还在用,肯定得学学啊!”
+
+这种观点完全是钻牛角尖!如果按这种逻辑,那你还需要去学 Struts2、SVN、JavaFX 等过时技术,因为它们也还有公司在用。我有一位大学同学毕业后去了武汉的一家国企,写了一年 JavaFX 就受不了跑了。他在之前从来没有接触过 JavaFX,招聘时也没被问过相关问题。
+
+一定不要假设自己要面对的是过时技术栈的项目。你要找工作肯定要用主流技术栈去找,还要尽量找能让自己技术有成长,干着也舒服点。真要是找不到合适的工作,去维护老项目,那都是后话,现学现卖就行了。
+
+**对于初学者来说别人劝了还非要学习淘汰的技术,多少脑子有点不够用,基本可以告别这一行了!**
diff --git a/docs/about-the-author/dog-that-copies-other-people-essay.md b/docs/about-the-author/dog-that-copies-other-people-essay.md
index 653b616eaab..2ae67150843 100644
--- a/docs/about-the-author/dog-that-copies-other-people-essay.md
+++ b/docs/about-the-author/dog-that-copies-other-people-essay.md
@@ -1,5 +1,6 @@
---
title: 抄袭狗,你冬天睡觉脚必冷!!!
+description: 原创文章被抄袭的无奈经历,知乎、CSDN多平台盗文现象吐槽,分享如何屏蔽低质量内容和维护原创权益。
category: 走近作者
tag:
- 杂谈
diff --git a/docs/about-the-author/feelings-after-one-month-of-induction-training.md b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
index ed57578a907..8ea32dd5c74 100644
--- a/docs/about-the-author/feelings-after-one-month-of-induction-training.md
+++ b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
@@ -1,5 +1,6 @@
---
title: 入职培训一个月后的感受
+description: ThoughtWorks入职培训一个月感受,从Windows切换到Mac的适应、TWU培训内容、Feedback反馈文化等新人入职体验分享。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md b/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
index cc9fe136749..d737f1a10b4 100644
--- a/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
+++ b/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
@@ -1,5 +1,6 @@
---
title: 从毕业到入职半年的感受
+description: 应届生入职半年的工作感受,CRUD业务代码的价值、技术积累靠工作之余、从学校到职场的转变心得分享。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/internet-addiction-teenager.md b/docs/about-the-author/internet-addiction-teenager.md
index 78f94e2a483..82788023c3c 100644
--- a/docs/about-the-author/internet-addiction-teenager.md
+++ b/docs/about-the-author/internet-addiction-teenager.md
@@ -1,5 +1,6 @@
---
title: 我曾经也是网瘾少年
+description: 从网瘾少年到程序员的成长经历,初中沉迷游戏、高中觉醒奋起直追、高考失眠的真实故事,分享如何克服网瘾专注学习。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/javaguide-100k-star.md b/docs/about-the-author/javaguide-100k-star.md
index e89060dbe27..da851386ee9 100644
--- a/docs/about-the-author/javaguide-100k-star.md
+++ b/docs/about-the-author/javaguide-100k-star.md
@@ -1,5 +1,6 @@
---
title: JavaGuide 开源项目 100K Star 了!
+description: JavaGuide开源项目达成100K Star里程碑,从2018年创建到突破十万星标的复盘总结,分享开源维护心得与未来规划。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md b/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
index 2fa306d2fe9..67306b969fa 100644
--- a/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
+++ b/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
@@ -1,5 +1,6 @@
---
title: 某培训机构盗我文章做成视频还上了B站热门
+description: 原创文章被培训机构盗用制作成B站视频的维权经历,揭露培训机构剽窃原创引流的套路,呼吁尊重原创内容。
category: 走近作者
tag:
- 杂谈
diff --git a/docs/about-the-author/my-college-life.md b/docs/about-the-author/my-college-life.md
index 43d96bd4186..4df47ca785d 100644
--- a/docs/about-the-author/my-college-life.md
+++ b/docs/about-the-author/my-college-life.md
@@ -1,5 +1,6 @@
---
title: 害,毕业三年了!
+description: 双非一本程序员的大学四年,从参加社团活动到办补习班赚钱、确定Java后端方向、创建JavaGuide、最终拿到ThoughtWorks offer的真实经历。
category: 走近作者
star: 1
tag:
diff --git a/docs/about-the-author/writing-technology-blog-six-years.md b/docs/about-the-author/writing-technology-blog-six-years.md
index 9e18a67d8c4..b03faf75e76 100644
--- a/docs/about-the-author/writing-technology-blog-six-years.md
+++ b/docs/about-the-author/writing-technology-blog-six-years.md
@@ -1,5 +1,6 @@
---
title: 坚持写技术博客六年了!
+description: 坚持写技术博客六年的心得分享,写博客的好处、如何坚持下去、写哪些方向的博客、实用写作技巧等经验总结。
category: 走近作者
tag:
- 杂谈
diff --git a/docs/about-the-author/zhishixingqiu-two-years.md b/docs/about-the-author/zhishixingqiu-two-years.md
index 644478b455a..f1f7885390a 100644
--- a/docs/about-the-author/zhishixingqiu-two-years.md
+++ b/docs/about-the-author/zhishixingqiu-two-years.md
@@ -1,14 +1,13 @@
---
-title: 我的知识星球 4 岁了!
+title: 我的知识星球 6 岁了!
+description: JavaGuide知识星球介绍,提供Java面试指北专栏、简历修改、一对一答疑等服务,已帮助9000+球友提升求职竞争力。
category: 知识星球
star: 2
---
-
+在 **2019 年 12 月 29 号**,经过了大概一年左右的犹豫期,我正式确定要开始做一个自己的星球,帮助学习 Java 和准备 Java 面试的同学。一转眼,已经六年了。感谢大家一路陪伴,我会信守承诺,继续认真维护这个纯粹的 Java 知识星球,不让信任我的读者失望。
-在 **2019 年 12 月 29 号**,经过了大概一年左右的犹豫期,我正式确定要开始做一个自己的星球,帮助学习 Java 和准备 Java 面试的同学。一转眼,已经四年多了。感谢大家一路陪伴,我会信守承诺,继续认真维护这个纯粹的 Java 知识星球,不让信任我的读者失望。
-
-
+
我是比较早一批做星球的技术号主,也是坚持做下来的那一少部人(大部分博主割一波韭菜就不维护星球了)。最开始的一两年,纯粹靠爱发电。当初定价非常低(一顿饭钱),加上刚工作的时候比较忙,提供的服务也没有现在这么多。
@@ -16,29 +15,58 @@ star: 2
**我有自己的原则,不割韭菜,用心做内容,真心希望帮助到他人!**
-## 什么是知识星球?
+## 我的知识星球评价如何?
+
+知识星球是一个私密、长期的知识社群,用来连接创作者和铁杆读者。相比微信群,它更适合沉淀内容、做系统化的学习和信息管理。
+
+下面是今年收到了部分好评,每一条都是真实存在的。我看到很多培训班或者机构通过虚构一些不存在的好评来欺骗他人购买高价服务(行业内非常常见),真的很难理解。
+
+
+
+在这里,不只有理论,更有具体、可落地的求职/转行指导:
+
+- 有球友入球后,在多次一对一建议下,很快就收到了美国大模型应用开发的面试并通过;
+- 有球友在指导下顺利转行,拿到满意的中厂 Offer。
+
+不少球友评价我是“良心博主”:深夜 11 点多还在帮忙改简历、给建议;对非科班、大龄转行等焦虑问题,也会耐心一一解答,做到有问必回。
+
+口碑是最好的证明!这里有连续续费三年的老球友,也有因为信任而把星球推荐给弟弟妹妹的朋友。
-简单来说,知识星球就是一个私密交流圈子,主要用途是知识创作者连接铁杆读者/粉丝。相比于微信群,知识星球内容沉淀、信息管理更高效。
+下面是部分球友今年的求职战绩分享(只是一小部分,有校招,也有社招),同样完全真实。每年面试季之后,星球就有大量的球友询问 offer 如何选择。
-
+
## 我的知识星球能为你提供什么?
-努力做一个最优质的 Java 面试交流星球!加入到我的星球之后,你将获得:
+致力于打造最优质的 Java 面试交流星球(后端面试通用)!加入我们,你将获得远超票价的一站式成长服务:
+
+💎 **核心面试求职服务**
+
+- **简历深度精修**:提供免费的一对一简历修改服务(已累计帮助 **9000+** 位球友,好评如潮)。
+- **6 大精品专栏**:永久阅读权限,内容涵盖高频面试题、源码解析、实战项目,构建完整知识体系。
+- **独家面试手册**:多本原创 PDF 后端面试手册免费领取,全网独家。
+- **有问必答**:一对一免费提问,提供专属求职指南,拒绝焦虑。
+
+**🚀 实战项目**
+
+星球已经推出的实战项目如下:
+
+- [⭐AI 智能面试辅助平台 + RAG 知识库](https://javaguide.cn/zhuanlan/interview-guide.html):基于 Spring Boot 4.0 + Java 21 + Spring AI 2.0 开发。非常适合作为学习和简历项目,学习门槛低,帮助提升求职竞争力,是主打就业的实战项目。
+- [手写 RPC 框架](https://javaguide.cn/zhuanlan/handwritten-rpc-framework.html):从零开始基于 Netty+Kyro+Zookeeper 实现一个简易的 RPC 框架。麻雀虽小五脏俱全,项目代码注释详细,结构清晰。
+
+今年陆续还会推出更多企业级实战案例(预告一下,下一个是大家期待的:**企业智能客服**)!
+
+🔥 **氛围与福利**
-1. 6 个高质量的专栏永久阅读,内容涵盖面试,源码解析,项目实战等内容!
-2. 多本原创 PDF 版本面试手册免费领取。
-3. 免费的简历修改服务(已经累计帮助 7000+ 位球友修改简历)。
-4. 一对一免费提问交流(专属建议,走心回答)。
-5. 专属求职指南和建议,让你少走弯路,效率翻倍!
-6. 海量 Java 优质面试资源分享。
-7. 打卡活动,读书交流,学习交流,让学习不再孤单,报团取暖。
-8. 不定期福利:节日抽奖、送书送课、球友线下聚会等等。
-9. ……
+- **海量资源**:Java 优质面试资源持续更新分享。
+- **抱团成长**:打卡活动、读书交流、线下聚会,让学习之路不再孤单。
+- **惊喜福利**:不定期节日抽奖、送书送课,福利拿到手软。
-其中的任何一项服务单独拎出来价值都远超星球门票了。
+💡 **总结**:这里的任何一项服务(尤其是简历修改和面试资料),单独拎出来的价值都已远超星球门票。
-这里再送一个 **30** 元的星球专属优惠券吧,数量有限(价格即将上调。老用户续费半价 ,微信扫码即可续费)!
+目前星球正在做活动,两本书的价格,就能让你拥有上万培训班的服务!
+
+这里再提供一张 **30**元的优惠卷(**价格马上上调,老用户扫码续费半价** ):

@@ -46,14 +74,25 @@ star: 2
星球更新了 **《Java 面试指北》**、**《Java 必读源码系列》**(目前已经整理了 Dubbo 2.6.x、Netty 4.x、SpringBoot2.1 的源码)、 **《从零开始写一个 RPC 框架》**(已更新完)、**《Kafka 常见面试题/知识点总结》** 等多个优质专栏。
-
+
《Java 面试指北》内容概览:
-
+
进入星球之后,这些专栏即可免费永久阅读,永久同步更新!
+### 实战项目
+
+星球已经推出的实战项目如下:
+
+- [⭐AI 智能面试辅助平台 + RAG 知识库](https://javaguide.cn/zhuanlan/interview-guide.html):基于 Spring Boot 4.0 + Java 21 + Spring AI 2.0 开发。非常适合作为学习和简历项目,学习门槛低,帮助提升求职竞争力,是主打就业的实战项目。
+- [手写 RPC 框架](https://javaguide.cn/zhuanlan/handwritten-rpc-framework.html):从零开始基于 Netty+Kyro+Zookeeper 实现一个简易的 RPC 框架。麻雀虽小五脏俱全,项目代码注释详细,结构清晰。
+
+今年陆续还会推出更多企业级实战案例!并且,星球还分享了很多高频项目经历的优化版介绍和面试准备(持续更新中)。
+
+
+
### PDF 面试手册
进入星球就免费赠送多本优质 PDF 面试手册。
@@ -82,7 +121,7 @@ JavaGuide 知识星球优质主题汇总传送门: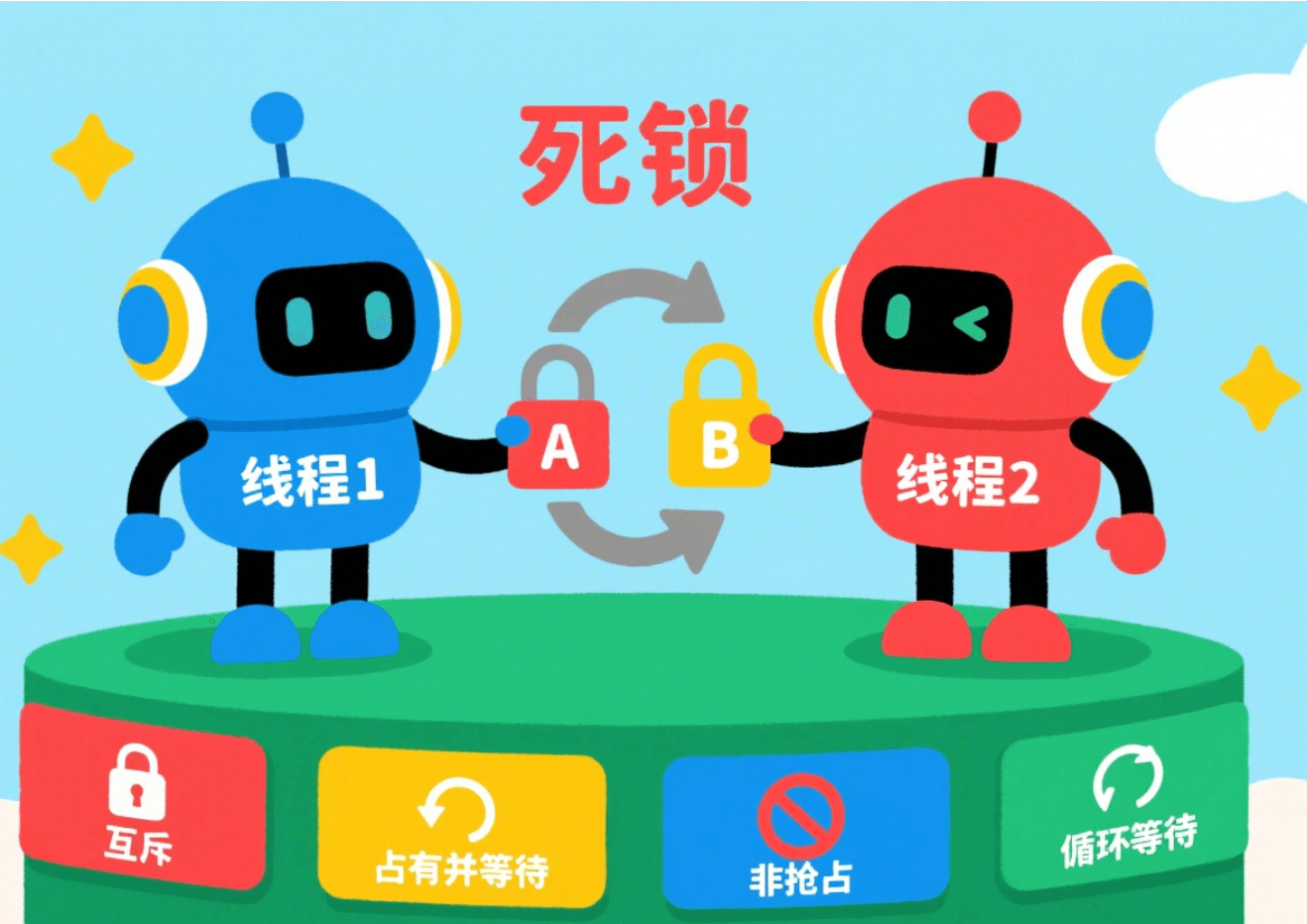 ### 产生死锁的四个必要条件是什么?
+死锁的发生并不是偶然的,它需要同时满足**四个必要条件**:
+
1. **互斥**:资源必须处于非共享模式,即一次只有一个进程可以使用。如果另一进程申请该资源,那么必须等待直到该资源被释放为止。
2. **占有并等待**:一个进程至少应该占有一个资源,并等待另一资源,而该资源被其他进程所占有。
3. **非抢占**:资源不能被抢占。只能在持有资源的进程完成任务后,该资源才会被释放。
-4. **循环等待**:有一组等待进程 `{P0, P1,..., Pn}`, `P0` 等待的资源被 `P1` 占有,`P1` 等待的资源被 `P2` 占有,……,`Pn-1` 等待的资源被 `Pn` 占有,`Pn` 等待的资源被 `P0` 占有。
+4. **循环等待**:有一组等待进程 {P0, P1,..., Pn}, P0 等待的资源被 P1 占有,P1 等待的资源被 P2 占有,……,Pn-1 等待的资源被 Pn 占有,Pn 等待的资源被 P0 占有。
**注意 ⚠️**:这四个条件是产生死锁的 **必要条件** ,也就是说只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
@@ -371,12 +378,9 @@ Thread[线程 2,5,main]waiting get resource1
解决死锁的方法可以从多个角度去分析,一般的情况下,有**预防,避免,检测和解除四种**。
-- **预防** 是采用某种策略,**限制并发进程对资源的请求**,从而使得死锁的必要条件在系统执行的任何时间上都不满足。
-
-- **避免**则是系统在分配资源时,根据资源的使用情况**提前做出预测**,从而**避免死锁的发生**
-
-- **检测**是指系统设有**专门的机构**,当死锁发生时,该机构能够检测死锁的发生,并精确地确定与死锁有关的进程和资源。
-- **解除** 是与检测相配套的一种措施,用于**将进程从死锁状态下解脱出来**。
+- **死锁预防:** 这是我们程序员最常用的方法。通过编码规范来破坏条件。最经典的就是**破坏循环等待**,比如规定所有线程都必须**按相同的顺序**来获取锁(比如先 A 后 B),这样就不会形成环路。
+- **死锁避免:** 这是一种更动态的方法,比如操作系统的**银行家算法**。它会在分配资源前进行预测,如果这次分配可能导致未来发生死锁,就拒绝分配。但这种方法开销很大,在通用系统中用得比较少。
+- **死锁检测与解除:** 这是一种“事后补救”的策略,就像乐观锁。系统允许死锁发生,但会有一个后台线程(或机制)定期检测是否存在死锁环路(比如通过分析线程等待图)。一旦发现,就会采取措施解除,比如**强制剥夺某个线程的资源或直接终止它**。数据库系统中的死锁处理就常常采用这种方式。
#### 死锁的预防
diff --git a/docs/cs-basics/operating-system/operating-system-basic-questions-02.md b/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
index 98de61c1340..51ed5fd65c3 100644
--- a/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
+++ b/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
@@ -1,17 +1,17 @@
---
title: 操作系统常见面试题总结(下)
+description: 最新操作系统高频面试题总结(下):虚拟内存映射、内存碎片/伙伴系统、TLB+页缺失处理、分页分段对比、页面置换算法详解、文件系统&磁盘调度,附图表+⭐️重点标注,一文掌握OS内存/文件考点,快速通关后端面试!
category: 计算机基础
tag:
- 操作系统
head:
- - meta
- name: keywords
- content: 操作系统,进程,进程通信方式,死锁,操作系统内存管理,块表,多级页表,虚拟内存,页面置换算法
- - - meta
- - name: description
- content: 很多读者抱怨计算操作系统的知识点比较繁杂,自己也没有多少耐心去看,但是面试的时候又经常会遇到。所以,我带着我整理好的操作系统的常见问题来啦!这篇文章总结了一些我觉得比较重要的操作系统相关的问题比如进程管理、内存管理、虚拟内存等等。
+ content: 操作系统面试题,虚拟内存详解,分页 vs 分段,页面置换算法,内存碎片,伙伴系统,TLB快表,页缺失,文件系统基础,磁盘调度算法,硬链接 vs 软链接
---
+
+
## 内存管理
### 内存管理主要做了什么?
@@ -211,7 +211,7 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
#### 单级页表有什么问题?为什么需要多级页表?
-以 32 位的环境为例,虚拟地址空间范围共有 2^32(4G)。假设 一个页的大小是 2^12(4KB),那页表项共有 4G / 4K = 2^20 个。每个页表项为一个地址,占用 4 字节,`2^20 * 2^2 / 1024 * 1024= 4MB`。也就是说一个程序啥都不干,页表大小就得占用 4M。
+以 32 位的环境为例,虚拟地址空间范围共有 2^32(4G)。假设 一个页的大小是 2^12(4KB),那页表项共有 4G / 4K = 2^20 个。每个页表项为一个地址,占用 4 字节,`(2^20 * 2^2) / (1024 * 1024)= 4MB`。也就是说一个程序啥都不干,页表大小就得占用 4M。
系统运行的应用程序多起来的话,页表的开销还是非常大的。而且,绝大部分应用程序可能只能用到页表中的几项,其他的白白浪费了。
@@ -317,12 +317,16 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
### 段页机制
-结合了段式管理和页式管理的一种内存管理机制,把物理内存先分成若干段,每个段又继续分成若干大小相等的页。
+结合了段式管理和页式管理的一种内存管理机制。程序视角中,内存被划分为多个逻辑段,每个逻辑段进一步被划分为固定大小的页。
在段页式机制下,地址翻译的过程分为两个步骤:
-1. 段式地址映射。
-2. 页式地址映射。
+1. **段式地址映射(虚拟地址 → 线性地址):**
+ - 虚拟地址 = 段选择符(段号)+ 段内偏移。
+ - 根据段号查段表,找到段基址,加上段内偏移得到线性地址。
+2. **页式地址映射(线性地址 → 物理地址):**
+ - 线性地址 = 页号 + 页内偏移。
+ - 根据页号查页表,找到物理页框号,加上页内偏移得到物理地址。
### 局部性原理
@@ -375,7 +379,7 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
### 提高文件系统性能的方式有哪些?
-- **优化硬件**:使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Inexpensive Disks)等技术提高磁盘性能。
+- **优化硬件**:使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Independent Disks)等技术提高磁盘性能。
- **选择合适的文件系统选型**:不同的文件系统具有不同的特性,对于不同的应用场景选择合适的文件系统可以提高系统性能。
- **运用缓存**:访问磁盘的效率比较低,可以运用缓存来减少磁盘的访问次数。不过,需要注意缓存命中率,缓存命中率过低的话,效果太差。
- **避免磁盘过度使用**:注意磁盘的使用率,避免将磁盘用满,尽量留一些剩余空间,以免对文件系统的性能产生负面影响。
diff --git a/docs/cs-basics/operating-system/shell-intro.md b/docs/cs-basics/operating-system/shell-intro.md
index 48066214c23..7554aa2760d 100644
--- a/docs/cs-basics/operating-system/shell-intro.md
+++ b/docs/cs-basics/operating-system/shell-intro.md
@@ -1,19 +1,36 @@
---
title: Shell 编程基础知识总结
+description: Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。这篇文章我会简单总结一下 Shell 编程基础知识,带你入门 Shell 编程!
category: 计算机基础
tag:
- 操作系统
- Linux
head:
- - meta
- - name: description
- content: Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。这篇文章我会简单总结一下 Shell 编程基础知识,带你入门 Shell 编程!
+ - name: keywords
+ content: Shell,脚本,命令,自动化,运维,Linux,基础语法
---
Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。
这篇文章我会简单总结一下 Shell 编程基础知识,带你入门 Shell 编程!
+## 版本说明
+
+**本文示例适用于 bash 4.0+ 版本**。不同版本的 bash 在某些特性上可能有差异,特别是:
+
+- **数组** :bash 2.0+ 支持,纯 POSIX sh(如 dash)不支持
+- **某些字符串操作** :如 `${var:offset:length}` 在较旧版本可能不支持
+- **算术扩展 `$((...))`** :bash 2.0+ 支持
+
+检查你的 bash 版本:
+
+```shell
+bash --version
+# 或
+echo $BASH_VERSION
+```
+
## 走进 Shell 编程的大门
### 为什么要学 Shell?
@@ -32,10 +49,17 @@ Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统
### 什么是 Shell?
-简单来说“Shell 编程就是对一堆 Linux 命令的逻辑化处理”。
+**Shell 是 Linux/Unix 系统的命令解释器**,它充当用户和操作系统内核之间的桥梁,负责接收用户输入的命令并调用相应的程序。
+
+**Shell 编程**是通过 Shell 解释器(如 bash)将命令、控制结构(if/for/while)、变量和函数组合成自动化脚本的过程。Shell 既是命令解释器,也是一门完整的编程语言(支持变量、数组、函数、流程控制、管道、重定向等)。
+
+**常见的 Shell 类型**:
-W3Cschool 上的一篇文章是这样介绍 Shell 的,如下图所示。
-
+- **bash**(Bourne Again Shell):Linux 系统默认 Shell,最常用
+- **sh**(Bourne Shell):Unix 传统 Shell,POSIX 标准
+- **zsh**:功能强大的交互式 Shell
+- **dash**:轻量级 Shell,Ubuntu 的 /bin/sh 默认指向它
+- **csh/tcsh**:C 风格的 Shell
### Shell 编程的 Hello World
@@ -51,8 +75,9 @@ helloworld.sh 内容如下:
```shell
#!/bin/bash
-#第一个shell小程序,echo 是linux中的输出命令。
-echo "helloworld!"
+set -euo pipefail # 严格模式:遇错退出、未定义变量报错、管道失败报错
+# 第一个 shell 小程序,echo 是 Linux 中的输出命令
+echo "helloworld!"
```
shell 中 # 符号表示注释。**shell 的第一行比较特殊,一般都会以#!开始来指定使用的 shell 类型。在 linux 中,除了 bash shell 以外,还有很多版本的 shell, 例如 zsh、dash 等等...不过 bash shell 还是我们使用最多的。**
@@ -67,20 +92,20 @@ shell 中 # 符号表示注释。**shell 的第一行比较特殊,一般都会
**Shell 编程中一般分为三种变量:**
-1. **我们自己定义的变量(自定义变量):** 仅在当前 Shell 实例中有效,其他 Shell 启动的程序不能访问局部变量。
-2. **Linux 已定义的环境变量**(环境变量, 例如:`PATH`, `HOME` 等..., 这类变量我们可以直接使用),使用 `env` 命令可以查看所有的环境变量,而 set 命令既可以查看环境变量也可以查看自定义变量。
-3. **Shell 变量**:Shell 变量是由 Shell 程序设置的特殊变量。Shell 变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了 Shell 的正常运行
+1. **自定义变量(局部变量)**:默认仅在当前 Shell 进程内有效,**子进程无法访问**。若需传递给子进程,需使用 `export` 声明为环境变量。
+2. **环境变量**:例如 `PATH`, `HOME` 等,可被子进程继承。使用 `env` 命令可以查看所有环境变量,`set` 命令可以查看所有变量(包括环境变量和局部变量)。
+3. **Shell 特殊变量**:由 Shell 设置的特殊变量(如 `$?`, `$$`, `$!` 等),用于保存进程状态、参数等信息。
**常用的环境变量:**
-> PATH 决定了 shell 将到哪些目录中寻找命令或程序
-> HOME 当前用户主目录
-> HISTSIZE 历史记录数
-> LOGNAME 当前用户的登录名
-> HOSTNAME 指主机的名称
-> SHELL 当前用户 Shell 类型
-> LANGUAGE 语言相关的环境变量,多语言可以修改此环境变量
-> MAIL 当前用户的邮件存放目录
+> PATH 决定了 shell 将到哪些目录中寻找命令或程序
+> HOME 当前用户主目录
+> HISTSIZE 历史记录数
+> LOGNAME 当前用户的登录名
+> HOSTNAME 指主机的名称
+> SHELL 当前用户 Shell 类型
+> LANGUAGE 语言相关的环境变量,多语言可以修改此环境变量
+> MAIL 当前用户的邮件存放目录
> PS1 基本提示符,对于 root 用户是#,对于普通用户是\$
**使用 Linux 已定义的环境变量:**
@@ -110,7 +135,17 @@ echo "helloworld!"
字符串是 shell 编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号。这点和 Java 中有所不同。
-在单引号中所有的特殊符号,如$和反引号都没有特殊含义。在双引号中,除了"$"、"\\"、反引号和感叹号(需开启 `history expansion`),其他的字符没有特殊含义。
+在单引号中,所有特殊字符(如 `$`、反引号、`\` 等)都失去特殊含义,被视为字面量。
+
+在双引号中,以下字符保留特殊含义:
+
+- `$`:变量扩展(如 `$var`)和命令替换(如 `$(cmd)` 或 `` `cmd` ``)
+- `\`:转义字符
+- `` ` `` 或 `$()`:命令替换(推荐使用 `$()` 语法)
+- `!`:历史扩展(仅在交互式 Shell 中默认开启)
+- `${}`:参数扩展
+
+**注意**:单引号中的字符串是**完全字面量**,双引号中的字符串会进行变量和命令替换。
**单引号字符串:**
@@ -167,33 +202,42 @@ echo $greeting_2 $greeting_3
```shell
#!/bin/bash
-#获取字符串长度
+# 获取字符串长度
name="SnailClimb"
-# 第一种方式
-echo ${#name} #输出 10
-# 第二种方式
-expr length "$name";
+# 第一种方式(推荐):bash 内置
+echo ${#name} # 输出 10
+# 第二种方式:外部命令(性能较差)
+expr length "$name"
```
-输出结果:
+输出结果:
```plain
10
10
```
-使用 expr 命令时,表达式中的运算符左右必须包含空格,如果不包含空格,将会输出表达式本身:
+**说明**:
+
+- 推荐使用 `${#var}` 语法,这是 bash 内置功能,性能更好
+- `expr` 是外部命令,需要 fork 进程,性能较差
+- **`expr length` 是 GNU 扩展**,非 POSIX 标准。在 macOS 的 BSD expr 或其他系统上可能不支持
+- 如需可移植性,推荐使用 `${#var}` 或 `expr "$var" : '.*'`(POSIX 兼容)
+
+使用 expr 命令时,表达式中的运算符左右必须包含空格:
```shell
-expr 5+6 // 直接输出 5+6
-expr 5 + 6 // 输出 11
+expr 5+6 # 直接输出 5+6(无空格)
+expr 5 + 6 # 输出 11(有空格)
+# 更推荐使用 bash 算术扩展:
+echo $((5 + 6)) # 输出 11
```
-对于某些运算符,还需要我们使用符号`\`进行转义,否则就会提示语法错误。
+对于某些运算符,还需要我们使用符号 `\` 进行转义:
```shell
-expr 5 * 6 // 输出错误
-expr 5 \* 6 // 输出30
+expr 5 * 6 # 输出错误(未转义)
+expr 5 \* 6 # 输出 30(正确转义)
```
**截取子字符串:**
@@ -201,7 +245,7 @@ expr 5 \* 6 // 输出30
简单的字符串截取:
```shell
-#从字符串第 1 个字符开始往后截取 10 个字符
+#从字符串第 0 个字符开始往后截取 10 个字符(索引从 0 开始)
str="SnailClimb is a great man"
echo ${str:0:10} #输出:SnailClimb
```
@@ -209,8 +253,8 @@ echo ${str:0:10} #输出:SnailClimb
根据表达式截取:
```shell
-#!bin/bash
-#author:amau
+#!/bin/bash
+# author: amau
var="https://www.runoob.com/linux/linux-shell-variable.html"
# %表示删除从后匹配, 最短结果
@@ -227,7 +271,11 @@ s5=${var##*/} #linux-shell-variable.html
### Shell 数组
-bash 支持一维数组(不支持多维数组),并且没有限定数组的大小。我下面给了大家一个关于数组操作的 Shell 代码示例,通过该示例大家可以知道如何创建数组、获取数组长度、获取/删除特定位置的数组元素、删除整个数组以及遍历数组。
+**bash 2.0+** 支持一维数组(不支持多维数组),并且没有限定数组的大小。
+
+**重要提示**:数组是 bash 的**非 POSIX 扩展特性**,纯 POSIX sh(如 dash)不支持数组。若需编写可移植脚本,应避免使用数组。
+
+下面是一个关于数组操作的 Shell 代码示例,通过该示例大家可以知道如何创建数组、获取数组长度、获取/删除特定位置的数组元素、删除整个数组以及遍历数组。
```shell
#!/bin/bash
@@ -247,9 +295,35 @@ unset array; # 删除数组中的所有元素
for i in ${array[@]};do echo $i ;done # 遍历数组,数组元素为空,没有任何输出内容
```
-## Shell 基本运算符
+**重要说明:数组索引空洞**:
+
+使用 `unset array[1]` 删除元素后,数组会产生**索引空洞**:
+
+```shell
+#!/bin/bash
+array=(1 2 3 4 5)
+echo "删除前: ${array[@]}" # 输出: 1 2 3 4 5
+echo "索引1的值: ${array[1]}" # 输出: 2
+
+unset array[1] # 删除索引1的元素
+echo "删除后: ${array[@]}" # 输出: 1 3 4 5
+echo "索引1的值: ${array[1]}" # 输出: (空值)
+echo "索引2的值: ${array[2]}" # 输出: 3 (索引2仍在)
+
+# 遍历时索引不连续
+for index in "${!array[@]}"; do
+ echo "索引[$index] = ${array[$index]}"
+done
+# 输出:
+# 索引[0] = 1
+# 索引[2] = 3
+# 索引[3] = 4
+# 索引[4] = 5
+```
+
+**注意**:删除元素后,如果使用 `${array[1]}` 访问会得到空值。遍历数组时建议使用 `"${!array[@]}"` 获取有效索引,或使用 `"${array[@]}"` 直接遍历值。
-> 说明:图片来自《菜鸟教程》
+## Shell 基本运算符
Shell 编程支持下面几种运算符
@@ -261,23 +335,51 @@ Shell 编程支持下面几种运算符
### 算数运算符
-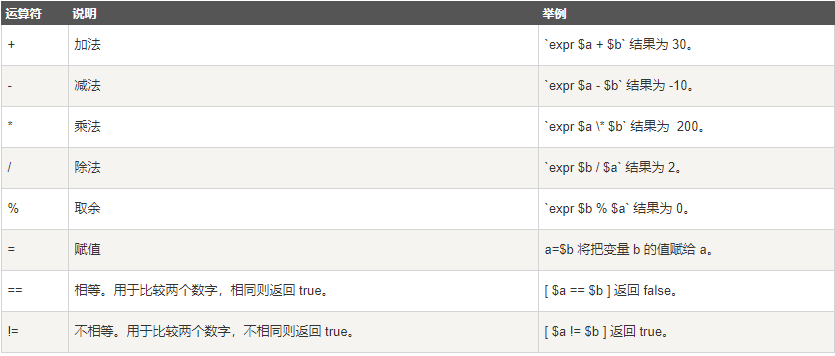
+| **运算符** | **说明** | **举例** |
+| ---------- | -------- | ------------------------------------------ |
+| **+** | 加法 | `expr $a + $b` |
+| **-** | 减法 | `expr $a - $b` |
+| **\*** | 乘法 | `expr $a \* $b` (注意星号需要转义) |
+| **/** | 除法 | `expr $b / $a` |
+| **%** | 取余 | `expr $b % $a` |
+| **=** | 赋值 | `a=$b` 将变量 b 的值赋给 a |
+| **==** | 相等 | `[ $a == $b ]` 用于数字比较,相同返回 true |
+| **!=** | 不相等 | `[ $a != $b ]` 用于数字比较,不同返回 true |
-我以加法运算符做一个简单的示例(注意:不是单引号,是反引号):
+**推荐使用 bash 内置算术扩展**:
```shell
#!/bin/bash
-a=3;b=3;
-val=`expr $a + $b`
-#输出:Total value : 6
-echo "Total value : $val"
+a=3; b=3
+val=$((a + b)) # bash 算术扩展(推荐)
+# 输出:Total value: 6
+echo "Total value: $val"
+```
+
+**说明**:
+
+- `$((...))` 是 bash 内置功能,无需 fork 外部进程,性能更好
+- **不推荐**使用 `expr` 命令(需 fork 进程,且运算符两边必须有空格)
+- **不推荐**使用反引号 `` `...` ``(已过时),应使用 `$(...)` 语法
+
+**如果需要兼容 POSIX sh**,可以使用:
+
+```shell
+val=$(expr "$a" + "$b") # POSIX 兼容,但性能较差
```
### 关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
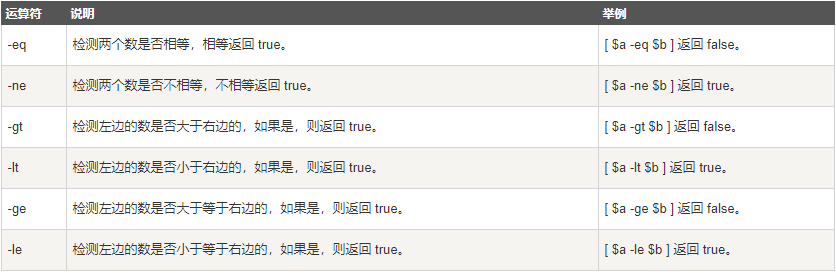
-
+| **运算符** | **说明** | **对应英文** |
+| ---------- | ---------------------------------- | ------------- |
+| **-eq** | 检测两个数是否**相等** | equal |
+| **-ne** | 检测两个数是否**不相等** | not equal |
+| **-gt** | 检测左边的数是否**大于**右边的 | greater than |
+| **-lt** | 检测左边的数是否**小于**右边的 | less than |
+| **-ge** | 检测左边的数是否**大于等于**右边的 | greater equal |
+| **-le** | 检测左边的数是否**小于等于**右边的 | less equal |
通过一个简单的示例演示关系运算符的使用,下面 shell 程序的作用是当 score=100 的时候输出 A 否则输出 B。
@@ -285,7 +387,7 @@ echo "Total value : $val"
#!/bin/bash
score=90;
maxscore=100;
-if [ $score -eq $maxscore ]
+if [[ $score -eq $maxscore ]]
then
echo "A"
else
@@ -301,9 +403,12 @@ B
### 逻辑运算符
-
+| **运算符** | **说明** | **举例** |
+| ---------- | -------------- | --------------------------------------------- | --- | --------------------------- |
+| **&&** | 逻辑的 **AND** | `[[ $a -lt 100 && $b -gt 100 ]]` (全真才为真) |
+| **\|\|** | 逻辑的 **OR** | `[[ $a -lt 100 | | $b -gt 100 ]]` (一真即为真) |
-示例:
+**算术扩展中的逻辑运算**:
```shell
#!/bin/bash
@@ -312,15 +417,71 @@ a=$(( 1 && 0))
echo $a;
```
-### 布尔运算符
+**命令短路执行(生产环境常用)**:
-
+在运维自动化和 CI/CD 管道中,经常使用 `&&` 和 `||` 来控制命令链路的执行流程,这称为**短路执行**:
-这里就不做演示了,应该挺简单的。
+```shell
+#!/bin/bash
+set -euo pipefail
+
+# &&:前一个命令成功(返回 0)时才执行后一个命令
+mkdir -p "/tmp/app_data" && echo "目录就绪"
+
+# ||:前一个命令失败(返回非 0)时才执行后一个命令
+mkdir -p "/tmp/app_data" || echo "目录创建失败"
+
+# 组合使用:生产环境典型的防御姿势
+mkdir -p "/tmp/app_data" && echo "目录就绪" || exit 1
+
+# 实际场景示例
+# 1. 检查文件存在后再删除
+[ -f "/tmp/old_file.log" ] && rm "/tmp/old_file.log"
+
+# 2. 命令失败时输出错误信息并退出
+cd /app/config || { echo "无法进入配置目录"; exit 1; }
+
+# 3. 条件执行命令
+command1 && command2 || command3
+# ⚠️ 注意:此写法有陷阱!
+# - 当 command1 成功时,执行 command2
+# - 当 command1 失败时,执行 command3
+# - 但如果 command1 成功但 command2 失败,command3 仍会执行!
+#
+# ✅ 更安全的写法(推荐):
+if command1; then
+ command2
+else
+ command3
+fi
+#
+# 或明确知道 command2 不会失败时才使用 && || 组合
+```
+
+**重要提示**:
+
+- 短路执行依赖命令的**退出码(Exit Code)**:成功返回 0,失败返回非 0
+- 这与 `[[ ]]` 内部的 `&&` 和 `||` 不同,后者用于条件测试
+- `command1 && command2 || command3` 存在陷阱:若 command1 成功但 command2 失败,command3 仍会执行
+- 生产环境中强烈建议使用 if-then-else 结构,确保逻辑清晰
+
+### 布尔运算符
+
+| **运算符** | **说明** | **举例** |
+| ---------- | -------------------------------------------------------------------- | ------------------------------------------ |
+| **!** | 将表达式的结果取反。如果表达式为 true,则返回 false;否则返回 true。 | `[ ! false ]` 返回 true。 |
+| **-o** | 有一个表达式为 true,则返回 true。 | `[ $a -lt 20 -o $b -gt 100 ]` 返回 true。 |
+| **-a** | 两个表达式都为 true 才会返回 true。 | `[ $a -lt 20 -a $b -gt 100 ]` 返回 false。 |
### 字符串运算符
-
+| **运算符** | **说明** | **举例** |
+| ---------- | --------------------------------- | ----------------------------- |
+| **=** | 检测两个字符串是否**相等** | `[ $a = $b ]` |
+| **!=** | 检测两个字符串是否**不相等** | `[ $a != $b ]` |
+| **-z** | 检测字符串长度是否为 **0** (zero) | `[ -z $a ]` 为空返回 true |
+| **-n** | 检测字符串长度是否**不为 0** | `[ -n "$a" ]` 不为空返回 true |
+| **str** | 直接检测字符串是否为空 | `[ $a ]` 不为空返回 true |
简单示例:
@@ -328,7 +489,7 @@ echo $a;
#!/bin/bash
a="abc";
b="efg";
-if [ $a = $b ]
+if [[ $a = $b ]]
then
echo "a 等于 b"
else
@@ -344,7 +505,20 @@ a 不等于 b
### 文件相关运算符
-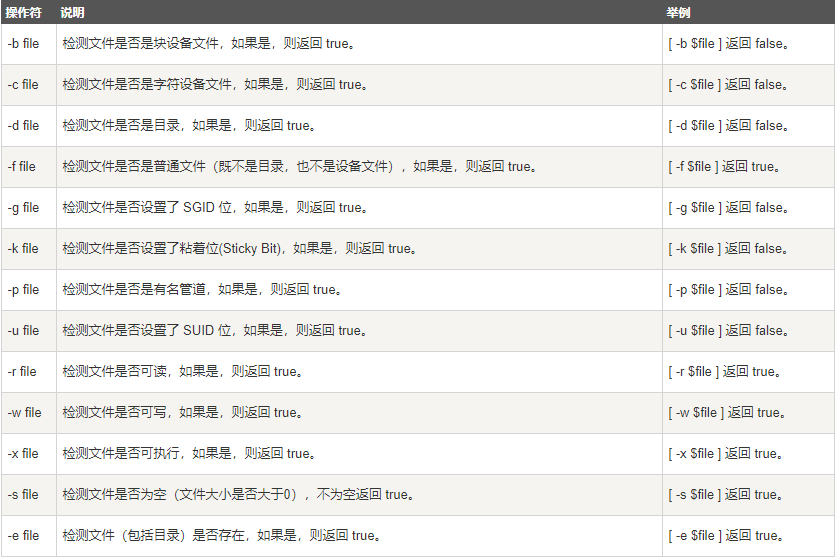
+用于检测 Unix/Linux 文件的各种属性(如权限、类型等)。
+
+- **存在与类型检测:**
+ - **-e file**: 检测文件(包括目录)是否存在。
+ - **-f file**: 检测是否为普通文件(既不是目录也不是设备文件)。
+ - **-d file**: 检测是否为目录。
+ - **-s file**: 检测文件是否为空(文件大小大于 0 返回 true)。
+ - **-b/-c/-p**: 分别检测是否为块设备、字符设备、有名管道。
+- **权限检测:**
+ - **-r file**: 检测文件是否可读。
+ - **-w file**: 检测文件是否可写。
+ - **-x file**: 检测文件是否可执行。
+- **特殊标识检测:**
+ - **-u / -g / -k**: 分别检测文件是否设置了 SUID、SGID 或粘着位 (Sticky Bit)。
使用方式很简单,比如我们定义好了一个文件路径`file="/usr/learnshell/test.sh"` 如果我们想判断这个文件是否可读,可以这样`if [ -r $file ]` 如果想判断这个文件是否可写,可以这样`-w $file`,是不是很简单。
@@ -358,10 +532,10 @@ a 不等于 b
#!/bin/bash
a=3;
b=9;
-if [ $a -eq $b ]
+if [[ $a -eq $b ]]
then
echo "a 等于 b"
-elif [ $a -gt $b ]
+elif [[ $a -gt $b ]]
then
echo "a 大于 b"
else
@@ -375,7 +549,22 @@ fi
a 小于 b
```
-相信大家通过上面的示例就已经掌握了 shell 编程中的 if 条件语句。不过,还要提到的一点是,不同于我们常见的 Java 以及 PHP 中的 if 条件语句,shell if 条件语句中不能包含空语句也就是什么都不做的语句。
+相信大家通过上面的示例就已经掌握了 shell 编程中的 if 条件语句。
+
+**空语句的处理**:Shell 中空语句可以使用 `:`(冒号命令)或 `true` 命令实现:
+
+```shell
+if [[ condition ]]; then
+ : # 空语句(什么都不做)
+fi
+
+# 或
+if [[ condition ]]; then
+ true # 空语句
+fi
+```
+
+这在某些场景下很有用,例如在 while 循环中作为占位符。
### for 循环语句
@@ -419,10 +608,10 @@ done;
```shell
#!/bin/bash
int=1
-while(( $int<=5 ))
+while (( int <= 5 )) # 算术上下文内变量无需 $
do
echo $int
- let "int++"
+ (( int++ )) # 推荐使用 (( )) 替代 let
done
```
@@ -431,7 +620,7 @@ done
```shell
echo '按下
### 产生死锁的四个必要条件是什么?
+死锁的发生并不是偶然的,它需要同时满足**四个必要条件**:
+
1. **互斥**:资源必须处于非共享模式,即一次只有一个进程可以使用。如果另一进程申请该资源,那么必须等待直到该资源被释放为止。
2. **占有并等待**:一个进程至少应该占有一个资源,并等待另一资源,而该资源被其他进程所占有。
3. **非抢占**:资源不能被抢占。只能在持有资源的进程完成任务后,该资源才会被释放。
-4. **循环等待**:有一组等待进程 `{P0, P1,..., Pn}`, `P0` 等待的资源被 `P1` 占有,`P1` 等待的资源被 `P2` 占有,……,`Pn-1` 等待的资源被 `Pn` 占有,`Pn` 等待的资源被 `P0` 占有。
+4. **循环等待**:有一组等待进程 {P0, P1,..., Pn}, P0 等待的资源被 P1 占有,P1 等待的资源被 P2 占有,……,Pn-1 等待的资源被 Pn 占有,Pn 等待的资源被 P0 占有。
**注意 ⚠️**:这四个条件是产生死锁的 **必要条件** ,也就是说只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
@@ -371,12 +378,9 @@ Thread[线程 2,5,main]waiting get resource1
解决死锁的方法可以从多个角度去分析,一般的情况下,有**预防,避免,检测和解除四种**。
-- **预防** 是采用某种策略,**限制并发进程对资源的请求**,从而使得死锁的必要条件在系统执行的任何时间上都不满足。
-
-- **避免**则是系统在分配资源时,根据资源的使用情况**提前做出预测**,从而**避免死锁的发生**
-
-- **检测**是指系统设有**专门的机构**,当死锁发生时,该机构能够检测死锁的发生,并精确地确定与死锁有关的进程和资源。
-- **解除** 是与检测相配套的一种措施,用于**将进程从死锁状态下解脱出来**。
+- **死锁预防:** 这是我们程序员最常用的方法。通过编码规范来破坏条件。最经典的就是**破坏循环等待**,比如规定所有线程都必须**按相同的顺序**来获取锁(比如先 A 后 B),这样就不会形成环路。
+- **死锁避免:** 这是一种更动态的方法,比如操作系统的**银行家算法**。它会在分配资源前进行预测,如果这次分配可能导致未来发生死锁,就拒绝分配。但这种方法开销很大,在通用系统中用得比较少。
+- **死锁检测与解除:** 这是一种“事后补救”的策略,就像乐观锁。系统允许死锁发生,但会有一个后台线程(或机制)定期检测是否存在死锁环路(比如通过分析线程等待图)。一旦发现,就会采取措施解除,比如**强制剥夺某个线程的资源或直接终止它**。数据库系统中的死锁处理就常常采用这种方式。
#### 死锁的预防
diff --git a/docs/cs-basics/operating-system/operating-system-basic-questions-02.md b/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
index 98de61c1340..51ed5fd65c3 100644
--- a/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
+++ b/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
@@ -1,17 +1,17 @@
---
title: 操作系统常见面试题总结(下)
+description: 最新操作系统高频面试题总结(下):虚拟内存映射、内存碎片/伙伴系统、TLB+页缺失处理、分页分段对比、页面置换算法详解、文件系统&磁盘调度,附图表+⭐️重点标注,一文掌握OS内存/文件考点,快速通关后端面试!
category: 计算机基础
tag:
- 操作系统
head:
- - meta
- name: keywords
- content: 操作系统,进程,进程通信方式,死锁,操作系统内存管理,块表,多级页表,虚拟内存,页面置换算法
- - - meta
- - name: description
- content: 很多读者抱怨计算操作系统的知识点比较繁杂,自己也没有多少耐心去看,但是面试的时候又经常会遇到。所以,我带着我整理好的操作系统的常见问题来啦!这篇文章总结了一些我觉得比较重要的操作系统相关的问题比如进程管理、内存管理、虚拟内存等等。
+ content: 操作系统面试题,虚拟内存详解,分页 vs 分段,页面置换算法,内存碎片,伙伴系统,TLB快表,页缺失,文件系统基础,磁盘调度算法,硬链接 vs 软链接
---
+
+
## 内存管理
### 内存管理主要做了什么?
@@ -211,7 +211,7 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
#### 单级页表有什么问题?为什么需要多级页表?
-以 32 位的环境为例,虚拟地址空间范围共有 2^32(4G)。假设 一个页的大小是 2^12(4KB),那页表项共有 4G / 4K = 2^20 个。每个页表项为一个地址,占用 4 字节,`2^20 * 2^2 / 1024 * 1024= 4MB`。也就是说一个程序啥都不干,页表大小就得占用 4M。
+以 32 位的环境为例,虚拟地址空间范围共有 2^32(4G)。假设 一个页的大小是 2^12(4KB),那页表项共有 4G / 4K = 2^20 个。每个页表项为一个地址,占用 4 字节,`(2^20 * 2^2) / (1024 * 1024)= 4MB`。也就是说一个程序啥都不干,页表大小就得占用 4M。
系统运行的应用程序多起来的话,页表的开销还是非常大的。而且,绝大部分应用程序可能只能用到页表中的几项,其他的白白浪费了。
@@ -317,12 +317,16 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
### 段页机制
-结合了段式管理和页式管理的一种内存管理机制,把物理内存先分成若干段,每个段又继续分成若干大小相等的页。
+结合了段式管理和页式管理的一种内存管理机制。程序视角中,内存被划分为多个逻辑段,每个逻辑段进一步被划分为固定大小的页。
在段页式机制下,地址翻译的过程分为两个步骤:
-1. 段式地址映射。
-2. 页式地址映射。
+1. **段式地址映射(虚拟地址 → 线性地址):**
+ - 虚拟地址 = 段选择符(段号)+ 段内偏移。
+ - 根据段号查段表,找到段基址,加上段内偏移得到线性地址。
+2. **页式地址映射(线性地址 → 物理地址):**
+ - 线性地址 = 页号 + 页内偏移。
+ - 根据页号查页表,找到物理页框号,加上页内偏移得到物理地址。
### 局部性原理
@@ -375,7 +379,7 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
### 提高文件系统性能的方式有哪些?
-- **优化硬件**:使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Inexpensive Disks)等技术提高磁盘性能。
+- **优化硬件**:使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Independent Disks)等技术提高磁盘性能。
- **选择合适的文件系统选型**:不同的文件系统具有不同的特性,对于不同的应用场景选择合适的文件系统可以提高系统性能。
- **运用缓存**:访问磁盘的效率比较低,可以运用缓存来减少磁盘的访问次数。不过,需要注意缓存命中率,缓存命中率过低的话,效果太差。
- **避免磁盘过度使用**:注意磁盘的使用率,避免将磁盘用满,尽量留一些剩余空间,以免对文件系统的性能产生负面影响。
diff --git a/docs/cs-basics/operating-system/shell-intro.md b/docs/cs-basics/operating-system/shell-intro.md
index 48066214c23..7554aa2760d 100644
--- a/docs/cs-basics/operating-system/shell-intro.md
+++ b/docs/cs-basics/operating-system/shell-intro.md
@@ -1,19 +1,36 @@
---
title: Shell 编程基础知识总结
+description: Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。这篇文章我会简单总结一下 Shell 编程基础知识,带你入门 Shell 编程!
category: 计算机基础
tag:
- 操作系统
- Linux
head:
- - meta
- - name: description
- content: Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。这篇文章我会简单总结一下 Shell 编程基础知识,带你入门 Shell 编程!
+ - name: keywords
+ content: Shell,脚本,命令,自动化,运维,Linux,基础语法
---
Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。
这篇文章我会简单总结一下 Shell 编程基础知识,带你入门 Shell 编程!
+## 版本说明
+
+**本文示例适用于 bash 4.0+ 版本**。不同版本的 bash 在某些特性上可能有差异,特别是:
+
+- **数组** :bash 2.0+ 支持,纯 POSIX sh(如 dash)不支持
+- **某些字符串操作** :如 `${var:offset:length}` 在较旧版本可能不支持
+- **算术扩展 `$((...))`** :bash 2.0+ 支持
+
+检查你的 bash 版本:
+
+```shell
+bash --version
+# 或
+echo $BASH_VERSION
+```
+
## 走进 Shell 编程的大门
### 为什么要学 Shell?
@@ -32,10 +49,17 @@ Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统
### 什么是 Shell?
-简单来说“Shell 编程就是对一堆 Linux 命令的逻辑化处理”。
+**Shell 是 Linux/Unix 系统的命令解释器**,它充当用户和操作系统内核之间的桥梁,负责接收用户输入的命令并调用相应的程序。
+
+**Shell 编程**是通过 Shell 解释器(如 bash)将命令、控制结构(if/for/while)、变量和函数组合成自动化脚本的过程。Shell 既是命令解释器,也是一门完整的编程语言(支持变量、数组、函数、流程控制、管道、重定向等)。
+
+**常见的 Shell 类型**:
-W3Cschool 上的一篇文章是这样介绍 Shell 的,如下图所示。
-
+- **bash**(Bourne Again Shell):Linux 系统默认 Shell,最常用
+- **sh**(Bourne Shell):Unix 传统 Shell,POSIX 标准
+- **zsh**:功能强大的交互式 Shell
+- **dash**:轻量级 Shell,Ubuntu 的 /bin/sh 默认指向它
+- **csh/tcsh**:C 风格的 Shell
### Shell 编程的 Hello World
@@ -51,8 +75,9 @@ helloworld.sh 内容如下:
```shell
#!/bin/bash
-#第一个shell小程序,echo 是linux中的输出命令。
-echo "helloworld!"
+set -euo pipefail # 严格模式:遇错退出、未定义变量报错、管道失败报错
+# 第一个 shell 小程序,echo 是 Linux 中的输出命令
+echo "helloworld!"
```
shell 中 # 符号表示注释。**shell 的第一行比较特殊,一般都会以#!开始来指定使用的 shell 类型。在 linux 中,除了 bash shell 以外,还有很多版本的 shell, 例如 zsh、dash 等等...不过 bash shell 还是我们使用最多的。**
@@ -67,20 +92,20 @@ shell 中 # 符号表示注释。**shell 的第一行比较特殊,一般都会
**Shell 编程中一般分为三种变量:**
-1. **我们自己定义的变量(自定义变量):** 仅在当前 Shell 实例中有效,其他 Shell 启动的程序不能访问局部变量。
-2. **Linux 已定义的环境变量**(环境变量, 例如:`PATH`, `HOME` 等..., 这类变量我们可以直接使用),使用 `env` 命令可以查看所有的环境变量,而 set 命令既可以查看环境变量也可以查看自定义变量。
-3. **Shell 变量**:Shell 变量是由 Shell 程序设置的特殊变量。Shell 变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了 Shell 的正常运行
+1. **自定义变量(局部变量)**:默认仅在当前 Shell 进程内有效,**子进程无法访问**。若需传递给子进程,需使用 `export` 声明为环境变量。
+2. **环境变量**:例如 `PATH`, `HOME` 等,可被子进程继承。使用 `env` 命令可以查看所有环境变量,`set` 命令可以查看所有变量(包括环境变量和局部变量)。
+3. **Shell 特殊变量**:由 Shell 设置的特殊变量(如 `$?`, `$$`, `$!` 等),用于保存进程状态、参数等信息。
**常用的环境变量:**
-> PATH 决定了 shell 将到哪些目录中寻找命令或程序
-> HOME 当前用户主目录
-> HISTSIZE 历史记录数
-> LOGNAME 当前用户的登录名
-> HOSTNAME 指主机的名称
-> SHELL 当前用户 Shell 类型
-> LANGUAGE 语言相关的环境变量,多语言可以修改此环境变量
-> MAIL 当前用户的邮件存放目录
+> PATH 决定了 shell 将到哪些目录中寻找命令或程序
+> HOME 当前用户主目录
+> HISTSIZE 历史记录数
+> LOGNAME 当前用户的登录名
+> HOSTNAME 指主机的名称
+> SHELL 当前用户 Shell 类型
+> LANGUAGE 语言相关的环境变量,多语言可以修改此环境变量
+> MAIL 当前用户的邮件存放目录
> PS1 基本提示符,对于 root 用户是#,对于普通用户是\$
**使用 Linux 已定义的环境变量:**
@@ -110,7 +135,17 @@ echo "helloworld!"
字符串是 shell 编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号。这点和 Java 中有所不同。
-在单引号中所有的特殊符号,如$和反引号都没有特殊含义。在双引号中,除了"$"、"\\"、反引号和感叹号(需开启 `history expansion`),其他的字符没有特殊含义。
+在单引号中,所有特殊字符(如 `$`、反引号、`\` 等)都失去特殊含义,被视为字面量。
+
+在双引号中,以下字符保留特殊含义:
+
+- `$`:变量扩展(如 `$var`)和命令替换(如 `$(cmd)` 或 `` `cmd` ``)
+- `\`:转义字符
+- `` ` `` 或 `$()`:命令替换(推荐使用 `$()` 语法)
+- `!`:历史扩展(仅在交互式 Shell 中默认开启)
+- `${}`:参数扩展
+
+**注意**:单引号中的字符串是**完全字面量**,双引号中的字符串会进行变量和命令替换。
**单引号字符串:**
@@ -167,33 +202,42 @@ echo $greeting_2 $greeting_3
```shell
#!/bin/bash
-#获取字符串长度
+# 获取字符串长度
name="SnailClimb"
-# 第一种方式
-echo ${#name} #输出 10
-# 第二种方式
-expr length "$name";
+# 第一种方式(推荐):bash 内置
+echo ${#name} # 输出 10
+# 第二种方式:外部命令(性能较差)
+expr length "$name"
```
-输出结果:
+输出结果:
```plain
10
10
```
-使用 expr 命令时,表达式中的运算符左右必须包含空格,如果不包含空格,将会输出表达式本身:
+**说明**:
+
+- 推荐使用 `${#var}` 语法,这是 bash 内置功能,性能更好
+- `expr` 是外部命令,需要 fork 进程,性能较差
+- **`expr length` 是 GNU 扩展**,非 POSIX 标准。在 macOS 的 BSD expr 或其他系统上可能不支持
+- 如需可移植性,推荐使用 `${#var}` 或 `expr "$var" : '.*'`(POSIX 兼容)
+
+使用 expr 命令时,表达式中的运算符左右必须包含空格:
```shell
-expr 5+6 // 直接输出 5+6
-expr 5 + 6 // 输出 11
+expr 5+6 # 直接输出 5+6(无空格)
+expr 5 + 6 # 输出 11(有空格)
+# 更推荐使用 bash 算术扩展:
+echo $((5 + 6)) # 输出 11
```
-对于某些运算符,还需要我们使用符号`\`进行转义,否则就会提示语法错误。
+对于某些运算符,还需要我们使用符号 `\` 进行转义:
```shell
-expr 5 * 6 // 输出错误
-expr 5 \* 6 // 输出30
+expr 5 * 6 # 输出错误(未转义)
+expr 5 \* 6 # 输出 30(正确转义)
```
**截取子字符串:**
@@ -201,7 +245,7 @@ expr 5 \* 6 // 输出30
简单的字符串截取:
```shell
-#从字符串第 1 个字符开始往后截取 10 个字符
+#从字符串第 0 个字符开始往后截取 10 个字符(索引从 0 开始)
str="SnailClimb is a great man"
echo ${str:0:10} #输出:SnailClimb
```
@@ -209,8 +253,8 @@ echo ${str:0:10} #输出:SnailClimb
根据表达式截取:
```shell
-#!bin/bash
-#author:amau
+#!/bin/bash
+# author: amau
var="https://www.runoob.com/linux/linux-shell-variable.html"
# %表示删除从后匹配, 最短结果
@@ -227,7 +271,11 @@ s5=${var##*/} #linux-shell-variable.html
### Shell 数组
-bash 支持一维数组(不支持多维数组),并且没有限定数组的大小。我下面给了大家一个关于数组操作的 Shell 代码示例,通过该示例大家可以知道如何创建数组、获取数组长度、获取/删除特定位置的数组元素、删除整个数组以及遍历数组。
+**bash 2.0+** 支持一维数组(不支持多维数组),并且没有限定数组的大小。
+
+**重要提示**:数组是 bash 的**非 POSIX 扩展特性**,纯 POSIX sh(如 dash)不支持数组。若需编写可移植脚本,应避免使用数组。
+
+下面是一个关于数组操作的 Shell 代码示例,通过该示例大家可以知道如何创建数组、获取数组长度、获取/删除特定位置的数组元素、删除整个数组以及遍历数组。
```shell
#!/bin/bash
@@ -247,9 +295,35 @@ unset array; # 删除数组中的所有元素
for i in ${array[@]};do echo $i ;done # 遍历数组,数组元素为空,没有任何输出内容
```
-## Shell 基本运算符
+**重要说明:数组索引空洞**:
+
+使用 `unset array[1]` 删除元素后,数组会产生**索引空洞**:
+
+```shell
+#!/bin/bash
+array=(1 2 3 4 5)
+echo "删除前: ${array[@]}" # 输出: 1 2 3 4 5
+echo "索引1的值: ${array[1]}" # 输出: 2
+
+unset array[1] # 删除索引1的元素
+echo "删除后: ${array[@]}" # 输出: 1 3 4 5
+echo "索引1的值: ${array[1]}" # 输出: (空值)
+echo "索引2的值: ${array[2]}" # 输出: 3 (索引2仍在)
+
+# 遍历时索引不连续
+for index in "${!array[@]}"; do
+ echo "索引[$index] = ${array[$index]}"
+done
+# 输出:
+# 索引[0] = 1
+# 索引[2] = 3
+# 索引[3] = 4
+# 索引[4] = 5
+```
+
+**注意**:删除元素后,如果使用 `${array[1]}` 访问会得到空值。遍历数组时建议使用 `"${!array[@]}"` 获取有效索引,或使用 `"${array[@]}"` 直接遍历值。
-> 说明:图片来自《菜鸟教程》
+## Shell 基本运算符
Shell 编程支持下面几种运算符
@@ -261,23 +335,51 @@ Shell 编程支持下面几种运算符
### 算数运算符
-
+| **运算符** | **说明** | **举例** |
+| ---------- | -------- | ------------------------------------------ |
+| **+** | 加法 | `expr $a + $b` |
+| **-** | 减法 | `expr $a - $b` |
+| **\*** | 乘法 | `expr $a \* $b` (注意星号需要转义) |
+| **/** | 除法 | `expr $b / $a` |
+| **%** | 取余 | `expr $b % $a` |
+| **=** | 赋值 | `a=$b` 将变量 b 的值赋给 a |
+| **==** | 相等 | `[ $a == $b ]` 用于数字比较,相同返回 true |
+| **!=** | 不相等 | `[ $a != $b ]` 用于数字比较,不同返回 true |
-我以加法运算符做一个简单的示例(注意:不是单引号,是反引号):
+**推荐使用 bash 内置算术扩展**:
```shell
#!/bin/bash
-a=3;b=3;
-val=`expr $a + $b`
-#输出:Total value : 6
-echo "Total value : $val"
+a=3; b=3
+val=$((a + b)) # bash 算术扩展(推荐)
+# 输出:Total value: 6
+echo "Total value: $val"
+```
+
+**说明**:
+
+- `$((...))` 是 bash 内置功能,无需 fork 外部进程,性能更好
+- **不推荐**使用 `expr` 命令(需 fork 进程,且运算符两边必须有空格)
+- **不推荐**使用反引号 `` `...` ``(已过时),应使用 `$(...)` 语法
+
+**如果需要兼容 POSIX sh**,可以使用:
+
+```shell
+val=$(expr "$a" + "$b") # POSIX 兼容,但性能较差
```
### 关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
-
+| **运算符** | **说明** | **对应英文** |
+| ---------- | ---------------------------------- | ------------- |
+| **-eq** | 检测两个数是否**相等** | equal |
+| **-ne** | 检测两个数是否**不相等** | not equal |
+| **-gt** | 检测左边的数是否**大于**右边的 | greater than |
+| **-lt** | 检测左边的数是否**小于**右边的 | less than |
+| **-ge** | 检测左边的数是否**大于等于**右边的 | greater equal |
+| **-le** | 检测左边的数是否**小于等于**右边的 | less equal |
通过一个简单的示例演示关系运算符的使用,下面 shell 程序的作用是当 score=100 的时候输出 A 否则输出 B。
@@ -285,7 +387,7 @@ echo "Total value : $val"
#!/bin/bash
score=90;
maxscore=100;
-if [ $score -eq $maxscore ]
+if [[ $score -eq $maxscore ]]
then
echo "A"
else
@@ -301,9 +403,12 @@ B
### 逻辑运算符
-
+| **运算符** | **说明** | **举例** |
+| ---------- | -------------- | --------------------------------------------- | --- | --------------------------- |
+| **&&** | 逻辑的 **AND** | `[[ $a -lt 100 && $b -gt 100 ]]` (全真才为真) |
+| **\|\|** | 逻辑的 **OR** | `[[ $a -lt 100 | | $b -gt 100 ]]` (一真即为真) |
-示例:
+**算术扩展中的逻辑运算**:
```shell
#!/bin/bash
@@ -312,15 +417,71 @@ a=$(( 1 && 0))
echo $a;
```
-### 布尔运算符
+**命令短路执行(生产环境常用)**:
-
+在运维自动化和 CI/CD 管道中,经常使用 `&&` 和 `||` 来控制命令链路的执行流程,这称为**短路执行**:
-这里就不做演示了,应该挺简单的。
+```shell
+#!/bin/bash
+set -euo pipefail
+
+# &&:前一个命令成功(返回 0)时才执行后一个命令
+mkdir -p "/tmp/app_data" && echo "目录就绪"
+
+# ||:前一个命令失败(返回非 0)时才执行后一个命令
+mkdir -p "/tmp/app_data" || echo "目录创建失败"
+
+# 组合使用:生产环境典型的防御姿势
+mkdir -p "/tmp/app_data" && echo "目录就绪" || exit 1
+
+# 实际场景示例
+# 1. 检查文件存在后再删除
+[ -f "/tmp/old_file.log" ] && rm "/tmp/old_file.log"
+
+# 2. 命令失败时输出错误信息并退出
+cd /app/config || { echo "无法进入配置目录"; exit 1; }
+
+# 3. 条件执行命令
+command1 && command2 || command3
+# ⚠️ 注意:此写法有陷阱!
+# - 当 command1 成功时,执行 command2
+# - 当 command1 失败时,执行 command3
+# - 但如果 command1 成功但 command2 失败,command3 仍会执行!
+#
+# ✅ 更安全的写法(推荐):
+if command1; then
+ command2
+else
+ command3
+fi
+#
+# 或明确知道 command2 不会失败时才使用 && || 组合
+```
+
+**重要提示**:
+
+- 短路执行依赖命令的**退出码(Exit Code)**:成功返回 0,失败返回非 0
+- 这与 `[[ ]]` 内部的 `&&` 和 `||` 不同,后者用于条件测试
+- `command1 && command2 || command3` 存在陷阱:若 command1 成功但 command2 失败,command3 仍会执行
+- 生产环境中强烈建议使用 if-then-else 结构,确保逻辑清晰
+
+### 布尔运算符
+
+| **运算符** | **说明** | **举例** |
+| ---------- | -------------------------------------------------------------------- | ------------------------------------------ |
+| **!** | 将表达式的结果取反。如果表达式为 true,则返回 false;否则返回 true。 | `[ ! false ]` 返回 true。 |
+| **-o** | 有一个表达式为 true,则返回 true。 | `[ $a -lt 20 -o $b -gt 100 ]` 返回 true。 |
+| **-a** | 两个表达式都为 true 才会返回 true。 | `[ $a -lt 20 -a $b -gt 100 ]` 返回 false。 |
### 字符串运算符
-
+| **运算符** | **说明** | **举例** |
+| ---------- | --------------------------------- | ----------------------------- |
+| **=** | 检测两个字符串是否**相等** | `[ $a = $b ]` |
+| **!=** | 检测两个字符串是否**不相等** | `[ $a != $b ]` |
+| **-z** | 检测字符串长度是否为 **0** (zero) | `[ -z $a ]` 为空返回 true |
+| **-n** | 检测字符串长度是否**不为 0** | `[ -n "$a" ]` 不为空返回 true |
+| **str** | 直接检测字符串是否为空 | `[ $a ]` 不为空返回 true |
简单示例:
@@ -328,7 +489,7 @@ echo $a;
#!/bin/bash
a="abc";
b="efg";
-if [ $a = $b ]
+if [[ $a = $b ]]
then
echo "a 等于 b"
else
@@ -344,7 +505,20 @@ a 不等于 b
### 文件相关运算符
-
+用于检测 Unix/Linux 文件的各种属性(如权限、类型等)。
+
+- **存在与类型检测:**
+ - **-e file**: 检测文件(包括目录)是否存在。
+ - **-f file**: 检测是否为普通文件(既不是目录也不是设备文件)。
+ - **-d file**: 检测是否为目录。
+ - **-s file**: 检测文件是否为空(文件大小大于 0 返回 true)。
+ - **-b/-c/-p**: 分别检测是否为块设备、字符设备、有名管道。
+- **权限检测:**
+ - **-r file**: 检测文件是否可读。
+ - **-w file**: 检测文件是否可写。
+ - **-x file**: 检测文件是否可执行。
+- **特殊标识检测:**
+ - **-u / -g / -k**: 分别检测文件是否设置了 SUID、SGID 或粘着位 (Sticky Bit)。
使用方式很简单,比如我们定义好了一个文件路径`file="/usr/learnshell/test.sh"` 如果我们想判断这个文件是否可读,可以这样`if [ -r $file ]` 如果想判断这个文件是否可写,可以这样`-w $file`,是不是很简单。
@@ -358,10 +532,10 @@ a 不等于 b
#!/bin/bash
a=3;
b=9;
-if [ $a -eq $b ]
+if [[ $a -eq $b ]]
then
echo "a 等于 b"
-elif [ $a -gt $b ]
+elif [[ $a -gt $b ]]
then
echo "a 大于 b"
else
@@ -375,7 +549,22 @@ fi
a 小于 b
```
-相信大家通过上面的示例就已经掌握了 shell 编程中的 if 条件语句。不过,还要提到的一点是,不同于我们常见的 Java 以及 PHP 中的 if 条件语句,shell if 条件语句中不能包含空语句也就是什么都不做的语句。
+相信大家通过上面的示例就已经掌握了 shell 编程中的 if 条件语句。
+
+**空语句的处理**:Shell 中空语句可以使用 `:`(冒号命令)或 `true` 命令实现:
+
+```shell
+if [[ condition ]]; then
+ : # 空语句(什么都不做)
+fi
+
+# 或
+if [[ condition ]]; then
+ true # 空语句
+fi
+```
+
+这在某些场景下很有用,例如在 while 循环中作为占位符。
### for 循环语句
@@ -419,10 +608,10 @@ done;
```shell
#!/bin/bash
int=1
-while(( $int<=5 ))
+while (( int <= 5 )) # 算术上下文内变量无需 $
do
echo $int
- let "int++"
+ (( int++ )) # 推荐使用 (( )) 替代 let
done
```
@@ -431,7 +620,7 @@ done
```shell
echo '按下  @@ -167,4 +193,10 @@ MySQL 中时间到底怎么存储才好?Datetime?Timestamp?还是数值时间
| TIMESTAMP | 4~7 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1970-01-01 00:00:01[.000000] ~ 2038-01-19 03:14:07[.999999] | 是 |
| 数值型时间戳 | 4 字节 | 全数字如 1578707612 | 1970-01-01 00:00:01 之后的时间 | 否 |
+**选择建议小结:**
+
+- `TIMESTAMP` 的核心优势在于其内建的时区处理能力。数据库负责 UTC 存储和基于会话时区的自动转换,简化了需要处理多时区应用的开发。如果应用需要处理多时区,或者希望数据库能自动管理时区转换,`TIMESTAMP` 是自然的选择(注意其时间范围限制,也就是 2038 年问题)。
+- 如果应用场景不涉及时区转换,或者希望应用程序完全控制时区逻辑,并且需要表示 2038 年之后的时间,`DATETIME` 是更稳妥的选择。
+- 如果极度关注比较性能,或者需要频繁跨系统传递时间数据,并且可以接受可读性的牺牲(或总是在应用层转换),数值时间戳是一个强大的选项。
+
diff --git a/docs/database/mysql/transaction-isolation-level.md b/docs/database/mysql/transaction-isolation-level.md
index 52ad40f4a47..4ee2cabc95a 100644
--- a/docs/database/mysql/transaction-isolation-level.md
+++ b/docs/database/mysql/transaction-isolation-level.md
@@ -1,8 +1,13 @@
---
title: MySQL事务隔离级别详解
+description: 详解MySQL四种事务隔离级别(读未提交、读已提交、可重复读、串行化)的特点与区别,分析脏读、不可重复读、幻读等并发问题,以及InnoDB如何通过MVCC和锁机制解决幻读。
category: 数据库
tag:
- MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL事务隔离级别,读未提交,读已提交,可重复读,串行化,脏读,不可重复读,幻读,MVCC,间隙锁
---
> 本文由 [SnailClimb](https://github.com/Snailclimb) 和 [guang19](https://github.com/guang19) 共同完成。
@@ -11,43 +16,46 @@ tag:
## 事务隔离级别总结
-SQL 标准定义了四个隔离级别:
+SQL 标准定义了四种事务隔离级别,用来平衡事务的隔离性(Isolation)和并发性能。级别越高,数据一致性越好,但并发性能可能越低。这四个级别是:
-- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
-- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
-- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
+- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。这种级别在实际应用中很少使用,因为它对数据一致性的保证太弱。
+- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。这是大多数数据库(如 Oracle, SQL Server)的默认隔离级别。
+- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。MySQL InnoDB 存储引擎的默认隔离级别正是 REPEATABLE READ。并且,InnoDB 在此级别下通过 MVCC(多版本并发控制) 和 Next-Key Locks(间隙锁+行锁) 机制,在很大程度上解决了幻读问题。
- **SERIALIZABLE(可串行化)** :最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
----
+| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (Non-Repeatable Read) | 幻读 (Phantom Read) |
+| ---------------- | ----------------- | -------------------------------- | ---------------------- |
+| READ UNCOMMITTED | √ | √ | √ |
+| READ COMMITTED | × | √ | √ |
+| REPEATABLE READ | × | × | √ (标准) / ≈× (InnoDB) |
+| SERIALIZABLE | × | × | × |
-| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
-| :--------------: | :--: | :--------: | :--: |
-| READ-UNCOMMITTED | √ | √ | √ |
-| READ-COMMITTED | × | √ | √ |
-| REPEATABLE-READ | × | × | √ |
-| SERIALIZABLE | × | × | × |
+**默认级别查询:**
-MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
+MySQL InnoDB 存储引擎的默认隔离级别是 **REPEATABLE READ**。可以通过以下命令查看:
-```sql
-MySQL> SELECT @@tx_isolation;
-+-----------------+
-| @@tx_isolation |
-+-----------------+
-| REPEATABLE-READ |
-+-----------------+
+- MySQL 8.0 之前:`SELECT @@tx_isolation;`
+- MySQL 8.0 及之后:`SELECT @@transaction_isolation;`
+
+```bash
+mysql> SELECT @@transaction_isolation;
++-------------------------+
+| @@transaction_isolation |
++-------------------------+
+| REPEATABLE-READ |
++-------------------------+
```
-从上面对 SQL 标准定义了四个隔离级别的介绍可以看出,标准的 SQL 隔离级别定义里,REPEATABLE-READ(可重复读)是不可以防止幻读的。
+**InnoDB 的 REPEATABLE READ 对幻读的处理:**
-但是!InnoDB 实现的 REPEATABLE-READ 隔离级别其实是可以解决幻读问题发生的,主要有下面两种情况:
+标准的 SQL 隔离级别定义里,REPEATABLE READ 是无法防止幻读的。但 InnoDB 的实现通过以下机制很大程度上避免了幻读:
-- **快照读**:由 MVCC 机制来保证不出现幻读。
-- **当前读**:使用 Next-Key Lock 进行加锁来保证不出现幻读,Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的结合,行锁只能锁住已经存在的行,为了避免插入新行,需要依赖间隙锁。
+- **快照读 (Snapshot Read)**:普通的 SELECT 语句,通过 **MVCC** 机制实现。事务启动时创建一个数据快照,后续的快照读都读取这个版本的数据,从而避免了看到其他事务新插入的行(幻读)或修改的行(不可重复读)。
+- **当前读 (Current Read)**:像 `SELECT ... FOR UPDATE`, `SELECT ... LOCK IN SHARE MODE`, `INSERT`, `UPDATE`, `DELETE` 这些操作。InnoDB 使用 **Next-Key Lock** 来锁定扫描到的索引记录及其间的范围(间隙),防止其他事务在这个范围内插入新的记录,从而避免幻读。Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的组合。
-因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED** ,但是你要知道的是 InnoDB 存储引擎默认使用 **REPEATABLE-READ** 并不会有任何性能损失。
+值得注意的是,虽然通常认为隔离级别越高、并发性越差,但 InnoDB 存储引擎通过 MVCC 机制优化了 REPEATABLE READ 级别。对于许多常见的只读或读多写少的场景,其性能**与 READ COMMITTED 相比可能没有显著差异**。不过,在写密集型且并发冲突较高的场景下,RR 的间隙锁机制可能会比 RC 带来更多的锁等待。
-InnoDB 存储引擎在分布式事务的情况下一般会用到 SERIALIZABLE 隔离级别。
+此外,在某些特定场景下,如需要严格一致性的分布式事务(XA Transactions),InnoDB 可能要求或推荐使用 SERIALIZABLE 隔离级别来确保全局数据的一致性。
《MySQL 技术内幕:InnoDB 存储引擎(第 2 版)》7.7 章这样写到:
diff --git a/docs/database/nosql.md b/docs/database/nosql.md
index d5ca59698bd..3a7e7929057 100644
--- a/docs/database/nosql.md
+++ b/docs/database/nosql.md
@@ -1,10 +1,15 @@
---
title: NoSQL基础知识总结
+description: NoSQL数据库基础知识总结,包括NoSQL与SQL的区别、NoSQL的优势、四种NoSQL数据库类型(键值、文档、图形、宽列)及其代表产品Redis、MongoDB、Neo4j等的应用场景。
category: 数据库
tag:
- NoSQL
- MongoDB
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: NoSQL,Redis,MongoDB,HBase,Cassandra,键值数据库,文档数据库,图数据库,宽列存储,SQL与NoSQL区别
---
## NoSQL 是什么?
diff --git a/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md b/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md
index 7ad88958704..be12e83c288 100644
--- a/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md
+++ b/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md
@@ -1,8 +1,13 @@
---
title: 3种常用的缓存读写策略详解
+description: 深入对比 Cache Aside、Read/Write Through、Write Behind 三种缓存读写策略,附详细时序图、一致性问题分析及生产级解决方案,Redis 实战必备!
category: 数据库
tag:
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: 缓存读写策略,Cache Aside,Read Through,Write Through,Write Behind,Write Back,缓存一致性,缓存失效,旁路缓存,读写穿透,异步缓存写入,Redis缓存策略,缓存更新策略
---
看到很多小伙伴简历上写了“**熟练使用缓存**”,但是被我问到“**缓存常用的 3 种读写策略**”的时候却一脸懵逼。
@@ -15,26 +20,28 @@ tag:
### Cache Aside Pattern(旁路缓存模式)
-**Cache Aside Pattern 是我们平时使用比较多的一个缓存读写模式,比较适合读请求比较多的场景。**
+这是我们日常开发中**最常用、最经典**的一种模式,几乎是互联网应用缓存方案的事实标准,尤其适合**读多写少**的业务场景。
-Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 db 的结果为准。
+这个模式之所以被称为**“旁路”(Aside)**,是因为应用程序的**写操作完全绕过了缓存,直接操作数据库**。
+
+应用程序扮演了数据流转的“指挥官”,需要同时维护 Cache 和 DB 两个数据源。
下面我们来看一下这个策略模式下的缓存读写步骤。
-**写**:
+**写操作 :**
-- 先更新 db
-- 然后直接删除 cache 。
+1. 应用**先更新 DB**。
+2. 然后**直接删除 Cache**中对应的数据。
简单画了一张图帮助大家理解写的步骤。

-**读** :
+**读操作:**
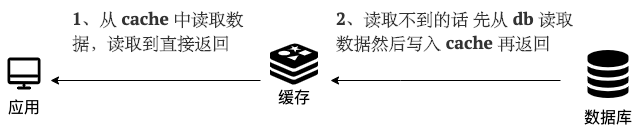
-- 从 cache 中读取数据,读取到就直接返回
-- cache 中读取不到的话,就从 db 中读取数据返回
-- 再把数据放到 cache 中。
+1. 应用先从 Cache 读取数据。
+2. 如果命中(Hit),则直接返回。
+3. 如果未命中(Miss),则从 DB 读取数据,成功读取后,**将数据写回 Cache**,然后返回。
简单画了一张图帮助大家理解读的步骤。
@@ -42,49 +49,69 @@ Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 d
你仅仅了解了上面这些内容的话是远远不够的,我们还要搞懂其中的原理。
-比如说面试官很可能会追问:“**在写数据的过程中,可以先删除 cache ,后更新 db 么?**”
+比如说面试官很可能会追问:
+
+1. 为什么写操作是“先更新 DB,后删除 Cache”?顺序能反过来吗?
+2. 那“先更新 DB,后删除 Cache”就绝对安全吗?
+3. 为什么是“删除 Cache”,而不是“更新 Cache”?
-**答案:** 那肯定是不行的!因为这样可能会造成 **数据库(db)和缓存(Cache)数据不一致**的问题。
+接下来我会以此分析解答这些问题。
-举例:请求 1 先写数据 A,请求 2 随后读数据 A 的话,就很有可能产生数据不一致性的问题。
+**1. 为什么写操作是“先更新 DB,后删除 Cache”?顺序能反过来吗?**
-这个过程可以简单描述为:
+**答:** 绝对不能。如果“先删 Cache,后更新 DB”,在高并发下会引入经典的数据不一致问题。
-> 请求 1 先把 cache 中的 A 数据删除 -> 请求 2 从 db 中读取数据->请求 1 再把 db 中的 A 数据更新
+- **时序分析 (请求 A 写, 请求 B 读):**
+ 1. 请求 A: 先将 Cache 中的数据删除。
+ 2. 请求 B: 此时发现 Cache 为空,于是去 DB 读取**旧值**,并准备写入 Cache。
+ 3. 请求 A : 将**新值**写入 DB。
+ 4. 请求 B: 将之前读到的**旧值**写入了 Cache。
+- **结果:** DB 中是新值,而 Cache 中是旧值,数据不一致。
-当你这样回答之后,面试官可能会紧接着就追问:“**在写数据的过程中,先更新 db,后删除 cache 就没有问题了么?**”
+**2. 那“先更新 DB,后删除 Cache”就绝对安全吗?**
-**答案:** 理论上来说还是可能会出现数据不一致性的问题,不过概率非常小,因为缓存的写入速度是比数据库的写入速度快很多。
+**答案:** 也不是绝对安全的!因为这样也可能会造成 **数据库和缓存数据不一致**的问题。
-举例:请求 1 先读数据 A,请求 2 随后写数据 A,并且数据 A 在请求 1 请求之前不在缓存中的话,也有可能产生数据不一致性的问题。
+- **时序分析 (请求 A 读, 请求 B 写):**
+ 1. 请求 A : 缓存未命中,从 DB 读取到**旧值**。
+ 2. 请求 B: 迅速完成了 DB 的更新,并将 Cache 删除。
+ 3. 请求 A : 将自己之前拿到的**旧值**写入了 Cache。
+- **结果:** DB 中是新值,Cache 中又是旧值。
+- **为什么概率极小?** 这个问题本质上是一个并发时序问题:只要“读 DB → 写 Cache”这段时间窗口内,恰好有写请求完成了 DB 更新,就有可能产生不一致。在大多数业务里,这个窗口时间相对较短,而且还需要与写请求并发“撞车”,所以发生概率不算高,但绝不是不可能。
-这个过程可以简单描述为:
+**3. 为什么是“删除 Cache”,而不是“更新 Cache”?**
-> 请求 1 从 db 读数据 A-> 请求 2 更新 db 中的数据 A(此时缓存中无数据 A ,故不用执行删除缓存操作 ) -> 请求 1 将数据 A 写入 cache
+- **性能开销:** 写操作往往只更新了对象的部分字段,如果为了“更新 Cache”而去重新查询或计算整个缓存对象,开销可能很大。相比之下,“删除”是一个轻量级操作。
+- **懒加载思想:** “删除”操作遵循懒加载原则。只有当数据下一次被真正需要(被读取)时,才触发从 DB 加载并写入缓存,避免了无效的缓存更新。
+- **并发安全:** “更新缓存”在高并发下可能出现更新顺序错乱的问题导致脏数据的概率会更大。
+
+当然,这一切都建立在一个重要的前提之上:我们缓存的数据,是可以通过数据库进行确定性重建的,并且业务上可以容忍从‘缓存删除’到‘下一次读取并回填’之间这个极短时间窗口内的数据不一致。
现在我们再来分析一下 **Cache Aside Pattern 的缺陷**。
-**缺陷 1:首次请求数据一定不在 cache 的问题**
+**缺陷 1:首次请求数据一定不在 Cache 的问题**
-解决办法:可以将热点数据可以提前放入 cache 中。
+解决办法:对于访问量巨大的热点数据,可以在系统启动或低峰期进行缓存预热。
-**缺陷 2:写操作比较频繁的话导致 cache 中的数据会被频繁被删除,这样会影响缓存命中率 。**
+**缺陷 2:写操作比较频繁的话导致 Cache 中的数据会被频繁被删除,这样会影响缓存命中率 。**
解决办法:
-- 数据库和缓存数据强一致场景:更新 db 的时候同样更新 cache,不过我们需要加一个锁/分布式锁来保证更新 cache 的时候不存在线程安全问题。
-- 可以短暂地允许数据库和缓存数据不一致的场景:更新 db 的时候同样更新 cache,但是给缓存加一个比较短的过期时间,这样的话就可以保证即使数据不一致的话影响也比较小。
+- 数据库和缓存数据强一致场景:更新 DB 的时候同样更新 Cache,不过我们需要加一个锁/分布式锁来保证更新 Cache 的时候不存在线程安全问题。
+- 可以短暂地允许数据库和缓存数据不一致的场景:更新 DB 的时候同样更新 Cache,但是给缓存加一个比较短的过期时间(如 1 分钟),这样的话就可以保证即使数据不一致的话影响也比较小。
### Read/Write Through Pattern(读写穿透)
-Read/Write Through Pattern 中服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务负责将此数据读取和写入 db,从而减轻了应用程序的职责。
+在这种模式下,应用程序将**Cache 视为唯一的、主要的存储**。所有的读写请求都直接打向 Cache,而 Cache 服务自身负责与 DB 进行数据同步。
+
+对应用程序**透明**,应用开发者无需关心 DB 的存在。
-这种缓存读写策略小伙伴们应该也发现了在平时在开发过程中非常少见。抛去性能方面的影响,大概率是因为我们经常使用的分布式缓存 Redis 并没有提供 cache 将数据写入 db 的功能。
+这种缓存读写策略小伙伴们应该也发现了在平时在开发过程中非常少见。抛去性能方面的影响,大概率是因为我们经常使用的分布式缓存 Redis 本身并没有提供 Cache 将数据写入 DB 的功能,需要我们在业务侧或中间件里自己实现。
**写(Write Through):**
-- 先查 cache,cache 中不存在,直接更新 db。
-- cache 中存在,则先更新 cache,然后 cache 服务自己更新 db(**同步更新 cache 和 db**)。
+- 先查 Cache,Cache 中不存在,直接更新 DB。
+- Cache 中存在,则先更新 Cache,然后 Cache 服务自己更新 DB。只有当 Cache 和 DB 都写入成功后,才向上层返回成功。
简单画了一张图帮助大家理解写的步骤。
@@ -92,27 +119,38 @@ Read/Write Through Pattern 中服务端把 cache 视为主要数据存储,从
**读(Read Through):**
-- 从 cache 中读取数据,读取到就直接返回 。
-- 读取不到的话,先从 db 加载,写入到 cache 后返回响应。
+- 应用从 Cache 读取数据。
+- 如果命中,直接返回。
+- 如果未命中,由**Cache 服务自己**负责从 DB 加载数据,加载成功后先写入自身,再返回给应用。
简单画了一张图帮助大家理解读的步骤。
-Read-Through Pattern 实际只是在 Cache-Aside Pattern 之上进行了封装。在 Cache-Aside Pattern 下,发生读请求的时候,如果 cache 中不存在对应的数据,是由客户端自己负责把数据写入 cache,而 Read Through Pattern 则是 cache 服务自己来写入缓存的,这对客户端是透明的。
+Read-Through 实际只是在 Cache-Aside 之上进行了封装。在 Cache-Aside 下,发生读请求的时候,如果 Cache 中不存在对应的数据,是由客户端自己负责把数据写入 Cache,而 Read Through 则是 Cache 服务自己来写入缓存的,这对客户端是透明的。
-和 Cache Aside Pattern 一样, Read-Through Pattern 也有首次请求数据一定不再 cache 的问题,对于热点数据可以提前放入缓存中。
+从实现角度看,Read-Through 本质上是把 Cache-Aside 中“读 Miss → 读 DB → 回填 Cache”的逻辑,下沉到了缓存服务内部,对客户端透明。
+
+和 Cache Aside 一样, Read-Through 也有首次请求数据一定不再 Cache 的问题,对于热点数据可以提前放入缓存中。
### Write Behind Pattern(异步缓存写入)
-Write Behind Pattern 和 Read/Write Through Pattern 很相似,两者都是由 cache 服务来负责 cache 和 db 的读写。
+Write Behind(也常被称为 Write-Back) Pattern 和 Read/Write Through Pattern 很相似,两者都是由 Cache 服务来负责 Cache 和 DB 的读写。
+
+但是,两个又有很大的不同:**Read/Write Through 是同步更新 Cache 和 DB,而 Write Behind 则是只更新缓存,不直接更新 DB,而是改为异步批量的方式来更新 DB。**
+
+**写操作 (Write Behind):**
-但是,两个又有很大的不同:**Read/Write Through 是同步更新 cache 和 db,而 Write Behind 则是只更新缓存,不直接更新 db,而是改为异步批量的方式来更新 db。**
+1. 应用将数据写入 Cache,然后**立即返回**。
+2. Cache 服务将这个写操作放入一个队列中。
+3. 通过一个独立的异步线程/任务,将队列中的写操作**批量地、合并地**写入 DB。
-很明显,这种方式对数据一致性带来了更大的挑战,比如 cache 数据可能还没异步更新 db 的话,cache 服务可能就就挂掉了。
+这种模式对数据一致性带来了挑战(例如:Cache 中的数据还没来得及写回 DB,系统就宕机了),因此不适用于需要强一致性的场景(如交易、库存)。
-这种策略在我们平时开发过程中也非常非常少见,但是不代表它的应用场景少,比如消息队列中消息的异步写入磁盘、MySQL 的 Innodb Buffer Pool 机制都用到了这种策略。
+但是,它的异步和批量特性,带来了**无与伦比的写性能**。它在很多高性能系统中都有广泛应用:
-Write Behind Pattern 下 db 的写性能非常高,非常适合一些数据经常变化又对数据一致性要求没那么高的场景,比如浏览量、点赞量。
+- **MySQL 的 InnoDB Buffer Pool 机制:** 数据修改先在内存 Buffer Pool 中完成,然后由后台线程异步刷写到磁盘。
+- **操作系统的页缓存(Page Cache):** 文件写入也是先写到内存,再由操作系统异步刷盘。
+- **高频计数场景:** 对于文章浏览量、帖子点赞数这类允许短暂数据不一致、但写入极其频繁的场景,可以先在 Redis 中快速累加,再通过定时任务异步同步回数据库。
diff --git a/docs/database/redis/cache-basics.md b/docs/database/redis/cache-basics.md
index 391e5bec82d..15cb0eb33bb 100644
--- a/docs/database/redis/cache-basics.md
+++ b/docs/database/redis/cache-basics.md
@@ -1,14 +1,195 @@
---
-title: 缓存基础常见面试题总结(付费)
+title: 缓存基础常见面试题总结
+description: 深入讲解缓存的核心思想、本地缓存与分布式缓存的区别、多级缓存架构设计。涵盖Caffeine、Redis等主流缓存方案,以及缓存一致性的解决方案。适合Java开发者学习缓存架构设计。
category: 数据库
tag:
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: 缓存,本地缓存,分布式缓存,多级缓存,Caffeine,Redis,缓存一致性,系统设计,Java缓存,Guava Cache
---
-**缓存基础** 相关的面试题为我的 [知识星球](../../about-the-author/zhishixingqiu-two-years.md)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](../../zhuanlan/java-mian-shi-zhi-bei.md)中。
+> **相关面试题** :
+>
+> - 为什么要用缓存?
+> - 本地缓存应该怎么做?
+> - 为什么要有分布式缓存?/为什么不直接用本地缓存?
+> - 为什么要用多级缓存?
+> - 多级缓存适合哪些业务场景?
-
+## 缓存的基本思想
-
+很多同学只知道缓存可以提高系统性能以及减少请求 **响应时间**(Response Time),但是,不太清楚缓存的本质思想是什么。
-
+缓存的基本思想其实很简单,就是我们非常熟悉的 **空间换时间** 这一经典性能优化策略的运用。所谓空间换时间,也就是用更多的存储空间来存储一些可能重复使用或计算的数据,从而减少数据的重新获取或计算的时间。
+
+说到空间换时间,除了缓存之外,你还能想到什么其他的例子吗?这里再列举几个常见的:
+
+- **索引**:索引是一种将数据库表中的某些列或字段按照一定的排序规则组织成一个单独的数据结构,虽然需要额外占用空间,但可以大大提高检索效率,降低数据排序成本。
+- **数据库表字段冗余**:将经常联合查询的数据冗余存储在同一张表中,以减少对多张表的关联查询,进而提升查询性能,减轻数据库压力。
+- **CDN(内容分发网络)**:将静态资源分发到多个边缘节点以实现就近访问,进而加快静态资源的访问速度,减轻源站服务器以及带宽的负担。
+
+编程需要要学会归纳总结,将自己学到的东西串联起来!假如你在面试的时候,能聊到这些,面试官一定会对你有一个好印象的。
+
+不要把缓存想的太高大上,虽然,它的确对系统的性能提升的性价比非常高。当我们在学习并应用缓存的时候,你会发现缓存的思想实际在 CPU、操作系统或者其他很多地方都被大量用到。
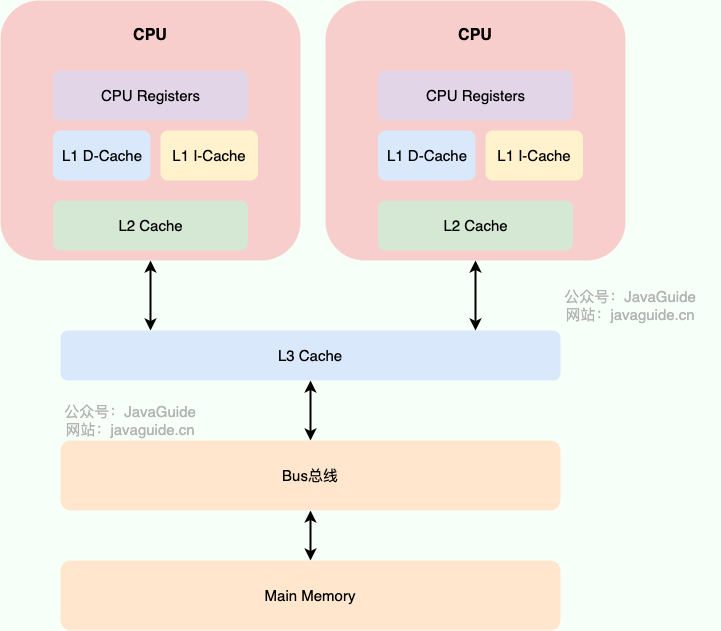
+
+比如,**CPU Cache** 缓存的是内存数据,用于解决 **CPU** 处理速度与内存访问速度不匹配的问题;内存缓存的是硬盘数据,用于解决硬盘 **I/O** 速度过慢的问题。
+
+
+
+再比如,为了提高虚拟地址到物理地址的转换速度,操作系统在页表方案基础之上引入了 **转址旁路缓存**(Translation Lookaside Buffer,**TLB**,也被称为快表)。
+
+
+
+拿日常使用的浏览器来说,它会对访问过的图片或静态文件进行缓存(浏览器缓存),这样下次访问相同页面时加载速度会显著提升。
+
+
+
+我们日常开发中用到的缓存,其中的数据通常存储于 **RAM**(内存)中,访问速度极快。为了避免内存数据在重启或宕机后丢失,许多缓存中间件(如 **Redis**)提供了磁盘持久化机制。相比于关系型数据库(如 **MySQL**),缓存的访问速度和并发支持量都要高出几个数量级。在数据库之上增加一层缓存,是保护底层存储、提升系统吞吐量的核心手段。
+
+## 缓存的分类
+
+接下来,我们来看看日常开发中用到的缓存通常被分为哪几种。
+
+### 本地缓存
+
+#### 什么是本地缓存?
+
+这个实际在很多项目中用的蛮多,特别是单体架构的时候。数据量不大,并且没有分布式要求的话,使用本地缓存还是可以的。
+
+本地缓存位于应用内部,其最大的优点是应用存在于同一个进程内部,请求本地缓存的速度非常快,不存在额外的网络开销。
+
+常见的单体架构图如下,我们使用 **Nginx** 来做**负载均衡**,部署两个相同的应用到服务器,两个服务使用同一个数据库,并且使用的是本地缓存。
+
+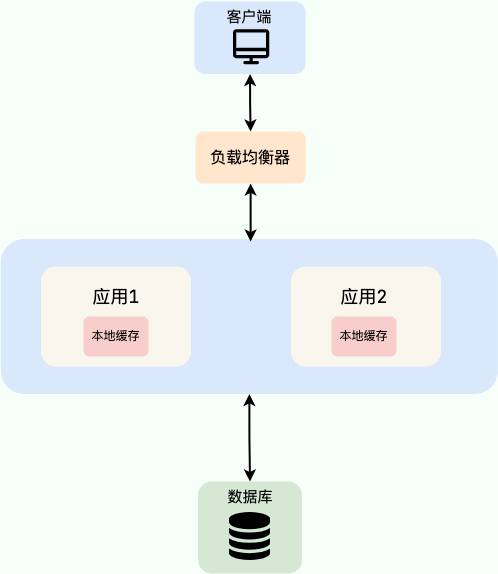
+
+**注意:** 在集群模式下使用本地缓存,必须考虑**负载均衡策略**。如果 Nginx 使用默认的**轮询(Round-Robin)**,同一个用户的请求会随机落在不同机器,导致本地缓存命中率极低。解决方案如下:
+
+1. **网关层**:使用一致性哈希或 Sticky Session,保证同一用户的请求固定打到同一台机器。
+2. **应用层**:仅将本地缓存用于**“全局几乎不变”**的数据(如配置字典),而非用户维度数据。
+
+#### 本地缓存的方案有哪些?
+
+**1、JDK 自带的 `HashMap` 和 `ConcurrentHashMap` 了。**
+
+`ConcurrentHashMap` 可以看作是线程安全版本的 `HashMap` ,两者都是存放 key/value 形式的键值对。但是,大部分场景来说不会使用这两者当做缓存,因为只提供了缓存的功能,并没有提供其他诸如过期时间之类的功能。一个稍微完善一点的缓存框架至少要提供:**过期时间**、**淘汰机制**、**命中率统计**这三点。
+
+**2、 `Ehcache` 、 `Guava Cache` 、 `Spring Cache` 这三者是使用的比较多的本地缓存框架。**
+
+- `Ehcache` 的话相比于其他两者更加重量。不过,相比于 `Guava Cache` 、 `Spring Cache` 来说, `Ehcache` 支持可以嵌入到 hibernate 和 mybatis 作为多级缓存,并且可以将缓存的数据持久化到本地磁盘中、同时也提供了集群方案(比较鸡肋,可忽略)。
+- `Guava Cache` 和 `Spring Cache` 两者的话比较像。`Guava` 相比于 `Spring Cache` 的话使用的更多一点,它提供了 API 非常方便我们使用,同时也提供了设置缓存有效时间等功能。它的内部实现也比较干净,很多地方都和 `ConcurrentHashMap` 的思想有异曲同工之妙。
+- 使用 `Spring Cache` 的注解实现缓存的话,代码会看着很干净和优雅,但是很容易出现问题比如缓存穿透、内存溢出。
+
+**3、后起之秀 Caffeine。**
+
+相比于 `Guava` 来说 `Caffeine` 在各个方面比如性能都要更加优秀,一般建议使用其来替代 `Guava` 。并且, `Guava` 和 `Caffeine` 的使用方式很像!
+
+使用 `Caffeine` 创建本地缓存的代码示例,用到了建造者模式:
+
+```java
+// 使用 Caffeine 创建本地缓存示例
+Cache
@@ -167,4 +193,10 @@ MySQL 中时间到底怎么存储才好?Datetime?Timestamp?还是数值时间
| TIMESTAMP | 4~7 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1970-01-01 00:00:01[.000000] ~ 2038-01-19 03:14:07[.999999] | 是 |
| 数值型时间戳 | 4 字节 | 全数字如 1578707612 | 1970-01-01 00:00:01 之后的时间 | 否 |
+**选择建议小结:**
+
+- `TIMESTAMP` 的核心优势在于其内建的时区处理能力。数据库负责 UTC 存储和基于会话时区的自动转换,简化了需要处理多时区应用的开发。如果应用需要处理多时区,或者希望数据库能自动管理时区转换,`TIMESTAMP` 是自然的选择(注意其时间范围限制,也就是 2038 年问题)。
+- 如果应用场景不涉及时区转换,或者希望应用程序完全控制时区逻辑,并且需要表示 2038 年之后的时间,`DATETIME` 是更稳妥的选择。
+- 如果极度关注比较性能,或者需要频繁跨系统传递时间数据,并且可以接受可读性的牺牲(或总是在应用层转换),数值时间戳是一个强大的选项。
+
diff --git a/docs/database/mysql/transaction-isolation-level.md b/docs/database/mysql/transaction-isolation-level.md
index 52ad40f4a47..4ee2cabc95a 100644
--- a/docs/database/mysql/transaction-isolation-level.md
+++ b/docs/database/mysql/transaction-isolation-level.md
@@ -1,8 +1,13 @@
---
title: MySQL事务隔离级别详解
+description: 详解MySQL四种事务隔离级别(读未提交、读已提交、可重复读、串行化)的特点与区别,分析脏读、不可重复读、幻读等并发问题,以及InnoDB如何通过MVCC和锁机制解决幻读。
category: 数据库
tag:
- MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL事务隔离级别,读未提交,读已提交,可重复读,串行化,脏读,不可重复读,幻读,MVCC,间隙锁
---
> 本文由 [SnailClimb](https://github.com/Snailclimb) 和 [guang19](https://github.com/guang19) 共同完成。
@@ -11,43 +16,46 @@ tag:
## 事务隔离级别总结
-SQL 标准定义了四个隔离级别:
+SQL 标准定义了四种事务隔离级别,用来平衡事务的隔离性(Isolation)和并发性能。级别越高,数据一致性越好,但并发性能可能越低。这四个级别是:
-- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
-- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
-- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
+- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。这种级别在实际应用中很少使用,因为它对数据一致性的保证太弱。
+- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。这是大多数数据库(如 Oracle, SQL Server)的默认隔离级别。
+- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。MySQL InnoDB 存储引擎的默认隔离级别正是 REPEATABLE READ。并且,InnoDB 在此级别下通过 MVCC(多版本并发控制) 和 Next-Key Locks(间隙锁+行锁) 机制,在很大程度上解决了幻读问题。
- **SERIALIZABLE(可串行化)** :最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
----
+| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (Non-Repeatable Read) | 幻读 (Phantom Read) |
+| ---------------- | ----------------- | -------------------------------- | ---------------------- |
+| READ UNCOMMITTED | √ | √ | √ |
+| READ COMMITTED | × | √ | √ |
+| REPEATABLE READ | × | × | √ (标准) / ≈× (InnoDB) |
+| SERIALIZABLE | × | × | × |
-| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
-| :--------------: | :--: | :--------: | :--: |
-| READ-UNCOMMITTED | √ | √ | √ |
-| READ-COMMITTED | × | √ | √ |
-| REPEATABLE-READ | × | × | √ |
-| SERIALIZABLE | × | × | × |
+**默认级别查询:**
-MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
+MySQL InnoDB 存储引擎的默认隔离级别是 **REPEATABLE READ**。可以通过以下命令查看:
-```sql
-MySQL> SELECT @@tx_isolation;
-+-----------------+
-| @@tx_isolation |
-+-----------------+
-| REPEATABLE-READ |
-+-----------------+
+- MySQL 8.0 之前:`SELECT @@tx_isolation;`
+- MySQL 8.0 及之后:`SELECT @@transaction_isolation;`
+
+```bash
+mysql> SELECT @@transaction_isolation;
++-------------------------+
+| @@transaction_isolation |
++-------------------------+
+| REPEATABLE-READ |
++-------------------------+
```
-从上面对 SQL 标准定义了四个隔离级别的介绍可以看出,标准的 SQL 隔离级别定义里,REPEATABLE-READ(可重复读)是不可以防止幻读的。
+**InnoDB 的 REPEATABLE READ 对幻读的处理:**
-但是!InnoDB 实现的 REPEATABLE-READ 隔离级别其实是可以解决幻读问题发生的,主要有下面两种情况:
+标准的 SQL 隔离级别定义里,REPEATABLE READ 是无法防止幻读的。但 InnoDB 的实现通过以下机制很大程度上避免了幻读:
-- **快照读**:由 MVCC 机制来保证不出现幻读。
-- **当前读**:使用 Next-Key Lock 进行加锁来保证不出现幻读,Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的结合,行锁只能锁住已经存在的行,为了避免插入新行,需要依赖间隙锁。
+- **快照读 (Snapshot Read)**:普通的 SELECT 语句,通过 **MVCC** 机制实现。事务启动时创建一个数据快照,后续的快照读都读取这个版本的数据,从而避免了看到其他事务新插入的行(幻读)或修改的行(不可重复读)。
+- **当前读 (Current Read)**:像 `SELECT ... FOR UPDATE`, `SELECT ... LOCK IN SHARE MODE`, `INSERT`, `UPDATE`, `DELETE` 这些操作。InnoDB 使用 **Next-Key Lock** 来锁定扫描到的索引记录及其间的范围(间隙),防止其他事务在这个范围内插入新的记录,从而避免幻读。Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的组合。
-因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED** ,但是你要知道的是 InnoDB 存储引擎默认使用 **REPEATABLE-READ** 并不会有任何性能损失。
+值得注意的是,虽然通常认为隔离级别越高、并发性越差,但 InnoDB 存储引擎通过 MVCC 机制优化了 REPEATABLE READ 级别。对于许多常见的只读或读多写少的场景,其性能**与 READ COMMITTED 相比可能没有显著差异**。不过,在写密集型且并发冲突较高的场景下,RR 的间隙锁机制可能会比 RC 带来更多的锁等待。
-InnoDB 存储引擎在分布式事务的情况下一般会用到 SERIALIZABLE 隔离级别。
+此外,在某些特定场景下,如需要严格一致性的分布式事务(XA Transactions),InnoDB 可能要求或推荐使用 SERIALIZABLE 隔离级别来确保全局数据的一致性。
《MySQL 技术内幕:InnoDB 存储引擎(第 2 版)》7.7 章这样写到:
diff --git a/docs/database/nosql.md b/docs/database/nosql.md
index d5ca59698bd..3a7e7929057 100644
--- a/docs/database/nosql.md
+++ b/docs/database/nosql.md
@@ -1,10 +1,15 @@
---
title: NoSQL基础知识总结
+description: NoSQL数据库基础知识总结,包括NoSQL与SQL的区别、NoSQL的优势、四种NoSQL数据库类型(键值、文档、图形、宽列)及其代表产品Redis、MongoDB、Neo4j等的应用场景。
category: 数据库
tag:
- NoSQL
- MongoDB
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: NoSQL,Redis,MongoDB,HBase,Cassandra,键值数据库,文档数据库,图数据库,宽列存储,SQL与NoSQL区别
---
## NoSQL 是什么?
diff --git a/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md b/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md
index 7ad88958704..be12e83c288 100644
--- a/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md
+++ b/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md
@@ -1,8 +1,13 @@
---
title: 3种常用的缓存读写策略详解
+description: 深入对比 Cache Aside、Read/Write Through、Write Behind 三种缓存读写策略,附详细时序图、一致性问题分析及生产级解决方案,Redis 实战必备!
category: 数据库
tag:
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: 缓存读写策略,Cache Aside,Read Through,Write Through,Write Behind,Write Back,缓存一致性,缓存失效,旁路缓存,读写穿透,异步缓存写入,Redis缓存策略,缓存更新策略
---
看到很多小伙伴简历上写了“**熟练使用缓存**”,但是被我问到“**缓存常用的 3 种读写策略**”的时候却一脸懵逼。
@@ -15,26 +20,28 @@ tag:
### Cache Aside Pattern(旁路缓存模式)
-**Cache Aside Pattern 是我们平时使用比较多的一个缓存读写模式,比较适合读请求比较多的场景。**
+这是我们日常开发中**最常用、最经典**的一种模式,几乎是互联网应用缓存方案的事实标准,尤其适合**读多写少**的业务场景。
-Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 db 的结果为准。
+这个模式之所以被称为**“旁路”(Aside)**,是因为应用程序的**写操作完全绕过了缓存,直接操作数据库**。
+
+应用程序扮演了数据流转的“指挥官”,需要同时维护 Cache 和 DB 两个数据源。
下面我们来看一下这个策略模式下的缓存读写步骤。
-**写**:
+**写操作 :**
-- 先更新 db
-- 然后直接删除 cache 。
+1. 应用**先更新 DB**。
+2. 然后**直接删除 Cache**中对应的数据。
简单画了一张图帮助大家理解写的步骤。

-**读** :
+**读操作:**
-- 从 cache 中读取数据,读取到就直接返回
-- cache 中读取不到的话,就从 db 中读取数据返回
-- 再把数据放到 cache 中。
+1. 应用先从 Cache 读取数据。
+2. 如果命中(Hit),则直接返回。
+3. 如果未命中(Miss),则从 DB 读取数据,成功读取后,**将数据写回 Cache**,然后返回。
简单画了一张图帮助大家理解读的步骤。
@@ -42,49 +49,69 @@ Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 d
你仅仅了解了上面这些内容的话是远远不够的,我们还要搞懂其中的原理。
-比如说面试官很可能会追问:“**在写数据的过程中,可以先删除 cache ,后更新 db 么?**”
+比如说面试官很可能会追问:
+
+1. 为什么写操作是“先更新 DB,后删除 Cache”?顺序能反过来吗?
+2. 那“先更新 DB,后删除 Cache”就绝对安全吗?
+3. 为什么是“删除 Cache”,而不是“更新 Cache”?
-**答案:** 那肯定是不行的!因为这样可能会造成 **数据库(db)和缓存(Cache)数据不一致**的问题。
+接下来我会以此分析解答这些问题。
-举例:请求 1 先写数据 A,请求 2 随后读数据 A 的话,就很有可能产生数据不一致性的问题。
+**1. 为什么写操作是“先更新 DB,后删除 Cache”?顺序能反过来吗?**
-这个过程可以简单描述为:
+**答:** 绝对不能。如果“先删 Cache,后更新 DB”,在高并发下会引入经典的数据不一致问题。
-> 请求 1 先把 cache 中的 A 数据删除 -> 请求 2 从 db 中读取数据->请求 1 再把 db 中的 A 数据更新
+- **时序分析 (请求 A 写, 请求 B 读):**
+ 1. 请求 A: 先将 Cache 中的数据删除。
+ 2. 请求 B: 此时发现 Cache 为空,于是去 DB 读取**旧值**,并准备写入 Cache。
+ 3. 请求 A : 将**新值**写入 DB。
+ 4. 请求 B: 将之前读到的**旧值**写入了 Cache。
+- **结果:** DB 中是新值,而 Cache 中是旧值,数据不一致。
-当你这样回答之后,面试官可能会紧接着就追问:“**在写数据的过程中,先更新 db,后删除 cache 就没有问题了么?**”
+**2. 那“先更新 DB,后删除 Cache”就绝对安全吗?**
-**答案:** 理论上来说还是可能会出现数据不一致性的问题,不过概率非常小,因为缓存的写入速度是比数据库的写入速度快很多。
+**答案:** 也不是绝对安全的!因为这样也可能会造成 **数据库和缓存数据不一致**的问题。
-举例:请求 1 先读数据 A,请求 2 随后写数据 A,并且数据 A 在请求 1 请求之前不在缓存中的话,也有可能产生数据不一致性的问题。
+- **时序分析 (请求 A 读, 请求 B 写):**
+ 1. 请求 A : 缓存未命中,从 DB 读取到**旧值**。
+ 2. 请求 B: 迅速完成了 DB 的更新,并将 Cache 删除。
+ 3. 请求 A : 将自己之前拿到的**旧值**写入了 Cache。
+- **结果:** DB 中是新值,Cache 中又是旧值。
+- **为什么概率极小?** 这个问题本质上是一个并发时序问题:只要“读 DB → 写 Cache”这段时间窗口内,恰好有写请求完成了 DB 更新,就有可能产生不一致。在大多数业务里,这个窗口时间相对较短,而且还需要与写请求并发“撞车”,所以发生概率不算高,但绝不是不可能。
-这个过程可以简单描述为:
+**3. 为什么是“删除 Cache”,而不是“更新 Cache”?**
-> 请求 1 从 db 读数据 A-> 请求 2 更新 db 中的数据 A(此时缓存中无数据 A ,故不用执行删除缓存操作 ) -> 请求 1 将数据 A 写入 cache
+- **性能开销:** 写操作往往只更新了对象的部分字段,如果为了“更新 Cache”而去重新查询或计算整个缓存对象,开销可能很大。相比之下,“删除”是一个轻量级操作。
+- **懒加载思想:** “删除”操作遵循懒加载原则。只有当数据下一次被真正需要(被读取)时,才触发从 DB 加载并写入缓存,避免了无效的缓存更新。
+- **并发安全:** “更新缓存”在高并发下可能出现更新顺序错乱的问题导致脏数据的概率会更大。
+
+当然,这一切都建立在一个重要的前提之上:我们缓存的数据,是可以通过数据库进行确定性重建的,并且业务上可以容忍从‘缓存删除’到‘下一次读取并回填’之间这个极短时间窗口内的数据不一致。
现在我们再来分析一下 **Cache Aside Pattern 的缺陷**。
-**缺陷 1:首次请求数据一定不在 cache 的问题**
+**缺陷 1:首次请求数据一定不在 Cache 的问题**
-解决办法:可以将热点数据可以提前放入 cache 中。
+解决办法:对于访问量巨大的热点数据,可以在系统启动或低峰期进行缓存预热。
-**缺陷 2:写操作比较频繁的话导致 cache 中的数据会被频繁被删除,这样会影响缓存命中率 。**
+**缺陷 2:写操作比较频繁的话导致 Cache 中的数据会被频繁被删除,这样会影响缓存命中率 。**
解决办法:
-- 数据库和缓存数据强一致场景:更新 db 的时候同样更新 cache,不过我们需要加一个锁/分布式锁来保证更新 cache 的时候不存在线程安全问题。
-- 可以短暂地允许数据库和缓存数据不一致的场景:更新 db 的时候同样更新 cache,但是给缓存加一个比较短的过期时间,这样的话就可以保证即使数据不一致的话影响也比较小。
+- 数据库和缓存数据强一致场景:更新 DB 的时候同样更新 Cache,不过我们需要加一个锁/分布式锁来保证更新 Cache 的时候不存在线程安全问题。
+- 可以短暂地允许数据库和缓存数据不一致的场景:更新 DB 的时候同样更新 Cache,但是给缓存加一个比较短的过期时间(如 1 分钟),这样的话就可以保证即使数据不一致的话影响也比较小。
### Read/Write Through Pattern(读写穿透)
-Read/Write Through Pattern 中服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务负责将此数据读取和写入 db,从而减轻了应用程序的职责。
+在这种模式下,应用程序将**Cache 视为唯一的、主要的存储**。所有的读写请求都直接打向 Cache,而 Cache 服务自身负责与 DB 进行数据同步。
+
+对应用程序**透明**,应用开发者无需关心 DB 的存在。
-这种缓存读写策略小伙伴们应该也发现了在平时在开发过程中非常少见。抛去性能方面的影响,大概率是因为我们经常使用的分布式缓存 Redis 并没有提供 cache 将数据写入 db 的功能。
+这种缓存读写策略小伙伴们应该也发现了在平时在开发过程中非常少见。抛去性能方面的影响,大概率是因为我们经常使用的分布式缓存 Redis 本身并没有提供 Cache 将数据写入 DB 的功能,需要我们在业务侧或中间件里自己实现。
**写(Write Through):**
-- 先查 cache,cache 中不存在,直接更新 db。
-- cache 中存在,则先更新 cache,然后 cache 服务自己更新 db(**同步更新 cache 和 db**)。
+- 先查 Cache,Cache 中不存在,直接更新 DB。
+- Cache 中存在,则先更新 Cache,然后 Cache 服务自己更新 DB。只有当 Cache 和 DB 都写入成功后,才向上层返回成功。
简单画了一张图帮助大家理解写的步骤。
@@ -92,27 +119,38 @@ Read/Write Through Pattern 中服务端把 cache 视为主要数据存储,从
**读(Read Through):**
-- 从 cache 中读取数据,读取到就直接返回 。
-- 读取不到的话,先从 db 加载,写入到 cache 后返回响应。
+- 应用从 Cache 读取数据。
+- 如果命中,直接返回。
+- 如果未命中,由**Cache 服务自己**负责从 DB 加载数据,加载成功后先写入自身,再返回给应用。
简单画了一张图帮助大家理解读的步骤。

-Read-Through Pattern 实际只是在 Cache-Aside Pattern 之上进行了封装。在 Cache-Aside Pattern 下,发生读请求的时候,如果 cache 中不存在对应的数据,是由客户端自己负责把数据写入 cache,而 Read Through Pattern 则是 cache 服务自己来写入缓存的,这对客户端是透明的。
+Read-Through 实际只是在 Cache-Aside 之上进行了封装。在 Cache-Aside 下,发生读请求的时候,如果 Cache 中不存在对应的数据,是由客户端自己负责把数据写入 Cache,而 Read Through 则是 Cache 服务自己来写入缓存的,这对客户端是透明的。
-和 Cache Aside Pattern 一样, Read-Through Pattern 也有首次请求数据一定不再 cache 的问题,对于热点数据可以提前放入缓存中。
+从实现角度看,Read-Through 本质上是把 Cache-Aside 中“读 Miss → 读 DB → 回填 Cache”的逻辑,下沉到了缓存服务内部,对客户端透明。
+
+和 Cache Aside 一样, Read-Through 也有首次请求数据一定不再 Cache 的问题,对于热点数据可以提前放入缓存中。
### Write Behind Pattern(异步缓存写入)
-Write Behind Pattern 和 Read/Write Through Pattern 很相似,两者都是由 cache 服务来负责 cache 和 db 的读写。
+Write Behind(也常被称为 Write-Back) Pattern 和 Read/Write Through Pattern 很相似,两者都是由 Cache 服务来负责 Cache 和 DB 的读写。
+
+但是,两个又有很大的不同:**Read/Write Through 是同步更新 Cache 和 DB,而 Write Behind 则是只更新缓存,不直接更新 DB,而是改为异步批量的方式来更新 DB。**
+
+**写操作 (Write Behind):**
-但是,两个又有很大的不同:**Read/Write Through 是同步更新 cache 和 db,而 Write Behind 则是只更新缓存,不直接更新 db,而是改为异步批量的方式来更新 db。**
+1. 应用将数据写入 Cache,然后**立即返回**。
+2. Cache 服务将这个写操作放入一个队列中。
+3. 通过一个独立的异步线程/任务,将队列中的写操作**批量地、合并地**写入 DB。
-很明显,这种方式对数据一致性带来了更大的挑战,比如 cache 数据可能还没异步更新 db 的话,cache 服务可能就就挂掉了。
+这种模式对数据一致性带来了挑战(例如:Cache 中的数据还没来得及写回 DB,系统就宕机了),因此不适用于需要强一致性的场景(如交易、库存)。
-这种策略在我们平时开发过程中也非常非常少见,但是不代表它的应用场景少,比如消息队列中消息的异步写入磁盘、MySQL 的 Innodb Buffer Pool 机制都用到了这种策略。
+但是,它的异步和批量特性,带来了**无与伦比的写性能**。它在很多高性能系统中都有广泛应用:
-Write Behind Pattern 下 db 的写性能非常高,非常适合一些数据经常变化又对数据一致性要求没那么高的场景,比如浏览量、点赞量。
+- **MySQL 的 InnoDB Buffer Pool 机制:** 数据修改先在内存 Buffer Pool 中完成,然后由后台线程异步刷写到磁盘。
+- **操作系统的页缓存(Page Cache):** 文件写入也是先写到内存,再由操作系统异步刷盘。
+- **高频计数场景:** 对于文章浏览量、帖子点赞数这类允许短暂数据不一致、但写入极其频繁的场景,可以先在 Redis 中快速累加,再通过定时任务异步同步回数据库。
diff --git a/docs/database/redis/cache-basics.md b/docs/database/redis/cache-basics.md
index 391e5bec82d..15cb0eb33bb 100644
--- a/docs/database/redis/cache-basics.md
+++ b/docs/database/redis/cache-basics.md
@@ -1,14 +1,195 @@
---
-title: 缓存基础常见面试题总结(付费)
+title: 缓存基础常见面试题总结
+description: 深入讲解缓存的核心思想、本地缓存与分布式缓存的区别、多级缓存架构设计。涵盖Caffeine、Redis等主流缓存方案,以及缓存一致性的解决方案。适合Java开发者学习缓存架构设计。
category: 数据库
tag:
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: 缓存,本地缓存,分布式缓存,多级缓存,Caffeine,Redis,缓存一致性,系统设计,Java缓存,Guava Cache
---
-**缓存基础** 相关的面试题为我的 [知识星球](../../about-the-author/zhishixingqiu-two-years.md)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](../../zhuanlan/java-mian-shi-zhi-bei.md)中。
+> **相关面试题** :
+>
+> - 为什么要用缓存?
+> - 本地缓存应该怎么做?
+> - 为什么要有分布式缓存?/为什么不直接用本地缓存?
+> - 为什么要用多级缓存?
+> - 多级缓存适合哪些业务场景?
-
+## 缓存的基本思想
-
+很多同学只知道缓存可以提高系统性能以及减少请求 **响应时间**(Response Time),但是,不太清楚缓存的本质思想是什么。
-
+缓存的基本思想其实很简单,就是我们非常熟悉的 **空间换时间** 这一经典性能优化策略的运用。所谓空间换时间,也就是用更多的存储空间来存储一些可能重复使用或计算的数据,从而减少数据的重新获取或计算的时间。
+
+说到空间换时间,除了缓存之外,你还能想到什么其他的例子吗?这里再列举几个常见的:
+
+- **索引**:索引是一种将数据库表中的某些列或字段按照一定的排序规则组织成一个单独的数据结构,虽然需要额外占用空间,但可以大大提高检索效率,降低数据排序成本。
+- **数据库表字段冗余**:将经常联合查询的数据冗余存储在同一张表中,以减少对多张表的关联查询,进而提升查询性能,减轻数据库压力。
+- **CDN(内容分发网络)**:将静态资源分发到多个边缘节点以实现就近访问,进而加快静态资源的访问速度,减轻源站服务器以及带宽的负担。
+
+编程需要要学会归纳总结,将自己学到的东西串联起来!假如你在面试的时候,能聊到这些,面试官一定会对你有一个好印象的。
+
+不要把缓存想的太高大上,虽然,它的确对系统的性能提升的性价比非常高。当我们在学习并应用缓存的时候,你会发现缓存的思想实际在 CPU、操作系统或者其他很多地方都被大量用到。
+
+比如,**CPU Cache** 缓存的是内存数据,用于解决 **CPU** 处理速度与内存访问速度不匹配的问题;内存缓存的是硬盘数据,用于解决硬盘 **I/O** 速度过慢的问题。
+
+
+
+再比如,为了提高虚拟地址到物理地址的转换速度,操作系统在页表方案基础之上引入了 **转址旁路缓存**(Translation Lookaside Buffer,**TLB**,也被称为快表)。
+
+
+
+拿日常使用的浏览器来说,它会对访问过的图片或静态文件进行缓存(浏览器缓存),这样下次访问相同页面时加载速度会显著提升。
+
+
+
+我们日常开发中用到的缓存,其中的数据通常存储于 **RAM**(内存)中,访问速度极快。为了避免内存数据在重启或宕机后丢失,许多缓存中间件(如 **Redis**)提供了磁盘持久化机制。相比于关系型数据库(如 **MySQL**),缓存的访问速度和并发支持量都要高出几个数量级。在数据库之上增加一层缓存,是保护底层存储、提升系统吞吐量的核心手段。
+
+## 缓存的分类
+
+接下来,我们来看看日常开发中用到的缓存通常被分为哪几种。
+
+### 本地缓存
+
+#### 什么是本地缓存?
+
+这个实际在很多项目中用的蛮多,特别是单体架构的时候。数据量不大,并且没有分布式要求的话,使用本地缓存还是可以的。
+
+本地缓存位于应用内部,其最大的优点是应用存在于同一个进程内部,请求本地缓存的速度非常快,不存在额外的网络开销。
+
+常见的单体架构图如下,我们使用 **Nginx** 来做**负载均衡**,部署两个相同的应用到服务器,两个服务使用同一个数据库,并且使用的是本地缓存。
+
+
+
+**注意:** 在集群模式下使用本地缓存,必须考虑**负载均衡策略**。如果 Nginx 使用默认的**轮询(Round-Robin)**,同一个用户的请求会随机落在不同机器,导致本地缓存命中率极低。解决方案如下:
+
+1. **网关层**:使用一致性哈希或 Sticky Session,保证同一用户的请求固定打到同一台机器。
+2. **应用层**:仅将本地缓存用于**“全局几乎不变”**的数据(如配置字典),而非用户维度数据。
+
+#### 本地缓存的方案有哪些?
+
+**1、JDK 自带的 `HashMap` 和 `ConcurrentHashMap` 了。**
+
+`ConcurrentHashMap` 可以看作是线程安全版本的 `HashMap` ,两者都是存放 key/value 形式的键值对。但是,大部分场景来说不会使用这两者当做缓存,因为只提供了缓存的功能,并没有提供其他诸如过期时间之类的功能。一个稍微完善一点的缓存框架至少要提供:**过期时间**、**淘汰机制**、**命中率统计**这三点。
+
+**2、 `Ehcache` 、 `Guava Cache` 、 `Spring Cache` 这三者是使用的比较多的本地缓存框架。**
+
+- `Ehcache` 的话相比于其他两者更加重量。不过,相比于 `Guava Cache` 、 `Spring Cache` 来说, `Ehcache` 支持可以嵌入到 hibernate 和 mybatis 作为多级缓存,并且可以将缓存的数据持久化到本地磁盘中、同时也提供了集群方案(比较鸡肋,可忽略)。
+- `Guava Cache` 和 `Spring Cache` 两者的话比较像。`Guava` 相比于 `Spring Cache` 的话使用的更多一点,它提供了 API 非常方便我们使用,同时也提供了设置缓存有效时间等功能。它的内部实现也比较干净,很多地方都和 `ConcurrentHashMap` 的思想有异曲同工之妙。
+- 使用 `Spring Cache` 的注解实现缓存的话,代码会看着很干净和优雅,但是很容易出现问题比如缓存穿透、内存溢出。
+
+**3、后起之秀 Caffeine。**
+
+相比于 `Guava` 来说 `Caffeine` 在各个方面比如性能都要更加优秀,一般建议使用其来替代 `Guava` 。并且, `Guava` 和 `Caffeine` 的使用方式很像!
+
+使用 `Caffeine` 创建本地缓存的代码示例,用到了建造者模式:
+
+```java
+// 使用 Caffeine 创建本地缓存示例
+Cache +
对于技术八股文来说,尽量不要死记硬背,这种方式非常枯燥且对自身能力提升有限!但是!想要一点不背是不太现实的,只是说要结合实际应用场景和实战来理解记忆。
我一直觉得面试八股文最好是和实际应用场景和实战相结合。很多同学现在的方向都错了,上来就是直接背八股文,硬生生学成了文科,那当然无趣了。
@@ -41,3 +54,7 @@ icon: star
另外,准备八股文的过程中,强烈建议你花个几个小时去根据你的简历(主要是项目经历部分)思考一下哪些地方可能被深挖,然后把你自己的思考以面试问题的形式体现出来。面试之后,你还要根据当下的面试情况复盘一波,对之前自己整理的面试问题进行完善补充。这个过程对于个人进一步熟悉自己的简历(尤其是项目经历)部分,非常非常有用。这些问题你也一定要多花一些时间搞懂吃透,能够流畅地表达出来。面试问题可以参考 [Java 面试常见问题总结(2024 最新版)](https://t.zsxq.com/0eRq7EJPy),记得根据自己项目经历去深入拓展即可!
最后,准备技术面试的同学一定要定期复习(自测的方式非常好),不然确实会遗忘的。
+
+## 详细面试准备计划(后端通用)
+
+[Java 后端面试重点和详细准备计划](https://javaguide.cn/interview-preparation/backend-interview-plan.html)
diff --git a/docs/interview-preparation/pdf-interview-javaguide.md b/docs/interview-preparation/pdf-interview-javaguide.md
new file mode 100644
index 00000000000..67d0da97125
--- /dev/null
+++ b/docs/interview-preparation/pdf-interview-javaguide.md
@@ -0,0 +1,62 @@
+---
+title: 2026 最新后端面试 PDF 资料
+description: 2026 版后端面试 PDF 资料整理(JavaGuide):梳理校招/社招高频考点与复习优先级,覆盖 Java 基础、集合、并发、MySQL、Redis、Spring/Spring Boot、JVM、系统设计与项目经验准备,帮你抓重点高效备战。
+category: 面试准备
+icon: pdf
+head:
+ - - meta
+ - name: keywords
+ content: 后端面试PDF,Java面试PDF,PDF面试资料,Java八股文PDF,面试突击PDF,校招社招,Java后端面试,Java基础,Java集合,Java并发,JVM,MySQL,Redis,Spring Boot,系统设计,项目经验
+---
+
+大家好,我是 Guide。
+
+**2026 版后端 PDF 面试资料终于搞定了!这次的更新量大得惊人,熬了几个通宵,总算能拿出来见人了。**
+
+在上一版的基础上,我把内容又往深里挖了挖。目前这份资料已经涵盖了 **Java 核心、计算机基础、数据库、缓存、分布式、设计模式、智力题、学习路线、面经**等全方位内容。毫不夸张地说,你备战后端面试需要的硬核干货,这一份全包了!
+
+为了让大家看得更爽,我对其中大部分 PDF 进行了“推倒重来式”的优化:
+
+- **重构面试突击系列**:将原先臃肿的内容拆分成多篇,逻辑更清晰。
+- **重写设计模式总结**:新增多道高频设计模式面试题,优化内容表达。
+- **全方位细节完善**:每一个知识点都反复推敲,确保没有逻辑断层。
+
+
+
+这些 PDF 面试资料的质量都非常高,绝大部分都是 Guide 的原创,也会有一些其他优质技术博主分享的原创资料。
+
+之所以一直坚持出 PDF 版,是因为有一些朋友比较喜欢看 PDF 资料,甚至把 PDF 资料打印出来学习。
+
+
+
+截止到目前,这套资料在各个渠道的汇总下载量已经突破了 **35w+** 。 说实话,这个数字对我来说不只是流量,更是沉甸甸的信任和责任。
+
+老规矩,没有任何花里胡哨的套路,直接**白嫖**: 在 **JavaGuide** 公众号后台回复 **PDF** 即可获取。
+
+
+
+由于 PDF 的时效性问题,如果想要更完美的体验,个人其实还是更建议大家去 [JavaGuide](https://javaguide.cn/) 网站上在线阅读,内容更新,一直在持续完善。
+
+## 部分内容概览
+
+**《JavaGuide 面试突击》— Java 集合**:
+
+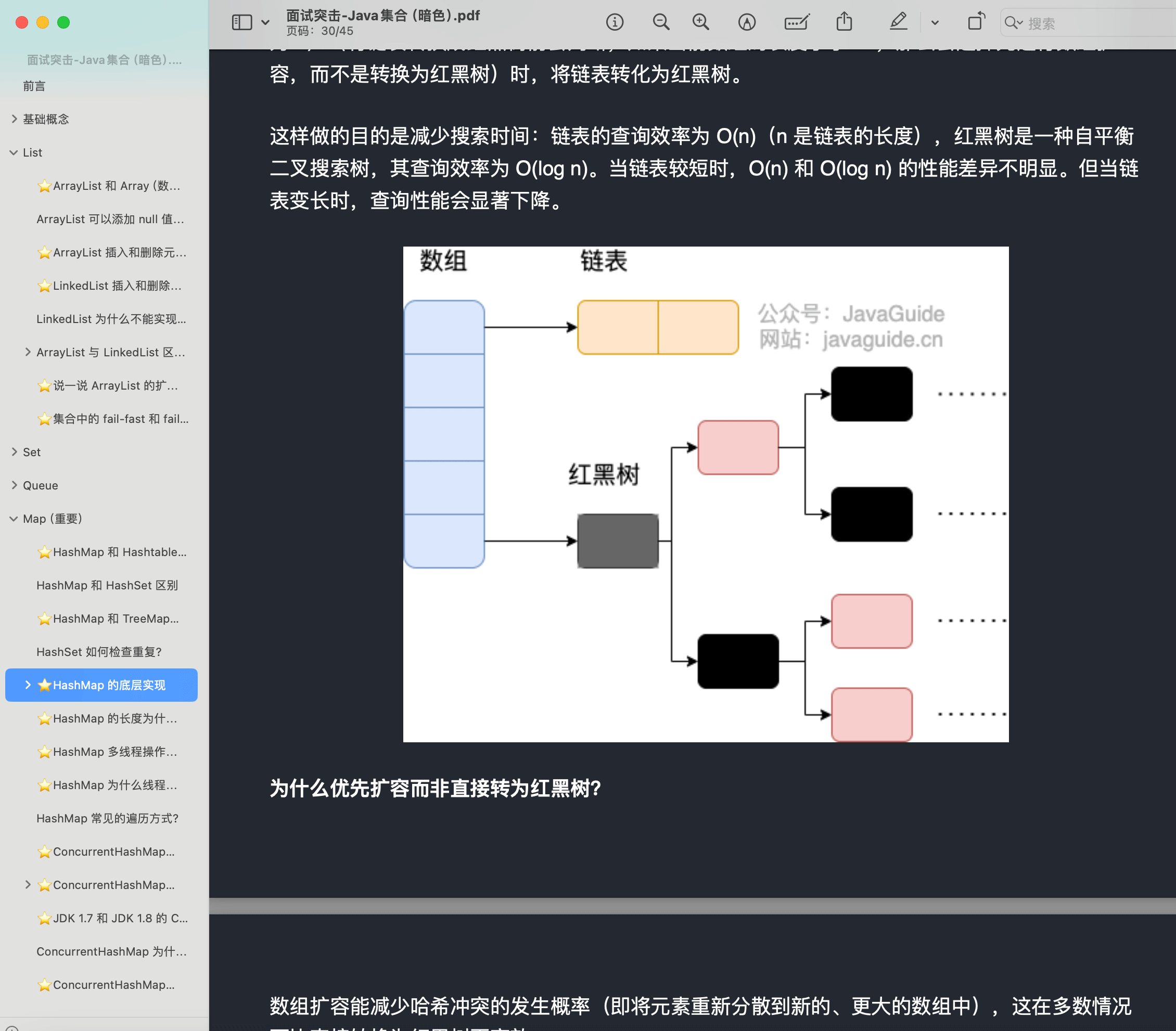
+
+**《JavaGuide 面试突击》— JVM**:
+
+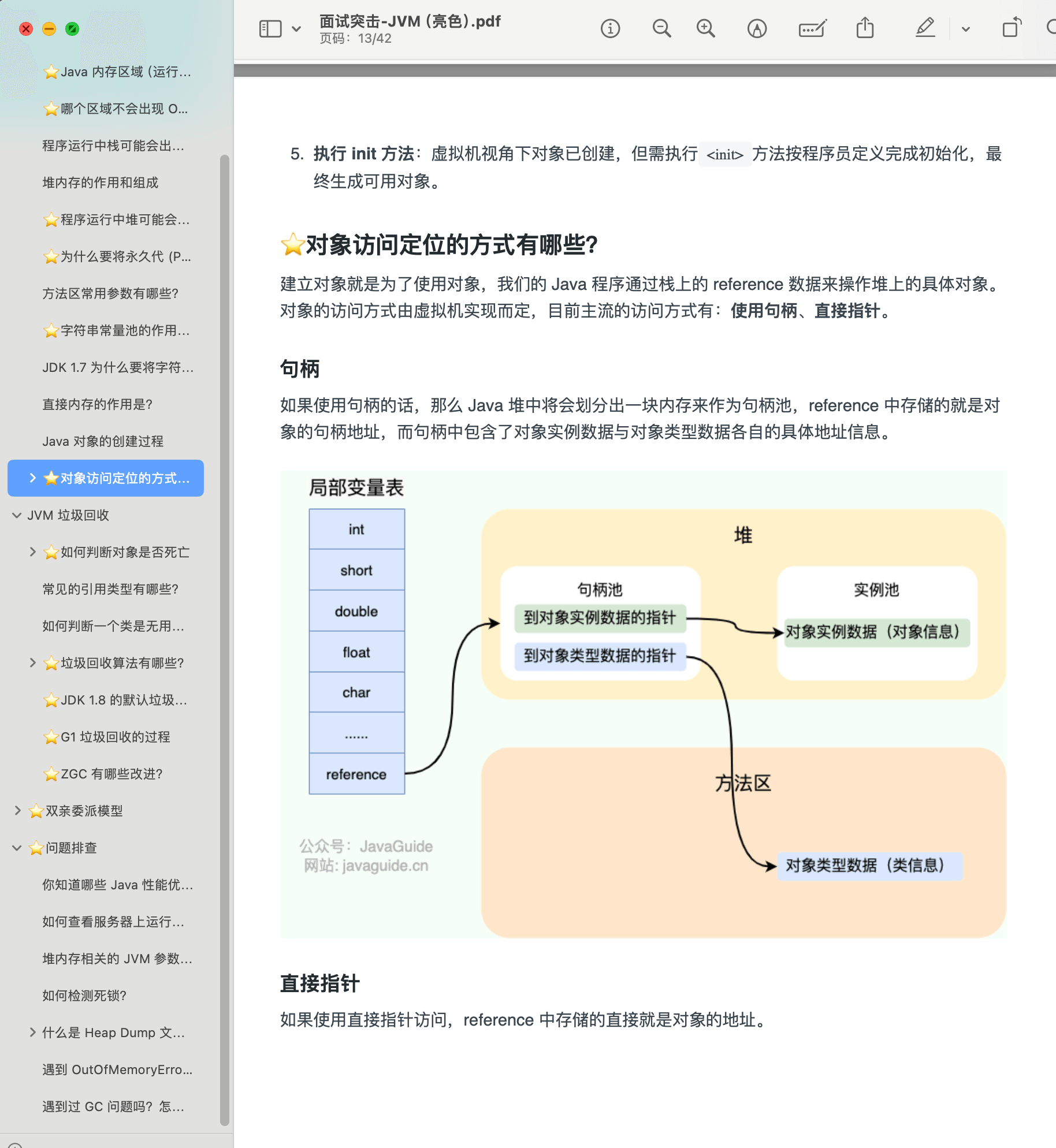
+
+**《JavaGuide 面试突击》—设计模式**:
+
+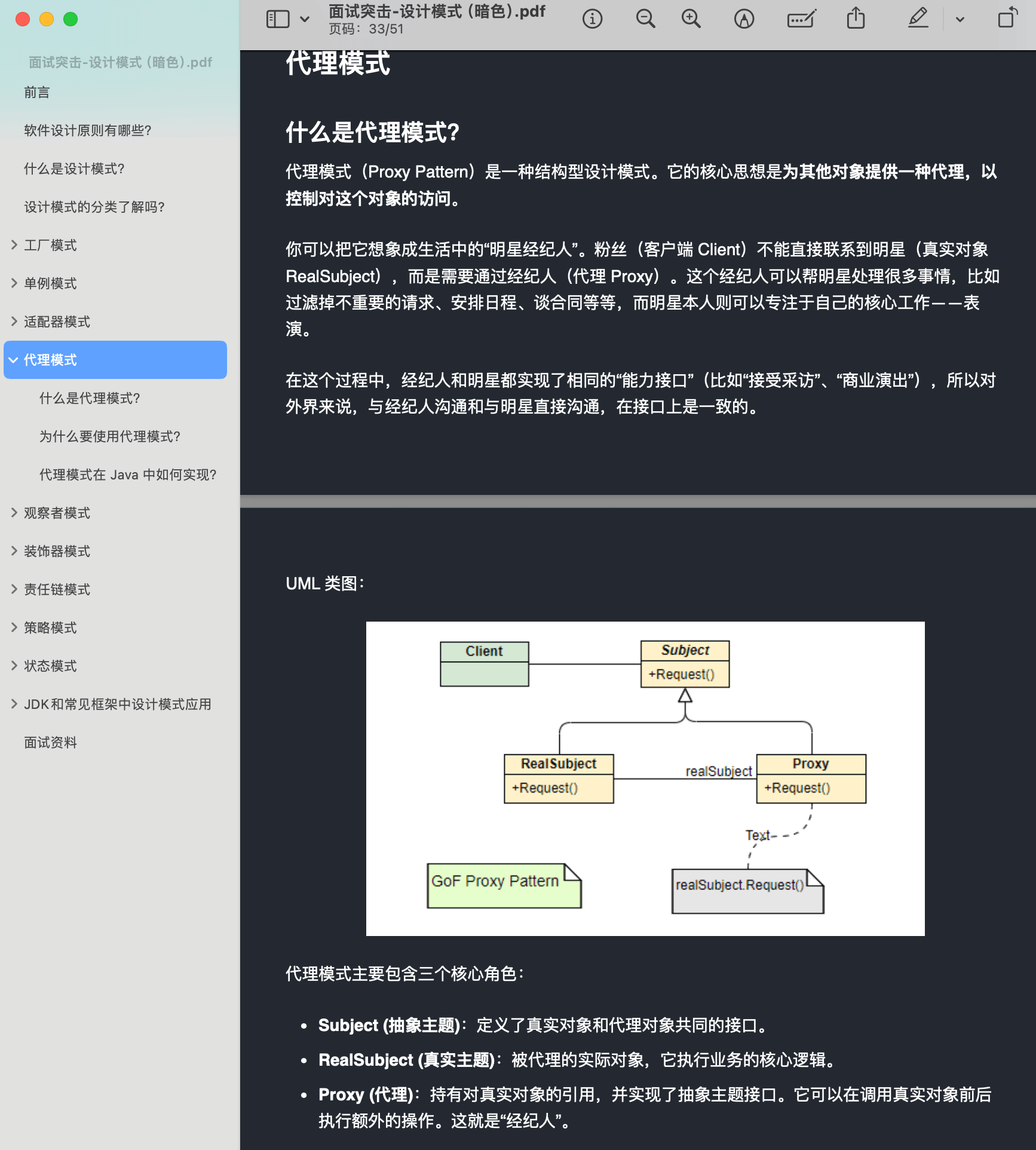
+
+**Java 学习路线**:
+
+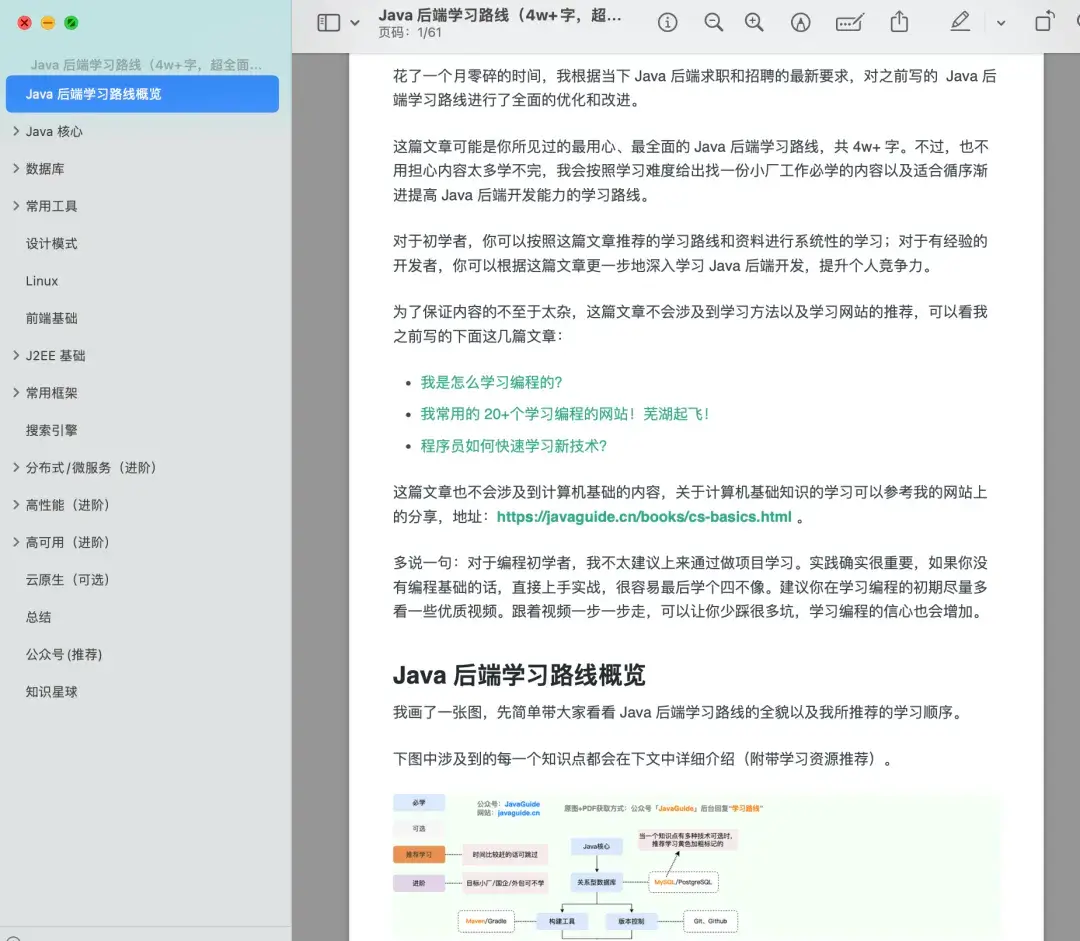
+
+## 如何获取?
+
+老规矩,没有任何花里胡哨的套路,直接**白嫖**: 在 **JavaGuide** 公众号后台回复 **PDF** 即可获取。
+
+
diff --git a/docs/interview-preparation/project-experience-guide.md b/docs/interview-preparation/project-experience-guide.md
index f2e93df82b3..2b9a3c1026a 100644
--- a/docs/interview-preparation/project-experience-guide.md
+++ b/docs/interview-preparation/project-experience-guide.md
@@ -1,11 +1,16 @@
---
title: 项目经验指南
+description: 项目经验指南:针对没有项目/项目平淡的求职者,给出获取实战项目经验的方法与选择建议,并讲清如何做出项目亮点、如何复盘与表达,提升简历与面试竞争力。
category: 面试准备
icon: project
+head:
+ - - meta
+ - name: keywords
+ content: 项目经验,校招项目,实战项目,项目亮点,简历项目描述,后端项目,面试项目准备,项目复盘
---
::: tip 友情提示
-本文节选自 **[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)**。这是一份教你如何更高效地准备面试的小册,涵盖常见八股文(系统设计、常见框架、分布式、高并发 ……)、优质面经等内容。
+本文节选自 **[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)**。这是一份教你如何更高效地准备面试的专栏,内容和 JavaGuide 互补,涵盖常见八股文(系统设计、常见框架、分布式、高并发 ……)、优质面经等内容。
:::
## 没有项目经验怎么办?
@@ -72,9 +77,9 @@ GitHub 或者码云上面有很多实战类别项目,你可以选择一个来
## 有没有还不错的项目推荐?
-**[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)** 的「面试准备篇」中有一篇文章专门整理了一些比较高质量的实战项目,非常适合用来学习或者作为项目经验。
+**[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)** 的「面试准备篇」中有一篇文章专门整理了一些比较高质量的实战项目,包含业务项目、轮子项目、国外公开课 Lab 和视频类实战项目教程推荐,非常适合用来学习或者作为项目经验。
-
+
这篇文章一共推荐了 15+ 个实战项目,有业务类的,也有轮子类的,有开源项目、也有视频教程。对于参加校招的小伙伴,我更建议做一个业务类项目加上一个轮子类的项目。
diff --git a/docs/interview-preparation/resume-guide.md b/docs/interview-preparation/resume-guide.md
index 818274601e0..f0cd20b003b 100644
--- a/docs/interview-preparation/resume-guide.md
+++ b/docs/interview-preparation/resume-guide.md
@@ -1,7 +1,12 @@
---
-title: 程序员简历编写指南(重要)
+title: 程序员简历编写指南
+description: 程序员简历编写指南:从筛选逻辑出发讲清简历结构、项目经历与技能描述写法,提供简历模板与避坑建议,帮助你提高简历通过率并让面试官更好地深挖你的亮点。
category: 面试准备
icon: jianli
+head:
+ - - meta
+ - name: keywords
+ content: 程序员简历,Java简历,简历优化,项目经历写法,简历模板,校招简历,社招简历,面试准备
---
::: tip 友情提示
diff --git a/docs/interview-preparation/self-test-of-common-interview-questions.md b/docs/interview-preparation/self-test-of-common-interview-questions.md
index 85b0e236c01..c3d8c038eb2 100644
--- a/docs/interview-preparation/self-test-of-common-interview-questions.md
+++ b/docs/interview-preparation/self-test-of-common-interview-questions.md
@@ -1,19 +1,22 @@
---
title: 常见面试题自测(付费)
+description: 常见面试题自测:按面试提问方式整理Java后端高频问题,提供提示与重要程度标注,适合面试前自测、定位短板、针对性复习。
category: 知识星球
icon: security-fill
+head:
+ - - meta
+ - name: keywords
+ content: 面试题自测,Java面试题,八股文自测,查缺补漏,面试复习,高频考点,Java后端面试,付费内容
---
面试之前,强烈建议大家多拿常见的面试题来进行自测,检查一下自己的掌握情况,这是一种非常实用的备战技术面试的小技巧。
在 **[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)** 的 **「技术面试题自测篇」** ,我总结了 Java 面试中最重要的知识点的最常见的面试题并按照面试提问的方式展现出来。
-
+
-每一道用于自测的面试题我都会给出重要程度,方便大家在时间比较紧张的时候根据自身情况来选择性自测。并且,我还会给出提示,方便你回忆起对应的知识点。
+每道题我都会给出**提示与思路**,并用 ⭐ 标注重要程度:⭐ 越多,说明面试越爱问,就越值得多花一些时间准备。
-在面试中如果你实在没有头绪的话,一个好的面试官也是会给你提示的。
-
-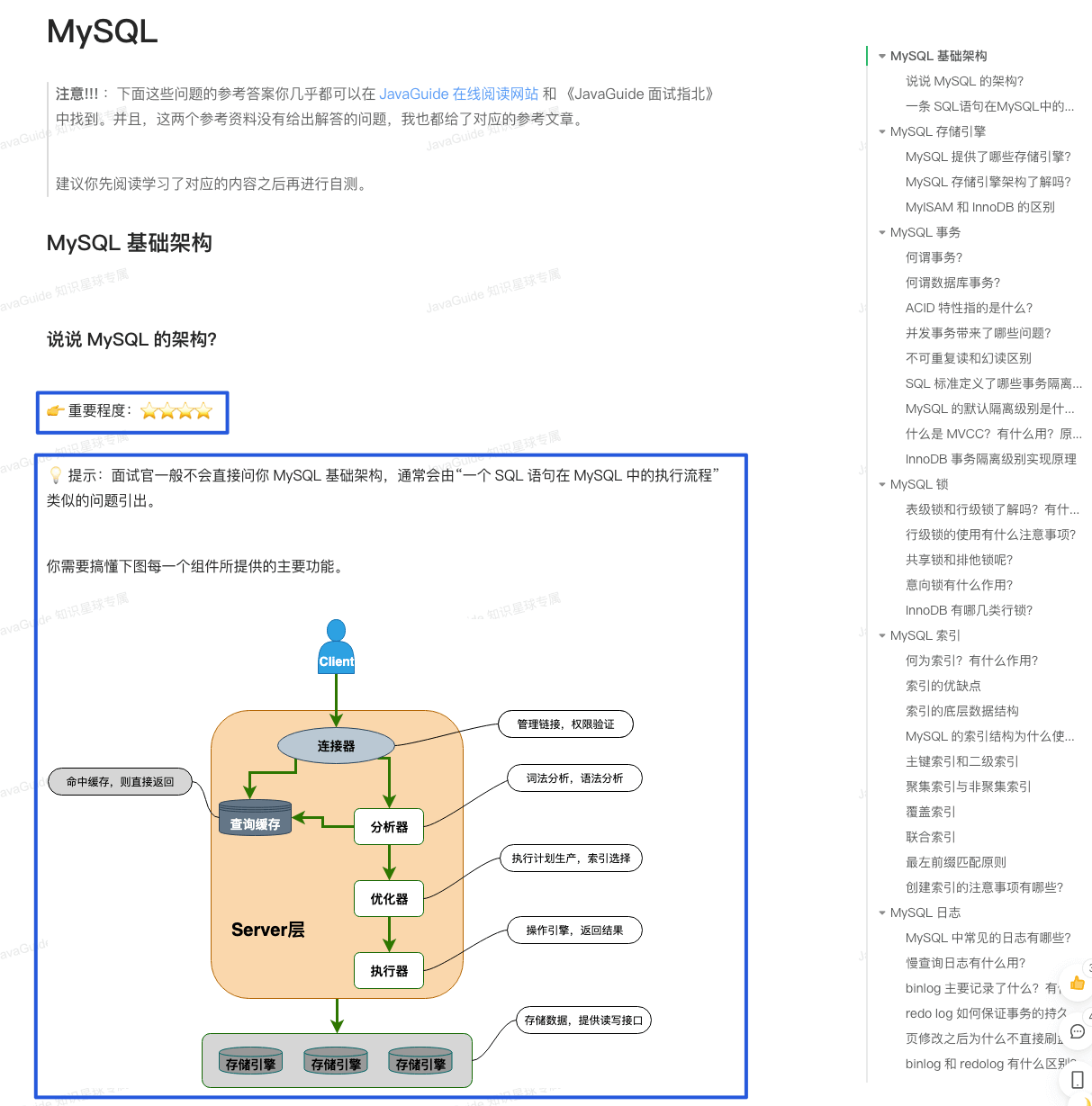
+
diff --git a/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md b/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
index 7cc0797bcf2..beba0d99cbd 100644
--- a/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
+++ b/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
@@ -1,20 +1,23 @@
---
-title: 手把手教你如何准备Java面试(重要)
+title: 如何高效准备Java面试?
+description: 如何高效准备Java面试:从求职导向学习、技能清单制定到简历优化与面试冲刺,提供系统化备战方法,帮助你少走弯路、提高面试通过率。
category: 知识星球
icon: path
+head:
+ - - meta
+ - name: keywords
+ content: Java面试准备,高效备战面试,求职导向学习,面试冲刺,简历优化,项目准备,校招,Java后端
---
::: tip 友情提示
-本文节选自 **[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)**。这是一份教你如何更高效地准备面试的小册,涵盖常见八股文(系统设计、常见框架、分布式、高并发 ……)、优质面经等内容。
+本文节选自 **[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)**。这是一份教你如何更高效地准备面试的专栏,内容和 JavaGuide 互补,涵盖常见八股文(系统设计、常见框架、分布式、高并发 ……)、优质面经等内容。
:::
-你的身边一定有很多编程比你厉害但是找的工作并没有你好的朋友!**技术面试不同于编程,编程厉害不代表技术面试就一定能过。**
+你身边是否有这样的朋友:编程能力比你强,求职结果却不如你?其实**技术好≠面试能过** —— 如今的面试早已不是 “会写代码就行”,不做准备就去面,大概率是 “撞枪口”。
-现在你去面个试,不认真准备一下,那简直就是往枪口上撞。我们大部分都只是普通人,没有发过顶级周刊或者获得过顶级大赛奖项。在这样一个技术面试氛围下,我们需要花费很多精力来准备面试,来提高自己的技术能力。“[面试造火箭,工作拧螺丝钉](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247491596&idx=1&sn=36fbf80922f71c200990de11514955f7&chksm=cea1afc7f9d626d1c70d5e54505495ac499ce6eb5e05ba4f4bb079a8563a84e27f17ceff38af&token=353590436&lang=zh_CN&scene=21#wechat_redirect)” 就是目前的一个常态,预计未来很长很长一段时间也还是会是这样。
+我们大多是普通开发者,没有顶会论文或竞赛大奖加持,面对 “面试造火箭,工作拧螺丝钉” 的常态,只能靠扎实准备突围。但准备面试不等于耍小聪明或者死记硬背面试题。 **一定不要对面试抱有侥幸心理。打铁还需自身硬!** 千万不要觉得自己看几篇面经,看几篇面试题解析就能通过面试了。一定要静下心来深入学习!
-准备面试不等于耍小聪明或者死记硬背面试题。 **一定不要对面试抱有侥幸心理。打铁还需自身硬!** 千万不要觉得自己看几篇面经,看几篇面试题解析就能通过面试了。一定要静下心来深入学习!
-
-这篇我会从宏观面出发简单聊聊如何准备 Java 面试,让你少走弯路!
+这篇文章就从宏观视角,带你搞懂程序员该如何系统准备面试:从求职导向学习,到简历优化、面试冲刺,帮你少走弯路,高效拿下心仪 offer。
## 尽早以求职为导向来学习
@@ -138,7 +141,7 @@ Java 后端面试复习的重点请看这篇文章:[Java 面试重点总结(
一定不要抱着一种思想,觉得八股文或者基础问题的考查意义不大。如果你抱着这种思想复习的话,那效果可能不会太好。实际上,个人认为还是很有意义的,八股文或者基础性的知识在日常开发中也会需要经常用到。例如,线程池这块的拒绝策略、核心参数配置什么的,如果你不了解,实际项目中使用线程池可能就用的不是很明白,容易出现问题。而且,其实这种基础性的问题是最容易准备的,像各种底层原理、系统设计、场景题以及深挖你的项目这类才是最难的!
-八股文资料首推我的 [《Java 面试指北》](https://t.zsxq.com/11rZ6D7Wk) (配合 JavaGuide 使用,会根据每一年的面试情况对内容进行更新完善)和 [JavaGuide](https://javaguide.cn/) 。里面不仅仅是原创八股文,还有很多对实际开发有帮助的干货。除了我的资料之外,你还可以去网上找一些其他的优质的文章、视频来看。
+八股文资料首推我的 [《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) (配合 JavaGuide 使用,会根据每一年的面试情况对内容进行更新完善)和 [JavaGuide](https://javaguide.cn/) 。里面不仅仅是原创八股文,还有很多对实际开发有帮助的干货。除了我的资料之外,你还可以去网上找一些其他的优质的文章、视频来看。

diff --git a/docs/java/basis/bigdecimal.md b/docs/java/basis/bigdecimal.md
index 5af0c460579..7978438f298 100644
--- a/docs/java/basis/bigdecimal.md
+++ b/docs/java/basis/bigdecimal.md
@@ -1,8 +1,13 @@
---
title: BigDecimal 详解
+description: 详解BigDecimal使用方法:解决浮点数精度丢失问题,掌握加减乘除运算、RoundingMode舍入规则、compareTo比较方法,适用金融计算等高精度场景。
category: Java
tag:
- Java基础
+head:
+ - - meta
+ - name: keywords
+ content: BigDecimal,浮点数精度,小数运算,RoundingMode舍入模式,BigDecimal比较,金额计算,精度丢失
---
《阿里巴巴 Java 开发手册》中提到:“为了避免精度丢失,可以使用 `BigDecimal` 来进行浮点数的运算”。
@@ -21,7 +26,7 @@ System.out.println(a == b);// false
**为什么浮点数 `float` 或 `double` 运算的时候会有精度丢失的风险呢?**
-这个和计算机保存浮点数的机制有很大关系。我们知道计算机是二进制的,而且计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况。这也就是解释了为什么浮点数没有办法用二进制精确表示。
+这个和计算机保存小数的机制有很大关系。我们知道计算机是二进制的,而且计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况。这也就解释了为什么十进制小数没有办法用二进制精确表示。
就比如说十进制下的 0.2 就没办法精确转换成二进制小数:
@@ -40,9 +45,9 @@ System.out.println(a == b);// false
## BigDecimal 介绍
-`BigDecimal` 可以实现对浮点数的运算,不会造成精度丢失。
+`BigDecimal` 可以实现对小数的运算,不会造成精度丢失。
-通常情况下,大部分需要浮点数精确运算结果的业务场景(比如涉及到钱的场景)都是通过 `BigDecimal` 来做的。
+通常情况下,大部分需要小数精确运算结果的业务场景(比如涉及到钱的场景)都是通过 `BigDecimal` 来做的。
《阿里巴巴 Java 开发手册》中提到:**浮点数之间的等值判断,基本数据类型不能用 == 来比较,包装数据类型不能用 equals 来判断。**
@@ -50,7 +55,7 @@ System.out.println(a == b);// false
具体原因我们在上面已经详细介绍了,这里就不多提了。
-想要解决浮点数运算精度丢失这个问题,可以直接使用 `BigDecimal` 来定义浮点数的值,然后再进行浮点数的运算操作即可。
+想要解决浮点数运算精度丢失这个问题,可以直接使用 `BigDecimal` 来定义小数的值,然后再进行小数的运算操作即可。
```java
BigDecimal a = new BigDecimal("1.0");
@@ -99,20 +104,20 @@ public BigDecimal divide(BigDecimal divisor, int scale, RoundingMode roundingMod
```java
public enum RoundingMode {
- // 2.5 -> 3 , 1.6 -> 2
- // -1.6 -> -2 , -2.5 -> -3
+ // 2.4 -> 3 , 1.6 -> 2
+ // -1.6 -> -2 , -2.4 -> -3
UP(BigDecimal.ROUND_UP),
- // 2.5 -> 2 , 1.6 -> 1
- // -1.6 -> -1 , -2.5 -> -2
+ // 2.4 -> 2 , 1.6 -> 1
+ // -1.6 -> -1 , -2.4 -> -2
DOWN(BigDecimal.ROUND_DOWN),
- // 2.5 -> 3 , 1.6 -> 2
- // -1.6 -> -1 , -2.5 -> -2
+ // 2.4 -> 3 , 1.6 -> 2
+ // -1.6 -> -1 , -2.4 -> -2
CEILING(BigDecimal.ROUND_CEILING),
// 2.5 -> 2 , 1.6 -> 1
// -1.6 -> -2 , -2.5 -> -3
FLOOR(BigDecimal.ROUND_FLOOR),
- // 2.5 -> 3 , 1.6 -> 2
- // -1.6 -> -2 , -2.5 -> -3
+ // 2.4 -> 2 , 1.6 -> 2
+ // -1.6 -> -2 , -2.4 -> -2
HALF_UP(BigDecimal.ROUND_HALF_UP),
//......
}
@@ -230,7 +235,7 @@ public class BigDecimalUtil {
/**
* 提供(相对)精确的除法运算,当发生除不尽的情况时,精确到
- * 小数点以后10位,以后的数字四舍五入。
+ * 小数点以后10位,以后的数字四舍六入五成双。
*
* @param v1 被除数
* @param v2 除数
@@ -242,7 +247,7 @@ public class BigDecimalUtil {
/**
* 提供(相对)精确的除法运算。当发生除不尽的情况时,由scale参数指
- * 定精度,以后的数字四舍五入。
+ * 定精度,以后的数字四舍六入五成双。
*
* @param v1 被除数
* @param v2 除数
@@ -260,11 +265,11 @@ public class BigDecimalUtil {
}
/**
- * 提供精确的小数位四舍五入处理。
+ * 提供精确的小数位四舍六入五成双处理。
*
- * @param v 需要四舍五入的数字
+ * @param v 需要四舍六入五成双的数字
* @param scale 小数点后保留几位
- * @return 四舍五入后的结果
+ * @return 四舍六入五成双后的结果
*/
public static double round(double v, int scale) {
if (scale < 0) {
@@ -283,18 +288,18 @@ public class BigDecimalUtil {
* @return 返回转换结果
*/
public static float convertToFloat(double v) {
- BigDecimal b = new BigDecimal(v);
+ BigDecimal b = BigDecimal.valueOf(v);
return b.floatValue();
}
/**
- * 提供精确的类型转换(Int)不进行四舍五入
+ * 提供精确的类型转换(Int)不进行四舍六入五成双
*
* @param v 需要被转换的数字
* @return 返回转换结果
*/
public static int convertsToInt(double v) {
- BigDecimal b = new BigDecimal(v);
+ BigDecimal b = BigDecimal.valueOf(v);
return b.intValue();
}
@@ -305,7 +310,7 @@ public class BigDecimalUtil {
* @return 返回转换结果
*/
public static long convertsToLong(double v) {
- BigDecimal b = new BigDecimal(v);
+ BigDecimal b = BigDecimal.valueOf(v);
return b.longValue();
}
@@ -317,8 +322,8 @@ public class BigDecimalUtil {
* @return 返回两个数中大的一个值
*/
public static double returnMax(double v1, double v2) {
- BigDecimal b1 = new BigDecimal(v1);
- BigDecimal b2 = new BigDecimal(v2);
+ BigDecimal b1 = BigDecimal.valueOf(v1);
+ BigDecimal b2 = BigDecimal.valueOf(v2);
return b1.max(b2).doubleValue();
}
@@ -330,8 +335,8 @@ public class BigDecimalUtil {
* @return 返回两个数中小的一个值
*/
public static double returnMin(double v1, double v2) {
- BigDecimal b1 = new BigDecimal(v1);
- BigDecimal b2 = new BigDecimal(v2);
+ BigDecimal b1 = BigDecimal.valueOf(v1);
+ BigDecimal b2 = BigDecimal.valueOf(v2);
return b1.min(b2).doubleValue();
}
diff --git a/docs/java/basis/generics-and-wildcards.md b/docs/java/basis/generics-and-wildcards.md
index bd9cd4b00bf..1740999940c 100644
--- a/docs/java/basis/generics-and-wildcards.md
+++ b/docs/java/basis/generics-and-wildcards.md
@@ -1,20 +1,362 @@
---
title: 泛型&通配符详解
+description: 全面解析Java泛型与通配符:深入理解类型擦除机制、上界下界通配符用法、PECS原则应用,掌握泛型编程核心技巧。
category: Java
tag:
- Java基础
+head:
+ - - meta
+ - name: keywords
+ content: Java泛型,通配符,类型擦除,泛型边界,PECS原则,泛型方法,上界下界通配符,泛型接口
---
-**泛型&通配符** 相关的面试题为我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)(点击链接即可查看详细介绍以及获取方法)中。
+## 泛型
-[《Java 面试指北》](hhttps://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 的部分内容展示如下,你可以将其看作是 [JavaGuide](https://javaguide.cn/#/) 的补充完善,两者可以配合使用。
+### 什么是泛型?有什么作用?
-
+**Java 泛型(Generics)** 是 JDK 5 中引入的一个新特性。使用泛型参数,可以增强代码的可读性以及稳定性。**如无特别说明,以下行为以 Java 8 为准。**
-[《Java 面试指北》](hhttps://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)只是星球内部众多资料中的一个,星球还有很多其他优质资料比如[专属专栏](https://javaguide.cn/zhuanlan/)、Java 编程视频、PDF 资料。
+编译器可以对泛型参数进行检测,并且通过泛型参数可以指定传入的对象类型。比如 `ArrayList
+
对于技术八股文来说,尽量不要死记硬背,这种方式非常枯燥且对自身能力提升有限!但是!想要一点不背是不太现实的,只是说要结合实际应用场景和实战来理解记忆。
我一直觉得面试八股文最好是和实际应用场景和实战相结合。很多同学现在的方向都错了,上来就是直接背八股文,硬生生学成了文科,那当然无趣了。
@@ -41,3 +54,7 @@ icon: star
另外,准备八股文的过程中,强烈建议你花个几个小时去根据你的简历(主要是项目经历部分)思考一下哪些地方可能被深挖,然后把你自己的思考以面试问题的形式体现出来。面试之后,你还要根据当下的面试情况复盘一波,对之前自己整理的面试问题进行完善补充。这个过程对于个人进一步熟悉自己的简历(尤其是项目经历)部分,非常非常有用。这些问题你也一定要多花一些时间搞懂吃透,能够流畅地表达出来。面试问题可以参考 [Java 面试常见问题总结(2024 最新版)](https://t.zsxq.com/0eRq7EJPy),记得根据自己项目经历去深入拓展即可!
最后,准备技术面试的同学一定要定期复习(自测的方式非常好),不然确实会遗忘的。
+
+## 详细面试准备计划(后端通用)
+
+[Java 后端面试重点和详细准备计划](https://javaguide.cn/interview-preparation/backend-interview-plan.html)
diff --git a/docs/interview-preparation/pdf-interview-javaguide.md b/docs/interview-preparation/pdf-interview-javaguide.md
new file mode 100644
index 00000000000..67d0da97125
--- /dev/null
+++ b/docs/interview-preparation/pdf-interview-javaguide.md
@@ -0,0 +1,62 @@
+---
+title: 2026 最新后端面试 PDF 资料
+description: 2026 版后端面试 PDF 资料整理(JavaGuide):梳理校招/社招高频考点与复习优先级,覆盖 Java 基础、集合、并发、MySQL、Redis、Spring/Spring Boot、JVM、系统设计与项目经验准备,帮你抓重点高效备战。
+category: 面试准备
+icon: pdf
+head:
+ - - meta
+ - name: keywords
+ content: 后端面试PDF,Java面试PDF,PDF面试资料,Java八股文PDF,面试突击PDF,校招社招,Java后端面试,Java基础,Java集合,Java并发,JVM,MySQL,Redis,Spring Boot,系统设计,项目经验
+---
+
+大家好,我是 Guide。
+
+**2026 版后端 PDF 面试资料终于搞定了!这次的更新量大得惊人,熬了几个通宵,总算能拿出来见人了。**
+
+在上一版的基础上,我把内容又往深里挖了挖。目前这份资料已经涵盖了 **Java 核心、计算机基础、数据库、缓存、分布式、设计模式、智力题、学习路线、面经**等全方位内容。毫不夸张地说,你备战后端面试需要的硬核干货,这一份全包了!
+
+为了让大家看得更爽,我对其中大部分 PDF 进行了“推倒重来式”的优化:
+
+- **重构面试突击系列**:将原先臃肿的内容拆分成多篇,逻辑更清晰。
+- **重写设计模式总结**:新增多道高频设计模式面试题,优化内容表达。
+- **全方位细节完善**:每一个知识点都反复推敲,确保没有逻辑断层。
+
+
+
+这些 PDF 面试资料的质量都非常高,绝大部分都是 Guide 的原创,也会有一些其他优质技术博主分享的原创资料。
+
+之所以一直坚持出 PDF 版,是因为有一些朋友比较喜欢看 PDF 资料,甚至把 PDF 资料打印出来学习。
+
+
+
+截止到目前,这套资料在各个渠道的汇总下载量已经突破了 **35w+** 。 说实话,这个数字对我来说不只是流量,更是沉甸甸的信任和责任。
+
+老规矩,没有任何花里胡哨的套路,直接**白嫖**: 在 **JavaGuide** 公众号后台回复 **PDF** 即可获取。
+
+
+
+由于 PDF 的时效性问题,如果想要更完美的体验,个人其实还是更建议大家去 [JavaGuide](https://javaguide.cn/) 网站上在线阅读,内容更新,一直在持续完善。
+
+## 部分内容概览
+
+**《JavaGuide 面试突击》— Java 集合**:
+
+
+
+**《JavaGuide 面试突击》— JVM**:
+
+
+
+**《JavaGuide 面试突击》—设计模式**:
+
+
+
+**Java 学习路线**:
+
+
+
+## 如何获取?
+
+老规矩,没有任何花里胡哨的套路,直接**白嫖**: 在 **JavaGuide** 公众号后台回复 **PDF** 即可获取。
+
+
diff --git a/docs/interview-preparation/project-experience-guide.md b/docs/interview-preparation/project-experience-guide.md
index f2e93df82b3..2b9a3c1026a 100644
--- a/docs/interview-preparation/project-experience-guide.md
+++ b/docs/interview-preparation/project-experience-guide.md
@@ -1,11 +1,16 @@
---
title: 项目经验指南
+description: 项目经验指南:针对没有项目/项目平淡的求职者,给出获取实战项目经验的方法与选择建议,并讲清如何做出项目亮点、如何复盘与表达,提升简历与面试竞争力。
category: 面试准备
icon: project
+head:
+ - - meta
+ - name: keywords
+ content: 项目经验,校招项目,实战项目,项目亮点,简历项目描述,后端项目,面试项目准备,项目复盘
---
::: tip 友情提示
-本文节选自 **[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)**。这是一份教你如何更高效地准备面试的小册,涵盖常见八股文(系统设计、常见框架、分布式、高并发 ……)、优质面经等内容。
+本文节选自 **[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)**。这是一份教你如何更高效地准备面试的专栏,内容和 JavaGuide 互补,涵盖常见八股文(系统设计、常见框架、分布式、高并发 ……)、优质面经等内容。
:::
## 没有项目经验怎么办?
@@ -72,9 +77,9 @@ GitHub 或者码云上面有很多实战类别项目,你可以选择一个来
## 有没有还不错的项目推荐?
-**[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)** 的「面试准备篇」中有一篇文章专门整理了一些比较高质量的实战项目,非常适合用来学习或者作为项目经验。
+**[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)** 的「面试准备篇」中有一篇文章专门整理了一些比较高质量的实战项目,包含业务项目、轮子项目、国外公开课 Lab 和视频类实战项目教程推荐,非常适合用来学习或者作为项目经验。
-
+
这篇文章一共推荐了 15+ 个实战项目,有业务类的,也有轮子类的,有开源项目、也有视频教程。对于参加校招的小伙伴,我更建议做一个业务类项目加上一个轮子类的项目。
diff --git a/docs/interview-preparation/resume-guide.md b/docs/interview-preparation/resume-guide.md
index 818274601e0..f0cd20b003b 100644
--- a/docs/interview-preparation/resume-guide.md
+++ b/docs/interview-preparation/resume-guide.md
@@ -1,7 +1,12 @@
---
-title: 程序员简历编写指南(重要)
+title: 程序员简历编写指南
+description: 程序员简历编写指南:从筛选逻辑出发讲清简历结构、项目经历与技能描述写法,提供简历模板与避坑建议,帮助你提高简历通过率并让面试官更好地深挖你的亮点。
category: 面试准备
icon: jianli
+head:
+ - - meta
+ - name: keywords
+ content: 程序员简历,Java简历,简历优化,项目经历写法,简历模板,校招简历,社招简历,面试准备
---
::: tip 友情提示
diff --git a/docs/interview-preparation/self-test-of-common-interview-questions.md b/docs/interview-preparation/self-test-of-common-interview-questions.md
index 85b0e236c01..c3d8c038eb2 100644
--- a/docs/interview-preparation/self-test-of-common-interview-questions.md
+++ b/docs/interview-preparation/self-test-of-common-interview-questions.md
@@ -1,19 +1,22 @@
---
title: 常见面试题自测(付费)
+description: 常见面试题自测:按面试提问方式整理Java后端高频问题,提供提示与重要程度标注,适合面试前自测、定位短板、针对性复习。
category: 知识星球
icon: security-fill
+head:
+ - - meta
+ - name: keywords
+ content: 面试题自测,Java面试题,八股文自测,查缺补漏,面试复习,高频考点,Java后端面试,付费内容
---
面试之前,强烈建议大家多拿常见的面试题来进行自测,检查一下自己的掌握情况,这是一种非常实用的备战技术面试的小技巧。
在 **[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)** 的 **「技术面试题自测篇」** ,我总结了 Java 面试中最重要的知识点的最常见的面试题并按照面试提问的方式展现出来。
-
+
-每一道用于自测的面试题我都会给出重要程度,方便大家在时间比较紧张的时候根据自身情况来选择性自测。并且,我还会给出提示,方便你回忆起对应的知识点。
+每道题我都会给出**提示与思路**,并用 ⭐ 标注重要程度:⭐ 越多,说明面试越爱问,就越值得多花一些时间准备。
-在面试中如果你实在没有头绪的话,一个好的面试官也是会给你提示的。
-
-
+
diff --git a/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md b/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
index 7cc0797bcf2..beba0d99cbd 100644
--- a/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
+++ b/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
@@ -1,20 +1,23 @@
---
-title: 手把手教你如何准备Java面试(重要)
+title: 如何高效准备Java面试?
+description: 如何高效准备Java面试:从求职导向学习、技能清单制定到简历优化与面试冲刺,提供系统化备战方法,帮助你少走弯路、提高面试通过率。
category: 知识星球
icon: path
+head:
+ - - meta
+ - name: keywords
+ content: Java面试准备,高效备战面试,求职导向学习,面试冲刺,简历优化,项目准备,校招,Java后端
---
::: tip 友情提示
-本文节选自 **[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)**。这是一份教你如何更高效地准备面试的小册,涵盖常见八股文(系统设计、常见框架、分布式、高并发 ……)、优质面经等内容。
+本文节选自 **[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)**。这是一份教你如何更高效地准备面试的专栏,内容和 JavaGuide 互补,涵盖常见八股文(系统设计、常见框架、分布式、高并发 ……)、优质面经等内容。
:::
-你的身边一定有很多编程比你厉害但是找的工作并没有你好的朋友!**技术面试不同于编程,编程厉害不代表技术面试就一定能过。**
+你身边是否有这样的朋友:编程能力比你强,求职结果却不如你?其实**技术好≠面试能过** —— 如今的面试早已不是 “会写代码就行”,不做准备就去面,大概率是 “撞枪口”。
-现在你去面个试,不认真准备一下,那简直就是往枪口上撞。我们大部分都只是普通人,没有发过顶级周刊或者获得过顶级大赛奖项。在这样一个技术面试氛围下,我们需要花费很多精力来准备面试,来提高自己的技术能力。“[面试造火箭,工作拧螺丝钉](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247491596&idx=1&sn=36fbf80922f71c200990de11514955f7&chksm=cea1afc7f9d626d1c70d5e54505495ac499ce6eb5e05ba4f4bb079a8563a84e27f17ceff38af&token=353590436&lang=zh_CN&scene=21#wechat_redirect)” 就是目前的一个常态,预计未来很长很长一段时间也还是会是这样。
+我们大多是普通开发者,没有顶会论文或竞赛大奖加持,面对 “面试造火箭,工作拧螺丝钉” 的常态,只能靠扎实准备突围。但准备面试不等于耍小聪明或者死记硬背面试题。 **一定不要对面试抱有侥幸心理。打铁还需自身硬!** 千万不要觉得自己看几篇面经,看几篇面试题解析就能通过面试了。一定要静下心来深入学习!
-准备面试不等于耍小聪明或者死记硬背面试题。 **一定不要对面试抱有侥幸心理。打铁还需自身硬!** 千万不要觉得自己看几篇面经,看几篇面试题解析就能通过面试了。一定要静下心来深入学习!
-
-这篇我会从宏观面出发简单聊聊如何准备 Java 面试,让你少走弯路!
+这篇文章就从宏观视角,带你搞懂程序员该如何系统准备面试:从求职导向学习,到简历优化、面试冲刺,帮你少走弯路,高效拿下心仪 offer。
## 尽早以求职为导向来学习
@@ -138,7 +141,7 @@ Java 后端面试复习的重点请看这篇文章:[Java 面试重点总结(
一定不要抱着一种思想,觉得八股文或者基础问题的考查意义不大。如果你抱着这种思想复习的话,那效果可能不会太好。实际上,个人认为还是很有意义的,八股文或者基础性的知识在日常开发中也会需要经常用到。例如,线程池这块的拒绝策略、核心参数配置什么的,如果你不了解,实际项目中使用线程池可能就用的不是很明白,容易出现问题。而且,其实这种基础性的问题是最容易准备的,像各种底层原理、系统设计、场景题以及深挖你的项目这类才是最难的!
-八股文资料首推我的 [《Java 面试指北》](https://t.zsxq.com/11rZ6D7Wk) (配合 JavaGuide 使用,会根据每一年的面试情况对内容进行更新完善)和 [JavaGuide](https://javaguide.cn/) 。里面不仅仅是原创八股文,还有很多对实际开发有帮助的干货。除了我的资料之外,你还可以去网上找一些其他的优质的文章、视频来看。
+八股文资料首推我的 [《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) (配合 JavaGuide 使用,会根据每一年的面试情况对内容进行更新完善)和 [JavaGuide](https://javaguide.cn/) 。里面不仅仅是原创八股文,还有很多对实际开发有帮助的干货。除了我的资料之外,你还可以去网上找一些其他的优质的文章、视频来看。

diff --git a/docs/java/basis/bigdecimal.md b/docs/java/basis/bigdecimal.md
index 5af0c460579..7978438f298 100644
--- a/docs/java/basis/bigdecimal.md
+++ b/docs/java/basis/bigdecimal.md
@@ -1,8 +1,13 @@
---
title: BigDecimal 详解
+description: 详解BigDecimal使用方法:解决浮点数精度丢失问题,掌握加减乘除运算、RoundingMode舍入规则、compareTo比较方法,适用金融计算等高精度场景。
category: Java
tag:
- Java基础
+head:
+ - - meta
+ - name: keywords
+ content: BigDecimal,浮点数精度,小数运算,RoundingMode舍入模式,BigDecimal比较,金额计算,精度丢失
---
《阿里巴巴 Java 开发手册》中提到:“为了避免精度丢失,可以使用 `BigDecimal` 来进行浮点数的运算”。
@@ -21,7 +26,7 @@ System.out.println(a == b);// false
**为什么浮点数 `float` 或 `double` 运算的时候会有精度丢失的风险呢?**
-这个和计算机保存浮点数的机制有很大关系。我们知道计算机是二进制的,而且计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况。这也就是解释了为什么浮点数没有办法用二进制精确表示。
+这个和计算机保存小数的机制有很大关系。我们知道计算机是二进制的,而且计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况。这也就解释了为什么十进制小数没有办法用二进制精确表示。
就比如说十进制下的 0.2 就没办法精确转换成二进制小数:
@@ -40,9 +45,9 @@ System.out.println(a == b);// false
## BigDecimal 介绍
-`BigDecimal` 可以实现对浮点数的运算,不会造成精度丢失。
+`BigDecimal` 可以实现对小数的运算,不会造成精度丢失。
-通常情况下,大部分需要浮点数精确运算结果的业务场景(比如涉及到钱的场景)都是通过 `BigDecimal` 来做的。
+通常情况下,大部分需要小数精确运算结果的业务场景(比如涉及到钱的场景)都是通过 `BigDecimal` 来做的。
《阿里巴巴 Java 开发手册》中提到:**浮点数之间的等值判断,基本数据类型不能用 == 来比较,包装数据类型不能用 equals 来判断。**
@@ -50,7 +55,7 @@ System.out.println(a == b);// false
具体原因我们在上面已经详细介绍了,这里就不多提了。
-想要解决浮点数运算精度丢失这个问题,可以直接使用 `BigDecimal` 来定义浮点数的值,然后再进行浮点数的运算操作即可。
+想要解决浮点数运算精度丢失这个问题,可以直接使用 `BigDecimal` 来定义小数的值,然后再进行小数的运算操作即可。
```java
BigDecimal a = new BigDecimal("1.0");
@@ -99,20 +104,20 @@ public BigDecimal divide(BigDecimal divisor, int scale, RoundingMode roundingMod
```java
public enum RoundingMode {
- // 2.5 -> 3 , 1.6 -> 2
- // -1.6 -> -2 , -2.5 -> -3
+ // 2.4 -> 3 , 1.6 -> 2
+ // -1.6 -> -2 , -2.4 -> -3
UP(BigDecimal.ROUND_UP),
- // 2.5 -> 2 , 1.6 -> 1
- // -1.6 -> -1 , -2.5 -> -2
+ // 2.4 -> 2 , 1.6 -> 1
+ // -1.6 -> -1 , -2.4 -> -2
DOWN(BigDecimal.ROUND_DOWN),
- // 2.5 -> 3 , 1.6 -> 2
- // -1.6 -> -1 , -2.5 -> -2
+ // 2.4 -> 3 , 1.6 -> 2
+ // -1.6 -> -1 , -2.4 -> -2
CEILING(BigDecimal.ROUND_CEILING),
// 2.5 -> 2 , 1.6 -> 1
// -1.6 -> -2 , -2.5 -> -3
FLOOR(BigDecimal.ROUND_FLOOR),
- // 2.5 -> 3 , 1.6 -> 2
- // -1.6 -> -2 , -2.5 -> -3
+ // 2.4 -> 2 , 1.6 -> 2
+ // -1.6 -> -2 , -2.4 -> -2
HALF_UP(BigDecimal.ROUND_HALF_UP),
//......
}
@@ -230,7 +235,7 @@ public class BigDecimalUtil {
/**
* 提供(相对)精确的除法运算,当发生除不尽的情况时,精确到
- * 小数点以后10位,以后的数字四舍五入。
+ * 小数点以后10位,以后的数字四舍六入五成双。
*
* @param v1 被除数
* @param v2 除数
@@ -242,7 +247,7 @@ public class BigDecimalUtil {
/**
* 提供(相对)精确的除法运算。当发生除不尽的情况时,由scale参数指
- * 定精度,以后的数字四舍五入。
+ * 定精度,以后的数字四舍六入五成双。
*
* @param v1 被除数
* @param v2 除数
@@ -260,11 +265,11 @@ public class BigDecimalUtil {
}
/**
- * 提供精确的小数位四舍五入处理。
+ * 提供精确的小数位四舍六入五成双处理。
*
- * @param v 需要四舍五入的数字
+ * @param v 需要四舍六入五成双的数字
* @param scale 小数点后保留几位
- * @return 四舍五入后的结果
+ * @return 四舍六入五成双后的结果
*/
public static double round(double v, int scale) {
if (scale < 0) {
@@ -283,18 +288,18 @@ public class BigDecimalUtil {
* @return 返回转换结果
*/
public static float convertToFloat(double v) {
- BigDecimal b = new BigDecimal(v);
+ BigDecimal b = BigDecimal.valueOf(v);
return b.floatValue();
}
/**
- * 提供精确的类型转换(Int)不进行四舍五入
+ * 提供精确的类型转换(Int)不进行四舍六入五成双
*
* @param v 需要被转换的数字
* @return 返回转换结果
*/
public static int convertsToInt(double v) {
- BigDecimal b = new BigDecimal(v);
+ BigDecimal b = BigDecimal.valueOf(v);
return b.intValue();
}
@@ -305,7 +310,7 @@ public class BigDecimalUtil {
* @return 返回转换结果
*/
public static long convertsToLong(double v) {
- BigDecimal b = new BigDecimal(v);
+ BigDecimal b = BigDecimal.valueOf(v);
return b.longValue();
}
@@ -317,8 +322,8 @@ public class BigDecimalUtil {
* @return 返回两个数中大的一个值
*/
public static double returnMax(double v1, double v2) {
- BigDecimal b1 = new BigDecimal(v1);
- BigDecimal b2 = new BigDecimal(v2);
+ BigDecimal b1 = BigDecimal.valueOf(v1);
+ BigDecimal b2 = BigDecimal.valueOf(v2);
return b1.max(b2).doubleValue();
}
@@ -330,8 +335,8 @@ public class BigDecimalUtil {
* @return 返回两个数中小的一个值
*/
public static double returnMin(double v1, double v2) {
- BigDecimal b1 = new BigDecimal(v1);
- BigDecimal b2 = new BigDecimal(v2);
+ BigDecimal b1 = BigDecimal.valueOf(v1);
+ BigDecimal b2 = BigDecimal.valueOf(v2);
return b1.min(b2).doubleValue();
}
diff --git a/docs/java/basis/generics-and-wildcards.md b/docs/java/basis/generics-and-wildcards.md
index bd9cd4b00bf..1740999940c 100644
--- a/docs/java/basis/generics-and-wildcards.md
+++ b/docs/java/basis/generics-and-wildcards.md
@@ -1,20 +1,362 @@
---
title: 泛型&通配符详解
+description: 全面解析Java泛型与通配符:深入理解类型擦除机制、上界下界通配符用法、PECS原则应用,掌握泛型编程核心技巧。
category: Java
tag:
- Java基础
+head:
+ - - meta
+ - name: keywords
+ content: Java泛型,通配符,类型擦除,泛型边界,PECS原则,泛型方法,上界下界通配符,泛型接口
---
-**泛型&通配符** 相关的面试题为我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)(点击链接即可查看详细介绍以及获取方法)中。
+## 泛型
-[《Java 面试指北》](hhttps://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 的部分内容展示如下,你可以将其看作是 [JavaGuide](https://javaguide.cn/#/) 的补充完善,两者可以配合使用。
+### 什么是泛型?有什么作用?
-
+**Java 泛型(Generics)** 是 JDK 5 中引入的一个新特性。使用泛型参数,可以增强代码的可读性以及稳定性。**如无特别说明,以下行为以 Java 8 为准。**
-[《Java 面试指北》](hhttps://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)只是星球内部众多资料中的一个,星球还有很多其他优质资料比如[专属专栏](https://javaguide.cn/zhuanlan/)、Java 编程视频、PDF 资料。
+编译器可以对泛型参数进行检测,并且通过泛型参数可以指定传入的对象类型。比如 `ArrayList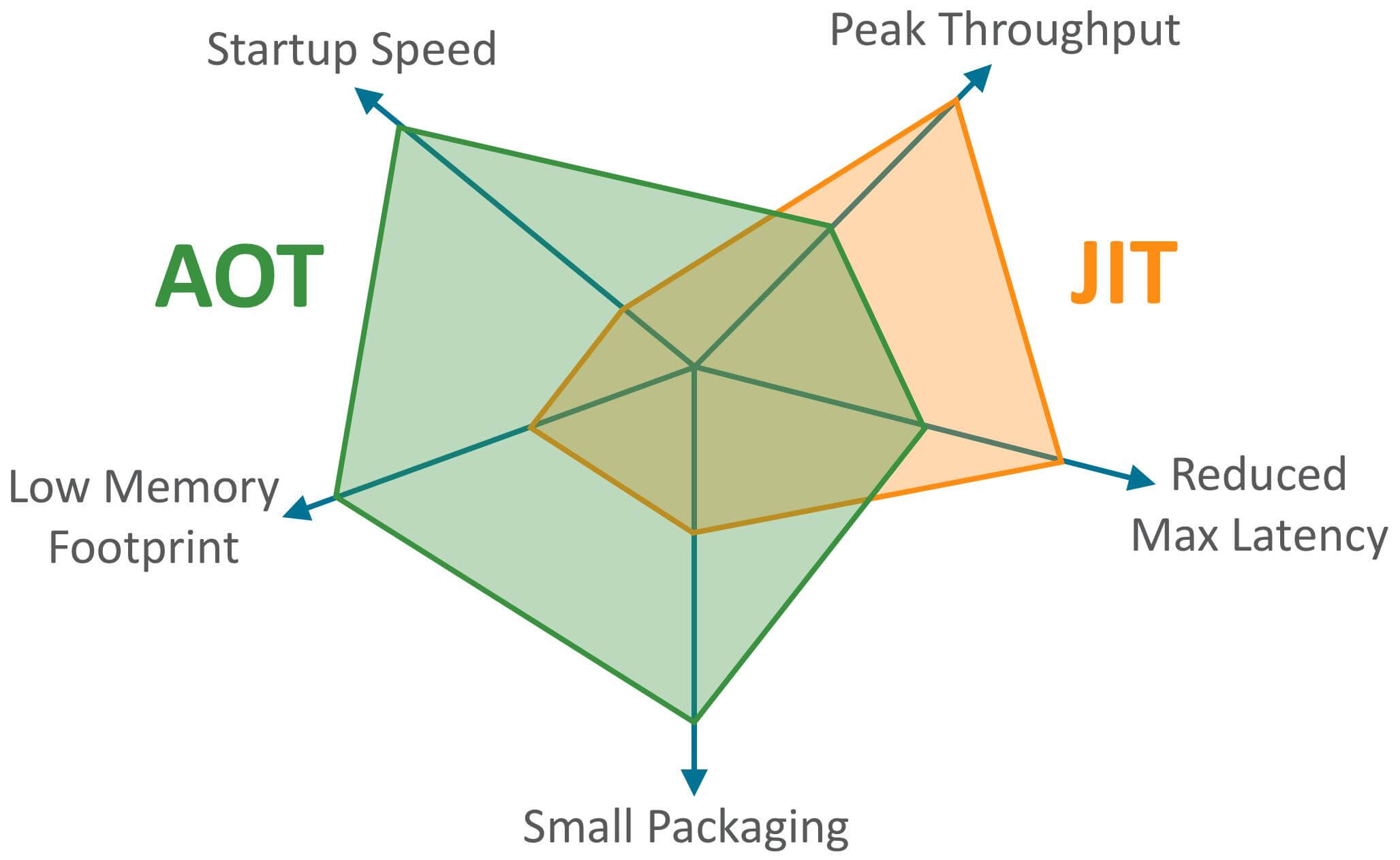 -可以看出,AOT 的主要优势在于启动时间、内存占用和打包体积。JIT 的主要优势在于具备更高的极限处理能力,可以降低请求的最大延迟。
+可以看出,**AOT 的主要优势在于启动时间、内存占用和打包体积**。**JIT 的主要优势在于具备更高的极限处理能力**,可以降低请求的最大延迟。
提到 AOT 就不得不提 [GraalVM](https://www.graalvm.org/) 了!GraalVM 是一种高性能的 JDK(完整的 JDK 发行版本),它可以运行 Java 和其他 JVM 语言,以及 JavaScript、Python 等非 JVM 语言。 GraalVM 不仅能提供 AOT 编译,还能提供 JIT 编译。感兴趣的同学,可以去看看 GraalVM 的官方文档:
-可以看出,AOT 的主要优势在于启动时间、内存占用和打包体积。JIT 的主要优势在于具备更高的极限处理能力,可以降低请求的最大延迟。
+可以看出,**AOT 的主要优势在于启动时间、内存占用和打包体积**。**JIT 的主要优势在于具备更高的极限处理能力**,可以降低请求的最大延迟。
提到 AOT 就不得不提 [GraalVM](https://www.graalvm.org/) 了!GraalVM 是一种高性能的 JDK(完整的 JDK 发行版本),它可以运行 Java 和其他 JVM 语言,以及 JavaScript、Python 等非 JVM 语言。 GraalVM 不仅能提供 AOT 编译,还能提供 JIT 编译。感兴趣的同学,可以去看看 GraalVM 的官方文档: +
**性能**
每次对 `String` 类型进行改变的时候,都会生成一个新的 `String` 对象,然后将指针指向新的 `String` 对象。`StringBuffer` 每次都会对 `StringBuffer` 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 `StringBuilder` 相比使用 `StringBuffer` 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
@@ -589,7 +639,7 @@ abstract class AbstractStringBuilder implements Appendable, CharSequence {
- 单线程操作字符串缓冲区下操作大量数据: 适用 `StringBuilder`
- 多线程操作字符串缓冲区下操作大量数据: 适用 `StringBuffer`
-### String 为什么是不可变的?
+### ⭐️String 为什么是不可变的?
`String` 类中使用 `final` 关键字修饰字符数组来保存字符串,~~所以`String` 对象是不可变的。~~
@@ -636,7 +686,7 @@ public final class String implements java.io.Serializable, Comparable
+
**性能**
每次对 `String` 类型进行改变的时候,都会生成一个新的 `String` 对象,然后将指针指向新的 `String` 对象。`StringBuffer` 每次都会对 `StringBuffer` 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 `StringBuilder` 相比使用 `StringBuffer` 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
@@ -589,7 +639,7 @@ abstract class AbstractStringBuilder implements Appendable, CharSequence {
- 单线程操作字符串缓冲区下操作大量数据: 适用 `StringBuilder`
- 多线程操作字符串缓冲区下操作大量数据: 适用 `StringBuffer`
-### String 为什么是不可变的?
+### ⭐️String 为什么是不可变的?
`String` 类中使用 `final` 关键字修饰字符数组来保存字符串,~~所以`String` 对象是不可变的。~~
@@ -636,7 +686,7 @@ public final class String implements java.io.Serializable, Comparable{@code ...}` 。
@@ -74,15 +77,15 @@ URL: http://127.0.0.1:8000/
`@snippet` 这种方式生成的效果更好且使用起来更方便一些。
-## JEP 416:使用方法句柄重新实现反射核心
+## JEP 416: Reimplement Core Reflection with Method Handles(方法句柄重构核心反射,转正)
-Java 18 改进了 `java.lang.reflect.Method`、`Constructor` 的实现逻辑,使之性能更好,速度更快。这项改动不会改动相关 API ,这意味着开发中不需要改动反射相关代码,就可以体验到性能更好反射。
+Java 18 改进了 `java.lang.reflect.Method`、`Constructor` 的实现逻辑,使之性能更好,速度更快。这项改动不会改动相关 API ,这意味着开发中不需要改动反射相关代码,就可以体验到性能更好的反射。
OpenJDK 官方给出了新老实现的反射性能基准测试结果。
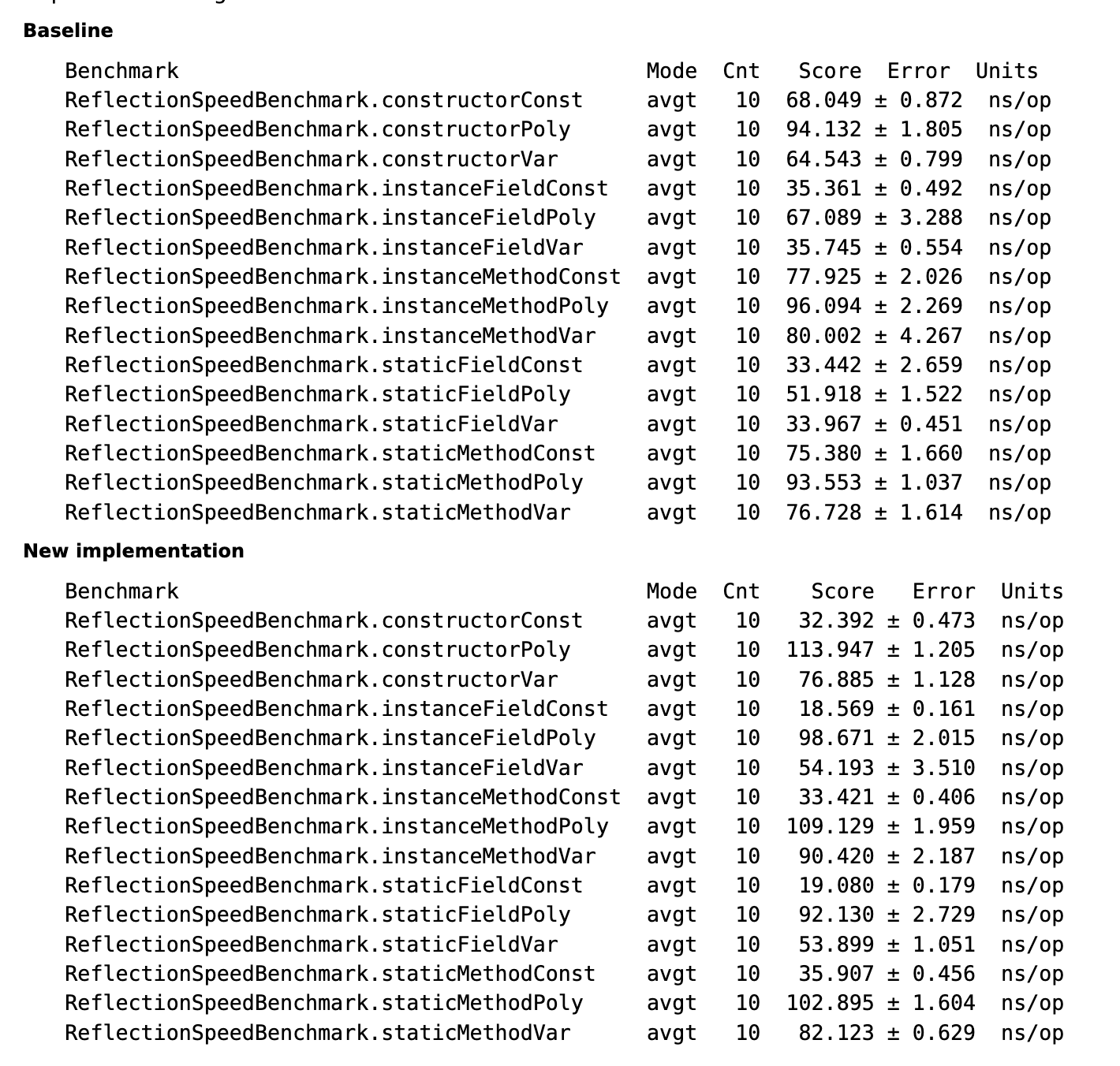
-## JEP 417: 向量 API(第三次孵化)
+## JEP 417: Vector API(向量 API,第三次孵化)
向量(Vector) API 最初由 [JEP 338](https://openjdk.java.net/jeps/338) 提出,并作为[孵化 API](http://openjdk.java.net/jeps/11)集成到 Java 16 中。第二轮孵化由 [JEP 414](https://openjdk.java.net/jeps/414) 提出并集成到 Java 17 中,第三轮孵化由 [JEP 417](https://openjdk.java.net/jeps/417) 提出并集成到 Java 18 中,第四轮由 [JEP 426](https://openjdk.java.net/jeps/426) 提出并集成到了 Java 19 中。
@@ -126,11 +129,11 @@ void vectorComputation(float[] a, float[] b, float[] c) {
在 JDK 18 中,向量 API 的性能得到了进一步的优化。
-## JEP 418:互联网地址解析 SPI
+## JEP 418: Internet-Address Resolution SPI(互联网地址解析 SPI,转正)
Java 18 定义了一个全新的 SPI(service-provider interface),用于主要名称和地址的解析,以便 `java.net.InetAddress` 可以使用平台之外的第三方解析器。
-## JEP 419:Foreign Function & Memory API(第二次孵化)
+## JEP 419: Foreign Function & Memory API(外部函数和内存 API,第二次孵化)
Java 程序可以通过该 API 与 Java 运行时之外的代码和数据进行互操作。通过高效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存(即不受 JVM 管理的内存),该 API 使 Java 程序能够调用本机库并处理本机数据,而不会像 JNI 那样危险和脆弱。
diff --git a/docs/java/new-features/java19.md b/docs/java/new-features/java19.md
index a207bc6830a..13cc1b771a2 100644
--- a/docs/java/new-features/java19.md
+++ b/docs/java/new-features/java19.md
@@ -1,25 +1,27 @@
---
title: Java 19 新特性概览
+description: 介绍 JDK 19 的预览特性与并发相关更新,为后续虚拟线程铺垫。
category: Java
tag:
- Java新特性
+head:
+ - - meta
+ - name: keywords
+ content: Java 19,JDK19,虚拟线程预览,结构化并发,外部函数 API,JEP
---
-JDK 19 定于 2022 年 9 月 20 日正式发布以供生产使用,非长期支持版本。不过,JDK 19 中有一些比较重要的新特性值得关注。
+JDK 19 于 2022 年 9 月 20 日正式发布,非长期支持版本。
-JDK 19 只有 7 个新特性:
+JDK 19 共有 7 个新特性,这篇文章会挑选其中较为重要的一些新特性进行详细介绍:
-- [JEP 405: Record Patterns(记录模式)](https://openjdk.org/jeps/405)(预览)
-- [JEP 422: Linux/RISC-V Port](https://openjdk.org/jeps/422)
- [JEP 424: Foreign Function & Memory API(外部函数和内存 API)](https://openjdk.org/jeps/424)(预览)
- [JEP 425: Virtual Threads(虚拟线程)](https://openjdk.org/jeps/425)(预览)
-- [JEP 426: Vector(向量)API](https://openjdk.java.net/jeps/426)(第四次孵化)
-- [JEP 427: Pattern Matching for switch(switch 模式匹配)](https://openjdk.java.net/jeps/427)
+- [JEP 426: Vector API(向量 API)](https://openjdk.java.net/jeps/426)(第四次孵化)
- [JEP 428: Structured Concurrency(结构化并发)](https://openjdk.org/jeps/428)(孵化)
-这里只对 424、425、426、428 这 4 个我觉得比较重要的新特性进行详细介绍。
+下图是从 JDK 8 到 JDK 25 每个版本的更新带来的新特性数量和更新时间:
-相关阅读:[OpenJDK Java 19 文档](https://openjdk.org/projects/jdk/19/)
+
## JEP 424: 外部函数和内存 API(预览)
@@ -30,21 +32,21 @@ Java 程序可以通过该 API 与 Java 运行时之外的代码和数据进行
在没有外部函数和内存 API 之前:
- Java 通过 [`sun.misc.Unsafe`](https://hg.openjdk.java.net/jdk/jdk/file/tip/src/jdk.unsupported/share/classes/sun/misc/Unsafe.java) 提供一些执行低级别、不安全操作的方法(如直接访问系统内存资源、自主管理内存资源等),`Unsafe` 类让 Java 语言拥有了类似 C 语言指针一样操作内存空间的能力的同时,也增加了 Java 语言的不安全性,不正确使用 `Unsafe` 类会使得程序出错的概率变大。
-- Java 1.1 就已通过 Java 原生接口(JNI)支持了原生方法调用,但并不好用。JNI 实现起来过于复杂,步骤繁琐(具体的步骤可以参考这篇文章:[Guide to JNI (Java Native Interface)](https://www.baeldung.com/jni) ),不受 JVM 的语言安全机制控制,影响 Java 语言的跨平台特性。并且,JNI 的性能也不行,因为 JNI 方法调用不能从许多常见的 JIT 优化(如内联)中受益。虽然[JNA](https://github.com/java-native-access/jna)、[JNR](https://github.com/jnr/jnr-ffi)和[JavaCPP](https://github.com/bytedeco/javacpp)等框架对 JNI 进行了改进,但效果还是不太理想。
+- Java 1.1 就已通过 Java 原生接口(JNI)支持了原生方法调用,但并不好用。JNI 实现起来过于复杂,步骤繁琐(具体的步骤可以参考这篇文章:[Guide to JNI (Java Native Interface)](https://www.baeldung.com/jni)),不受 JVM 的语言安全机制控制,影响 Java 语言的跨平台特性。并且,JNI 的性能也不行,因为 JNI 方法调用不能从许多常见的 JIT 优化(如内联)中受益。虽然 [JNA](https://github.com/java-native-access/jna)、[JNR](https://github.com/jnr/jnr-ffi) 和 [JavaCPP](https://github.com/bytedeco/javacpp) 等框架对 JNI 进行了改进,但效果还是不太理想。
引入外部函数和内存 API 就是为了解决 Java 访问外部函数和外部内存存在的一些痛点。
Foreign Function & Memory API (FFM API) 定义了类和接口:
-- 分配外部内存:`MemorySegment`、`MemoryAddress`和`SegmentAllocator`;
-- 操作和访问结构化的外部内存:`MemoryLayout`, `VarHandle`;
-- 控制外部内存的分配和释放:`MemorySession`;
-- 调用外部函数:`Linker`、`FunctionDescriptor`和`SymbolLookup`。
+- 分配外部内存:`MemorySegment`、`MemoryAddress` 和 `SegmentAllocator`
+- 操作和访问结构化的外部内存:`MemoryLayout`、`VarHandle`
+- 控制外部内存的分配和释放:`MemorySession`
+- 调用外部函数:`Linker`、`FunctionDescriptor` 和 `SymbolLookup`
下面是 FFM API 使用示例,这段代码获取了 C 库函数的 `radixsort` 方法句柄,然后使用它对 Java 数组中的四个字符串进行排序。
```java
-// 1. 在C库路径上查找外部函数
+// 1. 在 C 库路径上查找外部函数
Linker linker = Linker.nativeLinker();
SymbolLookup stdlib = linker.defaultLookup();
MethodHandle radixSort = linker.downcallHandle(
@@ -62,7 +64,7 @@ for (int i = 0; i < javaStrings.length; i++) {
}
// 5. 通过调用外部函数对堆外数据进行排序
radixSort.invoke(offHeap, javaStrings.length, MemoryAddress.NULL, '\0');
-// 6. 将(重新排序的)字符串从堆外复制到堆上
+// 6. 将(重新排序的)字符串从堆外复制到堆上
for (int i = 0; i < javaStrings.length; i++) {
MemoryAddress cStringPtr = offHeap.getAtIndex(ValueLayout.ADDRESS, i);
javaStrings[i] = cStringPtr.getUtf8String(0);
@@ -72,7 +74,7 @@ assert Arrays.equals(javaStrings, new String[] {"car", "cat", "dog", "mouse"});
## JEP 425: 虚拟线程(预览)
-虚拟线程(Virtual Thread-)是 JDK 而不是 OS 实现的轻量级线程(Lightweight Process,LWP),许多虚拟线程共享同一个操作系统线程,虚拟线程的数量可以远大于操作系统线程的数量。
+虚拟线程(Virtual Thread)是 JDK 而不是 OS 实现的轻量级线程(Lightweight Process,LWP),许多虚拟线程共享同一个操作系统线程,虚拟线程的数量可以远大于操作系统线程的数量。
虚拟线程在其他多线程语言中已经被证实是十分有用的,比如 Go 中的 Goroutine、Erlang 中的进程。
diff --git a/docs/java/new-features/java20.md b/docs/java/new-features/java20.md
index 9dd86a71c70..c7678fe3e09 100644
--- a/docs/java/new-features/java20.md
+++ b/docs/java/new-features/java20.md
@@ -1,27 +1,34 @@
---
title: Java 20 新特性概览
+description: 总结 JDK 20 的语言与并发改动,延续虚拟线程与模式匹配相关增强。
category: Java
tag:
- Java新特性
+head:
+ - - meta
+ - name: keywords
+ content: Java 20,JDK20,记录模式预览,虚拟线程改进,语言增强,JEP
---
JDK 20 于 2023 年 3 月 21 日发布,非长期支持版本。
根据开发计划,下一个 LTS 版本就是将于 2023 年 9 月发布的 JDK 21。
-
+JDK 20 共有 7 个新特性,这篇文章会挑选其中较为重要的一些新特性进行详细介绍:
-JDK 20 只有 7 个新特性:
-
-- [JEP 429:Scoped Values(作用域值)](https://openjdk.org/jeps/429)(第一次孵化)
-- [JEP 432:Record Patterns(记录模式)](https://openjdk.org/jeps/432)(第二次预览)
-- [JEP 433:switch 模式匹配](https://openjdk.org/jeps/433)(第四次预览)
+- [JEP 429: Scoped Values(作用域值)](https://openjdk.org/jeps/429)(第一次孵化)
+- [JEP 432: Record Patterns(记录模式)](https://openjdk.org/jeps/432)(第二次预览)
+- [JEP 433: Pattern Matching for switch(switch 模式匹配)](https://openjdk.org/jeps/433)(第四次预览)
- [JEP 434: Foreign Function & Memory API(外部函数和内存 API)](https://openjdk.org/jeps/434)(第二次预览)
- [JEP 436: Virtual Threads(虚拟线程)](https://openjdk.org/jeps/436)(第二次预览)
-- [JEP 437:Structured Concurrency(结构化并发)](https://openjdk.org/jeps/437)(第二次孵化)
-- [JEP 432:向量 API(](https://openjdk.org/jeps/438)第五次孵化)
+- [JEP 437: Structured Concurrency(结构化并发)](https://openjdk.org/jeps/437)(第二次孵化)
+- [JEP 438: Vector API(向量 API)](https://openjdk.org/jeps/438)(第五次孵化)
+
+下图是从 JDK 8 到 JDK 25 每个版本的更新带来的新特性数量和更新时间:
+
+
-## JEP 429:作用域值(第一次孵化)
+## JEP 429: Scoped Values(作用域值,第一次孵化)
作用域值(Scoped Values)它可以在线程内和线程间共享不可变的数据,优于线程局部变量,尤其是在使用大量虚拟线程时。
@@ -40,7 +47,7 @@ ScopedValue.where(V,