+3.
## POP3/IMAP:邮件接收的协议
@@ -74,7 +107,7 @@ FTP 是基于客户—服务器(C/S)模型而设计的,在客户端与 FTP
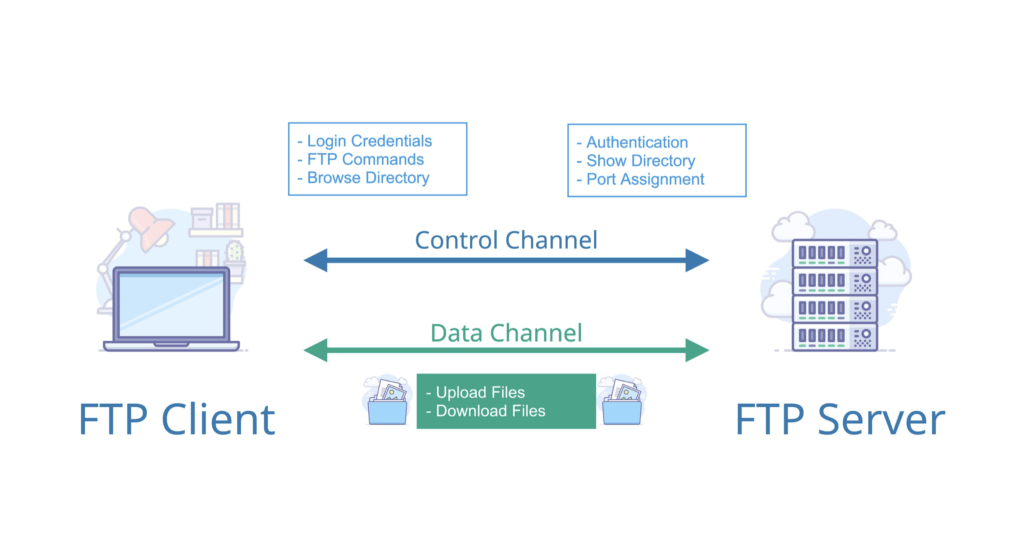
-注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。因此,FTP 传输的文件可能会被窃听或篡改。建议在传输敏感数据时使用更安全的协议,如 SFTP(一种基于 SSH 协议的安全文件传输协议,用于在网络上安全地传输文件)。
+注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。因此,FTP 传输的文件可能会被窃听或篡改。建议在传输敏感数据时使用更安全的协议,如 SFTP(SSH File Transfer Protocol,一种基于 SSH 协议的安全文件传输协议,用于在网络上安全地传输文件)。
## Telnet:远程登陆协议
@@ -86,10 +119,12 @@ FTP 是基于客户—服务器(C/S)模型而设计的,在客户端与 FTP
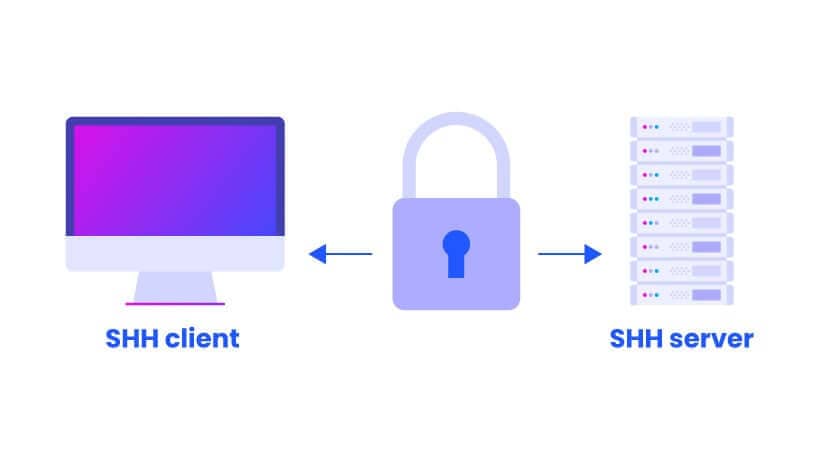
**SSH(Secure Shell)** 基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务。
-SSH 的经典用途是登录到远程电脑中执行命令。除此之外,SSH 也支持隧道协议、端口映射和 X11 连接。借助 SFTP 或 SCP 协议,SSH 还可以传输文件。
+SSH 的经典用途是登录到远程电脑中执行命令。除此之外,SSH 也支持隧道协议、端口映射和 X11 连接(允许用户在本地运行远程服务器上的图形应用程序)。借助 SFTP(SSH File Transfer Protocol) 或 SCP(Secure Copy Protocol) 协议,SSH 还可以安全传输文件。
SSH 使用客户端-服务器模型,默认端口是 22。SSH 是一个守护进程,负责实时监听客户端请求,并进行处理。大多数现代操作系统都提供了 SSH。
+如下图所示,SSH Client(SSH 客户端)和 SSH Server(SSH 服务器)通过公钥交换生成共享的对称加密密钥,用于后续的加密通信。
+
## RTP:实时传输协议
@@ -103,11 +138,13 @@ RTP 协议分为两种子协议:
## DNS:域名系统
-DNS(Domain Name System,域名管理系统)基于 UDP 协议,用于解决域名和 IP 地址的映射问题。
+DNS(Domain Name System,域名管理系统)通常基于 UDP 协议(端口 53),用于解决域名和 IP 地址的映射问题。当响应数据超过 UDP 长度限制或进行区域传送时会改用 TCP。

## 参考
- 《计算机网络自顶向下方法》(第七版)
-- RTP 协议介绍:https://mthli.xyz/rtp-introduction/
+- RTP 协议介绍:
+
+
diff --git a/docs/cs-basics/network/arp.md b/docs/cs-basics/network/arp.md
index ba485ba2e54..10c01312b06 100644
--- a/docs/cs-basics/network/arp.md
+++ b/docs/cs-basics/network/arp.md
@@ -1,8 +1,13 @@
---
title: ARP 协议详解(网络层)
+description: 讲解 ARP 的地址解析机制与报文流程,结合 ARP 表与广播/单播详解常见攻击与防御策略。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: ARP,地址解析,IP到MAC,广播问询,单播响应,ARP表,欺骗
---
每当我们学习一个新的网络协议的时候,都要把他结合到 OSI 七层模型中,或者是 TCP/IP 协议栈中来学习,一是要学习该协议在整个网络协议栈中的位置,二是要学习该协议解决了什么问题,地位如何?三是要学习该协议的工作原理,以及一些更深入的细节。
@@ -11,9 +16,9 @@ tag:
开始阅读这篇文章之前,你可以先看看下面几个问题:
-1. **ARP 协议在协议栈中的位置?** ARP 协议在协议栈中的位置非常重要,在理解了它的工作原理之后,也很难说它到底是网络层协议,还是链路层协议,因为它恰恰串联起了网络层和链路层。国外的大部分教程通常将 ARP 协议放在网络层。
-2. **ARP 协议解决了什么问题,地位如何?** ARP 协议,全称 **地址解析协议(Address Resolution Protocol)**,它解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
-3. **ARP 工作原理?** 只希望大家记住几个关键词:**ARP 表、广播问询、单播响应**。
+1. **ARP 协议在协议栈中的位置?** ARP 协议在协议栈中的位置非常重要,在理解了它的工作原理之后,也很难说它到底是网络层协议,还是链路层协议,因为它恰恰串联起了网络层和链路层。国外的大部分教程通常将 ARP 协议放在网络层。
+2. **ARP 协议解决了什么问题,地位如何?** ARP 协议,全称 **地址解析协议(Address Resolution Protocol)**,它解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
+3. **ARP 工作原理?** 只希望大家记住几个关键词:**ARP 表、广播问询、单播响应**。
## MAC 地址
@@ -21,7 +26,7 @@ tag:
MAC 地址的全称是 **媒体访问控制地址(Media Access Control Address)**。如果说,互联网中每一个资源都由 IP 地址唯一标识(IP 协议内容),那么一切网络设备都由 MAC 地址唯一标识。
-
+
可以理解为,MAC 地址是一个网络设备真正的身份证号,IP 地址只是一种不重复的定位方式(比如说住在某省某市某街道的张三,这种逻辑定位是 IP 地址,他的身份证号才是他的 MAC 地址),也可以理解为 MAC 地址是身份证号,IP 地址是邮政地址。MAC 地址也有一些别称,如 LAN 地址、物理地址、以太网地址等。
@@ -80,7 +85,7 @@ ARP 的工作原理将分两种场景讨论:
更复杂的情况是,发送主机 A 和接收主机 B 不在同一个子网中,假设一个一般场景,两台主机所在的子网由一台路由器联通。这里需要注意的是,一般情况下,我们说网络设备都有一个 IP 地址和一个 MAC 地址,这里说的网络设备,更严谨的说法应该是一个接口。路由器作为互联设备,具有多个接口,每个接口同样也应该具备不重复的 IP 地址和 MAC 地址。因此,在讨论 ARP 表时,路由器的多个接口都各自维护一个 ARP 表,而非一个路由器只维护一个 ARP 表。
-接下来,回顾同一子网内的 MAC 寻址,如果主机 A 发送一个广播问询分组,那么 A 所在的子网内所有设备(接口)都将会捕获该分组,因为该分组的目的 IP 与发送主机A的IP在同一个子网中。但是当目的IP与A不在同一子网时,A所在子网内将不会有设备成功接收该分组。那么,主机 A 应该发送怎样的查询分组呢?整个过程按照时间顺序发生的事件如下:
+接下来,回顾同一子网内的 MAC 寻址,如果主机 A 发送一个广播问询分组,那么 A 所在的子网内所有设备(接口)都将会捕获该分组,因为该分组的目的 IP 与发送主机 A 的 IP 在同一个子网中。但是当目的 IP 与 A 不在同一子网时,A 所在子网内将不会有设备成功接收该分组。那么,主机 A 应该发送怎样的查询分组呢?整个过程按照时间顺序发生的事件如下:
1. 主机 A 查询 ARP 表,期望寻找到目标路由器的本子网接口的 MAC 地址。
@@ -101,3 +106,5 @@ ARP 的工作原理将分两种场景讨论:
7. 路由器接口将对 IP 数据报重新封装成链路层帧,目标 MAC 地址为主机 B 的 MAC 地址,单播发送,直到目的地。

+
+
diff --git a/docs/cs-basics/network/computer-network-xiexiren-summary.md b/docs/cs-basics/network/computer-network-xiexiren-summary.md
index 9e87de2242a..35bd988e6a5 100644
--- a/docs/cs-basics/network/computer-network-xiexiren-summary.md
+++ b/docs/cs-basics/network/computer-network-xiexiren-summary.md
@@ -1,13 +1,18 @@
---
title: 《计算机网络》(谢希仁)内容总结
+description: 基于《计算机网络》教材的学习笔记,梳理术语与分层模型等核心知识点,便于期末复习与面试巩固。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 计算机网络,谢希仁,术语,分层模型,链路,主机,教材总结
---
-本文是我在大二学习计算机网络期间整理, 大部分内容都来自于谢希仁老师的[《计算机网络》第七版 ](https://www.elias.ltd/usr/local/etc/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%EF%BC%88%E7%AC%AC7%E7%89%88%EF%BC%89%E8%B0%A2%E5%B8%8C%E4%BB%81.pdf)这本书。为了内容更容易理解,我对之前的整理进行了一波重构,并配上了一些相关的示意图便于理解。
+本文是我在大二学习计算机网络期间整理, 大部分内容都来自于谢希仁老师的[《计算机网络》第七版](https://www.elias.ltd/usr/local/etc/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%EF%BC%88%E7%AC%AC7%E7%89%88%EF%BC%89%E8%B0%A2%E5%B8%8C%E4%BB%81.pdf)这本书。为了内容更容易理解,我对之前的整理进行了一波重构,并配上了一些相关的示意图便于理解。
-
+
相关问题:[如何评价谢希仁的计算机网络(第七版)? - 知乎](https://www.zhihu.com/question/327872966) 。
@@ -20,42 +25,42 @@ tag:
3. **主机(host)**:连接在因特网上的计算机。
4. **ISP(Internet Service Provider)**:因特网服务提供者(提供商)。
-
+ 
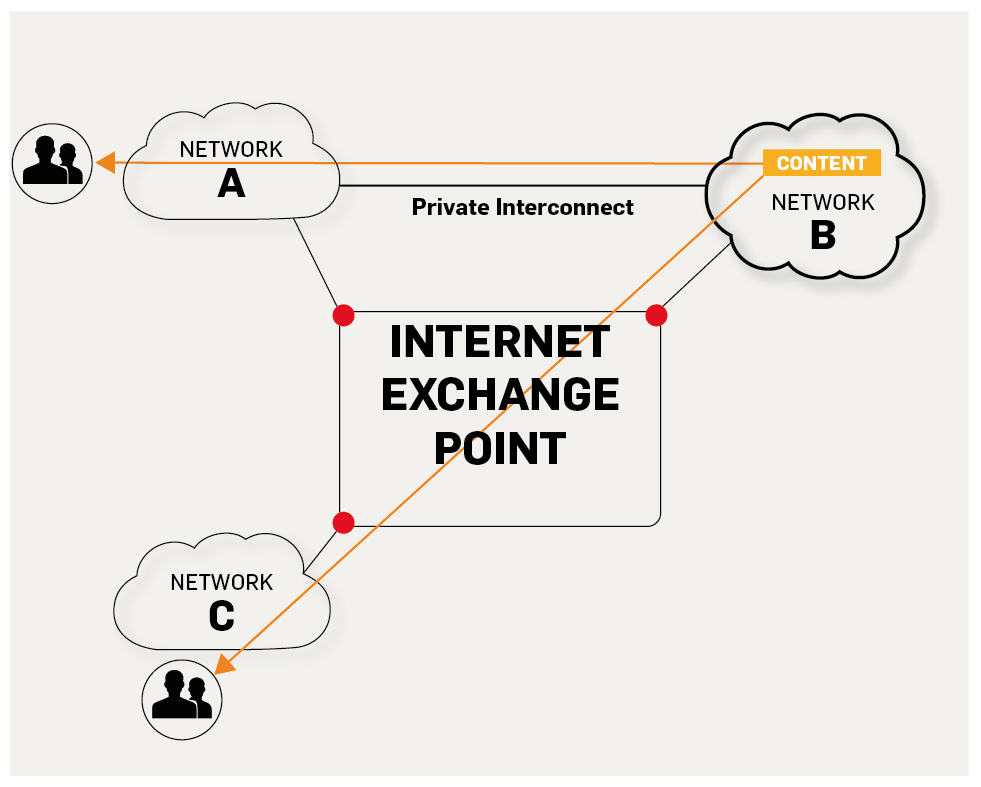
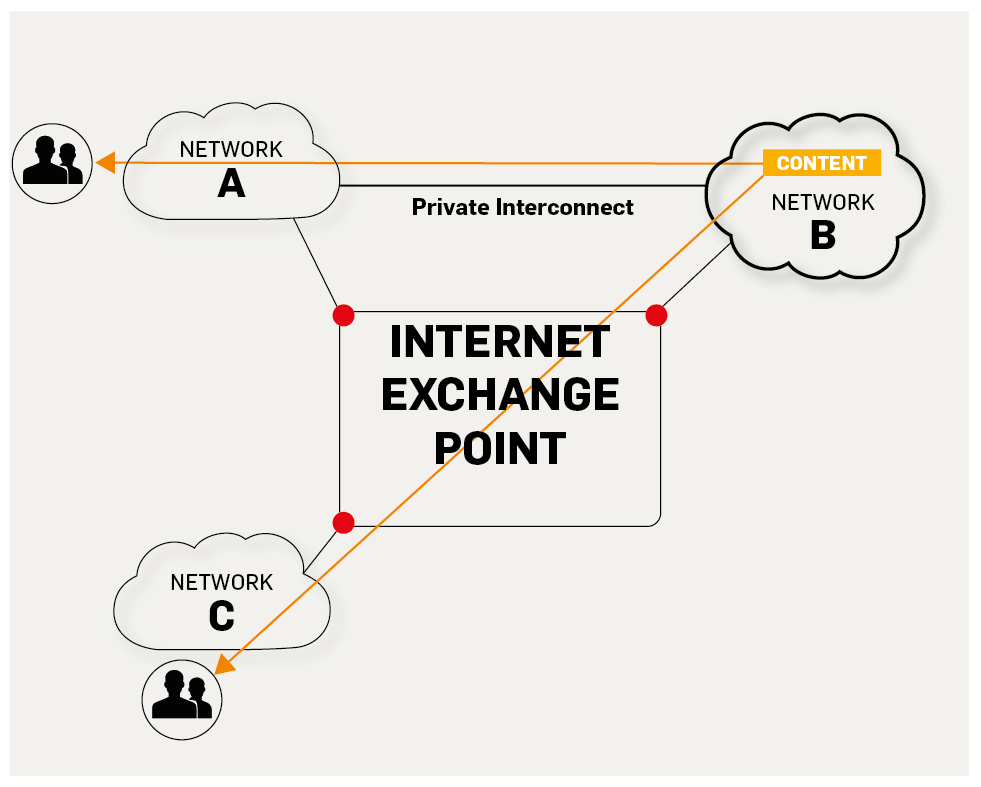
5. **IXP(Internet eXchange Point)**:互联网交换点 IXP 的主要作用就是允许两个网络直接相连并交换分组,而不需要再通过第三个网络来转发分组。
-
+ 
-https://labs.ripe.net/Members/fergalc/ixp-traffic-during-stratos-skydive
+ https://labs.ripe.net/Members/fergalc/ixp-traffic-during-stratos-skydive
6. **RFC(Request For Comments)**:意思是“请求评议”,包含了关于 Internet 几乎所有的重要的文字资料。
7. **广域网 WAN(Wide Area Network)**:任务是通过长距离运送主机发送的数据。
8. **城域网 MAN(Metropolitan Area Network)**:用来将多个局域网进行互连。
9. **局域网 LAN(Local Area Network)**:学校或企业大多拥有多个互连的局域网。
-
+ 
-http://conexionesmanwman.blogspot.com/
+ http://conexionesmanwman.blogspot.com/
10. **个人区域网 PAN(Personal Area Network)**:在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络 。
-
+ 
-https://www.itrelease.com/2018/07/advantages-and-disadvantages-of-personal-area-network-pan/
+ https://www.itrelease.com/2018/07/advantages-and-disadvantages-of-personal-area-network-pan/
-12. **分组(packet )**:因特网中传送的数据单元。由首部 header 和数据段组成。分组又称为包,首部可称为包头。
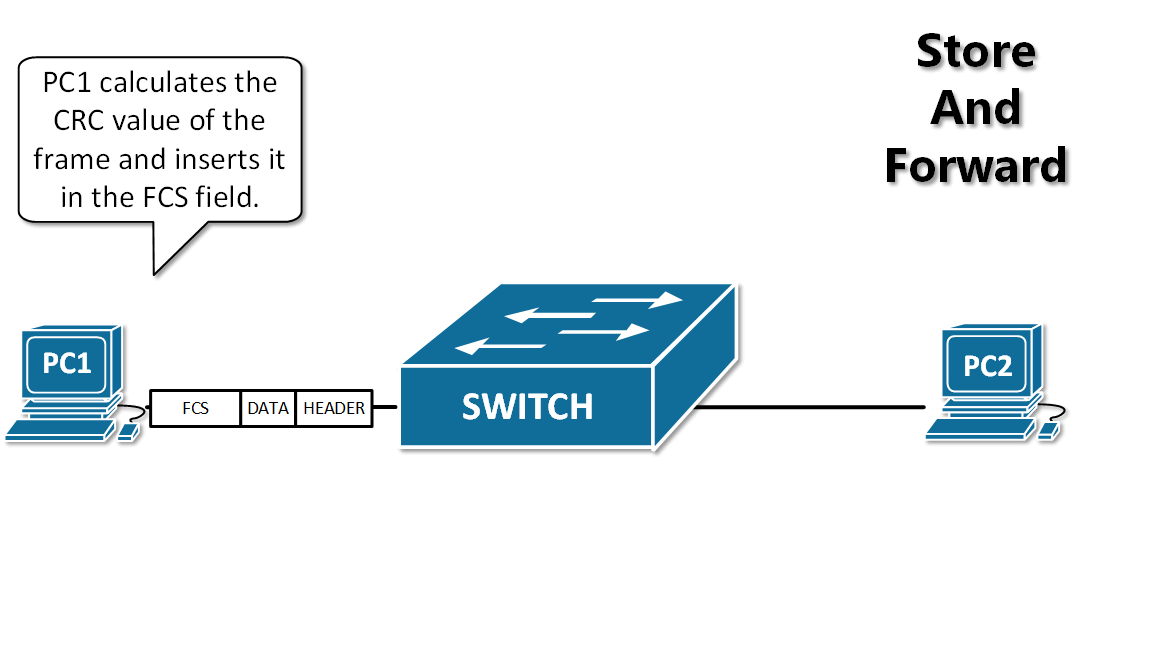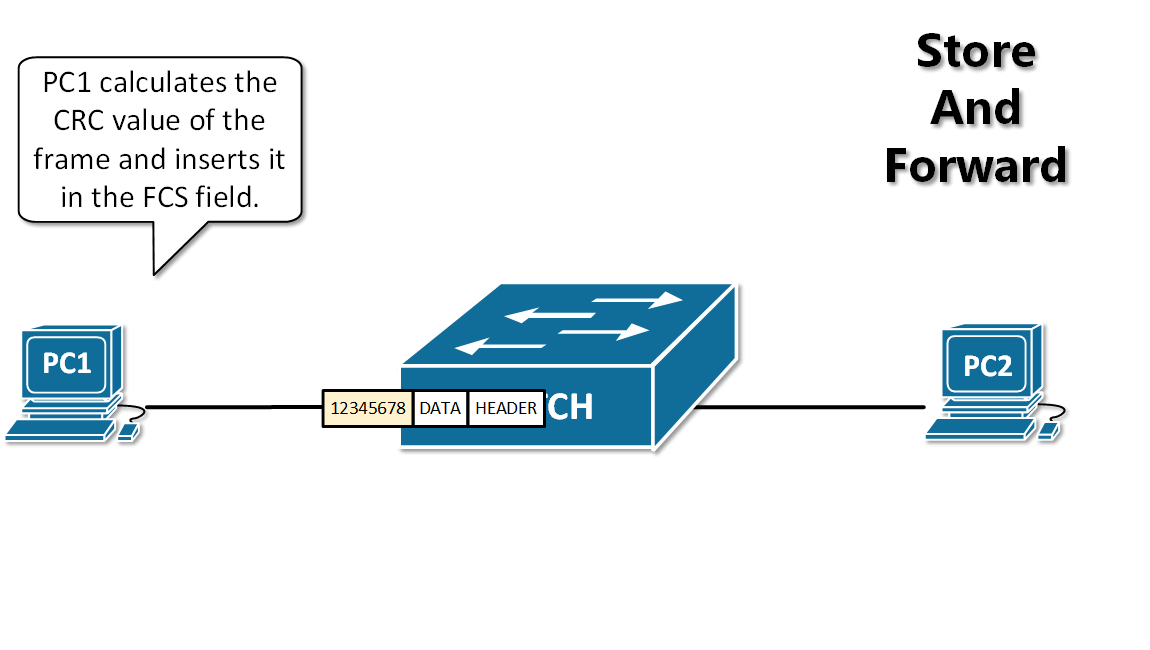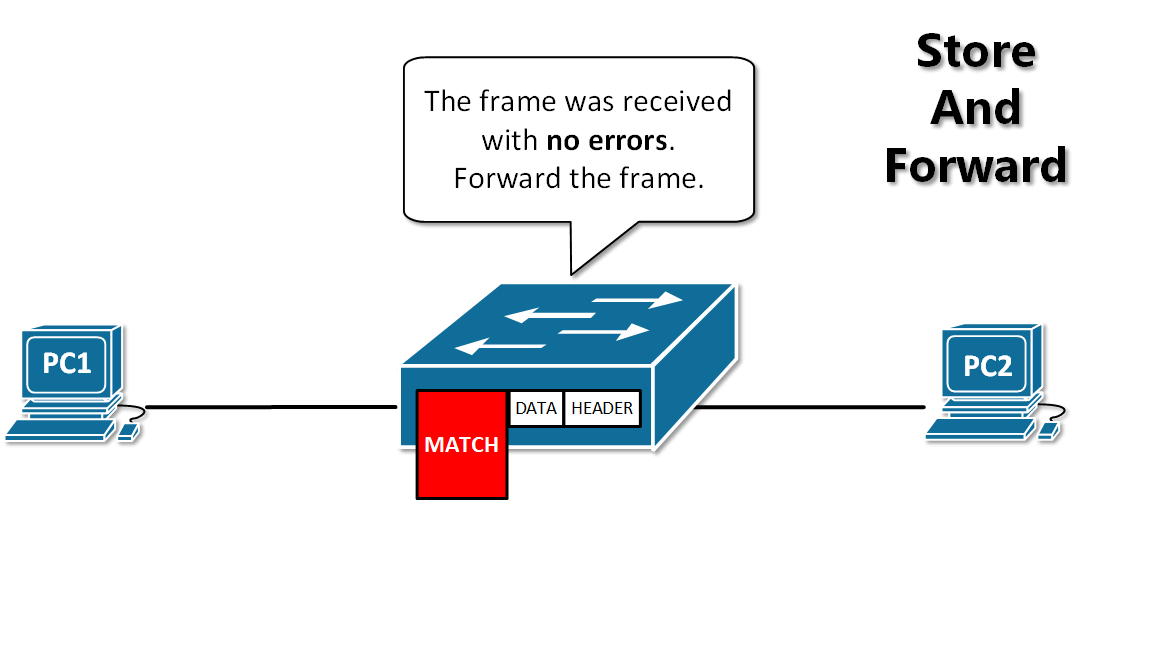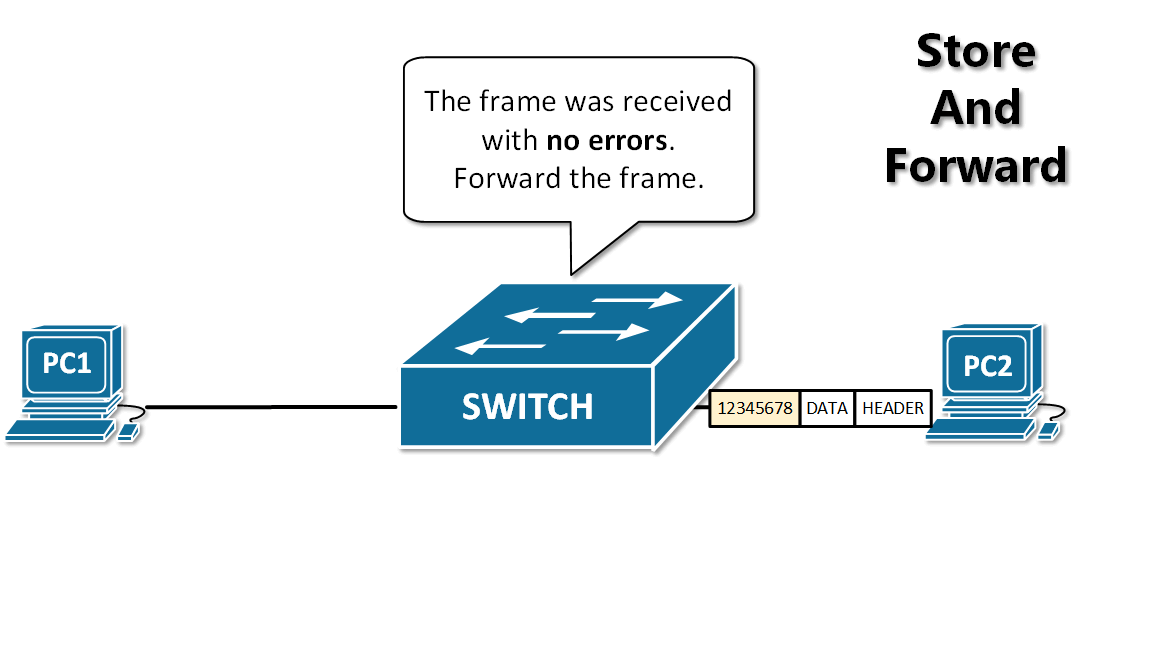
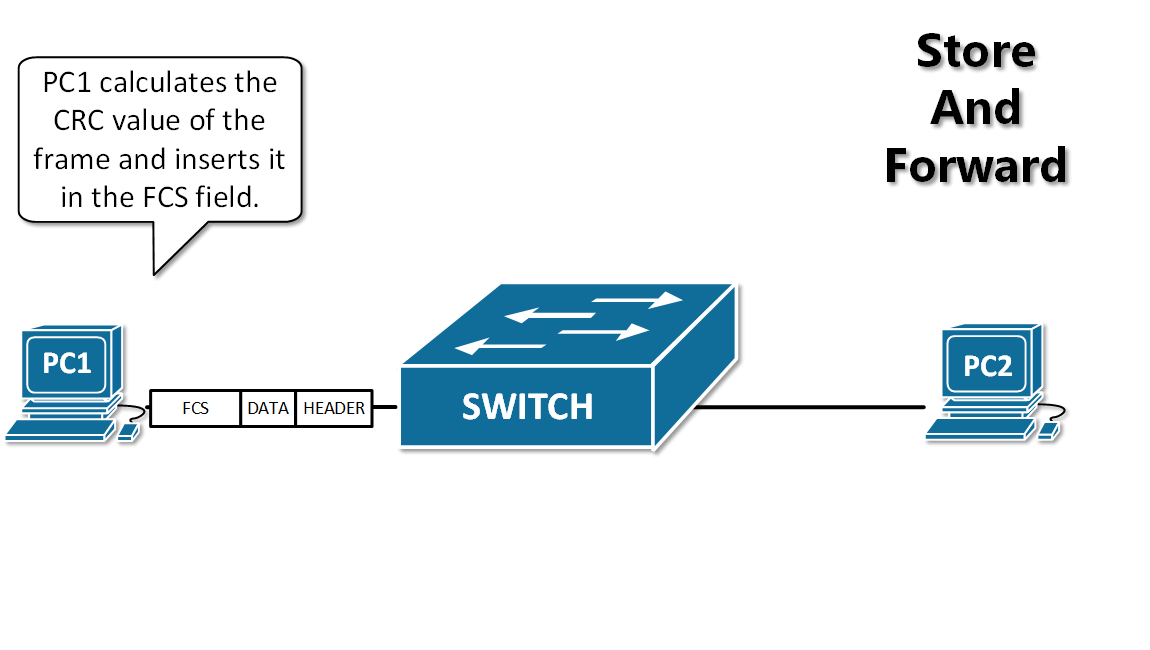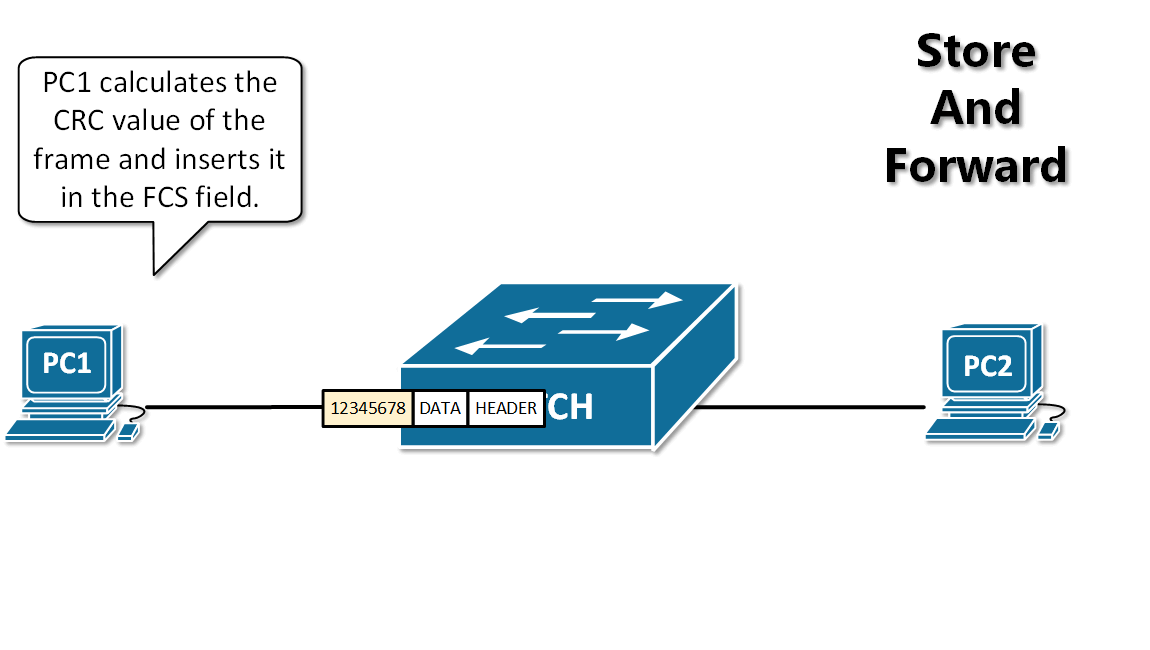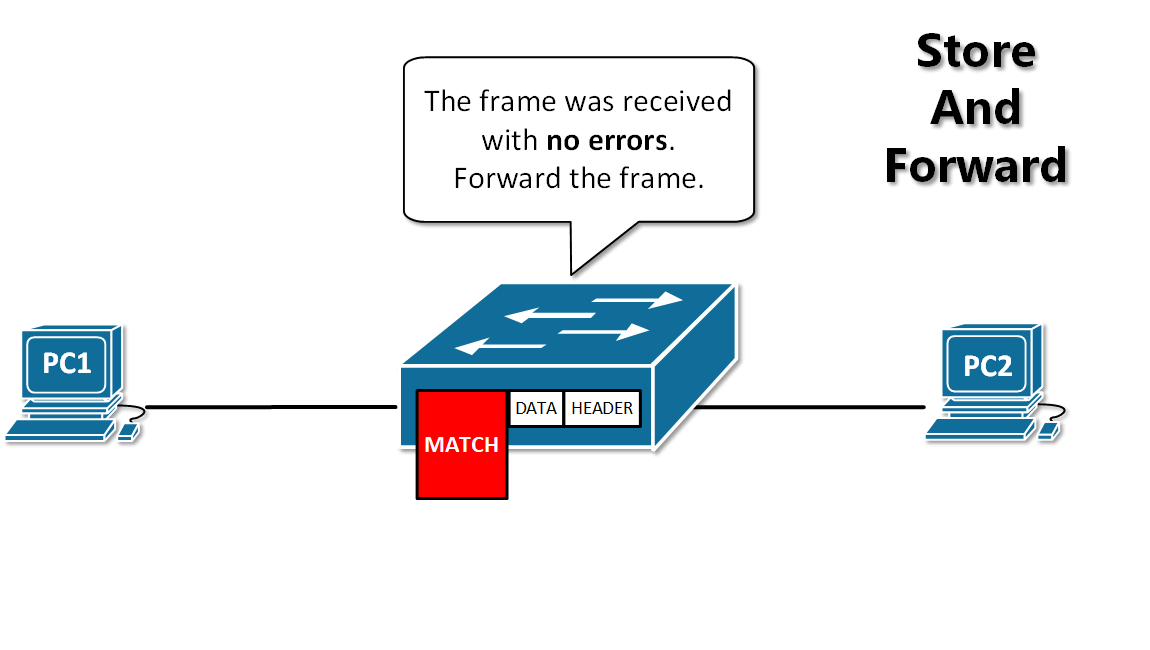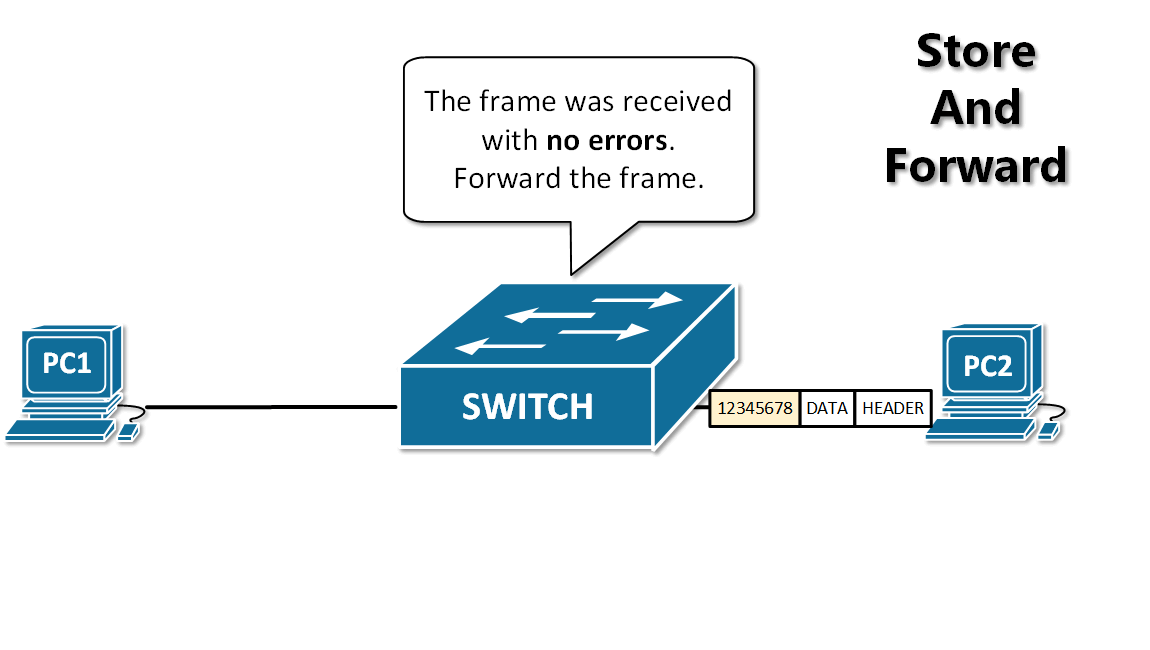
-13. **存储转发(store and forward )**:路由器收到一个分组,先检查分组是否正确,并过滤掉冲突包错误。确定包正确后,取出目的地址,通过查找表找到想要发送的输出端口地址,然后将该包发送出去。
+11. **分组(packet )**:因特网中传送的数据单元。由首部 header 和数据段组成。分组又称为包,首部可称为包头。
+12. **存储转发(store and forward )**:路由器收到一个分组,先检查分组是否正确,并过滤掉冲突包错误。确定包正确后,取出目的地址,通过查找表找到想要发送的输出端口地址,然后将该包发送出去。
-
+ 
-14. **带宽(bandwidth)**:在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为 b/s。
-15. **吞吐量(throughput )**:表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
+13. **带宽(bandwidth)**:在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为 b/s。
+14. **吞吐量(throughput )**:表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
### 1.2. 重要知识点总结
1. **计算机网络(简称网络)把许多计算机连接在一起,而互联网把许多网络连接在一起,是网络的网络。**
2. 小写字母 i 开头的 internet(互联网)是通用名词,它泛指由多个计算机网络相互连接而成的网络。在这些网络之间的通信协议(即通信规则)可以是任意的。大写字母 I 开头的 Internet(互联网)是专用名词,它指全球最大的,开放的,由众多网络相互连接而成的特定的互联网,并采用 TCP/IP 协议作为通信规则,其前身为 ARPANET。Internet 的推荐译名为因特网,现在一般流行称为互联网。
-3. 路由器是实现分组交换的关键构件,其任务是转发收到的分组,这是网络核心部分最重要的功能。分组交换采用存储转发技术,表示把一个报文(要发送的整块数据)分为几个分组后再进行传送。在发送报文之前,先把较长的报文划分成为一个个更小的等长数据段。在每个数据端的前面加上一些由必要的控制信息组成的首部后,就构成了一个分组。分组又称为包。分组是在互联网中传送的数据单元,正是由于分组的头部包含了诸如目的地址和源地址等重要控制信息,每一个分组才能在互联网中独立的选择传输路径,并正确地交付到分组传输的终点。
+3. 路由器是实现分组交换的关键构件,其任务是转发收到的分组,这是网络核心部分最重要的功能。分组交换采用存储转发技术,表示把一个报文(要发送的整块数据)分为几个分组后再进行传送。在发送报文之前,先把较长的报文划分成为一个个更小的等长数据段。在每个数据段的前面加上一些由必要的控制信息组成的首部后,就构成了一个分组。分组又称为包。分组是在互联网中传送的数据单元,正是由于分组的头部包含了诸如目的地址和源地址等重要控制信息,每一个分组才能在互联网中独立的选择传输路径,并正确地交付到分组传输的终点。
4. 互联网按工作方式可划分为边缘部分和核心部分。主机在网络的边缘部分,其作用是进行信息处理。由大量网络和连接这些网络的路由器组成核心部分,其作用是提供连通性和交换。
5. 计算机通信是计算机中进程(即运行着的程序)之间的通信。计算机网络采用的通信方式是客户-服务器方式(C/S 方式)和对等连接方式(P2P 方式)。
6. 客户和服务器都是指通信中所涉及的应用进程。客户是服务请求方,服务器是服务提供方。
@@ -64,44 +69,44 @@ tag:
9. 网络协议即协议,是为进行网络中的数据交换而建立的规则。计算机网络的各层以及其协议集合,称为网络的体系结构。
10. **五层体系结构由应用层,运输层,网络层(网际层),数据链路层,物理层组成。运输层最主要的协议是 TCP 和 UDP 协议,网络层最重要的协议是 IP 协议。**
-
+
下面的内容会介绍计算机网络的五层体系结构:**物理层+数据链路层+网络层(网际层)+运输层+应用层**。
## 2. 物理层(Physical Layer)
-
+
### 2.1. 基本术语
-1. **数据(data)** :运送消息的实体。
+1. **数据(data)**:运送消息的实体。
2. **信号(signal)**:数据的电气的或电磁的表现。或者说信号是适合在传输介质上传输的对象。
3. **码元( code)**:在使用时间域(或简称为时域)的波形来表示数字信号时,代表不同离散数值的基本波形。
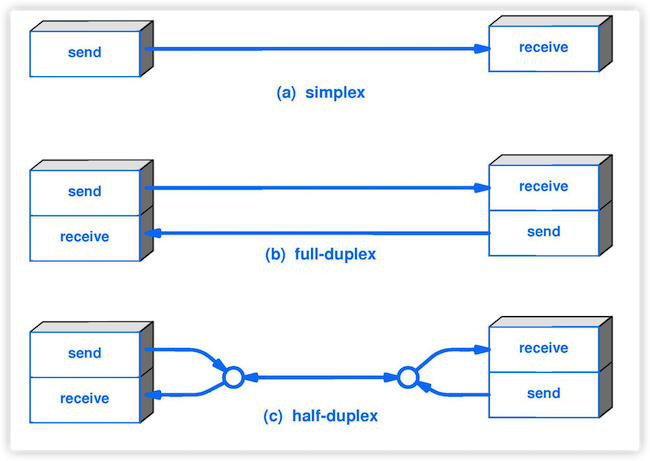
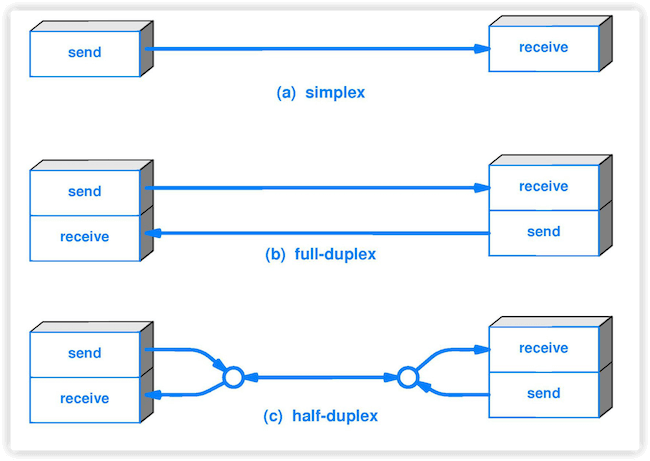
-4. **单工(simplex )** : 只能有一个方向的通信而没有反方向的交互。
+4. **单工(simplex )**:只能有一个方向的通信而没有反方向的交互。
5. **半双工(half duplex )**:通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
-6. **全双工(full duplex)** : 通信的双方可以同时发送和接收信息。
+6. **全双工(full duplex)**:通信的双方可以同时发送和接收信息。
-
+ 
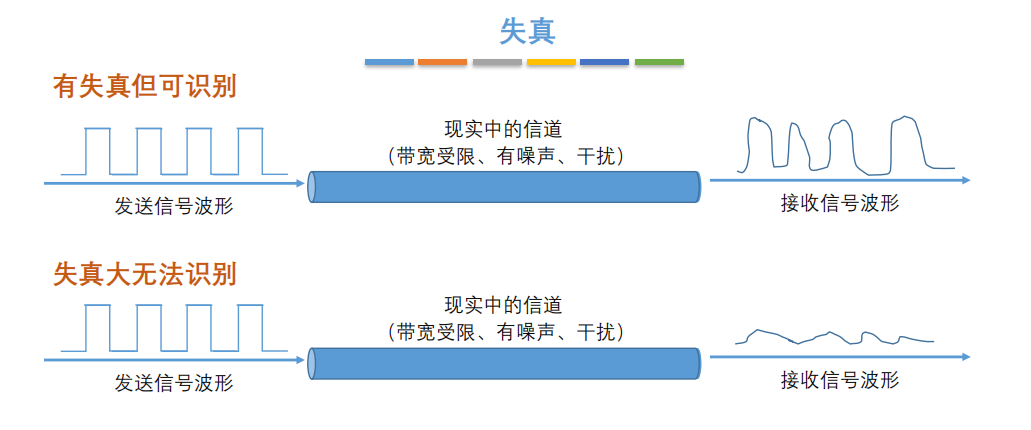
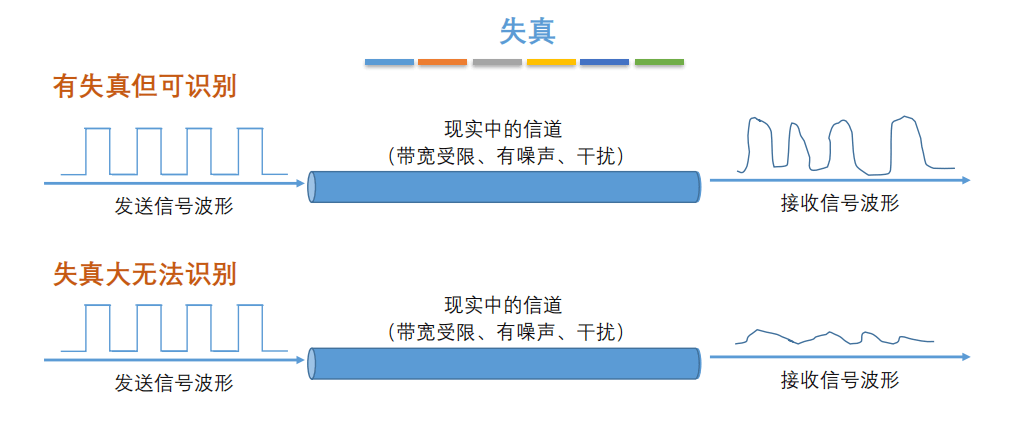
7. **失真**:失去真实性,主要是指接受到的信号和发送的信号不同,有磨损和衰减。影响失真程度的因素:1.码元传输速率 2.信号传输距离 3.噪声干扰 4.传输媒体质量
-
+ 
-8. **奈氏准则** : 在任何信道中,码元的传输的效率是有上限的,传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的判决(即识别)成为不可能。
+8. **奈氏准则**:在任何信道中,码元的传输的效率是有上限的,传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的判决(即识别)成为不可能。
9. **香农定理**:在带宽受限且有噪声的信道中,为了不产生误差,信息的数据传输速率有上限值。
-10. **基带信号(baseband signal)** : 来自信源的信号。指没有经过调制的数字信号或模拟信号。
+10. **基带信号(baseband signal)**:来自信源的信号。指没有经过调制的数字信号或模拟信号。
11. **带通(频带)信号(bandpass signal)**:把基带信号经过载波调制后,把信号的频率范围搬移到较高的频段以便在信道中传输(即仅在一段频率范围内能够通过信道),这里调制过后的信号就是带通信号。
-12. **调制(modulation )** : 对信号源的信息进行处理后加到载波信号上,使其变为适合在信道传输的形式的过程。
-13. **信噪比(signal-to-noise ratio )** : 指信号的平均功率和噪声的平均功率之比,记为 S/N。信噪比(dB)=10\*log10(S/N)。
+12. **调制(modulation )**:对信号源的信息进行处理后加到载波信号上,使其变为适合在信道传输的形式的过程。
+13. **信噪比(signal-to-noise ratio )**:指信号的平均功率和噪声的平均功率之比,记为 S/N。信噪比(dB)=10\*log10(S/N)。
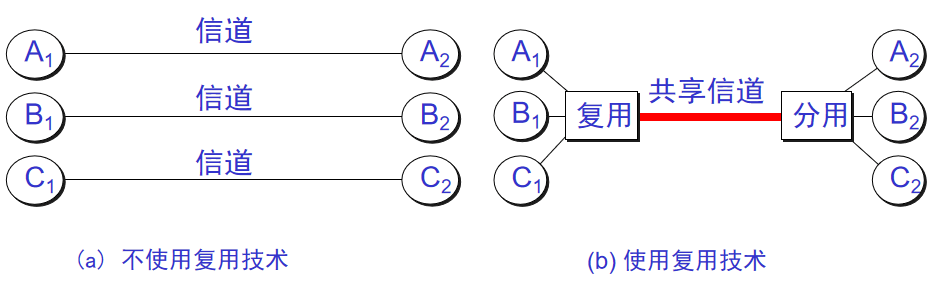
14. **信道复用(channel multiplexing )**:指多个用户共享同一个信道。(并不一定是同时)。
-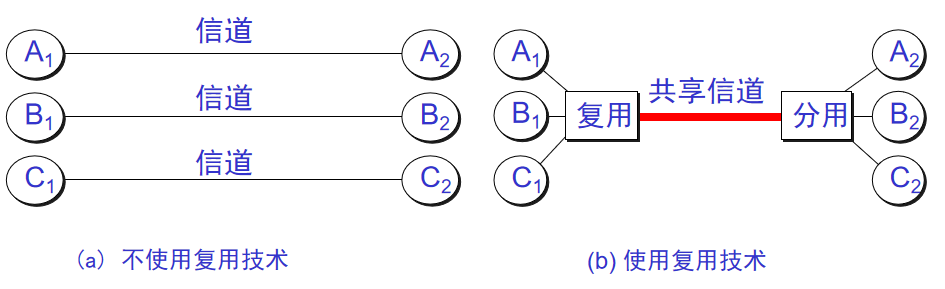
+ 
15. **比特率(bit rate )**:单位时间(每秒)内传送的比特数。
16. **波特率(baud rate)**:单位时间载波调制状态改变的次数。针对数据信号对载波的调制速率。
17. **复用(multiplexing)**:共享信道的方法。
18. **ADSL(Asymmetric Digital Subscriber Line )**:非对称数字用户线。
-19. **光纤同轴混合网(HFC 网)** :在目前覆盖范围很广的有线电视网的基础上开发的一种居民宽带接入网
+19. **光纤同轴混合网(HFC 网)**:在目前覆盖范围很广的有线电视网的基础上开发的一种居民宽带接入网
### 2.2. 重要知识点总结
@@ -137,7 +142,7 @@ tag:
## 3. 数据链路层(Data Link Layer)
-
+
### 3.1. 基本术语
@@ -145,13 +150,13 @@ tag:
2. **数据链路(data link)**:把实现控制数据运输的协议的硬件和软件加到链路上就构成了数据链路。
3. **循环冗余检验 CRC(Cyclic Redundancy Check)**:为了保证数据传输的可靠性,CRC 是数据链路层广泛使用的一种检错技术。
4. **帧(frame)**:一个数据链路层的传输单元,由一个数据链路层首部和其携带的封包所组成协议数据单元。
-5. **MTU(Maximum Transfer Uint )**:最大传送单元。帧的数据部分的的长度上限。
+5. **MTU(Maximum Transfer Uint )**:最大传送单元。帧的数据部分的长度上限。
6. **误码率 BER(Bit Error Rate )**:在一段时间内,传输错误的比特占所传输比特总数的比率。
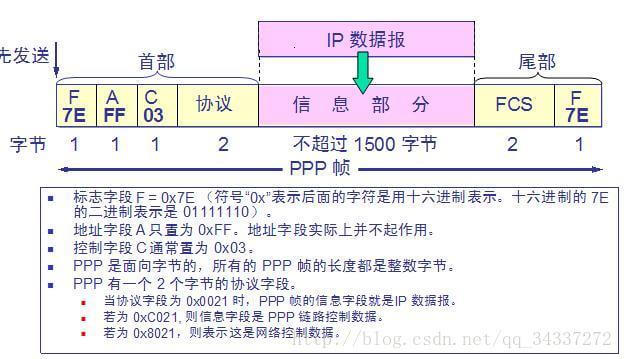
7. **PPP(Point-to-Point Protocol )**:点对点协议。即用户计算机和 ISP 进行通信时所使用的数据链路层协议。以下是 PPP 帧的示意图:
- 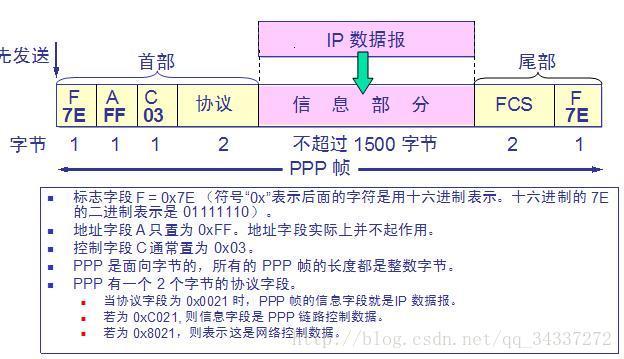
+ 
8. **MAC 地址(Media Access Control 或者 Medium Access Control)**:意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。在 OSI 模型中,第三层网络层负责 IP 地址,第二层数据链路层则负责 MAC 地址。因此一个主机会有一个 MAC 地址,而每个网络位置会有一个专属于它的 IP 地址 。地址是识别某个系统的重要标识符,“名字指出我们所要寻找的资源,地址指出资源所在的地方,路由告诉我们如何到达该处。”
-
+ 
9. **网桥(bridge)**:一种用于数据链路层实现中继,连接两个或多个局域网的网络互连设备。
10. **交换机(switch )**:广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
@@ -180,7 +185,7 @@ tag:
## 4. 网络层(Network Layer)
-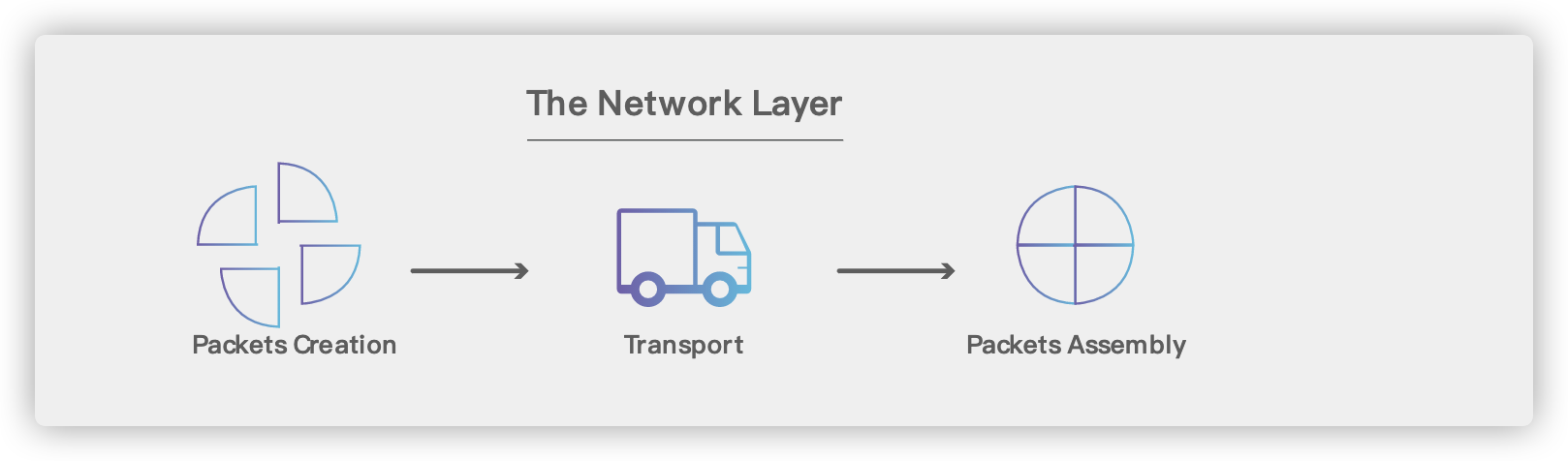
+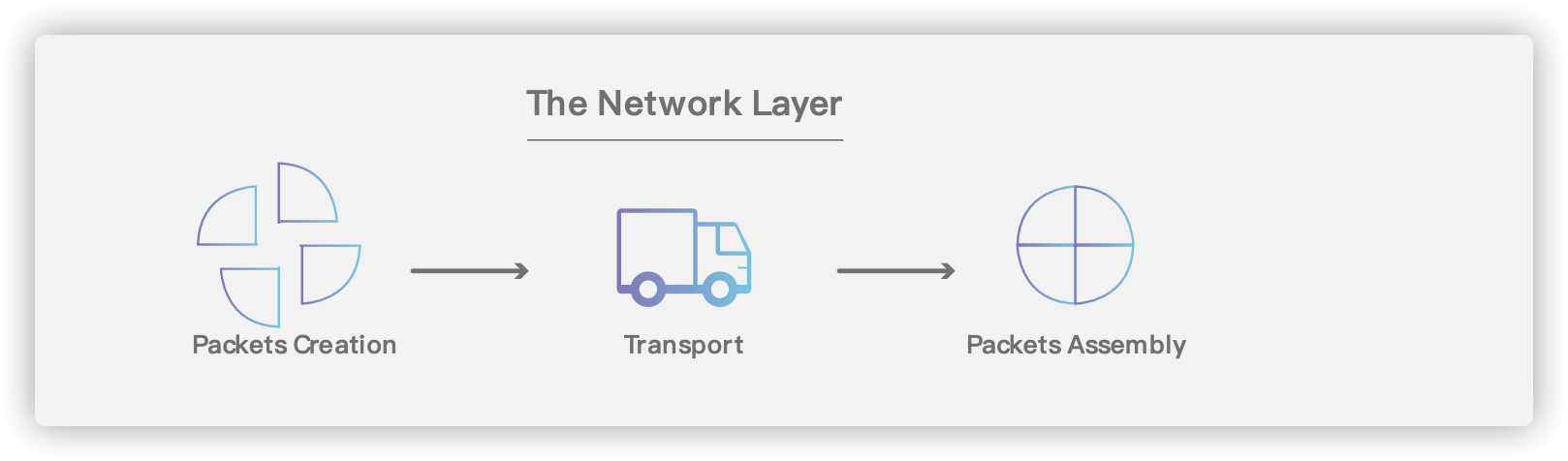
### 4.1. 基本术语
@@ -191,11 +196,11 @@ tag:
5. **子网掩码(subnet mask )**:它是一种用来指明一个 IP 地址的哪些位标识的是主机所在的子网以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合 IP 地址一起使用。
6. **CIDR( Classless Inter-Domain Routing )**:无分类域间路由选择 (特点是消除了传统的 A 类、B 类和 C 类地址以及划分子网的概念,并使用各种长度的“网络前缀”(network-prefix)来代替分类地址中的网络号和子网号)。
7. **默认路由(default route)**:当在路由表中查不到能到达目的地址的路由时,路由器选择的路由。默认路由还可以减小路由表所占用的空间和搜索路由表所用的时间。
-8. **路由选择算法(Virtual Circuit)**:路由选择协议的核心部分。因特网采用自适应的,分层次的路由选择协议。
+8. **路由选择算法(Routing Algorithm)**:路由选择协议的核心部分。因特网采用自适应的,分层次的路由选择协议。
### 4.2. 重要知识点总结
-1. **TCP/IP 协议中的网络层向上只提供简单灵活的,无连接的,尽最大努力交付的数据报服务。网络层不提供服务质量的承诺,不保证分组交付的时限所传送的分组可能出错,丢失,重复和失序。进程之间通信的可靠性由运输层负责**
+1. **TCP/IP 协议中的网络层向上只提供简单灵活的,无连接的,尽最大努力交付的数据报服务。网络层不提供服务质量的承诺,不保证分组交付的时限,所传送的分组可能出错、丢失、重复和失序。进程之间通信的可靠性由运输层负责**
2. 在互联网的交付有两种,一是在本网络直接交付不用经过路由器,另一种是和其他网络的间接交付,至少经过一个路由器,但最后一次一定是直接交付
3. 分类的 IP 地址由网络号字段(指明网络)和主机号字段(指明主机)组成。网络号字段最前面的类别指明 IP 地址的类别。IP 地址是一种分等级的地址结构。IP 地址管理机构分配 IP 地址时只分配网络号,主机号由得到该网络号的单位自行分配。路由器根据目的主机所连接的网络号来转发分组。一个路由器至少连接到两个网络,所以一个路由器至少应当有两个不同的 IP 地址
4. IP 数据报分为首部和数据两部分。首部的前一部分是固定长度,共 20 字节,是所有 IP 数据包必须具有的(源地址,目的地址,总长度等重要地段都固定在首部)。一些长度可变的可选字段固定在首部的后面。IP 首部中的生存时间给出了 IP 数据报在互联网中所能经过的最大路由器数。可防止 IP 数据报在互联网中无限制的兜圈子。
@@ -208,7 +213,7 @@ tag:
## 5. 传输层(Transport Layer)
-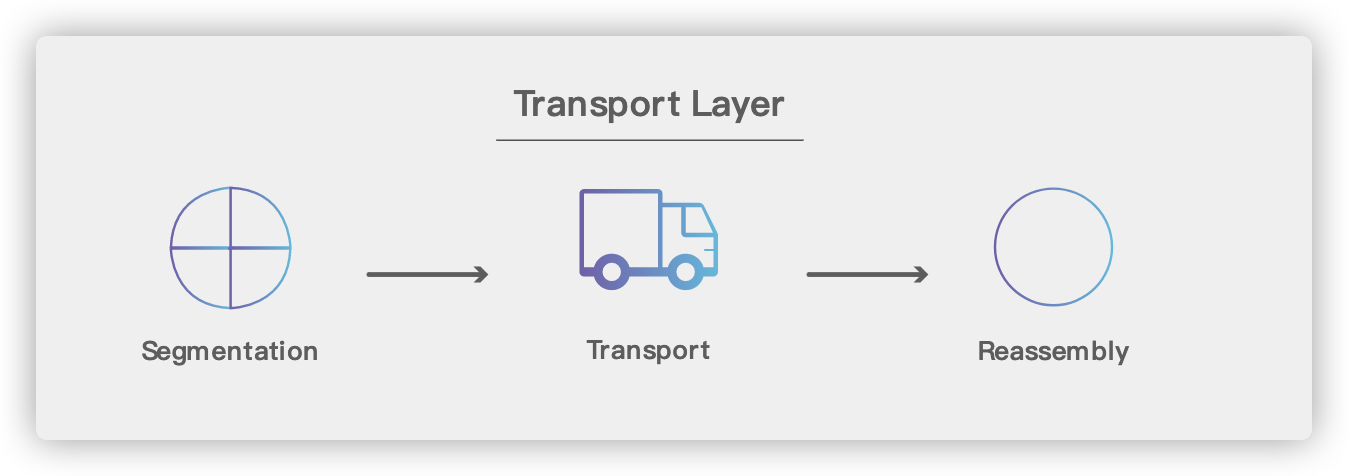
+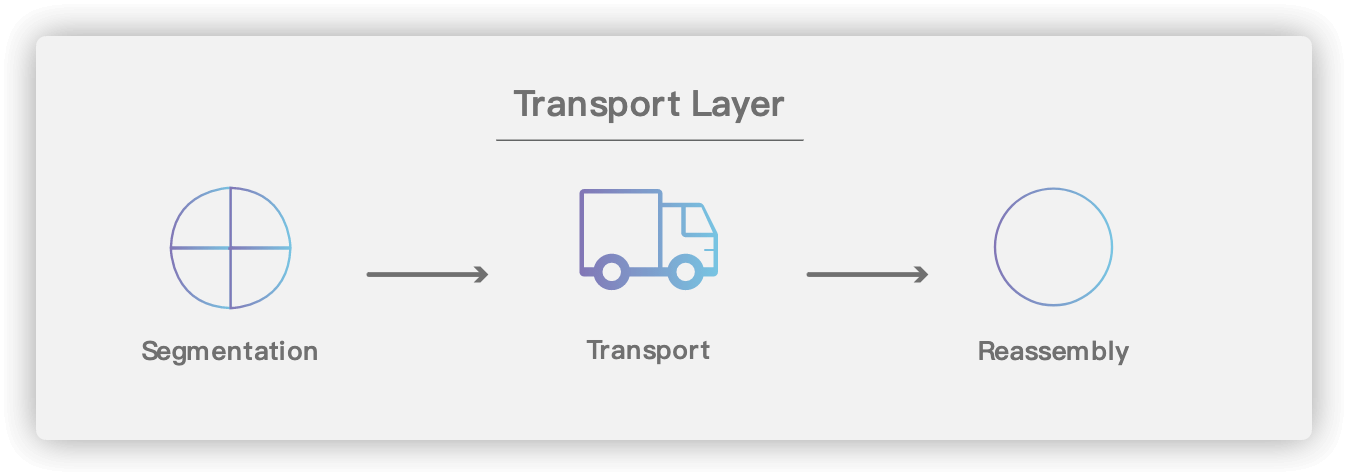
### 5.1. 基本术语
@@ -218,7 +223,7 @@ tag:
4. **TCP(Transmission Control Protocol)**:传输控制协议。
5. **UDP(User Datagram Protocol)**:用户数据报协议。
-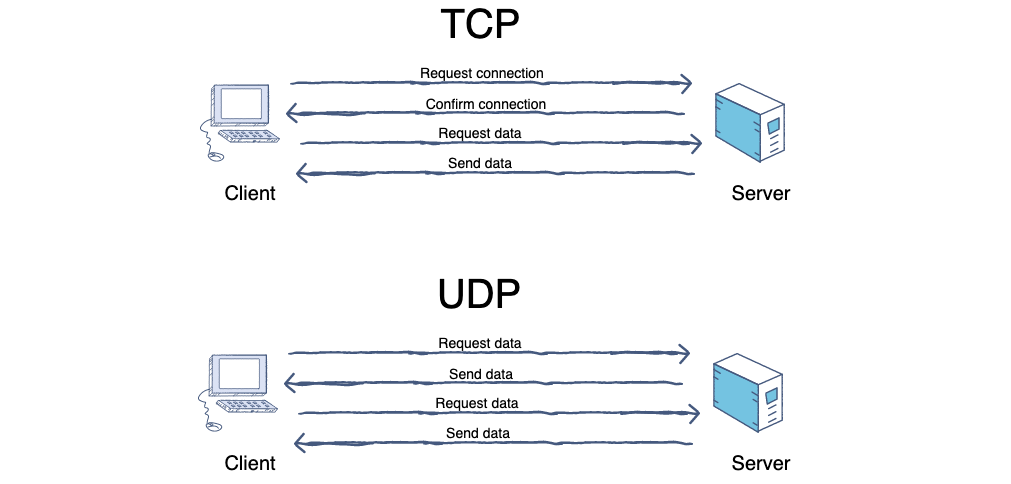
+ 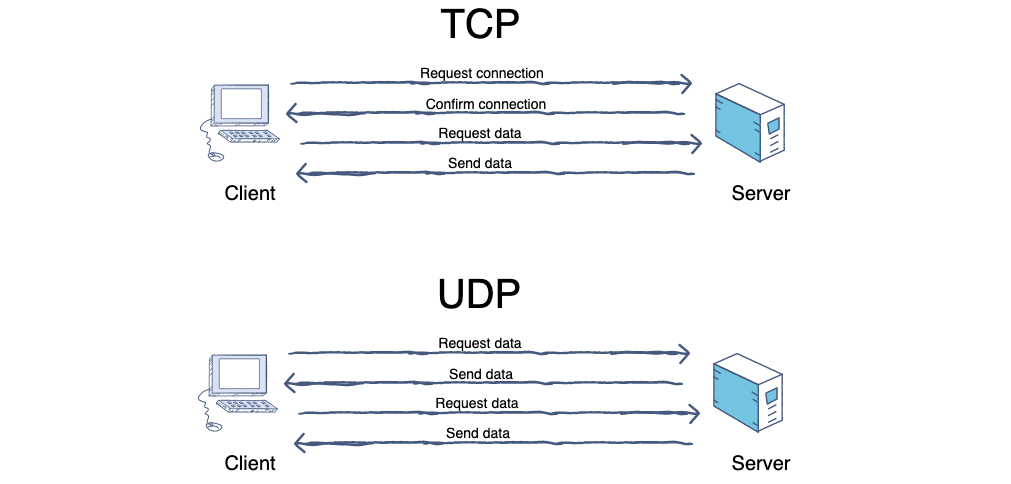
6. **端口(port)**:端口的目的是为了确认对方机器的哪个进程在与自己进行交互,比如 MSN 和 QQ 的端口不同,如果没有端口就可能出现 QQ 进程和 MSN 交互错误。端口又称协议端口号。
7. **停止等待协议(stop-and-wait)**:指发送方每发送完一个分组就停止发送,等待对方确认,在收到确认之后在发送下一个分组。
@@ -261,45 +266,43 @@ tag:
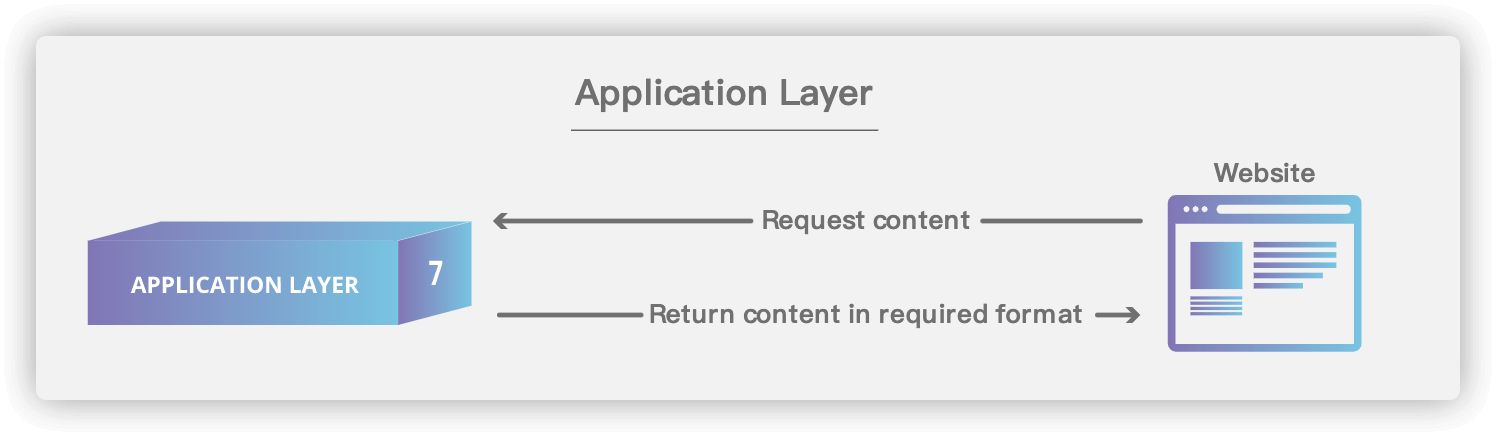
## 6. 应用层(Application Layer)
-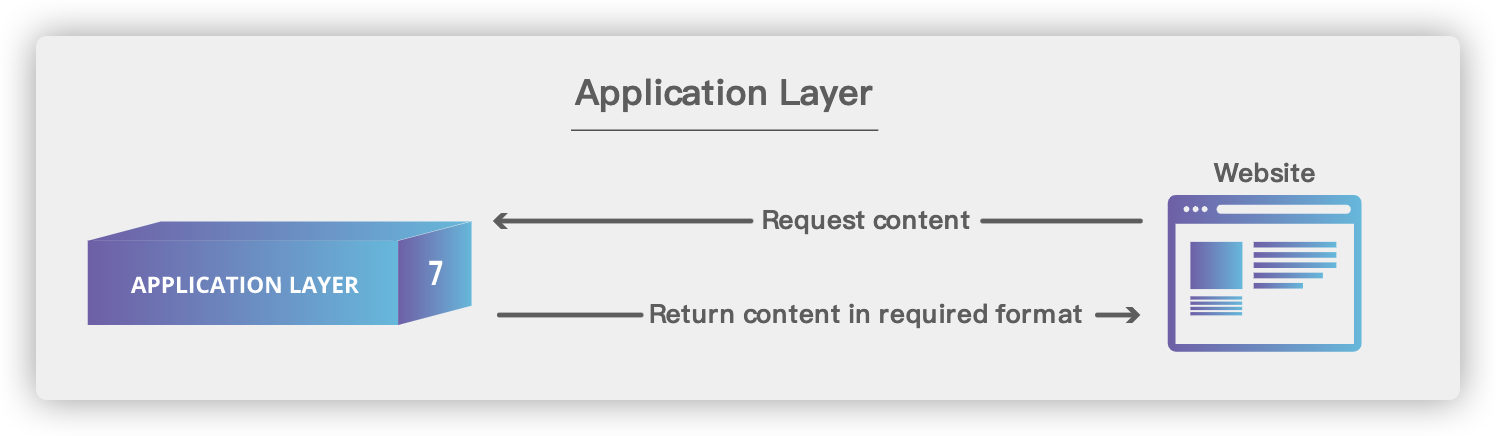
+
### 6.1. 基本术语
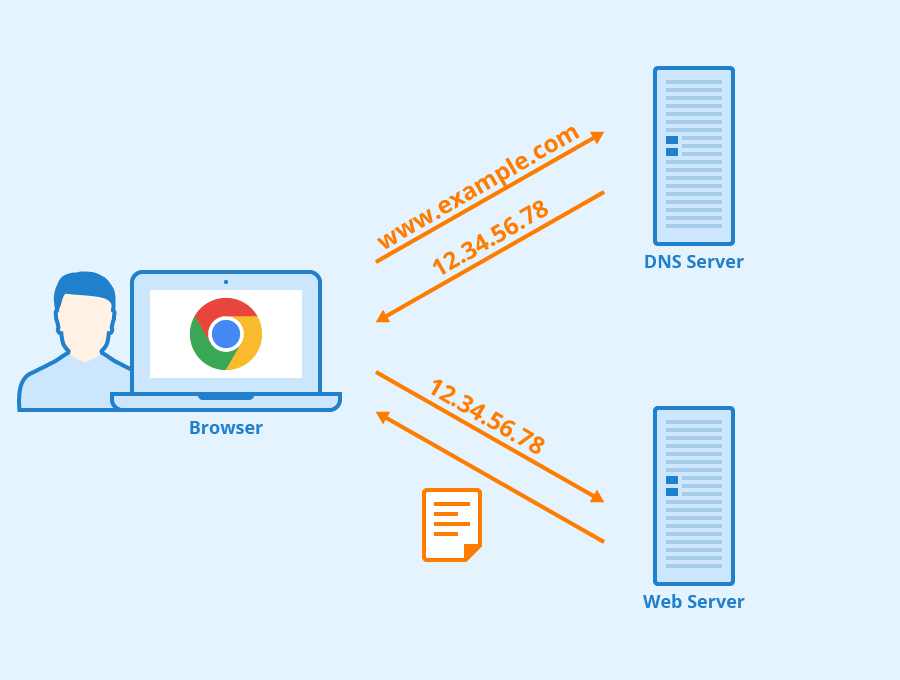
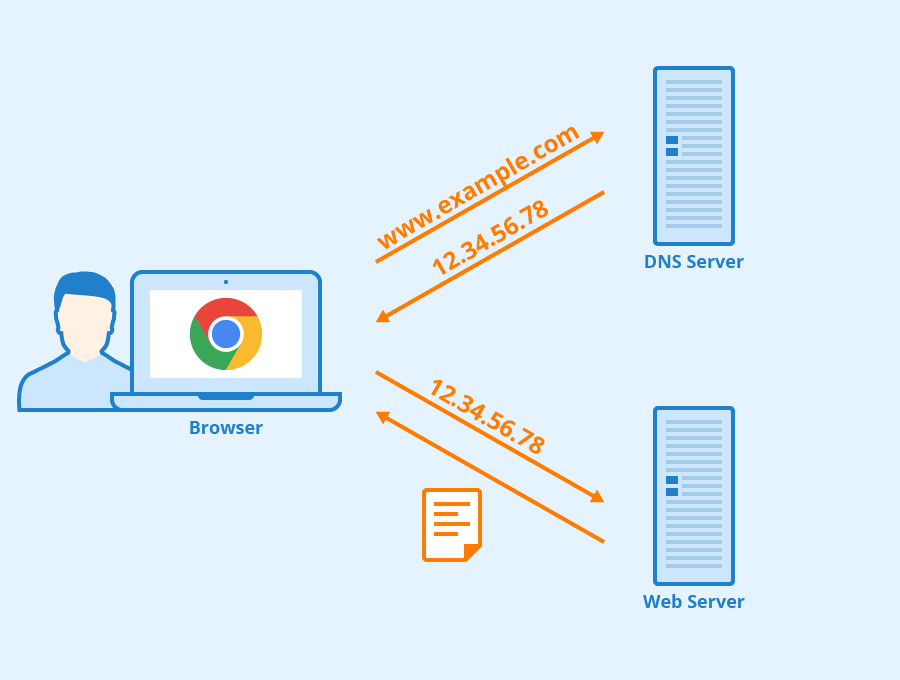
1. **域名系统(DNS)**:域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。我们可以将其理解为专为互联网设计的电话薄。
-
+ 
-https://www.seobility.net/en/wiki/HTTP_headers
+ https://www.seobility.net/en/wiki/HTTP_headers
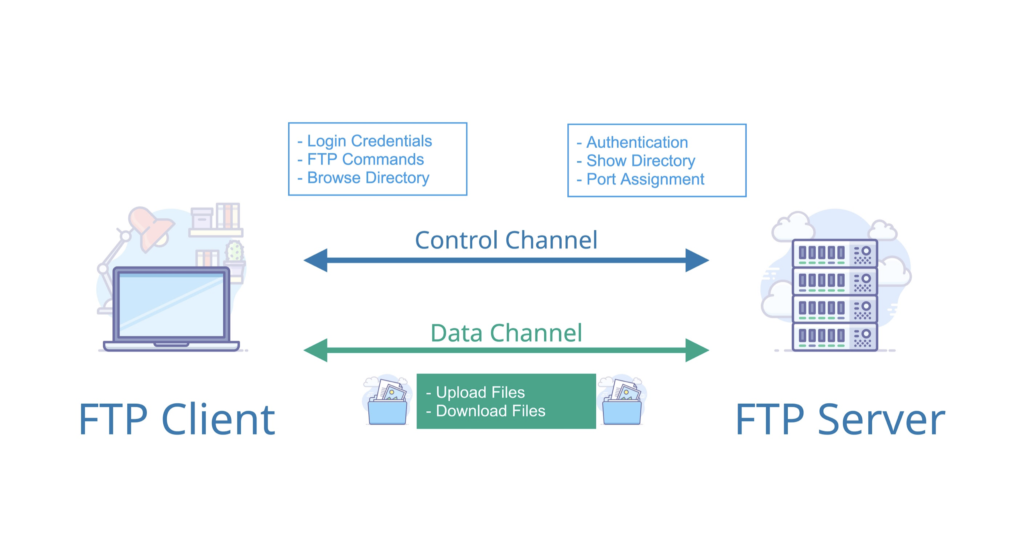
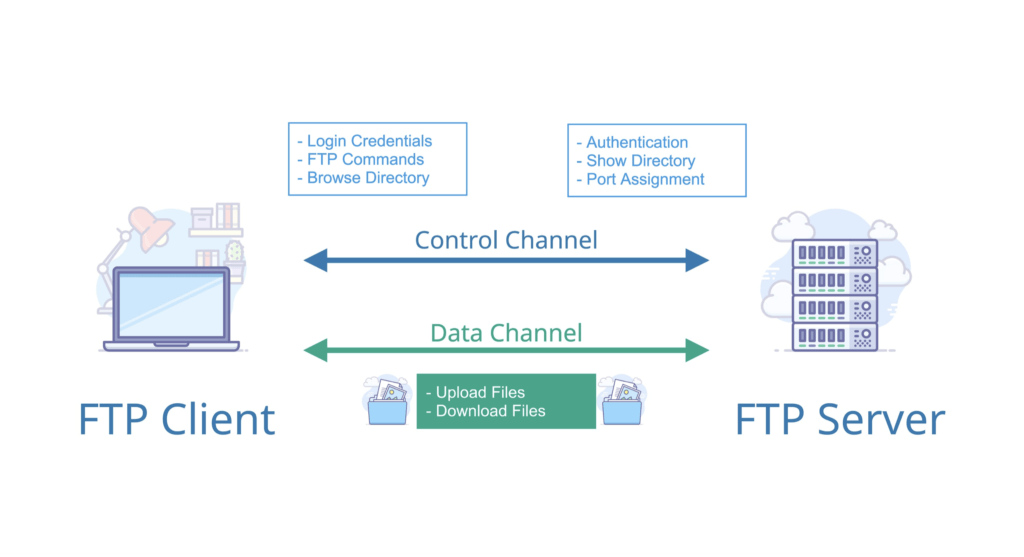
2. **文件传输协议(FTP)**:FTP 是 File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于 Internet 上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的 FTP 应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在 FTP 的使用当中,用户经常遇到两个概念:"下载"(Download)和"上传"(Upload)。 "下载"文件就是从远程主机拷贝文件至自己的计算机上;"上传"文件就是将文件从自己的计算机中拷贝至远程主机上。用 Internet 语言来说,用户可通过客户机程序向(从)远程主机上传(下载)文件。
-
+ 
3. **简单文件传输协议(TFTP)**:TFTP(Trivial File Transfer Protocol,简单文件传输协议)是 TCP/IP 协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。端口号为 69。
4. **远程终端协议(TELNET)**:Telnet 协议是 TCP/IP 协议族中的一员,是 Internet 远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用 telnet 程序,用它连接到服务器。终端使用者可以在 telnet 程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个 telnet 会话,必须输入用户名和密码来登录服务器。Telnet 是常用的远程控制 Web 服务器的方法。
5. **万维网(WWW)**:WWW 是环球信息网的缩写,(亦作“Web”、“WWW”、“'W3'”,英文全称为“World Wide Web”),中文名字为“万维网”,"环球网"等,常简称为 Web。分为 Web 客户端和 Web 服务器程序。WWW 可以让 Web 客户端(常用浏览器)访问浏览 Web 服务器上的页面。是一个由许多互相链接的超文本组成的系统,通过互联网访问。在这个系统中,每个有用的事物,称为一样“资源”;并且由一个全局“统一资源标识符”(URI)标识;这些资源通过超文本传输协议(Hypertext Transfer Protocol)传送给用户,而后者通过点击链接来获得资源。万维网联盟(英语:World Wide Web Consortium,简称 W3C),又称 W3C 理事会。1994 年 10 月在麻省理工学院(MIT)计算机科学实验室成立。万维网联盟的创建者是万维网的发明者蒂姆·伯纳斯-李。万维网并不等同互联网,万维网只是互联网所能提供的服务其中之一,是靠着互联网运行的一项服务。
6. **万维网的大致工作工程:**
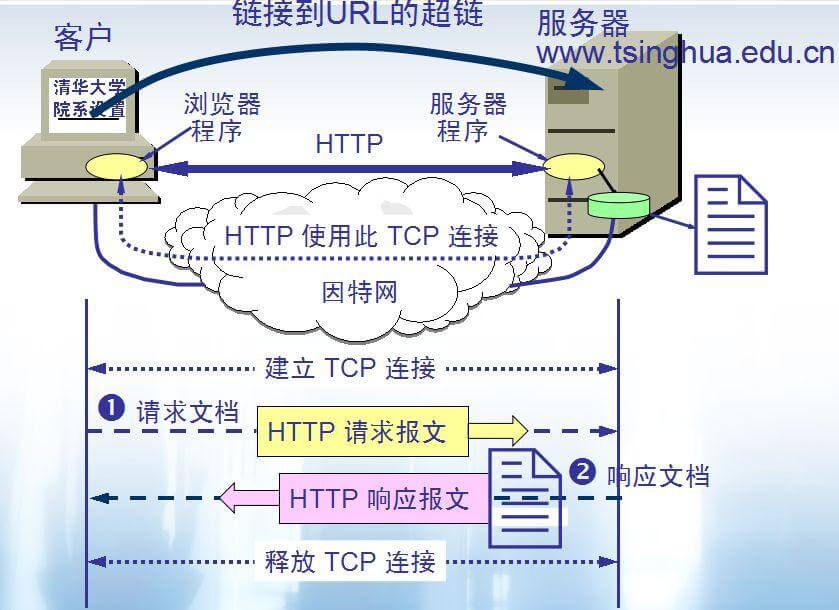
-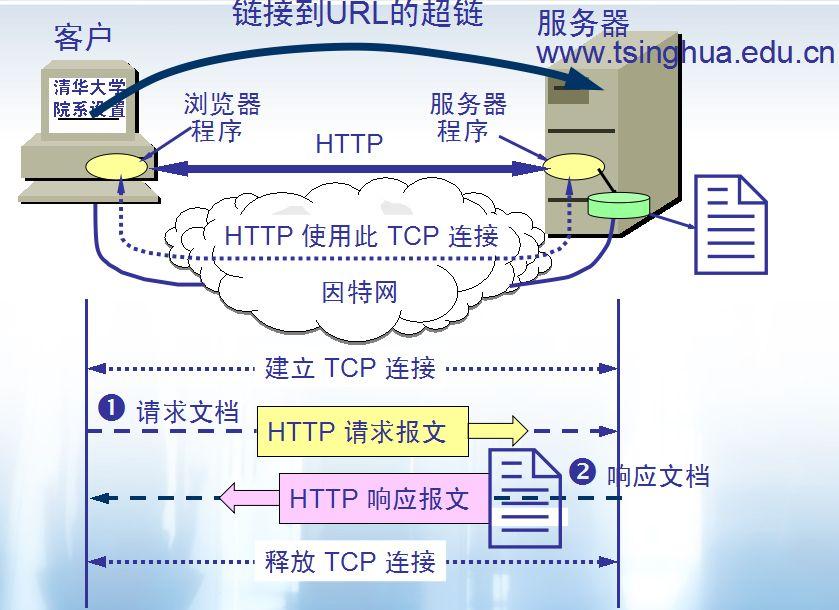
+ 
7. **统一资源定位符(URL)**:统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
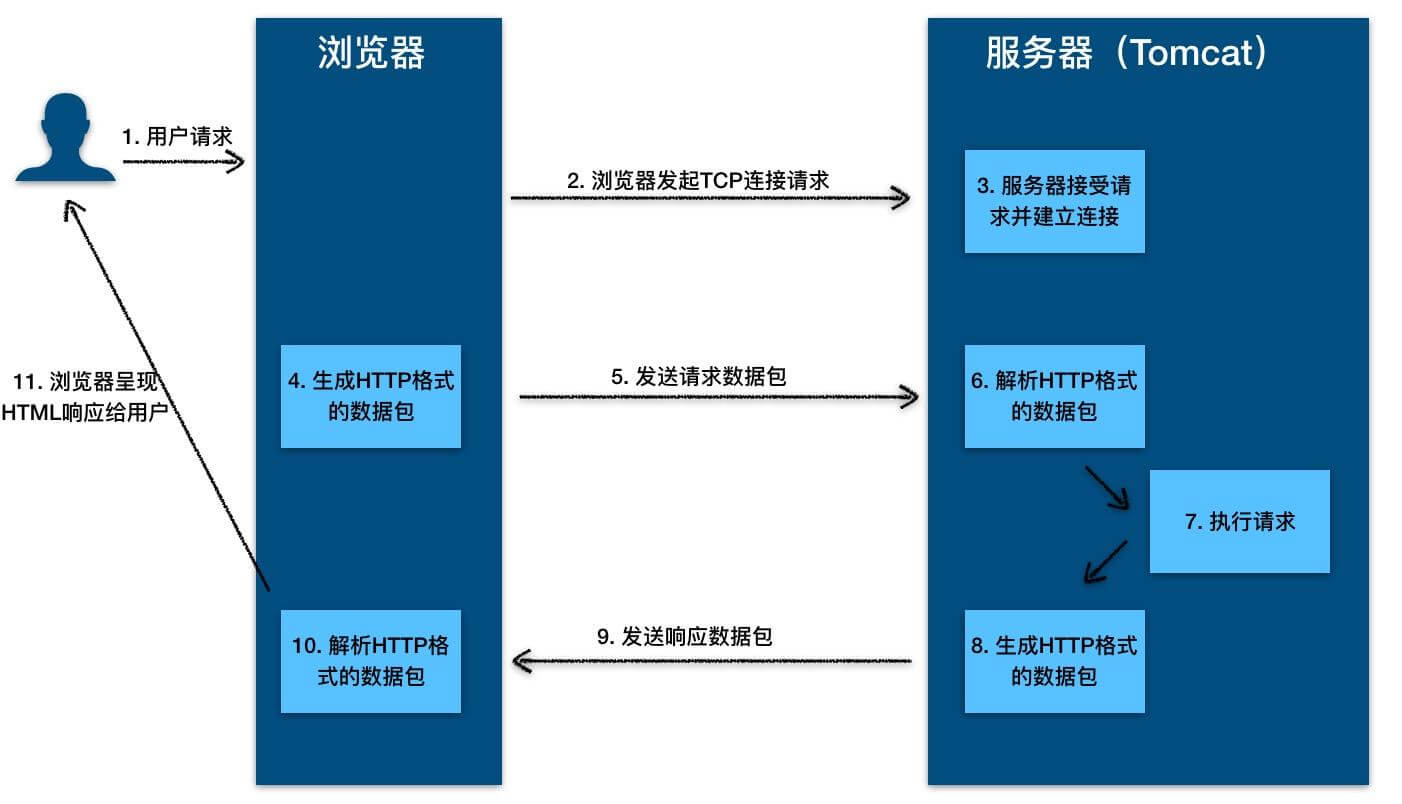
8. **超文本传输协议(HTTP)**:超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。1960 年美国人 Ted Nelson 构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了 HTTP 超文本传输协议标准架构的发展根基。
-HTTP 协议的本质就是一种浏览器与服务器之间约定好的通信格式。HTTP 的原理如下图所示:
+ HTTP 协议的本质就是一种浏览器与服务器之间约定好的通信格式。HTTP 的原理如下图所示:
-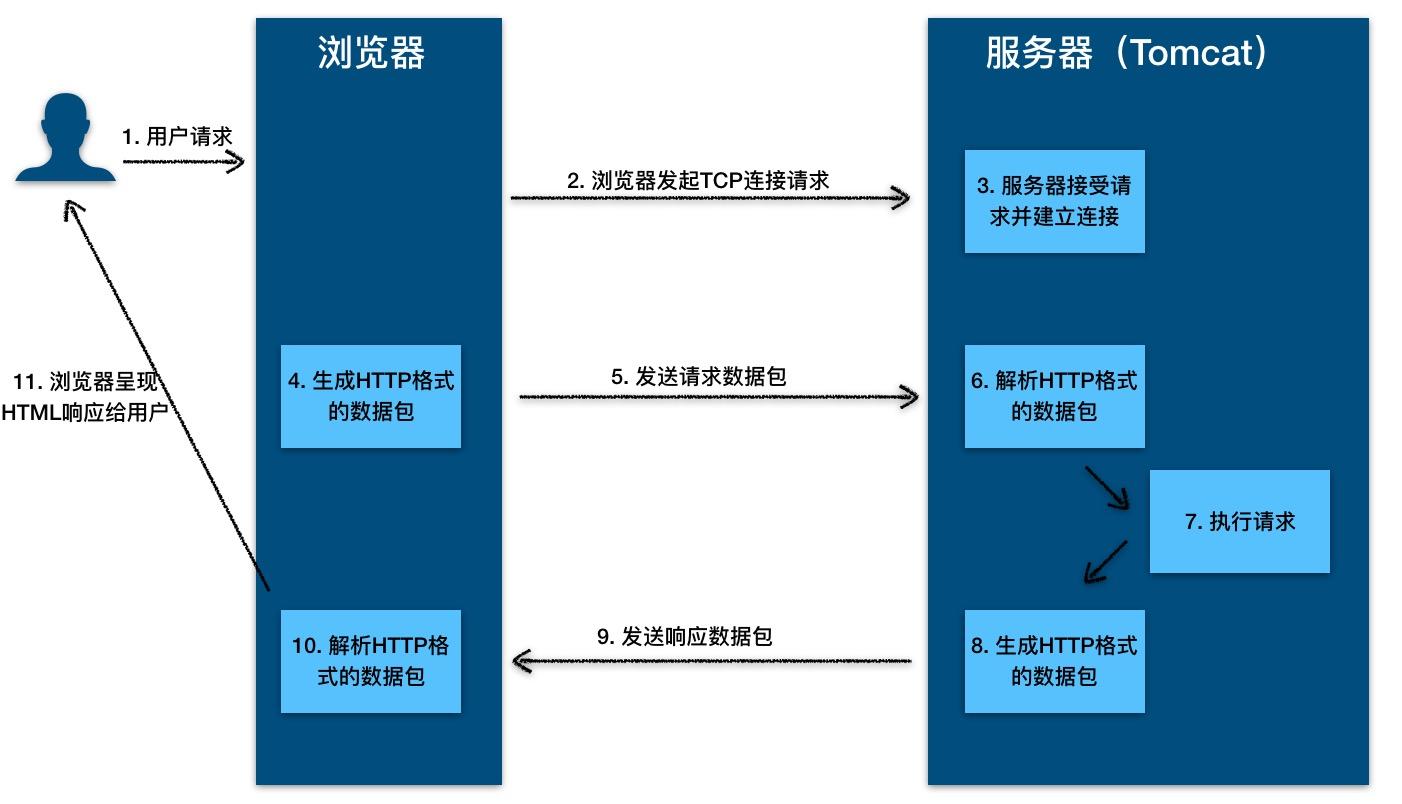
+ 
-10. **代理服务器(Proxy Server)**:代理服务器(Proxy Server)是一种网络实体,它又称为万维网高速缓存。 代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的的请求相同,就返回暂存的响应,而不需要按 URL 的地址再次去互联网访问该资源。代理服务器可在客户端或服务器工作,也可以在中间系统工作。
-11. **简单邮件传输协议(SMTP)** : SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。 SMTP 协议属于 TCP/IP 协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。 通过 SMTP 协议所指定的服务器,就可以把 E-mail 寄到收信人的服务器上了,整个过程只要几分钟。SMTP 服务器则是遵循 SMTP 协议的发送邮件服务器,用来发送或中转发出的电子邮件。
+9. **代理服务器(Proxy Server)**:代理服务器(Proxy Server)是一种网络实体,它又称为万维网高速缓存。 代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的请求相同,就返回暂存的响应,而不需要按 URL 的地址再次去互联网访问该资源。代理服务器可在客户端或服务器工作,也可以在中间系统工作。
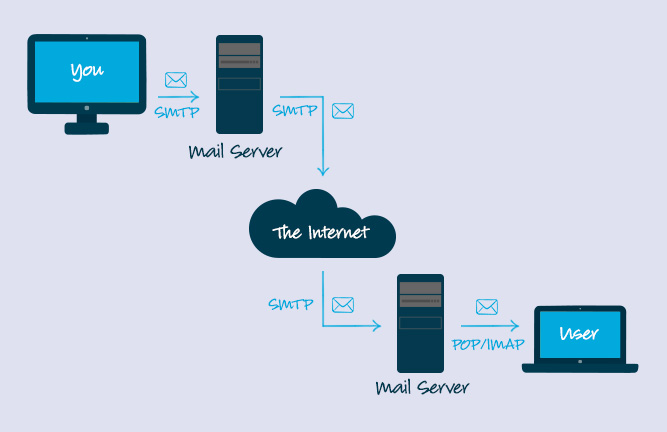
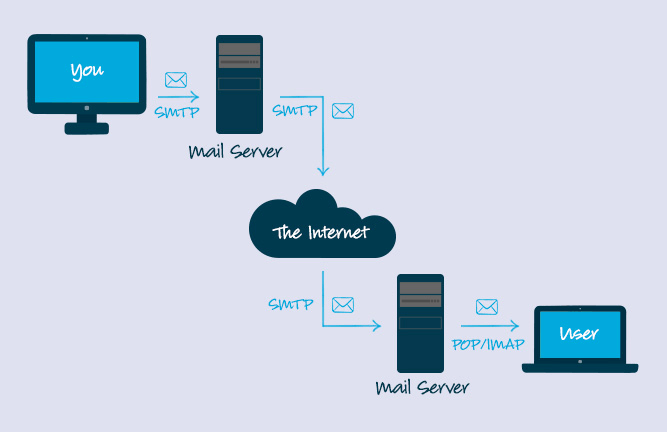
+10. **简单邮件传输协议(SMTP)** : SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。 SMTP 协议属于 TCP/IP 协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。 通过 SMTP 协议所指定的服务器,就可以把 E-mail 寄到收信人的服务器上了,整个过程只要几分钟。SMTP 服务器则是遵循 SMTP 协议的发送邮件服务器,用来发送或中转发出的电子邮件。
-
+ 
-https://www.campaignmonitor.com/resources/knowledge-base/what-is-the-code-that-makes-bcc-or-cc-operate-in-an-email/
+ https://www.campaignmonitor.com/resources/knowledge-base/what-is-the-code-that-makes-bcc-or-cc-operate-in-an-email/
11. **搜索引擎** :搜索引擎(Search Engine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
-
-
12. **垂直搜索引擎**:垂直搜索引擎是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。垂直搜索是相对通用搜索引擎的信息量大、查询不准确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。
13. **全文索引** :全文索引技术是目前搜索引擎的关键技术。试想在 1M 大小的文件中搜索一个词,可能需要几秒,在 100M 的文件中可能需要几十秒,如果在更大的文件中搜索那么就需要更大的系统开销,这样的开销是不现实的。所以在这样的矛盾下出现了全文索引技术,有时候有人叫倒排文档技术。
14. **目录索引**:目录索引( search index/directory),顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。
@@ -319,3 +322,5 @@ HTTP 协议的本质就是一种浏览器与服务器之间约定好的通信格
2. 域名系统-从域名解析出 IP 地址
3. 访问一个网站大致的过程
4. 系统调用和应用编程接口概念
+
+
diff --git a/docs/cs-basics/network/dns.md b/docs/cs-basics/network/dns.md
index 21eae6a0ff3..6d51538b932 100644
--- a/docs/cs-basics/network/dns.md
+++ b/docs/cs-basics/network/dns.md
@@ -1,8 +1,13 @@
---
title: DNS 域名系统详解(应用层)
+description: 详解 DNS 的层次结构与解析流程,覆盖递归/迭代、缓存与权威服务器,明确应用层端口与性能优化要点。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: DNS,域名解析,递归查询,迭代查询,缓存,权威DNS,端口53,UDP
---
DNS(Domain Name System)域名管理系统,是当用户使用浏览器访问网址之后,使用的第一个重要协议。DNS 要解决的是**域名和 IP 地址的映射问题**。
@@ -11,10 +16,12 @@ DNS(Domain Name System)域名管理系统,是当用户使用浏览器访
在实际使用中,有一种情况下,浏览器是可以不必动用 DNS 就可以获知域名和 IP 地址的映射的。浏览器在本地会维护一个`hosts`列表,一般来说浏览器要先查看要访问的域名是否在`hosts`列表中,如果有的话,直接提取对应的 IP 地址记录,就好了。如果本地`hosts`列表内没有域名-IP 对应记录的话,那么 DNS 就闪亮登场了。
-目前 DNS 的设计采用的是分布式、层次数据库结构,**DNS 是应用层协议,基于 UDP 协议之上,端口为 53** 。
+目前 DNS 的设计采用的是分布式、层次数据库结构,**DNS 是应用层协议,通常基于 UDP 协议,端口为 53**。当响应数据超过 UDP 报文长度限制(512 字节,EDNS0 可扩展至更大)或进行区域传送(Zone Transfer)时,会改用 TCP 协议以保证数据完整性。
+## DNS 服务器
+
DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务器都属于以下四个类别之一):
- 根 DNS 服务器。根 DNS 服务器提供 TLD 服务器的 IP 地址。目前世界上只有 13 组根服务器,我国境内目前仍没有根服务器。
@@ -22,6 +29,20 @@ DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务
- 权威 DNS 服务器。在因特网上具有公共可访问主机的每个组织机构必须提供公共可访问的 DNS 记录,这些记录将这些主机的名字映射为 IP 地址。
- 本地 DNS 服务器。每个 ISP(互联网服务提供商)都有一个自己的本地 DNS 服务器。当主机发出 DNS 请求时,该请求被发往本地 DNS 服务器,它起着代理的作用,并将该请求转发到 DNS 层次结构中。严格说来,不属于 DNS 层级结构。
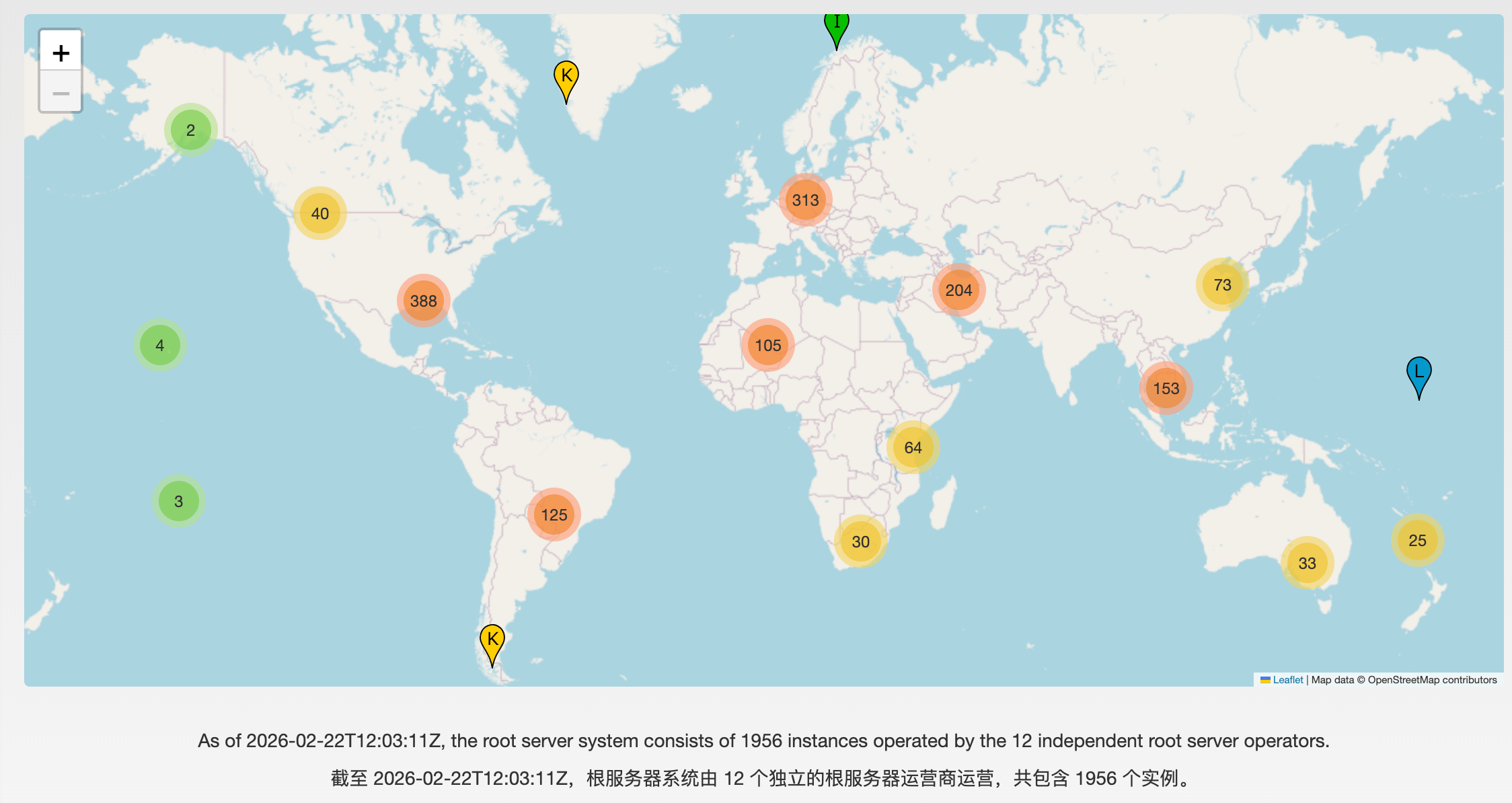
+**世界上真的只有 13 台根服务器吗?** 这是一个流传已久的技术误解。如果你在网上搜索,仍能看到许多陈旧文章宣称“全球仅有 13 台根服务器,且全部由美国控制”。
+
+**事实并非如此。**
+
+最初在设计 DNS(域名系统)架构时,受限于早期 IPv4 数据包的大小限制(UDP 报文需控制在 512 字节以内),预留给根服务器地址的空间确实只够容纳 13 个 IP 地址,每个 IP 地址对应一个不同的根 DNS 服务器。这 13 个地址分别被命名为 `a.root-servers.net` 到 `m.root-servers.net`。
+
+虽然**逻辑上**只有 13 个 IP 地址,但随着互联网规模的爆发,物理上的“单一服务器”早已无法承载全球的查询压力。为了提升 DNS 的可靠性、安全性和响应速度,技术人员引入了 **IP 任播(Anycast)** 技术。
+
+通过任播技术,每一个逻辑 IP 地址背后都可以对应成百上千台分布在全球各地的物理服务器。当你发起查询请求时,互联网路由协议(BGP)会自动将请求引导至地理位置或网络路径上离你**最近**的那台物理实例。
+
+截止到 2023 年底,全球根服务器物理实例总数已超过 1700 台。根据 **[Root-Servers.org](https://root-servers.org/)** 的最新实时监测数据,到 **2026 年,全球根服务器物理实例已突破 1900+ 台**,并正向 2000 台大关迈进。
+
+
+
## DNS 工作流程
以下图为例,介绍 DNS 的查询解析过程。DNS 的查询解析过程分为两种模式:
@@ -48,7 +69,7 @@ DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务
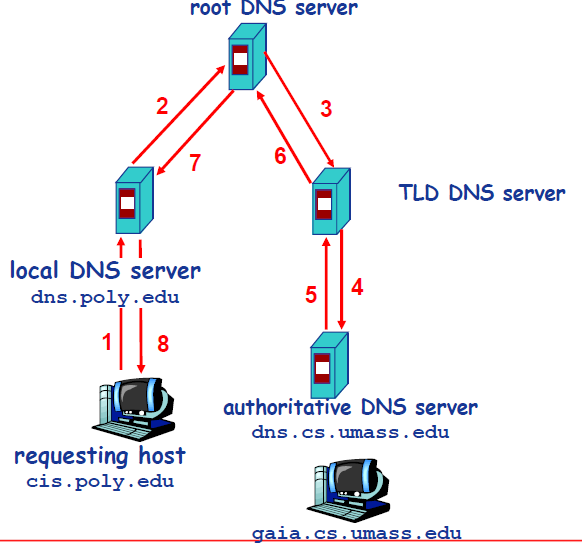
-另外,DNS 的缓存位于本地 DNS 服务器。由于全世界的根服务器甚少,只有 400 多台,分为 13 组,且顶级域的数量也在一个可数的范围内,因此本地 DNS 通常已经缓存了很多 TLD DNS 服务器,所以在实际查找过程中,无需访问根服务器。根服务器通常是被跳过的,不请求的。
+另外,DNS 的缓存位于本地 DNS 服务器。由于全世界的根服务器甚少,只有 600 多台,分为 13 组,且顶级域的数量也在一个可数的范围内,因此本地 DNS 通常已经缓存了很多 TLD DNS 服务器,所以在实际查找过程中,无需访问根服务器。根服务器通常是被跳过的,不请求的。这样可以提高 DNS 查询的效率和速度,减少对根服务器和 TLD 服务器的负担。
## DNS 报文格式
@@ -68,7 +89,7 @@ DNS 报文分为查询和回答报文,两种形式的报文结构相同。
## DNS 记录
-DNS 服务器在响应查询时,需要查询自己的数据库,数据库中的条目被称为**资源记录(Resource Record,RR)**。RR 提供了主机名到 IP 地址的映射。RR 是一个包含了`Name`, `Value`, `Type`, `TTL`四个字段的四元组。
+DNS 服务器在响应查询时,需要查询自己的数据库,数据库中的条目被称为 **资源记录(Resource Record,RR)** 。RR 提供了主机名到 IP 地址的映射。RR 是一个包含了`Name`, `Value`, `Type`, `TTL`四个字段的四元组。
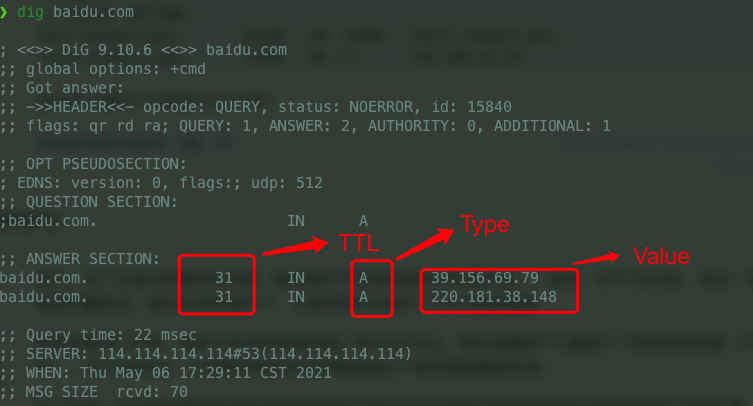
@@ -86,7 +107,7 @@ DNS 服务器在响应查询时,需要查询自己的数据库,数据库中
`CNAME`记录总是指向另一则域名,而非 IP 地址。假设有下述 DNS zone:
-```
+```plain
NAME TYPE VALUE
--------------------------------------------------
bar.example.com. CNAME foo.example.com.
@@ -97,6 +118,8 @@ foo.example.com. A 192.0.2.23
## 参考
-- DNS 服务器类型:https://www.cloudflare.com/zh-cn/learning/dns/dns-server-types/
-- DNS Message Resource Record Field Formats:http://www.tcpipguide.com/free/t_DNSMessageResourceRecordFieldFormats-2.htm
-- Understanding Different Types of Record in DNS Server:https://www.mustbegeek.com/understanding-different-types-of-record-in-dns-server/
+- DNS 服务器类型:
+- DNS Message Resource Record Field Formats:
+- Understanding Different Types of Record in DNS Server:
+
+
diff --git a/docs/cs-basics/network/http-status-codes.md b/docs/cs-basics/network/http-status-codes.md
index 4cacb50cd42..bd2bcd99c3d 100644
--- a/docs/cs-basics/network/http-status-codes.md
+++ b/docs/cs-basics/network/http-status-codes.md
@@ -1,8 +1,13 @@
---
title: HTTP 常见状态码总结(应用层)
+description: 汇总常见 HTTP 状态码含义与使用场景,强调 201/204 等易混淆点,提升接口设计与调试效率。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: HTTP 状态码,2xx,3xx,4xx,5xx,重定向,错误码,201 Created,204 No Content
---
HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被成功处理。
@@ -15,10 +20,14 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
### 2xx Success(成功状态码)
-- **200 OK**:请求被成功处理。比如我们发送一个查询用户数据的 HTTP 请求到服务端,服务端正确返回了用户数据。这个是我们平时最常见的一个 HTTP 状态码。
-- **201 Created**:请求被成功处理并且在服务端创建了一个新的资源。比如我们通过 POST 请求创建一个新的用户。
-- **202 Accepted**:服务端已经接收到了请求,但是还未处理。
-- **204 No Content**:服务端已经成功处理了请求,但是没有返回任何内容。
+- **200 OK**:请求被成功处理。例如,发送一个查询用户数据的 HTTP 请求到服务端,服务端正确返回了用户数据。这个是我们平时最常见的一个 HTTP 状态码。
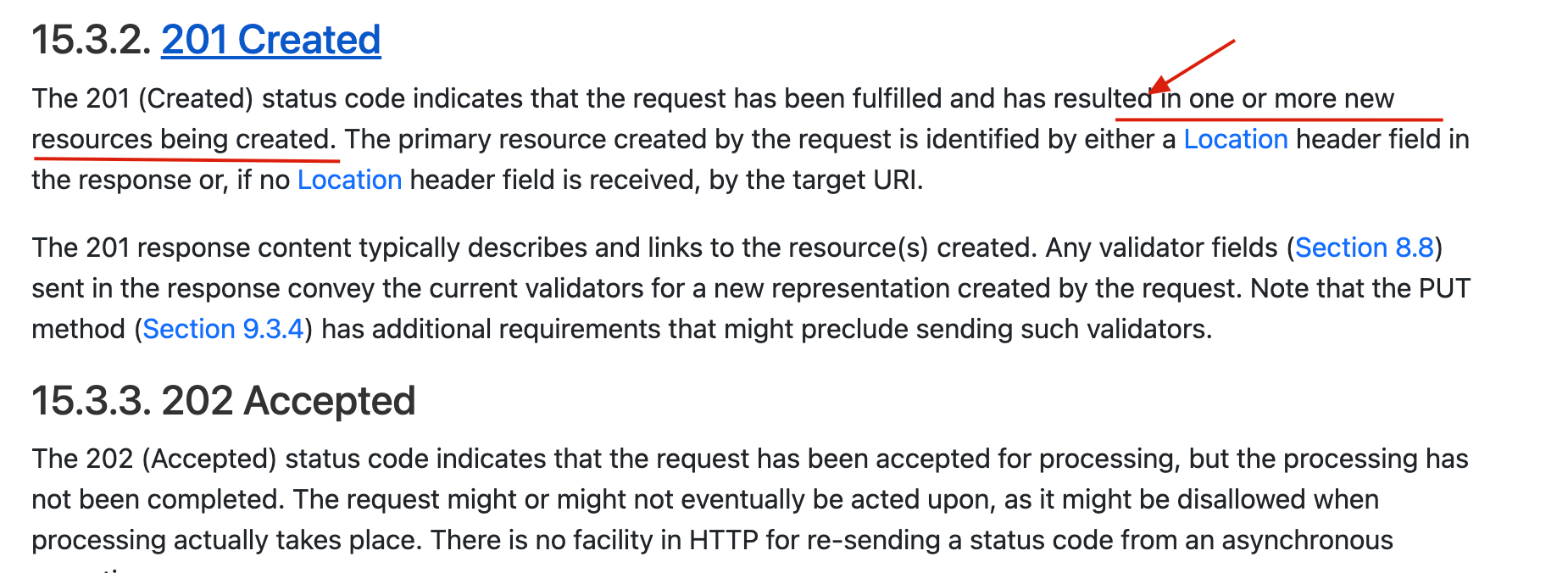
+- **201 Created**:请求被成功处理并且在服务端创建了~~一个新的资源~~。例如,通过 POST 请求创建一个新的用户。
+- **202 Accepted**:服务端已经接收到了请求,但是还未处理。例如,发送一个需要服务端花费较长时间处理的请求(如报告生成、Excel 导出),服务端接收了请求但尚未处理完毕。
+- **204 No Content**:服务端已经成功处理了请求,但是没有返回任何内容。例如,发送请求删除一个用户,服务器成功处理了删除操作但没有返回任何内容。
+
+🐛 修正(参见:[issue#2458](https://github.com/Snailclimb/JavaGuide/issues/2458)):201 Created 状态码更准确点来说是创建一个或多个新的资源,可以参考:。
+
+
这里格外提一下 204 状态码,平时学习/工作中见到的次数并不多。
@@ -64,7 +73,9 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
### 参考
-- https://www.restapitutorial.com/httpstatuscodes.html
-- https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status
-- https://en.wikipedia.org/wiki/List_of_HTTP_status_codes
-- https://segmentfault.com/a/1190000018264501
+-
+-
+-
+-
+
+
diff --git a/docs/cs-basics/network/http-vs-https.md b/docs/cs-basics/network/http-vs-https.md
index 98742292577..74303aba536 100644
--- a/docs/cs-basics/network/http-vs-https.md
+++ b/docs/cs-basics/network/http-vs-https.md
@@ -1,8 +1,13 @@
---
title: HTTP vs HTTPS(应用层)
+description: 对比 HTTP 与 HTTPS 的协议与安全机制,解析 SSL/TLS 工作原理与握手流程,明确应用层安全落地细节。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: HTTP,HTTPS,SSL,TLS,加密,认证,端口,安全性,握手流程
---
## HTTP 协议
@@ -33,7 +38,7 @@ HTTP 是应用层协议,它以 TCP(传输层)作为底层协议,默认
HTTPS 协议(Hyper Text Transfer Protocol Secure),是 HTTP 的加强安全版本。HTTPS 是基于 HTTP 的,也是用 TCP 作为底层协议,并额外使用 SSL/TLS 协议用作加密和安全认证。默认端口号是 443.
-HTTPS 协议中,SSL 通道通常使用基于密钥的加密算法,密钥长度通常是 40 比特或 128 比特。
+HTTPS 中,TLS 握手完成后,通信数据使用对称加密算法(如 AES-128-GCM 或 AES-256-GCM)保护,密钥通过非对称加密(如 RSA-2048/4096 或 ECDH)在握手阶段协商生成。早期 SSL 使用的 40 比特密钥因强度不足已被废弃,现代 TLS 要求对称密钥至少 128 比特。
### HTTPS 协议优点
@@ -47,7 +52,7 @@ HTTPS 之所以能达到较高的安全性要求,就是结合了 SSL/TLS 和 T
**SSL 和 TLS 没有太大的区别。**
-SSL 指安全套接字协议(Secure Sockets Layer),首次发布与 1996 年。SSL 的首次发布其实已经是他的 3.0 版本,SSL 1.0 从未面世,SSL 2.0 则具有较大的缺陷(DROWN 缺陷——Decrypting RSA with Obsolete and Weakened eNcryption)。很快,在 1999 年,SSL 3.0 进一步升级,**新版本被命名为 TLS 1.0**。因此,TLS 是基于 SSL 之上的,但由于习惯叫法,通常把 HTTPS 中的核心加密协议混称为 SSL/TLS。
+SSL 指安全套接字协议(Secure Sockets Layer),首次发布于 1996 年(SSL 3.0)。SSL 1.0 从未面世,SSL 2.0 则具有较大的缺陷(DROWN 缺陷——Decrypting RSA with Obsolete and Weakened eNcryption)。很快,在 1999 年,SSL 3.0 进一步升级,**新版本被命名为 TLS 1.0**。因此,TLS 是基于 SSL 之上的,但由于习惯叫法,通常把 HTTPS 中的核心加密协议混称为 SSL/TLS。目前 SSL 已完全废弃,TLS 1.2 和 TLS 1.3 是现代 HTTPS 的实际标准。
### SSL/TLS 的工作原理
@@ -138,3 +143,5 @@ SSL/TLS 介绍到这里,了解信息安全的朋友又会想到一个安全隐
- **端口号**:HTTP 默认是 80,HTTPS 默认是 443。
- **URL 前缀**:HTTP 的 URL 前缀是 `http://`,HTTPS 的 URL 前缀是 `https://`。
- **安全性和资源消耗**:HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
+
+
diff --git a/docs/cs-basics/network/http1.0-vs-http1.1.md b/docs/cs-basics/network/http1.0-vs-http1.1.md
index cc27c0e0974..19210ebb9a0 100644
--- a/docs/cs-basics/network/http1.0-vs-http1.1.md
+++ b/docs/cs-basics/network/http1.0-vs-http1.1.md
@@ -1,8 +1,13 @@
---
title: HTTP 1.0 vs HTTP 1.1(应用层)
+description: 细致对比 HTTP/1.0 与 HTTP/1.1 的协议差异,涵盖长连接、管道化、缓存与状态码增强等关键变更与实践影响。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: HTTP/1.0,HTTP/1.1,长连接,管道化,缓存,状态码,Host,带宽优化
---
这篇文章会从下面几个维度来对比 HTTP 1.0 和 HTTP 1.1:
@@ -53,11 +58,11 @@ HTTP/1.1 的缓存机制在 HTTP/1.0 的基础上,大大增加了灵活性和
## Host 头处理
-域名系统(DNS)允许多个主机名绑定到同一个 IP 地址上,但是 HTTP/1.0 并没有考虑这个问题,假设我们有一个资源 URL 是http://example1.org/home.html,HTTP/1.0的请求报文中,将会请求的是`GET /home.html HTTP/1.0`.也就是不会加入主机名。这样的报文送到服务器端,服务器是理解不了客户端想请求的真正网址。
+域名系统(DNS)允许多个主机名绑定到同一个 IP 地址上,但是 HTTP/1.0 并没有考虑这个问题,假设我们有一个资源 URL 是 的请求报文中,将会请求的是`GET /home.html HTTP/1.0`.也就是不会加入主机名。这样的报文送到服务器端,服务器是理解不了客户端想请求的真正网址。
因此,HTTP/1.1 在请求头中加入了`Host`字段。加入`Host`字段的报文头部将会是:
-```
+```plain
GET /home.html HTTP/1.1
Host: example1.org
```
@@ -70,9 +75,70 @@ Host: example1.org
HTTP/1.1 引入了范围请求(range request)机制,以避免带宽的浪费。当客户端想请求一个文件的一部分,或者需要继续下载一个已经下载了部分但被终止的文件,HTTP/1.1 可以在请求中加入`Range`头部,以请求(并只能请求字节型数据)数据的一部分。服务器端可以忽略`Range`头部,也可以返回若干`Range`响应。
-如果一个响应包含部分数据的话,那么将带有`206 (Partial Content)`状态码。该状态码的意义在于避免了 HTTP/1.0 代理缓存错误地把该响应认为是一个完整的数据响应,从而把他当作为一个请求的响应缓存。
+`206 (Partial Content)` 状态码的主要作用是确保客户端和代理服务器能正确识别部分内容响应,避免将其误认为完整资源并错误地缓存。这对于正确处理范围请求和缓存管理非常重要。
+
+一个典型的 HTTP/1.1 范围请求示例:
+
+```bash
+# 获取一个文件的前 1024 个字节
+GET /z4d4kWk.jpg HTTP/1.1
+Host: i.imgur.com
+Range: bytes=0-1023
+```
+
+`206 Partial Content` 响应:
+
+```bash
+
+HTTP/1.1 206 Partial Content
+Content-Range: bytes 0-1023/146515
+Content-Length: 1024
+…
+(二进制内容)
+```
+
+简单解释一下 HTTP 范围响应头部中的字段:
+
+- **`Content-Range` 头部**:指示返回数据在整个资源中的位置,包括起始和结束字节以及资源的总长度。例如,`Content-Range: bytes 0-1023/146515` 表示服务器端返回了第 0 到 1023 字节的数据(共 1024 字节),而整个资源的总长度是 146,515 字节。
+- **`Content-Length` 头部**:指示此次响应中实际传输的字节数。例如,`Content-Length: 1024` 表示服务器端传输了 1024 字节的数据。
+
+`Range` 请求头不仅可以请求单个字节范围,还可以一次性请求多个范围。这种方式被称为“多重范围请求”(multiple range requests)。
+
+客户端想要获取资源的第 0 到 499 字节以及第 1000 到 1499 字节:
-在范围响应中,`Content-Range`头部标志指示出了该数据块的偏移量和数据块的长度。
+```bash
+GET /path/to/resource HTTP/1.1
+Host: example.com
+Range: bytes=0-499,1000-1499
+```
+
+服务器端返回多个字节范围,每个范围的内容以分隔符分开:
+
+```bash
+HTTP/1.1 206 Partial Content
+Content-Type: multipart/byteranges; boundary=3d6b6a416f9b5
+Content-Length: 376
+
+--3d6b6a416f9b5
+Content-Type: application/octet-stream
+Content-Range: bytes 0-99/2000
+
+(第 0 到 99 字节的数据块)
+
+--3d6b6a416f9b5
+Content-Type: application/octet-stream
+Content-Range: bytes 500-599/2000
+
+(第 500 到 599 字节的数据块)
+
+--3d6b6a416f9b5
+Content-Type: application/octet-stream
+Content-Range: bytes 1000-1099/2000
+
+(第 1000 到 1099 字节的数据块)
+
+--3d6b6a416f9b5--
+```
### 状态码 100
@@ -95,11 +161,13 @@ HTTP/1.0 包含了`Content-Encoding`头部,对消息进行端到端编码。HT
## 总结
1. **连接方式** : HTTP 1.0 为短连接,HTTP 1.1 支持长连接。
-1. **状态响应码** : HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
-1. **缓存处理** : 在 HTTP1.0 中主要使用 header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
-1. **带宽优化及网络连接的使用** :HTTP1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
-1. **Host 头处理** : HTTP/1.1 在请求头中加入了`Host`字段。
+2. **状态响应码** : HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
+3. **缓存处理** : 在 HTTP1.0 中主要使用 header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
+4. **带宽优化及网络连接的使用** :HTTP1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
+5. **Host 头处理** : HTTP/1.1 在请求头中加入了`Host`字段。
## 参考资料
[Key differences between HTTP/1.0 and HTTP/1.1](http://www.ra.ethz.ch/cdstore/www8/data/2136/pdf/pd1.pdf)
+
+
diff --git a/docs/cs-basics/network/images/arp/2008410143049281.png b/docs/cs-basics/network/images/arp/2008410143049281.png
deleted file mode 100644
index 759fb441f6c..00000000000
Binary files a/docs/cs-basics/network/images/arp/2008410143049281.png and /dev/null differ
diff --git a/docs/cs-basics/network/images/network-model/nerwork-layer-protocol.png b/docs/cs-basics/network/images/network-model/nerwork-layer-protocol.png
new file mode 100644
index 00000000000..a94274cce32
Binary files /dev/null and b/docs/cs-basics/network/images/network-model/nerwork-layer-protocol.png differ
diff --git a/docs/cs-basics/network/nat.md b/docs/cs-basics/network/nat.md
index 814df5e0139..630f4866bef 100644
--- a/docs/cs-basics/network/nat.md
+++ b/docs/cs-basics/network/nat.md
@@ -1,8 +1,13 @@
---
title: NAT 协议详解(网络层)
+description: 解析 NAT 的地址转换与端口映射机制,结合 LAN/WAN 通信与转换表,理解家庭与企业网络的实践细节。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: NAT,地址转换,端口映射,LAN,WAN,连接跟踪,DHCP
---
## 应用场景
@@ -21,7 +26,7 @@ SOHO 子网的“代理人”,也就是和外界的窗口,通常由路由器
首先,针对以上信息,我们有如下事实需要说明:
-1. 路由器的右侧子网的网络号为`10.0.0/24`,主机号为`10.0.0/8`,三台主机地址,以及路由器的 LAN 侧接口地址,均由 DHCP 协议规定。而且,该 DHCP 运行在路由器内部(路由器自维护一个小 DHCP 服务器),从而为子网内提供 DHCP 服务。
+1. 路由器右侧子网的网络地址为 `10.0.0.0/24`(网络前缀 24 位,主机号占 8 位),三台主机地址以及路由器的 LAN 侧接口地址,均由 DHCP 协议规定。而且,该 DHCP 运行在路由器内部(路由器自维护一个小 DHCP 服务器),从而为子网内提供 DHCP 服务。
2. 路由器的 WAN 侧接口地址同样由 DHCP 协议规定,但该地址是路由器从 ISP(网络服务提供商)处获得,也就是该 DHCP 通常运行在路由器所在区域的 DHCP 服务器上。
现在,路由器内部还运行着 NAT 协议,从而为 LAN-WAN 间通信提供地址转换服务。为此,一个很重要的结构是 **NAT 转换表**。为了说明 NAT 的运行细节,假设有以下请求发生:
@@ -45,7 +50,7 @@ SOHO 子网的“代理人”,也就是和外界的窗口,通常由路由器
针对以上过程,有以下几个重点需要强调:
1. 当请求报文到达路由器,并被指定了新端口号时,由于端口号有 16 位,因此,通常来说,一个路由器管理的 LAN 中的最大主机数 $≈65500$($2^{16}$ 的地址空间),但通常 SOHO 子网内不会有如此多的主机数量。
-2. 对于目的服务器来说,从来不知道“到底是哪个主机给我发送的请求”,它只知道是来自`138.76.29.7:5001`的路由器转发的请求。因此,可以说,**路由器在 WAN 和 LAN 之间起到了屏蔽作用,**所有内部主机发送到外部的报文,都具有同一个 IP 地址(不同的端口号),所有外部发送到内部的报文,也都只有一个目的地(不同端口号),是经过了 NAT 转换后,外部报文才得以正确地送达内部主机。
+2. 对于目的服务器来说,从来不知道“到底是哪个主机给我发送的请求”,它只知道是来自`138.76.29.7:5001`的路由器转发的请求。因此,可以说,**路由器在 WAN 和 LAN 之间起到了屏蔽作用**,所有内部主机发送到外部的报文,都具有同一个 IP 地址(不同的端口号),所有外部发送到内部的报文,也都只有一个目的地(不同端口号),是经过了 NAT 转换后,外部报文才得以正确地送达内部主机。
3. 在报文穿过路由器,发生 NAT 转换时,如果 LAN 主机 IP 已经在 NAT 转换表中注册过了,则不需要路由器新指派端口,而是直接按照转换记录穿过路由器。同理,外部报文发送至内部时也如此。
总结 NAT 协议的特点,有以下几点:
@@ -55,4 +60,6 @@ SOHO 子网的“代理人”,也就是和外界的窗口,通常由路由器
3. WAN 的 ISP 变更接口地址时,无需通告 LAN 内主机。
4. LAN 主机对 WAN 不可见,不可直接寻址,可以保证一定程度的安全性。
-然而,NAT 协议由于其独特性,存在着一些争议。比如,可能你已经注意到了,**NAT 协议在 LAN 以外,标识一个内部主机时,使用的是端口号,因为 IP 地址都是相同的。**这种将端口号作为主机寻址的行为,可能会引发一些误会。此外,路由器作为网络层的设备,修改了传输层的分组内容(修改了源 IP 地址和端口号),同样是不规范的行为。但是,尽管如此,NAT 协议作为 IPv4 时代的产物,极大地方便了一些本来棘手的问题,一直被沿用至今。
+然而,NAT 协议由于其独特性,存在着一些争议。比如,可能你已经注意到了,**NAT 协议在 LAN 以外,标识一个内部主机时,使用的是端口号,因为 IP 地址都是相同的**。这种将端口号作为主机寻址的行为,可能会引发一些误会。此外,路由器作为网络层的设备,修改了传输层的分组内容(修改了源 IP 地址和端口号),同样是不规范的行为。但是,尽管如此,NAT 协议作为 IPv4 时代的产物,极大地方便了一些本来棘手的问题,一直被沿用至今。
+
+
diff --git a/docs/cs-basics/network/network-attack-means.md b/docs/cs-basics/network/network-attack-means.md
index 48892cfee9f..876299718a6 100644
--- a/docs/cs-basics/network/network-attack-means.md
+++ b/docs/cs-basics/network/network-attack-means.md
@@ -1,8 +1,13 @@
---
title: 网络攻击常见手段总结
+description: 总结常见 TCP/IP 攻击与防护思路,覆盖 DDoS、IP/ARP 欺骗、中间人等手段,强调工程防护实践。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 网络攻击,DDoS,IP 欺骗,ARP 欺骗,中间人攻击,扫描,防护
---
> 本文整理完善自[TCP/IP 常见攻击手段 - 暖蓝笔记 - 2021](https://mp.weixin.qq.com/s/AZwWrOlLxRSSi-ywBgZ0fA)这篇文章。
@@ -21,7 +26,7 @@ tag:
**IP 头部格式** :
-
+
### IP 欺骗技术是什么?
@@ -29,11 +34,11 @@ tag:
IP 欺骗技术就是**伪造**某台主机的 IP 地址的技术。通过 IP 地址的伪装使得某台主机能够**伪装**另外的一台主机,而这台主机往往具有某种特权或者被另外的主机所信任。
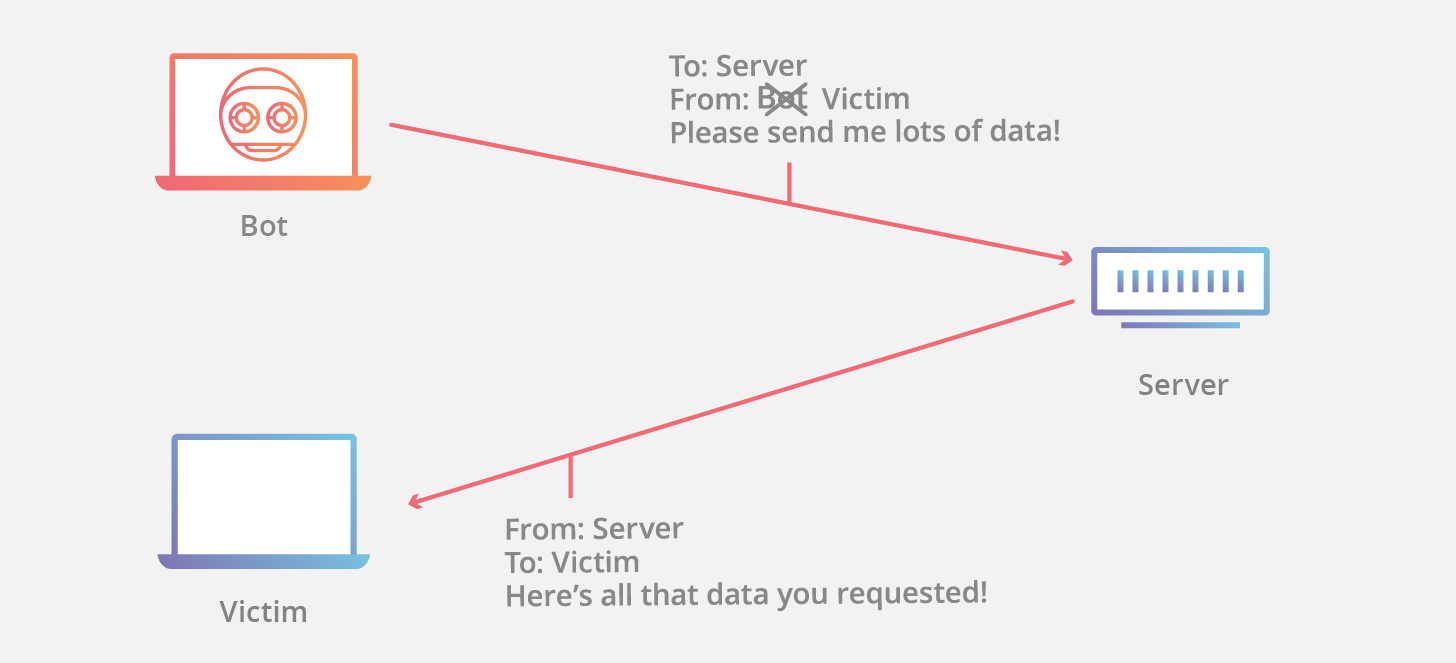
-假设现在有一个合法用户 **(1.1.1.1)** 已经同服务器建立正常的连接,攻击者构造攻击的 TCP 数据,伪装自己的 IP 为 **1.1.1.1**,并向服务器发送一个带有 RSI 位的 TCP 数据段。服务器接收到这样的数据后,认为从 **1.1.1.1** 发送的连接有错误,就会清空缓冲区中建立好的连接。
+假设现在有一个合法用户 **(1.1.1.1)** 已经同服务器建立正常的连接,攻击者构造攻击的 TCP 数据,伪装自己的 IP 为 **1.1.1.1**,并向服务器发送一个带有 RST 位的 TCP 数据段。服务器接收到这样的数据后,认为从 **1.1.1.1** 发送的连接有错误,就会清空缓冲区中建立好的连接。
这时,如果合法用户 **1.1.1.1** 再发送合法数据,服务器就已经没有这样的连接了,该用户就必须从新开始建立连接。攻击时,伪造大量的 IP 地址,向目标发送 RST 数据,使服务器不对合法用户服务。虽然 IP 地址欺骗攻击有着相当难度,但我们应该清醒地意识到,这种攻击非常广泛,入侵往往从这种攻击开始。
-
+
### 如何缓解 IP 欺骗?
@@ -48,13 +53,13 @@ SYN Flood 是互联网上最原始、最经典的 DDoS(Distributed Denial of S
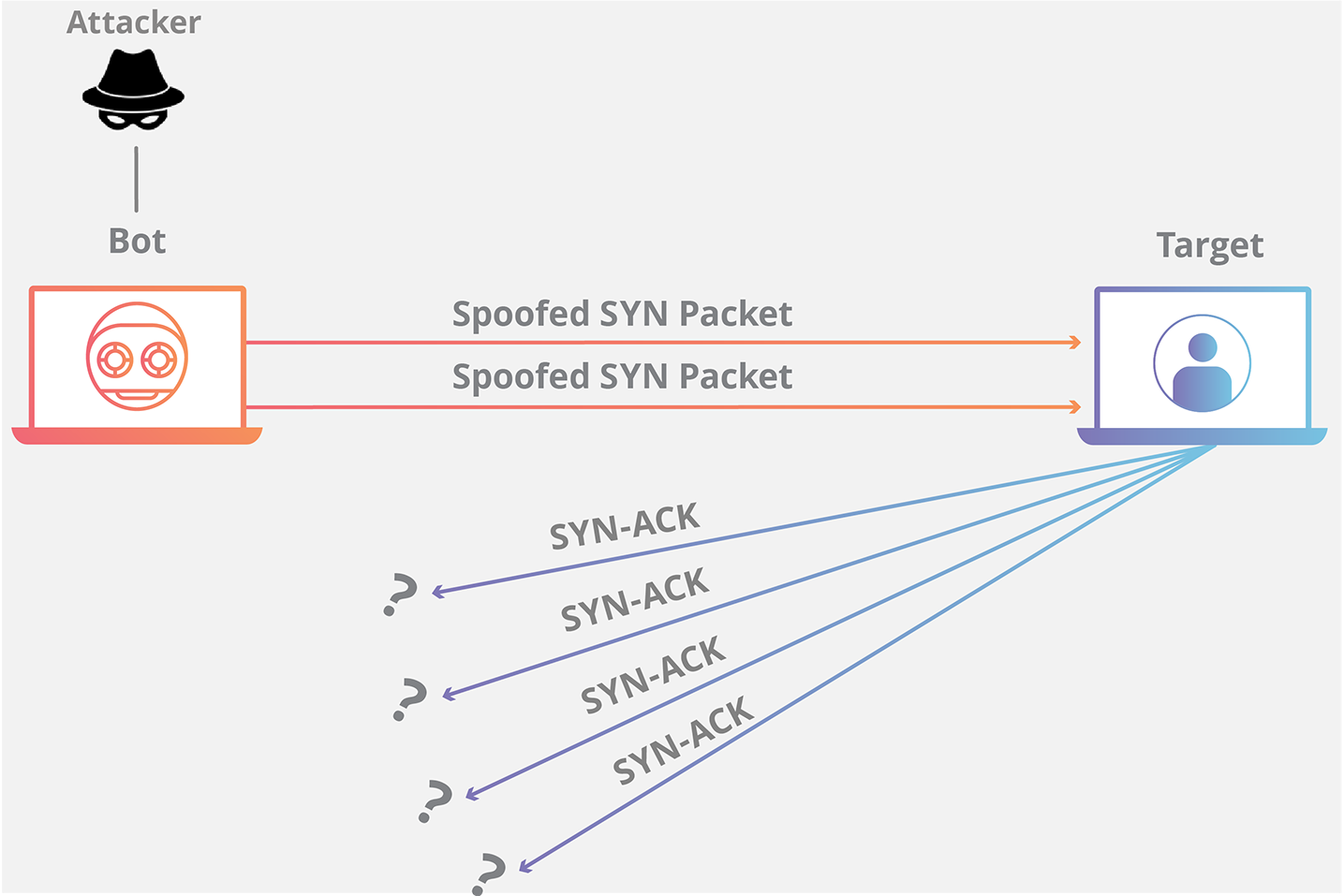
SYN Flood 利用了 TCP 协议的三次握手机制,攻击者通常利用工具或者控制僵尸主机向服务器发送海量的变源 IP 地址或变源端口的 TCP SYN 报文,服务器响应了这些报文后就会生成大量的半连接,当系统资源被耗尽后,服务器将无法提供正常的服务。
增加服务器性能,提供更多的连接能力对于 SYN Flood 的海量报文来说杯水车薪,防御 SYN Flood 的关键在于判断哪些连接请求来自于真实源,屏蔽非真实源的请求以保障正常的业务请求能得到服务。
-
+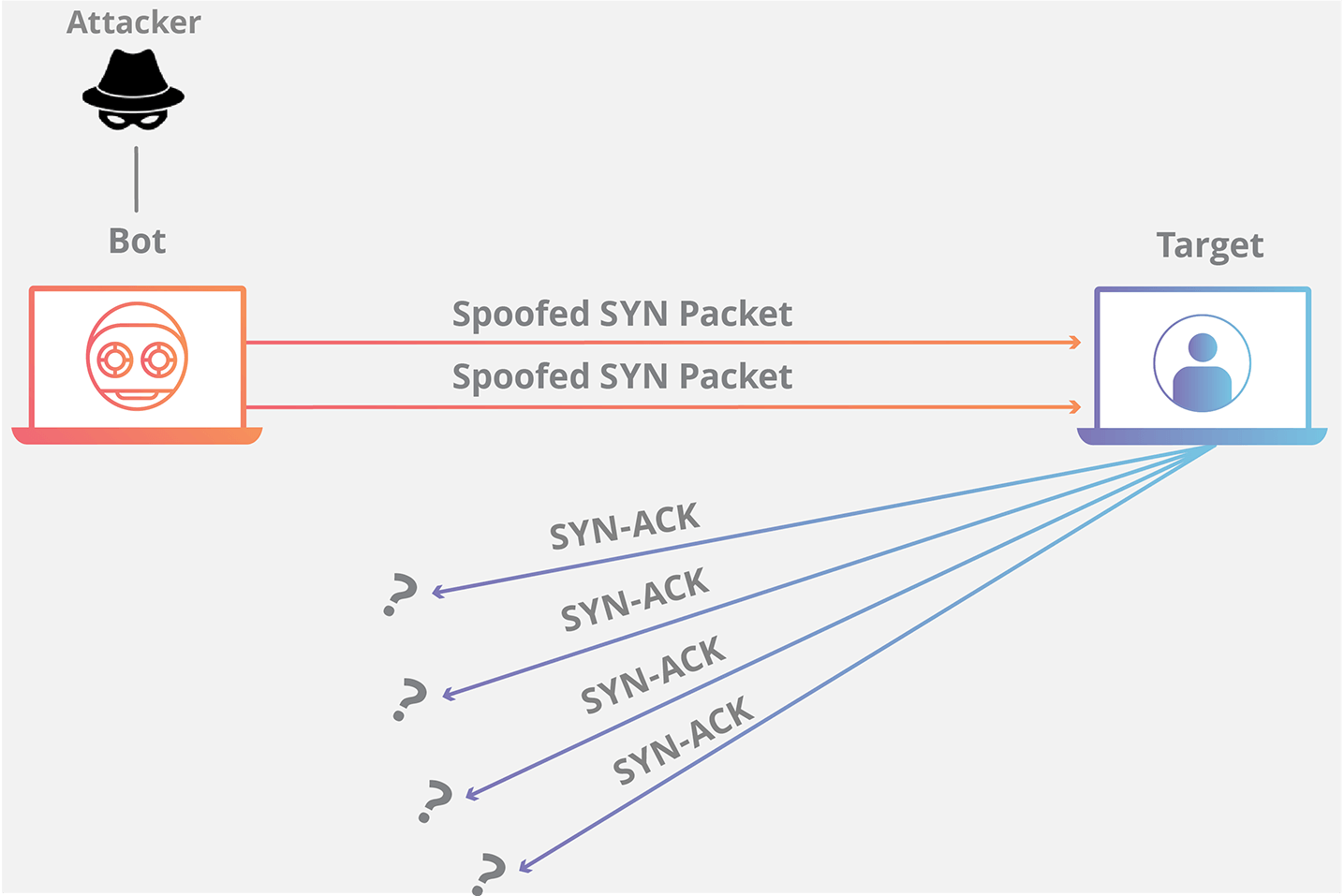
### TCP SYN Flood 攻击原理是什么?
**TCP SYN Flood** 攻击利用的是 **TCP** 的三次握手(**SYN -> SYN/ACK -> ACK**),假设连接发起方是 A,连接接受方是 B,即 B 在某个端口(**Port**)上监听 A 发出的连接请求,过程如下图所示,左边是 A,右边是 B。
-
+
A 首先发送 **SYN**(Synchronization)消息给 B,要求 B 做好接收数据的准备;B 收到后反馈 **SYN-ACK**(Synchronization-Acknowledgement) 消息给 A,这个消息的目的有两个:
@@ -71,7 +76,7 @@ A 首先发送 **SYN**(Synchronization)消息给 B,要求 B 做好接收
假设 B 通过某 **TCP** 端口提供服务,B 在收到 A 的 **SYN** 消息时,积极的反馈了 **SYN-ACK** 消息,使连接进入**半开状态**,因为 B 不确定自己发给 A 的 **SYN-ACK** 消息或 A 反馈的 ACK 消息是否会丢在半路,所以会给每个待完成的半开连接都设一个**Timer**,如果超过时间还没有收到 A 的 **ACK** 消息,则重新发送一次 **SYN-ACK** 消息给 A,直到重试超过一定次数时才会放弃。
-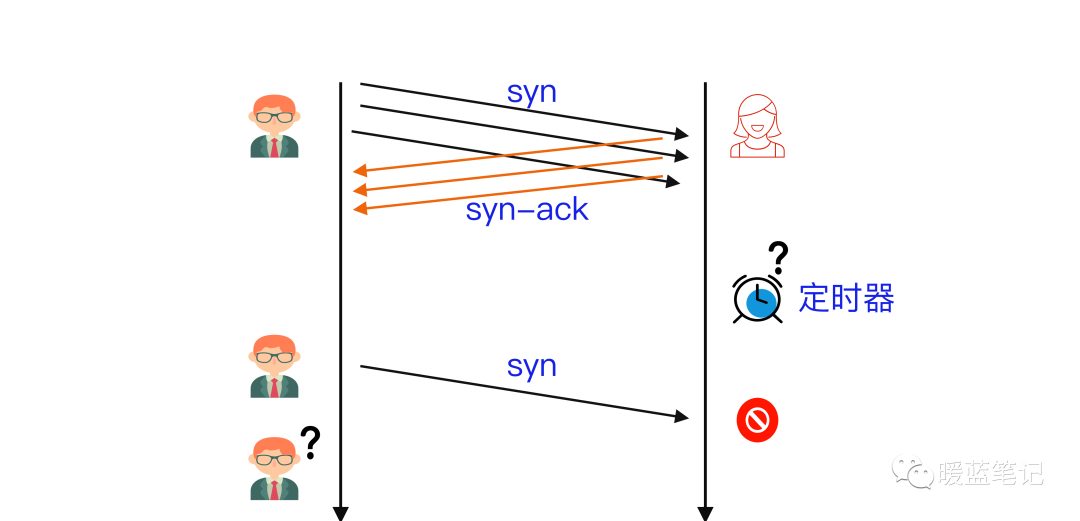
+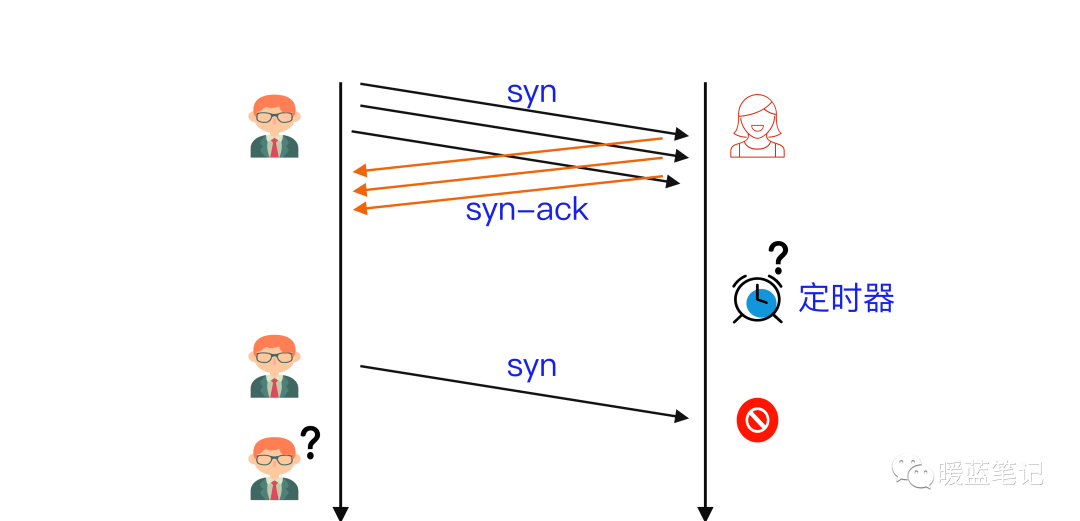
B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接,那么当 B 面临海量的连接 A 时,如上图所示,**SYN Flood** 攻击就形成了。攻击方 A 可以控制肉鸡向 B 发送大量 SYN 消息但不响应 ACK 消息,或者干脆伪造 SYN 消息中的 **Source IP**,使 B 反馈的 **SYN-ACK** 消息石沉大海,导致 B 被大量注定不能完成的半开连接占据,直到资源耗尽,停止响应正常的连接请求。
@@ -79,9 +84,9 @@ B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接
**恶意用户可通过三种不同方式发起 SYN Flood 攻击**:
-1. **直接攻击:**不伪造 IP 地址的 SYN 洪水攻击称为直接攻击。在此类攻击中,攻击者完全不屏蔽其 IP 地址。由于攻击者使用具有真实 IP 地址的单一源设备发起攻击,因此很容易发现并清理攻击者。为使目标机器呈现半开状态,黑客将阻止个人机器对服务器的 SYN-ACK 数据包做出响应。为此,通常采用以下两种方式实现:部署防火墙规则,阻止除 SYN 数据包以外的各类传出数据包;或者,对传入的所有 SYN-ACK 数据包进行过滤,防止其到达恶意用户机器。实际上,这种方法很少使用(即便使用过也不多见),因为此类攻击相当容易缓解 – 只需阻止每个恶意系统的 IP 地址。哪怕攻击者使用僵尸网络(如 [Mirai 僵尸网络](https://www.cloudflare.com/learning/ddos/glossary/mirai-botnet/)),通常也不会刻意屏蔽受感染设备的 IP。
-2. **欺骗攻击:**恶意用户还可以伪造其发送的各个 SYN 数据包的 IP 地址,以便阻止缓解措施并加大身份暴露难度。虽然数据包可能经过伪装,但还是可以通过这些数据包追根溯源。此类检测工作很难开展,但并非不可实现;特别是,如果 Internet 服务提供商 (ISP) 愿意提供帮助,则更容易实现。
-3. **分布式攻击(DDoS):**如果使用僵尸网络发起攻击,则追溯攻击源头的可能性很低。随着混淆级别的攀升,攻击者可能还会命令每台分布式设备伪造其发送数据包的 IP 地址。哪怕攻击者使用僵尸网络(如 Mirai 僵尸网络),通常也不会刻意屏蔽受感染设备的 IP。
+1. **直接攻击:** 不伪造 IP 地址的 SYN 洪水攻击称为直接攻击。在此类攻击中,攻击者完全不屏蔽其 IP 地址。由于攻击者使用具有真实 IP 地址的单一源设备发起攻击,因此很容易发现并清理攻击者。为使目标机器呈现半开状态,黑客将阻止个人机器对服务器的 SYN-ACK 数据包做出响应。为此,通常采用以下两种方式实现:部署防火墙规则,阻止除 SYN 数据包以外的各类传出数据包;或者,对传入的所有 SYN-ACK 数据包进行过滤,防止其到达恶意用户机器。实际上,这种方法很少使用(即便使用过也不多见),因为此类攻击相当容易缓解 – 只需阻止每个恶意系统的 IP 地址。哪怕攻击者使用僵尸网络(如 [Mirai 僵尸网络](https://www.cloudflare.com/learning/ddos/glossary/mirai-botnet/)),通常也不会刻意屏蔽受感染设备的 IP。
+2. **欺骗攻击:** 恶意用户还可以伪造其发送的各个 SYN 数据包的 IP 地址,以便阻止缓解措施并加大身份暴露难度。虽然数据包可能经过伪装,但还是可以通过这些数据包追根溯源。此类检测工作很难开展,但并非不可实现;特别是,如果 Internet 服务提供商 (ISP) 愿意提供帮助,则更容易实现。
+3. **分布式攻击(DDoS):** 如果使用僵尸网络发起攻击,则追溯攻击源头的可能性很低。随着混淆级别的攀升,攻击者可能还会命令每台分布式设备伪造其发送数据包的 IP 地址。哪怕攻击者使用僵尸网络(如 Mirai 僵尸网络),通常也不会刻意屏蔽受感染设备的 IP。
### 如何缓解 SYN Flood?
@@ -118,7 +123,7 @@ B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接
由于目标服务器利用资源检查并响应每个接收到的 **UDP** 数据包的结果,当接收到大量 **UDP** 数据包时,目标的资源可能会迅速耗尽,导致对正常流量的拒绝服务。
-
+
### 如何缓解 UDP Flooding?
@@ -130,7 +135,7 @@ B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接
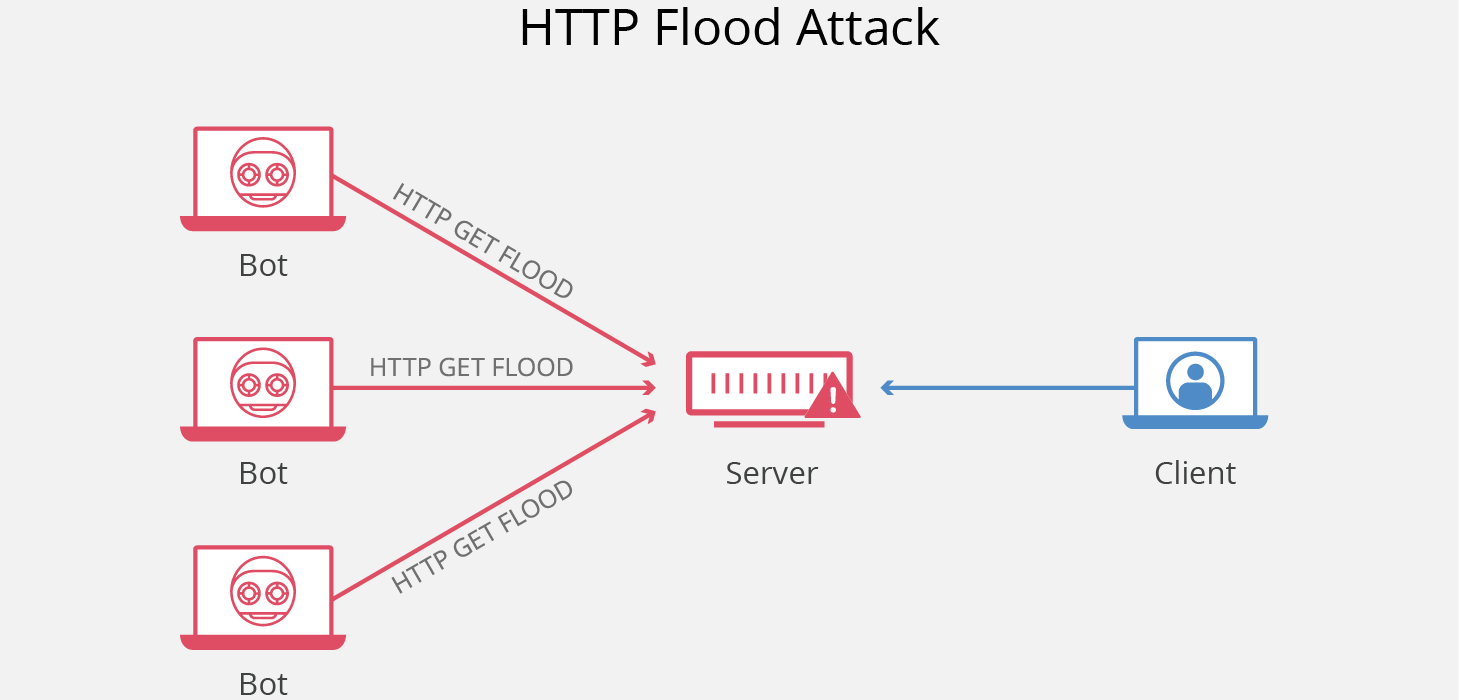
HTTP Flood 是一种大规模的 DDoS(Distributed Denial of Service,分布式拒绝服务)攻击,旨在利用 HTTP 请求使目标服务器不堪重负。目标因请求而达到饱和,且无法响应正常流量后,将出现拒绝服务,拒绝来自实际用户的其他请求。
-
+
### HTTP Flood 的攻击原理是什么?
@@ -157,7 +162,7 @@ HTTP 洪水攻击有两种:
### DNS Flood 的攻击原理是什么?
-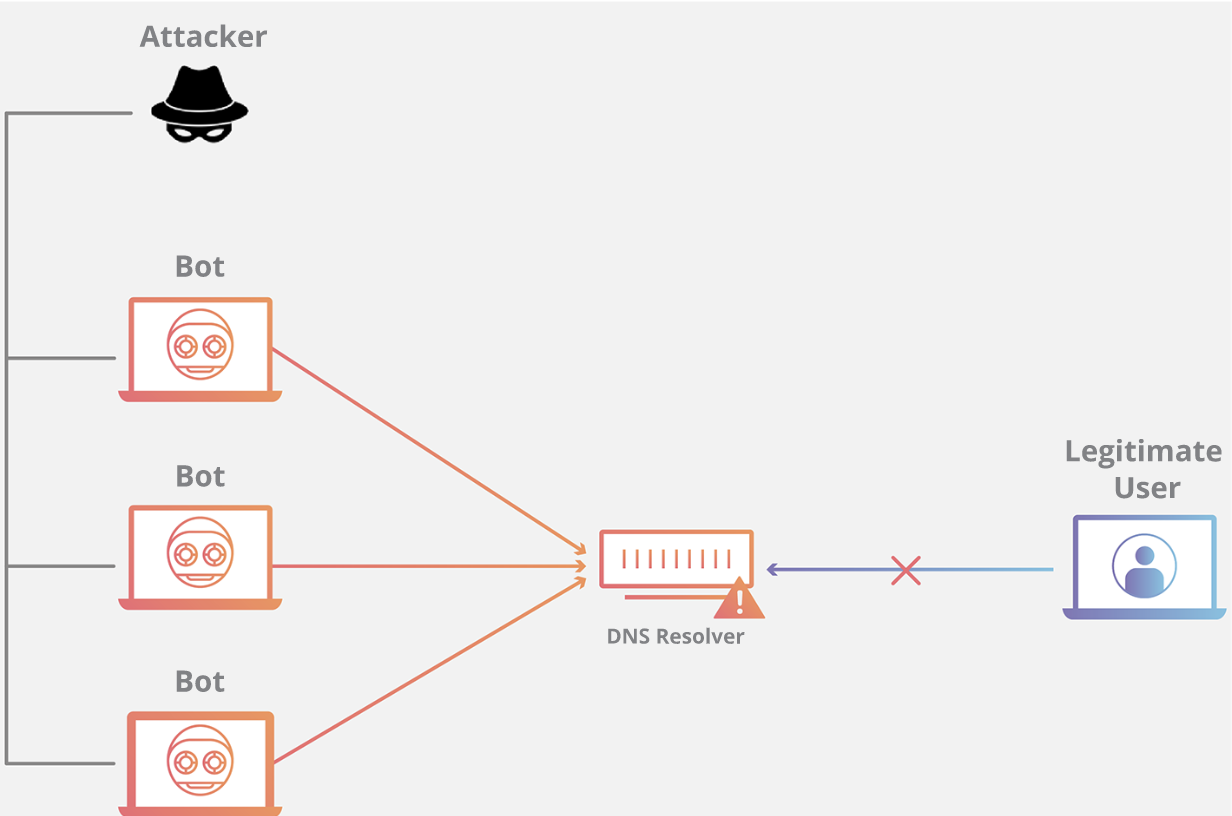
+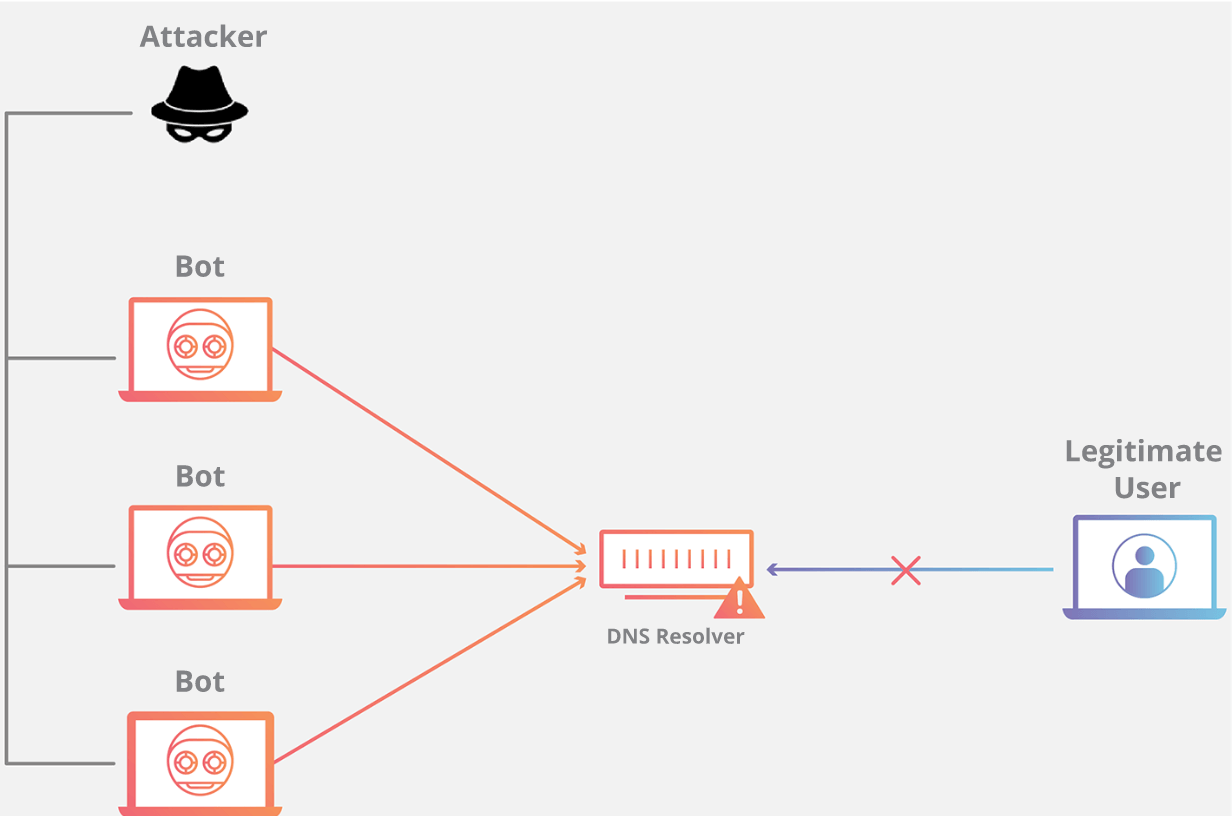
域名系统的功能是将易于记忆的名称(例如 example.com)转换成难以记住的网站服务器地址(例如 192.168.0.1),因此成功攻击 DNS 基础设施将导致大多数人无法使用互联网。DNS Flood 攻击是一种相对较新的基于 DNS 的攻击,这种攻击是在高带宽[物联网(IoT)](https://www.cloudflare.com/learning/ddos/glossary/internet-of-things-iot/)[僵尸网络](https://www.cloudflare.com/learning/ddos/what-is-a-ddos-botnet/)(如 [Mirai](https://www.cloudflare.com/learning/ddos/glossary/mirai-botnet/))兴起后激增的。DNS Flood 攻击使用 IP 摄像头、DVR 盒和其他 IoT 设备的高带宽连接直接淹没主要提供商的 DNS 服务器。来自 IoT 设备的大量请求淹没 DNS 提供商的服务,阻止合法用户访问提供商的 DNS 服务器。
@@ -196,27 +201,27 @@ DNS Flood 对传统上基于放大的攻击方法做出了改变。借助轻易
> 建立 TCP 连接
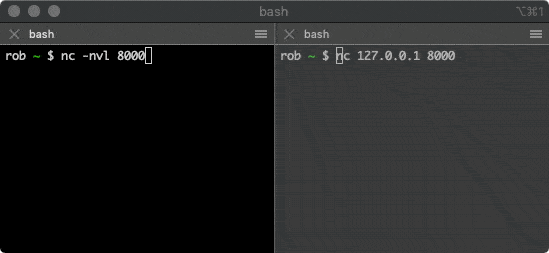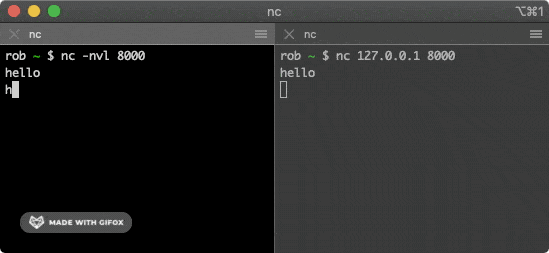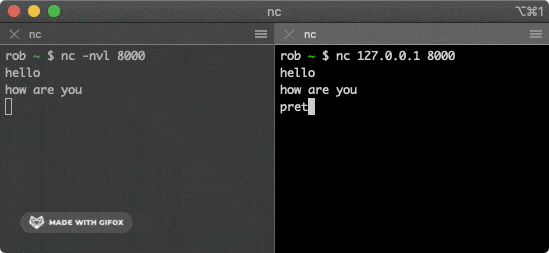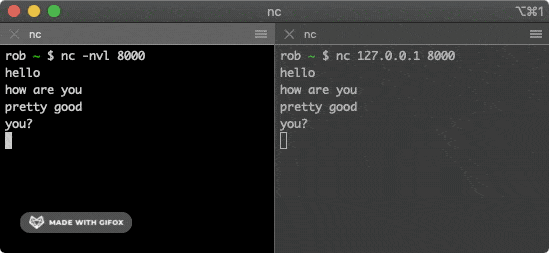
-可以使用 netcat 工具来建立 TCP 连接,这个工很多操作系统都预装了。打开第一个终端窗口,运行以下命令:
+可以使用 netcat 工具来建立 TCP 连接,这个工具很多操作系统都预装了。打开第一个终端窗口,运行以下命令:
```bash
-$ nc -nvl 8000
+nc -nvl 8000
```
这个命令会启动一个 TCP 服务,监听端口为 `8000`。接着再打开第二个终端窗口,运行以下命令:
```bash
-$ nc 127.0.0.1 8000
+nc 127.0.0.1 8000
```
该命令会尝试与上面的服务建立连接,在其中一个窗口输入一些字符,就会通过 TCP 连接发送给另一个窗口并打印出来。
-
+
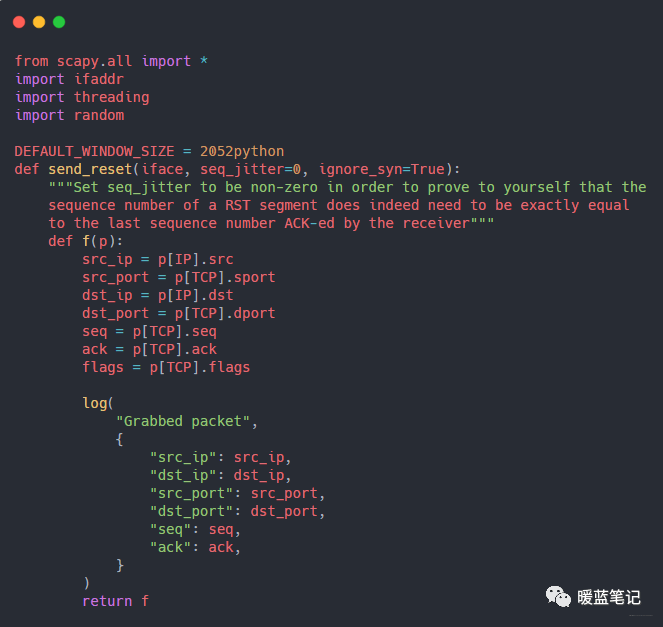
> 嗅探流量
编写一个攻击程序,使用 Python 网络库 `scapy` 来读取两个终端窗口之间交换的数据,并将其打印到终端上。代码比较长,下面为一部份,完整代码后台回复 TCP 攻击,代码的核心是调用 `scapy` 的嗅探方法:
-
+
这段代码告诉 `scapy` 在 `lo0` 网络接口上嗅探数据包,并记录所有 TCP 连接的详细信息。
@@ -252,7 +257,7 @@ $ nc 127.0.0.1 8000
攻击中间人攻击英文名叫 Man-in-the-MiddleAttack,简称「MITM 攻击」。指攻击者与通讯的两端分别创建独立的联系,并交换其所收到的数据,使通讯的两端认为他们正在通过一个私密的连接与对方 直接对话,但事实上整个会话都被攻击者完全控制。我们画一张图:
-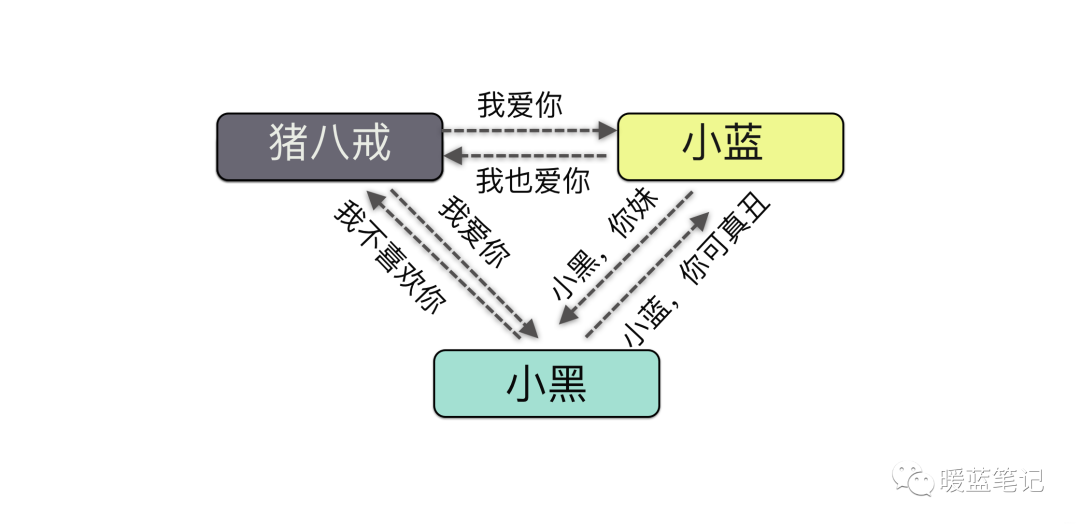
+
从这张图可以看到,中间人其实就是攻击者。通过这种原理,有很多实现的用途,比如说,你在手机上浏览不健康网站的时候,手机就会提示你,此网站可能含有病毒,是否继续访问还是做其他的操作等等。
@@ -292,7 +297,7 @@ $ nc 127.0.0.1 8000
同样的,举个例子。Sum 和 Mike 两个人签合同。Sum 首先用 **SHA** 算法计算合同的摘要,然后用自己私钥将摘要加密,得到数字签名。Sum 将合同原文、签名,以及公钥三者都交给 Mike
-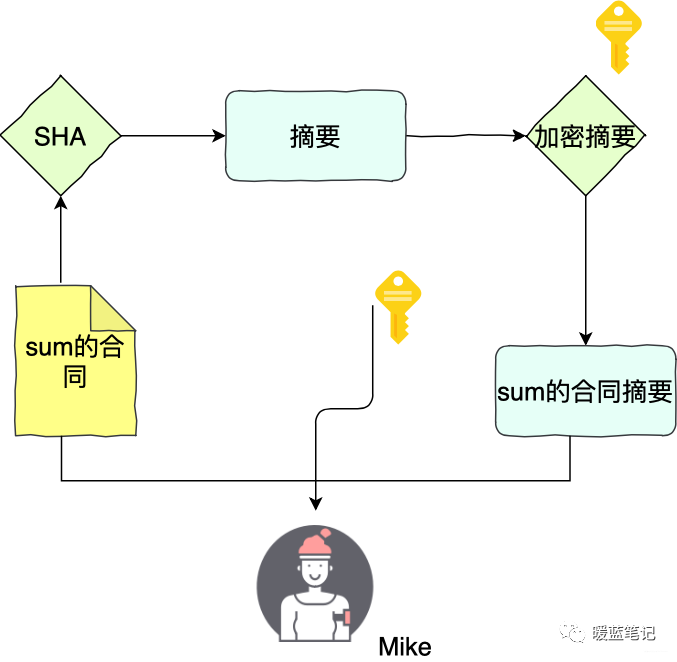
+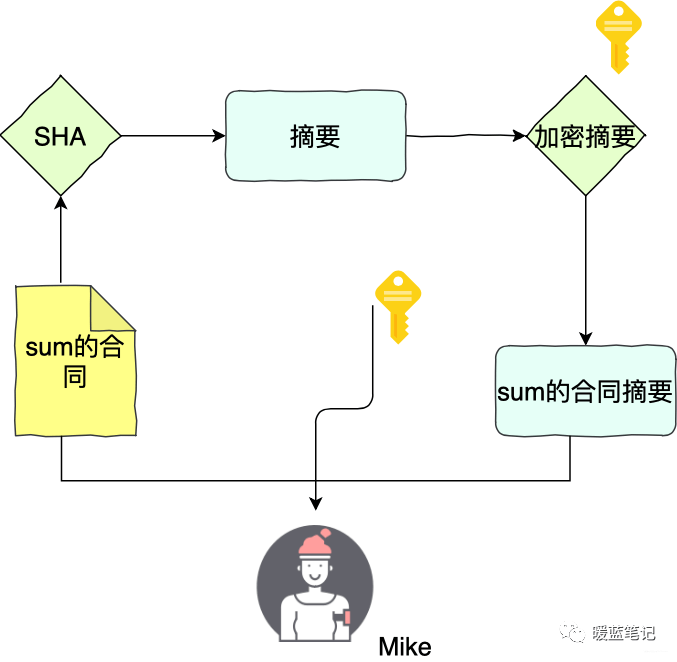
如果 Sum 想要证明合同是 Mike 的,那么就要使用 Mike 的公钥,将这个签名解密得到摘要 x,然后 Mike 计算原文的 sha 摘要 Y,随后对比 x 和 y,如果两者相等,就认为数据没有被篡改
@@ -308,7 +313,7 @@ $ nc 127.0.0.1 8000
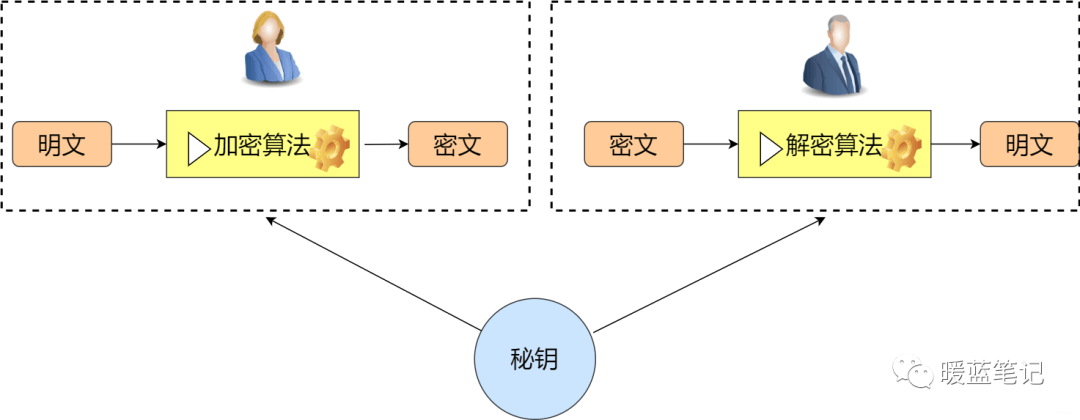
对称加密,顾名思义,加密方与解密方使用同一钥匙(秘钥)。具体一些就是,发送方通过使用相应的加密算法和秘钥,对将要发送的信息进行加密;对于接收方而言,使用解密算法和相同的秘钥解锁信息,从而有能力阅读信息。
-
+
#### 常见的对称加密算法有哪些?
@@ -316,7 +321,7 @@ $ nc 127.0.0.1 8000
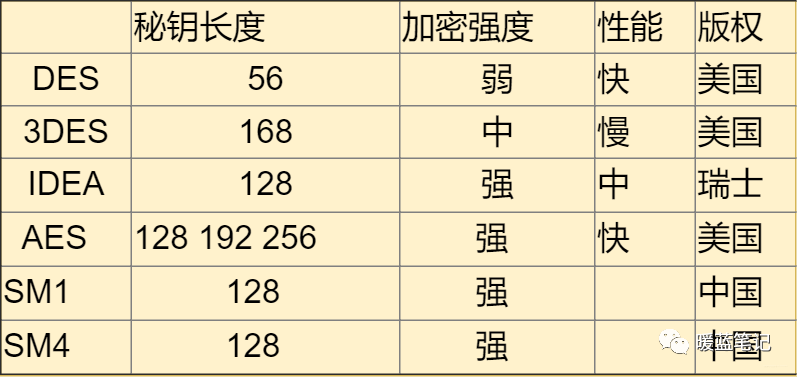
DES 使用的密钥表面上是 64 位的,然而只有其中的 56 位被实际用于算法,其余 8 位可以被用于奇偶校验,并在算法中被丢弃。因此,**DES** 的有效密钥长度为 56 位,通常称 **DES** 的密钥长度为 56 位。假设秘钥为 56 位,采用暴力破 Jie 的方式,其秘钥个数为 2 的 56 次方,那么每纳秒执行一次解密所需要的时间差不多 1 年的样子。当然,没人这么干。**DES** 现在已经不是一种安全的加密方法,主要因为它使用的 56 位密钥过短。
-
+
**IDEA**
@@ -328,50 +333,50 @@ DES 使用的密钥表面上是 64 位的,然而只有其中的 56 位被实
**SM1 和 SM4**
-之前几种都是国外的,我们国内自行研究了国密 **SM1 **和 **SM4**。其中 S 都属于国家标准,算法公开。优点就是国家的大力支持和认可
+之前几种都是国外的,我们国内自行研究了国密 **SM1**和 **SM4**。其中 S 都属于国家标准,算法公开。优点就是国家的大力支持和认可
**总结**:
-
+
#### 常见的非对称加密算法有哪些?
在对称加密中,发送方与接收方使用相同的秘钥。那么在非对称加密中则是发送方与接收方使用的不同的秘钥。其主要解决的问题是防止在秘钥协商的过程中发生泄漏。比如在对称加密中,小蓝将需要发送的消息加密,然后告诉你密码是 123balala,ok,对于其他人而言,很容易就能劫持到密码是 123balala。那么在非对称的情况下,小蓝告诉所有人密码是 123balala,对于中间人而言,拿到也没用,因为没有私钥。所以,非对称密钥其实主要解决了密钥分发的难题。如下图
-
+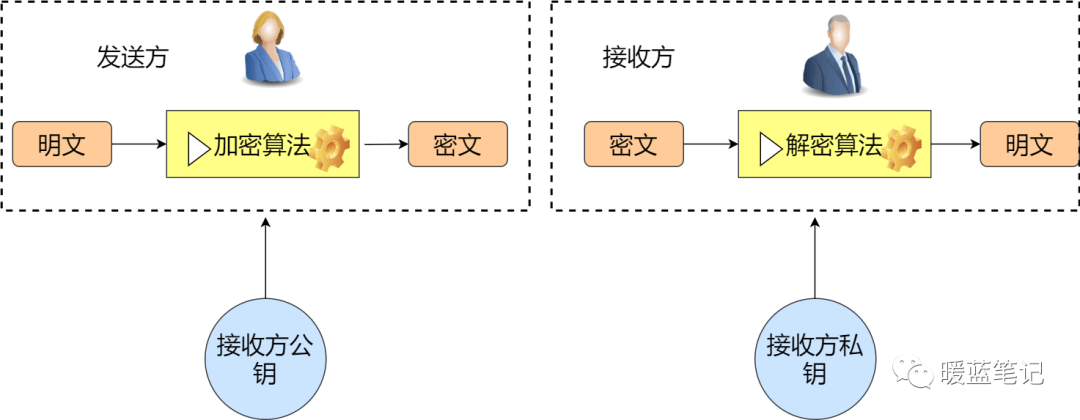
其实我们经常都在使用非对称加密,比如使用多台服务器搭建大数据平台 hadoop,为了方便多台机器设置免密登录,是不是就会涉及到秘钥分发。再比如搭建 docker 集群也会使用相关非对称加密算法。
常见的非对称加密算法:
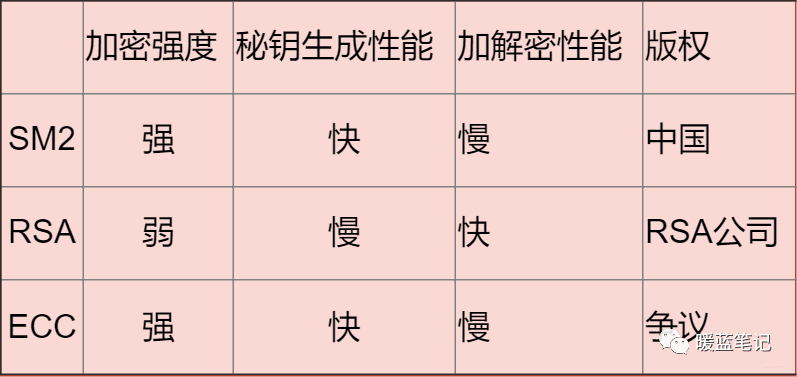
-- RSA(RSA 加密算法,RSA Algorithm):优势是性能比较快,如果想要较高的加密难度,需要很长的秘钥。
+- RSA(RSA 加密算法,RSA Algorithm):安全性基于大整数分解的计算难度,应用广泛,兼容性好。缺点是性能相对较慢,且密钥越长(如 2048/4096 位)安全性越高,但运算开销也随之增大。
- ECC:基于椭圆曲线提出。是目前加密强度最高的非对称加密算法
- SM2:同样基于椭圆曲线问题设计。最大优势就是国家认可和大力支持。
总结:
-
+
#### 常见的散列算法有哪些?
这个大家应该更加熟悉了,比如我们平常使用的 MD5 校验,在很多时候,我并不是拿来进行加密,而是用来获得唯一性 ID。在做系统的过程中,存储用户的各种密码信息,通常都会通过散列算法,最终存储其散列值。
-**MD5**
+**MD5**(不推荐)
MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较普遍的散列算法,具体的应用场景你可以自行 参阅。虽然,因为算法的缺陷,它的唯一性已经被破解了,但是大部分场景下,这并不会构成安全问题。但是,如果不是长度受限(32 个字符),我还是不推荐你继续使用 **MD5** 的。
**SHA**
-安全散列算法。**SHA** 分为 **SHA1** 和 **SH2** 两个版本。该算法的思想是接收一段明文,然后以一种不可逆的方式将它转换成一段(通常更小)密文,也可以简单的理解为取一串输入码(称为预映射或信息),并把它们转化为长度较短、位数固定的输出序列即散列值(也称为信息摘要或信息认证代码)的过程。
+安全散列算法。**SHA** 包括**SHA-1**、**SHA-2**和**SHA-3**三个版本。该算法的基本思想是:接收一段明文数据,通过不可逆的方式将其转换为固定长度的密文。简单来说,SHA 将输入数据(即预映射或消息)转化为固定长度、较短的输出值,称为散列值(或信息摘要、信息认证码)。SHA-1 已被证明不够安全,因此逐渐被 SHA-2 取代,而 SHA-3 则作为 SHA 系列的最新版本,采用不同的结构(Keccak 算法)提供更高的安全性和灵活性。
**SM3**
-国密算法**SM3**。加密强度和 SHA-256 想不多。主要是收到国家的支持。
+国密算法**SM3**。加密强度和 SHA-256 算法 相差不多。主要是受到了国家的支持。
**总结**:
-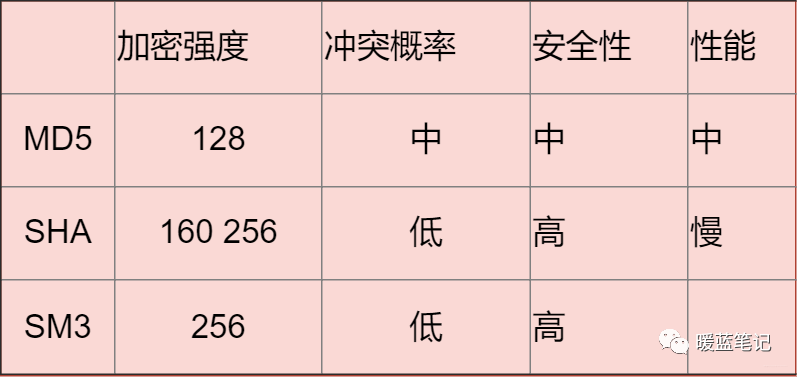
+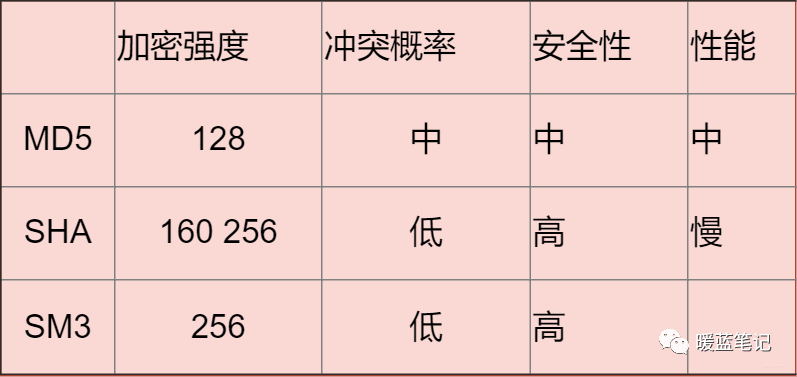
**大部分情况下使用对称加密,具有比较不错的安全性。如果需要分布式进行秘钥分发,考虑非对称。如果不需要可逆计算则散列算法。** 因为这段时间有这方面需求,就看了一些这方面的资料,入坑信息安全,就怕以后洗发水都不用买。谢谢大家查看!
@@ -383,7 +388,7 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
证书之所以会有信用,是因为证书的签发方拥有信用。所以如果 Sum 想让 Mike 承认自己的公钥,Sum 不会直接将公钥给 Mike ,而是提供由第三方机构,含有公钥的证书。如果 Mike 也信任这个机构,法律都认可,那 ik,信任关系成立
-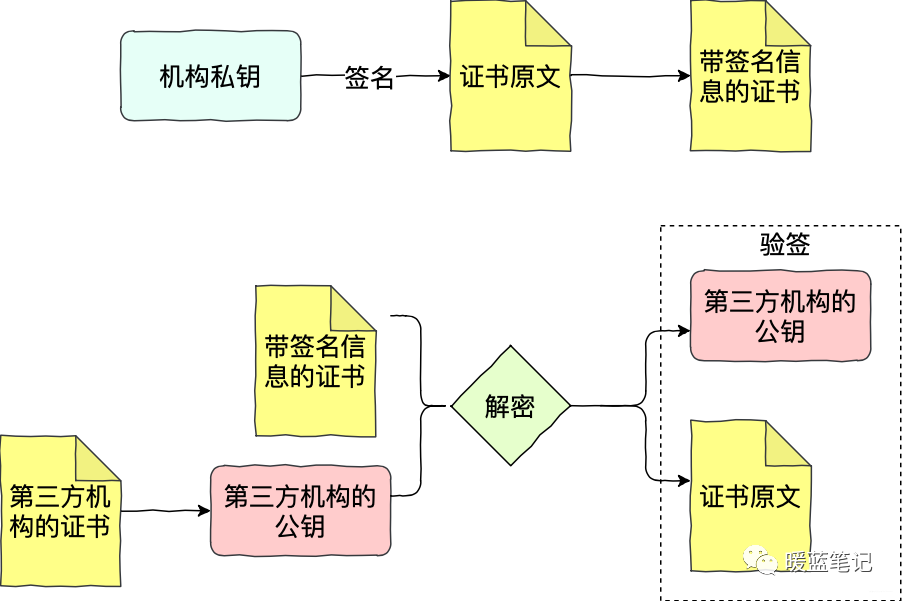
+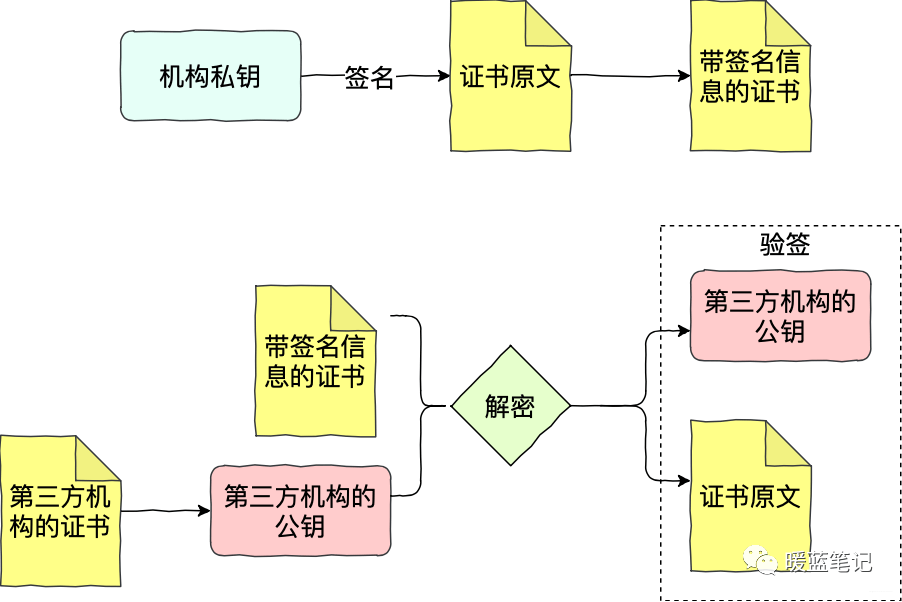
如上图所示,Sum 将自己的申请提交给机构,产生证书的原文。机构用自己的私钥签名 Sum 的申请原文(先根据原文内容计算摘要,再用私钥加密),得到带有签名信息的证书。Mike 拿到带签名信息的证书,通过第三方机构的公钥进行解密,获得 Sum 证书的摘要、证书的原文。有了 Sum 证书的摘要和原文,Mike 就可以进行验签。验签通过,Mike 就可以确认 Sum 的证书的确是第三方机构签发的。
@@ -391,7 +396,7 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
为了让这个信任条更加稳固,就需要环环相扣,打造更长的信任链,避免单点信任风险
-
+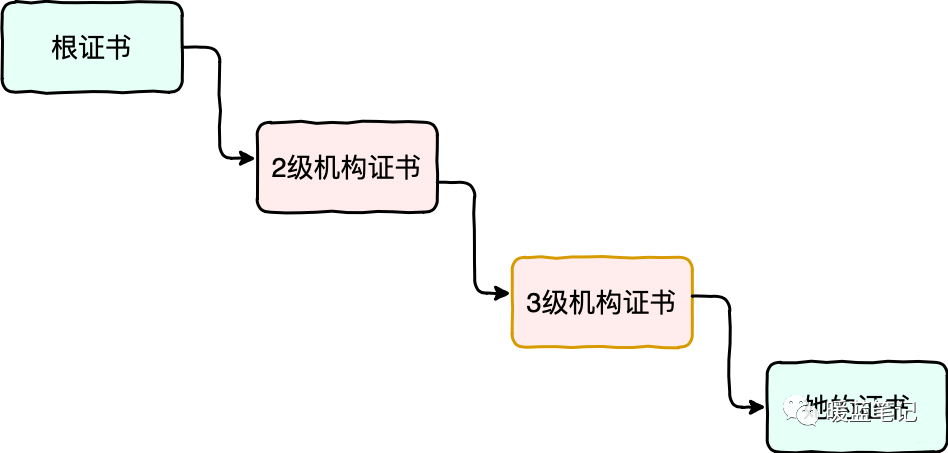
上图中,由信誉最好的根证书机构提供根证书,然后根证书机构去签发二级机构的证书;二级机构去签发三级机构的证书;最后有由三级机构去签发 Sum 证书。
@@ -407,7 +412,7 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
既然知道了中间人攻击的原理也知道了他的危险,现在我们看看如何避免。相信我们都遇到过下面这种状况:
-
+
出现这个界面的很多情况下,都是遇到了中间人攻击的现象,需要对安全证书进行及时地监测。而且大名鼎鼎的 github 网站,也曾遭遇过中间人攻击:
@@ -462,7 +467,9 @@ CDN 加速,我们可以这么理解:为了减少流氓骚扰,我干脆将
## 参考
-- HTTP 洪水攻击 - CloudFlare:https://www.cloudflare.com/zh-cn/learning/ddos/http-flood-ddos-attack/
-- SYN 洪水攻击:https://www.cloudflare.com/zh-cn/learning/ddos/syn-flood-ddos-attack/
-- 什么是 IP 欺骗?:https://www.cloudflare.com/zh-cn/learning/ddos/glossary/ip-spoofing/
-- 什么是 DNS 洪水?| DNS 洪水 DDoS 攻击:https://www.cloudflare.com/zh-cn/learning/ddos/dns-flood-ddos-attack/
+- HTTP 洪水攻击 - CloudFlare:
+- SYN 洪水攻击:
+- 什么是 IP 欺骗?:
+- 什么是 DNS 洪水?| DNS 洪水 DDoS 攻击:
+
+
diff --git a/docs/cs-basics/network/osi-and-tcp-ip-model.md b/docs/cs-basics/network/osi-and-tcp-ip-model.md
index 4fc5d81c6da..49f2c8ccb00 100644
--- a/docs/cs-basics/network/osi-and-tcp-ip-model.md
+++ b/docs/cs-basics/network/osi-and-tcp-ip-model.md
@@ -1,8 +1,13 @@
---
title: OSI 和 TCP/IP 网络分层模型详解(基础)
+description: 详解 OSI 与 TCP/IP 的分层模型与职责划分,结合历史与实践对比两者差异与工程取舍。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: OSI 七层,TCP/IP 四层,分层模型,职责划分,协议栈,对比
---
## OSI 七层模型
@@ -19,7 +24,7 @@ tag:
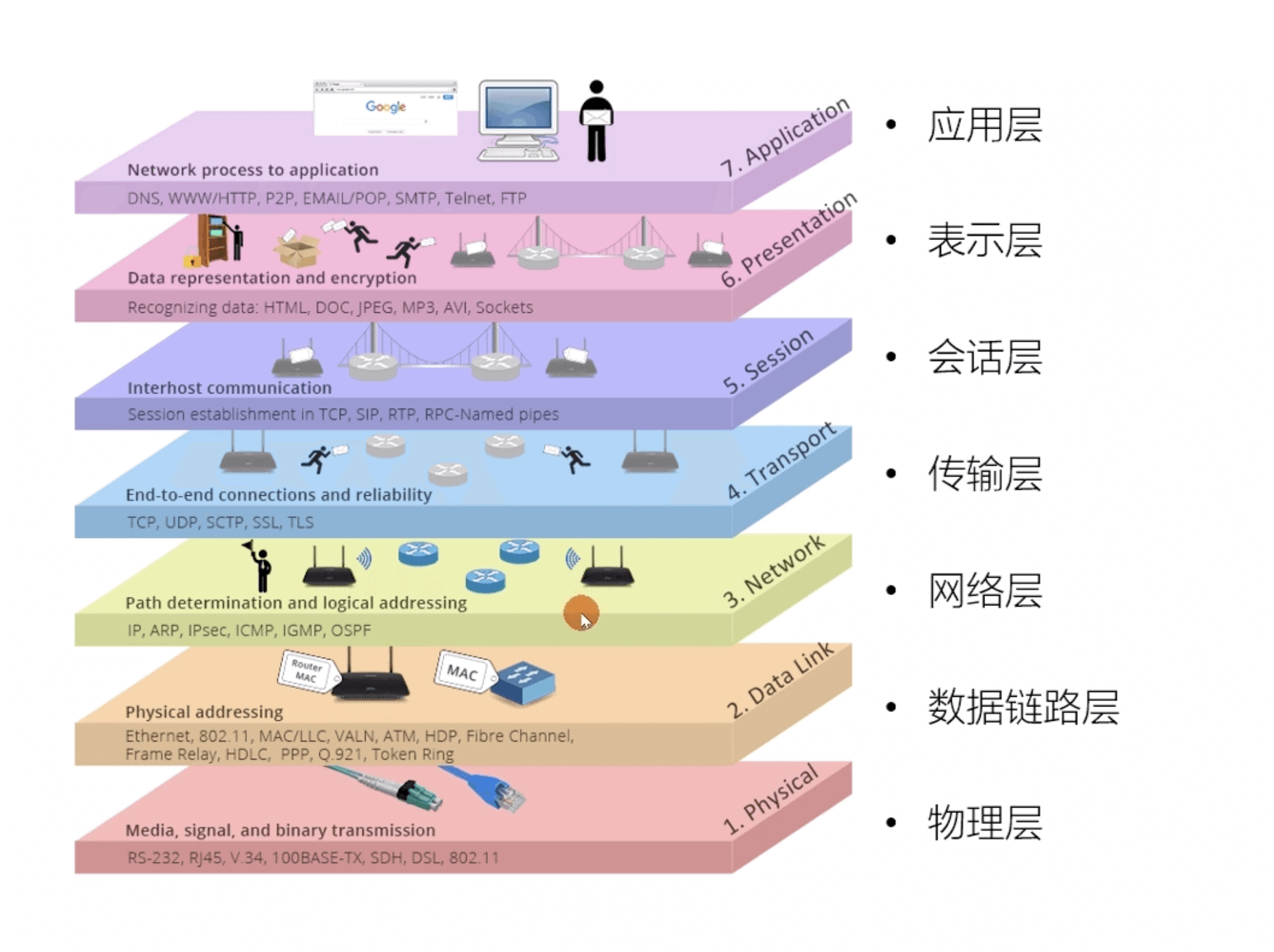
-**既然 OSI 七层模型这么厉害,为什么干不过 TCP/IP 四 层模型呢?**
+**既然 OSI 七层模型这么厉害,为什么干不过 TCP/IP 四层模型呢?**
的确,OSI 七层模型当时一直被一些大公司甚至一些国家政府支持。这样的背景下,为什么会失败呢?我觉得主要有下面几方面原因:
@@ -66,7 +71,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
- **Telnet(远程登陆协议)**:基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
- **SSH(Secure Shell Protocol,安全的网络传输协议)**:基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
- **RTP(Real-time Transport Protocol,实时传输协议)**:通常基于 UDP 协议,但也支持 TCP 协议。它提供了端到端的实时传输数据的功能,但不包含资源预留存、不保证实时传输质量,这些功能由 WebRTC 实现。
-- **DNS(Domain Name System,域名管理系统)**: 基于 UDP 协议,用于解决域名和 IP 地址的映射问题。
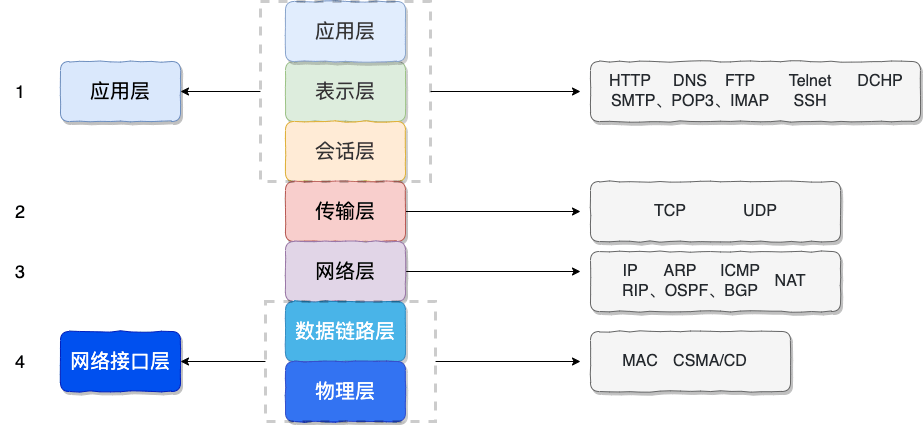
+- **DNS(Domain Name System,域名管理系统)**: 通常基于 UDP 协议(端口 53),用于解决域名和 IP 地址的映射问题。当响应数据过大或进行区域传送时会改用 TCP。
关于这些协议的详细介绍请看 [应用层常见协议总结(应用层)](./application-layer-protocol.md) 这篇文章。
@@ -78,7 +83,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础

-- **TCP(Transmisson Control Protocol,传输控制协议 )**:提供 **面向连接** 的,**可靠** 的数据传输服务。
+- **TCP(Transmission Control Protocol,传输控制协议 )**:提供 **面向连接** 的,**可靠** 的数据传输服务。
- **UDP(User Datagram Protocol,用户数据协议)**:提供 **无连接** 的,**尽最大努力** 的数据传输服务(不保证数据传输的可靠性),简单高效。
### 网络层(Network layer)
@@ -95,7 +100,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
**网络层常见协议**:
-
+
- **IP(Internet Protocol,网际协议)**:TCP/IP 协议中最重要的协议之一,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
- **ARP(Address Resolution Protocol,地址解析协议)**:ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
@@ -132,7 +137,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
- SSH(Secure Shell Protocol,安全的网络传输协议)
- RTP(Real-time Transport Protocol,实时传输协议)
- DNS(Domain Name System,域名管理系统)
-- ......
+- ……
**传输层协议** :
@@ -154,7 +159,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
- OSPF(Open Shortest Path First,开放式最短路径优先)
- RIP(Routing Information Protocol,路由信息协议)
- BGP(Border Gateway Protocol,边界网关协议)
-- ......
+- ……
**网络接口层** :
@@ -163,7 +168,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
- CSMA/CD 协议
- MAC 协议
- 以太网技术
-- ......
+- ……
## 网络分层的原因
@@ -189,5 +194,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
## 参考
-- TCP/IP model vs OSI model:https://fiberbit.com.tw/tcpip-model-vs-osi-model/
-- Data Encapsulation and the TCP/IP Protocol Stack:https://docs.oracle.com/cd/E19683-01/806-4075/ipov-32/index.html
+- TCP/IP model vs OSI model:
+- Data Encapsulation and the TCP/IP Protocol Stack:
+
+
diff --git a/docs/cs-basics/network/other-network-questions.md b/docs/cs-basics/network/other-network-questions.md
index 038b4ef794e..df59c7a47b7 100644
--- a/docs/cs-basics/network/other-network-questions.md
+++ b/docs/cs-basics/network/other-network-questions.md
@@ -1,8 +1,13 @@
---
title: 计算机网络常见面试题总结(上)
+description: 最新计算机网络高频面试题总结(上):TCP/IP四层模型、HTTP全版本对比、TCP三次握手、DNS解析、WebSocket/SSE实时推送等,附图解+⭐️重点标注,一文搞定应用层&传输层&网络层核心考点,快速备战后端面试!
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 计算机网络面试题,TCP/IP四层模型,HTTP面试,HTTPS vs HTTP,HTTP/1.1 vs HTTP/2,HTTP/3 QUIC,TCP三次握手,UDP区别,DNS解析,WebSocket vs SSE,GET vs POST,应用层协议,网络分层,队头阻塞,PING命令,ARP协议
---
@@ -15,7 +20,7 @@ tag:
#### OSI 七层模型是什么?每一层的作用是什么?
-**OSI 七层模型** 是国际标准化组织提出一个网络分层模型,其大体结构以及每一层提供的功能如下图所示:
+**OSI 七层模型** 是国际标准化组织提出的一个网络分层模型,其大体结构以及每一层提供的功能如下图所示:
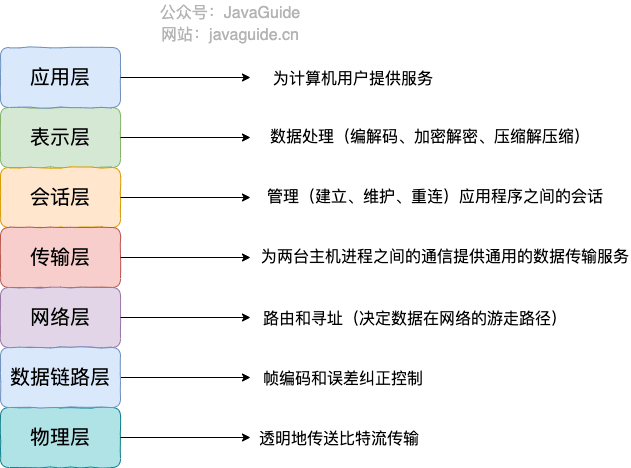
@@ -27,7 +32,7 @@ tag:

-#### TCP/IP 四层模型是什么?每一层的作用是什么?
+#### ⭐️TCP/IP 四层模型是什么?每一层的作用是什么?
**TCP/IP 四层模型** 是目前被广泛采用的一种模型,我们可以将 TCP / IP 模型看作是 OSI 七层模型的精简版本,由以下 4 层组成:
@@ -40,7 +45,7 @@ tag:

-关于每一层作用的详细介绍,请看 [OSI 和 TCP/IP 网络分层模型详解(基础)](./osi-and-tcp-ip-model.md) 这篇文章。
+关于每一层作用的详细介绍,请看 [OSI 和 TCP/IP 网络分层模型详解(基础)](https://javaguide.cn/cs-basics/network/osi-and-tcp-ip-model.html) 这篇文章。
#### 为什么网络要分层?
@@ -55,7 +60,7 @@ tag:
好了,再来说回:“为什么网络要分层?”。我觉得主要有 3 方面的原因:
1. **各层之间相互独立**:各层之间相互独立,各层之间不需要关心其他层是如何实现的,只需要知道自己如何调用下层提供好的功能就可以了(可以简单理解为接口调用)**。这个和我们对开发时系统进行分层是一个道理。**
-2. **提高了整体灵活性**:每一层都可以使用最适合的技术来实现,你只需要保证你提供的功能以及暴露的接口的规则没有改变就行了。**这个和我们平时开发系统的时候要求的高内聚、低耦合的原则也是可以对应上的。**
+2. **提高了灵活性和可替换性**:每一层都可以使用最适合的技术来实现,你只需要保证你提供的功能以及暴露的接口的规则没有改变就行了。并且,每一层都可以根据需要进行修改或替换,而不会影响到整个网络的结构。**这个和我们平时开发系统的时候要求的高内聚、低耦合的原则也是可以对应上的。**
3. **大问题化小**:分层可以将复杂的网络问题分解为许多比较小的、界线比较清晰简单的小问题来处理和解决。这样使得复杂的计算机网络系统变得易于设计,实现和标准化。 **这个和我们平时开发的时候,一般会将系统功能分解,然后将复杂的问题分解为容易理解的更小的问题是相对应的,这些较小的问题具有更好的边界(目标和接口)定义。**
我想到了计算机世界非常非常有名的一句话,这里分享一下:
@@ -64,7 +69,7 @@ tag:
### 常见网络协议
-#### 应用层有哪些常见的协议?
+#### ⭐️应用层有哪些常见的协议?
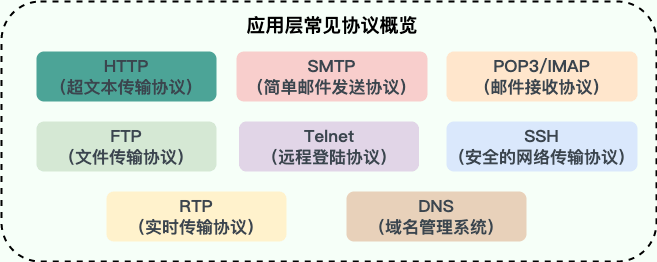
@@ -75,7 +80,7 @@ tag:
- **Telnet(远程登陆协议)**:基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
- **SSH(Secure Shell Protocol,安全的网络传输协议)**:基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
- **RTP(Real-time Transport Protocol,实时传输协议)**:通常基于 UDP 协议,但也支持 TCP 协议。它提供了端到端的实时传输数据的功能,但不包含资源预留存、不保证实时传输质量,这些功能由 WebRTC 实现。
-- **DNS(Domain Name System,域名管理系统)**: 基于 UDP 协议,用于解决域名和 IP 地址的映射问题。
+- **DNS(Domain Name System,域名管理系统)**: 通常基于 UDP 协议(端口 53),用于解决域名和 IP 地址的映射问题。当响应数据过大或进行区域传送时会改用 TCP。
关于这些协议的详细介绍请看 [应用层常见协议总结(应用层)](./application-layer-protocol.md) 这篇文章。
@@ -88,138 +93,234 @@ tag:
#### 网络层有哪些常见的协议?
-
+
- **IP(Internet Protocol,网际协议)**:TCP/IP 协议中最重要的协议之一,属于网络层的协议,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
- **ARP(Address Resolution Protocol,地址解析协议)**:ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
- **ICMP(Internet Control Message Protocol,互联网控制报文协议)**:一种用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性。
- **NAT(Network Address Translation,网络地址转换协议)**:NAT 协议的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
-- **OSPF(Open Shortest Path First,开放式最短路径优先)** ):一种内部网关协议(Interior Gateway Protocol,IGP),也是广泛使用的一种动态路由协议,基于链路状态算法,考虑了链路的带宽、延迟等因素来选择最佳路径。
+- **OSPF(Open Shortest Path First,开放式最短路径优先)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是广泛使用的一种动态路由协议,基于链路状态算法,考虑了链路的带宽、延迟等因素来选择最佳路径。
- **RIP(Routing Information Protocol,路由信息协议)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
- **BGP(Border Gateway Protocol,边界网关协议)**:一种用来在路由选择域之间交换网络层可达性信息(Network Layer Reachability Information,NLRI)的路由选择协议,具有高度的灵活性和可扩展性。
## HTTP
-### 从输入 URL 到页面展示到底发生了什么?(非常重要)
+### ⭐️从输入 URL 到页面展示到底发生了什么?(非常重要)
> 类似的问题:打开一个网页,整个过程会使用哪些协议?
-图解(图片来源:《图解 HTTP》):
+先来看一张图(来源于《图解 HTTP》):
-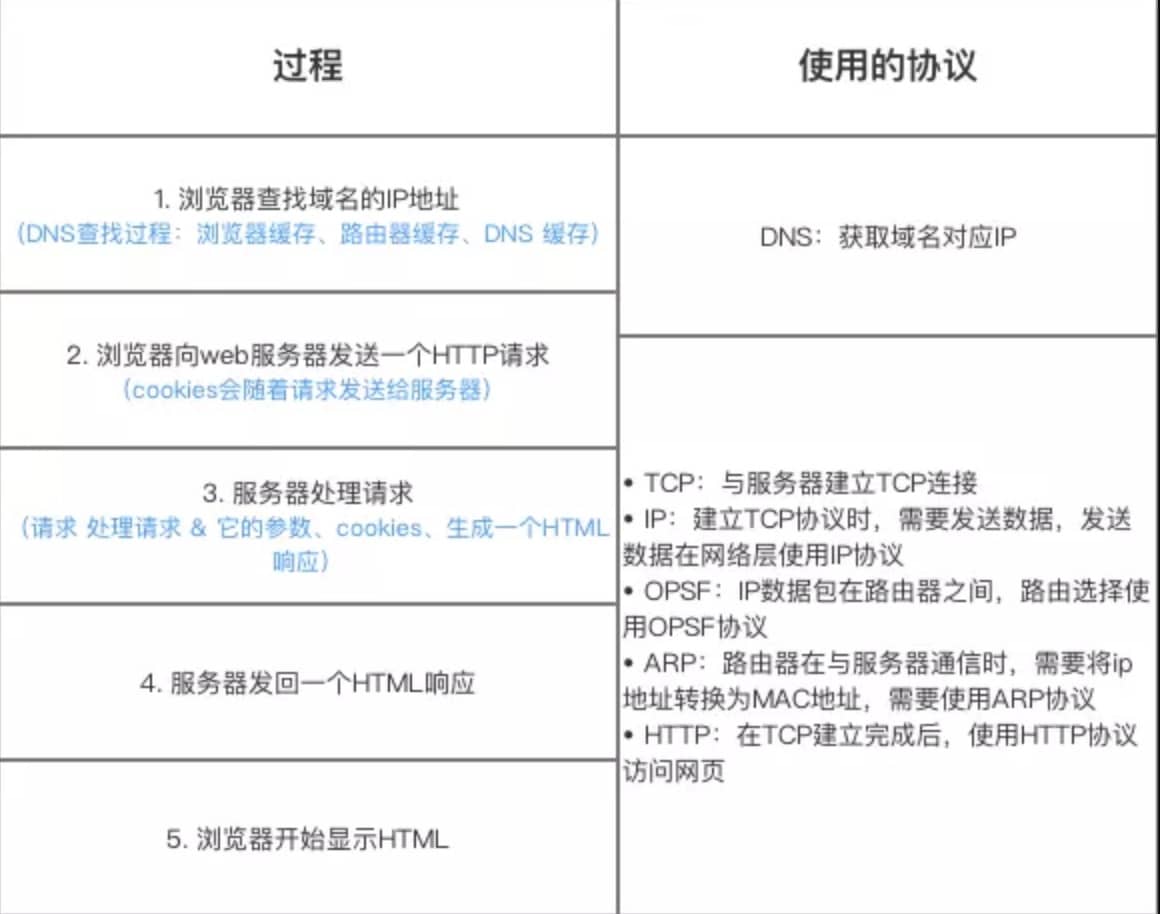 +
-> 上图有一个错误,请注意,是 OSPF 不是 OPSF。 OSPF(Open Shortest Path First,ospf)开放最短路径优先协议, 是由 Internet 工程任务组开发的路由选择协议
+上图有一个错误需要注意:是 OSPF 不是 OPSF。 OSPF(Open Shortest Path First,ospf)开放最短路径优先协议, 是由 Internet 工程任务组开发的路由选择协议
-总体来说分为以下几个过程:
+总体来说分为以下几个步骤:
-1. DNS 解析
-2. TCP 连接
-3. 发送 HTTP 请求
-4. 服务器处理请求并返回 HTTP 报文
-5. 浏览器解析渲染页面
-6. 连接结束
+1. 在浏览器中输入指定网页的 URL。
+2. 浏览器通过 DNS 协议,获取域名对应的 IP 地址。
+3. 浏览器根据 IP 地址和端口号,向目标服务器发起一个 TCP 连接请求。
+4. 浏览器在 TCP 连接上,向服务器发送一个 HTTP 请求报文,请求获取网页的内容。
+5. 服务器收到 HTTP 请求报文后,处理请求,并返回 HTTP 响应报文给浏览器。
+6. 浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示。
+7. 浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求。
-具体可以参考下面这两篇文章:
+详细介绍可以查看这篇文章:[访问网页的全过程(知识串联)](https://javaguide.cn/cs-basics/network/the-whole-process-of-accessing-web-pages.html)(强烈推荐)。
-- [从输入 URL 到页面加载发生了什么?](https://segmentfault.com/a/1190000006879700)
-- [浏览器从输入网址到页面展示的过程](https://cloud.tencent.com/developer/article/1879758)
-
-### HTTP 状态码有哪些?
+### ⭐️HTTP 状态码有哪些?
HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被成功处理。
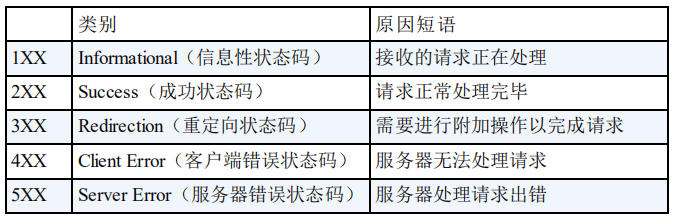
-关于 HTTP 状态码更详细的总结,可以看我写的这篇文章:[HTTP 常见状态码总结(应用层)](./http-status-codes.md)。
+关于 HTTP 状态码更详细的总结,可以看我写的这篇文章:[HTTP 常见状态码总结(应用层)](https://javaguide.cn/cs-basics/network/http-status-codes.html)。
### HTTP Header 中常见的字段有哪些?
-| 请求头字段名 | 说明 | 示例 |
-| :------------------ | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | :----------------------------------------------------------------------------------------- |
-| Accept | 能够接受的回应内容类型(Content-Types)。 | Accept: text/plain |
-| Accept-Charset | 能够接受的字符集 | Accept-Charset: utf-8 |
-| Accept-Datetime | 能够接受的按照时间来表示的版本 | Accept-Datetime: Thu, 31 May 2007 20:35:00 GMT |
-| Accept-Encoding | 能够接受的编码方式列表。参考 HTTP 压缩。 | Accept-Encoding: gzip, deflate |
-| Accept-Language | 能够接受的回应内容的自然语言列表。 | Accept-Language: en-US |
-| Authorization | 用于超文本传输协议的认证的认证信息 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
-| Cache-Control | 用来指定在这次的请求/响应链中的所有缓存机制 都必须 遵守的指令 | Cache-Control: no-cache |
-| Connection | 该浏览器想要优先使用的连接类型 | Connection: keep-alive Connection: Upgrade |
-| Content-Length | 以 八位字节数组 (8 位的字节)表示的请求体的长度 | Content-Length: 348 |
-| Content-MD5 | 请求体的内容的二进制 MD5 散列值,以 Base64 编码的结果 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
-| Content-Type | 请求体的 多媒体类型 (用于 POST 和 PUT 请求中) | Content-Type: application/x-www-form-urlencoded |
-| Cookie | 之前由服务器通过 Set- Cookie (下文详述)发送的一个 超文本传输协议 Cookie | Cookie: \$Version=1; Skin=new; |
-| Date | 发送该消息的日期和时间(按照 RFC 7231 中定义的"超文本传输协议日期"格式来发送) | Date: Tue, 15 Nov 1994 08:12:31 GMT |
-| Expect | 表明客户端要求服务器做出特定的行为 | Expect: 100-continue |
-| From | 发起此请求的用户的邮件地址 | From: [user@example.com](mailto:user@example.com) |
-| Host | 服务器的域名(用于虚拟主机 ),以及服务器所监听的传输控制协议端口号。如果所请求的端口是对应的服务的标准端口,则端口号可被省略。 | Host: en.wikipedia.org:80 |
-| If-Match | 仅当客户端提供的实体与服务器上对应的实体相匹配时,才进行对应的操作。主要作用时,用作像 PUT 这样的方法中,仅当从用户上次更新某个资源以来,该资源未被修改的情况下,才更新该资源。 | If-Match: “737060cd8c284d8af7ad3082f209582d” |
-| If-Modified-Since | 允许在对应的内容未被修改的情况下返回 304 未修改( 304 Not Modified ) | If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
-| If-None-Match | 允许在对应的内容未被修改的情况下返回 304 未修改( 304 Not Modified ) | If-None-Match: “737060cd8c284d8af7ad3082f209582d” |
-| If-Range | 如果该实体未被修改过,则向我发送我所缺少的那一个或多个部分;否则,发送整个新的实体 | If-Range: “737060cd8c284d8af7ad3082f209582d” |
-| If-Unmodified-Since | 仅当该实体自某个特定时间已来未被修改的情况下,才发送回应。 | If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
-| Max-Forwards | 限制该消息可被代理及网关转发的次数。 | Max-Forwards: 10 |
-| Origin | 发起一个针对 跨来源资源共享 的请求。 | Origin: [http://www.example-social-network.com](http://www.example-social-network.com/) |
-| Pragma | 与具体的实现相关,这些字段可能在请求/回应链中的任何时候产生多种效果。 | Pragma: no-cache |
-| Proxy-Authorization | 用来向代理进行认证的认证信息。 | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
-| Range | 仅请求某个实体的一部分。字节偏移以 0 开始。参见字节服务。 | Range: bytes=500-999 |
-| Referer | 表示浏览器所访问的前一个页面,正是那个页面上的某个链接将浏览器带到了当前所请求的这个页面。 | Referer: [http://en.wikipedia.org/wiki/Main_Page](https://en.wikipedia.org/wiki/Main_Page) |
-| TE | 浏览器预期接受的传输编码方式:可使用回应协议头 Transfer-Encoding 字段中的值; | TE: trailers, deflate |
-| Upgrade | 要求服务器升级到另一个协议。 | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
-| User-Agent | 浏览器的浏览器身份标识字符串 | User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:12.0) Gecko/20100101 Firefox/21.0 |
-| Via | 向服务器告知,这个请求是由哪些代理发出的。 | Via: 1.0 fred, 1.1 example.com (Apache/1.1) |
-| Warning | 一个一般性的警告,告知,在实体内容体中可能存在错误。 | Warning: 199 Miscellaneous warning |
-
-### HTTP 和 HTTPS 有什么区别?(重要)
-
-
+| 请求头字段名 | 说明 | 示例 |
+| :------------------ | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------------------------------------------------------------- |
+| Accept | 能够接受的回应内容类型(Content-Types)。 | Accept: text/plain |
+| Accept-Charset | 能够接受的字符集 | Accept-Charset: utf-8 |
+| Accept-Datetime | 能够接受的按照时间来表示的版本 | Accept-Datetime: Thu, 31 May 2007 20:35:00 GMT |
+| Accept-Encoding | 能够接受的编码方式列表。参考 HTTP 压缩。 | Accept-Encoding: gzip, deflate |
+| Accept-Language | 能够接受的回应内容的自然语言列表。 | Accept-Language: en-US |
+| Authorization | 用于超文本传输协议的认证的认证信息 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
+| Cache-Control | 用来指定在这次的请求/响应链中的所有缓存机制 都必须 遵守的指令 | Cache-Control: no-cache |
+| Connection | 该浏览器想要优先使用的连接类型 | Connection: keep-alive |
+| Content-Length | 以八位字节数组(8 位的字节)表示的请求体的长度 | Content-Length: 348 |
+| Content-MD5 | 请求体的内容的二进制 MD5 散列值,以 Base64 编码的结果 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
+| Content-Type | 请求体的多媒体类型(用于 POST 和 PUT 请求中) | Content-Type: application/x-www-form-urlencoded |
+| Cookie | 之前由服务器通过 Set-Cookie(下文详述)发送的一个超文本传输协议 Cookie | Cookie: $Version=1; Skin=new; |
+| Date | 发送该消息的日期和时间(按照 RFC 7231 中定义的"超文本传输协议日期"格式来发送) | Date: Tue, 15 Nov 1994 08:12:31 GMT |
+| Expect | 表明客户端要求服务器做出特定的行为 | Expect: 100-continue |
+| From | 发起此请求的用户的邮件地址 | From: `user@example.com` |
+| Host | 服务器的域名(用于虚拟主机),以及服务器所监听的传输控制协议端口号。如果所请求的端口是对应的服务的标准端口,则端口号可被省略。 | Host: en.wikipedia.org |
+| If-Match | 仅当客户端提供的实体与服务器上对应的实体相匹配时,才进行对应的操作。主要作用是用于像 PUT 这样的方法中,仅当从用户上次更新某个资源以来,该资源未被修改的情况下,才更新该资源。 | If-Match: "737060cd8c284d8af7ad3082f209582d" |
+| If-Modified-Since | 允许服务器在请求的资源自指定的日期以来未被修改的情况下返回 `304 Not Modified` 状态码 | If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
+| If-None-Match | 允许服务器在请求的资源的 ETag 未发生变化的情况下返回 `304 Not Modified` 状态码 | If-None-Match: "737060cd8c284d8af7ad3082f209582d" |
+| If-Range | 如果该实体未被修改过,则向我发送我所缺少的那一个或多个部分;否则,发送整个新的实体 | If-Range: "737060cd8c284d8af7ad3082f209582d" |
+| If-Unmodified-Since | 仅当该实体自某个特定时间以来未被修改的情况下,才发送回应。 | If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
+| Max-Forwards | 限制该消息可被代理及网关转发的次数。 | Max-Forwards: 10 |
+| Origin | 发起一个针对跨来源资源共享的请求。 | `Origin: http://www.example-social-network.com` |
+| Pragma | 与具体的实现相关,这些字段可能在请求/回应链中的任何时候产生多种效果。 | Pragma: no-cache |
+| Proxy-Authorization | 用来向代理进行认证的认证信息。 | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
+| Range | 仅请求某个实体的一部分。字节偏移以 0 开始。参见字节服务。 | Range: bytes=500-999 |
+| Referer | 表示浏览器所访问的前一个页面,正是那个页面上的某个链接将浏览器带到了当前所请求的这个页面。 | `Referer: http://en.wikipedia.org/wiki/Main_Page` |
+| TE | 浏览器预期接受的传输编码方式:可使用回应协议头 Transfer-Encoding 字段中的值; | TE: trailers, deflate |
+| Upgrade | 要求服务器升级到另一个协议。 | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
+| User-Agent | 浏览器的浏览器身份标识字符串 | User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:12.0) Gecko/20100101 Firefox/21.0 |
+| Via | 向服务器告知,这个请求是由哪些代理发出的。 | Via: 1.0 fred, 1.1 example.com (Apache/1.1) |
+| Warning | 一个一般性的警告,告知,在实体内容体中可能存在错误。 | Warning: 199 Miscellaneous warning |
+
+### ⭐️HTTP 和 HTTPS 有什么区别?(重要)
+
+
- **端口号**:HTTP 默认是 80,HTTPS 默认是 443。
- **URL 前缀**:HTTP 的 URL 前缀是 `http://`,HTTPS 的 URL 前缀是 `https://`。
- **安全性和资源消耗**:HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
- **SEO(搜索引擎优化)**:搜索引擎通常会更青睐使用 HTTPS 协议的网站,因为 HTTPS 能够提供更高的安全性和用户隐私保护。使用 HTTPS 协议的网站在搜索结果中可能会被优先显示,从而对 SEO 产生影响。
-关于 HTTP 和 HTTPS 更详细的对比总结,可以看我写的这篇文章:[HTTP vs HTTPS(应用层)](./http-vs-https.md) 。
+关于 HTTP 和 HTTPS 更详细的对比总结,可以看我写的这篇文章:[HTTP vs HTTPS(应用层)](https://javaguide.cn/cs-basics/network/http-vs-https.html) 。
### HTTP/1.0 和 HTTP/1.1 有什么区别?

-- **连接方式** : HTTP/1.0 为短连接,HTTP/1.1 支持长连接。
+- **连接方式** : HTTP/1.0 为短连接,HTTP/1.1 支持长连接。HTTP 协议的长连接和短连接,实质上是 TCP 协议的长连接和短连接。
- **状态响应码** : HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
- **缓存机制** : 在 HTTP/1.0 中主要使用 Header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP/1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
- **带宽**:HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP/1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
- **Host 头(Host Header)处理** :HTTP/1.1 引入了 Host 头字段,允许在同一 IP 地址上托管多个域名,从而支持虚拟主机的功能。而 HTTP/1.0 没有 Host 头字段,无法实现虚拟主机。
-关于 HTTP/1.0 和 HTTP/1.1 更详细的对比总结,可以看我写的这篇文章:[HTTP/1.0 vs HTTP/1.1(应用层)](./http1.0-vs-http1.1.md) 。
+关于 HTTP/1.0 和 HTTP/1.1 更详细的对比总结,可以看我写的这篇文章:[HTTP/1.0 vs HTTP/1.1(应用层)](https://javaguide.cn/cs-basics/network/http1.0-vs-http1.1.html) 。
-### HTTP/1.1 和 HTTP/2.0 有什么区别?
+### ⭐️HTTP/1.1 和 HTTP/2.0 有什么区别?

-- **IO 多路复用(Multiplexing)**:HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本)。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
+- **多路复用(Multiplexing)**:HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本),互不干扰。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接,而浏览器为了控制资源会有 6-8 个 TCP 连接的限制。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
- **二进制帧(Binary Frames)**:HTTP/2.0 使用二进制帧进行数据传输,而 HTTP/1.1 则使用文本格式的报文。二进制帧更加紧凑和高效,减少了传输的数据量和带宽消耗。
-- **头部压缩(Header Compression)**:HTTP/1.1 支持`Body`压缩,`Header`不支持压缩。HTTP/2.0 支持对`Header`压缩,减少了网络开销。
+- **队头阻塞**:HTTP/2 引入了多路复用技术,允许多个请求和响应在单个 TCP 连接上并行交错传输,解决了 HTTP/1.1 应用层的队头阻塞问题,但 HTTP/2 依然受到 TCP 层队头阻塞 的影响。
+- **头部压缩(Header Compression)**:HTTP/1.1 支持`Body`压缩,`Header`不支持压缩。HTTP/2.0 支持对`Header`压缩,使用了专门为`Header`压缩而设计的 HPACK 算法,减少了网络开销。
- **服务器推送(Server Push)**:HTTP/2.0 支持服务器推送,可以在客户端请求一个资源时,将其他相关资源一并推送给客户端,从而减少了客户端的请求次数和延迟。而 HTTP/1.1 需要客户端自己发送请求来获取相关资源。
+HTTP/2.0 多路复用效果图(图源: [HTTP/2 For Web Developers](https://blog.cloudflare.com/http-2-for-web-developers/)):
+
+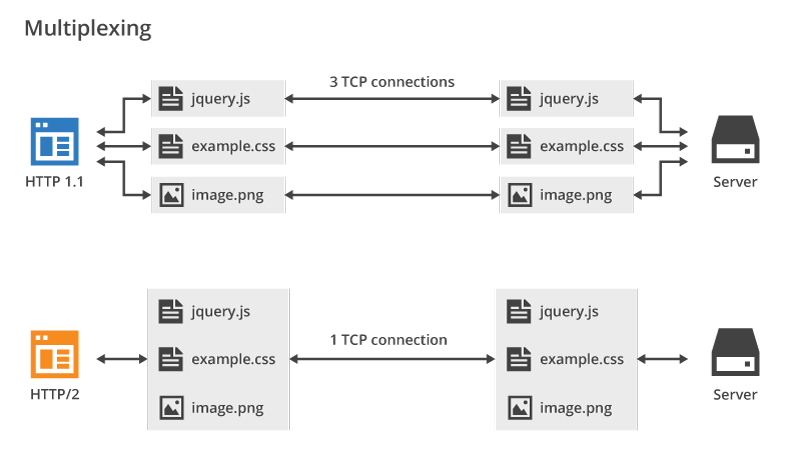
+
+可以看到,HTTP/2 的多路复用机制允许多个请求和响应共享一个 TCP 连接,从而避免了 HTTP/1.1 在应对并发请求时需要建立多个并行连接的情况,减少了重复连接建立和维护的额外开销。而在 HTTP/1.1 中,尽管支持持久连接,但为了缓解队头阻塞问题,浏览器通常会为同一域名建立多个并行连接。
+
### HTTP/2.0 和 HTTP/3.0 有什么区别?

- **传输协议**:HTTP/2.0 是基于 TCP 协议实现的,HTTP/3.0 新增了 QUIC(Quick UDP Internet Connections) 协议来实现可靠的传输,提供与 TLS/SSL 相当的安全性,具有较低的连接和传输延迟。你可以将 QUIC 看作是 UDP 的升级版本,在其基础上新增了很多功能比如加密、重传等等。HTTP/3.0 之前名为 HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3 最大的改造就是使用了 QUIC。
-- **连接建立**:HTTP/2.0 需要经过经典的 TCP 三次握手过程(一般是 3 个 RTT)。由于 QUIC 协议的特性,HTTP/3.0 可以避免 TCP 三次握手的延迟,允许在第一次连接时发送数据(0 个 RTT ,零往返时间)。
+- **连接建立**:HTTP/2.0 需要经过经典的 TCP 三次握手过程(由于安全的 HTTPS 连接建立还需要 TLS 握手,共需要大约 3 个 RTT)。由于 QUIC 协议的特性(TLS 1.3,TLS 1.3 除了支持 1 个 RTT 的握手,还支持 0 个 RTT 的握手)连接建立仅需 0-RTT 或者 1-RTT。这意味着 QUIC 在最佳情况下不需要任何的额外往返时间就可以建立新连接。
+- **头部压缩**:HTTP/2.0 使用 HPACK 算法进行头部压缩,而 HTTP/3.0 使用更高效的 QPACK 头压缩算法。
- **队头阻塞**:HTTP/2.0 多请求复用一个 TCP 连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。由于 QUIC 协议的特性,HTTP/3.0 在一定程度上解决了队头阻塞(Head-of-Line blocking, 简写:HOL blocking)问题,一个连接建立多个不同的数据流,这些数据流之间独立互不影响,某个数据流发生丢包了,其数据流不受影响(本质上是多路复用+轮询)。
+- **连接迁移**:HTTP/3.0 支持连接迁移,因为 QUIC 使用 64 位 ID 标识连接,只要 ID 不变就不会中断,网络环境改变时(如从 Wi-Fi 切换到移动数据)也能保持连接。而 TCP 连接是由(源 IP,源端口,目的 IP,目的端口)组成,这个四元组中一旦有一项值发生改变,这个连接也就不能用了。
- **错误恢复**:HTTP/3.0 具有更好的错误恢复机制,当出现丢包、延迟等网络问题时,可以更快地进行恢复和重传。而 HTTP/2.0 则需要依赖于 TCP 的错误恢复机制。
-- **安全性**:HTTP/2.0 和 HTTP/3.0 在安全性上都有较高的要求,支持加密通信,但在实现上有所不同。HTTP/2.0 使用 TLS 协议进行加密,而 HTTP/3.0 基于 QUIC 协议,包含了内置的加密和身份验证机制,可以提供更强的安全性。
+- **安全性**:在 HTTP/2.0 中,TLS 用于加密和认证整个 HTTP 会话,包括所有的 HTTP 头部和数据负载。TLS 的工作是在 TCP 层之上,它加密的是在 TCP 连接中传输的应用层的数据,并不会对 TCP 头部以及 TLS 记录层头部进行加密,所以在传输的过程中 TCP 头部可能会被攻击者篡改来干扰通信。而 HTTP/3.0 的 QUIC 对整个数据包(包括报文头和报文体)进行了加密与认证处理,保障安全性。
+
+HTTP/1.0、HTTP/2.0 和 HTTP/3.0 的协议栈比较:
+
+
+
+下图是一个更详细的 HTTP/2.0 和 HTTP/3.0 对比图:
+
+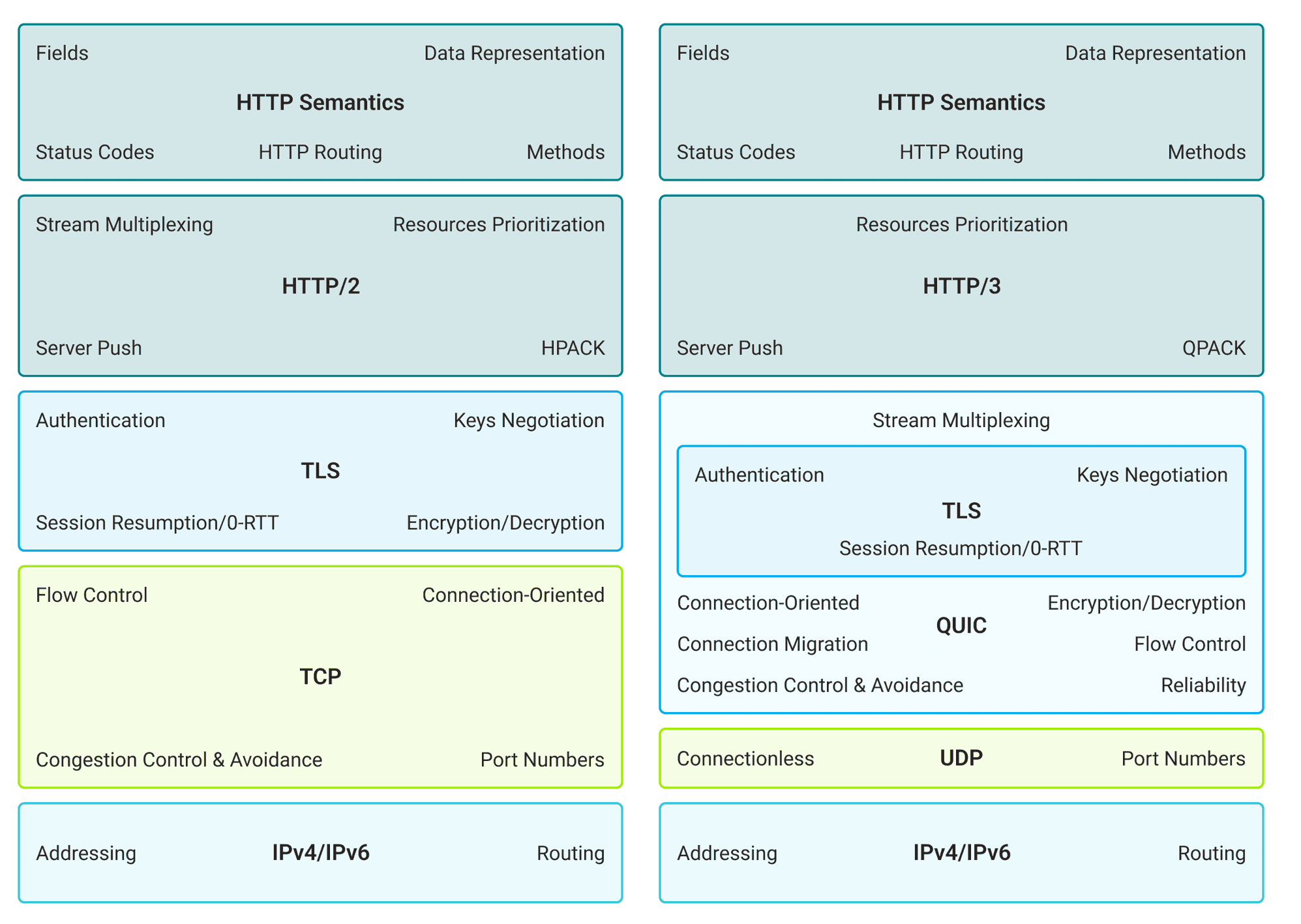
+
+从上图可以看出:
+
+- **HTTP/2.0**:使用 TCP 作为传输协议、使用 HPACK 进行头部压缩、依赖 TLS 进行加密。
+- **HTTP/3.0**:使用基于 UDP 的 QUIC 协议、使用更高效的 QPACK 进行头部压缩、在 QUIC 中直接集成了 TLS。QUIC 协议具备连接迁移、拥塞控制与避免、流量控制等特性。
+
+关于 HTTP/1.0 -> HTTP/3.0 更详细的演进介绍,推荐阅读[HTTP1 到 HTTP3 的工程优化](https://dbwu.tech/posts/http_evolution/)。
+
+### HTTP/1.1 和 HTTP/2.0 的队头阻塞有什么不同?
+
+HTTP/1.1 队头阻塞的主要原因是无法多路复用:
+
+- 在一个 TCP 连接中,资源的请求和响应是按顺序处理的。如果一个大的资源(如一个大文件)正在传输,后续的小资源(如较小的 CSS 文件)需要等待前面的资源传输完成后才能被发送。
+- 如果浏览器需要同时加载多个资源(如多个 CSS、JS 文件等),它通常会开启多个并行的 TCP 连接(一般限制为 6 个)。但每个连接仍然受限于顺序的请求-响应机制,因此仍然会发生 **应用层的队头阻塞**。
+
+虽然 HTTP/2.0 引入了多路复用技术,允许多个请求和响应在单个 TCP 连接上并行交错传输,解决了 **HTTP/1.1 应用层的队头阻塞问题**,但 HTTP/2.0 依然受到 **TCP 层队头阻塞** 的影响:
+
+- HTTP/2.0 通过帧(frame)机制将每个资源分割成小块,并为每个资源分配唯一的流 ID,这样多个资源的数据可以在同一 TCP 连接中交错传输。
+- TCP 作为传输层协议,要求数据按顺序交付。如果某个数据包在传输过程中丢失,即使后续的数据包已经到达,也必须等待丢失的数据包重传后才能继续处理。这种传输层的顺序性导致了 **TCP 层的队头阻塞**。
+- 举例来说,如果 HTTP/2 的一个 TCP 数据包中携带了多个资源的数据(例如 JS 和 CSS),而该数据包丢失了,那么后续数据包中的所有资源数据都需要等待丢失的数据包重传回来,导致所有流(streams)都被阻塞。
+
+最后,来一张表格总结补充一下:
+
+| **方面** | **HTTP/1.1 的队头阻塞** | **HTTP/2.0 的队头阻塞** |
+| -------------- | ---------------------------------------- | ---------------------------------------------------------------- |
+| **层级** | 应用层(HTTP 协议本身的限制) | 传输层(TCP 协议的限制) |
+| **根本原因** | 无法多路复用,请求和响应必须按顺序传输 | TCP 要求数据包按顺序交付,丢包时阻塞整个连接 |
+| **受影响范围** | 单个 HTTP 请求/响应会阻塞后续请求/响应。 | 单个 TCP 包丢失会影响所有 HTTP/2.0 流(依赖于同一个底层 TCP 连接) |
+| **缓解方法** | 开启多个并行的 TCP 连接 | 减少网络掉包或者使用基于 UDP 的 QUIC 协议 |
+| **影响场景** | 每次都会发生,尤其是大文件阻塞小文件时。 | 丢包率较高的网络环境下更容易发生。 |
+
+### ⭐️HTTP 是不保存状态的协议, 如何保存用户状态?
+
+HTTP 协议本身是 **无状态的 (stateless)** 。这意味着服务器默认情况下无法区分两个连续的请求是否来自同一个用户,或者同一个用户之前的操作是什么。这就像一个“健忘”的服务员,每次你跟他说话,他都不知道你是谁,也不知道你之前点过什么菜。
-### HTTP 是不保存状态的协议, 如何保存用户状态?
+但在实际的 Web 应用中,比如网上购物、用户登录等场景,我们显然需要记住用户的状态(例如购物车里的商品、用户的登录信息)。为了解决这个问题,主要有以下几种常用机制:
-HTTP 是一种不保存状态,即无状态(stateless)协议。也就是说 HTTP 协议自身不对请求和响应之间的通信状态进行保存。那么我们保存用户状态呢?Session 机制的存在就是为了解决这个问题,Session 的主要作用就是通过服务端记录用户的状态。典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了(一般情况下,服务器会在一定时间内保存这个 Session,过了时间限制,就会销毁这个 Session)。
+**方案一:Session (会话) 配合 Cookie (主流方式):**
-在服务端保存 Session 的方法很多,最常用的就是内存和数据库(比如是使用内存数据库 redis 保存)。既然 Session 存放在服务器端,那么我们如何实现 Session 跟踪呢?大部分情况下,我们都是通过在 Cookie 中附加一个 Session ID 来方式来跟踪。
+
-**Cookie 被禁用怎么办?**
+这可以说是最经典也是最常用的方法了。基本流程是这样的:
-最常用的就是利用 URL 重写把 Session ID 直接附加在 URL 路径的后面。
+1. 用户向服务器发送用户名、密码、验证码用于登陆系统。
+2. 服务器验证通过后,会为这个用户创建一个专属的 Session 对象(可以理解为服务器上的一块内存,存放该用户的状态数据,如购物车、登录信息等)存储起来,并给这个 Session 分配一个唯一的 `SessionID`。
+3. 服务器通过 HTTP 响应头中的 `Set-Cookie` 指令,把这个 `SessionID` 发送给用户的浏览器。
+4. 浏览器接收到 `SessionID` 后,会将其以 Cookie 的形式保存在本地。当用户保持登录状态时,每次向该服务器发请求,浏览器都会自动带上这个存有 `SessionID` 的 Cookie。
+5. 服务器收到请求后,从 Cookie 中拿出 `SessionID`,就能找到之前保存的那个 Session 对象,从而知道这是哪个用户以及他之前的状态了。
+
+使用 Session 的时候需要注意下面几个点:
+
+- **客户端 Cookie 支持**:依赖 Session 的核心功能要确保用户浏览器开启了 Cookie。
+- **Session 过期管理**:合理设置 Session 的过期时间,平衡安全性和用户体验。
+- **Session ID 安全**:为包含 `SessionID` 的 Cookie 设置 `HttpOnly` 标志可以防止客户端脚本(如 JavaScript)窃取,设置 Secure 标志可以保证 `SessionID` 只在 HTTPS 连接下传输,增加安全性。
+
+Session 数据本身存储在服务器端。常见的存储方式有:
+
+- **服务器内存**:实现简单,访问速度快,但服务器重启数据会丢失,且不利于多服务器间的负载均衡。这种方式适合简单且用户量不大的业务场景。
+- **数据库 (如 MySQL, PostgreSQL)**:数据持久化,但读写性能相对较低,一般不会使用这种方式。
+- **分布式缓存 (如 Redis)**:性能高,支持分布式部署,是目前大规模应用中非常主流的方案。
+
+**方案二:当 Cookie 被禁用时:URL 重写 (URL Rewriting)**
+
+如果用户的浏览器禁用了 Cookie,或者某些情况下不便使用 Cookie,还有一种备选方案是 URL 重写。这种方式会将 `SessionID` 直接附加到 URL 的末尾,作为参数传递。例如:。服务器端会解析 URL 中的 `sessionid` 参数来获取 `SessionID`,进而找到对应的 Session 数据。
+
+这种方法一般不会使用,存在以下缺点:
+
+- URL 会变长且不美观;
+- `SessionID` 暴露在 URL 中,安全性较低(容易被复制、分享或记录在日志中);
+- 对搜索引擎优化 (SEO) 可能不友好。
+
+**方案三:Token-based 认证 (如 JWT - JSON Web Tokens)**
+
+这是一种越来越流行的无状态认证方式,尤其适用于前后端分离的架构和微服务。
+
+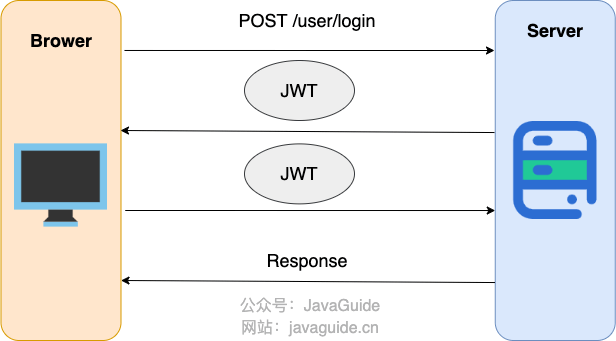
+
+以 JWT 为例(普通 Token 方案也可以),简化后的步骤如下
+
+1. 用户向服务器发送用户名、密码以及验证码用于登陆系统;
+2. 如果用户用户名、密码以及验证码校验正确的话,服务端会返回已经签名的 Token,也就是 JWT;
+3. 客户端收到 Token 后自己保存起来(比如浏览器的 `localStorage` );
+4. 用户以后每次向后端发请求都在 Header 中带上这个 JWT ;
+5. 服务端检查 JWT 并从中获取用户相关信息。
+
+JWT 详细介绍可以查看这两篇文章:
+
+- [JWT 基础概念详解](https://javaguide.cn/system-design/security/jwt-intro.html)
+- [JWT 身份认证优缺点分析](https://javaguide.cn/system-design/security/advantages-and-disadvantages-of-jwt.html)
+
+总结来说,虽然 HTTP 本身是无状态的,但通过 Cookie + Session、URL 重写或 Token 等机制,我们能够有效地在 Web 应用中跟踪和管理用户状态。其中,**Cookie + Session 是最传统也最广泛使用的方式,而 Token-based 认证则在现代 Web 应用中越来越受欢迎。**
### URI 和 URL 的区别是什么?
@@ -230,7 +331,129 @@ URI 的作用像身份证号一样,URL 的作用更像家庭住址一样。URL
### Cookie 和 Session 有什么区别?
-准确点来说,这个问题属于认证授权的范畴,你可以在 [认证授权基础概念详解](../../system-design/security/basis-of-authority-certification.md) 这篇文章中找到详细的答案。
+准确点来说,这个问题属于认证授权的范畴,你可以在 [认证授权基础概念详解](https://javaguide.cn/system-design/security/basis-of-authority-certification.html) 这篇文章中找到详细的答案。
+
+### ⭐️GET 和 POST 的区别
+
+这个问题在知乎上被讨论的挺火热的,地址: 。
+
+GET 和 POST 是 HTTP 协议中两种常用的请求方法,它们在不同的场景和目的下有不同的特点和用法。一般来说,可以从以下几个方面来区分二者(重点搞清两者在语义上的区别即可):
+
+- 语义(主要区别):GET 通常用于获取或查询资源,而 POST 通常用于创建或修改资源。
+- 幂等:GET 请求是幂等的,即多次重复执行不会改变资源的状态,而 POST 请求是不幂等的,即每次执行可能会产生不同的结果或影响资源的状态。
+- 格式:GET 请求的参数通常放在 URL 中,形成查询字符串(querystring),而 POST 请求的参数通常放在请求体(body)中,可以有多种编码格式,如 application/x-www-form-urlencoded、multipart/form-data、application/json 等。GET 请求的 URL 长度受到浏览器和服务器的限制,而 POST 请求的 body 大小则没有明确的限制。不过,实际上 GET 请求也可以用 body 传输数据,只是并不推荐这样做,因为这样可能会导致一些兼容性或者语义上的问题。
+- 缓存:由于 GET 请求是幂等的,它可以被浏览器或其他中间节点(如代理、网关)缓存起来,以提高性能和效率。而 POST 请求则不适合被缓存,因为它可能有副作用,每次执行可能需要实时的响应。
+- 安全性:GET 请求和 POST 请求如果使用 HTTP 协议的话,那都不安全,因为 HTTP 协议本身是明文传输的,必须使用 HTTPS 协议来加密传输数据。另外,GET 请求相比 POST 请求更容易泄露敏感数据,因为 GET 请求的参数通常放在 URL 中。
+
+再次提示,重点搞清两者在语义上的区别即可,实际使用过程中,也是通过语义来区分使用 GET 还是 POST。不过,也有一些项目所有的请求都用 POST,这个并不是固定的,项目组达成共识即可。
+
+## WebSocket
+
+### 什么是 WebSocket?
+
+WebSocket 是一种基于 TCP 连接的全双工通信协议,即客户端和服务器可以同时发送和接收数据。
+
+WebSocket 协议在 2008 年诞生,2011 年成为国际标准,几乎所有主流较新版本的浏览器都支持该协议。不过,WebSocket 不只能在基于浏览器的应用程序中使用,很多编程语言、框架和服务器都提供了 WebSocket 支持。
+
+WebSocket 协议本质上是应用层的协议,用于弥补 HTTP 协议在持久通信能力上的不足。客户端和服务器仅需一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。
+
+
+
+下面是 WebSocket 的常见应用场景:
+
+- 视频弹幕
+- 实时消息推送,详见[Web 实时消息推送详解](https://javaguide.cn/system-design/web-real-time-message-push.html)这篇文章
+- 实时游戏对战
+- 多用户协同编辑
+- 社交聊天
+- ……
+
+### ⭐️WebSocket 和 HTTP 有什么区别?
+
+WebSocket 和 HTTP 两者都是基于 TCP 的应用层协议,都可以在网络中传输数据。
+
+下面是二者的主要区别:
+
+- WebSocket 是一种双向实时通信协议,而 HTTP 是一种单向通信协议。并且,HTTP 协议下的通信只能由客户端发起,服务器无法主动通知客户端。
+- WebSocket 使用 ws:// 或 wss://(使用 SSL/TLS 加密后的协议,类似于 HTTP 和 HTTPS 的关系) 作为协议前缀,HTTP 使用 http:// 或 https:// 作为协议前缀。
+- WebSocket 可以支持扩展,用户可以扩展协议,实现部分自定义的子协议,如支持压缩、加密等。
+- WebSocket 通信数据格式比较轻量,用于协议控制的数据包头部相对较小,网络开销小,而 HTTP 通信每次都要携带完整的头部,网络开销较大(HTTP/2.0 使用二进制帧进行数据传输,还支持头部压缩,减少了网络开销)。
+
+### WebSocket 的工作过程是什么样的?
+
+WebSocket 的工作过程可以分为以下几个步骤:
+
+1. 客户端向服务器发送一个 HTTP 请求,请求头中包含 `Upgrade: websocket` 和 `Sec-WebSocket-Key` 等字段,表示要求升级协议为 WebSocket;
+2. 服务器收到这个请求后,会进行升级协议的操作,如果支持 WebSocket,它将回复一个 HTTP 101 状态码,响应头中包含 ,`Connection: Upgrade`和 `Sec-WebSocket-Accept: xxx` 等字段、表示成功升级到 WebSocket 协议。
+3. 客户端和服务器之间建立了一个 WebSocket 连接,可以进行双向的数据传输。数据以帧(frames)的形式进行传送,WebSocket 的每条消息可能会被切分成多个数据帧(最小单位)。发送端会将消息切割成多个帧发送给接收端,接收端接收消息帧,并将关联的帧重新组装成完整的消息。
+4. 客户端或服务器可以主动发送一个关闭帧,表示要断开连接。另一方收到后,也会回复一个关闭帧,然后双方关闭 TCP 连接。
+
+另外,建立 WebSocket 连接之后,通过心跳机制来保持 WebSocket 连接的稳定性和活跃性。
+
+### ⭐️WebSocket 与短轮询、长轮询的区别
+
+这三种方式,都是为了解决“**客户端如何及时获取服务器最新数据,实现实时更新**”的问题。它们的实现方式和效率、实时性差异较大。
+
+**1.短轮询(Short Polling)**
+
+- **原理**:客户端每隔固定时间(如 5 秒)发起一次 HTTP 请求,询问服务器是否有新数据。服务器收到请求后立即响应。
+- **优点**:实现简单,兼容性好,直接用常规 HTTP 请求即可。
+- **缺点**:
+ - **实时性一般**:消息可能在两次轮询间到达,用户需等到下次请求才知晓。
+ - **资源浪费大**:反复建立/关闭连接,且大多数请求收到的都是“无新消息”,极大增加服务器和网络压力。
+
+**2.长轮询(Long Polling)**
+
+- **原理**:客户端发起请求后,若服务器暂时无新数据,则会保持连接,直到有新数据或超时才响应。客户端收到响应后立即发起下一次请求,实现“伪实时”。
+- **优点**:
+ - **实时性较好**:一旦有新数据可立即推送,无需等待下次定时请求。
+ - **空响应减少**:减少了无效的空响应,提升了效率。
+- **缺点**:
+ - **服务器资源占用高**:需长时间维护大量连接,消耗服务器线程/连接数。
+ - **资源浪费大**:每次响应后仍需重新建立连接,且依然基于 HTTP 单向请求-响应机制。
+
+**3. WebSocket**
+
+- **原理**:客户端与服务器通过一次 HTTP Upgrade 握手后,建立一条持久的 TCP 连接。之后,双方可以随时、主动地发送数据,实现真正的全双工、低延迟通信。
+- **优点**:
+ - **实时性强**:数据可即时双向收发,延迟极低。
+ - **资源效率高**:连接持续,无需反复建立/关闭,减少资源消耗。
+ - **功能强大**:支持服务端主动推送消息、客户端主动发起通信。
+- **缺点**:
+ - **使用限制**:需要服务器和客户端都支持 WebSocket 协议。对连接管理有一定要求(如心跳保活、断线重连等)。
+ - **实现麻烦**:实现起来比短轮询和长轮询要更麻烦一些。
+
+
+
+### ⭐️SSE 与 WebSocket 有什么区别?
+
+SSE (Server-Sent Events) 和 WebSocket 都是用来实现服务器向浏览器实时推送消息的技术,让网页内容能自动更新,而不需要用户手动刷新。虽然目标相似,但它们在工作方式和适用场景上有几个关键区别:
+
+1. **通信方式:**
+ - **SSE:** **单向通信**。只有服务器能向客户端(浏览器)发送数据。客户端不能通过同一个连接向服务器发送数据(需要发起新的 HTTP 请求)。
+ - **WebSocket:** **双向通信 (全双工)**。客户端和服务器可以随时互相发送消息,实现真正的实时交互。
+2. **底层协议:**
+ - **SSE:** 基于**标准的 HTTP/HTTPS 协议**。它本质上是一个“长连接”的 HTTP 请求,服务器保持连接打开并持续发送事件流。不需要特殊的服务器或协议支持,现有的 HTTP 基础设施就能用。
+ - **WebSocket:** 使用**独立的 ws:// 或 wss:// 协议**。它需要通过一个特定的 HTTP "Upgrade" 请求来建立连接,并且服务器需要明确支持 WebSocket 协议来处理连接和消息帧。
+3. **实现复杂度和成本:**
+ - **SSE:** **实现相对简单**,主要在服务器端处理。浏览器端有标准的 EventSource API,使用方便。开发和维护成本较低。
+ - **WebSocket:** **稍微复杂一些**。需要服务器端专门处理 WebSocket 连接和协议,客户端也需要使用 WebSocket API。如果需要考虑兼容性、心跳、重连等,开发成本会更高。
+4. **断线重连:**
+ - **SSE:** **浏览器原生支持**。EventSource API 提供了自动断线重连的机制。
+ - **WebSocket:** **需要手动实现**。开发者需要自己编写逻辑来检测断线并进行重连尝试。
+5. **数据类型:**
+ - **SSE:** **主要设计用来传输文本** (UTF-8 编码)。如果需要传输二进制数据,需要先进行 Base64 等编码转换成文本。
+ - **WebSocket:** **原生支持传输文本和二进制数据**,无需额外编码。
+
+为了提供更好的用户体验和利用其简单、高效、基于标准 HTTP 的特性,**Server-Sent Events (SSE) 是目前大型语言模型 API(如 OpenAI、DeepSeek 等)实现流式响应的常用甚至可以说是标准的技术选择**。
+
+这里以 DeepSeek 为例,我们发送一个请求并打开浏览器控制台验证一下:
+
+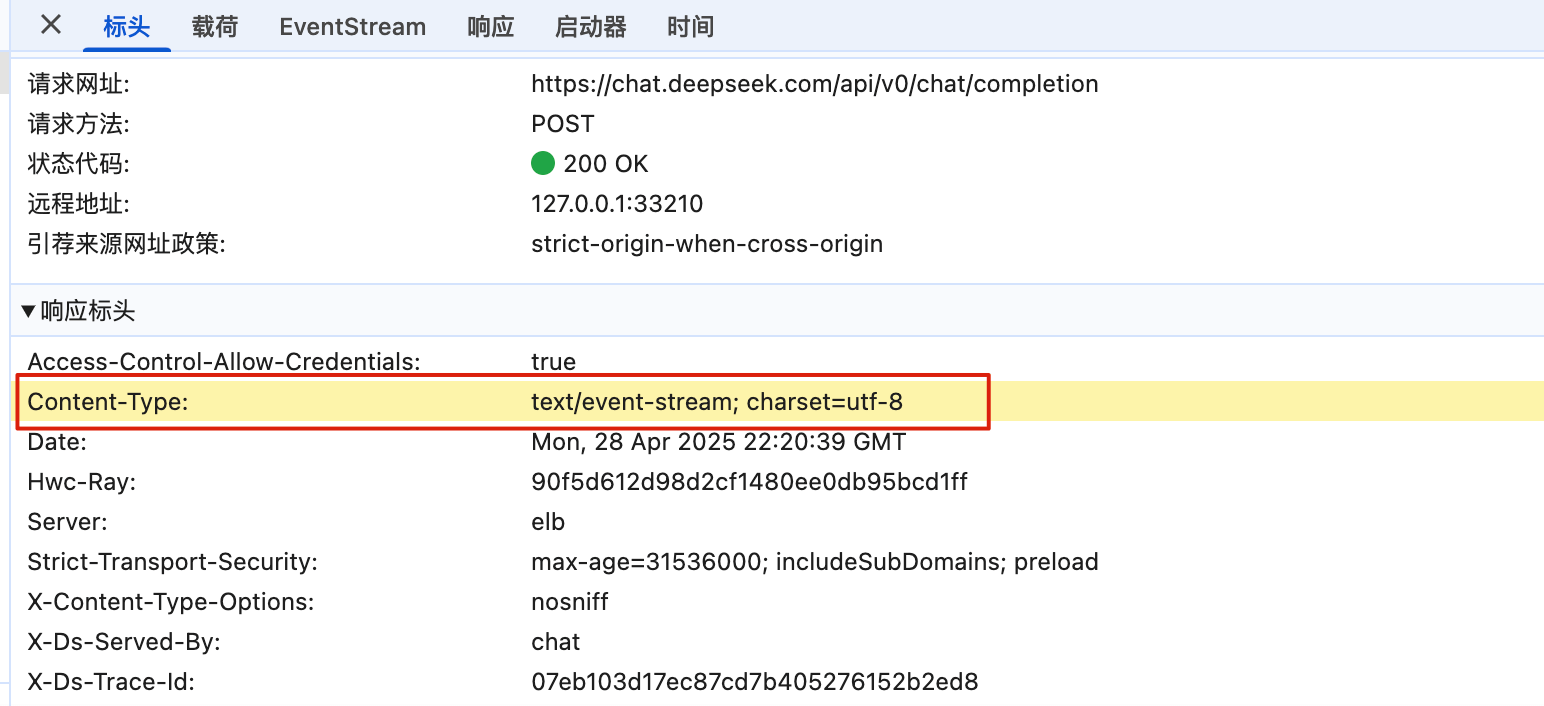
+
+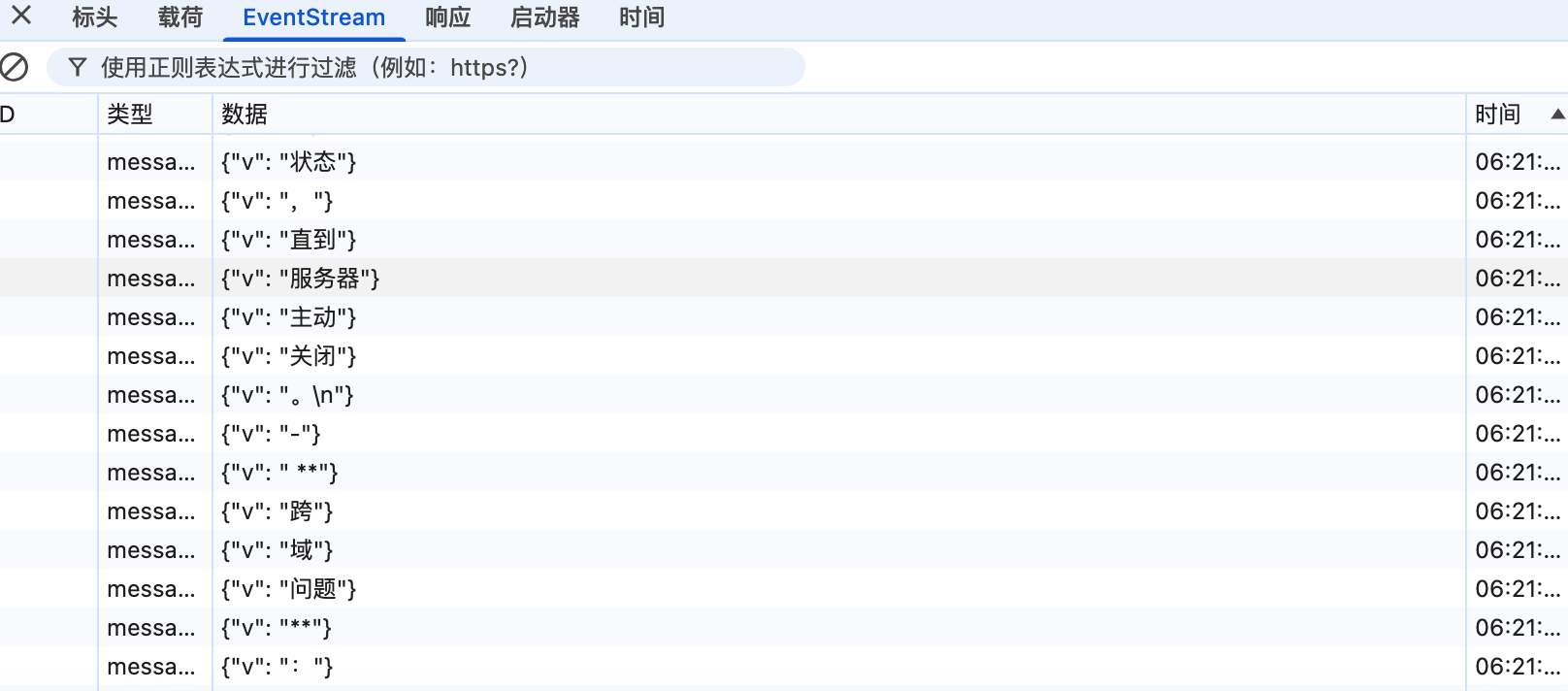
+
+可以看到,响应头应里包含了 `text/event-stream`,说明使用的确实是 SSE。并且,响应数据也确实是持续分块传输。
## PING
@@ -262,7 +485,7 @@ PING 命令的输出结果通常包括以下几部分信息:
3. **往返时间(RTT,Round-Trip Time)**:从发送 ICMP Echo Request(请求报文)到接收到 ICMP Echo Reply(响应报文)的总时间,用来衡量网络连接的延迟。
4. **统计结果(Statistics)**:包括发送的 ICMP 请求数据包数量、接收到的 ICMP 响应数据包数量、丢包率、往返时间(RTT)的最小、平均、最大和标准偏差值。
-如果 PING 对应的目标主机无法得到正确的响应,则表明这两个主机之间的连通性存在问题。如果往返时间(RTT)过高,则表明网络延迟过高。
+如果 PING 对应的目标主机无法得到正确的响应,则表明这两个主机之间的连通性存在问题(有些主机或网络管理员可能禁用了对 ICMP 请求的回复,这样也会导致无法得到正确的响应)。如果往返时间(RTT)过高,则表明网络延迟过高。
### PING 命令的工作原理是什么?
@@ -286,11 +509,11 @@ DNS(Domain Name System)域名管理系统,是当用户使用浏览器访

-在实际使用中,有一种情况下,浏览器是可以不必动用 DNS 就可以获知域名和 IP 地址的映射的。浏览器在本地会维护一个`hosts`列表,一般来说浏览器要先查看要访问的域名是否在`hosts`列表中,如果有的话,直接提取对应的 IP 地址记录,就好了。如果本地`hosts`列表内没有域名-IP 对应记录的话,那么 DNS 就闪亮登场了。
+在一台电脑上,可能存在浏览器 DNS 缓存,操作系统 DNS 缓存,路由器 DNS 缓存。如果以上缓存都查询不到,那么 DNS 就闪亮登场了。
-目前 DNS 的设计采用的是分布式、层次数据库结构,**DNS 是应用层协议,基于 UDP 协议之上,端口为 53** 。
+目前 DNS 的设计采用的是分布式、层次数据库结构,**DNS 是应用层协议,它可以在 UDP 或 TCP 协议之上运行,端口为 53** 。
-### DNS 服务器有哪些?
+### DNS 服务器有哪些?根服务器有多少个?
DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务器都属于以下四个类别之一):
@@ -299,13 +522,23 @@ DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务
- 权威 DNS 服务器。在因特网上具有公共可访问主机的每个组织机构必须提供公共可访问的 DNS 记录,这些记录将这些主机的名字映射为 IP 地址。
- 本地 DNS 服务器。每个 ISP(互联网服务提供商)都有一个自己的本地 DNS 服务器。当主机发出 DNS 请求时,该请求被发往本地 DNS 服务器,它起着代理的作用,并将该请求转发到 DNS 层次结构中。严格说来,不属于 DNS 层级结构
-### DNS 解析的过程是什么样的?
+世界上并不是只有 13 台根服务器,这是很多人普遍的误解,网上很多文章也是这么写的。实际上,现在根服务器数量远远超过这个数量。最初确实是为 DNS 根服务器分配了 13 个 IP 地址,每个 IP 地址对应一个不同的根 DNS 服务器。然而,由于互联网的快速发展和增长,这个原始的架构变得不太适应当前的需求。为了提高 DNS 的可靠性、安全性和性能,目前这 13 个 IP 地址中的每一个都有多个服务器,截止到 2023 年底,所有根服务器之和达到了 1700 多台,未来还会继续增加。
-整个过程的步骤比较多,我单独写了一篇文章详细介绍:[DNS 域名系统详解(应用层)](./dns.md) 。
+### ⭐️DNS 解析的过程是什么样的?
+
+整个过程的步骤比较多,我单独写了一篇文章详细介绍:[DNS 域名系统详解(应用层)](https://javaguide.cn/cs-basics/network/dns.html) 。
+
+### DNS 劫持了解吗?如何应对?
+
+DNS 劫持是一种网络攻击,它通过修改 DNS 服务器的解析结果,使用户访问的域名指向错误的 IP 地址,从而导致用户无法访问正常的网站,或者被引导到恶意的网站。DNS 劫持有时也被称为 DNS 重定向、DNS 欺骗或 DNS 污染。
## 参考
- 《图解 HTTP》
- 《计算机网络自顶向下方法》(第七版)
-- 详解 HTTP/2.0 及 HTTPS 协议:https://juejin.cn/post/7034668672262242318
-- HTTP 请求头字段大全| HTTP Request Headers:https://www.flysnow.org/tools/table/http-request-headers/
+- 详解 HTTP/2.0 及 HTTPS 协议:
+- HTTP 请求头字段大全| HTTP Request Headers:
+- HTTP1、HTTP2、HTTP3:
+- 如何看待 HTTP/3 ? - 车小胖的回答 - 知乎:
+
+
diff --git a/docs/cs-basics/network/other-network-questions2.md b/docs/cs-basics/network/other-network-questions2.md
index dd0d7047db9..0a75cd7d0f8 100644
--- a/docs/cs-basics/network/other-network-questions2.md
+++ b/docs/cs-basics/network/other-network-questions2.md
@@ -1,73 +1,149 @@
---
title: 计算机网络常见面试题总结(下)
+description: 最新计算机网络高频面试题总结(下):TCP/UDP深度对比、三次握手四次挥手、HTTP/3 QUIC优化、IPv6优势、NAT/ARP详解,附表格+⭐️重点标注,一文掌握传输层&网络层核心考点,快速通关后端技术面试!
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 计算机网络面试题,TCP vs UDP,TCP三次握手,HTTP/3 QUIC,IPv4 vs IPv6,TCP可靠性,IP地址,NAT协议,ARP协议,传输层面试,网络层高频题,基于TCP协议,基于UDP协议,队头阻塞,四次挥手
---
+
+
下篇主要是传输层和网络层相关的内容。
## TCP 与 UDP
-### TCP 与 UDP 的区别(重要)
+### ⭐️TCP 与 UDP 的区别(重要)
+
+1. **是否面向连接**:
+ - TCP 是面向连接的。在传输数据之前,必须先通过“三次握手”建立连接;数据传输完成后,还需要通过“四次挥手”来释放连接。这保证了双方都准备好通信。
+ - UDP 是无连接的。发送数据前不需要建立任何连接,直接把数据包(数据报)扔出去。
+2. **是否是可靠传输**:
+ - TCP 提供可靠的数据传输服务。它通过序列号、确认应答 (ACK)、超时重传、流量控制、拥塞控制等一系列机制,来确保数据能够无差错、不丢失、不重复且按顺序地到达目的地。
+ - UDP 提供不可靠的传输。它尽最大努力交付 (best-effort delivery),但不保证数据一定能到达,也不保证到达的顺序,更不会自动重传。收到报文后,接收方也不会主动发确认。
+3. **是否有状态**:
+ - TCP 是有状态的。因为要保证可靠性,TCP 需要在连接的两端维护连接状态信息,比如序列号、窗口大小、哪些数据发出去了、哪些收到了确认等。
+ - UDP 是无状态的。它不维护连接状态,发送方发出数据后就不再关心它是否到达以及如何到达,因此开销更小(**这很“渣男”!**)。
+4. **传输效率**:
+ - TCP 因为需要建立连接、发送确认、处理重传等,其开销较大,传输效率相对较低。
+ - UDP 结构简单,没有复杂的控制机制,开销小,传输效率更高,速度更快。
+5. **传输形式**:
+ - TCP 是面向字节流 (Byte Stream) 的。它将应用程序交付的数据视为一连串无结构的字节流,可能会对数据进行拆分或合并。
+ - UDP 是面向报文 (Message Oriented) 的。应用程序交给 UDP 多大的数据块,UDP 就照样发送,既不拆分也不合并,保留了应用程序消息的边界。
+6. **首部开销**:
+ - TCP 的头部至少需要 20 字节,如果包含选项字段,最多可达 60 字节。
+ - UDP 的头部非常简单,固定只有 8 字节。
+7. **是否提供广播或多播服务**:
+ - TCP 只支持点对点 (Point-to-Point) 的单播通信。
+ - UDP 支持一对一 (单播)、一对多 (多播/Multicast) 和一对所有 (广播/Broadcast) 的通信方式。
+8. ……
+
+为了更直观地对比,可以看下面这个表格:
+
+| 特性 | TCP | UDP |
+| ------------ | -------------------------- | ----------------------------------- |
+| **连接性** | 面向连接 | 无连接 |
+| **可靠性** | 可靠 | 不可靠 (尽力而为) |
+| **状态维护** | 有状态 | 无状态 |
+| **传输效率** | 较低 | 较高 |
+| **传输形式** | 面向字节流 | 面向数据报 (报文) |
+| **头部开销** | 20 - 60 字节 | 8 字节 |
+| **通信模式** | 点对点 (单播) | 单播、多播、广播 |
+| **常见应用** | HTTP/HTTPS, FTP, SMTP, SSH | DNS, DHCP, SNMP, TFTP, VoIP, 视频流 |
+
+### ⭐️什么时候选择 TCP,什么时候选 UDP?
+
+选择 TCP 还是 UDP,主要取决于你的应用**对数据传输的可靠性要求有多高,以及对实时性和效率的要求有多高**。
+
+当**数据准确性和完整性至关重要,一点都不能出错**时,通常选择 TCP。因为 TCP 提供了一整套机制(三次握手、确认应答、重传、流量控制等)来保证数据能够可靠、有序地送达。典型应用场景如下:
+
+- **Web 浏览 (HTTP/HTTPS):** 网页内容、图片、脚本必须完整加载才能正确显示。
+- **文件传输 (FTP, SCP):** 文件内容不允许有任何字节丢失或错序。
+- **邮件收发 (SMTP, POP3, IMAP):** 邮件内容需要完整无误地送达。
+- **远程登录 (SSH, Telnet):** 命令和响应需要准确传输。
+- ……
+
+当**实时性、速度和效率优先,并且应用能容忍少量数据丢失或乱序**时,通常选择 UDP。UDP 开销小、传输快,没有建立连接和保证可靠性的复杂过程。典型应用场景如下:
+
+- **实时音视频通信 (VoIP, 视频会议, 直播):** 偶尔丢失一两个数据包(可能导致画面或声音短暂卡顿)通常比因为等待重传(TCP 机制)导致长时间延迟更可接受。应用层可能会有自己的补偿机制。
+- **在线游戏:** 需要快速传输玩家位置、状态等信息,对实时性要求极高,旧的数据很快就没用了,丢失少量数据影响通常不大。
+- **DHCP (动态主机配置协议):** 客户端在请求 IP 时自身没有 IP 地址,无法满足 TCP 建立连接的前提条件,并且 DHCP 有广播需求、交互模式简单以及自带可靠性机制。
+- **物联网 (IoT) 数据上报:** 某些场景下,传感器定期上报数据,丢失个别数据点可能不影响整体趋势分析。
+- ……
+
+### HTTP 基于 TCP 还是 UDP?
-1. **是否面向连接**:UDP 在传送数据之前不需要先建立连接。而 TCP 提供面向连接的服务,在传送数据之前必须先建立连接,数据传送结束后要释放连接。
-2. **是否是可靠传输**:远地主机在收到 UDP 报文后,不需要给出任何确认,并且不保证数据不丢失,不保证是否顺序到达。TCP 提供可靠的传输服务,TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制。通过 TCP 连接传输的数据,无差错、不丢失、不重复、并且按序到达。
-3. **是否有状态**:这个和上面的“是否可靠传输”相对应。TCP 传输是有状态的,这个有状态说的是 TCP 会去记录自己发送消息的状态比如消息是否发送了、是否被接收了等等。为此 ,TCP 需要维持复杂的连接状态表。而 UDP 是无状态服务,简单来说就是不管发出去之后的事情了(**这很渣男!**)。
-4. **传输效率**:由于使用 TCP 进行传输的时候多了连接、确认、重传等机制,所以 TCP 的传输效率要比 UDP 低很多。
-5. **传输形式**:TCP 是面向字节流的,UDP 是面向报文的。
-6. **首部开销**:TCP 首部开销(20 ~ 60 字节)比 UDP 首部开销(8 字节)要大。
-7. **是否提供广播或多播服务**:TCP 只支持点对点通信,UDP 支持一对一、一对多、多对一、多对多;
-8. ......
+~~**HTTP 协议是基于 TCP 协议的**,所以发送 HTTP 请求之前首先要建立 TCP 连接也就是要经历 3 次握手。~~
-我把上面总结的内容通过表格形式展示出来了!确定不点个赞嘛?
+🐛 修正(参见 [issue#1915](https://github.com/Snailclimb/JavaGuide/issues/1915)):
-| | TCP | UDP |
-| ---------------------- | -------------- | ---------- |
-| 是否面向连接 | 是 | 否 |
-| 是否可靠 | 是 | 否 |
-| 是否有状态 | 是 | 否 |
-| 传输效率 | 较慢 | 较快 |
-| 传输形式 | 字节流 | 数据报文段 |
-| 首部开销 | 20 ~ 60 bytes | 8 bytes |
-| 是否提供广播或多播服务 | 否 | 是 |
+HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **基于 UDP 的 QUIC 协议** :
-### 什么时候选择 TCP,什么时候选 UDP?
+- **HTTP/1.x 和 HTTP/2.0**:这两个版本的 HTTP 协议都明确建立在 TCP 之上。TCP 提供了可靠的、面向连接的传输,确保数据按序、无差错地到达,这对于网页内容的正确展示非常重要。发送 HTTP 请求前,需要先通过 TCP 的三次握手建立连接。
+- **HTTP/3.0**:这是一个重大的改变。HTTP/3 弃用了 TCP,转而使用 QUIC 协议,而 QUIC 是构建在 UDP 之上的。
-- **UDP 一般用于即时通信**,比如:语音、 视频、直播等等。这些场景对传输数据的准确性要求不是特别高,比如你看视频即使少个一两帧,实际给人的感觉区别也不大。
-- **TCP 用于对传输准确性要求特别高的场景**,比如文件传输、发送和接收邮件、远程登录等等。
+
-### HTTP 基于 TCP 还是 UDP?
+**为什么 HTTP/3 要做这个改变呢?主要有两大原因:**
-~~**HTTP 协议是基于 TCP 协议的**,所以发送 HTTP 请求之前首先要建立 TCP 连接也就是要经历 3 次握手。~~
+1. 解决队头阻塞 (Head-of-Line Blocking,简写:HOL blocking) 问题。
+2. 减少连接建立的延迟。
-🐛 修正(参见 [issue#1915](https://github.com/Snailclimb/JavaGuide/issues/1915)):HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **基于 UDP 的 QUIC 协议** 。此变化解决了 HTTP/2 中存在的队头阻塞问题。由于 HTTP/2 在单个 TCP 连接上使用了多路复用,受到 TCP 拥塞控制的影响,少量的丢包就可能导致整个 TCP 连接上的所有流被阻塞。另外,HTTP/2.0 需要经过经典的 TCP 三次握手过程(一般是 3 个 RTT)。由于 QUIC 协议的特性,HTTP/3.0 可以避免 TCP 三次握手的延迟,允许在第一次连接时发送数据(0 个 RTT ,零往返时间)。
+下面我们来详细介绍这两大优化。
+
+在 HTTP/2 中,虽然可以在一个 TCP 连接上并发传输多个请求/响应流(多路复用),但 TCP 本身的特性(保证有序、可靠)意味着如果其中一个流的某个 TCP 报文丢失或延迟,整个 TCP 连接都会被阻塞,等待该报文重传。这会导致所有在这个 TCP 连接上的 HTTP/2 流都受到影响,即使其他流的数据包已经到达。**QUIC (运行在 UDP 上) 解决了这个问题**。QUIC 内部实现了自己的多路复用和流控制机制。不同的 HTTP 请求/响应流在 QUIC 层面是真正独立的。如果一个流的数据包丢失,它只会阻塞该流,而不会影响同一 QUIC 连接上的其他流(本质上是多路复用+轮询),大大提高了并发传输的效率。
+
+除了解决队头阻塞问题,HTTP/3.0 还可以减少握手过程的延迟。在 HTTP/2.0 中,如果要建立一个安全的 HTTPS 连接,需要经过 TCP 三次握手和 TLS 握手:
+
+1. TCP 三次握手:客户端和服务器交换 SYN 和 ACK 包,建立一个 TCP 连接。这个过程需要 1.5 个 RTT(round-trip time),即一个数据包从发送到接收的时间。
+2. TLS 握手:客户端和服务器交换密钥和证书,建立一个 TLS 加密层。这个过程需要至少 1 个 RTT(TLS 1.3)或者 2 个 RTT(TLS 1.2)。
+
+所以,HTTP/2.0 的连接建立就至少需要 2.5 个 RTT(TLS 1.3)或者 3.5 个 RTT(TLS 1.2)。而在 HTTP/3.0 中,使用的 QUIC 协议(TLS 1.3,TLS 1.3 除了支持 1 个 RTT 的握手,还支持 0 个 RTT 的握手)连接建立仅需 0-RTT 或者 1-RTT。这意味着 QUIC 在最佳情况下不需要任何的额外往返时间就可以建立新连接。
相关证明可以参考下面这两个链接:
-- https://zh.wikipedia.org/zh/HTTP/3
-- https://datatracker.ietf.org/doc/rfc9114/
+-
+-
+
+### 你知道哪些基于 TCP/UDP 的协议?
+
+TCP (传输控制协议) 和 UDP (用户数据报协议) 是互联网传输层的两大核心协议,它们为各种应用层协议提供了基础的通信服务。以下是一些常见的、分别构建在 TCP 和 UDP 之上的应用层协议:
-### 使用 TCP 的协议有哪些?使用 UDP 的协议有哪些?
+**运行于 TCP 协议之上的协议 (强调可靠、有序传输):**
-**运行于 TCP 协议之上的协议**:
+| 中文全称 (缩写) | 英文全称 | 主要用途 | 说明与特性 |
+| -------------------------- | ---------------------------------- | ---------------------------- | --------------------------------------------------------------------------------------------------------------------------- |
+| 超文本传输协议 (HTTP) | HyperText Transfer Protocol | 传输网页、超文本、多媒体内容 | **HTTP/1.x 和 HTTP/2 基于 TCP**。早期版本不加密,是 Web 通信的基础。 |
+| 安全超文本传输协议 (HTTPS) | HyperText Transfer Protocol Secure | 加密的网页传输 | 在 HTTP 和 TCP 之间增加了 SSL/TLS 加密层,确保数据传输的机密性和完整性。 |
+| 文件传输协议 (FTP) | File Transfer Protocol | 文件传输 | 传统的 FTP **明文传输**,不安全。推荐使用其安全版本 **SFTP (SSH File Transfer Protocol)** 或 **FTPS (FTP over SSL/TLS)** 。 |
+| 简单邮件传输协议 (SMTP) | Simple Mail Transfer Protocol | **发送**电子邮件 | 负责将邮件从客户端发送到服务器,或在邮件服务器之间传递。可通过 **STARTTLS** 升级到加密传输。 |
+| 邮局协议第 3 版 (POP3) | Post Office Protocol version 3 | **接收**电子邮件 | 通常将邮件从服务器**下载到本地设备后删除服务器副本** (可配置保留)。**POP3S** 是其 SSL/TLS 加密版本。 |
+| 互联网消息访问协议 (IMAP) | Internet Message Access Protocol | **接收和管理**电子邮件 | 邮件保留在服务器,支持多设备同步邮件状态、文件夹管理、在线搜索等。**IMAPS** 是其 SSL/TLS 加密版本。现代邮件服务首选。 |
+| 远程终端协议 (Telnet) | Teletype Network | 远程终端登录 | **明文传输**所有数据 (包括密码),安全性极差,基本已被 SSH 完全替代。 |
+| 安全外壳协议 (SSH) | Secure Shell | 安全远程管理、加密数据传输 | 提供了加密的远程登录和命令执行,以及安全的文件传输 (SFTP) 等功能,是 Telnet 的安全替代品。 |
-1. **HTTP 协议**:超文本传输协议(HTTP,HyperText Transfer Protocol)是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
-2. **HTTPS 协议**:更安全的超文本传输协议(HTTPS,Hypertext Transfer Protocol Secure),身披 SSL 外衣的 HTTP 协议
-3. **FTP 协议**:文件传输协议 FTP(File Transfer Protocol)是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
-4. **SMTP 协议**:简单邮件传输协议(SMTP,Simple Mail Transfer Protocol)的缩写,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
-5. **POP3/IMAP 协议**:两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
-6. **Telnet 协议**:用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
-7. **SSH 协议** : SSH( Secure Shell)是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。SSH 建立在可靠的传输协议 TCP 之上。
-8. ......
+**运行于 UDP 协议之上的协议 (强调快速、低开销传输):**
-**运行于 UDP 协议之上的协议**:
+| 中文全称 (缩写) | 英文全称 | 主要用途 | 说明与特性 |
+| ----------------------- | ------------------------------------- | -------------------------- | ------------------------------------------------------------------------------------------------------------ |
+| 超文本传输协议 (HTTP/3) | HyperText Transfer Protocol version 3 | 新一代网页传输 | 基于 **QUIC** 协议 (QUIC 本身构建于 UDP 之上),旨在减少延迟、解决 TCP 队头阻塞问题,支持 0-RTT 连接建立。 |
+| 动态主机配置协议 (DHCP) | Dynamic Host Configuration Protocol | 动态分配 IP 地址及网络配置 | 客户端从服务器自动获取 IP 地址、子网掩码、网关、DNS 服务器等信息。 |
+| 域名系统 (DNS) | Domain Name System | 域名到 IP 地址的解析 | **通常使用 UDP** 进行快速查询。当响应数据包过大或进行区域传送 (AXFR) 时,会**切换到 TCP** 以保证数据完整性。 |
+| 实时传输协议 (RTP) | Real-time Transport Protocol | 实时音视频数据流传输 | 常用于 VoIP、视频会议、直播等。追求低延迟,允许少量丢包。通常与 RTCP 配合使用。 |
+| RTP 控制协议 (RTCP) | RTP Control Protocol | RTP 流的质量监控和控制信息 | 配合 RTP 工作,提供丢包、延迟、抖动等统计信息,辅助流量控制和拥塞管理。 |
+| 简单文件传输协议 (TFTP) | Trivial File Transfer Protocol | 简化的文件传输 | 功能简单,常用于局域网内无盘工作站启动、网络设备固件升级等小文件传输场景。 |
+| 简单网络管理协议 (SNMP) | Simple Network Management Protocol | 网络设备的监控与管理 | 允许网络管理员查询和修改网络设备的状态信息。 |
+| 网络时间协议 (NTP) | Network Time Protocol | 同步计算机时钟 | 用于在网络中的计算机之间同步时间,确保时间的一致性。 |
-1. **DHCP 协议**:动态主机配置协议,动态配置 IP 地址
-2. **DNS**:**域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。** 我们可以将其理解为专为互联网设计的电话薄。实际上 DNS 同时支持 UDP 和 TCP 协议。
-3. ......
+**总结一下:**
-### TCP 三次握手和四次挥手(非常重要)
+- **TCP** 更适合那些对数据**可靠性、完整性和顺序性**要求高的应用,如网页浏览 (HTTP/HTTPS)、文件传输 (FTP/SFTP)、邮件收发 (SMTP/POP3/IMAP)。
+- **UDP** 则更适用于那些对**实时性要求高、能容忍少量数据丢失**的应用,如域名解析 (DNS)、实时音视频 (RTP)、在线游戏、网络管理 (SNMP) 等。
+
+### ⭐️TCP 三次握手和四次挥手(非常重要)
**相关面试题**:
@@ -78,11 +154,11 @@ tag:
- 如果第二次挥手时服务器的 ACK 没有送达客户端,会怎样?
- 为什么第四次挥手客户端需要等待 2\*MSL(报文段最长寿命)时间后才进入 CLOSED 状态?
-**参考答案**:[TCP 三次握手和四次挥手(传输层)](./tcp-connection-and-disconnection.md) 。
+**参考答案**:[TCP 三次握手和四次挥手(传输层)](https://javaguide.cn/cs-basics/network/tcp-connection-and-disconnection.html) 。
-### TCP 如何保证传输的可靠性?(重要)
+### ⭐️TCP 如何保证传输的可靠性?(重要)
-[TCP 传输可靠性保障(传输层)](./tcp-reliability-guarantee.md)
+[TCP 传输可靠性保障(传输层)](https://javaguide.cn/cs-basics/network/tcp-reliability-guarantee.html)
## IP
@@ -110,13 +186,13 @@ tag:
IP 地址过滤是一种简单的网络安全措施,实际应用中一般会结合其他网络安全措施,如认证、授权、加密等一起使用。单独使用 IP 地址过滤并不能完全保证网络的安全。
-### IPv4 和 IPv6 有什么区别?
+### ⭐️IPv4 和 IPv6 有什么区别?
**IPv4(Internet Protocol version 4)** 是目前广泛使用的 IP 地址版本,其格式是四组由点分隔的数字,例如:123.89.46.72。IPv4 使用 32 位地址作为其 Internet 地址,这意味着共有约 42 亿( 2^32)个可用 IP 地址。

-这么少当然不够用啦!为了解决 IP 地址耗尽的问题,最根本的办法是采用具有更大地址空间的新版本 IP 协议 - **IPv6(Internet Protocol version 6)**。IPv6 地址使用更复杂的格式,该格式使用由单或双冒号分隔的一组数字和字母,例如:2001:0db8:85a3:0000:0000:8a2e:0370:7334 。IPv4 使用 128 位互联网地址,这意味着越有 2^128(3 开头的 39 位数字,恐怖如斯) 个可用 IP 地址。
+这么少当然不够用啦!为了解决 IP 地址耗尽的问题,最根本的办法是采用具有更大地址空间的新版本 IP 协议 - **IPv6(Internet Protocol version 6)**。IPv6 地址使用更复杂的格式,该格式使用由单或双冒号分隔的一组数字和字母,例如:2001:0db8:85a3:0000:0000:8a2e:0370:7334 。IPv6 使用 128 位互联网地址,这意味着越有 2^128(3 开头的 39 位数字,恐怖如斯) 个可用 IP 地址。

@@ -127,7 +203,25 @@ IP 地址过滤是一种简单的网络安全措施,实际应用中一般会
- **对标头结构进行了改进**:IPv6 标头结构相较于 IPv4 更加简化和高效,减少了处理开销,提高了网络性能。
- **可选的扩展头**:允许在 IPv6 标头中添加不同的扩展头(Extension Headers),用于实现不同类型的功能和选项。
- **ICMPv6(Internet Control Message Protocol for IPv6)**:IPv6 中的 ICMPv6 相较于 IPv4 中的 ICMP 有了一些改进,如邻居发现、路径 MTU 发现等功能的改进,从而提升了网络的可靠性和性能。
-- ......
+- ……
+
+### 如何获取客户端真实 IP?
+
+获取客户端真实 IP 的方法有多种,主要分为应用层方法、传输层方法和网络层方法。
+
+**应用层方法** :
+
+通过 [X-Forwarded-For](https://en.wikipedia.org/wiki/X-Forwarded-For) 请求头获取,简单方便。不过,这种方法无法保证获取到的是真实 IP,这是因为 X-Forwarded-For 字段可能会被伪造。如果经过多个代理服务器,X-Forwarded-For 字段可能会有多个值(附带了整个请求链中的所有代理服务器 IP 地址)。并且,这种方法只适用于 HTTP 和 SMTP 协议。
+
+**传输层方法**:
+
+利用 TCP Options 字段承载真实源 IP 信息。这种方法适用于任何基于 TCP 的协议,不受应用层的限制。不过,这并非是 TCP 标准所支持的,所以需要通信双方都进行改造。也就是:对于发送方来说,需要有能力把真实源 IP 插入到 TCP Options 里面。对于接收方来说,需要有能力把 TCP Options 里面的 IP 地址读取出来。
+
+也可以通过 Proxy Protocol 协议来传递客户端 IP 和 Port 信息。这种方法可以利用 Nginx 或者其他支持该协议的反向代理服务器来获取真实 IP 或者在业务服务器解析真实 IP。
+
+**网络层方法**:
+
+隧道 +DSR 模式。这种方法可以适用于任何协议,就是实施起来会比较麻烦,也存在一定限制,实际应用中一般不会使用这种方法。
### NAT 的作用是什么?
@@ -137,7 +231,7 @@ NAT 不光可以缓解 IPv4 地址资源短缺的问题,还可以隐藏内部
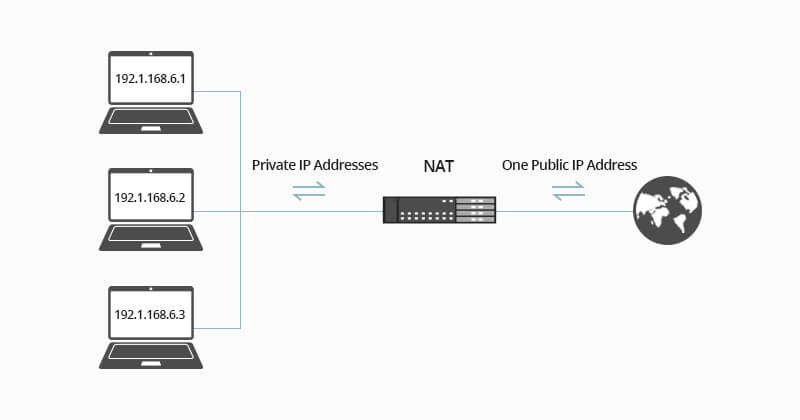
-相关阅读:[NAT 协议详解(网络层)](./nat.md)。
+相关阅读:[NAT 协议详解(网络层)](https://javaguide.cn/cs-basics/network/nat.html)。
## ARP
@@ -145,25 +239,25 @@ NAT 不光可以缓解 IPv4 地址资源短缺的问题,还可以隐藏内部
MAC 地址的全称是 **媒体访问控制地址(Media Access Control Address)**。如果说,互联网中每一个资源都由 IP 地址唯一标识(IP 协议内容),那么一切网络设备都由 MAC 地址唯一标识。
-
+
可以理解为,MAC 地址是一个网络设备真正的身份证号,IP 地址只是一种不重复的定位方式(比如说住在某省某市某街道的张三,这种逻辑定位是 IP 地址,他的身份证号才是他的 MAC 地址),也可以理解为 MAC 地址是身份证号,IP 地址是邮政地址。MAC 地址也有一些别称,如 LAN 地址、物理地址、以太网地址等。
> 还有一点要知道的是,不仅仅是网络资源才有 IP 地址,网络设备也有 IP 地址,比如路由器。但从结构上说,路由器等网络设备的作用是组成一个网络,而且通常是内网,所以它们使用的 IP 地址通常是内网 IP,内网的设备在与内网以外的设备进行通信时,需要用到 NAT 协议。
-MAC 地址的长度为 6 字节(48 比特),地址空间大小有 280 万亿之多($2^{48}$),MAC 地址由 IEEE 统一管理与分配,理论上,一个网络设备中的网卡上的 MAC 地址是永久的。不同的网卡生产商从 IEEE 那里购买自己的 MAC 地址空间(MAC 的前 24 比特),也就是前 24 比特由 IEEE 统一管理,保证不会重复。而后 24 比特,由各家生产商自己管理,同样保证生产的两块网卡的 MAC 地址不会重复。
+MAC 地址的长度为 6 字节(48 比特),地址空间大小有 280 万亿之多( $2^{48}$ ),MAC 地址由 IEEE 统一管理与分配,理论上,一个网络设备中的网卡上的 MAC 地址是永久的。不同的网卡生产商从 IEEE 那里购买自己的 MAC 地址空间(MAC 的前 24 比特),也就是前 24 比特由 IEEE 统一管理,保证不会重复。而后 24 比特,由各家生产商自己管理,同样保证生产的两块网卡的 MAC 地址不会重复。
MAC 地址具有可携带性、永久性,身份证号永久地标识一个人的身份,不论他到哪里都不会改变。而 IP 地址不具有这些性质,当一台设备更换了网络,它的 IP 地址也就可能发生改变,也就是它在互联网中的定位发生了变化。
最后,记住,MAC 地址有一个特殊地址:FF-FF-FF-FF-FF-FF(全 1 地址),该地址表示广播地址。
-### ARP 协议解决了什么问题地位如何?
+### ⭐️ARP 协议解决了什么问题?
ARP 协议,全称 **地址解析协议(Address Resolution Protocol)**,它解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
### ARP 协议的工作原理?
-[ARP 协议详解(网络层)](./arp.md)
+[ARP 协议详解(网络层)](https://javaguide.cn/cs-basics/network/arp.html)
## 复习建议
@@ -173,5 +267,8 @@ ARP 协议,全称 **地址解析协议(Address Resolution Protocol)**,
- 《图解 HTTP》
- 《计算机网络自顶向下方法》(第七版)
-- 什么是 Internet 协议(IP)?:https://www.cloudflare.com/zh-cn/learning/network-layer/internet-protocol/
-- What Is NAT and What Are the Benefits of NAT Firewalls?:https://community.fs.com/blog/what-is-nat-and-what-are-the-benefits-of-nat-firewalls.html
+- 什么是 Internet 协议(IP)?:
+- 透传真实源 IP 的各种方法 - 极客时间:
+- What Is NAT and What Are the Benefits of NAT Firewalls?:
+
+
diff --git a/docs/cs-basics/network/tcp-connection-and-disconnection.md b/docs/cs-basics/network/tcp-connection-and-disconnection.md
index 6b3efac77a1..b60e69075a2 100644
--- a/docs/cs-basics/network/tcp-connection-and-disconnection.md
+++ b/docs/cs-basics/network/tcp-connection-and-disconnection.md
@@ -1,11 +1,16 @@
---
title: TCP 三次握手和四次挥手(传输层)
+description: 一文讲清 TCP 三次握手与四次挥手:SEQ/ACK/SYN/FIN 如何同步,TIME_WAIT 与 2MSL 的原因,半连接队列(SYN Queue)与全连接队列(Accept Queue)的工作机制,以及 backlog/somaxconn/syncookies 在高并发与 SYN Flood 下的影响。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: TCP,三次握手,四次挥手,三次握手为什么,四次挥手为什么,TIME_WAIT,CLOSE_WAIT,2MSL,状态机,SEQ,ACK,SYN,FIN,RST,半连接队列,全连接队列,SYN队列,Accept队列,backlog,somaxconn,SYN Flood,syncookies
---
-为了准确无误地把数据送达目标处,TCP 协议采用了三次握手策略。
+TCP(Transmission Control Protocol)是一种**面向连接**、**可靠**的传输层协议。所谓“可靠”,通常体现在:按序交付、差错检测、丢包重传、流量控制与拥塞控制等。为了在不可靠的网络之上建立一条逻辑可靠的端到端连接,TCP 在传输数据前必须先完成连接建立过程,即 **三次握手(Three-way Handshake)**。
## 建立连接-TCP 三次握手
@@ -13,29 +18,156 @@ tag:
建立一个 TCP 连接需要“三次握手”,缺一不可:
-- **一次握手**:客户端发送带有 SYN(SEQ=x) 标志的数据包 -> 服务端,然后客户端进入 **SYN_SEND** 状态,等待服务器的确认;
-- **二次握手**:服务端发送带有 SYN+ACK(SEQ=y,ACK=x+1) 标志的数据包 –> 客户端,然后服务端进入 **SYN_RECV** 状态
-- **三次握手**:客户端发送带有 ACK(ACK=y+1) 标志的数据包 –> 服务端,然后客户端和服务器端都进入**ESTABLISHED** 状态,完成 TCP 三次握手。
+1. **第一次握手 (SYN)**: 客户端向服务端发送一个 SYN(Synchronize Sequence Numbers)报文段,其中包含一个由客户端随机生成的初始序列号(Initial Sequence Number, ISN),例如 seq=x。发送后,客户端进入 **SYN_SENT** 状态,等待服务端的确认。
+2. **第二次握手 (SYN+ACK)**: 服务端收到 SYN 报文段后,如果同意建立连接,会向客户端回复一个确认报文段。该报文段包含两个关键信息:
+ - **SYN**:服务端也需要同步自己的初始序列号,因此报文段中也包含一个由服务端随机生成的初始序列号,例如 seq=y。
+ - **ACK** (Acknowledgement):用于确认收到了客户端的请求。其确认号被设置为客户端初始序列号加一,即 ack=x+1。
+ - 发送该报文段后,服务端进入 **SYN_RCVD** (也称 SYN_RECV)状态。
+3. **第三次握手 (ACK)**: 客户端收到服务端的 SYN+ACK 报文段后,会向服务端发送一个最终的确认报文段。该报文段包含确认号 ack=y+1。发送后,客户端进入 **ESTABLISHED** 状态。服务端收到这个 ACK 报文段后,也进入 **ESTABLISHED** 状态。
-当建立了 3 次握手之后,客户端和服务端就可以传输数据啦!
+至此,双方都确认了连接的建立,TCP 连接成功创建,可以开始进行双向数据传输。
+
+### 什么是半连接队列和全连接队列?
+
+```mermaid
+sequenceDiagram
+ autonumber
+ participant C as 客户端 Client
+ participant K as 服务端内核 TCP
+ box 服务端内核队列
+ participant SQ as 半连接队列 SYN queue
+ participant AQ as 全连接队列 Accept queue
+ end
+ participant App as 用户态应用 Server app
+
+ C->>K: SYN
+ K-->>C: SYN 加 ACK
+ Note over SQ: 内核为该连接创建请求条目
+
-> 上图有一个错误,请注意,是 OSPF 不是 OPSF。 OSPF(Open Shortest Path First,ospf)开放最短路径优先协议, 是由 Internet 工程任务组开发的路由选择协议
+上图有一个错误需要注意:是 OSPF 不是 OPSF。 OSPF(Open Shortest Path First,ospf)开放最短路径优先协议, 是由 Internet 工程任务组开发的路由选择协议
-总体来说分为以下几个过程:
+总体来说分为以下几个步骤:
-1. DNS 解析
-2. TCP 连接
-3. 发送 HTTP 请求
-4. 服务器处理请求并返回 HTTP 报文
-5. 浏览器解析渲染页面
-6. 连接结束
+1. 在浏览器中输入指定网页的 URL。
+2. 浏览器通过 DNS 协议,获取域名对应的 IP 地址。
+3. 浏览器根据 IP 地址和端口号,向目标服务器发起一个 TCP 连接请求。
+4. 浏览器在 TCP 连接上,向服务器发送一个 HTTP 请求报文,请求获取网页的内容。
+5. 服务器收到 HTTP 请求报文后,处理请求,并返回 HTTP 响应报文给浏览器。
+6. 浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示。
+7. 浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求。
-具体可以参考下面这两篇文章:
+详细介绍可以查看这篇文章:[访问网页的全过程(知识串联)](https://javaguide.cn/cs-basics/network/the-whole-process-of-accessing-web-pages.html)(强烈推荐)。
-- [从输入 URL 到页面加载发生了什么?](https://segmentfault.com/a/1190000006879700)
-- [浏览器从输入网址到页面展示的过程](https://cloud.tencent.com/developer/article/1879758)
-
-### HTTP 状态码有哪些?
+### ⭐️HTTP 状态码有哪些?
HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被成功处理。

-关于 HTTP 状态码更详细的总结,可以看我写的这篇文章:[HTTP 常见状态码总结(应用层)](./http-status-codes.md)。
+关于 HTTP 状态码更详细的总结,可以看我写的这篇文章:[HTTP 常见状态码总结(应用层)](https://javaguide.cn/cs-basics/network/http-status-codes.html)。
### HTTP Header 中常见的字段有哪些?
-| 请求头字段名 | 说明 | 示例 |
-| :------------------ | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | :----------------------------------------------------------------------------------------- |
-| Accept | 能够接受的回应内容类型(Content-Types)。 | Accept: text/plain |
-| Accept-Charset | 能够接受的字符集 | Accept-Charset: utf-8 |
-| Accept-Datetime | 能够接受的按照时间来表示的版本 | Accept-Datetime: Thu, 31 May 2007 20:35:00 GMT |
-| Accept-Encoding | 能够接受的编码方式列表。参考 HTTP 压缩。 | Accept-Encoding: gzip, deflate |
-| Accept-Language | 能够接受的回应内容的自然语言列表。 | Accept-Language: en-US |
-| Authorization | 用于超文本传输协议的认证的认证信息 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
-| Cache-Control | 用来指定在这次的请求/响应链中的所有缓存机制 都必须 遵守的指令 | Cache-Control: no-cache |
-| Connection | 该浏览器想要优先使用的连接类型 | Connection: keep-alive Connection: Upgrade |
-| Content-Length | 以 八位字节数组 (8 位的字节)表示的请求体的长度 | Content-Length: 348 |
-| Content-MD5 | 请求体的内容的二进制 MD5 散列值,以 Base64 编码的结果 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
-| Content-Type | 请求体的 多媒体类型 (用于 POST 和 PUT 请求中) | Content-Type: application/x-www-form-urlencoded |
-| Cookie | 之前由服务器通过 Set- Cookie (下文详述)发送的一个 超文本传输协议 Cookie | Cookie: \$Version=1; Skin=new; |
-| Date | 发送该消息的日期和时间(按照 RFC 7231 中定义的"超文本传输协议日期"格式来发送) | Date: Tue, 15 Nov 1994 08:12:31 GMT |
-| Expect | 表明客户端要求服务器做出特定的行为 | Expect: 100-continue |
-| From | 发起此请求的用户的邮件地址 | From: [user@example.com](mailto:user@example.com) |
-| Host | 服务器的域名(用于虚拟主机 ),以及服务器所监听的传输控制协议端口号。如果所请求的端口是对应的服务的标准端口,则端口号可被省略。 | Host: en.wikipedia.org:80 |
-| If-Match | 仅当客户端提供的实体与服务器上对应的实体相匹配时,才进行对应的操作。主要作用时,用作像 PUT 这样的方法中,仅当从用户上次更新某个资源以来,该资源未被修改的情况下,才更新该资源。 | If-Match: “737060cd8c284d8af7ad3082f209582d” |
-| If-Modified-Since | 允许在对应的内容未被修改的情况下返回 304 未修改( 304 Not Modified ) | If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
-| If-None-Match | 允许在对应的内容未被修改的情况下返回 304 未修改( 304 Not Modified ) | If-None-Match: “737060cd8c284d8af7ad3082f209582d” |
-| If-Range | 如果该实体未被修改过,则向我发送我所缺少的那一个或多个部分;否则,发送整个新的实体 | If-Range: “737060cd8c284d8af7ad3082f209582d” |
-| If-Unmodified-Since | 仅当该实体自某个特定时间已来未被修改的情况下,才发送回应。 | If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
-| Max-Forwards | 限制该消息可被代理及网关转发的次数。 | Max-Forwards: 10 |
-| Origin | 发起一个针对 跨来源资源共享 的请求。 | Origin: [http://www.example-social-network.com](http://www.example-social-network.com/) |
-| Pragma | 与具体的实现相关,这些字段可能在请求/回应链中的任何时候产生多种效果。 | Pragma: no-cache |
-| Proxy-Authorization | 用来向代理进行认证的认证信息。 | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
-| Range | 仅请求某个实体的一部分。字节偏移以 0 开始。参见字节服务。 | Range: bytes=500-999 |
-| Referer | 表示浏览器所访问的前一个页面,正是那个页面上的某个链接将浏览器带到了当前所请求的这个页面。 | Referer: [http://en.wikipedia.org/wiki/Main_Page](https://en.wikipedia.org/wiki/Main_Page) |
-| TE | 浏览器预期接受的传输编码方式:可使用回应协议头 Transfer-Encoding 字段中的值; | TE: trailers, deflate |
-| Upgrade | 要求服务器升级到另一个协议。 | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
-| User-Agent | 浏览器的浏览器身份标识字符串 | User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:12.0) Gecko/20100101 Firefox/21.0 |
-| Via | 向服务器告知,这个请求是由哪些代理发出的。 | Via: 1.0 fred, 1.1 example.com (Apache/1.1) |
-| Warning | 一个一般性的警告,告知,在实体内容体中可能存在错误。 | Warning: 199 Miscellaneous warning |
-
-### HTTP 和 HTTPS 有什么区别?(重要)
-
-
+| 请求头字段名 | 说明 | 示例 |
+| :------------------ | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------------------------------------------------------------- |
+| Accept | 能够接受的回应内容类型(Content-Types)。 | Accept: text/plain |
+| Accept-Charset | 能够接受的字符集 | Accept-Charset: utf-8 |
+| Accept-Datetime | 能够接受的按照时间来表示的版本 | Accept-Datetime: Thu, 31 May 2007 20:35:00 GMT |
+| Accept-Encoding | 能够接受的编码方式列表。参考 HTTP 压缩。 | Accept-Encoding: gzip, deflate |
+| Accept-Language | 能够接受的回应内容的自然语言列表。 | Accept-Language: en-US |
+| Authorization | 用于超文本传输协议的认证的认证信息 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
+| Cache-Control | 用来指定在这次的请求/响应链中的所有缓存机制 都必须 遵守的指令 | Cache-Control: no-cache |
+| Connection | 该浏览器想要优先使用的连接类型 | Connection: keep-alive |
+| Content-Length | 以八位字节数组(8 位的字节)表示的请求体的长度 | Content-Length: 348 |
+| Content-MD5 | 请求体的内容的二进制 MD5 散列值,以 Base64 编码的结果 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
+| Content-Type | 请求体的多媒体类型(用于 POST 和 PUT 请求中) | Content-Type: application/x-www-form-urlencoded |
+| Cookie | 之前由服务器通过 Set-Cookie(下文详述)发送的一个超文本传输协议 Cookie | Cookie: $Version=1; Skin=new; |
+| Date | 发送该消息的日期和时间(按照 RFC 7231 中定义的"超文本传输协议日期"格式来发送) | Date: Tue, 15 Nov 1994 08:12:31 GMT |
+| Expect | 表明客户端要求服务器做出特定的行为 | Expect: 100-continue |
+| From | 发起此请求的用户的邮件地址 | From: `user@example.com` |
+| Host | 服务器的域名(用于虚拟主机),以及服务器所监听的传输控制协议端口号。如果所请求的端口是对应的服务的标准端口,则端口号可被省略。 | Host: en.wikipedia.org |
+| If-Match | 仅当客户端提供的实体与服务器上对应的实体相匹配时,才进行对应的操作。主要作用是用于像 PUT 这样的方法中,仅当从用户上次更新某个资源以来,该资源未被修改的情况下,才更新该资源。 | If-Match: "737060cd8c284d8af7ad3082f209582d" |
+| If-Modified-Since | 允许服务器在请求的资源自指定的日期以来未被修改的情况下返回 `304 Not Modified` 状态码 | If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
+| If-None-Match | 允许服务器在请求的资源的 ETag 未发生变化的情况下返回 `304 Not Modified` 状态码 | If-None-Match: "737060cd8c284d8af7ad3082f209582d" |
+| If-Range | 如果该实体未被修改过,则向我发送我所缺少的那一个或多个部分;否则,发送整个新的实体 | If-Range: "737060cd8c284d8af7ad3082f209582d" |
+| If-Unmodified-Since | 仅当该实体自某个特定时间以来未被修改的情况下,才发送回应。 | If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
+| Max-Forwards | 限制该消息可被代理及网关转发的次数。 | Max-Forwards: 10 |
+| Origin | 发起一个针对跨来源资源共享的请求。 | `Origin: http://www.example-social-network.com` |
+| Pragma | 与具体的实现相关,这些字段可能在请求/回应链中的任何时候产生多种效果。 | Pragma: no-cache |
+| Proxy-Authorization | 用来向代理进行认证的认证信息。 | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
+| Range | 仅请求某个实体的一部分。字节偏移以 0 开始。参见字节服务。 | Range: bytes=500-999 |
+| Referer | 表示浏览器所访问的前一个页面,正是那个页面上的某个链接将浏览器带到了当前所请求的这个页面。 | `Referer: http://en.wikipedia.org/wiki/Main_Page` |
+| TE | 浏览器预期接受的传输编码方式:可使用回应协议头 Transfer-Encoding 字段中的值; | TE: trailers, deflate |
+| Upgrade | 要求服务器升级到另一个协议。 | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
+| User-Agent | 浏览器的浏览器身份标识字符串 | User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:12.0) Gecko/20100101 Firefox/21.0 |
+| Via | 向服务器告知,这个请求是由哪些代理发出的。 | Via: 1.0 fred, 1.1 example.com (Apache/1.1) |
+| Warning | 一个一般性的警告,告知,在实体内容体中可能存在错误。 | Warning: 199 Miscellaneous warning |
+
+### ⭐️HTTP 和 HTTPS 有什么区别?(重要)
+
+
- **端口号**:HTTP 默认是 80,HTTPS 默认是 443。
- **URL 前缀**:HTTP 的 URL 前缀是 `http://`,HTTPS 的 URL 前缀是 `https://`。
- **安全性和资源消耗**:HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
- **SEO(搜索引擎优化)**:搜索引擎通常会更青睐使用 HTTPS 协议的网站,因为 HTTPS 能够提供更高的安全性和用户隐私保护。使用 HTTPS 协议的网站在搜索结果中可能会被优先显示,从而对 SEO 产生影响。
-关于 HTTP 和 HTTPS 更详细的对比总结,可以看我写的这篇文章:[HTTP vs HTTPS(应用层)](./http-vs-https.md) 。
+关于 HTTP 和 HTTPS 更详细的对比总结,可以看我写的这篇文章:[HTTP vs HTTPS(应用层)](https://javaguide.cn/cs-basics/network/http-vs-https.html) 。
### HTTP/1.0 和 HTTP/1.1 有什么区别?

-- **连接方式** : HTTP/1.0 为短连接,HTTP/1.1 支持长连接。
+- **连接方式** : HTTP/1.0 为短连接,HTTP/1.1 支持长连接。HTTP 协议的长连接和短连接,实质上是 TCP 协议的长连接和短连接。
- **状态响应码** : HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
- **缓存机制** : 在 HTTP/1.0 中主要使用 Header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP/1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
- **带宽**:HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP/1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
- **Host 头(Host Header)处理** :HTTP/1.1 引入了 Host 头字段,允许在同一 IP 地址上托管多个域名,从而支持虚拟主机的功能。而 HTTP/1.0 没有 Host 头字段,无法实现虚拟主机。
-关于 HTTP/1.0 和 HTTP/1.1 更详细的对比总结,可以看我写的这篇文章:[HTTP/1.0 vs HTTP/1.1(应用层)](./http1.0-vs-http1.1.md) 。
+关于 HTTP/1.0 和 HTTP/1.1 更详细的对比总结,可以看我写的这篇文章:[HTTP/1.0 vs HTTP/1.1(应用层)](https://javaguide.cn/cs-basics/network/http1.0-vs-http1.1.html) 。
-### HTTP/1.1 和 HTTP/2.0 有什么区别?
+### ⭐️HTTP/1.1 和 HTTP/2.0 有什么区别?

-- **IO 多路复用(Multiplexing)**:HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本)。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
+- **多路复用(Multiplexing)**:HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本),互不干扰。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接,而浏览器为了控制资源会有 6-8 个 TCP 连接的限制。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
- **二进制帧(Binary Frames)**:HTTP/2.0 使用二进制帧进行数据传输,而 HTTP/1.1 则使用文本格式的报文。二进制帧更加紧凑和高效,减少了传输的数据量和带宽消耗。
-- **头部压缩(Header Compression)**:HTTP/1.1 支持`Body`压缩,`Header`不支持压缩。HTTP/2.0 支持对`Header`压缩,减少了网络开销。
+- **队头阻塞**:HTTP/2 引入了多路复用技术,允许多个请求和响应在单个 TCP 连接上并行交错传输,解决了 HTTP/1.1 应用层的队头阻塞问题,但 HTTP/2 依然受到 TCP 层队头阻塞 的影响。
+- **头部压缩(Header Compression)**:HTTP/1.1 支持`Body`压缩,`Header`不支持压缩。HTTP/2.0 支持对`Header`压缩,使用了专门为`Header`压缩而设计的 HPACK 算法,减少了网络开销。
- **服务器推送(Server Push)**:HTTP/2.0 支持服务器推送,可以在客户端请求一个资源时,将其他相关资源一并推送给客户端,从而减少了客户端的请求次数和延迟。而 HTTP/1.1 需要客户端自己发送请求来获取相关资源。
+HTTP/2.0 多路复用效果图(图源: [HTTP/2 For Web Developers](https://blog.cloudflare.com/http-2-for-web-developers/)):
+
+
+
+可以看到,HTTP/2 的多路复用机制允许多个请求和响应共享一个 TCP 连接,从而避免了 HTTP/1.1 在应对并发请求时需要建立多个并行连接的情况,减少了重复连接建立和维护的额外开销。而在 HTTP/1.1 中,尽管支持持久连接,但为了缓解队头阻塞问题,浏览器通常会为同一域名建立多个并行连接。
+
### HTTP/2.0 和 HTTP/3.0 有什么区别?

- **传输协议**:HTTP/2.0 是基于 TCP 协议实现的,HTTP/3.0 新增了 QUIC(Quick UDP Internet Connections) 协议来实现可靠的传输,提供与 TLS/SSL 相当的安全性,具有较低的连接和传输延迟。你可以将 QUIC 看作是 UDP 的升级版本,在其基础上新增了很多功能比如加密、重传等等。HTTP/3.0 之前名为 HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3 最大的改造就是使用了 QUIC。
-- **连接建立**:HTTP/2.0 需要经过经典的 TCP 三次握手过程(一般是 3 个 RTT)。由于 QUIC 协议的特性,HTTP/3.0 可以避免 TCP 三次握手的延迟,允许在第一次连接时发送数据(0 个 RTT ,零往返时间)。
+- **连接建立**:HTTP/2.0 需要经过经典的 TCP 三次握手过程(由于安全的 HTTPS 连接建立还需要 TLS 握手,共需要大约 3 个 RTT)。由于 QUIC 协议的特性(TLS 1.3,TLS 1.3 除了支持 1 个 RTT 的握手,还支持 0 个 RTT 的握手)连接建立仅需 0-RTT 或者 1-RTT。这意味着 QUIC 在最佳情况下不需要任何的额外往返时间就可以建立新连接。
+- **头部压缩**:HTTP/2.0 使用 HPACK 算法进行头部压缩,而 HTTP/3.0 使用更高效的 QPACK 头压缩算法。
- **队头阻塞**:HTTP/2.0 多请求复用一个 TCP 连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。由于 QUIC 协议的特性,HTTP/3.0 在一定程度上解决了队头阻塞(Head-of-Line blocking, 简写:HOL blocking)问题,一个连接建立多个不同的数据流,这些数据流之间独立互不影响,某个数据流发生丢包了,其数据流不受影响(本质上是多路复用+轮询)。
+- **连接迁移**:HTTP/3.0 支持连接迁移,因为 QUIC 使用 64 位 ID 标识连接,只要 ID 不变就不会中断,网络环境改变时(如从 Wi-Fi 切换到移动数据)也能保持连接。而 TCP 连接是由(源 IP,源端口,目的 IP,目的端口)组成,这个四元组中一旦有一项值发生改变,这个连接也就不能用了。
- **错误恢复**:HTTP/3.0 具有更好的错误恢复机制,当出现丢包、延迟等网络问题时,可以更快地进行恢复和重传。而 HTTP/2.0 则需要依赖于 TCP 的错误恢复机制。
-- **安全性**:HTTP/2.0 和 HTTP/3.0 在安全性上都有较高的要求,支持加密通信,但在实现上有所不同。HTTP/2.0 使用 TLS 协议进行加密,而 HTTP/3.0 基于 QUIC 协议,包含了内置的加密和身份验证机制,可以提供更强的安全性。
+- **安全性**:在 HTTP/2.0 中,TLS 用于加密和认证整个 HTTP 会话,包括所有的 HTTP 头部和数据负载。TLS 的工作是在 TCP 层之上,它加密的是在 TCP 连接中传输的应用层的数据,并不会对 TCP 头部以及 TLS 记录层头部进行加密,所以在传输的过程中 TCP 头部可能会被攻击者篡改来干扰通信。而 HTTP/3.0 的 QUIC 对整个数据包(包括报文头和报文体)进行了加密与认证处理,保障安全性。
+
+HTTP/1.0、HTTP/2.0 和 HTTP/3.0 的协议栈比较:
+
+
+
+下图是一个更详细的 HTTP/2.0 和 HTTP/3.0 对比图:
+
+
+
+从上图可以看出:
+
+- **HTTP/2.0**:使用 TCP 作为传输协议、使用 HPACK 进行头部压缩、依赖 TLS 进行加密。
+- **HTTP/3.0**:使用基于 UDP 的 QUIC 协议、使用更高效的 QPACK 进行头部压缩、在 QUIC 中直接集成了 TLS。QUIC 协议具备连接迁移、拥塞控制与避免、流量控制等特性。
+
+关于 HTTP/1.0 -> HTTP/3.0 更详细的演进介绍,推荐阅读[HTTP1 到 HTTP3 的工程优化](https://dbwu.tech/posts/http_evolution/)。
+
+### HTTP/1.1 和 HTTP/2.0 的队头阻塞有什么不同?
+
+HTTP/1.1 队头阻塞的主要原因是无法多路复用:
+
+- 在一个 TCP 连接中,资源的请求和响应是按顺序处理的。如果一个大的资源(如一个大文件)正在传输,后续的小资源(如较小的 CSS 文件)需要等待前面的资源传输完成后才能被发送。
+- 如果浏览器需要同时加载多个资源(如多个 CSS、JS 文件等),它通常会开启多个并行的 TCP 连接(一般限制为 6 个)。但每个连接仍然受限于顺序的请求-响应机制,因此仍然会发生 **应用层的队头阻塞**。
+
+虽然 HTTP/2.0 引入了多路复用技术,允许多个请求和响应在单个 TCP 连接上并行交错传输,解决了 **HTTP/1.1 应用层的队头阻塞问题**,但 HTTP/2.0 依然受到 **TCP 层队头阻塞** 的影响:
+
+- HTTP/2.0 通过帧(frame)机制将每个资源分割成小块,并为每个资源分配唯一的流 ID,这样多个资源的数据可以在同一 TCP 连接中交错传输。
+- TCP 作为传输层协议,要求数据按顺序交付。如果某个数据包在传输过程中丢失,即使后续的数据包已经到达,也必须等待丢失的数据包重传后才能继续处理。这种传输层的顺序性导致了 **TCP 层的队头阻塞**。
+- 举例来说,如果 HTTP/2 的一个 TCP 数据包中携带了多个资源的数据(例如 JS 和 CSS),而该数据包丢失了,那么后续数据包中的所有资源数据都需要等待丢失的数据包重传回来,导致所有流(streams)都被阻塞。
+
+最后,来一张表格总结补充一下:
+
+| **方面** | **HTTP/1.1 的队头阻塞** | **HTTP/2.0 的队头阻塞** |
+| -------------- | ---------------------------------------- | ---------------------------------------------------------------- |
+| **层级** | 应用层(HTTP 协议本身的限制) | 传输层(TCP 协议的限制) |
+| **根本原因** | 无法多路复用,请求和响应必须按顺序传输 | TCP 要求数据包按顺序交付,丢包时阻塞整个连接 |
+| **受影响范围** | 单个 HTTP 请求/响应会阻塞后续请求/响应。 | 单个 TCP 包丢失会影响所有 HTTP/2.0 流(依赖于同一个底层 TCP 连接) |
+| **缓解方法** | 开启多个并行的 TCP 连接 | 减少网络掉包或者使用基于 UDP 的 QUIC 协议 |
+| **影响场景** | 每次都会发生,尤其是大文件阻塞小文件时。 | 丢包率较高的网络环境下更容易发生。 |
+
+### ⭐️HTTP 是不保存状态的协议, 如何保存用户状态?
+
+HTTP 协议本身是 **无状态的 (stateless)** 。这意味着服务器默认情况下无法区分两个连续的请求是否来自同一个用户,或者同一个用户之前的操作是什么。这就像一个“健忘”的服务员,每次你跟他说话,他都不知道你是谁,也不知道你之前点过什么菜。
-### HTTP 是不保存状态的协议, 如何保存用户状态?
+但在实际的 Web 应用中,比如网上购物、用户登录等场景,我们显然需要记住用户的状态(例如购物车里的商品、用户的登录信息)。为了解决这个问题,主要有以下几种常用机制:
-HTTP 是一种不保存状态,即无状态(stateless)协议。也就是说 HTTP 协议自身不对请求和响应之间的通信状态进行保存。那么我们保存用户状态呢?Session 机制的存在就是为了解决这个问题,Session 的主要作用就是通过服务端记录用户的状态。典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了(一般情况下,服务器会在一定时间内保存这个 Session,过了时间限制,就会销毁这个 Session)。
+**方案一:Session (会话) 配合 Cookie (主流方式):**
-在服务端保存 Session 的方法很多,最常用的就是内存和数据库(比如是使用内存数据库 redis 保存)。既然 Session 存放在服务器端,那么我们如何实现 Session 跟踪呢?大部分情况下,我们都是通过在 Cookie 中附加一个 Session ID 来方式来跟踪。
+
-**Cookie 被禁用怎么办?**
+这可以说是最经典也是最常用的方法了。基本流程是这样的:
-最常用的就是利用 URL 重写把 Session ID 直接附加在 URL 路径的后面。
+1. 用户向服务器发送用户名、密码、验证码用于登陆系统。
+2. 服务器验证通过后,会为这个用户创建一个专属的 Session 对象(可以理解为服务器上的一块内存,存放该用户的状态数据,如购物车、登录信息等)存储起来,并给这个 Session 分配一个唯一的 `SessionID`。
+3. 服务器通过 HTTP 响应头中的 `Set-Cookie` 指令,把这个 `SessionID` 发送给用户的浏览器。
+4. 浏览器接收到 `SessionID` 后,会将其以 Cookie 的形式保存在本地。当用户保持登录状态时,每次向该服务器发请求,浏览器都会自动带上这个存有 `SessionID` 的 Cookie。
+5. 服务器收到请求后,从 Cookie 中拿出 `SessionID`,就能找到之前保存的那个 Session 对象,从而知道这是哪个用户以及他之前的状态了。
+
+使用 Session 的时候需要注意下面几个点:
+
+- **客户端 Cookie 支持**:依赖 Session 的核心功能要确保用户浏览器开启了 Cookie。
+- **Session 过期管理**:合理设置 Session 的过期时间,平衡安全性和用户体验。
+- **Session ID 安全**:为包含 `SessionID` 的 Cookie 设置 `HttpOnly` 标志可以防止客户端脚本(如 JavaScript)窃取,设置 Secure 标志可以保证 `SessionID` 只在 HTTPS 连接下传输,增加安全性。
+
+Session 数据本身存储在服务器端。常见的存储方式有:
+
+- **服务器内存**:实现简单,访问速度快,但服务器重启数据会丢失,且不利于多服务器间的负载均衡。这种方式适合简单且用户量不大的业务场景。
+- **数据库 (如 MySQL, PostgreSQL)**:数据持久化,但读写性能相对较低,一般不会使用这种方式。
+- **分布式缓存 (如 Redis)**:性能高,支持分布式部署,是目前大规模应用中非常主流的方案。
+
+**方案二:当 Cookie 被禁用时:URL 重写 (URL Rewriting)**
+
+如果用户的浏览器禁用了 Cookie,或者某些情况下不便使用 Cookie,还有一种备选方案是 URL 重写。这种方式会将 `SessionID` 直接附加到 URL 的末尾,作为参数传递。例如:。服务器端会解析 URL 中的 `sessionid` 参数来获取 `SessionID`,进而找到对应的 Session 数据。
+
+这种方法一般不会使用,存在以下缺点:
+
+- URL 会变长且不美观;
+- `SessionID` 暴露在 URL 中,安全性较低(容易被复制、分享或记录在日志中);
+- 对搜索引擎优化 (SEO) 可能不友好。
+
+**方案三:Token-based 认证 (如 JWT - JSON Web Tokens)**
+
+这是一种越来越流行的无状态认证方式,尤其适用于前后端分离的架构和微服务。
+
+
+
+以 JWT 为例(普通 Token 方案也可以),简化后的步骤如下
+
+1. 用户向服务器发送用户名、密码以及验证码用于登陆系统;
+2. 如果用户用户名、密码以及验证码校验正确的话,服务端会返回已经签名的 Token,也就是 JWT;
+3. 客户端收到 Token 后自己保存起来(比如浏览器的 `localStorage` );
+4. 用户以后每次向后端发请求都在 Header 中带上这个 JWT ;
+5. 服务端检查 JWT 并从中获取用户相关信息。
+
+JWT 详细介绍可以查看这两篇文章:
+
+- [JWT 基础概念详解](https://javaguide.cn/system-design/security/jwt-intro.html)
+- [JWT 身份认证优缺点分析](https://javaguide.cn/system-design/security/advantages-and-disadvantages-of-jwt.html)
+
+总结来说,虽然 HTTP 本身是无状态的,但通过 Cookie + Session、URL 重写或 Token 等机制,我们能够有效地在 Web 应用中跟踪和管理用户状态。其中,**Cookie + Session 是最传统也最广泛使用的方式,而 Token-based 认证则在现代 Web 应用中越来越受欢迎。**
### URI 和 URL 的区别是什么?
@@ -230,7 +331,129 @@ URI 的作用像身份证号一样,URL 的作用更像家庭住址一样。URL
### Cookie 和 Session 有什么区别?
-准确点来说,这个问题属于认证授权的范畴,你可以在 [认证授权基础概念详解](../../system-design/security/basis-of-authority-certification.md) 这篇文章中找到详细的答案。
+准确点来说,这个问题属于认证授权的范畴,你可以在 [认证授权基础概念详解](https://javaguide.cn/system-design/security/basis-of-authority-certification.html) 这篇文章中找到详细的答案。
+
+### ⭐️GET 和 POST 的区别
+
+这个问题在知乎上被讨论的挺火热的,地址: 。
+
+GET 和 POST 是 HTTP 协议中两种常用的请求方法,它们在不同的场景和目的下有不同的特点和用法。一般来说,可以从以下几个方面来区分二者(重点搞清两者在语义上的区别即可):
+
+- 语义(主要区别):GET 通常用于获取或查询资源,而 POST 通常用于创建或修改资源。
+- 幂等:GET 请求是幂等的,即多次重复执行不会改变资源的状态,而 POST 请求是不幂等的,即每次执行可能会产生不同的结果或影响资源的状态。
+- 格式:GET 请求的参数通常放在 URL 中,形成查询字符串(querystring),而 POST 请求的参数通常放在请求体(body)中,可以有多种编码格式,如 application/x-www-form-urlencoded、multipart/form-data、application/json 等。GET 请求的 URL 长度受到浏览器和服务器的限制,而 POST 请求的 body 大小则没有明确的限制。不过,实际上 GET 请求也可以用 body 传输数据,只是并不推荐这样做,因为这样可能会导致一些兼容性或者语义上的问题。
+- 缓存:由于 GET 请求是幂等的,它可以被浏览器或其他中间节点(如代理、网关)缓存起来,以提高性能和效率。而 POST 请求则不适合被缓存,因为它可能有副作用,每次执行可能需要实时的响应。
+- 安全性:GET 请求和 POST 请求如果使用 HTTP 协议的话,那都不安全,因为 HTTP 协议本身是明文传输的,必须使用 HTTPS 协议来加密传输数据。另外,GET 请求相比 POST 请求更容易泄露敏感数据,因为 GET 请求的参数通常放在 URL 中。
+
+再次提示,重点搞清两者在语义上的区别即可,实际使用过程中,也是通过语义来区分使用 GET 还是 POST。不过,也有一些项目所有的请求都用 POST,这个并不是固定的,项目组达成共识即可。
+
+## WebSocket
+
+### 什么是 WebSocket?
+
+WebSocket 是一种基于 TCP 连接的全双工通信协议,即客户端和服务器可以同时发送和接收数据。
+
+WebSocket 协议在 2008 年诞生,2011 年成为国际标准,几乎所有主流较新版本的浏览器都支持该协议。不过,WebSocket 不只能在基于浏览器的应用程序中使用,很多编程语言、框架和服务器都提供了 WebSocket 支持。
+
+WebSocket 协议本质上是应用层的协议,用于弥补 HTTP 协议在持久通信能力上的不足。客户端和服务器仅需一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。
+
+
+
+下面是 WebSocket 的常见应用场景:
+
+- 视频弹幕
+- 实时消息推送,详见[Web 实时消息推送详解](https://javaguide.cn/system-design/web-real-time-message-push.html)这篇文章
+- 实时游戏对战
+- 多用户协同编辑
+- 社交聊天
+- ……
+
+### ⭐️WebSocket 和 HTTP 有什么区别?
+
+WebSocket 和 HTTP 两者都是基于 TCP 的应用层协议,都可以在网络中传输数据。
+
+下面是二者的主要区别:
+
+- WebSocket 是一种双向实时通信协议,而 HTTP 是一种单向通信协议。并且,HTTP 协议下的通信只能由客户端发起,服务器无法主动通知客户端。
+- WebSocket 使用 ws:// 或 wss://(使用 SSL/TLS 加密后的协议,类似于 HTTP 和 HTTPS 的关系) 作为协议前缀,HTTP 使用 http:// 或 https:// 作为协议前缀。
+- WebSocket 可以支持扩展,用户可以扩展协议,实现部分自定义的子协议,如支持压缩、加密等。
+- WebSocket 通信数据格式比较轻量,用于协议控制的数据包头部相对较小,网络开销小,而 HTTP 通信每次都要携带完整的头部,网络开销较大(HTTP/2.0 使用二进制帧进行数据传输,还支持头部压缩,减少了网络开销)。
+
+### WebSocket 的工作过程是什么样的?
+
+WebSocket 的工作过程可以分为以下几个步骤:
+
+1. 客户端向服务器发送一个 HTTP 请求,请求头中包含 `Upgrade: websocket` 和 `Sec-WebSocket-Key` 等字段,表示要求升级协议为 WebSocket;
+2. 服务器收到这个请求后,会进行升级协议的操作,如果支持 WebSocket,它将回复一个 HTTP 101 状态码,响应头中包含 ,`Connection: Upgrade`和 `Sec-WebSocket-Accept: xxx` 等字段、表示成功升级到 WebSocket 协议。
+3. 客户端和服务器之间建立了一个 WebSocket 连接,可以进行双向的数据传输。数据以帧(frames)的形式进行传送,WebSocket 的每条消息可能会被切分成多个数据帧(最小单位)。发送端会将消息切割成多个帧发送给接收端,接收端接收消息帧,并将关联的帧重新组装成完整的消息。
+4. 客户端或服务器可以主动发送一个关闭帧,表示要断开连接。另一方收到后,也会回复一个关闭帧,然后双方关闭 TCP 连接。
+
+另外,建立 WebSocket 连接之后,通过心跳机制来保持 WebSocket 连接的稳定性和活跃性。
+
+### ⭐️WebSocket 与短轮询、长轮询的区别
+
+这三种方式,都是为了解决“**客户端如何及时获取服务器最新数据,实现实时更新**”的问题。它们的实现方式和效率、实时性差异较大。
+
+**1.短轮询(Short Polling)**
+
+- **原理**:客户端每隔固定时间(如 5 秒)发起一次 HTTP 请求,询问服务器是否有新数据。服务器收到请求后立即响应。
+- **优点**:实现简单,兼容性好,直接用常规 HTTP 请求即可。
+- **缺点**:
+ - **实时性一般**:消息可能在两次轮询间到达,用户需等到下次请求才知晓。
+ - **资源浪费大**:反复建立/关闭连接,且大多数请求收到的都是“无新消息”,极大增加服务器和网络压力。
+
+**2.长轮询(Long Polling)**
+
+- **原理**:客户端发起请求后,若服务器暂时无新数据,则会保持连接,直到有新数据或超时才响应。客户端收到响应后立即发起下一次请求,实现“伪实时”。
+- **优点**:
+ - **实时性较好**:一旦有新数据可立即推送,无需等待下次定时请求。
+ - **空响应减少**:减少了无效的空响应,提升了效率。
+- **缺点**:
+ - **服务器资源占用高**:需长时间维护大量连接,消耗服务器线程/连接数。
+ - **资源浪费大**:每次响应后仍需重新建立连接,且依然基于 HTTP 单向请求-响应机制。
+
+**3. WebSocket**
+
+- **原理**:客户端与服务器通过一次 HTTP Upgrade 握手后,建立一条持久的 TCP 连接。之后,双方可以随时、主动地发送数据,实现真正的全双工、低延迟通信。
+- **优点**:
+ - **实时性强**:数据可即时双向收发,延迟极低。
+ - **资源效率高**:连接持续,无需反复建立/关闭,减少资源消耗。
+ - **功能强大**:支持服务端主动推送消息、客户端主动发起通信。
+- **缺点**:
+ - **使用限制**:需要服务器和客户端都支持 WebSocket 协议。对连接管理有一定要求(如心跳保活、断线重连等)。
+ - **实现麻烦**:实现起来比短轮询和长轮询要更麻烦一些。
+
+
+
+### ⭐️SSE 与 WebSocket 有什么区别?
+
+SSE (Server-Sent Events) 和 WebSocket 都是用来实现服务器向浏览器实时推送消息的技术,让网页内容能自动更新,而不需要用户手动刷新。虽然目标相似,但它们在工作方式和适用场景上有几个关键区别:
+
+1. **通信方式:**
+ - **SSE:** **单向通信**。只有服务器能向客户端(浏览器)发送数据。客户端不能通过同一个连接向服务器发送数据(需要发起新的 HTTP 请求)。
+ - **WebSocket:** **双向通信 (全双工)**。客户端和服务器可以随时互相发送消息,实现真正的实时交互。
+2. **底层协议:**
+ - **SSE:** 基于**标准的 HTTP/HTTPS 协议**。它本质上是一个“长连接”的 HTTP 请求,服务器保持连接打开并持续发送事件流。不需要特殊的服务器或协议支持,现有的 HTTP 基础设施就能用。
+ - **WebSocket:** 使用**独立的 ws:// 或 wss:// 协议**。它需要通过一个特定的 HTTP "Upgrade" 请求来建立连接,并且服务器需要明确支持 WebSocket 协议来处理连接和消息帧。
+3. **实现复杂度和成本:**
+ - **SSE:** **实现相对简单**,主要在服务器端处理。浏览器端有标准的 EventSource API,使用方便。开发和维护成本较低。
+ - **WebSocket:** **稍微复杂一些**。需要服务器端专门处理 WebSocket 连接和协议,客户端也需要使用 WebSocket API。如果需要考虑兼容性、心跳、重连等,开发成本会更高。
+4. **断线重连:**
+ - **SSE:** **浏览器原生支持**。EventSource API 提供了自动断线重连的机制。
+ - **WebSocket:** **需要手动实现**。开发者需要自己编写逻辑来检测断线并进行重连尝试。
+5. **数据类型:**
+ - **SSE:** **主要设计用来传输文本** (UTF-8 编码)。如果需要传输二进制数据,需要先进行 Base64 等编码转换成文本。
+ - **WebSocket:** **原生支持传输文本和二进制数据**,无需额外编码。
+
+为了提供更好的用户体验和利用其简单、高效、基于标准 HTTP 的特性,**Server-Sent Events (SSE) 是目前大型语言模型 API(如 OpenAI、DeepSeek 等)实现流式响应的常用甚至可以说是标准的技术选择**。
+
+这里以 DeepSeek 为例,我们发送一个请求并打开浏览器控制台验证一下:
+
+
+
+
+
+可以看到,响应头应里包含了 `text/event-stream`,说明使用的确实是 SSE。并且,响应数据也确实是持续分块传输。
## PING
@@ -262,7 +485,7 @@ PING 命令的输出结果通常包括以下几部分信息:
3. **往返时间(RTT,Round-Trip Time)**:从发送 ICMP Echo Request(请求报文)到接收到 ICMP Echo Reply(响应报文)的总时间,用来衡量网络连接的延迟。
4. **统计结果(Statistics)**:包括发送的 ICMP 请求数据包数量、接收到的 ICMP 响应数据包数量、丢包率、往返时间(RTT)的最小、平均、最大和标准偏差值。
-如果 PING 对应的目标主机无法得到正确的响应,则表明这两个主机之间的连通性存在问题。如果往返时间(RTT)过高,则表明网络延迟过高。
+如果 PING 对应的目标主机无法得到正确的响应,则表明这两个主机之间的连通性存在问题(有些主机或网络管理员可能禁用了对 ICMP 请求的回复,这样也会导致无法得到正确的响应)。如果往返时间(RTT)过高,则表明网络延迟过高。
### PING 命令的工作原理是什么?
@@ -286,11 +509,11 @@ DNS(Domain Name System)域名管理系统,是当用户使用浏览器访

-在实际使用中,有一种情况下,浏览器是可以不必动用 DNS 就可以获知域名和 IP 地址的映射的。浏览器在本地会维护一个`hosts`列表,一般来说浏览器要先查看要访问的域名是否在`hosts`列表中,如果有的话,直接提取对应的 IP 地址记录,就好了。如果本地`hosts`列表内没有域名-IP 对应记录的话,那么 DNS 就闪亮登场了。
+在一台电脑上,可能存在浏览器 DNS 缓存,操作系统 DNS 缓存,路由器 DNS 缓存。如果以上缓存都查询不到,那么 DNS 就闪亮登场了。
-目前 DNS 的设计采用的是分布式、层次数据库结构,**DNS 是应用层协议,基于 UDP 协议之上,端口为 53** 。
+目前 DNS 的设计采用的是分布式、层次数据库结构,**DNS 是应用层协议,它可以在 UDP 或 TCP 协议之上运行,端口为 53** 。
-### DNS 服务器有哪些?
+### DNS 服务器有哪些?根服务器有多少个?
DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务器都属于以下四个类别之一):
@@ -299,13 +522,23 @@ DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务
- 权威 DNS 服务器。在因特网上具有公共可访问主机的每个组织机构必须提供公共可访问的 DNS 记录,这些记录将这些主机的名字映射为 IP 地址。
- 本地 DNS 服务器。每个 ISP(互联网服务提供商)都有一个自己的本地 DNS 服务器。当主机发出 DNS 请求时,该请求被发往本地 DNS 服务器,它起着代理的作用,并将该请求转发到 DNS 层次结构中。严格说来,不属于 DNS 层级结构
-### DNS 解析的过程是什么样的?
+世界上并不是只有 13 台根服务器,这是很多人普遍的误解,网上很多文章也是这么写的。实际上,现在根服务器数量远远超过这个数量。最初确实是为 DNS 根服务器分配了 13 个 IP 地址,每个 IP 地址对应一个不同的根 DNS 服务器。然而,由于互联网的快速发展和增长,这个原始的架构变得不太适应当前的需求。为了提高 DNS 的可靠性、安全性和性能,目前这 13 个 IP 地址中的每一个都有多个服务器,截止到 2023 年底,所有根服务器之和达到了 1700 多台,未来还会继续增加。
-整个过程的步骤比较多,我单独写了一篇文章详细介绍:[DNS 域名系统详解(应用层)](./dns.md) 。
+### ⭐️DNS 解析的过程是什么样的?
+
+整个过程的步骤比较多,我单独写了一篇文章详细介绍:[DNS 域名系统详解(应用层)](https://javaguide.cn/cs-basics/network/dns.html) 。
+
+### DNS 劫持了解吗?如何应对?
+
+DNS 劫持是一种网络攻击,它通过修改 DNS 服务器的解析结果,使用户访问的域名指向错误的 IP 地址,从而导致用户无法访问正常的网站,或者被引导到恶意的网站。DNS 劫持有时也被称为 DNS 重定向、DNS 欺骗或 DNS 污染。
## 参考
- 《图解 HTTP》
- 《计算机网络自顶向下方法》(第七版)
-- 详解 HTTP/2.0 及 HTTPS 协议:https://juejin.cn/post/7034668672262242318
-- HTTP 请求头字段大全| HTTP Request Headers:https://www.flysnow.org/tools/table/http-request-headers/
+- 详解 HTTP/2.0 及 HTTPS 协议:
+- HTTP 请求头字段大全| HTTP Request Headers:
+- HTTP1、HTTP2、HTTP3:
+- 如何看待 HTTP/3 ? - 车小胖的回答 - 知乎:
+
+
diff --git a/docs/cs-basics/network/other-network-questions2.md b/docs/cs-basics/network/other-network-questions2.md
index dd0d7047db9..0a75cd7d0f8 100644
--- a/docs/cs-basics/network/other-network-questions2.md
+++ b/docs/cs-basics/network/other-network-questions2.md
@@ -1,73 +1,149 @@
---
title: 计算机网络常见面试题总结(下)
+description: 最新计算机网络高频面试题总结(下):TCP/UDP深度对比、三次握手四次挥手、HTTP/3 QUIC优化、IPv6优势、NAT/ARP详解,附表格+⭐️重点标注,一文掌握传输层&网络层核心考点,快速通关后端技术面试!
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 计算机网络面试题,TCP vs UDP,TCP三次握手,HTTP/3 QUIC,IPv4 vs IPv6,TCP可靠性,IP地址,NAT协议,ARP协议,传输层面试,网络层高频题,基于TCP协议,基于UDP协议,队头阻塞,四次挥手
---
+
+
下篇主要是传输层和网络层相关的内容。
## TCP 与 UDP
-### TCP 与 UDP 的区别(重要)
+### ⭐️TCP 与 UDP 的区别(重要)
+
+1. **是否面向连接**:
+ - TCP 是面向连接的。在传输数据之前,必须先通过“三次握手”建立连接;数据传输完成后,还需要通过“四次挥手”来释放连接。这保证了双方都准备好通信。
+ - UDP 是无连接的。发送数据前不需要建立任何连接,直接把数据包(数据报)扔出去。
+2. **是否是可靠传输**:
+ - TCP 提供可靠的数据传输服务。它通过序列号、确认应答 (ACK)、超时重传、流量控制、拥塞控制等一系列机制,来确保数据能够无差错、不丢失、不重复且按顺序地到达目的地。
+ - UDP 提供不可靠的传输。它尽最大努力交付 (best-effort delivery),但不保证数据一定能到达,也不保证到达的顺序,更不会自动重传。收到报文后,接收方也不会主动发确认。
+3. **是否有状态**:
+ - TCP 是有状态的。因为要保证可靠性,TCP 需要在连接的两端维护连接状态信息,比如序列号、窗口大小、哪些数据发出去了、哪些收到了确认等。
+ - UDP 是无状态的。它不维护连接状态,发送方发出数据后就不再关心它是否到达以及如何到达,因此开销更小(**这很“渣男”!**)。
+4. **传输效率**:
+ - TCP 因为需要建立连接、发送确认、处理重传等,其开销较大,传输效率相对较低。
+ - UDP 结构简单,没有复杂的控制机制,开销小,传输效率更高,速度更快。
+5. **传输形式**:
+ - TCP 是面向字节流 (Byte Stream) 的。它将应用程序交付的数据视为一连串无结构的字节流,可能会对数据进行拆分或合并。
+ - UDP 是面向报文 (Message Oriented) 的。应用程序交给 UDP 多大的数据块,UDP 就照样发送,既不拆分也不合并,保留了应用程序消息的边界。
+6. **首部开销**:
+ - TCP 的头部至少需要 20 字节,如果包含选项字段,最多可达 60 字节。
+ - UDP 的头部非常简单,固定只有 8 字节。
+7. **是否提供广播或多播服务**:
+ - TCP 只支持点对点 (Point-to-Point) 的单播通信。
+ - UDP 支持一对一 (单播)、一对多 (多播/Multicast) 和一对所有 (广播/Broadcast) 的通信方式。
+8. ……
+
+为了更直观地对比,可以看下面这个表格:
+
+| 特性 | TCP | UDP |
+| ------------ | -------------------------- | ----------------------------------- |
+| **连接性** | 面向连接 | 无连接 |
+| **可靠性** | 可靠 | 不可靠 (尽力而为) |
+| **状态维护** | 有状态 | 无状态 |
+| **传输效率** | 较低 | 较高 |
+| **传输形式** | 面向字节流 | 面向数据报 (报文) |
+| **头部开销** | 20 - 60 字节 | 8 字节 |
+| **通信模式** | 点对点 (单播) | 单播、多播、广播 |
+| **常见应用** | HTTP/HTTPS, FTP, SMTP, SSH | DNS, DHCP, SNMP, TFTP, VoIP, 视频流 |
+
+### ⭐️什么时候选择 TCP,什么时候选 UDP?
+
+选择 TCP 还是 UDP,主要取决于你的应用**对数据传输的可靠性要求有多高,以及对实时性和效率的要求有多高**。
+
+当**数据准确性和完整性至关重要,一点都不能出错**时,通常选择 TCP。因为 TCP 提供了一整套机制(三次握手、确认应答、重传、流量控制等)来保证数据能够可靠、有序地送达。典型应用场景如下:
+
+- **Web 浏览 (HTTP/HTTPS):** 网页内容、图片、脚本必须完整加载才能正确显示。
+- **文件传输 (FTP, SCP):** 文件内容不允许有任何字节丢失或错序。
+- **邮件收发 (SMTP, POP3, IMAP):** 邮件内容需要完整无误地送达。
+- **远程登录 (SSH, Telnet):** 命令和响应需要准确传输。
+- ……
+
+当**实时性、速度和效率优先,并且应用能容忍少量数据丢失或乱序**时,通常选择 UDP。UDP 开销小、传输快,没有建立连接和保证可靠性的复杂过程。典型应用场景如下:
+
+- **实时音视频通信 (VoIP, 视频会议, 直播):** 偶尔丢失一两个数据包(可能导致画面或声音短暂卡顿)通常比因为等待重传(TCP 机制)导致长时间延迟更可接受。应用层可能会有自己的补偿机制。
+- **在线游戏:** 需要快速传输玩家位置、状态等信息,对实时性要求极高,旧的数据很快就没用了,丢失少量数据影响通常不大。
+- **DHCP (动态主机配置协议):** 客户端在请求 IP 时自身没有 IP 地址,无法满足 TCP 建立连接的前提条件,并且 DHCP 有广播需求、交互模式简单以及自带可靠性机制。
+- **物联网 (IoT) 数据上报:** 某些场景下,传感器定期上报数据,丢失个别数据点可能不影响整体趋势分析。
+- ……
+
+### HTTP 基于 TCP 还是 UDP?
-1. **是否面向连接**:UDP 在传送数据之前不需要先建立连接。而 TCP 提供面向连接的服务,在传送数据之前必须先建立连接,数据传送结束后要释放连接。
-2. **是否是可靠传输**:远地主机在收到 UDP 报文后,不需要给出任何确认,并且不保证数据不丢失,不保证是否顺序到达。TCP 提供可靠的传输服务,TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制。通过 TCP 连接传输的数据,无差错、不丢失、不重复、并且按序到达。
-3. **是否有状态**:这个和上面的“是否可靠传输”相对应。TCP 传输是有状态的,这个有状态说的是 TCP 会去记录自己发送消息的状态比如消息是否发送了、是否被接收了等等。为此 ,TCP 需要维持复杂的连接状态表。而 UDP 是无状态服务,简单来说就是不管发出去之后的事情了(**这很渣男!**)。
-4. **传输效率**:由于使用 TCP 进行传输的时候多了连接、确认、重传等机制,所以 TCP 的传输效率要比 UDP 低很多。
-5. **传输形式**:TCP 是面向字节流的,UDP 是面向报文的。
-6. **首部开销**:TCP 首部开销(20 ~ 60 字节)比 UDP 首部开销(8 字节)要大。
-7. **是否提供广播或多播服务**:TCP 只支持点对点通信,UDP 支持一对一、一对多、多对一、多对多;
-8. ......
+~~**HTTP 协议是基于 TCP 协议的**,所以发送 HTTP 请求之前首先要建立 TCP 连接也就是要经历 3 次握手。~~
-我把上面总结的内容通过表格形式展示出来了!确定不点个赞嘛?
+🐛 修正(参见 [issue#1915](https://github.com/Snailclimb/JavaGuide/issues/1915)):
-| | TCP | UDP |
-| ---------------------- | -------------- | ---------- |
-| 是否面向连接 | 是 | 否 |
-| 是否可靠 | 是 | 否 |
-| 是否有状态 | 是 | 否 |
-| 传输效率 | 较慢 | 较快 |
-| 传输形式 | 字节流 | 数据报文段 |
-| 首部开销 | 20 ~ 60 bytes | 8 bytes |
-| 是否提供广播或多播服务 | 否 | 是 |
+HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **基于 UDP 的 QUIC 协议** :
-### 什么时候选择 TCP,什么时候选 UDP?
+- **HTTP/1.x 和 HTTP/2.0**:这两个版本的 HTTP 协议都明确建立在 TCP 之上。TCP 提供了可靠的、面向连接的传输,确保数据按序、无差错地到达,这对于网页内容的正确展示非常重要。发送 HTTP 请求前,需要先通过 TCP 的三次握手建立连接。
+- **HTTP/3.0**:这是一个重大的改变。HTTP/3 弃用了 TCP,转而使用 QUIC 协议,而 QUIC 是构建在 UDP 之上的。
-- **UDP 一般用于即时通信**,比如:语音、 视频、直播等等。这些场景对传输数据的准确性要求不是特别高,比如你看视频即使少个一两帧,实际给人的感觉区别也不大。
-- **TCP 用于对传输准确性要求特别高的场景**,比如文件传输、发送和接收邮件、远程登录等等。
+
-### HTTP 基于 TCP 还是 UDP?
+**为什么 HTTP/3 要做这个改变呢?主要有两大原因:**
-~~**HTTP 协议是基于 TCP 协议的**,所以发送 HTTP 请求之前首先要建立 TCP 连接也就是要经历 3 次握手。~~
+1. 解决队头阻塞 (Head-of-Line Blocking,简写:HOL blocking) 问题。
+2. 减少连接建立的延迟。
-🐛 修正(参见 [issue#1915](https://github.com/Snailclimb/JavaGuide/issues/1915)):HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **基于 UDP 的 QUIC 协议** 。此变化解决了 HTTP/2 中存在的队头阻塞问题。由于 HTTP/2 在单个 TCP 连接上使用了多路复用,受到 TCP 拥塞控制的影响,少量的丢包就可能导致整个 TCP 连接上的所有流被阻塞。另外,HTTP/2.0 需要经过经典的 TCP 三次握手过程(一般是 3 个 RTT)。由于 QUIC 协议的特性,HTTP/3.0 可以避免 TCP 三次握手的延迟,允许在第一次连接时发送数据(0 个 RTT ,零往返时间)。
+下面我们来详细介绍这两大优化。
+
+在 HTTP/2 中,虽然可以在一个 TCP 连接上并发传输多个请求/响应流(多路复用),但 TCP 本身的特性(保证有序、可靠)意味着如果其中一个流的某个 TCP 报文丢失或延迟,整个 TCP 连接都会被阻塞,等待该报文重传。这会导致所有在这个 TCP 连接上的 HTTP/2 流都受到影响,即使其他流的数据包已经到达。**QUIC (运行在 UDP 上) 解决了这个问题**。QUIC 内部实现了自己的多路复用和流控制机制。不同的 HTTP 请求/响应流在 QUIC 层面是真正独立的。如果一个流的数据包丢失,它只会阻塞该流,而不会影响同一 QUIC 连接上的其他流(本质上是多路复用+轮询),大大提高了并发传输的效率。
+
+除了解决队头阻塞问题,HTTP/3.0 还可以减少握手过程的延迟。在 HTTP/2.0 中,如果要建立一个安全的 HTTPS 连接,需要经过 TCP 三次握手和 TLS 握手:
+
+1. TCP 三次握手:客户端和服务器交换 SYN 和 ACK 包,建立一个 TCP 连接。这个过程需要 1.5 个 RTT(round-trip time),即一个数据包从发送到接收的时间。
+2. TLS 握手:客户端和服务器交换密钥和证书,建立一个 TLS 加密层。这个过程需要至少 1 个 RTT(TLS 1.3)或者 2 个 RTT(TLS 1.2)。
+
+所以,HTTP/2.0 的连接建立就至少需要 2.5 个 RTT(TLS 1.3)或者 3.5 个 RTT(TLS 1.2)。而在 HTTP/3.0 中,使用的 QUIC 协议(TLS 1.3,TLS 1.3 除了支持 1 个 RTT 的握手,还支持 0 个 RTT 的握手)连接建立仅需 0-RTT 或者 1-RTT。这意味着 QUIC 在最佳情况下不需要任何的额外往返时间就可以建立新连接。
相关证明可以参考下面这两个链接:
-- https://zh.wikipedia.org/zh/HTTP/3
-- https://datatracker.ietf.org/doc/rfc9114/
+-
+-
+
+### 你知道哪些基于 TCP/UDP 的协议?
+
+TCP (传输控制协议) 和 UDP (用户数据报协议) 是互联网传输层的两大核心协议,它们为各种应用层协议提供了基础的通信服务。以下是一些常见的、分别构建在 TCP 和 UDP 之上的应用层协议:
-### 使用 TCP 的协议有哪些?使用 UDP 的协议有哪些?
+**运行于 TCP 协议之上的协议 (强调可靠、有序传输):**
-**运行于 TCP 协议之上的协议**:
+| 中文全称 (缩写) | 英文全称 | 主要用途 | 说明与特性 |
+| -------------------------- | ---------------------------------- | ---------------------------- | --------------------------------------------------------------------------------------------------------------------------- |
+| 超文本传输协议 (HTTP) | HyperText Transfer Protocol | 传输网页、超文本、多媒体内容 | **HTTP/1.x 和 HTTP/2 基于 TCP**。早期版本不加密,是 Web 通信的基础。 |
+| 安全超文本传输协议 (HTTPS) | HyperText Transfer Protocol Secure | 加密的网页传输 | 在 HTTP 和 TCP 之间增加了 SSL/TLS 加密层,确保数据传输的机密性和完整性。 |
+| 文件传输协议 (FTP) | File Transfer Protocol | 文件传输 | 传统的 FTP **明文传输**,不安全。推荐使用其安全版本 **SFTP (SSH File Transfer Protocol)** 或 **FTPS (FTP over SSL/TLS)** 。 |
+| 简单邮件传输协议 (SMTP) | Simple Mail Transfer Protocol | **发送**电子邮件 | 负责将邮件从客户端发送到服务器,或在邮件服务器之间传递。可通过 **STARTTLS** 升级到加密传输。 |
+| 邮局协议第 3 版 (POP3) | Post Office Protocol version 3 | **接收**电子邮件 | 通常将邮件从服务器**下载到本地设备后删除服务器副本** (可配置保留)。**POP3S** 是其 SSL/TLS 加密版本。 |
+| 互联网消息访问协议 (IMAP) | Internet Message Access Protocol | **接收和管理**电子邮件 | 邮件保留在服务器,支持多设备同步邮件状态、文件夹管理、在线搜索等。**IMAPS** 是其 SSL/TLS 加密版本。现代邮件服务首选。 |
+| 远程终端协议 (Telnet) | Teletype Network | 远程终端登录 | **明文传输**所有数据 (包括密码),安全性极差,基本已被 SSH 完全替代。 |
+| 安全外壳协议 (SSH) | Secure Shell | 安全远程管理、加密数据传输 | 提供了加密的远程登录和命令执行,以及安全的文件传输 (SFTP) 等功能,是 Telnet 的安全替代品。 |
-1. **HTTP 协议**:超文本传输协议(HTTP,HyperText Transfer Protocol)是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
-2. **HTTPS 协议**:更安全的超文本传输协议(HTTPS,Hypertext Transfer Protocol Secure),身披 SSL 外衣的 HTTP 协议
-3. **FTP 协议**:文件传输协议 FTP(File Transfer Protocol)是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
-4. **SMTP 协议**:简单邮件传输协议(SMTP,Simple Mail Transfer Protocol)的缩写,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
-5. **POP3/IMAP 协议**:两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
-6. **Telnet 协议**:用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
-7. **SSH 协议** : SSH( Secure Shell)是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。SSH 建立在可靠的传输协议 TCP 之上。
-8. ......
+**运行于 UDP 协议之上的协议 (强调快速、低开销传输):**
-**运行于 UDP 协议之上的协议**:
+| 中文全称 (缩写) | 英文全称 | 主要用途 | 说明与特性 |
+| ----------------------- | ------------------------------------- | -------------------------- | ------------------------------------------------------------------------------------------------------------ |
+| 超文本传输协议 (HTTP/3) | HyperText Transfer Protocol version 3 | 新一代网页传输 | 基于 **QUIC** 协议 (QUIC 本身构建于 UDP 之上),旨在减少延迟、解决 TCP 队头阻塞问题,支持 0-RTT 连接建立。 |
+| 动态主机配置协议 (DHCP) | Dynamic Host Configuration Protocol | 动态分配 IP 地址及网络配置 | 客户端从服务器自动获取 IP 地址、子网掩码、网关、DNS 服务器等信息。 |
+| 域名系统 (DNS) | Domain Name System | 域名到 IP 地址的解析 | **通常使用 UDP** 进行快速查询。当响应数据包过大或进行区域传送 (AXFR) 时,会**切换到 TCP** 以保证数据完整性。 |
+| 实时传输协议 (RTP) | Real-time Transport Protocol | 实时音视频数据流传输 | 常用于 VoIP、视频会议、直播等。追求低延迟,允许少量丢包。通常与 RTCP 配合使用。 |
+| RTP 控制协议 (RTCP) | RTP Control Protocol | RTP 流的质量监控和控制信息 | 配合 RTP 工作,提供丢包、延迟、抖动等统计信息,辅助流量控制和拥塞管理。 |
+| 简单文件传输协议 (TFTP) | Trivial File Transfer Protocol | 简化的文件传输 | 功能简单,常用于局域网内无盘工作站启动、网络设备固件升级等小文件传输场景。 |
+| 简单网络管理协议 (SNMP) | Simple Network Management Protocol | 网络设备的监控与管理 | 允许网络管理员查询和修改网络设备的状态信息。 |
+| 网络时间协议 (NTP) | Network Time Protocol | 同步计算机时钟 | 用于在网络中的计算机之间同步时间,确保时间的一致性。 |
-1. **DHCP 协议**:动态主机配置协议,动态配置 IP 地址
-2. **DNS**:**域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。** 我们可以将其理解为专为互联网设计的电话薄。实际上 DNS 同时支持 UDP 和 TCP 协议。
-3. ......
+**总结一下:**
-### TCP 三次握手和四次挥手(非常重要)
+- **TCP** 更适合那些对数据**可靠性、完整性和顺序性**要求高的应用,如网页浏览 (HTTP/HTTPS)、文件传输 (FTP/SFTP)、邮件收发 (SMTP/POP3/IMAP)。
+- **UDP** 则更适用于那些对**实时性要求高、能容忍少量数据丢失**的应用,如域名解析 (DNS)、实时音视频 (RTP)、在线游戏、网络管理 (SNMP) 等。
+
+### ⭐️TCP 三次握手和四次挥手(非常重要)
**相关面试题**:
@@ -78,11 +154,11 @@ tag:
- 如果第二次挥手时服务器的 ACK 没有送达客户端,会怎样?
- 为什么第四次挥手客户端需要等待 2\*MSL(报文段最长寿命)时间后才进入 CLOSED 状态?
-**参考答案**:[TCP 三次握手和四次挥手(传输层)](./tcp-connection-and-disconnection.md) 。
+**参考答案**:[TCP 三次握手和四次挥手(传输层)](https://javaguide.cn/cs-basics/network/tcp-connection-and-disconnection.html) 。
-### TCP 如何保证传输的可靠性?(重要)
+### ⭐️TCP 如何保证传输的可靠性?(重要)
-[TCP 传输可靠性保障(传输层)](./tcp-reliability-guarantee.md)
+[TCP 传输可靠性保障(传输层)](https://javaguide.cn/cs-basics/network/tcp-reliability-guarantee.html)
## IP
@@ -110,13 +186,13 @@ tag:
IP 地址过滤是一种简单的网络安全措施,实际应用中一般会结合其他网络安全措施,如认证、授权、加密等一起使用。单独使用 IP 地址过滤并不能完全保证网络的安全。
-### IPv4 和 IPv6 有什么区别?
+### ⭐️IPv4 和 IPv6 有什么区别?
**IPv4(Internet Protocol version 4)** 是目前广泛使用的 IP 地址版本,其格式是四组由点分隔的数字,例如:123.89.46.72。IPv4 使用 32 位地址作为其 Internet 地址,这意味着共有约 42 亿( 2^32)个可用 IP 地址。

-这么少当然不够用啦!为了解决 IP 地址耗尽的问题,最根本的办法是采用具有更大地址空间的新版本 IP 协议 - **IPv6(Internet Protocol version 6)**。IPv6 地址使用更复杂的格式,该格式使用由单或双冒号分隔的一组数字和字母,例如:2001:0db8:85a3:0000:0000:8a2e:0370:7334 。IPv4 使用 128 位互联网地址,这意味着越有 2^128(3 开头的 39 位数字,恐怖如斯) 个可用 IP 地址。
+这么少当然不够用啦!为了解决 IP 地址耗尽的问题,最根本的办法是采用具有更大地址空间的新版本 IP 协议 - **IPv6(Internet Protocol version 6)**。IPv6 地址使用更复杂的格式,该格式使用由单或双冒号分隔的一组数字和字母,例如:2001:0db8:85a3:0000:0000:8a2e:0370:7334 。IPv6 使用 128 位互联网地址,这意味着越有 2^128(3 开头的 39 位数字,恐怖如斯) 个可用 IP 地址。

@@ -127,7 +203,25 @@ IP 地址过滤是一种简单的网络安全措施,实际应用中一般会
- **对标头结构进行了改进**:IPv6 标头结构相较于 IPv4 更加简化和高效,减少了处理开销,提高了网络性能。
- **可选的扩展头**:允许在 IPv6 标头中添加不同的扩展头(Extension Headers),用于实现不同类型的功能和选项。
- **ICMPv6(Internet Control Message Protocol for IPv6)**:IPv6 中的 ICMPv6 相较于 IPv4 中的 ICMP 有了一些改进,如邻居发现、路径 MTU 发现等功能的改进,从而提升了网络的可靠性和性能。
-- ......
+- ……
+
+### 如何获取客户端真实 IP?
+
+获取客户端真实 IP 的方法有多种,主要分为应用层方法、传输层方法和网络层方法。
+
+**应用层方法** :
+
+通过 [X-Forwarded-For](https://en.wikipedia.org/wiki/X-Forwarded-For) 请求头获取,简单方便。不过,这种方法无法保证获取到的是真实 IP,这是因为 X-Forwarded-For 字段可能会被伪造。如果经过多个代理服务器,X-Forwarded-For 字段可能会有多个值(附带了整个请求链中的所有代理服务器 IP 地址)。并且,这种方法只适用于 HTTP 和 SMTP 协议。
+
+**传输层方法**:
+
+利用 TCP Options 字段承载真实源 IP 信息。这种方法适用于任何基于 TCP 的协议,不受应用层的限制。不过,这并非是 TCP 标准所支持的,所以需要通信双方都进行改造。也就是:对于发送方来说,需要有能力把真实源 IP 插入到 TCP Options 里面。对于接收方来说,需要有能力把 TCP Options 里面的 IP 地址读取出来。
+
+也可以通过 Proxy Protocol 协议来传递客户端 IP 和 Port 信息。这种方法可以利用 Nginx 或者其他支持该协议的反向代理服务器来获取真实 IP 或者在业务服务器解析真实 IP。
+
+**网络层方法**:
+
+隧道 +DSR 模式。这种方法可以适用于任何协议,就是实施起来会比较麻烦,也存在一定限制,实际应用中一般不会使用这种方法。
### NAT 的作用是什么?
@@ -137,7 +231,7 @@ NAT 不光可以缓解 IPv4 地址资源短缺的问题,还可以隐藏内部

-相关阅读:[NAT 协议详解(网络层)](./nat.md)。
+相关阅读:[NAT 协议详解(网络层)](https://javaguide.cn/cs-basics/network/nat.html)。
## ARP
@@ -145,25 +239,25 @@ NAT 不光可以缓解 IPv4 地址资源短缺的问题,还可以隐藏内部
MAC 地址的全称是 **媒体访问控制地址(Media Access Control Address)**。如果说,互联网中每一个资源都由 IP 地址唯一标识(IP 协议内容),那么一切网络设备都由 MAC 地址唯一标识。
-
+
可以理解为,MAC 地址是一个网络设备真正的身份证号,IP 地址只是一种不重复的定位方式(比如说住在某省某市某街道的张三,这种逻辑定位是 IP 地址,他的身份证号才是他的 MAC 地址),也可以理解为 MAC 地址是身份证号,IP 地址是邮政地址。MAC 地址也有一些别称,如 LAN 地址、物理地址、以太网地址等。
> 还有一点要知道的是,不仅仅是网络资源才有 IP 地址,网络设备也有 IP 地址,比如路由器。但从结构上说,路由器等网络设备的作用是组成一个网络,而且通常是内网,所以它们使用的 IP 地址通常是内网 IP,内网的设备在与内网以外的设备进行通信时,需要用到 NAT 协议。
-MAC 地址的长度为 6 字节(48 比特),地址空间大小有 280 万亿之多($2^{48}$),MAC 地址由 IEEE 统一管理与分配,理论上,一个网络设备中的网卡上的 MAC 地址是永久的。不同的网卡生产商从 IEEE 那里购买自己的 MAC 地址空间(MAC 的前 24 比特),也就是前 24 比特由 IEEE 统一管理,保证不会重复。而后 24 比特,由各家生产商自己管理,同样保证生产的两块网卡的 MAC 地址不会重复。
+MAC 地址的长度为 6 字节(48 比特),地址空间大小有 280 万亿之多( $2^{48}$ ),MAC 地址由 IEEE 统一管理与分配,理论上,一个网络设备中的网卡上的 MAC 地址是永久的。不同的网卡生产商从 IEEE 那里购买自己的 MAC 地址空间(MAC 的前 24 比特),也就是前 24 比特由 IEEE 统一管理,保证不会重复。而后 24 比特,由各家生产商自己管理,同样保证生产的两块网卡的 MAC 地址不会重复。
MAC 地址具有可携带性、永久性,身份证号永久地标识一个人的身份,不论他到哪里都不会改变。而 IP 地址不具有这些性质,当一台设备更换了网络,它的 IP 地址也就可能发生改变,也就是它在互联网中的定位发生了变化。
最后,记住,MAC 地址有一个特殊地址:FF-FF-FF-FF-FF-FF(全 1 地址),该地址表示广播地址。
-### ARP 协议解决了什么问题地位如何?
+### ⭐️ARP 协议解决了什么问题?
ARP 协议,全称 **地址解析协议(Address Resolution Protocol)**,它解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
### ARP 协议的工作原理?
-[ARP 协议详解(网络层)](./arp.md)
+[ARP 协议详解(网络层)](https://javaguide.cn/cs-basics/network/arp.html)
## 复习建议
@@ -173,5 +267,8 @@ ARP 协议,全称 **地址解析协议(Address Resolution Protocol)**,
- 《图解 HTTP》
- 《计算机网络自顶向下方法》(第七版)
-- 什么是 Internet 协议(IP)?:https://www.cloudflare.com/zh-cn/learning/network-layer/internet-protocol/
-- What Is NAT and What Are the Benefits of NAT Firewalls?:https://community.fs.com/blog/what-is-nat-and-what-are-the-benefits-of-nat-firewalls.html
+- 什么是 Internet 协议(IP)?:
+- 透传真实源 IP 的各种方法 - 极客时间:
+- What Is NAT and What Are the Benefits of NAT Firewalls?:
+
+
diff --git a/docs/cs-basics/network/tcp-connection-and-disconnection.md b/docs/cs-basics/network/tcp-connection-and-disconnection.md
index 6b3efac77a1..b60e69075a2 100644
--- a/docs/cs-basics/network/tcp-connection-and-disconnection.md
+++ b/docs/cs-basics/network/tcp-connection-and-disconnection.md
@@ -1,11 +1,16 @@
---
title: TCP 三次握手和四次挥手(传输层)
+description: 一文讲清 TCP 三次握手与四次挥手:SEQ/ACK/SYN/FIN 如何同步,TIME_WAIT 与 2MSL 的原因,半连接队列(SYN Queue)与全连接队列(Accept Queue)的工作机制,以及 backlog/somaxconn/syncookies 在高并发与 SYN Flood 下的影响。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: TCP,三次握手,四次挥手,三次握手为什么,四次挥手为什么,TIME_WAIT,CLOSE_WAIT,2MSL,状态机,SEQ,ACK,SYN,FIN,RST,半连接队列,全连接队列,SYN队列,Accept队列,backlog,somaxconn,SYN Flood,syncookies
---
-为了准确无误地把数据送达目标处,TCP 协议采用了三次握手策略。
+TCP(Transmission Control Protocol)是一种**面向连接**、**可靠**的传输层协议。所谓“可靠”,通常体现在:按序交付、差错检测、丢包重传、流量控制与拥塞控制等。为了在不可靠的网络之上建立一条逻辑可靠的端到端连接,TCP 在传输数据前必须先完成连接建立过程,即 **三次握手(Three-way Handshake)**。
## 建立连接-TCP 三次握手
@@ -13,29 +18,156 @@ tag:
建立一个 TCP 连接需要“三次握手”,缺一不可:
-- **一次握手**:客户端发送带有 SYN(SEQ=x) 标志的数据包 -> 服务端,然后客户端进入 **SYN_SEND** 状态,等待服务器的确认;
-- **二次握手**:服务端发送带有 SYN+ACK(SEQ=y,ACK=x+1) 标志的数据包 –> 客户端,然后服务端进入 **SYN_RECV** 状态
-- **三次握手**:客户端发送带有 ACK(ACK=y+1) 标志的数据包 –> 服务端,然后客户端和服务器端都进入**ESTABLISHED** 状态,完成 TCP 三次握手。
+1. **第一次握手 (SYN)**: 客户端向服务端发送一个 SYN(Synchronize Sequence Numbers)报文段,其中包含一个由客户端随机生成的初始序列号(Initial Sequence Number, ISN),例如 seq=x。发送后,客户端进入 **SYN_SENT** 状态,等待服务端的确认。
+2. **第二次握手 (SYN+ACK)**: 服务端收到 SYN 报文段后,如果同意建立连接,会向客户端回复一个确认报文段。该报文段包含两个关键信息:
+ - **SYN**:服务端也需要同步自己的初始序列号,因此报文段中也包含一个由服务端随机生成的初始序列号,例如 seq=y。
+ - **ACK** (Acknowledgement):用于确认收到了客户端的请求。其确认号被设置为客户端初始序列号加一,即 ack=x+1。
+ - 发送该报文段后,服务端进入 **SYN_RCVD** (也称 SYN_RECV)状态。
+3. **第三次握手 (ACK)**: 客户端收到服务端的 SYN+ACK 报文段后,会向服务端发送一个最终的确认报文段。该报文段包含确认号 ack=y+1。发送后,客户端进入 **ESTABLISHED** 状态。服务端收到这个 ACK 报文段后,也进入 **ESTABLISHED** 状态。
-当建立了 3 次握手之后,客户端和服务端就可以传输数据啦!
+至此,双方都确认了连接的建立,TCP 连接成功创建,可以开始进行双向数据传输。
+
+### 什么是半连接队列和全连接队列?
+
+```mermaid
+sequenceDiagram
+ autonumber
+ participant C as 客户端 Client
+ participant K as 服务端内核 TCP
+ box 服务端内核队列
+ participant SQ as 半连接队列 SYN queue
+ participant AQ as 全连接队列 Accept queue
+ end
+ participant App as 用户态应用 Server app
+
+ C->>K: SYN
+ K-->>C: SYN 加 ACK
+ Note over SQ: 内核为该连接创建请求条目
连接状态 SYN_RCVD
放入 SYN queue
+
+ C->>K: ACK 第三次握手
+ Note over SQ,AQ: 内核收到 ACK 后完成握手
将连接从 SYN queue 迁移到 Accept queue
队列未满才可进入
+ Note over AQ: 连接已完成 可被 accept
连接状态 ESTABLISHED
+
+ App->>K: accept
+ K-->>App: 返回已就绪的 socket
+ Note over AQ: 该连接从 Accept queue 移除
+```
+
+在 TCP 三次握手过程中,服务端内核通常会用两个队列来管理连接请求(不同操作系统/内核版本实现细节可能略有差异,下面以常见 Linux 行为为例):
+
+1. **半连接队列**(也称 SYN Queue):
+ - 保存“握手未完成”的请求:服务端收到 SYN 并回 SYN+ACK 后,连接进入 SYN_RCVD,等待客户端最终 ACK。
+ - 如果一直收不到 ACK,内核会按重传策略重发 SYN+ACK,最终超时清理。
+ - 常见相关参数:`net.ipv4.tcp_max_syn_backlog`;在 SYN Flood 场景下可配合 `net.ipv4.tcp_syncookies`。
+2. **全连接队列**(也称 Accept Queue):
+ - 保存“握手已完成但应用还没 accept”的连接:服务端收到最终 ACK 后连接变为 `ESTABLISHED`,并进入 全连接队列,等待应用层 `accept()` 取走。
+ - 队列容量受 `listen(fd, backlog)` 与系统上限 `net.core.somaxconn` 共同影响;实践中常见有效上限近似为 `min(backlog, somaxconn)`(具体行为与内核版本相关)。
+
+总结:
+
+| 队列 | 作用 | 状态 | 移出条件 |
+| -------------------------- | ------------------ | ----------- | ----------------------- |
+| 半连接队列(SYN Queue) | 保存未完成握手连接 | SYN_RCVD | 收到 ACK / 超时重传失败 |
+| 全连接队列(Accept Queue) | 保存已完成握手连接 | ESTABLISHED | 被应用层 accept() 取出 |
+
+当全连接队列满时,`net.ipv4.tcp_abort_on_overflow` 会影响处理策略:
+
+- `0`(默认):通常不会立刻让连接快速失败,给应用留缓冲时间(可能表现为客户端重试/超时)。
+- `1`:直接对客户端回复 `RST`,让连接快速失败。
+
+当半连接队列满时,如果开启了 `tcp_syncookies`,服务端可能不会为该连接在半连接队列中分配常规条目,而是计算并返回一个 **SYN Cookie**。只有当收到合法的最终 `ACK` 时,才“重建”必要的连接信息。这是抵御 **SYN Flood** 的核心手段之一。
### 为什么要三次握手?
-三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。
+TCP 三次握手的核心目的是为了在客户端和服务器之间建立一个**可靠的**、**全双工的**通信信道。这需要实现两个主要目标:
+
+**1. 确认双方的收发能力,并同步初始序列号 (ISN)**
+
+```mermaid
+sequenceDiagram
+ autonumber
+ participant C as 客户端 Client
+ participant S as 服务端 Server
+
+ Note over C,S: 目标 同步双方 ISN 并确认双向可达
+
+ C->>S: SYN seq=ISN_C
+ Note right of S: 服务端确认 客户端到服务端方向可达
+ Note right of S: 服务端状态 SYN_RCVD
+
+ S->>C: SYN 加 ACK seq=ISN_S ack=ISN_C+1
+ Note left of C: 客户端确认
1 服务端到客户端方向可达
2 服务端已收到客户端 SYN
3 获得 ISN_S
+
+ C->>S: ACK seq=ISN_C+1 ack=ISN_S+1
+ Note left of C: 客户端状态 ESTABLISHED
+ Note right of S: 服务端确认 客户端已收到 SYN 加 ACK
双方 ISN 同步完成
+ Note right of S: 服务端状态 ESTABLISHED
+
+ Note over C,S: 连接建立 可以开始传输数据
+```
+
+TCP 依赖序列号(SEQ)与确认号(ACK)保证数据**有序、无重复、可重传**。三次握手通过交换并确认双方的 ISN,使两端对“从哪一个序号开始收发数据”达成一致,同时让握手过程形成闭环,避免仅凭单向信息就进入已建立状态。
+
+经过这三次交互,双方都确认了彼此的收发功能完好,并完成了初始序列号的同步,为后续可靠的数据传输奠定了基础。
+
+三次握手能力确认速记:
-1. **第一次握手**:Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常
-2. **第二次握手**:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:对方发送正常,自己接收正常
-3. **第三次握手**:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
+1. C→S:SYN → S 确认:C 能发,S 能收(C→S 通)。
+2. S→C:SYN+ACK → C 确认:S 能发,C 能收,且 S 已收到 C 的 SYN(对方 SEQ + 1)。
+3. C→S:ACK → S 确认:C 已收到 S 的 SYN+ACK,握手闭环,连接建立。
-三次握手就能确认双方收发功能都正常,缺一不可。
+**2. 防止已失效的连接请求被错误地建立**
-更详细的解答可以看这个:[TCP 为什么是三次握手,而不是两次或四次? - 车小胖的回答 - 知乎](https://www.zhihu.com/question/24853633/answer/115173386) 。
+```mermaid
+sequenceDiagram
+ participant C as 客户端 (Client)
+ participant S as 服务端 (Server)
+
+ Note over C,S: 场景:旧的 SYN 报文在网络中滞留
+
+ C->>S: 1. 发送 SYN (旧请求 - 滞留中)
+ Note over C: 客户端超时,放弃该请求
+
+ C->>S: 2. 发送 SYN (新请求)
+ S-->>C: 3. 建立连接并正常释放...
+
+ rect rgb(255, 240, 240)
+ Note right of S: 此时,旧的 SYN 终于到达服务端
+ S->>C: 4. 发送 SYN+ACK (针对旧请求)
+
+ alt 如果是【两次握手】
+ Note right of S: (假设服务端在回复 SYN+ACK 后即认为连接建立)
+ Note right of S: ❌ 错误建立连接 (Ghost Connection)
分配内存/资源,造成浪费
+ else 如果是【三次握手】
+ Note left of C: 客户端无该连接状态 / 非期望报文
+ C->>S: 5. 发送 RST (重置报文) 或 直接丢弃
+
+ Note right of S: 【服务端结果】
收到 RST 立即清理;
或未收到 ACK 则重传并最终超时清理
+ Note right of S: ✅ 避免错误建连,保护资源
+ end
+ end
+```
+
+设想一个场景:客户端发送的第一个连接请求(SYN1)因网络延迟而滞留,于是客户端重发了第二个请求(SYN2)并成功建立了连接,数据传输完毕后连接被释放。此时,延迟的 SYN1 才到达服务端。
+
+- **如果是两次握手**:服务端收到这个失效的 SYN1 后,会误认为是一个新的连接请求,并立即分配资源、建立连接。但这将导致服务端单方面维持一个无效连接,白白浪费系统资源,因为客户端并不会有任何响应。
+- **有了第三次握手**:服务端收到失效的 SYN1 并回复 SYN+ACK 后,会等待客户端的最终确认(ACK)。由于客户端当前并没有发起连接的意图,它会忽略这个 SYN+ACK 或者发送一个 RST (Reset) 报文。这样,服务端就无法收到第三次握手的 ACK,最终会超时关闭这个错误的连接,从而避免了资源浪费。
+
+因此,三次握手是确保 TCP 连接可靠性的**最小且必需**的步骤。它不仅确认了双方的通信能力,更重要的是增加了一个最终确认环节,以防止网络中延迟、重复的历史请求对连接建立造成干扰。
### 第 2 次握手传回了 ACK,为什么还要传回 SYN?
-服务端传回发送端所发送的 ACK 是为了告诉客户端:“我接收到的信息确实就是你所发送的信号了”,这表明从客户端到服务端的通信是正常的。回传 SYN 则是为了建立并确认从服务端到客户端的通信。
+第二次握手里的 ACK 是为了确认“服务端确实收到了客户端的 SYN”(即确认 C→S 的请求到达)。而同时携带 SYN 是为了把服务端自己的 ISN 也同步给客户端,并要求客户端对其进行确认(即建立并确认 S→C 方向的建立过程)。只有双方的 ISN 都同步完成,后续的可靠传输(按序、重传、去重)才有共同起点。
+
+简言之:ACK 用于“我收到了你的 SYN”,SYN 用于“我也要发起我的同步,请你确认”。
+
+> SYN 同步序列编号(Synchronize Sequence Numbers) 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务端之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务端使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement)消息响应。这样在客户机和服务端之间才能建立起可靠的 TCP 连接,数据才可以在客户机和服务端之间传递。
-> SYN 同步序列编号(Synchronize Sequence Numbers) 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement)消息响应。这样在客户机和服务器之间才能建立起可靠的 TCP 连接,数据才可以在客户机和服务器之间传递。
+### 三次握手过程中可以携带数据吗?
+
+在 TCP 三次握手过程中,第三次握手是可以携带数据的(客户端发送完 ACK 确认包之后就进入 ESTABLISHED 状态了),这一点在 RFC 793 文档中有提到。也就是说,一旦完成了前两次握手,TCP 协议允许数据在第三次握手时开始传输。
+
+如果第三次握手的 ACK 确认包丢失,但是客户端已经开始发送携带数据的包,那么服务端在收到这个携带数据的包时,如果该包中包含了 ACK 标记,服务端会将其视为有效的第三次握手确认。这样,连接就被认为是建立的,服务端会处理该数据包,并继续正常的数据传输流程。
## 断开连接-TCP 四次挥手
@@ -43,42 +175,77 @@ tag:
断开一个 TCP 连接则需要“四次挥手”,缺一不可:
-1. **第一次挥手**:客户端发送一个 FIN(SEQ=x) 标志的数据包->服务端,用来关闭客户端到服务器的数据传送。然后,客户端进入 **FIN-WAIT-1** 状态。
-2. **第二次挥手**:服务器收到这个 FIN(SEQ=X) 标志的数据包,它发送一个 ACK (ACK=x+1)标志的数据包->客户端 。然后,此时服务端进入 **CLOSE-WAIT** 状态,客户端进入 **FIN-WAIT-2** 状态。
-3. **第三次挥手**:服务端关闭与客户端的连接并发送一个 FIN (SEQ=y)标志的数据包->客户端请求关闭连接,然后,服务端进入 **LAST-ACK** 状态。
-4. **第四次挥手**:客户端发送 ACK (ACK=y+1)标志的数据包->服务端并且进入**TIME-WAIT**状态,服务端在收到 ACK (ACK=y+1)标志的数据包后进入 CLOSE 状态。此时,如果客户端等待 **2MSL** 后依然没有收到回复,就证明服务端已正常关闭,随后,客户端也可以关闭连接了。
+1. **第一次挥手 (FIN)**:当客户端(或任何一方)决定关闭连接时,它会向服务端发送一个 **FIN**(Finish)标志的报文段,表示自己已经没有数据要发送了。该报文段包含一个序列号 seq=u。发送后,客户端进入 **FIN-WAIT-1** 状态。
+2. **第二次挥手 (ACK)**:服务端收到 FIN 报文段后,会立即回复一个 **ACK** 确认报文段。其确认号为 ack=u+1。发送后,服务端进入 **CLOSE-WAIT** 状态。客户端收到这个 ACK 后,进入 **FIN-WAIT-2** 状态。此时,TCP 连接处于**半关闭(Half-Close)**状态:客户端到服务端的发送通道已关闭,但服务端到客户端的发送通道仍然可以传输数据。
+3. **第三次挥手 (FIN)**:当服务端确认所有待发送的数据都已发送完毕后,它也会向客户端发送一个 **FIN** 报文段,表示自己也准备关闭连接。该报文段同样包含一个序列号 seq=y。发送后,服务端进入 **LAST-ACK** 状态,等待客户端的最终确认。
+4. **第四次挥手**:客户端收到服务端的 FIN 报文段后,会回复一个最终的 **ACK** 确认报文段,确认号为 ack=y+1。发送后,客户端进入 **TIME-WAIT** 状态。服务端在收到这个 ACK 后,立即进入 **CLOSED** 状态,完成连接关闭。客户端则会在 **TIME-WAIT** 状态下等待 **2MSL**(Maximum Segment Lifetime,报文段最大生存时间)后,才最终进入 **CLOSED** 状态。
-**只要四次挥手没有结束,客户端和服务端就可以继续传输数据!**
+四次挥手期间连接可能处于**半关闭(Half-Close)**:**先发送 FIN 的一方不再发送应用数据**,但**另一方仍可继续发送剩余数据**,直到它也发送 FIN 并完成后续 ACK。
### 为什么要四次挥手?
-TCP 是全双工通信,可以双向传输数据。任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了 TCP 连接。
+TCP 是全双工通信:两端的发送方向彼此独立。断开连接时,往往需要“我不发了”与“你也不发了”分别被对方确认,因此通常表现为四个报文段(FIN/ACK/FIN/ACK)。这也对应了现实世界的“双方分别确认挂断”的过程。
举个例子:A 和 B 打电话,通话即将结束后。
-1. **第一次挥手**:A 说“我没啥要说的了”
-2. **第二次挥手**:B 回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话
-3. **第三次挥手**:于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”
-4. **第四次挥手**:A 回答“知道了”,这样通话才算结束。
+1. **第一次挥手**:A 说“我没啥要说的了”(A 发 FIN)
+2. **第二次挥手**:B 回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话(B 回 ACK,但可能还有话要说)
+3. **第三次挥手**:于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”(B 发 FIN)
+4. **第四次挥手**:A 回答“知道了”,这样通话才算结束(A 回 ACK)。
+
+### 为什么不能把服务端发送的 ACK 和 FIN 合并起来,变成三次挥手?
+
+```mermaid
+sequenceDiagram
+ autonumber
+ participant C as 客户端
+ participant K as 服务端内核
+ participant A as 服务端应用
+
+ Note over C,K: 客户端发起关闭
+ C->>K: FIN
+ Note right of K: 内核立即回复 ACK 用于确认对端 FIN
+ K-->>C: ACK
+ Note right of K: 服务端状态变为 CLOSE_WAIT
-### 为什么不能把服务器发送的 ACK 和 FIN 合并起来,变成三次挥手?
+ Note over K,A: 应用处理阶段
+ K->>A: 通知本端应用对端已关闭发送方向 例如 read 返回 0
+ A->>A: 读取和处理剩余数据
+ A->>A: 发送最后响应
+ A->>K: 调用 close 或 shutdown
-因为服务器收到客户端断开连接的请求时,可能还有一些数据没有发完,这时先回复 ACK,表示接收到了断开连接的请求。等到数据发完之后再发 FIN,断开服务器到客户端的数据传送。
+ Note right of K: 发送本端 FIN 并进入 LAST_ACK
+ K-->>C: FIN
+ Note left of C: 客户端回复 ACK 并进入 TIME_WAIT
+ C->>K: ACK
+ Note right of K: 服务端收到最终 ACK 后进入 CLOSED
-### 如果第二次挥手时服务器的 ACK 没有送达客户端,会怎样?
-客户端没有收到 ACK 确认,会重新发送 FIN 请求。
+```
+
+关键原因是:**回复 ACK** 与 **发送 FIN** 的触发时机往往不同步。
+
+- 当服务端收到客户端 FIN 时,内核协议栈会立即回 ACK,用于确认“我收到了你要关闭的请求”。此时服务端进入 CLOSE_WAIT,等待本端应用把剩余事情处理完。
+- 只有当服务端应用处理完毕并调用 `close()/shutdown()` 后,内核才会发送本端的 FIN。
+- 因此“内核自动回 ACK”和“应用决定发 FIN”在时间上是解耦的,通常无法合并。只有在服务端恰好也准备立即关闭时,才可能出现 FIN+ACK 合并在一个报文段中的情况。
+
+### 如果第二次挥手时服务端的 ACK 没有送达客户端,会怎样?
+
+- **客户端状态**:客户端发送第一次 `FIN` 后进入 **FIN_WAIT_1** 并启动重传计时器。
+- **重传逻辑**:若在超时时间内未收到对端对该 `FIN` 的确认 `ACK`,客户端会重传 `FIN`。
+- **服务端处理**:服务端若收到重复 `FIN`,通常会再次发送 `ACK`。如果由于网络问题 ACK 一直到不了,客户端在达到一定重试/超时阈值后可能报错或放弃(具体由实现与参数如 `tcp_retries2` 等影响)。
### 为什么第四次挥手客户端需要等待 2\*MSL(报文段最长寿命)时间后才进入 CLOSED 状态?
-第四次挥手时,客户端发送给服务器的 ACK 有可能丢失,如果服务端因为某些原因而没有收到 ACK 的话,服务端就会重发 FIN,如果客户端在 2\*MSL 的时间内收到了 FIN,就会重新发送 ACK 并再次等待 2MSL,防止 Server 没有收到 ACK 而不断重发 FIN。
+第四次挥手时,客户端发送给服务端的 ACK 有可能丢失,如果服务端因为某些原因而没有收到 ACK 的话,服务端就会重发 FIN,如果客户端在 2\*MSL 的时间内收到了 FIN,就会重新发送 ACK 并再次等待 2MSL,防止 Server 没有收到 ACK 而不断重发 FIN。
> **MSL(Maximum Segment Lifetime)** : 一个片段在网络中最大的存活时间,2MSL 就是一个发送和一个回复所需的最大时间。如果直到 2MSL,Client 都没有再次收到 FIN,那么 Client 推断 ACK 已经被成功接收,则结束 TCP 连接。
## 参考
- 《计算机网络(第 7 版)》
-
- 《图解 HTTP》
+- TCP and UDP Tutorial:
+- 从一次线上问题说起,详解 TCP 半连接队列、全连接队列:
-- TCP and UDP Tutorial:https://www.9tut.com/tcp-and-udp-tutorial
+
diff --git a/docs/cs-basics/network/tcp-reliability-guarantee.md b/docs/cs-basics/network/tcp-reliability-guarantee.md
index c2f081f2327..e9a43a11d1a 100644
--- a/docs/cs-basics/network/tcp-reliability-guarantee.md
+++ b/docs/cs-basics/network/tcp-reliability-guarantee.md
@@ -1,8 +1,13 @@
---
title: TCP 传输可靠性保障(传输层)
+description: 系统梳理 TCP 的可靠性保障机制,覆盖重传/选择确认、流量与拥塞控制,明确端到端可靠传输的实现要点。
category: 计算机基础
tag:
- 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: TCP,可靠性,重传,SACK,流量控制,拥塞控制,滑动窗口,校验和
---
## TCP 如何保证传输的可靠性?
@@ -10,9 +15,9 @@ tag:
1. **基于数据块传输**:应用数据被分割成 TCP 认为最适合发送的数据块,再传输给网络层,数据块被称为报文段或段。
2. **对失序数据包重新排序以及去重**:TCP 为了保证不发生丢包,就给每个包一个序列号,有了序列号能够将接收到的数据根据序列号排序,并且去掉重复序列号的数据就可以实现数据包去重。
3. **校验和** : TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
-4. **超时重传** : 当发送方发送数据之后,它启动一个定时器,等待目的端确认收到这个报文段。接收端实体对已成功收到的包发回一个相应的确认信息(ACK)。如果发送端实体在合理的往返时延(RTT)内未收到确认消息,那么对应的数据包就被假设为[已丢失](https://zh.wikipedia.org/wiki/丢包)并进行重传。
+4. **重传机制** : 在数据包丢失或延迟的情况下,重新发送数据包,直到收到对方的确认应答(ACK)。TCP 重传机制主要有:基于计时器的重传(也就是超时重传)、快速重传(基于接收端的反馈信息来引发重传)、SACK(在快速重传的基础上,返回最近收到的报文段的序列号范围,这样客户端就知道,哪些数据包已经到达服务器了)、D-SACK(重复 SACK,在 SACK 的基础上,额外携带信息,告知发送方有哪些数据包自己重复接收了)。关于重传机制的详细介绍,可以查看[详解 TCP 超时与重传机制](https://zhuanlan.zhihu.com/p/101702312)这篇文章。
5. **流量控制** : TCP 连接的每一方都有固定大小的缓冲空间,TCP 的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议(TCP 利用滑动窗口实现流量控制)。
-6. **拥塞控制** : 当网络拥塞时,减少数据的发送。
+6. **拥塞控制** : 当网络拥塞时,减少数据的发送。TCP 在发送数据的时候,需要考虑两个因素:一是接收方的接收能力,二是网络的拥塞程度。接收方的接收能力由滑动窗口表示,表示接收方还有多少缓冲区可以用来接收数据。网络的拥塞程度由拥塞窗口表示,它是发送方根据网络状况自己维护的一个值,表示发送方认为可以在网络中传输的数据量。发送方发送数据的大小是滑动窗口和拥塞窗口的最小值,这样可以保证发送方既不会超过接收方的接收能力,也不会造成网络的过度拥塞。
## TCP 如何实现流量控制?
@@ -68,7 +73,7 @@ TCP 为全双工(Full-Duplex, FDX)通信,双方可以进行双向通信,客
TCP 的拥塞控制采用了四种算法,即 **慢开始**、 **拥塞避免**、**快重传** 和 **快恢复**。在网络层也可以使路由器采用适当的分组丢弃策略(如主动队列管理 AQM),以减少网络拥塞的发生。
-- **慢开始:** 慢开始算法的思路是当主机开始发送数据时,如果立即把大量数据字节注入到网络,那么可能会引起网络阻塞,因为现在还不知道网络的符合情况。经验表明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是由小到大逐渐增大拥塞窗口数值。cwnd 初始值为 1,每经过一个传播轮次,cwnd 加倍。
+- **慢开始:** 慢开始算法的思路是当主机开始发送数据时,如果立即把大量数据字节注入到网络,那么可能会引起网络阻塞,因为现在还不知道网络的负荷情况。经验表明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是由小到大逐渐增大拥塞窗口数值。cwnd 初始值为 1,每经过一个传播轮次,cwnd 加倍。
- **拥塞避免:** 拥塞避免算法的思路是让拥塞窗口 cwnd 缓慢增大,即每经过一个往返时间 RTT 就把发送方的 cwnd 加 1.
- **快重传与快恢复:** 在 TCP/IP 中,快速重传和恢复(fast retransmit and recovery,FRR)是一种拥塞控制算法,它能快速恢复丢失的数据包。没有 FRR,如果数据包丢失了,TCP 将会使用定时器来要求传输暂停。在暂停的这段时间内,没有新的或复制的数据包被发送。有了 FRR,如果接收机接收到一个不按顺序的数据段,它会立即给发送机发送一个重复确认。如果发送机接收到三个重复确认,它会假定确认件指出的数据段丢失了,并立即重传这些丢失的数据段。有了 FRR,就不会因为重传时要求的暂停被耽误。 当有单独的数据包丢失时,快速重传和恢复(FRR)能最有效地工作。当有多个数据信息包在某一段很短的时间内丢失时,它则不能很有效地工作。
@@ -101,16 +106,28 @@ ARQ 包括停止等待 ARQ 协议和连续 ARQ 协议。
连续 ARQ 协议可提高信道利用率。发送方维持一个发送窗口,凡位于发送窗口内的分组可以连续发送出去,而不需要等待对方确认。接收方一般采用累计确认,对按序到达的最后一个分组发送确认,表明到这个分组为止的所有分组都已经正确收到了。
-**优点:** 信道利用率高,容易实现,即使确认丢失,也不必重传。
+- **优点:** 信道利用率高,容易实现,即使确认丢失,也不必重传。
+- **缺点:** 不能向发送方反映出接收方已经正确收到的所有分组的信息。 比如:发送方发送了 5 条 消息,中间第三条丢失(3 号),这时接收方只能对前两个发送确认。发送方无法知道后三个分组的下落,而只好把后三个全部重传一次。这也叫 Go-Back-N(回退 N),表示需要退回来重传已经发送过的 N 个消息。
-**缺点:** 不能向发送方反映出接收方已经正确收到的所有分组的信息。 比如:发送方发送了 5 条 消息,中间第三条丢失(3 号),这时接收方只能对前两个发送确认。发送方无法知道后三个分组的下落,而只好把后三个全部重传一次。这也叫 Go-Back-N(回退 N),表示需要退回来重传已经发送过的 N 个消息。
+## 超时重传如何实现?超时重传时间怎么确定?
-## Reference
+当发送方发送数据之后,它启动一个定时器,等待目的端确认收到这个报文段。接收端实体对已成功收到的包发回一个相应的确认信息(ACK)。如果发送端实体在合理的往返时延(RTT)内未收到确认消息,那么对应的数据包就被假设为[已丢失](https://zh.wikipedia.org/wiki/丢包)并进行重传。
+
+- RTT(Round Trip Time):往返时间,也就是数据包从发出去到收到对应 ACK 的时间。
+- RTO(Retransmission Time Out):重传超时时间,即从数据发送时刻算起,超过这个时间便执行重传。
+
+RTO 的确定是一个关键问题,因为它直接影响到 TCP 的性能和效率。如果 RTO 设置得太小,会导致不必要的重传,增加网络负担;如果 RTO 设置得太大,会导致数据传输的延迟,降低吞吐量。因此,RTO 应该根据网络的实际状况,动态地进行调整。
+
+RTT 的值会随着网络的波动而变化,所以 TCP 不能直接使用 RTT 作为 RTO。为了动态地调整 RTO,TCP 协议采用了一些算法,如加权移动平均(EWMA)算法,Karn 算法,Jacobson 算法等,这些算法都是根据往返时延(RTT)的测量和变化来估计 RTO 的值。
+
+## 参考
1. 《计算机网络(第 7 版)》
2. 《图解 HTTP》
3. [https://www.9tut.com/tcp-and-udp-tutorial](https://www.9tut.com/tcp-and-udp-tutorial)
4. [https://github.com/wolverinn/Waking-Up/blob/master/Computer%20Network.md](https://github.com/wolverinn/Waking-Up/blob/master/Computer%20Network.md)
5. TCP Flow Control—[https://www.brianstorti.com/tcp-flow-control/](https://www.brianstorti.com/tcp-flow-control/)
-6. TCP 流量控制(Flow Control):https://notfalse.net/24/tcp-flow-control
-7. TCP 之滑动窗口原理 : https://cloud.tencent.com/developer/article/1857363
+6. TCP 流量控制(Flow Control):
+7. TCP 之滑动窗口原理 :
+
+
diff --git a/docs/cs-basics/network/the-whole-process-of-accessing-web-pages.md b/docs/cs-basics/network/the-whole-process-of-accessing-web-pages.md
new file mode 100644
index 00000000000..2bacba2fdb1
--- /dev/null
+++ b/docs/cs-basics/network/the-whole-process-of-accessing-web-pages.md
@@ -0,0 +1,84 @@
+---
+title: 访问网页的全过程(知识串联)
+description: 串联从输入 URL 到页面渲染的完整链路,涵盖 DNS、TCP、HTTP 与静态资源加载,助力面试与实践理解。
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 访问网页流程,DNS,TCP 建连,HTTP 请求,资源加载,渲染,关闭连接
+---
+
+开发岗中总是会考很多计算机网络的知识点,但如果让面试官只考一道题,便涵盖最多的计网知识点,那可能就是 **网页浏览的全过程** 了。本篇文章将带大家从头到尾过一遍这道被考烂的面试题,必会!!!
+
+总的来说,网络通信模型可以用下图来表示,也就是大家只要熟记网络结构五层模型,按照这个体系,很多知识点都能顺出来了。访问网页的过程也是如此。
+
+
+
+开始之前,我们先简单过一遍完整流程:
+
+1. 在浏览器中输入指定网页的 URL。
+2. 浏览器通过 DNS 协议,获取域名对应的 IP 地址。
+3. 浏览器根据 IP 地址和端口号,向目标服务器发起一个 TCP 连接请求。
+4. 浏览器在 TCP 连接上,向服务器发送一个 HTTP 请求报文,请求获取网页的内容。
+5. 服务器收到 HTTP 请求报文后,处理请求,并返回 HTTP 响应报文给浏览器。
+6. 浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示。
+7. 浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求。
+
+## 应用层
+
+一切的开始——打开浏览器,在地址栏输入 URL,回车确认。那么,什么是 URL?访问 URL 有什么用?
+
+### URL
+
+URL(Uniform Resource Locators),即统一资源定位器。网络上的所有资源都靠 URL 来定位,每一个文件就对应着一个 URL,就像是路径地址。理论上,文件资源和 URL 一一对应。实际上也有例外,比如某些 URL 指向的文件已经被重定位到另一个位置,这样就有多个 URL 指向同一个文件。
+
+### URL 的组成结构
+
+
+
+1. 协议。URL 的前缀通常表示了该网址采用了何种应用层协议,通常有两种——HTTP 和 HTTPS。当然也有一些不太常见的前缀头,比如文件传输时用到的`ftp:`。
+2. 域名。域名便是访问网址的通用名,这里也有可能是网址的 IP 地址,域名可以理解为 IP 地址的可读版本,毕竟绝大部分人都不会选择记住一个网址的 IP 地址。
+3. 端口。如果指明了访问网址的端口的话,端口会紧跟在域名后面,并用一个冒号隔开。
+4. 资源路径。域名(端口)后紧跟的就是资源路径,从第一个`/`开始,表示从服务器上根目录开始进行索引到的文件路径,上图中要访问的文件就是服务器根目录下`/path/to/myfile.html`。早先的设计是该文件通常物理存储于服务器主机上,但现在随着网络技术的进步,该文件不一定会物理存储在服务器主机上,有可能存放在云上,而文件路径也有可能是虚拟的(遵循某种规则)。
+5. 参数。参数是浏览器在向服务器提交请求时,在 URL 中附带的参数。服务器解析请求时,会提取这些参数。参数采用键值对的形式`key=value`,每一个键值对使用`&`隔开。参数的具体含义和请求操作的具体方法有关。
+6. 锚点。锚点顾名思义,是在要访问的页面上的一个锚。要访问的页面大部分都多于一页,如果指定了锚点,那么在客户端显示该网页是就会定位到锚点处,相当于一个小书签。值得一提的是,在 URL 中,锚点以`#`开头,并且**不会**作为请求的一部分发送给服务端。
+
+### DNS
+
+键入了 URL 之后,第一个重头戏登场——DNS 服务器解析。DNS(Domain Name System)域名系统,要解决的是 **域名和 IP 地址的映射问题** 。毕竟,域名只是一个网址便于记住的名字,而网址真正存在的地址其实是 IP 地址。
+
+传送门:[DNS 域名系统详解(应用层)](https://javaguide.cn/cs-basics/network/dns.html)
+
+### HTTP/HTTPS
+
+利用 DNS 拿到了目标主机的 IP 地址之后,浏览器便可以向目标 IP 地址发送 HTTP 报文,请求需要的资源了。在这里,根据目标网站的不同,请求报文可能是 HTTP 协议或安全性增强的 HTTPS 协议。
+
+传送门:
+
+- [HTTP vs HTTPS(应用层)](https://javaguide.cn/cs-basics/network/http-vs-https.html)
+- [HTTP 1.0 vs HTTP 1.1(应用层)](https://javaguide.cn/cs-basics/network/http1.0-vs-http1.1.html)
+- [HTTP 常见状态码总结(应用层)](https://javaguide.cn/cs-basics/network/http-status-codes.html)
+
+## 传输层
+
+由于 HTTP 协议是基于 TCP 协议的,在应用层的数据封装好以后,要交给传输层,经 TCP 协议继续封装。
+
+TCP 协议保证了数据传输的可靠性,是数据包传输的主力协议。
+
+传送门:
+
+- [TCP 三次握手和四次挥手(传输层)](https://javaguide.cn/cs-basics/network/tcp-connection-and-disconnection.html)
+- [TCP 传输可靠性保障(传输层)](https://javaguide.cn/cs-basics/network/tcp-reliability-guarantee.html)
+
+## 网络层
+
+终于,来到网络层,此时我们的主机不再是和另一台主机进行交互了,而是在和中间系统进行交互。也就是说,应用层和传输层都是端到端的协议,而网络层及以下都是中间件的协议了。
+
+**网络层的核心功能——转发与路由**,必会!!!如果面试官问到了网络层,而你恰好又什么都不会的话,最最起码要说出这五个字——**转发与路由**。
+
+- 转发:将分组从路由器的输入端口转移到合适的输出端口。
+- 路由:确定分组从源到目的经过的路径。
+
+所以到目前为止,我们的数据包经过了应用层、传输层的封装,来到了网络层,终于开始准备在物理层面传输了,第一个要解决的问题就是——**往哪里传输?或者说,要把数据包发到哪个路由器上?** 这便是 BGP 协议要解决的问题。
diff --git a/docs/cs-basics/operating-system/linux-intro.md b/docs/cs-basics/operating-system/linux-intro.md
index c2dc881ea9f..acd46480bf9 100644
--- a/docs/cs-basics/operating-system/linux-intro.md
+++ b/docs/cs-basics/operating-system/linux-intro.md
@@ -1,15 +1,18 @@
---
title: Linux 基础知识总结
+description: 简单介绍一下 Java 程序员必知的 Linux 的一些概念以及常见命令。
category: 计算机基础
tag:
- 操作系统
- Linux
head:
- - meta
- - name: description
- content: 简单介绍一下 Java 程序员必知的 Linux 的一些概念以及常见命令。
+ - name: keywords
+ content: Linux,基础命令,发行版,文件系统,权限,进程,网络
---
+
+
简单介绍一下 Java 程序员必知的 Linux 的一些概念以及常见命令。
## 初探 Linux
@@ -68,7 +71,7 @@ inode 是 Linux/Unix 文件系统的基础。那 inode 到是什么?有什么作
通过以下五点可以概括 inode 到底是什么:
-1. 硬盘的最小存储单位是扇区(Sector),块(block)由多个扇区组成。文件数据存储在块中。块的最常见的大小是 4kb,约为 8 个连续的扇区组成(每个扇区存储 512 字节)。一个文件可能会占用多个 block,但是一个块只能存放一个文件。虽然,我们将文件存储在了块(block)中,但是我们还需要一个空间来存储文件的 **元信息 metadata**:如某个文件被分成几块、每一块在的地址、文件拥有者,创建时间,权限,大小等。这种 **存储文件元信息的区域就叫 inode**,译为索引节点:**i(index)+node**。 **每个文件都有一个唯一的 inode,存储文件的元信息。**
+1. 硬盘以扇区 (Sector) 为最小物理存储单位,而操作系统和文件系统以块 (Block) 为单位进行读写,块由多个扇区组成。文件数据存储在这些块中。现代硬盘扇区通常为 4KB,与一些常见块大小相同,但操作系统也支持更大的块大小,以提升大文件读写性能。文件元信息(例如权限、大小、修改时间以及数据块位置)存储在 inode(索引节点)中。每个文件都有唯一的 inode。inode 本身不存储文件数据,而是存储指向数据块的指针,操作系统通过这些指针找到并读取文件数据。 固态硬盘 (SSD) 虽然没有物理扇区,但使用逻辑块,其概念与传统硬盘的块类似。
2. inode 是一种固定大小的数据结构,其大小在文件系统创建时就确定了,并且在文件的生命周期内保持不变。
3. inode 的访问速度非常快,因为系统可以直接通过 inode 号码定位到文件的元数据信息,无需遍历整个文件系统。
4. inode 的数量是有限的,每个文件系统只能包含固定数量的 inode。这意味着当文件系统中的 inode 用完时,无法再创建新的文件或目录,即使磁盘上还有可用空间。因此,在创建文件系统时,需要根据文件和目录的预期数量来合理分配 inode 的数量。
@@ -101,7 +104,7 @@ inode 是 Linux/Unix 文件系统的基础。那 inode 到是什么?有什么作
**2、软链接(Symbolic Link 或 Symlink)**
- 软链接和源文件的 inode 节点号不同,而是指向一个文件路径。
-- 源文件删除后,硬链接依然存在,但是指向的是一个无效的文件路径。
+- 源文件删除后,软链接依然存在,但是指向的是一个无效的文件路径。
- 软连接类似于 Windows 系统中的快捷方式。
- 不同于硬链接,可以对目录或者不存在的文件创建软链接,并且,软链接可以跨越文件系统。
- `ln -s` 命令用于创建软链接。
@@ -164,7 +167,7 @@ Linux 使用一种称为目录树的层次结构来组织文件和目录。目
下面只是给出了一些比较常用的命令。
-推荐一个 Linux 命令快查网站,非常不错,大家如果遗忘某些命令或者对某些命令不理解都可以在这里得到解决。Linux 命令在线速查手册:https://wangchujiang.com/linux-command/ 。
+推荐一个 Linux 命令快查网站,非常不错,大家如果遗忘某些命令或者对某些命令不理解都可以在这里得到解决。Linux 命令在线速查手册: 。
@@ -183,8 +186,8 @@ Linux 使用一种称为目录树的层次结构来组织文件和目录。目
### 目录操作
- `ls`:显示目录中的文件和子目录的列表。例如:`ls /home`,显示 `/home` 目录下的文件和子目录列表。
-- `ll`:`ll` 是 `ls -l` 的别名,ll 命令可以看到该目录下的所有目录和文件的详细信息
-- `mkdir [选项] 目录名`:创建新目录(增)。例如:`mkdir -m 755 my_directory`,创建一个名为 `my_directory` 的新目录,并将其权限设置为 755,即所有用户对该目录有读、写和执行的权限。
+- `ll`:`ll` 是 `ls -l` 的别名,ll 命令可以看到该目录下的所有目录和文件的详细信息。
+- `mkdir [选项] 目录名`:创建新目录(增)。例如:`mkdir -m 755 my_directory`,创建一个名为 `my_directory` 的新目录,并将其权限设置为 755,其中所有者拥有读、写、执行权限,所属组和其他用户只有读、执行权限,无法修改目录内容(如创建或删除文件)。如果希望所有用户(包括所属组和其他用户)对目录都拥有读、写、执行权限,则应设置权限为 `777`,即:`mkdir -m 777 my_directory`。
- `find [路径] [表达式]`:在指定目录及其子目录中搜索文件或目录(查),非常强大灵活。例如:① 列出当前目录及子目录下所有文件和文件夹: `find .`;② 在`/home`目录下查找以 `.txt` 结尾的文件名:`find /home -name "*.txt"` ,忽略大小写: `find /home -i name "*.txt"` ;③ 当前目录及子目录下查找所有以 `.txt` 和 `.pdf` 结尾的文件:`find . \( -name "*.txt" -o -name "*.pdf" \)`或`find . -name "*.txt" -o -name "*.pdf"`。
- `pwd`:显示当前工作目录的路径。
- `rmdir [选项] 目录名`:删除空目录(删)。例如:`rmdir -p my_directory`,删除名为 `my_directory` 的空目录,并且会递归删除`my_directory`的空父目录,直到遇到非空目录或根目录。
@@ -235,7 +238,7 @@ Linux 中的打包文件一般是以 `.tar` 结尾的,压缩的命令一般是
### 文件权限
-操作系统中每个文件都拥有特定的权限、所属用户和所属组。权限是操作系统用来限制资源访问的机制,在 Linux 中权限一般分为读(readable)、写(writable)和执行(excutable),分为三组。分别对应文件的属主(owner),属组(group)和其他用户(other),通过这样的机制来限制哪些用户、哪些组可以对特定的文件进行什么样的操作。
+操作系统中每个文件都拥有特定的权限、所属用户和所属组。权限是操作系统用来限制资源访问的机制,在 Linux 中权限一般分为读(readable)、写(writable)和执行(executable),分为三组。分别对应文件的属主(owner),属组(group)和其他用户(other),通过这样的机制来限制哪些用户、哪些组可以对特定的文件进行什么样的操作。
通过 **`ls -l`** 命令我们可以 查看某个目录下的文件或目录的权限
@@ -283,11 +286,11 @@ Linux 中的打包文件一般是以 `.tar` 结尾的,压缩的命令一般是
需要注意的是:**超级用户可以无视普通用户的权限,即使文件目录权限是 000,依旧可以访问。**
-**在 linux 中的每个用户必须属于一个组,不能独立于组外。在 linux 中每个文件有所有者、所在组、其它组的概念。**
+**在 Linux 中的每个用户必须属于一个组,不能独立于组外。在 linux 中每个文件有所有者、所在组、其它组的概念。**
-- **所有者(u)**:一般为文件的创建者,谁创建了该文件,就天然的成为该文件的所有者,用 `ls ‐ahl` 命令可以看到文件的所有者 也可以使用 chown 用户名 文件名来修改文件的所有者 。
-- **文件所在组(g)**:当某个用户创建了一个文件后,这个文件的所在组就是该用户所在的组用 `ls ‐ahl`命令可以看到文件的所有组也可以使用 chgrp 组名 文件名来修改文件所在的组。
-- **其它组(o)**:除开文件的所有者和所在组的用户外,系统的其它用户都是文件的其它组。
+- **所有者(u)** :一般为文件的创建者,谁创建了该文件,就天然的成为该文件的所有者,用 `ls ‐ahl` 命令可以看到文件的所有者 也可以使用 chown 用户名 文件名来修改文件的所有者 。
+- **文件所在组(g)** :当某个用户创建了一个文件后,这个文件的所在组就是该用户所在的组用 `ls ‐ahl`命令可以看到文件的所有组也可以使用 chgrp 组名 文件名来修改文件所在的组。
+- **其它组(o)** :除开文件的所有者和所在组的用户外,系统的其它用户都是文件的其它组。
> 我们再来看看如何修改文件/目录的权限。
@@ -353,11 +356,13 @@ Linux 系统是一个多用户多任务的分时操作系统,任何一个要
- `ifconfig` 或 `ip`:用于查看系统的网络接口信息,包括网络接口的 IP 地址、MAC 地址、状态等。
- `netstat [选项]`:用于查看系统的网络连接状态和网络统计信息,可以查看当前的网络连接情况、监听端口、网络协议等。
- `ss [选项]`:比 `netstat` 更好用,提供了更快速、更详细的网络连接信息。
+- `nload`:`sar` 和 `nload` 都可以监控网络流量,但`sar` 的输出是文本形式的数据,不够直观。`nload` 则是一个专门用于实时监控网络流量的工具,提供图形化的终端界面,更加直观。不过,`nload` 不保存历史数据,所以它不适合用于长期趋势分析。并且,系统并没有默认安装它,需要手动安装。
+- `sudo hostnamectl set-hostname 新主机名`:更改主机名,并且重启后依然有效。`sudo hostname 新主机名`也可以更改主机名。不过需要注意的是,使用 `hostname` 命令直接更改主机名只是临时生效,系统重启后会恢复为原来的主机名。
### 其他
- `sudo + 其他命令`:以系统管理者的身份执行指令,也就是说,经由 sudo 所执行的指令就好像是 root 亲自执行。
-- `grep 要搜索的字符串 要搜索的文件 --color`:搜索命令,--color 代表高亮显示。
+- `grep [选项] "搜索内容" 文件路径`:非常强大且常用的文本搜索命令,它可以根据指定的字符串或正则表达式,在文件或命令输出中进行匹配查找,适用于日志分析、文本过滤、快速定位等多种场景。示例:忽略大小写搜索 syslog 中所有包含 error 的行:`grep -i "error" /var/log/syslog`,查找所有与 java 相关的进程:`ps -ef | grep "java"`。
- `kill -9 进程的pid`:杀死进程(-9 表示强制终止)先用 ps 查找进程,然后用 kill 杀掉。
- `shutdown`:`shutdown -h now`:指定现在立即关机;`shutdown +5 "System will shutdown after 5 minutes"`:指定 5 分钟后关机,同时送出警告信息给登入用户。
- `reboot`:`reboot`:重开机。`reboot -w`:做个重开机的模拟(只有纪录并不会真的重开机)。
@@ -425,3 +430,5 @@ vim ~/.bash_profile
```bash
source /etc/profile
```
+
+
diff --git a/docs/cs-basics/operating-system/operating-system-basic-questions-01.md b/docs/cs-basics/operating-system/operating-system-basic-questions-01.md
index 7498b83ebf4..61810c94a7b 100644
--- a/docs/cs-basics/operating-system/operating-system-basic-questions-01.md
+++ b/docs/cs-basics/operating-system/operating-system-basic-questions-01.md
@@ -1,15 +1,13 @@
---
title: 操作系统常见面试题总结(上)
+description: 最新操作系统高频面试题总结(上):用户态/内核态切换、进程线程区别、死锁四条件、系统调用详解、调度算法对比,附图表+⭐️重点标注,一文掌握OS核心考点,快速通关后端技术面试!
category: 计算机基础
tag:
- 操作系统
head:
- - meta
- name: keywords
- content: 操作系统,进程,进程通信方式,死锁,操作系统内存管理,块表,多级页表,虚拟内存,页面置换算法
- - - meta
- - name: description
- content: 很多读者抱怨计算操作系统的知识点比较繁杂,自己也没有多少耐心去看,但是面试的时候又经常会遇到。所以,我带着我整理好的操作系统的常见问题来啦!这篇文章总结了一些我觉得比较重要的操作系统相关的问题比如进程管理、内存管理、虚拟内存等等。
+ content: 操作系统面试题,用户态 vs 内核态,进程 vs 线程,死锁必要条件,系统调用过程,进程调度算法,PCB进程控制块,进程间通信IPC,死锁预防避免,操作系统基础高频题,虚拟内存管理
---
@@ -98,15 +96,17 @@ _玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Win
根据进程访问资源的特点,我们可以把进程在系统上的运行分为两个级别:
-- **用户态(User Mode)** : 用户态运行的进程可以直接读取用户程序的数据,拥有较低的权限。当应用程序需要执行某些需要特殊权限的操作,例如读写磁盘、网络通信等,就需要向操作系统发起系统调用请求,进入内核态。
-- **内核态(Kernel Mode)**:内核态运行的进程几乎可以访问计算机的任何资源包括系统的内存空间、设备、驱动程序等,不受限制,拥有非常高的权限。当操作系统接收到进程的系统调用请求时,就会从用户态切换到内核态,执行相应的系统调用,并将结果返回给进程,最后再从内核态切换回用户态。
-
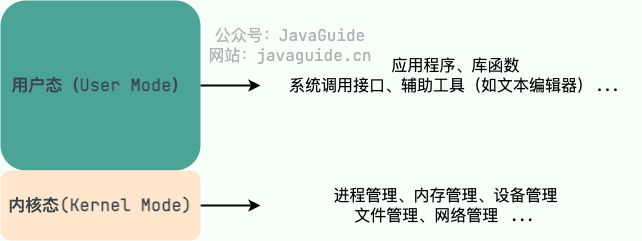
+- **用户态(User Mode)** : 用户态运行的进程可以直接读取用户程序的数据,拥有较低的权限。当应用程序需要执行某些需要特殊权限的操作,例如读写磁盘、网络通信等,就需要向操作系统发起系统调用请求,进入内核态。
+- **内核态(Kernel Mode)** :内核态运行的进程几乎可以访问计算机的任何资源包括系统的内存空间、设备、驱动程序等,不受限制,拥有非常高的权限。当操作系统接收到进程的系统调用请求时,就会从用户态切换到内核态,执行相应的系统调用,并将结果返回给进程,最后再从内核态切换回用户态。
+
内核态相比用户态拥有更高的特权级别,因此能够执行更底层、更敏感的操作。不过,由于进入内核态需要付出较高的开销(需要进行一系列的上下文切换和权限检查),应该尽量减少进入内核态的次数,以提高系统的性能和稳定性。
#### 为什么要有用户态和内核态?只有一个内核态不行么?
+这样设计主要是为了**安全**和**稳定**。
+
- 在 CPU 的所有指令中,有一些指令是比较危险的比如内存分配、设置时钟、IO 处理等,如果所有的程序都能使用这些指令的话,会对系统的正常运行造成灾难性地影响。因此,我们需要限制这些危险指令只能内核态运行。这些只能由操作系统内核态执行的指令也被叫做 **特权指令** 。
- 如果计算机系统中只有一个内核态,那么所有程序或进程都必须共享系统资源,例如内存、CPU、硬盘等,这将导致系统资源的竞争和冲突,从而影响系统性能和效率。并且,这样也会让系统的安全性降低,毕竟所有程序或进程都具有相同的特权级别和访问权限。
@@ -118,12 +118,14 @@ _玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Win
用户态切换到内核态的 3 种方式:
-1. **系统调用(Trap)**:用户态进程 **主动** 要求切换到内核态的一种方式,主要是为了使用内核态才能做的事情比如读取磁盘资源。系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现。
-2. **中断(Interrupt)**:当外围设备完成用户请求的操作后,会向 CPU 发出相应的中断信号,这时 CPU 会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
-3. **异常(Exception)**:当 CPU 在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
+1. **系统调用(Trap)**:这是最主要的方式,是应用程序**主动**发起的。比如,当我们的程序需要读取一个文件或者发送网络数据时,它无法直接操作磁盘或网卡,就必须调用操作系统提供的接口(如 `read()`,`send()`), 这会触发一次从用户态到内核态的切换。
+2. **中断(Interrupt)**:这是**被动**的,由外部硬件设备触发。比如,当硬盘完成了数据读取,会向 CPU 发送一个中断信号,CPU 会暂停当前用户态的程序,切换到内核态去处理这个中断。
+3. **异常(Exception)**:这也是**被动**的,由程序自身错误引起。比如,我们的代码执行了一个除以零的操作,或者访问了一个非法的内存地址(缺页异常),CPU 会捕获这个异常,并切换到内核态去处理它。
在系统的处理上,中断和异常类似,都是通过中断向量表来找到相应的处理程序进行处理。区别在于,中断来自处理器外部,不是由任何一条专门的指令造成,而异常是执行当前指令的结果。
+最后,需要强调的是,这种**状态切换是有性能开销的**。因为它涉及到保存用户态的上下文(寄存器等)、切换到内核态执行、再恢复用户态的上下文。因此,在高性能编程中,我们常常需要考虑如何减少这种切换次数,比如通过缓冲 I/O 来批量读写文件,就是一个典型的例子。
+
### 系统调用
#### 什么是系统调用?
@@ -151,18 +153,23 @@ _玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Win
1. 用户态的程序发起系统调用,因为系统调用中涉及一些特权指令(只能由操作系统内核态执行的指令),用户态程序权限不足,因此会中断执行,也就是 Trap(Trap 是一种中断)。
2. 发生中断后,当前 CPU 执行的程序会中断,跳转到中断处理程序。内核程序开始执行,也就是开始处理系统调用。
-3. 内核处理完成后,主动触发 Trap,这样会再次发生中断,切换回用户态工作。
+3. 当系统调用处理完成后,操作系统使用特权指令(如 `iret`、`sysret` 或 `eret`)切换回用户态,恢复用户态的上下文,继续执行用户程序。
## 进程和线程
-### 什么是进程和线程?
+### 进程和线程的区别是什么?
-- **进程(Process)** 是指计算机中正在运行的一个程序实例。举例:你打开的微信就是一个进程。
-- **线程(Thread)** 也被称为轻量级进程,更加轻量。多个线程可以在同一个进程中同时执行,并且共享进程的资源比如内存空间、文件句柄、网络连接等。举例:你打开的微信里就有一个线程专门用来拉取别人发你的最新的消息。
+进程和线程是操作系统中并发执行的两个核心概念,它们的关系可以理解为 **工厂和工人** 的关系。
-### 进程和线程的区别是什么?
+**进程(Process)就像一个工厂**。操作系统在分配资源时,是以进程为基本单位的。比如,当我启动一个微信,操作系统就为它建立了一个独立的工厂,分配给它专属的内存空间、文件句柄等资源。这个工厂与其他工厂(比如我打开的浏览器进程)是严格隔离的。
+
+**线程(Thread)则像是工厂里的工人**。一个工厂里可以有很多工人,他们共享这个工厂的资源,但每个工人有自己的工具箱和任务清单,让他们可以独立地执行不同的任务。比如微信这个工厂里,可以有一个工人(线程)负责接收消息,一个工人负责渲染界面。
+
+这是我用 AI 绘制的一张图片,可以说是非常形象了:
+
+
下图是 Java 内存区域,我们从 JVM 的角度来说一下线程和进程之间的关系吧!
@@ -170,18 +177,17 @@ _玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Win
从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的**堆**和**方法区 (JDK1.8 之后的元空间)**资源,但是每个线程有自己的**程序计数器**、**虚拟机栈** 和 **本地方法栈**。
-**总结:**
+这里从 3 个角度总结下线程和进程的核心区别:
-- 线程是进程划分成的更小的运行单位,一个进程在其执行的过程中可以产生多个线程。
-- 线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。
-- 线程执行开销小,但不利于资源的管理和保护;而进程正相反。
+1. **资源所有权:** 进程是资源分配的基本单位,拥有独立的地址空间;而线程是 CPU 调度的基本单位,几乎不拥有系统资源,只保留少量私有数据(PC、栈、寄存器),主要共享其所属进程的资源。
+2. **开销:** 创建或销毁一个工厂(进程)的开销很大,需要分配独立的资源。而雇佣或解雇一个工人(线程)的开销就小得多。同理,进程间的上下文切换开销远大于线程间的切换。
+3. **健壮性:** 工厂之间是隔离的,一个工厂倒闭(进程崩溃)不会影响其他工厂。但一个工厂内的工人之间是共享资源的,一个工人操作失误(比如一个线程访问了非法内存)可能会导致整个工厂停工(整个进程崩溃)。
### 有了进程为什么还需要线程?
-- 进程切换是一个开销很大的操作,线程切换的成本较低。
-- 线程更轻量,一个进程可以创建多个线程。
-- 多个线程可以并发处理不同的任务,更有效地利用了多处理器和多核计算机。而进程只能在一个时间干一件事,如果在执行过程中遇到阻塞问题比如 IO 阻塞就会挂起直到结果返回。
-- 同一进程内的线程共享内存和文件,因此它们之间相互通信无须调用内核。
+核心原因就是**为了在单个应用内实现低开销、高效率的并发**。如果我想让微信同时接收消息和发送文件,如果用两个进程来实现,不仅资源开销巨大,它们之间通信还非常麻烦(需要 IPC)。而使用两个线程,它们不仅切换成本低,还能直接通过共享内存高效通信,从而能更好地利用多核 CPU,提升应用的响应速度和吞吐量。
+
+再那我们上面举的工厂和工人为例:线程=同一屋檐下的轻量级工人,切换成本低、共享内存零拷贝;若换成两个独立进程,就得各建一座工厂(独立地址空间),既费砖又费电(资源与 IPC 开销)。
### 为什么要使用多线程?
@@ -201,10 +207,10 @@ _玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Win
下面是几种常见的线程同步的方式:
-1. **互斥锁(Mutex)**:采用互斥对象机制,只有拥有互斥对象的线程才有访问公共资源的权限。因为互斥对象只有一个,所以可以保证公共资源不会被多个线程同时访问。比如 Java 中的 `synchronized` 关键词和各种 `Lock` 都是这种机制。
-2. **读写锁(Read-Write Lock)**:允许多个线程同时读取共享资源,但只有一个线程可以对共享资源进行写操作。
-3. **信号量(Semaphore)**:它允许同一时刻多个线程访问同一资源,但是需要控制同一时刻访问此资源的最大线程数量。
-4. **屏障(Barrier)**:屏障是一种同步原语,用于等待多个线程到达某个点再一起继续执行。当一个线程到达屏障时,它会停止执行并等待其他线程到达屏障,直到所有线程都到达屏障后,它们才会一起继续执行。比如 Java 中的 `CyclicBarrier` 是这种机制。
+1. **互斥锁(Mutex)** :采用互斥对象机制,只有拥有互斥对象的线程才有访问公共资源的权限。因为互斥对象只有一个,所以可以保证公共资源不会被多个线程同时访问。比如 Java 中的 `synchronized` 关键词和各种 `Lock` 都是这种机制。
+2. **读写锁(Read-Write Lock)** :允许多个线程同时读取共享资源,但只有一个线程可以对共享资源进行写操作。
+3. **信号量(Semaphore)** :它允许同一时刻多个线程访问同一资源,但是需要控制同一时刻访问此资源的最大线程数量。
+4. **屏障(Barrier)** :屏障是一种同步原语,用于等待多个线程到达某个点再一起继续执行。当一个线程到达屏障时,它会停止执行并等待其他线程到达屏障,直到所有线程都到达屏障后,它们才会一起继续执行。比如 Java 中的 `CyclicBarrier` 是这种机制。
5. **事件(Event)** :Wait/Notify:通过通知操作的方式来保持多线程同步,还可以方便的实现多线程优先级的比较操作。
### PCB 是什么?包含哪些信息?
@@ -220,7 +226,7 @@ PCB 主要包含下面几部分的内容:
- 进程对资源的需求情况,包括 CPU 时间、内存空间、I/O 设备等等。
- 进程打开的文件信息,包括文件描述符、文件类型、打开模式等等。
- 处理机的状态信息(由处理机的各种寄存器中的内容组成的),包括通用寄存器、指令计数器、程序状态字 PSW、用户栈指针。
-- ......
+- ……
### 进程有哪几种状态?
@@ -238,48 +244,49 @@ PCB 主要包含下面几部分的内容:
> 下面这部分总结参考了:[《进程间通信 IPC (InterProcess Communication)》](https://www.jianshu.com/p/c1015f5ffa74) 这篇文章,推荐阅读,总结的非常不错。
-1. **管道/匿名管道(Pipes)**:用于具有亲缘关系的父子进程间或者兄弟进程之间的通信。
+1. **管道/匿名管道(Pipes)** :用于具有亲缘关系的父子进程间或者兄弟进程之间的通信。
2. **有名管道(Named Pipes)** : 匿名管道由于没有名字,只能用于亲缘关系的进程间通信。为了克服这个缺点,提出了有名管道。有名管道严格遵循 **先进先出(First In First Out)** 。有名管道以磁盘文件的方式存在,可以实现本机任意两个进程通信。
-3. **信号(Signal)**:信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生;
-4. **消息队列(Message Queuing)**:消息队列是消息的链表,具有特定的格式,存放在内存中并由消息队列标识符标识。管道和消息队列的通信数据都是先进先出的原则。与管道(无名管道:只存在于内存中的文件;命名管道:存在于实际的磁盘介质或者文件系统)不同的是消息队列存放在内核中,只有在内核重启(即,操作系统重启)或者显式地删除一个消息队列时,该消息队列才会被真正的删除。消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取.比 FIFO 更有优势。**消息队列克服了信号承载信息量少,管道只能承载无格式字 节流以及缓冲区大小受限等缺点。**
-5. **信号量(Semaphores)**:信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。这种通信方式主要用于解决与同步相关的问题并避免竞争条件。
-6. **共享内存(Shared memory)**:使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据的更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。可以说这是最有用的进程间通信方式。
+3. **信号(Signal)** :信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生;
+4. **消息队列(Message Queuing)** :消息队列是消息的链表,具有特定的格式,存放在内存中并由消息队列标识符标识。管道和消息队列的通信数据都是先进先出的原则。与管道(无名管道:只存在于内存中的文件;命名管道:存在于实际的磁盘介质或者文件系统)不同的是消息队列存放在内核中,只有在内核重启(即,操作系统重启)或者显式地删除一个消息队列时,该消息队列才会被真正的删除。消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取.比 FIFO 更有优势。消息队列克服了信号承载信息量少,管道只能承载无格式字 节流以及缓冲区大小受限等缺点。
+5. **信号量(Semaphores)** :信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。这种通信方式主要用于解决与同步相关的问题并避免竞争条件。
+6. **共享内存(Shared memory)** :使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据的更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。可以说这是最有用的进程间通信方式。
7. **套接字(Sockets)** : 此方法主要用于在客户端和服务器之间通过网络进行通信。套接字是支持 TCP/IP 的网络通信的基本操作单元,可以看做是不同主机之间的进程进行双向通信的端点,简单的说就是通信的两方的一种约定,用套接字中的相关函数来完成通信过程。
### 进程的调度算法有哪些?
-这是一个很重要的知识点!为了确定首先执行哪个进程以及最后执行哪个进程以实现最大 CPU 利用率,计算机科学家已经定义了一些算法,它们是:
+进程调度算法的核心目标是决定就绪队列中的哪个进程应该获得 CPU 资源,其设计目标通常是在**吞吐量、周转时间、响应时间**和**公平性**之间做权衡。
-- **先到先服务调度算法(FCFS,First Come, First Served)** : 从就绪队列中选择一个最先进入该队列的进程为之分配资源,使它立即执行并一直执行到完成或发生某事件而被阻塞放弃占用 CPU 时再重新调度。
-- **短作业优先的调度算法(SJF,Shortest Job First)** : 从就绪队列中选出一个估计运行时间最短的进程为之分配资源,使它立即执行并一直执行到完成或发生某事件而被阻塞放弃占用 CPU 时再重新调度。
-- **时间片轮转调度算法(RR,Round-Robin)** : 时间片轮转调度是一种最古老,最简单,最公平且使用最广的算法。每个进程被分配一个时间段,称作它的时间片,即该进程允许运行的时间。
-- **多级反馈队列调度算法(MFQ,Multi-level Feedback Queue)**:前面介绍的几种进程调度的算法都有一定的局限性。如**短进程优先的调度算法,仅照顾了短进程而忽略了长进程** 。多级反馈队列调度算法既能使高优先级的作业得到响应又能使短作业(进程)迅速完成。,因而它是目前**被公认的一种较好的进程调度算法**,UNIX 操作系统采取的便是这种调度算法。
-- **优先级调度算法(Priority)**:为每个流程分配优先级,首先执行具有最高优先级的进程,依此类推。具有相同优先级的进程以 FCFS 方式执行。可以根据内存要求,时间要求或任何其他资源要求来确定优先级。
+我习惯将这些算法分为两大类:**非抢占式**和**抢占式**。
-### 什么是僵尸进程和孤儿进程?
+**第一类:非抢占式调度 (Non-Preemptive)**
-在 Unix/Linux 系统中,子进程通常是通过 fork()系统调用创建的,该调用会创建一个新的进程,该进程是原有进程的一个副本。子进程和父进程的运行是相互独立的,它们各自拥有自己的 PCB,即使父进程结束了,子进程仍然可以继续运行。
+这种方式下,一旦 CPU 分配给一个进程,它就会一直运行下去,直到任务完成或主动放弃(比如等待 I/O)。
-当一个进程调用 exit()系统调用结束自己的生命时,内核会释放该进程的所有资源,包括打开的文件、占用的内存等,但是该进程对应的 PCB 依然存在于系统中。这些信息只有在父进程调用 wait()或 waitpid()系统调用时才会被释放,以便让父进程得到子进程的状态信息。
+1. **先到先服务调度算法(FCFS,First Come, First Served)** : 这是最简单的,就像排队,谁先来谁先用。优点是公平、实现简单。但缺点很明显,如果一个很长的任务先到了,后面无数个短任务都得等着,这会导致平均等待时间很长,我们称之为“护航效应”。
+2. **短作业优先的调度算法(SJF,Shortest Job First)** : 从就绪队列中选出一个估计运行时间最短的进程为之分配资源。理论上,它的平均等待时间是最短的,吞吐量很高。但缺点是,它需要预测运行时间,这很难做到,而且可能会导致长作业“饿死”,永远得不到执行。
-这样的设计可以让父进程在子进程结束时得到子进程的状态信息,并且可以防止出现“僵尸进程”(即子进程结束后 PCB 仍然存在但父进程无法得到状态信息的情况)。
+**第二类:抢占式调度 (Preemptive)**
-- **僵尸进程**:子进程已经终止,但是其父进程仍在运行,且父进程没有调用 wait()或 waitpid()等系统调用来获取子进程的状态信息,释放子进程占用的资源,导致子进程的 PCB 依然存在于系统中,但无法被进一步使用。这种情况下,子进程被称为“僵尸进程”。避免僵尸进程的产生,父进程需要及时调用 wait()或 waitpid()系统调用来回收子进程。
-- **孤儿进程**:一个进程的父进程已经终止或者不存在,但是该进程仍在运行。这种情况下,该进程就是孤儿进程。孤儿进程通常是由于父进程意外终止或未及时调用 wait()或 waitpid()等系统调用来回收子进程导致的。为了避免孤儿进程占用系统资源,操作系统会将孤儿进程的父进程设置为 init 进程(进程号为 1),由 init 进程来回收孤儿进程的资源。
+操作系统可以强制剥夺当前进程的 CPU 使用权,分配给其他更重要的进程。现代操作系统基本都采用这种方式。
-### 如何查看是否有僵尸进程?
+- **时间片轮转调度算法(RR,Round-Robin)** : 这是最经典、最公平的抢占式算法。它给每个进程分配一个固定的时间片,用完了就把它放到队尾,切换到下一个进程。它非常适合分时系统,保证了每个进程都能得到响应,但时间片的设置很关键:太长了退化成 FCFS,太短了则会导致过于频繁的上下文切换,增加系统开销。
+- **优先级调度算法(Priority)**:每个进程都有一个优先级,进程调度器总是选择优先级最高的进程,具有相同优先级的进程以 FCFS 方式执行。这很灵活,可以根据内存要求,时间要求或任何其他资源要求来确定优先级,但同样可能导致低优先级进程“饿死”。
-Linux 下可以使用 Top 命令查找,`zombie` 值表示僵尸进程的数量,为 0 则代表没有僵尸进程。
+前面介绍的几种进程调度的算法都有一定的局限性,如:**短进程优先的调度算法,仅照顾了短进程而忽略了长进程** 。那有没有一种结合了上面这些进程调度算法优点的呢?
-
+**多级反馈队列调度算法(MFQ,Multi-level Feedback Queue)** 是现实世界中最常用的一种算法,比如早期的 UNIX。它非常聪明,结合了 RR 和优先级调度。它设置了多个不同优先级的队列,每个队列使用 RR 调度,时间片大小也不同。新进程先进入最高优先级队列;如果在一个时间片内没执行完,就会被降级到下一个队列。这样既照顾了短作业(在高优先级队列中快速完成),也保证了长作业不会饿死(最终会在低优先级队列中得到执行),是一种非常均衡的方案。
-下面这个命令可以定位僵尸进程以及该僵尸进程的父进程:
+### 那究竟是谁来调度这个进程呢?
-```bash
-ps -A -ostat,ppid,pid,cmd |grep -e '^[Zz]'
-```
+负责进程调度的核心是操作系统内核中的两个紧密协作的组件:**调度程序(Scheduler)** 和 **分派程序(Dispatcher)**。我们可以把它们理解成一个团队:
+
+- **调度程序 (Scheduler):** 可以看作是决策者。当需要进行调度时,调度程序会被激活,它会根据预设的调度算法(比如我们前面聊到的多级反馈队列),从就绪队列中挑选出下一个应该占用 CPU 的进程。
+- **分派程序 (Dispatcher):** 可以看作是执行者。它负责完成具体的“交接”工作,也就是**上下文切换**。这个过程非常底层,主要包括:
+ - 保存当前进程的上下文(CPU 寄存器状态、程序计数器等)到其进程控制块(PCB)中。
+ - 加载下一个被选中进程的上下文,从其 PCB 中读取状态,恢复到 CPU 寄存器。
+ - 将 CPU 的控制权正式移交给新进程,让它开始运行。
## 死锁
@@ -287,23 +294,23 @@ ps -A -ostat,ppid,pid,cmd |grep -e '^[Zz]'
死锁(Deadlock)描述的是这样一种情况:多个进程/线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于进程/线程被无限期地阻塞,因此程序不可能正常终止。
-### 能列举一个操作系统发生死锁的例子吗?
+一个最经典的例子就是**“交叉持锁”**。想象有两个线程和两个锁:
-假设有两个进程 A 和 B,以及两个资源 X 和 Y,它们的分配情况如下:
+- 线程 1 先拿到了锁 A,然后尝试去获取锁 B。
+- 几乎同时,线程 2 拿到了锁 B,然后尝试去获取锁 A。
-| 进程 | 占用资源 | 需求资源 |
-| ---- | -------- | -------- |
-| A | X | Y |
-| B | Y | X |
+这时,线程 1 等着线程 2 释放锁 B,而线程 2 等着线程 1 释放锁 A,双方都持有对方需要的资源,并等待对方释放,就形成了一个“死结”。
-此时,进程 A 占用资源 X 并且请求资源 Y,而进程 B 已经占用了资源 Y 并请求资源 X。两个进程都在等待对方释放资源,无法继续执行,陷入了死锁状态。
+ ### 产生死锁的四个必要条件是什么?
+死锁的发生并不是偶然的,它需要同时满足**四个必要条件**:
+
1. **互斥**:资源必须处于非共享模式,即一次只有一个进程可以使用。如果另一进程申请该资源,那么必须等待直到该资源被释放为止。
2. **占有并等待**:一个进程至少应该占有一个资源,并等待另一资源,而该资源被其他进程所占有。
3. **非抢占**:资源不能被抢占。只能在持有资源的进程完成任务后,该资源才会被释放。
-4. **循环等待**:有一组等待进程 `{P0, P1,..., Pn}`, `P0` 等待的资源被 `P1` 占有,`P1` 等待的资源被 `P2` 占有,......,`Pn-1` 等待的资源被 `Pn` 占有,`Pn` 等待的资源被 `P0` 占有。
+4. **循环等待**:有一组等待进程 {P0, P1,..., Pn}, P0 等待的资源被 P1 占有,P1 等待的资源被 P2 占有,……,Pn-1 等待的资源被 Pn 占有,Pn 等待的资源被 P0 占有。
**注意 ⚠️**:这四个条件是产生死锁的 **必要条件** ,也就是说只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
@@ -315,7 +322,7 @@ ps -A -ostat,ppid,pid,cmd |grep -e '^[Zz]'
下面通过一个实际的例子来模拟下图展示的线程死锁:
-
+
```java
public class DeadLockDemo {
@@ -371,12 +378,9 @@ Thread[线程 2,5,main]waiting get resource1
解决死锁的方法可以从多个角度去分析,一般的情况下,有**预防,避免,检测和解除四种**。
-- **预防** 是采用某种策略,**限制并发进程对资源的请求**,从而使得死锁的必要条件在系统执行的任何时间上都不满足。
-
-- **避免**则是系统在分配资源时,根据资源的使用情况**提前做出预测**,从而**避免死锁的发生**
-
-- **检测**是指系统设有**专门的机构**,当死锁发生时,该机构能够检测死锁的发生,并精确地确定与死锁有关的进程和资源。
-- **解除** 是与检测相配套的一种措施,用于**将进程从死锁状态下解脱出来**。
+- **死锁预防:** 这是我们程序员最常用的方法。通过编码规范来破坏条件。最经典的就是**破坏循环等待**,比如规定所有线程都必须**按相同的顺序**来获取锁(比如先 A 后 B),这样就不会形成环路。
+- **死锁避免:** 这是一种更动态的方法,比如操作系统的**银行家算法**。它会在分配资源前进行预测,如果这次分配可能导致未来发生死锁,就拒绝分配。但这种方法开销很大,在通用系统中用得比较少。
+- **死锁检测与解除:** 这是一种“事后补救”的策略,就像乐观锁。系统允许死锁发生,但会有一个后台线程(或机制)定期检测是否存在死锁环路(比如通过分析线程等待图)。一旦发现,就会采取措施解除,比如**强制剥夺某个线程的资源或直接终止它**。数据库系统中的死锁处理就常常采用这种方式。
#### 死锁的预防
@@ -402,7 +406,7 @@ Thread[线程 2,5,main]waiting get resource1
上面提到的 **破坏** 死锁产生的四个必要条件之一就可以成功 **预防系统发生死锁** ,但是会导致 **低效的进程运行** 和 **资源使用率** 。而死锁的避免相反,它的角度是允许系统中**同时存在四个必要条件** ,只要掌握并发进程中与每个进程有关的资源动态申请情况,做出 **明智和合理的选择** ,仍然可以避免死锁,因为四大条件仅仅是产生死锁的必要条件。
-我们将系统的状态分为 **安全状态** 和 **不安全状态** ,每当在未申请者分配资源前先测试系统状态,若把系统资源分配给申请者会产生死锁,则拒绝分配,否则接受申请,并为它分配资源。
+我们将系统的状态分为 **安全状态** 和 **不安全状态** ,每当在为申请者分配资源前先测试系统状态,若把系统资源分配给申请者会产生死锁,则拒绝分配,否则接受申请,并为它分配资源。
> 如果操作系统能够保证所有的进程在有限的时间内得到需要的全部资源,则称系统处于安全状态,否则说系统是不安全的。很显然,系统处于安全状态则不会发生死锁,系统若处于不安全状态则可能发生死锁。
@@ -424,7 +428,7 @@ Thread[线程 2,5,main]waiting get resource1
操作系统中的每一刻时刻的**系统状态**都可以用**进程-资源分配图**来表示,进程-资源分配图是描述进程和资源申请及分配关系的一种有向图,可用于**检测系统是否处于死锁状态**。
-用一个方框表示每一个资源类,方框中的黑点表示该资源类中的各个资源,每个键进程用一个圆圈表示,用 **有向边** 来表示**进程申请资源和资源被分配的情况**。
+用一个方框表示每一个资源类,方框中的黑点表示该资源类中的各个资源,用一个圆圈表示每一个进程,用 **有向边** 来表示**进程申请资源和资源被分配的情况**。
图中 2-21 是**进程-资源分配图**的一个例子,其中共有三个资源类,每个进程的资源占有和申请情况已清楚地表示在图中。在这个例子中,由于存在 **占有和等待资源的环路** ,导致一组进程永远处于等待资源的状态,发生了 **死锁**。
@@ -454,6 +458,8 @@ Thread[线程 2,5,main]waiting get resource1
- 《计算机操作系统—汤小丹》第四版
- 《深入理解计算机系统》
- 《重学操作系统》
-- 操作系统为什么要分用户态和内核态:https://blog.csdn.net/chen134225/article/details/81783980
-- 从根上理解用户态与内核态:https://juejin.cn/post/6923863670132850701
-- 什么是僵尸进程与孤儿进程:https://blog.csdn.net/a745233700/article/details/120715371
+- 操作系统为什么要分用户态和内核态:
+- 从根上理解用户态与内核态:
+- 什么是僵尸进程与孤儿进程:
+
+
diff --git a/docs/cs-basics/operating-system/operating-system-basic-questions-02.md b/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
index 1c9d4f26822..51ed5fd65c3 100644
--- a/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
+++ b/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
@@ -1,17 +1,17 @@
---
title: 操作系统常见面试题总结(下)
+description: 最新操作系统高频面试题总结(下):虚拟内存映射、内存碎片/伙伴系统、TLB+页缺失处理、分页分段对比、页面置换算法详解、文件系统&磁盘调度,附图表+⭐️重点标注,一文掌握OS内存/文件考点,快速通关后端面试!
category: 计算机基础
tag:
- 操作系统
head:
- - meta
- name: keywords
- content: 操作系统,进程,进程通信方式,死锁,操作系统内存管理,块表,多级页表,虚拟内存,页面置换算法
- - - meta
- - name: description
- content: 很多读者抱怨计算操作系统的知识点比较繁杂,自己也没有多少耐心去看,但是面试的时候又经常会遇到。所以,我带着我整理好的操作系统的常见问题来啦!这篇文章总结了一些我觉得比较重要的操作系统相关的问题比如进程管理、内存管理、虚拟内存等等。
+ content: 操作系统面试题,虚拟内存详解,分页 vs 分段,页面置换算法,内存碎片,伙伴系统,TLB快表,页缺失,文件系统基础,磁盘调度算法,硬链接 vs 软链接
---
+
+
## 内存管理
### 内存管理主要做了什么?
@@ -26,14 +26,14 @@ head:
- **内存映射**:将一个文件直接映射到进程的进程空间中,这样可以通过内存指针用读写内存的办法直接存取文件内容,速度更快。
- **内存优化**:通过调整内存分配策略和回收算法来优化内存使用效率。
- **内存安全**:保证进程之间使用内存互不干扰,避免一些恶意程序通过修改内存来破坏系统的安全性。
-- ......
+- ……
### 什么是内存碎片?
内存碎片是由内存的申请和释放产生的,通常分为下面两种:
- **内部内存碎片(Internal Memory Fragmentation,简称为内存碎片)**:已经分配给进程使用但未被使用的内存。导致内部内存碎片的主要原因是,当采用固定比例比如 2 的幂次方进行内存分配时,进程所分配的内存可能会比其实际所需要的大。举个例子,一个进程只需要 65 字节的内存,但为其分配了 128(2^7) 大小的内存,那 63 字节的内存就成为了内部内存碎片。
-- **外部内存碎片(External Memory Fragmentation,简称为外部碎片)**:由于未分配的连续内存区域太小,以至于不能满足任意进程所需要的内存分配请求,这些小片段且不连续的内存空间被称为外部碎片。也就是说,外部内存碎片指的是那些并为分配给进程但又不能使用的内存。我们后面介绍的分段机制就会导致外部内存碎片。
+- **外部内存碎片(External Memory Fragmentation,简称为外部碎片)**:由于未分配的连续内存区域太小,以至于不能满足任意进程所需要的内存分配请求,这些小片段且不连续的内存空间被称为外部碎片。也就是说,外部内存碎片指的是那些并未分配给进程但又不能使用的内存。我们后面介绍的分段机制就会导致外部内存碎片。
@@ -68,8 +68,8 @@ head:
非连续内存管理存在下面 3 种方式:
-- **段式管理**:以段(—段连续的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。
-- **页式管理**:把物理内存分为连续等长的物理页,应用程序的虚拟地址空间划也被分为连续等长的虚拟页,现代操作系统广泛使用的一种内存管理方式。
+- **段式管理**:以段(一段连续的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。
+- **页式管理**:把物理内存分为连续等长的物理页,应用程序的虚拟地址空间也被划分为连续等长的虚拟页,是现代操作系统广泛使用的一种内存管理方式。
- **段页式管理机制**:结合了段式管理和页式管理的一种内存管理机制,把物理内存先分成若干段,每个段又继续分成若干大小相等的页。
### 虚拟内存
@@ -98,7 +98,7 @@ head:
1. 用户程序可以访问任意物理内存,可能会不小心操作到系统运行必需的内存,进而造成操作系统崩溃,严重影响系统的安全。
2. 同时运行多个程序容易崩溃。比如你想同时运行一个微信和一个 QQ 音乐,微信在运行的时候给内存地址 1xxx 赋值后,QQ 音乐也同样给内存地址 1xxx 赋值,那么 QQ 音乐对内存的赋值就会覆盖微信之前所赋的值,这就可能会造成微信这个程序会崩溃。
3. 程序运行过程中使用的所有数据或指令都要载入物理内存,根据局部性原理,其中很大一部分可能都不会用到,白白占用了宝贵的物理内存资源。
-4. ......
+4. ……
#### 什么是虚拟地址和物理地址?
@@ -131,7 +131,7 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
### 分段机制
-**分段机制(Segmentation)** 以段(—段 **连续** 的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。
+**分段机制(Segmentation)** 以段(一段 **连续** 的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。
#### 段表有什么用?地址翻译过程是怎样的?
@@ -188,7 +188,7 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
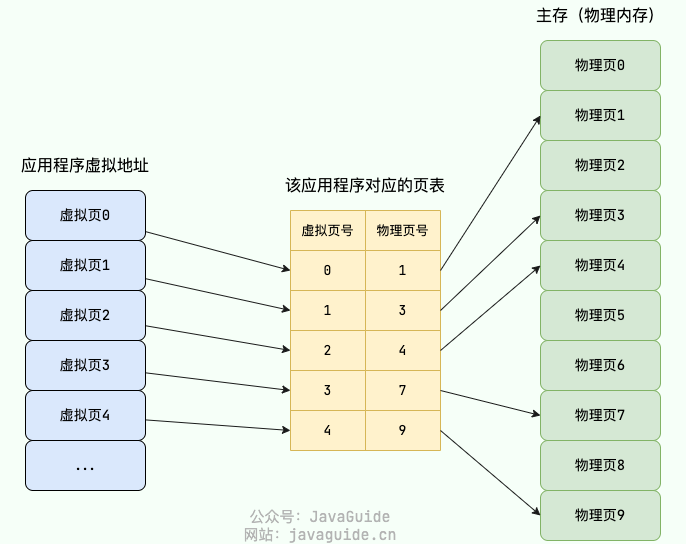
-在分页机制下,每个应用程序都会有一个对应的页表。
+在分页机制下,每个进程都会有一个对应的页表。
分页机制下的虚拟地址由两部分组成:
@@ -203,7 +203,7 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
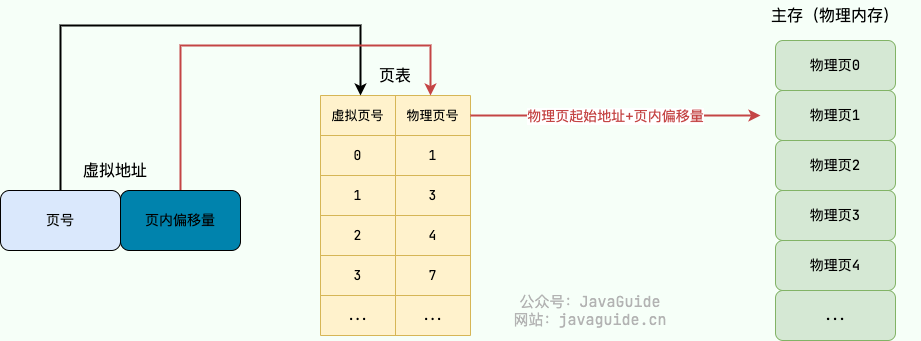
-页表中还存有诸如访问标志(标识该页面有没有被访问过)、页类型(该段的类型,例如代码段、数据段等)等信息。
+页表中还存有诸如访问标志(标识该页面有没有被访问过)、脏数据标识位等信息。
**通过虚拟页号一定要找到对应的物理页号吗?找到了物理页号得到最终的物理地址后对应的物理页一定存在吗?**
@@ -211,11 +211,11 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
#### 单级页表有什么问题?为什么需要多级页表?
-以 32 位的环境为例,虚拟地址空间范围共有 2^32(4G)。假设 一个页的大小是 2^12(4KB),那页表项共有 4G / 4K = 2^20 个。每个页表项为一个地址,占用 4 字节,2^20 * 2^2/1024*1024= 4MB。也就是说一个程序啥都不干,页表大小就得占用 4M。
+以 32 位的环境为例,虚拟地址空间范围共有 2^32(4G)。假设 一个页的大小是 2^12(4KB),那页表项共有 4G / 4K = 2^20 个。每个页表项为一个地址,占用 4 字节,`(2^20 * 2^2) / (1024 * 1024)= 4MB`。也就是说一个程序啥都不干,页表大小就得占用 4M。
系统运行的应用程序多起来的话,页表的开销还是非常大的。而且,绝大部分应用程序可能只能用到页表中的几项,其他的白白浪费了。
-为了解决这个问题,操作系统引入了 **多级页表** ,多级页表对应多个页表,每个页表也前一个页表相关联。32 位系统一般为二级页表,64 位系统一般为四级页表。
+为了解决这个问题,操作系统引入了 **多级页表** ,多级页表对应多个页表,每个页表与前一个页表相关联。32 位系统一般为二级页表,64 位系统一般为四级页表。
这里以二级页表为例进行介绍:二级列表分为一级页表和二级页表。一级页表共有 1024 个页表项,一级页表又关联二级页表,二级页表同样共有 1024 个页表项。二级页表中的一级页表项是一对多的关系,二级页表按需加载(只会用到很少一部分二级页表),进而节省空间占用。
@@ -227,7 +227,7 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
#### TLB 有什么用?使用 TLB 之后的地址翻译流程是怎样的?
-为了提高虚拟地址到物理地址的转换速度,操作系统在 **页表方案** 基础之上引入了 **转址旁路缓存(Translation Lookasjde Buffer,TLB,也被称为快表)** 。
+为了提高虚拟地址到物理地址的转换速度,操作系统在 **页表方案** 基础之上引入了 **转址旁路缓存(Translation Lookaside Buffer,TLB,也被称为快表)** 。

@@ -282,7 +282,7 @@ TLB 的设计思想非常简单,但命中率往往非常高,效果很好。
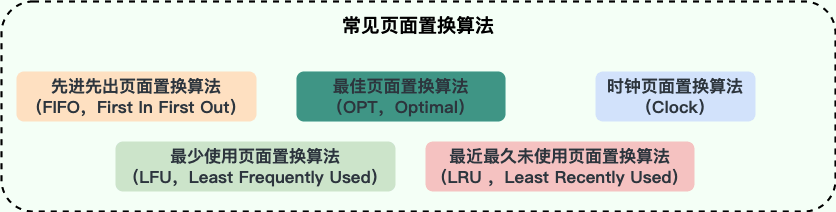
1. **最佳页面置换算法(OPT,Optimal)**:优先选择淘汰的页面是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若干页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现,只是理论最优的页面置换算法,可以作为衡量其他置换算法优劣的标准。
-2. **先进先出页面置换算法(FIFO,First In First Out)** : 最简单的一种页面置换算法,总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。该算法易于实现和理解,一般只需要通过一个 FIFO 队列即可需求。不过,它的性能并不是很好。
+2. **先进先出页面置换算法(FIFO,First In First Out)** : 最简单的一种页面置换算法,总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。该算法易于实现和理解,一般只需要通过一个 FIFO 队列即可满足需求。不过,它的性能并不是很好。
3. **最近最久未使用页面置换算法(LRU ,Least Recently Used)**:LRU 算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。LRU 算法是根据各页之前的访问情况来实现,因此是易于实现的。OPT 算法是根据各页未来的访问情况来实现,因此是不可实现的。
4. **最少使用页面置换算法(LFU,Least Frequently Used)** : 和 LRU 算法比较像,不过该置换算法选择的是之前一段时间内使用最少的页面作为淘汰页。
5. **时钟页面置换算法(Clock)**:可以认为是一种最近未使用算法,即逐出的页面都是最近没有使用的那个。
@@ -317,12 +317,16 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
### 段页机制
-结合了段式管理和页式管理的一种内存管理机制,把物理内存先分成若干段,每个段又继续分成若干大小相等的页。
+结合了段式管理和页式管理的一种内存管理机制。程序视角中,内存被划分为多个逻辑段,每个逻辑段进一步被划分为固定大小的页。
在段页式机制下,地址翻译的过程分为两个步骤:
-1. 段式地址映射。
-2. 页式地址映射。
+1. **段式地址映射(虚拟地址 → 线性地址):**
+ - 虚拟地址 = 段选择符(段号)+ 段内偏移。
+ - 根据段号查段表,找到段基址,加上段内偏移得到线性地址。
+2. **页式地址映射(线性地址 → 物理地址):**
+ - 线性地址 = 页号 + 页内偏移。
+ - 根据页号查页表,找到物理页框号,加上页内偏移得到物理地址。
### 局部性原理
@@ -362,7 +366,7 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
**2、软链接(Symbolic Link 或 Symlink)**
- 软链接和源文件的 inode 节点号不同,而是指向一个文件路径。
-- 源文件删除后,硬链接依然存在,但是指向的是一个无效的文件路径。
+- 源文件删除后,软链接依然存在,但是指向的是一个无效的文件路径。
- 软连接类似于 Windows 系统中的快捷方式。
- 不同于硬链接,可以对目录或者不存在的文件创建软链接,并且,软链接可以跨越文件系统。
- `ln -s` 命令用于创建软链接。
@@ -375,7 +379,7 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
### 提高文件系统性能的方式有哪些?
-- **优化硬件**:使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Inexpensive Disks)等技术提高磁盘性能。
+- **优化硬件**:使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Independent Disks)等技术提高磁盘性能。
- **选择合适的文件系统选型**:不同的文件系统具有不同的特性,对于不同的应用场景选择合适的文件系统可以提高系统性能。
- **运用缓存**:访问磁盘的效率比较低,可以运用缓存来减少磁盘的访问次数。不过,需要注意缓存命中率,缓存命中率过低的话,效果太差。
- **避免磁盘过度使用**:注意磁盘的使用率,避免将磁盘用满,尽量留一些剩余空间,以免对文件系统的性能产生负面影响。
@@ -404,8 +408,10 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
- 《深入理解计算机系统》
- 《重学操作系统》
- 《现代操作系统原理与实现》
-- 王道考研操作系统知识点整理:https://wizardforcel.gitbooks.io/wangdaokaoyan-os/content/13.html
-- 内存管理之伙伴系统与 SLAB:https://blog.csdn.net/qq_44272681/article/details/124199068
-- 为什么 Linux 需要虚拟内存:https://draveness.me/whys-the-design-os-virtual-memory/
-- 程序员的自我修养(七):内存缺页错误:https://liam.page/2017/09/01/page-fault/
-- 虚拟内存的那点事儿:https://juejin.cn/post/6844903507594575886
+- 王道考研操作系统知识点整理:
+- 内存管理之伙伴系统与 SLAB:
+- 为什么 Linux 需要虚拟内存:
+- 程序员的自我修养(七):内存缺页错误:
+- 虚拟内存的那点事儿:
+
+
diff --git a/docs/cs-basics/operating-system/shell-intro.md b/docs/cs-basics/operating-system/shell-intro.md
index a9f666fb7d5..7554aa2760d 100644
--- a/docs/cs-basics/operating-system/shell-intro.md
+++ b/docs/cs-basics/operating-system/shell-intro.md
@@ -1,19 +1,36 @@
---
title: Shell 编程基础知识总结
+description: Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。这篇文章我会简单总结一下 Shell 编程基础知识,带你入门 Shell 编程!
category: 计算机基础
tag:
- 操作系统
- Linux
head:
- - meta
- - name: description
- content: Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。这篇文章我会简单总结一下 Shell 编程基础知识,带你入门 Shell 编程!
+ - name: keywords
+ content: Shell,脚本,命令,自动化,运维,Linux,基础语法
---
Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。
这篇文章我会简单总结一下 Shell 编程基础知识,带你入门 Shell 编程!
+## 版本说明
+
+**本文示例适用于 bash 4.0+ 版本**。不同版本的 bash 在某些特性上可能有差异,特别是:
+
+- **数组** :bash 2.0+ 支持,纯 POSIX sh(如 dash)不支持
+- **某些字符串操作** :如 `${var:offset:length}` 在较旧版本可能不支持
+- **算术扩展 `$((...))`** :bash 2.0+ 支持
+
+检查你的 bash 版本:
+
+```shell
+bash --version
+# 或
+echo $BASH_VERSION
+```
+
## 走进 Shell 编程的大门
### 为什么要学 Shell?
@@ -28,14 +45,21 @@ Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统
另外,了解 shell 编程也是大部分互联网公司招聘后端开发人员的要求。下图是我截取的一些知名互联网公司对于 Shell 编程的要求。
-
+
### 什么是 Shell?
-简单来说“Shell 编程就是对一堆 Linux 命令的逻辑化处理”。
+**Shell 是 Linux/Unix 系统的命令解释器**,它充当用户和操作系统内核之间的桥梁,负责接收用户输入的命令并调用相应的程序。
+
+**Shell 编程**是通过 Shell 解释器(如 bash)将命令、控制结构(if/for/while)、变量和函数组合成自动化脚本的过程。Shell 既是命令解释器,也是一门完整的编程语言(支持变量、数组、函数、流程控制、管道、重定向等)。
-W3Cschool 上的一篇文章是这样介绍 Shell 的,如下图所示。
-
+**常见的 Shell 类型**:
+
+- **bash**(Bourne Again Shell):Linux 系统默认 Shell,最常用
+- **sh**(Bourne Shell):Unix 传统 Shell,POSIX 标准
+- **zsh**:功能强大的交互式 Shell
+- **dash**:轻量级 Shell,Ubuntu 的 /bin/sh 默认指向它
+- **csh/tcsh**:C 风格的 Shell
### Shell 编程的 Hello World
@@ -51,15 +75,16 @@ helloworld.sh 内容如下:
```shell
#!/bin/bash
-#第一个shell小程序,echo 是linux中的输出命令。
-echo "helloworld!"
+set -euo pipefail # 严格模式:遇错退出、未定义变量报错、管道失败报错
+# 第一个 shell 小程序,echo 是 Linux 中的输出命令
+echo "helloworld!"
```
shell 中 # 符号表示注释。**shell 的第一行比较特殊,一般都会以#!开始来指定使用的 shell 类型。在 linux 中,除了 bash shell 以外,还有很多版本的 shell, 例如 zsh、dash 等等...不过 bash shell 还是我们使用最多的。**
(4) 运行脚本:`./helloworld.sh` 。(注意,一定要写成 `./helloworld.sh` ,而不是 `helloworld.sh` ,运行其它二进制的程序也一样,直接写 `helloworld.sh` ,linux 系统会去 PATH 里寻找有没有叫 helloworld.sh 的,而只有 /bin, /sbin, /usr/bin,/usr/sbin 等在 PATH 里,你的当前目录通常不在 PATH 里,所以写成 `helloworld.sh` 是会找不到命令的,要用`./helloworld.sh` 告诉系统说,就在当前目录找。)
-
+
## Shell 变量
@@ -67,20 +92,20 @@ shell 中 # 符号表示注释。**shell 的第一行比较特殊,一般都会
**Shell 编程中一般分为三种变量:**
-1. **我们自己定义的变量(自定义变量):** 仅在当前 Shell 实例中有效,其他 Shell 启动的程序不能访问局部变量。
-2. **Linux 已定义的环境变量**(环境变量, 例如:`PATH`, `HOME` 等..., 这类变量我们可以直接使用),使用 `env` 命令可以查看所有的环境变量,而 set 命令既可以查看环境变量也可以查看自定义变量。
-3. **Shell 变量**:Shell 变量是由 Shell 程序设置的特殊变量。Shell 变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了 Shell 的正常运行
+1. **自定义变量(局部变量)**:默认仅在当前 Shell 进程内有效,**子进程无法访问**。若需传递给子进程,需使用 `export` 声明为环境变量。
+2. **环境变量**:例如 `PATH`, `HOME` 等,可被子进程继承。使用 `env` 命令可以查看所有环境变量,`set` 命令可以查看所有变量(包括环境变量和局部变量)。
+3. **Shell 特殊变量**:由 Shell 设置的特殊变量(如 `$?`, `$$`, `$!` 等),用于保存进程状态、参数等信息。
**常用的环境变量:**
-> PATH 决定了 shell 将到哪些目录中寻找命令或程序
-> HOME 当前用户主目录
-> HISTSIZE 历史记录数
-> LOGNAME 当前用户的登录名
-> HOSTNAME 指主机的名称
-> SHELL 当前用户 Shell 类型
-> LANGUAGE 语言相关的环境变量,多语言可以修改此环境变量
-> MAIL 当前用户的邮件存放目录
+> PATH 决定了 shell 将到哪些目录中寻找命令或程序
+> HOME 当前用户主目录
+> HISTSIZE 历史记录数
+> LOGNAME 当前用户的登录名
+> HOSTNAME 指主机的名称
+> SHELL 当前用户 Shell 类型
+> LANGUAGE 语言相关的环境变量,多语言可以修改此环境变量
+> MAIL 当前用户的邮件存放目录
> PS1 基本提示符,对于 root 用户是#,对于普通用户是\$
**使用 Linux 已定义的环境变量:**
@@ -97,7 +122,7 @@ echo $hello
echo "helloworld!"
```
-
+
**Shell 编程中的变量名的命名的注意事项:**
@@ -110,21 +135,31 @@ echo "helloworld!"
字符串是 shell 编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号。这点和 Java 中有所不同。
-在单引号中所有的特殊符号,如$和反引号都没有特殊含义。在双引号中,除了"$","\"和反引号,其他的字符没有特殊含义。
+在单引号中,所有特殊字符(如 `$`、反引号、`\` 等)都失去特殊含义,被视为字面量。
+
+在双引号中,以下字符保留特殊含义:
+
+- `$`:变量扩展(如 `$var`)和命令替换(如 `$(cmd)` 或 `` `cmd` ``)
+- `\`:转义字符
+- `` ` `` 或 `$()`:命令替换(推荐使用 `$()` 语法)
+- `!`:历史扩展(仅在交互式 Shell 中默认开启)
+- `${}`:参数扩展
+
+**注意**:单引号中的字符串是**完全字面量**,双引号中的字符串会进行变量和命令替换。
**单引号字符串:**
```shell
#!/bin/bash
name='SnailClimb'
-hello='Hello, I am '$name'!'
+hello='Hello, I am $name!'
echo $hello
```
输出内容:
-```
-Hello, I am '$name'!
+```plain
+Hello, I am $name!
```
**双引号字符串:**
@@ -132,13 +167,13 @@ Hello, I am '$name'!
```shell
#!/bin/bash
name='SnailClimb'
-hello="Hello, I am "$name"!"
+hello="Hello, I am $name!"
echo $hello
```
输出内容:
-```
+```plain
Hello, I am SnailClimb!
```
@@ -161,39 +196,48 @@ echo $greeting_2 $greeting_3
输出结果:
-
+
**获取字符串长度:**
```shell
#!/bin/bash
-#获取字符串长度
+# 获取字符串长度
name="SnailClimb"
-# 第一种方式
-echo ${#name} #输出 10
-# 第二种方式
-expr length "$name";
+# 第一种方式(推荐):bash 内置
+echo ${#name} # 输出 10
+# 第二种方式:外部命令(性能较差)
+expr length "$name"
```
-输出结果:
+输出结果:
-```
+```plain
10
10
```
-使用 expr 命令时,表达式中的运算符左右必须包含空格,如果不包含空格,将会输出表达式本身:
+**说明**:
+
+- 推荐使用 `${#var}` 语法,这是 bash 内置功能,性能更好
+- `expr` 是外部命令,需要 fork 进程,性能较差
+- **`expr length` 是 GNU 扩展**,非 POSIX 标准。在 macOS 的 BSD expr 或其他系统上可能不支持
+- 如需可移植性,推荐使用 `${#var}` 或 `expr "$var" : '.*'`(POSIX 兼容)
+
+使用 expr 命令时,表达式中的运算符左右必须包含空格:
```shell
-expr 5+6 // 直接输出 5+6
-expr 5 + 6 // 输出 11
+expr 5+6 # 直接输出 5+6(无空格)
+expr 5 + 6 # 输出 11(有空格)
+# 更推荐使用 bash 算术扩展:
+echo $((5 + 6)) # 输出 11
```
-对于某些运算符,还需要我们使用符号`\`进行转义,否则就会提示语法错误。
+对于某些运算符,还需要我们使用符号 `\` 进行转义:
```shell
-expr 5 * 6 // 输出错误
-expr 5 \* 6 // 输出30
+expr 5 * 6 # 输出错误(未转义)
+expr 5 \* 6 # 输出 30(正确转义)
```
**截取子字符串:**
@@ -201,7 +245,7 @@ expr 5 \* 6 // 输出30
简单的字符串截取:
```shell
-#从字符串第 1 个字符开始往后截取 10 个字符
+#从字符串第 0 个字符开始往后截取 10 个字符(索引从 0 开始)
str="SnailClimb is a great man"
echo ${str:0:10} #输出:SnailClimb
```
@@ -209,8 +253,8 @@ echo ${str:0:10} #输出:SnailClimb
根据表达式截取:
```shell
-#!bin/bash
-#author:amau
+#!/bin/bash
+# author: amau
var="https://www.runoob.com/linux/linux-shell-variable.html"
# %表示删除从后匹配, 最短结果
@@ -220,14 +264,18 @@ var="https://www.runoob.com/linux/linux-shell-variable.html"
# 注: *为通配符, 意为匹配任意数量的任意字符
s1=${var%%t*} #h
s2=${var%t*} #https://www.runoob.com/linux/linux-shell-variable.h
-s3=${var%%.*} #http://www
+s3=${var%%.*} #https://www
s4=${var#*/} #/www.runoob.com/linux/linux-shell-variable.html
s5=${var##*/} #linux-shell-variable.html
```
### Shell 数组
-bash 支持一维数组(不支持多维数组),并且没有限定数组的大小。我下面给了大家一个关于数组操作的 Shell 代码示例,通过该示例大家可以知道如何创建数组、获取数组长度、获取/删除特定位置的数组元素、删除整个数组以及遍历数组。
+**bash 2.0+** 支持一维数组(不支持多维数组),并且没有限定数组的大小。
+
+**重要提示**:数组是 bash 的**非 POSIX 扩展特性**,纯 POSIX sh(如 dash)不支持数组。若需编写可移植脚本,应避免使用数组。
+
+下面是一个关于数组操作的 Shell 代码示例,通过该示例大家可以知道如何创建数组、获取数组长度、获取/删除特定位置的数组元素、删除整个数组以及遍历数组。
```shell
#!/bin/bash
@@ -247,9 +295,35 @@ unset array; # 删除数组中的所有元素
for i in ${array[@]};do echo $i ;done # 遍历数组,数组元素为空,没有任何输出内容
```
-## Shell 基本运算符
+**重要说明:数组索引空洞**:
+
+使用 `unset array[1]` 删除元素后,数组会产生**索引空洞**:
+
+```shell
+#!/bin/bash
+array=(1 2 3 4 5)
+echo "删除前: ${array[@]}" # 输出: 1 2 3 4 5
+echo "索引1的值: ${array[1]}" # 输出: 2
+
+unset array[1] # 删除索引1的元素
+echo "删除后: ${array[@]}" # 输出: 1 3 4 5
+echo "索引1的值: ${array[1]}" # 输出: (空值)
+echo "索引2的值: ${array[2]}" # 输出: 3 (索引2仍在)
+
+# 遍历时索引不连续
+for index in "${!array[@]}"; do
+ echo "索引[$index] = ${array[$index]}"
+done
+# 输出:
+# 索引[0] = 1
+# 索引[2] = 3
+# 索引[3] = 4
+# 索引[4] = 5
+```
+
+**注意**:删除元素后,如果使用 `${array[1]}` 访问会得到空值。遍历数组时建议使用 `"${!array[@]}"` 获取有效索引,或使用 `"${array[@]}"` 直接遍历值。
-> 说明:图片来自《菜鸟教程》
+## Shell 基本运算符
Shell 编程支持下面几种运算符
@@ -261,23 +335,51 @@ Shell 编程支持下面几种运算符
### 算数运算符
-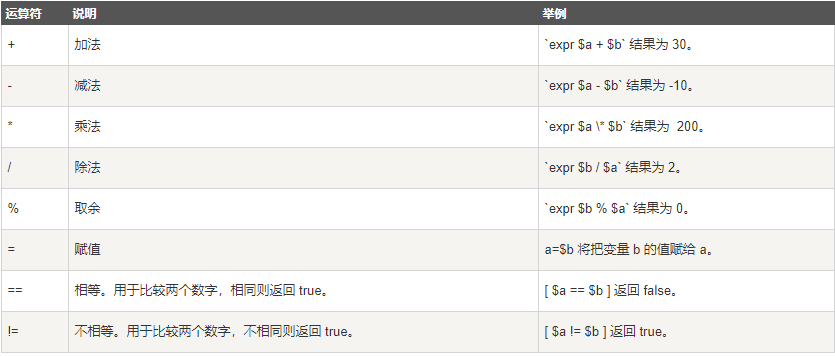
+| **运算符** | **说明** | **举例** |
+| ---------- | -------- | ------------------------------------------ |
+| **+** | 加法 | `expr $a + $b` |
+| **-** | 减法 | `expr $a - $b` |
+| **\*** | 乘法 | `expr $a \* $b` (注意星号需要转义) |
+| **/** | 除法 | `expr $b / $a` |
+| **%** | 取余 | `expr $b % $a` |
+| **=** | 赋值 | `a=$b` 将变量 b 的值赋给 a |
+| **==** | 相等 | `[ $a == $b ]` 用于数字比较,相同返回 true |
+| **!=** | 不相等 | `[ $a != $b ]` 用于数字比较,不同返回 true |
-我以加法运算符做一个简单的示例(注意:不是单引号,是反引号):
+**推荐使用 bash 内置算术扩展**:
```shell
#!/bin/bash
-a=3;b=3;
-val=`expr $a + $b`
-#输出:Total value : 6
-echo "Total value : $val"
+a=3; b=3
+val=$((a + b)) # bash 算术扩展(推荐)
+# 输出:Total value: 6
+echo "Total value: $val"
+```
+
+**说明**:
+
+- `$((...))` 是 bash 内置功能,无需 fork 外部进程,性能更好
+- **不推荐**使用 `expr` 命令(需 fork 进程,且运算符两边必须有空格)
+- **不推荐**使用反引号 `` `...` ``(已过时),应使用 `$(...)` 语法
+
+**如果需要兼容 POSIX sh**,可以使用:
+
+```shell
+val=$(expr "$a" + "$b") # POSIX 兼容,但性能较差
```
### 关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
-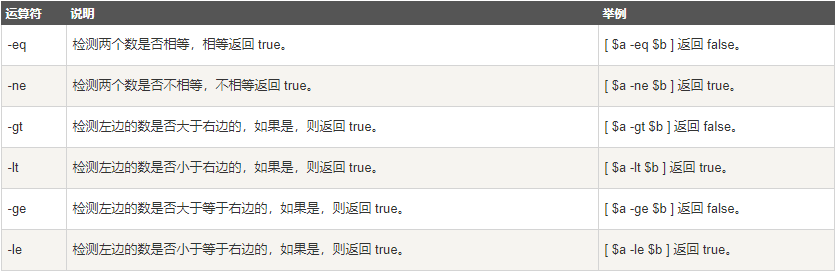
+| **运算符** | **说明** | **对应英文** |
+| ---------- | ---------------------------------- | ------------- |
+| **-eq** | 检测两个数是否**相等** | equal |
+| **-ne** | 检测两个数是否**不相等** | not equal |
+| **-gt** | 检测左边的数是否**大于**右边的 | greater than |
+| **-lt** | 检测左边的数是否**小于**右边的 | less than |
+| **-ge** | 检测左边的数是否**大于等于**右边的 | greater equal |
+| **-le** | 检测左边的数是否**小于等于**右边的 | less equal |
通过一个简单的示例演示关系运算符的使用,下面 shell 程序的作用是当 score=100 的时候输出 A 否则输出 B。
@@ -285,7 +387,7 @@ echo "Total value : $val"
#!/bin/bash
score=90;
maxscore=100;
-if [ $score -eq $maxscore ]
+if [[ $score -eq $maxscore ]]
then
echo "A"
else
@@ -295,15 +397,18 @@ fi
输出结果:
-```
+```plain
B
```
### 逻辑运算符
-
+| **运算符** | **说明** | **举例** |
+| ---------- | -------------- | --------------------------------------------- | --- | --------------------------- |
+| **&&** | 逻辑的 **AND** | `[[ $a -lt 100 && $b -gt 100 ]]` (全真才为真) |
+| **\|\|** | 逻辑的 **OR** | `[[ $a -lt 100 | | $b -gt 100 ]]` (一真即为真) |
-示例:
+**算术扩展中的逻辑运算**:
```shell
#!/bin/bash
@@ -312,15 +417,71 @@ a=$(( 1 && 0))
echo $a;
```
-### 布尔运算符
+**命令短路执行(生产环境常用)**:
+
+在运维自动化和 CI/CD 管道中,经常使用 `&&` 和 `||` 来控制命令链路的执行流程,这称为**短路执行**:
+
+```shell
+#!/bin/bash
+set -euo pipefail
+
+# &&:前一个命令成功(返回 0)时才执行后一个命令
+mkdir -p "/tmp/app_data" && echo "目录就绪"
+
+# ||:前一个命令失败(返回非 0)时才执行后一个命令
+mkdir -p "/tmp/app_data" || echo "目录创建失败"
+
+# 组合使用:生产环境典型的防御姿势
+mkdir -p "/tmp/app_data" && echo "目录就绪" || exit 1
+
+# 实际场景示例
+# 1. 检查文件存在后再删除
+[ -f "/tmp/old_file.log" ] && rm "/tmp/old_file.log"
+
+# 2. 命令失败时输出错误信息并退出
+cd /app/config || { echo "无法进入配置目录"; exit 1; }
+
+# 3. 条件执行命令
+command1 && command2 || command3
+# ⚠️ 注意:此写法有陷阱!
+# - 当 command1 成功时,执行 command2
+# - 当 command1 失败时,执行 command3
+# - 但如果 command1 成功但 command2 失败,command3 仍会执行!
+#
+# ✅ 更安全的写法(推荐):
+if command1; then
+ command2
+else
+ command3
+fi
+#
+# 或明确知道 command2 不会失败时才使用 && || 组合
+```
-
+**重要提示**:
-这里就不做演示了,应该挺简单的。
+- 短路执行依赖命令的**退出码(Exit Code)**:成功返回 0,失败返回非 0
+- 这与 `[[ ]]` 内部的 `&&` 和 `||` 不同,后者用于条件测试
+- `command1 && command2 || command3` 存在陷阱:若 command1 成功但 command2 失败,command3 仍会执行
+- 生产环境中强烈建议使用 if-then-else 结构,确保逻辑清晰
+
+### 布尔运算符
+
+| **运算符** | **说明** | **举例** |
+| ---------- | -------------------------------------------------------------------- | ------------------------------------------ |
+| **!** | 将表达式的结果取反。如果表达式为 true,则返回 false;否则返回 true。 | `[ ! false ]` 返回 true。 |
+| **-o** | 有一个表达式为 true,则返回 true。 | `[ $a -lt 20 -o $b -gt 100 ]` 返回 true。 |
+| **-a** | 两个表达式都为 true 才会返回 true。 | `[ $a -lt 20 -a $b -gt 100 ]` 返回 false。 |
### 字符串运算符
-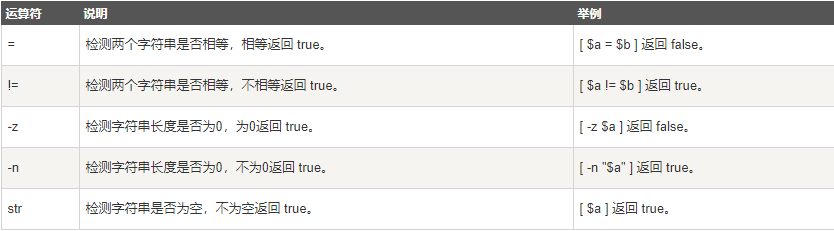
+| **运算符** | **说明** | **举例** |
+| ---------- | --------------------------------- | ----------------------------- |
+| **=** | 检测两个字符串是否**相等** | `[ $a = $b ]` |
+| **!=** | 检测两个字符串是否**不相等** | `[ $a != $b ]` |
+| **-z** | 检测字符串长度是否为 **0** (zero) | `[ -z $a ]` 为空返回 true |
+| **-n** | 检测字符串长度是否**不为 0** | `[ -n "$a" ]` 不为空返回 true |
+| **str** | 直接检测字符串是否为空 | `[ $a ]` 不为空返回 true |
简单示例:
@@ -328,7 +489,7 @@ echo $a;
#!/bin/bash
a="abc";
b="efg";
-if [ $a = $b ]
+if [[ $a = $b ]]
then
echo "a 等于 b"
else
@@ -338,17 +499,30 @@ fi
输出:
-```
+```plain
a 不等于 b
```
### 文件相关运算符
-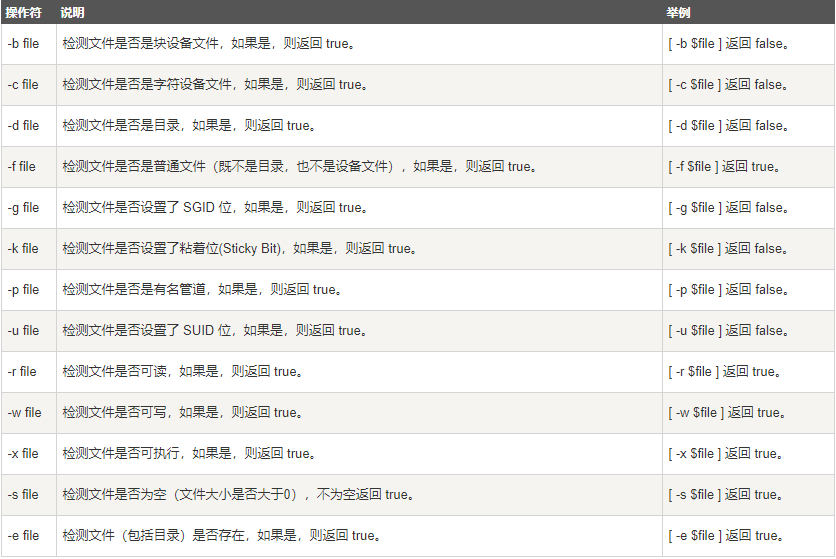
+用于检测 Unix/Linux 文件的各种属性(如权限、类型等)。
+
+- **存在与类型检测:**
+ - **-e file**: 检测文件(包括目录)是否存在。
+ - **-f file**: 检测是否为普通文件(既不是目录也不是设备文件)。
+ - **-d file**: 检测是否为目录。
+ - **-s file**: 检测文件是否为空(文件大小大于 0 返回 true)。
+ - **-b/-c/-p**: 分别检测是否为块设备、字符设备、有名管道。
+- **权限检测:**
+ - **-r file**: 检测文件是否可读。
+ - **-w file**: 检测文件是否可写。
+ - **-x file**: 检测文件是否可执行。
+- **特殊标识检测:**
+ - **-u / -g / -k**: 分别检测文件是否设置了 SUID、SGID 或粘着位 (Sticky Bit)。
使用方式很简单,比如我们定义好了一个文件路径`file="/usr/learnshell/test.sh"` 如果我们想判断这个文件是否可读,可以这样`if [ -r $file ]` 如果想判断这个文件是否可写,可以这样`-w $file`,是不是很简单。
-## shell 流程控制
+## Shell 流程控制
### if 条件语句
@@ -358,10 +532,10 @@ a 不等于 b
#!/bin/bash
a=3;
b=9;
-if [ $a -eq $b ]
+if [[ $a -eq $b ]]
then
echo "a 等于 b"
-elif [ $a -gt $b ]
+elif [[ $a -gt $b ]]
then
echo "a 大于 b"
else
@@ -371,11 +545,26 @@ fi
输出结果:
-```
+```plain
a 小于 b
```
-相信大家通过上面的示例就已经掌握了 shell 编程中的 if 条件语句。不过,还要提到的一点是,不同于我们常见的 Java 以及 PHP 中的 if 条件语句,shell if 条件语句中不能包含空语句也就是什么都不做的语句。
+相信大家通过上面的示例就已经掌握了 shell 编程中的 if 条件语句。
+
+**空语句的处理**:Shell 中空语句可以使用 `:`(冒号命令)或 `true` 命令实现:
+
+```shell
+if [[ condition ]]; then
+ : # 空语句(什么都不做)
+fi
+
+# 或
+if [[ condition ]]; then
+ true # 空语句
+fi
+```
+
+这在某些场景下很有用,例如在 while 循环中作为占位符。
### for 循环语句
@@ -406,7 +595,8 @@ done
```shell
#!/bin/bash
-for((i=1;i<=5;i++));do
+length=5
+for((i=1;i<=length;i++));do
echo $i;
done;
```
@@ -418,10 +608,10 @@ done;
```shell
#!/bin/bash
int=1
-while(( $int<=5 ))
+while (( int <= 5 )) # 算术上下文内变量无需 $
do
echo $int
- let "int++"
+ (( int++ )) # 推荐使用 (( )) 替代 let
done
```
@@ -430,7 +620,7 @@ done
```shell
echo '按下 退出'
echo -n '输入你最喜欢的电影: '
-while read FILM
+while read -r FILM # -r 选项禁止反斜杠转义,提高安全性
do
echo "是的!$FILM 是一个好电影"
done
@@ -438,7 +628,7 @@ done
输出内容:
-```
+```plain
按下 退出
输入你最喜欢的电影: 变形金刚
是的!变形金刚 是一个好电影
@@ -453,7 +643,7 @@ do
done
```
-## shell 函数
+## Shell 函数
### 不带参数没有返回值的函数
@@ -469,7 +659,7 @@ echo "-----函数执行完毕-----"
输出结果:
-```
+```plain
-----函数开始执行-----
这是我的第一个 shell 函数!
-----函数执行完毕-----
@@ -481,21 +671,37 @@ echo "-----函数执行完毕-----"
```shell
#!/bin/bash
+set -euo pipefail
+
funWithReturn(){
+ local aNum
+ local anotherNum
echo "输入第一个数字: "
- read aNum
+ read -r aNum
echo "输入第二个数字: "
- read anotherNum
+ read -r anotherNum
echo "两个数字分别为 $aNum 和 $anotherNum !"
- return $(($aNum+$anotherNum))
+ return $((aNum + anotherNum))
}
funWithReturn
echo "输入的两个数字之和为 $?"
```
+**重要说明**:
+
+- **`local` 关键字**:将变量限制在函数作用域内,避免污染全局命名空间
+- **`read -r`**:`-r` 选项禁止反斜杠转义,提高安全性
+- **函数返回值**:Shell 函数只能返回 0-255 的退出码,如需返回复杂数据应使用 `echo` 或全局变量
+
+**为什么使用 local?**
+
+- 在复杂脚本或引入多个外部脚本时,非 local 变量可能被意外覆盖
+- 全局变量污染会导致难以排查的配置漂移或逻辑越权
+- 使用 `local` 是函数编程的最佳实践,类似于其他编程语言的局部变量概念
+
输出结果:
-```
+```plain
输入第一个数字:
1
输入第二个数字:
@@ -509,25 +715,694 @@ echo "输入的两个数字之和为 $?"
```shell
#!/bin/bash
funWithParam(){
- echo "第一个参数为 $1 !"
- echo "第二个参数为 $2 !"
- echo "第十个参数为 $10 !"
- echo "第十个参数为 ${10} !"
- echo "第十一个参数为 ${11} !"
- echo "参数总数有 $# 个!"
- echo "作为一个字符串输出所有参数 $* !"
+ echo "第一个参数为 $1"
+ echo "第二个参数为 $2"
+ echo "脚本名称为 $0"
+ echo "第十个参数为 ${10}" # 注意:参数 ≥ 10 时必须用 ${n}
+ echo "第十一个参数为 ${11}"
+ echo "参数总数有 $# 个"
+ echo "所有参数为 $*" # 作为单个字符串输出
+ echo "所有参数为 $@" # 作为独立的参数输出(推荐)
}
funWithParam 1 2 3 4 5 6 7 8 9 34 73
```
输出结果:
+```plain
+第一个参数为 1
+第二个参数为 2
+脚本名称为 ./script.sh
+第十个参数为 34
+第十一个参数为 73
+参数总数有 11 个
+所有参数为 1 2 3 4 5 6 7 8 9 34 73
+所有参数为 1 2 3 4 5 6 7 8 9 34 73
```
-第一个参数为 1 !
-第二个参数为 2 !
-第十个参数为 10 !
-第十个参数为 34 !
-第十一个参数为 73 !
-参数总数有 11 个!
-作为一个字符串输出所有参数 1 2 3 4 5 6 7 8 9 34 73 !
+
+**重要提示**:
+
+- **位置参数 `$n` 当 `n ≥ 10` 时必须使用 `${n}` 语法**
+- 例如:`$10` 会被解析为 `$1` 和字面量 `0` 的拼接,而非第十个参数
+- `$0` 表示脚本本身的名称
+- `$#` 表示参数总数
+
+**`$*` 与 `$@` 的核心区别**:
+
+| 表达式 | 未引用 | 双引号包裹 |
+| ------ | -------------- | ---------------------------------------- |
+| `$*` | 展开为所有参数 | 展开为**单个字符串**(所有参数合并) |
+| `$@` | 展开为所有参数 | 展开为**独立的参数**(每个参数保持独立) |
+
+**示例对比**:
+
+```shell
+#!/bin/bash
+test_args() {
+ echo "--- 使用 \$* (无引号)---"
+ for arg in $*; do
+ echo "参数: [$arg]"
+ done
+
+ echo -e "\n--- 使用 \$@ (无引号)---"
+ for arg in $@; do
+ echo "参数: [$arg]"
+ done
+
+ echo -e "\n--- 使用 \"\$*\" (双引号)---"
+ for arg in "$*"; do
+ echo "参数: [$arg]"
+ done
+
+ echo -e "\n--- 使用 \"\$@\" (双引号,推荐)---"
+ for arg in "$@"; do
+ echo "参数: [$arg]"
+ done
+}
+
+# 调用函数,传递包含空格的参数
+test_args "hello world" "foo bar"
+```
+
+**输出结果**:
+
+```plain
+--- 使用 $* (无引号)---
+参数: [hello]
+参数: [world]
+参数: [foo]
+参数: [bar]
+
+--- 使用 $@ (无引号)---
+参数: [hello]
+参数: [world]
+参数: [foo]
+参数: [bar]
+
+--- 使用 "$*" (双引号)---
+参数: [hello world foo bar] # 所有参数合并为一个字符串
+
+--- 使用 "$@" (双引号,推荐)---
+参数: [hello world] # 每个参数保持独立
+参数: [foo bar]
```
+
+**结论**:在传递参数时,**始终使用 `"$@"`** 以确保每个参数的独立性(特别是当参数包含空格时)。
+
+## Shell 编程最佳实践
+
+在掌握了 Shell 编程的基础知识后,了解一些最佳实践能帮助你编写更安全、更高效的脚本。
+
+### 脚本基础规范
+
+**1. Shebang 规范**:
+
+```shell
+#!/usr/bin/env bash # 更可移植(自动查找 bash)
+set -euo pipefail # 严格模式:遇错退出、未定义变量报错、管道失败报错
+```
+
+**Shebang 两种写法**:
+
+- `#!/bin/bash`:直接指定 bash 路径,适用于你知道 bash 位置的固定环境
+- `#!/usr/bin/env bash`:通过 env 查找 bash,更可移植,适合不同系统(如 macOS / Linux)
+
+**本文示例选择**:
+
+- 教程示例使用 `#!/bin/bash`:简洁明了,适合初学者理解
+- 生产级示例使用 `#!/usr/bin/env bash`:强调可移植性
+
+**2. 变量引用**:
+
+```shell
+# 始终用双引号包裹变量
+echo "$var" # 推荐
+echo $var # 可能导致 word splitting 和 globbing 问题
+```
+
+**3. 使用 shellcheck**:
+
+```bash
+shellcheck your_script.sh # 静态分析,发现常见问题
+```
+
+**4. 推荐语法**:
+
+- 使用 `[[ ]]` 而非 `[ ]`(更安全、支持模式匹配)
+- 使用 `$((...))` 而非 `expr`(性能更好)
+- 使用 `$(...)` 而非反引号(可嵌套、更清晰)
+- 使用 `${n}` 访问位置参数 n ≥ 10
+
+### pipefail 工作原理
+
+默认情况下,管道命令的返回值只取决于最后一个命令。启用 `pipefail` 后,管道的返回值将是最后一个失败命令的返回值,这能避免隐藏中间步骤的错误。
+
+**示例对比**:
+
+```shell
+# 默认模式(危险)
+cat huge_file.txt | grep "pattern" | head -n 10
+# 即使 cat 失败(文件不存在),只要 head 成功,返回码就是 0
+
+# pipefail 模式(安全)
+set -o pipefail
+cat huge_file.txt | grep "pattern" | head -n 10
+# cat 失败会立即返回错误码,不会被忽略
+```
+
+## 生产环境最佳实践
+
+### 脚本安全性
+
+**1. 始终使用严格模式**:
+
+```shell
+#!/usr/bin/env bash
+set -euo pipefail # 遇错退出、未定义变量报错、管道失败报错
+```
+
+**2. 变量引用安全**:
+
+```shell
+# 始终用双引号包裹变量,防止 word splitting 和 globbing
+rm -rf "$temp_dir" # 推荐
+rm -rf $temp_dir # 危险:如果 temp_dir 包含空格会导致误删
+```
+
+**3. 使用 local 限制变量作用域**:
+
+```shell
+process_data() {
+ local input_file="$1"
+ local output_file="$2"
+ # ... 处理逻辑
+}
+```
+
+### 监控指标建议
+
+**关键指标**:
+
+- **脚本执行返回码(Exit Code)**:非 0 必须触发告警
+- **命令执行超时时间**:防御网络阻塞或 read 死锁(使用 `timeout` 命令)
+- **关键资源的并发争用**:临时文件、锁文件、网络连接等
+- **单机文件描述符(FD)使用率**:防止后台并发启动导致 FD 耗尽
+- **PID 饱和度**:监控进程数量,防止 PID 耗尽
+- **网络请求 P99 延迟**:监控 API 请求的尾延迟
+
+**超时控制示例**:
+
+```shell
+# 为整个脚本设置超时(5 分钟)
+timeout 300 ./your_script.sh || { echo "脚本执行超时"; exit 1; }
+
+# 为单个命令设置超时
+timeout 10 curl -s https://api.example.com/data || { echo "API 请求超时"; exit 1; }
+```
+
+**生产级 API 请求(带重试和退避)**:
+
+```shell
+# ⚠️ 重要:单纯拦截超时不够,必须考虑重试风暴
+# 下面的配置包含连接超时、总超时、重试机制和指数退避
+
+curl -s \
+ --connect-timeout 3 \ # 连接超时 3 秒
+ --max-time 10 \ # 总超时 10 秒
+ --retry 3 \ # 失败时重试 3 次
+ --retry-delay 2 \ # 重试间隔 2 秒
+ --retry-max-time 30 \ # 重试总时长不超过 30 秒
+ --retry-connrefused \ # 连接被拒绝时也重试
+ --retry-all-errors \ # 所有错误都重试
+ https://api.example.com/data || { echo "API 请求彻底失败"; exit 1; }
+```
+
+**重试风暴防护**:
+
+```shell
+# ❌ 危险:无节制的重试会导致级联雪崩
+for i in {1..10}; do
+ curl -s https://api.example.com/data && break || sleep 1
+done
+
+# ✅ 安全:带抖动(Jitter)的指数退避重试
+retry_with_backoff() {
+ local max_attempts=5
+ local base_delay=1
+ local max_delay=32
+ local attempt=1
+
+ while (( attempt <= max_attempts )); do
+ if curl -s --connect-timeout 3 --max-time 10 \
+ --retry 3 --retry-delay 2 --retry-max-time 30 \
+ "$@"; then
+ return 0
+ fi
+
+ if (( attempt < max_attempts )); then
+ # 指数退避 + 随机抖动(防止重试风暴)
+ local delay=$(( base_delay * (1 << (attempt - 1)) ))
+ delay=$(( delay > max_delay ? max_delay : delay ))
+ local jitter=$((RANDOM % 1000)) # 0-999ms 随机抖动
+ delay=$(( delay * 1000 + jitter ))
+ echo "请求失败,${delay}ms 后重试 (第 $attempt 次)" >&2
+ sleep "${delay}e-6"
+ fi
+
+ ((attempt++))
+ done
+
+ return 1
+}
+
+# 使用
+retry_with_backoff https://api.example.com/data
+```
+
+**重要提示**:
+
+- **重试风暴**:网络分区恢复后,无节制的重试会瞬间打满下游服务
+- **指数退避**:每次重试间隔呈指数增长(1s → 2s → 4s → 8s...)
+- **随机抖动**:添加随机延迟避免多个客户端同时重试(惊群效应)
+- **监控指标**:需监控超时丢包率与 P99 请求耗时
+
+### 压测建议
+
+**并发安全测试**:
+
+```shell
+# ❌ 危险:无限制并发可能导致 PID 耗尽或 OOM
+for i in {1..100}; do
+ ./your_script.sh &
+done
+wait
+
+# ✅ 安全:使用 xargs 控制并发度(推荐)
+# 限制最大并行数为 10,防止系统资源耗尽
+seq 1 100 | xargs -n 1 -P 10 -I {} ./your_script.sh
+
+# 或使用 GNU parallel(功能更强大)
+seq 1 100 | parallel -j 10 ./your_script.sh
+```
+
+**重要提示**:
+
+- **并发度控制**:生产环境的单机压测应使用 `xargs -P` 或 GNU parallel 限制并发进程数
+- **资源监控**:压测时监控文件描述符(FD)使用率和 PID 饱和度
+- **失败模式**:无限制的 `&` 会引发数百个进程在 D 状态挂起,导致节点内核级假死
+
+**常见问题检测**:
+
+- **固定路径冲突**:避免使用 `/tmp/test.log` 等固定路径,应使用 `$$` 引入进程 PID:
+
+ ```shell
+ temp_file="/tmp/myapp_$$/temp.log"
+ mkdir -p "$(dirname "$temp_file")"
+ ```
+
+- **锁机制**:使用 `flock` 防止并发执行:
+
+ ```shell
+ # ⚠️ 重要:flock 仅在本地文件系统(Ext4/XFS)保证强一致性
+ # 若锁文件位于 NFS 等网络存储,flock 可能静默失效(脑裂风险)
+
+ # 单机场景:确保同一时间只有一个实例在运行
+ exec 200>/var/lock/myapp.lock
+ flock -n 200 || { echo "脚本已在运行"; exit 1; }
+
+ # 分布式场景:需要使用分布式锁服务(如 Redis、etcd、ZooKeeper)
+ # 或通过数据库唯一索引、消息队列等机制实现互斥
+ ```
+
+ **flock 脑裂风险可视化**:
+
+ ```mermaid
+ sequenceDiagram
+ participant CronA as 节点A (定时任务)
+ participant CronB as 节点B (定时任务)
+ participant Storage as 存储层
+
+ CronA->>Storage: 请求 flock 互斥锁 (非阻塞)
+ Storage-->>CronA: 授予锁 (成功)
+ CronA->>CronA: 执行核心自动化逻辑
+
+ CronB->>Storage: 并发请求 flock 互斥锁 (非阻塞)
+ alt 本地文件系统 (Ext4/XFS)
+ Storage-->>CronB: 拒绝加锁 (返回非0)
+ CronB->>CronB: 安全退出,防御并发成功 ✓
+ else 网络文件系统 (NFS/配置异常)
+ Storage-->>CronB: 错误地授予锁 (静默失效)
+ CronB->>CronB: 🚨 执行核心逻辑,发生并发写与数据踩踏!
+ end
+ ```
+
+ **分布式锁方案建议**:
+
+ - **Redis**:使用 `SET key value NX PX timeout` 实现分布式锁
+ - **etcd**:使用事务 API 和租约机制
+ - **数据库**:使用 `UNIQUE INDEX` 约束
+ - **消息队列**:使用单消费者模式保证互斥
+
+**后台进程退出码捕获**:
+
+```shell
+# ❌ 问题:wait 默认不检查退出码,后台任务失败会被静默吃掉
+for i in {1..10}; do
+ ./task.sh &
+done
+wait # 只等待所有后台进程结束,不检查退出码
+
+# ✅ 正确:逐个检查后台进程的退出码
+pids=()
+for i in {1..10}; do
+ ./task.sh &
+ pids+=($!)
+done
+
+# 等待所有后台进程并检查退出码
+for pid in "${pids[@]}"; do
+ if ! wait "$pid"; then
+ echo "进程 $pid 执行失败" >&2
+ exit_code=1
+ fi
+done
+
+# 或使用 wait -n(bash 4.3+)等待任一进程并检查退出码
+while wait -n; do
+ : # 检查 $? 是否为 0
+done
+```
+
+### 常见误区
+
+**1. 吞掉错误上下文**:
+
+```shell
+# ❌ 错误:滥用 > /dev/null 2>&1
+command > /dev/null 2>&1
+
+# ✅ 正确:只屏蔽不需要的输出,保留错误信息
+command > /dev/null # 或
+command 2>/tmp/error.log
+```
+
+**2. 环境依赖假定**:
+
+```shell
+# ❌ 危险:依赖特定的 PATH 顺序,未验证命令是否存在
+curl -s https://api.example.com/data
+
+# ✅ 安全:验证命令存在后再使用
+command -v curl >/dev/null 2>&1 || { echo "curl 未安装"; exit 1; }
+curl -s https://api.example.com/data
+
+# 或者:明确指定完整路径(适用于关键生产环境)
+CURL_PATH="/usr/bin/curl"
+[[ -x "$CURL_PATH" ]] || { echo "curl 不存在或不可执行"; exit 1; }
+"$CURL_PATH" -s https://api.example.com/data
+```
+
+**说明**:验证命令存在可以防止因环境差异导致的运行时错误。若需更高安全性,可指定完整路径。
+
+**3. 未处理管道失败**:
+
+```shell
+# ❌ 问题:默认模式下管道只看最后一个命令的返回码
+cat huge_file.txt | grep "pattern" | head -n 10
+# 即使 cat 失败,只要 head 成功,整体返回码就是 0
+
+# ✅ 安全:使用 pipefail 确保任何命令失败都能被捕获
+set -o pipefail
+cat huge_file.txt | grep "pattern" | head -n 10
+```
+
+**4. 未清理临时资源**:
+
+```shell
+# ❌ 问题:脚本异常退出时临时文件未被清理
+temp_file="/tmp/data_$$"
+process_data "$temp_file"
+
+# ✅ 安全:使用 trap 确保清理
+temp_file="/tmp/data_$$"
+trap 'rm -f "$temp_file"' EXIT
+process_data "$temp_file"
+```
+
+### 错误处理模式
+
+**防御式编程模板**:
+
+```shell
+#!/usr/bin/env bash
+set -euo pipefail
+
+# 错误处理函数
+error_exit() {
+ echo "错误: $1" >&2
+ exit "${2:-1}"
+}
+
+# 验证依赖
+command -v curl >/dev/null 2>&1 || error_exit "curl 未安装"
+command -v jq >/dev/null 2>&1 || error_exit "jq 未安装"
+
+# 验证参数
+[[ $# -eq 1 ]] || error_exit "用法: $0 "
+
+# 验证文件存在
+[[ -f "$1" ]] || error_exit "配置文件不存在: $1"
+
+# 设置超时和清理
+temp_file="/tmp/process_$$"
+trap 'rm -f "$temp_file"' EXIT
+
+# 主要逻辑(带超时)
+timeout 300 process_data "$1" "$temp_file" || error_exit "数据处理失败或超时"
+
+echo "处理完成:$temp_file"
+```
+
+### 故障演练建议
+
+生产环境的脚本需要经过充分的故障测试,确保在各种异常情况下都能正确处理。以下是推荐的故障演练场景:
+
+**1. 网络分区测试**
+
+```shell
+# 使用 iptables 模拟 50% 丢包率
+sudo iptables -A OUTPUT -p tcp --dport 443 -m statistic --mode random --probability 0.5 -j DROP
+
+# 测试带有重试机制的 curl 是否引发雪崩
+retry_with_backoff https://api.example.com/data
+
+# 恢复网络
+sudo iptables -D OUTPUT -p tcp --dport 443 -m statistic --mode random --probability 0.5 -j DROP
+```
+
+**测试要点**:
+
+- 验证重试机制是否正常工作
+- 检查是否有指数退避和随机抖动
+- 确认不会因重试风暴导致级联失败
+
+**2. 慢响应拖垮测试**
+
+```shell
+# 模拟下游 API 长时间不返回(但不断开连接)
+# 使用 nc 监听端口但不发送数据
+nc -l 8080 &
+
+# 测试 timeout 是否能准确切断连接
+timeout 5 curl -s http://localhost:8080/data || echo "超时触发"
+
+# 清理
+pkill nc
+```
+
+**测试要点**:
+
+- 验证 `--max-time` 是否生效
+- 检查是否有资源泄漏(连接、内存)
+- 确认超时后脚本能正确退出
+
+**3. 时钟漂移测试**
+
+```shell
+# 模拟系统时钟回拨(需要 root 权限)
+sudo date -s "2 hours ago"
+
+# 测试基于 $PID 生成的临时文件是否有重复覆盖风险
+temp_file="/tmp/test_$$/data.txt"
+mkdir -p "$(dirname "$temp_file")"
+echo "data" > "$temp_file"
+echo "Created: $temp_file"
+
+# 恢复系统时钟
+sudo ntpdate -u time.nist.gov
+```
+
+**测试要点**:
+
+- 验证 PID 循环后临时文件是否会被覆盖
+- 检查是否需要添加时间戳或 UUID 增强唯一性
+- 确认脚本对时钟变化的鲁棒性
+
+**4. NFS 延迟测试**
+
+```shell
+# 模拟 NFS 存储高延迟(使用 tc 延迟网络)
+# 挂载测试用的 NFS 共享
+sudo mount -t nfs nfs-server:/share /mnt/nfs-test
+
+# 监控 I/O 延迟(P90 / P99)
+iostat -x 1 10 | grep dm-0
+
+# 在 NFS 共享上执行脚本,验证 flock 是否正常
+LOCK_FILE="/mnt/nfs-test/myapp.lock"
+exec 200>"$LOCK_FILE"
+flock -n 200 || { echo "获取锁失败"; exit 1; }
+
+# 清理
+sudo umount /mnt/nfs-test
+```
+
+**测试要点**:
+
+- 验证 flock 在网络存储上是否有效(预期可能失效)
+- 检查是否有脑裂风险(多个节点同时获取锁)
+- 确认是否需要使用分布式锁替代
+
+**5. 文件描述符耗尽测试**
+
+```shell
+# 查看当前进程的 FD 限制
+ulimit -n
+
+# 模拟大量并发连接,测试 FD 耗尽场景
+for i in {1..1000}; do
+ exec {fd}>"/tmp/file_$i" 2>/dev/null || break
+done
+
+# 检查 FD 使用情况
+ls -l /proc/$$/fd | wc -l
+
+# 清理
+for i in {1..1000}; do
+ eval "exec $fd>&-" 2>/dev/null
+done
+```
+
+**测试要点**:
+
+- 验证脚本在 FD 不足时的行为
+- 检查是否有资源泄漏
+- 确认并发度限制是否有效
+
+**6. 压测数据一致性测试**
+
+```shell
+# 在 NFS 共享存储目录下,由多个机器节点同时高频执行脚本
+# 验证数据恢复与幂等性边界
+
+# 节点 A
+for i in {1..100}; do
+ echo "nodeA_data_$i" >> /mnt/shared/data.txt
+ sleep 0.1
+done &
+
+# 节点 B(在另一台机器上同时执行)
+for i in {1..100}; do
+ echo "nodeB_data_$i" >> /mnt/shared/data.txt
+ sleep 0.1
+done &
+
+# 检查数据是否完整
+wait
+wc -l /mnt/shared/data.txt
+sort /mnt/shared/data.txt | uniq -c
+```
+
+**测试要点**:
+
+- 验证并发写入是否会导致数据混乱
+- 检查是否需要使用锁机制
+- 确认数据恢复策略是否有效
+
+## 总结
+
+Shell 编程是后端开发和运维人员必备的核心技能之一,掌握它能显著提升工作效率,实现自动化运维和系统管理。本文从入门到生产实践,系统介绍了 Shell 编程的核心知识点。
+
+### 核心知识点回顾
+
+| 知识模块 | 关键要点 |
+| ------------ | --------------------------------------------------------------------------------- | --- | ---------------- |
+| **变量** | 区分局部变量、环境变量和特殊变量;使用 `local` 避免全局污染;始终用双引号包裹变量 |
+| **字符串** | 推荐使用双引号;理解单引号和双引号的区别;掌握 `${#var}` 获取长度 |
+| **数组** | bash 2.0+ 支持数组(非 POSIX);注意删除元素后的索引空洞 |
+| **运算符** | 优先使用 `$((...))` 进行算术运算;`[[ ]]` 比 `[ ]` 更安全 |
+| **流程控制** | 使用 `[[ ]]` 进行条件测试;避免 `command1 && command2 | | command3` 的陷阱 |
+| **函数** | 使用 `local` 限制变量作用域;函数只能返回 0-255 的退出码 |
+| **命令替换** | 使用 `$(...)` 替代反引号;使用 `read -r` 提高安全性 |
+
+### 生产级脚本编写要点
+
+编写生产环境的 Shell 脚本时,务必遵循以下原则:
+
+**1. 严格模式**
+
+```shell
+#!/usr/bin/env bash
+set -euo pipefail # 遇错退出、未定义变量报错、管道失败报错
+```
+
+**2. 防御式编程**
+
+- 验证依赖:`command -v` 检查命令是否存在
+- 验证参数:检查参数数量和类型
+- 验证文件:确认文件存在且可访问
+- 超时控制:使用 `timeout` 防止死锁
+- 资源清理:使用 `trap` 确保临时资源被释放
+
+**3. 避免常见陷阱**
+
+- 不吞掉错误上下文(避免滥用 `>/dev/null 2>&1`)
+- 不依赖特定 PATH 顺序(验证或指定完整路径)
+- 不忽略管道失败(使用 `set -o pipefail`)
+- 不遗漏临时资源清理(使用 `trap`)
+
+**4. 并发安全**
+
+- 使用 `$$` 引入 PID 隔离临时文件
+- 使用 `flock` 防止脚本并发执行
+- 避免使用固定的临时文件路径
+
+### 学习建议
+
+**初学者**:
+
+1. 从简单的命令别名和脚本开始
+2. 重点掌握变量、条件判断和循环
+3. 使用 `shellcheck` 检查脚本错误
+4. 多练习,从实际场景出发(如日志分析、文件处理)
+
+**进阶学习**:
+
+1. 深入学习进程管理、信号处理
+2. 掌握 `sed`、`awk`、`grep` 等文本处理工具
+3. 学习正则表达式和文本处理技巧
+4. 了解性能优化和并发处理
+
+**生产实践**:
+
+1. 阅读 Google Shell Style Guide
+2. 研究开源项目的 Shell 脚本
+3. 在测试环境充分验证后再部署
+4. 建立完善的监控和告警机制
+
+### 参考资源
+
+- **官方文档**:Bash Reference Manual (GNU)
+- **代码检查**:ShellCheck - Shell Script Analysis Tool
+- **编码规范**:Google Shell Style Guide
+- **常见陷阱**:Bash Pitfalls (http://mywiki.wooledge.org/BashPitfalls)
diff --git a/docs/database/basis.md b/docs/database/basis.md
index 8848dcfbad3..154d59a0be5 100644
--- a/docs/database/basis.md
+++ b/docs/database/basis.md
@@ -1,28 +1,204 @@
---
title: 数据库基础知识总结
+description: 数据库基础知识总结,包括数据库、DBMS、数据库系统、DBA的概念区别,DBMS核心功能,元组、码、主键外键等关系型数据库核心概念,以及ER图的使用方法。
category: 数据库
tag:
- 数据库基础
+head:
+ - - meta
+ - name: keywords
+ content: 数据库,数据库管理系统,DBMS,数据库系统,DBA,SQL,DDL,DML,数据模型,关系型数据库,主键,外键,ER图
---
+
+
数据库知识基础,这部分内容一定要理解记忆。虽然这部分内容只是理论知识,但是非常重要,这是后面学习 MySQL 数据库的基础。PS: 这部分内容由于涉及太多概念性内容,所以参考了维基百科和百度百科相应的介绍。
## 什么是数据库, 数据库管理系统, 数据库系统, 数据库管理员?
-- **数据库** : 数据库(DataBase 简称 DB)就是信息的集合或者说数据库是由数据库管理系统管理的数据的集合。
-- **数据库管理系统** : 数据库管理系统(Database Management System 简称 DBMS)是一种操纵和管理数据库的大型软件,通常用于建立、使用和维护数据库。
-- **数据库系统** : 数据库系统(Data Base System,简称 DBS)通常由软件、数据库和数据管理员(DBA)组成。
-- **数据库管理员** : 数据库管理员(Database Administrator, 简称 DBA)负责全面管理和控制数据库系统。
+这四个概念描述了从数据本身到管理整个体系的不同层次,我们常用一个图书馆的例子来把它们串联起来理解。
+
+- **数据库 (Database - DB):** 它就像是图书馆里,书架上存放的所有书籍和资料。从技术上讲,数据库就是按照一定数据模型组织、描述和储存起来的、可以被各种用户共享的结构化数据的集合。它就是我们最终要存取的核心——信息本身。
+- **数据库管理系统 (Database Management System - DBMS):** 它就像是整个图书馆的管理系统,包括图书的分类编目规则、借阅归还流程、安全检查系统等等。从技术上讲,DBMS 是一种大型软件,比如我们常用的 MySQL、Oracle、PostgreSQL 软件。它的核心职责是科学地组织和存储数据、高效地获取和维护数据;为我们屏蔽了底层文件操作的复杂性,提供了一套标准接口(如 SQL)来操纵数据,并负责并发控制、事务管理、权限控制等复杂问题。
+- **数据库系统 (Database System - DBS):** 它就是整个正常运转的图书馆。这是一个更大的概念,不仅包括书(DB)和管理系统(DBMS),还包括了硬件、应用和使用的人。
+- **数据库管理员 (Database Administrator - DBA ):** 他就是图书馆的馆长,负责整个数据库系统正常运行。他的职责非常广泛,包括数据库的设计、安装、监控、性能调优、备份与恢复、安全管理等等,确保整个系统的稳定、高效和安全。
+
+DB 和 DBMS 我们通常会搞混,这里再简单提一下:**通常我们说“用 MySQL 数据库”,其实是用 MySQL(DBMS)来管理一个或多个数据库(DB)。**
+
+## DBMS 有哪些主要的功能
+
+```mermaid
+graph TD
+ DBMS["🗄️ DBMS
### 产生死锁的四个必要条件是什么?
+死锁的发生并不是偶然的,它需要同时满足**四个必要条件**:
+
1. **互斥**:资源必须处于非共享模式,即一次只有一个进程可以使用。如果另一进程申请该资源,那么必须等待直到该资源被释放为止。
2. **占有并等待**:一个进程至少应该占有一个资源,并等待另一资源,而该资源被其他进程所占有。
3. **非抢占**:资源不能被抢占。只能在持有资源的进程完成任务后,该资源才会被释放。
-4. **循环等待**:有一组等待进程 `{P0, P1,..., Pn}`, `P0` 等待的资源被 `P1` 占有,`P1` 等待的资源被 `P2` 占有,......,`Pn-1` 等待的资源被 `Pn` 占有,`Pn` 等待的资源被 `P0` 占有。
+4. **循环等待**:有一组等待进程 {P0, P1,..., Pn}, P0 等待的资源被 P1 占有,P1 等待的资源被 P2 占有,……,Pn-1 等待的资源被 Pn 占有,Pn 等待的资源被 P0 占有。
**注意 ⚠️**:这四个条件是产生死锁的 **必要条件** ,也就是说只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
@@ -315,7 +322,7 @@ ps -A -ostat,ppid,pid,cmd |grep -e '^[Zz]'
下面通过一个实际的例子来模拟下图展示的线程死锁:
-
+
```java
public class DeadLockDemo {
@@ -371,12 +378,9 @@ Thread[线程 2,5,main]waiting get resource1
解决死锁的方法可以从多个角度去分析,一般的情况下,有**预防,避免,检测和解除四种**。
-- **预防** 是采用某种策略,**限制并发进程对资源的请求**,从而使得死锁的必要条件在系统执行的任何时间上都不满足。
-
-- **避免**则是系统在分配资源时,根据资源的使用情况**提前做出预测**,从而**避免死锁的发生**
-
-- **检测**是指系统设有**专门的机构**,当死锁发生时,该机构能够检测死锁的发生,并精确地确定与死锁有关的进程和资源。
-- **解除** 是与检测相配套的一种措施,用于**将进程从死锁状态下解脱出来**。
+- **死锁预防:** 这是我们程序员最常用的方法。通过编码规范来破坏条件。最经典的就是**破坏循环等待**,比如规定所有线程都必须**按相同的顺序**来获取锁(比如先 A 后 B),这样就不会形成环路。
+- **死锁避免:** 这是一种更动态的方法,比如操作系统的**银行家算法**。它会在分配资源前进行预测,如果这次分配可能导致未来发生死锁,就拒绝分配。但这种方法开销很大,在通用系统中用得比较少。
+- **死锁检测与解除:** 这是一种“事后补救”的策略,就像乐观锁。系统允许死锁发生,但会有一个后台线程(或机制)定期检测是否存在死锁环路(比如通过分析线程等待图)。一旦发现,就会采取措施解除,比如**强制剥夺某个线程的资源或直接终止它**。数据库系统中的死锁处理就常常采用这种方式。
#### 死锁的预防
@@ -402,7 +406,7 @@ Thread[线程 2,5,main]waiting get resource1
上面提到的 **破坏** 死锁产生的四个必要条件之一就可以成功 **预防系统发生死锁** ,但是会导致 **低效的进程运行** 和 **资源使用率** 。而死锁的避免相反,它的角度是允许系统中**同时存在四个必要条件** ,只要掌握并发进程中与每个进程有关的资源动态申请情况,做出 **明智和合理的选择** ,仍然可以避免死锁,因为四大条件仅仅是产生死锁的必要条件。
-我们将系统的状态分为 **安全状态** 和 **不安全状态** ,每当在未申请者分配资源前先测试系统状态,若把系统资源分配给申请者会产生死锁,则拒绝分配,否则接受申请,并为它分配资源。
+我们将系统的状态分为 **安全状态** 和 **不安全状态** ,每当在为申请者分配资源前先测试系统状态,若把系统资源分配给申请者会产生死锁,则拒绝分配,否则接受申请,并为它分配资源。
> 如果操作系统能够保证所有的进程在有限的时间内得到需要的全部资源,则称系统处于安全状态,否则说系统是不安全的。很显然,系统处于安全状态则不会发生死锁,系统若处于不安全状态则可能发生死锁。
@@ -424,7 +428,7 @@ Thread[线程 2,5,main]waiting get resource1
操作系统中的每一刻时刻的**系统状态**都可以用**进程-资源分配图**来表示,进程-资源分配图是描述进程和资源申请及分配关系的一种有向图,可用于**检测系统是否处于死锁状态**。
-用一个方框表示每一个资源类,方框中的黑点表示该资源类中的各个资源,每个键进程用一个圆圈表示,用 **有向边** 来表示**进程申请资源和资源被分配的情况**。
+用一个方框表示每一个资源类,方框中的黑点表示该资源类中的各个资源,用一个圆圈表示每一个进程,用 **有向边** 来表示**进程申请资源和资源被分配的情况**。
图中 2-21 是**进程-资源分配图**的一个例子,其中共有三个资源类,每个进程的资源占有和申请情况已清楚地表示在图中。在这个例子中,由于存在 **占有和等待资源的环路** ,导致一组进程永远处于等待资源的状态,发生了 **死锁**。
@@ -454,6 +458,8 @@ Thread[线程 2,5,main]waiting get resource1
- 《计算机操作系统—汤小丹》第四版
- 《深入理解计算机系统》
- 《重学操作系统》
-- 操作系统为什么要分用户态和内核态:https://blog.csdn.net/chen134225/article/details/81783980
-- 从根上理解用户态与内核态:https://juejin.cn/post/6923863670132850701
-- 什么是僵尸进程与孤儿进程:https://blog.csdn.net/a745233700/article/details/120715371
+- 操作系统为什么要分用户态和内核态:
+- 从根上理解用户态与内核态:
+- 什么是僵尸进程与孤儿进程:
+
+
diff --git a/docs/cs-basics/operating-system/operating-system-basic-questions-02.md b/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
index 1c9d4f26822..51ed5fd65c3 100644
--- a/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
+++ b/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
@@ -1,17 +1,17 @@
---
title: 操作系统常见面试题总结(下)
+description: 最新操作系统高频面试题总结(下):虚拟内存映射、内存碎片/伙伴系统、TLB+页缺失处理、分页分段对比、页面置换算法详解、文件系统&磁盘调度,附图表+⭐️重点标注,一文掌握OS内存/文件考点,快速通关后端面试!
category: 计算机基础
tag:
- 操作系统
head:
- - meta
- name: keywords
- content: 操作系统,进程,进程通信方式,死锁,操作系统内存管理,块表,多级页表,虚拟内存,页面置换算法
- - - meta
- - name: description
- content: 很多读者抱怨计算操作系统的知识点比较繁杂,自己也没有多少耐心去看,但是面试的时候又经常会遇到。所以,我带着我整理好的操作系统的常见问题来啦!这篇文章总结了一些我觉得比较重要的操作系统相关的问题比如进程管理、内存管理、虚拟内存等等。
+ content: 操作系统面试题,虚拟内存详解,分页 vs 分段,页面置换算法,内存碎片,伙伴系统,TLB快表,页缺失,文件系统基础,磁盘调度算法,硬链接 vs 软链接
---
+
+
## 内存管理
### 内存管理主要做了什么?
@@ -26,14 +26,14 @@ head:
- **内存映射**:将一个文件直接映射到进程的进程空间中,这样可以通过内存指针用读写内存的办法直接存取文件内容,速度更快。
- **内存优化**:通过调整内存分配策略和回收算法来优化内存使用效率。
- **内存安全**:保证进程之间使用内存互不干扰,避免一些恶意程序通过修改内存来破坏系统的安全性。
-- ......
+- ……
### 什么是内存碎片?
内存碎片是由内存的申请和释放产生的,通常分为下面两种:
- **内部内存碎片(Internal Memory Fragmentation,简称为内存碎片)**:已经分配给进程使用但未被使用的内存。导致内部内存碎片的主要原因是,当采用固定比例比如 2 的幂次方进行内存分配时,进程所分配的内存可能会比其实际所需要的大。举个例子,一个进程只需要 65 字节的内存,但为其分配了 128(2^7) 大小的内存,那 63 字节的内存就成为了内部内存碎片。
-- **外部内存碎片(External Memory Fragmentation,简称为外部碎片)**:由于未分配的连续内存区域太小,以至于不能满足任意进程所需要的内存分配请求,这些小片段且不连续的内存空间被称为外部碎片。也就是说,外部内存碎片指的是那些并为分配给进程但又不能使用的内存。我们后面介绍的分段机制就会导致外部内存碎片。
+- **外部内存碎片(External Memory Fragmentation,简称为外部碎片)**:由于未分配的连续内存区域太小,以至于不能满足任意进程所需要的内存分配请求,这些小片段且不连续的内存空间被称为外部碎片。也就是说,外部内存碎片指的是那些并未分配给进程但又不能使用的内存。我们后面介绍的分段机制就会导致外部内存碎片。

@@ -68,8 +68,8 @@ head:
非连续内存管理存在下面 3 种方式:
-- **段式管理**:以段(—段连续的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。
-- **页式管理**:把物理内存分为连续等长的物理页,应用程序的虚拟地址空间划也被分为连续等长的虚拟页,现代操作系统广泛使用的一种内存管理方式。
+- **段式管理**:以段(一段连续的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。
+- **页式管理**:把物理内存分为连续等长的物理页,应用程序的虚拟地址空间也被划分为连续等长的虚拟页,是现代操作系统广泛使用的一种内存管理方式。
- **段页式管理机制**:结合了段式管理和页式管理的一种内存管理机制,把物理内存先分成若干段,每个段又继续分成若干大小相等的页。
### 虚拟内存
@@ -98,7 +98,7 @@ head:
1. 用户程序可以访问任意物理内存,可能会不小心操作到系统运行必需的内存,进而造成操作系统崩溃,严重影响系统的安全。
2. 同时运行多个程序容易崩溃。比如你想同时运行一个微信和一个 QQ 音乐,微信在运行的时候给内存地址 1xxx 赋值后,QQ 音乐也同样给内存地址 1xxx 赋值,那么 QQ 音乐对内存的赋值就会覆盖微信之前所赋的值,这就可能会造成微信这个程序会崩溃。
3. 程序运行过程中使用的所有数据或指令都要载入物理内存,根据局部性原理,其中很大一部分可能都不会用到,白白占用了宝贵的物理内存资源。
-4. ......
+4. ……
#### 什么是虚拟地址和物理地址?
@@ -131,7 +131,7 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
### 分段机制
-**分段机制(Segmentation)** 以段(—段 **连续** 的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。
+**分段机制(Segmentation)** 以段(一段 **连续** 的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。
#### 段表有什么用?地址翻译过程是怎样的?
@@ -188,7 +188,7 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:

-在分页机制下,每个应用程序都会有一个对应的页表。
+在分页机制下,每个进程都会有一个对应的页表。
分页机制下的虚拟地址由两部分组成:
@@ -203,7 +203,7 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:

-页表中还存有诸如访问标志(标识该页面有没有被访问过)、页类型(该段的类型,例如代码段、数据段等)等信息。
+页表中还存有诸如访问标志(标识该页面有没有被访问过)、脏数据标识位等信息。
**通过虚拟页号一定要找到对应的物理页号吗?找到了物理页号得到最终的物理地址后对应的物理页一定存在吗?**
@@ -211,11 +211,11 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
#### 单级页表有什么问题?为什么需要多级页表?
-以 32 位的环境为例,虚拟地址空间范围共有 2^32(4G)。假设 一个页的大小是 2^12(4KB),那页表项共有 4G / 4K = 2^20 个。每个页表项为一个地址,占用 4 字节,2^20 * 2^2/1024*1024= 4MB。也就是说一个程序啥都不干,页表大小就得占用 4M。
+以 32 位的环境为例,虚拟地址空间范围共有 2^32(4G)。假设 一个页的大小是 2^12(4KB),那页表项共有 4G / 4K = 2^20 个。每个页表项为一个地址,占用 4 字节,`(2^20 * 2^2) / (1024 * 1024)= 4MB`。也就是说一个程序啥都不干,页表大小就得占用 4M。
系统运行的应用程序多起来的话,页表的开销还是非常大的。而且,绝大部分应用程序可能只能用到页表中的几项,其他的白白浪费了。
-为了解决这个问题,操作系统引入了 **多级页表** ,多级页表对应多个页表,每个页表也前一个页表相关联。32 位系统一般为二级页表,64 位系统一般为四级页表。
+为了解决这个问题,操作系统引入了 **多级页表** ,多级页表对应多个页表,每个页表与前一个页表相关联。32 位系统一般为二级页表,64 位系统一般为四级页表。
这里以二级页表为例进行介绍:二级列表分为一级页表和二级页表。一级页表共有 1024 个页表项,一级页表又关联二级页表,二级页表同样共有 1024 个页表项。二级页表中的一级页表项是一对多的关系,二级页表按需加载(只会用到很少一部分二级页表),进而节省空间占用。
@@ -227,7 +227,7 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
#### TLB 有什么用?使用 TLB 之后的地址翻译流程是怎样的?
-为了提高虚拟地址到物理地址的转换速度,操作系统在 **页表方案** 基础之上引入了 **转址旁路缓存(Translation Lookasjde Buffer,TLB,也被称为快表)** 。
+为了提高虚拟地址到物理地址的转换速度,操作系统在 **页表方案** 基础之上引入了 **转址旁路缓存(Translation Lookaside Buffer,TLB,也被称为快表)** 。

@@ -282,7 +282,7 @@ TLB 的设计思想非常简单,但命中率往往非常高,效果很好。

1. **最佳页面置换算法(OPT,Optimal)**:优先选择淘汰的页面是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若干页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现,只是理论最优的页面置换算法,可以作为衡量其他置换算法优劣的标准。
-2. **先进先出页面置换算法(FIFO,First In First Out)** : 最简单的一种页面置换算法,总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。该算法易于实现和理解,一般只需要通过一个 FIFO 队列即可需求。不过,它的性能并不是很好。
+2. **先进先出页面置换算法(FIFO,First In First Out)** : 最简单的一种页面置换算法,总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。该算法易于实现和理解,一般只需要通过一个 FIFO 队列即可满足需求。不过,它的性能并不是很好。
3. **最近最久未使用页面置换算法(LRU ,Least Recently Used)**:LRU 算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。LRU 算法是根据各页之前的访问情况来实现,因此是易于实现的。OPT 算法是根据各页未来的访问情况来实现,因此是不可实现的。
4. **最少使用页面置换算法(LFU,Least Frequently Used)** : 和 LRU 算法比较像,不过该置换算法选择的是之前一段时间内使用最少的页面作为淘汰页。
5. **时钟页面置换算法(Clock)**:可以认为是一种最近未使用算法,即逐出的页面都是最近没有使用的那个。
@@ -317,12 +317,16 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
### 段页机制
-结合了段式管理和页式管理的一种内存管理机制,把物理内存先分成若干段,每个段又继续分成若干大小相等的页。
+结合了段式管理和页式管理的一种内存管理机制。程序视角中,内存被划分为多个逻辑段,每个逻辑段进一步被划分为固定大小的页。
在段页式机制下,地址翻译的过程分为两个步骤:
-1. 段式地址映射。
-2. 页式地址映射。
+1. **段式地址映射(虚拟地址 → 线性地址):**
+ - 虚拟地址 = 段选择符(段号)+ 段内偏移。
+ - 根据段号查段表,找到段基址,加上段内偏移得到线性地址。
+2. **页式地址映射(线性地址 → 物理地址):**
+ - 线性地址 = 页号 + 页内偏移。
+ - 根据页号查页表,找到物理页框号,加上页内偏移得到物理地址。
### 局部性原理
@@ -362,7 +366,7 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
**2、软链接(Symbolic Link 或 Symlink)**
- 软链接和源文件的 inode 节点号不同,而是指向一个文件路径。
-- 源文件删除后,硬链接依然存在,但是指向的是一个无效的文件路径。
+- 源文件删除后,软链接依然存在,但是指向的是一个无效的文件路径。
- 软连接类似于 Windows 系统中的快捷方式。
- 不同于硬链接,可以对目录或者不存在的文件创建软链接,并且,软链接可以跨越文件系统。
- `ln -s` 命令用于创建软链接。
@@ -375,7 +379,7 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
### 提高文件系统性能的方式有哪些?
-- **优化硬件**:使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Inexpensive Disks)等技术提高磁盘性能。
+- **优化硬件**:使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Independent Disks)等技术提高磁盘性能。
- **选择合适的文件系统选型**:不同的文件系统具有不同的特性,对于不同的应用场景选择合适的文件系统可以提高系统性能。
- **运用缓存**:访问磁盘的效率比较低,可以运用缓存来减少磁盘的访问次数。不过,需要注意缓存命中率,缓存命中率过低的话,效果太差。
- **避免磁盘过度使用**:注意磁盘的使用率,避免将磁盘用满,尽量留一些剩余空间,以免对文件系统的性能产生负面影响。
@@ -404,8 +408,10 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
- 《深入理解计算机系统》
- 《重学操作系统》
- 《现代操作系统原理与实现》
-- 王道考研操作系统知识点整理:https://wizardforcel.gitbooks.io/wangdaokaoyan-os/content/13.html
-- 内存管理之伙伴系统与 SLAB:https://blog.csdn.net/qq_44272681/article/details/124199068
-- 为什么 Linux 需要虚拟内存:https://draveness.me/whys-the-design-os-virtual-memory/
-- 程序员的自我修养(七):内存缺页错误:https://liam.page/2017/09/01/page-fault/
-- 虚拟内存的那点事儿:https://juejin.cn/post/6844903507594575886
+- 王道考研操作系统知识点整理:
+- 内存管理之伙伴系统与 SLAB:
+- 为什么 Linux 需要虚拟内存:
+- 程序员的自我修养(七):内存缺页错误:
+- 虚拟内存的那点事儿:
+
+
diff --git a/docs/cs-basics/operating-system/shell-intro.md b/docs/cs-basics/operating-system/shell-intro.md
index a9f666fb7d5..7554aa2760d 100644
--- a/docs/cs-basics/operating-system/shell-intro.md
+++ b/docs/cs-basics/operating-system/shell-intro.md
@@ -1,19 +1,36 @@
---
title: Shell 编程基础知识总结
+description: Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。这篇文章我会简单总结一下 Shell 编程基础知识,带你入门 Shell 编程!
category: 计算机基础
tag:
- 操作系统
- Linux
head:
- - meta
- - name: description
- content: Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。这篇文章我会简单总结一下 Shell 编程基础知识,带你入门 Shell 编程!
+ - name: keywords
+ content: Shell,脚本,命令,自动化,运维,Linux,基础语法
---
Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。
这篇文章我会简单总结一下 Shell 编程基础知识,带你入门 Shell 编程!
+## 版本说明
+
+**本文示例适用于 bash 4.0+ 版本**。不同版本的 bash 在某些特性上可能有差异,特别是:
+
+- **数组** :bash 2.0+ 支持,纯 POSIX sh(如 dash)不支持
+- **某些字符串操作** :如 `${var:offset:length}` 在较旧版本可能不支持
+- **算术扩展 `$((...))`** :bash 2.0+ 支持
+
+检查你的 bash 版本:
+
+```shell
+bash --version
+# 或
+echo $BASH_VERSION
+```
+
## 走进 Shell 编程的大门
### 为什么要学 Shell?
@@ -28,14 +45,21 @@ Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统
另外,了解 shell 编程也是大部分互联网公司招聘后端开发人员的要求。下图是我截取的一些知名互联网公司对于 Shell 编程的要求。
-
+
### 什么是 Shell?
-简单来说“Shell 编程就是对一堆 Linux 命令的逻辑化处理”。
+**Shell 是 Linux/Unix 系统的命令解释器**,它充当用户和操作系统内核之间的桥梁,负责接收用户输入的命令并调用相应的程序。
+
+**Shell 编程**是通过 Shell 解释器(如 bash)将命令、控制结构(if/for/while)、变量和函数组合成自动化脚本的过程。Shell 既是命令解释器,也是一门完整的编程语言(支持变量、数组、函数、流程控制、管道、重定向等)。
-W3Cschool 上的一篇文章是这样介绍 Shell 的,如下图所示。
-
+**常见的 Shell 类型**:
+
+- **bash**(Bourne Again Shell):Linux 系统默认 Shell,最常用
+- **sh**(Bourne Shell):Unix 传统 Shell,POSIX 标准
+- **zsh**:功能强大的交互式 Shell
+- **dash**:轻量级 Shell,Ubuntu 的 /bin/sh 默认指向它
+- **csh/tcsh**:C 风格的 Shell
### Shell 编程的 Hello World
@@ -51,15 +75,16 @@ helloworld.sh 内容如下:
```shell
#!/bin/bash
-#第一个shell小程序,echo 是linux中的输出命令。
-echo "helloworld!"
+set -euo pipefail # 严格模式:遇错退出、未定义变量报错、管道失败报错
+# 第一个 shell 小程序,echo 是 Linux 中的输出命令
+echo "helloworld!"
```
shell 中 # 符号表示注释。**shell 的第一行比较特殊,一般都会以#!开始来指定使用的 shell 类型。在 linux 中,除了 bash shell 以外,还有很多版本的 shell, 例如 zsh、dash 等等...不过 bash shell 还是我们使用最多的。**
(4) 运行脚本:`./helloworld.sh` 。(注意,一定要写成 `./helloworld.sh` ,而不是 `helloworld.sh` ,运行其它二进制的程序也一样,直接写 `helloworld.sh` ,linux 系统会去 PATH 里寻找有没有叫 helloworld.sh 的,而只有 /bin, /sbin, /usr/bin,/usr/sbin 等在 PATH 里,你的当前目录通常不在 PATH 里,所以写成 `helloworld.sh` 是会找不到命令的,要用`./helloworld.sh` 告诉系统说,就在当前目录找。)
-
+
## Shell 变量
@@ -67,20 +92,20 @@ shell 中 # 符号表示注释。**shell 的第一行比较特殊,一般都会
**Shell 编程中一般分为三种变量:**
-1. **我们自己定义的变量(自定义变量):** 仅在当前 Shell 实例中有效,其他 Shell 启动的程序不能访问局部变量。
-2. **Linux 已定义的环境变量**(环境变量, 例如:`PATH`, `HOME` 等..., 这类变量我们可以直接使用),使用 `env` 命令可以查看所有的环境变量,而 set 命令既可以查看环境变量也可以查看自定义变量。
-3. **Shell 变量**:Shell 变量是由 Shell 程序设置的特殊变量。Shell 变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了 Shell 的正常运行
+1. **自定义变量(局部变量)**:默认仅在当前 Shell 进程内有效,**子进程无法访问**。若需传递给子进程,需使用 `export` 声明为环境变量。
+2. **环境变量**:例如 `PATH`, `HOME` 等,可被子进程继承。使用 `env` 命令可以查看所有环境变量,`set` 命令可以查看所有变量(包括环境变量和局部变量)。
+3. **Shell 特殊变量**:由 Shell 设置的特殊变量(如 `$?`, `$$`, `$!` 等),用于保存进程状态、参数等信息。
**常用的环境变量:**
-> PATH 决定了 shell 将到哪些目录中寻找命令或程序
-> HOME 当前用户主目录
-> HISTSIZE 历史记录数
-> LOGNAME 当前用户的登录名
-> HOSTNAME 指主机的名称
-> SHELL 当前用户 Shell 类型
-> LANGUAGE 语言相关的环境变量,多语言可以修改此环境变量
-> MAIL 当前用户的邮件存放目录
+> PATH 决定了 shell 将到哪些目录中寻找命令或程序
+> HOME 当前用户主目录
+> HISTSIZE 历史记录数
+> LOGNAME 当前用户的登录名
+> HOSTNAME 指主机的名称
+> SHELL 当前用户 Shell 类型
+> LANGUAGE 语言相关的环境变量,多语言可以修改此环境变量
+> MAIL 当前用户的邮件存放目录
> PS1 基本提示符,对于 root 用户是#,对于普通用户是\$
**使用 Linux 已定义的环境变量:**
@@ -97,7 +122,7 @@ echo $hello
echo "helloworld!"
```
-
+
**Shell 编程中的变量名的命名的注意事项:**
@@ -110,21 +135,31 @@ echo "helloworld!"
字符串是 shell 编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号。这点和 Java 中有所不同。
-在单引号中所有的特殊符号,如$和反引号都没有特殊含义。在双引号中,除了"$","\"和反引号,其他的字符没有特殊含义。
+在单引号中,所有特殊字符(如 `$`、反引号、`\` 等)都失去特殊含义,被视为字面量。
+
+在双引号中,以下字符保留特殊含义:
+
+- `$`:变量扩展(如 `$var`)和命令替换(如 `$(cmd)` 或 `` `cmd` ``)
+- `\`:转义字符
+- `` ` `` 或 `$()`:命令替换(推荐使用 `$()` 语法)
+- `!`:历史扩展(仅在交互式 Shell 中默认开启)
+- `${}`:参数扩展
+
+**注意**:单引号中的字符串是**完全字面量**,双引号中的字符串会进行变量和命令替换。
**单引号字符串:**
```shell
#!/bin/bash
name='SnailClimb'
-hello='Hello, I am '$name'!'
+hello='Hello, I am $name!'
echo $hello
```
输出内容:
-```
-Hello, I am '$name'!
+```plain
+Hello, I am $name!
```
**双引号字符串:**
@@ -132,13 +167,13 @@ Hello, I am '$name'!
```shell
#!/bin/bash
name='SnailClimb'
-hello="Hello, I am "$name"!"
+hello="Hello, I am $name!"
echo $hello
```
输出内容:
-```
+```plain
Hello, I am SnailClimb!
```
@@ -161,39 +196,48 @@ echo $greeting_2 $greeting_3
输出结果:
-
+
**获取字符串长度:**
```shell
#!/bin/bash
-#获取字符串长度
+# 获取字符串长度
name="SnailClimb"
-# 第一种方式
-echo ${#name} #输出 10
-# 第二种方式
-expr length "$name";
+# 第一种方式(推荐):bash 内置
+echo ${#name} # 输出 10
+# 第二种方式:外部命令(性能较差)
+expr length "$name"
```
-输出结果:
+输出结果:
-```
+```plain
10
10
```
-使用 expr 命令时,表达式中的运算符左右必须包含空格,如果不包含空格,将会输出表达式本身:
+**说明**:
+
+- 推荐使用 `${#var}` 语法,这是 bash 内置功能,性能更好
+- `expr` 是外部命令,需要 fork 进程,性能较差
+- **`expr length` 是 GNU 扩展**,非 POSIX 标准。在 macOS 的 BSD expr 或其他系统上可能不支持
+- 如需可移植性,推荐使用 `${#var}` 或 `expr "$var" : '.*'`(POSIX 兼容)
+
+使用 expr 命令时,表达式中的运算符左右必须包含空格:
```shell
-expr 5+6 // 直接输出 5+6
-expr 5 + 6 // 输出 11
+expr 5+6 # 直接输出 5+6(无空格)
+expr 5 + 6 # 输出 11(有空格)
+# 更推荐使用 bash 算术扩展:
+echo $((5 + 6)) # 输出 11
```
-对于某些运算符,还需要我们使用符号`\`进行转义,否则就会提示语法错误。
+对于某些运算符,还需要我们使用符号 `\` 进行转义:
```shell
-expr 5 * 6 // 输出错误
-expr 5 \* 6 // 输出30
+expr 5 * 6 # 输出错误(未转义)
+expr 5 \* 6 # 输出 30(正确转义)
```
**截取子字符串:**
@@ -201,7 +245,7 @@ expr 5 \* 6 // 输出30
简单的字符串截取:
```shell
-#从字符串第 1 个字符开始往后截取 10 个字符
+#从字符串第 0 个字符开始往后截取 10 个字符(索引从 0 开始)
str="SnailClimb is a great man"
echo ${str:0:10} #输出:SnailClimb
```
@@ -209,8 +253,8 @@ echo ${str:0:10} #输出:SnailClimb
根据表达式截取:
```shell
-#!bin/bash
-#author:amau
+#!/bin/bash
+# author: amau
var="https://www.runoob.com/linux/linux-shell-variable.html"
# %表示删除从后匹配, 最短结果
@@ -220,14 +264,18 @@ var="https://www.runoob.com/linux/linux-shell-variable.html"
# 注: *为通配符, 意为匹配任意数量的任意字符
s1=${var%%t*} #h
s2=${var%t*} #https://www.runoob.com/linux/linux-shell-variable.h
-s3=${var%%.*} #http://www
+s3=${var%%.*} #https://www
s4=${var#*/} #/www.runoob.com/linux/linux-shell-variable.html
s5=${var##*/} #linux-shell-variable.html
```
### Shell 数组
-bash 支持一维数组(不支持多维数组),并且没有限定数组的大小。我下面给了大家一个关于数组操作的 Shell 代码示例,通过该示例大家可以知道如何创建数组、获取数组长度、获取/删除特定位置的数组元素、删除整个数组以及遍历数组。
+**bash 2.0+** 支持一维数组(不支持多维数组),并且没有限定数组的大小。
+
+**重要提示**:数组是 bash 的**非 POSIX 扩展特性**,纯 POSIX sh(如 dash)不支持数组。若需编写可移植脚本,应避免使用数组。
+
+下面是一个关于数组操作的 Shell 代码示例,通过该示例大家可以知道如何创建数组、获取数组长度、获取/删除特定位置的数组元素、删除整个数组以及遍历数组。
```shell
#!/bin/bash
@@ -247,9 +295,35 @@ unset array; # 删除数组中的所有元素
for i in ${array[@]};do echo $i ;done # 遍历数组,数组元素为空,没有任何输出内容
```
-## Shell 基本运算符
+**重要说明:数组索引空洞**:
+
+使用 `unset array[1]` 删除元素后,数组会产生**索引空洞**:
+
+```shell
+#!/bin/bash
+array=(1 2 3 4 5)
+echo "删除前: ${array[@]}" # 输出: 1 2 3 4 5
+echo "索引1的值: ${array[1]}" # 输出: 2
+
+unset array[1] # 删除索引1的元素
+echo "删除后: ${array[@]}" # 输出: 1 3 4 5
+echo "索引1的值: ${array[1]}" # 输出: (空值)
+echo "索引2的值: ${array[2]}" # 输出: 3 (索引2仍在)
+
+# 遍历时索引不连续
+for index in "${!array[@]}"; do
+ echo "索引[$index] = ${array[$index]}"
+done
+# 输出:
+# 索引[0] = 1
+# 索引[2] = 3
+# 索引[3] = 4
+# 索引[4] = 5
+```
+
+**注意**:删除元素后,如果使用 `${array[1]}` 访问会得到空值。遍历数组时建议使用 `"${!array[@]}"` 获取有效索引,或使用 `"${array[@]}"` 直接遍历值。
-> 说明:图片来自《菜鸟教程》
+## Shell 基本运算符
Shell 编程支持下面几种运算符
@@ -261,23 +335,51 @@ Shell 编程支持下面几种运算符
### 算数运算符
-
+| **运算符** | **说明** | **举例** |
+| ---------- | -------- | ------------------------------------------ |
+| **+** | 加法 | `expr $a + $b` |
+| **-** | 减法 | `expr $a - $b` |
+| **\*** | 乘法 | `expr $a \* $b` (注意星号需要转义) |
+| **/** | 除法 | `expr $b / $a` |
+| **%** | 取余 | `expr $b % $a` |
+| **=** | 赋值 | `a=$b` 将变量 b 的值赋给 a |
+| **==** | 相等 | `[ $a == $b ]` 用于数字比较,相同返回 true |
+| **!=** | 不相等 | `[ $a != $b ]` 用于数字比较,不同返回 true |
-我以加法运算符做一个简单的示例(注意:不是单引号,是反引号):
+**推荐使用 bash 内置算术扩展**:
```shell
#!/bin/bash
-a=3;b=3;
-val=`expr $a + $b`
-#输出:Total value : 6
-echo "Total value : $val"
+a=3; b=3
+val=$((a + b)) # bash 算术扩展(推荐)
+# 输出:Total value: 6
+echo "Total value: $val"
+```
+
+**说明**:
+
+- `$((...))` 是 bash 内置功能,无需 fork 外部进程,性能更好
+- **不推荐**使用 `expr` 命令(需 fork 进程,且运算符两边必须有空格)
+- **不推荐**使用反引号 `` `...` ``(已过时),应使用 `$(...)` 语法
+
+**如果需要兼容 POSIX sh**,可以使用:
+
+```shell
+val=$(expr "$a" + "$b") # POSIX 兼容,但性能较差
```
### 关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
-
+| **运算符** | **说明** | **对应英文** |
+| ---------- | ---------------------------------- | ------------- |
+| **-eq** | 检测两个数是否**相等** | equal |
+| **-ne** | 检测两个数是否**不相等** | not equal |
+| **-gt** | 检测左边的数是否**大于**右边的 | greater than |
+| **-lt** | 检测左边的数是否**小于**右边的 | less than |
+| **-ge** | 检测左边的数是否**大于等于**右边的 | greater equal |
+| **-le** | 检测左边的数是否**小于等于**右边的 | less equal |
通过一个简单的示例演示关系运算符的使用,下面 shell 程序的作用是当 score=100 的时候输出 A 否则输出 B。
@@ -285,7 +387,7 @@ echo "Total value : $val"
#!/bin/bash
score=90;
maxscore=100;
-if [ $score -eq $maxscore ]
+if [[ $score -eq $maxscore ]]
then
echo "A"
else
@@ -295,15 +397,18 @@ fi
输出结果:
-```
+```plain
B
```
### 逻辑运算符
-
+| **运算符** | **说明** | **举例** |
+| ---------- | -------------- | --------------------------------------------- | --- | --------------------------- |
+| **&&** | 逻辑的 **AND** | `[[ $a -lt 100 && $b -gt 100 ]]` (全真才为真) |
+| **\|\|** | 逻辑的 **OR** | `[[ $a -lt 100 | | $b -gt 100 ]]` (一真即为真) |
-示例:
+**算术扩展中的逻辑运算**:
```shell
#!/bin/bash
@@ -312,15 +417,71 @@ a=$(( 1 && 0))
echo $a;
```
-### 布尔运算符
+**命令短路执行(生产环境常用)**:
+
+在运维自动化和 CI/CD 管道中,经常使用 `&&` 和 `||` 来控制命令链路的执行流程,这称为**短路执行**:
+
+```shell
+#!/bin/bash
+set -euo pipefail
+
+# &&:前一个命令成功(返回 0)时才执行后一个命令
+mkdir -p "/tmp/app_data" && echo "目录就绪"
+
+# ||:前一个命令失败(返回非 0)时才执行后一个命令
+mkdir -p "/tmp/app_data" || echo "目录创建失败"
+
+# 组合使用:生产环境典型的防御姿势
+mkdir -p "/tmp/app_data" && echo "目录就绪" || exit 1
+
+# 实际场景示例
+# 1. 检查文件存在后再删除
+[ -f "/tmp/old_file.log" ] && rm "/tmp/old_file.log"
+
+# 2. 命令失败时输出错误信息并退出
+cd /app/config || { echo "无法进入配置目录"; exit 1; }
+
+# 3. 条件执行命令
+command1 && command2 || command3
+# ⚠️ 注意:此写法有陷阱!
+# - 当 command1 成功时,执行 command2
+# - 当 command1 失败时,执行 command3
+# - 但如果 command1 成功但 command2 失败,command3 仍会执行!
+#
+# ✅ 更安全的写法(推荐):
+if command1; then
+ command2
+else
+ command3
+fi
+#
+# 或明确知道 command2 不会失败时才使用 && || 组合
+```
-
+**重要提示**:
-这里就不做演示了,应该挺简单的。
+- 短路执行依赖命令的**退出码(Exit Code)**:成功返回 0,失败返回非 0
+- 这与 `[[ ]]` 内部的 `&&` 和 `||` 不同,后者用于条件测试
+- `command1 && command2 || command3` 存在陷阱:若 command1 成功但 command2 失败,command3 仍会执行
+- 生产环境中强烈建议使用 if-then-else 结构,确保逻辑清晰
+
+### 布尔运算符
+
+| **运算符** | **说明** | **举例** |
+| ---------- | -------------------------------------------------------------------- | ------------------------------------------ |
+| **!** | 将表达式的结果取反。如果表达式为 true,则返回 false;否则返回 true。 | `[ ! false ]` 返回 true。 |
+| **-o** | 有一个表达式为 true,则返回 true。 | `[ $a -lt 20 -o $b -gt 100 ]` 返回 true。 |
+| **-a** | 两个表达式都为 true 才会返回 true。 | `[ $a -lt 20 -a $b -gt 100 ]` 返回 false。 |
### 字符串运算符
-
+| **运算符** | **说明** | **举例** |
+| ---------- | --------------------------------- | ----------------------------- |
+| **=** | 检测两个字符串是否**相等** | `[ $a = $b ]` |
+| **!=** | 检测两个字符串是否**不相等** | `[ $a != $b ]` |
+| **-z** | 检测字符串长度是否为 **0** (zero) | `[ -z $a ]` 为空返回 true |
+| **-n** | 检测字符串长度是否**不为 0** | `[ -n "$a" ]` 不为空返回 true |
+| **str** | 直接检测字符串是否为空 | `[ $a ]` 不为空返回 true |
简单示例:
@@ -328,7 +489,7 @@ echo $a;
#!/bin/bash
a="abc";
b="efg";
-if [ $a = $b ]
+if [[ $a = $b ]]
then
echo "a 等于 b"
else
@@ -338,17 +499,30 @@ fi
输出:
-```
+```plain
a 不等于 b
```
### 文件相关运算符
-
+用于检测 Unix/Linux 文件的各种属性(如权限、类型等)。
+
+- **存在与类型检测:**
+ - **-e file**: 检测文件(包括目录)是否存在。
+ - **-f file**: 检测是否为普通文件(既不是目录也不是设备文件)。
+ - **-d file**: 检测是否为目录。
+ - **-s file**: 检测文件是否为空(文件大小大于 0 返回 true)。
+ - **-b/-c/-p**: 分别检测是否为块设备、字符设备、有名管道。
+- **权限检测:**
+ - **-r file**: 检测文件是否可读。
+ - **-w file**: 检测文件是否可写。
+ - **-x file**: 检测文件是否可执行。
+- **特殊标识检测:**
+ - **-u / -g / -k**: 分别检测文件是否设置了 SUID、SGID 或粘着位 (Sticky Bit)。
使用方式很简单,比如我们定义好了一个文件路径`file="/usr/learnshell/test.sh"` 如果我们想判断这个文件是否可读,可以这样`if [ -r $file ]` 如果想判断这个文件是否可写,可以这样`-w $file`,是不是很简单。
-## shell 流程控制
+## Shell 流程控制
### if 条件语句
@@ -358,10 +532,10 @@ a 不等于 b
#!/bin/bash
a=3;
b=9;
-if [ $a -eq $b ]
+if [[ $a -eq $b ]]
then
echo "a 等于 b"
-elif [ $a -gt $b ]
+elif [[ $a -gt $b ]]
then
echo "a 大于 b"
else
@@ -371,11 +545,26 @@ fi
输出结果:
-```
+```plain
a 小于 b
```
-相信大家通过上面的示例就已经掌握了 shell 编程中的 if 条件语句。不过,还要提到的一点是,不同于我们常见的 Java 以及 PHP 中的 if 条件语句,shell if 条件语句中不能包含空语句也就是什么都不做的语句。
+相信大家通过上面的示例就已经掌握了 shell 编程中的 if 条件语句。
+
+**空语句的处理**:Shell 中空语句可以使用 `:`(冒号命令)或 `true` 命令实现:
+
+```shell
+if [[ condition ]]; then
+ : # 空语句(什么都不做)
+fi
+
+# 或
+if [[ condition ]]; then
+ true # 空语句
+fi
+```
+
+这在某些场景下很有用,例如在 while 循环中作为占位符。
### for 循环语句
@@ -406,7 +595,8 @@ done
```shell
#!/bin/bash
-for((i=1;i<=5;i++));do
+length=5
+for((i=1;i<=length;i++));do
echo $i;
done;
```
@@ -418,10 +608,10 @@ done;
```shell
#!/bin/bash
int=1
-while(( $int<=5 ))
+while (( int <= 5 )) # 算术上下文内变量无需 $
do
echo $int
- let "int++"
+ (( int++ )) # 推荐使用 (( )) 替代 let
done
```
@@ -430,7 +620,7 @@ done
```shell
echo '按下 退出'
echo -n '输入你最喜欢的电影: '
-while read FILM
+while read -r FILM # -r 选项禁止反斜杠转义,提高安全性
do
echo "是的!$FILM 是一个好电影"
done
@@ -438,7 +628,7 @@ done
输出内容:
-```
+```plain
按下 退出
输入你最喜欢的电影: 变形金刚
是的!变形金刚 是一个好电影
@@ -453,7 +643,7 @@ do
done
```
-## shell 函数
+## Shell 函数
### 不带参数没有返回值的函数
@@ -469,7 +659,7 @@ echo "-----函数执行完毕-----"
输出结果:
-```
+```plain
-----函数开始执行-----
这是我的第一个 shell 函数!
-----函数执行完毕-----
@@ -481,21 +671,37 @@ echo "-----函数执行完毕-----"
```shell
#!/bin/bash
+set -euo pipefail
+
funWithReturn(){
+ local aNum
+ local anotherNum
echo "输入第一个数字: "
- read aNum
+ read -r aNum
echo "输入第二个数字: "
- read anotherNum
+ read -r anotherNum
echo "两个数字分别为 $aNum 和 $anotherNum !"
- return $(($aNum+$anotherNum))
+ return $((aNum + anotherNum))
}
funWithReturn
echo "输入的两个数字之和为 $?"
```
+**重要说明**:
+
+- **`local` 关键字**:将变量限制在函数作用域内,避免污染全局命名空间
+- **`read -r`**:`-r` 选项禁止反斜杠转义,提高安全性
+- **函数返回值**:Shell 函数只能返回 0-255 的退出码,如需返回复杂数据应使用 `echo` 或全局变量
+
+**为什么使用 local?**
+
+- 在复杂脚本或引入多个外部脚本时,非 local 变量可能被意外覆盖
+- 全局变量污染会导致难以排查的配置漂移或逻辑越权
+- 使用 `local` 是函数编程的最佳实践,类似于其他编程语言的局部变量概念
+
输出结果:
-```
+```plain
输入第一个数字:
1
输入第二个数字:
@@ -509,25 +715,694 @@ echo "输入的两个数字之和为 $?"
```shell
#!/bin/bash
funWithParam(){
- echo "第一个参数为 $1 !"
- echo "第二个参数为 $2 !"
- echo "第十个参数为 $10 !"
- echo "第十个参数为 ${10} !"
- echo "第十一个参数为 ${11} !"
- echo "参数总数有 $# 个!"
- echo "作为一个字符串输出所有参数 $* !"
+ echo "第一个参数为 $1"
+ echo "第二个参数为 $2"
+ echo "脚本名称为 $0"
+ echo "第十个参数为 ${10}" # 注意:参数 ≥ 10 时必须用 ${n}
+ echo "第十一个参数为 ${11}"
+ echo "参数总数有 $# 个"
+ echo "所有参数为 $*" # 作为单个字符串输出
+ echo "所有参数为 $@" # 作为独立的参数输出(推荐)
}
funWithParam 1 2 3 4 5 6 7 8 9 34 73
```
输出结果:
+```plain
+第一个参数为 1
+第二个参数为 2
+脚本名称为 ./script.sh
+第十个参数为 34
+第十一个参数为 73
+参数总数有 11 个
+所有参数为 1 2 3 4 5 6 7 8 9 34 73
+所有参数为 1 2 3 4 5 6 7 8 9 34 73
```
-第一个参数为 1 !
-第二个参数为 2 !
-第十个参数为 10 !
-第十个参数为 34 !
-第十一个参数为 73 !
-参数总数有 11 个!
-作为一个字符串输出所有参数 1 2 3 4 5 6 7 8 9 34 73 !
+
+**重要提示**:
+
+- **位置参数 `$n` 当 `n ≥ 10` 时必须使用 `${n}` 语法**
+- 例如:`$10` 会被解析为 `$1` 和字面量 `0` 的拼接,而非第十个参数
+- `$0` 表示脚本本身的名称
+- `$#` 表示参数总数
+
+**`$*` 与 `$@` 的核心区别**:
+
+| 表达式 | 未引用 | 双引号包裹 |
+| ------ | -------------- | ---------------------------------------- |
+| `$*` | 展开为所有参数 | 展开为**单个字符串**(所有参数合并) |
+| `$@` | 展开为所有参数 | 展开为**独立的参数**(每个参数保持独立) |
+
+**示例对比**:
+
+```shell
+#!/bin/bash
+test_args() {
+ echo "--- 使用 \$* (无引号)---"
+ for arg in $*; do
+ echo "参数: [$arg]"
+ done
+
+ echo -e "\n--- 使用 \$@ (无引号)---"
+ for arg in $@; do
+ echo "参数: [$arg]"
+ done
+
+ echo -e "\n--- 使用 \"\$*\" (双引号)---"
+ for arg in "$*"; do
+ echo "参数: [$arg]"
+ done
+
+ echo -e "\n--- 使用 \"\$@\" (双引号,推荐)---"
+ for arg in "$@"; do
+ echo "参数: [$arg]"
+ done
+}
+
+# 调用函数,传递包含空格的参数
+test_args "hello world" "foo bar"
+```
+
+**输出结果**:
+
+```plain
+--- 使用 $* (无引号)---
+参数: [hello]
+参数: [world]
+参数: [foo]
+参数: [bar]
+
+--- 使用 $@ (无引号)---
+参数: [hello]
+参数: [world]
+参数: [foo]
+参数: [bar]
+
+--- 使用 "$*" (双引号)---
+参数: [hello world foo bar] # 所有参数合并为一个字符串
+
+--- 使用 "$@" (双引号,推荐)---
+参数: [hello world] # 每个参数保持独立
+参数: [foo bar]
```
+
+**结论**:在传递参数时,**始终使用 `"$@"`** 以确保每个参数的独立性(特别是当参数包含空格时)。
+
+## Shell 编程最佳实践
+
+在掌握了 Shell 编程的基础知识后,了解一些最佳实践能帮助你编写更安全、更高效的脚本。
+
+### 脚本基础规范
+
+**1. Shebang 规范**:
+
+```shell
+#!/usr/bin/env bash # 更可移植(自动查找 bash)
+set -euo pipefail # 严格模式:遇错退出、未定义变量报错、管道失败报错
+```
+
+**Shebang 两种写法**:
+
+- `#!/bin/bash`:直接指定 bash 路径,适用于你知道 bash 位置的固定环境
+- `#!/usr/bin/env bash`:通过 env 查找 bash,更可移植,适合不同系统(如 macOS / Linux)
+
+**本文示例选择**:
+
+- 教程示例使用 `#!/bin/bash`:简洁明了,适合初学者理解
+- 生产级示例使用 `#!/usr/bin/env bash`:强调可移植性
+
+**2. 变量引用**:
+
+```shell
+# 始终用双引号包裹变量
+echo "$var" # 推荐
+echo $var # 可能导致 word splitting 和 globbing 问题
+```
+
+**3. 使用 shellcheck**:
+
+```bash
+shellcheck your_script.sh # 静态分析,发现常见问题
+```
+
+**4. 推荐语法**:
+
+- 使用 `[[ ]]` 而非 `[ ]`(更安全、支持模式匹配)
+- 使用 `$((...))` 而非 `expr`(性能更好)
+- 使用 `$(...)` 而非反引号(可嵌套、更清晰)
+- 使用 `${n}` 访问位置参数 n ≥ 10
+
+### pipefail 工作原理
+
+默认情况下,管道命令的返回值只取决于最后一个命令。启用 `pipefail` 后,管道的返回值将是最后一个失败命令的返回值,这能避免隐藏中间步骤的错误。
+
+**示例对比**:
+
+```shell
+# 默认模式(危险)
+cat huge_file.txt | grep "pattern" | head -n 10
+# 即使 cat 失败(文件不存在),只要 head 成功,返回码就是 0
+
+# pipefail 模式(安全)
+set -o pipefail
+cat huge_file.txt | grep "pattern" | head -n 10
+# cat 失败会立即返回错误码,不会被忽略
+```
+
+## 生产环境最佳实践
+
+### 脚本安全性
+
+**1. 始终使用严格模式**:
+
+```shell
+#!/usr/bin/env bash
+set -euo pipefail # 遇错退出、未定义变量报错、管道失败报错
+```
+
+**2. 变量引用安全**:
+
+```shell
+# 始终用双引号包裹变量,防止 word splitting 和 globbing
+rm -rf "$temp_dir" # 推荐
+rm -rf $temp_dir # 危险:如果 temp_dir 包含空格会导致误删
+```
+
+**3. 使用 local 限制变量作用域**:
+
+```shell
+process_data() {
+ local input_file="$1"
+ local output_file="$2"
+ # ... 处理逻辑
+}
+```
+
+### 监控指标建议
+
+**关键指标**:
+
+- **脚本执行返回码(Exit Code)**:非 0 必须触发告警
+- **命令执行超时时间**:防御网络阻塞或 read 死锁(使用 `timeout` 命令)
+- **关键资源的并发争用**:临时文件、锁文件、网络连接等
+- **单机文件描述符(FD)使用率**:防止后台并发启动导致 FD 耗尽
+- **PID 饱和度**:监控进程数量,防止 PID 耗尽
+- **网络请求 P99 延迟**:监控 API 请求的尾延迟
+
+**超时控制示例**:
+
+```shell
+# 为整个脚本设置超时(5 分钟)
+timeout 300 ./your_script.sh || { echo "脚本执行超时"; exit 1; }
+
+# 为单个命令设置超时
+timeout 10 curl -s https://api.example.com/data || { echo "API 请求超时"; exit 1; }
+```
+
+**生产级 API 请求(带重试和退避)**:
+
+```shell
+# ⚠️ 重要:单纯拦截超时不够,必须考虑重试风暴
+# 下面的配置包含连接超时、总超时、重试机制和指数退避
+
+curl -s \
+ --connect-timeout 3 \ # 连接超时 3 秒
+ --max-time 10 \ # 总超时 10 秒
+ --retry 3 \ # 失败时重试 3 次
+ --retry-delay 2 \ # 重试间隔 2 秒
+ --retry-max-time 30 \ # 重试总时长不超过 30 秒
+ --retry-connrefused \ # 连接被拒绝时也重试
+ --retry-all-errors \ # 所有错误都重试
+ https://api.example.com/data || { echo "API 请求彻底失败"; exit 1; }
+```
+
+**重试风暴防护**:
+
+```shell
+# ❌ 危险:无节制的重试会导致级联雪崩
+for i in {1..10}; do
+ curl -s https://api.example.com/data && break || sleep 1
+done
+
+# ✅ 安全:带抖动(Jitter)的指数退避重试
+retry_with_backoff() {
+ local max_attempts=5
+ local base_delay=1
+ local max_delay=32
+ local attempt=1
+
+ while (( attempt <= max_attempts )); do
+ if curl -s --connect-timeout 3 --max-time 10 \
+ --retry 3 --retry-delay 2 --retry-max-time 30 \
+ "$@"; then
+ return 0
+ fi
+
+ if (( attempt < max_attempts )); then
+ # 指数退避 + 随机抖动(防止重试风暴)
+ local delay=$(( base_delay * (1 << (attempt - 1)) ))
+ delay=$(( delay > max_delay ? max_delay : delay ))
+ local jitter=$((RANDOM % 1000)) # 0-999ms 随机抖动
+ delay=$(( delay * 1000 + jitter ))
+ echo "请求失败,${delay}ms 后重试 (第 $attempt 次)" >&2
+ sleep "${delay}e-6"
+ fi
+
+ ((attempt++))
+ done
+
+ return 1
+}
+
+# 使用
+retry_with_backoff https://api.example.com/data
+```
+
+**重要提示**:
+
+- **重试风暴**:网络分区恢复后,无节制的重试会瞬间打满下游服务
+- **指数退避**:每次重试间隔呈指数增长(1s → 2s → 4s → 8s...)
+- **随机抖动**:添加随机延迟避免多个客户端同时重试(惊群效应)
+- **监控指标**:需监控超时丢包率与 P99 请求耗时
+
+### 压测建议
+
+**并发安全测试**:
+
+```shell
+# ❌ 危险:无限制并发可能导致 PID 耗尽或 OOM
+for i in {1..100}; do
+ ./your_script.sh &
+done
+wait
+
+# ✅ 安全:使用 xargs 控制并发度(推荐)
+# 限制最大并行数为 10,防止系统资源耗尽
+seq 1 100 | xargs -n 1 -P 10 -I {} ./your_script.sh
+
+# 或使用 GNU parallel(功能更强大)
+seq 1 100 | parallel -j 10 ./your_script.sh
+```
+
+**重要提示**:
+
+- **并发度控制**:生产环境的单机压测应使用 `xargs -P` 或 GNU parallel 限制并发进程数
+- **资源监控**:压测时监控文件描述符(FD)使用率和 PID 饱和度
+- **失败模式**:无限制的 `&` 会引发数百个进程在 D 状态挂起,导致节点内核级假死
+
+**常见问题检测**:
+
+- **固定路径冲突**:避免使用 `/tmp/test.log` 等固定路径,应使用 `$$` 引入进程 PID:
+
+ ```shell
+ temp_file="/tmp/myapp_$$/temp.log"
+ mkdir -p "$(dirname "$temp_file")"
+ ```
+
+- **锁机制**:使用 `flock` 防止并发执行:
+
+ ```shell
+ # ⚠️ 重要:flock 仅在本地文件系统(Ext4/XFS)保证强一致性
+ # 若锁文件位于 NFS 等网络存储,flock 可能静默失效(脑裂风险)
+
+ # 单机场景:确保同一时间只有一个实例在运行
+ exec 200>/var/lock/myapp.lock
+ flock -n 200 || { echo "脚本已在运行"; exit 1; }
+
+ # 分布式场景:需要使用分布式锁服务(如 Redis、etcd、ZooKeeper)
+ # 或通过数据库唯一索引、消息队列等机制实现互斥
+ ```
+
+ **flock 脑裂风险可视化**:
+
+ ```mermaid
+ sequenceDiagram
+ participant CronA as 节点A (定时任务)
+ participant CronB as 节点B (定时任务)
+ participant Storage as 存储层
+
+ CronA->>Storage: 请求 flock 互斥锁 (非阻塞)
+ Storage-->>CronA: 授予锁 (成功)
+ CronA->>CronA: 执行核心自动化逻辑
+
+ CronB->>Storage: 并发请求 flock 互斥锁 (非阻塞)
+ alt 本地文件系统 (Ext4/XFS)
+ Storage-->>CronB: 拒绝加锁 (返回非0)
+ CronB->>CronB: 安全退出,防御并发成功 ✓
+ else 网络文件系统 (NFS/配置异常)
+ Storage-->>CronB: 错误地授予锁 (静默失效)
+ CronB->>CronB: 🚨 执行核心逻辑,发生并发写与数据踩踏!
+ end
+ ```
+
+ **分布式锁方案建议**:
+
+ - **Redis**:使用 `SET key value NX PX timeout` 实现分布式锁
+ - **etcd**:使用事务 API 和租约机制
+ - **数据库**:使用 `UNIQUE INDEX` 约束
+ - **消息队列**:使用单消费者模式保证互斥
+
+**后台进程退出码捕获**:
+
+```shell
+# ❌ 问题:wait 默认不检查退出码,后台任务失败会被静默吃掉
+for i in {1..10}; do
+ ./task.sh &
+done
+wait # 只等待所有后台进程结束,不检查退出码
+
+# ✅ 正确:逐个检查后台进程的退出码
+pids=()
+for i in {1..10}; do
+ ./task.sh &
+ pids+=($!)
+done
+
+# 等待所有后台进程并检查退出码
+for pid in "${pids[@]}"; do
+ if ! wait "$pid"; then
+ echo "进程 $pid 执行失败" >&2
+ exit_code=1
+ fi
+done
+
+# 或使用 wait -n(bash 4.3+)等待任一进程并检查退出码
+while wait -n; do
+ : # 检查 $? 是否为 0
+done
+```
+
+### 常见误区
+
+**1. 吞掉错误上下文**:
+
+```shell
+# ❌ 错误:滥用 > /dev/null 2>&1
+command > /dev/null 2>&1
+
+# ✅ 正确:只屏蔽不需要的输出,保留错误信息
+command > /dev/null # 或
+command 2>/tmp/error.log
+```
+
+**2. 环境依赖假定**:
+
+```shell
+# ❌ 危险:依赖特定的 PATH 顺序,未验证命令是否存在
+curl -s https://api.example.com/data
+
+# ✅ 安全:验证命令存在后再使用
+command -v curl >/dev/null 2>&1 || { echo "curl 未安装"; exit 1; }
+curl -s https://api.example.com/data
+
+# 或者:明确指定完整路径(适用于关键生产环境)
+CURL_PATH="/usr/bin/curl"
+[[ -x "$CURL_PATH" ]] || { echo "curl 不存在或不可执行"; exit 1; }
+"$CURL_PATH" -s https://api.example.com/data
+```
+
+**说明**:验证命令存在可以防止因环境差异导致的运行时错误。若需更高安全性,可指定完整路径。
+
+**3. 未处理管道失败**:
+
+```shell
+# ❌ 问题:默认模式下管道只看最后一个命令的返回码
+cat huge_file.txt | grep "pattern" | head -n 10
+# 即使 cat 失败,只要 head 成功,整体返回码就是 0
+
+# ✅ 安全:使用 pipefail 确保任何命令失败都能被捕获
+set -o pipefail
+cat huge_file.txt | grep "pattern" | head -n 10
+```
+
+**4. 未清理临时资源**:
+
+```shell
+# ❌ 问题:脚本异常退出时临时文件未被清理
+temp_file="/tmp/data_$$"
+process_data "$temp_file"
+
+# ✅ 安全:使用 trap 确保清理
+temp_file="/tmp/data_$$"
+trap 'rm -f "$temp_file"' EXIT
+process_data "$temp_file"
+```
+
+### 错误处理模式
+
+**防御式编程模板**:
+
+```shell
+#!/usr/bin/env bash
+set -euo pipefail
+
+# 错误处理函数
+error_exit() {
+ echo "错误: $1" >&2
+ exit "${2:-1}"
+}
+
+# 验证依赖
+command -v curl >/dev/null 2>&1 || error_exit "curl 未安装"
+command -v jq >/dev/null 2>&1 || error_exit "jq 未安装"
+
+# 验证参数
+[[ $# -eq 1 ]] || error_exit "用法: $0 "
+
+# 验证文件存在
+[[ -f "$1" ]] || error_exit "配置文件不存在: $1"
+
+# 设置超时和清理
+temp_file="/tmp/process_$$"
+trap 'rm -f "$temp_file"' EXIT
+
+# 主要逻辑(带超时)
+timeout 300 process_data "$1" "$temp_file" || error_exit "数据处理失败或超时"
+
+echo "处理完成:$temp_file"
+```
+
+### 故障演练建议
+
+生产环境的脚本需要经过充分的故障测试,确保在各种异常情况下都能正确处理。以下是推荐的故障演练场景:
+
+**1. 网络分区测试**
+
+```shell
+# 使用 iptables 模拟 50% 丢包率
+sudo iptables -A OUTPUT -p tcp --dport 443 -m statistic --mode random --probability 0.5 -j DROP
+
+# 测试带有重试机制的 curl 是否引发雪崩
+retry_with_backoff https://api.example.com/data
+
+# 恢复网络
+sudo iptables -D OUTPUT -p tcp --dport 443 -m statistic --mode random --probability 0.5 -j DROP
+```
+
+**测试要点**:
+
+- 验证重试机制是否正常工作
+- 检查是否有指数退避和随机抖动
+- 确认不会因重试风暴导致级联失败
+
+**2. 慢响应拖垮测试**
+
+```shell
+# 模拟下游 API 长时间不返回(但不断开连接)
+# 使用 nc 监听端口但不发送数据
+nc -l 8080 &
+
+# 测试 timeout 是否能准确切断连接
+timeout 5 curl -s http://localhost:8080/data || echo "超时触发"
+
+# 清理
+pkill nc
+```
+
+**测试要点**:
+
+- 验证 `--max-time` 是否生效
+- 检查是否有资源泄漏(连接、内存)
+- 确认超时后脚本能正确退出
+
+**3. 时钟漂移测试**
+
+```shell
+# 模拟系统时钟回拨(需要 root 权限)
+sudo date -s "2 hours ago"
+
+# 测试基于 $PID 生成的临时文件是否有重复覆盖风险
+temp_file="/tmp/test_$$/data.txt"
+mkdir -p "$(dirname "$temp_file")"
+echo "data" > "$temp_file"
+echo "Created: $temp_file"
+
+# 恢复系统时钟
+sudo ntpdate -u time.nist.gov
+```
+
+**测试要点**:
+
+- 验证 PID 循环后临时文件是否会被覆盖
+- 检查是否需要添加时间戳或 UUID 增强唯一性
+- 确认脚本对时钟变化的鲁棒性
+
+**4. NFS 延迟测试**
+
+```shell
+# 模拟 NFS 存储高延迟(使用 tc 延迟网络)
+# 挂载测试用的 NFS 共享
+sudo mount -t nfs nfs-server:/share /mnt/nfs-test
+
+# 监控 I/O 延迟(P90 / P99)
+iostat -x 1 10 | grep dm-0
+
+# 在 NFS 共享上执行脚本,验证 flock 是否正常
+LOCK_FILE="/mnt/nfs-test/myapp.lock"
+exec 200>"$LOCK_FILE"
+flock -n 200 || { echo "获取锁失败"; exit 1; }
+
+# 清理
+sudo umount /mnt/nfs-test
+```
+
+**测试要点**:
+
+- 验证 flock 在网络存储上是否有效(预期可能失效)
+- 检查是否有脑裂风险(多个节点同时获取锁)
+- 确认是否需要使用分布式锁替代
+
+**5. 文件描述符耗尽测试**
+
+```shell
+# 查看当前进程的 FD 限制
+ulimit -n
+
+# 模拟大量并发连接,测试 FD 耗尽场景
+for i in {1..1000}; do
+ exec {fd}>"/tmp/file_$i" 2>/dev/null || break
+done
+
+# 检查 FD 使用情况
+ls -l /proc/$$/fd | wc -l
+
+# 清理
+for i in {1..1000}; do
+ eval "exec $fd>&-" 2>/dev/null
+done
+```
+
+**测试要点**:
+
+- 验证脚本在 FD 不足时的行为
+- 检查是否有资源泄漏
+- 确认并发度限制是否有效
+
+**6. 压测数据一致性测试**
+
+```shell
+# 在 NFS 共享存储目录下,由多个机器节点同时高频执行脚本
+# 验证数据恢复与幂等性边界
+
+# 节点 A
+for i in {1..100}; do
+ echo "nodeA_data_$i" >> /mnt/shared/data.txt
+ sleep 0.1
+done &
+
+# 节点 B(在另一台机器上同时执行)
+for i in {1..100}; do
+ echo "nodeB_data_$i" >> /mnt/shared/data.txt
+ sleep 0.1
+done &
+
+# 检查数据是否完整
+wait
+wc -l /mnt/shared/data.txt
+sort /mnt/shared/data.txt | uniq -c
+```
+
+**测试要点**:
+
+- 验证并发写入是否会导致数据混乱
+- 检查是否需要使用锁机制
+- 确认数据恢复策略是否有效
+
+## 总结
+
+Shell 编程是后端开发和运维人员必备的核心技能之一,掌握它能显著提升工作效率,实现自动化运维和系统管理。本文从入门到生产实践,系统介绍了 Shell 编程的核心知识点。
+
+### 核心知识点回顾
+
+| 知识模块 | 关键要点 |
+| ------------ | --------------------------------------------------------------------------------- | --- | ---------------- |
+| **变量** | 区分局部变量、环境变量和特殊变量;使用 `local` 避免全局污染;始终用双引号包裹变量 |
+| **字符串** | 推荐使用双引号;理解单引号和双引号的区别;掌握 `${#var}` 获取长度 |
+| **数组** | bash 2.0+ 支持数组(非 POSIX);注意删除元素后的索引空洞 |
+| **运算符** | 优先使用 `$((...))` 进行算术运算;`[[ ]]` 比 `[ ]` 更安全 |
+| **流程控制** | 使用 `[[ ]]` 进行条件测试;避免 `command1 && command2 | | command3` 的陷阱 |
+| **函数** | 使用 `local` 限制变量作用域;函数只能返回 0-255 的退出码 |
+| **命令替换** | 使用 `$(...)` 替代反引号;使用 `read -r` 提高安全性 |
+
+### 生产级脚本编写要点
+
+编写生产环境的 Shell 脚本时,务必遵循以下原则:
+
+**1. 严格模式**
+
+```shell
+#!/usr/bin/env bash
+set -euo pipefail # 遇错退出、未定义变量报错、管道失败报错
+```
+
+**2. 防御式编程**
+
+- 验证依赖:`command -v` 检查命令是否存在
+- 验证参数:检查参数数量和类型
+- 验证文件:确认文件存在且可访问
+- 超时控制:使用 `timeout` 防止死锁
+- 资源清理:使用 `trap` 确保临时资源被释放
+
+**3. 避免常见陷阱**
+
+- 不吞掉错误上下文(避免滥用 `>/dev/null 2>&1`)
+- 不依赖特定 PATH 顺序(验证或指定完整路径)
+- 不忽略管道失败(使用 `set -o pipefail`)
+- 不遗漏临时资源清理(使用 `trap`)
+
+**4. 并发安全**
+
+- 使用 `$$` 引入 PID 隔离临时文件
+- 使用 `flock` 防止脚本并发执行
+- 避免使用固定的临时文件路径
+
+### 学习建议
+
+**初学者**:
+
+1. 从简单的命令别名和脚本开始
+2. 重点掌握变量、条件判断和循环
+3. 使用 `shellcheck` 检查脚本错误
+4. 多练习,从实际场景出发(如日志分析、文件处理)
+
+**进阶学习**:
+
+1. 深入学习进程管理、信号处理
+2. 掌握 `sed`、`awk`、`grep` 等文本处理工具
+3. 学习正则表达式和文本处理技巧
+4. 了解性能优化和并发处理
+
+**生产实践**:
+
+1. 阅读 Google Shell Style Guide
+2. 研究开源项目的 Shell 脚本
+3. 在测试环境充分验证后再部署
+4. 建立完善的监控和告警机制
+
+### 参考资源
+
+- **官方文档**:Bash Reference Manual (GNU)
+- **代码检查**:ShellCheck - Shell Script Analysis Tool
+- **编码规范**:Google Shell Style Guide
+- **常见陷阱**:Bash Pitfalls (http://mywiki.wooledge.org/BashPitfalls)
diff --git a/docs/database/basis.md b/docs/database/basis.md
index 8848dcfbad3..154d59a0be5 100644
--- a/docs/database/basis.md
+++ b/docs/database/basis.md
@@ -1,28 +1,204 @@
---
title: 数据库基础知识总结
+description: 数据库基础知识总结,包括数据库、DBMS、数据库系统、DBA的概念区别,DBMS核心功能,元组、码、主键外键等关系型数据库核心概念,以及ER图的使用方法。
category: 数据库
tag:
- 数据库基础
+head:
+ - - meta
+ - name: keywords
+ content: 数据库,数据库管理系统,DBMS,数据库系统,DBA,SQL,DDL,DML,数据模型,关系型数据库,主键,外键,ER图
---
+
+
数据库知识基础,这部分内容一定要理解记忆。虽然这部分内容只是理论知识,但是非常重要,这是后面学习 MySQL 数据库的基础。PS: 这部分内容由于涉及太多概念性内容,所以参考了维基百科和百度百科相应的介绍。
## 什么是数据库, 数据库管理系统, 数据库系统, 数据库管理员?
-- **数据库** : 数据库(DataBase 简称 DB)就是信息的集合或者说数据库是由数据库管理系统管理的数据的集合。
-- **数据库管理系统** : 数据库管理系统(Database Management System 简称 DBMS)是一种操纵和管理数据库的大型软件,通常用于建立、使用和维护数据库。
-- **数据库系统** : 数据库系统(Data Base System,简称 DBS)通常由软件、数据库和数据管理员(DBA)组成。
-- **数据库管理员** : 数据库管理员(Database Administrator, 简称 DBA)负责全面管理和控制数据库系统。
+这四个概念描述了从数据本身到管理整个体系的不同层次,我们常用一个图书馆的例子来把它们串联起来理解。
+
+- **数据库 (Database - DB):** 它就像是图书馆里,书架上存放的所有书籍和资料。从技术上讲,数据库就是按照一定数据模型组织、描述和储存起来的、可以被各种用户共享的结构化数据的集合。它就是我们最终要存取的核心——信息本身。
+- **数据库管理系统 (Database Management System - DBMS):** 它就像是整个图书馆的管理系统,包括图书的分类编目规则、借阅归还流程、安全检查系统等等。从技术上讲,DBMS 是一种大型软件,比如我们常用的 MySQL、Oracle、PostgreSQL 软件。它的核心职责是科学地组织和存储数据、高效地获取和维护数据;为我们屏蔽了底层文件操作的复杂性,提供了一套标准接口(如 SQL)来操纵数据,并负责并发控制、事务管理、权限控制等复杂问题。
+- **数据库系统 (Database System - DBS):** 它就是整个正常运转的图书馆。这是一个更大的概念,不仅包括书(DB)和管理系统(DBMS),还包括了硬件、应用和使用的人。
+- **数据库管理员 (Database Administrator - DBA ):** 他就是图书馆的馆长,负责整个数据库系统正常运行。他的职责非常广泛,包括数据库的设计、安装、监控、性能调优、备份与恢复、安全管理等等,确保整个系统的稳定、高效和安全。
+
+DB 和 DBMS 我们通常会搞混,这里再简单提一下:**通常我们说“用 MySQL 数据库”,其实是用 MySQL(DBMS)来管理一个或多个数据库(DB)。**
+
+## DBMS 有哪些主要的功能
+
+```mermaid
+graph TD
+ DBMS["🗄️ DBMS
数据库管理系统"]
+
+ subgraph define["数据定义"]
+ DDL["📐 DDL
Data Definition Language"]
+ DDL_Items["• 创建/修改/删除对象
• 定义表结构
• 定义视图、索引
• 定义触发器
• 定义存储过程"]
+ end
+
+ subgraph operate["数据操作"]
+ DML["⚡ DML
Data Manipulation Language"]
+ CRUD["CRUD 操作
• Create 创建
• Read 读取
• Update 更新
• Delete 删除"]
+ end
+
+ subgraph control["数据控制"]
+ DCL["🔐 数据控制功能"]
+ Control_Items["• 并发控制
• 事务管理
• 完整性约束
• 权限控制
• 安全性限制"]
+ end
+
+ subgraph maintain["数据库维护"]
+ Maintenance["🛠️ 维护功能"]
+ Maintain_Items["• 数据导入/导出
• 备份与恢复
• 性能监控与分析
• 系统日志管理"]
+ end
+
+ DBMS --> DDL
+ DBMS --> DML
+ DBMS --> DCL
+ DBMS --> Maintenance
+
+ DDL --> DDL_Items
+ DML --> CRUD
+ DCL --> Control_Items
+ Maintenance --> Maintain_Items
+
+ style DBMS fill:#005D7B,stroke:#00838F,stroke-width:4px,color:#fff
+
+ style DDL fill:#4CA497,stroke:#00838F,stroke-width:3px,color:#fff
+ style DDL_Items fill:#f0fffe,stroke:#4CA497,stroke-width:2px,color:#333
+
+ style DML fill:#E99151,stroke:#C44545,stroke-width:3px,color:#fff
+ style CRUD fill:#fff5e6,stroke:#E99151,stroke-width:2px,color:#333
+
+ style DCL fill:#00838F,stroke:#005D7B,stroke-width:3px,color:#fff
+ style Control_Items fill:#e6f7ff,stroke:#00838F,stroke-width:2px,color:#333
+
+ style Maintenance fill:#C44545,stroke:#8B0000,stroke-width:3px,color:#fff
+ style Maintain_Items fill:#ffe6e6,stroke:#C44545,stroke-width:2px,color:#333
+
+ style define fill:#E4C189,stroke:#E99151,stroke-width:2px,stroke-dasharray: 5 5,opacity:0.3
+ style operate fill:#E4C189,stroke:#E99151,stroke-width:2px,stroke-dasharray: 5 5,opacity:0.3
+ style control fill:#E4C189,stroke:#E99151,stroke-width:2px,stroke-dasharray: 5 5,opacity:0.3
+ style maintain fill:#E4C189,stroke:#E99151,stroke-width:2px,stroke-dasharray: 5 5,opacity:0.3
+```
+
+DBMS 通常提供四大核心功能:
+
+1. **数据定义:** 这是 DBMS 的基础。它提供了一套数据定义语言(Data Definition Language - DDL),让我们能够创建、修改和删除数据库中的各种对象。这不仅仅是定义表的结构(比如字段名、数据类型),还包括定义视图、索引、触发器、存储过程等。
+2. **数据操作:** 这是我们作为开发者日常使用最多的功能。它提供了一套数据操作语言(Data Manipulation Language - DML),核心就是我们熟悉的增、删、改、查(CRUD)操作。它让我们能够方便地对数据库中的数据进行操作和检索。
+3. **数据控制:** 这是保证数据正确、安全、可靠的关键。通常包含并发控制、事务管理、完整性约束、权限控制、安全性限制等功能。
+4. **数据库维护:** 这部分功能是为了保障数据库系统的长期稳定运行。它包括了数据的导入导出、数据库的备份与恢复、性能监控与分析、以及系统日志管理等。
+
+## 你知道哪些类型的 DBMS?
+
+### 关系型数据库
+
+除了我们最常用的关系型数据库(RDBMS),比如 MySQL(开源首选)、PostgreSQL(功能最全)、Oracle(企业级),它们基于严格的表结构和 SQL,非常适合结构化数据和需要事务保证的场景,例如银行交易、订单系统。
+
+近年来,为了应对互联网应用带来的海量数据、高并发和多样化数据结构的需求,涌现出了一大批 NoSQL 和 NewSQL 数据库。
+
+### NoSQL 数据库
+
+它们的共同特点是为了极致的性能和水平扩展能力,在某些方面(通常是事务)做了妥协。
+
+**1. 键值数据库,代表是 Redis。**
+
+- **特点:** 数据模型极其简单,就是一个巨大的 Map,通过 Key 来存取 Value。内存操作,性能极高。
+- **适用场景:** 非常适合做缓存、会话存储、计数器等对读写性能要求极高的场景。
+
+**2. 文档数据库,代表是 MongoDB。**
+
+- **特点:** 它存储的是半结构化的文档(比如 JSON/BSON),结构灵活,不需要预先定义表结构。
+- **适用场景:** 特别适合那些数据结构多变、快速迭代的业务,比如用户画像、内容管理系统、日志存储等。
+
+**3. 列式数据库,代表是 HBase, Cassandra。**
+
+- **特点:** 数据是按列族而不是按行来存储的。这使得它在对大量行进行少量列的读取时,性能极高。
+- **适用场景:** 专为海量数据存储和分析设计,非常适合做大数据分析、监控数据存储、推荐系统等需要高吞吐量写入和范围扫描的场景。
+
+**4. 图形数据库,代表是 Neo4j。**
+
+- **特点:** 数据模型是节点(Nodes)和边(Edges),专门用来存储和查询实体之间的复杂关系。
+- **适用场景:** 在社交网络(好友关系)、推荐引擎(用户-商品关系)、知识图谱、欺诈检测(资金流动关系)等场景下,表现远超关系型数据库。
+
+### NewSQL 数据库
+
+由于 NoSQL 不支持事务,很多对于数据安全要求非常高的系统(比如财务系统、订单系统、交易系统)就不太适合使用了。不过,这类系统往往有存储大量数据的需求。
+
+这些系统往往只能通过购买性能更强大的计算机,或者通过数据库中间件来提高存储能力。不过,前者的金钱成本太高,后者的开发成本太高。
+
+于是,**NewSQL** 就来了!
+
+简单来说,NewSQL 就是:**分布式存储+SQL+事务** 。NewSQL 不仅具有 NoSQL 对海量数据的存储管理能力,还保持了传统数据库支持 ACID 和 SQL 等特性。因此,NewSQL 也可以称为 **分布式关系型数据库**。
+
+NewSQL 数据库设计的一些目标:
+
+1. 横向扩展(Scale Out) : 通过增加机器的方式来提高系统的负载能力。与之类似的是 Scale Up(纵向扩展),升级硬件设备的方式来提高系统的负载能力。
+2. 强一致性(Strict Consistency):在任意时刻,所有节点中的数据是一样的。
+3. 高可用(High Availability):系统几乎可以一直提供服务。
+4. 支持标准 SQL(Structured Query Language) :PostgreSQL、MySQL、Oracle 等关系型数据库都支持 SQL 。
+5. 事务(ACID) : 原子性(Atomicity)、一致性(Consistency)、 隔离性(Isolation); 持久性(Durability)。
+6. 兼容主流关系型数据库 : 兼容 MySQL、Oracle、PostgreSQL 等常用关系型数据库。
+7. 云原生 (Cloud Native):可在公有云、私有云、混合云中实现部署工具化、自动化。
+8. HTAP(Hybrid Transactional/Analytical Processing) :支持 OLTP 和 OLAP 混合处理。
+
+NewSQL 数据库代表:Google 的 F1/Spanner、阿里的 [OceanBase](https://open.oceanbase.com/)、PingCAP 的 [TiDB](https://pingcap.com/zh/product-community/) 。
## 什么是元组, 码, 候选码, 主码, 外码, 主属性, 非主属性?
-- **元组**:元组(tuple)是关系数据库中的基本概念,关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。 在二维表里,元组也称为行。
-- **码**:码就是能唯一标识实体的属性,对应表中的列。
-- **候选码**:若关系中的某一属性或属性组的值能唯一的标识一个元组,而其任何、子集都不能再标识,则称该属性组为候选码。例如:在学生实体中,“学号”是能唯一的区分学生实体的,同时又假设“姓名”、“班级”的属性组合足以区分学生实体,那么{学号}和{姓名,班级}都是候选码。
-- **主码** : 主码也叫主键。主码是从候选码中选出来的。 一个实体集中只能有一个主码,但可以有多个候选码。
-- **外码** : 外码也叫外键。如果一个关系中的一个属性是另外一个关系中的主码则这个属性为外码。
-- **主属性**:候选码中出现过的属性称为主属性。比如关系 工人(工号,身份证号,姓名,性别,部门). 显然工号和身份证号都能够唯一标示这个关系,所以都是候选码。工号、身份证号这两个属性就是主属性。如果主码是一个属性组,那么属性组中的属性都是主属性。
-- **非主属性:** 不包含在任何一个候选码中的属性称为非主属性。比如在关系——学生(学号,姓名,年龄,性别,班级)中,主码是“学号”,那么其他的“姓名”、“年龄”、“性别”、“班级”就都可以称为非主属性。
+在关系型数据库理论中,理解元组、码、候选码、主码、外码、主属性和非主属性这些核心概念,对于数据库设计和规范化至关重要。这些概念构成了关系数据库的理论基础。
+
+```mermaid
+graph TD
+ A[关系数据库概念] --> B[数据组织]
+ A --> C[码的类型]
+ A --> D[属性分类]
+
+ B --> B1[元组
表中的行记录]
+ B --> B2[属性
表中的列]
+
+ C --> C1[码
唯一标识]
+ C1 --> C2[候选码
最小唯一标识集]
+ C2 --> C3[主码
选定的候选码]
+ C1 --> C4[外码
引用其他表主码]
+
+ D --> D1[主属性
候选码中的属性]
+ D --> D2[非主属性
不在候选码中的属性]
+
+ C3 -.关联.-> C4
+ C2 -.构成.-> D1
+
+ style A fill:#4CA497,stroke:#00838F,stroke-width:3px,color:#fff
+ style B fill:#00838F,stroke:#005D7B,stroke-width:2px,color:#fff
+ style C fill:#E99151,stroke:#005D7B,stroke-width:2px,color:#fff
+ style D fill:#005D7B,stroke:#00838F,stroke-width:2px,color:#fff
+
+ style B1 fill:#E4C189,stroke:#00838F,stroke-width:1px
+ style B2 fill:#E4C189,stroke:#00838F,stroke-width:1px
+
+ style C1 fill:#E4C189,stroke:#E99151,stroke-width:1px
+ style C2 fill:#E4C189,stroke:#E99151,stroke-width:1px
+ style C3 fill:#C44545,stroke:#005D7B,stroke-width:2px,color:#fff
+ style C4 fill:#E4C189,stroke:#E99151,stroke-width:1px
+
+ style D1 fill:#E4C189,stroke:#005D7B,stroke-width:1px
+ style D2 fill:#E4C189,stroke:#005D7B,stroke-width:1px
+```
+
+### 基础概念
+
+- **元组(Tuple):** 元组是关系数据库中的基本单位,在二维表中对应一行记录。每个元组包含了一个实体的完整信息。例如,在学生表中,每个学生的完整信息(学号、姓名、年龄等)构成一个元组。
+- **码(Key):** 码是能够唯一标识关系中元组的一个或多个属性的集合。码的主要作用是保证数据的唯一性和完整性。
+
+### 码的分类
+
+- **候选码(Candidate Key):** 候选码是能够唯一标识元组的最小属性集合,其任何真子集都不能唯一标识元组。一个关系可能有多个候选码。例如,在学生表中,如果"学号"能唯一标识学生,同时"身份证号"也能唯一标识学生,那么{学号}和{身份证号}都是候选码。
+- **主码/主键(Primary Key):** 主码是从候选码中选择的一个,用于唯一标识关系中的元组。每个关系只能有一个主码,但可以有多个候选码。选择主码时通常考虑:简单性、稳定性、无业务含义等因素。
+- **外码/外键(Foreign Key):** 外码是一个关系中的属性或属性组,它对应另一个关系的主码。外码用于建立和维护两个关系之间的联系,是实现参照完整性的重要机制。例如,在选课表中的"学号"如果引用学生表的主码"学号",则选课表中的"学号"就是外码。
+
+### 属性分类
+
+- **主属性(Prime Attribute):** 主属性是包含在任何一个候选码中的属性。如果一个关系有多个候选码,那么这些候选码中出现的所有属性都是主属性。例如,工人关系(工号,身份证号,姓名,性别,部门)中,如果{工号}和{身份证号}都是候选码,那么"工号"和"身份证号"都是主属性。
+- **非主属性(Non-prime Attribute):** 非主属性是不包含在任何候选码中的属性。这些属性完全依赖于候选码来确定其值。在上述工人关系中,"姓名"、"性别"、"部门"都是非主属性。
## 什么是 ER 图?
@@ -34,11 +210,41 @@ ER 图由下面 3 个要素组成:
- **实体**:通常是现实世界的业务对象,当然使用一些逻辑对象也可以。比如对于一个校园管理系统,会涉及学生、教师、课程、班级等等实体。在 ER 图中,实体使用矩形框表示。
- **属性**:即某个实体拥有的属性,属性用来描述组成实体的要素,对于产品设计来说可以理解为字段。在 ER 图中,属性使用椭圆形表示。
-- **联系**:即实体与实体之间的关系,这个关系不仅有业务关联关系,还能通过数字表示实体之间的数量对照关系。例如,一个班级会有多个学生就是一种实体间的联系。
+- **联系**:即实体与实体之间的关系,在 ER 图中用菱形表示,这个关系不仅有业务关联关系,还能通过数字表示实体之间的数量对照关系。例如,一个班级会有多个学生就是一种实体间的联系。
下图是一个学生选课的 ER 图,每个学生可以选若干门课程,同一门课程也可以被若干人选择,所以它们之间的关系是多对多(M: N)。另外,还有其他两种实体之间的关系是:1 对 1(1:1)、1 对多(1: N)。
-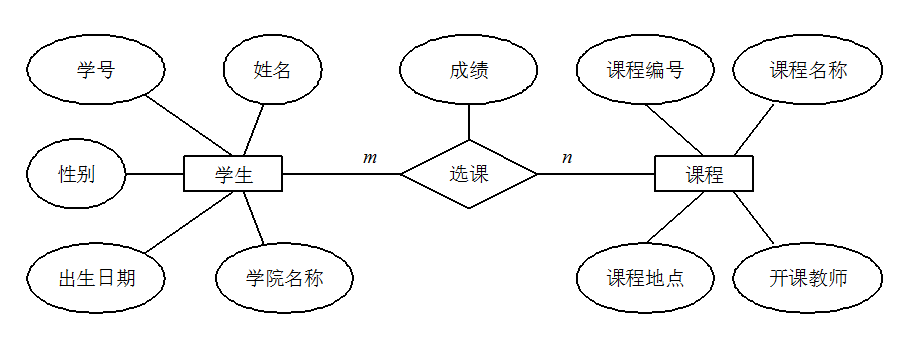
+```mermaid
+erDiagram
+ STUDENT {
+ string student_id PK "学号"
+ string name "姓名"
+ string gender "性别"
+ date birth_date "出生日期"
+ string department "学院名称"
+ }
+
+ COURSE {
+ string course_id PK "课程编号"
+ string course_name "课程名称"
+ string location "课程地点"
+ string instructor "开课教师"
+ float credits "成绩"
+ }
+
+ ENROLLMENT {
+ string student_id FK "学号"
+ string course_id FK "课程编号"
+ float grade "成绩"
+ }
+
+ STUDENT ||--o{ ENROLLMENT : "选课"
+ COURSE ||--o{ ENROLLMENT : "被选"
+
+ style STUDENT fill:#4CA497,stroke:#00838F,stroke-width:2px
+ style COURSE fill:#005D7B,stroke:#00838F,stroke-width:2px
+ style ENROLLMENT fill:#E99151,stroke:#C44545,stroke-width:2px
+```
## 数据库范式了解吗?
@@ -61,9 +267,9 @@ ER 图由下面 3 个要素组成:
一些重要的概念:
- **函数依赖(functional dependency)**:若在一张表中,在属性(或属性组)X 的值确定的情况下,必定能确定属性 Y 的值,那么就可以说 Y 函数依赖于 X,写作 X → Y。
-- **部分函数依赖(partial functional dependency)**:如果 X→Y,并且存在 X 的一个真子集 X0,使得 X0→Y,则称 Y 对 X 部分函数依赖。比如学生基本信息表 R 中(学号,身份证号,姓名)当然学号属性取值是唯一的,在 R 关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖与(学号,身份证号);
+- **部分函数依赖(partial functional dependency)**:如果 X→Y,并且存在 X 的一个真子集 X0,使得 X0→Y,则称 Y 对 X 部分函数依赖。比如学生基本信息表 R 中(学号,身份证号,姓名)当然学号属性取值是唯一的,在 R 关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖于(学号,身份证号);
- **完全函数依赖(Full functional dependency)**:在一个关系中,若某个非主属性数据项依赖于全部关键字称之为完全函数依赖。比如学生基本信息表 R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在 R 关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖与(学号,班级);
-- **传递函数依赖**:在关系模式 R(U)中,设 X,Y,Z 是 U 的不同的属性子集,如果 X 确定 Y、Y 确定 Z,且有 X 不包含 Y,Y 不确定 X,(X∪Y)∩Z=空集合,则称 Z 传递函数依赖(transitive functional dependency) 于 X。传递函数依赖会导致数据冗余和异常。传递函数依赖的 Y 和 Z 子集往往同属于某一个事物,因此可将其合并放到一个表中。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖。。
+- **传递函数依赖**:在关系模式 R(U)中,设 X,Y,Z 是 U 的不同的属性子集,如果 X 确定 Y、Y 确定 Z,且有 X 不包含 Y,Y 不确定 X,(X∪Y)∩Z=空集合,则称 Z 传递函数依赖(transitive functional dependency) 于 X。传递函数依赖会导致数据冗余和异常。传递函数依赖的 Y 和 Z 子集往往同属于某一个事物,因此可将其合并放到一个表中。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖。
### 3NF(第三范式)
@@ -71,8 +277,20 @@ ER 图由下面 3 个要素组成:
## 主键和外键有什么区别?
-- **主键(主码)**:主键用于唯一标识一个元组,不能有重复,不允许为空。一个表只能有一个主键。
-- **外键(外码)**:外键用来和其他表建立联系用,外键是另一表的主键,外键是可以有重复的,可以是空值。一个表可以有多个外键。
+从定义和属性上看,它们的区别是:
+
+- **主键 (Primary Key):** 它的核心作用是唯一标识表中的每一行数据。因此,主键列的值必须是唯一的 (Unique) 且不能为空 (Not Null)。一张表只能有一个主键。主键保证了实体完整性。
+- **外键 (Foreign Key):** 它的核心作用是建立并强制两张表之间的关联关系。一张表中的外键列,其值必须对应另一张表中某行的候选键值(通常是主键,也可以是唯一键),或者是一个 NULL 值。因此,外键的值可以重复,也可以为空。一张表可以有多个外键,分别关联到不同的表。外键保证了引用完整性。
+
+用一个简单的电商例子来说明:假设我们有两张表:`users` (用户表) 和 `orders` (订单表)。
+
+- 在 `users` 表中,`user_id` 列是**主键**。每个用户的 `user_id` 都是独一无二的,我们用它来区分张三和李四。
+- 在 `orders` 表中,`order_id` 是它自己的**主键**。同时,它会有一个 `user_id` 列,这个列就是一个**外键**,它引用了 `users` 表的 `user_id` 主键。
+
+这个外键约束就保证了:
+
+1. 你不能创建一个不属于任何已知用户的订单( `user_id` 在 `users` 表中不存在)。
+2. 你不能删除一个已经下了订单的用户(除非设置了级联删除等特殊规则)。
## 为什么不推荐使用外键与级联?
@@ -80,75 +298,263 @@ ER 图由下面 3 个要素组成:
> 【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
>
-> 说明: 以学生和成绩的关系为例,学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群; 级联更新是强阻塞,存在数据库更新风暴的风 险; 外键影响数据库的插入速度
+> 说明: 以学生和成绩的关系为例,学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度
为什么不要用外键呢?大部分人可能会这样回答:
-1. **增加了复杂性:** a. 每次做 DELETE 或者 UPDATE 都必须考虑外键约束,会导致开发的时候很痛苦, 测试数据极为不方便; b. 外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
-2. **增加了额外工作**:数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
+1. **增加了复杂性:** a. 每次做 DELETE 或者 UPDATE 都必须考虑外键约束,会导致开发的时候很痛苦, 测试数据极为不方便; b. 外键的主从关系是定的,假如哪天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
+2. **增加了额外工作**:数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的一致性和正确性,这样会不得不消耗数据库资源。如果在应用层面去维护的话,可以减小数据库压力;
3. **对分库分表不友好**:因为分库分表下外键是无法生效的。
-4. ......
+4. ……
我个人觉得上面这种回答不是特别的全面,只是说了外键存在的一个常见的问题。实际上,我们知道外键也是有很多好处的,比如:
1. 保证了数据库数据的一致性和完整性;
2. 级联操作方便,减轻了程序代码量;
-3. ......
+3. ……
所以说,不要一股脑的就抛弃了外键这个概念,既然它存在就有它存在的道理,如果系统不涉及分库分表,并发量不是很高的情况还是可以考虑使用外键的。
## 什么是存储过程?
-我们可以把存储过程看成是一些 SQL 语句的集合,中间加了点逻辑控制语句。存储过程在业务比较复杂的时候是非常实用的,比如很多时候我们完成一个操作可能需要写一大串 SQL 语句,这时候我们就可以写有一个存储过程,这样也方便了我们下一次的调用。存储过程一旦调试完成通过后就能稳定运行,另外,使用存储过程比单纯 SQL 语句执行要快,因为存储过程是预编译过的。
+```mermaid
+graph LR
+ A[存储过程] --> B[定义特征]
+ A --> C[优势]
+ A --> D[劣势]
+ A --> E[应用现状]
+
+ B --> B1[SQL语句集合]
+ B --> B2[包含逻辑控制]
+ B --> B3[预编译机制]
+
+ C --> C1[执行速度快]
+ C --> C2[运行稳定]
+ C --> C3[简化复杂操作]
+
+ D --> D1[调试困难]
+ D --> D2[扩展性差]
+ D --> D3[无移植性]
+ D --> D4[占用数据库资源]
+
+ E --> E1[传统企业
使用较多]
+ E --> E2[互联网公司
很少使用]
+ E --> E3[阿里规范
明确禁用]
+
+ style A fill:#4CA497,stroke:#00838F,stroke-width:3px,color:#fff
+ style B fill:#00838F,stroke:#005D7B,stroke-width:2px,color:#fff
+ style C fill:#E99151,stroke:#C44545,stroke-width:2px,color:#fff
+ style D fill:#C44545,stroke:#005D7B,stroke-width:2px,color:#fff
+ style E fill:#005D7B,stroke:#00838F,stroke-width:2px,color:#fff
+
+ style B1 fill:#E4C189,stroke:#00838F,stroke-width:1px
+ style B2 fill:#E4C189,stroke:#00838F,stroke-width:1px
+ style B3 fill:#E4C189,stroke:#00838F,stroke-width:1px
+
+ style C1 fill:#E4C189,stroke:#E99151,stroke-width:1px
+ style C2 fill:#E4C189,stroke:#E99151,stroke-width:1px
+ style C3 fill:#E4C189,stroke:#E99151,stroke-width:1px
-存储过程在互联网公司应用不多,因为存储过程难以调试和扩展,而且没有移植性,还会消耗数据库资源。
+ style D1 fill:#E4C189,stroke:#C44545,stroke-width:1px
+ style D2 fill:#E4C189,stroke:#C44545,stroke-width:1px
+ style D3 fill:#E4C189,stroke:#C44545,stroke-width:1px
+ style D4 fill:#E4C189,stroke:#C44545,stroke-width:1px
-阿里巴巴 Java 开发手册里要求禁止使用存储过程。
+ style E1 fill:#E4C189,stroke:#005D7B,stroke-width:1px
+ style E2 fill:#E4C189,stroke:#005D7B,stroke-width:1px
+ style E3 fill:#E4C189,stroke:#005D7B,stroke-width:1px
+```
+
+存储过程是数据库中预编译的SQL语句集合,它将多条SQL语句和程序逻辑控制语句(如IF-ELSE、WHILE循环等)封装在一起,形成一个可重复调用的数据库对象。
+
+**存储过程的优势:**
+
+在传统企业级应用中,存储过程具有一定的实用价值。当业务逻辑复杂时,需要执行大量SQL语句才能完成一个业务操作,此时可以将这些语句封装成存储过程,简化调用过程。由于存储过程在创建时就已经编译并存储在数据库中,执行时无需重新编译,因此相比动态SQL语句具有更好的执行性能。同时,一旦存储过程调试完成,其运行相对稳定可靠。
+
+**存储过程的局限性:**
+
+然而,在现代互联网架构中,存储过程的使用越来越少。主要原因包括:调试困难,缺乏成熟的调试工具;扩展性差,修改业务逻辑需要直接修改数据库对象;移植性差,不同数据库系统的存储过程语法差异较大;占用数据库资源,增加数据库服务器负担;版本管理困难,不便于进行代码版本控制。
+
+**行业规范:**
+
+基于以上原因,许多互联网公司的开发规范中明确限制或禁止使用存储过程。例如,《阿里巴巴Java开发手册》中明确规定禁止使用存储过程,推荐将业务逻辑放在应用层实现,保持数据库的简单和高效。

-## drop、delete 与 truncate 区别?
+## DROP、DELETE、TRUNCATE 有什么区别?
-### 用法不同
+在数据库操作中,`DROP`、`DELETE` 和 `TRUNCATE` 是三个常用的数据删除命令,它们在功能、性能和使用场景上存在显著差异。
-- `drop`(丢弃数据): `drop table 表名` ,直接将表都删除掉,在删除表的时候使用。
-- `truncate` (清空数据) : `truncate table 表名` ,只删除表中的数据,再插入数据的时候自增长 id 又从 1 开始,在清空表中数据的时候使用。
-- `delete`(删除数据) : `delete from 表名 where 列名=值`,删除某一行的数据,如果不加 `where` 子句和`truncate table 表名`作用类似。
+**DROP命令:**
-`truncate` 和不带 `where`子句的 `delete`、以及 `drop` 都会删除表内的数据,但是 **`truncate` 和 `delete` 只删除数据不删除表的结构(定义),执行 `drop` 语句,此表的结构也会删除,也就是执行`drop` 之后对应的表不复存在。**
+- 语法:`DROP TABLE 表名`
+- 作用:完全删除整个表,包括表结构、数据、索引、触发器、约束等所有相关对象
+- 使用场景:当表不再需要时使用
-### 属于不同的数据库语言
+**TRUNCATE命令:**
-`truncate` 和 `drop` 属于 DDL(数据定义语言)语句,操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。而 `delete` 语句是 DML (数据库操作语言)语句,这个操作会放到 rollback segment 中,事务提交之后才生效。
+- 语法:`TRUNCATE TABLE 表名`
+- 作用:清空表中所有数据,但保留表结构
+- 特点:自增长字段(AUTO_INCREMENT)会重置为初始值(通常为1)
+- 使用场景:需要快速清空表数据但保留表结构时使用
-**DML 语句和 DDL 语句区别:**
+**DELETE命令:**
-- DML 是数据库操作语言(Data Manipulation Language)的缩写,是指对数据库中表记录的操作,主要包括表记录的插入、更新、删除和查询,是开发人员日常使用最频繁的操作。
-- DDL (Data Definition Language)是数据定义语言的缩写,简单来说,就是对数据库内部的对象进行创建、删除、修改的操作语言。它和 DML 语言的最大区别是 DML 只是对表内部数据的操作,而不涉及到表的定义、结构的修改,更不会涉及到其他对象。DDL 语句更多的被数据库管理员(DBA)所使用,一般的开发人员很少使用。
+- 语法:`DELETE FROM 表名 WHERE 条件`
+- 作用:删除满足条件的数据行,不带WHERE子句时删除所有数据
+- 特点:自增长字段不会重置,继续从之前的值递增
+- 使用场景:需要有选择地删除部分数据时使用
+
+`TRUNCATE` 和不带 `WHERE`子句的 `DELETE`、以及 `DROP` 都会删除表内的数据,但是 **`TRUNCATE` 和 `DELETE` 只删除数据不删除表的结构(定义),执行 `DROP` 语句,此表的结构也会删除,也就是执行`DROP` 之后对应的表不复存在。**
+
+### 对表结构的影响
-另外,由于`select`不会对表进行破坏,所以有的地方也会把`select`单独区分开叫做数据库查询语言 DQL(Data Query Language)。
+- `DROP`:删除表结构和所有数据,表将不复存在
+- `TRUNCATE`:仅删除数据,保留表结构和定义
+- `DELETE`:仅删除数据,保留表结构和定义
-### 执行速度不同
+### 触发器
-一般来说:`drop` > `truncate` > `delete`(这个我没有设计测试过)。
+- `DELETE` 操作会触发相关的DELETE触发器
+- `TRUNCATE` 和 `DROP` 不会触发DELETE触发器
-- `delete`命令执行的时候会产生数据库的`binlog`日志,而日志记录是需要消耗时间的,但是也有个好处方便数据回滚恢复。
-- `truncate`命令执行的时候不会产生数据库日志,因此比`delete`要快。除此之外,还会把表的自增值重置和索引恢复到初始大小等。
-- `drop`命令会把表占用的空间全部释放掉。
+### 事务和回滚
+
+- `DROP` 和 `TRUNCATE` 属于DDL操作,执行后立即生效,不能回滚
+- `DELETE` 属于DML操作,可以回滚(在事务中)
+
+### 执行速度
+
+一般来说:`DROP` > `TRUNCATE` > `DELETE`(这个我没有实际测试过)。
+
+- `DELETE`命令执行的时候会产生数据库的`binlog`日志,而日志记录是需要消耗时间的,但是也有个好处方便数据回滚恢复。
+- `TRUNCATE`命令执行的时候不会产生数据库日志,因此比`DELETE`要快。除此之外,还会把表的自增值重置和索引恢复到初始大小等。
+- `DROP`命令会把表占用的空间全部释放掉。
Tips:你应该更多地关注在使用场景上,而不是执行效率。
+## DML 语句和 DDL 语句区别是?
+
+- DML 是数据库操作语言(Data Manipulation Language)的缩写,是指对数据库中表记录的操作,主要包括表记录的插入、更新、删除和查询,是开发人员日常使用最频繁的操作。
+- DDL (Data Definition Language)是数据定义语言的缩写,简单来说,就是对数据库内部的对象进行创建、删除、修改的操作语言。它和 DML 语言的最大区别是 DML 只是对表内部数据的操作,而不涉及到表的定义、结构的修改,更不会涉及到其他对象。DDL 语句更多的被数据库管理员(DBA)所使用,一般的开发人员很少使用。
+
+另外,由于`SELECT`不会对表进行破坏,所以有的地方也会把`SELECT`单独区分开叫做数据库查询语言 DQL(Data Query Language)。
+
## 数据库设计通常分为哪几步?
-1. **需求分析** : 分析用户的需求,包括数据、功能和性能需求。
-2. **概念结构设计** : 主要采用 E-R 模型进行设计,包括画 E-R 图。
-3. **逻辑结构设计** : 通过将 E-R 图转换成表,实现从 E-R 模型到关系模型的转换。
-4. **物理结构设计** : 主要是为所设计的数据库选择合适的存储结构和存取路径。
-5. **数据库实施** : 包括编程、测试和试运行
-6. **数据库的运行和维护** : 系统的运行与数据库的日常维护。
+```mermaid
+graph TD
+ A[数据库设计流程] --> B[1.需求分析]
+ B --> C[2.概念结构设计]
+ C --> D[3.逻辑结构设计]
+ D --> E[4.物理结构设计]
+ E --> F[5.数据库实施]
+ F --> G[6.运行和维护]
+
+ B --> B1[数据需求
功能需求
性能需求]
+ C --> C1[E-R建模
实体关系图]
+ D --> D1[关系模型
表结构设计
规范化]
+ E --> E1[存储结构
索引设计
分区策略]
+ F --> F1[编程开发
测试部署
数据迁移]
+ G --> G1[性能监控
备份恢复
优化调整]
+
+ G -.反馈.-> B
+
+ style A fill:#4CA497,stroke:#00838F,stroke-width:3px,color:#fff
+ style B fill:#00838F,stroke:#005D7B,stroke-width:2px,color:#fff
+ style C fill:#E99151,stroke:#005D7B,stroke-width:2px,color:#fff
+ style D fill:#005D7B,stroke:#00838F,stroke-width:2px,color:#fff
+ style E fill:#C44545,stroke:#005D7B,stroke-width:2px,color:#fff
+ style F fill:#E99151,stroke:#005D7B,stroke-width:2px,color:#fff
+ style G fill:#00838F,stroke:#005D7B,stroke-width:2px,color:#fff
+
+ style B1 fill:#E4C189,stroke:#00838F,stroke-width:1px
+ style C1 fill:#E4C189,stroke:#E99151,stroke-width:1px
+ style D1 fill:#E4C189,stroke:#005D7B,stroke-width:1px
+ style E1 fill:#E4C189,stroke:#C44545,stroke-width:1px
+ style F1 fill:#E4C189,stroke:#E99151,stroke-width:1px
+ style G1 fill:#E4C189,stroke:#00838F,stroke-width:1px
+```
+
+### 1. 需求分析阶段
+
+**目标:** 深入了解和分析用户需求,明确系统边界
+**主要工作:**
+
+- 收集和分析数据需求:确定需要存储哪些数据,数据量大小,数据更新频率
+- 明确功能需求:系统需要支持哪些业务操作,各操作的优先级
+- 定义性能需求:响应时间要求,并发用户数,数据吞吐量
+- 确定安全需求:数据访问权限,加密要求,审计要求
+ **产出物:** 需求规格说明书、数据字典初稿
+
+### 2. 概念结构设计阶段
+
+**目标:** 将需求转化为信息世界的概念模型
+**主要工作:**
+
+- 识别实体:确定系统中的主要对象
+- 定义属性:明确每个实体的特征
+- 建立联系:确定实体之间的关系(一对一、一对多、多对多)
+- 绘制E-R图(实体-关系图)
+ **产出物:** E-R图、概念数据模型文档
+
+### 3. 逻辑结构设计阶段
+
+**目标:** 将概念模型转换为特定DBMS支持的逻辑模型
+**主要工作:**
+
+- E-R图向关系模型转换:将实体转换为表,属性转换为字段
+- 规范化处理:通过范式化消除数据冗余和更新异常(通常达到3NF)
+- 定义完整性约束:主键、外键、唯一性约束、检查约束
+- 优化模型:根据性能需求进行适当的反规范化
+ **产出物:** 逻辑数据模型、表结构设计文档
+
+### 4. 物理结构设计阶段
+
+**目标:** 确定数据的物理存储方案和访问方法
+**主要工作:**
+
+- 选择存储引擎:如MySQL的InnoDB、MyISAM等
+- 设计索引策略:确定需要建立的索引类型和字段
+- 分区设计:对大表进行分区以提高性能
+- 确定存储参数:表空间大小、数据文件位置、缓冲区配置
+- 制定备份策略:全量备份、增量备份的频率和方式
+ **产出物:** 物理设计文档、索引设计方案
+
+### 5. 数据库实施阶段
+
+**目标:** 将设计转化为实际运行的数据库系统
+**主要工作:**
+
+- 创建数据库和表结构:编写和执行DDL语句
+- 开发存储过程和触发器(如需要)
+- 编写应用程序接口
+- 导入初始数据
+- 系统集成测试:功能测试、性能测试、压力测试
+- 用户培训和文档编写
+ **产出物:** 数据库脚本、测试报告、用户手册
+
+### 6. 运行和维护阶段
+
+**目标:** 确保数据库系统稳定高效运行
+**主要工作:**
+
+- 日常监控:性能监控、空间监控、错误日志分析
+- 性能优化:查询优化、索引调整、参数调优
+- 数据备份和恢复:定期备份、恢复演练
+- 安全管理:权限管理、安全补丁更新、审计
+- 容量规划:预测数据增长,提前扩容
+- 变更管理:需求变更的评估和实施
+ **产出物:** 运维报告、优化方案、变更记录
+
+### 设计原则
+
+在整个设计过程中应遵循:数据独立性原则、完整性原则、安全性原则、可扩展性原则和标准化原则。
## 参考
-
-
-
+
+
diff --git a/docs/database/character-set.md b/docs/database/character-set.md
index 2e5f829afc0..2e65c74a5b6 100644
--- a/docs/database/character-set.md
+++ b/docs/database/character-set.md
@@ -1,8 +1,13 @@
---
title: 字符集详解
+description: 详解字符集与字符编码原理,深入分析ASCII、GB2312、GBK、UTF-8、UTF-16等常见编码,解释MySQL中utf8与utf8mb4的区别以及emoji存储问题的解决方案。
category: 数据库
tag:
- 数据库基础
+head:
+ - - meta
+ - name: keywords
+ content: 字符集,字符编码,UTF-8,UTF-16,GBK,GB2312,utf8mb4,ASCII,Unicode,MySQL字符集,emoji存储
---
MySQL 字符编码集中有两套 UTF-8 编码实现:**`utf8`** 和 **`utf8mb4`**。
@@ -11,7 +16,7 @@ MySQL 字符编码集中有两套 UTF-8 编码实现:**`utf8`** 和 **`utf8mb4
为什么会这样呢?这篇文章可以从源头给你解答。
-## 何为字符集?
+## 字符集是什么?
字符是各种文字和符号的统称,包括各个国家文字、标点符号、表情、数字等等。 **字符集** 就是一系列字符的集合。字符集的种类较多,每个字符集可以表示的字符范围通常不同,就比如说有些字符集是无法表示汉字的。
@@ -19,9 +24,15 @@ MySQL 字符编码集中有两套 UTF-8 编码实现:**`utf8`** 和 **`utf8mb4
我们要将这些字符和二进制的数据一一对应起来,比如说字符“a”对应“01100001”,反之,“01100001”对应 “a”。我们将字符对应二进制数据的过程称为"**字符编码**",反之,二进制数据解析成字符的过程称为“**字符解码**”。
+## 字符编码是什么?
+
+字符编码是一种将字符集中的字符与计算机中的二进制数据相互转换的方法,可以看作是一种映射规则。也就是说,字符编码的目的是为了让计算机能够存储和传输各种文字信息。
+
+每种字符集都有自己的字符编码规则,常用的字符集编码规则有 ASCII 编码、 GB2312 编码、GBK 编码、GB18030 编码、Big5 编码、UTF-8 编码、UTF-16 编码等。
+
## 有哪些常见的字符集?
-常见的字符集有 ASCII、GB2312、GBK、UTF-8......。
+常见的字符集有:ASCII、GB2312、GB18030、GBK、Unicode……。
不同的字符集的主要区别在于:
@@ -64,7 +75,7 @@ GB18030 完全兼容 GB2312 和 GBK 字符集,纳入中国国内少数民族
BIG5 主要针对的是繁体中文,收录了 13000 多个汉字。
-### Unicode & UTF-8 编码
+### Unicode & UTF-8
为了更加适合本国语言,诞生了很多种字符集。
@@ -94,18 +105,181 @@ UTF-8 可以根据不同的符号自动选择编码的长短,像英文字符
UTF-32 的规则最简单,不过缺陷也比较明显,对于英文字母这类字符消耗的空间是 UTF-8 的 4 倍之多。
-**UTF-8** 是目前使用最广的一种字符编码,。
+**UTF-8** 是目前使用最广的一种字符编码。
## MySQL 字符集
-MySQL 支持很多种字符编码的方式,比如 UTF-8、GB2312、GBK、BIG5。
+MySQL 支持很多种字符集的方式,比如 GB2312、GBK、BIG5、多种 Unicode 字符集(UTF-8 编码、UTF-16 编码、UCS-2 编码、UTF-32 编码等等)。
-你可以通过 `SHOW CHARSET` 命令来查看。
+### 查看支持的字符集
+
+你可以通过 `SHOW CHARSET` 命令来查看,支持 like 和 where 子句。
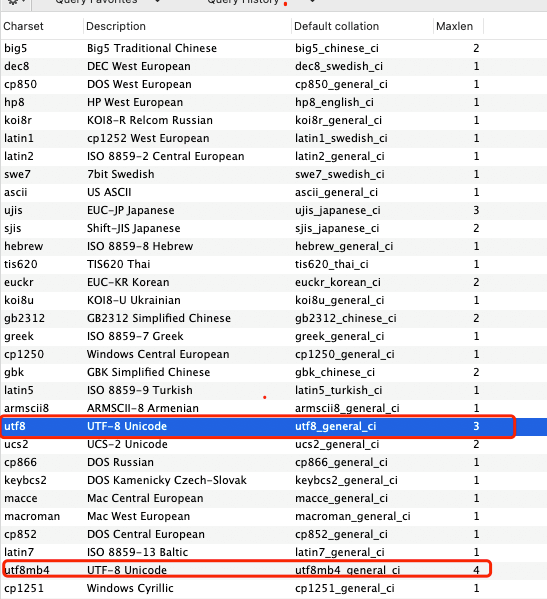
+### 默认字符集
+
+在 MySQL5.7 中,默认字符集是 `latin1` ;在 MySQL8.0 中,默认字符集是 `utf8mb4`
+
+### 字符集的层次级别
+
+MySQL 中的字符集有以下的层次级别:
+
+- `server`(MySQL 实例级别)
+- `database`(库级别)
+- `table`(表级别)
+- `column`(字段级别)
+
+它们的优先级可以简单的认为是从上往下依次增大,也即 `column` 的优先级会大于 `table` 等其余层次的。如指定 MySQL 实例级别字符集是`utf8mb4`,指定某个表字符集是`latin1`,那么这个表的所有字段如果不指定的话,编码就是`latin1`。
+
+#### server
+
+不同版本的 MySQL 其 `server` 级别的字符集默认值不同,在 MySQL5.7 中,其默认值是 `latin1` ;在 MySQL8.0 中,其默认值是 `utf8mb4` 。
+
+当然也可以通过在启动 `mysqld` 时指定 `--character-set-server` 来设置 `server` 级别的字符集。
+
+```bash
+mysqld
+mysqld --character-set-server=utf8mb4
+mysqld --character-set-server=utf8mb4 \
+ --collation-server=utf8mb4_0900_ai_ci
+```
+
+或者如果你是通过源码构建的方式启动的 MySQL,你可以在 `cmake` 命令中指定选项:
+
+```sh
+cmake . -DDEFAULT_CHARSET=latin1
+或者
+cmake . -DDEFAULT_CHARSET=latin1 \
+ -DDEFAULT_COLLATION=latin1_german1_ci
+```
+
+此外,你也可以在运行时改变 `character_set_server` 的值,从而达到修改 `server` 级别的字符集的目的。
+
+`server` 级别的字符集是 MySQL 服务器的全局设置,它不仅会作为创建或修改数据库时的默认字符集(如果没有指定其他字符集),还会影响到客户端和服务器之间的连接字符集,具体可以查看 [MySQL Connector/J 8.0 - 6.7 Using Character Sets and Unicode](https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-reference-charsets.html)。
+
+#### database
+
+`database` 级别的字符集是我们在创建数据库和修改数据库时指定的:
+
+```sql
+CREATE DATABASE db_name
+ [[DEFAULT] CHARACTER SET charset_name]
+ [[DEFAULT] COLLATE collation_name]
+
+ALTER DATABASE db_name
+ [[DEFAULT] CHARACTER SET charset_name]
+ [[DEFAULT] COLLATE collation_name]
+```
+
+如前面所说,如果在执行上述语句时未指定字符集,那么 MySQL 将会使用 `server` 级别的字符集。
+
+可以通过下面的方式查看某个数据库的字符集:
+
+```sql
+USE db_name;
+SELECT @@character_set_database, @@collation_database;
+```
+
+```sql
+SELECT DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME
+FROM INFORMATION_SCHEMA.SCHEMATA WHERE SCHEMA_NAME = 'db_name';
+```
+
+#### table
+
+`table` 级别的字符集是在创建表和修改表时指定的:
+
+```sql
+CREATE TABLE tbl_name (column_list)
+ [[DEFAULT] CHARACTER SET charset_name]
+ [COLLATE collation_name]]
+
+ALTER TABLE tbl_name
+ [[DEFAULT] CHARACTER SET charset_name]
+ [COLLATE collation_name]
+```
+
+如果在创建表和修改表时未指定字符集,那么将会使用 `database` 级别的字符集。
+
+#### column
+
+`column` 级别的字符集同样是在创建表和修改表时指定的,只不过它是定义在列中。下面是个例子:
+
+```sql
+CREATE TABLE t1
+(
+ col1 VARCHAR(5)
+ CHARACTER SET latin1
+ COLLATE latin1_german1_ci
+);
+```
+
+如果未指定列级别的字符集,那么将会使用表级别的字符集。
+
+### 连接字符集
+
+前面说到了字符集的层次级别,它们是和存储相关的。而连接字符集涉及的是和 MySQL 服务器的通信。
+
+连接字符集与下面这几个变量息息相关:
+
+- `character_set_client` :描述了客户端发送给服务器的 SQL 语句使用的是什么字符集。
+- `character_set_connection` :描述了服务器接收到 SQL 语句时使用什么字符集进行翻译。
+- `character_set_results` :描述了服务器返回给客户端的结果使用的是什么字符集。
+
+它们的值可以通过下面的 SQL 语句查询:
+
+```sql
+SELECT * FROM performance_schema.session_variables
+WHERE VARIABLE_NAME IN (
+'character_set_client', 'character_set_connection',
+'character_set_results', 'collation_connection'
+) ORDER BY VARIABLE_NAME;
+```
+
+```sql
+SHOW SESSION VARIABLES LIKE 'character\_set\_%';
+```
+
+如果要想修改前面提到的几个变量的值,有以下方式:
+
+1、修改配置文件
+
+```properties
+[mysql]
+# 只针对MySQL客户端程序
+default-character-set=utf8mb4
+```
+
+2、使用 SQL 语句
+
+```sql
+set names utf8mb4
+# 或者一个个进行修改
+# SET character_set_client = utf8mb4;
+# SET character_set_results = utf8mb4;
+# SET collation_connection = utf8mb4;
+```
+
+### JDBC 对连接字符集的影响
+
+不知道你们有没有碰到过存储 emoji 表情正常,但是使用类似 Navicat 之类的软件的进行查询的时候,发现 emoji 表情变成了问号的情况。这个问题很有可能就是 JDBC 驱动引起的。
+
+根据前面的内容,我们知道连接字符集也是会影响我们存储的数据的,而 JDBC 驱动会影响连接字符集。
+
+`mysql-connector-java` (JDBC 驱动)主要通过这几个属性影响连接字符集:
+
+- `characterEncoding`
+- `characterSetResults`
+
+以 `DataGrip 2023.1.2` 来说,在它配置数据源的高级对话框中,可以看到 `characterSetResults` 的默认值是 `utf8` ,在使用 `mysql-connector-java 8.0.25` 时,连接字符集最后会被设置成 `utf8mb3` 。那么这种情况下 emoji 表情就会被显示为问号,并且当前版本驱动还不支持把 `characterSetResults` 设置为 `utf8mb4` ,不过换成 `mysql-connector-java driver 8.0.29` 却是允许的。
+
+具体可以看一下 StackOverflow 的 [DataGrip MySQL stores emojis correctly but displays them as?](https://stackoverflow.com/questions/54815419/datagrip-mysql-stores-emojis-correctly-but-displays-them-as)这个回答。
+
+### UTF-8 使用
+
通常情况下,我们建议使用 UTF-8 作为默认的字符编码方式。
不过,这里有一个小坑。
@@ -127,10 +301,10 @@ MySQL 字符编码集中有两套 UTF-8 编码实现:
```sql
CREATE TABLE `user` (
- `id` varchar(66) CHARACTER SET utf8mb4 NOT NULL,
- `name` varchar(33) CHARACTER SET utf8mb4 NOT NULL,
- `phone` varchar(33) CHARACTER SET utf8mb4 DEFAULT NULL,
- `password` varchar(100) CHARACTER SET utf8mb4 DEFAULT NULL
+ `id` varchar(66) CHARACTER SET utf8mb3 NOT NULL,
+ `name` varchar(33) CHARACTER SET utf8mb3 NOT NULL,
+ `phone` varchar(33) CHARACTER SET utf8mb3 DEFAULT NULL,
+ `password` varchar(100) CHARACTER SET utf8mb3 DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
```
@@ -145,7 +319,7 @@ VALUES
报错信息如下:
-```
+```plain
Incorrect string value: '\xF0\x9F\x98\x98\xF0\x9F...' for column 'name' at row 1
```
@@ -157,3 +331,8 @@ Incorrect string value: '\xF0\x9F\x98\x98\xF0\x9F...' for column 'name' at row 1
- GB2312-维基百科:
- UTF-8-维基百科:
- GB18030-维基百科:
+- MySQL8 文档:
+- MySQL5.7 文档:
+- MySQL Connector/J 文档:
+
+
diff --git a/docs/database/elasticsearch/elasticsearch-questions-01.md b/docs/database/elasticsearch/elasticsearch-questions-01.md
index be3817a5949..2db51f16d7a 100644
--- a/docs/database/elasticsearch/elasticsearch-questions-01.md
+++ b/docs/database/elasticsearch/elasticsearch-questions-01.md
@@ -1,9 +1,14 @@
---
title: Elasticsearch常见面试题总结(付费)
+description: Elasticsearch常见面试题总结,涵盖ES核心概念、倒排索引原理、分片与副本机制、查询DSL、聚合分析、集群调优等高频面试知识点。
category: 数据库
tag:
- NoSQL
- Elasticsearch
+head:
+ - - meta
+ - name: keywords
+ content: Elasticsearch面试题,ES索引,倒排索引,分片副本,全文搜索,聚合查询,Lucene,ELK
---
**Elasticsearch** 相关的面试题为我的[知识星球](../../about-the-author/zhishixingqiu-two-years.md)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](../../zhuanlan/java-mian-shi-zhi-bei.md)中。
diff --git a/docs/database/mongodb/mongodb-questions-01.md b/docs/database/mongodb/mongodb-questions-01.md
index 699d11bd941..f60be69b0fb 100644
--- a/docs/database/mongodb/mongodb-questions-01.md
+++ b/docs/database/mongodb/mongodb-questions-01.md
@@ -1,9 +1,14 @@
---
title: MongoDB常见面试题总结(上)
+description: MongoDB常见面试题总结上篇,详解MongoDB基础概念、存储结构、数据类型、副本集高可用、分片集群水平扩展等核心知识点,助力后端面试准备。
category: 数据库
tag:
- NoSQL
- MongoDB
+head:
+ - - meta
+ - name: keywords
+ content: MongoDB面试题,文档数据库,BSON,副本集,分片集群,MongoDB索引,WiredTiger,聚合管道
---
> 少部分内容参考了 MongoDB 官方文档的描述,在此说明一下。
@@ -116,7 +121,7 @@ MongoDB 预留了几个特殊的数据库。
- 随着项目的发展,使用类 JSON 格式(BSON)保存数据是否满足项目需求?MongoDB 中的记录就是一个 BSON 文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。
- 是否需要大数据量的存储?是否需要快速水平扩展?MongoDB 支持分片集群,可以很方便地添加更多的节点(实例),让集群存储更多的数据,具备更强的性能。
- 是否需要更多类型索引来满足更多应用场景?MongoDB 支持多种类型的索引,包括单字段索引、复合索引、多键索引、哈希索引、文本索引、 地理位置索引等,每种类型的索引有不同的使用场合。
-- ......
+- ……
## MongoDB 存储引擎
@@ -143,13 +148,13 @@ MongoDB 预留了几个特殊的数据库。
上面也说了,自 MongoDB 3.2 以后,默认的存储引擎为 WiredTiger 存储引擎。在 WiredTiger 引擎官网上,我们发现 WiredTiger 使用的是 B+ 树作为其存储结构:
-```
+```plain
WiredTiger maintains a table's data in memory using a data structure called a B-Tree ( B+ Tree to be specific), referring to the nodes of a B-Tree as pages. Internal pages carry only keys. The leaf pages store both keys and values.
```
此外,WiredTiger 还支持 [LSM(Log Structured Merge)](https://source.wiredtiger.com/3.1.0/lsm.html) 树作为存储结构,MongoDB 在使用 WiredTiger 作为存储引擎时,默认使用的是 B+ 树。
-如果想要了解 MongoDB 使用 B 树的原因,可以看看这篇文章:[为什么 MongoDB 使用 B 树?](https://mp.weixin.qq.com/s/mMWdpbYRiT6LQcdaj4hgXQ)。
+如果想要了解 MongoDB 使用 B+ 树的原因,可以看看这篇文章:[【驳斥八股文系列】别瞎分析了,MongoDB 使用的是 B+ 树,不是你们以为的 B 树](https://zhuanlan.zhihu.com/p/519658576)。
使用 B+ 树时,WiredTiger 以 **page** 为基本单位往磁盘读写数据。B+ 树的每个节点为一个 page,共有三种类型的 page:
@@ -274,6 +279,63 @@ MongoDB 单文档原生支持原子性,也具备事务的特性。当谈论 Mo
WiredTiger 日志也会被压缩,默认使用的也是 Snappy 压缩算法。如果日志记录小于或等于 128 字节,WiredTiger 不会压缩该记录。
+## Amazon Document 与 MongoDB 的差异
+
+Amazon DocumentDB(与 MongoDB 兼容) 是一种快速、可靠、完全托管的数据库服务。Amazon DocumentDB 可在云中轻松设置、操作和扩展与 MongoDB 兼容的数据库。
+
+### `$vectorSearch` 运算符
+
+Amazon DocumentDB 不支持`$vectorSearch`作为独立运营商。相反,我们在`$search`运营商`vectorSearch`内部支持。有关更多信息,请参阅 [向量搜索 Amazon DocumentDB](https://docs.aws.amazon.com/zh_cn/documentdb/latest/developerguide/vector-search.html)。
+
+### `OpCountersCommand`
+
+Amazon DocumentDB 的`OpCountersCommand`行为偏离于 MongoDB 的`opcounters.command` 如下:
+
+- MongoDB 的`opcounters.command` 计入除插入、更新和删除之外的所有命令,而 Amazon DocumentDB 的 `OpCountersCommand` 也排除 `find` 命令。
+- Amazon DocumentDB 将内部命令(例如`getCloudWatchMetricsV2`)对 `OpCountersCommand` 计入。
+
+### 管理数据库和集合
+
+Amazon DocumentDB 不支持管理或本地数据库,MongoDB `system.*` 或 `startup_log` 集合也不支持。
+
+### `cursormaxTimeMS`
+
+在 Amazon DocumentDB 中,`cursor.maxTimeMS` 重置每个请求的计数器。`getMore`因此,如果指定了 3000MS `maxTimeMS`,则该查询耗时 2800MS,而每个后续`getMore`请求耗时 300MS,则游标不会超时。游标仅在单个操作(无论是查询还是单个`getMore`请求)耗时超过指定值时才将超时`maxTimeMS`。此外,检查游标执行时间的扫描器以五 (5) 分钟间隔尺寸运行。
+
+### explain()
+
+Amazon DocumentDB 在利用分布式、容错、自修复的存储系统的专用数据库引擎上模拟 MongoDB 4.0 API。因此,查询计划和`explain()` 的输出在 Amazon DocumentDB 和 MongoDB 之间可能有所不同。希望控制其查询计划的客户可以使用 `$hint` 运算符强制选择首选索引。
+
+### 字段名称限制
+
+Amazon DocumentDB 不支持点“。” 例如,文档字段名称中 `db.foo.insert({‘x.1’:1})`。
+
+Amazon DocumentDB 也不支持字段名称中的 $ 前缀。
+
+例如,在 Amazon DocumentDB 或 MongoDB 中尝试以下命令:
+
+```shell
+rs0:PRIMARY< db.foo.insert({"a":{"$a":1}})
+```
+
+MongoDB 将返回以下内容:
+
+```shell
+WriteResult({ "nInserted" : 1 })
+```
+
+Amazon DocumentDB 将返回一个错误:
+
+```shell
+WriteResult({
+ "nInserted" : 0,
+ "writeError" : {
+ "code" : 2,
+ "errmsg" : "Document can't have $ prefix field names: $a"
+ }
+})
+```
+
## 参考
- MongoDB 官方文档(主要参考资料,以官方文档为准):
@@ -282,3 +344,5 @@ WiredTiger 日志也会被压缩,默认使用的也是 Snappy 压缩算法。
- Transactions - MongoDB 官方文档:
- WiredTiger Storage Engine - MongoDB 官方文档:
- WiredTiger 存储引擎之一:基础数据结构分析:
+
+
diff --git a/docs/database/mongodb/mongodb-questions-02.md b/docs/database/mongodb/mongodb-questions-02.md
index 851981a8fd0..4a7af767d16 100644
--- a/docs/database/mongodb/mongodb-questions-02.md
+++ b/docs/database/mongodb/mongodb-questions-02.md
@@ -1,9 +1,14 @@
---
title: MongoDB常见面试题总结(下)
+description: MongoDB常见面试题总结下篇,深入讲解MongoDB各类索引(单字段、复合、多键、文本、地理位置、TTL)的原理、使用场景和查询优化技巧。
category: 数据库
tag:
- NoSQL
- MongoDB
+head:
+ - - meta
+ - name: keywords
+ content: MongoDB索引,复合索引,多键索引,文本索引,地理位置索引,TTL索引,MongoDB查询优化,索引设计
---
## MongoDB 索引
@@ -26,7 +31,7 @@ tag:
- **地理位置索引:** 基于经纬度的索引,适合 2D 和 3D 的位置查询。
- **唯一索引**:确保索引字段不会存储重复值。如果集合已经存在了违反索引的唯一约束的文档,则后台创建唯一索引会失败。
- **TTL 索引**:TTL 索引提供了一个过期机制,允许为每一个文档设置一个过期时间,当一个文档达到预设的过期时间之后就会被删除。
-- ......
+- ……
### 复合索引中字段的顺序有影响吗?
@@ -271,3 +276,5 @@ Rebalance 操作是比较耗费系统资源的,我们可以通过在业务低
- Sharding - MongoDB 官方文档:
- MongoDB 分片集群介绍 - 阿里云文档:
- 分片集群使用注意事项 - - 腾讯云文档:
+
+
diff --git a/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md b/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md
index 4dc48353eeb..b62c108458b 100644
--- a/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md
+++ b/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md
@@ -1,11 +1,16 @@
---
title: 一千行 MySQL 学习笔记
+description: 一千行MySQL学习笔记精华总结,涵盖数据库操作、表管理、SQL语法、索引、视图、存储过程、触发器等核心知识点,适合快速查阅和复习。
category: 数据库
tag:
- MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL学习笔记,MySQL命令大全,SQL语法,数据库操作,表操作,索引,视图,存储过程,触发器
---
-> 原文地址:https://shockerli.net/post/1000-line-mysql-note/ ,JavaGuide 对本文进行了简答排版,新增了目录。
+> 原文地址: ,JavaGuide 对本文进行了简答排版,新增了目录。
非常不错的总结,强烈建议保存下来,需要的时候看一看。
@@ -385,7 +390,7 @@ c. WHERE 子句
-- 运算符:
=, <=>, <>, !=, <=, <, >=, >, !, &&, ||,
in (not) null, (not) like, (not) in, (not) between and, is (not), and, or, not, xor
- is/is not 加上ture/false/unknown,检验某个值的真假
+ is/is not 加上true/false/unknown,检验某个值的真假
<=>与<>功能相同,<=>可用于null比较
d. GROUP BY 子句, 分组子句
GROUP BY 字段/别名 [排序方式]
@@ -621,7 +626,7 @@ CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW view_name
### 锁表
-```mysql
+```sql
/* 锁表 */
表锁定只用于防止其它客户端进行不正当地读取和写入
MyISAM 支持表锁,InnoDB 支持行锁
@@ -633,7 +638,7 @@ MyISAM 支持表锁,InnoDB 支持行锁
### 触发器
-```mysql
+```sql
/* 触发器 */ ------------------
触发程序是与表有关的命名数据库对象,当该表出现特定事件时,将激活该对象
监听:记录的增加、修改、删除。
@@ -686,7 +691,7 @@ end
### SQL 编程
-```mysql
+```sql
/* SQL编程 */ ------------------
--// 局部变量 ----------
-- 变量声明
@@ -792,7 +797,7 @@ default();
CREATE FUNCTION function_name (参数列表) RETURNS 返回值类型
函数体
- 函数名,应该合法的标识符,并且不应该与已有的关键字冲突。
- - 一个函数应该属于某个数据库,可以使用db_name.funciton_name的形式执行当前函数所属数据库,否则为当前数据库。
+ - 一个函数应该属于某个数据库,可以使用db_name.function_name的形式执行当前函数所属数据库,否则为当前数据库。
- 参数部分,由"参数名"和"参数类型"组成。多个参数用逗号隔开。
- 函数体由多条可用的mysql语句,流程控制,变量声明等语句构成。
- 多条语句应该使用 begin...end 语句块包含。
@@ -821,7 +826,7 @@ INOUT,表示混合型
### 存储过程
-```mysql
+```sql
/* 存储过程 */ ------------------
存储过程是一段可执行性代码的集合。相比函数,更偏向于业务逻辑。
调用:CALL 过程名
@@ -842,7 +847,7 @@ END
### 用户和权限管理
-```mysql
+```sql
/* 用户和权限管理 */ ------------------
-- root密码重置
1. 停止MySQL服务
@@ -924,7 +929,7 @@ GRANT OPTION -- 允许授予权限
### 表维护
-```mysql
+```sql
/* 表维护 */
-- 分析和存储表的关键字分布
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE 表名 ...
@@ -937,7 +942,7 @@ OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
### 杂项
-```mysql
+```sql
/* 杂项 */ ------------------
1. 可用反引号(`)为标识符(库名、表名、字段名、索引、别名)包裹,以避免与关键字重名!中文也可以作为标识符!
2. 每个库目录存在一个保存当前数据库的选项文件db.opt。
@@ -953,3 +958,5 @@ OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
6. SQL对大小写不敏感
7. 清除已有语句:\c
```
+
+
diff --git a/docs/database/mysql/how-sql-executed-in-mysql.md b/docs/database/mysql/how-sql-executed-in-mysql.md
index cdcde73a462..45a1d8d79ef 100644
--- a/docs/database/mysql/how-sql-executed-in-mysql.md
+++ b/docs/database/mysql/how-sql-executed-in-mysql.md
@@ -1,8 +1,13 @@
---
title: SQL语句在MySQL中的执行过程
+description: 详解SQL语句在MySQL中的完整执行流程,从连接器身份认证、查询缓存、分析器语法解析、优化器生成执行计划到执行器调用存储引擎的全过程。
category: 数据库
tag:
- MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL执行流程,SQL执行过程,连接器,解析器,优化器,执行器,Server层,存储引擎,InnoDB
---
> 本文来自[木木匠](https://github.com/kinglaw1204)投稿。
@@ -86,12 +91,7 @@ select * from tb_student A where A.age='18' and A.name=' 张三 ';
- 先检查该语句是否有权限,如果没有权限,直接返回错误信息,如果有权限,在 MySQL8.0 版本以前,会先查询缓存,以这条 SQL 语句为 key 在内存中查询是否有结果,如果有直接缓存,如果没有,执行下一步。
- 通过分析器进行词法分析,提取 SQL 语句的关键元素,比如提取上面这个语句是查询 select,提取需要查询的表名为 tb_student,需要查询所有的列,查询条件是这个表的 id='1'。然后判断这个 SQL 语句是否有语法错误,比如关键词是否正确等等,如果检查没问题就执行下一步。
-- 接下来就是优化器进行确定执行方案,上面的 SQL 语句,可以有两种执行方案:
-
- a.先查询学生表中姓名为“张三”的学生,然后判断是否年龄是 18。
- b.先找出学生中年龄 18 岁的学生,然后再查询姓名为“张三”的学生。
-
- 那么优化器根据自己的优化算法进行选择执行效率最好的一个方案(优化器认为,有时候不一定最好)。那么确认了执行计划后就准备开始执行了。
+- 接下来就是优化器进行确定执行方案,上面的 SQL 语句,可以有两种执行方案:a.先查询学生表中姓名为“张三”的学生,然后判断是否年龄是 18。b.先找出学生中年龄 18 岁的学生,然后再查询姓名为“张三”的学生。那么优化器根据自己的优化算法进行选择执行效率最好的一个方案(优化器认为,有时候不一定最好)。那么确认了执行计划后就准备开始执行了。
- 进行权限校验,如果没有权限就会返回错误信息,如果有权限就会调用数据库引擎接口,返回引擎的执行结果。
@@ -99,15 +99,16 @@ select * from tb_student A where A.age='18' and A.name=' 张三 ';
以上就是一条查询 SQL 的执行流程,那么接下来我们看看一条更新语句如何执行的呢?SQL 语句如下:
-```
+```plain
update tb_student A set A.age='19' where A.name=' 张三 ';
```
我们来给张三修改下年龄,在实际数据库肯定不会设置年龄这个字段的,不然要被技术负责人打的。其实这条语句也基本上会沿着上一个查询的流程走,只不过执行更新的时候肯定要记录日志啦,这就会引入日志模块了,MySQL 自带的日志模块是 **binlog(归档日志)** ,所有的存储引擎都可以使用,我们常用的 InnoDB 引擎还自带了一个日志模块 **redo log(重做日志)**,我们就以 InnoDB 模式下来探讨这个语句的执行流程。流程如下:
-- 先查询到张三这一条数据,如果有缓存,也是会用到缓存。
+- 先查询到张三这一条数据,不会走查询缓存,因为查询缓存的设计规则就是只服务于查询类语句。
- 然后拿到查询的语句,把 age 改为 19,然后调用引擎 API 接口,写入这一行数据,InnoDB 引擎把数据保存在内存中,同时记录 redo log,此时 redo log 进入 prepare 状态,然后告诉执行器,执行完成了,随时可以提交。
-- 执行器收到通知后记录 binlog,然后调用引擎接口,提交 redo log 为提交状态。
+- 执行器收到通知后记录 binlog,然后清空该表的查询缓存。此时清空能保证后续的 SELECT 不会读到旧缓存 —— 因为事务马上就要最终提交,数据即将变成最新状态,缓存失效的时机刚好匹配数据的实际更新。
+- 执行器调用引擎接口 ,提交 redo log 为 commit 状态。
- 更新完成。
**这里肯定有同学会问,为什么要用两个日志模块,用一个日志模块不行吗?**
@@ -119,11 +120,12 @@ update tb_student A set A.age='19' where A.name=' 张三 ';
- **先写 redo log 直接提交,然后写 binlog**,假设写完 redo log 后,机器挂了,binlog 日志没有被写入,那么机器重启后,这台机器会通过 redo log 恢复数据,但是这个时候 binlog 并没有记录该数据,后续进行机器备份的时候,就会丢失这一条数据,同时主从同步也会丢失这一条数据。
- **先写 binlog,然后写 redo log**,假设写完了 binlog,机器异常重启了,由于没有 redo log,本机是无法恢复这一条记录的,但是 binlog 又有记录,那么和上面同样的道理,就会产生数据不一致的情况。
-如果采用 redo log 两阶段提交的方式就不一样了,写完 binlog 后,然后再提交 redo log 就会防止出现上述的问题,从而保证了数据的一致性。那么问题来了,有没有一个极端的情况呢?假设 redo log 处于预提交状态,binlog 也已经写完了,这个时候发生了异常重启会怎么样呢?
+如果采用 redo log 两阶段提交的方式就不一样了,先写完 redo log,标记为 prepare,紧接着写完 binlog 后,然后再将 redo log 标记为 commit 就可以防止出现上述的问题,从而保证了数据的一致性。
+那么问题来了,有没有一个极端的情况呢?假设 redo log 处于 prepare 状态,binlog 也已经写完了,这个时候发生了异常重启会怎么样呢?
这个就要依赖于 MySQL 的处理机制了,MySQL 的处理过程如下:
-- 判断 redo log 是否完整,如果判断是完整的,就立即提交。
-- 如果 redo log 只是预提交但不是 commit 状态,这个时候就会去判断 binlog 是否完整,如果完整就提交 redo log, 不完整就回滚事务。
+- 判断 redo log 是否为 commit 状态,如果是,说明 binlog 一定已完成刷盘,就立即提交。
+- 如果 redo log 只是 prepare 状态但不是 commit 状态,这个时候就会拿着事物的XID,去 binlog 判断该事物是否完成刷盘,如果是就提交 redo log, 否则就回滚事务。
这样就解决了数据一致性的问题。
@@ -138,3 +140,5 @@ update tb_student A set A.age='19' where A.name=' 张三 ';
- 《MySQL 实战 45 讲》
- MySQL 5.6 参考手册:
+
+
diff --git a/docs/database/mysql/images/ACID.drawio b/docs/database/mysql/images/ACID.drawio
deleted file mode 100644
index e8805b8d958..00000000000
--- a/docs/database/mysql/images/ACID.drawio
+++ /dev/null
@@ -1 +0,0 @@
-7Zhdb5swFIZ/jS9b8R24BAJdp1Wamotply6Yj9VgZkyT7tfPBjvAIFK7LcqqNZHAfo99bJ/zxLIDzLA63FDYFHckRRgYWnoA5hYYhq4ZHn8J5XlQPM0chJyWqWw0CrvyB1I9pdqVKWpnDRkhmJXNXExIXaOEzTRIKdnPm2UEz0dtYI4Wwi6BeKl+KVNWDKprbEb9AyrzQo2sO3LBDzB5zCnpajkeMMzYiePYHcwVVL7kQtsCpmQ/kcwImCElhA2l6hAiLGKrwjb0i09Yj/OmqGYv6fD5/ttDl3wtnor7T9S9tRq/C6/swcsTxB1Sy+gny55VgPolIuFEB2awL0qGdg1MhHXPkeBawSoszVmJcUgwoX1f0wp9y9twvWWUPCJlqUmNhKgioonKI2JJISs5hm0ryxmp2cTl8JF6DKsSC/A+IhZQWNYtn/sdqYm070hH+5kWjHGeDNv0+YOHSDxEg/Y6JyTHCDZle52Qqjckbd80zgbvvDj1bxuBHGGZAZmUJ0QZOkwkmZEbRCrEKHepKasp6Xj+pb4fWTRtqRUTDg1LilDynx99jwzwgsTgFUjoK0g4mMmIzthwvndEGa7a/qfN46vpXnMYjbyUi7cPohgEIXBdENnAjYAXi4K/BZ4GIge4GvA3qo2nxgRDnpSTv0pnZovvKTpPcfdyat8+nZs5nYa2pFM3Vuh0zgWncSY4wwmcFghcQWPEnxsQWJeBM4XIzZI/3zrfPISm9a9BaJ4JwtsJhB7wfOBx9jbAd0AQjBCeYm+Q2wbWvz+DNcIHj+fYfrPMSN4JX9lmvUsTbp2J8O2EcM4zL+j9fusB177QGcBN0DuEa9vsxSF0FhD64e12kX2+PjZP8fpxbpJ3KUFc5jWvJjxqiOuBiFbJr4a+NFRlmophVpkaqVMMyMut8Z+dEo8EqDuMvSTHW7vCvB4cXh0vzL1t8q+EGf0E
\ No newline at end of file
diff --git a/docs/database/mysql/images/AID-C.drawio b/docs/database/mysql/images/AID-C.drawio
deleted file mode 100644
index 4ac724c8404..00000000000
--- a/docs/database/mysql/images/AID-C.drawio
+++ /dev/null
@@ -1 +0,0 @@
-5ZjZcpswFIafRpfJAGK9BBvStM1Fm+mS3skglkYgCvKWp68EwoCNM0k6HmdqZwZL/znazvmkIAM4yzc3FSrTOxphAjQl2gA4B5qmKprDv4SybRVHga2QVFkknXrhPnvCXUupLrMI1yNHRilhWTkWQ1oUOGQjDVUVXY/dYkrGo5YowQfCfYjIofoji1jaqrZm9foHnCVpN7JqygUvUPiYVHRZyPGABgMzCAK7Neeo60sutE5RRNcDCfoAzipKWVvKNzNMRGy7sLXtgiPW3bwrXLAXNSBfy+/et6cCXX26ib/o33+pqyvZS822XTxwxMMjq7RiKU1ogYjfq16zZix6VXit9/lMaclFlYu/MWNbmWu0ZJRLKcuJtOJNxn6K5teGrD0MLPON7LmpbLtKwartoJGoPgxtfbOm1rWrHzELU1mJacEClGdEWD9i5lUoK2q+/jtaUGm/p8sqFPNOGeMIagZ0+YNHVTyEQ32dUJoQjMqsvg5p3hjCunEN4rZ3Xhz2b2jecIQ2LqpYcM0q+rgDjzPhHaa1y1E3sWO51OTuQVWC2TN+eusnEj0YQEJzg2mOeQC5Q4UJYtlqvE+Q3G7Jzq9Hjhckda8gUM56hcgSdxtpD8keOBGydZoxfF+iJhZrfiiN4dpts4PsJwTVdUdCRsiMElo1I0B95uqOtcvHwGI2H5m5gd5+3gVTR4lZ4YrhzbM5llYNykNNHuKaIg+tdX8kQkNq6eA41HTlRFzACS5MwmRER4CYf5a0M1zVze7i8VVUp9z0Rl5KxLcL/AB4M2DbwDeA7QMnEAV3DhwF+CawFeBanY/TjQnaPHWd/Buie/DFhvh7E3wvhP2/QNTWx4hah4iq2gSi5qkI1U9E6GxAqA48WyDp86cFPP08hEYI23E4SWho40V8WSRCY0yioZ6bRONEJN4OSHSA4wKHA2gB1wSe15N4DMBWrktUvH0GU5i3PZ7iII5jLZzEPDIXpmFeGubjdwJonhtz80SYzweYc6h5QW1OXgfYxpleCewQT5O4sA3dUC6LRB2+t3/91gGJ7u38gAC+PLZ3ORmls6AF3su9lBDJkoJXQx40zHVPBCsLEXGlIc+iqLmMT3E1vqAPrpzahb0zQmsPHO0QHGfqVvN6bni1/ymnsQ1+L4P+Xw==
\ No newline at end of file
diff --git a/docs/database/mysql/images/concurrency-consistency-issues-dirty-reading.drawio b/docs/database/mysql/images/concurrency-consistency-issues-dirty-reading.drawio
deleted file mode 100644
index 6e4e61ba50c..00000000000
--- a/docs/database/mysql/images/concurrency-consistency-issues-dirty-reading.drawio
+++ /dev/null
@@ -1 +0,0 @@
-7Vpbk6I4FP41eWxLQG6P4KV3e2d2ZrZramYfIwZINxIWYqv96zeBIGKi7Uwp2jOWVZqchJPL+c53TiLAGM5X9znM4o9khhKg92crYIyArpuuzr65YF0JbMOsBFGOZ5VIawSP+BUJYV9IF3iGilZHSkhCcdYWBiRNUUBbMpjnZNnuFpKkPWoGIyQJHgOYyNJveEbjSurodiP/A+EorkfWLLdqmcLgOcrJIhXjAd2YWJPJxKma57DWJRZaxHBGllsiYwyMYU4IrUrz1RAlfGvrbauem+xp3cw7Ryk95oE//x4YTj8YYPr11f7y9OmfuWPdibUUdF3vB5qx7RFVktOYRCSFybiR+uWaEdfaZ7WmzwdCMibUmPAJUboWtoYLSpgopvNEtLIJ5+vv4vmy8i+v9My6OlptN47WohaSlAqlminqEzjHCe/wgKifQ5wWbDkfSUrq/mSRB/yJmFKGKN00PPbFNol/8Q5FLyIkShDMcNELyLxsCIqy6ySstLPitn5T98UIsg2EWYp62H0bX0Md5hGiB/oNqn7cKlsDCAvfIzJHbIdYhxwlkOKXNqih8I1o06/BBysIiPwAXITeF5gsUI36XfwkCXNdjpNljCl6zGC5D0tGHm0UwCKr/DnEK44mP8RJMiQJyUtFRhgiKwiYvKA5eUZ1S0pS9L6w8IJyilYHrSdaN1whuFSzRH3ZMFMtirdIqZad3N7Gzd7ntLejXZm96/nc4kHX8WBwZDwwryseuBJBeHWQ2MHQBzhliWObERIcpawcsN1CzNd97jmYpWaeaJjj2ayCGCrwK5yW+rjlM4KZpbhy0wfmSIGFhA/nb1K0LZ4RSdp1wuWgV0rEssmKxda0MksV4dz1ezzKtEmnqh0NGKH8MzdBo9lU6awfJ2FYMFTvom0zv58H4EDGH/vRZRprSEp7O1RJkSnUf7PIZFg7kcmWI5OtiEyDE0SmEcqGeP0AA/8B+/lf3/wv0+fa0N0Gpl3TKrn35/jelPleuW69I3pXDm7K6d/YBK4P3DEYW8BnBe8SZH8kucumO5pB20bdj8iDTGu3SdE4CdFaKp3nJ1oZCpxoNfn+4Ea0P0S05u6Rr0OiVRraVvj8APgecHzu/I4HPE3O8Nhqadu0ahNu2VuIjucFFZbaFP9LIkQzdhFiSghRHRKNcyHEOQIh8j3BDSGdIUR3ukOIMjSqT4Dv5BbhhEle7QZvnuo1s6M07+A0b9d83Vzr6ooY3+01n/OeHfSKMfE2IyjOfeqOtpKHLkYRt/z/TPm/uxu7L5z/a4oDwC0YnO8/n4sHg80S2rc8LIf0hmViPwSuXUomwGeFSSnxHuALvOfvbgDdSnhmP81bILH+W/A3G0qj3BWlFZkl+pqZrcqNrNtZKSp/xzbwR8DVeMHzgetuhnpiQ5WvifSC9ErPFXtupA4AecsL/PJT6qSMy0kqlBbPiAYxaO4i3z349V22G8jg1xwF+rVzHVWMS2RCpzly7L8vPiK/MDrKJg5N8vavjexeihtqCQZ73cuyO7tMZNXm1bXqkrl5PdAY/w8=
\ No newline at end of file
diff --git a/docs/database/mysql/images/concurrency-consistency-issues-dirty-reading.png b/docs/database/mysql/images/concurrency-consistency-issues-dirty-reading.png
deleted file mode 100644
index db90c6ea22c..00000000000
Binary files a/docs/database/mysql/images/concurrency-consistency-issues-dirty-reading.png and /dev/null differ
diff --git a/docs/database/mysql/images/concurrency-consistency-issues-missing-modifications.drawio b/docs/database/mysql/images/concurrency-consistency-issues-missing-modifications.drawio
deleted file mode 100644
index 68c79b9da73..00000000000
--- a/docs/database/mysql/images/concurrency-consistency-issues-missing-modifications.drawio
+++ /dev/null
@@ -1 +0,0 @@
-7VrbcqM4EP0aPcZl7vjR+DI7U3PZ3dTW7j4qWIASgRiQYztfvxJIXAzOkKnx4JqlUuVILalB3UenW10AYxUf32UwjT7RHSJAn++OwFgDXbfnC/4rBKdS4BhaKQgzvCtFDcE9fkFSOJfSPd6hvDWRUUoYTttCnyYJ8llLBrOMHtrTAkraT01hiDqCex+SrvRvvGNRKXV1p5b/hnAYqSdrttzwA/SfwozuE/k8oBtbe7vduuVwDJUuudE8gjt6aIiMDTBWGaWsbMXHFSLCtMps5brthdHqvTOUsCEL3n82DXfum5j99eL88fjlz9i17+RecnZS9kA7bh7ZpRmLaEgTSDa11Cv2jITWOe/Vcz5SmnKhxoWPiLGT9DXcM8pFEYuJHOUvnJ3+keuLzr+iM7NUd31sDq5PshfQhEmlmiX7WxhjIiZ8QMzLIE5yvp1PNKFqPt1nvlgRMcYRpVvGkv9wI4kfMSGfhZSGBMEU5zOfxsWAnxdTt0GpnTeb+i3dk08orSdMdtEpUpSr97jkCYV9mIWIvTLPrKDDTySiMeIW4usyRCDDz+33gPJshNW8Gh+8ISHyBrhIvc+Q7JFC/Tl+COFHV+DkEGGG7lNYbPvAyaONApin5XkO8FGgyQswIStKaFYoMoIA2b7P5TnL6BNSIwlN0A1j4RllDB1fR0PXe3JBxRWSSzVb9g81MylR1CAlJfvh/jYmf1/T37Z7Y/5WQXmKB6PHA3NgPLBGjQeLDkEsVZA4w9BH+MATxzYjEBwmvO1z4yB+1j1xmDBPzZZyIMa7XQkxlOMX+FDoE55PKeaeEsotD1jrHiwQ8TivStEaPCOTtNuBSw+FyGRX7rjOIZtAeuUAXyScu/lMRJk26ZS9wYCRyn8XLqg1W3061XIaBDkH8Tnaqvf7fgCaXfzxf3qXxmqS0r4dqjqRKdD/Z5HJsM8ik9ONTE5PZDKvFpnsKTLdSGSyBkYmY8zIZPUSg9a9707E8CZisM6vKGMTg9O9omxM4C2B64GNBdwlWGrdjIQbgLVd2+/Chr+laHjS0oelNiP9kgjRjHOEWIMuNca1EOIOQAifYBOBiIeMt0JWmWLCzBiY0d2RMdNDGVO6MVJhVB+Yb2jjlkb1Ls1MtbLr1Ub1nsTj59bKjIkiboUihhbLtFGrZQrBU7XsVqplF66odbVMU4Wt7y2PXb8Epk01sOtEHFNZtkpKx66BuVPEuZWIM7QIpjmjJqVTGexKZTD3/MI6Njf01MGm68ePc7hzXqEY+/qhttAqa1nAtcByVdS3VmDhFJIt8HhjW0iWH+AzfCc+uWsWvBogsb/uxQdphVPu8sKL3BNzzUiPhSHVeFUl2zjAW4OFJhpLDywW1aMe+aOKr/tmftLB4m0U0y7kvT1ANmS/cQq84q/QyTiX00QqzZ8Q8yNFlb8C+PXFGfjNLvg1twf92tvRz7v1N5Fljlx/d2ps/gM=
\ No newline at end of file
diff --git a/docs/database/mysql/images/concurrency-consistency-issues-missing-modifications.png b/docs/database/mysql/images/concurrency-consistency-issues-missing-modifications.png
deleted file mode 100644
index 1718e7ce0dc..00000000000
Binary files a/docs/database/mysql/images/concurrency-consistency-issues-missing-modifications.png and /dev/null differ
diff --git a/docs/database/mysql/images/concurrency-consistency-issues-phantom-read.drawio b/docs/database/mysql/images/concurrency-consistency-issues-phantom-read.drawio
deleted file mode 100644
index 350470274c5..00000000000
--- a/docs/database/mysql/images/concurrency-consistency-issues-phantom-read.drawio
+++ /dev/null
@@ -1 +0,0 @@
-7Vptb+I4EP41lvZOKsIJeftIgHRV7UordU/78uXkBudl68TZxBS4X3+2YxNCQkvvSqG7CAnsx/bYmXk8M3YA5iRbXZeoSD7SOSbAGM5XwJwCw4BwaPMfgaxrxDGtGojLdK46NcBt+g9W4FChi3SOq1ZHRilhadEGQ5rnOGQtDJUlXba7RZS0Zy1QjDvAbYhIF/2SzllSo67hNPh7nMaJnhnaXt1yh8L7uKSLXM0HDDOwgyBw6+YMaVnqQasEzelyCzJnwJyUlLK6lK0mmAjdarXV44I9rZt1lzhnhwy4uV0Ff/3tf86+uHH86frm+3v680pJeUBkofQBZjZwA+DxggVcC4wtgXgW8IeyaQrGM/VAbK2ViOdcp6pKS5bQmOaIzBrUl4rCYilDXmv6fKC04CDk4A/M2FoRBC0Y5VDCMqJa+VOW669qvKx8E5WBpavT1XbjdK1qBN1h4m9sNaGElnLR2lqmH9GcqXnhSNUDlKVEyLjBzC9Rmlf8iT/SnOr+dFGGYkTCGGeqYZlj/sWVL75Eh2oQUxoTjIq0GoQ0kw1hJbsGUS2dF7flW4avZqgVLLS619gKqvQ69lnYUHsKlTFmj/QzN5TkWx3TDHMl8nFqn18NB+bIVrJKTBBLH9prQ2ofxpuxG3GfaMpX3XShUVTxtWyRlRe2Zm0gSeFn0Nno0rlDVUK4axGUXCYpw7cFkupbcu/WJhyqitrfROlKENePUkK26BNF2A5DjlespPdYt+Q0xzucss6IUw+4ZHj1OKv2sgBaypcpXw9tVV82nlNDyZbT1FgfR1oUeK69zYu9j2lvxzwze496wtUI+GPg+jJcjcEYwg4FuAJY29b9Jtyyt4IQSeOcV0OuMMxxX6gz5cnDWDVk6XxO9pGrHfN+SYbYOwRxrIMIYh6LINYBBOn6iAtBXosghntigthvKXc9V0a8SGLqHpiYwj0EOzgL/V98cXoyDJsIb1EVKG8xyf65EGc5aYWrSpqNq34IR8VKak6381IsfkNOK/buzz+0QL6+Wmbd3EvUD+I0s5O3HOyCSsxXhe6kPEGvQuTlUmGWD6zp2z4s9XgpdWWgnnhzQG6xdb+TeOwsBA3Xbvu1cz8ZuZdM+TVPRoZz4kzZe2tx7hwo8CJxTR9Ang5s1ikDm75/vUS23ymyeU9GNgeOWp5MXxH/19CmF270Sj1+4IPdK+58kfHC5l6+4WHjAOHTUbAT9CLjNwt65m7Qc7tBz+kJeqNjBT1NskuW8zr3gSfPcmDPBbB6bTWRFz8T4DkSCYDPC4FExjfoAV2L9446QN2VB8U7c0+8AzMH+FPgQVEY+8DzNlP94FPJV5yDMO9w8TzunfaExh4im6q+tQt8+ZEyGY8PNFdCq3vMwkS7yl+B/ObuVdaoS37o9rAfHo39o1Mk+edizJdJ1q1Dk3XjpMl6915bJTHdtx2XJOZZ29rq3FAfLYnh1ebvHnV+2/ynxpz9Cw==
\ No newline at end of file
diff --git a/docs/database/mysql/images/concurrency-consistency-issues-phantom-read.png b/docs/database/mysql/images/concurrency-consistency-issues-phantom-read.png
deleted file mode 100644
index 4bea3c32953..00000000000
Binary files a/docs/database/mysql/images/concurrency-consistency-issues-phantom-read.png and /dev/null differ
diff --git a/docs/database/mysql/images/concurrency-consistency-issues-unrepeatable-read.drawio b/docs/database/mysql/images/concurrency-consistency-issues-unrepeatable-read.drawio
deleted file mode 100644
index 212d68f7f92..00000000000
--- a/docs/database/mysql/images/concurrency-consistency-issues-unrepeatable-read.drawio
+++ /dev/null
@@ -1 +0,0 @@
-7Vptc5s4EP41+hiPQYDxR/BLern27nq5m14/3cggQImMKMiOnV9fCYQBQxy3jR3SejyDpZVYIe2jfXYFAE6Wm+sUJdEH5mMK9KG/AXAKdH1kQHGVgq0SQLMQhCnxC5FWCW7JI1bCoZKuiI+zRkfOGOUkaQo9FsfY4w0ZSlP20OwWMNocNUEhbgluPUTb0k/E51EhtfVRJX+HSRiVI2vWuGhZIO8+TNkqVuMBHc6t+XxuF81LVOpSE80i5LOHmgjOAJykjPGitNxMMJVLWy5bcd/8idbdc6c45sfc8NsfBrSHnkH4v4+jj3d//r20rSs1l4xvy/XAvlgeVWUpj1jIYkRnldTN54yl1qGoVX3eM5YIoSaEd5jzrbI1WnEmRBFfUtUqHjjd/qfuzyufZWVgltXppt443apawGKulGqmqs/RklDZ4QZzN0UkzsR0PrCYlf3ZKvXkHRHnAlG6CR1xEYskL7JDNggZCylGCckGHlvmDV6Wd50HhXZRrOs3dVeN0LaBMktWDvvUwpdQR2mI+YF+RtFPWqU2gLLwNWZLLFZIdEgxRZysm6BGam+Eu34VPkRBQeQb4KL0rhFd4RL1+/ihVGxdiZOHiHB8m6B8HR6E82iiAGVJsZ8DspFocgNC6YRRluaKYBBgy/OEPOMpu8dlS8xi/LawsMYpx5uD1lOtO1+hfKlmqfpD5ZlKUVRzSqXsxe0NL/Y+pb1trWf2Lp/nwgfn5gPjSD4w+8UH45aDcEqS2MPQe7QQgWPTI1ASxqLsidXCYq+7cucQEZo5qmFJfL+AGM7II1rk+qTlE0aEpaRy0wXmtAMLVA7n7kK0mp9RQVo/4XJwV7Ycyy4qVkvTiCy7HM7VcCBZpul0itrRgFHK/5ImqDSbXTrL21kQZALV+2jbPd/3A9Bo40/86W03Vjkp7XmqajFToP9izAStPWYatZlp1MFMxgsw05c7///P0EE4SG+tNWf/DBm/0joij/4y05vwPnXgwh8iL/NI8oK9Ii+z03do7ZT44ju+yXeYr+g7Og09amcxMwO4DrBdMDOB7QBHawctYra8adpuE9bsrUTHxzVdWGo6rZ8SIRrcR4h5VN4DT4UQ+wiEtAnogpCzIUS3z4eQKU4mZHuDPPeGuOnvn9yPi/snkpqehh/7kPh+Zi9R/yy1az1LTPX2jr6cXJ3upFLv4PhTnVx15wfGW9qgv1h+oHUkCN1W7FeGoHWnCJfjhZc+XtDtV04RtI4c4cIXp3vTcU6+6DT4bgr1kF9E+iZwJnnsPwHjUS6ZA1cU5rnEuUFrdC2/WAC6RWXwv0gbILG+rOT7/NwoV1luRWGJoQaTTb6QZbsohfn/bATcKRhrsuC4YDzeDXUnhso/jhh4cU9TjydorAPIUNVru8DNf7lOLnw5i5XS7B5zLypd5c8Afn28B36jDX7N7kC/drJoybxES32Ilg4GQc/nXKPXipYOPvflQPWF/Ydlni1aEtXqi7TiJV311R+cfQU=
\ No newline at end of file
diff --git a/docs/database/mysql/images/concurrency-consistency-issues-unrepeatable-read.png b/docs/database/mysql/images/concurrency-consistency-issues-unrepeatable-read.png
deleted file mode 100644
index c734138cf8e..00000000000
Binary files a/docs/database/mysql/images/concurrency-consistency-issues-unrepeatable-read.png and /dev/null differ
diff --git a/docs/database/mysql/images/redo-log.png b/docs/database/mysql/images/redo-log.png
new file mode 100644
index 00000000000..87070397390
Binary files /dev/null and b/docs/database/mysql/images/redo-log.png differ
diff --git "a/docs/database/mysql/images/\344\272\213\345\212\241\347\244\272\346\204\217\345\233\276.drawio" "b/docs/database/mysql/images/\344\272\213\345\212\241\347\244\272\346\204\217\345\233\276.drawio"
deleted file mode 100644
index 4f649c952cc..00000000000
--- "a/docs/database/mysql/images/\344\272\213\345\212\241\347\244\272\346\204\217\345\233\276.drawio"
+++ /dev/null
@@ -1 +0,0 @@
-7XtZd6u4tu6vyRj3PtQedAb8KNEZMGBs09hvmEZgYzCNafzrj5Q4WWsl2VW176m656FO1soApsSUNNtvCuWFla6T1ka33KqTtHxhqGR6YeUXhqEpZokvhDK/UZYU+0ZAbZE8O/0g7IpH+v7mk3ovkrT7pWNf12Vf3H4lxnVVpXH/Cy1q23r8tVtWl7+OeotQ+oWwi6PyKzUokj5/o4qM8IO+SguUv49M888Fn6L4gtr6Xj3He2FYlVdVVXxrvkbvvJ4L7fIoqcefSKzywkptXfdvd9dJSksi23exvb2n/pvWj3m3adX/mRe0zJgy2oFeyjRhNdZm84C/MfwbmyEq7+n7Ol5n28/vEsITv5HbeC6LKknbFxaOedGnu1sUE/qIDQPT8v5a4ica356IVNJkffogfMjKufeYS/qkZ3XVP02CXuDn7pL2MREbRRqLspTqsm5fp8GqqsJLEqZ/XfhTFkPa9un0E+kpCC2tr2nfzrjLs5VfPtX7NFqWFv+1eKOMP4yAZp+qy382gMWzY/Q0PPTB/Yfw8c1T/v+BLoRvVMGXPRHLLap+0Qnf3InZwPhNPAA3tuj0fxZ41Xhs6sf1/77KiyJy/i2LrkU5v/W+pm1bjCm2UazP176YaXQlenyyvvVkxLQtss8tb/3xsltURN+/3BdX7NMMVaUjmVp9JfP/jkvXd3WFnvevg/2Y73O5ZLpV3V6j8q2tTPs+bX/DMokL/OqXdmwC/W/EUIl1kEbqNv3U0rdR1WW4//ubxBhJ61i3ya9cf30xSeO6jfqirj6/mRTdrYyeki2qN/t+XUZZR/3n3j984bdP6mM4/k0SDLGx1xtOfNMg/yE1Hj2vr5ZBBPWtZbxJ8NW1CHt68VzLF0bK4gVSL6L6ovAvS/FFVF4U8QXwLyL9oggvEL4slz/1wRTwAhjSB8ovQHq94Uh/PAZFUcQWcG8R/2ff54id4W2av04dk9/s+p38KewQof9xqPndiPEWjp9h5sn5m7j5H4cPnOR+DR889TV4LL8JHu8B5S+PHe/Z9Cf5pQnOc8/Huu3zGtVVVCo/qLB9C9NP4f3os67r21O8Z+xs8zNCR/e+/h3hd31bXz5yKPN7gZpM7Xfl3KYl9rTh1xT9ndCer27q4tUP3vUjfNLP8lPM7up7G6fPt37OmZ8YceIfMOqjFqX9F0avOvxYz39Drdwfp+cfWqT/2F0+eUiWZUwcfyjvp5aEP/EL/rOO/wLfEahPqVf8JvHS3/jO4m/zncVXIX+NeCTJwY8o932s+tk1fhHoM/r/LP0nKSoLVBFwhSX6Cq2IJAsMT8Gz4Vokyau3fqfZXz34d9HUX6K65TtKeiqPo79RHrX4qjzmb1PeNwD2a0pjqN/+4ap7DxwfgexrxhK/cbq/T2/i/yasn+uRL3nmX38u03xhteD+kNW/yX5/VdL6sM4/UVMW19fy/MN11tEpLTd1V7zhbPlU932NoTosSQP8gM6/5jD884379cQoYNTd3rYNsmIipgNfhwTvVOqdgu+TqI8wXH57ZNTba2FS+NDZjpSpoRrgH3vn5YqH8J1OHiX874Cvsry5rtb4RpW8UnH9LRfemXiIls5u2mvZZGB+INH0XNkXV8q97IrGlmpmU2/2W/6+M8eWVm6Zv9UbrfBNVBtZfM03uW6Aws435GXj6IjobpfsmXrwi4Jets7JW8zHPkjTZdI9Hsub8ChLIGid34HsAK8jKC/8FWetccHJ9rg6IWs4dMPILy+9JLdTH8Pbwcbtlih0sAJa+kjwiuF+7egAjnCNVBlbjnrAvzGcOaWIBIuaLo2CHvlmPu8zjhhIc4ndw21qz6ZGBuO3QEZaqM0X3GZrUwu2W2AjfaM1HqbA/dUS4F02OCQhiUU2ZQOvyC9nRaTk/JpgDkoB1uBI5rXUmSTc7kRXB5vRrmRd4qTtyBY5ozLKGazgIDbrldsDYVT49bhmMVEGKSMZlwgOyPG17tTp2qiBhV30LZkRcJsBbWLXB2v8tEFIrlGytrS1q/qSextRjZRHPgPbFIhjMOoeT4S9GzstKPLo7hzSXPX0oFDWO2hvJrZh1CAfhd3d5lbLc2Az6syZwLiDfGT9fRSW6R3exkWe5HUtudAIK85aK3qnuMYNcy5GK+dPg8S4eh+GkQEv0HTPrXU58Erpz2fHPc/+cdaBuVvcYivmfblm88ttpx+GlVvbA+aRbeid1QAy2eoeHGdP2wuTvV1m80Oc0+0hlW+WWE2aZ+l0MS7AXd/R1Q2AyGTqjkXSqFZSgJYhWG8DWr2IAHvHIWJW5ggjE/OvuwrBsWzlYJw80G59Wu3EM7DuYBXLwRzjLv50a4hyHU6SZ2Iv7NRmJ1qQ03GDQAUOgTwPZoXTkJshs5ILefkadxgYUEsQQGJm614JcKZWI/wbYn+BYRFt8X1vr/DDdWNXzYLCSlhuV8YydSFSMjB0pv64+SIMOGlTHeiWWgERGDgswEU8lO7JiQbxdH+MSw44IIpXpCU+t/W+T6HL2Xxinw5ghLcmZWn5sc0SAdGyt7bAKC3vGWEDqsGlVp6P3V3bJBtZq+7IH4E1k0khGhnoomIXZwfXU3uQHRcJXgDMedGupe2FHwAEIEetly8Oq8bOxn7SKEwwBV1NwQ5HDhjUZFZsrvu67xnLip4aftXODDJWe3MECjIVaRmtSpDWtA9x3DMVEZkrECDFmjwmX7iKBbMjaEfgAv1g0nrGiFA2wHJfMadAw3ljWAfyZQlwBAuk2l3RdXqAvJx5xazmMpaljE6epOlNq1Irjasa5M8nVwE69LCHwzscWTx6+xDUm0xzm1A9wzlFAZm8V8s8tcETzKt6ezTnfKNL+ajWULZCv5jhOd6zrjlhYegKaGAWIu40g42/SBoGC0ltpUla7uNWuXsD3WrSIrwbD0HZHULtUuyw+ofSXoV0Omruno6Vsz8JSJ3NHXYe9UJV/EI8nfnM3fG7yT4y3dJHlSOrLljkO0na9jWZv3zdBki7FgaJwqvh1nrHVqcqYWn6YKrReR0wb2P1/mzTmY/HelAX5YwFswDa1ZokKPRmOay3WdbRI63oYGFYvruze5DUUg/CmugceLDQuxPvC2lwfQse5ilvdA/MUtyiC1m3DkQkv143M449vLRxw4usKO7bYKsLeLtewd2dlGalrh/Yt4bF1UKLRAOFlDUuimZ3b0KrVmb0fsWOAj0KXC0rP7W9oZTDac1Qx9V6p3OsTZ6Pj9IWRA+EwJG3Oy1COE4EaL5IPtrVsu9GjbyZITiW4BpLIrgxrCmx1W7o6XWXjlxwUWenw2t2fvRX3WMjG+4xkk3XCKAy+h5M80e85hTJNLcNgj6IaskHvnVIwdqYwxCFRrehPZI6wc7zna25kA66TjL5Xw96GfoT6F3wX0Gv+BX0vtP+ctD7DoT+kcjILC4fyCg5CoDebjVtNY8jif2g23ruDfqWkdW6oQB/O+nugYAB1Oy2KrQiXdl6W/dhgmI8AMU49sDbKopCKRMqr+No6UCTJX8zzzR0Gj8mScRrwmFYdg9H2JwojCzUdhBS5siH1b3q2bS6C34hURsQHgDOcJ1kjo8g5exRIc6841YbghGgLhyi0heSiNIJgFFlZKXrxZQFsbwdYaiRkeRG8RROCkHOrbw+oaQBPLidcU7s3XihvYt24Z1mgCoXiOJxtg5C2t/qxWDowBnXmVm4ZMce8k0/GjVOyEomnd1bN1hCLJl0pB45vQbGuD6poguMakdQmnbPA4a3phgnwhj69GkWNu02nDAE2uB0aEMTrEeYqnHJzIK1RTK6XK7oxh3l9SgxbbA6FCJFcBUMzPvOZUW7VTOjR/eH4squwna4NoAuQY9pwZ5X94cD/Bw/kqR9AKkpUYdReFQcSK/TPpfPZD9XUh8q8OUuJHFW0M4k3srRI6djHdclGloh3hahgxa7++3AeJvNPDF8nMLQbU+JFt8lhOfOLg7Uuuf7cDyIG0eySyYqkAkqeSBcjRkGkgv6zbiTdiu+HWRGVkUm9S4UWLvG7n50d2XhtLKJhTs4hVsAujle5CJQN91SR1uBK6FLMMaZWASN4QRe12ExRvutoVT7XGhu/UbKHjdDouN53vsYN5m3rRsjVo/8sAcxsvX0FD/SlS5rdvOgEicG5eZYE9xzugJ5xxyioHLGFPVKfOoe8apeK7b5YBPHlcpN0hwG/wA8bTtsGNhylnJ+3VlS84gzB2DF8mZ7W6wFIusTUKQTbhJLwzAJrEKoizxpP90jWqawo9mxsCxTXCXggsK1zS4FGVJjeXq0LMakQH7cU26xcUXAg40Tt9xwTB6Lue5DkjBO12IcuOkKuqk152BgzHUZApWzKmcvbtglk1adbDxiBsMzuJV2F6cTWAEsYol3xymIwZgYK0oUjbtkN/eTWKEVNhLOywKfnipUizBNvEfYpbWNbAaSDbSuS/ZSm46wkuVj9OAUEYSQ5dQ7aKo7szZrHKFheUbrmerG3ALmoF3ZDTb/ZrqoR5pa0xzwdG/YZmNR7EylyHe8ikTQAlVc0VI/UOf5wMAzR+qalNiqB5HpQHoqktsm6YYdCSqPKM+CO1VwagY2l5MsjEkaLd0E498OGJw5m5eAihQ725YiMfdiSlgG6wE60mXdaM7N75VOXXTedpKPzAgGZHdR+eCyg5yBoJPZEaTH9Xwv7Rs9whMQOIVGx7udt+J6Y0W1I5wjbCg1cA75lIeDs3GIp6kLRCCnQ9+SfQqncTwG48ldeco6WjecEDRX9ayFtFGtgUxV1azG6WkALh9RiU9seZ3a9CLZMePDXQV9lBjGofTqXmxzo7KcwlmcnQBItR/fg7z0CRJm16fQe9AbByxg3pW+zK1O61TR005cN/2B2m+Fc2CBWJbHfedYfuTLVEwi3jrSBHHe+g9NanruthsePJ3DcCGukz0pGYtAE6eEiq45jgdnow/pnptbm3OHhJkTjVj8rVR620v5bNEycQB6Xwoav1tqYnjIS526OUtljXg3kun20KfnA0ddpeEsti0yLQsOrurR4nwnlrlGkENhXLhAylnhfJabTlxV19C9cE1RrMSVcN17ezoUDFYOc61I6Sahk+7aDo7LyxjHmleuvaycUO6Ir2mJTGq/lkTkjXymkzmwzQvcu4t9FyWVy59W9Na3B9kajM0o0X1pe7HvHqUabgDbhMJklLR01i+zYY5m4RdN6NlW32chrpEgGphwhBSvVorTqRvTvQ61jFZA4rSNtouG67osFvy1uHOnVL02+nCvMl10xjAn5Wsk5HdSkUIP0RxdJjUwtV1zVi9LaidWd/9KF8U+WN/La7aTkpCU0ycUWwLdMOxq5bGYhe/Qq5QbQ9gBOVwOLqm5djuW8j1uXC6EOVshuK/ykHjipnAkYpkS8V2r80UjkPZwuIbTiZcdNuxjBxuHBDcBLl0hxWl2tLQokVS291C+puTaZ42wjTPncY0jLFO1SC7M0t2d7zEx9htBUj7cTaETHserluuAOC2AChXKqhXsTRB2ubobwBAnekZHqVuQotQMTLfnzMzrKeryhrbhMq205lpuHtgQSKxx4brt+fkibOn9gfJrxerIkIc+EfVGIf6cPuj0vgxbRc/68mEE2K/iWL+iNT+d55UZZudUA5tQa20VrDntpIZrfUszw8iJUbSbmvFx0pC8geuFO21tph5ve5MeE7esZVfyj6qiJ950nBUxjV1Bm4LRRMcOsXSkLPR07VnuaXsar+BarDJfy6q8zvcTf72zYw1cbit6CybRZsNZRWmToQ5EOs/6G18aKnUpRsPx/sAZWT12hzYYIZoNaaAComJP7GwlSh2PYjNnlPnLarvvkyC0TtN4MAOrP2h9ChJ0NuDA5ydK2mrVufRj9mGB8wiJAlYPNXFHIsVKPs/n5hFau+Y4yhqGc9fTRXroAU5WUk6HUnVZH8rdcAxn9rjlYAzlWU5ofdFZStgpHPDPBtVchWH2htxAxHr7CU8ylcIU7YEnIjbxnEiaVAFQYEGwzdJZnuoH7pPEm1ide8YwlyCBVLDyG194LBKvRBuFps5mnU0Zvz+ih+3nzs32FsMdZ4i7lI3Tkm/FwEftweXdZmOzoAPH0RTO90h1kNOyonpPvDnsyA4HBNDnYtUa6+NEbJTpjXznewfLxHKCgOQ/JxXso0x85YTnDkj96T28IallsKID4itX5ZCbj0ggD/EOEeyYlEvjXi2Y/gA9e2svs0t/QXdi4XlcO3m5C1ACtP2FT67BNgTQW16D2uWLINnu/WjLAJ0DrLZndhIHTHe7uK5Ma9EnmJtFQehTHeG2682mrko92lIgYi7Myedw5m/c+np0MWShgXq4Jk6Ii3kZJ98Hnd1q5bbyQKLcDk1gBbPrgxun+WLuv85nPuahFsZXdYS+HVxKJwnrgmw0tb3Lg2gwjjPPXkAj85vGChPlkQappbauPfZUSTbVuo6PkVw3ZX5P1nZmHwYc71WLIJrl7Xqbbnx51SwHKLeNx7NyB3UIbO+YmTDPWR14VhXWYbfXjsfdvvBwIdFGN7WRw6Muo019bIrcD/QLQBv/ESMOCIR7tSy8B0CwWQTm7X6jZGQ28Xra0YLTt+UyWQEHKgeN7AYkrAUc6YqRQ55Lw8LTkYSSgltp5XwCIizWaWe5QnBWkAIIUGRwdIYSFmMkd7EO1FyQ0hh0NmjvBobtKh/vjlsEkUrhqllldoCDOzoJLb2ZFOBgo4Ox7SxceVwfCCA+KDapI6SK8F+mW79YXu6zi1EM56YTzZ5xTlMnAQLZQ95e1U71BY6yb5x4fmbldcaJAK0DLwQc2B9xucaBIy60BEDqsoZeBp6Ve8AOsU89brQ8Ui3B84t+5Ph9EYkdRtp7Q4e7NpROw+PC+SrwwMpSE+qknpqVJ6nN9cYaBOon7YxAYzNd1edrFq2oY7tSebn3UtfYAhvAfYvjs1uCXZ495r73HuzoAYsbVc3W8XTc0qUObcILVUrYeTWWXTSbsXSxLZ7t0rvRjQXG/Py4KmvuKII+TOnVebLj9WWgdwisNLmebyUPaclBuybMjwfMA/FF40mKeXgEVrOPozsljFJMZIqqg5IhVj0khxvNlvIA6BrMqWojgauVuTnRnFn5OEJCgcJ1FgKLKVTRCVHuZbVf0n278iXPhdjX4H4jhQNYG7dNmDfLUywMeD68eU8GVARQAc/ty9t9Gm8bXj4RAMY2bpHOg0FqYACNrbdQ2ouBEHrd3vg7dji4zwcdFsKXHQ7hmx0O4W/b4WD/1OfYf+Q3WIblf1UW+/UbLPf/8xss883pkm8OPvwjlcWJy1+VxfxPK+u746Gfv6BXCSBHoomMy6jrivjT6Z9PQkunog+fbeT+QOT3r/cWeXqK8/Vhfv9q/v/4Cf3to/PvnQjg/uS39p80sPidc0L/zU/y4uLX0MpRnzT7Z8+QLanPMfoTo7/5DBkjfuPlOBK/Ojq+EeUXoLz6PXhZsv9Qdxc+n5pgv34q+M7Y/j53X36jtY+DudwLXL6I4ouyJOdsofyqx+ULEF770C+i9EoRX5Zvx3GxZnFEV1+g9Nr0H/FZvADcjX4/6bv4h1rIx1+E/E5C+KtMhOw+ffxdyFsc+PHHN6zyXw==
\ No newline at end of file
diff --git "a/docs/database/mysql/images/\346\225\260\346\215\256\345\272\223\344\272\213\345\212\241\347\244\272\346\204\217\345\233\276.drawio" "b/docs/database/mysql/images/\346\225\260\346\215\256\345\272\223\344\272\213\345\212\241\347\244\272\346\204\217\345\233\276.drawio"
deleted file mode 100644
index 6ab55e05746..00000000000
--- "a/docs/database/mysql/images/\346\225\260\346\215\256\345\272\223\344\272\213\345\212\241\347\244\272\346\204\217\345\233\276.drawio"
+++ /dev/null
@@ -1 +0,0 @@
-7Zpbc5s4GIZ/jS6TscCAuAQb0sm0s9tmOtvuTUcBGdPIyAtyYu+vX0kIc3TidJOYepLMJNKnE0iP3k8HgDlbba9yvF5+YjGhwJjEW2DOgWHAieGKf9KyKy3uxCwNSZ7GOlNtuEn/JVVJbd2kMSlaGTljlKfrtjFiWUYi3rLhPGcP7WwLRtutrnFCeoabCNO+9a805svSigyntn8gabKsWoa2fuFbHN0lOdtkuj1gmKEdhiEqk1e4qku/aLHEMXtomMwAmLOcMV6GVtsZobJvq24ry4UHUvfPnZOMH1OAJjfh359XhXPNrY9WEH0prr9cyAKymntMN6R6D/W0fFf1kHpHImuBwPQfliknN2scydQHwYSwLfmK6uQFy7geZGiJ+P6tJzJyR3i01JFFSumMUZarVsy5FaD5VGbiObsjVUrGMqKrDfEqpZKya8L9HKdZIZ7zE8tY1Szb5OqplpwLeAzL9MQf0R/yj8xQXCaMJZTgdVpcRmylEqJCZQ0XZe0i2KzfMnzdQr+79Qjck5yTbcOku/+KsBXhuahysq2mRllCzxRHRx8a2CFtWzaQM21txBr1ZF9zPdwioEf8GaNv98aaxGJy6CjL+ZIlLMM0qK1+TYMcxDrPR8bWmoGfhPOdhgBvOGsTIvov333T5VXku4xcWlV0vm0mzncVPAdJKompZq8xblyKqtlDg6Llk+M8IfyRfFaZT47Yo/DlhGKe3rfl7sVRMgd0xKZc93ULMvufDasSLgqFiej5CXTW2zpRhBL1P7CAPwNiXoiAmEBeCIIp8D2AVBLygAerlkA5bvuiPbgpFV6FHCFibWmKMUGL6JA0PaJw46XweNGCVlu19v6sIVvQGJAt57VUC55Eto53bOclRy8uM7ronyxVuqAxc6ZtzGDX6ZV6qEt1CNo/xv+AyjmJL9ym/Fsj3PCEIlY7Qhmp/OA7iK8LYkfvTPM4EL08x7tGtrXMUBxux+4Ab1hWe/n+RP7quep5UD7Bi84K66V3B23HulgsjOgXHGtCcVGck5PdQ9ZVv4aT3e+Ym04Wuq/mZWFvqEflZUc87k9KmXPkEh+Naonv9MTg5vNHENjANQGaq2X5HLizPjdiEvD2MA/v8RvioE2YpkkmopHoYiLsvpxSaYSppxNWaRzTQyv6No1ngdYzJKVz2gDRwHHDgKIYryYofd/xpqcN9QHDd9A8Xxg+bTgLWp4UInSkEFWuZyRKhI5Toj5w70o0AiUyzFMr0eQ4frJ3fsbIjwlPzU//sPNS/fwmvOSMC5Fmshb38ZP18+AHdfRn6OLlTfk54L8sgCzgIRC4AJkqYAPkAs8BAZLH3GimLEieg5dn3274myB35oh1D2fgyV2c20NM+beZBEr6N6SuVFTA87T367ImYBQZoLT4U+BZ76yNgrXuAaV1YtaM/nLqpe7+BJOhUjt15SdofL/7e0vUHLsjaye/+9u/w2vcM7s+cAMJnS8C3tuztkAR+ZXj8PNgzenI2uQNWfPx2vpw95XAmJtft1v7jx8/0osB1PQSbabYmAHXUZYQ+CIQKot3je/xlfymraLlNj+KSltQqXDsgemo3SiUAU+A6e6b+imaUp/PXUZj3apSfEuov/9SbuCrrspz2zremA+++m1vWFrwwxHB3yN9YD4chH8Kp22hHdjiwiGnDp8Pv4jWHx2WF4X1l51m8B8=
\ No newline at end of file
diff --git a/docs/database/mysql/index-invalidation-caused-by-implicit-conversion.md b/docs/database/mysql/index-invalidation-caused-by-implicit-conversion.md
index b433a40e571..69375c00a0b 100644
--- a/docs/database/mysql/index-invalidation-caused-by-implicit-conversion.md
+++ b/docs/database/mysql/index-invalidation-caused-by-implicit-conversion.md
@@ -1,14 +1,19 @@
---
title: MySQL隐式转换造成索引失效
+description: 深入分析MySQL中隐式类型转换导致索引失效的原因和场景,通过实际案例演示字符串与数字比较时的性能问题,并给出避免索引失效的最佳实践。
category: 数据库
tag:
- MySQL
- 性能优化
+head:
+ - - meta
+ - name: keywords
+ content: MySQL隐式转换,索引失效,类型转换,MySQL性能优化,数据类型不匹配,全表扫描,SQL优化
---
> 本次测试使用的 MySQL 版本是 `5.7.26`,随着 MySQL 版本的更新某些特性可能会发生改变,本文不代表所述观点和结论于 MySQL 所有版本均准确无误,版本差异请自行甄别。
>
-> 原文:https://www.guitu18.com/post/2019/11/24/61.html
+> 原文:
## 前言
@@ -117,9 +122,9 @@ CALL pre_test1();
根据官方文档的描述,我们的第 23 两条 SQL 都发生了隐式转换,第 2 条 SQL 的查询条件`num1 = '10000'`,左边是`int`类型右边是字符串,第 3 条 SQL 相反,那么根据官方转换规则第 7 条,左右两边都会转换为浮点数再进行比较。
-先看第 2 条 SQL:`SELECT * FROM`test1`WHERE num1 = '10000';` **左边为 int 类型**`10000`,转换为浮点数还是`10000`,右边字符串类型`'10000'`,转换为浮点数也是`10000`。两边的转换结果都是唯一确定的,所以不影响使用索引。
+先看第 2 条 SQL:``SELECT * FROM `test1` WHERE num1 = '10000';`` **左边为 int 类型**`10000`,转换为浮点数还是`10000`,右边字符串类型`'10000'`,转换为浮点数也是`10000`。两边的转换结果都是唯一确定的,所以不影响使用索引。
-第 3 条 SQL:`SELECT * FROM`test1`WHERE num2 = 10000;` **左边是字符串类型**`'10000'`,转浮点数为 10000 是唯一的,右边`int`类型`10000`转换结果也是唯一的。但是,因为左边是检索条件,`'10000'`转到`10000`虽然是唯一,但是其他字符串也可以转换为`10000`,比如`'10000a'`,`'010000'`,`'10000'`等等都能转为浮点数`10000`,这样的情况下,是不能用到索引的。
+第 3 条 SQL:``SELECT * FROM `test1` WHERE num2 = 10000;`` **左边是字符串类型**`'10000'`,转浮点数为 10000 是唯一的,右边`int`类型`10000`转换结果也是唯一的。但是,因为左边是检索条件,`'10000'`转到`10000`虽然是唯一,但是其他字符串也可以转换为`10000`,比如`'10000a'`,`'010000'`,`'10000'`等等都能转为浮点数`10000`,这样的情况下,是不能用到索引的。
关于这个**隐式转换**我们可以通过查询测试验证一下,先插入几条数据,其中`num2='10000a'`、`'010000'`和`'10000'`:
@@ -129,7 +134,7 @@ INSERT INTO `test1` (`id`, `num1`, `num2`, `type1`, `type2`, `str1`, `str2`) VAL
INSERT INTO `test1` (`id`, `num1`, `num2`, `type1`, `type2`, `str1`, `str2`) VALUES ('10000003', '10000', ' 10000', '0', '0', '2df3d9465ty2e4hd523', '2df3d9465ty2e4hd523');
```
-然后使用第三条 SQL 语句`SELECT * FROM`test1`WHERE num2 = 10000;`进行查询:
+然后使用第三条 SQL 语句``SELECT * FROM `test1` WHERE num2 = 10000;``进行查询:
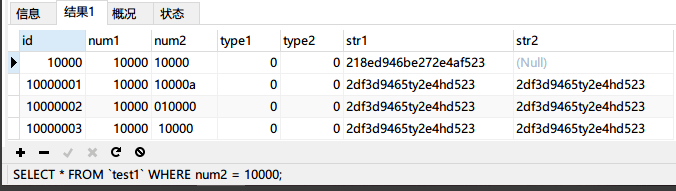
@@ -144,7 +149,7 @@ INSERT INTO `test1` (`id`, `num1`, `num2`, `type1`, `type2`, `str1`, `str2`) VAL
如此也就印证了之前的查询结果了。
-再次写一条 SQL 查询 str1 字段:`SELECT * FROM`test1`WHERE str1 = 1234;`
+再次写一条 SQL 查询 str1 字段:``SELECT * FROM `test1` WHERE str1 = 1234;``
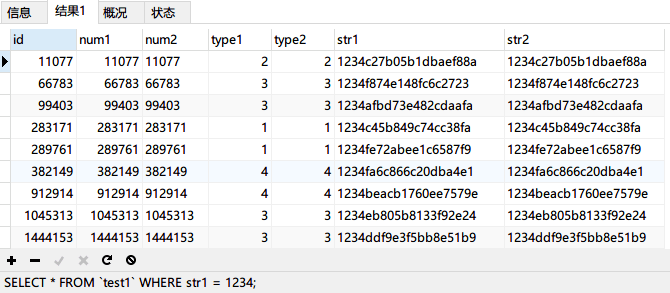
@@ -158,3 +163,5 @@ INSERT INTO `test1` (`id`, `num1`, `num2`, `type1`, `type2`, `str1`, `str2`) VAL
4. 字符串转换为数值类型时,非数字开头的字符串会转化为`0`,以数字开头的字符串会截取从第一个字符到第一个非数字内容为止的值为转化结果。
所以,我们在写 SQL 时一定要养成良好的习惯,查询的字段是什么类型,等号右边的条件就写成对应的类型。特别当查询的字段是字符串时,等号右边的条件一定要用引号引起来标明这是一个字符串,否则会造成索引失效触发全表扫描。
+
+
diff --git a/docs/database/mysql/innodb-implementation-of-mvcc.md b/docs/database/mysql/innodb-implementation-of-mvcc.md
index 3712827f0bc..b4df7745026 100644
--- a/docs/database/mysql/innodb-implementation-of-mvcc.md
+++ b/docs/database/mysql/innodb-implementation-of-mvcc.md
@@ -1,10 +1,46 @@
---
title: InnoDB存储引擎对MVCC的实现
+description: 深入剖析InnoDB存储引擎MVCC的实现原理,详解隐藏列、undo log版本链、ReadView机制,以及快照读与当前读的区别,理解MySQL如何实现事务隔离。
category: 数据库
tag:
- MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MVCC,多版本并发控制,InnoDB,快照读,当前读,一致性视图,ReadView,undo log,隐藏列,事务隔离
---
+## 多版本并发控制 (Multi-Version Concurrency Control)
+
+MVCC 是一种并发控制机制,用于在多个并发事务同时读写数据库时保持数据的一致性和隔离性。它是通过在每个数据行上维护多个版本的数据来实现的。当一个事务要对数据库中的数据进行修改时,MVCC 会为该事务创建一个数据快照,而不是直接修改实际的数据行。
+
+1、读操作(SELECT):
+
+当一个事务执行读操作时,它会使用快照读取。快照读取是基于事务开始时数据库中的状态创建的,因此事务不会读取其他事务尚未提交的修改。具体工作情况如下:
+
+- 对于读取操作,事务会查找符合条件的数据行,并选择符合其事务开始时间的数据版本进行读取。
+- 如果某个数据行有多个版本,事务会选择不晚于其开始时间的最新版本,确保事务只读取在它开始之前已经存在的数据。
+- 事务读取的是快照数据,因此其他并发事务对数据行的修改不会影响当前事务的读取操作。
+
+2、写操作(INSERT、UPDATE、DELETE):
+
+当一个事务执行写操作时,它会生成一个新的数据版本,并将修改后的数据写入数据库。具体工作情况如下:
+
+- 对于写操作,事务会为要修改的数据行创建一个新的版本,并将修改后的数据写入新版本。
+- 新版本的数据会带有当前事务的版本号,以便其他事务能够正确读取相应版本的数据。
+- 原始版本的数据仍然存在,供其他事务使用快照读取,这保证了其他事务不受当前事务的写操作影响。
+
+3、事务提交和回滚:
+
+- 当一个事务提交时,它所做的修改将成为数据库的最新版本,并且对其他事务可见。
+- 当一个事务回滚时,它所做的修改将被撤销,对其他事务不可见。
+
+4、版本的回收:
+
+为了防止数据库中的版本无限增长,MVCC 会定期进行版本的回收。回收机制会删除已经不再需要的旧版本数据,从而释放空间。
+
+MVCC 通过创建数据的多个版本和使用快照读取来实现并发控制。读操作使用旧版本数据的快照,写操作创建新版本,并确保原始版本仍然可用。这样,不同的事务可以在一定程度上并发执行,而不会相互干扰,从而提高了数据库的并发性能和数据一致性。
+
## 一致性非锁定读和锁定读
### 一致性非锁定读
@@ -224,3 +260,5 @@ private:
- [Innodb 中的事务隔离级别和锁的关系](https://tech.meituan.com/2014/08/20/innodb-lock.html)
- [MySQL 事务与 MVCC 如何实现的隔离级别](https://blog.csdn.net/qq_35190492/article/details/109044141)
- [InnoDB 事务分析-MVCC](https://leviathan.vip/2019/03/20/InnoDB%E7%9A%84%E4%BA%8B%E5%8A%A1%E5%88%86%E6%9E%90-MVCC/)
+
+
diff --git a/docs/database/mysql/mysql-auto-increment-primary-key-continuous.md b/docs/database/mysql/mysql-auto-increment-primary-key-continuous.md
index 92c0ad13d93..029f7dd1243 100644
--- a/docs/database/mysql/mysql-auto-increment-primary-key-continuous.md
+++ b/docs/database/mysql/mysql-auto-increment-primary-key-continuous.md
@@ -1,14 +1,19 @@
---
title: MySQL自增主键一定是连续的吗
+description: 详解MySQL自增主键不连续的原因,分析唯一键冲突、事务回滚、批量插入等场景下自增值的分配机制,以及InnoDB自增锁模式的配置与影响。
category: 数据库
tag:
- MySQL
- 大厂面试
+head:
+ - - meta
+ - name: keywords
+ content: MySQL自增主键,AUTO_INCREMENT,主键不连续,事务回滚,批量插入,唯一键冲突,innodb_autoinc_lock_mode
---
> 作者:飞天小牛肉
>
-> 原文:https://mp.weixin.qq.com/s/qci10h9rJx_COZbHV3aygQ
+> 原文:
众所周知,自增主键可以让聚集索引尽量地保持递增顺序插入,避免了随机查询,从而提高了查询效率。
@@ -16,17 +21,17 @@ tag:
下面举个例子来看下,如下所示创建一张表:
-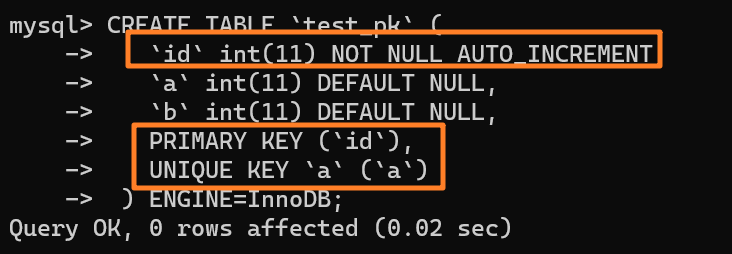
+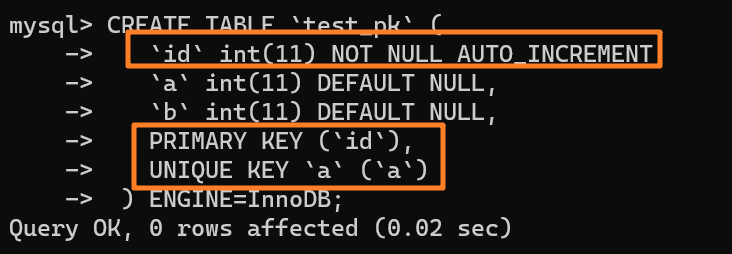
## 自增值保存在哪里?
使用 `insert into test_pk values(null, 1, 1)` 插入一行数据,再执行 `show create table` 命令来看一下表的结构定义:
-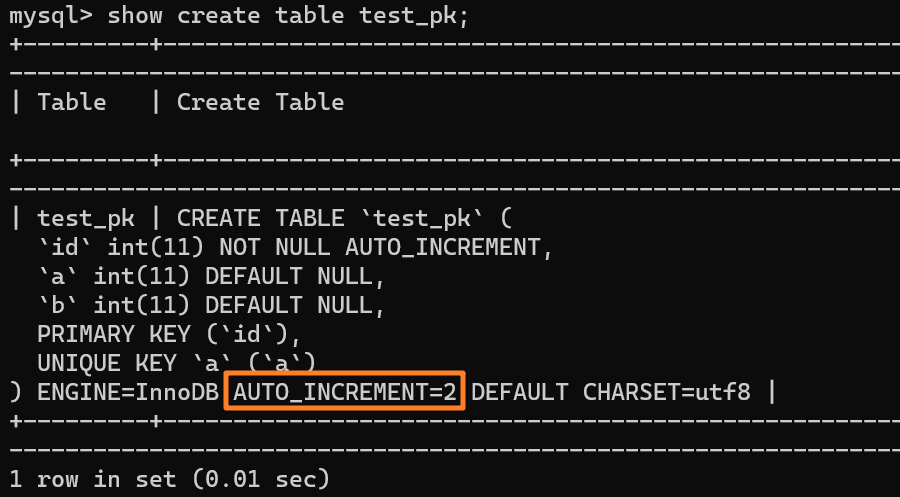
+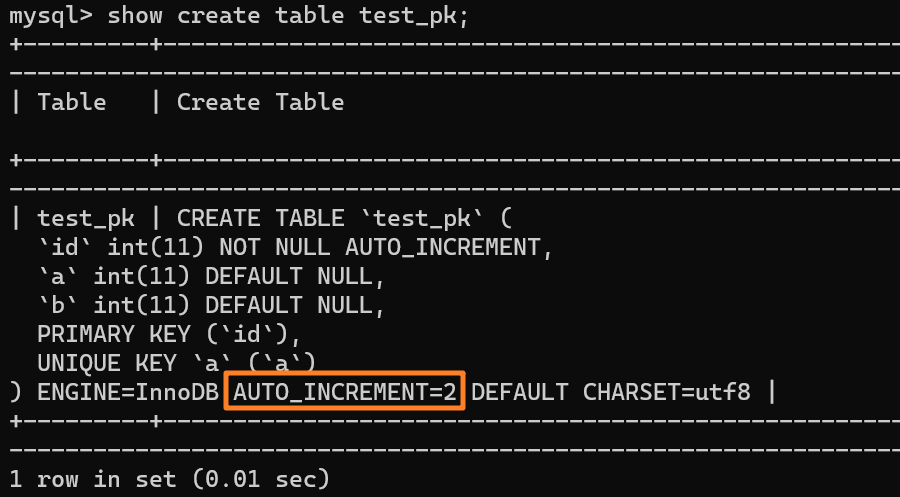
上述表的结构定义存放在后缀名为 `.frm` 的本地文件中,在 MySQL 安装目录下的 data 文件夹下可以找到这个 `.frm` 文件:
-
+
从上述表结构可以看到,表定义里面出现了一个 `AUTO_INCREMENT=2`,表示下一次插入数据时,如果需要自动生成自增值,会生成 id = 2。
@@ -38,13 +43,13 @@ tag:
举个例子:我们现在表里当前数据行里最大的 id 是 1,AUTO_INCREMENT=2,对吧。这时候,我们删除 id=1 的行,AUTO_INCREMENT 还是 2。
-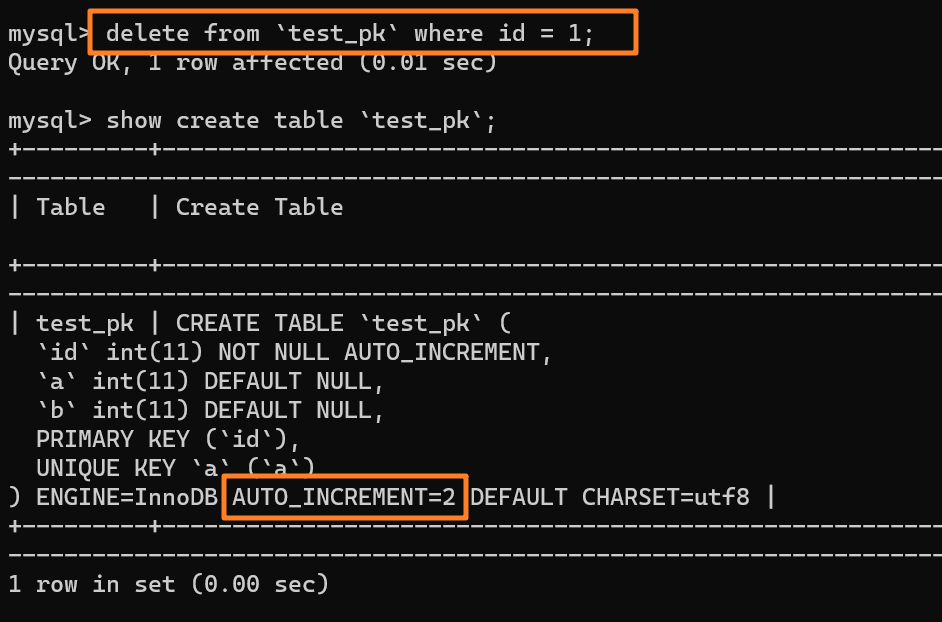
+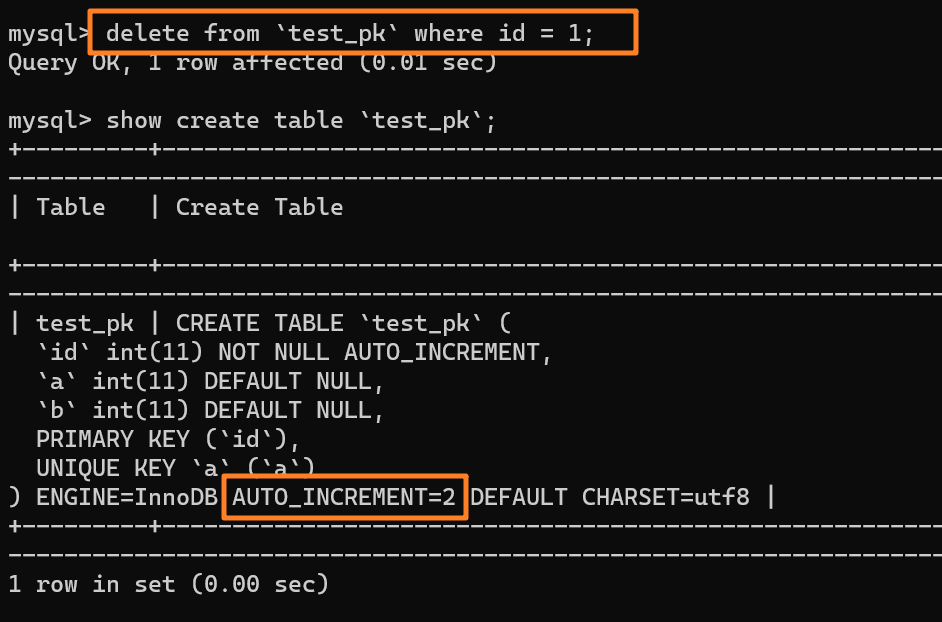
但如果马上重启 MySQL 实例,重启后这个表的 AUTO_INCREMENT 就会变成 1。 也就是说,MySQL 重启可能会修改一个表的 AUTO_INCREMENT 的值。
-
+
-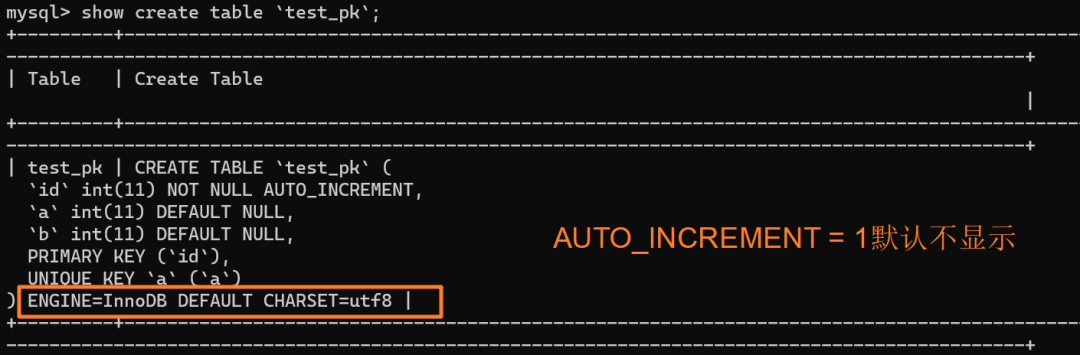
+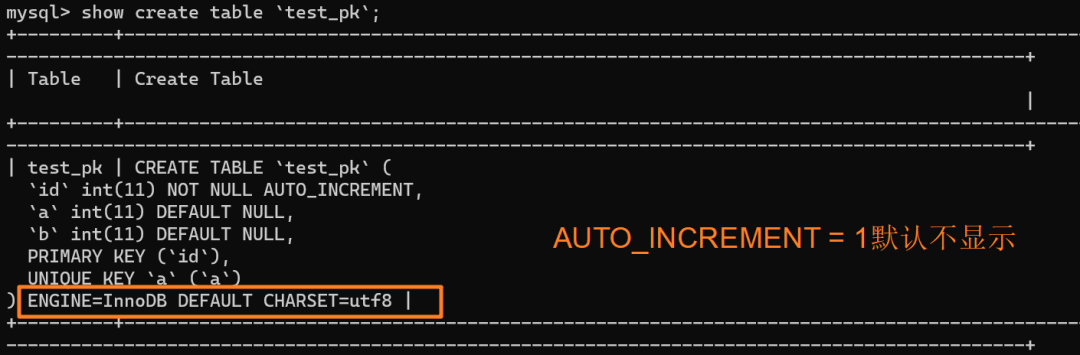
以上,是在我本地 MySQL 5.x 版本的实验,实际上,**到了 MySQL 8.0 版本后,自增值的变更记录被放在了 redo log 中,提供了自增值持久化的能力** ,也就是实现了“如果发生重启,表的自增值可以根据 redo log 恢复为 MySQL 重启前的值”
@@ -86,11 +91,11 @@ tag:
举个例子,我们现在往表里插入一条 (null,1,1) 的记录,生成的主键是 1,AUTO_INCREMENT= 2,对吧
-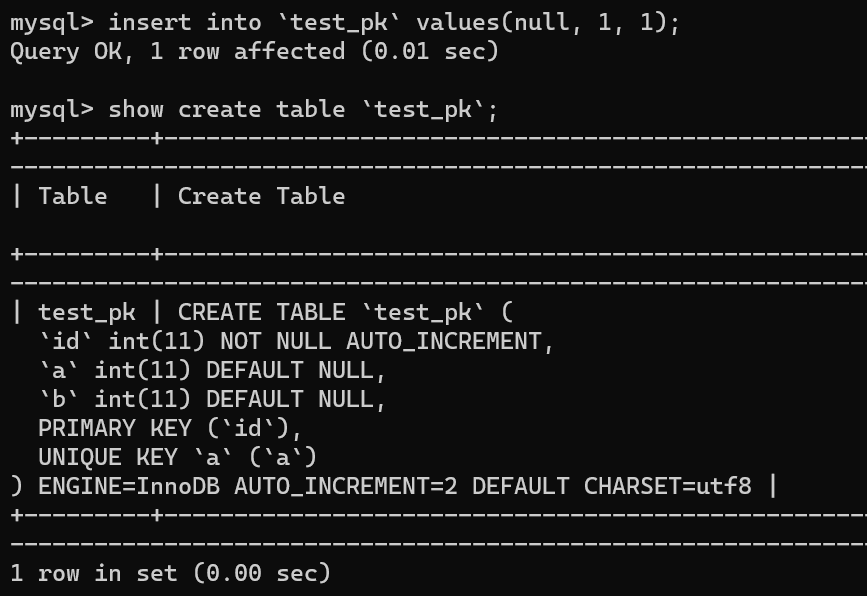
+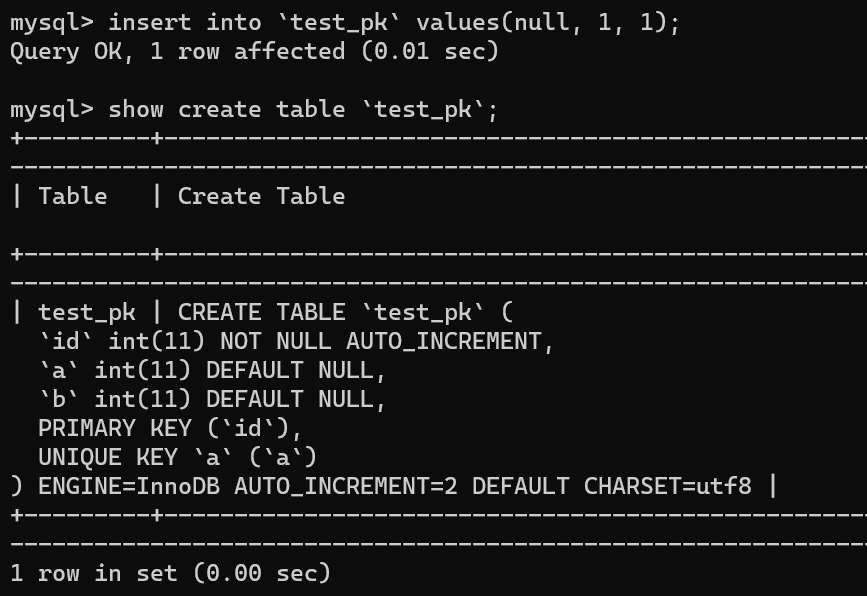
这时我再执行一条插入 `(null,1,1)` 的命令,很显然会报错 `Duplicate entry`,因为我们设置了一个唯一索引字段 `a`:
-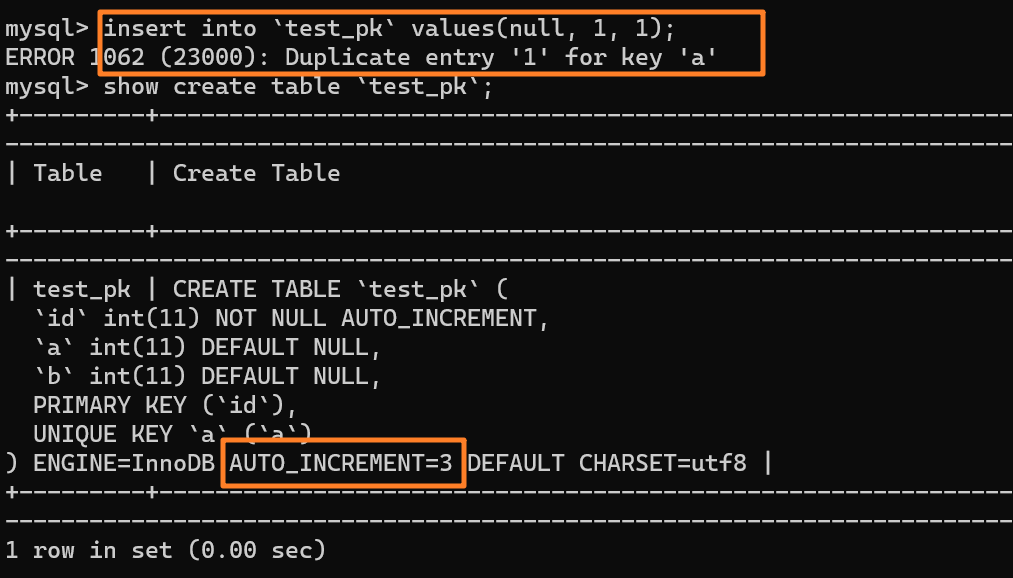
+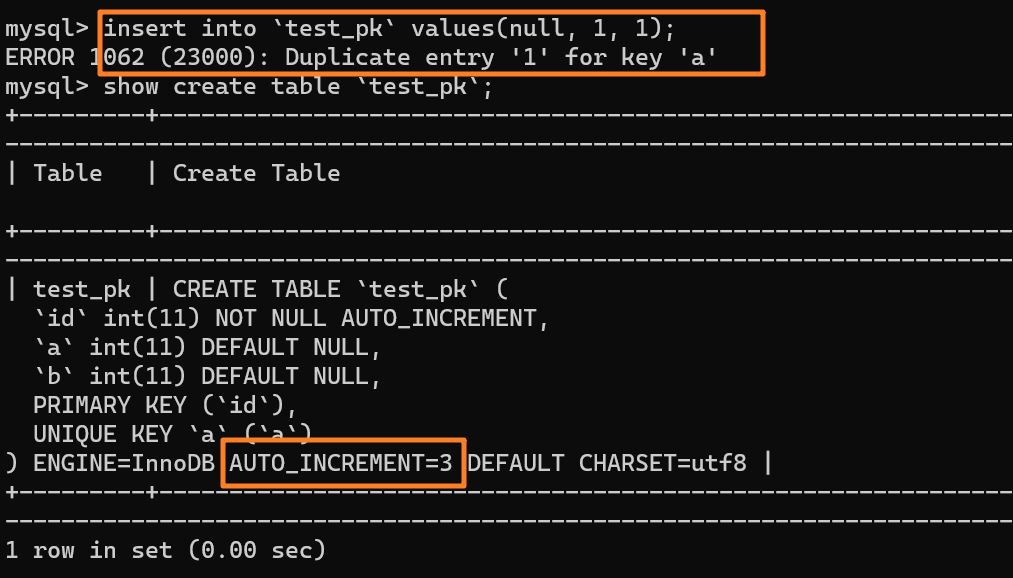
但是,你会惊奇的发现,虽然插入失败了,但自增值仍然从 2 增加到了 3!
@@ -119,27 +124,27 @@ tag:
我们现在表里有一行 `(1,1,1)` 的记录,AUTO_INCREMENT = 3:
-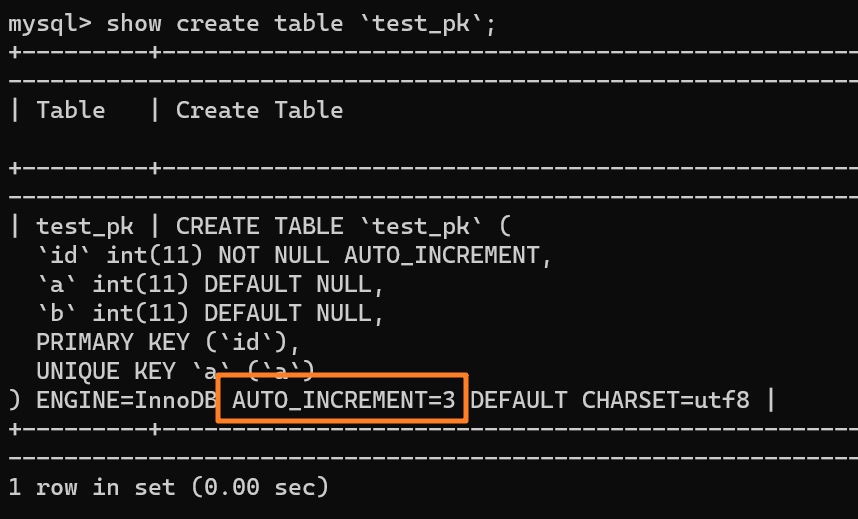
+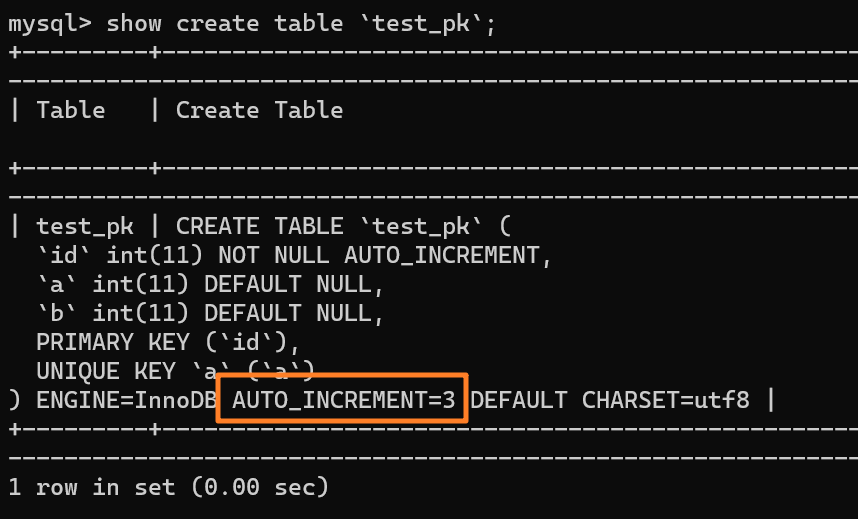
我们先插入一行数据 `(null, 2, 2)`,也就是 (3, 2, 2) 嘛,并且 AUTO_INCREMENT 变为 4:
-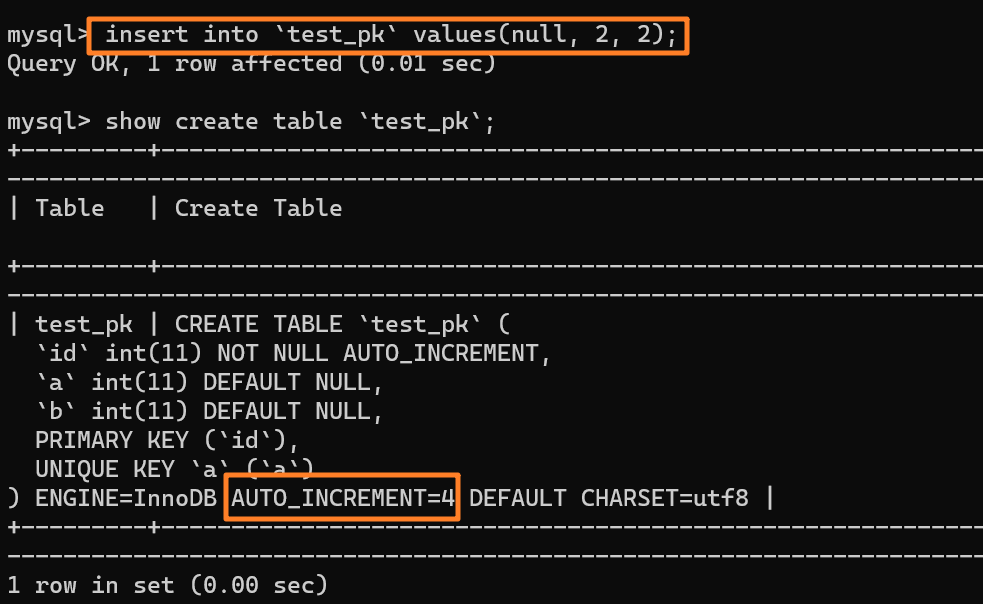
+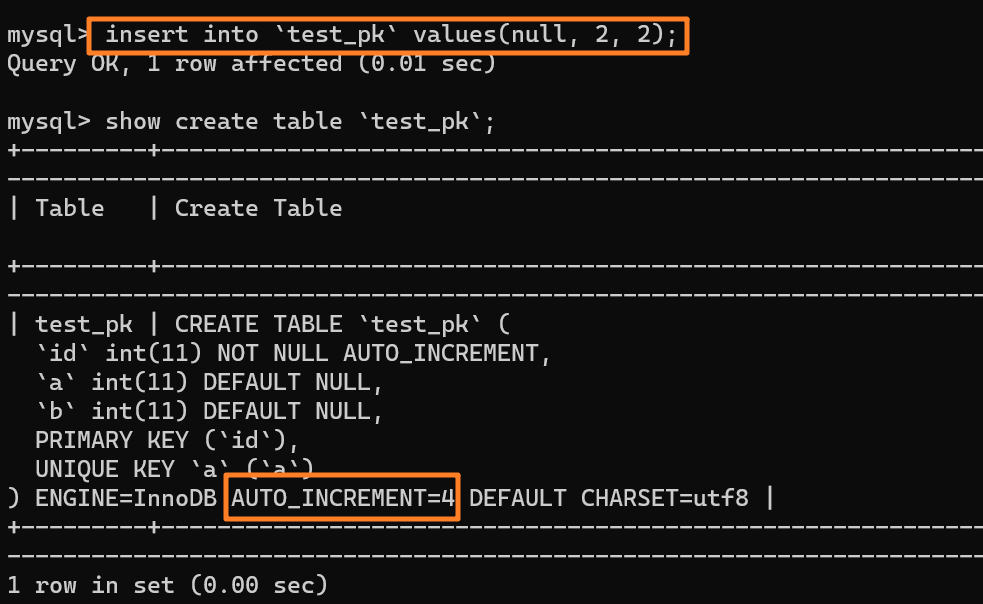
再去执行这样一段 SQL:
-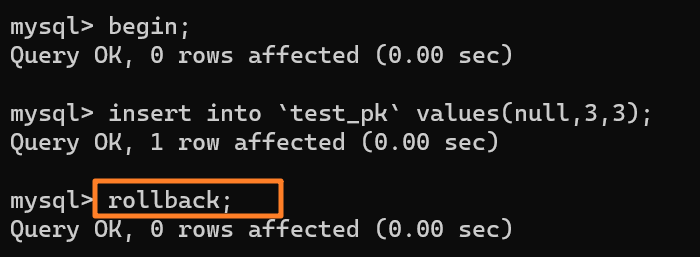
+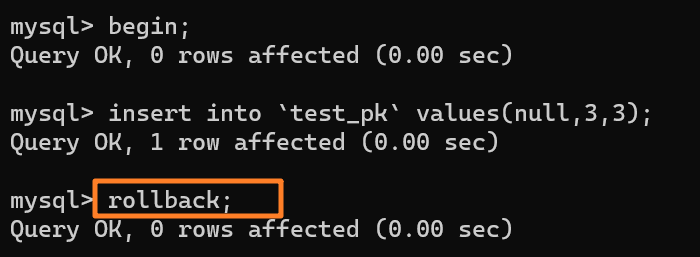
虽然我们插入了一条 (null, 3, 3) 记录,但是使用 rollback 进行回滚了,所以数据库中是没有这条记录的:
-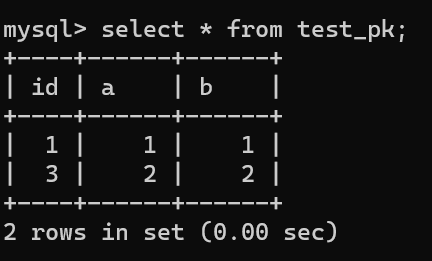
+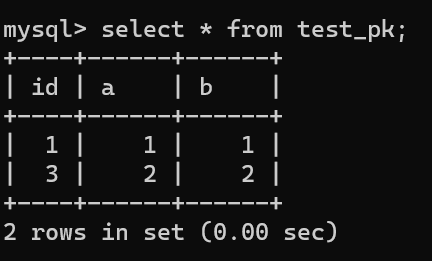
在这种事务回滚的情况下,自增值并没有同样发生回滚!如下图所示,自增值仍然固执地从 4 增加到了 5:
-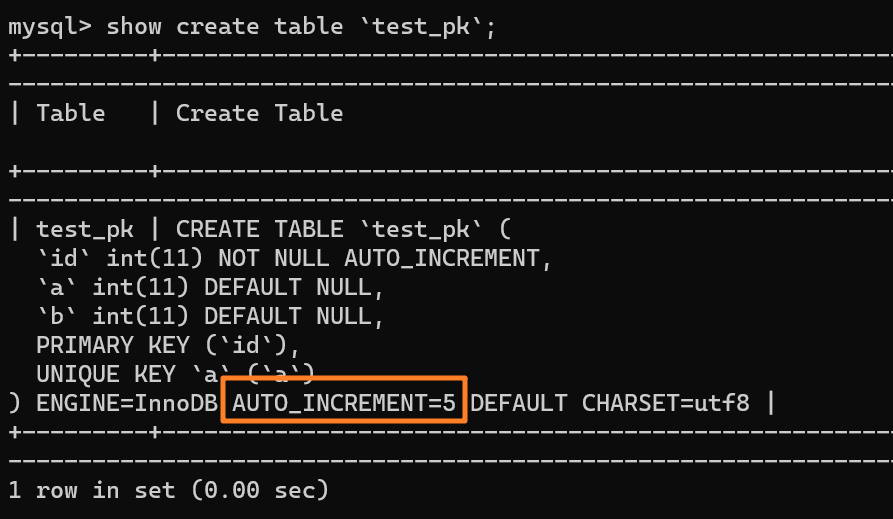
+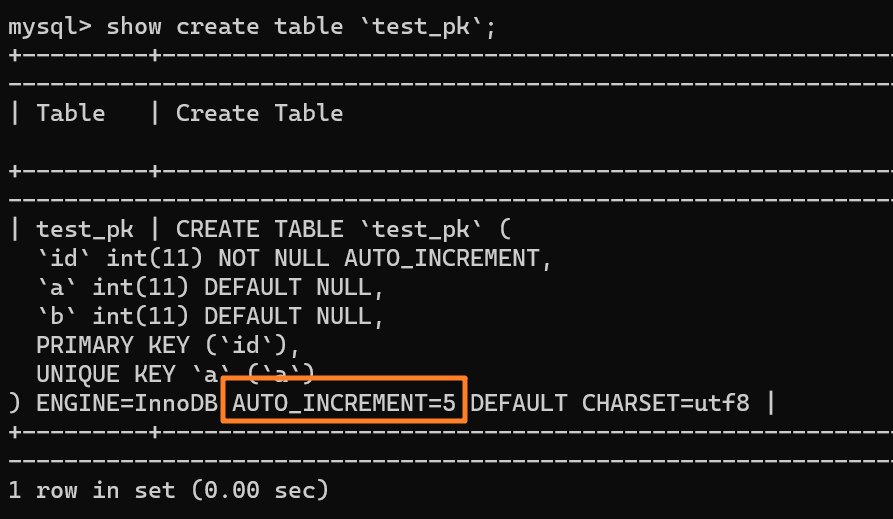
所以这时候我们再去插入一条数据(null, 3, 3)的时候,主键 id 就会被自动赋为 `5` 了:
-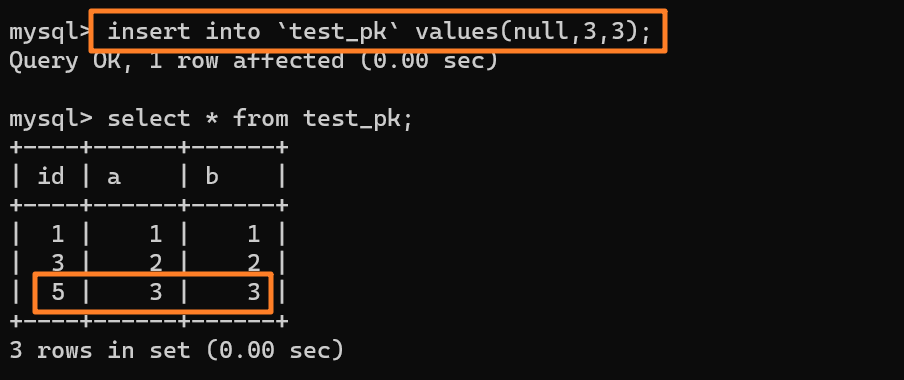
+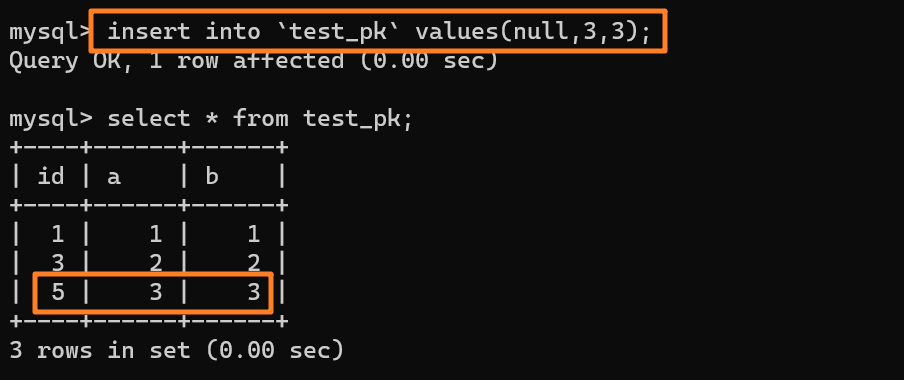
那么,为什么在出现唯一键冲突或者回滚的时候,MySQL 没有把表的自增值改回去呢?回退回去的话不就不会发生自增 id 不连续了吗?
@@ -153,7 +158,7 @@ tag:
2. 事务 B 正确提交了,但事务 A 出现了唯一键冲突,也就是 id = 1 的那行记录插入失败了,那如果允许事务 A 把自增 id 回退,也就是把表的当前自增值改回 1,那么就会出现这样的情况:表里面已经有 id = 2 的行,而当前的自增 id 值是 1。
3. 接下来,继续执行的其他事务就会申请到 id=2。这时,就会出现插入语句报错“主键冲突”。
-
+
而为了解决这个主键冲突,有两种方法:
@@ -177,29 +182,29 @@ tag:
注意,这里说的批量插入数据,不是在普通的 insert 语句里面包含多个 value 值!!!,因为这类语句在申请自增 id 的时候,是可以精确计算出需要多少个 id 的,然后一次性申请,申请完成后锁就可以释放了。
-而对于 `insert … select`、replace … select 和 load data 这种类型的语句来说,MySQL 并不知道到底需要申请多少 id,所以就采用了这种批量申请的策略,毕竟一个一个申请的话实在太慢了。
+而对于 `insert … select`、replace …… select 和 load data 这种类型的语句来说,MySQL 并不知道到底需要申请多少 id,所以就采用了这种批量申请的策略,毕竟一个一个申请的话实在太慢了。
举个例子,假设我们现在这个表有下面这些数据:
-
+
我们创建一个和当前表 `test_pk` 有相同结构定义的表 `test_pk2`:
-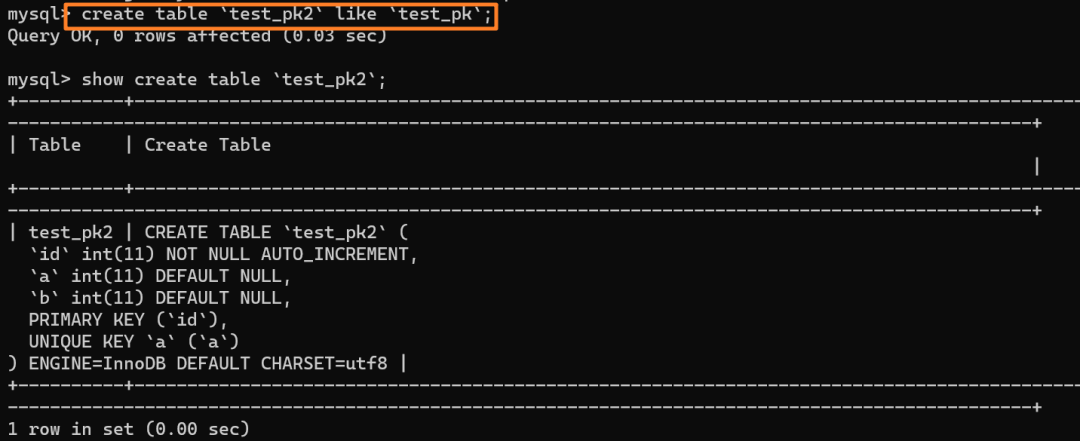
+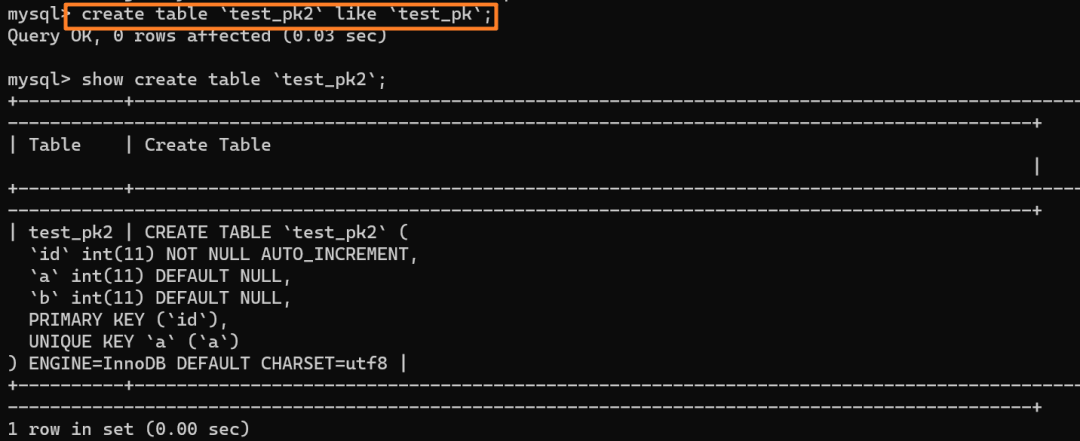
然后使用 `insert...select` 往 `teset_pk2` 表中批量插入数据:
-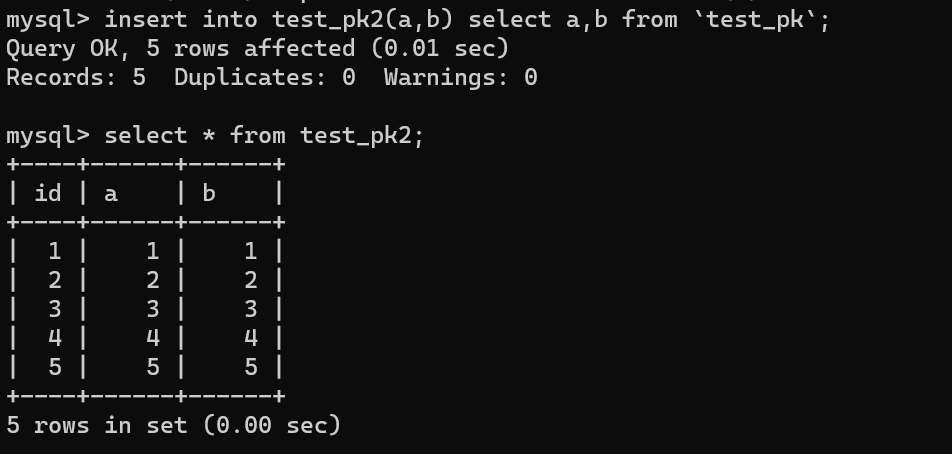
+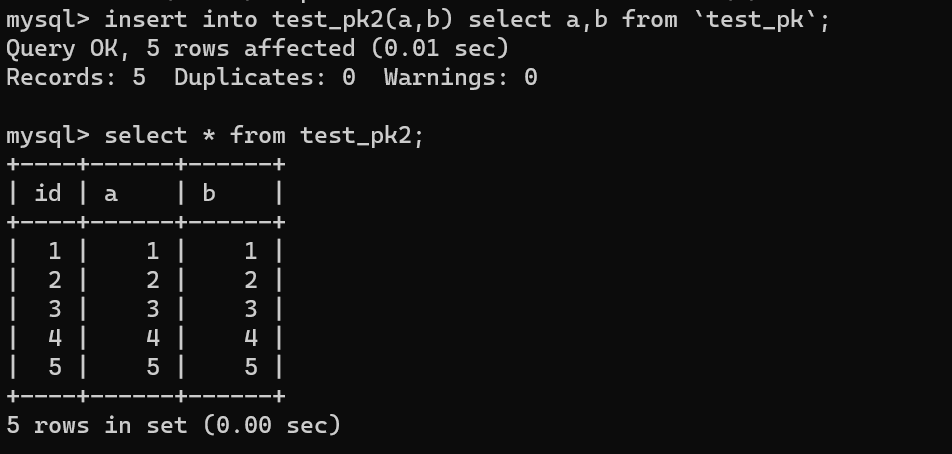
可以看到,成功导入了数据。
再来看下 `test_pk2` 的自增值是多少:
-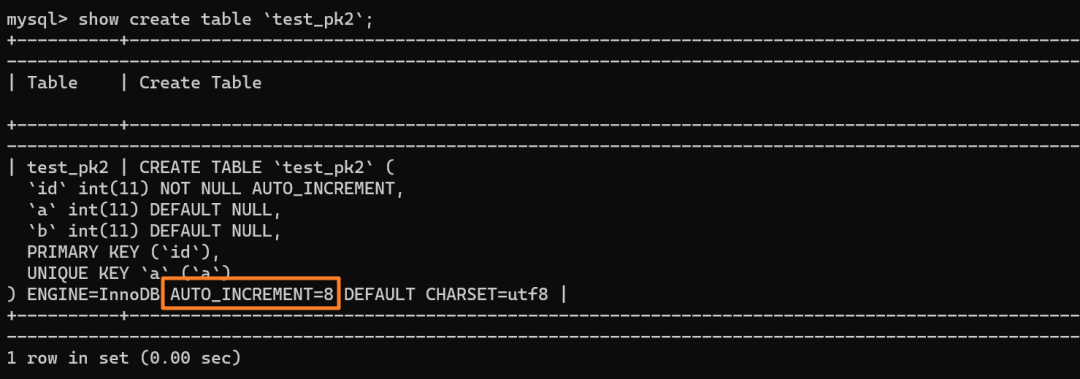
+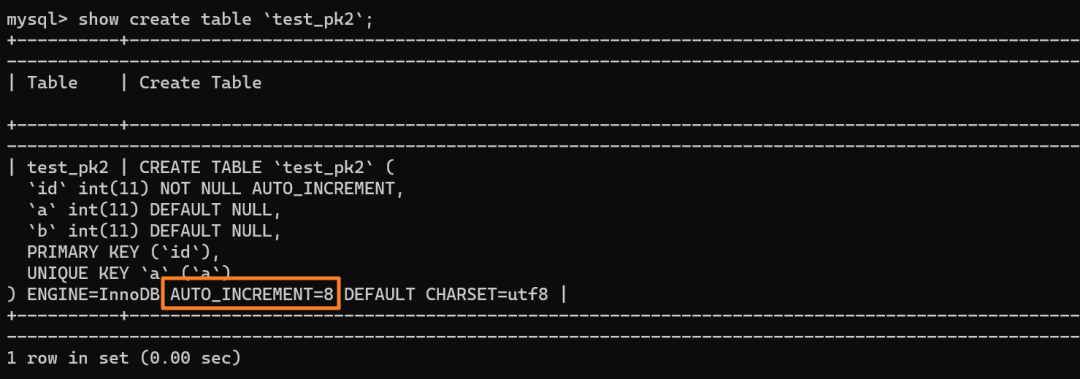
如上分析,是 8 而不是 6
-具体来说,insert…select 实际上往表中插入了 5 行数据 (1 1)(2 2)(3 3)(4 4)(5 5)。但是,这五行数据是分三次申请的自增 id,结合批量申请策略,每次申请到的自增 id 个数都是上一次的两倍,所以:
+具体来说,insert……select 实际上往表中插入了 5 行数据 (1 1)(2 2)(3 3)(4 4)(5 5)。但是,这五行数据是分三次申请的自增 id,结合批量申请策略,每次申请到的自增 id 个数都是上一次的两倍,所以:
- 第一次申请到了一个 id:id=1
- 第二次被分配了两个 id:id=2 和 id=3
@@ -207,7 +212,7 @@ tag:
由于这条语句实际只用上了 5 个 id,所以 id=6 和 id=7 就被浪费掉了。之后,再执行 `insert into test_pk2 values(null,6,6)`,实际上插入的数据就是(8,6,6):
-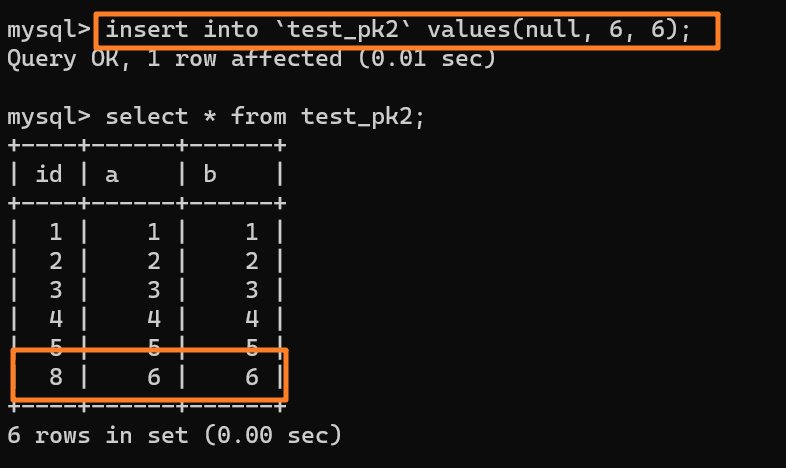
+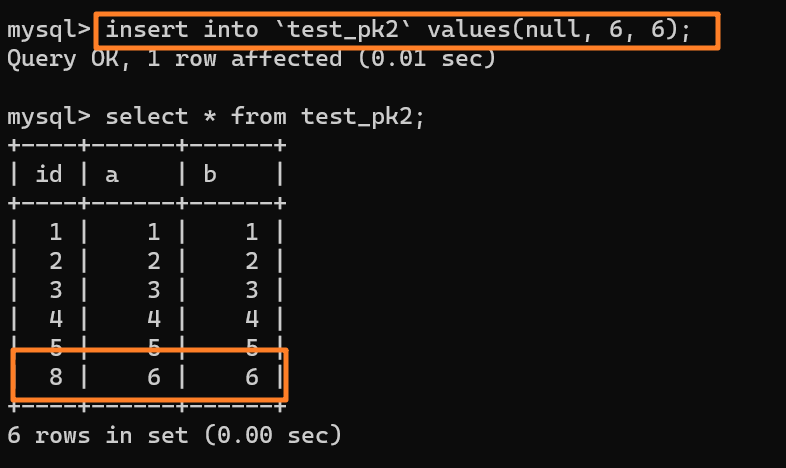
## 小结
@@ -217,3 +222,5 @@ tag:
2. 唯一键冲突
3. 事务回滚
4. 批量插入(如 `insert...select` 语句)
+
+
diff --git a/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md b/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md
index 584f3938217..00e783de034 100644
--- a/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md
+++ b/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md
@@ -1,27 +1,32 @@
---
title: MySQL高性能优化规范建议总结
+description: MySQL高性能优化规范建议总结,涵盖数据库命名规范、表设计规范、字段设计规范、索引设计规范、SQL编写规范等,帮助你构建高效稳定的数据库系统。
category: 数据库
tag:
- MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL优化规范,数据库设计规范,索引设计,SQL编写规范,慢查询优化,字段类型选择,表结构设计
---
> 作者: 听风 原文地址: 。
>
-> JavaGuide 已获得作者授权,并对原文内容进行了完善。
+> JavaGuide 已获得作者授权,并对原文内容进行了完善补充。
## 数据库命名规范
-- 所有数据库对象名称必须使用小写字母并用下划线分割
-- 所有数据库对象名称禁止使用 MySQL 保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来)
-- 数据库对象的命名要能做到见名识意,并且最后不要超过 32 个字符
-- 临时库表必须以 `tmp_` 为前缀并以日期为后缀,备份表必须以 `bak_` 为前缀并以日期 (时间戳) 为后缀
-- 所有存储相同数据的列名和列类型必须一致(一般作为关联列,如果查询时关联列类型不一致会自动进行数据类型隐式转换,会造成列上的索引失效,导致查询效率降低)
+- 所有数据库对象名称必须使用小写字母并用下划线分割。
+- 所有数据库对象名称禁止使用 MySQL 保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来)。
+- 数据库对象的命名要能做到见名识义,并且最好不要超过 32 个字符。
+- 临时库表必须以 `tmp_` 为前缀并以日期为后缀,备份表必须以 `bak_` 为前缀并以日期 (时间戳) 为后缀。
+- 所有存储相同数据的列名和列类型必须一致(一般作为关联列,如果查询时关联列类型不一致会自动进行数据类型隐式转换,会造成列上的索引失效,导致查询效率降低)。
## 数据库基本设计规范
### 所有表必须使用 InnoDB 存储引擎
-没有特殊要求(即 InnoDB 无法满足的功能如:列存储,存储空间数据等)的情况下,所有表必须使用 InnoDB 存储引擎(MySQL5.5 之前默认使用 Myisam,5.6 以后默认的为 InnoDB)。
+没有特殊要求(即 InnoDB 无法满足的功能如:列存储、存储空间数据等)的情况下,所有表必须使用 InnoDB 存储引擎(MySQL5.5 之前默认使用 MyISAM,5.6 以后默认的为 InnoDB)。
InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能更好。
@@ -29,26 +34,23 @@ InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能
兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同的字符集进行比较前需要进行转换会造成索引失效,如果数据库中有存储 emoji 表情的需要,字符集需要采用 utf8mb4 字符集。
-参考文章:
-
-- [MySQL 字符集不一致导致索引失效的一个真实案例](https://blog.csdn.net/horses/article/details/107243447)
-- [MySQL 字符集详解](../character-set.md)
+推荐阅读一下我写的这篇文章:[MySQL 字符集详解](../character-set.md) 。
### 所有表和字段都需要添加注释
-使用 comment 从句添加表和列的备注,从一开始就进行数据字典的维护
+使用 comment 从句添加表和列的备注,从一开始就进行数据字典的维护。
### 尽量控制单表数据量的大小,建议控制在 500 万以内
500 万并不是 MySQL 数据库的限制,过大会造成修改表结构,备份,恢复都会有很大的问题。
-可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小
+可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小。
### 谨慎使用 MySQL 分区表
-分区表在物理上表现为多个文件,在逻辑上表现为一个表;
+分区表在物理上表现为多个文件,在逻辑上表现为一个表。
-谨慎选择分区键,跨分区查询效率可能更低;
+谨慎选择分区键,跨分区查询效率可能更低。
建议采用物理分表的方式管理大数据。
@@ -74,7 +76,7 @@ InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能
### 禁止在线上做数据库压力测试
-### 禁止从开发环境,测试环境直接连接生产环境数据库
+### 禁止从开发环境、测试环境直接连接生产环境数据库
安全隐患极大,要对生产环境抱有敬畏之心!
@@ -82,22 +84,22 @@ InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能
### 优先选择符合存储需要的最小的数据类型
-存储字节越小,占用也就空间越小,性能也越好。
+存储字节越小,占用空间也就越小,性能也越好。
-**a.某些字符串可以转换成数字类型存储比如可以将 IP 地址转换成整型数据。**
+**a.某些字符串可以转换成数字类型存储,比如可以将 IP 地址转换成整型数据。**
数字是连续的,性能更好,占用空间也更小。
-MySQL 提供了两个方法来处理 ip 地址
+MySQL 提供了两个方法来处理 ip 地址:
-- `INET_ATON()`:把 ip 转为无符号整型 (4-8 位)
-- `INET_NTOA()` :把整型的 ip 转为地址
+- `INET_ATON()`:把 ip 转为无符号整型 (4-8 位);
+- `INET_NTOA()`:把整型的 ip 转为地址。
-插入数据前,先用 `INET_ATON()` 把 ip 地址转为整型,显示数据时,使用 `INET_NTOA()` 把整型的 ip 地址转为地址显示即可。
+插入数据前,先用 `INET_ATON()` 把 ip 地址转为整型;显示数据时,使用 `INET_NTOA()` 把整型的 ip 地址转为地址显示即可。
-**b.对于非负型的数据 (如自增 ID,整型 IP,年龄) 来说,要优先使用无符号整型来存储。**
+**b.对于非负型的数据 (如自增 ID、整型 IP、年龄) 来说,要优先使用无符号整型来存储。**
-无符号相对于有符号可以多出一倍的存储空间
+无符号相对于有符号可以多出一倍的存储空间:
```sql
SIGNED INT -2147483648~2147483647
@@ -106,7 +108,7 @@ UNSIGNED INT 0~4294967295
**c.小数值类型(比如年龄、状态表示如 0/1)优先使用 TINYINT 类型。**
-### 避免使用 TEXT,BLOB 数据类型,最常见的 TEXT 类型可以存储 64k 的数据
+### 避免使用 TEXT、BLOB 数据类型,最常见的 TEXT 类型可以存储 64k 的数据
**a. 建议把 BLOB 或是 TEXT 列分离到单独的扩展表中。**
@@ -116,44 +118,45 @@ MySQL 内存临时表不支持 TEXT、BLOB 这样的大数据类型,如果查
**2、TEXT 或 BLOB 类型只能使用前缀索引**
-因为 MySQL 对索引字段长度是有限制的,所以 TEXT 类型只能使用前缀索引,并且 TEXT 列上是不能有默认值的
+因为 MySQL 对索引字段长度是有限制的,所以 TEXT 类型只能使用前缀索引,并且 TEXT 列上是不能有默认值的。
### 避免使用 ENUM 类型
-- 修改 ENUM 值需要使用 ALTER 语句;
-- ENUM 类型的 ORDER BY 操作效率低,需要额外操作;
-- ENUM 数据类型存在一些限制比如建议不要使用数值作为 ENUM 的枚举值。
+- 修改 ENUM 值需要使用 ALTER 语句。
+- ENUM 类型的 ORDER BY 操作效率低,需要额外操作。
+- ENUM 数据类型存在一些限制,比如建议不要使用数值作为 ENUM 的枚举值。
相关阅读:[是否推荐使用 MySQL 的 enum 类型? - 架构文摘 - 知乎](https://www.zhihu.com/question/404422255/answer/1661698499) 。
### 尽可能把所有列定义为 NOT NULL
-除非有特别的原因使用 NULL 值,应该总是让字段保持 NOT NULL。
+除非有特别的原因使用 NULL 值,否则应该总是让字段保持 NOT NULL。
-- 索引 NULL 列需要额外的空间来保存,所以要占用更多的空间;
+- 索引 NULL 列需要额外的空间来保存,所以要占用更多的空间。
- 进行比较和计算时要对 NULL 值做特别的处理。
相关阅读:[技术分享 | MySQL 默认值选型(是空,还是 NULL)](https://opensource.actionsky.com/20190710-mysql/) 。
-### 使用 TIMESTAMP(4 个字节) 或 DATETIME 类型 (8 个字节) 存储时间
-
-TIMESTAMP 存储的时间范围 1970-01-01 00:00:01 ~ 2038-01-19-03:14:07
+### 一定不要用字符串存储日期
-TIMESTAMP 占用 4 字节和 INT 相同,但比 INT 可读性高
+对于日期类型来说,一定不要用字符串存储日期。可以考虑 DATETIME、TIMESTAMP 和数值型时间戳。
-超出 TIMESTAMP 取值范围的使用 DATETIME 类型存储
+这三种种方式都有各自的优势,根据实际场景选择最合适的才是王道。下面再对这三种方式做一个简单的对比,以供大家在实际开发中选择正确的存放时间的数据类型:
-**经常会有人用字符串存储日期型的数据(不正确的做法)**
+| 类型 | 存储空间 | 日期格式 | 日期范围 | 是否带时区信息 |
+| ------------ | -------- | ------------------------------ | ------------------------------------------------------------ | -------------- |
+| DATETIME | 5~8 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1000-01-01 00:00:00[.000000] ~ 9999-12-31 23:59:59[.999999] | 否 |
+| TIMESTAMP | 4~7 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1970-01-01 00:00:01[.000000] ~ 2038-01-19 03:14:07[.999999] | 是 |
+| 数值型时间戳 | 4 字节 | 全数字如 1578707612 | 1970-01-01 00:00:01 之后的时间 | 否 |
-- 缺点 1:无法用日期函数进行计算和比较
-- 缺点 2:用字符串存储日期要占用更多的空间
+MySQL 时间类型选择的详细介绍请看这篇:[MySQL 时间类型数据存储建议](https://javaguide.cn/database/mysql/some-thoughts-on-database-storage-time.html)。
### 同财务相关的金额类数据必须使用 decimal 类型
-- **非精准浮点**:float,double
+- **非精准浮点**:float、double
- **精准浮点**:decimal
-decimal 类型为精准浮点数,在计算时不会丢失精度。占用空间由定义的宽度决定,每 4 个字节可以存储 9 位数字,并且小数点要占用一个字节。并且,decimal 可用于存储比 bigint 更大的整型数据
+decimal 类型为精准浮点数,在计算时不会丢失精度。占用空间由定义的宽度决定,每 4 个字节可以存储 9 位数字,并且小数点要占用一个字节。并且,decimal 可用于存储比 bigint 更大的整型数据。
不过, 由于 decimal 需要额外的空间和计算开销,应该尽量只在需要对数据进行精确计算时才使用 decimal 。
@@ -163,13 +166,13 @@ decimal 类型为精准浮点数,在计算时不会丢失精度。占用空间
## 索引设计规范
-### 限制每张表上的索引数量,建议单张表索引不超过 5 个
+### 限制每张表上的索引数量,建议单张表索引不超过 5 个
-索引并不是越多越好!索引可以提高效率同样可以降低效率。
+索引并不是越多越好!索引可以提高效率,同样可以降低效率。
索引可以增加查询效率,但同样也会降低插入和更新的效率,甚至有些情况下会降低查询效率。
-因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
+因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划。如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
### 禁止使用全文索引
@@ -177,46 +180,46 @@ decimal 类型为精准浮点数,在计算时不会丢失精度。占用空间
### 禁止给表中的每一列都建立单独的索引
-5.6 版本之前,一个 sql 只能使用到一个表中的一个索引,5.6 以后,虽然有了合并索引的优化方式,但是还是远远没有使用一个联合索引的查询方式好。
+5.6 版本之前,一个 sql 只能使用到一个表中的一个索引;5.6 以后,虽然有了合并索引的优化方式,但是还是远远没有使用一个联合索引的查询方式好。
### 每个 InnoDB 表必须有个主键
InnoDB 是一种索引组织表:数据的存储的逻辑顺序和索引的顺序是相同的。每个表都可以有多个索引,但是表的存储顺序只能有一种。
-InnoDB 是按照主键索引的顺序来组织表的
+InnoDB 是按照主键索引的顺序来组织表的。
-- 不要使用更新频繁的列作为主键,不适用多列主键(相当于联合索引)
-- 不要使用 UUID,MD5,HASH,字符串列作为主键(无法保证数据的顺序增长)
-- 主键建议使用自增 ID 值
+- 不要使用更新频繁的列作为主键,不使用多列主键(相当于联合索引)。
+- 不要使用 UUID、MD5、HASH、字符串列作为主键(无法保证数据的顺序增长)。
+- 主键建议使用自增 ID 值。
### 常见索引列建议
-- 出现在 SELECT、UPDATE、DELETE 语句的 WHERE 从句中的列
-- 包含在 ORDER BY、GROUP BY、DISTINCT 中的字段
-- 并不要将符合 1 和 2 中的字段的列都建立一个索引, 通常将 1、2 中的字段建立联合索引效果更好
-- 多表 join 的关联列
+- 出现在 SELECT、UPDATE、DELETE 语句的 WHERE 从句中的列。
+- 包含在 ORDER BY、GROUP BY、DISTINCT 中的字段。
+- 不要将符合 1 和 2 中的字段的列都建立一个索引,通常将 1、2 中的字段建立联合索引效果更好。
+- 多表 join 的关联列。
### 如何选择索引列的顺序
-建立索引的目的是:希望通过索引进行数据查找,减少随机 IO,增加查询性能 ,索引能过滤出越少的数据,则从磁盘中读入的数据也就越少。
+建立索引的目的是:希望通过索引进行数据查找,减少随机 IO,增加查询性能,索引能过滤出越少的数据,则从磁盘中读入的数据也就越少。
-- 区分度最高的放在联合索引的最左侧(区分度=列中不同值的数量/列的总行数)
-- 尽量把字段长度小的列放在联合索引的最左侧(因为字段长度越小,一页能存储的数据量越大,IO 性能也就越好)
-- 使用最频繁的列放到联合索引的左侧(这样可以比较少的建立一些索引)
+- **区分度最高的列放在联合索引的最左侧**:这是最重要的原则。区分度越高,通过索引筛选出的数据就越少,I/O 操作也就越少。计算区分度的方法是 `count(distinct column) / count(*)`。
+- **最频繁使用的列放在联合索引的左侧**:这符合最左前缀匹配原则。将最常用的查询条件列放在最左侧,可以最大程度地利用索引。
+- **字段长度**:字段长度对联合索引非叶子节点的影响很小,因为它存储了所有联合索引字段的值。字段长度主要影响主键和包含在其他索引中的字段的存储空间,以及这些索引的叶子节点的大小。因此,在选择联合索引列的顺序时,字段长度的优先级最低。对于主键和包含在其他索引中的字段,选择较短的字段长度可以节省存储空间和提高 I/O 性能。
### 避免建立冗余索引和重复索引(增加了查询优化器生成执行计划的时间)
-- 重复索引示例:primary key(id)、index(id)、unique index(id)
-- 冗余索引示例:index(a,b,c)、index(a,b)、index(a)
+- 重复索引示例:primary key(id)、index(id)、unique index(id)。
+- 冗余索引示例:index(a,b,c)、index(a,b)、index(a)。
-### 对于频繁的查询优先考虑使用覆盖索引
+### 对于频繁的查询,优先考虑使用覆盖索引
-> 覆盖索引:就是包含了所有查询字段 (where,select,order by,group by 包含的字段) 的索引
+> 覆盖索引:就是包含了所有查询字段 (where、select、order by、group by 包含的字段) 的索引
-**覆盖索引的好处:**
+**覆盖索引的好处**:
-- **避免 InnoDB 表进行索引的二次查询:** InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询 ,减少了 IO 操作,提升了查询效率。
-- **可以把随机 IO 变成顺序 IO 加快查询效率:** 由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围查找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序 IO。
+- **避免 InnoDB 表进行索引的二次查询,也就是回表操作**:InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询(回表),减少了 IO 操作,提升了查询效率。
+- **可以把随机 IO 变成顺序 IO 加快查询效率**:由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围查找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序 IO。
---
@@ -224,19 +227,23 @@ InnoDB 是按照主键索引的顺序来组织表的
**尽量避免使用外键约束**
-- 不建议使用外键约束(foreign key),但一定要在表与表之间的关联键上建立索引
-- 外键可用于保证数据的参照完整性,但建议在业务端实现
-- 外键会影响父表和子表的写操作从而降低性能
+- 不建议使用外键约束(foreign key),但一定要在表与表之间的关联键上建立索引。
+- 外键可用于保证数据的参照完整性,但建议在业务端实现。
+- 外键会影响父表和子表的写操作从而降低性能。
## 数据库 SQL 开发规范
+### 尽量不在数据库做运算,复杂运算需移到业务应用里完成
+
+尽量不在数据库做运算,复杂运算需移到业务应用里完成。这样可以避免数据库的负担过重,影响数据库的性能和稳定性。数据库的主要作用是存储和管理数据,而不是处理数据。
+
### 优化对性能影响较大的 SQL 语句
-要找到最需要优化的 SQL 语句。要么是使用最频繁的语句,要么是优化后提高最明显的语句,可以通过查询 MySQL 的慢查询日志来发现需要进行优化的 SQL 语句;
+要找到最需要优化的 SQL 语句。要么是使用最频繁的语句,要么是优化后提高最明显的语句,可以通过查询 MySQL 的慢查询日志来发现需要进行优化的 SQL 语句。
### 充分利用表上已经存在的索引
-避免使用双%号的查询条件。如:`a like '%123%'`,(如果无前置%,只有后置%,是可以用到列上的索引的)
+避免使用双%号的查询条件。如:`a like '%123%'`(如果无前置%,只有后置%,是可以用到列上的索引的)。
一个 SQL 只能利用到复合索引中的一列进行范围查询。如:有 a,b,c 列的联合索引,在查询条件中有 a 列的范围查询,则在 b,c 列上的索引将不会被用到。
@@ -244,19 +251,20 @@ InnoDB 是按照主键索引的顺序来组织表的
### 禁止使用 SELECT \* 必须使用 SELECT <字段列表> 查询
-- `SELECT *` 消耗更多的 CPU 和 IO 以网络带宽资源
-- `SELECT *` 无法使用覆盖索引
-- `SELECT <字段列表>` 可减少表结构变更带来的影响
+- `SELECT *` 会消耗更多的 CPU。
+- `SELECT *` 无用字段增加网络带宽资源消耗,增加数据传输时间,尤其是大字段(如 varchar、blob、text)。
+- `SELECT *` 无法使用 MySQL 优化器覆盖索引的优化(基于 MySQL 优化器的“覆盖索引”策略又是速度极快、效率极高、业界极为推荐的查询优化方式)。
+- `SELECT <字段列表>` 可减少表结构变更带来的影响。
### 禁止使用不含字段列表的 INSERT 语句
-如:
+**不推荐**:
```sql
insert into t values ('a','b','c');
```
-应使用:
+**推荐**:
```sql
insert into t(c1,c2,c3) values ('a','b','c');
@@ -270,7 +278,7 @@ insert into t(c1,c2,c3) values ('a','b','c');
### 避免数据类型的隐式转换
-隐式转换会导致索引失效如:
+隐式转换会导致索引失效,如:
```sql
select name,phone from customer where id = '111';
@@ -280,9 +288,9 @@ select name,phone from customer where id = '111';
### 避免使用子查询,可以把子查询优化为 join 操作
-通常子查询在 in 子句中,且子查询中为简单 SQL(不包含 union、group by、order by、limit 从句) 时,才可以把子查询转化为关联查询进行优化。
+通常子查询在 in 子句中,且子查询中为简单 SQL(不包含 union、group by、order by、limit 从句) 时,才可以把子查询转化为关联查询进行优化。
-**子查询性能差的原因:** 子查询的结果集无法使用索引,通常子查询的结果集会被存储到临时表中,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。特别是对于返回结果集比较大的子查询,其对查询性能的影响也就越大。由于子查询会产生大量的临时表也没有索引,所以会消耗过多的 CPU 和 IO 资源,产生大量的慢查询。
+**子查询性能差的原因**:子查询的结果集无法使用索引,通常子查询的结果集会被存储到临时表中,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。特别是对于返回结果集比较大的子查询,其对查询性能的影响也就越大。由于子查询会产生大量的临时表也没有索引,所以会消耗过多的 CPU 和 IO 资源,产生大量的慢查询。
### 避免使用 JOIN 关联太多的表
@@ -290,7 +298,7 @@ select name,phone from customer where id = '111';
在 MySQL 中,对于同一个 SQL 多关联(join)一个表,就会多分配一个关联缓存,如果在一个 SQL 中关联的表越多,所占用的内存也就越大。
-如果程序中大量的使用了多表关联的操作,同时 join_buffer_size 设置的也不合理的情况下,就容易造成服务器内存溢出的情况,就会影响到服务器数据库性能的稳定性。
+如果程序中大量地使用了多表关联的操作,同时 join_buffer_size 设置得也不合理,就容易造成服务器内存溢出的情况,就会影响到服务器数据库性能的稳定性。
同时对于关联操作来说,会产生临时表操作,影响查询效率,MySQL 最多允许关联 61 个表,建议不超过 5 个。
@@ -300,25 +308,25 @@ select name,phone from customer where id = '111';
### 对应同一列进行 or 判断时,使用 in 代替 or
-in 的值不要超过 500 个,in 操作可以更有效的利用索引,or 大多数情况下很少能利用到索引。
+in 的值不要超过 500 个。in 操作可以更有效的利用索引,or 大多数情况下很少能利用到索引。
### 禁止使用 order by rand() 进行随机排序
-order by rand() 会把表中所有符合条件的数据装载到内存中,然后在内存中对所有数据根据随机生成的值进行排序,并且可能会对每一行都生成一个随机值,如果满足条件的数据集非常大,就会消耗大量的 CPU 和 IO 及内存资源。
+order by rand() 会把表中所有符合条件的数据装载到内存中,然后在内存中对所有数据根据随机生成的值进行排序,并且可能会对每一行都生成一个随机值。如果满足条件的数据集非常大,就会消耗大量的 CPU 和 IO 及内存资源。
推荐在程序中获取一个随机值,然后从数据库中获取数据的方式。
### WHERE 从句中禁止对列进行函数转换和计算
-对列进行函数转换或计算时会导致无法使用索引
+对列进行函数转换或计算时会导致无法使用索引。
-**不推荐:**
+**不推荐**:
```sql
where date(create_time)='20190101'
```
-**推荐:**
+**推荐**:
```sql
where create_time >= '20190101' and create_time < '20190102'
@@ -326,43 +334,43 @@ where create_time >= '20190101' and create_time < '20190102'
### 在明显不会有重复值时使用 UNION ALL 而不是 UNION
-- UNION 会把两个结果集的所有数据放到临时表中后再进行去重操作
-- UNION ALL 不会再对结果集进行去重操作
+- UNION 会把两个结果集的所有数据放到临时表中后再进行去重操作。
+- UNION ALL 不会再对结果集进行去重操作。
### 拆分复杂的大 SQL 为多个小 SQL
-- 大 SQL 逻辑上比较复杂,需要占用大量 CPU 进行计算的 SQL
-- MySQL 中,一个 SQL 只能使用一个 CPU 进行计算
-- SQL 拆分后可以通过并行执行来提高处理效率
+- 大 SQL 逻辑上比较复杂,需要占用大量 CPU 进行计算的 SQL。
+- MySQL 中,一个 SQL 只能使用一个 CPU 进行计算。
+- SQL 拆分后可以通过并行执行来提高处理效率。
### 程序连接不同的数据库使用不同的账号,禁止跨库查询
-- 为数据库迁移和分库分表留出余地
-- 降低业务耦合度
-- 避免权限过大而产生的安全风险
+- 为数据库迁移和分库分表留出余地。
+- 降低业务耦合度。
+- 避免权限过大而产生的安全风险。
## 数据库操作行为规范
-### 超 100 万行的批量写 (UPDATE,DELETE,INSERT) 操作,要分批多次进行操作
+### 超 100 万行的批量写 (UPDATE、DELETE、INSERT) 操作,要分批多次进行操作
**大批量操作可能会造成严重的主从延迟**
-主从环境中,大批量操作可能会造成严重的主从延迟,大批量的写操作一般都需要执行一定长的时间,而只有当主库上执行完成后,才会在其他从库上执行,所以会造成主库与从库长时间的延迟情况
+主从环境中,大批量操作可能会造成严重的主从延迟,大批量的写操作一般都需要执行一定长的时间,而只有当主库上执行完成后,才会在其他从库上执行,所以会造成主库与从库长时间的延迟情况。
**binlog 日志为 row 格式时会产生大量的日志**
-大批量写操作会产生大量日志,特别是对于 row 格式二进制数据而言,由于在 row 格式中会记录每一行数据的修改,我们一次修改的数据越多,产生的日志量也就会越多,日志的传输和恢复所需要的时间也就越长,这也是造成主从延迟的一个原因
+大批量写操作会产生大量日志,特别是对于 row 格式二进制数据而言,由于在 row 格式中会记录每一行数据的修改,我们一次修改的数据越多,产生的日志量也就会越多,日志的传输和恢复所需要的时间也就越长,这也是造成主从延迟的一个原因。
**避免产生大事务操作**
大批量修改数据,一定是在一个事务中进行的,这就会造成表中大批量数据进行锁定,从而导致大量的阻塞,阻塞会对 MySQL 的性能产生非常大的影响。
-特别是长时间的阻塞会占满所有数据库的可用连接,这会使生产环境中的其他应用无法连接到数据库,因此一定要注意大批量写操作要进行分批
+特别是长时间的阻塞会占满所有数据库的可用连接,这会使生产环境中的其他应用无法连接到数据库,因此一定要注意大批量写操作要进行分批。
### 对于大表使用 pt-online-schema-change 修改表结构
-- 避免大表修改产生的主从延迟
-- 避免在对表字段进行修改时进行锁表
+- 避免大表修改产生的主从延迟。
+- 避免在对表字段进行修改时进行锁表。
对大表数据结构的修改一定要谨慎,会造成严重的锁表操作,尤其是生产环境,是不能容忍的。
@@ -370,10 +378,17 @@ pt-online-schema-change 它会首先建立一个与原表结构相同的新表
### 禁止为程序使用的账号赋予 super 权限
-- 当达到最大连接数限制时,还运行 1 个有 super 权限的用户连接
-- super 权限只能留给 DBA 处理问题的账号使用
+- 当达到最大连接数限制时,还运行 1 个有 super 权限的用户连接。
+- super 权限只能留给 DBA 处理问题的账号使用。
+
+### 对于程序连接数据库账号,遵循权限最小原则
+
+- 程序使用数据库账号只能在一个 DB 下使用,不准跨库。
+- 程序使用的账号原则上不准有 drop 权限。
+
+## 推荐阅读
-### 对于程序连接数据库账号,遵循权限最小原则
+- [技术同学必会的 MySQL 设计规约,都是惨痛的教训 - 阿里开发者](https://mp.weixin.qq.com/s/XC8e5iuQtfsrEOERffEZ-Q)
+- [聊聊数据库建表的 15 个小技巧](https://mp.weixin.qq.com/s/NM-aHaW6TXrnO6la6Jfl5A)
-- 程序使用数据库账号只能在一个 DB 下使用,不准跨库
-- 程序使用的账号原则上不准有 drop 权限
+
diff --git a/docs/database/mysql/mysql-index-invalidation.md b/docs/database/mysql/mysql-index-invalidation.md
new file mode 100644
index 00000000000..04d5db4de38
--- /dev/null
+++ b/docs/database/mysql/mysql-index-invalidation.md
@@ -0,0 +1,213 @@
+---
+title: MySQL索引失效场景总结
+description: 全面总结MySQL索引失效的常见场景,包括SELECT *查询、违背最左前缀原则、索引列计算函数转换、LIKE模糊查询、OR连接、IN/NOT IN使用不当、隐式类型转换以及ORDER BY排序优化陷阱,帮助你避免索引失效导致的性能问题。
+category: 数据库
+tag:
+ - MySQL
+ - 性能优化
+head:
+ - - meta
+ - name: keywords
+ - content: MySQL索引失效,索引失效场景,最左前缀原则,覆盖索引,索引下推,隐式类型转换,SQL优化,MySQL性能优化,全表扫描,回表查询
+---
+
+在数据库性能优化中,索引是最直接有效的优化手段之一。然而,**建了索引并不等于一定能用上索引**。实际开发中,我们经常遇到这样的困惑:明明在字段上建立了索引,查询却依然慢如蜗牛,通过 `EXPLAIN` 分析发现居然是全表扫描。
+
+导致索引失效的原因多种多样,既有 SQL 语句写法问题,也有索引设计不当的因素。有些失效场景是显性的(如违背最左前缀原则),有些则非常隐蔽(如隐式类型转换)。如果不深入了解这些失效场景,很容易在生产环境中埋下性能隐患。
+
+本文将系统总结 MySQL 索引失效的常见场景,分析失效背后的原理机制,并提供相应的优化建议,帮助你在日常开发和排查问题中快速定位并解决索引失效问题。
+
+### SELECT \* 查询(成本权衡)
+
+- **核心定义**:`SELECT *` 本身**不会直接导致索引失效**。它是一种“非覆盖索引”查询,如果 `WHERE` 条件命中了索引,索引依然会被初步考虑。
+- **回表成本决策**:当查询需要的字段不在索引树中时,MySQL 必须拿着主键回聚簇索引查找整行数据(回表)。优化器会对比“索引扫描 + 回表”与“直接全表扫描”的成本。如果查询结果占总数据量的比例较高(通常阈值在 20%~30%),优化器会认为全表扫描的顺序 IO 效率高于回表的随机 IO,从而**主动放弃索引**。
+- **落地建议**:严禁在生产环境无脑使用 `SELECT *`。应遵循**覆盖索引**原则,只查询必要的字段,将 `Extra` 列从空值优化为 `Using index`,从而彻底规避回表开销。
+
+**注意**:后文使用 `SELECT *` 仅仅是为了演示方便。
+
+### 违背最左前缀原则
+
+- **核心定义**:最左前缀匹配原则指的是在使用联合索引时,MySQL 会根据索引中的字段顺序,从左到右依次匹配查询条件中的字段。如果查询条件与索引中的最左侧字段相匹配,那么 MySQL 就会使用索引来过滤数据。
+- **范围查询的中断效应**:在联合索引中,如果某个字段使用了范围查询(例如 >、<、BETWEEN、前缀匹配 LIKE "abc%"),该字段本身以及其之前的列可以正常匹配并用于索引的精确定位,但该字段之后的列将无法利用
+ 索引进行快速定位(即无法使用 ref 类型的二分查找)。这是因为在 B+Tree 索引结构中,只有当前导列完全相等时,后续列才是有序的。一旦前导列变成一个范围,后续列在整个扫描区间内就呈现相对无序状态,从而中断了精准定位能力。不过,在 MySQL 5.6 及以上版本中,这些后续列并未完全失效,而是降级为使用**索引下推(Index Condition Pushdown, ICP)机制**,在范围扫描的过程中直接进行条件过滤,以此来减少回表次数。
+- **索引跳跃扫描 (ISS)**:MySQL 8.0.13 引入了**索引跳跃扫描(Index Skip Scan)**,允许在缺失最左前缀时,通过枚举前导列的所有 Distinct 值来跳跃扫描后续索引树。
+
+ - **版本避坑指南**:在 **MySQL 8.0.31** 中,ISS 存在严重 Bug([[Bug #109145]](https://bugs.mysql.com/bug.php?id=109145)),在跨 Range 读取时未清理陈旧的边界值,会导致查询直接**丢失数据**。
+ - **落地建议**:ISS 在前导列基数(Cardinality)极低(如性别、状态枚举)时性能最优,因为优化器需要枚举前导列的所有 distinct 值逐一跳跃扫描——distinct 值越少,跳跃次数越少。但"基数低"本身并非官方限制条件,优化器会综合评估成本决定是否触发 ISS。在生产环境中,**严禁依赖 ISS 来弥补糟糕的索引设计**,必须通过调整联合索引顺序或补齐前导列条件来满足最左前缀。
+
+ **Index Skip Scan 失败路径图:**
+
+```mermaid
+sequenceDiagram
+ participant Executor
+ participant InnoDB_Index
+
+ Note over Executor, InnoDB_Index: MySQL 8.0.31 触发 ISS Bug 场景
+ Executor->>InnoDB_Index: Read Range 1 (Prefix A)
+ InnoDB_Index-->>Executor: Return Rows, Set End-of-Range = X
+ Executor->>InnoDB_Index: Read Range 2 (Prefix B)
+ Note right of InnoDB_Index: [BUG] 未清理上一个 Range 的 End-of-Range X
+ InnoDB_Index-->>Executor: 发现当前值 > X,错误判定越界,提前终止!
+ Note over Executor: 导致结果集丢失 (Incorrect Result)
+```
+
+失效示例:
+
+```sql
+-- 索引:(sname, s_code, address)
+SELECT * FROM students WHERE s_code = 1; -- 跳过最左列 sname,索引失效
+SELECT * FROM students WHERE sname = 'A' AND address = 'Shanghai'; -- 跳过中间列,仅 sname 走索引(索引下推 ICP 可优化过滤)
+SELECT * FROM students WHERE sname = 'A' AND s_code > 1 AND address = 'Shanghai'; -- 范围查询后,address 无法用于定位,仅用于过滤
+```
+
+### 在索引列上进行计算、函数或类型转换
+
+- **核心定义**:索引 B+Tree 存储的是字段的**原始值**。一旦在 `WHERE` 条件中对索引列应用了函数(如 `ABS()`、`DATE()`)或算术运算,该列的值在逻辑上发生了改变。
+- **有序性破坏效应**:由于 B+Tree 是基于原始值排序的,经过函数处理后的结果在索引树中是**无序**的。数据库无法利用二分查找快速定位,只能被迫进行全表扫描。
+- **函数索引**:MySQL 8.0 支持**函数索引**(Functional Index),可针对计算后的值建索引,但使用场景有限,首选还是优化 SQL 写法。
+
+失效示例:
+
+```sql
+SELECT * FROM students WHERE height + 1 = 170; -- 对索引列进行计算
+SELECT * FROM students WHERE DATE(create_time) = '2022-01-01'; -- 对索引列使用函数
+```
+
+优化建议:
+
+```sql
+SELECT * FROM students WHERE height = 169; -- 将计算移到等号右边
+SELECT * FROM students WHERE create_time BETWEEN '2022-01-01 00:00:00' AND '2022-01-01 23:59:59';
+```
+
+### LIKE 模糊查询以通配符开头
+
+- **核心定义**:`LIKE` 查询必须以具体字符开头才能利用索引有序性,例如 `WHERE sname LIKE 'Guide%';`。这是因为 B+ 树是从左到右排序的。前缀通配符(`%`)破坏了有序性,无法定位起始点。
+- **前缀通配符的失效机制**:如果以 `%` 开头(如 `'%abc'`),由于索引是按字符从左到右排序的,前缀不确定意味着可能出现在索引树的任何位置,导致无法定位搜索区间的起始点。
+- **落地建议**:
+ - 如果必须进行全模糊查询,尽量只查询索引覆盖的列,此时 `EXPLAIN` 会显示 `type: index`(**Index Full Scan**),虽然扫描了整棵树,但无需回表,性能仍优于 `ALL`。
+ - 核心业务的大规模模糊搜索应通过 **ElasticSearch** 或其他搜索引擎实现。
+
+失效示例:
+
+```sql
+SELECT * FROM students WHERE sname LIKE '%Guide'; -- 前缀模糊,全表扫描
+SELECT * FROM students WHERE sname LIKE '%Guide%'; -- 前后模糊,全表扫描
+```
+
+### OR 连接与 Index Merge
+
+- **核心定义**:在 `OR` 连接的多个条件中,只要有**任意一列没有索引**,MySQL 就会放弃所有索引转而执行全表扫描。
+- **Index Merge 机制**:若 `OR` 两侧都有索引,MySQL 5.1+ 可能会触发**索引合并(Index Merge)**优化,分别扫描两个索引后取并集。不过,如果两个索引过滤后的数据量都很大,合并结果集的成本可能高于全表扫描,依然会放弃索引。
+- **落地建议**:
+ - 优先将 `OR` 改写为 `UNION ALL`。`UNION ALL` 可以让每一段查询独立使用索引,且规避了优化器对 `OR` 成本估算不准的问题。
+ - 注意:只有当确定结果集不重复时才用 `UNION ALL`,否则需用 `UNION`(涉及临时表去重,有额外开销)。
+
+失效示例:
+
+```sql
+-- 假设 sname 和 address 都有索引,但各匹配 30%+ 数据
+SELECT * FROM students WHERE sname = '学生 1' OR address = '上海'; -- 可能放弃索引,全表扫描
+
+-- 建议改写为
+SELECT * FROM students WHERE sname = '学生 1'
+UNION ALL
+SELECT * FROM students WHERE address = '上海'; -- 各自走索引
+```
+
+**验证方式**:`EXPLAIN` 中若出现 `type: index_merge` 和 `Extra: Using union; Using where`,说明使用了 Index Merge。
+
+### IN / NOT IN 使用不当
+
+**`IN` 列表长度**:
+
+- `eq_range_index_dive_limit`(默认 **200**)并不直接导致索引失效,而是影响**行数估算策略**:
+ - **<= 200**:MySQL 使用 **Index Dive**(深入索引树探测)精确估算行数,成本估算准确,索引大概率有效。
+ - **> 200**:当 `IN` 列表长度超过 `eq_range_index_dive_limit`(MySQL 5.7.4+ 默认为 200)时,优化器从精确的 Index Dive 切换为基于 `index_statistics` 的估算。若表数据的基数(Cardinality)统计陈旧,可能导致估算成本异常,从而放弃走范围扫描(Range Scan)而选择全表扫描。
+- 可通过调大 `eq_range_index_dive_limit` 或改写为 `JOIN` 临时表来规避。
+
+**`NOT IN`** :
+
+- **常量列表**(如 `NOT IN (1,2,3)`):通常全表扫描,因需遍历整个 B+ 树证明"不在集合中"。
+- **子查询关联索引列**:`WHERE id NOT IN (SELECT user_id FROM orders WHERE user_id > 1000)` 可用 `orders` 表的 `user_id` 索引。
+- **推荐替代**:优先使用 `NOT EXISTS` 或 `LEFT JOIN / IS NULL`,性能更优且语义更清晰。
+
+失效示例:
+
+```sql
+SELECT * FROM students WHERE s_code IN (1, 2, 3, ..., 500); -- 列表过长,可能改用统计估算导致误判
+SELECT * FROM students WHERE s_code NOT IN (1, 2, 3); -- 常量列表,全表扫描
+```
+
+### 隐式类型转换
+
+这是开发中最隐蔽的坑,**转换的方向决定了索引的生死**。
+
+| 场景 | 示例 | 转换方向 | 索引是否有效 |
+| --------------------- | ------------------- | ---------------------------- | ------------ |
+| **字符串列 + 数字值** | `varchar_col = 123` | 字符串转数字(发生在索引列) | ❌ 失效 |
+| **数字列 + 字符串值** | `int_col = '123'` | 字符串转数字(发生在常量) | ✅ 有效 |
+
+**关键点**:
+
+- 只有当**转换发生在索引列上**时,索引才会失效。
+- 当字符串与数字进行比较时,MySQL 默认将字符串转换为**浮点数(DOUBLE)**进行比较(详见 [MySQL 官方文档规则 7](https://dev.mysql.com/doc/refman/8.0/en/type-conversion.html))。对索引列发生隐式类型转换等同于在索引列上应用了不可逆的转换函数,破坏了 B+ 树的有序性,导致只能走全表扫描。
+- `int_col = '123'` 会被转换为 `int_col = CAST('123' AS DOUBLE)`,转换发生在常量侧,不影响索引使用。
+
+**详细介绍**:[MySQL隐式转换造成索引失效](https://javaguide.cn/database/mysql/index-invalidation-caused-by-implicit-conversion.html)
+
+### ORDER BY 排序优化陷阱
+
+即使 `WHERE` 条件精准,如果 `ORDER BY` 处理不好,依然会出现慢查询。
+
+**触发 `Using filesort` 的条件**:
+
+- 排序字段不在索引中
+- 索引顺序与 `ORDER BY` 不一致(如索引 `(a,b)` 但 `ORDER BY b,a`)
+- `WHERE` 与 `ORDER BY` 分别使用不同索引
+- 排序列包含 `SELECT *` 中非索引列(需回表排序)
+
+**优化方案**:
+
+- 利用**覆盖索引**同时满足 `WHERE` 和 `ORDER BY`。例如索引为 `(name, age)`,查询 `SELECT name, age FROM users WHERE name = 'A' ORDER BY age`。
+- 调整索引顺序以匹配 `ORDER BY`。
+
+**验证方式**:`EXPLAIN` 中 `Extra` 列出现 `Using filesort` 即表示触发了排序。
+
+### 总结
+
+本文系统梳理了 MySQL 索引失效的常见场景,从底层机制上可归纳为以下两大核心类:
+
+**1. SQL 写法与底层逻辑冲突(破坏 B+Tree 有序性)**
+
+此类问题最为常见,本质是查询条件让底层的 B+Tree 失去了“二分查找”的快速定位能力。
+
+- **违背最左前缀原则**:跳过联合索引前导列,或遇到范围查询(如 `>`、`<`、`BETWEEN`、`LIKE "abc%"`)导致后续列中断精确定位,降级为范围扫描加过滤。
+- **对索引列进行加工**:在 `WHERE` 左侧对索引列进行数学计算或应用函数,导致原始数据发生逻辑改变,在索引树中呈现无序状态。
+- **隐式类型转换(隐蔽且致命)**:当“字符串类型的列”去比较“数字类型的值”时,MySQL 会默认在列上套用转换函数,直接破坏树的有序性。
+- **LIKE 模糊查询前置通配符**:如 `LIKE "%abc"`,前缀字符的不确定性使得优化器无法锁定扫描区间的起始点。
+- **ORDER BY 排序陷阱**:排序列未命中索引、排序方向与索引结构不一致等触发额外的内存或磁盘排序(`Using filesort`)。
+
+**2. 优化器的成本决策(基于 I/O 成本妥协)**
+
+此类问题并非索引本身不可用,而是 MySQL 优化器经过计算后,认为“不走普通索引”整体开销反而更小。
+
+- **无脑 `SELECT \*` 导致回表成本超载**:查询大量非索引覆盖列时,若命中数据量较大(通常超 20%~30%),优化器会判定全表扫描的顺序 I/O 优于频繁回表的随机 I/O,从而主动放弃索引。
+- **`OR` 条件导致全表扫描**:只要 `OR` 连接的任意一侧条件没有对应索引,就会触发全表扫描。即使两侧都有索引,若 Index Merge(索引合并)的预期成本过高,依然会被放弃。
+- **`IN` 列表过长引发估算失真**:当 `IN` 列表长度超过系统阈值(默认 200)时,优化器会从精准的深入探测(Index Dive)切换为粗略的统计估算,极易因统计信息陈旧而产生执行成本的误判。
+
+**实战建议**:
+
+1. **养成 `EXPLAIN` 分析习惯**:在编写复杂 SQL 后,务必使用 `EXPLAIN` 分析执行计划,重点关注 `type`、`key`、`rows`、`Extra` 字段。
+2. **遵循覆盖索引原则**:尽量避免 `SELECT *`,只查询必要字段,让索引覆盖查询需求,减少回表开销。
+3. **规范数据类型使用**:保持查询条件与字段类型一致,避免隐式类型转换。
+4. **合理设计联合索引**:按照查询频率和选择性安排字段顺序,优先满足高频查询场景。
+5. **大规模模糊搜索考虑 ES**:对于前后模糊查询(`%keyword%`),建议使用 Elasticsearch 等搜索引擎。
+
+索引优化是数据库性能优化的基本功,但也需要结合实际业务场景和数据分布进行权衡。理解索引失效的根本原因,才能在遇到性能问题时快速定位并解决。
+
+**延伸阅读**:
+
+- [MySQL 索引详解](https://javaguide.cn/database/mysql/mysql-index.html)
+- [MySQL 执行计划分析](https://javaguide.cn/database/mysql/mysql-query-execution-plan.html)
+- [MySQL 隐式转换造成索引失效](https://javaguide.cn/database/mysql/index-invalidation-caused-by-implicit-conversion.html)
diff --git a/docs/database/mysql/mysql-index.md b/docs/database/mysql/mysql-index.md
index 38ebdd0f373..dfdf5aa0330 100644
--- a/docs/database/mysql/mysql-index.md
+++ b/docs/database/mysql/mysql-index.md
@@ -1,11 +1,16 @@
---
title: MySQL索引详解
+description: MySQL索引详解,深入剖析B+树索引结构、聚簇索引与二级索引的区别、联合索引与最左前缀原则、覆盖索引与索引下推优化,以及常见的索引失效场景。
category: 数据库
tag:
- MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL索引,B+树索引,聚簇索引,覆盖索引,联合索引,索引下推,回表查询,索引失效,最左前缀原则
---
-> 感谢[WT-AHA](https://github.com/WT-AHA)对本文的完善,相关 PR:https://github.com/Snailclimb/JavaGuide/pull/1648 。
+> 感谢[WT-AHA](https://github.com/WT-AHA)对本文的完善,相关 PR: 。
但凡经历过几场面试的小伙伴,应该都清楚,数据库索引这个知识点在面试中出现的频率高到离谱。
@@ -15,31 +20,37 @@ tag:
**索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。**
-索引的作用就相当于书的目录。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
+索引的作用就相当于书的目录。打个比方:我们在查字典的时候,如果没有目录,那我们就只能一页一页地去找我们需要查的那个字,速度很慢;如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
-索引底层数据结构存在很多种类型,常见的索引结构有: B 树, B+树 和 Hash、红黑树。在 MySQL 中,无论是 Innodb 还是 MyIsam,都使用了 B+树作为索引结构。
+索引底层数据结构存在很多种类型,常见的索引结构有:B 树、 B+ 树 和 Hash、红黑树。在 MySQL 中,无论是 Innodb 还是 MyISAM,都使用了 B+ 树作为索引结构。
## 索引的优缺点
-**优点**:
+**索引的优点:**
-- 使用索引可以大大加快 数据的检索速度(大大减少检索的数据量), 这也是创建索引的最主要的原因。
-- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
+1. **查询速度起飞 (主要目的)**:通过索引,数据库可以**大幅减少需要扫描的数据量**,直接定位到符合条件的记录,从而显著加快数据检索速度,减少磁盘 I/O 次数。
+2. **保证数据唯一性**:通过创建**唯一索引 (Unique Index)**,可以确保表中的某一列(或几列组合)的值是独一无二的,比如用户 ID、邮箱等。主键本身就是一种唯一索引。
+3. **加速排序和分组**:如果查询中的 ORDER BY 或 GROUP BY 子句涉及的列建有索引,数据库往往可以直接利用索引已经排好序的特性,避免额外的排序操作,从而提升性能。
-**缺点**:
+**索引的缺点:**
-- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
-- 索引需要使用物理文件存储,也会耗费一定空间。
+1. **创建和维护耗时**:创建索引本身需要时间,特别是对大表操作时。更重要的是,当对表中的数据进行**增、删、改 (DML 操作)** 时,不仅要操作数据本身,相关的索引也必须动态更新和维护,这会**降低这些 DML 操作的执行效率**。
+2. **占用存储空间**:索引本质上也是一种数据结构,需要以物理文件(或内存结构)的形式存储,因此会**额外占用一定的磁盘空间**。索引越多、越大,占用的空间也就越多。
+3. **可能被误用或失效**:如果索引设计不当,或者查询语句写得不好,数据库优化器可能不会选择使用索引(或者选错索引),反而导致性能下降。
-但是,**使用索引一定能提高查询性能吗?**
+**那么,用了索引就一定能提高查询性能吗?**
-大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
+**不一定。** 大多数情况下,合理使用索引确实比全表扫描快得多。但也有例外:
+
+- **数据量太小**:如果表里的数据非常少(比如就几百条),全表扫描可能比通过索引查找更快,因为走索引本身也有开销。
+- **查询结果集占比过大**:如果要查询的数据占了整张表的大部分(比如超过 20%-30%),优化器可能会认为全表扫描更划算,因为通过索引多次回表(随机 I/O)的成本可能高于一次顺序的全表扫描。
+- **索引维护不当或统计信息过时**:导致优化器做出错误判断。
## 索引底层数据结构选型
### Hash 表
-哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
+哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
**为何能够通过 key 快速取出 value 呢?** 原因在于 **哈希算法**(也叫散列算法)。通过哈希算法,我们可以快速找到 key 对应的 index,找到了 index 也就找到了对应的 value。
@@ -50,23 +61,25 @@ index = hash % array_size
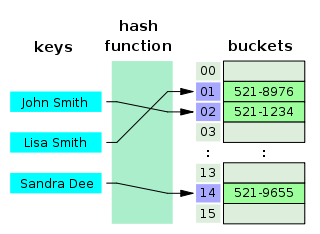
-但是!哈希算法有个 **Hash 冲突** 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 **链地址法**。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 `HashMap` 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后`HashMap`为了减少链表过长的时候搜索时间过长引入了红黑树。
+但是!哈希算法有个 **Hash 冲突** 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 **链地址法**。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 `HashMap` 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后`HashMap`为了提高链表过长时的搜索效率,引入了红黑树。
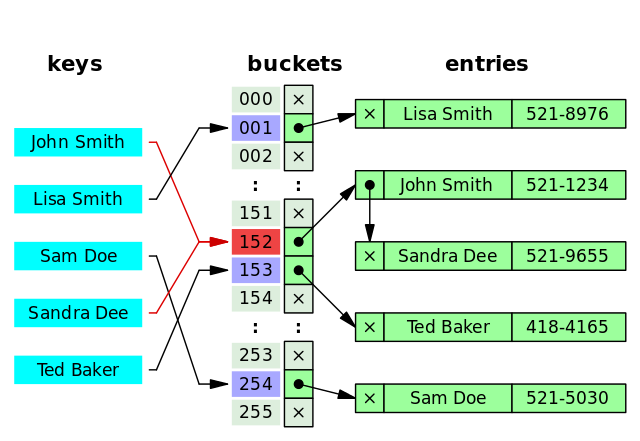
为了减少 Hash 冲突的发生,一个好的哈希函数应该“均匀地”将数据分布在整个可能的哈希值集合中。
+MySQL 的 InnoDB 存储引擎不直接支持常规的哈希索引,但是,InnoDB 存储引擎中存在一种特殊的“自适应哈希索引”(Adaptive Hash Index),自适应哈希索引并不是传统意义上的纯哈希索引,而是结合了 B+Tree 和哈希索引的特点,以便更好地适应实际应用中的数据访问模式和性能需求。自适应哈希索引的每个哈希桶实际上是一个小型的 B+Tree 结构。这个 B+Tree 结构可以存储多个键值对,而不仅仅是一个键。这有助于减少哈希冲突链的长度,提高了索引的效率。关于 Adaptive Hash Index 的详细介绍,可以查看 [MySQL 各种“Buffer”之 Adaptive Hash Index](https://mp.weixin.qq.com/s/ra4v1XR5pzSWc-qtGO-dBg) 这篇文章。
+
既然哈希表这么快,**为什么 MySQL 没有使用其作为索引的数据结构呢?** 主要是因为 Hash 索引不支持顺序和范围查询。假如我们要对表中的数据进行排序或者进行范围查询,那 Hash 索引可就不行了。并且,每次 IO 只能取一个。
-试想一种情况:
+试想一种情况:
```java
SELECT * FROM tb1 WHERE id < 500;
```
-在这种范围查询中,优势非常大,直接遍历比 500 小的叶子节点就够了。而 Hash 索引是根据 hash 算法来定位的,难不成还要把 1 - 499 的数据,每个都进行一次 hash 计算来定位吗?这就是 Hash 最大的缺点了。
+在这种范围查询中,优势非常大,直接遍历比 500 小的叶子节点就够了。而 Hash 索引是根据 hash 算法来定位的,难不成还要把 1 - 499 的数据,每个都进行一次 hash 计算来定位吗?这就是 Hash 最大的缺点了。
-### 二叉查找树(BST)
+### 二叉查找树(BST)
二叉查找树(Binary Search Tree)是一种基于二叉树的数据结构,它具有以下特点:
@@ -74,7 +87,7 @@ SELECT * FROM tb1 WHERE id < 500;
2. 右子树所有节点的值均大于根节点的值。
3. 左右子树也分别为二叉查找树。
-当二叉查找树是平衡的时候,也就是树的每个节点的左右子树深度相差不超过 1 的时候,查询的时间复杂度为 O(log2(N)),具有比较高的效率。然而,当二叉查找树不平衡时,例如在最坏情况下(有序插入节点),树会退化成线性链表(也被称为斜树),导致查询效率急剧下降,时间复杂退化为 O(N)。
+当二叉查找树是平衡的时候,也就是树的每个节点的左右子树深度相差不超过 1 的时候,查询的时间复杂度为 O(log2(N)),具有比较高的效率。然而,当二叉查找树不平衡时,例如在最坏情况下(有序插入节点),树会退化成线性链表(也被称为斜树),导致查询效率急剧下降,时间复杂退化为 O(N)。
@@ -86,11 +99,11 @@ SELECT * FROM tb1 WHERE id < 500;
AVL 树是计算机科学中最早被发明的自平衡二叉查找树,它的名称来自于发明者 G.M. Adelson-Velsky 和 E.M. Landis 的名字缩写。AVL 树的特点是保证任何节点的左右子树高度之差不超过 1,因此也被称为高度平衡二叉树,它的查找、插入和删除在平均和最坏情况下的时间复杂度都是 O(logn)。
-
+
AVL 树采用了旋转操作来保持平衡。主要有四种旋转操作:LL 旋转、RR 旋转、LR 旋转和 RL 旋转。其中 LL 旋转和 RR 旋转分别用于处理左左和右右失衡,而 LR 旋转和 RL 旋转则用于处理左右和右左失衡。
-由于 AVL 树需要频繁地进行旋转操作来保持平衡,因此会有较大的计算开销进而降低了查询性能。并且, 在使用 AVL 树时,每个树节点仅存储一个数据,而每次进行磁盘 IO 时只能读取一个节点的数据,如果需要查询的数据分布在多个节点上,那么就需要进行多次磁盘 IO。 **磁盘 IO 是一项耗时的操作,在设计数据库索引时,我们需要优先考虑如何最大限度地减少磁盘 IO 操作的次数。**
+由于 AVL 树需要频繁地进行旋转操作来保持平衡,因此会有较大的计算开销进而降低了数据库写操作的性能。并且, 在使用 AVL 树时,每个树节点仅存储一个数据,而每次进行磁盘 IO 时只能读取一个节点的数据,如果需要查询的数据分布在多个节点上,那么就需要进行多次磁盘 IO。**磁盘 IO 是一项耗时的操作,在设计数据库索引时,我们需要优先考虑如何最大限度地减少磁盘 IO 操作的次数。**
实际应用中,AVL 树使用的并不多。
@@ -102,7 +115,7 @@ AVL 树采用了旋转操作来保持平衡。主要有四种旋转操作:LL
2. 根节点总是黑色的;
3. 每个叶子节点都是黑色的空节点(NIL 节点);
4. 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
-5. 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)。
+5. 从任意节点到它的叶子节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)。
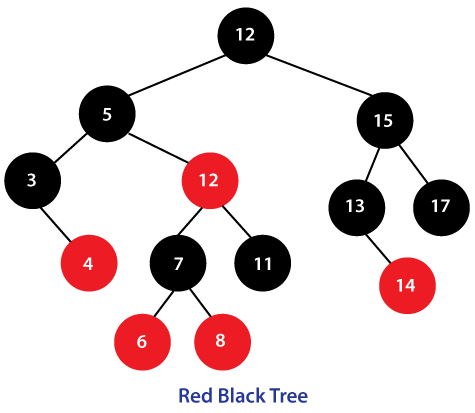
@@ -110,26 +123,26 @@ AVL 树采用了旋转操作来保持平衡。主要有四种旋转操作:LL
**红黑树的应用还是比较广泛的,TreeMap、TreeSet 以及 JDK1.8 的 HashMap 底层都用到了红黑树。对于数据在内存中的这种情况来说,红黑树的表现是非常优异的。**
-### B 树& B+树
+### B 树& B+ 树
-B 树也称 B-树,全称为 **多路平衡查找树** ,B+ 树是 B 树的一种变体。B 树和 B+树中的 B 是 `Balanced` (平衡)的意思。
+B 树也称 B- 树,全称为 **多路平衡查找树**,B+ 树是 B 树的一种变体。B 树和 B+ 树中的 B 是 `Balanced`(平衡)的意思。
目前大部分数据库系统及文件系统都采用 B-Tree 或其变种 B+Tree 作为索引结构。
-**B 树& B+树两者有何异同呢?**
+**B 树& B+ 树两者有何异同呢?**
-- B 树的所有节点既存放键(key) 也存放数据(data),而 B+树只有叶子节点存放 key 和 data,其他内节点只存放 key。
-- B 树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
-- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
-- 在 B 树中进行范围查询时,首先找到要查找的下限,然后对 B 树进行中序遍历,直到找到查找的上限;而 B+树的范围查询,只需要对链表进行遍历即可。
+- B 树的所有节点既存放键(key)也存放数据(data),而 B+ 树只有叶子节点存放 key 和 data,其他内节点只存放 key。
+- B 树的叶子节点都是独立的;B+ 树的叶子节点有一条引用链指向与它相邻的叶子节点。
+- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+ 树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
+- 在 B 树中进行范围查询时,首先找到要查找的下限,然后对 B 树进行中序遍历,直到找到查找的上限;而 B+ 树的范围查询,只需要对链表进行遍历即可。
-综上,B+树与 B 树相比,具备更少的 IO 次数、更稳定的查询效率和更适于范围查询这些优势。
+综上,B+ 树与 B 树相比,具备更少的 IO 次数、更稳定的查询效率和更适于范围查询这些优势。
在 MySQL 中,MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是,两者的实现方式不太一样。(下面的内容整理自《Java 工程师修炼之道》)
> MyISAM 引擎中,B+Tree 叶节点的 data 域存放的是数据记录的地址。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“**非聚簇索引(非聚集索引)**”。
>
-> InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“**聚簇索引(聚集索引)**”,而其余的索引都作为 **辅助索引** ,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
+> InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“**聚簇索引(聚集索引)**”,而其余的索引都作为 **辅助索引**,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
## 索引类型总结
@@ -138,12 +151,12 @@ B 树也称 B-树,全称为 **多路平衡查找树** ,B+ 树是 B 树的一
- BTree 索引:MySQL 里默认和最常用的索引类型。只有叶子节点存储 value,非叶子节点只有指针和 key。存储引擎 MyISAM 和 InnoDB 实现 BTree 索引都是使用 B+Tree,但二者实现方式不一样(前面已经介绍了)。
- 哈希索引:类似键值对的形式,一次即可定位。
- RTree 索引:一般不会使用,仅支持 geometry 数据类型,优势在于范围查找,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
-- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR` ,`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
+- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR`、`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
按照底层存储方式角度划分:
- 聚簇索引(聚集索引):索引结构和数据一起存放的索引,InnoDB 中的主键索引就属于聚簇索引。
-- 非聚簇索引(非聚集索引):索引结构和数据分开存放的索引,二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
+- 非聚簇索引(非聚集索引):索引结构和数据分开存放的索引,二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
按照应用维度划分:
@@ -152,7 +165,8 @@ B 树也称 B-树,全称为 **多路平衡查找树** ,B+ 树是 B 树的一
- 唯一索引:加速查询 + 列值唯一(可以有 NULL)。
- 覆盖索引:一个索引包含(或者说覆盖)所有需要查询的字段的值。
- 联合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并。
-- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR` ,`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
+- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR`、`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
+- 前缀索引:对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符。
MySQL 8.x 中实现的索引新特性:
@@ -160,7 +174,7 @@ MySQL 8.x 中实现的索引新特性:
- 降序索引:之前的版本就支持通过 desc 来指定索引为降序,但实际上创建的仍然是常规的升序索引。直到 MySQL 8.x 版本才开始真正支持降序索引。另外,在 MySQL 8.x 版本中,不再对 GROUP BY 语句进行隐式排序。
- 函数索引:从 MySQL 8.0.13 版本开始支持在索引中使用函数或者表达式的值,也就是在索引中可以包含函数或者表达式。
-## 主键索引(Primary Key)
+## 主键索引(Primary Key)
数据表的主键列使用的就是主键索引。
@@ -172,19 +186,18 @@ MySQL 8.x 中实现的索引新特性:
## 二级索引
-**二级索引(Secondary Index)又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。**
+二级索引(Secondary Index)的叶子节点存储的数据是主键的值,也就是说,通过二级索引可以定位主键的位置,二级索引又称为辅助索引/非主键索引。
-唯一索引,普通索引,前缀索引等索引属于二级索引。
+唯一索引、普通索引、前缀索引等索引都属于二级索引。
-PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。
+PS:不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。
-1. **唯一索引(Unique Key)**:唯一索引也是一种约束。**唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。** 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
-2. **普通索引(Index)**:**普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。**
-3. **前缀索引(Prefix)**:前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,
- 因为只取前几个字符。
-4. **全文索引(Full Text)**:全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
+1. **唯一索引(Unique Key)**:唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
+2. **普通索引(Index)**:普通索引的唯一作用就是为了快速查询数据。一张表允许创建多个普通索引,并允许数据重复和 NULL。
+3. **前缀索引(Prefix)**:前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符。
+4. **全文索引(Full Text)**:全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MyISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
-二级索引:
+二级索引:
@@ -194,27 +207,27 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
#### 聚簇索引介绍
-**聚簇索引(Clustered Index)即索引结构和数据一起存放的索引,并不是一种单独的索引类型。InnoDB 中的主键索引就属于聚簇索引。**
+聚簇索引(Clustered Index)即索引结构和数据一起存放的索引,并不是一种单独的索引类型。InnoDB 中的主键索引就属于聚簇索引。
-在 MySQL 中,InnoDB 引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
+在 MySQL 中,InnoDB 引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+ 树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
#### 聚簇索引的优缺点
**优点**:
-- **查询速度非常快**:聚簇索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。相比于非聚簇索引, 聚簇索引少了一次读取数据的 IO 操作。
+- **查询速度非常快**:聚簇索引的查询速度非常的快,因为整个 B+ 树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。相比于非聚簇索引, 聚簇索引少了一次读取数据的 IO 操作。
- **对排序查找和范围查找优化**:聚簇索引对于主键的排序查找和范围查找速度非常快。
**缺点**:
-- **依赖于有序的数据**:因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
+- **依赖于有序的数据**:因为 B+ 树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
- **更新代价大**:如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且聚簇索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。
### 非聚簇索引(非聚集索引)
#### 非聚簇索引介绍
-**非聚簇索引(Non-Clustered Index)即索引结构和数据分开存放的索引,并不是一种单独的索引类型。二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。**
+非聚簇索引(Non-Clustered Index)即索引结构和数据分开存放的索引,并不是一种单独的索引类型。二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
非聚簇索引的叶子节点并不一定存放数据的指针,因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。
@@ -222,22 +235,22 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
**优点**:
-更新代价比聚簇索引要小 。非聚簇索引的更新代价就没有聚簇索引那么大了,非聚簇索引的叶子节点是不存放数据的
+更新代价比聚簇索引要小。非聚簇索引的更新代价就没有聚簇索引那么大了,非聚簇索引的叶子节点是不存放数据的。
**缺点**:
-- **依赖于有序的数据**:跟聚簇索引一样,非聚簇索引也依赖于有序的数据
-- **可能会二次查询(回表)**:这应该是非聚簇索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
+- **依赖于有序的数据**:跟聚簇索引一样,非聚簇索引也依赖于有序的数据。
+- **可能会二次查询(回表)**:这应该是非聚簇索引最大的缺点了。当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
-这是 MySQL 的表的文件截图:
+这是 MySQL 的表的文件截图:
-聚簇索引和非聚簇索引:
+聚簇索引和非聚簇索引:
-#### 非聚簇索引一定回表查询吗(覆盖索引)?
+#### 非聚簇索引一定回表查询吗(覆盖索引)?
**非聚簇索引不一定回表查询。**
@@ -249,7 +262,7 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
那么这个索引的 key 本身就是 name,查到对应的 name 直接返回就行了,无需回表查询。
-即使是 MYISAM 也是这样,虽然 MYISAM 的主键索引确实需要回表,因为它的主键索引的叶子节点存放的是指针。但是!**如果 SQL 查的就是主键呢?**
+即使是 MyISAM 也是这样,虽然 MyISAM 的主键索引确实需要回表,因为它的主键索引的叶子节点存放的是指针。但是!**如果 SQL 查的就是主键呢?**
```sql
SELECT id FROM table WHERE id=1;
@@ -261,7 +274,9 @@ SELECT id FROM table WHERE id=1;
### 覆盖索引
-如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为 **覆盖索引(Covering Index)** 。我们知道在 InnoDB 存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次,这样就会比较慢。而覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为 **覆盖索引(Covering Index)**。
+
+在 InnoDB 存储引擎中,非主键索引的叶子节点包含的是主键的值。这意味着,当使用非主键索引进行查询时,数据库会先找到对应的主键值,然后再通过主键索引来定位和检索完整的行数据。这个过程被称为“回表”。
**覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了,而无需回表查询。**
@@ -272,7 +287,7 @@ SELECT id FROM table WHERE id=1;
我们这里简单演示一下覆盖索引的效果。
-1、创建一个名为 `cus_order` 的表,来实际测试一下这种排序方式。为了测试方便, `cus_order` 这张表只有 `id`、`score`、`name`这 3 个字段。
+1、创建一个名为 `cus_order` 的表,来实际测试一下这种排序方式。为了测试方便,`cus_order` 这张表只有 `id`、`score`、`name` 这 3 个字段。
```sql
CREATE TABLE `cus_order` (
@@ -312,10 +327,11 @@ CALL BatchinsertDataToCusOder(1, 1000000); # 插入100w+的随机数据
为了能够对这 100w 数据按照 `score` 进行排序,我们需要执行下面的 SQL 语句。
```sql
-SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;#降序排序
+#降序排序
+SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
```
-使用 `EXPLAIN` 命令分析这条 SQL 语句,通过 `Extra` 这一列的 `Using filesort` ,我们发现是没有用到覆盖索引的。
+使用 `EXPLAIN` 命令分析这条 SQL 语句,通过 `Extra` 这一列的 `Using filesort`,我们发现是没有用到覆盖索引的。

@@ -331,7 +347,7 @@ ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);

-通过 `Extra` 这一列的 `Using index` ,说明这条 SQL 语句成功使用了覆盖索引。
+通过 `Extra` 这一列的 `Using index`,说明这条 SQL 语句成功使用了覆盖索引。
关于 `EXPLAIN` 命令的详细介绍请看:[MySQL 执行计划分析](./mysql-query-execution-plan.md)这篇文章。
@@ -347,67 +363,174 @@ ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
### 最左前缀匹配原则
-最左前缀匹配原则指的是,在使用联合索引时,**MySQL** 会根据联合索引中的字段顺序,从左到右依次到查询条件中去匹配,如果查询条件中存在与联合索引中最左侧字段相匹配的字段,则就会使用该字段过滤一批数据,直至联合索引中全部字段匹配完成,或者在执行过程中遇到范围查询(如 **`>`**、**`<`**)才会停止匹配。对于 **`>=`**、**`<=`**、**`BETWEEN`**、**`like`** 前缀匹配的范围查询,并不会停止匹配。所以,我们在使用联合索引时,可以将区分度高的字段放在最左边,这也可以过滤更多数据。
+最左前缀匹配原则指的是在使用联合索引时,MySQL 会根据索引中的字段顺序,从左到右依次匹配查询条件中的字段。如果查询条件与索引中的最左侧字段相匹配,那么 MySQL 就会使用索引来过滤数据,这样可以提高查询效率。
+
+最左匹配原则会一直向右匹配,直到遇到范围查询(如 >、<)为止。对于 >=、<=、BETWEEN 以及前缀匹配 LIKE 的范围查询,不会停止匹配。
+
+假设有一个联合索引 `(column1, column2, column3)`,其从左到右的所有前缀为 `(column1)`、`(column1, column2)`、`(column1, column2, column3)`(创建 1 个联合索引相当于创建了 3 个索引),包含这些列的所有查询都会走索引而不会全表扫描。
+
+我们在使用联合索引时,可以将区分度高的字段放在最左边,这也可以过滤更多数据。
+
+我们这里简单演示一下最左前缀匹配的效果。
+
+1、创建一个名为 `student` 的表,这张表只有 `id`、`name`、`class` 这 3 个字段。
+
+```sql
+CREATE TABLE `student` (
+ `id` int NOT NULL,
+ `name` varchar(100) DEFAULT NULL,
+ `class` varchar(100) DEFAULT NULL,
+ PRIMARY KEY (`id`),
+ KEY `name_class_idx` (`name`,`class`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+```
+
+2、下面我们分别测试三条不同的 SQL 语句。
-相关阅读:[联合索引的最左匹配原则全网都在说的一个错误结论](https://mp.weixin.qq.com/s/8qemhRg5MgXs1So5YCv0fQ)。
+
+
+```sql
+# 可以命中索引
+SELECT * FROM student WHERE name = 'Anne Henry';
+EXPLAIN SELECT * FROM student WHERE name = 'Anne Henry' AND class = 'lIrm08RYVk';
+# 无法命中索引
+SELECT * FROM student WHERE class = 'lIrm08RYVk';
+```
+
+再来看一个常见的面试题:如果有索引 `联合索引(a,b,c)`,查询 `a=1 AND c=1` 会走索引么?`c=1` 呢?`b=1 AND c=1` 呢? `b = 1 AND a = 1 AND c = 1` 呢?
+
+先不要往下看答案,给自己 3 分钟时间想一想。
+
+1. 查询 `a=1 AND c=1`:根据最左前缀匹配原则,查询可以使用索引的前缀部分。因此,该查询仅在 `a=1` 上使用索引,然后对结果进行 `c=1` 的过滤。
+2. 查询 `c=1`:由于查询中不包含最左列 `a`,根据最左前缀匹配原则,整个索引都无法被使用。
+3. 查询 `b=1 AND c=1`:和第二种一样的情况,整个索引都不会使用。
+4. 查询 `b=1 AND a=1 AND c=1`:这个查询是可以用到索引的。查询优化器分析 SQL 语句时,对于联合索引,会对查询条件进行重排序,以便用到索引。会将 `b=1` 和 `a=1` 的条件进行重排序,变成 `a=1 AND b=1 AND c=1`。
+
+MySQL 8.0.13 版本引入了索引跳跃扫描(Index Skip Scan,简称 ISS),它可以在某些索引查询场景下提高查询效率。在没有 ISS 之前,不满足最左前缀匹配原则的联合索引查询中会执行全表扫描。而 ISS 允许 MySQL 在某些情况下避免全表扫描,即使查询条件不符合最左前缀。不过,这个功能比较鸡肋, 和 Oracle 中的没法比,MySQL 8.0.31 还报告了一个 bug:[Bug #109145 Using index for skip scan cause incorrect result](https://bugs.mysql.com/bug.php?id=109145)(后续版本已经修复)。个人建议知道有这个东西就好,不需要深究,实际项目也不一定能用上。
## 索引下推
-**索引下推(Index Condition Pushdown)** 是 **MySQL 5.6** 版本中提供的一项索引优化功能,可以在非聚簇索引遍历过程中,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表次数。
+**索引下推(Index Condition Pushdown,简称 ICP)** 是 **MySQL 5.6** 版本中提供的一项索引优化功能,它允许存储引擎在索引遍历过程中,执行部分 `WHERE` 字句的判断条件,直接过滤掉不满足条件的记录,从而减少回表次数,提高查询效率。
+
+假设我们有一个名为 `user` 的表,其中包含 `id`、`username`、`zipcode` 和 `birthdate` 4 个字段,创建了联合索引 `(zipcode, birthdate)`。
+
+```sql
+CREATE TABLE `user` (
+ `id` int NOT NULL AUTO_INCREMENT,
+ `username` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
+ `zipcode` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
+ `birthdate` date NOT NULL,
+ PRIMARY KEY (`id`),
+ KEY `idx_username_birthdate` (`zipcode`,`birthdate`) ) ENGINE=InnoDB AUTO_INCREMENT=1001 DEFAULT CHARSET=utf8mb4;
+
+# 查询 zipcode 为 431200 且生日在 3 月的用户
+# birthdate 字段使用函数索引失效
+SELECT * FROM user WHERE zipcode = '431200' AND MONTH(birthdate) = 3;
+```
+
+- 没有索引下推之前,即使 `zipcode` 字段利用索引可以帮助我们快速定位到 `zipcode = '431200'` 的用户,但我们仍然需要对每一个找到的用户进行回表操作,获取完整的用户数据,再去判断 `MONTH(birthdate) = 3`。
+- 有了索引下推之后,存储引擎会在使用 `zipcode` 字段索引查找 `zipcode = '431200'` 的用户时,同时判断 `MONTH(birthdate) = 3`。这样,只有同时满足条件的记录才会被返回,减少了回表次数。
+
+
+
+
+
+再来讲讲索引下推的具体原理,先看下面这张 MySQL 简要架构图。
+
+
+
+MySQL 可以简单分为 Server 层和存储引擎层这两层。Server 层处理查询解析、分析、优化、缓存以及与客户端的交互等操作,而存储引擎层负责数据的存储和读取,MySQL 支持 InnoDB、MyISAM、Memory 等多种存储引擎。
+
+索引下推的 **下推** 其实就是指将部分上层(Server 层)负责的事情,交给了下层(存储引擎层)去处理。
+
+我们这里结合索引下推原理再对上面提到的例子进行解释。
+
+没有索引下推之前:
+
+- 存储引擎层先根据 `zipcode` 索引字段找到所有 `zipcode = '431200'` 的用户的主键 ID,然后二次回表查询,获取完整的用户数据;
+- 存储引擎层把所有 `zipcode = '431200'` 的用户数据全部交给 Server 层,Server 层根据 `MONTH(birthdate) = 3` 这一条件再进一步做筛选。
+
+有了索引下推之后:
+
+- 存储引擎层先根据 `zipcode` 索引字段找到所有 `zipcode = '431200'` 的用户,然后直接判断 `MONTH(birthdate) = 3`,筛选出符合条件的主键 ID;
+- 二次回表查询,根据符合条件的主键 ID 去获取完整的用户数据;
+- 存储引擎层把符合条件的用户数据全部交给 Server 层。
+
+可以看出,**除了可以减少回表次数之外,索引下推还可以减少存储引擎层和 Server 层的数据传输量。**
+
+最后,总结一下索引下推应用范围:
+
+1. 适用于 InnoDB 引擎和 MyISAM 引擎的查询。
+2. 适用于执行计划是 range、ref、eq_ref、ref_or_null 的范围查询。
+3. 对于 InnoDB 表,仅用于非聚簇索引。索引下推的目标是减少全行读取次数,从而减少 I/O 操作。对于 InnoDB 聚集索引,完整的记录已经读入 InnoDB 缓冲区。在这种情况下使用索引下推不会减少 I/O。
+4. 子查询不能使用索引下推,因为子查询通常会创建临时表来处理结果,而这些临时表是没有索引的。
+5. 存储过程不能使用索引下推,因为存储引擎无法调用存储函数。
## 正确使用索引的一些建议
### 选择合适的字段创建索引
-- **不为 NULL 的字段**:索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代。
+- **不为 NULL 的字段**:索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0、1、true、false 这样语义较为清晰的短值或短字符作为替代。
- **被频繁查询的字段**:我们创建索引的字段应该是查询操作非常频繁的字段。
- **被作为条件查询的字段**:被作为 WHERE 条件查询的字段,应该被考虑建立索引。
- **频繁需要排序的字段**:索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
- **被经常频繁用于连接的字段**:经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
+### 避免索引失效
+
+索引失效也是慢查询的主要原因之一,常见的导致索引失效的情况有下面这两类:
+
+**1. SQL 写法与底层逻辑冲突(破坏 B+Tree 有序性)**
+
+此类问题最为常见,本质是查询条件让底层的 B+Tree 失去了“二分查找”的快速定位能力。
+
+- **违背最左前缀原则**:跳过联合索引前导列,或遇到范围查询(如 `>`、`<`、`BETWEEN`、`LIKE "abc%"`)导致后续列中断精确定位,降级为范围扫描加过滤。
+- **对索引列进行加工**:在 `WHERE` 左侧对索引列进行数学计算或应用函数,导致原始数据发生逻辑改变,在索引树中呈现无序状态。
+- **隐式类型转换(隐蔽且致命)**:当“字符串类型的列”去比较“数字类型的值”时,MySQL 会默认在列上套用转换函数,直接破坏树的有序性。
+- **LIKE 模糊查询前置通配符**:如 `LIKE "%abc"`,前缀字符的不确定性使得优化器无法锁定扫描区间的起始点。
+- **ORDER BY 排序陷阱**:排序列未命中索引、排序方向与索引结构不一致等触发额外的内存或磁盘排序(`Using filesort`)。
+
+**2. 优化器的成本决策(基于 I/O 成本妥协)**
+
+此类问题并非索引本身不可用,而是 MySQL 优化器经过计算后,认为“不走普通索引”整体开销反而更小。
+
+- **无脑 `SELECT \*` 导致回表成本超载**:查询大量非索引覆盖列时,若命中数据量较大(通常超 20%~30%),优化器会判定全表扫描的顺序 I/O 优于频繁回表的随机 I/O,从而主动放弃索引。
+- **`OR` 条件导致全表扫描**:只要 `OR` 连接的任意一侧条件没有对应索引,就会触发全表扫描。即使两侧都有索引,若 Index Merge(索引合并)的预期成本过高,依然会被放弃。
+- **`IN` 列表过长引发估算失真**:当 `IN` 列表长度超过系统阈值(默认 200)时,优化器会从精准的深入探测(Index Dive)切换为粗略的统计估算,极易因统计信息陈旧而产生执行成本的误判。
+
+详细介绍:[MySQL索引失效场景总结](https://javaguide.cn/database/mysql/mysql-index-invalidation.html)。
+
### 被频繁更新的字段应该慎重建立索引
虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。 如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。
### 限制每张表上的索引数量
-索引并不是越多越好,建议单张表索引不超过 5 个!索引可以提高效率同样可以降低效率。
+索引并不是越多越好,建议单张表索引不超过 5 个!索引可以提高效率,同样可以降低效率。
索引可以增加查询效率,但同样也会降低插入和更新的效率,甚至有些情况下会降低查询效率。
-因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
+因为 MySQL 优化器在选择如何优化查询时,会根据统计信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
### 尽可能的考虑建立联合索引而不是单列索引
-因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗 B+树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
+因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗 B+ 树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
### 注意避免冗余索引
-冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。如(name,city )和(name )这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
+冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。如(name,city)和(name)这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的。在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
### 字符串类型的字段使用前缀索引代替普通索引
前缀索引仅限于字符串类型,较普通索引会占用更小的空间,所以可以考虑使用前缀索引带替普通索引。
-### 避免索引失效
-
-索引失效也是慢查询的主要原因之一,常见的导致索引失效的情况有下面这些:
-
-- ~~使用 `SELECT *` 进行查询;~~ `SELECT *` 不会直接导致索引失效(如果不走索引大概率是因为 where 查询范围过大导致的),但它可能会带来一些其他的性能问题比如造成网络传输和数据处理的浪费、无法使用索引覆盖;
-- 创建了组合索引,但查询条件未遵守最左匹配原则;
-- 在索引列上进行计算、函数、类型转换等操作;
-- 以 `%` 开头的 LIKE 查询比如 `like '%abc'`;
-- 查询条件中使用 or,且 or 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
-- 发生[隐式转换](./index-invalidation-caused-by-implicit-conversion.md);
-- ......
-
### 删除长期未使用的索引
删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗。
MySQL 5.7 可以通过查询 `sys` 库的 `schema_unused_indexes` 视图来查询哪些索引从未被使用。
-### 知道如何分析语句是否走索引查询
+### 知道如何分析 SQL 语句是否走索引查询
我们可以使用 `EXPLAIN` 命令来分析 SQL 的 **执行计划** ,这样就知道语句是否命中索引了。执行计划是指一条 SQL 语句在经过 MySQL 查询优化器的优化会后,具体的执行方式。
@@ -443,3 +566,5 @@ mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
| Extra | 附加信息 |
篇幅问题,我这里只是简单介绍了一下 MySQL 执行计划,详细介绍请看:[MySQL 执行计划分析](./mysql-query-execution-plan.md)这篇文章。
+
+
diff --git a/docs/database/mysql/mysql-logs.md b/docs/database/mysql/mysql-logs.md
index f3888285905..bc484746517 100644
--- a/docs/database/mysql/mysql-logs.md
+++ b/docs/database/mysql/mysql-logs.md
@@ -1,35 +1,40 @@
---
title: MySQL三大日志(binlog、redo log和undo log)详解
+description: 深入解析MySQL三大日志binlog、redo log和undo log的作用与原理,详解两阶段提交保证数据一致性的机制,以及日志在崩溃恢复和主从复制中的应用。
category: 数据库
tag:
- MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL日志,binlog,redo log,undo log,两阶段提交,崩溃恢复,主从复制,WAL,事务日志
---
> 本文来自公号程序猿阿星投稿,JavaGuide 对其做了补充完善。
## 前言
-`MySQL` 日志 主要包括错误日志、查询日志、慢查询日志、事务日志、二进制日志几大类。其中,比较重要的还要属二进制日志 `binlog`(归档日志)和事务日志 `redo log`(重做日志)和 `undo log`(回滚日志)。
+MySQL 日志 主要包括错误日志、查询日志、慢查询日志、事务日志、二进制日志几大类。其中,比较重要的还要属二进制日志 binlog(归档日志)和事务日志 redo log(重做日志)和 undo log(回滚日志)。
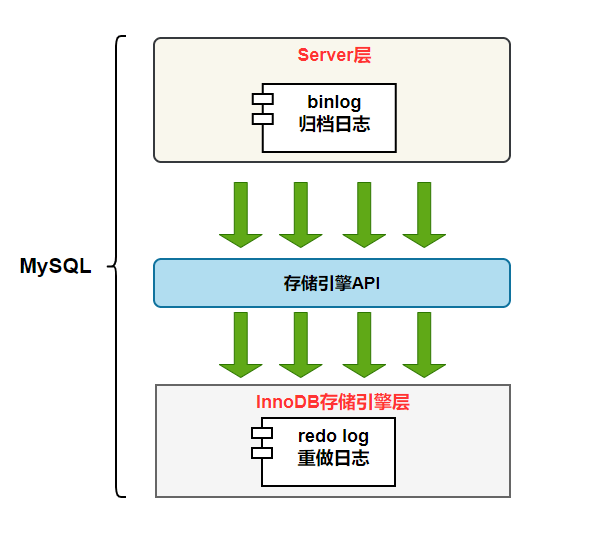
-今天就来聊聊 `redo log`(重做日志)、`binlog`(归档日志)、两阶段提交、`undo log` (回滚日志)。
+今天就来聊聊 redo log(重做日志)、binlog(归档日志)、两阶段提交、undo log(回滚日志)。
## redo log
-`redo log`(重做日志)是`InnoDB`存储引擎独有的,它让`MySQL`拥有了崩溃恢复能力。
+redo log(重做日志)是 InnoDB 存储引擎独有的,它让 MySQL 拥有了崩溃恢复能力。
-比如 `MySQL` 实例挂了或宕机了,重启时,`InnoDB`存储引擎会使用`redo log`恢复数据,保证数据的持久性与完整性。
+比如 MySQL 实例挂了或宕机了,重启时,InnoDB 存储引擎会使用 redo log 恢复数据,保证数据的持久性与完整性。
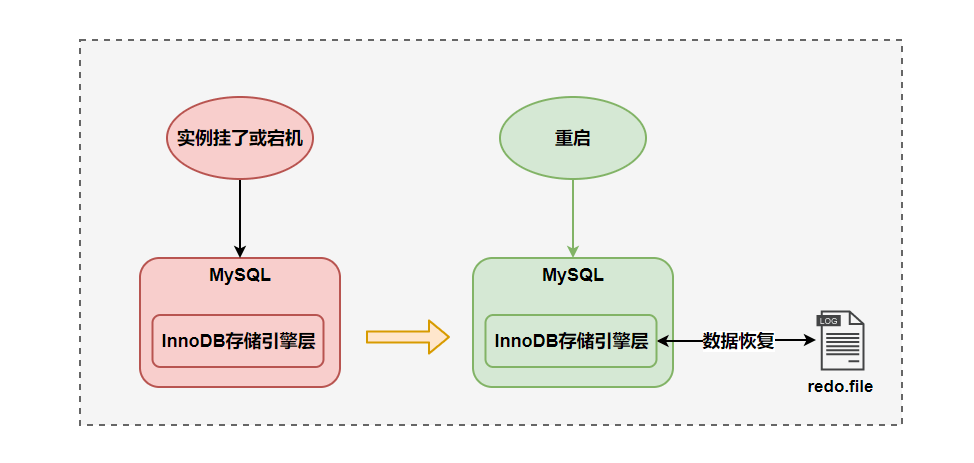
-`MySQL` 中数据是以页为单位,你查询一条记录,会从硬盘把一页的数据加载出来,加载出来的数据叫数据页,会放入到 `Buffer Pool` 中。
+MySQL 中数据是以页为单位,你查询一条记录,会从硬盘把一页的数据加载出来,加载出来的数据叫数据页,会放入到 `Buffer Pool` 中。
-后续的查询都是先从 `Buffer Pool` 中找,没有命中再去硬盘加载,减少硬盘 `IO` 开销,提升性能。
+后续的查询都是先从 `Buffer Pool` 中找,没有命中再去硬盘加载,减少硬盘 IO 开销,提升性能。
更新表数据的时候,也是如此,发现 `Buffer Pool` 里存在要更新的数据,就直接在 `Buffer Pool` 里更新。
-然后会把“在某个数据页上做了什么修改”记录到重做日志缓存(`redo log buffer`)里,接着刷盘到 `redo log` 文件里。
+然后会把“在某个数据页上做了什么修改”记录到重做日志缓存(`redo log buffer`)里,接着刷盘到 redo log 文件里。
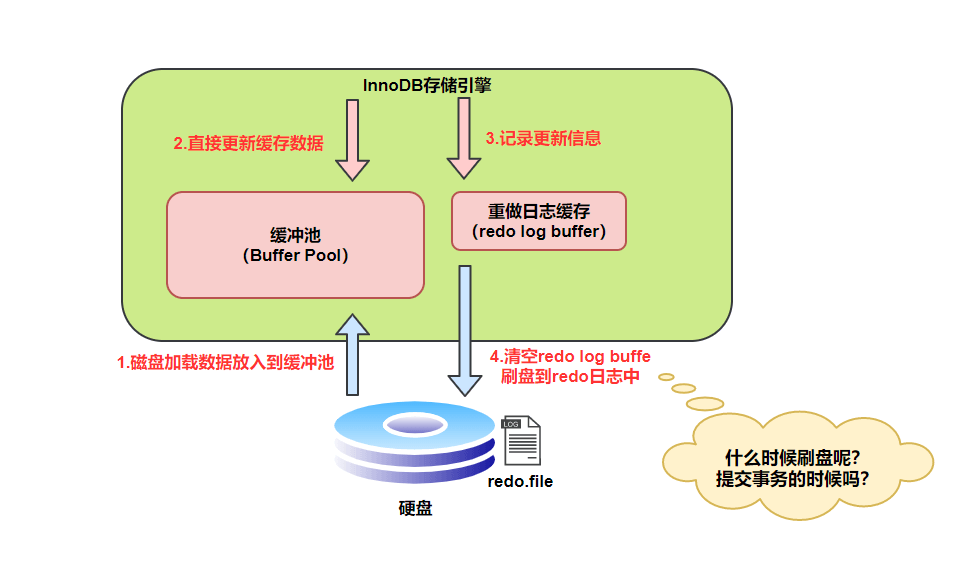
@@ -41,23 +46,38 @@ tag:
### 刷盘时机
-`InnoDB` 存储引擎为 `redo log` 的刷盘策略提供了 `innodb_flush_log_at_trx_commit` 参数,它支持三种策略:
+在 InnoDB 存储引擎中,**redo log buffer**(重做日志缓冲区)是一块用于暂存 redo log 的内存区域。为了确保事务的持久性和数据的一致性,InnoDB 会在特定时机将这块缓冲区中的日志数据刷新到磁盘上的 redo log 文件中。这些时机可以归纳为以下六种:
-- **0**:设置为 0 的时候,表示每次事务提交时不进行刷盘操作
-- **1**:设置为 1 的时候,表示每次事务提交时都将进行刷盘操作(默认值)
-- **2**:设置为 2 的时候,表示每次事务提交时都只把 redo log buffer 内容写入 page cache
+1. **事务提交时(最核心)**:当事务提交时,log buffer 里的 redo log 会被刷新到磁盘(可以通过`innodb_flush_log_at_trx_commit`参数控制,后文会提到)。
+2. **redo log buffer 空间不足时**:这是 InnoDB 的一种主动容量管理策略,旨在避免因缓冲区写满而导致用户线程阻塞。
+ - 当 redo log buffer 的已用空间超过其总容量的**一半 (50%)** 时,后台线程会**主动**将这部分日志刷新到磁盘,为后续的日志写入腾出空间,这是一种“未雨绸缪”的优化。
+ - 如果因为大事务或 I/O 繁忙导致 buffer 被**完全写满**,那么所有试图写入新日志的用户线程都会被**阻塞**,并强制进行一次同步刷盘,直到有可用空间为止。这种情况会影响数据库性能,应尽量避免。
+3. **触发检查点 (Checkpoint) 时**:Checkpoint 是 InnoDB 为了缩短崩溃恢复时间而设计的核心机制。当 Checkpoint 被触发时,InnoDB 需要将在此检查点之前的所有脏页刷写到磁盘。根据 **Write-Ahead Logging (WAL)** 原则,数据页写入磁盘前,其对应的 redo log 必须先落盘。因此,执行 Checkpoint 操作必然会确保相关的 redo log 也已经被刷新到了磁盘。
+4. **后台线程周期性刷新**:InnoDB 有一个后台的 master thread,它会大约每秒执行一次例行任务,其中就包括将 redo log buffer 中的日志刷新到磁盘。这个机制是 `innodb_flush_log_at_trx_commit` 设置为 0 或 2 时的主要持久化保障。
+5. **正常关闭服务器**:在 MySQL 服务器正常关闭的过程中,为了确保所有已提交事务的数据都被完整保存,InnoDB 会执行一次最终的刷盘操作,将 redo log buffer 中剩余的全部日志都清空并写入磁盘文件。
+6. **binlog 切换时**:当开启 binlog 后,在 MySQL 采用 `innodb_flush_log_at_trx_commit=1` 和 `sync_binlog=1` 的 双一配置下,为了保证 redo log 和 binlog 之间状态的一致性(用于崩溃恢复或主从复制),在 binlog 文件写满或者手动执行 flush logs 进行切换时,会触发 redo log 的刷盘动作。
-`innodb_flush_log_at_trx_commit` 参数默认为 1 ,也就是说当事务提交时会调用 `fsync` 对 redo log 进行刷盘
+总之,InnoDB 在多种情况下会刷新重做日志,以保证数据的持久性和一致性。
-另外,`InnoDB` 存储引擎有一个后台线程,每隔`1` 秒,就会把 `redo log buffer` 中的内容写到文件系统缓存(`page cache`),然后调用 `fsync` 刷盘。
+我们要注意设置正确的刷盘策略`innodb_flush_log_at_trx_commit` 。根据 MySQL 配置的刷盘策略的不同,MySQL 宕机之后可能会存在轻微的数据丢失问题。
+
+`innodb_flush_log_at_trx_commit` 的值有 3 种,也就是共有 3 种刷盘策略:
+
+- **0**:设置为 0 的时候,表示每次事务提交时不进行刷盘操作。这种方式性能最高,但是也最不安全,因为如果 MySQL 挂了或宕机了,可能会丢失最近 1 秒内的事务。
+- **1**:设置为 1 的时候,表示每次事务提交时都将进行刷盘操作。这种方式性能最低,但是也最安全,因为只要事务提交成功,redo log 记录就一定在磁盘里,不会有任何数据丢失。
+- **2**:设置为 2 的时候,表示每次事务提交时都只把 log buffer 里的 redo log 内容写入 page cache(文件系统缓存)。page cache 是专门用来缓存文件的,这里被缓存的文件就是 redo log 文件。这种方式的性能和安全性都介于前两者中间。
+
+刷盘策略`innodb_flush_log_at_trx_commit` 的默认值为 1,设置为 1 的时候才不会丢失任何数据。为了保证事务的持久性,我们必须将其设置为 1。
+
+另外,InnoDB 存储引擎有一个后台线程,每隔`1` 秒,就会把 `redo log buffer` 中的内容写到文件系统缓存(`page cache`),然后调用 `fsync` 刷盘。
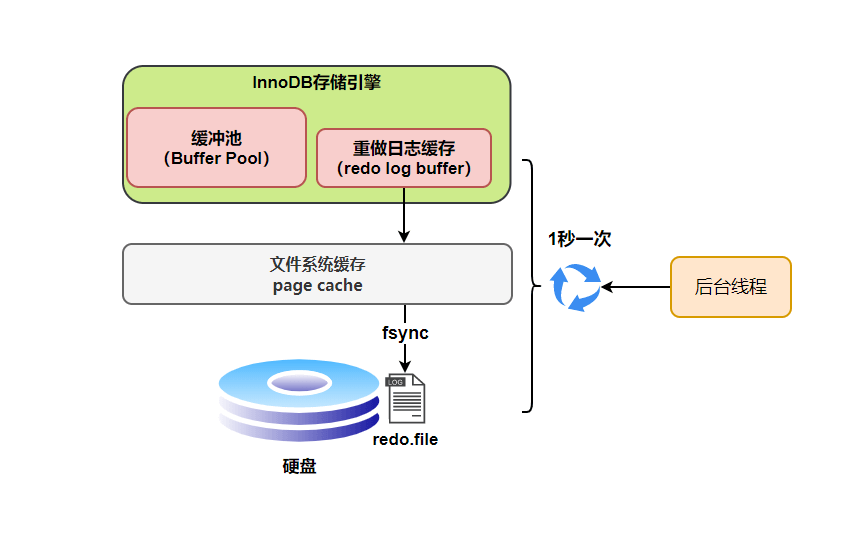
-也就是说,一个没有提交事务的 `redo log` 记录,也可能会刷盘。
+也就是说,一个没有提交事务的 redo log 记录,也可能会刷盘。
**为什么呢?**
-因为在事务执行过程 `redo log` 记录是会写入`redo log buffer` 中,这些 `redo log` 记录会被后台线程刷盘。
+因为在事务执行过程 redo log 记录是会写入`redo log buffer` 中,这些 redo log 记录会被后台线程刷盘。

@@ -69,15 +89,15 @@ tag:

-为`0`时,如果`MySQL`挂了或宕机可能会有`1`秒数据的丢失。
+为`0`时,如果 MySQL 挂了或宕机可能会有`1`秒数据的丢失。
#### innodb_flush_log_at_trx_commit=1
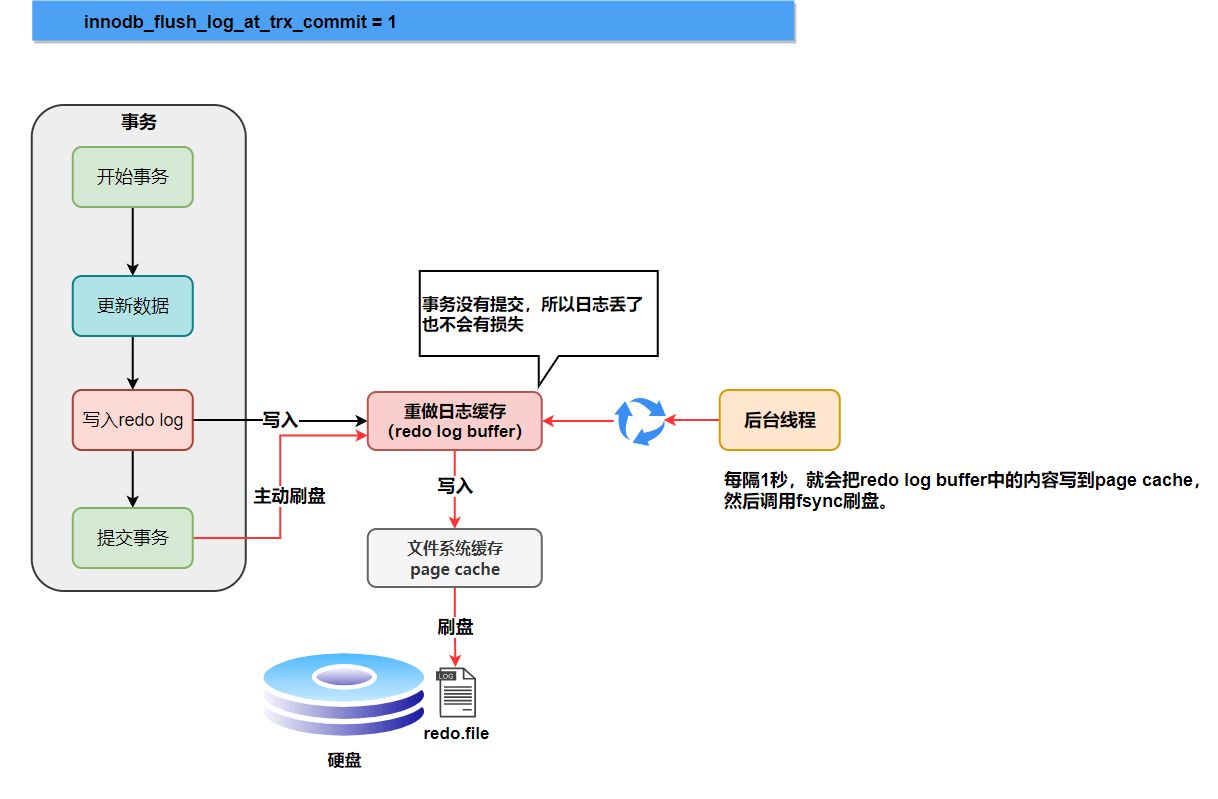
-为`1`时, 只要事务提交成功,`redo log`记录就一定在硬盘里,不会有任何数据丢失。
+为`1`时, 只要事务提交成功,redo log 记录就一定在硬盘里,不会有任何数据丢失。
-如果事务执行期间`MySQL`挂了或宕机,这部分日志丢了,但是事务并没有提交,所以日志丢了也不会有损失。
+如果事务执行期间 MySQL 挂了或宕机,这部分日志丢了,但是事务并没有提交,所以日志丢了也不会有损失。
#### innodb_flush_log_at_trx_commit=2
@@ -85,40 +105,81 @@ tag:
为`2`时, 只要事务提交成功,`redo log buffer`中的内容只写入文件系统缓存(`page cache`)。
-如果仅仅只是`MySQL`挂了不会有任何数据丢失,但是宕机可能会有`1`秒数据的丢失。
+如果仅仅只是 MySQL 挂了不会有任何数据丢失,但是宕机可能会有`1`秒数据的丢失。
### 日志文件组
-硬盘上存储的 `redo log` 日志文件不只一个,而是以一个**日志文件组**的形式出现的,每个的`redo`日志文件大小都是一样的。
+硬盘上存储的 redo log 日志文件不只一个,而是以一个**日志文件组**的形式出现的,每个的`redo`日志文件大小都是一样的。
-比如可以配置为一组`4`个文件,每个文件的大小是 `1GB`,整个 `redo log` 日志文件组可以记录`4G`的内容。
+比如可以配置为一组`4`个文件,每个文件的大小是 `1GB`,整个 redo log 日志文件组可以记录`4G`的内容。
它采用的是环形数组形式,从头开始写,写到末尾又回到头循环写,如下图所示。
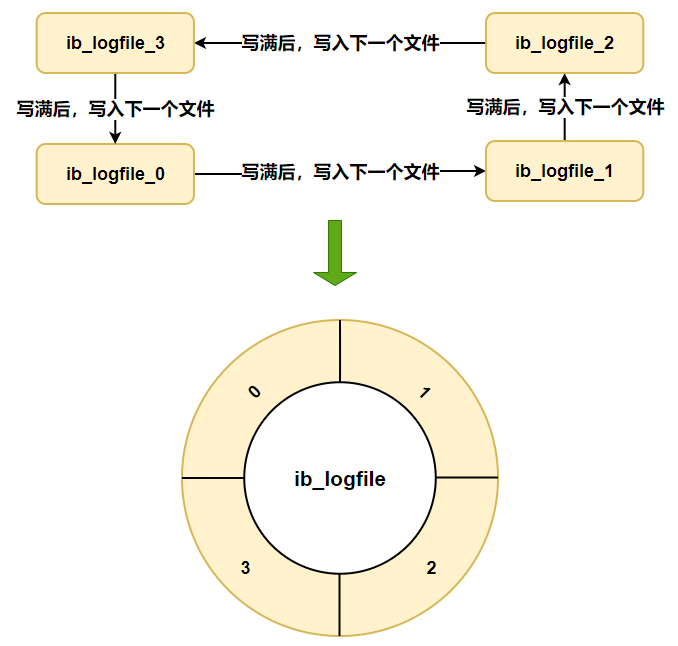
-在个**日志文件组**中还有两个重要的属性,分别是 `write pos、checkpoint`
+在这个**日志文件组**中还有两个重要的属性,分别是 `write pos、checkpoint`
- **write pos** 是当前记录的位置,一边写一边后移
- **checkpoint** 是当前要擦除的位置,也是往后推移
-每次刷盘 `redo log` 记录到**日志文件组**中,`write pos` 位置就会后移更新。
+每次刷盘 redo log 记录到**日志文件组**中,`write pos` 位置就会后移更新。
-每次 `MySQL` 加载**日志文件组**恢复数据时,会清空加载过的 `redo log` 记录,并把 `checkpoint` 后移更新。
+每次 MySQL 加载**日志文件组**恢复数据时,会清空加载过的 redo log 记录,并把 `checkpoint` 后移更新。
-`write pos` 和 `checkpoint` 之间的还空着的部分可以用来写入新的 `redo log` 记录。
+`write pos` 和 `checkpoint` 之间的还空着的部分可以用来写入新的 redo log 记录。
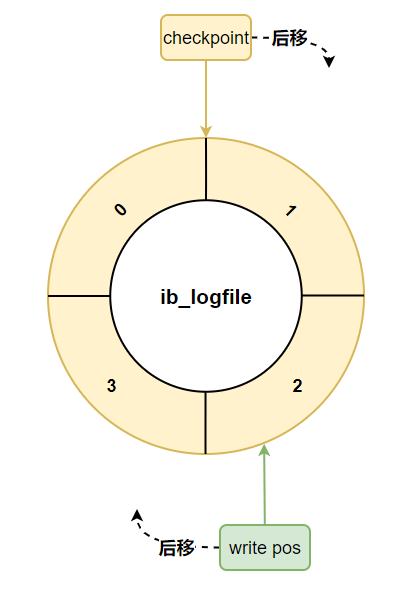
-如果 `write pos` 追上 `checkpoint` ,表示**日志文件组**满了,这时候不能再写入新的 `redo log` 记录,`MySQL` 得停下来,清空一些记录,把 `checkpoint` 推进一下。
+如果 `write pos` 追上 `checkpoint` ,表示**日志文件组**满了,这时候不能再写入新的 redo log 记录,MySQL 得停下来,清空一些记录,把 `checkpoint` 推进一下。

+注意从 MySQL 8.0.30 开始,日志文件组有了些许变化:
+
+> The innodb_redo_log_capacity variable supersedes the innodb_log_files_in_group and innodb_log_file_size variables, which are deprecated. When the innodb_redo_log_capacity setting is defined, the innodb_log_files_in_group and innodb_log_file_size settings are ignored; otherwise, these settings are used to compute the innodb_redo_log_capacity setting (innodb_log_files_in_group \* innodb_log_file_size = innodb_redo_log_capacity). If none of those variables are set, redo log capacity is set to the innodb_redo_log_capacity default value, which is 104857600 bytes (100MB). The maximum redo log capacity is 128GB.
+
+> Redo log files reside in the #innodb_redo directory in the data directory unless a different directory was specified by the innodb_log_group_home_dir variable. If innodb_log_group_home_dir was defined, the redo log files reside in the #innodb_redo directory in that directory. There are two types of redo log files, ordinary and spare. Ordinary redo log files are those being used. Spare redo log files are those waiting to be used. InnoDB tries to maintain 32 redo log files in total, with each file equal in size to 1/32 \* innodb_redo_log_capacity; however, file sizes may differ for a time after modifying the innodb_redo_log_capacity setting.
+
+意思是在 MySQL 8.0.30 之前可以通过 `innodb_log_files_in_group` 和 `innodb_log_file_size` 配置日志文件组的文件数和文件大小,但在 MySQL 8.0.30 及之后的版本中,这两个变量已被废弃,即使被指定也是用来计算 `innodb_redo_log_capacity` 的值。而日志文件组的文件数则固定为 32,文件大小则为 `innodb_redo_log_capacity / 32` 。
+
+关于这一点变化,我们可以验证一下。
+
+首先创建一个配置文件,里面配置一下 `innodb_log_files_in_group` 和 `innodb_log_file_size` 的值:
+
+```properties
+[mysqld]
+innodb_log_file_size = 10485760
+innodb_log_files_in_group = 64
+```
+
+docker 启动一个 MySQL 8.0.32 的容器:
+
+```bash
+docker run -d -p 3312:3309 -e MYSQL_ROOT_PASSWORD=your-password -v /path/to/your/conf:/etc/mysql/conf.d --name
+MySQL830 mysql:8.0.32
+```
+
+现在我们来看一下启动日志:
+
+```plain
+2023-08-03T02:05:11.720357Z 0 [Warning] [MY-013907] [InnoDB] Deprecated configuration parameters innodb_log_file_size and/or innodb_log_files_in_group have been used to compute innodb_redo_log_capacity=671088640. Please use innodb_redo_log_capacity instead.
+```
+
+这里也表明了 `innodb_log_files_in_group` 和 `innodb_log_file_size` 这两个变量是用来计算 `innodb_redo_log_capacity` ,且已经被废弃。
+
+我们再看下日志文件组的文件数是多少:
+
+
+
+可以看到刚好是 32 个,并且每个日志文件的大小是 `671088640 / 32 = 20971520`
+
+所以在使用 MySQL 8.0.30 及之后的版本时,推荐使用 `innodb_redo_log_capacity` 变量配置日志文件组
+
### redo log 小结
-相信大家都知道 `redo log` 的作用和它的刷盘时机、存储形式。
+相信大家都知道 redo log 的作用和它的刷盘时机、存储形式。
-现在我们来思考一个问题:**只要每次把修改后的数据页直接刷盘不就好了,还有 `redo log` 什么事?**
+现在我们来思考一个问题:**只要每次把修改后的数据页直接刷盘不就好了,还有 redo log 什么事?**
它们不都是刷盘么?差别在哪里?
@@ -134,32 +195,32 @@ tag:
而且数据页刷盘是随机写,因为一个数据页对应的位置可能在硬盘文件的随机位置,所以性能是很差。
-如果是写 `redo log`,一行记录可能就占几十 `Byte`,只包含表空间号、数据页号、磁盘文件偏移
+如果是写 redo log,一行记录可能就占几十 `Byte`,只包含表空间号、数据页号、磁盘文件偏移
量、更新值,再加上是顺序写,所以刷盘速度很快。
-所以用 `redo log` 形式记录修改内容,性能会远远超过刷数据页的方式,这也让数据库的并发能力更强。
+所以用 redo log 形式记录修改内容,性能会远远超过刷数据页的方式,这也让数据库的并发能力更强。
> 其实内存的数据页在一定时机也会刷盘,我们把这称为页合并,讲 `Buffer Pool`的时候会对这块细说
## binlog
-`redo log` 它是物理日志,记录内容是“在某个数据页上做了什么修改”,属于 `InnoDB` 存储引擎。
+redo log 它是物理日志,记录内容是“在某个数据页上做了什么修改”,属于 InnoDB 存储引擎。
-而 `binlog` 是逻辑日志,记录内容是语句的原始逻辑,类似于“给 ID=2 这一行的 c 字段加 1”,属于`MySQL Server` 层。
+而 binlog 是逻辑日志,记录内容是语句的原始逻辑,类似于“给 ID=2 这一行的 c 字段加 1”,属于`MySQL Server` 层。
-不管用什么存储引擎,只要发生了表数据更新,都会产生 `binlog` 日志。
+不管用什么存储引擎,只要发生了表数据更新,都会产生 binlog 日志。
-那 `binlog` 到底是用来干嘛的?
+那 binlog 到底是用来干嘛的?
-可以说`MySQL`数据库的**数据备份、主备、主主、主从**都离不开`binlog`,需要依靠`binlog`来同步数据,保证数据一致性。
+可以说 MySQL 数据库的**数据备份、主备、主主、主从**都离不开 binlog,需要依靠 binlog 来同步数据,保证数据一致性。
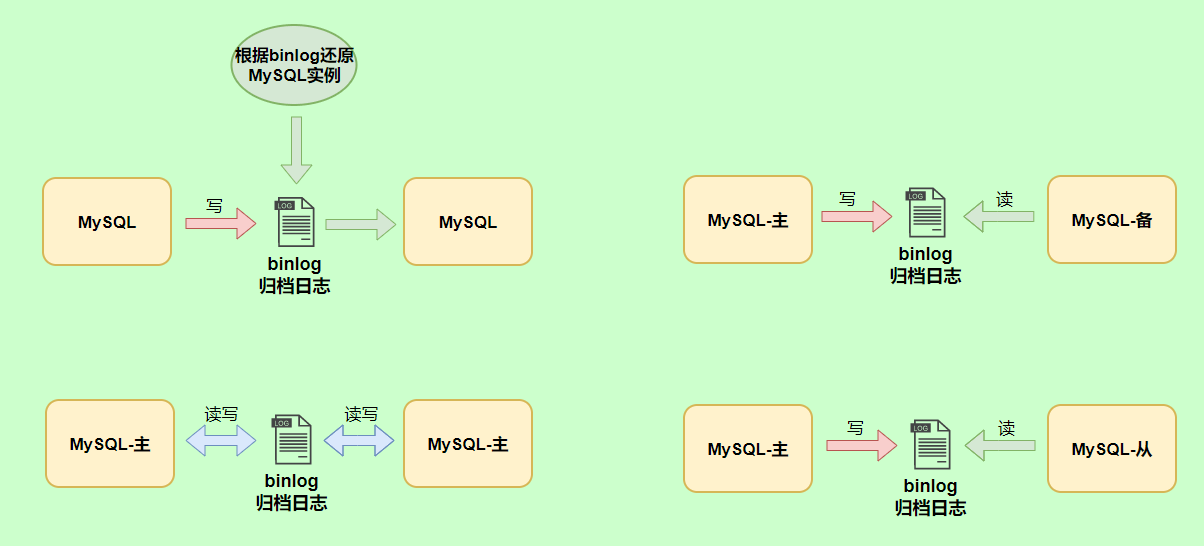
-`binlog`会记录所有涉及更新数据的逻辑操作,并且是顺序写。
+binlog 会记录所有涉及更新数据的逻辑操作,并且是顺序写。
### 记录格式
-`binlog` 日志有三种格式,可以通过`binlog_format`参数指定。
+binlog 日志有三种格式,可以通过`binlog_format`参数指定。
- **statement**
- **row**
@@ -181,28 +242,28 @@ tag:
这样就能保证同步数据的一致性,通常情况下都是指定为`row`,这样可以为数据库的恢复与同步带来更好的可靠性。
-但是这种格式,需要更大的容量来记录,比较占用空间,恢复与同步时会更消耗`IO`资源,影响执行速度。
+但是这种格式,需要更大的容量来记录,比较占用空间,恢复与同步时会更消耗 IO 资源,影响执行速度。
所以就有了一种折中的方案,指定为`mixed`,记录的内容是前两者的混合。
-`MySQL`会判断这条`SQL`语句是否可能引起数据不一致,如果是,就用`row`格式,否则就用`statement`格式。
+MySQL 会判断这条`SQL`语句是否可能引起数据不一致,如果是,就用`row`格式,否则就用`statement`格式。
### 写入机制
-`binlog`的写入时机也非常简单,事务执行过程中,先把日志写到`binlog cache`,事务提交的时候,再把`binlog cache`写到`binlog`文件中。
+binlog 的写入时机也非常简单,事务执行过程中,先把日志写到`binlog cache`,事务提交的时候,再把`binlog cache`写到 binlog 文件中。
-因为一个事务的`binlog`不能被拆开,无论这个事务多大,也要确保一次性写入,所以系统会给每个线程分配一个块内存作为`binlog cache`。
+因为一个事务的 binlog 不能被拆开,无论这个事务多大,也要确保一次性写入,所以系统会给每个线程分配一个块内存作为`binlog cache`。
我们可以通过`binlog_cache_size`参数控制单个线程 binlog cache 大小,如果存储内容超过了这个参数,就要暂存到磁盘(`Swap`)。
-`binlog`日志刷盘流程如下
+binlog 日志刷盘流程如下
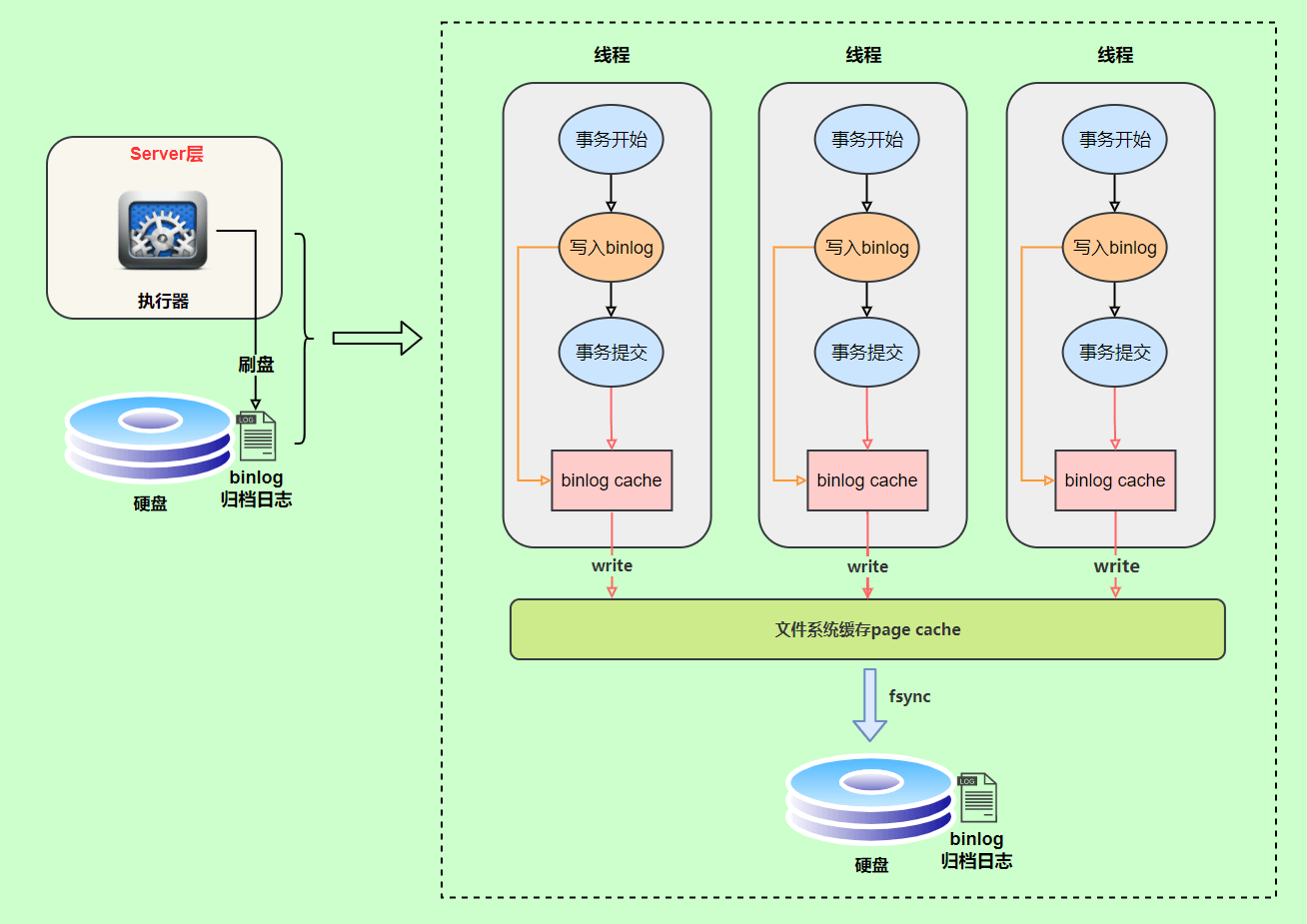
- **上图的 write,是指把日志写入到文件系统的 page cache,并没有把数据持久化到磁盘,所以速度比较快**
- **上图的 fsync,才是将数据持久化到磁盘的操作**
-`write`和`fsync`的时机,可以由参数`sync_binlog`控制,默认是`0`。
+`write`和`fsync`的时机,可以由参数`sync_binlog`控制,默认是`1`。
为`0`的时候,表示每次提交事务都只`write`,由系统自行判断什么时候执行`fsync`。
@@ -216,57 +277,63 @@ tag:
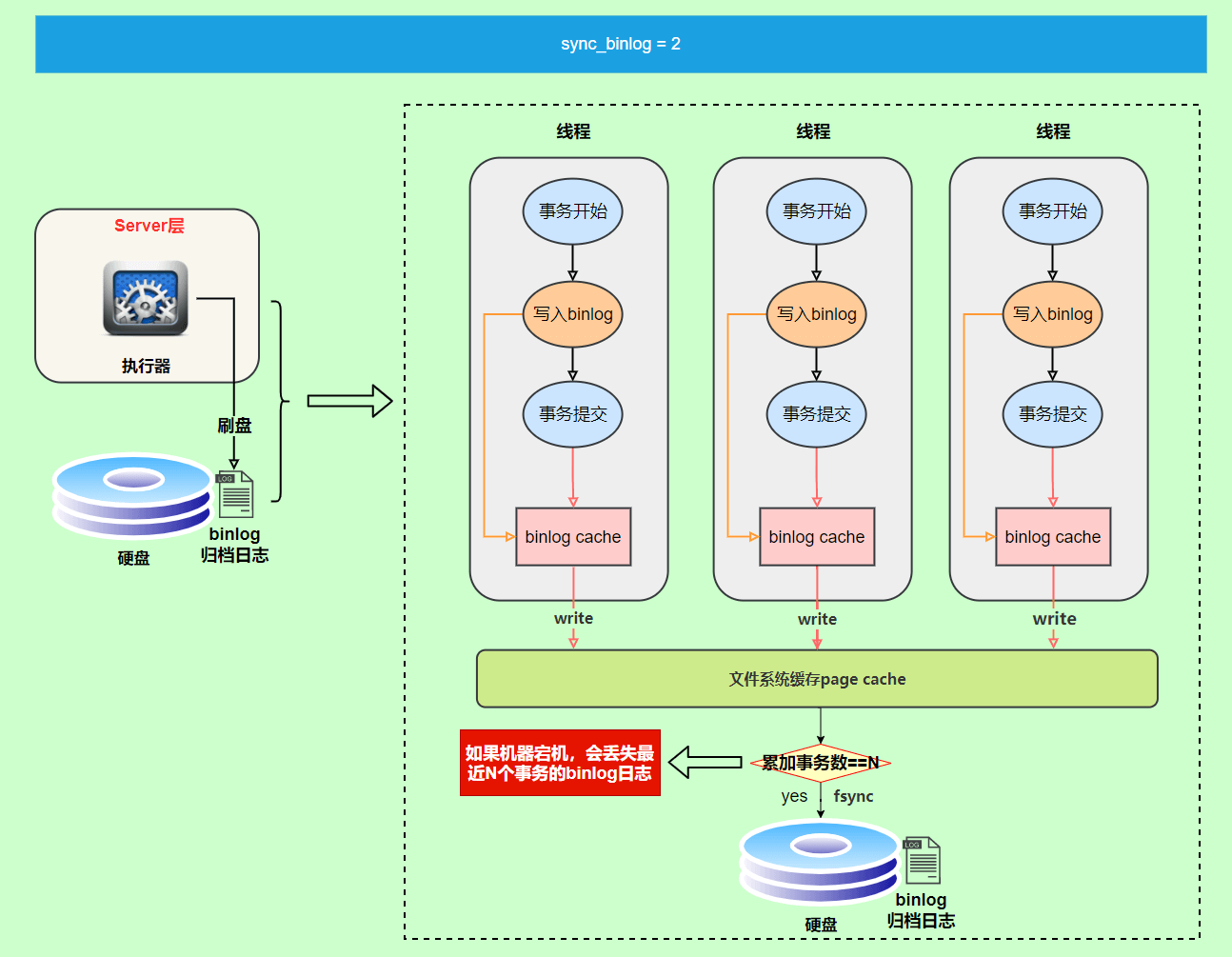
-在出现`IO`瓶颈的场景里,将`sync_binlog`设置成一个比较大的值,可以提升性能。
+在出现 IO 瓶颈的场景里,将`sync_binlog`设置成一个比较大的值,可以提升性能。
-同样的,如果机器宕机,会丢失最近`N`个事务的`binlog`日志。
+同样的,如果机器宕机,会丢失最近`N`个事务的 binlog 日志。
## 两阶段提交
-`redo log`(重做日志)让`InnoDB`存储引擎拥有了崩溃恢复能力。
+redo log(重做日志)让 InnoDB 存储引擎拥有了崩溃恢复能力。
-`binlog`(归档日志)保证了`MySQL`集群架构的数据一致性。
+binlog(归档日志)保证了 MySQL 集群架构的数据一致性。
虽然它们都属于持久化的保证,但是侧重点不同。
-在执行更新语句过程,会记录`redo log`与`binlog`两块日志,以基本的事务为单位,`redo log`在事务执行过程中可以不断写入,而`binlog`只有在提交事务时才写入,所以`redo log`与`binlog`的写入时机不一样。
+在执行更新语句过程,会记录 redo log 与 binlog 两块日志,以基本的事务为单位,redo log 在事务执行过程中可以不断写入,而 binlog 只有在提交事务时才写入,所以 redo log 与 binlog 的写入时机不一样。

-回到正题,`redo log`与`binlog`两份日志之间的逻辑不一致,会出现什么问题?
+回到正题,redo log 与 binlog 两份日志之间的逻辑不一致,会出现什么问题?
我们以`update`语句为例,假设`id=2`的记录,字段`c`值是`0`,把字段`c`值更新成`1`,`SQL`语句为`update T set c=1 where id=2`。
-假设执行过程中写完`redo log`日志后,`binlog`日志写期间发生了异常,会出现什么情况呢?
+假设执行过程中写完 redo log 日志后,binlog 日志写期间发生了异常,会出现什么情况呢?
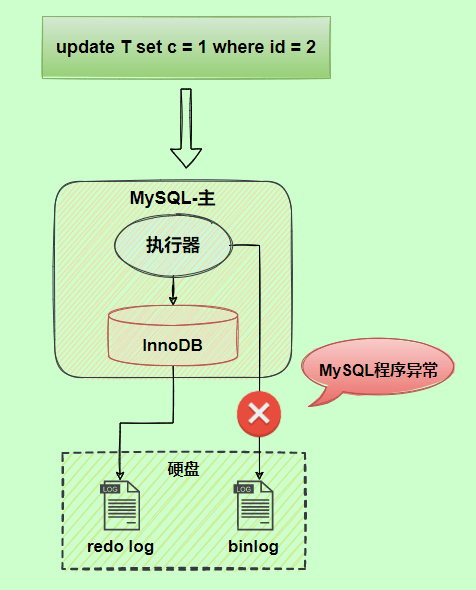
-由于`binlog`没写完就异常,这时候`binlog`里面没有对应的修改记录。因此,之后用`binlog`日志恢复数据时,就会少这一次更新,恢复出来的这一行`c`值是`0`,而原库因为`redo log`日志恢复,这一行`c`值是`1`,最终数据不一致。
+由于 binlog 没写完就异常,这时候 binlog 里面没有对应的修改记录。因此,之后用 binlog 日志恢复数据时,就会少这一次更新,恢复出来的这一行`c`值是`0`,而原库因为 redo log 日志恢复,这一行`c`值是`1`,最终数据不一致。
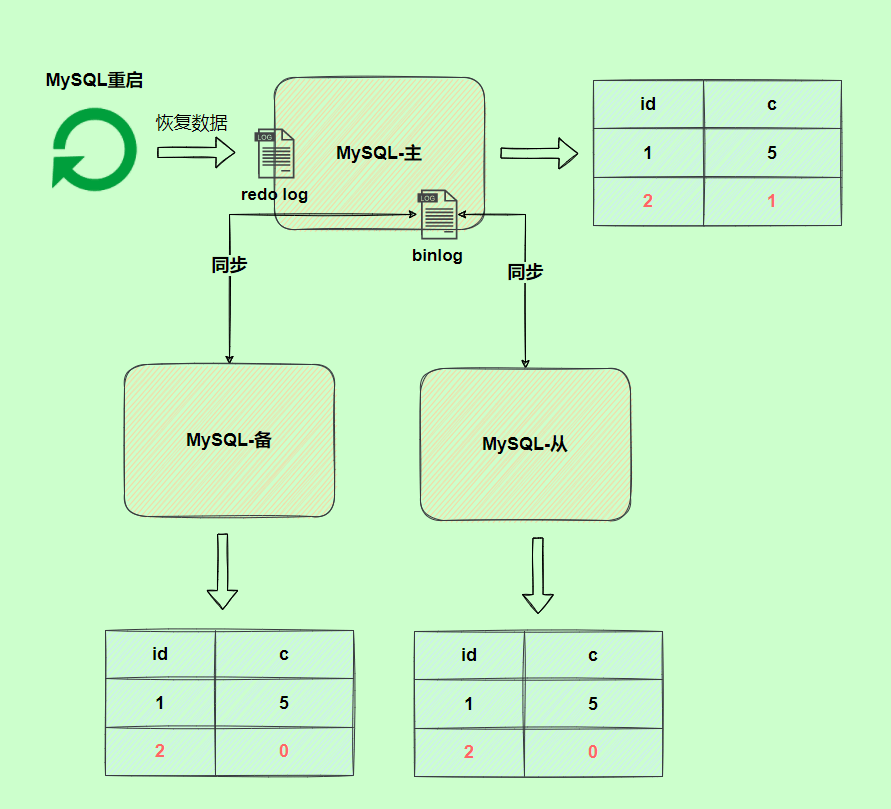
-为了解决两份日志之间的逻辑一致问题,`InnoDB`存储引擎使用**两阶段提交**方案。
+为了解决两份日志之间的逻辑一致问题,InnoDB 存储引擎使用**两阶段提交**方案。
-原理很简单,将`redo log`的写入拆成了两个步骤`prepare`和`commit`,这就是**两阶段提交**。
+原理很简单,将 redo log 的写入拆成了两个步骤`prepare`和`commit`,这就是**两阶段提交**。
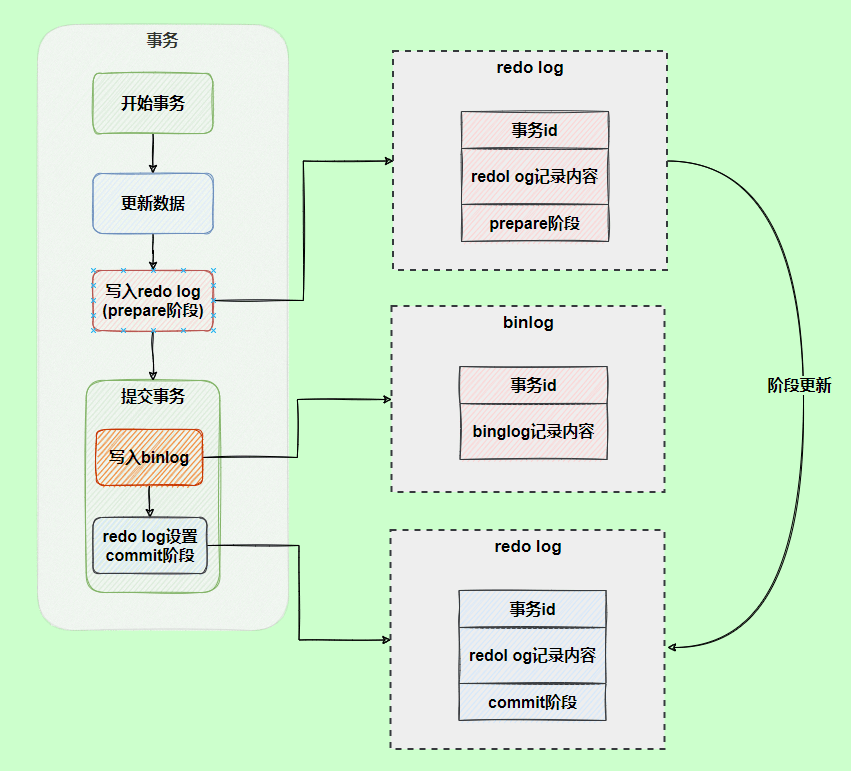
-使用**两阶段提交**后,写入`binlog`时发生异常也不会有影响,因为`MySQL`根据`redo log`日志恢复数据时,发现`redo log`还处于`prepare`阶段,并且没有对应`binlog`日志,就会回滚该事务。
+使用**两阶段提交**后,写入 binlog 时发生异常也不会有影响,因为 MySQL 根据 redo log 日志恢复数据时,发现 redo log 还处于`prepare`阶段,并且没有对应 binlog 日志,就会回滚该事务。
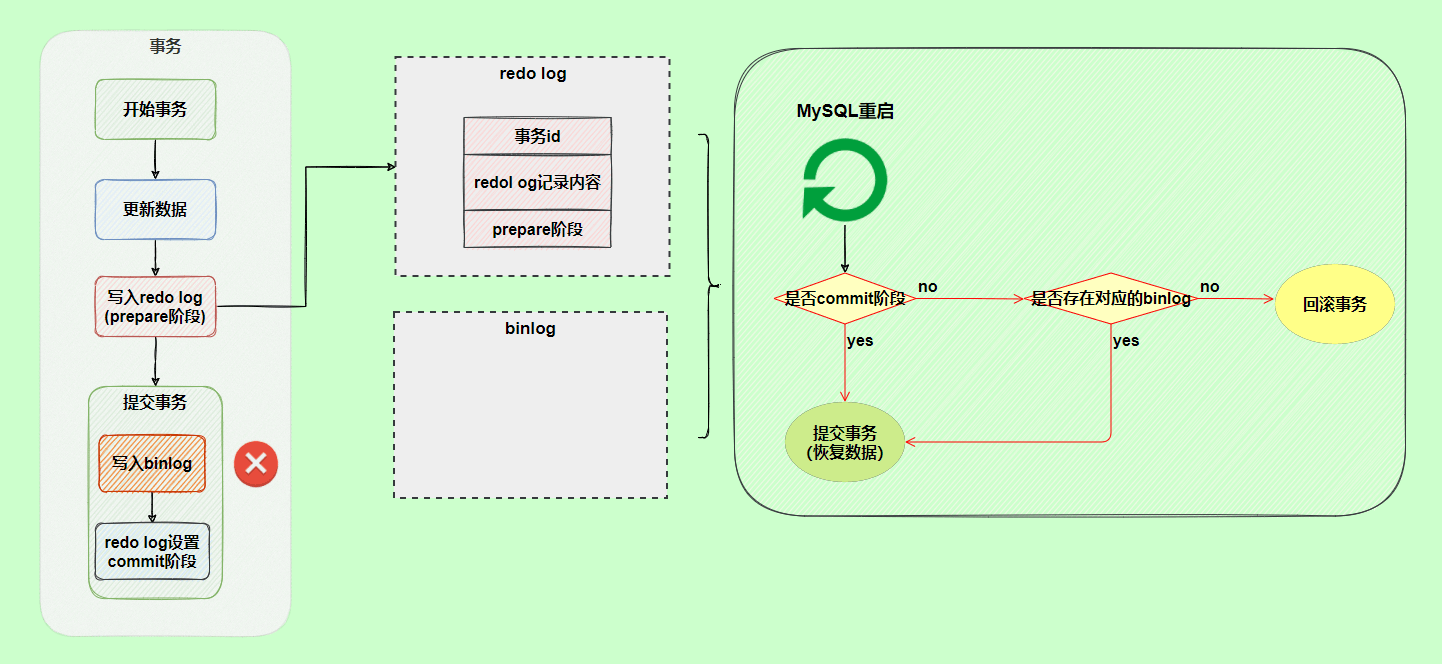
-再看一个场景,`redo log`设置`commit`阶段发生异常,那会不会回滚事务呢?
+再看一个场景,redo log 设置`commit`阶段发生异常,那会不会回滚事务呢?
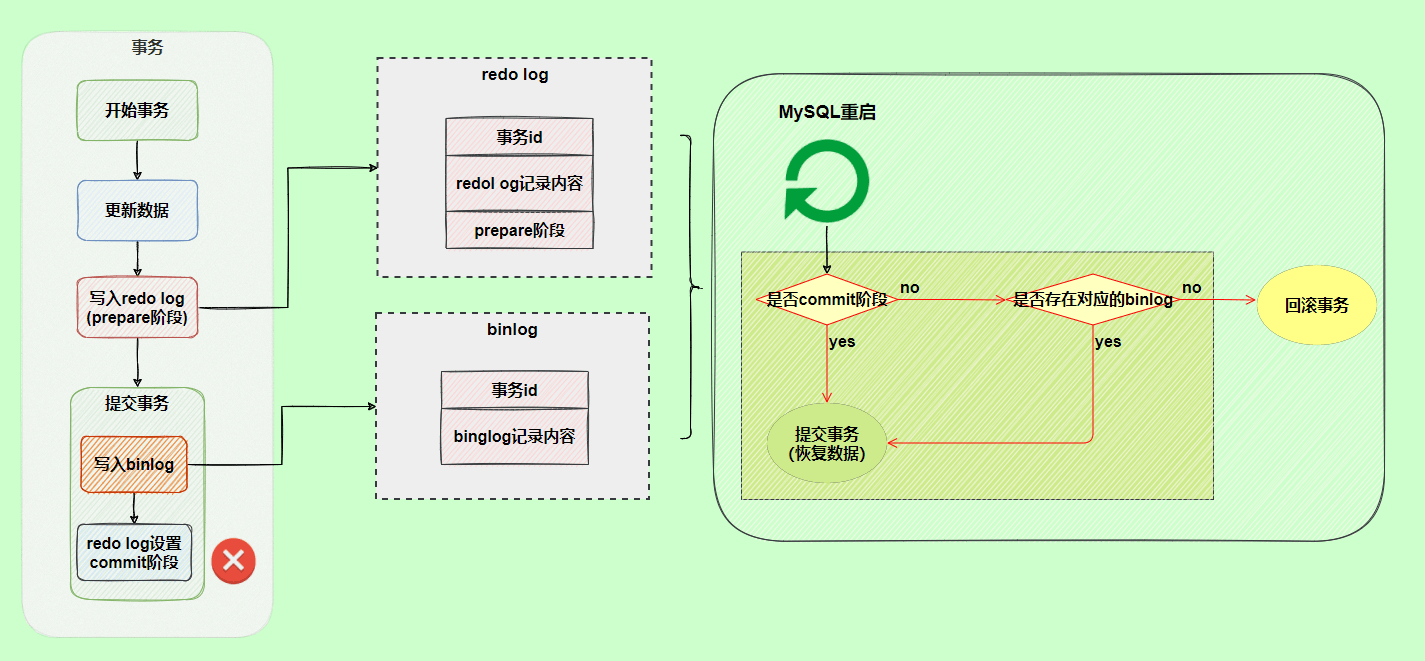
-并不会回滚事务,它会执行上图框住的逻辑,虽然`redo log`是处于`prepare`阶段,但是能通过事务`id`找到对应的`binlog`日志,所以`MySQL`认为是完整的,就会提交事务恢复数据。
+并不会回滚事务,它会执行上图框住的逻辑,虽然 redo log 是处于`prepare`阶段,但是能通过事务`id`找到对应的 binlog 日志,所以 MySQL 认为是完整的,就会提交事务恢复数据。
## undo log
> 这部分内容为 JavaGuide 的补充:
-我们知道如果想要保证事务的原子性,就需要在异常发生时,对已经执行的操作进行**回滚**,在 MySQL 中,恢复机制是通过 **回滚日志(undo log)** 实现的,所有事务进行的修改都会先记录到这个回滚日志中,然后再执行相关的操作。如果执行过程中遇到异常的话,我们直接利用 **回滚日志** 中的信息将数据回滚到修改之前的样子即可!并且,回滚日志会先于数据持久化到磁盘上。这样就保证了即使遇到数据库突然宕机等情况,当用户再次启动数据库的时候,数据库还能够通过查询回滚日志来回滚将之前未完成的事务。
+每一个事务对数据的修改都会被记录到 undo log ,当执行事务过程中出现错误或者需要执行回滚操作的话,MySQL 可以利用 undo log 将数据恢复到事务开始之前的状态。
+
+undo log 属于逻辑日志,记录的是 SQL 语句,比如说事务执行一条 DELETE 语句,那 undo log 就会记录一条相对应的 INSERT 语句。同时,undo log 的信息也会被记录到 redo log 中,因为 undo log 也要实现持久性保护。并且,undo-log 本身是会被删除清理的,例如 INSERT 操作,在事务提交之后就可以清除掉了;UPDATE/DELETE 操作在事务提交不会立即删除,会加入 history list,由后台线程 purge 进行清理。
-另外,`MVCC` 的实现依赖于:**隐藏字段、Read View、undo log**。在内部实现中,`InnoDB` 通过数据行的 `DB_TRX_ID` 和 `Read View` 来判断数据的可见性,如不可见,则通过数据行的 `DB_ROLL_PTR` 找到 `undo log` 中的历史版本。每个事务读到的数据版本可能是不一样的,在同一个事务中,用户只能看到该事务创建 `Read View` 之前已经提交的修改和该事务本身做的修改
+undo log 是采用 segment(段)的方式来记录的,每个 undo 操作在记录的时候占用一个 **undo log segment**(undo 日志段),undo log segment 包含在 **rollback segment**(回滚段)中。事务开始时,需要为其分配一个 rollback segment。每个 rollback segment 有 1024 个 undo log segment,这有助于管理多个并发事务的回滚需求。
+
+通常情况下, **rollback segment header**(通常在回滚段的第一个页)负责管理 rollback segment。rollback segment header 是 rollback segment 的一部分,通常在回滚段的第一个页。**history list** 是 rollback segment header 的一部分,它的主要作用是记录所有已经提交但还没有被清理(purge)的事务的 undo log。这个列表使得 purge 线程能够找到并清理那些不再需要的 undo log 记录。
+
+另外,`MVCC` 的实现依赖于:**隐藏字段、Read View、undo log**。在内部实现中,InnoDB 通过数据行的 `DB_TRX_ID` 和 `Read View` 来判断数据的可见性,如不可见,则通过数据行的 `DB_ROLL_PTR` 找到 undo log 中的历史版本。每个事务读到的数据版本可能是不一样的,在同一个事务中,用户只能看到该事务创建 `Read View` 之前已经提交的修改和该事务本身做的修改
## 总结
@@ -274,16 +341,13 @@ tag:
MySQL InnoDB 引擎使用 **redo log(重做日志)** 保证事务的**持久性**,使用 **undo log(回滚日志)** 来保证事务的**原子性**。
-`MySQL`数据库的**数据备份、主备、主主、主从**都离不开`binlog`,需要依靠`binlog`来同步数据,保证数据一致性。
+MySQL 数据库的**数据备份、主备、主主、主从**都离不开 binlog,需要依靠 binlog 来同步数据,保证数据一致性。
-## 站在巨人的肩膀上
+## 参考
- 《MySQL 实战 45 讲》
- 《从零开始带你成为 MySQL 实战优化高手》
- 《MySQL 是怎样运行的:从根儿上理解 MySQL》
- 《MySQL 技术 Innodb 存储引擎》
-## MySQL 好文推荐
-
-- [CURD 这么多年,你有了解过 MySQL 的架构设计吗?](https://mp.weixin.qq.com/s/R-1km7r0z3oWfwYQV8iiqA)
-- [浅谈 MySQL InnoDB 的内存组件](https://mp.weixin.qq.com/s/7Kab4IQsNcU_bZdbv_MuOg)
+
diff --git a/docs/database/mysql/mysql-query-cache.md b/docs/database/mysql/mysql-query-cache.md
index 760a197ab4a..f1241aef69e 100644
--- a/docs/database/mysql/mysql-query-cache.md
+++ b/docs/database/mysql/mysql-query-cache.md
@@ -1,18 +1,16 @@
---
title: MySQL查询缓存详解
+description: 深入解析MySQL查询缓存的工作原理、配置管理及其优缺点,分析为什么MySQL 8.0移除了查询缓存功能,以及生产环境中的最佳实践建议。
category: 数据库
tag:
- MySQL
head:
- - meta
- name: keywords
- content: MySQL查询缓存,MySQL缓存机制中的内存管理
- - - meta
- - name: description
- content: 为了提高完全相同的查询语句的响应速度,MySQL Server 会对查询语句进行 Hash 计算得到一个 Hash 值。MySQL Server 不会对 SQL 做任何处理,SQL 必须完全一致 Hash 值才会一样。得到 Hash 值之后,通过该 Hash 值到查询缓存中匹配该查询的结果。MySQL 中的查询缓存虽然能够提升数据库的查询性能,但是查询同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。
+ content: MySQL查询缓存,Query Cache,MySQL缓存机制,缓存失效,MySQL 8.0,查询性能优化,MySQL内存管理
---
-缓存是一个有效且实用的系统性能优化的手段,不论是操作系统还是各种软件和网站或多或少都用到了缓存。
+缓存是一个有效且实用的系统性能优化手段,无论是操作系统,还是各类应用软件与 Web 服务,均广泛采用了缓存机制。
然而,有经验的 DBA 都建议生产环境中把 MySQL 自带的 Query Cache(查询缓存)给关掉。而且,从 MySQL 5.7.20 开始,就已经默认弃用查询缓存了。在 MySQL 8.0 及之后,更是直接删除了查询缓存的功能。
@@ -75,14 +73,14 @@ mysql> show variables like '%query_cache%';
我们这里对 8.0 版本之前`show variables like '%query_cache%';`命令打印出来的信息进行解释。
-- **`have_query_cache`:** 该 MySQL Server 是否支持查询缓存,如果是 YES 表示支持,否则则是不支持。
+- **`have_query_cache`:** 该 MySQL Server 是否支持查询缓存,如果是 YES 表示支持,否则表示不支持。
- **`query_cache_limit`:** MySQL 查询缓存的最大查询结果,查询结果大于该值时不会被缓存。
-- **`query_cache_min_res_unit`:** 查询缓存分配的最小块的大小(字节)。当查询进行的时候,MySQL 把查询结果保存在查询缓存中,但如果要保存的结果比较大,超过 `query_cache_min_res_unit` 的值 ,这时候 MySQL 将一边检索结果,一边进行保存结果,也就是说,有可能在一次查询中,MySQL 要进行多次内存分配的操作。适当的调节 `query_cache_min_res_unit` 可以优化内存。
-- **`query_cache_size`:** 为缓存查询结果分配的内存的数量,单位是字节,且数值必须是 1024 的整数倍。默认值是 0,即禁用查询缓存。
+- **`query_cache_min_res_unit`:** 查询缓存分配的最小块的大小(字节)。当查询进行的时候,MySQL 把查询结果保存在查询缓存中,但如果要保存的结果比较大,超过 `query_cache_min_res_unit` 的值,此时 MySQL 将在检索结果的同时保存数据,也就是说,有可能在一次查询中,MySQL 要进行多次内存分配的操作。适当的调节 `query_cache_min_res_unit` 可以优化内存。
+- **`query_cache_size`:** 为缓存查询结果分配的内存的数量,单位是字节,且数值必须是 1024 的整数倍。MySQL 5.7 官方文档显示默认值为 `1048576`(1 MB),设置为 0 时禁用查询缓存。不同小版本的默认值存在差异,建议在配置文件中显式指定,不依赖默认行为。
- **`query_cache_type`:** 设置查询缓存类型,默认为 ON。设置 GLOBAL 值可以设置后面的所有客户端连接的类型。客户端可以设置 SESSION 值以影响他们自己对查询缓存的使用。
-- **`query_cache_wlock_invalidate`**:如果某个表被锁住,是否返回缓存中的数据,默认关闭,也是建议的。
+- **`query_cache_wlock_invalidate`**:如果某个表被锁住,是否返回缓存中的数据,默认处于关闭状态,生产环境通常建议保持此默认配置。
-`query_cache_type` 可能的值(修改 `query_cache_type` 需要重启 MySQL Server):
+`query_cache_type` 可能的值(`query_cache_type` 在 MySQL 5.6/5.7 中是动态变量,**但有前提**:若实例启动时 `query_cache_type=0`,服务器会跳过查询缓存互斥锁的分配,此时通过 `SET GLOBAL` 动态修改将报错,必须修改配置文件并重启;若启动时非 0,则可通过 `SET GLOBAL query_cache_type=N` 在线生效,无需重启):
- 0 或 OFF:关闭查询功能。
- 1 或 ON:开启查询缓存功能,但不缓存 `Select SQL_NO_CACHE` 开头的查询。
@@ -90,45 +88,45 @@ mysql> show variables like '%query_cache%';
**建议**:
-- `query_cache_size`不建议设置的过大。过大的空间不但挤占实例其他内存结构的空间,而且会增加在缓存中搜索的开销。建议根据实例规格,初始值设置为 10MB 到 100MB 之间的值,而后根据运行使用情况调整。
-- 建议通过调整 `query_cache_size` 的值来开启、关闭查询缓存,因为修改`query_cache_type` 参数需要重启 MySQL Server 生效。
+- `query_cache_size` 不建议设置得过大。过大的空间不但挤占实例其他内存结构的空间,而且会增加在缓存中搜索的开销。建议根据实例规格,初始值设置为 10MB 到 100MB 之间的值,而后根据运行使用情况调整。
+- 建议通过将 `query_cache_size` 设置为 0 来禁用查询缓存,而非仅依赖 `query_cache_type`。两者虽都是动态变量,但 `query_cache_size=0` 会完全跳过缓存内存分配和检查路径,禁用更彻底。
8.0 版本之前,`my.cnf` 加入以下配置,重启 MySQL 开启查询缓存
```properties
query_cache_type=1
-query_cache_size=600000
+query_cache_size=614400
```
-或者,MySQL 执行以下命令也可以开启查询缓存
+或者,当实例启动时 `query_cache_type` 非 0 的情况下,也可以通过以下命令在线开启查询缓存(若启动值为 0 则该命令会报错,需修改配置文件后重启):
-```properties
-set global query_cache_type=1;
-set global query_cache_size=600000;
+```sql
+set global query_cache_type=1;
+set global query_cache_size=614400;
```
手动清理缓存可以使用下面三个 SQL:
- `flush query cache;`:清理查询缓存内存碎片。
- `reset query cache;`:从查询缓存中移除所有查询。
-- `flush tables;` 关闭所有打开的表,同时该操作会清空查询缓存中的内容。
+- `flush tables;` 关闭所有打开的表,同时该操作会清空查询缓存中的内容。
## MySQL 缓存机制
### 缓存规则
-- 查询缓存会将查询语句和结果集保存到内存(一般是 key-value 的形式,key 是查询语句,value 是查询的结果集),下次再查直接从内存中取。
+- 查询缓存会将查询语句和结果集保存到内存(一般是 key-value 的形式,其中 Key 是由查询语句文本、当前所在的 Database、客户端字符集以及协议版本等环境参数共同计算生成的 Hash 值,Value 则是查询的结果集),下次再查直接从内存中取。
- 缓存的结果是通过 sessions 共享的,所以一个 client 查询的缓存结果,另一个 client 也可以使用。
-- SQL 必须完全一致才会导致查询缓存命中(大小写、空格、使用的数据库、协议版本、字符集等必须一致)。检查查询缓存时,MySQL Server 不会对 SQL 做任何处理,它精确的使用客户端传来的查询。
+- SQL 必须完全一致才会导致查询缓存命中(大小写、空格、使用的数据库、协议版本、字符集等必须一致)。检查查询缓存时,MySQL Server 不会对 SQL 做任何处理,它精确地使用客户端传来的查询。
- 不缓存查询中的子查询结果集,仅缓存查询最终结果集。
- 不确定的函数将永远不会被缓存, 比如 `now()`、`curdate()`、`last_insert_id()`、`rand()` 等。
- 不缓存产生告警(Warnings)的查询。
-- 太大的结果集不会被缓存 (< query_cache_limit)。
+- 结果集超过 `query_cache_limit`(默认 1 MB)时不会被缓存。
- 如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL 库中的系统表,其查询结果也不会被缓存。
- 缓存建立之后,MySQL 的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
-- MySQL 缓存在分库分表环境下是不起作用的。
+- MySQL 缓存在分库分表环境下几乎不起作用。原因在于:查询通常经由中间件(如 ShardingSphere、MyCat)路由到不同的 MySQL 实例,各实例维护各自独立的 Query Cache;中间件在路由时往往会改写 SQL(添加分片键条件等),导致改写后的语句与原始语句 Hash 值不一致,缓存无法命中。
- 不缓存使用 `SQL_NO_CACHE` 的查询。
-- ......
+- ……
查询缓存 `SELECT` 选项示例:
@@ -143,22 +141,22 @@ SELECT SQL_NO_CACHE id, name FROM customer;# 不会缓存
MySQL 查询缓存使用内存池技术,自己管理内存释放和分配,而不是通过操作系统。内存池使用的基本单位是变长的 block, 用来存储类型、大小、数据等信息。一个结果集的缓存通过链表把这些 block 串起来。block 最短长度为 `query_cache_min_res_unit`。
-当服务器启动的时候,会初始化缓存需要的内存,是一个完整的空闲块。当查询结果需要缓存的时候,先从空闲块中申请一个数据块为参数 `query_cache_min_res_unit` 配置的空间,即使缓存数据很小,申请数据块也是这个,因为查询开始返回结果的时候就分配空间,此时无法预知结果多大。
+当服务器启动的时候,会初始化缓存需要的内存,是一个完整的空闲块。当查询开始返回结果时,由于此时无法预知完整的结果集有多大,MySQL 会先向内存池申请一个大小为 `query_cache_min_res_unit` 的基础数据块。如果结果集超出该块容量,则会在生成结果的过程中持续按需申请新的数据块,并将其通过链表拼接起来。
分配内存块需要先锁住空间块,所以操作很慢,MySQL 会尽量避免这个操作,选择尽可能小的内存块,如果不够,继续申请,如果存储完时有空余则释放多余的。
-但是如果并发的操作,余下的需要回收的空间很小,小于 `query_cache_min_res_unit`,不能再次被使用,就会产生碎片。
+随着并发读写的进行,不同大小的缓存块被无序且随机地释放,加上分配时剩余的微小空间(小于 `query_cache_min_res_unit`)无法被复用,内存池中会迅速产生大量不连续的空闲内存块(类似操作系统层面的外部碎片),进而触发更频繁的内存整理消耗。
## MySQL 查询缓存的优缺点
**优点:**
- 查询缓存的查询,发生在 MySQL 接收到客户端的查询请求、查询权限验证之后和查询 SQL 解析之前。也就是说,当 MySQL 接收到客户端的查询 SQL 之后,仅仅只需要对其进行相应的权限验证之后,就会通过查询缓存来查找结果,甚至都不需要经过 Optimizer 模块进行执行计划的分析优化,更不需要发生任何存储引擎的交互。
-- 由于查询缓存是基于内存的,直接从内存中返回相应的查询结果,因此减少了大量的磁盘 I/O 和 CPU 计算,导致效率非常高。
+- 由于查询缓存是基于内存的,直接从内存中返回相应的查询结果,因此减少了大量的磁盘 I/O 和 CPU 计算。**但此优势仅在低并发且读多写少的静态场景下成立**;在多核高并发环境下,`LOCK_query_cache` 全局互斥锁的激烈竞争会导致大量线程处于等锁状态(可通过 `SHOW PROCESSLIST` 看到 `Waiting for query cache lock`),实际 TPS/QPS 反而大幅下降。
**缺点:**
-- MySQL 会对每条接收到的 SELECT 类型的查询进行 Hash 计算,然后查找这个查询的缓存结果是否存在。虽然 Hash 计算和查找的效率已经足够高了,一条查询语句所带来的开销可以忽略,但一旦涉及到高并发,有成千上万条查询语句时,hash 计算和查找所带来的开销就必须重视了。
+- MySQL 会对每条接收到的 SELECT 类型的查询进行 Hash 计算,然后查找这个查询的缓存结果是否存在。虽然 Hash 计算和查找本身的 CPU 开销微乎其微,但 Query Cache 底层依赖单一全局互斥锁(`LOCK_query_cache`)来保证并发安全。一旦涉及到高并发,成千上万条查询语句同时争抢该互斥锁进行缓存检查或写入,极其激烈的锁冲突和线程上下文切换开销将成为致命的性能瓶颈。
- 查询缓存的失效问题。如果表的变更比较频繁,则会造成查询缓存的失效率非常高。表的变更不仅仅指表中的数据发生变化,还包括表结构或者索引的任何变化。
- 查询语句不同,但查询结果相同的查询都会被缓存,这样便会造成内存资源的过度消耗。查询语句的字符大小写、空格或者注释的不同,查询缓存都会认为是不同的查询(因为他们的 Hash 值会不同)。
- 相关系统变量设置不合理会造成大量的内存碎片,这样便会导致查询缓存频繁清理内存。
@@ -167,14 +165,38 @@ MySQL 查询缓存使用内存池技术,自己管理内存释放和分配,
在 MySQL Server 中打开查询缓存对数据库的读和写都会带来额外的消耗:
-- 读查询开始之前必须检查是否命中缓存。
-- 如果读查询可以缓存,那么执行完查询操作后,会查询结果和查询语句写入缓存。
-- 当向某个表写入数据的时候,必须将这个表所有的缓存设置为失效,如果缓存空间很大,则消耗也会很大,可能使系统僵死一段时间,因为这个操作是靠全局锁操作来保护的。
-- 对 InnoDB 表,当修改一个表时,设置了缓存失效,但是多版本特性会暂时将这修改对其他事务屏蔽,在这个事务提交之前,所有查询都无法使用缓存,直到这个事务被提交,所以长时间的事务,会大大降低查询缓存的命中。
+- **读操作需持锁检查**:读查询开始前必须检查缓存命中,这需要获取 `LOCK_query_cache` 共享锁。高并发下,大量读请求同时争抢锁会形成排队。
+- **缓存写入开销**:若读查询可缓存,执行后需将结果写入缓存,涉及内存分配和链表拼接操作,同样需要持有锁。
+- **写操作触发全局失效**:向表写入数据时,必须使该表所有缓存失效。这需要获取独占锁扫描整个缓存区,`query_cache_size` 越大持锁时间越长。Query Cache 的单一全局互斥锁设计导致写操作会阻塞所有其他读写请求,这也是 MySQL 8.0 移除它的首要原因。
+- **InnoDB 长事务加剧问题**:MVCC 特性下,事务提交前相关缓存无法使用。长事务不仅降低缓存命中率,写操作触发的独占锁还会阻塞对**其他不相关表**的缓存读取。
+
+可以通过以下命令查看查询缓存的使用情况,判断是否值得开启:
+
+```sql
+SHOW STATUS LIKE 'Qcache%';
+```
+
+关键指标说明:
+
+| 状态变量 | 含义 |
+| :--------------------- | :----------------------------------------------------------------- |
+| `Qcache_hits` | 缓存命中次数 |
+| `Qcache_inserts` | 写入缓存的查询次数 |
+| `Qcache_not_cached` | 未被缓存的查询次数(不可缓存或未命中) |
+| `Qcache_lowmem_prunes` | 因内存不足而被淘汰的缓存条目数,持续升高说明缓存空间不足或碎片严重 |
+| `Qcache_free_memory` | 缓存剩余空闲内存(字节) |
+
+命中率参考公式:
+
+```
+命中率 = Qcache_hits / (Qcache_hits + Qcache_inserts + Qcache_not_cached)
+```
+
+若命中率长期低于 50%,说明工作负载不适合 Query Cache,建议关闭。此外,还需关注 `Qcache_lowmem_prunes` 与 `Qcache_inserts` 的比值:若比值极高,意味着刚写入缓存的数据很快因内存碎片或空间不足被剔除,此时开启缓存是纯负收益。`Qcache_lowmem_prunes` 持续增长时,可执行 `FLUSH QUERY CACHE` 整理内存碎片,或适当降低 `query_cache_min_res_unit` 的值。
## 总结
-MySQL 中的查询缓存虽然能够提升数据库的查询性能,但是查询同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。
+MySQL 中的查询缓存虽然能够提升数据库的查询性能,但查询缓存机制本身也引入了额外的管理开销,每次查询后都要做一次缓存操作,失效后还要销毁。
查询缓存是一个适用较少情况的缓存机制。如果你的应用对数据库的更新很少,那么查询缓存将会作用显著。比较典型的如博客系统,一般博客更新相对较慢,数据表相对稳定不变,这时候查询缓存的作用会比较明显。
@@ -184,7 +206,7 @@ MySQL 中的查询缓存虽然能够提升数据库的查询性能,但是查
- 查询(Select)重复度高。
- 查询结果集小于 1 MB。
-对于一个更新频繁的系统来说,查询缓存缓存的作用是很微小的,在某些情况下开启查询缓存会带来性能的下降。
+对于一个更新频繁的系统来说,查询缓存的作用是很微小的,在某些情况下开启查询缓存会带来性能的下降。
简单总结一下查询缓存不适用的场景:
@@ -204,3 +226,5 @@ MySQL 中的查询缓存虽然能够提升数据库的查询性能,但是查
- MySQL 缓存机制:
- RDS MySQL 查询缓存(Query Cache)的设置和使用 - 阿里元云数据库 RDS 文档:
- 8.10.3 The MySQL Query Cache - MySQL 官方文档:
+
+
diff --git a/docs/database/mysql/mysql-query-execution-plan.md b/docs/database/mysql/mysql-query-execution-plan.md
index 696fcbb407b..522b39516b1 100644
--- a/docs/database/mysql/mysql-query-execution-plan.md
+++ b/docs/database/mysql/mysql-query-execution-plan.md
@@ -1,24 +1,22 @@
---
title: MySQL执行计划分析
+description: 详解MySQL EXPLAIN执行计划的各列含义,包括id、select_type、type、key、rows、Extra等关键字段解读,帮助你分析SQL性能瓶颈并进行针对性优化。
category: 数据库
tag:
- MySQL
head:
- - meta
- name: keywords
- content: MySQL基础,MySQL执行计划,EXPLAIN,查询优化器
- - - meta
- - name: description
- content: 执行计划是指一条 SQL 语句在经过MySQL 查询优化器的优化会后,具体的执行方式。优化 SQL 的第一步应该是读懂 SQL 的执行计划。
+ content: MySQL执行计划,EXPLAIN,查询优化器,SQL性能分析,索引命中,type访问类型,Extra字段,慢查询优化
---
-> 本文来自公号 MySQL 技术,JavaGuide 对其做了补充完善。原文地址:https://mp.weixin.qq.com/s/d5OowNLtXBGEAbT31sSH4g
-
优化 SQL 的第一步应该是读懂 SQL 的执行计划。本篇文章,我们一起来学习下 MySQL `EXPLAIN` 执行计划相关知识。
+> **版本说明**:本文内容基于 MySQL 5.7+ 和 8.0+ 版本。`filtered` 和 `partitions` 列在 MySQL 5.7+ 可用,`EXPLAIN ANALYZE` 和 Hash Join 特性需要 MySQL 8.0.18+ 和 8.0.20+。
+
## 什么是执行计划?
-**执行计划** 是指一条 SQL 语句在经过 **MySQL 查询优化器** 的优化会后,具体的执行方式。
+**执行计划** 是指一条 SQL 语句在经过 **MySQL 查询优化器** 的优化后,具体的执行方式。
执行计划通常用于 SQL 性能分析、优化等场景。通过 `EXPLAIN` 的结果,可以了解到如数据表的查询顺序、数据查询操作的操作类型、哪些索引可以被命中、哪些索引实际会命中、每个数据表有多少行记录被查询等信息。
@@ -26,24 +24,71 @@ head:
MySQL 为我们提供了 `EXPLAIN` 命令,来获取执行计划的相关信息。
-需要注意的是,`EXPLAIN` 语句并不会真的去执行相关的语句,而是通过查询优化器对语句进行分析,找出最优的查询方案,并显示对应的信息。
+需要注意的是,标准 `EXPLAIN` 语句并不会真的去执行相关的语句,而是通过查询优化器对语句进行分析,找出最优的查询方案,并显示对应的信息。
+
+MySQL 8.0.18 引入了 `EXPLAIN ANALYZE`,它会**真正执行**查询并输出每个步骤的实际耗时与行数,比标准 `EXPLAIN` 的估算数据更可靠,适合在测试环境深度排查慢查询:
+
+```sql
+mysql> EXPLAIN ANALYZE SELECT * FROM users WHERE age = 25\G
+*************************** 1. row ***************************
+EXPLAIN: -> Covering index lookup on users using idx_age_score_name (age=25)
+(cost=1.52 rows=12) (actual time=0.0272..0.0344 rows=12 loops=1)
+```
+
+此外,`EXPLAIN FORMAT=JSON` 可以输出优化器的成本模型数据(`query_cost`),比表格形式更能反映各步骤的实际代价,在多表 JOIN 或子查询调优时尤为有用:
+
+```sql
+mysql> EXPLAIN FORMAT=JSON SELECT * FROM users WHERE age = 25\G
+*************************** 1. row ***************************
+EXPLAIN: {
+ "query_block": {
+ "select_id": 1,
+ "cost_info": {
+ "query_cost": "1.52"
+ },
+ "table": {
+ "table_name": "users",
+ "access_type": "ref",
+ "key": "idx_age_score_name",
+ "rows_examined_per_scan": 12,
+ "filtered": "100.00",
+ "using_index": true
+ }
+ }
+}
+```
`EXPLAIN` 执行计划支持 `SELECT`、`DELETE`、`INSERT`、`REPLACE` 以及 `UPDATE` 语句。我们一般多用于分析 `SELECT` 查询语句,使用起来非常简单,语法如下:
```sql
-EXPLAIN + SELECT 查询语句;
+EXPLAIN SELECT 查询语句;
```
我们简单来看下一条查询语句的执行计划:
+**示例 1:单表查询(使用索引)**
+
```sql
-mysql> explain SELECT * FROM dept_emp WHERE emp_no IN (SELECT emp_no FROM dept_emp GROUP BY emp_no HAVING COUNT(emp_no)>1);
-+----+-------------+----------+------------+-------+-----------------+---------+---------+------+--------+----------+-------------+
-| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
-+----+-------------+----------+------------+-------+-----------------+---------+---------+------+--------+----------+-------------+
-| 1 | PRIMARY | dept_emp | NULL | ALL | NULL | NULL | NULL | NULL | 331143 | 100.00 | Using where |
-| 2 | SUBQUERY | dept_emp | NULL | index | PRIMARY,dept_no | PRIMARY | 16 | NULL | 331143 | 100.00 | Using index |
-+----+-------------+----------+------------+-------+-----------------+---------+---------+------+--------+----------+-------------+
+-- 表结构:users(id, age, score, name, address),联合索引 idx_age_score_name(age, score, name)
+mysql> EXPLAIN SELECT * FROM users WHERE age = 25;
++----+-------------+-------+------------+------+---------------------+---------------------+---------+-------+------+----------+-------------+
+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
++----+-------------+-------+------------+------+---------------------+---------------------+---------+-------+------+----------+-------------+
+| 1 | SIMPLE | users | NULL | ref | idx_age_score_name | idx_age_score_name | 5 | const | 12 | 100.00 | Using index |
++----+-------------+-------+------------+------+---------------------+---------------------+---------+-------+------+----------+-------------+
+```
+
+**示例 2:UNION 查询(id 为 NULL 的场景)**
+
+```sql
+mysql> EXPLAIN SELECT * FROM users WHERE id = 1 UNION SELECT * FROM users WHERE id = 2;
++----+--------------+------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
++----+--------------+------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
+| 1 | PRIMARY | users | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+| 2 | UNION | users | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+| 3 | UNION RESULT | | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |
++----+--------------+------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
```
可以看到,执行计划结果中共有 12 列,各列代表的含义总结如下表:
@@ -69,9 +114,39 @@ mysql> explain SELECT * FROM dept_emp WHERE emp_no IN (SELECT emp_no FROM dept_e
### id
-SELECT 标识符,是查询中 SELECT 的序号,用来标识整个查询中 SELELCT 语句的顺序。
+`SELECT` 标识符,用于标识每个 `SELECT` 语句的执行顺序。
+
+`id` 列的解读规则:
+
+- **id 相同**:从上往下依次执行(通常出现在多表 JOIN 场景)
+- **id 不同**:id 值越大,执行优先级越高(子查询先于外层查询执行)
+- **id 为 NULL**:表示这是 UNION RESULT 或 DERIVED 表的结果集,不需要单独执行查询
-id 如果相同,从上往下依次执行。id 不同,id 值越大,执行优先级越高,如果行引用其他行的并集结果,则该值可以为 NULL。
+**示例**:
+
+```sql
+mysql> EXPLAIN SELECT * FROM users WHERE id = 1
+ -> UNION
+ -> SELECT * FROM users WHERE id = 2\G
+*************************** 1. row ***************************
+ id: 1
+ select_type: PRIMARY
+ table: users
+ type: const
+*************************** 2. row ***************************
+ id: 2
+ select_type: UNION
+ table: users
+ type: const
+*************************** 3. row ***************************
+ id: NULL
+ select_type: UNION RESULT
+ table:
+ type: ALL
+ Extra: Using temporary
+```
+
+第三行的 `id = NULL`,table = ``,表示这是前两个查询结果的合并。
### select_type
@@ -89,26 +164,50 @@ id 如果相同,从上往下依次执行。id 不同,id 值越大,执行
查询用到的表名,每行都有对应的表名,表名除了正常的表之外,也可能是以下列出的值:
- **``** : 本行引用了 id 为 M 和 N 的行的 UNION 结果;
-- **``** : 本行引用了 id 为 N 的表所产生的的派生表结果。派生表有可能产生自 FROM 语句中的子查询。 -**``** : 本行引用了 id 为 N 的表所产生的的物化子查询结果。
+- **``** : 本行引用了 id 为 N 的表所产生的派生表结果。派生表有可能产生自 FROM 语句中的子查询。
+- **``** : 本行引用了 id 为 N 的表所产生的物化子查询结果。
### type(重要)
-查询执行的类型,描述了查询是如何执行的。所有值的顺序从最优到最差排序为:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
+查询执行的类型,描述了查询是如何执行的。**从最优到最差的排序为**:
+
+`system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL`
+
+**性能判断经验法则**:
+
+- **优秀**(至少达到):`system`、`const`、`eq_ref`、`ref`、`range`
+- **需关注**:`index_merge`、`index`(全索引扫描,大数据量下仍有性能风险)
+- **需优化**:`ALL`(全表扫描)
+
+**注意**:此排序反映的是**单表访问效率**,不代表整体查询性能。例如 `type=ref` 配合大量回表,可能比 `type=index` 的覆盖索引更慢。
常见的几种类型具体含义如下:
-- **system**:如果表使用的引擎对于表行数统计是精确的(如:MyISAM),且表中只有一行记录的情况下,访问方法是 system ,是 const 的一种特例。
+- **system**:表中只有一行记录(或者是空表),且存储引擎能够精确统计行数。适用于 MyISAM、Memory、InnoDB(当表只有 1 行时,InnoDB 会优化为 const)等引擎。是 const 访问类型的特例。
- **const**:表中最多只有一行匹配的记录,一次查询就可以找到,常用于使用主键或唯一索引的所有字段作为查询条件。
-- **eq_ref**:当连表查询时,前一张表的行在当前这张表中只有一行与之对应。是除了 system 与 const 之外最好的 join 方式,常用于使用主键或唯一索引的所有字段作为连表条件。
-- **ref**:使用普通索引作为查询条件,查询结果可能找到多个符合条件的行。
-- **index_merge**:当查询条件使用了多个索引时,表示开启了 Index Merge 优化,此时执行计划中的 key 列列出了使用到的索引。
+- **eq_ref**:当连表查询时,前一张表的行在当前这张表中只有一行与之对应。是除了 system 与 const 之外最好的 join 方式,常用于使用主键或唯一非空索引的所有字段作为连表条件(严格保证一对一匹配)。
+- **ref**:使用普通索引作为查询条件,查询结果可能找到多个符合条件的行(与 eq_ref 的区别:一个驱动行可能匹配多个被驱动行)。
+- **index_merge**:当 WHERE 子句包含多个范围条件,且每个条件可以使用不同索引时,MySQL 会合并多个索引的扫描结果。key 列列出使用的索引,Extra 列显示合并算法:
+
+ - `Using union(...)`:对多个索引结果取并集(OR 条件)
+ - `Using sort_union(...)`:先对索引结果排序再取并集(OR 条件,索引列非有序)
+ - `Using intersection(...)`:对多个索引结果取交集(AND 条件)
+
+ **示例**:
+
+ ```sql
+ -- OR 条件触发 index merge union
+ EXPLAIN SELECT * FROM employees WHERE emp_no = 10001 OR dept_no = 'd001';
+ -- Extra: Using union(PRIMARY,dept_no_index)
+ ```
+
- **range**:对索引列进行范围查询,执行计划中的 key 列表示哪个索引被使用了。
-- **index**:查询遍历了整棵索引树,与 ALL 类似,只不过扫描的是索引,而索引一般在内存中,速度更快。
+- **index**:Full Index Scan,查询遍历了整棵索引树。与 ALL(全表扫描)类似,但通常开销更低:索引记录的体积远小于完整行数据,读取相同行数所需的 I/O 页数更少;若同时满足覆盖索引条件,还可避免回表。但在超大表(亿级以上)上,全索引扫描同样可能产生大量 I/O,不可因 type 级别高于 ALL 就忽视其代价。
- **ALL**:全表扫描。
### possible_keys
-possible_keys 列表示 MySQL 执行查询时可能用到的索引。如果这一列为 NULL ,则表示没有可能用到的索引;这种情况下,需要检查 WHERE 语句中所使用的的列,看是否可以通过给这些列中某个或多个添加索引的方法来提高查询性能。
+possible_keys 列表示 MySQL 执行查询时可能用到的索引。如果这一列为 NULL ,则表示没有可能用到的索引;这种情况下,需要检查 WHERE 语句中所使用的列,看是否可以通过给这些列中某个或多个添加索引的方法来提高查询性能。
### key(重要)
@@ -120,22 +219,68 @@ key_len 列表示 MySQL 实际使用的索引的最大长度;当使用到联
### rows
-rows 列表示根据表统计信息及选用情况,大致估算出找到所需的记录或所需读取的行数,数值越小越好。
+rows 列表示根据表统计信息及索引选用情况,**估算**出找到所需记录需要读取的行数,数值越小越好。
+
+需要注意的是,该值是估算值而非精确值。InnoDB 的统计信息基于对索引页的随机采样:
+
+- 采样页数由 `innodb_stats_persistent_sample_pages` 控制(默认 20 页)
+- 在表数据频繁变动或批量导入后,估算值与真实行数的偏差可能达到 10%~50% 甚至更大
+- **小表陷阱**:当表行数极少(如 < 100 行)时,优化器可能忽略索引而选择全表扫描,因为全表扫描的成本估算更低
+
+**验证方法**:
+
+```sql
+-- 执行计划估算行数
+mysql> EXPLAIN SELECT * FROM users WHERE age = 25\G
+rows: 12
+
+-- 实际行数(注意:在大表上慎用 COUNT(*))
+mysql> SELECT COUNT(*) FROM users WHERE age = 25;
++----------+
+| COUNT(*) |
++----------+
+| 12 |
++----------+
+```
+
+遇到执行计划与实际性能不符时,可以执行 `ANALYZE TABLE` 重新采样,再观察执行计划的变化。
+
+### filtered
+
+filtered 列表示存储引擎返回的数据在 Server 层经 WHERE 条件过滤后,**估算**留存的记录占比(百分比,0~100)。计算公式为:`filtered = (条件过滤后的行数 / 存储引擎返回的行数) × 100`。
+
+**解读规则**:
+
+- 当 `filtered = 100`:存储引擎返回的所有行都满足 WHERE 条件(理想情况)
+- 当 `filtered < 100`:部分行被 Server 层过滤掉,说明索引未能覆盖所有查询条件
+- **JOIN 场景**:优化器用 `rows × (filtered / 100)` 估算当前表传递给下一张表的行数(扇出)
+
+该字段在多表 JOIN 场景中尤为重要:扇出越大,驱动表需要匹配的被驱动表行数就越多。因此当 `filtered` 值很低时,说明过滤效率较好;而当 `rows` 很大且 `filtered` 又不高时,则是潜在性能瓶颈的信号,应优先考虑通过索引下推(ICP)或更合适的索引来减少扇出。
### Extra(重要)
这列包含了 MySQL 解析查询的额外信息,通过这些信息,可以更准确的理解 MySQL 到底是如何执行查询的。常见的值如下:
-- **Using filesort**:在排序时使用了外部的索引排序,没有用到表内索引进行排序。
+- **Using filesort**:MySQL 无法利用索引完成 ORDER BY 或 GROUP BY 的排序要求,需要在返回结果集后额外执行一次排序操作。当结果集大小在 `sort_buffer_size` 以内时,排序在内存中完成;超出则借助临时磁盘文件。"filesort" 是历史遗留名称,并不代表一定产生磁盘 I/O。
- **Using temporary**:MySQL 需要创建临时表来存储查询的结果,常见于 ORDER BY 和 GROUP BY。
- **Using index**:表明查询使用了覆盖索引,不用回表,查询效率非常高。
- **Using index condition**:表示查询优化器选择使用了索引条件下推这个特性。
-- **Using where**:表明查询使用了 WHERE 子句进行条件过滤。一般在没有使用到索引的时候会出现。
-- **Using join buffer (Block Nested Loop)**:连表查询的方式,表示当被驱动表的没有使用索引的时候,MySQL 会先将驱动表读出来放到 join buffer 中,再遍历被驱动表与驱动表进行查询。
+- **Using where**:MySQL Server 层对存储引擎返回的行应用了额外的 WHERE 条件过滤。即使已命中索引(如 `type=ref`),若索引只能满足部分查询条件,剩余条件仍需在 Server 层过滤,此时同样会出现 `Using where`。
+- **Using join buffer (Block Nested Loop)**:连表查询时,被驱动表未使用索引,MySQL 会先将驱动表数据读入 join buffer,再遍历被驱动表进行匹配(复杂度 O(N×M))。
+- **Using join buffer (hash join)**:MySQL 8.0.18 引入了 Hash Join 算法,**仅用于等值 JOIN**(如 `t1.id = t2.id`),8.0.20 起默认替代 BNL。Hash Join 复杂度为构建阶段 O(N) + 探测阶段 O(M),比 BNL 的 O(N×M) 更高效。
+
+ **例外场景**(仍会退回 BNL):
+
+ - 非等值 JOIN(如 `t1.id > t2.id`)
+ - JOIN 条件包含函数或表达式
+ - 被驱动表上有索引可用时(此时会使用 Index Nested Loop)
这里提醒下,当 Extra 列包含 Using filesort 或 Using temporary 时,MySQL 的性能可能会存在问题,需要尽可能避免。
## 参考
-- https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
-- https://juejin.cn/post/6953444668973514789
+-
+-
+-
+
+
diff --git a/docs/database/mysql/mysql-questions-01.md b/docs/database/mysql/mysql-questions-01.md
index db72c16eb59..0f7ecc08942 100644
--- a/docs/database/mysql/mysql-questions-01.md
+++ b/docs/database/mysql/mysql-questions-01.md
@@ -1,5 +1,6 @@
---
title: MySQL常见面试题总结
+description: MySQL高频面试题精讲:基础架构、InnoDB引擎、索引原理、B+树、事务ACID、MVCC、redo/undo/binlog日志、行锁/表锁、慢查询优化,一文速通大厂必考点!
category: 数据库
tag:
- MySQL
@@ -7,10 +8,7 @@ tag:
head:
- - meta
- name: keywords
- content: MySQL基础,MySQL基础架构,MySQL存储引擎,MySQL查询缓存,MySQL事务,MySQL锁等内容。
- - - meta
- - name: description
- content: 一篇文章总结MySQL常见的知识点和面试题,涵盖MySQL基础、MySQL基础架构、MySQL存储引擎、MySQL查询缓存、MySQL事务、MySQL锁等内容。
+ content: MySQL面试题,MySQL基础架构,InnoDB存储引擎,MySQL索引,B+树索引,事务隔离级别,redo log,undo log,binlog,MVCC,行级锁,慢查询优化
---
@@ -19,7 +17,7 @@ head:
### 什么是关系型数据库?
-顾名思义,关系型数据库(RDBMS,Relational Database Management System)就是一种建立在关系模型的基础上的数据库。关系模型表明了数据库中所存储的数据之间的联系(一对一、一对多、多对多)。
+顾名思义,关系型数据库(RDB,Relational Database)就是一种建立在关系模型的基础上的数据库。关系模型表明了数据库中所存储的数据之间的联系(一对一、一对多、多对多)。
关系型数据库中,我们的数据都被存放在了各种表中(比如用户表),表中的每一行就存放着一条数据(比如一个用户的信息)。
@@ -29,7 +27,7 @@ head:
**有哪些常见的关系型数据库呢?**
-MySQL、PostgreSQL、Oracle、SQL Server、SQLite(微信本地的聊天记录的存储就是用的 SQLite) ......。
+MySQL、PostgreSQL、Oracle、SQL Server、SQLite(微信本地的聊天记录的存储就是用的 SQLite) ……。
### 什么是 SQL?
@@ -45,7 +43,7 @@ SQL 可以帮助我们:
- 对数据库中的数据进行简单的数据分析;
- 搭配 Hive,Spark SQL 做大数据;
- 搭配 SQLFlow 做机器学习;
-- ......
+- ……
### 什么是 MySQL?
@@ -55,20 +53,182 @@ SQL 可以帮助我们:
由于 MySQL 是开源免费并且比较成熟的数据库,因此,MySQL 被大量使用在各种系统中。任何人都可以在 GPL(General Public License) 的许可下下载并根据个性化的需要对其进行修改。MySQL 的默认端口号是**3306**。
-### MySQL 有什么优点?
+### ⭐️MySQL 有什么优点?
这个问题本质上是在问 MySQL 如此流行的原因。
-MySQL 主要具有下面这些优点:
+MySQL 成功可以归功于在**生态、功能和运维**这三个层面上的综合优势。
+
+**第一,从生态和成本角度看,它的护城河非常深。**
+
+- **开源免费:** 这是它得以广泛普及的基石。任何公司和个人都可以免费使用,极大地降低了技术门槛和初期成本。
+- **社区庞大,生态完善:** 经过几十年的发展,MySQL 拥有极其活跃的社区和丰富的生态系统。这意味着无论你遇到什么问题,几乎都能在网上找到解决方案;同时,市面上所有的主流编程语言、框架、ORM 工具、监控系统都对 MySQL 有完美的支持。它的文档也非常丰富,学习资源唾手可得。
+
+**第二,从核心技术功能上看,它非常强大且均衡。**
+
+- **强大的事务支持:** 这是它作为关系型数据库的立身之本。值得一提的是,InnoDB 默认的可重复读(REPEATABLE-READ)隔离级别,通过 MVCC 和 Next-Key Lock 机制,很大程度上避免了幻读问题,这在很多其他数据库中都需要更高的隔离级别才能做到,兼顾了性能和一致性。详细介绍可以阅读笔者写的这篇文章:[MySQL 事务隔离级别详解](https://javaguide.cn/database/mysql/transaction-isolation-level.html)。
+- **优秀的性能和可扩展性:** MySQL 本身经过了海量互联网业务的严酷考验,单机性能非常出色。更重要的是,它围绕着水平扩展,形成了一套非常成熟的架构方案,比如主从复制、读写分离、以及通过中间件实现的分库分表。这让它能够支撑从初创公司到大型互联网平台的各种规模的业务。
+
+**第三,从运维和使用角度看,它非常‘亲民’。**
+
+- **开箱即用,上手简单:** 相比于 Oracle 等大型商业数据库,MySQL 的安装、配置和日常使用都非常简单直观,学习曲线平缓,对于开发者和初级 DBA 非常友好。
+- **维护成本低:** 由于其简单性和庞大的社区,找到相关的运维人才和解决方案都相对容易,整体的维护成本也更低。
+
+值得一提的是最近几年,PostgreSQL 的势头很猛,甚至压过了 MySQL。网上出现了很多抨击诋毁 MySQL 的文章,笔者认为任何无脑抨击其中一方或者吹捧另外一方的行为都是不可取的。
+
+笔者也写过一篇文章分享对这两个关系型数据库代表的看法,感兴趣的可以看看:[MySQL 被干成老二了?](https://mp.weixin.qq.com/s/APWD-PzTcTqGUuibAw7GGw)。
+
+## MySQL 字段类型
+
+MySQL 字段类型可以简单分为三大类:
+
+- **数值类型**:整型(TINYINT、SMALLINT、MEDIUMINT、INT 和 BIGINT)、浮点型(FLOAT 和 DOUBLE)、定点型(DECIMAL)
+- **字符串类型**:CHAR、VARCHAR、TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT、TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB 等,最常用的是 CHAR 和 VARCHAR。
+- **日期时间类型**:YEAR、TIME、DATE、DATETIME 和 TIMESTAMP 等。
+
+下面这张图不是我画的,忘记是从哪里保存下来的了,总结的还蛮不错的。
+
+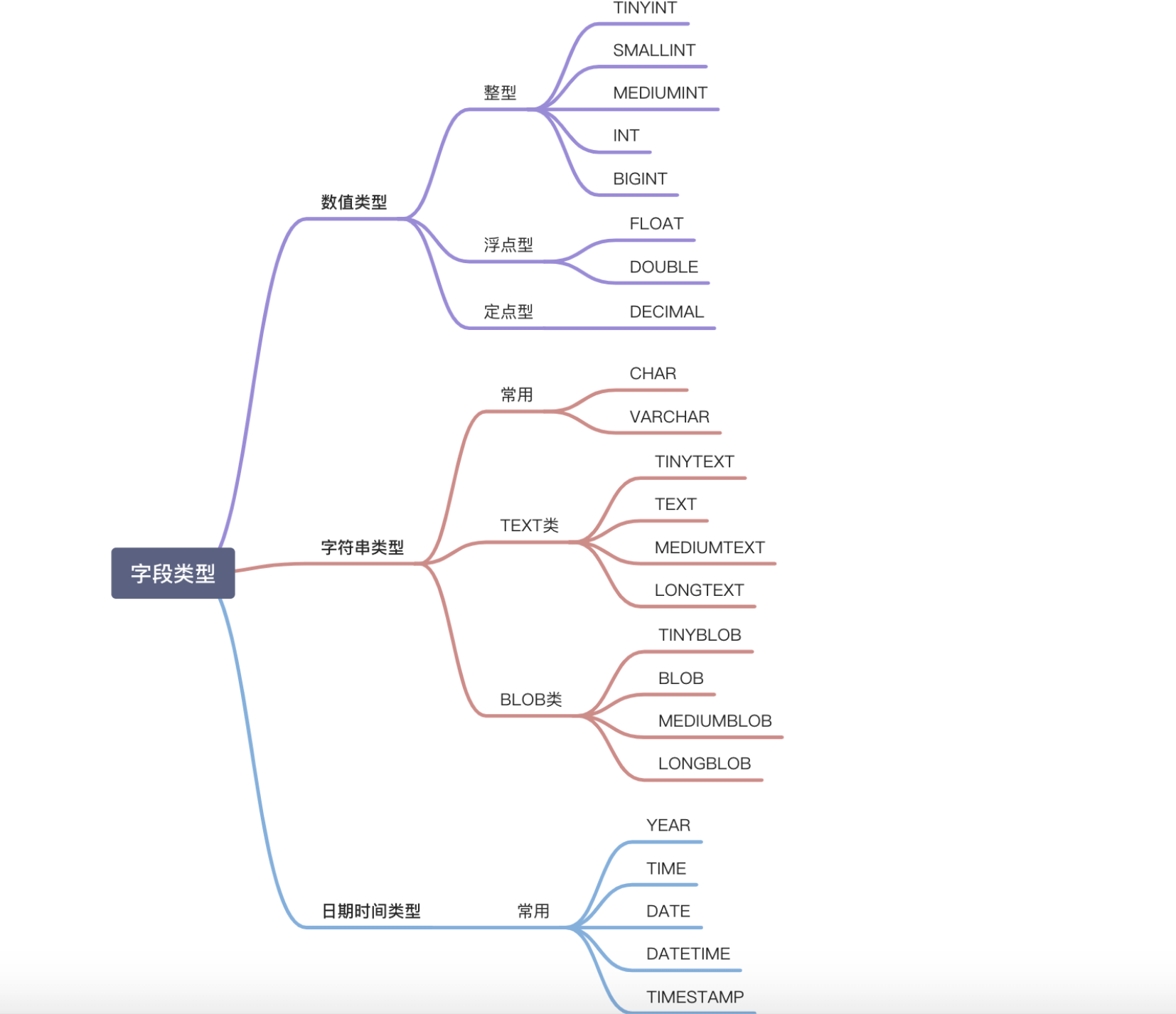
+
+MySQL 字段类型比较多,我这里会挑选一些日常开发使用很频繁且面试常问的字段类型,以面试问题的形式来详细介绍。如无特殊说明,针对的都是 InnoDB 存储引擎。
+
+另外,推荐阅读一下《高性能 MySQL(第三版)》的第四章,有详细介绍 MySQL 字段类型优化。
+
+### ⭐️整数类型的 UNSIGNED 属性有什么用?
+
+MySQL 中的整数类型可以使用可选的 UNSIGNED 属性来表示不允许负值的无符号整数。使用 UNSIGNED 属性可以将正整数的上限提高一倍,因为它不需要存储负数值。
+
+例如, TINYINT UNSIGNED 类型的取值范围是 0 ~ 255,而普通的 TINYINT 类型的值范围是 -128 ~ 127。INT UNSIGNED 类型的取值范围是 0 ~ 4,294,967,295,而普通的 INT 类型的值范围是 -2,147,483,648 ~ 2,147,483,647。
+
+对于从 0 开始递增的 ID 列,使用 UNSIGNED 属性可以非常适合,因为不允许负值并且可以拥有更大的上限范围,提供了更多的 ID 值可用。
+
+### CHAR 和 VARCHAR 的区别是什么?
+
+CHAR 和 VARCHAR 是最常用到的字符串类型,两者的主要区别在于:**CHAR 是定长字符串,VARCHAR 是变长字符串。**
+
+CHAR 在存储时会在右边填充空格以达到指定的长度,检索时会去掉空格;VARCHAR 在存储时需要使用 1 或 2 个额外字节记录字符串的长度,检索时不需要处理。
+
+CHAR 更适合存储长度较短或者长度都差不多的字符串,例如 Bcrypt 算法、MD5 算法加密后的密码、身份证号码。VARCHAR 类型适合存储长度不确定或者差异较大的字符串,例如用户昵称、文章标题等。
+
+CHAR(M) 和 VARCHAR(M) 的 M 都代表能够保存的字符数的最大值,无论是字母、数字还是中文,每个都只占用一个字符。
+
+### VARCHAR(100)和 VARCHAR(10)的区别是什么?
+
+VARCHAR(100)和 VARCHAR(10)都是变长类型,表示能存储最多 100 个字符和 10 个字符。因此,VARCHAR (100) 可以满足更大范围的字符存储需求,有更好的业务拓展性。而 VARCHAR(10)存储超过 10 个字符时,就需要修改表结构才可以。
+
+虽说 VARCHAR(100)和 VARCHAR(10)能存储的字符范围不同,但二者存储相同的字符串,所占用磁盘的存储空间其实是一样的,这也是很多人容易误解的一点。
+
+不过,VARCHAR(100) 会消耗更多的内存。这是因为 VARCHAR 类型在内存中操作时,通常会分配固定大小的内存块来保存值,即使用字符类型中定义的长度。例如在进行排序的时候,VARCHAR(100)是按照 100 这个长度来进行的,也就会消耗更多内存。
+
+### DECIMAL 和 FLOAT/DOUBLE 的区别是什么?
+
+DECIMAL 和 FLOAT 的区别是:**DECIMAL 是定点数,FLOAT/DOUBLE 是浮点数。DECIMAL 可以存储精确的小数值,FLOAT/DOUBLE 只能存储近似的小数值。**
+
+DECIMAL 用于存储具有精度要求的小数,例如与货币相关的数据,可以避免浮点数带来的精度损失。
+
+在 Java 中,MySQL 的 DECIMAL 类型对应的是 Java 类 `java.math.BigDecimal`。
+
+### 为什么不推荐使用 TEXT 和 BLOB?
+
+TEXT 类型类似于 CHAR(0-255 字节)和 VARCHAR(0-65,535 字节),但可以存储更长的字符串,即长文本数据,例如博客内容。
+
+| 类型 | 可存储大小 | 用途 |
+| ---------- | -------------------- | -------------- |
+| TINYTEXT | 0-255 字节 | 一般文本字符串 |
+| TEXT | 0-65,535 字节 | 长文本字符串 |
+| MEDIUMTEXT | 0-16,772,150 字节 | 较大文本数据 |
+| LONGTEXT | 0-4,294,967,295 字节 | 极大文本数据 |
+
+BLOB 类型主要用于存储二进制大对象,例如图片、音视频等文件。
+
+| 类型 | 可存储大小 | 用途 |
+| ---------- | ---------- | ------------------------ |
+| TINYBLOB | 0-255 字节 | 短文本二进制字符串 |
+| BLOB | 0-65KB | 二进制字符串 |
+| MEDIUMBLOB | 0-16MB | 二进制形式的长文本数据 |
+| LONGBLOB | 0-4GB | 二进制形式的极大文本数据 |
+
+在日常开发中,很少使用 TEXT 类型,但偶尔会用到,而 BLOB 类型则基本不常用。如果预期长度范围可以通过 VARCHAR 来满足,建议避免使用 TEXT。
+
+数据库规范通常不推荐使用 BLOB 和 TEXT 类型,这两种类型具有一些缺点和限制,例如:
+
+- 不能有默认值。
+- 在使用临时表时无法使用内存临时表,只能在磁盘上创建临时表(《高性能 MySQL》书中有提到)。
+- 检索效率较低。
+- 不能直接创建索引,需要指定前缀长度。
+- 可能会消耗大量的网络和 IO 带宽。
+- 可能导致表上的 DML 操作变慢。
+- ……
+
+### ⭐️DATETIME 和 TIMESTAMP 的区别是什么?如何选择?
+
+DATETIME 类型没有时区信息,TIMESTAMP 和时区有关。
-1. 成熟稳定,功能完善。
-2. 开源免费。
-3. 文档丰富,既有详细的官方文档,又有非常多优质文章可供参考学习。
-4. 开箱即用,操作简单,维护成本低。
-5. 兼容性好,支持常见的操作系统,支持多种开发语言。
-6. 社区活跃,生态完善。
-7. 事务支持优秀, InnoDB 存储引擎默认使用 REPEATABLE-READ 并不会有任何性能损失,并且,InnoDB 实现的 REPEATABLE-READ 隔离级别其实是可以解决幻读问题发生的。
-8. 支持分库分表、读写分离、高可用。
+TIMESTAMP 只需要使用 4 个字节的存储空间,但是 DATETIME 需要耗费 8 个字节的存储空间。但是,这样同样造成了一个问题,Timestamp 表示的时间范围更小。
+
+- DATETIME:'1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999'
+- Timestamp:'1970-01-01 00:00:01.000000' UTC 到 '2038-01-19 03:14:07.999999' UTC
+
+`TIMESTAMP` 的核心优势在于其内建的时区处理能力。数据库负责 UTC 存储和基于会话时区的自动转换,简化了需要处理多时区应用的开发。如果应用需要处理多时区,或者希望数据库能自动管理时区转换,`TIMESTAMP` 是自然的选择(注意其时间范围限制,也就是 2038 年问题)。
+
+如果应用场景不涉及时区转换,或者希望应用程序完全控制时区逻辑,并且需要表示 2038 年之后的时间,`DATETIME` 是更稳妥的选择。
+
+关于两者的详细对比以及日期存储类型选择建议,请参考我写的这篇文章: [MySQL 时间类型数据存储建议](./some-thoughts-on-database-storage-time.md)。
+
+### NULL 和 '' 的区别是什么?
+
+`NULL` 和 `''` (空字符串) 是两个完全不同的值,它们分别表示不同的含义,并在数据库中有着不同的行为。`NULL` 代表缺失或未知的数据,而 `''` 表示一个已知存在的空字符串。它们的主要区别如下:
+
+1. **含义**:
+ - `NULL` 代表一个不确定的值,它不等于任何值,包括它自身。因此,`SELECT NULL = NULL` 的结果是 `NULL`,而不是 `true` 或 `false`。 `NULL` 意味着缺失或未知的信息。虽然 `NULL` 不等于任何值,但在某些操作中,数据库系统会将 `NULL` 值视为相同的类别进行处理,例如:`DISTINCT`,`GROUP BY`,`ORDER BY`。需要注意的是,这些操作将 `NULL` 值视为相同的类别进行处理,并不意味着 `NULL` 值之间是相等的。 它们只是在特定操作中被特殊处理,以保证结果的正确性和一致性。 这种处理方式是为了方便数据操作,而不是改变了 `NULL` 的语义。
+ - `''` 表示一个空字符串,它是一个已知的值。
+2. **存储空间**:
+ - `NULL` 的存储空间占用取决于数据库的实现,通常需要一些空间来标记该值为空。
+ - `''` 的存储空间占用通常较小,因为它只存储一个空字符串的标志,不需要存储实际的字符。
+3. **比较运算**:
+ - 任何值与 `NULL` 进行比较(例如 `=`, `!=`, `>`, `<` 等)的结果都是 `NULL`,表示结果不确定。要判断一个值是否为 `NULL`,必须使用 `IS NULL` 或 `IS NOT NULL`。
+ - `''` 可以像其他字符串一样进行比较运算。例如,`'' = ''` 的结果是 `true`。
+4. **聚合函数**:
+ - 大多数聚合函数(例如 `SUM`, `AVG`, `MIN`, `MAX`)会忽略 `NULL` 值。
+ - `COUNT(*)` 会统计所有行数,包括包含 `NULL` 值的行。`COUNT(列名)` 会统计指定列中非 `NULL` 值的行数。
+ - 空字符串 `''` 会被聚合函数计算在内。例如,`SUM` 会将其视为 0,`MIN` 和 `MAX` 会将其视为一个空字符串。
+
+看了上面的介绍之后,相信你对另外一个高频面试题:“为什么 MySQL 不建议使用 `NULL` 作为列默认值?”也有了答案。
+
+### ⭐️Boolean 类型如何表示?
+
+MySQL 中没有专门的布尔类型,而是用 `TINYINT(1)` 类型来表示布尔值。`TINYINT(1)` 类型可以存储 0 或 1,分别对应 false 或 true。
+
+### ⭐️手机号存储用 INT 还是 VARCHAR?
+
+存储手机号,**强烈推荐使用 VARCHAR 类型**,而不是 INT 或 BIGINT。主要原因如下:
+
+1. **格式兼容性与完整性:**
+ - 手机号可能包含前导零(如某些地区的固话区号)、国家代码前缀('+'),甚至可能带有分隔符('-' 或空格)。INT 或 BIGINT 这种数字类型会自动丢失这些重要的格式信息(比如前导零会被去掉,'+' 和 '-' 无法存储)。
+ - VARCHAR 可以原样存储各种格式的号码,无论是国内的 11 位手机号,还是带有国家代码的国际号码,都能完美兼容。
+2. **非算术性:** 手机号虽然看起来是数字,但我们从不对它进行数学运算(比如求和、平均值)。它本质上是一个标识符,更像是一个字符串。用 VARCHAR 更符合其数据性质。
+3. **查询灵活性:**
+ - 业务中常常需要根据号段(前缀)进行查询,例如查找所有 "138" 开头的用户。使用 VARCHAR 类型配合 `LIKE '138%'` 这样的 SQL 查询既直观又高效。
+ - 如果使用数字类型,进行类似的前缀匹配通常需要复杂的函数转换(如 CAST 或 SUBSTRING),或者使用范围查询(如 `WHERE phone >= 13800000000 AND phone < 13900000000`),这不仅写法繁琐,而且可能无法有效利用索引,导致性能下降。
+4. **加密存储的要求(非常关键):**
+ - 出于数据安全和隐私合规的要求,手机号这类敏感个人信息通常必须加密存储在数据库中。
+ - 加密后的数据(密文)是一长串字符串(通常由字母、数字、符号组成,或经过 Base64/Hex 编码),INT 或 BIGINT 类型根本无法存储这种密文。只有 VARCHAR、TEXT 或 BLOB 等类型可以。
+
+**关于 VARCHAR 长度的选择:**
+
+- **如果不加密存储(强烈不推荐!):** 考虑到国际号码和可能的格式符,VARCHAR(20) 到 VARCHAR(32) 通常是一个比较安全的范围,足以覆盖全球绝大多数手机号格式。VARCHAR(15) 可能对某些带国家码和格式符的号码来说不够用。
+- **如果进行加密存储(推荐的标准做法):** 长度必须根据所选加密算法产生的密文最大长度,以及可能的编码方式(如 Base64 会使长度增加约 1/3)来精确计算和设定。通常会需要更长的 VARCHAR 长度,例如 VARCHAR(128), VARCHAR(256) 甚至更长。
+
+最后,来一张表格总结一下:
+
+| 对比维度 | VARCHAR 类型(推荐) | INT/BIGINT 类型(不推荐) | 说明/备注 |
+| ---------------- | --------------------------------- | ---------------------------- | --------------------------------------------------------------------------- |
+| **格式兼容性** | ✔ 能存前导零、"+"、"-"、空格等 | ✘ 自动丢失前导零,不能存符号 | VARCHAR 能原样存储各种手机号格式,INT/BIGINT 只支持单纯数字,且前导零会消失 |
+| **完整性** | ✔ 不丢失任何格式信息 | ✘ 丢失格式信息 | 例如 "013800012345" 存进 INT 会变成 13800012345,"+" 也无法存储 |
+| **非算术性** | ✔ 适合存储“标识符” | ✘ 只适合做数值运算 | 手机号本质是字符串标识符,不做数学运算,VARCHAR 更贴合实际用途 |
+| **查询灵活性** | ✔ 支持 `LIKE '138%'` 等 | ✘ 查询前缀不方便或性能差 | 使用 VARCHAR 可高效按号段/前缀查询,数字类型需转为字符串或其他复杂处理 |
+| **加密存储支持** | ✔ 可存储加密密文(字母、符号等) | ✘ 无法存储密文 | 加密手机号后密文是字符串/二进制,只有 VARCHAR、TEXT、BLOB 等能兼容 |
+| **长度设置建议** | 15~20(未加密),加密视情况而定 | 无意义 | 不加密时 VARCHAR(15~20) 通用,加密后长度取决于算法和编码方式 |
## MySQL 基础架构
@@ -85,7 +245,7 @@ MySQL 主要具有下面这些优点:
- **分析器:** 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
- **优化器:** 按照 MySQL 认为最优的方案去执行。
- **执行器:** 执行语句,然后从存储引擎返回数据。 执行语句之前会先判断是否有权限,如果没有权限的话,就会报错。
-- **插件式存储引擎**:主要负责数据的存储和读取,采用的是插件式架构,支持 InnoDB、MyISAM、Memory 等多种存储引擎。
+- **插件式存储引擎**:主要负责数据的存储和读取,采用的是插件式架构,支持 InnoDB、MyISAM、Memory 等多种存储引擎。InnoDB 是 MySQL 的默认存储引擎,绝大部分场景使用 InnoDB 就是最好的选择。
## MySQL 存储引擎
@@ -115,7 +275,7 @@ mysql> SELECT VERSION();
1 row in set (0.00 sec)
```
-你也可以通过 `SHOW VARIABLES LIKE '%storage_engine%'` 命令直接查看 MySQL 当前默认的存储引擎。
+你也可以通过 `SHOW VARIABLES LIKE '%storage_engine%'` 命令直接查看 MySQL 当前默认的存储引擎。
```bash
mysql> SHOW VARIABLES LIKE '%storage_engine%';
@@ -141,11 +301,15 @@ mysql> SHOW VARIABLES LIKE '%storage_engine%';
MySQL 存储引擎采用的是 **插件式架构** ,支持多种存储引擎,我们甚至可以为不同的数据库表设置不同的存储引擎以适应不同场景的需要。**存储引擎是基于表的,而不是数据库。**
-并且,你还可以根据 MySQL 定义的存储引擎实现标准接口来编写一个属于自己的存储引擎。这些非官方提供的存储引擎可以称为第三方存储引擎,区别于官方存储引擎。像目前最常用的 InnoDB 其实刚开始就是一个第三方存储引擎,后面由于过于优秀,其被 Oracle 直接收购了。
+下图展示了具有可插拔存储引擎的 MySQL 架构:
+
+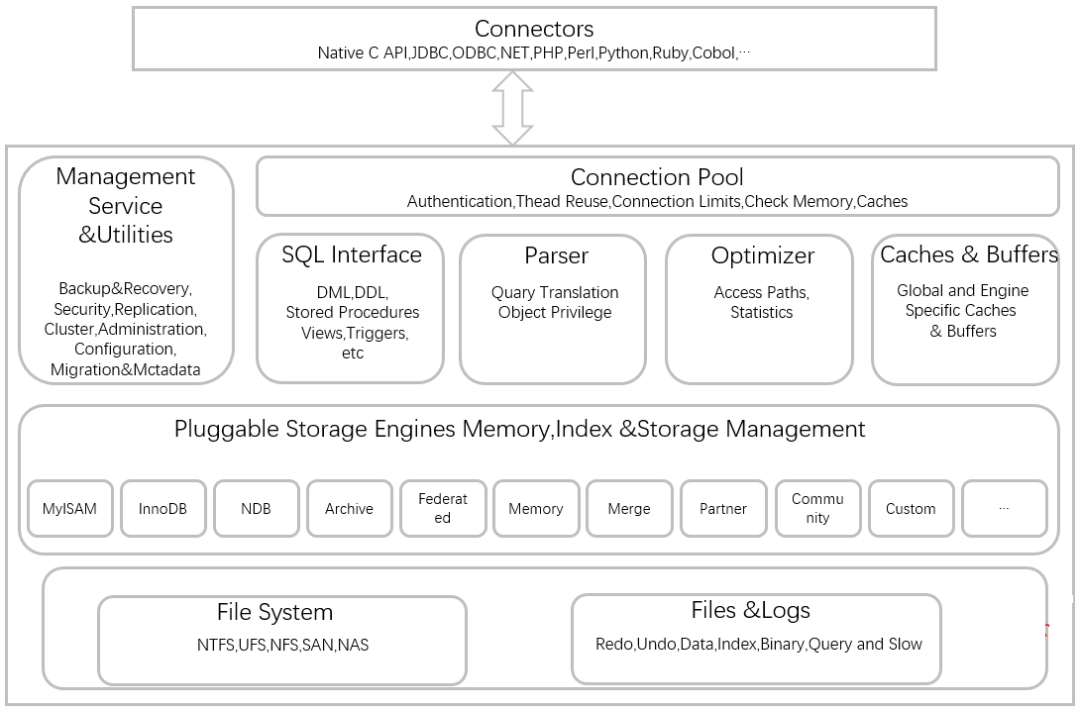
+
+你还可以根据 MySQL 定义的存储引擎实现标准接口来编写一个属于自己的存储引擎。这些非官方提供的存储引擎可以称为第三方存储引擎,区别于官方存储引擎。像目前最常用的 InnoDB 其实刚开始就是一个第三方存储引擎,后面由于过于优秀,其被 Oracle 直接收购了。
MySQL 官方文档也有介绍到如何编写一个自定义存储引擎,地址: 。
-### MyISAM 和 InnoDB 有什么区别?
+### ⭐️MyISAM 和 InnoDB 有什么区别?
MySQL 5.5 之前,MyISAM 引擎是 MySQL 的默认存储引擎,可谓是风光一时。
@@ -155,13 +319,13 @@ MySQL 5.5 版本之后,InnoDB 是 MySQL 的默认存储引擎。
言归正传!咱们下面还是来简单对比一下两者:
-**1.是否支持行级锁**
+**1、是否支持行级锁**
MyISAM 只有表级锁(table-level locking),而 InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
也就说,MyISAM 一锁就是锁住了整张表,这在并发写的情况下是多么滴憨憨啊!这也是为什么 InnoDB 在并发写的时候,性能更牛皮了!
-**2.是否支持事务**
+**2、是否支持事务**
MyISAM 不提供事务支持。
@@ -169,7 +333,7 @@ InnoDB 提供事务支持,实现了 SQL 标准定义了四个隔离级别,
关于 MySQL 事务的详细介绍,可以看看我写的这篇文章:[MySQL 事务隔离级别详解](./transaction-isolation-level.md)。
-**3.是否支持外键**
+**3、是否支持外键**
MyISAM 不支持,而 InnoDB 支持。
@@ -183,19 +347,19 @@ MyISAM 不支持,而 InnoDB 支持。
总结:一般我们也是不建议在数据库层面使用外键的,应用层面可以解决。不过,这样会对数据的一致性造成威胁。具体要不要使用外键还是要根据你的项目来决定。
-**4.是否支持数据库异常崩溃后的安全恢复**
+**4、是否支持数据库异常崩溃后的安全恢复**
MyISAM 不支持,而 InnoDB 支持。
使用 InnoDB 的数据库在异常崩溃后,数据库重新启动的时候会保证数据库恢复到崩溃前的状态。这个恢复的过程依赖于 `redo log` 。
-**5.是否支持 MVCC**
+**5、是否支持 MVCC**
MyISAM 不支持,而 InnoDB 支持。
讲真,这个对比有点废话,毕竟 MyISAM 连行级锁都不支持。MVCC 可以看作是行级锁的一个升级,可以有效减少加锁操作,提高性能。
-**6.索引实现不一样。**
+**6、索引实现不一样。**
虽然 MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是两者的实现方式不太一样。
@@ -203,12 +367,16 @@ InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索
详细区别,推荐你看看我写的这篇文章:[MySQL 索引详解](./mysql-index.md)。
-**7.性能有差别。**
+**7、性能有差别。**
InnoDB 的性能比 MyISAM 更强大,不管是在读写混合模式下还是只读模式下,随着 CPU 核数的增加,InnoDB 的读写能力呈线性增长。MyISAM 因为读写不能并发,它的处理能力跟核数没关系。
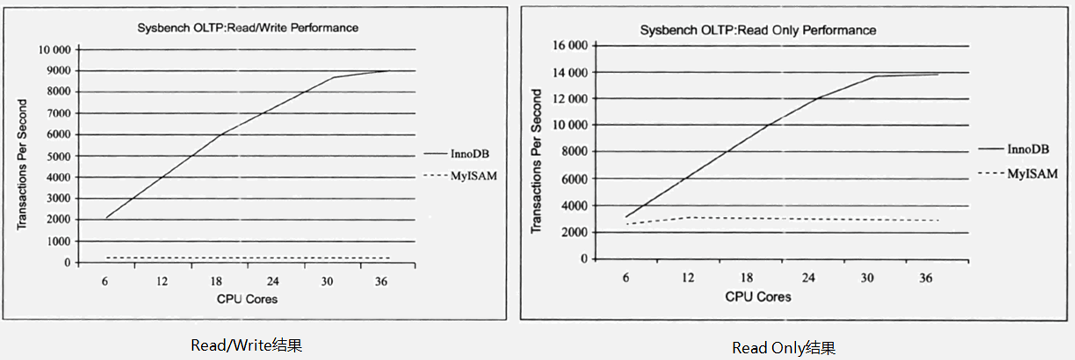
+**8、数据缓存策略和机制实现不同。**
+
+InnoDB 使用缓冲池(Buffer Pool)缓存数据页和索引页,MyISAM 使用键缓存(Key Cache)仅缓存索引页而不缓存数据页。
+
**总结**:
- InnoDB 支持行级别的锁粒度,MyISAM 不支持,只支持表级别的锁粒度。
@@ -225,23 +393,175 @@ InnoDB 的性能比 MyISAM 更强大,不管是在读写混合模式下还是
### MyISAM 和 InnoDB 如何选择?
-大多数时候我们使用的都是 InnoDB 存储引擎,在某些读密集的情况下,使用 MyISAM 也是合适的。不过,前提是你的项目不介意 MyISAM 不支持事务、崩溃恢复等缺点(可是~我们一般都会介意啊!)。
+大多数时候我们使用的都是 InnoDB 存储引擎,在某些读密集的情况下,使用 MyISAM 也是合适的。不过,前提是你的项目不介意 MyISAM 不支持事务、崩溃恢复等缺点(可是~我们一般都会介意啊)。
《MySQL 高性能》上面有一句话这样写到:
> 不要轻易相信“MyISAM 比 InnoDB 快”之类的经验之谈,这个结论往往不是绝对的。在很多我们已知场景中,InnoDB 的速度都可以让 MyISAM 望尘莫及,尤其是用到了聚簇索引,或者需要访问的数据都可以放入内存的应用。
-一般情况下我们选择 InnoDB 都是没有问题的,但是某些情况下你并不在乎可扩展能力和并发能力,也不需要事务支持,也不在乎崩溃后的安全恢复问题的话,选择 MyISAM 也是一个不错的选择。但是一般情况下,我们都是需要考虑到这些问题的。
+因此,对于咱们日常开发的业务系统来说,你几乎找不到什么理由使用 MyISAM 了,老老实实用默认的 InnoDB 就可以了!
+
+## ⭐️MySQL 索引
-因此,对于咱们日常开发的业务系统来说,你几乎找不到什么理由再使用 MyISAM 作为自己的 MySQL 数据库的存储引擎。
+MySQL 索引相关的问题比较多,也非常重要,更详细的介绍可以阅读笔者写的这篇文章:[MySQL 索引详解](./mysql-index.md) 。
+
+### 索引是什么?
+
+**索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。**
+
+索引的作用就相当于书的目录。打个比方:我们在查字典的时候,如果没有目录,那我们就只能一页一页地去找我们需要查的那个字,速度很慢;如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
+
+索引底层数据结构存在很多种类型,常见的索引结构有:B 树、 B+ 树 和 Hash、红黑树。在 MySQL 中,无论是 Innodb 还是 MyISAM,都使用了 B+ 树作为索引结构。
+
+**索引的优点:**
+
+1. **查询速度起飞 (主要目的)**:通过索引,数据库可以**大幅减少需要扫描的数据量**,直接定位到符合条件的记录,从而显著加快数据检索速度,减少磁盘 I/O 次数。
+2. **保证数据唯一性**:通过创建**唯一索引 (Unique Index)**,可以确保表中的某一列(或几列组合)的值是独一无二的,比如用户 ID、邮箱等。主键本身就是一种唯一索引。
+3. **加速排序和分组**:如果查询中的 ORDER BY 或 GROUP BY 子句涉及的列建有索引,数据库往往可以直接利用索引已经排好序的特性,避免额外的排序操作,从而提升性能。
+
+**索引的缺点:**
+
+1. **创建和维护耗时**:创建索引本身需要时间,特别是对大表操作时。更重要的是,当对表中的数据进行**增、删、改 (DML 操作)** 时,不仅要操作数据本身,相关的索引也必须动态更新和维护,这会**降低这些 DML 操作的执行效率**。
+2. **占用存储空间**:索引本质上也是一种数据结构,需要以物理文件(或内存结构)的形式存储,因此会**额外占用一定的磁盘空间**。索引越多、越大,占用的空间也就越多。
+3. **可能被误用或失效**:如果索引设计不当,或者查询语句写得不好,数据库优化器可能不会选择使用索引(或者选错索引),反而导致性能下降。
+
+**那么,用了索引就一定能提高查询性能吗?**
+
+**不一定。** 大多数情况下,合理使用索引确实比全表扫描快得多。但也有例外:
+
+- **数据量太小**:如果表里的数据非常少(比如就几百条),全表扫描可能比通过索引查找更快,因为走索引本身也有开销。
+- **查询结果集占比过大**:如果要查询的数据占了整张表的大部分(比如超过 20%-30%),优化器可能会认为全表扫描更划算,因为通过索引多次回表(随机 I/O)的成本可能高于一次顺序的全表扫描。
+- **索引维护不当或统计信息过时**:导致优化器做出错误判断。
+
+### 索引为什么快?
+
+索引之所以快,核心原因是它**大大减少了磁盘 I/O 的次数**。
+
+它的本质是一种**排好序的数据结构**,就像书的目录,让我们不用一页一页地翻(全表扫描)。
+
+在 MySQL 中,这个数据结构是**B+树**。B+树结构主要从两方面做了优化:
+
+1. B+树的特点是“矮胖”,一个千万数据的表,索引树的高度可能只有 3-4 层。这意味着,最多只需要**3-4 次磁盘 I/O**,就能精确定位到我想要的数据,而全表扫描可能需要成千上万次,所以速度极快。
+2. B+树的叶子节点是**用链表连起来的**。找到开头后,就能顺着链表**顺序读**下去,这对磁盘非常友好,还能触发预读。
+
+### MySQL 索引底层数据结构是什么?
+
+在 MySQL 中,MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,详细介绍可以参考笔者写的这篇文章:[MySQL 索引详解](https://javaguide.cn/database/mysql/mysql-index.html)。
+
+### 为什么 InnoDB 没有使用哈希作为索引的数据结构?
+
+> 我发现很多求职者甚至是面试官对这个问题都有误解,他们相当然的认为 MySQL 底层并没有使用哈希或者 B 树作为索引的数据结构。
+>
+> 实际上,不论是提问还是回答这个问题都要区分好存储引擎。像 MEMORY 引擎就同时支持哈希和 B 树。
-## MySQL 索引
+哈希索引的底层是哈希表。它的优点是,在进行**精确的等值查询**时,理论上时间复杂度是 **O(1)** ,速度极快。比如 `WHERE id = 123`。
-MySQL 索引相关的问题比较多,对于面试和工作都比较重要,于是,我单独抽了一篇文章专门来总结 MySQL 索引相关的知识点和问题:[MySQL 索引详解](./mysql-index.md) 。
+但是,它有几个对于通用数据库来说是致命的缺点:
+
+1. **不支持范围查询:** 这是最主要的原因。哈希函数的一个特点是它会把相邻的输入值(比如 `id=100` 和 `id=101`)映射到哈希表中完全不相邻的位置。这种顺序的破坏,使得我们无法处理像 `WHERE age > 30` 或 `BETWEEN 100 AND 200`这样的范围查询。要完成这种查询,哈希索引只能退化为全表扫描。
+2. **不支持排序:** 同理,因为哈希值是无序的,所以我们无法利用哈希索引来优化 `ORDER BY` 子句。
+3. **不支持部分索引键查询:** 对于联合索引,比如`(col1, col2)`,哈希索引必须使用所有索引列进行查询,它无法单独利用 `col1` 来加速查询。
+4. **哈希冲突问题:** 当不同的键产生相同的哈希值时,需要额外的链表或开放寻址来解决,这会降低性能。
+
+鉴于数据库查询中范围查询和排序是极其常见的操作,一个不支持这些功能的索引结构,显然不能作为默认的、通用的索引类型。
+
+### 为什么 InnoDB 没有使用 B 树作为索引的数据结构?
+
+B 树和 B+树都是优秀的多路平衡搜索树,非常适合磁盘存储,因为它们都很“矮胖”,能最大化地利用每一次磁盘 I/O。
+
+但 B+树是 B 树的一个增强版,它针对数据库场景做了几个关键优化:
+
+1. **I/O 效率更高:** 在 B+树中,只有叶子节点才存储数据(或数据指针),而非叶子节点只存储索引键。因为非叶子节点不存数据,所以它们可以容纳更多的索引键。这意味着 B+树的“扇出”更大,在同样的数据量下,B+树通常会比 B 树更矮,也就意味着查找数据所需的磁盘 I/O 次数更少。
+2. **查询性能更稳定:** 在 B+树中,任何一次查询都必须从根节点走到叶子节点才能找到数据,所以查询路径的长度是固定的。而在 B 树中,如果运气好,可能在非叶子节点就找到了数据,但运气不好也得走到叶子,这导致查询性能不稳定。
+3. **对范围查询极其友好:** 这是 B+树最核心的优势。它的所有叶子节点之间通过一个双向链表连接。当我们执行一个范围查询(比如 `WHERE id > 100`)时,只需要通过树形结构找到 `id=100` 的叶子节点,然后就可以沿着链表向后顺序扫描,而无需再回溯到上层节点。这使得范围查询的效率大大提高。
+
+### 什么是覆盖索引?
+
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为 **覆盖索引(Covering Index)**。
+
+在 InnoDB 存储引擎中,非主键索引的叶子节点包含的是主键的值。这意味着,当使用非主键索引进行查询时,数据库会先找到对应的主键值,然后再通过主键索引来定位和检索完整的行数据。这个过程被称为“回表”。
+
+**覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了,而无需回表查询。**
+
+### 请解释一下 MySQL 的联合索引及其最左前缀原则
+
+使用表中的多个字段创建索引,就是 **联合索引**,也叫 **组合索引** 或 **复合索引**。
+
+以 `score` 和 `name` 两个字段建立联合索引:
+
+```sql
+ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
+```
+
+最左前缀匹配原则指的是在使用联合索引时,MySQL 会根据索引中的字段顺序,从左到右依次匹配查询条件中的字段。如果查询条件与索引中的最左侧字段相匹配,那么 MySQL 就会使用索引来过滤数据,这样可以提高查询效率。
+
+最左匹配原则会一直向右匹配,直到遇到范围查询(如 >、<)为止。对于 >=、<=、BETWEEN 以及前缀匹配 LIKE 的范围查询,不会停止匹配(相关阅读:[联合索引的最左匹配原则全网都在说的一个错误结论](https://mp.weixin.qq.com/s/8qemhRg5MgXs1So5YCv0fQ))。
+
+假设有一个联合索引 `(column1, column2, column3)`,其从左到右的所有前缀为 `(column1)`、`(column1, column2)`、`(column1, column2, column3)`(创建 1 个联合索引相当于创建了 3 个索引),包含这些列的所有查询都会走索引而不会全表扫描。
+
+我们在使用联合索引时,可以将区分度高的字段放在最左边,这也可以过滤更多数据。
+
+我们这里简单演示一下最左前缀匹配的效果。
+
+1、创建一个名为 `student` 的表,这张表只有 `id`、`name`、`class` 这 3 个字段。
+
+```sql
+CREATE TABLE `student` (
+ `id` int NOT NULL,
+ `name` varchar(100) DEFAULT NULL,
+ `class` varchar(100) DEFAULT NULL,
+ PRIMARY KEY (`id`),
+ KEY `name_class_idx` (`name`,`class`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+```
+
+2、下面我们分别测试三条不同的 SQL 语句。
+
+
+
+```sql
+# 可以命中索引
+SELECT * FROM student WHERE name = 'Anne Henry';
+EXPLAIN SELECT * FROM student WHERE name = 'Anne Henry' AND class = 'lIrm08RYVk';
+# 无法命中索引
+SELECT * FROM student WHERE class = 'lIrm08RYVk';
+```
+
+再来看一个常见的面试题:如果有索引 `联合索引(a,b,c)`,查询 `a=1 AND c=1` 会走索引么?`c=1` 呢?`b=1 AND c=1` 呢? `b = 1 AND a = 1 AND c = 1` 呢?
+
+先不要往下看答案,给自己 3 分钟时间想一想。
+
+1. 查询 `a=1 AND c=1`:根据最左前缀匹配原则,查询可以使用索引的前缀部分。因此,该查询仅在 `a=1` 上使用索引,然后对结果进行 `c=1` 的过滤。
+2. 查询 `c=1`:由于查询中不包含最左列 `a`,根据最左前缀匹配原则,整个索引都无法被使用。
+3. 查询 `b=1 AND c=1`:和第二种一样的情况,整个索引都不会使用。
+4. 查询 `b=1 AND a=1 AND c=1`:这个查询是可以用到索引的。查询优化器分析 SQL 语句时,对于联合索引,会对查询条件进行重排序,以便用到索引。会将 `b=1` 和 `a=1` 的条件进行重排序,变成 `a=1 AND b=1 AND c=1`。
+
+MySQL 8.0.13 版本引入了索引跳跃扫描(Index Skip Scan,简称 ISS),它可以在某些索引查询场景下提高查询效率。在没有 ISS 之前,不满足最左前缀匹配原则的联合索引查询中会执行全表扫描。而 ISS 允许 MySQL 在某些情况下避免全表扫描,即使查询条件不符合最左前缀。不过,这个功能比较鸡肋, 和 Oracle 中的没法比,MySQL 8.0.31 还报告了一个 bug:[Bug #109145 Using index for skip scan cause incorrect result](https://bugs.mysql.com/bug.php?id=109145)(后续版本已经修复)。个人建议知道有这个东西就好,不需要深究,实际项目也不一定能用上。
+
+### SELECT \* 会导致索引失效吗?
+
+`SELECT *` 不会直接导致索引失效(如果不走索引大概率是因为 where 查询范围过大导致的),但它可能会带来一些其他的性能问题比如造成网络传输和数据处理的浪费、无法使用索引覆盖。
+
+### 哪些字段适合创建索引?
+
+- **不为 NULL 的字段**:索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代。
+- **被频繁查询的字段**:我们创建索引的字段应该是查询操作非常频繁的字段。
+- **被作为条件查询的字段**:被作为 WHERE 条件查询的字段,应该被考虑建立索引。
+- **频繁需要排序的字段**:索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
+- **被经常频繁用于连接的字段**:经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
+
+### 索引失效的原因有哪些?
+
+1. 创建了组合索引,但查询条件未遵守最左匹配原则;
+2. 在索引列上进行计算、函数、类型转换等操作;
+3. 以 % 开头的 LIKE 查询比如 `LIKE '%abc';`;
+4. 查询条件中使用 OR,且 OR 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
+5. IN 的取值范围较大时会导致索引失效,走全表扫描(NOT IN 和 IN 的失效场景相同);
+6. 发生[隐式转换](https://javaguide.cn/database/mysql/index-invalidation-caused-by-implicit-conversion.html "隐式转换");
## MySQL 查询缓存
-执行查询语句的时候,会先查询缓存。不过,MySQL 8.0 版本后移除,因为这个功能不太实用
+MySQL 查询缓存是查询结果缓存。执行查询语句的时候,会先查询缓存,如果缓存中有对应的查询结果,就会直接返回。
`my.cnf` 加入以下配置,重启 MySQL 开启查询缓存
@@ -257,7 +577,7 @@ set global query_cache_type=1;
set global query_cache_size=600000;
```
-如上,**开启查询缓存后在同样的查询条件以及数据情况下,会直接在缓存中返回结果**。这里的查询条件包括查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息。
+查询缓存会在同样的查询条件和数据情况下,直接返回缓存中的结果。但需要注意的是,查询缓存的匹配条件非常严格,任何细微的差异都会导致缓存无法命中。这里的查询条件包括查询语句本身、当前使用的数据库、以及其他可能影响结果的因素,如客户端协议版本号等。
**查询缓存不命中的情况:**
@@ -265,37 +585,34 @@ set global query_cache_size=600000;
2. 如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL 库中的系统表,其查询结果也不会被缓存。
3. 缓存建立之后,MySQL 的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
-**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启查询缓存要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十 MB 比较合适。此外,**还可以通过 `sql_cache` 和 `sql_no_cache` 来控制某个查询语句是否需要缓存:**
+**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启查询缓存要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十 MB 比较合适。此外,还可以通过 `sql_cache` 和 `sql_no_cache` 来控制某个查询语句是否需要缓存:
```sql
SELECT sql_no_cache COUNT(*) FROM usr;
```
-## MySQL 日志
+MySQL 5.6 开始,查询缓存已默认禁用。MySQL 8.0 开始,已经不再支持查询缓存了(具体可以参考这篇文章:[MySQL 8.0: Retiring Support for the Query Cache](https://dev.mysql.com/blog-archive/mysql-8-0-retiring-support-for-the-query-cache/))。
+
+
-- MySQL 中常见的日志有哪些?
-- 慢查询日志有什么用?
-- binlog 主要记录了什么?
-- redo log 如何保证事务的持久性?
-- 页修改之后为什么不直接刷盘呢?
-- binlog 和 redolog 有什么区别?
-- undo log 如何保证事务的原子性?
-- ......
+## ⭐️MySQL 日志
-上诉问题的答案可以在[《Java 面试指北》(付费)](../../zhuanlan/java-mian-shi-zhi-bei.md) 的 **「技术面试题篇」** 中找到。
+上诉问题的答案可以在[《Java 面试指北》(付费,点击链接领取优惠卷)](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 的 **「技术面试题篇」** 中找到。

-## MySQL 事务
+文章地址: (密码获取:)。
-### 何谓事务?
+## ⭐️MySQL 事务
+
+### 什么是事务?
我们设想一个场景,这个场景中我们需要插入多条相关联的数据到数据库,不幸的是,这个过程可能会遇到下面这些问题:
- 数据库中途突然因为某些原因挂掉了。
- 客户端突然因为网络原因连接不上数据库了。
- 并发访问数据库时,多个线程同时写入数据库,覆盖了彼此的更改。
-- ......
+- ……
上面的任何一个问题都可能会导致数据的不一致性。为了保证数据的一致性,系统必须能够处理这些问题。事务就是我们抽象出来简化这些问题的首选机制。事务的概念起源于数据库,目前,已经成为一个比较广泛的概念。
@@ -310,7 +627,7 @@ SELECT sql_no_cache COUNT(*) FROM usr;

-### 何谓数据库事务?
+### 什么是数据库事务?
大多数情况下,我们在谈论事务的时候,如果没有特指**分布式事务**,往往指的就是**数据库事务**。
@@ -365,9 +682,9 @@ COMMIT;
一个事务读取数据并且对数据进行了修改,这个修改对其他事务来说是可见的,即使当前事务没有提交。这时另外一个事务读取了这个还未提交的数据,但第一个事务突然回滚,导致数据并没有被提交到数据库,那第二个事务读取到的就是脏数据,这也就是脏读的由来。
-例如:事务 1 读取某表中的数据 A=20,事务 1 修改 A=A-1,事务 2 读取到 A = 19,事务 1 回滚导致对 A 的修改并为提交到数据库, A 的值还是 20。
+例如:事务 1 读取某表中的数据 A=20,事务 1 修改 A=A-1,事务 2 读取到 A = 19,事务 1 回滚导致对 A 的修改并未提交到数据库, A 的值还是 20。
-
+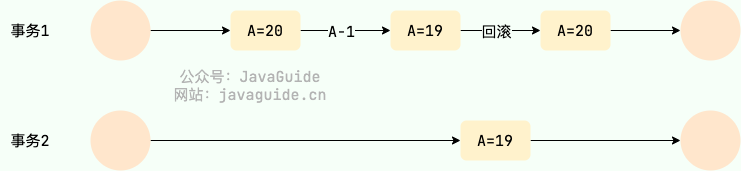
#### 丢失修改(Lost to modify)
@@ -375,7 +692,7 @@ COMMIT;
例如:事务 1 读取某表中的数据 A=20,事务 2 也读取 A=20,事务 1 先修改 A=A-1,事务 2 后来也修改 A=A-1,最终结果 A=19,事务 1 的修改被丢失。
-
+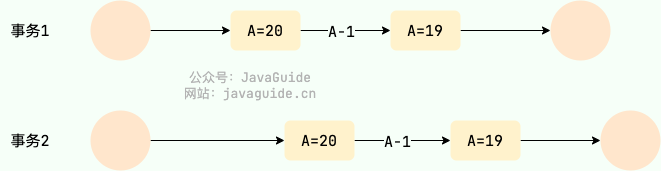
#### 不可重复读(Unrepeatable read)
@@ -383,7 +700,7 @@ COMMIT;
例如:事务 1 读取某表中的数据 A=20,事务 2 也读取 A=20,事务 1 修改 A=A-1,事务 2 再次读取 A =19,此时读取的结果和第一次读取的结果不同。
-
+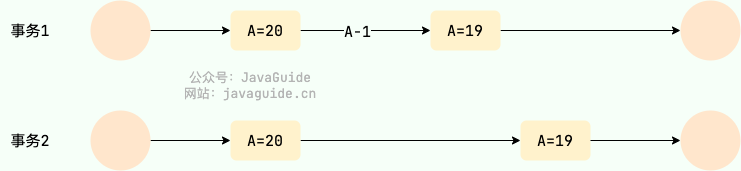
#### 幻读(Phantom read)
@@ -391,14 +708,14 @@ COMMIT;
例如:事务 2 读取某个范围的数据,事务 1 在这个范围插入了新的数据,事务 2 再次读取这个范围的数据发现相比于第一次读取的结果多了新的数据。
-
+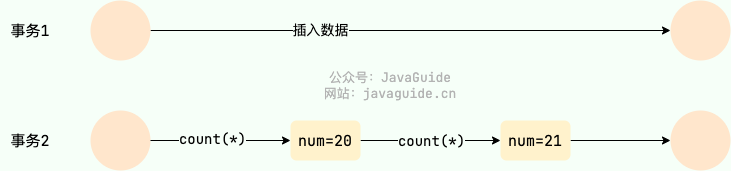
### 不可重复读和幻读有什么区别?
- 不可重复读的重点是内容修改或者记录减少比如多次读取一条记录发现其中某些记录的值被修改;
- 幻读的重点在于记录新增比如多次执行同一条查询语句(DQL)时,发现查到的记录增加了。
-幻读其实可以看作是不可重复读的一种特殊情况,单独把区分幻读的原因主要是解决幻读和不可重复读的方案不一样。
+幻读其实可以看作是不可重复读的一种特殊情况,单独把幻读区分出来的原因主要是解决幻读和不可重复读的方案不一样。
举个例子:执行 `delete` 和 `update` 操作的时候,可以直接对记录加锁,保证事务安全。而执行 `insert` 操作的时候,由于记录锁(Record Lock)只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁(Gap Lock)。也就是说执行 `insert` 操作的时候需要依赖 Next-Key Lock(Record Lock+Gap Lock) 进行加锁来保证不出现幻读。
@@ -406,7 +723,7 @@ COMMIT;
MySQL 中并发事务的控制方式无非就两种:**锁** 和 **MVCC**。锁可以看作是悲观控制的模式,多版本并发控制(MVCC,Multiversion concurrency control)可以看作是乐观控制的模式。
-**锁** 控制方式下会通过锁来显示控制共享资源而不是通过调度手段,MySQL 中主要是通过 **读写锁** 来实现并发控制。
+**锁** 控制方式下会通过锁来显式控制共享资源而不是通过调度手段,MySQL 中主要是通过 **读写锁** 来实现并发控制。
- **共享锁(S 锁)**:又称读锁,事务在读取记录的时候获取共享锁,允许多个事务同时获取(锁兼容)。
- **排他锁(X 锁)**:又称写锁/独占锁,事务在修改记录的时候获取排他锁,不允许多个事务同时获取。如果一个记录已经被加了排他锁,那其他事务不能再对这条记录加任何类型的锁(锁不兼容)。
@@ -424,31 +741,26 @@ MVCC 在 MySQL 中实现所依赖的手段主要是: **隐藏字段、read view
### SQL 标准定义了哪些事务隔离级别?
-SQL 标准定义了四个隔离级别:
-
-- **READ-UNCOMMITTED(读取未提交)**:最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
-- **READ-COMMITTED(读取已提交)**:允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
-- **REPEATABLE-READ(可重复读)**:对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
-- **SERIALIZABLE(可串行化)**:最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
-
----
+SQL 标准定义了四种事务隔离级别,用来平衡事务的隔离性(Isolation)和并发性能。级别越高,数据一致性越好,但并发性能可能越低。这四个级别是:
-| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
-| :--------------: | :--: | :--------: | :--: |
-| READ-UNCOMMITTED | √ | √ | √ |
-| READ-COMMITTED | × | √ | √ |
-| REPEATABLE-READ | × | × | √ |
-| SERIALIZABLE | × | × | × |
+- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。这种级别在实际应用中很少使用,因为它对数据一致性的保证太弱。
+- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。这是大多数数据库(如 Oracle, SQL Server)的默认隔离级别。
+- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。MySQL InnoDB 存储引擎的默认隔离级别正是 REPEATABLE READ。并且,InnoDB 在此级别下通过 MVCC(多版本并发控制) 和 Next-Key Locks(间隙锁+行锁) 机制,在很大程度上解决了幻读问题。
+- **SERIALIZABLE(可串行化)** :最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
-### MySQL 的隔离级别是基于锁实现的吗?
-
-MySQL 的隔离级别基于锁和 MVCC 机制共同实现的。
-
-SERIALIZABLE 隔离级别是通过锁来实现的,READ-COMMITTED 和 REPEATABLE-READ 隔离级别是基于 MVCC 实现的。不过, SERIALIZABLE 之外的其他隔离级别可能也需要用到锁机制,就比如 REPEATABLE-READ 在当前读情况下需要使用加锁读来保证不会出现幻读。
+| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (Non-Repeatable Read) | 幻读 (Phantom Read) |
+| ---------------- | ----------------- | -------------------------------- | ---------------------- |
+| READ UNCOMMITTED | √ | √ | √ |
+| READ COMMITTED | × | √ | √ |
+| REPEATABLE READ | × | × | √ (标准) / ≈× (InnoDB) |
+| SERIALIZABLE | × | × | × |
### MySQL 的默认隔离级别是什么?
-MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
+MySQL InnoDB 存储引擎的默认隔离级别是 **REPEATABLE READ**。可以通过以下命令查看:
+
+- MySQL 8.0 之前:`SELECT @@tx_isolation;`
+- MySQL 8.0 及之后:`SELECT @@transaction_isolation;`
```sql
mysql> SELECT @@tx_isolation;
@@ -461,6 +773,12 @@ mysql> SELECT @@tx_isolation;
关于 MySQL 事务隔离级别的详细介绍,可以看看我写的这篇文章:[MySQL 事务隔离级别详解](./transaction-isolation-level.md)。
+### MySQL 的隔离级别是基于锁实现的吗?
+
+MySQL 的隔离级别基于锁和 MVCC 机制共同实现的。
+
+SERIALIZABLE 隔离级别是通过锁来实现的,READ-COMMITTED 和 REPEATABLE-READ 隔离级别是基于 MVCC 实现的。不过, SERIALIZABLE 之外的其他隔离级别可能也需要用到锁机制,就比如 REPEATABLE-READ 在当前读情况下需要使用加锁读来保证不会出现幻读。
+
## MySQL 锁
锁是一种常见的并发事务的控制方式。
@@ -486,14 +804,12 @@ InnoDB 的行锁是针对索引字段加的锁,表级锁是针对非索引字
InnoDB 行锁是通过对索引数据页上的记录加锁实现的,MySQL InnoDB 支持三种行锁定方式:
-- **记录锁(Record Lock)**:也被称为记录锁,属于单个行记录上的锁。
+- **记录锁(Record Lock)**:属于单个行记录上的锁。
- **间隙锁(Gap Lock)**:锁定一个范围,不包括记录本身。
- **临键锁(Next-Key Lock)**:Record Lock+Gap Lock,锁定一个范围,包含记录本身,主要目的是为了解决幻读问题(MySQL 事务部分提到过)。记录锁只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁。
**在 InnoDB 默认的隔离级别 REPEATABLE-READ 下,行锁默认使用的是 Next-Key Lock。但是,如果操作的索引是唯一索引或主键,InnoDB 会对 Next-Key Lock 进行优化,将其降级为 Record Lock,即仅锁住索引本身,而不是范围。**
-一些大厂面试中可能会问到 Next-Key Lock 的加锁范围,这里推荐一篇文章:[MySQL next-key lock 加锁范围是什么? - 程序员小航 - 2021](https://segmentfault.com/a/1190000040129107) 。
-
### 共享锁和排他锁呢?
不论是表级锁还是行级锁,都存在共享锁(Share Lock,S 锁)和排他锁(Exclusive Lock,X 锁)这两类:
@@ -511,8 +827,10 @@ InnoDB 行锁是通过对索引数据页上的记录加锁实现的,MySQL Inno
由于 MVCC 的存在,对于一般的 `SELECT` 语句,InnoDB 不会加任何锁。不过, 你可以通过以下语句显式加共享锁或排他锁。
```sql
-# 共享锁
+# 共享锁 可以在 MySQL 5.7 和 MySQL 8.0 中使用
SELECT ... LOCK IN SHARE MODE;
+# 共享锁 可以在 MySQL 8.0 中使用
+SELECT ... FOR SHARE;
# 排他锁
SELECT ... FOR UPDATE;
```
@@ -526,7 +844,7 @@ SELECT ... FOR UPDATE;
- **意向共享锁(Intention Shared Lock,IS 锁)**:事务有意向对表中的某些记录加共享锁(S 锁),加共享锁前必须先取得该表的 IS 锁。
- **意向排他锁(Intention Exclusive Lock,IX 锁)**:事务有意向对表中的某些记录加排他锁(X 锁),加排他锁之前必须先取得该表的 IX 锁。
-**意向锁是由数据引擎自己维护的,用户无法手动操作意向锁,在为数据行加共享/排他锁之前,InooDB 会先获取该数据行所在在数据表的对应意向锁。**
+**意向锁是由数据引擎自己维护的,用户无法手动操作意向锁,在为数据行加共享/排他锁之前,InnoDB 会先获取该数据行所在在数据表的对应意向锁。**
意向锁之间是互相兼容的。
@@ -552,7 +870,10 @@ SELECT ... FOR UPDATE;
```sql
SELECT ... FOR UPDATE
-SELECT ... LOCK IN SHARE MODE
+# 共享锁 可以在 MySQL 5.7 和 MySQL 8.0 中使用
+SELECT ... LOCK IN SHARE MODE;
+# 共享锁 可以在 MySQL 8.0 中使用
+SELECT ... FOR SHARE;
```
快照即记录的历史版本,每行记录可能存在多个历史版本(多版本技术)。
@@ -575,6 +896,8 @@ SELECT ... LOCK IN SHARE MODE
SELECT...FOR UPDATE
# 对读的记录加一个S锁
SELECT...LOCK IN SHARE MODE
+# 对读的记录加一个S锁
+SELECT...FOR SHARE
# 对修改的记录加一个X锁
INSERT...
UPDATE...
@@ -589,8 +912,8 @@ DELETE...
```sql
CREATE TABLE `sequence_id` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
- `stub` char(10) NOT NULL DEFAULT '',
+ `id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT,
+ `stub` CHAR(10) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
@@ -614,7 +937,7 @@ CREATE TABLE `sequence_id` (
最后,再推荐一篇文章:[为什么 MySQL 的自增主键不单调也不连续](https://draveness.me/whys-the-design-mysql-auto-increment/) 。
-## MySQL 性能优化
+## ⭐️MySQL 性能优化
关于 MySQL 性能优化的建议总结,请看这篇文章:[MySQL 高性能优化规范建议总结](./mysql-high-performance-optimization-specification-recommendations.md) 。
@@ -630,8 +953,6 @@ CREATE TABLE `sequence_id` (
**数据库只存储文件地址信息,文件由文件存储服务负责存储。**
-相关阅读:[Spring Boot 整合 MinIO 实现分布式文件服务](https://www.51cto.com/article/716978.html) 。
-
### MySQL 如何存储 IP 地址?
可以将 IP 地址转换成整形数据存储,性能更好,占用空间也更小。
@@ -645,10 +966,12 @@ MySQL 提供了两个方法来处理 ip 地址
### 有哪些常见的 SQL 优化手段?
-[《Java 面试指北》(付费)](../../zhuanlan/java-mian-shi-zhi-bei.md) 的 **「技术面试题篇」** 有一篇文章详细介绍了常见的 SQL 优化手段,非常全面,清晰易懂!
+[《Java 面试指北》(付费)](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 的 **「技术面试题篇」** 有一篇文章详细介绍了常见的 SQL 优化手段,非常全面,清晰易懂!

+文章地址:https://www.yuque.com/snailclimb/mf2z3k/abc2sv (密码获取:)。
+
### 如何分析 SQL 的性能?
我们可以使用 `EXPLAIN` 命令来分析 SQL 的 **执行计划** 。执行计划是指一条 SQL 语句在经过 MySQL 查询优化器的优化会后,具体的执行方式。
@@ -694,6 +1017,53 @@ mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
读写分离和分库分表相关的问题比较多,于是,我单独写了一篇文章来介绍:[读写分离和分库分表详解](../../high-performance/read-and-write-separation-and-library-subtable.md)。
+### 深度分页如何优化?
+
+[深度分页介绍及优化建议](../../high-performance/deep-pagination-optimization.md)
+
+### 数据冷热分离如何做?
+
+[数据冷热分离详解](../../high-performance/data-cold-hot-separation.md)
+
+### MySQL 性能怎么优化?
+
+MySQL 性能优化是一个系统性工程,涉及多个方面,在面试中不可能面面俱到。因此,建议按照“点-线-面”的思路展开,从核心问题入手,再逐步扩展,展示出你对问题的思考深度和解决能力。
+
+**1. 抓住核心:慢 SQL 定位与分析**
+
+性能优化的第一步永远是找到瓶颈。面试时,建议先从 **慢 SQL 定位和分析** 入手,这不仅能展示你解决问题的思路,还能体现你对数据库性能监控的熟练掌握:
+
+- **监控工具:** 介绍常用的慢 SQL 监控工具,如 **MySQL 慢查询日志**、**Performance Schema** 等,说明你对这些工具的熟悉程度以及如何通过它们定位问题。
+- **EXPLAIN 命令:** 详细说明 `EXPLAIN` 命令的使用,分析查询计划、索引使用情况,可以结合实际案例展示如何解读分析结果,比如执行顺序、索引使用情况、全表扫描等。
+
+**2. 由点及面:索引、表结构和 SQL 优化**
+
+定位到慢 SQL 后,接下来就要针对具体问题进行优化。 这里可以重点介绍索引、表结构和 SQL 编写规范等方面的优化技巧:
+
+- **索引优化:** 这是 MySQL 性能优化的重点,可以介绍索引的创建原则、覆盖索引、最左前缀匹配原则等。如果能结合你项目的实际应用来说明如何选择合适的索引,会更加分一些。
+- **表结构优化:** 优化表结构设计,包括选择合适的字段类型、避免冗余字段、合理使用范式和反范式设计等等。
+- **SQL 优化:** 避免使用 `SELECT *`、尽量使用具体字段、使用连接查询代替子查询、合理使用分页查询、批量操作等,都是 SQL 编写过程中需要注意的细节。
+
+**3. 进阶方案:架构优化**
+
+当面试官对基础优化知识比较满意时,可能会深入探讨一些架构层面的优化方案。以下是一些常见的架构优化策略:
+
+- **读写分离:** 将读操作和写操作分离到不同的数据库实例,提升数据库的并发处理能力。
+- **分库分表:** 将数据分散到多个数据库实例或数据表中,降低单表数据量,提升查询效率。但要权衡其带来的复杂性和维护成本,谨慎使用。
+- **数据冷热分离**:根据数据的访问频率和业务重要性,将数据分为冷数据和热数据,冷数据一般存储在低成本、低性能的介质中,热数据存储在高性能存储介质中。
+- **缓存机制:** 使用 Redis 等缓存中间件,将热点数据缓存到内存中,减轻数据库压力。这个非常常用,提升效果非常明显,性价比极高!
+
+**4. 其他优化手段**
+
+除了慢 SQL 定位、索引优化和架构优化,还可以提及一些其他优化手段,展示你对 MySQL 性能调优的全面理解:
+
+- **连接池配置:** 配置合理的数据库连接池(如 **连接池大小**、**超时时间** 等),能够有效提升数据库连接的效率,避免频繁的连接开销。
+- **硬件配置:** 提升硬件性能也是优化的重要手段之一。使用高性能服务器、增加内存、使用 **SSD** 硬盘等硬件升级,都可以有效提升数据库的整体性能。
+
+**5.总结**
+
+在面试中,建议按优先级依次介绍慢 SQL 定位、[索引优化](./mysql-index.md)、表结构设计和 [SQL 优化](../../high-performance/sql-optimization.md)等内容。架构层面的优化,如[读写分离和分库分表](../../high-performance/read-and-write-separation-and-library-subtable.md)、[数据冷热分离](../../high-performance/data-cold-hot-separation.md) 应作为最后的手段,除非在特定场景下有明显的性能瓶颈,否则不应轻易使用,因其引入的复杂性会带来额外的维护成本。
+
## MySQL 学习资料推荐
[**书籍推荐**](../../books/database.md#mysql) 。
@@ -712,6 +1082,7 @@ mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
- 《高性能 MySQL》第 7 章 MySQL 高级特性
- 《MySQL 技术内幕 InnoDB 存储引擎》第 6 章 锁
- Relational Database:
+- 一篇文章看懂 mysql 中 varchar 能存多少汉字、数字,以及 varchar(100)和 varchar(10)的区别:
- 技术分享 | 隔离级别:正确理解幻读:
- MySQL Server Logs - MySQL 5.7 Reference Manual:
- Redo Log - MySQL 5.7 Reference Manual:
@@ -720,3 +1091,5 @@ mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
- 详解 MySQL InnoDB 中意向锁的作用:
- 深入剖析 MySQL 自增锁:
- 在数据库中不可重复读和幻读到底应该怎么分?:
+
+
diff --git a/docs/database/mysql/some-thoughts-on-database-storage-time.md b/docs/database/mysql/some-thoughts-on-database-storage-time.md
index e295fb44f4b..2cca50eb2a8 100644
--- a/docs/database/mysql/some-thoughts-on-database-storage-time.md
+++ b/docs/database/mysql/some-thoughts-on-database-storage-time.md
@@ -1,34 +1,46 @@
---
-title: MySQL时间类型数据存储建议
+title: MySQL日期类型选择建议
+description: 深入对比MySQL中DATETIME和TIMESTAMP的区别,分析时区处理、存储空间、取值范围等差异,给出日期类型选择的最佳实践建议。
category: 数据库
tag:
- MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL时间存储,DATETIME,TIMESTAMP,时间戳,时区处理,日期类型选择,MySQL日期函数
---
-我们平时开发中不可避免的就是要存储时间,比如我们要记录操作表中这条记录的时间、记录转账的交易时间、记录出发时间等等。你会发现时间这个东西与我们开发的联系还是非常紧密的,用的好与不好会给我们的业务甚至功能带来很大的影响。所以,我们有必要重新出发,好好认识一下这个东西。
+在日常的软件开发工作中,存储时间是一项基础且常见的需求。无论是记录数据的操作时间、金融交易的发生时间,还是行程的出发时间、用户的下单时间等等,时间信息与我们的业务逻辑和系统功能紧密相关。因此,正确选择和使用 MySQL 的日期时间类型至关重要,其恰当与否甚至可能对业务的准确性和系统的稳定性产生显著影响。
-这是一篇短小精悍的文章,仔细阅读一定能学到不少东西!
+本文旨在帮助开发者重新审视并深入理解 MySQL 中不同的时间存储方式,以便做出更合适项目业务场景的选择。
## 不要用字符串存储日期
-我记得我在大学的时候就这样干过,而且现在很多对数据库不太了解的新手也会这样干,可见,这种存储日期的方式的优点还是有的,就是简单直白,容易上手。
+和许多数据库初学者一样,笔者在早期学习阶段也曾尝试使用字符串(如 VARCHAR)类型来存储日期和时间,甚至一度认为这是一种简单直观的方法。毕竟,'YYYY-MM-DD HH:MM:SS' 这样的格式看起来清晰易懂。
但是,这是不正确的做法,主要会有下面两个问题:
-1. 字符串占用的空间更大!
-2. 字符串存储的日期效率比较低(逐个字符进行比对),无法用日期相关的 API 进行计算和比较。
+1. **空间效率**:与 MySQL 内建的日期时间类型相比,字符串通常需要占用更多的存储空间来表示相同的时间信息。
+2. **查询与计算效率低下**:
+ - **比较操作复杂且低效**:基于字符串的日期比较需要按照字典序逐字符进行,这不仅不直观(例如,'2024-05-01' 会小于 '2024-1-10'),而且效率远低于使用原生日期时间类型进行的数值或时间点比较。
+ - **计算功能受限**:无法直接利用数据库提供的丰富日期时间函数进行运算(例如,计算两个日期之间的间隔、对日期进行加减操作等),需要先转换格式,增加了复杂性。
+ - **索引性能不佳**:基于字符串的索引在处理范围查询(如查找特定时间段内的数据)时,其效率和灵活性通常不如原生日期时间类型的索引。
-## Datetime 和 Timestamp 之间抉择
+## DATETIME 和 TIMESTAMP 选择
-Datetime 和 Timestamp 是 MySQL 提供的两种比较相似的保存时间的数据类型。他们两者究竟该如何选择呢?
+`DATETIME` 和 `TIMESTAMP` 是 MySQL 中两种非常常用的、用于存储包含日期和时间信息的数据类型。它们都可以存储精确到秒(MySQL 5.6.4+ 支持更高精度的小数秒)的时间值。那么,在实际应用中,我们应该如何在这两者之间做出选择呢?
-**通常我们都会首选 Timestamp。** 下面说一下为什么这样做!
+下面我们从几个关键维度对它们进行对比:
-### DateTime 类型没有时区信息
+### 时区信息
-**DateTime 类型是没有时区信息的(时区无关)** ,DateTime 类型保存的时间都是当前会话所设置的时区对应的时间。这样就会有什么问题呢?当你的时区更换之后,比如你的服务器更换地址或者更换客户端连接时区设置的话,就会导致你从数据库中读出的时间错误。不要小看这个问题,很多系统就是因为这个问题闹出了很多笑话。
+`DATETIME` 类型存储的是**字面量的日期和时间值**,它本身**不包含任何时区信息**。当你插入一个 `DATETIME` 值时,MySQL 存储的就是你提供的那个确切的时间,不会进行任何时区转换。
-**Timestamp 和时区有关**。Timestamp 类型字段的值会随着服务器时区的变化而变化,自动换算成相应的时间,说简单点就是在不同时区,查询到同一个条记录此字段的值会不一样。
+**这样就会有什么问题呢?** 如果你的应用需要支持多个时区,或者服务器、客户端的时区可能发生变化,那么使用 `DATETIME` 时,应用程序需要自行处理时区的转换和解释。如果处理不当(例如,假设所有存储的时间都属于同一个时区,但实际环境变化了),可能会导致时间显示或计算上的混乱。
+
+**`TIMESTAMP` 和时区有关**。存储时,MySQL 会将当前会话时区下的时间值转换成 UTC(协调世界时)进行内部存储。当查询 `TIMESTAMP` 字段时,MySQL 又会将存储的 UTC 时间转换回当前会话所设置的时区来显示。
+
+这意味着,对于同一条记录的 `TIMESTAMP` 字段,在不同的会话时区设置下查询,可能会看到不同的本地时间表示,但它们都对应着同一个绝对时间点(UTC 时间)。这对于需要全球化、多时区支持的应用来说非常有用。
下面实际演示一下!
@@ -43,21 +55,21 @@ CREATE TABLE `time_zone_test` (
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
```
-插入数据:
+插入一条数据(假设当前会话时区为系统默认,例如 UTC+0)::
```sql
INSERT INTO time_zone_test(date_time,time_stamp) VALUES(NOW(),NOW());
```
-查看数据:
+查询数据(在同一时区会话下):
```sql
-select date_time,time_stamp from time_zone_test;
+SELECT date_time, time_stamp FROM time_zone_test;
```
结果:
-```
+```plain
+---------------------+---------------------+
| date_time | time_stamp |
+---------------------+---------------------+
@@ -65,17 +77,16 @@ select date_time,time_stamp from time_zone_test;
+---------------------+---------------------+
```
-现在我们运行
-
-修改当前会话的时区:
+现在,修改当前会话的时区为东八区 (UTC+8):
```sql
-set time_zone='+8:00';
+SET time_zone = '+8:00';
```
-再次查看数据:
+再次查询数据:
-```
+```bash
+# TIMESTAMP 的值自动转换为 UTC+8 时间
+---------------------+---------------------+
| date_time | time_stamp |
+---------------------+---------------------+
@@ -83,7 +94,7 @@ set time_zone='+8:00';
+---------------------+---------------------+
```
-**扩展:一些关于 MySQL 时区设置的一个常用 sql 命令**
+**扩展:MySQL 时区设置常用 SQL 命令**
```sql
# 查看当前会话时区
@@ -98,30 +109,32 @@ SET GLOBAL time_zone = '+8:00';
SET GLOBAL time_zone = 'Europe/Helsinki';
```
-### DateTime 类型耗费空间更大
+### 占用空间
-Timestamp 只需要使用 4 个字节的存储空间,但是 DateTime 需要耗费 8 个字节的存储空间。但是,这样同样造成了一个问题,Timestamp 表示的时间范围更小。
+下图是 MySQL 日期类型所占的存储空间(官方文档传送门:):
-- DateTime:1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
-- Timestamp:1970-01-01 00:00:01 ~ 2037-12-31 23:59:59
+
-> Timestamp 在不同版本的 MySQL 中有细微差别。
+在 MySQL 5.6.4 之前,DateTime 和 TIMESTAMP 的存储空间是固定的,分别为 8 字节和 4 字节。但是从 MySQL 5.6.4 开始,它们的存储空间会根据毫秒精度的不同而变化,DateTime 的范围是 5~8 字节,TIMESTAMP 的范围是 4~7 字节。
-## 再看 MySQL 日期类型存储空间
+### 表示范围
-下图是 MySQL 5.6 版本中日期类型所占的存储空间:
+`TIMESTAMP` 表示的时间范围更小,只能到 2038 年:
-
+- `DATETIME`:'1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999'
+- `TIMESTAMP`:'1970-01-01 00:00:01.000000' UTC 到 '2038-01-19 03:14:07.999999' UTC
-可以看出 5.6.4 之后的 MySQL 多出了一个需要 0 ~ 3 字节的小数位。DateTime 和 Timestamp 会有几种不同的存储空间占用。
+### 性能
-为了方便,本文我们还是默认 Timestamp 只需要使用 4 个字节的存储空间,但是 DateTime 需要耗费 8 个字节的存储空间。
+由于 `TIMESTAMP` 在存储和检索时需要进行 UTC 与当前会话时区的转换,这个过程可能涉及到额外的计算开销,尤其是在需要调用操作系统底层接口获取或处理时区信息时。虽然现代数据库和操作系统对此进行了优化,但在某些极端高并发或对延迟极其敏感的场景下,`DATETIME` 因其不涉及时区转换,处理逻辑相对更简单直接,可能会表现出微弱的性能优势。
-## 数值型时间戳是更好的选择吗?
+为了获得可预测的行为并可能减少 `TIMESTAMP` 的转换开销,推荐的做法是在应用程序层面统一管理时区,或者在数据库连接/会话级别显式设置 `time_zone` 参数,而不是依赖服务器的默认或操作系统时区。
-很多时候,我们也会使用 int 或者 bigint 类型的数值也就是时间戳来表示时间。
+## 数值时间戳是更好的选择吗?
-这种存储方式的具有 Timestamp 类型的所具有一些优点,并且使用它的进行日期排序以及对比等操作的效率会更高,跨系统也很方便,毕竟只是存放的数值。缺点也很明显,就是数据的可读性太差了,你无法直观的看到具体时间。
+除了上述两种类型,实践中也常用整数类型(`INT` 或 `BIGINT`)来存储所谓的“Unix 时间戳”(即从 1970 年 1 月 1 日 00:00:00 UTC 起至目标时间的总秒数,或毫秒数)。
+
+这种存储方式的具有 `TIMESTAMP` 类型的所具有一些优点,并且使用它的进行日期排序以及对比等操作的效率会更高,跨系统也很方便,毕竟只是存放的数值。缺点也很明显,就是数据的可读性太差了,你无法直观的看到具体时间。
时间戳的定义如下:
@@ -130,7 +143,8 @@ Timestamp 只需要使用 4 个字节的存储空间,但是 DateTime 需要耗
数据库中实际操作:
```sql
-mysql> select UNIX_TIMESTAMP('2020-01-11 09:53:32');
+-- 将日期时间字符串转换为 Unix 时间戳 (秒)
+mysql> SELECT UNIX_TIMESTAMP('2020-01-11 09:53:32');
+---------------------------------------+
| UNIX_TIMESTAMP('2020-01-11 09:53:32') |
+---------------------------------------+
@@ -138,7 +152,8 @@ mysql> select UNIX_TIMESTAMP('2020-01-11 09:53:32');
+---------------------------------------+
1 row in set (0.00 sec)
-mysql> select FROM_UNIXTIME(1578707612);
+-- 将 Unix 时间戳 (秒) 转换为日期时间格式
+mysql> SELECT FROM_UNIXTIME(1578707612);
+---------------------------+
| FROM_UNIXTIME(1578707612) |
+---------------------------+
@@ -147,14 +162,41 @@ mysql> select FROM_UNIXTIME(1578707612);
1 row in set (0.01 sec)
```
+## PostgreSQL 中没有 DATETIME
+
+由于有读者提到 PostgreSQL(PG) 的时间类型,因此这里拓展补充一下。PG 官方文档对时间类型的描述地址:。
+
+
+
+可以看到,PG 没有名为 `DATETIME` 的类型:
+
+- PG 的 `TIMESTAMP WITHOUT TIME ZONE`在功能上最接近 MySQL 的 `DATETIME`。它存储日期和时间,但不包含任何时区信息,存储的是字面值。
+- PG 的`TIMESTAMP WITH TIME ZONE` (或 `TIMESTAMPTZ`) 相当于 MySQL 的 `TIMESTAMP`。它在存储时会将输入值转换为 UTC,并在检索时根据当前会话的时区进行转换显示。
+
+对于绝大多数需要记录精确发生时间点的应用场景,`TIMESTAMPTZ`是 PostgreSQL 中最推荐、最健壮的选择,因为它能最好地处理时区复杂性。
+
## 总结
-MySQL 中时间到底怎么存储才好?Datetime?Timestamp? 数值保存的时间戳?
+MySQL 中时间到底怎么存储才好?`DATETIME`?`TIMESTAMP`?还是数值时间戳?
-好像并没有一个银弹,很多程序员会觉得数值型时间戳是真的好,效率又高还各种兼容,但是很多人又觉得它表现的不够直观。这里插一嘴,《高性能 MySQL 》这本神书的作者就是推荐 Timestamp,原因是数值表示时间不够直观。下面是原文:
+并没有一个银弹,很多程序员会觉得数值型时间戳是真的好,效率又高还各种兼容,但是很多人又觉得它表现的不够直观。
+
+《高性能 MySQL 》这本神书的作者就是推荐 TIMESTAMP,原因是数值表示时间不够直观。下面是原文:
 -每种方式都有各自的优势,根据实际场景才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
+每种方式都有各自的优势,根据实际场景选择最合适的才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
+
+| 类型 | 存储空间 | 日期格式 | 日期范围 | 是否带时区信息 |
+| ------------ | -------- | ------------------------------ | ------------------------------------------------------------ | -------------- |
+| DATETIME | 5~8 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1000-01-01 00:00:00[.000000] ~ 9999-12-31 23:59:59[.999999] | 否 |
+| TIMESTAMP | 4~7 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1970-01-01 00:00:01[.000000] ~ 2038-01-19 03:14:07[.999999] | 是 |
+| 数值型时间戳 | 4 字节 | 全数字如 1578707612 | 1970-01-01 00:00:01 之后的时间 | 否 |
+
+**选择建议小结:**
+
+- `TIMESTAMP` 的核心优势在于其内建的时区处理能力。数据库负责 UTC 存储和基于会话时区的自动转换,简化了需要处理多时区应用的开发。如果应用需要处理多时区,或者希望数据库能自动管理时区转换,`TIMESTAMP` 是自然的选择(注意其时间范围限制,也就是 2038 年问题)。
+- 如果应用场景不涉及时区转换,或者希望应用程序完全控制时区逻辑,并且需要表示 2038 年之后的时间,`DATETIME` 是更稳妥的选择。
+- 如果极度关注比较性能,或者需要频繁跨系统传递时间数据,并且可以接受可读性的牺牲(或总是在应用层转换),数值时间戳是一个强大的选项。
-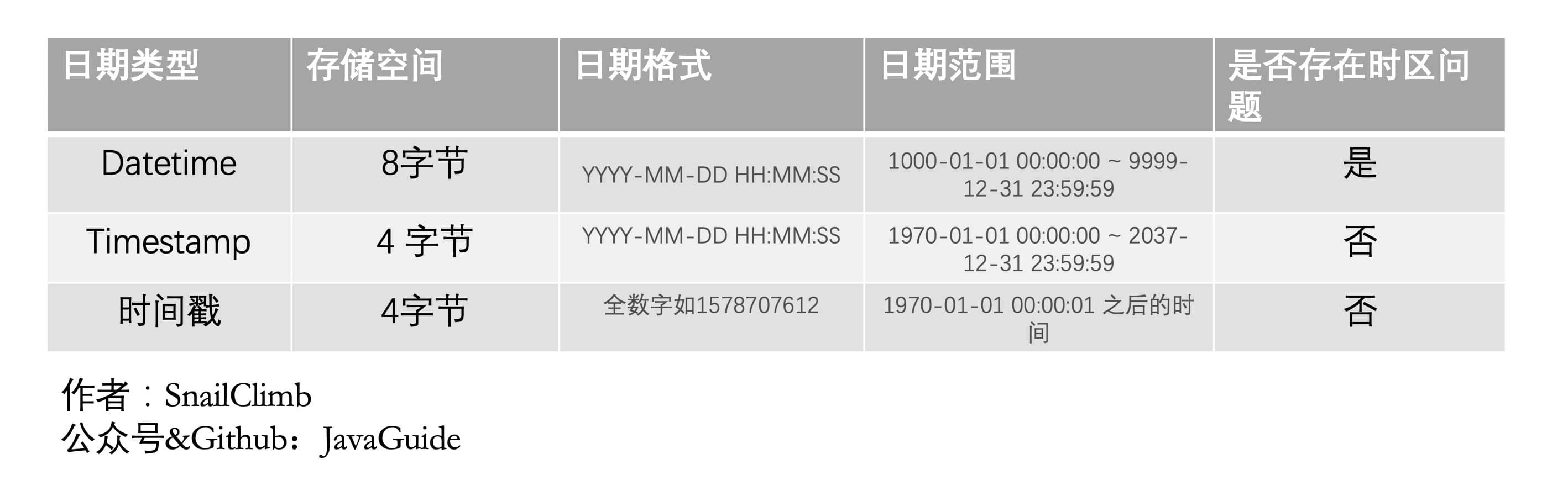
+
diff --git a/docs/database/mysql/transaction-isolation-level.md b/docs/database/mysql/transaction-isolation-level.md
index 647b80ee6eb..4ee2cabc95a 100644
--- a/docs/database/mysql/transaction-isolation-level.md
+++ b/docs/database/mysql/transaction-isolation-level.md
@@ -1,8 +1,13 @@
---
title: MySQL事务隔离级别详解
+description: 详解MySQL四种事务隔离级别(读未提交、读已提交、可重复读、串行化)的特点与区别,分析脏读、不可重复读、幻读等并发问题,以及InnoDB如何通过MVCC和锁机制解决幻读。
category: 数据库
tag:
- MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL事务隔离级别,读未提交,读已提交,可重复读,串行化,脏读,不可重复读,幻读,MVCC,间隙锁
---
> 本文由 [SnailClimb](https://github.com/Snailclimb) 和 [guang19](https://github.com/guang19) 共同完成。
@@ -11,43 +16,46 @@ tag:
## 事务隔离级别总结
-SQL 标准定义了四个隔离级别:
+SQL 标准定义了四种事务隔离级别,用来平衡事务的隔离性(Isolation)和并发性能。级别越高,数据一致性越好,但并发性能可能越低。这四个级别是:
-- **READ-UNCOMMITTED(读取未提交)**:最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
-- **READ-COMMITTED(读取已提交)**:允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
-- **REPEATABLE-READ(可重复读)**:对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
-- **SERIALIZABLE(可串行化)**:最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
+- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。这种级别在实际应用中很少使用,因为它对数据一致性的保证太弱。
+- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。这是大多数数据库(如 Oracle, SQL Server)的默认隔离级别。
+- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。MySQL InnoDB 存储引擎的默认隔离级别正是 REPEATABLE READ。并且,InnoDB 在此级别下通过 MVCC(多版本并发控制) 和 Next-Key Locks(间隙锁+行锁) 机制,在很大程度上解决了幻读问题。
+- **SERIALIZABLE(可串行化)** :最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
----
+| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (Non-Repeatable Read) | 幻读 (Phantom Read) |
+| ---------------- | ----------------- | -------------------------------- | ---------------------- |
+| READ UNCOMMITTED | √ | √ | √ |
+| READ COMMITTED | × | √ | √ |
+| REPEATABLE READ | × | × | √ (标准) / ≈× (InnoDB) |
+| SERIALIZABLE | × | × | × |
-| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
-| :--------------: | :--: | :--------: | :--: |
-| READ-UNCOMMITTED | √ | √ | √ |
-| READ-COMMITTED | × | √ | √ |
-| REPEATABLE-READ | × | × | √ |
-| SERIALIZABLE | × | × | × |
+**默认级别查询:**
-MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
+MySQL InnoDB 存储引擎的默认隔离级别是 **REPEATABLE READ**。可以通过以下命令查看:
-```sql
-MySQL> SELECT @@tx_isolation;
-+-----------------+
-| @@tx_isolation |
-+-----------------+
-| REPEATABLE-READ |
-+-----------------+
+- MySQL 8.0 之前:`SELECT @@tx_isolation;`
+- MySQL 8.0 及之后:`SELECT @@transaction_isolation;`
+
+```bash
+mysql> SELECT @@transaction_isolation;
++-------------------------+
+| @@transaction_isolation |
++-------------------------+
+| REPEATABLE-READ |
++-------------------------+
```
-从上面对 SQL 标准定义了四个隔离级别的介绍可以看出,标准的 SQL 隔离级别定义里,REPEATABLE-READ(可重复读)是不可以防止幻读的。
+**InnoDB 的 REPEATABLE READ 对幻读的处理:**
-但是!InnoDB 实现的 REPEATABLE-READ 隔离级别其实是可以解决幻读问题发生的,主要有下面两种情况:
+标准的 SQL 隔离级别定义里,REPEATABLE READ 是无法防止幻读的。但 InnoDB 的实现通过以下机制很大程度上避免了幻读:
-- **快照读**:由 MVCC 机制来保证不出现幻读。
-- **当前读**:使用 Next-Key Lock 进行加锁来保证不出现幻读,Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的结合,行锁只能锁住已经存在的行,为了避免插入新行,需要依赖间隙锁。
+- **快照读 (Snapshot Read)**:普通的 SELECT 语句,通过 **MVCC** 机制实现。事务启动时创建一个数据快照,后续的快照读都读取这个版本的数据,从而避免了看到其他事务新插入的行(幻读)或修改的行(不可重复读)。
+- **当前读 (Current Read)**:像 `SELECT ... FOR UPDATE`, `SELECT ... LOCK IN SHARE MODE`, `INSERT`, `UPDATE`, `DELETE` 这些操作。InnoDB 使用 **Next-Key Lock** 来锁定扫描到的索引记录及其间的范围(间隙),防止其他事务在这个范围内插入新的记录,从而避免幻读。Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的组合。
-因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED** ,但是你要知道的是 InnoDB 存储引擎默认使用 **REPEATABLE-READ** 并不会有任何性能损失。
+值得注意的是,虽然通常认为隔离级别越高、并发性越差,但 InnoDB 存储引擎通过 MVCC 机制优化了 REPEATABLE READ 级别。对于许多常见的只读或读多写少的场景,其性能**与 READ COMMITTED 相比可能没有显著差异**。不过,在写密集型且并发冲突较高的场景下,RR 的间隙锁机制可能会比 RC 带来更多的锁等待。
-InnoDB 存储引擎在分布式事务的情况下一般会用到 SERIALIZABLE 隔离级别。
+此外,在某些特定场景下,如需要严格一致性的分布式事务(XA Transactions),InnoDB 可能要求或推荐使用 SERIALIZABLE 隔离级别来确保全局数据的一致性。
《MySQL 技术内幕:InnoDB 存储引擎(第 2 版)》7.7 章这样写到:
@@ -111,3 +119,5 @@ SQL 脚本 1 在第一次查询工资为 500 的记录时只有一条,SQL 脚
-
- [Mysql 锁:灵魂七拷问](https://tech.youzan.com/seven-questions-about-the-lock-of-MySQL/)
- [Innodb 中的事务隔离级别和锁的关系](https://tech.meituan.com/2014/08/20/innodb-lock.html)
+
+
diff --git a/docs/database/nosql.md b/docs/database/nosql.md
index fd70056fd2c..3a7e7929057 100644
--- a/docs/database/nosql.md
+++ b/docs/database/nosql.md
@@ -1,10 +1,15 @@
---
title: NoSQL基础知识总结
+description: NoSQL数据库基础知识总结,包括NoSQL与SQL的区别、NoSQL的优势、四种NoSQL数据库类型(键值、文档、图形、宽列)及其代表产品Redis、MongoDB、Neo4j等的应用场景。
category: 数据库
tag:
- NoSQL
- MongoDB
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: NoSQL,Redis,MongoDB,HBase,Cassandra,键值数据库,文档数据库,图数据库,宽列存储,SQL与NoSQL区别
---
## NoSQL 是什么?
@@ -57,3 +62,5 @@ NoSQL 数据库主要可以分为下面四种类型:
- NoSQL 是什么?- MongoDB 官方文档:
- 什么是 NoSQL? - AWS:
- NoSQL vs. SQL Databases - MongoDB 官方文档:
+
+
diff --git a/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md b/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md
index 91427109697..be12e83c288 100644
--- a/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md
+++ b/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md
@@ -1,13 +1,18 @@
---
title: 3种常用的缓存读写策略详解
+description: 深入对比 Cache Aside、Read/Write Through、Write Behind 三种缓存读写策略,附详细时序图、一致性问题分析及生产级解决方案,Redis 实战必备!
category: 数据库
tag:
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: 缓存读写策略,Cache Aside,Read Through,Write Through,Write Behind,Write Back,缓存一致性,缓存失效,旁路缓存,读写穿透,异步缓存写入,Redis缓存策略,缓存更新策略
---
看到很多小伙伴简历上写了“**熟练使用缓存**”,但是被我问到“**缓存常用的 3 种读写策略**”的时候却一脸懵逼。
-在我看来,造成这个问题的原因是我们在学习 Redis 的时候,可能只是简单了写一些 Demo,并没有去关注缓存的读写策略,或者说压根不知道这回事。
+在我看来,造成这个问题的原因是我们在学习 Redis 的时候,可能只是简单写了一些 Demo,并没有去关注缓存的读写策略,或者说压根不知道这回事。
但是,搞懂 3 种常见的缓存读写策略对于实际工作中使用缓存以及面试中被问到缓存都是非常有帮助的!
@@ -15,26 +20,28 @@ tag:
### Cache Aside Pattern(旁路缓存模式)
-**Cache Aside Pattern 是我们平时使用比较多的一个缓存读写模式,比较适合读请求比较多的场景。**
+这是我们日常开发中**最常用、最经典**的一种模式,几乎是互联网应用缓存方案的事实标准,尤其适合**读多写少**的业务场景。
-Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 db 的结果为准。
+这个模式之所以被称为**“旁路”(Aside)**,是因为应用程序的**写操作完全绕过了缓存,直接操作数据库**。
+
+应用程序扮演了数据流转的“指挥官”,需要同时维护 Cache 和 DB 两个数据源。
下面我们来看一下这个策略模式下的缓存读写步骤。
-**写**:
+**写操作 :**
-- 先更新 db
-- 然后直接删除 cache 。
+1. 应用**先更新 DB**。
+2. 然后**直接删除 Cache**中对应的数据。
简单画了一张图帮助大家理解写的步骤。

-**读** :
+**读操作:**
-- 从 cache 中读取数据,读取到就直接返回
-- cache 中读取不到的话,就从 db 中读取数据返回
-- 再把数据放到 cache 中。
+1. 应用先从 Cache 读取数据。
+2. 如果命中(Hit),则直接返回。
+3. 如果未命中(Miss),则从 DB 读取数据,成功读取后,**将数据写回 Cache**,然后返回。
简单画了一张图帮助大家理解读的步骤。
@@ -42,49 +49,69 @@ Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 d
你仅仅了解了上面这些内容的话是远远不够的,我们还要搞懂其中的原理。
-比如说面试官很可能会追问:“**在写数据的过程中,可以先删除 cache ,后更新 db 么?**”
+比如说面试官很可能会追问:
+
+1. 为什么写操作是“先更新 DB,后删除 Cache”?顺序能反过来吗?
+2. 那“先更新 DB,后删除 Cache”就绝对安全吗?
+3. 为什么是“删除 Cache”,而不是“更新 Cache”?
-**答案:** 那肯定是不行的!因为这样可能会造成 **数据库(db)和缓存(Cache)数据不一致**的问题。
+接下来我会以此分析解答这些问题。
-举例:请求 1 先写数据 A,请求 2 随后读数据 A 的话,就很有可能产生数据不一致性的问题。
+**1. 为什么写操作是“先更新 DB,后删除 Cache”?顺序能反过来吗?**
-这个过程可以简单描述为:
+**答:** 绝对不能。如果“先删 Cache,后更新 DB”,在高并发下会引入经典的数据不一致问题。
-> 请求 1 先把 cache 中的 A 数据删除 -> 请求 2 从 db 中读取数据->请求 1 再把 db 中的 A 数据更新
+- **时序分析 (请求 A 写, 请求 B 读):**
+ 1. 请求 A: 先将 Cache 中的数据删除。
+ 2. 请求 B: 此时发现 Cache 为空,于是去 DB 读取**旧值**,并准备写入 Cache。
+ 3. 请求 A : 将**新值**写入 DB。
+ 4. 请求 B: 将之前读到的**旧值**写入了 Cache。
+- **结果:** DB 中是新值,而 Cache 中是旧值,数据不一致。
-当你这样回答之后,面试官可能会紧接着就追问:“**在写数据的过程中,先更新 db,后删除 cache 就没有问题了么?**”
+**2. 那“先更新 DB,后删除 Cache”就绝对安全吗?**
-**答案:** 理论上来说还是可能会出现数据不一致性的问题,不过概率非常小,因为缓存的写入速度是比数据库的写入速度快很多。
+**答案:** 也不是绝对安全的!因为这样也可能会造成 **数据库和缓存数据不一致**的问题。
-举例:请求 1 先读数据 A,请求 2 随后写数据 A,并且数据 A 在请求 1 请求之前不在缓存中的话,也有可能产生数据不一致性的问题。
+- **时序分析 (请求 A 读, 请求 B 写):**
+ 1. 请求 A : 缓存未命中,从 DB 读取到**旧值**。
+ 2. 请求 B: 迅速完成了 DB 的更新,并将 Cache 删除。
+ 3. 请求 A : 将自己之前拿到的**旧值**写入了 Cache。
+- **结果:** DB 中是新值,Cache 中又是旧值。
+- **为什么概率极小?** 这个问题本质上是一个并发时序问题:只要“读 DB → 写 Cache”这段时间窗口内,恰好有写请求完成了 DB 更新,就有可能产生不一致。在大多数业务里,这个窗口时间相对较短,而且还需要与写请求并发“撞车”,所以发生概率不算高,但绝不是不可能。
-这个过程可以简单描述为:
+**3. 为什么是“删除 Cache”,而不是“更新 Cache”?**
-> 请求 1 从 db 读数据 A-> 请求 2 更新 db 中的数据 A(此时缓存中无数据 A ,故不用执行删除缓存操作 ) -> 请求 1 将数据 A 写入 cache
+- **性能开销:** 写操作往往只更新了对象的部分字段,如果为了“更新 Cache”而去重新查询或计算整个缓存对象,开销可能很大。相比之下,“删除”是一个轻量级操作。
+- **懒加载思想:** “删除”操作遵循懒加载原则。只有当数据下一次被真正需要(被读取)时,才触发从 DB 加载并写入缓存,避免了无效的缓存更新。
+- **并发安全:** “更新缓存”在高并发下可能出现更新顺序错乱的问题导致脏数据的概率会更大。
+
+当然,这一切都建立在一个重要的前提之上:我们缓存的数据,是可以通过数据库进行确定性重建的,并且业务上可以容忍从‘缓存删除’到‘下一次读取并回填’之间这个极短时间窗口内的数据不一致。
现在我们再来分析一下 **Cache Aside Pattern 的缺陷**。
-**缺陷 1:首次请求数据一定不在 cache 的问题**
+**缺陷 1:首次请求数据一定不在 Cache 的问题**
-解决办法:可以将热点数据可以提前放入 cache 中。
+解决办法:对于访问量巨大的热点数据,可以在系统启动或低峰期进行缓存预热。
-**缺陷 2:写操作比较频繁的话导致 cache 中的数据会被频繁被删除,这样会影响缓存命中率 。**
+**缺陷 2:写操作比较频繁的话导致 Cache 中的数据会被频繁被删除,这样会影响缓存命中率 。**
解决办法:
-- 数据库和缓存数据强一致场景:更新 db 的时候同样更新 cache,不过我们需要加一个锁/分布式锁来保证更新 cache 的时候不存在线程安全问题。
-- 可以短暂地允许数据库和缓存数据不一致的场景:更新 db 的时候同样更新 cache,但是给缓存加一个比较短的过期时间,这样的话就可以保证即使数据不一致的话影响也比较小。
+- 数据库和缓存数据强一致场景:更新 DB 的时候同样更新 Cache,不过我们需要加一个锁/分布式锁来保证更新 Cache 的时候不存在线程安全问题。
+- 可以短暂地允许数据库和缓存数据不一致的场景:更新 DB 的时候同样更新 Cache,但是给缓存加一个比较短的过期时间(如 1 分钟),这样的话就可以保证即使数据不一致的话影响也比较小。
### Read/Write Through Pattern(读写穿透)
-Read/Write Through Pattern 中服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务负责将此数据读取和写入 db,从而减轻了应用程序的职责。
+在这种模式下,应用程序将**Cache 视为唯一的、主要的存储**。所有的读写请求都直接打向 Cache,而 Cache 服务自身负责与 DB 进行数据同步。
+
+对应用程序**透明**,应用开发者无需关心 DB 的存在。
-这种缓存读写策略小伙伴们应该也发现了在平时在开发过程中非常少见。抛去性能方面的影响,大概率是因为我们经常使用的分布式缓存 Redis 并没有提供 cache 将数据写入 db 的功能。
+这种缓存读写策略小伙伴们应该也发现了在平时在开发过程中非常少见。抛去性能方面的影响,大概率是因为我们经常使用的分布式缓存 Redis 本身并没有提供 Cache 将数据写入 DB 的功能,需要我们在业务侧或中间件里自己实现。
**写(Write Through):**
-- 先查 cache,cache 中不存在,直接更新 db。
-- cache 中存在,则先更新 cache,然后 cache 服务自己更新 db(**同步更新 cache 和 db**)。
+- 先查 Cache,Cache 中不存在,直接更新 DB。
+- Cache 中存在,则先更新 Cache,然后 Cache 服务自己更新 DB。只有当 Cache 和 DB 都写入成功后,才向上层返回成功。
简单画了一张图帮助大家理解写的步骤。
@@ -92,25 +119,38 @@ Read/Write Through Pattern 中服务端把 cache 视为主要数据存储,从
**读(Read Through):**
-- 从 cache 中读取数据,读取到就直接返回 。
-- 读取不到的话,先从 db 加载,写入到 cache 后返回响应。
+- 应用从 Cache 读取数据。
+- 如果命中,直接返回。
+- 如果未命中,由**Cache 服务自己**负责从 DB 加载数据,加载成功后先写入自身,再返回给应用。
简单画了一张图帮助大家理解读的步骤。
-Read-Through Pattern 实际只是在 Cache-Aside Pattern 之上进行了封装。在 Cache-Aside Pattern 下,发生读请求的时候,如果 cache 中不存在对应的数据,是由客户端自己负责把数据写入 cache,而 Read Through Pattern 则是 cache 服务自己来写入缓存的,这对客户端是透明的。
+Read-Through 实际只是在 Cache-Aside 之上进行了封装。在 Cache-Aside 下,发生读请求的时候,如果 Cache 中不存在对应的数据,是由客户端自己负责把数据写入 Cache,而 Read Through 则是 Cache 服务自己来写入缓存的,这对客户端是透明的。
-和 Cache Aside Pattern 一样, Read-Through Pattern 也有首次请求数据一定不再 cache 的问题,对于热点数据可以提前放入缓存中。
+从实现角度看,Read-Through 本质上是把 Cache-Aside 中“读 Miss → 读 DB → 回填 Cache”的逻辑,下沉到了缓存服务内部,对客户端透明。
+
+和 Cache Aside 一样, Read-Through 也有首次请求数据一定不再 Cache 的问题,对于热点数据可以提前放入缓存中。
### Write Behind Pattern(异步缓存写入)
-Write Behind Pattern 和 Read/Write Through Pattern 很相似,两者都是由 cache 服务来负责 cache 和 db 的读写。
+Write Behind(也常被称为 Write-Back) Pattern 和 Read/Write Through Pattern 很相似,两者都是由 Cache 服务来负责 Cache 和 DB 的读写。
+
+但是,两个又有很大的不同:**Read/Write Through 是同步更新 Cache 和 DB,而 Write Behind 则是只更新缓存,不直接更新 DB,而是改为异步批量的方式来更新 DB。**
+
+**写操作 (Write Behind):**
+
+1. 应用将数据写入 Cache,然后**立即返回**。
+2. Cache 服务将这个写操作放入一个队列中。
+3. 通过一个独立的异步线程/任务,将队列中的写操作**批量地、合并地**写入 DB。
-但是,两个又有很大的不同:**Read/Write Through 是同步更新 cache 和 db,而 Write Behind 则是只更新缓存,不直接更新 db,而是改为异步批量的方式来更新 db。**
+这种模式对数据一致性带来了挑战(例如:Cache 中的数据还没来得及写回 DB,系统就宕机了),因此不适用于需要强一致性的场景(如交易、库存)。
-很明显,这种方式对数据一致性带来了更大的挑战,比如 cache 数据可能还没异步更新 db 的话,cache 服务可能就就挂掉了。
+但是,它的异步和批量特性,带来了**无与伦比的写性能**。它在很多高性能系统中都有广泛应用:
-这种策略在我们平时开发过程中也非常非常少见,但是不代表它的应用场景少,比如消息队列中消息的异步写入磁盘、MySQL 的 Innodb Buffer Pool 机制都用到了这种策略。
+- **MySQL 的 InnoDB Buffer Pool 机制:** 数据修改先在内存 Buffer Pool 中完成,然后由后台线程异步刷写到磁盘。
+- **操作系统的页缓存(Page Cache):** 文件写入也是先写到内存,再由操作系统异步刷盘。
+- **高频计数场景:** 对于文章浏览量、帖子点赞数这类允许短暂数据不一致、但写入极其频繁的场景,可以先在 Redis 中快速累加,再通过定时任务异步同步回数据库。
-Write Behind Pattern 下 db 的写性能非常高,非常适合一些数据经常变化又对数据一致性要求没那么高的场景,比如浏览量、点赞量。
+
diff --git a/docs/database/redis/cache-basics.md b/docs/database/redis/cache-basics.md
index 2a9aee57354..15cb0eb33bb 100644
--- a/docs/database/redis/cache-basics.md
+++ b/docs/database/redis/cache-basics.md
@@ -1,12 +1,195 @@
---
-title: 缓存基础常见面试题总结(付费)
+title: 缓存基础常见面试题总结
+description: 深入讲解缓存的核心思想、本地缓存与分布式缓存的区别、多级缓存架构设计。涵盖Caffeine、Redis等主流缓存方案,以及缓存一致性的解决方案。适合Java开发者学习缓存架构设计。
category: 数据库
tag:
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: 缓存,本地缓存,分布式缓存,多级缓存,Caffeine,Redis,缓存一致性,系统设计,Java缓存,Guava Cache
---
-**缓存基础** 相关的面试题为我的 [知识星球](../../about-the-author/zhishixingqiu-two-years.md)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](../../zhuanlan/java-mian-shi-zhi-bei.md)中。
+> **相关面试题** :
+>
+> - 为什么要用缓存?
+> - 本地缓存应该怎么做?
+> - 为什么要有分布式缓存?/为什么不直接用本地缓存?
+> - 为什么要用多级缓存?
+> - 多级缓存适合哪些业务场景?
-
+## 缓存的基本思想
-
+很多同学只知道缓存可以提高系统性能以及减少请求 **响应时间**(Response Time),但是,不太清楚缓存的本质思想是什么。
+
+缓存的基本思想其实很简单,就是我们非常熟悉的 **空间换时间** 这一经典性能优化策略的运用。所谓空间换时间,也就是用更多的存储空间来存储一些可能重复使用或计算的数据,从而减少数据的重新获取或计算的时间。
+
+说到空间换时间,除了缓存之外,你还能想到什么其他的例子吗?这里再列举几个常见的:
+
+- **索引**:索引是一种将数据库表中的某些列或字段按照一定的排序规则组织成一个单独的数据结构,虽然需要额外占用空间,但可以大大提高检索效率,降低数据排序成本。
+- **数据库表字段冗余**:将经常联合查询的数据冗余存储在同一张表中,以减少对多张表的关联查询,进而提升查询性能,减轻数据库压力。
+- **CDN(内容分发网络)**:将静态资源分发到多个边缘节点以实现就近访问,进而加快静态资源的访问速度,减轻源站服务器以及带宽的负担。
+
+编程需要要学会归纳总结,将自己学到的东西串联起来!假如你在面试的时候,能聊到这些,面试官一定会对你有一个好印象的。
+
+不要把缓存想的太高大上,虽然,它的确对系统的性能提升的性价比非常高。当我们在学习并应用缓存的时候,你会发现缓存的思想实际在 CPU、操作系统或者其他很多地方都被大量用到。
+
+比如,**CPU Cache** 缓存的是内存数据,用于解决 **CPU** 处理速度与内存访问速度不匹配的问题;内存缓存的是硬盘数据,用于解决硬盘 **I/O** 速度过慢的问题。
+
+
+
+再比如,为了提高虚拟地址到物理地址的转换速度,操作系统在页表方案基础之上引入了 **转址旁路缓存**(Translation Lookaside Buffer,**TLB**,也被称为快表)。
+
+
+
+拿日常使用的浏览器来说,它会对访问过的图片或静态文件进行缓存(浏览器缓存),这样下次访问相同页面时加载速度会显著提升。
+
+
+
+我们日常开发中用到的缓存,其中的数据通常存储于 **RAM**(内存)中,访问速度极快。为了避免内存数据在重启或宕机后丢失,许多缓存中间件(如 **Redis**)提供了磁盘持久化机制。相比于关系型数据库(如 **MySQL**),缓存的访问速度和并发支持量都要高出几个数量级。在数据库之上增加一层缓存,是保护底层存储、提升系统吞吐量的核心手段。
+
+## 缓存的分类
+
+接下来,我们来看看日常开发中用到的缓存通常被分为哪几种。
+
+### 本地缓存
+
+#### 什么是本地缓存?
+
+这个实际在很多项目中用的蛮多,特别是单体架构的时候。数据量不大,并且没有分布式要求的话,使用本地缓存还是可以的。
+
+本地缓存位于应用内部,其最大的优点是应用存在于同一个进程内部,请求本地缓存的速度非常快,不存在额外的网络开销。
+
+常见的单体架构图如下,我们使用 **Nginx** 来做**负载均衡**,部署两个相同的应用到服务器,两个服务使用同一个数据库,并且使用的是本地缓存。
+
+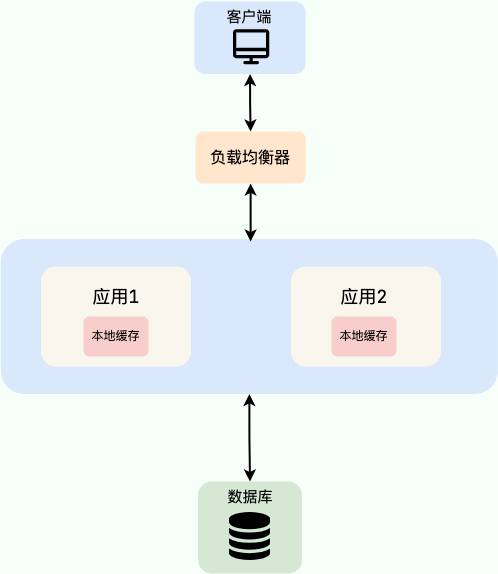
+
+**注意:** 在集群模式下使用本地缓存,必须考虑**负载均衡策略**。如果 Nginx 使用默认的**轮询(Round-Robin)**,同一个用户的请求会随机落在不同机器,导致本地缓存命中率极低。解决方案如下:
+
+1. **网关层**:使用一致性哈希或 Sticky Session,保证同一用户的请求固定打到同一台机器。
+2. **应用层**:仅将本地缓存用于**“全局几乎不变”**的数据(如配置字典),而非用户维度数据。
+
+#### 本地缓存的方案有哪些?
+
+**1、JDK 自带的 `HashMap` 和 `ConcurrentHashMap` 了。**
+
+`ConcurrentHashMap` 可以看作是线程安全版本的 `HashMap` ,两者都是存放 key/value 形式的键值对。但是,大部分场景来说不会使用这两者当做缓存,因为只提供了缓存的功能,并没有提供其他诸如过期时间之类的功能。一个稍微完善一点的缓存框架至少要提供:**过期时间**、**淘汰机制**、**命中率统计**这三点。
+
+**2、 `Ehcache` 、 `Guava Cache` 、 `Spring Cache` 这三者是使用的比较多的本地缓存框架。**
+
+- `Ehcache` 的话相比于其他两者更加重量。不过,相比于 `Guava Cache` 、 `Spring Cache` 来说, `Ehcache` 支持可以嵌入到 hibernate 和 mybatis 作为多级缓存,并且可以将缓存的数据持久化到本地磁盘中、同时也提供了集群方案(比较鸡肋,可忽略)。
+- `Guava Cache` 和 `Spring Cache` 两者的话比较像。`Guava` 相比于 `Spring Cache` 的话使用的更多一点,它提供了 API 非常方便我们使用,同时也提供了设置缓存有效时间等功能。它的内部实现也比较干净,很多地方都和 `ConcurrentHashMap` 的思想有异曲同工之妙。
+- 使用 `Spring Cache` 的注解实现缓存的话,代码会看着很干净和优雅,但是很容易出现问题比如缓存穿透、内存溢出。
+
+**3、后起之秀 Caffeine。**
+
+相比于 `Guava` 来说 `Caffeine` 在各个方面比如性能都要更加优秀,一般建议使用其来替代 `Guava` 。并且, `Guava` 和 `Caffeine` 的使用方式很像!
+
+使用 `Caffeine` 创建本地缓存的代码示例,用到了建造者模式:
+
+```java
+// 使用 Caffeine 创建本地缓存示例
+Cache cache = Caffeine.newBuilder()
+ // 设置写入后 60 天过期
+ .expireAfterWrite(60, TimeUnit.DAYS)
+ // 初始容量
+ .initialCapacity(100)
+ // 最大条数限制
+ .maximumSize(500)
+ // 开启统计功能
+ .recordStats()
+ .build();
+```
+
+#### 本地缓存有什么痛点?
+
+本地的缓存的优势非常明显:**低依赖**、**轻量**、**简单**、**成本低**。
+
+但是,本地缓存存在下面这些缺陷:
+
+- **本地缓存应用耦合,对分布式架构支持不友好**,比如同一个相同的服务部署在多台机器上的时候,各个服务之间的缓存是无法共享的,因为本地缓存只在当前机器上有。
+- **本地缓存容量受服务部署所在的机器限制明显。** 如果当前系统服务所耗费的内存多,那么本地缓存可用的容量就很少。
+
+### 分布式缓存
+
+#### 什么是分布式缓存?
+
+我们可以把分布式缓存(Distributed Cache) 看作是一种内存数据库的服务,它的最终作用就是提供缓存数据的服务。
+
+分布式缓存脱离于应用独立存在,多个应用可直接的共同使用同一个分布式缓存服务。
+
+如下图所示,就是一个简单的使用分布式缓存的架构图。我们使用 Nginx 来做负载均衡,部署两个相同的应用到服务器,两个服务使用同一个数据库和缓存。
+
+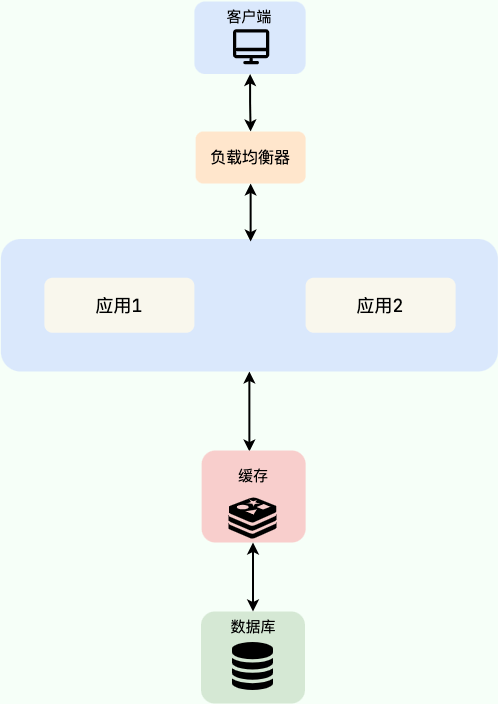
+
+使用分布式缓存之后,缓存服务可以部署在一台单独的服务器上,即使同一个相同的服务部署在多台机器上,也是使用的同一份缓存。 并且,单独的分布式缓存服务的性能、容量和提供的功能都要更加强大。
+
+**软件系统设计中没有银弹,往往任何技术的引入都像是把双刃剑。** 你使用的方式得当,就能为系统带来很大的收益。否则,只是费了精力不讨好。
+
+简单来说,为系统引入分布式缓存之后往往会带来下面这些问题:
+
+- **系统复杂性增加** :引入缓存之后,你要维护缓存和数据库的数据一致性、维护热点缓存、保证缓存服务的高可用等等。
+- **系统开发成本往往会增加** :引入缓存意味着系统需要一个单独的缓存服务,这是需要花费相应的成本的,并且这个成本还是很贵的,毕竟耗费的是宝贵的内存。
+
+#### 分布式缓存的方案有哪些?
+
+分布式缓存的话,比较老牌同时也是使用的比较多的还是 **Memcached** 和 **Redis**。不过,现在基本没有看过还有项目使用 **Memcached** 来做缓存,都是直接用 **Redis**。
+
+Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
+
+有一些大厂也开源了类似于 Redis 的分布式高性能 KV 存储数据库,例如,腾讯开源的 [Tendis](https://github.com/Tencent/Tendis) 。Tendis 基于知名开源项目 [RocksDB](https://github.com/facebook/rocksdb) 作为存储引擎 ,100% 兼容 Redis 协议和 Redis4.0 所有数据模型。关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:[Redis vs Tendis:冷热混合存储版架构揭秘](https://mp.weixin.qq.com/s/MeYkfOIdnU6LYlsGb24KjQ) ,可以简单参考一下。
+
+不过,从 Tendis 这个项目的 Github 提交记录可以看出,Tendis 开源版几乎已经没有被维护更新了,加上其关注度并不高,使用的公司也比较少。因此,不建议你使用 Tendis 来实现分布式缓存。
+
+目前,比较业界认可的 Redis 替代品还是下面这两个开源分布式缓存(都是通过碰瓷 Redis 火的):
+
+- [Dragonfly](https://github.com/dragonflydb/dragonfly):一种针对现代应用程序负荷需求而构建的内存数据库,完全兼容 Redis 和 Memcached 的 API,迁移时无需修改任何代码,号称全世界最快的内存数据库。
+- [KeyDB](https://github.com/Snapchat/KeyDB): Redis 的一个高性能分支,专注于多线程、内存效率和高吞吐量。
+
+不过,个人还是建议分布式缓存首选 Redis ,毕竟经过这么多年的生产考验,生态也这么优秀,资料也很全面。
+
+### 多级缓存
+
+#### 什么是多级缓存?为什么要用?
+
+我们这里只来简单聊聊 **本地缓存 + 分布式缓存** 的多级缓存方案,这也是最常用的多级缓存实现方式。
+
+这个时候估计有很多小伙伴就会问了:**既然用了分布式缓存,为什么还要用本地缓存呢?** 。
+
+本地缓存和分布式缓存虽然都属于缓存,但本地缓存的访问速度要远大于分布式缓存,这是因为访问本地缓存不存在额外的网络开销,我们在上面也提到了。
+
+不过,一般情况下,我们也是不建议使用多级缓存的,这会增加维护负担(比如你需要保证一级缓存和二级缓存的数据一致性)。而且,其实际带来的提升效果对于绝大部分业务场景来说其实并不是很大。
+
+这里简单总结一下适合多级缓存的两种业务场景:
+
+- 缓存的数据不会频繁修改,比较稳定;
+- 数据访问量特别大比如秒杀场景。
+
+多级缓存方案中,第一级缓存(L1)使用本地内存(比如 Caffeine)),第二级缓存(L2)使用分布式缓存(比如 Redis)。
+
+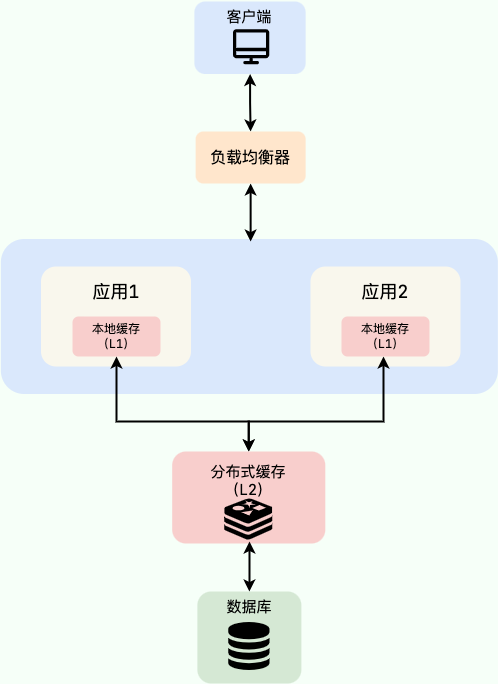
+
+读取缓存数据的时候,我们先从 L1 中读取,读取不到的时候再去 L2 读取。这样可以降低 L2 的压力,减少 L2 的读次数。如果 L2 也没有此数据的话,再去数据库查询,数据查询成功后再将数据写入到 L1 和 L2 中。
+
+多级缓存开源实现推荐:
+
+- [J2Cache](https://gitee.com/ld/J2Cache):基于本地内存和 Redis 的两级 Java 缓存框架。
+- [JetCache](https://github.com/alibaba/jetcache):阿里开源的缓存框架,支持多级缓存、分布式缓存自动刷新、 TTL 等功能。
+
+#### 多级缓存一致性如何保证?
+
+在多级缓存系统中,保证强一致性成本太高,业界的几个提供多级缓存功能的缓存框架基本都是最终一致性保证。例如,可以使用 Redis 的发布/订阅机制、Redis Stream 或者消息队列来确保当一个实例的本地缓存发生变化时,其他实例能够及时更新其本地缓存,以保持缓存一致性。
+
+政采云技术的方案是 Canal + 广播消息,这里简单介绍一下:
+
+1. DB 修改数据:首先在数据库中进行数据修改。
+2. 通过监听 Canal 消息,触发缓存的更新:使用 Canal 监听数据库的变更操作,当检测到数据变化时,触发缓存更新。
+3. 同步 Redis 缓存:对于 Redis 缓存,因为集群中只共享一份数据,所以直接同步缓存即可。
+4. 同步本地缓存:由于本地缓存分布在不同的 JVM 实例中,需要借助广播消息队列(MQ)机制,将更新通知广播到各个业务实例,从而同步本地缓存。
+
+详细介绍:[分布式多级缓存系统设计与实战](https://juejin.cn/post/7225634879152570405)
+
+## 参考
+
+- 缓存那些事:https://tech.meituan.com/2017/03/17/cache-about.html
+- 解析分布式系统的缓存设计:https://segmentfault.com/a/1190000041689802
diff --git a/docs/database/redis/images/why-redis-so-fast.png b/docs/database/redis/images/why-redis-so-fast.png
deleted file mode 100644
index 279e1955473..00000000000
Binary files a/docs/database/redis/images/why-redis-so-fast.png and /dev/null differ
diff --git a/docs/database/redis/redis-cluster.md b/docs/database/redis/redis-cluster.md
index 2db4feda7e3..4d8b2ead452 100644
--- a/docs/database/redis/redis-cluster.md
+++ b/docs/database/redis/redis-cluster.md
@@ -1,12 +1,17 @@
---
title: Redis集群详解(付费)
+description: Redis集群相关面试题详解,包括Redis Sentinel哨兵模式、Redis Cluster分片集群的原理、配置和使用,以及主从复制、故障转移等高可用方案。
category: 数据库
tag:
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis集群,Redis Cluster,Redis Sentinel,主从复制,哨兵模式,分片集群,高可用
---
**Redis 集群** 相关的面试题为我的 [知识星球](../../about-the-author/zhishixingqiu-two-years.md)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](../../zhuanlan/java-mian-shi-zhi-bei.md)中。
-
+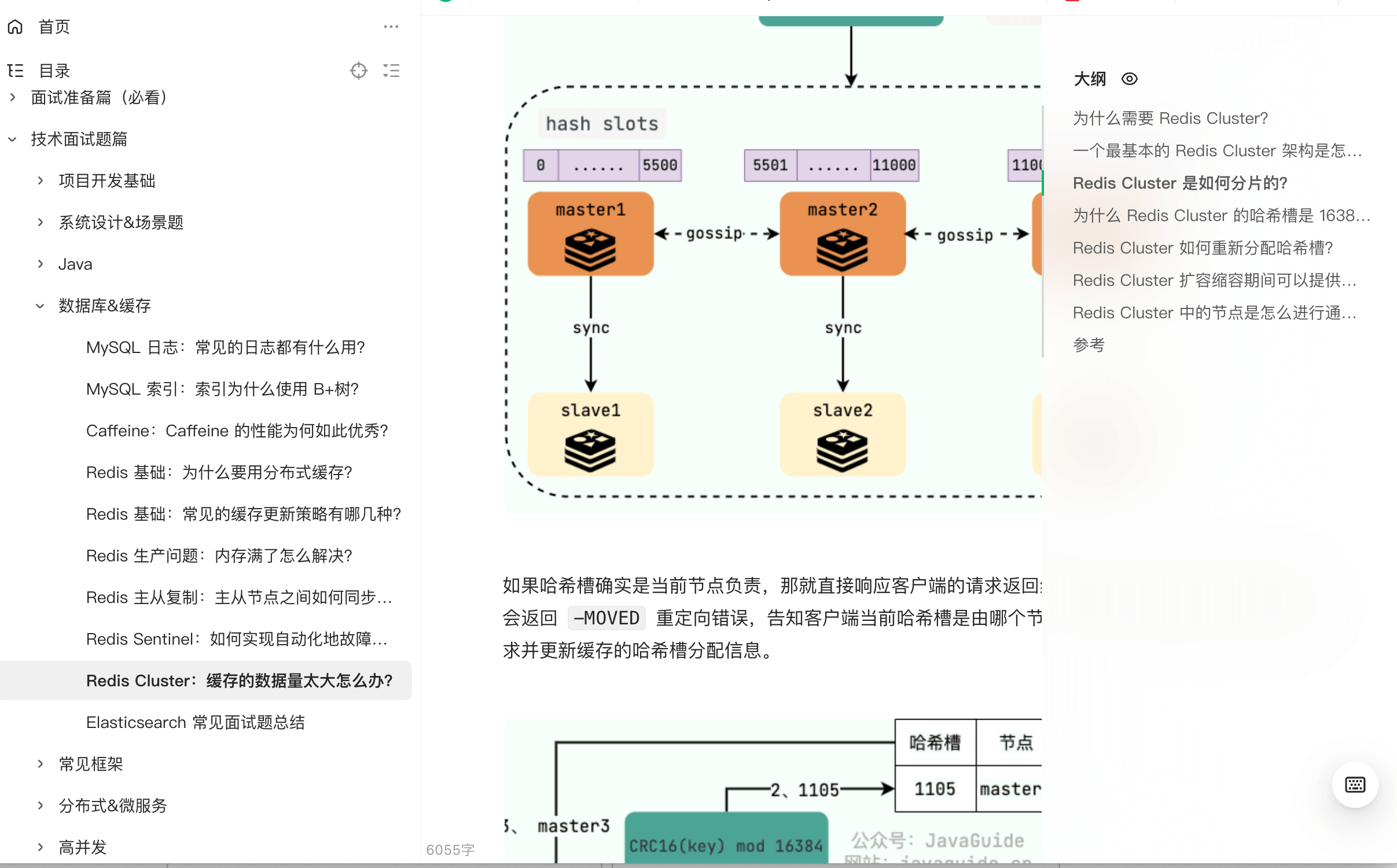
diff --git a/docs/database/redis/redis-common-blocking-problems-summary.md b/docs/database/redis/redis-common-blocking-problems-summary.md
index facf3e3ac9b..95041edee60 100644
--- a/docs/database/redis/redis-common-blocking-problems-summary.md
+++ b/docs/database/redis/redis-common-blocking-problems-summary.md
@@ -1,11 +1,18 @@
---
title: Redis常见阻塞原因总结
+description: 全面总结Redis常见的阻塞原因,包括O(n)复杂度命令、bigkey操作、AOF日志刷盘、RDB快照创建、主从同步等场景,帮助你排查和预防Redis性能问题。
category: 数据库
tag:
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis阻塞,Redis性能问题,O(n)命令,bigkey,AOF刷盘,RDB快照,主从同步,内存达上限
---
-> 本文整理完善自:https://mp.weixin.qq.com/s/0Nqfq_eQrUb12QH6eBbHXA ,作者:阿 Q 说代码
+
+
+> 本文整理完善自: ,作者:阿 Q 说代码
这篇文章会详细总结一下可能导致 Redis 阻塞的情况,这些情况也是影响 Redis 性能的关键因素,使用 Redis 的时候应该格外注意!
@@ -18,7 +25,7 @@ Redis 中的大部分命令都是 O(1)时间复杂度,但也有少部分 O(n)
- `LRANGE`:会返回 List 中指定范围内的元素。
- `SMEMBERS`:返回 Set 中的所有元素。
- `SINTER`/`SUNION`/`SDIFF`:计算多个 Set 的交集/并集/差集。
-- ......
+- ……
由于这些命令时间复杂度是 O(n),有时候也会全表扫描,随着 n 的增大,执行耗时也会越长,从而导致客户端阻塞。不过, 这些命令并不是一定不能使用,但是需要明确 N 的值。另外,有遍历的需求可以使用 `HSCAN`、`SSCAN`、`ZSCAN` 代替。
@@ -26,7 +33,7 @@ Redis 中的大部分命令都是 O(1)时间复杂度,但也有少部分 O(n)
- `ZRANGE`/`ZREVRANGE`:返回指定 Sorted Set 中指定排名范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 为返回的元素数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
- `ZREMRANGEBYRANK`/`ZREMRANGEBYSCORE`:移除 Sorted Set 中指定排名范围/指定 score 范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 被删除元素的数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
-- ......
+- ……
## SAVE 创建 RDB 快照
@@ -81,7 +88,10 @@ Redis AOF 持久化机制是在执行完命令之后再记录日志,这和关
## 大 Key
-如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:string 类型的 value 超过 10 kb,复合类型的 value 包含的元素超过 5000 个(对于复合类型的 value 来说,不一定包含的元素越多,占用的内存就越多)。
+如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:
+
+- string 类型的 value 超过 1MB
+- 复合类型(列表、哈希、集合、有序集合等)的 value 包含的元素超过 5000 个(对于复合类型的 value 来说,不一定包含的元素越多,占用的内存就越多)。
大 key 造成的阻塞问题如下:
@@ -126,14 +136,14 @@ Redis 集群可以进行节点的动态扩容缩容,这一过程目前还处
**什么是 Swap?** Swap 直译过来是交换的意思,Linux 中的 Swap 常被称为内存交换或者交换分区。类似于 Windows 中的虚拟内存,就是当内存不足的时候,把一部分硬盘空间虚拟成内存使用,从而解决内存容量不足的情况。因此,Swap 分区的作用就是牺牲硬盘,增加内存,解决 VPS 内存不够用或者爆满的问题。
-Swap 对于 Redis 来说是非常致命的,Redis 保证高性能的一个重要前提是所有的数据在内存中。如果操作系统把 Redis 使用的部分内存换出硬盘,由于内存与硬盘读写的速度并几个数量级,会导致发生交换后的 Redis 性能急剧下降。
+Swap 对于 Redis 来说是非常致命的,Redis 保证高性能的一个重要前提是所有的数据在内存中。如果操作系统把 Redis 使用的部分内存换出硬盘,由于内存与硬盘的读写速度差几个数量级,会导致发生交换后的 Redis 性能急剧下降。
识别 Redis 发生 Swap 的检查方法如下:
1、查询 Redis 进程号
```bash
-reids-cli -p 6383 info server | grep process_id
+redis-cli -p 6383 info server | grep process_id
process_id: 4476
```
@@ -161,7 +171,7 @@ Swap: 0kB
Redis 是典型的 CPU 密集型应用,不建议和其他多核 CPU 密集型服务部署在一起。当其他进程过度消耗 CPU 时,将严重影响 Redis 的吞吐量。
-可以通过`reids-cli --stat`获取当前 Redis 使用情况。通过`top`命令获取进程对 CPU 的利用率等信息 通过`info commandstats`统计信息分析出命令不合理开销时间,查看是否是因为高算法复杂度或者过度的内存优化问题。
+可以通过`redis-cli --stat`获取当前 Redis 使用情况。通过`top`命令获取进程对 CPU 的利用率等信息 通过`info commandstats`统计信息分析出命令不合理开销时间,查看是否是因为高算法复杂度或者过度的内存优化问题。
## 网络问题
@@ -169,5 +179,7 @@ Redis 是典型的 CPU 密集型应用,不建议和其他多核 CPU 密集型
## 参考
-- Redis 阻塞的 6 大类场景分析与总结:https://mp.weixin.qq.com/s/eaZCEtTjTuEmXfUubVHjew
-- Redis 开发与运维笔记-Redis 的噩梦-阻塞:https://mp.weixin.qq.com/s/TDbpz9oLH6ifVv6ewqgSgA
+- Redis 阻塞的 6 大类场景分析与总结:
+- Redis 开发与运维笔记-Redis 的噩梦-阻塞:
+
+
diff --git a/docs/database/redis/redis-data-structures-01.md b/docs/database/redis/redis-data-structures-01.md
index a8e0e1d742b..64468c03f02 100644
--- a/docs/database/redis/redis-data-structures-01.md
+++ b/docs/database/redis/redis-data-structures-01.md
@@ -1,30 +1,28 @@
---
-title: Redis 5 种基本数据结构详解
+title: Redis 5 种基本数据类型详解
+description: 详解Redis五种基本数据类型String、List、Set、Hash、Zset的使用方法和应用场景,深入分析SDS、跳表、压缩列表等底层数据结构实现原理。
category: 数据库
tag:
- Redis
head:
- - meta
- name: keywords
- content: Redis常见数据结构
- - - meta
- - name: description
- content: Redis基础数据结构总结:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)
+ content: Redis数据类型,String,List,Set,Hash,Zset,SDS,跳表,压缩列表,Redis命令
---
-Redis 共有 5 种基本数据结构:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
+Redis 共有 5 种基本数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
-这 5 种数据结构是直接提供给用户使用的,是数据的保存形式,其底层实现主要依赖这 8 种数据结构:简单动态字符串(SDS)、LinkedList(双向链表)、Hash Table(哈希表)、SkipList(跳跃表)、Intset(整数集合)、ZipList(压缩列表)、QuickList(快速列表)。
+这 5 种数据类型是直接提供给用户使用的,是数据的保存形式,其底层实现主要依赖这 8 种数据结构:简单动态字符串(SDS)、LinkedList(双向链表)、Dict(哈希表/字典)、SkipList(跳跃表)、Intset(整数集合)、ZipList(压缩列表)、QuickList(快速列表)。
-Redis 基本数据结构的底层数据结构实现如下:
+Redis 5 种基本数据类型对应的底层数据结构实现如下表所示:
-| String | List | Hash | Set | Zset |
-| :----- | :--------------------------- | :------------------ | :-------------- | :---------------- |
-| SDS | LinkedList/ZipList/QuickList | Hash Table、ZipList | ZipList、Intset | ZipList、SkipList |
+| String | List | Hash | Set | Zset |
+| :----- | :--------------------------- | :------------ | :----------- | :---------------- |
+| SDS | LinkedList/ZipList/QuickList | Dict、ZipList | Dict、Intset | ZipList、SkipList |
-Redis 3.2 之前,List 底层实现是 LinkedList 或者 ZipList。 Redis 3.2 之后,引入了 LinkedList 和 ZipList 的结合 QuickList,List 的底层实现变为 QuickList。
+Redis 3.2 之前,List 底层实现是 LinkedList 或者 ZipList。 Redis 3.2 之后,引入了 LinkedList 和 ZipList 的结合 QuickList,List 的底层实现变为 QuickList。从 Redis 7.0 开始, ZipList 被 ListPack 取代。
-你可以在 Redis 官网上找到 Redis 数据结构非常详细的介绍:
+你可以在 Redis 官网上找到 Redis 数据类型/结构非常详细的介绍:
- [Redis Data Structures](https://redis.com/redis-enterprise/data-structures/)
- [Redis Data types tutorial](https://redis.io/docs/manual/data-types/data-types-tutorial/)
@@ -37,9 +35,9 @@ Redis 3.2 之前,List 底层实现是 LinkedList 或者 ZipList。 Redis 3.2
### 介绍
-String 是 Redis 中最简单同时也是最常用的一个数据结构。
+String 是 Redis 中最简单同时也是最常用的一个数据类型。
-String 是一种二进制安全的数据结构,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
+String 是一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
@@ -47,19 +45,19 @@ String 是一种二进制安全的数据结构,可以用来存储任何类型
### 常用命令
-| 命令 | 介绍 |
-| ------------------------------ | -------------------------------- |
-| SET key value | 设置指定 key 的值 |
-| SETNX key value | 只有在 key 不存在时设置 key 的值 |
-| GET key | 获取指定 key 的值 |
-| MSET key1 value1 key2 value2 … | 设置一个或多个指定 key 的值 |
-| MGET key1 key2 ... | 获取一个或多个指定 key 的值 |
-| STRLEN key | 返回 key 所储存的字符串值的长度 |
-| INCR key | 将 key 中储存的数字值增一 |
-| DECR key | 将 key 中储存的数字值减一 |
-| EXISTS key | 判断指定 key 是否存在 |
-| DEL key(通用) | 删除指定的 key |
-| EXPIRE key seconds(通用) | 给指定 key 设置过期时间 |
+| 命令 | 介绍 |
+| ------------------------------- | -------------------------------- |
+| SET key value | 设置指定 key 的值 |
+| SETNX key value | 只有在 key 不存在时设置 key 的值 |
+| GET key | 获取指定 key 的值 |
+| MSET key1 value1 key2 value2 …… | 设置一个或多个指定 key 的值 |
+| MGET key1 key2 ... | 获取一个或多个指定 key 的值 |
+| STRLEN key | 返回 key 所储存的字符串值的长度 |
+| INCR key | 将 key 中储存的数字值增一 |
+| DECR key | 将 key 中储存的数字值减一 |
+| EXISTS key | 判断指定 key 是否存在 |
+| DEL key(通用) | 删除指定的 key |
+| EXPIRE key seconds(通用) | 给指定 key 设置过期时间 |
更多 Redis String 命令以及详细使用指南,请查看 Redis 官网对应的介绍: 。
@@ -110,7 +108,7 @@ OK
```bash
> EXPIRE key 60
(integer) 1
-> SETNX key 60 value # 设置值并设置过期时间
+> SETEX key 60 value # 设置值并设置过期时间
OK
> TTL key
(integer) 56
@@ -120,7 +118,7 @@ OK
**需要存储常规数据的场景**
-- 举例:缓存 session、token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
+- 举例:缓存 Session、Token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
- 相关命令:`SET`、`GET`。
**需要计数的场景**
@@ -178,11 +176,11 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
```bash
> RPUSH myList2 value1 value2 value3
(integer) 3
-> RPOP myList2 # 将 list的头部(最右边)元素取出
+> RPOP myList2 # 将 list的最右边的元素取出
"value3"
```
-我专门画了一个图方便大家理解 `RPUSH` , `LPOP` , `lpush` , `RPOP` 命令:
+我专门画了一个图方便大家理解 `RPUSH` , `LPOP` , `LPUSH` , `RPOP` 命令:

@@ -218,7 +216,7 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
**消息队列**
-Redis List 数据结构可以用来做消息队列,只是功能过于简单且存在很多缺陷,不建议这样做。
+`List` 可以用来做消息队列,只是功能过于简单且存在很多缺陷,不建议这样做。
相对来说,Redis 5.0 新增加的一个数据结构 `Stream` 更适合做消息队列一些,只是功能依然非常简陋。和专业的消息队列相比,还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。
@@ -474,7 +472,7 @@ value1

-[《Java 面试指北》](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7) 的「技术面试题篇」就有一篇文章详细介绍如何使用 Sorted Set 来设计制作一个排行榜。
+[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 的「技术面试题篇」就有一篇文章详细介绍如何使用 Sorted Set 来设计制作一个排行榜。
@@ -483,9 +481,21 @@ value1
- 举例:优先级任务队列。
- 相关命令:`ZRANGE` (从小到大排序)、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
+## 总结
+
+| 数据类型 | 说明 |
+| -------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| String | 一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。 |
+| List | Redis 的 List 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。 |
+| Hash | 一个 String 类型的 field-value(键值对) 的映射表,特别适合用于存储对象,后续操作的时候,你可以直接修改这个对象中的某些字段的值。 |
+| Set | 无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 `HashSet` 。 |
+| Zset | 和 Set 相比,Sorted Set 增加了一个权重参数 `score`,使得集合中的元素能够按 `score` 进行有序排列,还可以通过 `score` 的范围来获取元素的列表。有点像是 Java 中 `HashMap` 和 `TreeSet` 的结合体。 |
+
## 参考
- Redis Data Structures: 。
- Redis Commands: 。
- Redis Data types tutorial: 。
- Redis 存储对象信息是用 Hash 还是 String :
+
+
diff --git a/docs/database/redis/redis-data-structures-02.md b/docs/database/redis/redis-data-structures-02.md
index 4a1c5ad1396..78e98365bff 100644
--- a/docs/database/redis/redis-data-structures-02.md
+++ b/docs/database/redis/redis-data-structures-02.md
@@ -1,23 +1,27 @@
---
-title: Redis 3 种特殊数据结构详解
+title: Redis 3 种特殊数据类型详解
+description: 详解Redis三种特殊数据类型Bitmap、HyperLogLog、GEO的使用方法和应用场景,包括签到统计、UV统计、附近的人等典型业务场景实现。
category: 数据库
tag:
- Redis
head:
- - meta
- name: keywords
- content: Redis常见数据结构
- - - meta
- - name: description
- content: Redis特殊数据结构总结:HyperLogLogs(基数统计)、Bitmap (位存储)、Geospatial (地理位置)。
+ content: Redis特殊数据类型,Bitmap,HyperLogLog,GEO,位图,基数统计,地理位置,签到统计,UV统计
---
-除了 5 种基本的数据结构之外,Redis 还支持 3 种特殊的数据结构:Bitmap、HyperLogLog、GEO。
+除了 5 种基本的数据类型之外,Redis 还支持 3 种特殊的数据类型:Bitmap、HyperLogLog、GEO。
-## Bitmap
+## Bitmap (位图)
### 介绍
+根据官网介绍:
+
+> Bitmaps are not an actual data type, but a set of bit-oriented operations defined on the String type which is treated like a bit vector. Since strings are binary safe blobs and their maximum length is 512 MB, they are suitable to set up to 2^32 different bits.
+>
+> Bitmap 不是 Redis 中的实际数据类型,而是在 String 类型上定义的一组面向位的操作,将其视为位向量。由于字符串是二进制安全的块,且最大长度为 512 MB,它们适合用于设置最多 2^32 个不同的位。
+
Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。
@@ -30,7 +34,7 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
| ------------------------------------- | ---------------------------------------------------------------- |
| SETBIT key offset value | 设置指定 offset 位置的值 |
| GETBIT key offset | 获取指定 offset 位置的值 |
-| BITCOUNT key start end | 获取 start 和 end 之前值为 1 的元素个数 |
+| BITCOUNT key start end | 获取 start 和 end 之间值为 1 的元素个数 |
| BITOP operation destkey key1 key2 ... | 对一个或多个 Bitmap 进行运算,可用运算符有 AND, OR, XOR 以及 NOT |
**Bitmap 基本操作演示**:
@@ -59,7 +63,7 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
- 举例:用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)。
- 相关命令:`SETBIT`、`GETBIT`、`BITCOUNT`、`BITOP`。
-## HyperLogLog
+## HyperLogLog(基数统计)
### 介绍
@@ -74,7 +78,7 @@ Redis 官方文档中有对应的详细说明:

-基数计数概率算法为了节省内存并不会直接存储元数据,而是通过一定的概率统计方法预估基数值(集合中包含元素的个数)。因此, HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为 `0.81%` 。)。
+基数计数概率算法为了节省内存并不会直接存储元数据,而是通过一定的概率统计方法预估基数值(集合中包含元素的个数)。因此, HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为 `0.81%` )。
@@ -82,6 +86,8 @@ HyperLogLog 的使用非常简单,但原理非常复杂。HyperLogLog 的原
再推荐一个可以帮助理解 HyperLogLog 原理的工具:[Sketch of the Day: HyperLogLog — Cornerstone of a Big Data Infrastructure](http://content.research.neustar.biz/blog/hll.html) 。
+除了 HyperLogLog 之外,Redis 还提供了其他的概率数据结构,对应的官方文档地址: 。
+
### 常用命令
HyperLogLog 相关的命令非常少,最常用的也就 3 个。
@@ -115,12 +121,12 @@ HyperLogLog 相关的命令非常少,最常用的也就 3 个。
### 应用场景
-**数量量巨大(百万、千万级别以上)的计数场景**
+**数量巨大(百万、千万级别以上)的计数场景**
-- 举例:热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计、
+- 举例:热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计。
- 相关命令:`PFADD`、`PFCOUNT` 。
-## Geospatial index
+## Geospatial (地理位置)
### 介绍
@@ -201,8 +207,18 @@ user2
- 举例:附近的人。
- 相关命令: `GEOADD`、`GEORADIUS`、`GEORADIUSBYMEMBER` 。
+## 总结
+
+| 数据类型 | 说明 |
+| ---------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| Bitmap | 你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。 |
+| HyperLogLog | Redis 提供的 HyperLogLog 占用空间非常非常小,只需要 12k 的空间就能存储接近`2^64`个不同元素。不过,HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为 `0.81%` )。 |
+| Geospatial index | Geospatial index(地理空间索引,简称 GEO) 主要用于存储地理位置信息,基于 Sorted Set 实现。 |
+
## 参考
-- Redis Data Structures:https://redis.com/redis-enterprise/data-structures/ 。
+- Redis Data Structures: 。
- 《Redis 深度历险:核心原理与应用实践》1.6 四两拨千斤——HyperLogLog
-- 布隆过滤器,位图,HyperLogLog:https://hogwartsrico.github.io/2020/06/08/BloomFilter-HyperLogLog-BitMap/index.html
+- 布隆过滤器,位图,HyperLogLog:
+
+
diff --git a/docs/database/redis/redis-delayed-task.md b/docs/database/redis/redis-delayed-task.md
new file mode 100644
index 00000000000..35c14ab7329
--- /dev/null
+++ b/docs/database/redis/redis-delayed-task.md
@@ -0,0 +1,87 @@
+---
+title: 如何基于Redis实现延时任务
+description: 详解基于Redis实现延时任务的两种方案:过期事件监听和Redisson延时队列,分析各方案的优缺点、可靠性问题和适用场景。
+category: 数据库
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis延时任务,延时队列,过期事件监听,Redisson DelayedQueue,订单超时,定时任务
+---
+
+基于 Redis 实现延时任务的功能无非就下面两种方案:
+
+1. Redis 过期事件监听
+2. Redisson 内置的延时队列
+
+面试的时候,你可以先说自己考虑了这两种方案,但最后发现 Redis 过期事件监听这种方案存在很多问题,因此你最终选择了 Redisson 内置的 DelayedQueue 这种方案。
+
+这个时候面试官可能会追问你一些相关的问题,我们后面会提到,提前准备就好了。
+
+另外,除了下面介绍到的这些问题之外,Redis 相关的常见问题建议你都复习一遍,不排除面试官会顺带问你一些 Redis 的其他问题。
+
+### Redis 过期事件监听实现延时任务功能的原理?
+
+Redis 2.0 引入了发布订阅 (pub/sub) 功能。在 pub/sub 中,引入了一个叫做 **channel(频道)** 的概念,有点类似于消息队列中的 **topic(主题)**。
+
+pub/sub 涉及发布者(publisher)和订阅者(subscriber,也叫消费者)两个角色:
+
+- 发布者通过 `PUBLISH` 投递消息给指定 channel。
+- 订阅者通过`SUBSCRIBE`订阅它关心的 channel。并且,订阅者可以订阅一个或者多个 channel。
+
+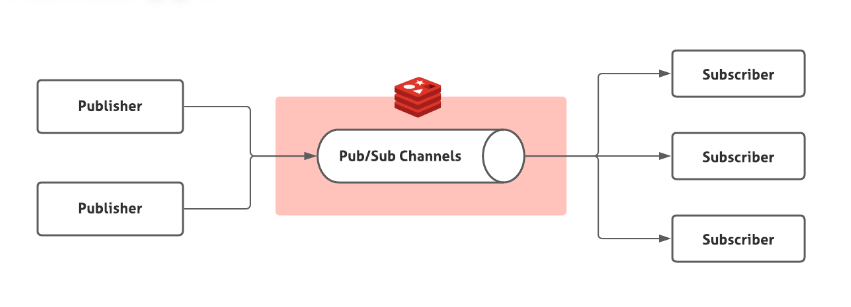
+
+在 pub/sub 模式下,生产者需要指定消息发送到哪个 channel 中,而消费者则订阅对应的 channel 以获取消息。
+
+Redis 中有很多默认的 channel,这些 channel 是由 Redis 本身向它们发送消息的,而不是我们自己编写的代码。其中,`__keyevent@0__:expired` 就是一个默认的 channel,负责监听 key 的过期事件。也就是说,当一个 key 过期之后,Redis 会发布一个 key 过期的事件到`__keyevent@__:expired`这个 channel 中。
+
+我们只需要监听这个 channel,就可以拿到过期的 key 的消息,进而实现了延时任务功能。
+
+这个功能被 Redis 官方称为 **keyspace notifications** ,作用是实时监控 Redis 键和值的变化。
+
+### Redis 过期事件监听实现延时任务功能有什么缺陷?
+
+**1、时效性差**
+
+官方文档的一段介绍解释了时效性差的原因,地址: 。
+
+
+
+这段话的核心是:过期事件消息是在 Redis 服务器删除 key 时发布的,而不是一个 key 过期之后就会就会直接发布。
+
+我们知道常用的过期数据的删除策略就两个:
+
+1. **惰性删除**:只会在取出 key 的时候才对数据进行过期检查。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
+2. **定期删除**:每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
+
+定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,所以 Redis 采用的是 **定期删除+惰性/懒汉式删除** 。
+
+因此,就会存在我设置了 key 的过期时间,但到了指定时间 key 还未被删除,进而没有发布过期事件的情况。
+
+**2、丢消息**
+
+Redis 的 pub/sub 模式中的消息并不支持持久化,这与消息队列不同。在 Redis 的 pub/sub 模式中,发布者将消息发送给指定的频道,订阅者监听相应的频道以接收消息。当没有订阅者时,消息会被直接丢弃,在 Redis 中不会存储该消息。
+
+**3、多服务实例下消息重复消费**
+
+Redis 的 pub/sub 模式目前只有广播模式,这意味着当生产者向特定频道发布一条消息时,所有订阅相关频道的消费者都能够收到该消息。
+
+这个时候,我们需要注意多个服务实例重复处理消息的问题,这会增加代码开发量和维护难度。
+
+### Redisson 延迟队列原理是什么?有什么优势?
+
+Redisson 是一个开源的 Java 语言 Redis 客户端,提供了很多开箱即用的功能,比如多种分布式锁的实现、延时队列。
+
+我们可以借助 Redisson 内置的延时队列 RDelayedQueue 来实现延时任务功能。
+
+Redisson 的延迟队列 RDelayedQueue 是基于 Redis 的 SortedSet 来实现的。SortedSet 是一个有序集合,其中的每个元素都可以设置一个分数,代表该元素的权重。Redisson 利用这一特性,将需要延迟执行的任务插入到 SortedSet 中,并给它们设置相应的过期时间作为分数。
+
+Redisson 定期使用 `zrangebyscore` 命令扫描 SortedSet 中过期的元素,然后将这些过期元素从 SortedSet 中移除,并将它们加入到就绪消息列表中。就绪消息列表是一个阻塞队列,有消息进入就会被消费者监听到。这样做可以避免消费者对整个 SortedSet 进行轮询,提高了执行效率。
+
+相比于 Redis 过期事件监听实现延时任务功能,这种方式具备下面这些优势:
+
+1. **减少了丢消息的可能**:DelayedQueue 中的消息会被持久化,即使 Redis 宕机了,根据持久化机制,也只可能丢失一点消息,影响不大。当然了,你也可以使用扫描数据库的方法作为补偿机制。
+2. **消息不存在重复消费问题**:每个客户端都是从同一个目标队列中获取任务的,不存在重复消费的问题。
+
+跟 Redisson 内置的延时队列相比,消息队列可以通过保障消息消费的可靠性、控制消息生产者和消费者的数量等手段来实现更高的吞吐量和更强的可靠性,实际项目中首选使用消息队列的延时消息这种方案。
diff --git a/docs/database/redis/redis-memory-fragmentation.md b/docs/database/redis/redis-memory-fragmentation.md
index 799e2131acc..e2d0ea272b9 100644
--- a/docs/database/redis/redis-memory-fragmentation.md
+++ b/docs/database/redis/redis-memory-fragmentation.md
@@ -1,8 +1,13 @@
---
title: Redis内存碎片详解
+description: 深入解析Redis内存碎片产生的原因、判断方法和优化方案,包括内存碎片率计算、jemalloc分配器原理、自动内存碎片清理配置等。
category: 数据库
tag:
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis内存碎片,内存碎片率,jemalloc,内存分配,activedefrag,内存优化,Redis内存管理
---
## 什么是内存碎片?
@@ -19,7 +24,7 @@ Redis 内存碎片虽然不会影响 Redis 性能,但是会增加内存消耗
Redis 内存碎片产生比较常见的 2 个原因:
-**1、Redis 存储存储数据的时候向操作系统申请的内存空间可能会大于数据实际需要的存储空间。**
+**1、Redis 存储数据的时候向操作系统申请的内存空间可能会大于数据实际需要的存储空间。**
以下是这段 Redis 官方的原话:
@@ -27,7 +32,7 @@ Redis 内存碎片产生比较常见的 2 个原因:
Redis 使用 `zmalloc` 方法(Redis 自己实现的内存分配方法)进行内存分配的时候,除了要分配 `size` 大小的内存之外,还会多分配 `PREFIX_SIZE` 大小的内存。
-`zmalloc` 方法源码如下(源码地址:https://github.com/antirez/redis-tools/blob/master/zmalloc.c):
+`zmalloc` 方法源码如下(源码地址:
```java
void *zmalloc(size_t size) {
@@ -45,7 +50,7 @@ void *zmalloc(size_t size) {
}
```
-另外,Redis 可以使用多种内存分配器来分配内存( libc、jemalloc、tcmalloc),默认使用 [jemalloc](https://github.com/jemalloc/jemalloc),而 jemalloc 按照一系列固定的大小(8 字节、16 字节、32 字节......)来分配内存的。jemalloc 划分的内存单元如下图所示:
+另外,Redis 可以使用多种内存分配器来分配内存( libc、jemalloc、tcmalloc),默认使用 [jemalloc](https://github.com/jemalloc/jemalloc),而 jemalloc 按照一系列固定的大小(8 字节、16 字节、32 字节……)来分配内存的。jemalloc 划分的内存单元如下图所示:
@@ -59,11 +64,11 @@ void *zmalloc(size_t size) {

-文档地址:https://redis.io/topics/memory-optimization 。
+文档地址: 。
## 如何查看 Redis 内存碎片的信息?
-使用 `info memory` 命令即可查看 Redis 内存相关的信息。下图中每个参数具体的含义,Redis 官方文档有详细的介绍:https://redis.io/commands/INFO 。
+使用 `info memory` 命令即可查看 Redis 内存相关的信息。下图中每个参数具体的含义,Redis 官方文档有详细的介绍: 。
@@ -117,6 +122,8 @@ config set active-defrag-cycle-max 50
## 参考
-- Redis 官方文档:https://redis.io/topics/memory-optimization
-- Redis 核心技术与实战 - 极客时间 - 删除数据后,为什么内存占用率还是很高?:https://time.geekbang.org/column/article/289140
-- Redis 源码解析——内存分配:
+- Redis 官方文档:
+- Redis 核心技术与实战 - 极客时间 - 删除数据后,为什么内存占用率还是很高?:
+- Redis 源码解析——内存分配:< 源码解析——内存管理>
+
+
diff --git a/docs/database/redis/redis-persistence.md b/docs/database/redis/redis-persistence.md
index 499994cb8e4..8dc2110013e 100644
--- a/docs/database/redis/redis-persistence.md
+++ b/docs/database/redis/redis-persistence.md
@@ -1,15 +1,13 @@
---
title: Redis持久化机制详解
+description: 深入解析Redis三种持久化机制RDB快照、AOF日志和混合持久化的工作原理、配置方法和优缺点对比,帮助你选择适合业务场景的持久化策略。
category: 数据库
tag:
- Redis
head:
- - meta
- name: keywords
- content: Redis持久化机制详解
- - - meta
- - name: description
- content: Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:快照(snapshotting,RDB)、只追加文件(append-only file, AOF)、RDB 和 AOF 的混合持久化(Redis 4.0 新增)。
+ content: Redis持久化,RDB,AOF,混合持久化,bgsave,数据恢复,Redis备份,fork子进程
---
使用缓存的时候,我们经常需要对内存中的数据进行持久化也就是将内存中的数据写入到硬盘中。大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了做数据同步(比如 Redis 集群的主从节点通过 RDB 文件同步数据)。
@@ -20,10 +18,35 @@ Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而
- 只追加文件(append-only file, AOF)
- RDB 和 AOF 的混合持久化(Redis 4.0 新增)
-官方文档地址:https://redis.io/topics/persistence 。
+官方文档地址: 。

+**本文基于 Redis 7.0+ 版本**。不同版本的持久化机制有重要差异,使用前请确认你的 Redis 版本:
+
+| 版本 | 持久化默认方式 | 重要特性 |
+| -------------- | -------------- | ----------------------- |
+| **Redis 4.0** | RDB | 引入 RDB+AOF 混合持久化 |
+| **Redis 6.0** | RDB | AOF 仍需手动开启 |
+| **Redis 7.0** | RDB | 引入 Multi-Part AOF |
+| **Redis 7.2+** | RDB | 进一步优化持久化性能 |
+
+**关键行为差异**:
+
+- **AOF rewrite 内存占用**:Redis 7.0 之前重写期间增量数据需在内存中保留,7.0+ 使用 Multi-Part AOF 解决
+- **混合持久化**:Redis 4.0-6.x 需手动开启,Redis 7.0+ 默认启用。
+
+检查你的 Redis 版本:
+
+```bash
+redis-cli INFO server | grep redis_version
+# 输出示例:redis_version:7.0.12
+```
+
+下面这张图展示了 Redis 持久化机制的完整流程,包含了本文的核心内容:
+
+
+
## RDB 持久化
### 什么是 RDB 持久化?
@@ -33,11 +56,18 @@ Redis 可以通过创建快照来获得存储在内存里面的数据在 **某
快照持久化是 Redis 默认采用的持久化方式,在 `redis.conf` 配置文件中默认有此下配置:
```clojure
-save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发bgsave命令创建快照。
-
-save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发bgsave命令创建快照。
-
-save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发bgsave命令创建快照。
+# Redis 7.0 默认配置(单行格式)
+save 3600 1 300 100 60 10000
+
+# 各条件含义:
+# - 3600 秒(1 小时)内至少有 1 个 key 变化
+# - 300 秒(5 分钟)内至少有 100 个 key 变化
+# - 60 秒(1 分钟)内至少有 10000 个 key 变化
+
+# 等价于旧版多行格式:
+# save 3600 1
+# save 300 100
+# save 60 10000
```
### RDB 创建快照时会阻塞主线程吗?
@@ -45,15 +75,85 @@ save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生
Redis 提供了两个命令来生成 RDB 快照文件:
- `save` : 同步保存操作,会阻塞 Redis 主线程;
-- `bgsave` : fork 出一个子进程,子进程执行,不会阻塞 Redis 主线程,默认选项。
+- `bgsave` : fork 出一个子进程,子进程执行。
> 这里说 Redis 主线程而不是主进程的主要是因为 Redis 启动之后主要是通过单线程的方式完成主要的工作。如果你想将其描述为 Redis 主进程,也没毛病。
+#### fork 性能开销分析
+
+虽然 `bgsave` 在子进程中执行,不会阻塞主线程处理命令请求,但 **fork 操作本身是阻塞的**,且会带来额外的内存开销(下表中的为参考值,实际数值受到 CPU 性能、内存碎片率、系统负载等因素影响):
+
+| 数据集大小 | fork 延迟 | 额外内存占用 | 风险等级 |
+| ---------- | --------- | ---------------- | -------- |
+| < 1GB | < 10ms | ~10MB (页表复制) | 低 |
+| 1-10GB | 10-100ms | 10-100MB | 中 |
+| 10-50GB | 100ms-1s | 100-500MB | 高 |
+| > 50GB | > 1s | > 500MB | 极高 |
+
+> 本文以 RDB 的 `bgsave` 为例说明 fork 性能影响,但**同样的机制也适用于 AOF 重写(`BGREWRITEAOF` 命令)**。AOF 重写同样需要 fork 子进程,同样面临 fork 延迟、COW 内存开销和 THP 风险。生产环境中,无论是 RDB 还是 AOF 重写,都需要关注 fork 相关的性能指标。
+
+#### Copy-on-Write (COW) 机制
+
+- fork 后,子进程共享父进程的内存页(标准页 4KB)
+- 当父进程或子进程修改内存页时,内核复制该页(Copy-on-Write)
+- 大数据集 + 高写负载时,会导致大量页面复制,影响性能
+
+#### THP(透明大页)导致的内存雪崩问题
+
+Linux 发行版默认开启 **THP(Transparent Huge Pages,透明大页)**,大小为 2MB。THP 会增加大页被 COW 的概率,**最坏情况下**,如果内存被合并为 2MB 大页,即使客户端仅修改 10 字节的数据,内核也会复制完整的 2MB 内存页,导致 COW 的内存开销**放大 512 倍**(2MB / 4KB = 512)。
+
+**实际行为**:内核不会强制所有内存都使用 2MB 大页,而是根据情况动态决定是否合并。只有在 THP 成功合并为大页后,修改才会触发 2MB 的 COW。但在高并发写入场景下,这仍会显著增加内存消耗,可能瞬间吸干宿主机内存,触发 **OOM Killer 强杀 Redis 进程**。
+
+**验证方式**:
+
+```bash
+cat /sys/kernel/mm/transparent_hugepage/enabled
+# 输出 [always] madvise never 表示已开启(危险!)
+# 应该输出 always madvise [never]
+```
+
+**解决方案**:在 Redis 启动脚本中添加 `echo never > /sys/kernel/mm/transparent_hugepage/enabled`,或使用 `redis-server --disable-thp yes`(Redis 6.0+ 支持)。
+
+**启动警告**:Redis 检测到 THP 开启时会在启动日志中打印 `WARNING you have Transparent Huge Pages (THP) support enabled in your kernel`,必须立即处理。
+
+#### 生产环境建议
+
+```bash
+# 1. 监控 fork 风险指标
+redis-cli INFO memory | grep -E "(used_memory|used_memory_rss)"
+
+# 输出示例:
+# used_memory:1073741824
+# used_memory_rss:1226833920
+# used_memory_rss_human:1.14G
+
+# 计算 RSS/USED 比值,fork 时应 < 2
+# 如果接近或超过 2,说明 fork 风险高
+
+# 2. 设置 maxmemory 限制 Redis 内存占用,为 fork 预留空间
+# 在 redis.conf 中设置:
+# maxmemory 8gb
+# maxmemory-policy allkeys-lru
+
+# 3. 避免在高峰期手动触发 BGSAVE
+# 让 Redis 根据配置规则自动触发
+
+# 4. 考虑主从复制 + 从节点持久化架构
+# 将持久化操作转移到从节点,避免主节点 fork 开销
+```
+
+**监控告警**:
+
+- `rdb_last_bgsave_time_sec`:上次 bgsave 耗时,应 < 5s
+- `rdb_last_cow_size`:上次 fork 的 COW 内存大小,应 < 10% `used_memory`
+
## AOF 持久化
### 什么是 AOF 持久化?
-与快照持久化相比,AOF 持久化的实时性更好。默认情况下 Redis 没有开启 AOF(append only file)方式的持久化(Redis 6.0 之后已经默认是开启了),可以通过 `appendonly` 参数开启:
+与快照持久化相比,AOF 持久化的实时性更好。默认情况下 Redis 没有开启 AOF(append only file)方式的持久化,可以通过 `appendonly` 参数开启:
+
+> **版本说明**:Redis 默认使用 RDB 持久化方式。若需使用 AOF,需要手动设置 `appendonly yes`。Redis 7.0 引入了 Multi-Part AOF 机制优化 AOF 性能,但并未改变默认持久化方式。
```bash
appendonly yes
@@ -71,7 +171,7 @@ AOF 持久化功能的实现可以简单分为 5 步:
1. **命令追加(append)**:所有的写命令会追加到 AOF 缓冲区中。
2. **文件写入(write)**:将 AOF 缓冲区的数据写入到 AOF 文件中。这一步需要调用`write`函数(系统调用),`write`将数据写入到了系统内核缓冲区之后直接返回了(延迟写)。注意!!!此时并没有同步到磁盘。
-3. **文件同步(fsync)**:AOF 缓冲区根据对应的持久化方式( `fsync` 策略)向硬盘做同步操作。这一步需要调用 `fsync` 函数(系统调用), `fsync` 针对单个文件操作,对其进行强制硬盘同步,`fsync` 将阻塞直到写入磁盘完成后返回,保证了数据持久化。
+3. **文件同步(fsync)**:这一步才是持久化的核心!根据你在 `redis.conf` 文件里 `appendfsync` 配置的策略,Redis 会在不同的时机,调用 `fsync` 函数(系统调用)。`fsync` 针对单个文件操作,对其进行强制硬盘同步(文件在内核缓冲区里的数据写到硬盘),`fsync` 将阻塞直到写入磁盘完成后返回,保证了数据持久化。
4. **文件重写(rewrite)**:随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
5. **重启加载(load)**:当 Redis 重启时,可以加载 AOF 文件进行数据恢复。
@@ -79,8 +179,12 @@ AOF 持久化功能的实现可以简单分为 5 步:
这里对上面提到的一些 Linux 系统调用再做一遍解释:
-- `write`:写入系统内核缓冲区之后直接返回(仅仅是写到缓冲区),不会立即同步到硬盘。虽然提高了效率,但也带来了数据丢失的风险。同步硬盘操作通常依赖于系统调度机制,Linux 内核通常为 30s 同步一次,具体值取决于写出的数据量和 I/O 缓冲区的状态。
-- `fsync`:`fsync`用于强制刷新系统内核缓冲区(同步到到磁盘),确保写磁盘操作结束才会返回。
+- `write`:写入系统内核缓冲区之后直接返回(仅仅是写到缓冲区),不会立即同步到硬盘。虽然提高了效率,但也带来了数据丢失的风险。**同步硬盘操作取决于 Linux 内核的脏页回写策略(Dirty Page Writeback)**,主要受以下参数影响:
+ - `/proc/sys/vm/dirty_expire_centisecs`:脏页过期时间(默认 30 秒)
+ - `/proc/sys/vm/dirty_writeback_centisecs`:内核回写线程的唤醒间隔(默认 5 秒)
+ - 系统内存压力:内存不足时会更积极触发同步
+- **这意味着 `appendfsync no` 模式下宕机时,可能丢失的数据量是不可控且不可预测的**,取决于上次内核同步的时间点。
+- `fsync`:`fsync`用于强制刷新系统内核缓冲区(同步到磁盘),确保写磁盘操作结束才会返回。
AOF 工作流程图如下:
@@ -90,13 +194,24 @@ AOF 工作流程图如下:
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
-1. `appendfsync always`:主线程调用 `write` 执行写操作后,后台线程( `aof_fsync` 线程)立即会调用 `fsync` 函数同步 AOF 文件(刷盘),`fsync` 完成后线程返回,这样会严重降低 Redis 的性能(`write` + `fsync`)。
-2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)
-3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。
+1. `appendfsync always`:主线程调用 `write` 执行写操作后,会立刻调用 `fsync` 函数同步 AOF 文件(刷盘)。主线程会阻塞,直到 `fsync` 将数据完全刷到磁盘后才会返回。这种方式数据最安全,理论上不会有任何数据丢失。但因为每个写操作都会同步阻塞主线程,所以性能极差。
+2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)。这种方式主线程的性能基本不受影响。在性能和数据安全之间做出了绝佳的平衡。不过,在 Redis 异常宕机时,通常可能丢失最近 1 秒内的数据。
+
+> **生产级真相(2 秒丢失与阻塞风险)**:
+>
+> "最多丢失 1 秒"是理想情况。当磁盘 I/O 繁忙时,后台 fsync 执行时间过长,主线程在执行写命令时会检查上一次 fsync 的完成时间。如果距离上次成功 fsync 超过 2 秒,主线程将被**强制阻塞**以保护内存不被撑爆(Redis 源码 `aof.c` 中的 `aof_background_fsync` 阻塞判断逻辑)。
+>
+> 因此,**极端宕机情况下,可能会丢失最多 2 秒的数据**,且磁盘抖动会直接导致 Redis P99 延迟飙升。
+>
+> **必须监控指标**:`redis-cli INFO persistence | grep aof_delayed_fsync`(记录主线程被 fsync 阻塞的累计次数,只有启用了 AOF 才有这个字段)。
+
+3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。 这种方式性能最好,因为避免了 `fsync` 的阻塞。但数据安全性最差,宕机时丢失的数据量不可控,取决于操作系统上一次同步的时间点。
可以看出:**这 3 种持久化方式的主要区别在于 `fsync` 同步 AOF 文件的时机(刷盘)**。
-为了兼顾数据和写入性能,可以考虑 `appendfsync everysec` 选项 ,让 Redis 每秒同步一次 AOF 文件,Redis 性能受到的影响较小。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis 还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
+为了兼顾数据和写入性能,可以考虑 `appendfsync everysec` 选项 ,让 Redis 每秒同步一次 AOF 文件,Redis 性能受到的影响较小。通常情况下,即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis 还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
+
+> ⚠️ **注意**:当磁盘 I/O 瓶颈严重时,Redis 主线程可能因等待 fsync 而阻塞长达 2 秒,期间数据丢失窗口扩大至 2 秒。生产环境应监控 `aof_delayed_fsync` 指标来评估磁盘健康度。
从 Redis 7.0.0 开始,Redis 使用了 **Multi Part AOF** 机制。顾名思义,Multi Part AOF 就是将原来的单个 AOF 文件拆分成多个 AOF 文件。在 Multi Part AOF 中,AOF 文件被分为三种类型,分别为:
@@ -141,6 +256,36 @@ AOF 文件重写期间,Redis 还会维护一个 **AOF 重写缓冲区**,该
- `auto-aof-rewrite-min-size`:如果 AOF 文件大小小于该值,则不会触发 AOF 重写。默认值为 64 MB;
- `auto-aof-rewrite-percentage`:执行 AOF 重写时,当前 AOF 大小(aof_current_size)和上一次重写时 AOF 大小(aof_base_size)的比值。如果当前 AOF 文件大小增加了这个百分比值,将触发 AOF 重写。将此值设置为 0 将禁用自动 AOF 重写。默认值为 100。
+**AOF rewrite 的失败边界与风险场景**:
+
+虽然 AOF rewrite 放在子进程执行,但仍存在以下风险需要了解:
+
+| 风险场景 | 影响 | 触发条件 | 应对措施 |
+| ---------------- | --------------------------- | ------------------------ | ------------------------------------------- |
+| **fork 失败** | 无法创建 rewrite 子进程 | 内存不足、系统限制 | 监控内存使用率,设置 `maxmemory` |
+| **磁盘满** | 新 AOF 文件写入失败 | rewrite 期间数据量增长快 | 监控磁盘使用率(`df -h`),设置告警阈值 70% |
+| **inode 耗尽** | 无法创建新文件 | 小文件过多的系统 | 监控 inode 使用率(`df -i`),清理临时文件 |
+| **时间戳回拨** | Multi-Part AOF 文件管理混乱 | 虚拟机时钟同步问题 | 配置 NTP 服务,设置 `aof-timestamp-enabled` |
+| **SIGTERM 信号** | rewrite 被中断 | 运维人员手动重启 | 配置优雅关闭(`shutdown-timeout`) |
+
+**生产环境监控建议**:
+
+```bash
+# 监控 AOF rewrite 状态
+redis-cli INFO persistence | grep aof_rewrite_in_progress
+
+# 监控 AOF 文件大小增长
+redis-cli INFO persistence | grep aof_current_size
+redis-cli INFO persistence | grep aof_base_size
+
+# 检查磁盘和 inode 使用率
+df -h /var/lib/redis
+df -i /var/lib/redis
+
+# 设置 AOF rewrite 期间增量 fsync 策略(Redis 7.0+)
+# aof-rewrite-incremental-sync yes
+```
+
Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
Redis 7.0 版本之后,AOF 重写机制得到了优化改进。下面这段内容摘自阿里开发者的[从 Redis7.0 发布看 Redis 的过去与未来](https://mp.weixin.qq.com/s/RnoPPL7jiFSKkx3G4p57Pg) 这篇文章。
@@ -153,45 +298,428 @@ Redis 7.0 版本之后,AOF 重写机制得到了优化改进。下面这段内
### AOF 校验机制了解吗?
-AOF 校验机制是 Redis 在启动时对 AOF 文件进行检查,以判断文件是否完整,是否有损坏或者丢失的数据。这个机制的原理其实非常简单,就是通过使用一种叫做 **校验和(checksum)** 的数字来验证 AOF 文件。这个校验和是通过对整个 AOF 文件内容进行 CRC64 算法计算得出的数字。如果文件内容发生了变化,那么校验和也会随之改变。因此,Redis 在启动时会比较计算出的校验和与文件末尾保存的校验和(计算的时候会把最后一行保存校验和的内容给忽略点),从而判断 AOF 文件是否完整。如果发现文件有问题,Redis 就会拒绝启动并提供相应的错误信息。AOF 校验机制十分简单有效,可以提高 Redis 数据的可靠性。
+纯 AOF 模式下,Redis 不会对整个 AOF 文件使用校验和(如 CRC64),而是通过逐条解析文件中的命令来验证文件的有效性。如果解析过程中发现语法错误(如命令不完整、格式错误),Redis 会终止加载并报错,从而避免错误数据载入内存。
+
+> **尾部截断容灾(自动恢复)**:
+>
+> 在遭遇意外断电或 `kill -9` 强制终止时,AOF 文件的最后一条命令极可能写入不完整(只写了一半)。此时的恢复行为由 **`aof-load-truncated`** 配置决定:
+>
+> | 配置值 | 行为 | 适用场景 |
+> | ------------- | ------------------------------------------------------------------------------- | ---------------------------------------- |
+> | `yes`(默认) | Redis 自动丢弃文件尾部不完整的命令,继续完成启动并在日志中打印警告信息 | 生产环境推荐,允许少量数据丢失换取可用性 |
+> | `no` | Redis 拒绝启动并直接报错,强制要求人工使用 `redis-check-aof` 工具确认并修复数据 | 金融等对数据完整性要求极高的场景 |
+>
+> **验证截断恢复**:
+>
+> ```bash
+> # 模拟断电场景:向 AOF 文件追加无意义的乱码
+> echo "truncated garbage data" >> /var/lib/redis/appendonly.aof
+>
+> # 重启 Redis(aof-load-truncated=yes 时会自动恢复)
+> redis-server /path/to/redis.conf
+> # 日志输出:# Bad file format reading the append only file: make a backup of your AOF file, then use ./redis-check-aof --fix
+> ```
+>
+> **失败模式**:如果 AOF 文件的**中间部分**(而非尾部)因为磁盘静默损坏出现乱码,自动截断机制无效,Redis 将直接宕机拒绝服务。此时需要使用 `redis-check-aof --fix` 工具修复。
+
+**redis-check-aof 工作原理**:
+
+- **检测阶段**:根据 AOF 文件格式逐一读取命令,判断命令参数个数、参数字符串长度等,提供错误/不完整命令的文件位置
+- **修复阶段**:从错误位置截断后续文件内容(**注意:会丢失截断点之后的所有数据**),原文件会被备份为 `appendonly.aof.broken`
+
+**人工修补**(高级用户):
+
+- 如果不想通过截断来修复 AOF 文件,可以尝试人工修补
+- 使用文本编辑器打开 AOF 文件(纯文本格式),手动删除或修复错误命令
+- 适用于明确知道错误位置的特定场景
+
+在 **混合持久化模式**(Redis 4.0 引入)下,AOF 文件由两部分组成:
+
+- **RDB 快照部分**:文件以固定的 `REDIS` 字符开头,存储某一时刻的内存数据快照,并在快照数据末尾附带一个 CRC64 校验和(位于 RDB 数据块尾部、AOF 增量部分之前)。
+- **AOF 增量部分**:紧随 RDB 快照部分之后,记录 RDB 快照生成后的增量写命令。这部分增量命令以 Redis 协议格式逐条记录,无整体或全局校验和。
+
+RDB 文件结构的核心部分如下:
+
+| **字段** | **解释** |
+| ----------------- | ---------------------------------------------- |
+| `"REDIS"` | 固定以该字符串开始 |
+| `RDB_VERSION` | RDB 文件的版本号 |
+| `DB_NUM` | Redis 数据库编号,指明数据需要存放到哪个数据库 |
+| `KEY_VALUE_PAIRS` | Redis 中具体键值对的存储 |
+| `EOF` | RDB 文件结束标志 |
+| `CHECK_SUM` | 8 字节确保 RDB 完整性的校验和 |
+
+Redis 启动并加载 AOF 文件时,首先会校验文件开头 RDB 快照部分的数据完整性,即计算该部分数据的 CRC64 校验和,并与紧随 RDB 数据之后、AOF 增量部分之前存储的 CRC64 校验和值进行比较。如果 CRC64 校验和不匹配,Redis 将拒绝启动并报告错误。
+
+RDB 部分校验通过后,Redis 随后逐条解析 AOF 部分的增量命令。如果解析过程中出现错误(如不完整的命令或格式错误),Redis 会停止继续加载后续命令,并报告错误,但此时 Redis 已经成功加载了 RDB 快照部分的数据。
+
+## 新版本优化
+
+### Redis 4.0 对于持久化机制做了什么优化?
+
+由于 RDB 和 AOF 各有优势,于是,Redis 4.0 开始支持 RDB 和 AOF 的混合持久化。
+
+#### 配置说明
+
+```bash
+# 开启 AOF
+appendonly yes
+
+# 开启混合持久化(Redis 7.0+ 默认启用)
+aof-use-rdb-preamble yes
+
+# 优化重写触发条件
+auto-aof-rewrite-percentage 100 # AOF 文件大小比上次重写后增长 100% 时触发
+auto-aof-rewrite-min-size 64mb # AOF 文件至少达到 64MB 才触发重写
+```
+
+**版本差异**:
+
+- **Redis 4.0-6.x**:混合持久化默认关闭,需手动配置 `aof-use-rdb-preamble yes`
+- **Redis 7.0+**:混合持久化**默认启用**,无需额外配置
+
+#### 工作原理
+
+如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。
+
+**混合持久化文件结构**:
+
+```
+┌───────────────────┐
+│ RDB Header │ ← 二进制快照(压缩格式)
+│ REDIS0009 │
+│ ... │
+├───────────────────┤
+│ AOF Log Entries │ ← 文本格式命令
+│ *3\r\n$3\r\nSET\r\n$5\r\nkey01\r\n...
+│ INCR counter │
+│ ... │
+└───────────────────┘
+```
+
+**核心工作流程**:
+
+1. **写处理阶段**:
+
+ - 客户端执行写命令(`SET/INCR` 等)
+ - Redis 立即更新内存数据
+ - 将命令追加到 AOF 缓冲区(文本格式)
+
+2. **持久化触发阶段**:
+
+ - AOF 文件大小达到阈值(默认 64MB)或增长 100%
+ - 触发 AOF 重写(`BGREWRITEAOF`)
+
+3. **文件构建阶段**:
+
+ - 子进程将当前内存数据以 RDB 格式写入新 AOF 文件开头
+ - 父进程继续处理写命令,增量数据记录到重写缓冲区
+ - 重写完成后,将重写缓冲区的增量命令追加到新 AOF 文件末尾
+
+4. **数据恢复阶段**:
+ - Redis 启动时优先加载 RDB 部分(快速恢复基础数据)
+ - 然后顺序重放 AOF 增量命令(恢复最新数据)
+
+#### 优势对比
+
+| 指标 | 纯 RDB | 纯 AOF | 混合持久化 |
+| ---------------- | ------------ | -------------- | -------------- |
+| **恢复速度** | 快(秒级) | 慢(分钟级) | 快(秒级) |
+| **数据丢失窗口** | 分钟级 | ≤2 秒 | ≤2 秒 |
+| **文件大小** | 小(压缩) | 大(文本日志) | 中等 |
+| **写入影响** | 低 | 高 | 中等 |
+| **可读性** | 差(二进制) | 好(文本) | 差(RDB 部分) |
+
+**基准数据**(1GB 数据集,SSD):
+
+- 纯 AOF 恢复:30-60 秒
+- 混合持久化恢复:2-5 秒(**快 5-10 倍**)
+
+**混合持久化缺点**:
-类似地,RDB 文件也有类似的校验机制来保证 RDB 文件的正确性,这里就不重复进行介绍了。
+- AOF 文件里面的 RDB 部分是压缩格式,不再是 AOF 格式,可读性较差。
+- 需要额外消耗 CPU 进行 RDB 压缩和解压。
-## Redis 4.0 对于持久化机制做了什么优化?
+#### 常见问题及解决方案
-由于 RDB 和 AOF 各有优势,于是,Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
+**1. 配置验证**:
-如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
+```bash
+# 方法 1:检查文件头(输出 REDIS 表示启用了混合持久化)
+head -c 5 appendonly.aof
+
+# 方法 2:CLI 验证
+redis-cli CONFIG GET aof-use-rdb-preamble
+# 输出:1) "aof-use-rdb-preamble"
+# 2) "yes"
+```
+
+**2. 文件损坏恢复**:
+
+**工具说明**:
+
+| 工具 | 工作原理 | 错误检测 | 修复功能 |
+| ------------------- | ----------------------------------------------------------------- | ------------------------------------ | --------------------------------------------------- |
+| **redis-check-aof** | 根据 AOF 文件格式逐一读取命令,判断命令参数个数、参数字符串长度等 | 检测命令正确性和完整性,提供错误位置 | ✅ **支持修复**:从错误位置截断后续内容,或人工修补 |
+| **redis-check-rdb** | 按照 RDB 文件格式依次读取文件头、数据部分、文件尾 | 在读取过程中判断内容是否正确并报错 | ❌ **不支持修复**:仅检测问题,需人工修复 |
+
+**恢复步骤**:
+
+```bash
+# 步骤 1:检测 AOF 文件问题
+redis-check-aof appendonly.aof
+# 输出错误位置和原因
+
+# 步骤 2:修复 AOF 文件(从错误位置截断)
+redis-check-aof --fix appendonly.aof
+# 原 AOF 文件会被备份为 appendonly.aof.broken
+
+# 步骤 3:检测 RDB 部分
+redis-check-rdb appendonly.aof
+# 仅检测,不支持 --fix 参数
+
+# 步骤 4:如果 RDB 部分有问题,需人工修复或丢弃整个文件
+# 选项 A:人工修复(需了解 RDB 二进制格式)
+# 选项 B:删除混合持久化文件,仅使用纯 RDB 或纯 AOF 恢复
+
+# 步骤 5:启动 Redis
+redis-server --appendonly yes --appendfilename appendonly.aof
+```
+
+> **⚠️ 重要提示**:
+>
+> - **AOF 文件**:`redis-check-aof --fix` 会从错误位置截断文件,**丢失截断点之后的所有数据**
+> - **RDB 文件**:`redis-check-rdb` **不支持修复**,如果 RDB 部分损坏,整个混合持久化文件无法恢复,只能依赖备份或纯 AOF 文件
+> - **人工修复**:对于 RDB 部分,如果必须修复,需要使用十六进制编辑器(如 `hexdump`、`xxd`)手动修改二进制格式
+
+#### 生产配置建议
+
+```bash
+# 完整生产配置示例
+appendonly yes
+aof-use-rdb-preamble yes
+
+# 性能优化
+aof-rewrite-incremental-fsync yes # 增量 fsync,减少磁盘 I/O 峰值
+# 延迟敏感场景(推荐 yes)
+no-appendfsync-on-rewrite yes # 重写期间暂停 fsync,避免阻塞
+# 数据安全场景(推荐 no)
+no-appendfsync-on-rewrite no # 重写期间仍执行 fsync,可能阻塞但更安全
+
+# 容量规划建议:
+# - 预留 2x 内存作为磁盘空间
+# - 保持单个 AOF 文件 < 16GB
+# - 监控 aof_delayed_fsync 指标
+```
-官方文档地址:https://redis.io/topics/persistence
+官方文档地址:

+### Redis 7.0 对于持久化机制做了什么优化?
+
+由于 AOF 重写过程中存在内存缓冲增量数据和磁盘双写的问题,于是,Redis 7.0 开始支持 Multi-Part AOF(默认启用,可以通过配置项 `appenddirname` 指定目录)。
+
+如果把 Multi-Part AOF 启用,AOF 文件将被拆分为 base 文件(最多一个,初始全量快照,可为 RDB 或 AOF 格式)和多个 incr 文件(增量命令日志),重写期间新增命令直接写入新的 incr 文件,由 manifest 文件跟踪所有部分。这样做的好处是可以消除重写时的内存缓冲开销和双重 I/O 写入,提高性能并减少潜在的 fsync 阻塞。由于文件结构分离,INCR 文件在重写前保持只读,单文件拷贝相对安全;但跨文件的一致性备份仍需暂停重写,整体备份流程比单文件 AOF 更复杂,且在极大数据集下仍可能需监控资源。
+
+> **核心单点故障风险:manifest 文件损坏**
+>
+> Multi-Part AOF 依赖 **manifest 文件**来跟踪和管理所有 `base/incr/history` 文件,这是整个增量日志体系的核心元数据。如果 manifest 文件损坏或丢失:
+>
+> | 风险场景 | 影响 | 恢复难度 |
+> | ------------------------------ | ------------------------------------------------------- | --------------------------- |
+> | **manifest 静默损坏** | Redis 启动时无法正确识别和加载 AOF 文件,数据库无法恢复 | 极高(需手动重建 manifest) |
+> | **磁盘故障导致 manifest 丢失** | 即使 base/incr 文件完整,Redis 也无法重构文件依赖关系 | 极高(需人工干预) |
+>
+> **缓解措施**:
+>
+> ```bash
+> # 1. 备份 manifest 文件(与数据文件同等重要)
+> cp /var/lib/redis/appendonlydir/appendonly.aof.manifest /backup/
+>
+> # 2. 监控磁盘健康度(提前发现故障)
+> smartctl -a /dev/sda | grep -E "SMART overall-health self-assessment|Media_Errors"
+>
+> # 3. 定期验证 manifest 完整性(Redis 启动时会自动校验)
+> redis-check-aof /var/lib/redis/appendonlydir/appendonly.aof.manifest
+> ```
+>
+> **官方未提供自动化修复工具**,生产环境必须将 manifest 文件纳入备份策略,其重要性等同于 RDB/AOF 数据文件本身。
+
+## 生产环境监控指标
+
+### 持久化性能指标
+
+```bash
+# RDB 相关指标
+redis-cli INFO persistence | grep rdb_last_bgsave_time_sec
+# 建议:< 5s。超过 5s 说明数据集过大或 I/O 性能瓶颈
+
+redis-cli INFO persistence | grep rdb_last_cow_size
+# 建议:< 10% used_memory。超过说明 fork 的 Copy-on-Write 内存开销大
+
+redis-cli INFO memory | grep used_memory_rss
+redis-cli INFO memory | grep used_memory
+# 计算:used_memory_rss / used_memory,fork 时应 < 2
+
+# AOF 相关指标
+redis-cli INFO persistence | grep aof_rewrite_in_progress
+# 期望:0(未在重写)或 1(正在重写)
+
+redis-cli INFO persistence | grep aof_current_size
+redis-cli INFO persistence | grep aof_base_size
+# 监控增长率,避免 rewrite 过于频繁
+
+redis-cli INFO persistence | grep aof_buffer_length
+# 建议:< 4MB。过大说明主线程写入速度快于 fsync 速度
+```
+
+### 系统资源监控
+
+```bash
+# 磁盘使用率和 I/O 等待
+iostat -x 1 5 | grep dm-0
+# 关注:%util(I/O 使用率)、await(平均等待时间)
+
+# 磁盘空间(预留空间给 rewrite 生成新文件)
+df -h /var/lib/redis
+# 建议:使用率 < 70%
+
+# inode 使用率(小文件多的场景)
+df -i /var/lib/redis
+# 建议:使用率 < 90%
+
+# 内存使用率
+free -h
+# 建议:为 fork 预留至少 20% 空闲内存
+```
+
+### 告警规则建议
+
+> **指标来源说明**:
+>
+> - **Redis 指标**:通过 `redis-cli INFO` 或 Redis exporter 获取(如 `redis_rss_memory`、`aof_current_size`)
+> - **节点级指标**:通过 node_exporter 或系统命令获取(如 `disk_usage`、系统内存、CPU 使用率)
+>
+> 以下告警规则假设使用 Prometheus + Redis exporter + node_exporter 监控体系。
+
+```yaml
+alert_rules:
+ # ── Redis 持久化相关告警 ────────────────────────────────────────
+ - name: "RedisHighMemFragmentation"
+ expr: redis_memory_rss_bytes / redis_memory_used_bytes > 2
+ for: 5m
+ labels:
+ severity: warning
+ annotations:
+ summary: "Redis 内存碎片率过高,fork COW 风险上升"
+ description: >
+ 实例 {{ $labels.instance }} 的 mem_fragmentation_ratio = {{ $value | humanize }},
+ 超过阈值 2。碎片率过高意味着 OS 实际分配的物理页远多于 Redis 自身统计,
+ 执行 BGSAVE / BGREWRITEAOF 触发 fork 后,COW 需复制的页数会显著增加,
+ 在高写入负载下可能导致内存暴涨,OOM 风险上升。
+ 建议执行 MEMORY PURGE 或在低峰期重启实例整理碎片。
+
+ - name: "RedisAofGrowthTooFast"
+ expr: deriv(redis_aof_current_size_bytes[5m]) * 60 > 10485760
+ for: 5m
+ labels:
+ severity: warning
+ annotations:
+ summary: "Redis AOF 文件写入速率过高"
+ description: >
+ 实例 {{ $labels.instance }} 的 AOF 增长速率超过 10 MB/min
+ (当前约 {{ $value | humanize1024 }}B/min)。
+ 高速写入会持续触发 auto-aof-rewrite,加剧磁盘 I/O 压力,
+ 并可能产生写入放大。建议检查业务是否存在大量小命令风暴或 KEYS 类全量扫描。
+
+ - name: "RedisAofFsyncDelayed"
+ expr: rate(redis_aof_delayed_fsync_total[5m]) > 0
+ for: 2m
+ labels:
+ severity: critical
+ annotations:
+ summary: "Redis AOF fsync 延迟,主线程响应受阻"
+ description: >
+ 实例 {{ $labels.instance }} 持续出现 aof_delayed_fsync 增长,
+ 主线程因等待 AOF fsync 完成而被阻塞,直接导致命令响应 P99 劣化。
+ 常见原因:① 磁盘 I/O 带宽饱和;② appendfsync 设置为 always;
+ ③ 与其他高 I/O 进程共用磁盘。建议切换为 everysec 策略或迁移至独立磁盘。
+
+ # ── 节点级资源告警 ─────────────────────────────────────────────
+ - name: "RedisDiskUsageHigh"
+ expr: >
+ (1 - node_filesystem_avail_bytes{mountpoint="/var/lib/redis"}
+ / node_filesystem_size_bytes{mountpoint="/var/lib/redis"}) * 100 > 70
+ for: 5m
+ labels:
+ severity: warning
+ annotations:
+ summary: "Redis 数据盘使用率超过 70%"
+ description: >
+ 挂载点 /var/lib/redis 当前使用率为 {{ $value | humanize }}%。
+ AOF rewrite 期间会临时生成新文件,需预留约 1.5x 当前 AOF 大小的空间,
+ 磁盘不足将导致 rewrite 失败并触发 Redis 错误日志 "MISCONF"。
+ RDB bgsave 同理。
+ remediation: >
+ 1. 清理过期 RDB 快照与历史 AOF 文件;
+ 2. 调高 auto-aof-rewrite-min-size 降低 rewrite 频率;
+ 3. 磁盘扩容或将数据目录迁移至更大分区。
+```
+
## 如何选择 RDB 和 AOF?
关于 RDB 和 AOF 的优缺点,官网上面也给了比较详细的说明[Redis persistence](https://redis.io/docs/manual/persistence/),这里结合自己的理解简单总结一下。
**RDB 比 AOF 优秀的地方**:
-- RDB 文件存储的内容是经过压缩的二进制数据, 保存着某个时间点的数据集,文件很小,适合做数据的备份,灾难恢复。AOF 文件存储的是每一次写命令,类似于 MySQL 的 binlog 日志,通常会比 RDB 文件大很多。当 AOF 变得太大时,Redis 能够在后台自动重写 AOF。新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。不过, Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
-- 使用 RDB 文件恢复数据,直接解析还原数据即可,不需要一条一条地执行命令,速度非常快。而 AOF 则需要依次执行每个写命令,速度非常慢。也就是说,与 AOF 相比,恢复大数据集的时候,RDB 速度更快。
+- **文件紧凑,适合备份和灾难恢复**:RDB 文件存储的内容是经过压缩的二进制数据,保存着某个时间点的数据集,文件很小,非常适合做数据的备份和灾难恢复。AOF 文件存储的是每一次写命令,类似于 MySQL 的 binlog 日志,通常会比 RDB 文件大很多。当 AOF 变得太大时,Redis 能够在后台自动重写 AOF,新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。不过,Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
+- **恢复速度快**:使用 RDB 文件恢复数据,直接解析还原数据即可,不需要一条一条地执行命令,速度非常快。而 AOF 则需要依次执行每个写命令,速度非常慢。也就是说,与 AOF 相比,恢复大数据集的时候,RDB 速度更快。
+- **主从复制优势**:在副本(replica)上,RDB 支持重启和故障转移后的**部分重新同步**(Partial Resynchronization)。副本可以使用 RDB 快照快速同步到主节点的某个时间点状态,而不需要全量同步。
+- **性能开销小**:RDB 最大化 Redis 性能,因为 Redis 父进程需要做的唯一持久化工作就是 fork 子进程,子进程将完成所有其余工作。父进程永远不会执行磁盘 I/O 或类似操作。
**AOF 比 RDB 优秀的地方**:
-- RDB 的数据安全性不如 AOF,没有办法实时或者秒级持久化数据。生成 RDB 文件的过程是比较繁重的, 虽然 BGSAVE 子进程写入 RDB 文件的工作不会阻塞主线程,但会对机器的 CPU 资源和内存资源产生影响,严重的情况下甚至会直接把 Redis 服务干宕机。AOF 支持秒级数据丢失(取决 fsync 策略,如果是 everysec,最多丢失 1 秒的数据),仅仅是追加命令到 AOF 文件,操作轻量。
-- RDB 文件是以特定的二进制格式保存的,并且在 Redis 版本演进中有多个版本的 RDB,所以存在老版本的 Redis 服务不兼容新版本的 RDB 格式的问题。
-- AOF 以一种易于理解和解析的格式包含所有操作的日志。你可以轻松地导出 AOF 文件进行分析,你也可以直接操作 AOF 文件来解决一些问题。比如,如果执行`FLUSHALL`命令意外地刷新了所有内容后,只要 AOF 文件没有被重写,删除最新命令并重启即可恢复之前的状态。
+- **数据安全性更高,支持秒级持久化**:RDB 的数据安全性不如 AOF,没有办法实时或者秒级持久化数据。生成 RDB 文件的过程是比较繁重的,虽然 BGSAVE 子进程写入 RDB 文件的工作不会阻塞主线程,但会对机器的 CPU 资源和内存资源产生影响,严重的情况下甚至会直接把 Redis 服务干宕机。AOF 支持秒级数据丢失(取决于 `fsync` 策略,如果是 `everysec`,通常最多丢失 1 秒的数据;但磁盘 I/O 繁忙时可能丢失 2 秒且主线程会阻塞),仅仅是追加命令到 AOF 文件,操作轻量。
+- **版本兼容性好**:RDB 文件是以特定的二进制格式保存的,并且在 Redis 版本演进中有多个版本的 RDB,所以存在老版本的 Redis 服务不兼容新版本的 RDB 格式的问题。
+- **可读性和可操作性强**:AOF 以一种易于理解和解析的格式包含所有操作的日志。你可以轻松地导出 AOF 文件进行分析,也可以直接操作 AOF 文件来解决一些问题。比如,如果执行`FLUSHALL`命令意外地刷新了所有内容后,只要 AOF 文件没有被重写,删除最新命令并重启即可恢复之前的状态。
+- **追加日志无损坏风险**:AOF 日志是追加日志,没有寻道,也没有断电损坏问题。即使日志由于某种原因(磁盘已满或其他原因)以半写入命令结尾,`redis-check-aof` 工具也能轻松修复。
+
+**版本演进对选型的影响**:
+
+| 版本 | 关键改进 | 对 AOF 的影响 | 对选型的意义 |
+| ------------- | ---------------------------------------- | ------------------------------------------------------- | -------------------------------------------------------------- |
+| **Redis 4.0** | 引入混合持久化(`aof-use-rdb-preamble`) | AOF 重写时 base 文件使用 RDB 格式,恢复速度提升 5-10 倍 | 缓解了纯 AOF 加载慢的问题,但仍需关注重写期间的内存和 I/O 开销 |
+| **Redis 7.0** | 引入 Multi-Part AOF | 彻底消除重写期间的双写问题,内存和 I/O 开销大幅降低 | 单独使用 AOF 在生产环境更具可行性,但 fork 阻塞问题仍未解决 |
+
+**未解决的核心问题**:
-**综上**:
+- **fork 阻塞**:无论是 RDB bgsave 还是 AOF 重写,fork 操作本身都会阻塞主线程(数据集越大,阻塞时间越长)
+- **官方建议**:Redis 官方文档至今仍建议**同时开启 RDB 和 AOF**,RDB 作为额外的冷备手段,应对 AOF 文件损坏或写入错误等极端场景
-- Redis 保存的数据丢失一些也没什么影响的话,可以选择使用 RDB。
-- 不建议单独使用 AOF,因为时不时地创建一个 RDB 快照可以进行数据库备份、更快的重启以及解决 AOF 引擎错误。
-- 如果保存的数据要求安全性比较高的话,建议同时开启 RDB 和 AOF 持久化或者开启 RDB 和 AOF 混合持久化。
+**AOF 和 RDB 的交互**:
+
+当 AOF 和 RDB 持久化同时启用时:
+
+- **避免同时进行重 I/O 操作**:Redis 2.4+ 确保避免在 RDB 快照进行时触发 AOF 重写,或允许在 AOF 重写期间进行 BGSAVE。这防止两个 Redis 后台进程同时进行繁重的磁盘 I/O。
+- **AOF 重写调度**:当快照正在进行且用户显式请求日志重写操作(使用 BGREWRITEAOF)时,服务器将返回 OK 状态码,告诉用户操作已调度,重写将在快照完成后开始。
+- **重启恢复优先级**:如果 AOF 和 RDB 持久化都启用且 Redis 重启,**AOF 文件将用于重建原始数据集**,因为它被保证是最完整的。
+
+**选型建议**:
+
+| 场景 | 推荐方案 | 说明 |
+| -------------------------------- | -------------------------------------------------------------------- | ----------------------------------------------------------- |
+| **纯缓存(可丢失)** | **关闭持久化** 或仅 RDB(低频) | 完全关闭开销最小;若需冷备则保留低频 RDB |
+| **数据重要性中等**(会话、配置) | **RDB + AOF 混合持久化**(Redis 4.0+) | RDB 加速恢复,AOF 增量补充,`everysec` 最多丢 1s |
+| **数据重要性高**(业务核心数据) | **RDB + AOF(MP-AOF,Redis 7.0+)**,且 Redis 作为缓存层而非唯一存储 | MP-AOF 降低重写开销;真正的持久化由主数据库(MySQL 等)负责 |
+| **主从架构** | **主节点关闭持久化,从节点开启 AOF** | 主节点禁止配置自动重启,防止空数据集覆盖从节点 |
## 参考
- 《Redis 设计与实现》
-- Redis persistence - Redis 官方文档:https://redis.io/docs/management/persistence/
-- The difference between AOF and RDB persistence:https://www.sobyte.net/post/2022-04/redis-rdb-and-aof/
-- Redis AOF 持久化详解 - 程序员历小冰:http://remcarpediem.net/article/376c55d8/
-- Redis RDB 与 AOF 持久化 · Analyze:https://wingsxdu.com/posts/database/redis/rdb-and-aof/
+- Redis persistence - Redis 官方文档:
+- The difference between AOF and RDB persistence:
+- Redis AOF 持久化详解 - 程序员历小冰:
+- Redis RDB 与 AOF 持久化 · Analyze:
+
+
diff --git a/docs/database/redis/redis-questions-01.md b/docs/database/redis/redis-questions-01.md
index 4041cfe3d5d..284fa4367b1 100644
--- a/docs/database/redis/redis-questions-01.md
+++ b/docs/database/redis/redis-questions-01.md
@@ -1,15 +1,13 @@
---
title: Redis常见面试题总结(上)
+description: 最新Redis面试题总结(上):深入讲解Redis基础、五大常用数据结构、单线程模型原理、持久化机制、内存淘汰与过期策略、分布式锁与消息队列实现。适合准备后端面试的开发者!
category: 数据库
tag:
- Redis
head:
- - meta
- name: keywords
- content: Redis基础,Redis常见数据结构,Redis线程模型,Redis内存管理,Redis事务,Redis性能优化
- - - meta
- - name: description
- content: 一篇文章总结Redis常见的知识点和面试题,涵盖Redis基础、Redis常见数据结构、Redis线程模型、Redis内存管理、Redis事务、Redis性能优化等内容。
+ content: Redis面试题,Redis基础,Redis数据结构,Redis线程模型,Redis持久化,Redis内存管理,Redis性能优化,Redis分布式锁,Redis消息队列,Redis延时队列,Redis缓存策略,Redis单线程,Redis多线程,Redis过期策略,Redis淘汰策略
---
@@ -18,9 +16,11 @@ head:
### 什么是 Redis?
-[Redis](https://redis.io/) 是一个基于 C 语言开发的开源数据库(BSD 许可),与传统数据库不同的是 Redis 的数据是存在内存中的(内存数据库),读写速度非常快,被广泛应用于缓存方向。并且,Redis 存储的是 KV 键值对数据。
+[Redis](https://redis.io/) (**RE**mote **DI**ctionary **S**erver)是一个基于 C 语言开发的开源 NoSQL 数据库(BSD 许可)。与传统数据库不同的是,Redis 的数据是保存在内存中的(内存数据库,支持持久化),因此读写速度非常快,被广泛应用于分布式缓存方向。并且,Redis 存储的是 KV 键值对数据。
+
+为了满足不同的业务场景,Redis 内置了多种数据类型实现(比如 String、Hash、Sorted Set、Bitmap、HyperLogLog、GEO)。并且,Redis 还支持事务、持久化、Lua 脚本、发布订阅模型、多种开箱即用的集群方案(Redis Sentinel、Redis Cluster)。
-为了满足不同的业务场景,Redis 内置了多种数据类型实现(比如 String、Hash、Sorted Set、Bitmap、HyperLogLog、GEO)。并且,Redis 还支持事务、持久化、Lua 脚本、多种开箱即用的集群方案(Redis Sentinel、Redis Cluster)。
+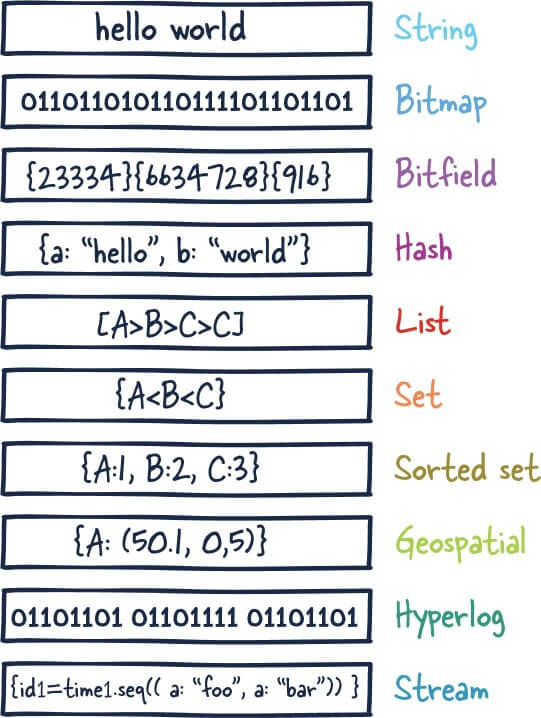
Redis 没有外部依赖,Linux 和 OS X 是 Redis 开发和测试最多的两个操作系统,官方推荐生产环境使用 Linux 部署 Redis。
@@ -28,31 +28,50 @@ Redis 没有外部依赖,Linux 和 OS X 是 Redis 开发和测试最多的两
-全世界有非常多的网站使用到了 Redis ,[techstacks.io](https://techstacks.io/) 专门维护了一个[使用 Redis 的热门站点列表](https://techstacks.io/tech/redis) ,感兴趣的话可以看看。
+全世界有非常多的网站使用到了 Redis,[techstacks.io](https://techstacks.io/) 专门维护了一个[使用 Redis 的热门站点列表](https://techstacks.io/tech/redis),感兴趣的话可以看看。
+
+### ⭐️Redis 为什么这么快?
+
+Redis 内部做了非常多的性能优化,比较重要的有下面 4 点:
+
+1. **纯内存操作 (Memory-Based Storage)** :这是最主要的原因。Redis 数据读写操作都发生在内存中,访问速度是纳秒级别,而传统数据库频繁读写磁盘的速度是毫秒级别,两者相差数个数量级。
+2. **高效的 I/O 模型 (I/O Multiplexing & Single-Threaded Event Loop)** :Redis 使用单线程事件循环配合 I/O 多路复用技术,让单个线程可以同时处理多个网络连接上的 I/O 事件(如读写),避免了多线程模型中的上下文切换和锁竞争问题。虽然是单线程,但结合内存操作的高效性和 I/O 多路复用,使得 Redis 能轻松处理大量并发请求(Redis 线程模型会在后文中详细介绍到)。
+3. **优化的内部数据结构 (Optimized Data Structures)** :Redis 提供多种数据类型(如 String, List, Hash, Set, Sorted Set 等),其内部实现采用高度优化的编码方式(如 ziplist, quicklist, skiplist, hashtable 等)。Redis 会根据数据大小和类型动态选择最合适的内部编码,以在性能和空间效率之间取得最佳平衡。
+4. **简洁高效的通信协议 (Simple Protocol - RESP)** :Redis 使用的是自己设计的 RESP (REdis Serialization Protocol) 协议。这个协议实现简单、解析性能好,并且是二进制安全的。客户端和服务端之间通信的序列化/反序列化开销很小,有助于提升整体的交互速度。
+
+> 下面这张图片总结的挺不错的,分享一下,出自 [Why is Redis so fast?](https://twitter.com/alexxubyte/status/1498703822528544770)。
+
+
-### Redis 为什么这么快?
+那既然都这么快了,为什么不直接用 Redis 当主数据库呢?主要是因为内存成本太高,并且 Redis 提供的数据持久化仍然有数据丢失的风险。
-Redis 内部做了非常多的性能优化,比较重要的有下面 3 点:
+### 除了 Redis,你还知道其他分布式缓存方案吗?
-1. Redis 基于内存,内存的访问速度是磁盘的上千倍;
-2. Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型,主要是单线程事件循环和 IO 多路复用(Redis 线程模式后面会详细介绍到);
-3. Redis 内置了多种优化过后的数据结构实现,性能非常高。
+如果面试中被问到这个问题的话,面试官主要想看看:
-下面这张图片总结的挺不错的,分享一下,出自 [Why is Redis so fast?](https://twitter.com/alexxubyte/status/1498703822528544770) 。
+1. 你在选择 Redis 作为分布式缓存方案时,是否是经过严谨的调研和思考,还是只是因为 Redis 是当前的“热门”技术。
+2. 你在分布式缓存方向的技术广度。
-
+如果你了解其他方案,并且能解释为什么最终选择了 Redis(更进一步!),这会对你面试表现加分不少!
-### 分布式缓存常见的技术选型方案有哪些?
+下面简单聊聊常见的分布式缓存技术选型。
分布式缓存的话,比较老牌同时也是使用的比较多的还是 **Memcached** 和 **Redis**。不过,现在基本没有看过还有项目使用 **Memcached** 来做缓存,都是直接用 **Redis**。
Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
-另外,腾讯也开源了一款类似于 Redis 的分布式高性能 KV 存储数据库,基于知名的开源项目 [RocksDB](https://github.com/facebook/rocksdb) 作为存储引擎 ,100% 兼容 Redis 协议和 Redis4.0 所有数据模型,名为 [Tendis](https://github.com/Tencent/Tendis)。
+有一些大厂也开源了类似于 Redis 的分布式高性能 KV 存储数据库,例如,腾讯开源的 [**Tendis**](https://github.com/Tencent/Tendis)。Tendis 基于知名开源项目 [RocksDB](https://github.com/facebook/rocksdb) 作为存储引擎 ,100% 兼容 Redis 协议和 Redis4.0 所有数据模型。关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:[Redis vs Tendis:冷热混合存储版架构揭秘](https://mp.weixin.qq.com/s/MeYkfOIdnU6LYlsGb24KjQ),可以简单参考一下。
-关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:[Redis vs Tendis:冷热混合存储版架构揭秘](https://mp.weixin.qq.com/s/MeYkfOIdnU6LYlsGb24KjQ) ,可以简单参考一下。
+不过,从 Tendis 这个项目的 Github 提交记录可以看出,Tendis 开源版几乎已经没有被维护更新了,加上其关注度并不高,使用的公司也比较少。因此,不建议你使用 Tendis 来实现分布式缓存。
-从这个项目的 GitHub 提交记录可以看出,Tendis 开源版几乎已经没有被维护更新了,加上其关注度并不高,使用的公司也比较少。因此,不建议你使用 Tendis 来实现分布式缓存。
+目前,比较业界认可的 Redis 替代品还是下面这两个开源分布式缓存(都是通过碰瓷 Redis 火的):
+
+- [Dragonfly](https://github.com/dragonflydb/dragonfly):一种针对现代应用程序负荷需求而构建的内存数据库,完全兼容 Redis 和 Memcached 的 API,迁移时无需修改任何代码,号称全世界最快的内存数据库。
+- [KeyDB](https://github.com/Snapchat/KeyDB):Redis 的一个高性能分支,专注于多线程、内存效率和高吞吐量。
+
+不过,个人还是建议分布式缓存首选 Redis,毕竟经过了这么多年的考验,生态非常优秀,资料也很全面!
+
+PS:篇幅问题,我这并没有对上面提到的分布式缓存选型做详细介绍和对比,感兴趣的话,可以自行研究一下。
### 说一下 Redis 和 Memcached 的区别和共同点
@@ -66,155 +85,164 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
**区别**:
-1. **Redis 支持更丰富的数据类型(支持更复杂的应用场景)**。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型。
-2. **Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memcached 把数据全部存在内存之中。**
-3. **Redis 有灾难恢复机制。** 因为可以把缓存中的数据持久化到磁盘上。
-4. **Redis 在服务器内存使用完之后,可以将不用的数据放到磁盘上。但是,Memcached 在服务器内存使用完之后,就会直接报异常。**
-5. **Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 cluster 模式的。**
-6. **Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。** (Redis 6.0 针对网络数据的读写引入了多线程)
-7. **Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。**
-8. **Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。**
+1. **数据类型**:Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list、set、zset、hash 等数据结构的存储;而 Memcached 只支持最简单的 k/v 数据类型。
+2. **数据持久化**:Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用;而 Memcached 把数据全部存在内存之中。也就是说,Redis 有灾难恢复机制,而 Memcached 没有。
+3. **集群模式支持**:Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;而 Redis 自 3.0 版本起是原生支持集群模式的。
+4. **线程模型**:Memcached 是多线程、非阻塞 IO 复用的网络模型;而 Redis 使用单线程的多路 IO 复用模型(Redis 6.0 针对网络数据的读写引入了多线程)。
+5. **特性支持**:Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。
+6. **过期数据删除**:Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。
相信看了上面的对比之后,我们已经没有什么理由可以选择使用 Memcached 来作为自己项目的分布式缓存了。
-### 为什么要用 Redis/为什么要用缓存?
+### ⭐️为什么要用 Redis?
-下面我们主要从“高性能”和“高并发”这两点来回答这个问题。
+**1、访问速度更快**
-**1、高性能**
-
-假如用户第一次访问数据库中的某些数据的话,这个过程是比较慢,毕竟是从硬盘中读取的。但是,如果说,用户访问的数据属于高频数据并且不会经常改变的话,那么我们就可以很放心地将该用户访问的数据存在缓存中。
-
-**这样有什么好处呢?** 那就是保证用户下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。
+传统数据库数据保存在磁盘,而 Redis 基于内存,内存的访问速度比磁盘快很多。引入 Redis 之后,我们可以把一些高频访问的数据放到 Redis 中,这样下次就可以直接从内存中读取,速度可以提升几十倍甚至上百倍。
**2、高并发**
-一般像 MySQL 这类的数据库的 QPS 大概都在 1w 左右(4 核 8g) ,但是使用 Redis 缓存之后很容易达到 10w+,甚至最高能达到 30w+(就单机 Redis 的情况,Redis 集群的话会更高)。
+一般像 MySQL 这类的数据库的 QPS 大概都在 4k 左右(4 核 8g),但是使用 Redis 缓存之后很容易达到 5w+,甚至能达到 10w+(就单机 Redis 的情况,Redis 集群的话会更高)。
> QPS(Query Per Second):服务器每秒可以执行的查询次数;
由此可见,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高了系统整体的并发。
-### 常见的缓存读写策略有哪些?
+**3、功能全面**
-关于常见的缓存读写策略的详细介绍,可以看我写的这篇文章:[3 种常用的缓存读写策略详解](https://javaguide.cn/database/redis/3-commonly-used-cache-read-and-write-strategies.html) 。
+Redis 除了可以用作缓存之外,还可以用于分布式锁、限流、消息队列、延时队列等场景,功能强大!
-## Redis 应用
+### ⭐️为什么用 Redis 而不用本地缓存呢?
-### Redis 除了做缓存,还能做什么?
+| 特性 | 本地缓存 | Redis |
+| ------------ | ------------------------------------ | -------------------------------- |
+| 数据一致性 | 多服务器部署时存在数据不一致问题 | 数据一致 |
+| 内存限制 | 受限于单台服务器内存 | 独立部署,内存空间更大 |
+| 数据丢失风险 | 服务器宕机数据丢失 | 可持久化,数据不易丢失 |
+| 管理维护 | 分散,管理不便 | 集中管理,提供丰富的管理工具 |
+| 功能丰富性 | 功能有限,通常只提供简单的键值对存储 | 功能丰富,支持多种数据结构和功能 |
-- **分布式锁**:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 。
-- **限流**:一般是通过 Redis + Lua 脚本的方式来实现限流。相关阅读:[《我司用了 6 年的 Redis 分布式限流器,可以说是非常厉害了!》](https://mp.weixin.qq.com/s/kyFAWH3mVNJvurQDt4vchA)。
-- **消息队列**:Redis 自带的 list 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
-- **复杂业务场景**:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 bitmap 统计活跃用户、通过 sorted set 维护排行榜。
-- ......
+关于本地缓存、分布式缓存和多级缓存的详细介绍,可以看我写的这篇文章:[缓存基础常见面试题总结](http://localhost:8080/database/redis/cache-basics.html)。
-### 如何基于 Redis 实现分布式锁?
+### 常见的缓存读写策略有哪些?
-关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 。
+关于常见的缓存读写策略的详细介绍,可以看我写的这篇文章:[3 种常用的缓存读写策略详解](https://javaguide.cn/database/redis/3-commonly-used-cache-read-and-write-strategies.html)。
-### Redis 可以做消息队列么?
+### 什么是 Redis Module?有什么用?
-> 实际项目中也没见谁使用 Redis 来做消息队列,对于这部分知识点大家了解就好了。
+Redis 从 4.0 版本开始,支持通过 Module 来扩展其功能以满足特殊的需求。这些 Module 以动态链接库(so 文件)的形式被加载到 Redis 中,这是一种非常灵活的动态扩展功能的实现方式,值得借鉴学习!
-先说结论:可以是可以,但不建议使用 Redis 来做消息队列。和专业的消息队列相比,还是有很多欠缺的地方。
+我们每个人都可以基于 Redis 去定制化开发自己的 Module,比如实现搜索引擎功能、自定义分布式锁和分布式限流。
-**Redis 2.0 之前,如果想要使用 Redis 来做消息队列的话,只能通过 List 来实现。**
+目前,被 Redis 官方推荐的 Module 有:
-通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`即可实现简易版消息队列:
+- [RediSearch](https://github.com/RediSearch/RediSearch):用于实现搜索引擎的模块。
+- [RedisJSON](https://github.com/RedisJSON/RedisJSON):用于处理 JSON 数据的模块。
+- [RedisGraph](https://github.com/RedisGraph/RedisGraph):用于实现图形数据库的模块。
+- [RedisTimeSeries](https://github.com/RedisTimeSeries/RedisTimeSeries):用于处理时间序列数据的模块。
+- [RedisBloom](https://github.com/RedisBloom/RedisBloom):用于实现布隆过滤器的模块。
+- [RedisAI](https://github.com/RedisAI/RedisAI):用于执行深度学习/机器学习模型并管理其数据的模块。
+- [RedisCell](https://github.com/brandur/redis-cell):用于实现分布式限流的模块。
+- ……
-```bash
-# 生产者生产消息
-> RPUSH myList msg1 msg2
-(integer) 2
-> RPUSH myList msg3
-(integer) 3
-# 消费者消费消息
-> LPOP myList
-"msg1"
-```
+关于 Redis 模块的详细介绍,可以查看官方文档:。
-不过,通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`这样的方式存在性能问题,我们需要不断轮询去调用 `RPOP` 或 `LPOP` 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
+## ⭐️Redis 应用
-因此,Redis 还提供了 `BLPOP`、`BRPOP` 这种阻塞式读取的命令(带 B-Bloking 的都是阻塞式),并且还支持一个超时参数。如果 List 为空,Redis 服务端不会立刻返回结果,它会等待 List 中有新数据后在返回或者是等待最多一个超时时间后返回空。如果将超时时间设置为 0 时,即可无限等待,直到弹出消息
+### Redis 除了做缓存,还能做什么?
-```bash
-# 超时时间为 10s
-# 如果有数据立刻返回,否则最多等待10秒
-> BRPOP myList 10
-null
-```
+- **分布式锁**:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html)。
+- **限流**:一般是通过 Redis + Lua 脚本的方式来实现限流。如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的 `RRateLimiter` 来实现分布式限流,其底层实现就是基于 Lua 代码+令牌桶算法。
+- **消息队列**:Redis 自带的 List 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
+- **延时队列**:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
+- **分布式 Session**:利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
+- **复杂业务场景**:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景,比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜、通过 HyperLogLog 统计网站 UV 和 PV。
+- ……
+
+### 如何基于 Redis 实现分布式锁?
-**List 实现消息队列功能太简单,像消息确认机制等功能还需要我们自己实现,最要命的是没有广播机制,消息也只能被消费一次。**
+关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock-implementations.html)。
-**Redis 2.0 引入了发布订阅 (pub/sub) 功能,解决了 List 实现消息队列没有广播机制的问题。**
+### Redis 可以做消息队列么?怎么实现?
-
+先说结论:
-pub/sub 中引入了一个概念叫 **channel(频道)**,发布订阅机制的实现就是基于这个 channel 来做的。
+- **如果业务简单、量小、追求极致性能**,且能容忍极小概率的数据丢失,使用 **Redis Stream** 是最优解,因为它省去了部署维护 MQ 的成本,可以复用现有的 Redis 组件(大部分需要用到 MQ 的项目,通常都会需要 Redis)。
+- **如果是金融级业务、海量数据、需要严格保证不丢消息**,必须选择 **Kafka、RabbitMQ** 等更成熟的 MQ。
-pub/sub 涉及发布者(Publisher)和订阅者(Subscriber,也叫消费者)两个角色:
+这个问题还是挺重要,技术选型也能用上,我专门写了一篇文章详细介绍和分析,推荐时间充足的同学抽空认真看几遍,收藏一下:[Redis 能做消息队列吗?怎么实现?](https://javaguide.cn/database/redis/redis-stream-mq.html)。
-- 发布者通过 `PUBLISH` 投递消息给指定 channel。
-- 订阅者通过`SUBSCRIBE`订阅它关心的 channel。并且,订阅者可以订阅一个或者多个 channel。
+### 如何基于 Redis 实现延时任务?
-我们这里启动 3 个 Redis 客户端来简单演示一下:
+> 类似的问题:
+>
+> - 订单在 10 分钟后未支付就失效,如何用 Redis 实现?
+> - 红包 24 小时未被查收自动退还,如何用 Redis 实现?
-
+基于 Redis 实现延时任务的功能无非就下面两种方案:
-pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不过,消息丢失(客户端断开连接或者 Redis 宕机都会导致消息丢失)、消息堆积(发布者发布消息的时候不会管消费者的具体消费能力如何)等问题依然没有一个比较好的解决办法。
+1. Redis 过期事件监听。
+2. Redisson 内置的延时队列。
-为此,Redis 5.0 新增加的一个数据结构 `Stream` 来做消息队列。`Stream` 支持:
+Redis 过期事件监听存在时效性较差、丢消息、多服务实例下消息重复消费等问题,不被推荐使用。
-- 发布 / 订阅模式
-- 按照消费者组进行消费
-- 消息持久化( RDB 和 AOF)
+Redisson 内置的延时队列具备下面这些优势:
-`Stream` 使用起来相对要麻烦一些,这里就不演示了。而且,`Stream` 在实际使用中依然会有一些小问题不太好解决比如在 Redis 发生故障恢复后不能保证消息至少被消费一次。
+1. **减少了丢消息的可能**:DelayedQueue 中的消息会被持久化,即使 Redis 宕机了,根据持久化机制,也只可能丢失一点消息,影响不大。当然了,你也可以使用扫描数据库的方法作为补偿机制。
+2. **消息不存在重复消费问题**:每个客户端都是从同一个目标队列中获取任务的,不存在重复消费的问题。
-综上,和专业的消息队列相比,使用 Redis 来实现消息队列还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。因此,我们通常建议不要使用 Redis 来做消息队列,你完全可以选择市面上比较成熟的一些消息队列比如 RocketMQ、Kafka。
+关于 Redis 实现延时任务的详细介绍,可以看我写的这篇文章:[如何基于 Redis 实现延时任务?](./redis-delayed-task.md)。
-相关阅读:[Redis 消息队列发展历程 - 阿里开发者 - 2022](https://mp.weixin.qq.com/s/gCUT5TcCQRAxYkTJfTRjJw)。
+## ⭐️Redis 数据类型
-## Redis 数据结构
+关于 Redis 5 种基础数据类型和 3 种特殊数据类型的详细介绍请看下面这两篇文章以及 [Redis 官方文档](https://redis.io/docs/data-types/):
-> 关于 Redis 5 种基础数据结构和 3 种特殊数据结构的详细介绍请看下面这两篇文章:
->
-> - [Redis 5 种基本数据结构详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)
-> - [Redis 3 种特殊数据结构详解](https://javaguide.cn/database/redis/redis-data-structures-02.html)
+- [Redis 5 种基本数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)
+- [Redis 3 种特殊数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-02.html)
-### Redis 常用的数据结构有哪些?
+### Redis 常用的数据类型有哪些?
-- **5 种基础数据结构**:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
-- **3 种特殊数据结构**:HyperLogLogs(基数统计)、Bitmap (位存储)、Geospatial (地理位置)。
+Redis 中比较常见的数据类型有下面这些:
+
+- **5 种基础数据类型**:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
+- **3 种特殊数据类型**:HyperLogLog(基数统计)、Bitmap (位图)、Geospatial (地理位置)。
+
+除了上面提到的之外,还有一些其他的比如 [Bloom filter(布隆过滤器)](https://javaguide.cn/cs-basics/data-structure/bloom-filter.html)、Bitfield(位域)。
### String 的应用场景有哪些?
-String 是 Redis 中最简单同时也是最常用的一个数据结构。String 是一种二进制安全的数据结构,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
+String 是 Redis 中最简单同时也是最常用的一个数据类型。它是一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
String 的常见应用场景如下:
-- 常规数据(比如 session、token、序列化后的对象、图片的路径)的缓存;
+- 常规数据(比如 Session、Token、序列化后的对象、图片的路径)的缓存;
- 计数比如用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数;
-- 分布式锁(利用 `SETNX key value` 命令可以实现一个最简易的分布式锁);
-- ......
+- 分布式锁(利用 `SETNX key value` 命令可以实现一个最简易的分布式锁);
+- ……
-关于 String 的详细介绍请看这篇文章:[Redis 5 种基本数据结构详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)。
+关于 String 的详细介绍请看这篇文章:[Redis 5 种基本数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)。
### String 还是 Hash 存储对象数据更好呢?
-- String 存储的是序列化后的对象数据,存放的是整个对象。Hash 是对对象的每个字段单独存储,可以获取部分字段的信息,也可以修改或者添加部分字段,节省网络流量。如果对象中某些字段需要经常变动或者经常需要单独查询对象中的个别字段信息,Hash 就非常适合。
-- String 存储相对来说更加节省内存,缓存相同数量的对象数据,String 消耗的内存约是 Hash 的一半。并且,存储具有多层嵌套的对象时也方便很多。如果系统对性能和资源消耗非常敏感的话,String 就非常适合。
+简单对比一下二者:
+
+- **对象存储方式**:String 存储的是序列化后的对象数据,存放的是整个对象,操作简单直接。Hash 是对对象的每个字段单独存储,可以获取部分字段的信息,也可以修改或者添加部分字段,节省网络流量。如果对象中某些字段需要经常变动或者经常需要单独查询对象中的个别字段信息,Hash 就非常适合。
+- **内存消耗**:Hash 通常比 String 更节省内存,特别是在字段较多且字段长度较短时。Redis 对小型 Hash 进行优化(如使用 ziplist 存储),进一步降低内存占用。
+- **复杂对象存储**:String 在处理多层嵌套或复杂结构的对象时更方便,因为无需处理每个字段的独立存储和操作。
+- **性能**:String 的操作通常具有 O(1) 的时间复杂度,因为它存储的是整个对象,操作简单直接,整体读写的性能较好。Hash 由于需要处理多个字段的增删改查操作,在字段较多且经常变动的情况下,可能会带来额外的性能开销。
+
+总结:
-在绝大部分情况,我们建议使用 String 来存储对象数据即可!
+- 在绝大多数情况下,**String** 更适合存储对象数据,尤其是当对象结构简单且整体读写是主要操作时。
+- 如果你需要频繁操作对象的部分字段或节省内存,**Hash** 可能是更好的选择。
### String 的底层实现是什么?
-Redis 是基于 C 语言编写的,但 Redis 的 String 类型的底层实现并不是 C 语言中的字符串(即以空字符 `\0` 结尾的字符数组),而是自己编写了 [SDS](https://github.com/antirez/sds)(Simple Dynamic String,简单动态字符串) 来作为底层实现。
+Redis 是基于 C 语言编写的,但 Redis 的 String 类型的底层实现并不是 C 语言中的字符串(即以空字符 `\0` 结尾的字符数组),而是自己编写了 [SDS](https://github.com/antirez/sds)(Simple Dynamic String,简单动态字符串)来作为底层实现。
SDS 最早是 Redis 作者为日常 C 语言开发而设计的 C 字符串,后来被应用到了 Redis 上,并经过了大量的修改完善以适合高性能操作。
-Redis7.0 的 SDS 的部分源码如下(https://github.com/redis/redis/blob/7.0/src/sds.h):
+Redis7.0 的 SDS 的部分源码如下():
```c
/* Note: sdshdr5 is never used, we just access the flags byte directly.
@@ -249,7 +277,7 @@ struct __attribute__ ((__packed__)) sdshdr64 {
};
```
-通过源码可以看出,SDS 共有五种实现方式 SDS_TYPE_5(并未用到)、SDS_TYPE_8、SDS_TYPE_16、SDS_TYPE_32、SDS_TYPE_64,其中只有后四种实际用到。Redis 会根据初始化的长度决定使用哪种类型,从而减少内存的使用。
+通过源码可以看出,SDS 共有五种实现方式:SDS_TYPE_5(并未用到)、SDS_TYPE_8、SDS_TYPE_16、SDS_TYPE_32、SDS_TYPE_64,其中只有后四种实际用到。Redis 会根据初始化的长度决定使用哪种类型,从而减少内存的使用。
| 类型 | 字节 | 位 |
| -------- | ---- | --- |
@@ -261,10 +289,10 @@ struct __attribute__ ((__packed__)) sdshdr64 {
对于后四种实现都包含了下面这 4 个属性:
-- `len`:字符串的长度也就是已经使用的字节数
-- `alloc`:总共可用的字符空间大小,alloc-len 就是 SDS 剩余的空间大小
-- `buf[]`:实际存储字符串的数组
-- `flags`:低三位保存类型标志
+- `len`:字符串的长度也就是已经使用的字节数。
+- `alloc`:总共可用的字符空间大小,alloc-len 就是 SDS 剩余的空间大小。
+- `buf[]`:实际存储字符串的数组。
+- `flags`:低三位保存类型标志。
SDS 相比于 C 语言中的字符串有如下提升:
@@ -306,9 +334,9 @@ struct sdshdr {
### 使用 Redis 实现一个排行榜怎么做?
-Redis 中有一个叫做 `sorted set` 的数据结构经常被用在各种排行榜的场景,比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
+Redis 中有一个叫做 `Sorted Set`(有序集合)的数据类型经常被用在各种排行榜的场景,比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
-相关的一些 Redis 命令: `ZRANGE` (从小到大排序)、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
+相关的一些 Redis 命令:`ZRANGE`(从小到大排序)、`ZREVRANGE`(从大到小排序)、`ZREVRANK`(指定元素排名)。

@@ -316,27 +344,37 @@ Redis 中有一个叫做 `sorted set` 的数据结构经常被用在各种排行

+### Redis 的有序集合底层为什么要用跳表,而不用平衡树、红黑树或者 B+ 树?
+
+这道面试题很多大厂比较喜欢问,难度还是有点大的。
+
+- 平衡树 vs 跳表:平衡树的插入、删除和查询的时间复杂度和跳表一样都是 **O(log n)**。对于范围查询来说,平衡树也可以通过中序遍历的方式达到和跳表一样的效果。但是它的每一次插入或者删除操作都需要保证整颗树左右节点的绝对平衡,只要不平衡就要通过旋转操作来保持平衡,这个过程是比较耗时的。跳表诞生的初衷就是为了克服平衡树的一些缺点。跳表使用概率平衡而不是严格强制的平衡,因此,跳表中的插入和删除算法比平衡树的等效算法简单得多,速度也快得多。
+- 红黑树 vs 跳表:相比较于红黑树来说,跳表的实现也更简单一些,不需要通过旋转和染色(红黑变换)来保证黑平衡。并且,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
+- B+ 树 vs 跳表:B+ 树更适合作为数据库和文件系统中常用的索引结构之一,它的核心思想是通过可能少的 IO 定位到尽可能多的索引来获得查询数据。对于 Redis 这种内存数据库来说,它对这些并不感冒,因为 Redis 作为内存数据库它不可能存储大量的数据,所以对于索引不需要通过 B+ 树这种方式进行维护,只需按照概率进行随机维护即可,节约内存。而且使用跳表实现 zset 时相较前者来说更简单一些,在进行插入时只需通过索引将数据插入到链表中合适的位置再随机维护一定高度的索引即可,也不需要像 B+ 树那样插入时发现失衡时还需要对节点分裂与合并。
+
+另外,我还单独写了一篇文章从有序集合的基本使用到跳表的源码分析和实现,让你会对 Redis 的有序集合底层实现的跳表有着更深刻的理解和掌握:[Redis 为什么用跳表实现有序集合](https://javaguide.cn/database/redis/redis-skiplist.html)。
+
### Set 的应用场景是什么?
Redis 中 `Set` 是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 `HashSet` 。
-Set 的常见应用场景如下:
+`Set` 的常见应用场景如下:
-- 存放的数据不能重复的场景:网站 UV 统计(数据量巨大的场景还是 `HyperLogLog`更适合一些)、文章点赞、动态点赞等等。
-- 需要获取多个数据源交集、并集和差集的场景:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集) 等等。
+- 存放的数据不能重复的场景:网站 UV 统计(数据量巨大的场景还是 `HyperLogLog` 更适合一些)、文章点赞、动态点赞等等。
+- 需要获取多个数据源交集、并集和差集的场景:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集)等等。
- 需要随机获取数据源中的元素的场景:抽奖系统、随机点名等等。
### 使用 Set 实现抽奖系统怎么做?
-如果想要使用 Set 实现一个简单的抽奖系统的话,直接使用下面这几个命令就可以了:
+如果想要使用 `Set` 实现一个简单的抽奖系统的话,直接使用下面这几个命令就可以了:
- `SADD key member1 member2 ...`:向指定集合添加一个或多个元素。
- `SPOP key count`:随机移除并获取指定集合中一个或多个元素,适合不允许重复中奖的场景。
-- `SRANDMEMBER key count` : 随机获取指定集合中指定数量的元素,适合允许重复中奖的场景。
+- `SRANDMEMBER key count`:随机获取指定集合中指定数量的元素,适合允许重复中奖的场景。
### 使用 Bitmap 统计活跃用户怎么做?
-Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
+Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap,只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。
@@ -355,7 +393,7 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
(integer) 0
```
-统计 20210308~20210309 总活跃用户数:
+统计 20210308~20210309 总活跃用户数:
```bash
> BITOP and desk1 20210308 20210309
@@ -364,7 +402,7 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
(integer) 1
```
-统计 20210308~20210309 在线活跃用户数:
+统计 20210308~20210309 在线活跃用户数:
```bash
> BITOP or desk2 20210308 20210309
@@ -373,6 +411,27 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
(integer) 2
```
+### HyperLogLog 适合什么场景?
+
+HyperLogLog (HLL) 是一种非常巧妙的概率性数据结构,它专门解决一类非常棘手的大数据问题:在海量数据中,用极小的内存,估算一个集合中不重复元素的数量,也就是我们常说的基数(Cardinality)
+
+HLL 做的最核心的权衡,就是用一点点精确度的损失,来换取巨大的内存空间节省。它给出的不是一个 100%精确的数字,而是一个带有很小标准误差(Redis 中默认是 0.81%)的近似值。
+
+**基于这个核心权衡,HyperLogLog 最适合以下特征的场景:**
+
+1. **数据量巨大,内存敏感:** 这是 HLL 的主战场。比如,要统计一个亿级日活 App 的每日独立访客数。如果用传统的 Set 来存储用户 ID,一个 ID 占几十个字节,上亿个 ID 可能需要几个 GB 甚至几十 GB 的内存,这在很多场景下是不可接受的。而 HLL,在 Redis 中只需要固定的 12KB 内存,就能处理天文数字级别的基数,这是一个颠覆性的优势。
+2. **对结果的精确度要求不是 100%:** 这是使用 HLL 的前提。比如,产品经理想知道一个热门帖子的 UV(独立访客数)是大约 1000 万还是 1010 万,这个细微的差别通常不影响商业决策。但如果场景是统计一个交易系统的准确交易笔数,那 HLL 就完全不适用,因为金融场景要求 100%的精确。
+
+**所以,HyperLogLog 具体的应用场景就非常清晰了:**
+
+- **网站/App 的 UV(Unique Visitor)统计:** 比如统计首页每天有多少个不同的 IP 或用户 ID 访问过。
+- **搜索引擎关键词统计:** 统计每天有多少个不同的用户搜索了某个关键词。
+- **社交网络互动统计:** 比如统计一条微博被多少个不同的用户转发过。
+
+在这些场景下,我们关心的是数量级和趋势,而不是个位数的差异。
+
+最后,Redis 的实现还非常智能,它内部会根据基数的大小,在**稀疏矩阵**(占用空间更小)和**稠密矩阵**(固定的 12KB)之间自动切换,进一步优化了内存使用。总而言之,当您需要对海量数据进行去重计数,并且可以接受微小误差时,HyperLogLog 就是不二之选。
+
### 使用 HyperLogLog 统计页面 UV 怎么做?
使用 HyperLogLog 统计页面 UV 主要需要用到下面这两个命令:
@@ -392,19 +451,31 @@ PFADD PAGE_1:UV USER1 USER2 ...... USERn
PFCOUNT PAGE_1:UV
```
-## Redis 持久化机制(重要)
+### 如果我想判断一个元素是否不在海量元素集合中,用什么数据类型?
+
+这是布隆过滤器的经典应用场景。布隆过滤器可以告诉你一个元素一定不存在或者可能存在,它也有极高的空间效率和一定的误判率,但绝不会漏报。也就是说,布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
+
+Bloom Filter 的简单原理图如下:
+
+
-Redis 持久化机制(RDB 持久化、AOF 持久化、RDB 和 AOF 的混合持久化) 相关的问题比较多,也比较重要,于是我单独抽了一篇文章来总结 Redis 持久化机制相关的知识点和问题:[Redis 持久化机制详解](https://javaguide.cn/database/redis/redis-persistence.html) 。
+当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后将对应的位数组的下标设置为 1(当位数组初始化时,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
-## Redis 线程模型(重要)
+如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
-对于读写命令来说,Redis 一直是单线程模型。不过,在 Redis 4.0 版本之后引入了多线程来执行一些大键值对的异步删除操作, Redis 6.0 版本之后引入了多线程来处理网络请求(提高网络 IO 读写性能)。
+## ⭐️Redis 持久化机制(重要)
+
+Redis 持久化机制(RDB 持久化、AOF 持久化、RDB 和 AOF 的混合持久化)相关的问题比较多,也比较重要,于是我单独抽了一篇文章来总结 Redis 持久化机制相关的知识点和问题:[Redis 持久化机制详解](https://javaguide.cn/database/redis/redis-persistence.html)。
+
+## ⭐️Redis 线程模型(重要)
+
+对于读写命令来说,Redis 一直是单线程模型。不过,在 Redis 4.0 版本之后引入了多线程来执行一些大键值对的异步删除操作,Redis 6.0 版本之后引入了多线程来处理网络请求(提高网络 IO 读写性能)。
### Redis 单线程模型了解吗?
-**Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型** (Netty 的线程模型也基于 Reactor 模式,Reactor 模式不愧是高性能 IO 的基石),这套事件处理模型对应的是 Redis 中的文件事件处理器(file event handler)。由于文件事件处理器(file event handler)是单线程方式运行的,所以我们一般都说 Redis 是单线程模型。
+**Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型**(Netty 的线程模型也基于 Reactor 模式,Reactor 模式不愧是高性能 IO 的基石),这套事件处理模型对应的是 Redis 中的文件事件处理器(file event handler)。由于文件事件处理器(file event handler)是单线程方式运行的,所以我们一般都说 Redis 是单线程模型。
-《Redis 设计与实现》有一段话是如是介绍文件事件处理器的,我觉得写得挺不错。
+《Redis 设计与实现》有一段话是这样介绍文件事件处理器的,我觉得写得挺不错。
> Redis 基于 Reactor 模式开发了自己的网络事件处理器:这个处理器被称为文件事件处理器(file event handler)。
>
@@ -428,27 +499,29 @@ Redis 通过 **IO 多路复用程序** 来监听来自客户端的大量连接
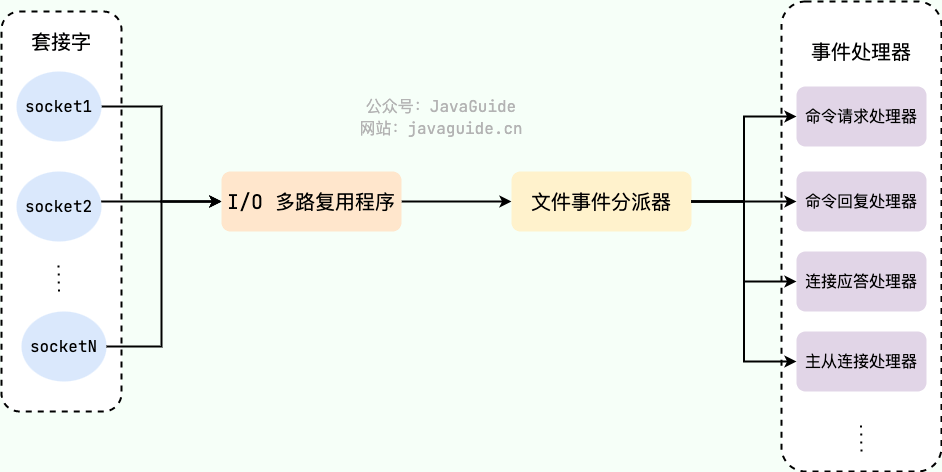
-相关阅读:[Redis 事件机制详解](http://remcarpediem.net/article/1aa2da89/) 。
-
### Redis6.0 之前为什么不使用多线程?
-虽然说 Redis 是单线程模型,但是,实际上,**Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。**
+虽然说 Redis 是单线程模型,但实际上,**Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。**
+
+不过,Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主线程之外的其他线程来“异步处理”,从而减少对主线程的影响。
-不过,Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主线程之外的其他线程来“异步处理”。
+为此,Redis 4.0 之后新增了几个异步命令:
-为此,Redis 4.0 之后新增了`UNLINK`(可以看作是 `DEL` 的异步版本)、`FLUSHALL ASYNC`(清空所有数据库的所有 key,不仅仅是当前 `SELECT` 的数据库)、`FLUSHDB ASYNC`(清空当前 `SELECT` 数据库中的所有 key)等异步命令。
+- `UNLINK`:可以看作是 `DEL` 命令的异步版本。
+- `FLUSHALL ASYNC`:用于清空所有数据库的所有键,不限于当前 `SELECT` 的数据库。
+- `FLUSHDB ASYNC`:用于清空当前 `SELECT` 数据库中的所有键。
-大体上来说,Redis 6.0 之前主要还是单线程处理。
+总的来说,直到 Redis 6.0 之前,Redis 的主要操作仍然是单线程处理的。
**那 Redis6.0 之前为什么不使用多线程?** 我觉得主要原因有 3 点:
- 单线程编程容易并且更容易维护;
-- Redis 的性能瓶颈不在 CPU ,主要在内存和网络;
+- Redis 的性能瓶颈不在 CPU,主要在内存和网络;
- 多线程就会存在死锁、线程上下文切换等问题,甚至会影响性能。
-相关阅读:[为什么 Redis 选择单线程模型?](https://draveness.me/whys-the-design-redis-single-thread/) 。
+相关阅读:[为什么 Redis 选择单线程模型?](https://draveness.me/whys-the-design-redis-single-thread/)。
### Redis6.0 之后为何引入了多线程?
@@ -467,13 +540,13 @@ io-threads 4 #设置1的话只会开启主线程,官网建议4核的机器建
- io-threads 的个数一旦设置,不能通过 config 动态设置。
- 当设置 ssl 后,io-threads 将不工作。
-开启多线程后,默认只会使用多线程进行 IO 写入 writes,即发送数据给客户端,如果需要开启多线程 IO 读取 reads,同样需要修改 redis 配置文件 `redis.conf` :
+开启多线程后,默认只会使用多线程进行 IO 写入 writes,即发送数据给客户端,如果需要开启多线程 IO 读取 reads,同样需要修改 redis 配置文件 `redis.conf`:
```bash
io-threads-do-reads yes
```
-但是官网描述开启多线程读并不能有太大提升,因此一般情况下并不建议开启
+但是官网描述开启多线程读并不能有太大提升,因此一般情况下并不建议开启。
相关阅读:
@@ -485,10 +558,10 @@ io-threads-do-reads yes
我们虽然经常说 Redis 是单线程模型(主要逻辑是单线程完成的),但实际还有一些后台线程用于执行一些比较耗时的操作:
- 通过 `bio_close_file` 后台线程来释放 AOF / RDB 等过程中产生的临时文件资源。
-- 通过 `bio_aof_fsync` 后台线程调用 `fsync` 函数将系统内核缓冲区还未同步到到磁盘的数据强制刷到磁盘( AOF 文件)。
-- 通过 `bio_lazy_free`后台线程释放大对象(已删除)占用的内存空间.
+- 通过 `bio_aof_fsync` 后台线程调用 `fsync` 函数将系统内核缓冲区还未同步到到磁盘的数据强制刷到磁盘(AOF 文件)。
+- 通过 `bio_lazy_free` 后台线程释放大对象(已删除)占用的内存空间.
-在`bio.h` 文件中有定义(Redis 6.0 版本,源码地址:https://github.com/redis/redis/blob/6.0/src/bio.h):
+在`bio.h` 文件中有定义(Redis 6.0 版本,源码地址:):
```java
#ifndef __BIO_H
@@ -513,13 +586,13 @@ void bioKillThreads(void);
关于 Redis 后台线程的详细介绍可以查看 [Redis 6.0 后台线程有哪些?](https://juejin.cn/post/7102780434739626014) 这篇就文章。
-## Redis 内存管理
+## ⭐️Redis 内存管理
-### Redis 给缓存数据设置过期时间有啥用?
+### Redis 给缓存数据设置过期时间有什么用?
一般情况下,我们设置保存的缓存数据的时候都会设置一个过期时间。为什么呢?
-因为内存是有限的,如果缓存中的所有数据都是一直保存的话,分分钟直接 Out of memory。
+内存是有限且珍贵的,如果不对缓存数据设置过期时间,那内存占用就会一直增长,最终可能会导致 OOM 问题。通过设置合理的过期时间,Redis 会自动删除暂时不需要的数据,为新的缓存数据腾出空间。
Redis 自带了给缓存数据设置过期时间的功能,比如:
@@ -532,19 +605,19 @@ OK
(integer) 56
```
-注意:**Redis 中除了字符串类型有自己独有设置过期时间的命令 `setex` 外,其他方法都需要依靠 `expire` 命令来设置过期时间 。另外, `persist` 命令可以移除一个键的过期时间。**
+注意 ⚠️:Redis 中除了字符串类型有自己独有设置过期时间的命令 `setex` 外,其他方法都需要依靠 `expire` 命令来设置过期时间 。另外,`persist` 命令可以移除一个键的过期时间。
**过期时间除了有助于缓解内存的消耗,还有什么其他用么?**
-很多时候,我们的业务场景就是需要某个数据只在某一时间段内存在,比如我们的短信验证码可能只在 1 分钟内有效,用户登录的 token 可能只在 1 天内有效。
+很多时候,我们的业务场景就是需要某个数据只在某一时间段内存在,比如我们的短信验证码可能只在 1 分钟内有效,用户登录的 Token 可能只在 1 天内有效。
如果使用传统的数据库来处理的话,一般都是自己判断过期,这样更麻烦并且性能要差很多。
### Redis 是如何判断数据是否过期的呢?
-Redis 通过一个叫做过期字典(可以看作是 hash 表)来保存数据过期的时间。过期字典的键指向 Redis 数据库中的某个 key(键),过期字典的值是一个 long long 类型的整数,这个整数保存了 key 所指向的数据库键的过期时间(毫秒精度的 UNIX 时间戳)。
+Redis 通过一个叫做过期字典(可以看作是 hash 表)来保存数据过期的时间。过期字典的键指向 Redis 数据库中的某个 key(键),过期字典的值是一个 long long 类型的整数,这个整数保存了 key 所指向的数据库键的过期时间(毫秒精度的 UNIX 时间戳)。
-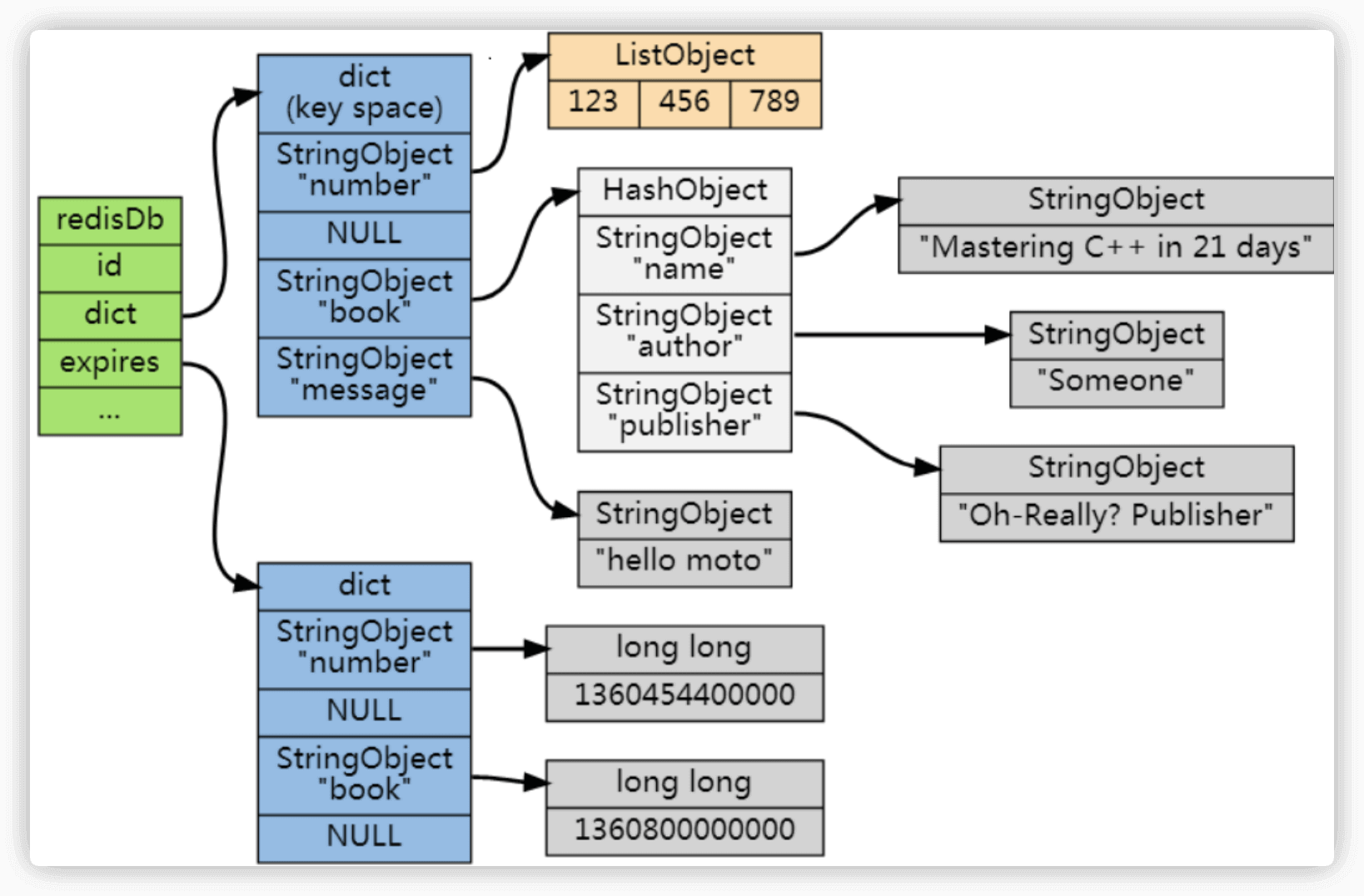
+
过期字典是存储在 redisDb 这个结构里的:
@@ -558,42 +631,164 @@ typedef struct redisDb {
} redisDb;
```
-### 过期的数据的删除策略了解么?
+在查询一个 key 的时候,Redis 首先检查该 key 是否存在于过期字典中(时间复杂度为 O(1)),如果不在就直接返回,在的话需要判断一下这个 key 是否过期,过期直接删除 key 然后返回 null。
+
+### Redis 过期 key 删除策略了解么?
如果假设你设置了一批 key 只能存活 1 分钟,那么 1 分钟后,Redis 是怎么对这批 key 进行删除的呢?
-常用的过期数据的删除策略就两个(重要!自己造缓存轮子的时候需要格外考虑的东西):
+常用的过期数据的删除策略就下面这几种:
-1. **惰性删除**:只会在取出 key 的时候才对数据进行过期检查。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
-2. **定期删除**:每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
+1. **惰性删除**:只会在取出/查询 key 的时候才对数据进行过期检查。这种方式对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
+2. **定期删除**:周期性地随机从设置了过期时间的 key 中抽查一批,然后逐个检查这些 key 是否过期,过期就删除 key。相比于惰性删除,定期删除对内存更友好,对 CPU 不太友好。
+3. **延迟队列**:把设置过期时间的 key 放到一个延迟队列里,到期之后就删除 key。这种方式可以保证每个过期 key 都能被删除,但维护延迟队列太麻烦,队列本身也要占用资源。
+4. **定时删除**:每个设置了过期时间的 key 都会在设置的时间到达时立即被删除。这种方法可以确保内存中不会有过期的键,但是它对 CPU 的压力最大,因为它需要为每个键都设置一个定时器。
-定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,所以 Redis 采用的是 **定期删除+惰性/懒汉式删除** 。
+**Redis 采用的是那种删除策略呢?**
-但是,仅仅通过给 key 设置过期时间还是有问题的。因为还是可能存在定期删除和惰性删除漏掉了很多过期 key 的情况。这样就导致大量过期 key 堆积在内存里,然后就 Out of memory 了。
+Redis 采用的是 **定期删除+惰性/懒汉式删除** 结合的策略,这也是大部分缓存框架的选择。定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,结合起来使用既能兼顾 CPU 友好,又能兼顾内存友好。
-怎么解决这个问题呢?答案就是:**Redis 内存淘汰机制。**
+下面是我们详细介绍一下 Redis 中的定期删除具体是如何做的。
-### Redis 内存淘汰机制了解么?
+Redis 的定期删除过程是随机的(周期性地随机从设置了过期时间的 key 中抽查一批),所以并不保证所有过期键都会被立即删除。这也就解释了为什么有的 key 过期了,并没有被删除。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
+
+另外,定期删除还会受到执行时间和过期 key 的比例的影响:
+
+- 执行时间已经超过了阈值,那么就中断这一次定期删除循环,以避免使用过多的 CPU 时间。
+- 如果这一批过期的 key 比例超过一个比例,就会重复执行此删除流程,以更积极地清理过期 key。相应地,如果过期的 key 比例低于这个比例,就会中断这一次定期删除循环,避免做过多的工作而获得很少的内存回收。
+
+Redis 7.2 版本的执行时间阈值是 **25ms**,过期 key 比例设定值是 **10%**。
+
+```c
+#define ACTIVE_EXPIRE_CYCLE_FAST_DURATION 1000 /* Microseconds. */
+#define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25 /* Max % of CPU to use. */
+#define ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE 10 /* % of stale keys after which
+ we do extra efforts. */
+```
+
+**每次随机抽查数量是多少?**
+
+`expire.c` 中定义了每次随机抽查的数量,Redis 7.2 版本为 20,也就是说每次会随机选择 20 个设置了过期时间的 key 判断是否过期。
+
+```c
+#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /* Keys for each DB loop. */
+```
+
+**如何控制定期删除的执行频率?**
+
+在 Redis 中,定期删除的频率是由 **hz** 参数控制的。hz 默认为 10,代表每秒执行 10 次,也就是每秒钟进行 10 次尝试来查找并删除过期的 key。
+
+hz 的取值范围为 1~500。增大 hz 参数的值会提升定期删除的频率。如果你想要更频繁地执行定期删除任务,可以适当增加 hz 的值,但这会增加 CPU 的使用率。根据 Redis 官方建议,hz 的值不建议超过 100,对于大部分用户使用默认的 10 就足够了。
+
+下面是 hz 参数的官方注释,我翻译了其中的重要信息(Redis 7.2 版本)。
+
+
+
+类似的参数还有一个 **dynamic-hz**,这个参数开启之后 Redis 就会在 hz 的基础上动态计算一个值。Redis 提供并默认启用了使用自适应 hz 值的能力,
+
+这两个参数都在 Redis 配置文件 `redis.conf` 中:
+
+```properties
+# 默认为 10
+hz 10
+# 默认开启
+dynamic-hz yes
+```
+
+多提一嘴,除了定期删除过期 key 这个定期任务之外,还有一些其他定期任务例如关闭超时的客户端连接、更新统计信息,这些定期任务的执行频率也是通过 hz 参数决定。
+
+**为什么定期删除不是把所有过期 key 都删除呢?**
+
+这样会对性能造成太大的影响。如果我们 key 数量非常庞大的话,挨个遍历检查是非常耗时的,会严重影响性能。Redis 设计这种策略的目的是为了平衡内存和性能。
+
+**为什么 key 过期之后不立马把它删掉呢?这样不是会浪费很多内存空间吗?**
+
+因为不太好办到,或者说这种删除方式的成本太高了。假如我们使用延迟队列作为删除策略,这样存在下面这些问题:
+
+1. 队列本身的开销可能很大:key 多的情况下,一个延迟队列可能无法容纳。
+2. 维护延迟队列太麻烦:修改 key 的过期时间就需要调整其在延迟队列中的位置,并且还需要引入并发控制。
+
+### 大量 key 集中过期怎么办?
+
+当 Redis 中存在大量 key 在同一时间点集中过期时,可能会导致以下问题:
+
+- **请求延迟增加**:Redis 在处理过期 key 时需要消耗 CPU 资源,如果过期 key 数量庞大,会导致 Redis 实例的 CPU 占用率升高,进而影响其他请求的处理速度,造成延迟增加。
+- **内存占用过高**:过期的 key 虽然已经失效,但在 Redis 真正删除它们之前,仍然会占用内存空间。如果过期 key 没有及时清理,可能会导致内存占用过高,甚至引发内存溢出。
+
+为了避免这些问题,可以采取以下方案:
+
+1. **尽量避免 key 集中过期**:在设置键的过期时间时尽量随机一点。
+2. **开启 lazy free 机制**:修改 `redis.conf` 配置文件,将 `lazyfree-lazy-expire` 参数设置为 `yes`,即可开启 lazy free 机制。开启 lazy free 机制后,Redis 会在后台异步删除过期的 key,不会阻塞主线程的运行,从而降低对 Redis 性能的影响。
+
+### Redis 内存淘汰策略了解么?
> 相关问题:MySQL 里有 2000w 数据,Redis 中只存 20w 的数据,如何保证 Redis 中的数据都是热点数据?
-Redis 提供 6 种数据淘汰策略:
+Redis 的内存淘汰策略只有在运行内存达到了配置的最大内存阈值时才会触发,这个阈值是通过 `redis.conf` 的 `maxmemory` 参数来定义的。64 位操作系统下,`maxmemory` 默认为 0,表示不限制内存大小。32 位操作系统下,默认的最大内存值是 3GB。
+
+你可以使用命令 `config get maxmemory` 来查看 `maxmemory` 的值。
+
+```bash
+> config get maxmemory
+maxmemory
+0
+```
+
+Redis 提供了 6 种内存淘汰策略:
1. **volatile-lru(least recently used)**:从已设置过期时间的数据集(`server.db[i].expires`)中挑选最近最少使用的数据淘汰。
2. **volatile-ttl**:从已设置过期时间的数据集(`server.db[i].expires`)中挑选将要过期的数据淘汰。
3. **volatile-random**:从已设置过期时间的数据集(`server.db[i].expires`)中任意选择数据淘汰。
-4. **allkeys-lru(least recently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)。
+4. **allkeys-lru(least recently used)**:从数据集(`server.db[i].dict`)中移除最近最少使用的数据淘汰。
5. **allkeys-random**:从数据集(`server.db[i].dict`)中任意选择数据淘汰。
-6. **no-eviction**:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
+6. **no-eviction**(默认内存淘汰策略):禁止驱逐数据,当内存不足以容纳新写入数据时,新写入操作会报错。
4.0 版本后增加以下两种:
7. **volatile-lfu(least frequently used)**:从已设置过期时间的数据集(`server.db[i].expires`)中挑选最不经常使用的数据淘汰。
-8. **allkeys-lfu(least frequently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key。
+8. **allkeys-lfu(least frequently used)**:从数据集(`server.db[i].dict`)中移除最不经常使用的数据淘汰。
+
+`allkeys-xxx` 表示从所有的键值中淘汰数据,而 `volatile-xxx` 表示从设置了过期时间的键值中淘汰数据。
+
+`config.c` 中定义了内存淘汰策略的枚举数组:
+
+```c
+configEnum maxmemory_policy_enum[] = {
+ {"volatile-lru", MAXMEMORY_VOLATILE_LRU},
+ {"volatile-lfu", MAXMEMORY_VOLATILE_LFU},
+ {"volatile-random",MAXMEMORY_VOLATILE_RANDOM},
+ {"volatile-ttl",MAXMEMORY_VOLATILE_TTL},
+ {"allkeys-lru",MAXMEMORY_ALLKEYS_LRU},
+ {"allkeys-lfu",MAXMEMORY_ALLKEYS_LFU},
+ {"allkeys-random",MAXMEMORY_ALLKEYS_RANDOM},
+ {"noeviction",MAXMEMORY_NO_EVICTION},
+ {NULL, 0}
+};
+```
+
+你可以使用 `config get maxmemory-policy` 命令来查看当前 Redis 的内存淘汰策略。
+
+```bash
+> config get maxmemory-policy
+maxmemory-policy
+noeviction
+```
+
+可以通过 `config set maxmemory-policy 内存淘汰策略` 命令修改内存淘汰策略,立即生效,但这种方式重启 Redis 之后就失效了。修改 `redis.conf` 中的 `maxmemory-policy` 参数不会因为重启而失效,不过,需要重启之后修改才能生效。
+
+```properties
+maxmemory-policy noeviction
+```
+
+关于淘汰策略的详细说明可以参考 Redis 官方文档:。
## 参考
- 《Redis 开发与运维》
- 《Redis 设计与实现》
-- Redis 命令手册:https://www.redis.com.cn/commands.html
+- 《Redis 核心原理与实战》
+- Redis 命令手册:
+- RedisSearch 终极使用指南,你值得拥有!:
- WHY Redis choose single thread (vs multi threads): [https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153](https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153)
+
+
diff --git a/docs/database/redis/redis-questions-02.md b/docs/database/redis/redis-questions-02.md
index f3de97645d6..7e68719b9c8 100644
--- a/docs/database/redis/redis-questions-02.md
+++ b/docs/database/redis/redis-questions-02.md
@@ -1,17 +1,17 @@
---
title: Redis常见面试题总结(下)
+description: 最新Redis面试题总结(下):深度剖析Redis事务原理、性能优化(pipeline/Lua/bigkey/hotkey)、缓存穿透/击穿/雪崩解决方案、慢查询与内存碎片、Redis Sentinel与Cluster集群详解。助你轻松应对后端技术面试!
category: 数据库
tag:
- Redis
head:
- - meta
- name: keywords
- content: Redis基础,Redis常见数据结构,Redis线程模型,Redis内存管理,Redis事务,Redis性能优化
- - - meta
- - name: description
- content: 一篇文章总结Redis常见的知识点和面试题,涵盖Redis基础、Redis常见数据结构、Redis线程模型、Redis内存管理、Redis事务、Redis性能优化等内容。
+ content: Redis面试题,Redis事务,Redis性能优化,Redis缓存穿透,Redis缓存击穿,Redis缓存雪崩,Redis bigkey,Redis hotkey,Redis慢查询,Redis内存碎片,Redis集群,Redis Sentinel,Redis Cluster,Redis pipeline,Redis Lua脚本
---
+
+
## Redis 事务
### 什么是 Redis 事务?
@@ -26,7 +26,7 @@ Redis 事务实际开发中使用的非常少,功能比较鸡肋,不要将
### 如何使用 Redis 事务?
-Redis 可以通过 **`MULTI`,`EXEC`,`DISCARD` 和 `WATCH`** 等命令来实现事务(Transaction)功能。
+Redis 可以通过 **`MULTI`、`EXEC`、`DISCARD` 和 `WATCH`** 等命令来实现事务(Transaction)功能。
```bash
> MULTI
@@ -45,8 +45,8 @@ QUEUED
这个过程是这样的:
1. 开始事务(`MULTI`);
-2. 命令入队(批量操作 Redis 的命令,先进先出(FIFO)的顺序执行);
-3. 执行事务(`EXEC`)。
+2. 命令入队(批量操作 Redis 的命令,先进先出(FIFO)的顺序执行);
+3. 执行事务(`EXEC`)。
你也可以通过 [`DISCARD`](https://redis.io/commands/discard) 命令取消一个事务,它会清空事务队列中保存的所有命令。
@@ -136,10 +136,10 @@ Redis 官网相关介绍 [https://redis.io/topics/transactions](https://redis.io
Redis 的事务和我们平时理解的关系型数据库的事务不同。我们知道事务具有四大特性:**1. 原子性**,**2. 隔离性**,**3. 持久性**,**4. 一致性**。
-1. **原子性(Atomicity):** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
-2. **隔离性(Isolation):** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
-3. **持久性(Durability):** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
-4. **一致性(Consistency):** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
+1. **原子性(Atomicity)**:事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
+2. **隔离性(Isolation)**:并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
+3. **持久性(Durability)**:一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响;
+4. **一致性(Consistency)**:执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的。
Redis 事务在运行错误的情况下,除了执行过程中出现错误的命令外,其他命令都能正常执行。并且,Redis 事务是不支持回滚(roll back)操作的。因此,Redis 事务其实是不满足原子性的。
@@ -147,28 +147,28 @@ Redis 官网也解释了自己为啥不支持回滚。简单来说就是 Redis

-**相关 issue** :
+**相关 issue**:
-- [issue#452: 关于 Redis 事务不满足原子性的问题](https://github.com/Snailclimb/JavaGuide/issues/452) 。
-- [Issue#491:关于 Redis 没有事务回滚?](https://github.com/Snailclimb/JavaGuide/issues/491)
+- [issue#452: 关于 Redis 事务不满足原子性的问题](https://github.com/Snailclimb/JavaGuide/issues/452)。
+- [Issue#491:关于 Redis 没有事务回滚?](https://github.com/Snailclimb/JavaGuide/issues/491)。
### Redis 事务支持持久性吗?
-Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:
+Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:
-- 快照(snapshotting,RDB)
-- 只追加文件(append-only file, AOF)
-- RDB 和 AOF 的混合持久化(Redis 4.0 新增)
+- 快照(snapshotting,RDB);
+- 只追加文件(append-only file,AOF);
+- RDB 和 AOF 的混合持久化(Redis 4.0 新增)。
-与 RDB 持久化相比,AOF 持久化的实时性更好。在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
+与 RDB 持久化相比,AOF 持久化的实时性更好。在 Redis 的配置文件中存在三种不同的 AOF 持久化方式(`fsync` 策略),它们分别是:
```bash
-appendfsync always #每次有数据修改发生时都会调用fsync函数同步AOF文件,fsync完成后线程返回,这样会严重降低Redis的速度
+appendfsync always #每次有数据修改发生时,都会调用fsync函数同步AOF文件,fsync完成后线程返回,这样会严重降低Redis的速度
appendfsync everysec #每秒钟调用fsync函数同步一次AOF文件
appendfsync no #让操作系统决定何时进行同步,一般为30秒一次
```
-AOF 持久化的`fsync`策略为 no、everysec 时都会存在数据丢失的情况 。always 下可以基本是可以满足持久性要求的,但性能太差,实际开发过程中不会使用。
+AOF 持久化的 `fsync` 策略为 no、everysec 时都会存在数据丢失的情况。always 下可以基本是可以满足持久性要求的,但性能太差,实际开发过程中不会使用。
因此,Redis 事务的持久性也是没办法保证的。
@@ -178,44 +178,44 @@ Redis 从 2.6 版本开始支持执行 Lua 脚本,它的功能和事务非常
一段 Lua 脚本可以视作一条命令执行,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰。
-不过,如果 Lua 脚本运行时出错并中途结束,出错之后的命令是不会被执行的。并且,出错之前执行的命令是无法被撤销的,无法实现类似关系型数据库执行失败可以回滚的那种原子性效果。因此, **严格来说的话,通过 Lua 脚本来批量执行 Redis 命令实际也是不完全满足原子性的。**
+不过,如果 Lua 脚本运行时出错并中途结束,出错之后的命令是不会被执行的。并且,出错之前执行的命令是无法被撤销的,无法实现类似关系型数据库执行失败可以回滚的那种原子性效果。因此,**严格来说的话,通过 Lua 脚本来批量执行 Redis 命令实际也是不完全满足原子性的。**
如果想要让 Lua 脚本中的命令全部执行,必须保证语句语法和命令都是对的。
-另外,Redis 7.0 新增了 [Redis functions](https://redis.io/docs/manual/programmability/functions-intro/) 特性,你可以将 Redis functions 看作是比 Lua 更强大的脚本。
+另外,Redis 7.0 新增了 [Redis functions](https://redis.io/docs/latest/develop/programmability/functions-intro/) 特性,你可以将 Redis functions 看作是比 Lua 更强大的脚本。
-## Redis 性能优化(重要)
+## ⭐️Redis 性能优化(重要)
除了下面介绍的内容之外,再推荐两篇不错的文章:
-- [你的 Redis 真的变慢了吗?性能优化如何做 - 阿里开发者](https://mp.weixin.qq.com/s/nNEuYw0NlYGhuKKKKoWfcQ)
-- [Redis 常见阻塞原因总结 - JavaGuide](https://javaguide.cn/database/redis/redis-common-blocking-problems-summary.html)
+- [你的 Redis 真的变慢了吗?性能优化如何做 - 阿里开发者](https://mp.weixin.qq.com/s/nNEuYw0NlYGhuKKKKoWfcQ)。
+- [Redis 常见阻塞原因总结 - JavaGuide](https://javaguide.cn/database/redis/redis-common-blocking-problems-summary.html)。
### 使用批量操作减少网络传输
一个 Redis 命令的执行可以简化为以下 4 步:
-1. 发送命令
-2. 命令排队
-3. 命令执行
-4. 返回结果
+1. 发送命令;
+2. 命令排队;
+3. 命令执行;
+4. 返回结果。
-其中,第 1 步和第 4 步耗费时间之和称为 **Round Trip Time (RTT,往返时间)** ,也就是数据在网络上传输的时间。
+其中,第 1 步和第 4 步耗费时间之和称为 **Round Trip Time(RTT,往返时间)**,也就是数据在网络上传输的时间。
使用批量操作可以减少网络传输次数,进而有效减小网络开销,大幅减少 RTT。
-另外,除了能减少 RTT 之外,发送一次命令的 socket I/O 成本也比较高(涉及上下文切换,存在`read()`和`write()`系统调用),批量操作还可以减少 socket I/O 成本。这个在官方对 pipeline 的介绍中有提到:https://redis.io/docs/manual/pipelining/ 。
+另外,除了能减少 RTT 之外,发送一次命令的 socket I/O 成本也比较高(涉及上下文切换,存在 `read()` 和 `write()` 系统调用),批量操作还可以减少 socket I/O 成本。这个在官方对 pipeline 的介绍中有提到:。
#### 原生批量操作命令
Redis 中有一些原生支持批量操作的命令,比如:
-- `MGET`(获取一个或多个指定 key 的值)、`MSET`(设置一个或多个指定 key 的值)、
-- `HMGET`(获取指定哈希表中一个或者多个指定字段的值)、`HMSET`(同时将一个或多个 field-value 对设置到指定哈希表中)、
+- `MGET`(获取一个或多个指定 key 的值)、`MSET`(设置一个或多个指定 key 的值)、
+- `HMGET`(获取指定哈希表中一个或者多个指定字段的值)、`HMSET`(同时将一个或多个 field-value 对设置到指定哈希表中)、
- `SADD`(向指定集合添加一个或多个元素)
-- ......
+- ……
-不过,在 Redis 官方提供的分片集群解决方案 Redis Cluster 下,使用这些原生批量操作命令可能会存在一些小问题需要解决。就比如说 `MGET` 无法保证所有的 key 都在同一个 **hash slot**(哈希槽)上,`MGET`可能还是需要多次网络传输,原子操作也无法保证了。不过,相较于非批量操作,还是可以节省不少网络传输次数。
+不过,在 Redis 官方提供的分片集群解决方案 Redis Cluster 下,使用这些原生批量操作命令可能会存在一些小问题需要解决。就比如说 `MGET` 无法保证所有的 key 都在同一个 **hash slot(哈希槽)** 上,`MGET`可能还是需要多次网络传输,原子操作也无法保证了。不过,相较于非批量操作,还是可以节省不少网络传输次数。
整个步骤的简化版如下(通常由 Redis 客户端实现,无需我们自己再手动实现):
@@ -225,15 +225,15 @@ Redis 中有一些原生支持批量操作的命令,比如:
如果想要解决这个多次网络传输的问题,比较常用的办法是自己维护 key 与 slot 的关系。不过这样不太灵活,虽然带来了性能提升,但同样让系统复杂性提升。
-> Redis Cluster 并没有使用一致性哈希,采用的是 **哈希槽分区** ,每一个键值对都属于一个 **hash slot**(哈希槽) 。当客户端发送命令请求的时候,需要先根据 key 通过上面的计算公示找到的对应的哈希槽,然后再查询哈希槽和节点的映射关系,即可找到目标 Redis 节点。
+> Redis Cluster 并没有使用一致性哈希,采用的是 **哈希槽分区**,每一个键值对都属于一个 **hash slot(哈希槽)**。当客户端发送命令请求的时候,需要先根据 key 通过上面的计算公式找到的对应的哈希槽,然后再查询哈希槽和节点的映射关系,即可找到目标 Redis 节点。
>
> 我在 [Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html) 这篇文章中详细介绍了 Redis Cluster 这部分的内容,感兴趣地可以看看。
#### pipeline
-对于不支持批量操作的命令,我们可以利用 **pipeline(流水线)** 将一批 Redis 命令封装成一组,这些 Redis 命令会被一次性提交到 Redis 服务器,只需要一次网络传输。不过,需要注意控制一次批量操作的 **元素个数**(例如 500 以内,实际也和元素字节数有关),避免网络传输的数据量过大。
+对于不支持批量操作的命令,我们可以利用 **pipeline(流水线)** 将一批 Redis 命令封装成一组,这些 Redis 命令会被一次性提交到 Redis 服务器,只需要一次网络传输。不过,需要注意控制一次批量操作的 **元素个数**(例如 500 以内,实际也和元素字节数有关),避免网络传输的数据量过大。
-与`MGET`、`MSET`等原生批量操作命令一样,pipeline 同样在 Redis Cluster 上使用会存在一些小问题。原因类似,无法保证所有的 key 都在同一个 **hash slot**(哈希槽)上。如果想要使用的话,客户端需要自己维护 key 与 slot 的关系。
+与 `MGET`、`MSET` 等原生批量操作命令一样,pipeline 同样在 Redis Cluster 上使用会存在一些小问题。原因类似,无法保证所有的 key 都在同一个 **hash slot(哈希槽)** 上。如果想要使用的话,客户端需要自己维护 key 与 slot 的关系。
原生批量操作命令和 pipeline 的是有区别的,使用的时候需要注意:
@@ -250,18 +250,18 @@ Redis 中有一些原生支持批量操作的命令,比如:
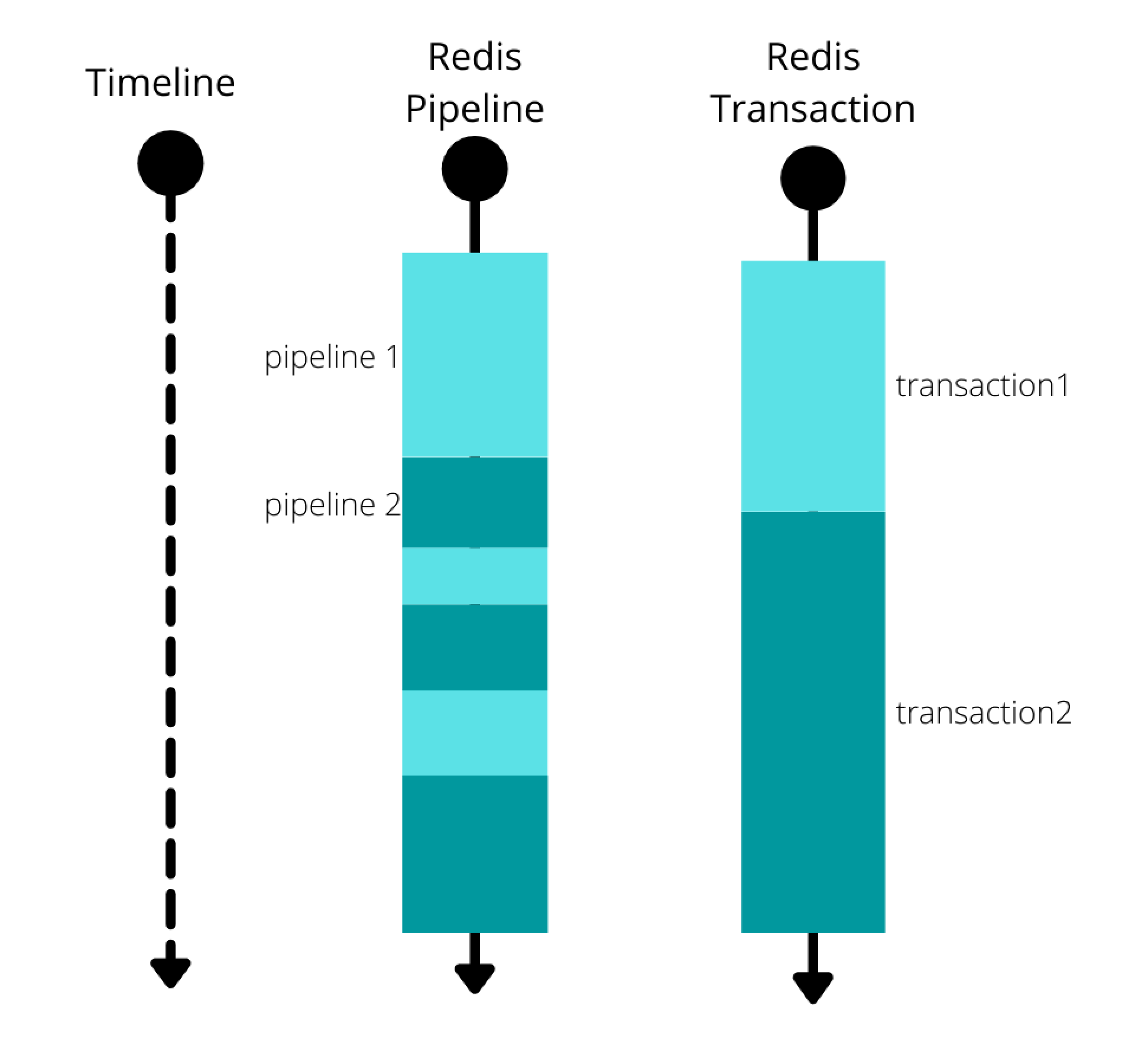
-另外,pipeline 不适用于执行顺序有依赖关系的一批命令。就比如说,你需要将前一个命令的结果给后续的命令使用,pipeline 就没办法满足你的需求了。对于这种需求,我们可以使用 **Lua 脚本** 。
+另外,pipeline 不适用于执行顺序有依赖关系的一批命令。就比如说,你需要将前一个命令的结果给后续的命令使用,pipeline 就没办法满足你的需求了。对于这种需求,我们可以使用 **Lua 脚本**。
#### Lua 脚本
-Lua 脚本同样支持批量操作多条命令。一段 Lua 脚本可以视作一条命令执行,可以看作是 **原子操作** 。也就是说,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰,这是 pipeline 所不具备的。
+Lua 脚本同样支持批量操作多条命令。一段 Lua 脚本可以视作一条命令执行,可以看作是 **原子操作**。也就是说,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰,这是 pipeline 所不具备的。
并且,Lua 脚本中支持一些简单的逻辑处理比如使用命令读取值并在 Lua 脚本中进行处理,这同样是 pipeline 所不具备的。
不过, Lua 脚本依然存在下面这些缺陷:
- 如果 Lua 脚本运行时出错并中途结束,之后的操作不会进行,但是之前已经发生的写操作不会撤销,所以即使使用了 Lua 脚本,也不能实现类似数据库回滚的原子性。
-- Redis Cluster 下 Lua 脚本的原子操作也无法保证了,原因同样是无法保证所有的 key 都在同一个 **hash slot**(哈希槽)上。
+- Redis Cluster 下 Lua 脚本的原子操作也无法保证了,原因同样是无法保证所有的 key 都在同一个 **hash slot(哈希槽)** 上。
### 大量 key 集中过期问题
@@ -272,7 +272,7 @@ Lua 脚本同样支持批量操作多条命令。一段 Lua 脚本可以视作
**如何解决呢?** 下面是两种常见的方法:
1. 给 key 设置随机过期时间。
-2. 开启 lazy-free(惰性删除/延迟释放) 。lazy-free 特性是 Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
+2. 开启 lazy-free(惰性删除/延迟释放)。lazy-free 特性是 Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
个人建议不管是否开启 lazy-free,我们都尽量给 key 设置随机过期时间。
@@ -280,11 +280,32 @@ Lua 脚本同样支持批量操作多条命令。一段 Lua 脚本可以视作
#### 什么是 bigkey?
-简单来说,如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:string 类型的 value 超过 10 kb,复合类型的 value 包含的元素超过 5000 个(对于复合类型的 value 来说,不一定包含的元素越多,占用的内存就越多)。
+简单来说,如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:
+
+- String 类型的 value 超过 1MB
+- 复合类型(List、Hash、Set、Sorted Set 等)的 value 包含的元素超过 5000 个(不过,对于复合类型的 value 来说,不一定包含的元素越多,占用的内存就越多)。
+
+
+
+#### bigkey 是怎么产生的?有什么危害?
+
+bigkey 通常是由于下面这些原因产生的:
+
+- 程序设计不当,比如直接使用 String 类型存储较大的文件对应的二进制数据。
+- 对于业务的数据规模考虑不周到,比如使用集合类型的时候没有考虑到数据量的快速增长。
+- 未及时清理垃圾数据,比如哈希中冗余了大量的无用键值对。
+
+bigkey 除了会消耗更多的内存空间和带宽,还会对性能造成比较大的影响。
+
+在 [Redis 常见阻塞原因总结](./redis-common-blocking-problems-summary.md) 这篇文章中我们提到:大 key 还会造成阻塞问题。具体来说,主要体现在下面三个方面:
-#### bigkey 有什么危害?
+1. 客户端超时阻塞:由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
+2. 网络阻塞:每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
+3. 工作线程阻塞:如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
-bigkey 除了会消耗更多的内存空间和带宽,还会对性能造成比较大的影响。因此,我们应该尽量避免 Redis 中存在 bigkey。
+大 key 造成的阻塞问题还会进一步影响到主从同步和集群扩容。
+
+综上,大 key 带来的潜在问题是非常多的,我们应该尽量避免 Redis 中存在 bigkey。
#### 如何发现 bigkey?
@@ -316,24 +337,38 @@ Biggest string found '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28
0 zsets with 0 members (00.00% of keys, avg size 0.00
```
-从这个命令的运行结果,我们可以看出:这个命令会扫描(Scan) Redis 中的所有 key ,会对 Redis 的性能有一点影响。并且,这种方式只能找出每种数据结构 top 1 bigkey(占用内存最大的 string 数据类型,包含元素最多的复合数据类型)。然而,一个 key 的元素多并不代表占用内存也多,需要我们根据具体的业务情况来进一步判断。
+从这个命令的运行结果,我们可以看出:这个命令会扫描(Scan)Redis 中的所有 key,会对 Redis 的性能有一点影响。并且,这种方式只能找出每种数据结构 top 1 bigkey(占用内存最大的 String 数据类型,包含元素最多的复合数据类型)。然而,一个 key 的元素多并不代表占用内存也多,需要我们根据具体的业务情况来进一步判断。
在线上执行该命令时,为了降低对 Redis 的影响,需要指定 `-i` 参数控制扫描的频率。`redis-cli -p 6379 --bigkeys -i 3` 表示扫描过程中每次扫描后休息的时间间隔为 3 秒。
-**2、借助开源工具分析 RDB 文件。**
+**2、使用 Redis 自带的 SCAN 命令**
+
+`SCAN` 命令可以按照一定的模式和数量返回匹配的 key。获取了 key 之后,可以利用 `STRLEN`、`HLEN`、`LLEN` 等命令返回其长度或成员数量。
+
+| 数据结构 | 命令 | 复杂度 | 结果(对应 key) |
+| ---------- | ------ | ------ | ------------------ |
+| String | STRLEN | O(1) | 字符串值的长度 |
+| Hash | HLEN | O(1) | 哈希表中字段的数量 |
+| List | LLEN | O(1) | 列表元素数量 |
+| Set | SCARD | O(1) | 集合元素数量 |
+| Sorted Set | ZCARD | O(1) | 有序集合的元素数量 |
+
+对于集合类型还可以使用 `MEMORY USAGE` 命令(Redis 4.0+),这个命令会返回键值对占用的内存空间。
+
+**3、借助开源工具分析 RDB 文件。**
通过分析 RDB 文件来找出 big key。这种方案的前提是你的 Redis 采用的是 RDB 持久化。
网上有现成的代码/工具可以直接拿来使用:
-- [redis-rdb-tools](https://github.com/sripathikrishnan/redis-rdb-tools):Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具
-- [rdb_bigkeys](https://github.com/weiyanwei412/rdb_bigkeys) : Go 语言写的用来分析 Redis 的 RDB 快照文件用的工具,性能更好。
+- [redis-rdb-tools](https://github.com/sripathikrishnan/redis-rdb-tools):Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具。
+- [rdb_bigkeys](https://github.com/weiyanwei412/rdb_bigkeys):Go 语言写的用来分析 Redis 的 RDB 快照文件用的工具,性能更好。
-**3、借助公有云的 Redis 分析服务。**
+**4、借助公有云的 Redis 分析服务。**
如果你用的是公有云的 Redis 服务的话,可以看看其是否提供了 key 分析功能(一般都提供了)。
-这里以阿里云 Redis 为例说明,它支持 bigkey 实时分析、发现,文档地址: 。
+这里以阿里云 Redis 为例说明,它支持 bigkey 实时分析、发现,文档地址:。
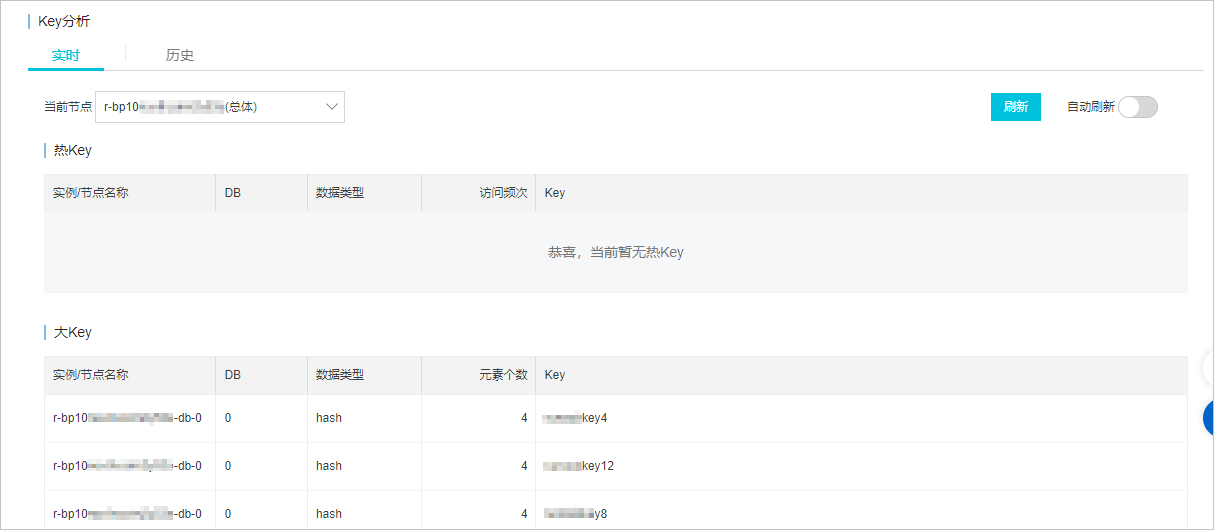
@@ -341,16 +376,16 @@ Biggest string found '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28
bigkey 的常见处理以及优化办法如下(这些方法可以配合起来使用):
-- **分割 bigkey**:将一个 bigkey 分割为多个小 key。这种方式需要修改业务层的代码,一般不推荐这样做。
+- **分割 bigkey**:将一个 bigkey 分割为多个小 key。例如,将一个含有上万字段数量的 Hash 按照一定策略(比如二次哈希)拆分为多个 Hash。
- **手动清理**:Redis 4.0+ 可以使用 `UNLINK` 命令来异步删除一个或多个指定的 key。Redis 4.0 以下可以考虑使用 `SCAN` 命令结合 `DEL` 命令来分批次删除。
-- **采用合适的数据结构**:比如使用 HyperLogLog 统计页面 UV。
-- **开启 lazy-free(惰性删除/延迟释放)** :lazy-free 特性是 Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
+- **采用合适的数据结构**:例如,文件二进制数据不使用 String 保存、使用 HyperLogLog 统计页面 UV、Bitmap 保存状态信息(0/1)。
+- **开启 lazy-free(惰性删除/延迟释放)**:lazy-free 特性是 Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
### Redis hotkey(热 Key)
#### 什么是 hotkey?
-简单来说,如果一个 key 的访问次数比较多且明显多于其他 key 的话,那这个 key 就可以看作是 hotkey。例如在 Redis 实例的每秒处理请求达到 5000 次,而其中某个 key 的每秒访问量就高达 2000 次,那这个 key 就可以看作是 hotkey。
+如果一个 key 的访问次数比较多且明显多于其他 key 的话,那这个 key 就可以看作是 **hotkey(热 Key)**。例如在 Redis 实例的每秒处理请求达到 5000 次,而其中某个 key 的每秒访问量就高达 2000 次,那这个 key 就可以看作是 hotkey。
hotkey 出现的原因主要是某个热点数据访问量暴增,如重大的热搜事件、参与秒杀的商品。
@@ -395,13 +430,13 @@ maxmemory-policy allkeys-lfu
需要注意的是,`hotkeys` 参数命令也会增加 Redis 实例的 CPU 和内存消耗(全局扫描),因此需要谨慎使用。
-**2、使用`MONITOR` 命令。**
+**2、使用 `MONITOR` 命令。**
`MONITOR` 命令是 Redis 提供的一种实时查看 Redis 的所有操作的方式,可以用于临时监控 Redis 实例的操作情况,包括读写、删除等操作。
由于该命令对 Redis 性能的影响比较大,因此禁止长时间开启 `MONITOR`(生产环境中建议谨慎使用该命令)。
-```java
+```bash
# redis-cli
127.0.0.1:6379> MONITOR
OK
@@ -436,7 +471,7 @@ OK
如果你用的是公有云的 Redis 服务的话,可以看看其是否提供了 key 分析功能(一般都提供了)。
-这里以阿里云 Redis 为例说明,它支持 hotkey 实时分析、发现,文档地址: 。
+这里以阿里云 Redis 为例说明,它支持 hotkey 实时分析、发现,文档地址:。

@@ -460,43 +495,45 @@ hotkey 的常见处理以及优化办法如下(这些方法可以配合起来
我们知道一个 Redis 命令的执行可以简化为以下 4 步:
-1. 发送命令
-2. 命令排队
-3. 命令执行
-4. 返回结果
+1. 发送命令;
+2. 命令排队;
+3. 命令执行;
+4. 返回结果。
Redis 慢查询统计的是命令执行这一步骤的耗时,慢查询命令也就是那些命令执行时间较长的命令。
Redis 为什么会有慢查询命令呢?
-Redis 中的大部分命令都是 O(1)时间复杂度,但也有少部分 O(n) 时间复杂度的命令,例如:
+Redis 中的大部分命令都是 O(1) 时间复杂度,但也有少部分 O(n) 时间复杂度的命令,例如:
- `KEYS *`:会返回所有符合规则的 key。
- `HGETALL`:会返回一个 Hash 中所有的键值对。
- `LRANGE`:会返回 List 中指定范围内的元素。
- `SMEMBERS`:返回 Set 中的所有元素。
- `SINTER`/`SUNION`/`SDIFF`:计算多个 Set 的交集/并集/差集。
-- ......
+- ……
由于这些命令时间复杂度是 O(n),有时候也会全表扫描,随着 n 的增大,执行耗时也会越长。不过, 这些命令并不是一定不能使用,但是需要明确 N 的值。另外,有遍历的需求可以使用 `HSCAN`、`SSCAN`、`ZSCAN` 代替。
-除了这些 O(n)时间复杂度的命令可能会导致慢查询之外, 还有一些时间复杂度可能在 O(N) 以上的命令,例如:
+除了这些 O(n) 时间复杂度的命令可能会导致慢查询之外,还有一些时间复杂度可能在 O(N) 以上的命令,例如:
-- `ZRANGE`/`ZREVRANGE`:返回指定 Sorted Set 中指定排名范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 为返回的元素数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
-- `ZREMRANGEBYRANK`/`ZREMRANGEBYSCORE`:移除 Sorted Set 中指定排名范围/指定 score 范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 被删除元素的数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
-- ......
+- `ZRANGE`/`ZREVRANGE`:返回指定 Sorted Set 中指定排名范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量,m 为返回的元素数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
+- `ZREMRANGEBYRANK`/`ZREMRANGEBYSCORE`:移除 Sorted Set 中指定排名范围/指定 score 范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量,m 被删除元素的数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
+- ……
#### 如何找到慢查询命令?
+Redis 提供了一个内置的**慢查询日志 (Slow Log)** 功能,专门用来记录执行时间超过指定阈值的命令。这对于排查性能瓶颈、找出导致 Redis 阻塞的“慢”操作非常有帮助,原理和 MySQL 的慢查询日志类似。
+
在 `redis.conf` 文件中,我们可以使用 `slowlog-log-slower-than` 参数设置耗时命令的阈值,并使用 `slowlog-max-len` 参数设置耗时命令的最大记录条数。
-当 Redis 服务器检测到执行时间超过 `slowlog-log-slower-than`阈值的命令时,就会将该命令记录在慢查询日志(slow log) 中,这点和 MySQL 记录慢查询语句类似。当慢查询日志超过设定的最大记录条数之后,Redis 会把最早的执行命令依次舍弃。
+当 Redis 服务器检测到执行时间超过 `slowlog-log-slower-than` 阈值的命令时,就会将该命令记录在慢查询日志(slow log)中,这点和 MySQL 记录慢查询语句类似。当慢查询日志超过设定的最大记录条数之后,Redis 会把最早的执行命令依次舍弃。
-⚠️注意:由于慢查询日志会占用一定内存空间,如果设置最大记录条数过大,可能会导致内存占用过高的问题。
+⚠️ 注意:由于慢查询日志会占用一定内存空间,如果设置最大记录条数过大,可能会导致内存占用过高的问题。
- `slowlog-log-slower-than`和`slowlog-max-len`的默认配置如下(可以自行修改):
+`slowlog-log-slower-than` 和 `slowlog-max-len` 的默认配置如下(可以自行修改):
-```nginx
+```properties
# The following time is expressed in microseconds, so 1000000 is equivalent
# to one second. Note that a negative number disables the slow log, while
# a value of zero forces the logging of every command.
@@ -516,9 +553,9 @@ CONFIG SET slowlog-log-slower-than 10000
CONFIG SET slowlog-max-len 128
```
-获取慢查询日志的内容很简单,直接使用`SLOWLOG GET` 命令即可。
+获取慢查询日志的内容很简单,直接使用 `SLOWLOG GET` 命令即可。
-```java
+```bash
127.0.0.1:6379> SLOWLOG GET #慢日志查询
1) 1) (integer) 5
2) (integer) 1684326682
@@ -532,14 +569,14 @@ CONFIG SET slowlog-max-len 128
慢查询日志中的每个条目都由以下六个值组成:
-1. 唯一渐进的日志标识符。
-2. 处理记录命令的 Unix 时间戳。
-3. 执行所需的时间量,以微秒为单位。
-4. 组成命令参数的数组。
-5. 客户端 IP 地址和端口。
-6. 客户端名称。
+1. **唯一 ID**: 日志条目的唯一标识符。
+2. **时间戳 (Timestamp)**: 命令执行完成时的 Unix 时间戳。
+3. **耗时 (Duration)**: 命令执行所花费的时间,单位是**微秒**。
+4. **命令及参数 (Command)**: 执行的具体命令及其参数数组。
+5. **客户端信息 (Client IP:Port)**: 执行命令的客户端地址和端口。
+6. **客户端名称 (Client Name)**: 如果客户端设置了名称 (CLIENT SETNAME)。
-`SLOWLOG GET` 命令默认返回最近 10 条的的慢查询命令,你也自己可以指定返回的慢查询命令的数量 `SLOWLOG GET N`。
+`SLOWLOG GET` 命令默认返回最近 10 条的慢查询命令,你也自己可以指定返回的慢查询命令的数量 `SLOWLOG GET N`。
下面是其他比较常用的慢查询相关的命令:
@@ -556,18 +593,18 @@ OK
**相关问题**:
-1. 什么是内存碎片?为什么会有 Redis 内存碎片?
+1. 什么是内存碎片?为什么会有 Redis 内存碎片?
2. 如何清理 Redis 内存碎片?
**参考答案**:[Redis 内存碎片详解](https://javaguide.cn/database/redis/redis-memory-fragmentation.html)。
-## Redis 生产问题(重要)
+## ⭐️Redis 生产问题(重要)
### 缓存穿透
#### 什么是缓存穿透?
-缓存穿透说简单点就是大量请求的 key 是不合理的,**根本不存在于缓存中,也不存在于数据库中** 。这就导致这些请求直接到了数据库上,根本没有经过缓存这一层,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
+缓存穿透说简单点就是大量请求的 key 是不合理的,**根本不存在于缓存中,也不存在于数据库中**。这就导致这些请求直接到了数据库上,根本没有经过缓存这一层,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
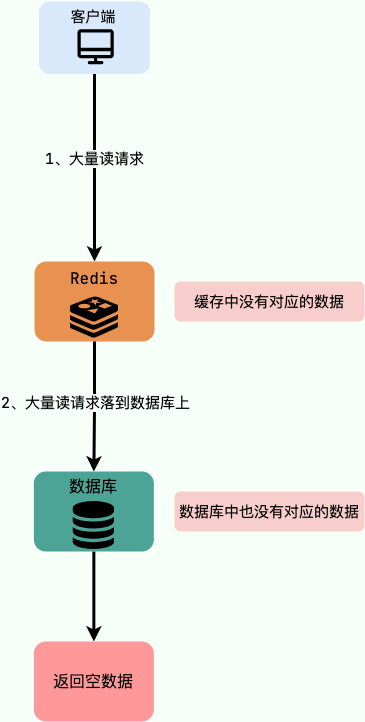
@@ -579,9 +616,9 @@ OK
**1)缓存无效 key**
-如果缓存和数据库都查不到某个 key 的数据就写一个到 Redis 中去并设置过期时间,具体命令如下:`SET key value EX 10086` 。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建不同的请求 key,会导致 Redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
+如果缓存和数据库都查不到某个 key 的数据,就写一个到 Redis 中去并设置过期时间,具体命令如下:`SET key value EX 10086`。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建不同的请求 key,会导致 Redis 中缓存大量无效的 key。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点,比如 1 分钟。
-另外,这里多说一嘴,一般情况下我们是这样设计 key 的:`表名:列名:主键名:主键值` 。
+另外,这里多说一嘴,一般情况下我们是这样设计 key 的:`表名:列名:主键名:主键值`。
如果用 Java 代码展示的话,差不多是下面这样的:
@@ -608,37 +645,35 @@ public Object getObjectInclNullById(Integer id) {
**2)布隆过滤器**
-布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。
+布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时常用的 List、Map、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。
-具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
+
-加入布隆过滤器之后的缓存处理流程图如下。
+Bloom Filter 会使用一个较大的 bit 数组来保存所有的数据,数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1(代表 false 或者 true),这也是 Bloom Filter 节省内存的核心所在。这样来算的话,申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 KB ≈ 122KB 的空间。
-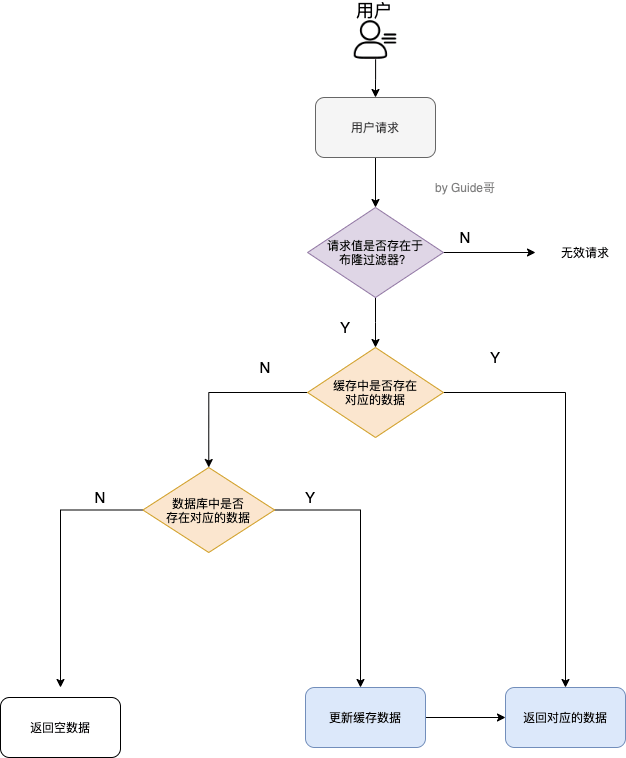
+
-但是,需要注意的是布隆过滤器可能会存在误判的情况。总结来说就是:**布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。**
+具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
-_为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理来说!_
+加入布隆过滤器之后的缓存处理流程图如下:
-我们先来看一下,**当一个元素加入布隆过滤器中的时候,会进行哪些操作:**
+
-1. 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
-2. 根据得到的哈希值,在位数组中把对应下标的值置为 1。
+更多关于布隆过滤器的详细介绍可以看看我的这篇原创:[不了解布隆过滤器?一文给你整的明明白白!](https://javaguide.cn/cs-basics/data-structure/bloom-filter.html),强烈推荐。
-我们再来看一下,**当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行哪些操作:**
+**3)接口限流**
-1. 对给定元素再次进行相同的哈希计算;
-2. 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
+根据用户或者 IP 对接口进行限流,对于异常频繁的访问行为,还可以采取黑名单机制,例如将异常 IP 列入黑名单。
-然后,一定会出现这样一种情况:**不同的字符串可能哈希出来的位置相同。** (可以适当增加位数组大小或者调整我们的哈希函数来降低概率)
+后面提到的缓存击穿和雪崩都可以配合接口限流来解决,毕竟这些问题的关键都是有很多请求落到了数据库上造成数据库压力过大。
-更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://javaguide.cn/cs-basics/data-structure/bloom-filter/) ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
+限流的具体方案可以参考这篇文章:[服务限流详解](https://javaguide.cn/high-availability/limit-request.html)。
### 缓存击穿
#### 什么是缓存击穿?
-缓存击穿中,请求的 key 对应的是 **热点数据** ,该数据 **存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期)** 。这就可能会导致瞬时大量的请求直接打到了数据库上,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
+缓存击穿中,请求的 key 对应的是 **热点数据**,该数据 **存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期)**。这就可能会导致瞬时大量的请求直接打到了数据库上,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
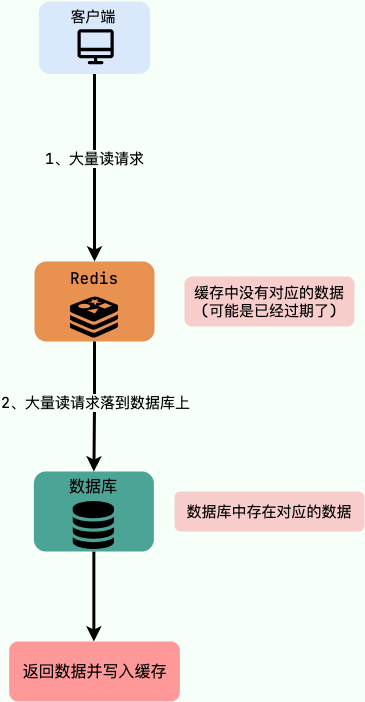
@@ -646,9 +681,9 @@ _为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理
#### 有哪些解决办法?
-- 设置热点数据永不过期或者过期时间比较长。
-- 针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
-- 请求数据库写数据到缓存之前,先获取互斥锁,保证只有一个请求会落到数据库上,减少数据库的压力。
+1. **永不过期**(不推荐):设置热点数据永不过期或者过期时间比较长。
+2. **提前预热**(推荐):针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
+3. **加锁**(看情况):在缓存失效后,通过设置互斥锁确保只有一个请求去查询数据库并更新缓存。
#### 缓存穿透和缓存击穿有什么区别?
@@ -668,61 +703,94 @@ _为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理
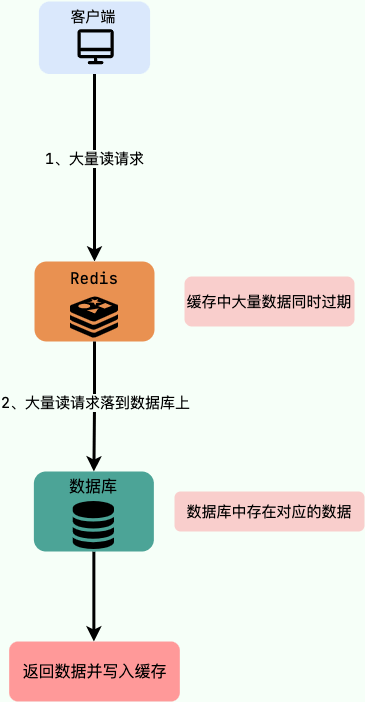
-举个例子:数据库中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。
+举个例子:缓存中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。
#### 有哪些解决办法?
-**针对 Redis 服务不可用的情况:**
+**针对 Redis 服务不可用的情况**:
+
+1. **Redis 集群**:采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。Redis Cluster 和 Redis Sentinel 是两种最常用的 Redis 集群实现方案,详细介绍可以参考:[Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html)。
+2. **多级缓存**:设置多级缓存,例如本地缓存+Redis 缓存的二级缓存组合,当 Redis 缓存出现问题时,还可以从本地缓存中获取到部分数据。
+
+**针对大量缓存同时失效的情况**:
-1. 采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。
-2. 限流,避免同时处理大量的请求。
+1. **设置随机失效时间**(可选):为缓存设置随机的失效时间,例如在固定过期时间的基础上加上一个随机值,这样可以避免大量缓存同时到期,从而减少缓存雪崩的风险。
+2. **提前预热**(推荐):针对热点数据提前预热,将其存入缓存中并设置合理的过期时间,比如秒杀场景下的数据在秒杀结束之前不过期。
+3. **持久缓存策略**(看情况):虽然一般不推荐设置缓存永不过期,但对于某些关键性和变化不频繁的数据,可以考虑这种策略。
-**针对热点缓存失效的情况:**
+#### 缓存预热如何实现?
-1. 设置不同的失效时间比如随机设置缓存的失效时间。
-2. 缓存永不失效(不太推荐,实用性太差)。
-3. 设置二级缓存。
+常见的缓存预热方式有两种:
+
+1. 使用定时任务,比如 xxl-job,来定时触发缓存预热的逻辑,将数据库中的热点数据查询出来并存入缓存中。
+2. 使用消息队列,比如 Kafka,来异步地进行缓存预热,将数据库中的热点数据的主键或者 ID 发送到消息队列中,然后由缓存服务消费消息队列中的数据,根据主键或者 ID 查询数据库并更新缓存。
#### 缓存雪崩和缓存击穿有什么区别?
-缓存雪崩和缓存击穿比较像,但缓存雪崩导致的原因是缓存中的大量或者所有数据失效,缓存击穿导致的原因主要是某个热点数据不存在与缓存中(通常是因为缓存中的那份数据已经过期)。
+缓存雪崩和缓存击穿比较像,但缓存雪崩导致的原因是缓存中的大量或者所有数据失效,缓存击穿导致的原因主要是某个热点数据不存在于缓存中(通常是因为缓存中的那份数据已经过期)。
### 如何保证缓存和数据库数据的一致性?
-细说的话可以扯很多,但是我觉得其实没太大必要(小声 BB:很多解决方案我也没太弄明白)。我个人觉得引入缓存之后,如果为了短时间的不一致性问题,选择让系统设计变得更加复杂的话,完全没必要。
+缓存和数据库一致性是个挺常见的技术挑战。引入缓存主要是为了提升性能、减轻数据库压力,但确实会带来数据不一致的风险。绝对的一致性往往意味着更高的系统复杂度和性能开销,所以实践中我们通常会根据业务场景选择合适的策略,在性能和一致性之间找到一个平衡点。
+
+下面单独对 **Cache Aside Pattern(旁路缓存模式)** 来聊聊。这是非常常用的一种缓存读写策略,它的读写逻辑是这样的:
+
+- **读操作**:
+ 1. 先尝试从缓存读取数据。
+ 2. 如果缓存命中,直接返回数据。
+ 3. 如果缓存未命中,从数据库查询数据,将查到的数据放入缓存并返回数据。
+- **写操作**:
+ 1. 先更新数据库。
+ 2. 再直接删除缓存中对应的数据。
+
+图解如下:
-下面单独对 **Cache Aside Pattern(旁路缓存模式)** 来聊聊。
+
-Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删除 cache 。
+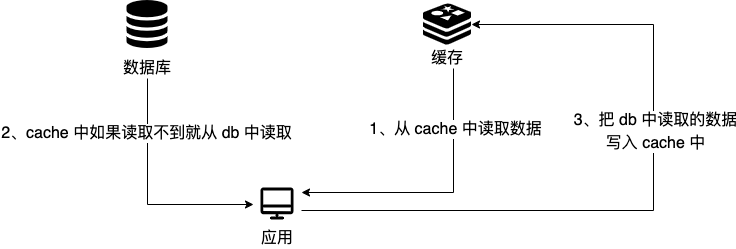
-如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说两个解决方案:
+如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说有两个解决方案:
-1. **缓存失效时间变短(不推荐,治标不治本)**:我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
-2. **增加 cache 更新重试机制(常用)**:如果 cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存入队列中,等缓存服务可用之后,再将缓存中对应的 key 删除即可。
+1. **缓存失效时间(TTL - Time To Live)变短**(不推荐,治标不治本):我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
+2. **增加缓存更新重试机制**(常用):如果缓存服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。不过,这里更适合引入消息队列实现异步重试,将删除缓存重试的消息投递到消息队列,然后由专门的消费者来重试,直到成功。虽然说多引入了一个消息队列,但其整体带来的收益还是要更高一些。
相关文章推荐:[缓存和数据库一致性问题,看这篇就够了 - 水滴与银弹](https://mp.weixin.qq.com/s?__biz=MzIyOTYxNDI5OA==&mid=2247487312&idx=1&sn=fa19566f5729d6598155b5c676eee62d&chksm=e8beb8e5dfc931f3e35655da9da0b61c79f2843101c130cf38996446975014f958a6481aacf1&scene=178&cur_album_id=1699766580538032128#rd)。
### 哪些情况可能会导致 Redis 阻塞?
-单独抽了一篇文章来总结可能会导致 Redis 阻塞的情况:[Redis 常见阻塞原因总结](https://javaguide.cn/database/redis/redis-common-blocking-problems-summary.html)。
+常见的导致 Redis 阻塞原因有:
+
+- `O(n)` 复杂度命令执行(如 `KEYS *`、`HGETALL`、`LRANGE`、`SMEMBERS` 等),随着数据量增大导致执行时间过长。
+- 执行 `SAVE` 命令生成 RDB 快照时同步阻塞主线程,而 `BGSAVE` 通过 `fork` 子进程避免阻塞。
+- AOF 记录日志在主线程中进行,可能因命令执行后写日志而阻塞后续命令。
+- AOF 刷盘(fsync)时后台线程同步到磁盘,磁盘压力大导致 `fsync` 阻塞,进而阻塞主线程 `write` 操作,尤其在 `appendfsync always` 或 `everysec` 配置下明显。
+- AOF 重写过程中将重写缓冲区内容追加到新 AOF 文件时产生阻塞。
+- 操作大 key(string > 1MB 或复合类型元素 > 5000)导致客户端超时、网络阻塞和工作线程阻塞。
+- 使用 `flushdb` 或 `flushall` 清空数据库时涉及大量键值对删除和内存释放,造成主线程阻塞。
+- 集群扩容缩容时数据迁移为同步操作,大 key 迁移导致两端节点长时间阻塞,可能触发故障转移
+- 内存不足触发 Swap,操作系统将 Redis 内存换出到硬盘,读写性能急剧下降。
+- 其他进程过度占用 CPU 导致 Redis 吞吐量下降。
+- 网络问题如连接拒绝、延迟高、网卡软中断等导致 Redis 阻塞。
+
+详细介绍可以阅读这篇文章:[Redis 常见阻塞原因总结](https://javaguide.cn/database/redis/redis-common-blocking-problems-summary.html)。
## Redis 集群
**Redis Sentinel**:
1. 什么是 Sentinel? 有什么用?
-2. Sentinel 如何检测节点是否下线?主观下线与客观下线的区别?
+2. Sentinel 如何检测节点是否下线?主观下线与客观下线的区别?
3. Sentinel 是如何实现故障转移的?
4. 为什么建议部署多个 sentinel 节点(哨兵集群)?
-5. Sentinel 如何选择出新的 master(选举机制)?
-6. 如何从 Sentinel 集群中选择出 Leader ?
+5. Sentinel 如何选择出新的 master(选举机制)?
+6. 如何从 Sentinel 集群中选择出 Leader?
7. Sentinel 可以防止脑裂吗?
**Redis Cluster**:
1. 为什么需要 Redis Cluster?解决了什么问题?有什么优势?
2. Redis Cluster 是如何分片的?
-3. 为什么 Redis Cluster 的哈希槽是 16384 个?
+3. 为什么 Redis Cluster 的哈希槽是 16384 个?
4. 如何确定给定 key 的应该分布到哪个哈希槽中?
5. Redis Cluster 支持重新分配哈希槽吗?
6. Redis Cluster 扩容缩容期间可以提供服务吗?
@@ -735,20 +803,21 @@ Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删
实际使用 Redis 的过程中,我们尽量要准守一些常见的规范,比如:
1. 使用连接池:避免频繁创建关闭客户端连接。
-2. 尽量不使用 O(n)指令,使用 O(n) 命令时要关注 n 的数量:像 `KEYS *`、`HGETALL`、`LRANGE`、`SMEMBERS`、`SINTER`/`SUNION`/`SDIFF`等 O(n) 命令并非不能使用,但是需要明确 n 的值。另外,有遍历的需求可以使用 `HSCAN`、`SSCAN`、`ZSCAN` 代替。
-3. 使用批量操作减少网络传输:原生批量操作命令(比如 `MGET`、`MSET`等等)、pipeline、Lua 脚本。
-4. 尽量不适用 Redis 事务:Redis 事务实现的功能比较鸡肋,可以使用 Lua 脚本代替。
+2. 尽量不使用 O(n) 指令,使用 O(n) 命令时要关注 n 的数量:像 `KEYS *`、`HGETALL`、`LRANGE`、`SMEMBERS`、`SINTER`/`SUNION`/`SDIFF` 等 O(n) 命令并非不能使用,但是需要明确 n 的值。另外,有遍历的需求可以使用 `HSCAN`、`SSCAN`、`ZSCAN` 代替。
+3. 使用批量操作减少网络传输:原生批量操作命令(比如 `MGET`、`MSET` 等等)、pipeline、Lua 脚本。
+4. 尽量不使用 Redis 事务:Redis 事务实现的功能比较鸡肋,可以使用 Lua 脚本代替。
5. 禁止长时间开启 monitor:对性能影响比较大。
6. 控制 key 的生命周期:避免 Redis 中存放了太多不经常被访问的数据。
-7. ......
-
-相关文章推荐:[阿里云 Redis 开发规范](https://developer.aliyun.com/article/531067) 。
+7. ……
## 参考
- 《Redis 开发与运维》
- 《Redis 设计与实现》
-- Redis Transactions :
+- Redis Transactions:
- What is Redis Pipeline:
- 一文详解 Redis 中 BigKey、HotKey 的发现与处理:
-- Redis延迟问题全面排障指南:https://mp.weixin.qq.com/s/mIc6a9mfEGdaNDD3MmfFsg
+- Bigkey 问题的解决思路与方式探索:
+- Redis 延迟问题全面排障指南:
+
+
diff --git a/docs/database/redis/redis-skiplist.md b/docs/database/redis/redis-skiplist.md
new file mode 100644
index 00000000000..d50ee58706f
--- /dev/null
+++ b/docs/database/redis/redis-skiplist.md
@@ -0,0 +1,727 @@
+---
+title: Redis为什么用跳表实现有序集合
+description: 深入讲解Redis有序集合Zset为何选择跳表而非红黑树、B+树实现,详解跳表的数据结构原理、时间复杂度分析和Redis源码实现。
+category: 数据库
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis跳表,SkipList,有序集合,Zset,跳表原理,平衡树对比,Redis数据结构
+---
+
+## 前言
+
+近几年针对 Redis 面试时会涉及常见数据结构的底层设计,其中就有这么一道比较有意思的面试题:“Redis 的有序集合底层为什么要用跳表,而不用平衡树、红黑树或者 B+树?”。
+
+本文就以这道大厂常问的面试题为切入点,带大家详细了解一下跳表这个数据结构。
+
+本文整体脉络如下图所示,笔者会从有序集合的基本使用到跳表的源码分析和实现,让你会对 Redis 的有序集合底层实现的跳表有着更深刻的理解和掌握。
+
+
+
+## 跳表在 Redis 中的运用
+
+这里我们需要先了解一下 Redis 用到跳表的数据结构有序集合的使用,Redis 有个比较常用的数据结构叫**有序集合(sorted set,简称 zset)**,正如其名它是一个可以保证有序且元素唯一的集合,所以它经常用于排行榜等需要进行统计排列的场景。
+
+这里我们通过命令行的形式演示一下排行榜的实现,可以看到笔者分别输入 3 名用户:**xiaoming**、**xiaohong**、**xiaowang**,它们的**score**分别是 60、80、60,最终按照成绩升级降序排列。
+
+```bash
+
+127.0.0.1:6379> zadd rankList 60 xiaoming
+(integer) 1
+127.0.0.1:6379> zadd rankList 80 xiaohong
+(integer) 1
+127.0.0.1:6379> zadd rankList 60 xiaowang
+(integer) 1
+
+# 返回有序集中指定区间内的成员,通过索引,分数从高到低
+127.0.0.1:6379> ZREVRANGE rankList 0 100 WITHSCORES
+1) "xiaohong"
+2) "80"
+3) "xiaowang"
+4) "60"
+5) "xiaoming"
+6) "60"
+```
+
+此时我们通过 `object` 指令查看 zset 的数据结构,可以看到当前有序集合存储的还是**ziplist(压缩列表)**。
+
+```bash
+127.0.0.1:6379> object encoding rankList
+"ziplist"
+```
+
+因为设计者考虑到 Redis 数据存放于内存,为了节约宝贵的内存空间,在有序集合元素小于 64 字节且个数小于 128 的时候,会使用 ziplist,而这个阈值的默认值的设置就来自下面这两个配置项。
+
+```bash
+zset-max-ziplist-value 64
+zset-max-ziplist-entries 128
+```
+
+一旦有序集合中的某个元素超出这两个其中的一个阈值它就会转为 **skiplist**(实际是 dict+skiplist,还会借用字典来提高获取指定元素的效率)。
+
+我们不妨在添加一个大于 64 字节的元素,可以看到有序集合的底层存储转为 skiplist。
+
+```bash
+127.0.0.1:6379> zadd rankList 90 yigemingzihuichaoguo64zijiedeyonghumingchengyongyuceshitiaobiaodeshijiyunyong
+(integer) 1
+
+# 超过阈值,转为跳表
+127.0.0.1:6379> object encoding rankList
+"skiplist"
+```
+
+也就是说,ZSet 有两种不同的实现,分别是 ziplist 和 skiplist,具体使用哪种结构进行存储的规则如下:
+
+- 当有序集合对象同时满足以下两个条件时,使用 ziplist:
+ 1. ZSet 保存的键值对数量少于 128 个;
+ 2. 每个元素的长度小于 64 字节。
+- 如果不满足上述两个条件,那么使用 skiplist 。
+
+## 手写一个跳表
+
+为了更好的回答上述问题以及更好的理解和掌握跳表,这里可以通过手写一个简单的跳表的形式来帮助读者理解跳表这个数据结构。
+
+我们都知道有序链表在添加、查询、删除的平均时间复杂都都是 **O(n)** 即线性增长,所以一旦节点数量达到一定体量后其性能表现就会非常差劲。而跳表我们完全可以理解为在原始链表基础上,建立多级索引,通过多级索引检索定位将增删改查的时间复杂度变为 **O(log n)** 。
+
+可能这里说的有些抽象,我们举个例子,以下图跳表为例,其原始链表存储按序存储 1-10,有 2 级索引,每级索引的索引个数都是基于下层元素个数的一半。
+
+
+
+假如我们需要查询元素 6,其工作流程如下:
+
+1. 从 2 级索引开始,先来到节点 4。
+2. 查看 4 的后继节点,是 8 的 2 级索引,这个值大于 6,说明 2 级索引后续的索引都是大于 6 的,没有再往后搜寻的必要,我们索引向下查找。
+3. 来到 4 的 1 级索引,比对其后继节点为 6,查找结束。
+
+相较于原始有序链表需要 6 次,我们的跳表通过建立多级索引,我们只需两次就直接定位到了目标元素,其查寻的复杂度被直接优化为**O(log n)**。
+
+
+
+对应的添加也是一个道理,假如我们需要在这个有序集合中添加一个元素 7,那么我们就需要通过跳表找到**小于元素 7 的最大值**,也就是下图元素 6 的位置,将其插入到元素 6 的后面,让元素 6 的索引指向新插入的节点 7,其工作流程如下:
+
+1. 从 2 级索引开始定位到了元素 4 的索引。
+2. 查看索引 4 的后继索引为 8,索引向下推进。
+3. 来到 1 级索引,发现索引 4 后继索引为 6,小于插入元素 7,指针推进到索引 6 位置。
+4. 继续比较 6 的后继节点为索引 8,大于元素 7,索引继续向下。
+5. 最终我们来到 6 的原始节点,发现其后继节点为 7,指针没有继续向下的空间,自此我们可知元素 6 就是小于插入元素 7 的最大值,于是便将元素 7 插入。
+
+
+
+这里我们又面临一个问题,我们是否需要为元素 7 建立索引,索引多高合适?
+
+我们上文提到,理想情况是每一层索引是下一层元素个数的二分之一,假设我们的总共有 16 个元素,对应各级索引元素个数应该是:
+
+```bash
+1. 一级索引:16/2=8
+2. 二级索引:8/2 =4
+3. 三级索引:4/2=2
+```
+
+由此我们用数学归纳法可知:
+
+```bash
+1. 一级索引:16/2=16/2^1=8
+2. 二级索引:8/2 => 16/2^2 =4
+3. 三级索引:4/2=>16/2^3=2
+```
+
+假设元素个数为 n,那么对应 k 层索引的元素个数 r 计算公式为:
+
+```bash
+r=n/2^k
+```
+
+同理我们再来推断以下索引的最大高度,一般来说最高级索引的元素个数为 2,我们设元素总个数为 n,索引高度为 h,代入上述公式可得:
+
+```bash
+2= n/2^h
+=> 2*2^h=n
+=> 2^(h+1)=n
+=> h+1=log2^n
+=> h=log2^n -1
+```
+
+而 Redis 又是内存数据库,我们假设元素最大个数是**65536**,我们把**65536**代入上述公式可知最大高度为 16。所以我们建议添加一个元素后为其建立的索引高度不超过 16。
+
+因为我们要求尽可能保证每一个上级索引都是下级索引的一半,在实现高度生成算法时,我们可以这样设计:
+
+1. 跳表的高度计算从原始链表开始,即默认情况下插入的元素的高度为 1,代表没有索引,只有元素节点。
+2. 设计一个为插入元素生成节点索引高度 level 的方法。
+3. 进行一次随机运算,随机数值范围为 0-1 之间。
+4. 如果随机数大于 0.5 则为当前元素添加一级索引,自此我们保证生成一级索引的概率为 **50%** ,这也就保证了 1 级索引理想情况下只有一半的元素会生成索引。
+5. 同理后续每次随机算法得到的值大于 0.5 时,我们的索引高度就加 1,这样就可以保证节点生成的 2 级索引概率为 **25%** ,3 级索引为 **12.5%** ……
+
+我们回过头,上述插入 7 之后,我们通过随机算法得到 2,即要为其建立 1 级索引:
+
+
+
+最后我们再来说说删除,假设我们这里要删除元素 10,我们必须定位到当前跳表**各层**元素小于 10 的最大值,索引执行步骤为:
+
+1. 2 级索引 4 的后继节点为 8,指针推进。
+2. 索引 8 无后继节点,该层无要删除的元素,指针直接向下。
+3. 1 级索引 8 后继节点为 10,说明 1 级索引 8 在进行删除时需要将自己的指针和 1 级索引 10 断开联系,将 10 删除。
+4. 1 级索引完成定位后,指针向下,后继节点为 9,指针推进。
+5. 9 的后继节点为 10,同理需要让其指向 null,将 10 删除。
+
+
+
+### 模板定义
+
+有了整体的思路之后,我们可以开始实现一个跳表了,首先定义一下跳表中的节点**Node**,从上文的演示中可以看出每一个**Node**它都包含以下几个元素:
+
+1. 存储的**value**值。
+2. 后继节点的地址。
+3. 多级索引。
+
+为了更方便统一管理**Node**后继节点地址和多级索引指向的元素地址,笔者在**Node**中设置了一个**forwards**数组,用于记录原始链表节点的后继节点和多级索引的后继节点指向。
+
+以下图为例,我们**forwards**数组长度为 5,其中**索引 0**记录的是原始链表节点的后继节点地址,而其余自底向上表示从 1 级索引到 4 级索引的后继节点指向。
+
+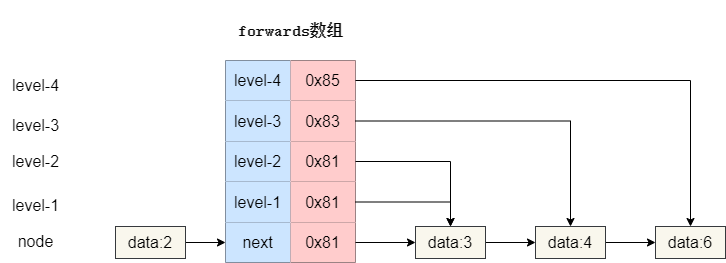
+
+于是我们的就有了这样一个代码定义,可以看出笔者对于数组的长度设置为固定的 16**(上文的推算最大高度建议是 16)**,默认**data**为-1,节点最大高度**maxLevel**初始化为 1,注意这个**maxLevel**的值代表原始链表加上索引的总高度。
+
+```java
+/**
+ * 跳表索引最大高度为16
+ */
+private static final int MAX_LEVEL = 16;
+
+class Node {
+ private int data = -1;
+ private Node[] forwards = new Node[MAX_LEVEL];
+ private int maxLevel = 0;
+
+}
+```
+
+### 元素添加
+
+定义好节点之后,我们先实现以下元素的添加,添加元素时首先自然是设置**data**这一步我们直接根据将传入的**value**设置到**data**上即可。
+
+然后就是高度**maxLevel**的设置 ,我们在上文也已经给出了思路,默认高度为 1,即只有一个原始链表节点,通过随机算法每次大于 0.5 索引高度加 1,由此我们得出高度计算的算法`randomLevel()`:
+
+```java
+/**
+ * 理论来讲,一级索引中元素个数应该占原始数据的 50%,二级索引中元素个数占 25%,三级索引12.5% ,一直到最顶层。
+ * 因为这里每一层的晋升概率是 50%。对于每一个新插入的节点,都需要调用 randomLevel 生成一个合理的层数。
+ * 该 randomLevel 方法会随机生成 1~MAX_LEVEL 之间的数,且 :
+ * 50%的概率返回 1
+ * 25%的概率返回 2
+ * 12.5%的概率返回 3 ...
+ * @return
+ */
+private int randomLevel() {
+ int level = 1;
+ while (Math.random() > PROB && level < MAX_LEVEL) {
+ ++level;
+ }
+ return level;
+}
+```
+
+然后再设置当前要插入的**Node**和**Node**索引的后继节点地址,这一步稍微复杂一点,我们假设当前节点的高度为 4,即 1 个节点加 3 个索引,所以我们创建一个长度为 4 的数组**maxOfMinArr** ,遍历各级索引节点中小于当前**value**的最大值。
+
+假设我们要插入的**value**为 5,我们的数组查找结果当前节点的前驱节点和 1 级索引、2 级索引的前驱节点都为 4,三级索引为空。
+
+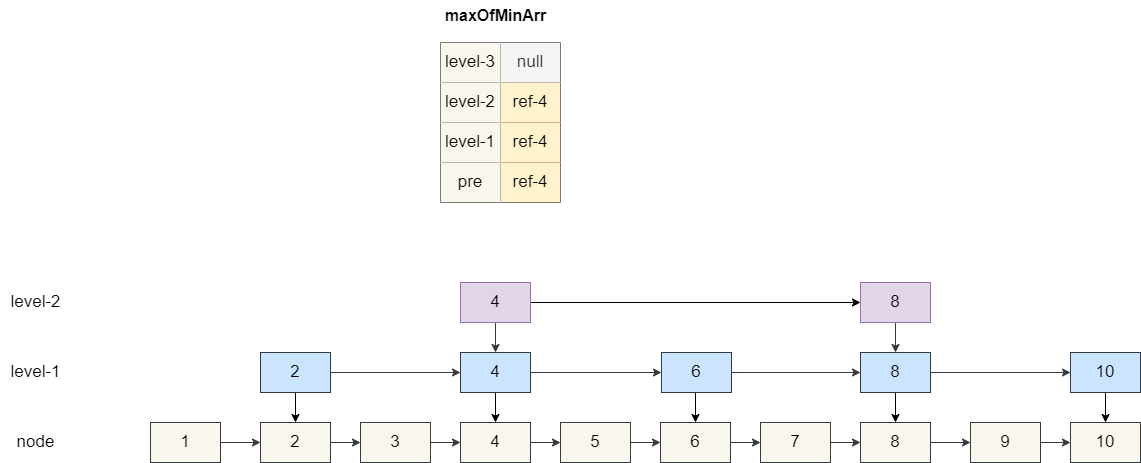
+
+然后我们基于这个数组**maxOfMinArr** 定位到各级的后继节点,让插入的元素 5 指向这些后继节点,而**maxOfMinArr**指向 5,结果如下图:
+
+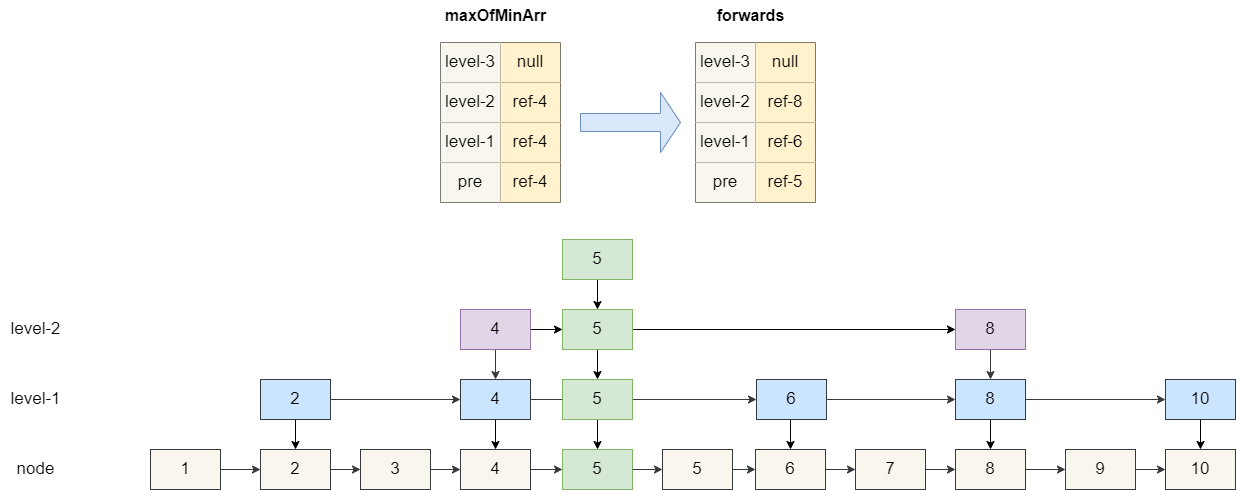
+
+转化成代码就是下面这个形式,是不是很简单呢?我们继续:
+
+```java
+/**
+ * 默认情况下的高度为1,即只有自己一个节点
+ */
+private int levelCount = 1;
+
+/**
+ * 跳表最底层的节点,即头节点
+ */
+private Node h = new Node();
+
+public void add(int value) {
+ int level = randomLevel(); // 新节点的随机高度
+
+ Node newNode = new Node();
+ newNode.data = value;
+ newNode.maxLevel = level;
+
+ // 用于记录每层前驱节点的数组
+ Node[] update = new Node[level];
+ for (int i = 0; i < level; i++) {
+ update[i] = h;
+ }
+
+ Node p = h;
+ // 关键修正:从跳表的当前最高层开始查找
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ // 只记录需要更新的层的前驱节点
+ if (i < level) {
+ update[i] = p;
+ }
+ }
+
+ // 插入新节点
+ for (int i = 0; i < level; i++) {
+ newNode.forwards[i] = update[i].forwards[i];
+ update[i].forwards[i] = newNode;
+ }
+
+ // 更新跳表的总高度
+ if (levelCount < level) {
+ levelCount = level;
+ }
+}
+```
+
+### 元素查询
+
+查询逻辑比较简单,从跳表最高级的索引开始定位找到小于要查的 value 的最大值,以下图为例,我们希望查找到节点 8:
+
+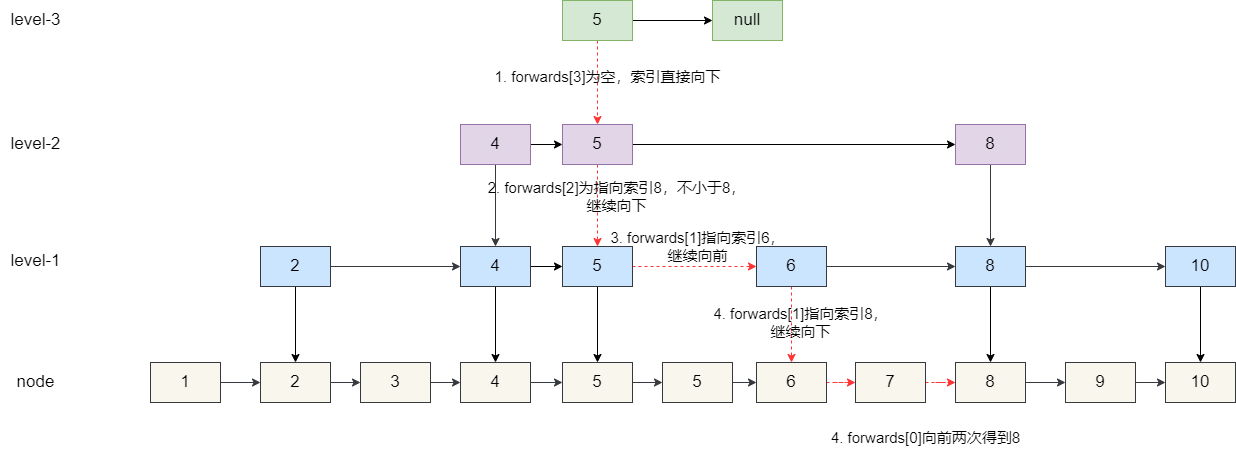
+
+- **从最高层级开始 (3 级索引)** :查找指针 `p` 从头节点开始。在 3 级索引上,`p` 的后继 `forwards[2]`(假设最高 3 层,索引从 0 开始)指向节点 `5`。由于 `5 < 8`,指针 `p` 向右移动到节点 `5`。节点 `5` 在 3 级索引上的后继 `forwards[2]` 为 `null`(或指向一个大于 `8` 的节点,图中未画出)。当前层级向右查找结束,指针 `p` 保持在节点 `5`,**向下移动到 2 级索引**。
+- **在 2 级索引**:当前指针 `p` 为节点 `5`。`p` 的后继 `forwards[1]` 指向节点 `8`。由于 `8` 不小于 `8`(即 `8 < 8` 为 `false`),当前层级向右查找结束(`p` 不会移动到节点 `8`)。指针 `p` 保持在节点 `5`,**向下移动到 1 级索引**。
+- **在 1 级索引** :当前指针 `p` 为节点 `5`。`p` 的后继 `forwards[0]` 指向最底层的节点 `5`。由于 `5 < 8`,指针 `p` 向右移动到最底层的节点 `5`。此时,当前指针 `p` 为最底层的节点 `5`。其后继 `forwards[0]` 指向最底层的节点 `6`。由于 `6 < 8`,指针 `p` 向右移动到最底层的节点 `6`。当前指针 `p` 为最底层的节点 `6`。其后继 `forwards[0]` 指向最底层的节点 `7`。由于 `7 < 8`,指针 `p` 向右移动到最底层的节点 `7`。当前指针 `p` 为最底层的节点 `7`。其后继 `forwards[0]` 指向最底层的节点 `8`。由于 `8` 不小于 `8`(即 `8 < 8` 为 `false`),当前层级向右查找结束。此时,已经遍历完所有层级,`for` 循环结束。
+- **最终定位与检查** :经过所有层级的查找,指针 `p` 最终停留在最底层(0 级索引)的节点 `7`。这个节点是整个跳表中值小于目标值 `8` 的那个最大的节点。检查节点 `7` 的**后继节点**(即 `p.forwards[0]`):`p.forwards[0]` 指向节点 `8`。判断 `p.forwards[0].data`(即节点 `8` 的值)是否等于目标值 `8`。条件满足(`8 == 8`),**查找成功,找到节点 `8`**。
+
+所以我们的代码实现也很上述步骤差不多,从最高级索引开始向前查找,如果不为空且小于要查找的值,则继续向前搜寻,遇到不小于的节点则继续向下,如此往复,直到得到当前跳表中小于查找值的最大节点,查看其前驱是否等于要查找的值:
+
+```java
+public Node get(int value) {
+ Node p = h; // 从头节点开始
+
+ // 从最高层级索引开始,逐层向下
+ for (int i = levelCount - 1; i >= 0; i--) {
+ // 在当前层级向右查找,直到 p.forwards[i] 为 null
+ // 或者 p.forwards[i].data 大于等于目标值 value
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i]; // 向右移动
+ }
+ // 此时 p.forwards[i] 为 null,或者 p.forwards[i].data >= value
+ // 或者 p 是当前层级中小于 value 的最大节点(如果存在这样的节点)
+ }
+
+ // 经过所有层级的查找,p 现在是原始链表(0级索引)中
+ // 小于目标值 value 的最大节点(或者头节点,如果所有元素都大于等于 value)
+
+ // 检查 p 在原始链表中的下一个节点是否是目标值
+ if (p.forwards[0] != null && p.forwards[0].data == value) {
+ return p.forwards[0]; // 找到了,返回该节点
+ }
+
+ return null; // 未找到
+}
+```
+
+### 元素删除
+
+最后是删除逻辑,需要查找各层级小于要删除节点的最大值,假设我们要删除 10:
+
+1. 3 级索引得到小于 10 的最大值为 5,继续向下。
+2. 2 级索引从索引 5 开始查找,发现小于 10 的最大值为 8,继续向下。
+3. 同理 1 级索引得到 8,继续向下。
+4. 原始节点找到 9。
+5. 从最高级索引开始,查看每个小于 10 的节点后继节点是否为 10,如果等于 10,则让这个节点指向 10 的后继节点,将节点 10 及其索引交由 GC 回收。
+
+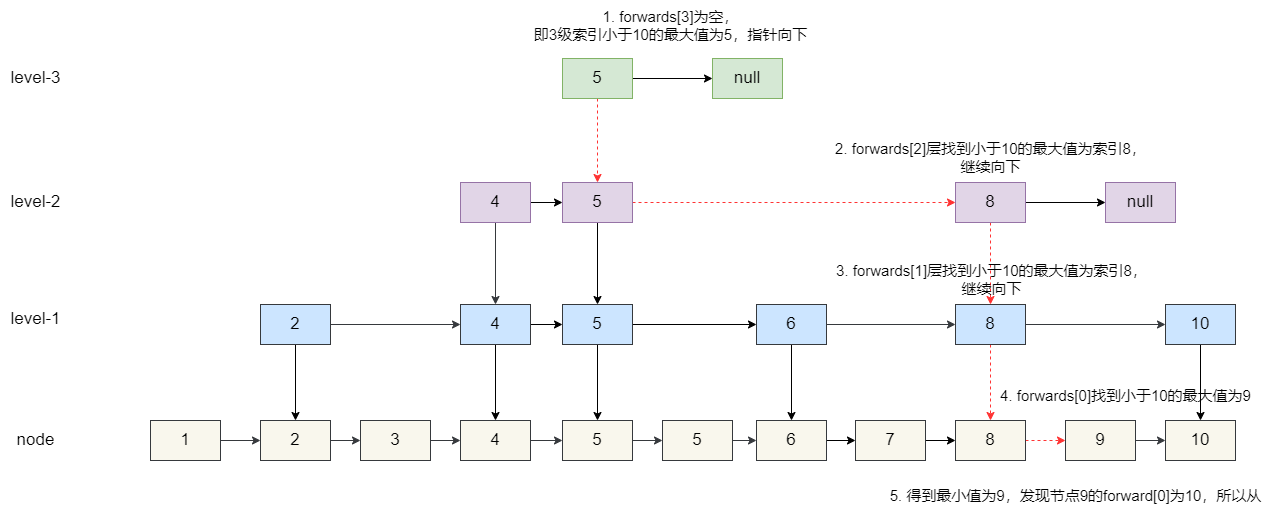
+
+```java
+/**
+ * 删除
+ *
+ * @param value
+ */
+public void delete(int value) {
+ Node p = h;
+ //找到各级节点小于value的最大值
+ Node[] updateArr = new Node[levelCount];
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ updateArr[i] = p;
+ }
+ //查看原始层节点前驱是否等于value,若等于则说明存在要删除的值
+ if (p.forwards[0] != null && p.forwards[0].data == value) {
+ //从最高级索引开始查看其前驱是否等于value,若等于则将当前节点指向value节点的后继节点
+ for (int i = levelCount - 1; i >= 0; i--) {
+ if (updateArr[i].forwards[i] != null && updateArr[i].forwards[i].data == value) {
+ updateArr[i].forwards[i] = updateArr[i].forwards[i].forwards[i];
+ }
+ }
+ }
+
+ //从最高级开始查看是否有一级索引为空,若为空则层级减1
+ while (levelCount > 1 && h.forwards[levelCount - 1] == null) {
+ levelCount--;
+ }
+
+}
+```
+
+### 完整代码以及测试
+
+完整代码如下,读者可自行参阅:
+
+```java
+public class SkipList {
+
+ /**
+ * 跳表索引最大高度为16
+ */
+ private static final int MAX_LEVEL = 16;
+
+ /**
+ * 每个节点添加一层索引高度的概率为二分之一
+ */
+ private static final float PROB = 0.5f;
+
+ /**
+ * 默认情况下的高度为1,即只有自己一个节点
+ */
+ private int levelCount = 1;
+
+ /**
+ * 跳表最底层的节点,即头节点
+ */
+ private Node h = new Node();
+
+ public SkipList() {
+ }
+
+ public class Node {
+
+ private int data = -1;
+ /**
+ *
+ */
+ private Node[] forwards = new Node[MAX_LEVEL];
+ private int maxLevel = 0;
+
+ @Override
+ public String toString() {
+ return "Node{"
+ + "data=" + data
+ + ", maxLevel=" + maxLevel
+ + '}';
+ }
+ }
+
+ public void add(int value) {
+ int level = randomLevel(); // 新节点的随机高度
+
+ Node newNode = new Node();
+ newNode.data = value;
+ newNode.maxLevel = level;
+
+ // 用于记录每层前驱节点的数组
+ Node[] update = new Node[level];
+ for (int i = 0; i < level; i++) {
+ update[i] = h;
+ }
+
+ Node p = h;
+ // 关键修正:从跳表的当前最高层开始查找
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ // 只记录需要更新的层的前驱节点
+ if (i < level) {
+ update[i] = p;
+ }
+ }
+
+ // 插入新节点
+ for (int i = 0; i < level; i++) {
+ newNode.forwards[i] = update[i].forwards[i];
+ update[i].forwards[i] = newNode;
+ }
+
+ // 更新跳表的总高度
+ if (levelCount < level) {
+ levelCount = level;
+ }
+ }
+
+ /**
+ * 理论来讲,一级索引中元素个数应该占原始数据的 50%,二级索引中元素个数占 25%,三级索引12.5% ,一直到最顶层。
+ * 因为这里每一层的晋升概率是 50%。对于每一个新插入的节点,都需要调用 randomLevel 生成一个合理的层数。 该 randomLevel
+ * 方法会随机生成 1~MAX_LEVEL 之间的数,且 : 50%的概率返回 1 25%的概率返回 2 12.5%的概率返回 3 ...
+ *
+ * @return
+ */
+ private int randomLevel() {
+ int level = 1;
+ while (Math.random() > PROB && level < MAX_LEVEL) {
+ ++level;
+ }
+ return level;
+ }
+
+ public Node get(int value) {
+ Node p = h;
+ //找到小于value的最大值
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ }
+ //如果p的前驱节点等于value则直接返回
+ if (p.forwards[0] != null && p.forwards[0].data == value) {
+ return p.forwards[0];
+ }
+
+ return null;
+ }
+
+ /**
+ * 删除
+ *
+ * @param value
+ */
+ public void delete(int value) {
+ Node p = h;
+ //找到各级节点小于value的最大值
+ Node[] updateArr = new Node[levelCount];
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ updateArr[i] = p;
+ }
+ //查看原始层节点前驱是否等于value,若等于则说明存在要删除的值
+ if (p.forwards[0] != null && p.forwards[0].data == value) {
+ //从最高级索引开始查看其前驱是否等于value,若等于则将当前节点指向value节点的后继节点
+ for (int i = levelCount - 1; i >= 0; i--) {
+ if (updateArr[i].forwards[i] != null && updateArr[i].forwards[i].data == value) {
+ updateArr[i].forwards[i] = updateArr[i].forwards[i].forwards[i];
+ }
+ }
+ }
+
+ //从最高级开始查看是否有一级索引为空,若为空则层级减1
+ while (levelCount > 1 && h.forwards[levelCount - 1] == null) {
+ levelCount--;
+ }
+
+ }
+
+ public void printAll() {
+ Node p = h;
+ //基于最底层的非索引层进行遍历,只要后继节点不为空,则速速出当前节点,并移动到后继节点
+ while (p.forwards[0] != null) {
+ System.out.println(p.forwards[0]);
+ p = p.forwards[0];
+ }
+
+ }
+}
+
+```
+
+测试代码:
+
+```java
+public static void main(String[] args) {
+ SkipList skipList = new SkipList();
+ for (int i = 0; i < 24; i++) {
+ skipList.add(i);
+ }
+
+ System.out.println("**********输出添加结果**********");
+ skipList.printAll();
+
+ SkipList.Node node = skipList.get(22);
+ System.out.println("**********查询结果:" + node+" **********");
+
+ skipList.delete(22);
+ System.out.println("**********删除结果**********");
+ skipList.printAll();
+
+
+ }
+```
+
+**Redis 跳表的特点**:
+
+1. 采用**双向链表**,不同于上面的示例,存在一个回退指针。主要用于简化操作,例如删除某个元素时,还需要找到该元素的前驱节点,使用回退指针会非常方便。
+2. `score` 值可以重复,如果 `score` 值一样,则按照 ele(节点存储的值,为 sds)字典排序
+3. Redis 跳跃表默认允许最大的层数是 32,被源码中 `ZSKIPLIST_MAXLEVEL` 定义。
+
+## 和其余三种数据结构的比较
+
+最后,我们再来回答一下文章开头的那道面试题: “Redis 的有序集合底层为什么要用跳表,而不用平衡树、红黑树或者 B+树?”。
+
+### 平衡树 vs 跳表
+
+先来说说它和平衡树的比较,平衡树我们又会称之为 **AVL 树**,是一个严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过 1,即平衡因子为范围为 `[-1,1]`)。平衡树的插入、删除和查询的时间复杂度和跳表一样都是 **O(log n)** 。
+
+对于范围查询来说,它也可以通过中序遍历的方式达到和跳表一样的效果。但是它的每一次插入或者删除操作都需要保证整颗树左右节点的绝对平衡,只要不平衡就要通过旋转操作来保持平衡,这个过程是比较耗时的。
+
+
+
+跳表诞生的初衷就是为了克服平衡树的一些缺点,跳表的发明者在论文[《Skip lists: a probabilistic alternative to balanced trees》](https://15721.courses.cs.cmu.edu/spring2018/papers/08-oltpindexes1/pugh-skiplists-cacm1990.pdf)中有详细提到:
+
+
+
+> Skip lists are a data structure that can be used in place of balanced trees. Skip lists use probabilistic balancing rather than strictly enforced balancing and as a result the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.
+>
+> 跳表是一种可以用来代替平衡树的数据结构。跳表使用概率平衡而不是严格强制的平衡,因此,跳表中的插入和删除算法比平衡树的等效算法简单得多,速度也快得多。
+
+笔者这里也贴出了 AVL 树插入操作的核心代码,可以看出每一次添加操作都需要进行一次递归定位插入位置,然后还需要根据回溯到根节点检查沿途的各层节点是否失衡,再通过旋转节点的方式进行调整。
+
+```java
+// 向二分搜索树中添加新的元素(key, value)
+public void add(K key, V value) {
+ root = add(root, key, value);
+}
+
+// 向以node为根的二分搜索树中插入元素(key, value),递归算法
+// 返回插入新节点后二分搜索树的根
+private Node add(Node node, K key, V value) {
+
+ if (node == null) {
+ size++;
+ return new Node(key, value);
+ }
+
+ if (key.compareTo(node.key) < 0)
+ node.left = add(node.left, key, value);
+ else if (key.compareTo(node.key) > 0)
+ node.right = add(node.right, key, value);
+ else // key.compareTo(node.key) == 0
+ node.value = value;
+
+ node.height = 1 + Math.max(getHeight(node.left), getHeight(node.right));
+
+ int balanceFactor = getBalanceFactor(node);
+
+ // LL型需要右旋
+ if (balanceFactor > 1 && getBalanceFactor(node.left) >= 0) {
+ return rightRotate(node);
+ }
+
+ //RR型失衡需要左旋
+ if (balanceFactor < -1 && getBalanceFactor(node.right) <= 0) {
+ return leftRotate(node);
+ }
+
+ //LR需要先左旋成LL型,然后再右旋
+ if (balanceFactor > 1 && getBalanceFactor(node.left) < 0) {
+ node.left = leftRotate(node.left);
+ return rightRotate(node);
+ }
+
+ //RL
+ if (balanceFactor < -1 && getBalanceFactor(node.right) > 0) {
+ node.right = rightRotate(node.right);
+ return leftRotate(node);
+ }
+ return node;
+}
+```
+
+### 红黑树 vs 跳表
+
+红黑树(Red Black Tree)也是一种自平衡二叉查找树,它的查询性能略微逊色于 AVL 树,但插入和删除效率更高。红黑树的插入、删除和查询的时间复杂度和跳表一样都是 **O(log n)** 。
+
+红黑树是一个**黑平衡树**,即从任意节点到另外一个叶子叶子节点,它所经过的黑节点是一样的。当对它进行插入操作时,需要通过旋转和染色(红黑变换)来保证黑平衡。不过,相较于 AVL 树为了维持平衡的开销要小一些。关于红黑树的详细介绍,可以查看这篇文章:[红黑树](https://javaguide.cn/cs-basics/data-structure/red-black-tree.html)。
+
+相比较于红黑树来说,跳表的实现也更简单一些。并且,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
+
+
+
+对应红黑树添加的核心代码如下,读者可自行参阅理解:
+
+```java
+private Node < K, V > add(Node < K, V > node, K key, V val) {
+
+ if (node == null) {
+ size++;
+ return new Node(key, val);
+
+ }
+
+ if (key.compareTo(node.key) < 0) {
+ node.left = add(node.left, key, val);
+ } else if (key.compareTo(node.key) > 0) {
+ node.right = add(node.right, key, val);
+ } else {
+ node.val = val;
+ }
+
+ //左节点不为红,右节点为红,左旋
+ if (isRed(node.right) && !isRed(node.left)) {
+ node = leftRotate(node);
+ }
+
+ //左链右旋
+ if (isRed(node.left) && isRed(node.left.left)) {
+ node = rightRotate(node);
+ }
+
+ //颜色翻转
+ if (isRed(node.left) && isRed(node.right)) {
+ flipColors(node);
+ }
+
+ return node;
+}
+```
+
+### B+树 vs 跳表
+
+想必使用 MySQL 的读者都知道 B+树这个数据结构,B+树是一种常用的数据结构,具有以下特点:
+
+1. **多叉树结构**:它是一棵多叉树,每个节点可以包含多个子节点,减小了树的高度,查询效率高。
+2. **存储效率高**:其中非叶子节点存储多个 key,叶子节点存储 value,使得每个节点更够存储更多的键,根据索引进行范围查询时查询效率更高。-
+3. **平衡性**:它是绝对的平衡,即树的各个分支高度相差不大,确保查询和插入时间复杂度为 **O(log n)** 。
+4. **顺序访问**:叶子节点间通过链表指针相连,范围查询表现出色。
+5. **数据均匀分布**:B+树插入时可能会导致数据重新分布,使得数据在整棵树分布更加均匀,保证范围查询和删除效率。
+
+
+
+所以,B+树更适合作为数据库和文件系统中常用的索引结构之一,它的核心思想是通过可能少的 IO 定位到尽可能多的索引来获得查询数据。对于 Redis 这种内存数据库来说,它对这些并不感冒,因为 Redis 作为内存数据库它不可能存储大量的数据,所以对于索引不需要通过 B+树这种方式进行维护,只需按照概率进行随机维护即可,节约内存。而且使用跳表实现 zset 时相较前者来说更简单一些,在进行插入时只需通过索引将数据插入到链表中合适的位置再随机维护一定高度的索引即可,也不需要像 B+树那样插入时发现失衡时还需要对节点分裂与合并。
+
+### Redis 作者给出的理由
+
+当然我们也可以通过 Redis 的作者自己给出的理由:
+
+> There are a few reasons:
+> 1、They are not very memory intensive. It's up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
+> 2、A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
+> 3、They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
+
+翻译过来的意思就是:
+
+> 有几个原因:
+>
+> 1、它们不是很占用内存。这主要取决于你。改变节点拥有给定层数的概率的参数,会使它们比 B 树更节省内存。
+>
+> 2、有序集合经常是许多 ZRANGE 或 ZREVRANGE 操作的目标,也就是说,以链表的方式遍历跳表。通过这种操作,跳表的缓存局部性至少和其他类型的平衡树一样好。
+>
+> 3、它们更容易实现、调试等等。例如,由于跳表的简单性,我收到了一个补丁(已经在 Redis 主分支中),用增强的跳表实现了 O(log(N))的 ZRANK。它只需要对代码做很少的修改。
+
+## 小结
+
+本文通过大量篇幅介绍跳表的工作原理和实现,帮助读者更进一步的熟悉跳表这一数据结构的优劣,最后再结合各个数据结构操作的特点进行比对,从而帮助读者更好的理解这道面试题,建议读者实现理解跳表时,尽可能配合执笔模拟来了解跳表的增删改查详细过程。
+
+## 参考
+
+- 为啥 redis 使用跳表(skiplist)而不是使用 red-black?:
+- Skip List--跳表(全网最详细的跳表文章没有之一):
+- Redis 对象与底层数据结构详解:
+- Redis 有序集合(sorted set):
+- 红黑树和跳表比较:
+- 为什么 redis 的 zset 用跳跃表而不用 b+ tree?:
diff --git a/docs/database/redis/redis-stream-mq.md b/docs/database/redis/redis-stream-mq.md
new file mode 100644
index 00000000000..2ba128e0f6d
--- /dev/null
+++ b/docs/database/redis/redis-stream-mq.md
@@ -0,0 +1,223 @@
+---
+title: Redis 能做消息队列吗?怎么实现?
+description: 讲解 Redis 做消息队列的三种方式:List、Pub/Sub、Stream。对比生产级 MQ 核心能力,详解 Redis 5.0 Stream 的消费者组、ACK 机制及与 Kafka/RabbitMQ 的适用场景对比。
+category: 数据库
+tag:
+ - Redis
+ - 消息队列
+head:
+ - - meta
+ - name: keywords
+ content: Redis消息队列,Redis Stream,Redis List,Redis Pub/Sub,消息队列,消费者组,ACK机制,XREADGROUP,XADD,XACK
+---
+
+先说结论:**可以是可以,但要看具体场景。和专业的消息队列(如 Kafka、RabbitMQ)相比,还是有一些欠缺的地方。**
+
+正式开始介绍之前,我们先来看看:**一个生产级 MQ 需要具备哪些核心能力?**
+
+| 能力维度 | 定义 | 关键指标/特征 |
+| :--------------- | :------------------------------ | :---------------------------------- |
+| **持久化** | 消息写入后不因进程/节点故障丢失 | 同步刷盘/多副本确认、RPO ≈ 0 |
+| **至少一次投递** | 消息最终被消费,允许重复 | 需配合消费者幂等性 |
+| **消费确认** | 消费者显式告知处理成功 | ACK 机制、超时重试、死信队列 |
+| **消息重试** | 消费失败可自动重新投递 | 退避策略、最大重试次数、死信转移 |
+| **消费者组** | 多消费者协作消费,故障自动转移 | 组内负载均衡、分区分配、Rebalance |
+| **消息堆积能力** | 生产速率 > 消费速率时的缓冲能力 | 磁盘存储、TTL、堆积告警 |
+| **顺序保证** | 消息按发送顺序被消费 | 分区有序/全局有序、乱序惩罚 |
+| **可扩展性** | 水平扩展以提升吞吐或容灾 | 分片机制、无状态 Broker、动态扩缩容 |
+
+Redis 提供了多种实现 MQ 的方式,从早期的 `List` 到 `Pub/Sub`,再到 Redis 5.0 新增的 `Stream` 数据结构(基于有序链表实现,支持消费者组和 ACK 机制,可用于构建轻量级消息队列)。
+
+### 第一阶段:早期用 List 数据结构
+
+**Redis 2.0 之前,如果想要使用 Redis 来做消息队列的话,只能通过 List 来实现。**
+
+通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP` 即可实现简易版消息队列:
+
+```bash
+# 生产者生产消息
+> RPUSH myList msg1 msg2
+(integer) 2
+> RPUSH myList msg3
+(integer) 3
+# 消费者消费消息
+> LPOP myList
+"msg1"
+```
+
+不过,通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP` 这样的方式存在性能问题,我们需要不断轮询去调用 `RPOP` 或 `LPOP` 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
+
+因此,Redis 还提供了 `BLPOP`、`BRPOP` 这种阻塞式读取的命令(带 B-Blocking 的都是阻塞式),并且还支持一个超时参数。如果 List 为空,Redis 服务端不会立刻返回结果,它会等待 List 中有新数据后再返回或者是等待最多一个超时时间后返回空。如果将超时时间设置为 0 时,即可无限等待,直到弹出消息
+
+```bash
+# 超时时间为 10s
+# 如果有数据立刻返回,否则最多等待10秒
+> BRPOP myList 10
+null
+```
+
+List 实现消息队列功能太简单,像消息确认机制等功能还需要我们自己实现。**最致命的是,它不支持一个消息被多个消费者消费(广播),而且消息一旦被取出,就没有了,如果消费者处理失败,消息就永久丢失了。**
+
+### 第二阶段:引入 Pub/Sub(发布/订阅)模式
+
+**Redis 2.0 引入了发布订阅 (Pub/Sub) 功能,解决了 List 实现消息队列没有广播机制的问题。**
+
+
+
+Pub/Sub 中引入了一个概念叫 **Channel(频道)**,发布订阅机制的实现就是基于这个 Channel 来做的。
+
+Pub/Sub 涉及发布者(Publisher)和订阅者(Subscriber,也叫消费者)两个角色:
+
+- 发布者通过 `PUBLISH` 投递消息给指定 Channel。
+- 订阅者通过`SUBSCRIBE`订阅它关心的 Channel。并且,订阅者可以订阅一个或者多个 Channel。
+
+也就是说,多个消费者可以订阅同一个 Channel,生产者向这个 Channel 发布消息,所有订阅者都能收到。
+
+我们这里启动 3 个 Redis 客户端来简单演示一下:
+
+
+
+Pub/Sub 既能单播又能广播,还支持 Channel 的简单正则匹配。
+
+Pub/Sub 有一个致命的缺陷:**它发后即忘,完全没有持久化和可靠性保证**。 如果消息发布时,某个消费者不在线,或者网络抖动了一下,那这条消息对它来说就永远丢失了。此外,它也**没有 ACK 机制**,无法知道消费者是否成功处理,更别提**消息堆积**的问题了。所以,Pub/Sub 只适合做一些对可靠性要求极低的实时通知,绝对不能用于任何严肃的业务消息队列。
+
+### 第三阶段:Redis 5.0 新增 Stream
+
+Redis 5.0 新增了 `Stream` 数据结构。这是一个基于 Radix Tree(基数树)实现的有序消息日志,天然支持消费者组和 ACK 机制,可用于构建轻量级消息队列。
+
+**为什么要用 Radix Tree?** 很多人好奇,为什么不继续用 `List/LinkedList`?
+
+1. **内存极度压缩**:`Stream` 的消息 ID(如 `1625000000000-0`)是高度有序且前缀高度重合的。Radix Tree 是一种压缩前缀树,它会将具有相同前缀的节点合并。而 List/LinkedList
+ 每个元素都要完整的链表节点开销,并且无法利用 ID 的前缀重复特性来节省空间。
+2. **高效检索**:在处理数百万级消息堆积时,Radix Tree 能保持极高的查询效率,这也是 `Stream` 能支持大数据量范围查询(`XRANGE`)的底层底气。相比之下,`List/LinkedList`只能从头尾操作,无法高效按 ID 范围查询,执行 `XRANGE` 需要遍历整个列表。
+
+它借鉴了 Kafka 等专业 MQ 的核心概念:
+
+1. **消费者组(Consumer Groups)**:实现消息在多个消费者间的负载均衡,支持故障自动转移。
+2. **持久化**:可以通过 RDB 和 AOF 保证消息在 Redis 重启后不丢失(取决于 `appendfsync` 配置,`everysec` 模式下通常最多丢失 1 秒数据)。
+3. **ACK 机制**:消费者处理完消息后,需要手动 `XACK` 确认,否则消息会保留在 `Pending List` 中。这保证了消息至少被成功消费一次。
+4. **消息回溯与转移**:支持 `XRANGE` 按时间范围回溯消息,以及 `XCLAIM` 将挂起的消息转移到其他消费者处理。
+
+> 🌈 版本演进:
+>
+> - Redis 8.2:`XACKDEL`、`XDELEX`、`XADD` 和 `XTRIM 命令提供了对流操作如何与多个消费者组交互的细粒度控制,简化了跨不同应用程序的消息处理协调。
+> - Redis 8.6:支持幂等消息处理(最多一次生产),防止在使用至少一次交付模式时出现重复条目。此功能可实现可靠的消息提交,并自动去重。
+
+`Stream` 的结构如下:
+
+
+
+这是一个有序的消息链表,每个消息都有一个唯一的 ID 和对应的内容。ID 是一个时间戳和序列号的组合,用来保证消息的唯一性和递增性。内容是一个或多个键值对(类似 Hash 基本数据类型),用来存储消息的数据。
+
+这里再对图中涉及到的一些概念,进行简单解释:
+
+- `Consumer Group`:消费者组用于组织和管理多个消费者。消费者组本身不处理消息,而是再将消息分发给消费者,由消费者进行真正的消费。
+- `last_delivered_id`:标识消费者组当前消费位置的游标,消费者组中任意一个消费者读取了消息都会使 last_delivered_id 往前移动。
+- `pending_ids`:记录已经被客户端消费但没有 ack 的消息的 ID。
+
+下面是`Stream` 用作消息队列时常用的命令:
+
+- `XADD`:向流中添加新的消息。
+- `XREAD`:从流中读取消息。
+- `XREADGROUP`:从消费组中读取消息。
+- `XRANGE`:根据消息 ID 范围读取流中的消息。
+- `XREVRANGE`:与 `XRANGE` 类似,但以相反顺序返回结果。
+- `XDEL`:从流中删除消息。
+- `XTRIM`:修剪流的长度,可以指定修建策略(`MAXLEN`/`MINID`)。
+- `XLEN`:获取流的长度。
+- `XGROUP CREATE`:创建消费者组。
+- `XGROUP DESTROY`:删除消费者组。
+- `XGROUP DELCONSUMER`:从消费者组中删除一个消费者。
+- `XGROUP SETID`:为消费者组设置新的最后递送消息 ID。
+- `XACK`:确认消费组中的消息已被处理。
+- `XPENDING`:查询消费组中挂起(未确认)的消息。
+- `XCLAIM`:将挂起的消息从一个消费者转移到另一个消费者。
+- `XINFO`:获取流(`XINFO STREAM`)、消费组(`XINFO GROUPS`)或消费者(`XINFO CONSUMERS`)的详细信息。
+
+下面这张时序图展示了 Stream 消费者组消息流转与 ACK 机制:
+
+```mermaid
+sequenceDiagram
+ participant P as Producer
+ participant R as Redis Stream
-每种方式都有各自的优势,根据实际场景才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
+每种方式都有各自的优势,根据实际场景选择最合适的才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
+
+| 类型 | 存储空间 | 日期格式 | 日期范围 | 是否带时区信息 |
+| ------------ | -------- | ------------------------------ | ------------------------------------------------------------ | -------------- |
+| DATETIME | 5~8 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1000-01-01 00:00:00[.000000] ~ 9999-12-31 23:59:59[.999999] | 否 |
+| TIMESTAMP | 4~7 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1970-01-01 00:00:01[.000000] ~ 2038-01-19 03:14:07[.999999] | 是 |
+| 数值型时间戳 | 4 字节 | 全数字如 1578707612 | 1970-01-01 00:00:01 之后的时间 | 否 |
+
+**选择建议小结:**
+
+- `TIMESTAMP` 的核心优势在于其内建的时区处理能力。数据库负责 UTC 存储和基于会话时区的自动转换,简化了需要处理多时区应用的开发。如果应用需要处理多时区,或者希望数据库能自动管理时区转换,`TIMESTAMP` 是自然的选择(注意其时间范围限制,也就是 2038 年问题)。
+- 如果应用场景不涉及时区转换,或者希望应用程序完全控制时区逻辑,并且需要表示 2038 年之后的时间,`DATETIME` 是更稳妥的选择。
+- 如果极度关注比较性能,或者需要频繁跨系统传递时间数据,并且可以接受可读性的牺牲(或总是在应用层转换),数值时间戳是一个强大的选项。
-
+
diff --git a/docs/database/mysql/transaction-isolation-level.md b/docs/database/mysql/transaction-isolation-level.md
index 647b80ee6eb..4ee2cabc95a 100644
--- a/docs/database/mysql/transaction-isolation-level.md
+++ b/docs/database/mysql/transaction-isolation-level.md
@@ -1,8 +1,13 @@
---
title: MySQL事务隔离级别详解
+description: 详解MySQL四种事务隔离级别(读未提交、读已提交、可重复读、串行化)的特点与区别,分析脏读、不可重复读、幻读等并发问题,以及InnoDB如何通过MVCC和锁机制解决幻读。
category: 数据库
tag:
- MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL事务隔离级别,读未提交,读已提交,可重复读,串行化,脏读,不可重复读,幻读,MVCC,间隙锁
---
> 本文由 [SnailClimb](https://github.com/Snailclimb) 和 [guang19](https://github.com/guang19) 共同完成。
@@ -11,43 +16,46 @@ tag:
## 事务隔离级别总结
-SQL 标准定义了四个隔离级别:
+SQL 标准定义了四种事务隔离级别,用来平衡事务的隔离性(Isolation)和并发性能。级别越高,数据一致性越好,但并发性能可能越低。这四个级别是:
-- **READ-UNCOMMITTED(读取未提交)**:最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
-- **READ-COMMITTED(读取已提交)**:允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
-- **REPEATABLE-READ(可重复读)**:对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
-- **SERIALIZABLE(可串行化)**:最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
+- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。这种级别在实际应用中很少使用,因为它对数据一致性的保证太弱。
+- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。这是大多数数据库(如 Oracle, SQL Server)的默认隔离级别。
+- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。MySQL InnoDB 存储引擎的默认隔离级别正是 REPEATABLE READ。并且,InnoDB 在此级别下通过 MVCC(多版本并发控制) 和 Next-Key Locks(间隙锁+行锁) 机制,在很大程度上解决了幻读问题。
+- **SERIALIZABLE(可串行化)** :最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
----
+| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (Non-Repeatable Read) | 幻读 (Phantom Read) |
+| ---------------- | ----------------- | -------------------------------- | ---------------------- |
+| READ UNCOMMITTED | √ | √ | √ |
+| READ COMMITTED | × | √ | √ |
+| REPEATABLE READ | × | × | √ (标准) / ≈× (InnoDB) |
+| SERIALIZABLE | × | × | × |
-| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
-| :--------------: | :--: | :--------: | :--: |
-| READ-UNCOMMITTED | √ | √ | √ |
-| READ-COMMITTED | × | √ | √ |
-| REPEATABLE-READ | × | × | √ |
-| SERIALIZABLE | × | × | × |
+**默认级别查询:**
-MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
+MySQL InnoDB 存储引擎的默认隔离级别是 **REPEATABLE READ**。可以通过以下命令查看:
-```sql
-MySQL> SELECT @@tx_isolation;
-+-----------------+
-| @@tx_isolation |
-+-----------------+
-| REPEATABLE-READ |
-+-----------------+
+- MySQL 8.0 之前:`SELECT @@tx_isolation;`
+- MySQL 8.0 及之后:`SELECT @@transaction_isolation;`
+
+```bash
+mysql> SELECT @@transaction_isolation;
++-------------------------+
+| @@transaction_isolation |
++-------------------------+
+| REPEATABLE-READ |
++-------------------------+
```
-从上面对 SQL 标准定义了四个隔离级别的介绍可以看出,标准的 SQL 隔离级别定义里,REPEATABLE-READ(可重复读)是不可以防止幻读的。
+**InnoDB 的 REPEATABLE READ 对幻读的处理:**
-但是!InnoDB 实现的 REPEATABLE-READ 隔离级别其实是可以解决幻读问题发生的,主要有下面两种情况:
+标准的 SQL 隔离级别定义里,REPEATABLE READ 是无法防止幻读的。但 InnoDB 的实现通过以下机制很大程度上避免了幻读:
-- **快照读**:由 MVCC 机制来保证不出现幻读。
-- **当前读**:使用 Next-Key Lock 进行加锁来保证不出现幻读,Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的结合,行锁只能锁住已经存在的行,为了避免插入新行,需要依赖间隙锁。
+- **快照读 (Snapshot Read)**:普通的 SELECT 语句,通过 **MVCC** 机制实现。事务启动时创建一个数据快照,后续的快照读都读取这个版本的数据,从而避免了看到其他事务新插入的行(幻读)或修改的行(不可重复读)。
+- **当前读 (Current Read)**:像 `SELECT ... FOR UPDATE`, `SELECT ... LOCK IN SHARE MODE`, `INSERT`, `UPDATE`, `DELETE` 这些操作。InnoDB 使用 **Next-Key Lock** 来锁定扫描到的索引记录及其间的范围(间隙),防止其他事务在这个范围内插入新的记录,从而避免幻读。Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的组合。
-因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED** ,但是你要知道的是 InnoDB 存储引擎默认使用 **REPEATABLE-READ** 并不会有任何性能损失。
+值得注意的是,虽然通常认为隔离级别越高、并发性越差,但 InnoDB 存储引擎通过 MVCC 机制优化了 REPEATABLE READ 级别。对于许多常见的只读或读多写少的场景,其性能**与 READ COMMITTED 相比可能没有显著差异**。不过,在写密集型且并发冲突较高的场景下,RR 的间隙锁机制可能会比 RC 带来更多的锁等待。
-InnoDB 存储引擎在分布式事务的情况下一般会用到 SERIALIZABLE 隔离级别。
+此外,在某些特定场景下,如需要严格一致性的分布式事务(XA Transactions),InnoDB 可能要求或推荐使用 SERIALIZABLE 隔离级别来确保全局数据的一致性。
《MySQL 技术内幕:InnoDB 存储引擎(第 2 版)》7.7 章这样写到:
@@ -111,3 +119,5 @@ SQL 脚本 1 在第一次查询工资为 500 的记录时只有一条,SQL 脚
-
- [Mysql 锁:灵魂七拷问](https://tech.youzan.com/seven-questions-about-the-lock-of-MySQL/)
- [Innodb 中的事务隔离级别和锁的关系](https://tech.meituan.com/2014/08/20/innodb-lock.html)
+
+
diff --git a/docs/database/nosql.md b/docs/database/nosql.md
index fd70056fd2c..3a7e7929057 100644
--- a/docs/database/nosql.md
+++ b/docs/database/nosql.md
@@ -1,10 +1,15 @@
---
title: NoSQL基础知识总结
+description: NoSQL数据库基础知识总结,包括NoSQL与SQL的区别、NoSQL的优势、四种NoSQL数据库类型(键值、文档、图形、宽列)及其代表产品Redis、MongoDB、Neo4j等的应用场景。
category: 数据库
tag:
- NoSQL
- MongoDB
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: NoSQL,Redis,MongoDB,HBase,Cassandra,键值数据库,文档数据库,图数据库,宽列存储,SQL与NoSQL区别
---
## NoSQL 是什么?
@@ -57,3 +62,5 @@ NoSQL 数据库主要可以分为下面四种类型:
- NoSQL 是什么?- MongoDB 官方文档:
- 什么是 NoSQL? - AWS:
- NoSQL vs. SQL Databases - MongoDB 官方文档:
+
+
diff --git a/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md b/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md
index 91427109697..be12e83c288 100644
--- a/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md
+++ b/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md
@@ -1,13 +1,18 @@
---
title: 3种常用的缓存读写策略详解
+description: 深入对比 Cache Aside、Read/Write Through、Write Behind 三种缓存读写策略,附详细时序图、一致性问题分析及生产级解决方案,Redis 实战必备!
category: 数据库
tag:
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: 缓存读写策略,Cache Aside,Read Through,Write Through,Write Behind,Write Back,缓存一致性,缓存失效,旁路缓存,读写穿透,异步缓存写入,Redis缓存策略,缓存更新策略
---
看到很多小伙伴简历上写了“**熟练使用缓存**”,但是被我问到“**缓存常用的 3 种读写策略**”的时候却一脸懵逼。
-在我看来,造成这个问题的原因是我们在学习 Redis 的时候,可能只是简单了写一些 Demo,并没有去关注缓存的读写策略,或者说压根不知道这回事。
+在我看来,造成这个问题的原因是我们在学习 Redis 的时候,可能只是简单写了一些 Demo,并没有去关注缓存的读写策略,或者说压根不知道这回事。
但是,搞懂 3 种常见的缓存读写策略对于实际工作中使用缓存以及面试中被问到缓存都是非常有帮助的!
@@ -15,26 +20,28 @@ tag:
### Cache Aside Pattern(旁路缓存模式)
-**Cache Aside Pattern 是我们平时使用比较多的一个缓存读写模式,比较适合读请求比较多的场景。**
+这是我们日常开发中**最常用、最经典**的一种模式,几乎是互联网应用缓存方案的事实标准,尤其适合**读多写少**的业务场景。
-Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 db 的结果为准。
+这个模式之所以被称为**“旁路”(Aside)**,是因为应用程序的**写操作完全绕过了缓存,直接操作数据库**。
+
+应用程序扮演了数据流转的“指挥官”,需要同时维护 Cache 和 DB 两个数据源。
下面我们来看一下这个策略模式下的缓存读写步骤。
-**写**:
+**写操作 :**
-- 先更新 db
-- 然后直接删除 cache 。
+1. 应用**先更新 DB**。
+2. 然后**直接删除 Cache**中对应的数据。
简单画了一张图帮助大家理解写的步骤。

-**读** :
+**读操作:**
-- 从 cache 中读取数据,读取到就直接返回
-- cache 中读取不到的话,就从 db 中读取数据返回
-- 再把数据放到 cache 中。
+1. 应用先从 Cache 读取数据。
+2. 如果命中(Hit),则直接返回。
+3. 如果未命中(Miss),则从 DB 读取数据,成功读取后,**将数据写回 Cache**,然后返回。
简单画了一张图帮助大家理解读的步骤。
@@ -42,49 +49,69 @@ Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 d
你仅仅了解了上面这些内容的话是远远不够的,我们还要搞懂其中的原理。
-比如说面试官很可能会追问:“**在写数据的过程中,可以先删除 cache ,后更新 db 么?**”
+比如说面试官很可能会追问:
+
+1. 为什么写操作是“先更新 DB,后删除 Cache”?顺序能反过来吗?
+2. 那“先更新 DB,后删除 Cache”就绝对安全吗?
+3. 为什么是“删除 Cache”,而不是“更新 Cache”?
-**答案:** 那肯定是不行的!因为这样可能会造成 **数据库(db)和缓存(Cache)数据不一致**的问题。
+接下来我会以此分析解答这些问题。
-举例:请求 1 先写数据 A,请求 2 随后读数据 A 的话,就很有可能产生数据不一致性的问题。
+**1. 为什么写操作是“先更新 DB,后删除 Cache”?顺序能反过来吗?**
-这个过程可以简单描述为:
+**答:** 绝对不能。如果“先删 Cache,后更新 DB”,在高并发下会引入经典的数据不一致问题。
-> 请求 1 先把 cache 中的 A 数据删除 -> 请求 2 从 db 中读取数据->请求 1 再把 db 中的 A 数据更新
+- **时序分析 (请求 A 写, 请求 B 读):**
+ 1. 请求 A: 先将 Cache 中的数据删除。
+ 2. 请求 B: 此时发现 Cache 为空,于是去 DB 读取**旧值**,并准备写入 Cache。
+ 3. 请求 A : 将**新值**写入 DB。
+ 4. 请求 B: 将之前读到的**旧值**写入了 Cache。
+- **结果:** DB 中是新值,而 Cache 中是旧值,数据不一致。
-当你这样回答之后,面试官可能会紧接着就追问:“**在写数据的过程中,先更新 db,后删除 cache 就没有问题了么?**”
+**2. 那“先更新 DB,后删除 Cache”就绝对安全吗?**
-**答案:** 理论上来说还是可能会出现数据不一致性的问题,不过概率非常小,因为缓存的写入速度是比数据库的写入速度快很多。
+**答案:** 也不是绝对安全的!因为这样也可能会造成 **数据库和缓存数据不一致**的问题。
-举例:请求 1 先读数据 A,请求 2 随后写数据 A,并且数据 A 在请求 1 请求之前不在缓存中的话,也有可能产生数据不一致性的问题。
+- **时序分析 (请求 A 读, 请求 B 写):**
+ 1. 请求 A : 缓存未命中,从 DB 读取到**旧值**。
+ 2. 请求 B: 迅速完成了 DB 的更新,并将 Cache 删除。
+ 3. 请求 A : 将自己之前拿到的**旧值**写入了 Cache。
+- **结果:** DB 中是新值,Cache 中又是旧值。
+- **为什么概率极小?** 这个问题本质上是一个并发时序问题:只要“读 DB → 写 Cache”这段时间窗口内,恰好有写请求完成了 DB 更新,就有可能产生不一致。在大多数业务里,这个窗口时间相对较短,而且还需要与写请求并发“撞车”,所以发生概率不算高,但绝不是不可能。
-这个过程可以简单描述为:
+**3. 为什么是“删除 Cache”,而不是“更新 Cache”?**
-> 请求 1 从 db 读数据 A-> 请求 2 更新 db 中的数据 A(此时缓存中无数据 A ,故不用执行删除缓存操作 ) -> 请求 1 将数据 A 写入 cache
+- **性能开销:** 写操作往往只更新了对象的部分字段,如果为了“更新 Cache”而去重新查询或计算整个缓存对象,开销可能很大。相比之下,“删除”是一个轻量级操作。
+- **懒加载思想:** “删除”操作遵循懒加载原则。只有当数据下一次被真正需要(被读取)时,才触发从 DB 加载并写入缓存,避免了无效的缓存更新。
+- **并发安全:** “更新缓存”在高并发下可能出现更新顺序错乱的问题导致脏数据的概率会更大。
+
+当然,这一切都建立在一个重要的前提之上:我们缓存的数据,是可以通过数据库进行确定性重建的,并且业务上可以容忍从‘缓存删除’到‘下一次读取并回填’之间这个极短时间窗口内的数据不一致。
现在我们再来分析一下 **Cache Aside Pattern 的缺陷**。
-**缺陷 1:首次请求数据一定不在 cache 的问题**
+**缺陷 1:首次请求数据一定不在 Cache 的问题**
-解决办法:可以将热点数据可以提前放入 cache 中。
+解决办法:对于访问量巨大的热点数据,可以在系统启动或低峰期进行缓存预热。
-**缺陷 2:写操作比较频繁的话导致 cache 中的数据会被频繁被删除,这样会影响缓存命中率 。**
+**缺陷 2:写操作比较频繁的话导致 Cache 中的数据会被频繁被删除,这样会影响缓存命中率 。**
解决办法:
-- 数据库和缓存数据强一致场景:更新 db 的时候同样更新 cache,不过我们需要加一个锁/分布式锁来保证更新 cache 的时候不存在线程安全问题。
-- 可以短暂地允许数据库和缓存数据不一致的场景:更新 db 的时候同样更新 cache,但是给缓存加一个比较短的过期时间,这样的话就可以保证即使数据不一致的话影响也比较小。
+- 数据库和缓存数据强一致场景:更新 DB 的时候同样更新 Cache,不过我们需要加一个锁/分布式锁来保证更新 Cache 的时候不存在线程安全问题。
+- 可以短暂地允许数据库和缓存数据不一致的场景:更新 DB 的时候同样更新 Cache,但是给缓存加一个比较短的过期时间(如 1 分钟),这样的话就可以保证即使数据不一致的话影响也比较小。
### Read/Write Through Pattern(读写穿透)
-Read/Write Through Pattern 中服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务负责将此数据读取和写入 db,从而减轻了应用程序的职责。
+在这种模式下,应用程序将**Cache 视为唯一的、主要的存储**。所有的读写请求都直接打向 Cache,而 Cache 服务自身负责与 DB 进行数据同步。
+
+对应用程序**透明**,应用开发者无需关心 DB 的存在。
-这种缓存读写策略小伙伴们应该也发现了在平时在开发过程中非常少见。抛去性能方面的影响,大概率是因为我们经常使用的分布式缓存 Redis 并没有提供 cache 将数据写入 db 的功能。
+这种缓存读写策略小伙伴们应该也发现了在平时在开发过程中非常少见。抛去性能方面的影响,大概率是因为我们经常使用的分布式缓存 Redis 本身并没有提供 Cache 将数据写入 DB 的功能,需要我们在业务侧或中间件里自己实现。
**写(Write Through):**
-- 先查 cache,cache 中不存在,直接更新 db。
-- cache 中存在,则先更新 cache,然后 cache 服务自己更新 db(**同步更新 cache 和 db**)。
+- 先查 Cache,Cache 中不存在,直接更新 DB。
+- Cache 中存在,则先更新 Cache,然后 Cache 服务自己更新 DB。只有当 Cache 和 DB 都写入成功后,才向上层返回成功。
简单画了一张图帮助大家理解写的步骤。
@@ -92,25 +119,38 @@ Read/Write Through Pattern 中服务端把 cache 视为主要数据存储,从
**读(Read Through):**
-- 从 cache 中读取数据,读取到就直接返回 。
-- 读取不到的话,先从 db 加载,写入到 cache 后返回响应。
+- 应用从 Cache 读取数据。
+- 如果命中,直接返回。
+- 如果未命中,由**Cache 服务自己**负责从 DB 加载数据,加载成功后先写入自身,再返回给应用。
简单画了一张图帮助大家理解读的步骤。

-Read-Through Pattern 实际只是在 Cache-Aside Pattern 之上进行了封装。在 Cache-Aside Pattern 下,发生读请求的时候,如果 cache 中不存在对应的数据,是由客户端自己负责把数据写入 cache,而 Read Through Pattern 则是 cache 服务自己来写入缓存的,这对客户端是透明的。
+Read-Through 实际只是在 Cache-Aside 之上进行了封装。在 Cache-Aside 下,发生读请求的时候,如果 Cache 中不存在对应的数据,是由客户端自己负责把数据写入 Cache,而 Read Through 则是 Cache 服务自己来写入缓存的,这对客户端是透明的。
-和 Cache Aside Pattern 一样, Read-Through Pattern 也有首次请求数据一定不再 cache 的问题,对于热点数据可以提前放入缓存中。
+从实现角度看,Read-Through 本质上是把 Cache-Aside 中“读 Miss → 读 DB → 回填 Cache”的逻辑,下沉到了缓存服务内部,对客户端透明。
+
+和 Cache Aside 一样, Read-Through 也有首次请求数据一定不再 Cache 的问题,对于热点数据可以提前放入缓存中。
### Write Behind Pattern(异步缓存写入)
-Write Behind Pattern 和 Read/Write Through Pattern 很相似,两者都是由 cache 服务来负责 cache 和 db 的读写。
+Write Behind(也常被称为 Write-Back) Pattern 和 Read/Write Through Pattern 很相似,两者都是由 Cache 服务来负责 Cache 和 DB 的读写。
+
+但是,两个又有很大的不同:**Read/Write Through 是同步更新 Cache 和 DB,而 Write Behind 则是只更新缓存,不直接更新 DB,而是改为异步批量的方式来更新 DB。**
+
+**写操作 (Write Behind):**
+
+1. 应用将数据写入 Cache,然后**立即返回**。
+2. Cache 服务将这个写操作放入一个队列中。
+3. 通过一个独立的异步线程/任务,将队列中的写操作**批量地、合并地**写入 DB。
-但是,两个又有很大的不同:**Read/Write Through 是同步更新 cache 和 db,而 Write Behind 则是只更新缓存,不直接更新 db,而是改为异步批量的方式来更新 db。**
+这种模式对数据一致性带来了挑战(例如:Cache 中的数据还没来得及写回 DB,系统就宕机了),因此不适用于需要强一致性的场景(如交易、库存)。
-很明显,这种方式对数据一致性带来了更大的挑战,比如 cache 数据可能还没异步更新 db 的话,cache 服务可能就就挂掉了。
+但是,它的异步和批量特性,带来了**无与伦比的写性能**。它在很多高性能系统中都有广泛应用:
-这种策略在我们平时开发过程中也非常非常少见,但是不代表它的应用场景少,比如消息队列中消息的异步写入磁盘、MySQL 的 Innodb Buffer Pool 机制都用到了这种策略。
+- **MySQL 的 InnoDB Buffer Pool 机制:** 数据修改先在内存 Buffer Pool 中完成,然后由后台线程异步刷写到磁盘。
+- **操作系统的页缓存(Page Cache):** 文件写入也是先写到内存,再由操作系统异步刷盘。
+- **高频计数场景:** 对于文章浏览量、帖子点赞数这类允许短暂数据不一致、但写入极其频繁的场景,可以先在 Redis 中快速累加,再通过定时任务异步同步回数据库。
-Write Behind Pattern 下 db 的写性能非常高,非常适合一些数据经常变化又对数据一致性要求没那么高的场景,比如浏览量、点赞量。
+
diff --git a/docs/database/redis/cache-basics.md b/docs/database/redis/cache-basics.md
index 2a9aee57354..15cb0eb33bb 100644
--- a/docs/database/redis/cache-basics.md
+++ b/docs/database/redis/cache-basics.md
@@ -1,12 +1,195 @@
---
-title: 缓存基础常见面试题总结(付费)
+title: 缓存基础常见面试题总结
+description: 深入讲解缓存的核心思想、本地缓存与分布式缓存的区别、多级缓存架构设计。涵盖Caffeine、Redis等主流缓存方案,以及缓存一致性的解决方案。适合Java开发者学习缓存架构设计。
category: 数据库
tag:
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: 缓存,本地缓存,分布式缓存,多级缓存,Caffeine,Redis,缓存一致性,系统设计,Java缓存,Guava Cache
---
-**缓存基础** 相关的面试题为我的 [知识星球](../../about-the-author/zhishixingqiu-two-years.md)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](../../zhuanlan/java-mian-shi-zhi-bei.md)中。
+> **相关面试题** :
+>
+> - 为什么要用缓存?
+> - 本地缓存应该怎么做?
+> - 为什么要有分布式缓存?/为什么不直接用本地缓存?
+> - 为什么要用多级缓存?
+> - 多级缓存适合哪些业务场景?
-
+## 缓存的基本思想
-
+很多同学只知道缓存可以提高系统性能以及减少请求 **响应时间**(Response Time),但是,不太清楚缓存的本质思想是什么。
+
+缓存的基本思想其实很简单,就是我们非常熟悉的 **空间换时间** 这一经典性能优化策略的运用。所谓空间换时间,也就是用更多的存储空间来存储一些可能重复使用或计算的数据,从而减少数据的重新获取或计算的时间。
+
+说到空间换时间,除了缓存之外,你还能想到什么其他的例子吗?这里再列举几个常见的:
+
+- **索引**:索引是一种将数据库表中的某些列或字段按照一定的排序规则组织成一个单独的数据结构,虽然需要额外占用空间,但可以大大提高检索效率,降低数据排序成本。
+- **数据库表字段冗余**:将经常联合查询的数据冗余存储在同一张表中,以减少对多张表的关联查询,进而提升查询性能,减轻数据库压力。
+- **CDN(内容分发网络)**:将静态资源分发到多个边缘节点以实现就近访问,进而加快静态资源的访问速度,减轻源站服务器以及带宽的负担。
+
+编程需要要学会归纳总结,将自己学到的东西串联起来!假如你在面试的时候,能聊到这些,面试官一定会对你有一个好印象的。
+
+不要把缓存想的太高大上,虽然,它的确对系统的性能提升的性价比非常高。当我们在学习并应用缓存的时候,你会发现缓存的思想实际在 CPU、操作系统或者其他很多地方都被大量用到。
+
+比如,**CPU Cache** 缓存的是内存数据,用于解决 **CPU** 处理速度与内存访问速度不匹配的问题;内存缓存的是硬盘数据,用于解决硬盘 **I/O** 速度过慢的问题。
+
+
+
+再比如,为了提高虚拟地址到物理地址的转换速度,操作系统在页表方案基础之上引入了 **转址旁路缓存**(Translation Lookaside Buffer,**TLB**,也被称为快表)。
+
+
+
+拿日常使用的浏览器来说,它会对访问过的图片或静态文件进行缓存(浏览器缓存),这样下次访问相同页面时加载速度会显著提升。
+
+
+
+我们日常开发中用到的缓存,其中的数据通常存储于 **RAM**(内存)中,访问速度极快。为了避免内存数据在重启或宕机后丢失,许多缓存中间件(如 **Redis**)提供了磁盘持久化机制。相比于关系型数据库(如 **MySQL**),缓存的访问速度和并发支持量都要高出几个数量级。在数据库之上增加一层缓存,是保护底层存储、提升系统吞吐量的核心手段。
+
+## 缓存的分类
+
+接下来,我们来看看日常开发中用到的缓存通常被分为哪几种。
+
+### 本地缓存
+
+#### 什么是本地缓存?
+
+这个实际在很多项目中用的蛮多,特别是单体架构的时候。数据量不大,并且没有分布式要求的话,使用本地缓存还是可以的。
+
+本地缓存位于应用内部,其最大的优点是应用存在于同一个进程内部,请求本地缓存的速度非常快,不存在额外的网络开销。
+
+常见的单体架构图如下,我们使用 **Nginx** 来做**负载均衡**,部署两个相同的应用到服务器,两个服务使用同一个数据库,并且使用的是本地缓存。
+
+
+
+**注意:** 在集群模式下使用本地缓存,必须考虑**负载均衡策略**。如果 Nginx 使用默认的**轮询(Round-Robin)**,同一个用户的请求会随机落在不同机器,导致本地缓存命中率极低。解决方案如下:
+
+1. **网关层**:使用一致性哈希或 Sticky Session,保证同一用户的请求固定打到同一台机器。
+2. **应用层**:仅将本地缓存用于**“全局几乎不变”**的数据(如配置字典),而非用户维度数据。
+
+#### 本地缓存的方案有哪些?
+
+**1、JDK 自带的 `HashMap` 和 `ConcurrentHashMap` 了。**
+
+`ConcurrentHashMap` 可以看作是线程安全版本的 `HashMap` ,两者都是存放 key/value 形式的键值对。但是,大部分场景来说不会使用这两者当做缓存,因为只提供了缓存的功能,并没有提供其他诸如过期时间之类的功能。一个稍微完善一点的缓存框架至少要提供:**过期时间**、**淘汰机制**、**命中率统计**这三点。
+
+**2、 `Ehcache` 、 `Guava Cache` 、 `Spring Cache` 这三者是使用的比较多的本地缓存框架。**
+
+- `Ehcache` 的话相比于其他两者更加重量。不过,相比于 `Guava Cache` 、 `Spring Cache` 来说, `Ehcache` 支持可以嵌入到 hibernate 和 mybatis 作为多级缓存,并且可以将缓存的数据持久化到本地磁盘中、同时也提供了集群方案(比较鸡肋,可忽略)。
+- `Guava Cache` 和 `Spring Cache` 两者的话比较像。`Guava` 相比于 `Spring Cache` 的话使用的更多一点,它提供了 API 非常方便我们使用,同时也提供了设置缓存有效时间等功能。它的内部实现也比较干净,很多地方都和 `ConcurrentHashMap` 的思想有异曲同工之妙。
+- 使用 `Spring Cache` 的注解实现缓存的话,代码会看着很干净和优雅,但是很容易出现问题比如缓存穿透、内存溢出。
+
+**3、后起之秀 Caffeine。**
+
+相比于 `Guava` 来说 `Caffeine` 在各个方面比如性能都要更加优秀,一般建议使用其来替代 `Guava` 。并且, `Guava` 和 `Caffeine` 的使用方式很像!
+
+使用 `Caffeine` 创建本地缓存的代码示例,用到了建造者模式:
+
+```java
+// 使用 Caffeine 创建本地缓存示例
+Cache cache = Caffeine.newBuilder()
+ // 设置写入后 60 天过期
+ .expireAfterWrite(60, TimeUnit.DAYS)
+ // 初始容量
+ .initialCapacity(100)
+ // 最大条数限制
+ .maximumSize(500)
+ // 开启统计功能
+ .recordStats()
+ .build();
+```
+
+#### 本地缓存有什么痛点?
+
+本地的缓存的优势非常明显:**低依赖**、**轻量**、**简单**、**成本低**。
+
+但是,本地缓存存在下面这些缺陷:
+
+- **本地缓存应用耦合,对分布式架构支持不友好**,比如同一个相同的服务部署在多台机器上的时候,各个服务之间的缓存是无法共享的,因为本地缓存只在当前机器上有。
+- **本地缓存容量受服务部署所在的机器限制明显。** 如果当前系统服务所耗费的内存多,那么本地缓存可用的容量就很少。
+
+### 分布式缓存
+
+#### 什么是分布式缓存?
+
+我们可以把分布式缓存(Distributed Cache) 看作是一种内存数据库的服务,它的最终作用就是提供缓存数据的服务。
+
+分布式缓存脱离于应用独立存在,多个应用可直接的共同使用同一个分布式缓存服务。
+
+如下图所示,就是一个简单的使用分布式缓存的架构图。我们使用 Nginx 来做负载均衡,部署两个相同的应用到服务器,两个服务使用同一个数据库和缓存。
+
+
+
+使用分布式缓存之后,缓存服务可以部署在一台单独的服务器上,即使同一个相同的服务部署在多台机器上,也是使用的同一份缓存。 并且,单独的分布式缓存服务的性能、容量和提供的功能都要更加强大。
+
+**软件系统设计中没有银弹,往往任何技术的引入都像是把双刃剑。** 你使用的方式得当,就能为系统带来很大的收益。否则,只是费了精力不讨好。
+
+简单来说,为系统引入分布式缓存之后往往会带来下面这些问题:
+
+- **系统复杂性增加** :引入缓存之后,你要维护缓存和数据库的数据一致性、维护热点缓存、保证缓存服务的高可用等等。
+- **系统开发成本往往会增加** :引入缓存意味着系统需要一个单独的缓存服务,这是需要花费相应的成本的,并且这个成本还是很贵的,毕竟耗费的是宝贵的内存。
+
+#### 分布式缓存的方案有哪些?
+
+分布式缓存的话,比较老牌同时也是使用的比较多的还是 **Memcached** 和 **Redis**。不过,现在基本没有看过还有项目使用 **Memcached** 来做缓存,都是直接用 **Redis**。
+
+Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
+
+有一些大厂也开源了类似于 Redis 的分布式高性能 KV 存储数据库,例如,腾讯开源的 [Tendis](https://github.com/Tencent/Tendis) 。Tendis 基于知名开源项目 [RocksDB](https://github.com/facebook/rocksdb) 作为存储引擎 ,100% 兼容 Redis 协议和 Redis4.0 所有数据模型。关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:[Redis vs Tendis:冷热混合存储版架构揭秘](https://mp.weixin.qq.com/s/MeYkfOIdnU6LYlsGb24KjQ) ,可以简单参考一下。
+
+不过,从 Tendis 这个项目的 Github 提交记录可以看出,Tendis 开源版几乎已经没有被维护更新了,加上其关注度并不高,使用的公司也比较少。因此,不建议你使用 Tendis 来实现分布式缓存。
+
+目前,比较业界认可的 Redis 替代品还是下面这两个开源分布式缓存(都是通过碰瓷 Redis 火的):
+
+- [Dragonfly](https://github.com/dragonflydb/dragonfly):一种针对现代应用程序负荷需求而构建的内存数据库,完全兼容 Redis 和 Memcached 的 API,迁移时无需修改任何代码,号称全世界最快的内存数据库。
+- [KeyDB](https://github.com/Snapchat/KeyDB): Redis 的一个高性能分支,专注于多线程、内存效率和高吞吐量。
+
+不过,个人还是建议分布式缓存首选 Redis ,毕竟经过这么多年的生产考验,生态也这么优秀,资料也很全面。
+
+### 多级缓存
+
+#### 什么是多级缓存?为什么要用?
+
+我们这里只来简单聊聊 **本地缓存 + 分布式缓存** 的多级缓存方案,这也是最常用的多级缓存实现方式。
+
+这个时候估计有很多小伙伴就会问了:**既然用了分布式缓存,为什么还要用本地缓存呢?** 。
+
+本地缓存和分布式缓存虽然都属于缓存,但本地缓存的访问速度要远大于分布式缓存,这是因为访问本地缓存不存在额外的网络开销,我们在上面也提到了。
+
+不过,一般情况下,我们也是不建议使用多级缓存的,这会增加维护负担(比如你需要保证一级缓存和二级缓存的数据一致性)。而且,其实际带来的提升效果对于绝大部分业务场景来说其实并不是很大。
+
+这里简单总结一下适合多级缓存的两种业务场景:
+
+- 缓存的数据不会频繁修改,比较稳定;
+- 数据访问量特别大比如秒杀场景。
+
+多级缓存方案中,第一级缓存(L1)使用本地内存(比如 Caffeine)),第二级缓存(L2)使用分布式缓存(比如 Redis)。
+
+
+
+读取缓存数据的时候,我们先从 L1 中读取,读取不到的时候再去 L2 读取。这样可以降低 L2 的压力,减少 L2 的读次数。如果 L2 也没有此数据的话,再去数据库查询,数据查询成功后再将数据写入到 L1 和 L2 中。
+
+多级缓存开源实现推荐:
+
+- [J2Cache](https://gitee.com/ld/J2Cache):基于本地内存和 Redis 的两级 Java 缓存框架。
+- [JetCache](https://github.com/alibaba/jetcache):阿里开源的缓存框架,支持多级缓存、分布式缓存自动刷新、 TTL 等功能。
+
+#### 多级缓存一致性如何保证?
+
+在多级缓存系统中,保证强一致性成本太高,业界的几个提供多级缓存功能的缓存框架基本都是最终一致性保证。例如,可以使用 Redis 的发布/订阅机制、Redis Stream 或者消息队列来确保当一个实例的本地缓存发生变化时,其他实例能够及时更新其本地缓存,以保持缓存一致性。
+
+政采云技术的方案是 Canal + 广播消息,这里简单介绍一下:
+
+1. DB 修改数据:首先在数据库中进行数据修改。
+2. 通过监听 Canal 消息,触发缓存的更新:使用 Canal 监听数据库的变更操作,当检测到数据变化时,触发缓存更新。
+3. 同步 Redis 缓存:对于 Redis 缓存,因为集群中只共享一份数据,所以直接同步缓存即可。
+4. 同步本地缓存:由于本地缓存分布在不同的 JVM 实例中,需要借助广播消息队列(MQ)机制,将更新通知广播到各个业务实例,从而同步本地缓存。
+
+详细介绍:[分布式多级缓存系统设计与实战](https://juejin.cn/post/7225634879152570405)
+
+## 参考
+
+- 缓存那些事:https://tech.meituan.com/2017/03/17/cache-about.html
+- 解析分布式系统的缓存设计:https://segmentfault.com/a/1190000041689802
diff --git a/docs/database/redis/images/why-redis-so-fast.png b/docs/database/redis/images/why-redis-so-fast.png
deleted file mode 100644
index 279e1955473..00000000000
Binary files a/docs/database/redis/images/why-redis-so-fast.png and /dev/null differ
diff --git a/docs/database/redis/redis-cluster.md b/docs/database/redis/redis-cluster.md
index 2db4feda7e3..4d8b2ead452 100644
--- a/docs/database/redis/redis-cluster.md
+++ b/docs/database/redis/redis-cluster.md
@@ -1,12 +1,17 @@
---
title: Redis集群详解(付费)
+description: Redis集群相关面试题详解,包括Redis Sentinel哨兵模式、Redis Cluster分片集群的原理、配置和使用,以及主从复制、故障转移等高可用方案。
category: 数据库
tag:
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis集群,Redis Cluster,Redis Sentinel,主从复制,哨兵模式,分片集群,高可用
---
**Redis 集群** 相关的面试题为我的 [知识星球](../../about-the-author/zhishixingqiu-two-years.md)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](../../zhuanlan/java-mian-shi-zhi-bei.md)中。
-
+
diff --git a/docs/database/redis/redis-common-blocking-problems-summary.md b/docs/database/redis/redis-common-blocking-problems-summary.md
index facf3e3ac9b..95041edee60 100644
--- a/docs/database/redis/redis-common-blocking-problems-summary.md
+++ b/docs/database/redis/redis-common-blocking-problems-summary.md
@@ -1,11 +1,18 @@
---
title: Redis常见阻塞原因总结
+description: 全面总结Redis常见的阻塞原因,包括O(n)复杂度命令、bigkey操作、AOF日志刷盘、RDB快照创建、主从同步等场景,帮助你排查和预防Redis性能问题。
category: 数据库
tag:
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis阻塞,Redis性能问题,O(n)命令,bigkey,AOF刷盘,RDB快照,主从同步,内存达上限
---
-> 本文整理完善自:https://mp.weixin.qq.com/s/0Nqfq_eQrUb12QH6eBbHXA ,作者:阿 Q 说代码
+
+
+> 本文整理完善自: ,作者:阿 Q 说代码
这篇文章会详细总结一下可能导致 Redis 阻塞的情况,这些情况也是影响 Redis 性能的关键因素,使用 Redis 的时候应该格外注意!
@@ -18,7 +25,7 @@ Redis 中的大部分命令都是 O(1)时间复杂度,但也有少部分 O(n)
- `LRANGE`:会返回 List 中指定范围内的元素。
- `SMEMBERS`:返回 Set 中的所有元素。
- `SINTER`/`SUNION`/`SDIFF`:计算多个 Set 的交集/并集/差集。
-- ......
+- ……
由于这些命令时间复杂度是 O(n),有时候也会全表扫描,随着 n 的增大,执行耗时也会越长,从而导致客户端阻塞。不过, 这些命令并不是一定不能使用,但是需要明确 N 的值。另外,有遍历的需求可以使用 `HSCAN`、`SSCAN`、`ZSCAN` 代替。
@@ -26,7 +33,7 @@ Redis 中的大部分命令都是 O(1)时间复杂度,但也有少部分 O(n)
- `ZRANGE`/`ZREVRANGE`:返回指定 Sorted Set 中指定排名范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 为返回的元素数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
- `ZREMRANGEBYRANK`/`ZREMRANGEBYSCORE`:移除 Sorted Set 中指定排名范围/指定 score 范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 被删除元素的数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
-- ......
+- ……
## SAVE 创建 RDB 快照
@@ -81,7 +88,10 @@ Redis AOF 持久化机制是在执行完命令之后再记录日志,这和关
## 大 Key
-如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:string 类型的 value 超过 10 kb,复合类型的 value 包含的元素超过 5000 个(对于复合类型的 value 来说,不一定包含的元素越多,占用的内存就越多)。
+如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:
+
+- string 类型的 value 超过 1MB
+- 复合类型(列表、哈希、集合、有序集合等)的 value 包含的元素超过 5000 个(对于复合类型的 value 来说,不一定包含的元素越多,占用的内存就越多)。
大 key 造成的阻塞问题如下:
@@ -126,14 +136,14 @@ Redis 集群可以进行节点的动态扩容缩容,这一过程目前还处
**什么是 Swap?** Swap 直译过来是交换的意思,Linux 中的 Swap 常被称为内存交换或者交换分区。类似于 Windows 中的虚拟内存,就是当内存不足的时候,把一部分硬盘空间虚拟成内存使用,从而解决内存容量不足的情况。因此,Swap 分区的作用就是牺牲硬盘,增加内存,解决 VPS 内存不够用或者爆满的问题。
-Swap 对于 Redis 来说是非常致命的,Redis 保证高性能的一个重要前提是所有的数据在内存中。如果操作系统把 Redis 使用的部分内存换出硬盘,由于内存与硬盘读写的速度并几个数量级,会导致发生交换后的 Redis 性能急剧下降。
+Swap 对于 Redis 来说是非常致命的,Redis 保证高性能的一个重要前提是所有的数据在内存中。如果操作系统把 Redis 使用的部分内存换出硬盘,由于内存与硬盘的读写速度差几个数量级,会导致发生交换后的 Redis 性能急剧下降。
识别 Redis 发生 Swap 的检查方法如下:
1、查询 Redis 进程号
```bash
-reids-cli -p 6383 info server | grep process_id
+redis-cli -p 6383 info server | grep process_id
process_id: 4476
```
@@ -161,7 +171,7 @@ Swap: 0kB
Redis 是典型的 CPU 密集型应用,不建议和其他多核 CPU 密集型服务部署在一起。当其他进程过度消耗 CPU 时,将严重影响 Redis 的吞吐量。
-可以通过`reids-cli --stat`获取当前 Redis 使用情况。通过`top`命令获取进程对 CPU 的利用率等信息 通过`info commandstats`统计信息分析出命令不合理开销时间,查看是否是因为高算法复杂度或者过度的内存优化问题。
+可以通过`redis-cli --stat`获取当前 Redis 使用情况。通过`top`命令获取进程对 CPU 的利用率等信息 通过`info commandstats`统计信息分析出命令不合理开销时间,查看是否是因为高算法复杂度或者过度的内存优化问题。
## 网络问题
@@ -169,5 +179,7 @@ Redis 是典型的 CPU 密集型应用,不建议和其他多核 CPU 密集型
## 参考
-- Redis 阻塞的 6 大类场景分析与总结:https://mp.weixin.qq.com/s/eaZCEtTjTuEmXfUubVHjew
-- Redis 开发与运维笔记-Redis 的噩梦-阻塞:https://mp.weixin.qq.com/s/TDbpz9oLH6ifVv6ewqgSgA
+- Redis 阻塞的 6 大类场景分析与总结:
+- Redis 开发与运维笔记-Redis 的噩梦-阻塞:
+
+
diff --git a/docs/database/redis/redis-data-structures-01.md b/docs/database/redis/redis-data-structures-01.md
index a8e0e1d742b..64468c03f02 100644
--- a/docs/database/redis/redis-data-structures-01.md
+++ b/docs/database/redis/redis-data-structures-01.md
@@ -1,30 +1,28 @@
---
-title: Redis 5 种基本数据结构详解
+title: Redis 5 种基本数据类型详解
+description: 详解Redis五种基本数据类型String、List、Set、Hash、Zset的使用方法和应用场景,深入分析SDS、跳表、压缩列表等底层数据结构实现原理。
category: 数据库
tag:
- Redis
head:
- - meta
- name: keywords
- content: Redis常见数据结构
- - - meta
- - name: description
- content: Redis基础数据结构总结:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)
+ content: Redis数据类型,String,List,Set,Hash,Zset,SDS,跳表,压缩列表,Redis命令
---
-Redis 共有 5 种基本数据结构:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
+Redis 共有 5 种基本数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
-这 5 种数据结构是直接提供给用户使用的,是数据的保存形式,其底层实现主要依赖这 8 种数据结构:简单动态字符串(SDS)、LinkedList(双向链表)、Hash Table(哈希表)、SkipList(跳跃表)、Intset(整数集合)、ZipList(压缩列表)、QuickList(快速列表)。
+这 5 种数据类型是直接提供给用户使用的,是数据的保存形式,其底层实现主要依赖这 8 种数据结构:简单动态字符串(SDS)、LinkedList(双向链表)、Dict(哈希表/字典)、SkipList(跳跃表)、Intset(整数集合)、ZipList(压缩列表)、QuickList(快速列表)。
-Redis 基本数据结构的底层数据结构实现如下:
+Redis 5 种基本数据类型对应的底层数据结构实现如下表所示:
-| String | List | Hash | Set | Zset |
-| :----- | :--------------------------- | :------------------ | :-------------- | :---------------- |
-| SDS | LinkedList/ZipList/QuickList | Hash Table、ZipList | ZipList、Intset | ZipList、SkipList |
+| String | List | Hash | Set | Zset |
+| :----- | :--------------------------- | :------------ | :----------- | :---------------- |
+| SDS | LinkedList/ZipList/QuickList | Dict、ZipList | Dict、Intset | ZipList、SkipList |
-Redis 3.2 之前,List 底层实现是 LinkedList 或者 ZipList。 Redis 3.2 之后,引入了 LinkedList 和 ZipList 的结合 QuickList,List 的底层实现变为 QuickList。
+Redis 3.2 之前,List 底层实现是 LinkedList 或者 ZipList。 Redis 3.2 之后,引入了 LinkedList 和 ZipList 的结合 QuickList,List 的底层实现变为 QuickList。从 Redis 7.0 开始, ZipList 被 ListPack 取代。
-你可以在 Redis 官网上找到 Redis 数据结构非常详细的介绍:
+你可以在 Redis 官网上找到 Redis 数据类型/结构非常详细的介绍:
- [Redis Data Structures](https://redis.com/redis-enterprise/data-structures/)
- [Redis Data types tutorial](https://redis.io/docs/manual/data-types/data-types-tutorial/)
@@ -37,9 +35,9 @@ Redis 3.2 之前,List 底层实现是 LinkedList 或者 ZipList。 Redis 3.2
### 介绍
-String 是 Redis 中最简单同时也是最常用的一个数据结构。
+String 是 Redis 中最简单同时也是最常用的一个数据类型。
-String 是一种二进制安全的数据结构,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
+String 是一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。

@@ -47,19 +45,19 @@ String 是一种二进制安全的数据结构,可以用来存储任何类型
### 常用命令
-| 命令 | 介绍 |
-| ------------------------------ | -------------------------------- |
-| SET key value | 设置指定 key 的值 |
-| SETNX key value | 只有在 key 不存在时设置 key 的值 |
-| GET key | 获取指定 key 的值 |
-| MSET key1 value1 key2 value2 … | 设置一个或多个指定 key 的值 |
-| MGET key1 key2 ... | 获取一个或多个指定 key 的值 |
-| STRLEN key | 返回 key 所储存的字符串值的长度 |
-| INCR key | 将 key 中储存的数字值增一 |
-| DECR key | 将 key 中储存的数字值减一 |
-| EXISTS key | 判断指定 key 是否存在 |
-| DEL key(通用) | 删除指定的 key |
-| EXPIRE key seconds(通用) | 给指定 key 设置过期时间 |
+| 命令 | 介绍 |
+| ------------------------------- | -------------------------------- |
+| SET key value | 设置指定 key 的值 |
+| SETNX key value | 只有在 key 不存在时设置 key 的值 |
+| GET key | 获取指定 key 的值 |
+| MSET key1 value1 key2 value2 …… | 设置一个或多个指定 key 的值 |
+| MGET key1 key2 ... | 获取一个或多个指定 key 的值 |
+| STRLEN key | 返回 key 所储存的字符串值的长度 |
+| INCR key | 将 key 中储存的数字值增一 |
+| DECR key | 将 key 中储存的数字值减一 |
+| EXISTS key | 判断指定 key 是否存在 |
+| DEL key(通用) | 删除指定的 key |
+| EXPIRE key seconds(通用) | 给指定 key 设置过期时间 |
更多 Redis String 命令以及详细使用指南,请查看 Redis 官网对应的介绍: 。
@@ -110,7 +108,7 @@ OK
```bash
> EXPIRE key 60
(integer) 1
-> SETNX key 60 value # 设置值并设置过期时间
+> SETEX key 60 value # 设置值并设置过期时间
OK
> TTL key
(integer) 56
@@ -120,7 +118,7 @@ OK
**需要存储常规数据的场景**
-- 举例:缓存 session、token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
+- 举例:缓存 Session、Token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
- 相关命令:`SET`、`GET`。
**需要计数的场景**
@@ -178,11 +176,11 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
```bash
> RPUSH myList2 value1 value2 value3
(integer) 3
-> RPOP myList2 # 将 list的头部(最右边)元素取出
+> RPOP myList2 # 将 list的最右边的元素取出
"value3"
```
-我专门画了一个图方便大家理解 `RPUSH` , `LPOP` , `lpush` , `RPOP` 命令:
+我专门画了一个图方便大家理解 `RPUSH` , `LPOP` , `LPUSH` , `RPOP` 命令:

@@ -218,7 +216,7 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
**消息队列**
-Redis List 数据结构可以用来做消息队列,只是功能过于简单且存在很多缺陷,不建议这样做。
+`List` 可以用来做消息队列,只是功能过于简单且存在很多缺陷,不建议这样做。
相对来说,Redis 5.0 新增加的一个数据结构 `Stream` 更适合做消息队列一些,只是功能依然非常简陋。和专业的消息队列相比,还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。
@@ -474,7 +472,7 @@ value1

-[《Java 面试指北》](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7) 的「技术面试题篇」就有一篇文章详细介绍如何使用 Sorted Set 来设计制作一个排行榜。
+[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 的「技术面试题篇」就有一篇文章详细介绍如何使用 Sorted Set 来设计制作一个排行榜。

@@ -483,9 +481,21 @@ value1
- 举例:优先级任务队列。
- 相关命令:`ZRANGE` (从小到大排序)、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
+## 总结
+
+| 数据类型 | 说明 |
+| -------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| String | 一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。 |
+| List | Redis 的 List 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。 |
+| Hash | 一个 String 类型的 field-value(键值对) 的映射表,特别适合用于存储对象,后续操作的时候,你可以直接修改这个对象中的某些字段的值。 |
+| Set | 无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 `HashSet` 。 |
+| Zset | 和 Set 相比,Sorted Set 增加了一个权重参数 `score`,使得集合中的元素能够按 `score` 进行有序排列,还可以通过 `score` 的范围来获取元素的列表。有点像是 Java 中 `HashMap` 和 `TreeSet` 的结合体。 |
+
## 参考
- Redis Data Structures: 。
- Redis Commands: 。
- Redis Data types tutorial: 。
- Redis 存储对象信息是用 Hash 还是 String :
+
+
diff --git a/docs/database/redis/redis-data-structures-02.md b/docs/database/redis/redis-data-structures-02.md
index 4a1c5ad1396..78e98365bff 100644
--- a/docs/database/redis/redis-data-structures-02.md
+++ b/docs/database/redis/redis-data-structures-02.md
@@ -1,23 +1,27 @@
---
-title: Redis 3 种特殊数据结构详解
+title: Redis 3 种特殊数据类型详解
+description: 详解Redis三种特殊数据类型Bitmap、HyperLogLog、GEO的使用方法和应用场景,包括签到统计、UV统计、附近的人等典型业务场景实现。
category: 数据库
tag:
- Redis
head:
- - meta
- name: keywords
- content: Redis常见数据结构
- - - meta
- - name: description
- content: Redis特殊数据结构总结:HyperLogLogs(基数统计)、Bitmap (位存储)、Geospatial (地理位置)。
+ content: Redis特殊数据类型,Bitmap,HyperLogLog,GEO,位图,基数统计,地理位置,签到统计,UV统计
---
-除了 5 种基本的数据结构之外,Redis 还支持 3 种特殊的数据结构:Bitmap、HyperLogLog、GEO。
+除了 5 种基本的数据类型之外,Redis 还支持 3 种特殊的数据类型:Bitmap、HyperLogLog、GEO。
-## Bitmap
+## Bitmap (位图)
### 介绍
+根据官网介绍:
+
+> Bitmaps are not an actual data type, but a set of bit-oriented operations defined on the String type which is treated like a bit vector. Since strings are binary safe blobs and their maximum length is 512 MB, they are suitable to set up to 2^32 different bits.
+>
+> Bitmap 不是 Redis 中的实际数据类型,而是在 String 类型上定义的一组面向位的操作,将其视为位向量。由于字符串是二进制安全的块,且最大长度为 512 MB,它们适合用于设置最多 2^32 个不同的位。
+
Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。
@@ -30,7 +34,7 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
| ------------------------------------- | ---------------------------------------------------------------- |
| SETBIT key offset value | 设置指定 offset 位置的值 |
| GETBIT key offset | 获取指定 offset 位置的值 |
-| BITCOUNT key start end | 获取 start 和 end 之前值为 1 的元素个数 |
+| BITCOUNT key start end | 获取 start 和 end 之间值为 1 的元素个数 |
| BITOP operation destkey key1 key2 ... | 对一个或多个 Bitmap 进行运算,可用运算符有 AND, OR, XOR 以及 NOT |
**Bitmap 基本操作演示**:
@@ -59,7 +63,7 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
- 举例:用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)。
- 相关命令:`SETBIT`、`GETBIT`、`BITCOUNT`、`BITOP`。
-## HyperLogLog
+## HyperLogLog(基数统计)
### 介绍
@@ -74,7 +78,7 @@ Redis 官方文档中有对应的详细说明:

-基数计数概率算法为了节省内存并不会直接存储元数据,而是通过一定的概率统计方法预估基数值(集合中包含元素的个数)。因此, HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为 `0.81%` 。)。
+基数计数概率算法为了节省内存并不会直接存储元数据,而是通过一定的概率统计方法预估基数值(集合中包含元素的个数)。因此, HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为 `0.81%` )。

@@ -82,6 +86,8 @@ HyperLogLog 的使用非常简单,但原理非常复杂。HyperLogLog 的原
再推荐一个可以帮助理解 HyperLogLog 原理的工具:[Sketch of the Day: HyperLogLog — Cornerstone of a Big Data Infrastructure](http://content.research.neustar.biz/blog/hll.html) 。
+除了 HyperLogLog 之外,Redis 还提供了其他的概率数据结构,对应的官方文档地址: 。
+
### 常用命令
HyperLogLog 相关的命令非常少,最常用的也就 3 个。
@@ -115,12 +121,12 @@ HyperLogLog 相关的命令非常少,最常用的也就 3 个。
### 应用场景
-**数量量巨大(百万、千万级别以上)的计数场景**
+**数量巨大(百万、千万级别以上)的计数场景**
-- 举例:热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计、
+- 举例:热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计。
- 相关命令:`PFADD`、`PFCOUNT` 。
-## Geospatial index
+## Geospatial (地理位置)
### 介绍
@@ -201,8 +207,18 @@ user2
- 举例:附近的人。
- 相关命令: `GEOADD`、`GEORADIUS`、`GEORADIUSBYMEMBER` 。
+## 总结
+
+| 数据类型 | 说明 |
+| ---------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| Bitmap | 你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。 |
+| HyperLogLog | Redis 提供的 HyperLogLog 占用空间非常非常小,只需要 12k 的空间就能存储接近`2^64`个不同元素。不过,HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为 `0.81%` )。 |
+| Geospatial index | Geospatial index(地理空间索引,简称 GEO) 主要用于存储地理位置信息,基于 Sorted Set 实现。 |
+
## 参考
-- Redis Data Structures:https://redis.com/redis-enterprise/data-structures/ 。
+- Redis Data Structures: 。
- 《Redis 深度历险:核心原理与应用实践》1.6 四两拨千斤——HyperLogLog
-- 布隆过滤器,位图,HyperLogLog:https://hogwartsrico.github.io/2020/06/08/BloomFilter-HyperLogLog-BitMap/index.html
+- 布隆过滤器,位图,HyperLogLog:
+
+
diff --git a/docs/database/redis/redis-delayed-task.md b/docs/database/redis/redis-delayed-task.md
new file mode 100644
index 00000000000..35c14ab7329
--- /dev/null
+++ b/docs/database/redis/redis-delayed-task.md
@@ -0,0 +1,87 @@
+---
+title: 如何基于Redis实现延时任务
+description: 详解基于Redis实现延时任务的两种方案:过期事件监听和Redisson延时队列,分析各方案的优缺点、可靠性问题和适用场景。
+category: 数据库
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis延时任务,延时队列,过期事件监听,Redisson DelayedQueue,订单超时,定时任务
+---
+
+基于 Redis 实现延时任务的功能无非就下面两种方案:
+
+1. Redis 过期事件监听
+2. Redisson 内置的延时队列
+
+面试的时候,你可以先说自己考虑了这两种方案,但最后发现 Redis 过期事件监听这种方案存在很多问题,因此你最终选择了 Redisson 内置的 DelayedQueue 这种方案。
+
+这个时候面试官可能会追问你一些相关的问题,我们后面会提到,提前准备就好了。
+
+另外,除了下面介绍到的这些问题之外,Redis 相关的常见问题建议你都复习一遍,不排除面试官会顺带问你一些 Redis 的其他问题。
+
+### Redis 过期事件监听实现延时任务功能的原理?
+
+Redis 2.0 引入了发布订阅 (pub/sub) 功能。在 pub/sub 中,引入了一个叫做 **channel(频道)** 的概念,有点类似于消息队列中的 **topic(主题)**。
+
+pub/sub 涉及发布者(publisher)和订阅者(subscriber,也叫消费者)两个角色:
+
+- 发布者通过 `PUBLISH` 投递消息给指定 channel。
+- 订阅者通过`SUBSCRIBE`订阅它关心的 channel。并且,订阅者可以订阅一个或者多个 channel。
+
+
+
+在 pub/sub 模式下,生产者需要指定消息发送到哪个 channel 中,而消费者则订阅对应的 channel 以获取消息。
+
+Redis 中有很多默认的 channel,这些 channel 是由 Redis 本身向它们发送消息的,而不是我们自己编写的代码。其中,`__keyevent@0__:expired` 就是一个默认的 channel,负责监听 key 的过期事件。也就是说,当一个 key 过期之后,Redis 会发布一个 key 过期的事件到`__keyevent@__:expired`这个 channel 中。
+
+我们只需要监听这个 channel,就可以拿到过期的 key 的消息,进而实现了延时任务功能。
+
+这个功能被 Redis 官方称为 **keyspace notifications** ,作用是实时监控 Redis 键和值的变化。
+
+### Redis 过期事件监听实现延时任务功能有什么缺陷?
+
+**1、时效性差**
+
+官方文档的一段介绍解释了时效性差的原因,地址: 。
+
+
+
+这段话的核心是:过期事件消息是在 Redis 服务器删除 key 时发布的,而不是一个 key 过期之后就会就会直接发布。
+
+我们知道常用的过期数据的删除策略就两个:
+
+1. **惰性删除**:只会在取出 key 的时候才对数据进行过期检查。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
+2. **定期删除**:每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
+
+定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,所以 Redis 采用的是 **定期删除+惰性/懒汉式删除** 。
+
+因此,就会存在我设置了 key 的过期时间,但到了指定时间 key 还未被删除,进而没有发布过期事件的情况。
+
+**2、丢消息**
+
+Redis 的 pub/sub 模式中的消息并不支持持久化,这与消息队列不同。在 Redis 的 pub/sub 模式中,发布者将消息发送给指定的频道,订阅者监听相应的频道以接收消息。当没有订阅者时,消息会被直接丢弃,在 Redis 中不会存储该消息。
+
+**3、多服务实例下消息重复消费**
+
+Redis 的 pub/sub 模式目前只有广播模式,这意味着当生产者向特定频道发布一条消息时,所有订阅相关频道的消费者都能够收到该消息。
+
+这个时候,我们需要注意多个服务实例重复处理消息的问题,这会增加代码开发量和维护难度。
+
+### Redisson 延迟队列原理是什么?有什么优势?
+
+Redisson 是一个开源的 Java 语言 Redis 客户端,提供了很多开箱即用的功能,比如多种分布式锁的实现、延时队列。
+
+我们可以借助 Redisson 内置的延时队列 RDelayedQueue 来实现延时任务功能。
+
+Redisson 的延迟队列 RDelayedQueue 是基于 Redis 的 SortedSet 来实现的。SortedSet 是一个有序集合,其中的每个元素都可以设置一个分数,代表该元素的权重。Redisson 利用这一特性,将需要延迟执行的任务插入到 SortedSet 中,并给它们设置相应的过期时间作为分数。
+
+Redisson 定期使用 `zrangebyscore` 命令扫描 SortedSet 中过期的元素,然后将这些过期元素从 SortedSet 中移除,并将它们加入到就绪消息列表中。就绪消息列表是一个阻塞队列,有消息进入就会被消费者监听到。这样做可以避免消费者对整个 SortedSet 进行轮询,提高了执行效率。
+
+相比于 Redis 过期事件监听实现延时任务功能,这种方式具备下面这些优势:
+
+1. **减少了丢消息的可能**:DelayedQueue 中的消息会被持久化,即使 Redis 宕机了,根据持久化机制,也只可能丢失一点消息,影响不大。当然了,你也可以使用扫描数据库的方法作为补偿机制。
+2. **消息不存在重复消费问题**:每个客户端都是从同一个目标队列中获取任务的,不存在重复消费的问题。
+
+跟 Redisson 内置的延时队列相比,消息队列可以通过保障消息消费的可靠性、控制消息生产者和消费者的数量等手段来实现更高的吞吐量和更强的可靠性,实际项目中首选使用消息队列的延时消息这种方案。
diff --git a/docs/database/redis/redis-memory-fragmentation.md b/docs/database/redis/redis-memory-fragmentation.md
index 799e2131acc..e2d0ea272b9 100644
--- a/docs/database/redis/redis-memory-fragmentation.md
+++ b/docs/database/redis/redis-memory-fragmentation.md
@@ -1,8 +1,13 @@
---
title: Redis内存碎片详解
+description: 深入解析Redis内存碎片产生的原因、判断方法和优化方案,包括内存碎片率计算、jemalloc分配器原理、自动内存碎片清理配置等。
category: 数据库
tag:
- Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis内存碎片,内存碎片率,jemalloc,内存分配,activedefrag,内存优化,Redis内存管理
---
## 什么是内存碎片?
@@ -19,7 +24,7 @@ Redis 内存碎片虽然不会影响 Redis 性能,但是会增加内存消耗
Redis 内存碎片产生比较常见的 2 个原因:
-**1、Redis 存储存储数据的时候向操作系统申请的内存空间可能会大于数据实际需要的存储空间。**
+**1、Redis 存储数据的时候向操作系统申请的内存空间可能会大于数据实际需要的存储空间。**
以下是这段 Redis 官方的原话:
@@ -27,7 +32,7 @@ Redis 内存碎片产生比较常见的 2 个原因:
Redis 使用 `zmalloc` 方法(Redis 自己实现的内存分配方法)进行内存分配的时候,除了要分配 `size` 大小的内存之外,还会多分配 `PREFIX_SIZE` 大小的内存。
-`zmalloc` 方法源码如下(源码地址:https://github.com/antirez/redis-tools/blob/master/zmalloc.c):
+`zmalloc` 方法源码如下(源码地址:
```java
void *zmalloc(size_t size) {
@@ -45,7 +50,7 @@ void *zmalloc(size_t size) {
}
```
-另外,Redis 可以使用多种内存分配器来分配内存( libc、jemalloc、tcmalloc),默认使用 [jemalloc](https://github.com/jemalloc/jemalloc),而 jemalloc 按照一系列固定的大小(8 字节、16 字节、32 字节......)来分配内存的。jemalloc 划分的内存单元如下图所示:
+另外,Redis 可以使用多种内存分配器来分配内存( libc、jemalloc、tcmalloc),默认使用 [jemalloc](https://github.com/jemalloc/jemalloc),而 jemalloc 按照一系列固定的大小(8 字节、16 字节、32 字节……)来分配内存的。jemalloc 划分的内存单元如下图所示:

@@ -59,11 +64,11 @@ void *zmalloc(size_t size) {

-文档地址:https://redis.io/topics/memory-optimization 。
+文档地址: 。
## 如何查看 Redis 内存碎片的信息?
-使用 `info memory` 命令即可查看 Redis 内存相关的信息。下图中每个参数具体的含义,Redis 官方文档有详细的介绍:https://redis.io/commands/INFO 。
+使用 `info memory` 命令即可查看 Redis 内存相关的信息。下图中每个参数具体的含义,Redis 官方文档有详细的介绍: 。

@@ -117,6 +122,8 @@ config set active-defrag-cycle-max 50
## 参考
-- Redis 官方文档:https://redis.io/topics/memory-optimization
-- Redis 核心技术与实战 - 极客时间 - 删除数据后,为什么内存占用率还是很高?:https://time.geekbang.org/column/article/289140
-- Redis 源码解析——内存分配:
+- Redis 官方文档:
+- Redis 核心技术与实战 - 极客时间 - 删除数据后,为什么内存占用率还是很高?:
+- Redis 源码解析——内存分配:< 源码解析——内存管理>
+
+
diff --git a/docs/database/redis/redis-persistence.md b/docs/database/redis/redis-persistence.md
index 499994cb8e4..8dc2110013e 100644
--- a/docs/database/redis/redis-persistence.md
+++ b/docs/database/redis/redis-persistence.md
@@ -1,15 +1,13 @@
---
title: Redis持久化机制详解
+description: 深入解析Redis三种持久化机制RDB快照、AOF日志和混合持久化的工作原理、配置方法和优缺点对比,帮助你选择适合业务场景的持久化策略。
category: 数据库
tag:
- Redis
head:
- - meta
- name: keywords
- content: Redis持久化机制详解
- - - meta
- - name: description
- content: Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:快照(snapshotting,RDB)、只追加文件(append-only file, AOF)、RDB 和 AOF 的混合持久化(Redis 4.0 新增)。
+ content: Redis持久化,RDB,AOF,混合持久化,bgsave,数据恢复,Redis备份,fork子进程
---
使用缓存的时候,我们经常需要对内存中的数据进行持久化也就是将内存中的数据写入到硬盘中。大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了做数据同步(比如 Redis 集群的主从节点通过 RDB 文件同步数据)。
@@ -20,10 +18,35 @@ Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而
- 只追加文件(append-only file, AOF)
- RDB 和 AOF 的混合持久化(Redis 4.0 新增)
-官方文档地址:https://redis.io/topics/persistence 。
+官方文档地址: 。

+**本文基于 Redis 7.0+ 版本**。不同版本的持久化机制有重要差异,使用前请确认你的 Redis 版本:
+
+| 版本 | 持久化默认方式 | 重要特性 |
+| -------------- | -------------- | ----------------------- |
+| **Redis 4.0** | RDB | 引入 RDB+AOF 混合持久化 |
+| **Redis 6.0** | RDB | AOF 仍需手动开启 |
+| **Redis 7.0** | RDB | 引入 Multi-Part AOF |
+| **Redis 7.2+** | RDB | 进一步优化持久化性能 |
+
+**关键行为差异**:
+
+- **AOF rewrite 内存占用**:Redis 7.0 之前重写期间增量数据需在内存中保留,7.0+ 使用 Multi-Part AOF 解决
+- **混合持久化**:Redis 4.0-6.x 需手动开启,Redis 7.0+ 默认启用。
+
+检查你的 Redis 版本:
+
+```bash
+redis-cli INFO server | grep redis_version
+# 输出示例:redis_version:7.0.12
+```
+
+下面这张图展示了 Redis 持久化机制的完整流程,包含了本文的核心内容:
+
+
+
## RDB 持久化
### 什么是 RDB 持久化?
@@ -33,11 +56,18 @@ Redis 可以通过创建快照来获得存储在内存里面的数据在 **某
快照持久化是 Redis 默认采用的持久化方式,在 `redis.conf` 配置文件中默认有此下配置:
```clojure
-save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发bgsave命令创建快照。
-
-save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发bgsave命令创建快照。
-
-save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发bgsave命令创建快照。
+# Redis 7.0 默认配置(单行格式)
+save 3600 1 300 100 60 10000
+
+# 各条件含义:
+# - 3600 秒(1 小时)内至少有 1 个 key 变化
+# - 300 秒(5 分钟)内至少有 100 个 key 变化
+# - 60 秒(1 分钟)内至少有 10000 个 key 变化
+
+# 等价于旧版多行格式:
+# save 3600 1
+# save 300 100
+# save 60 10000
```
### RDB 创建快照时会阻塞主线程吗?
@@ -45,15 +75,85 @@ save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生
Redis 提供了两个命令来生成 RDB 快照文件:
- `save` : 同步保存操作,会阻塞 Redis 主线程;
-- `bgsave` : fork 出一个子进程,子进程执行,不会阻塞 Redis 主线程,默认选项。
+- `bgsave` : fork 出一个子进程,子进程执行。
> 这里说 Redis 主线程而不是主进程的主要是因为 Redis 启动之后主要是通过单线程的方式完成主要的工作。如果你想将其描述为 Redis 主进程,也没毛病。
+#### fork 性能开销分析
+
+虽然 `bgsave` 在子进程中执行,不会阻塞主线程处理命令请求,但 **fork 操作本身是阻塞的**,且会带来额外的内存开销(下表中的为参考值,实际数值受到 CPU 性能、内存碎片率、系统负载等因素影响):
+
+| 数据集大小 | fork 延迟 | 额外内存占用 | 风险等级 |
+| ---------- | --------- | ---------------- | -------- |
+| < 1GB | < 10ms | ~10MB (页表复制) | 低 |
+| 1-10GB | 10-100ms | 10-100MB | 中 |
+| 10-50GB | 100ms-1s | 100-500MB | 高 |
+| > 50GB | > 1s | > 500MB | 极高 |
+
+> 本文以 RDB 的 `bgsave` 为例说明 fork 性能影响,但**同样的机制也适用于 AOF 重写(`BGREWRITEAOF` 命令)**。AOF 重写同样需要 fork 子进程,同样面临 fork 延迟、COW 内存开销和 THP 风险。生产环境中,无论是 RDB 还是 AOF 重写,都需要关注 fork 相关的性能指标。
+
+#### Copy-on-Write (COW) 机制
+
+- fork 后,子进程共享父进程的内存页(标准页 4KB)
+- 当父进程或子进程修改内存页时,内核复制该页(Copy-on-Write)
+- 大数据集 + 高写负载时,会导致大量页面复制,影响性能
+
+#### THP(透明大页)导致的内存雪崩问题
+
+Linux 发行版默认开启 **THP(Transparent Huge Pages,透明大页)**,大小为 2MB。THP 会增加大页被 COW 的概率,**最坏情况下**,如果内存被合并为 2MB 大页,即使客户端仅修改 10 字节的数据,内核也会复制完整的 2MB 内存页,导致 COW 的内存开销**放大 512 倍**(2MB / 4KB = 512)。
+
+**实际行为**:内核不会强制所有内存都使用 2MB 大页,而是根据情况动态决定是否合并。只有在 THP 成功合并为大页后,修改才会触发 2MB 的 COW。但在高并发写入场景下,这仍会显著增加内存消耗,可能瞬间吸干宿主机内存,触发 **OOM Killer 强杀 Redis 进程**。
+
+**验证方式**:
+
+```bash
+cat /sys/kernel/mm/transparent_hugepage/enabled
+# 输出 [always] madvise never 表示已开启(危险!)
+# 应该输出 always madvise [never]
+```
+
+**解决方案**:在 Redis 启动脚本中添加 `echo never > /sys/kernel/mm/transparent_hugepage/enabled`,或使用 `redis-server --disable-thp yes`(Redis 6.0+ 支持)。
+
+**启动警告**:Redis 检测到 THP 开启时会在启动日志中打印 `WARNING you have Transparent Huge Pages (THP) support enabled in your kernel`,必须立即处理。
+
+#### 生产环境建议
+
+```bash
+# 1. 监控 fork 风险指标
+redis-cli INFO memory | grep -E "(used_memory|used_memory_rss)"
+
+# 输出示例:
+# used_memory:1073741824
+# used_memory_rss:1226833920
+# used_memory_rss_human:1.14G
+
+# 计算 RSS/USED 比值,fork 时应 < 2
+# 如果接近或超过 2,说明 fork 风险高
+
+# 2. 设置 maxmemory 限制 Redis 内存占用,为 fork 预留空间
+# 在 redis.conf 中设置:
+# maxmemory 8gb
+# maxmemory-policy allkeys-lru
+
+# 3. 避免在高峰期手动触发 BGSAVE
+# 让 Redis 根据配置规则自动触发
+
+# 4. 考虑主从复制 + 从节点持久化架构
+# 将持久化操作转移到从节点,避免主节点 fork 开销
+```
+
+**监控告警**:
+
+- `rdb_last_bgsave_time_sec`:上次 bgsave 耗时,应 < 5s
+- `rdb_last_cow_size`:上次 fork 的 COW 内存大小,应 < 10% `used_memory`
+
## AOF 持久化
### 什么是 AOF 持久化?
-与快照持久化相比,AOF 持久化的实时性更好。默认情况下 Redis 没有开启 AOF(append only file)方式的持久化(Redis 6.0 之后已经默认是开启了),可以通过 `appendonly` 参数开启:
+与快照持久化相比,AOF 持久化的实时性更好。默认情况下 Redis 没有开启 AOF(append only file)方式的持久化,可以通过 `appendonly` 参数开启:
+
+> **版本说明**:Redis 默认使用 RDB 持久化方式。若需使用 AOF,需要手动设置 `appendonly yes`。Redis 7.0 引入了 Multi-Part AOF 机制优化 AOF 性能,但并未改变默认持久化方式。
```bash
appendonly yes
@@ -71,7 +171,7 @@ AOF 持久化功能的实现可以简单分为 5 步:
1. **命令追加(append)**:所有的写命令会追加到 AOF 缓冲区中。
2. **文件写入(write)**:将 AOF 缓冲区的数据写入到 AOF 文件中。这一步需要调用`write`函数(系统调用),`write`将数据写入到了系统内核缓冲区之后直接返回了(延迟写)。注意!!!此时并没有同步到磁盘。
-3. **文件同步(fsync)**:AOF 缓冲区根据对应的持久化方式( `fsync` 策略)向硬盘做同步操作。这一步需要调用 `fsync` 函数(系统调用), `fsync` 针对单个文件操作,对其进行强制硬盘同步,`fsync` 将阻塞直到写入磁盘完成后返回,保证了数据持久化。
+3. **文件同步(fsync)**:这一步才是持久化的核心!根据你在 `redis.conf` 文件里 `appendfsync` 配置的策略,Redis 会在不同的时机,调用 `fsync` 函数(系统调用)。`fsync` 针对单个文件操作,对其进行强制硬盘同步(文件在内核缓冲区里的数据写到硬盘),`fsync` 将阻塞直到写入磁盘完成后返回,保证了数据持久化。
4. **文件重写(rewrite)**:随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
5. **重启加载(load)**:当 Redis 重启时,可以加载 AOF 文件进行数据恢复。
@@ -79,8 +179,12 @@ AOF 持久化功能的实现可以简单分为 5 步:
这里对上面提到的一些 Linux 系统调用再做一遍解释:
-- `write`:写入系统内核缓冲区之后直接返回(仅仅是写到缓冲区),不会立即同步到硬盘。虽然提高了效率,但也带来了数据丢失的风险。同步硬盘操作通常依赖于系统调度机制,Linux 内核通常为 30s 同步一次,具体值取决于写出的数据量和 I/O 缓冲区的状态。
-- `fsync`:`fsync`用于强制刷新系统内核缓冲区(同步到到磁盘),确保写磁盘操作结束才会返回。
+- `write`:写入系统内核缓冲区之后直接返回(仅仅是写到缓冲区),不会立即同步到硬盘。虽然提高了效率,但也带来了数据丢失的风险。**同步硬盘操作取决于 Linux 内核的脏页回写策略(Dirty Page Writeback)**,主要受以下参数影响:
+ - `/proc/sys/vm/dirty_expire_centisecs`:脏页过期时间(默认 30 秒)
+ - `/proc/sys/vm/dirty_writeback_centisecs`:内核回写线程的唤醒间隔(默认 5 秒)
+ - 系统内存压力:内存不足时会更积极触发同步
+- **这意味着 `appendfsync no` 模式下宕机时,可能丢失的数据量是不可控且不可预测的**,取决于上次内核同步的时间点。
+- `fsync`:`fsync`用于强制刷新系统内核缓冲区(同步到磁盘),确保写磁盘操作结束才会返回。
AOF 工作流程图如下:
@@ -90,13 +194,24 @@ AOF 工作流程图如下:
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
-1. `appendfsync always`:主线程调用 `write` 执行写操作后,后台线程( `aof_fsync` 线程)立即会调用 `fsync` 函数同步 AOF 文件(刷盘),`fsync` 完成后线程返回,这样会严重降低 Redis 的性能(`write` + `fsync`)。
-2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)
-3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。
+1. `appendfsync always`:主线程调用 `write` 执行写操作后,会立刻调用 `fsync` 函数同步 AOF 文件(刷盘)。主线程会阻塞,直到 `fsync` 将数据完全刷到磁盘后才会返回。这种方式数据最安全,理论上不会有任何数据丢失。但因为每个写操作都会同步阻塞主线程,所以性能极差。
+2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)。这种方式主线程的性能基本不受影响。在性能和数据安全之间做出了绝佳的平衡。不过,在 Redis 异常宕机时,通常可能丢失最近 1 秒内的数据。
+
+> **生产级真相(2 秒丢失与阻塞风险)**:
+>
+> "最多丢失 1 秒"是理想情况。当磁盘 I/O 繁忙时,后台 fsync 执行时间过长,主线程在执行写命令时会检查上一次 fsync 的完成时间。如果距离上次成功 fsync 超过 2 秒,主线程将被**强制阻塞**以保护内存不被撑爆(Redis 源码 `aof.c` 中的 `aof_background_fsync` 阻塞判断逻辑)。
+>
+> 因此,**极端宕机情况下,可能会丢失最多 2 秒的数据**,且磁盘抖动会直接导致 Redis P99 延迟飙升。
+>
+> **必须监控指标**:`redis-cli INFO persistence | grep aof_delayed_fsync`(记录主线程被 fsync 阻塞的累计次数,只有启用了 AOF 才有这个字段)。
+
+3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。 这种方式性能最好,因为避免了 `fsync` 的阻塞。但数据安全性最差,宕机时丢失的数据量不可控,取决于操作系统上一次同步的时间点。
可以看出:**这 3 种持久化方式的主要区别在于 `fsync` 同步 AOF 文件的时机(刷盘)**。
-为了兼顾数据和写入性能,可以考虑 `appendfsync everysec` 选项 ,让 Redis 每秒同步一次 AOF 文件,Redis 性能受到的影响较小。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis 还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
+为了兼顾数据和写入性能,可以考虑 `appendfsync everysec` 选项 ,让 Redis 每秒同步一次 AOF 文件,Redis 性能受到的影响较小。通常情况下,即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis 还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
+
+> ⚠️ **注意**:当磁盘 I/O 瓶颈严重时,Redis 主线程可能因等待 fsync 而阻塞长达 2 秒,期间数据丢失窗口扩大至 2 秒。生产环境应监控 `aof_delayed_fsync` 指标来评估磁盘健康度。
从 Redis 7.0.0 开始,Redis 使用了 **Multi Part AOF** 机制。顾名思义,Multi Part AOF 就是将原来的单个 AOF 文件拆分成多个 AOF 文件。在 Multi Part AOF 中,AOF 文件被分为三种类型,分别为:
@@ -141,6 +256,36 @@ AOF 文件重写期间,Redis 还会维护一个 **AOF 重写缓冲区**,该
- `auto-aof-rewrite-min-size`:如果 AOF 文件大小小于该值,则不会触发 AOF 重写。默认值为 64 MB;
- `auto-aof-rewrite-percentage`:执行 AOF 重写时,当前 AOF 大小(aof_current_size)和上一次重写时 AOF 大小(aof_base_size)的比值。如果当前 AOF 文件大小增加了这个百分比值,将触发 AOF 重写。将此值设置为 0 将禁用自动 AOF 重写。默认值为 100。
+**AOF rewrite 的失败边界与风险场景**:
+
+虽然 AOF rewrite 放在子进程执行,但仍存在以下风险需要了解:
+
+| 风险场景 | 影响 | 触发条件 | 应对措施 |
+| ---------------- | --------------------------- | ------------------------ | ------------------------------------------- |
+| **fork 失败** | 无法创建 rewrite 子进程 | 内存不足、系统限制 | 监控内存使用率,设置 `maxmemory` |
+| **磁盘满** | 新 AOF 文件写入失败 | rewrite 期间数据量增长快 | 监控磁盘使用率(`df -h`),设置告警阈值 70% |
+| **inode 耗尽** | 无法创建新文件 | 小文件过多的系统 | 监控 inode 使用率(`df -i`),清理临时文件 |
+| **时间戳回拨** | Multi-Part AOF 文件管理混乱 | 虚拟机时钟同步问题 | 配置 NTP 服务,设置 `aof-timestamp-enabled` |
+| **SIGTERM 信号** | rewrite 被中断 | 运维人员手动重启 | 配置优雅关闭(`shutdown-timeout`) |
+
+**生产环境监控建议**:
+
+```bash
+# 监控 AOF rewrite 状态
+redis-cli INFO persistence | grep aof_rewrite_in_progress
+
+# 监控 AOF 文件大小增长
+redis-cli INFO persistence | grep aof_current_size
+redis-cli INFO persistence | grep aof_base_size
+
+# 检查磁盘和 inode 使用率
+df -h /var/lib/redis
+df -i /var/lib/redis
+
+# 设置 AOF rewrite 期间增量 fsync 策略(Redis 7.0+)
+# aof-rewrite-incremental-sync yes
+```
+
Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
Redis 7.0 版本之后,AOF 重写机制得到了优化改进。下面这段内容摘自阿里开发者的[从 Redis7.0 发布看 Redis 的过去与未来](https://mp.weixin.qq.com/s/RnoPPL7jiFSKkx3G4p57Pg) 这篇文章。
@@ -153,45 +298,428 @@ Redis 7.0 版本之后,AOF 重写机制得到了优化改进。下面这段内
### AOF 校验机制了解吗?
-AOF 校验机制是 Redis 在启动时对 AOF 文件进行检查,以判断文件是否完整,是否有损坏或者丢失的数据。这个机制的原理其实非常简单,就是通过使用一种叫做 **校验和(checksum)** 的数字来验证 AOF 文件。这个校验和是通过对整个 AOF 文件内容进行 CRC64 算法计算得出的数字。如果文件内容发生了变化,那么校验和也会随之改变。因此,Redis 在启动时会比较计算出的校验和与文件末尾保存的校验和(计算的时候会把最后一行保存校验和的内容给忽略点),从而判断 AOF 文件是否完整。如果发现文件有问题,Redis 就会拒绝启动并提供相应的错误信息。AOF 校验机制十分简单有效,可以提高 Redis 数据的可靠性。
+纯 AOF 模式下,Redis 不会对整个 AOF 文件使用校验和(如 CRC64),而是通过逐条解析文件中的命令来验证文件的有效性。如果解析过程中发现语法错误(如命令不完整、格式错误),Redis 会终止加载并报错,从而避免错误数据载入内存。
+
+> **尾部截断容灾(自动恢复)**:
+>
+> 在遭遇意外断电或 `kill -9` 强制终止时,AOF 文件的最后一条命令极可能写入不完整(只写了一半)。此时的恢复行为由 **`aof-load-truncated`** 配置决定:
+>
+> | 配置值 | 行为 | 适用场景 |
+> | ------------- | ------------------------------------------------------------------------------- | ---------------------------------------- |
+> | `yes`(默认) | Redis 自动丢弃文件尾部不完整的命令,继续完成启动并在日志中打印警告信息 | 生产环境推荐,允许少量数据丢失换取可用性 |
+> | `no` | Redis 拒绝启动并直接报错,强制要求人工使用 `redis-check-aof` 工具确认并修复数据 | 金融等对数据完整性要求极高的场景 |
+>
+> **验证截断恢复**:
+>
+> ```bash
+> # 模拟断电场景:向 AOF 文件追加无意义的乱码
+> echo "truncated garbage data" >> /var/lib/redis/appendonly.aof
+>
+> # 重启 Redis(aof-load-truncated=yes 时会自动恢复)
+> redis-server /path/to/redis.conf
+> # 日志输出:# Bad file format reading the append only file: make a backup of your AOF file, then use ./redis-check-aof --fix
+> ```
+>
+> **失败模式**:如果 AOF 文件的**中间部分**(而非尾部)因为磁盘静默损坏出现乱码,自动截断机制无效,Redis 将直接宕机拒绝服务。此时需要使用 `redis-check-aof --fix` 工具修复。
+
+**redis-check-aof 工作原理**:
+
+- **检测阶段**:根据 AOF 文件格式逐一读取命令,判断命令参数个数、参数字符串长度等,提供错误/不完整命令的文件位置
+- **修复阶段**:从错误位置截断后续文件内容(**注意:会丢失截断点之后的所有数据**),原文件会被备份为 `appendonly.aof.broken`
+
+**人工修补**(高级用户):
+
+- 如果不想通过截断来修复 AOF 文件,可以尝试人工修补
+- 使用文本编辑器打开 AOF 文件(纯文本格式),手动删除或修复错误命令
+- 适用于明确知道错误位置的特定场景
+
+在 **混合持久化模式**(Redis 4.0 引入)下,AOF 文件由两部分组成:
+
+- **RDB 快照部分**:文件以固定的 `REDIS` 字符开头,存储某一时刻的内存数据快照,并在快照数据末尾附带一个 CRC64 校验和(位于 RDB 数据块尾部、AOF 增量部分之前)。
+- **AOF 增量部分**:紧随 RDB 快照部分之后,记录 RDB 快照生成后的增量写命令。这部分增量命令以 Redis 协议格式逐条记录,无整体或全局校验和。
+
+RDB 文件结构的核心部分如下:
+
+| **字段** | **解释** |
+| ----------------- | ---------------------------------------------- |
+| `"REDIS"` | 固定以该字符串开始 |
+| `RDB_VERSION` | RDB 文件的版本号 |
+| `DB_NUM` | Redis 数据库编号,指明数据需要存放到哪个数据库 |
+| `KEY_VALUE_PAIRS` | Redis 中具体键值对的存储 |
+| `EOF` | RDB 文件结束标志 |
+| `CHECK_SUM` | 8 字节确保 RDB 完整性的校验和 |
+
+Redis 启动并加载 AOF 文件时,首先会校验文件开头 RDB 快照部分的数据完整性,即计算该部分数据的 CRC64 校验和,并与紧随 RDB 数据之后、AOF 增量部分之前存储的 CRC64 校验和值进行比较。如果 CRC64 校验和不匹配,Redis 将拒绝启动并报告错误。
+
+RDB 部分校验通过后,Redis 随后逐条解析 AOF 部分的增量命令。如果解析过程中出现错误(如不完整的命令或格式错误),Redis 会停止继续加载后续命令,并报告错误,但此时 Redis 已经成功加载了 RDB 快照部分的数据。
+
+## 新版本优化
+
+### Redis 4.0 对于持久化机制做了什么优化?
+
+由于 RDB 和 AOF 各有优势,于是,Redis 4.0 开始支持 RDB 和 AOF 的混合持久化。
+
+#### 配置说明
+
+```bash
+# 开启 AOF
+appendonly yes
+
+# 开启混合持久化(Redis 7.0+ 默认启用)
+aof-use-rdb-preamble yes
+
+# 优化重写触发条件
+auto-aof-rewrite-percentage 100 # AOF 文件大小比上次重写后增长 100% 时触发
+auto-aof-rewrite-min-size 64mb # AOF 文件至少达到 64MB 才触发重写
+```
+
+**版本差异**:
+
+- **Redis 4.0-6.x**:混合持久化默认关闭,需手动配置 `aof-use-rdb-preamble yes`
+- **Redis 7.0+**:混合持久化**默认启用**,无需额外配置
+
+#### 工作原理
+
+如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。
+
+**混合持久化文件结构**:
+
+```
+┌───────────────────┐
+│ RDB Header │ ← 二进制快照(压缩格式)
+│ REDIS0009 │
+│ ... │
+├───────────────────┤
+│ AOF Log Entries │ ← 文本格式命令
+│ *3\r\n$3\r\nSET\r\n$5\r\nkey01\r\n...
+│ INCR counter │
+│ ... │
+└───────────────────┘
+```
+
+**核心工作流程**:
+
+1. **写处理阶段**:
+
+ - 客户端执行写命令(`SET/INCR` 等)
+ - Redis 立即更新内存数据
+ - 将命令追加到 AOF 缓冲区(文本格式)
+
+2. **持久化触发阶段**:
+
+ - AOF 文件大小达到阈值(默认 64MB)或增长 100%
+ - 触发 AOF 重写(`BGREWRITEAOF`)
+
+3. **文件构建阶段**:
+
+ - 子进程将当前内存数据以 RDB 格式写入新 AOF 文件开头
+ - 父进程继续处理写命令,增量数据记录到重写缓冲区
+ - 重写完成后,将重写缓冲区的增量命令追加到新 AOF 文件末尾
+
+4. **数据恢复阶段**:
+ - Redis 启动时优先加载 RDB 部分(快速恢复基础数据)
+ - 然后顺序重放 AOF 增量命令(恢复最新数据)
+
+#### 优势对比
+
+| 指标 | 纯 RDB | 纯 AOF | 混合持久化 |
+| ---------------- | ------------ | -------------- | -------------- |
+| **恢复速度** | 快(秒级) | 慢(分钟级) | 快(秒级) |
+| **数据丢失窗口** | 分钟级 | ≤2 秒 | ≤2 秒 |
+| **文件大小** | 小(压缩) | 大(文本日志) | 中等 |
+| **写入影响** | 低 | 高 | 中等 |
+| **可读性** | 差(二进制) | 好(文本) | 差(RDB 部分) |
+
+**基准数据**(1GB 数据集,SSD):
+
+- 纯 AOF 恢复:30-60 秒
+- 混合持久化恢复:2-5 秒(**快 5-10 倍**)
+
+**混合持久化缺点**:
-类似地,RDB 文件也有类似的校验机制来保证 RDB 文件的正确性,这里就不重复进行介绍了。
+- AOF 文件里面的 RDB 部分是压缩格式,不再是 AOF 格式,可读性较差。
+- 需要额外消耗 CPU 进行 RDB 压缩和解压。
-## Redis 4.0 对于持久化机制做了什么优化?
+#### 常见问题及解决方案
-由于 RDB 和 AOF 各有优势,于是,Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
+**1. 配置验证**:
-如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
+```bash
+# 方法 1:检查文件头(输出 REDIS 表示启用了混合持久化)
+head -c 5 appendonly.aof
+
+# 方法 2:CLI 验证
+redis-cli CONFIG GET aof-use-rdb-preamble
+# 输出:1) "aof-use-rdb-preamble"
+# 2) "yes"
+```
+
+**2. 文件损坏恢复**:
+
+**工具说明**:
+
+| 工具 | 工作原理 | 错误检测 | 修复功能 |
+| ------------------- | ----------------------------------------------------------------- | ------------------------------------ | --------------------------------------------------- |
+| **redis-check-aof** | 根据 AOF 文件格式逐一读取命令,判断命令参数个数、参数字符串长度等 | 检测命令正确性和完整性,提供错误位置 | ✅ **支持修复**:从错误位置截断后续内容,或人工修补 |
+| **redis-check-rdb** | 按照 RDB 文件格式依次读取文件头、数据部分、文件尾 | 在读取过程中判断内容是否正确并报错 | ❌ **不支持修复**:仅检测问题,需人工修复 |
+
+**恢复步骤**:
+
+```bash
+# 步骤 1:检测 AOF 文件问题
+redis-check-aof appendonly.aof
+# 输出错误位置和原因
+
+# 步骤 2:修复 AOF 文件(从错误位置截断)
+redis-check-aof --fix appendonly.aof
+# 原 AOF 文件会被备份为 appendonly.aof.broken
+
+# 步骤 3:检测 RDB 部分
+redis-check-rdb appendonly.aof
+# 仅检测,不支持 --fix 参数
+
+# 步骤 4:如果 RDB 部分有问题,需人工修复或丢弃整个文件
+# 选项 A:人工修复(需了解 RDB 二进制格式)
+# 选项 B:删除混合持久化文件,仅使用纯 RDB 或纯 AOF 恢复
+
+# 步骤 5:启动 Redis
+redis-server --appendonly yes --appendfilename appendonly.aof
+```
+
+> **⚠️ 重要提示**:
+>
+> - **AOF 文件**:`redis-check-aof --fix` 会从错误位置截断文件,**丢失截断点之后的所有数据**
+> - **RDB 文件**:`redis-check-rdb` **不支持修复**,如果 RDB 部分损坏,整个混合持久化文件无法恢复,只能依赖备份或纯 AOF 文件
+> - **人工修复**:对于 RDB 部分,如果必须修复,需要使用十六进制编辑器(如 `hexdump`、`xxd`)手动修改二进制格式
+
+#### 生产配置建议
+
+```bash
+# 完整生产配置示例
+appendonly yes
+aof-use-rdb-preamble yes
+
+# 性能优化
+aof-rewrite-incremental-fsync yes # 增量 fsync,减少磁盘 I/O 峰值
+# 延迟敏感场景(推荐 yes)
+no-appendfsync-on-rewrite yes # 重写期间暂停 fsync,避免阻塞
+# 数据安全场景(推荐 no)
+no-appendfsync-on-rewrite no # 重写期间仍执行 fsync,可能阻塞但更安全
+
+# 容量规划建议:
+# - 预留 2x 内存作为磁盘空间
+# - 保持单个 AOF 文件 < 16GB
+# - 监控 aof_delayed_fsync 指标
+```
-官方文档地址:https://redis.io/topics/persistence
+官方文档地址:

+### Redis 7.0 对于持久化机制做了什么优化?
+
+由于 AOF 重写过程中存在内存缓冲增量数据和磁盘双写的问题,于是,Redis 7.0 开始支持 Multi-Part AOF(默认启用,可以通过配置项 `appenddirname` 指定目录)。
+
+如果把 Multi-Part AOF 启用,AOF 文件将被拆分为 base 文件(最多一个,初始全量快照,可为 RDB 或 AOF 格式)和多个 incr 文件(增量命令日志),重写期间新增命令直接写入新的 incr 文件,由 manifest 文件跟踪所有部分。这样做的好处是可以消除重写时的内存缓冲开销和双重 I/O 写入,提高性能并减少潜在的 fsync 阻塞。由于文件结构分离,INCR 文件在重写前保持只读,单文件拷贝相对安全;但跨文件的一致性备份仍需暂停重写,整体备份流程比单文件 AOF 更复杂,且在极大数据集下仍可能需监控资源。
+
+> **核心单点故障风险:manifest 文件损坏**
+>
+> Multi-Part AOF 依赖 **manifest 文件**来跟踪和管理所有 `base/incr/history` 文件,这是整个增量日志体系的核心元数据。如果 manifest 文件损坏或丢失:
+>
+> | 风险场景 | 影响 | 恢复难度 |
+> | ------------------------------ | ------------------------------------------------------- | --------------------------- |
+> | **manifest 静默损坏** | Redis 启动时无法正确识别和加载 AOF 文件,数据库无法恢复 | 极高(需手动重建 manifest) |
+> | **磁盘故障导致 manifest 丢失** | 即使 base/incr 文件完整,Redis 也无法重构文件依赖关系 | 极高(需人工干预) |
+>
+> **缓解措施**:
+>
+> ```bash
+> # 1. 备份 manifest 文件(与数据文件同等重要)
+> cp /var/lib/redis/appendonlydir/appendonly.aof.manifest /backup/
+>
+> # 2. 监控磁盘健康度(提前发现故障)
+> smartctl -a /dev/sda | grep -E "SMART overall-health self-assessment|Media_Errors"
+>
+> # 3. 定期验证 manifest 完整性(Redis 启动时会自动校验)
+> redis-check-aof /var/lib/redis/appendonlydir/appendonly.aof.manifest
+> ```
+>
+> **官方未提供自动化修复工具**,生产环境必须将 manifest 文件纳入备份策略,其重要性等同于 RDB/AOF 数据文件本身。
+
+## 生产环境监控指标
+
+### 持久化性能指标
+
+```bash
+# RDB 相关指标
+redis-cli INFO persistence | grep rdb_last_bgsave_time_sec
+# 建议:< 5s。超过 5s 说明数据集过大或 I/O 性能瓶颈
+
+redis-cli INFO persistence | grep rdb_last_cow_size
+# 建议:< 10% used_memory。超过说明 fork 的 Copy-on-Write 内存开销大
+
+redis-cli INFO memory | grep used_memory_rss
+redis-cli INFO memory | grep used_memory
+# 计算:used_memory_rss / used_memory,fork 时应 < 2
+
+# AOF 相关指标
+redis-cli INFO persistence | grep aof_rewrite_in_progress
+# 期望:0(未在重写)或 1(正在重写)
+
+redis-cli INFO persistence | grep aof_current_size
+redis-cli INFO persistence | grep aof_base_size
+# 监控增长率,避免 rewrite 过于频繁
+
+redis-cli INFO persistence | grep aof_buffer_length
+# 建议:< 4MB。过大说明主线程写入速度快于 fsync 速度
+```
+
+### 系统资源监控
+
+```bash
+# 磁盘使用率和 I/O 等待
+iostat -x 1 5 | grep dm-0
+# 关注:%util(I/O 使用率)、await(平均等待时间)
+
+# 磁盘空间(预留空间给 rewrite 生成新文件)
+df -h /var/lib/redis
+# 建议:使用率 < 70%
+
+# inode 使用率(小文件多的场景)
+df -i /var/lib/redis
+# 建议:使用率 < 90%
+
+# 内存使用率
+free -h
+# 建议:为 fork 预留至少 20% 空闲内存
+```
+
+### 告警规则建议
+
+> **指标来源说明**:
+>
+> - **Redis 指标**:通过 `redis-cli INFO` 或 Redis exporter 获取(如 `redis_rss_memory`、`aof_current_size`)
+> - **节点级指标**:通过 node_exporter 或系统命令获取(如 `disk_usage`、系统内存、CPU 使用率)
+>
+> 以下告警规则假设使用 Prometheus + Redis exporter + node_exporter 监控体系。
+
+```yaml
+alert_rules:
+ # ── Redis 持久化相关告警 ────────────────────────────────────────
+ - name: "RedisHighMemFragmentation"
+ expr: redis_memory_rss_bytes / redis_memory_used_bytes > 2
+ for: 5m
+ labels:
+ severity: warning
+ annotations:
+ summary: "Redis 内存碎片率过高,fork COW 风险上升"
+ description: >
+ 实例 {{ $labels.instance }} 的 mem_fragmentation_ratio = {{ $value | humanize }},
+ 超过阈值 2。碎片率过高意味着 OS 实际分配的物理页远多于 Redis 自身统计,
+ 执行 BGSAVE / BGREWRITEAOF 触发 fork 后,COW 需复制的页数会显著增加,
+ 在高写入负载下可能导致内存暴涨,OOM 风险上升。
+ 建议执行 MEMORY PURGE 或在低峰期重启实例整理碎片。
+
+ - name: "RedisAofGrowthTooFast"
+ expr: deriv(redis_aof_current_size_bytes[5m]) * 60 > 10485760
+ for: 5m
+ labels:
+ severity: warning
+ annotations:
+ summary: "Redis AOF 文件写入速率过高"
+ description: >
+ 实例 {{ $labels.instance }} 的 AOF 增长速率超过 10 MB/min
+ (当前约 {{ $value | humanize1024 }}B/min)。
+ 高速写入会持续触发 auto-aof-rewrite,加剧磁盘 I/O 压力,
+ 并可能产生写入放大。建议检查业务是否存在大量小命令风暴或 KEYS 类全量扫描。
+
+ - name: "RedisAofFsyncDelayed"
+ expr: rate(redis_aof_delayed_fsync_total[5m]) > 0
+ for: 2m
+ labels:
+ severity: critical
+ annotations:
+ summary: "Redis AOF fsync 延迟,主线程响应受阻"
+ description: >
+ 实例 {{ $labels.instance }} 持续出现 aof_delayed_fsync 增长,
+ 主线程因等待 AOF fsync 完成而被阻塞,直接导致命令响应 P99 劣化。
+ 常见原因:① 磁盘 I/O 带宽饱和;② appendfsync 设置为 always;
+ ③ 与其他高 I/O 进程共用磁盘。建议切换为 everysec 策略或迁移至独立磁盘。
+
+ # ── 节点级资源告警 ─────────────────────────────────────────────
+ - name: "RedisDiskUsageHigh"
+ expr: >
+ (1 - node_filesystem_avail_bytes{mountpoint="/var/lib/redis"}
+ / node_filesystem_size_bytes{mountpoint="/var/lib/redis"}) * 100 > 70
+ for: 5m
+ labels:
+ severity: warning
+ annotations:
+ summary: "Redis 数据盘使用率超过 70%"
+ description: >
+ 挂载点 /var/lib/redis 当前使用率为 {{ $value | humanize }}%。
+ AOF rewrite 期间会临时生成新文件,需预留约 1.5x 当前 AOF 大小的空间,
+ 磁盘不足将导致 rewrite 失败并触发 Redis 错误日志 "MISCONF"。
+ RDB bgsave 同理。
+ remediation: >
+ 1. 清理过期 RDB 快照与历史 AOF 文件;
+ 2. 调高 auto-aof-rewrite-min-size 降低 rewrite 频率;
+ 3. 磁盘扩容或将数据目录迁移至更大分区。
+```
+
## 如何选择 RDB 和 AOF?
关于 RDB 和 AOF 的优缺点,官网上面也给了比较详细的说明[Redis persistence](https://redis.io/docs/manual/persistence/),这里结合自己的理解简单总结一下。
**RDB 比 AOF 优秀的地方**:
-- RDB 文件存储的内容是经过压缩的二进制数据, 保存着某个时间点的数据集,文件很小,适合做数据的备份,灾难恢复。AOF 文件存储的是每一次写命令,类似于 MySQL 的 binlog 日志,通常会比 RDB 文件大很多。当 AOF 变得太大时,Redis 能够在后台自动重写 AOF。新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。不过, Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
-- 使用 RDB 文件恢复数据,直接解析还原数据即可,不需要一条一条地执行命令,速度非常快。而 AOF 则需要依次执行每个写命令,速度非常慢。也就是说,与 AOF 相比,恢复大数据集的时候,RDB 速度更快。
+- **文件紧凑,适合备份和灾难恢复**:RDB 文件存储的内容是经过压缩的二进制数据,保存着某个时间点的数据集,文件很小,非常适合做数据的备份和灾难恢复。AOF 文件存储的是每一次写命令,类似于 MySQL 的 binlog 日志,通常会比 RDB 文件大很多。当 AOF 变得太大时,Redis 能够在后台自动重写 AOF,新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。不过,Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
+- **恢复速度快**:使用 RDB 文件恢复数据,直接解析还原数据即可,不需要一条一条地执行命令,速度非常快。而 AOF 则需要依次执行每个写命令,速度非常慢。也就是说,与 AOF 相比,恢复大数据集的时候,RDB 速度更快。
+- **主从复制优势**:在副本(replica)上,RDB 支持重启和故障转移后的**部分重新同步**(Partial Resynchronization)。副本可以使用 RDB 快照快速同步到主节点的某个时间点状态,而不需要全量同步。
+- **性能开销小**:RDB 最大化 Redis 性能,因为 Redis 父进程需要做的唯一持久化工作就是 fork 子进程,子进程将完成所有其余工作。父进程永远不会执行磁盘 I/O 或类似操作。
**AOF 比 RDB 优秀的地方**:
-- RDB 的数据安全性不如 AOF,没有办法实时或者秒级持久化数据。生成 RDB 文件的过程是比较繁重的, 虽然 BGSAVE 子进程写入 RDB 文件的工作不会阻塞主线程,但会对机器的 CPU 资源和内存资源产生影响,严重的情况下甚至会直接把 Redis 服务干宕机。AOF 支持秒级数据丢失(取决 fsync 策略,如果是 everysec,最多丢失 1 秒的数据),仅仅是追加命令到 AOF 文件,操作轻量。
-- RDB 文件是以特定的二进制格式保存的,并且在 Redis 版本演进中有多个版本的 RDB,所以存在老版本的 Redis 服务不兼容新版本的 RDB 格式的问题。
-- AOF 以一种易于理解和解析的格式包含所有操作的日志。你可以轻松地导出 AOF 文件进行分析,你也可以直接操作 AOF 文件来解决一些问题。比如,如果执行`FLUSHALL`命令意外地刷新了所有内容后,只要 AOF 文件没有被重写,删除最新命令并重启即可恢复之前的状态。
+- **数据安全性更高,支持秒级持久化**:RDB 的数据安全性不如 AOF,没有办法实时或者秒级持久化数据。生成 RDB 文件的过程是比较繁重的,虽然 BGSAVE 子进程写入 RDB 文件的工作不会阻塞主线程,但会对机器的 CPU 资源和内存资源产生影响,严重的情况下甚至会直接把 Redis 服务干宕机。AOF 支持秒级数据丢失(取决于 `fsync` 策略,如果是 `everysec`,通常最多丢失 1 秒的数据;但磁盘 I/O 繁忙时可能丢失 2 秒且主线程会阻塞),仅仅是追加命令到 AOF 文件,操作轻量。
+- **版本兼容性好**:RDB 文件是以特定的二进制格式保存的,并且在 Redis 版本演进中有多个版本的 RDB,所以存在老版本的 Redis 服务不兼容新版本的 RDB 格式的问题。
+- **可读性和可操作性强**:AOF 以一种易于理解和解析的格式包含所有操作的日志。你可以轻松地导出 AOF 文件进行分析,也可以直接操作 AOF 文件来解决一些问题。比如,如果执行`FLUSHALL`命令意外地刷新了所有内容后,只要 AOF 文件没有被重写,删除最新命令并重启即可恢复之前的状态。
+- **追加日志无损坏风险**:AOF 日志是追加日志,没有寻道,也没有断电损坏问题。即使日志由于某种原因(磁盘已满或其他原因)以半写入命令结尾,`redis-check-aof` 工具也能轻松修复。
+
+**版本演进对选型的影响**:
+
+| 版本 | 关键改进 | 对 AOF 的影响 | 对选型的意义 |
+| ------------- | ---------------------------------------- | ------------------------------------------------------- | -------------------------------------------------------------- |
+| **Redis 4.0** | 引入混合持久化(`aof-use-rdb-preamble`) | AOF 重写时 base 文件使用 RDB 格式,恢复速度提升 5-10 倍 | 缓解了纯 AOF 加载慢的问题,但仍需关注重写期间的内存和 I/O 开销 |
+| **Redis 7.0** | 引入 Multi-Part AOF | 彻底消除重写期间的双写问题,内存和 I/O 开销大幅降低 | 单独使用 AOF 在生产环境更具可行性,但 fork 阻塞问题仍未解决 |
+
+**未解决的核心问题**:
-**综上**:
+- **fork 阻塞**:无论是 RDB bgsave 还是 AOF 重写,fork 操作本身都会阻塞主线程(数据集越大,阻塞时间越长)
+- **官方建议**:Redis 官方文档至今仍建议**同时开启 RDB 和 AOF**,RDB 作为额外的冷备手段,应对 AOF 文件损坏或写入错误等极端场景
-- Redis 保存的数据丢失一些也没什么影响的话,可以选择使用 RDB。
-- 不建议单独使用 AOF,因为时不时地创建一个 RDB 快照可以进行数据库备份、更快的重启以及解决 AOF 引擎错误。
-- 如果保存的数据要求安全性比较高的话,建议同时开启 RDB 和 AOF 持久化或者开启 RDB 和 AOF 混合持久化。
+**AOF 和 RDB 的交互**:
+
+当 AOF 和 RDB 持久化同时启用时:
+
+- **避免同时进行重 I/O 操作**:Redis 2.4+ 确保避免在 RDB 快照进行时触发 AOF 重写,或允许在 AOF 重写期间进行 BGSAVE。这防止两个 Redis 后台进程同时进行繁重的磁盘 I/O。
+- **AOF 重写调度**:当快照正在进行且用户显式请求日志重写操作(使用 BGREWRITEAOF)时,服务器将返回 OK 状态码,告诉用户操作已调度,重写将在快照完成后开始。
+- **重启恢复优先级**:如果 AOF 和 RDB 持久化都启用且 Redis 重启,**AOF 文件将用于重建原始数据集**,因为它被保证是最完整的。
+
+**选型建议**:
+
+| 场景 | 推荐方案 | 说明 |
+| -------------------------------- | -------------------------------------------------------------------- | ----------------------------------------------------------- |
+| **纯缓存(可丢失)** | **关闭持久化** 或仅 RDB(低频) | 完全关闭开销最小;若需冷备则保留低频 RDB |
+| **数据重要性中等**(会话、配置) | **RDB + AOF 混合持久化**(Redis 4.0+) | RDB 加速恢复,AOF 增量补充,`everysec` 最多丢 1s |
+| **数据重要性高**(业务核心数据) | **RDB + AOF(MP-AOF,Redis 7.0+)**,且 Redis 作为缓存层而非唯一存储 | MP-AOF 降低重写开销;真正的持久化由主数据库(MySQL 等)负责 |
+| **主从架构** | **主节点关闭持久化,从节点开启 AOF** | 主节点禁止配置自动重启,防止空数据集覆盖从节点 |
## 参考
- 《Redis 设计与实现》
-- Redis persistence - Redis 官方文档:https://redis.io/docs/management/persistence/
-- The difference between AOF and RDB persistence:https://www.sobyte.net/post/2022-04/redis-rdb-and-aof/
-- Redis AOF 持久化详解 - 程序员历小冰:http://remcarpediem.net/article/376c55d8/
-- Redis RDB 与 AOF 持久化 · Analyze:https://wingsxdu.com/posts/database/redis/rdb-and-aof/
+- Redis persistence - Redis 官方文档:
+- The difference between AOF and RDB persistence:
+- Redis AOF 持久化详解 - 程序员历小冰:
+- Redis RDB 与 AOF 持久化 · Analyze:
+
+
diff --git a/docs/database/redis/redis-questions-01.md b/docs/database/redis/redis-questions-01.md
index 4041cfe3d5d..284fa4367b1 100644
--- a/docs/database/redis/redis-questions-01.md
+++ b/docs/database/redis/redis-questions-01.md
@@ -1,15 +1,13 @@
---
title: Redis常见面试题总结(上)
+description: 最新Redis面试题总结(上):深入讲解Redis基础、五大常用数据结构、单线程模型原理、持久化机制、内存淘汰与过期策略、分布式锁与消息队列实现。适合准备后端面试的开发者!
category: 数据库
tag:
- Redis
head:
- - meta
- name: keywords
- content: Redis基础,Redis常见数据结构,Redis线程模型,Redis内存管理,Redis事务,Redis性能优化
- - - meta
- - name: description
- content: 一篇文章总结Redis常见的知识点和面试题,涵盖Redis基础、Redis常见数据结构、Redis线程模型、Redis内存管理、Redis事务、Redis性能优化等内容。
+ content: Redis面试题,Redis基础,Redis数据结构,Redis线程模型,Redis持久化,Redis内存管理,Redis性能优化,Redis分布式锁,Redis消息队列,Redis延时队列,Redis缓存策略,Redis单线程,Redis多线程,Redis过期策略,Redis淘汰策略
---
@@ -18,9 +16,11 @@ head:
### 什么是 Redis?
-[Redis](https://redis.io/) 是一个基于 C 语言开发的开源数据库(BSD 许可),与传统数据库不同的是 Redis 的数据是存在内存中的(内存数据库),读写速度非常快,被广泛应用于缓存方向。并且,Redis 存储的是 KV 键值对数据。
+[Redis](https://redis.io/) (**RE**mote **DI**ctionary **S**erver)是一个基于 C 语言开发的开源 NoSQL 数据库(BSD 许可)。与传统数据库不同的是,Redis 的数据是保存在内存中的(内存数据库,支持持久化),因此读写速度非常快,被广泛应用于分布式缓存方向。并且,Redis 存储的是 KV 键值对数据。
+
+为了满足不同的业务场景,Redis 内置了多种数据类型实现(比如 String、Hash、Sorted Set、Bitmap、HyperLogLog、GEO)。并且,Redis 还支持事务、持久化、Lua 脚本、发布订阅模型、多种开箱即用的集群方案(Redis Sentinel、Redis Cluster)。
-为了满足不同的业务场景,Redis 内置了多种数据类型实现(比如 String、Hash、Sorted Set、Bitmap、HyperLogLog、GEO)。并且,Redis 还支持事务、持久化、Lua 脚本、多种开箱即用的集群方案(Redis Sentinel、Redis Cluster)。
+
Redis 没有外部依赖,Linux 和 OS X 是 Redis 开发和测试最多的两个操作系统,官方推荐生产环境使用 Linux 部署 Redis。
@@ -28,31 +28,50 @@ Redis 没有外部依赖,Linux 和 OS X 是 Redis 开发和测试最多的两

-全世界有非常多的网站使用到了 Redis ,[techstacks.io](https://techstacks.io/) 专门维护了一个[使用 Redis 的热门站点列表](https://techstacks.io/tech/redis) ,感兴趣的话可以看看。
+全世界有非常多的网站使用到了 Redis,[techstacks.io](https://techstacks.io/) 专门维护了一个[使用 Redis 的热门站点列表](https://techstacks.io/tech/redis),感兴趣的话可以看看。
+
+### ⭐️Redis 为什么这么快?
+
+Redis 内部做了非常多的性能优化,比较重要的有下面 4 点:
+
+1. **纯内存操作 (Memory-Based Storage)** :这是最主要的原因。Redis 数据读写操作都发生在内存中,访问速度是纳秒级别,而传统数据库频繁读写磁盘的速度是毫秒级别,两者相差数个数量级。
+2. **高效的 I/O 模型 (I/O Multiplexing & Single-Threaded Event Loop)** :Redis 使用单线程事件循环配合 I/O 多路复用技术,让单个线程可以同时处理多个网络连接上的 I/O 事件(如读写),避免了多线程模型中的上下文切换和锁竞争问题。虽然是单线程,但结合内存操作的高效性和 I/O 多路复用,使得 Redis 能轻松处理大量并发请求(Redis 线程模型会在后文中详细介绍到)。
+3. **优化的内部数据结构 (Optimized Data Structures)** :Redis 提供多种数据类型(如 String, List, Hash, Set, Sorted Set 等),其内部实现采用高度优化的编码方式(如 ziplist, quicklist, skiplist, hashtable 等)。Redis 会根据数据大小和类型动态选择最合适的内部编码,以在性能和空间效率之间取得最佳平衡。
+4. **简洁高效的通信协议 (Simple Protocol - RESP)** :Redis 使用的是自己设计的 RESP (REdis Serialization Protocol) 协议。这个协议实现简单、解析性能好,并且是二进制安全的。客户端和服务端之间通信的序列化/反序列化开销很小,有助于提升整体的交互速度。
+
+> 下面这张图片总结的挺不错的,分享一下,出自 [Why is Redis so fast?](https://twitter.com/alexxubyte/status/1498703822528544770)。
+
+
-### Redis 为什么这么快?
+那既然都这么快了,为什么不直接用 Redis 当主数据库呢?主要是因为内存成本太高,并且 Redis 提供的数据持久化仍然有数据丢失的风险。
-Redis 内部做了非常多的性能优化,比较重要的有下面 3 点:
+### 除了 Redis,你还知道其他分布式缓存方案吗?
-1. Redis 基于内存,内存的访问速度是磁盘的上千倍;
-2. Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型,主要是单线程事件循环和 IO 多路复用(Redis 线程模式后面会详细介绍到);
-3. Redis 内置了多种优化过后的数据结构实现,性能非常高。
+如果面试中被问到这个问题的话,面试官主要想看看:
-下面这张图片总结的挺不错的,分享一下,出自 [Why is Redis so fast?](https://twitter.com/alexxubyte/status/1498703822528544770) 。
+1. 你在选择 Redis 作为分布式缓存方案时,是否是经过严谨的调研和思考,还是只是因为 Redis 是当前的“热门”技术。
+2. 你在分布式缓存方向的技术广度。
-
+如果你了解其他方案,并且能解释为什么最终选择了 Redis(更进一步!),这会对你面试表现加分不少!
-### 分布式缓存常见的技术选型方案有哪些?
+下面简单聊聊常见的分布式缓存技术选型。
分布式缓存的话,比较老牌同时也是使用的比较多的还是 **Memcached** 和 **Redis**。不过,现在基本没有看过还有项目使用 **Memcached** 来做缓存,都是直接用 **Redis**。
Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
-另外,腾讯也开源了一款类似于 Redis 的分布式高性能 KV 存储数据库,基于知名的开源项目 [RocksDB](https://github.com/facebook/rocksdb) 作为存储引擎 ,100% 兼容 Redis 协议和 Redis4.0 所有数据模型,名为 [Tendis](https://github.com/Tencent/Tendis)。
+有一些大厂也开源了类似于 Redis 的分布式高性能 KV 存储数据库,例如,腾讯开源的 [**Tendis**](https://github.com/Tencent/Tendis)。Tendis 基于知名开源项目 [RocksDB](https://github.com/facebook/rocksdb) 作为存储引擎 ,100% 兼容 Redis 协议和 Redis4.0 所有数据模型。关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:[Redis vs Tendis:冷热混合存储版架构揭秘](https://mp.weixin.qq.com/s/MeYkfOIdnU6LYlsGb24KjQ),可以简单参考一下。
-关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:[Redis vs Tendis:冷热混合存储版架构揭秘](https://mp.weixin.qq.com/s/MeYkfOIdnU6LYlsGb24KjQ) ,可以简单参考一下。
+不过,从 Tendis 这个项目的 Github 提交记录可以看出,Tendis 开源版几乎已经没有被维护更新了,加上其关注度并不高,使用的公司也比较少。因此,不建议你使用 Tendis 来实现分布式缓存。
-从这个项目的 GitHub 提交记录可以看出,Tendis 开源版几乎已经没有被维护更新了,加上其关注度并不高,使用的公司也比较少。因此,不建议你使用 Tendis 来实现分布式缓存。
+目前,比较业界认可的 Redis 替代品还是下面这两个开源分布式缓存(都是通过碰瓷 Redis 火的):
+
+- [Dragonfly](https://github.com/dragonflydb/dragonfly):一种针对现代应用程序负荷需求而构建的内存数据库,完全兼容 Redis 和 Memcached 的 API,迁移时无需修改任何代码,号称全世界最快的内存数据库。
+- [KeyDB](https://github.com/Snapchat/KeyDB):Redis 的一个高性能分支,专注于多线程、内存效率和高吞吐量。
+
+不过,个人还是建议分布式缓存首选 Redis,毕竟经过了这么多年的考验,生态非常优秀,资料也很全面!
+
+PS:篇幅问题,我这并没有对上面提到的分布式缓存选型做详细介绍和对比,感兴趣的话,可以自行研究一下。
### 说一下 Redis 和 Memcached 的区别和共同点
@@ -66,155 +85,164 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
**区别**:
-1. **Redis 支持更丰富的数据类型(支持更复杂的应用场景)**。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型。
-2. **Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memcached 把数据全部存在内存之中。**
-3. **Redis 有灾难恢复机制。** 因为可以把缓存中的数据持久化到磁盘上。
-4. **Redis 在服务器内存使用完之后,可以将不用的数据放到磁盘上。但是,Memcached 在服务器内存使用完之后,就会直接报异常。**
-5. **Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 cluster 模式的。**
-6. **Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。** (Redis 6.0 针对网络数据的读写引入了多线程)
-7. **Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。**
-8. **Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。**
+1. **数据类型**:Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list、set、zset、hash 等数据结构的存储;而 Memcached 只支持最简单的 k/v 数据类型。
+2. **数据持久化**:Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用;而 Memcached 把数据全部存在内存之中。也就是说,Redis 有灾难恢复机制,而 Memcached 没有。
+3. **集群模式支持**:Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;而 Redis 自 3.0 版本起是原生支持集群模式的。
+4. **线程模型**:Memcached 是多线程、非阻塞 IO 复用的网络模型;而 Redis 使用单线程的多路 IO 复用模型(Redis 6.0 针对网络数据的读写引入了多线程)。
+5. **特性支持**:Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。
+6. **过期数据删除**:Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。
相信看了上面的对比之后,我们已经没有什么理由可以选择使用 Memcached 来作为自己项目的分布式缓存了。
-### 为什么要用 Redis/为什么要用缓存?
+### ⭐️为什么要用 Redis?
-下面我们主要从“高性能”和“高并发”这两点来回答这个问题。
+**1、访问速度更快**
-**1、高性能**
-
-假如用户第一次访问数据库中的某些数据的话,这个过程是比较慢,毕竟是从硬盘中读取的。但是,如果说,用户访问的数据属于高频数据并且不会经常改变的话,那么我们就可以很放心地将该用户访问的数据存在缓存中。
-
-**这样有什么好处呢?** 那就是保证用户下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。
+传统数据库数据保存在磁盘,而 Redis 基于内存,内存的访问速度比磁盘快很多。引入 Redis 之后,我们可以把一些高频访问的数据放到 Redis 中,这样下次就可以直接从内存中读取,速度可以提升几十倍甚至上百倍。
**2、高并发**
-一般像 MySQL 这类的数据库的 QPS 大概都在 1w 左右(4 核 8g) ,但是使用 Redis 缓存之后很容易达到 10w+,甚至最高能达到 30w+(就单机 Redis 的情况,Redis 集群的话会更高)。
+一般像 MySQL 这类的数据库的 QPS 大概都在 4k 左右(4 核 8g),但是使用 Redis 缓存之后很容易达到 5w+,甚至能达到 10w+(就单机 Redis 的情况,Redis 集群的话会更高)。
> QPS(Query Per Second):服务器每秒可以执行的查询次数;
由此可见,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高了系统整体的并发。
-### 常见的缓存读写策略有哪些?
+**3、功能全面**
-关于常见的缓存读写策略的详细介绍,可以看我写的这篇文章:[3 种常用的缓存读写策略详解](https://javaguide.cn/database/redis/3-commonly-used-cache-read-and-write-strategies.html) 。
+Redis 除了可以用作缓存之外,还可以用于分布式锁、限流、消息队列、延时队列等场景,功能强大!
-## Redis 应用
+### ⭐️为什么用 Redis 而不用本地缓存呢?
-### Redis 除了做缓存,还能做什么?
+| 特性 | 本地缓存 | Redis |
+| ------------ | ------------------------------------ | -------------------------------- |
+| 数据一致性 | 多服务器部署时存在数据不一致问题 | 数据一致 |
+| 内存限制 | 受限于单台服务器内存 | 独立部署,内存空间更大 |
+| 数据丢失风险 | 服务器宕机数据丢失 | 可持久化,数据不易丢失 |
+| 管理维护 | 分散,管理不便 | 集中管理,提供丰富的管理工具 |
+| 功能丰富性 | 功能有限,通常只提供简单的键值对存储 | 功能丰富,支持多种数据结构和功能 |
-- **分布式锁**:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 。
-- **限流**:一般是通过 Redis + Lua 脚本的方式来实现限流。相关阅读:[《我司用了 6 年的 Redis 分布式限流器,可以说是非常厉害了!》](https://mp.weixin.qq.com/s/kyFAWH3mVNJvurQDt4vchA)。
-- **消息队列**:Redis 自带的 list 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
-- **复杂业务场景**:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 bitmap 统计活跃用户、通过 sorted set 维护排行榜。
-- ......
+关于本地缓存、分布式缓存和多级缓存的详细介绍,可以看我写的这篇文章:[缓存基础常见面试题总结](http://localhost:8080/database/redis/cache-basics.html)。
-### 如何基于 Redis 实现分布式锁?
+### 常见的缓存读写策略有哪些?
-关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 。
+关于常见的缓存读写策略的详细介绍,可以看我写的这篇文章:[3 种常用的缓存读写策略详解](https://javaguide.cn/database/redis/3-commonly-used-cache-read-and-write-strategies.html)。
-### Redis 可以做消息队列么?
+### 什么是 Redis Module?有什么用?
-> 实际项目中也没见谁使用 Redis 来做消息队列,对于这部分知识点大家了解就好了。
+Redis 从 4.0 版本开始,支持通过 Module 来扩展其功能以满足特殊的需求。这些 Module 以动态链接库(so 文件)的形式被加载到 Redis 中,这是一种非常灵活的动态扩展功能的实现方式,值得借鉴学习!
-先说结论:可以是可以,但不建议使用 Redis 来做消息队列。和专业的消息队列相比,还是有很多欠缺的地方。
+我们每个人都可以基于 Redis 去定制化开发自己的 Module,比如实现搜索引擎功能、自定义分布式锁和分布式限流。
-**Redis 2.0 之前,如果想要使用 Redis 来做消息队列的话,只能通过 List 来实现。**
+目前,被 Redis 官方推荐的 Module 有:
-通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`即可实现简易版消息队列:
+- [RediSearch](https://github.com/RediSearch/RediSearch):用于实现搜索引擎的模块。
+- [RedisJSON](https://github.com/RedisJSON/RedisJSON):用于处理 JSON 数据的模块。
+- [RedisGraph](https://github.com/RedisGraph/RedisGraph):用于实现图形数据库的模块。
+- [RedisTimeSeries](https://github.com/RedisTimeSeries/RedisTimeSeries):用于处理时间序列数据的模块。
+- [RedisBloom](https://github.com/RedisBloom/RedisBloom):用于实现布隆过滤器的模块。
+- [RedisAI](https://github.com/RedisAI/RedisAI):用于执行深度学习/机器学习模型并管理其数据的模块。
+- [RedisCell](https://github.com/brandur/redis-cell):用于实现分布式限流的模块。
+- ……
-```bash
-# 生产者生产消息
-> RPUSH myList msg1 msg2
-(integer) 2
-> RPUSH myList msg3
-(integer) 3
-# 消费者消费消息
-> LPOP myList
-"msg1"
-```
+关于 Redis 模块的详细介绍,可以查看官方文档:。
-不过,通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`这样的方式存在性能问题,我们需要不断轮询去调用 `RPOP` 或 `LPOP` 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
+## ⭐️Redis 应用
-因此,Redis 还提供了 `BLPOP`、`BRPOP` 这种阻塞式读取的命令(带 B-Bloking 的都是阻塞式),并且还支持一个超时参数。如果 List 为空,Redis 服务端不会立刻返回结果,它会等待 List 中有新数据后在返回或者是等待最多一个超时时间后返回空。如果将超时时间设置为 0 时,即可无限等待,直到弹出消息
+### Redis 除了做缓存,还能做什么?
-```bash
-# 超时时间为 10s
-# 如果有数据立刻返回,否则最多等待10秒
-> BRPOP myList 10
-null
-```
+- **分布式锁**:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html)。
+- **限流**:一般是通过 Redis + Lua 脚本的方式来实现限流。如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的 `RRateLimiter` 来实现分布式限流,其底层实现就是基于 Lua 代码+令牌桶算法。
+- **消息队列**:Redis 自带的 List 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
+- **延时队列**:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
+- **分布式 Session**:利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
+- **复杂业务场景**:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景,比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜、通过 HyperLogLog 统计网站 UV 和 PV。
+- ……
+
+### 如何基于 Redis 实现分布式锁?
-**List 实现消息队列功能太简单,像消息确认机制等功能还需要我们自己实现,最要命的是没有广播机制,消息也只能被消费一次。**
+关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock-implementations.html)。
-**Redis 2.0 引入了发布订阅 (pub/sub) 功能,解决了 List 实现消息队列没有广播机制的问题。**
+### Redis 可以做消息队列么?怎么实现?
-
+先说结论:
-pub/sub 中引入了一个概念叫 **channel(频道)**,发布订阅机制的实现就是基于这个 channel 来做的。
+- **如果业务简单、量小、追求极致性能**,且能容忍极小概率的数据丢失,使用 **Redis Stream** 是最优解,因为它省去了部署维护 MQ 的成本,可以复用现有的 Redis 组件(大部分需要用到 MQ 的项目,通常都会需要 Redis)。
+- **如果是金融级业务、海量数据、需要严格保证不丢消息**,必须选择 **Kafka、RabbitMQ** 等更成熟的 MQ。
-pub/sub 涉及发布者(Publisher)和订阅者(Subscriber,也叫消费者)两个角色:
+这个问题还是挺重要,技术选型也能用上,我专门写了一篇文章详细介绍和分析,推荐时间充足的同学抽空认真看几遍,收藏一下:[Redis 能做消息队列吗?怎么实现?](https://javaguide.cn/database/redis/redis-stream-mq.html)。
-- 发布者通过 `PUBLISH` 投递消息给指定 channel。
-- 订阅者通过`SUBSCRIBE`订阅它关心的 channel。并且,订阅者可以订阅一个或者多个 channel。
+### 如何基于 Redis 实现延时任务?
-我们这里启动 3 个 Redis 客户端来简单演示一下:
+> 类似的问题:
+>
+> - 订单在 10 分钟后未支付就失效,如何用 Redis 实现?
+> - 红包 24 小时未被查收自动退还,如何用 Redis 实现?
-
+基于 Redis 实现延时任务的功能无非就下面两种方案:
-pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不过,消息丢失(客户端断开连接或者 Redis 宕机都会导致消息丢失)、消息堆积(发布者发布消息的时候不会管消费者的具体消费能力如何)等问题依然没有一个比较好的解决办法。
+1. Redis 过期事件监听。
+2. Redisson 内置的延时队列。
-为此,Redis 5.0 新增加的一个数据结构 `Stream` 来做消息队列。`Stream` 支持:
+Redis 过期事件监听存在时效性较差、丢消息、多服务实例下消息重复消费等问题,不被推荐使用。
-- 发布 / 订阅模式
-- 按照消费者组进行消费
-- 消息持久化( RDB 和 AOF)
+Redisson 内置的延时队列具备下面这些优势:
-`Stream` 使用起来相对要麻烦一些,这里就不演示了。而且,`Stream` 在实际使用中依然会有一些小问题不太好解决比如在 Redis 发生故障恢复后不能保证消息至少被消费一次。
+1. **减少了丢消息的可能**:DelayedQueue 中的消息会被持久化,即使 Redis 宕机了,根据持久化机制,也只可能丢失一点消息,影响不大。当然了,你也可以使用扫描数据库的方法作为补偿机制。
+2. **消息不存在重复消费问题**:每个客户端都是从同一个目标队列中获取任务的,不存在重复消费的问题。
-综上,和专业的消息队列相比,使用 Redis 来实现消息队列还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。因此,我们通常建议不要使用 Redis 来做消息队列,你完全可以选择市面上比较成熟的一些消息队列比如 RocketMQ、Kafka。
+关于 Redis 实现延时任务的详细介绍,可以看我写的这篇文章:[如何基于 Redis 实现延时任务?](./redis-delayed-task.md)。
-相关阅读:[Redis 消息队列发展历程 - 阿里开发者 - 2022](https://mp.weixin.qq.com/s/gCUT5TcCQRAxYkTJfTRjJw)。
+## ⭐️Redis 数据类型
-## Redis 数据结构
+关于 Redis 5 种基础数据类型和 3 种特殊数据类型的详细介绍请看下面这两篇文章以及 [Redis 官方文档](https://redis.io/docs/data-types/):
-> 关于 Redis 5 种基础数据结构和 3 种特殊数据结构的详细介绍请看下面这两篇文章:
->
-> - [Redis 5 种基本数据结构详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)
-> - [Redis 3 种特殊数据结构详解](https://javaguide.cn/database/redis/redis-data-structures-02.html)
+- [Redis 5 种基本数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)
+- [Redis 3 种特殊数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-02.html)
-### Redis 常用的数据结构有哪些?
+### Redis 常用的数据类型有哪些?
-- **5 种基础数据结构**:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
-- **3 种特殊数据结构**:HyperLogLogs(基数统计)、Bitmap (位存储)、Geospatial (地理位置)。
+Redis 中比较常见的数据类型有下面这些:
+
+- **5 种基础数据类型**:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
+- **3 种特殊数据类型**:HyperLogLog(基数统计)、Bitmap (位图)、Geospatial (地理位置)。
+
+除了上面提到的之外,还有一些其他的比如 [Bloom filter(布隆过滤器)](https://javaguide.cn/cs-basics/data-structure/bloom-filter.html)、Bitfield(位域)。
### String 的应用场景有哪些?
-String 是 Redis 中最简单同时也是最常用的一个数据结构。String 是一种二进制安全的数据结构,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
+String 是 Redis 中最简单同时也是最常用的一个数据类型。它是一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
String 的常见应用场景如下:
-- 常规数据(比如 session、token、序列化后的对象、图片的路径)的缓存;
+- 常规数据(比如 Session、Token、序列化后的对象、图片的路径)的缓存;
- 计数比如用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数;
-- 分布式锁(利用 `SETNX key value` 命令可以实现一个最简易的分布式锁);
-- ......
+- 分布式锁(利用 `SETNX key value` 命令可以实现一个最简易的分布式锁);
+- ……
-关于 String 的详细介绍请看这篇文章:[Redis 5 种基本数据结构详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)。
+关于 String 的详细介绍请看这篇文章:[Redis 5 种基本数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)。
### String 还是 Hash 存储对象数据更好呢?
-- String 存储的是序列化后的对象数据,存放的是整个对象。Hash 是对对象的每个字段单独存储,可以获取部分字段的信息,也可以修改或者添加部分字段,节省网络流量。如果对象中某些字段需要经常变动或者经常需要单独查询对象中的个别字段信息,Hash 就非常适合。
-- String 存储相对来说更加节省内存,缓存相同数量的对象数据,String 消耗的内存约是 Hash 的一半。并且,存储具有多层嵌套的对象时也方便很多。如果系统对性能和资源消耗非常敏感的话,String 就非常适合。
+简单对比一下二者:
+
+- **对象存储方式**:String 存储的是序列化后的对象数据,存放的是整个对象,操作简单直接。Hash 是对对象的每个字段单独存储,可以获取部分字段的信息,也可以修改或者添加部分字段,节省网络流量。如果对象中某些字段需要经常变动或者经常需要单独查询对象中的个别字段信息,Hash 就非常适合。
+- **内存消耗**:Hash 通常比 String 更节省内存,特别是在字段较多且字段长度较短时。Redis 对小型 Hash 进行优化(如使用 ziplist 存储),进一步降低内存占用。
+- **复杂对象存储**:String 在处理多层嵌套或复杂结构的对象时更方便,因为无需处理每个字段的独立存储和操作。
+- **性能**:String 的操作通常具有 O(1) 的时间复杂度,因为它存储的是整个对象,操作简单直接,整体读写的性能较好。Hash 由于需要处理多个字段的增删改查操作,在字段较多且经常变动的情况下,可能会带来额外的性能开销。
+
+总结:
-在绝大部分情况,我们建议使用 String 来存储对象数据即可!
+- 在绝大多数情况下,**String** 更适合存储对象数据,尤其是当对象结构简单且整体读写是主要操作时。
+- 如果你需要频繁操作对象的部分字段或节省内存,**Hash** 可能是更好的选择。
### String 的底层实现是什么?
-Redis 是基于 C 语言编写的,但 Redis 的 String 类型的底层实现并不是 C 语言中的字符串(即以空字符 `\0` 结尾的字符数组),而是自己编写了 [SDS](https://github.com/antirez/sds)(Simple Dynamic String,简单动态字符串) 来作为底层实现。
+Redis 是基于 C 语言编写的,但 Redis 的 String 类型的底层实现并不是 C 语言中的字符串(即以空字符 `\0` 结尾的字符数组),而是自己编写了 [SDS](https://github.com/antirez/sds)(Simple Dynamic String,简单动态字符串)来作为底层实现。
SDS 最早是 Redis 作者为日常 C 语言开发而设计的 C 字符串,后来被应用到了 Redis 上,并经过了大量的修改完善以适合高性能操作。
-Redis7.0 的 SDS 的部分源码如下(https://github.com/redis/redis/blob/7.0/src/sds.h):
+Redis7.0 的 SDS 的部分源码如下():
```c
/* Note: sdshdr5 is never used, we just access the flags byte directly.
@@ -249,7 +277,7 @@ struct __attribute__ ((__packed__)) sdshdr64 {
};
```
-通过源码可以看出,SDS 共有五种实现方式 SDS_TYPE_5(并未用到)、SDS_TYPE_8、SDS_TYPE_16、SDS_TYPE_32、SDS_TYPE_64,其中只有后四种实际用到。Redis 会根据初始化的长度决定使用哪种类型,从而减少内存的使用。
+通过源码可以看出,SDS 共有五种实现方式:SDS_TYPE_5(并未用到)、SDS_TYPE_8、SDS_TYPE_16、SDS_TYPE_32、SDS_TYPE_64,其中只有后四种实际用到。Redis 会根据初始化的长度决定使用哪种类型,从而减少内存的使用。
| 类型 | 字节 | 位 |
| -------- | ---- | --- |
@@ -261,10 +289,10 @@ struct __attribute__ ((__packed__)) sdshdr64 {
对于后四种实现都包含了下面这 4 个属性:
-- `len`:字符串的长度也就是已经使用的字节数
-- `alloc`:总共可用的字符空间大小,alloc-len 就是 SDS 剩余的空间大小
-- `buf[]`:实际存储字符串的数组
-- `flags`:低三位保存类型标志
+- `len`:字符串的长度也就是已经使用的字节数。
+- `alloc`:总共可用的字符空间大小,alloc-len 就是 SDS 剩余的空间大小。
+- `buf[]`:实际存储字符串的数组。
+- `flags`:低三位保存类型标志。
SDS 相比于 C 语言中的字符串有如下提升:
@@ -306,9 +334,9 @@ struct sdshdr {
### 使用 Redis 实现一个排行榜怎么做?
-Redis 中有一个叫做 `sorted set` 的数据结构经常被用在各种排行榜的场景,比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
+Redis 中有一个叫做 `Sorted Set`(有序集合)的数据类型经常被用在各种排行榜的场景,比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
-相关的一些 Redis 命令: `ZRANGE` (从小到大排序)、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
+相关的一些 Redis 命令:`ZRANGE`(从小到大排序)、`ZREVRANGE`(从大到小排序)、`ZREVRANK`(指定元素排名)。

@@ -316,27 +344,37 @@ Redis 中有一个叫做 `sorted set` 的数据结构经常被用在各种排行

+### Redis 的有序集合底层为什么要用跳表,而不用平衡树、红黑树或者 B+ 树?
+
+这道面试题很多大厂比较喜欢问,难度还是有点大的。
+
+- 平衡树 vs 跳表:平衡树的插入、删除和查询的时间复杂度和跳表一样都是 **O(log n)**。对于范围查询来说,平衡树也可以通过中序遍历的方式达到和跳表一样的效果。但是它的每一次插入或者删除操作都需要保证整颗树左右节点的绝对平衡,只要不平衡就要通过旋转操作来保持平衡,这个过程是比较耗时的。跳表诞生的初衷就是为了克服平衡树的一些缺点。跳表使用概率平衡而不是严格强制的平衡,因此,跳表中的插入和删除算法比平衡树的等效算法简单得多,速度也快得多。
+- 红黑树 vs 跳表:相比较于红黑树来说,跳表的实现也更简单一些,不需要通过旋转和染色(红黑变换)来保证黑平衡。并且,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
+- B+ 树 vs 跳表:B+ 树更适合作为数据库和文件系统中常用的索引结构之一,它的核心思想是通过可能少的 IO 定位到尽可能多的索引来获得查询数据。对于 Redis 这种内存数据库来说,它对这些并不感冒,因为 Redis 作为内存数据库它不可能存储大量的数据,所以对于索引不需要通过 B+ 树这种方式进行维护,只需按照概率进行随机维护即可,节约内存。而且使用跳表实现 zset 时相较前者来说更简单一些,在进行插入时只需通过索引将数据插入到链表中合适的位置再随机维护一定高度的索引即可,也不需要像 B+ 树那样插入时发现失衡时还需要对节点分裂与合并。
+
+另外,我还单独写了一篇文章从有序集合的基本使用到跳表的源码分析和实现,让你会对 Redis 的有序集合底层实现的跳表有着更深刻的理解和掌握:[Redis 为什么用跳表实现有序集合](https://javaguide.cn/database/redis/redis-skiplist.html)。
+
### Set 的应用场景是什么?
Redis 中 `Set` 是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 `HashSet` 。
-Set 的常见应用场景如下:
+`Set` 的常见应用场景如下:
-- 存放的数据不能重复的场景:网站 UV 统计(数据量巨大的场景还是 `HyperLogLog`更适合一些)、文章点赞、动态点赞等等。
-- 需要获取多个数据源交集、并集和差集的场景:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集) 等等。
+- 存放的数据不能重复的场景:网站 UV 统计(数据量巨大的场景还是 `HyperLogLog` 更适合一些)、文章点赞、动态点赞等等。
+- 需要获取多个数据源交集、并集和差集的场景:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集)等等。
- 需要随机获取数据源中的元素的场景:抽奖系统、随机点名等等。
### 使用 Set 实现抽奖系统怎么做?
-如果想要使用 Set 实现一个简单的抽奖系统的话,直接使用下面这几个命令就可以了:
+如果想要使用 `Set` 实现一个简单的抽奖系统的话,直接使用下面这几个命令就可以了:
- `SADD key member1 member2 ...`:向指定集合添加一个或多个元素。
- `SPOP key count`:随机移除并获取指定集合中一个或多个元素,适合不允许重复中奖的场景。
-- `SRANDMEMBER key count` : 随机获取指定集合中指定数量的元素,适合允许重复中奖的场景。
+- `SRANDMEMBER key count`:随机获取指定集合中指定数量的元素,适合允许重复中奖的场景。
### 使用 Bitmap 统计活跃用户怎么做?
-Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
+Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap,只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。
@@ -355,7 +393,7 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
(integer) 0
```
-统计 20210308~20210309 总活跃用户数:
+统计 20210308~20210309 总活跃用户数:
```bash
> BITOP and desk1 20210308 20210309
@@ -364,7 +402,7 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
(integer) 1
```
-统计 20210308~20210309 在线活跃用户数:
+统计 20210308~20210309 在线活跃用户数:
```bash
> BITOP or desk2 20210308 20210309
@@ -373,6 +411,27 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
(integer) 2
```
+### HyperLogLog 适合什么场景?
+
+HyperLogLog (HLL) 是一种非常巧妙的概率性数据结构,它专门解决一类非常棘手的大数据问题:在海量数据中,用极小的内存,估算一个集合中不重复元素的数量,也就是我们常说的基数(Cardinality)
+
+HLL 做的最核心的权衡,就是用一点点精确度的损失,来换取巨大的内存空间节省。它给出的不是一个 100%精确的数字,而是一个带有很小标准误差(Redis 中默认是 0.81%)的近似值。
+
+**基于这个核心权衡,HyperLogLog 最适合以下特征的场景:**
+
+1. **数据量巨大,内存敏感:** 这是 HLL 的主战场。比如,要统计一个亿级日活 App 的每日独立访客数。如果用传统的 Set 来存储用户 ID,一个 ID 占几十个字节,上亿个 ID 可能需要几个 GB 甚至几十 GB 的内存,这在很多场景下是不可接受的。而 HLL,在 Redis 中只需要固定的 12KB 内存,就能处理天文数字级别的基数,这是一个颠覆性的优势。
+2. **对结果的精确度要求不是 100%:** 这是使用 HLL 的前提。比如,产品经理想知道一个热门帖子的 UV(独立访客数)是大约 1000 万还是 1010 万,这个细微的差别通常不影响商业决策。但如果场景是统计一个交易系统的准确交易笔数,那 HLL 就完全不适用,因为金融场景要求 100%的精确。
+
+**所以,HyperLogLog 具体的应用场景就非常清晰了:**
+
+- **网站/App 的 UV(Unique Visitor)统计:** 比如统计首页每天有多少个不同的 IP 或用户 ID 访问过。
+- **搜索引擎关键词统计:** 统计每天有多少个不同的用户搜索了某个关键词。
+- **社交网络互动统计:** 比如统计一条微博被多少个不同的用户转发过。
+
+在这些场景下,我们关心的是数量级和趋势,而不是个位数的差异。
+
+最后,Redis 的实现还非常智能,它内部会根据基数的大小,在**稀疏矩阵**(占用空间更小)和**稠密矩阵**(固定的 12KB)之间自动切换,进一步优化了内存使用。总而言之,当您需要对海量数据进行去重计数,并且可以接受微小误差时,HyperLogLog 就是不二之选。
+
### 使用 HyperLogLog 统计页面 UV 怎么做?
使用 HyperLogLog 统计页面 UV 主要需要用到下面这两个命令:
@@ -392,19 +451,31 @@ PFADD PAGE_1:UV USER1 USER2 ...... USERn
PFCOUNT PAGE_1:UV
```
-## Redis 持久化机制(重要)
+### 如果我想判断一个元素是否不在海量元素集合中,用什么数据类型?
+
+这是布隆过滤器的经典应用场景。布隆过滤器可以告诉你一个元素一定不存在或者可能存在,它也有极高的空间效率和一定的误判率,但绝不会漏报。也就是说,布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
+
+Bloom Filter 的简单原理图如下:
+
+
-Redis 持久化机制(RDB 持久化、AOF 持久化、RDB 和 AOF 的混合持久化) 相关的问题比较多,也比较重要,于是我单独抽了一篇文章来总结 Redis 持久化机制相关的知识点和问题:[Redis 持久化机制详解](https://javaguide.cn/database/redis/redis-persistence.html) 。
+当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后将对应的位数组的下标设置为 1(当位数组初始化时,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
-## Redis 线程模型(重要)
+如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
-对于读写命令来说,Redis 一直是单线程模型。不过,在 Redis 4.0 版本之后引入了多线程来执行一些大键值对的异步删除操作, Redis 6.0 版本之后引入了多线程来处理网络请求(提高网络 IO 读写性能)。
+## ⭐️Redis 持久化机制(重要)
+
+Redis 持久化机制(RDB 持久化、AOF 持久化、RDB 和 AOF 的混合持久化)相关的问题比较多,也比较重要,于是我单独抽了一篇文章来总结 Redis 持久化机制相关的知识点和问题:[Redis 持久化机制详解](https://javaguide.cn/database/redis/redis-persistence.html)。
+
+## ⭐️Redis 线程模型(重要)
+
+对于读写命令来说,Redis 一直是单线程模型。不过,在 Redis 4.0 版本之后引入了多线程来执行一些大键值对的异步删除操作,Redis 6.0 版本之后引入了多线程来处理网络请求(提高网络 IO 读写性能)。
### Redis 单线程模型了解吗?
-**Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型** (Netty 的线程模型也基于 Reactor 模式,Reactor 模式不愧是高性能 IO 的基石),这套事件处理模型对应的是 Redis 中的文件事件处理器(file event handler)。由于文件事件处理器(file event handler)是单线程方式运行的,所以我们一般都说 Redis 是单线程模型。
+**Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型**(Netty 的线程模型也基于 Reactor 模式,Reactor 模式不愧是高性能 IO 的基石),这套事件处理模型对应的是 Redis 中的文件事件处理器(file event handler)。由于文件事件处理器(file event handler)是单线程方式运行的,所以我们一般都说 Redis 是单线程模型。
-《Redis 设计与实现》有一段话是如是介绍文件事件处理器的,我觉得写得挺不错。
+《Redis 设计与实现》有一段话是这样介绍文件事件处理器的,我觉得写得挺不错。
> Redis 基于 Reactor 模式开发了自己的网络事件处理器:这个处理器被称为文件事件处理器(file event handler)。
>
@@ -428,27 +499,29 @@ Redis 通过 **IO 多路复用程序** 来监听来自客户端的大量连接

-相关阅读:[Redis 事件机制详解](http://remcarpediem.net/article/1aa2da89/) 。
-
### Redis6.0 之前为什么不使用多线程?
-虽然说 Redis 是单线程模型,但是,实际上,**Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。**
+虽然说 Redis 是单线程模型,但实际上,**Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。**
+
+不过,Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主线程之外的其他线程来“异步处理”,从而减少对主线程的影响。
-不过,Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主线程之外的其他线程来“异步处理”。
+为此,Redis 4.0 之后新增了几个异步命令:
-为此,Redis 4.0 之后新增了`UNLINK`(可以看作是 `DEL` 的异步版本)、`FLUSHALL ASYNC`(清空所有数据库的所有 key,不仅仅是当前 `SELECT` 的数据库)、`FLUSHDB ASYNC`(清空当前 `SELECT` 数据库中的所有 key)等异步命令。
+- `UNLINK`:可以看作是 `DEL` 命令的异步版本。
+- `FLUSHALL ASYNC`:用于清空所有数据库的所有键,不限于当前 `SELECT` 的数据库。
+- `FLUSHDB ASYNC`:用于清空当前 `SELECT` 数据库中的所有键。

-大体上来说,Redis 6.0 之前主要还是单线程处理。
+总的来说,直到 Redis 6.0 之前,Redis 的主要操作仍然是单线程处理的。
**那 Redis6.0 之前为什么不使用多线程?** 我觉得主要原因有 3 点:
- 单线程编程容易并且更容易维护;
-- Redis 的性能瓶颈不在 CPU ,主要在内存和网络;
+- Redis 的性能瓶颈不在 CPU,主要在内存和网络;
- 多线程就会存在死锁、线程上下文切换等问题,甚至会影响性能。
-相关阅读:[为什么 Redis 选择单线程模型?](https://draveness.me/whys-the-design-redis-single-thread/) 。
+相关阅读:[为什么 Redis 选择单线程模型?](https://draveness.me/whys-the-design-redis-single-thread/)。
### Redis6.0 之后为何引入了多线程?
@@ -467,13 +540,13 @@ io-threads 4 #设置1的话只会开启主线程,官网建议4核的机器建
- io-threads 的个数一旦设置,不能通过 config 动态设置。
- 当设置 ssl 后,io-threads 将不工作。
-开启多线程后,默认只会使用多线程进行 IO 写入 writes,即发送数据给客户端,如果需要开启多线程 IO 读取 reads,同样需要修改 redis 配置文件 `redis.conf` :
+开启多线程后,默认只会使用多线程进行 IO 写入 writes,即发送数据给客户端,如果需要开启多线程 IO 读取 reads,同样需要修改 redis 配置文件 `redis.conf`:
```bash
io-threads-do-reads yes
```
-但是官网描述开启多线程读并不能有太大提升,因此一般情况下并不建议开启
+但是官网描述开启多线程读并不能有太大提升,因此一般情况下并不建议开启。
相关阅读:
@@ -485,10 +558,10 @@ io-threads-do-reads yes
我们虽然经常说 Redis 是单线程模型(主要逻辑是单线程完成的),但实际还有一些后台线程用于执行一些比较耗时的操作:
- 通过 `bio_close_file` 后台线程来释放 AOF / RDB 等过程中产生的临时文件资源。
-- 通过 `bio_aof_fsync` 后台线程调用 `fsync` 函数将系统内核缓冲区还未同步到到磁盘的数据强制刷到磁盘( AOF 文件)。
-- 通过 `bio_lazy_free`后台线程释放大对象(已删除)占用的内存空间.
+- 通过 `bio_aof_fsync` 后台线程调用 `fsync` 函数将系统内核缓冲区还未同步到到磁盘的数据强制刷到磁盘(AOF 文件)。
+- 通过 `bio_lazy_free` 后台线程释放大对象(已删除)占用的内存空间.
-在`bio.h` 文件中有定义(Redis 6.0 版本,源码地址:https://github.com/redis/redis/blob/6.0/src/bio.h):
+在`bio.h` 文件中有定义(Redis 6.0 版本,源码地址:):
```java
#ifndef __BIO_H
@@ -513,13 +586,13 @@ void bioKillThreads(void);
关于 Redis 后台线程的详细介绍可以查看 [Redis 6.0 后台线程有哪些?](https://juejin.cn/post/7102780434739626014) 这篇就文章。
-## Redis 内存管理
+## ⭐️Redis 内存管理
-### Redis 给缓存数据设置过期时间有啥用?
+### Redis 给缓存数据设置过期时间有什么用?
一般情况下,我们设置保存的缓存数据的时候都会设置一个过期时间。为什么呢?
-因为内存是有限的,如果缓存中的所有数据都是一直保存的话,分分钟直接 Out of memory。
+内存是有限且珍贵的,如果不对缓存数据设置过期时间,那内存占用就会一直增长,最终可能会导致 OOM 问题。通过设置合理的过期时间,Redis 会自动删除暂时不需要的数据,为新的缓存数据腾出空间。
Redis 自带了给缓存数据设置过期时间的功能,比如:
@@ -532,19 +605,19 @@ OK
(integer) 56
```
-注意:**Redis 中除了字符串类型有自己独有设置过期时间的命令 `setex` 外,其他方法都需要依靠 `expire` 命令来设置过期时间 。另外, `persist` 命令可以移除一个键的过期时间。**
+注意 ⚠️:Redis 中除了字符串类型有自己独有设置过期时间的命令 `setex` 外,其他方法都需要依靠 `expire` 命令来设置过期时间 。另外,`persist` 命令可以移除一个键的过期时间。
**过期时间除了有助于缓解内存的消耗,还有什么其他用么?**
-很多时候,我们的业务场景就是需要某个数据只在某一时间段内存在,比如我们的短信验证码可能只在 1 分钟内有效,用户登录的 token 可能只在 1 天内有效。
+很多时候,我们的业务场景就是需要某个数据只在某一时间段内存在,比如我们的短信验证码可能只在 1 分钟内有效,用户登录的 Token 可能只在 1 天内有效。
如果使用传统的数据库来处理的话,一般都是自己判断过期,这样更麻烦并且性能要差很多。
### Redis 是如何判断数据是否过期的呢?
-Redis 通过一个叫做过期字典(可以看作是 hash 表)来保存数据过期的时间。过期字典的键指向 Redis 数据库中的某个 key(键),过期字典的值是一个 long long 类型的整数,这个整数保存了 key 所指向的数据库键的过期时间(毫秒精度的 UNIX 时间戳)。
+Redis 通过一个叫做过期字典(可以看作是 hash 表)来保存数据过期的时间。过期字典的键指向 Redis 数据库中的某个 key(键),过期字典的值是一个 long long 类型的整数,这个整数保存了 key 所指向的数据库键的过期时间(毫秒精度的 UNIX 时间戳)。
-
+
过期字典是存储在 redisDb 这个结构里的:
@@ -558,42 +631,164 @@ typedef struct redisDb {
} redisDb;
```
-### 过期的数据的删除策略了解么?
+在查询一个 key 的时候,Redis 首先检查该 key 是否存在于过期字典中(时间复杂度为 O(1)),如果不在就直接返回,在的话需要判断一下这个 key 是否过期,过期直接删除 key 然后返回 null。
+
+### Redis 过期 key 删除策略了解么?
如果假设你设置了一批 key 只能存活 1 分钟,那么 1 分钟后,Redis 是怎么对这批 key 进行删除的呢?
-常用的过期数据的删除策略就两个(重要!自己造缓存轮子的时候需要格外考虑的东西):
+常用的过期数据的删除策略就下面这几种:
-1. **惰性删除**:只会在取出 key 的时候才对数据进行过期检查。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
-2. **定期删除**:每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
+1. **惰性删除**:只会在取出/查询 key 的时候才对数据进行过期检查。这种方式对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
+2. **定期删除**:周期性地随机从设置了过期时间的 key 中抽查一批,然后逐个检查这些 key 是否过期,过期就删除 key。相比于惰性删除,定期删除对内存更友好,对 CPU 不太友好。
+3. **延迟队列**:把设置过期时间的 key 放到一个延迟队列里,到期之后就删除 key。这种方式可以保证每个过期 key 都能被删除,但维护延迟队列太麻烦,队列本身也要占用资源。
+4. **定时删除**:每个设置了过期时间的 key 都会在设置的时间到达时立即被删除。这种方法可以确保内存中不会有过期的键,但是它对 CPU 的压力最大,因为它需要为每个键都设置一个定时器。
-定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,所以 Redis 采用的是 **定期删除+惰性/懒汉式删除** 。
+**Redis 采用的是那种删除策略呢?**
-但是,仅仅通过给 key 设置过期时间还是有问题的。因为还是可能存在定期删除和惰性删除漏掉了很多过期 key 的情况。这样就导致大量过期 key 堆积在内存里,然后就 Out of memory 了。
+Redis 采用的是 **定期删除+惰性/懒汉式删除** 结合的策略,这也是大部分缓存框架的选择。定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,结合起来使用既能兼顾 CPU 友好,又能兼顾内存友好。
-怎么解决这个问题呢?答案就是:**Redis 内存淘汰机制。**
+下面是我们详细介绍一下 Redis 中的定期删除具体是如何做的。
-### Redis 内存淘汰机制了解么?
+Redis 的定期删除过程是随机的(周期性地随机从设置了过期时间的 key 中抽查一批),所以并不保证所有过期键都会被立即删除。这也就解释了为什么有的 key 过期了,并没有被删除。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
+
+另外,定期删除还会受到执行时间和过期 key 的比例的影响:
+
+- 执行时间已经超过了阈值,那么就中断这一次定期删除循环,以避免使用过多的 CPU 时间。
+- 如果这一批过期的 key 比例超过一个比例,就会重复执行此删除流程,以更积极地清理过期 key。相应地,如果过期的 key 比例低于这个比例,就会中断这一次定期删除循环,避免做过多的工作而获得很少的内存回收。
+
+Redis 7.2 版本的执行时间阈值是 **25ms**,过期 key 比例设定值是 **10%**。
+
+```c
+#define ACTIVE_EXPIRE_CYCLE_FAST_DURATION 1000 /* Microseconds. */
+#define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25 /* Max % of CPU to use. */
+#define ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE 10 /* % of stale keys after which
+ we do extra efforts. */
+```
+
+**每次随机抽查数量是多少?**
+
+`expire.c` 中定义了每次随机抽查的数量,Redis 7.2 版本为 20,也就是说每次会随机选择 20 个设置了过期时间的 key 判断是否过期。
+
+```c
+#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /* Keys for each DB loop. */
+```
+
+**如何控制定期删除的执行频率?**
+
+在 Redis 中,定期删除的频率是由 **hz** 参数控制的。hz 默认为 10,代表每秒执行 10 次,也就是每秒钟进行 10 次尝试来查找并删除过期的 key。
+
+hz 的取值范围为 1~500。增大 hz 参数的值会提升定期删除的频率。如果你想要更频繁地执行定期删除任务,可以适当增加 hz 的值,但这会增加 CPU 的使用率。根据 Redis 官方建议,hz 的值不建议超过 100,对于大部分用户使用默认的 10 就足够了。
+
+下面是 hz 参数的官方注释,我翻译了其中的重要信息(Redis 7.2 版本)。
+
+
+
+类似的参数还有一个 **dynamic-hz**,这个参数开启之后 Redis 就会在 hz 的基础上动态计算一个值。Redis 提供并默认启用了使用自适应 hz 值的能力,
+
+这两个参数都在 Redis 配置文件 `redis.conf` 中:
+
+```properties
+# 默认为 10
+hz 10
+# 默认开启
+dynamic-hz yes
+```
+
+多提一嘴,除了定期删除过期 key 这个定期任务之外,还有一些其他定期任务例如关闭超时的客户端连接、更新统计信息,这些定期任务的执行频率也是通过 hz 参数决定。
+
+**为什么定期删除不是把所有过期 key 都删除呢?**
+
+这样会对性能造成太大的影响。如果我们 key 数量非常庞大的话,挨个遍历检查是非常耗时的,会严重影响性能。Redis 设计这种策略的目的是为了平衡内存和性能。
+
+**为什么 key 过期之后不立马把它删掉呢?这样不是会浪费很多内存空间吗?**
+
+因为不太好办到,或者说这种删除方式的成本太高了。假如我们使用延迟队列作为删除策略,这样存在下面这些问题:
+
+1. 队列本身的开销可能很大:key 多的情况下,一个延迟队列可能无法容纳。
+2. 维护延迟队列太麻烦:修改 key 的过期时间就需要调整其在延迟队列中的位置,并且还需要引入并发控制。
+
+### 大量 key 集中过期怎么办?
+
+当 Redis 中存在大量 key 在同一时间点集中过期时,可能会导致以下问题:
+
+- **请求延迟增加**:Redis 在处理过期 key 时需要消耗 CPU 资源,如果过期 key 数量庞大,会导致 Redis 实例的 CPU 占用率升高,进而影响其他请求的处理速度,造成延迟增加。
+- **内存占用过高**:过期的 key 虽然已经失效,但在 Redis 真正删除它们之前,仍然会占用内存空间。如果过期 key 没有及时清理,可能会导致内存占用过高,甚至引发内存溢出。
+
+为了避免这些问题,可以采取以下方案:
+
+1. **尽量避免 key 集中过期**:在设置键的过期时间时尽量随机一点。
+2. **开启 lazy free 机制**:修改 `redis.conf` 配置文件,将 `lazyfree-lazy-expire` 参数设置为 `yes`,即可开启 lazy free 机制。开启 lazy free 机制后,Redis 会在后台异步删除过期的 key,不会阻塞主线程的运行,从而降低对 Redis 性能的影响。
+
+### Redis 内存淘汰策略了解么?
> 相关问题:MySQL 里有 2000w 数据,Redis 中只存 20w 的数据,如何保证 Redis 中的数据都是热点数据?
-Redis 提供 6 种数据淘汰策略:
+Redis 的内存淘汰策略只有在运行内存达到了配置的最大内存阈值时才会触发,这个阈值是通过 `redis.conf` 的 `maxmemory` 参数来定义的。64 位操作系统下,`maxmemory` 默认为 0,表示不限制内存大小。32 位操作系统下,默认的最大内存值是 3GB。
+
+你可以使用命令 `config get maxmemory` 来查看 `maxmemory` 的值。
+
+```bash
+> config get maxmemory
+maxmemory
+0
+```
+
+Redis 提供了 6 种内存淘汰策略:
1. **volatile-lru(least recently used)**:从已设置过期时间的数据集(`server.db[i].expires`)中挑选最近最少使用的数据淘汰。
2. **volatile-ttl**:从已设置过期时间的数据集(`server.db[i].expires`)中挑选将要过期的数据淘汰。
3. **volatile-random**:从已设置过期时间的数据集(`server.db[i].expires`)中任意选择数据淘汰。
-4. **allkeys-lru(least recently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)。
+4. **allkeys-lru(least recently used)**:从数据集(`server.db[i].dict`)中移除最近最少使用的数据淘汰。
5. **allkeys-random**:从数据集(`server.db[i].dict`)中任意选择数据淘汰。
-6. **no-eviction**:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
+6. **no-eviction**(默认内存淘汰策略):禁止驱逐数据,当内存不足以容纳新写入数据时,新写入操作会报错。
4.0 版本后增加以下两种:
7. **volatile-lfu(least frequently used)**:从已设置过期时间的数据集(`server.db[i].expires`)中挑选最不经常使用的数据淘汰。
-8. **allkeys-lfu(least frequently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key。
+8. **allkeys-lfu(least frequently used)**:从数据集(`server.db[i].dict`)中移除最不经常使用的数据淘汰。
+
+`allkeys-xxx` 表示从所有的键值中淘汰数据,而 `volatile-xxx` 表示从设置了过期时间的键值中淘汰数据。
+
+`config.c` 中定义了内存淘汰策略的枚举数组:
+
+```c
+configEnum maxmemory_policy_enum[] = {
+ {"volatile-lru", MAXMEMORY_VOLATILE_LRU},
+ {"volatile-lfu", MAXMEMORY_VOLATILE_LFU},
+ {"volatile-random",MAXMEMORY_VOLATILE_RANDOM},
+ {"volatile-ttl",MAXMEMORY_VOLATILE_TTL},
+ {"allkeys-lru",MAXMEMORY_ALLKEYS_LRU},
+ {"allkeys-lfu",MAXMEMORY_ALLKEYS_LFU},
+ {"allkeys-random",MAXMEMORY_ALLKEYS_RANDOM},
+ {"noeviction",MAXMEMORY_NO_EVICTION},
+ {NULL, 0}
+};
+```
+
+你可以使用 `config get maxmemory-policy` 命令来查看当前 Redis 的内存淘汰策略。
+
+```bash
+> config get maxmemory-policy
+maxmemory-policy
+noeviction
+```
+
+可以通过 `config set maxmemory-policy 内存淘汰策略` 命令修改内存淘汰策略,立即生效,但这种方式重启 Redis 之后就失效了。修改 `redis.conf` 中的 `maxmemory-policy` 参数不会因为重启而失效,不过,需要重启之后修改才能生效。
+
+```properties
+maxmemory-policy noeviction
+```
+
+关于淘汰策略的详细说明可以参考 Redis 官方文档:。
## 参考
- 《Redis 开发与运维》
- 《Redis 设计与实现》
-- Redis 命令手册:https://www.redis.com.cn/commands.html
+- 《Redis 核心原理与实战》
+- Redis 命令手册:
+- RedisSearch 终极使用指南,你值得拥有!:
- WHY Redis choose single thread (vs multi threads): [https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153](https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153)
+
+
diff --git a/docs/database/redis/redis-questions-02.md b/docs/database/redis/redis-questions-02.md
index f3de97645d6..7e68719b9c8 100644
--- a/docs/database/redis/redis-questions-02.md
+++ b/docs/database/redis/redis-questions-02.md
@@ -1,17 +1,17 @@
---
title: Redis常见面试题总结(下)
+description: 最新Redis面试题总结(下):深度剖析Redis事务原理、性能优化(pipeline/Lua/bigkey/hotkey)、缓存穿透/击穿/雪崩解决方案、慢查询与内存碎片、Redis Sentinel与Cluster集群详解。助你轻松应对后端技术面试!
category: 数据库
tag:
- Redis
head:
- - meta
- name: keywords
- content: Redis基础,Redis常见数据结构,Redis线程模型,Redis内存管理,Redis事务,Redis性能优化
- - - meta
- - name: description
- content: 一篇文章总结Redis常见的知识点和面试题,涵盖Redis基础、Redis常见数据结构、Redis线程模型、Redis内存管理、Redis事务、Redis性能优化等内容。
+ content: Redis面试题,Redis事务,Redis性能优化,Redis缓存穿透,Redis缓存击穿,Redis缓存雪崩,Redis bigkey,Redis hotkey,Redis慢查询,Redis内存碎片,Redis集群,Redis Sentinel,Redis Cluster,Redis pipeline,Redis Lua脚本
---
+
+
## Redis 事务
### 什么是 Redis 事务?
@@ -26,7 +26,7 @@ Redis 事务实际开发中使用的非常少,功能比较鸡肋,不要将
### 如何使用 Redis 事务?
-Redis 可以通过 **`MULTI`,`EXEC`,`DISCARD` 和 `WATCH`** 等命令来实现事务(Transaction)功能。
+Redis 可以通过 **`MULTI`、`EXEC`、`DISCARD` 和 `WATCH`** 等命令来实现事务(Transaction)功能。
```bash
> MULTI
@@ -45,8 +45,8 @@ QUEUED
这个过程是这样的:
1. 开始事务(`MULTI`);
-2. 命令入队(批量操作 Redis 的命令,先进先出(FIFO)的顺序执行);
-3. 执行事务(`EXEC`)。
+2. 命令入队(批量操作 Redis 的命令,先进先出(FIFO)的顺序执行);
+3. 执行事务(`EXEC`)。
你也可以通过 [`DISCARD`](https://redis.io/commands/discard) 命令取消一个事务,它会清空事务队列中保存的所有命令。
@@ -136,10 +136,10 @@ Redis 官网相关介绍 [https://redis.io/topics/transactions](https://redis.io
Redis 的事务和我们平时理解的关系型数据库的事务不同。我们知道事务具有四大特性:**1. 原子性**,**2. 隔离性**,**3. 持久性**,**4. 一致性**。
-1. **原子性(Atomicity):** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
-2. **隔离性(Isolation):** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
-3. **持久性(Durability):** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
-4. **一致性(Consistency):** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
+1. **原子性(Atomicity)**:事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
+2. **隔离性(Isolation)**:并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
+3. **持久性(Durability)**:一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响;
+4. **一致性(Consistency)**:执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的。
Redis 事务在运行错误的情况下,除了执行过程中出现错误的命令外,其他命令都能正常执行。并且,Redis 事务是不支持回滚(roll back)操作的。因此,Redis 事务其实是不满足原子性的。
@@ -147,28 +147,28 @@ Redis 官网也解释了自己为啥不支持回滚。简单来说就是 Redis

-**相关 issue** :
+**相关 issue**:
-- [issue#452: 关于 Redis 事务不满足原子性的问题](https://github.com/Snailclimb/JavaGuide/issues/452) 。
-- [Issue#491:关于 Redis 没有事务回滚?](https://github.com/Snailclimb/JavaGuide/issues/491)
+- [issue#452: 关于 Redis 事务不满足原子性的问题](https://github.com/Snailclimb/JavaGuide/issues/452)。
+- [Issue#491:关于 Redis 没有事务回滚?](https://github.com/Snailclimb/JavaGuide/issues/491)。
### Redis 事务支持持久性吗?
-Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:
+Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:
-- 快照(snapshotting,RDB)
-- 只追加文件(append-only file, AOF)
-- RDB 和 AOF 的混合持久化(Redis 4.0 新增)
+- 快照(snapshotting,RDB);
+- 只追加文件(append-only file,AOF);
+- RDB 和 AOF 的混合持久化(Redis 4.0 新增)。
-与 RDB 持久化相比,AOF 持久化的实时性更好。在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
+与 RDB 持久化相比,AOF 持久化的实时性更好。在 Redis 的配置文件中存在三种不同的 AOF 持久化方式(`fsync` 策略),它们分别是:
```bash
-appendfsync always #每次有数据修改发生时都会调用fsync函数同步AOF文件,fsync完成后线程返回,这样会严重降低Redis的速度
+appendfsync always #每次有数据修改发生时,都会调用fsync函数同步AOF文件,fsync完成后线程返回,这样会严重降低Redis的速度
appendfsync everysec #每秒钟调用fsync函数同步一次AOF文件
appendfsync no #让操作系统决定何时进行同步,一般为30秒一次
```
-AOF 持久化的`fsync`策略为 no、everysec 时都会存在数据丢失的情况 。always 下可以基本是可以满足持久性要求的,但性能太差,实际开发过程中不会使用。
+AOF 持久化的 `fsync` 策略为 no、everysec 时都会存在数据丢失的情况。always 下可以基本是可以满足持久性要求的,但性能太差,实际开发过程中不会使用。
因此,Redis 事务的持久性也是没办法保证的。
@@ -178,44 +178,44 @@ Redis 从 2.6 版本开始支持执行 Lua 脚本,它的功能和事务非常
一段 Lua 脚本可以视作一条命令执行,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰。
-不过,如果 Lua 脚本运行时出错并中途结束,出错之后的命令是不会被执行的。并且,出错之前执行的命令是无法被撤销的,无法实现类似关系型数据库执行失败可以回滚的那种原子性效果。因此, **严格来说的话,通过 Lua 脚本来批量执行 Redis 命令实际也是不完全满足原子性的。**
+不过,如果 Lua 脚本运行时出错并中途结束,出错之后的命令是不会被执行的。并且,出错之前执行的命令是无法被撤销的,无法实现类似关系型数据库执行失败可以回滚的那种原子性效果。因此,**严格来说的话,通过 Lua 脚本来批量执行 Redis 命令实际也是不完全满足原子性的。**
如果想要让 Lua 脚本中的命令全部执行,必须保证语句语法和命令都是对的。
-另外,Redis 7.0 新增了 [Redis functions](https://redis.io/docs/manual/programmability/functions-intro/) 特性,你可以将 Redis functions 看作是比 Lua 更强大的脚本。
+另外,Redis 7.0 新增了 [Redis functions](https://redis.io/docs/latest/develop/programmability/functions-intro/) 特性,你可以将 Redis functions 看作是比 Lua 更强大的脚本。
-## Redis 性能优化(重要)
+## ⭐️Redis 性能优化(重要)
除了下面介绍的内容之外,再推荐两篇不错的文章:
-- [你的 Redis 真的变慢了吗?性能优化如何做 - 阿里开发者](https://mp.weixin.qq.com/s/nNEuYw0NlYGhuKKKKoWfcQ)
-- [Redis 常见阻塞原因总结 - JavaGuide](https://javaguide.cn/database/redis/redis-common-blocking-problems-summary.html)
+- [你的 Redis 真的变慢了吗?性能优化如何做 - 阿里开发者](https://mp.weixin.qq.com/s/nNEuYw0NlYGhuKKKKoWfcQ)。
+- [Redis 常见阻塞原因总结 - JavaGuide](https://javaguide.cn/database/redis/redis-common-blocking-problems-summary.html)。
### 使用批量操作减少网络传输
一个 Redis 命令的执行可以简化为以下 4 步:
-1. 发送命令
-2. 命令排队
-3. 命令执行
-4. 返回结果
+1. 发送命令;
+2. 命令排队;
+3. 命令执行;
+4. 返回结果。
-其中,第 1 步和第 4 步耗费时间之和称为 **Round Trip Time (RTT,往返时间)** ,也就是数据在网络上传输的时间。
+其中,第 1 步和第 4 步耗费时间之和称为 **Round Trip Time(RTT,往返时间)**,也就是数据在网络上传输的时间。
使用批量操作可以减少网络传输次数,进而有效减小网络开销,大幅减少 RTT。
-另外,除了能减少 RTT 之外,发送一次命令的 socket I/O 成本也比较高(涉及上下文切换,存在`read()`和`write()`系统调用),批量操作还可以减少 socket I/O 成本。这个在官方对 pipeline 的介绍中有提到:https://redis.io/docs/manual/pipelining/ 。
+另外,除了能减少 RTT 之外,发送一次命令的 socket I/O 成本也比较高(涉及上下文切换,存在 `read()` 和 `write()` 系统调用),批量操作还可以减少 socket I/O 成本。这个在官方对 pipeline 的介绍中有提到:。
#### 原生批量操作命令
Redis 中有一些原生支持批量操作的命令,比如:
-- `MGET`(获取一个或多个指定 key 的值)、`MSET`(设置一个或多个指定 key 的值)、
-- `HMGET`(获取指定哈希表中一个或者多个指定字段的值)、`HMSET`(同时将一个或多个 field-value 对设置到指定哈希表中)、
+- `MGET`(获取一个或多个指定 key 的值)、`MSET`(设置一个或多个指定 key 的值)、
+- `HMGET`(获取指定哈希表中一个或者多个指定字段的值)、`HMSET`(同时将一个或多个 field-value 对设置到指定哈希表中)、
- `SADD`(向指定集合添加一个或多个元素)
-- ......
+- ……
-不过,在 Redis 官方提供的分片集群解决方案 Redis Cluster 下,使用这些原生批量操作命令可能会存在一些小问题需要解决。就比如说 `MGET` 无法保证所有的 key 都在同一个 **hash slot**(哈希槽)上,`MGET`可能还是需要多次网络传输,原子操作也无法保证了。不过,相较于非批量操作,还是可以节省不少网络传输次数。
+不过,在 Redis 官方提供的分片集群解决方案 Redis Cluster 下,使用这些原生批量操作命令可能会存在一些小问题需要解决。就比如说 `MGET` 无法保证所有的 key 都在同一个 **hash slot(哈希槽)** 上,`MGET`可能还是需要多次网络传输,原子操作也无法保证了。不过,相较于非批量操作,还是可以节省不少网络传输次数。
整个步骤的简化版如下(通常由 Redis 客户端实现,无需我们自己再手动实现):
@@ -225,15 +225,15 @@ Redis 中有一些原生支持批量操作的命令,比如:
如果想要解决这个多次网络传输的问题,比较常用的办法是自己维护 key 与 slot 的关系。不过这样不太灵活,虽然带来了性能提升,但同样让系统复杂性提升。
-> Redis Cluster 并没有使用一致性哈希,采用的是 **哈希槽分区** ,每一个键值对都属于一个 **hash slot**(哈希槽) 。当客户端发送命令请求的时候,需要先根据 key 通过上面的计算公示找到的对应的哈希槽,然后再查询哈希槽和节点的映射关系,即可找到目标 Redis 节点。
+> Redis Cluster 并没有使用一致性哈希,采用的是 **哈希槽分区**,每一个键值对都属于一个 **hash slot(哈希槽)**。当客户端发送命令请求的时候,需要先根据 key 通过上面的计算公式找到的对应的哈希槽,然后再查询哈希槽和节点的映射关系,即可找到目标 Redis 节点。
>
> 我在 [Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html) 这篇文章中详细介绍了 Redis Cluster 这部分的内容,感兴趣地可以看看。
#### pipeline
-对于不支持批量操作的命令,我们可以利用 **pipeline(流水线)** 将一批 Redis 命令封装成一组,这些 Redis 命令会被一次性提交到 Redis 服务器,只需要一次网络传输。不过,需要注意控制一次批量操作的 **元素个数**(例如 500 以内,实际也和元素字节数有关),避免网络传输的数据量过大。
+对于不支持批量操作的命令,我们可以利用 **pipeline(流水线)** 将一批 Redis 命令封装成一组,这些 Redis 命令会被一次性提交到 Redis 服务器,只需要一次网络传输。不过,需要注意控制一次批量操作的 **元素个数**(例如 500 以内,实际也和元素字节数有关),避免网络传输的数据量过大。
-与`MGET`、`MSET`等原生批量操作命令一样,pipeline 同样在 Redis Cluster 上使用会存在一些小问题。原因类似,无法保证所有的 key 都在同一个 **hash slot**(哈希槽)上。如果想要使用的话,客户端需要自己维护 key 与 slot 的关系。
+与 `MGET`、`MSET` 等原生批量操作命令一样,pipeline 同样在 Redis Cluster 上使用会存在一些小问题。原因类似,无法保证所有的 key 都在同一个 **hash slot(哈希槽)** 上。如果想要使用的话,客户端需要自己维护 key 与 slot 的关系。
原生批量操作命令和 pipeline 的是有区别的,使用的时候需要注意:
@@ -250,18 +250,18 @@ Redis 中有一些原生支持批量操作的命令,比如:

-另外,pipeline 不适用于执行顺序有依赖关系的一批命令。就比如说,你需要将前一个命令的结果给后续的命令使用,pipeline 就没办法满足你的需求了。对于这种需求,我们可以使用 **Lua 脚本** 。
+另外,pipeline 不适用于执行顺序有依赖关系的一批命令。就比如说,你需要将前一个命令的结果给后续的命令使用,pipeline 就没办法满足你的需求了。对于这种需求,我们可以使用 **Lua 脚本**。
#### Lua 脚本
-Lua 脚本同样支持批量操作多条命令。一段 Lua 脚本可以视作一条命令执行,可以看作是 **原子操作** 。也就是说,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰,这是 pipeline 所不具备的。
+Lua 脚本同样支持批量操作多条命令。一段 Lua 脚本可以视作一条命令执行,可以看作是 **原子操作**。也就是说,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰,这是 pipeline 所不具备的。
并且,Lua 脚本中支持一些简单的逻辑处理比如使用命令读取值并在 Lua 脚本中进行处理,这同样是 pipeline 所不具备的。
不过, Lua 脚本依然存在下面这些缺陷:
- 如果 Lua 脚本运行时出错并中途结束,之后的操作不会进行,但是之前已经发生的写操作不会撤销,所以即使使用了 Lua 脚本,也不能实现类似数据库回滚的原子性。
-- Redis Cluster 下 Lua 脚本的原子操作也无法保证了,原因同样是无法保证所有的 key 都在同一个 **hash slot**(哈希槽)上。
+- Redis Cluster 下 Lua 脚本的原子操作也无法保证了,原因同样是无法保证所有的 key 都在同一个 **hash slot(哈希槽)** 上。
### 大量 key 集中过期问题
@@ -272,7 +272,7 @@ Lua 脚本同样支持批量操作多条命令。一段 Lua 脚本可以视作
**如何解决呢?** 下面是两种常见的方法:
1. 给 key 设置随机过期时间。
-2. 开启 lazy-free(惰性删除/延迟释放) 。lazy-free 特性是 Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
+2. 开启 lazy-free(惰性删除/延迟释放)。lazy-free 特性是 Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
个人建议不管是否开启 lazy-free,我们都尽量给 key 设置随机过期时间。
@@ -280,11 +280,32 @@ Lua 脚本同样支持批量操作多条命令。一段 Lua 脚本可以视作
#### 什么是 bigkey?
-简单来说,如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:string 类型的 value 超过 10 kb,复合类型的 value 包含的元素超过 5000 个(对于复合类型的 value 来说,不一定包含的元素越多,占用的内存就越多)。
+简单来说,如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:
+
+- String 类型的 value 超过 1MB
+- 复合类型(List、Hash、Set、Sorted Set 等)的 value 包含的元素超过 5000 个(不过,对于复合类型的 value 来说,不一定包含的元素越多,占用的内存就越多)。
+
+
+
+#### bigkey 是怎么产生的?有什么危害?
+
+bigkey 通常是由于下面这些原因产生的:
+
+- 程序设计不当,比如直接使用 String 类型存储较大的文件对应的二进制数据。
+- 对于业务的数据规模考虑不周到,比如使用集合类型的时候没有考虑到数据量的快速增长。
+- 未及时清理垃圾数据,比如哈希中冗余了大量的无用键值对。
+
+bigkey 除了会消耗更多的内存空间和带宽,还会对性能造成比较大的影响。
+
+在 [Redis 常见阻塞原因总结](./redis-common-blocking-problems-summary.md) 这篇文章中我们提到:大 key 还会造成阻塞问题。具体来说,主要体现在下面三个方面:
-#### bigkey 有什么危害?
+1. 客户端超时阻塞:由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
+2. 网络阻塞:每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
+3. 工作线程阻塞:如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
-bigkey 除了会消耗更多的内存空间和带宽,还会对性能造成比较大的影响。因此,我们应该尽量避免 Redis 中存在 bigkey。
+大 key 造成的阻塞问题还会进一步影响到主从同步和集群扩容。
+
+综上,大 key 带来的潜在问题是非常多的,我们应该尽量避免 Redis 中存在 bigkey。
#### 如何发现 bigkey?
@@ -316,24 +337,38 @@ Biggest string found '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28
0 zsets with 0 members (00.00% of keys, avg size 0.00
```
-从这个命令的运行结果,我们可以看出:这个命令会扫描(Scan) Redis 中的所有 key ,会对 Redis 的性能有一点影响。并且,这种方式只能找出每种数据结构 top 1 bigkey(占用内存最大的 string 数据类型,包含元素最多的复合数据类型)。然而,一个 key 的元素多并不代表占用内存也多,需要我们根据具体的业务情况来进一步判断。
+从这个命令的运行结果,我们可以看出:这个命令会扫描(Scan)Redis 中的所有 key,会对 Redis 的性能有一点影响。并且,这种方式只能找出每种数据结构 top 1 bigkey(占用内存最大的 String 数据类型,包含元素最多的复合数据类型)。然而,一个 key 的元素多并不代表占用内存也多,需要我们根据具体的业务情况来进一步判断。
在线上执行该命令时,为了降低对 Redis 的影响,需要指定 `-i` 参数控制扫描的频率。`redis-cli -p 6379 --bigkeys -i 3` 表示扫描过程中每次扫描后休息的时间间隔为 3 秒。
-**2、借助开源工具分析 RDB 文件。**
+**2、使用 Redis 自带的 SCAN 命令**
+
+`SCAN` 命令可以按照一定的模式和数量返回匹配的 key。获取了 key 之后,可以利用 `STRLEN`、`HLEN`、`LLEN` 等命令返回其长度或成员数量。
+
+| 数据结构 | 命令 | 复杂度 | 结果(对应 key) |
+| ---------- | ------ | ------ | ------------------ |
+| String | STRLEN | O(1) | 字符串值的长度 |
+| Hash | HLEN | O(1) | 哈希表中字段的数量 |
+| List | LLEN | O(1) | 列表元素数量 |
+| Set | SCARD | O(1) | 集合元素数量 |
+| Sorted Set | ZCARD | O(1) | 有序集合的元素数量 |
+
+对于集合类型还可以使用 `MEMORY USAGE` 命令(Redis 4.0+),这个命令会返回键值对占用的内存空间。
+
+**3、借助开源工具分析 RDB 文件。**
通过分析 RDB 文件来找出 big key。这种方案的前提是你的 Redis 采用的是 RDB 持久化。
网上有现成的代码/工具可以直接拿来使用:
-- [redis-rdb-tools](https://github.com/sripathikrishnan/redis-rdb-tools):Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具
-- [rdb_bigkeys](https://github.com/weiyanwei412/rdb_bigkeys) : Go 语言写的用来分析 Redis 的 RDB 快照文件用的工具,性能更好。
+- [redis-rdb-tools](https://github.com/sripathikrishnan/redis-rdb-tools):Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具。
+- [rdb_bigkeys](https://github.com/weiyanwei412/rdb_bigkeys):Go 语言写的用来分析 Redis 的 RDB 快照文件用的工具,性能更好。
-**3、借助公有云的 Redis 分析服务。**
+**4、借助公有云的 Redis 分析服务。**
如果你用的是公有云的 Redis 服务的话,可以看看其是否提供了 key 分析功能(一般都提供了)。
-这里以阿里云 Redis 为例说明,它支持 bigkey 实时分析、发现,文档地址: 。
+这里以阿里云 Redis 为例说明,它支持 bigkey 实时分析、发现,文档地址:。

@@ -341,16 +376,16 @@ Biggest string found '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28
bigkey 的常见处理以及优化办法如下(这些方法可以配合起来使用):
-- **分割 bigkey**:将一个 bigkey 分割为多个小 key。这种方式需要修改业务层的代码,一般不推荐这样做。
+- **分割 bigkey**:将一个 bigkey 分割为多个小 key。例如,将一个含有上万字段数量的 Hash 按照一定策略(比如二次哈希)拆分为多个 Hash。
- **手动清理**:Redis 4.0+ 可以使用 `UNLINK` 命令来异步删除一个或多个指定的 key。Redis 4.0 以下可以考虑使用 `SCAN` 命令结合 `DEL` 命令来分批次删除。
-- **采用合适的数据结构**:比如使用 HyperLogLog 统计页面 UV。
-- **开启 lazy-free(惰性删除/延迟释放)** :lazy-free 特性是 Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
+- **采用合适的数据结构**:例如,文件二进制数据不使用 String 保存、使用 HyperLogLog 统计页面 UV、Bitmap 保存状态信息(0/1)。
+- **开启 lazy-free(惰性删除/延迟释放)**:lazy-free 特性是 Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
### Redis hotkey(热 Key)
#### 什么是 hotkey?
-简单来说,如果一个 key 的访问次数比较多且明显多于其他 key 的话,那这个 key 就可以看作是 hotkey。例如在 Redis 实例的每秒处理请求达到 5000 次,而其中某个 key 的每秒访问量就高达 2000 次,那这个 key 就可以看作是 hotkey。
+如果一个 key 的访问次数比较多且明显多于其他 key 的话,那这个 key 就可以看作是 **hotkey(热 Key)**。例如在 Redis 实例的每秒处理请求达到 5000 次,而其中某个 key 的每秒访问量就高达 2000 次,那这个 key 就可以看作是 hotkey。
hotkey 出现的原因主要是某个热点数据访问量暴增,如重大的热搜事件、参与秒杀的商品。
@@ -395,13 +430,13 @@ maxmemory-policy allkeys-lfu
需要注意的是,`hotkeys` 参数命令也会增加 Redis 实例的 CPU 和内存消耗(全局扫描),因此需要谨慎使用。
-**2、使用`MONITOR` 命令。**
+**2、使用 `MONITOR` 命令。**
`MONITOR` 命令是 Redis 提供的一种实时查看 Redis 的所有操作的方式,可以用于临时监控 Redis 实例的操作情况,包括读写、删除等操作。
由于该命令对 Redis 性能的影响比较大,因此禁止长时间开启 `MONITOR`(生产环境中建议谨慎使用该命令)。
-```java
+```bash
# redis-cli
127.0.0.1:6379> MONITOR
OK
@@ -436,7 +471,7 @@ OK
如果你用的是公有云的 Redis 服务的话,可以看看其是否提供了 key 分析功能(一般都提供了)。
-这里以阿里云 Redis 为例说明,它支持 hotkey 实时分析、发现,文档地址: 。
+这里以阿里云 Redis 为例说明,它支持 hotkey 实时分析、发现,文档地址:。

@@ -460,43 +495,45 @@ hotkey 的常见处理以及优化办法如下(这些方法可以配合起来
我们知道一个 Redis 命令的执行可以简化为以下 4 步:
-1. 发送命令
-2. 命令排队
-3. 命令执行
-4. 返回结果
+1. 发送命令;
+2. 命令排队;
+3. 命令执行;
+4. 返回结果。
Redis 慢查询统计的是命令执行这一步骤的耗时,慢查询命令也就是那些命令执行时间较长的命令。
Redis 为什么会有慢查询命令呢?
-Redis 中的大部分命令都是 O(1)时间复杂度,但也有少部分 O(n) 时间复杂度的命令,例如:
+Redis 中的大部分命令都是 O(1) 时间复杂度,但也有少部分 O(n) 时间复杂度的命令,例如:
- `KEYS *`:会返回所有符合规则的 key。
- `HGETALL`:会返回一个 Hash 中所有的键值对。
- `LRANGE`:会返回 List 中指定范围内的元素。
- `SMEMBERS`:返回 Set 中的所有元素。
- `SINTER`/`SUNION`/`SDIFF`:计算多个 Set 的交集/并集/差集。
-- ......
+- ……
由于这些命令时间复杂度是 O(n),有时候也会全表扫描,随着 n 的增大,执行耗时也会越长。不过, 这些命令并不是一定不能使用,但是需要明确 N 的值。另外,有遍历的需求可以使用 `HSCAN`、`SSCAN`、`ZSCAN` 代替。
-除了这些 O(n)时间复杂度的命令可能会导致慢查询之外, 还有一些时间复杂度可能在 O(N) 以上的命令,例如:
+除了这些 O(n) 时间复杂度的命令可能会导致慢查询之外,还有一些时间复杂度可能在 O(N) 以上的命令,例如:
-- `ZRANGE`/`ZREVRANGE`:返回指定 Sorted Set 中指定排名范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 为返回的元素数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
-- `ZREMRANGEBYRANK`/`ZREMRANGEBYSCORE`:移除 Sorted Set 中指定排名范围/指定 score 范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 被删除元素的数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
-- ......
+- `ZRANGE`/`ZREVRANGE`:返回指定 Sorted Set 中指定排名范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量,m 为返回的元素数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
+- `ZREMRANGEBYRANK`/`ZREMRANGEBYSCORE`:移除 Sorted Set 中指定排名范围/指定 score 范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量,m 被删除元素的数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
+- ……
#### 如何找到慢查询命令?
+Redis 提供了一个内置的**慢查询日志 (Slow Log)** 功能,专门用来记录执行时间超过指定阈值的命令。这对于排查性能瓶颈、找出导致 Redis 阻塞的“慢”操作非常有帮助,原理和 MySQL 的慢查询日志类似。
+
在 `redis.conf` 文件中,我们可以使用 `slowlog-log-slower-than` 参数设置耗时命令的阈值,并使用 `slowlog-max-len` 参数设置耗时命令的最大记录条数。
-当 Redis 服务器检测到执行时间超过 `slowlog-log-slower-than`阈值的命令时,就会将该命令记录在慢查询日志(slow log) 中,这点和 MySQL 记录慢查询语句类似。当慢查询日志超过设定的最大记录条数之后,Redis 会把最早的执行命令依次舍弃。
+当 Redis 服务器检测到执行时间超过 `slowlog-log-slower-than` 阈值的命令时,就会将该命令记录在慢查询日志(slow log)中,这点和 MySQL 记录慢查询语句类似。当慢查询日志超过设定的最大记录条数之后,Redis 会把最早的执行命令依次舍弃。
-⚠️注意:由于慢查询日志会占用一定内存空间,如果设置最大记录条数过大,可能会导致内存占用过高的问题。
+⚠️ 注意:由于慢查询日志会占用一定内存空间,如果设置最大记录条数过大,可能会导致内存占用过高的问题。
- `slowlog-log-slower-than`和`slowlog-max-len`的默认配置如下(可以自行修改):
+`slowlog-log-slower-than` 和 `slowlog-max-len` 的默认配置如下(可以自行修改):
-```nginx
+```properties
# The following time is expressed in microseconds, so 1000000 is equivalent
# to one second. Note that a negative number disables the slow log, while
# a value of zero forces the logging of every command.
@@ -516,9 +553,9 @@ CONFIG SET slowlog-log-slower-than 10000
CONFIG SET slowlog-max-len 128
```
-获取慢查询日志的内容很简单,直接使用`SLOWLOG GET` 命令即可。
+获取慢查询日志的内容很简单,直接使用 `SLOWLOG GET` 命令即可。
-```java
+```bash
127.0.0.1:6379> SLOWLOG GET #慢日志查询
1) 1) (integer) 5
2) (integer) 1684326682
@@ -532,14 +569,14 @@ CONFIG SET slowlog-max-len 128
慢查询日志中的每个条目都由以下六个值组成:
-1. 唯一渐进的日志标识符。
-2. 处理记录命令的 Unix 时间戳。
-3. 执行所需的时间量,以微秒为单位。
-4. 组成命令参数的数组。
-5. 客户端 IP 地址和端口。
-6. 客户端名称。
+1. **唯一 ID**: 日志条目的唯一标识符。
+2. **时间戳 (Timestamp)**: 命令执行完成时的 Unix 时间戳。
+3. **耗时 (Duration)**: 命令执行所花费的时间,单位是**微秒**。
+4. **命令及参数 (Command)**: 执行的具体命令及其参数数组。
+5. **客户端信息 (Client IP:Port)**: 执行命令的客户端地址和端口。
+6. **客户端名称 (Client Name)**: 如果客户端设置了名称 (CLIENT SETNAME)。
-`SLOWLOG GET` 命令默认返回最近 10 条的的慢查询命令,你也自己可以指定返回的慢查询命令的数量 `SLOWLOG GET N`。
+`SLOWLOG GET` 命令默认返回最近 10 条的慢查询命令,你也自己可以指定返回的慢查询命令的数量 `SLOWLOG GET N`。
下面是其他比较常用的慢查询相关的命令:
@@ -556,18 +593,18 @@ OK
**相关问题**:
-1. 什么是内存碎片?为什么会有 Redis 内存碎片?
+1. 什么是内存碎片?为什么会有 Redis 内存碎片?
2. 如何清理 Redis 内存碎片?
**参考答案**:[Redis 内存碎片详解](https://javaguide.cn/database/redis/redis-memory-fragmentation.html)。
-## Redis 生产问题(重要)
+## ⭐️Redis 生产问题(重要)
### 缓存穿透
#### 什么是缓存穿透?
-缓存穿透说简单点就是大量请求的 key 是不合理的,**根本不存在于缓存中,也不存在于数据库中** 。这就导致这些请求直接到了数据库上,根本没有经过缓存这一层,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
+缓存穿透说简单点就是大量请求的 key 是不合理的,**根本不存在于缓存中,也不存在于数据库中**。这就导致这些请求直接到了数据库上,根本没有经过缓存这一层,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。

@@ -579,9 +616,9 @@ OK
**1)缓存无效 key**
-如果缓存和数据库都查不到某个 key 的数据就写一个到 Redis 中去并设置过期时间,具体命令如下:`SET key value EX 10086` 。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建不同的请求 key,会导致 Redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
+如果缓存和数据库都查不到某个 key 的数据,就写一个到 Redis 中去并设置过期时间,具体命令如下:`SET key value EX 10086`。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建不同的请求 key,会导致 Redis 中缓存大量无效的 key。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点,比如 1 分钟。
-另外,这里多说一嘴,一般情况下我们是这样设计 key 的:`表名:列名:主键名:主键值` 。
+另外,这里多说一嘴,一般情况下我们是这样设计 key 的:`表名:列名:主键名:主键值`。
如果用 Java 代码展示的话,差不多是下面这样的:
@@ -608,37 +645,35 @@ public Object getObjectInclNullById(Integer id) {
**2)布隆过滤器**
-布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。
+布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时常用的 List、Map、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。
-具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
+
-加入布隆过滤器之后的缓存处理流程图如下。
+Bloom Filter 会使用一个较大的 bit 数组来保存所有的数据,数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1(代表 false 或者 true),这也是 Bloom Filter 节省内存的核心所在。这样来算的话,申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 KB ≈ 122KB 的空间。
-
+
-但是,需要注意的是布隆过滤器可能会存在误判的情况。总结来说就是:**布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。**
+具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
-_为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理来说!_
+加入布隆过滤器之后的缓存处理流程图如下:
-我们先来看一下,**当一个元素加入布隆过滤器中的时候,会进行哪些操作:**
+
-1. 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
-2. 根据得到的哈希值,在位数组中把对应下标的值置为 1。
+更多关于布隆过滤器的详细介绍可以看看我的这篇原创:[不了解布隆过滤器?一文给你整的明明白白!](https://javaguide.cn/cs-basics/data-structure/bloom-filter.html),强烈推荐。
-我们再来看一下,**当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行哪些操作:**
+**3)接口限流**
-1. 对给定元素再次进行相同的哈希计算;
-2. 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
+根据用户或者 IP 对接口进行限流,对于异常频繁的访问行为,还可以采取黑名单机制,例如将异常 IP 列入黑名单。
-然后,一定会出现这样一种情况:**不同的字符串可能哈希出来的位置相同。** (可以适当增加位数组大小或者调整我们的哈希函数来降低概率)
+后面提到的缓存击穿和雪崩都可以配合接口限流来解决,毕竟这些问题的关键都是有很多请求落到了数据库上造成数据库压力过大。
-更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://javaguide.cn/cs-basics/data-structure/bloom-filter/) ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
+限流的具体方案可以参考这篇文章:[服务限流详解](https://javaguide.cn/high-availability/limit-request.html)。
### 缓存击穿
#### 什么是缓存击穿?
-缓存击穿中,请求的 key 对应的是 **热点数据** ,该数据 **存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期)** 。这就可能会导致瞬时大量的请求直接打到了数据库上,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
+缓存击穿中,请求的 key 对应的是 **热点数据**,该数据 **存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期)**。这就可能会导致瞬时大量的请求直接打到了数据库上,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。

@@ -646,9 +681,9 @@ _为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理
#### 有哪些解决办法?
-- 设置热点数据永不过期或者过期时间比较长。
-- 针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
-- 请求数据库写数据到缓存之前,先获取互斥锁,保证只有一个请求会落到数据库上,减少数据库的压力。
+1. **永不过期**(不推荐):设置热点数据永不过期或者过期时间比较长。
+2. **提前预热**(推荐):针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
+3. **加锁**(看情况):在缓存失效后,通过设置互斥锁确保只有一个请求去查询数据库并更新缓存。
#### 缓存穿透和缓存击穿有什么区别?
@@ -668,61 +703,94 @@ _为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理

-举个例子:数据库中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。
+举个例子:缓存中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。
#### 有哪些解决办法?
-**针对 Redis 服务不可用的情况:**
+**针对 Redis 服务不可用的情况**:
+
+1. **Redis 集群**:采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。Redis Cluster 和 Redis Sentinel 是两种最常用的 Redis 集群实现方案,详细介绍可以参考:[Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html)。
+2. **多级缓存**:设置多级缓存,例如本地缓存+Redis 缓存的二级缓存组合,当 Redis 缓存出现问题时,还可以从本地缓存中获取到部分数据。
+
+**针对大量缓存同时失效的情况**:
-1. 采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。
-2. 限流,避免同时处理大量的请求。
+1. **设置随机失效时间**(可选):为缓存设置随机的失效时间,例如在固定过期时间的基础上加上一个随机值,这样可以避免大量缓存同时到期,从而减少缓存雪崩的风险。
+2. **提前预热**(推荐):针对热点数据提前预热,将其存入缓存中并设置合理的过期时间,比如秒杀场景下的数据在秒杀结束之前不过期。
+3. **持久缓存策略**(看情况):虽然一般不推荐设置缓存永不过期,但对于某些关键性和变化不频繁的数据,可以考虑这种策略。
-**针对热点缓存失效的情况:**
+#### 缓存预热如何实现?
-1. 设置不同的失效时间比如随机设置缓存的失效时间。
-2. 缓存永不失效(不太推荐,实用性太差)。
-3. 设置二级缓存。
+常见的缓存预热方式有两种:
+
+1. 使用定时任务,比如 xxl-job,来定时触发缓存预热的逻辑,将数据库中的热点数据查询出来并存入缓存中。
+2. 使用消息队列,比如 Kafka,来异步地进行缓存预热,将数据库中的热点数据的主键或者 ID 发送到消息队列中,然后由缓存服务消费消息队列中的数据,根据主键或者 ID 查询数据库并更新缓存。
#### 缓存雪崩和缓存击穿有什么区别?
-缓存雪崩和缓存击穿比较像,但缓存雪崩导致的原因是缓存中的大量或者所有数据失效,缓存击穿导致的原因主要是某个热点数据不存在与缓存中(通常是因为缓存中的那份数据已经过期)。
+缓存雪崩和缓存击穿比较像,但缓存雪崩导致的原因是缓存中的大量或者所有数据失效,缓存击穿导致的原因主要是某个热点数据不存在于缓存中(通常是因为缓存中的那份数据已经过期)。
### 如何保证缓存和数据库数据的一致性?
-细说的话可以扯很多,但是我觉得其实没太大必要(小声 BB:很多解决方案我也没太弄明白)。我个人觉得引入缓存之后,如果为了短时间的不一致性问题,选择让系统设计变得更加复杂的话,完全没必要。
+缓存和数据库一致性是个挺常见的技术挑战。引入缓存主要是为了提升性能、减轻数据库压力,但确实会带来数据不一致的风险。绝对的一致性往往意味着更高的系统复杂度和性能开销,所以实践中我们通常会根据业务场景选择合适的策略,在性能和一致性之间找到一个平衡点。
+
+下面单独对 **Cache Aside Pattern(旁路缓存模式)** 来聊聊。这是非常常用的一种缓存读写策略,它的读写逻辑是这样的:
+
+- **读操作**:
+ 1. 先尝试从缓存读取数据。
+ 2. 如果缓存命中,直接返回数据。
+ 3. 如果缓存未命中,从数据库查询数据,将查到的数据放入缓存并返回数据。
+- **写操作**:
+ 1. 先更新数据库。
+ 2. 再直接删除缓存中对应的数据。
+
+图解如下:
-下面单独对 **Cache Aside Pattern(旁路缓存模式)** 来聊聊。
+
-Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删除 cache 。
+
-如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说两个解决方案:
+如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说有两个解决方案:
-1. **缓存失效时间变短(不推荐,治标不治本)**:我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
-2. **增加 cache 更新重试机制(常用)**:如果 cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存入队列中,等缓存服务可用之后,再将缓存中对应的 key 删除即可。
+1. **缓存失效时间(TTL - Time To Live)变短**(不推荐,治标不治本):我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
+2. **增加缓存更新重试机制**(常用):如果缓存服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。不过,这里更适合引入消息队列实现异步重试,将删除缓存重试的消息投递到消息队列,然后由专门的消费者来重试,直到成功。虽然说多引入了一个消息队列,但其整体带来的收益还是要更高一些。
相关文章推荐:[缓存和数据库一致性问题,看这篇就够了 - 水滴与银弹](https://mp.weixin.qq.com/s?__biz=MzIyOTYxNDI5OA==&mid=2247487312&idx=1&sn=fa19566f5729d6598155b5c676eee62d&chksm=e8beb8e5dfc931f3e35655da9da0b61c79f2843101c130cf38996446975014f958a6481aacf1&scene=178&cur_album_id=1699766580538032128#rd)。
### 哪些情况可能会导致 Redis 阻塞?
-单独抽了一篇文章来总结可能会导致 Redis 阻塞的情况:[Redis 常见阻塞原因总结](https://javaguide.cn/database/redis/redis-common-blocking-problems-summary.html)。
+常见的导致 Redis 阻塞原因有:
+
+- `O(n)` 复杂度命令执行(如 `KEYS *`、`HGETALL`、`LRANGE`、`SMEMBERS` 等),随着数据量增大导致执行时间过长。
+- 执行 `SAVE` 命令生成 RDB 快照时同步阻塞主线程,而 `BGSAVE` 通过 `fork` 子进程避免阻塞。
+- AOF 记录日志在主线程中进行,可能因命令执行后写日志而阻塞后续命令。
+- AOF 刷盘(fsync)时后台线程同步到磁盘,磁盘压力大导致 `fsync` 阻塞,进而阻塞主线程 `write` 操作,尤其在 `appendfsync always` 或 `everysec` 配置下明显。
+- AOF 重写过程中将重写缓冲区内容追加到新 AOF 文件时产生阻塞。
+- 操作大 key(string > 1MB 或复合类型元素 > 5000)导致客户端超时、网络阻塞和工作线程阻塞。
+- 使用 `flushdb` 或 `flushall` 清空数据库时涉及大量键值对删除和内存释放,造成主线程阻塞。
+- 集群扩容缩容时数据迁移为同步操作,大 key 迁移导致两端节点长时间阻塞,可能触发故障转移
+- 内存不足触发 Swap,操作系统将 Redis 内存换出到硬盘,读写性能急剧下降。
+- 其他进程过度占用 CPU 导致 Redis 吞吐量下降。
+- 网络问题如连接拒绝、延迟高、网卡软中断等导致 Redis 阻塞。
+
+详细介绍可以阅读这篇文章:[Redis 常见阻塞原因总结](https://javaguide.cn/database/redis/redis-common-blocking-problems-summary.html)。
## Redis 集群
**Redis Sentinel**:
1. 什么是 Sentinel? 有什么用?
-2. Sentinel 如何检测节点是否下线?主观下线与客观下线的区别?
+2. Sentinel 如何检测节点是否下线?主观下线与客观下线的区别?
3. Sentinel 是如何实现故障转移的?
4. 为什么建议部署多个 sentinel 节点(哨兵集群)?
-5. Sentinel 如何选择出新的 master(选举机制)?
-6. 如何从 Sentinel 集群中选择出 Leader ?
+5. Sentinel 如何选择出新的 master(选举机制)?
+6. 如何从 Sentinel 集群中选择出 Leader?
7. Sentinel 可以防止脑裂吗?
**Redis Cluster**:
1. 为什么需要 Redis Cluster?解决了什么问题?有什么优势?
2. Redis Cluster 是如何分片的?
-3. 为什么 Redis Cluster 的哈希槽是 16384 个?
+3. 为什么 Redis Cluster 的哈希槽是 16384 个?
4. 如何确定给定 key 的应该分布到哪个哈希槽中?
5. Redis Cluster 支持重新分配哈希槽吗?
6. Redis Cluster 扩容缩容期间可以提供服务吗?
@@ -735,20 +803,21 @@ Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删
实际使用 Redis 的过程中,我们尽量要准守一些常见的规范,比如:
1. 使用连接池:避免频繁创建关闭客户端连接。
-2. 尽量不使用 O(n)指令,使用 O(n) 命令时要关注 n 的数量:像 `KEYS *`、`HGETALL`、`LRANGE`、`SMEMBERS`、`SINTER`/`SUNION`/`SDIFF`等 O(n) 命令并非不能使用,但是需要明确 n 的值。另外,有遍历的需求可以使用 `HSCAN`、`SSCAN`、`ZSCAN` 代替。
-3. 使用批量操作减少网络传输:原生批量操作命令(比如 `MGET`、`MSET`等等)、pipeline、Lua 脚本。
-4. 尽量不适用 Redis 事务:Redis 事务实现的功能比较鸡肋,可以使用 Lua 脚本代替。
+2. 尽量不使用 O(n) 指令,使用 O(n) 命令时要关注 n 的数量:像 `KEYS *`、`HGETALL`、`LRANGE`、`SMEMBERS`、`SINTER`/`SUNION`/`SDIFF` 等 O(n) 命令并非不能使用,但是需要明确 n 的值。另外,有遍历的需求可以使用 `HSCAN`、`SSCAN`、`ZSCAN` 代替。
+3. 使用批量操作减少网络传输:原生批量操作命令(比如 `MGET`、`MSET` 等等)、pipeline、Lua 脚本。
+4. 尽量不使用 Redis 事务:Redis 事务实现的功能比较鸡肋,可以使用 Lua 脚本代替。
5. 禁止长时间开启 monitor:对性能影响比较大。
6. 控制 key 的生命周期:避免 Redis 中存放了太多不经常被访问的数据。
-7. ......
-
-相关文章推荐:[阿里云 Redis 开发规范](https://developer.aliyun.com/article/531067) 。
+7. ……
## 参考
- 《Redis 开发与运维》
- 《Redis 设计与实现》
-- Redis Transactions :
+- Redis Transactions:
- What is Redis Pipeline:
- 一文详解 Redis 中 BigKey、HotKey 的发现与处理:
-- Redis延迟问题全面排障指南:https://mp.weixin.qq.com/s/mIc6a9mfEGdaNDD3MmfFsg
+- Bigkey 问题的解决思路与方式探索:
+- Redis 延迟问题全面排障指南:
+
+
diff --git a/docs/database/redis/redis-skiplist.md b/docs/database/redis/redis-skiplist.md
new file mode 100644
index 00000000000..d50ee58706f
--- /dev/null
+++ b/docs/database/redis/redis-skiplist.md
@@ -0,0 +1,727 @@
+---
+title: Redis为什么用跳表实现有序集合
+description: 深入讲解Redis有序集合Zset为何选择跳表而非红黑树、B+树实现,详解跳表的数据结构原理、时间复杂度分析和Redis源码实现。
+category: 数据库
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis跳表,SkipList,有序集合,Zset,跳表原理,平衡树对比,Redis数据结构
+---
+
+## 前言
+
+近几年针对 Redis 面试时会涉及常见数据结构的底层设计,其中就有这么一道比较有意思的面试题:“Redis 的有序集合底层为什么要用跳表,而不用平衡树、红黑树或者 B+树?”。
+
+本文就以这道大厂常问的面试题为切入点,带大家详细了解一下跳表这个数据结构。
+
+本文整体脉络如下图所示,笔者会从有序集合的基本使用到跳表的源码分析和实现,让你会对 Redis 的有序集合底层实现的跳表有着更深刻的理解和掌握。
+
+
+
+## 跳表在 Redis 中的运用
+
+这里我们需要先了解一下 Redis 用到跳表的数据结构有序集合的使用,Redis 有个比较常用的数据结构叫**有序集合(sorted set,简称 zset)**,正如其名它是一个可以保证有序且元素唯一的集合,所以它经常用于排行榜等需要进行统计排列的场景。
+
+这里我们通过命令行的形式演示一下排行榜的实现,可以看到笔者分别输入 3 名用户:**xiaoming**、**xiaohong**、**xiaowang**,它们的**score**分别是 60、80、60,最终按照成绩升级降序排列。
+
+```bash
+
+127.0.0.1:6379> zadd rankList 60 xiaoming
+(integer) 1
+127.0.0.1:6379> zadd rankList 80 xiaohong
+(integer) 1
+127.0.0.1:6379> zadd rankList 60 xiaowang
+(integer) 1
+
+# 返回有序集中指定区间内的成员,通过索引,分数从高到低
+127.0.0.1:6379> ZREVRANGE rankList 0 100 WITHSCORES
+1) "xiaohong"
+2) "80"
+3) "xiaowang"
+4) "60"
+5) "xiaoming"
+6) "60"
+```
+
+此时我们通过 `object` 指令查看 zset 的数据结构,可以看到当前有序集合存储的还是**ziplist(压缩列表)**。
+
+```bash
+127.0.0.1:6379> object encoding rankList
+"ziplist"
+```
+
+因为设计者考虑到 Redis 数据存放于内存,为了节约宝贵的内存空间,在有序集合元素小于 64 字节且个数小于 128 的时候,会使用 ziplist,而这个阈值的默认值的设置就来自下面这两个配置项。
+
+```bash
+zset-max-ziplist-value 64
+zset-max-ziplist-entries 128
+```
+
+一旦有序集合中的某个元素超出这两个其中的一个阈值它就会转为 **skiplist**(实际是 dict+skiplist,还会借用字典来提高获取指定元素的效率)。
+
+我们不妨在添加一个大于 64 字节的元素,可以看到有序集合的底层存储转为 skiplist。
+
+```bash
+127.0.0.1:6379> zadd rankList 90 yigemingzihuichaoguo64zijiedeyonghumingchengyongyuceshitiaobiaodeshijiyunyong
+(integer) 1
+
+# 超过阈值,转为跳表
+127.0.0.1:6379> object encoding rankList
+"skiplist"
+```
+
+也就是说,ZSet 有两种不同的实现,分别是 ziplist 和 skiplist,具体使用哪种结构进行存储的规则如下:
+
+- 当有序集合对象同时满足以下两个条件时,使用 ziplist:
+ 1. ZSet 保存的键值对数量少于 128 个;
+ 2. 每个元素的长度小于 64 字节。
+- 如果不满足上述两个条件,那么使用 skiplist 。
+
+## 手写一个跳表
+
+为了更好的回答上述问题以及更好的理解和掌握跳表,这里可以通过手写一个简单的跳表的形式来帮助读者理解跳表这个数据结构。
+
+我们都知道有序链表在添加、查询、删除的平均时间复杂都都是 **O(n)** 即线性增长,所以一旦节点数量达到一定体量后其性能表现就会非常差劲。而跳表我们完全可以理解为在原始链表基础上,建立多级索引,通过多级索引检索定位将增删改查的时间复杂度变为 **O(log n)** 。
+
+可能这里说的有些抽象,我们举个例子,以下图跳表为例,其原始链表存储按序存储 1-10,有 2 级索引,每级索引的索引个数都是基于下层元素个数的一半。
+
+
+
+假如我们需要查询元素 6,其工作流程如下:
+
+1. 从 2 级索引开始,先来到节点 4。
+2. 查看 4 的后继节点,是 8 的 2 级索引,这个值大于 6,说明 2 级索引后续的索引都是大于 6 的,没有再往后搜寻的必要,我们索引向下查找。
+3. 来到 4 的 1 级索引,比对其后继节点为 6,查找结束。
+
+相较于原始有序链表需要 6 次,我们的跳表通过建立多级索引,我们只需两次就直接定位到了目标元素,其查寻的复杂度被直接优化为**O(log n)**。
+
+
+
+对应的添加也是一个道理,假如我们需要在这个有序集合中添加一个元素 7,那么我们就需要通过跳表找到**小于元素 7 的最大值**,也就是下图元素 6 的位置,将其插入到元素 6 的后面,让元素 6 的索引指向新插入的节点 7,其工作流程如下:
+
+1. 从 2 级索引开始定位到了元素 4 的索引。
+2. 查看索引 4 的后继索引为 8,索引向下推进。
+3. 来到 1 级索引,发现索引 4 后继索引为 6,小于插入元素 7,指针推进到索引 6 位置。
+4. 继续比较 6 的后继节点为索引 8,大于元素 7,索引继续向下。
+5. 最终我们来到 6 的原始节点,发现其后继节点为 7,指针没有继续向下的空间,自此我们可知元素 6 就是小于插入元素 7 的最大值,于是便将元素 7 插入。
+
+
+
+这里我们又面临一个问题,我们是否需要为元素 7 建立索引,索引多高合适?
+
+我们上文提到,理想情况是每一层索引是下一层元素个数的二分之一,假设我们的总共有 16 个元素,对应各级索引元素个数应该是:
+
+```bash
+1. 一级索引:16/2=8
+2. 二级索引:8/2 =4
+3. 三级索引:4/2=2
+```
+
+由此我们用数学归纳法可知:
+
+```bash
+1. 一级索引:16/2=16/2^1=8
+2. 二级索引:8/2 => 16/2^2 =4
+3. 三级索引:4/2=>16/2^3=2
+```
+
+假设元素个数为 n,那么对应 k 层索引的元素个数 r 计算公式为:
+
+```bash
+r=n/2^k
+```
+
+同理我们再来推断以下索引的最大高度,一般来说最高级索引的元素个数为 2,我们设元素总个数为 n,索引高度为 h,代入上述公式可得:
+
+```bash
+2= n/2^h
+=> 2*2^h=n
+=> 2^(h+1)=n
+=> h+1=log2^n
+=> h=log2^n -1
+```
+
+而 Redis 又是内存数据库,我们假设元素最大个数是**65536**,我们把**65536**代入上述公式可知最大高度为 16。所以我们建议添加一个元素后为其建立的索引高度不超过 16。
+
+因为我们要求尽可能保证每一个上级索引都是下级索引的一半,在实现高度生成算法时,我们可以这样设计:
+
+1. 跳表的高度计算从原始链表开始,即默认情况下插入的元素的高度为 1,代表没有索引,只有元素节点。
+2. 设计一个为插入元素生成节点索引高度 level 的方法。
+3. 进行一次随机运算,随机数值范围为 0-1 之间。
+4. 如果随机数大于 0.5 则为当前元素添加一级索引,自此我们保证生成一级索引的概率为 **50%** ,这也就保证了 1 级索引理想情况下只有一半的元素会生成索引。
+5. 同理后续每次随机算法得到的值大于 0.5 时,我们的索引高度就加 1,这样就可以保证节点生成的 2 级索引概率为 **25%** ,3 级索引为 **12.5%** ……
+
+我们回过头,上述插入 7 之后,我们通过随机算法得到 2,即要为其建立 1 级索引:
+
+
+
+最后我们再来说说删除,假设我们这里要删除元素 10,我们必须定位到当前跳表**各层**元素小于 10 的最大值,索引执行步骤为:
+
+1. 2 级索引 4 的后继节点为 8,指针推进。
+2. 索引 8 无后继节点,该层无要删除的元素,指针直接向下。
+3. 1 级索引 8 后继节点为 10,说明 1 级索引 8 在进行删除时需要将自己的指针和 1 级索引 10 断开联系,将 10 删除。
+4. 1 级索引完成定位后,指针向下,后继节点为 9,指针推进。
+5. 9 的后继节点为 10,同理需要让其指向 null,将 10 删除。
+
+
+
+### 模板定义
+
+有了整体的思路之后,我们可以开始实现一个跳表了,首先定义一下跳表中的节点**Node**,从上文的演示中可以看出每一个**Node**它都包含以下几个元素:
+
+1. 存储的**value**值。
+2. 后继节点的地址。
+3. 多级索引。
+
+为了更方便统一管理**Node**后继节点地址和多级索引指向的元素地址,笔者在**Node**中设置了一个**forwards**数组,用于记录原始链表节点的后继节点和多级索引的后继节点指向。
+
+以下图为例,我们**forwards**数组长度为 5,其中**索引 0**记录的是原始链表节点的后继节点地址,而其余自底向上表示从 1 级索引到 4 级索引的后继节点指向。
+
+
+
+于是我们的就有了这样一个代码定义,可以看出笔者对于数组的长度设置为固定的 16**(上文的推算最大高度建议是 16)**,默认**data**为-1,节点最大高度**maxLevel**初始化为 1,注意这个**maxLevel**的值代表原始链表加上索引的总高度。
+
+```java
+/**
+ * 跳表索引最大高度为16
+ */
+private static final int MAX_LEVEL = 16;
+
+class Node {
+ private int data = -1;
+ private Node[] forwards = new Node[MAX_LEVEL];
+ private int maxLevel = 0;
+
+}
+```
+
+### 元素添加
+
+定义好节点之后,我们先实现以下元素的添加,添加元素时首先自然是设置**data**这一步我们直接根据将传入的**value**设置到**data**上即可。
+
+然后就是高度**maxLevel**的设置 ,我们在上文也已经给出了思路,默认高度为 1,即只有一个原始链表节点,通过随机算法每次大于 0.5 索引高度加 1,由此我们得出高度计算的算法`randomLevel()`:
+
+```java
+/**
+ * 理论来讲,一级索引中元素个数应该占原始数据的 50%,二级索引中元素个数占 25%,三级索引12.5% ,一直到最顶层。
+ * 因为这里每一层的晋升概率是 50%。对于每一个新插入的节点,都需要调用 randomLevel 生成一个合理的层数。
+ * 该 randomLevel 方法会随机生成 1~MAX_LEVEL 之间的数,且 :
+ * 50%的概率返回 1
+ * 25%的概率返回 2
+ * 12.5%的概率返回 3 ...
+ * @return
+ */
+private int randomLevel() {
+ int level = 1;
+ while (Math.random() > PROB && level < MAX_LEVEL) {
+ ++level;
+ }
+ return level;
+}
+```
+
+然后再设置当前要插入的**Node**和**Node**索引的后继节点地址,这一步稍微复杂一点,我们假设当前节点的高度为 4,即 1 个节点加 3 个索引,所以我们创建一个长度为 4 的数组**maxOfMinArr** ,遍历各级索引节点中小于当前**value**的最大值。
+
+假设我们要插入的**value**为 5,我们的数组查找结果当前节点的前驱节点和 1 级索引、2 级索引的前驱节点都为 4,三级索引为空。
+
+
+
+然后我们基于这个数组**maxOfMinArr** 定位到各级的后继节点,让插入的元素 5 指向这些后继节点,而**maxOfMinArr**指向 5,结果如下图:
+
+
+
+转化成代码就是下面这个形式,是不是很简单呢?我们继续:
+
+```java
+/**
+ * 默认情况下的高度为1,即只有自己一个节点
+ */
+private int levelCount = 1;
+
+/**
+ * 跳表最底层的节点,即头节点
+ */
+private Node h = new Node();
+
+public void add(int value) {
+ int level = randomLevel(); // 新节点的随机高度
+
+ Node newNode = new Node();
+ newNode.data = value;
+ newNode.maxLevel = level;
+
+ // 用于记录每层前驱节点的数组
+ Node[] update = new Node[level];
+ for (int i = 0; i < level; i++) {
+ update[i] = h;
+ }
+
+ Node p = h;
+ // 关键修正:从跳表的当前最高层开始查找
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ // 只记录需要更新的层的前驱节点
+ if (i < level) {
+ update[i] = p;
+ }
+ }
+
+ // 插入新节点
+ for (int i = 0; i < level; i++) {
+ newNode.forwards[i] = update[i].forwards[i];
+ update[i].forwards[i] = newNode;
+ }
+
+ // 更新跳表的总高度
+ if (levelCount < level) {
+ levelCount = level;
+ }
+}
+```
+
+### 元素查询
+
+查询逻辑比较简单,从跳表最高级的索引开始定位找到小于要查的 value 的最大值,以下图为例,我们希望查找到节点 8:
+
+
+
+- **从最高层级开始 (3 级索引)** :查找指针 `p` 从头节点开始。在 3 级索引上,`p` 的后继 `forwards[2]`(假设最高 3 层,索引从 0 开始)指向节点 `5`。由于 `5 < 8`,指针 `p` 向右移动到节点 `5`。节点 `5` 在 3 级索引上的后继 `forwards[2]` 为 `null`(或指向一个大于 `8` 的节点,图中未画出)。当前层级向右查找结束,指针 `p` 保持在节点 `5`,**向下移动到 2 级索引**。
+- **在 2 级索引**:当前指针 `p` 为节点 `5`。`p` 的后继 `forwards[1]` 指向节点 `8`。由于 `8` 不小于 `8`(即 `8 < 8` 为 `false`),当前层级向右查找结束(`p` 不会移动到节点 `8`)。指针 `p` 保持在节点 `5`,**向下移动到 1 级索引**。
+- **在 1 级索引** :当前指针 `p` 为节点 `5`。`p` 的后继 `forwards[0]` 指向最底层的节点 `5`。由于 `5 < 8`,指针 `p` 向右移动到最底层的节点 `5`。此时,当前指针 `p` 为最底层的节点 `5`。其后继 `forwards[0]` 指向最底层的节点 `6`。由于 `6 < 8`,指针 `p` 向右移动到最底层的节点 `6`。当前指针 `p` 为最底层的节点 `6`。其后继 `forwards[0]` 指向最底层的节点 `7`。由于 `7 < 8`,指针 `p` 向右移动到最底层的节点 `7`。当前指针 `p` 为最底层的节点 `7`。其后继 `forwards[0]` 指向最底层的节点 `8`。由于 `8` 不小于 `8`(即 `8 < 8` 为 `false`),当前层级向右查找结束。此时,已经遍历完所有层级,`for` 循环结束。
+- **最终定位与检查** :经过所有层级的查找,指针 `p` 最终停留在最底层(0 级索引)的节点 `7`。这个节点是整个跳表中值小于目标值 `8` 的那个最大的节点。检查节点 `7` 的**后继节点**(即 `p.forwards[0]`):`p.forwards[0]` 指向节点 `8`。判断 `p.forwards[0].data`(即节点 `8` 的值)是否等于目标值 `8`。条件满足(`8 == 8`),**查找成功,找到节点 `8`**。
+
+所以我们的代码实现也很上述步骤差不多,从最高级索引开始向前查找,如果不为空且小于要查找的值,则继续向前搜寻,遇到不小于的节点则继续向下,如此往复,直到得到当前跳表中小于查找值的最大节点,查看其前驱是否等于要查找的值:
+
+```java
+public Node get(int value) {
+ Node p = h; // 从头节点开始
+
+ // 从最高层级索引开始,逐层向下
+ for (int i = levelCount - 1; i >= 0; i--) {
+ // 在当前层级向右查找,直到 p.forwards[i] 为 null
+ // 或者 p.forwards[i].data 大于等于目标值 value
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i]; // 向右移动
+ }
+ // 此时 p.forwards[i] 为 null,或者 p.forwards[i].data >= value
+ // 或者 p 是当前层级中小于 value 的最大节点(如果存在这样的节点)
+ }
+
+ // 经过所有层级的查找,p 现在是原始链表(0级索引)中
+ // 小于目标值 value 的最大节点(或者头节点,如果所有元素都大于等于 value)
+
+ // 检查 p 在原始链表中的下一个节点是否是目标值
+ if (p.forwards[0] != null && p.forwards[0].data == value) {
+ return p.forwards[0]; // 找到了,返回该节点
+ }
+
+ return null; // 未找到
+}
+```
+
+### 元素删除
+
+最后是删除逻辑,需要查找各层级小于要删除节点的最大值,假设我们要删除 10:
+
+1. 3 级索引得到小于 10 的最大值为 5,继续向下。
+2. 2 级索引从索引 5 开始查找,发现小于 10 的最大值为 8,继续向下。
+3. 同理 1 级索引得到 8,继续向下。
+4. 原始节点找到 9。
+5. 从最高级索引开始,查看每个小于 10 的节点后继节点是否为 10,如果等于 10,则让这个节点指向 10 的后继节点,将节点 10 及其索引交由 GC 回收。
+
+
+
+```java
+/**
+ * 删除
+ *
+ * @param value
+ */
+public void delete(int value) {
+ Node p = h;
+ //找到各级节点小于value的最大值
+ Node[] updateArr = new Node[levelCount];
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ updateArr[i] = p;
+ }
+ //查看原始层节点前驱是否等于value,若等于则说明存在要删除的值
+ if (p.forwards[0] != null && p.forwards[0].data == value) {
+ //从最高级索引开始查看其前驱是否等于value,若等于则将当前节点指向value节点的后继节点
+ for (int i = levelCount - 1; i >= 0; i--) {
+ if (updateArr[i].forwards[i] != null && updateArr[i].forwards[i].data == value) {
+ updateArr[i].forwards[i] = updateArr[i].forwards[i].forwards[i];
+ }
+ }
+ }
+
+ //从最高级开始查看是否有一级索引为空,若为空则层级减1
+ while (levelCount > 1 && h.forwards[levelCount - 1] == null) {
+ levelCount--;
+ }
+
+}
+```
+
+### 完整代码以及测试
+
+完整代码如下,读者可自行参阅:
+
+```java
+public class SkipList {
+
+ /**
+ * 跳表索引最大高度为16
+ */
+ private static final int MAX_LEVEL = 16;
+
+ /**
+ * 每个节点添加一层索引高度的概率为二分之一
+ */
+ private static final float PROB = 0.5f;
+
+ /**
+ * 默认情况下的高度为1,即只有自己一个节点
+ */
+ private int levelCount = 1;
+
+ /**
+ * 跳表最底层的节点,即头节点
+ */
+ private Node h = new Node();
+
+ public SkipList() {
+ }
+
+ public class Node {
+
+ private int data = -1;
+ /**
+ *
+ */
+ private Node[] forwards = new Node[MAX_LEVEL];
+ private int maxLevel = 0;
+
+ @Override
+ public String toString() {
+ return "Node{"
+ + "data=" + data
+ + ", maxLevel=" + maxLevel
+ + '}';
+ }
+ }
+
+ public void add(int value) {
+ int level = randomLevel(); // 新节点的随机高度
+
+ Node newNode = new Node();
+ newNode.data = value;
+ newNode.maxLevel = level;
+
+ // 用于记录每层前驱节点的数组
+ Node[] update = new Node[level];
+ for (int i = 0; i < level; i++) {
+ update[i] = h;
+ }
+
+ Node p = h;
+ // 关键修正:从跳表的当前最高层开始查找
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ // 只记录需要更新的层的前驱节点
+ if (i < level) {
+ update[i] = p;
+ }
+ }
+
+ // 插入新节点
+ for (int i = 0; i < level; i++) {
+ newNode.forwards[i] = update[i].forwards[i];
+ update[i].forwards[i] = newNode;
+ }
+
+ // 更新跳表的总高度
+ if (levelCount < level) {
+ levelCount = level;
+ }
+ }
+
+ /**
+ * 理论来讲,一级索引中元素个数应该占原始数据的 50%,二级索引中元素个数占 25%,三级索引12.5% ,一直到最顶层。
+ * 因为这里每一层的晋升概率是 50%。对于每一个新插入的节点,都需要调用 randomLevel 生成一个合理的层数。 该 randomLevel
+ * 方法会随机生成 1~MAX_LEVEL 之间的数,且 : 50%的概率返回 1 25%的概率返回 2 12.5%的概率返回 3 ...
+ *
+ * @return
+ */
+ private int randomLevel() {
+ int level = 1;
+ while (Math.random() > PROB && level < MAX_LEVEL) {
+ ++level;
+ }
+ return level;
+ }
+
+ public Node get(int value) {
+ Node p = h;
+ //找到小于value的最大值
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ }
+ //如果p的前驱节点等于value则直接返回
+ if (p.forwards[0] != null && p.forwards[0].data == value) {
+ return p.forwards[0];
+ }
+
+ return null;
+ }
+
+ /**
+ * 删除
+ *
+ * @param value
+ */
+ public void delete(int value) {
+ Node p = h;
+ //找到各级节点小于value的最大值
+ Node[] updateArr = new Node[levelCount];
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ updateArr[i] = p;
+ }
+ //查看原始层节点前驱是否等于value,若等于则说明存在要删除的值
+ if (p.forwards[0] != null && p.forwards[0].data == value) {
+ //从最高级索引开始查看其前驱是否等于value,若等于则将当前节点指向value节点的后继节点
+ for (int i = levelCount - 1; i >= 0; i--) {
+ if (updateArr[i].forwards[i] != null && updateArr[i].forwards[i].data == value) {
+ updateArr[i].forwards[i] = updateArr[i].forwards[i].forwards[i];
+ }
+ }
+ }
+
+ //从最高级开始查看是否有一级索引为空,若为空则层级减1
+ while (levelCount > 1 && h.forwards[levelCount - 1] == null) {
+ levelCount--;
+ }
+
+ }
+
+ public void printAll() {
+ Node p = h;
+ //基于最底层的非索引层进行遍历,只要后继节点不为空,则速速出当前节点,并移动到后继节点
+ while (p.forwards[0] != null) {
+ System.out.println(p.forwards[0]);
+ p = p.forwards[0];
+ }
+
+ }
+}
+
+```
+
+测试代码:
+
+```java
+public static void main(String[] args) {
+ SkipList skipList = new SkipList();
+ for (int i = 0; i < 24; i++) {
+ skipList.add(i);
+ }
+
+ System.out.println("**********输出添加结果**********");
+ skipList.printAll();
+
+ SkipList.Node node = skipList.get(22);
+ System.out.println("**********查询结果:" + node+" **********");
+
+ skipList.delete(22);
+ System.out.println("**********删除结果**********");
+ skipList.printAll();
+
+
+ }
+```
+
+**Redis 跳表的特点**:
+
+1. 采用**双向链表**,不同于上面的示例,存在一个回退指针。主要用于简化操作,例如删除某个元素时,还需要找到该元素的前驱节点,使用回退指针会非常方便。
+2. `score` 值可以重复,如果 `score` 值一样,则按照 ele(节点存储的值,为 sds)字典排序
+3. Redis 跳跃表默认允许最大的层数是 32,被源码中 `ZSKIPLIST_MAXLEVEL` 定义。
+
+## 和其余三种数据结构的比较
+
+最后,我们再来回答一下文章开头的那道面试题: “Redis 的有序集合底层为什么要用跳表,而不用平衡树、红黑树或者 B+树?”。
+
+### 平衡树 vs 跳表
+
+先来说说它和平衡树的比较,平衡树我们又会称之为 **AVL 树**,是一个严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过 1,即平衡因子为范围为 `[-1,1]`)。平衡树的插入、删除和查询的时间复杂度和跳表一样都是 **O(log n)** 。
+
+对于范围查询来说,它也可以通过中序遍历的方式达到和跳表一样的效果。但是它的每一次插入或者删除操作都需要保证整颗树左右节点的绝对平衡,只要不平衡就要通过旋转操作来保持平衡,这个过程是比较耗时的。
+
+
+
+跳表诞生的初衷就是为了克服平衡树的一些缺点,跳表的发明者在论文[《Skip lists: a probabilistic alternative to balanced trees》](https://15721.courses.cs.cmu.edu/spring2018/papers/08-oltpindexes1/pugh-skiplists-cacm1990.pdf)中有详细提到:
+
+
+
+> Skip lists are a data structure that can be used in place of balanced trees. Skip lists use probabilistic balancing rather than strictly enforced balancing and as a result the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.
+>
+> 跳表是一种可以用来代替平衡树的数据结构。跳表使用概率平衡而不是严格强制的平衡,因此,跳表中的插入和删除算法比平衡树的等效算法简单得多,速度也快得多。
+
+笔者这里也贴出了 AVL 树插入操作的核心代码,可以看出每一次添加操作都需要进行一次递归定位插入位置,然后还需要根据回溯到根节点检查沿途的各层节点是否失衡,再通过旋转节点的方式进行调整。
+
+```java
+// 向二分搜索树中添加新的元素(key, value)
+public void add(K key, V value) {
+ root = add(root, key, value);
+}
+
+// 向以node为根的二分搜索树中插入元素(key, value),递归算法
+// 返回插入新节点后二分搜索树的根
+private Node add(Node node, K key, V value) {
+
+ if (node == null) {
+ size++;
+ return new Node(key, value);
+ }
+
+ if (key.compareTo(node.key) < 0)
+ node.left = add(node.left, key, value);
+ else if (key.compareTo(node.key) > 0)
+ node.right = add(node.right, key, value);
+ else // key.compareTo(node.key) == 0
+ node.value = value;
+
+ node.height = 1 + Math.max(getHeight(node.left), getHeight(node.right));
+
+ int balanceFactor = getBalanceFactor(node);
+
+ // LL型需要右旋
+ if (balanceFactor > 1 && getBalanceFactor(node.left) >= 0) {
+ return rightRotate(node);
+ }
+
+ //RR型失衡需要左旋
+ if (balanceFactor < -1 && getBalanceFactor(node.right) <= 0) {
+ return leftRotate(node);
+ }
+
+ //LR需要先左旋成LL型,然后再右旋
+ if (balanceFactor > 1 && getBalanceFactor(node.left) < 0) {
+ node.left = leftRotate(node.left);
+ return rightRotate(node);
+ }
+
+ //RL
+ if (balanceFactor < -1 && getBalanceFactor(node.right) > 0) {
+ node.right = rightRotate(node.right);
+ return leftRotate(node);
+ }
+ return node;
+}
+```
+
+### 红黑树 vs 跳表
+
+红黑树(Red Black Tree)也是一种自平衡二叉查找树,它的查询性能略微逊色于 AVL 树,但插入和删除效率更高。红黑树的插入、删除和查询的时间复杂度和跳表一样都是 **O(log n)** 。
+
+红黑树是一个**黑平衡树**,即从任意节点到另外一个叶子叶子节点,它所经过的黑节点是一样的。当对它进行插入操作时,需要通过旋转和染色(红黑变换)来保证黑平衡。不过,相较于 AVL 树为了维持平衡的开销要小一些。关于红黑树的详细介绍,可以查看这篇文章:[红黑树](https://javaguide.cn/cs-basics/data-structure/red-black-tree.html)。
+
+相比较于红黑树来说,跳表的实现也更简单一些。并且,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
+
+
+
+对应红黑树添加的核心代码如下,读者可自行参阅理解:
+
+```java
+private Node < K, V > add(Node < K, V > node, K key, V val) {
+
+ if (node == null) {
+ size++;
+ return new Node(key, val);
+
+ }
+
+ if (key.compareTo(node.key) < 0) {
+ node.left = add(node.left, key, val);
+ } else if (key.compareTo(node.key) > 0) {
+ node.right = add(node.right, key, val);
+ } else {
+ node.val = val;
+ }
+
+ //左节点不为红,右节点为红,左旋
+ if (isRed(node.right) && !isRed(node.left)) {
+ node = leftRotate(node);
+ }
+
+ //左链右旋
+ if (isRed(node.left) && isRed(node.left.left)) {
+ node = rightRotate(node);
+ }
+
+ //颜色翻转
+ if (isRed(node.left) && isRed(node.right)) {
+ flipColors(node);
+ }
+
+ return node;
+}
+```
+
+### B+树 vs 跳表
+
+想必使用 MySQL 的读者都知道 B+树这个数据结构,B+树是一种常用的数据结构,具有以下特点:
+
+1. **多叉树结构**:它是一棵多叉树,每个节点可以包含多个子节点,减小了树的高度,查询效率高。
+2. **存储效率高**:其中非叶子节点存储多个 key,叶子节点存储 value,使得每个节点更够存储更多的键,根据索引进行范围查询时查询效率更高。-
+3. **平衡性**:它是绝对的平衡,即树的各个分支高度相差不大,确保查询和插入时间复杂度为 **O(log n)** 。
+4. **顺序访问**:叶子节点间通过链表指针相连,范围查询表现出色。
+5. **数据均匀分布**:B+树插入时可能会导致数据重新分布,使得数据在整棵树分布更加均匀,保证范围查询和删除效率。
+
+
+
+所以,B+树更适合作为数据库和文件系统中常用的索引结构之一,它的核心思想是通过可能少的 IO 定位到尽可能多的索引来获得查询数据。对于 Redis 这种内存数据库来说,它对这些并不感冒,因为 Redis 作为内存数据库它不可能存储大量的数据,所以对于索引不需要通过 B+树这种方式进行维护,只需按照概率进行随机维护即可,节约内存。而且使用跳表实现 zset 时相较前者来说更简单一些,在进行插入时只需通过索引将数据插入到链表中合适的位置再随机维护一定高度的索引即可,也不需要像 B+树那样插入时发现失衡时还需要对节点分裂与合并。
+
+### Redis 作者给出的理由
+
+当然我们也可以通过 Redis 的作者自己给出的理由:
+
+> There are a few reasons:
+> 1、They are not very memory intensive. It's up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
+> 2、A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
+> 3、They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
+
+翻译过来的意思就是:
+
+> 有几个原因:
+>
+> 1、它们不是很占用内存。这主要取决于你。改变节点拥有给定层数的概率的参数,会使它们比 B 树更节省内存。
+>
+> 2、有序集合经常是许多 ZRANGE 或 ZREVRANGE 操作的目标,也就是说,以链表的方式遍历跳表。通过这种操作,跳表的缓存局部性至少和其他类型的平衡树一样好。
+>
+> 3、它们更容易实现、调试等等。例如,由于跳表的简单性,我收到了一个补丁(已经在 Redis 主分支中),用增强的跳表实现了 O(log(N))的 ZRANK。它只需要对代码做很少的修改。
+
+## 小结
+
+本文通过大量篇幅介绍跳表的工作原理和实现,帮助读者更进一步的熟悉跳表这一数据结构的优劣,最后再结合各个数据结构操作的特点进行比对,从而帮助读者更好的理解这道面试题,建议读者实现理解跳表时,尽可能配合执笔模拟来了解跳表的增删改查详细过程。
+
+## 参考
+
+- 为啥 redis 使用跳表(skiplist)而不是使用 red-black?:
+- Skip List--跳表(全网最详细的跳表文章没有之一):
+- Redis 对象与底层数据结构详解:
+- Redis 有序集合(sorted set):
+- 红黑树和跳表比较:
+- 为什么 redis 的 zset 用跳跃表而不用 b+ tree?:
diff --git a/docs/database/redis/redis-stream-mq.md b/docs/database/redis/redis-stream-mq.md
new file mode 100644
index 00000000000..2ba128e0f6d
--- /dev/null
+++ b/docs/database/redis/redis-stream-mq.md
@@ -0,0 +1,223 @@
+---
+title: Redis 能做消息队列吗?怎么实现?
+description: 讲解 Redis 做消息队列的三种方式:List、Pub/Sub、Stream。对比生产级 MQ 核心能力,详解 Redis 5.0 Stream 的消费者组、ACK 机制及与 Kafka/RabbitMQ 的适用场景对比。
+category: 数据库
+tag:
+ - Redis
+ - 消息队列
+head:
+ - - meta
+ - name: keywords
+ content: Redis消息队列,Redis Stream,Redis List,Redis Pub/Sub,消息队列,消费者组,ACK机制,XREADGROUP,XADD,XACK
+---
+
+先说结论:**可以是可以,但要看具体场景。和专业的消息队列(如 Kafka、RabbitMQ)相比,还是有一些欠缺的地方。**
+
+正式开始介绍之前,我们先来看看:**一个生产级 MQ 需要具备哪些核心能力?**
+
+| 能力维度 | 定义 | 关键指标/特征 |
+| :--------------- | :------------------------------ | :---------------------------------- |
+| **持久化** | 消息写入后不因进程/节点故障丢失 | 同步刷盘/多副本确认、RPO ≈ 0 |
+| **至少一次投递** | 消息最终被消费,允许重复 | 需配合消费者幂等性 |
+| **消费确认** | 消费者显式告知处理成功 | ACK 机制、超时重试、死信队列 |
+| **消息重试** | 消费失败可自动重新投递 | 退避策略、最大重试次数、死信转移 |
+| **消费者组** | 多消费者协作消费,故障自动转移 | 组内负载均衡、分区分配、Rebalance |
+| **消息堆积能力** | 生产速率 > 消费速率时的缓冲能力 | 磁盘存储、TTL、堆积告警 |
+| **顺序保证** | 消息按发送顺序被消费 | 分区有序/全局有序、乱序惩罚 |
+| **可扩展性** | 水平扩展以提升吞吐或容灾 | 分片机制、无状态 Broker、动态扩缩容 |
+
+Redis 提供了多种实现 MQ 的方式,从早期的 `List` 到 `Pub/Sub`,再到 Redis 5.0 新增的 `Stream` 数据结构(基于有序链表实现,支持消费者组和 ACK 机制,可用于构建轻量级消息队列)。
+
+### 第一阶段:早期用 List 数据结构
+
+**Redis 2.0 之前,如果想要使用 Redis 来做消息队列的话,只能通过 List 来实现。**
+
+通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP` 即可实现简易版消息队列:
+
+```bash
+# 生产者生产消息
+> RPUSH myList msg1 msg2
+(integer) 2
+> RPUSH myList msg3
+(integer) 3
+# 消费者消费消息
+> LPOP myList
+"msg1"
+```
+
+不过,通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP` 这样的方式存在性能问题,我们需要不断轮询去调用 `RPOP` 或 `LPOP` 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
+
+因此,Redis 还提供了 `BLPOP`、`BRPOP` 这种阻塞式读取的命令(带 B-Blocking 的都是阻塞式),并且还支持一个超时参数。如果 List 为空,Redis 服务端不会立刻返回结果,它会等待 List 中有新数据后再返回或者是等待最多一个超时时间后返回空。如果将超时时间设置为 0 时,即可无限等待,直到弹出消息
+
+```bash
+# 超时时间为 10s
+# 如果有数据立刻返回,否则最多等待10秒
+> BRPOP myList 10
+null
+```
+
+List 实现消息队列功能太简单,像消息确认机制等功能还需要我们自己实现。**最致命的是,它不支持一个消息被多个消费者消费(广播),而且消息一旦被取出,就没有了,如果消费者处理失败,消息就永久丢失了。**
+
+### 第二阶段:引入 Pub/Sub(发布/订阅)模式
+
+**Redis 2.0 引入了发布订阅 (Pub/Sub) 功能,解决了 List 实现消息队列没有广播机制的问题。**
+
+
+
+Pub/Sub 中引入了一个概念叫 **Channel(频道)**,发布订阅机制的实现就是基于这个 Channel 来做的。
+
+Pub/Sub 涉及发布者(Publisher)和订阅者(Subscriber,也叫消费者)两个角色:
+
+- 发布者通过 `PUBLISH` 投递消息给指定 Channel。
+- 订阅者通过`SUBSCRIBE`订阅它关心的 Channel。并且,订阅者可以订阅一个或者多个 Channel。
+
+也就是说,多个消费者可以订阅同一个 Channel,生产者向这个 Channel 发布消息,所有订阅者都能收到。
+
+我们这里启动 3 个 Redis 客户端来简单演示一下:
+
+
+
+Pub/Sub 既能单播又能广播,还支持 Channel 的简单正则匹配。
+
+Pub/Sub 有一个致命的缺陷:**它发后即忘,完全没有持久化和可靠性保证**。 如果消息发布时,某个消费者不在线,或者网络抖动了一下,那这条消息对它来说就永远丢失了。此外,它也**没有 ACK 机制**,无法知道消费者是否成功处理,更别提**消息堆积**的问题了。所以,Pub/Sub 只适合做一些对可靠性要求极低的实时通知,绝对不能用于任何严肃的业务消息队列。
+
+### 第三阶段:Redis 5.0 新增 Stream
+
+Redis 5.0 新增了 `Stream` 数据结构。这是一个基于 Radix Tree(基数树)实现的有序消息日志,天然支持消费者组和 ACK 机制,可用于构建轻量级消息队列。
+
+**为什么要用 Radix Tree?** 很多人好奇,为什么不继续用 `List/LinkedList`?
+
+1. **内存极度压缩**:`Stream` 的消息 ID(如 `1625000000000-0`)是高度有序且前缀高度重合的。Radix Tree 是一种压缩前缀树,它会将具有相同前缀的节点合并。而 List/LinkedList
+ 每个元素都要完整的链表节点开销,并且无法利用 ID 的前缀重复特性来节省空间。
+2. **高效检索**:在处理数百万级消息堆积时,Radix Tree 能保持极高的查询效率,这也是 `Stream` 能支持大数据量范围查询(`XRANGE`)的底层底气。相比之下,`List/LinkedList`只能从头尾操作,无法高效按 ID 范围查询,执行 `XRANGE` 需要遍历整个列表。
+
+它借鉴了 Kafka 等专业 MQ 的核心概念:
+
+1. **消费者组(Consumer Groups)**:实现消息在多个消费者间的负载均衡,支持故障自动转移。
+2. **持久化**:可以通过 RDB 和 AOF 保证消息在 Redis 重启后不丢失(取决于 `appendfsync` 配置,`everysec` 模式下通常最多丢失 1 秒数据)。
+3. **ACK 机制**:消费者处理完消息后,需要手动 `XACK` 确认,否则消息会保留在 `Pending List` 中。这保证了消息至少被成功消费一次。
+4. **消息回溯与转移**:支持 `XRANGE` 按时间范围回溯消息,以及 `XCLAIM` 将挂起的消息转移到其他消费者处理。
+
+> 🌈 版本演进:
+>
+> - Redis 8.2:`XACKDEL`、`XDELEX`、`XADD` 和 `XTRIM 命令提供了对流操作如何与多个消费者组交互的细粒度控制,简化了跨不同应用程序的消息处理协调。
+> - Redis 8.6:支持幂等消息处理(最多一次生产),防止在使用至少一次交付模式时出现重复条目。此功能可实现可靠的消息提交,并自动去重。
+
+`Stream` 的结构如下:
+
+
+
+这是一个有序的消息链表,每个消息都有一个唯一的 ID 和对应的内容。ID 是一个时间戳和序列号的组合,用来保证消息的唯一性和递增性。内容是一个或多个键值对(类似 Hash 基本数据类型),用来存储消息的数据。
+
+这里再对图中涉及到的一些概念,进行简单解释:
+
+- `Consumer Group`:消费者组用于组织和管理多个消费者。消费者组本身不处理消息,而是再将消息分发给消费者,由消费者进行真正的消费。
+- `last_delivered_id`:标识消费者组当前消费位置的游标,消费者组中任意一个消费者读取了消息都会使 last_delivered_id 往前移动。
+- `pending_ids`:记录已经被客户端消费但没有 ack 的消息的 ID。
+
+下面是`Stream` 用作消息队列时常用的命令:
+
+- `XADD`:向流中添加新的消息。
+- `XREAD`:从流中读取消息。
+- `XREADGROUP`:从消费组中读取消息。
+- `XRANGE`:根据消息 ID 范围读取流中的消息。
+- `XREVRANGE`:与 `XRANGE` 类似,但以相反顺序返回结果。
+- `XDEL`:从流中删除消息。
+- `XTRIM`:修剪流的长度,可以指定修建策略(`MAXLEN`/`MINID`)。
+- `XLEN`:获取流的长度。
+- `XGROUP CREATE`:创建消费者组。
+- `XGROUP DESTROY`:删除消费者组。
+- `XGROUP DELCONSUMER`:从消费者组中删除一个消费者。
+- `XGROUP SETID`:为消费者组设置新的最后递送消息 ID。
+- `XACK`:确认消费组中的消息已被处理。
+- `XPENDING`:查询消费组中挂起(未确认)的消息。
+- `XCLAIM`:将挂起的消息从一个消费者转移到另一个消费者。
+- `XINFO`:获取流(`XINFO STREAM`)、消费组(`XINFO GROUPS`)或消费者(`XINFO CONSUMERS`)的详细信息。
+
+下面这张时序图展示了 Stream 消费者组消息流转与 ACK 机制:
+
+```mermaid
+sequenceDiagram
+ participant P as Producer
+ participant R as Redis Stream
(my_stream)
+ participant CG as Consumer Group
(group_a)
+ participant C1 as Consumer-1
+ participant C2 as Consumer-2
+
+ %% 生产消息
+ P->>R: XADD my_stream * field value
+ R-->>P: 返回 ID = 1001
+
+ %% 消费新消息
+ C1->>R: XREADGROUP GROUP group_a consumer-1
STREAMS my_stream >
+ R-->>C1: 返回消息 1001
+
+ Note over CG: 1️⃣ last_delivered_id 推进到 1001
+ Note over CG: 2️⃣ 1001 进入 PEL (Pending Entries List)
+
+ %% 正常消费
+ alt 正常处理完成
+ C1->>R: XACK my_stream group_a 1001
+ R-->>C1: OK
+ Note over CG: 1001 从 PEL 移除
+ else 消费者崩溃
+ Note over C1: 未 ACK,连接断开
+ Note over CG: 1001 仍在 PEL 中
idle time 持续增长
+
+ C2->>R: XPENDING my_stream group_a
+ R-->>C2: 返回 1001 + idle time
+
+ C2->>R: XCLAIM my_stream group_a consumer-2 60000 1001
+ R-->>C2: 返回 1001
+
+ Note over CG: 1001 转移到 consumer-2
+
+ C2->>R: XACK my_stream group_a 1001
+ R-->>C2: OK
+ end
+
+```
+
+总的来说,`Stream` 已经可以满足一个消息队列的基本要求了。不过,`Stream` 在实际使用中需要注意以下几点:
+
+1. **持久化限制**:Redis 5.0 的 Stream 依赖 RDB/AOF 异步持久化,在故障恢复时可能丢失最近未持久化的消息(取决于 `appendfsync` 配置)。AOF 的 `everysec` 模式下通常最多丢失 1 秒数据。
+2. **消息堆积受限**:Redis Stream 的数据存储在内存中,受服务器内存容量限制。相比 Kafka 基于磁盘的存储,Redis Stream 不适合海量堆积场景。
+3. **消费组管理**:Consumer Group 的状态信息(如 `last_delivered_id`)需要定期维护,长时间未处理的 Pending 消息会占用内存。
+
+下面这张表格是 Redis Stream 和常见 MQ 的对比:
+
+| 维度 | Redis Stream | RabbitMQ | Kafka | 内存队列 |
+| :------------- | :------------------------- | :------------------------------- | :---------------------------------- | :----------------------- |
+| **吞吐量** | 高(十万级 QPS) | 中(万级 QPS) | **极高(百万级,靠分区水平扩展)** | 极高(受限于 CPU/内存) |
+| **延迟** | **极低(亚毫秒级)** | **低(微秒/毫秒级,实时性强)** | 中(毫秒级,受批处理影响) | 极低(纳秒/微秒级) |
+| **持久化** | 支持(RDB/AOF 异步) | 支持(磁盘) | **强支持(原生磁盘顺序写)** | 无 |
+| **消息堆积** | 一般(受内存限制) | 中(堆积多时性能下降明显) | **极强(TB 级磁盘存储,性能稳定)** | 差(易 OOM) |
+| **消息回溯** | 支持(按 ID/时间) | **不支持(传统队列模式下)** | **强支持(按 Offset/时间)** | 不支持 |
+| **可靠性** | 中(AOF 丢数据风险) | **高(Confirm/确认机制成熟)** | **极高(多副本 + 强一致性配置)** | 低 |
+| **运维复杂度** | 低(运维 Redis 即可) | 中(Erlang 环境,集群管理) | 高(依赖 ZK 或 KRaft) | 极低 |
+| **适用场景** | 轻量级、低延迟、已有 Redis | **复杂路由、高可靠性、金融业务** | **大数据、日志聚合、高吞吐流处理** | 进程内解耦、极致性能要求 |
+
+### 总结
+
+**回到最初的问题:Redis 到底能不能做 MQ?**
+
+- **如果业务简单、量小、追求极致性能**,且能容忍极小概率的数据丢失,使用 **Redis Stream** 是最优解,因为它省去了部署维护 MQ 的成本,可以复用现有的 Redis 组件(大部分需要用到 MQ 的项目,通常都会需要 Redis)。
+- **如果是金融级业务、海量数据、需要严格保证不丢消息**,必须选择 **Kafka、RabbitMQ** 等更成熟的 MQ。
+
+更多 Redis 高频知识点和面试题总结,可以阅读笔者写的这几篇文章:
+
+- [Redis 常见面试题总结(上)](https://javaguide.cn/database/redis/redis-questions-01.html "Redis 常见面试题总结(上)")(Redis 基础、应用、数据类型、持久化机制、线程模型等)
+- [Redis 常见面试题总结(下)](https://javaguide.cn/database/redis/redis-questions-02.html "Redis 常见面试题总结(下)")(Redis 事务、性能优化、生产问题、集群、使用规范等)
+- [如何基于Redis实现延时任务](https://javaguide.cn/database/redis/redis-delayed-task.html "如何基于Redis实现延时任务")
+- [Redis 5 种基本数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-01.html "Redis 5 种基本数据类型详解")
+- [Redis 3 种特殊数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-02.html "Redis 3 种特殊数据类型详解")
+- [Redis为什么用跳表实现有序集合](https://javaguide.cn/database/redis/redis-skiplist.html "Redis为什么用跳表实现有序集合")
+- [Redis 持久化机制详解](https://javaguide.cn/database/redis/redis-persistence.html "Redis 持久化机制详解")
+- [Redis 内存碎片详解](https://javaguide.cn/database/redis/redis-memory-fragmentation.html "Redis 内存碎片详解")
+- [Redis 常见阻塞原因总结](https://javaguide.cn/database/redis/redis-common-blocking-problems-summary.html "Redis 常见阻塞原因总结")
+
+我的 [《SpringAI 智能面试平台+RAG 知识库》](https://javaguide.cn/zhuanlan/interview-guide.html)项目就是用的 Redis Stream 作为消息队列。在我的项目的场景下,它几乎是最合适的选择,完全够用了。
+
+
+
+
diff --git a/docs/database/sql/sql-questions-01.md b/docs/database/sql/sql-questions-01.md
index 068487d78c5..b61d0f07c1e 100644
--- a/docs/database/sql/sql-questions-01.md
+++ b/docs/database/sql/sql-questions-01.md
@@ -1,9 +1,14 @@
---
-title: SQL常见面试题总结
+title: SQL常见面试题总结(1)
+description: SQL常见面试题总结第一篇,涵盖SELECT检索数据、WHERE条件过滤、ORDER BY排序、DISTINCT去重、LIMIT分页等基础查询操作及牛客真题解析。
category: 数据库
tag:
- 数据库基础
- SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL面试题,SELECT查询,WHERE条件,ORDER BY排序,DISTINCT去重,LIMIT分页,SQL基础
---
> 题目来源于:[牛客题霸 - SQL 必知必会](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=298)
@@ -189,17 +194,17 @@ ORDER BY vend_name DESC
下面的运算符可以在 `WHERE` 子句中使用:
-| 运算符 | 描述 |
-| :------ | :--------------------------------------------------------- |
-| = | 等于 |
-| <> | 不等于。**注释:**在 SQL 的一些版本中,该操作符可被写成 != |
-| > | 大于 |
-| < | 小于 |
-| >= | 大于等于 |
-| <= | 小于等于 |
-| BETWEEN | 在某个范围内 |
-| LIKE | 搜索某种模式 |
-| IN | 指定针对某个列的多个可能值 |
+| 运算符 | 描述 |
+| :------ | :----------------------------------------------------------- |
+| = | 等于 |
+| <> | 不等于。 **注释:** 在 SQL 的一些版本中,该操作符可被写成 != |
+| > | 大于 |
+| < | 小于 |
+| >= | 大于等于 |
+| <= | 小于等于 |
+| BETWEEN | 在某个范围内 |
+| LIKE | 搜索某种模式 |
+| IN | 指定针对某个列的多个可能值 |
### 返回固定价格的产品
@@ -358,7 +363,7 @@ WHERE prod_id IN ('BR01', 'BR02', 'BR03') AND quantity >= 100
```sql
SELECT prod_name, prod_price
FROM Products
-WHERE prod_price BETWEEN 3 AND 6
+WHERE prod_price >= 3 and prod_price <= 6
ORDER BY prod_price
```
@@ -953,10 +958,9 @@ WHERE condition;
```sql
SELECT cust_id
FROM Orders
-WHERE order_num IN (SELECT order_num
+WHERE order_num IN (SELECT DISTINCT order_num
FROM OrderItems
- GROUP BY order_num
- HAVING Sum(item_price) >= 10)
+ where item_price >= 10)
```
### 确定哪些订单购买了 prod_id 为 BR01 的产品(一)
@@ -1028,11 +1032,11 @@ ORDER BY order_date
`Customers` 表代表顾客信息,`cust_id` 为顾客 id,`cust_email` 为顾客 email
-| cust_id | cust_email |
-| ------- | --------------- |
-| cust10 | cust10@cust.com |
-| cust1 | cust1@cust.com |
-| cust2 | cust2@cust.com |
+| cust_id | cust_email |
+| ------- | ----------------- |
+| cust10 | |
+| cust1 | |
+| cust2 | |
【问题】返回购买 `prod_id` 为 `BR01` 的产品的所有顾客的电子邮件(`Customers` 表中的 `cust_email`),结果无需排序。
@@ -1096,13 +1100,14 @@ WHERE b.prod_id = 'BR01'
```sql
# 写法 1:子查询
-SELECT o.cust_id AS cust_id, tb.total_ordered AS total_ordered
-FROM (SELECT order_num, Sum(item_price * quantity) AS total_ordered
+SELECT o.cust_id, SUM(tb.total_ordered) AS `total_ordered`
+FROM (SELECT order_num, SUM(item_price * quantity) AS total_ordered
FROM OrderItems
GROUP BY order_num) AS tb,
Orders o
WHERE tb.order_num = o.order_num
-ORDER BY total_ordered DESC
+GROUP BY o.cust_id
+ORDER BY total_ordered DESC;
# 写法 2:连接表
SELECT b.cust_id, Sum(a.quantity * a.item_price) AS total_ordered
@@ -1112,6 +1117,8 @@ GROUP BY cust_id
ORDER BY total_ordered DESC
```
+关于写法一详细介绍可以参考: [issue#2402:写法 1 存在的错误以及修改方法](https://github.com/Snailclimb/JavaGuide/issues/2402)。
+
### 从 Products 表中检索所有的产品名称以及对应的销售总数
`Products` 表中检索所有的产品名称:`prod_name`、产品 id:`prod_id`
@@ -1337,7 +1344,7 @@ ORDER BY c.cust_name,o.order_num
这是错误的!只对 `cust_name` 进行聚类确实符合题意,但是不符合 `GROUP BY` 的语法。
-select 语句中,如果没有 `GROUP BY` 语句,那么 `cust_name`、`order_num` 会返回若干个值,而 `sum(quantity _ item_price)` 只返回一个值,通过 `group by` `cust_name` 可以让 `cust_name` 和 `sum(quantity _ item_price)` 一一对应起来,或者说**聚类**,所以同样的,也要对 `order_num` 进行聚类。
+select 语句中,如果没有 `GROUP BY` 语句,那么 `cust_name`、`order_num` 会返回若干个值,而 `sum(quantity * item_price)` 只返回一个值,通过 `group by` `cust_name` 可以让 `cust_name` 和 `sum(quantity * item_price)` 一一对应起来,或者说**聚类**,所以同样的,也要对 `order_num` 进行聚类。
> **一句话,select 中的字段要么都聚类,要么都不聚类**
@@ -1418,11 +1425,11 @@ ORDER BY order_date
`Customers` 表代表顾客信息,`cust_id` 为顾客 id,`cust_email` 为顾客 email
-| cust_id | cust_email |
-| ------- | --------------- |
-| cust10 | cust10@cust.com |
-| cust1 | cust1@cust.com |
-| cust2 | cust2@cust.com |
+| cust_id | cust_email |
+| ------- | ----------------- |
+| cust10 | |
+| cust1 | |
+| cust2 | |
【问题】返回购买 `prod_id` 为 BR01 的产品的所有顾客的电子邮件(`Customers` 表中的 `cust_email`),结果无需排序。
@@ -1654,12 +1661,12 @@ ORDER BY prod_name
注意:`vend_id` 列会显示在多个表中,因此在每次引用它时都需要完全限定它。
```sql
-SELECT vend_id, COUNT(prod_id) AS prod_id
-FROM Vendors
-LEFT JOIN Products
+SELECT v.vend_id, COUNT(prod_id) AS prod_id
+FROM Vendors v
+LEFT JOIN Products p
USING(vend_id)
-GROUP BY vend_id
-ORDER BY vend_id
+GROUP BY v.vend_id
+ORDER BY v.vend_id
```
## 组合查询
@@ -1780,11 +1787,11 @@ ORDER BY prod_name
表 `Customers` 含有字段 `cust_name` 顾客名、`cust_contact` 顾客联系方式、`cust_state` 顾客州、`cust_email` 顾客 `email`
-| cust_name | cust_contact | cust_state | cust_email |
-| --------- | ------------ | ---------- | --------------- |
-| cust10 | 8695192 | MI | cust10@cust.com |
-| cust1 | 8695193 | MI | cust1@cust.com |
-| cust2 | 8695194 | IL | cust2@cust.com |
+| cust_name | cust_contact | cust_state | cust_email |
+| --------- | ------------ | ---------- | ----------------- |
+| cust10 | 8695192 | MI | |
+| cust1 | 8695193 | MI | |
+| cust2 | 8695194 | IL | |
【问题】修正下面错误的 SQL
@@ -1822,3 +1829,5 @@ FROM Customers
WHERE cust_state = 'MI' or cust_state = 'IL'
ORDER BY cust_name;
```
+
+
diff --git a/docs/database/sql/sql-questions-02.md b/docs/database/sql/sql-questions-02.md
new file mode 100644
index 00000000000..b0ce5fa2499
--- /dev/null
+++ b/docs/database/sql/sql-questions-02.md
@@ -0,0 +1,455 @@
+---
+title: SQL常见面试题总结(2)
+description: SQL常见面试题总结第二篇,详解INSERT、UPDATE、DELETE等DML数据操作语句,包括批量插入、从其他表导入、带更新的插入等实战技巧。
+category: 数据库
+tag:
+ - 数据库基础
+ - SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL面试题,INSERT插入,UPDATE更新,DELETE删除,批量插入,REPLACE INTO,数据操作
+---
+
+> 题目来源于:[牛客题霸 - SQL 进阶挑战](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=240)
+
+## 增删改操作
+
+SQL 插入记录的方式汇总:
+
+- **普通插入(全字段)** :`INSERT INTO table_name VALUES (value1, value2, ...)`
+- **普通插入(限定字段)** :`INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...)`
+- **多条一次性插入** :`INSERT INTO table_name (column1, column2, ...) VALUES (value1_1, value1_2, ...), (value2_1, value2_2, ...), ...`
+- **从另一个表导入** :`INSERT INTO table_name SELECT * FROM table_name2 [WHERE key=value]`
+- **带更新的插入** :`REPLACE INTO table_name VALUES (value1, value2, ...)`(注意这种原理是检测到主键或唯一性索引键重复就删除原记录后重新插入)
+
+### 插入记录(一)
+
+**描述**:牛客后台会记录每个用户的试卷作答记录到 `exam_record` 表,现在有两个用户的作答记录详情如下:
+
+- 用户 1001 在 2021 年 9 月 1 日晚上 10 点 11 分 12 秒开始作答试卷 9001,并在 50 分钟后提交,得了 90 分;
+- 用户 1002 在 2021 年 9 月 4 日上午 7 点 1 分 2 秒开始作答试卷 9002,并在 10 分钟后退出了平台。
+
+试卷作答记录表`exam_record`中,表已建好,其结构如下,请用一条语句将这两条记录插入表中。
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | ---- | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | 自增 ID |
+| uid | int(11) | NO | | | (NULL) | 用户 ID |
+| exam_id | int(11) | NO | | | (NULL) | 试卷 ID |
+| start_time | datetime | NO | | | (NULL) | 开始时间 |
+| submit_time | datetime | YES | | | (NULL) | 提交时间 |
+| score | tinyint(4) | YES | | | (NULL) | 得分 |
+
+**答案**:
+
+```sql
+// 存在自增主键,无需手动赋值
+INSERT INTO exam_record (uid, exam_id, start_time, submit_time, score) VALUES
+(1001, 9001, '2021-09-01 22:11:12', '2021-09-01 23:01:12', 90),
+(1002, 9002, '2021-09-04 07:01:02', NULL, NULL);
+```
+
+### 插入记录(二)
+
+**描述**:现有一张试卷作答记录表`exam_record`,结构如下表,其中包含多年来的用户作答试卷记录,由于数据越来越多,维护难度越来越大,需要对数据表内容做精简,历史数据做备份。
+
+表`exam_record`:
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | ---- | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | 自增 ID |
+| uid | int(11) | NO | | | (NULL) | 用户 ID |
+| exam_id | int(11) | NO | | | (NULL) | 试卷 ID |
+| start_time | datetime | NO | | | (NULL) | 开始时间 |
+| submit_time | datetime | YES | | | (NULL) | 提交时间 |
+| score | tinyint(4) | YES | | | (NULL) | 得分 |
+
+我们已经创建了一张新表`exam_record_before_2021`用来备份 2021 年之前的试题作答记录,结构和`exam_record`表一致,请将 2021 年之前的已完成了的试题作答纪录导入到该表。
+
+**答案**:
+
+```sql
+INSERT INTO exam_record_before_2021 (uid, exam_id, start_time, submit_time, score)
+SELECT uid,exam_id,start_time,submit_time,score
+FROM exam_record
+WHERE YEAR(submit_time) < 2021;
+```
+
+### 插入记录(三)
+
+**描述**:现在有一套 ID 为 9003 的高难度 SQL 试卷,时长为一个半小时,请你将 2021-01-01 00:00:00 作为发布时间插入到试题信息表`examination_info`,不管该 ID 试卷是否存在,都要插入成功,请尝试插入它。
+
+试题信息表`examination_info`:
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ------------ | ----------- | ---- | --- | -------------- | ------- | ------------ |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | 自增 ID |
+| exam_id | int(11) | NO | UNI | | (NULL) | 试卷 ID |
+| tag | varchar(32) | YES | | | (NULL) | 类别标签 |
+| difficulty | varchar(8) | YES | | | (NULL) | 难度 |
+| duration | int(11) | NO | | | (NULL) | 时长(分钟数) |
+| release_time | datetime | YES | | | (NULL) | 发布时间 |
+
+**答案**:
+
+```sql
+REPLACE INTO examination_info VALUES
+ (NULL, 9003, "SQL", "hard", 90, "2021-01-01 00:00:00");
+```
+
+### 更新记录(一)
+
+**描述**:现在有一张试卷信息表 `examination_info`, 表结构如下图所示:
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ------------ | -------- | ---- | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | 自增 ID |
+| exam_id | int(11) | NO | UNI | | (NULL) | 试卷 ID |
+| tag | char(32) | YES | | | (NULL) | 类别标签 |
+| difficulty | char(8) | YES | | | (NULL) | 难度 |
+| duration | int(11) | NO | | | (NULL) | 时长 |
+| release_time | datetime | YES | | | (NULL) | 发布时间 |
+
+请把**examination_info**表中`tag`为`PYTHON`的`tag`字段全部修改为`Python`。
+
+**思路**:这题有两种解题思路,最容易想到的是直接`update + where`来指定条件更新,第二种就是根据要修改的字段进行查找替换
+
+**答案一**:
+
+```sql
+UPDATE examination_info SET tag = 'Python' WHERE tag='PYTHON'
+```
+
+**答案二**:
+
+```sql
+UPDATE examination_info
+SET tag = REPLACE(tag,'PYTHON','Python')
+
+# REPLACE (目标字段,"查找内容","替换内容")
+```
+
+### 更新记录(二)
+
+**描述**:现有一张试卷作答记录表 exam_record,其中包含多年来的用户作答试卷记录,结构如下表:作答记录表 `exam_record`: **`submit_time`** 为 完成时间 (注意这句话)
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | ---- | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | 自增 ID |
+| uid | int(11) | NO | | | (NULL) | 用户 ID |
+| exam_id | int(11) | NO | | | (NULL) | 试卷 ID |
+| start_time | datetime | NO | | | (NULL) | 开始时间 |
+| submit_time | datetime | YES | | | (NULL) | 提交时间 |
+| score | tinyint(4) | YES | | | (NULL) | 得分 |
+
+**题目要求**:请把 `exam_record` 表中 2021 年 9 月 1 日==之前==开始作答的==未完成==记录全部改为被动完成,即:将完成时间改为'2099-01-01 00:00:00',分数改为 0。
+
+**思路**:注意题干中的关键字(已经高亮) `" xxx 时间 "`之前这个条件, 那么这里马上就要想到要进行时间的比较 可以直接 `xxx_time < "2021-09-01 00:00:00",` 也可以采用`date()`函数来进行比较;第二个条件就是 `"未完成"`, 即完成时间为 NULL,也就是题目中的提交时间 ----- `submit_time 为 NULL`。
+
+**答案**:
+
+```sql
+UPDATE exam_record SET submit_time = '2099-01-01 00:00:00', score = 0 WHERE DATE(start_time) < "2021-09-01" AND submit_time IS null
+```
+
+### 删除记录(一)
+
+**描述**:现有一张试卷作答记录表 `exam_record`,其中包含多年来的用户作答试卷记录,结构如下表:
+
+作答记录表`exam_record:` **`start_time`** 是试卷开始时间`submit_time` 是交卷,即结束时间。
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | ---- | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | 自增 ID |
+| uid | int(11) | NO | | | (NULL) | 用户 ID |
+| exam_id | int(11) | NO | | | (NULL) | 试卷 ID |
+| start_time | datetime | NO | | | (NULL) | 开始时间 |
+| submit_time | datetime | YES | | | (NULL) | 提交时间 |
+| score | tinyint(4) | YES | | | (NULL) | 得分 |
+
+**要求**:请删除`exam_record`表中作答时间小于 5 分钟整且分数不及格(及格线为 60 分)的记录;
+
+**思路**:这一题虽然是练习删除,仔细看确是考察对时间函数的用法,这里提及的分钟数比较,常用的函数有 **`TIMEDIFF`**和**`TIMESTAMPDIFF`** ,两者用法稍有区别,后者更为灵活,这都是看个人习惯。
+
+1. `TIMEDIFF`:两个时间之间的差值
+
+```sql
+TIMEDIFF(time1, time2)
+```
+
+两者参数都是必须的,都是一个时间或者日期时间表达式。如果指定的参数不合法或者是 NULL,那么函数将返回 NULL。
+
+对于这题而言,可以用在 minute 函数里面,因为 TIMEDIFF 计算出来的是时间的差值,在外面套一个 MINUTE 函数,计算出来的就是分钟数。
+
+2. `TIMESTAMPDIFF`:用于计算两个日期的时间差
+
+```sql
+TIMESTAMPDIFF(unit,datetime_expr1,datetime_expr2)
+# 参数说明
+#unit: 日期比较返回的时间差单位,常用可选值如下:
+SECOND:秒
+MINUTE:分钟
+HOUR:小时
+DAY:天
+WEEK:星期
+MONTH:月
+QUARTER:季度
+YEAR:年
+# TIMESTAMPDIFF函数返回datetime_expr2 - datetime_expr1的结果(人话: 后面的 - 前面的 即2-1),其中datetime_expr1和datetime_expr2可以是DATE或DATETIME类型值(人话:可以是“2023-01-01”, 也可以是“2023-01-01- 00:00:00”)
+```
+
+这题需要进行分钟的比较,那么就是 TIMESTAMPDIFF(MINUTE, 开始时间, 结束时间) < 5
+
+**答案**:
+
+```sql
+DELETE FROM exam_record WHERE MINUTE (TIMEDIFF(submit_time , start_time)) < 5 AND score < 60
+```
+
+```sql
+DELETE FROM exam_record WHERE TIMESTAMPDIFF(MINUTE, start_time, submit_time) < 5 AND score < 60
+```
+
+### 删除记录(二)
+
+**描述**:现有一张试卷作答记录表`exam_record`,其中包含多年来的用户作答试卷记录,结构如下表:
+
+作答记录表`exam_record`:`start_time` 是试卷开始时间,`submit_time` 是交卷时间,即结束时间,如果未完成的话,则为空。
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | :--: | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | 自增 ID |
+| uid | int(11) | NO | | | (NULL) | 用户 ID |
+| exam_id | int(11) | NO | | | (NULL) | 试卷 ID |
+| start_time | datetime | NO | | | (NULL) | 开始时间 |
+| submit_time | datetime | YES | | | (NULL) | 提交时间 |
+| score | tinyint(4) | YES | | | (NULL) | 分数 |
+
+**要求**:请删除`exam_record`表中未完成作答==或==作答时间小于 5 分钟整的记录中,开始作答时间最早的 3 条记录。
+
+**思路**:这题比较简单,但是要注意题干中给出的信息,结束时间,如果未完成的话,则为空,这个其实就是一个条件
+
+还有一个条件就是小于 5 分钟,跟上题类似,但是这里是**或**,即两个条件满足一个就行;另外就是稍微考察到了排序和 limit 的用法。
+
+**答案**:
+
+```sql
+DELETE FROM exam_record WHERE submit_time IS null OR TIMESTAMPDIFF(MINUTE, start_time, submit_time) < 5
+ORDER BY start_time
+LIMIT 3
+# 默认就是asc, desc是降序排列
+```
+
+### 删除记录(三)
+
+**描述**:现有一张试卷作答记录表 exam_record,其中包含多年来的用户作答试卷记录,结构如下表:
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | :--: | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | 自增 ID |
+| uid | int(11) | NO | | | (NULL) | 用户 ID |
+| exam_id | int(11) | NO | | | (NULL) | 试卷 ID |
+| start_time | datetime | NO | | | (NULL) | 开始时间 |
+| submit_time | datetime | YES | | | (NULL) | 提交时间 |
+| score | tinyint(4) | YES | | | (NULL) | 分数 |
+
+**要求**:请删除`exam_record`表中所有记录,==并重置自增主键==
+
+**思路**:这题考察对三种删除语句的区别,注意高亮部分,要求重置主键;
+
+- `DROP`: 清空表,删除表结构,不可逆
+- `TRUNCATE`: 格式化表,不删除表结构,不可逆
+- `DELETE`:删除数据,可逆
+
+这里选用`TRUNCATE`的原因是:TRUNCATE 只能作用于表;`TRUNCATE`会清空表中的所有行,但表结构及其约束、索引等保持不变;`TRUNCATE`会重置表的自增值;使用`TRUNCATE`后会使表和索引所占用的空间会恢复到初始大小。
+
+这题也可以采用`DELETE`来做,但是在删除后,还需要手动`ALTER`表结构来设置主键初始值;
+
+同理也可以采用`DROP`来做,直接删除整张表,包括表结构,然后再新建表即可。
+
+**答案**:
+
+```sql
+TRUNCATE exam_record;
+```
+
+## 表与索引操作
+
+### 创建一张新表
+
+**描述**:现有一张用户信息表,其中包含多年来在平台注册过的用户信息,随着牛客平台的不断壮大,用户量飞速增长,为了高效地为高活跃用户提供服务,现需要将部分用户拆分出一张新表。
+
+原来的用户信息表:
+
+| Filed | Type | Null | Key | Default | Extra | Comment |
+| ------------- | ----------- | ---- | --- | ----------------- | -------------- | -------- |
+| id | int(11) | NO | PRI | (NULL) | auto_increment | 自增 ID |
+| uid | int(11) | NO | UNI | (NULL) | | 用户 ID |
+| nick_name | varchar(64) | YES | | (NULL) | | 昵称 |
+| achievement | int(11) | YES | | 0 | | 成就值 |
+| level | int(11) | YES | | (NULL) | | 用户等级 |
+| job | varchar(32) | YES | | (NULL) | | 职业方向 |
+| register_time | datetime | YES | | CURRENT_TIMESTAMP | | 注册时间 |
+
+作为数据分析师,请**创建一张优质用户信息表 user_info_vip**,表结构和用户信息表一致。
+
+你应该返回的输出如下表格所示,请写出建表语句将表格中所有限制和说明记录到表里。
+
+| Filed | Type | Null | Key | Default | Extra | Comment |
+| ------------- | ----------- | ---- | --- | ----------------- | -------------- | -------- |
+| id | int(11) | NO | PRI | (NULL) | auto_increment | 自增 ID |
+| uid | int(11) | NO | UNI | (NULL) | | 用户 ID |
+| nick_name | varchar(64) | YES | | (NULL) | | 昵称 |
+| achievement | int(11) | YES | | 0 | | 成就值 |
+| level | int(11) | YES | | (NULL) | | 用户等级 |
+| job | varchar(32) | YES | | (NULL) | | 职业方向 |
+| register_time | datetime | YES | | CURRENT_TIMESTAMP | | 注册时间 |
+
+**思路**:如果这题给出了旧表的名称,可直接`create table 新表 as select * from 旧表;` 但是这题并没有给出旧表名称,所以需要自己创建,注意默认值和键的创建即可,比较简单。(注意:如果是在牛客网上面执行,请注意 comment 中要和题目中的 comment 保持一致,包括大小写,否则不通过,还有字符也要设置)
+
+答案:
+
+```sql
+CREATE TABLE IF NOT EXISTS user_info_vip(
+ id INT(11) PRIMARY KEY AUTO_INCREMENT COMMENT'自增ID',
+ uid INT(11) UNIQUE NOT NULL COMMENT '用户ID',
+ nick_name VARCHAR(64) COMMENT'昵称',
+ achievement INT(11) DEFAULT 0 COMMENT '成就值',
+ `level` INT(11) COMMENT '用户等级',
+ job VARCHAR(32) COMMENT '职业方向',
+ register_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '注册时间'
+)CHARACTER SET UTF8
+```
+
+### 修改表
+
+**描述**: 现有一张用户信息表`user_info`,其中包含多年来在平台注册过的用户信息。
+
+**用户信息表 `user_info`:**
+
+| Filed | Type | Null | Key | Default | Extra | Comment |
+| ------------- | ----------- | ---- | --- | ----------------- | -------------- | -------- |
+| id | int(11) | NO | PRI | (NULL) | auto_increment | 自增 ID |
+| uid | int(11) | NO | UNI | (NULL) | | 用户 ID |
+| nick_name | varchar(64) | YES | | (NULL) | | 昵称 |
+| achievement | int(11) | YES | | 0 | | 成就值 |
+| level | int(11) | YES | | (NULL) | | 用户等级 |
+| job | varchar(32) | YES | | (NULL) | | 职业方向 |
+| register_time | datetime | YES | | CURRENT_TIMESTAMP | | 注册时间 |
+
+**要求:**请在用户信息表,字段 `level` 的后面增加一列最多可保存 15 个汉字的字段 `school`;并将表中 `job` 列名改为 `profession`,同时 `varchar` 字段长度变为 10;`achievement` 的默认值设置为 0。
+
+**思路**:首先做这题之前,需要了解 ALTER 语句的基本用法:
+
+- 添加一列:`ALTER TABLE 表名 ADD COLUMN 列名 类型 【first | after 字段名】;`(first : 在某列之前添加,after 反之)
+- 修改列的类型或约束:`ALTER TABLE 表名 MODIFY COLUMN 列名 新类型 【新约束】;`
+- 修改列名:`ALTER TABLE 表名 change COLUMN 旧列名 新列名 类型;`
+- 删除列:`ALTER TABLE 表名 drop COLUMN 列名;`
+- 修改表名:`ALTER TABLE 表名 rename 【to】 新表名;`
+- 将某一列放到第一列:`ALTER TABLE 表名 MODIFY COLUMN 列名 类型 first;`
+
+`COLUMN` 关键字其实可以省略不写,这里基于规范还是罗列出来了。
+
+在修改时,如果有多个修改项,可以写到一起,但要注意格式
+
+**答案**:
+
+```sql
+ALTER TABLE user_info
+ ADD school VARCHAR(15) AFTER level,
+ CHANGE job profession VARCHAR(10),
+ MODIFY achievement INT(11) DEFAULT 0;
+```
+
+### 删除表
+
+**描述**:现有一张试卷作答记录表 `exam_record`,其中包含多年来的用户作答试卷记录。一般每年都会为 `exam_record` 表建立一张备份表 `exam_record_{YEAR},{YEAR}` 为对应年份。
+
+现在随着数据越来越多,存储告急,请你把很久前的(2011 到 2014 年)备份表都删掉(如果存在的话)。
+
+**思路**:这题很简单,直接删就行,如果嫌麻烦,可以将要删除的表用逗号隔开,写到一行;这里肯定会有小伙伴问:如果要删除很多张表呢?放心,如果要删除很多张表,可以写脚本来进行删除。
+
+**答案**:
+
+```sql
+DROP TABLE IF EXISTS exam_record_2011;
+DROP TABLE IF EXISTS exam_record_2012;
+DROP TABLE IF EXISTS exam_record_2013;
+DROP TABLE IF EXISTS exam_record_2014;
+```
+
+### 创建索引
+
+**描述**:现有一张试卷信息表 `examination_info`,其中包含各种类型试卷的信息。为了对表更方便快捷地查询,需要在 `examination_info` 表创建以下索引,
+
+规则如下:在 `duration` 列创建普通索引 `idx_duration`、在 `exam_id` 列创建唯一性索引 `uniq_idx_exam_id`、在 `tag` 列创建全文索引 `full_idx_tag`。
+
+根据题意,将返回如下结果:
+
+| examination_info | 0 | PRIMARY | 1 | id | A | 0 | | | | BTREE |
+| ---------------- | --- | ---------------- | --- | -------- | --- | --- | --- | --- | --- | -------- |
+| examination_info | 0 | uniq_idx_exam_id | 1 | exam_id | A | 0 | | | YES | BTREE |
+| examination_info | 1 | idx_duration | 1 | duration | A | 0 | | | | BTREE |
+| examination_info | 1 | full_idx_tag | 1 | tag | | 0 | | | YES | FULLTEXT |
+
+备注:后台会通过 `SHOW INDEX FROM examination_info` 语句来对比输出结果
+
+**思路**:做这题首先需要了解常见的索引类型:
+
+- B-Tree 索引:B-Tree(或称为平衡树)索引是最常见和默认的索引类型。它适用于各种查询条件,可以快速定位到符合条件的数据。B-Tree 索引适用于普通的查找操作,支持等值查询、范围查询和排序。
+- 唯一索引:唯一索引与普通的 B-Tree 索引类似,不同之处在于它要求被索引的列的值是唯一的。这意味着在插入或更新数据时,MySQL 会验证索引列的唯一性。
+- 主键索引:主键索引是一种特殊的唯一索引,它用于唯一标识表中的每一行数据。每个表只能有一个主键索引,它可以帮助提高数据的访问速度和数据完整性。
+- 全文索引:全文索引用于在文本数据中进行全文搜索。它支持在文本字段中进行关键字搜索,而不仅仅是简单的等值或范围查找。全文索引适用于需要进行全文搜索的应用场景。
+
+```sql
+-- 示例:
+-- 添加B-Tree索引:
+ CREATE INDEX idx_name(索引名) ON 表名 (字段名); -- idx_name为索引名,以下都是
+-- 创建唯一索引:
+ CREATE UNIQUE INDEX idx_name ON 表名 (字段名);
+-- 创建一个主键索引:
+ ALTER TABLE 表名 ADD PRIMARY KEY (字段名);
+-- 创建一个全文索引
+ ALTER TABLE 表名 ADD FULLTEXT INDEX idx_name (字段名);
+
+-- 通过以上示例,可以看出create 和 alter 都可以添加索引
+```
+
+有了以上的基础知识之后,该题答案也就浮出水面了。
+
+**答案**:
+
+```sql
+ALTER TABLE examination_info
+ ADD INDEX idx_duration(duration),
+ ADD UNIQUE INDEX uniq_idx_exam_id(exam_id),
+ ADD FULLTEXT INDEX full_idx_tag(tag);
+```
+
+### 删除索引
+
+**描述**:请删除`examination_info`表上的唯一索引 uniq_idx_exam_id 和全文索引 full_idx_tag。
+
+**思路**:该题考察删除索引的基本语法:
+
+```sql
+-- 使用 DROP INDEX 删除索引
+DROP INDEX idx_name ON 表名;
+
+-- 使用 ALTER TABLE 删除索引
+ALTER TABLE employees DROP INDEX idx_email;
+```
+
+这里需要注意的是:在 MySQL 中,一次删除多个索引的操作是不支持的。每次删除索引时,只能指定一个索引名称进行删除。
+
+而且 **DROP** 命令需要慎用!!!
+
+**答案**:
+
+```sql
+DROP INDEX uniq_idx_exam_id ON examination_info;
+DROP INDEX full_idx_tag ON examination_info;
+```
+
+
diff --git a/docs/database/sql/sql-questions-03.md b/docs/database/sql/sql-questions-03.md
new file mode 100644
index 00000000000..a445fef8280
--- /dev/null
+++ b/docs/database/sql/sql-questions-03.md
@@ -0,0 +1,1306 @@
+---
+title: SQL常见面试题总结(3)
+description: SQL常见面试题总结第三篇,深入讲解聚合函数COUNT、SUM、AVG、MAX、MIN的使用,以及GROUP BY分组、HAVING过滤、截断平均值计算等进阶技巧。
+category: 数据库
+tag:
+ - 数据库基础
+ - SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL面试题,聚合函数,COUNT,SUM,AVG,MAX,MIN,GROUP BY,HAVING,截断平均值
+---
+
+> 题目来源于:[牛客题霸 - SQL 进阶挑战](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=240)
+
+较难或者困难的题目可以根据自身实际情况和面试需要来决定是否要跳过。
+
+## 聚合函数
+
+### SQL 类别高难度试卷得分的截断平均值(较难)
+
+**描述**: 牛客的运营同学想要查看大家在 SQL 类别中高难度试卷的得分情况。
+
+请你帮她从`exam_record`数据表中计算所有用户完成 SQL 类别高难度试卷得分的截断平均值(去掉一个最大值和一个最小值后的平均值)。
+
+示例数据:`examination_info`(`exam_id` 试卷 ID, tag 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间)
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
+
+示例数据:`exam_record`(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分)
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
+| 3 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:31:01 | 84 |
+| 4 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 5 | 1001 | 9001 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 7 | 1002 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 8 | 1002 | 9001 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+| 9 | 1003 | 9001 | 2021-09-07 12:01:01 | 2021-09-07 10:31:01 | 50 |
+| 10 | 1004 | 9001 | 2021-09-06 10:01:01 | (NULL) | (NULL) |
+
+根据输入你的查询结果如下:
+
+| tag | difficulty | clip_avg_score |
+| --- | ---------- | -------------- |
+| SQL | hard | 81.7 |
+
+从`examination_info`表可知,试卷 9001 为高难度 SQL 试卷,该试卷被作答的得分有[80,81,84,90,50],去除最高分和最低分后为[80,81,84],平均分为 81.6666667,保留一位小数后为 81.7
+
+**输入描述:**
+
+输入数据中至少有 3 个有效分数
+
+**思路一:** 要找出高难度 sql 试卷,肯定需要联 examination_info 这张表,然后找出高难度的课程,由 examination_info 得知,高难度 sql 的 exam_id 为 9001,那么等下就以 exam_id = 9001 作为条件去查询;
+
+先找出 9001 号考试 `select * from exam_record where exam_id = 9001`
+
+然后,找出最高分 `select max(score) 最高分 from exam_record where exam_id = 9001`
+
+接着,找出最低分 `select min(score) 最低分 from exam_record where exam_id = 9001`
+
+在查询出来的分数结果集当中,去掉最高分和最低分,最直观能想到的就是 NOT IN 或者 用 NOT EXISTS 也行,这里以 NOT IN 来做
+
+首先将主体写出来`select tag, difficulty, round(avg(score), 1) clip_avg_score from examination_info info INNER JOIN exam_record record`
+
+**小 tips** : MYSQL 的 `ROUND()` 函数 ,`ROUND(X)`返回参数 X 最近似的整数 `ROUND(X,D)`返回 X ,其值保留到小数点后 D 位,第 D 位的保留方式为四舍五入。
+
+再将上面的 "碎片" 语句拼凑起来即可, 注意在 NOT IN 中两个子查询用 UNION ALL 来关联,用 union 把 max 和 min 的结果集中在一行当中,这样形成一列多行的效果。
+
+**答案一:**
+
+```sql
+SELECT tag, difficulty, ROUND(AVG(score), 1) clip_avg_score
+ FROM examination_info info INNER JOIN exam_record record
+ WHERE info.exam_id = record.exam_id
+ AND record.exam_id = 9001
+ AND record.score NOT IN(
+ SELECT MAX(score)
+ FROM exam_record
+ WHERE exam_id = 9001
+ UNION ALL
+ SELECT MIN(score)
+ FROM exam_record
+ WHERE exam_id = 9001
+ )
+```
+
+这是最直观,也是最容易想到的解法,但是还有待改进,这算是投机取巧过关,其实严格按照题目要求应该这么写:
+
+```sql
+SELECT tag,
+ difficulty,
+ ROUND(AVG(score), 1) clip_avg_score
+FROM examination_info info
+INNER JOIN exam_record record
+WHERE info.exam_id = record.exam_id
+ AND record.exam_id =
+ (SELECT examination_info.exam_id
+ FROM examination_info
+ WHERE tag = 'SQL'
+ AND difficulty = 'hard' )
+ AND record.score NOT IN
+ (SELECT MAX(score)
+ FROM exam_record
+ WHERE exam_id =
+ (SELECT examination_info.exam_id
+ FROM examination_info
+ WHERE tag = 'SQL'
+ AND difficulty = 'hard' )
+ UNION ALL SELECT MIN(score)
+ FROM exam_record
+ WHERE exam_id =
+ (SELECT examination_info.exam_id
+ FROM examination_info
+ WHERE tag = 'SQL'
+ AND difficulty = 'hard' ) )
+```
+
+然而你会发现,重复的语句非常多,所以可以利用`WITH`来抽取公共部分
+
+**`WITH` 子句介绍**:
+
+`WITH` 子句,也称为公共表表达式(Common Table Expression,CTE),是在 SQL 查询中定义临时表的方式。它可以让我们在查询中创建一个临时命名的结果集,并且可以在同一查询中引用该结果集。
+
+基本用法:
+
+```sql
+WITH cte_name (column1, column2, ..., columnN) AS (
+ -- 查询体
+ SELECT ...
+ FROM ...
+ WHERE ...
+)
+-- 主查询
+SELECT ...
+FROM cte_name
+WHERE ...
+```
+
+`WITH` 子句由以下几个部分组成:
+
+- `cte_name`: 给临时表起一个名称,可以在主查询中引用。
+- `(column1, column2, ..., columnN)`: 可选,指定临时表的列名。
+- `AS`: 必需,表示开始定义临时表。
+- `CTE 查询体`: 实际的查询语句,用于定义临时表中的数据。
+
+`WITH` 子句的主要用途之一是增强查询的可读性和可维护性,尤其在涉及多个嵌套子查询或需要重复使用相同的查询逻辑时。通过将这些逻辑放在一个命名的临时表中,我们可以更清晰地组织查询,并消除重复代码。
+
+此外,`WITH` 子句还可以在复杂的查询中实现递归查询。递归查询允许我们在单个查询中执行对同一表的多次迭代,逐步构建结果集。这在处理层次结构数据、组织结构和树状结构等场景中非常有用。
+
+**小细节**:MySQL 5.7 版本以及之前的版本不支持在 `WITH` 子句中直接使用别名。
+
+下面是改进后的答案:
+
+```sql
+WITH t1 AS
+ (SELECT record.*,
+ info.tag,
+ info.difficulty
+ FROM exam_record record
+ INNER JOIN examination_info info ON record.exam_id = info.exam_id
+ WHERE info.tag = "SQL"
+ AND info.difficulty = "hard" )
+SELECT tag,
+ difficulty,
+ ROUND(AVG(score), 1)
+FROM t1
+WHERE score NOT IN
+ (SELECT max(score)
+ FROM t1
+ UNION SELECT min(score)
+ FROM t1)
+```
+
+**思路二:**
+
+- 筛选 SQL 高难度试卷:`where tag="SQL" and difficulty="hard"`
+- 计算截断平均值:`(和-最大值-最小值) / (总个数-2)`:
+ - `(sum(score) - max(score) - min(score)) / (count(score) - 2)`
+ - 有一个缺点就是,如果最大值和最小值有多个,这个方法就很难筛选出来, 但是题目中说了----->**`去掉一个最大值和一个最小值后的平均值`**, 所以这里可以用这个公式。
+
+**答案二:**
+
+```sql
+SELECT info.tag,
+ info.difficulty,
+ ROUND((SUM(record.score)- MIN(record.score)- MAX(record.score)) / (COUNT(record.score)- 2), 1) AS clip_avg_score
+FROM examination_info info,
+ exam_record record
+WHERE info.exam_id = record.exam_id
+ AND info.tag = "SQL"
+ AND info.difficulty = "hard";
+```
+
+### 统计作答次数
+
+有一个试卷作答记录表 `exam_record`,请从中统计出总作答次数 `total_pv`、试卷已完成作答数 `complete_pv`、已完成的试卷数 `complete_exam_cnt`。
+
+示例数据 `exam_record` 表(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
+| 3 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:31:01 | 84 |
+| 4 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 5 | 1001 | 9001 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 7 | 1002 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 8 | 1002 | 9001 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+| 9 | 1003 | 9001 | 2021-09-07 12:01:01 | 2021-09-07 10:31:01 | 50 |
+| 10 | 1004 | 9001 | 2021-09-06 10:01:01 | (NULL) | (NULL) |
+
+示例输出:
+
+| total_pv | complete_pv | complete_exam_cnt |
+| -------- | ----------- | ----------------- |
+| 10 | 7 | 2 |
+
+解释:表示截止当前,有 10 次试卷作答记录,已完成的作答次数为 7 次(中途退出的为未完成状态,其交卷时间和份数为 NULL),已完成的试卷有 9001 和 9002 两份。
+
+**思路**: 这题一看到统计次数,肯定第一时间就要想到用`COUNT`这个函数来解决,问题是要统计不同的记录,该怎么来写?使用子查询就能解决这个题目(这题用 case when 也能写出来,解法类似,逻辑不同而已);首先在做这个题之前,让我们先来了解一下`COUNT`的基本用法;
+
+`COUNT()` 函数的基本语法如下所示:
+
+```sql
+COUNT(expression)
+```
+
+其中,`expression` 可以是列名、表达式、常量或通配符。下面是一些常见的用法示例:
+
+1. 计算表中所有行的数量:
+
+```sql
+SELECT COUNT(*) FROM table_name;
+```
+
+2. 计算特定列非空(不为 NULL)值的数量:
+
+```sql
+SELECT COUNT(column_name) FROM table_name;
+```
+
+3. 计算满足条件的行数:
+
+```sql
+SELECT COUNT(*) FROM table_name WHERE condition;
+```
+
+4. 结合 `GROUP BY` 使用,计算分组后每个组的行数:
+
+```sql
+SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name;
+```
+
+5. 计算不同列组合的唯一组合数:
+
+```sql
+SELECT COUNT(DISTINCT column_name1, column_name2) FROM table_name;
+```
+
+在使用 `COUNT()` 函数时,如果不指定任何参数或者使用 `COUNT(*)`,将会计算所有行的数量。而如果使用列名,则只会计算该列非空值的数量。
+
+另外,`COUNT()` 函数的结果是一个整数值。即使结果是零,也不会返回 NULL,这点需要谨记。
+
+**答案**:
+
+```sql
+SELECT
+ count(*) total_pv,
+ ( SELECT count(*) FROM exam_record WHERE submit_time IS NOT NULL ) complete_pv,
+ ( SELECT COUNT( DISTINCT exam_id, score IS NOT NULL OR NULL ) FROM exam_record ) complete_exam_cnt
+FROM
+ exam_record
+```
+
+这里着重说一下`COUNT( DISTINCT exam_id, score IS NOT NULL OR NULL )`这一句,判断 score 是否为 null ,如果是即为真,如果不是返回 null;注意这里如果不加 `or null` 在不是 null 的情况下只会返回 false 也就是返回 0;
+
+`COUNT`本身是不可以对多列求行数的,`distinct`的加入是的多列成为一个整体,可以求出现的行数了;`count distinct`在计算时只返回非 null 的行, 这个也要注意;
+
+另外通过本题 get 到了------>count 加条件常用句式`count( 列判断 or null)`
+
+### 得分不小于平均分的最低分
+
+**描述**: 请从试卷作答记录表中找到 SQL 试卷得分不小于该类试卷平均得分的用户最低得分。
+
+示例数据 exam_record 表(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
+| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 5 | 1002 | 9001 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 6 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+| 7 | 1003 | 9002 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
+| 8 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 9 | 1004 | 9003 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+
+`examination_info` 表(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间)
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | SQL | easy | 60 | 2020-02-01 10:00:00 |
+| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
+
+示例输出数据:
+
+| min_score_over_avg |
+| ------------------ |
+| 87 |
+
+**解释**:试卷 9001 和 9002 为 SQL 类别,作答这两份试卷的得分有[80,89,87,90],平均分为 86.5,不小于平均分的最小分数为 87
+
+**思路**:这类题目第一眼看确实很复杂, 因为不知道从哪入手,但是当我们仔细读题审题后,要学会抓住题干中的关键信息。以本题为例:`请从试卷作答记录表中找到SQL试卷得分不小于该类试卷平均得分的用户最低得分。`你能一眼从中提取哪些有效信息来作为解题思路?
+
+第一条:找到==SQL==试卷得分
+
+第二条:该类试卷==平均得分==
+
+第三条:该类试卷的==用户最低得分==
+
+然后中间的 “桥梁” 就是==不小于==
+
+将条件拆分后,先逐步完成
+
+```sql
+-- 找出tag为‘SQL’的得分 【80, 89,87,90】
+-- 再算出这一组的平均得分
+select ROUND(AVG(score), 1) from examination_info info INNER JOIN exam_record record
+ where info.exam_id = record.exam_id
+ and tag= 'SQL'
+```
+
+然后再找出该类试卷的最低得分,接着将结果集`【80, 89,87,90】` 去和平均分数作比较,方可得出最终答案。
+
+**答案**:
+
+```sql
+SELECT MIN(score) AS min_score_over_avg
+FROM examination_info info
+INNER JOIN exam_record record
+WHERE info.exam_id = record.exam_id
+ AND tag= 'SQL'
+ AND score >=
+ (SELECT ROUND(AVG(score), 1)
+ FROM examination_info info
+ INNER JOIN exam_record record
+ WHERE info.exam_id = record.exam_id
+ AND tag= 'SQL' )
+```
+
+其实这类题目给出的要求看似很 “绕”,但其实仔细梳理一遍,将大条件拆分成小条件,逐个拆分完以后,最后将所有条件拼凑起来。反正只要记住:**抓主干,理分支**,问题便迎刃而解。
+
+## 分组查询
+
+### 平均活跃天数和月活人数
+
+**描述**:用户在牛客试卷作答区作答记录存储在表 `exam_record` 中,内容如下:
+
+`exam_record` 表(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分)
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-07-02 09:21:01 | 80 |
+| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
+| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 5 | 1002 | 9001 | 2021-07-02 19:01:01 | 2021-07-02 19:30:01 | 82 |
+| 6 | 1002 | 9002 | 2021-07-05 18:01:01 | 2021-07-05 18:59:02 | 90 |
+| 7 | 1003 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
+| 8 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 9 | 1004 | 9003 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 10 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
+| 11 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 12 | 1006 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
+| 13 | 1007 | 9002 | 2020-09-02 12:11:01 | 2020-09-02 12:31:01 | 89 |
+
+请计算 2021 年每个月里试卷作答区用户平均月活跃天数 `avg_active_days` 和月度活跃人数 `mau`,上面数据的示例输出如下:
+
+| month | avg_active_days | mau |
+| ------ | --------------- | --- |
+| 202107 | 1.50 | 2 |
+| 202109 | 1.25 | 4 |
+
+**解释**:2021 年 7 月有 2 人活跃,共活跃了 3 天(1001 活跃 1 天,1002 活跃 2 天),平均活跃天数 1.5;2021 年 9 月有 4 人活跃,共活跃了 5 天,平均活跃天数 1.25,结果保留 2 位小数。
+
+注:此处活跃指有==交卷==行为。
+
+**思路**:读完题先注意高亮部分;一般求天数和月活跃人数马上就要想到相关的日期函数;这一题我们同样来进行拆分,把问题细化再解决;首先求活跃人数,肯定要用到`COUNT()`,那这里首先就有一个坑,不知道大家注意了没有?用户 1002 在 9 月份做了两种不同的试卷,所以这里要注意去重,不然在统计的时候,活跃人数是错的;第二个就是要知道日期的格式化,如上表,题目要求以`202107`这种日期格式展现,要用到`DATE_FORMAT`来进行格式化。
+
+基本用法:
+
+`DATE_FORMAT(date_value, format)`
+
+- `date_value` 参数是待格式化的日期或时间值。
+- `format` 参数是指定的日期或时间格式(这个和 Java 里面的日期格式一样)。
+
+**答案**:
+
+```sql
+SELECT DATE_FORMAT(submit_time, '%Y%m') MONTH,
+ round(count(DISTINCT UID, DATE_FORMAT(submit_time, '%Y%m%d')) / count(DISTINCT UID), 2) avg_active_days,
+ COUNT(DISTINCT UID) mau
+FROM exam_record
+WHERE YEAR (submit_time) = 2021
+GROUP BY MONTH
+```
+
+这里多说一句, 使用`COUNT(DISTINCT uid, DATE_FORMAT(submit_time, '%Y%m%d'))` 可以统计在 `uid` 列和 `submit_time` 列按照年份、月份和日期进行格式化后的组合值的数量。
+
+### 月总刷题数和日均刷题数
+
+**描述**:现有一张题目练习记录表 `practice_record`,示例内容如下:
+
+| id | uid | question_id | submit_time | score |
+| --- | ---- | ----------- | ------------------- | ----- |
+| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
+| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
+| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
+| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
+| 5 | 1003 | 8002 | 2021-08-01 19:38:01 | 80 |
+
+请从中统计出 2021 年每个月里用户的月总刷题数 `month_q_cnt` 和日均刷题数 `avg_day_q_cnt`(按月份升序排序)以及该年的总体情况,示例数据输出如下:
+
+| submit_month | month_q_cnt | avg_day_q_cnt |
+| ------------ | ----------- | ------------- |
+| 202108 | 2 | 0.065 |
+| 202109 | 3 | 0.100 |
+| 2021 汇总 | 5 | 0.161 |
+
+**解释**:2021 年 8 月共有 2 次刷题记录,日均刷题数为 2/31=0.065(保留 3 位小数);2021 年 9 月共有 3 次刷题记录,日均刷题数为 3/30=0.100;2021 年共有 5 次刷题记录(年度汇总平均无实际意义,这里我们按照 31 天来算 5/31=0.161)
+
+> 牛客已经采用最新的 Mysql 版本,如果您运行结果出现错误:ONLY_FULL_GROUP_BY,意思是:对于 GROUP BY 聚合操作,如果在 SELECT 中的列,没有在 GROUP BY 中出现,那么这个 SQL 是不合法的,因为列不在 GROUP BY 从句中,也就是说查出来的列必须在 group by 后面出现否则就会报错,或者这个字段出现在聚合函数里面。
+
+**思路:**
+
+看到实例数据就要马上联想到相关的函数,比如`submit_month`就要用到`DATE_FORMAT`来格式化日期。然后查出每月的刷题数量。
+
+每月的刷题数量
+
+```sql
+SELECT MONTH ( submit_time ), COUNT( question_id )
+FROM
+ practice_record
+GROUP BY
+ MONTH (submit_time)
+```
+
+接着第三列这里要用到`DAY(LAST_DAY(date_value))`函数来查找给定日期的月份中的天数。
+
+示例代码如下:
+
+```sql
+SELECT DAY(LAST_DAY('2023-07-08')) AS days_in_month;
+-- 输出:31
+
+SELECT DAY(LAST_DAY('2023-02-01')) AS days_in_month;
+-- 输出:28 (闰年中的二月份)
+
+SELECT DAY(LAST_DAY(NOW())) AS days_in_current_month;
+-- 输出:31 (当前月份的天数)
+```
+
+使用 `LAST_DAY()` 函数获取给定日期的当月最后一天,然后使用 `DAY()` 函数提取该日期的天数。这样就能获得指定月份的天数。
+
+需要注意的是,`LAST_DAY()` 函数返回的是日期值,而 `DAY()` 函数用于提取日期值中的天数部分。
+
+有了上述的分析之后,即可马上写出答案,这题复杂就复杂在处理日期上,其中的逻辑并不难。
+
+**答案**:
+
+```sql
+SELECT DATE_FORMAT(submit_time, '%Y%m') submit_month,
+ count(question_id) month_q_cnt,
+ ROUND(COUNT(question_id) / DAY (LAST_DAY(submit_time)), 3) avg_day_q_cnt
+FROM practice_record
+WHERE DATE_FORMAT(submit_time, '%Y') = '2021'
+GROUP BY submit_month
+UNION ALL
+SELECT '2021汇总' AS submit_month,
+ count(question_id) month_q_cnt,
+ ROUND(COUNT(question_id) / 31, 3) avg_day_q_cnt
+FROM practice_record
+WHERE DATE_FORMAT(submit_time, '%Y') = '2021'
+ORDER BY submit_month
+```
+
+在实例数据输出中因为最后一行需要得出汇总数据,所以这里要 `UNION ALL`加到结果集中;别忘了最后要排序!
+
+### 未完成试卷数大于 1 的有效用户(较难)
+
+**描述**:现有试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分),示例数据如下:
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-07-02 09:21:01 | 80 |
+| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
+| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 5 | 1002 | 9001 | 2021-07-02 19:01:01 | 2021-07-02 19:30:01 | 82 |
+| 6 | 1002 | 9002 | 2021-07-05 18:01:01 | 2021-07-05 18:59:02 | 90 |
+| 7 | 1003 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
+| 8 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 9 | 1004 | 9003 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 10 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
+| 11 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 12 | 1006 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
+| 13 | 1007 | 9002 | 2020-09-02 12:11:01 | 2020-09-02 12:31:01 | 89 |
+
+还有一张试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间),示例数据如下:
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | SQL | easy | 60 | 2020-02-01 10:00:00 |
+| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
+
+请统计 2021 年每个未完成试卷作答数大于 1 的有效用户的数据(有效用户指完成试卷作答数至少为 1 且未完成数小于 5),输出用户 ID、未完成试卷作答数、完成试卷作答数、作答过的试卷 tag 集合,按未完成试卷数量由多到少排序。示例数据的输出结果如下:
+
+| uid | incomplete_cnt | complete_cnt | detail |
+| ---- | -------------- | ------------ | --------------------------------------------------------------------------- |
+| 1002 | 2 | 4 | 2021-09-01:算法;2021-07-02:SQL;2021-09-02:SQL;2021-09-05:SQL;2021-07-05:SQL |
+
+**解释**:2021 年的作答记录中,除了 1004,其他用户均满足有效用户定义,但只有 1002 未完成试卷数大于 1,因此只输出 1002,detail 中是 1002 作答过的试卷{日期:tag}集合,日期和 tag 间用 **:** 连接,多元素间用 **;** 连接。
+
+**思路:**
+
+仔细读题后,分析出:首先要联表,因为后面要输出`tag`;
+
+筛选出 2021 年的数据
+
+```sql
+SELECT *
+FROM exam_record er
+LEFT JOIN examination_info ei ON er.exam_id = ei.exam_id
+WHERE YEAR (er.start_time)= 2021
+```
+
+根据 uid 进行分组,然后对每个用户进行条件进行判断,题目中要求`完成试卷数至少为1,未完成试卷数要大于1,小于5`
+
+那么等会儿写 sql 的时候条件应该是:`未完成 > 1 and 已完成 >=1 and 未完成 < 5`
+
+因为最后要用到字符串的拼接,而且还要组合拼接,这个可以用`GROUP_CONCAT`函数,下面简单介绍一下该函数的用法:
+
+基本格式:
+
+```sql
+GROUP_CONCAT([DISTINCT] expr [ORDER BY {unsigned_integer | col_name | expr} [ASC | DESC] [, ...]] [SEPARATOR sep])
+```
+
+- `expr`:要连接的列或表达式。
+- `DISTINCT`:可选参数,用于去重。当指定了 `DISTINCT`,相同的值只会出现一次。
+- `ORDER BY`:可选参数,用于排序连接后的值。可以选择升序 (`ASC`) 或降序 (`DESC`) 排序。
+- `SEPARATOR sep`:可选参数,用于设置连接后的值的分隔符。(本题要用这个参数设置 ; 号 )
+
+`GROUP_CONCAT()` 函数常用于 `GROUP BY` 子句中,将一组行的值连接为一个字符串,并在结果集中以聚合的形式返回。
+
+**答案**:
+
+```sql
+SELECT a.uid,
+ SUM(CASE
+ WHEN a.submit_time IS NULL THEN 1
+ END) AS incomplete_cnt,
+ SUM(CASE
+ WHEN a.submit_time IS NOT NULL THEN 1
+ END) AS complete_cnt,
+ GROUP_CONCAT(DISTINCT CONCAT(DATE_FORMAT(a.start_time, '%Y-%m-%d'), ':', b.tag)
+ ORDER BY start_time SEPARATOR ";") AS detail
+FROM exam_record a
+LEFT JOIN examination_info b ON a.exam_id = b.exam_id
+WHERE YEAR (a.start_time)= 2021
+GROUP BY a.uid
+HAVING incomplete_cnt > 1
+AND complete_cnt >= 1
+AND incomplete_cnt < 5
+ORDER BY incomplete_cnt DESC
+```
+
+- `SUM(CASE WHEN a.submit_time IS NULL THEN 1 END)` 统计了每个用户未完成的记录数量。
+- `SUM(CASE WHEN a.submit_time IS NOT NULL THEN 1 END)` 统计了每个用户已完成的记录数量。
+- `GROUP_CONCAT(DISTINCT CONCAT(DATE_FORMAT(a.start_time, '%Y-%m-%d'), ':', b.tag) ORDER BY a.start_time SEPARATOR ';')` 将每个用户的考试日期和标签以逗号分隔的形式连接成一个字符串,并按考试开始时间进行排序。
+
+## 嵌套子查询
+
+### 月均完成试卷数不小于 3 的用户爱作答的类别(较难)
+
+**描述**:现有试卷作答记录表 `exam_record`(`uid`:用户 ID, `exam_id`:试卷 ID, `start_time`:开始作答时间, `submit_time`:交卷时间,没提交的话为 NULL, `score`:得分),示例数据如下:
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | (NULL) | (NULL) |
+| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
+| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | 2021-09-02 12:31:01 | 70 |
+| 4 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
+| 5 | 1002 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
+| 6 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 7 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
+| 8 | 1003 | 9001 | 2021-09-08 13:01:01 | (NULL) | (NULL) |
+| 9 | 1003 | 9002 | 2021-09-08 14:01:01 | (NULL) | (NULL) |
+| 10 | 1003 | 9003 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
+| 11 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 12 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 13 | 1005 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
+
+试卷信息表 `examination_info`(`exam_id`:试卷 ID, `tag`:试卷类别, `difficulty`:试卷难度, `duration`:考试时长, `release_time`:发布时间),示例数据如下:
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | C++ | easy | 60 | 2020-02-01 10:00:00 |
+| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
+
+请从表中统计出 “当月均完成试卷数”不小于 3 的用户们爱作答的类别及作答次数,按次数降序输出,示例输出如下:
+
+| tag | tag_cnt |
+| ---- | ------- |
+| C++ | 4 |
+| SQL | 2 |
+| 算法 | 1 |
+
+**解释**:用户 1002 和 1005 在 2021 年 09 月的完成试卷数目均为 3,其他用户均小于 3;然后用户 1002 和 1005 作答过的试卷 tag 分布结果按作答次数降序排序依次为 C++、SQL、算法。
+
+**思路**:这题考察联合子查询,重点在于`月均回答>=3`, 但是个人认为这里没有表述清楚,应该直接说查 9 月的就容易理解多了;这里不是每个月都要>=3 或者是所有答题次数/答题月份。不要理解错误了。
+
+先查询出哪些用户月均答题大于三次
+
+```sql
+SELECT UID
+FROM exam_record record
+GROUP BY UID,
+ MONTH (start_time)
+HAVING count(submit_time) >= 3
+```
+
+有了这一步之后再进行深入,只要能理解上一步(我的意思是不被题目中的月均所困扰),然后再套一个子查询,查哪些用户包含其中,然后查出题目中所需的列即可。记得排序!!
+
+```sql
+SELECT tag,
+ count(start_time) AS tag_cnt
+FROM exam_record record
+INNER JOIN examination_info info ON record.exam_id = info.exam_id
+WHERE UID IN
+ (SELECT UID
+ FROM exam_record record
+ GROUP BY UID,
+ MONTH (start_time)
+ HAVING count(submit_time) >= 3)
+GROUP BY tag
+ORDER BY tag_cnt DESC
+```
+
+### 试卷发布当天作答人数和平均分
+
+**描述**:现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间),示例数据如下:
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | 牛客 1 号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
+| 2 | 1002 | 牛客 2 号 | 2100 | 6 | 算法 | 2020-01-01 10:00:00 |
+| 3 | 1003 | 牛客 3 号 | 1500 | 5 | 算法 | 2020-01-01 10:00:00 |
+| 4 | 1004 | 牛客 4 号 | 1100 | 4 | 算法 | 2020-01-01 10:00:00 |
+| 5 | 1005 | 牛客 5 号 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | 牛客 6 号 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+**释义**:用户 1001 昵称为牛客 1 号,成就值为 3100,用户等级是 7 级,职业方向为算法,注册时间 2020-01-01 10:00:00
+
+试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间) 示例数据如下:
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | easy | 60 | 2020-02-01 10:00:00 |
+| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
+
+试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分) 示例数据如下:
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-09-01 09:41:01 | 70 |
+| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
+| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | 2021-09-02 12:31:01 | 70 |
+| 4 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 80 |
+| 5 | 1002 | 9003 | 2021-08-01 12:01:01 | 2021-08-01 12:21:01 | 60 |
+| 6 | 1002 | 9002 | 2021-08-02 12:01:01 | 2021-08-02 12:31:01 | 70 |
+| 7 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 85 |
+| 8 | 1002 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
+| 9 | 1003 | 9002 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 10 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
+| 11 | 1003 | 9003 | 2021-09-01 13:01:01 | 2021-09-01 13:41:01 | 70 |
+| 12 | 1003 | 9001 | 2021-09-08 14:01:01 | (NULL) | (NULL) |
+| 13 | 1003 | 9002 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
+| 14 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 90 |
+| 15 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 16 | 1005 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
+
+请计算每张 SQL 类别试卷发布后,当天 5 级以上的用户作答的人数 `uv` 和平均分 `avg_score`,按人数降序,相同人数的按平均分升序,示例数据结果输出如下:
+
+| exam_id | uv | avg_score |
+| ------- | --- | --------- |
+| 9001 | 3 | 81.3 |
+
+解释:只有一张 SQL 类别的试卷,试卷 ID 为 9001,发布当天(2021-09-01)有 1001、1002、1003、1005 作答过,但是 1003 是 5 级用户,其他 3 位为 5 级以上,他们三的得分有[70,80,85,90],平均分为 81.3(保留 1 位小数)。
+
+**思路**:这题看似很复杂,但是先逐步将“外边”条件拆分,然后合拢到一起,答案就出来,多表查询反正记住:由外向里,抽丝剥茧。
+
+先把三种表连起来,同时给定一些条件,比如题目中要求`等级> 5`的用户,那么可以先查出来
+
+```sql
+SELECT DISTINCT u_info.uid
+FROM examination_info e_info
+INNER JOIN exam_record record
+INNER JOIN user_info u_info
+WHERE e_info.exam_id = record.exam_id
+ AND u_info.uid = record.uid
+ AND u_info.LEVEL > 5
+```
+
+接着注意题目中要求:`每张sql类别试卷发布后,当天作答用户`,注意其中的==当天==,那我们马上就要想到要用到时间的比较。
+
+对试卷发布日期和开始考试日期进行比较:`DATE(e_info.release_time) = DATE(record.start_time)`;不用担心`submit_time` 为 null 的问题,后续在 where 中会给过滤掉。
+
+**答案**:
+
+```sql
+SELECT record.exam_id AS exam_id,
+ COUNT(DISTINCT u_info.uid) AS uv,
+ ROUND(SUM(record.score) / COUNT(u_info.uid), 1) AS avg_score
+FROM examination_info e_info
+INNER JOIN exam_record record
+INNER JOIN user_info u_info
+WHERE e_info.exam_id = record.exam_id
+ AND u_info.uid = record.uid
+ AND DATE (e_info.release_time) = DATE (record.start_time)
+ AND submit_time IS NOT NULL
+ AND tag = 'SQL'
+ AND u_info.LEVEL > 5
+GROUP BY record.exam_id
+ORDER BY uv DESC,
+ avg_score ASC
+```
+
+注意最后的分组排序!先按人数排,若一致,按平均分排。
+
+### 作答试卷得分大于过 80 的人的用户等级分布
+
+**描述**:
+
+现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | 牛客 1 号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
+| 2 | 1002 | 牛客 2 号 | 2100 | 6 | 算法 | 2020-01-01 10:00:00 |
+| 3 | 1003 | 牛客 3 号 | 1500 | 5 | 算法 | 2020-01-01 10:00:00 |
+| 4 | 1004 | 牛客 4 号 | 1100 | 4 | 算法 | 2020-01-01 10:00:00 |
+| 5 | 1005 | 牛客 5 号 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | 牛客 6 号 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | easy | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
+
+试卷作答信息表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:41:01 | 79 |
+| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
+| 3 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
+| 4 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 80 |
+| 5 | 1002 | 9003 | 2021-08-01 12:01:01 | 2021-08-01 12:21:01 | 60 |
+| 6 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
+| 7 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 85 |
+| 8 | 1002 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 9 | 1003 | 9002 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 10 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
+| 11 | 1003 | 9003 | 2021-09-01 13:01:01 | 2021-09-01 13:41:01 | 81 |
+| 12 | 1003 | 9001 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
+| 13 | 1003 | 9002 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
+| 14 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 90 |
+| 15 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 16 | 1005 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
+
+统计作答 SQL 类别的试卷得分大于过 80 的人的用户等级分布,按数量降序排序(保证数量都不同)。示例数据结果输出如下:
+
+| level | level_cnt |
+| ----- | --------- |
+| 6 | 2 |
+| 5 | 1 |
+
+解释:9001 为 SQL 类试卷,作答该试卷大于 80 分的人有 1002、1003、1005 共 3 人,6 级两人,5 级一人。
+
+**思路:**这题和上一题都是一样的数据,只是查询条件改变了而已,上一题理解了,这题分分钟做出来。
+
+**答案**:
+
+```sql
+SELECT u_info.LEVEL AS LEVEL,
+ count(u_info.uid) AS level_cnt
+FROM examination_info e_info
+INNER JOIN exam_record record
+INNER JOIN user_info u_info
+WHERE e_info.exam_id = record.exam_id
+ AND u_info.uid = record.uid
+ AND record.score > 80
+ AND submit_time IS NOT NULL
+ AND tag = 'SQL'
+GROUP BY LEVEL
+ORDER BY level_cnt DESC
+```
+
+## 合并查询
+
+### 每个题目和每份试卷被作答的人数和次数
+
+**描述**:
+
+现有试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:41:01 | 81 |
+| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
+| 3 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 80 |
+| 4 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
+| 5 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 85 |
+| 6 | 1002 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+
+题目练习表 practice_record(uid 用户 ID, question_id 题目 ID, submit_time 提交时间, score 得分):
+
+| id | uid | question_id | submit_time | score |
+| --- | ---- | ----------- | ------------------- | ----- |
+| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
+| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
+| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
+| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
+| 5 | 1003 | 8001 | 2021-08-02 19:38:01 | 70 |
+| 6 | 1003 | 8001 | 2021-08-02 19:48:01 | 90 |
+| 7 | 1003 | 8002 | 2021-08-01 19:38:01 | 80 |
+
+请统计每个题目和每份试卷被作答的人数和次数,分别按照"试卷"和"题目"的 uv & pv 降序显示,示例数据结果输出如下:
+
+| tid | uv | pv |
+| ---- | --- | --- |
+| 9001 | 3 | 3 |
+| 9002 | 1 | 3 |
+| 8001 | 3 | 5 |
+| 8002 | 2 | 2 |
+
+**解释**:“试卷”有 3 人共练习 3 次试卷 9001,1 人作答 3 次 9002;“刷题”有 3 人刷 5 次 8001,有 2 人刷 2 次 8002
+
+**思路**:这题的难点和易错点在于`UNION`和`ORDER BY` 同时使用的问题
+
+有以下几种情况:使用`union`和多个`order by`不加括号,报错!
+
+`order by`在`union`连接的子句中不起作用;
+
+比如不加括号:
+
+```sql
+SELECT exam_id AS tid,
+ COUNT(DISTINCT UID) AS uv,
+ COUNT(UID) AS pv
+FROM exam_record
+GROUP BY exam_id
+ORDER BY uv DESC,
+ pv DESC
+UNION
+SELECT question_id AS tid,
+ COUNT(DISTINCT UID) AS uv,
+ COUNT(UID) AS pv
+FROM practice_record
+GROUP BY question_id
+ORDER BY uv DESC,
+ pv DESC
+```
+
+直接报语法错误,如果没有括号,只能有一个`order by`
+
+还有一种`order by`不起作用的情况,但是能在子句的子句中起作用,这里的解决方案就是在外面再套一层查询。
+
+**答案**:
+
+```sql
+SELECT *
+FROM
+ (SELECT exam_id AS tid,
+ COUNT(DISTINCT exam_record.uid) uv,
+ COUNT(*) pv
+ FROM exam_record
+ GROUP BY exam_id
+ ORDER BY uv DESC, pv DESC) t1
+UNION
+SELECT *
+FROM
+ (SELECT question_id AS tid,
+ COUNT(DISTINCT practice_record.uid) uv,
+ COUNT(*) pv
+ FROM practice_record
+ GROUP BY question_id
+ ORDER BY uv DESC, pv DESC) t2;
+```
+
+### 分别满足两个活动的人
+
+**描述**: 为了促进更多用户在牛客平台学习和刷题进步,我们会经常给一些既活跃又表现不错的用户发放福利。假使以前我们有两拨运营活动,分别给每次试卷得分都能到 85 分的人(activity1)、至少有一次用了一半时间就完成高难度试卷且分数大于 80 的人(activity2)发了福利券。
+
+现在,需要你一次性将这两个活动满足的人筛选出来,交给运营同学。请写出一个 SQL 实现:输出 2021 年里,所有每次试卷得分都能到 85 分的人以及至少有一次用了一半时间就完成高难度试卷且分数大于 80 的人的 id 和活动号,按用户 ID 排序输出。
+
+现有试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | easy | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
+
+试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
+| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
+| 3 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | **86** |
+| 4 | 1003 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 89 |
+| 5 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
+
+示例数据输出结果:
+
+| uid | activity |
+| ---- | --------- |
+| 1001 | activity2 |
+| 1003 | activity1 |
+| 1004 | activity1 |
+| 1004 | activity2 |
+
+**解释**:用户 1001 最小分数 81 不满足活动 1,但 29 分 59 秒完成了 60 分钟长的试卷得分 81,满足活动 2;1003 最小分数 86 满足活动 1,完成时长都大于试卷时长的一半,不满足活动 2;用户 1004 刚好用了一半时间(30 分钟整)完成了试卷得分 85,满足活动 1 和活动 2。
+
+**思路**: 这一题需要涉及到时间的减法,需要用到 `TIMESTAMPDIFF()` 函数计算两个时间戳之间的分钟差值。
+
+下面我们来看一下基本用法
+
+示例:
+
+```sql
+TIMESTAMPDIFF(MINUTE, start_time, end_time)
+```
+
+`TIMESTAMPDIFF()` 函数的第一个参数是时间单位,这里我们选择 `MINUTE` 表示返回分钟差值。第二个参数是较早的时间戳,第三个参数是较晚的时间戳。函数会返回它们之间的分钟差值
+
+了解了这个函数的用法之后,我们再回过头来看`activity1`的要求,求分数大于 85 即可,那我们还是先把这个写出来,后续思路就会清晰很多
+
+```sql
+SELECT DISTINCT UID
+FROM exam_record
+WHERE score >= 85
+ AND YEAR (start_time) = '2021'
+```
+
+根据条件 2,接着写出`在一半时间内完成高难度试卷且分数大于80的人`
+
+```sql
+SELECT UID
+FROM examination_info info
+INNER JOIN exam_record record
+WHERE info.exam_id = record.exam_id
+ AND (TIMESTAMPDIFF(MINUTE, start_time, submit_time)) < (info.duration / 2)
+ AND difficulty = 'hard'
+ AND score >= 80
+```
+
+然后再把两者`UNION` 起来即可。(这里特别要注意括号问题和`order by`位置,具体用法在上一篇中已提及)
+
+**答案**:
+
+```sql
+SELECT DISTINCT UID UID,
+ 'activity1' activity
+FROM exam_record
+WHERE UID not in
+ (SELECT UID
+ FROM exam_record
+ WHERE score<85
+ AND YEAR(submit_time) = 2021 )
+UNION
+SELECT DISTINCT UID UID,
+ 'activity2' activity
+FROM exam_record e_r
+LEFT JOIN examination_info e_i ON e_r.exam_id = e_i.exam_id
+WHERE YEAR(submit_time) = 2021
+ AND difficulty = 'hard'
+ AND TIMESTAMPDIFF(SECOND, start_time, submit_time) <= duration *30
+ AND score>80
+ORDER BY UID
+```
+
+## 连接查询
+
+### 满足条件的用户的试卷完成数和题目练习数(困难)
+
+**描述**:
+
+现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | 牛客 1 号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
+| 2 | 1002 | 牛客 2 号 | 2300 | 7 | 算法 | 2020-01-01 10:00:00 |
+| 3 | 1003 | 牛客 3 号 | 2500 | 7 | 算法 | 2020-01-01 10:00:00 |
+| 4 | 1004 | 牛客 4 号 | 1200 | 5 | 算法 | 2020-01-01 10:00:00 |
+| 5 | 1005 | 牛客 5 号 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | 牛客 6 号 | 2000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | hard | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
+
+试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ----- |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
+| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
+| 3 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 86 |
+| 4 | 1003 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:51 | 89 |
+| 5 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
+| 6 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:02 | 85 |
+| 7 | 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 84 |
+| 8 | 1006 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 80 |
+
+题目练习记录表 practice_record(uid 用户 ID, question_id 题目 ID, submit_time 提交时间, score 得分):
+
+| id | uid | question_id | submit_time | score |
+| --- | ---- | ----------- | ------------------- | ----- |
+| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
+| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
+| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
+| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
+| 5 | 1004 | 8001 | 2021-08-02 19:38:01 | 70 |
+| 6 | 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
+| 7 | 1001 | 8002 | 2021-08-02 19:38:01 | 70 |
+| 8 | 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
+| 9 | 1004 | 8002 | 2021-08-02 19:58:01 | 94 |
+| 10 | 1004 | 8003 | 2021-08-02 19:38:01 | 70 |
+| 11 | 1004 | 8003 | 2021-08-02 19:48:01 | 90 |
+| 12 | 1004 | 8003 | 2021-08-01 19:38:01 | 80 |
+
+请你找到高难度 SQL 试卷得分平均值大于 80 并且是 7 级的红名大佬,统计他们的 2021 年试卷总完成次数和题目总练习次数,只保留 2021 年有试卷完成记录的用户。结果按试卷完成数升序,按题目练习数降序。
+
+示例数据输出如下:
+
+| uid | exam_cnt | question_cnt |
+| ---- | -------- | ------------ |
+| 1001 | 1 | 2 |
+| 1003 | 2 | 0 |
+
+解释:用户 1001、1003、1004、1006 满足高难度 SQL 试卷得分平均值大于 80,但只有 1001、1003 是 7 级红名大佬;1001 完成了 1 次试卷 1001,练习了 2 次题目;1003 完成了 2 次试卷 9001、9002,未练习题目(因此计数为 0)
+
+**思路:**
+
+先将条件进行初步筛选,比如先查出做过高难度 sql 试卷的用户
+
+```sql
+SELECT
+ record.uid
+FROM
+ exam_record record
+ INNER JOIN examination_info e_info ON record.exam_id = e_info.exam_id
+ JOIN user_info u_info ON record.uid = u_info.uid
+WHERE
+ e_info.tag = 'SQL'
+ AND e_info.difficulty = 'hard'
+```
+
+然后根据题目要求,接着再往里叠条件即可;
+
+但是这里又要注意:
+
+第一:不能`YEAR(submit_time)= 2021`这个条件放到最后,要在`ON`条件里,因为左连接存在返回左表全部行,右表为 null 的情形,放在 `JOIN`条件的 `ON` 子句中的目的是为了确保在连接两个表时,只有满足年份条件的记录会进行连接。这样可以避免其他年份的记录被包含在结果中。即 1001 做过 2021 年的试卷,但没有练习过,如果把条件放到最后,就会排除掉这种情况。
+
+第二,必须是`COUNT(distinct er.exam_id) exam_cnt, COUNT(distinct pr.id) question_cnt,`要加 distinct,因为有左连接产生很多重复值。
+
+**答案**:
+
+```sql
+SELECT er.uid AS UID,
+ count(DISTINCT er.exam_id) AS exam_cnt,
+ count(DISTINCT pr.id) AS question_cnt
+FROM exam_record er
+LEFT JOIN practice_record pr ON er.uid = pr.uid
+AND YEAR (er.submit_time)= 2021
+AND YEAR (pr.submit_time)= 2021
+WHERE er.uid IN
+ (SELECT er.uid
+ FROM exam_record er
+ LEFT JOIN examination_info ei ON er.exam_id = ei.exam_id
+ LEFT JOIN user_info ui ON er.uid = ui.uid
+ WHERE tag = 'SQL'
+ AND difficulty = 'hard'
+ AND LEVEL = 7
+ GROUP BY er.uid
+ HAVING avg(score) > 80)
+GROUP BY er.uid
+ORDER BY exam_cnt,
+ question_cnt DESC
+```
+
+可能细心的小伙伴会发现,为什么明明将条件限制了`tag = 'SQL' AND difficulty = 'hard'`,但是用户 1003 仍然能查出两条考试记录,其中一条的考试`tag`为 `C++`; 这是由于`LEFT JOIN`的特性,即使没有与右表匹配的行,左表的所有记录仍然会被保留。
+
+### 每个 6/7 级用户活跃情况(困难)
+
+**描述**:
+
+现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | 牛客 1 号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
+| 2 | 1002 | 牛客 2 号 | 2300 | 7 | 算法 | 2020-01-01 10:00:00 |
+| 3 | 1003 | 牛客 3 号 | 2500 | 7 | 算法 | 2020-01-01 10:00:00 |
+| 4 | 1004 | 牛客 4 号 | 1200 | 5 | 算法 | 2020-01-01 10:00:00 |
+| 5 | 1005 | 牛客 5 号 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | 牛客 6 号 | 2600 | 7 | C++ | 2020-01-01 10:00:00 |
+
+试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | easy | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
+
+试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| uid | exam_id | start_time | submit_time | score |
+| ---- | ------- | ------------------- | ------------------- | ------ |
+| 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 78 |
+| 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
+| 1005 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
+| 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:02 | 85 |
+| 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:59 | 84 |
+| 1006 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 81 |
+| 1002 | 9001 | 2020-09-01 13:01:01 | 2020-09-01 13:41:01 | 81 |
+| 1005 | 9001 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
+
+题目练习记录表 `practice_record`(`uid` 用户 ID, `question_id` 题目 ID, `submit_time` 提交时间, `score` 得分):
+
+| uid | question_id | submit_time | score |
+| ---- | ----------- | ------------------- | ----- |
+| 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
+| 1004 | 8001 | 2021-08-02 19:38:01 | 70 |
+| 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
+| 1001 | 8002 | 2021-08-02 19:38:01 | 70 |
+| 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
+| 1006 | 8002 | 2021-08-04 19:58:01 | 94 |
+| 1006 | 8003 | 2021-08-03 19:38:01 | 70 |
+| 1006 | 8003 | 2021-08-02 19:48:01 | 90 |
+| 1006 | 8003 | 2020-08-01 19:38:01 | 80 |
+
+请统计每个 6/7 级用户总活跃月份数、2021 年活跃天数、2021 年试卷作答活跃天数、2021 年答题活跃天数,按照总活跃月份数、2021 年活跃天数降序排序。由示例数据结果输出如下:
+
+| uid | act_month_total | act_days_2021 | act_days_2021_exam |
+| ---- | --------------- | ------------- | ------------------ |
+| 1006 | 3 | 4 | 1 |
+| 1001 | 2 | 2 | 1 |
+| 1005 | 1 | 1 | 1 |
+| 1002 | 1 | 0 | 0 |
+| 1003 | 0 | 0 | 0 |
+
+**解释**:6/7 级用户共有 5 个,其中 1006 在 202109、202108、202008 共 3 个月活跃过,2021 年活跃的日期有 20210907、20210804、20210803、20210802 共 4 天,2021 年在试卷作答区 20210907 活跃 1 天,在题目练习区活跃了 3 天。
+
+**思路:**
+
+这题的关键在于`CASE WHEN THEN`的使用,不然要写很多的`left join` 因为会产生很多的结果集。
+
+`CASE WHEN THEN`语句是一种条件表达式,用于在 SQL 中根据条件执行不同的操作或返回不同的结果。
+
+语法结构如下:
+
+```sql
+CASE
+ WHEN condition1 THEN result1
+ WHEN condition2 THEN result2
+ ...
+ ELSE result
+END
+```
+
+在这个结构中,可以根据需要添加多个`WHEN`子句,每个`WHEN`子句后面跟着一个条件(condition)和一个结果(result)。条件可以是任何逻辑表达式,如果满足条件,将返回对应的结果。
+
+最后的`ELSE`子句是可选的,用于指定当所有前面的条件都不满足时的默认返回结果。如果没有提供`ELSE`子句,则默认返回`NULL`。
+
+例如:
+
+```sql
+SELECT score,
+ CASE
+ WHEN score >= 90 THEN '优秀'
+ WHEN score >= 80 THEN '良好'
+ WHEN score >= 60 THEN '及格'
+ ELSE '不及格'
+ END AS grade
+FROM student_scores;
+```
+
+在上述示例中,根据学生成绩(score)的不同范围,使用 CASE WHEN THEN 语句返回相应的等级(grade)。如果成绩大于等于 90,则返回"优秀";如果成绩大于等于 80,则返回"良好";如果成绩大于等于 60,则返回"及格";否则返回"不及格"。
+
+那了解到了上述的用法之后,回过头看看该题,要求列出不同的活跃天数。
+
+```sql
+count(distinct act_month) as act_month_total,
+count(distinct case when year(act_time)='2021'then act_day end) as act_days_2021,
+count(distinct case when year(act_time)='2021' and tag='exam' then act_day end) as act_days_2021_exam,
+count(distinct case when year(act_time)='2021' and tag='question'then act_day end) as act_days_2021_question
+```
+
+这里的 tag 是先给标记,方便对查询进行区分,将考试和答题分开。
+
+找出试卷作答区的用户
+
+```sql
+SELECT
+ uid,
+ exam_id AS ans_id,
+ start_time AS act_time,
+ date_format( start_time, '%Y%m' ) AS act_month,
+ date_format( start_time, '%Y%m%d' ) AS act_day,
+ 'exam' AS tag
+ FROM
+ exam_record
+```
+
+紧接着就是答题作答区的用户
+
+```sql
+SELECT
+ uid,
+ question_id AS ans_id,
+ submit_time AS act_time,
+ date_format( submit_time, '%Y%m' ) AS act_month,
+ date_format( submit_time, '%Y%m%d' ) AS act_day,
+ 'question' AS tag
+ FROM
+ practice_record
+```
+
+最后将两个结果进行`UNION` 最后别忘了将结果进行排序 (这题有点类似于分治法的思想)
+
+**答案**:
+
+```sql
+SELECT user_info.uid,
+ count(DISTINCT act_month) AS act_month_total,
+ count(DISTINCT CASE
+ WHEN YEAR (act_time)= '2021' THEN act_day
+ END) AS act_days_2021,
+ count(DISTINCT CASE
+ WHEN YEAR (act_time)= '2021'
+ AND tag = 'exam' THEN act_day
+ END) AS act_days_2021_exam,
+ count(DISTINCT CASE
+ WHEN YEAR (act_time)= '2021'
+ AND tag = 'question' THEN act_day
+ END) AS act_days_2021_question
+FROM
+ (SELECT UID,
+ exam_id AS ans_id,
+ start_time AS act_time,
+ date_format(start_time, '%Y%m') AS act_month,
+ date_format(start_time, '%Y%m%d') AS act_day,
+ 'exam' AS tag
+ FROM exam_record
+ UNION ALL SELECT UID,
+ question_id AS ans_id,
+ submit_time AS act_time,
+ date_format(submit_time, '%Y%m') AS act_month,
+ date_format(submit_time, '%Y%m%d') AS act_day,
+ 'question' AS tag
+ FROM practice_record) total
+RIGHT JOIN user_info ON total.uid = user_info.uid
+WHERE user_info.LEVEL IN (6,
+ 7)
+GROUP BY user_info.uid
+ORDER BY act_month_total DESC,
+ act_days_2021 DESC
+```
+
+
diff --git a/docs/database/sql/sql-questions-04.md b/docs/database/sql/sql-questions-04.md
new file mode 100644
index 00000000000..8dd989cd9b0
--- /dev/null
+++ b/docs/database/sql/sql-questions-04.md
@@ -0,0 +1,837 @@
+---
+title: SQL常见面试题总结(4)
+description: SQL常见面试题总结第四篇,详解MySQL 8.0窗口函数ROW_NUMBER、RANK、DENSE_RANK、NTILE、LAG、LEAD等的用法和应用场景。
+category: 数据库
+tag:
+ - 数据库基础
+ - SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL面试题,窗口函数,ROW_NUMBER,RANK,DENSE_RANK,NTILE,LAG,LEAD,MySQL 8.0
+---
+
+> 题目来源于:[牛客题霸 - SQL 进阶挑战](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=240)
+
+较难或者困难的题目可以根据自身实际情况和面试需要来决定是否要跳过。
+
+## 专用窗口函数
+
+MySQL 8.0 版本引入了窗口函数的支持,下面是 MySQL 中常见的窗口函数及其用法:
+
+1. `ROW_NUMBER()`: 为查询结果集中的每一行分配一个唯一的整数值。
+
+```sql
+SELECT col1, col2, ROW_NUMBER() OVER (ORDER BY col1) AS row_num
+FROM table;
+```
+
+2. `RANK()`: 计算每一行在排序结果中的排名。
+
+```sql
+SELECT col1, col2, RANK() OVER (ORDER BY col1 DESC) AS ranking
+FROM table;
+```
+
+3. `DENSE_RANK()`: 计算每一行在排序结果中的排名,保留相同的排名。
+
+```sql
+SELECT col1, col2, DENSE_RANK() OVER (ORDER BY col1 DESC) AS ranking
+FROM table;
+```
+
+4. `NTILE(n)`: 将结果分成 n 个基本均匀的桶,并为每个桶分配一个标识号。
+
+```sql
+SELECT col1, col2, NTILE(4) OVER (ORDER BY col1) AS bucket
+FROM table;
+```
+
+5. `SUM()`, `AVG()`,`COUNT()`, `MIN()`, `MAX()`: 这些聚合函数也可以与窗口函数结合使用,计算窗口内指定列的汇总、平均值、计数、最小值和最大值。
+
+```sql
+SELECT col1, col2, SUM(col1) OVER () AS sum_col
+FROM table;
+```
+
+6. `LEAD()` 和 `LAG()`: LEAD 函数用于获取当前行之后的某个偏移量的行的值,而 LAG 函数用于获取当前行之前的某个偏移量的行的值。
+
+```sql
+SELECT col1, col2, LEAD(col1, 1) OVER (ORDER BY col1) AS next_col1,
+ LAG(col1, 1) OVER (ORDER BY col1) AS prev_col1
+FROM table;
+```
+
+7. `FIRST_VALUE()` 和 `LAST_VALUE()`: FIRST_VALUE 函数用于获取窗口内指定列的第一个值,LAST_VALUE 函数用于获取窗口内指定列的最后一个值。
+
+```sql
+SELECT col1, col2, FIRST_VALUE(col2) OVER (PARTITION BY col1 ORDER BY col2) AS first_val,
+ LAST_VALUE(col2) OVER (PARTITION BY col1 ORDER BY col2) AS last_val
+FROM table;
+```
+
+窗口函数通常需要配合 OVER 子句一起使用,用于定义窗口的大小、排序规则和分组方式。
+
+### 每类试卷得分前三名
+
+**描述**:
+
+现有试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
+
+试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, score 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 78 |
+| 2 | 1002 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
+| 3 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
+| 4 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 86 |
+| 5 | 1003 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:51 | 89 |
+| 6 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
+| 7 | 1005 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:31:02 | 85 |
+| 8 | 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 84 |
+| 9 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
+| 10 | 1003 | 9002 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
+
+找到每类试卷得分的前 3 名,如果两人最大分数相同,选择最小分数大者,如果还相同,选择 uid 大者。由示例数据结果输出如下:
+
+| tid | uid | ranking |
+| ---- | ---- | ------- |
+| SQL | 1003 | 1 |
+| SQL | 1004 | 2 |
+| SQL | 1002 | 3 |
+| 算法 | 1005 | 1 |
+| 算法 | 1006 | 2 |
+| 算法 | 1003 | 3 |
+
+**解释**:有作答得分记录的试卷 tag 有 SQL 和算法,SQL 试卷用户 1001、1002、1003、1004 有作答得分,最高得分分别为 81、81、89、85,最低得分分别为 78、81、86、40,因此先按最高得分排名再按最低得分排名取前三为 1003、1004、1002。
+
+**答案**:
+
+```sql
+SELECT tag,
+ UID,
+ ranking
+FROM
+ (SELECT b.tag AS tag,
+ a.uid AS UID,
+ ROW_NUMBER() OVER (PARTITION BY b.tag
+ ORDER BY b.tag,
+ max(a.score) DESC,
+ min(a.score) DESC,
+ a.uid DESC) AS ranking
+ FROM exam_record a
+ LEFT JOIN examination_info b ON a.exam_id = b.exam_id
+ GROUP BY b.tag,
+ a.uid) t
+WHERE ranking <= 3
+```
+
+### 第二快/慢用时之差大于试卷时长一半的试卷(较难)
+
+**描述**:
+
+现有试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | hard | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
+
+试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:51:01 | 78 |
+| 2 | 1001 | 9002 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
+| 3 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
+| 4 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:59:01 | 86 |
+| 5 | 1003 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:51 | 89 |
+| 6 | 1004 | 9002 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
+| 7 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:02 | 85 |
+| 8 | 1006 | 9001 | 2021-09-07 10:02:01 | 2021-09-07 10:21:01 | 84 |
+| 9 | 1003 | 9001 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
+| 10 | 1003 | 9002 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
+| 11 | 1005 | 9001 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
+| 12 | 1003 | 9003 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
+
+找到第二快和第二慢用时之差大于试卷时长的一半的试卷信息,按试卷 ID 降序排序。由示例数据结果输出如下:
+
+| exam_id | duration | release_time |
+| ------- | -------- | ------------------- |
+| 9001 | 60 | 2021-09-01 06:00:00 |
+
+**解释**:试卷 9001 被作答用时有 50 分钟、58 分钟、30 分 1 秒、19 分钟、10 分钟,第二快和第二慢用时之差为 50 分钟-19 分钟=31 分钟,试卷时长为 60 分钟,因此满足大于试卷时长一半的条件,输出试卷 ID、时长、发布时间。
+
+**思路:**
+
+第一步,找到每张试卷完成时间的顺序排名和倒序排名 也就是表 a;
+
+第二步,与通过试卷信息表 b 建立内连接,并根据试卷 id 分组,利用`having`筛选排名为第二个数据,将秒转化为分钟并进行比较,最后再根据试卷 id 倒序排序就行
+
+**答案**:
+
+```sql
+SELECT a.exam_id,
+ b.duration,
+ b.release_time
+FROM
+ (SELECT exam_id,
+ row_number() OVER (PARTITION BY exam_id
+ ORDER BY timestampdiff(SECOND, start_time, submit_time) DESC) rn1,
+ row_number() OVER (PARTITION BY exam_id
+ ORDER BY timestampdiff(SECOND, start_time, submit_time) ASC) rn2,
+ timestampdiff(SECOND, start_time, submit_time) timex
+ FROM exam_record
+ WHERE score IS NOT NULL ) a
+INNER JOIN examination_info b ON a.exam_id = b.exam_id
+GROUP BY a.exam_id
+HAVING (max(IF (rn1 = 2, a.timex, 0))- max(IF (rn2 = 2, a.timex, 0)))/ 60 > b.duration / 2
+ORDER BY a.exam_id DESC
+```
+
+### 连续两次作答试卷的最大时间窗(较难)
+
+**描述**
+
+现有试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ----- |
+| 1 | 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:02 | 84 |
+| 2 | 1006 | 9001 | 2021-09-01 12:11:01 | 2021-09-01 12:31:01 | 89 |
+| 3 | 1006 | 9002 | 2021-09-06 10:01:01 | 2021-09-06 10:21:01 | 81 |
+| 4 | 1005 | 9002 | 2021-09-05 10:01:01 | 2021-09-05 10:21:01 | 81 |
+| 5 | 1005 | 9001 | 2021-09-05 10:31:01 | 2021-09-05 10:51:01 | 81 |
+
+请计算在 2021 年至少有两天作答过试卷的人中,计算该年连续两次作答试卷的最大时间窗 `days_window`,那么根据该年的历史规律他在 `days_window` 天里平均会做多少套试卷,按最大时间窗和平均做答试卷套数倒序排序。由示例数据结果输出如下:
+
+| uid | days_window | avg_exam_cnt |
+| ---- | ----------- | ------------ |
+| 1006 | 6 | 2.57 |
+
+**解释**:用户 1006 分别在 20210901、20210906、20210907 作答过 3 次试卷,连续两次作答最大时间窗为 6 天(1 号到 6 号),他 1 号到 7 号这 7 天里共做了 3 张试卷,平均每天 3/7=0.428571 张,那么 6 天里平均会做 0.428571\*6=2.57 张试卷(保留两位小数);用户 1005 在 20210905 做了两张试卷,但是只有一天的作答记录,过滤掉。
+
+**思路:**
+
+上面这个解释中提示要对作答记录去重,千万别被骗了,不要去重!去重就通不过测试用例。注意限制时间是 2021 年;
+
+而且要注意时间差要+1 天;还要注意==没交卷也算在内==!!!! (反正感觉这题描述不清,出的不是很好)
+
+**答案**:
+
+```sql
+SELECT UID,
+ max(datediff(next_time, start_time)) + 1 AS days_window,
+ round(count(start_time)/(datediff(max(start_time), min(start_time))+ 1) * (max(datediff(next_time, start_time))+ 1), 2) AS avg_exam_cnt
+FROM
+ (SELECT UID,
+ start_time,
+ lead(start_time, 1) OVER (PARTITION BY UID
+ ORDER BY start_time) AS next_time
+ FROM exam_record
+ WHERE YEAR (start_time) = '2021' ) a
+GROUP BY UID
+HAVING count(DISTINCT date(start_time)) > 1
+ORDER BY days_window DESC,
+ avg_exam_cnt DESC
+```
+
+### 近三个月未完成为 0 的用户完成情况
+
+**描述**:
+
+现有试卷作答记录表 `exam_record`(`uid`:用户 ID, `exam_id`:试卷 ID, `start_time`:开始作答时间, `submit_time`:交卷时间,为空的话则代表未完成, `score`:得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1006 | 9003 | 2021-09-06 10:01:01 | 2021-09-06 10:21:02 | 84 |
+| 2 | 1006 | 9001 | 2021-08-02 12:11:01 | 2021-08-02 12:31:01 | 89 |
+| 3 | 1006 | 9002 | 2021-06-06 10:01:01 | 2021-06-06 10:21:01 | 81 |
+| 4 | 1006 | 9002 | 2021-05-06 10:01:01 | 2021-05-06 10:21:01 | 81 |
+| 5 | 1006 | 9001 | 2021-05-01 12:01:01 | (NULL) | (NULL) |
+| 6 | 1001 | 9001 | 2021-09-05 10:31:01 | 2021-09-05 10:51:01 | 81 |
+| 7 | 1001 | 9003 | 2021-08-01 09:01:01 | 2021-08-01 09:51:11 | 78 |
+| 8 | 1001 | 9002 | 2021-07-01 09:01:01 | 2021-07-01 09:31:00 | 81 |
+| 9 | 1001 | 9002 | 2021-07-01 12:01:01 | 2021-07-01 12:31:01 | 81 |
+| 10 | 1001 | 9002 | 2021-07-01 12:01:01 | (NULL) | (NULL) |
+
+找到每个人近三个有试卷作答记录的月份中没有试卷是未完成状态的用户的试卷作答完成数,按试卷完成数和用户 ID 降序排名。由示例数据结果输出如下:
+
+| uid | exam_complete_cnt |
+| ---- | ----------------- |
+| 1006 | 3 |
+
+**解释**:用户 1006 近三个有作答试卷的月份为 202109、202108、202106,作答试卷数为 3,全部完成;用户 1001 近三个有作答试卷的月份为 202109、202108、202107,作答试卷数为 5,完成试卷数为 4,因为有未完成试卷,故过滤掉。
+
+**思路:**
+
+1. `找到每个人近三个有试卷作答记录的月份中没有试卷是未完成状态的用户的试卷作答完成数`首先看这句话,肯定要先根据人进行分组
+2. 最近三个月,可以采用连续重复排名,倒序排列,排名<=3
+3. 统计作答数
+4. 拼装剩余条件
+5. 排序
+
+**答案**:
+
+```sql
+SELECT UID,
+ count(score) exam_complete_cnt
+FROM
+ (SELECT *, DENSE_RANK() OVER (PARTITION BY UID
+ ORDER BY date_format(start_time, '%Y%m') DESC) dr
+ FROM exam_record) t1
+WHERE dr <= 3
+GROUP BY UID
+HAVING count(dr)= count(score)
+ORDER BY exam_complete_cnt DESC,
+ UID DESC
+```
+
+### 未完成率较高的 50%用户近三个月答卷情况(困难)
+
+**描述**:
+
+现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | 牛客 1 号 | 3200 | 7 | 算法 | 2020-01-01 10:00:00 |
+| 2 | 1002 | 牛客 2 号 | 2500 | 6 | 算法 | 2020-01-01 10:00:00 |
+| 3 | 1003 | 牛客 3 号 ♂ | 2200 | 5 | 算法 | 2020-01-01 10:00:00 |
+
+试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ------ | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | SQL | hard | 80 | 2020-01-01 10:00:00 |
+| 3 | 9003 | 算法 | hard | 80 | 2020-01-01 10:00:00 |
+| 4 | 9004 | PYTHON | medium | 70 | 2020-01-01 10:00:00 |
+
+试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ----- |
+| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 90 |
+| 15 | 1002 | 9001 | 2020-01-01 18:01:01 | 2020-01-01 18:59:02 | 90 |
+| 13 | 1001 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
+| 2 | 1002 | 9001 | 2020-01-20 10:01:01 | | |
+| 3 | 1002 | 9001 | 2020-02-01 12:11:01 | | |
+| 5 | 1001 | 9001 | 2020-03-01 12:01:01 | | |
+| 6 | 1002 | 9001 | 2020-03-01 12:01:01 | 2020-03-01 12:41:01 | 90 |
+| 4 | 1003 | 9001 | 2020-03-01 19:01:01 | | |
+| 7 | 1002 | 9001 | 2020-05-02 19:01:01 | 2020-05-02 19:32:00 | 90 |
+| 14 | 1001 | 9002 | 2020-01-01 12:11:01 | | |
+| 8 | 1001 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:59:01 | 69 |
+| 9 | 1001 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
+| 10 | 1002 | 9002 | 2020-02-02 12:01:01 | | |
+| 11 | 1002 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:43:01 | 81 |
+| 12 | 1002 | 9002 | 2020-03-02 12:11:01 | | |
+| 17 | 1001 | 9002 | 2020-05-05 18:01:01 | | |
+| 16 | 1002 | 9003 | 2020-05-06 12:01:01 | | |
+
+请统计 SQL 试卷上未完成率较高的 50%用户中,6 级和 7 级用户在有试卷作答记录的近三个月中,每个月的答卷数目和完成数目。按用户 ID、月份升序排序。
+
+由示例数据结果输出如下:
+
+| uid | start_month | total_cnt | complete_cnt |
+| ---- | ----------- | --------- | ------------ |
+| 1002 | 202002 | 3 | 1 |
+| 1002 | 202003 | 2 | 1 |
+| 1002 | 202005 | 2 | 1 |
+
+解释:各个用户对 SQL 试卷的未完成数、作答总数、未完成率如下:
+
+| uid | incomplete_cnt | total_cnt | incomplete_rate |
+| ---- | -------------- | --------- | --------------- |
+| 1001 | 3 | 7 | 0.4286 |
+| 1002 | 4 | 8 | 0.5000 |
+| 1003 | 1 | 1 | 1.0000 |
+
+1001、1002、1003 分别排在 1.0、0.5、0.0 的位置,因此较高的 50%用户(排位<=0.5)为 1002、1003;
+
+1003 不是 6 级或 7 级;
+
+有试卷作答记录的近三个月为 202005、202003、202002;
+
+这三个月里 1002 的作答题数分别为 3、2、2,完成数目分别为 1、1、1。
+
+**思路:**
+
+注意点:这题注意求的是所有的答题次数和完成次数,而 sql 类别的试卷是限制未完成率排名,6, 7 级用户限制的是做题记录。
+
+先求出未完成率的排名
+
+```sql
+SELECT UID,
+ count(submit_time IS NULL
+ OR NULL)/ count(start_time) AS num,
+ PERCENT_RANK() OVER (
+ ORDER BY count(submit_time IS NULL
+ OR NULL)/ count(start_time)) AS ranking
+FROM exam_record
+LEFT JOIN examination_info USING (exam_id)
+WHERE tag = 'SQL'
+GROUP BY UID
+```
+
+再求出最近三个月的练习记录
+
+```sql
+SELECT UID,
+ date_format(start_time, '%Y%m') AS month_d,
+ submit_time,
+ exam_id,
+ dense_rank() OVER (PARTITION BY UID
+ ORDER BY date_format(start_time, '%Y%m') DESC) AS ranking
+FROM exam_record
+LEFT JOIN user_info USING (UID)
+WHERE LEVEL IN (6,7)
+```
+
+**答案**:
+
+```sql
+SELECT t1.uid,
+ t1.month_d,
+ count(*) AS total_cnt,
+ count(t1.submit_time) AS complete_cnt
+FROM-- 先求出未完成率的排名
+
+ (SELECT UID,
+ count(submit_time IS NULL OR NULL)/ count(start_time) AS num,
+ PERCENT_RANK() OVER (
+ ORDER BY count(submit_time IS NULL OR NULL)/ count(start_time)) AS ranking
+ FROM exam_record
+ LEFT JOIN examination_info USING (exam_id)
+ WHERE tag = 'SQL'
+ GROUP BY UID) t
+INNER JOIN
+ (-- 再求出近三个月的练习记录
+ SELECT UID,
+ date_format(start_time, '%Y%m') AS month_d,
+ submit_time,
+ exam_id,
+ dense_rank() OVER (PARTITION BY UID
+ ORDER BY date_format(start_time, '%Y%m') DESC) AS ranking
+ FROM exam_record
+ LEFT JOIN user_info USING (UID)
+ WHERE LEVEL IN (6,7) ) t1 USING (UID)
+WHERE t1.ranking <= 3 AND t.ranking >= 0.5 -- 使用限制找到符合条件的记录
+
+GROUP BY t1.uid,
+ t1.month_d
+ORDER BY t1.uid,
+ t1.month_d
+```
+
+### 试卷完成数同比 2020 年的增长率及排名变化(困难)
+
+**描述**:
+
+现有试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ------ | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-01-01 10:00:00 |
+| 2 | 9002 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 3 | 9003 | 算法 | hard | 80 | 2021-01-01 10:00:00 |
+| 4 | 9004 | PYTHON | medium | 70 | 2021-01-01 10:00:00 |
+
+试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ----- |
+| 1 | 1001 | 9001 | 2020-08-02 10:01:01 | 2020-08-02 10:31:01 | 89 |
+| 2 | 1002 | 9001 | 2020-04-01 18:01:01 | 2020-04-01 18:59:02 | 90 |
+| 3 | 1001 | 9001 | 2020-04-01 09:01:01 | 2020-04-01 09:21:59 | 80 |
+| 5 | 1002 | 9001 | 2021-03-02 19:01:01 | 2021-03-02 19:32:00 | 20 |
+| 8 | 1003 | 9001 | 2021-05-02 12:01:01 | 2021-05-02 12:31:01 | 98 |
+| 13 | 1003 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
+| 9 | 1001 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
+| 10 | 1002 | 9002 | 2021-02-02 12:01:01 | 2020-02-02 12:43:01 | 81 |
+| 11 | 1001 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:59:01 | 69 |
+| 16 | 1002 | 9002 | 2020-02-02 12:01:01 | | |
+| 17 | 1002 | 9002 | 2020-03-02 12:11:01 | | |
+| 18 | 1001 | 9002 | 2021-05-05 18:01:01 | | |
+| 4 | 1002 | 9003 | 2021-01-20 10:01:01 | 2021-01-20 10:10:01 | 81 |
+| 6 | 1001 | 9003 | 2021-04-02 19:01:01 | 2021-04-02 19:40:01 | 89 |
+| 15 | 1002 | 9003 | 2021-01-01 18:01:01 | 2021-01-01 18:59:02 | 90 |
+| 7 | 1004 | 9004 | 2020-05-02 12:01:01 | 2020-05-02 12:20:01 | 99 |
+| 12 | 1001 | 9004 | 2021-09-02 12:11:01 | | |
+| 14 | 1002 | 9004 | 2020-01-01 12:11:01 | 2020-01-01 12:31:01 | 83 |
+
+请计算 2021 年上半年各类试卷的做完次数相比 2020 年上半年同期的增长率(百分比格式,保留 1 位小数),以及做完次数排名变化,按增长率和 21 年排名降序输出。
+
+由示例数据结果输出如下:
+
+| tag | exam_cnt_20 | exam_cnt_21 | growth_rate | exam_cnt_rank_20 | exam_cnt_rank_21 | rank_delta |
+| --- | ----------- | ----------- | ----------- | ---------------- | ---------------- | ---------- |
+| SQL | 3 | 2 | -33.3% | 1 | 2 | 1 |
+
+解释:2020 年上半年有 3 个 tag 有作答完成的记录,分别是 C++、SQL、PYTHON,它们被做完的次数分别是 3、3、2,做完次数排名为 1、1(并列)、3;
+
+2021 年上半年有 2 个 tag 有作答完成的记录,分别是算法、SQL,它们被做完的次数分别是 3、2,做完次数排名为 1、2;具体如下:
+
+| tag | start_year | exam_cnt | exam_cnt_rank |
+| ------ | ---------- | -------- | ------------- |
+| C++ | 2020 | 3 | 1 |
+| SQL | 2020 | 3 | 1 |
+| PYTHON | 2020 | 2 | 3 |
+| 算法 | 2021 | 3 | 1 |
+| SQL | 2021 | 2 | 2 |
+
+因此能输出同比结果的 tag 只有 SQL,从 2020 到 2021 年,做完次数 3=>2,减少 33.3%(保留 1 位小数);排名 1=>2,后退 1 名。
+
+**思路:**
+
+本题难点在于长整型的数据类型要求不能有负号产生,用 cast 函数转换数据类型为 signed。
+
+以及用到的`增长率计算公式:(exam_cnt_21-exam_cnt_20)/exam_cnt_20`
+
+做完次数排名变化(2021 年和 2020 年比排名升了或者降了多少)
+
+计算公式:`exam_cnt_rank_21 - exam_cnt_rank_20`
+
+在 MySQL 中,`CAST()` 函数用于将一个表达式的数据类型转换为另一个数据类型。它的基本语法如下:
+
+```sql
+CAST(expression AS data_type)
+
+-- 将一个字符串转换成整数
+SELECT CAST('123' AS INT);
+```
+
+示例就不一一举例了,这个函数很简单
+
+**答案**:
+
+```sql
+SELECT
+ tag,
+ exam_cnt_20,
+ exam_cnt_21,
+ concat(
+ round(
+ 100 * (exam_cnt_21 - exam_cnt_20) / exam_cnt_20,
+ 1
+ ),
+ '%'
+ ) AS growth_rate,
+ exam_cnt_rank_20,
+ exam_cnt_rank_21,
+ cast(exam_cnt_rank_21 AS signed) - cast(exam_cnt_rank_20 AS signed) AS rank_delta
+FROM
+ (
+ #2020年、2021年上半年各类试卷的做完次数和做完次数排名
+ SELECT
+ tag,
+ count(
+ IF (
+ date_format(start_time, '%Y%m%d') BETWEEN '20200101'
+ AND '20200630',
+ start_time,
+ NULL
+ )
+ ) AS exam_cnt_20,
+ count(
+ IF (
+ substring(start_time, 1, 10) BETWEEN '2021-01-01'
+ AND '2021-06-30',
+ start_time,
+ NULL
+ )
+ ) AS exam_cnt_21,
+ rank() over (
+ ORDER BY
+ count(
+ IF (
+ date_format(start_time, '%Y%m%d') BETWEEN '20200101'
+ AND '20200630',
+ start_time,
+ NULL
+ )
+ ) DESC
+ ) AS exam_cnt_rank_20,
+ rank() over (
+ ORDER BY
+ count(
+ IF (
+ substring(start_time, 1, 10) BETWEEN '2021-01-01'
+ AND '2021-06-30',
+ start_time,
+ NULL
+ )
+ ) DESC
+ ) AS exam_cnt_rank_21
+ FROM
+ examination_info
+ JOIN exam_record USING (exam_id)
+ WHERE
+ submit_time IS NOT NULL
+ GROUP BY
+ tag
+ ) main
+WHERE
+ exam_cnt_21 * exam_cnt_20 <> 0
+ORDER BY
+ growth_rate DESC,
+ exam_cnt_rank_21 DESC
+```
+
+## 聚合窗口函数
+
+### 对试卷得分做 min-max 归一化
+
+**描述**:
+
+现有试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ------ | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | C++ | hard | 80 | 2020-01-01 10:00:00 |
+| 3 | 9003 | 算法 | hard | 80 | 2020-01-01 10:00:00 |
+| 4 | 9004 | PYTHON | medium | 70 | 2020-01-01 10:00:00 |
+
+试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 6 | 1003 | 9001 | 2020-01-02 12:01:01 | 2020-01-02 12:31:01 | 68 |
+| 9 | 1001 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
+| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 90 |
+| 12 | 1002 | 9002 | 2021-05-05 18:01:01 | (NULL) | (NULL) |
+| 3 | 1004 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:11:01 | 60 |
+| 2 | 1003 | 9002 | 2020-01-01 19:01:01 | 2020-01-01 19:30:01 | 75 |
+| 7 | 1001 | 9002 | 2020-01-02 12:01:01 | 2020-01-02 12:43:01 | 81 |
+| 10 | 1002 | 9002 | 2020-01-01 12:11:01 | 2020-01-01 12:31:01 | 83 |
+| 4 | 1003 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:41:01 | 90 |
+| 5 | 1002 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:32:00 | 90 |
+| 11 | 1002 | 9004 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 8 | 1001 | 9005 | 2020-01-02 12:11:01 | (NULL) | (NULL) |
+
+在物理学及统计学数据计算时,有个概念叫 min-max 标准化,也被称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。
+
+转换函数为:
+
+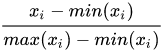
+
+请你将用户作答高难度试卷的得分在每份试卷作答记录内执行 min-max 归一化后缩放到[0,100]区间,并输出用户 ID、试卷 ID、归一化后分数平均值;最后按照试卷 ID 升序、归一化分数降序输出。(注:得分区间默认为[0,100],如果某个试卷作答记录中只有一个得分,那么无需使用公式,归一化并缩放后分数仍为原分数)。
+
+由示例数据结果输出如下:
+
+| uid | exam_id | avg_new_score |
+| ---- | ------- | ------------- |
+| 1001 | 9001 | 98 |
+| 1003 | 9001 | 0 |
+| 1002 | 9002 | 88 |
+| 1003 | 9002 | 75 |
+| 1001 | 9002 | 70 |
+| 1004 | 9002 | 0 |
+
+解释:高难度试卷有 9001、9002、9003;
+
+作答了 9001 的记录有 3 条,分数分别为 68、89、90,按给定公式归一化后分数为:0、95、100,而后两个得分都是用户 1001 作答的,因此用户 1001 对试卷 9001 的新得分为(95+100)/2≈98(只保留整数部分),用户 1003 对于试卷 9001 的新得分为 0。最后结果按照试卷 ID 升序、归一化分数降序输出。
+
+**思路:**
+
+注意点:
+
+1. 将高难度的试卷,按每类试卷的得分,利用 max/min (col) over()窗口函数求得各组内最大最小值,然后进行归一化公式计算,缩放区间为[0,100],即 min_max\*100
+2. 若某类试卷只有一个得分,则无需使用归一化公式,因只有一个分 max_score=min_score,score,公式后结果可能会变成 0。
+3. 最后结果按 uid、exam_id 分组求归一化后均值,score 为 NULL 的要过滤掉。
+
+最后就是仔细看上面公式 (说实话,这题看起来就很绕)
+
+**答案**:
+
+```sql
+SELECT
+ uid,
+ exam_id,
+ round(sum(min_max) / count(score), 0) AS avg_new_score
+FROM
+ (
+ SELECT
+ *,
+ IF (
+ max_score = min_score,
+ score,
+ (score - min_score) / (max_score - min_score) * 100
+ ) AS min_max
+ FROM
+ (
+ SELECT
+ uid,
+ a.exam_id,
+ score,
+ max(score) over (PARTITION BY a.exam_id) AS max_score,
+ min(score) over (PARTITION BY a.exam_id) AS min_score
+ FROM
+ exam_record a
+ LEFT JOIN examination_info b USING (exam_id)
+ WHERE
+ difficulty = 'hard'
+ ) t
+ WHERE
+ score IS NOT NULL
+ ) t1
+GROUP BY
+ uid,
+ exam_id
+ORDER BY
+ exam_id ASC,
+ avg_new_score DESC;
+```
+
+### 每份试卷每月作答数和截止当月的作答总数
+
+**描述:**
+
+现有试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 90 |
+| 2 | 1002 | 9001 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 89 |
+| 3 | 1002 | 9001 | 2020-02-01 12:11:01 | 2020-02-01 12:31:01 | 83 |
+| 4 | 1003 | 9001 | 2020-03-01 19:01:01 | 2020-03-01 19:30:01 | 75 |
+| 5 | 1004 | 9001 | 2020-03-01 12:01:01 | 2020-03-01 12:11:01 | 60 |
+| 6 | 1003 | 9001 | 2020-03-01 12:01:01 | 2020-03-01 12:41:01 | 90 |
+| 7 | 1002 | 9001 | 2020-05-02 19:01:01 | 2020-05-02 19:32:00 | 90 |
+| 8 | 1001 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:59:01 | 69 |
+| 9 | 1004 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
+| 10 | 1003 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:31:01 | 68 |
+| 11 | 1001 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:43:01 | 81 |
+| 12 | 1001 | 9002 | 2020-03-02 12:11:01 | (NULL) | (NULL) |
+
+请输出每份试卷每月作答数和截止当月的作答总数。
+由示例数据结果输出如下:
+
+| exam_id | start_month | month_cnt | cum_exam_cnt |
+| ------- | ----------- | --------- | ------------ |
+| 9001 | 202001 | 2 | 2 |
+| 9001 | 202002 | 1 | 3 |
+| 9001 | 202003 | 3 | 6 |
+| 9001 | 202005 | 1 | 7 |
+| 9002 | 202001 | 1 | 1 |
+| 9002 | 202002 | 3 | 4 |
+| 9002 | 202003 | 1 | 5 |
+
+解释:试卷 9001 在 202001、202002、202003、202005 共 4 个月有被作答记录,每个月被作答数分别为 2、1、3、1,截止当月累积作答总数为 2、3、6、7。
+
+**思路:**
+
+这题就两个关键点:统计截止当月的作答总数、输出每份试卷每月作答数和截止当月的作答总数
+
+这个是关键`**sum(count(*)) over(partition by exam_id order by date_format(start_time,'%Y%m'))**`
+
+**答案**:
+
+```sql
+SELECT exam_id,
+ date_format(start_time, '%Y%m') AS start_month,
+ count(*) AS month_cnt,
+ sum(count(*)) OVER (PARTITION BY exam_id
+ ORDER BY date_format(start_time, '%Y%m')) AS cum_exam_cnt
+FROM exam_record
+GROUP BY exam_id,
+ start_month
+```
+
+### 每月及截止当月的答题情况(较难)
+
+**描述**:现有试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 90 |
+| 2 | 1002 | 9001 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 89 |
+| 3 | 1002 | 9001 | 2020-02-01 12:11:01 | 2020-02-01 12:31:01 | 83 |
+| 4 | 1003 | 9001 | 2020-03-01 19:01:01 | 2020-03-01 19:30:01 | 75 |
+| 5 | 1004 | 9001 | 2020-03-01 12:01:01 | 2020-03-01 12:11:01 | 60 |
+| 6 | 1003 | 9001 | 2020-03-01 12:01:01 | 2020-03-01 12:41:01 | 90 |
+| 7 | 1002 | 9001 | 2020-05-02 19:01:01 | 2020-05-02 19:32:00 | 90 |
+| 8 | 1001 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:59:01 | 69 |
+| 9 | 1004 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
+| 10 | 1003 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:31:01 | 68 |
+| 11 | 1001 | 9002 | 2020-01-02 19:01:01 | 2020-02-02 12:43:01 | 81 |
+| 12 | 1001 | 9002 | 2020-03-02 12:11:01 | (NULL) | (NULL) |
+
+请输出自从有用户作答记录以来,每月的试卷作答记录中月活用户数、新增用户数、截止当月的单月最大新增用户数、截止当月的累积用户数。结果按月份升序输出。
+
+由示例数据结果输出如下:
+
+| start_month | mau | month_add_uv | max_month_add_uv | cum_sum_uv |
+| ----------- | --- | ------------ | ---------------- | ---------- |
+| 202001 | 2 | 2 | 2 | 2 |
+| 202002 | 4 | 2 | 2 | 4 |
+| 202003 | 3 | 0 | 2 | 4 |
+| 202005 | 1 | 0 | 2 | 4 |
+
+| month | 1001 | 1002 | 1003 | 1004 |
+| ------ | ---- | ---- | ---- | ---- |
+| 202001 | 1 | 1 | | |
+| 202002 | 1 | 1 | 1 | 1 |
+| 202003 | 1 | | 1 | 1 |
+| 202005 | | 1 | | |
+
+由上述矩阵可以看出,2020 年 1 月有 2 个用户活跃(mau=2),当月新增用户数为 2;
+
+2020 年 2 月有 4 个用户活跃,当月新增用户数为 2,最大单月新增用户数为 2,当前累积用户数为 4。
+
+**思路:**
+
+难点:
+
+1.如何求每月新增用户
+
+2.截至当月的答题情况
+
+大致流程:
+
+(1)统计每个人的首次登陆月份 `min()`
+
+(2)统计每月的月活和新增用户数:先得到每个人的首次登陆月份,再对首次登陆月份分组求和是该月份的新增人数
+
+(3)统计截止当月的单月最大新增用户数、截止当月的累积用户数 ,最终按照按月份升序输出
+
+**答案**:
+
+```sql
+-- 截止当月的单月最大新增用户数、截止当月的累积用户数,按月份升序输出
+SELECT
+ start_month,
+ mau,
+ month_add_uv,
+ max( month_add_uv ) over ( ORDER BY start_month ),
+ sum( month_add_uv ) over ( ORDER BY start_month )
+FROM
+ (
+ -- 统计每月的月活和新增用户数
+ SELECT
+ date_format( a.start_time, '%Y%m' ) AS start_month,
+ count( DISTINCT a.uid ) AS mau,
+ count( DISTINCT b.uid ) AS month_add_uv
+ FROM
+ exam_record a
+ LEFT JOIN (
+ -- 统计每个人的首次登陆月份
+ SELECT uid, min( date_format( start_time, '%Y%m' )) AS first_month FROM exam_record GROUP BY uid ) b ON date_format( a.start_time, '%Y%m' ) = b.first_month
+ GROUP BY
+ start_month
+ ) main
+ORDER BY
+ start_month
+```
+
+
diff --git a/docs/database/sql/sql-questions-05.md b/docs/database/sql/sql-questions-05.md
new file mode 100644
index 00000000000..39171bfe08f
--- /dev/null
+++ b/docs/database/sql/sql-questions-05.md
@@ -0,0 +1,1045 @@
+---
+title: SQL常见面试题总结(5)
+description: SQL常见面试题总结第五篇,详解NULL空值处理技巧,包括IFNULL、COALESCE函数,以及使用CASE WHEN进行条件统计和完成率计算。
+category: 数据库
+tag:
+ - 数据库基础
+ - SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL面试题,NULL空值处理,IFNULL,COALESCE,CASE WHEN,条件统计,完成率计算
+---
+
+> 题目来源于:[牛客题霸 - SQL 进阶挑战](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=240)
+
+较难或者困难的题目可以根据自身实际情况和面试需要来决定是否要跳过。
+
+## 空值处理
+
+### 统计有未完成状态的试卷的未完成数和未完成率
+
+**描述**:
+
+现有试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分),数据如下:
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
+| 3 | 1001 | 9001 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+
+请统计有未完成状态的试卷的未完成数 incomplete_cnt 和未完成率 incomplete_rate。由示例数据结果输出如下:
+
+| exam_id | incomplete_cnt | complete_rate |
+| ------- | -------------- | ------------- |
+| 9001 | 1 | 0.333 |
+
+解释:试卷 9001 有 3 次被作答的记录,其中两次完成,1 次未完成,因此未完成数为 1,未完成率为 0.333(保留 3 位小数)
+
+**思路**:
+
+这题只需要注意一个是有条件限制,一个是没条件限制的;要么分别查询条件,然后合并;要么直接在 select 里面进行条件判断。
+
+**答案**:
+
+写法 1:
+
+```sql
+SELECT
+ exam_id,
+ (COUNT(*) - COUNT(submit_time)) AS incomplete_cnt,
+ ROUND((COUNT(*) - COUNT(submit_time)) / COUNT(*), 3) AS incomplete_rate
+FROM
+ exam_record
+GROUP BY
+ exam_id
+HAVING
+ (COUNT(*) - COUNT(submit_time)) > 0;
+```
+
+利用 `COUNT(*)`统计分组内的总记录数,`COUNT(submit_time)` 只统计 `submit_time` 字段不为 NULL 的记录数(即已完成数)。两者相减,就是未完成数。
+
+写法 2:
+
+```sql
+SELECT
+ exam_id,
+ COUNT(CASE WHEN submit_time IS NULL THEN 1 END) AS incomplete_cnt,
+ ROUND(COUNT(CASE WHEN submit_time IS NULL THEN 1 END) / COUNT(*), 3) AS incomplete_rate
+FROM
+ exam_record
+GROUP BY
+ exam_id
+HAVING
+ COUNT(CASE WHEN submit_time IS NULL THEN 1 END) > 0;
+```
+
+使用 `CASE` 表达式,当条件满足时返回一个非 `NULL` 值(例如 1),否则返回 `NULL`。然后用 `COUNT` 函数来统计非 `NULL` 值的数量。
+
+写法 3:
+
+```sql
+SELECT
+ exam_id,
+ SUM(submit_time IS NULL) AS incomplete_cnt,
+ ROUND(SUM(submit_time IS NULL) / COUNT(*), 3) AS incomplete_rate
+FROM
+ exam_record
+GROUP BY
+ exam_id
+HAVING
+ incomplete_cnt > 0;
+```
+
+利用 `SUM` 函数对一个表达式求和。当 `submit_time` 为 `NULL` 时,表达式 `(submit_time IS NULL)` 的值为 1 (TRUE),否则为 0 (FALSE)。将这些 1 和 0 加起来,就得到了未完成的数量。
+
+### 0 级用户高难度试卷的平均用时和平均得分
+
+**描述**:
+
+现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间),数据如下:
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | 牛客 1 号 | 10 | 0 | 算法 | 2020-01-01 10:00:00 |
+| 2 | 1002 | 牛客 2 号 | 2100 | 6 | 算法 | 2020-01-01 10:00:00 |
+
+试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间),数据如下:
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | SQL | easy | 60 | 2020-01-01 10:00:00 |
+| 3 | 9004 | 算法 | medium | 80 | 2020-01-01 10:00:00 |
+
+试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分),数据如下:
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
+| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 4 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
+| 5 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 7 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+
+请输出每个 0 级用户所有的高难度试卷考试平均用时和平均得分,未完成的默认试卷最大考试时长和 0 分处理。由示例数据结果输出如下:
+
+| uid | avg_score | avg_time_took |
+| ---- | --------- | ------------- |
+| 1001 | 33 | 36.7 |
+
+解释:0 级用户有 1001,高难度试卷有 9001,1001 作答 9001 的记录有 3 条,分别用时 20 分钟、未完成(试卷时长 60 分钟)、30 分钟(未满 31 分钟),分别得分为 80 分、未完成(0 分处理)、20 分。因此他的平均用时为 110/3=36.7(保留一位小数),平均得分为 33 分(取整)
+
+**思路**:这题用`IF`是判断的最方便的,因为涉及到 NULL 值的判断。当然 `case when`也可以,大同小异。这题的难点就在于空值的处理,其他的这些查询条件什么的,我相信难不倒大家。
+
+**答案**:
+
+```sql
+SELECT UID,
+ round(avg(new_socre)) AS avg_score,
+ round(avg(time_diff), 1) AS avg_time_took
+FROM
+ (SELECT er.uid,
+ IF (er.submit_time IS NOT NULL, TIMESTAMPDIFF(MINUTE, start_time, submit_time), ef.duration) AS time_diff,
+ IF (er.submit_time IS NOT NULL,er.score,0) AS new_socre
+ FROM exam_record er
+ LEFT JOIN user_info uf ON er.uid = uf.uid
+ LEFT JOIN examination_info ef ON er.exam_id = ef.exam_id
+ WHERE uf.LEVEL = 0 AND ef.difficulty = 'hard' ) t
+GROUP BY UID
+ORDER BY UID
+```
+
+## 高级条件语句
+
+### 筛选限定昵称成就值活跃日期的用户(较难)
+
+**描述**:
+
+现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ----------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | 牛客 1 号 | 1000 | 2 | 算法 | 2020-01-01 10:00:00 |
+| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
+| 3 | 1003 | 进击的 3 号 | 2200 | 5 | 算法 | 2020-01-01 10:00:00 |
+| 4 | 1004 | 牛客 4 号 | 2500 | 6 | 算法 | 2020-01-01 10:00:00 |
+| 5 | 1005 | 牛客 5 号 | 3000 | 7 | C++ | 2020-01-01 10:00:00 |
+
+试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
+| 4 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
+| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 5 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 11 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 81 |
+| 12 | 1002 | 9002 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
+| 13 | 1002 | 9002 | 2020-02-02 12:11:01 | 2020-02-02 12:31:01 | 83 |
+| 7 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+| 16 | 1002 | 9001 | 2021-09-06 12:01:01 | 2021-09-06 12:21:01 | 80 |
+| 17 | 1002 | 9001 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 18 | 1002 | 9001 | 2021-09-07 12:01:01 | (NULL) | (NULL) |
+| 8 | 1003 | 9003 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
+| 9 | 1003 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 89 |
+| 10 | 1004 | 9002 | 2021-08-06 12:01:01 | (NULL) | (NULL) |
+| 14 | 1005 | 9001 | 2021-02-01 11:01:01 | 2021-02-01 11:31:01 | 84 |
+| 15 | 1006 | 9001 | 2021-02-01 11:01:01 | 2021-02-01 11:31:01 | 84 |
+
+题目练习记录表 `practice_record`(`uid` 用户 ID, `question_id` 题目 ID, `submit_time` 提交时间, `score` 得分):
+
+| id | uid | question_id | submit_time | score |
+| --- | ---- | ----------- | ------------------- | ----- |
+| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
+| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
+| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
+| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
+| 5 | 1003 | 8002 | 2021-09-01 19:38:01 | 80 |
+
+请找到昵称以『牛客』开头『号』结尾、成就值在 1200~2500 之间,且最近一次活跃(答题或作答试卷)在 2021 年 9 月的用户信息。
+
+由示例数据结果输出如下:
+
+| uid | nick_name | achievement |
+| ---- | --------- | ----------- |
+| 1002 | 牛客 2 号 | 1200 |
+
+**解释**:昵称以『牛客』开头『号』结尾且成就值在 1200~2500 之间的有 1002、1004;
+
+1002 最近一次试卷区活跃为 2021 年 9 月,最近一次题目区活跃为 2021 年 9 月;1004 最近一次试卷区活跃为 2021 年 8 月,题目区未活跃。
+
+因此最终满足条件的只有 1002。
+
+**思路**:
+
+先根据条件列出主要查询语句
+
+昵称以『牛客』开头『号』结尾: `nick_name LIKE "牛客%号"`
+
+成就值在 1200~2500 之间:`achievement BETWEEN 1200 AND 2500`
+
+第三个条件因为限定了为 9 月,所以直接写就行:`( date_format( record.submit_time, '%Y%m' )= 202109 OR date_format( pr.submit_time, '%Y%m' )= 202109 )`
+
+**答案**:
+
+```sql
+SELECT DISTINCT u_info.uid,
+ u_info.nick_name,
+ u_info.achievement
+FROM user_info u_info
+LEFT JOIN exam_record record ON record.uid = u_info.uid
+LEFT JOIN practice_record pr ON u_info.uid = pr.uid
+WHERE u_info.nick_name LIKE "牛客%号"
+ AND u_info.achievement BETWEEN 1200
+ AND 2500
+ AND (date_format(record.submit_time, '%Y%m')= 202109
+ OR date_format(pr.submit_time, '%Y%m')= 202109)
+GROUP BY u_info.uid
+```
+
+### 筛选昵称规则和试卷规则的作答记录(较难)
+
+**描述**:
+
+现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | 牛客 1 号 | 1900 | 2 | 算法 | 2020-01-01 10:00:00 |
+| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
+| 3 | 1003 | 牛客 3 号 ♂ | 2200 | 5 | 算法 | 2020-01-01 10:00:00 |
+| 4 | 1004 | 牛客 4 号 | 2500 | 6 | 算法 | 2020-01-01 10:00:00 |
+| 5 | 1005 | 牛客 555 号 | 2000 | 7 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | --- | ---------- | -------- | ------------------- |
+| 1 | 9001 | C++ | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | c# | hard | 80 | 2020-01-01 10:00:00 |
+| 3 | 9003 | SQL | medium | 70 | 2020-01-01 10:00:00 |
+
+试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
+| 4 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
+| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 5 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 11 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 81 |
+| 16 | 1002 | 9001 | 2021-09-06 12:01:01 | 2021-09-06 12:21:01 | 80 |
+| 17 | 1002 | 9001 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 18 | 1002 | 9001 | 2021-09-07 12:01:01 | (NULL) | (NULL) |
+| 7 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+| 12 | 1002 | 9002 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
+| 13 | 1002 | 9002 | 2020-02-02 12:11:01 | 2020-02-02 12:31:01 | 83 |
+| 9 | 1003 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 89 |
+| 8 | 1003 | 9003 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
+| 10 | 1004 | 9002 | 2021-08-06 12:01:01 | (NULL) | (NULL) |
+| 14 | 1005 | 9001 | 2021-02-01 11:01:01 | 2021-02-01 11:31:01 | 84 |
+| 15 | 1006 | 9001 | 2021-02-01 11:01:01 | 2021-09-01 11:31:01 | 84 |
+
+找到昵称以"牛客"+纯数字+"号"或者纯数字组成的用户对于字母 c 开头的试卷类别(如 C,C++,c#等)的已完成的试卷 ID 和平均得分,按用户 ID、平均分升序排序。由示例数据结果输出如下:
+
+| uid | exam_id | avg_score |
+| ---- | ------- | --------- |
+| 1002 | 9001 | 81 |
+| 1002 | 9002 | 85 |
+| 1005 | 9001 | 84 |
+| 1006 | 9001 | 84 |
+
+解释:昵称满足条件的用户有 1002、1004、1005、1006;
+
+c 开头的试卷有 9001、9002;
+
+满足上述条件的作答记录中,1002 完成 9001 的得分有 81、80,平均分为 81(80.5 取整四舍五入得 81);
+
+1002 完成 9002 的得分有 90、82、83,平均分为 85;
+
+**思路**:
+
+还是老样子,既然给出了条件,就先把各个条件先写出来
+
+找到昵称以"牛客"+纯数字+"号"或者纯数字组成的用户: 我最开始是这么写的:`nick_name LIKE '牛客%号' OR nick_name REGEXP '^[0-9]+$'`,如果表中有个 “牛客 H 号” ,那也能通过。
+
+所以这里还得用正则: `nick_name LIKE '^牛客[0-9]+号'`
+
+对于字母 c 开头的试卷类别: `e_info.tag LIKE 'c%'` 或者 `tag regexp '^c|^C'` 第一个也能匹配到大写 C
+
+**答案**:
+
+```sql
+SELECT UID,
+ exam_id,
+ ROUND(AVG(score), 0) avg_score
+FROM exam_record
+WHERE UID IN
+ (SELECT UID
+ FROM user_info
+ WHERE nick_name RLIKE "^牛客[0-9]+号 $"
+ OR nick_name RLIKE "^[0-9]+$")
+ AND exam_id IN
+ (SELECT exam_id
+ FROM examination_info
+ WHERE tag RLIKE "^[cC]")
+ AND score IS NOT NULL
+GROUP BY UID,exam_id
+ORDER BY UID,avg_score;
+```
+
+### 根据指定记录是否存在输出不同情况(困难)
+
+**描述**:
+
+现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ----------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | 牛客 1 号 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
+| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
+| 3 | 1003 | 进击的 3 号 | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
+| 4 | 1004 | 牛客 4 号 | 25 | 0 | 算法 | 2020-01-01 10:00:00 |
+| 5 | 1005 | 牛客 555 号 | 2000 | 7 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
+| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 4 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 5 | 1001 | 9003 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 6 | 1001 | 9004 | 2021-09-03 12:01:01 | (NULL) | (NULL) |
+| 7 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 99 |
+| 8 | 1002 | 9003 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
+| 9 | 1002 | 9003 | 2020-02-02 12:11:01 | (NULL) | (NULL) |
+| 10 | 1002 | 9002 | 2021-05-05 18:01:01 | (NULL) | (NULL) |
+| 11 | 1002 | 9001 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 12 | 1003 | 9003 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
+| 13 | 1003 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 89 |
+
+请你筛选表中的数据,当有任意一个 0 级用户未完成试卷数大于 2 时,输出每个 0 级用户的试卷未完成数和未完成率(保留 3 位小数);若不存在这样的用户,则输出所有有作答记录的用户的这两个指标。结果按未完成率升序排序。
+
+由示例数据结果输出如下:
+
+| uid | incomplete_cnt | incomplete_rate |
+| ---- | -------------- | --------------- |
+| 1004 | 0 | 0.000 |
+| 1003 | 1 | 0.500 |
+| 1001 | 4 | 0.667 |
+
+**解释**:0 级用户有 1001、1003、1004;他们作答试卷数和未完成数分别为:6:4、2:1、0:0;
+
+存在 1001 这个 0 级用户未完成试卷数大于 2,因此输出这三个用户的未完成数和未完成率(1004 未作答过试卷,未完成率默认填 0,保留 3 位小数后是 0.000);
+
+结果按照未完成率升序排序。
+
+附:如果 1001 不满足『未完成试卷数大于 2』,则需要输出 1001、1002、1003 的这两个指标,因为试卷作答记录表里只有这三个用户的作答记录。
+
+**思路**:
+
+先把可能满足条件**“0 级用户未完成试卷数大于 2”**的 SQL 写出来
+
+```sql
+SELECT ui.uid UID
+FROM user_info ui
+LEFT JOIN exam_record er ON ui.uid = er.uid
+WHERE ui.uid IN
+ (SELECT ui.uid
+ FROM user_info ui
+ LEFT JOIN exam_record er ON ui.uid = er.uid
+ WHERE er.submit_time IS NULL
+ AND ui.LEVEL = 0 )
+GROUP BY ui.uid
+HAVING sum(IF(er.submit_time IS NULL, 1, 0)) > 2
+```
+
+然后再分别写出两种情况的 SQL 查询语句:
+
+情况 1. 查询存在条件要求的 0 级用户的试卷未完成率
+
+```sql
+SELECT
+ tmp1.uid uid,
+ sum(
+ IF
+ ( er.submit_time IS NULL AND er.start_time IS NOT NULL, 1, 0 )) incomplete_cnt,
+ round(
+ sum(
+ IF
+ ( er.submit_time IS NULL AND er.start_time IS NOT NULL, 1, 0 ))/ count( tmp1.uid ),
+ 3
+ ) incomplete_rate
+FROM
+ (
+ SELECT DISTINCT
+ ui.uid
+ FROM
+ user_info ui
+ LEFT JOIN exam_record er ON ui.uid = er.uid
+ WHERE
+ er.submit_time IS NULL
+ AND ui.LEVEL = 0
+ ) tmp1
+ LEFT JOIN exam_record er ON tmp1.uid = er.uid
+GROUP BY
+ tmp1.uid
+ORDER BY
+ incomplete_rate
+```
+
+情况 2. 查询不存在条件要求时所有有作答记录的 yong 用户的试卷未完成率
+
+```sql
+SELECT
+ ui.uid uid,
+ sum( CASE WHEN er.submit_time IS NULL AND er.start_time IS NOT NULL THEN 1 ELSE 0 END ) incomplete_cnt,
+ round(
+ sum(
+ IF
+ ( er.submit_time IS NULL AND er.start_time IS NOT NULL, 1, 0 ))/ count( ui.uid ),
+ 3
+ ) incomplete_rate
+FROM
+ user_info ui
+ JOIN exam_record er ON ui.uid = er.uid
+GROUP BY
+ ui.uid
+ORDER BY
+ incomplete_rate
+```
+
+拼在一起,就是答案
+
+```sql
+WITH host_user AS
+ (SELECT ui.uid UID
+ FROM user_info ui
+ LEFT JOIN exam_record er ON ui.uid = er.uid
+ WHERE ui.uid IN
+ (SELECT ui.uid
+ FROM user_info ui
+ LEFT JOIN exam_record er ON ui.uid = er.uid
+ WHERE er.submit_time IS NULL
+ AND ui.LEVEL = 0 )
+ GROUP BY ui.uid
+ HAVING sum(IF (er.submit_time IS NULL, 1, 0))> 2),
+ tt1 AS
+ (SELECT tmp1.uid UID,
+ sum(IF (er.submit_time IS NULL
+ AND er.start_time IS NOT NULL, 1, 0)) incomplete_cnt,
+ round(sum(IF (er.submit_time IS NULL
+ AND er.start_time IS NOT NULL, 1, 0))/ count(tmp1.uid), 3) incomplete_rate
+ FROM
+ (SELECT DISTINCT ui.uid
+ FROM user_info ui
+ LEFT JOIN exam_record er ON ui.uid = er.uid
+ WHERE er.submit_time IS NULL
+ AND ui.LEVEL = 0 ) tmp1
+ LEFT JOIN exam_record er ON tmp1.uid = er.uid
+ GROUP BY tmp1.uid
+ ORDER BY incomplete_rate),
+ tt2 AS
+ (SELECT ui.uid UID,
+ sum(CASE
+ WHEN er.submit_time IS NULL
+ AND er.start_time IS NOT NULL THEN 1
+ ELSE 0
+ END) incomplete_cnt,
+ round(sum(IF (er.submit_time IS NULL
+ AND er.start_time IS NOT NULL, 1, 0))/ count(ui.uid), 3) incomplete_rate
+ FROM user_info ui
+ JOIN exam_record er ON ui.uid = er.uid
+ GROUP BY ui.uid
+ ORDER BY incomplete_rate)
+ (SELECT tt1.*
+ FROM tt1
+ LEFT JOIN
+ (SELECT UID
+ FROM host_user) t1 ON 1 = 1
+ WHERE t1.uid IS NOT NULL )
+UNION ALL
+ (SELECT tt2.*
+ FROM tt2
+ LEFT JOIN
+ (SELECT UID
+ FROM host_user) t2 ON 1 = 1
+ WHERE t2.uid IS NULL)
+```
+
+V2 版本(根据上面做出的改进,答案缩短了,逻辑更强):
+
+```sql
+SELECT
+ ui.uid,
+ SUM(
+ IF
+ ( start_time IS NOT NULL AND score IS NULL, 1, 0 )) AS incomplete_cnt,#3.试卷未完成数
+ ROUND( AVG( IF ( start_time IS NOT NULL AND score IS NULL, 1, 0 )), 3 ) AS incomplete_rate #4.未完成率
+
+FROM
+ user_info ui
+ LEFT JOIN exam_record USING ( uid )
+WHERE
+CASE
+
+ WHEN (#1.当有任意一个0级用户未完成试卷数大于2时
+ SELECT
+ MAX( lv0_incom_cnt )
+ FROM
+ (
+ SELECT
+ SUM(
+ IF
+ ( score IS NULL, 1, 0 )) AS lv0_incom_cnt
+ FROM
+ user_info
+ JOIN exam_record USING ( uid )
+ WHERE
+ LEVEL = 0
+ GROUP BY
+ uid
+ ) table1
+ )> 2 THEN
+ uid IN ( #1.1找出每个0级用户
+ SELECT uid FROM user_info WHERE LEVEL = 0 ) ELSE uid IN ( #2.若不存在这样的用户,找出有作答记录的用户
+ SELECT DISTINCT uid FROM exam_record )
+ END
+ GROUP BY
+ ui.uid
+ ORDER BY
+ incomplete_rate #5.结果按未完成率升序排序
+```
+
+### 各用户等级的不同得分表现占比(较难)
+
+**描述**:
+
+现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | 牛客 1 号 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
+| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
+| 3 | 1003 | 牛客 3 号 ♂ | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
+| 4 | 1004 | 牛客 4 号 | 25 | 0 | 算法 | 2020-01-01 10:00:00 |
+| 5 | 1005 | 牛客 555 号 | 2000 | 7 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
+| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 75 |
+| 4 | 1001 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:11:01 | 60 |
+| 5 | 1001 | 9003 | 2021-09-02 12:01:01 | 2021-09-02 12:41:01 | 90 |
+| 6 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
+| 7 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 8 | 1001 | 9004 | 2021-09-03 12:01:01 | (NULL) | (NULL) |
+| 9 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 99 |
+| 10 | 1002 | 9003 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
+| 11 | 1002 | 9003 | 2020-02-02 12:11:01 | 2020-02-02 12:41:01 | 76 |
+
+为了得到用户试卷作答的定性表现,我们将试卷得分按分界点[90,75,60]分为优良中差四个得分等级(分界点划分到左区间),请统计不同用户等级的人在完成过的试卷中各得分等级占比(结果保留 3 位小数),未完成过试卷的用户无需输出,结果按用户等级降序、占比降序排序。
+
+由示例数据结果输出如下:
+
+| level | score_grade | ratio |
+| ----- | ----------- | ----- |
+| 3 | 良 | 0.667 |
+| 3 | 优 | 0.333 |
+| 0 | 良 | 0.500 |
+| 0 | 中 | 0.167 |
+| 0 | 优 | 0.167 |
+| 0 | 差 | 0.167 |
+
+解释:完成过试卷的用户有 1001、1002;完成了的试卷对应的用户等级和分数等级如下:
+
+| uid | exam_id | score | level | score_grade |
+| ---- | ------- | ----- | ----- | ----------- |
+| 1001 | 9001 | 80 | 0 | 良 |
+| 1001 | 9002 | 75 | 0 | 良 |
+| 1001 | 9002 | 60 | 0 | 中 |
+| 1001 | 9003 | 90 | 0 | 优 |
+| 1001 | 9001 | 20 | 0 | 差 |
+| 1001 | 9002 | 89 | 0 | 良 |
+| 1002 | 9001 | 99 | 3 | 优 |
+| 1002 | 9003 | 82 | 3 | 良 |
+| 1002 | 9003 | 76 | 3 | 良 |
+
+因此 0 级用户(只有 1001)的各分数等级比例为:优 1/6,良 1/6,中 1/6,差 3/6;3 级用户(只有 1002)各分数等级比例为:优 1/3,良 2/3。结果保留 3 位小数。
+
+**思路**:
+
+先把 **“将试卷得分按分界点[90,75,60]分为优良中差四个得分等级”**这个条件写出来,这里可以用到`case when`
+
+```sql
+CASE
+ WHEN a.score >= 90 THEN
+ '优'
+ WHEN a.score < 90 AND a.score >= 75 THEN
+ '良'
+ WHEN a.score < 75 AND a.score >= 60 THEN
+ '中' ELSE '差'
+END
+```
+
+这题的关键点就在于这,其他剩下的就是条件拼接了
+
+**答案**:
+
+```sql
+SELECT a.LEVEL,
+ a.score_grade,
+ ROUND(a.cur_count / b.total_num, 3) AS ratio
+FROM
+ (SELECT b.LEVEL AS LEVEL,
+ (CASE
+ WHEN a.score >= 90 THEN '优'
+ WHEN a.score < 90
+ AND a.score >= 75 THEN '良'
+ WHEN a.score < 75
+ AND a.score >= 60 THEN '中'
+ ELSE '差'
+ END) AS score_grade,
+ count(1) AS cur_count
+ FROM exam_record a
+ LEFT JOIN user_info b ON a.uid = b.uid
+ WHERE a.submit_time IS NOT NULL
+ GROUP BY b.LEVEL,
+ score_grade) a
+LEFT JOIN
+ (SELECT b.LEVEL AS LEVEL,
+ count(b.LEVEL) AS total_num
+ FROM exam_record a
+ LEFT JOIN user_info b ON a.uid = b.uid
+ WHERE a.submit_time IS NOT NULL
+ GROUP BY b.LEVEL) b ON a.LEVEL = b.LEVEL
+ORDER BY a.LEVEL DESC,
+ ratio DESC
+```
+
+## 限量查询
+
+### 注册时间最早的三个人
+
+**描述**:
+
+现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | 牛客 1 号 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
+| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-02-01 10:00:00 |
+| 3 | 1003 | 牛客 3 号 ♂ | 22 | 0 | 算法 | 2020-01-02 10:00:00 |
+| 4 | 1004 | 牛客 4 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
+| 5 | 1005 | 牛客 555 号 | 4000 | 7 | C++ | 2020-01-11 10:00:00 |
+| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-11-01 10:00:00 |
+
+请从中找到注册时间最早的 3 个人。由示例数据结果输出如下:
+
+| uid | nick_name | register_time |
+| ---- | ------------ | ------------------- |
+| 1001 | 牛客 1 | 2020-01-01 10:00:00 |
+| 1003 | 牛客 3 号 ♂ | 2020-01-02 10:00:00 |
+| 1004 | 牛客 4 号 | 2020-01-02 11:00:00 |
+
+解释:按注册时间排序后选取前三名,输出其用户 ID、昵称、注册时间。
+
+**答案**:
+
+```sql
+SELECT uid, nick_name, register_time
+ FROM user_info
+ ORDER BY register_time
+ LIMIT 3
+```
+
+### 注册当天就完成了试卷的名单第三页(较难)
+
+**描述**:现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | 牛客 1 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
+| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
+| 3 | 1003 | 牛客 3 号 ♂ | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
+| 4 | 1004 | 牛客 4 号 | 25 | 0 | 算法 | 2020-01-01 10:00:00 |
+| 5 | 1005 | 牛客 555 号 | 4000 | 7 | 算法 | 2020-01-11 10:00:00 |
+| 6 | 1006 | 牛客 6 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
+| 7 | 1007 | 牛客 7 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
+| 8 | 1008 | 牛客 8 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
+| 9 | 1009 | 牛客 9 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
+| 10 | 1010 | 牛客 10 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
+| 11 | 1011 | 666666 | 3000 | 6 | C++ | 2020-01-02 10:00:00 |
+
+试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | 算法 | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | 算法 | hard | 80 | 2020-01-01 10:00:00 |
+| 3 | 9003 | SQL | medium | 70 | 2020-01-01 10:00:00 |
+
+试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ----- |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 2 | 1002 | 9003 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 81 |
+| 3 | 1002 | 9002 | 2020-01-01 12:11:01 | 2020-01-01 12:31:01 | 83 |
+| 4 | 1003 | 9002 | 2020-01-01 19:01:01 | 2020-01-01 19:30:01 | 75 |
+| 5 | 1004 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:11:01 | 60 |
+| 6 | 1005 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:41:01 | 90 |
+| 7 | 1006 | 9001 | 2020-01-02 19:01:01 | 2020-01-02 19:32:00 | 20 |
+| 8 | 1007 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:40:01 | 89 |
+| 9 | 1008 | 9003 | 2020-01-02 12:01:01 | 2020-01-02 12:20:01 | 99 |
+| 10 | 1008 | 9001 | 2020-01-02 12:01:01 | 2020-01-02 12:31:01 | 98 |
+| 11 | 1009 | 9002 | 2020-01-02 12:01:01 | 2020-01-02 12:31:01 | 82 |
+| 12 | 1010 | 9002 | 2020-01-02 12:11:01 | 2020-01-02 12:41:01 | 76 |
+| 13 | 1011 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
+
+
+
+找到求职方向为算法工程师,且注册当天就完成了算法类试卷的人,按参加过的所有考试最高得分排名。排名榜很长,我们将采用分页展示,每页 3 条,现在需要你取出第 3 页(页码从 1 开始)的人的信息。
+
+由示例数据结果输出如下:
+
+| uid | level | register_time | max_score |
+| ---- | ----- | ------------------- | --------- |
+| 1010 | 0 | 2020-01-02 11:00:00 | 76 |
+| 1003 | 0 | 2020-01-01 10:00:00 | 75 |
+| 1004 | 0 | 2020-01-01 11:00:00 | 60 |
+
+解释:除了 1011 其他用户的求职方向都为算法工程师;算法类试卷有 9001 和 9002,11 个用户注册当天都完成了算法类试卷;计算他们的所有考试最大分时,只有 1002 和 1008 完成了两次考试,其他人只完成了一场考试,1002 两场考试最高分为 81,1008 最高分为 99。
+
+按最高分排名如下:
+
+| uid | level | register_time | max_score |
+| ---- | ----- | ------------------- | --------- |
+| 1008 | 0 | 2020-01-02 11:00:00 | 99 |
+| 1005 | 7 | 2020-01-01 10:00:00 | 90 |
+| 1007 | 0 | 2020-01-02 11:00:00 | 89 |
+| 1002 | 3 | 2020-01-01 10:00:00 | 83 |
+| 1009 | 0 | 2020-01-02 11:00:00 | 82 |
+| 1001 | 0 | 2020-01-01 10:00:00 | 80 |
+| 1010 | 0 | 2020-01-02 11:00:00 | 76 |
+| 1003 | 0 | 2020-01-01 10:00:00 | 75 |
+| 1004 | 0 | 2020-01-01 11:00:00 | 60 |
+| 1006 | 0 | 2020-01-02 11:00:00 | 20 |
+
+每页 3 条,第三页也就是第 7~9 条,返回 1010、1003、1004 的行记录即可。
+
+**思路**:
+
+1. 每页三条,即需要取出第三页的人的信息,要用到`limit`
+
+2. 统计求职方向为算法工程师且注册当天就完成了算法类试卷的人的**信息和每次记录的得分**,先求满足条件的用户,后用 left join 做连接查找信息和每次记录的得分
+
+**答案**:
+
+```sql
+SELECT t1.uid,
+ LEVEL,
+ register_time,
+ max(score) AS max_score
+FROM exam_record t
+JOIN examination_info USING (exam_id)
+JOIN user_info t1 ON t.uid = t1.uid
+AND date(t.submit_time) = date(t1.register_time)
+WHERE job = '算法'
+ AND tag = '算法'
+GROUP BY t1.uid,
+ LEVEL,
+ register_time
+ORDER BY max_score DESC
+LIMIT 6,3
+```
+
+## 文本转换函数
+
+### 修复串列了的记录
+
+**描述**:现有试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | -------------- | ---------- | -------- | ------------------- |
+| 1 | 9001 | 算法 | hard | 60 | 2021-01-01 10:00:00 |
+| 2 | 9002 | 算法 | hard | 80 | 2021-01-01 10:00:00 |
+| 3 | 9003 | SQL | medium | 70 | 2021-01-01 10:00:00 |
+| 4 | 9004 | 算法,medium,80 | | 0 | 2021-01-01 10:00:00 |
+
+录题同学有一次手误将部分记录的试题类别 tag、难度、时长同时录入到了 tag 字段,请帮忙找出这些录错了的记录,并拆分后按正确的列类型输出。
+
+由示例数据结果输出如下:
+
+| exam_id | tag | difficulty | duration |
+| ------- | ---- | ---------- | -------- |
+| 9004 | 算法 | medium | 80 |
+
+**思路**:
+
+先来学习下本题要用到的函数
+
+`SUBSTRING_INDEX` 函数用于提取字符串中指定分隔符的部分。它接受三个参数:原始字符串、分隔符和指定要返回的部分的数量。
+
+以下是 `SUBSTRING_INDEX` 函数的语法:
+
+```sql
+SUBSTRING_INDEX(str, delimiter, count)
+```
+
+- `str`:要进行分割的原始字符串。
+- `delimiter`:用作分割的字符串或字符。
+- `count`:指定要返回的部分的数量。
+ - 如果 `count` 大于 0,则返回从左边开始的前 `count` 个部分(以分隔符为界)。
+ - 如果 `count` 小于 0,则返回从右边开始的前 `count` 个部分(以分隔符为界),即从右侧向左计数。
+
+下面是一些示例,演示了 `SUBSTRING_INDEX` 函数的使用:
+
+1. 提取字符串中的第一个部分:
+
+ ```sql
+ SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', 1);
+ -- 输出结果:'apple'
+ ```
+
+2. 提取字符串中的最后一个部分:
+
+ ```sql
+ SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', -1);
+ -- 输出结果:'cherry'
+ ```
+
+3. 提取字符串中的前两个部分:
+
+ ```sql
+ SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', 2);
+ -- 输出结果:'apple,banana'
+ ```
+
+4. 提取字符串中的最后两个部分:
+
+ ```sql
+ SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', -2);
+ -- 输出结果:'banana,cherry'
+ ```
+
+**答案**:
+
+```sql
+SELECT
+ exam_id,
+ substring_index( tag, ',', 1 ) tag,
+ substring_index( substring_index( tag, ',', 2 ), ',',- 1 ) difficulty,
+ substring_index( tag, ',',- 1 ) duration
+FROM
+ examination_info
+WHERE
+ difficulty = ''
+```
+
+### 对过长的昵称截取处理
+
+**描述**:现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ---------------------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | 牛客 1 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
+| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
+| 3 | 1003 | 牛客 3 号 ♂ | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
+| 4 | 1004 | 牛客 4 号 | 25 | 0 | 算法 | 2020-01-01 11:00:00 |
+| 5 | 1005 | 牛客 5678901234 号 | 4000 | 7 | 算法 | 2020-01-11 10:00:00 |
+| 6 | 1006 | 牛客 67890123456789 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
+
+有的用户的昵称特别长,在一些展示场景会导致样式混乱,因此需要将特别长的昵称转换一下再输出,请输出字符数大于 10 的用户信息,对于字符数大于 13 的用户输出前 10 个字符然后加上三个点号:『...』。
+
+由示例数据结果输出如下:
+
+| uid | nick_name |
+| ---- | ------------------ |
+| 1005 | 牛客 5678901234 号 |
+| 1006 | 牛客 67890123... |
+
+解释:字符数大于 10 的用户有 1005 和 1006,长度分别为 13、17;因此需要对 1006 的昵称截断输出。
+
+**思路**:
+
+这题涉及到字符的计算,要计算字符串的字符数(即字符串的长度),可以使用 `LENGTH` 函数或 `CHAR_LENGTH` 函数。这两个函数的区别在于对待多字节字符的方式。
+
+1. `LENGTH` 函数:它返回给定字符串的字节数。对于包含多字节字符的字符串,每个字符都会被当作一个字节来计算。
+
+示例:
+
+```sql
+SELECT LENGTH('你好'); -- 输出结果:6,因为 '你好' 中的每个汉字每个占3个字节
+```
+
+1. `CHAR_LENGTH` 函数:它返回给定字符串的字符数。对于包含多字节字符的字符串,每个字符会被当作一个字符来计算。
+
+示例:
+
+```sql
+SELECT CHAR_LENGTH('你好'); -- 输出结果:2,因为 '你好' 中有两个字符,即两个汉字
+```
+
+**答案**:
+
+```sql
+SELECT
+ uid,
+CASE
+
+ WHEN CHAR_LENGTH( nick_name ) > 13 THEN
+ CONCAT( SUBSTR( nick_name, 1, 10 ), '...' ) ELSE nick_name
+ END AS nick_name
+FROM
+ user_info
+WHERE
+ CHAR_LENGTH( nick_name ) > 10
+GROUP BY
+ uid;
+```
+
+### 大小写混乱时的筛选统计(较难)
+
+**描述**:
+
+现有试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | 算法 | hard | 60 | 2021-01-01 10:00:00 |
+| 2 | 9002 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 3 | 9003 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 4 | 9004 | sql | medium | 70 | 2021-01-01 10:00:00 |
+| 5 | 9005 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 6 | 9006 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 7 | 9007 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 8 | 9008 | SQL | medium | 70 | 2021-01-01 10:00:00 |
+| 9 | 9009 | SQL | medium | 70 | 2021-01-01 10:00:00 |
+| 10 | 9010 | SQL | medium | 70 | 2021-01-01 10:00:00 |
+
+试卷作答信息表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 80 |
+| 2 | 1002 | 9003 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 81 |
+| 3 | 1002 | 9002 | 2020-02-01 12:11:01 | 2020-02-01 12:31:01 | 83 |
+| 4 | 1003 | 9002 | 2020-03-01 19:01:01 | 2020-03-01 19:30:01 | 75 |
+| 5 | 1004 | 9002 | 2020-03-01 12:01:01 | 2020-03-01 12:11:01 | 60 |
+| 6 | 1005 | 9002 | 2020-03-01 12:01:01 | 2020-03-01 12:41:01 | 90 |
+| 7 | 1006 | 9001 | 2020-05-02 19:01:01 | 2020-05-02 19:32:00 | 20 |
+| 8 | 1007 | 9003 | 2020-01-02 19:01:01 | 2020-01-02 19:40:01 | 89 |
+| 9 | 1008 | 9004 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
+| 10 | 1008 | 9001 | 2020-02-02 12:01:01 | 2020-02-02 12:31:01 | 98 |
+| 11 | 1009 | 9002 | 2020-02-02 12:01:01 | 2020-01-02 12:43:01 | 81 |
+| 12 | 1010 | 9001 | 2020-01-02 12:11:01 | (NULL) | (NULL) |
+| 13 | 1010 | 9001 | 2020-02-02 12:01:01 | 2020-01-02 10:31:01 | 89 |
+
+试卷的类别 tag 可能出现大小写混乱的情况,请先筛选出试卷作答数小于 3 的类别 tag,统计将其转换为大写后对应的原本试卷作答数。
+
+如果转换后 tag 并没有发生变化,不输出该条结果。
+
+由示例数据结果输出如下:
+
+| tag | answer_cnt |
+| --- | ---------- |
+| C++ | 6 |
+
+解释:被作答过的试卷有 9001、9002、9003、9004,他们的 tag 和被作答次数如下:
+
+| exam_id | tag | answer_cnt |
+| ------- | ---- | ---------- |
+| 9001 | 算法 | 4 |
+| 9002 | C++ | 6 |
+| 9003 | c++ | 2 |
+| 9004 | sql | 2 |
+
+作答次数小于 3 的 tag 有 c++和 sql,而转为大写后只有 C++本来就有作答数,于是输出 c++转化大写后的作答次数为 6。
+
+**思路**:
+
+首先,这题有点混乱,9004 根据示例数据查出来只有 1 次,这里显示有 2 次。
+
+先看一下大小写转换函数:
+
+1.`UPPER(s)`或`UCASE(s)`函数可以将字符串 s 中的字母字符全部转换成大写字母;
+
+2.`LOWER(s)`或者`LCASE(s)`函数可以将字符串 s 中的字母字符全部转换成小写字母。
+
+难点在于相同表做连接要查询不同的值
+
+**答案**:
+
+```sql
+WITH a AS
+ (SELECT tag,
+ COUNT(start_time) AS answer_cnt
+ FROM exam_record er
+ JOIN examination_info ei ON er.exam_id = ei.exam_id
+ GROUP BY tag)
+SELECT a.tag,
+ b.answer_cnt
+FROM a
+INNER JOIN a AS b ON UPPER(a.tag)= b.tag #a小写 b大写
+AND a.tag != b.tag
+WHERE a.answer_cnt < 3;
+```
+
+
diff --git a/docs/database/sql/sql-syntax-summary.md b/docs/database/sql/sql-syntax-summary.md
index cc51b15f2a8..679c1b59255 100644
--- a/docs/database/sql/sql-syntax-summary.md
+++ b/docs/database/sql/sql-syntax-summary.md
@@ -1,9 +1,14 @@
---
title: SQL语法基础知识总结
+description: SQL语法基础知识总结,系统讲解DDL数据定义、DML数据操作、DQL数据查询、DCL数据控制语言,涵盖表操作、约束、索引、事务、连接查询等核心知识点。
category: 数据库
tag:
- 数据库基础
- SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL语法,DDL,DML,DQL,DCL,CREATE,SELECT,INSERT,UPDATE,DELETE,JOIN连接,子查询
---
> 本文整理完善自下面这两份资料:
@@ -28,7 +33,7 @@ SQL(Structured Query Language),标准 SQL 由 ANSI 标准委员会管理,
#### SQL 语法结构
-
+
SQL 语法结构包括:
@@ -148,7 +153,7 @@ WHERE username = 'root';
### 删除数据
- `DELETE` 语句用于删除表中的记录。
-- `TRUNCATE TABLE` 可以清空表,也就是删除所有行。
+- `TRUNCATE TABLE` 可以清空表,也就是删除所有行。说明:`TRUNCATE` 语句不属于 DML 语法而是 DDL 语法。
**删除表中的指定数据**
@@ -257,11 +262,11 @@ ORDER BY cust_name DESC;
**使用 WHERE 和 HAVING 过滤数据**
```sql
-SELECT cust_name, COUNT(*) AS num
+SELECT cust_name, COUNT(*) AS NumberOfOrders
FROM Customers
WHERE cust_email IS NOT NULL
GROUP BY cust_name
-HAVING COUNT(*) >= 1;
+HAVING COUNT(*) > 1;
```
**`having` vs `where`**:
@@ -322,7 +327,7 @@ WHERE cust_id IN (SELECT cust_id
内部查询首先在其父查询之前执行,以便可以将内部查询的结果传递给外部查询。执行过程可以参考下图:
-
+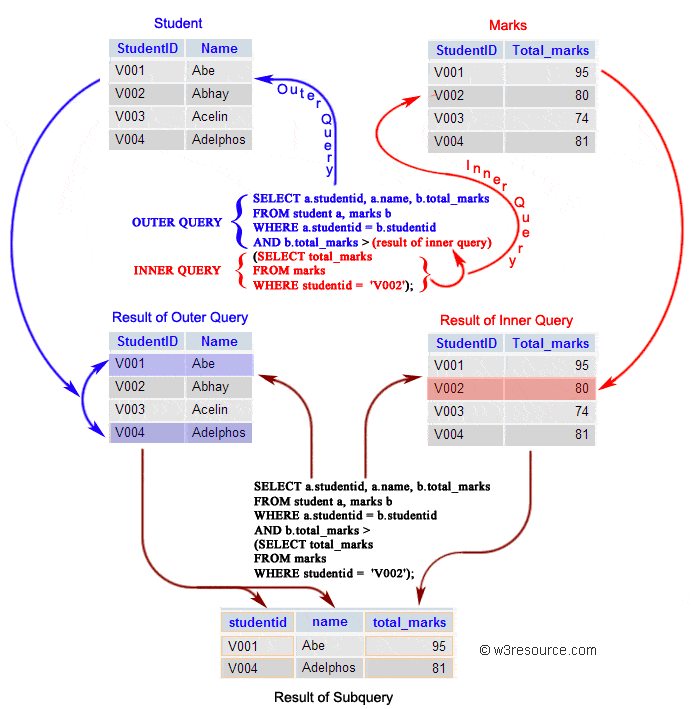
### WHERE
@@ -396,7 +401,7 @@ WHERE prod_price BETWEEN 3 AND 5;
**AND 示例**
-```ini
+```sql
SELECT prod_id, prod_name, prod_price
FROM products
WHERE vend_id = 'DLL01' AND prod_price <= 4;
@@ -500,11 +505,11 @@ SQL 允许在 `JOIN` 左边加上一些修饰性的关键词,从而形成不
下图展示了 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 相关的 7 种用法。
-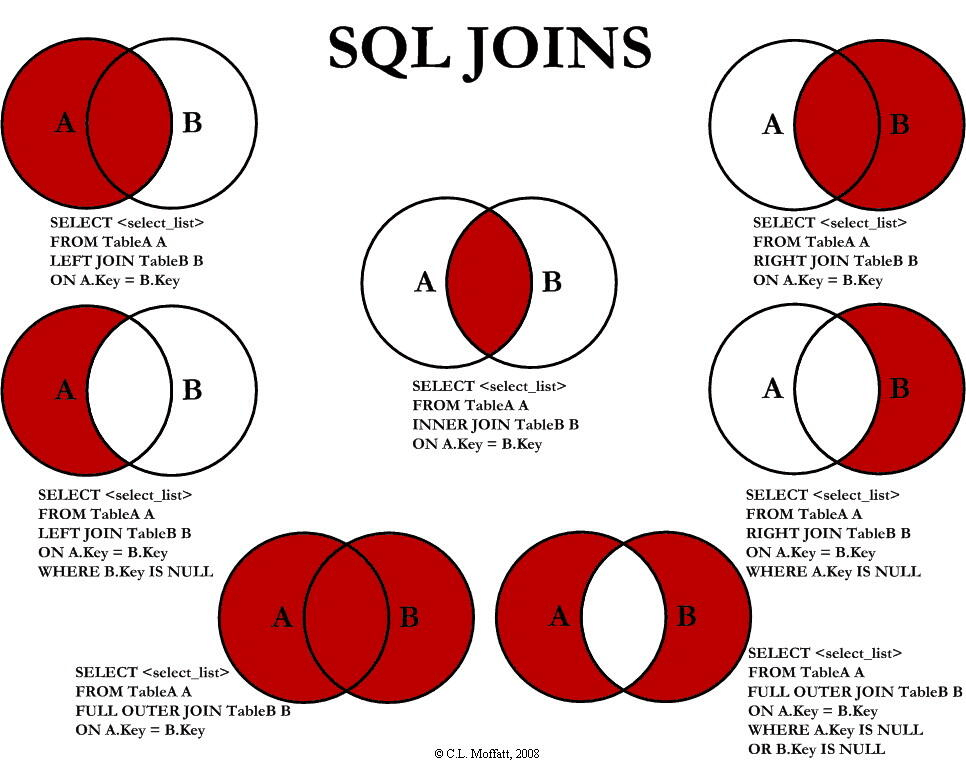
+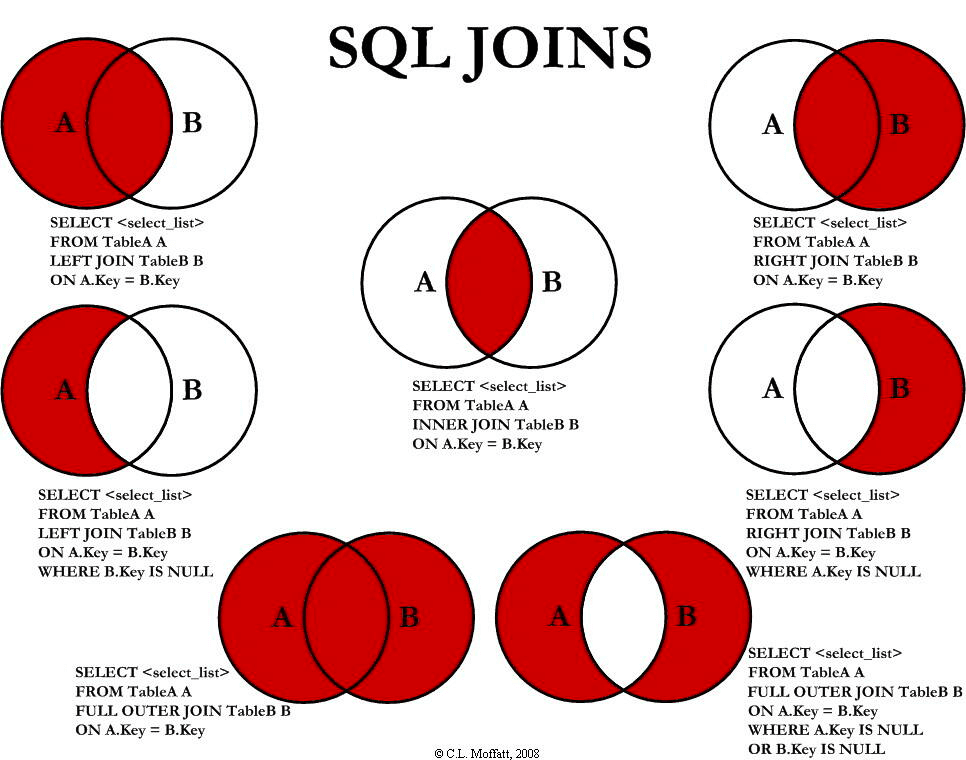
-如果不加任何修饰词,只写 `JOIN`,那么默认为 `INNER JOIIN`
+如果不加任何修饰词,只写 `JOIN`,那么默认为 `INNER JOIN`
-对于 `INNER JOIIN` 来说,还有一种隐式的写法,称为 “**隐式内连接**”,也就是没有 `INNER JOIIN` 关键字,使用 `WHERE` 语句实现内连接的功能
+对于 `INNER JOIN` 来说,还有一种隐式的写法,称为 “**隐式内连接**”,也就是没有 `INNER JOIN` 关键字,使用 `WHERE` 语句实现内连接的功能
```sql
# 隐式内连接
@@ -556,7 +561,7 @@ SELECT column_name(s) FROM table2;
| `LEFT()`、`RIGHT()` | 左边或者右边的字符 |
| `LOWER()`、`UPPER()` | 转换为小写或者大写 |
| `LTRIM()`、`RTRIM()` | 去除左边或者右边的空格 |
-| `LENGTH()` | 长度 |
+| `LENGTH()` | 长度,以字节为单位 |
| `SOUNDEX()` | 转换为语音值 |
其中, **`SOUNDEX()`** 可以将一个字符串转换为描述其语音表示的字母数字模式。
@@ -728,7 +733,7 @@ DROP PRIMARY KEY;
- 通过只给用户访问视图的权限,保证数据的安全性;
- 更改数据格式和表示。
-
+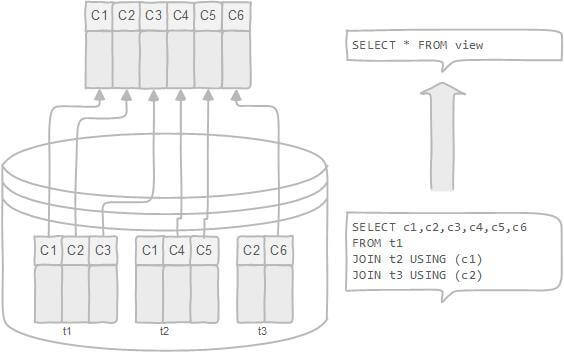
#### 创建视图
@@ -867,7 +872,7 @@ COMMIT;
## 权限控制
-要授予用户帐户权限,可以用`GRANT`命令。有撤销用户的权限,可以用`REVOKE`命令。这里以 MySQl 为例,介绍权限控制实际应用。
+要授予用户帐户权限,可以用`GRANT`命令。要撤销用户的权限,可以用`REVOKE`命令。这里以 MySQL 为例,介绍权限控制实际应用。
`GRANT`授予权限语法:
@@ -1001,7 +1006,7 @@ SET PASSWORD FOR myuser = 'mypass';
存储过程可以看成是对一系列 SQL 操作的批处理。存储过程可以由触发器,其他存储过程以及 Java, Python,PHP 等应用程序调用。
-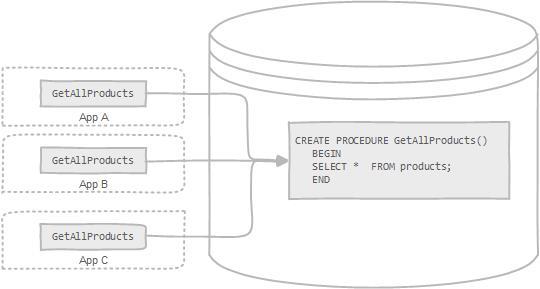
+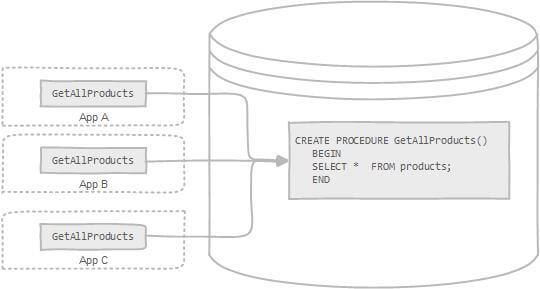
使用存储过程的好处:
@@ -1018,7 +1023,7 @@ SET PASSWORD FOR myuser = 'mypass';
需要注意的是:**阿里巴巴《Java 开发手册》强制禁止使用存储过程。因为存储过程难以调试和扩展,更没有移植性。**
-
+
至于到底要不要在项目中使用,还是要看项目实际需求,权衡好利弊即可!
@@ -1127,7 +1132,7 @@ MySQL 不允许在触发器中使用 CALL 语句 ,也就是不能调用存储
> 注意:在 MySQL 中,分号 `;` 是语句结束的标识符,遇到分号表示该段语句已经结束,MySQL 可以开始执行了。因此,解释器遇到触发器执行动作中的分号后就开始执行,然后会报错,因为没有找到和 BEGIN 匹配的 END。
>
-> 这时就会用到 `DELIMITER` 命令(DELIMITER 是定界符,分隔符的意思)。它是一条命令,不需要语句结束标识,语法为:`DELIMITER new_delemiter`。`new_delemiter` 可以设为 1 个或多个长度的符号,默认的是分号 `;`,我们可以把它修改为其他符号,如 `$` - `DELIMITER $` 。在这之后的语句,以分号结束,解释器不会有什么反应,只有遇到了 `$`,才认为是语句结束。注意,使用完之后,我们还应该记得把它给修改回来。
+> 这时就会用到 `DELIMITER` 命令(DELIMITER 是定界符,分隔符的意思)。它是一条命令,不需要语句结束标识,语法为:`DELIMITER new_delimiter`。`new_delimiter` 可以设为 1 个或多个长度的符号,默认的是分号 `;`,我们可以把它修改为其他符号,如 `$` - `DELIMITER $` 。在这之后的语句,以分号结束,解释器不会有什么反应,只有遇到了 `$`,才认为是语句结束。注意,使用完之后,我们还应该记得把它给修改回来。
在 MySQL 5.7.2 版之前,可以为每个表定义最多六个触发器。
@@ -1208,3 +1213,5 @@ DROP TRIGGER IF EXISTS trigger_insert_user;
- [后端程序员必备:SQL 高性能优化指南!35+条优化建议立马 GET!](https://mp.weixin.qq.com/s/I-ZT3zGTNBZ6egS7T09jyQ)
- [后端程序员必备:书写高质量 SQL 的 30 条建议](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486461&idx=1&sn=60a22279196d084cc398936fe3b37772&chksm=cea24436f9d5cd20a4fa0e907590f3e700d7378b3f608d7b33bb52cfb96f503b7ccb65a1deed&token=1987003517&lang=zh_CN#rd)
+
+
diff --git a/docs/distributed-system/api-gateway.md b/docs/distributed-system/api-gateway.md
index 8ced73cafe3..091bd1b079f 100644
--- a/docs/distributed-system/api-gateway.md
+++ b/docs/distributed-system/api-gateway.md
@@ -1,27 +1,47 @@
---
title: API网关基础知识总结
+description: API网关基础知识详解,涵盖网关核心功能、请求转发、安全认证、流量控制及常见网关选型对比。
category: 分布式
---
## 什么是网关?
-微服务背景下,一个系统被拆分为多个服务,但是像安全认证,流量控制,日志,监控等功能是每个服务都需要的,没有网关的话,我们就需要在每个服务中单独实现,这使得我们做了很多重复的事情并且没有一个全局的视图来统一管理这些功能。
+API 网关(API Gateway)是位于客户端与后端服务之间的**统一入口**,所有客户端请求先经过网关,再由网关路由到具体的目标服务。
+
+### 核心价值
+
+在微服务架构下,一个系统被拆分为多个服务。像**安全认证、流量控制、日志、监控**等功能是每个服务都需要的。如果没有网关,我们需要在每个服务中单独实现这些功能,导致:
+
+- **代码重复**:相同逻辑在多个服务中冗余实现
+- **管理分散**:缺乏统一的配置和监控视图
+- **维护成本高**:功能变更需要修改所有服务
-一般情况下,网关可以为我们提供请求转发、安全认证(身份/权限认证)、流量控制、负载均衡、降级熔断、日志、监控、参数校验、协议转换等功能。
+### 核心职责
+
+网关的功能虽然繁多,但核心可以概括为两件事:
+
+| 职责 | 说明 | 典型功能 |
+| ------------ | ----------------------------------- | -------------------------------------- |
+| **请求转发** | 将客户端请求路由到正确的目标服务 | 动态路由、负载均衡、协议转换 |
+| **请求过滤** | 在请求到达后端服务前/后进行拦截处理 | 身份认证、权限校验、限流熔断、日志记录 |
-上面介绍了这么多功能,实际上,网关主要做了两件事情:**请求转发** + **请求过滤**。
+网关可以提供请求转发、安全认证(身份/权限认证)、流量控制、负载均衡、降级熔断、日志、监控、参数校验、协议转换等功能。
-由于引入网关之后,会多一步网络转发,因此性能会有一点影响(几乎可以忽略不计,尤其是内网访问的情况下)。 另外,我们需要保障网关服务的高可用,避免单点风险。
+**网关在微服务架构中的位置**:所有客户端请求先到达网关,网关负责统一的认证鉴权、流量控制、路由分发,后端服务专注于业务逻辑处理。
-如下图所示,网关服务外层通过 Nginx(其他负载均衡设备/软件也行) 进⾏负载转发以达到⾼可⽤。Nginx 在部署的时候,尽量也要考虑高可用,避免单点风险。
+### 高可用部署
+
+引入网关后会增加一次网络转发(性能损耗在内网环境下通常可忽略),但同时也引入了新的单点风险。因此,网关服务本身必须保障高可用:
+
+如下图所示,网关服务外层通过 Nginx(或其他负载均衡设备/软件)进行负载转发以达到高可用。Nginx 在部署时也应考虑高可用,避免单点风险。
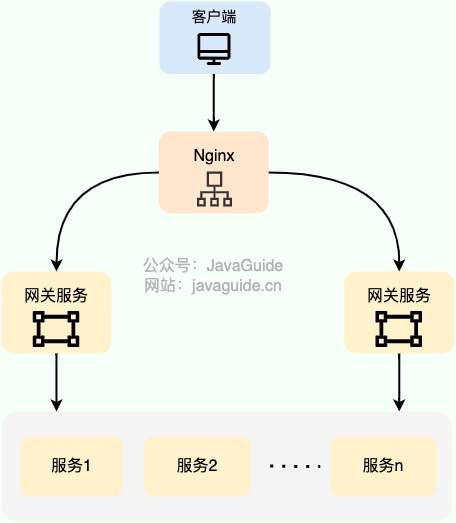
## 网关能提供哪些功能?
-绝大部分网关可以提供下面这些功能:
+绝大部分网关可以提供下面这些功能(有一些功能需要借助其他框架或者中间件):
- **请求转发**:将请求转发到目标微服务。
- **负载均衡**:根据各个微服务实例的负载情况或者具体的负载均衡策略配置对请求实现动态的负载均衡。
@@ -37,10 +57,11 @@ category: 分布式
- **异常处理**:对于业务服务返回的异常响应,可以在网关层在返回给用户之前做转换处理。这样可以把一些业务侧返回的异常细节隐藏,转换成用户友好的错误提示返回。
- **API 文档:** 如果计划将 API 暴露给组织以外的开发人员,那么必须考虑使用 API 文档,例如 Swagger 或 OpenAPI。
- **协议转换**:通过协议转换整合后台基于 REST、AMQP、Dubbo 等不同风格和实现技术的微服务,面向 Web Mobile、开放平台等特定客户端提供统一服务。
+- **证书管理**:将 SSL 证书部署到 API 网关,由一个统一的入口管理接口,降低了证书更换时的复杂度。
下图来源于[百亿规模 API 网关服务 Shepherd 的设计与实现 - 美团技术团队 - 2021](https://mp.weixin.qq.com/s/iITqdIiHi3XGKq6u6FRVdg)这篇文章。
-
+
## 有哪些常见的网关系统?
@@ -50,7 +71,7 @@ Zuul 是 Netflix 开发的一款提供动态路由、监控、弹性、安全的
Zuul 核心架构如下:
-
+
Zuul 主要通过过滤器(类似于 AOP)来过滤请求,从而实现网关必备的各种功能。
@@ -72,38 +93,83 @@ Zuul 主要通过过滤器(类似于 AOP)来过滤请求,从而实现网
[Zuul 1.x](https://netflixtechblog.com/announcing-zuul-edge-service-in-the-cloud-ab3af5be08ee) 基于同步 IO,性能较差。[Zuul 2.x](https://netflixtechblog.com/open-sourcing-zuul-2-82ea476cb2b3) 基于 Netty 实现了异步 IO,性能得到了大幅改进。
-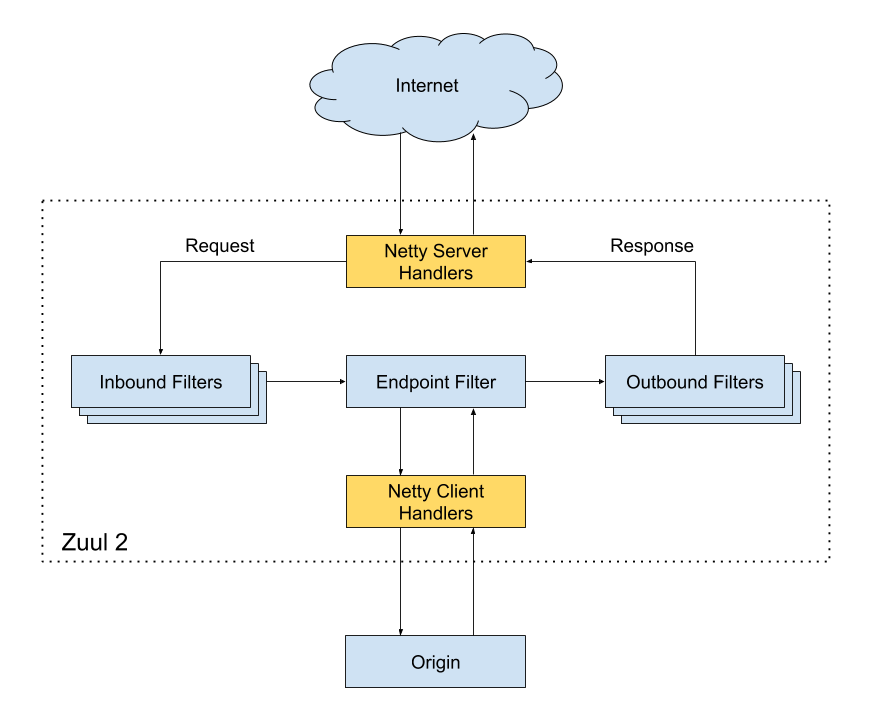
+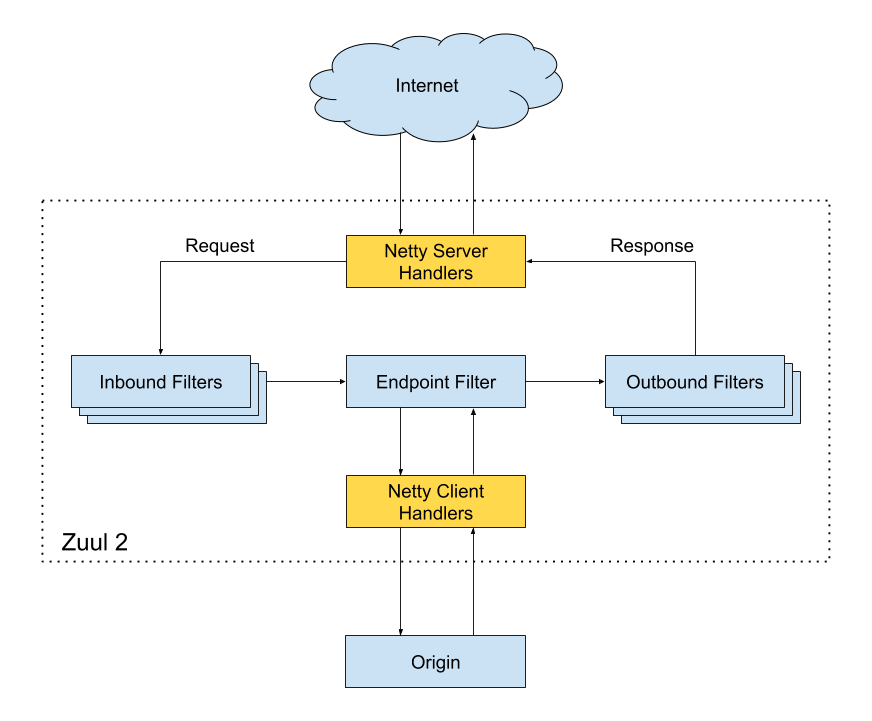
+
+> **重要提示**:Spring Cloud 官方已在 **Hoxton 版之后将 Zuul 1.x 移除**。尽管 Netflix 开源了 Zuul 2.x,但 Zuul 2.x 并未被集成到 Spring Cloud 主流版本中。对于 Spring Cloud 技术栈的新项目,**严禁选用 Zuul 1.x**,推荐直接使用 Spring Cloud Gateway。
- GitHub 地址:
- 官方 Wiki:
### Spring Cloud Gateway
-SpringCloud Gateway 属于 Spring Cloud 生态系统中的网关,其诞生的目标是为了替代老牌网关 **Zuul**。准确点来说,应该是 Zuul 1.x。SpringCloud Gateway 起步要比 Zuul 2.x 更早。
+Spring Cloud Gateway 属于 Spring Cloud 生态系统中的网关,其诞生的目标是为了替代老牌网关 **Zuul**(准确说是 Zuul 1.x)。值得注意的是,Spring Cloud Gateway 的起步时间早于 Zuul 2.x,两者属于不同的技术演进路线。
+
+#### 为什么 Spring Cloud Gateway 性能更好?
-为了提升网关的性能,SpringCloud Gateway 基于 Spring WebFlux 。Spring WebFlux 使用 Reactor 库来实现响应式编程模型,底层基于 Netty 实现同步非阻塞的 I/O。
+| 版本 | IO 模型 | 线程模型 | 吞吐量 | 延迟 |
+| ------------------------ | ------------------- | ------------ | ------ | ---- |
+| **Zuul 1.x** | 同步阻塞(Servlet) | 每请求一线程 | 低 | 高 |
+| **Zuul 2.x** | 异步非阻塞(Netty) | 事件循环 | 高 | 低 |
+| **Spring Cloud Gateway** | 异步非阻塞(Netty) | 事件循环 | 高 | 低 |
-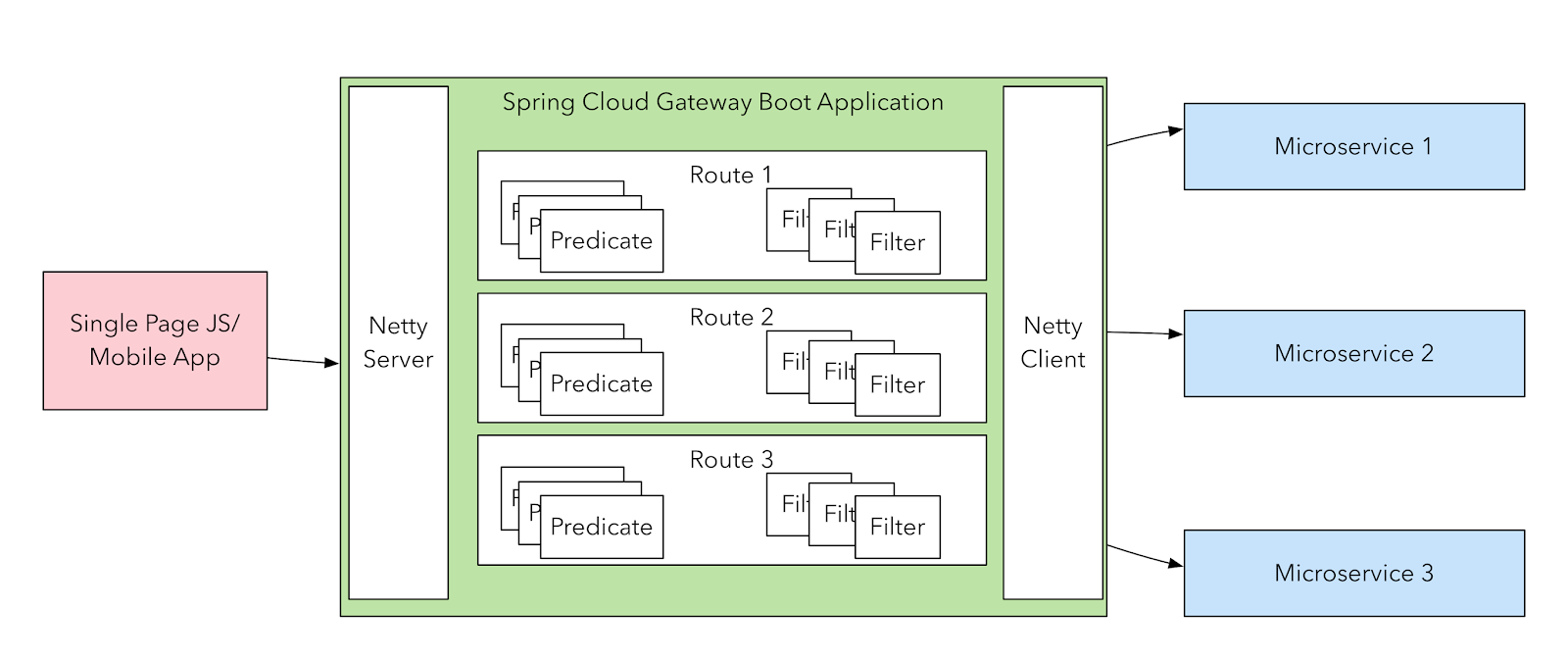
+Spring Cloud Gateway 基于 **Spring WebFlux** 实现,而不是传统的 Spring WebMVC。Spring WebFlux 使用 **Reactor** 库来实现响应式编程模型,底层基于 **Netty** 实现异步非阻塞的 I/O。
-Spring Cloud Gateway 不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,例如:安全,监控/指标,限流。
+**响应式编程的优势**:
-Spring Cloud Gateway 和 Zuul 2.x 的差别不大,也是通过过滤器来处理请求。不过,目前更加推荐使用 Spring Cloud Gateway 而非 Zuul,Spring Cloud 生态对其支持更加友好。
+- **非阻塞 I/O**:无需为每个请求分配独立线程,少量线程即可处理大量并发连接
+- **背压机制**:当下游服务处理能力不足时,自动调节上游请求速率,防止雪崩
+- **资源利用率高**:线程上下文切换开销大幅降低
+
+#### 核心概念
+
+Spring Cloud Gateway 的核心组件包括三个部分:
+
+1. **Route(路由)**:网关的基本构建块,由 ID、目标 URI、断言集合和过滤器集合组成
+2. **Predicate(断言)**:这是 Java 8 的 `Predicate` 函数,用于匹配 HTTP 请求(如路径、方法、请求头等)
+3. **Filter(过滤器)**:`GatewayFilter` 的实例,用于在请求被发送到下游服务之前或之后修改请求和响应
+
+Spring Cloud Gateway 和 Zuul 2.x 都是通过过滤器来处理请求,但 Spring Cloud Gateway 与 Spring 生态系统(如 Eureka、Consul、Config)集成更加紧密。目前,对于 Java 技术栈的项目,Spring Cloud Gateway 是推荐的选择。
- Github 地址:
- 官网:
+### OpenResty
+
+根据官方介绍:
+
+> OpenResty 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
+
+
+
+OpenResty 基于 Nginx,主要还是看中了其优秀的高并发能力。不过,由于 Nginx 采用 C 语言开发,二次开发门槛较高。如果想在 Nginx 上实现一些自定义的逻辑或功能,就需要编写 C 语言的模块,并重新编译 Nginx。
+
+为了解决这个问题,OpenResty 通过实现 `ngx_lua` 和 `stream_lua` 等 Nginx 模块,把 Lua/LuaJIT 完美地整合进了 Nginx,从而让我们能够在 Nginx 内部里嵌入 Lua 脚本,使得可以通过简单的 Lua 语言来扩展网关的功能,比如实现自定义的路由规则、过滤器、缓存策略等。
+
+> Lua 是一种非常快速的动态脚本语言,它的运行速度接近于 C 语言。LuaJIT 是 Lua 的一个即时编译器,它可以显著提高 Lua 代码的执行效率。LuaJIT 将一些常用的 Lua 函数和工具库预编译并缓存,这样在下次调用时就可以直接使用缓存的字节码,从而大大加快了执行速度。
+
+关于 OpenResty 的入门以及网关安全实战推荐阅读这篇文章:[每个后端都应该了解的 OpenResty 入门以及网关安全实战](https://mp.weixin.qq.com/s/3HglZs06W95vF3tSa3KrXw)。
+
+- Github 地址:
+- 官网地址:
+
### Kong
-Kong 是一款基于 [OpenResty](https://github.com/openresty/) (Nginx + Lua)的高性能、云原生、可扩展的网关系统,主要由 3 个组件组成:
+Kong 是一款基于 [OpenResty](https://github.com/openresty/) (Nginx + Lua)的高性能、云原生、可扩展、生态丰富的网关系统,主要由 3 个组件组成:
- Kong Server:基于 Nginx 的服务器,用来接收 API 请求。
-- Apache Cassandra/PostgreSQL:用来存储操作数据。
-- Kong Dashboard:官方推荐 UI 管理工具,当然,也可以使用 RESTful 方式 管理 Admin api。
-
-> OpenResty 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
+- Apache Cassandra/PostgreSQL:用来存储操作数据(传统模式)。
+- Kong Manager:官方 UI 管理工具,提供可视化的 API 管理、监控和配置功能(有 OSS 开源版和 Enterprise 企业版)。也可使用 RESTful Admin API 进行管理。
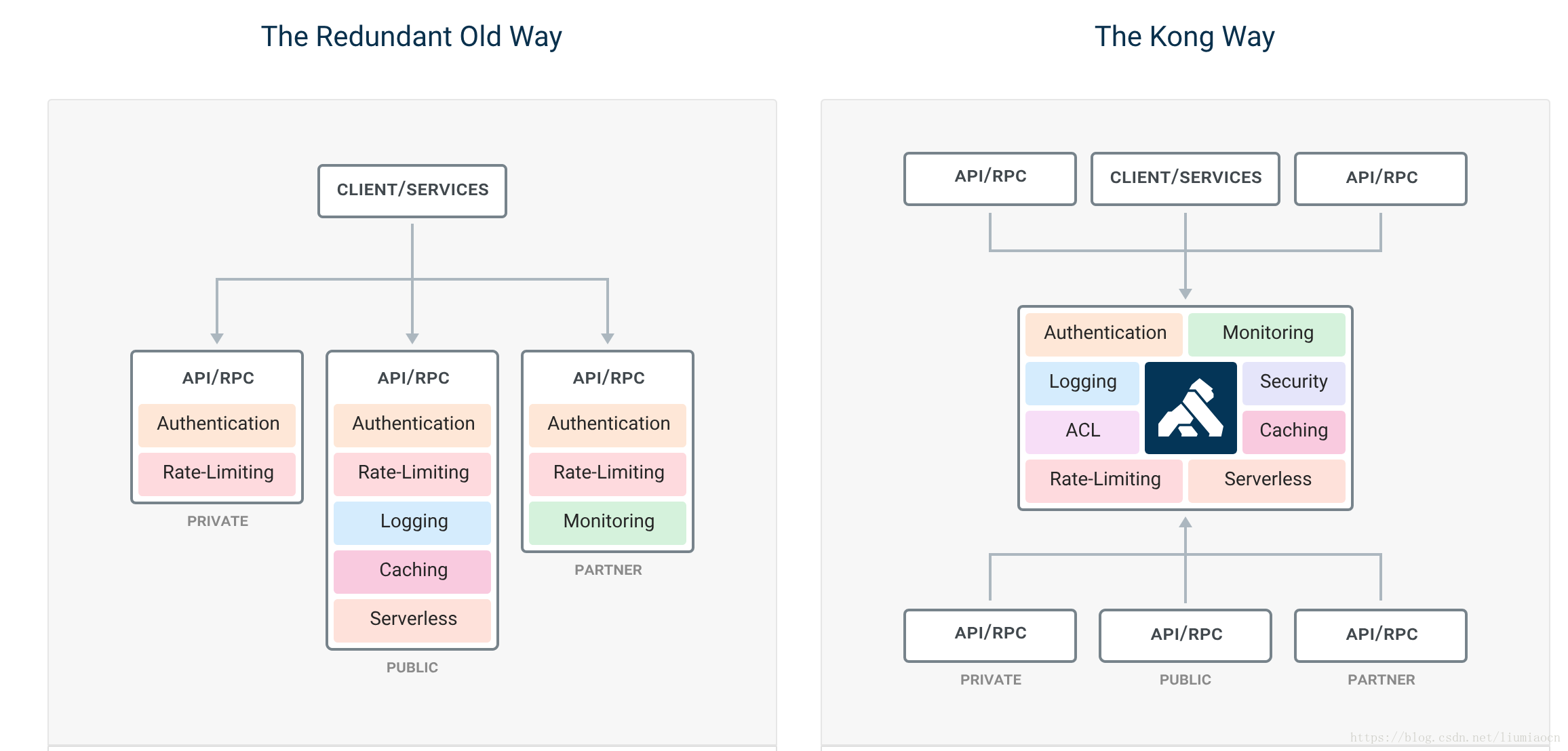
+Kong 早期确实依赖外部数据库存储配置,架构相对复杂,需要额外保障数据库层的高可用。但自 **Kong 1.1** 版本起,已支持 **DB-less 模式(无库模式)**:
+
+- **传统模式**:使用 PostgreSQL 或 Cassandra 存储配置,适合需要持久化 API 数据的场景
+- **DB-less 模式**:通过声明式配置文件管理,无需部署数据库,架构更加轻量
+- **Kubernetes Ingress 模式**:通过 ConfigMap 或 CRD(Kubernetes Custom Resource Definitions)管理配置,无需数据库,是 K8s 环境下的主流用法
+
+> **注意**:本文后续讨论的 Kong 高可用问题,主要针对传统模式。在 K8s 环境使用 Ingress Controller 模式时,架构已大幅简化。
+
Kong 提供了插件机制来扩展其功能,插件在 API 请求响应循环的生命周期中被执行。比如在服务上启用 Zipkin 插件:
```shell
@@ -113,24 +179,28 @@ $ curl -X POST http://kong:8001/services/{service}/plugins \
--data "config.sample_ratio=0.001"
```
-> Kong 本身就是一个 Lua 应用程序,并且是在 Openresty 的基础之上做了一层封装的应用。归根结底就是利用 Lua 嵌入 Nginx 的方式,赋予了 Nginx 可编程的能力,这样以插件的形式在 Nginx 这一层能够做到无限想象的事情。例如限流、安全访问策略、路由、负载均衡等等。编写一个 Kong 插件,就是按照 Kong 插件编写规范,写一个自己自定义的 Lua 脚本,然后加载到 Kong 中,最后引用即可。
+Kong 本身就是一个 Lua 应用程序,并且是在 Openresty 的基础之上做了一层封装的应用。归根结底就是利用 Lua 嵌入 Nginx 的方式,赋予了 Nginx 可编程的能力,这样以插件的形式在 Nginx 这一层能够做到无限想象的事情。例如限流、安全访问策略、路由、负载均衡等等。编写一个 Kong 插件,就是按照 Kong 插件编写规范,写一个自己自定义的 Lua 脚本,然后加载到 Kong 中,最后引用即可。
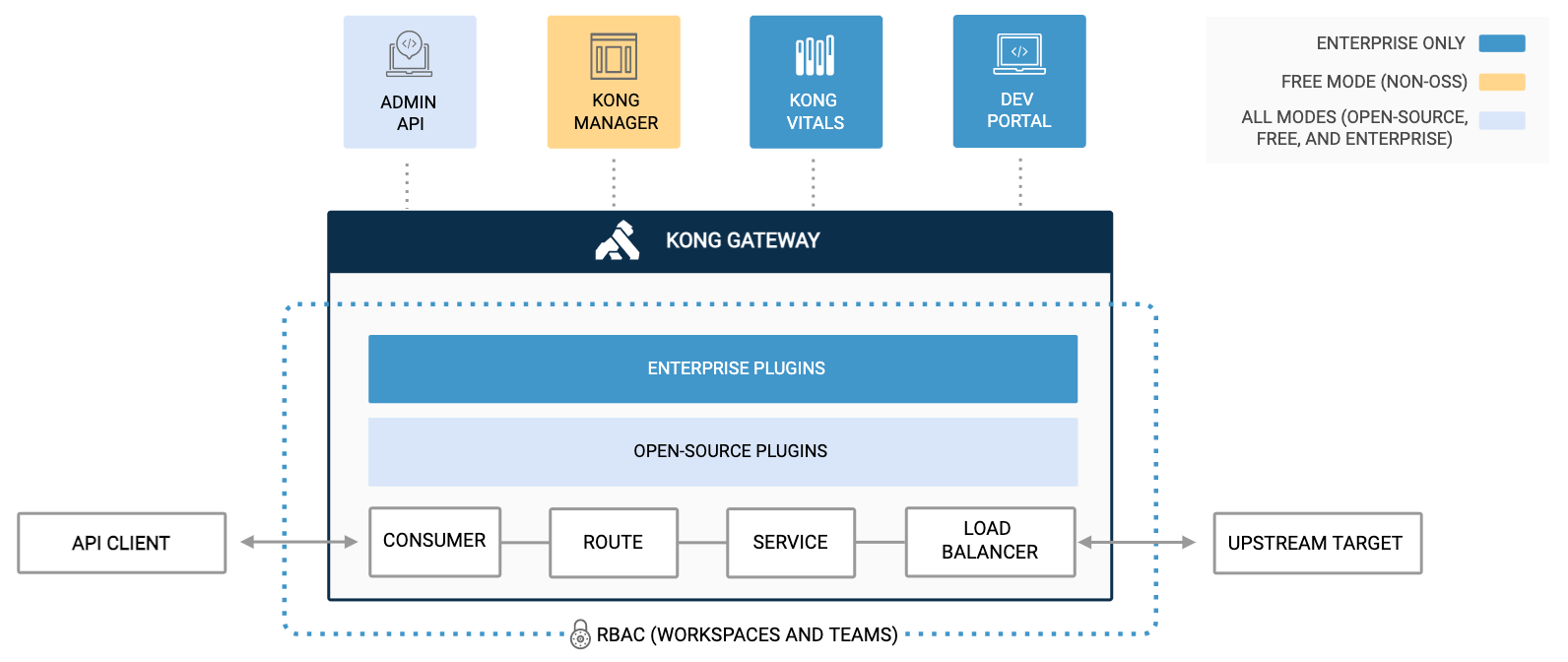
+除了 Lua,Kong 还可以基于 Go 、JavaScript、Python 等语言开发插件,得益于对应的 PDK(插件开发工具包)。
+
+关于 Kong 插件的详细介绍,推荐阅读官方文档:,写的比较详细。
+
- Github 地址:
- 官网地址:
### APISIX
-APISIX 是一款基于 Nginx 和 etcd 的高性能、云原生、可扩展的网关系统。
+APISIX 是一款基于 OpenResty 和 etcd 的高性能、云原生、可扩展的网关系统。
> etcd 是使用 Go 语言开发的一个开源的、高可用的分布式 key-value 存储系统,使用 Raft 协议做分布式共识。
与传统 API 网关相比,APISIX 具有动态路由和插件热加载,特别适合微服务系统下的 API 管理。并且,APISIX 与 SkyWalking(分布式链路追踪系统)、Zipkin(分布式链路追踪系统)、Prometheus(监控系统) 等 DevOps 生态工具对接都十分方便。
-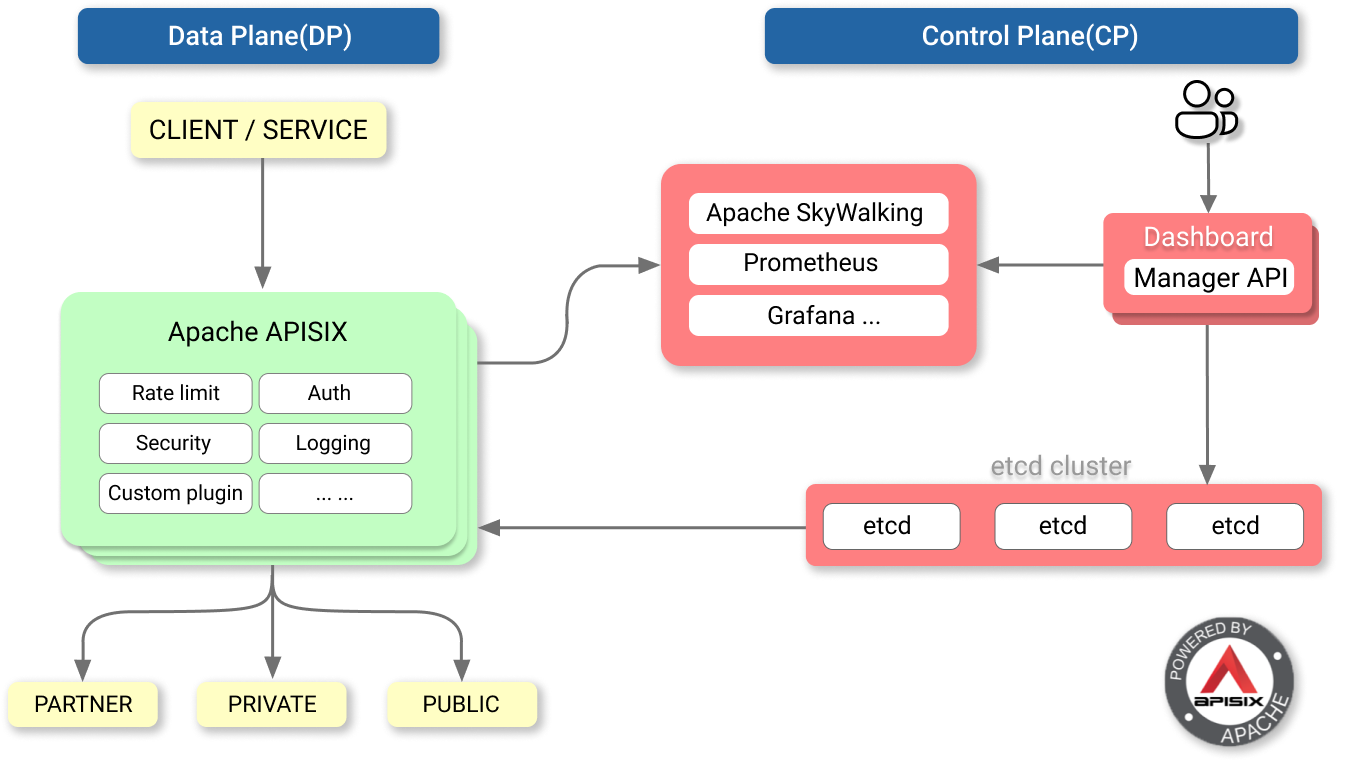
+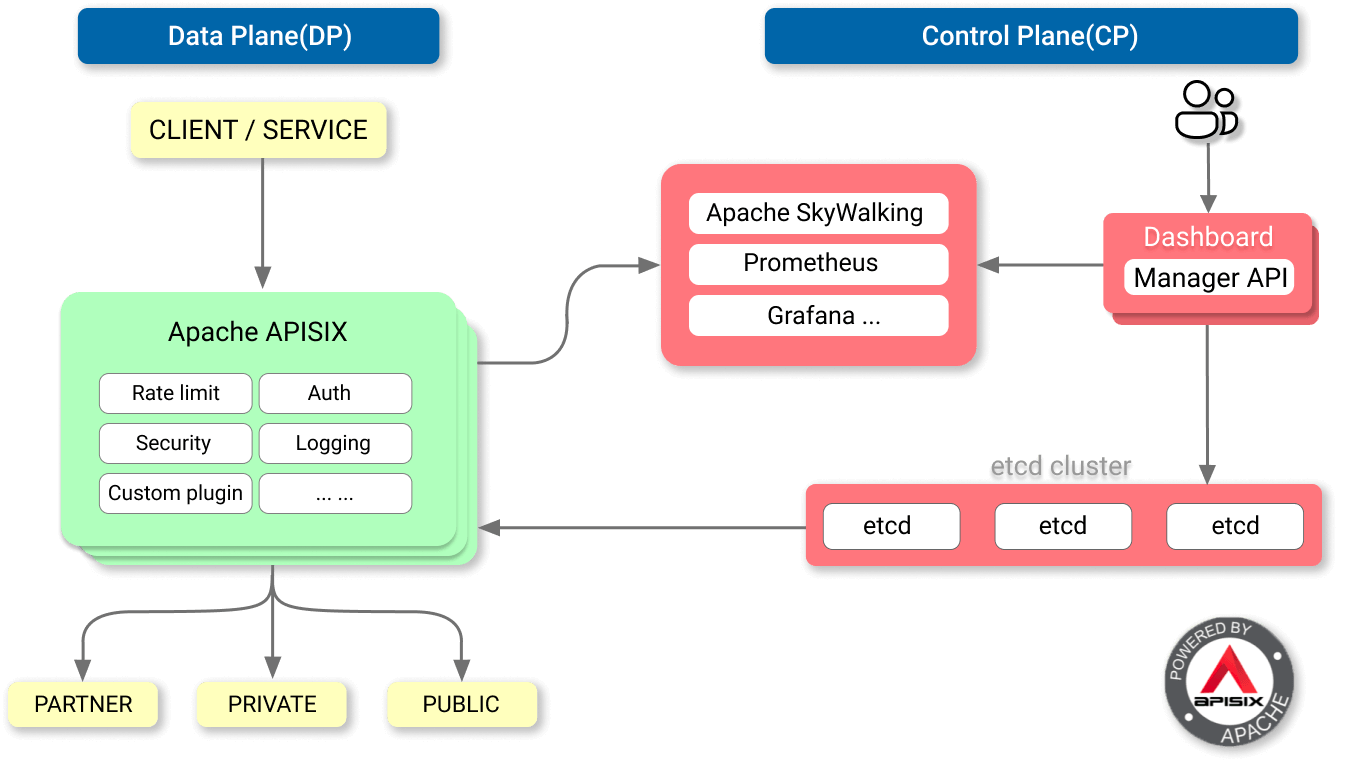
-作为 NGINX 和 Kong 的替代项目,APISIX 目前已经是 Apache 顶级开源项目,并且是最快毕业的国产开源项目。国内目前已经有很多知名企业(比如金山、有赞、爱奇艺、腾讯、贝壳)使用 APISIX 处理核心的业务流量。
+作为 Nginx 和 Kong 的替代项目,APISIX 目前已经是 Apache 顶级开源项目,并且是最快毕业的国产开源项目。国内目前已经有很多知名企业(比如金山、有赞、爱奇艺、腾讯、贝壳)使用 APISIX 处理核心的业务流量。
根据官网介绍:“APISIX 已经生产可用,功能、性能、架构全面优于 Kong”。
@@ -141,31 +211,54 @@ APISIX 同样支持定制化的插件开发。开发者除了能够使用 Lua
> Wasm 是基于堆栈的虚拟机的二进制指令格式,一种低级汇编语言,旨在非常接近已编译的机器代码,并且非常接近本机性能。Wasm 最初是为浏览器构建的,但是随着技术的成熟,在服务器端看到了越来越多的用例。
-
+
- Github 地址:
- 官网地址:
-相关阅读:
-
-- [为什么说 Apache APISIX 是最好的 API 网关?](https://mp.weixin.qq.com/s/j8ggPGEHFu3x5ekJZyeZnA)
-- [有了 NGINX 和 Kong,为什么还需要 Apache APISIX](https://www.apiseven.com/zh/blog/why-we-need-Apache-APISIX)
-- [APISIX 技术博客](https://www.apiseven.com/zh/blog)
-- [APISIX 用户案例](https://www.apiseven.com/zh/usercases)
-
### Shenyu
Shenyu 是一款基于 WebFlux 的可扩展、高性能、响应式网关,Apache 顶级开源项目。
-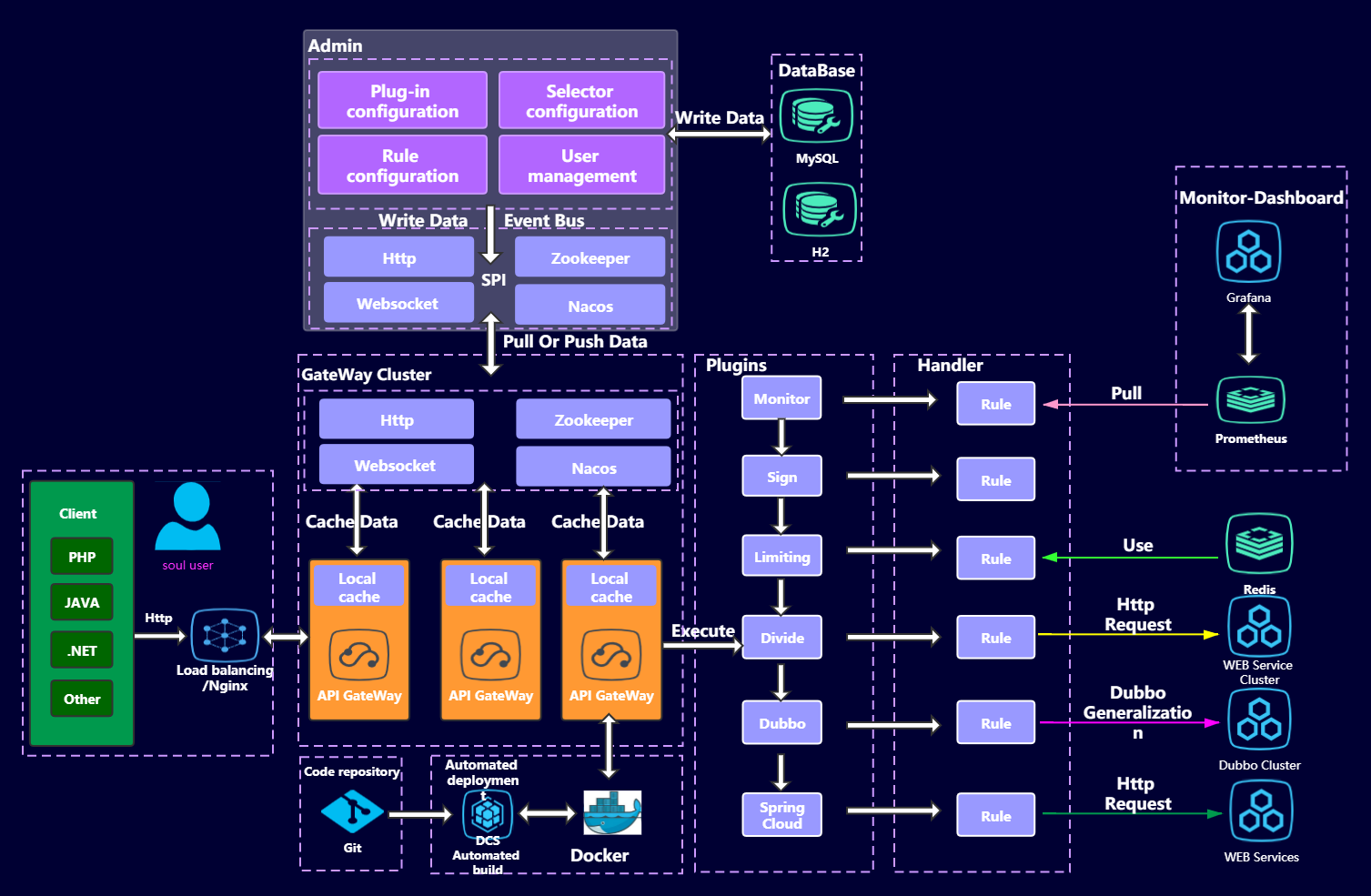
+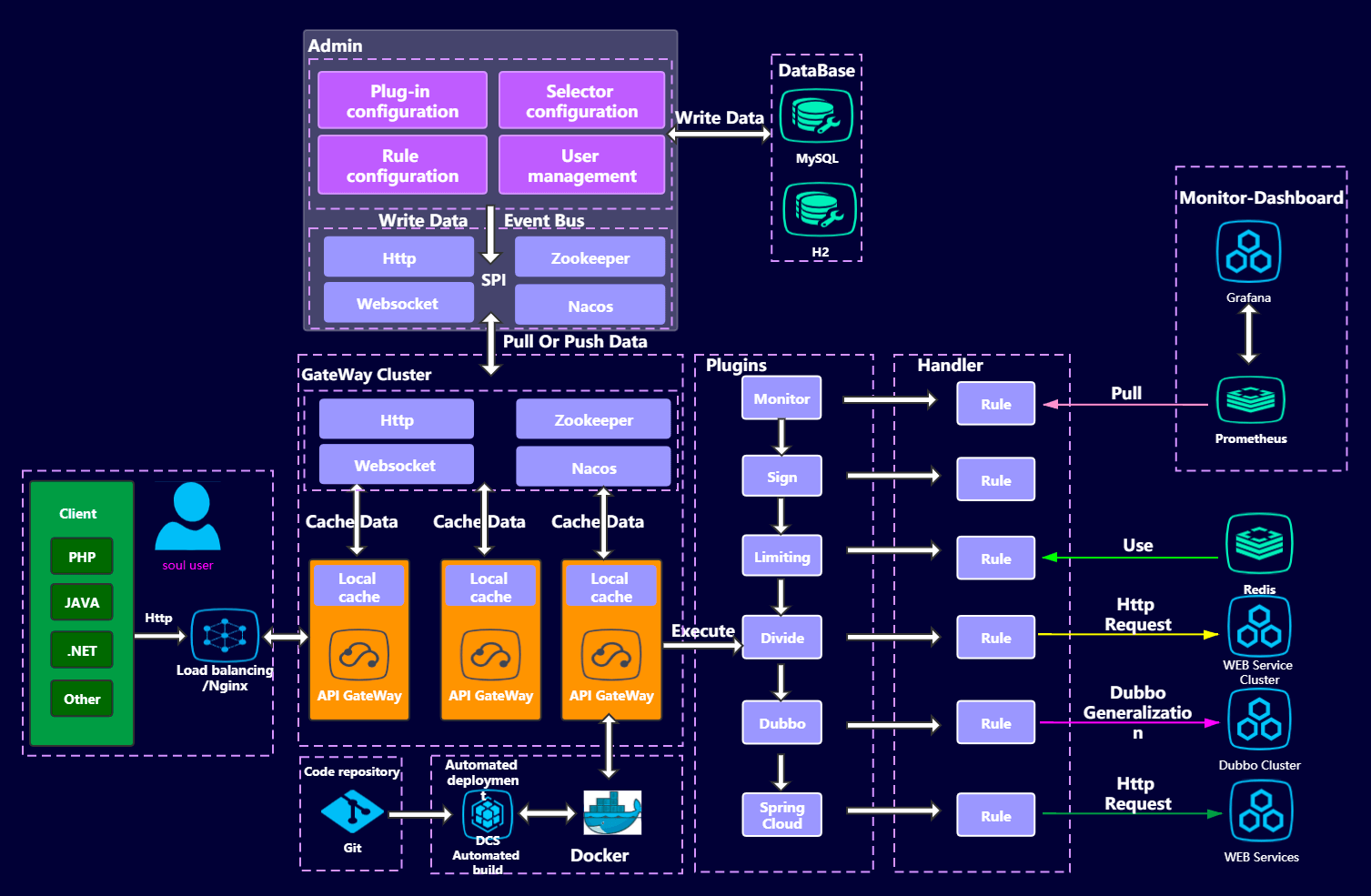
Shenyu 通过插件扩展功能,插件是 ShenYu 的灵魂,并且插件也是可扩展和热插拔的。不同的插件实现不同的功能。Shenyu 自带了诸如限流、熔断、转发、重写、重定向、和路由监控等插件。
-- Github 地址:
+- Github 地址:
- 官网地址:
+### 网关对比一览
+
+| 特性 | Zuul 1.x | Zuul 2.x | Spring Cloud Gateway | Kong | APISIX | Shenyu |
+| -------------- | -------- | -------------- | ------------------------- | ----------------------------- | ---------------- | --------------- |
+| **IO 模型** | 同步阻塞 | 异步非阻塞 | 异步非阻塞 | 异步非阻塞 | 异步非阻塞 | 异步非阻塞 |
+| **底层技术** | Servlet | Netty | WebFlux + Netty | OpenResty (Nginx + Lua) | OpenResty + etcd | WebFlux + Netty |
+| **性能** | 低 | 高 | 高 | 很高 | 很高 | 高 |
+| **动态配置** | 需重启 | 支持 | 支持 | 支持 | 支持(热更新) | 支持 |
+| **配置存储** | 内存 | 内存 | 内存 | 数据库 / YAML / K8s CRD | etcd(分布式) | 内存/数据库 |
+| **限流熔断** | 需集成 | 需集成 | 内置(集成 Resilience4j) | 插件 | 插件 | 插件 |
+| **生态系统** | Netflix | Netflix | Spring Cloud | CNCF / Kong | Apache | Apache |
+| **运维复杂度** | 低 | 中 | 低 | 中(DB-less) / 高(DB Mode) | 中 | 中 |
+| **学习曲线** | 平缓 | 平缓 | 平缓 | 陡峭(Lua) | 陡峭(Lua) | 平缓(Java) |
+| **适用场景** | 遗留系统 | Netflix 技术栈 | Spring Cloud 生态 | 云原生、多语言 | 云原生、高性能 | Java 生态 |
+
+## 如何选择?
+
+选择 API 网关需要综合考虑技术栈、性能要求、团队能力和运维成本。
+
+| 场景 | 推荐方案 | 理由 |
+| --------------------- | ---------------------------------------------------------- | ----------------------------------------------------------------- |
+| **Spring Cloud 生态** | Spring Cloud Gateway | 与 Spring Boot/Spring Cloud 无缝集成,配置简单 |
+| **高性能 / 云原生** | APISIX | 基于 etcd 的热更新、性能优异、云原生架构 |
+| **多语言生态** | Kong | 插件丰富、支持多语言开发、社区成熟 |
+| **Netflix 技术栈** | Zuul 2.x | 与 Eureka、Ribbon、Hystrix 等组件无缝配合 |
+| **双层架构(推荐)** | Kong/APISIX(流量网关) + Spring Cloud Gateway(业务网关) | 流量网关处理 SSL、WAF、全局限流;业务网关处理微服务鉴权、参数聚合 |
+
## 参考
- Kong 插件开发教程[通俗易懂]:
- API 网关 Kong 实战:
- Spring Cloud Gateway 原理介绍和应用:
+- 微服务为什么要用到 API 网关?:
+
+
diff --git a/docs/distributed-system/distributed-configuration-center.md b/docs/distributed-system/distributed-configuration-center.md
index e10ba19d9eb..0c71c519cdb 100644
--- a/docs/distributed-system/distributed-configuration-center.md
+++ b/docs/distributed-system/distributed-configuration-center.md
@@ -1,5 +1,6 @@
---
title: 分布式配置中心常见问题总结(付费)
+description: 分布式配置中心核心概念与面试题解析,涵盖Apollo、Nacos等主流配置中心原理与实践要点。
category: 分布式
---
diff --git a/docs/distributed-system/distributed-id-design.md b/docs/distributed-system/distributed-id-design.md
index c3172737e66..57077904251 100644
--- a/docs/distributed-system/distributed-id-design.md
+++ b/docs/distributed-system/distributed-id-design.md
@@ -1,5 +1,6 @@
---
title: 分布式ID设计指南
+description: 分布式ID设计实战指南,结合订单系统、优惠券等业务场景讲解分布式ID的设计要点与技术选型。
category: 分布式
---
@@ -91,9 +92,7 @@ UA 是一个特殊字符串头,服务器依次可以识别出客户使用的
4.支持用后核销;
-5.优惠券、兑换券属于广撒网的策略,所以利用率低,也就不适合使用数据。
-
-**库进行存储(占空间,有效的数据有少)**
+5.优惠券、兑换券属于广撒网的策略,所以利用率低,也就不适合使用数据库进行存储 **(占空间,有效的数据又少)**。
设计思路上,需要设计一种有效的兑换码生成策略,支持预先生成,支持校验,内容简洁,生成的兑换码都具有唯一性,那么这种策略就是一种特殊的编解码策略,按照约定的编解码规则支撑上述需求。
@@ -101,7 +100,7 @@ UA 是一个特殊字符串头,服务器依次可以识别出客户使用的
abcdefghijklmnopqrstuvwxyzABCDEFGHJKLMNPQRSTUVWXZY0123456789
-之前说过,兑换码要求近可能简洁,那么设计时就需要考虑兑换码的字符数,假设上限为 12 位,而字符空间有 60 位,那么可以表示的空间范围为 60^12=130606940160000000000000(也就是可以 12 位的兑换码可以生成天量,应该够运营同学挥霍了),转换成 2 进制:
+之前说过,兑换码要求尽可能简洁,那么设计时就需要考虑兑换码的字符数,假设上限为 12 位,而字符空间有 60 位,那么可以表示的空间范围为 60^12=130606940160000000000000(也就是可以 12 位的兑换码可以生成天量,应该够运营同学挥霍了),转换成 2 进制:
1001000100000000101110011001101101110011000000000000000000000(61 位)
@@ -171,3 +170,5 @@ span 是层的意思,比如在第一个实例算是第一层, 请求代理
- 客户的长网址:
- ID 映射的短网址: (演示使用,可能无法正确打开)
- 转进制后的短网址: (演示使用,可能无法正确打开)
+
+
diff --git a/docs/distributed-system/distributed-id.md b/docs/distributed-system/distributed-id.md
index 6a46aca00ad..fd117f94e2c 100644
--- a/docs/distributed-system/distributed-id.md
+++ b/docs/distributed-system/distributed-id.md
@@ -1,15 +1,18 @@
---
title: 分布式ID介绍&实现方案总结
+description: 分布式ID生成方案详解,涵盖UUID、数据库自增、号段模式、雪花算法等主流方案的原理与优缺点对比。
category: 分布式
---
+
+
## 分布式 ID 介绍
### 什么是 ID?
日常开发中,我们需要对系统中的各种数据使用 ID 唯一表示,比如用户 ID 对应且仅对应一个人,商品 ID 对应且仅对应一件商品,订单 ID 对应且仅对应一个订单。
-我们现实生活中也有各种 ID,比如身份证 ID 对应且仅对应一个人、地址 ID 对应且仅对应
+我们现实生活中也有各种 ID,比如身份证 ID 对应且仅对应一个人、地址 ID 对应且仅对应一个地址。
简单来说,**ID 就是数据的唯一标识**。
@@ -47,11 +50,9 @@ category: 分布式
- **有具体的业务含义**:生成的 ID 如果能有具体的业务含义,可以让定位问题以及开发更透明化(通过 ID 就能确定是哪个业务)。
- **独立部署**:也就是分布式系统单独有一个发号器服务,专门用来生成分布式 ID。这样就生成 ID 的服务可以和业务相关的服务解耦。不过,这样同样带来了网络调用消耗增加的问题。总的来说,如果需要用到分布式 ID 的场景比较多的话,独立部署的发号器服务还是很有必要的。
-## 分布式 ID 常见解决方案
-
-### 数据库
+## 基于数据库的生成方案(有状态)
-#### 数据库主键自增
+### 数据库主键自增
这种方式就比较简单直白了,就是通过关系型数据库的自增主键产生来唯一的 ID。
@@ -81,24 +82,28 @@ SELECT LAST_INSERT_ID();
COMMIT;
```
-插入数据这里,我们没有使用 `insert into` 而是使用 `replace into` 来插入数据,具体步骤是这样的:
+**⚠️ REPLACE INTO 的生产隐患**:
-- 第一步:尝试把数据插入到表中。
+`REPLACE INTO` 本质是 **`DELETE` + `INSERT`** 的组合操作:
-- 第二步:如果主键或唯一索引字段出现重复数据错误而插入失败时,先从表中删除含有重复关键字值的冲突行,然后再次尝试把数据插入到表中。
+- 如果主键或唯一索引字段出现重复数据错误而插入失败时,先从表中删除含有重复关键字值的冲突行,然后再次尝试把数据插入到表中。
+- 每次操作都会触发索引删除和重建,对数据库压力较大。
+- 如果表上有触发器,DELETE 操作会意外触发。
+
+**替代方案**:生产环境推荐使用号段模式(下面会介绍),或改用 `INSERT ... ON DUPLICATE KEY UPDATE` 减少索引震荡。
这种方式的优缺点也比较明显:
-- **优点**:实现起来比较简单、ID 有序递增、存储消耗空间小
-- **缺点**:支持的并发量不大、存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )、每次获取 ID 都要访问一次数据库(增加了对数据库的压力,获取速度也慢)
+- **优点**:实现起来比较简单、ID 有序递增、存储消耗空间小。
+- **缺点**:支持的并发量不大、存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )、每次获取 ID 都要访问一次数据库(增加了对数据库的压力,获取速度也慢)。
-#### 数据库号段模式
+### 数据库号段模式
数据库主键自增这种模式,每次获取 ID 都要访问一次数据库,ID 需求比较大的时候,肯定是不行的。
如果我们可以批量获取,然后存在在内存里面,需要用到的时候,直接从内存里面拿就舒服了!这也就是我们说的 **基于数据库的号段模式来生成分布式 ID。**
-数据库的号段模式也是目前比较主流的一种分布式 ID 生成方式。像滴滴开源的[Tinyid](https://github.com/didi/tinyid/wiki/tinyid%E5%8E%9F%E7%90%86%E4%BB%8B%E7%BB%8D) 就是基于这种方式来做的。不过,TinyId 使用了双号段缓存、增加多 db 支持等方式来进一步优化。
+数据库的号段模式也是目前比较主流的一种分布式 ID 生成方式。像滴滴开源的[Tinyid](https://github.com/didi/tinyid/wiki/tinyid原理介绍) 就是基于这种方式来做的。不过,TinyId 使用了双号段缓存、增加多 db 支持等方式来进一步优化。
以 MySQL 举例,我们通过下面的方式即可。
@@ -119,7 +124,21 @@ CREATE TABLE `sequence_id_generator` (
-`version` 字段主要用于解决并发问题(乐观锁),`biz_type` 主要用于表示业务类型。
+`version` 字段主要用于解决并发问题(乐观锁),完整流程如下:
+
+```sql
+-- 1. 读取当前值
+SELECT current_max_id, step, version FROM sequence_id_generator WHERE biz_type = 101;
+-- 2. CAS 更新(version 作为乐观锁版本号)
+UPDATE sequence_id_generator
+SET current_max_id = current_max_id + step, version = version + 1
+WHERE version = {当前读取的version} AND biz_type = 101;
+-- 3. 检查 affected_rows,为 1 表示成功,为 0 表示被其他线程抢先,需重试
+```
+
+> **⚠️ 高并发重试提醒**:在号段耗尽瞬间,多个线程可能同时争抢新号段,CAS 更新可能失败。代码层面需要实现**有限次数的重试循环**(如 3 次),确保请求稳定性。若重试仍失败,应降级为阻塞等待或返回降级 ID。
+
+`biz_type` 主要用于表示业务类型。
**2. 先插入一行数据。**
@@ -137,7 +156,7 @@ SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `bi
结果:
-```
+```plain
id current_max_id step version biz_type
1 0 100 0 101
```
@@ -151,7 +170,7 @@ SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `bi
结果:
-```
+```plain
id current_max_id step version biz_type
1 100 100 1 101
```
@@ -165,7 +184,7 @@ id current_max_id step version biz_type
- **优点**:ID 有序递增、存储消耗空间小
- **缺点**:存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )
-#### NoSQL
+### NoSQL
@@ -186,32 +205,55 @@ OK
除了高可用和并发之外,我们知道 Redis 基于内存,我们需要持久化数据,避免重启机器或者机器故障后数据丢失。Redis 支持两种不同的持久化方式:**快照(snapshotting,RDB)**、**只追加文件(append-only file, AOF)**。 并且,Redis 4.0 开始支持 **RDB 和 AOF 的混合持久化**(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
-关于 Redis 持久化,我这里就不过多介绍。不了解这部分内容的小伙伴,可以看看 [JavaGuide 对于 Redis 知识点的总结](https://snailclimb.gitee.io/javaguide/#/docs/database/Redis/redis-all)。
+关于 Redis 持久化,我这里就不过多介绍。不了解这部分内容的小伙伴,可以看看 [Redis 持久化机制详解](https://javaguide.cn/database/redis/redis-persistence.html)这篇文章。
+
+虽然 Redis `INCR` 性能优异,但存在以下失败路径需要特别注意:
+
+1. **持久化延迟导致 ID 回退**
+
+ - **场景**:执行 `INCR` 后,Redis 在 RDB/AOF 刷盘前崩溃。
+ - **后果**:重启后 ID 回退到上次持久化的值,可能产生重复 ID。
+
+2. **AOF 重写导致短暂阻塞**
+ - **场景**:AOF 文件过大触发重写。
+ - **后果**:主进程 fork 子进程可能导致短暂的性能抖动。
+
+**生产配置建议**:
+
+```conf
+# Redis 7.0+ 推荐配置
+appendonly yes
+appendfsync everysec
+aof-use-rdb-preamble yes # 混合持久化,RDB+AOF 组合
+```
+
+- **Redis 7.0+ 优化**:多部分 AOF(Multi-part AOF)机制进一步降低重写时的 IO 阻塞风险。
+- **替代方案**:使用 Lua 脚本 + `SETNX` 实现幂等检查,或对 ID 唯一性要求极高的场景使用数据库号段模式。
**Redis 方案的优缺点:**
-- **优点**:性能不错并且生成的 ID 是有序递增的
-- **缺点**:和数据库主键自增方案的缺点类似
+- **优点**:性能不错并且生成的 ID 是有序递增的。
+- **缺点**:和数据库主键自增方案的缺点类似,且存在持久化导致 ID 回退的风险。
除了 Redis 之外,MongoDB ObjectId 经常也会被拿来当做分布式 ID 的解决方案。
-
+
MongoDB ObjectId 一共需要 12 个字节存储:
-- 0~3:时间戳
+- 0~3:Unix 时间戳(**秒级精度**,4 字节)
- 3~6:代表机器 ID
- 7~8:机器进程 ID
- 9~11:自增值
**MongoDB 方案的优缺点:**
-- **优点**:性能不错并且生成的 ID 是有序递增的
-- **缺点**:需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)、有安全性问题(ID 生成有规律性)
+- **优点**:性能不错并且生成的 ID 是有序递增的。
+- **缺点**:需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)、有安全性问题(ID 生成有规律性)。
-### 算法
+## 基于算法的生成方案(无状态)
-#### UUID
+### UUID
UUID 是 Universally Unique Identifier(通用唯一标识符) 的缩写。UUID 包含 32 个 16 进制数字(8-4-4-4-12)。
@@ -222,18 +264,22 @@ JDK 就提供了现成的生成 UUID 的方法,一行代码就行了。
UUID.randomUUID()
```
-[RFC 4122](https://tools.ietf.org/html/rfc4122) 中关于 UUID 的示例是这样的:
+[RFC 4122](https://tools.ietf.org/html/rfc4122) 定义了 UUID v1-v5,2024 年发布的 [RFC 9562](https://www.rfc-editor.org/rfc/rfc9562.html) 新增了 v6、v7、v8。RFC 9562 中关于 UUID 的示例是这样的:
我们这里重点关注一下这个 Version(版本),不同的版本对应的 UUID 的生成规则是不同的。
-5 种不同的 Version(版本)值分别对应的含义(参考[维基百科对于 UUID 的介绍](https://zh.wikipedia.org/wiki/%E9%80%9A%E7%94%A8%E5%94%AF%E4%B8%80%E8%AF%86%E5%88%AB%E7%A0%81)):
+8 种不同的 Version(版本)值分别对应的含义(参考[维基百科对于 UUID 的介绍](https://zh.wikipedia.org/wiki/通用唯一识别码)):
-- **版本 1** : UUID 是根据时间和节点 ID(通常是 MAC 地址)生成;
-- **版本 2** : UUID 是根据标识符(通常是组或用户 ID)、时间和节点 ID 生成;
-- **版本 3、版本 5** : 版本 5 - 确定性 UUID 通过散列(hashing)名字空间(namespace)标识符和名称生成;
-- **版本 4** : UUID 使用[随机性](https://zh.wikipedia.org/wiki/随机性)或[伪随机性](https://zh.wikipedia.org/wiki/伪随机性)生成。
+- **版本 1 (基于时间和节点 ID)** : 基于时间戳(通常是当前时间)和节点 ID(通常为设备的 MAC 地址)生成。当包含 MAC 地址时,可以保证全球唯一性,但也因此存在隐私泄露的风险。
+- **版本 2 (基于标识符、时间和节点 ID)** : 与版本 1 类似,也基于时间和节点 ID,但额外包含了本地标识符(例如用户 ID 或组 ID)。
+- **版本 3 (基于命名空间和名称的 MD5 哈希)**:使用 MD5 哈希算法,将命名空间标识符(一个 UUID)和名称字符串组合计算得到。相同的命名空间和名称总是生成相同的 UUID(**确定性生成**)。
+- **版本 4 (基于随机数)**:几乎完全基于随机数生成,通常使用伪随机数生成器(PRNG)或加密安全随机数生成器(CSPRNG)来生成。 虽然理论上存在碰撞的可能性,但理论上碰撞概率极低(2^122 的可能性),可以认为在实际应用中是唯一的。
+- **版本 5 (基于命名空间和名称的 SHA-1 哈希)**:类似于版本 3,但使用 SHA-1 哈希算法。
+- **版本 6 (基于时间戳、计数器和节点 ID)**:改进了版本 1,将时间戳放在最高有效位(Most Significant Bit,MSB),使得 UUID 可以直接按时间排序。
+- **版本 7 (基于 Unix 毫秒时间戳)**:**48 位 Unix 毫秒时间戳 + 74 位随机/单调字段**。时间戳位于最高有效位,支持按时间排序。RFC 9562 **推荐使用 v7 替代 v1/v6**。可选的 12 位亚毫秒时间戳 + 计数器可保证毫秒内的单调性。
+- **版本 8 (实验性/供应商定制)**:**122 位留给实现自定义**,仅要求版本和变体位固定。适用于嵌入额外信息或特殊应用限制的场景。**唯一性由实现保证,不可假设**。
下面是 Version 1 版本下生成的 UUID 的示例:
@@ -259,40 +305,105 @@ int version = uuid.version();// 4
- 数据库主键要尽量越短越好,而 UUID 的消耗的存储空间比较大(32 个字符串,128 位)。
- UUID 是无顺序的,InnoDB 引擎下,数据库主键的无序性会严重影响数据库性能。
+UUID v7([RFC 9562](https://www.rfc-editor.org/rfc/rfc9562))是目前**替代 Snowflake 的最佳无中心化方案**:
+
+**RFC 9562 官方推荐**:实现应尽可能使用 UUID v7 替代 UUID v1/v6。
+
+| 特性 | Snowflake | UUID v7 |
+| ------------------ | ------------------------- | -------------------------------------- |
+| **Worker ID 管理** | 需要中心化分配(ZK/etcd) | 无需分配,开箱即用 |
+| **时钟回拨风险** | 需要额外处理 | 毫秒内允许乱序,天然规避 |
+| **B+ 树友好** | 趋势递增 | 天然有序 |
+| **标准化** | 各家实现不一 | RFC 标准,跨语言兼容 |
+| **结构** | 64 位(自定义) | 128 位(48 位时间戳 + 74 位随机/单调) |
+
+**适用场景**:中小规模分布式系统、无需 Snowflake 级性能的场景。
+
+**UUID v8(实验性用途)**:如果需要嵌入额外信息(如业务标识、集群信息)或有特殊应用限制,可考虑 UUID v8。但需注意:**v8 的唯一性由实现保证,不可假设与其他实现兼容**。
+
+⚠️ **注意**:部分数据库(MySQL 8.0.37 以下、PostgreSQL 15 以下)需通过函数生成 UUID v7,原生支持尚在普及中。
+
最后,我们再简单分析一下 **UUID 的优缺点** (面试的时候可能会被问到的哦!) :
-- **优点**:生成速度比较快、简单易用
-- **缺点**:存储消耗空间大(32 个字符串,128 位)、 不安全(基于 MAC 地址生成 UUID 的算法会造成 MAC 地址泄露)、无序(非自增)、没有具体业务含义、需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)
+- **优点**:生成速度通常比较快、简单易用。
+- **缺点**:存储消耗空间大(32 个字符串,128 位)、 不安全(基于 MAC 地址生成 UUID 的算法会造成 MAC 地址泄露)、无序(非自增)、没有具体业务含义、需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)。
-#### Snowflake(雪花算法)
+### Snowflake(雪花算法)
Snowflake 是 Twitter 开源的分布式 ID 生成算法。Snowflake 由 64 bit 的二进制数字组成,这 64bit 的二进制被分成了几部分,每一部分存储的数据都有特定的含义:
-- **第 0 位**:符号位(标识正负),始终为 0,没有用,不用管。
-- **第 1~41 位**:一共 41 位,用来表示时间戳,单位是毫秒,可以支撑 2 ^41 毫秒(约 69 年)
-- **第 42~52 位**:一共 10 位,一般来说,前 5 位表示机房 ID,后 5 位表示机器 ID(实际项目中可以根据实际情况调整)。这样就可以区分不同集群/机房的节点。
-- **第 53~64 位**:一共 12 位,用来表示序列号。 序列号为自增值,代表单台机器每毫秒能够产生的最大 ID 数(2^12 = 4096),也就是说单台机器每毫秒最多可以生成 4096 个 唯一 ID。
+
+
+- **sign(1bit)**:符号位(标识正负),始终为 0,代表生成的 ID 为正数。
+- **timestamp (41 bits)**:一共 41 位,用来表示**相对时间戳**(距自定义基点的毫秒数),可支撑 2^41 毫秒(约 69 年)。通常基点设为系统上线时间(如 2020-01-01),而非 Unix 纪元
+- **datacenter id + worker id (10 bits)**:一般来说,前 5 位表示机房 ID,后 5 位表示机器 ID(实际项目中可以根据实际情况调整)。这样就可以区分不同集群/机房的节点。
+- **sequence (12 bits)**:一共 12 位,用来表示序列号。 序列号为自增值,代表单台机器每毫秒能够产生的最大 ID 数(2^12 = 4096),也就是说单台机器每毫秒最多可以生成 4096 个 唯一 ID。
+
+> **⚠️ 高并发警示**:如果某一毫秒内的并发请求超过 4096 个,算法会**阻塞等待直到下一毫秒**。这可能导致在高并发瞬间(如秒杀、大促)出现响应延迟毛刺(Latency Spike)。生产环境需评估峰值 QPS,必要时采用多实例分片或改造算法增加 sequence 位数。
+
+在实际项目中,我们一般也会对 Snowflake 算法进行改造,最常见的就是在 Snowflake 算法生成的 ID 中加入业务类型信息。
-
+#### Snowflake 时钟回拨问题与解决
-如果你想要使用 Snowflake 算法的话,一般不需要你自己再造轮子。有很多基于 Snowflake 算法的开源实现比如美团 的 Leaf、百度的 UidGenerator,并且这些开源实现对原有的 Snowflake 算法进行了优化。
+**问题根因**:NTP 同步、人工调整时间、硬件时钟漂移可能导致系统时间倒退。
-另外,在实际项目中,我们一般也会对 Snowflake 算法进行改造,最常见的就是在 Snowflake 算法生成的 ID 中加入业务类型信息。
+**解决方案对比**:
+
+| 方案 | 优点 | 缺点 | 适用场景 |
+| ------------------ | -------------- | ------------------------ | ---------------------- |
+| **拒绝服务** | 实现简单 | 时钟回拨期间完全不可用 | 对可用性要求不高的场景 |
+| **等待追回** | 保证 ID 唯一性 | 可能长时间阻塞 | 时钟稳定的内网环境 |
+| **备用 Worker ID** | 高可用 | 实现复杂,需考虑 ZK 脑裂 | 生产环境推荐 |
+
+**推荐**:生产环境使用美团 Leaf 或 IdGenerator,它们已内置时钟回拨处理。
+
+#### Snowflake Worker ID 分配难题
+
+在**容器化部署(Kubernetes)** 环境下,Snowflake 的 Worker ID 分配成为最大痛点:
+
+**问题场景**:
+
+- Pod 的 IP 和名称是动态的,重启后会变化。
+- 无法像物理机一样预先配置固定的 Worker ID。
+- 自动扩缩容时需要动态申领和释放 Worker ID。
+
+**主流解决方案**:
+
+| 方案 | 实现方式 | 优点 | 缺点 |
+| ------------------ | ---------------------------------------------------- | -------------------- | ----------------------- |
+| **ZooKeeper 注册** | 服务启动时在 ZK 创建临时节点,节点序号作为 Worker ID | 自动回收,崩溃后释放 | 依赖 ZK,增加运维复杂度 |
+| **Redis 注册** | 使用 `SETNX` + 过期时间实现 Worker ID 申领 | 轻量,无额外组件 | 需处理 Redis 宕机场景 |
+| **数据库分配** | 启动时从数据库分配并持久化到本地文件 | 简单可靠 | 依赖数据库 |
+| **动态 Worker ID** | 使用 Pod IP 或 UID 哈希生成 | 无需中心化组件 | 可能产生哈希冲突 |
+
+**推荐**:生产环境使用美团 Leaf(基于 ZooKeeper)或滴滴 Tinyid(基于数据库),它们已内置 Worker ID 自动管理。
我们再来看看 Snowflake 算法的优缺点:
-- **优点**:生成速度比较快、生成的 ID 有序递增、比较灵活(可以对 Snowflake 算法进行简单的改造比如加入业务 ID)
-- **缺点**:需要解决重复 ID 问题(依赖时间,当机器时间不对的情况下,可能导致会产生重复 ID)。
+- **优点**:生成速度比较快、生成的 ID 有序递增、比较灵活(可以对 Snowflake 算法进行简单的改造比如加入业务 ID)。
+- **缺点**:**时钟回拨风险**(需额外处理,详见上方解决方案)、依赖机器 ID 对分布式环境不友好(当需要自动启停或增减机器时,固定的机器 ID 可能不够灵活)。
+
+如果你想要使用 Snowflake 算法的话,一般不需要你自己再造轮子。有很多基于 Snowflake 算法的开源实现比如美团 的 Leaf、百度的 UidGenerator(后面会提到),并且这些开源实现对原有的 Snowflake 算法进行了优化,性能更优秀,还解决了 Snowflake 算法的时间回拨问题和依赖机器 ID 的问题。
-### 开源框架
+并且,Seata 还提出了“改良版雪花算法”,针对原版雪花算法进行了一定的优化改良,解决了时间回拨问题,大幅提高的 QPS。具体介绍和改进原理,可以参考下面这两篇文章:
-#### UidGenerator(百度)
+- [Seata 基于改良版雪花算法的分布式 UUID 生成器分析](https://seata.io/zh-cn/blog/seata-analysis-UUID-generator.html)
+- [在开源项目中看到一个改良版的雪花算法,现在它是你的了。](https://www.cnblogs.com/thisiswhy/p/17611163.html)
+
+## 工业级分布式 ID 开源框架对比
+
+### UidGenerator(百度)
[UidGenerator](https://github.com/baidu/uid-generator) 是百度开源的一款基于 Snowflake(雪花算法)的唯一 ID 生成器。
-不过,UidGenerator 对 Snowflake(雪花算法)进行了改进,生成的唯一 ID 组成如下。
+不过,UidGenerator 对 Snowflake(雪花算法)进行了改进,生成的唯一 ID 组成如下:
+
+
-
+- **sign(1bit)**:符号位(标识正负),始终为 0,代表生成的 ID 为正数。
+- **delta seconds (28 bits)**:当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约 8.7 年
+- **worker id (22 bits)**:机器 id,最多可支持约 420w 次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。
+- **sequence (13 bits)**:每秒下的并发序列,13 bits 可支持每秒 8192 个并发。
可以看出,和原始 Snowflake(雪花算法)生成的唯一 ID 的组成不太一样。并且,上面这些参数我们都可以自定义。
@@ -302,21 +413,25 @@ UidGenerator 官方文档中的介绍如下:
自 18 年后,UidGenerator 就基本没有再维护了,我这里也不过多介绍。想要进一步了解的朋友,可以看看 [UidGenerator 的官方介绍](https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md)。
-#### Leaf(美团)
+### Leaf(美团)
-**[Leaf](https://github.com/Meituan-Dianping/Leaf)** 是美团开源的一个分布式 ID 解决方案 。这个项目的名字 Leaf(树叶) 起源于德国哲学家、数学家莱布尼茨的一句话:“There are no two identical leaves in the world”(世界上没有两片相同的树叶) 。这名字起得真心挺不错的,有点文艺青年那味了!
+[Leaf](https://github.com/Meituan-Dianping/Leaf) 是美团开源的一个分布式 ID 解决方案 。这个项目的名字 Leaf(树叶) 起源于德国哲学家、数学家莱布尼茨的一句话:“There are no two identical leaves in the world”(世界上没有两片相同的树叶) 。这名字起得真心挺不错的,有点文艺青年那味了!
-Leaf 提供了 **号段模式** 和 **Snowflake(雪花算法)** 这两种模式来生成分布式 ID。并且,它支持双号段,还解决了雪花 ID 系统时钟回拨问题。不过,时钟问题的解决需要弱依赖于 Zookeeper 。
+Leaf 提供了 **号段模式** 和 **Snowflake(雪花算法)** 这两种模式来生成分布式 ID。并且,它支持双号段,还解决了雪花 ID 系统时钟回拨问题。不过,时钟问题的解决需要弱依赖于 Zookeeper(使用 Zookeeper 作为注册中心,通过在特定路径下读取和创建子节点来管理 workId) 。
Leaf 的诞生主要是为了解决美团各个业务线生成分布式 ID 的方法多种多样以及不可靠的问题。
-Leaf 对原有的号段模式进行改进,比如它这里增加了双号段避免获取 DB 在获取号段的时候阻塞请求获取 ID 的线程。简单来说,就是我一个号段还没用完之前,我自己就主动提前去获取下一个号段(图片来自于美团官方文章:[《Leaf——美团点评分布式 ID 生成系统》](https://tech.meituan.com/2017/04/21/mt-leaf.html))。
+Leaf 对原有的号段模式进行了核心优化——**双 Buffer 机制(Double Buffer Optimization)**:
-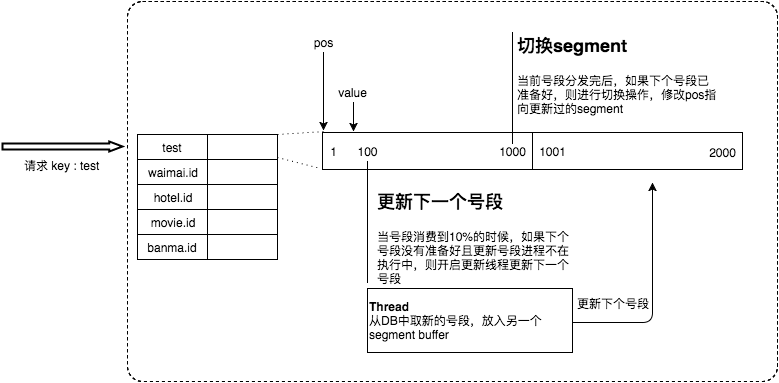
+> **设计原理**:Leaf 不会在号段用尽时才去 DB 申请,而是在当前号段使用率达到一定阈值(如 10%~20%)时,异步线程**提前**去 DB 申请下一个号段并预加载到内存。这使得 ID 获取的 TP999 极其平稳,彻底消除了 DB 访问带来的延迟抖动。
+
+(图片来自于美团官方文章:[《Leaf——美团点评分布式 ID 生成系统》](https://tech.meituan.com/2017/04/21/mt-leaf.html))
+
+
根据项目 README 介绍,在 4C8G VM 基础上,通过公司 RPC 方式调用,QPS 压测结果近 5w/s,TP999 1ms。
-#### Tinyid(滴滴)
+### Tinyid(滴滴)
[Tinyid](https://github.com/didi/tinyid) 是滴滴开源的一款基于数据库号段模式的唯一 ID 生成器。
@@ -324,7 +439,7 @@ Leaf 对原有的号段模式进行改进,比如它这里增加了双号段避
为了搞清楚这个问题,我们先来看看基于数据库号段模式的简单架构方案。(图片来自于 Tinyid 的官方 wiki:[《Tinyid 原理介绍》](https://github.com/didi/tinyid/wiki/tinyid%E5%8E%9F%E7%90%86%E4%BB%8B%E7%BB%8D))
-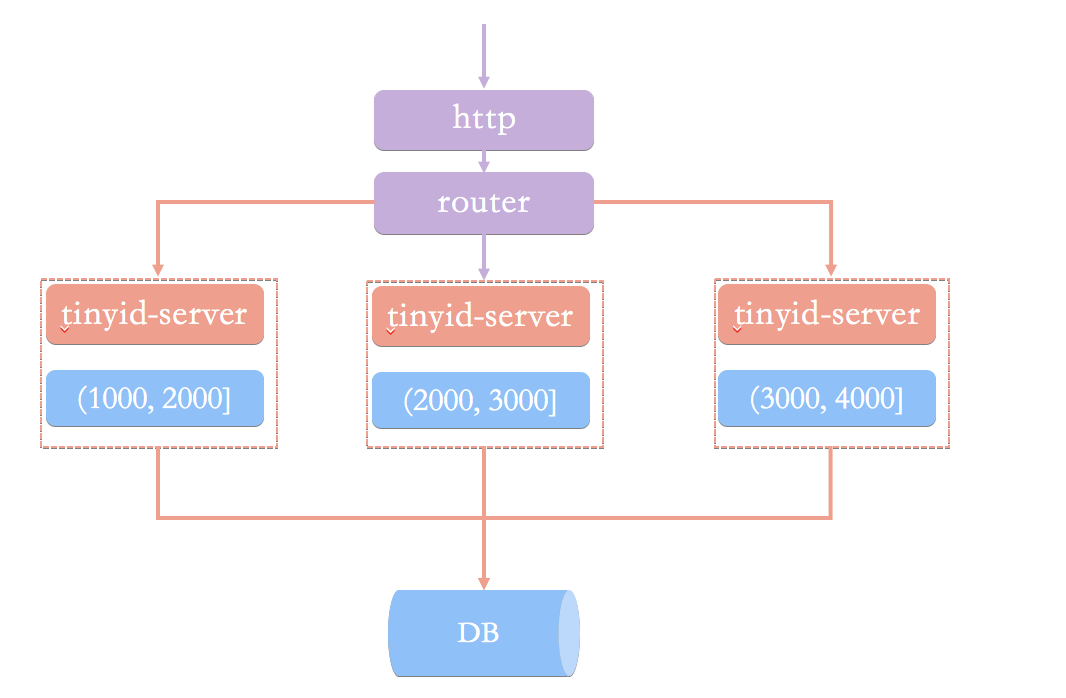
+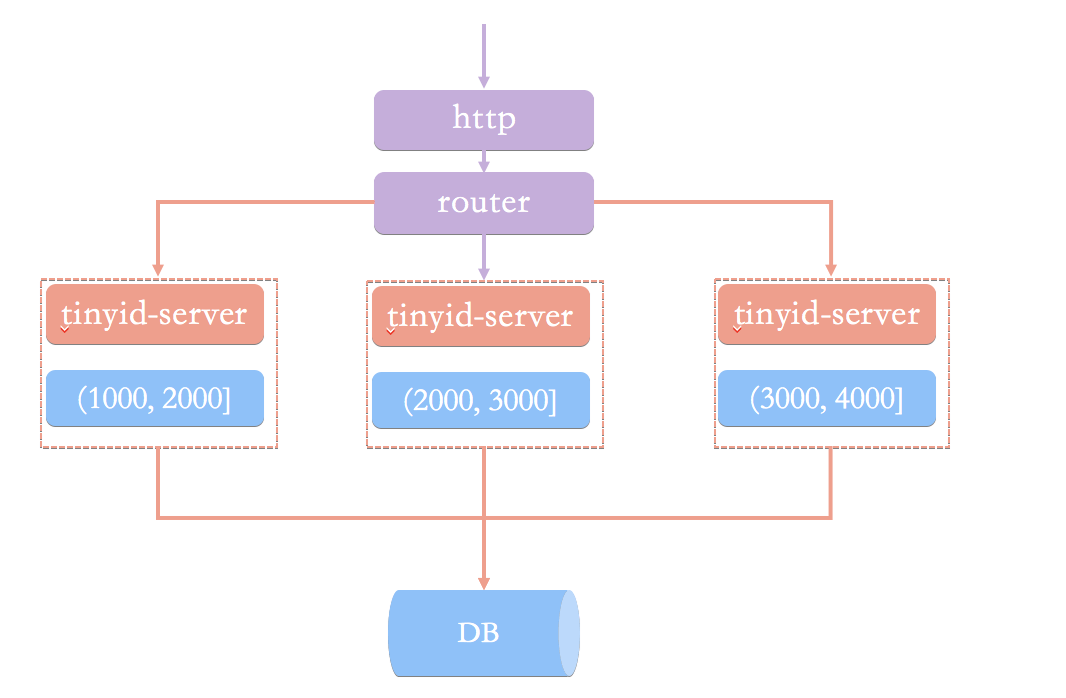
在这种架构模式下,我们通过 HTTP 请求向发号器服务申请唯一 ID。负载均衡 router 会把我们的请求送往其中的一台 tinyid-server。
@@ -337,7 +452,7 @@ Leaf 对原有的号段模式进行改进,比如它这里增加了双号段避
Tinyid 的原理比较简单,其架构如下图所示:
-
+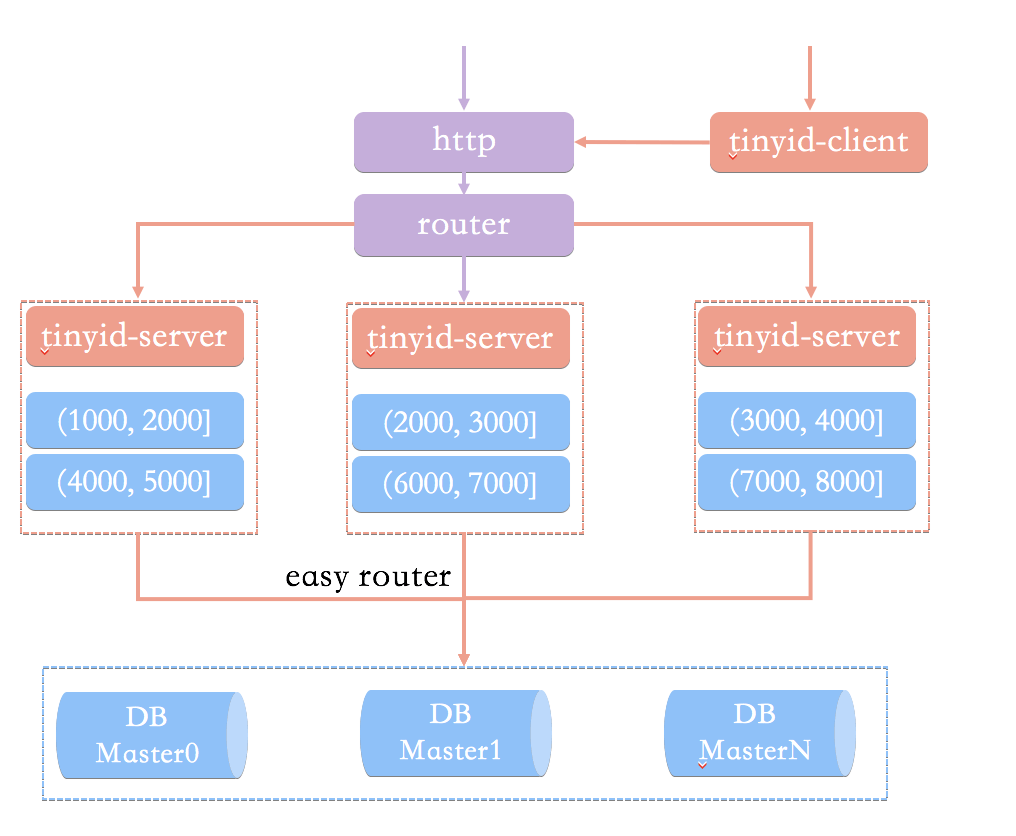
相比于基于数据库号段模式的简单架构方案,Tinyid 方案主要做了下面这些优化:
@@ -347,10 +462,45 @@ Tinyid 的原理比较简单,其架构如下图所示:
Tinyid 的优缺点这里就不分析了,结合数据库号段模式的优缺点和 Tinyid 的原理就能知道。
+### IdGenerator(个人)
+
+和 UidGenerator、Leaf 一样,[IdGenerator](https://github.com/yitter/IdGenerator) 也是一款基于 Snowflake(雪花算法)的唯一 ID 生成器。
+
+IdGenerator 有如下特点:
+
+- 生成的唯一 ID 更短;
+- 兼容所有雪花算法(号段模式或经典模式,大厂或小厂);
+- 原生支持 C#/Java/Go/C/Rust/Python/Node.js/PHP(C 扩展)/SQL/ 等语言,并提供多线程安全调用动态库(FFI);
+- 解决了时间回拨问题,支持手工插入新 ID(当业务需要在历史时间生成新 ID 时,用本算法的预留位能生成 5000 个每秒);
+- 不依赖外部存储系统;
+- 默认配置下,ID 可用 71000 年不重复。
+
+IdGenerator 生成的唯一 ID 组成如下:
+
+
+
+- **timestamp (位数不固定)**:时间差,是生成 ID 时的系统时间减去 BaseTime(基础时间,也称基点时间、原点时间、纪元时间,默认值为 2020 年) 的总时间差(毫秒单位)。初始为 5bits,随着运行时间而增加。如果觉得默认值太老,你可以重新设置,不过要注意,这个值以后最好不变。
+- **worker id (默认 6 bits)**:机器 id,机器码,最重要参数,是区分不同机器或不同应用的唯一 ID,最大值由 `WorkerIdBitLength`(默认 6)限定。如果一台服务器部署多个独立服务,需要为每个服务指定不同的 WorkerId。
+- **sequence (默认 6 bits)**:序列数,是每毫秒下的序列数,由参数中的 `SeqBitLength`(默认 6)限定。增加 `SeqBitLength` 会让性能更高,但生成的 ID 也会更长。
+
+Java 语言使用示例:。
+
## 总结
通过这篇文章,我基本上已经把最常见的分布式 ID 生成方案都总结了一波。
除了上面介绍的方式之外,像 ZooKeeper 这类中间件也可以帮助我们生成唯一 ID。**没有银弹,一定要结合实际项目来选择最适合自己的方案。**
-不过,本文主要介绍的是分布式 ID 的理论知识。在实际的面试中,面试官可能会结合具体的业务场景来考察你对分布式 ID 的设计,你可以参考这篇文章:[分布式 ID 设计指南](https://chat.yqcloud.top/distributed-id-design.md)(对于实际工作中分布式 ID 的设计也非常有帮助)。
+**核心方案横向对比表:**
+
+| **方案** | **性能** | **有序性** | **运维成本** | **适用场景** |
+| -------------- | -------- | ---------- | ------------ | --------------------------------------- |
+| **数据库自增** | 低 | 严格递增 | 低 | 业务量小、单机架构、后台系统 |
+| **号段模式** | 高 | 趋势递增 | 中 | 高并发、追求极致吞吐量的互联网业务 |
+| **Redis 方案** | 很高 | 严格递增 | 中 | 已有 Redis 集群,能容忍极小概率 ID 回退 |
+| **Snowflake** | 高 | 趋势递增 | 低/中 | 大中型分布式系统、Java 生态(最主流) |
+| **UUID v7** | 高 | 趋势递增 | 极低 | 云原生、无中心化集群、追求开箱即用 |
+
+不过,本文主要介绍的是分布式 ID 的理论知识。在实际的面试中,面试官可能会结合具体的业务场景来考察你对分布式 ID 的设计,你可以参考这篇文章:[分布式 ID 设计指南](./distributed-id-design)(对于实际工作中分布式 ID 的设计也非常有帮助)。
+
+
diff --git a/docs/distributed-system/distributed-lock-implementations.md b/docs/distributed-system/distributed-lock-implementations.md
index 1d7e5494988..d38726a4d63 100644
--- a/docs/distributed-system/distributed-lock-implementations.md
+++ b/docs/distributed-system/distributed-lock-implementations.md
@@ -1,8 +1,11 @@
---
title: 分布式锁常见实现方案总结
+description: 分布式锁常见实现方案详解,包括基于Redis、ZooKeeper实现分布式锁的原理、优缺点及最佳实践。
category: 分布式
---
+
+
通常情况下,我们一般会选择基于 Redis 或者 ZooKeeper 实现分布式锁,Redis 用的要更多一点,我这里也先以 Redis 为例介绍分布式锁的实现。
## 基于 Redis 实现分布式锁
@@ -54,7 +57,7 @@ OK
```
- **lockKey**:加锁的锁名;
-- **uniqueValue**:能够唯一标示锁的随机字符串;
+- **uniqueValue**:能够唯一标识锁的随机字符串;
- **NX**:只有当 lockKey 对应的 key 值不存在的时候才能 SET 成功;
- **EX**:过期时间设置(秒为单位)EX 3 标示这个锁有一个 3 秒的自动过期时间。与 EX 对应的是 PX(毫秒为单位),这两个都是过期时间设置。
@@ -200,13 +203,11 @@ Redlock 是直接操作 Redis 节点的,并不是通过 Redis 集群操作的
Redlock 实现比较复杂,性能比较差,发生时钟变迁的情况下还存在安全性隐患。《数据密集型应用系统设计》一书的作者 Martin Kleppmann 曾经专门发文([How to do distributed locking - Martin Kleppmann - 2016](https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html))怼过 Redlock,他认为这是一个很差的分布式锁实现。感兴趣的朋友可以看看[Redis 锁从面试连环炮聊到神仙打架](https://mp.weixin.qq.com/s?__biz=Mzg3NjU3NTkwMQ==&mid=2247505097&idx=1&sn=5c03cb769c4458350f4d4a321ad51f5a&source=41#wechat_redirect)这篇文章,有详细介绍到 antirez 和 Martin Kleppmann 关于 Redlock 的激烈辩论。
-实际项目中不建议使用 Redlock 算法,成本和收益不成正比。
-
-如果不是非要实现绝对可靠的分布式锁的话,其实单机版 Redis 就完全够了,实现简单,性能也非常高。如果你必须要实现一个绝对可靠的分布式锁的话,可以基于 ZooKeeper 来做,只是性能会差一些。
+实际项目中不建议使用 Redlock 算法,成本和收益不成正比,可以考虑基于 Redis 主从复制+哨兵模式实现分布式锁。
## 基于 ZooKeeper 实现分布式锁
-Redis 实现分布式锁性能较高,ZooKeeper 实现分布式锁可靠性更高。实际项目中,我们应该根据业务的具体需求来选择。
+ZooKeeper 相比于 Redis 实现分布式锁,除了提供相对更高的可靠性之外,在功能层面还有一个非常有用的特性:**Watch 机制**。这个机制可以用来实现公平的分布式锁。不过,使用 ZooKeeper 实现的分布式锁在性能方面相对较差,因此如果对性能要求比较高的话,ZooKeeper 可能就不太适合了。
### 如何基于 ZooKeeper 实现分布式锁?
@@ -279,7 +280,7 @@ client.close();
使用 Redis 实现分布式锁的时候,我们是通过过期时间来避免锁无法被释放导致死锁问题的,而 ZooKeeper 直接利用临时节点的特性即可。
-假设不适用顺序节点的话,所有尝试获取锁的客户端都会对持有锁的子节点加监听器。当该锁被释放之后,势必会造成所有尝试获取锁的客户端来争夺锁,这样对性能不友好。使用顺序节点之后,只需要监听前一个节点就好了,对性能更友好。
+假设不使用顺序节点的话,所有尝试获取锁的客户端都会对持有锁的子节点加监听器。当该锁被释放之后,势必会造成所有尝试获取锁的客户端来争夺锁,这样对性能不友好。使用顺序节点之后,只需要监听前一个节点就好了,对性能更友好。
### 为什么要设置对前一个节点的监听?
@@ -363,4 +364,13 @@ private static class LockData
## 总结
-这篇文章我们介绍了实现分布式锁的两种常见方式。至于具体选择 Redis 还是 ZooKeeper 来实现分布式锁,还是要看业务的具体需求。如果对性能要求比较高的话,建议使用 Redis 实现分布式锁。如果对可靠性要求比较高的话,建议使用 ZooKeeper 实现分布式锁。
\ No newline at end of file
+在这篇文章中,我介绍了实现分布式锁的两种常见方式:**Redis** 和 **ZooKeeper**。至于具体选择 Redis 还是 ZooKeeper 来实现分布式锁,还是要根据业务的具体需求来决定。
+
+- 如果对性能要求比较高的话,建议使用 Redis 实现分布式锁。推荐优先选择 **Redisson** 提供的现成分布式锁,而不是自己实现。实际项目中不建议使用 Redlock 算法,成本和收益不成正比,可以考虑基于 Redis 主从复制+哨兵模式实现分布式锁。
+- 如果对可靠性要求比较高,建议使用 ZooKeeper 实现分布式锁,推荐基于 **Curator** 框架来实现。不过,现在很多项目都不会用到 ZooKeeper,如果单纯是因为分布式锁而引入 ZooKeeper 的话,那是不太可取的,不建议这样做,为了一个小小的功能增加了系统的复杂度。
+
+需要注意的是,无论选择哪种方式实现分布式锁,包括 Redis、ZooKeeper 或 Etcd(本文没介绍,但也经常用来实现分布式锁),都无法保证 100% 的安全性,特别是在遇到进程垃圾回收(GC)、网络延迟等异常情况下。
+
+为了进一步提高系统的可靠性,建议引入一个兜底机制。例如,可以通过 **版本号(Fencing Token)机制** 来避免并发冲突。
+
+
diff --git a/docs/distributed-system/distributed-lock.md b/docs/distributed-system/distributed-lock.md
index b1277415e3b..1f48e5dc071 100644
--- a/docs/distributed-system/distributed-lock.md
+++ b/docs/distributed-system/distributed-lock.md
@@ -1,8 +1,11 @@
---
title: 分布式锁介绍
+description: 分布式锁基础概念详解,讲解为什么需要分布式锁、分布式锁的核心特性及常见应用场景分析。
category: 分布式
---
+
+
网上有很多分布式锁相关的文章,写了一个相对简洁易懂的版本,针对面试和工作应该够用了。
这篇文章我们先介绍一下分布式锁的基本概念。
@@ -28,7 +31,7 @@ category: 分布式
悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,**共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程**。
-对于单机多线程来说,在 Java 中,我们通常使用 `ReetrantLock` 类、`synchronized` 关键字这类 JDK 自带的 **本地锁** 来控制一个 JVM 进程内的多个线程对本地共享资源的访问。
+对于单机多线程来说,在 Java 中,我们通常使用 `ReentrantLock` 类、`synchronized` 关键字这类 JDK 自带的 **本地锁** 来控制一个 JVM 进程内的多个线程对本地共享资源的访问。
下面是我对本地锁画的一张示意图。
@@ -78,3 +81,5 @@ category: 分布式
- 分布式锁的用途:分布式系统下,不同的服务/客户端通常运行在独立的 JVM 进程上。如果多个 JVM 进程共享同一份资源的话,使用本地锁就没办法实现资源的互斥访问了。
- 分布式锁的应该具备的条件:互斥、高可用、可重入、高性能、非阻塞。
- 分布式锁的常见实现方式:关系型数据库比如 MySQL、分布式协调服务 ZooKeeper、分布式键值存储系统比如 Redis 、Etcd 。
+
+
diff --git a/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-in-action.md b/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-in-action.md
index 04e49a7d218..06389b2986d 100644
--- a/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-in-action.md
+++ b/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-in-action.md
@@ -1,10 +1,13 @@
---
title: ZooKeeper 实战
+description: ZooKeeper实战教程,涵盖Docker安装部署、常用命令操作及Curator客户端的使用方法详解。
category: 分布式
tag:
- ZooKeeper
---
+
+
这篇文章简单给演示一下 ZooKeeper 常见命令的使用以及 ZooKeeper Java 客户端 Curator 的基本使用。介绍到的内容都是最基本的操作,能满足日常工作的基本需要。
如果文章有任何需要改善和完善的地方,欢迎在评论区指出,共同进步!
@@ -293,3 +296,5 @@ zkClient.setData().forPath("/node1/00001","c++".getBytes());//更新节点数据
```java
List childrenPaths = zkClient.getChildren().forPath("/node1");
```
+
+
diff --git a/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.md b/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.md
index f4102f61e6d..b2a21d8ed62 100644
--- a/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.md
+++ b/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.md
@@ -1,10 +1,13 @@
---
title: ZooKeeper相关概念总结(入门)
+description: ZooKeeper入门指南,讲解ZooKeeper核心概念、数据模型、Watcher机制及作为注册中心和分布式锁的应用。
category: 分布式
tag:
- ZooKeeper
---
+
+
相信大家对 ZooKeeper 应该不算陌生。但是你真的了解 ZooKeeper 到底有啥用不?如果别人/面试官让你给他讲讲对于 ZooKeeper 的认识,你能回答到什么地步呢?
拿我自己来说吧!我本人在大学曾经使用 Dubbo 来做分布式项目的时候,使用了 ZooKeeper 作为注册中心。为了保证分布式系统能够同步访问某个资源,我还使用 ZooKeeper 做过分布式锁。另外,我在学习 Kafka 的时候,知道 Kafka 很多功能的实现依赖了 ZooKeeper。
@@ -39,7 +42,7 @@ _如果文章有任何需要改善和完善的地方,欢迎在评论区指出
ZooKeeper 是一个开源的**分布式协调服务**,它的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
-> **原语:** 操作系统或计算机网络用语范畴。是由若干条指令组成的,用于完成一定功能的一个过程。具有不可分割性·即原语的执行必须是连续的,在执行过程中不允许被中断。
+> **原语:** 操作系统或计算机网络用语范畴。是由若干条指令组成的,用于完成一定功能的一个过程。具有不可分割性,即原语的执行必须是连续的,在执行过程中不允许被中断。
ZooKeeper 为我们提供了高可用、高性能、稳定的分布式数据一致性解决方案,通常被用于实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。这些功能的实现主要依赖于 ZooKeeper 提供的 **数据存储+事件监听** 功能(后文会详细介绍到) 。
@@ -57,6 +60,9 @@ ZooKeeper 将数据保存在内存中,性能是不错的。 在“读”多于
- **原子性:** 所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用。
- **单一系统映像:** 无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
- **可靠性:** 一旦一次更改请求被应用,更改的结果就会被持久化,直到被下一次更改覆盖。
+- **顺序一致性**:所有客户端看到的数据变更顺序是一致的,按照操作被提交的全局 FIFO 顺序进行更新。但这并不保证变更会立即传播到所有节点。
+- **集群部署**:3~5 台(最好奇数台)机器就可以组成一个集群,每台机器都在内存保存了 ZooKeeper 的全部数据,机器之间互相通信同步数据,客户端连接任何一台机器都可以。
+- **高可用:**如果某台机器宕机,会保证数据不丢失。集群中挂掉不超过一半的机器,都能保证集群可用。比如 3 台机器可以挂 1 台,5 台机器可以挂 2 台。
### ZooKeeper 应用场景
@@ -76,9 +82,9 @@ _破音:拿出小本本,下面的内容非常重要哦!_
### Data model(数据模型)
-ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都可以存储数据,这些数据可以是数字、字符串或者是二级制序列。并且。每个节点还可以拥有 N 个子节点,最上层是根节点以“/”来代表。每个数据节点在 ZooKeeper 中被称为 **znode**,它是 ZooKeeper 中数据的最小单元。并且,每个 znode 都一个唯一的路径标识。
+ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都可以存储数据,这些数据可以是数字、字符串或者是二进制序列。并且。每个节点还可以拥有 N 个子节点,最上层是根节点以“/”来代表。每个数据节点在 ZooKeeper 中被称为 **znode**,它是 ZooKeeper 中数据的最小单元。并且,每个 znode 都有一个唯一的路径标识。
-强调一句:**ZooKeeper 主要是用来协调服务的,而不是用来存储业务数据的,所以不要放比较大的数据在 znode 上,ZooKeeper 给出的上限是每个结点的数据大小最大是 1M。**
+强调一句:**ZooKeeper 主要是用来协调服务的,而不是用来存储业务数据的,所以不要放比较大的数据在 znode 上,ZooKeeper 给出的每个节点的数据大小上限是 1M 。**
从下图可以更直观地看出:ZooKeeper 节点路径标识方式和 Unix 文件系统路径非常相似,都是由一系列使用斜杠"/"进行分割的路径表示,开发人员可以向这个节点中写入数据,也可以在节点下面创建子节点。这些操作我们后面都会介绍到。
@@ -91,7 +97,7 @@ ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都
我们通常是将 znode 分为 4 大类:
- **持久(PERSISTENT)节点**:一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
-- **临时(EPHEMERAL)节点**:临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,**临时节点只能做叶子节点** ,不能创建子节点。
+- **临时(EPHEMERAL)节点**:临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失**。并且,**临时节点只能做叶子节点** ,不能创建子节点。
- **持久顺序(PERSISTENT_SEQUENTIAL)节点**:除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001`、`/node1/app0000000002` 。
- **临时顺序(EPHEMERAL_SEQUENTIAL)节点**:除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性
@@ -215,8 +221,8 @@ ZooKeeper 集群中的所有机器通过一个 **Leader 选举过程** 来选定
1. **Leader election(选举阶段)**:节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准 leader。
2. **Discovery(发现阶段)**:在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
-3. **Synchronization(同步阶段)** :同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后准 leader 才会成为真正的 leader。
-4. **Broadcast(广播阶段)** :到了这个阶段,ZooKeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
+3. **Synchronization(同步阶段)**:同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后准 leader 才会成为真正的 leader。
+4. **Broadcast(广播阶段)**:到了这个阶段,ZooKeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
ZooKeeper 集群中的服务器状态有下面几种:
@@ -229,8 +235,8 @@ ZooKeeper 集群中的服务器状态有下面几种:
ZooKeeper 集群在宕掉几个 ZooKeeper 服务器之后,如果剩下的 ZooKeeper 服务器个数大于宕掉的个数的话整个 ZooKeeper 才依然可用。假如我们的集群中有 n 台 ZooKeeper 服务器,那么也就是剩下的服务数必须大于 n/2。先说一下结论,2n 和 2n-1 的容忍度是一样的,都是 n-1,大家可以先自己仔细想一想,这应该是一个很简单的数学问题了。
-比如假如我们有 3 台,那么最大允许宕掉 1 台 ZooKeeper 服务器,如果我们有 4 台的的时候也同样只允许宕掉 1 台。
-假如我们有 5 台,那么最大允许宕掉 2 台 ZooKeeper 服务器,如果我们有 6 台的的时候也同样只允许宕掉 2 台。
+比如假如我们有 3 台,那么最大允许宕掉 1 台 ZooKeeper 服务器,如果我们有 4 台的时候也同样只允许宕掉 1 台。
+假如我们有 5 台,那么最大允许宕掉 2 台 ZooKeeper 服务器,如果我们有 6 台的时候也同样只允许宕掉 2 台。
综上,何必增加那一个不必要的 ZooKeeper 呢?
@@ -252,7 +258,7 @@ Paxos 算法应该可以说是 ZooKeeper 的灵魂了。但是,ZooKeeper 并
### ZAB 协议介绍
-ZAB(ZooKeeper Atomic Broadcast 原子广播) 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。 在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
+ZAB(ZooKeeper Atomic Broadcast,原子广播) 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。 在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
### ZAB 协议两种基本的模式:崩溃恢复和消息广播
@@ -261,12 +267,41 @@ ZAB 协议包括两种基本的模式,分别是
- **崩溃恢复**:当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进入恢复模式并选举产生新的 Leader 服务器。当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该 Leader 服务器完成了状态同步之后,ZAB 协议就会退出恢复模式。其中,**所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和 Leader 服务器的数据状态保持一致**。
- **消息广播**:**当集群中已经有过半的 Follower 服务器完成了和 Leader 服务器的状态同步,那么整个服务框架就可以进入消息广播模式了。** 当一台同样遵守 ZAB 协议的服务器启动后加入到集群中时,如果此时集群中已经存在一个 Leader 服务器在负责进行消息广播,那么新加入的服务器就会自觉地进入数据恢复模式:找到 Leader 所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。
+### ZAB 协议&Paxos 算法文章推荐
+
关于 **ZAB 协议&Paxos 算法** 需要讲和理解的东西太多了,具体可以看下面这几篇文章:
- [Paxos 算法详解](https://javaguide.cn/distributed-system/protocol/paxos-algorithm.html)
-- [Zookeeper ZAB 协议分析](https://dbaplus.cn/news-141-1875-1.html)
+- [Zab 协议详解](https://javaguide.cn/distributed-system/protocol/zab.html)
- [Raft 算法详解](https://javaguide.cn/distributed-system/protocol/raft-algorithm.html)
+## ZooKeeper VS ETCD
+
+[ETCD](https://etcd.io/) 是一种强一致性的分布式键值存储,它提供了一种可靠的方式来存储需要由分布式系统或机器集群访问的数据。ETCD 内部采用 [Raft 算法](https://javaguide.cn/distributed-system/protocol/raft-algorithm.html)作为一致性算法,基于 Go 语言实现。
+
+与 ZooKeeper 类似,ETCD 也可用于数据发布/订阅、负载均衡、命名服务、分布式协调/通知、分布式锁等场景。那二者如何选择呢?
+
+得物技术的[浅析如何基于 ZooKeeper 实现高可用架构](https://mp.weixin.qq.com/s/pBI3rjv5NdS1124Z7HQ-JA)这篇文章给出了如下的对比表格(我进一步做了优化),可以作为参考:
+
+| | ZooKeeper | ETCD |
+| ---------------- | --------------------------------------------------------------------- | ------------------------------------------------------ |
+| **语言** | Java | Go |
+| **协议** | TCP | Grpc |
+| **接口调用** | 必须要使用自己的 client 进行调用 | 可通过 HTTP 传输,即可通过 CURL 等命令实现调用 |
+| **一致性算法** | Zab 协议 | Raft 算法 |
+| **Watcher 机制** | 较局限,一次性触发器 | 一次 Watch 可以监听所有的事件 |
+| **数据模型** | 基于目录的层次模式 | 参考了 zk 的数据模型,是个扁平的 kv 模型 |
+| **存储** | kv 存储,使用的是 ConcurrentHashMap,内存存储,一般不建议存储较多数据 | kv 存储,使用 bbolt 存储引擎,可以处理几个 GB 的数据。 |
+| **MVCC** | 不支持 | 支持,通过两个 B+ Tree 进行版本控制 |
+| **全局 Session** | 存在缺陷 | 实现更灵活,避免了安全性问题 |
+| **权限校验** | ACL | RBAC |
+| **事务能力** | 提供了简易的事务能力 | 只提供了版本号的检查能力 |
+| **部署维护** | 复杂 | 简单 |
+
+ZooKeeper 在存储性能、全局 Session、Watcher 机制等方面存在一定局限性,越来越多的开源项目在替换 ZooKeeper 为 Raft 实现或其它分布式协调服务,例如:[Kafka Needs No Keeper - Removing ZooKeeper Dependency (confluent.io)](https://www.confluent.io/blog/removing-zookeeper-dependency-in-kafka/)、[Moving Toward a ZooKeeper-Less Apache Pulsar (streamnative.io)](https://streamnative.io/blog/moving-toward-zookeeper-less-apache-pulsar)。
+
+ETCD 相对来说更优秀一些,提供了更稳定的高负载读写能力,对 ZooKeeper 暴露的许多问题进行了改进优化。并且,ETCD 基本能够覆盖 ZooKeeper 的所有应用场景,实现对其的替代。
+
## 总结
1. ZooKeeper 本身就是一个分布式程序(只要半数以上节点存活,ZooKeeper 就能正常服务)。
@@ -279,3 +314,6 @@ ZAB 协议包括两种基本的模式,分别是
## 参考
- 《从 Paxos 到 ZooKeeper 分布式一致性原理与实践》
+- 谈谈 ZooKeeper 的局限性:
+
+
diff --git a/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.md b/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.md
index f046e189788..a2c70bf827d 100644
--- a/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.md
+++ b/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.md
@@ -1,5 +1,6 @@
---
title: ZooKeeper相关概念总结(进阶)
+description: ZooKeeper进阶详解,深入讲解ZAB协议、Leader选举机制、集群部署及与Eureka等注册中心的对比。
category: 分布式
tag:
- ZooKeeper
@@ -9,9 +10,7 @@ tag:
## 什么是 ZooKeeper
-`ZooKeeper` 由 `Yahoo` 开发,后来捐赠给了 `Apache` ,现已成为 `Apache` 顶级项目。`ZooKeeper` 是一个开源的分布式应用程序协调服务器,其为分布式系统提供一致性服务。其一致性是通过基于 `Paxos` 算法的 `ZAB` 协议完成的。其主要功能包括:配置维护、分布式同步、集群管理、分布式事务等。
-
-
+`ZooKeeper` 由 `Yahoo` 开发,后来捐赠给了 `Apache` ,现已成为 `Apache` 顶级项目。`ZooKeeper` 是一个开源的分布式应用程序协调服务器,其为分布式系统提供一致性服务。其一致性是通过专门为 ZooKeeper 设计的 **ZAB(ZooKeeper Atomic Broadcast)** 协议完成的。其主要功能包括:配置维护、分布式同步、集群管理等。
简单来说, `ZooKeeper` 是一个 **分布式协调服务框架** 。分布式?协调服务?这啥玩意?🤔🤔
@@ -19,15 +18,15 @@ tag:
比如,我现在有一个秒杀服务,并发量太大单机系统承受不住,那我加几台服务器也 **一样** 提供秒杀服务,这个时候就是 **`Cluster` 集群** 。
-
+
但是,我现在换一种方式,我将一个秒杀服务 **拆分成多个子服务** ,比如创建订单服务,增加积分服务,扣优惠券服务等等,**然后我将这些子服务都部署在不同的服务器上** ,这个时候就是 **`Distributed` 分布式** 。
-
+
而我为什么反驳同学所说的分布式就是加机器呢?因为我认为加机器更加适用于构建集群,因为它真是只有加机器。而对于分布式来说,你首先需要将业务进行拆分,然后再加机器(不仅仅是加机器那么简单),同时你还要去解决分布式带来的一系列问题。
-
+
比如各个分布式组件如何协调起来,如何减少各个系统之间的耦合度,分布式事务的处理,如何去配置整个分布式系统等等。`ZooKeeper` 主要就是解决这些问题的。
@@ -37,7 +36,7 @@ tag:
理解起来其实很简单,比如说把一个班级作为整个系统,而学生是系统中的一个个独立的子系统。这个时候班里的小红小明偷偷谈恋爱被班里的大嘴巴小花发现了,小花欣喜若狂告诉了周围的人,然后小红小明谈恋爱的消息在班级里传播起来了。当在消息的传播(散布)过程中,你抓到一个同学问他们的情况,如果回答你不知道,那么说明整个班级系统出现了数据不一致的问题(因为小花已经知道这个消息了)。而如果他直接不回答你,因为整个班级有消息在进行传播(为了保证一致性,需要所有人都知道才可提供服务),这个时候就出现了系统的可用性问题。
-
+
而上述前者就是 `Eureka` 的处理方式,它保证了 AP(可用性),后者就是我们今天所要讲的 `ZooKeeper` 的处理方式,它保证了 CP(数据一致性)。
@@ -47,7 +46,7 @@ tag:
这时候请你思考一个问题,同学之间如果采用传纸条的方式去传播消息,那么就会出现一个问题——我咋知道我的小纸条有没有传到我想要传递的那个人手中呢?万一被哪个小家伙给劫持篡改了呢,对吧?
-
+
这个时候就引申出一个概念—— **拜占庭将军问题** 。它意指 **在不可靠信道上试图通过消息传递的方式达到一致性是不可能的**, 所以所有的一致性算法的 **必要前提** 就是安全可靠的消息通道。
@@ -73,11 +72,11 @@ tag:
而如果在第一阶段并不是所有参与者都返回了准备好了的消息,那么此时协调者将会给所有参与者发送 **回滚事务的 `rollback` 请求**,参与者收到之后将会 **回滚它在第一阶段所做的事务处理** ,然后再将处理情况返回给协调者,最终协调者收到响应后便给事务发起者返回处理失败的结果。
-
+
个人觉得 2PC 实现得还是比较鸡肋的,因为事实上它只解决了各个事务的原子性问题,随之也带来了很多的问题。
-
+
- **单点故障问题**,如果协调者挂了那么整个系统都处于不可用的状态了。
- **阻塞问题**,即当协调者发送 `prepare` 请求,参与者收到之后如果能处理那么它将会进行事务的处理但并不提交,这个时候会一直占用着资源不释放,如果此时协调者挂了,那么这些资源都不会再释放了,这会极大影响性能。
@@ -93,11 +92,11 @@ tag:
2. **PreCommit 阶段**:协调者根据参与者返回的响应来决定是否可以进行下面的 `PreCommit` 操作。如果上面参与者返回的都是 YES,那么协调者将向所有参与者发送 `PreCommit` 预提交请求,**参与者收到预提交请求后,会进行事务的执行操作,并将 `Undo` 和 `Redo` 信息写入事务日志中** ,最后如果参与者顺利执行了事务则给协调者返回成功的响应。如果在第一阶段协调者收到了 **任何一个 NO** 的信息,或者 **在一定时间内** 并没有收到全部的参与者的响应,那么就会中断事务,它会向所有参与者发送中断请求(abort),参与者收到中断请求之后会立即中断事务,或者在一定时间内没有收到协调者的请求,它也会中断事务。
3. **DoCommit 阶段**:这个阶段其实和 `2PC` 的第二阶段差不多,如果协调者收到了所有参与者在 `PreCommit` 阶段的 YES 响应,那么协调者将会给所有参与者发送 `DoCommit` 请求,**参与者收到 `DoCommit` 请求后则会进行事务的提交工作**,完成后则会给协调者返回响应,协调者收到所有参与者返回的事务提交成功的响应之后则完成事务。若协调者在 `PreCommit` 阶段 **收到了任何一个 NO 或者在一定时间内没有收到所有参与者的响应** ,那么就会进行中断请求的发送,参与者收到中断请求后则会 **通过上面记录的回滚日志** 来进行事务的回滚操作,并向协调者反馈回滚状况,协调者收到参与者返回的消息后,中断事务。
-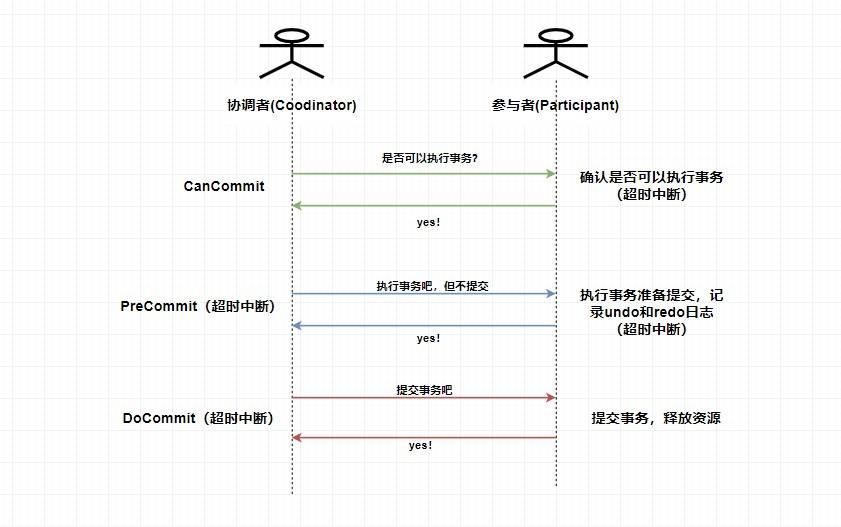
+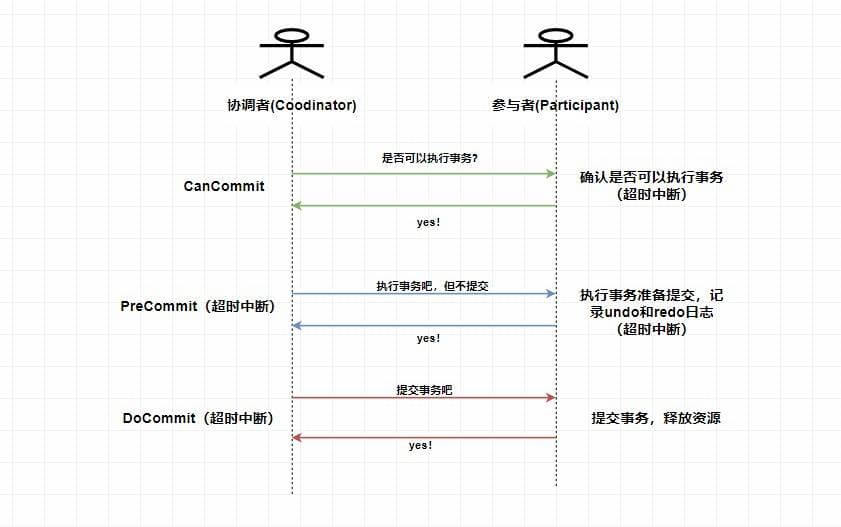
> 这里是 `3PC` 在成功的环境下的流程图,你可以看到 `3PC` 在很多地方进行了超时中断的处理,比如协调者在指定时间内未收到全部的确认消息则进行事务中断的处理,这样能 **减少同步阻塞的时间** 。还有需要注意的是,**`3PC` 在 `DoCommit` 阶段参与者如未收到协调者发送的提交事务的请求,它会在一定时间内进行事务的提交**。为什么这么做呢?是因为这个时候我们肯定**保证了在第一阶段所有的协调者全部返回了可以执行事务的响应**,这个时候我们有理由**相信其他系统都能进行事务的执行和提交**,所以**不管**协调者有没有发消息给参与者,进入第三阶段参与者都会进行事务的提交操作。
-总之,`3PC` 通过一系列的超时机制很好的缓解了阻塞问题,但是最重要的一致性并没有得到根本的解决,比如在 `PreCommit` 阶段,当一个参与者收到了请求之后其他参与者和协调者挂了或者出现了网络分区,这个时候收到消息的参与者都会进行事务提交,这就会出现数据不一致性问题。
+总之,`3PC` 通过一系列的超时机制很好的缓解了阻塞问题,但是最重要的一致性并没有得到根本的解决,比如在 `DoCommit` 阶段,当一个参与者收到了请求之后其他参与者和协调者挂了或者出现了网络分区,这个时候收到消息的参与者都会进行事务提交,这就会出现数据不一致性问题。
所以,要解决一致性问题还需要靠 `Paxos` 算法 ⭐️ ⭐️ ⭐️ 。
@@ -114,7 +113,7 @@ tag:
> 下面是 `prepare` 阶段的流程图,你可以对照着参考一下。
-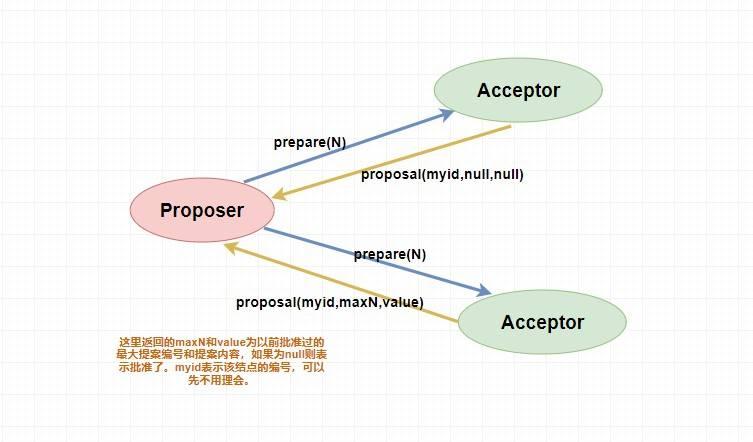
+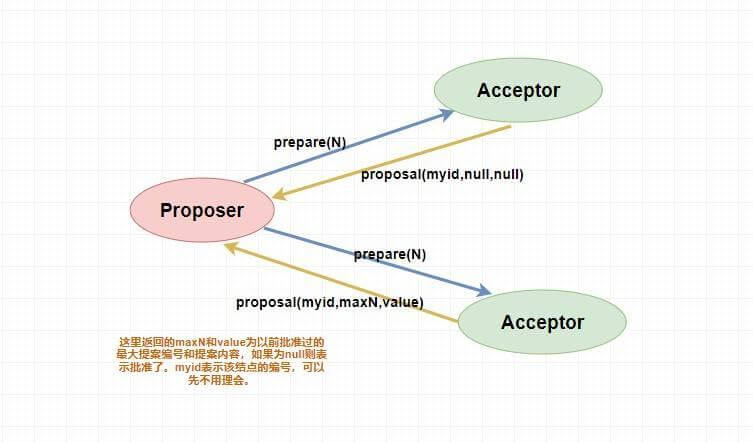
#### accept 阶段
@@ -122,11 +121,11 @@ tag:
表决者收到提案请求后会再次比较本身已经批准过的最大提案编号和该提案编号,如果该提案编号 **大于等于** 已经批准过的最大提案编号,那么就 `accept` 该提案(此时执行提案内容但不提交),随后将情况返回给 `Proposer` 。如果不满足则不回应或者返回 NO 。
-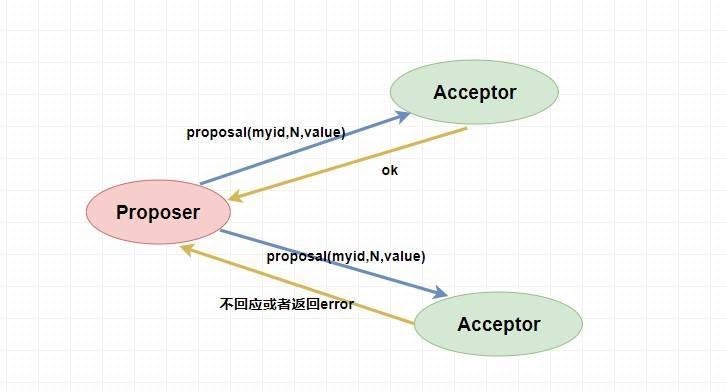
+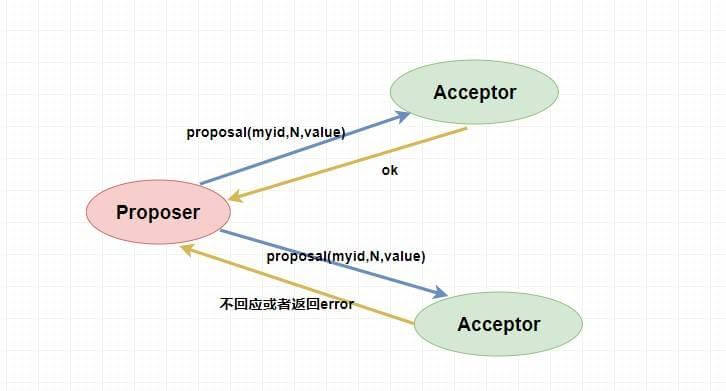
当 `Proposer` 收到超过半数的 `accept` ,那么它这个时候会向所有的 `acceptor` 发送提案的提交请求。需要注意的是,因为上述仅仅是超过半数的 `acceptor` 批准执行了该提案内容,其他没有批准的并没有执行该提案内容,所以这个时候需要**向未批准的 `acceptor` 发送提案内容和提案编号并让它无条件执行和提交**,而对于前面已经批准过该提案的 `acceptor` 来说 **仅仅需要发送该提案的编号** ,让 `acceptor` 执行提交就行了。
-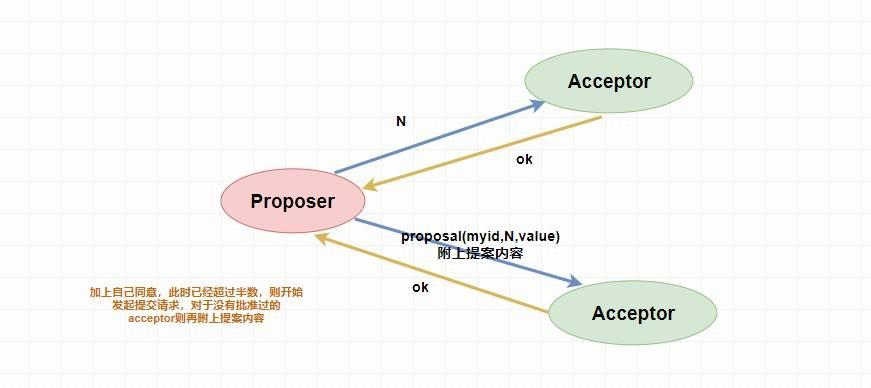
+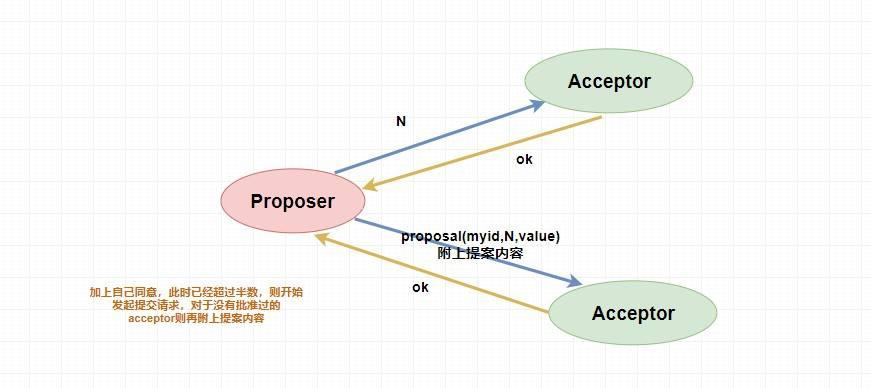
而如果 `Proposer` 如果没有收到超过半数的 `accept` 那么它将会将 **递增** 该 `Proposal` 的编号,然后 **重新进入 `Prepare` 阶段** 。
@@ -140,7 +139,7 @@ tag:
就这样无休无止的永远提案下去,这就是 `paxos` 算法的死循环问题。
-
+
那么如何解决呢?很简单,人多了容易吵架,我现在 **就允许一个能提案** 就行了。
@@ -150,7 +149,7 @@ tag:
作为一个优秀高效且可靠的分布式协调框架,`ZooKeeper` 在解决分布式数据一致性问题时并没有直接使用 `Paxos` ,而是专门定制了一致性协议叫做 `ZAB(ZooKeeper Atomic Broadcast)` 原子广播协议,该协议能够很好地支持 **崩溃恢复** 。
-
+
### ZAB 中的三个角色
@@ -168,11 +167,9 @@ tag:
不就是 **在整个集群中保持数据的一致性** 嘛?如果是你,你会怎么做呢?
-
-
废话,第一步肯定需要 `Leader` 将写请求 **广播** 出去呀,让 `Leader` 问问 `Followers` 是否同意更新,如果超过半数以上的同意那么就进行 `Follower` 和 `Observer` 的更新(和 `Paxos` 一样)。当然这么说有点虚,画张图理解一下。
-
+
嗯。。。看起来很简单,貌似懂了 🤥🤥🤥。这两个 `Queue` 哪冒出来的?答案是 **`ZAB` 需要让 `Follower` 和 `Observer` 保证顺序性** 。何为顺序性,比如我现在有一个写请求 A,此时 `Leader` 将请求 A 广播出去,因为只需要半数同意就行,所以可能这个时候有一个 `Follower` F1 因为网络原因没有收到,而 `Leader` 又广播了一个请求 B,因为网络原因,F1 竟然先收到了请求 B 然后才收到了请求 A,这个时候请求处理的顺序不同就会导致数据的不同,从而 **产生数据不一致问题** 。
@@ -214,7 +211,7 @@ tag:
假设 `Leader (server2)` 发送 `commit` 请求(忘了请看上面的消息广播模式),他发送给了 `server3`,然后要发给 `server1` 的时候突然挂了。这个时候重新选举的时候我们如果把 `server1` 作为 `Leader` 的话,那么肯定会产生数据不一致性,因为 `server3` 肯定会提交刚刚 `server2` 发送的 `commit` 请求的提案,而 `server1` 根本没收到所以会丢弃。
-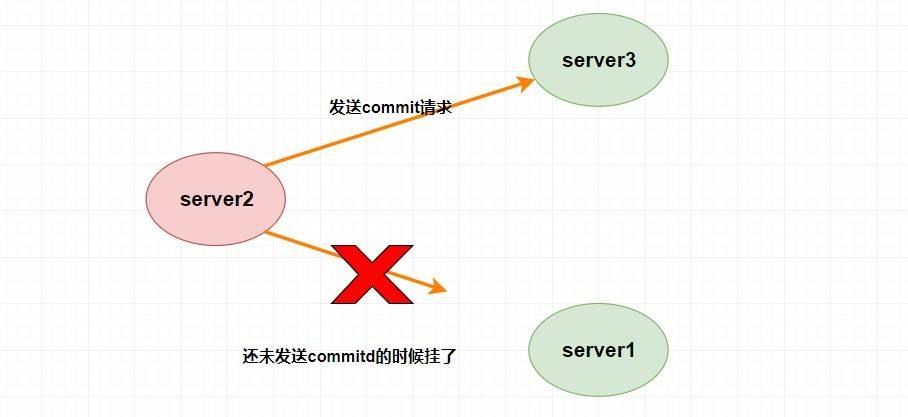
+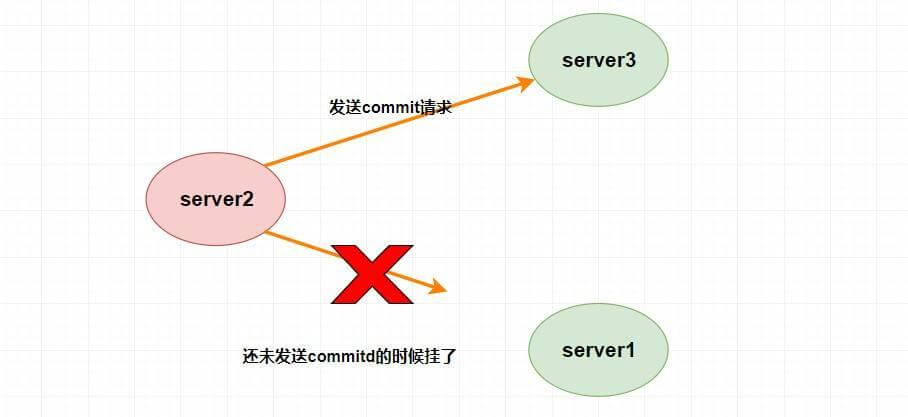
那怎么解决呢?
@@ -224,7 +221,7 @@ tag:
假设 `Leader (server2)` 此时同意了提案 N1,自身提交了这个事务并且要发送给所有 `Follower` 要 `commit` 的请求,却在这个时候挂了,此时肯定要重新进行 `Leader` 的选举,比如说此时选 `server1` 为 `Leader` (这无所谓)。但是过了一会,这个 **挂掉的 `Leader` 又重新恢复了** ,此时它肯定会作为 `Follower` 的身份进入集群中,需要注意的是刚刚 `server2` 已经同意提交了提案 N1,但其他 `server` 并没有收到它的 `commit` 信息,所以其他 `server` 不可能再提交这个提案 N1 了,这样就会出现数据不一致性问题了,所以 **该提案 N1 最终需要被抛弃掉** 。
-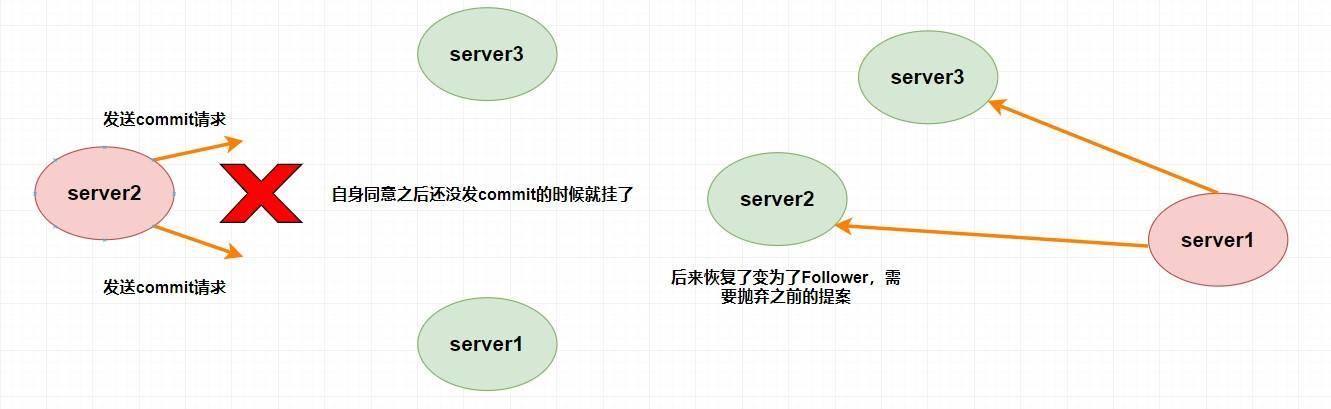
+
## Zookeeper 的几个理论知识
@@ -236,7 +233,7 @@ tag:
`zookeeper` 数据存储结构与标准的 `Unix` 文件系统非常相似,都是在根节点下挂很多子节点(树型)。但是 `zookeeper` 中没有文件系统中目录与文件的概念,而是 **使用了 `znode` 作为数据节点** 。`znode` 是 `zookeeper` 中的最小数据单元,每个 `znode` 上都可以保存数据,同时还可以挂载子节点,形成一个树形化命名空间。
-
+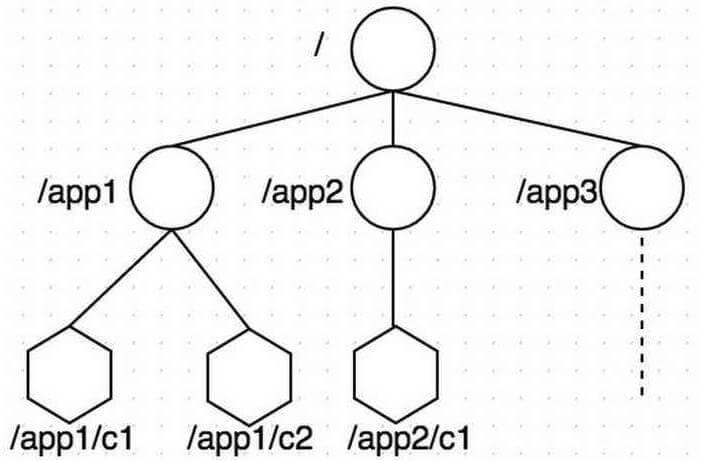
每个 `znode` 都有自己所属的 **节点类型** 和 **节点状态**。
@@ -281,13 +278,13 @@ tag:
`Watcher` 为事件监听器,是 `zk` 非常重要的一个特性,很多功能都依赖于它,它有点类似于订阅的方式,即客户端向服务端 **注册** 指定的 `watcher` ,当服务端符合了 `watcher` 的某些事件或要求则会 **向客户端发送事件通知** ,客户端收到通知后找到自己定义的 `Watcher` 然后 **执行相应的回调方法** 。
-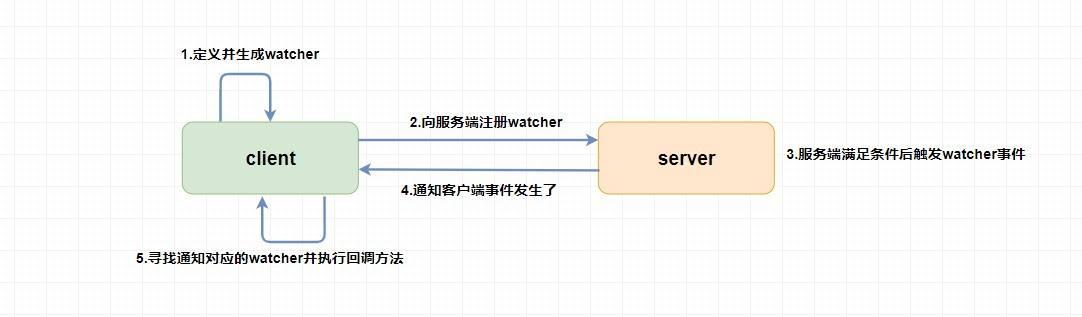
+
## Zookeeper 的几个典型应用场景
前面说了这么多的理论知识,你可能听得一头雾水,这些玩意有啥用?能干啥事?别急,听我慢慢道来。
-
+
### 选主
@@ -299,10 +296,28 @@ tag:
你想想为什么我们要创建临时节点?还记得临时节点的生命周期吗?`master` 挂了是不是代表会话断了?会话断了是不是意味着这个节点没了?还记得 `watcher` 吗?我们是不是可以 **让其他不是 `master` 的节点监听节点的状态** ,比如说我们监听这个临时节点的父节点,如果子节点个数变了就代表 `master` 挂了,这个时候我们 **触发回调函数进行重新选举** ,或者我们直接监听节点的状态,我们可以通过节点是否已经失去连接来判断 `master` 是否挂了等等。
-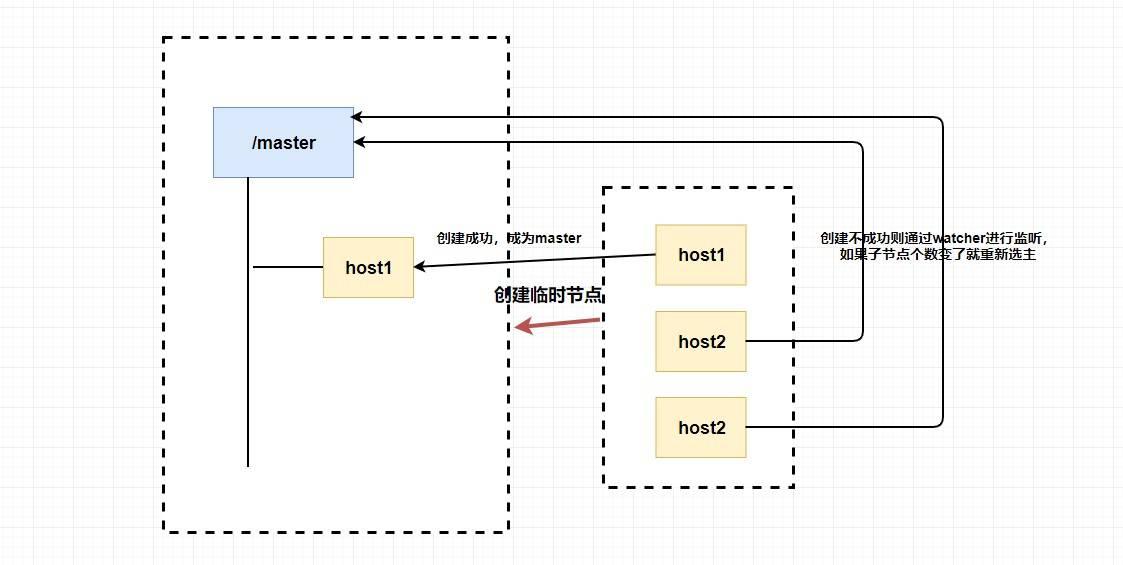
+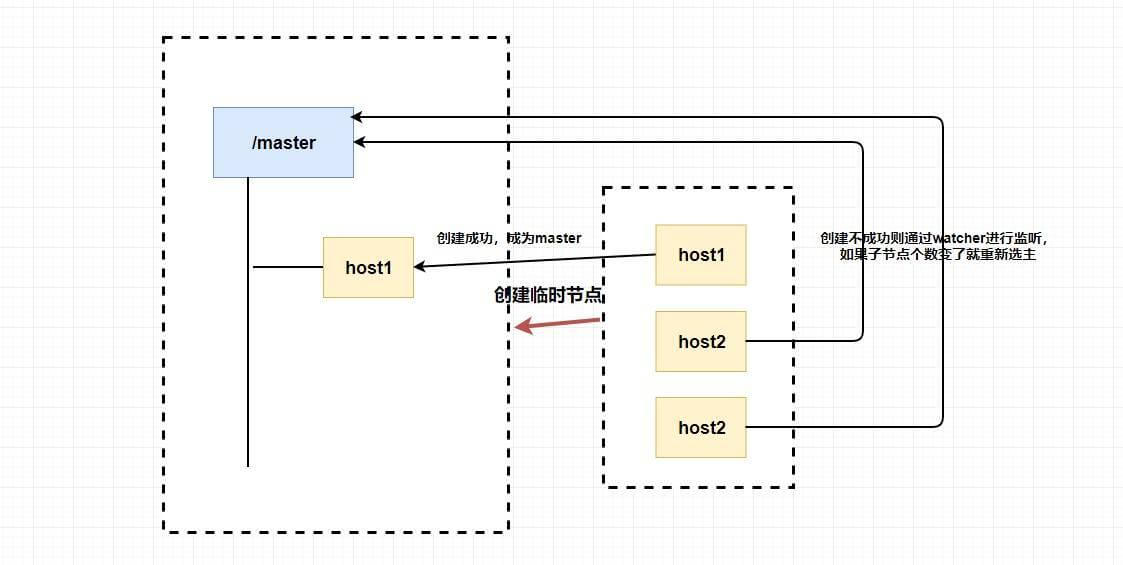
总的来说,我们可以完全 **利用 临时节点、节点状态 和 `watcher` 来实现选主的功能**,临时节点主要用来选举,节点状态和`watcher` 可以用来判断 `master` 的活性和进行重新选举。
+### 数据发布/订阅
+
+还记得 Zookeeper 的 `Watcher` 机制吗? Zookeeper 通过这种推拉相结合的方式实现客户端与服务端的交互:客户端向服务端注册节点,一旦相应节点的数据变更,服务端就会向“监听”该节点的客户端发送 `Watcher` 事件通知,客户端接收到通知后需要 **主动** 到服务端获取最新的数据。基于这种方式,Zookeeper 实现了 **数据发布/订阅** 功能。
+
+一个典型的应用场景为 **全局配置信息的集中管理**。 客户端在启动时会主动到 Zookeeper 服务端获取配置信息,同时 **在指定节点注册一个** `Watcher` **监听**。当配置信息发生变更,服务端通知所有订阅的客户端重新获取配置信息,实现配置信息的实时更新。
+
+上面所提到的全局配置信息通常包括机器列表信息、运行时的开关配置、数据库配置信息等。需要注意的是,这类全局配置信息通常具备以下特性:
+
+- 数据量较小
+- 数据内容在运行时动态变化
+- 集群中机器共享一致配置
+
+### 负载均衡
+
+可以通过 Zookeeper 的 **临时节点** 实现负载均衡。回顾一下临时节点的特性:当创建节点的客户端与服务端之间断开连接,即客户端会话(session)消失时,对应节点也会自动消失。因此,我们可以使用临时节点来维护 Server 的地址列表,从而保证请求不会被分配到已停机的服务上。
+
+具体地,我们需要在集群的每一个 Server 中都使用 Zookeeper 客户端连接 Zookeeper 服务端,同时用 Server **自身的地址信息**在服务端指定目录下创建临时节点。当客户端请求调用集群服务时,首先通过 Zookeeper 获取该目录下的节点列表 (即所有可用的 Server),随后根据不同的负载均衡策略将请求转发到某一具体的 Server。
+
### 分布式锁
分布式锁的实现方式有很多种,比如 `Redis`、数据库、`zookeeper` 等。个人认为 `zookeeper` 在实现分布式锁这方面是非常非常简单的。
@@ -341,19 +356,19 @@ tag:
而 `zookeeper` 天然支持的 `watcher` 和 临时节点能很好的实现这些需求。我们可以为每条机器创建临时节点,并监控其父节点,如果子节点列表有变动(我们可能创建删除了临时节点),那么我们可以使用在其父节点绑定的 `watcher` 进行状态监控和回调。
-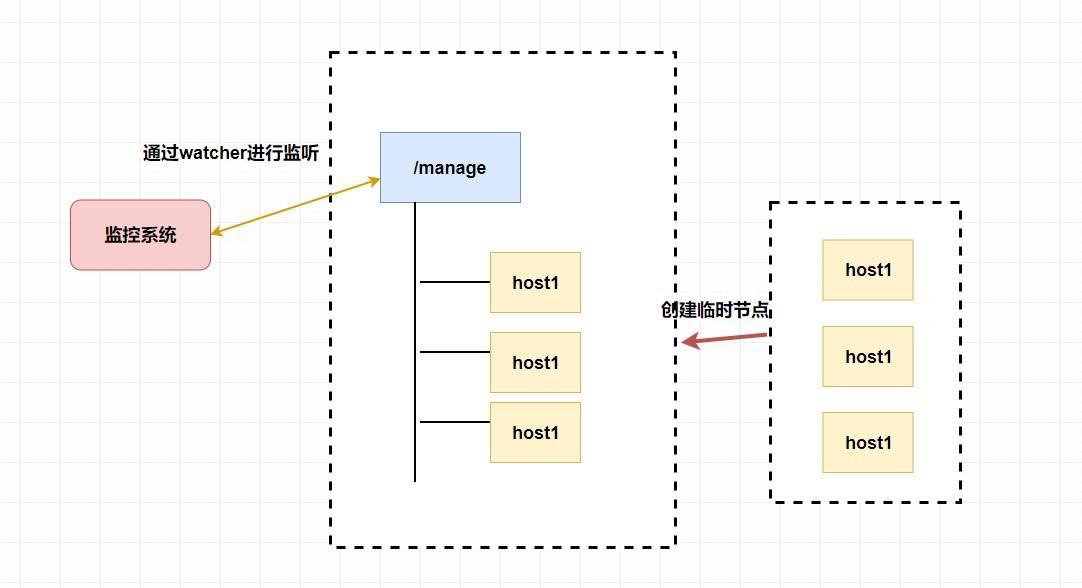
+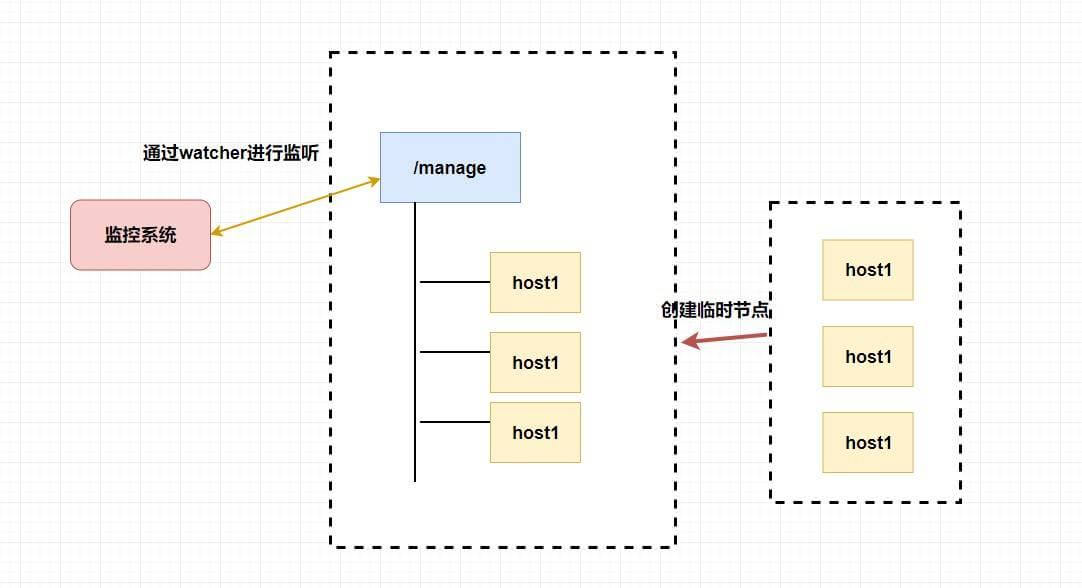
至于注册中心也很简单,我们同样也是让 **服务提供者** 在 `zookeeper` 中创建一个临时节点并且将自己的 `ip、port、调用方式` 写入节点,当 **服务消费者** 需要进行调用的时候会 **通过注册中心找到相应的服务的地址列表(IP 端口什么的)** ,并缓存到本地(方便以后调用),当消费者调用服务时,不会再去请求注册中心,而是直接通过负载均衡算法从地址列表中取一个服务提供者的服务器调用服务。
当服务提供者的某台服务器宕机或下线时,相应的地址会从服务提供者地址列表中移除。同时,注册中心会将新的服务地址列表发送给服务消费者的机器并缓存在消费者本机(当然你可以让消费者进行节点监听,我记得 `Eureka` 会先试错,然后再更新)。
-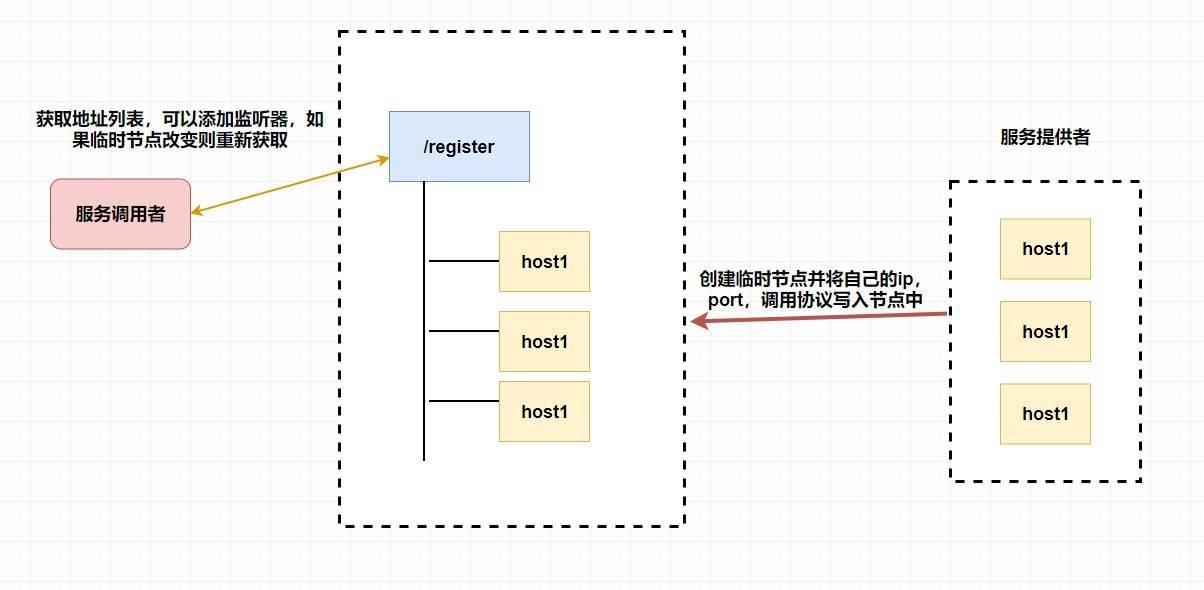
+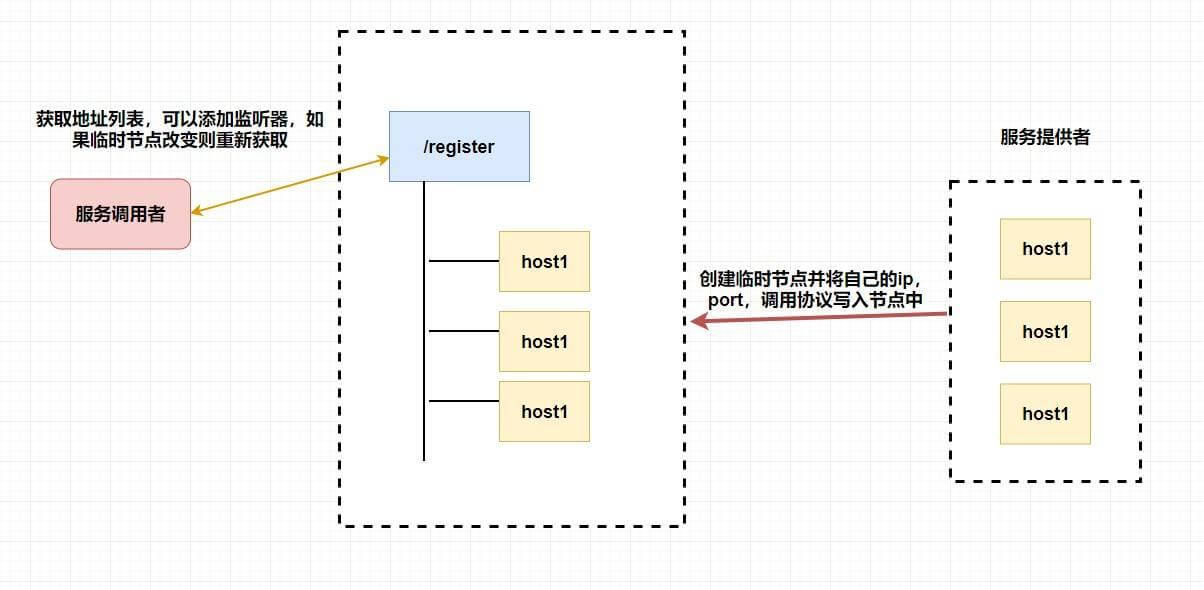
## 总结
看到这里的同学实在是太有耐心了 👍👍👍 不知道大家是否还记得我讲了什么 😒。
-
+
这篇文章中我带大家入门了 `zookeeper` 这个强大的分布式协调框架。现在我们来简单梳理一下整篇文章的内容。
@@ -368,3 +383,5 @@ tag:
- `zookeeper` 的典型应用场景,比如选主,注册中心等等。
如果忘了可以回去看看再次理解一下,如果有疑问和建议欢迎提出 🤝🤝🤝。
+
+
diff --git a/docs/distributed-system/distributed-transaction.md b/docs/distributed-system/distributed-transaction.md
index 2e3d3cf57a4..cfb8ac6bde5 100644
--- a/docs/distributed-system/distributed-transaction.md
+++ b/docs/distributed-system/distributed-transaction.md
@@ -1,10 +1,11 @@
---
-title: 分布式事务常见问题总结(付费)
+title: 分布式事务常见解决方案总结(付费)
+description: 分布式事务常见解决方案详解,包括2PC、3PC、TCC、Saga、本地消息表等方案的原理与适用场景分析。
category: 分布式
---
**分布式事务** 相关的面试题为我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了《Java 面试指北》中。
-
+
diff --git a/docs/distributed-system/protocol/cap-and-base-theorem.md b/docs/distributed-system/protocol/cap-and-base-theorem.md
index 781d47c00ad..3611c58ea78 100644
--- a/docs/distributed-system/protocol/cap-and-base-theorem.md
+++ b/docs/distributed-system/protocol/cap-and-base-theorem.md
@@ -1,13 +1,16 @@
---
title: CAP & BASE理论详解
+description: CAP定理与BASE理论详解,深入讲解分布式系统一致性、可用性、分区容错性的权衡与实际应用。
category: 分布式
tag:
- 分布式理论
---
-经历过技术面试的小伙伴想必对 CAP & BASE 这个两个理论已经再熟悉不过了!
+
-我当年参加面试的时候,不夸张地说,只要问到分布式相关的内容,面试官几乎是必定会问这两个分布式相关的理论。一是因为这两个分布式基础理论是学习分布式知识的必备前置基础,二是因为很多面试官自己比较熟悉这两个理论(方便提问)。
+经历过技术面试的小伙伴想必对 CAP & BASE 这两个理论再熟悉不过了!
+
+我当年参加面试的时候,不夸张地说,只要问到分布式相关的内容,面试官几乎都会问到这两个基础理论。一是因为这是学习分布式知识的必备前置基础,二是因为很多面试官自己比较熟悉(方便提问)。
我们非常有必要将这两个理论搞懂,并且能够用自己的理解给别人讲出来。
@@ -19,47 +22,208 @@ tag:
### 简介
-**CAP** 也就是 **Consistency(一致性)**、**Availability(可用性)**、**Partition Tolerance(分区容错性)** 这三个单词首字母组合。
+CAP 定理讨论 Consistency(一致性)、Availability(可用性)和 Partition Tolerance(分区容错)。
+
+> **重要说明**:下文使用「偏 CP / 偏 AP」仅作直觉描述。严格按 CAP 定义(C=Linearizability,A=每个非故障节点都必须响应)时,许多系统并不能被干净归类——同一系统内不同操作的一致性/可用性特征不同,很多系统既不满足 CAP-C 也不满足 CAP-A。
-CAP 理论的提出者布鲁尔在提出 CAP 猜想的时候,并没有详细定义 **Consistency**、**Availability**、**Partition Tolerance** 三个单词的明确定义。
+CAP 理论的提出者布鲁尔在提出 CAP 猜想的时候,并没有对 **Consistency**、**Availability**、**Partition Tolerance** 给出严格定义。
-因此,对于 CAP 的民间解读有很多,一般比较被大家推荐的是下面 👇 这种版本的解读。
+因此,对于 CAP 的民间解读有很多,比较常见、也更推荐的一种解读如下。
在理论计算机科学中,CAP 定理(CAP theorem)指出对于一个分布式系统来说,当设计读写操作时,只能同时满足以下三点中的两个:
-- **一致性(Consistency)** : 所有节点访问同一份最新的数据副本
-- **可用性(Availability)**: 非故障的节点在合理的时间内返回合理的响应(不是错误或者超时的响应)。
-- **分区容错性(Partition Tolerance)** : 分布式系统出现网络分区的时候,仍然能够对外提供服务。
+- **一致性(Consistency)**:在 Gilbert/Lynch(2002)的证明语境里,CAP 的一致性 C 指的是 **Atomic Consistency**,通常等同于 **Linearizability(线性一致性)**。即所有操作按实时顺序线性化,即写操作一旦完成,后续所有读操作都必须返回该写入的值(或更新的值)。**注意:** 这里的 Consistency 与数据库 ACID 中的 Consistency(一致性约束)含义不同,后者指事务执行前后数据库状态满足完整性约束。
+- **可用性(Availability)**:非故障的节点必须对每个请求返回响应(不讨论响应快慢)。**注意**:这是 CAP 理论中的严格定义,不包含工程中的延迟/SLA 指标(如「1s 内返回」)。
+- **分区容错性(Partition Tolerance)**:CAP 里的 P 本质上是在假设异步网络(可能延迟/丢包/分区),不是一个你「选择要不要」的功能。真正的权衡是:当分区发生时,你必须在**线性一致(CAP 的 Consistency=Linearizability)**与**CAP-Availability(任何非故障节点都要对请求给非错误响应)**之间做选择。
**什么是网络分区?**
-分布式系统中,多个节点之前的网络本来是连通的,但是因为某些故障(比如部分节点网络出了问题)某些节点之间不连通了,整个网络就分成了几块区域,这就叫 **网络分区**。
+分布式系统中,多个节点之间的网络本来是连通的,但是因为某些故障(比如部分节点网络出了问题)某些节点之间不连通了,整个网络就分成了几块区域,这就叫 **网络分区**。

-### 不是所谓的“3 选 2”
+### 不是所谓的「3 选 2」
+
+大部分人解释这一定律时,常常简单地表述为:「一致性、可用性、分区容忍性三者你只能同时达到其中两个,不可能同时达到」。实际上这是很有误导性的说法,而且在 CAP 理论诞生 12 年之后,CAP 之父也在 2012 年重写了之前的论文。
+
+> **当发生网络分区的时候,如果我们要继续服务,那么强一致性和可用性只能 2 选 1。**
+>
+> 简而言之:CAP 理论中分区容错性 P 不是一定要满足的,但当选择满足 P 时,在此基础上只能满足可用性 A 或者一致性 C。
+
+**为啥不可能选择 CA 架构呢?**
+
+因为分布式系统离不开网络通信,而网络故障是常态:
+
+- 心跳检测可能因网络抖动丢包,导致误判节点故障
+- 数据同步过程中可能因包丢失导致不一致,系统为达成一致会不断重试,造成请求阻塞
+
+**因此,在异步网络模型下(分区可能发生),当分区发生时,必须在线性一致性与 CAP-可用性之间取舍。** 能够保证 CA 的只有单机系统——因为只有一个节点,数据写入成功后所有请求都能看到相同数据;只要这个节点活着,系统就可用。
+
+下面这张图展示了 CAP 理论的核心权衡和常见系统的倾向:
+
+```mermaid
+flowchart TB
+ %% 核心语义配色
+ classDef cap fill:#E99151,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef cp fill:#3498DB,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef ap fill:#27AE60,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef caution fill:#F39C12,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef danger fill:#C44545,color:#FFFFFF,stroke:none,rx:10,ry:10
+
+ P[分区容错性 P
Partition Tolerance]:::cap
+ P -->|网络分区发生| Choice{分区时权衡 C 与 A}:::caution
+ Choice -->|倾向 C| CP[一致性优先
牺牲可用性]:::cp
+ Choice -->|倾向 A| AP[可用性优先
牺牲一致性]:::ap
+
+ CP --> ZK[ ZooKeeper
etcd ]:::cp
+ CP --> UseCP[应用场景:
分布式锁、配置管理]:::cp
+
+ AP --> Eureka[ Eureka
Cassandra ]:::ap
+ AP --> UseAP[应用场景:
服务注册中心、社交动态]:::ap
+
+ CA[仅单机系统
可实现 CA]:::danger -.->|有分区时不可行| Choice
+
+ linkStyle default stroke-width:2px,stroke:#333333,opacity:0.8
+```
+
+这里需要引入 **PACELC 理论**(CAP 的扩展)来更全面地解释:
+
+Daniel J. Abadi 提出的 PACELC 理论指出:**如果存在分区(P),必须在可用性(A)和一致性(C)之间选择;否则(E,Else),必须在延迟(L)和一致性(C)之间选择。**
+
+```mermaid
+flowchart TB
+ %% 核心语义配色
+ classDef question fill:#95A5A6,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef choice fill:#E99151,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef consistency fill:#3498DB,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef availability fill:#27AE60,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef latency fill:#9B59B6,color:#FFFFFF,stroke:none,rx:10,ry:10
+
+ Q{是否存在分区 P?}:::question
+
+ Q -->|是 Partition| PAC[权衡 A 与 C]:::choice
+ Q -->|否 Else| ELC[权衡 L 与 C]:::choice
+
+ PAC --> PA[选择可用性 A
Cassandra AP]:::availability
+ PAC --> PC[选择一致性 C
ZooKeeper CP]:::consistency
+
+ ELC --> LC[选择低延迟 L
MySQL 异步复制]:::latency
+ ELC --> EC[选择强一致 C
MySQL 半同步复制]:::consistency
+
+ linkStyle default stroke-width:2px,stroke:#333333,opacity:0.8
+```
+
+实际意义:即使无网络分区,分布式系统仍需在低延迟(异步复制)和强一致(同步复制)之间权衡。例如:
+
+- **Cassandra**:可通过调整读写一致性级别(ONE/QUORUM/ALL)在延迟与一致性间权衡
+- **MySQL 主从**:可选择异步复制(低延迟)或半同步复制(强一致)
+
+比如 ZooKeeper、HBase 就是 CP 架构,Cassandra、Eureka 就是 AP 架构,Nacos 不仅支持 CP 架构也支持 AP 架构。
+
+**选择 CP 还是 AP 的关键在于当前的业务场景,没有定论**:比如对于需要确保强一致性的场景如分布式锁、配置管理会选择 CP;对于高可用优先的场景如微服务注册中心会选择 AP。
+
+**另外,需要补充说明的一点**:在无分区时,可以同时做到线性一致与「会响应」的 CAP-可用性;但工程上通常还要在延迟与一致性之间权衡(这便是 PACELC 理论中 ELC 部分讨论的内容)。
+
+### CAP 理论的适用范围
+
+**重要结论**:CAP 理论主要讨论单个数据对象在副本复制场景下的一致性与可用性权衡。
+
+| 更贴近 CAP 讨论模型 | 需要拆分到分片/对象/操作级别分析 |
+| ------------------- | ------------------------------------ |
+| Redis 主从/哨兵集群 | 业务系统(无状态服务)\* |
+| MySQL 主从/多主集群 | Redis-Cluster(每个 shard 仍有副本) |
+| MongoDB 副本集 | MongoDB-Cluster(分片 + 副本并存) |
+| ZooKeeper、etcd | 分库分表(跨分片事务需额外协调) |
+| Kafka、RocketMQ | 大多数微服务应用\* |
-大部分人解释这一定律时,常常简单的表述为:“一致性、可用性、分区容忍性三者你只能同时达到其中两个,不可能同时达到”。实际上这是一个非常具有误导性质的说法,而且在 CAP 理论诞生 12 年之后,CAP 之父也在 2012 年重写了之前的论文。
+**说明**:
-> **当发生网络分区的时候,如果我们要继续服务,那么强一致性和可用性只能 2 选 1。也就是说当网络分区之后 P 是前提,决定了 P 之后才有 C 和 A 的选择。也就是说分区容错性(Partition tolerance)我们是必须要实现的。**
+- **CAP 讨论模型**:单个读写寄存器(single register)的副本复制语义
+- **复杂系统**:需要拆解到「每个对象/分区/操作」的一致性语义讨论
+- **分片 + 副本**:分片系统每个 shard 通常仍有副本复制,一致性与可用性权衡仍在
+
+> **业务系统与 CAP 的深度关联**:
+>
+> 业务系统本身虽不涉及副本同步,但**深受底层组件 CAP 属性的影响**。忽视这一点会导致系统在遭遇网络分区时发生级联雪崩(Cascading Failure)。
+>
+> **受 CAP 属性影响的业务场景**:
+>
+> | 业务场景 | 底层组件 | CP 组件的影响 | AP 组件的影响 |
+> | -------- | ---------------------------- | -------------------------- | ------------------------------ |
+> | RPC 路由 | 注册中心(如 Nacos CP 模式) | 注册期间不可用,请求被拒绝 | 可能路由到已下线实例,需要重试 |
+> | 分布式锁 | Redis(AP)/ ZooKeeper(CP) | 性能较低但可靠 | 性能高但可能锁失效 |
+> | 限流熔断 | Redis 计数器 | 可能读到旧计数,限流失效 | 同左 |
+> | 缓存更新 | Redis 主从 | 主从切换时可能丢数据 | 同左 |
+> | 消息消费 | Kafka | 消费进度同步慢,重复消费 | 同左 |
>
-> 简而言之就是:CAP 理论中分区容错性 P 是一定要满足的,在此基础上,只能满足可用性 A 或者一致性 C。
+> **实践建议**:业务开发者虽然不需要「实践」CAP 理论,但**必须理解 CAP 理论**,以便:
+>
+> - 为不同业务场景选择合适的组件(CP 或 AP)
+> - 理解所选组件在网络分区时的行为特征
+> - 设计符合业务需求的容错机制(重试、熔断、降级)
+
+很多开发者认为自己在「实践 CAP 理论」,实际上只是站在已有组件上做选择(用 CP 还是 AP),而非真正实践该理论。真正需要实践 CAP 的是研发 Redis、MySQL 这类分布式存储组件的工程师。
+
+### 在业务中应用 CAP 思想
+
+除研发分布式存储组件外,业务开发中更多是**选择**合适的架构,而非实践 CAP 理论本身:
+
+| 场景 | 偏向 CP 的选择 | 偏向 AP 的选择 | 业务权衡 |
+| -------------- | ---------------------------- | ------------------------ | ------------------------ |
+| 数据库主从复制 | 同步复制(强一致) | 异步复制(高性能) | 数据一致性 vs 响应速度 |
+| 分布式锁实现 | ZooKeeper(强一致) | Redis(高性能) | 锁的可靠性 vs 获取速度 |
+| 服务注册中心 | ZooKeeper、Consul(CP 模式) | Eureka、Nacos(AP 模式) | 注册准确性 vs 发现可用性 |
+| 限流计数器 | Redis(强一致命令) | Redis(允许过期) | 限流精度 vs 性能 |
+
+**选型原则**:
+
+- **关注性能**:倾向选择允许异步复制的组件,写入主节点即可返回成功,响应快;但存在数据丢失/读取到旧数据的风险,需配合重试机制
+- **关注数据安全**:倾向选择要求多数派确认的组件,写入需等待 quorum 节点确认,响应慢;但能降低数据丢失风险
+
+**注意**:数据丢失与否更取决于持久化、复制确认策略、故障模型,不能简单地用「CP/AP 标签」来判断。
+
+**级联雪崩案例**:
+
+一个典型的忽视 CAP 导致的级联雪崩场景:
+
+```mermaid
+flowchart TB
+ %% 核心语义配色
+ classDef start fill:#95A5A6,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef process fill:#3498DB,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef warning fill:#F39C12,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef danger fill:#C44545,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef solution fill:#27AE60,color:#FFFFFF,stroke:none,rx:10,ry:10
+
+ Start[网络分区发生]:::start --> P1[Redis 集群主从分离
AP 架构数据不一致]:::process
+ P1 --> P2[限流计数器读到旧值
以为未限流]:::warning
+ P2 --> P3[大量请求同时打到后端]:::warning
+ P3 --> P4[服务线程池耗尽]:::danger
+ P4 --> P5[RPC 调用超时堆积]:::danger
+ P5 --> P6[整个调用链路雪崩]:::danger
-因此,**分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构。** 比如 ZooKeeper、HBase 就是 CP 架构,Cassandra、Eureka 就是 AP 架构,Nacos 不仅支持 CP 架构也支持 AP 架构。
+ P2 -.->|理解 CAP 属性| S1[选择合适组件]:::solution
+ P3 -.->|多层防护| S2[本地缓存 + 熔断降级]:::solution
+ P4 -.->|超时重试| S3[合理设置超时时间]:::solution
+ P5 -.->|隔离机制| S4[不同业务隔离实例]:::solution
-**为啥不可能选择 CA 架构呢?** 举个例子:若系统出现“分区”,系统中的某个节点在进行写操作。为了保证 C, 必须要禁止其他节点的读写操作,这就和 A 发生冲突了。如果为了保证 A,其他节点的读写操作正常的话,那就和 C 发生冲突了。
+ linkStyle default stroke-width:2px,stroke:#333333,opacity:0.8
+```
-**选择 CP 还是 AP 的关键在于当前的业务场景,没有定论,比如对于需要确保强一致性的场景如银行一般会选择保证 CP 。**
+**防护措施**:
-另外,需要补充说明的一点是:**如果网络分区正常的话(系统在绝大部分时候所处的状态),也就说不需要保证 P 的时候,C 和 A 能够同时保证。**
+1. **理解底层组件的 CAP 属性**:知道在网络分区时组件的行为
+2. **多层防护**:不只依赖单一组件,结合本地缓存、熔断、降级
+3. **超时与重试**:合理设置超时时间,避免无限等待
+4. **隔离机制**:不同业务使用不同的底层组件实例,避免故障扩散
### CAP 实际应用案例
我这里以注册中心来探讨一下 CAP 的实际应用。考虑到很多小伙伴不知道注册中心是干嘛的,这里简单以 Dubbo 为例说一说。
-下图是 Dubbo 的架构图。**注册中心 Registry 在其中扮演了什么角色呢?提供了什么服务呢?**
+下图是 Dubbo 的架构图。**注册中心 Registry 在其中扮演什么角色呢?提供了什么服务呢?**
注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小。
@@ -67,55 +231,156 @@ CAP 理论的提出者布鲁尔在提出 CAP 猜想的时候,并没有详细
常见的可以作为注册中心的组件有:ZooKeeper、Eureka、Nacos...。
-1. **ZooKeeper 保证的是 CP。** 任何时刻对 ZooKeeper 的读请求都能得到一致性的结果,但是, ZooKeeper 不保证每次请求的可用性比如在 Leader 选举过程中或者半数以上的机器不可用的时候服务就是不可用的。
-2. **Eureka 保证的则是 AP。** Eureka 在设计的时候就是优先保证 A (可用性)。在 Eureka 中不存在什么 Leader 节点,每个节点都是一样的、平等的。因此 Eureka 不会像 ZooKeeper 那样出现选举过程中或者半数以上的机器不可用的时候服务就是不可用的情况。 Eureka 保证即使大部分节点挂掉也不会影响正常提供服务,只要有一个节点是可用的就行了。只不过这个节点上的数据可能并不是最新的。
-3. **Nacos 不仅支持 CP 也支持 AP。**
+#### ZooKeeper 3.8.x(CP 架构)
-**🐛 修正(参见:[issue#1906](https://github.com/Snailclimb/JavaGuide/issues/1906))**:
+ZooKeeper 倾向 **CP 架构**。ZooKeeper 3.x 通过 ZAB 协议提供 **Linearizable Writes(线性化写入)**,但读取行为需区分:
-ZooKeeper 通过可线性化(Linearizable)写入、全局 FIFO 顺序访问等机制来保障数据一致性。多节点部署的情况下, ZooKeeper 集群处于 Quorum 模式。Quorum 模式下的 ZooKeeper 集群, 是一组 ZooKeeper 服务器节点组成的集合,其中大多数节点必须同意任何变更才能被视为有效。
+- **Sync 读取**:强制与 Leader 同步,保证线性一致性(Linearizability)。
+- **普通读取**:默认提供 **顺序一致性(Sequential Consistency)**,保证全局更新操作的顺序,同一会话内客户端视图绝不会发生回退,但可能读到稍旧数据(存在读取滞后)。
-由于 Quorum 模式下的读请求不会触发各个 ZooKeeper 节点之间的数据同步,因此在某些情况下还是可能会存在读取到旧数据的情况,导致不同的客户端视图上看到的结果不同,这可能是由于网络延迟、丢包、重传等原因造成的。ZooKeeper 为了解决这个问题,提供了 Watcher 机制和版本号机制来帮助客户端检测数据的变化和版本号的变更,以保证数据的一致性。
+> **重要区别**:顺序一致性 ≠ 最终一致性。ZooKeeper 的普通读取保证所有客户端看到相同的**更新顺序**(全局 zxid 顺序),只是存在读取滞后;而最终一致性不保证全局顺序,仅保证最终收敛。ZK 的默认读更像是「stale-but-ordered」的读(顺序/会话保证很强),而不是 Dynamo 系那种 eventual consistency 语境。
-### 总结
+在 Leader 选举期间或 Follower 节点数不足 Quorum(N/2+1)时,ZooKeeper 会拒绝服务以维持一致性,表现为不可用(牺牲 A)。
+
+在多节点部署下,集群采用 Quorum 模式:多数派节点(n/2+1)必须同意变更才有效。
+
+ZooKeeper 提供 Watcher 机制(异步通知变更)和版本号机制(zxid 校验新鲜度)以缓解读取滞后问题。
+
+失败路径与状态机表现:
+
+| 故障场景 | 系统状态 | 客户端表现 |
+| ------------------------------- | ------------------------------- | ------------------------------------------------------------ |
+| Quorum 失效(半数以上节点故障) | **LOOKING** 状态,Leader 选举中 | 写入请求拒绝,读取请求可能返回旧数据或超时 |
+| Follower 与 Leader 分区 | Follower 进入 **ELECTION** 状态 | 该 Follower 无法参与投票,但可响应读取(滞后数据) |
+| Leader 与多数派分区 | Leader 自动降级,集群重新选举 | 原Leader的写入丢失,需客户端重试(检测到 zxid 回退) |
+| Watcher 丢失 | 网络抖动或 GC 压力导致 | 客户端需重试(指数退避 + Jitter),监控 `Watches` 队列防背压 |
+
+#### Eureka(AP 架构)
+
+Eureka 采用 AP 架构:节点对等,通过 Peer 复制/同步(定期全量拉取 + 增量更新)保持数据一致,无 Leader 选举。**注意**:Spring Cloud 生态中历史上更常见 1.x 依赖形态;Netflix/eureka 的 2.x 仍在维护并持续发布。
+
+失败路径与状态机表现:
+
+| 故障场景 | 系统状态 | 客户端表现 | 自我保护机制 |
+| ---------------------------- | ---------------------------------------- | ----------------------------------------------------------------------------------------------- | --------------------------------------------------------------------- |
+| 网络分区(脑裂) | 分区两侧**独立运行**,均可读写 | 客户端可能读到旧注册信息(不一致窗口 = 心跳间隔 30s + gossip 传播延迟,10 节点拓扑中 P99 <60s) | 当续约阈值 < 85% 时触发**自我保护**,暂停实例剔除,避免"误杀"健康实例 |
+| 半数节点故障 | 剩余节点继续服务,但数据可能分叉 | 读操作正常,写入可能仅存于少数派节点 | 自我保护触发,待节点恢复后通过 gossip 自动合并 |
+| 节点短暂重启 | 从 Peer 批量拉取注册表(Registry Fetch) | 服务发现短暂不可用(< 1min),缓存起作用 | 正常模式,自动恢复 |
+| 注册风暴(大量实例同时注册) | 写队列堆积,可能导致请求丢弃 | 部分注册请求超时,需客户端重试 | 可配置限流与背压(如 Ribbon 重试策略) |
+
+**自我保护机制详细说明**:
+
+Eureka Server 通过以下逻辑判断是否进入自我保护:
+
+```
+每分钟期望续约数 E = 当前实例数 N × (60 / 心跳间隔秒数)
+阈值 T = E × 0.85
+若最近 1 分钟实际续约数 R < T,则进入自我保护:暂停剔除(eviction)
+(E/T 会按固定周期根据 N 更新,常见周期约 15 分钟)
+```
+
+默认心跳间隔为 30 秒时,每分钟期望续约数 = 实例数 × 2。
+
+当 `实际续约率 < 85%` 时:
+
+1. 进入 **SELF PRESERVATION** 模式
+2. 停止剔除过期实例(EvictionTask 暂停)
+3. 日志输出:`ENTER SELF PRESERVATION MODE`
+
+**设计权衡**:宁可保留「僵尸」实例,也不误杀健康实例——因为在微服务场景下,短暂的服务降级好过大规模服务不可用。客户端通常配置重试与熔断来处理不可用实例。
-在进行分布式系统设计和开发时,我们不应该仅仅局限在 CAP 问题上,还要关注系统的扩展性、可用性等等
+#### 总结
-在系统发生“分区”的情况下,CAP 理论只能满足 CP 或者 AP。要注意的是,这里的前提是系统发生了“分区”
+选择 CP 或 AP 取决于场景:ZooKeeper 适合强一致需求,如配置管理;Eureka 适合高可用注册,如微服务发现。
-如果系统没有发生“分区”的话,节点间的网络连接通信正常的话,也就不存在 P 了。这个时候,我们就可以同时保证 C 和 A 了。
+Nacos 不仅支持 CP 也支持 AP。
-总结:**如果系统发生“分区”,我们要考虑选择 CP 还是 AP。如果系统没有发生“分区”的话,我们要思考如何保证 CA 。**
+### 总结
+
+CAP 理论指导我们:在分布式系统可能出现网络分区(P)的前提下,我们必须在强一致性(C)和高可用性(A)之间做出权衡。
+
+- **CP 架构**:牺牲可用性,保证强一致性。适用于对数据一致性要求极高的场景(如金融交易、分布式锁)。
+- **AP 架构**:牺牲一致性,保证高可用性。适用于对系统可用性要求较高,能容忍短暂数据不一致的场景(如社交动态、商品搜索)。
+- **PACELC**:在无分区(E)时,需在延迟(L)和一致性(C)之间权衡。
### 推荐阅读
1. [CAP 定理简化](https://medium.com/@ravindraprasad/cap-theorem-simplified-28499a67eab4) (英文,有趣的案例)
2. [神一样的 CAP 理论被应用在何方](https://juejin.im/post/6844903936718012430) (中文,列举了很多实际的例子)
-3. [请停止呼叫数据库 CP 或 AP ](https://martin.kleppmann.com/2015/05/11/please-stop-calling-databases-cp-or-ap.html) (英文,带给你不一样的思考)
+3. [请停止呼叫数据库 CP 或 AP](https://martin.kleppmann.com/2015/05/11/please-stop-calling-databases-cp-or-ap.html) (英文,带给你不一样的思考)
## BASE 理论
-[BASE 理论](https://dl.acm.org/doi/10.1145/1394127.1394128)起源于 2008 年, 由 eBay 的架构师 Dan Pritchett 在 ACM 上发表。
+[BASE 理论](https://dl.acm.org/doi/10.1145/1394127.1394128)起源于 2008 年,由 eBay 的架构师 Dan Pritchett 在 ACM 上发表,论文标题为《Base: An ACID Alternative》。
+
+> **关键洞察**:从论文标题可以看出,**BASE 首先是 ACID 的替代品**。但同时需要注意,BASE 与 CAP 理论也存在密切关系——**最终一致性正是 CAP 中 AP 架构在工程实践中达到系统收敛的指导原则**。
### 简介
-**BASE** 是 **Basically Available(基本可用)**、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE 理论是对 CAP 中一致性 C 和可用性 A 权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,它大大降低了我们对系统的要求。
+**BASE** 是 **Basically Available(基本可用)**、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE 理论来源于对大规模互联网系统分布式实践的总结。
+
+### BASE 与 ACID 的关系
+
+要理解 BASE 理论,首先需要回顾 ACID 理论中的 **一致性(Consistency)**:
+
+**ACID 的一致性定义**:事务执行前后,数据库只能从一个一致状态转变为另一个一致状态。
+
+以转账为例:小竹向熊猫转账 1000W。
-### BASE 理论的核心思想
+- **初始态**:小竹 1001W,熊猫 888W,合计 1889W
+- **结果态**:小竹 1W,熊猫 1888W,合计 1889W
-即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
+无论事务成功或失败,整体数据的变化必须一致——类似于能量守恒定律。
-> 也就是牺牲数据的一致性来满足系统的高可用性,系统中一部分数据不可用或者不一致时,仍需要保持系统整体“主要可用”。
+**分布式场景的挑战**:
-**BASE 理论本质上是对 CAP 的延伸和补充,更具体地说,是对 CAP 中 AP 方案的一个补充。**
+在分布式系统中,商品服务和订单服务分离部署,[扣减库存、创建订单]需要通过网络调用,这中间必然存在时间差:
-**为什么这样说呢?**
+```
+时刻 T1:库存 8888 → 8887(扣减成功)
+时刻 T2:网络调用订单服务...
+时刻 T3:订单创建成功
+```
-CAP 理论这节我们也说过了:
+在 T1~T3 期间,系统处于 **中间态**:库存已减,订单未创建。跨服务后无法用单库 ACID 事务保证整体原子提交与隔离,系统会客观存在中间态;BASE 接受中间态并通过补偿/重试让状态最终收敛。
-> 如果系统没有发生“分区”的话,节点间的网络连接通信正常的话,也就不存在 P 了。这个时候,我们就可以同时保证 C 和 A 了。因此,**如果系统发生“分区”,我们要考虑选择 CP 还是 AP。如果系统没有发生“分区”的话,我们要思考如何保证 CA 。**
+**BASE 理论的解决方案**:
-因此,AP 方案只是在系统发生分区的时候放弃一致性,而不是永远放弃一致性。在分区故障恢复后,系统应该达到最终一致性。这一点其实就是 BASE 理论延伸的地方。
+BASE 理论承认并允许这种中间态的存在:
+
+- **Soft-state(软状态)**:允许系统存在中间态,且该中间态不影响系统整体可用性
+- **Eventually consistent(最终一致性)**:中间态最终会演变成终态(要么成功,要么回滚)
+
+下面通过一个对比图来直观理解 ACID 和 BASE 在事务处理上的不同模式:
+
+```mermaid
+flowchart LR
+ %% 核心语义配色
+ classDef acid fill:#3498DB,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef base fill:#27AE60,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef state fill:#95A5A6,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef success fill:#4CA497,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef fail fill:#C44545,color:#FFFFFF,stroke:none,rx:10,ry:10
+
+ subgraph ACID [ACID 模式:无中间态]
+ direction TB
+ A1[初始态
小竹1001W + 熊猫888W]:::state
+ A1 -->|事务执行| A2[终态:成功
小竹1W + 熊猫1888W]:::success
+ A1 -->|事务失败| A3[终态:失败
小竹1001W + 熊猫888W]:::fail
+ end
+
+ subgraph BASE [BASE 模式:允许中间态]
+ direction TB
+ B1[初始态
库存8888]:::state
+ B1 -->|扣减成功| B2[中间态
库存8887 订单未创建]:::base
+ B2 -->|订单创建成功| B3[终态:成功
库存8887 订单已创建]:::success
+ B2 -->|订单创建失败| B4[终态:失败
库存回滚到8888]:::fail
+ end
+
+ linkStyle default stroke-width:2px,stroke:#333333,opacity:0.8
+```
+
+因此,**BASE 理论是 ACID 在分布式场景中的替代品**,而非 CAP 理论的补充。
### BASE 理论三要素
@@ -127,35 +392,177 @@ CAP 理论这节我们也说过了:
**什么叫允许损失部分可用性呢?**
-- **响应时间上的损失**: 正常情况下,处理用户请求需要 0.5s 返回结果,但是由于系统出现故障,处理用户请求的时间变为 3 s。
+- **响应时间上的损失**:正常情况下,处理用户请求需要 0.5s 返回结果,但是由于系统出现故障,处理用户请求的时间变为 3s。
- **系统功能上的损失**:正常情况下,用户可以使用系统的全部功能,但是由于系统访问量突然剧增,系统的部分非核心功能无法使用。
#### 软状态
-软状态指允许系统中的数据存在中间状态(**CAP 理论中的数据不一致**),并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
+软状态(Soft State)是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性。
+
+> **与 ACID 的区别**:ACID 理论要求事务执行后立即进入终态(成功或失败),不允许中间态;而 BASE 理论承认中间态是分布式系统的客观存在,只要中间态最终会演变成终态即可。
+
+举例说明:
+
+- **ACID 模式**:银行转账事务中,扣款和入账必须同时成功或同时失败,不允许「扣款成功但入账未完成」的中间态
+- **BASE 模式**:电商下单事务中,允许「库存已减但订单未创建」的中间态存在,只要最终会达到一致(要么订单创建成功,要么库存回滚)
#### 最终一致性
-最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
+最终一致性(Eventual Consistency)强调:**若系统在一段时间内无新的更新操作,则所有副本最终收敛到相同值。**
-> 分布式一致性的 3 种级别:
->
-> 1. **强一致性**:系统写入了什么,读出来的就是什么。
->
-> 2. **弱一致性**:不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
+需要注意的是,「最终一致性」这个词在两个不同语境下有不同含义:
+
+| 语境 | 含义 | 典型场景 |
+| ------------------------------ | ------------------------ | -------------------------- |
+| **副本式存储(CAP 语境)** | 数据副本最终同步一致 | Cassandra 数据复制 |
+| **事务状态(BASE/ACID 语境)** | 事务中间态最终演变成终态 | 分布式事务(如 TCC、Saga) |
+
+**副本式存储的最终一致性**:
+
+「一段时间」是未界定的——可能是毫秒级(局域网同步)或分钟级(跨地域复制)。生产环境中需通过 **Read Repair(读修复)**、**Anti-Entropy(反熵/后台同步)** 或 **Quorum 写入** 主动加速收敛。
+
+**事务状态的最终一致性**:
+
+以分布式事务为例:[扣减库存、创建订单、扣减余额]
+
+- 时刻 T1:库存已减(中间态)
+- 时刻 T2:订单已创建(中间态)
+- 时刻 T3:余额已扣(终态:事务成功)
+
+或在失败场景:
+
+- 时刻 T1:库存已减(中间态)
+- 时刻 T2:订单创建失败(触发回滚)
+- 时刻 T3:库存回滚(终态:事务失败)
+
+系统会保证在一定时间内达到数据一致的状态,而不需要实时保证系统数据的强一致性。
+
+分布式一致性的 3 种级别:
+
+1. **强一致性**:系统写入了什么,读出来的就是什么。
+2. **弱一致性**:不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
+3. **最终一致性**:弱一致性的升级版,系统会保证在一定时间内达到数据一致的状态。
+
+**业界比较推崇最终一致性级别,但是某些对数据一致要求十分严格的场景比如银行转账还是要保证强一致性。**
+
+那实现最终一致性的具体方式是什么呢?
+
+- **读时修复(Read Repair)**:在读取数据时,检测数据的不一致,进行修复。适合读多写少场景。
+- **写时修复(Hinted Handoff)**:在写入数据时,如果目标节点不可用,将数据缓存下来,待节点恢复后重传。**写时修复** 优化了写入延迟,但增加了读取时的不一致风险(数据可能还在缓存队列中未落盘到目标节点)。
+- **异步修复(Anti-Entropy/反熵)**:通过后台比对副本数据差异并修复。工程实现中关键挑战是**高效检测数据差异**——暴力逐条比对(O(n))在大规模数据集下不可行,生产系统采用**默克尔树(Merkle Tree)**实现低开销差异定位:
+
+**选择建议**:
+
+- **写时修复**:适合写多读少,优化写入性能,但牺牲一致性窗口。
+- **读时修复**:适合读多写少,保证读取数据的准确性。
+- **Anti-Entropy**:后台兜底保障,适合数据规模大但对最终一致性要求高的场景。
+
+### 为什么很多人把 BASE 当作 CAP 的补充?
+
+这是一个**部分正确但表述不够精确**的说法。更准确的理解是:
+
+1. **BASE 首先是 ACID 的替代品**:从论文标题[《Base: An ACID Alternative》](https://spawn-queue.acm.org/doi/10.1145/1394127.1394128)可以看出,BASE 理论的初衷是解决分布式事务场景下 ACID 过于严格的问题。
+
+2. **BASE 与 CAP 的 AP 架构存在内在联系**:
+
+ - 选择 AP 架构意味着放弃强一致性(C)
+ - 放弃强一致性后,系统如何达到收敛?答案是**最终一致性**
+ - 因此,BASE 理论(特别是最终一致性)是 AP 架构在工程实践中**必须采用**的指导原则
+
+3. **误解产生的根源**:很多人把"BASE 与 AP 相关"误解为"BASE 是 CAP 的补充"。实际上:
+ - **BASE 不是对 CAP 理论的补充或修正**
+ - **BASE 是 AP 架构选择的工程实践指南**——当你选择了 AP,BASE 告诉你如何在工程实践中让系统最终达到一致
+
+**正确的理解**:
+
+```mermaid
+flowchart TB
+ %% 核心语义配色
+ classDef cap fill:#E99151,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef base fill:#27AE60,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef acid fill:#3498DB,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef relation fill:#9B59B6,color:#FFFFFF,stroke:none,rx:10,ry:10
+
+ CAP[CAP 理论
分布式存储系统设计约束]:::cap
+ ACID[ACID 理论
数据库事务完整性]:::acid
+ BASE[BASE 理论
ACID 的分布式替代品]:::base
+
+ CAP -->|AP 架构放弃强一致性| BASE
+ ACID -->|分布式场景放宽| BASE
+
+ CAP -->|约束:不能同时满足 C+A| R1[实践意义]:::relation
+ BASE -->|实现:如何达到最终一致| R1
+
+ R1 --> Result[CAP 告诉我们限制
BASE 告诉我们做法]:::relation
+
+ linkStyle default stroke-width:2px,stroke:#333333,opacity:0.8
+```
+
+| 维度 | CAP 理论 | BASE 理论 |
+| ---------- | ------------------------ | ------------------------------------------------ |
+| 关注领域 | 分布式存储系统(带副本) | 所有分布式系统 |
+| 一致性含义 | 数据一致性(副本同步) | 状态一致性(事务终态) |
+| 可用性含义 | 节点故障时系统可用 | 部分节点故障时部分功能可用 |
+| 核心关系 | - | ① ACID 的分布式替代品
② AP 架构的工程实践指南 |
+
+> **实践意义**:CAP 告诉我们在 AP 架构下无法保证强一致性,BASE 告诉我们在 AP 架构下如何通过最终一致性让系统达到收敛——两者是**约束与实现**的关系,而非补充关系。
+
+如果说 CAP 是分布式存储系统的设计约束(告诉我们不能做什么),那么 BASE 就是分布式系统(尤其是业务系统)的实践指导(告诉我们如何做)——它告诉我们:**绝大多数应用场景不需要强一致性,通过接受中间态并最终达到一致性,是更务实的选择。**
+
+### 总结
+
+**ACID 是数据库事务完整性的理论,CAP 是分布式存储系统的设计理论,BASE 是 ACID 在分布式场景中的替代品,同时也是 AP 架构的工程实践指南。**
+
+> **关键对应关系**:
>
-> 3. **最终一致性**:弱一致性的升级版,系统会保证在一定时间内达到数据一致的状态。
+> - **CAP 的一致性** = 数据一致性(副本节点间的数据同步)
+> - **BASE 的一致性** = 状态一致性(事务终态的一致)= ACID 的一致性
+> - **CAP 的可用性** = 主从集群的可用性(节点故障时系统仍可用)
+> - **BASE 的可用性** = 分片式集群的可用性(部分节点故障只影响部分用户)
+> - **CAP 与 BASE 的关系**:选择 AP 架构后,BASE 理论指导如何在工程实践中通过最终一致性达到系统收敛
+
+## 生产落地建议
+
+### 选择 CP 还是 AP 的决策框架
+
+> **重要提示**:简单给系统贴「CP/AP」标签是有风险的。在网络分区下:
>
-> **业界比较推崇是最终一致性级别,但是某些对数据一致要求十分严格的场景比如银行转账还是要保证强一致性。**
+> - **X 的写更倾向于优先保持线性一致**(可能拒绝服务/降级)
+> - **Y 更倾向于优先保持可用**(允许短时间读到旧数据)
+> 具体取决于操作类型与配置。
-那实现最终一致性的具体方式是什么呢? [《分布式协议与算法实战》](http://gk.link/a/10rZM) 中是这样介绍:
+| 场景特征 | 倾向选择 | 典型系统说明 |
+| ------------------------------ | -------------- | ----------------------------------------------------------- |
+| 强一致性要求(金融转账) | 倾向线性一致写 | ZooKeeper(写入需 Quorum 确认)、etcd、Consul(CP 模式) |
+| 高可用优先(服务发现) | 倾向可用性 | Eureka(允许读到旧实例)、Consul(可切换模式) |
+| 可调一致性(根据业务动态选择) | 可配置 | Nacos(支持 CP/AP 切换)、Cassandra(可调节读写一致性级别) |
+| 写多读少 | 倾向异步写优化 | Cassandra(可配置 QUORUM 写)、HBase |
+| 读多写少 | 倾向低延迟读 | DynamoDB(可调节最终一致性级别) |
-> - **读时修复** : 在读取数据时,检测数据的不一致,进行修复。比如 Cassandra 的 Read Repair 实现,具体来说,在向 Cassandra 系统查询数据的时候,如果检测到不同节点的副本数据不一致,系统就自动修复数据。
-> - **写时修复** : 在写入数据,检测数据的不一致时,进行修复。比如 Cassandra 的 Hinted Handoff 实现。具体来说,Cassandra 集群的节点之间远程写数据的时候,如果写失败 就将数据缓存下来,然后定时重传,修复数据的不一致性。
-> - **异步修复** : 这个是最常用的方式,通过定时对账检测副本数据的一致性,并修复。
+### 监控指标
-比较推荐 **写时修复**,这种方式对性能消耗比较低。
+- **分区检测时间**:多久发现网络分区
+- **收敛时间(Convergence Time)**:副本从不一致到一致的时间
+- **读写延迟 P99**:CAP 权衡的直接体现
+- **不一致窗口**:业务可接受的数据延迟
-### 总结
+### 常见误区
+
+#### CAP 相关误区
+
+- ❌ 「选择了 AP 就永远放弃一致性」→ ✅ AP 系统可通过 Read Repair、Anti-Entropy(Merkle Tree)达到最终一致
+- ❌ 「ZooKeeper 是强一致的」→ ✅ ZooKeeper 提供**线性化写入** + **顺序一致性读取**(非最终一致性),读取存在滞后但保证全局顺序
+- ❌ 「顺序一致性 = 最终一致性」→ ✅ 顺序一致性保证全局更新顺序,最终一致性不保证顺序;ZooKeeper 普通读取是前者而非后者
+- ❌ 「银行系统必须 CP」→ ✅ 实际银行采用 BASE + 补偿事务(Saga),核心账务强一致,查询服务可最终一致
+- ❌ 「业务系统不需要考虑 CAP」→ ✅ 业务系统虽不直接实践 CAP,但 RPC 路由、限流熔断、分布式锁等均受底层组件 CAP 属性影响,忽视会导致级联雪崩
+- ❌ 「分库分表不需要考虑 CAP」→ ✅ 分片式存储通常仍然需要为每个 shard 做副本复制,因此仍需面对 CAP 的权衡
+- ❌ 「CAP 的 A 等于低延迟/高 SLA」→ ✅ CAP 的可用性定义不包含延迟要求,只要求非故障节点必须返回响应(可以很慢)
+
+#### BASE 相关误区
+
+- ❌ 「BASE 是 CAP 的补充/延伸」→ ✅ BASE 首先是 ACID 的替代品;同时 BASE 是 AP 架构的工程实践指南(AP 选择了放弃强一致性,BASE 告诉你如何达到最终一致)
+- ❌ 「BASE 的一致性 = CAP 的一致性」→ ✅ BASE 的一致性是状态一致性(= ACID 一致性),CAP 的一致性是数据一致性
+- ❌ 「BASE 只适用于主从集群」→ ✅ BASE 适用于所有分布式系统;其「基本可用」概念在分片式集群中表现更明显(部分节点故障只影响部分用户)
+- ❌ 「最终一致性是弱一致性」→ ✅ 最终一致性是弱一致性的升级版,保证系统最终会达到一致状态,而弱一致性不提供此保证
-**ACID 是数据库事务完整性的理论,CAP 是分布式系统设计理论,BASE 是 CAP 理论中 AP 方案的延伸。**
+
diff --git a/docs/distributed-system/protocol/consistent-hashing.md b/docs/distributed-system/protocol/consistent-hashing.md
new file mode 100644
index 00000000000..10bebe8197c
--- /dev/null
+++ b/docs/distributed-system/protocol/consistent-hashing.md
@@ -0,0 +1,132 @@
+---
+title: 一致性哈希算法详解
+description: 一致性哈希算法原理详解,讲解哈希环、虚拟节点机制及在分布式缓存、负载均衡中的应用场景。
+category: 分布式
+tag:
+ - 分布式协议&算法
+ - 哈希算法
+---
+
+开始之前,先说两个常见的场景:
+
+1. **负载均衡**:由于访问人数太多,我们的网站部署了多台服务器个共同提供相同的服务,但每台服务器上存储的数据不同。为了保证请求的正确响应,相同参数(key)的请求(比如同个 IP 的请求、同一个用户的请求)需要发到同一台服务器处理。
+2. **分布式缓存**:由于缓存数据量太大,我们部署了多台缓存服务器共同提供缓存服务。缓存数据需要尽可能均匀地分布式在这些缓存服务器上,通过 key 可以找到对应的缓存服务器。
+
+这两种场景的本质,都是需要建立一个**从 key 到服务器/节点的稳定映射关系**。
+
+为了实现这个目标,你首先会想到什么方案呢?
+
+## 普通哈希算法
+
+相信大家很快就能想到 **“哈希+取模”** 这个经典组合。通过哈希函数计算出 key 的哈希值,再对服务器数量取模,从而将 key 映射到固定的服务器上。
+
+公式也很简单:
+
+```java
+node_number = hash(key) % N
+```
+
+- `hash(key)`: 使用哈希函数(建议使用性能较好的非加密哈希函数,例如 SipHash、MurMurHash3、CRC32、DJB)对唯一键进行哈希。
+- `% N`: 对哈希值取模,将哈希值映射到一个介于 0 到 N-1 之间的值,N 为节点数/服务器数。
+
+
+
+然而,传统的哈希取模算法有一个比较大的缺陷就是:**无法很好的解决机器/节点动态减少(比如某台机器宕机)或者增加的场景(比如又增加了一台机器)。**
+
+想象一下,服务器的初始数量为 4 台 (N = 4),如果其中一台服务器宕机,N 就变成了 3。此时,对于同一个 key,`hash(key) % 3` 的结果很可能与 `hash(key) % 4` 完全不同。
+
+
+
+这意味着几乎所有的数据映射关系都会错乱。在分布式缓存场景下,这会导致**大规模的缓存失效和缓存穿透**,瞬间将压力全部打到后端的数据库上,引发系统雪崩。
+
+据估算,当节点数量从 N 变为 N-1 时,平均有 (N-1)/N 比例的数据需要迁移,这个比例 **趋近于 100%** 。这种“牵一发而动全身”的效应,在生产环境中是完全不可接受的。
+
+为了更好地解决这个问题,一致性哈希算法诞生了。
+
+## 一致性哈希算法
+
+一致性哈希算法在 1997 年由麻省理工学院提出(这篇论文的 PDF 在线阅读地址:),是一种特殊的哈希算法,在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。一致性哈希解决了传统哈希算法在分布式[哈希表](https://baike.baidu.com/item/哈希表/5981869)(Distributed Hash Table,DHT)中存在的动态伸缩等问题 。
+
+一致性哈希算法的底层原理也很简单,关键在于**哈希环**的引入。
+
+### 哈希环
+
+一致性哈希算法将哈希空间组织成一个环形结构,将数据和节点都映射到这个环上,然后根据顺时针的规则确定数据或请求应该分配到哪个节点上。通常情况下,哈希环的起点是 0,终点是 2^32 - 1,并且起点与终点连接,故这个环的整数分布范围是 **[0, 2^32-1]** 。
+
+传统哈希算法是对服务器数量取模,一致性哈希算法是对哈希环的范围取模,固定值,通常为 2^32:
+
+```java
+node_number = hash(key) % 2^32
+```
+
+服务器/节点如何映射到哈希环上呢?也是哈希取模。例如,一般我们会根据服务器的 IP 或者主机名进行哈希,然后再取模。
+
+```java
+hash(服务器ip)% 2^32
+```
+
+如下图所示:
+
+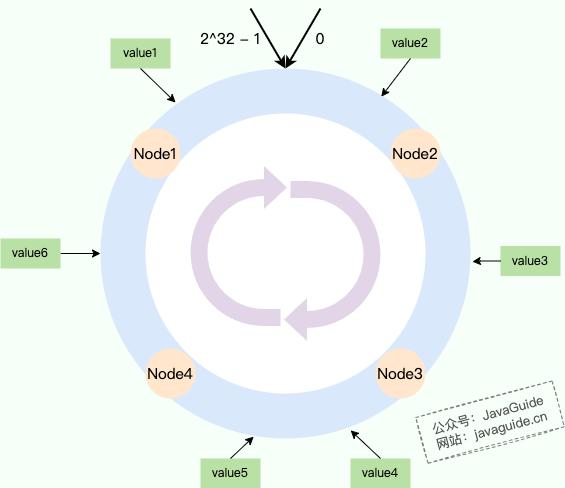
+
+我们将数据和节点都映射到哈希环上,环上的每个节点都负责一个区间。对于上图来说,每个节点负责的数据情况如下:
+
+- **Node1:** 负责 Node4 到 Node1 之间的区域(包含 value6)。
+- **Node2:** 负责 Node1 到 Node2 之间的区域(包含 value1, value2)。
+- **Node3:** 负责 Node2 到 Node3 之间的区域(包含 value3)。
+- **Node4:** 负责 Node3 到 Node4 之间的区域(包含 value4, value5)。
+
+### 节点移除/增加
+
+新增节点和移除节点的情况下,哈希环的引入可以避免影响范围太大,减少需要迁移的数据。
+
+还是用上面分享的哈希环示意图为例,假设 Node2 节点被移除的话,那 Node3 就要负责 Node2 的数据,直接迁移 Node2 的数据到 Node3 即可,其他节点不受影响。
+
+
+
+同样地,如果我们在 Node1 和 Node2 之间新增一个节点 Node5,那么原本应该由 Node2 负责的一部分数据(即哈希值落在 Node1 和 Node5 之间的数据,如图中的 value1)现在会由 Node5 负责。我们只需要将这部分数据从 Node2 迁移到 Node5 即可,同样只影响了相邻的节点,影响范围非常小。
+
+
+
+### 数据倾斜问题
+
+理想情况下,节点在环上是均匀分布的。然而,现实可能并不是这样的,尤其是节点数量比较少的时候。节点可能被映射到附近的区域,这样的话,就会导致绝大部分数据都由其中一个节点负责。
+
+
+
+对于上图来说,每个节点负责的数据情况如下:
+
+- **Node1:** 负责 Node4 到 Node1 之间的区域(包含 value6)。
+- **Node2:** 负责 Node1 到 Node2 之间的区域(包含 value1)。
+- **Node3:** 负责 Node2 到 Node3 之间的区域(包含 value2,value3, value4, value5)。
+- **Node4:** 负责 Node3 到 Node4 之间的区域。
+
+除了数据倾斜问题,还有一个隐患。当新增或者删除节点的时候,数据分配不均衡。例如,Node3 被移除的话,Node3 负责的所有数据都要交给 Node4,随后所有的请求都要达到 Node4 上。假设 Node4 的服务器处理能力比较差的话,那可能直接就被干崩了。理想情况下,应该有更多节点来分担压力。
+
+如何解决这些问题呢?答案是引入**虚拟节点**。
+
+### 虚拟节点
+
+虚拟节点就是对真实的物理节点在哈希环上虚拟出几个它的分身节点。数据落到分身节点上实际上就是落到真实的物理节点上,通过将虚拟节点均匀分散在哈希环的各个部分。
+
+如下图所示,Node1、Node2、Node3、Node4 这 4 个节点都对应 3 个虚拟节点(下图只是为了演示,实际情况节点分布不会这么有规律)。
+
+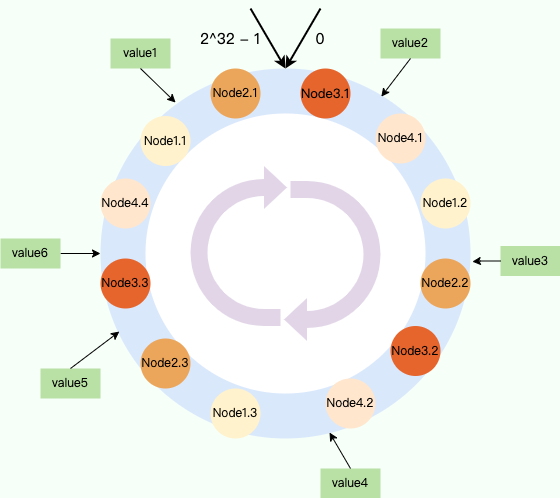
+
+对于上图来说,每个节点最终负责的数据情况如下:
+
+- **Node1**:value4
+- **Node2**:value1,value3
+- **Node3**:value5
+- **Node4**:value2,value6
+
+**引入虚拟节点的好处是巨大的:**
+
+1. **数据均衡:** 虚拟节点越多,环上的“服务器点”就越密集,数据分布自然就越均匀,从根本上解决了数据倾斜问题。通常,每个真实节点对应的虚拟节点数在 100 到 200 之间,例如 Nginx 选择为每个权重分配 160 个虚拟节点。这里的权重的是为了区分服务器,例如处理能力更强的服务器权重越高,进而导致对应的虚拟节点越多,被命中的概率越大。
+2. **容错性增强:** 这才是虚拟节点最精妙的地方。当一个物理节点宕机,它相当于在环上的多个虚拟节点同时下线。这些虚拟节点原本负责的数据和流量,会**自然地、均匀地分散**给环上其他**多个不同**的物理节点去接管,而不会将压力集中于某一个邻居节点。这极大地提升了系统的稳定性和容错能力。
+
+## 参考
+
+- 深入剖析 Nginx 负载均衡算法:
+- 读源码学架构系列:一致性哈希:
+- 一致性 Hash 算法原理总结:
diff --git a/docs/distributed-system/protocol/gossip-protocl.md b/docs/distributed-system/protocol/gossip-protocl.md
deleted file mode 100644
index 69b588cc75c..00000000000
--- a/docs/distributed-system/protocol/gossip-protocl.md
+++ /dev/null
@@ -1,143 +0,0 @@
----
-title: Gossip 协议详解
-category: 分布式
-tag:
- - 分布式协议&算法
- - 共识算法
----
-
-## 背景
-
-在分布式系统中,不同的节点进行数据/信息共享是一个基本的需求。
-
-一种比较简单粗暴的方法就是 **集中式发散消息**,简单来说就是一个主节点同时共享最新信息给其他所有节点,比较适合中心化系统。这种方法的缺陷也很明显,节点多的时候不光同步消息的效率低,还太依赖与中心节点,存在单点风险问题。
-
-于是,**分散式发散消息** 的 **Gossip 协议** 就诞生了。
-
-## Gossip 协议介绍
-
-Gossip 直译过来就是闲话、流言蜚语的意思。流言蜚语有什么特点呢?容易被传播且传播速度还快,你传我我传他,然后大家都知道了。
-
-
-
-**Gossip 协议** 也叫 Epidemic 协议(流行病协议)或者 Epidemic propagation 算法(疫情传播算法),别名很多。不过,这些名字的特点都具有 **随机传播特性** (联想一下病毒传播、癌细胞扩散等生活中常见的情景),这也正是 Gossip 协议最主要的特点。
-
-Gossip 协议最早是在 ACM 上的一篇 1987 年发表的论文 [《Epidemic Algorithms for Replicated Database Maintenance》](https://dl.acm.org/doi/10.1145/41840.41841)中被提出的。根据论文标题,我们大概就能知道 Gossip 协议当时提出的主要应用是在分布式数据库系统中各个副本节点同步数据。
-
-正如 Gossip 协议其名一样,这是一种随机且带有传染性的方式将信息传播到整个网络中,并在一定时间内,使得系统内的所有节点数据一致。
-
-在 Gossip 协议下,没有所谓的中心节点,每个节点周期性地随机找一个节点互相同步彼此的信息,理论上来说,各个节点的状态最终会保持一致。
-
-下面我们来对 Gossip 协议的定义做一个总结:**Gossip 协议是一种允许在分布式系统中共享状态的去中心化通信协议,通过这种通信协议,我们可以将信息传播给网络或集群中的所有成员。**
-
-## Gossip 协议应用
-
-NoSQL 数据库 Redis 和 Apache Cassandra、服务网格解决方案 Consul 等知名项目都用到了 Gossip 协议,学习 Gossip 协议有助于我们搞清很多技术的底层原理。
-
-我们这里以 Redis Cluster 为例说明 Gossip 协议的实际应用。
-
-我们经常使用的分布式缓存 Redis 的官方集群解决方案(3.0 版本引入) Redis Cluster 就是基于 Gossip 协议来实现集群中各个节点数据的最终一致性。
-
-
-
-Redis Cluster 是一个典型的分布式系统,分布式系统中的各个节点需要互相通信。既然要相互通信就要遵循一致的通信协议,Redis Cluster 中的各个节点基于 **Gossip 协议** 来进行通信共享信息,每个 Redis 节点都维护了一份集群的状态信息。
-
-Redis Cluster 的节点之间会相互发送多种 Gossip 消息:
-
-- **MEET**:在 Redis Cluster 中的某个 Redis 节点上执行 `CLUSTER MEET ip port` 命令,可以向指定的 Redis 节点发送一条 MEET 信息,用于将其添加进 Redis Cluster 成为新的 Redis 节点。
-- **PING/PONG**:Redis Cluster 中的节点都会定时地向其他节点发送 PING 消息,来交换各个节点状态信息,检查各个节点状态,包括在线状态、疑似下线状态 PFAIL 和已下线状态 FAIL。
-- **FAIL**:Redis Cluster 中的节点 A 发现 B 节点 PFAIL ,并且在下线报告的有效期限内集群中半数以上的节点将 B 节点标记为 PFAIL,节点 A 就会向集群广播一条 FAIL 消息,通知其他节点将故障节点 B 标记为 FAIL 。
-- ......
-
-下图就是主从架构的 Redis Cluster 的示意图,图中的虚线代表的就是各个节点之间使用 Gossip 进行通信 ,实线表示主从复制。
-
-
-
-有了 Redis Cluster 之后,不需要专门部署 Sentinel 集群服务了。Redis Cluster 相当于是内置了 Sentinel 机制,Redis Cluster 内部的各个 Redis 节点通过 Gossip 协议互相探测健康状态,在故障时可以自动切换。
-
-关于 Redis Cluster 的详细介绍,可以查看这篇文章 [Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html) 。
-
-## Gossip 协议消息传播模式
-
-Gossip 设计了两种可能的消息传播模式:**反熵(Anti-Entropy)** 和 **传谣(Rumor-Mongering)**。
-
-### 反熵(Anti-entropy)
-
-根据维基百科:
-
-> 熵的概念最早起源于[物理学](https://zh.wikipedia.org/wiki/物理学),用于度量一个热力学系统的混乱程度。熵最好理解为不确定性的量度而不是确定性的量度,因为越随机的信源的熵越大。
-
-在这里,你可以把反熵中的熵了解为节点之间数据的混乱程度/差异性,反熵就是指消除不同节点中数据的差异,提升节点间数据的相似度,从而降低熵值。
-
-具体是如何反熵的呢?集群中的节点,每隔段时间就随机选择某个其他节点,然后通过互相交换自己的所有数据来消除两者之间的差异,实现数据的最终一致性。
-
-在实现反熵的时候,主要有推、拉和推拉三种方式:
-
-- 推方式,就是将自己的所有副本数据,推给对方,修复对方副本中的熵。
-- 拉方式,就是拉取对方的所有副本数据,修复自己副本中的熵。
-- 推拉就是同时修复自己副本和对方副本中的熵。
-
-伪代码如下:
-
-
-
-在我们实际应用场景中,一般不会采用随机的节点进行反熵,而是需要可以的设计一个闭环。这样的话,我们能够在一个确定的时间范围内实现各个节点数据的最终一致性,而不是基于随机的概率。像 InfluxDB 就是这样来实现反熵的。
-
-
-
-1. 节点 A 推送数据给节点 B,节点 B 获取到节点 A 中的最新数据。
-2. 节点 B 推送数据给 C,节点 C 获取到节点 A,B 中的最新数据。
-3. 节点 C 推送数据给 A,节点 A 获取到节点 B,C 中的最新数据。
-4. 节点 A 再推送数据给 B 形成闭环,这样节点 B 就获取到节点 C 中的最新数据。
-
-虽然反熵很简单实用,但是,节点过多或者节点动态变化的话,反熵就不太适用了。这个时候,我们想要实现最终一致性就要靠 **谣言传播(Rumor mongering)** 。
-
-### 谣言传播(Rumor mongering)
-
-谣言传播指的是分布式系统中的一个节点一旦有了新数据之后,就会变为活跃节点,活跃节点会周期性地联系其他节点向其发送新数据,直到所有的节点都存储了该新数据。
-
-如下图所示(下图来自于[INTRODUCTION TO GOSSIP](https://managementfromscratch.wordpress.com/2016/04/01/introduction-to-gossip/) 这篇文章):
-
-
-
-伪代码如下:
-
-
-
-谣言传播比较适合节点数量比较多的情况,不过,这种模式下要尽量避免传播的信息包不能太大,避免网络消耗太大。
-
-### 总结
-
-- 反熵(Anti-Entropy)会传播节点的所有数据,而谣言传播(Rumor-Mongering)只会传播节点新增的数据。
-- 我们一般会给反熵设计一个闭环。
-- 谣言传播(Rumor-Mongering)比较适合节点数量比较多或者节点动态变化的场景。
-
-## Gossip 协议优势和缺陷
-
-**优势:**
-
-1、相比于其他分布式协议/算法来说,Gossip 协议理解起来非常简单。
-
-2、能够容忍网络上节点的随意地增加或者减少,宕机或者重启,因为 Gossip 协议下这些节点都是平等的,去中心化的。新增加或者重启的节点在理想情况下最终是一定会和其他节点的状态达到一致。
-
-3、速度相对较快。节点数量比较多的情况下,扩散速度比一个主节点向其他节点传播信息要更快(多播)。
-
-**缺陷** :
-
-1、消息需要通过多个传播的轮次才能传播到整个网络中,因此,必然会出现各节点状态不一致的情况。毕竟,Gossip 协议强调的是最终一致,至于达到各个节点的状态一致需要多长时间,谁也无从得知。
-
-2、由于拜占庭将军问题,不允许存在恶意节点。
-
-3、可能会出现消息冗余的问题。由于消息传播的随机性,同一个节点可能会重复收到相同的消息。
-
-## 总结
-
-- Gossip 协议是一种允许在分布式系统中共享状态的通信协议,通过这种通信协议,我们可以将信息传播给网络或集群中的所有成员。
-- Gossip 协议被 Redis、Apache Cassandra、Consul 等项目应用。
-- 谣言传播(Rumor-Mongering)比较适合节点数量比较多或者节点动态变化的场景。
-
-## 参考
-
-- 一万字详解 Redis Cluster Gossip 协议:https://segmentfault.com/a/1190000038373546
-- 《分布式协议与算法实战》
-- 《Redis 设计与实现》
diff --git a/docs/distributed-system/protocol/gossip-protocol.md b/docs/distributed-system/protocol/gossip-protocol.md
new file mode 100644
index 00000000000..e03af2e583d
--- /dev/null
+++ b/docs/distributed-system/protocol/gossip-protocol.md
@@ -0,0 +1,202 @@
+---
+title: Gossip 协议详解
+description: Gossip协议原理详解,讲解去中心化信息传播机制、两种典型传播模式(反熵与谣言传播)及在Redis Cluster等系统中的应用。
+category: 分布式
+tag:
+ - 分布式协议&算法
+ - 数据复制协议
+ - 最终一致性
+---
+
+## 背景
+
+在分布式系统中,不同节点间共享状态是一个基本需求。
+
+一种简单的方法是 **集中式广播**:由中心节点向所有其他节点同步信息。这种方式适合中心化系统,但存在明显缺陷:当节点数量增加时,同步效率下降(O(N) 复杂度),且过度依赖中心节点,存在单点故障风险。
+
+**分散式传播** 的 **Gossip 协议** 提供了一种去中心化的替代方案。
+
+
+
+## Gossip 协议介绍
+
+**Gossip**(闲话协议)也称 **Epidemic 协议**(流行病协议),灵感来源于流行病传播的随机特性。其核心思想是:每个节点周期性地随机选择若干其他节点交换信息,使数据像病毒传播一样扩散至整个网络。
+
+
+
+Gossip 协议最早由 Demers 等人在 1987 年的论文 [《Epidemic Algorithms for Replicated Database Maintenance》](https://dl.acm.org/doi/10.1145/41840.41841) 中提出,用于解决分布式数据库的副本同步问题。
+
+**定义**:Gossip 协议是一种**去中心化**的通信协议,通过节点间的随机信息交换,在**非拜占庭且不存在永久网络分区**、节点持续周期性交换的前提下,使集群内所有节点的状态达到**最终一致性**。
+
+> **重要区分**:Gossip 是信息传播协议,**不是共识算法**(如 Raft/Paxos)。共识算法保证强一致性与安全性,Gossip 只保证最终一致性,不适用于选主或状态机复制等需要强一致的场景。
+
+**关键特性**:
+
+- **去中心化**:无中心节点,所有节点地位平等
+- **容错性强**:容忍节点宕机、网络分区、动态增删节点
+- **概率收敛**:在均匀随机选点、fanout 为常数的经典模型下,传播轮次期望为 O(log N)(如 N=100 时约 5-7 轮,具体取决于 fanout 与丢包率)
+- **消息冗余**:同一消息可能被多次接收,需去重机制
+
+## Gossip 协议应用
+
+Gossip 协议被广泛应用于分布式系统:
+
+- **Redis Cluster**:用于节点间状态同步与故障检测
+- **Apache Cassandra**:用于节点成员与状态信息传播;副本修复采用反熵/repair(基于 Merkle Tree)
+- **Consul**:用于成员发现、故障探测与事件广播(基于 SWIM 协议)
+- **Amazon Dynamo**:用于分布式存储的最终一致性
+
+以 **Redis Cluster**(3.0+)为例:
+
+Redis Cluster 是一个去中心化的分布式缓存方案,各节点通过 Gossip 协议交换集群状态,包括:节点信息、槽位分配、节点状态(在线/PFAIL/FAIL)。
+
+
+
+**Gossip 消息类型**:
+
+| 消息类型 | 用途 |
+| -------- | --------------------------- |
+| MEET | 将指定节点添加进集群 |
+| PING | 周期性发送,交换节点状态 |
+| PONG | 响应 PING,携带自身状态信息 |
+| FAIL | 广播节点故障标记 |
+
+> 注:在实现上,MEET/PING/PONG 共享同一类消息结构;PONG 是对 PING/MEET 的响应,MEET 相当于"强制握手"的 PING。
+
+**故障检测流程**:
+
+1. 节点 A 若在 `cluster-node-timeout`(常见为 15s,具体以配置为准)内未收到 B 的响应,将 B 标记为 **PFAIL**(疑似下线)
+2. 若 A 收到其他主节点对 B 的 PFAIL 报告,且**半数以上的主节点**确认 B 为 PFAIL(报告未过期),则 A 将 B 标记为 **FAIL**(已下线)并向集群广播
+
+下图就是主从架构的 Redis Cluster 的示意图,图中的虚线代表的就是各个节点之间使用 Gossip 进行通信,实线表示主从复制。
+
+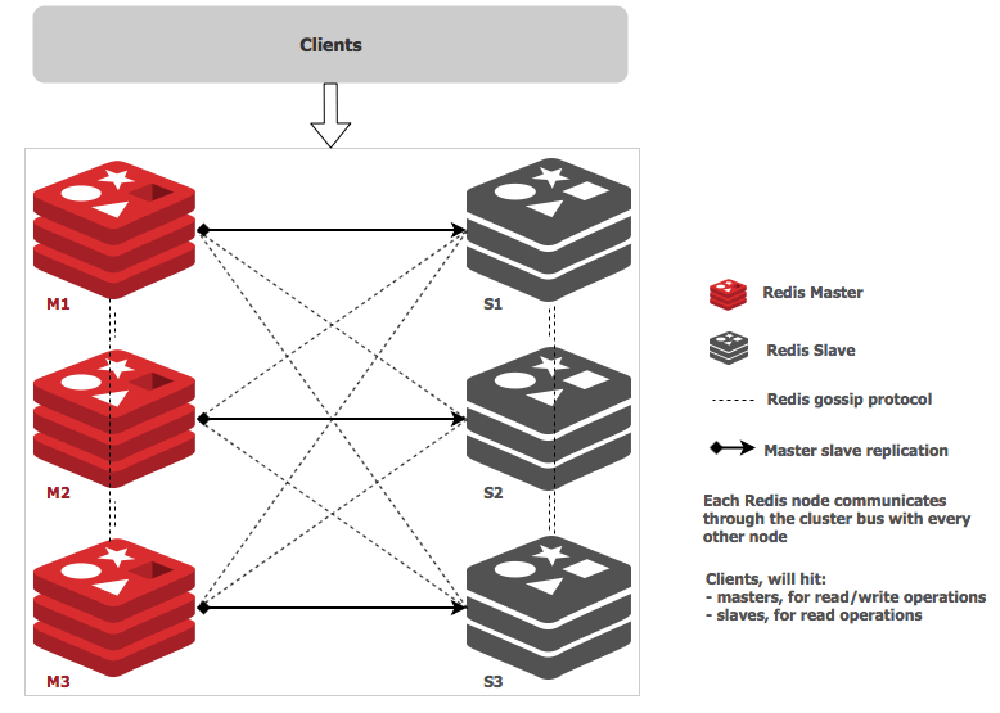
+
+> 注:Redis Cluster 主要通过 PING/PONG 的增量 gossip 传播节点/槽位/故障信息(带时间戳/标志位等),而不是采用像 Dynamo 那样基于 Merkle tree 的反熵对账流程。
+
+关于 Redis Cluster 的详细介绍,可以查看这篇文章 [Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html)。
+
+## Gossip 协议传播模式
+
+Gossip 协议有两种主要传播模式:**反熵** 和 **谣言传播**。
+
+### 反熵
+
+**定义**:节点间交换**完整数据**(或数据摘要),消除差异,实现最终一致。
+
+**熵**的物理含义是系统混乱程度;反熵即**降低节点间数据差异,提升一致性**。
+
+根据维基百科:
+
+> 熵的概念最早起源于[物理学](https://zh.wikipedia.org/wiki/物理学),用于度量一个热力学系统的混乱程度。熵最好理解为不确定性的量度而不是确定性的量度,因为越随机的信源的熵越大。
+
+在这里,你可以把反熵中的熵理解为节点之间数据的混乱程度/差异性,反熵就是指消除不同节点中数据的差异,提升节点间数据的相似度,从而降低熵值。
+
+**三种实现方式**:
+
+| 方式 | 描述 | 适用场景 |
+| --------- | ---------------------------------- | -------------- |
+| Push | 发送方将自己的全部数据推送给接收方 | 发送方有新数据 |
+| Pull | 接收方拉取发送方的全部数据 | 接收方数据陈旧 |
+| Push-Pull | 双向交换数据,并比较差异 | 最高效,最常用 |
+
+
+
+伪代码如下:
+
+
+
+**收敛特性**:在均匀随机选点、fanout 为常数的模型下,期望 O(log N) 轮覆盖全部节点(常见估算可用 log₂N 量级)
+
+部分系统(如 InfluxDB)采用**确定性闭环调度**(如环形拓扑)代替随机选择,可在确定轮次内完成同步。这属于反熵的**工程衍生实现**,而非标准 Gossip 协议的核心机制。确定性调度牺牲了随机性的容错优势,换取可预测的收敛时间。
+
+
+
+1. 节点 A 推送数据给节点 B,节点 B 获取到节点 A 中的最新数据。
+2. 节点 B 推送数据给 C,节点 C 获取到节点 A,B 中的最新数据。
+3. 节点 C 推送数据给 A,节点 A 获取到节点 B,C 中的最新数据。
+4. 节点 A 再推送数据给 B 形成闭环,这样节点 B 就获取到节点 C 中的最新数据。
+
+**权衡**:闭环调度可在确定时间内完成同步,但牺牲了**容错性**(环中节点故障影响传播路径),且难以适应节点动态增删。
+
+**适用场景**:需要较低残留率(尽量不漏更新)、允许后台周期性对账修复;数据量大时必须依赖摘要/树等增量比对以控制成本。
+
+> **生产级优化**:在大规模分布式存储(如 Cassandra、DynamoDB)中,节点数据量可达 TB 级,直接交换完整数据不现实。生产系统使用 **Merkle Tree(默克尔树)** 进行增量差异比对:两节点先交换 Merkle Tree 根哈希,若有差异则递归比对子树,在树高 O(log M) 的层级上定位差异(M 为该范围内条目数),随后仅传输增量数据。
+
+### 谣言传播
+
+**定义**:当节点有**新数据**时,变为活跃节点,周期性地向随机节点广播该数据,直到所有节点都收到。
+
+**与反熵的区别**:
+
+- 只传播**新增数据**(Delta),非完整数据
+- 节点收到更新后进入活跃状态周期性传播,多次接触到已知该更新的节点后按策略(计数/概率/TTL)停止传播
+- 适合**节点数量大**、**增量数据小**的场景
+
+> **去重机制**:生产环境(如 Redis Cluster)通过**版本号**或**消息 ID** 去重,避免重复处理相同消息。
+
+如下图所示(下图来自于[INTRODUCTION TO GOSSIP](https://managementfromscratch.wordpress.com/2016/04/01/introduction-to-gossip/) 这篇文章):
+
+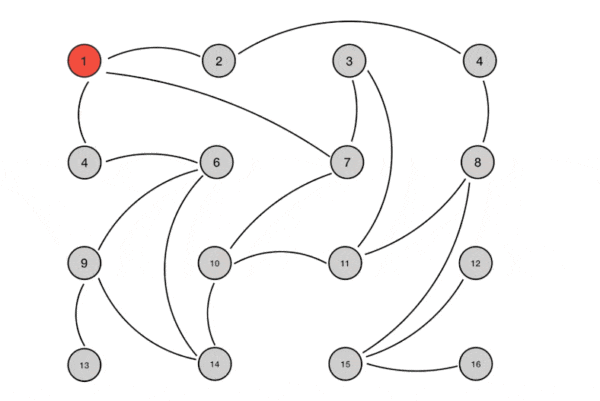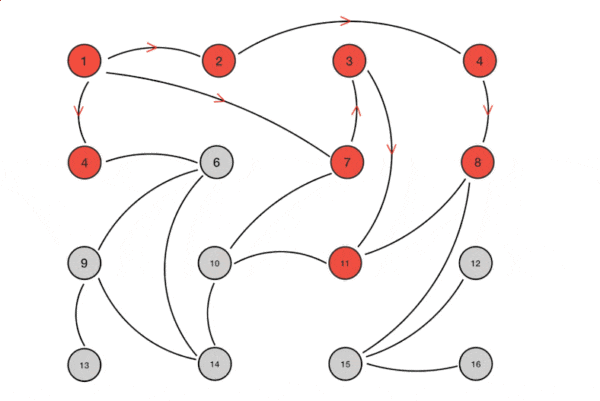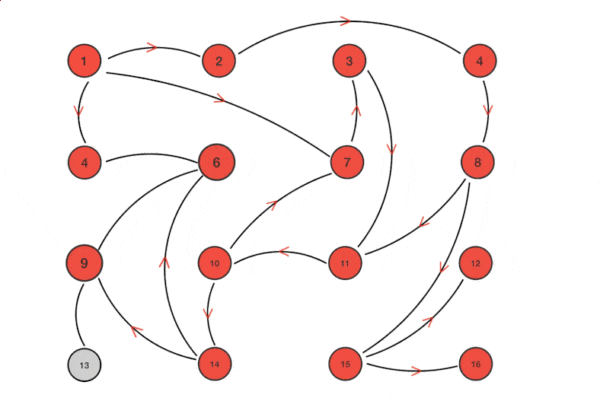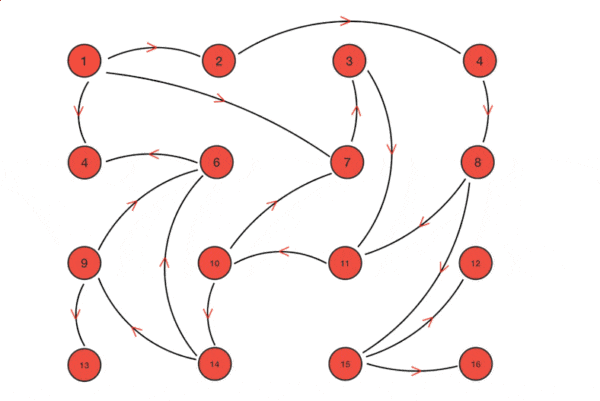
+
+伪代码如下:
+
+
+
+**收敛特性**:在均匀随机选点、fanout 为常数的模型下,O(log N) 轮后以高概率覆盖全部节点。
+
+**注意事项**:
+
+- 控制消息包大小,尽量避免分片(视路径 MTU 而定,通常控制在单个网络包内)
+- 配合去重机制(如消息 ID、版本号)
+- 避免高频更新导致消息风暴
+- 使用 **Jitter(随机抖动)**打散同步时间,避免多节点同时发起传播造成雪崩
+
+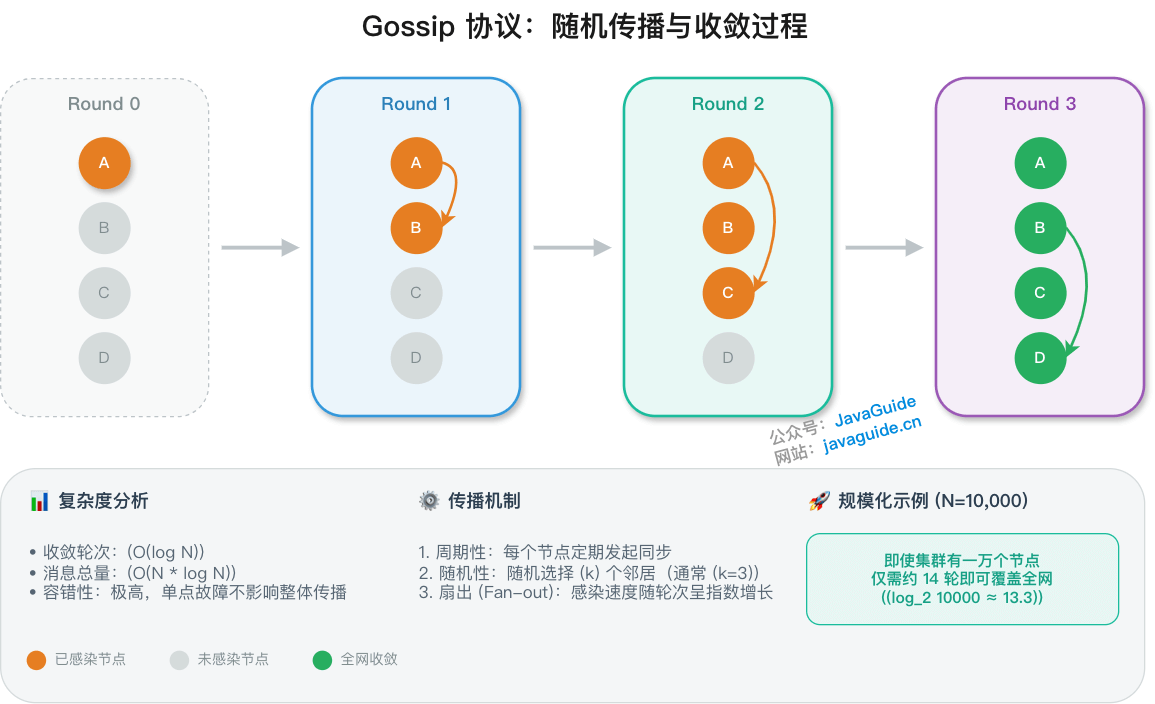
+
+### 总结
+
+| 要点 | 反熵 | 谣言传播 |
+| -------- | -------------------------- | -------------------------- |
+| 传播内容 | 完整数据(或摘要) | 仅新增数据(Delta) |
+| 适用场景 | 节点数量适中 | 节点数量较多/动态变化 |
+| 消息开销 | 较大 | 较小 |
+| 收敛范围 | 收敛到最新数据(全量同步) | 收敛到已知数据(增量传播) |
+
+## Gossip 协议优势与缺陷
+
+**优势**:
+
+1. **实现简单**:协议逻辑简单,易于理解
+
+2. **容错性强**:容忍节点宕机、网络分区、动态增删节点。新增或重启的节点在理想情况下最终一定会和其他节点的状态达到一致。
+
+3. **扩展性好**:收敛时间为 O(log N),当 N 较大(如 N > 100)时,并行传播通常比中心节点单播更快(后者需 O(N) 轮次)。在典型 rumor spreading 模型下代价是**消息总量为 O(N log N)**(具体取决于实现策略与停止条件),存在冗余开销。
+
+**缺陷**:
+
+1. **最终一致**:消息需通过多轮传播才能覆盖整个网络,存在不一致窗口期。达到一致的具体时间取决于网络状况、gossip 间隔(**视实现配置而定,常见 100ms-1s**)与节点规模。
+
+2. **不适用拜占庭环境**:Gossip 协议的设计假设是非拜占庭环境,不处理恶意节点的情况(节点不会伪造或篡改消息)。
+
+3. **消息冗余**:由于传播的随机性,同一节点可能重复收到相同消息,需配合去重机制。
+
+## 总结
+
+- Gossip 协议是一种**去中心化**的通信协议,通过节点间的随机信息交换,使集群内所有节点的状态达到**最终一致性**
+- **不是共识算法**:Gossip 不保证强一致性/线性一致性,不能用于选主或状态机复制;共识算法(Raft/Paxos)才保证安全性与线性一致
+- 核心特性:去中心化、容错性强、O(log N) 收敛
+- 两种传播模式:**反熵**(完整数据/摘要)、**谣言传播**(增量数据)
+- 典型应用:元数据传播(Redis Cluster)、最终一致存储(Cassandra/DynamoDB)
+- 权衡:简单性与容错性 vs 最终一致延迟与消息冗余
+
+## 参考
+
+- [Epidemic Algorithms for Replicated Database Maintenance](https://dl.acm.org/doi/10.1145/41840.41841) - Demers et al., 1987
+- [Amazon Dynamo: All Things Distributed](https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf) - DeCandia et al., 2007
+- [Redis Cluster Specification](https://redis.io/docs/management/scaling/)
+- 一万字详解 Redis Cluster Gossip 协议:
+- 《分布式协议与算法实战》
+- 《Redis 设计与实现》
+
+
diff --git a/docs/distributed-system/protocol/images/gossip/gossip-rumor- mongering.gif b/docs/distributed-system/protocol/images/gossip/gossip-rumor- mongering.gif
deleted file mode 100644
index 5dfa2ccb7f9..00000000000
Binary files a/docs/distributed-system/protocol/images/gossip/gossip-rumor- mongering.gif and /dev/null differ
diff --git a/docs/distributed-system/protocol/images/gossip/gossip.png b/docs/distributed-system/protocol/images/gossip/gossip.png
deleted file mode 100644
index 2d85b8d9ee3..00000000000
Binary files a/docs/distributed-system/protocol/images/gossip/gossip.png and /dev/null differ
diff --git a/docs/distributed-system/protocol/images/gossip/redis-cluster-gossip.png b/docs/distributed-system/protocol/images/gossip/redis-cluster-gossip.png
deleted file mode 100644
index 0485ae3e1da..00000000000
Binary files a/docs/distributed-system/protocol/images/gossip/redis-cluster-gossip.png and /dev/null differ
diff --git "a/docs/distributed-system/protocol/images/gossip/\345\217\215\347\206\265-\351\227\255\347\216\257.drawio" "b/docs/distributed-system/protocol/images/gossip/\345\217\215\347\206\265-\351\227\255\347\216\257.drawio"
deleted file mode 100644
index bc00005d2b3..00000000000
--- "a/docs/distributed-system/protocol/images/gossip/\345\217\215\347\206\265-\351\227\255\347\216\257.drawio"
+++ /dev/null
@@ -1 +0,0 @@
-5VhNc5swEP01HONBYDAcjeOm06bTTHNoc+ooIIwaQIyQY5NfXwkkg4w/iJukziQHR/skFmnf7mPBsGfZ+orCIvlGIpQalhmtDfvSsCwATJf/E0jVIL4/aYAFxZFc1AK3+AlJ0JToEkeo1BYyQlKGCx0MSZ6jkGkYpJSs9GUxSfW7FnCBesBtCNM++hNHLGlQz5q0+GeEF4m6M3D9ZiaDarE8SZnAiKw6kD037BklhDWjbD1DqQieiktz3ac9s5uNUZSzIRcEfoFuKoCmflF8L77+dn58yS6kl0eYLuWBjblneFPD44OJ+A38qdw/q1RQuGMef24EqwQzdFvAUMyseApwLGFZyi3Ah7AsGlJivEZ8H0GM03RGUkJrR3Ycx1YYcrxklDygzkzk3ruOK2ZU2ExhPCAWJtJ5THImEwZ43O4HRJ0OUYbWHUgG6AqRDDFa8SVy1lZpJ7PVGkt71eFeQkmHdoVBmW2LjeeWED6QnDyDn/EAfmYfhx9rix/b+8/8+P3YR1w/pEkoS8iC5DCdt2hAyTKPRLTrkLVrrgkpZOj+IMYqGTu4ZERnbXBgS7KkITqwfUcqKqQLxI6noTjbQZooSiHDj7p2vnjQQb8qrJ08XMN7/jjSMz7Fi5yPQx4rxHM5EMmHud5P5USGo6ihCZX4Cd7X/gRRBcE5q4/iBIZzOYiHQznTy/rNQ0zeVHtO7KoGc2R66vlaaY4G8yB934izdZaQOC55QmwTtdnC6dw5AwQt+DiCNla5fC6CNunz0yMjj6aisxJVlMKyxOFheUJrzH4JY2RajrTvRHxHrrQu1zLctVEpI+cH+lUvdJR5151rL6utquPkBlHMAyIqvMZOl0jVdB6TSGegRHaIdXYQq7BTK1g1Mt5Eb2R8X3fRnFte1e0atxyNna0E9bcyrwlMz9FL6QWwewmpmHsPWq/K6Z+1/oKLPXBsjYsL+9zV3nsFNdmogqYJrUQcUIWOmEgNAgcV6MOphuOP/O7fVu2D3dPP1hTLHfl63zI2zQ30Vsri9pJz/I6URZXWSygLFxZPV5az7yPBji8XryMt4Iiw7BWJo8UPzqr4LXfPu/Vzy3v7I4ptv3HL0H/HsN9RYYN9LxEn9QwTxz+bnoGb7efOZnn70die/wU=
\ No newline at end of file
diff --git "a/docs/distributed-system/protocol/images/gossip/\345\217\215\347\206\265-\351\227\255\347\216\257.png" "b/docs/distributed-system/protocol/images/gossip/\345\217\215\347\206\265-\351\227\255\347\216\257.png"
deleted file mode 100644
index 0bf4e605046..00000000000
Binary files "a/docs/distributed-system/protocol/images/gossip/\345\217\215\347\206\265-\351\227\255\347\216\257.png" and /dev/null differ
diff --git a/docs/distributed-system/protocol/images/paxos/paxos-made-simple.png b/docs/distributed-system/protocol/images/paxos/paxos-made-simple.png
deleted file mode 100644
index 4e51f58db4b..00000000000
Binary files a/docs/distributed-system/protocol/images/paxos/paxos-made-simple.png and /dev/null differ
diff --git a/docs/distributed-system/protocol/paxos-algorithm.md b/docs/distributed-system/protocol/paxos-algorithm.md
index fb62f923212..1aace26b109 100644
--- a/docs/distributed-system/protocol/paxos-algorithm.md
+++ b/docs/distributed-system/protocol/paxos-algorithm.md
@@ -1,18 +1,19 @@
---
title: Paxos 算法详解
+description: Paxos 共识算法原理详解,涵盖 Basic Paxos 两阶段提交流程、Multi-Paxos 优化思想及与 Raft 的对比分析。
category: 分布式
-tag:
+tags:
- 分布式协议&算法
- 共识算法
---
## 背景
-Paxos 算法是 Leslie Lamport([莱斯利·兰伯特](https://zh.wikipedia.org/wiki/莱斯利·兰伯特))在 **1990** 年提出了一种分布式系统 **共识** 算法。这也是第一个被证明完备的共识算法(前提是不存在拜占庭将军问题,也就是没有恶意节点)。
+Paxos 算法是 Leslie Lamport(莱斯利·兰伯特)在 **1990** 年提出的一种分布式系统 **共识** 算法。这是最早被广泛认可的分布式共识算法之一(前提是不存在拜占庭将军问题,也就是没有恶意节点)。
为了介绍 Paxos 算法,兰伯特专门写了一篇幽默风趣的论文。在这篇论文中,他虚拟了一个叫做 Paxos 的希腊城邦来更形象化地介绍 Paxos 算法。
-不过,审稿人并不认可这篇论文的幽默。于是,他们就给兰伯特说:“如果你想要成功发表这篇论文的话,必须删除所有 Paxos 相关的故事背景”。兰伯特一听就不开心了:“我凭什么修改啊,你们这些审稿人就是缺乏幽默细胞,发不了就不发了呗!”。
+不过,审稿人并不认可这篇论文的幽默。于是,他们就给兰伯特说:"如果你想要成功发表这篇论文的话,必须删除所有 Paxos 相关的故事背景"。兰伯特一听就不开心了:"我凭什么修改啊,你们这些审稿人就是缺乏幽默细胞,发不了就不发了呗!"。
于是乎,提出 Paxos 算法的那篇论文在当时并没有被成功发表。
@@ -22,7 +23,7 @@ Paxos 算法是 Leslie Lamport([莱斯利·兰伯特](https://zh.wikipedia.org
《Paxos Made Simple》这篇论文就 14 页,相比于 《The Part-Time Parliament》的 33 页精简了不少。最关键的是这篇论文的摘要就一句话:
-
+
> The Paxos algorithm, when presented in plain English, is very simple.
@@ -32,50 +33,426 @@ Paxos 算法是 Leslie Lamport([莱斯利·兰伯特](https://zh.wikipedia.org
## 介绍
-Paxos 算法是第一个被证明完备的分布式系统共识算法。共识算法的作用是让分布式系统中的多个节点之间对某个提案(Proposal)达成一致的看法。提案的含义在分布式系统中十分宽泛,像哪一个节点是 Leader 节点、多个事件发生的顺序等等都可以是一个提案。
+本文将 Paxos 分为两部分进行讲解:
-兰伯特当时提出的 Paxos 算法主要包含 2 个部分:
+- **Basic Paxos 算法**:描述多节点之间如何就单个值(value)达成共识。
+- **Multi-Paxos 思想**:通过执行多个 Basic Paxos 实例,就一系列值达成共识。
-- **Basic Paxos 算法**:描述的是多节点之间如何就某个值(提案 Value)达成共识。
-- **Multi-Paxos 思想**:描述的是执行多个 Basic Paxos 实例,就一系列值达成共识。Multi-Paxos 说白了就是执行多次 Basic Paxos ,核心还是 Basic Paxos 。
+共识算法的作用是让分布式系统中的多个节点对某个提案(proposal)达成一致。"提案"在不同系统里可指代的对象很广,如选主、事件排序等都可以是提案。
-由于 Paxos 算法在国际上被公认的非常难以理解和实现,因此不断有人尝试简化这一算法。到了 2013 年才诞生了一个比 Paxos 算法更易理解和实现的共识算法—[Raft 算法](https://javaguide.cn/distributed-system/theorem&algorithm&protocol/raft-algorithm.html) 。更具体点来说,Raft 是 Multi-Paxos 的一个变种,其简化了 Multi-Paxos 的思想,变得更容易被理解以及工程实现。
+由于 Paxos 算法公认难以理解和实现,2013 年诞生了更易理解的 [Raft 算法](https://javaguide.cn/distributed-system/theorem&algorithm&protocol/raft-algorithm.html)。
-针对没有恶意节点的情况,除了 Raft 算法之外,当前最常用的一些共识算法比如 **ZAB 协议**、 **Fast Paxos** 算法都是基于 Paxos 算法改进的。
+**关于 Raft 与 Paxos 的关系**:从学术角度,Raft 并非 Paxos 的严格变体——两者在底层设计哲学(如日志空洞、Leader 权限)上存在本质差异。但从工程实践角度,Raft 的设计灵感源于 Multi-Paxos,可理解为"受 Multi-Paxos 启发的重新设计"。本文后文将详细对比二者区别。
-针对存在恶意节点的情况,一般使用的是 **工作量证明(POW,Proof-of-Work)**、 **权益证明(PoS,Proof-of-Stake )** 等共识算法。这类共识算法最典型的应用就是区块链,就比如说前段时间以太坊官方宣布其共识机制正在从工作量证明(PoW)转变为权益证明(PoS)。
+针对非拜占庭场景(无恶意节点),除 Raft 外,**ZAB 协议**、**Fast Paxos** 等都是基于 Paxos 改进的共识算法。
-区块链系统使用的共识算法需要解决的核心问题是 **拜占庭将军问题** ,这和我们日常接触到的 ZooKeeper、Etcd、Consul 等分布式中间件不太一样。
-
-下面我们来对 Paxos 算法的定义做一个总结:
-
-- Paxos 算法是兰伯特在 **1990** 年提出了一种分布式系统共识算法。
-- 兰伯特当时提出的 Paxos 算法主要包含 2 个部分: Basic Paxos 算法和 Multi-Paxos 思想。
-- Raft 算法、ZAB 协议、 Fast Paxos 算法都是基于 Paxos 算法改进而来。
+针对拜占庭场景(存在恶意节点),通常使用 **工作量证明(PoW,Proof-of-Work)**、**权益证明(PoS,Proof-of-Stake)** 等共识算法,典型应用为区块链系统。
## Basic Paxos 算法
+### 角色定义
+
Basic Paxos 中存在 3 个重要的角色:
-1. **提议者(Proposer)**:也可以叫做协调者(coordinator),提议者负责接受客户端的请求并发起提案。提案信息通常包括提案编号 (Proposal ID) 和提议的值 (Value)。
-2. **接受者(Acceptor)**:也可以叫做投票员(voter),负责对提议者的提案进行投票,同时需要记住自己的投票历史;
-3. **学习者(Learner)**:如果有超过半数接受者就某个提议达成了共识,那么学习者就需要接受这个提议,并就该提议作出运算,然后将运算结果返回给客户端。
+1. **提议者(Proposer)**:也可以叫做协调者(coordinator),负责接受客户端请求并发起提案。提案信息通常包括提案编号(proposal ID)和提议的值(value)。
+2. **接受者(Acceptor)**:也可以叫做投票员(voter),负责对提案进行投票,同时需要记住自己的投票历史。
+3. **学习者(Learner)**:负责学习(learn)已被选定的值。在复制状态机(RSM)实现中,该值通常对应一条待执行的命令,由状态机按序 apply 后再由对外服务层返回结果。
+
+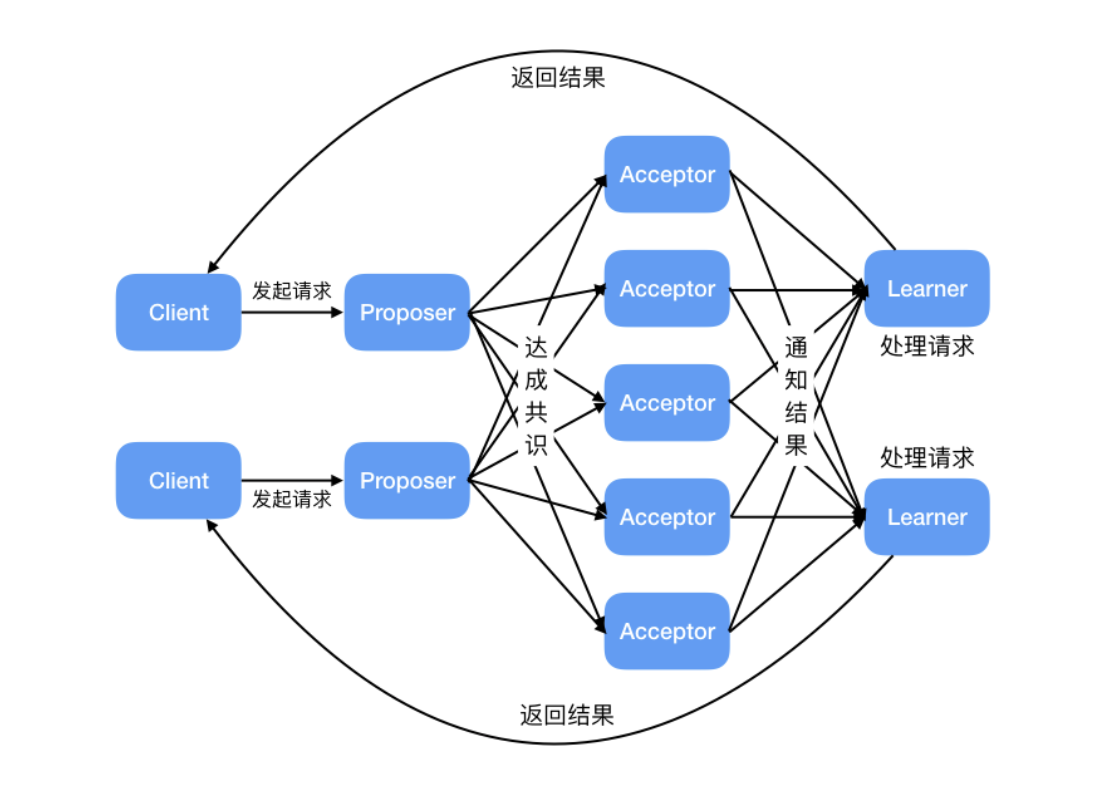
+
+**角色交互关系图**:
+
+```mermaid
+flowchart LR
+ subgraph Roles["Paxos 三个核心角色"]
+ direction LR
+ Prop[Proposer
提议者
发起提案]
+ Acc[Acceptor
接受者
投票表决]
+ Lear[Learner
学习者
获取结果]
+ end
+
+ Prop -->|Prepare| Acc
+ Acc -->|Promise| Prop
+ Prop -->|Accept| Acc
+ Acc -->|Accepted| Prop
+ Prop -->|通知选定| Lear
-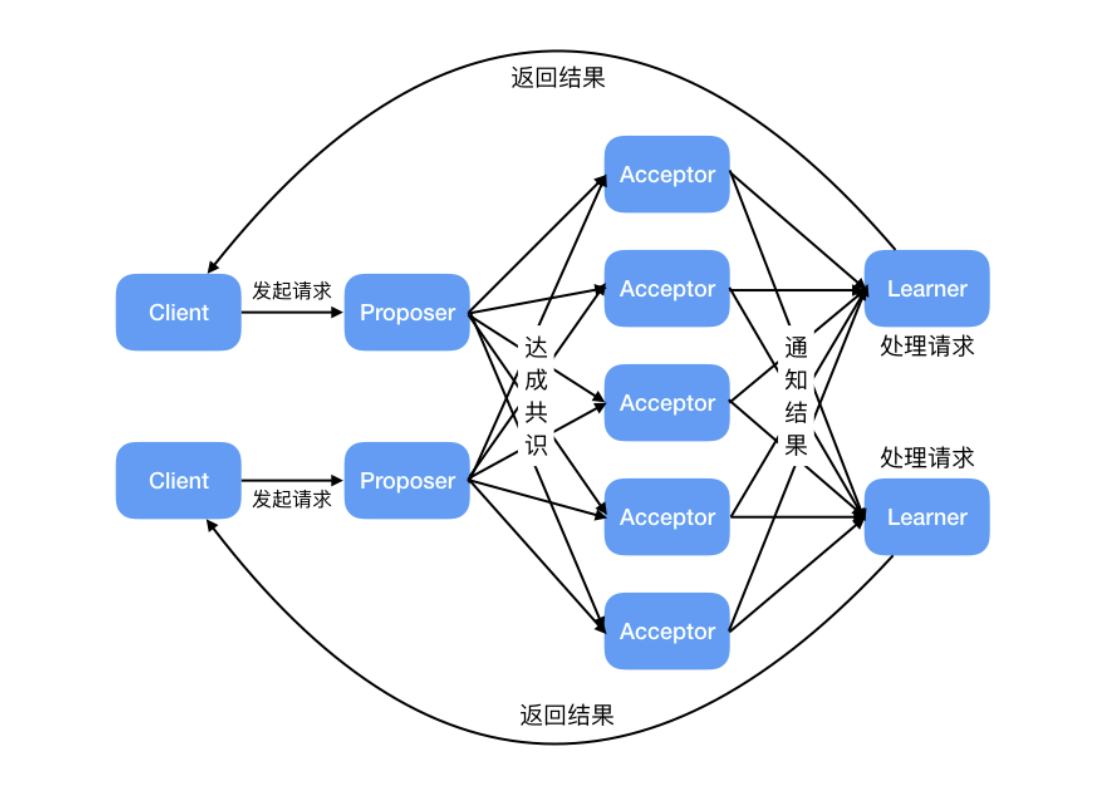
+ style Roles fill:#F5F7FA,color:#333,stroke:#005D7B,stroke-width:2px
+ classDef role fill:#E99151,color:#FFFFFF,stroke:none,rx:10,ry:10
+
+ class Prop,Acc,Lear role
+```
为了减少实现该算法所需的节点数,一个节点可以身兼多个角色。并且,一个提案被选定需要被半数以上的 Acceptor 接受。这样的话,Basic Paxos 算法还具备容错性,在少于一半的节点出现故障时,集群仍能正常工作。
-## Multi Paxos 思想
+### 执行流程
+
+Basic Paxos 通过两个阶段达成共识:**Prepare/Promise(准备/承诺)阶段**和 **Accept/Accepted(接受/已接受)阶段**。
+
+```mermaid
+sequenceDiagram
+ participant P as Proposer
+ participant A1 as Acceptor 1
+ participant A2 as Acceptor 2
+ participant A3 as Acceptor 3
+
+ note over P, A3: Phase 1: 准备阶段 (Prepare) - 争夺锁与获取历史
+ P->>A1: Prepare(ID=N)
+ P->>A2: Prepare(ID=N)
+ P->>A3: Prepare(ID=N)
+
+ A1-->>P: Promise(ID=N, 已接受值=null)
+ A2-->>P: Promise(ID=N, 已接受值=null)
+ note right of A3: 假设 A3 网络延迟未响应
+
+ note over P, A3: Phase 2: 接受阶段 (Accept) - 提交决议
+ P->>A1: Accept(ID=N, Value="Set X=1")
+ P->>A2: Accept(ID=N, Value="Set X=1")
+
+ A1-->>P: Accepted(ID=N)
+ A2-->>P: Accepted(ID=N)
+ note over P: 收到多数派 (2个) Accepted,决议达成 (Chosen)
+```
+
+#### Phase 1: Prepare/Promise(准备/承诺阶段)
+
+Proposer 选择一个提案编号 n(必须全局唯一且递增),向超过半数的 Acceptor 发送 `Prepare(n)` 请求。
+
+**Acceptor 的处理逻辑**(对每个提案编号 n 的处理逻辑):
+
+- 若 n > 该 Acceptor 见过的最大提案编号 max_n
+ - 返回 `Promise(n, max_v)`,其中 max_v 是之前接受过的最大编号提案的值(若有)
+ - 承诺不再接受编号 < n 的提案
+- 若 n ≤ max_n
+ - 拒绝或忽略该请求
+
+**目的**:让 Proposer 了解当前系统中已被接受或准备接受的提案,避免提出冲突的值。
+
+#### Phase 2: Accept/Accepted(接受/已接受阶段)
+
+当 Proposer 收到超过半数 Acceptor 的 Promise 响应后,选择响应中 max_v 最大的值(若无则任意选择一个值),向超过半数的 Acceptor 发送 `Accept(n, v)` 请求。
+
+**Acceptor 的处理逻辑**:
+
+- 若 n ≥ 该 Acceptor 在 Phase 1 承诺的 max_n
+ - 接受该提案,记录 (n, v),并返回 `Accepted(n, v)`
+- 否则
+ - 拒绝该请求
+
+#### 收敛条件
+
+当 Proposer 收到超过半数 Acceptor 对 `Accept(n, v)` 的响应时,提案 v 被**选定(chosen)**。Proposer 通知所有 Learner 提案已被选定。
+
+### 安全性保证
+
+Basic Paxos 保证以下安全性:
+
+1. **一致性**:一旦某个值被选定,所有后续选定的值都是该值
+2. **可终止性**:若无 Proposer 竞争且通信可靠,最终能选定一个值
+
+**核心机制**:通过 Phase 1 收集 Promise,Proposer 只能选择已经被 Acceptors 承诺过的值(或选择新值),保证了不会有冲突的值被选定。
+
+### 活性问题
+
+Basic Paxos 存在**活锁(Livelock)**风险:
+
+- 若多个 Proposer 同时发起提案,且提案编号交错递增
+- 可能导致没有提案能获得超过半数的 Accept
+- 系统陷入无限竞争,无法达成共识
+
+**活锁示例**(Dueling Proposers):
+
+假设有两个 Proposer P1 和 P2 同时发起提案:
+
+1. P1 发送 `Prepare(1)`,P2 发送 `Prepare(2)`
+2. Acceptor 们承诺给编号较大的 P2
+3. P1 发现编号被超越,发送 `Prepare(3)`
+4. P2 发现编号被超越,发送 `Prepare(4)`
+5. ... 循环往复,永远无法进入 Phase 2
+
+**活锁时序图**:
+
+```mermaid
+sequenceDiagram
+ participant P1 as Proposer 1
+ participant A as Acceptors
+ participant P2 as Proposer 2
+
+ Note over P1,P2: 活锁场景:Dueling Proposers
+
+ P1->>A: Prepare(N=1)
+ P2->>A: Prepare(N=2)
+ A-->>P1: Promise(拒绝, N=2 更大)
+ A-->>P2: Promise(接受, N=2)
+
+ Note over P1: 编号被超越,递增
+ P1->>A: Prepare(N=3)
+ A-->>P2: Promise(拒绝, N=3 更大)
+ A-->>P1: Promise(接受, N=3)
+
+ Note over P2: 编号被超越,递增
+ P2->>A: Prepare(N=4)
+ A-->>P1: Promise(拒绝, N=4 更大)
+ A-->>P2: Promise(接受, N=4)
+
+ Note over P1,P2: ... 循环往复,永远无法进入 Phase 2
+```
+
+**解决方案**:通过 Multi-Paxos 引入稳定的 Leader 机制。
+
+**随机退避算法(Randomized Exponential Backoff)**:
+
+为防止多个 Proposer 竞争导致活锁,生产级实现通常引入随机退避:
+
+当 Proposer 的 Prepare 请求被拒绝(编号过小)时:
+
+1. 等待随机时间:`base_delay * random(1, 2^attempt)`
+2. 选择更大的提案编号(如:`n = n + k`,`k > 0`)
+3. 重试 Prepare 阶段
+
+参数示例:
+
+- `base_delay`: 10ms
+- `attempt`: 重试次数(1, 2, 3...)
+- 最大退避时间:`max(1s, base_delay * 2^10)`
+
+这种机制确保竞争者不会同时重试,最终某个 Proposer 能成功完成 Phase 1。
+
+**分区处理**:若发生网络分区,多数派一侧可继续选举 Leader 并提交新提案;少数派无法形成法定人数(quorum),只能等待分区恢复。
+
+## Multi-Paxos 思想
+
+### 核心思想
+
+Basic Paxos 算法仅能就单个值达成共识,为了能够对一系列的值达成共识,我们需要用到 Multi-Paxos 思想。
+
+Multi-Paxos 的核心优化思想是**复用 Leader**:通过 Basic Paxos 选出一个稳定的 Proposer 作为 Leader,后续提案直接由该 Leader 发起,跳过 Phase 1 的 Prepare/Promise 阶段。
-Basic Paxos 算法的仅能就单个值达成共识,为了能够对一系列的值达成共识,我们需要用到 Basic Paxos 思想。
+### 优化机制
-⚠️**注意**:Multi-Paxos 只是一种思想,这种思想的核心就是通过多个 Basic Paxos 实例就一系列值达成共识。也就是说,Basic Paxos 是 Multi-Paxos 思想的核心,Multi-Paxos 就是多执行几次 Basic Paxos。
+#### 1. Leader 稳定选举
-由于兰伯特提到的 Multi-Paxos 思想缺少代码实现的必要细节(比如怎么选举领导者),所以在理解和实现上比较困难。
+- 通过 Basic Paxos 选出唯一的 Proposer 作为 Leader
+- Leader 崩溃后,通过新一轮 Basic Paxos 选举新 Leader
+- 避免多 Proposer 竞争导致的活锁
-不过,也不需要担心,我们并不需要自己实现基于 Multi-Paxos 思想的共识算法,业界已经有了比较出名的实现。像 Raft 算法就是 Multi-Paxos 的一个变种,其简化了 Multi-Paxos 的思想,变得更容易被理解以及工程实现,实际项目中可以优先考虑 Raft 算法。
+#### 2. 跳过 Phase 1
+
+- Leader 稳定后,后续提案直接进入 Phase 2(Accept 阶段)
+- 无需每次都执行 Prepare/Promise,减少一轮 RPC
+- **延迟优化**:Basic Paxos 每个提案需要 2-RTT(Prepare + Accept),Multi-Paxos 后续提案仅需 1-RTT(仅 Accept),**提案提交延迟降低 50%**(2-RTT → 1-RTT)
+
+**性能优化对比图**:
+
+```mermaid
+flowchart LR
+ subgraph Basic["Basic Paxos (首次提案)"]
+ direction TB
+ C1[客户端请求] --> P1[Phase 1: Prepare/Promise
1-RTT]
+ P1 --> P2[Phase 2: Accept/Accepted
1-RTT]
+ P2 --> D1[提案选定
总延迟: 2-RTT]
+ end
+
+ subgraph Multi["Multi-Paxos (Leader 稳定后)"]
+ direction TB
+ C2[客户端请求] --> A[Phase 2: Accept/Accepted
1-RTT
跳过 Phase 1]
+ A --> D2[提案选定
总延迟: 1-RTT]
+ end
+
+ style Basic fill:#FFF5F5,color:#333,stroke:#C44545,stroke-width:2px
+ style Multi fill:#F0FFF4,color:#333,stroke:#4CA497,stroke-width:2px
+ classDef phase fill:#F39C12,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef client fill:#00838F,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef done fill:#4CA497,color:#FFFFFF,stroke:none,rx:10,ry:10
+
+ class C1,C2 client
+ class P1,P2,A phase
+ class D1,D2 done
+```
+
+#### 3. 日志序号
+
+- 为每个提案分配递增的**日志索引(log index)**
+- 保证全局顺序:Leader 按顺序追加日志,Acceptor 按序号接受
+- 支持**空洞**:某位置的提案可能因 Leader 切换而暂时缺失,后续可补齐
+
+#### 4. 日志空洞(gap)与 NOP 填补
+
+**问题描述**:当新 Leader 上线时,可能遇到一种棘手场景——前任 Leader 已经在某个日志位置上达成了共识,但新 Leader 不知道这个值。如果新 Leader 试图在该位置提交新值,就会覆盖已经选定的值,破坏一致性。
+
+**解决方案:NOP(No-Operation)日志**
+
+Multi-Paxos 通过引入 NOP 日志来解决这个问题:
+
+1. **场景检测**:新 Leader 在 Phase 1(Prepare)阶段,收集到 Acceptor 返回的已接受值
+2. **必须复用**:如果发现某位置已有被选定的值,新 Leader **必须**复用该值,不能提出新值
+3. **NOP 占位**:对于空洞位置(无任何已接受值),新 Leader 可以提交特殊值——NOP(空操作)
+4. **状态机跳过**:NOP 日志虽然占用日志位置,但状态机回放时会跳过,不执行任何业务逻辑
+
+**示例流程**:
+
+```
+前任 Leader 崩溃前:
+Index 1: Value=A (chosen)
+Index 2: Value=B (chosen)
+Index 3: <空洞> (未完成)
+
+新 Leader 上线后:
+Index 1: 复用 Value=A
+Index 2: 复用 Value=B
+Index 3: 提交 NOP (填补空洞,不执行业务逻辑)
+Index 4: 提交 Value=C (正常业务日志)
+```
+
+**空洞与已接受值恢复流程**:
+
+```mermaid
+sequenceDiagram
+ participant OldL as 前任 Leader
+ participant A1 as Acceptor 1
+ participant A2 as Acceptor 2
+ participant NewL as 新 Leader
+ participant SM as 状态机
+
+ Note over OldL, A2: 前任 Leader 崩溃前
+ OldL->>A1: Accept(ID=5, Value="X")
+ OldL->>A2: Accept(ID=5, Value="X")
+ A1-->>OldL: Accepted(ID=5)
+ Note over OldL: 崩溃!未收到 A2 响应
Value="X" 已被 A1 接受
+
+ Note over NewL, A2: 新 Leader 上线
+ NewL->>A1: Prepare(ID=10, index=5)
+ NewL->>A2: Prepare(ID=10, index=5)
+ A1-->>NewL: Promise(已接受值="X")
+ A2-->>NewL: Promise(已接受值=null)
+
+ Note over NewL: 发现 A1 已接受 "X"
必须复用该值
+ NewL->>A1: Accept(ID=10, index=5, Value="X")
+ NewL->>A2: Accept(ID=10, index=5, Value="X")
+ A1-->>NewL: Accepted(ID=10)
+ A2-->>NewL: Accepted(ID=10)
+
+ Note over NewL, SM: 提交并回放
+ NewL->>SM: Apply Value="X"
+ Note over SM: 状态机执行 "X"
(空洞/已接受值已安全处理)
+```
+
+### 执行流程
+
+1. **Leader 选举**:通过 Basic Paxos 选出 Leader
+2. **日志复制**:Leader 接收客户端请求,追加到本地日志,分配递增索引
+3. **直接 Accept**:Leader 向 Acceptor 发送 `Accept(index, value)`(跳过 Prepare)
+4. **响应处理**:Acceptor 按序号接受日志,记录到本地
+5. **提交确认**:当超过半数 Acceptor 接受某位置的日志后,该位置可提交
+
+### 容错与恢复
+
+- **Leader 崩溃**:新 Leader 通过日志比对找出已提交位置,补齐未提交日志
+- **网络分区**:多数派一侧继续服务,少数派等待恢复
+- **日志空洞**:新 Leader 可填补前任 Leader 未提交的日志位置
+
+**新 Leader 恢复流程图**:
+
+```mermaid
+flowchart TB
+ subgraph Recovery["新 Leader 恢复流程"]
+ direction TB
+ Start[新 Leader 上线] --> Phase1[执行 Phase 1: Prepare
收集已接受值]
+
+ Phase1 --> Check{有空洞位置?}
+
+ Check -->|是| NOP[提交 NOP 日志
填补空洞]
+ Check -->|否| Next[继续下一条]
+
+ NOP --> Next
+ Next --> More{还有未处理?}
+
+ More -->|是| Phase1
+ More -->|否| Done[恢复完成
开始正常服务]
+ end
+
+ style Recovery fill:#F5F7FA,color:#333,stroke:#005D7B,stroke-width:2px
+ classDef step fill:#E99151,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef decision fill:#3498DB,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef success fill:#4CA497,color:#FFFFFF,stroke:none,rx:10,ry:10
+
+ class Start,Phase1,NOP,Next step
+ class Check,More decision
+ class Done success
+```
+
+⚠️ **注意**:Multi-Paxos 只是一种思想,这种思想的核心就是通过多个 Basic Paxos 实例就一系列值达成共识。也就是说,Basic Paxos 是 Multi-Paxos 思想的核心,Multi-Paxos 就是多执行几次 Basic Paxos。
+
+由于 Lamport 提出的 Multi-Paxos 思想缺少代码实现的必要细节(比如怎么选举领导者、日志空洞如何处理),所以在理解和实现上比较困难。
+
+不过,也不需要担心,我们并不需要自己实现基于 Multi-Paxos 思想的共识算法,业界已经有了比较出名的实现。如 Raft 算法虽非 Paxos 严格变体,但借鉴了其核心思想(Leader 选举、日志复制),并简化了实现细节,变得更容易被理解以及工程实现,实际项目中可以优先考虑 Raft 算法。
+
+## Paxos vs Raft
+
+在 2014 年之后,Raft 算法凭借其极致的可理解性成为了工业界的新宠。必须明确,Raft 并非 Paxos 的变体,两者在底层设计哲学上存在硬性分歧。
+
+| **对比维度** | **Multi-Paxos** | **Raft** | **核心工程影响** |
+| --------------------- | ----------------------------------------------------------- | --------------------------------------------------------------------------- | ------------------------------------------------------------------------------- |
+| **日志流向与约束** | 允许乱序提交,允许出现**日志空洞**。 | 强制按序追加(Append-Only),**绝对不允许日志空洞**。 | Raft 实现简单,状态机回放极其顺滑;Paxos 并发上限更高,但实现难度呈指数级增加。 |
+| **Leader 选举与权限** | Leader 仅是一个性能优化手段(省略 Phase 1),非必须角色。 | **强 Leader 模型**。一切数据以 Leader 为准,日志只从 Leader 流向 Follower。 | Raft 通过限制只能选取“日志最完整”的节点当选 Leader,简化了数据恢复逻辑。 |
+| **活锁防御** | 需额外引入随机退避或外部选主算法。 | 协议内置基于随机超时(Randomized Timeout)的选主防御机制。 | Raft 的开箱即用性(Out-of-the-box)远高于 Paxos。 |
+| **工业级落地代表** | Apache ZooKeeper (基于 ZAB, 类 Multi-Paxos), Google Spanner | etcd, HashiCorp Consul, TiKV | 现代微服务基础设施倾向于选择 Raft。 |
+
+## 实际应用
+
+基于 Paxos 算法或其变体的系统包括:
+
+- **Google Chubby**:基于 Paxos 实现的分布式锁服务
+- **Apache ZooKeeper 3.8+**:基于 ZAB 协议(类 Multi-Paxos,写入通过 Leader 广播,支持 FIFO 顺序)
+- **etcd 3.5+**:基于 Raft 算法(强一致性共识,支持动态成员变更、轻量级事务 Txn)
+- **HashiCorp Consul**:基于 Raft 算法(服务发现与配置管理)
+
+这些系统在分布式协调、配置管理、服务发现等领域发挥着关键作用。
+
+> **版本说明**:上述系统随版本演进会有协议优化(如 etcd 3.4 引入租约 Keep-Alive 优化、ZooKeeper 3.5 引入动态重配置),生产部署前建议查阅对应版本的 Release Notes。
+
+## 生产落地建议
+
+### 可观测性指标(Observability Checklist)
+
+| 类别 | 关键指标 | 告警阈值建议 | 说明 |
+| -------- | ------------------ | ----------------- | ---------------------------- |
+| **延迟** | 提案提交延迟 (p99) | > 100ms | 从客户端请求到收到多数派确认 |
+| **吞吐** | 提案处理速率 | < 预期 QPS 的 50% | 可能网络分区或节点故障 |
+| **选主** | Leader 切换次数 | > 3 次/小时 | 频繁切主说明集群不稳定 |
+| **空洞** | 未提交日志位置数 | > 100 | 过多空洞影响状态机回放 |
+| **脑裂** | 多 Leader 竞争事件 | = 0 | 绝不允许出现 |
+
+### 混沌工程建议
+
+| 测试场景 | 验证目标 | 推荐工具 |
+| --------------- | ------------------------------ | ------------------------ |
+| **Leader 崩溃** | 验证快速选主与数据零丢失 | Chaos Mesh, Chaos Monkey |
+| **网络分区** | 验证多数派继续服务、少数派等待 | Toxiproxy |
+| **网络抖动** | 验证随机退避机制避免活锁 | tc (netem) |
+| **时钟漂移** | 验证提案编号唯一性不受影响 | -- |
+
+### 常见反模式(Anti-Patterns)
+
+1. **忽略空洞处理**:状态机回放时遇到空洞位置直接跳过,可能导致客户端请求丢失
+2. **固定提案编号**:使用时间戳或节点 ID 作为提案编号,无法保证全局递增
+3. **无超时机制**:Prepare/Accept 请求无限等待,导致系统挂起
+4. **忽略已接受值**:新 Leader 强制提交自己的值,破坏一致性
+
+## 总结
+
+- Paxos 算法是 Lamport 在 1990 年提出的分布式共识算法,是强一致性共识的理论基础
+- Basic Paxos 通过两阶段(Prepare/Promise、Accept/Accepted)就单个值达成共识
+- Multi-Paxos 通过复用 Leader 和跳过 Phase 1 优化,实现一系列值的共识(提案延迟从 2-RTT 降至 1-RTT)
+- Raft 算法借鉴了 Multi-Paxos 思想但重新设计了实现细节(强 Leader 模型、禁止日志空洞),更易于理解和工程实现
+- 在实际项目中,建议优先选择 Raft、etcd、ZooKeeper 等已完善的实现
## 参考
-- https://zh.wikipedia.org/wiki/Paxos
-- 分布式系统中的一致性与共识算法:http://www.xuyasong.com/?p=1970
+- [《Paxos Made Simple》](http://lamport.azurewebsites.net/pubs/paxos-simple.pdf) - Lamport, 2001
+- [《The Part-Time Parliament》](http://lamport.azurewebsites.net/pubs/lamport-paxos.pdf) - Lamport, 1998
+- [《In Search of an Understandable Consensus Algorithm》](https://raft.github.io/raft.pdf) - Ongaro & Ousterhout, 2014 (Raft 论文)
+-
+- 分布式系统中的一致性与共识算法:
+
+
diff --git a/docs/distributed-system/protocol/raft-algorithm.md b/docs/distributed-system/protocol/raft-algorithm.md
index 61462eb0a5d..1e86ca1c182 100644
--- a/docs/distributed-system/protocol/raft-algorithm.md
+++ b/docs/distributed-system/protocol/raft-algorithm.md
@@ -1,5 +1,6 @@
---
title: Raft 算法详解
+description: Raft共识算法原理详解,涵盖Leader选举、日志复制、安全性保证等核心机制及与Paxos的对比分析。
category: 分布式
tag:
- 分布式协议&算法
@@ -10,84 +11,87 @@ tag:
## 1 背景
-当今的数据中心和应用程序在高度动态的环境中运行,为了应对高度动态的环境,它们通过额外的服务器进行横向扩展,并且根据需求进行扩展和收缩。同时,服务器和网络故障也很常见。
+在如今的互联网架构中,为了扛住海量流量,系统往往需要横向堆机器。机器一多,宕机、断网这些破事就成了家常便饭。怎么让这群随时可能掉线的服务器保持步调一致,不对外提供错乱的数据?这就轮到**分布式共识算法**出场了。
-因此,系统必须在正常操作期间处理服务器的上下线。它们必须对变故做出反应并在几秒钟内自动适应;对客户来说的话,明显的中断通常是不可接受的。
-
-幸运的是,分布式共识可以帮助应对这些挑战。
-
-### 1.1 拜占庭将军
+2014年,Diego Ongaro 等人发表了 Raft 算法。它的诞生有一个很明确的使命:**拯救被 Paxos 算法折磨的程序员**。Raft 主打一个“易于理解”,它将复杂的共识问题拆解成了几个独立的模块:
-在介绍共识算法之前,先介绍一个简化版拜占庭将军的例子来帮助理解共识算法。
+- **Leader 选举**:使用随机化选举超时(工程上常见如 150–300ms 或更大范围,具体取决于网络与故障模型)。
+- **日志复制**:Leader 通过 AppendEntries RPC 广播日志。
+- **安全性**:包括选举限制和日志匹配。
-> 假设多位拜占庭将军中没有叛军,信使的信息可靠但有可能被暗杀的情况下,将军们如何达成是否要进攻的一致性决定?
+Raft 在实际生产中得到了广泛应用,基于 Raft 的实现如 etcd、Consul 等已成为分布式系统的重要组成部分。后续学术界和工业界也对 Raft 进行了多项扩展和优化,包括:
-解决方案大致可以理解成:先在所有的将军中选出一个大将军,用来做出所有的决定。
+- **Pre-Vote**(2014):防止网络分区的节点干扰稳定集群的选举
+- **Read Index**(2014):在 Leader 任期内通过线性一致性读优化读性能
+- **Lease Read**:基于租约的线性一致性读方案
+- **Joint Consensus**:用于集群成员变更的联合一致机制(通过引入过渡配置,典型过程为旧配置 → 联合配置 → 新配置)
-举例如下:假如现在一共有 3 个将军 A,B 和 C,每个将军都有一个随机时间的倒计时器,倒计时一结束,这个将军就把自己当成大将军候选人,然后派信使传递选举投票的信息给将军 B 和 C,如果将军 B 和 C 还没有把自己当作候选人(自己的倒计时还没有结束),并且没有把选举票投给其他人,它们就会把票投给将军 A,信使回到将军 A 时,将军 A 知道自己收到了足够的票数,成为大将军。在有了大将军之后,是否需要进攻就由大将军 A 决定,然后再去派信使通知另外两个将军,自己已经成为了大将军。如果一段时间还没收到将军 B 和 C 的回复(信使可能会被暗杀),那就再重派一个信使,直到收到回复。
-
-### 1.2 共识算法
+因此,系统必须在正常操作期间处理服务器的上下线。它们必须对变故做出反应并在几秒钟内自动适应;对客户来说的话,明显的中断通常是不可接受的。
-共识是可容错系统中的一个基本问题:即使面对故障,服务器也可以在共享状态上达成一致。
+幸运的是,分布式共识可以帮助应对这些挑战。
-共识算法允许一组节点像一个整体一样一起工作,即使其中的一些节点出现故障也能够继续工作下去,其正确性主要是源于复制状态机的性质:一组`Server`的状态机计算相同状态的副本,即使有一部分的`Server`宕机了它们仍然能够继续运行。
+### 1.1 非拜占庭条件下的"选主"类比
-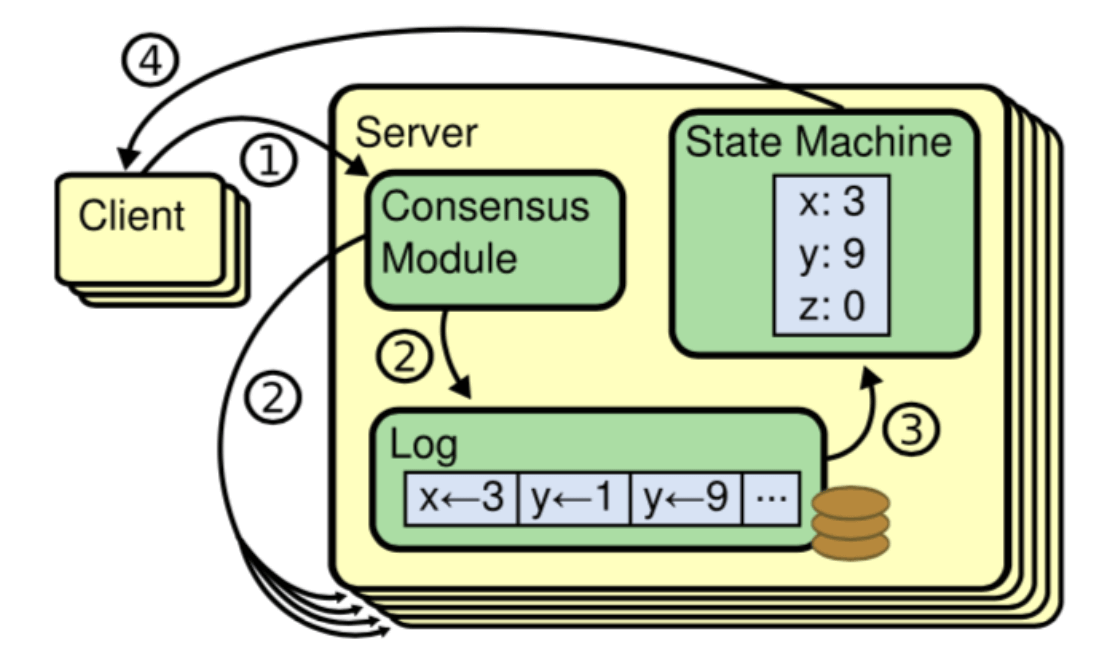
+Raft 有一个前提假设:**非拜占庭容错(CFT)**。说白了就是,兄弟们可能会死机、会断网,但绝对不会出内鬼传递假情报。
-`图-1 复制状态机架构`
+我们可以用“将军选帅”来粗略理解这个过程: 假设有 A、B、C 三个将军,目前群龙无首。每个人心里都有个随机的倒计时(选举超时)。谁的倒计时先结束,谁就站出来大喊:“我要当大将军,请给我投票!” 如果其他将军还没开始竞选,也没把票投给别人,就会顺水推舟同意他。当这位将军拿到**过半数**的赞成票,他就成了大当家(Leader)。以后打不打仗,全听他的。如果信使半路阵亡,大家都没收到回音,那就重置倒计时,再来一轮。
-一般通过使用复制日志来实现复制状态机。每个`Server`存储着一份包括命令序列的日志文件,状态机会按顺序执行这些命令。因为每个日志包含相同的命令,并且顺序也相同,所以每个状态机处理相同的命令序列。由于状态机是确定性的,所以处理相同的状态,得到相同的输出。
+### 1.2 到底什么是共识算法?
-因此共识算法的工作就是保持复制日志的一致性。服务器上的共识模块从客户端接收命令并将它们添加到日志中。它与其他服务器上的共识模块通信,以确保即使某些服务器发生故障。每个日志最终包含相同顺序的请求。一旦命令被正确地复制,它们就被称为已提交。每个服务器的状态机按照日志顺序处理已提交的命令,并将输出返回给客户端,因此,这些服务器形成了一个单一的、高度可靠的状态机。
+共识算法的核心目标,就是**让一群机器看起来像一台机器**。只要集群里超过半数的机器还活着,整个系统就能正常接客。
-适用于实际系统的共识算法通常具有以下特性:
+这通常是通过**复制状态机**来实现的:给每个节点发一本一模一样的账本(日志)。只要大家按照同样的顺序去执行账本上的命令,最后得到的结果自然完全一样。所以,共识算法本质上干的就是一件事——**保证所有节点的账本绝对一致**。共识是可容错系统中的一个基本问题:即使面对故障,服务器也可以在共享状态上达成一致。
-- 安全。确保在非拜占庭条件(也就是上文中提到的简易版拜占庭)下的安全性,包括网络延迟、分区、包丢失、复制和重新排序。
-- 高可用。只要大多数服务器都是可操作的,并且可以相互通信,也可以与客户端进行通信,那么这些服务器就可以看作完全功能可用的。因此,一个典型的由五台服务器组成的集群可以容忍任何两台服务器端故障。假设服务器因停止而发生故障;它们稍后可能会从稳定存储上的状态中恢复并重新加入集群。
-- 一致性不依赖时序。错误的时钟和极端的消息延迟,在最坏的情况下也只会造成可用性问题,而不会产生一致性问题。
+
-- 在集群中大多数服务器响应,命令就可以完成,不会被少数运行缓慢的服务器来影响整体系统性能。
+## 2 基础概念
-## 2 基础
+在深入 Raft 之前,我们得先认识里面的三大核心角色、任期机制和日志结构。
### 2.1 节点类型
一个 Raft 集群包括若干服务器,以典型的 5 服务器集群举例。在任意的时间,每个服务器一定会处于以下三个状态中的一个:
-- `Leader`:负责发起心跳,响应客户端,创建日志,同步日志。
-- `Candidate`:Leader 选举过程中的临时角色,由 Follower 转化而来,发起投票参与竞选。
-- `Follower`:接受 Leader 的心跳和日志同步数据,投票给 Candidate。
+- **Leader(领导者)**:大当家。全权负责接待客户端、写账本、并把账本同步给小弟。为了防止别人篡位,他必须不断地向全员发送心跳,宣告“我还活着”。
+- **Follower(跟随者)**:安分守己的小弟。平时绝对不主动发起请求,只被动接收老大的心跳和账本同步。
+- **Candidate(候选人)**:临时状态。如果小弟迟迟等不到老大的心跳,就会觉得自己行了,变身候选人开始拉票。
在正常的情况下,只有一个服务器是 Leader,剩下的服务器是 Follower。Follower 是被动的,它们不会发送任何请求,只是响应来自 Leader 和 Candidate 的请求。
-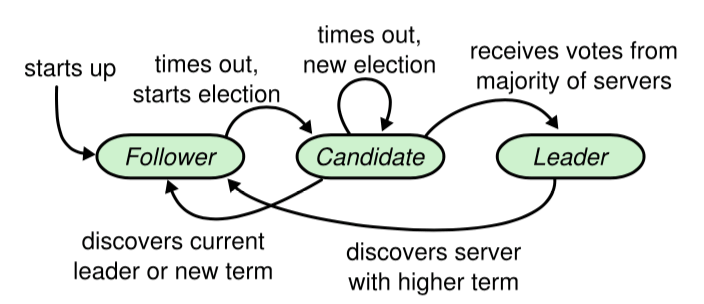
-
-`图-2:服务器的状态`
+
### 2.2 任期
-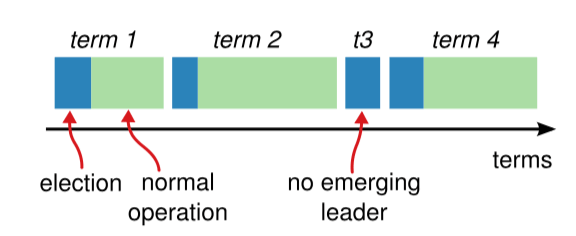
-
-`图-3:任期`
+
-如图 3 所示,raft 算法将时间划分为任意长度的任期(term),任期用连续的数字表示,看作当前 term 号。每一个任期的开始都是一次选举,在选举开始时,一个或多个 Candidate 会尝试成为 Leader。如果一个 Candidate 赢得了选举,它就会在该任期内担任 Leader。如果没有选出 Leader,将会开启另一个任期,并立刻开始下一次选举。raft 算法保证在给定的一个任期最少要有一个 Leader。
+Raft 算法将时间划分为任意长度的任期(term),任期用连续的数字表示,看作当前 term 号。每一个任期的开始都是一次选举,在选举开始时,一个或多个 Candidate 会尝试成为 Leader。如果一个 Candidate 赢得了选举,它就会在该任期内担任 Leader。如果没有选出 Leader(例如出现分票 split vote),该任期可能没有 Leader;随后在新的选举超时后会进入下一个任期并重新发起选举。只要多数节点可用且网络最终可达,系统通常能够在若干轮选举后选出 Leader。
每个节点都会存储当前的 term 号,当服务器之间进行通信时会交换当前的 term 号;如果有服务器发现自己的 term 号比其他人小,那么他会更新到较大的 term 值。如果一个 Candidate 或者 Leader 发现自己的 term 过期了,他会立即退回成 Follower。如果一台服务器收到的请求的 term 号是过期的,那么它会拒绝此次请求。
+下面这张图是我手绘的,更容易理解一些,就很贴心:
+
+
+
### 2.3 日志
-- `entry`:每一个事件成为 entry,只有 Leader 可以创建 entry。entry 的内容为``其中 cmd 是可以应用到状态机的操作。
-- `log`:由 entry 构成的数组,每一个 entry 都有一个表明自己在 log 中的 index。只有 Leader 才可以改变其他节点的 log。entry 总是先被 Leader 添加到自己的 log 数组中,然后再发起共识请求,获得同意后才会被 Leader 提交给状态机。Follower 只能从 Leader 获取新日志和当前的 commitIndex,然后把对应的 entry 应用到自己的状态机中。
+只有 Leader 有资格往账本里追加记录(Entry)。一条日志包含三个核心要素:`<当前任期, 索引号, 具体操作指令>`。
+
+这里有两个非常关键的进度指针:
+
+- **commitIndex**:大家公认已经安全落地的日志进度(已经被复制到过半数节点)。
+- **lastApplied**:这台机器本地真正执行完的日志进度。
## 3 领导人选举
-raft 使用心跳机制来触发 Leader 的选举。
+
+
+Raft 使用心跳机制来触发 Leader 的选举。
-如果一台服务器能够收到来自 Leader 或者 Candidate 的有效信息,那么它会一直保持为 Follower 状态,并且刷新自己的 electionElapsed,重新计时。
+如果一台服务器持续收到来自 Leader 的 AppendEntries(心跳或日志复制)等合法 RPC,它会保持为 Follower 状态并刷新选举计时器。
Leader 会向所有的 Follower 周期性发送心跳来保证自己的 Leader 地位。如果一个 Follower 在一个周期内没有收到心跳信息,就叫做选举超时,然后它就会认为此时没有可用的 Leader,并且开始进行一次选举以选出一个新的 Leader。
-为了开始新的选举,Follower 会自增自己的 term 号并且转换状态为 Candidate。然后他会向所有节点发起 RequestVoteRPC 请求, Candidate 的状态会持续到以下情况发生:
+为了开始新的选举,Follower 会自增自己的 term 号并且转换状态为 Candidate。然后他会向所有节点发起 RequestVote RPC 请求, Candidate 的状态会持续到以下情况发生:
- 赢得选举
- 其他节点赢得选举
@@ -102,30 +106,84 @@ Leader 会向所有的 Follower 周期性发送心跳来保证自己的 Leader
由于可能同一时刻出现多个 Candidate,导致没有 Candidate 获得大多数选票,如果没有其他手段来重新分配选票的话,那么可能会无限重复下去。
-raft 使用了随机的选举超时时间来避免上述情况。每一个 Candidate 在发起选举后,都会随机化一个新的枚举超时时间,这种机制使得各个服务器能够分散开来,在大多数情况下只有一个服务器会率先超时;它会在其他服务器超时之前赢得选举。
+Raft 使用了随机的选举超时时间来避免上述情况。每一个 Candidate 在发起选举后,都会随机化一个新的选举超时时间,这种机制使得各个服务器能够分散开来,在大多数情况下只有一个服务器会率先超时;它会在其他服务器超时之前赢得选举。
## 4 日志复制
-一旦选出了 Leader,它就开始接受客户端的请求。每一个客户端的请求都包含一条需要被复制状态机(`Replicated State Mechine`)执行的命令。
+一旦选出了 Leader,它就开始接受客户端的请求。每一个客户端的请求都包含一条需要被复制状态机(`Replicated State Machine`)执行的命令。
Leader 收到客户端请求后,会生成一个 entry,包含``,再将这个 entry 添加到自己的日志末尾后,向所有的节点广播该 entry,要求其他服务器复制这条 entry。
如果 Follower 接受该 entry,则会将 entry 添加到自己的日志后面,同时返回给 Leader 同意。
-如果 Leader 收到了多数的成功响应,Leader 会将这个 entry 应用到自己的状态机中,之后可以成为这个 entry 是 committed 的,并且向客户端返回执行结果。
+如果 Leader 收到了多数 Follower 对该日志复制成功的响应,Leader 会推进自己的 commitIndex,并在随后将这些已提交(committed)的日志按顺序应用(apply)到状态机后再向客户端返回结果。
+
+需要注意一个关键限制:Leader 只能基于"当前任期(current term)内产生的日志在多数派上复制成功"来推进 commitIndex。对于之前任期遗留的日志,即使它们已经被复制到多数节点,Leader 也不应仅凭多数派直接提交;通常会通过提交当前任期的一条新日志(常见做法是当选后追加并提交一条 no-op 日志)来间接推动历史日志一并提交。
+
+Follower 不会自行决定提交点;它们从 Leader 的 AppendEntries RPC 中携带的 leaderCommit 得知当前可提交的最大索引,并将本地 commitIndex 更新为 min(leaderCommit, lastLogIndex),再按序 apply 到状态机。
+
+### 4.1 日志匹配属性(Log Matching Property)
+
+Raft 通过 **日志匹配属性(Log Matching Property)** 保证日志绝对不会分叉,这是 Raft 安全性的基石之一。该属性包含两个核心保证:
+
+- **保证一**:如果两个日志在相同 index 位置的 entry 具有相同的 term,那么它们存储的 cmd 一定相同
+- **保证二**:如果两个日志在相同 index 位置的 entry 具有相同的 term,那么该位置之前的所有 entry 也完全相同
+
+#### 归纳法证明
+
+日志匹配属性通过归纳法得以保证:
+
+1. **基础情况**:日志为空时,属性自然成立
+2. **归纳步骤**:假设日志在 index N 之前完全一致,当 Leader 尝试追加 entry N+1 时,通过 **AppendEntries RPC 的一致性检查** 确保:
+
+```
+AppendEntries RPC 参数:
+- prevLogIndex:前一条日志的索引(Leader 认为与 Follower 对齐的位置)
+- prevLogTerm:前一条日志的任期
+- entries[]:待追加的新日志条目
+```
+
+**一致性检查逻辑**:
+
+- Follower 收到 AppendEntries 请求后,检查本地日志中 index = prevLogIndex 的位置
+- 如果该位置的 entry.term == prevLogTerm,说明Leader和Follower在prevLogIndex之前的日志完全一致,通过检查
+- 如果不存在或 term 不匹配,拒绝追加,返回失败
+
+**关键点**:通过检查 prevLogIndex 和 prevLogTerm 的配对,Leader 和 Follower 能够**数学上确保**它们对日志历史达成一致。只有当"最后一个已知一致点"确实一致时,才会追加新日志。这形成了归纳证明的传递链条:
+
+```
+entry[0] 一致 → entry[1] 一致 → entry[2] 一致 → ... → entry[N] 一致
+ ↑_____________通过 prevLogIndex/prevLogTerm 递归验证_____________↑
+```
-raft 保证以下两个性质:
+因此,日志绝不会出现两个不同的值在同一 index 位置被"提交"的情况——即日志不分叉。
-- 在两个日志里,有两个 entry 拥有相同的 index 和 term,那么它们一定有相同的 cmd
-- 在两个日志里,有两个 entry 拥有相同的 index 和 term,那么它们前面的 entry 也一定相同
+#### 工程实现优化
-通过“仅有 Leader 可以生存 entry”来保证第一个性质,第二个性质需要一致性检查来进行保证。
+在实际生产实现(如 etcd 3.5.x)中,除了上述基础的一致性检查外,还包含多项工程优化:
-一般情况下,Leader 和 Follower 的日志保持一致,然后,Leader 的崩溃会导致日志不一样,这样一致性检查会产生失败。Leader 通过强制 Follower 复制自己的日志来处理日志的不一致。这就意味着,在 Follower 上的冲突日志会被领导者的日志覆盖。
+- **快速回退(Fast Backup)**:当 AppendEntries 一致性检查失败时,Follower 返回冲突日志对应的 term 及其边界索引(该 term 的第一条和最后一条 index),Leader 据此一次性跳过整段冲突区间,而非逐条递减 nextIndex 重试。
-为了使得 Follower 的日志和自己的日志一致,Leader 需要找到 Follower 与它日志一致的地方,然后删除 Follower 在该位置之后的日志,接着把这之后的日志发送给 Follower。
+- **重试风暴防护**:高负载下可能出现大量 AppendEntries 失败重试,实现中通常会加入:
+ - **Jitter 退避**:重试间隔加入随机抖动,避免多个 Follower 同时重试
+ - **背压机制**:限制单个 Follower 的重试速率,防止占用过多网络带宽
-`Leader` 给每一个`Follower` 维护了一个 `nextIndex`,它表示 `Leader` 将要发送给该追随者的下一条日志条目的索引。当一个 `Leader` 开始掌权时,它会将 `nextIndex` 初始化为它的最新的日志条目索引数+1。如果一个 `Follower` 的日志和 `Leader` 的不一致,`AppendEntries` 一致性检查会在下一次 `AppendEntries RPC` 时返回失败。在失败之后,`Leader` 会将 `nextIndex` 递减然后重试 `AppendEntries RPC`。最终 `nextIndex` 会达到一个 `Leader` 和 `Follower` 日志一致的地方。这时,`AppendEntries` 会返回成功,`Follower` 中冲突的日志条目都被移除了,并且添加所缺少的上了 `Leader` 的日志条目。一旦 `AppendEntries` 返回成功,`Follower` 和 `Leader` 的日志就一致了,这样的状态会保持到该任期结束。
+这些优化不影响日志匹配属性的理论正确性,而是提升了系统在异常场景下的恢复效率。
+
+### 4.2 日志不一致的恢复
+
+正常运作时,大当家(Leader)和小弟(Follower)的账本是完全同步的。然而,一旦老 Leader 突然宕机,新老交替之际往往会在集群中遗留大量未对齐的脏数据。
+
+这时,新 Leader 发起 AppendEntries 同步请求就会触发“一致性检查报错”。Raft 解决数据冲突的逻辑非常霸道:**一切以现任 Leader 的账本为最高准则**,Follower 本地任何不一致的记录都必须被无情抹除并强行覆盖。
+
+具体怎么做呢?Leader 会像“拉链”一样顺藤摸瓜,往前倒推寻找双方最后一次完美吻合的历史节点。找到这个“分叉点”后,Follower 会把分叉点之后的烂摊子全部咔嚓掉,老老实实地拷贝 Leader 提供的最新日志。
+
+在代码层面,Leader 会在内存里给每个 Follower 单独记一本账,核心指针叫 `nextIndex`(预估要发给该小弟的下一条日志位置)。新官上任三把火,Leader 刚接盘时,会盲目自信地把所有小弟的 `nextIndex` 都预设为自己最新日志的索引加一。如果小弟的数据其实比较落后或者有冲突,第一发 AppendEntries 必然惨遭拒绝。接下来就是找分叉点的两种流派:
+
+- **传统的朴素做法(逐条试探)**:撞了南墙就退一步。Leader 会把 `nextIndex` 减一,再发一次 RPC 试探。如果还不行,就继续减一,犹如乌龟漫步般逐条往前回退,直到彻底对上暗号。
+- **工业级提速优化(Fast Backup 快速回退)**:在真实的生产环境中,逐条回退绝对是性能灾难。因此,工业界引入了快速回退机制。小弟在拒绝同步时不再是单纯地摇摇头,而是直接亮出底牌:“我这批错乱日志属于哪个历史任期(term),以及这个任期的头尾边界在哪里”。Leader 拿到这份情报,直接大刀阔斧地一次性跨越整段错误任期,极大地削减了冗余的网络重试次数。
+
+经过这番拉扯,`nextIndex` 终将精准锚定双方的共识起点。此时,AppendEntries 终于收获成功回执,Follower 上的冲突数据被彻底清空,缺失的正统日志被严丝合缝地填补。一旦跨过这个坎,双方的账本就能在整个任期内保持如影随形、高度一致。
## 5 安全性
@@ -133,19 +191,76 @@ raft 保证以下两个性质:
Leader 需要保证自己存储全部已经提交的日志条目。这样才可以使日志条目只有一个流向:从 Leader 流向 Follower,Leader 永远不会覆盖已经存在的日志条目。
-每个 Candidate 发送 RequestVoteRPC 时,都会带上最后一个 entry 的信息。所有节点收到投票信息时,会对该 entry 进行比较,如果发现自己的更新,则拒绝投票给该 Candidate。
+每个 Candidate 发送 RequestVote RPC 时,都会带上最后一个 entry 的信息。所有节点收到投票信息时,会对该 entry 进行比较,如果发现自己的更新,则拒绝投票给该 Candidate。
判断日志新旧的方式:如果两个日志的 term 不同,term 大的更新;如果 term 相同,更长的 index 更新。
-### 5.2 节点崩溃
+### 5.2 提交规则(只提交当前任期日志)
+
+Leader 推进 commitIndex 时,需要满足"当前任期产生的某条日志已复制到多数派"这一条件。对于旧任期遗留的日志,即使它们已经复制到多数派,Leader 也不应仅凭此直接提交;通常通过提交当前任期的一条新日志(常见为 no-op)来间接提交历史日志。这一限制用于避免 Leader 频繁切换时出现已提交日志被覆盖的安全性问题。
+
+### 5.3 节点崩溃与网络分区
+
+如果 Follower 和 Candidate 崩溃,处理方式会简单很多。之后发送给它的 RequestVote RPC 和 AppendEntries RPC 会失败。由于 Raft 的所有请求都是幂等的,所以失败的话会无限的重试。如果崩溃恢复后,就可以收到新的请求,然后选择追加或者拒绝 entry。
+
+如果 Leader 崩溃,节点在 electionTimeout 内收不到心跳会触发新一轮选主;在选主完成前,系统通常无法对外提供线性一致的写入(以及线性一致读),表现为一段不可用窗口。
+
+**量化分析**:在 5 节点集群中,Leader 崩溃后的不可用窗口通常小于 1 秒(P99 < 500ms 选举超时 + 一轮选举时间)。这是 **PACELC 定理**的体现:发生分区(P)时,系统选择牺牲可用性(A)以保证一致性(C)。幂等重试机制确保节点恢复后能安全追赶数据状态。
+
+#### 单节点隔离与 Term 暴增问题
+
+在标准 Raft 算法中,**单节点网络隔离**可能导致 **Term 暴增(Term Inflation)** 问题,造成"劣币驱逐良币"——一个被隔离的少数派节点在恢复后破坏健康集群的稳定性。
-如果 Leader 崩溃,集群中的节点在 electionTimeout 时间内没有收到 Leader 的心跳信息就会触发新一轮的选主,在选主期间整个集群对外是不可用的。
+**场景推演**:
-如果 Follower 和 Candidate 崩溃,处理方式会简单很多。之后发送给它的 RequestVoteRPC 和 AppendEntriesRPC 会失败。由于 raft 的所有请求都是幂等的,所以失败的话会无限的重试。如果崩溃恢复后,就可以收到新的请求,然后选择追加或者拒绝 entry。
+假设一个 5 节点集群,Leader 为节点 A,Follower 为 B、C、D、E。此时节点 E 发生网络分区,被彻底隔离:
-### 5.3 时间与可用性
+```
+正常区域:{A, B, C, D} (Leader A + 多数派,可正常服务)
+隔离区域:{E} (单节点隔离,无法收到心跳)
+```
-raft 的要求之一就是安全性不依赖于时间:系统不能仅仅因为一些事件发生的比预想的快一些或者慢一些就产生错误。为了保证上述要求,最好能满足以下的时间条件:
+| 时间线 | 正常区域 {A, B, C, D} | 隔离区域 {E} |
+| ------ | ------------------------------------------------- | ---------------------------------------------- |
+| T0 | Leader A 正常服务,Term = 5 | E 收不到心跳,选举超时 |
+| T1 | 集群继续正常工作 | E 自增 Term 发起选举(Term 6),但无响应 |
+| T2 | ... | E 继续自增(Term 7, 8, ...),假设涨到 Term 99 |
+| T3 | 网络恢复,E 带着 Term 99 接入集群 | E 向 {A, B, C, D} 广播 RequestVote (Term 99) |
+| T4 | 节点 A 收到 Term 99 > 自己的 Term 5,**被迫退位** | E 的"高 Term"破坏了健康集群 |
+
+**问题分析**:
+
+- {A, B, C, D} 是**合法的多数派**(4/5),系统本应继续正常工作
+- 节点 E 是**少数派**(1/5),它的隔离不应影响集群整体
+- **关键问题**:E 的 Term 暴涨导致健康的 Leader A 被迫下线
+- **后果**:整个集群需要重新选举,造成不必要的写入中断
+
+这是标准 Raft 的一个已知边界问题:少数派节点的"疯狂选举"会干扰多数派的正常运行。
+
+#### Pre-Vote 机制
+
+为了解决上述问题,Raft 的扩展方案 **Pre-Vote** 被提出。Pre-Vote 要求节点在真正发起选举前,先进行一次"预投票":
+
+1. **预投票阶段**:Candidate 向其他节点发送 PreVoteRequest,携带自己的日志信息
+2. **预投票条件**:
+ - 候选人的日志至少与接收者一样新(选举限制)
+ - **接收者确认自己与 Leader 的连接已断开**(超过 electionTimeout 未收到心跳)
+3. **正式选举**:只有收到多数节点的 PreVote 响应后,才真正增加 term 并发起 RequestVote
+
+**Pre-Vote 如何防止 Term 暴增**:
+
+- 在上述单节点隔离场景中,E 在隔离期间发起 Pre-Vote 时,**其他节点仍能收到 Leader A 的心跳**
+- 因此其他节点会**拒绝 E 的 PreVote 请求**(因为与 Leader 连接正常)
+- E 无法获得多数 PreVote 响应,**不会真正增加 Term**
+- 网络恢复后,E 的 Term 仍然较低,不会干扰健康的 Leader A
+
+**核心思想**:只有确认自己与 Leader 失去连接后,节点才开始真正增加 Term。这有效防止了少数派节点的 Term 暴涨干扰多数派。
+
+Pre-Vote 机制已广泛应用于 etcd、TiKV、Consul 等生产级 Raft 实现。
+
+### 5.4 时间与可用性
+
+Raft 的要求之一就是安全性不依赖于时间:系统不能仅仅因为一些事件发生的比预想的快一些或者慢一些就产生错误。为了保证上述要求,最好能满足以下的时间条件:
`broadcastTime << electionTimeout << MTBF`
@@ -159,11 +274,13 @@ raft 的要求之一就是安全性不依赖于时间:系统不能仅仅因为
由于`broadcastTime`和`MTBF`是由系统决定的属性,因此需要决定`electionTimeout`的时间。
-一般来说,broadcastTime 一般为 `0.5~20ms`,electionTimeout 可以设置为 `10~500ms`,MTBF 一般为一两个月。
+一般来说,broadcastTime 一般为 `0.5~20ms`,electionTimeout 可以设置为 `10~500ms`(工程上常见如 150–300ms),MTBF 一般为一两个月。
## 6 参考
-- https://tanxinyu.work/raft/
-- https://github.com/OneSizeFitsQuorum/raft-thesis-zh_cn/blob/master/raft-thesis-zh_cn.md
-- https://github.com/ongardie/dissertation/blob/master/stanford.pdf
-- https://knowledge-sharing.gitbooks.io/raft/content/chapter5.html
+-
+-
+-
+-
+
+
diff --git a/docs/distributed-system/protocol/zab.md b/docs/distributed-system/protocol/zab.md
new file mode 100644
index 00000000000..7fcf708ea50
--- /dev/null
+++ b/docs/distributed-system/protocol/zab.md
@@ -0,0 +1,108 @@
+---
+title: ZAB 协议详解
+description: ZooKeeper 的核心共识协议 ZAB(原子广播协议)详解,包括消息广播模式、崩溃恢复模式、Leader 选举和数据恢复机制
+category: 分布式系统
+tag: 分布式理论
+head:
+ - - meta
+ - name: keywords
+ content: ZAB协议,ZooKeeper,原子广播,分布式一致性,Leader选举,崩溃恢复
+---
+
+作为一款极其优秀的分布式协调框架,ZooKeeper 的高可用和数据一致性备受业界推崇。很多人误以为 ZooKeeper 使用的是大名鼎鼎的 Paxos 算法,但实际上,它的"灵魂"是一个专门为其定制的共识协议——**ZAB(ZooKeeper Atomic Broadcast,原子广播协议)**。
+
+ZAB 并非像 Paxos 那样是通用的分布式一致性算法,它是一种**特别为 ZooKeeper 设计的、支持崩溃可恢复的原子消息广播算法**。基于 ZAB 协议,ZooKeeper 实现了一种主备模式的架构,来保持集群中各个副本之间的数据一致性。
+
+## ZAB 集群的核心角色与状态
+
+在深入协议运作之前,我们需要先了解 ZooKeeper 集群中的三个主要角色:
+
+- **Leader(领导者):** 集群中**唯一**的写请求处理者。它负责发起投票和协调事务,所有的写操作都必须经过 Leader。
+- **Follower(跟随者):** 可以直接处理客户端的读请求。收到写请求时,会将其转发给 Leader。在 Leader 选举过程中,Follower 拥有选举权和被选举权。
+- **Observer(观察者):** 功能与 Follower 类似,但**没有**选举权和被选举权。它的存在是为了在不影响集群共识性能(即不增加需要等待的投票数)的前提下,横向扩展集群的读性能。
+
+对应的,集群中的节点通常处于以下四种状态之一:
+
+- `LOOKING`:寻找 Leader 状态(正在进行选举)。
+- `LEADING`:当前节点是 Leader,正在领导集群。
+- `FOLLOWING`:当前节点是 Follower,服从 Leader 领导。
+- `OBSERVING`:当前节点是 Observer。
+
+## 核心标识:ZXID 与 Epoch
+
+为了保证分布式环境下消息的绝对顺序性,ZAB 协议引入了一个全局单调递增的事务 ID——**ZXID**。
+
+ZXID 是一个 64 位的长整型(long):
+
+- **高 32 位(Epoch 纪元):** 代表当前 Leader 的任期年代。当选出一个新的 Leader 时,Epoch 就会在前一个的基础上加 1。这相当于朝代更替。
+- **低 32 位(事务 ID):** 一个简单的递增计数器。针对客户端的每一个写请求,计数器都会加 1。新 Leader 上位时,这个低 32 位会被清零重置。
+
+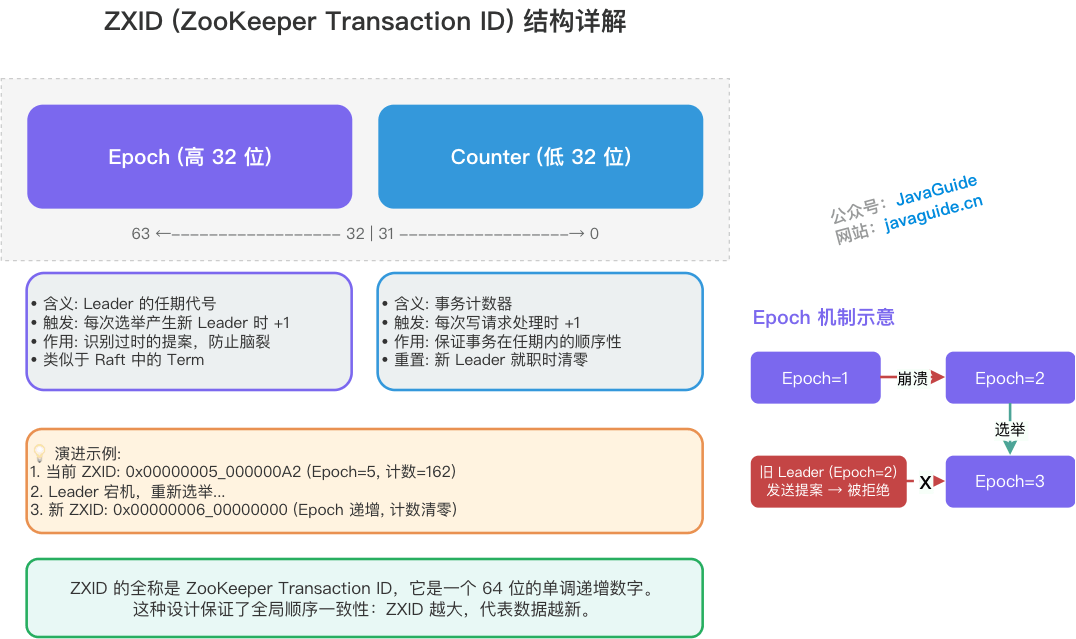
+
+## ZAB 的两种基本模式
+
+ZAB 协议的运作可以精简为两种基本模式的交替:**消息广播**(正常工作状态)和**崩溃恢复**(异常或启动状态)。
+
+### 1. 消息广播模式(正常处理写请求)
+
+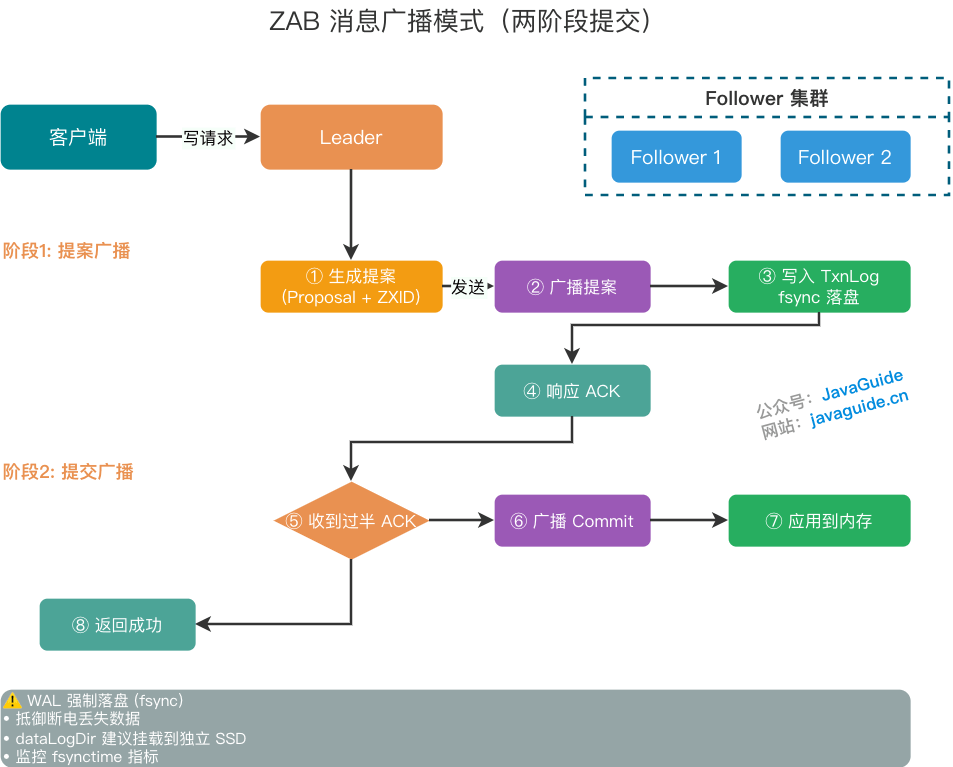
+
+当集群拥有健康的 Leader,且过半的节点完成了状态同步后,就会进入消息广播模式。这个过程类似于一个简化的“两阶段提交(2PC)”:
+
+1. **生成提案:** Leader 接收到写请求后,将其转化为一个带有 ZXID 的提案(Proposal)。
+2. **顺序发送:** Leader 为每个 Follower 维护了一个先进先出(FIFO)的网络队列(基于 TCP 协议),确保提案按生成顺序发送给 Follower。
+3. **写入与反馈(WAL 强制落盘):** Follower 收到提案后,必须将其追加到本地的事务日志(TxnLog)中,并强制执行系统调用 `fsync` 将内核缓冲区的数据物理刷入磁盘。只有确认数据切实落盘,才会向 Leader 响应 `ACK`。这一过程是 ZAB 抵御断电丢失数据的核心防线。因此,在物理部署上,强烈建议将 ZooKeeper 的事务日志目录(`dataLogDir`)挂载到独立且无锁的 SSD 上,避免与其他高 I/O 进程争用磁盘,从而规避因 `fsync` 阻塞导致的 P99 响应时间恶化。生产环境中必须重点监控节点的 `fsynctime` 指标,若平均刷盘耗时经常超过 100ms,集群随时可能崩溃。
+4. **广播提交:** 当 Leader 收到**过半数** 节点的 `ACK` 响应后,就会认为该写操作成功。Leader 在本地写日志时会更新内部的 quorum 计数器(而非显式向自己发送 ACK),确认过半后向客户端返回成功响应,并向所有节点广播 `Commit` 消息。Follower 收到 `Commit` 后,正式将数据应用到内存中。
+
+### 2. 崩溃恢复模式(Leader 宕机或网络异常)
+
+当系统刚启动,或者 Leader 服务器崩溃、与过半 Follower 失去联系时,整个集群就会暂停对外服务,进入 `LOOKING` 状态,触发崩溃恢复模式。崩溃恢复主要包含两个阶段:**Leader 选举**和**数据恢复**。
+
+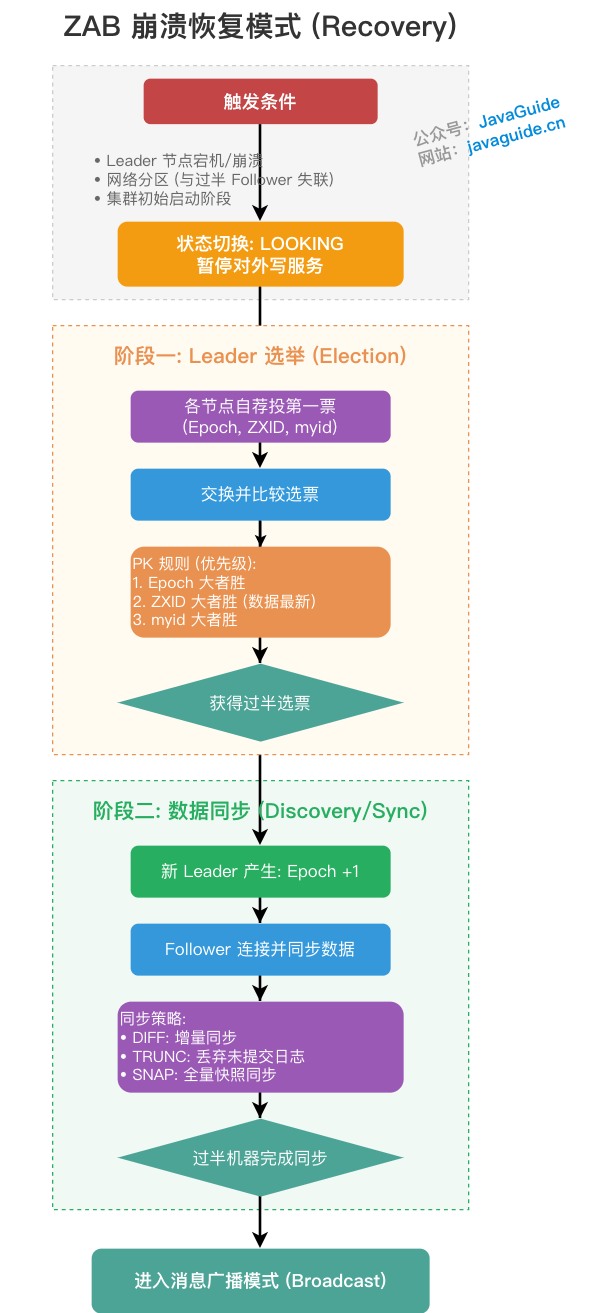
+
+#### 阶段一:Leader 选举
+
+选举的核心原则是:**拥有最新数据的节点优先当选**。 每个节点都会先投自己一票,投票信息包含 `(Epoch, ZXID, myid)`。随后节点会交换选票,并按照以下顺序进行 PK:
+
+1. **比较 Epoch:** 纪元大的优先。
+2. **比较 ZXID:** 如果 Epoch 相同,ZXID 大的优先(代表数据越新)。
+3. **比较 myid:** 如果前两者都相同,服务器唯一标识 `myid` 大的优先。
+
+一旦某个节点获得了**过半数**的选票,它就会成为新的 Leader。_(这也是为什么 ZooKeeper 推荐部署奇数台服务器的原因,能以最低的成本实现半数以上的容错。)_
+
+#### 阶段二:数据恢复
+
+选出新 Leader 只是第一步,为了保证数据一致性,ZAB 必须在数据同步阶段实现两个极其重要的保证:
+
+1. **确保已经在旧 Leader 上提交的事务,最终被所有节点提交。** (防止数据丢失)
+2. **丢弃那些只在旧 Leader 上提出,但还没来得及提交的事务。** (防止脏数据干扰)
+
+新 Leader 会找到当前最大的 `Epoch` 并加 1 作为新纪元,随后与所有 Follower 进行比对。Follower 会发送自己事务日志中最新记录的 `lastZxid`(包含已提议但尚未提交的提案),Leader 根据这个值采取多态同步策略:**差异化增量同步(DIFF)**、**强制丢弃未提交日志(TRUNC)** 或 **全量快照传输(SNAP)**。
+
+这一设计至关重要:Leader 需要准确识别 Follower 日志中是否残留着旧 Leader 未完成提交的"幽灵提案",才能正确下发 TRUNC 指令让其截断回滚。如果只上报已提交的 ZXID,这些未提交的脏数据将无法被感知,TRUNC 分支就永远不会被触发。
+
+更关键的是,此时新的 Epoch 已经生效。若原 Leader 因 JVM 触发长达数十秒的 Full GC 而发生"假死",当其苏醒并试图向集群下发旧 Epoch 的提案时,由于过半节点已记录了更高的新 Epoch 且已向新 Leader 提交 quorum,这些幽灵提案将被节点无情拒绝并抛弃。ZAB 正是通过 **Epoch 机制 + 多数派 quorum** 的组合,从根本上免疫了网络环境下的脑裂现象——单靠 Epoch 拒绝还不够,必须有过半节点已经连上新 Leader,旧 Leader 才真正失去写入能力。
+
+当过半的机器与新 Leader 完成了状态和数据同步,ZAB 协议就会平滑退出崩溃恢复模式,重新进入消息广播模式。
+
+## 与 Raft 对比
+
+**ZAB 与 Raft 的高度相似性:** 如果你了解过 Raft 算法,会发现它们非常相似。它们都有唯一的主节点,都使用 Epoch/Term 来标识任期,并且都采用了只要半数以上节点确认即可提交的策略。这说明在现代分布式共识领域,这种基于主备和多数派选举的架构已经成为了事实上的标准。
+
+在当前的分布式系统实践中,Raft 算法通常被视为比 ZAB 更实用和受欢迎的选择。 这是因为 Raft 从设计之初就强调易懂性和可实现性,它将领导者选举、日志复制和安全性明确分离,这使得开发者更容易正确实施和调试,而 ZAB 作为 ZooKeeper 的专有协议,更侧重于原子广播的特定需求,导致其通用性较差。
+
+Raft 已广泛应用于现代系统,如 Kubernetes 的 etcd、Hashicorp Consul、Apache Kafka(在其 KIP-500 版本中去除 ZooKeeper 依赖,转向 Raft-based KRaft)、TiKV 等,这极大“民主化”了分布式共识的开发。
+
+相比之下,ZAB 主要绑定在 ZooKeeper 上,虽然 ZooKeeper 仍是经典的协调服务,但许多新项目倾向于选择 Raft 以避免 ZooKeeper 的额外复杂性和潜在瓶颈(如在大规模下共识开销)。
+
+此外,Raft 的社区支持更活跃,衍生出多种优化变体(如用于区块链的改进版本),使其在效率和适用场景上更具优势。 然而,如果你的系统已深度集成 ZooKeeper,ZAB 仍是最优化的选择;否则,对于新设计或通用共识需求,Raft 是当前更实用的标准。
+
+## 总结
+
+ZAB 协议通过精心设计的 Leader 选举和多数派确认机制,在分布式系统的分区容错性(P)和一致性(C)之间做出了选择(满足 CP 属性)。当出现网络分区时,ZAB 宁愿牺牲短暂的可用性(A)进行选举,也要保证数据的一致性。
+
+需要特别强调的是,**ZAB 协议默认不保证严格的强一致性(线性一致性),而是提供顺序一致性(Sequential Consistency)**。
+
+由于 Follower 可以直接处理客户端的读请求且不强求数据绝对同步,客户端完全可能读取到落后于 Leader 的陈旧数据(Stale Read)。在生产环境中,若业务涉及如分布式锁等对数据新鲜度要求极高的场景,必须在执行 `read()` 操作前显式调用 `sync()` 原语,强制要求连接的 Follower 追平 Leader 的事务状态机。
+
+当发生网络分区时,客户端若连接至被隔离的少数派 Follower,虽然写操作会失败,但仍可读出过期数据,这是使用 ZAB 协议时必须考虑的边界场景。
diff --git a/docs/distributed-system/rpc/dubbo.md b/docs/distributed-system/rpc/dubbo.md
index ee6c6a39a35..02cc37a8c0c 100644
--- a/docs/distributed-system/rpc/dubbo.md
+++ b/docs/distributed-system/rpc/dubbo.md
@@ -1,5 +1,6 @@
---
title: Dubbo常见问题总结
+description: Dubbo核心知识与面试题详解,涵盖Dubbo架构原理、SPI机制、负载均衡策略及服务治理等核心内容。
category: 分布式
tag:
- rpc
@@ -56,7 +57,7 @@ Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出
1. **负载均衡**:同一个服务部署在不同的机器时该调用哪一台机器上的服务。
2. **服务调用链路生成**:随着系统的发展,服务越来越多,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。Dubbo 可以为我们解决服务之间互相是如何调用的。
3. **服务访问压力以及时长统计、资源调度和治理**:基于访问压力实时管理集群容量,提高集群利用率。
-4. ......
+4. ……
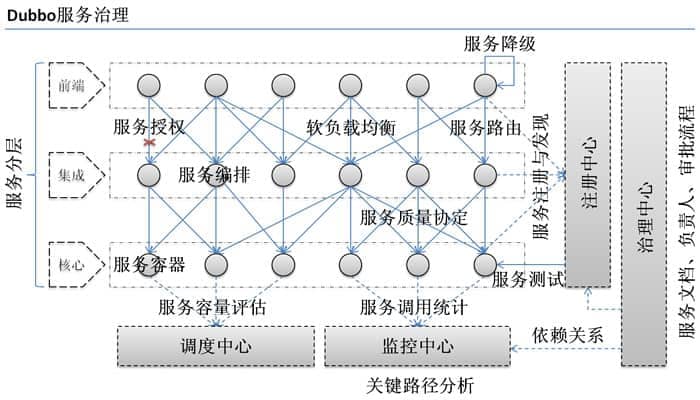
@@ -171,7 +172,7 @@ src
`org.apache.dubbo.rpc.cluster.LoadBalance`
-```
+```plain
xxx=com.xxx.XxxLoadBalance
```
@@ -262,7 +263,7 @@ public abstract class AbstractLoadBalance implements LoadBalance {
根据权重随机选择(对加权随机算法的实现)。这是 Dubbo 默认采用的一种负载均衡策略。
-` RandomLoadBalance` 具体的实现原理非常简单,假如有两个提供相同服务的服务器 S1,S2,S1 的权重为 7,S2 的权重为 3。
+`RandomLoadBalance` 具体的实现原理非常简单,假如有两个提供相同服务的服务器 S1,S2,S1 的权重为 7,S2 的权重为 3。
我们把这些权重值分布在坐标区间会得到:S1->[0, 7) ,S2->[7, 10)。我们生成[0, 10) 之间的随机数,随机数落到对应的区间,我们就选择对应的服务器来处理请求。
@@ -456,4 +457,6 @@ Kryo 和 FST 这两种序列化方式是 Dubbo 后来才引入的,性能非常
Dubbo 官方文档中还有一个关于这些[序列化协议的性能对比图](https://dubbo.apache.org/zh/docs/v2.7/user/serialization/#m-zhdocsv27userserialization)可供参考。
-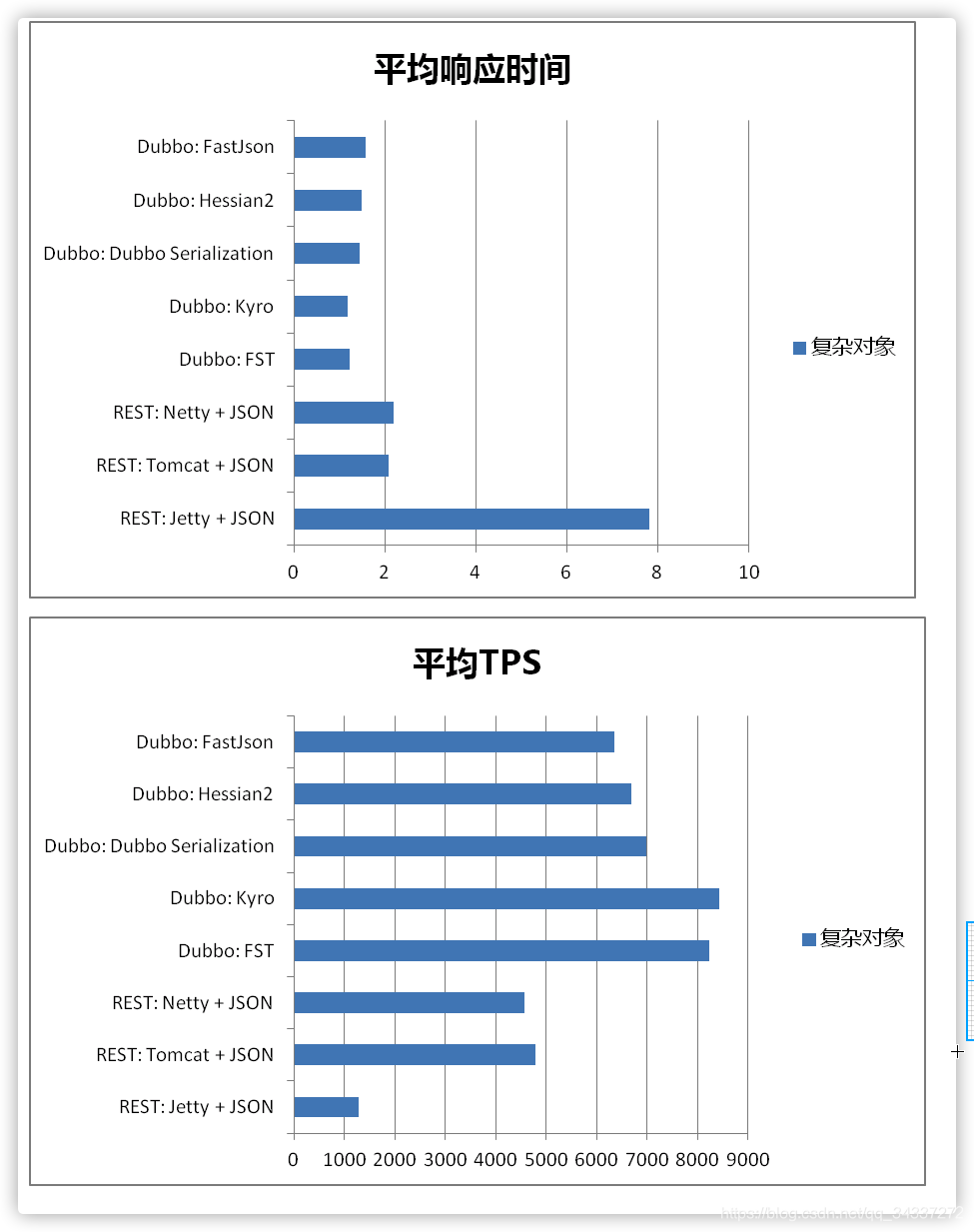
+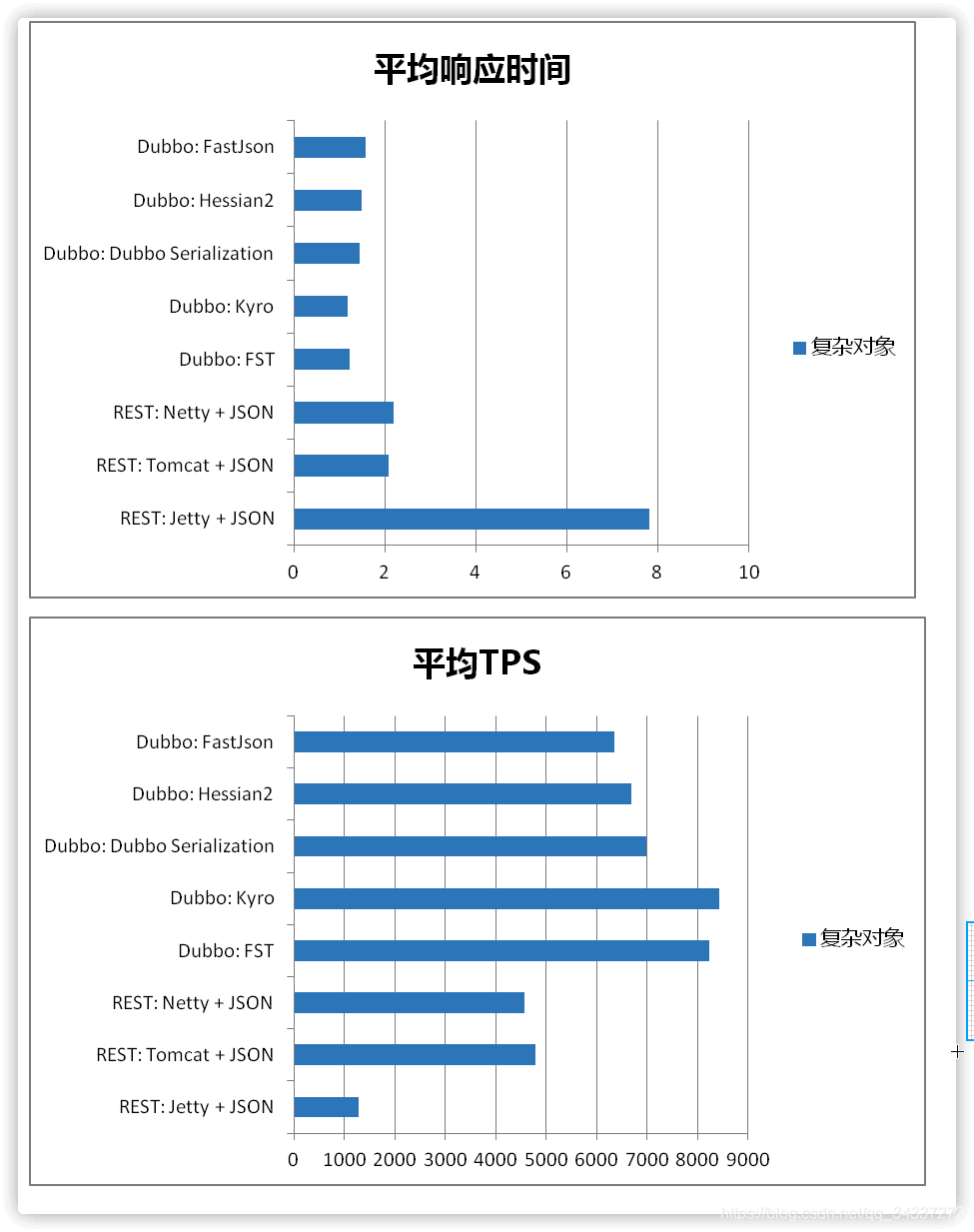
+
+
diff --git a/docs/distributed-system/rpc/http&rpc.md b/docs/distributed-system/rpc/http&rpc.md
index 88ac10b03fe..e3ac8ad5b7f 100644
--- a/docs/distributed-system/rpc/http&rpc.md
+++ b/docs/distributed-system/rpc/http&rpc.md
@@ -1,11 +1,12 @@
---
title: 有了 HTTP 协议,为什么还要有 RPC ?
+description: HTTP与RPC对比详解,讲解两种通信方式的本质区别、性能差异及在微服务架构中的选型建议。
category: 分布式
tag:
- rpc
---
-> 本文来自[小白 debug](https://juejin.cn/user/4001878057422087)投稿,原文:https://juejin.cn/post/7121882245605883934 。
+> 本文来自[小白 debug](https://juejin.cn/user/4001878057422087)投稿,原文: 。
我想起了我刚工作的时候,第一次接触 RPC 协议,当时就很懵,我 HTTP 协议用的好好的,为什么还要用 RPC 协议?
@@ -177,7 +178,7 @@ res = remoteFunc(req)
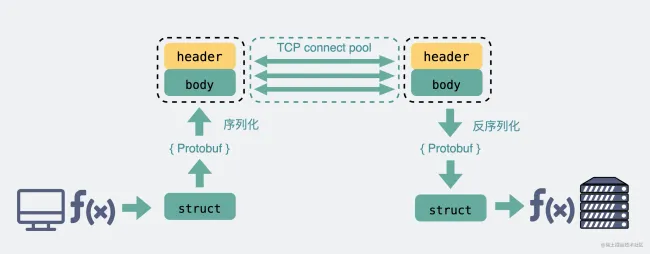
-当然上面说的 HTTP,其实 **特指的是现在主流使用的 HTTP1.1**,`HTTP2`在前者的基础上做了很多改进,所以 **性能可能比很多 RPC 协议还要好**,甚至连`gRPC`底层都直接用的`HTTP2`。
+当然上面说的 HTTP,其实 **特指的是现在主流使用的 HTTP1.1**,`HTTP2`在前者的基础上做了很多改进,所以 **性能可能比很多 RPC 协议还要好**。而 gRPC 正是基于 HTTP/2 实现的(虽然它基于 HTTP/2 的帧格式定义了自己的协议,但传输层仍是 HTTP/2)。
那么问题又来了。
@@ -192,3 +193,5 @@ res = remoteFunc(req)
- 从发展历史来说,**HTTP 主要用于 B/S 架构,而 RPC 更多用于 C/S 架构。但现在其实已经没分那么清了,B/S 和 C/S 在慢慢融合。** 很多软件同时支持多端,所以对外一般用 HTTP 协议,而内部集群的微服务之间则采用 RPC 协议进行通讯。
- RPC 其实比 HTTP 出现的要早,且比目前主流的 HTTP1.1 性能要更好,所以大部分公司内部都还在使用 RPC。
- **HTTP2.0** 在 **HTTP1.1** 的基础上做了优化,性能可能比很多 RPC 协议都要好,但由于是这几年才出来的,所以也不太可能取代掉 RPC。
+
+
diff --git a/docs/distributed-system/rpc/rpc-intro.md b/docs/distributed-system/rpc/rpc-intro.md
index b65ed37e4ab..1c2de76ef6a 100644
--- a/docs/distributed-system/rpc/rpc-intro.md
+++ b/docs/distributed-system/rpc/rpc-intro.md
@@ -1,5 +1,6 @@
---
title: RPC基础知识总结
+description: RPC远程过程调用基础详解,讲解RPC核心原理、调用流程、序列化协议及常见RPC框架对比分析。
category: 分布式
tag:
- rpc
@@ -25,13 +26,13 @@ tag:
1. **客户端(服务消费端)**:调用远程方法的一端。
1. **客户端 Stub(桩)**:这其实就是一代理类。代理类主要做的事情很简单,就是把你调用方法、类、方法参数等信息传递到服务端。
-1. **网络传输**:网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最近基本的 Socket 或者性能以及封装更加优秀的 Netty(推荐)。
+1. **网络传输**:网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最基本的 Socket 或者性能以及封装更加优秀的 Netty(推荐)。
1. **服务端 Stub(桩)**:这个桩就不是代理类了。我觉得理解为桩实际不太好,大家注意一下就好。这里的服务端 Stub 实际指的就是接收到客户端执行方法的请求后,去执行对应的方法然后返回结果给客户端的类。
1. **服务端(服务提供端)**:提供远程方法的一端。
具体原理图如下,后面我会串起来将整个 RPC 的过程给大家说一下。
-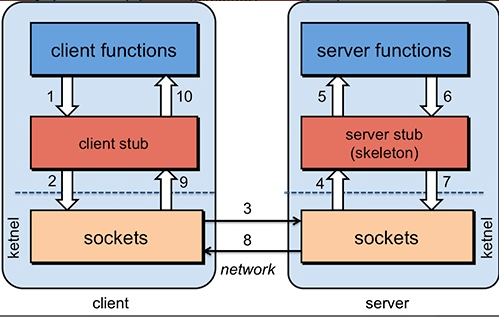
+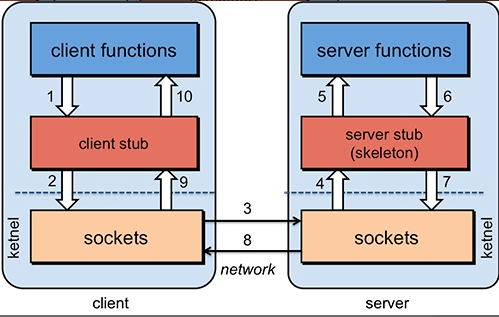
1. 服务消费端(client)以本地调用的方式调用远程服务;
1. 客户端 Stub(client stub) 接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体(序列化):`RpcRequest`;
@@ -67,7 +68,7 @@ Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出
Dubbo 算的是比较优秀的国产开源项目了,它的源码也是非常值得学习和阅读的!
- GitHub:[https://github.com/apache/incubator-dubbo](https://github.com/apache/incubator-dubbo "https://github.com/apache/incubator-dubbo")
-- 官网:https://dubbo.apache.org/zh/
+- 官网:
### Motan
@@ -82,7 +83,7 @@ Motan 是新浪微博开源的一款 RPC 框架,据说在新浪微博正支撑
### gRPC
-
+
gRPC 是 Google 开源的一个高性能、通用的开源 RPC 框架。其由主要面向移动应用开发并基于 HTTP/2 协议标准而设计(支持双向流、消息头压缩等功能,更加节省带宽),基于 ProtoBuf 序列化协议开发,并且支持众多开发语言。
@@ -114,11 +115,11 @@ Dubbo 不论是从功能完善程度、生态系统还是社区活跃度来说
下图展示了 Dubbo 的生态系统。
-
+
Dubbo 也是 Spring Cloud Alibaba 里面的一个组件。
-
+
但是,Dubbo 和 Motan 主要是给 Java 语言使用。虽然,Dubbo 和 Motan 目前也能兼容部分语言,但是不太推荐。如果需要跨多种语言调用的话,可以考虑使用 gRPC。
@@ -137,3 +138,5 @@ Dubbo 也是 Spring Cloud Alibaba 里面的一个组件。
## 既然有了 HTTP 协议,为什么还要有 RPC ?
关于这个问题的详细答案,请看这篇文章:[有了 HTTP 协议,为什么还要有 RPC ?](http&rpc.md) 。
+
+
diff --git a/docs/distributed-system/spring-cloud-gateway-questions.md b/docs/distributed-system/spring-cloud-gateway-questions.md
index a85c8ee189e..75c4ba50812 100644
--- a/docs/distributed-system/spring-cloud-gateway-questions.md
+++ b/docs/distributed-system/spring-cloud-gateway-questions.md
@@ -1,5 +1,6 @@
---
title: Spring Cloud Gateway常见问题总结
+description: Spring Cloud Gateway核心原理详解,包括路由配置、过滤器机制、限流熔断等常见面试题与实践要点。
category: 分布式
---
@@ -7,7 +8,7 @@ category: 分布式
## 什么是 Spring Cloud Gateway?
-Spring Cloud Gateway 属于 Spring Cloud 生态系统中的网关,其诞生的目标是为了替代老牌网关 **Zuul**。准确点来说,应该是 Zuul 1.x。Spring Cloud Gateway 起步要比 Zuul 2.x 更早。
+Spring Cloud Gateway 属于 Spring Cloud 生态系统中的网关,其诞生的目标主要是为了替代 **Zuul 1.x**。Zuul 1.x 基于 Servlet 阻塞 I/O 架构,在高并发场景下性能有限。而 Zuul 2.x 虽然采用了 Netty 非阻塞架构,但 Spring Cloud 官方并未正式集成 Zuul 2.x。Spring Cloud Gateway 起步要比 Zuul 2.x 更早。
为了提升网关的性能,Spring Cloud Gateway 基于 Spring WebFlux 。Spring WebFlux 使用 Reactor 库来实现响应式编程模型,底层基于 Netty 实现同步非阻塞的 I/O。
@@ -68,7 +69,7 @@ Route 路由和 Predicate 断言的对应关系如下::
Spring Cloud Gateway 作为微服务的入口,需要尽量避免重启,而现在配置更改需要重启服务不能满足实际生产过程中的动态刷新、实时变更的业务需求,所以我们需要在 Spring Cloud Gateway 运行时动态配置网关。
-实现动态路由的方式有很多种,其中一种推荐的方式是基于 Nacos 配置中心来做。简单来说,我们将将路由配置放在 Nacos 中存储,然后写个监听器监听 Nacos 上配置的变化,将变化后的配置更新到 GateWay 应用的进程内。
+实现动态路由的方式有很多种,其中一种推荐的方式是基于 Nacos 注册中心来做。 Spring Cloud Gateway 可以从注册中心获取服务的元数据(例如服务名称、路径等),然后根据这些信息自动生成路由规则。这样,当你添加、移除或更新服务实例时,网关会自动感知并相应地调整路由规则,无需手动维护路由配置。
其实这些复杂的步骤并不需要我们手动实现,通过 Nacos Server 和 Spring Cloud Alibaba Nacos Config 即可实现配置的动态变更,官方文档地址: 。
@@ -153,3 +154,5 @@ public class GlobalErrorWebExceptionHandler implements ErrorWebExceptionHandler
- Spring Cloud Gateway 官方文档:
- Creating a custom Spring Cloud Gateway Filter:
- 全局异常处理:
+
+
diff --git a/docs/high-availability/fallback-and-circuit-breaker.md b/docs/high-availability/fallback-and-circuit-breaker.md
index bc2e477b753..ecd724eac53 100644
--- a/docs/high-availability/fallback-and-circuit-breaker.md
+++ b/docs/high-availability/fallback-and-circuit-breaker.md
@@ -1,8 +1,229 @@
---
-title: 降级&熔断详解(付费)
+title: 降级&熔断详解
+description: 服务降级与熔断机制详解,讲解降级策略、熔断器原理及 Hystrix、Sentinel、Resilience4j 等框架的应用实践,涵盖雪崩效应、熔断状态机、隔离策略与系统自适应保护。
category: 高可用
+icon: circuit
+head:
+ - - meta
+ - name: keywords
+ content: 服务降级,熔断器,熔断机制,Sentinel,Hystrix,Resilience4j,雪崩效应,熔断状态机,Fallback,限流降级熔断区别,微服务高可用,系统自适应保护,线程池隔离,信号量隔离
---
-**降级&熔断** 相关的面试题为我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)中。
+## 什么是降级?
-
+服务降级(Service Degradation)是从系统功能优先级视角应对故障的策略:在负载(如 CPU 使用率 > 80%、线程池饱和、响应时间 P99 > 1s)接近阈值时,有策略地降低非核心服务质量,释放资源确保核心路径可用性。
+
+### 降级的特征
+
+| 维度 | 说明 | 示例 |
+| ------------ | ----------------------- | -------------------------------------------------------------------- |
+| **触发原因** | 整体负荷超出阈值 | CPU 使用率 > 80%、P99 RT > 1s、P999 RT > 3s、队列积压深度 > 容量 80% |
+| **目的** | 保核心、弃非核心 | 关闭推荐、保留下单 |
+| **粒度** | 服务/页面/接口/功能三级 | 关闭商品推荐模块 |
+| **可控性** | 配置中心动态开关 | Nacos 2.0+ gRPC 长连接(毫秒级推送) |
+| **优先级** | 1-10 级,从外围到核心 | L10:下单 > L5:评论 > L1:推荐 |
+
+### 降级方式有哪些?
+
+| 方式 | 说明 | 适用场景 | 失败路径与风险 |
+| ---------------- | ------------------------------------------------------ | ------------------ | ------------------------------------------------------------- |
+| **延迟服务** | 将非实时操作异步化,写入 MQ/缓存 | 评论积分、数据统计 | MQ 积压需背压(如 Jitter 重试避免风暴) |
+| **页面片段降级** | 直接关闭非核心功能区块 | 推荐区、广告位 | 无 |
+| **异步请求降级** | 页面内异步加载接口返回兜底数据 | 配送至、价格预测 | 兜底数据需预加载缓存 |
+| **页面跳转降级** | 将流量导流到静态/简版页面 | 静态活动页、维护页 | 需预设静态页版本 |
+| **写降级** | 优先写入 Redis/本地 WAL,通过可靠 MQ 或定时任务同步 DB | 秒杀库存扣减 | 需保证最终一致性(对账/补偿);内存队列在节点宕机时会丢失数据 |
+| **读降级** | 只读缓存,屏蔽后端调用 | 商品详情读多写少 | 缓存穿透时需返回降级页 |
+
+### 降级开关实现方案
+
+| 方案 | 实时性 | 一致性 | 复杂度 | 适用场景 |
+| ----------------------------------- | ---------------- | ----------------------- | ------ | ------------------ |
+| **配置文件 + 重启** | 低 | 强 | 低 | 非紧急、不频繁变更 |
+| **数据库开关表** | 中 | 中 | 中 | 需要审计日志的场景 |
+| **配置中心(Nacos 2.0+ / Apollo)** | 高(毫秒级推送) | 最终一致(gRPC 双向流) | 高 | 生产环境推荐 |
+| **Redis/Diamond** | 高 | 最终一致 | 中 | 轻量级方案 |
+
+> 注:Nacos 2.0+ 基于 **gRPC 持久长连接**(Persistent Connection)和**双向流**(Bidirectional Streaming)实现服务端主动推送,推送生效时间达毫秒级。与 1.x 的 HTTP 长轮询(Polling)相比,gRPC 模式避免了重复 TPS,利用 NIO 机制提升吞吐量,整体性能提升约 **10 倍**,内存占用降低 **50%**,单机可支撑 **10W+** 实例连接。
+>
+> **一致性机制**:Nacos 2.0+ 并非采用严格的 ACK 机制,而是依赖 **HTTP/2 PING 帧**(Keepalive)检测连接健康和快速感知断开,确保推送可靠。连接丢失时客户端自动重连并同步数据实现最终一致收敛。
+>
+> **网络分区场景**:Nacos 的注册中心(Naming)模块偏向 AP,但**配置中心(Config)模块基于 Raft 协议保证强一致性(CP)**。降级开关属于配置中心范畴,发生网络分区时,处于少数派(Minority)的 Nacos 节点将拒绝写入并可能导致客户端配置漂移。此时客户端需依赖本地缓存文件(Failover 配置)作为最终兜底,并忍受降级规则无法实时推送的风险。
+>
+> **升级兼容性**:Nacos 2.0 服务器兼容 1.x 客户端(通过 HTTP 协议),但 2.0 客户端不兼容 1.x 服务器(gRPC 协议)。
+>
+> **客户端线程管理注意**:gRPC 执行器核心线程数基于 CPU 核数配置(如 200 核心、800 最大),需注意避免资源耗尽。
+
+### 服务降级有哪些分类?
+
+降级按照是否自动化可分为:
+
+- **自动开关降级**(超时、失败次数、故障、限流)
+- **人工开关降级**(秒杀、电商大促等)
+
+自动降级分类:
+
+| 类型 | 触发阈值 | 兜底方案 | 失败路径要求 |
+| ------------ | -------------------------------------- | ------------------ | -------------------------- |
+| **超时降级** | RT > 阈值(如 P99 > 500ms)且持续 N 次 | 默认值 | 需幂等性保护,避免重试风暴 |
+| **失败降级** | 异常率 > 阈值(如 50%) | 兜底数据 | 兜底数据需预热缓存 |
+| **故障降级** | HTTP 5xx/RPC 异常/DNS 解析失败 | 缓存数据 | 缓存未命中时返回默认值 |
+| **限流降级** | QPS > 阈值 | 排队页/无货/错误页 | 排队页需防重入(幂等令牌) |
+
+> 重试风暴:当服务恢复但大量客户端同时重试时,可能导致服务再次崩溃。防御措施包括:Jitter 重试(随机退避)、令牌桶限流、分组分批恢复。
+
+## 大规模分布式系统如何降级?
+
+在大规模分布式系统中,经常会有成百上千的服务。在大促前往往会根据业务的重要程度和业务间的关系批量降级。
+
+### 降级平台能力
+
+大型互联网公司通常会有统一的降级平台,核心能力包括:
+
+| 能力 | 说明 | 实现要点 |
+| ------------ | ------------------- | -------------------------------------- |
+| **分级管理** | 1-10 级服务优先级 | 核心业务评审、依赖关系梳理 |
+| **批量降级** | 按级别/分组批量执行 | 降级顺序编排、原子性保证(二阶段提交) |
+| **动态开关** | 配置中心实时推送 | Nacos 2.0+ gRPC 或 WebSocket |
+| **效果验证** | 灰度验证 + 监控观测 | A/B 测试、指标对比 |
+| **一键回滚** | 版本管理 + 快速回滚 | 配置版本化、变更审计 |
+
+### 降级预案制定
+
+1. **业务分级**:梳理服务核心度,定义 L1-L10 优先级
+2. **依赖分析**:绘制服务调用链,识别关键路径和单点依赖
+3. **降级策略**:为每个非核心服务设计降级方案(含失败路径)
+4. **演练验证**:定期进行降级演练,确保预案有效性(含网络分区场景)
+
+> 网络分区场景:依据 PACELC 定理,分区时需权衡可用性(A)与一致性(C)。降级预案应明确分区期间的行为模式(如继续服务本地缓存、暂停跨区调用)。
+>
+> **详细介绍:** [CAP & BASE理论详解](https://javaguide.cn/distributed-system/protocol/cap-and-base-theorem.html)。
+
+## 什么是熔断?
+
+熔断器模式(Circuit Breaker Pattern)是应对微服务雪崩效应的一种链路保护机制,类似电路中的保险丝。
+
+### 雪崩效应
+
+正常调用链路:服务 A ──> 服务 B ──> 服务 C
+
+雪崩场景:
+
+- 服务 C 响应变慢/不可用
+- 对服务 C 的调用排队(线程池耗尽)
+- 服务 B 的调用线程阻塞
+- 服务 A 也被拖垮,雪崩扩散到整个系统
+
+### 熔断器状态机
+
+熔断器包含三种状态:
+
+| 状态 | 说明 | 行为 | 状态转换条件 |
+| -------------------- | ---------------------- | --------------------------------- | --------------------------------------------------------- |
+| **Closed(关闭)** | 正常状态,允许请求通过 | 记录失败率/慢调用比例 | 失败率/慢调用比例 > 阈值 → Open |
+| **Open(打开)** | 熔断触发,拒绝请求 | 快速返回 Fallback,不再调用下游 | 经过冷却时间(sleepWindow,如 10s) → HalfOpen |
+| **HalfOpen(半开)** | 探测服务是否恢复 | 释放配置数量(如 3 个)的探路请求 | 所有探测成功(或满足成功率阈值)→ Closed;任一失败 → Open |
+
+> Half-Open 风险与 Warm Up 预热:探测请求可能触发重试风暴或二次雪崩。建议限制探测请求数(如 Sentinel 默认 3 个),并要求所有探测成功(或满足配置的成功率阈值)才转为 Closed。若放行条件过于宽松(如单次成功即 Closed),面对刚从宕机中拉起的冷节点,瞬间涌入的并发流量会直接打满线程池,造成二次击穿(冷启动杀手)。
+>
+> **Warm Up 预热机制**:需配合基于令牌桶/漏桶算法的预热限流,按照冷却因子(默认 3)在预热周期内(如 10s)将放行 QPS 阈值从 `maxQps / 3` 平滑拉升至最大容量,防止冷节点由于 CPU Cache Miss 和数据库连接池未初始化被二次击穿。监控冷启动期间的 **P99 延迟** 和 **数据库连接池活跃连接数** 以验证预热效果。
+
+### 熔断策略
+
+Sentinel 1.8.2+ 支持三种熔断策略:
+
+| 策略 | 触发条件 | 典型阈值配置 | 版本要求 |
+| -------------- | ------------------------------------ | ---------------------- | -------- |
+| **慢调用比例** | P99 RT > 最大慢调用 RT 且比例 > 阈值 | RT > 500ms,比例 > 50% | 1.8.0+ |
+| **异常比例** | 异常比例 > 阈值 | 异常率 > 50% | 全版本 |
+| **异常数** | 异常数 > 阈值 | 1 分钟内异常 > 50 | 全版本 |
+
+> P99 vs 平均 RT:使用平均 RT 可能掩盖长尾延迟。生产环境建议监控 P99/P999,避免"大部分请求快但少数请求极慢"的场景。
+
+## 降级和熔断有什么区别?
+
+| 维度 | 降级 | 熔断 |
+| ------------ | -------------------- | ---------------------- |
+| **核心关注** | 资源优先级分配 | 调用链路保护 |
+| **触发方式** | 主动(系统/人工) | 被动(依赖异常触发) |
+| **作用范围** | 当前服务或下游 | 调用链的上游 |
+| **恢复方式** | 手动关闭或自动检测 | 自动(Half-Open 探测) |
+| **返回内容** | 兜底值/缓存/静态页面 | Fallback 方法 |
+
+**三者关系**:
+
+- 限流:保护自身不被打垮(限制进入流量)
+- 降级:自身主动牺牲非核心功能(降低服务质量)
+- 熔断:防止被下游拖垮(切断异常依赖)
+
+> 比喻:限流是"限流进入商场的客流",降级是"商场关闭部分楼层",熔断是"发现供应商出问题后停止与其合作"。
+
+## 有哪些现成解决方案?
+
+Spring Cloud 生态中常用的熔断降级组件:
+
+- **Hystrix 1.5.18**(2018 年停止维护)
+- **Sentinel 1.8.2+**(阿里开源,推荐)
+- **Resilience4j 1.7.1+**(轻量级)
+- **Spring Retry**(重试组件)
+
+### Hystrix vs Sentinel vs Resilience4j
+
+| 维度 | Sentinel 1.8.2+ | Hystrix 1.5.18 | Resilience4j 1.7.1+ |
+| ------------------ | ------------------------------- | -------------------------- | ------------------------------------------- |
+| **维护状态** | ✅ 活跃维护 | ❌ 2018 年停止维护 | ✅ 活跃维护 |
+| **隔离策略** | 并发线程数隔离(信号量) | 线程池隔离(默认)/ 信号量 | SemaphoreBulkhead / FixedThreadPoolBulkhead |
+| **熔断策略** | 慢调用比例/异常比例/异常数 | 异常比例 | 异常比例/异常数 |
+| **实时指标** | 滑动窗口 | 滑动窗口(RxJava) | 环形缓冲 |
+| **限流** | QPS/并发线程/调用关系 | 有限支持 | RateLimiter |
+| **流量整形** | 慢启动/匀速排队 | ❌ | ❌ |
+| **系统自适应保护** | ✅ Load/RT/线程数/QPS | ❌ | ❌ |
+| **控制台** | ✅ 开箱即用 | ⚠️ 简陋 | ⚠️ 需自行搭建 |
+| **框架适配** | Servlet/Spring Cloud/Dubbo/gRPC | Spring Cloud Netflix | Reactor/Vert.x |
+
+### 隔离策略对比
+
+| 策略 | Sentinel | Hystrix | Resilience4j | Trade-offs |
+| -------------- | --------------------- | --------- | -------------------------- | --------------------------------------------------------------------------------------------------------------------- |
+| **线程池隔离** | - | ✅ 默认 | ✅ FixedThreadPoolBulkhead | 优势:超时控制独立、资源隔离彻底、支持异步
劣势:OS 级别上下文切换开销(P99 恶化)、线程池大小难确定、增加 GC 压力 |
+| **信号量隔离** | ✅ 轻量级、无线程切换 | ✅ 轻量级 | ✅ SemaphoreBulkhead | 优势:无额外线程开销、内存占用小
劣势:不能做超时控制(依赖业务层)、不支持异步 |
+
+> **GC 与调度压力**:线程池隔离会创建大量独立线程。在高并发下,真正的瓶颈在于 CPU 在海量线程间进行 **OS 级别的调度唤醒与挂起**。这种频繁的**上下文切换** 会无谓消耗大量 CPU 的 Us/Sy 时间,并直接导致业务请求的 **P99 尾延迟急剧恶化**。锁争用仅是并发争用的表象,真正的杀手是线程调度开销。Resilience4j 的 `FixedThreadPoolBulkhead` 基于 `ArrayBlockingQueue`,极高并发下也存在锁争用,但相比上下文切换开销通常次要。
+
+### 系统自适应保护(Sentinel 独有)
+
+Sentinel 1.8+ 提供**系统自适应保护**(System Rule),其核心是引入类似 **TCP BBR** 的动态容量评估逻辑:
+
+**隐性核心条件**:`当前并发线程数 > (系统最大 QPS × 最小 RT)`
+
+| 指标 | 说明 | 典型阈值 | 版本要求 |
+| -------------------- | -------------------------- | --------------------- | --------------- |
+| **Load(系统负载)** | Linux `load1` 值 | > CPU 核数 × 2 | 全版本 |
+| **平均 RT** | 所有入口流量的平均响应时间 | > 500ms(建议用 P99) | 1.8.0+ 支持 P99 |
+| **并发线程数** | 当前并发线程数 | > 500 | 全版本 |
+| **入口 QPS** | 入口流量的 QPS | > 1000 | 全版本 |
+
+触发后,系统会自动拒绝部分请求,避免系统崩溃。相比静态阈值,BBR 风格的动态容量评估能防止静态阈值滞后导致的系统崩溃。
+
+### 选型建议与迁移 Trade-offs
+
+| 场景 | 推荐方案 | 迁移 Trade-offs |
+| ------------------------------ | -------------------------- | ------------------------------------------ |
+| 新项目(Spring Cloud Alibaba) | **Sentinel 1.8.2+** | 无迁移成本 |
+| 新项目(响应式/轻量级) | **Resilience4j 1.7.1+** | 需自行实现控制台 |
+| 存量项目(Hystrix) | 继续使用 Hystrix,规划迁移 | 迁移成本:API 变更 + 控制台搭建 + 规则迁移 |
+| 需要系统自适应保护 | **Sentinel**(独有) | 无替代方案 |
+
+## 推荐阅读
+
+- [Circuit Breaker Pattern - Martin Fowler](https://martinfowler.com/bliki/CircuitBreaker.html)
+- [Sentinel 官方文档](https://sentinelguard.io/zh-cn/docs/introduction.html)
+- [Release It! - Michael Nygard(生产级降级与熔断实践)](https://www.pragprog.com/titles/mnee2/release-it-second-edition/)
+- [PACELC: A Simple Perspective on Latency and Consistency](https://www.cs.berkeley.edu/~brewer/cs262/PACELC.pdf)
+
+## 参考
+
+- [Sentinel 与 Hystrix 的对比](https://github.com/alibaba/Sentinel/wiki/Sentinel-%E4%B8%8E-Hystrix-%E7%9A%84%E5%AF%B9%E6%AF%94)
+- [Spring Cloud Alibaba 官方文档](https://spring-cloud-alibaba-group.github.io/github-pages/2022/zh-cn/index.html)
+- [高并发之服务降级与熔断](https://suprisemf.github.io/2018/08/03/%E9%AB%98%E5%B9%B6%E5%8F%91%E4%B9%8B%E6%9C%8D%E5%8A%A1%E9%99%8D%E7%BA%A7%E4%B8%8E%E7%86%94%E6%96%AD/)
+
+
diff --git a/docs/high-availability/high-availability-system-design.md b/docs/high-availability/high-availability-system-design.md
index 67547074c01..4f95cf5e32f 100644
--- a/docs/high-availability/high-availability-system-design.md
+++ b/docs/high-availability/high-availability-system-design.md
@@ -1,68 +1,202 @@
---
title: 高可用系统设计指南
+description: 本文系统讲解高可用系统设计的核心知识,涵盖可用性衡量标准(SLA/多少个9)、常见故障原因(硬件故障/代码缺陷/流量激增/网络攻击)、以及10+种提升系统可用性的方法(集群/限流/熔断/降级/缓存/异步/灰度发布等),助力高可用架构设计与面试。
category: 高可用
+icon: design
+head:
+ - - meta
+ - name: keywords
+ content: 高可用,系统可用性,SLA,可用性指标,限流,熔断,降级,集群,灰度发布,高可用架构,系统稳定性
---
## 什么是高可用?可用性的判断标准是啥?
-高可用描述的是一个系统在大部分时间都是可用的,可以为我们提供服务的。高可用代表系统即使在发生硬件故障或者系统升级的时候,服务仍然是可用的。
+**高可用(High Availability,简称 HA)** 描述的是一个系统在大部分时间都是可用的,可以为我们提供服务的。高可用代表系统即使在发生硬件故障或者系统升级的时候,服务仍然是可用的。
-一般情况下,我们使用多少个 9 来评判一个系统的可用性,比如 99.9999% 就是代表该系统在所有的运行时间中只有 0.0001% 的时间是不可用的,这样的系统就是非常非常高可用的了!当然,也会有系统如果可用性不太好的话,可能连 9 都上不了。
+一般情况下,我们使用 **多少个 9** 来评判一个系统的可用性,比如 99.9999% 就是代表该系统在所有的运行时间中只有 0.0001% 的时间是不可用的,这样的系统就是非常非常高可用的了!当然,也会有系统如果可用性不太好的话,可能连 9 都上不了。
-除此之外,系统的可用性还可以用某功能的失败次数与总的请求次数之比来衡量,比如对网站请求 1000 次,其中有 10 次请求失败,那么可用性就是 99%。
+| 可用性等级 | 可用性百分比 | 年度停机时间 | 典型场景 |
+| ---------- | ------------ | ------------ | ------------ |
+| 1 个 9 | 90% | 36.5 天 | 个人博客 |
+| 2 个 9 | 99% | 3.65 天 | 普通企业系统 |
+| 3 个 9 | 99.9% | 8.76 小时 | 在线服务 |
+| 4 个 9 | 99.99% | 52.6 分钟 | 金融交易系统 |
+| 5 个 9 | 99.999% | 5.26 分钟 | 电信级系统 |
+
+除此之外,系统的可用性还可以用 **某功能的失败次数与总的请求次数之比** 来衡量,比如对网站请求 1000 次,其中有 10 次请求失败,那么可用性就是 99%。
+
+**SLA(Service Level Agreement,服务级别协议)** 是服务提供商与客户之间的正式承诺,通常会明确规定可用性目标。例如,云服务商承诺 99.95% 的 SLA,意味着每月最多允许约 22 分钟的停机时间。
## 哪些情况会导致系统不可用?
-1. 黑客攻击;
-2. 硬件故障,比如服务器坏掉。
-3. 并发量/用户请求量激增导致整个服务宕掉或者部分服务不可用。
-4. 代码中的坏味道导致内存泄漏或者其他问题导致程序挂掉。
-5. 网站架构某个重要的角色比如 Nginx 或者数据库突然不可用。
-6. 自然灾害或者人为破坏。
-7. ......
+导致系统不可用的原因可以从 **内部因素** 和 **外部因素** 两个维度来分析:
+
+**内部因素:**
+
+1. **代码缺陷**:比如内存泄漏、死锁、循环依赖、空指针异常等代码质量问题,是导致线上故障的最常见原因之一。
+2. **架构设计缺陷**:单点故障、缺少限流保护、服务间强耦合等架构问题,会在流量高峰时暴露出来。
+3. **资源耗尽**:CPU、内存、磁盘、连接池等资源耗尽会直接导致服务不可用。
+4. **配置错误**:错误的配置变更(如数据库连接串、超时时间配置不当)可能导致服务异常。
+
+**外部因素:**
+
+1. **硬件故障**:服务器宕机、磁盘损坏、网络设备故障等。
+2. **流量激增**:突发的用户请求量(如秒杀活动)超过系统承载能力。
+3. **网络攻击**:DDoS 攻击、CC 攻击等恶意攻击会耗尽系统资源。
+4. **依赖服务故障**:数据库、缓存、消息队列、第三方 API 等依赖服务不可用。
+5. **自然灾害**:机房停电、火灾、地震等不可抗力因素。
## 有哪些提高系统可用性的方法?
+提高系统可用性的方法可以从 **预防**、**容错**、**恢复** 三个阶段来考虑:
+
+```mermaid
+flowchart TB
+ subgraph Resilience["🛡️ 系统韧性三阶段
"]
+ direction TB
+
+ %% ================= 预防 =================
+ subgraph Prevention["🧯 预防:把风险前置
"]
+ direction TB
+ A["🧹 质量与测试
Review / 静态扫描 / 单元测试"]
+ B["🧩 高可用架构
多副本 / 多 AZ / 负载均衡"]
+ C["🧊 缓存与本地化
降延迟 / 减下游压力"]
+ D["🧪 灰度发布
Canary / 分批 / 快速回滚"]
+ end
+
+ P2T["⬇️ 从“少出错”到“扛得住”
进入故障控制面"]
+
+ %% ================= 容错 =================
+ subgraph Tolerance["🧱 容错:隔离止血,保核心链路
"]
+ direction TB
+ E["🚦 限流
令牌桶 / 并发控制"]
+ F["⏱️ 超时与重试
超时预算 / 指数退避 / 幂等"]
+ G["🧨 熔断
错误率阈值 / 半开探测"]
+ H["🪂 降级
兜底返回 / 关非核心"]
+ I["🧵 异步与队列
削峰填谷 / 解耦 / 最终一致"]
+ end
+
+ T2R["⬇️ 从“止血”到“恢复”
进入定位与处置"]
+
+ %% ================= 恢复 =================
+ subgraph Recovery["🔧 恢复:定位修复,回到 SLO
"]
+ direction TB
+ J["📡 可观测与告警
指标 / 日志 / Trace(SLI/SLO)"]
+ K["⏪ 回滚与灾备
版本回退 / 数据回放 / 切换"]
+ end
+
+ %% 主链路
+ Prevention --> P2T --> Tolerance --> T2R --> Recovery
+ end
+
+ %% =============== 样式(统一、少而清) ===============
+ classDef prevent fill:#52B788,stroke:#2E8B57,color:#fff;
+ classDef tolerate fill:#3498DB,stroke:#2980B9,color:#fff;
+ classDef recover fill:#F4D03F,stroke:#D35400,color:#333;
+ classDef pivot fill:#2C3E50,stroke:#1A252F,color:#fff;
+
+ class A,B,C,D prevent;
+ class E,F,G,H,I tolerate;
+ class J,K recover;
+ class P2T,T2R pivot;
+
+ style Prevention fill:#FFF3E0,stroke:#FFCC80,stroke-dasharray: 5 5;
+ style Tolerance fill:#E3F2FD,stroke:#90CAF9,stroke-dasharray: 5 5;
+ style Recovery fill:#E8F5E9,stroke:#A5D6A7,stroke-dasharray: 5 5;
+
+ style Resilience fill:#F5F5F5,stroke:#BDBDBD,rx:20,ry:20;
+```
+
### 注重代码质量,测试严格把关
-我觉得这个是最最最重要的,代码质量有问题比如比较常见的内存泄漏、循环依赖都是对系统可用性极大的损害。大家都喜欢谈限流、降级、熔断,但是我觉得从代码质量这个源头把关是首先要做好的一件很重要的事情。如何提高代码质量?比较实际可用的就是 CodeReview,不要在乎每天多花的那 1 个小时左右的时间,作用可大着呢!
+**代码质量是系统可用性的根基**。代码质量有问题比如比较常见的内存泄漏、循环依赖都是对系统可用性极大的损害。大家都喜欢谈限流、降级、熔断,但是从代码质量这个源头把关是首先要做好的一件很重要的事情。
-另外,安利几个对提高代码质量有实际效果的神器:
+如何提高代码质量?比较实际可用的就是 **Code Review**,不要在乎每天多花的那 1 个小时左右的时间,作用可大着呢!
-- [Sonarqube](https://www.sonarqube.org/);
-- Alibaba 开源的 Java 诊断工具 [Arthas](https://arthas.aliyun.com/doc/);
-- [阿里巴巴 Java 代码规范](https://github.com/alibaba/p3c)(Alibaba Java Code Guidelines);
+另外,安利几个对提高代码质量有实际效果的工具:
+
+- [Sonarqube](https://www.sonarqube.org/):静态代码分析平台,可检测代码坏味道、安全漏洞和 Bug。
+- Alibaba 开源的 Java 诊断工具 [Arthas](https://arthas.aliyun.com/doc/):可在线排查 JVM 问题,支持热更新代码。
+- [阿里巴巴 Java 代码规范](https://github.com/alibaba/p3c)(Alibaba Java Code Guidelines):配套 IDEA 插件,实时检查代码规范。
- IDEA 自带的代码分析等工具。
### 使用集群,减少单点故障
-先拿常用的 Redis 举个例子!我们如何保证我们的 Redis 缓存高可用呢?答案就是使用集群,避免单点故障。当我们使用一个 Redis 实例作为缓存的时候,这个 Redis 实例挂了之后,整个缓存服务可能就挂了。使用了集群之后,即使一台 Redis 实例挂了,不到一秒就会有另外一台 Redis 实例顶上。
+**单点故障(Single Point of Failure,SPOF)** 是高可用的大敌。先拿常用的 Redis 举个例子!我们如何保证我们的 Redis 缓存高可用呢?答案就是使用集群,避免单点故障。
+
+当我们使用一个 Redis 实例作为缓存的时候,这个 Redis 实例挂了之后,整个缓存服务可能就挂了。使用了集群之后,即使一台 Redis 实例挂了,不到一秒就会有另外一台 Redis 实例顶上。
+
+常见的集群模式:
+
+- **主从复制(Master-Slave)**:一主多从,主节点负责写,从节点负责读,主节点故障时需要手动或借助哨兵进行故障转移。
+- **哨兵模式(Sentinel)**:在主从复制基础上增加哨兵节点,实现自动故障检测和转移。
+- **分布式集群(Cluster)**:数据分片存储在多个节点,每个分片有主从副本,兼顾高可用和水平扩展。
### 限流
-流量控制(flow control),其原理是监控应用流量的 QPS 或并发线程数等指标,当达到指定的阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮,从而保障应用的高可用性。——来自 [alibaba-Sentinel](https://github.com/alibaba/Sentinel "Sentinel") 的 wiki。
+**限流(Rate Limiting)** 是保护系统的第一道防线。其原理是监控应用流量的 QPS 或并发线程数等指标,当达到指定的阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮,从而保障应用的高可用性。——来自 [alibaba-Sentinel](https://github.com/alibaba/Sentinel "Sentinel") 的 wiki。
+
+常见的限流算法包括:
+
+- **固定窗口计数器**:实现简单,但存在临界点突刺问题。
+- **滑动窗口计数器**:解决了固定窗口的临界问题,更加平滑。
+- **漏桶算法**:以固定速率处理请求,适合流量整形。
+- **令牌桶算法**:允许一定程度的突发流量,更加灵活。
### 超时和重试机制设置
-一旦用户请求超过某个时间的得不到响应,就抛出异常。这个是非常重要的,很多线上系统故障都是因为没有进行超时设置或者超时设置的方式不对导致的。我们在读取第三方服务的时候,尤其适合设置超时和重试机制。一般我们使用一些 RPC 框架的时候,这些框架都自带的超时重试的配置。如果不进行超时设置可能会导致请求响应速度慢,甚至导致请求堆积进而让系统无法再处理请求。重试的次数一般设为 3 次,再多次的重试没有好处,反而会加重服务器压力(部分场景使用失败重试机制会不太适合)。
+一旦用户请求超过某个时间的得不到响应,就抛出异常。这个是非常重要的,很多线上系统故障都是因为 **没有进行超时设置或者超时设置的方式不对** 导致的。
+
+我们在读取第三方服务的时候,尤其适合设置超时和重试机制。一般我们使用一些 RPC 框架的时候,这些框架都自带的超时重试的配置。如果不进行超时设置可能会导致请求响应速度慢,甚至导致请求堆积进而让系统无法再处理请求。
+
+**重试的次数一般设为 3 次**,再多次的重试没有好处,反而会加重服务器压力(部分场景使用失败重试机制会不太适合)。同时,重试需要配合 **指数退避** 策略,避免重试风暴。
### 熔断机制
-超时和重试机制设置之外,熔断机制也是很重要的。 熔断机制说的是系统自动收集所依赖服务的资源使用情况和性能指标,当所依赖的服务恶化或者调用失败次数达到某个阈值的时候就迅速失败,让当前系统立即切换依赖其他备用服务。 比较常用的流量控制和熔断降级框架是 Netflix 的 Hystrix 和 alibaba 的 Sentinel。
+超时和重试机制设置之外,**熔断机制** 也是很重要的。熔断机制说的是系统自动收集所依赖服务的资源使用情况和性能指标,当所依赖的服务恶化或者调用失败次数达到某个阈值的时候就迅速失败,让当前系统立即切换依赖其他备用服务。
+
+熔断器有三种状态:
+
+- **关闭(Closed)**:正常状态,请求正常通过。
+- **打开(Open)**:熔断状态,请求直接失败,不调用下游服务。
+- **半开(Half-Open)**:尝试恢复状态,放行少量请求探测下游服务是否恢复。
+
+比较常用的流量控制和熔断降级框架是 Netflix 的 Hystrix 和 alibaba 的 Sentinel。
+
+### 降级
+
+**降级(Degradation)** 是在系统压力过大或部分服务不可用时,暂时关闭一些非核心功能,保证核心功能的可用性。
+
+降级策略包括:
+
+- **功能降级**:关闭推荐、评论等非核心功能。
+- **数据降级**:返回缓存数据或默认数据,而非实时查询。
+- **页面降级**:返回静态页面或简化版页面。
### 异步调用
-异步调用的话我们不需要关心最后的结果,这样我们就可以用户请求完成之后就立即返回结果,具体处理我们可以后续再做,秒杀场景用这个还是蛮多的。但是,使用异步之后我们可能需要 **适当修改业务流程进行配合**,比如**用户在提交订单之后,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功**。除了可以在程序中实现异步之外,我们常常还使用消息队列,消息队列可以通过异步处理提高系统性能(削峰、减少响应所需时间)并且可以降低系统耦合性。
+异步调用的话我们不需要关心最后的结果,这样我们就可以用户请求完成之后就立即返回结果,具体处理我们可以后续再做,秒杀场景用这个还是蛮多的。
+
+但是,使用异步之后我们可能需要 **适当修改业务流程进行配合**,比如 **用户在提交订单之后,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功**。
+
+除了可以在程序中实现异步之外,我们常常还使用 **消息队列**,消息队列可以通过异步处理提高系统性能(削峰、减少响应所需时间)并且可以降低系统耦合性。
### 使用缓存
如果我们的系统属于并发量比较高的话,如果我们单纯使用数据库的话,当大量请求直接落到数据库可能数据库就会直接挂掉。使用缓存缓存热点数据,因为缓存存储在内存中,所以速度相当地快!
+缓存的典型应用场景:
+
+- **热点数据缓存**:将访问频繁的数据放入 Redis 等缓存中。
+- **页面缓存**:将渲染后的页面缓存起来,减少服务器压力。
+- **本地缓存**:使用 Caffeine、Guava Cache 等本地缓存,减少网络开销。
+
### 其他
-- **核心应用和服务优先使用更好的硬件**
-- **监控系统资源使用情况增加报警设置。**
-- **注意备份,必要时候回滚。**
-- **灰度发布:** 将服务器集群分成若干部分,每天只发布一部分机器,观察运行稳定没有故障,第二天继续发布一部分机器,持续几天才把整个集群全部发布完毕,期间如果发现问题,只需要回滚已发布的一部分服务器即可
-- **定期检查/更换硬件:** 如果不是购买的云服务的话,定期还是需要对硬件进行一波检查的,对于一些需要更换或者升级的硬件,要及时更换或者升级。
-- .....
+- **核心应用和服务优先使用更好的硬件**:核心服务使用更高配置的服务器、SSD 硬盘等。
+- **监控系统资源使用情况增加报警设置**:使用 Prometheus + Grafana 等监控方案,设置合理的告警阈值。
+- **注意备份,必要时候回滚**:数据库定期备份,代码版本可追溯,支持快速回滚。
+- **灰度发布**:将服务器集群分成若干部分,每天只发布一部分机器,观察运行稳定没有故障,第二天继续发布一部分机器,持续几天才把整个集群全部发布完毕,期间如果发现问题,只需要回滚已发布的一部分服务器即可。
+- **定期检查/更换硬件**:如果不是购买的云服务的话,定期还是需要对硬件进行一波检查的,对于一些需要更换或者升级的硬件,要及时更换或者升级。
+
+
diff --git a/docs/high-availability/idempotency.md b/docs/high-availability/idempotency.md
new file mode 100644
index 00000000000..d06e0002fa0
--- /dev/null
+++ b/docs/high-availability/idempotency.md
@@ -0,0 +1,12 @@
+---
+title: 接口幂等方案总结(付费)
+description: 接口幂等性设计详解,涵盖幂等性概念、常见实现方案及在支付、订单等场景中的应用实践。
+category: 高可用
+icon: security-fill
+---
+
+**接口幂等** 相关的面试题为我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)中。
+
+
+
+
diff --git a/docs/high-availability/limit-request.md b/docs/high-availability/limit-request.md
index 72593d3c713..0123a4711f5 100644
--- a/docs/high-availability/limit-request.md
+++ b/docs/high-availability/limit-request.md
@@ -1,11 +1,13 @@
---
title: 服务限流详解
+description: 服务限流原理与实现详解,涵盖固定窗口、滑动窗口、令牌桶、漏桶等主流限流算法的原理与应用。
category: 高可用
+icon: limit_rate
---
针对软件系统来说,限流就是对请求的速率进行限制,避免瞬时的大量请求击垮软件系统。毕竟,软件系统的处理能力是有限的。如果说超过了其处理能力的范围,软件系统可能直接就挂掉了。
-限流可能会导致用户的请求无法被正确处理,不过,这往往也是权衡了软件系统的稳定性之后得到的最优解。
+限流可能会导致用户的请求无法被正确处理或者无法立即被处理,不过,这往往也是权衡了软件系统的稳定性之后得到的最优解。
现实生活中,处处都有限流的实际应用,就比如排队买票是为了避免大量用户涌入购票而导致售票员无法处理。
@@ -17,32 +19,46 @@ category: 高可用
### 固定窗口计数器算法
-固定窗口其实就是时间窗口。**固定窗口计数器算法** 规定了我们单位时间处理的请求数量。
+固定窗口其实就是时间窗口,其原理是将时间划分为固定大小的窗口,在每个窗口内限制请求的数量或速率,即固定窗口计数器算法规定了系统单位时间处理的请求数量。
-假如我们规定系统中某个接口 1 分钟只能访问 33 次的话,使用固定窗口计数器算法的实现思路如下:
+假如我们规定系统中某个接口 1 分钟只能被访问 33 次的话,使用固定窗口计数器算法的实现思路如下:
+- 将时间划分固定大小窗口,这里是 1 分钟一个窗口。
- 给定一个变量 `counter` 来记录当前接口处理的请求数量,初始值为 0(代表接口当前 1 分钟内还未处理请求)。
- 1 分钟之内每处理一个请求之后就将 `counter+1` ,当 `counter=33` 之后(也就是说在这 1 分钟内接口已经被访问 33 次的话),后续的请求就会被全部拒绝。
- 等到 1 分钟结束后,将 `counter` 重置 0,重新开始计数。
-**这种限流算法无法保证限流速率,因而无法保证突然激增的流量。**
+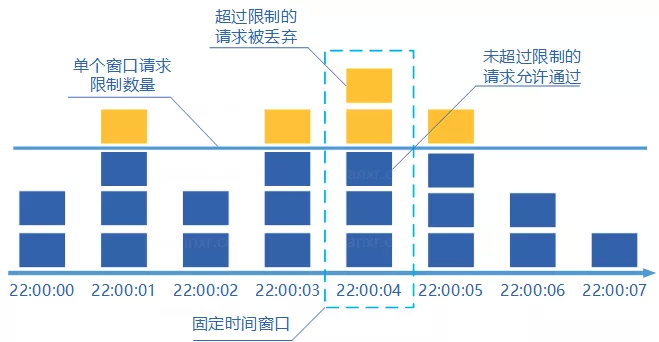
-就比如说我们限制某个接口 1 分钟只能访问 1000 次,该接口的 QPS 为 500,前 55s 这个接口 1 个请求没有接收,后 1s 突然接收了 1000 个请求。然后,在当前场景下,这 1000 个请求在 1s 内是没办法被处理的,系统直接就被瞬时的大量请求给击垮了。
+优点:实现简单,易于理解。
-
+缺点:
+
+- 限流不够平滑。例如,我们限制某个接口每分钟只能访问 30 次,假设前 30 秒就有 30 个请求到达的话,那后续 30 秒将无法处理请求,这是不可取的,用户体验极差!
+- 无法保证限流速率,因而无法应对突然激增的流量。例如,我们限制某个接口 1 分钟只能访问 1000 次,该接口的 QPS 为 500,前 55s 这个接口 1 个请求没有接收,后 1s 突然接收了 1000 个请求。然后,在当前场景下,这 1000 个请求在 1s 内是没办法被处理的,系统直接就被瞬时的大量请求给击垮了。
### 滑动窗口计数器算法
-**滑动窗口计数器算法** 算的上是固定窗口计数器算法的升级版。
+**滑动窗口计数器算法** 算的上是固定窗口计数器算法的升级版,限流的颗粒度更小。
滑动窗口计数器算法相比于固定窗口计数器算法的优化在于:**它把时间以一定比例分片** 。
-例如我们的接口限流每分钟处理 60 个请求,我们可以把 1 分钟分为 60 个窗口。每隔 1 秒移动一次,每个窗口一秒只能处理 不大于 `60(请求数)/60(窗口数)` 的请求, 如果当前窗口的请求计数总和超过了限制的数量的话就不再处理其他请求。
+例如我们的接口限流每分钟处理 60 个请求,我们可以把 1 分钟分为 60 个窗口。每隔 1 秒移动一次,每个窗口一秒只能处理不大于 `60(请求数)/60(窗口数)` 的请求, 如果当前窗口的请求计数总和超过了限制的数量的话就不再处理其他请求。
很显然, **当滑动窗口的格子划分的越多,滑动窗口的滚动就越平滑,限流的统计就会越精确。**
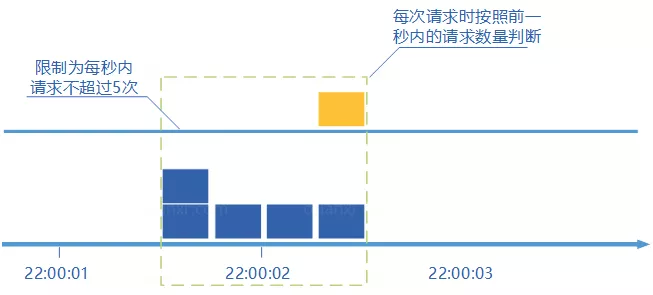
+优点:
+
+- 相比于固定窗口算法,滑动窗口计数器算法可以应对突然激增的流量。
+- 相比于固定窗口算法,滑动窗口计数器算法的颗粒度更小,可以提供更精确的限流控制。
+
+缺点:
+
+- 与固定窗口计数器算法类似,滑动窗口计数器算法依然存在限流不够平滑的问题。
+- 相比较于固定窗口计数器算法,滑动窗口计数器算法实现和理解起来更复杂一些。
+
### 漏桶算法
我们可以把发请求的动作比作成注水到桶中,我们处理请求的过程可以比喻为漏桶漏水。我们往桶中以任意速率流入水,以一定速率流出水。当水超过桶流量则丢弃,因为桶容量是不变的,保证了整体的速率。
@@ -51,12 +67,48 @@ category: 高可用
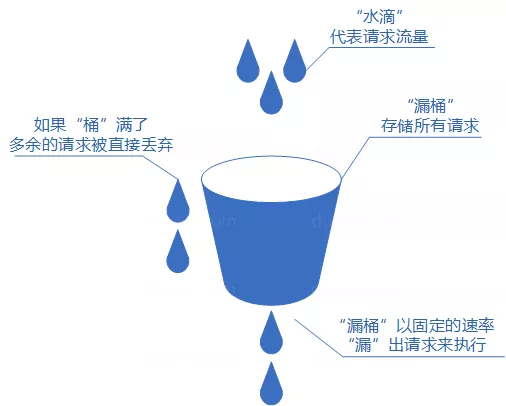
+优点:
+
+- 实现简单,易于理解。
+- 可以控制限流速率,避免网络拥塞和系统过载。
+
+缺点:
+
+- 无法应对突然激增的流量,因为只能以固定的速率处理请求,对系统资源利用不够友好。
+- 桶流入水(发请求)的速率如果一直大于桶流出水(处理请求)的速率的话,那么桶会一直是满的,一部分新的请求会被丢弃,导致服务质量下降。
+
+实际业务场景中,基本不会使用漏桶算法。
+
### 令牌桶算法
令牌桶算法也比较简单。和漏桶算法算法一样,我们的主角还是桶(这限流算法和桶过不去啊)。不过现在桶里装的是令牌了,请求在被处理之前需要拿到一个令牌,请求处理完毕之后将这个令牌丢弃(删除)。我们根据限流大小,按照一定的速率往桶里添加令牌。如果桶装满了,就不能继续往里面继续添加令牌了。
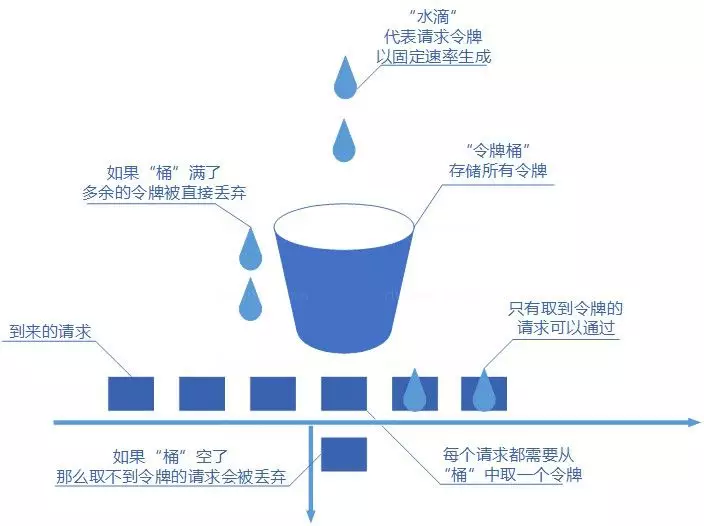
+优点:
+
+- 可以限制平均速率和应对突然激增的流量。
+- 可以动态调整生成令牌的速率。
+
+缺点:
+
+- 如果令牌产生速率和桶的容量设置不合理,可能会出现问题比如大量的请求被丢弃、系统过载。
+- 相比于其他限流算法,实现和理解起来更复杂一些。
+
+## 针对什么来进行限流?
+
+实际项目中,还需要确定限流对象,也就是针对什么来进行限流。常见的限流对象如下:
+
+- IP :针对 IP 进行限流,适用面较广,简单粗暴。
+- 业务 ID:挑选唯一的业务 ID 以实现更针对性地限流。例如,基于用户 ID 进行限流。
+- 个性化:根据用户的属性或行为,进行不同的限流策略。例如, VIP 用户不限流,而普通用户限流。根据系统的运行指标(如 QPS、并发调用数、系统负载等),动态调整限流策略。例如,当系统负载较高的时候,控制每秒通过的请求减少。
+
+针对 IP 进行限流是目前比较常用的一个方案。不过,实际应用中需要注意用户真实 IP 地址的正确获取。常用的真实 IP 获取方法有 X-Forwarded-For 和 TCP Options 字段承载真实源 IP 信息。虽然 X-Forwarded-For 字段可能会被伪造,但因为其实现简单方便,很多项目还是直接用的这种方法。
+
+除了我上面介绍到的限流对象之外,还有一些其他较为复杂的限流对象策略,比如阿里的 Sentinel 还支持 [基于调用关系的限流](https://github.com/alibaba/Sentinel/wiki/流量控制#基于调用关系的流量控制)(包括基于调用方限流、基于调用链入口限流、关联流量限流等)以及更细维度的 [热点参数限流](https://github.com/alibaba/Sentinel/wiki/热点参数限流)(实时的统计热点参数并针对热点参数的资源调用进行流量控制)。
+
+另外,一个项目可以根据具体的业务需求选择多种不同的限流对象搭配使用。
+
## 单机限流怎么做?
单机限流针对的是单体架构应用。
@@ -188,7 +240,7 @@ Resilience4j 不仅提供限流,还提供了熔断、负载保护、自动重
分布式限流常见的方案:
-- **借助中间件架限流**:可以借助 Sentinel 或者使用 Redis 来自己实现对应的限流逻辑。
+- **借助中间件限流**:可以借助 Sentinel 或者使用 Redis 来自己实现对应的限流逻辑。
- **网关层限流**:比较常用的一种方案,直接在网关层把限流给安排上了。不过,通常网关层限流通常也需要借助到中间件/框架。就比如 Spring Cloud Gateway 的分布式限流实现`RedisRateLimiter`就是基于 Redis+Lua 来实现的,再比如 Spring Cloud Gateway 还可以整合 Sentinel 来做限流。
如果你要基于 Redis 来手动实现限流逻辑的话,建议配合 Lua 脚本来做。
@@ -202,10 +254,46 @@ Resilience4j 不仅提供限流,还提供了熔断、负载保护、自动重
> ShenYu 地址:
-
+
+
+另外,如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的 `RRateLimiter` 来实现分布式限流,其底层实现就是基于 Lua 代码+令牌桶算法。
-## 相关阅读
+Redisson 是一个开源的 Java 语言 Redis 客户端,提供了很多开箱即用的功能,比如 Java 中常用的数据结构实现、分布式锁、延迟队列等等。并且,Redisson 还支持 Redis 单机、Redis Sentinel、Redis Cluster 等多种部署架构。
+
+`RRateLimiter` 的使用方式非常简单。我们首先需要获取一个`RRateLimiter`对象,直接通过 Redisson 客户端获取即可。然后,设置限流规则就好。
+
+```java
+// 创建一个 Redisson 客户端实例
+RedissonClient redissonClient = Redisson.create();
+// 获取一个名为 "javaguide.limiter" 的限流器对象
+RRateLimiter rateLimiter = redissonClient.getRateLimiter("javaguide.limiter");
+// 尝试设置限流器的速率为每小时 100 次
+// RateType 有两种,OVERALL是全局限流,ER_CLIENT是单Client限流(可以认为就是单机限流)
+rateLimiter.trySetRate(RateType.OVERALL, 100, 1, RateIntervalUnit.HOURS);
+```
+
+接下来我们调用`acquire()`方法或`tryAcquire()`方法即可获取许可。
+
+```java
+// 获取一个许可,如果超过限流器的速率则会等待
+// acquire()是同步方法,对应的异步方法:acquireAsync()
+rateLimiter.acquire(1);
+// 尝试在 5 秒内获取一个许可,如果成功则返回 true,否则返回 false
+// tryAcquire()是同步方法,对应的异步方法:tryAcquireAsync()
+boolean res = rateLimiter.tryAcquire(1, 5, TimeUnit.SECONDS);
+```
+
+## 总结
+
+这篇文章主要介绍了常见的限流算法、限流对象的选择以及单机限流和分布式限流分别应该怎么做。
+
+## 参考
- 服务治理之轻量级熔断框架 Resilience4j:
- 超详细的 Guava RateLimiter 限流原理解析:
- 实战 Spring Cloud Gateway 之限流篇 👍:
+- 详解 Redisson 分布式限流的实现原理:
+- 一文详解 Java 限流接口实现 - 阿里云开发者:
+- 分布式限流方案的探索与实践 - 腾讯云开发者:
+
+
diff --git a/docs/high-availability/performance-test.md b/docs/high-availability/performance-test.md
index e6e9f9d1f03..0cccfec6a91 100644
--- a/docs/high-availability/performance-test.md
+++ b/docs/high-availability/performance-test.md
@@ -1,149 +1,251 @@
---
title: 性能测试入门
+description: 本文系统讲解性能测试核心知识,涵盖响应时间分位值(P90/P99/P999)、QPS/TPS、Little's Law 与曲棍球棒曲线、背压与自愈验证、性能测试分类(负载/压力/稳定性)、压测工具(JMeter/Gatling/ab)选型及性能优化策略。
category: 高可用
+icon: et-performance
+head:
+ - - meta
+ - name: keywords
+ content: 性能测试,压力测试,负载测试,QPS,TPS,RT响应时间,P99分位值,并发数,吞吐量,背压,利特尔法则,JMeter,Gatling,性能优化
---
性能测试一般情况下都是由测试这个职位去做的,那还需要我们开发学这个干嘛呢?了解性能测试的指标、分类以及工具等知识有助于我们更好地去写出性能更好的程序,另外作为开发这个角色,如果你会性能测试的话,相信也会为你的履历加分不少。
这篇文章是我会结合自己的实际经历以及在测试这里取的经所得,除此之外,我还借鉴了一些优秀书籍,希望对你有帮助。
-## 一 不同角色看网站性能
+## 不同角色看网站性能
-### 1.1 用户
+### 用户
-当用户打开一个网站的时候,最关注的是什么?当然是网站响应速度的快慢。比如我们点击了淘宝的主页,淘宝需要多久将首页的内容呈现在我的面前,我点击了提交订单按钮需要多久返回结果等等。
+当用户打开一个网站的时候,最关注的是什么?当然是 **网站响应速度的快慢**。比如我们点击了淘宝的主页,淘宝需要多久将首页的内容呈现在我的面前,我点击了提交订单按钮需要多久返回结果等等。
所以,用户在体验我们系统的时候往往根据你的响应速度的快慢来评判你的网站的性能。
-### 1.2 开发人员
+### 开发人员
-用户与开发人员都关注速度,这个速度实际上就是我们的系统**处理用户请求的速度**。
+用户与开发人员都关注速度,这个速度实际上就是我们的系统 **处理用户请求的速度**。
-开发人员一般情况下很难直观的去评判自己网站的性能,我们往往会根据网站当前的架构以及基础设施情况给一个大概的值,比如:
+开发人员一般情况下很难直观的去评判自己网站的性能,我们往往会根据网站当前的架构以及基础设施情况给一个大概的值,比如:
1. 项目架构是分布式的吗?
2. 用到了缓存和消息队列没有?
3. 高并发的业务有没有特殊处理?
4. 数据库设计是否合理?
5. 系统用到的算法是否还需要优化?
-6. 系统是否存在内存泄露的问题?
+6. 系统是否存在内存泄漏的问题?
7. 项目使用的 Redis 缓存多大?服务器性能如何?用的是机械硬盘还是固态硬盘?
-8. ......
+8. ……
-### 1.3 测试人员
+### 测试人员
测试人员一般会根据性能测试工具来测试,然后一般会做出一个表格。这个表格可能会涵盖下面这些重要的内容:
1. 响应时间;
2. 请求成功率;
3. 吞吐量;
-4. ......
+4. ……
-### 1.4 运维人员
+### 运维人员
-运维人员会倾向于根据基础设施和资源的利用率来判断网站的性能,比如我们的服务器资源使用是否合理、数据库资源是否存在滥用的情况、当然,这是传统的运维人员,现在 Devops 火起来后,单纯干运维的很少了。我们这里暂且还保留有这个角色。
+运维人员会倾向于根据 **基础设施和资源的利用率** 来判断网站的性能,比如我们的服务器资源使用是否合理、数据库资源是否存在滥用的情况、当然,这是传统的运维人员,现在 Devops 火起来后,单纯干运维的很少了。我们这里暂且还保留有这个角色。
-## 二 性能测试需要注意的点
+## 性能测试需要注意的点
几乎没有文章在讲性能测试的时候提到这个问题,大家都会讲如何去性能测试,有哪些性能测试指标这些东西。
-### 2.1 了解系统的业务场景
+### 了解系统的业务场景
-**性能测试之前更需要你了解当前的系统的业务场景。** 对系统业务了解的不够深刻,我们很容易犯测试方向偏执的错误,从而导致我们忽略了对系统某些更需要性能测试的地方进行测试。比如我们的系统可以为用户提供发送邮件的功能,用户配置成功邮箱后只需输入相应的邮箱之后就能发送,系统每天大概能处理上万次发邮件的请求。很多人看到这个可能就直接开始使用相关工具测试邮箱发送接口,但是,发送邮件这个场景可能不是当前系统的性能瓶颈,这么多人用我们的系统发邮件, 还可能有很多人一起发邮件,单单这个场景就这么人用,那用户管理可能才是性能瓶颈吧!
+**性能测试之前更需要你了解当前的系统的业务场景。** 对系统业务了解的不够深刻,我们很容易犯测试方向偏执的错误,从而导致我们忽略了对系统某些更需要性能测试的地方进行测试。
-### 2.2 历史数据非常有用
+比如我们的系统可以为用户提供发送邮件的功能,用户配置成功邮箱后只需输入相应的邮箱之后就能发送,系统每天大概能处理上万次发邮件的请求。很多人看到这个可能就直接开始使用相关工具测试邮箱发送接口,但是,发送邮件这个场景可能不是当前系统的性能瓶颈,这么多人用我们的系统发邮件,还可能有很多人一起发邮件,单单这个场景就这么人用,那用户管理可能才是性能瓶颈吧!
-当前系统所留下的历史数据非常重要,一般情况下,我们可以通过相应的些历史数据初步判定这个系统哪些接口调用的比较多、哪些 service 承受的压力最大,这样的话,我们就可以针对这些地方进行更细致的性能测试与分析。
+### 历史数据非常有用
+
+当前系统所留下的历史数据非常重要,一般情况下,我们可以通过相应的些历史数据初步判定这个系统哪些接口调用的比较多、哪些服务承受的压力最大,这样的话,我们就可以针对这些地方进行更细致的性能测试与分析。
另外,这些地方也就像这个系统的一个短板一样,优化好了这些地方会为我们的系统带来质的提升。
-### 三 性能测试的指标
+## 常见性能指标
+
+性能指标是衡量系统性能的核心度量标准,理解各指标之间的关系对于性能分析至关重要。
+
+```mermaid
+flowchart LR
+ subgraph Input["输入参数"]
+ style Input fill:#F5F7FA,color:#333333,stroke:#005D7B,stroke-width:2px
+ A["并发数
Concurrency"]
+ end
+
+ subgraph Process["处理过程"]
+ style Process fill:#F5F7FA,color:#333333,stroke:#005D7B,stroke-width:2px
+ B["响应时间
RT"]
+ end
+
+ subgraph Output["输出指标"]
+ style Output fill:#F5F7FA,color:#333333,stroke:#005D7B,stroke-width:2px
+ C["QPS/TPS
吞吐量"]
+ end
+
+ A -->|"请求"| B
+ B -->|"计算"| C
+
+ D["QPS = 并发数 / RT"]
+
+ classDef core fill:#4CA497,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef process fill:#00838F,color:#FFFFFF,stroke:none,rx:10,ry:10
+ classDef highlight fill:#E99151,color:#FFFFFF,stroke:none,rx:10,ry:10
+
+ class A core
+ class B process
+ class C,D highlight
+
+ linkStyle default stroke-width:2px,stroke:#333333,opacity:0.8
+```
+
+### 响应时间
+
+**响应时间 RT(Response Time)** 是用户发出请求到收到系统处理结果所需的时间,包括网络传输、服务端处理与客户端渲染等环节。
+
+**响应时间指标(Latency Percentiles)**:生产环境中看平均 RT 毫无意义,必须监控 **P90、P99 和 P999** 分位值。例如 P99 = 500ms 意味着 99% 的请求在 500ms 内返回。那 1% 的长尾慢调用(可能由 Cache Miss、慢 SQL 或 GC STW 引起)在极高并发下会发生排队效应,瞬间打满网关或 RPC 框架的底层工作线程池,直接引发雪崩。大量超快响应会拉低平均值,掩盖致命的长尾问题,此为典型的 **"均值陷阱"**。
+
+分位值参考标准如下:
-### 3.1 响应时间
+| 分位值 | RT 范围(示例) | 说明 |
+| ------ | --------------- | ------------------------ |
+| P90 | < 200ms | 90% 的请求在此时间内返回 |
+| P99 | < 500ms | 重点关注,长尾用户体感 |
+| P999 | < 1s | 极端场景,易触发雪崩 |
-**响应时间就是用户发出请求到用户收到系统处理结果所需要的时间。** 重要吗?实在太重要!
+> **失败模式**:当发生网络偶发抖动时,P999 RT 会急剧飙升。若上游缺乏超时截断机制(Timeout & Circuit Breaking),大量并发请求将被挂起,导致上游节点内存 OOM。
-比较出名的 2-5-8 原则是这样描述的:通常来说,2 到 5 秒,页面体验会比较好,5 到 8 秒还可以接受,8 秒以上基本就很难接受了。另外,据统计当网站慢一秒就会流失十分之一的客户。
+### 并发数
-但是,在某些场景下我们也并不需要太看重 2-5-8 原则 ,比如我觉得系统导出导入大数据量这种就不需要,系统生成系统报告这种也不需要。
+**并发数可以简单理解为系统能够同时供多少人访问使用,也就是说系统同时能处理的请求数量。**
-### 3.2 并发数
+并发数反应了系统的 **负载能力**。需要注意区分以下概念:
-**并发数是系统能同时处理请求的数目即同时提交请求的用户数目。**
+- **并发用户数**:同时在线的用户数量。
+- **并发请求数**:同一时刻系统正在处理的请求数量。
+- **最大并发数**:系统能够承受的最大并发请求数,超过此值系统可能出现性能下降或崩溃。
-不得不说,高并发是现在后端架构中非常非常火热的一个词了,这个与当前的互联网环境以及中国整体的互联网用户量都有很大关系。一般情况下,你的系统并发量越大,说明你的产品做的就越大。但是,并不是每个系统都需要达到像淘宝、12306 这种亿级并发量的。
+### QPS 和 TPS
-### 3.3 吞吐量
+- **QPS(Query Per Second)**:服务器每秒可执行的查询次数;
+- **TPS(Transaction Per Second)**:服务器每秒处理的事务数(一次完整业务操作)。
-吞吐量指的是系统单位时间内系统处理的请求数量。衡量吞吐量有几个重要的参数:QPS(TPS)、并发数、响应时间。
+> QPS vs TPS:一次页面访问形成 1 个 TPS,但可能产生多次对服务器的请求(计入 QPS)。**TPS 偏向业务视角,QPS 偏向技术视角。**
-1. QPS(Query Per Second):服务器每秒可以执行的查询次数;
-2. TPS(Transaction Per Second):服务器每秒处理的事务数(这里的一个事务可以理解为客户发出请求到收到服务器的过程);
-3. 并发数;系统能同时处理请求的数目即同时提交请求的用户数目。
-4. 响应时间:一般取多次请求的平均响应时间
+### 吞吐量
-理清他们的概念,就很容易搞清楚他们之间的关系了。
+**吞吐量** 指系统单位时间内处理的请求数量。TPS、QPS 是常用量化指标。
-- **QPS(TPS)** = 并发数/平均响应时间
-- **并发数** = QPS\*平均响应时间
+**Little's Law(利特尔法则)**:在系统未饱和的稳态下,`并发数 = QPS × RT`,亦即 `QPS = 并发数 / RT`。该公式仅在系统处于线性响应区间时成立。随着并发用户数持续增加,CPU 调度消耗、锁争用(Lock Contention)加剧,RT 会呈现 **指数级上升**,吞吐量达到拐点后急速下降,形成典型的 **"曲棍球棒曲线"(Hockey Stick Curve)**。下图直观展示「为什么不能用公式硬算」:拐点之后 QPS 不升反降,系统已进入非线性区。
-书中是这样描述 QPS 和 TPS 的区别的。
+```mermaid
+xychart-beta
+ title "QPS vs 并发数(曲棍球棒曲线)"
+ x-axis "并发数" [200, 500, 1000, 1500, 2000, 2500, 3000, 3500, 4000]
+ y-axis "QPS" 0 --> 5000
+ line [1200, 2800, 4200, 4800, 5000, 4750, 3800, 2400, 1200]
+```
-> QPS vs TPS:QPS 基本类似于 TPS,但是不同的是,对于一个页面的一次访问,形成一个 TPS;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“QPS”之中。如,访问一个页面会请求服务器 2 次,一次访问,产生一个“T”,产生 2 个“Q”。
+因此,绝不能仅靠公式推算生产容量,必须通过全链路压测验证真实极限。
-### 3.4 性能计数器
+## 系统活跃度指标
-**性能计数器是描述服务器或者操作系统的一些数据指标如内存使用、CPU 使用、磁盘与网络 I/O 等情况。**
+### PV(Page View)
-### 四 几种常见的性能测试
+**访问量**,即页面浏览量或点击量,衡量网站用户访问的网页数量;在一定统计周期内用户每打开或刷新一个页面就记录 1 次,多次打开或刷新同一页面则浏览量累计。PV 从网页打开的数量/刷新的次数的角度来统计的。
+
+### UV(Unique Visitor)
+
+**独立访客**,统计 1 天内访问某站点的用户数。1 天内相同访客多次访问网站,只计算为 1 个独立访客。UV 是从用户个体的角度来统计的。
+
+### DAU(Daily Active User)
+
+**日活跃用户数量**,指一天内登录或使用产品的用户数(去重)。
+
+### MAU(Monthly Active Users)
+
+**月活跃用户人数**,指一个月内登录或使用产品的用户数(去重)。
+
+### 实战计算示例
+
+> **生产级容量评估**:绝不能用 DAU 乘以固定系数去估算峰值。真实峰值往往来自特定业务场景(如整点秒杀、大促开抢)。随着并发用户数(Virtual Users)持续增加,系统 CPU 调度消耗、锁争用加剧,RT 会呈现指数级上升,此时吞吐量会达到拐点并急速下降。必须通过 **全链路压测**(结合真实流量录制与回放,如 [GoReplay](https://goreplay.org/))来摸底真实的吞吐量极限,而非纸上公式推算。
+
+## 性能测试分类
+
+| 测试类型 | 目的 | 测试方法 |
+| -------------- | -------------------------- | --------------------------------------- |
+| **性能测试** | 验证系统性能是否满足预期 | 在已知性能指标下验证 |
+| **负载测试** | 找到系统的性能上限 | 逐步加压直到资源饱和 |
+| **压力测试** | 测试极限、背压与自愈能力 | 持续加压验证崩溃后行为(429/503、自愈) |
+| **稳定性测试** | 验证系统长时间运行的稳定性 | 模拟真实场景持续运行 |
+
+**负载测试 vs 压力测试的水位边界**:二者区别在于「加压到哪里为止」。下图帮助建立直观水位线:负载测试在**资源饱和线**止步(找到上限);压力测试继续加压**越过饱和线**,直到崩溃并验证背压与自愈。
### 性能测试
性能测试方法是通过测试工具模拟用户请求系统,目的主要是为了测试系统的性能是否满足要求。通俗地说,这种方法就是要在特定的运行条件下验证系统的能力状态。
-性能测试是你在对系统性能已经有了解的前提之后进行的,并且有明确的性能指标。
+性能测试是你在 **对系统性能已经有了解的前提之后** 进行的,并且有明确的性能指标。
### 负载测试
对被测试的系统继续加大请求压力,直到服务器的某个资源已经达到饱和了,比如系统的缓存已经不够用了或者系统的响应时间已经不满足要求了。
-负载测试说白点就是测试系统的上限。
+**负载测试说白点就是测试系统的上限。**
### 压力测试
-不去管系统资源的使用情况,对系统继续加大请求压力,直到服务器崩溃无法再继续提供服务。
+不去管系统资源的使用情况,对系统持续加大请求压力,**直到系统崩溃**。压力测试的核心目的不仅是寻找崩溃点,更是验证系统在过载状态下的 **背压(Backpressure)容错性**。当并发数超越承载极限时,必须验证系统能否主动阻断流量(如返回 HTTP 429 Too Many Requests、503 Service Unavailable),避免节点假死。同时,需验证在撤除越线流量后,系统是否能自动释放挂起的连接并恢复至正常吞吐能力(**自愈性**)。这种"崩溃后行为"的验证是混沌工程与高可用架构的最佳实践。
### 稳定性测试
-模拟真实场景,给系统一定压力,看看业务是否能稳定运行。
+模拟真实场景,给系统一定压力,看看业务是否能稳定运行。稳定性测试通常需要运行较长时间(如 7×24 小时),观察系统是否存在 **内存泄漏、连接泄漏** 等问题。
+
+## 常用性能测试工具
+
+### 后端常用
+
+既然系统设计涉及到系统性能方面的问题,那在面试的时候,面试官就很可能会问:**你是如何进行性能测试的?**
-## 五 常用性能测试工具
+推荐 4 个比较常用的性能测试工具:
-这里就不多扩展了,有时间的话会单独拎一个熟悉的说一下。
+| 工具 | 开发语言 | 特点 | 适用场景 |
+| -------------- | -------- | ------------------------------------- | ------------------------ |
+| **JMeter** | Java | 功能全面,支持 GUI 和命令行,插件丰富 | 复杂场景测试、企业级应用 |
+| **Gatling** | Scala | 基于 Akka,代码驱动,报告美观 | 高并发场景、CI/CD 集成 |
+| **ab** | C | 轻量简单,Apache 自带 | 快速接口测试、基准测试 |
+| **LoadRunner** | - | 商业软件,功能强大 | 企业级大规模测试 |
-### 5.1 后端常用
+没记错的话,除了 **LoadRunner** 其他几款性能测试工具都是开源免费的。
-没记错的话,除了 LoadRunner 其他几款性能测试工具都是开源免费的。
+**选型建议:**
-1. Jmeter:Apache JMeter 是 JAVA 开发的性能测试工具。
-2. LoadRunner:一款商业的性能测试工具。
-3. Galtling:一款基于 Scala 开发的高性能服务器性能测试工具。
-4. ab:全称为 Apache Bench 。Apache 旗下的一款测试工具,非常实用。
+- **快速验证**:使用 `ab` 或 `wrk` 进行简单的接口压测。
+- **复杂场景**:使用 `JMeter`,支持录制脚本、参数化、断言等功能。
+- **代码驱动**:使用 `Gatling`,适合开发人员,易于版本控制和 CI 集成。
-### 5.2 前端常用
+### 前端常用
-1. Fiddler:抓包工具,它可以修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是 Web 调试的利器。
-2. HttpWatch: 可用于录制 HTTP 请求信息的工具。
+1. **Fiddler**:抓包工具,它可以修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是 Web 调试的利器。
+2. **HttpWatch**:可用于录制 HTTP 请求信息的工具。
-## 六 常见的性能优化策略
+## 常见的性能优化策略
性能优化之前我们需要对请求经历的各个环节进行分析,排查出可能出现性能瓶颈的地方,定位问题。
下面是一些性能优化时,我经常拿来自问的一些问题:
-1. 系统是否需要缓存?
-2. 系统架构本身是不是就有问题?
-3. 系统是否存在死锁的地方?
-4. 系统是否存在内存泄漏?(Java 的自动回收内存虽然很方便,但是,有时候代码写的不好真的会造成内存泄漏)
-5. 数据库索引使用是否合理?
-6. ......
+| 优化方向 | 检查项 |
+| ---------- | -------------------------------------------------------- |
+| **缓存** | 系统是否需要缓存?热点数据是否已缓存? |
+| **架构** | 系统架构本身是不是就有问题?是否需要读写分离、分库分表? |
+| **并发** | 系统是否存在死锁的地方?锁的粒度是否合理? |
+| **内存** | 系统是否存在内存泄漏?GC 是否频繁? |
+| **数据库** | 数据库索引使用是否合理?是否存在慢 SQL? |
+| **算法** | 核心算法的时间复杂度是否可以优化? |
+| **IO** | 是否存在不必要的网络调用?是否可以批量操作? |
+
+
diff --git a/docs/high-availability/redundancy.md b/docs/high-availability/redundancy.md
index 71b86b46f72..25b088bad36 100644
--- a/docs/high-availability/redundancy.md
+++ b/docs/high-availability/redundancy.md
@@ -1,44 +1,197 @@
---
title: 冗余设计详解
+description: 本文系统讲解冗余设计核心知识,涵盖冗余类型(硬件/软件/数据/服务冗余)、RTO/RPO 指标、高可用集群(主备/主主模式)、同城灾备、异地灾备、同城多活、异地多活架构对比及故障转移机制,助力高可用架构设计与面试。
category: 高可用
+icon: cluster
+head:
+ - - meta
+ - name: keywords
+ content: 冗余设计,高可用集群,同城灾备,异地灾备,同城多活,异地多活,故障转移,RTO,RPO,容灾架构
---
-冗余设计是保证系统和数据高可用的最常的手段。
+## 什么是冗余?
-对于服务来说,冗余的思想就是相同的服务部署多份,如果正在使用的服务突然挂掉的话,系统可以很快切换到备份服务上,大大减少系统的不可用时间,提高系统的可用性。
+**冗余(Redundancy)** 是保证系统和数据高可用的最常用手段,其核心思想是 **通过部署多份相同的资源,当某一份资源出现故障时,其他资源可以接管其工作,从而保证系统的持续可用**。
-对于数据来说,冗余的思想就是相同的数据备份多份,这样就可以很简单地提高数据的安全性。
+冗余设计可以从以下几个维度来理解:
-实际上,日常生活中就有非常多的冗余思想的应用。
+| 冗余类型 | 说明 | 典型实现 |
+| ------------ | ---------------------- | -------------------------------- |
+| **硬件冗余** | 关键硬件设备部署多份 | 双电源、双网卡、RAID 磁盘阵列 |
+| **软件冗余** | 应用服务部署多个实例 | 集群部署、容器化多副本 |
+| **数据冗余** | 数据存储多份副本 | 数据库主从复制、分布式存储多副本 |
+| **网络冗余** | 网络链路和设备冗余 | 多运营商接入、双活负载均衡 |
+| **地域冗余** | 在不同地理位置部署系统 | 同城灾备、异地多活 |
-拿我自己来说,我对于重要文件的保存方法就是冗余思想的应用。我日常所使用的重要文件都会同步一份在 GitHub 以及个人云盘上,这样就可以保证即使电脑硬盘损坏,我也可以通过 GitHub 或者个人云盘找回自己的重要文件。
+对于 **服务** 来说,冗余的思想就是相同的服务部署多份,如果正在使用的服务突然挂掉的话,系统可以很快切换到备份服务上,大大减少系统的不可用时间,提高系统的可用性。
+
+对于 **数据** 来说,冗余的思想就是相同的数据备份多份,这样就可以很简单地提高数据的安全性。
+
+实际上,日常生活中就有非常多的冗余思想的应用。拿我自己来说,我对于重要文件的保存方法就是冗余思想的应用。我日常所使用的重要文件都会同步一份在 GitHub 以及个人云盘上,这样就可以保证即使电脑硬盘损坏,我也可以通过 GitHub 或者个人云盘找回自己的重要文件。
+
+## 容灾核心指标:RTO 和 RPO
+
+在讨论容灾架构之前,需要先理解两个核心指标:
+
+```mermaid
+flowchart TB
+ subgraph Timeline["时间线"]
+ direction LR
+ A["上次备份"] --> B["故障发生"] --> C["系统恢复"]
+ end
+ A -.->|"数据丢失窗口(RPO)"| B
+ B -.->|"恢复时间窗口(RTO)"| C
+
+ classDef core fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef highlight fill:#E99151,color:#fff,rx:10,ry:10
+
+ class A,B,C core
+
+ style Timeline fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
+
+- **RPO(Recovery Point Objective,恢复点目标)**:可容忍的 **最大数据丢失量**,即从上次备份到故障发生之间的数据。RPO = 0 表示不允许丢失任何数据。
+- **RTO(Recovery Time Objective,恢复时间目标)**:可容忍的 **最大恢复时间**,即从故障发生到系统恢复正常服务的时间。RTO = 0 表示服务不能中断。
+
+| 架构方案 | RPO | RTO | 成本 |
+| ---------- | -------------- | ----------- | ---- |
+| 单机无备份 | 可能全部丢失 | 不可预估 | 低 |
+| 本地备份 | 取决于备份周期 | 小时级 | 低 |
+| 同城灾备 | 分钟级 | 分钟~小时级 | 中 |
+| 异地灾备 | 分钟~小时级 | 小时级 | 中高 |
+| 同城多活 | 秒级 | 秒级 | 高 |
+| 异地多活 | 秒级 | 秒级 | 很高 |
+
+## 冗余架构方案对比
高可用集群(High Availability Cluster,简称 HA Cluster)、同城灾备、异地灾备、同城多活和异地多活是冗余思想在高可用系统设计中最典型的应用。
-- **高可用集群** : 同一份服务部署两份或者多份,当正在使用的服务突然挂掉的话,可以切换到另外一台服务,从而保证服务的高可用。
-- **同城灾备**:一整个集群可以部署在同一个机房,而同城灾备中相同服务部署在同一个城市的不同机房中。并且,备用服务不处理请求。这样可以避免机房出现意外情况比如停电、火灾。
-- **异地灾备**:类似于同城灾备,不同的是,相同服务部署在异地(通常距离较远,甚至是在不同的城市或者国家)的不同机房中
-- **同城多活**:类似于同城灾备,但备用服务可以处理请求,这样可以充分利用系统资源,提高系统的并发。
-- **异地多活** : 将服务部署在异地的不同机房中,并且,它们可以同时对外提供服务。
+```mermaid
+flowchart TB
+ subgraph Grid["冗余架构方案对比"]
+ direction LR
+ style Grid fill:#F0F2F5,stroke:#E0E6ED,stroke-width:1.5px
+
+ subgraph HACluster["高可用集群"]
+ direction LR
+ style HACluster fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ A1["主节点"] --> A2["从节点"]
+ end
+
+ subgraph LocalDR["同城灾备"]
+ direction LR
+ style LocalDR fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ B1["主机房
(处理请求)"] -.->|"同步"| B2["备机房
(不处理请求)"]
+ end
+
+ subgraph RemoteDR["异地灾备"]
+ direction LR
+ style RemoteDR fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ C1["主机房
北京"] -.->|"异步同步"| C2["备机房
上海"]
+ end
+
+ subgraph LocalActive["同城多活"]
+ direction LR
+ style LocalActive fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ D1["机房A
(处理请求)"] <-->|"双向同步"| D2["机房B
(处理请求)"]
+ end
+
+ subgraph RemoteActive["异地多活"]
+ direction LR
+ style RemoteActive fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ E1["北京机房
(处理请求)"] <-->|"双向同步"| E2["上海机房
(处理请求)"]
+ end
+ end
+
+ classDef core fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef external fill:#005D7B,color:#fff,rx:10,ry:10
+
+ class A1,B1,C1,D1,D2,E1,E2 core
+ class A2,B2,C2 external
+
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
+
+### 高可用集群
+
+**高可用集群** 是指同一份服务部署两份或者多份,当正在使用的服务突然挂掉的话,可以切换到另外一台服务,从而保证服务的高可用。
+
+高可用集群有两种常见模式:
+
+| 模式 | 说明 | 优点 | 缺点 |
+| ------------------------------ | -------------------------- | ------------------------ | ------------------------------ |
+| **主备模式(Active-Standby)** | 主节点提供服务,备节点待命 | 实现简单,数据一致性好 | 资源利用率低,备节点闲置 |
+| **主主模式(Active-Active)** | 多个节点同时提供服务 | 资源利用率高,无单点故障 | 数据同步复杂,可能有一致性问题 |
+
+高可用集群单纯是服务的冗余,**并没有强调地域**。同城灾备、异地灾备、同城多活和异地多活实现了地域上的冗余。
+
+### 同城灾备
+
+**同城灾备** 是指一整个集群可以部署在同一个机房,而同城灾备中相同服务部署在 **同一个城市的不同机房** 中。并且,**备用服务不处理请求**。这样可以避免机房出现意外情况比如停电、火灾。
+
+- **适用场景**:对 RTO 要求较高(分钟级),成本有限的企业。
+- **典型配置**:两个机房距离 30~100 公里,通过专线连接。
+
+### 异地灾备
+
+**异地灾备** 类似于同城灾备,不同的是,相同服务部署在 **异地(通常距离较远,甚至是在不同的城市或者国家)的不同机房中**。
+
+- **适用场景**:需要防范区域性灾难(地震、洪水)的核心业务系统。
+- **挑战**:网络延迟较大,数据同步通常采用异步方式,可能存在数据丢失。
+
+### 同城多活
+
+**同城多活** 类似于同城灾备,但 **备用服务可以处理请求**,这样可以充分利用系统资源,提高系统的并发。
+
+- **适用场景**:对性能和可用性都有较高要求的系统。
+- **技术要点**:需要解决数据同步、流量调度、会话管理等问题。
+
+### 异地多活
+
+**异地多活** 将服务部署在 **异地的不同机房** 中,并且,它们可以 **同时对外提供服务**。
+
+和传统的灾备设计相比,同城多活和异地多活最明显的改变在于 **"多活"**,即所有站点都是同时在对外提供服务的。异地多活是为了应对突发状况比如火灾、地震等自然或者人为灾害。
+
+同城和异地的主要区别在于 **机房之间的距离**。异地通常距离较远,甚至是在不同的城市或者国家。
+
+## 故障转移机制
+
+光做好冗余还不够,必须要配合上 **故障转移(Failover)** 才可以!所谓故障转移,简单来说就是 **实现不可用服务快速且自动地切换到可用服务,整个过程不需要人为干涉**。
+
+故障转移通常包含以下几个步骤:
+
+1. **故障检测**:通过心跳检测、健康检查等机制发现故障节点。
+2. **故障确认**:避免误判,通常需要多次检测确认。
+3. **故障切换**:将流量切换到备用节点。
+4. **故障通知**:发送告警通知运维人员。
+5. **故障恢复**:故障节点恢复后重新加入集群。
-高可用集群单纯是服务的冗余,并没有强调地域。同城灾备、异地灾备、同城多活和异地多活实现了地域上的冗余。
+### Redis 哨兵模式示例
-同城和异地的主要区别在于机房之间的距离。异地通常距离较远,甚至是在不同的城市或者国家。
+哨兵模式的 Redis 集群中,如果 Sentinel(哨兵)检测到 master 节点出现故障的话,它就会帮助我们实现故障转移,自动将某一台 slave 升级为 master,确保整个 Redis 系统的可用性。整个过程完全自动,不需要人工介入。
-和传统的灾备设计相比,同城多活和异地多活最明显的改变在于“多活”,即所有站点都是同时在对外提供服务的。异地多活是为了应对突发状况比如火灾、地震等自然或者人为灾害。
+### Nginx + Keepalived 示例
-光做好冗余还不够,必须要配合上 **故障转移** 才可以! 所谓故障转移,简单来说就是实现不可用服务快速且自动地切换到可用服务,整个过程不需要人为干涉。
+Nginx 可以结合 Keepalived 来实现高可用。如果 Nginx 主服务器宕机的话,Keepalived 可以自动进行故障转移,备用 Nginx 主服务器升级为主服务。并且,这个切换对外是透明的,因为使用的 **虚拟 IP(VIP)**,虚拟 IP 不会改变。
-举个例子:哨兵模式的 Redis 集群中,如果 Sentinel(哨兵) 检测到 master 节点出现故障的话, 它就会帮助我们实现故障转移,自动将某一台 slave 升级为 master,确保整个 Redis 系统的可用性。整个过程完全自动,不需要人工介入。我在[《Java 面试指北》](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7)的「技术面试题篇」中的数据库部分详细介绍了 Redis 集群相关的知识点&面试题,感兴趣的小伙伴可以看看。
+## 异地多活的挑战
-再举个例子:Nginx 可以结合 Keepalived 来实现高可用。如果 Nginx 主服务器宕机的话,Keepalived 可以自动进行故障转移,备用 Nginx 主服务器升级为主服务。并且,这个切换对外是透明的,因为使用的虚拟 IP,虚拟 IP 不会改变。我在[《Java 面试指北》](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7)的「技术面试题篇」中的「服务器」部分详细介绍了 Nginx 相关的知识点&面试题,感兴趣的小伙伴可以看看。
+异地多活架构实施起来非常难,需要考虑的因素非常多:
-异地多活架构实施起来非常难,需要考虑的因素非常多。本人不才,实际项目中并没有实践过异地多活架构,我对其了解还停留在书本知识。
+| 挑战 | 说明 | 解决思路 |
+| -------------- | ------------------------------ | ------------------------ |
+| **数据一致性** | 多个机房数据如何保持一致 | 最终一致性、冲突解决机制 |
+| **网络延迟** | 异地机房之间网络延迟较大 | 就近接入、数据分区 |
+| **流量调度** | 如何将用户请求分配到合适的机房 | DNS 智能解析、GSLB |
+| **会话管理** | 用户会话如何在多机房之间共享 | 分布式会话、无状态设计 |
+| **成本** | 多机房建设和运维成本高 | 按业务重要性分级部署 |
-如果你想要深入学习异地多活相关的知识,我这里推荐几篇我觉得还不错的文章:
+如果你想要深入学习异地多活相关的知识,推荐以下资料:
-- [搞懂异地多活,看这篇就够了- 水滴与银弹 - 2021](https://mp.weixin.qq.com/s/T6mMDdtTfBuIiEowCpqu6Q)
+- [搞懂异地多活,看这篇就够了 - 水滴与银弹 - 2021](https://mp.weixin.qq.com/s/T6mMDdtTfBuIiEowCpqu6Q)
- [四步构建异地多活](https://mp.weixin.qq.com/s/hMD-IS__4JE5_nQhYPYSTg)
- [《从零开始学架构》— 28 | 业务高可用的保障:异地多活架构](http://gk.link/a/10pKZ)
-不过,这些文章大多也都是在介绍概念知识。目前,网上还缺少真正介绍具体要如何去实践落地异地多活架构的资料。
+
diff --git a/docs/high-availability/timeout-and-retry.md b/docs/high-availability/timeout-and-retry.md
index 2dc78454ac1..c2bcabe8144 100644
--- a/docs/high-availability/timeout-and-retry.md
+++ b/docs/high-availability/timeout-and-retry.md
@@ -1,6 +1,12 @@
---
title: 超时&重试详解
+description: 本文系统讲解超时与重试机制核心知识,涵盖连接超时/读取超时设置原则、重试策略对比(固定间隔/指数退避/抖动退避)、重试风险(重试风暴/雪崩效应)及规避方法、幂等性设计、Java 重试框架(Spring Retry/Resilience4j)选型,助力微服务高可用设计与面试。
category: 高可用
+icon: retry
+head:
+ - - meta
+ - name: keywords
+ content: 超时机制,重试机制,指数退避,重试风暴,幂等性,连接超时,读取超时,Spring Retry,Resilience4j,微服务高可用
---
由于网络问题、系统或者服务内部的 Bug、服务器宕机、操作系统崩溃等问题的不确定性,我们的系统或者服务永远不可能保证时刻都是可用的状态。
@@ -15,56 +21,181 @@ category: 高可用
### 什么是超时机制?
-超时机制说的是当一个请求超过指定的时间(比如 1s)还没有被处理的话,这个请求就会直接被取消并抛出指定的异常或者错误(比如 `504 Gateway Timeout`)。
+**超时机制** 说的是当一个请求超过指定的时间(比如 1s)还没有被处理的话,这个请求就会直接被取消并抛出指定的异常或者错误(比如 `504 Gateway Timeout`)。
我们平时接触到的超时可以简单分为下面 2 种:
-- **连接超时(ConnectTimeout)**:客户端与服务端建立连接的最长等待时间。
-- **读取超时(ReadTimeout)**:客户端和服务端已经建立连接,客户端等待服务端处理完请求的最长时间。实际项目中,我们关注比较多的还是读取超时。
+| 超时类型 | 说明 | 建议值 |
+| ------------------------------ | ---------------------------------------------------------- | --------------- |
+| **连接超时(ConnectTimeout)** | 客户端与服务端建立连接的最长等待时间 | 1000ms ~ 5000ms |
+| **读取超时(ReadTimeout)** | 客户端和服务端已建立连接后,等待服务端处理完请求的最长时间 | 1000ms ~ 3000ms |
-一些连接池客户端框架中可能还会有获取连接超时和空闲连接清理超时。
+实际项目中,我们关注比较多的还是 **读取超时**。一些连接池客户端框架中可能还会有 **获取连接超时** 和 **空闲连接清理超时**。
-如果没有设置超时的话,就可能会导致服务端连接数爆炸和大量请求堆积的问题。
+### 为什么需要超时机制?
+
+如果没有设置超时的话,就可能会导致 **服务端连接数爆炸** 和 **大量请求堆积** 的问题。
这些堆积的连接和请求会消耗系统资源,影响新收到的请求的处理。严重的情况下,甚至会拖垮整个系统或者服务。
-我之前在实际项目就遇到过类似的问题,整个网站无法正常处理请求,服务器负载直接快被拉满。后面发现原因是项目超时设置错误加上客户端请求处理异常,导致服务端连接数直接接近 40w+,这么多堆积的连接直接把系统干趴了。
+> 我之前在实际项目就遇到过类似的问题,整个网站无法正常处理请求,服务器负载直接快被拉满。后面发现原因是项目超时设置错误加上客户端请求处理异常,导致服务端连接数直接接近 40w+,这么多堆积的连接直接把系统干趴了。
### 超时时间应该如何设置?
-超时到底设置多长时间是一个难题!超时值设置太高或者太低都有风险。如果设置太高的话,会降低超时机制的有效性,比如你设置超时为 10s 的话,那设置超时就没啥意义了,系统依然可能会出现大量慢请求堆积的问题。如果设置太低的话,就可能会导致在系统或者服务在某些处理请求速度变慢的情况下(比如请求突然增多),大量请求重试(超时通常会结合重试)继续加重系统或者服务的压力,进而导致整个系统或者服务被拖垮的问题。
+超时到底设置多长时间是一个难题!**超时值设置太高或者太低都有风险**:
+
+| 设置方式 | 风险 |
+| ------------ | ------------------------------------------------------------------------------------ |
+| **设置太高** | 降低超时机制的有效性,系统依然可能出现大量慢请求堆积的问题 |
+| **设置太低** | 在系统处理速度变慢时(如请求突然增多),大量请求超时重试,加重系统压力,可能导致雪崩 |
-通常情况下,我们建议读取超时设置为 **1500ms** ,这是一个比较普适的值。如果你的系统或者服务对于延迟比较敏感的话,那读取超时值可以适当在 **1500ms** 的基础上进行缩短。反之,读取超时值也可以在 **1500ms** 的基础上进行加长,不过,尽量还是不要超过 **1500ms** 。连接超时可以适当设置长一些,建议在 **1000ms ~ 5000ms** 之内。
+通常情况下,我们建议:
-没有银弹!超时值具体该设置多大,还是要根据实际项目的需求和情况慢慢调整优化得到。
+- **读取超时**:设置为 **1500ms**,这是一个比较普适的值。如果系统对延迟比较敏感,可以适当缩短;反之也可以加长,但尽量不要超过 **3000ms**。
+- **连接超时**:可以适当设置长一些,建议在 **1000ms ~ 5000ms** 之内。
-更上一层,参考[美团的 Java 线程池参数动态配置](https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html)思想,我们也可以将超时弄成可配置化的参数而不是固定的,比较简单的一种办法就是将超时的值放在配置中心中。这样的话,我们就可以根据系统或者服务的状态动态调整超时值了。
+**没有银弹!** 超时值具体该设置多大,还是要根据实际项目的需求和情况慢慢调整优化得到。
+
+更上一层,参考 [美团的 Java 线程池参数动态配置](https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html) 思想,我们也可以将超时弄成 **可配置化的参数** 而不是固定的,比较简单的一种办法就是将超时的值放在配置中心中。这样的话,我们就可以根据系统或者服务的状态动态调整超时值了。
## 重试机制
### 什么是重试机制?
-重试机制一般配合超时机制一起使用,指的是多次发送相同的请求来避免瞬态故障和偶然性故障。
+**重试机制** 一般配合超时机制一起使用,指的是 **多次发送相同的请求来避免瞬态故障和偶然性故障**。
+
+- **瞬态故障**:某一瞬间系统偶然出现的故障,并不会持久。
+- **偶然性故障**:在某些情况下偶尔出现的故障,频率通常较低。
+
+重试的核心思想是 **通过消耗服务器的资源来尽可能获得请求更大概率被成功处理**。由于瞬态故障和偶然性故障是很少发生的,因此,重试对于服务器的资源消耗几乎是可以被忽略的。
+
+### 常见的重试策略有哪些?
+
+```mermaid
+flowchart TB
+ A["请求失败"] --> B{"是否可重试?"}
+ B -->|"否"| C["返回错误"]
+ B -->|"是"| D{"重试次数
是否超限?"}
+ D -->|"是"| C
+ D -->|"否"| E{"选择退避策略"}
+
+ E --> F["固定间隔"]
+ E --> G["线性退避"]
+ E --> H["指数退避"]
+ E --> I["指数退避+抖动"]
+
+ F --> J["等待固定时间"]
+ G --> K["等待 n × interval"]
+ H --> L["等待 2^n × interval"]
+ I --> M["等待 2^n × interval + random"]
+
+ J --> N["重试请求"]
+ K --> N
+ L --> N
+ M --> N
+
+ N --> O{"请求成功?"}
+ O -->|"是"| P["返回结果"]
+ O -->|"否"| D
+
+ classDef core fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef decision fill:#00838F,color:#fff,rx:10,ry:10
+ classDef alert fill:#C44545,color:#fff,rx:10,ry:10
+ classDef highlight fill:#E99151,color:#fff,rx:10,ry:10
+
+ class A,N core
+ class B,D,E,O decision
+ class C alert
+ class P highlight
+ class F,G,H,I,J,K,L,M core
+
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
+
+常见的重试策略对比如下:
-瞬态故障可以简单理解为某一瞬间系统偶然出现的故障,并不会持久。偶然性故障可以理解为哪些在某些情况下偶尔出现的故障,频率通常较低。
+| 策略 | 说明 | 优点 | 缺点 | 适用场景 |
+| ----------------- | --------------------------------- | ---------------------- | ---------------- | ------------------------------ |
+| **固定间隔重试** | 每次重试间隔相同(如每隔 1s) | 实现简单 | 可能造成重试风暴 | 目标系统恢复时间稳定可预测 |
+| **线性退避重试** | 间隔线性增长(如 1s、2s、3s) | 比固定间隔更温和 | 增长速度较慢 | 一般场景 |
+| **指数退避重试** | 间隔指数增长(如 1s、2s、4s、8s) | 能有效避免重试风暴 | 等待时间可能过长 | 目标系统恢复时间较长或不可预测 |
+| **指数退避+抖动** | 指数退避基础上加随机抖动 | 避免多个客户端同时重试 | 实现稍复杂 | 分布式系统推荐 |
-重试的核心思想是通过消耗服务器的资源来尽可能获得请求更大概率被成功处理。由于瞬态故障和偶然性故障是很少发生的,因此,重试对于服务器的资源消耗几乎是可以被忽略的。
+**大部分情况下,我们更建议使用指数退避+抖动策略**,可以有效避免重试风暴。
### 重试的次数如何设置?
重试的次数不宜过多,否则依然会对系统负载造成比较大的压力。
-重试的次数通常建议设为 3 次。并且,我们通常还会设置重试的间隔,比如说我们要重试 3 次的话,第 1 次请求失败后,等待 1 秒再进行重试,第 2 次请求失败后,等待 2 秒再进行重试,第 3 次请求失败后,等待 3 秒再进行重试。
+**重试的次数通常建议设为 3 次**。比如说我们要重试 3 次的话:
-### 重试幂等
+- 第 1 次请求失败后,等待 1 秒再进行重试
+- 第 2 次请求失败后,等待 2 秒再进行重试
+- 第 3 次请求失败后,等待 4 秒再进行重试
-超时和重试机制在实际项目中使用的话,需要注意保证同一个请求没有被多次执行。
+### 重试的风险有哪些?
+
+重试机制虽然能提高系统的可用性,但使用不当也会带来风险:
+
+| 风险 | 说明 | 规避方法 |
+| ------------ | -------------------------------------------- | ---------------------------- |
+| **重试风暴** | 大量客户端同时重试,进一步压垮下游服务 | 使用指数退避+抖动策略 |
+| **雪崩效应** | 重试导致上游服务也开始超时重试,形成连锁反应 | 设置重试预算、熔断机制 |
+| **重复操作** | 非幂等操作被重复执行,导致数据不一致 | 确保操作幂等性 |
+| **资源浪费** | 对永久性故障进行无意义的重试 | 区分可重试错误和不可重试错误 |
+
+**重试预算(Retry Budget)** 是一种有效的规避策略:限制在一定时间窗口内的重试次数占总请求数的比例,如不超过 10%。
+
+### 什么是重试幂等?
+
+超时和重试机制在实际项目中使用的话,需要注意保证 **同一个请求没有被多次执行**。
什么情况下会出现一个请求被多次执行呢?客户端等待服务端完成请求完成超时但此时服务端已经执行了请求,只是由于短暂的网络波动导致响应在发送给客户端的过程中延迟了。
-举个例子:用户支付购买某个课程,结果用户支付的请求由于重试的问题导致用户购买同一门课程支付了两次。对于这种情况,我们在执行用户购买课程的请求的时候需要判断一下用户是否已经购买过。这样的话,就不会因为重试的问题导致重复购买了。
+> 举个例子:用户支付购买某个课程,结果用户支付的请求由于重试的问题导致用户购买同一门课程支付了两次。对于这种情况,我们在执行用户购买课程的请求的时候需要判断一下用户是否已经购买过。这样的话,就不会因为重试的问题导致重复购买了。
+
+实现幂等的常见方法:
+
+| 方法 | 说明 | 适用场景 |
+| ------------------ | -------------------------------------- | ---------------- |
+| **唯一请求 ID** | 每个请求携带唯一 ID,服务端去重 | 通用场景 |
+| **数据库唯一约束** | 利用数据库唯一索引防止重复插入 | 创建类操作 |
+| **乐观锁** | 通过版本号控制更新 | 更新类操作 |
+| **状态机** | 通过状态流转控制,已处理的状态不再处理 | 订单、支付等场景 |
+
+### Java 中如何实现重试?
+
+如果要手动编写代码实现重试逻辑的话,可以通过循环(例如 while 或 for 循环)或者递归实现。不过,一般不建议自己动手实现,有很多第三方开源库提供了更完善的重试机制实现:
+
+| 框架 | 特点 | 适用场景 |
+| ------------------ | ------------------------------------ | -------------------- |
+| **Spring Retry** | Spring 生态,注解驱动,配置简单 | Spring 项目 |
+| **Resilience4j** | 轻量级,函数式风格,支持熔断、限流等 | 微服务项目 |
+| **Guava Retrying** | 灵活的重试策略配置 | 通用 Java 项目 |
+| **Failsafe** | 支持异步重试、超时、熔断等 | 需要细粒度控制的场景 |
+
+使用 Spring Retry 的简单示例:
+
+```java
+@Retryable(
+ value = {RemoteAccessException.class},
+ maxAttempts = 3,
+ backoff = @Backoff(delay = 1000, multiplier = 2)
+)
+public String callRemoteService() {
+ // 调用远程服务
+}
+
+@Recover
+public String recover(RemoteAccessException e) {
+ // 重试失败后的兜底逻辑
+ return "fallback";
+}
+```
## 参考
- 微服务之间调用超时的设置治理:
- 超时、重试和抖动回退:
+
+
diff --git a/docs/high-performance/cdn.md b/docs/high-performance/cdn.md
index c5ffc53bd41..d16d2f0e46b 100644
--- a/docs/high-performance/cdn.md
+++ b/docs/high-performance/cdn.md
@@ -1,13 +1,11 @@
---
-title: CDN常见问题总结
+title: CDN工作原理详解
+description: 本文详解 CDN(内容分发网络)的核心原理,涵盖 GSLB 全局负载均衡调度机制、CDN 缓存策略(预热/回源/刷新)、命中率与回源率优化,以及 Referer 防盗链与时间戳防盗链等安全机制,帮助你全面掌握 CDN 加速技术。
category: 高性能
head:
- - meta
- name: keywords
- content: CDN,内容分发网络
- - - meta
- - name: description
- content: CDN 就是将静态资源分发到多个不同的地方以实现就近访问,进而加快静态资源的访问速度,减轻服务器以及带宽的负担。
+ content: CDN,内容分发网络,GSLB,CDN缓存,CDN回源,CDN预热,防盗链,时间戳防盗链,静态资源加速
---
## 什么是 CDN ?
@@ -16,35 +14,41 @@ head:
我们可以将内容分发网络拆开来看:
-- 内容:指的是静态资源比如图片、视频、文档、JS、CSS、HTML。
-- 分发网络:指的是将这些静态资源分发到位于多个不同的地理位置机房中的服务器上,这样,就可以实现静态资源的就近访问比如北京的用户直接访问北京机房的数据。
+- **内容**:指的是静态资源,包括图片、视频、文档、JS、CSS、HTML 等。
+- **分发网络**:指的是将这些静态资源分发到位于多个不同地理位置机房中的服务器上,从而实现**就近访问**——例如北京的用户直接访问北京机房的数据。
-所以,简单来说,**CDN 就是将静态资源分发到多个不同的地方以实现就近访问,进而加快静态资源的访问速度,减轻服务器以及带宽的负担。**
+简单来说,**CDN 就是将静态资源分发到多个不同的地方以实现就近访问,进而加快静态资源的访问速度,减轻源站服务器以及带宽的负担。**
-类似于京东建立的庞大的仓储运输体系,京东物流在全国拥有非常多的仓库,仓储网络几乎覆盖全国所有区县。这样的话,用户下单的第一时间,商品就从距离用户最近的仓库,直接发往对应的配送站,再由京东小哥送到你家。
+类似于京东建立的庞大仓储运输体系,京东物流在全国拥有非常多的仓库,仓储网络几乎覆盖全国所有区县。这样的话,用户下单的第一时间,商品就从距离用户最近的仓库直接发往对应的配送站,再由京东小哥送到你家。
-你可以将 CDN 看作是服务上一层的特殊缓存服务,分布在全国各地,主要用来处理静态资源的请求。
+你可以将 CDN 看作是服务上一层的**特殊缓存服务**,分布在全国各地,主要用来处理静态资源的请求。

-我们经常拿全站加速和内容分发网络做对比,不要把两者搞混了!全站加速(不同云服务商叫法不同,腾讯云叫 ECDN、阿里云叫 DCDN)既可以加速静态资源又可以加速动态资源,内容分发网络(CDN)主要针对的是 **静态资源** 。
+我们经常拿全站加速和内容分发网络做对比,不要把两者搞混了!**全站加速**(不同云服务商叫法不同,腾讯云叫 ECDN、阿里云叫 DCDN)既可以加速静态资源又可以加速动态资源,而**内容分发网络(CDN)** 主要针对的是 **静态资源** 。

-绝大部分公司都会在项目开发中交使用 CDN 服务,但很少会有自建 CDN 服务的公司。基于成本、稳定性和易用性考虑,建议直接选择专业的云厂商(比如阿里云、腾讯云、华为云、青云)或者 CDN 厂商(比如网宿、蓝汛)提供的开箱即用的 CDN 服务。
+绝大部分公司都会在项目开发中使用 CDN 服务,但很少会有自建 CDN 服务的公司。基于成本、稳定性和易用性考虑,建议直接选择专业的云厂商(比如阿里云、腾讯云、华为云、青云)或者 CDN 厂商(比如网宿、蓝汛)提供的开箱即用的 CDN 服务。
+
+### 为什么不直接将服务部署在多个不同的地方?
很多朋友可能要问了:**既然是就近访问,为什么不直接将服务部署在多个不同的地方呢?**
-- 成本太高,需要部署多份相同的服务。
-- 静态资源通常占用空间比较大且经常会被访问到,如果直接使用服务器或者缓存来处理静态资源请求的话,对系统资源消耗非常大,可能会影响到系统其他服务的正常运行。
+这涉及到**静态资源与动态请求的架构分离**问题:
+
+1. **成本问题**:多地部署完整服务需要部署多套应用、数据库、中间件,成本极高;而 CDN 只需存储静态资源,成本可控。
+2. **资源特性不同**:静态资源(图片、JS、CSS)具有**体积大、访问频繁、内容不变**的特点,非常适合缓存分发;动态请求需要实时计算,必须回源处理。
+3. **系统资源消耗**:如果用应用服务器直接处理静态资源请求,会大量占用 CPU、内存和带宽资源,可能影响核心业务的正常运行。
+4. **专业优化**:CDN 针对静态资源传输进行了大量优化(如智能压缩、协议优化、边缘计算),这些能力是普通应用服务器不具备的。
-同一个服务在在多个不同的地方部署多份(比如同城灾备、异地灾备、同城多活、异地多活)是为了实现系统的高可用而不是就近访问。
+> **注意**:同一个服务在多个不同地方部署多份(比如同城灾备、异地灾备、同城多活、异地多活)是为了实现系统的**高可用**,而不是就近访问。
## CDN 工作原理是什么?
-搞懂下面 3 个问题也就搞懂了 CDN 的工作原理:
+理解 CDN 的工作原理,需要搞懂以下三个核心问题:
1. 静态资源是如何被缓存到 CDN 节点中的?
2. 如何找到最合适的 CDN 节点?
@@ -52,82 +56,132 @@ head:
### 静态资源是如何被缓存到 CDN 节点中的?
-你可以通过 **预热** 的方式将源站的资源同步到 CDN 的节点中。这样的话,用户首次请求资源可以直接从 CDN 节点中取,无需回源。这样可以降低源站压力,提升用户体验。
+CDN 缓存静态资源的方式主要有两种:**预热**和**回源**。
-如果不预热的话,你访问的资源可能不在 CDN 节点中,这个时候 CDN 节点将请求源站获取资源,这个过程是大家经常说的 **回源**。
+- **预热(Prefetch)**:主动将源站的资源推送到 CDN 节点中。这样用户首次请求资源时可以直接从 CDN 节点获取,无需回源,适用于大促活动、热点内容发布等场景。
-> - 回源:当 CDN 节点上没有用户请求的资源或该资源的缓存已经过期时,CDN 节点需要从原始服务器获取最新的资源内容,这个过程就是回源。当用户请求发生回源的话,会导致该请求的响应速度比未使用 CDN 还慢,因为相比于未使用 CDN 还多了一层 CDN 的调用流程。
-> - 预热:预热是指在 CDN 上提前将内容缓存到 CDN 节点上。这样当用户在请求这些资源时,能够快速地从最近的 CDN 节点获取到而不需要回源,进而减少了对源站的访问压力,提高了访问速度。
+- **回源(Origin Pull)**:当 CDN 节点上没有用户请求的资源或该资源的缓存已过期时,CDN 节点需要从源站获取最新的资源内容。
-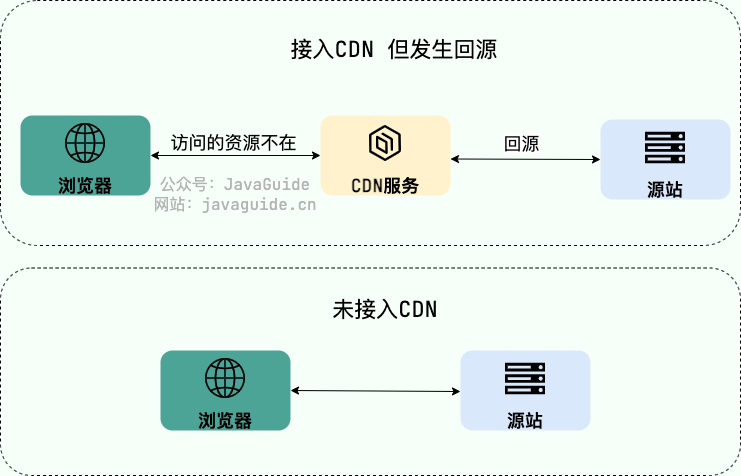
+> **注意**:当用户请求触发回源时,该请求的响应速度会比未使用 CDN 还慢,因为相比于直接访问源站,多了一层 CDN 节点的调用流程。因此,提高**缓存命中率**是 CDN 优化的关键目标。
-如果资源有更新的话,你也可以对其 **刷新** ,删除 CDN 节点上缓存的旧资源,并强制 CDN 节点回源站获取最新资源。
+CDN 缓存的完整生命周期如下图所示:
+
+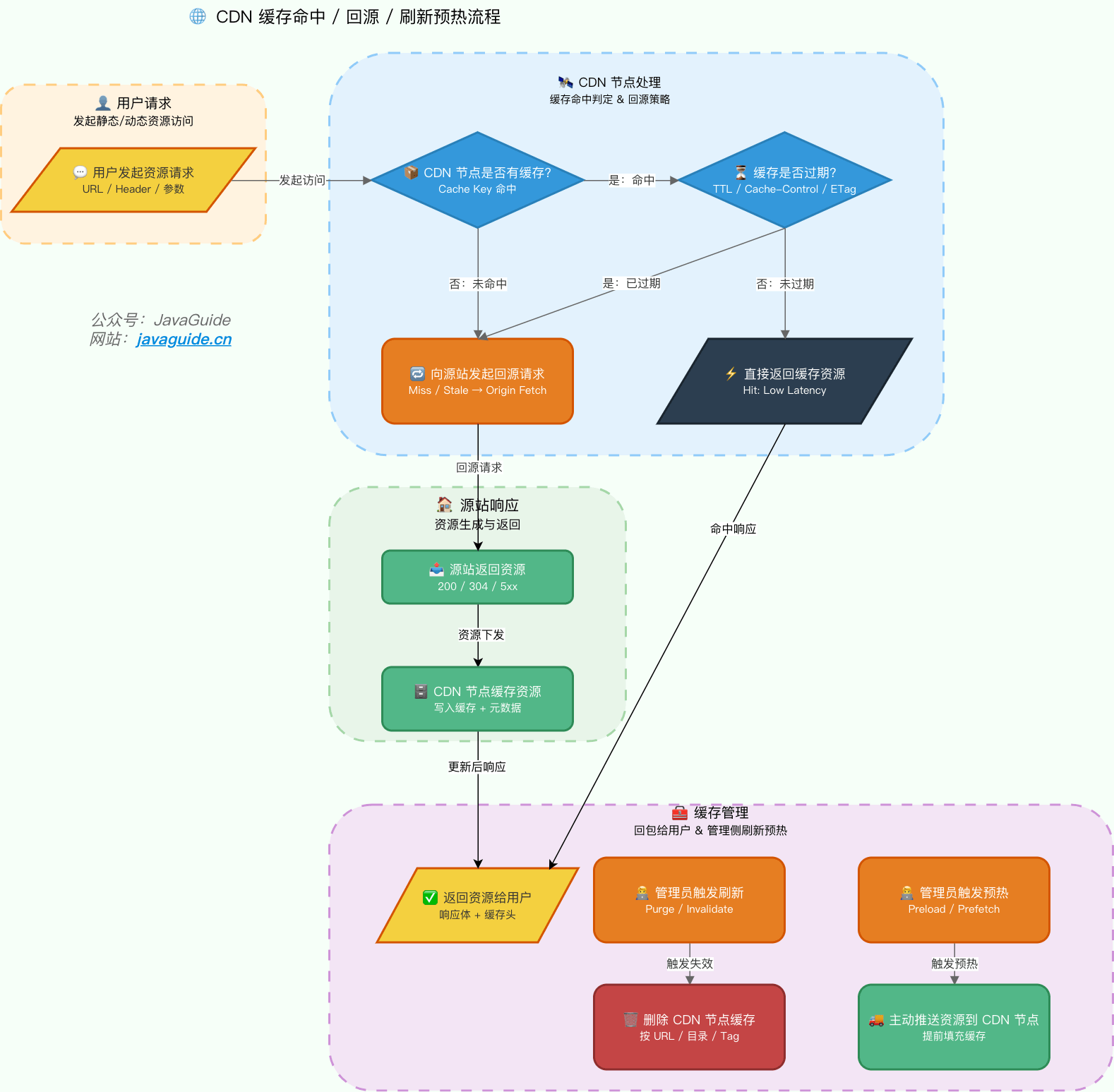
+
+如果资源有更新,可以对其进行**刷新(Purge)**操作,删除 CDN 节点上缓存的旧资源,并强制 CDN 节点在下次请求时回源获取最新资源。
几乎所有云厂商提供的 CDN 服务都具备缓存的刷新和预热功能(下图是阿里云 CDN 服务提供的相应功能):

-**命中率** 和 **回源率** 是衡量 CDN 服务质量两个重要指标。命中率越高越好,回源率越低越好。
+**命中率**和**回源率**是衡量 CDN 服务质量的两个核心指标:
+
+- **命中率**:用户请求直接由 CDN 节点响应的比例,**越高越好**。
+- **回源率**:用户请求需要回源站获取的比例,**越低越好**。
### 如何找到最合适的 CDN 节点?
-GSLB (Global Server Load Balance,全局负载均衡)是 CDN 的大脑,负责多个 CDN 节点之间相互协作,最常用的是基于 DNS 的 GSLB。
+**GSLB(Global Server Load Balance,全局负载均衡)** 是 CDN 的大脑,负责多个 CDN 节点之间的协调调度,最常用的实现方式是**基于 DNS 的 GSLB**。
+
+CDN 请求的完整调度流程如下图所示:
+
+```mermaid
+sequenceDiagram
+ participant User as 用户浏览器
+ participant LocalDNS as 本地 DNS
+ participant AuthDNS as 权威 DNS
+ participant GSLB as CDN 全局负载均衡
+ participant Edge as CDN 边缘节点
+ participant Origin as 源站服务器
+
+ User->>LocalDNS: 1. 请求解析 cdn.example.com
+ LocalDNS->>AuthDNS: 2. 查询域名
+ AuthDNS-->>LocalDNS: 3. 返回 CNAME 记录指向 CDN
+ LocalDNS->>GSLB: 4. 请求 CDN 域名解析
+
+ Note over GSLB: 根据用户 IP、节点负载、
网络状况等选择最优节点
+
+ GSLB-->>LocalDNS: 5. 返回最优 CDN 节点 IP
+ LocalDNS-->>User: 6. 返回 CDN 节点 IP
+ User->>Edge: 7. 请求静态资源
+
+ alt 缓存命中
+ Edge-->>User: 8a. 直接返回缓存资源
+ else 缓存未命中
+ Edge->>Origin: 8b. 回源请求
+ Origin-->>Edge: 9. 返回资源
+ Note over Edge: 缓存资源
+ Edge-->>User: 10. 返回资源
+ end
+```
-CDN 会通过 GSLB 找到最合适的 CDN 节点,更具体点来说是下面这样的:
+**详细流程说明**:
-1. 浏览器向 DNS 服务器发送域名请求;
-2. DNS 服务器向根据 CNAME( Canonical Name ) 别名记录向 GSLB 发送请求;
-3. GSLB 返回性能最好(通常距离请求地址最近)的 CDN 节点(边缘服务器,真正缓存内容的地方)的地址给浏览器;
-4. 浏览器直接访问指定的 CDN 节点。
+1. 用户浏览器向本地 DNS 服务器发送域名解析请求。
+2. 本地 DNS 向权威 DNS 查询,发现该域名配置了 **CNAME(Canonical Name)别名记录**,指向 CDN 服务商的域名。
+3. 本地 DNS 继续向 CDN 的 **GSLB** 发起解析请求。
+4. GSLB 根据**用户 IP 地址、CDN 节点状态(负载、性能、响应时间、带宽)** 等指标,综合判断并返回最优 CDN 节点的 IP 地址。
+5. 用户浏览器直接向该 CDN 节点(边缘服务器)发起资源请求。
+6. CDN 节点检查本地缓存,若命中则直接返回;若未命中或已过期,则回源获取后再返回给用户。
-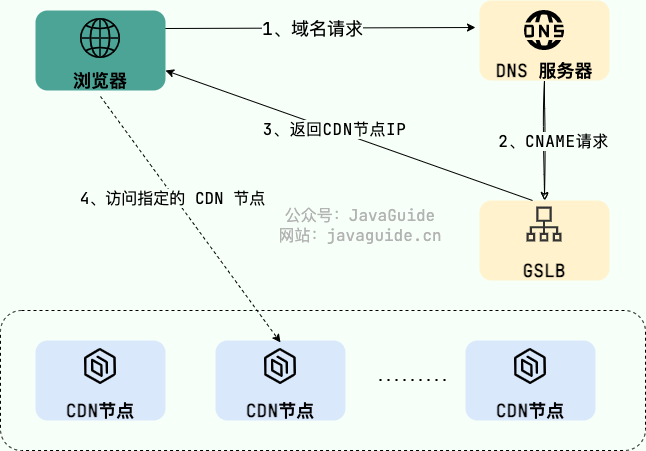
+> **补充说明**:上图做了一定简化。实际上,GSLB 内部可以看作是 **CDN 专用 DNS 服务器**和**负载均衡系统**的组合。CDN 专用 DNS 服务器会返回负载均衡系统的 IP 地址,浏览器通过该 IP 请求负载均衡系统,进而找到对应的 CDN 节点。
-为了方便理解,上图其实做了一点简化。GSLB 内部可以看作是 CDN 专用 DNS 服务器和负载均衡系统组合。CDN 专用 DNS 服务器会返回负载均衡系统 IP 地址给浏览器,浏览器使用 IP 地址请求负载均衡系统进而找到对应的 CDN 节点。
+### 如何防止资源被盗刷?
-**GSLB 是如何选择出最合适的 CDN 节点呢?** GSLB 会根据请求的 IP 地址、CDN 节点状态(比如负载情况、性能、响应时间、带宽)等指标来综合判断具体返回哪一个 CDN 节点的地址。
+如果静态资源被其他用户或网站非法盗刷,将会产生大量额外的带宽费用。常见的防盗链机制有以下几种:
-### 如何防止资源被盗刷?
+| 防盗链机制 | 原理 | 安全强度 | 实现成本 | 绕过难度 |
+| ------------------ | --------------------------------------------- | -------- | -------- | -------------------------- |
+| **Referer 防盗链** | 根据 HTTP 请求头中的 Referer 字段判断请求来源 | 低 | 低 | 低(可伪造或置空 Referer) |
+| **时间戳防盗链** | URL 中携带签名和过期时间,过期后 URL 失效 | 中 | 中 | 中(需要获取签名算法) |
+| **IP 黑白名单** | 限制或允许特定 IP 地址访问 | 中 | 低 | 中(可通过代理绕过) |
+| **Token 鉴权** | 业务服务器生成 Token,CDN 节点校验 | 高 | 高 | 高 |
-如果我们的资源被其他用户或者网站非法盗刷的话,将会是一笔不小的开支。
+#### Referer 防盗链
-解决这个问题最常用最简单的办法设置 **Referer 防盗链**,具体来说就是根据 HTTP 请求的头信息里面的 Referer 字段对请求进行限制。我们可以通过 Referer 字段获取到当前请求页面的来源页面的网站地址,这样我们就能确定请求是否来自合法的网站。
+通过检查 HTTP 请求头中的 **Referer** 字段来判断请求来源是否合法。可以配置允许访问的域名白名单,非白名单来源的请求将被拒绝。
-CDN 服务提供商几乎都提供了这种比较基础的防盗链机制。
+CDN 服务提供商几乎都支持这种基础的防盗链机制:
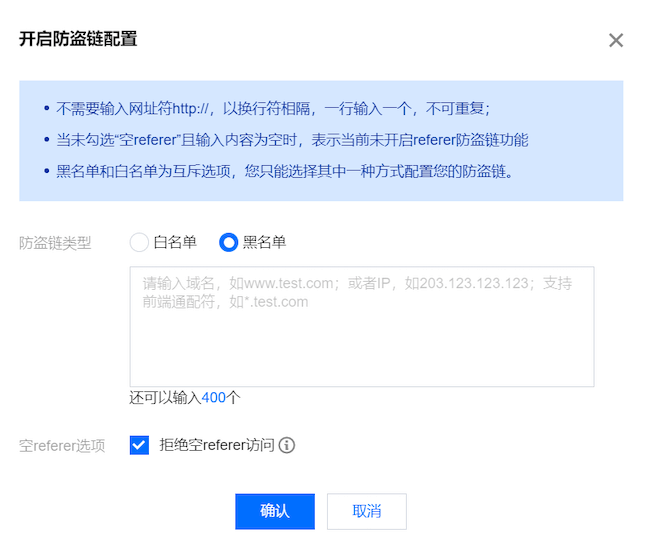
-不过,如果站点的防盗链配置允许 Referer 为空的话,通过隐藏 Referer,可以直接绕开防盗链。
+> **注意**:如果防盗链配置允许 Referer 为空,攻击者可以通过隐藏 Referer 的方式绕过防盗链检查。因此,Referer 防盗链通常需要配合其他机制一起使用。
-通常情况下,我们会配合其他机制来确保静态资源被盗用,一种常用的机制是 **时间戳防盗链** 。相比之下,**时间戳防盗链** 的安全性更强一些。时间戳防盗链加密的 URL 具有时效性,过期之后就无法再被允许访问。
+#### 时间戳防盗链
-时间戳防盗链的 URL 通常会有两个参数一个是签名字符串,一个是过期时间。签名字符串一般是通过对用户设定的加密字符串、请求路径、过期时间通过 MD5 哈希算法取哈希的方式获得。
+**时间戳防盗链**的安全性更强,其核心原理是:URL 中携带**签名字符串**和**过期时间**,CDN 节点在处理请求时会校验签名并检查是否过期,过期的 URL 将被拒绝访问。
+
+签名字符串通常通过对**加密密钥 + 请求路径 + 过期时间**进行 MD5 哈希计算得到。
时间戳防盗链 URL 示例:
-```
-http://cdn.wangsu.com/4/123.mp3? wsSecret=79aead3bd7b5db4adeffb93a010298b5&wsTime=1601026312
+```plain
+http://cdn.example.com/video/123.mp4?wsSecret=79aead3bd7b5db4adeffb93a010298b5&wsTime=1601026312
```
-- `wsSecret`:签名字符串。
-- `wsTime`: 过期时间。
+- `wsSecret`:签名字符串,由服务端根据密钥和请求信息计算生成。
+- `wsTime`:过期时间戳(Unix 时间戳格式)。
-时间戳防盗链的实现也比较简单,并且可靠性较高,推荐使用。并且,绝大部分 CDN 服务提供商都提供了开箱即用的时间戳防盗链机制。
+绝大部分 CDN 服务提供商都支持开箱即用的时间戳防盗链机制:

-除了 Referer 防盗链和时间戳防盗链之外,你还可以 IP 黑白名单配置、IP 访问限频配置等机制来防盗刷。
+> **推荐实践**:生产环境建议采用 **Referer 防盗链 + 时间戳防盗链**的组合方案,兼顾安全性与实现成本。对于安全性要求极高的场景(如付费内容),可进一步引入 Token 鉴权机制。
## 总结
-- CDN 就是将静态资源分发到多个不同的地方以实现就近访问,进而加快静态资源的访问速度,减轻服务器以及带宽的负担。
-- 基于成本、稳定性和易用性考虑,建议直接选择专业的云厂商(比如阿里云、腾讯云、华为云、青云)或者 CDN 厂商(比如网宿、蓝汛)提供的开箱即用的 CDN 服务。
-- GSLB (Global Server Load Balance,全局负载均衡)是 CDN 的大脑,负责多个 CDN 节点之间相互协作,最常用的是基于 DNS 的 GSLB。CDN 会通过 GSLB 找到最合适的 CDN 节点。
-- 为了防止静态资源被盗用,我们可以利用 **Referer 防盗链** + **时间戳防盗链** 。
+- **CDN 的核心价值**:将静态资源分发到多个不同的地方以实现**就近访问**,加快静态资源的访问速度,减轻源站服务器及带宽的负担。
+- **CDN 服务选型**:基于成本、稳定性和易用性考虑,建议直接选择专业的云厂商(如阿里云、腾讯云、华为云)或 CDN 厂商(如网宿、蓝汛)提供的开箱即用服务。
+- **GSLB 的作用**:GSLB(全局负载均衡)是 CDN 的大脑,负责根据用户位置、节点状态等因素,将用户请求调度到**最优的 CDN 节点**。
+- **核心指标**:**命中率**越高越好,**回源率**越低越好。
+- **防盗链机制**:推荐采用 **Referer 防盗链 + 时间戳防盗链**的组合方案,平衡安全性与实现成本。
## 参考
- 时间戳防盗链 - 七牛云 CDN:
- CDN 是个啥玩意?一文说个明白:
- 《透视 HTTP 协议》- 37 | CDN:加速我们的网络服务:
+
+
diff --git a/docs/high-performance/data-cold-hot-separation.md b/docs/high-performance/data-cold-hot-separation.md
new file mode 100644
index 00000000000..7fa47c7501f
--- /dev/null
+++ b/docs/high-performance/data-cold-hot-separation.md
@@ -0,0 +1,136 @@
+---
+title: 数据冷热分离详解
+description: 本文详解数据冷热分离的核心原理与实践方案,涵盖冷热数据的判定策略(时间维度/访问频率)、三种主流迁移方案对比(任务调度/Binlog监听)、冷数据存储选型(HBase/TiDB/对象存储),以及 TiDB Placement Rules 实现自动化冷热分离。
+category: 高性能
+head:
+ - - meta
+ - name: keywords
+ content: 数据冷热分离,冷数据迁移,冷数据存储,分层存储,TiDB冷热分离,HBase,数据归档,存储成本优化
+---
+
+## 什么是数据冷热分离?
+
+数据冷热分离是指根据数据的**访问频率**和**业务重要性**,将数据划分为冷数据和热数据,并分别存储在不同性能和成本的存储介质中的架构策略。
+
+这种架构的核心目标有三个:
+
+1. **提升查询性能**:热数据存储在高性能介质(如 SSD、内存)中,保障核心业务的响应速度。
+2. **降低存储成本**:冷数据迁移至低成本介质(如 HDD、对象存储),大幅削减存储开支。
+3. **满足合规要求**:部分行业(如金融、医疗)要求数据长期归档,冷热分离可兼顾合规与成本。
+
+### 冷数据和热数据
+
+**热数据**是指被频繁访问和修改、且需要快速响应的数据;**冷数据**是指访问频率极低、对当前业务价值较小、但需要长期保留的数据。
+
+冷热数据的区分方法主要有两种:
+
+1. **时间维度区分**:按照数据的创建时间、更新时间或过期时间划分。例如,订单系统将 **1 年前**的订单数据标记为冷数据,1 年内的订单数据作为热数据。该方法适用于**数据访问频率与时间强相关**的场景,实现简单、成本低。
+2. **访问频率区分**:将高频访问的数据视为热数据,低频访问的数据视为冷数据。例如,内容系统将**浏览量低于阈值**的文章标记为冷数据。该方法需要额外记录访问频率,适用于**访问频率与数据本身特性强相关**的场景。
+
+**如何选择区分策略?**
+
+- 若业务数据天然具有时效性(如订单、日志、账单),优先选择**时间维度**,实现成本最低。
+- 若数据价值与时间无关(如文章、商品、用户画像),需结合**访问频率**进行判定。
+- 实际项目中,可将两者结合使用:以时间维度为主、访问频率为辅,覆盖更多业务场景。
+
+### 冷热分离的思想
+
+冷热分离的核心思想是**分层存储(Tiered Storage)**,根据数据的访问特性将其分配到不同层级的存储介质中。在企业级存储架构中,通常划分为以下层级:
+
+| 层级 | 数据特性 | 典型存储介质 | 访问延迟 |
+| --------------------- | ------------------ | -------------------- | ----------- |
+| **Hot(热层)** | 高频访问、实时响应 | NVMe SSD、内存 | 毫秒级 |
+| **Warm(温层)** | 中频访问、近期数据 | SATA SSD、高速 HDD | 百毫秒级 |
+| **Cold(冷层)** | 低频访问、历史数据 | 大容量 HDD、对象存储 | 秒级 |
+| **Archive(归档层)** | 极少访问、合规留存 | 磁带库、冰川存储 | 分钟~小时级 |
+
+这种分层思想在 IT 基础设施中被广泛应用,不仅限于数据库,还包括文件系统、对象存储、CDN 缓存等场景。
+
+### 数据冷热分离的优缺点
+
+**优点:**
+
+- **热数据查询性能优化**:热数据集中在高性能存储上,表数据量大幅减少,索引效率显著提升,用户的绝大部分操作体验会更好。
+- **存储成本大幅降低**:冷数据可迁移至 HDD 或对象存储,**SSD 与 HDD 的单位成本差距可达 5~10 倍**,对于海量数据场景节省效果显著。
+- **系统可维护性增强**:热库数据量可控,备份恢复速度更快,DDL 操作(如加索引)耗时更短。
+
+**缺点:**
+
+- **系统复杂性增加**:需要额外的迁移组件、路由逻辑和监控体系,数据一致性风险增加。
+- **跨库查询效率低**:若业务需要同时查询冷热数据(如年度统计报表),需进行跨库关联或数据聚合,查询性能和开发成本均会上升。
+- **迁移策略维护成本**:冷热数据的判定规则需要持续调优,避免误判导致热数据被错误迁移。
+
+## 冷数据如何迁移?
+
+冷数据迁移是冷热分离的核心环节,主流方案有以下三种:
+
+| 方案 | 实现原理 | 优点 | 缺点 | 适用场景 |
+| ------------------- | ---------------------------------------- | ---------------------- | -------------------------------------------- | ---------------------------- |
+| **业务层代码实现** | 写操作时判断冷热,直接路由到对应库 | 实时性高 | 侵入业务代码、判定逻辑复杂 | 几乎不使用 |
+| **任务调度迁移** | 定时任务扫描热库,批量迁移符合条件的数据 | 实现简单、对业务无侵入 | 存在迁移延迟、扫描大表有性能压力 | **时间维度区分场景(推荐)** |
+| **Binlog 监听迁移** | 监听数据库变更日志,实时或准实时迁移 | 实时性好、对业务无侵入 | 需要额外组件(如 Canal)、不适合时间维度判定 | 访问频率区分场景 |
+
+**任务调度迁移**是最常用的方案,可借助 XXL-Job、Elastic-Job 等分布式任务调度平台实现。关于任务调度的方案,我也写过文章详细介绍,可以查看这篇文章:[Java 定时任务详解](https://javaguide.cn/system-design/schedule-task.html) 。
+
+典型流程如下:
+
+
+
+> **实践建议**:若公司有 DBA 支持,可先进行一次**存量冷数据的人工迁移**,将历史数据批量导入冷库;后续再通过任务调度实现**增量迁移**的自动化。
+
+## 冷数据如何存储?
+
+冷数据存储方案的选型原则是:**容量大、成本低、可靠性高,访问速度可适当牺牲**。
+
+### 中小厂方案
+
+直接使用 **MySQL/PostgreSQL** 即可,保持与热库相同的数据库类型,降低运维复杂度。具体实现方式:
+
+- **同库分表**:在同一数据库中新增冷数据表(如 `order_history`),通过表名区分冷热数据。
+- **独立冷库**:部署单独的数据库实例作为冷库,热库与冷库通过应用层路由访问。
+
+> **注意**:独立冷库方案涉及**跨库查询**,若业务存在冷热数据联合查询需求,需评估是否引入数据同步或聚合层。
+
+### 大厂方案
+
+大厂通常采用专门针对海量数据优化的存储引擎:
+
+| 存储方案 | 特点 | 适用场景 |
+| ---------------------- | -------------------------------- | -------------------------------- |
+| **HBase** | 列式存储、高吞吐、支持 PB 级数据 | 日志、用户行为、IoT 数据归档 |
+| **RocksDB** | 高性能 KV 存储、LSM-Tree 结构 | 嵌入式场景、作为其他系统底层存储 |
+| **Doris/ClickHouse** | OLAP 引擎、支持实时分析 | 冷数据需要进行聚合分析的场景 |
+| **Cassandra** | 分布式、高可用、无单点故障 | 跨地域部署、高可用要求的归档场景 |
+| **对象存储(OSS/S3)** | 成本极低、无限扩展 | 超大规模冷数据、合规归档 |
+
+### TiDB 方案(推荐)
+
+如果公司技术栈允许,可以直接使用 **TiDB** 这类分布式关系型数据库,原生支持冷热分离,一步到位。
+
+TiDB 6.0 引入了 **基于 SQL 接口的数据放置框架(Placement Rules in SQL)** 功能,用于通过 SQL 接口配置数据在 TiKV 集群中的放置位置。
+
+- **热数据**:通过 Placement Rules 指定存储在 **SSD 节点**上,保障查询性能。
+- **冷数据**:指定存储在 **HDD 节点**上,降低存储成本。
+
+```sql
+-- 创建放置策略:热数据存储在 SSD 节点
+CREATE PLACEMENT POLICY hot_data
+ CONSTRAINTS="[+disk=ssd]";
+
+-- 创建放置策略:冷数据存储在 HDD 节点
+CREATE PLACEMENT POLICY cold_data
+ CONSTRAINTS="[+disk=hdd]";
+
+-- 对表或分区应用放置策略
+ALTER TABLE orders PLACEMENT POLICY = hot_data;
+ALTER TABLE orders PARTITION p2022 PLACEMENT POLICY = cold_data;
+```
+
+这种方案的优势在于:**业务无需感知冷热分离逻辑**,数据路由由 TiDB 自动完成,大幅降低了应用层的复杂度。
+
+## 案例分享
+
+- [如何快速优化几千万数据量的订单表 - 程序员济癫 - 2023](https://www.cnblogs.com/fulongyuanjushi/p/17910420.html)
+- [海量数据冷热分离方案与实践 - 字节跳动技术团队 - 2022](https://mp.weixin.qq.com/s/ZKRkZP6rLHuTE1wvnqmAPQ)
+
+
diff --git a/docs/high-performance/deep-pagination-optimization.md b/docs/high-performance/deep-pagination-optimization.md
new file mode 100644
index 00000000000..c43c057b527
--- /dev/null
+++ b/docs/high-performance/deep-pagination-optimization.md
@@ -0,0 +1,156 @@
+---
+title: 深度分页介绍及优化建议
+description: 深度分页是指查询偏移量过大导致性能下降的场景,本文详解深度分页产生的原因及四种优化方案:范围查询、子查询优化、INNER JOIN 延迟关联、覆盖索引,并分析各方案的适用场景与优缺点。
+category: 高性能
+head:
+ - - meta
+ - name: keywords
+ content: 深度分页,分页优化,LIMIT优化,MySQL分页,延迟关联,覆盖索引,游标分页
+---
+
+## 深度分页介绍
+
+查询偏移量过大的场景我们称为深度分页,这会导致查询性能较低,例如:
+
+```sql
+# MySQL 在无法利用索引的情况下跳过1000000条记录后,再获取10条记录
+SELECT * FROM t_order ORDER BY id LIMIT 1000000, 10
+```
+
+## 深度分页问题的原因
+
+当查询偏移量过大时,MySQL 的查询优化器可能会选择全表扫描而不是利用索引来优化查询。这是因为扫描索引和跳过大量记录可能比直接全表扫描更耗费资源。
+
+
+
+不同机器上这个查询偏移量过大的临界点可能不同,取决于多个因素,包括硬件配置(如 CPU 性能、磁盘速度)、表的大小、索引的类型和统计信息等。
+
+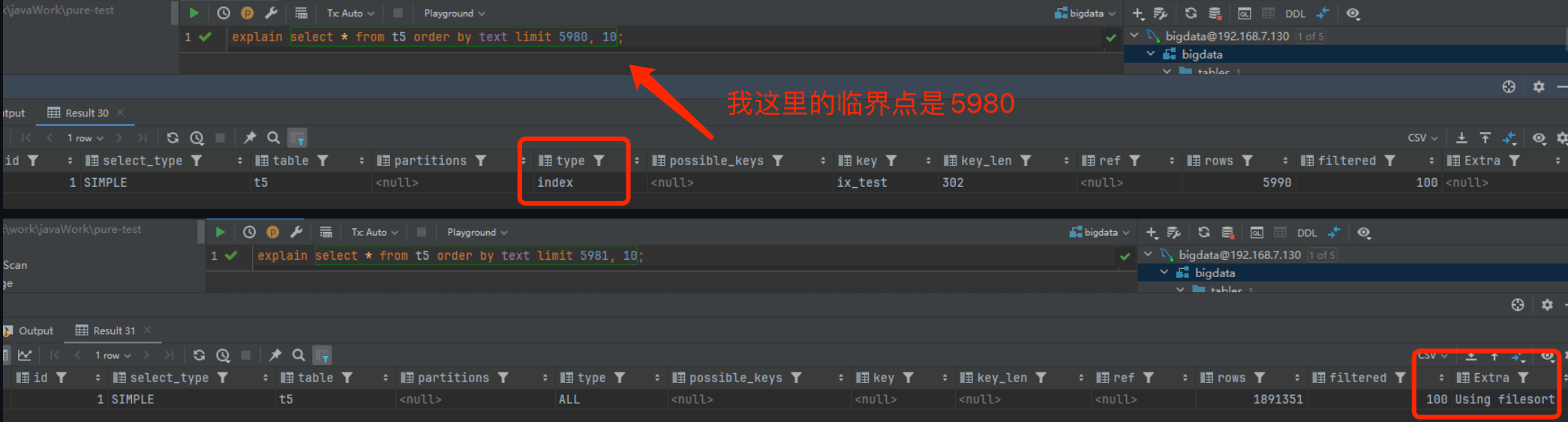
+
+MySQL 的查询优化器采用基于成本的策略来选择最优的查询执行计划。它会根据 CPU 和 I/O 的成本来决定是否使用索引扫描或全表扫描。如果优化器认为全表扫描的成本更低,它就会放弃使用索引。不过,即使偏移量很大,如果查询中使用了覆盖索引(covering index),MySQL 仍然可能会使用索引,避免回表操作。
+
+## 深度分页优化建议
+
+这里以 MySQL 数据库为例介绍一下如何优化深度分页。
+
+### 范围查询
+
+当可以保证 ID 的连续性时,根据 ID 范围进行分页是比较好的解决方案:
+
+```sql
+# 查询指定 ID 范围的数据
+SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id
+# 也可以通过记录上次查询结果的最后一条记录的ID进行下一页的查询:
+SELECT * FROM t_order WHERE id > 100000 LIMIT 10
+```
+
+这种基于 ID 范围的深度分页优化方式存在很大限制:
+
+1. **ID 连续性要求高**: 实际项目中,数据库自增 ID 往往因为各种原因(例如删除数据、事务回滚等)导致 ID 不连续,难以保证连续性。
+2. **排序问题**: 如果查询需要按照其他字段(例如创建时间、更新时间等)排序,而不是按照 ID 排序,那么这种方法就不再适用。
+3. **并发场景**: 在高并发场景下,单纯依赖记录上次查询的最后一条记录的 ID 进行分页,容易出现数据重复或遗漏的问题。
+
+### 子查询
+
+我们先查询出 limit 第一个参数对应的主键值,再根据这个主键值再去过滤并 limit,这样效率会更快一些。
+
+阿里巴巴《Java 开发手册》中也有对应的描述:
+
+> 利用延迟关联或者子查询优化超多分页场景。
+>
+> 
+
+```sql
+-- 先通过子查询在主键索引上进行偏移,快速找到起始ID
+SELECT * FROM t_order WHERE id >= (SELECT id FROM t_order LIMIT 1000000, 1) LIMIT 10;
+```
+
+**工作原理**:
+
+1. 子查询 `(SELECT id FROM t_order where id > 1000000 limit 1)` 会利用主键索引快速定位到第 1000001 条记录,并返回其 ID 值。
+2. 主查询 `SELECT * FROM t_order WHERE id >= ... LIMIT 10` 将子查询返回的起始 ID 作为过滤条件,使用 `id >=` 获取从该 ID 开始的后续 10 条记录。
+
+不过,子查询的结果会产生一张新表,会影响性能,应该尽量避免大量使用子查询。并且,这种方法只适用于 ID 是正序的。在复杂分页场景,往往需要通过过滤条件,筛选到符合条件的 ID,此时的 ID 是离散且不连续的。
+
+当然,我们也可以利用子查询先去获取目标分页的 ID 集合,然后再根据 ID 集合获取内容,但这种写法非常繁琐,不如使用 INNER JOIN 延迟关联。
+
+### 延迟关联
+
+延迟关联与子查询的优化思路类似,都是通过将 `LIMIT` 操作转移到主键索引树上,减少回表次数。相比直接使用子查询,延迟关联通过 `INNER JOIN` 将子查询结果集成到主查询中,避免了子查询可能产生的临时表。在执行 `INNER JOIN` 时,MySQL 优化器能够利用索引进行高效的连接操作(如索引扫描或其他优化策略),因此在深度分页场景下,性能通常优于直接使用子查询。
+
+```sql
+-- 使用 INNER JOIN 进行延迟关联
+SELECT t1.*
+FROM t_order t1
+INNER JOIN (
+ -- 这里的子查询可以利用覆盖索引,性能极高
+ SELECT id FROM t_order LIMIT 1000000, 10
+) t2 ON t1.id = t2.id;
+```
+
+**工作原理**:
+
+1. 子查询 `(SELECT id FROM t_order where id > 1000000 LIMIT 10)` 利用主键索引快速定位目标分页的 10 条记录的 ID。
+2. 通过 `INNER JOIN` 将子查询结果与主表 `t_order` 关联,获取完整的记录数据。
+
+除了使用 INNER JOIN 之外,还可以使用逗号连接子查询。
+
+```sql
+-- 使用逗号进行延迟关联
+SELECT t1.* FROM t_order t1,
+(SELECT id FROM t_order where id > 1000000 LIMIT 10) t2
+WHERE t1.id = t2.id;
+```
+
+**注意**: 虽然逗号连接子查询也能实现类似的效果,但为了代码可读性和可维护性,建议使用更规范的 `INNER JOIN` 语法。
+
+### 覆盖索引
+
+索引中已经包含了所有需要获取的字段的查询方式称为覆盖索引。
+
+**覆盖索引的好处:**
+
+- **避免 InnoDB 表进行索引的二次查询,也就是回表操作:** InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询(回表),减少了 IO 操作,提升了查询效率。
+- **可以把随机 IO 变成顺序 IO 加快查询效率:** 由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围查找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序 IO。
+
+```sql
+# 如果只需要查询 id, code, type 这三列,可建立 code 和 type 的覆盖索引
+SELECT id, code, type FROM t_order
+ORDER BY code
+LIMIT 1000000, 10;
+```
+
+**⚠️注意**:
+
+- 当查询的结果集占表的总行数的很大一部分时,MySQL 查询优化器可能选择放弃使用索引,自动转换为全表扫描。
+- 虽然可以使用 `FORCE INDEX` 强制查询优化器走索引,但这种方式可能会导致查询优化器无法选择更优的执行计划,效果并不总是理想。
+
+## 总结
+
+深度分页问题的根本原因在于:当 `LIMIT` 的偏移量过大时,MySQL 需要扫描并跳过大量记录才能获取目标数据,查询优化器可能放弃索引而选择全表扫描。此时即使有索引,也无法避免大量的回表操作,导致查询性能急剧下降。
+
+本文介绍了四种常见的深度分页优化方案,各方案的特点及适用场景对比如下:
+
+| 优化方案 | 核心思路 | 适用场景 | 限制 |
+| ------------ | ------------------------------------------------------------------- | ----------------------------------- | ------------------------------------------------ |
+| **范围查询** | 记录上一页最后一条 ID,通过 `WHERE id > last_id LIMIT n` 获取下一页 | ID 连续、按 ID 排序、允许游标式翻页 | 不支持跳页、ID 不连续时失效、非 ID 排序不适用 |
+| **子查询** | 先通过子查询获取起始主键,再根据主键过滤 | 需要支持传统 OFFSET 翻页 | 子查询可能产生临时表、仅适用于 ID 正序 |
+| **延迟关联** | 用 `INNER JOIN` 将分页转移到主键索引,减少回表 | 大数据量分页、需要传统翻页逻辑 | SQL 相对复杂 |
+| **覆盖索引** | 建立包含查询字段的联合索引,避免回表 | 查询字段固定、可建立合适索引 | 字段较多时索引维护成本高、大结果集可能走全表扫描 |
+
+**方案选择建议**:
+
+- **优先使用延迟关联**:对于大多数需要支持传统 `LIMIT offset, size` 翻页逻辑的场景,延迟关联是性能和可维护性较好的选择。
+- **考虑范围查询(游标分页)**:如果业务允许使用"下一页"式的游标翻页(如社交媒体 feed 流、无限滚动),范围查询性能最佳且稳定。
+- **覆盖索引作为补充**:当查询字段固定且数量不多时,可配合其他方案建立覆盖索引进一步优化。
+
+**注意事项**:
+
+- 无论采用哪种方案,都应注意监控实际执行计划(`EXPLAIN`),确保优化器按预期使用索引。
+- 对于超深分页(如百万级偏移量),应从业务层面评估是否真的需要支持,考虑限制最大翻页数或采用其他检索方式(如搜索引擎)。
+
+## 参考
+
+- 聊聊如何解决 MySQL 深分页问题 - 捡田螺的小男孩:
+- 数据库深分页介绍及优化方案 - 京东零售技术:
+- MySQL 深分页优化 - 得物技术:
diff --git a/docs/high-performance/images/message-queue/message-queue-pub-sub-model.drawio b/docs/high-performance/images/message-queue/message-queue-pub-sub-model.drawio
deleted file mode 100644
index 7a28c60d6db..00000000000
--- a/docs/high-performance/images/message-queue/message-queue-pub-sub-model.drawio
+++ /dev/null
@@ -1 +0,0 @@
-7Zttc6M2EIB/DTN3H+IRCPHy0SSmnfZuejPpTNtPHQwy5oIRB3Li3K+vBBLmRY59iR27PpwZB62EAO2j3dUKa/B2tfmlCPLlZxLhVDNAtNHgnWYYOjBc9o9LnmuJC2AtiIskEo22gvvkO5ZnCuk6iXDZaUgJSWmSd4UhyTIc0o4sKAry1G22IGn3qnkQ44HgPgzSofSvJKLLWuoY9lb+K07ipbyybokHngfhQ1yQdSaupxnQt3zfd+rqVSD7Eg9aLoOIPLVEcKbB24IQWh+tNrc45WMrh60+z99R29x3gTN6yAnfpnfu796j+zA34Hcr/Pz17rt9o4vHfAzSNZbPUd0tfZYjVD0j5r3oGvSelgnF93kQ8tonxgSTLekqFdWLJE1vSUqK6lyI9Qhhm8lLWpAH3KpxLRsGFj+DZNQPVknKAfoNU68Ikqxkt/CZZETU35N1UV1wSSnjwkBwyr7Yo/Iv3qCcxITEKQ7ypJyEZFVVhGXV1F/UvbPDdv/I8MQVxBDgguLNzsHVG5WxqYDJCtOCdQnECQgYE1SfJOaBaQq9P22pMpAtWy3bTIFGHAia4+YKW42yA6HUH1GwQr9WSsW4dhRtfVsTWXFTVhOVjTLQUb7ZVrKjmP//UpBoHeJC9qbVepDVA4jYrbIZjfcDFJR5Pc0XyYZD1yfKvJ2arpIoK3TwfMFrHjAN+ZADXpDTDlwLa4YDuqRZQ9JkkzZmUnZ0xoz9NgRn0ZQba1YK06Ask7BnNvjA175BR6LcUi2zqgBwBeJNQv8W5/Djf7hiJ0iU7jZCz1XhWRKwE4caIWn2jQsCBEcDr9XDgw2vvI8X5/4QoxYmSIGJlBU4DWjy2L0NFTviCl9IUhkUQSm0u5QivYdfffvirLbf6nWEQK8j0OuIBkWM6aCjCuXmsV9PN9xPdwtkPrMTFl18CuY4/ULKhCYkY3VzQikjgdm3NIm5IGTqZOYTeilv6TXBRIv6RfVpdToV51KSK+kdmEQAHOAPsI+Ccln5c1GT88dYbWIe4E0SUtqThEVb5QRnjzglOf73wwqXJQuEPv7ATO3MukuZVm+yu9Dt2V1b4eEVE8o4ld0195MptRs+pwkL4or9/ndeR3uf5o2gQfOPNWW9YCEvCA0E3C4Y+ukF4n9KP119hujUn+v338jqcQSb2LFFElQFivBUYSIajdxo5GoYL8zIWSOZI5mV2UQ9Mt0zk3lA6mQk86cg07gwMh0FmXWapsyD7PVJn1um/PVqm/SZF9t8T5MGqi9x6jTQwglxGKrQnjvIRC+v+6+COre3LoZIFUa+ayLI3W8RW4mgjPC1xFuyQPL42FmgkgYFHearKrGfpPJ22bOI0mVAxcApnpvsGC+0BoYXtyNTleTQaMdLOQnLU6dkXminO2q23yc3Zbu9XL31ytyU3U8J9Ds6cW7KPIKlh8zScwZaG1o3YT3peH0Rzz8Y/DrsDgFzbeIAgY+12e+5CG1maZ6lOY42czTP1Dy3JWHfujb1D3YWjMgqXOq5hn6g1I+CVkkU8T68ArPnDOZVfxz0nOuh0gzyNHR3wKTdaafFdqToXGt8eXvS7LaRO436DZiYyHWOQrmcjILNm14HZLEo8Umo1BWbTjOkOb7m6trM1Zj/YRwosOjpn4057aq+6+yFA2lHBkJ0OCKqMGS74bk/jJDuCl6EBzhCWGH20+36MJi13jOY1RXbS0N2GFZs2rh+BRo7sP/XNMng517cvn4tdKF+eunAvcvT0XVAEn1cxf8Mq3inZ/hM48yreOgqIyJpE4Rx6poXUtAliUnGCCWcograr5jSZ6HUYE1J1wo2q4ZmYXDYquESN89f83rAEVc/+qHLH8NUo/jWdU0vRTrYKt+xrjnacsQaiT3j6x4H0wffSN/bPO5wzfonyZNwgM5b3jtcLLClTg9GtjsHV+O0LKeXyXAOi9bhCd84VGQBZ6bmOZrn8TB9amhygTtG5xdGk70jL3au6Fx2rM4kIA6VA3mmaTrjXNWLQDYl2LJwyoRVG3emOcPc0pC3loYNWe7E2gD4/rVouv8OKVTYDVtlN06madVrduOe1ZXvWZnImdhn3rQyVBmAkbwrJw9Z9rl3S02FcxtTT2PqiefcVXC+77vF49tNI5zqvOi53wg1Va+ZjJveF7LpvQcmBCYAmBA40NWhZXa3qE2XhYMmggjquuPw31CeCCGkcr0jQleAEI/rTLeF0A8TxIrbH2XXmfHtL9/h7D8=
\ No newline at end of file
diff --git a/docs/high-performance/images/message-queue/message-queue-pub-sub-model.png b/docs/high-performance/images/message-queue/message-queue-pub-sub-model.png
deleted file mode 100644
index a5a77736493..00000000000
Binary files a/docs/high-performance/images/message-queue/message-queue-pub-sub-model.png and /dev/null differ
diff --git a/docs/high-performance/images/message-queue/message-queue-queue-model.drawio b/docs/high-performance/images/message-queue/message-queue-queue-model.drawio
deleted file mode 100644
index ea1c6caca4b..00000000000
--- a/docs/high-performance/images/message-queue/message-queue-queue-model.drawio
+++ /dev/null
@@ -1 +0,0 @@
-7Zrbcts2EEC/hjPtQzS8iLdHSRGTdpLUidpp89SBSIjCGCRoELKkfH0XJCDxZstJ7Vp2Jc9YwAJcAtyDXWBFw5llu3ccFeuPLMHUsM1kZzhvDdu2TDuELynZ15LQdGpBykmiOh0FC/IN6yuVdEMSXLY6CsaoIEVbGLM8x7FoyRDnbNvutmK0fdcCpbgnWMSI9qV/kkSsa2lg+0f5e0zStb6z5akJL1F8nXK2ydX9DNuJvCiKgro5Q1qXmmi5RgnbNkTO3HBmnDFRl7LdDFP5bPVjq6+L7mg9jJvjXDzkgpvpl6Vd7vPZ+yj8vP32x++/5J/eKC23iG6wnoZHQd90xUAtjFrs1ZPybjZMN7wpKztOoIPlFrtjI5RS+X3FWbKJMdfaYFi1wrpZPZGDbhuGCgaHynS7JgIvChTLli0wB7K1yCjULCiisqgpWJEdTuRwCKUzRhmvFDnj2WQc+iAvBWfXuNHixQFermTLNRaxtI0pK9oqpppahDJCJcu/YjHliOQljPQjy5lqX7ANr8a2FgIQtV35FFx46vKf7FCOUsZSilFBylHMsqohLquu0arWDsWmfteeqjv0jaothLnAu4ZIGfkdZhkWHFSaqnWsgVML0nFUfdvAW4nWDbK1DKkFlR40H6GCguLqOxizBxjrmj9PJnItQy2mqCxJ3LZ69eBr12G5qt4wLSw605QGxDsi/lLXyPJXadiRq2pvd8rOVWWvCbgThxoh7RXs8wak1Lc9sdRx0vKHfYwamLgDmGgZxxQJctv2okPsqDtcMVI5FEWpa3Uo7eJXz0dd1XRrHUXeuKPI7ygSiKdY9BRVKB+m/eN0O6fpboAslzGB4PMBLTG9YiURhOXQtmRCAAng3yhJpSAG+4L7dKZU9pweYk2D+lX1aSidqGsFKwbp7blE0wzMqId9gsq1dK16QRRyGtkulfF/RFjpjwgE43KE81tMWYH//inDZQlx8ufvWKmtVXfGy+rhftd1OiCO+37XHlhQ9lP53fFpMrV14z0leVLxdiL+LiWEOPmwPAgOaP62EaAFKzlnAim4Q7Mfp1eu/BuM09Wnj079ef3x2zc7HJk2RLAuSY7bJ8nSwkdHyb04uYuTq5ycf2ZOzruQeSGz2geGHTK9ZybTv5B5IbMi0zszMoMBMus0TVmg/MeTPjMw/iY7Jn2W/JjvOaSB6ls8dRpoFcQ4jofQXgbu2L3/3P8qqAu7B+znTgOFp/1hIw2UM3mS+Dc5IF1+7BxQKRAX/WxVJY4I1cOFuajamSN1MnGk3EWdR7mnnzpvnkmCye/uB7p5oYcmmAL3eRNMeh1fNhL/941Ej8TnPnxZAz8fzV0jiIzQMuahAbEkgIJnTD0jCGQBqpOohy/MX7SdfRskFQyaMV6JejB3Sc1IktC7NhS8TmadDAJN5JzXQpPbTZwHfZq8/5SmgVR6nx3AKgyMMKpAg4L/omnSDmyhhm+9Frq8bqLogdvPp6NrIB3eZwkwmwTGxJKScG4E/SNKn66GPW1db4VA04yi13/g6P7ufNjINSzuD1jceQSLz/fO18+EF5vC/fTF5zdsnHiD7zZc9k0vc9/Uw3AA1rv3Tab/bPumQTLt+wJdYEzHxjS8bJteCExPt22C6vH1sPo4eXwHz5n/Aw==
\ No newline at end of file
diff --git a/docs/high-performance/images/message-queue/message-queue-queue-model.png b/docs/high-performance/images/message-queue/message-queue-queue-model.png
deleted file mode 100644
index 8fb2cd6a7ba..00000000000
Binary files a/docs/high-performance/images/message-queue/message-queue-queue-model.png and /dev/null differ
diff --git a/docs/high-performance/load-balancing.md b/docs/high-performance/load-balancing.md
index a41af365247..a7724eff5e5 100644
--- a/docs/high-performance/load-balancing.md
+++ b/docs/high-performance/load-balancing.md
@@ -1,13 +1,11 @@
---
-title: 负载均衡常见问题总结
+title: 负载均衡原理及算法详解
+description: 本文详解负载均衡的核心原理,涵盖四层/七层负载均衡区别、服务端与客户端负载均衡对比,深入讲解轮询、加权轮询、随机、一致性哈希等常见负载均衡算法,以及 Nginx、LVS 等主流实现方案。
category: 高性能
head:
- - meta
- name: keywords
- content: 客户端负载均衡,服务负载均衡,Nginx,负载均衡算法,七层负载均衡,DNS解析
- - - meta
- - name: description
- content: 负载均衡指的是将用户请求分摊到不同的服务器上处理,以提高系统整体的并发处理能力。负载均衡可以简单分为服务端负载均衡和客户端负载均衡 这两种。服务端负载均衡涉及到的知识点更多,工作中遇到的也比较多,因为,我会花更多时间来介绍。
+ content: 负载均衡,四层负载均衡,七层负载均衡,Nginx负载均衡,LVS,负载均衡算法,轮询,一致性哈希,客户端负载均衡
---
## 什么是负载均衡?
@@ -24,7 +22,7 @@ head:
负载均衡可以简单分为 **服务端负载均衡** 和 **客户端负载均衡** 这两种。
-服务端负载均衡涉及到的知识点更多,工作中遇到的也比较多,因为,我会花更多时间来介绍。
+服务端负载均衡涉及到的知识点更多,工作中遇到的也比较多,因此,我会花更多时间来介绍。
### 服务端负载均衡
@@ -61,7 +59,7 @@ head:
七层负载均衡比四层负载均衡会消耗更多的性能,不过,也相对更加灵活,能够更加智能地路由网络请求,比如说你可以根据请求的内容进行优化如缓存、压缩、加密。
-简单来说,**四层负载均衡性能更强,七层负载均衡功能更强!** 不过,对于绝大部分业务场景来说,四层负载均衡和七层负载均衡的性能差异基本可以忽略不计的。
+简单来说,**四层负载均衡性能很强,七层负载均衡功能更强!** 不过,对于绝大部分业务场景来说,四层负载均衡和七层负载均衡的性能差异基本可以忽略不计的。
下面这段话摘自 Nginx 官网的 [What Is Layer 4 Load Balancing?](https://www.nginx.com/resources/glossary/layer-4-load-balancing/) 这篇文章。
@@ -85,7 +83,7 @@ head:
客户端负载均衡器和服务运行在同一个进程或者说 Java 程序里,不存在额外的网络开销。不过,客户端负载均衡的实现会受到编程语言的限制,比如说 Spring Cloud Load Balancer 就只能用于 Java 语言。
-Java 领域主流的微服务框架 Dubbo、Spring Cloud 等都内置了开箱即用的客户端负载均衡实现。Dubbo 属于是默认自带了负载均衡功能,Spring Cloud 是通过组件的形式实现的负载均衡,属于可选项,比较常用的是 Spring Cloud Load Balancer(官方,推荐) 和 Ribbon(Netflix,已被启用)。
+Java 领域主流的微服务框架 Dubbo、Spring Cloud 等都内置了开箱即用的客户端负载均衡实现。Dubbo 属于是默认自带了负载均衡功能,Spring Cloud 是通过组件的形式实现的负载均衡,属于可选项,比较常用的是 Spring Cloud Load Balancer(官方,推荐) 和 Ribbon(Netflix,已被弃用)。
下图是我画的一个简单的基于 Spring Cloud Load Balancer(Ribbon 也类似) 的客户端负载均衡示意图:
@@ -113,15 +111,45 @@ Java 领域主流的微服务框架 Dubbo、Spring Cloud 等都内置了开箱
未加权重的轮询算法适合于服务器性能相近的集群,其中每个服务器承载相同的负载。加权轮询算法适合于服务器性能不等的集群,权重的存在可以使请求分配更加合理化。
+在加权轮询的基础上,还有进一步改进得到的负载均衡算法,比如平滑的加权轮训算法。
+
+平滑的加权轮训算法最早是在 Nginx 中被实现,可以参考这个 commit:。如果你认真学习过 Dubbo 负载均衡策略的话,就会发现 Dubbo 的加权轮询就借鉴了该算法实现并进一步做了优化。
+
+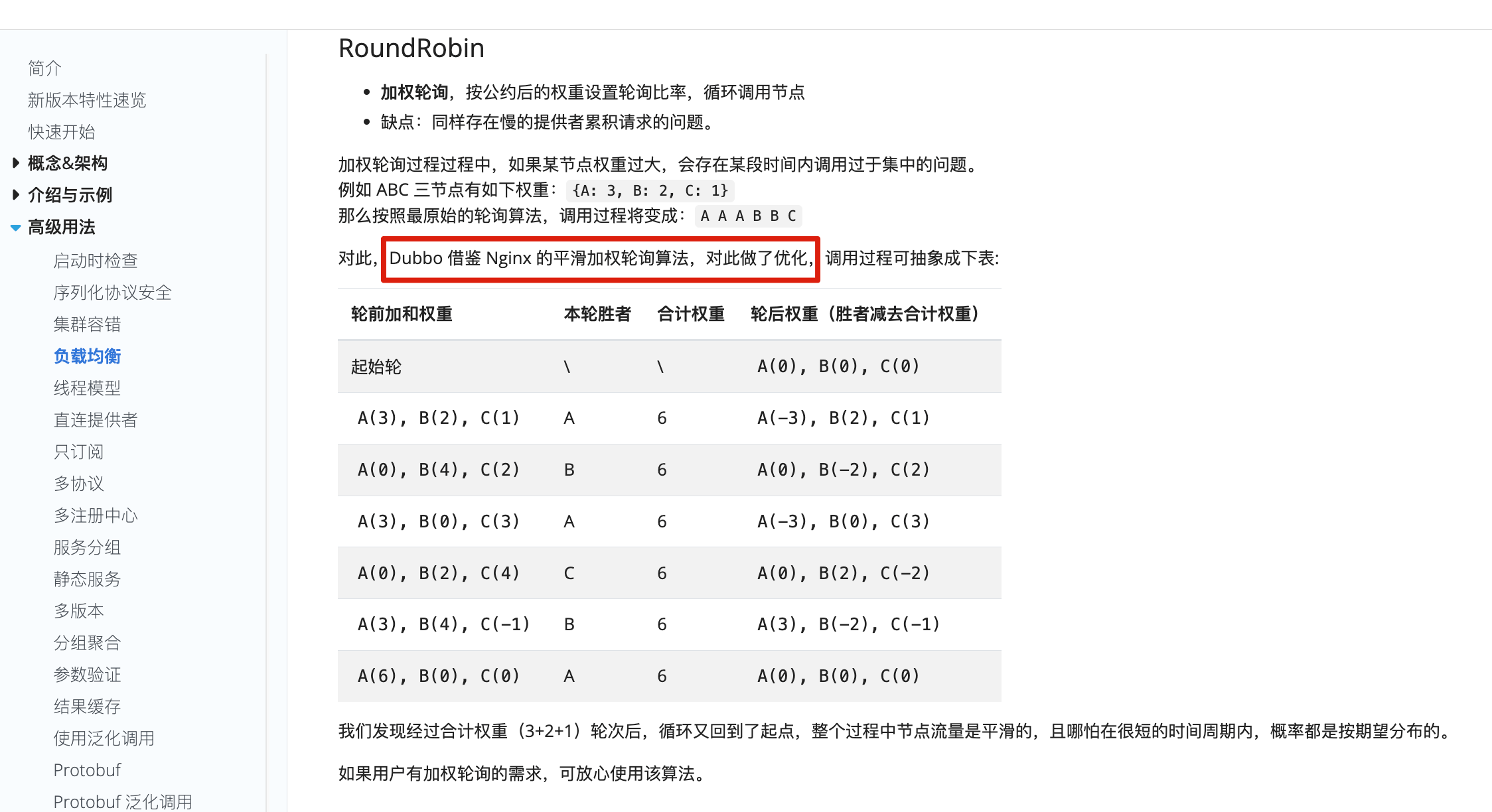
+
+### 两次随机法
+
+两次随机法在随机法的基础上多增加了一次随机,多选出一个服务器。随后再根据两台服务器的负载等情况,从其中选择出一个最合适的服务器。
+
+两次随机法的好处是可以动态地调节后端节点的负载,使其更加均衡。如果只使用一次随机法,可能会导致某些服务器过载,而某些服务器空闲。
+
+### 哈希法
+
+将请求的参数信息通过哈希函数转换成一个哈希值,然后根据哈希值来决定请求被哪一台服务器处理。
+
+在服务器数量不变的情况下,相同参数的请求总是发到同一台服务器处理,比如同个 IP 的请求、同一个用户的请求。
+
### 一致性 Hash 法
-相同参数的请求总是发到同一台服务器处理,比如同个 IP 的请求。
+和哈希法类似,一致性 Hash 法也可以让相同参数的请求总是发到同一台服务器处理。不过,它解决了哈希法存在的一些问题。
+
+常规哈希法在服务器数量变化时,哈希值会重新落在不同的服务器上,这明显违背了使用哈希法的本意。而一致性哈希法的核心思想是将数据和节点都映射到一个哈希环上,然后根据哈希值的顺序来确定数据属于哪个节点。当服务器增加或删除时,只影响该服务器的哈希,而不会导致整个服务集群的哈希键值重新分布。
### 最小连接法
-当有新的请求出现时,遍历服务器节点列表并选取其中活动连接数最小的一台服务器来响应当前请求。活动连接数可以理解为当前正在处理的请求数。
+当有新的请求出现时,遍历服务器节点列表并选取其中连接数最小的一台服务器来响应当前请求。相同连接的情况下,可以进行加权随机。
+
+最少连接数基于一个服务器连接数越多,负载就越高这一理想假设。然而, 实际情况是连接数并不能代表服务器的实际负载,有些连接耗费系统资源更多,有些连接不怎么耗费系统资源。
+
+### 最少活跃法
-最小连接法可以尽可能最大地使请求分配更加合理化,提高服务器的利用率。不过,这种方法实现起来也最复杂,需要监控每一台服务器处理的请求连接数。
+最少活跃法和最小连接法类似,但要更科学一些。最少活跃法以活动连接数为标准,活动连接数可以理解为当前正在处理的请求数。活跃数越低,说明处理能力越强,这样就可以使处理能力强的服务器处理更多请求。相同活跃数的情况下,可以进行加权随机。
+
+### 最快响应时间法
+
+不同于最小连接法和最少活跃法,最快响应时间法以响应时间为标准来选择具体是哪一台服务器处理。客户端会维持每个服务器的响应时间,每次请求挑选响应时间最短的。相同响应时间的情况下,可以进行加权随机。
+
+这种算法可以使得请求被更快处理,但可能会造成流量过于集中于高性能服务器的问题。
## 七层负载均衡可以怎么做?
@@ -233,3 +261,5 @@ Spring Cloud 2020.0.0 版本移除了 Netflix 除 Eureka 外的所有组件。Sp
- 干货 | eBay 的 4 层软件负载均衡实现:
- HTTP Load Balancing(Nginx 官方文档):
- 深入浅出负载均衡 - vivo 互联网技术:
+
+
diff --git a/docs/high-performance/message-queue/disruptor-questions.md b/docs/high-performance/message-queue/disruptor-questions.md
index e8f01100491..efd7f24be0b 100644
--- a/docs/high-performance/message-queue/disruptor-questions.md
+++ b/docs/high-performance/message-queue/disruptor-questions.md
@@ -1,8 +1,13 @@
---
title: Disruptor常见问题总结
+description: 本文总结 Disruptor 高性能内存队列的核心知识与面试要点,涵盖 Disruptor 架构(RingBuffer/Sequencer/WaitStrategy)、高性能原理(无锁设计/缓存行填充/预分配内存)、与 ArrayBlockingQueue 对比、生产者消费者模式等,助力 Disruptor 学习与面试。
category: 高性能
tag:
- 消息队列
+head:
+ - - meta
+ - name: keywords
+ content: Disruptor,高性能队列,RingBuffer,无锁队列,缓存行填充,LMAX,内存队列,Disruptor面试
---
Disruptor 是一个相对冷门一些的知识点,不过,如果你的项目经历中用到了 Disruptor 的话,那面试中就很可能会被问到。
@@ -25,7 +30,7 @@ LMAX 公司 2010 年在 QCon 演讲后,Disruptor 获得了业界关注,并
> “Duke 选择大奖”旨在表彰过去一年里全球个人或公司开发的、最具影响力的 Java 技术应用,由甲骨文公司主办。含金量非常高!
-我专门找到了 Oracle 官方当年颁布获得 Duke's Choice Awards 项目的那篇文章(文章地址:https://blogs.oracle.com/java/post/and-the-winners-arethe-dukes-choice-award) 。从文中可以看出,同年获得此大奖荣誉的还有大名鼎鼎的 Netty、JRebel 等项目。
+我专门找到了 Oracle 官方当年颁布获得 Duke's Choice Awards 项目的那篇文章(文章地址: 。从文中可以看出,同年获得此大奖荣誉的还有大名鼎鼎的 Netty、JRebel 等项目。
@@ -49,7 +54,7 @@ Disruptor 主要解决了 JDK 内置线程安全队列的性能和内存安全
| `LinkedTransferQueue` | 无锁(`CAS`) | 无界 |
| `ConcurrentLinkedQueue` | 无锁(`CAS`) | 无界 |
-从上表中可以看出:这些队列要不就是加锁有界,要不就是无锁无界。而加锁的的队列势必会影响性能,无界的队列又存在内存溢出的风险。
+从上表中可以看出:这些队列要不就是加锁有界,要不就是无锁无界。而加锁的队列势必会影响性能,无界的队列又存在内存溢出的风险。
因此,一般情况下,我们都是不建议使用 JDK 内置线程安全队列。
@@ -76,7 +81,7 @@ Disruptor 真的很快,关于它为什么这么快这个问题,会在后文
- **SOFATracer**:SOFATracer 是蚂蚁金服开源的分布式应用链路追踪工具,它基于 Disruptor 来实现异步日志。
- **Storm** : Storm 是一个开源的分布式实时计算系统,它基于 Disruptor 来实现工作进程内发生的消息传递(同一 Storm 节点上的线程间,无需网络通信)。
- **HBase**:HBase 是一个分布式列存储数据库系统,它基于 Disruptor 来提高写并发性能。
-- ......
+- ……
## Disruptor 核心概念有哪些?
@@ -115,7 +120,7 @@ Disruptor 真的很快,关于它为什么这么快这个问题,会在后文
## Disruptor 为什么这么快?
- **RingBuffer(环形数组)** : Disruptor 内部的 RingBuffer 是通过数组实现的。由于这个数组中的所有元素在初始化时一次性全部创建,因此这些元素的内存地址一般来说是连续的。这样做的好处是,当生产者不断往 RingBuffer 中插入新的事件对象时,这些事件对象的内存地址就能够保持连续,从而利用 CPU 缓存的局部性原理,将相邻的事件对象一起加载到缓存中,提高程序的性能。这类似于 MySQL 的预读机制,将连续的几个页预读到内存里。除此之外,RingBuffer 基于数组还支持批量操作(一次处理多个元素)、还可以避免频繁的内存分配和垃圾回收(RingBuffer 是一个固定大小的数组,当向数组中添加新元素时,如果数组已满,则新元素将覆盖掉最旧的元素)。
-- **避免了伪共享问题**:CPU 缓存内部是按照 Cache Line(缓存行)管理的,一般的 Cache Line 大小在 64 字节左右。Disruptor 为了确保目标字段独占一个 Cache Line,会在目标字段前后增加了 64 个字节的填充(前 56 个字节和后 8 个字节),这样可以避免 Cache Line 的伪共享(False Sharing)问题。
+- **避免了伪共享问题**:CPU 缓存内部是按照 Cache Line(缓存行)管理的,一般的 Cache Line 大小在 64 字节左右。Disruptor 为了确保目标字段独占一个 Cache Line,会在目标字段前后增加字节填充(前 56 个字节和后 56 个字节),这样可以避免 Cache Line 的伪共享(False Sharing)问题。同时,为了让 RingBuffer 存放数据的数组独占缓存行,数组的设计为 无效填充(128 字节)+ 有效数据。
- **无锁设计**:Disruptor 采用无锁设计,避免了传统锁机制带来的竞争和延迟。Disruptor 的无锁实现起来比较复杂,主要是基于 CAS、内存屏障(Memory Barrier)、RingBuffer 等技术实现的。
综上所述,Disruptor 之所以能够如此快,是基于一系列优化策略的综合作用,既充分利用了现代 CPU 缓存结构的特点,又避免了常见的并发问题和性能瓶颈。
@@ -134,5 +139,7 @@ CPU 缓存是通过将最近使用的数据存储在高速缓存中来实现更
## 参考
-- Disruptor 高性能之道-等待策略:
+- Disruptor 高性能之道-等待策略:< 高性能之道-等待策略/>
- 《Java 并发编程实战》- 40 | 案例分析(三):高性能队列 Disruptor:
+
+
diff --git a/docs/high-performance/message-queue/kafka-questions-01.md b/docs/high-performance/message-queue/kafka-questions-01.md
index 7f124abbca5..b8034f7c875 100644
--- a/docs/high-performance/message-queue/kafka-questions-01.md
+++ b/docs/high-performance/message-queue/kafka-questions-01.md
@@ -1,10 +1,17 @@
---
title: Kafka常见问题总结
+description: 本文总结 Kafka 常见面试题与核心知识点,涵盖 Kafka 架构(Broker/Topic/Partition/Consumer Group)、高性能原理(零拷贝/顺序写/批量处理)、消息可靠性(ACK机制/ISR副本)、消息顺序性、Rebalance 机制、Kafka 与 RocketMQ 对比等,助力 Kafka 学习与面试。
category: 高性能
tag:
- 消息队列
+head:
+ - - meta
+ - name: keywords
+ content: Kafka,消息队列,Kafka分区,Kafka副本,ISR,消费者组,Rebalance,零拷贝,Kafka面试
---
+## Kafka 基础
+
### Kafka 是什么?主要应用场景有哪些?
Kafka 是一个分布式流式处理平台。这到底是什么意思呢?
@@ -37,7 +44,7 @@ Kafka 主要有两大应用场景:
#### 队列模型:早期的消息模型
-
+
**使用队列(Queue)作为消息通信载体,满足生产者与消费者模式,一条消息只能被一个消费者使用,未被消费的消息在队列中保留直到被消费或超时。** 比如:我们生产者发送 100 条消息的话,两个消费者来消费一般情况下两个消费者会按照消息发送的顺序各自消费一半(也就是你一个我一个的消费。)
@@ -61,6 +68,8 @@ Kafka 主要有两大应用场景:
> **RocketMQ 的消息模型和 Kafka 基本是完全一样的。唯一的区别是 Kafka 中没有队列这个概念,与之对应的是 Partition(分区)。**
+## Kafka 核心概念
+
### 什么是 Producer、Consumer、Broker、Topic、Partition?
Kafka 将生产者发布的消息发送到 **Topic(主题)** 中,需要这些消息的消费者可以订阅这些 **Topic(主题)**,如下图所示:
@@ -91,13 +100,15 @@ Kafka 将生产者发布的消息发送到 **Topic(主题)** 中,需要这
1. Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力(负载均衡)。
2. Partition 可以指定对应的 Replica 数, 这也极大地提高了消息存储的安全性, 提高了容灾能力,不过也相应的增加了所需要的存储空间。
-### Zookeeper 在 Kafka 中的作用知道吗?
+## Zookeeper 和 Kafka
+
+### Zookeeper 在 Kafka 中的作用是什么?
-> **要想搞懂 zookeeper 在 Kafka 中的作用 一定要自己搭建一个 Kafka 环境然后自己进 zookeeper 去看一下有哪些文件夹和 Kafka 有关,每个节点又保存了什么信息。** 一定不要光看不实践,这样学来的也终会忘记!这部分内容参考和借鉴了这篇文章:https://www.jianshu.com/p/a036405f989c 。
+> 要想搞懂 zookeeper 在 Kafka 中的作用 一定要自己搭建一个 Kafka 环境然后自己进 zookeeper 去看一下有哪些文件夹和 Kafka 有关,每个节点又保存了什么信息。 一定不要光看不实践,这样学来的也终会忘记!这部分内容参考和借鉴了这篇文章: 。
下图就是我的本地 Zookeeper ,它成功和我本地的 Kafka 关联上(以下文件夹结构借助 idea 插件 Zookeeper tool 实现)。
- +
+ ZooKeeper 主要为 Kafka 提供元数据的管理的功能。
@@ -106,7 +117,17 @@ ZooKeeper 主要为 Kafka 提供元数据的管理的功能。
1. **Broker 注册**:在 Zookeeper 上会有一个专门**用来进行 Broker 服务器列表记录**的节点。每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到 `/brokers/ids` 下创建属于自己的节点。每个 Broker 就会将自己的 IP 地址和端口等信息记录到该节点中去
2. **Topic 注册**:在 Kafka 中,同一个**Topic 的消息会被分成多个分区**并将其分布在多个 Broker 上,**这些分区信息及与 Broker 的对应关系**也都是由 Zookeeper 在维护。比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这些文件夹:`/brokers/topics/my-topic/Partitions/0`、`/brokers/topics/my-topic/Partitions/1`
3. **负载均衡**:上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力。 对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
-4. ......
+4. ……
+
+### 使用 Kafka 能否不引入 Zookeeper?
+
+在 Kafka 2.8 之前,Kafka 最被大家诟病的就是其重度依赖于 Zookeeper。在 Kafka 2.8 之后,引入了基于 Raft 协议的 KRaft 模式,不再依赖 Zookeeper,大大简化了 Kafka 的架构,让你可以以一种轻量级的方式来使用 Kafka。
+
+不过,要提示一下:**如果要使用 KRaft 模式的话,建议选择较高版本的 Kafka,因为这个功能还在持续完善优化中。Kafka 3.3.1 版本是第一个将 KRaft(Kafka Raft)共识协议标记为生产就绪的版本。**
+
+
+
+## Kafka 消费顺序、消息丢失和重复消费
### Kafka 如何保证消息的消费顺序?
@@ -119,7 +140,7 @@ ZooKeeper 主要为 Kafka 提供元数据的管理的功能。
我们知道 Kafka 中 Partition(分区)是真正保存消息的地方,我们发送的消息都被放在了这里。而我们的 Partition(分区) 又存在于 Topic(主题) 这个概念中,并且我们可以给特定 Topic 指定多个 Partition。
-
+
每次添加消息到 Partition(分区) 的时候都会采用尾加法,如上图所示。 **Kafka 只能为我们保证 Partition(分区) 中的消息有序。**
@@ -136,7 +157,7 @@ Kafka 中发送 1 条消息的时候,可以指定 topic, partition, key,data
当然不仅仅只有上面两种方法,上面两种方法是我觉得比较好理解的,
-### Kafka 如何保证消息不丢失
+### Kafka 如何保证消息不丢失?
#### 生产者丢失消息的情况
@@ -164,13 +185,13 @@ if (sendResult.getRecordMetadata() != null) {
如果消息发送失败的话,我们检查失败的原因之后重新发送即可!
-**另外这里推荐为 Producer 的`retries `(重试次数)设置一个比较合理的值,一般是 3 ,但是为了保证消息不丢失的话一般会设置比较大一点。设置完成之后,当出现网络问题之后能够自动重试消息发送,避免消息丢失。另外,建议还要设置重试间隔,因为间隔太小的话重试的效果就不明显了,网络波动一次你 3 次一下子就重试完了**
+另外,这里推荐为 Producer 的`retries`(重试次数)设置一个比较合理的值,一般是 3 ,但是为了保证消息不丢失的话一般会设置比较大一点。设置完成之后,当出现网络问题之后能够自动重试消息发送,避免消息丢失。另外,建议还要设置重试间隔,因为间隔太小的话重试的效果就不明显了,网络波动一次你 3 次一下子就重试完了。
#### 消费者丢失消息的情况
我们知道消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。偏移量(offset)表示 Consumer 当前消费到的 Partition(分区)的所在的位置。Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性。
-
+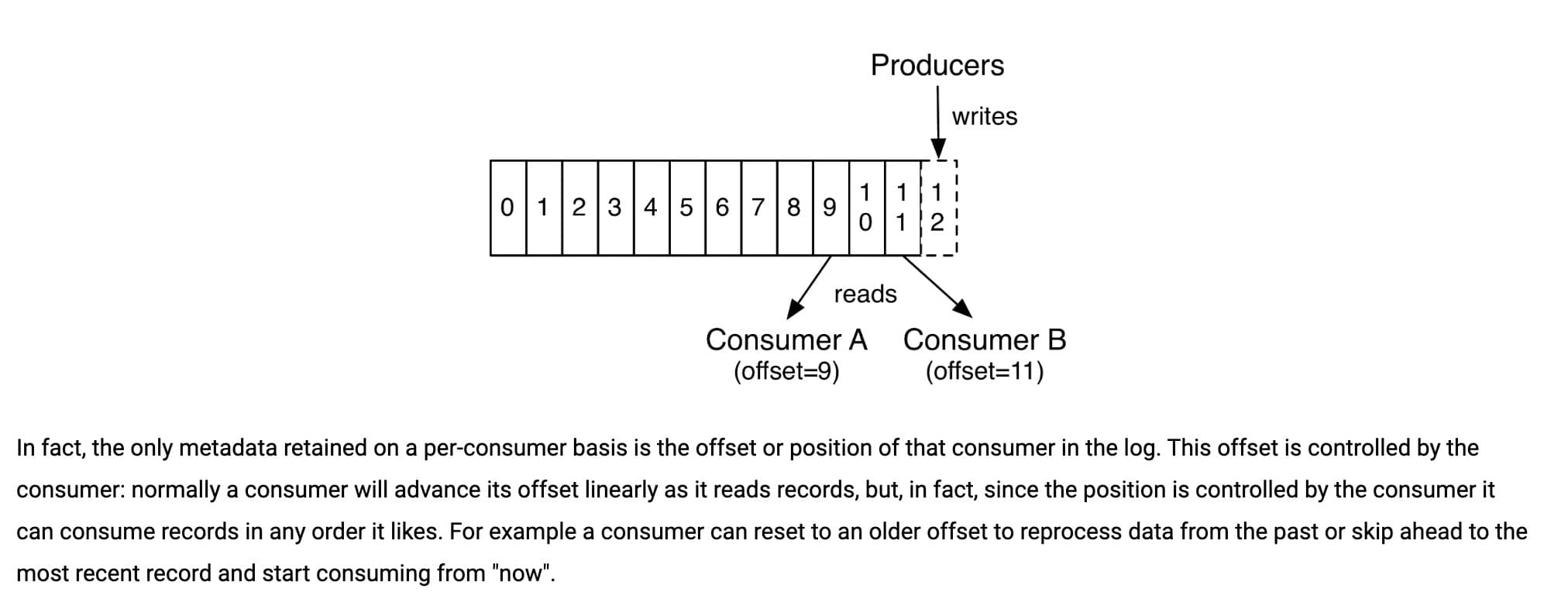
当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。自动提交的话会有一个问题,试想一下,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。
@@ -204,7 +225,7 @@ acks 的默认值即为 1,代表我们的消息被 leader 副本接收之后
我们最开始也说了我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。多个 follower 副本之间的消息同步情况不一样,当我们配置了 **unclean.leader.election.enable = false** 的话,当 leader 副本发生故障时就不会从 follower 副本中和 leader 同步程度达不到要求的副本中选择出 leader ,这样降低了消息丢失的可能性。
-### Kafka 如何保证消息不重复消费
+### Kafka 如何保证消息不重复消费?
**kafka 出现消息重复消费的原因:**
@@ -218,7 +239,208 @@ acks 的默认值即为 1,代表我们的消息被 leader 副本接收之后
- 处理完消息再提交:依旧有消息重复消费的风险,和自动提交一样
- 拉取到消息即提交:会有消息丢失的风险。允许消息延时的场景,一般会采用这种方式。然后,通过定时任务在业务不繁忙(比如凌晨)的时候做数据兜底。
-### Reference
+## Kafka 重试机制
+
+在 Kafka 如何保证消息不丢失这里,我们提到了 Kafka 的重试机制。由于这部分内容较为重要,我们这里再来详细介绍一下。
+
+网上关于 Spring Kafka 的默认重试机制文章很多,但大多都是过时的,和实际运行结果完全不一样。以下是根据 [spring-kafka-2.9.3](https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka/2.9.3) 源码重新梳理一下。
+
+### 消费失败会怎么样?
+
+在消费过程中,当其中一个消息消费异常时,会不会卡住后续队列消息的消费?这样业务岂不是卡住了?
+
+生产者代码:
+
+```Java
+ for (int i = 0; i < 10; i++) {
+ kafkaTemplate.send(KafkaConst.TEST_TOPIC, String.valueOf(i))
+ }
+```
+
+消费者消代码:
+
+```Java
+ @KafkaListener(topics = {KafkaConst.TEST_TOPIC},groupId = "apple")
+ private void customer(String message) throws InterruptedException {
+ log.info("kafka customer:{}",message);
+ Integer n = Integer.parseInt(message);
+ if (n%5==0){
+ throw new RuntimeException();
+ }
+ }
+```
+
+在默认配置下,当消费异常会进行重试,重试多次后会跳过当前消息,继续进行后续消息的消费,不会一直卡在当前消息。下面是一段消费的日志,可以看出当 `test-0@95` 重试多次后会被跳过。
-- Kafka 官方文档:https://kafka.apache.org/documentation/
+```Java
+2023-08-10 12:03:32.918 DEBUG 9700 --- [ntainer#0-0-C-1] o.s.kafka.listener.DefaultErrorHandler : Skipping seek of: test-0@95
+2023-08-10 12:03:32.918 TRACE 9700 --- [ntainer#0-0-C-1] o.s.kafka.listener.DefaultErrorHandler : Seeking: test-0 to: 96
+2023-08-10 12:03:32.918 INFO 9700 --- [ntainer#0-0-C-1] o.a.k.clients.consumer.KafkaConsumer : [Consumer clientId=consumer-apple-1, groupId=apple] Seeking to offset 96 for partition test-0
+
+```
+
+因此,即使某个消息消费异常,Kafka 消费者仍然能够继续消费后续的消息,不会一直卡在当前消息,保证了业务的正常进行。
+
+### 默认会重试多少次?
+
+默认配置下,消费异常会进行重试,重试次数是多少, 重试是否有时间间隔?
+
+看源码 `FailedRecordTracker` 类有个 `recovered` 函数,返回 Boolean 值判断是否要进行重试,下面是这个函数中判断是否重试的逻辑:
+
+```java
+ @Override
+ public boolean recovered(ConsumerRecord << ? , ? > record, Exception exception,
+ @Nullable MessageListenerContainer container,
+ @Nullable Consumer << ? , ? > consumer) throws InterruptedException {
+
+ if (this.noRetries) {
+ // 不支持重试
+ attemptRecovery(record, exception, null, consumer);
+ return true;
+ }
+ // 取已经失败的消费记录集合
+ Map < TopicPartition, FailedRecord > map = this.failures.get();
+ if (map == null) {
+ this.failures.set(new HashMap < > ());
+ map = this.failures.get();
+ }
+ // 获取消费记录所在的Topic和Partition
+ TopicPartition topicPartition = new TopicPartition(record.topic(), record.partition());
+ FailedRecord failedRecord = getFailedRecordInstance(record, exception, map, topicPartition);
+ // 通知注册的重试监听器,消息投递失败
+ this.retryListeners.forEach(rl - >
+ rl.failedDelivery(record, exception, failedRecord.getDeliveryAttempts().get()));
+ // 获取下一次重试的时间间隔
+ long nextBackOff = failedRecord.getBackOffExecution().nextBackOff();
+ if (nextBackOff != BackOffExecution.STOP) {
+ this.backOffHandler.onNextBackOff(container, exception, nextBackOff);
+ return false;
+ } else {
+ attemptRecovery(record, exception, topicPartition, consumer);
+ map.remove(topicPartition);
+ if (map.isEmpty()) {
+ this.failures.remove();
+ }
+ return true;
+ }
+ }
+```
+
+其中, `BackOffExecution.STOP` 的值为 -1。
+
+```java
+@FunctionalInterface
+public interface BackOffExecution {
+
+ long STOP = -1;
+ long nextBackOff();
+
+}
+```
+
+`nextBackOff` 的值调用 `BackOff` 类的 `nextBackOff()` 函数。如果当前执行次数大于最大执行次数则返回 `STOP`,既超过这个最大执行次数后才会停止重试。
+
+```Java
+public long nextBackOff() {
+ this.currentAttempts++;
+ if (this.currentAttempts <= getMaxAttempts()) {
+ return getInterval();
+ }
+ else {
+ return STOP;
+ }
+}
+```
+
+那么这个 `getMaxAttempts` 的值又是多少呢?回到最开始,当执行出错会进入 `DefaultErrorHandler` 。`DefaultErrorHandler` 默认的构造函数是:
+
+```Java
+public DefaultErrorHandler() {
+ this(null, SeekUtils.DEFAULT_BACK_OFF);
+}
+```
+
+`SeekUtils.DEFAULT_BACK_OFF` 定义的是:
+
+```Java
+public static final int DEFAULT_MAX_FAILURES = 10;
+
+public static final FixedBackOff DEFAULT_BACK_OFF = new FixedBackOff(0, DEFAULT_MAX_FAILURES - 1);
+```
+
+`DEFAULT_MAX_FAILURES` 的值是 10,`currentAttempts` 从 0 到 9,所以总共会执行 10 次,每次重试的时间间隔为 0。
+
+最后,简单总结一下:Kafka 消费者在默认配置下会进行最多 10 次 的重试,每次重试的时间间隔为 0,即立即进行重试。如果在 10 次重试后仍然无法成功消费消息,则不再进行重试,消息将被视为消费失败。
+
+### 如何自定义重试次数以及时间间隔?
+
+从上面的代码可以知道,默认错误处理器的重试次数以及时间间隔是由 `FixedBackOff` 控制的,`FixedBackOff` 是 `DefaultErrorHandler` 初始化时默认的。所以自定义重试次数以及时间间隔,只需要在 `DefaultErrorHandler` 初始化的时候传入自定义的 `FixedBackOff` 即可。重新实现一个 `KafkaListenerContainerFactory` ,调用 `setCommonErrorHandler` 设置新的自定义的错误处理器就可以实现。
+
+```Java
+@Bean
+public KafkaListenerContainerFactory kafkaListenerContainerFactory(ConsumerFactory consumerFactory) {
+ ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory();
+ // 自定义重试时间间隔以及次数
+ FixedBackOff fixedBackOff = new FixedBackOff(1000, 5);
+ factory.setCommonErrorHandler(new DefaultErrorHandler(fixedBackOff));
+ factory.setConsumerFactory(consumerFactory);
+ return factory;
+}
+```
+
+### 如何在重试失败后进行告警?
+
+自定义重试失败后逻辑,需要手动实现,以下是一个简单的例子,重写 `DefaultErrorHandler` 的 `handleRemaining` 函数,加上自定义的告警等操作。
+
+```Java
+@Slf4j
+public class DelErrorHandler extends DefaultErrorHandler {
+
+ public DelErrorHandler(FixedBackOff backOff) {
+ super(null,backOff);
+ }
+
+ @Override
+ public void handleRemaining(Exception thrownException, List> records, Consumer consumer, MessageListenerContainer container) {
+ super.handleRemaining(thrownException, records, consumer, container);
+ log.info("重试多次失败");
+ // 自定义操作
+ }
+}
+```
+
+`DefaultErrorHandler` 只是默认的一个错误处理器,Spring Kafka 还提供了 `CommonErrorHandler` 接口。手动实现 `CommonErrorHandler` 就可以实现更多的自定义操作,有很高的灵活性。例如根据不同的错误类型,实现不同的重试逻辑以及业务逻辑等。
+
+### 重试失败后的数据如何再次处理?
+
+当达到最大重试次数后,数据会直接被跳过,继续向后进行。当代码修复后,如何重新消费这些重试失败的数据呢?
+
+**死信队列(Dead Letter Queue,简称 DLQ)** 是消息中间件中的一种特殊队列。它主要用于处理无法被消费者正确处理的消息,通常是因为消息格式错误、处理失败、消费超时等情况导致的消息被"丢弃"或"死亡"的情况。当消息进入队列后,消费者会尝试处理它。如果处理失败,或者超过一定的重试次数仍无法被成功处理,消息可以发送到死信队列中,而不是被永久性地丢弃。在死信队列中,可以进一步分析、处理这些无法正常消费的消息,以便定位问题、修复错误,并采取适当的措施。
+
+`@RetryableTopic` 是 Spring Kafka 中的一个注解,它用于配置某个 Topic 支持消息重试,更推荐使用这个注解来完成重试。
+
+```Java
+// 重试 5 次,重试间隔 100 毫秒,最大间隔 1 秒
+@RetryableTopic(
+ attempts = "5",
+ backoff = @Backoff(delay = 100, maxDelay = 1000)
+)
+@KafkaListener(topics = {KafkaConst.TEST_TOPIC}, groupId = "apple")
+private void customer(String message) {
+ log.info("kafka customer:{}", message);
+ Integer n = Integer.parseInt(message);
+ if (n % 5 == 0) {
+ throw new RuntimeException();
+ }
+ System.out.println(n);
+}
+```
+
+当达到最大重试次数后,如果仍然无法成功处理消息,消息会被发送到对应的死信队列中。对于死信队列的处理,既可以用 `@DltHandler` 处理,也可以使用 `@KafkaListener` 重新消费。
+
+## 参考
+
+- Kafka 官方文档:
- 极客时间—《Kafka 核心技术与实战》第 11 节:无消息丢失配置怎么实现?
+
+
diff --git a/docs/high-performance/message-queue/message-queue.md b/docs/high-performance/message-queue/message-queue.md
index 4d7b6717ce9..ea8a25c6613 100644
--- a/docs/high-performance/message-queue/message-queue.md
+++ b/docs/high-performance/message-queue/message-queue.md
@@ -1,8 +1,13 @@
---
title: 消息队列基础知识总结
+description: 本文系统总结消息队列的核心知识,涵盖消息队列的应用场景(异步处理/解耦/削峰)、消息模型(点对点/发布订阅)、如何保证消息不丢失、消息幂等性、消息顺序性、消息积压处理等常见问题,以及 Kafka、RocketMQ、RabbitMQ 技术选型对比。
category: 高性能
tag:
- 消息队列
+head:
+ - - meta
+ - name: keywords
+ content: 消息队列,MQ,异步解耦,削峰填谷,消息丢失,消息幂等,消息顺序,Kafka,RocketMQ,RabbitMQ
---
::: tip
@@ -19,13 +24,13 @@ tag:
我们可以把消息队列看作是一个存放消息的容器,当我们需要使用消息的时候,直接从容器中取出消息供自己使用即可。由于队列 Queue 是一种先进先出的数据结构,所以消费消息时也是按照顺序来消费的。
-
+
参与消息传递的双方称为 **生产者** 和 **消费者** ,生产者负责发送消息,消费者负责处理消息。
-
+
-我们知道操作系统中的进程通信的一种很重要的方式就是消息队列。我们这里提到的消息队列稍微有点区别,更多指的是各个服务以及系统内部各个组件/模块之前的通信,属于一种 **中间件** 。
+操作系统中的进程通信的一种很重要的方式就是消息队列。我们这里提到的消息队列稍微有点区别,更多指的是各个服务以及系统内部各个组件/模块之前的通信,属于一种 **中间件** 。
维基百科是这样介绍中间件的:
@@ -35,25 +40,27 @@ tag:
除了消息队列之外,常见的中间件还有 RPC 框架、分布式组件、HTTP 服务器、任务调度框架、配置中心、数据库层的分库分表工具和数据迁移工具等等。
-关于中间件比较详细的介绍可以参考阿里巴巴淘系技术的一篇回答:https://www.zhihu.com/question/19730582/answer/1663627873 。
+关于中间件比较详细的介绍可以参考阿里巴巴淘系技术的一篇回答: 。
随着分布式和微服务系统的发展,消息队列在系统设计中有了更大的发挥空间,使用消息队列可以降低系统耦合性、实现任务异步、有效地进行流量削峰,是分布式和微服务系统中重要的组件之一。
## 消息队列有什么用?
-通常来说,使用消息队列能为我们的系统带来下面三点好处:
+通常来说,使用消息队列主要能为我们的系统带来下面三点好处:
-1. **通过异步处理提高系统性能(减少响应所需时间)**
-2. **削峰/限流**
-3. **降低系统耦合性。**
+1. 异步处理
+2. 削峰/限流
+3. 降低系统耦合性
+
+除了这三点之外,消息队列还有其他的一些应用场景,例如实现分布式事务、顺序保证和数据流处理。
如果在面试的时候你被面试官问到这个问题的话,一般情况是你在你的简历上涉及到消息队列这方面的内容,这个时候推荐你结合你自己的项目来回答。
-### 通过异步处理提高系统性能(减少响应所需时间)
+### 异步处理
-将用户的请求数据存储到消息队列之后就立即返回结果。随后,系统再对消息进行消费。
+将用户请求中包含的耗时操作,通过消息队列实现异步处理,将对应的消息发送到消息队列之后就立即返回结果,减少响应时间,提高用户体验。随后,系统再对消息进行消费。
因为用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败。因此,**使用消息队列进行异步处理之后,需要适当修改业务流程进行配合**,比如用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
@@ -67,15 +74,17 @@ tag:
### 降低系统耦合性
-使用消息队列还可以降低系统耦合性。我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。还是直接上图吧:
+使用消息队列还可以降低系统耦合性。如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
-
+生产者(客户端)发送消息到消息队列中去,消费者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合,这显然也提高了系统的扩展性。
-生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合,这显然也提高了系统的扩展性。
+
**消息队列使用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。** 从上图可以看到**消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合**,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。**对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计**。
-消息接受者对消息进行过滤、处理、包装后,构造成一个新的消息类型,将消息继续发送出去,等待其他消息接受者订阅该消息。因此基于事件(消息对象)驱动的业务架构可以是一系列流程。
+例如,我们商城系统分为用户、订单、财务、仓储、消息通知、物流、风控等多个服务。用户在完成下单后,需要调用财务(扣款)、仓储(库存管理)、物流(发货)、消息通知(通知用户发货)、风控(风险评估)等服务。使用消息队列后,下单操作和后续的扣款、发货、通知等操作就解耦了,下单完成发送一个消息到消息队列,需要用到的地方去订阅这个消息进行消费即可。
+
+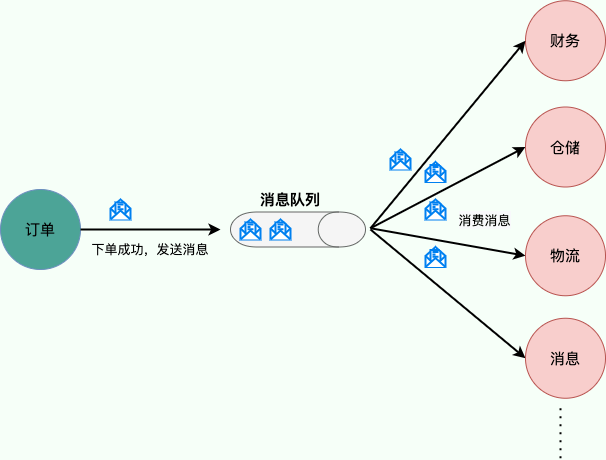
另外,为了避免消息队列服务器宕机造成消息丢失,会将成功发送到消息队列的消息存储在消息生产者服务器上,等消息真正被消费者服务器处理后才删除消息。在消息队列服务器宕机后,生产者服务器会选择分布式消息队列服务器集群中的其他服务器发布消息。
@@ -83,7 +92,7 @@ tag:
### 实现分布式事务
-我们知道分布式事务的解决方案之一就是 MQ 事务。
+分布式事务的解决方案之一就是 MQ 事务。
RocketMQ、 Kafka、Pulsar、QMQ 都提供了事务相关的功能。事务允许事件流应用将消费,处理,生产消息整个过程定义为一个原子操作。
@@ -91,6 +100,26 @@ RocketMQ、 Kafka、Pulsar、QMQ 都提供了事务相关的功能。事务允

+### 顺序保证
+
+在很多应用场景中,处理数据的顺序至关重要。消息队列保证数据按照特定的顺序被处理,适用于那些对数据顺序有严格要求的场景。大部分消息队列,例如 RocketMQ、RabbitMQ、Pulsar、Kafka,都支持顺序消息。
+
+### 延时/定时处理
+
+消息发送后不会立即被消费,而是指定一个时间,到时间后再消费。大部分消息队列,例如 RocketMQ、RabbitMQ、Pulsar,都支持定时/延时消息。
+
+
+
+### 即时通讯
+
+MQTT(消息队列遥测传输协议)是一种轻量级的通讯协议,采用发布/订阅模式,非常适合于物联网(IoT)等需要在低带宽、高延迟或不可靠网络环境下工作的应用。它支持即时消息传递,即使在网络条件较差的情况下也能保持通信的稳定性。
+
+RabbitMQ 内置了 MQTT 插件用于实现 MQTT 功能(默认不启用,需要手动开启)。
+
+### 数据流处理
+
+针对分布式系统产生的海量数据流,如业务日志、监控数据、用户行为等,消息队列可以实时或批量收集这些数据,并将其导入到大数据处理引擎中,实现高效的数据流管理和处理。
+
## 使用消息队列会带来哪些问题?
- **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了!
@@ -117,15 +146,15 @@ JMS 定义了五种不同的消息正文格式以及调用的消息类型,允
#### 点到点(P2P)模型
-
+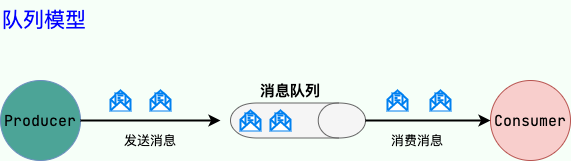
使用**队列(Queue)**作为消息通信载体;满足**生产者与消费者模式**,一条消息只能被一个消费者使用,未被消费的消息在队列中保留直到被消费或超时。比如:我们生产者发送 100 条消息的话,两个消费者来消费一般情况下两个消费者会按照消息发送的顺序各自消费一半(也就是你一个我一个的消费。)
#### 发布/订阅(Pub/Sub)模型
-
+
-发布订阅模型(Pub/Sub) 使用**主题(Topic)**作为消息通信载体,类似于**广播模式**;发布者发布一条消息,该消息通过主题传递给所有的订阅者,**在一条消息广播之后才订阅的用户则是收不到该条消息的**。
+发布订阅模型(Pub/Sub) 使用**主题(Topic)**作为消息通信载体,类似于**广播模式**;发布者发布一条消息,该消息通过主题传递给所有的订阅者。
### AMQP 是什么?
@@ -182,11 +211,11 @@ Kafka 是一个分布式系统,由通过高性能 TCP 网络协议进行通信
不过,要提示一下:**如果要使用 KRaft 模式的话,建议选择较高版本的 Kafka,因为这个功能还在持续完善优化中。Kafka 3.3.1 版本是第一个将 KRaft(Kafka Raft)共识协议标记为生产就绪的版本。**
-
+
-Kafka 官网:http://kafka.apache.org/
+Kafka 官网:
-Kafka 更新记录(可以直观看到项目是否还在维护):https://kafka.apache.org/downloads
+Kafka 更新记录(可以直观看到项目是否还在维护):
#### RocketMQ
@@ -207,9 +236,9 @@ RocketMQ 的核心特性(摘自 RocketMQ 官网):
> Apache RocketMQ 自诞生以来,因其架构简单、业务功能丰富、具备极强可扩展性等特点被众多企业开发者以及云厂商广泛采用。历经十余年的大规模场景打磨,RocketMQ 已经成为业内共识的金融级可靠业务消息首选方案,被广泛应用于互联网、大数据、移动互联网、物联网等领域的业务场景。
-RocketMQ 官网:https://rocketmq.apache.org/ (文档很详细,推荐阅读)
+RocketMQ 官网: (文档很详细,推荐阅读)
-RocketMQ 更新记录(可以直观看到项目是否还在维护):https://github.com/apache/rocketmq/releases
+RocketMQ 更新记录(可以直观看到项目是否还在维护):
#### RabbitMQ
@@ -228,9 +257,9 @@ RabbitMQ 发展到今天,被越来越多的人认可,这和它在易用性
- **易用的管理界面:** RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息、集群中的节点等。在安装 RabbitMQ 的时候会介绍到,安装好 RabbitMQ 就自带管理界面。
- **插件机制:** RabbitMQ 提供了许多插件,以实现从多方面进行扩展,当然也可以编写自己的插件。感觉这个有点类似 Dubbo 的 SPI 机制
-RabbitMQ 官网:https://www.rabbitmq.com/ 。
+RabbitMQ 官网: 。
-RabbitMQ 更新记录(可以直观看到项目是否还在维护):https://www.rabbitmq.com/news.html
+RabbitMQ 更新记录(可以直观看到项目是否还在维护):
#### Pulsar
@@ -253,9 +282,9 @@ Pulsar 的关键特性如下(摘自官网):
- 基于 Pulsar Functions 的 serverless connector 框架 Pulsar IO 使得数据更易移入、移出 Apache Pulsar。
- 分层式存储可在数据陈旧时,将数据从热存储卸载到冷/长期存储(如 S3、GCS)中。
-Pulsar 官网:https://pulsar.apache.org/
+Pulsar 官网:
-Pulsar 更新记录(可以直观看到项目是否还在维护):https://github.com/apache/pulsar/releases
+Pulsar 更新记录(可以直观看到项目是否还在维护):
#### ActiveMQ
@@ -284,5 +313,7 @@ Pulsar 更新记录(可以直观看到项目是否还在维护):https://gi
## 参考
- 《大型网站技术架构 》
-- KRaft: Apache Kafka Without ZooKeeper:https://developer.confluent.io/learn/kraft/
-- 消息队列的使用场景是什么样的?:https://mp.weixin.qq.com/s/4V1jI6RylJr7Jr9JsQe73A
+- KRaft: Apache Kafka Without ZooKeeper:
+- 消息队列的使用场景是什么样的?:
+
+
diff --git a/docs/high-performance/message-queue/rabbitmq-questions.md b/docs/high-performance/message-queue/rabbitmq-questions.md
index 0f0d9f8e519..0b044d255b6 100644
--- a/docs/high-performance/message-queue/rabbitmq-questions.md
+++ b/docs/high-performance/message-queue/rabbitmq-questions.md
@@ -1,18 +1,18 @@
---
title: RabbitMQ常见问题总结
+description: 本文总结 RabbitMQ 常见面试题与核心知识点,涵盖 AMQP 协议、Exchange 交换机类型(Direct/Topic/Fanout)、消息确认机制、死信队列、延迟队列、优先级队列、高可用集群(镜像队列)等,助力 RabbitMQ 学习与面试准备。
category: 高性能
tag:
- 消息队列
head:
- - meta
- name: keywords
- content: RabbitMQ,AMQP,Broker,Exchange,优先级队列,延迟队列
- - - meta
- - name: description
- content: RabbitMQ 是一个在 AMQP(Advanced Message Queuing Protocol )基础上实现的,可复用的企业消息系统。它可以用于大型软件系统各个模块之间的高效通信,支持高并发,支持可扩展。它支持多种客户端如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX,持久化,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
+ content: RabbitMQ,AMQP协议,Exchange交换机,消息确认,死信队列,延迟队列,优先级队列,RabbitMQ集群,消息队列面试
---
-> 本篇文章由 JavaGuide 收集自网络,原出处不明。
+RabbitMQ 作为老牌消息中间件,凭借其成熟的路由机制、丰富的协议支持和完善的可靠性保障,在企业级应用中占据重要地位。但自 RabbitMQ 3.8 引入 Quorum Queue、3.9 引入 Streams、4.0 移除镜像队列以来,其技术架构发生了重大变化,许多传统的最佳实践已不再适用。
+
+本文已针对 RabbitMQ 4.0 进行全面更新,明确标注各特性的版本依赖,特别强调了镜像队列(已移除)、Quorum Queue(推荐)和 Streams(3.9+)的选型差异。
## RabbitMQ 是什么?
@@ -20,14 +20,12 @@ RabbitMQ 是一个在 AMQP(Advanced Message Queuing Protocol )基础上实
RabbitMQ 是使用 Erlang 编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正是如此,使的它变的非常重量级,更适合于企业级的开发。它同时实现了一个 Broker 构架,这意味着消息在发送给客户端时先在中心队列排队,对路由(Routing)、负载均衡(Load balance)或者数据持久化都有很好的支持。
-PS:也可能直接问什么是消息队列?消息队列就是一个使用队列来通信的组件。
-
## RabbitMQ 特点?
- **可靠性**: RabbitMQ 使用一些机制来保证可靠性, 如持久化、传输确认及发布确认等。
-- **灵活的路由** : 在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能, RabbitMQ 己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个 交换器绑定在一起, 也可以通过插件机制来实现自己的交换器。
+- **灵活的路由** : 在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能, RabbitMQ 己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个交换器绑定在一起, 也可以通过插件机制来实现自己的交换器。
- **扩展性**: 多个 RabbitMQ 节点可以组成一个集群,也可以根据实际业务情况动态地扩展 集群中节点。
-- **高可用性** : 队列可以在集群中的机器上设置镜像,使得在部分节点出现问题的情况下队 列仍然可用。
+- **高可用性** : Quorum Queue 基于 Raft 协议实现数据复制,Streams 支持多节点副本,在部分节点出现问题的情况下队列仍然可用。
- **多种协议**: RabbitMQ 除了原生支持 AMQP 协议,还支持 STOMP, MQTT 等多种消息 中间件协议。
- **多语言客户端** :RabbitMQ 几乎支持所有常用语言,比如 Java、 Python、 Ruby、 PHP、 C#、 JavaScript 等。
- **管理界面** : RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息、集 群中的节点等。
@@ -39,7 +37,7 @@ RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、
RabbitMQ 的整体模型架构如下:
-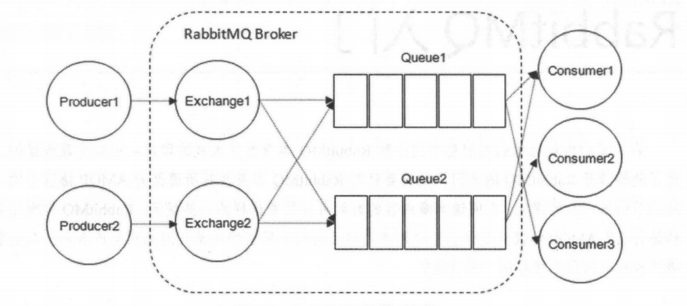
+
下面我会一一介绍上图中的一些概念。
@@ -56,19 +54,13 @@ RabbitMQ 的整体模型架构如下:
**Exchange(交换器)** 用来接收生产者发送的消息并将这些消息路由给服务器中的队列中,如果路由不到,或许会返回给 **Producer(生产者)** ,或许会被直接丢弃掉 。这里可以将 RabbitMQ 中的交换器看作一个简单的实体。
-**RabbitMQ 的 Exchange(交换器) 有 4 种类型,不同的类型对应着不同的路由策略**:**direct(默认)**,**fanout**, **topic**, 和 **headers**,不同类型的 Exchange 转发消息的策略有所区别。这个会在介绍 **Exchange Types(交换器类型)** 的时候介绍到。
-
-Exchange(交换器) 示意图如下:
+**RabbitMQ 的 Exchange(交换器) 有 4 种类型,不同的类型对应着不同的路由策略**:**direct**,**fanout**, **topic**, 和 **headers**,不同类型的 Exchange 转发消息的策略有所区别。这个会在介绍 **Exchange Types(交换器类型)** 的时候介绍到。
-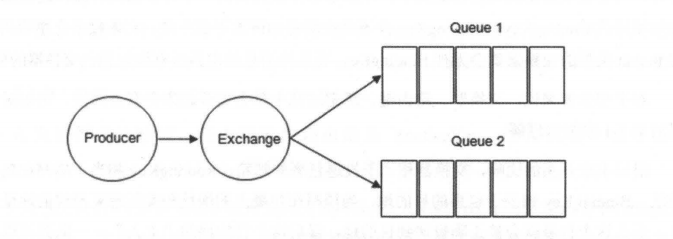
+> 注意:AMQP 规范定义了一个默认交换器(Default Exchange),它是一个 pre-declared 的 direct 类型交换器,但创建新交换器时必须显式指定类型,不能省略。
生产者将消息发给交换器的时候,一般会指定一个 **RoutingKey(路由键)**,用来指定这个消息的路由规则,而这个 **RoutingKey 需要与交换器类型和绑定键(BindingKey)联合使用才能最终生效**。
-RabbitMQ 中通过 **Binding(绑定)** 将 **Exchange(交换器)** 与 **Queue(消息队列)** 关联起来,在绑定的时候一般会指定一个 **BindingKey(绑定建)** ,这样 RabbitMQ 就知道如何正确将消息路由到队列了,如下图所示。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。Exchange 和 Queue 的绑定可以是多对多的关系。
-
-Binding(绑定) 示意图:
-
-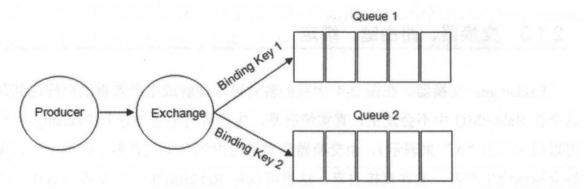
+RabbitMQ 中通过 **Binding(绑定)** 将 **Exchange(交换器)** 与 **Queue(消息队列)** 关联起来,在绑定的时候一般会指定一个 **BindingKey(绑定键)** ,这样 RabbitMQ 就知道如何正确将消息路由到队列了,如下图所示。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。Exchange 和 Queue 的绑定可以是多对多的关系。
生产者将消息发送给交换器时,需要一个 RoutingKey,当 BindingKey 和 RoutingKey 相匹配时,消息会被路由到对应的队列中。在绑定多个队列到同一个交换器的时候,这些绑定允许使用相同的 BindingKey。BindingKey 并不是在所有的情况下都生效,它依赖于交换器类型,比如 fanout 类型的交换器就会无视,而是将消息路由到所有绑定到该交换器的队列中。
@@ -76,9 +68,19 @@ Binding(绑定) 示意图:
**Queue(消息队列)** 用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。
-**RabbitMQ** 中消息只能存储在 **队列** 中,这一点和 **Kafka** 这种消息中间件相反。Kafka 将消息存储在 **topic(主题)** 这个逻辑层面,而相对应的队列逻辑只是 topic 实际存储文件中的位移标识。 RabbitMQ 的生产者生产消息并最终投递到队列中,消费者可以从队列中获取消息并消费。
+**RabbitMQ** 在经典架构中,消息只能存储在 **队列** 中,这一点和 **Kafka** 这种消息中间件相反。Kafka 将消息存储在 **topic(主题)** 这个逻辑层面,而相对应的队列逻辑只是 topic 实际存储文件中的位移标识。RabbitMQ 的生产者生产消息并最终投递到队列中,消费者可以从队列中获取消息并消费。
+
+> **版本说明(3.9+ 重要更新)**:从 RabbitMQ 3.9 版本开始,官方引入了 **Streams** 数据结构。Streams 提供了一种类似 Kafka 的 append-only 日志存储模型,支持非破坏性消费、大规模消息堆积以及基于 Offset 的历史数据重放(Replay)。
+>
+> **架构选型建议**:
+>
+> - **普通队列**:适用于传统消息队列场景,消息被消费后即删除
+> - **Streams**:适用于需要高频重放、海量堆积或事件溯源的场景
+> - **核心瓶颈差异**:使用 Stream 时,磁盘 I/O 吞吐量(MB/s)取代了传统的每秒入队率(msg/s)成为核心瓶颈指标
+
+**多个消费者可以订阅同一个队列**,默认情况下队列中的消息会被平均分摊(Round-Robin,即轮询)给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理,这样避免消息被重复消费。
-**多个消费者可以订阅同一个队列**,这时队列中的消息会被平均分摊(Round-Robin,即轮询)给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理,这样避免消息被重复消费。
+> 注意:实际分发策略受 `prefetch_count` 参数影响。默认行为(`prefetch_count=0`)会尽可能多地分发消息给各 Consumer,可能导致负载不均。推荐设置 `prefetch_count=1` 或更高值,让 Consumer 确认后再发送下一条,实现公平分发。
**RabbitMQ** 不支持队列层面的广播消费,如果有广播消费的需求,需要在其上进行二次开发,这样会很麻烦,不建议这样做。
@@ -86,26 +88,20 @@ Binding(绑定) 示意图:
对于 RabbitMQ 来说,一个 RabbitMQ Broker 可以简单地看作一个 RabbitMQ 服务节点,或者 RabbitMQ 服务实例。大多数情况下也可以将一个 RabbitMQ Broker 看作一台 RabbitMQ 服务器。
-下图展示了生产者将消息存入 RabbitMQ Broker,以及消费者从 Broker 中消费数据的整个流程。
-
-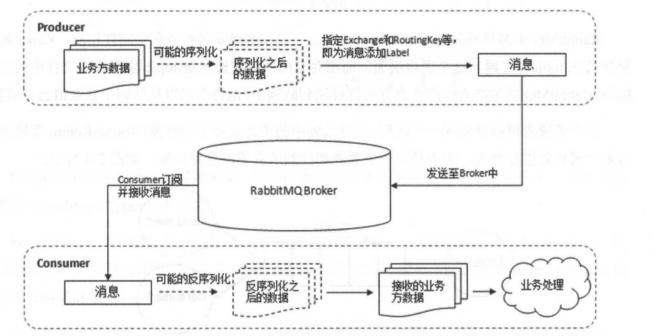
-
-这样图 1 中的一些关于 RabbitMQ 的基本概念我们就介绍完毕了,下面再来介绍一下 **Exchange Types(交换器类型)** 。
-
### Exchange Types(交换器类型)
-RabbitMQ 常用的 Exchange Type 有 **fanout**、**direct**、**topic**、**headers** 这四种(AMQP 规范里还提到两种 Exchange Type,分别为 system 与 自定义,这里不予以描述)。
+RabbitMQ 常用的 Exchange Type 有 **fanout**、**direct**、**topic**、**headers** 这四种(AMQP 规范里还提到两种 Exchange Type,分别为 system 与自定义,这里不予以描述)。
+
+
**1、fanout**
-fanout 类型的 Exchange 路由规则非常简单,它会把所有发送到该 Exchange 的消息路由到所有与它绑定的 Queue 中,不需要做任何判断操作,所以 fanout 类型是所有的交换机类型里面速度最快的。fanout 类型常用来广播消息。
+fanout 类型的 Exchange 路由规则非常简单,它会把所有发送到该 Exchange 的消息路由到所有与它绑定的 Queue 中,**忽略 BindingKey**,不需要做任何判断操作,所以 fanout 类型是所有的交换机类型里面速度最快的。fanout 类型常用来广播消息。
**2、direct**
direct 类型的 Exchange 路由规则也很简单,它会把消息路由到那些 Bindingkey 与 RoutingKey 完全匹配的 Queue 中。
-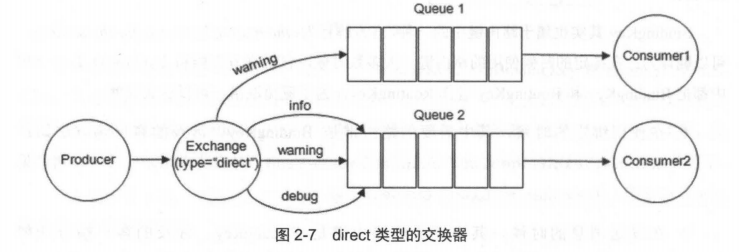
-
以上图为例,如果发送消息的时候设置路由键为“warning”,那么消息会路由到 Queue1 和 Queue2。如果在发送消息的时候设置路由键为"Info”或者"debug”,消息只会路由到 Queue2。如果以其他的路由键发送消息,则消息不会路由到这两个队列中。
direct 类型常用在处理有优先级的任务,根据任务的优先级把消息发送到对应的队列,这样可以指派更多的资源去处理高优先级的队列。
@@ -118,31 +114,27 @@ direct 类型常用在处理有优先级的任务,根据任务的优先级把
- BindingKey 和 RoutingKey 一样也是点号“.”分隔的字符串;
- BindingKey 中可以存在两种特殊字符串“\*”和“#”,用于做模糊匹配,其中“\*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)。
-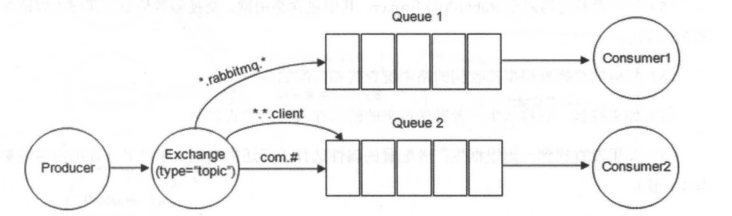
-
-以上图为例:
-
-- 路由键为 “com.rabbitmq.client” 的消息会同时路由到 Queue1 和 Queue2;
-- 路由键为 “com.hidden.client” 的消息只会路由到 Queue2 中;
-- 路由键为 “com.hidden.demo” 的消息只会路由到 Queue2 中;
-- 路由键为 “java.rabbitmq.demo” 的消息只会路由到 Queue1 中;
-- 路由键为 “java.util.concurrent” 的消息将会被丢弃或者返回给生产者(需要设置 mandatory 参数),因为它没有匹配任何路由键。
-
**4、headers(不推荐)**
headers 类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中的 headers 属性进行匹配。在绑定队列和交换器时指定一组键值对,当发送消息到交换器时,RabbitMQ 会获取到该消息的 headers(也是一个键值对的形式),对比其中的键值对是否完全匹配队列和交换器绑定时指定的键值对,如果完全匹配则消息会路由到该队列,否则不会路由到该队列。headers 类型的交换器性能会很差,而且也不实用,基本上不会看到它的存在。
## AMQP 是什么?
-RabbitMQ 就是 AMQP 协议的 `Erlang` 的实现(当然 RabbitMQ 还支持 `STOMP2`、 `MQTT3` 等协议 ) AMQP 的模型架构 和 RabbitMQ 的模型架构是一样的,生产者将消息发送给交换器,交换器和队列绑定 。
+RabbitMQ 就是 AMQP 协议的 `Erlang` 的实现(当然 RabbitMQ 还支持 `STOMP`、`MQTT` 等协议)。AMQP 的模型架构 和 RabbitMQ 的模型架构是一样的,生产者将消息发送给交换器,交换器和队列绑定。
-RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都是遵循的 AMQP 协议中相 应的概念。目前 RabbitMQ 最新版本默认支持的是 AMQP 0-9-1。
+RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都是遵循的 AMQP 协议中相 应的概念。
+
+> **版本说明**:
+>
+> - **AMQP 0-9-1**:RabbitMQ 的传统协议,广泛使用,功能完整
+> - **AMQP 1.0**:RabbitMQ 4.x 已将其提升为一等公民协议,改进了互操作性和性能
+> - 新项目可考虑使用 AMQP 1.0 以获得更好的跨平台兼容性
**AMQP 协议的三层**:
- **Module Layer**:协议最高层,主要定义了一些客户端调用的命令,客户端可以用这些命令实现自己的业务逻辑。
- **Session Layer**:中间层,主要负责客户端命令发送给服务器,再将服务端应答返回客户端,提供可靠性同步机制和错误处理。
-- **TransportLayer**:最底层,主要传输二进制数据流,提供帧的处理、信道服用、错误检测和数据表示等。
+- **TransportLayer**:最底层,主要传输二进制数据流,提供帧的处理、信道复用、错误检测和数据表示等。
**AMQP 模型的三大组件**:
@@ -164,13 +156,13 @@ RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都
## 说说 Broker 服务节点、Queue 队列、Exchange 交换器?
-- **Broker**:可以看做 RabbitMQ 的服务节点。一般请下一个 Broker 可以看做一个 RabbitMQ 服务器。
-- **Queue** :RabbitMQ 的内部对象,用于存储消息。多个消费者可以订阅同一队列,这时队列中的消息会被平摊(轮询)给多个消费者进行处理。
-- **Exchange** : 生产者将消息发送到交换器,由交换器将消息路由到一个或者多个队列中。当路由不到时,或返回给生产者或直接丢弃。
+- **Broker**:可以看做 RabbitMQ 的服务节点。一般情况下一个 Broker 可以看做一个 RabbitMQ 服务器。
+- **Queue**:RabbitMQ 的内部对象,用于存储消息。多个消费者可以订阅同一队列,这时队列中的消息会被平摊(轮询)给多个消费者进行处理。
+- **Exchange**:生产者将消息发送到交换器,由交换器将消息路由到一个或者多个队列中。当路由不到时,或返回给生产者或直接丢弃。
## 什么是死信队列?如何导致的?
-DLX,全称为 `Dead-Letter-Exchange`,死信交换器,死信邮箱。当消息在一个队列中变成死信 (`dead message`) 之后,它能被重新被发送到另一个交换器中,这个交换器就是 DLX,绑定 DLX 的队列就称之为死信队列。
+DLX,全称为 `Dead-Letter-Exchange`,死信交换器,死信邮箱。当消息在一个队列中变成死信 (`dead message`) 之后,它能被重新发送到另一个交换器中,这个交换器就是 DLX,绑定 DLX 的队列就称之为死信队列。
**导致的死信的几种原因**:
@@ -185,7 +177,13 @@ DLX,全称为 `Dead-Letter-Exchange`,死信交换器,死信邮箱。当消
RabbitMQ 本身是没有延迟队列的,要实现延迟消息,一般有两种方式:
1. 通过 RabbitMQ 本身队列的特性来实现,需要使用 RabbitMQ 的死信交换机(Exchange)和消息的存活时间 TTL(Time To Live)。
-2. 在 RabbitMQ 3.5.7 及以上的版本提供了一个插件(rabbitmq-delayed-message-exchange)来实现延迟队列功能。同时,插件依赖 Erlang/OPT 18.0 及以上。
+
+ - 缺点:消息按队列过期而非单消息级别(除非给每个消息单独队列)
+
+2. 在 RabbitMQ 3.5.7 及以上的版本提供了一个插件(rabbitmq-delayed-message-exchange)来实现延迟队列功能。同时,插件依赖 Erlang/OTP 18.0 及以上。
+ - 原理:将消息暂存在 Mnesia 表中,定时轮询并投递到目标交换器
+ - **容量边界警告(严重)**:该插件将延迟消息全部暂存在 Erlang 的 Mnesia 内部数据库中,**不具备良好的磁盘换页(Paging)能力**。如果单节点堆积**数十万到上百万级别**的延迟消息,会导致 Broker 内存剧增甚至触发**内存高水位(Memory Watermark)告警**,进而产生**全局背压(Global Backpressure)**阻塞所有生产者的 TCP 连接。
+ - **生产建议**:针对海量延迟(千万级以上),必须退化使用外部定时任务(如时间轮、SchedulerX、XXL-JOB)调度或死信链表方案
也就是说,AMQP 协议以及 RabbitMQ 本身没有直接支持延迟队列的功能,但是可以通过 TTL 和 DLX 模拟出延迟队列的功能。
@@ -205,24 +203,163 @@ RabbitMQ 自 V3.5.0 有优先级队列实现,优先级高的队列会先被消
## RabbitMQ 消息怎么传输?
-由于 TCP 链接的创建和销毁开销较大,且并发数受系统资源限制,会造成性能瓶颈,所以 RabbitMQ 使用信道的方式来传输数据。信道(Channel)是生产者、消费者与 RabbitMQ 通信的渠道,信道是建立在 TCP 链接上的虚拟链接,且每条 TCP 链接上的信道数量没有限制。就是说 RabbitMQ 在一条 TCP 链接上建立成百上千个信道来达到多个线程处理,这个 TCP 被多个线程共享,每个信道在 RabbitMQ 都有唯一的 ID,保证了信道私有性,每个信道对应一个线程使用。
+由于 TCP 链接的创建和销毁开销较大(三次握手、慢启动等),且并发数受系统资源限制,会造成性能瓶颈,所以 RabbitMQ 使用信道的方式来传输数据。信道(Channel)是生产者、消费者与 RabbitMQ 通信的渠道,信道是建立在 TCP 链接上的虚拟链接。
+
+> 注意:
+>
+> - 单个 TCP 连接可承载多个 Channel,但官方建议不超过 100-200 个/连接
+> - 每个 Channel 有独立的编号,但共享同一 TCP 连接的流量控制
+> - **Channel 不是线程安全的**,多线程应使用不同 Channel 实例
+
+## 如何保证消息的可靠性?
+
+
+
+消息可能在三个环节丢失:生产者 → Broker、Broker 存储期间、Broker → 消费者
+
+**1. 生产者 → Broker**
+
+保证生产者端零丢失需要**双重机制兜底**:
+
+- **Publisher Confirms**(异步确认):确认消息是否到达 Broker
+
+ ```java
+ channel.confirmSelect();
+ channel.addConfirmListener((sequenceNumber, multiple) -> {
+ // 消息已到达 Broker 并落盘/同步到镜像
+ }, (sequenceNumber, multiple) -> {
+ // 消息未到达 Broker,记录日志并重试
+ });
+ ```
+
+- **Mandatory + Return Listener**(路由失败处理):捕获消息到达 Exchange 但无法路由到 Queue 的情况
+
+ ```java
+ // 开启 mandatory 模式
+ channel.basicPublish("exchange", "routingKey",
+ true, // mandatory=true
+ null,
+ messageBody);
+
+ // 配置 Return Listener
+ channel.addReturnListener((replyCode, replyText, exchange, routingKey, properties, body) -> {
+ // 消息到达 Exchange 但路由失败,记录日志或发送到备用交换器
+ log.error("Message returned: {}", replyText);
+ });
+ ```
+
+> **关键警告**:若仅开启 Confirm 未处理 Return,配置漂移(如误删队列或绑定)会导致生产者认为发送成功,但消息在 Broker 内部被静默丢弃,形成**消息黑洞**。
+
+- **事务机制**(不推荐):同步阻塞,**性能显著下降(官方文档未给出具体倍数,实际影响取决于消息大小和网络延迟)**
+ - 注意:事务机制和 Confirm 机制是互斥的,两者不能共存
+
+**2. Broker 存储期间**
-## **如何保证消息的可靠性?**
+- **消息持久化**:`delivery_mode=2`,消息写入磁盘
+- **队列持久化**:`durable=true`,重启后队列重建
+- **集群模式**:
+ - **镜像队列**(Classic Queue Mirroring,已于 4.0 移除):主从同步,仅用于老版本维护
+ - **Quorum Queue**(3.8+ 推荐,4.0 后为默认):基于 Raft 协议,支持更严格的仲裁写入(N/2 + 1)
+ - **Streams**(3.9+):适用于事件溯源和高频重放场景
-消息到 MQ 的过程中搞丢,MQ 自己搞丢,MQ 到消费过程中搞丢。
+**3. Broker → 消费者**
-- 生产者到 RabbitMQ:事务机制和 Confirm 机制,注意:事务机制和 Confirm 机制是互斥的,两者不能共存,会导致 RabbitMQ 报错。
-- RabbitMQ 自身:持久化、集群、普通模式、镜像模式。
-- RabbitMQ 到消费者:basicAck 机制、死信队列、消息补偿机制。
+- **手动 Ack**:`basicAck(deliveryTag, multiple)`,确保消费成功后再确认
+- **重试机制**:消费失败时 `basicNack` 或 `basicReject` 并 `requeue=true`
+- **死信队列**:达到最大重试次数后路由到 DLQ 人工介入
+- **幂等性**:业务层实现(如唯一 ID 去重表)
+
+以下时序图展示了从生产者到消费者的完整消息流转及各环节的异常处理策略:
+
+```mermaid
+sequenceDiagram
+ participant P as 生产者 (Producer)
+ participant E as 交换器 (Exchange)
+ participant DLX as 死信交换器 (DLX)
+ participant Q as 队列 (Quorum Queue)
+ participant C as 消费者 (Consumer)
+
+ P->>E: 1. 发送消息 (开启 Confirm & Mandatory)
+ alt 路由成功
+ E->>Q: 2. 消息进入队列
+ Q-->>P: 3. Raft 多数派落盘后返回 Confirm Ack
+ else 路由失败 (无匹配 Queue, mandatory=true)
+ E-->>P: 2a. 触发 Return Listener 返回消息
+ Note over P: 记录日志或告警
+ end
+
+ Q->>C: 4. 推送消息 (开启手动 Ack)
+
+ alt 消费成功
+ C-->>Q: 5. 发送 basic.ack
+ Q->>Q: 6. 标记消息可删除
+ else 业务异常且可重试
+ C-->>Q: 5a. basic.nack (requeue=true)
+ Q->>Q: 6a. 消息重回队列尾部 (注意:顺序破坏)
+ else 致命异常 / 重试超限
+ C-->>Q: 5b. basic.reject (requeue=false)
+ Q->>DLX: 6b. 路由至死信交换机 (DLX)
+ end
+```
+
+**关键路径说明**:
+
+- **Confirm + Returns**(互为补充):
+ - Confirm 确认消息是否到达 Broker 并落盘/同步
+ - Mandatory + Return Listener 捕获路由失败事件(消息到达 Exchange 但无法进入 Queue)
+- **Quorum Queue**:Raft 多数派确认后才返回 Ack,保证数据不丢
+- **手动 Ack**:确保消费成功后才删除消息
+- **DLQ 兜底**:重试超限后路由到死信队列,避免消息无限重试
+
+> **注意**:Alternate Exchange(备用交换器)是另一种独立的路由失败处理机制,与 Mandatory + Return Listener 互斥。配置 Alternate Exchange 后,路由失败的消息会被转发到备用交换器,生产者收到的是正常的 Confirm Ack 而非 Return。
## 如何保证 RabbitMQ 消息的顺序性?
-- 拆分多个 queue(消息队列),每个 queue(消息队列) 一个 consumer(消费者),就是多一些 queue (消息队列)而已,确实是麻烦点;
-- 或者就一个 queue (消息队列)但是对应一个 consumer(消费者),然后这个 consumer(消费者)内部用内存队列做排队,然后分发给底层不同的 worker 来处理。
+RabbitMQ 仅保证**单个 Queue 内的 FIFO 顺序**,但多消费者场景下可能出现乱序。解决方案:
+
+**1. 单 Consumer 模式**
+
+- 一个 Queue 只绑定一个 Consumer
+- 优点:保证顺序
+- 缺点:成为瓶颈,吞吐量受限
+
+**2. 分区有序**(推荐,但需注意失效模式)
+
+- 按业务 key(如订单ID)哈希到不同 Queue
+- 每个 Queue 独立 Consumer
+- 优点:既保证顺序又提高吞吐量
+
+> **失效模式警告**:
+>
+> - **拓扑变更乱序**:当后端队列扩缩容导致哈希环发生变化时,同一个业务 Key 的新老消息可能进入不同队列
+> - **重试乱序**:若消费者内部处理失败执行 Nack 并 Requeue,该消息会被重新推入队列**尾部**,导致后续消息先被消费
+> - **应用层防护**:极端严格顺序场景下,消费者业务表必须设计基于**状态机**或**版本号**的幂等与防并发覆盖机制
+
+**3. 内部内存队列**(慎重)
+
+- 单一 Consumer 内部维护内存队列分发到 Worker 线程池
+- 需处理:
+ - Consumer 挂掉时内存队列丢失风险
+ - 需实现背压机制防止 OOM
+ - 增加 ack 复杂度(需追踪具体 Worker 处理状态)
+- 生产环境慎用此方案
## 如何保证 RabbitMQ 高可用的?
-RabbitMQ 是比较有代表性的,因为是基于主从(非分布式)做高可用性的,我们就以 RabbitMQ 为例子讲解第一种 MQ 的高可用性怎么实现。RabbitMQ 有三种模式:单机模式、普通集群模式、镜像集群模式。
+RabbitMQ 是比较有代表性的,因为是基于主从(非分布式)做高可用性的,我们就以 RabbitMQ 为例子讲解第一种 MQ 的高可用性怎么实现。RabbitMQ 有四种模式:单机模式、普通集群模式、镜像集群模式(已废弃)、Quorum Queue(推荐)。
+
+> **版本演进说明**:
+>
+> - **3.8 前**:镜像队列(Classic Queue Mirroring)是主要高可用方案
+> - **3.8+**:Quorum Queue 作为推荐替代方案,镜像队列被标记为 deprecated
+> - **3.13**:镜像队列仍可用但已废弃
+> - **4.0+**:镜像队列**完全移除**,Quorum Queue 成为默认高可用方案
+>
+> **网络分区警告(严重)**:无论是普通集群还是早期的镜像集群,均依赖 Erlang 内部的分布式同步机制,对网络抖动极度敏感。在多机房或跨可用区部署时,极易发生**网络分区(Split-brain)**。必须在 `rabbitmq.conf` 中明确配置分区恢复策略:
+>
+> - `pause_minority`:少数派节点自动暂停服务以防数据分化(推荐)
+> - `autoheal`:自动选择一方继续运行(有数据丢失风险)
+> - 对于 3.8 以上版本,强烈建议直接使用基于 Raft 一致性算法的 Quorum Queue,从根本上解决网络分区导致的消息丢失与状态不一致问题
**单机模式**
@@ -234,12 +371,269 @@ Demo 级别的,一般就是你本地启动了玩玩儿的?,没人生产用
你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从 queue 所在实例上拉取数据过来。这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个 queue 的读写操作。
-**镜像集群模式**
+**镜像集群模式**(Classic Queue Mirroring,已废弃)
+
+> ⚠️ **重要警告**:镜像队列已在 RabbitMQ 4.0 中被**完全移除**。RabbitMQ 3.8 引入 Quorum Queue 作为推荐替代方案,3.13 版本镜像队列仍可用但已废弃,4.0 版本正式移除。新项目请使用 Quorum Queue 或 Streams。
+
+这种模式是 RabbitMQ 早期版本的高可用方案。跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据。每次写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。
-这种模式,才是所谓的 RabbitMQ 的高可用模式。跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。RabbitMQ 有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
+**工作原理**:
-这样的好处在于,你任何一个机器宕机了,没事儿,其它机器(节点)还包含了这个 queue 的完整数据,别的 consumer 都可以到其它节点上去消费数据。坏处在于,第一,这个性能开销也太大了吧,消息需要同步到所有机器上,导致网络带宽压力和消耗很重!RabbitMQ 一个 queue 的数据都是放在一个节点里的,镜像集群下,也是每个节点都放这个 queue 的完整数据。
+- Queue 主节点接收消息,同步到 N 个镜像节点
+- 主节点宕机时,最老的镜像节点升级为主节点
+- 通过管理控制台新增策略,指定数据同步到所有节点或指定数量的节点
+
+**优点**:
+
+- 任何机器宕机,其他节点包含该 queue 的完整数据
+- Consumer 可以切换到其他节点继续消费
+
+**缺点**:
+
+- 性能开销大,消息需要同步到所有机器上
+- 网络带宽压力和消耗重
+- 不是真正的分布式架构,是主从复制
+
+**Quorum Queue**(3.8+ 推荐,4.0 后为默认高可用方案)
+
+基于 Raft 协议的复制队列,是 RabbitMQ 3.8+ 推荐的高可用方案,4.0 后成为默认选项:
+
+- **基于 Raft 协议**:通过日志复制和选举实现一致性
+- **仲裁写入**:需要多数节点确认(N/2 + 1)才认为写入成功
+- **更严格的一致性**:避免镜像队列的脑裂风险
+- **适用场景**:对可靠性要求高的场景
+
+**声明方式(客户端)**:
+
+Java:
+
+```java
+// Java 客户端声明 Quorum Queue
+Map args = new HashMap<>();
+args.put("x-queue-type", "quorum"); // 关键参数,必须在声明时指定
+channel.queueDeclare("my-queue", true, false, false, args);
+```
+
+Python:
+
+```python
+# Python (pika) 客户端声明 Quorum Queue
+channel.queue_declare(
+ queue='my-queue',
+ durable=True,
+ arguments={'x-queue-type': 'quorum'} # 关键参数
+)
+```
+
+> **重要提示**:`x-queue-type` 参数必须在队列声明时由客户端提供,**不能通过 Policy 设置或修改**。Policy 只能配置 max-length、delivery-limit 等运行时参数。
## 如何解决消息队列的延时以及过期失效问题?
-RabbtiMQ 是可以设置过期时间的,也就是 TTL。如果消息在 queue 中积压超过一定的时间就会被 RabbitMQ 给清理掉,这个数据就没了。那这就是第二个坑了。这就不是说数据会大量积压在 mq 里,而是大量的数据会直接搞丢。我们可以采取一个方案,就是批量重导,这个我们之前线上也有类似的场景干过。就是大量积压的时候,我们当时就直接丢弃数据了,然后等过了高峰期以后,比如大家一起喝咖啡熬夜到晚上 12 点以后,用户都睡觉了。这个时候我们就开始写程序,将丢失的那批数据,写个临时程序,一点一点的查出来,然后重新灌入 mq 里面去,把白天丢的数据给他补回来。也只能是这样了。假设 1 万个订单积压在 mq 里面,没有处理,其中 1000 个订单都丢了,你只能手动写程序把那 1000 个订单给查出来,手动发到 mq 里去再补一次。
+RabbitMQ 可以设置消息过期时间(TTL)。如果消息在 queue 中积压超过一定的时间就会被 RabbitMQ 清理掉,导致数据丢失。
+
+**批量重导方案**(适用于数据可恢复的场景):
+
+当大量消息积压或过期时,可采取以下步骤:
+
+1. **临时丢弃**:高峰期直接丢弃无法及时处理的数据,保证系统可用性
+2. **低峰期恢复**:在业务低峰期(如凌晨),编写临时程序从数据库中查询丢失的数据
+3. **重新投递**:将查询到的数据重新发送到 MQ 中进行补偿
+
+**示例场景**:
+
+- 假设 1 万个订单积压在 MQ 中未处理
+- 其中 1000 个订单因 TTL 过期被丢弃
+- 处理方案:编写临时程序从数据库查询这 1000 个订单,手动重新发送到 MQ 补偿
+
+**注意事项**:
+
+- 确保数据源(如数据库)中有完整的历史数据
+- 补偿过程需要做好幂等性处理,避免重复消费
+- 建议设置监控告警,及时发现消息积压情况
+
+## 生产环境最佳实践与监控告警
+
+### 核心监控指标
+
+**1. 内存水位线告警(严重)**
+
+- 监控 `rabbitmq_memory_limit` 占比
+- 告警阈值:默认高水位为 0.4(40%)
+- **影响**:一旦达到高水位,RabbitMQ 会直接 **block 所有生产者的 TCP Socket**(全局背压)
+- 建议配置:
+ ```erlang
+ {rabbit, [
+ {vm_memory_high_watermark, 0.4}, % 内存高水位 40%
+ {vm_memory_high_watermark_paging_ratio, 0.5} % 开始分页的比例
+ ]}
+ ```
+
+**2. 文件句柄消耗**
+
+- 监控 File Descriptors 使用率
+- **风险**:连接数风暴或海量未确认消息会耗尽句柄导致节点 Crash
+- 建议值:系统限制至少 100,000+(`ulimit -n 100000`)
+
+**3. Channel Churn Rate**
+
+- 监控信道的创建与销毁速率
+- **风险**:高频创建销毁(而非复用)会导致 Erlang 进程抖动,引发 CPU 飙升
+- 生产建议:单连接 Channel 数建议 50-100,避免频繁创建/销毁
+
+**4. 消息积压深度**
+
+- 监控 Queue 消息数量和 Consumer Lag
+- 告警阈值:根据业务定义(如 > 10,000 条)
+- 工具:RabbitMQ Management UI、Prometheus + Grafana
+
+**5. 磁盘空间与 I/O**
+
+- 监控磁盘剩余空间和 IOPS
+- **告警阈值**:磁盘剩余 < 20% 触发告警
+- Quorum Queue 对磁盘 I/O 要求较高,建议使用 NVMe SSD
+
+### 常见生产误区与避坑指南
+
+**误区 1:Quorum Queue 是银弹,能解决所有问题**
+
+- **真相**:Quorum Queue 的 Raft 日志在 flush 时会 fsync,且 Confirm 需等待多数节点 fsync 后才返回。如果底层不是高性能 NVMe SSD,其吞吐量会受到影响
+- **限制**:Quorum Queue 会将所有消息(包括 `delivery_mode=1` 的非持久化消息)强制持久化存储到磁盘
+- **选型建议**:
+ - 高吞吐量场景:考虑 Classic Queue(非镜像,单节点)或 Streams(3.9+)
+ - 高可靠性场景:使用 Quorum Queue(3.8+)
+
+**误区 2:Prefetch Count 设置越大越好**
+
+- **真相**:客户端批量拉取大量消息但在本地卡死,导致服务端队列看似空闲,实则消息全部处于 Unacked 状态,拖垮客户端本地内存并阻碍其他消费者接盘
+- **生产建议**:核心业务初始值设为 **10 到 50** 之间,根据处理耗时调整
+ ```java
+ channel.basicQos(20); // 推荐起始值
+ ```
+
+**误区 3:延迟队列插件可以无限制使用**
+
+- **真相**:延迟插件将所有延迟消息存储在 Mnesia 内存表中,**不支持磁盘换页**
+- **风险**:单节点堆积百万级延迟消息会触发 OOM 或全局背压
+- **替代方案**:海量延迟场景使用外部定时任务系统(如 XXL-JOB、SchedulerX)
+
+**误区 4:网络分区不会发生在我们环境**
+
+- **真相**:跨机房部署或网络抖动都会触发 Erlang 的网络分区检测
+- **后果**:Split-brain 导致消息丢失、状态不一致
+- **防护**:
+ - 3.8+ 使用 Quorum Queue(基于 Raft,天然抗分区)
+ - 配置分区恢复策略:`cluster_partition_handling = pause_minority`
+
+**误区 5:开启了事务机制就万无一失**
+
+- **真相**:事务机制是同步阻塞模式,性能显著低于 Publisher Confirms(官方文档未给出具体倍数,实际影响取决于消息大小和网络延迟)
+- **替代方案**:使用 Publisher Confirms + Mandatory Returns(异步且高性能)
+
+### 生产配置参考
+
+> **重要说明**:RabbitMQ 3.7+ 使用新的 `rabbitmq.conf` 格式(sysctl 风格),而非旧的 `advanced.config`(Erlang 术语格式)。以下配置适用于 `rabbitmq.conf`:
+
+```ini
+# rabbitmq.conf 生产环境推荐配置
+
+# 内存管理
+vm_memory_high_watermark.relative = 0.4
+vm_memory_high_watermark_paging_ratio = 0.5
+
+# 磁盘管理
+disk_free_limit.absolute = 5GB
+
+# 连接与通道
+channel_max = 200
+connection_max = infinity
+
+# 心跳检测(秒)
+heartbeat = 60
+
+# 网络分区处理(重要)
+cluster_partition_handling = pause_minority
+
+# 默认用户(生产环境请修改或删除)
+default_user = guest
+default_pass = guest
+loopback_users = none
+
+# 管理插件监听端口
+management.tcp.port = 15672
+```
+
+如需使用 Erlang 术语格式(高级配置),请使用 `advanced.config` 文件,但**不要与 `rabbitmq.conf` 混用**。
+
+## 总结
+
+本文系统梳理了 RabbitMQ 的核心知识点,从基础概念到生产实践,涵盖了面试和实际应用中最重要的内容。让我们回顾一下关键要点:
+
+### 核心技术架构演进
+
+| 版本里程碑 | 重要变化 | 生产影响 |
+| ---------- | --------------------------------------- | -------------------------------------- |
+| **3.8 前** | 镜像队列(Classic Queue Mirroring)时代 | 主从复制,脑裂风险 |
+| **3.8+** | Quorum Queue 引入 | 基于 Raft,推荐用于高可靠场景 |
+| **3.9+** | Streams 引入 | Kafka-like 架构,支持事件溯源 |
+| **4.0+** | 镜像队列完全移除 | 新项目必须使用 Quorum Queue 或 Streams |
+
+### 面试高频考点
+
+**必知必会**:
+
+1. **AMQP 模型**:Exchange、Queue、Binding 三大核心组件
+2. **Exchange 类型**:direct、fanout、topic、headers 的路由规则
+3. **消息可靠性**:Publisher Confirms + Mandatory Returns + 手动 Ack + DLQ
+4. **消息顺序性**:单 Queue 内 FIFO,多消费者需分区有序或单 Consumer
+5. **高可用方案**:Quorum Queue(3.8+)替代镜像队列(4.0 已移除)
+
+**常见追问**:
+
+- 为什么镜像队列被移除?(脑裂问题、主从复制非分布式)
+- Quorum Queue 和 Classic Queue 如何选型?(可靠性 vs 吞吐量)
+- 如何保证消息不丢失?(三环节:生产者→Broker→消费者)
+- 如何保证消息顺序?(单 Queue、分区有序、慎用内存队列)
+
+### 生产环境关键决策
+
+**1. 队列类型选型**
+
+```
+高可靠性需求 → Quorum Queue(默认推荐)
+高吞吐量需求 → Classic Queue(单节点)或 Streams(3.9+)
+事件溯源需求 → Streams(支持非破坏性消费)
+```
+
+**2. 消息可靠性配置**
+
+```java
+// 生产者端:双重保障
+channel.confirmSelect(); // Confirm
+channel.basicPublish(exchange, routingKey, true, ...); // Mandatory
+channel.addReturnListener(...); // Return Listener
+
+// 消费者端:手动确认
+channel.basicQos(20); // Fair dispatch
+channel.basicConsume(queue, false, ...); // Manual ack
+```
+
+**3. 高可用配置要点**
+
+```ini
+# 网络分区处理(跨机房部署必配)
+cluster_partition_handling = pause_minority
+
+# 使用 Quorum Queue(客户端声明)
+arguments.put("x-queue-type", "quorum");
+```
+
+**4. 监控告警指标**
+
+- **内存水位线**:触发全局背压的阈值(默认 40%)
+- **磁盘剩余空间**:低于 20% 触发告警
+- **消息积压深度**:Queue 消息数量和 Consumer Lag
+- **Channel Churn Rate**:高频创建销毁会导致 CPU 飙升
+
+---
+
+
diff --git a/docs/high-performance/message-queue/rocketmq-questions.md b/docs/high-performance/message-queue/rocketmq-questions.md
index 81c467201c5..03ad07e9b90 100644
--- a/docs/high-performance/message-queue/rocketmq-questions.md
+++ b/docs/high-performance/message-queue/rocketmq-questions.md
@@ -1,18 +1,27 @@
---
title: RocketMQ常见问题总结
+description: 本文总结 RocketMQ 常见面试题与核心知识点,涵盖 RocketMQ 架构(NameServer/Broker/Proxy)、消息类型(普通/顺序/事务/定时消息)、消息存储机制(CommitLog/ConsumeQueue)、高性能原理(零拷贝/顺序写)、消息可靠性保障、RocketMQ 5.x 新特性等,助力 RocketMQ 学习与面试。
category: 高性能
tag:
- RocketMQ
- 消息队列
+head:
+ - - meta
+ - name: keywords
+ content: RocketMQ,消息队列,NameServer,Broker,Proxy,顺序消息,事务消息,定时消息,消息存储,RocketMQ面试,RocketMQ5.x
---
-> [本文由 FrancisQ 投稿!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485969&idx=1&sn=6bd53abde30d42a778d5a35ec104428c&chksm=cea245daf9d5cccce631f93115f0c2c4a7634e55f5bef9009fd03f5a0ffa55b745b5ef4f0530&token=294077121&lang=zh_CN#rd)
+> 本文由 FrancisQ 投稿!相比原文主要进行了下面这些完善:
+>
+> - [分析了 RocketMQ 高性能读写的原因和顺序消费的具体实现](https://github.com/Snailclimb/JavaGuide/pull/2133)
+> - [增加了消息类型、消费者类型、消费者组和生产者组的介绍](https://github.com/Snailclimb/JavaGuide/pull/2134)
+> - [RocketMQ 5.x 支持按消息粒度分配](https://github.com/Snailclimb/JavaGuide/issues/2778)
## 消息队列扫盲
-消息队列顾名思义就是存放消息的队列,队列我就不解释了,别告诉我你连队列都不知道是啥吧?
+消息队列(Message Queue,简称 MQ)是一种应用程序之间的通信方式,用于在分布式系统中传递消息。消息队列的核心概念是生产者将消息发送到队列,消费者从队列中获取消息进行处理。
-所以问题并不是消息队列是什么,而是 **消息队列为什么会出现?消息队列能用来干什么?用它来干这些事会带来什么好处?消息队列会带来副作用吗?**
+理解消息队列,关键是要回答以下几个问题:**消息队列为什么会出现?消息队列能用来干什么?使用消息队列能带来什么好处?消息队列会带来哪些副作用?**
### 消息队列为什么会出现?
@@ -22,39 +31,37 @@ tag:
#### 异步
-你可能会反驳我,应用之间的通信又不是只能由消息队列解决,好好的通信为什么中间非要插一个消息队列呢?我不能直接进行通信吗?
+你可能会问,应用之间的通信又不是只能由消息队列解决,为什么中间非要插一个消息队列?直接进行通信不行吗?
-很好 👍,你又提出了一个概念,**同步通信**。就比如现在业界使用比较多的 `Dubbo` 就是一个适用于各个系统之间同步通信的 `RPC` 框架。
+这就引出了另一个概念——**同步通信**。比如业界使用较多的 Dubbo 就是一个适用于各个系统之间同步通信的 RPC 框架。
-我来举个 🌰 吧,比如我们有一个购票系统,需求是用户在购买完之后能接收到购买完成的短信。
+以购票系统为例,需求是用户在购买完成之后能接收到购买完成的短信通知。
-
+
我们省略中间的网络通信时间消耗,假如购票系统处理需要 150ms ,短信系统处理需要 200ms ,那么整个处理流程的时间消耗就是 150ms + 200ms = 350ms。
-当然,乍看没什么问题。可是仔细一想你就感觉有点问题,我用户购票在购票系统的时候其实就已经完成了购买,而我现在通过同步调用非要让整个请求拉长时间,而短信系统这玩意又不是很有必要,它仅仅是一个辅助功能增强用户体验感而已。我现在整个调用流程就有点 **头重脚轻** 的感觉了,购票是一个不太耗时的流程,而我现在因为同步调用,非要等待发送短信这个比较耗时的操作才返回结果。那我如果再加一个发送邮件呢?
+当然,乍看没什么问题。但仔细分析会发现问题:用户购票在购票系统处理完成时就已经完成了购买动作,而现在通过同步调用非要让整个请求时间变长。短信系统只是一个辅助功能,用于增强用户体验感,并非核心业务。整个调用流程显得 **头重脚轻**——购票是一个不太耗时的流程,但因为同步调用,必须等待发送短信这个较耗时的操作完成才能返回结果。如果再加一个发送邮件的需求呢?
-
+
这样整个系统的调用链又变长了,整个时间就变成了 550ms。
-当我们在学生时代需要在食堂排队的时候,我们和食堂大妈就是一个同步的模型。
-
-我们需要告诉食堂大妈:“姐姐,给我加个鸡腿,再加个酸辣土豆丝,帮我浇点汁上去,多打点饭哦 😋😋😋” 咦~~~ 为了多吃点,真恶心。
+当我们在食堂排队打饭时,我们和食堂工作人员之间就是一个同步模型。
-然后大妈帮我们打饭配菜,我们看着大妈那颤抖的手和掉落的土豆丝不禁咽了咽口水。
+我们需要告诉工作人员:"请帮我加个鸡腿,再加个酸辣土豆丝,多打点饭"。
-最终我们从大妈手中接过饭菜然后去寻找座位了...
+然后工作人员帮我们打饭配菜,我们需要等待这个过程完成。
-回想一下,我们在给大妈发送需要的信息之后我们是 **同步等待大妈给我配好饭菜** 的,上面我们只是加了鸡腿和土豆丝,万一我再加一个番茄牛腩,韭菜鸡蛋,这样是不是大妈打饭配菜的流程就会变长,我们等待的时间也会相应的变长。
+最终我们从工作人员手中接过饭菜然后去寻找座位。
-
+回想一下,我们在传达需求之后是 **同步等待工作人员配好饭菜** 的。如果增加更多菜品,工作人员打饭配菜的流程就会变长,我们等待的时间也会相应增加。
-那后来,我们工作赚钱了有钱去饭店吃饭了,我们告诉服务员来一碗牛肉面加个荷包蛋 **(传达一个消息)** ,然后我们就可以在饭桌上安心的玩手机了 **(干自己其他事情)** ,等到我们的牛肉面上了我们就可以吃了。这其中我们也就传达了一个消息,然后我们又转过头干其他事情了。这其中虽然做面的时间没有变短,但是我们只需要传达一个消息就可以干其他事情了,这是一个 **异步** 的概念。
+而在餐厅用餐时,我们告诉服务员来一碗牛肉面加个荷包蛋 **(传达一个消息)** ,然后可以在餐桌上做自己的事情 **(干自己其他事情)** ,等到牛肉面上桌我们再开始用餐。虽然做面的时间没有变短,但是我们只需要传达一个消息就可以干其他事情了,这就是 **异步** 的概念。
所以,为了解决这一个问题,聪明的程序员在中间也加了个类似于服务员的中间件——消息队列。这个时候我们就可以把模型给改造了。
-
+
这样,我们在将消息存入消息队列之后我们就可以直接返回了(我们告诉服务员我们要吃什么然后玩手机),所以整个耗时只是 150ms + 10ms = 160ms。
@@ -64,41 +71,68 @@ tag:
回到最初同步调用的过程,我们写个伪代码简单概括一下。
-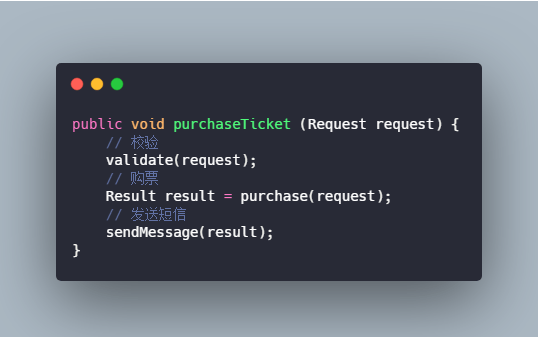
+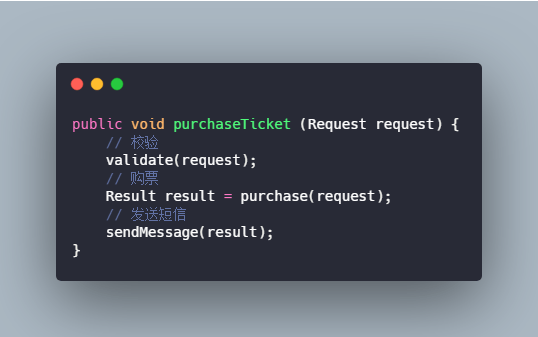
那么第二步,我们又添加了一个发送邮件,我们就得重新去修改代码,如果我们又加一个需求:用户购买完还需要给他加积分,这个时候我们是不是又得改代码?
-
+
-如果你觉得还行,那么我这个时候不要发邮件这个服务了呢,我是不是又得改代码,又得重启应用?
+如果还觉得可以接受,那么当需要移除发送邮件服务时,是不是又得改代码、又得重启应用?
-
+
-这样改来改去是不是很麻烦,那么 **此时我们就用一个消息队列在中间进行解耦** 。你需要注意的是,我们后面的发送短信、发送邮件、添加积分等一些操作都依赖于上面的 `result` ,这东西抽象出来就是购票的处理结果呀,比如订单号,用户账号等等,也就是说我们后面的一系列服务都是需要同样的消息来进行处理。既然这样,我们是不是可以通过 **“广播消息”** 来实现。
+这样频繁改动代码显然很麻烦,此时可以 **使用消息队列进行解耦** 。需要注意的是,后面的发送短信、发送邮件、添加积分等操作都依赖于 `result`,即购票的处理结果(如订单号、用户账号等),也就是说后续服务都需要相同的消息来进行处理。因此可以通过 **"广播消息"** 模式来实现。
-我上面所讲的“广播”并不是真正的广播,而是接下来的系统作为消费者去 **订阅** 特定的主题。比如我们这里的主题就可以叫做 `订票` ,我们购买系统作为一个生产者去生产这条消息放入消息队列,然后消费者订阅了这个主题,会从消息队列中拉取消息并消费。就比如我们刚刚画的那张图,你会发现,在生产者这边我们只需要关注 **生产消息到指定主题中** ,而 **消费者只需要关注从指定主题中拉取消息** 就行了。
+这里所说的"广播"并不是真正的广播,而是下游系统作为消费者去 **订阅** 特定的主题。比如主题可以命名为 `订票`,购买系统作为生产者将消息发送到消息队列,消费者订阅该主题后,从消息队列中拉取消息并消费。在生产者端只需要关注 **生产消息到指定主题** ,**消费者只需要关注从指定主题中拉取消息** 。
-
+
> 如果没有消息队列,每当一个新的业务接入,我们都要在主系统调用新接口、或者当我们取消某些业务,我们也得在主系统删除某些接口调用。有了消息队列,我们只需要关心消息是否送达了队列,至于谁希望订阅,接下来收到消息如何处理,是下游的事情,无疑极大地减少了开发和联调的工作量。
#### 削峰
-我们再次回到一开始我们使用同步调用系统的情况,并且思考一下,如果此时有大量用户请求购票整个系统会变成什么样?
+回到同步调用系统的场景,思考一下:如果此时有大量用户请求购票,整个系统会变成什么样?
+
+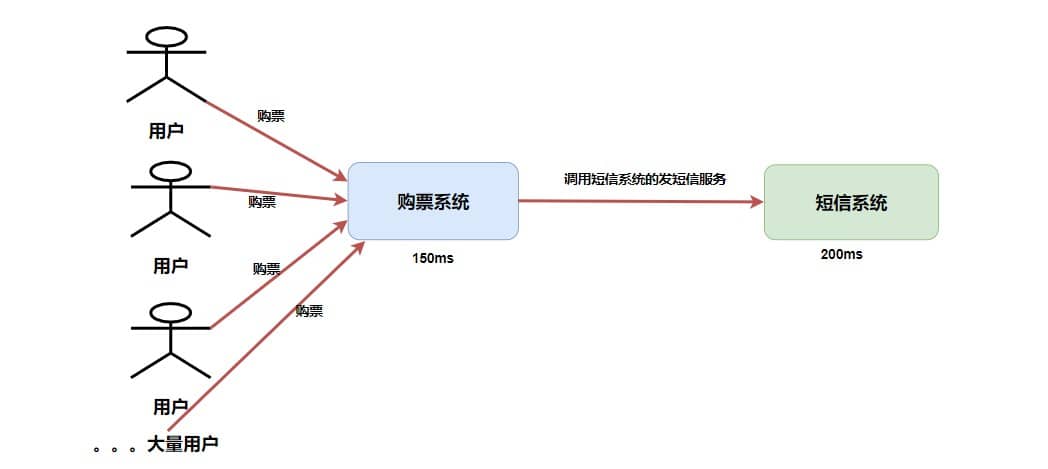
+
+假设有一万个请求进入购票系统,运行主业务的服务器配置通常较好,购票系统可以承受这一万个用户请求。但这意味着同时也会产生一万个调用短信服务的请求。短信系统并非主要业务,配备的硬件资源不会太高。此时短信系统能否承受这一万的峰值?很可能系统会 **直接崩溃** 。
+
+短信业务并非主业务,能否 **折中处理** ?如果我们把购买完成的信息发送到消息队列中,而短信系统 **尽自己所能地去消息队列中取消息和消费消息** ,即使处理速度慢一点也无所谓,只要系统没有崩溃就可以接受。
+
+系统可用性是最重要的,验证码短信的延迟几秒到达用户手机,通常是可以接受的。
+
+### 消息队列能带来什么好处?
+
+总结起来就是三个关键词:**异步、解耦、削峰**。这不仅是消息队列的核心价值,更是分布式架构设计的重要思想。
-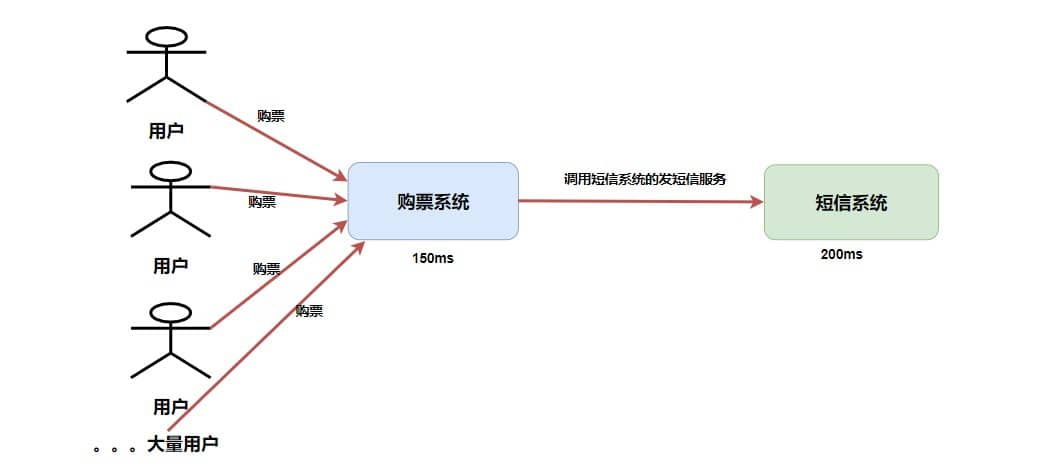
+```mermaid
+flowchart LR
+ subgraph MQ["消息队列三大应用场景"]
+ style MQ fill:#F0F2F5,stroke:#E0E6ED,stroke-width:1.5px
+ Async["异步处理"]
+ Decouple["解耦"]
+ Peak["削峰"]
+ end
-如果,此时有一万的请求进入购票系统,我们知道运行我们主业务的服务器配置一般会比较好,所以这里我们假设购票系统能承受这一万的用户请求,那么也就意味着我们同时也会出现一万调用发短信服务的请求。而对于短信系统来说并不是我们的主要业务,所以我们配备的硬件资源并不会太高,那么你觉得现在这个短信系统能承受这一万的峰值么,且不说能不能承受,系统会不会 **直接崩溃** 了?
+ Async --> A1["提高响应速度"]
+ Async --> A2["提升用户体验"]
-短信业务又不是我们的主业务,我们能不能 **折中处理** 呢?如果我们把购买完成的信息发送到消息队列中,而短信系统 **尽自己所能地去消息队列中取消息和消费消息** ,即使处理速度慢一点也无所谓,只要我们的系统没有崩溃就行了。
+ Decouple --> D1["降低系统耦合"]
+ Decouple --> D2["提高扩展性"]
-留得江山在,还怕没柴烧?你敢说每次发送验证码的时候是一发你就收到了的么?
+ Peak --> P1["缓解系统压力"]
+ Peak --> P2["保证系统稳定"]
-#### 消息队列能带来什么好处?
+ classDef app fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef benefit fill:#00838F,color:#fff,rx:10,ry:10
-其实上面我已经说了。**异步、解耦、削峰。** 哪怕你上面的都没看懂也千万要记住这六个字,因为他不仅是消息队列的精华,更是编程和架构的精华。
+ class Async,Decouple,Peak app
+ class A1,A2,D1,D2,P1,P2 benefit
-#### 消息队列会带来副作用吗?
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
+
+### 消息队列会带来副作用吗?
没有哪一门技术是“银弹”,消息队列也有它的副作用。
@@ -126,45 +160,60 @@ tag:
那么,又如何 **解决消息堆积的问题** 呢?
-可用性降低,复杂度上升,又带来一系列的重复消费,顺序消费,分布式事务,消息堆积的问题,这消息队列还怎么用啊 😵?
+可用性降低、复杂度上升,同时还带来重复消费、顺序消费、分布式事务、消息堆积等一系列问题。这些问题如何解决?
-
+
-别急,办法总是有的。
+下面我们逐一讨论这些问题的解决方案。
## RocketMQ 是什么?
-
-
-哇,你个混蛋!上面给我抛出那么多问题,你现在又讲 `RocketMQ` ,还让不让人活了?!🤬
+
-别急别急,话说你现在清楚 `MQ` 的构造吗,我还没讲呢,我们先搞明白 `MQ` 的内部构造,再来看看如何解决上面的一系列问题吧,不过你最好带着问题去阅读和了解喔。
+在讨论上述问题的解决方案之前,我们先来了解一下 RocketMQ 的内部构造。建议带着问题去阅读和了解。
-`RocketMQ` 是一个 **队列模型** 的消息中间件,具有**高性能、高可靠、高实时、分布式** 的特点。它是一个采用 `Java` 语言开发的分布式的消息系统,由阿里巴巴团队开发,在 2016 年底贡献给 `Apache`,成为了 `Apache` 的一个顶级项目。 在阿里内部,`RocketMQ` 很好地服务了集团大大小小上千个应用,在每年的双十一当天,更有不可思议的万亿级消息通过 `RocketMQ` 流转。
+RocketMQ 是一个 **队列模型** 的消息中间件,具有**高性能、高可靠、高实时、分布式** 的特点。它是一个采用 Java 语言开发的分布式消息系统,由阿里巴巴团队开发,在 2016 年底贡献给 Apache,成为了 Apache 的顶级项目。在阿里内部,RocketMQ 很好地服务了集团大大小小上千个应用,在每年的双十一当天,更有万亿级消息通过 RocketMQ 流转。
-废话不多说,想要了解 `RocketMQ` 历史的同学可以自己去搜寻资料。听完上面的介绍,你只要知道 `RocketMQ` 很快、很牛、而且经历过双十一的实践就行了!
+RocketMQ 具备高吞吐、低延迟、高可用的特点,经过了双十一等大规模场景的验证。
## 队列模型和主题模型是什么?
-在谈 `RocketMQ` 的技术架构之前,我们先来了解一下两个名词概念——**队列模型** 和 **主题模型** 。
+在谈 RocketMQ 的技术架构之前,我们先来了解一下两个名词概念——**队列模型** 和 **主题模型** 。
-首先我问一个问题,消息队列为什么要叫消息队列?
+首先,为什么消息队列叫消息队列?
-你可能觉得很弱智,这玩意不就是存放消息的队列嘛?不叫消息队列叫什么?
+实际上,早期的消息中间件是通过 **队列** 这一模型来实现的,可能是历史原因,我们都习惯把消息中间件称为消息队列。
-的确,早期的消息中间件是通过 **队列** 这一模型来实现的,可能是历史原因,我们都习惯把消息中间件成为消息队列。
-
-但是,如今例如 `RocketMQ`、`Kafka` 这些优秀的消息中间件不仅仅是通过一个 **队列** 来实现消息存储的。
+但是,如今例如 RocketMQ、Kafka 这些优秀的消息中间件不仅仅是通过一个 **队列** 来实现消息存储的。
### 队列模型
-就像我们理解队列一样,消息中间件的队列模型就真的只是一个队列。。。我画一张图给大家理解。
+就像我们理解队列一样,消息中间件的队列模型就真的只是一个队列。
+
+
+
+队列模型的特点:**一个消息只能被一个消费者消费**。
+
+```mermaid
+flowchart LR
+ P["生产者"] --> Q["队列"]
+ Q --> C1["消费者1"]
+ Q --> C2["消费者2"]
+
+ classDef producer fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef queue fill:#E99151,color:#fff,rx:10,ry:10
+ classDef consumer fill:#00838F,color:#fff,rx:10,ry:10
-
+ class P producer
+ class Q queue
+ class C1,C2 consumer
-在一开始我跟你提到了一个 **“广播”** 的概念,也就是说如果我们此时我们需要将一个消息发送给多个消费者(比如此时我需要将信息发送给短信系统和邮件系统),这个时候单个队列即不能满足需求了。
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
-当然你可以让 `Producer` 生产消息放入多个队列中,然后每个队列去对应每一个消费者。问题是可以解决,创建多个队列并且复制多份消息是会很影响资源和性能的。而且,这样子就会导致生产者需要知道具体消费者个数然后去复制对应数量的消息队列,这就违背我们消息中间件的 **解耦** 这一原则。
+在一开始我跟你提到了一个 **"广播"** 的概念,也就是说如果我们此时我们需要将一个消息发送给多个消费者(比如此时我需要将信息发送给短信系统和邮件系统),这个时候单个队列即不能满足需求了。
+
+当然你可以让 Producer 生产消息放入多个队列中,然后每个队列去对应每一个消费者。问题是可以解决,创建多个队列并且复制多份消息是会很影响资源和性能的。而且,这样子就会导致生产者需要知道具体消费者个数然后去复制对应数量的消息队列,这就违背我们消息中间件的 **解耦** 这一原则。
### 主题模型
@@ -176,133 +225,1135 @@ tag:
其中,发布者将消息发送到指定主题中,订阅者需要 **提前订阅主题** 才能接受特定主题的消息。
-
+
+
+主题模型的特点:**一个消息可以被多个消费者消费**。
+
+```mermaid
+flowchart LR
+ P1["发布者1"] --> T["主题"]
+ P2["发布者2"] --> T
+ T --> S1["订阅者1"]
+ T --> S2["订阅者2"]
+ T --> S3["订阅者3"]
+
+ classDef publisher fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef topic fill:#E99151,color:#fff,rx:10,ry:10
+ classDef subscriber fill:#00838F,color:#fff,rx:10,ry:10
+
+ class P1,P2 publisher
+ class T topic
+ class S1,S2,S3 subscriber
+
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
### RocketMQ 中的消息模型
-`RocketMQ` 中的消息模型就是按照 **主题模型** 所实现的。你可能会好奇这个 **主题** 到底是怎么实现的呢?你上面也没有讲到呀!
+RocketMQ 中的消息模型就是按照 **主题模型** 所实现的。那么 **主题** 到底是怎么实现的呢?
-其实对于主题模型的实现来说每个消息中间件的底层设计都是不一样的,就比如 `Kafka` 中的 **分区** ,`RocketMQ` 中的 **队列** ,`RabbitMQ` 中的 `Exchange` 。我们可以理解为 **主题模型/发布订阅模型** 就是一个标准,那些中间件只不过照着这个标准去实现而已。
+其实对于主题模型的实现来说每个消息中间件的底层设计都是不一样的,就比如 Kafka 中的 **分区** ,RocketMQ 中的 **队列** ,RabbitMQ 中的 Exchange 。我们可以理解为 **主题模型/发布订阅模型** 就是一个标准,那些中间件只不过照着这个标准去实现而已。
-所以,`RocketMQ` 中的 **主题模型** 到底是如何实现的呢?首先我画一张图,大家尝试着去理解一下。
+所以,RocketMQ 中的 **主题模型** 到底是如何实现的呢?先看一张图:
-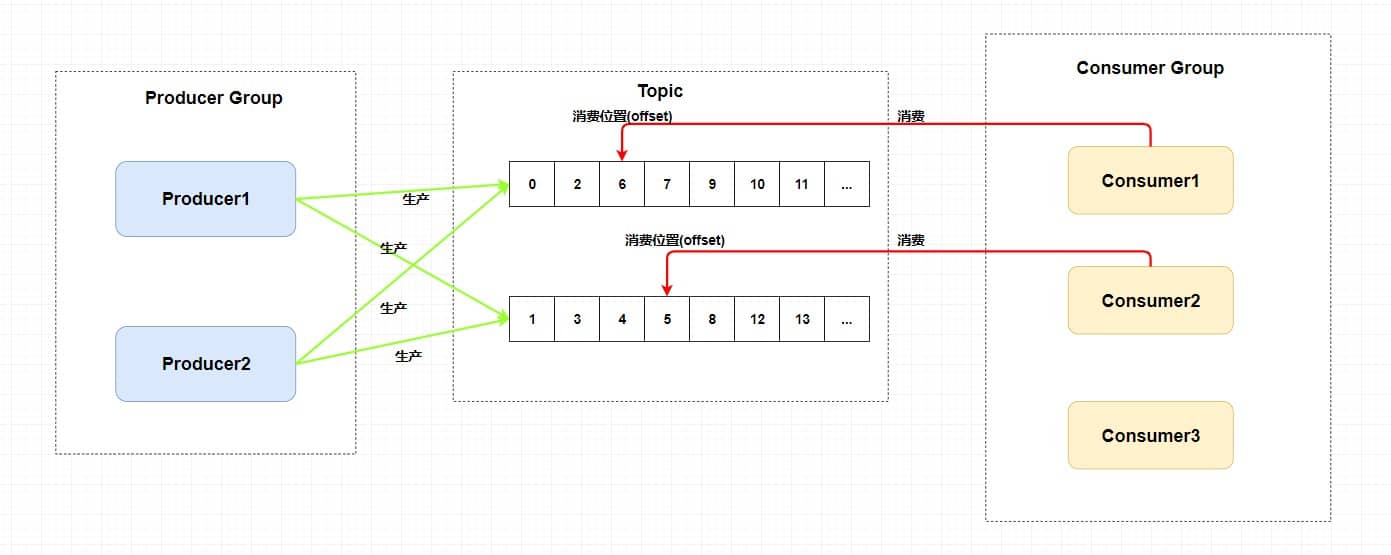
+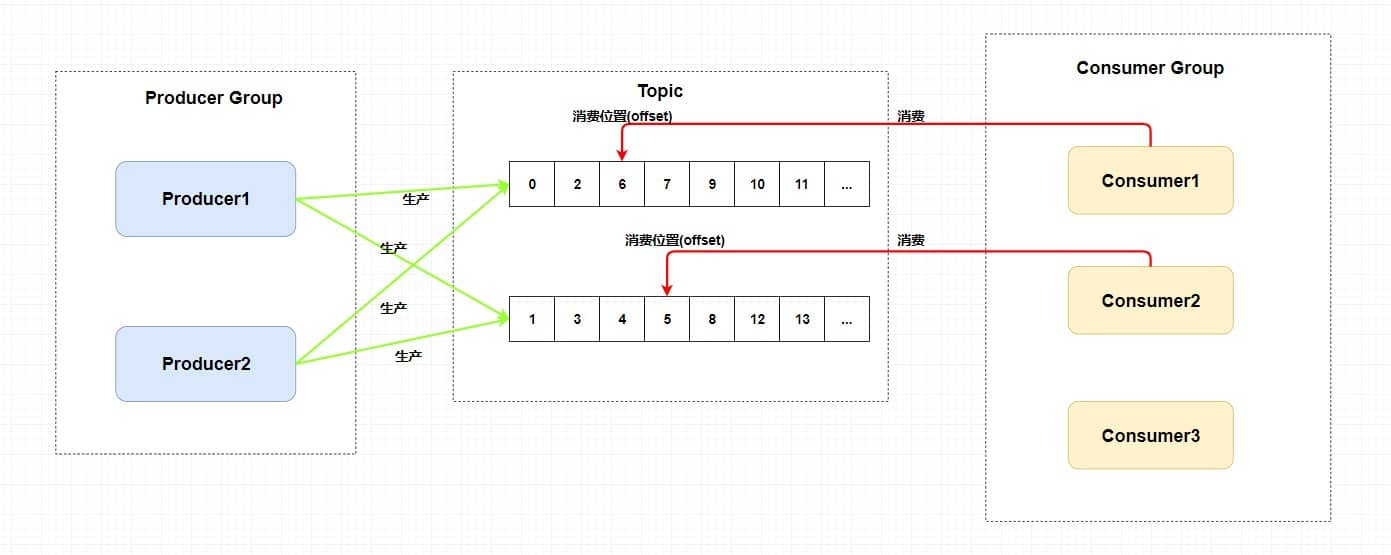
-我们可以看到在整个图中有 `Producer Group`、`Topic`、`Consumer Group` 三个角色,我来分别介绍一下他们。
+我们可以看到在整个图中有 `Producer Group`、Topic、`Consumer Group` 三个角色,我来分别介绍一下他们。
- `Producer Group` 生产者组:代表某一类的生产者,比如我们有多个秒杀系统作为生产者,这多个合在一起就是一个 `Producer Group` 生产者组,它们一般生产相同的消息。
- `Consumer Group` 消费者组:代表某一类的消费者,比如我们有多个短信系统作为消费者,这多个合在一起就是一个 `Consumer Group` 消费者组,它们一般消费相同的消息。
-- `Topic` 主题:代表一类消息,比如订单消息,物流消息等等。
+- Topic 主题:代表一类消息,比如订单消息,物流消息等等。
你可以看到图中生产者组中的生产者会向主题发送消息,而 **主题中存在多个队列**,生产者每次生产消息之后是指定主题中的某个队列发送消息的。
-每个主题中都有多个队列(分布在不同的 `Broker`中,如果是集群的话,`Broker`又分布在不同的服务器中),集群消费模式下,一个消费者集群多台机器共同消费一个 `topic` 的多个队列,**一个队列只会被一个消费者消费**。如果某个消费者挂掉,分组内其它消费者会接替挂掉的消费者继续消费。就像上图中 `Consumer1` 和 `Consumer2` 分别对应着两个队列,而 `Consumer3` 是没有队列对应的,所以一般来讲要控制 **消费者组中的消费者个数和主题中队列个数相同** 。
+每个主题中都有多个队列(分布在不同的 Broker 中,如果是集群的话,Broker 又分布在不同的服务器中),集群消费模式下,一个消费者集群多台机器共同消费一个 `topic` 的多个队列。
+
+**负载均衡策略对比**
+
+```mermaid
+flowchart TB
+ subgraph Queue["队列粒度负载均衡 4.x"]
+ style Queue fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ direction TB
+ Q1["队列1"] --> C1["消费者1"]
+ Q2["队列2"] --> C2["消费者2"]
+ Q3["队列3"] --> C3["消费者3"]
+ Q4["队列4"] -.-> C4["消费者4
ZooKeeper 主要为 Kafka 提供元数据的管理的功能。
@@ -106,7 +117,17 @@ ZooKeeper 主要为 Kafka 提供元数据的管理的功能。
1. **Broker 注册**:在 Zookeeper 上会有一个专门**用来进行 Broker 服务器列表记录**的节点。每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到 `/brokers/ids` 下创建属于自己的节点。每个 Broker 就会将自己的 IP 地址和端口等信息记录到该节点中去
2. **Topic 注册**:在 Kafka 中,同一个**Topic 的消息会被分成多个分区**并将其分布在多个 Broker 上,**这些分区信息及与 Broker 的对应关系**也都是由 Zookeeper 在维护。比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这些文件夹:`/brokers/topics/my-topic/Partitions/0`、`/brokers/topics/my-topic/Partitions/1`
3. **负载均衡**:上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力。 对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
-4. ......
+4. ……
+
+### 使用 Kafka 能否不引入 Zookeeper?
+
+在 Kafka 2.8 之前,Kafka 最被大家诟病的就是其重度依赖于 Zookeeper。在 Kafka 2.8 之后,引入了基于 Raft 协议的 KRaft 模式,不再依赖 Zookeeper,大大简化了 Kafka 的架构,让你可以以一种轻量级的方式来使用 Kafka。
+
+不过,要提示一下:**如果要使用 KRaft 模式的话,建议选择较高版本的 Kafka,因为这个功能还在持续完善优化中。Kafka 3.3.1 版本是第一个将 KRaft(Kafka Raft)共识协议标记为生产就绪的版本。**
+
+
+
+## Kafka 消费顺序、消息丢失和重复消费
### Kafka 如何保证消息的消费顺序?
@@ -119,7 +140,7 @@ ZooKeeper 主要为 Kafka 提供元数据的管理的功能。
我们知道 Kafka 中 Partition(分区)是真正保存消息的地方,我们发送的消息都被放在了这里。而我们的 Partition(分区) 又存在于 Topic(主题) 这个概念中,并且我们可以给特定 Topic 指定多个 Partition。
-
+
每次添加消息到 Partition(分区) 的时候都会采用尾加法,如上图所示。 **Kafka 只能为我们保证 Partition(分区) 中的消息有序。**
@@ -136,7 +157,7 @@ Kafka 中发送 1 条消息的时候,可以指定 topic, partition, key,data
当然不仅仅只有上面两种方法,上面两种方法是我觉得比较好理解的,
-### Kafka 如何保证消息不丢失
+### Kafka 如何保证消息不丢失?
#### 生产者丢失消息的情况
@@ -164,13 +185,13 @@ if (sendResult.getRecordMetadata() != null) {
如果消息发送失败的话,我们检查失败的原因之后重新发送即可!
-**另外这里推荐为 Producer 的`retries `(重试次数)设置一个比较合理的值,一般是 3 ,但是为了保证消息不丢失的话一般会设置比较大一点。设置完成之后,当出现网络问题之后能够自动重试消息发送,避免消息丢失。另外,建议还要设置重试间隔,因为间隔太小的话重试的效果就不明显了,网络波动一次你 3 次一下子就重试完了**
+另外,这里推荐为 Producer 的`retries`(重试次数)设置一个比较合理的值,一般是 3 ,但是为了保证消息不丢失的话一般会设置比较大一点。设置完成之后,当出现网络问题之后能够自动重试消息发送,避免消息丢失。另外,建议还要设置重试间隔,因为间隔太小的话重试的效果就不明显了,网络波动一次你 3 次一下子就重试完了。
#### 消费者丢失消息的情况
我们知道消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。偏移量(offset)表示 Consumer 当前消费到的 Partition(分区)的所在的位置。Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性。
-
+
当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。自动提交的话会有一个问题,试想一下,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。
@@ -204,7 +225,7 @@ acks 的默认值即为 1,代表我们的消息被 leader 副本接收之后
我们最开始也说了我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。多个 follower 副本之间的消息同步情况不一样,当我们配置了 **unclean.leader.election.enable = false** 的话,当 leader 副本发生故障时就不会从 follower 副本中和 leader 同步程度达不到要求的副本中选择出 leader ,这样降低了消息丢失的可能性。
-### Kafka 如何保证消息不重复消费
+### Kafka 如何保证消息不重复消费?
**kafka 出现消息重复消费的原因:**
@@ -218,7 +239,208 @@ acks 的默认值即为 1,代表我们的消息被 leader 副本接收之后
- 处理完消息再提交:依旧有消息重复消费的风险,和自动提交一样
- 拉取到消息即提交:会有消息丢失的风险。允许消息延时的场景,一般会采用这种方式。然后,通过定时任务在业务不繁忙(比如凌晨)的时候做数据兜底。
-### Reference
+## Kafka 重试机制
+
+在 Kafka 如何保证消息不丢失这里,我们提到了 Kafka 的重试机制。由于这部分内容较为重要,我们这里再来详细介绍一下。
+
+网上关于 Spring Kafka 的默认重试机制文章很多,但大多都是过时的,和实际运行结果完全不一样。以下是根据 [spring-kafka-2.9.3](https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka/2.9.3) 源码重新梳理一下。
+
+### 消费失败会怎么样?
+
+在消费过程中,当其中一个消息消费异常时,会不会卡住后续队列消息的消费?这样业务岂不是卡住了?
+
+生产者代码:
+
+```Java
+ for (int i = 0; i < 10; i++) {
+ kafkaTemplate.send(KafkaConst.TEST_TOPIC, String.valueOf(i))
+ }
+```
+
+消费者消代码:
+
+```Java
+ @KafkaListener(topics = {KafkaConst.TEST_TOPIC},groupId = "apple")
+ private void customer(String message) throws InterruptedException {
+ log.info("kafka customer:{}",message);
+ Integer n = Integer.parseInt(message);
+ if (n%5==0){
+ throw new RuntimeException();
+ }
+ }
+```
+
+在默认配置下,当消费异常会进行重试,重试多次后会跳过当前消息,继续进行后续消息的消费,不会一直卡在当前消息。下面是一段消费的日志,可以看出当 `test-0@95` 重试多次后会被跳过。
-- Kafka 官方文档:https://kafka.apache.org/documentation/
+```Java
+2023-08-10 12:03:32.918 DEBUG 9700 --- [ntainer#0-0-C-1] o.s.kafka.listener.DefaultErrorHandler : Skipping seek of: test-0@95
+2023-08-10 12:03:32.918 TRACE 9700 --- [ntainer#0-0-C-1] o.s.kafka.listener.DefaultErrorHandler : Seeking: test-0 to: 96
+2023-08-10 12:03:32.918 INFO 9700 --- [ntainer#0-0-C-1] o.a.k.clients.consumer.KafkaConsumer : [Consumer clientId=consumer-apple-1, groupId=apple] Seeking to offset 96 for partition test-0
+
+```
+
+因此,即使某个消息消费异常,Kafka 消费者仍然能够继续消费后续的消息,不会一直卡在当前消息,保证了业务的正常进行。
+
+### 默认会重试多少次?
+
+默认配置下,消费异常会进行重试,重试次数是多少, 重试是否有时间间隔?
+
+看源码 `FailedRecordTracker` 类有个 `recovered` 函数,返回 Boolean 值判断是否要进行重试,下面是这个函数中判断是否重试的逻辑:
+
+```java
+ @Override
+ public boolean recovered(ConsumerRecord << ? , ? > record, Exception exception,
+ @Nullable MessageListenerContainer container,
+ @Nullable Consumer << ? , ? > consumer) throws InterruptedException {
+
+ if (this.noRetries) {
+ // 不支持重试
+ attemptRecovery(record, exception, null, consumer);
+ return true;
+ }
+ // 取已经失败的消费记录集合
+ Map < TopicPartition, FailedRecord > map = this.failures.get();
+ if (map == null) {
+ this.failures.set(new HashMap < > ());
+ map = this.failures.get();
+ }
+ // 获取消费记录所在的Topic和Partition
+ TopicPartition topicPartition = new TopicPartition(record.topic(), record.partition());
+ FailedRecord failedRecord = getFailedRecordInstance(record, exception, map, topicPartition);
+ // 通知注册的重试监听器,消息投递失败
+ this.retryListeners.forEach(rl - >
+ rl.failedDelivery(record, exception, failedRecord.getDeliveryAttempts().get()));
+ // 获取下一次重试的时间间隔
+ long nextBackOff = failedRecord.getBackOffExecution().nextBackOff();
+ if (nextBackOff != BackOffExecution.STOP) {
+ this.backOffHandler.onNextBackOff(container, exception, nextBackOff);
+ return false;
+ } else {
+ attemptRecovery(record, exception, topicPartition, consumer);
+ map.remove(topicPartition);
+ if (map.isEmpty()) {
+ this.failures.remove();
+ }
+ return true;
+ }
+ }
+```
+
+其中, `BackOffExecution.STOP` 的值为 -1。
+
+```java
+@FunctionalInterface
+public interface BackOffExecution {
+
+ long STOP = -1;
+ long nextBackOff();
+
+}
+```
+
+`nextBackOff` 的值调用 `BackOff` 类的 `nextBackOff()` 函数。如果当前执行次数大于最大执行次数则返回 `STOP`,既超过这个最大执行次数后才会停止重试。
+
+```Java
+public long nextBackOff() {
+ this.currentAttempts++;
+ if (this.currentAttempts <= getMaxAttempts()) {
+ return getInterval();
+ }
+ else {
+ return STOP;
+ }
+}
+```
+
+那么这个 `getMaxAttempts` 的值又是多少呢?回到最开始,当执行出错会进入 `DefaultErrorHandler` 。`DefaultErrorHandler` 默认的构造函数是:
+
+```Java
+public DefaultErrorHandler() {
+ this(null, SeekUtils.DEFAULT_BACK_OFF);
+}
+```
+
+`SeekUtils.DEFAULT_BACK_OFF` 定义的是:
+
+```Java
+public static final int DEFAULT_MAX_FAILURES = 10;
+
+public static final FixedBackOff DEFAULT_BACK_OFF = new FixedBackOff(0, DEFAULT_MAX_FAILURES - 1);
+```
+
+`DEFAULT_MAX_FAILURES` 的值是 10,`currentAttempts` 从 0 到 9,所以总共会执行 10 次,每次重试的时间间隔为 0。
+
+最后,简单总结一下:Kafka 消费者在默认配置下会进行最多 10 次 的重试,每次重试的时间间隔为 0,即立即进行重试。如果在 10 次重试后仍然无法成功消费消息,则不再进行重试,消息将被视为消费失败。
+
+### 如何自定义重试次数以及时间间隔?
+
+从上面的代码可以知道,默认错误处理器的重试次数以及时间间隔是由 `FixedBackOff` 控制的,`FixedBackOff` 是 `DefaultErrorHandler` 初始化时默认的。所以自定义重试次数以及时间间隔,只需要在 `DefaultErrorHandler` 初始化的时候传入自定义的 `FixedBackOff` 即可。重新实现一个 `KafkaListenerContainerFactory` ,调用 `setCommonErrorHandler` 设置新的自定义的错误处理器就可以实现。
+
+```Java
+@Bean
+public KafkaListenerContainerFactory kafkaListenerContainerFactory(ConsumerFactory consumerFactory) {
+ ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory();
+ // 自定义重试时间间隔以及次数
+ FixedBackOff fixedBackOff = new FixedBackOff(1000, 5);
+ factory.setCommonErrorHandler(new DefaultErrorHandler(fixedBackOff));
+ factory.setConsumerFactory(consumerFactory);
+ return factory;
+}
+```
+
+### 如何在重试失败后进行告警?
+
+自定义重试失败后逻辑,需要手动实现,以下是一个简单的例子,重写 `DefaultErrorHandler` 的 `handleRemaining` 函数,加上自定义的告警等操作。
+
+```Java
+@Slf4j
+public class DelErrorHandler extends DefaultErrorHandler {
+
+ public DelErrorHandler(FixedBackOff backOff) {
+ super(null,backOff);
+ }
+
+ @Override
+ public void handleRemaining(Exception thrownException, List> records, Consumer consumer, MessageListenerContainer container) {
+ super.handleRemaining(thrownException, records, consumer, container);
+ log.info("重试多次失败");
+ // 自定义操作
+ }
+}
+```
+
+`DefaultErrorHandler` 只是默认的一个错误处理器,Spring Kafka 还提供了 `CommonErrorHandler` 接口。手动实现 `CommonErrorHandler` 就可以实现更多的自定义操作,有很高的灵活性。例如根据不同的错误类型,实现不同的重试逻辑以及业务逻辑等。
+
+### 重试失败后的数据如何再次处理?
+
+当达到最大重试次数后,数据会直接被跳过,继续向后进行。当代码修复后,如何重新消费这些重试失败的数据呢?
+
+**死信队列(Dead Letter Queue,简称 DLQ)** 是消息中间件中的一种特殊队列。它主要用于处理无法被消费者正确处理的消息,通常是因为消息格式错误、处理失败、消费超时等情况导致的消息被"丢弃"或"死亡"的情况。当消息进入队列后,消费者会尝试处理它。如果处理失败,或者超过一定的重试次数仍无法被成功处理,消息可以发送到死信队列中,而不是被永久性地丢弃。在死信队列中,可以进一步分析、处理这些无法正常消费的消息,以便定位问题、修复错误,并采取适当的措施。
+
+`@RetryableTopic` 是 Spring Kafka 中的一个注解,它用于配置某个 Topic 支持消息重试,更推荐使用这个注解来完成重试。
+
+```Java
+// 重试 5 次,重试间隔 100 毫秒,最大间隔 1 秒
+@RetryableTopic(
+ attempts = "5",
+ backoff = @Backoff(delay = 100, maxDelay = 1000)
+)
+@KafkaListener(topics = {KafkaConst.TEST_TOPIC}, groupId = "apple")
+private void customer(String message) {
+ log.info("kafka customer:{}", message);
+ Integer n = Integer.parseInt(message);
+ if (n % 5 == 0) {
+ throw new RuntimeException();
+ }
+ System.out.println(n);
+}
+```
+
+当达到最大重试次数后,如果仍然无法成功处理消息,消息会被发送到对应的死信队列中。对于死信队列的处理,既可以用 `@DltHandler` 处理,也可以使用 `@KafkaListener` 重新消费。
+
+## 参考
+
+- Kafka 官方文档:
- 极客时间—《Kafka 核心技术与实战》第 11 节:无消息丢失配置怎么实现?
+
+
diff --git a/docs/high-performance/message-queue/message-queue.md b/docs/high-performance/message-queue/message-queue.md
index 4d7b6717ce9..ea8a25c6613 100644
--- a/docs/high-performance/message-queue/message-queue.md
+++ b/docs/high-performance/message-queue/message-queue.md
@@ -1,8 +1,13 @@
---
title: 消息队列基础知识总结
+description: 本文系统总结消息队列的核心知识,涵盖消息队列的应用场景(异步处理/解耦/削峰)、消息模型(点对点/发布订阅)、如何保证消息不丢失、消息幂等性、消息顺序性、消息积压处理等常见问题,以及 Kafka、RocketMQ、RabbitMQ 技术选型对比。
category: 高性能
tag:
- 消息队列
+head:
+ - - meta
+ - name: keywords
+ content: 消息队列,MQ,异步解耦,削峰填谷,消息丢失,消息幂等,消息顺序,Kafka,RocketMQ,RabbitMQ
---
::: tip
@@ -19,13 +24,13 @@ tag:
我们可以把消息队列看作是一个存放消息的容器,当我们需要使用消息的时候,直接从容器中取出消息供自己使用即可。由于队列 Queue 是一种先进先出的数据结构,所以消费消息时也是按照顺序来消费的。
-
+
参与消息传递的双方称为 **生产者** 和 **消费者** ,生产者负责发送消息,消费者负责处理消息。
-
+
-我们知道操作系统中的进程通信的一种很重要的方式就是消息队列。我们这里提到的消息队列稍微有点区别,更多指的是各个服务以及系统内部各个组件/模块之前的通信,属于一种 **中间件** 。
+操作系统中的进程通信的一种很重要的方式就是消息队列。我们这里提到的消息队列稍微有点区别,更多指的是各个服务以及系统内部各个组件/模块之前的通信,属于一种 **中间件** 。
维基百科是这样介绍中间件的:
@@ -35,25 +40,27 @@ tag:
除了消息队列之外,常见的中间件还有 RPC 框架、分布式组件、HTTP 服务器、任务调度框架、配置中心、数据库层的分库分表工具和数据迁移工具等等。
-关于中间件比较详细的介绍可以参考阿里巴巴淘系技术的一篇回答:https://www.zhihu.com/question/19730582/answer/1663627873 。
+关于中间件比较详细的介绍可以参考阿里巴巴淘系技术的一篇回答: 。
随着分布式和微服务系统的发展,消息队列在系统设计中有了更大的发挥空间,使用消息队列可以降低系统耦合性、实现任务异步、有效地进行流量削峰,是分布式和微服务系统中重要的组件之一。
## 消息队列有什么用?
-通常来说,使用消息队列能为我们的系统带来下面三点好处:
+通常来说,使用消息队列主要能为我们的系统带来下面三点好处:
-1. **通过异步处理提高系统性能(减少响应所需时间)**
-2. **削峰/限流**
-3. **降低系统耦合性。**
+1. 异步处理
+2. 削峰/限流
+3. 降低系统耦合性
+
+除了这三点之外,消息队列还有其他的一些应用场景,例如实现分布式事务、顺序保证和数据流处理。
如果在面试的时候你被面试官问到这个问题的话,一般情况是你在你的简历上涉及到消息队列这方面的内容,这个时候推荐你结合你自己的项目来回答。
-### 通过异步处理提高系统性能(减少响应所需时间)
+### 异步处理

-将用户的请求数据存储到消息队列之后就立即返回结果。随后,系统再对消息进行消费。
+将用户请求中包含的耗时操作,通过消息队列实现异步处理,将对应的消息发送到消息队列之后就立即返回结果,减少响应时间,提高用户体验。随后,系统再对消息进行消费。
因为用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败。因此,**使用消息队列进行异步处理之后,需要适当修改业务流程进行配合**,比如用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
@@ -67,15 +74,17 @@ tag:
### 降低系统耦合性
-使用消息队列还可以降低系统耦合性。我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。还是直接上图吧:
+使用消息队列还可以降低系统耦合性。如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
-
+生产者(客户端)发送消息到消息队列中去,消费者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合,这显然也提高了系统的扩展性。
-生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合,这显然也提高了系统的扩展性。
+
**消息队列使用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。** 从上图可以看到**消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合**,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。**对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计**。
-消息接受者对消息进行过滤、处理、包装后,构造成一个新的消息类型,将消息继续发送出去,等待其他消息接受者订阅该消息。因此基于事件(消息对象)驱动的业务架构可以是一系列流程。
+例如,我们商城系统分为用户、订单、财务、仓储、消息通知、物流、风控等多个服务。用户在完成下单后,需要调用财务(扣款)、仓储(库存管理)、物流(发货)、消息通知(通知用户发货)、风控(风险评估)等服务。使用消息队列后,下单操作和后续的扣款、发货、通知等操作就解耦了,下单完成发送一个消息到消息队列,需要用到的地方去订阅这个消息进行消费即可。
+
+
另外,为了避免消息队列服务器宕机造成消息丢失,会将成功发送到消息队列的消息存储在消息生产者服务器上,等消息真正被消费者服务器处理后才删除消息。在消息队列服务器宕机后,生产者服务器会选择分布式消息队列服务器集群中的其他服务器发布消息。
@@ -83,7 +92,7 @@ tag:
### 实现分布式事务
-我们知道分布式事务的解决方案之一就是 MQ 事务。
+分布式事务的解决方案之一就是 MQ 事务。
RocketMQ、 Kafka、Pulsar、QMQ 都提供了事务相关的功能。事务允许事件流应用将消费,处理,生产消息整个过程定义为一个原子操作。
@@ -91,6 +100,26 @@ RocketMQ、 Kafka、Pulsar、QMQ 都提供了事务相关的功能。事务允

+### 顺序保证
+
+在很多应用场景中,处理数据的顺序至关重要。消息队列保证数据按照特定的顺序被处理,适用于那些对数据顺序有严格要求的场景。大部分消息队列,例如 RocketMQ、RabbitMQ、Pulsar、Kafka,都支持顺序消息。
+
+### 延时/定时处理
+
+消息发送后不会立即被消费,而是指定一个时间,到时间后再消费。大部分消息队列,例如 RocketMQ、RabbitMQ、Pulsar,都支持定时/延时消息。
+
+
+
+### 即时通讯
+
+MQTT(消息队列遥测传输协议)是一种轻量级的通讯协议,采用发布/订阅模式,非常适合于物联网(IoT)等需要在低带宽、高延迟或不可靠网络环境下工作的应用。它支持即时消息传递,即使在网络条件较差的情况下也能保持通信的稳定性。
+
+RabbitMQ 内置了 MQTT 插件用于实现 MQTT 功能(默认不启用,需要手动开启)。
+
+### 数据流处理
+
+针对分布式系统产生的海量数据流,如业务日志、监控数据、用户行为等,消息队列可以实时或批量收集这些数据,并将其导入到大数据处理引擎中,实现高效的数据流管理和处理。
+
## 使用消息队列会带来哪些问题?
- **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了!
@@ -117,15 +146,15 @@ JMS 定义了五种不同的消息正文格式以及调用的消息类型,允
#### 点到点(P2P)模型
-
+
使用**队列(Queue)**作为消息通信载体;满足**生产者与消费者模式**,一条消息只能被一个消费者使用,未被消费的消息在队列中保留直到被消费或超时。比如:我们生产者发送 100 条消息的话,两个消费者来消费一般情况下两个消费者会按照消息发送的顺序各自消费一半(也就是你一个我一个的消费。)
#### 发布/订阅(Pub/Sub)模型
-
+
-发布订阅模型(Pub/Sub) 使用**主题(Topic)**作为消息通信载体,类似于**广播模式**;发布者发布一条消息,该消息通过主题传递给所有的订阅者,**在一条消息广播之后才订阅的用户则是收不到该条消息的**。
+发布订阅模型(Pub/Sub) 使用**主题(Topic)**作为消息通信载体,类似于**广播模式**;发布者发布一条消息,该消息通过主题传递给所有的订阅者。
### AMQP 是什么?
@@ -182,11 +211,11 @@ Kafka 是一个分布式系统,由通过高性能 TCP 网络协议进行通信
不过,要提示一下:**如果要使用 KRaft 模式的话,建议选择较高版本的 Kafka,因为这个功能还在持续完善优化中。Kafka 3.3.1 版本是第一个将 KRaft(Kafka Raft)共识协议标记为生产就绪的版本。**
-
+
-Kafka 官网:http://kafka.apache.org/
+Kafka 官网:
-Kafka 更新记录(可以直观看到项目是否还在维护):https://kafka.apache.org/downloads
+Kafka 更新记录(可以直观看到项目是否还在维护):
#### RocketMQ
@@ -207,9 +236,9 @@ RocketMQ 的核心特性(摘自 RocketMQ 官网):
> Apache RocketMQ 自诞生以来,因其架构简单、业务功能丰富、具备极强可扩展性等特点被众多企业开发者以及云厂商广泛采用。历经十余年的大规模场景打磨,RocketMQ 已经成为业内共识的金融级可靠业务消息首选方案,被广泛应用于互联网、大数据、移动互联网、物联网等领域的业务场景。
-RocketMQ 官网:https://rocketmq.apache.org/ (文档很详细,推荐阅读)
+RocketMQ 官网: (文档很详细,推荐阅读)
-RocketMQ 更新记录(可以直观看到项目是否还在维护):https://github.com/apache/rocketmq/releases
+RocketMQ 更新记录(可以直观看到项目是否还在维护):
#### RabbitMQ
@@ -228,9 +257,9 @@ RabbitMQ 发展到今天,被越来越多的人认可,这和它在易用性
- **易用的管理界面:** RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息、集群中的节点等。在安装 RabbitMQ 的时候会介绍到,安装好 RabbitMQ 就自带管理界面。
- **插件机制:** RabbitMQ 提供了许多插件,以实现从多方面进行扩展,当然也可以编写自己的插件。感觉这个有点类似 Dubbo 的 SPI 机制
-RabbitMQ 官网:https://www.rabbitmq.com/ 。
+RabbitMQ 官网: 。
-RabbitMQ 更新记录(可以直观看到项目是否还在维护):https://www.rabbitmq.com/news.html
+RabbitMQ 更新记录(可以直观看到项目是否还在维护):
#### Pulsar
@@ -253,9 +282,9 @@ Pulsar 的关键特性如下(摘自官网):
- 基于 Pulsar Functions 的 serverless connector 框架 Pulsar IO 使得数据更易移入、移出 Apache Pulsar。
- 分层式存储可在数据陈旧时,将数据从热存储卸载到冷/长期存储(如 S3、GCS)中。
-Pulsar 官网:https://pulsar.apache.org/
+Pulsar 官网:
-Pulsar 更新记录(可以直观看到项目是否还在维护):https://github.com/apache/pulsar/releases
+Pulsar 更新记录(可以直观看到项目是否还在维护):
#### ActiveMQ
@@ -284,5 +313,7 @@ Pulsar 更新记录(可以直观看到项目是否还在维护):https://gi
## 参考
- 《大型网站技术架构 》
-- KRaft: Apache Kafka Without ZooKeeper:https://developer.confluent.io/learn/kraft/
-- 消息队列的使用场景是什么样的?:https://mp.weixin.qq.com/s/4V1jI6RylJr7Jr9JsQe73A
+- KRaft: Apache Kafka Without ZooKeeper:
+- 消息队列的使用场景是什么样的?:
+
+
diff --git a/docs/high-performance/message-queue/rabbitmq-questions.md b/docs/high-performance/message-queue/rabbitmq-questions.md
index 0f0d9f8e519..0b044d255b6 100644
--- a/docs/high-performance/message-queue/rabbitmq-questions.md
+++ b/docs/high-performance/message-queue/rabbitmq-questions.md
@@ -1,18 +1,18 @@
---
title: RabbitMQ常见问题总结
+description: 本文总结 RabbitMQ 常见面试题与核心知识点,涵盖 AMQP 协议、Exchange 交换机类型(Direct/Topic/Fanout)、消息确认机制、死信队列、延迟队列、优先级队列、高可用集群(镜像队列)等,助力 RabbitMQ 学习与面试准备。
category: 高性能
tag:
- 消息队列
head:
- - meta
- name: keywords
- content: RabbitMQ,AMQP,Broker,Exchange,优先级队列,延迟队列
- - - meta
- - name: description
- content: RabbitMQ 是一个在 AMQP(Advanced Message Queuing Protocol )基础上实现的,可复用的企业消息系统。它可以用于大型软件系统各个模块之间的高效通信,支持高并发,支持可扩展。它支持多种客户端如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX,持久化,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
+ content: RabbitMQ,AMQP协议,Exchange交换机,消息确认,死信队列,延迟队列,优先级队列,RabbitMQ集群,消息队列面试
---
-> 本篇文章由 JavaGuide 收集自网络,原出处不明。
+RabbitMQ 作为老牌消息中间件,凭借其成熟的路由机制、丰富的协议支持和完善的可靠性保障,在企业级应用中占据重要地位。但自 RabbitMQ 3.8 引入 Quorum Queue、3.9 引入 Streams、4.0 移除镜像队列以来,其技术架构发生了重大变化,许多传统的最佳实践已不再适用。
+
+本文已针对 RabbitMQ 4.0 进行全面更新,明确标注各特性的版本依赖,特别强调了镜像队列(已移除)、Quorum Queue(推荐)和 Streams(3.9+)的选型差异。
## RabbitMQ 是什么?
@@ -20,14 +20,12 @@ RabbitMQ 是一个在 AMQP(Advanced Message Queuing Protocol )基础上实
RabbitMQ 是使用 Erlang 编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正是如此,使的它变的非常重量级,更适合于企业级的开发。它同时实现了一个 Broker 构架,这意味着消息在发送给客户端时先在中心队列排队,对路由(Routing)、负载均衡(Load balance)或者数据持久化都有很好的支持。
-PS:也可能直接问什么是消息队列?消息队列就是一个使用队列来通信的组件。
-
## RabbitMQ 特点?
- **可靠性**: RabbitMQ 使用一些机制来保证可靠性, 如持久化、传输确认及发布确认等。
-- **灵活的路由** : 在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能, RabbitMQ 己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个 交换器绑定在一起, 也可以通过插件机制来实现自己的交换器。
+- **灵活的路由** : 在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能, RabbitMQ 己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个交换器绑定在一起, 也可以通过插件机制来实现自己的交换器。
- **扩展性**: 多个 RabbitMQ 节点可以组成一个集群,也可以根据实际业务情况动态地扩展 集群中节点。
-- **高可用性** : 队列可以在集群中的机器上设置镜像,使得在部分节点出现问题的情况下队 列仍然可用。
+- **高可用性** : Quorum Queue 基于 Raft 协议实现数据复制,Streams 支持多节点副本,在部分节点出现问题的情况下队列仍然可用。
- **多种协议**: RabbitMQ 除了原生支持 AMQP 协议,还支持 STOMP, MQTT 等多种消息 中间件协议。
- **多语言客户端** :RabbitMQ 几乎支持所有常用语言,比如 Java、 Python、 Ruby、 PHP、 C#、 JavaScript 等。
- **管理界面** : RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息、集 群中的节点等。
@@ -39,7 +37,7 @@ RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、
RabbitMQ 的整体模型架构如下:
-
+
下面我会一一介绍上图中的一些概念。
@@ -56,19 +54,13 @@ RabbitMQ 的整体模型架构如下:
**Exchange(交换器)** 用来接收生产者发送的消息并将这些消息路由给服务器中的队列中,如果路由不到,或许会返回给 **Producer(生产者)** ,或许会被直接丢弃掉 。这里可以将 RabbitMQ 中的交换器看作一个简单的实体。
-**RabbitMQ 的 Exchange(交换器) 有 4 种类型,不同的类型对应着不同的路由策略**:**direct(默认)**,**fanout**, **topic**, 和 **headers**,不同类型的 Exchange 转发消息的策略有所区别。这个会在介绍 **Exchange Types(交换器类型)** 的时候介绍到。
-
-Exchange(交换器) 示意图如下:
+**RabbitMQ 的 Exchange(交换器) 有 4 种类型,不同的类型对应着不同的路由策略**:**direct**,**fanout**, **topic**, 和 **headers**,不同类型的 Exchange 转发消息的策略有所区别。这个会在介绍 **Exchange Types(交换器类型)** 的时候介绍到。
-
+> 注意:AMQP 规范定义了一个默认交换器(Default Exchange),它是一个 pre-declared 的 direct 类型交换器,但创建新交换器时必须显式指定类型,不能省略。
生产者将消息发给交换器的时候,一般会指定一个 **RoutingKey(路由键)**,用来指定这个消息的路由规则,而这个 **RoutingKey 需要与交换器类型和绑定键(BindingKey)联合使用才能最终生效**。
-RabbitMQ 中通过 **Binding(绑定)** 将 **Exchange(交换器)** 与 **Queue(消息队列)** 关联起来,在绑定的时候一般会指定一个 **BindingKey(绑定建)** ,这样 RabbitMQ 就知道如何正确将消息路由到队列了,如下图所示。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。Exchange 和 Queue 的绑定可以是多对多的关系。
-
-Binding(绑定) 示意图:
-
-
+RabbitMQ 中通过 **Binding(绑定)** 将 **Exchange(交换器)** 与 **Queue(消息队列)** 关联起来,在绑定的时候一般会指定一个 **BindingKey(绑定键)** ,这样 RabbitMQ 就知道如何正确将消息路由到队列了,如下图所示。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。Exchange 和 Queue 的绑定可以是多对多的关系。
生产者将消息发送给交换器时,需要一个 RoutingKey,当 BindingKey 和 RoutingKey 相匹配时,消息会被路由到对应的队列中。在绑定多个队列到同一个交换器的时候,这些绑定允许使用相同的 BindingKey。BindingKey 并不是在所有的情况下都生效,它依赖于交换器类型,比如 fanout 类型的交换器就会无视,而是将消息路由到所有绑定到该交换器的队列中。
@@ -76,9 +68,19 @@ Binding(绑定) 示意图:
**Queue(消息队列)** 用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。
-**RabbitMQ** 中消息只能存储在 **队列** 中,这一点和 **Kafka** 这种消息中间件相反。Kafka 将消息存储在 **topic(主题)** 这个逻辑层面,而相对应的队列逻辑只是 topic 实际存储文件中的位移标识。 RabbitMQ 的生产者生产消息并最终投递到队列中,消费者可以从队列中获取消息并消费。
+**RabbitMQ** 在经典架构中,消息只能存储在 **队列** 中,这一点和 **Kafka** 这种消息中间件相反。Kafka 将消息存储在 **topic(主题)** 这个逻辑层面,而相对应的队列逻辑只是 topic 实际存储文件中的位移标识。RabbitMQ 的生产者生产消息并最终投递到队列中,消费者可以从队列中获取消息并消费。
+
+> **版本说明(3.9+ 重要更新)**:从 RabbitMQ 3.9 版本开始,官方引入了 **Streams** 数据结构。Streams 提供了一种类似 Kafka 的 append-only 日志存储模型,支持非破坏性消费、大规模消息堆积以及基于 Offset 的历史数据重放(Replay)。
+>
+> **架构选型建议**:
+>
+> - **普通队列**:适用于传统消息队列场景,消息被消费后即删除
+> - **Streams**:适用于需要高频重放、海量堆积或事件溯源的场景
+> - **核心瓶颈差异**:使用 Stream 时,磁盘 I/O 吞吐量(MB/s)取代了传统的每秒入队率(msg/s)成为核心瓶颈指标
+
+**多个消费者可以订阅同一个队列**,默认情况下队列中的消息会被平均分摊(Round-Robin,即轮询)给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理,这样避免消息被重复消费。
-**多个消费者可以订阅同一个队列**,这时队列中的消息会被平均分摊(Round-Robin,即轮询)给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理,这样避免消息被重复消费。
+> 注意:实际分发策略受 `prefetch_count` 参数影响。默认行为(`prefetch_count=0`)会尽可能多地分发消息给各 Consumer,可能导致负载不均。推荐设置 `prefetch_count=1` 或更高值,让 Consumer 确认后再发送下一条,实现公平分发。
**RabbitMQ** 不支持队列层面的广播消费,如果有广播消费的需求,需要在其上进行二次开发,这样会很麻烦,不建议这样做。
@@ -86,26 +88,20 @@ Binding(绑定) 示意图:
对于 RabbitMQ 来说,一个 RabbitMQ Broker 可以简单地看作一个 RabbitMQ 服务节点,或者 RabbitMQ 服务实例。大多数情况下也可以将一个 RabbitMQ Broker 看作一台 RabbitMQ 服务器。
-下图展示了生产者将消息存入 RabbitMQ Broker,以及消费者从 Broker 中消费数据的整个流程。
-
-
-
-这样图 1 中的一些关于 RabbitMQ 的基本概念我们就介绍完毕了,下面再来介绍一下 **Exchange Types(交换器类型)** 。
-
### Exchange Types(交换器类型)
-RabbitMQ 常用的 Exchange Type 有 **fanout**、**direct**、**topic**、**headers** 这四种(AMQP 规范里还提到两种 Exchange Type,分别为 system 与 自定义,这里不予以描述)。
+RabbitMQ 常用的 Exchange Type 有 **fanout**、**direct**、**topic**、**headers** 这四种(AMQP 规范里还提到两种 Exchange Type,分别为 system 与自定义,这里不予以描述)。
+
+
**1、fanout**
-fanout 类型的 Exchange 路由规则非常简单,它会把所有发送到该 Exchange 的消息路由到所有与它绑定的 Queue 中,不需要做任何判断操作,所以 fanout 类型是所有的交换机类型里面速度最快的。fanout 类型常用来广播消息。
+fanout 类型的 Exchange 路由规则非常简单,它会把所有发送到该 Exchange 的消息路由到所有与它绑定的 Queue 中,**忽略 BindingKey**,不需要做任何判断操作,所以 fanout 类型是所有的交换机类型里面速度最快的。fanout 类型常用来广播消息。
**2、direct**
direct 类型的 Exchange 路由规则也很简单,它会把消息路由到那些 Bindingkey 与 RoutingKey 完全匹配的 Queue 中。
-
-
以上图为例,如果发送消息的时候设置路由键为“warning”,那么消息会路由到 Queue1 和 Queue2。如果在发送消息的时候设置路由键为"Info”或者"debug”,消息只会路由到 Queue2。如果以其他的路由键发送消息,则消息不会路由到这两个队列中。
direct 类型常用在处理有优先级的任务,根据任务的优先级把消息发送到对应的队列,这样可以指派更多的资源去处理高优先级的队列。
@@ -118,31 +114,27 @@ direct 类型常用在处理有优先级的任务,根据任务的优先级把
- BindingKey 和 RoutingKey 一样也是点号“.”分隔的字符串;
- BindingKey 中可以存在两种特殊字符串“\*”和“#”,用于做模糊匹配,其中“\*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)。
-
-
-以上图为例:
-
-- 路由键为 “com.rabbitmq.client” 的消息会同时路由到 Queue1 和 Queue2;
-- 路由键为 “com.hidden.client” 的消息只会路由到 Queue2 中;
-- 路由键为 “com.hidden.demo” 的消息只会路由到 Queue2 中;
-- 路由键为 “java.rabbitmq.demo” 的消息只会路由到 Queue1 中;
-- 路由键为 “java.util.concurrent” 的消息将会被丢弃或者返回给生产者(需要设置 mandatory 参数),因为它没有匹配任何路由键。
-
**4、headers(不推荐)**
headers 类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中的 headers 属性进行匹配。在绑定队列和交换器时指定一组键值对,当发送消息到交换器时,RabbitMQ 会获取到该消息的 headers(也是一个键值对的形式),对比其中的键值对是否完全匹配队列和交换器绑定时指定的键值对,如果完全匹配则消息会路由到该队列,否则不会路由到该队列。headers 类型的交换器性能会很差,而且也不实用,基本上不会看到它的存在。
## AMQP 是什么?
-RabbitMQ 就是 AMQP 协议的 `Erlang` 的实现(当然 RabbitMQ 还支持 `STOMP2`、 `MQTT3` 等协议 ) AMQP 的模型架构 和 RabbitMQ 的模型架构是一样的,生产者将消息发送给交换器,交换器和队列绑定 。
+RabbitMQ 就是 AMQP 协议的 `Erlang` 的实现(当然 RabbitMQ 还支持 `STOMP`、`MQTT` 等协议)。AMQP 的模型架构 和 RabbitMQ 的模型架构是一样的,生产者将消息发送给交换器,交换器和队列绑定。
-RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都是遵循的 AMQP 协议中相 应的概念。目前 RabbitMQ 最新版本默认支持的是 AMQP 0-9-1。
+RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都是遵循的 AMQP 协议中相 应的概念。
+
+> **版本说明**:
+>
+> - **AMQP 0-9-1**:RabbitMQ 的传统协议,广泛使用,功能完整
+> - **AMQP 1.0**:RabbitMQ 4.x 已将其提升为一等公民协议,改进了互操作性和性能
+> - 新项目可考虑使用 AMQP 1.0 以获得更好的跨平台兼容性
**AMQP 协议的三层**:
- **Module Layer**:协议最高层,主要定义了一些客户端调用的命令,客户端可以用这些命令实现自己的业务逻辑。
- **Session Layer**:中间层,主要负责客户端命令发送给服务器,再将服务端应答返回客户端,提供可靠性同步机制和错误处理。
-- **TransportLayer**:最底层,主要传输二进制数据流,提供帧的处理、信道服用、错误检测和数据表示等。
+- **TransportLayer**:最底层,主要传输二进制数据流,提供帧的处理、信道复用、错误检测和数据表示等。
**AMQP 模型的三大组件**:
@@ -164,13 +156,13 @@ RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都
## 说说 Broker 服务节点、Queue 队列、Exchange 交换器?
-- **Broker**:可以看做 RabbitMQ 的服务节点。一般请下一个 Broker 可以看做一个 RabbitMQ 服务器。
-- **Queue** :RabbitMQ 的内部对象,用于存储消息。多个消费者可以订阅同一队列,这时队列中的消息会被平摊(轮询)给多个消费者进行处理。
-- **Exchange** : 生产者将消息发送到交换器,由交换器将消息路由到一个或者多个队列中。当路由不到时,或返回给生产者或直接丢弃。
+- **Broker**:可以看做 RabbitMQ 的服务节点。一般情况下一个 Broker 可以看做一个 RabbitMQ 服务器。
+- **Queue**:RabbitMQ 的内部对象,用于存储消息。多个消费者可以订阅同一队列,这时队列中的消息会被平摊(轮询)给多个消费者进行处理。
+- **Exchange**:生产者将消息发送到交换器,由交换器将消息路由到一个或者多个队列中。当路由不到时,或返回给生产者或直接丢弃。
## 什么是死信队列?如何导致的?
-DLX,全称为 `Dead-Letter-Exchange`,死信交换器,死信邮箱。当消息在一个队列中变成死信 (`dead message`) 之后,它能被重新被发送到另一个交换器中,这个交换器就是 DLX,绑定 DLX 的队列就称之为死信队列。
+DLX,全称为 `Dead-Letter-Exchange`,死信交换器,死信邮箱。当消息在一个队列中变成死信 (`dead message`) 之后,它能被重新发送到另一个交换器中,这个交换器就是 DLX,绑定 DLX 的队列就称之为死信队列。
**导致的死信的几种原因**:
@@ -185,7 +177,13 @@ DLX,全称为 `Dead-Letter-Exchange`,死信交换器,死信邮箱。当消
RabbitMQ 本身是没有延迟队列的,要实现延迟消息,一般有两种方式:
1. 通过 RabbitMQ 本身队列的特性来实现,需要使用 RabbitMQ 的死信交换机(Exchange)和消息的存活时间 TTL(Time To Live)。
-2. 在 RabbitMQ 3.5.7 及以上的版本提供了一个插件(rabbitmq-delayed-message-exchange)来实现延迟队列功能。同时,插件依赖 Erlang/OPT 18.0 及以上。
+
+ - 缺点:消息按队列过期而非单消息级别(除非给每个消息单独队列)
+
+2. 在 RabbitMQ 3.5.7 及以上的版本提供了一个插件(rabbitmq-delayed-message-exchange)来实现延迟队列功能。同时,插件依赖 Erlang/OTP 18.0 及以上。
+ - 原理:将消息暂存在 Mnesia 表中,定时轮询并投递到目标交换器
+ - **容量边界警告(严重)**:该插件将延迟消息全部暂存在 Erlang 的 Mnesia 内部数据库中,**不具备良好的磁盘换页(Paging)能力**。如果单节点堆积**数十万到上百万级别**的延迟消息,会导致 Broker 内存剧增甚至触发**内存高水位(Memory Watermark)告警**,进而产生**全局背压(Global Backpressure)**阻塞所有生产者的 TCP 连接。
+ - **生产建议**:针对海量延迟(千万级以上),必须退化使用外部定时任务(如时间轮、SchedulerX、XXL-JOB)调度或死信链表方案
也就是说,AMQP 协议以及 RabbitMQ 本身没有直接支持延迟队列的功能,但是可以通过 TTL 和 DLX 模拟出延迟队列的功能。
@@ -205,24 +203,163 @@ RabbitMQ 自 V3.5.0 有优先级队列实现,优先级高的队列会先被消
## RabbitMQ 消息怎么传输?
-由于 TCP 链接的创建和销毁开销较大,且并发数受系统资源限制,会造成性能瓶颈,所以 RabbitMQ 使用信道的方式来传输数据。信道(Channel)是生产者、消费者与 RabbitMQ 通信的渠道,信道是建立在 TCP 链接上的虚拟链接,且每条 TCP 链接上的信道数量没有限制。就是说 RabbitMQ 在一条 TCP 链接上建立成百上千个信道来达到多个线程处理,这个 TCP 被多个线程共享,每个信道在 RabbitMQ 都有唯一的 ID,保证了信道私有性,每个信道对应一个线程使用。
+由于 TCP 链接的创建和销毁开销较大(三次握手、慢启动等),且并发数受系统资源限制,会造成性能瓶颈,所以 RabbitMQ 使用信道的方式来传输数据。信道(Channel)是生产者、消费者与 RabbitMQ 通信的渠道,信道是建立在 TCP 链接上的虚拟链接。
+
+> 注意:
+>
+> - 单个 TCP 连接可承载多个 Channel,但官方建议不超过 100-200 个/连接
+> - 每个 Channel 有独立的编号,但共享同一 TCP 连接的流量控制
+> - **Channel 不是线程安全的**,多线程应使用不同 Channel 实例
+
+## 如何保证消息的可靠性?
+
+
+
+消息可能在三个环节丢失:生产者 → Broker、Broker 存储期间、Broker → 消费者
+
+**1. 生产者 → Broker**
+
+保证生产者端零丢失需要**双重机制兜底**:
+
+- **Publisher Confirms**(异步确认):确认消息是否到达 Broker
+
+ ```java
+ channel.confirmSelect();
+ channel.addConfirmListener((sequenceNumber, multiple) -> {
+ // 消息已到达 Broker 并落盘/同步到镜像
+ }, (sequenceNumber, multiple) -> {
+ // 消息未到达 Broker,记录日志并重试
+ });
+ ```
+
+- **Mandatory + Return Listener**(路由失败处理):捕获消息到达 Exchange 但无法路由到 Queue 的情况
+
+ ```java
+ // 开启 mandatory 模式
+ channel.basicPublish("exchange", "routingKey",
+ true, // mandatory=true
+ null,
+ messageBody);
+
+ // 配置 Return Listener
+ channel.addReturnListener((replyCode, replyText, exchange, routingKey, properties, body) -> {
+ // 消息到达 Exchange 但路由失败,记录日志或发送到备用交换器
+ log.error("Message returned: {}", replyText);
+ });
+ ```
+
+> **关键警告**:若仅开启 Confirm 未处理 Return,配置漂移(如误删队列或绑定)会导致生产者认为发送成功,但消息在 Broker 内部被静默丢弃,形成**消息黑洞**。
+
+- **事务机制**(不推荐):同步阻塞,**性能显著下降(官方文档未给出具体倍数,实际影响取决于消息大小和网络延迟)**
+ - 注意:事务机制和 Confirm 机制是互斥的,两者不能共存
+
+**2. Broker 存储期间**
-## **如何保证消息的可靠性?**
+- **消息持久化**:`delivery_mode=2`,消息写入磁盘
+- **队列持久化**:`durable=true`,重启后队列重建
+- **集群模式**:
+ - **镜像队列**(Classic Queue Mirroring,已于 4.0 移除):主从同步,仅用于老版本维护
+ - **Quorum Queue**(3.8+ 推荐,4.0 后为默认):基于 Raft 协议,支持更严格的仲裁写入(N/2 + 1)
+ - **Streams**(3.9+):适用于事件溯源和高频重放场景
-消息到 MQ 的过程中搞丢,MQ 自己搞丢,MQ 到消费过程中搞丢。
+**3. Broker → 消费者**
-- 生产者到 RabbitMQ:事务机制和 Confirm 机制,注意:事务机制和 Confirm 机制是互斥的,两者不能共存,会导致 RabbitMQ 报错。
-- RabbitMQ 自身:持久化、集群、普通模式、镜像模式。
-- RabbitMQ 到消费者:basicAck 机制、死信队列、消息补偿机制。
+- **手动 Ack**:`basicAck(deliveryTag, multiple)`,确保消费成功后再确认
+- **重试机制**:消费失败时 `basicNack` 或 `basicReject` 并 `requeue=true`
+- **死信队列**:达到最大重试次数后路由到 DLQ 人工介入
+- **幂等性**:业务层实现(如唯一 ID 去重表)
+
+以下时序图展示了从生产者到消费者的完整消息流转及各环节的异常处理策略:
+
+```mermaid
+sequenceDiagram
+ participant P as 生产者 (Producer)
+ participant E as 交换器 (Exchange)
+ participant DLX as 死信交换器 (DLX)
+ participant Q as 队列 (Quorum Queue)
+ participant C as 消费者 (Consumer)
+
+ P->>E: 1. 发送消息 (开启 Confirm & Mandatory)
+ alt 路由成功
+ E->>Q: 2. 消息进入队列
+ Q-->>P: 3. Raft 多数派落盘后返回 Confirm Ack
+ else 路由失败 (无匹配 Queue, mandatory=true)
+ E-->>P: 2a. 触发 Return Listener 返回消息
+ Note over P: 记录日志或告警
+ end
+
+ Q->>C: 4. 推送消息 (开启手动 Ack)
+
+ alt 消费成功
+ C-->>Q: 5. 发送 basic.ack
+ Q->>Q: 6. 标记消息可删除
+ else 业务异常且可重试
+ C-->>Q: 5a. basic.nack (requeue=true)
+ Q->>Q: 6a. 消息重回队列尾部 (注意:顺序破坏)
+ else 致命异常 / 重试超限
+ C-->>Q: 5b. basic.reject (requeue=false)
+ Q->>DLX: 6b. 路由至死信交换机 (DLX)
+ end
+```
+
+**关键路径说明**:
+
+- **Confirm + Returns**(互为补充):
+ - Confirm 确认消息是否到达 Broker 并落盘/同步
+ - Mandatory + Return Listener 捕获路由失败事件(消息到达 Exchange 但无法进入 Queue)
+- **Quorum Queue**:Raft 多数派确认后才返回 Ack,保证数据不丢
+- **手动 Ack**:确保消费成功后才删除消息
+- **DLQ 兜底**:重试超限后路由到死信队列,避免消息无限重试
+
+> **注意**:Alternate Exchange(备用交换器)是另一种独立的路由失败处理机制,与 Mandatory + Return Listener 互斥。配置 Alternate Exchange 后,路由失败的消息会被转发到备用交换器,生产者收到的是正常的 Confirm Ack 而非 Return。
## 如何保证 RabbitMQ 消息的顺序性?
-- 拆分多个 queue(消息队列),每个 queue(消息队列) 一个 consumer(消费者),就是多一些 queue (消息队列)而已,确实是麻烦点;
-- 或者就一个 queue (消息队列)但是对应一个 consumer(消费者),然后这个 consumer(消费者)内部用内存队列做排队,然后分发给底层不同的 worker 来处理。
+RabbitMQ 仅保证**单个 Queue 内的 FIFO 顺序**,但多消费者场景下可能出现乱序。解决方案:
+
+**1. 单 Consumer 模式**
+
+- 一个 Queue 只绑定一个 Consumer
+- 优点:保证顺序
+- 缺点:成为瓶颈,吞吐量受限
+
+**2. 分区有序**(推荐,但需注意失效模式)
+
+- 按业务 key(如订单ID)哈希到不同 Queue
+- 每个 Queue 独立 Consumer
+- 优点:既保证顺序又提高吞吐量
+
+> **失效模式警告**:
+>
+> - **拓扑变更乱序**:当后端队列扩缩容导致哈希环发生变化时,同一个业务 Key 的新老消息可能进入不同队列
+> - **重试乱序**:若消费者内部处理失败执行 Nack 并 Requeue,该消息会被重新推入队列**尾部**,导致后续消息先被消费
+> - **应用层防护**:极端严格顺序场景下,消费者业务表必须设计基于**状态机**或**版本号**的幂等与防并发覆盖机制
+
+**3. 内部内存队列**(慎重)
+
+- 单一 Consumer 内部维护内存队列分发到 Worker 线程池
+- 需处理:
+ - Consumer 挂掉时内存队列丢失风险
+ - 需实现背压机制防止 OOM
+ - 增加 ack 复杂度(需追踪具体 Worker 处理状态)
+- 生产环境慎用此方案
## 如何保证 RabbitMQ 高可用的?
-RabbitMQ 是比较有代表性的,因为是基于主从(非分布式)做高可用性的,我们就以 RabbitMQ 为例子讲解第一种 MQ 的高可用性怎么实现。RabbitMQ 有三种模式:单机模式、普通集群模式、镜像集群模式。
+RabbitMQ 是比较有代表性的,因为是基于主从(非分布式)做高可用性的,我们就以 RabbitMQ 为例子讲解第一种 MQ 的高可用性怎么实现。RabbitMQ 有四种模式:单机模式、普通集群模式、镜像集群模式(已废弃)、Quorum Queue(推荐)。
+
+> **版本演进说明**:
+>
+> - **3.8 前**:镜像队列(Classic Queue Mirroring)是主要高可用方案
+> - **3.8+**:Quorum Queue 作为推荐替代方案,镜像队列被标记为 deprecated
+> - **3.13**:镜像队列仍可用但已废弃
+> - **4.0+**:镜像队列**完全移除**,Quorum Queue 成为默认高可用方案
+>
+> **网络分区警告(严重)**:无论是普通集群还是早期的镜像集群,均依赖 Erlang 内部的分布式同步机制,对网络抖动极度敏感。在多机房或跨可用区部署时,极易发生**网络分区(Split-brain)**。必须在 `rabbitmq.conf` 中明确配置分区恢复策略:
+>
+> - `pause_minority`:少数派节点自动暂停服务以防数据分化(推荐)
+> - `autoheal`:自动选择一方继续运行(有数据丢失风险)
+> - 对于 3.8 以上版本,强烈建议直接使用基于 Raft 一致性算法的 Quorum Queue,从根本上解决网络分区导致的消息丢失与状态不一致问题
**单机模式**
@@ -234,12 +371,269 @@ Demo 级别的,一般就是你本地启动了玩玩儿的?,没人生产用
你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从 queue 所在实例上拉取数据过来。这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个 queue 的读写操作。
-**镜像集群模式**
+**镜像集群模式**(Classic Queue Mirroring,已废弃)
+
+> ⚠️ **重要警告**:镜像队列已在 RabbitMQ 4.0 中被**完全移除**。RabbitMQ 3.8 引入 Quorum Queue 作为推荐替代方案,3.13 版本镜像队列仍可用但已废弃,4.0 版本正式移除。新项目请使用 Quorum Queue 或 Streams。
+
+这种模式是 RabbitMQ 早期版本的高可用方案。跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据。每次写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。
-这种模式,才是所谓的 RabbitMQ 的高可用模式。跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。RabbitMQ 有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
+**工作原理**:
-这样的好处在于,你任何一个机器宕机了,没事儿,其它机器(节点)还包含了这个 queue 的完整数据,别的 consumer 都可以到其它节点上去消费数据。坏处在于,第一,这个性能开销也太大了吧,消息需要同步到所有机器上,导致网络带宽压力和消耗很重!RabbitMQ 一个 queue 的数据都是放在一个节点里的,镜像集群下,也是每个节点都放这个 queue 的完整数据。
+- Queue 主节点接收消息,同步到 N 个镜像节点
+- 主节点宕机时,最老的镜像节点升级为主节点
+- 通过管理控制台新增策略,指定数据同步到所有节点或指定数量的节点
+
+**优点**:
+
+- 任何机器宕机,其他节点包含该 queue 的完整数据
+- Consumer 可以切换到其他节点继续消费
+
+**缺点**:
+
+- 性能开销大,消息需要同步到所有机器上
+- 网络带宽压力和消耗重
+- 不是真正的分布式架构,是主从复制
+
+**Quorum Queue**(3.8+ 推荐,4.0 后为默认高可用方案)
+
+基于 Raft 协议的复制队列,是 RabbitMQ 3.8+ 推荐的高可用方案,4.0 后成为默认选项:
+
+- **基于 Raft 协议**:通过日志复制和选举实现一致性
+- **仲裁写入**:需要多数节点确认(N/2 + 1)才认为写入成功
+- **更严格的一致性**:避免镜像队列的脑裂风险
+- **适用场景**:对可靠性要求高的场景
+
+**声明方式(客户端)**:
+
+Java:
+
+```java
+// Java 客户端声明 Quorum Queue
+Map args = new HashMap<>();
+args.put("x-queue-type", "quorum"); // 关键参数,必须在声明时指定
+channel.queueDeclare("my-queue", true, false, false, args);
+```
+
+Python:
+
+```python
+# Python (pika) 客户端声明 Quorum Queue
+channel.queue_declare(
+ queue='my-queue',
+ durable=True,
+ arguments={'x-queue-type': 'quorum'} # 关键参数
+)
+```
+
+> **重要提示**:`x-queue-type` 参数必须在队列声明时由客户端提供,**不能通过 Policy 设置或修改**。Policy 只能配置 max-length、delivery-limit 等运行时参数。
## 如何解决消息队列的延时以及过期失效问题?
-RabbtiMQ 是可以设置过期时间的,也就是 TTL。如果消息在 queue 中积压超过一定的时间就会被 RabbitMQ 给清理掉,这个数据就没了。那这就是第二个坑了。这就不是说数据会大量积压在 mq 里,而是大量的数据会直接搞丢。我们可以采取一个方案,就是批量重导,这个我们之前线上也有类似的场景干过。就是大量积压的时候,我们当时就直接丢弃数据了,然后等过了高峰期以后,比如大家一起喝咖啡熬夜到晚上 12 点以后,用户都睡觉了。这个时候我们就开始写程序,将丢失的那批数据,写个临时程序,一点一点的查出来,然后重新灌入 mq 里面去,把白天丢的数据给他补回来。也只能是这样了。假设 1 万个订单积压在 mq 里面,没有处理,其中 1000 个订单都丢了,你只能手动写程序把那 1000 个订单给查出来,手动发到 mq 里去再补一次。
+RabbitMQ 可以设置消息过期时间(TTL)。如果消息在 queue 中积压超过一定的时间就会被 RabbitMQ 清理掉,导致数据丢失。
+
+**批量重导方案**(适用于数据可恢复的场景):
+
+当大量消息积压或过期时,可采取以下步骤:
+
+1. **临时丢弃**:高峰期直接丢弃无法及时处理的数据,保证系统可用性
+2. **低峰期恢复**:在业务低峰期(如凌晨),编写临时程序从数据库中查询丢失的数据
+3. **重新投递**:将查询到的数据重新发送到 MQ 中进行补偿
+
+**示例场景**:
+
+- 假设 1 万个订单积压在 MQ 中未处理
+- 其中 1000 个订单因 TTL 过期被丢弃
+- 处理方案:编写临时程序从数据库查询这 1000 个订单,手动重新发送到 MQ 补偿
+
+**注意事项**:
+
+- 确保数据源(如数据库)中有完整的历史数据
+- 补偿过程需要做好幂等性处理,避免重复消费
+- 建议设置监控告警,及时发现消息积压情况
+
+## 生产环境最佳实践与监控告警
+
+### 核心监控指标
+
+**1. 内存水位线告警(严重)**
+
+- 监控 `rabbitmq_memory_limit` 占比
+- 告警阈值:默认高水位为 0.4(40%)
+- **影响**:一旦达到高水位,RabbitMQ 会直接 **block 所有生产者的 TCP Socket**(全局背压)
+- 建议配置:
+ ```erlang
+ {rabbit, [
+ {vm_memory_high_watermark, 0.4}, % 内存高水位 40%
+ {vm_memory_high_watermark_paging_ratio, 0.5} % 开始分页的比例
+ ]}
+ ```
+
+**2. 文件句柄消耗**
+
+- 监控 File Descriptors 使用率
+- **风险**:连接数风暴或海量未确认消息会耗尽句柄导致节点 Crash
+- 建议值:系统限制至少 100,000+(`ulimit -n 100000`)
+
+**3. Channel Churn Rate**
+
+- 监控信道的创建与销毁速率
+- **风险**:高频创建销毁(而非复用)会导致 Erlang 进程抖动,引发 CPU 飙升
+- 生产建议:单连接 Channel 数建议 50-100,避免频繁创建/销毁
+
+**4. 消息积压深度**
+
+- 监控 Queue 消息数量和 Consumer Lag
+- 告警阈值:根据业务定义(如 > 10,000 条)
+- 工具:RabbitMQ Management UI、Prometheus + Grafana
+
+**5. 磁盘空间与 I/O**
+
+- 监控磁盘剩余空间和 IOPS
+- **告警阈值**:磁盘剩余 < 20% 触发告警
+- Quorum Queue 对磁盘 I/O 要求较高,建议使用 NVMe SSD
+
+### 常见生产误区与避坑指南
+
+**误区 1:Quorum Queue 是银弹,能解决所有问题**
+
+- **真相**:Quorum Queue 的 Raft 日志在 flush 时会 fsync,且 Confirm 需等待多数节点 fsync 后才返回。如果底层不是高性能 NVMe SSD,其吞吐量会受到影响
+- **限制**:Quorum Queue 会将所有消息(包括 `delivery_mode=1` 的非持久化消息)强制持久化存储到磁盘
+- **选型建议**:
+ - 高吞吐量场景:考虑 Classic Queue(非镜像,单节点)或 Streams(3.9+)
+ - 高可靠性场景:使用 Quorum Queue(3.8+)
+
+**误区 2:Prefetch Count 设置越大越好**
+
+- **真相**:客户端批量拉取大量消息但在本地卡死,导致服务端队列看似空闲,实则消息全部处于 Unacked 状态,拖垮客户端本地内存并阻碍其他消费者接盘
+- **生产建议**:核心业务初始值设为 **10 到 50** 之间,根据处理耗时调整
+ ```java
+ channel.basicQos(20); // 推荐起始值
+ ```
+
+**误区 3:延迟队列插件可以无限制使用**
+
+- **真相**:延迟插件将所有延迟消息存储在 Mnesia 内存表中,**不支持磁盘换页**
+- **风险**:单节点堆积百万级延迟消息会触发 OOM 或全局背压
+- **替代方案**:海量延迟场景使用外部定时任务系统(如 XXL-JOB、SchedulerX)
+
+**误区 4:网络分区不会发生在我们环境**
+
+- **真相**:跨机房部署或网络抖动都会触发 Erlang 的网络分区检测
+- **后果**:Split-brain 导致消息丢失、状态不一致
+- **防护**:
+ - 3.8+ 使用 Quorum Queue(基于 Raft,天然抗分区)
+ - 配置分区恢复策略:`cluster_partition_handling = pause_minority`
+
+**误区 5:开启了事务机制就万无一失**
+
+- **真相**:事务机制是同步阻塞模式,性能显著低于 Publisher Confirms(官方文档未给出具体倍数,实际影响取决于消息大小和网络延迟)
+- **替代方案**:使用 Publisher Confirms + Mandatory Returns(异步且高性能)
+
+### 生产配置参考
+
+> **重要说明**:RabbitMQ 3.7+ 使用新的 `rabbitmq.conf` 格式(sysctl 风格),而非旧的 `advanced.config`(Erlang 术语格式)。以下配置适用于 `rabbitmq.conf`:
+
+```ini
+# rabbitmq.conf 生产环境推荐配置
+
+# 内存管理
+vm_memory_high_watermark.relative = 0.4
+vm_memory_high_watermark_paging_ratio = 0.5
+
+# 磁盘管理
+disk_free_limit.absolute = 5GB
+
+# 连接与通道
+channel_max = 200
+connection_max = infinity
+
+# 心跳检测(秒)
+heartbeat = 60
+
+# 网络分区处理(重要)
+cluster_partition_handling = pause_minority
+
+# 默认用户(生产环境请修改或删除)
+default_user = guest
+default_pass = guest
+loopback_users = none
+
+# 管理插件监听端口
+management.tcp.port = 15672
+```
+
+如需使用 Erlang 术语格式(高级配置),请使用 `advanced.config` 文件,但**不要与 `rabbitmq.conf` 混用**。
+
+## 总结
+
+本文系统梳理了 RabbitMQ 的核心知识点,从基础概念到生产实践,涵盖了面试和实际应用中最重要的内容。让我们回顾一下关键要点:
+
+### 核心技术架构演进
+
+| 版本里程碑 | 重要变化 | 生产影响 |
+| ---------- | --------------------------------------- | -------------------------------------- |
+| **3.8 前** | 镜像队列(Classic Queue Mirroring)时代 | 主从复制,脑裂风险 |
+| **3.8+** | Quorum Queue 引入 | 基于 Raft,推荐用于高可靠场景 |
+| **3.9+** | Streams 引入 | Kafka-like 架构,支持事件溯源 |
+| **4.0+** | 镜像队列完全移除 | 新项目必须使用 Quorum Queue 或 Streams |
+
+### 面试高频考点
+
+**必知必会**:
+
+1. **AMQP 模型**:Exchange、Queue、Binding 三大核心组件
+2. **Exchange 类型**:direct、fanout、topic、headers 的路由规则
+3. **消息可靠性**:Publisher Confirms + Mandatory Returns + 手动 Ack + DLQ
+4. **消息顺序性**:单 Queue 内 FIFO,多消费者需分区有序或单 Consumer
+5. **高可用方案**:Quorum Queue(3.8+)替代镜像队列(4.0 已移除)
+
+**常见追问**:
+
+- 为什么镜像队列被移除?(脑裂问题、主从复制非分布式)
+- Quorum Queue 和 Classic Queue 如何选型?(可靠性 vs 吞吐量)
+- 如何保证消息不丢失?(三环节:生产者→Broker→消费者)
+- 如何保证消息顺序?(单 Queue、分区有序、慎用内存队列)
+
+### 生产环境关键决策
+
+**1. 队列类型选型**
+
+```
+高可靠性需求 → Quorum Queue(默认推荐)
+高吞吐量需求 → Classic Queue(单节点)或 Streams(3.9+)
+事件溯源需求 → Streams(支持非破坏性消费)
+```
+
+**2. 消息可靠性配置**
+
+```java
+// 生产者端:双重保障
+channel.confirmSelect(); // Confirm
+channel.basicPublish(exchange, routingKey, true, ...); // Mandatory
+channel.addReturnListener(...); // Return Listener
+
+// 消费者端:手动确认
+channel.basicQos(20); // Fair dispatch
+channel.basicConsume(queue, false, ...); // Manual ack
+```
+
+**3. 高可用配置要点**
+
+```ini
+# 网络分区处理(跨机房部署必配)
+cluster_partition_handling = pause_minority
+
+# 使用 Quorum Queue(客户端声明)
+arguments.put("x-queue-type", "quorum");
+```
+
+**4. 监控告警指标**
+
+- **内存水位线**:触发全局背压的阈值(默认 40%)
+- **磁盘剩余空间**:低于 20% 触发告警
+- **消息积压深度**:Queue 消息数量和 Consumer Lag
+- **Channel Churn Rate**:高频创建销毁会导致 CPU 飙升
+
+---
+
+
diff --git a/docs/high-performance/message-queue/rocketmq-questions.md b/docs/high-performance/message-queue/rocketmq-questions.md
index 81c467201c5..03ad07e9b90 100644
--- a/docs/high-performance/message-queue/rocketmq-questions.md
+++ b/docs/high-performance/message-queue/rocketmq-questions.md
@@ -1,18 +1,27 @@
---
title: RocketMQ常见问题总结
+description: 本文总结 RocketMQ 常见面试题与核心知识点,涵盖 RocketMQ 架构(NameServer/Broker/Proxy)、消息类型(普通/顺序/事务/定时消息)、消息存储机制(CommitLog/ConsumeQueue)、高性能原理(零拷贝/顺序写)、消息可靠性保障、RocketMQ 5.x 新特性等,助力 RocketMQ 学习与面试。
category: 高性能
tag:
- RocketMQ
- 消息队列
+head:
+ - - meta
+ - name: keywords
+ content: RocketMQ,消息队列,NameServer,Broker,Proxy,顺序消息,事务消息,定时消息,消息存储,RocketMQ面试,RocketMQ5.x
---
-> [本文由 FrancisQ 投稿!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485969&idx=1&sn=6bd53abde30d42a778d5a35ec104428c&chksm=cea245daf9d5cccce631f93115f0c2c4a7634e55f5bef9009fd03f5a0ffa55b745b5ef4f0530&token=294077121&lang=zh_CN#rd)
+> 本文由 FrancisQ 投稿!相比原文主要进行了下面这些完善:
+>
+> - [分析了 RocketMQ 高性能读写的原因和顺序消费的具体实现](https://github.com/Snailclimb/JavaGuide/pull/2133)
+> - [增加了消息类型、消费者类型、消费者组和生产者组的介绍](https://github.com/Snailclimb/JavaGuide/pull/2134)
+> - [RocketMQ 5.x 支持按消息粒度分配](https://github.com/Snailclimb/JavaGuide/issues/2778)
## 消息队列扫盲
-消息队列顾名思义就是存放消息的队列,队列我就不解释了,别告诉我你连队列都不知道是啥吧?
+消息队列(Message Queue,简称 MQ)是一种应用程序之间的通信方式,用于在分布式系统中传递消息。消息队列的核心概念是生产者将消息发送到队列,消费者从队列中获取消息进行处理。
-所以问题并不是消息队列是什么,而是 **消息队列为什么会出现?消息队列能用来干什么?用它来干这些事会带来什么好处?消息队列会带来副作用吗?**
+理解消息队列,关键是要回答以下几个问题:**消息队列为什么会出现?消息队列能用来干什么?使用消息队列能带来什么好处?消息队列会带来哪些副作用?**
### 消息队列为什么会出现?
@@ -22,39 +31,37 @@ tag:
#### 异步
-你可能会反驳我,应用之间的通信又不是只能由消息队列解决,好好的通信为什么中间非要插一个消息队列呢?我不能直接进行通信吗?
+你可能会问,应用之间的通信又不是只能由消息队列解决,为什么中间非要插一个消息队列?直接进行通信不行吗?
-很好 👍,你又提出了一个概念,**同步通信**。就比如现在业界使用比较多的 `Dubbo` 就是一个适用于各个系统之间同步通信的 `RPC` 框架。
+这就引出了另一个概念——**同步通信**。比如业界使用较多的 Dubbo 就是一个适用于各个系统之间同步通信的 RPC 框架。
-我来举个 🌰 吧,比如我们有一个购票系统,需求是用户在购买完之后能接收到购买完成的短信。
+以购票系统为例,需求是用户在购买完成之后能接收到购买完成的短信通知。
-
+
我们省略中间的网络通信时间消耗,假如购票系统处理需要 150ms ,短信系统处理需要 200ms ,那么整个处理流程的时间消耗就是 150ms + 200ms = 350ms。
-当然,乍看没什么问题。可是仔细一想你就感觉有点问题,我用户购票在购票系统的时候其实就已经完成了购买,而我现在通过同步调用非要让整个请求拉长时间,而短信系统这玩意又不是很有必要,它仅仅是一个辅助功能增强用户体验感而已。我现在整个调用流程就有点 **头重脚轻** 的感觉了,购票是一个不太耗时的流程,而我现在因为同步调用,非要等待发送短信这个比较耗时的操作才返回结果。那我如果再加一个发送邮件呢?
+当然,乍看没什么问题。但仔细分析会发现问题:用户购票在购票系统处理完成时就已经完成了购买动作,而现在通过同步调用非要让整个请求时间变长。短信系统只是一个辅助功能,用于增强用户体验感,并非核心业务。整个调用流程显得 **头重脚轻**——购票是一个不太耗时的流程,但因为同步调用,必须等待发送短信这个较耗时的操作完成才能返回结果。如果再加一个发送邮件的需求呢?
-
+
这样整个系统的调用链又变长了,整个时间就变成了 550ms。
-当我们在学生时代需要在食堂排队的时候,我们和食堂大妈就是一个同步的模型。
-
-我们需要告诉食堂大妈:“姐姐,给我加个鸡腿,再加个酸辣土豆丝,帮我浇点汁上去,多打点饭哦 😋😋😋” 咦~~~ 为了多吃点,真恶心。
+当我们在食堂排队打饭时,我们和食堂工作人员之间就是一个同步模型。
-然后大妈帮我们打饭配菜,我们看着大妈那颤抖的手和掉落的土豆丝不禁咽了咽口水。
+我们需要告诉工作人员:"请帮我加个鸡腿,再加个酸辣土豆丝,多打点饭"。
-最终我们从大妈手中接过饭菜然后去寻找座位了...
+然后工作人员帮我们打饭配菜,我们需要等待这个过程完成。
-回想一下,我们在给大妈发送需要的信息之后我们是 **同步等待大妈给我配好饭菜** 的,上面我们只是加了鸡腿和土豆丝,万一我再加一个番茄牛腩,韭菜鸡蛋,这样是不是大妈打饭配菜的流程就会变长,我们等待的时间也会相应的变长。
+最终我们从工作人员手中接过饭菜然后去寻找座位。
-
+回想一下,我们在传达需求之后是 **同步等待工作人员配好饭菜** 的。如果增加更多菜品,工作人员打饭配菜的流程就会变长,我们等待的时间也会相应增加。
-那后来,我们工作赚钱了有钱去饭店吃饭了,我们告诉服务员来一碗牛肉面加个荷包蛋 **(传达一个消息)** ,然后我们就可以在饭桌上安心的玩手机了 **(干自己其他事情)** ,等到我们的牛肉面上了我们就可以吃了。这其中我们也就传达了一个消息,然后我们又转过头干其他事情了。这其中虽然做面的时间没有变短,但是我们只需要传达一个消息就可以干其他事情了,这是一个 **异步** 的概念。
+而在餐厅用餐时,我们告诉服务员来一碗牛肉面加个荷包蛋 **(传达一个消息)** ,然后可以在餐桌上做自己的事情 **(干自己其他事情)** ,等到牛肉面上桌我们再开始用餐。虽然做面的时间没有变短,但是我们只需要传达一个消息就可以干其他事情了,这就是 **异步** 的概念。
所以,为了解决这一个问题,聪明的程序员在中间也加了个类似于服务员的中间件——消息队列。这个时候我们就可以把模型给改造了。
-
+
这样,我们在将消息存入消息队列之后我们就可以直接返回了(我们告诉服务员我们要吃什么然后玩手机),所以整个耗时只是 150ms + 10ms = 160ms。
@@ -64,41 +71,68 @@ tag:
回到最初同步调用的过程,我们写个伪代码简单概括一下。
-
+
那么第二步,我们又添加了一个发送邮件,我们就得重新去修改代码,如果我们又加一个需求:用户购买完还需要给他加积分,这个时候我们是不是又得改代码?
-
+
-如果你觉得还行,那么我这个时候不要发邮件这个服务了呢,我是不是又得改代码,又得重启应用?
+如果还觉得可以接受,那么当需要移除发送邮件服务时,是不是又得改代码、又得重启应用?
-
+
-这样改来改去是不是很麻烦,那么 **此时我们就用一个消息队列在中间进行解耦** 。你需要注意的是,我们后面的发送短信、发送邮件、添加积分等一些操作都依赖于上面的 `result` ,这东西抽象出来就是购票的处理结果呀,比如订单号,用户账号等等,也就是说我们后面的一系列服务都是需要同样的消息来进行处理。既然这样,我们是不是可以通过 **“广播消息”** 来实现。
+这样频繁改动代码显然很麻烦,此时可以 **使用消息队列进行解耦** 。需要注意的是,后面的发送短信、发送邮件、添加积分等操作都依赖于 `result`,即购票的处理结果(如订单号、用户账号等),也就是说后续服务都需要相同的消息来进行处理。因此可以通过 **"广播消息"** 模式来实现。
-我上面所讲的“广播”并不是真正的广播,而是接下来的系统作为消费者去 **订阅** 特定的主题。比如我们这里的主题就可以叫做 `订票` ,我们购买系统作为一个生产者去生产这条消息放入消息队列,然后消费者订阅了这个主题,会从消息队列中拉取消息并消费。就比如我们刚刚画的那张图,你会发现,在生产者这边我们只需要关注 **生产消息到指定主题中** ,而 **消费者只需要关注从指定主题中拉取消息** 就行了。
+这里所说的"广播"并不是真正的广播,而是下游系统作为消费者去 **订阅** 特定的主题。比如主题可以命名为 `订票`,购买系统作为生产者将消息发送到消息队列,消费者订阅该主题后,从消息队列中拉取消息并消费。在生产者端只需要关注 **生产消息到指定主题** ,**消费者只需要关注从指定主题中拉取消息** 。
-
+
> 如果没有消息队列,每当一个新的业务接入,我们都要在主系统调用新接口、或者当我们取消某些业务,我们也得在主系统删除某些接口调用。有了消息队列,我们只需要关心消息是否送达了队列,至于谁希望订阅,接下来收到消息如何处理,是下游的事情,无疑极大地减少了开发和联调的工作量。
#### 削峰
-我们再次回到一开始我们使用同步调用系统的情况,并且思考一下,如果此时有大量用户请求购票整个系统会变成什么样?
+回到同步调用系统的场景,思考一下:如果此时有大量用户请求购票,整个系统会变成什么样?
+
+
+
+假设有一万个请求进入购票系统,运行主业务的服务器配置通常较好,购票系统可以承受这一万个用户请求。但这意味着同时也会产生一万个调用短信服务的请求。短信系统并非主要业务,配备的硬件资源不会太高。此时短信系统能否承受这一万的峰值?很可能系统会 **直接崩溃** 。
+
+短信业务并非主业务,能否 **折中处理** ?如果我们把购买完成的信息发送到消息队列中,而短信系统 **尽自己所能地去消息队列中取消息和消费消息** ,即使处理速度慢一点也无所谓,只要系统没有崩溃就可以接受。
+
+系统可用性是最重要的,验证码短信的延迟几秒到达用户手机,通常是可以接受的。
+
+### 消息队列能带来什么好处?
+
+总结起来就是三个关键词:**异步、解耦、削峰**。这不仅是消息队列的核心价值,更是分布式架构设计的重要思想。
-
+```mermaid
+flowchart LR
+ subgraph MQ["消息队列三大应用场景"]
+ style MQ fill:#F0F2F5,stroke:#E0E6ED,stroke-width:1.5px
+ Async["异步处理"]
+ Decouple["解耦"]
+ Peak["削峰"]
+ end
-如果,此时有一万的请求进入购票系统,我们知道运行我们主业务的服务器配置一般会比较好,所以这里我们假设购票系统能承受这一万的用户请求,那么也就意味着我们同时也会出现一万调用发短信服务的请求。而对于短信系统来说并不是我们的主要业务,所以我们配备的硬件资源并不会太高,那么你觉得现在这个短信系统能承受这一万的峰值么,且不说能不能承受,系统会不会 **直接崩溃** 了?
+ Async --> A1["提高响应速度"]
+ Async --> A2["提升用户体验"]
-短信业务又不是我们的主业务,我们能不能 **折中处理** 呢?如果我们把购买完成的信息发送到消息队列中,而短信系统 **尽自己所能地去消息队列中取消息和消费消息** ,即使处理速度慢一点也无所谓,只要我们的系统没有崩溃就行了。
+ Decouple --> D1["降低系统耦合"]
+ Decouple --> D2["提高扩展性"]
-留得江山在,还怕没柴烧?你敢说每次发送验证码的时候是一发你就收到了的么?
+ Peak --> P1["缓解系统压力"]
+ Peak --> P2["保证系统稳定"]
-#### 消息队列能带来什么好处?
+ classDef app fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef benefit fill:#00838F,color:#fff,rx:10,ry:10
-其实上面我已经说了。**异步、解耦、削峰。** 哪怕你上面的都没看懂也千万要记住这六个字,因为他不仅是消息队列的精华,更是编程和架构的精华。
+ class Async,Decouple,Peak app
+ class A1,A2,D1,D2,P1,P2 benefit
-#### 消息队列会带来副作用吗?
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
+
+### 消息队列会带来副作用吗?
没有哪一门技术是“银弹”,消息队列也有它的副作用。
@@ -126,45 +160,60 @@ tag:
那么,又如何 **解决消息堆积的问题** 呢?
-可用性降低,复杂度上升,又带来一系列的重复消费,顺序消费,分布式事务,消息堆积的问题,这消息队列还怎么用啊 😵?
+可用性降低、复杂度上升,同时还带来重复消费、顺序消费、分布式事务、消息堆积等一系列问题。这些问题如何解决?
-
+
-别急,办法总是有的。
+下面我们逐一讨论这些问题的解决方案。
## RocketMQ 是什么?
-
-
-哇,你个混蛋!上面给我抛出那么多问题,你现在又讲 `RocketMQ` ,还让不让人活了?!🤬
+
-别急别急,话说你现在清楚 `MQ` 的构造吗,我还没讲呢,我们先搞明白 `MQ` 的内部构造,再来看看如何解决上面的一系列问题吧,不过你最好带着问题去阅读和了解喔。
+在讨论上述问题的解决方案之前,我们先来了解一下 RocketMQ 的内部构造。建议带着问题去阅读和了解。
-`RocketMQ` 是一个 **队列模型** 的消息中间件,具有**高性能、高可靠、高实时、分布式** 的特点。它是一个采用 `Java` 语言开发的分布式的消息系统,由阿里巴巴团队开发,在 2016 年底贡献给 `Apache`,成为了 `Apache` 的一个顶级项目。 在阿里内部,`RocketMQ` 很好地服务了集团大大小小上千个应用,在每年的双十一当天,更有不可思议的万亿级消息通过 `RocketMQ` 流转。
+RocketMQ 是一个 **队列模型** 的消息中间件,具有**高性能、高可靠、高实时、分布式** 的特点。它是一个采用 Java 语言开发的分布式消息系统,由阿里巴巴团队开发,在 2016 年底贡献给 Apache,成为了 Apache 的顶级项目。在阿里内部,RocketMQ 很好地服务了集团大大小小上千个应用,在每年的双十一当天,更有万亿级消息通过 RocketMQ 流转。
-废话不多说,想要了解 `RocketMQ` 历史的同学可以自己去搜寻资料。听完上面的介绍,你只要知道 `RocketMQ` 很快、很牛、而且经历过双十一的实践就行了!
+RocketMQ 具备高吞吐、低延迟、高可用的特点,经过了双十一等大规模场景的验证。
## 队列模型和主题模型是什么?
-在谈 `RocketMQ` 的技术架构之前,我们先来了解一下两个名词概念——**队列模型** 和 **主题模型** 。
+在谈 RocketMQ 的技术架构之前,我们先来了解一下两个名词概念——**队列模型** 和 **主题模型** 。
-首先我问一个问题,消息队列为什么要叫消息队列?
+首先,为什么消息队列叫消息队列?
-你可能觉得很弱智,这玩意不就是存放消息的队列嘛?不叫消息队列叫什么?
+实际上,早期的消息中间件是通过 **队列** 这一模型来实现的,可能是历史原因,我们都习惯把消息中间件称为消息队列。
-的确,早期的消息中间件是通过 **队列** 这一模型来实现的,可能是历史原因,我们都习惯把消息中间件成为消息队列。
-
-但是,如今例如 `RocketMQ`、`Kafka` 这些优秀的消息中间件不仅仅是通过一个 **队列** 来实现消息存储的。
+但是,如今例如 RocketMQ、Kafka 这些优秀的消息中间件不仅仅是通过一个 **队列** 来实现消息存储的。
### 队列模型
-就像我们理解队列一样,消息中间件的队列模型就真的只是一个队列。。。我画一张图给大家理解。
+就像我们理解队列一样,消息中间件的队列模型就真的只是一个队列。
+
+
+
+队列模型的特点:**一个消息只能被一个消费者消费**。
+
+```mermaid
+flowchart LR
+ P["生产者"] --> Q["队列"]
+ Q --> C1["消费者1"]
+ Q --> C2["消费者2"]
+
+ classDef producer fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef queue fill:#E99151,color:#fff,rx:10,ry:10
+ classDef consumer fill:#00838F,color:#fff,rx:10,ry:10
-
+ class P producer
+ class Q queue
+ class C1,C2 consumer
-在一开始我跟你提到了一个 **“广播”** 的概念,也就是说如果我们此时我们需要将一个消息发送给多个消费者(比如此时我需要将信息发送给短信系统和邮件系统),这个时候单个队列即不能满足需求了。
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
-当然你可以让 `Producer` 生产消息放入多个队列中,然后每个队列去对应每一个消费者。问题是可以解决,创建多个队列并且复制多份消息是会很影响资源和性能的。而且,这样子就会导致生产者需要知道具体消费者个数然后去复制对应数量的消息队列,这就违背我们消息中间件的 **解耦** 这一原则。
+在一开始我跟你提到了一个 **"广播"** 的概念,也就是说如果我们此时我们需要将一个消息发送给多个消费者(比如此时我需要将信息发送给短信系统和邮件系统),这个时候单个队列即不能满足需求了。
+
+当然你可以让 Producer 生产消息放入多个队列中,然后每个队列去对应每一个消费者。问题是可以解决,创建多个队列并且复制多份消息是会很影响资源和性能的。而且,这样子就会导致生产者需要知道具体消费者个数然后去复制对应数量的消息队列,这就违背我们消息中间件的 **解耦** 这一原则。
### 主题模型
@@ -176,133 +225,1135 @@ tag:
其中,发布者将消息发送到指定主题中,订阅者需要 **提前订阅主题** 才能接受特定主题的消息。
-
+
+
+主题模型的特点:**一个消息可以被多个消费者消费**。
+
+```mermaid
+flowchart LR
+ P1["发布者1"] --> T["主题"]
+ P2["发布者2"] --> T
+ T --> S1["订阅者1"]
+ T --> S2["订阅者2"]
+ T --> S3["订阅者3"]
+
+ classDef publisher fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef topic fill:#E99151,color:#fff,rx:10,ry:10
+ classDef subscriber fill:#00838F,color:#fff,rx:10,ry:10
+
+ class P1,P2 publisher
+ class T topic
+ class S1,S2,S3 subscriber
+
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
### RocketMQ 中的消息模型
-`RocketMQ` 中的消息模型就是按照 **主题模型** 所实现的。你可能会好奇这个 **主题** 到底是怎么实现的呢?你上面也没有讲到呀!
+RocketMQ 中的消息模型就是按照 **主题模型** 所实现的。那么 **主题** 到底是怎么实现的呢?
-其实对于主题模型的实现来说每个消息中间件的底层设计都是不一样的,就比如 `Kafka` 中的 **分区** ,`RocketMQ` 中的 **队列** ,`RabbitMQ` 中的 `Exchange` 。我们可以理解为 **主题模型/发布订阅模型** 就是一个标准,那些中间件只不过照着这个标准去实现而已。
+其实对于主题模型的实现来说每个消息中间件的底层设计都是不一样的,就比如 Kafka 中的 **分区** ,RocketMQ 中的 **队列** ,RabbitMQ 中的 Exchange 。我们可以理解为 **主题模型/发布订阅模型** 就是一个标准,那些中间件只不过照着这个标准去实现而已。
-所以,`RocketMQ` 中的 **主题模型** 到底是如何实现的呢?首先我画一张图,大家尝试着去理解一下。
+所以,RocketMQ 中的 **主题模型** 到底是如何实现的呢?先看一张图:
-
+
-我们可以看到在整个图中有 `Producer Group`、`Topic`、`Consumer Group` 三个角色,我来分别介绍一下他们。
+我们可以看到在整个图中有 `Producer Group`、Topic、`Consumer Group` 三个角色,我来分别介绍一下他们。
- `Producer Group` 生产者组:代表某一类的生产者,比如我们有多个秒杀系统作为生产者,这多个合在一起就是一个 `Producer Group` 生产者组,它们一般生产相同的消息。
- `Consumer Group` 消费者组:代表某一类的消费者,比如我们有多个短信系统作为消费者,这多个合在一起就是一个 `Consumer Group` 消费者组,它们一般消费相同的消息。
-- `Topic` 主题:代表一类消息,比如订单消息,物流消息等等。
+- Topic 主题:代表一类消息,比如订单消息,物流消息等等。
你可以看到图中生产者组中的生产者会向主题发送消息,而 **主题中存在多个队列**,生产者每次生产消息之后是指定主题中的某个队列发送消息的。
-每个主题中都有多个队列(分布在不同的 `Broker`中,如果是集群的话,`Broker`又分布在不同的服务器中),集群消费模式下,一个消费者集群多台机器共同消费一个 `topic` 的多个队列,**一个队列只会被一个消费者消费**。如果某个消费者挂掉,分组内其它消费者会接替挂掉的消费者继续消费。就像上图中 `Consumer1` 和 `Consumer2` 分别对应着两个队列,而 `Consumer3` 是没有队列对应的,所以一般来讲要控制 **消费者组中的消费者个数和主题中队列个数相同** 。
+每个主题中都有多个队列(分布在不同的 Broker 中,如果是集群的话,Broker 又分布在不同的服务器中),集群消费模式下,一个消费者集群多台机器共同消费一个 `topic` 的多个队列。
+
+**负载均衡策略对比**
+
+```mermaid
+flowchart TB
+ subgraph Queue["队列粒度负载均衡 4.x"]
+ style Queue fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ direction TB
+ Q1["队列1"] --> C1["消费者1"]
+ Q2["队列2"] --> C2["消费者2"]
+ Q3["队列3"] --> C3["消费者3"]
+ Q4["队列4"] -.-> C4["消费者4
(无队列可消费)"]
+ end
+
+ subgraph Message["消息粒度负载均衡 5.x"]
+ style Message fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ direction TB
+ MQ1["队列1"] --> MC1["消费者1
消费消息1"]
+ MQ1 --> MC2["消费者2
消费消息2"]
+ MQ1 --> MC3["消费者3
消费消息3"]
+ end
+
+ classDef queue fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef consumer4x fill:#E99151,color:#fff,rx:10,ry:10
+ classDef consumer5x fill:#00838F,color:#fff,rx:10,ry:10
+
+ class Q1,Q2,Q3,Q4,MQ1 queue
+ class C1,C2,C3,C4 consumer4x
+ class MC1,MC2,MC3 consumer5x
+
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
+
+- **队列粒度负载均衡(4.x 默认策略)**:一个队列只会被一个消费者消费。如果某个消费者挂掉,分组内其它消费者会接替挂掉的消费者继续消费。就像上图中 `Consumer1` 和 `Consumer2` 分别对应着两个队列,而 `Consumer3` 是没有队列对应的,所以一般来讲要控制 **消费者组中的消费者个数和主题中队列个数相同** 。这种模式的缺点是容易产生 **长尾效应**:如果某个消费者处理速度较慢,会导致其对应的队列消息堆积,而其他消费者却处于空闲状态。
+- **消息粒度负载均衡(5.x 新增策略)**:同一消费者分组内的多个消费者将按照消息粒度平均分摊主题中的所有消息,即同一个队列中的消息,可被平均分配给多个消费者共同消费。消费者获取某条消息后,服务端会将该消息加锁,保证这条消息对其他消费者不可见,直到该消息消费成功或消费超时。这种模式有效解决了长尾效应问题,因为消息不再静态绑定到某个消费者,而是动态分配给空闲的消费者。
当然也可以消费者个数小于队列个数,只不过不太建议。如下图。
-
+
**每个消费组在每个队列上维护一个消费位置** ,为什么呢?
因为我们刚刚画的仅仅是一个消费者组,我们知道在发布订阅模式中一般会涉及到多个消费者组,而每个消费者组在每个队列中的消费位置都是不同的。如果此时有多个消费者组,那么消息被一个消费者组消费完之后是不会删除的(因为其它消费者组也需要呀),它仅仅是为每个消费者组维护一个 **消费位移(offset)** ,每次消费者组消费完会返回一个成功的响应,然后队列再把维护的消费位移加一,这样就不会出现刚刚消费过的消息再一次被消费了。
-
+
可能你还有一个问题,**为什么一个主题中需要维护多个队列** ?
答案是 **提高并发能力** 。的确,每个主题中只存在一个队列也是可行的。你想一下,如果每个主题中只存在一个队列,这个队列中也维护着每个消费者组的消费位置,这样也可以做到 **发布订阅模式** 。如下图。
-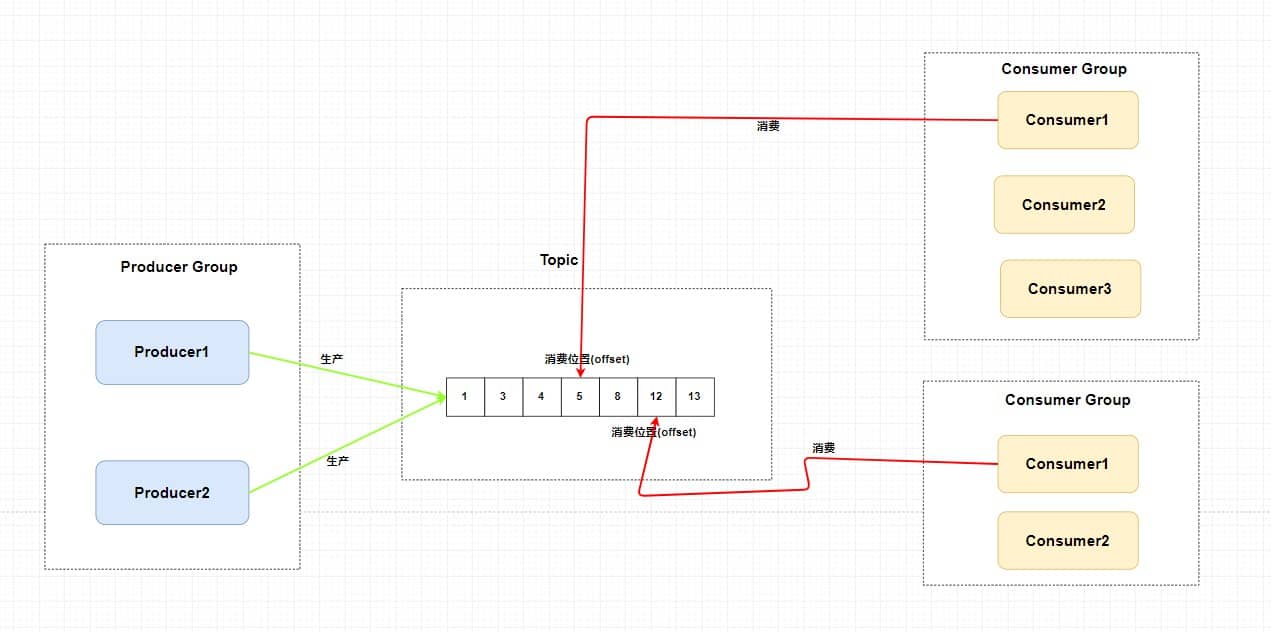
+
+
+但是,这样我生产者是不是只能向一个队列发送消息?又因为需要维护消费位置所以一个队列只能对应一个消费者组中的消费者,这样是不是其他的 Consumer 就没有用武之地了?从这两个角度来讲,并发度一下子就小了很多。
+
+所以总结来说,RocketMQ 通过**使用在一个 Topic 中配置多个队列并且每个队列维护每个消费者组的消费位置** 实现了 **主题模式/发布订阅模式** 。
+
+## RocketMQ 架构
+
+讲完了消息模型,我们理解起 RocketMQ 的技术架构起来就容易多了。
+
+RocketMQ 的核心组件包括 **NameServer、Broker、Producer、Consumer**,在 5.0 版本中还引入了 **Proxy** 组件。
+
+```mermaid
+flowchart TB
+ subgraph RocketMQ["RocketMQ 系统架构"]
+ direction TB
+ style RocketMQ fill:#F0F2F5,stroke:#E0E6ED,stroke-width:1.5px
+
+ subgraph Components["核心组件"]
+ direction TB
+ style Components fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ NS["NameServer
注册中心"]
+ BK["Broker
消息存储"]
+ PX["Proxy
代理层(5.0+)"]
+ PD["Producer
生产者"]
+ CM["Consumer
消费者"]
+ end
+
+ subgraph Protocol["通信协议"]
+ direction LR
+ style Protocol fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ RP["Remoting
私有协议"]
+ GP["gRPC
云原生协议"]
+ end
+
+ subgraph Network["网络层"]
+ style Network fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ NB["Netty
高性能通信框架"]
+ end
+ end
+
+ NS <--> BK
+ NS <--> PD
+ NS <--> CM
+ PD <--> PX
+ CM <--> PX
+ PX <--> BK
+ PD -.->|Remoting 直连| BK
+ CM -.->|Remoting 直连| BK
+ BK --> NB
+ RP --> NB
+ GP --> NB
+
+ classDef ns fill:#E99151,color:#fff,rx:10,ry:10
+ classDef broker fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef proxy fill:#005D7B,color:#fff,rx:10,ry:10
+ classDef producer fill:#00838F,color:#fff,rx:10,ry:10
+ classDef consumer fill:#7E57C2,color:#fff,rx:10,ry:10
+ classDef remoting fill:#FFC107,color:#333,rx:10,ry:10
+ classDef grpc fill:#26A69A,color:#fff,rx:10,ry:10
+ classDef netty fill:#EF5350,color:#fff,rx:10,ry:10
+
+ class NS ns
+ class BK broker
+ class PX proxy
+ class PD producer
+ class CM consumer
+ class RP remoting
+ class GP grpc
+ class NB netty
+
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
+
+### 核心组件要点
+
+| 组件 | 技术要点 |
+| -------------- | ---------------------------------------- |
+| **NameServer** | 轻量级注册中心,各节点无数据同步 |
+| **Broker** | 消息存储与投递,支持主从部署 |
+| **Proxy** | 5.0 新增,协议适配与计算卸载(可选组件) |
+| **Producer** | 同步、异步、单向多种发送方式 |
+| **Consumer** | Push/Pull/Simple 三种消费模式 |
+
+### NameServer(注册中心)
+
+NameServer 负责元数据的存储,扮演着集群"中枢神经系统"的角色,其核心作用是为生产者和消费者提供路由信息,帮助它们找到对应的 Broker 地址。
+
+**核心功能:**
+
+1. **Broker 管理**:Broker 启动时主动连接 NameServer,上报元数据信息。
+2. **路由信息管理**:生产者和消费者从 NameServer 获取 Broker 路由表。
+
+**心跳机制:**
+
+```mermaid
+flowchart LR
+ subgraph Heartbeat["心跳机制"]
+ style Heartbeat fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ direction TB
+ BK["Broker"] -->|启动时| Reg["注册元数据"]
+ BK -->|每隔30秒| HB["发送心跳包"]
+ HB --> NS["NameServer
更新路由表"]
+ NS -->|每隔10秒检查| Check["检查心跳
(120秒超时)"]
+ Check -->|超时| Down["标记Broker宕机"]
+ end
+
+ classDef broker fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef ns fill:#E99151,color:#fff,rx:10,ry:10
+ classDef check fill:#FFC107,color:#333,rx:10,ry:10
+ classDef down fill:#EF5350,color:#fff,rx:10,ry:10
+ classDef default fill:#4CA497,color:#fff,rx:10,ry:10
+
+ class BK broker
+ class NS ns
+ class Check check
+ class Down down
+ class Reg,HB default
+
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
+
+**元数据包含:**
+
+- Broker 的地址、名称、BrokerId
+- 主节点地址
+- 该 Broker 上的所有 Topic 的队列配置
+
+### Broker(消息存储)
+
+Broker 负责消息的存储、投递和查询以及服务高可用保证。
+
+**存储机制:**
+
+1. **消息写入**:收到消息后顺序追加到 CommitLog 文件
+2. **文件分割**:文件超过固定大小(默认 1G)生成新文件
+3. **逻辑分片**:MessageQueue 是逻辑分片,ConsumeQueue 是消息索引
+
+**一个 Topic 分布在多个 Broker 上,一个 Broker 可以配置多个 Topic ,它们是多对多的关系**。
+
+如果某个 Topic 消息量很大,应该给它多配置几个队列(上文中提到了提高并发能力),并且 **尽量多分布在不同 Broker 上,以减轻某个 Broker 的压力** 。
+
+Topic 消息量都比较均匀的情况下,如果某个 Broker 上的队列越多,则该 Broker 压力越大。
+
+
+
+### Producer(生产者)
+
+**发送流程:**
+
+```mermaid
+flowchart TB
+ subgraph ProducerFlow["生产者发送流程"]
+ direction TB
+ style ProducerFlow fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+
+ P["Producer 启动"] -->|1.建立长连接| NS1["连接 NameServer
获取路由表"]
+ NS1 -->|2.选择队列| LB["负载均衡算法
选择 MessageQueue"]
+ LB -->|3.建立连接| BK["与 Broker 建立长连接"]
+ BK -->|4.发送消息| MSG["发送消息到
MessageQueue"]
+ end
+
+ classDef producer fill:#00838F,color:#fff,rx:10,ry:10
+ classDef ns fill:#E99151,color:#fff,rx:10,ry:10
+ classDef lb fill:#FFC107,color:#333,rx:10,ry:10
+ classDef broker fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef msg fill:#7E57C2,color:#fff,rx:10,ry:10
+
+ class P producer
+ class NS1 ns
+ class LB lb
+ class BK broker
+ class MSG msg
+
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
+
+**三种发送方式:**
+
+- **单向发送(Oneway)**:发送后立即返回,不关心是否成功
+- **同步发送(Sync)**:发送后等待响应
+- **异步发送(Async)**:发送后立即返回,在回调方法中处理响应
+
+### Consumer(消费者)
+
+**消费流程:**
+
+```mermaid
+flowchart TB
+ subgraph ConsumerFlow["消费者消费流程"]
+ direction TB
+ style ConsumerFlow fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+
+ C["Consumer 启动"] -->|1.建立长连接| NS2["连接 NameServer
获取路由表"]
+ NS2 -->|2.建立连接| BK2["与 Broker 建立连接"]
+ BK2 -->|3.消费消息| CONS["开始消费消息"]
+ CONS -->|4.提交位点| OFFSET["提交消费位点
保存消费进度"]
+ end
+
+ classDef consumer fill:#7E57C2,color:#fff,rx:10,ry:10
+ classDef ns fill:#E99151,color:#fff,rx:10,ry:10
+ classDef broker fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef consume fill:#00838F,color:#fff,rx:10,ry:10
+ classDef offset fill:#FFC107,color:#333,rx:10,ry:10
+
+ class C consumer
+ class NS2 ns
+ class BK2 broker
+ class CONS consume
+ class OFFSET offset
+
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
+
+**三种消费模式:**
+
+- **拉取模式(Pull)**:消费者主动向 Broker 发送拉取请求
+- **推模式(Push)**:长轮询机制,Broker 有消息时才返回
+- **无状态模式(Pop)**:RocketMQ 5.0 新增,服务端管理重平衡和位点
+
+### 网络协议
+
+RocketMQ 支持两种协议:
+
+| 协议 | Remoting(私有协议) | gRPC(云原生) |
+| -------------- | -------------------- | ------------------------- |
+| **性能** | 极致(私有协议优化) | 稍低(HTTP/2 头部开销) |
+| **多语言支持** | 高成本(需重复实现) | 低成本(官方/社区实现) |
+| **云原生集成** | 困难(需额外适配) | 原生支持(Istio/K8s) |
+| **可观测性** | 需额外开发 | 原生支持(OpenTelemetry) |
+| **适用场景** | 内部高性能场景 | 面向用户和云原生 |
+
+### 网络模块(基于 Netty)
+
+RocketMQ 的 RPC 通信采用 Netty 作为底层通信库,基于 Reactor 多线程模型进行了深度扩展和优化。
+
+**线程模型总结:**
+
+- **Reactor 主线程**:1 个,负责监听连接
+- **Reactor 线程池**:默认 3 个,负责网络数据处理
+- **业务线程池**:动态调整,根据 CPU 核心数
+
+### Proxy(代理层,5.0 新增)
+
+RocketMQ 5.0 引入了 **Proxy** 组件,这是 **计算与存储分离** 架构的核心体现。Proxy 作为客户端与 Broker 之间的代理层,将客户端协议适配、权限管理、消费管理等计算逻辑从 Broker 中剥离出来,使 Broker 更专注于消息存储和高可用。这种设计对于云原生架构非常重要,使得计算层可以独立弹性扩展。
+
+**两种部署模式:**
+
+| 模式 | 说明 | 适用场景 |
+| ---------------- | ----------------------------------------------- | ---------------------------------------- |
+| **Local 模式** | Proxy 和 Broker 同进程部署,只需新增 Proxy 配置 | 从旧版本平滑升级,或无特殊需求的场景 |
+| **Cluster 模式** | Proxy 和 Broker 分别独立部署 | 需要弹性扩展或对协议适配有定制需求的场景 |
+
+**核心作用:**
+
+- **协议适配**:支持 gRPC 协议接入,方便多语言客户端接入
+- **计算卸载**:将认证鉴权、消费管理等计算逻辑从 Broker 剥离,降低 Broker 负载
+- **弹性扩展**:Proxy 无状态,可独立水平扩展
+
+> **注意**:在 5.0 版本中,使用新版 SDK(gRPC 协议)的客户端需要通过 Proxy 接入,而旧版 SDK(Remoting 协议)仍然可以直连 Broker。
+
+### 为什么必须要 NameServer?
+
+先看一个简单的架构模型:
+
+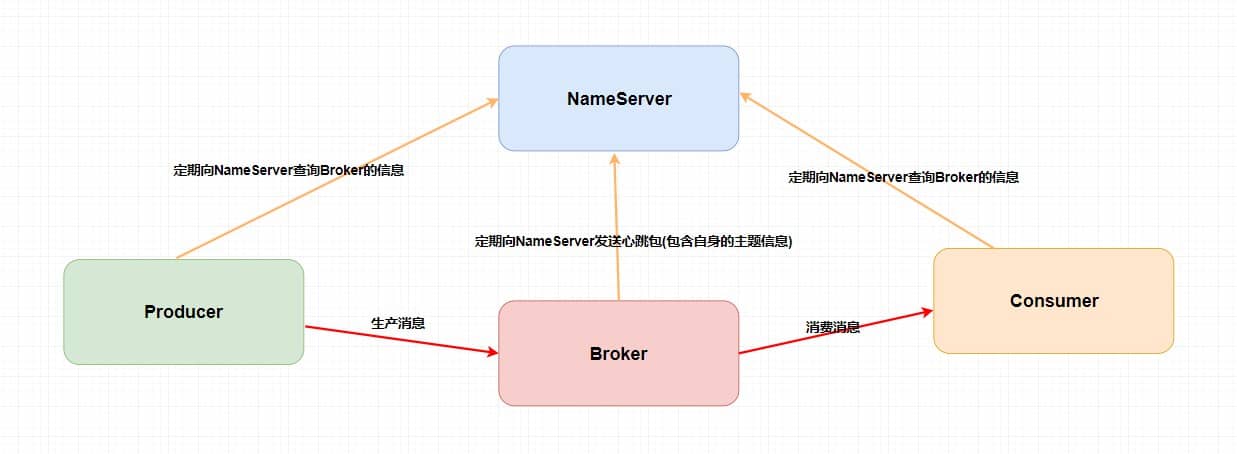
+
+你可能会发现一个问题:NameServer 是做什么的?直接让 Producer、Consumer 和 Broker 进行生产和消费消息不行吗?
+
+Broker 需要保证高可用,如果整个系统仅靠一个 Broker 来维持,压力会非常大,所以需要使用多个 Broker 来保证 **负载均衡**。如果消费者和生产者直接和多个 Broker 相连,当 Broker 变更时会牵连每个生产者和消费者,产生耦合问题。NameServer 注册中心就是用来解决这个问题的。
+
+**NameServer 的设计哲学:**
+
+NameServer 是 **无状态的、各节点之间互不通信** 的。这与 ZooKeeper 的强一致性(需要选举机制)形成了鲜明对比,体现了 RocketMQ 追求 **极致性能和简单架构** 的设计哲学。每个 Broker 与所有 NameServer 保持长连接,定期上报自身信息,即使某个 NameServer 节点宕机,也不会影响整个集群的可用性。
+
+下面是官网的架构图:
+
+
+
+和前面的简化架构图相比,主要是一些细节上的差别:
+
+第一、Broker **做了集群并且还进行了主从部署** ,由于消息分布在各个 Broker 上,一旦某个 Broker 宕机,则该 Broker 上的消息读写都会受到影响。所以 RocketMQ 提供了 `master/slave` 的结构,`slave` 定时从 `master` 同步数据(同步刷盘或者异步刷盘),如果 `master` 宕机,**则 `slave` 提供消费服务,但是不能写入消息** (后面还会详细说明)。
+
+第二、为了保证 HA,NameServer 也做了集群部署,但它是 **去中心化** 的。也就意味着它没有主节点,可以明显看出 NameServer 的所有节点之间没有进行 `Info Replicate`。在 RocketMQ 中,**单个 Broker 和所有 NameServer 保持长连接**,并且 **每隔 30 秒** Broker 会向所有 NameServer 发送心跳,心跳包含了自身的 Topic 配置信息。NameServer **每隔 10 秒** 检查一次心跳,如果某个 Broker **超过 120 秒** 没有心跳,则认为该 Broker 已宕机。
+
+第三、在生产者需要向 Broker 发送消息的时候,**需要先从 NameServer 获取关于 Broker 的路由信息**,然后通过 **轮询** 的方法去向每个队列中生产数据以达到 **负载均衡** 的效果。
+
+第四、消费者通过 NameServer 获取所有 Broker 的路由信息后,向 Broker 发送 `Pull` 请求来获取消息数据。Consumer 可以以两种模式启动—— **广播(Broadcast)和集群(Cluster)**。广播模式下,一条消息会发送给 **同一个消费组中的所有消费者** ,集群模式下消息只会发送给一个消费者。
+
+## RocketMQ 消息
+
+### 普通消息
+
+普通消息一般应用于微服务解耦、事件驱动、数据集成等场景,这些场景大多数要求数据传输通道具有可靠传输的能力,且对消息的处理时机、处理顺序没有特别要求。以在线的电商交易场景为例,上游订单系统将用户下单支付这一业务事件封装成独立的普通消息并发送至 RocketMQ 服务端,下游按需从服务端订阅消息并按照本地消费逻辑处理下游任务。每个消息之间都是相互独立的,且不需要产生关联。另外还有日志系统,以离线的日志收集场景为例,通过埋点组件收集前端应用的相关操作日志,并转发到 RocketMQ 。
+
+**普通消息生命周期**
+
+```mermaid
+ flowchart LR
+ N1["初始化"] --> N2["待消费"] --> N3["消费中"] --> N4["消费提交"] --> N5["消息删除"]
+
+ classDef default fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef final fill:#00838F,color:#fff,rx:10,ry:10
+
+ class N1,N2,N3,N4 default
+ class N5 final
+
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
+
+- 初始化:消息被生产者构建并完成初始化,待发送到服务端的状态。
+- 待消费:消息被发送到服务端,对消费者可见,等待消费者消费的状态。
+- 消费中:消息被消费者获取,并按照消费者本地的业务逻辑进行处理的过程。 此时服务端会等待消费者完成消费并提交消费结果,如果一定时间后没有收到消费者的响应,RocketMQ 会对消息进行重试处理。
+- 消费提交:消费者完成消费处理,并向服务端提交消费结果,服务端标记当前消息已经被处理(包括消费成功和失败)。RocketMQ 默认支持保留所有消息,此时消息数据并不会立即被删除,只是逻辑标记已消费。消息在保存时间到期或存储空间不足被删除前,消费者仍然可以回溯消息重新消费。
+- 消息删除:RocketMQ 按照消息保存机制滚动清理最早的消息数据,将消息从物理文件中删除。
+
+### 定时/延时消息
+
+> **备注:定时消息和延时消息本质相同,都是服务端根据消息设置的定时时间在某一固定时刻将消息投递给消费者消费。**
+
+在分布式定时调度触发、任务超时处理等场景,需要实现精准、可靠的定时事件触发。使用 RocketMQ 的定时消息可以简化定时调度任务的开发逻辑,实现高性能、可扩展、高可靠的定时触发能力。
+
+**典型场景一:分布式定时调度**
+
+在分布式定时调度场景下,需要实现各类精度的定时任务,例如每天 5 点执行文件清理,每隔 2 分钟触发一次消息推送等需求。传统基于数据库的定时调度方案在分布式场景下,性能不高,实现复杂。
+
+**典型场景二:任务超时处理**
+
+以电商交易场景为例,订单下单后暂未支付,此时不可以直接关闭订单,而是需要等待一段时间后才能关闭订单。使用 RocketMQ 定时消息可以实现超时任务的检查触发。
+
+基于定时消息的超时任务处理具备如下优势:
+
+- **精度高、开发门槛低**:基于消息通知方式不存在定时阶梯间隔。可以轻松实现任意精度事件触发,无需业务去重。
+- **高性能可扩展**:传统的数据库扫描方式较为复杂,需要频繁调用接口扫描,容易产生性能瓶颈。RocketMQ 的定时消息具有高并发和水平扩展的能力。
+
+**定时时间设置原则**
+
+RocketMQ 定时消息设置的定时时间是一个预期触发的系统时间戳,延时时间也需要转换成当前系统时间后的某一个时间戳,而不是一段延时时长。
+
+- **时间格式**:毫秒级的 Unix 时间戳
+- **定时时长最大值**:默认为 24 小时,不支持自定义修改
+- **定时时间必须设置在当前时间之后**,否则定时不生效,服务端会立即投递消息
+
+**示例**:
+
+- 定时消息:当前系统时间为 2022-06-09 17:30:00,希望消息在 19:20:00 投递,则定时时间戳为 1654773600000
+- 延时消息:当前系统时间为 2022-06-09 17:30:00,希望延时 1 小时后投递,则定时时间戳为 1654770600000
+
+**4.x 版本与 5.x 版本的区别**
+
+- **4.x 版本**:只支持延时消息,默认分为 18 个等级(1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h),也可以在配置文件中增加自定义的延时等级和时长。
+- **5.x 版本**:支持任意精度的定时消息,通过设置定时时间戳(毫秒级)来实现。底层采用了 **时间轮(TimingWheel)** 算法来高效管理大量定时任务,相比 4.x 版本的固定等级方式,大幅提升了灵活性和精度。
+
+**定时消息生命周期**
+
+```mermaid
+ flowchart LR
+ T1["初始化"] --> T2["定时中"] --> T3["待消费"] --> T4["消费中"] --> T5["消费提交"] --> T6["消息删除"]
+
+ classDef default fill:#E99151,color:#fff,rx:10,ry:10
+ classDef final fill:#00838F,color:#fff,rx:10,ry:10
+
+ class T1,T2,T3,T4,T5 default
+ class T6 final
+
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
+
+- **初始化**:消息被生产者构建并完成初始化,待发送到服务端的状态。
+- **定时中**:消息被发送到服务端,和普通消息不同的是,服务端不会直接构建消息索引,而是会将定时消息**单独存储在定时存储系统中**,等待定时时刻到达。
+- **待消费**:定时时刻到达后,服务端将消息重新写入普通存储引擎,对下游消费者可见,等待消费者消费的状态。
+- **消费中**:消息被消费者获取,并按照消费者本地的业务逻辑进行处理的过程。此时服务端会等待消费者完成消费并提交消费结果,如果一定时间后没有收到消费者的响应,RocketMQ 会对消息进行重试处理。
+- **消费提交**:消费者完成消费处理,并向服务端提交消费结果,服务端标记当前消息已经被处理(包括消费成功和失败)。RocketMQ 默认支持保留所有消息,此时消息数据并不会立即被删除,只是逻辑标记已消费。消息在保存时间到期或存储空间不足被删除前,消费者仍然可以回溯消息重新消费。
+- **消息删除**:Apache RocketMQ 按照消息保存机制滚动清理最早的消息数据,将消息从物理文件中删除。
+
+**使用限制**
+
+1. **消息类型一致性**:定时消息仅支持在 MessageType 为 Delay 的主题内使用
+2. **定时精度约束**:定时时长参数精确到毫秒级,但默认精度为 1000ms(秒级精度)
+
+**使用建议**
+
+定时消息的实现逻辑需要先经过定时存储等待触发,定时时间到达后才会被投递给消费者。因此,如果将大量定时消息的定时时间设置为同一时刻,则到达该时刻后会有大量消息同时需要被处理,会造成系统压力过大,导致消息分发延迟,影响定时精度。
-但是,这样我生产者是不是只能向一个队列发送消息?又因为需要维护消费位置所以一个队列只能对应一个消费者组中的消费者,这样是不是其他的 `Consumer` 就没有用武之地了?从这两个角度来讲,并发度一下子就小了很多。
+### 顺序消息
-所以总结来说,`RocketMQ` 通过**使用在一个 `Topic` 中配置多个队列并且每个队列维护每个消费者组的消费位置** 实现了 **主题模式/发布订阅模式** 。
+**什么是顺序消息**
-## RocketMQ 的架构图
+顺序消息是 Apache RocketMQ 提供的一种高级消息类型,支持消费者按照发送消息的先后顺序获取消息,从而实现业务场景中的顺序处理。
-讲完了消息模型,我们理解起 `RocketMQ` 的技术架构起来就容易多了。
+**应用场景**
-`RocketMQ` 技术架构中有四大角色 `NameServer`、`Broker`、`Producer`、`Consumer` 。我来向大家分别解释一下这四个角色是干啥的。
+在有序事件处理、撮合交易、数据实时增量同步等场景下,异构系统间需要维持强一致的状态同步,上游的事件变更需要按照顺序传递到下游进行处理。
-- `Broker`:主要负责消息的存储、投递和查询以及服务高可用保证。说白了就是消息队列服务器嘛,生产者生产消息到 `Broker` ,消费者从 `Broker` 拉取消息并消费。
+- **撮合交易**:以证券、股票交易撮合场景为例,对于出价相同的交易单,坚持按照先出价先交易的原则,下游处理订单的系统需要严格按照出价顺序来处理订单。
+- **数据实时增量同步**:以数据库变更增量同步场景为例,上游源端数据库按需执行增删改操作,将二进制操作日志作为消息,通过 RocketMQ 传输到下游搜索系统,下游系统按顺序还原消息数据,实现状态数据按序刷新。
- 这里,我还得普及一下关于 `Broker`、`Topic` 和 队列的关系。上面我讲解了 `Topic` 和队列的关系——一个 `Topic` 中存在多个队列,那么这个 `Topic` 和队列存放在哪呢?
+**如何保证消息的顺序性**
- **一个 `Topic` 分布在多个 `Broker`上,一个 `Broker` 可以配置多个 `Topic` ,它们是多对多的关系**。
+RocketMQ 的消息顺序性分为两部分:**生产顺序性**和**消费顺序性**。
- 如果某个 `Topic` 消息量很大,应该给它多配置几个队列(上文中提到了提高并发能力),并且 **尽量多分布在不同 `Broker` 上,以减轻某个 `Broker` 的压力** 。
+**生产顺序性**
- `Topic` 消息量都比较均匀的情况下,如果某个 `broker` 上的队列越多,则该 `broker` 压力越大。
+如需保证消息生产的顺序性,则必须满足以下条件:
- 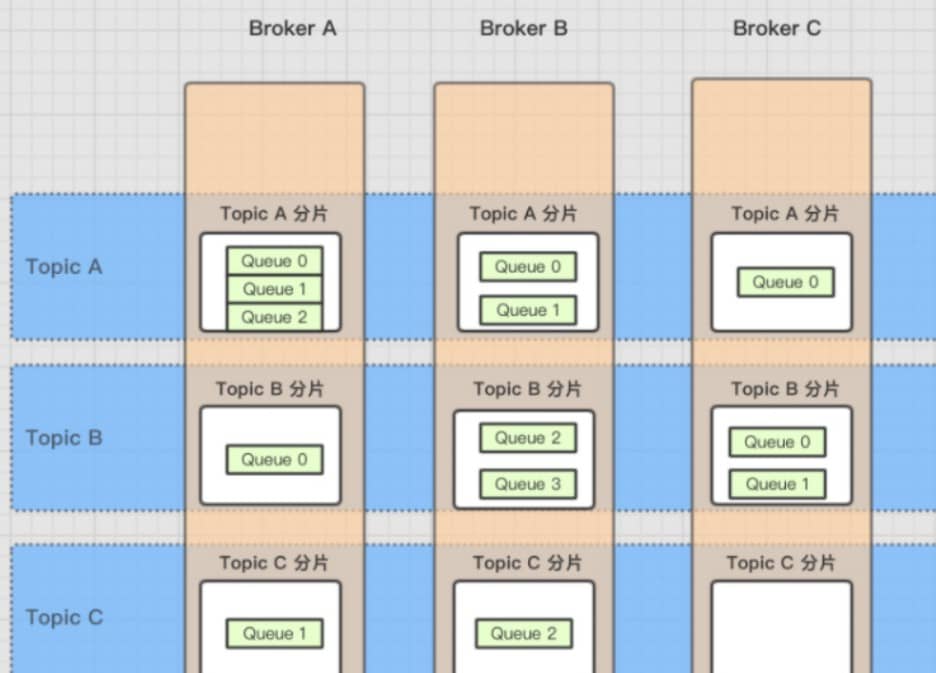
+1. **单一生产者**:消息生产的顺序性仅支持单一生产者
+2. **串行发送**:生产者使用多线程并行发送时,不同线程间产生的消息将无法判定其先后顺序
- > 所以说我们需要配置多个 Broker。
+满足以上条件的生产者,将顺序消息发送至 RocketMQ 后,会保证设置了同一**消息组**的消息,按照发送顺序存储在同一队列中。
-- `NameServer`:不知道你们有没有接触过 `ZooKeeper` 和 `Spring Cloud` 中的 `Eureka` ,它其实也是一个 **注册中心** ,主要提供两个功能:**Broker 管理** 和 **路由信息管理** 。说白了就是 `Broker` 会将自己的信息注册到 `NameServer` 中,此时 `NameServer` 就存放了很多 `Broker` 的信息(Broker 的路由表),消费者和生产者就从 `NameServer` 中获取路由表然后照着路由表的信息和对应的 `Broker` 进行通信(生产者和消费者定期会向 `NameServer` 去查询相关的 `Broker` 的信息)。
+**消息组(MessageGroup)**
-- `Producer`:消息发布的角色,支持分布式集群方式部署。说白了就是生产者。
+RocketMQ 顺序消息的顺序关系通过消息组(MessageGroup)判定和识别,发送顺序消息时需要为每条消息设置归属的消息组。
-- `Consumer`:消息消费的角色,支持分布式集群方式部署。支持以 push 推,pull 拉两种模式对消息进行消费。同时也支持集群方式和广播方式的消费,它提供实时消息订阅机制。说白了就是消费者。
+- **相同消息组**的多条消息之间遵循先进先出的顺序关系
+- **不同消息组**、无消息组的消息之间不涉及顺序性
-听完了上面的解释你可能会觉得,这玩意好简单。不就是这样的么?
+基于消息组的顺序判定逻辑,支持按照业务逻辑做细粒度拆分,可以在满足业务局部顺序的前提下提高系统的并行度和吞吐能力。
-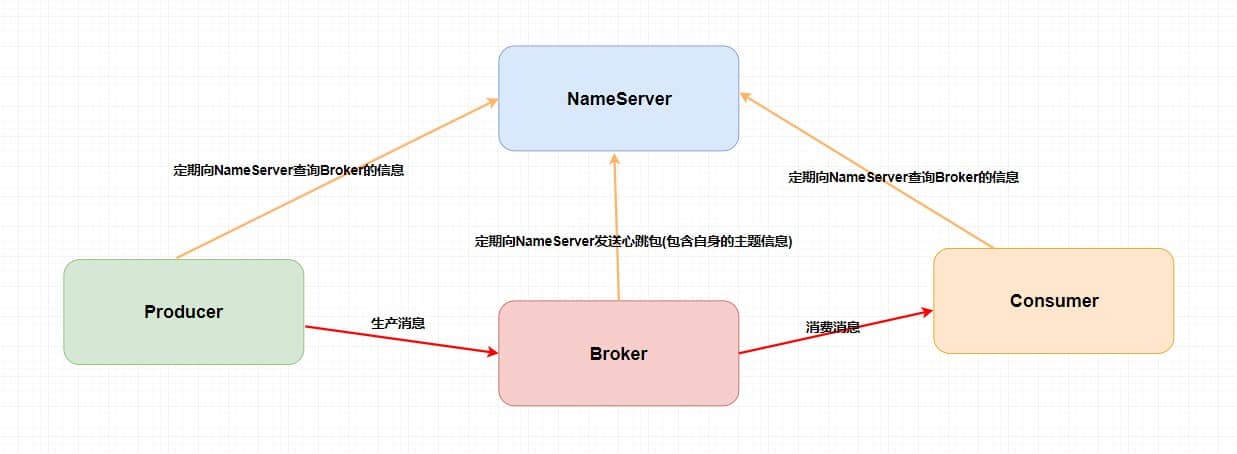
+```mermaid
+flowchart TB
+ subgraph Order["订单系统"]
+ style Order fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ O1["订单A
消息组: orderA"]
+ O2["订单B
消息组: orderB"]
+ O3["订单C
消息组: orderC"]
+ end
-嗯?你可能会发现一个问题,这老家伙 `NameServer` 干啥用的,这不多余吗?直接 `Producer`、`Consumer` 和 `Broker` 直接进行生产消息,消费消息不就好了么?
+ subgraph Queue["队列"]
+ style Queue fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ Q["队列1
(混合存储不同消息组)"]
+ end
-但是,我们上文提到过 `Broker` 是需要保证高可用的,如果整个系统仅仅靠着一个 `Broker` 来维持的话,那么这个 `Broker` 的压力会不会很大?所以我们需要使用多个 `Broker` 来保证 **负载均衡** 。
+ subgraph Storage["存储顺序"]
+ style Storage fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ direction LR
+ S1["orderA-M1
↓"]
+ S2["orderB-M1
↓"]
+ S3["orderA-M2
↓"]
+ S4["orderC-M1
↓"]
+ S5["orderB-M2
↓"]
+ end
-如果说,我们的消费者和生产者直接和多个 `Broker` 相连,那么当 `Broker` 修改的时候必定会牵连着每个生产者和消费者,这样就会产生耦合问题,而 `NameServer` 注册中心就是用来解决这个问题的。
+ O1 --> Q
+ O2 --> Q
+ O3 --> Q
+ Q --> Storage
-> 如果还不是很理解的话,可以去看我介绍 `Spring Cloud` 的那篇文章,其中介绍了 `Eureka` 注册中心。
+ classDef orderA fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef orderB fill:#E99151,color:#fff,rx:10,ry:10
+ classDef orderC fill:#7E57C2,color:#fff,rx:10,ry:10
+ classDef queue fill:#00838F,color:#fff,rx:10,ry:10
+ classDef storage fill:#FFC107,color:#333,rx:10,ry:10
-当然,`RocketMQ` 中的技术架构肯定不止前面那么简单,因为上面图中的四个角色都是需要做集群的。我给出一张官网的架构图,大家尝试理解一下。
+ class O1 orderA
+ class O2 orderB
+ class O3 orderC
+ class Q queue
+ class S1,S2,S3,S4,S5 storage
-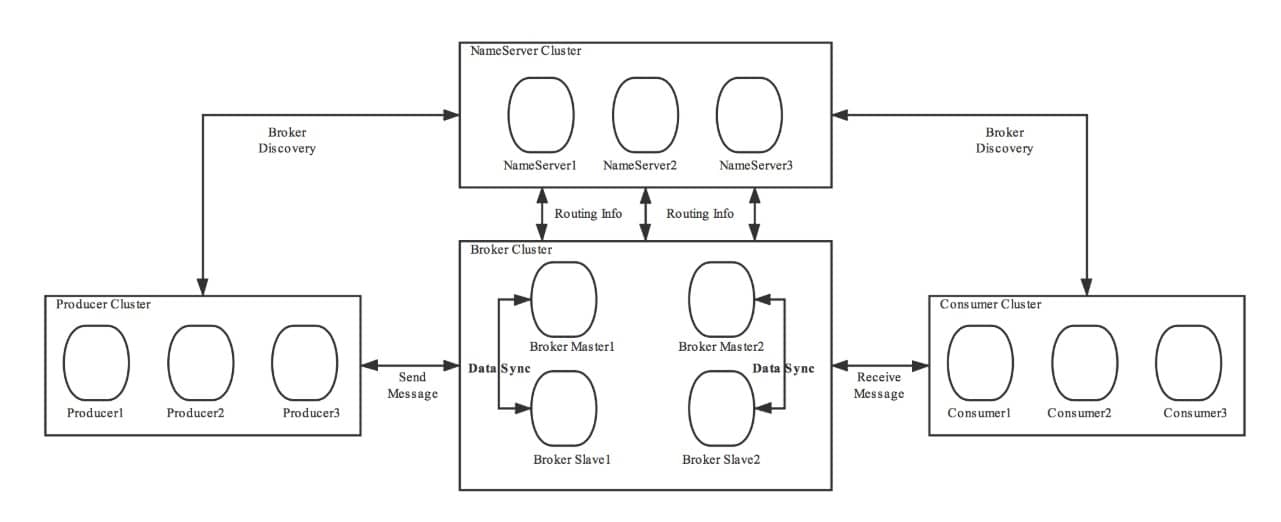
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
-其实和我们最开始画的那张乞丐版的架构图也没什么区别,主要是一些细节上的差别。听我细细道来 🤨。
+**说明**:
-第一、我们的 `Broker` **做了集群并且还进行了主从部署** ,由于消息分布在各个 `Broker` 上,一旦某个 `Broker` 宕机,则该`Broker` 上的消息读写都会受到影响。所以 `Rocketmq` 提供了 `master/slave` 的结构,` salve` 定时从 `master` 同步数据(同步刷盘或者异步刷盘),如果 `master` 宕机,**则 `slave` 提供消费服务,但是不能写入消息** (后面我还会提到哦)。
+- orderA 消息组的 M1、M2 保持顺序
+- orderB 消息组的 M1、M2 保持顺序
+- 不同消息组可以混合存储在同一个队列中
-第二、为了保证 `HA` ,我们的 `NameServer` 也做了集群部署,但是请注意它是 **去中心化** 的。也就意味着它没有主节点,你可以很明显地看出 `NameServer` 的所有节点是没有进行 `Info Replicate` 的,在 `RocketMQ` 中是通过 **单个 Broker 和所有 NameServer 保持长连接** ,并且在每隔 30 秒 `Broker` 会向所有 `Nameserver` 发送心跳,心跳包含了自身的 `Topic` 配置信息,这个步骤就对应这上面的 `Routing Info` 。
+**消费顺序性**
-第三、在生产者需要向 `Broker` 发送消息的时候,**需要先从 `NameServer` 获取关于 `Broker` 的路由信息**,然后通过 **轮询** 的方法去向每个队列中生产数据以达到 **负载均衡** 的效果。
+如需保证消息消费的顺序性,则必须满足以下条件:
-第四、消费者通过 `NameServer` 获取所有 `Broker` 的路由信息后,向 `Broker` 发送 `Pull` 请求来获取消息数据。`Consumer` 可以以两种模式启动—— **广播(Broadcast)和集群(Cluster)**。广播模式下,一条消息会发送给 **同一个消费组中的所有消费者** ,集群模式下消息只会发送给一个消费者。
+1. **投递顺序**:RocketMQ 通过客户端 SDK 和服务端通信协议保障消息按照服务端存储顺序投递
+2. **有限重试**:顺序消息投递仅在重试次数限定范围内,超过最大重试次数后将不再重试,跳过这条消息消费
+
+**消费者类型对顺序消费的影响**
+
+- **PushConsumer**:RocketMQ 保证消息按照存储顺序一条一条投递给消费者
+- **SimpleConsumer**:消费者可能一次拉取多条消息,此时消息消费的顺序性需要由业务方自行保证
+
+**生产顺序性和消费顺序性组合**
+
+| 生产顺序 | 消费顺序 | 顺序性效果 |
+| ---------------------------- | -------- | -------------------------------- |
+| 设置消息组,保证消息顺序发送 | 顺序消费 | 按照消息组粒度,严格保证消息顺序 |
+| 设置消息组,保证消息顺序发送 | 并发消费 | 并发消费,尽可能按时间顺序处理 |
+| 未设置消息组,消息乱序发送 | 顺序消费 | 按队列存储粒度,严格顺序 |
+| 未设置消息组,消息乱序发送 | 并发消费 | 并发消费,尽可能按照时间顺序处理 |
+
+**使用限制**
+
+1. **消息类型一致性**:顺序消息仅支持在 MessageType 为 FIFO 的主题内使用
+2. 顺序消息消费失败进行消费重试时,为保障消息的顺序性,后续消息不可被消费,必须等待前面的消息消费完成后才能被处理
+
+**使用建议**
+
+1. **串行消费**:消息消费建议串行处理,避免一次消费多条消息导致乱序
+2. **消息组尽可能打散**:建议将业务以消息组粒度进行拆分,例如将订单 ID、用户 ID 作为消息组关键字,可实现同一终端用户的消息按照顺序处理,不同用户的消息无需保证顺序
+
+### 事务消息
+
+**什么是事务消息**
+
+事务消息是 Apache RocketMQ 提供的一种高级消息类型,支持在分布式场景下保障消息生产和本地事务的最终一致性。简单来讲,就是将本地事务(数据库的 DML 操作)与发送消息合并在同一个事务中。
+
+**应用场景**
+
+在分布式系统调用的特点为一个核心业务逻辑的执行,同时需要调用多个下游业务进行处理。如何保证核心业务和多个下游业务的执行结果完全一致,是分布式事务需要解决的主要问题。
+
+以电商交易场景为例,用户支付订单这一核心操作的同时会涉及到下游物流发货、积分变更、购物车状态清空等多个子系统的变更:
+
+- **主分支订单系统状态更新**:由未支付变更为支付成功
+- **物流系统状态新增**:新增待发货物流记录,创建订单物流记录
+- **积分系统状态变更**:变更用户积分,更新用户积分表
+- **购物车系统状态变更**:清空购物车,更新用户购物车记录
+
+**传统方案的问题**
+
+- **传统 XA 事务方案**:基于 XA 协议的分布式事务系统可以实现一致性,但多分支环境下资源锁定范围大,并发度低
+- **基于普通消息方案**:普通消息和订单事务无法保证一致,容易出现消息发送成功但订单没有执行成功、订单执行成功但消息没有发送成功等情况
+
+**RocketMQ 事务消息方案**
+
+RocketMQ 事务消息的方案,具备高性能、可扩展、业务开发简单的优势,支持二阶段的提交能力,将二阶段提交和本地事务绑定,实现全局提交结果的一致性。
+
+**事务消息处理流程**
+
+```mermaid
+flowchart TB
+ subgraph Phase1["阶段一: 发送半事务消息"]
+ direction TB
+ style Phase1 fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ M1["生产者构建消息"] --> M2["发送至服务端"]
+ M2 --> M3["服务端持久化消息"]
+ M3 --> M4["返回 Ack 确认"]
+ M4 --> M5["消息标记为
'暂不能投递'
(半事务消息)"]
+ end
+
+ subgraph Phase2["阶段二: 执行本地事务"]
+ direction TB
+ style Phase2 fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ L1["生产者开始执行
本地事务逻辑"] --> L2{"本地事务
执行结果"}
+ L2 -->|Commit| L3["提交二次确认 Commit"]
+ L2 -->|Rollback| L4["提交二次确认 Rollback"]
+ L2 -->|Unknown| L5["等待事务回查"]
+ end
+
+ subgraph Phase3["阶段三: 事务回查机制"]
+ direction TB
+ style Phase3 fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ C1["服务端未收到确认
或收到 Unknown"] --> C2["固定时间后
发起消息回查"]
+ C2 --> C3["生产者检查本地事务
最终状态"]
+ C3 --> C4["再次提交二次确认"]
+ end
+
+ subgraph Result["最终处理"]
+ style Result fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ direction TB
+ R1["Commit: 消息投递给消费者"]
+ R2["Rollback: 回滚事务
不投递消息"]
+ end
+
+ Phase1 --> Phase2
+ L3 --> R1
+ L4 --> R2
+ L5 --> Phase3
+ C4 --> R1
+
+ classDef normal fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef decision fill:#E99151,color:#fff,rx:10,ry:10
+ classDef result fill:#00838F,color:#fff,rx:10,ry:10
+
+ class M1,M2,M3,M4,M5,L1,C1,C2,C3,C4 normal
+ class L2,L3,L4,L5 decision
+ class R1,R2 result
+
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
+
+1. 生产者将消息发送至 RocketMQ 服务端
+2. 服务端将消息持久化成功之后,向生产者返回 Ack 确认消息已经发送成功,此时消息被标记为"暂不能投递",这种状态下的消息即为**半事务消息**
+3. 生产者开始执行本地事务逻辑
+4. 生产者根据本地事务执行结果向服务端提交二次确认结果(Commit 或 Rollback)
+5. 如果服务端未收到二次确认结果,或收到的结果为 Unknown,经过固定时间后,服务端将对消息生产者发起**消息回查**
+6. 生产者收到消息回查后,需要检查对应消息的本地事务执行的最终结果
+7. 生产者根据检查到的本地事务的最终状态再次提交二次确认
+
+**事务消息生命周期**
+
+- **初始化**:半事务消息被生产者构建并完成初始化,待发送到服务端的状态
+- **事务待提交**:半事务消息被发送到服务端,并不会直接被服务端持久化,而是会被单独存储到事务存储系统中,等待第二阶段本地事务返回执行结果后再提交。此时消息对下游消费者不可见
+- **消息回滚**:第二阶段如果事务执行结果明确为回滚,服务端会将半事务消息回滚,该事务消息流程终止
+- **提交待消费**:第二阶段如果事务执行结果明确为提交,服务端会将半事务消息重新存储到普通存储系统中,此时消息对下游消费者可见
+- **消费中**:消息被消费者获取,并按照消费者本地的业务逻辑进行处理的过程
+- **消费提交**:消费者完成消费处理,并向服务端提交消费结果
+- **消息删除**:RocketMQ 按照消息保存机制滚动清理最早的消息数据
+
+**使用限制**
+
+1. **消息类型一致性**:事务消息仅支持在 MessageType 为 Transaction 的主题内使用
+2. **消费事务性**:RocketMQ 事务消息保证本地主分支事务和下游消息发送事务的一致性,但不保证消息消费结果和上游事务的一致性
+3. **中间状态可见性**:事务消息为最终一致性,即消息提交到下游消费端处理完成之前,下游分支和上游事务之间的状态会不一致
+4. **事务超时机制**:事务消息的生命周期存在超时机制,半事务消息被生产者发送服务端后,如果在指定时间内服务端无法确认提交或者回滚状态,则消息默认会被回滚
+5. **事务回查机制**:服务端默认 **每隔 60 秒** 对未确认的半事务消息发起回查,**最多回查 15 次**。超过最大回查次数后,消息将被丢弃或进入死信队列
+
+**使用建议**
+
+1. **避免大量未决事务导致超时**:生产者应该尽量避免本地事务返回未知结果,大量的事务检查会导致系统性能受损
+2. **正确处理"进行中"的事务**:消息回查时,对于正在进行中的事务不要返回 Rollback 或 Commit 结果,应继续保持 Unknown 的状态
+
+### 关于发送消息
+
+#### 不建议单一进程创建大量生产者
+
+Apache RocketMQ 的生产者和主题是多对多的关系,支持同一个生产者向多个主题发送消息。对于生产者的创建和初始化,建议遵循够用即可、最大化复用原则,如果有需要发送消息到多个主题的场景,无需为每个主题都创建一个生产者。
+
+#### 不建议频繁创建和销毁生产者
+
+Apache RocketMQ 的生产者是可以重复利用的底层资源,类似数据库的连接池。因此不需要在每次发送消息时动态创建生产者,且在发送结束后销毁生产者。这样频繁的创建销毁会在服务端产生大量短连接请求,严重影响系统性能。
+
+正确示例:
+
+```java
+Producer p = ProducerBuilder.build();
+for (int i =0;i msgs,
+ ConsumeConcurrentlyContext context) {
+ System.out.printf("Receive New Messages: %s %n", msgs);
+ // 业务处理逻辑
+ return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
+ }
+ });
+
+ consumer.start();
+}
+```
+
+**消费监听器执行结果:**
+
+- **返回消费成功**:表示该消息处理成功,服务端按照消费结果更新消费进度
+- **返回消费失败**:表示该消息处理失败,需要根据消费重试逻辑判断是否进行重试消费
+- **抛出异常**:按消费失败处理,需要根据消费重试逻辑判断是否进行重试消费
+
+**使用注意事项:**
+
+PushConsumer 消费时,不允许使用以下方式处理消息:
+
+1. **错误方式一**:消息还未处理完成,就提前返回消费成功结果。此时如果消息消费失败,RocketMQ 服务端是无法感知的,因此不会进行消费重试。
+
+2. **错误方式二**:在消费监听器内将消息再次分发到自定义的其他线程,消费监听器提前返回消费结果。此时如果消息消费失败,RocketMQ 服务端同样无法感知,因此也不会进行消费重试。
+
+**Push 模式工作原理:**
+
+1. **负载均衡**:RebalanceService 线程根据队列数量和消费者个数做负载均衡,将分配到的队列发布 pullRequest 到 pullRequestQueue
+2. **消息拉取**:PullMessageService 线程不断从 pullRequestQueue 获取 pullRequest,从 Broker 拉取消息并缓存到 ProcessQueue
+3. **消息消费**:ConsumeMessageService 线程从 ProcessQueue 获取消息,调用监听器处理业务逻辑
+4. **位点提交**:消费完成后自动提交消费位点
+5. **流控保护**:拉取前检查缓存阈值(1000 消息或 100M),超过则延迟拉取
+
+### SimpleConsumer
+
+SimpleConsumer 是一种接口原子型的消费者类型,消息的获取、消费状态提交以及消费重试都是通过消费者业务逻辑主动发起调用完成。
+
+**消息不可见时间(Invisible Time):**
+
+SimpleConsumer 的核心机制是 **消息不可见时间**。当消费者获取消息后,该消息在指定的不可见时间内对其他消费者不可见。如果在不可见时间内完成消费并提交 ACK,消息被标记为已消费;如果超时未提交 ACK,消息会重新变为可见状态,可被其他消费者获取。这与 PushConsumer 的定时重试队列机制不同,SimpleConsumer 通过动态修改不可见时间来实现更灵活的重试控制。
+
+一个来自官网的例子:
+
+```java
+// 消费示例:使用 SimpleConsumer 消费普通消息,主动获取消息处理并提交。
+ClientServiceProvider provider = ClientServiceProvider.loadService();
+String topic = "YourTopic";
+FilterExpression filterExpression = new FilterExpression("YourFilterTag", FilterExpressionType.TAG);
+SimpleConsumer simpleConsumer = provider.newSimpleConsumerBuilder()
+ // 设置消费者分组。
+ .setConsumerGroup("YourConsumerGroup")
+ // 设置接入点。
+ .setClientConfiguration(ClientConfiguration.newBuilder().setEndpoints("YourEndpoint").build())
+ // 设置预绑定的订阅关系。
+ .setSubscriptionExpressions(Collections.singletonMap(topic, filterExpression))
+ // 设置从服务端接受消息的最大等待时间
+ .setAwaitDuration(Duration.ofSeconds(1))
+ .build();
+try {
+ // SimpleConsumer 需要主动获取消息,并处理。
+ List messageViewList = simpleConsumer.receive(10, Duration.ofSeconds(30));
+ messageViewList.forEach(messageView -> {
+ System.out.println(messageView);
+ // 消费处理完成后,需要主动调用 ACK 提交消费结果。
+ try {
+ simpleConsumer.ack(messageView);
+ } catch (ClientException e) {
+ logger.error("Failed to ack message, messageId={}", messageView.getMessageId(), e);
+ }
+ });
+} catch (ClientException e) {
+ // 如果遇到系统流控等原因造成拉取失败,需要重新发起获取消息请求。
+ logger.error("Failed to receive message", e);
+}
+```
+
+SimpleConsumer 适用于以下场景:
+
+- 消息处理时长不可控:如果消息处理时长无法预估,经常有长时间耗时的消息处理情况。建议使用 SimpleConsumer 消费类型,可以在消费时自定义消息的预估处理时长,若实际业务中预估的消息处理时长不符合预期,也可以通过接口提前修改。
+- 需要异步化、批量消费等高级定制场景:SimpleConsumer 在 SDK 内部没有复杂的线程封装,完全由业务逻辑自由定制,可以实现异步分发、批量消费等高级定制场景。
+- 需要自定义消费速率:SimpleConsumer 是由业务逻辑主动调用接口获取消息,因此可以自由调整获取消息的频率,自定义控制消费速率。
+
+**SimpleConsumer 工作原理:**
+
+1. **主动获取消息**:业务方调用 receive() 接口主动获取消息
+2. **业务处理**:获取到的消息由业务方自行处理
+3. **主动提交 ACK**:消费处理完成后,业务方主动调用 ack() 接口提交消费结果
+4. **高可控性**:业务方可完全控制消息处理时机和消费速率
+
+### PullConsumer(拉模式消费者)
+
+**核心特点:**
+
+Pull 模式下,**应用程序对消息的拉取过程参与度高,可控性强**,可以自主决定何时进行消息拉取,从什么位置 offset 拉取消息。
+
+**与 Push 模式的对比:**
+
+| 特性 | Push 模式 | Pull 模式 |
+| -------------- | -------------------- | ---------------- |
+| **控制权** | 客户端 SDK 自动拉取 | 应用程序主动拉取 |
+| **可控性** | 可控性不足 | 可控性高 |
+| **开发复杂度** | 简单,只需实现监听器 | 需要管理拉取过程 |
+| **适用场景** | 消息处理可预估 | 需要精细控制拉取 |
+
+**使用示例(DefaultMQPullConsumer):**
+
+```java
+@Test
+public void testPullConsumer() throws Exception {
+ DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("group1_pull");
+ consumer.setNamesrvAddr(this.nameServer);
+ String topic = "topic1";
+ consumer.start();
+
+ // 获取 Topic 对应的消息队列
+ Set messageQueues = consumer.fetchSubscribeMessageQueues(topic);
+ int maxNums = 10; // 每次拉取消息的最大数量
+
+ while (true) {
+ boolean found = false;
+ for (MessageQueue messageQueue : messageQueues) {
+ // 获取消费位置
+ long offset = consumer.fetchConsumeOffset(messageQueue, false);
+ // 拉取消息
+ PullResult pullResult = consumer.pull(messageQueue, "tag8", offset, maxNums);
+
+ switch (pullResult.getPullStatus()) {
+ case FOUND:
+ found = true;
+ List msgs = pullResult.getMsgFoundList();
+ System.out.println("收到消息,数量----" + msgs.size());
+ // 处理消息
+ for (MessageExt msg : msgs) {
+ System.out.println("处理消息——" + msg.getMsgId());
+ }
+ // 更新消费位置
+ long nextOffset = pullResult.getNextBeginOffset();
+ consumer.updateConsumeOffset(messageQueue, nextOffset);
+ break;
+ case NO_NEW_MSG:
+ System.out.println("没有新消息");
+ break;
+ case NO_MATCHED_MSG:
+ System.out.println("没有匹配的消息");
+ break;
+ case OFFSET_ILLEGAL:
+ System.err.println("offset 错误");
+ break;
+ }
+ }
+ if (!found) {
+ // 没有队列中有新消息,则暂停一会
+ TimeUnit.MILLISECONDS.sleep(5000);
+ }
+ }
+}
+```
+
+**使用示例(DefaultLitePullConsumer - 推荐):**
+
+```java
+DefaultLitePullConsumer litePullConsumer =
+ new DefaultLitePullConsumer("lite_pull_consumer_test");
+litePullConsumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
+litePullConsumer.subscribe("TopicTest", "*");
+litePullConsumer.start();
+
+try {
+ while (running) {
+ // 应用程序主动调用 poll 方法拉取消息
+ List messageExts = litePullConsumer.poll();
+ System.out.printf("%s%n", messageExts);
+ }
+} finally {
+ litePullConsumer.shutdown();
+}
+```
+
+**适用场景:**
+
+- **需要精细控制拉取时机**:可以根据业务需求自主决定何时拉取消息
+- **需要控制消费速率**:可以灵活调整拉取频率
+- **批量消费场景**:可以一次性拉取大量消息进行批量处理
+- **特殊消费需求**:如需要从特定 offset 开始消费、需要暂停消费等
+
+**Pull 模式工作原理:**
+
+1. **负载均衡**:RebalanceService 线程发现消费快照发生变化时,启动消息拉取线程
+2. **消息拉取**:PullTaskImpl 拉取到消息后,把消息放到 consumeRequestCache
+3. **消息消费**:应用程序调用 poll 方法,不停地从 consumeRequestCache 拉取消息进行业务处理
+
+### 三种消费者类型对比
+
+| 对比项 | PushConsumer | SimpleConsumer | PullConsumer |
+| -------------- | ------------------------------------------------------------------------ | ---------------------------------------------------- | -------------------------------------------------- |
+| 接口方式 | 使用监听器回调接口返回消费结果,消费者仅允许在监听器范围内处理消费逻辑。 | 业务方自行实现消息处理,并主动调用接口返回消费结果。 | 业务方自行按队列拉取消息,并可选择性地提交消费结果 |
+| 消费并发度管理 | 由 SDK 管理消费并发度。 | 由业务方消费逻辑自行管理消费线程。 | 由业务方消费逻辑自行管理消费线程。 |
+| 负载均衡粒度 | 5.0 SDK 是消息粒度,更均衡,早期版本是队列维度 | 消息粒度,更均衡 | 队列粒度,吞吐攒批性能更好,但容易不均衡 |
+| 接口灵活度 | 高度封装,不够灵活。 | 原子接口,可灵活自定义。 | 原子接口,可灵活自定义。 |
+| 适用场景 | 适用于无自定义流程的业务消息开发场景。 | 适用于需要高度自定义业务流程的业务开发场景。 | 仅推荐在流处理框架场景下集成使用 |
+
+**选择建议:**
+
+- **普通场景**:优先使用 **PushConsumer**,开发简单,SDK 自动管理拉取和提交
+- **消息处理时长不可控**:使用 **SimpleConsumer**,可以自定义处理时长
+- **需要精细控制**:使用 **PullConsumer**,完全自主控制拉取过程
+
+**注意**:生产环境中相同的 ConsumerGroup 下严禁混用 PullConsumer 和其他两种消费者,否则会导致消息消费异常。
+
+## 消费者分组和生产者分组
+
+### 生产者分组
+
+RocketMQ 服务端 5.x 版本开始,**生产者是匿名的**,无需管理生产者分组(ProducerGroup);对于历史版本服务端 3.x 和 4.x 版本,已经使用的生产者分组可以废弃无需再设置,且不会对当前业务产生影响。
+
+### 消费者分组
+
+消费者分组是多个消费行为一致的消费者的负载均衡分组。消费者分组不是具体实体而是一个逻辑资源。通过消费者分组实现消费性能的水平扩展以及高可用容灾。
+
+**消费者组的核心作用:**
+
+```mermaid
+flowchart TB
+ subgraph ConsumerGroup["消费者组概念"]
+ direction TB
+ style ConsumerGroup fill:#F0F2F5,stroke:#E0E6ED,stroke-width:1.5px
+
+ subgraph Cluster["集群消费模式"]
+ direction TB
+ style Cluster fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ CG["消费者组"] --> C1["消费者1
消费队列1、2"]
+ CG --> C2["消费者2
消费队列3、4"]
+ CG --> C3["消费者3
空闲"]
+ Note1["任意一条消息
只需被消费组内
任意一个消费者处理"]
+ end
+
+ subgraph Broadcast["广播消费模式"]
+ direction TB
+ style Broadcast fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px
+ BG["消费者组"] --> B1["消费者1
消费所有消息"]
+ BG --> B2["消费者2
消费所有消息"]
+ BG --> B3["消费者3
消费所有消息"]
+ Note2["每条消息
推送给消费组
所有消费者"]
+ end
+
+ %% 优化:调整注释连线,避免跨子图渲染异常
+ C1 -.-> Note1
+ C2 -.-> Note1
+ C3 -.-> Note1
+ B1 -.-> Note2
+ B2 -.-> Note2
+ B3 -.-> Note2
+ end
+
+ classDef cg fill:#4CA497,color:#fff,rx:10,ry:10
+ classDef consumer fill:#E99151,color:#fff,rx:10,ry:10
+ classDef note fill:#00838F,color:#fff,rx:10,ry:10
+
+ class CG,BG cg
+ class C1,C2,C3,B1,B2,B3 consumer
+ class Note1,Note2 note
+
+ linkStyle default stroke-width:1.5px,opacity:0.8
+```
+
+消费者分组中的订阅关系、投递顺序性、消费重试策略是一致的。
+
+- 订阅关系:Apache RocketMQ 以消费者分组的粒度管理订阅关系,实现订阅关系的管理和追溯。
+- 投递顺序性:Apache RocketMQ 的服务端将消息投递给消费者消费时,支持顺序投递和并发投递,投递方式在消费者分组中统一配置。
+- 消费重试策略: 消费者消费消息失败时的重试策略,包括重试次数、死信队列设置等。
+
+RocketMQ 服务端 5.x 版本:上述消费者的消费行为从关联的消费者分组中统一获取,因此,同一分组内所有消费者的消费行为必然是一致的,客户端无需关注。
+
+RocketMQ 服务端 3.x/4.x 历史版本:上述消费逻辑由消费者客户端接口定义,因此,您需要自己在消费者客户端设置时保证同一分组下的消费者的消费行为一致。(来自官方网站)
+
+**两种消费模式对比:**
+
+| 对比维度 | 集群消费模式 | 广播消费模式 |
+| ------------ | ---------------------------------------------- | ------------------------------------ |
+| **消息消费** | 任意一条消息只需被消费组内的任意一个消费者处理 | 每条消息推送给消费组所有消费者 |
+| **扩缩容** | 可通过扩缩消费者数量来提升或降低消费能力 | 扩缩消费者数量无法提升或降低消费能力 |
+| **适用场景** | 需要提升消费能力、避免重复消费 | 需要所有消费者都收到消息 |
## 如何解决顺序消费和重复消费?
-其实,这些东西都是我在介绍消息队列带来的一些副作用的时候提到的,也就是说,这些问题不仅仅挂钩于 `RocketMQ` ,而是应该每个消息中间件都需要去解决的。
+其实,这些东西都是我在介绍消息队列带来的一些副作用的时候提到的,也就是说,这些问题不仅仅挂钩于 RocketMQ ,而是应该每个消息中间件都需要去解决的。
-在上面我介绍 `RocketMQ` 的技术架构的时候我已经向你展示了 **它是如何保证高可用的** ,这里不涉及运维方面的搭建,如果你感兴趣可以自己去官网上照着例子搭建属于你自己的 `RocketMQ` 集群。
+在上面我介绍 RocketMQ 的技术架构的时候我已经向你展示了 **它是如何保证高可用的** ,这里不涉及运维方面的搭建,如果你感兴趣可以自己去官网上照着例子搭建属于你自己的 RocketMQ 集群。
-> 其实 `Kafka` 的架构基本和 `RocketMQ` 类似,只是它注册中心使用了 `Zookeeper`、它的 **分区** 就相当于 `RocketMQ` 中的 **队列** 。还有一些小细节不同会在后面提到。
+> 其实 Kafka 的架构基本和 RocketMQ 类似,只是它注册中心使用了 Zookeeper、它的 **分区** 就相当于 RocketMQ 中的 **队列** 。还有一些小细节不同会在后面提到。
### 顺序消费
-在上面的技术架构介绍中,我们已经知道了 **`RocketMQ` 在主题上是无序的、它只有在队列层面才是保证有序** 的。
+在上面的技术架构介绍中,我们已经知道了 **RocketMQ 在主题上是无序的、它只有在队列层面才是保证有序** 的。
这又扯到两个概念——**普通顺序** 和 **严格顺序** 。
-所谓普通顺序是指 消费者通过 **同一个消费队列收到的消息是有顺序的** ,不同消息队列收到的消息则可能是无顺序的。普通顺序消息在 `Broker` **重启情况下不会保证消息顺序性** (短暂时间) 。
+所谓普通顺序是指 消费者通过 **同一个消费队列收到的消息是有顺序的** ,不同消息队列收到的消息则可能是无顺序的。普通顺序消息在 Broker **重启情况下不会保证消息顺序性** (短暂时间) 。
所谓严格顺序是指 消费者收到的 **所有消息** 均是有顺序的。严格顺序消息 **即使在异常情况下也会保证消息的顺序性** 。
-但是,严格顺序看起来虽好,实现它可会付出巨大的代价。如果你使用严格顺序模式,`Broker` 集群中只要有一台机器不可用,则整个集群都不可用。你还用啥?现在主要场景也就在 `binlog` 同步。
+但是,严格顺序看起来虽好,实现它可会付出巨大的代价。如果你使用严格顺序模式,Broker 集群中只要有一台机器不可用,则整个集群都不可用。你还用啥?现在主要场景也就在 `binlog` 同步。
一般而言,我们的 `MQ` 都是能容忍短暂的乱序,所以推荐使用普通顺序模式。
-那么,我们现在使用了 **普通顺序模式** ,我们从上面学习知道了在 `Producer` 生产消息的时候会进行轮询(取决你的负载均衡策略)来向同一主题的不同消息队列发送消息。那么如果此时我有几个消息分别是同一个订单的创建、支付、发货,在轮询的策略下这 **三个消息会被发送到不同队列** ,因为在不同的队列此时就无法使用 `RocketMQ` 带来的队列有序特性来保证消息有序性了。
+那么,我们现在使用了 **普通顺序模式** ,我们从上面学习知道了在 Producer 生产消息的时候会进行轮询(取决你的负载均衡策略)来向同一主题的不同消息队列发送消息。那么如果此时我有几个消息分别是同一个订单的创建、支付、发货,在轮询的策略下这 **三个消息会被发送到不同队列** ,因为在不同的队列此时就无法使用 RocketMQ 带来的队列有序特性来保证消息有序性了。
-
+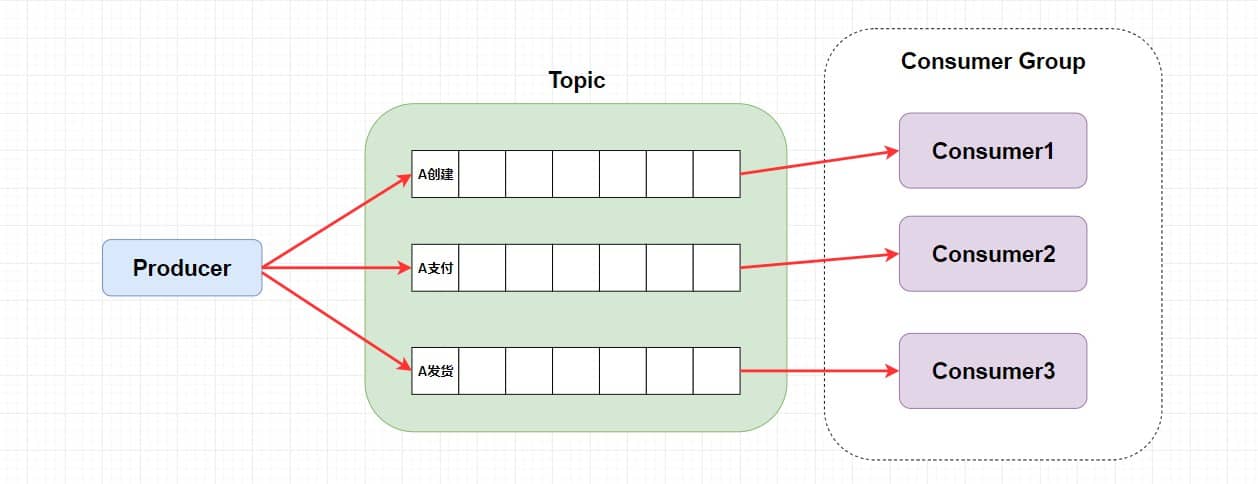
那么,怎么解决呢?
其实很简单,我们需要处理的仅仅是将同一语义下的消息放入同一个队列(比如这里是同一个订单),那我们就可以使用 **Hash 取模法** 来保证同一个订单在同一个队列中就行了。
+**4.x 版本:使用 MessageQueueSelector**
+
+RocketMQ 4.x 版本通过继承 `MessageQueueSelector` 来实现自定义队列选择逻辑:
+
+```java
+SendResult sendResult = producer.send(msg, new MessageQueueSelector() {
+ @Override
+ public MessageQueue select(List mqs, Message msg, Object arg) {
+ //根据订单ID等业务关键字计算队列索引
+ Integer orderId = (Integer) arg;
+ int index = orderId % mqs.size();
+ return mqs.get(index);
+ }
+}, orderId);
+```
+
+**5.x 版本:使用消息组(MessageGroup)**
+
+RocketMQ 5.x 版本引入了**消息组**的概念,通过设置消息组来保证同一组内消息的顺序性:
+
+```java
+Message message = messageBuilder.setTopic("topic")
+ .setTag("messageTag")
+ //设置顺序消息的排序分组
+ .setMessageGroup("fifoGroup001") // 比如使用订单ID作为消息组
+ .setBody("messageBody".getBytes())
+ .build();
+```
+
+**队列选择算法**
+
+RocketMQ 实现了两种队列选择算法:
+
+- **轮询算法**(默认):向消息指定的 topic 所在队列中依次发送消息,保证消息均匀分布
+- **最小投递延迟算法**:每次消息投递的时候统计消息投递的延迟,选择队列时优先选择消息延时小的队列
+
+```java
+// 启用最小投递延迟算法
+producer.setSendLatencyFaultEnable(true);
+```
+
+### 特殊情况处理
+
+#### 发送异常
+
+选择队列后会与 Broker 建立连接,通过网络请求将消息发送到 Broker 上,如果 Broker 挂了或者网络波动发送消息超时此时 RocketMQ 会进行重试。
+
+重新选择其他 Broker 中的消息队列进行发送,默认重试两次,可以手动设置。
+
+```java
+producer.setRetryTimesWhenSendFailed(5);
+```
+
+#### 消息过大
+
+消息超过 4k 时 RocketMQ 会将消息压缩后在发送到 Broker 上,减少网络资源的占用。
+
### 重复消费
-emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。比如说,这个时候我们有一个订单的处理积分的系统,每当来一个消息的时候它就负责为创建这个订单的用户的积分加上相应的数值。可是有一次,消息队列发送给订单系统 FrancisQ 的订单信息,其要求是给 FrancisQ 的积分加上 500。但是积分系统在收到 FrancisQ 的订单信息处理完成之后返回给消息队列处理成功的信息的时候出现了网络波动(当然还有很多种情况,比如 Broker 意外重启等等),这条回应没有发送成功。
+解决重复消费的核心思路就是两个字—— **幂等** 。在编程中,一个*幂等*操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。比如说,这个时候我们有一个订单的处理积分的系统,每当来一个消息的时候它就负责为创建这个订单的用户的积分加上相应的数值。可是有一次,消息队列发送给订单系统 FrancisQ 的订单信息,其要求是给 FrancisQ 的积分加上 500。但是积分系统在收到 FrancisQ 的订单信息处理完成之后返回给消息队列处理成功的信息的时候出现了网络波动(当然还有很多种情况,比如 Broker 意外重启等等),这条回应没有发送成功。
那么,消息队列没收到积分系统的回应会不会尝试重发这个消息?问题就来了,我再发这个消息,万一它又给 FrancisQ 的账户加上 500 积分怎么办呢?
@@ -312,7 +1363,7 @@ emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特
不过最主要的还是需要 **根据特定场景使用特定的解决方案** ,你要知道你的消息消费是否是完全不可重复消费还是可以忍受重复消费的,然后再选择强校验和弱校验的方式。毕竟在 CS 领域还是很少有技术银弹的说法。
-而在整个互联网领域,幂等不仅仅适用于消息队列的重复消费问题,这些实现幂等的方法,也同样适用于,**在其他场景中来解决重复请求或者重复调用的问题** 。比如将 HTTP 服务设计成幂等的,**解决前端或者 APP 重复提交表单数据的问题** ,也可以将一个微服务设计成幂等的,解决 `RPC` 框架自动重试导致的 **重复调用问题** 。
+而在整个互联网领域,幂等不仅仅适用于消息队列的重复消费问题,这些实现幂等的方法,也同样适用于,**在其他场景中来解决重复请求或者重复调用的问题** 。比如将 HTTP 服务设计成幂等的,**解决前端或者 APP 重复提交表单数据的问题** ,也可以将一个微服务设计成幂等的,解决 RPC 框架自动重试导致的 **重复调用问题** 。
## RocketMQ 如何实现分布式事务?
@@ -322,18 +1373,238 @@ emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特
如今比较常见的分布式事务实现有 2PC、TCC 和事务消息(half 半消息机制)。每一种实现都有其特定的使用场景,但是也有各自的问题,**都不是完美的解决方案**。
-在 `RocketMQ` 中使用的是 **事务消息加上事务反查机制** 来解决分布式事务问题的。我画了张图,大家可以对照着图进行理解。
+在 RocketMQ 中使用的是 **事务消息加上事务反查机制** 来解决分布式事务问题的。我画了张图,大家可以对照着图进行理解。
-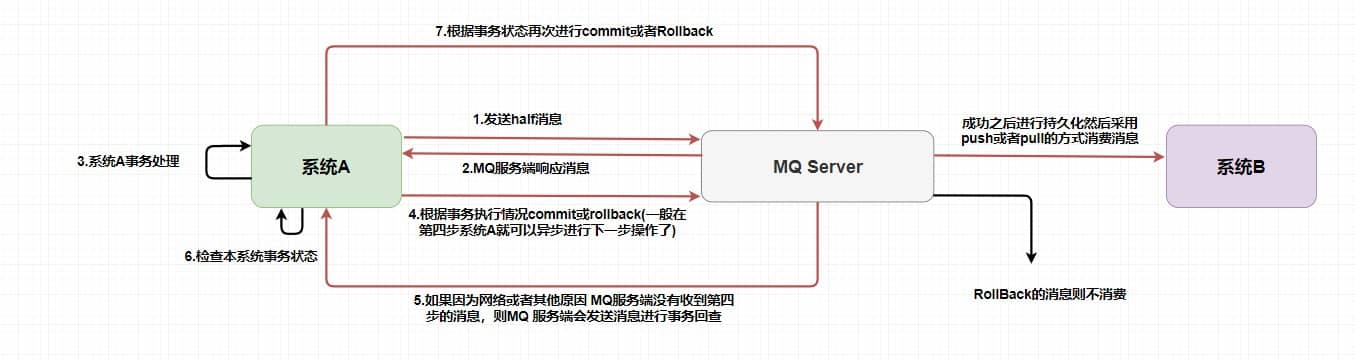
+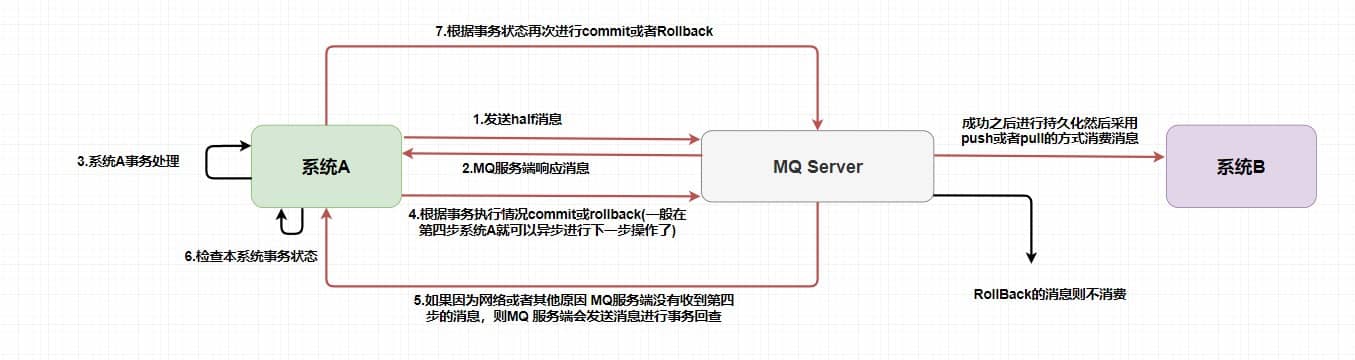
+
+**事务消息处理流程详解**
+
+1. **发送半事务消息**:生产者将消息发送至 RocketMQ 服务端
+2. **服务端确认**:服务端将消息持久化成功之后,向生产者返回 Ack 确认消息已经发送成功,此时消息被标记为"暂不能投递",这种状态下的消息即为**半事务消息**
+3. **执行本地事务**:生产者开始执行本地事务逻辑
+4. **提交二次确认**:生产者根据本地事务执行结果向服务端提交二次确认结果(Commit 或 Rollback)
+5. **事务回查**:如果服务端未收到二次确认结果,或收到的结果为 Unknown,经过固定时间后,服务端将对消息生产者发起**消息回查**
+6. **检查本地事务**:生产者收到消息回查后,需要检查对应消息的本地事务执行的最终结果
+7. **再次提交确认**:生产者根据检查到的本地事务的最终状态再次提交二次确认
在第一步发送的 half 消息 ,它的意思是 **在事务提交之前,对于消费者来说,这个消息是不可见的** 。
> 那么,如何做到写入消息但是对用户不可见呢?RocketMQ 事务消息的做法是:如果消息是 half 消息,将备份原消息的主题与消息消费队列,然后 **改变主题** 为 RMQ_SYS_TRANS_HALF_TOPIC。由于消费组未订阅该主题,故消费端无法消费 half 类型的消息,**然后 RocketMQ 会开启一个定时任务,从 Topic 为 RMQ_SYS_TRANS_HALF_TOPIC 中拉取消息进行消费**,根据生产者组获取一个服务提供者发送回查事务状态请求,根据事务状态来决定是提交或回滚消息。
-你可以试想一下,如果没有从第 5 步开始的 **事务反查机制** ,如果出现网路波动第 4 步没有发送成功,这样就会产生 MQ 不知道是不是需要给消费者消费的问题,他就像一个无头苍蝇一样。在 `RocketMQ` 中就是使用的上述的事务反查来解决的,而在 `Kafka` 中通常是直接抛出一个异常让用户来自行解决。
+你可以试想一下,如果没有从第 5 步开始的 **事务回查机制** ,如果出现网路波动第 4 步没有发送成功,这样就会产生 MQ 不知道是不是需要给消费者消费的问题。在 RocketMQ 中就是使用的上述的事务回查来解决的,而在 Kafka 中通常是直接抛出一个异常让用户来自行解决。
你还需要注意的是,在 `MQ Server` 指向系统 B 的操作已经和系统 A 不相关了,也就是说在消息队列中的分布式事务是——**本地事务和存储消息到消息队列才是同一个事务**。这样也就产生了事务的**最终一致性**,因为整个过程是异步的,**每个系统只要保证它自己那一部分的事务就行了**。
+实践中会遇到的问题:事务消息需要一个事务监听器来监听本地事务是否成功,并且事务监听器接口只允许被实现一次。那就意味着需要把各种事务消息的本地事务都写在一个接口方法里面,必将会产生大量的耦合和类型判断。采用函数 Function 接口来包装整个业务过程,作为一个参数传递到监听器的接口方法中。再调用 Function 的 apply() 方法来执行业务,事务也会在 apply() 方法中执行。让监听器与业务之间实现解耦,使之具备了真实生产环境中的可行性。
+
+1.模拟一个添加用户浏览记录的需求
+
+```java
+@PostMapping("/add")
+@ApiOperation("添加用户浏览记录")
+public Result add(Long userId, Long forecastLogId) {
+
+ // 函数式编程:浏览记录入库
+ Function function = transactionId -> viewHistoryHandler.addViewHistory(transactionId, userId, forecastLogId);
+
+ Map hashMap = new HashMap<>();
+ hashMap.put("userId", userId);
+ hashMap.put("forecastLogId", forecastLogId);
+ String jsonString = JSON.toJSONString(hashMap);
+
+ // 发送事务消息;将本地的事务操作,用函数Function接口接收,作为一个参数传入到方法中
+ TransactionSendResult transactionSendResult = mqProducerService.sendTransactionMessage(jsonString, MQDestination.TAG_ADD_VIEW_HISTORY, function);
+ return Result.success(transactionSendResult);
+}
+```
+
+2.发送事务消息的方法
+
+```java
+/**
+ * 发送事务消息
+ *
+ * @param msgBody
+ * @param tag
+ * @param function
+ * @return
+ */
+public TransactionSendResult sendTransactionMessage(String msgBody, String tag, Function function) {
+ // 构建消息体
+ Message message = buildMessage(msgBody);
+
+ // 构建消息投递信息
+ String destination = buildDestination(tag);
+
+ TransactionSendResult result = rocketMQTemplate.sendMessageInTransaction(destination, message, function);
+ return result;
+}
+```
+
+3.生产者消息监听器,只允许一个类去实现该监听器
+
+```java
+@Slf4j
+@RocketMQTransactionListener
+public class TransactionMsgListener implements RocketMQLocalTransactionListener {
+
+ @Autowired
+ private RedisService redisService;
+
+ /**
+ * 执行本地事务(在发送消息成功时执行)
+ *
+ * @param message
+ * @param o
+ * @return commit or rollback or unknown
+ */
+ @Override
+ public RocketMQLocalTransactionState executeLocalTransaction(Message message, Object o) {
+
+ // 1、获取事务ID
+ String transactionId = null;
+ try {
+ transactionId = message.getHeaders().get("rocketmq_TRANSACTION_ID").toString();
+ // 2、判断传入函数对象是否为空,如果为空代表没有要执行的业务直接抛弃消息
+ if (o == null) {
+ //返回ROLLBACK状态的消息会被丢弃
+ log.info("事务消息回滚,没有需要处理的业务 transactionId={}", transactionId);
+ return RocketMQLocalTransactionState.ROLLBACK;
+ }
+ // 将Object o转换成Function对象
+ Function function = (Function) o;
+ // 执行业务 事务也会在function.apply中执行
+ Boolean apply = function.apply(transactionId);
+ if (apply) {
+ log.info("事务提交,消息正常处理 transactionId={}", transactionId);
+ //返回COMMIT状态的消息会立即被消费者消费到
+ return RocketMQLocalTransactionState.COMMIT;
+ }
+ } catch (Exception e) {
+ log.info("出现异常 返回ROLLBACK transactionId={}", transactionId);
+ return RocketMQLocalTransactionState.ROLLBACK;
+ }
+ return RocketMQLocalTransactionState.ROLLBACK;
+ }
+
+ /**
+ * 事务回查机制,检查本地事务的状态
+ *
+ * @param message
+ * @return
+ */
+ @Override
+ public RocketMQLocalTransactionState checkLocalTransaction(Message message) {
+
+ String transactionId = message.getHeaders().get("rocketmq_TRANSACTION_ID").toString();
+
+ // 查redis
+ MqTransaction mqTransaction = redisService.getCacheObject("mqTransaction:" + transactionId);
+ if (Objects.isNull(mqTransaction)) {
+ return RocketMQLocalTransactionState.ROLLBACK;
+ }
+ return RocketMQLocalTransactionState.COMMIT;
+ }
+}
+```
+
+4.模拟的业务场景,这里的方法必须提取出来,放在别的类里面.如果调用方与被调用方在同一个类中,会发生事务失效的问题.
+
+```java
+@Component
+public class ViewHistoryHandler {
+
+ @Autowired
+ private IViewHistoryService viewHistoryService;
+
+ @Autowired
+ private IMqTransactionService mqTransactionService;
+
+ @Autowired
+ private RedisService redisService;
+
+ /**
+ * 浏览记录入库
+ *
+ * @param transactionId
+ * @param userId
+ * @param forecastLogId
+ * @return
+ */
+ @Transactional
+ public Boolean addViewHistory(String transactionId, Long userId, Long forecastLogId) {
+ // 构建浏览记录
+ ViewHistory viewHistory = new ViewHistory();
+ viewHistory.setUserId(userId);
+ viewHistory.setForecastLogId(forecastLogId);
+ viewHistory.setCreateTime(LocalDateTime.now());
+ boolean save = viewHistoryService.save(viewHistory);
+
+ // 本地事务信息
+ MqTransaction mqTransaction = new MqTransaction();
+ mqTransaction.setTransactionId(transactionId);
+ mqTransaction.setCreateTime(new Date());
+ mqTransaction.setStatus(MqTransaction.StatusEnum.VALID.getStatus());
+
+ // 1.可以把事务信息存数据库
+ mqTransactionService.save(mqTransaction);
+
+ // 2.也可以选择存redis,4个小时有效期,'4个小时'是RocketMQ内置的最大回查超时时长,过期未确认将强制回滚
+ redisService.setCacheObject("mqTransaction:" + transactionId, mqTransaction, 4L, TimeUnit.HOURS);
+
+ // 放开注释,模拟异常,事务回滚
+ // int i = 10 / 0;
+
+ return save;
+ }
+}
+```
+
+5.消费消息,以及幂等处理
+
+```java
+@Service
+@RocketMQMessageListener(topic = MQDestination.TOPIC, selectorExpression = MQDestination.TAG_ADD_VIEW_HISTORY, consumerGroup = MQDestination.TAG_ADD_VIEW_HISTORY)
+public class ConsumerAddViewHistory implements RocketMQListener {
+ // 监听到消息就会执行此方法
+ @Override
+ public void onMessage(Message message) {
+ // 幂等校验
+ String transactionId = message.getTransactionId();
+
+ // 查redis
+ MqTransaction mqTransaction = redisService.getCacheObject("mqTransaction:" + transactionId);
+
+ // 不存在事务记录
+ if (Objects.isNull(mqTransaction)) {
+ return;
+ }
+
+ // 已消费
+ if (Objects.equals(mqTransaction.getStatus(), MqTransaction.StatusEnum.CONSUMED.getStatus())) {
+ return;
+ }
+
+ String msg = new String(message.getBody());
+ Map map = JSON.parseObject(msg, new TypeReference>() {
+ });
+ Long userId = map.get("userId");
+ Long forecastLogId = map.get("forecastLogId");
+
+ // 下游的业务处理
+ // TODO 记录用户喜好,更新用户画像
+
+ // TODO 更新'证券预测文章'的浏览量,重新计算文章的曝光排序
+
+ // 更新状态为已消费
+ mqTransaction.setUpdateTime(new Date());
+ mqTransaction.setStatus(MqTransaction.StatusEnum.CONSUMED.getStatus());
+ redisService.setCacheObject("mqTransaction:" + transactionId, mqTransaction, 4L, TimeUnit.HOURS);
+ log.info("监听到消息:msg={}", JSON.toJSONString(map));
+ }
+}
+```
+
## 如何解决消息堆积问题?
在上面我们提到了消息队列一个很重要的功能——**削峰** 。那么如果这个峰值太大了导致消息堆积在队列中怎么办呢?
@@ -344,41 +1615,97 @@ emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特
> 当然,最快速解决消息堆积问题的方法还是增加消费者实例,不过 **同时你还需要增加每个主题的队列数量** 。
>
-> 别忘了在 `RocketMQ` 中,**一个队列只会被一个消费者消费** ,如果你仅仅是增加消费者实例就会出现我一开始给你画架构图的那种情况。
+> **注意**:在 RocketMQ 4.x 及之前的版本中,**一个队列只会被一个消费者消费**,如果你仅仅是增加消费者实例就会出现我一开始给你画架构图的那种情况(部分消费者没有队列可消费)。
+>
+> 但在 RocketMQ 5.x 及之后的版本中,引入了**消息粒度负载均衡策略**,同一消费者分组内的多个消费者可以按照消息粒度共同消费同一个队列中的消息,因此即使消费者数量多于队列数量,所有消费者也能参与到消费中。
-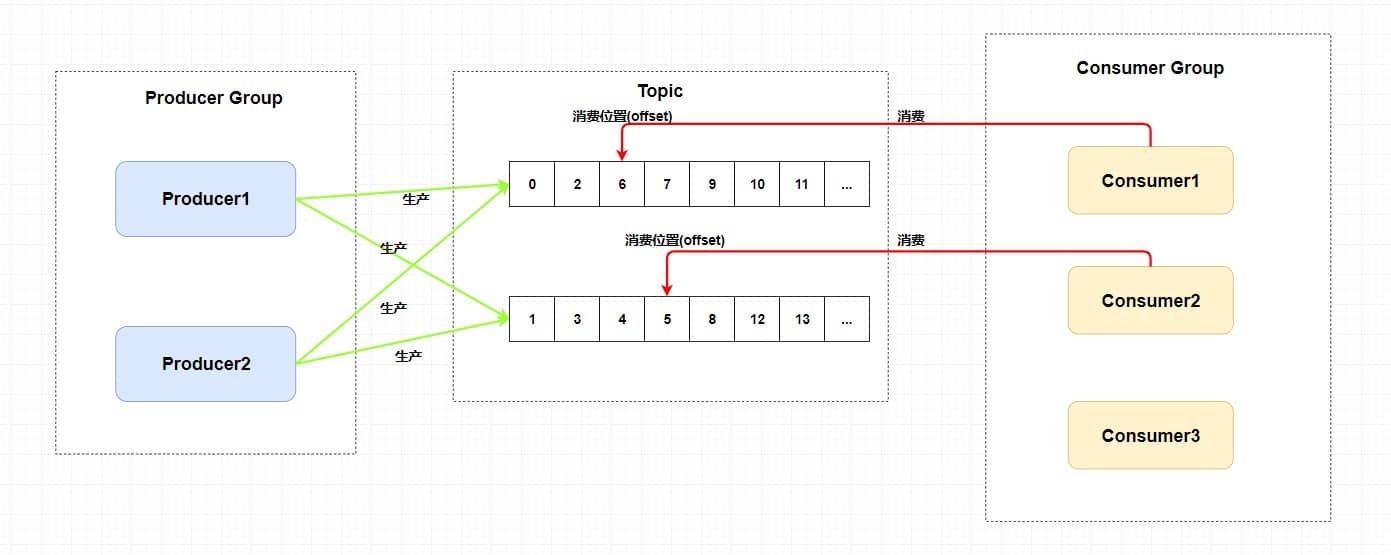
+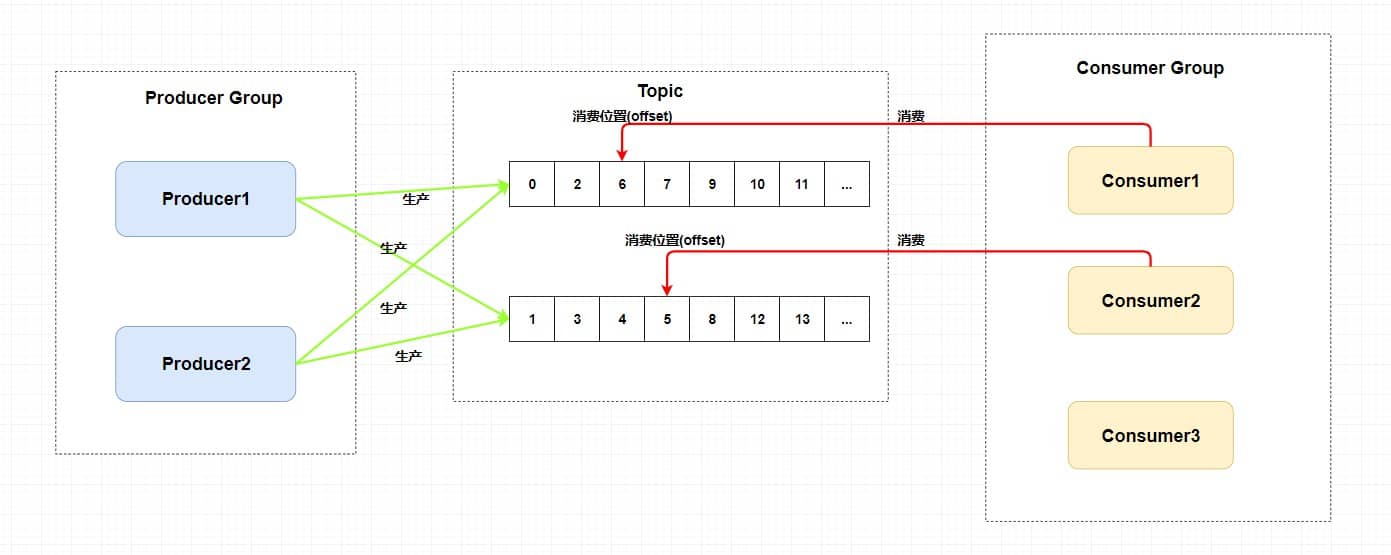
-## 什么事回溯消费?
+## 什么是回溯消费?
-回溯消费是指 `Consumer` 已经消费成功的消息,由于业务上需求需要重新消费,在`RocketMQ` 中, `Broker` 在向`Consumer` 投递成功消息后,**消息仍然需要保留** 。并且重新消费一般是按照时间维度,例如由于 `Consumer` 系统故障,恢复后需要重新消费 1 小时前的数据,那么 `Broker` 要提供一种机制,可以按照时间维度来回退消费进度。`RocketMQ` 支持按照时间回溯消费,时间维度精确到毫秒。
+回溯消费是指 Consumer 已经消费成功的消息,由于业务上需求需要重新消费,在 RocketMQ 中, Broker 在向 Consumer 投递成功消息后,**消息仍然需要保留** 。并且重新消费一般是按照时间维度,例如由于 Consumer 系统故障,恢复后需要重新消费 1 小时前的数据,那么 Broker 要提供一种机制,可以按照时间维度来回退消费进度。RocketMQ 支持按照时间回溯消费,时间维度精确到毫秒。
-这是官方文档的解释,我直接照搬过来就当科普了 😁😁😁。
+## RocketMQ 如何保证高性能读写
-## RocketMQ 的刷盘机制
+### 传统 IO 方式
+
+
+
+传统的 IO 读写其实就是 read + write 的操作,整个过程会分为如下几步
-上面我讲了那么多的 `RocketMQ` 的架构和设计原理,你有没有好奇
+- 用户调用 read()方法,开始读取数据,此时发生一次上下文从用户态到内核态的切换,也就是图示的切换 1
+- 将磁盘数据通过 DMA 拷贝到内核缓存区
+- 将内核缓存区的数据拷贝到用户缓冲区,这样用户,也就是我们写的代码就能拿到文件的数据
+- read()方法返回,此时就会从内核态切换到用户态,也就是图示的切换 2
+- 当我们拿到数据之后,就可以调用 write()方法,此时上下文会从用户态切换到内核态,即图示切换 3
+- CPU 将用户缓冲区的数据拷贝到 Socket 缓冲区
+- 将 Socket 缓冲区数据拷贝至网卡
+- write()方法返回,上下文重新从内核态切换到用户态,即图示切换 4
-在 `Topic` 中的 **队列是以什么样的形式存在的?**
+整个过程发生了 4 次上下文切换和 4 次数据的拷贝,这在高并发场景下肯定会严重影响读写性能故引入了零拷贝技术
-**队列中的消息又是如何进行存储持久化的呢?**
+### 零拷贝技术
-我在上文中提到的 **同步刷盘** 和 **异步刷盘** 又是什么呢?它们会给持久化带来什么样的影响呢?
+#### mmap
-下面我将给你们一一解释。
+mmap(memory map)是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。
+
+简单地说就是内核缓冲区和应用缓冲区共享,从而减少了从读缓冲区到用户缓冲区的一次 CPU 拷贝。基于此上述架构图可变为:
+
+
+
+基于 mmap IO 读写其实就变成 mmap + write 的操作,也就是用 mmap 替代传统 IO 中的 read 操作。
+
+当用户发起 mmap 调用的时候会发生上下文切换 1,进行内存映射,然后数据被拷贝到内核缓冲区,mmap 返回,发生上下文切换 2;随后用户调用 write,发生上下文切换 3,将内核缓冲区的数据拷贝到 Socket 缓冲区,write 返回,发生上下文切换 4。
+
+发生 4 次上下文切换和 3 次 IO 拷贝操作,在 Java 中的实现:
+
+```java
+FileChannel fileChannel = new RandomAccessFile("test.txt", "rw").getChannel();
+MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, fileChannel.size());
+```
+
+#### sendfile
+
+sendfile()跟 mmap()一样,也会减少一次 CPU 拷贝,但是它同时也会减少两次上下文切换。
+
+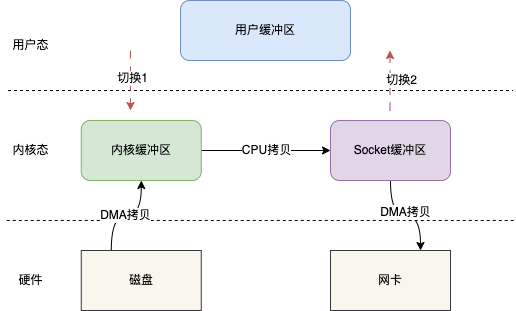
+
+如图,用户在发起 sendfile()调用时会发生切换 1,之后数据通过 DMA 拷贝到内核缓冲区,之后再将内核缓冲区的数据 CPU 拷贝到 Socket 缓冲区,最后拷贝到网卡,sendfile()返回,发生切换 2。发生了 3 次拷贝和两次切换。Java 也提供了相应 api:
+
+```java
+FileChannel channel = FileChannel.open(Paths.get("./test.txt"), StandardOpenOption.WRITE, StandardOpenOption.CREATE);
+//调用transferTo方法向目标数据传输
+channel.transferTo(position, len, target);
+```
+
+在如上代码中,并没有文件的读写操作,而是直接将文件的数据传输到 target 目标缓冲区,也就是说,sendfile 是无法知道文件的具体的数据的;但是 mmap 不一样,他是可以修改内核缓冲区的数据的。假设如果需要对文件的内容进行修改之后再传输,只有 mmap 可以满足。
+
+通过上面的一些介绍,结论是基于零拷贝技术,可以减少 CPU 的拷贝次数和上下文切换次数,从而可以实现文件高效的读写操作。
+
+RocketMQ 内部主要是使用基于 mmap 实现的零拷贝(其实就是调用上述提到的 api),用来读写文件,这也是 RocketMQ 为什么快的一个很重要原因。
+
+## RocketMQ 的刷盘机制
+
+了解了 RocketMQ 的架构和设计原理后,接下来探讨几个核心问题:
+
+- 在 Topic 中的 **队列是以什么样的形式存在的?**
+- **队列中的消息又是如何进行存储持久化的呢?**
+- **同步刷盘** 和 **异步刷盘** 是什么?它们会给持久化带来什么样的影响?
### 同步刷盘和异步刷盘
-
+
-如上图所示,在同步刷盘中需要等待一个刷盘成功的 `ACK` ,同步刷盘对 `MQ` 消息可靠性来说是一种不错的保障,但是 **性能上会有较大影响** ,一般地适用于金融等特定业务场景。
+如上图所示,在同步刷盘中需要等待一个刷盘成功的 ACK ,同步刷盘对 `MQ` 消息可靠性来说是一种不错的保障,但是 **性能上会有较大影响** ,一般地适用于金融等特定业务场景。
而异步刷盘往往是开启一个线程去异步地执行刷盘操作。消息刷盘采用后台异步线程提交的方式进行, **降低了读写延迟** ,提高了 `MQ` 的性能和吞吐量,一般适用于如发验证码等对于消息保证要求不太高的业务场景。
-一般地,**异步刷盘只有在 `Broker` 意外宕机的时候会丢失部分数据**,你可以设置 `Broker` 的参数 `FlushDiskType` 来调整你的刷盘策略(ASYNC_FLUSH 或者 SYNC_FLUSH)。
+一般地,**异步刷盘只有在 Broker 意外宕机的时候会丢失部分数据**,你可以设置 Broker 的参数 `FlushDiskType` 来调整你的刷盘策略(ASYNC_FLUSH 或者 SYNC_FLUSH)。
### 同步复制和异步复制
-上面的同步刷盘和异步刷盘是在单个结点层面的,而同步复制和异步复制主要是指的 `Borker` 主从模式下,主节点返回消息给客户端的时候是否需要同步从节点。
+上面的同步刷盘和异步刷盘是在单个节点层面的,而同步复制和异步复制主要是指 `Broker` 主从模式下,主节点返回消息给客户端的时候是否需要同步从节点。
- 同步复制:也叫 “同步双写”,也就是说,**只有消息同步双写到主从节点上时才返回写入成功** 。
- 异步复制:**消息写入主节点之后就直接返回写入成功** 。
@@ -387,72 +1714,103 @@ emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特
那么,**异步复制会不会也像异步刷盘那样影响消息的可靠性呢?**
-答案是不会的,因为两者就是不同的概念,对于消息可靠性是通过不同的刷盘策略保证的,而像异步同步复制策略仅仅是影响到了 **可用性** 。为什么呢?其主要原因**是 `RocketMQ` 是不支持自动主从切换的,当主节点挂掉之后,生产者就不能再给这个主节点生产消息了**。
+答案是不会的,因为两者是不同的概念,消息可靠性是通过刷盘策略保证的,而同步/异步复制策略仅仅影响 **可用性** 。原因是**在默认配置下,RocketMQ 不支持自动主从切换,当主节点挂掉之后,生产者就不能再给这个主节点生产消息了**(但使用 DLedger 模式可以实现自动切换)。
比如这个时候采用异步复制的方式,在主节点还未发送完需要同步的消息的时候主节点挂掉了,这个时候从节点就少了一部分消息。但是此时生产者无法再给主节点生产消息了,**消费者可以自动切换到从节点进行消费**(仅仅是消费),所以在主节点挂掉的时间只会产生主从结点短暂的消息不一致的情况,降低了可用性,而当主节点重启之后,从节点那部分未来得及复制的消息还会继续复制。
-在单主从架构中,如果一个主节点挂掉了,那么也就意味着整个系统不能再生产了。那么这个可用性的问题能否解决呢?**一个主从不行那就多个主从的呗**,别忘了在我们最初的架构图中,每个 `Topic` 是分布在不同 `Broker` 中的。
+在单主从架构中,如果一个主节点挂掉了,那么整个系统就不能再生产消息了。那么这个可用性的问题能否解决呢?**可以通过多主从架构来解决**,在最初的架构图中,每个 Topic 是分布在不同 Broker 中的。
-
+
-但是这种复制方式同样也会带来一个问题,那就是无法保证 **严格顺序** 。在上文中我们提到了如何保证的消息顺序性是通过将一个语义的消息发送在同一个队列中,使用 `Topic` 下的队列来保证顺序性的。如果此时我们主节点 A 负责的是订单 A 的一系列语义消息,然后它挂了,这样其他节点是无法代替主节点 A 的,如果我们任意节点都可以存入任何消息,那就没有顺序性可言了。
+但是这种复制方式同样也会带来一个问题,那就是无法保证 **严格顺序** 。在上文中我们提到了如何保证的消息顺序性是通过将一个语义的消息发送在同一个队列中,使用 Topic 下的队列来保证顺序性的。如果此时我们主节点 A 负责的是订单 A 的一系列语义消息,然后它挂了,这样其他节点是无法代替主节点 A 的,如果我们任意节点都可以存入任何消息,那就没有顺序性可言了。
-而在 `RocketMQ` 中采用了 `Dledger` 解决这个问题。他要求在写入消息的时候,要求**至少消息复制到半数以上的节点之后**,才给客⼾端返回写⼊成功,并且它是⽀持通过选举来动态切换主节点的。这里我就不展开说明了,读者可以自己去了解。
+而在 RocketMQ 中采用了 DLedger 解决这个问题。DLedger 要求在写入消息的时候,**至少消息复制到半数以上的节点之后**,才给客户端返回写入成功,并且支持通过选举来动态切换主节点。
-> 也不是说 `Dledger` 是个完美的方案,至少在 `Dledger` 选举过程中是无法提供服务的,而且他必须要使用三个节点或以上,如果多数节点同时挂掉他也是无法保证可用性的,而且要求消息复制半数以上节点的效率和直接异步复制还是有一定的差距的。
+> DLedger 也不是完美的方案:在选举过程中是无法提供服务的;必须使用三个节点或以上;如果多数节点同时挂掉也无法保证可用性;要求消息复制到半数以上节点的效率和直接异步复制还是有一定差距的。
### 存储机制
-还记得上面我们一开始的三个问题吗?到这里第三个问题已经解决了。
+至此,刷盘和复制的问题已经解决了。
-但是,在 `Topic` 中的 **队列是以什么样的形式存在的?队列中的消息又是如何进行存储持久化的呢?** 还未解决,其实这里涉及到了 `RocketMQ` 是如何设计它的存储结构了。我首先想大家介绍 `RocketMQ` 消息存储架构中的三大角色——`CommitLog`、`ConsumeQueue` 和 `IndexFile` 。
+接下来讨论 **队列是以什么样的形式存在的?队列中的消息又是如何进行存储持久化的?** 这涉及到 RocketMQ 的存储结构设计。首先介绍 RocketMQ 消息存储架构中的三大角色——CommitLog、ConsumeQueue 和 IndexFile。
-- `CommitLog`:**消息主体以及元数据的存储主体**,存储 `Producer` 端写入的消息主体内容,消息内容不是定长的。单个文件大小默认 1G ,文件名长度为 20 位,左边补零,剩余为起始偏移量,比如 00000000000000000000 代表了第一个文件,起始偏移量为 0,文件大小为 1G=1073741824;当第一个文件写满了,第二个文件为 00000000001073741824,起始偏移量为 1073741824,以此类推。消息主要是**顺序写入日志文件**,当文件满了,写入下一个文件。
-- `ConsumeQueue`:消息消费队列,**引入的目的主要是提高消息消费的性能**(我们再前面也讲了),由于`RocketMQ` 是基于主题 `Topic` 的订阅模式,消息消费是针对主题进行的,如果要遍历 `commitlog` 文件中根据 `Topic` 检索消息是非常低效的。`Consumer` 即可根据 `ConsumeQueue` 来查找待消费的消息。其中,`ConsumeQueue`(逻辑消费队列)**作为消费消息的索引**,保存了指定 `Topic` 下的队列消息在 `CommitLog` 中的**起始物理偏移量 `offset` **,消息大小 `size` 和消息 `Tag` 的 `HashCode` 值。**`consumequeue` 文件可以看成是基于 `topic` 的 `commitlog` 索引文件**,故 `consumequeue` 文件夹的组织方式如下:topic/queue/file 三层组织结构,具体存储路径为:$HOME/store/consumequeue/{topic}/{queueId}/{fileName}。同样 `consumequeue` 文件采取定长设计,每一个条目共 20 个字节,分别为 8 字节的 `commitlog` 物理偏移量、4 字节的消息长度、8 字节 tag `hashcode`,单个文件由 30W 个条目组成,可以像数组一样随机访问每一个条目,每个 `ConsumeQueue`文件大小约 5.72M;
-- `IndexFile`:`IndexFile`(索引文件)提供了一种可以通过 key 或时间区间来查询消息的方法。这里只做科普不做详细介绍。
+**存储架构三大组件:**
-总结来说,整个消息存储的结构,最主要的就是 `CommitLoq` 和 `ConsumeQueue` 。而 `ConsumeQueue` 你可以大概理解为 `Topic` 中的队列。
+- **CommitLog**:**消息主体以及元数据的存储主体**,存储 Producer 端写入的消息主体内容,消息内容不是定长的。单个文件大小默认 **1G**,文件名长度为 20 位,左边补零,剩余为起始偏移量,比如 00000000000000000000 代表第一个文件,起始偏移量为 0;当第一个文件写满后,第二个文件为 00000000001073741824,起始偏移量为 1073741824,以此类推。消息主要是 **顺序写入日志文件**,当文件满了,写入下一个文件。
+- **ConsumeQueue**:消息消费队列,**引入的目的主要是提高消息消费的性能**。由于 RocketMQ 是基于主题 Topic 的订阅模式,如果要遍历 CommitLog 文件根据 Topic 检索消息是非常低效的。ConsumeQueue(逻辑消费队列)**作为消费消息的索引**,保存了指定 Topic 下的队列消息在 CommitLog 中的 **起始物理偏移量 offset**、消息大小 size 和消息 Tag 的 HashCode 值。ConsumeQueue 文件夹的组织方式为:topic/queue/file 三层组织结构,具体存储路径为:`$HOME/store/consumequeue/{topic}/{queueId}/{fileName}`。ConsumeQueue 文件采取定长设计,每一个条目共 **20 个字节**(8 字节 commitlog 物理偏移量 + 4 字节消息长度 + 8 字节 tag hashcode),单个文件由 **30 万个条目** 组成,每个 ConsumeQueue 文件大小约 **5.72M**。
+- **IndexFile**:索引文件,提供了一种可以通过 key 或时间区间来查询消息的方法。
-
+总结来说,整个消息存储的结构,最主要的就是 `CommitLog` 和 ConsumeQueue 。而 ConsumeQueue 可以理解为 Topic 中的队列。
-`RocketMQ` 采用的是 **混合型的存储结构** ,即为 `Broker` 单个实例下所有的队列共用一个日志数据文件来存储消息。有意思的是在同样高并发的 `Kafka` 中会为每个 `Topic` 分配一个存储文件。这就有点类似于我们有一大堆书需要装上书架,`RockeMQ` 是不分书的种类直接成批的塞上去的,而 `Kafka` 是将书本放入指定的分类区域的。
+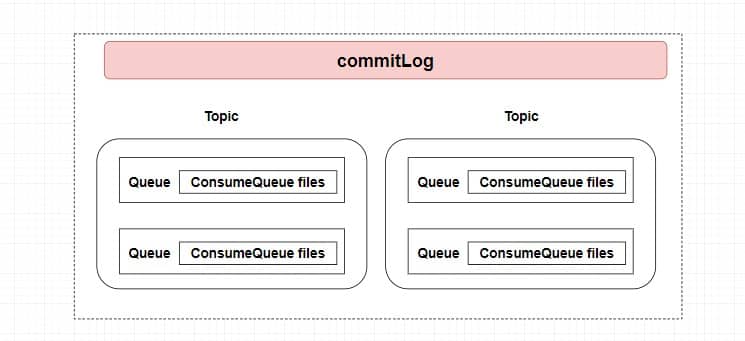
-而 `RocketMQ` 为什么要这么做呢?原因是 **提高数据的写入效率** ,不分 `Topic` 意味着我们有更大的几率获取 **成批** 的消息进行数据写入,但也会带来一个麻烦就是读取消息的时候需要遍历整个大文件,这是非常耗时的。
+RocketMQ 采用的是 **混合型的存储结构** ,即 Broker 单个实例下所有的队列共用一个日志数据文件(CommitLog)来存储消息。而 Kafka 会为每个分区(Partition)分配一个独立的存储文件。
-所以,在 `RocketMQ` 中又使用了 `ConsumeQueue` 作为每个队列的索引文件来 **提升读取消息的效率**。我们可以直接根据队列的消息序号,计算出索引的全局位置(索引序号\*索引固定⻓度 20),然后直接读取这条索引,再根据索引中记录的消息的全局位置,找到消息。
+RocketMQ 这么做的原因是 **提高数据的写入效率** ,不分 Topic 意味着有更大的几率获取 **成批** 的消息进行顺序写入,但也带来一个问题:读取消息时如果遍历整个 CommitLog 文件,效率很低。
-讲到这里,你可能对 `RockeMQ` 的存储架构还有些模糊,没事,我们结合着图来理解一下。
+所以,RocketMQ 使用 ConsumeQueue 作为每个队列的索引文件来 **提升读取消息的效率**。可以直接根据队列的消息序号,计算出索引的全局位置(索引序号 × 索引固定长度 20),然后直接读取这条索引,再根据索引中记录的消息的全局位置找到消息。
-
+下面结合架构图来理解存储结构:
-emmm,是不是有一点复杂 🤣,看英文图片和英文文档的时候就不要怂,硬着头皮往下看就行。
+
> 如果上面没看懂的读者一定要认真看下面的流程分析!
-首先,在最上面的那一块就是我刚刚讲的你现在可以直接 **把 `ConsumerQueue` 理解为 `Queue`**。
-
-在图中最左边说明了红色方块代表被写入的消息,虚线方块代表等待被写入的。左边的生产者发送消息会指定 `Topic`、`QueueId` 和具体消息内容,而在 `Broker` 中管你是哪门子消息,他直接 **全部顺序存储到了 CommitLog**。而根据生产者指定的 `Topic` 和 `QueueId` 将这条消息本身在 `CommitLog` 的偏移(offset),消息本身大小,和 tag 的 hash 值存入对应的 `ConsumeQueue` 索引文件中。而在每个队列中都保存了 `ConsumeOffset` 即每个消费者组的消费位置(我在架构那里提到了,忘了的同学可以回去看一下),而消费者拉取消息进行消费的时候只需要根据 `ConsumeOffset` 获取下一个未被消费的消息就行了。
+首先,在图的最上面可以直接 **把 `ConsumerQueue` 理解为 Queue**。
-上述就是我对于整个消息存储架构的大概理解(这里不涉及到一些细节讨论,比如稀疏索引等等问题),希望对你有帮助。
+在图中最左边说明了红色方块代表被写入的消息,虚线方块代表等待被写入的消息。左边的生产者发送消息会指定 Topic、`QueueId` 和具体消息内容,而在 Broker 中不区分消息类型,直接 **全部顺序存储到 CommitLog**。根据生产者指定的 Topic 和 `QueueId`,将这条消息在 CommitLog 中的偏移量(offset)、消息大小和 tag 的 hash 值存入对应的 ConsumeQueue 索引文件中。
-因为有一个知识点因为写嗨了忘讲了,想想在哪里加也不好,所以我留给大家去思考 🤔🤔 一下吧。
+在每个队列中都保存了 `ConsumeOffset` 即每个消费者组的消费位置,消费者拉取消息进行消费时只需要根据 `ConsumeOffset` 获取下一个未被消费的消息即可。
-
+以上就是 RocketMQ 存储架构的核心原理。
-为什么 `CommitLog` 文件要设计成固定大小的长度呢?提醒:**内存映射机制**。
+最后留一个思考题:**为什么 CommitLog 文件要设计成固定大小的长度呢?** 提示:与 **内存映射机制(mmap)** 有关。
## 总结
-总算把这篇博客写完了。我讲的你们还记得吗 😅?
+本文系统地介绍了 RocketMQ 的核心知识点,以下是关键内容回顾:
+
+**消息队列核心价值**
+
+- **异步**:提升系统响应速度,非核心流程异步化处理
+- **解耦**:降低系统间耦合度,通过发布订阅模式实现松耦合
+- **削峰**:缓解瞬时流量压力,保护下游系统不被冲垮
+
+**RocketMQ 架构要点**
+
+| 组件 | 核心职责 |
+| -------------- | -------------------------------------------- |
+| **NameServer** | 无状态注册中心,各节点互不通信,追求简单高效 |
+| **Broker** | 消息存储与投递,支持主从架构和 DLedger 模式 |
+| **Proxy** | 5.0 新增,计算与存储分离,支持 gRPC 协议 |
+| **Producer** | 消息生产者,支持同步、异步、单向发送 |
+| **Consumer** | 消息消费者,支持 Push、Pull、Simple 三种模式 |
+
+**消息类型对比**
+
+| 消息类型 | 适用场景 | 关键特性 |
+| ------------ | -------------------- | ------------------------ |
+| **普通消息** | 微服务解耦、事件驱动 | 无顺序要求,消息相互独立 |
+| **顺序消息** | 订单处理、数据同步 | 同一消息组内严格有序 |
+| **定时消息** | 延迟任务、超时处理 | 5.x 支持任意精度定时 |
+| **事务消息** | 分布式事务 | 半消息机制 + 事务回查 |
+
+**5.x 版本核心升级**
+
+- **消息粒度负载均衡**:解决长尾效应问题,消息动态分配给空闲消费者
+- **计算与存储分离**:Proxy 组件承担协议适配和计算逻辑,Broker 专注存储
+- **任意精度定时消息**:不再受限于固定延迟等级,支持毫秒级定时
+
+**高性能设计**
+
+- **顺序写**:CommitLog 采用顺序写入,充分利用磁盘顺序 IO 的高性能
+- **零拷贝**:基于 mmap 内存映射,减少数据拷贝次数和上下文切换
+- **索引设计**:ConsumeQueue 作为消息索引,避免遍历 CommitLog
-这篇文章中我主要想大家介绍了
+**可靠性保障**
-1. 消息队列出现的原因
-2. 消息队列的作用(异步,解耦,削峰)
-3. 消息队列带来的一系列问题(消息堆积、重复消费、顺序消费、分布式事务等等)
-4. 消息队列的两种消息模型——队列和主题模式
-5. 分析了 `RocketMQ` 的技术架构(`NameServer`、`Broker`、`Producer`、`Comsumer`)
-6. 结合 `RocketMQ` 回答了消息队列副作用的解决方案
-7. 介绍了 `RocketMQ` 的存储机制和刷盘策略。
+- **刷盘策略**:同步刷盘保证消息不丢失,异步刷盘提升性能
+- **主从复制**:同步复制(双写)保证数据一致性,异步复制提升可用性
+- **DLedger**:基于 Raft 协议实现自动主从切换,提升高可用能力
-等等。。。
+
diff --git a/docs/high-performance/read-and-write-separation-and-library-subtable.md b/docs/high-performance/read-and-write-separation-and-library-subtable.md
index 6847b6ad5c8..1873aaa32fb 100644
--- a/docs/high-performance/read-and-write-separation-and-library-subtable.md
+++ b/docs/high-performance/read-and-write-separation-and-library-subtable.md
@@ -1,13 +1,11 @@
---
-title: 读写分离和分库分表常见问题总结
+title: 读写分离和分库分表详解
+description: 本文深入讲解数据库读写分离与分库分表的核心原理,涵盖主从复制机制、读写分离实现方案(代理/组件)、垂直分库分表与水平分库分表的区别,以及分库分表后的分布式事务、分布式ID、跨库JOIN等常见问题的解决方案。
category: 高性能
head:
- - meta
- name: keywords
- content: 读写分离,分库分表,主从复制
- - - meta
- - name: description
- content: 读写分离主要是为了将对数据库的读写操作分散到不同的数据库节点上。 这样的话,就能够小幅提升写性能,大幅提升读性能。 读写分离基于主从复制,MySQL 主从复制是依赖于 binlog 。分库就是将数据库中的数据分散到不同的数据库上。分表就是对单表的数据进行拆分,可以是垂直拆分,也可以是水平拆分。引入分库分表之后,需要系统解决事务、分布式 id、无法 join 操作问题。
+ content: 读写分离,分库分表,主从复制,水平分表,垂直分库,ShardingSphere,MyCat,分布式ID,跨库查询
---
## 读写分离
@@ -22,34 +20,6 @@ head:
一般情况下,我们都会选择一主多从,也就是一台主数据库负责写,其他的从数据库负责读。主库和从库之间会进行数据同步,以保证从库中数据的准确性。这样的架构实现起来比较简单,并且也符合系统的写少读多的特点。
-### 读写分离会带来什么问题?如何解决?
-
-读写分离对于提升数据库的并发非常有效,但是,同时也会引来一个问题:主库和从库的数据存在延迟,比如你写完主库之后,主库的数据同步到从库是需要时间的,这个时间差就导致了主库和从库的数据不一致性问题。这也就是我们经常说的 **主从同步延迟** 。
-
-主从同步延迟问题的解决,没有特别好的一种方案(可能是我太菜了,欢迎评论区补充)。你可以根据自己的业务场景,参考一下下面几种解决办法。
-
-**1.强制将读请求路由到主库处理。**
-
-既然你从库的数据过期了,那我就直接从主库读取嘛!这种方案虽然会增加主库的压力,但是,实现起来比较简单,也是我了解到的使用最多的一种方式。
-
-比如 `Sharding-JDBC` 就是采用的这种方案。通过使用 Sharding-JDBC 的 `HintManager` 分片键值管理器,我们可以强制使用主库。
-
-```java
-HintManager hintManager = HintManager.getInstance();
-hintManager.setMasterRouteOnly();
-// 继续JDBC操作
-```
-
-对于这种方案,你可以将那些必须获取最新数据的读请求都交给主库处理。
-
-**2.延迟读取。**
-
-还有一些朋友肯定会想既然主从同步存在延迟,那我就在延迟之后读取啊,比如主从同步延迟 0.5s,那我就 1s 之后再读取数据。这样多方便啊!方便是方便,但是也很扯淡。
-
-不过,如果你是这样设计业务流程就会好很多:对于一些对数据比较敏感的场景,你可以在完成写请求之后,避免立即进行请求操作。比如你支付成功之后,跳转到一个支付成功的页面,当你点击返回之后才返回自己的账户。
-
-另外,[《MySQL 实战 45 讲》](https://time.geekbang.org/column/intro/100020801?code=ieY8HeRSlDsFbuRtggbBQGxdTh-1jMASqEIeqzHAKrI%3D)这个专栏中的[《读写分离有哪些坑?》](https://time.geekbang.org/column/article/77636)这篇文章还介绍了很多其他比较实际的解决办法,感兴趣的小伙伴可以自行研究一下。
-
### 如何实现读写分离?
不论是使用哪一种读写分离具体的实现方案,想要实现读写分离一般包含如下几步:
@@ -66,7 +36,9 @@ hintManager.setMasterRouteOnly();
我们可以在应用和数据中间加了一个代理层。应用程序所有的数据请求都交给代理层处理,代理层负责分离读写请求,将它们路由到对应的数据库中。
-提供类似功能的中间件有 **MySQL Router**(官方)、**Atlas**(基于 MySQL Proxy)、**MaxScale**、**MyCat**。
+提供类似功能的中间件有 **MySQL Router**(官方, MySQL Proxy 的替代方案)、**Atlas**(基于 MySQL Proxy)、**MaxScale**、**MyCat**。
+
+关于 MySQL Router 多提一点:在 MySQL 8.2 的版本中,MySQL Router 能自动分辨对数据库读写/操作并把这些操作路由到正确的实例上。这是一项有价值的功能,可以优化数据库性能和可扩展性,而无需在应用程序中进行任何更改。具体介绍可以参考官方博客:[MySQL 8.2 – transparent read/write splitting](https://blogs.oracle.com/mysql/post/mysql-82-transparent-readwrite-splitting)。
**2. 组件方式**
@@ -89,7 +61,7 @@ MySQL binlog(binary log 即二进制日志文件) 主要记录了 MySQL 数据
3. 从库会创建一个 I/O 线程向主库请求更新的 binlog
4. 主库会创建一个 binlog dump 线程来发送 binlog ,从库中的 I/O 线程负责接收
5. 从库的 I/O 线程将接收的 binlog 写入到 relay log 中。
-6. 从库的 SQL 线程读取 relay log 同步数据本地(也就是再执行一遍 SQL )。
+6. 从库的 SQL 线程读取 relay log 同步数据到本地(也就是再执行一遍 SQL )。
怎么样?看了我对主从复制这个过程的讲解,你应该搞明白了吧!
@@ -105,6 +77,75 @@ MySQL binlog(binary log 即二进制日志文件) 主要记录了 MySQL 数据
**MySQL 主从复制是依赖于 binlog 。另外,常见的一些同步 MySQL 数据到其他数据源的工具(比如 canal)的底层一般也是依赖 binlog 。**
+### 如何避免主从延迟?
+
+读写分离对于提升数据库的并发非常有效,但是,同时也会引来一个问题:主库和从库的数据存在延迟,比如你写完主库之后,主库的数据同步到从库是需要时间的,这个时间差就导致了主库和从库的数据不一致性问题。这也就是我们经常说的 **主从同步延迟** 。
+
+如果我们的业务场景无法容忍主从同步延迟的话,应该如何避免呢(注意:我这里说的是避免而不是减少延迟)?
+
+这里提供两种我知道的方案(能力有限,欢迎补充),你可以根据自己的业务场景参考一下。
+
+#### 强制将读请求路由到主库处理
+
+既然你从库的数据过期了,那我就直接从主库读取嘛!这种方案虽然会增加主库的压力,但是,实现起来比较简单,也是我了解到的使用最多的一种方式。
+
+比如 `Sharding-JDBC` 就是采用的这种方案。通过使用 Sharding-JDBC 的 `HintManager` 分片键值管理器,我们可以强制使用主库。
+
+```java
+HintManager hintManager = HintManager.getInstance();
+hintManager.setMasterRouteOnly();
+// 继续JDBC操作
+```
+
+对于这种方案,你可以将那些必须获取最新数据的读请求都交给主库处理。
+
+#### 延迟读取
+
+还有一些朋友肯定会想既然主从同步存在延迟,那我就在延迟之后读取啊,比如主从同步延迟 0.5s,那我就 1s 之后再读取数据。这样多方便啊!方便是方便,但是也很扯淡。
+
+不过,如果你是这样设计业务流程就会好很多:对于一些对数据比较敏感的场景,你可以在完成写请求之后,避免立即进行请求操作。比如你支付成功之后,跳转到一个支付成功的页面,当你点击返回之后才返回自己的账户。
+
+#### 总结
+
+关于如何避免主从延迟,我们这里介绍了两种方案。实际上,延迟读取这种方案没办法完全避免主从延迟,只能说可以减少出现延迟的概率而已,实际项目中一般不会使用。
+
+总的来说,要想不出现延迟问题,一般还是要强制将那些必须获取最新数据的读请求都交给主库处理。如果你的项目的大部分业务场景对数据准确性要求不是那么高的话,这种方案还是可以选择的。
+
+### 什么情况下会出现主从延迟?如何尽量减少延迟?
+
+我们在上面的内容中也提到了主从延迟以及避免主从延迟的方法,这里我们再来详细分析一下主从延迟出现的原因以及应该如何尽量减少主从延迟。
+
+要搞懂什么情况下会出现主从延迟,我们需要先搞懂什么是主从延迟。
+
+MySQL 主从同步延时是指从库的数据落后于主库的数据,这种情况可能由以下两个原因造成:
+
+1. 从库 I/O 线程接收 binlog 的速度跟不上主库写入 binlog 的速度,导致从库 relay log 的数据滞后于主库 binlog 的数据;
+2. 从库 SQL 线程执行 relay log 的速度跟不上从库 I/O 线程接收 binlog 的速度,导致从库的数据滞后于从库 relay log 的数据。
+
+与主从同步有关的时间点主要有 3 个:
+
+1. 主库执行完一个事务,写入 binlog,将这个时刻记为 T1;
+2. 从库 I/O 线程接收到 binlog 并写入 relay log 的时刻记为 T2;
+3. 从库 SQL 线程读取 relay log 同步数据本地的时刻记为 T3。
+
+结合我们上面讲到的主从复制原理,可以得出:
+
+- T2 和 T1 的差值反映了从库 I/O 线程的性能和网络传输的效率,这个差值越小说明从库 I/O 线程的性能和网络传输效率越高。
+- T3 和 T2 的差值反映了从库 SQL 线程执行的速度,这个差值越小,说明从库 SQL 线程执行速度越快。
+
+那什么情况下会出现出从延迟呢?这里列举几种常见的情况:
+
+1. **从库机器性能比主库差**:从库接收 binlog 并写入 relay log 以及执行 SQL 语句的速度会比较慢(也就是 T2-T1 和 T3-T2 的值会较大),进而导致延迟。解决方法是选择与主库一样规格或更高规格的机器作为从库,或者对从库进行性能优化,比如调整参数、增加缓存、使用 SSD 等。
+2. **从库处理的读请求过多**:从库需要执行主库的所有写操作,同时还要响应读请求,如果读请求过多,会占用从库的 CPU、内存、网络等资源,影响从库的复制效率(也就是 T2-T1 和 T3-T2 的值会较大,和前一种情况类似)。解决方法是引入缓存(推荐)、使用一主多从的架构,将读请求分散到不同的从库,或者使用其他系统来提供查询的能力,比如将 binlog 接入到 Hadoop、Elasticsearch 等系统中。
+3. **大事务**:运行时间比较长,长时间未提交的事务就可以称为大事务。由于大事务执行时间长,并且从库上的大事务会比主库上的大事务花费更多的时间和资源,因此非常容易造成主从延迟。解决办法是避免大批量修改数据,尽量分批进行。类似的情况还有执行时间较长的慢 SQL ,实际项目遇到慢 SQL 应该进行优化。
+4. **从库太多**:主库需要将 binlog 同步到所有的从库,如果从库数量太多,会增加同步的时间和开销(也就是 T2-T1 的值会比较大,但这里是因为主库同步压力大导致的)。解决方案是减少从库的数量,或者将从库分为不同的层级,让上层的从库再同步给下层的从库,减少主库的压力。
+5. **网络延迟**:如果主从之间的网络传输速度慢,或者出现丢包、抖动等问题,那么就会影响 binlog 的传输效率,导致从库延迟。解决方法是优化网络环境,比如提升带宽、降低延迟、增加稳定性等。
+6. **单线程复制**:MySQL5.5 及之前,只支持单线程复制。为了优化复制性能,MySQL 5.6 引入了 **多线程复制**,MySQL 5.7 还进一步完善了多线程复制。
+7. **复制模式**:MySQL 默认的复制是异步的,必然会存在延迟问题。全同步复制不存在延迟问题,但性能太差了。半同步复制是一种折中方案,相对于异步复制,半同步复制提高了数据的安全性,减少了主从延迟(还是有一定程度的延迟)。MySQL 5.5 开始,MySQL 以插件的形式支持 **semi-sync 半同步复制**。并且,MySQL 5.7 引入了 **增强半同步复制** 。
+8. ……
+
+[《MySQL 实战 45 讲》](https://time.geekbang.org/column/intro/100020801?code=ieY8HeRSlDsFbuRtggbBQGxdTh-1jMASqEIeqzHAKrI%3D)这个专栏中的[读写分离有哪些坑?](https://time.geekbang.org/column/article/77636)这篇文章也有对主从延迟解决方案这一话题进行探讨,感兴趣的可以阅读学习一下。
+
## 分库分表
读写分离主要应对的是数据库读并发,没有解决数据库存储问题。试想一下:**如果 MySQL 一张表的数据量过大怎么办?**
@@ -151,17 +192,36 @@ MySQL binlog(binary log 即二进制日志文件) 主要记录了 MySQL 数据
- 单表的数据达到千万级别以上,数据库读写速度比较缓慢。
- 数据库中的数据占用的空间越来越大,备份时间越来越长。
-- 应用的并发量太大。
+- 应用的并发量太大(应该优先考虑其他性能优化方法,而非分库分表)。
+
+不过,分库分表的成本太高,如非必要尽量不要采用。而且,并不一定是单表千万级数据量就要分表,毕竟每张表包含的字段不同,它们在不错的性能下能够存放的数据量也不同,还是要具体情况具体分析。
+
+之前看过一篇文章分析 “[InnoDB 中高度为 3 的 B+ 树最多可以存多少数据](https://juejin.cn/post/7165689453124517896)”,写的挺不错,感兴趣的可以看看。
### 常见的分片算法有哪些?
分片算法主要解决了数据被水平分片之后,数据究竟该存放在哪个表的问题。
-- **哈希分片**:求指定 key(比如 id) 的哈希,然后根据哈希值确定数据应被放置在哪个表中。哈希分片比较适合随机读写的场景,不太适合经常需要范围查询的场景。
-- **范围分片**:按照特性的范围区间(比如时间区间、ID 区间)来分配数据,比如 将 `id` 为 `1~299999` 的记录分到第一个库, `300000~599999` 的分到第二个库。范围分片适合需要经常进行范围查找的场景,不太适合随机读写的场景(数据未被分散,容易出现热点数据的问题)。
+常见的分片算法有:
+
+- **哈希分片**:求指定分片键的哈希,然后根据哈希值确定数据应被放置在哪个表中。哈希分片比较适合随机读写的场景,不太适合经常需要范围查询的场景。哈希分片可以使每个表的数据分布相对均匀,但对动态伸缩(例如新增一个表或者库)不友好。
+- **范围分片**:按照特定的范围区间(比如时间区间、ID 区间)来分配数据,比如 将 `id` 为 `1~299999` 的记录分到第一个表, `300000~599999` 的分到第二个表。范围分片适合需要经常进行范围查找且数据分布均匀的场景,不太适合随机读写的场景(数据未被分散,容易出现热点数据的问题)。
+- **映射表分片**:使用一个单独的表(称为映射表)来存储分片键和分片位置的对应关系。映射表分片策略可以支持任何类型的分片算法,如哈希分片、范围分片等。映射表分片策略是可以灵活地调整分片规则,不需要修改应用程序代码或重新分布数据。不过,这种方式需要维护额外的表,还增加了查询的开销和复杂度。
+- **一致性哈希分片**:将哈希空间组织成一个环形结构,将分片键和节点(数据库或表)都映射到这个环上,然后根据顺时针的规则确定数据或请求应该分配到哪个节点上,解决了传统哈希对动态伸缩不友好的问题。
- **地理位置分片**:很多 NewSQL 数据库都支持地理位置分片算法,也就是根据地理位置(如城市、地域)来分配数据。
-- **融合算法**:灵活组合多种分片算法,比如将哈希分片和范围分片组合。
-- ......
+- **融合算法分片**:灵活组合多种分片算法,比如将哈希分片和范围分片组合。
+- ……
+
+### 分片键如何选择?
+
+分片键(Sharding Key)是数据分片的关键字段。分片键的选择非常重要,它关系着数据的分布和查询效率。一般来说,分片键应该具备以下特点:
+
+- 具有共性,即能够覆盖绝大多数的查询场景,尽量减少单次查询所涉及的分片数量,降低数据库压力;
+- 具有离散性,即能够将数据均匀地分散到各个分片上,避免数据倾斜和热点问题;
+- 具有稳定性,即分片键的值不会发生变化,避免数据迁移和一致性问题;
+- 具有扩展性,即能够支持分片的动态增加和减少,避免数据重新分片的开销。
+
+实际项目中,分片键很难满足上面提到的所有特点,需要权衡一下。并且,分片键可以是表中多个字段的组合,例如取用户 ID 后四位作为订单 ID 后缀。
### 分库分表会带来什么问题呢?
@@ -169,24 +229,39 @@ MySQL binlog(binary log 即二进制日志文件) 主要记录了 MySQL 数据
引入分库分表之后,会给系统带来什么挑战呢?
-- **join 操作**:同一个数据库中的表分布在了不同的数据库中,导致无法使用 join 操作。这样就导致我们需要手动进行数据的封装,比如你在一个数据库中查询到一个数据之后,再根据这个数据去另外一个数据库中找对应的数据。
-- **事务问题**:同一个数据库中的表分布在了不同的数据库中,如果单个操作涉及到多个数据库,那么数据库自带的事务就无法满足我们的要求了。
-- **分布式 id**:分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。我们如何为不同的数据节点生成全局唯一主键呢?这个时候,我们就需要为我们的系统引入分布式 id 了。
-- ......
+- **join 操作**:同一个数据库中的表分布在了不同的数据库中,导致无法使用 join 操作。这样就导致我们需要手动进行数据的封装,比如你在一个数据库中查询到一个数据之后,再根据这个数据去另外一个数据库中找对应的数据。不过,很多大厂的资深 DBA 都是建议尽量不要使用 join 操作。因为 join 的效率低,并且会对分库分表造成影响。对于需要用到 join 操作的地方,可以采用多次查询业务层进行数据组装的方法。不过,这种方法需要考虑业务上多次查询的事务性的容忍度。
+- **事务问题**:同一个数据库中的表分布在了不同的数据库中,如果单个操作涉及到多个数据库,那么数据库自带的事务就无法满足我们的要求了。这个时候,我们就需要引入分布式事务了。关于分布式事务常见解决方案总结,网站上也有对应的总结: 。
+- **分布式 ID**:分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。我们如何为不同的数据节点生成全局唯一主键呢?这个时候,我们就需要为我们的系统引入分布式 ID 了。关于分布式 ID 的详细介绍&实现方案总结,可以看我写的这篇文章:[分布式 ID 介绍&实现方案总结](https://javaguide.cn/distributed-system/distributed-id.html)。
+- **跨库聚合查询问题**:分库分表会导致常规聚合查询操作,如 group by,order by 等变得异常复杂。这是因为这些操作需要在多个分片上进行数据汇总和排序,而不是在单个数据库上进行。为了实现这些操作,需要编写复杂的业务代码,或者使用中间件来协调分片间的通信和数据传输。这样会增加开发和维护的成本,以及影响查询的性能和可扩展性。
+- ……
另外,引入分库分表之后,一般需要 DBA 的参与,同时还需要更多的数据库服务器,这些都属于成本。
### 分库分表有没有什么比较推荐的方案?
+Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
+
ShardingSphere 项目(包括 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar)是当当捐入 Apache 的,目前主要由京东数科的一些巨佬维护。
-
+ShardingSphere 绝对可以说是当前分库分表的首选!ShardingSphere 的功能完善,除了支持读写分离和分库分表,还提供分布式事务、数据库治理、影子库、数据加密和脱敏等功能。
-ShardingSphere 绝对可以说是当前分库分表的首选!ShardingSphere 的功能完善,除了支持读写分离和分库分表,还提供分布式事务、数据库治理等功能。
+ShardingSphere 提供的功能如下:
+
+
+
+ShardingSphere 的优势如下(摘自 ShardingSphere 官方文档:):
+
+- 极致性能:驱动程序端历经长年打磨,效率接近原生 JDBC,性能极致。
+- 生态兼容:代理端支持任何通过 MySQL/PostgreSQL 协议的应用访问,驱动程序端可对接任意实现 JDBC 规范的数据库。
+- 业务零侵入:面对数据库替换场景,ShardingSphere 可满足业务无需改造,实现平滑业务迁移。
+- 运维低成本:在保留原技术栈不变前提下,对 DBA 学习、管理成本低,交互友好。
+- 安全稳定:基于成熟数据库底座之上提供增量能力,兼顾安全性及稳定性。
+- 弹性扩展:具备计算、存储平滑在线扩展能力,可满足业务多变的需求。
+- 开放生态:通过多层次(内核、功能、生态)插件化能力,为用户提供可定制满足自身特殊需求的独有系统。
另外,ShardingSphere 的生态体系完善,社区活跃,文档完善,更新和发布比较频繁。
-艿艿之前写了一篇分库分表的实战文章,各位朋友可以看看:[《芋道 Spring Boot 分库分表入门》](https://mp.weixin.qq.com/s/A2MYOFT7SP-7kGOon8qJaw) 。
+不过,还是要多提一句:**现在很多公司都是用的类似于 TiDB 这种分布式关系型数据库,不需要我们手动进行分库分表(数据库层面已经帮我们做了),也不需要解决手动分库分表引入的各种问题,直接一步到位,内置很多实用的功能(如无感扩容和缩容、冷热存储分离)!如果公司条件允许的话,个人也是比较推荐这种方式!**
### 分库分表后,数据怎么迁移呢?
@@ -208,4 +283,7 @@ ShardingSphere 绝对可以说是当前分库分表的首选!ShardingSphere
- 读写分离基于主从复制,MySQL 主从复制是依赖于 binlog 。
- **分库** 就是将数据库中的数据分散到不同的数据库上。**分表** 就是对单表的数据进行拆分,可以是垂直拆分,也可以是水平拆分。
- 引入分库分表之后,需要系统解决事务、分布式 id、无法 join 操作问题。
-- ShardingSphere 绝对可以说是当前分库分表的首选!ShardingSphere 的功能完善,除了支持读写分离和分库分表,还提供分布式事务、数据库治理等功能。另外,ShardingSphere 的生态体系完善,社区活跃,文档完善,更新和发布比较频繁。
+- 现在很多公司都是用的类似于 TiDB 这种分布式关系型数据库,不需要我们手动进行分库分表(数据库层面已经帮我们做了),也不需要解决手动分库分表引入的各种问题,直接一步到位,内置很多实用的功能(如无感扩容和缩容、冷热存储分离)!如果公司条件允许的话,个人也是比较推荐这种方式!
+- 如果必须要手动分库分表的话,ShardingSphere 是首选!ShardingSphere 的功能完善,除了支持读写分离和分库分表,还提供分布式事务、数据库治理等功能。另外,ShardingSphere 的生态体系完善,社区活跃,文档完善,更新和发布比较频繁。
+
+
diff --git a/docs/high-performance/sql-optimization.md b/docs/high-performance/sql-optimization.md
index ffd444fc3dc..540b1c7afe3 100644
--- a/docs/high-performance/sql-optimization.md
+++ b/docs/high-performance/sql-optimization.md
@@ -1,17 +1,399 @@
---
-title: 常见SQL优化手段总结(付费)
+title: 常见SQL优化手段总结
+description: 本文系统总结常见的 SQL 优化手段,涵盖慢 SQL 定位与分析(EXPLAIN、Show Profile)、索引优化策略、查询重写技巧、分页优化等实战方法,帮助你快速提升数据库查询性能。
category: 高性能
head:
- - meta
- name: keywords
- content: 分页优化,索引,Show Profile,慢 SQL
- - - meta
- - name: description
- content: SQL 优化是一个大家都比较关注的热门话题,无论你在面试,还是工作中,都很有可能会遇到。如果某天你负责的某个线上接口,出现了性能问题,需要做优化。那么你首先想到的很有可能是优化 SQL 优化,因为它的改造成本相对于代码来说也要小得多。
+ content: SQL优化,慢SQL,EXPLAIN执行计划,索引优化,MySQL优化,查询优化,分页优化,Show Profile
---
-**常见 SQL 优化手段总结** 相关的内容为我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)中。
+## 避免使用 SELECT \*
+
+- `SELECT *` 会消耗更多的 CPU。
+- `SELECT *` 无用字段增加网络带宽资源消耗,增加数据传输时间,尤其是大字段(如 varchar、blob、text)。
+- `SELECT *` 无法使用 MySQL 优化器覆盖索引的优化(基于 MySQL 优化器的“覆盖索引”策略又是速度极快,效率极高,业界极为推荐的查询优化方式)
+- `SELECT <字段列表>` 可减少表结构变更带来的影响。
+
+## 尽量避免多表做 join
+
+阿里巴巴《Java 开发手册》中有这样一段描述:
+
+> 【强制】超过三个表禁止 join。需要 join 的字段,数据类型保持绝对一致;多表关联查询时,保证被关联 的字段需要有索引。
+
+
+
+join 的效率比较低,主要原因是因为其使用嵌套循环(Nested Loop)来实现关联查询,以前常见的实现效率都不是很高:
+
+- **Simple Nested-Loop Join** :直接使用笛卡尔积实现 join,逐行遍历/全表扫描,效率最低。
+- **Block Nested-Loop Join (BNL)** :利用 JOIN BUFFER 进行优化。**注意:在 MySQL 8.0.20 及更高版本中,BNL 已被 Hash Join 取代**,Hash Join 通常能将非索引列关联的复杂度从 O(M\*N) 降低到接近 O(M+N)。
+- **Index Nested-Loop Join** :在必要的字段上增加索引,性能得到进一步提升。
+
+实际业务场景避免多表 join 常见的做法有两种:
+
+1. **单表查询后在内存中自己做关联** :对数据库做单表查询,再根据查询结果进行二次查询,以此类推,最后再进行关联。
+2. **数据冗余**,把一些重要的数据在表中做冗余,尽可能地避免关联查询。很笨的一种做法,表结构比较稳定的情况下才会考虑这种做法。进行冗余设计之前,思考一下自己的表结构设计的是否有问题。
+
+更加推荐第一种,这种在实际项目中的使用率比较高,除了性能不错之外,还有如下优势:
+
+1. **拆分后的单表查询代码可复用性更高** :join 联表 SQL 基本不太可能被复用。
+2. **单表查询更利于后续的维护** :不论是后续修改表结构还是进行分库分表,单表查询维护起来都更容易。
+
+不过,如果系统要求的并发量不大的话,我觉得多表 join 也是没问题的。很多公司内部复杂的系统,要求的并发量不高,很多数据必须 join 5 张以上的表才能查出来。
+
+## 深度分页优化
+
+深度分页问题的根本原因在于:当 `LIMIT` 的偏移量过大时,MySQL 需要扫描并跳过大量记录才能获取目标数据,查询优化器可能放弃索引而选择全表扫描。此时即使有索引,也无法避免大量的回表操作,导致查询性能急剧下降。
+
+本文介绍了四种常见的深度分页优化方案,各方案的特点及适用场景对比如下:
+
+| 优化方案 | 核心思路 | 适用场景 | 限制 |
+| ------------ | ------------------------------------------------------------------- | ----------------------------------- | ------------------------------------------------ |
+| **范围查询** | 记录上一页最后一条 ID,通过 `WHERE id > last_id LIMIT n` 获取下一页 | ID 连续、按 ID 排序、允许游标式翻页 | 不支持跳页、ID 不连续时失效、非 ID 排序不适用 |
+| **子查询** | 先通过子查询获取起始主键,再根据主键过滤 | 需要支持传统 OFFSET 翻页 | 子查询可能产生临时表、仅适用于 ID 正序 |
+| **延迟关联** | 用 `INNER JOIN` 将分页转移到主键索引,减少回表 | 大数据量分页、需要传统翻页逻辑 | SQL 相对复杂 |
+| **覆盖索引** | 建立包含查询字段的联合索引,避免回表 | 查询字段固定、可建立合适索引 | 字段较多时索引维护成本高、大结果集可能走全表扫描 |
+
+**方案选择建议**:
+
+- **优先使用延迟关联**:对于大多数需要支持传统 `LIMIT offset, size` 翻页逻辑的场景,延迟关联是性能和可维护性较好的选择。
+- **考虑范围查询(游标分页)**:如果业务允许使用"下一页"式的游标翻页(如社交媒体 feed 流、无限滚动),范围查询性能最佳且稳定。
+- **覆盖索引作为补充**:当查询字段固定且数量不多时,可配合其他方案建立覆盖索引进一步优化。
+
+**注意事项**:
+
+- 无论采用哪种方案,都应注意监控实际执行计划(`EXPLAIN`),确保优化器按预期使用索引。
+- 对于超深分页(如百万级偏移量),应从业务层面评估是否真的需要支持,考虑限制最大翻页数或采用其他检索方式(如搜索引擎)。
+
+详细介绍可以阅读这篇文章:[深度分页介绍及优化建议](https://javaguide.cn/high-performance/deep-pagination-optimization.html)。
+
+## 建议不要使用外键与级联
+
+阿里巴巴《Java 开发手册》中有这样一段描述:
+
+> 不得使用外键与级联,一切外键概念必须在应用层解决。
+
+
+
+网络上已经有非常多分析外键与级联缺陷的文章了,个人认为不建议使用外键主要是因为对分库分表不友好,性能方面的影响其实是比较小的。
+
+## 选择合适的字段类型
+
+存储字节越小,占用也就空间越小,性能也越好。
+
+**a.某些字符串可以转换成数字类型存储比如可以将 IP 地址转换成整型数据。**
+
+数字是连续的,性能更好,占用空间也更小。
+
+MySQL 提供了两个方法来处理 ip 地址
+
+- `INET_ATON()` : 把 IPv4 转为无符号整型(4 字节,32 位)。对于 IPv6,可使用 `INET6_ATON()` 转为 16 字节(128 位)的二进制字符串。
+- `INET_NTOA()` :把整型的 ip 转为地址
+
+插入数据前,先用 `INET_ATON()` 把 ip 地址转为整型,显示数据时,使用 `INET_NTOA()` 把整型的 ip 地址转为地址显示即可。
+
+**b.对于非负型的数据 (如自增 ID,整型 IP,年龄) 来说,要优先使用无符号整型来存储。**
+
+无符号相对于有符号可以多出一倍的存储空间
+
+```sql
+SIGNED INT -2147483648~2147483647
+UNSIGNED INT 0~4294967295
+```
+
+**c.小数值类型(比如年龄、状态表示如 0/1)优先使用 TINYINT 类型。**
+
+**d.对于日期类型来说, 一定不要用字符串存储日期。可以考虑 DATETIME、TIMESTAMP 和 数值型时间戳。**
+
+这三种种方式都有各自的优势,根据实际场景选择最合适的才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
+
+| 类型 | 存储空间 | 日期格式 | 日期范围 | 是否带时区信息 |
+| ------------ | -------- | ------------------------------ | ------------------------------------------------------------ | -------------- |
+| DATETIME | 5~8 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1000-01-01 00:00:00[.000000] ~ 9999-12-31 23:59:59[.999999] | 否 |
+| TIMESTAMP | 4~7 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1970-01-01 00:00:01[.000000] ~ 2038-01-19 03:14:07[.999999] | 是 |
+| 数值型时间戳 | 4 字节 | 全数字如 1578707612 | 1970-01-01 00:00:01 之后的时间 | 否 |
+
+MySQL 时间类型选择的详细介绍请看这篇:[MySQL 时间类型数据存储建议](https://javaguide.cn/database/mysql/some-thoughts-on-database-storage-time.html)。
+
+**e.金额字段用 decimal,避免精度丢失。**
+
+decimal 用于存储有精度要求的小数比如与金钱相关的数据,可以避免浮点数带来的精度损失。
+
+在 Java 中,MySQL 的 decimal 类型对应的是 Java 类 `java.math.BigDecimal` 。
+
+`BigDecimal`的详细介绍请参考这篇:[BigDecimal 详解](https://javaguide.cn/java/basis/bigdecimal.html)。
+
+**f.尽量使用自增 id 作为主键。**
+
+如果主键为自增 id 的话,每次都会将数据加在 B+树尾部(本质是双向链表),时间复杂度为 O(1)。在写满一个数据页的时候,直接申请另一个新数据页接着写就可以了。
+
+如果主键是非自增 id 的话,为了让新加入数据后 B+树的叶子节点还能保持有序,它就需要往叶子结点的中间找,查找过程的时间复杂度是 O(lgn)。如果这个也被写满的话,就需要进行页分裂。页分裂操作需要加悲观锁,性能非常低。
+
+不过, 像分库分表这类场景就不建议使用自增 id 作为主键,应该使用分布式 ID 比如 uuid 。
+
+相关阅读:[数据库主键一定要自增吗?有哪些场景不建议自增?](https://mp.weixin.qq.com/s/vNRIFKjbe7itRTxmq-bkAA)。
+
+**g.不建议使用 `NULL` 作为列默认值。**
+
+`NULL` 跟 `''`(空字符串)是两个完全不一样的值,区别如下:
+
+- `NULL` 代表一个不确定的值,就算是两个 `NULL`,它俩也不一定相等。例如,`SELECT NULL=NULL`的结果为 false,但是在我们使用`DISTINCT`,`GROUP BY`,`ORDER BY`时,`NULL`又被认为是相等的。
+- `''`的长度是 0,是不占用空间的,而`NULL` 是需要占用空间的。
+- `NULL` 会影响聚合函数的结果。例如,`SUM`、`AVG`、`MIN`、`MAX` 等聚合函数会忽略 `NULL` 值。 `COUNT` 的处理方式取决于参数的类型。如果参数是 `*`(`COUNT(*)`),则会统计所有的记录数,包括 `NULL` 值;如果参数是某个字段名(`COUNT(列名)`),则会忽略 `NULL` 值,只统计非空值的个数。
+- 查询 `NULL` 值时,必须使用 `IS NULL` 或 `IS NOT NULLl` 来判断,而不能使用 =、!=、 <、> 之类的比较运算符。而`''`是可以使用这些比较运算符的。
+
+## 尽量用 UNION ALL 代替 UNION
+
+UNION 会把两个结果集的所有数据放到临时表中后再进行去重操作,更耗时,更消耗 CPU 资源。
+
+UNION ALL 不会再对结果集进行去重操作,获取到的数据包含重复的项。
+
+不过,如果实际业务场景中不允许产生重复数据的话,还是可以使用 UNION。
+
+## 优先使用批量操作
+
+对于数据库中的数据更新,如果能使用批量操作就要尽量使用,减少请求数据库的次数,提高性能。
+
+```sql
+# 反例
+INSERT INTO `cus_order` (`id`, `score`, `name`) VALUES (1, 426547, 'user1');
+INSERT INTO `cus_order` (`id`, `score`, `name`) VALUES (1, 33, 'user2');
+INSERT INTO `cus_order` (`id`, `score`, `name`) VALUES (1, 293854, 'user3');
+
+# 正例
+INSERT into `cus_order` (`id`, `score`, `name`) values(1, 426547, 'user1'),(1, 33, 'user2'),(1, 293854, 'user3');
+```
+
+## Show Profile 分析 SQL 执行性能
+
+为了更精准定位一条 SQL 语句的性能问题,需要清楚地知道这条 SQL 语句运行时消耗了多少系统资源。 [`SHOW PROFILE`](https://dev.mysql.com/doc/refman/5.7/en/show-profile.html) 和 [`SHOW PROFILES`](https://dev.mysql.com/doc/refman/5.7/en/show-profiles.html) 展示 SQL 语句的资源使用情况,展示的消息包括 CPU 的使用,CPU 上下文切换,IO 等待,内存使用等。
+
+MySQL 在 5.0.37 版本之后才支持 Profiling,`select @@have_profiling` 命令返回 `YES` 表示该功能可以使用。
+
+```sql
+ mysql> SELECT @@have_profiling;
++------------------+
+| @@have_profiling |
++------------------+
+| YES |
++------------------+
+1 row in set (0.00 sec)
+```
+
+> **注意** :`SHOW PROFILE` 和 `SHOW PROFILES` 已经被弃用,未来的 MySQL 版本中可能会被删除,取而代之的是使用 [Performance Schema](https://dev.mysql.com/doc/refman/8.0/en/performance-schema.html)。在该功能被删除之前,我们简单介绍一下其基本使用方法。
+
+想要使用 Profiling,请确保你的 `profiling` 是开启(on)的状态。
+
+你可以通过 `SHOW VARIABLES` 命令查看其状态:
+
+
+
+也可以通过 `SELECT @@profiling`命令进行查看:
+
+```sql
+mysql> SELECT @@profiling;
++-------------+
+| @@profiling |
++-------------+
+| 0 |
++-------------+
+1 row in set (0.00 sec)
+```
+
+默认情况下, `Profiling` 是关闭(off)的状态,你直接通过`SET @@profiling=1`命令即可开启。
+
+开启成功之后,我们执行几条 SQL 语句。执行完成之后,使用 `SHOW PROFILES` 可以展示当前 Session 下所有 SQL 语句的简要的信息包括 Query_ID(SQL 语句的 ID 编号) 和 Duration(耗时)。
+
+具体能收集多少个 SQL,由参数 `profiling_history_size` 决定,默认值为 15,最大值为 100。如果设置为 0,等同于关闭 Profiling。
+
+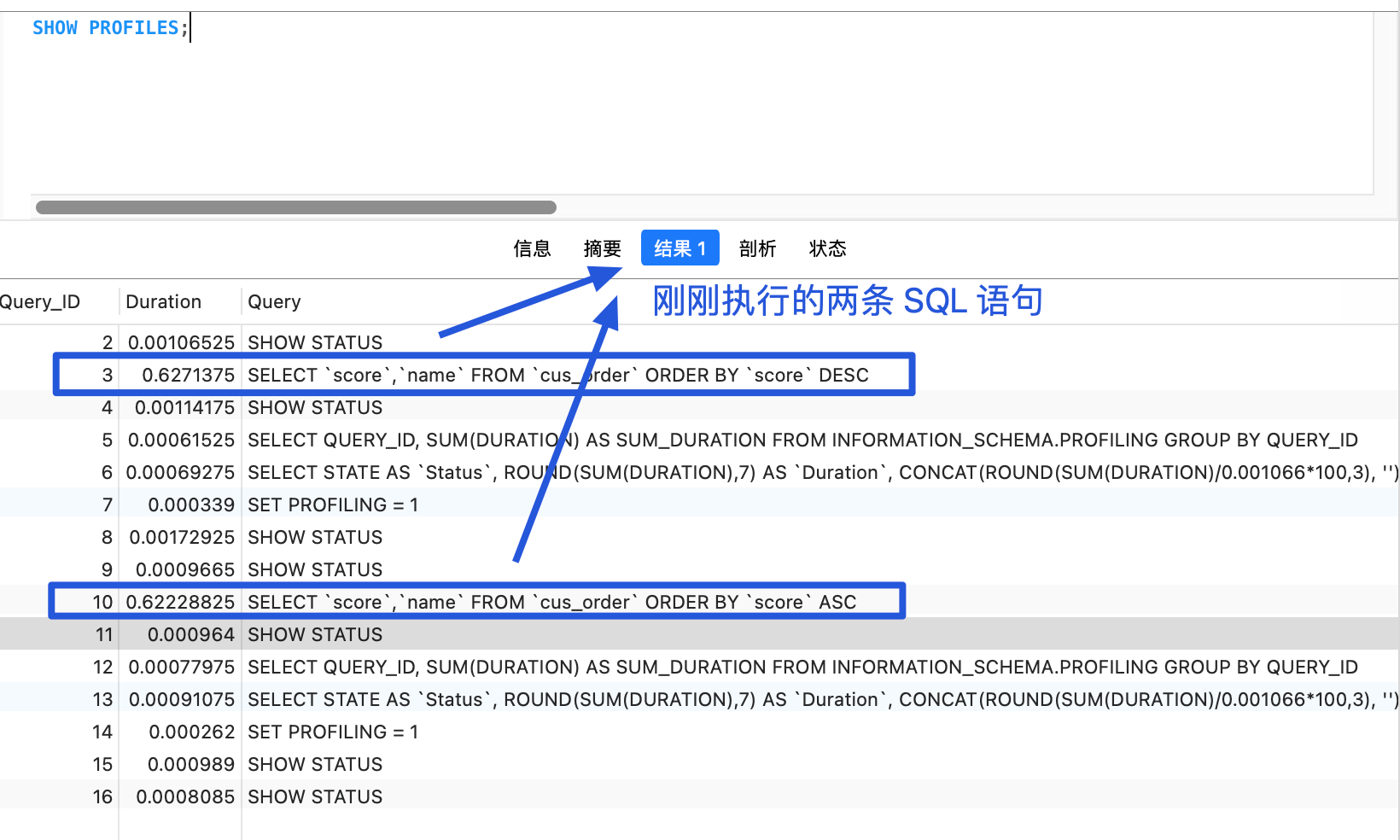
+
+如果想要展示一个 SQL 语句的执行耗时细节,可以使用`SHOW PROFILE` 命令。
+
+`SHOW PROFILE` 命令的具体用法如下:
+
+```sql
+SHOW PROFILE [type [, type] ... ]
+ [FOR QUERY n]
+ [LIMIT row_count [OFFSET offset]]
+
+type: {
+ ALL
+ | BLOCK IO
+ | CONTEXT SWITCHES
+ | CPU
+ | IPC
+ | MEMORY
+ | PAGE FAULTS
+ | SOURCE
+ | SWAPS
+}
+```
+
+在执行`SHOW PROFILE` 命令时,可以加上类型子句,比如 CPU、IPC、MEMORY 等,查看具体某类资源的消耗情况:
+
+```sql
+SHOW PROFILE CPU,IPC FOR QUERY 8;
+```
+
+如果不加 `FOR QUERY {n}`子句,默认展示最新的一次 SQL 的执行情况,加了 `FOR QUERY {n}`,表示展示 Query_ID 为 n 的 SQL 的执行情况。
+
+
+
+## 优化慢 SQL
+
+为了优化慢 SQL ,我们首先要找到哪些 SQL 语句执行速度比较慢。
+
+MySQL 慢查询日志是用来记录 MySQL 在执行命令中,响应时间超过预设阈值的 SQL 语句。因此,通过分析慢查询日志我们就可以找出执行速度比较慢的 SQL 语句。
+
+出于性能层面的考虑,慢查询日志功能默认是关闭的,你可以通过以下命令开启:
+
+```sql
+# 开启慢查询日志功能
+SET GLOBAL slow_query_log = 'ON';
+# 慢查询日志存放位置
+SET GLOBAL slow_query_log_file = '/var/lib/mysql/ranking-list-slow.log';
+# 无论是否超时,未被索引的记录也会记录下来。
+SET GLOBAL log_queries_not_using_indexes = 'ON';
+# 慢查询阈值(秒),SQL 执行超过这个阈值将被记录在日志中。
+SET SESSION long_query_time = 1;
+# 慢查询仅记录扫描行数大于此参数的 SQL
+SET SESSION min_examined_row_limit = 100;
+```
+
+设置成功之后,使用 `show variables like 'slow%';` 命令进行查看。
+
+```bash
+| Variable_name | Value |
++---------------------+--------------------------------------+
+| slow_launch_time | 2 |
+| slow_query_log | ON |
+| slow_query_log_file | /var/lib/mysql/ranking-list-slow.log |
++---------------------+--------------------------------------+
+3 rows in set (0.01 sec)
+```
+
+我们故意在百万数据量的表(未使用索引)中执行一条排序的语句:
+
+```sql
+SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
+```
+
+确保自己有对应目录的访问权限:
+
+```bash
+chmod 755 /var/lib/mysql/
+```
+
+查看对应的慢查询日志:
+
+```bash
+ cat /var/lib/mysql/ranking-list-slow.log
+```
+
+我们刚刚故意执行的 SQL 语句已经被慢查询日志记录了下来:
+
+```plain
+# Time: 2022-10-09T08:55:37.486797Z
+# User@Host: root[root] @ [172.17.0.1] Id: 14
+# Query_time: 0.978054 Lock_time: 0.000164 Rows_sent: 999999 Rows_examined: 1999998
+SET timestamp=1665305736;
+SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
+```
+
+这里对日志中的一些信息进行说明:
+
+- `Time` :被日志记录的代码在服务器上的运行时间。
+- `User@Host`:谁执行的这段代码。
+- `Query_time`:这段代码运行时长。
+- `Lock_time`:执行这段代码时,锁定了多久。
+- `Rows_sent`:慢查询返回的记录。
+- `Rows_examined`:慢查询扫描过的行数。
+
+实际项目中,慢查询日志通常会比较复杂,我们需要借助一些工具对其进行分析。像 MySQL 内置的 `mysqldumpslow` 工具就可以把相同的 SQL 归为一类,并统计出归类项的执行次数和每次执行的耗时等一系列对应的情况。
+
+找到了慢 SQL 之后,我们可以通过 `EXPLAIN` 命令分析对应的 `SELECT` 语句:
+
+```sql
+mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
++----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
++----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
+| 1 | SIMPLE | cus_order | NULL | ALL | NULL | NULL | NULL | NULL | 997572 | 100.00 | Using filesort |
++----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
+1 row in set, 1 warning (0.00 sec)
+```
+
+比较重要的字段说明:
+
+- `select_type` :查询的类型,常用的取值有 SIMPLE(普通查询,即没有联合查询、子查询)、PRIMARY(主查询)、UNION(UNION 中后面的查询)、SUBQUERY(子查询)等。
+- `table` :表示查询涉及的表或衍生表。
+- `type` :执行方式,判断查询是否高效的重要参考指标,结果值从差到好依次是:ALL < index < range ~ index_merge < ref < eq_ref < const < system。
+- `rows` : SQL 要查找到结果集需要扫描读取的数据行数,原则上 rows 越少越好。
+- ……
+
+关于 Explain 的详细介绍,请看这篇文章:[MySQL 执行计划分析](https://javaguide.cn/database/mysql/mysql-query-execution-plan.html)。另外,再推荐一下阿里的这篇文章:[慢 SQL 治理经验总结](https://mp.weixin.qq.com/s/LZRSQJufGRpRw6u4h_Uyww),总结的挺不错。
+
+## 正确使用索引
+
+正确使用索引可以大大加快数据的检索速度(大大减少检索的数据量)。
+
+### 选择合适的字段创建索引
+
+- **不为 NULL 的字段** :索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代。
+- **被频繁查询的字段** :我们创建索引的字段应该是查询操作非常频繁的字段。
+- **被作为条件查询的字段** :被作为 WHERE 条件查询的字段,应该被考虑建立索引。
+- **频繁需要排序的字段** :索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
+- **被经常频繁用于连接的字段** :经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
+
+### 避免索引失效
+
+索引失效也是慢查询的主要原因之一,常见的导致索引失效的情况有下面这两类:
+
+**1. SQL 写法与底层逻辑冲突(破坏 B+Tree 有序性)**
+
+此类问题最为常见,本质是查询条件让底层的 B+Tree 失去了“二分查找”的快速定位能力。
+
+- **违背最左前缀原则**:跳过联合索引前导列,或遇到范围查询(如 `>`、`<`、`BETWEEN`、`LIKE "abc%"`)导致后续列中断精确定位,降级为范围扫描加过滤。
+- **对索引列进行加工**:在 `WHERE` 左侧对索引列进行数学计算或应用函数,导致原始数据发生逻辑改变,在索引树中呈现无序状态。
+- **隐式类型转换(隐蔽且致命)**:当“字符串类型的列”去比较“数字类型的值”时,MySQL 会默认在列上套用转换函数,直接破坏树的有序性。
+- **LIKE 模糊查询前置通配符**:如 `LIKE "%abc"`,前缀字符的不确定性使得优化器无法锁定扫描区间的起始点。
+- **ORDER BY 排序陷阱**:排序列未命中索引、排序方向与索引结构不一致等触发额外的内存或磁盘排序(`Using filesort`)。
+
+**2. 优化器的成本决策(基于 I/O 成本妥协)**
+
+此类问题并非索引本身不可用,而是 MySQL 优化器经过计算后,认为“不走普通索引”整体开销反而更小。
+
+- **无脑 `SELECT \*` 导致回表成本超载**:查询大量非索引覆盖列时,若命中数据量较大(通常超 20%~30%),优化器会判定全表扫描的顺序 I/O 优于频繁回表的随机 I/O,从而主动放弃索引。
+- **`OR` 条件导致全表扫描**:只要 `OR` 连接的任意一侧条件没有对应索引,就会触发全表扫描。即使两侧都有索引,若 Index Merge(索引合并)的预期成本过高,依然会被放弃。
+- **`IN` 列表过长引发估算失真**:当 `IN` 列表长度超过系统阈值(默认 200)时,优化器会从精准的深入探测(Index Dive)切换为粗略的统计估算,极易因统计信息陈旧而产生执行成本的误判。
+
+详细介绍:[MySQL索引失效场景总结](https://javaguide.cn/database/mysql/mysql-index-invalidation.html)。
+
+### 被频繁更新的字段应该慎重建立索引
+
+虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。 如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。
+
+### 尽可能的考虑建立联合索引而不是单列索引
+
+因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗 B+树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
+
+### 注意避免冗余索引
+
+冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。如(name,city )和(name )这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
+
+### 考虑在字符串类型的字段上使用前缀索引代替普通索引
+
+前缀索引仅限于字符串类型,较普通索引会占用更小的空间,所以可以考虑使用前缀索引带替普通索引。
+
+### 删除长期未使用的索引
+
+删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 schema_unused_indexes 视图来查询哪些索引从未被使用
-
+## 参考
-
+- MySQL 8.2 Optimizing SQL Statements:https://dev.mysql.com/doc/refman/8.0/en/statement-optimization.html
+- 为什么阿里巴巴禁止数据库中做多表 join - Hollis:https://mp.weixin.qq.com/s/GSGVFkDLz1hZ1OjGndUjZg
+- MySQL 的 COUNT 语句,竟然都能被面试官虐的这么惨 - Hollis:https://mp.weixin.qq.com/s/IOHvtel2KLNi-Ol4UBivbQ
+- MySQL 性能优化神器 Explain 使用分析:https://segmentfault.com/a/1190000008131735
+- 如何使用 MySQL 慢查询日志进行性能优化 :https://kalacloud.com/blog/how-to-use-mysql-slow-query-log-profiling-mysqldumpslow/
diff --git a/docs/high-quality-technical-articles/readme.md b/docs/high-quality-technical-articles/README.md
similarity index 77%
rename from docs/high-quality-technical-articles/readme.md
rename to docs/high-quality-technical-articles/README.md
index 62d8a285673..149ddba7a4f 100644
--- a/docs/high-quality-technical-articles/readme.md
+++ b/docs/high-quality-technical-articles/README.md
@@ -1,17 +1,15 @@
# 程序人生
-::: tip 这是一则或许对你有用的小广告
-👉 欢迎准备 Java 面试以及学习 Java 的同学加入我的[知识星球](./../about-the-author/zhishixingqiu-two-years.md),干货很多!收费虽然是白菜价,但星球里的内容或许比你参加上万的培训班质量还要高。
+
-👉 [《Java 面试指北》](./../zhuanlan/java-mian-shi-zhi-bei.md)持续更新完善中!这是一份教你如何更高效地准备面试的小册,涵盖常见八股文(系统设计、常见框架、分布式、高并发 ......)、优质面经等内容。
-:::
-
-这里主要会收录一些我看到的和程序员密切相关的非技术类的优质文章,每一篇都值得你阅读 3 遍以上!常看常新!
+这里主要会收录一些我看到的或者我自己写的和程序员密切相关的非技术类的优质文章,每一篇都值得你阅读 3 遍以上!常看常新!
## 练级攻略
+- [程序员如何快速学习新技术](./advanced-programmer/programmer-quickly-learn-new-technology.md)
- [程序员的技术成长战略](./advanced-programmer/the-growth-strategy-of-the-technological-giant.md)
- [十年大厂成长之路](./advanced-programmer/ten-years-of-dachang-growth-road.md)
+- [美团三年,总结的 10 条血泪教训](./advanced-programmer/meituan-three-year-summary-lesson-10.md)
- [给想成长为高级别开发同学的七条建议](./advanced-programmer/seven-tips-for-becoming-an-advanced-programmer.md)
- [糟糕程序员的 20 个坏习惯](./advanced-programmer/20-bad-habits-of-bad-programmers.md)
- [工作五年之后,对技术和业务的思考](./advanced-programmer/thinking-about-technology-and-business-after-five-years-of-work.md)
@@ -25,6 +23,7 @@
## 程序员
+- [程序员最该拿的几种高含金量证书](./programmer/high-value-certifications-for-programmers.md)
- [程序员怎样出版一本技术书](./programmer/how-do-programmers-publish-a-technical-book.md)
- [程序员高效出书避坑和实践指南](./programmer/efficient-book-publishing-and-practice-guide.md)
@@ -44,3 +43,5 @@
- [新入职一家公司如何快速进入工作状态](./work/get-into-work-mode-quickly-when-you-join-a-company.md)
- [32 条总结教你提升职场经验](./work/32-tips-improving-career.md)
- [聊聊大厂的绩效考核](./work/employee-performance.md)
+
+
diff --git a/docs/high-quality-technical-articles/advanced-programmer/20-bad-habits-of-bad-programmers.md b/docs/high-quality-technical-articles/advanced-programmer/20-bad-habits-of-bad-programmers.md
index bb7fb8f3b15..e6dfd10f5d6 100644
--- a/docs/high-quality-technical-articles/advanced-programmer/20-bad-habits-of-bad-programmers.md
+++ b/docs/high-quality-technical-articles/advanced-programmer/20-bad-habits-of-bad-programmers.md
@@ -1,15 +1,18 @@
---
title: 糟糕程序员的 20 个坏习惯
+description: "糟糕程序员的 20 个坏习惯:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
author: Kaito
tag:
- 练级攻略
+head:
+ - - meta
+ - name: keywords
+ content: 程序员坏习惯,编程规范,代码注释,技术文档,团队协作,代码提交,职业素养,编程修养
---
> **推荐语**:Kaito 大佬的一篇文章,很实用的建议!
>
->
->
> **原文地址:**
我想你肯定遇到过这样一类程序员:**他们无论是写代码,还是写文档,又或是和别人沟通,都显得特别专业**。每次遇到这类人,我都在想,他们到底是怎么做到的?
@@ -144,3 +147,5 @@ tag:
优秀程序员的专业技能,我们可能很难在短时间内学会,但这些基本的职业素养,是可以在短期内做到的。
希望你我可以有则改之,无则加勉。
+
+
diff --git a/docs/high-quality-technical-articles/advanced-programmer/meituan-three-year-summary-lesson-10.md b/docs/high-quality-technical-articles/advanced-programmer/meituan-three-year-summary-lesson-10.md
new file mode 100644
index 00000000000..e43e0932b11
--- /dev/null
+++ b/docs/high-quality-technical-articles/advanced-programmer/meituan-three-year-summary-lesson-10.md
@@ -0,0 +1,177 @@
+---
+title: 美团三年,总结的10条血泪教训
+description: "美团三年,总结的10条血泪教训:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
+category: 技术文章精选集
+author: CityDreamer部落
+tag:
+ - 练级攻略
+head:
+ - - meta
+ - name: keywords
+ content: 美团工作经验,职场成长,结构化思考,数据思维,职场沟通,金字塔原理,工作效率,职业发展
+---
+
+> **推荐语**:作者用了很多生动的例子和故事展示了自己在美团的成长和感悟,看了之后受益颇多!
+>
+> **内容概览**:
+>
+> 本文的作者提出了以下十条建议,希望能对其他职场人有所启发和帮助:
+>
+> 1. 结构化思考与表达,提高个人影响力
+> 2. 忘掉职级,该怼就怼,推动事情往前走
+> 3. 用好平台资源,结识优秀的人,学习通识课
+> 4. 一切都是争取来的,不要等待机会,要主动寻求
+> 5. 关注商业,升维到老板思维,看清趋势,及时止损
+> 6. 培养数据思维,利用数据了解世界,指导决策
+> 7. 做一个好"销售",无论是自己还是产品,都要学会展示和说服
+> 8. 少加班多运动,保持身心健康,提高工作效率
+> 9. 有随时可以离开的底气,不要被职场所困,借假修真,提升自己
+> 10. 只是一份工作,不要过分纠结,相信自己,走出去看看
+>
+> **原文地址**:
+
+在美团的三年多时光,如同一部悠长的交响曲,高高低低,而今离开已有一段时间。闲暇之余,梳理了三年多的收获与感慨,总结成 10 条,既是对过去一段时光的一个深情回眸,也是对未来之路的一份期许。
+
+倘若一些感悟能为刚步入职场的年轻人,或是刚在职业生涯中崭露头角的后起之秀,带来一点点启示与帮助,也是莫大的荣幸。
+
+## 01 结构化思考与表达
+
+美团是一家特别讲究方法论的公司,人人都要熟读四大名著《高效能人士的七个习惯》、《金字塔原理》、《用图表说话》和《学会提问》。
+
+与结构化思考和表达相关的,是《金字塔原理》,作者是麦肯锡公司第一位女性咨询顾问。这本书告诉我们,思考和表达的过程,就像构建金字塔(或者构建一棵树),先有整体结论,再寻找证据,证据之间要讲究相互独立、而且能穷尽(MECE 原则),论证的过程也要按特定的顺序进行,比如时间顺序、空间顺序、重要性顺序……
+
+作为大厂社畜,日常很大一部分工作就是写文档、看别人文档。大家做的事,但最后呈现的结果却有很大差异。一篇逻辑清晰、详略得当的文档,给人一种如沐春风的感受,能提炼出重要信息,是好的参考指南。
+
+结构化思考与表达算是职场最通用的能力,也是打造个人影响力最重要的途径之一。
+
+## 02 忘掉职级,该怼就怼
+
+在阿里工作时,能看到每个人的 Title,看到江湖地位高(职级高+入职时间早)的同学,即便跟自己没有汇报关系,不自然的会多一层敬畏。推进工作时,会多一层压力,对方未读或已读未回时,不知如何应对。
+
+美团只能看到每个人的坑位信息,还有 Ta 的上级。工作相关的问题,可以向任何人提问,如果协同方没有及时响应,隔段时间@一次,甚至"怼一怼",都没啥问题,事情一直往前推进才最重要。除了大象消息直接提问外,还有个大杀器--TT(公司级问题流转系统),在上面提问时,加上对方主管,如果对方未及时回应,问题会自动升级,每天定时 Push,直到解决为止。
+
+我见到一些很年轻的同事,他们在推动 OKR、要资源的事上,很有一套,只要能达到自己的目标,不会考虑别人的感受,最终,他们还真能把事办成。
+
+当然了,段位越高的人,越能用自己的人格魅力、影响力、资源等,去影响和推动事情的进程,而不是靠对他人的 Push。只是在拿结果的事上,不要把自己太当回事,把别人太当回事,大家在一起,也只是为了完成各自的任务,忘掉职级,该怼时还得怼。
+
+## 03 用好平台资源
+
+没有人能在一家公司待一辈子,公司再牛,跟自己关系不大,重要的是,在有限的时间内,最大化用好平台资源。
+
+在美团除了认识自己节点的同事外,有幸认识一群特别棒的协作方,还有其他 BU 的同学。
+
+这些优秀的人身上,有很多共同的特质:谦虚、利他、乐于分享、双赢思维。
+
+有两位做运营的同学。
+
+一位是无意中关注他公众号结识上的。他公众号记录了很多职场成长、家庭建造上的思考和收获,还有定期个人复盘。他和太太都是大厂中层管理者,从文章中看到的不是他多厉害,而是非常接地气的故事。我们约饭了两次,有很多共同话题,现在还时不时有一些互动。
+
+一位职级更高的同学,他在内网发起了一个"请我喝一杯咖啡,和我一起聊聊个人困惑"的活动,我报名参与了一期。和他聊天的过程,特别像是一场教练对话(最近学习教练课程时才感受到的),帮我排除干扰、聚焦目标的同时,也从他分享个人成长蜕变的过程,收获很多动力。(刚好自己最近也学习了教练技术,后面也准备采用类似的方式,去帮助曾经像我一样迷茫的人)
+
+还有一些协作方同学。他们工作做得超级到位,能感受到,他们在乎他人时间;稍微有点出彩的事儿,不忘记拉上更多人。利他和双赢思维,在他们身上是最好的阐释。
+
+除了结识优秀的人,向他们学习外,还可以关注各个通道/工种的课程资源。
+
+在大厂,多数人的角色都是螺丝钉,但千万不要局限于做一颗螺丝钉。多去学习一些通识课,了解商业交付的各个环节,看清商业世界,明白自己的定位,超越自己的定位。
+
+## 04 一切都是争取来的
+
+工作很多年了,很晚才明白这个道理。
+
+之前一直认为,只要做好自己该做的,一定会被看见,被赏识,也会得到更多机会。但很多时候,这只是个人的一厢情愿。除了自己,不会有人关心你的权益。
+
+社会主义初级阶段,我国国内的主要矛盾是人民日益增长的物质文化需要同落后的社会生产之间的矛盾。无论在哪里,资源都是稀缺的,自己在乎的,就得去争取。
+
+想成长某个技能、想参与哪个模块、想做哪个项目,升职加薪……自己不提,不去争取,不会有人主动给你。
+
+争不争取是一回事,能不能得到是一回事,只有争取,才有可能得到。争取了,即便没有得到,最终也没失去什么。
+
+## 05 关注商业
+
+大公司,极度关注效率,大部分岗位,拆解的粒度越细,效率会越高,这些对组织是有利的。但对个人来说,则很容易螺丝钉化。
+
+做技术的同学,更是这样。
+
+做前端的同学,不会关注数据是如何落库的;做后端的同学,不会思考页面是否存在兼容性问题;做业务开发的,不用考虑微服务诸多中间件是如何搭建起来的……
+
+大部分人都想着怎么把自己这摊子事搞好,不会去思考上下游同学在做些什么,更少有人真正关注商业,关心公司的盈利模式,关心每一次产品迭代到底带来哪些业务价值。
+
+把手头的事做好是应该的,但绝不能停留在此。所有的产品,只有在商业社会产生交付,让客户真正获益,才是有价值的。
+
+关注商业,能帮我们升维到老板思维,明白投入产出比,抓大放小;也帮助我们,在碰到不好的业务时,及时止损;更重要的是,它帮助我们真正看清趋势,提前做好准备。
+
+《五分钟商学院》系列,是很好的商业入门级书籍。尽管作者刘润最近存在争议,但不可否认,他比我们大多数人段位还是高很多,他的书值得一读。
+
+## 06 培养数据思维
+
+当今数字化时代,数据思维显得尤为重要。数据不仅可以帮助我们更好地了解世界,还可以指导我们的决策和行动。
+
+非常幸运的是,在阿里和美团的两份经历,都是做商业化广告业务,在离钱💰最近的地方,也培养了数据的敏感性。见过商业数据指标的定义、加工、生产和应用全流程,也在不断熏陶下,能看懂大部分指标背后的价值。
+
+除了直接面向业务的数据,还有研发协作全流程产生的数据。数据被记录和汇总统计后,能直观地看到每个环节的效率和质量。螺丝钉们的工作,也彻彻底底被数字量化,除了积极面对虚拟化、线上化、数字化外,我们别无他法。
+
+受工作数据化的影响,生活中,我也渐渐变成了一个数据记录狂,日常运动(骑行、跑步、健走等)必须通过智能手表记录下来,没带 Apple Watch,感觉这次白运动了。每天也在很努力地完成三个圆环。
+
+数据时代,我们沦为了透明人。也得益于数据被记录和分析,我们做任何事,都能快速得到反馈,这也是自我提升的一个重要环节。
+
+## 07 做一个好"销售"
+
+就某种程度来说,所有的工作,本质都是销售。
+
+这是很多大咖的观点,我也是很晚才明白这个道理。
+
+我们去一家公司应聘,本质上是在讲一个「我很牛」的故事,销售的是自己;日常工作汇报、季度/年度述职、晋升答辩,是在销售自己;在任何一个场合曝光,也是在销售自己。
+
+如果我们所服务的组织,对外提供的是一件产品或一项服务,所有上下游协作的同学,唯一在做的事就是,齐心协力把产品/服务卖出去, 我们本质做的还是销售。
+
+所以, 千万不要看不起任何销售,也不要认为认为销售是一件很丢面子的事。
+
+真正的大佬,随时随地都在销售。
+
+## 08 少加班多运动
+
+在职场,大家都认同一个观点,工作是做不完的。
+
+我们要做的是,用好时间管理四象限法,识别重要程度和优先级,有限时间,聚焦在固定几件事上。
+
+这要求我们不断提高自己的问题识别能力、拆解能力,还有专注力。
+
+我们会因为部分项目的需要而加班,但不会长期加班。
+
+加班时间短一点,就能腾出更多时间运动。
+
+最近一次线下培训课,认识一位老师 Hubert,Hubert 是一位超级有魅力的中年大叔(可以通过「有意思教练」的课程链接到他),从外企高管的位置离开后,和太太一起创办了一家培训机构。作为公司高层,日常工作非常忙,头发也有些花白了,但一身腱子肉胜过很多健身教练,给人的状态也是很年轻。聊天得知,Hubert 经常 5 点多起来泡健身房~
+
+我身边还有一些同事,跟我年龄差不多,因为长期加班,发福严重,比实际年龄看起来苍老 10+岁;
+
+还有同事曾经加班进 ICU,幸好后面身体慢慢恢复过来。
+
+某某厂员工长期加班猝死的例子,更是屡见不鲜。
+
+减少加班,增加运动,绝对是一件性价比极高的事。
+
+## 09 有随时可以离开的底气
+
+当今职场,跟父辈时候完全不一样,职业的多样性和变化性越来越快,很少有人能够在同一份工作或同一个公司待一辈子。除了某些特定的岗位,如公务员、事业单位等,大多数人都会在职业生涯中经历多次的职业变化和调整。
+
+在商业组织里,个体是弱势群体,但不要做弱者。每一段职场,每一项工作,都是上天给我们的修炼。
+
+我很喜欢"借假修真"这个词。我们参与的大大小小的项目, 重要吗?对公司来说可能重要,对个人来说,则未必。我们去做,一方面是迫于生计;
+
+另外一方面,参与每个项目的感悟、心得、体会,是真实存在的,很多的能力,都是在这个过程得到提升。
+
+明白这一点,就不会被职场所困,会刻意在各样事上提升自己,积累的越多,对事务的本质理解的越深、越广,也越发相信很多底层知识是通用的,内心越平静,也会建立起随时都可以离开的底气。
+
+## 10 只是一份工作
+
+工作中,我们时常会遇到各种挑战和困难,如发展瓶颈、难以处理的人和事,甚至职场 PUA 等。这些经历可能会让我们感到疲惫、沮丧,甚至怀疑自己的能力和价值。然而,重要的是要明白,困难只是成长道路上的暂时阻碍,而不是我们的定义。
+
+写总结和复盘是很好的方式,可以帮我们理清思路,找到问题的根源,并学习如何应对类似的情况。但也要注意不要陷入自我怀疑和内耗的陷阱。遇到困难时,应该学会相信自己,积极寻找解决问题的方法,而不是过分纠结于自己的不足和错误。
+
+内网常有同学匿名分享工作压力过大,常常失眠甚至中度抑郁,每次看到这些话题,非常难过。大环境不好,是不争的事实,但并不代表个体就没有出路。
+
+我们容易预设困难,容易加很多"可是",当窗户布满灰尘时,不要试图努力把窗户擦干净,走出去吧,你将看到一片蔚蓝的天空。
+
+## 最后
+
+写到最后,特别感恩美团三年多的经历。感谢我的 Leader 们,感谢曾经并肩作战过的小伙伴,感谢遇到的每一位和我一样在平凡的岗位,努力想带给身边一片微光的同学。所有的相遇,都是缘分。
diff --git a/docs/high-quality-technical-articles/advanced-programmer/programmer-quickly-learn-new-technology.md b/docs/high-quality-technical-articles/advanced-programmer/programmer-quickly-learn-new-technology.md
new file mode 100644
index 00000000000..13827588777
--- /dev/null
+++ b/docs/high-quality-technical-articles/advanced-programmer/programmer-quickly-learn-new-technology.md
@@ -0,0 +1,55 @@
+---
+title: 程序员如何快速学习新技术
+description: "程序员如何快速学习新技术:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
+category: 技术文章精选集
+tag:
+ - 练级攻略
+head:
+ - - meta
+ - name: keywords
+ content: 程序员学习,技术学习方法,快速学习,官方文档,技术面试,八股文,知行合一,学习技巧
+---
+
+> **推荐语**:这是[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)练级攻略篇中的一篇文章,分享了我对于如何快速学习一门新技术的看法。
+>
+> 
+
+很多时候,我们因为工作原因需要快速学习某项技术,进而在项目中应用。或者说,我们想要去面试的公司要求的某项技术我们之前没有接触过,为了应对面试需要,我们需要快速掌握这项技术。
+
+作为一个人纯自学出生的程序员,这篇文章简单聊聊自己对于如何快速学习某项技术的看法。
+
+学习任何一门技术的时候,一定要先搞清楚这个技术是为了解决什么问题的。深入学习这个技术的之前,一定先从全局的角度来了解这个技术,思考一下它是由哪些模块构成的,提供了哪些功能,和同类的技术想必它有什么优势。
+
+比如说我们在学习 Spring 的时候,通过 Spring 官方文档你就可以知道 Spring 最新的技术动态,Spring 包含哪些模块 以及 Spring 可以帮你解决什么问题。
+
+
+
+再比如说我在学习消息队列的时候,我会先去了解这个消息队列一般在系统中有什么作用,帮助我们解决了什么问题。消息队列的种类很多,具体学习研究某个消息队列的时候,我会将其和自己已经学习过的消息队列作比较。像我自己在学习 RocketMQ 的时候,就会先将其和自己曾经学习过的第 1 个消息队列 ActiveMQ 进行比较,思考 RocketMQ 相对于 ActiveMQ 有了哪些提升,解决了 ActiveMQ 的哪些痛点,两者有哪些相似的地方,又有哪些不同的地方。
+
+**学习一个技术最有效最快的办法就是将这个技术和自己之前学到的技术建立连接,形成一个网络。**
+
+然后,我建议你先去看看官方文档的教程,运行一下相关的 Demo ,做一些小项目。
+
+不过,官方文档通常是英文的,通常只有国产项目以及少部分国外的项目提供了中文文档。并且,官方文档介绍的往往也比较粗糙,不太适合初学者作为学习资料。
+
+如果你看不太懂官网的文档,你也可以搜索相关的关键词找一些高质量的博客或者视频来看。 **一定不要一上来就想着要搞懂这个技术的原理。**
+
+就比如说我们在学习 Spring 框架的时候,我建议你在搞懂 Spring 框架所解决的问题之后,不是直接去开始研究 Spring 框架的原理或者源码,而是先实际去体验一下 Spring 框架提供的核心功能 IoC(Inverse of Control:控制反转) 和 AOP(Aspect-Oriented Programming:面向切面编程),使用 Spring 框架写一些 Demo,甚至是使用 Spring 框架做一些小项目。
+
+一言以蔽之, **在研究这个技术的原理之前,先要搞懂这个技术是怎么使用的。**
+
+这样的循序渐进的学习过程,可以逐渐帮你建立学习的快感,获得即时的成就感,避免直接研究原理性的知识而被劝退。
+
+**研究某个技术原理的时候,为了避免内容过于抽象,我们同样可以动手实践。**
+
+比如说我们学习 Tomcat 原理的时候,我们发现 Tomcat 的自定义线程池挺有意思,那我们自己也可以手写一个定制版的线程池。再比如我们学习 Dubbo 原理的时候,可以自己动手造一个简易版的 RPC 框架。
+
+另外,学习项目中需要用到的技术和面试中需要用到的技术其实还是有一些差别的。
+
+如果你学习某一项技术是为了在实际项目中使用的话,那你的侧重点就是学习这项技术的使用以及最佳实践,了解这项技术在使用过程中可能会遇到的问题。你的最终目标就是这项技术为项目带来了实际的效果,并且,这个效果是正面的。
+
+如果你学习某一项技术仅仅是为了面试的话,那你的侧重点就应该放在这项技术在面试中最常见的一些问题上,也就是我们常说的八股文。
+
+很多人一提到八股文,就是一脸不屑。在我看来,如果你不是死记硬背八股文,而是去所思考这些面试题的本质。那你在准备八股文的过程中,同样也能让你加深对这项技术的了解。
+
+最后,最重要同时也是最难的还是 **知行合一!知行合一!知行合一!** 不论是编程还是其他领域,最重要不是你知道的有多少,而是要尽量做到知行合一。
diff --git a/docs/high-quality-technical-articles/advanced-programmer/seven-tips-for-becoming-an-advanced-programmer.md b/docs/high-quality-technical-articles/advanced-programmer/seven-tips-for-becoming-an-advanced-programmer.md
index 0284e68abca..b57e8e88664 100644
--- a/docs/high-quality-technical-articles/advanced-programmer/seven-tips-for-becoming-an-advanced-programmer.md
+++ b/docs/high-quality-technical-articles/advanced-programmer/seven-tips-for-becoming-an-advanced-programmer.md
@@ -1,15 +1,18 @@
---
title: 给想成长为高级别开发同学的七条建议
+description: "给想成长为高级别开发同学的七条建议:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
author: Kaito
tag:
- 练级攻略
+head:
+ - - meta
+ - name: keywords
+ content: 程序员成长,高级开发,需求评审,技术内功,性能优化,线上问题排查,归纳总结,职业发展
---
> **推荐语**:普通程序员要想成长为高级程序员甚至是专家等更高级别,应该注意在哪些方面注意加强?开发内功修炼号主飞哥在这篇文章中就给出了七条实用的建议。
>
->
->
> **内容概览**:
>
> 1. 刻意加强需求评审能力
@@ -105,3 +108,5 @@ tag:
普通程序员往往是工作的事情做完就拉到,很少回头去对自己的技术,对业务进行归纳和总结。
而高级的程序员往往都会在一件比较大的事情做完之后总结一下,做个 ppt,写个博客啥的记录下来。这样既对自己的工作是一个归纳,也可以分享给其它同学,促进团队的共同成长。
+
+
diff --git a/docs/high-quality-technical-articles/advanced-programmer/ten-years-of-dachang-growth-road.md b/docs/high-quality-technical-articles/advanced-programmer/ten-years-of-dachang-growth-road.md
index 8a69e8f5862..1cb1bd2c706 100644
--- a/docs/high-quality-technical-articles/advanced-programmer/ten-years-of-dachang-growth-road.md
+++ b/docs/high-quality-technical-articles/advanced-programmer/ten-years-of-dachang-growth-road.md
@@ -1,15 +1,18 @@
---
title: 十年大厂成长之路
+description: "十年大厂成长之路:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
author: CodingBetterLife
tag:
- 练级攻略
+head:
+ - - meta
+ - name: keywords
+ content: 大厂成长,程序员职业发展,技术专家,技术管理,转岗跳槽,职场选择,十年规划,技术领导
---
> **推荐语**:这篇文章的作者有着丰富的工作经验,曾在大厂工作了 12 年。结合自己走过的弯路和接触过的优秀技术人,他总结出了一些对于个人成长具有普遍指导意义的经验和特质。
>
->
->
> **原文地址:**
最近这段时间,有好几个年轻的同学和我聊到自己的迷茫。其中有关于技术成长的、有关于晋升的、有关于择业的。我很高兴他们愿意听我这个“过来人”分享自己的经验。
@@ -134,3 +137,5 @@ tag:
## 结语
以上就是我对互联网从业技术人员十年成长之路的心得,希望在你困惑和关键选择的时候可以帮助到你。如果我的只言片语能够在未来的某个时间帮助到你哪怕一点,那将是我莫大的荣幸。
+
+
diff --git a/docs/high-quality-technical-articles/advanced-programmer/the-growth-strategy-of-the-technological-giant.md b/docs/high-quality-technical-articles/advanced-programmer/the-growth-strategy-of-the-technological-giant.md
index 19822da68cc..19084abe803 100644
--- a/docs/high-quality-technical-articles/advanced-programmer/the-growth-strategy-of-the-technological-giant.md
+++ b/docs/high-quality-technical-articles/advanced-programmer/the-growth-strategy-of-the-technological-giant.md
@@ -1,15 +1,18 @@
---
title: 程序员的技术成长战略
+description: "程序员的技术成长战略:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
author: 波波微课
tag:
- 练级攻略
+head:
+ - - meta
+ - name: keywords
+ content: 技术成长战略,程序员成长,学习金字塔,刻意练习,技术大牛,职业规划,十年规划,持续产出
---
> **推荐语**:波波老师的一篇文章,写的非常好,不光是对技术成长有帮助,其他领域也是同样适用的!建议反复阅读,形成一套自己的技术成长策略。
>
->
->
> **原文地址:**
## 1. 前言
@@ -148,7 +151,7 @@ Brendan Gregg,Jay Kreps 和 Brad Traversy 三个人走的技术路线各不相
## 四、战略思维的诞生
-
+
一般毕业生刚进入企业工作的时候,思考大都是以天/星期/月为单位的,基本上都是今天学个什么技术,明天学个什么语言,很少会去思考一年甚至更长的目标。这是个眼前漆黑看不到的懵懂时期,捕捉到机会点的能力和概率都非常小。
@@ -204,4 +207,4 @@ Brendan Gregg,Jay Kreps 和 Brad Traversy 三个人走的技术路线各不相
>
> 实现战略目标,就像种树一样。刚开始只是一个小根芽,树干还没有长出来;树干长出来了,枝叶才能慢慢长出来;树枝长出来,然后才能开花和结果。刚开始种树的时候,只管栽培灌溉,别老是纠结枝什么时候长出来,花什么时候开,果实什么时候结出来。纠结有什么好处呢?只要你坚持投入栽培,还怕没有枝叶花实吗?
-
+
diff --git a/docs/high-quality-technical-articles/advanced-programmer/thinking-about-technology-and-business-after-five-years-of-work.md b/docs/high-quality-technical-articles/advanced-programmer/thinking-about-technology-and-business-after-five-years-of-work.md
index a35672c2f23..5933e7005bf 100644
--- a/docs/high-quality-technical-articles/advanced-programmer/thinking-about-technology-and-business-after-five-years-of-work.md
+++ b/docs/high-quality-technical-articles/advanced-programmer/thinking-about-technology-and-business-after-five-years-of-work.md
@@ -1,15 +1,18 @@
---
title: 工作五年之后,对技术和业务的思考
+description: "工作五年之后,对技术和业务的思考:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
author: 知了一笑
tag:
- 练级攻略
+head:
+ - - meta
+ - name: keywords
+ content: 程序员五年,技术与业务,职业发展,能力积累,业务思维,技术深度,职场选择,二八原则
---
> **推荐语**:这是我在两年前看到的一篇对我触动比较深的文章。确实要学会适应变化,并积累能力。积累解决问题的能力,优化思考方式,拓宽自己的认知。
>
->
->
> **原文地址:**
苦海无边,回头无岸。
@@ -42,7 +45,7 @@ tag:
首先聊聊技术,大部分小白级别的,都希望自己的技术能力不断提高,争取做到架构师级别,但是站在当前的互联网环境中,这种想法实现难度还是偏高,这里既不是打击也不是为了抬杠。
-可以观察一下现状,技术团队大的20-30人,小的10-15人,能有一个架构师去专门管理底层框架都是少有现象。
+可以观察一下现状,技术团队大的 20-30 人,小的 10-15 人,能有一个架构师去专门管理底层框架都是少有现象。
这个问题的原因很多,首先架构师的成本过高,环境架构也不是需要经常升级,说的难听点可能框架比项目生命周期更高。
@@ -78,7 +81,7 @@ tag:
从理性的角度看技术和业务两个方面,能让大部分人职场走的平稳顺利,但是不同的阶段对两者的平衡和选择是不一样的。
-在思考如何选择的时候,可以参考二八原则的逻辑,即在任何一组东西中,最重要的只占其中一小部分,约20%,其余80%尽管是多数,却是次要的,因此又称二八定律。
+在思考如何选择的时候,可以参考二八原则的逻辑,即在任何一组东西中,最重要的只占其中一小部分,约 20%,其余 80%尽管是多数,却是次要的,因此又称二八定律。
个人真的非常喜欢这个原则,大部分人都不是天才,所以很难三心二意同时做好几件事情,在同一时间段内应该集中精力做好一件事件。
@@ -86,9 +89,9 @@ tag:
当然这些东西不是都要用心刻意学习,但是合理安排二二六原则或其他组合是更明智的,首先是专业能力要重点练习,其次可以根据自己的兴趣合理选择一到两个方面去慢慢了解,例如产品,运营,运维,数据等,毕竟三五年以后会不会继续写代码很难说,多给自己留个机会总是有备无患。
-在职场初期,基本都是从技术角度去思考问题,如何快速提升自己的编码能力,在公司能稳定是首要目标,因此大部分时间都是在做基础编码和学习规范,这时可能90%的心思都是放在基础编码上,另外10%会学习环境架构。
+在职场初期,基本都是从技术角度去思考问题,如何快速提升自己的编码能力,在公司能稳定是首要目标,因此大部分时间都是在做基础编码和学习规范,这时可能 90%的心思都是放在基础编码上,另外 10%会学习环境架构。
-最多一到两年,就会开始独立负责模块需求开发,需要自己设计整个代码思路,这里业务就会进入视野,要懂得业务上下游关联关系,学会思考如何设计代码结构,才能在需求变动的情况下代码改动较少,这个时候可能就会放20%的心思在业务方面,30%学习架构方式。
+最多一到两年,就会开始独立负责模块需求开发,需要自己设计整个代码思路,这里业务就会进入视野,要懂得业务上下游关联关系,学会思考如何设计代码结构,才能在需求变动的情况下代码改动较少,这个时候可能就会放 20%的心思在业务方面,30%学习架构方式。
三到五年这个时间段,是解决问题能力提升最快的时候,因为这个阶段的程序员基本都是在开发核心业务链路,例如交易、支付、结算、智能商业等模块,需要对业务整体有较清晰的把握能力,不然就是给自己挖坑,这个阶段要对业务流付出大量心血思考。
@@ -106,4 +109,6 @@ tag:
人的精力是有限的,而且面对三十这个天花板,各种事件也会接连而至,在职场中学会合理安排时间并不断提升核心能力,这样才能保证自己的竞争力。
-职场就像苦海无边,回首望去可能也没有岸边停泊,但是要具有换船的能力或者有个小木筏也就大差不差了。
\ No newline at end of file
+职场就像苦海无边,回首望去可能也没有岸边停泊,但是要具有换船的能力或者有个小木筏也就大差不差了。
+
+
diff --git a/docs/high-quality-technical-articles/interview/how-to-examine-the-technical-ability-of-programmers-in-the-first-test-of-technology.md b/docs/high-quality-technical-articles/interview/how-to-examine-the-technical-ability-of-programmers-in-the-first-test-of-technology.md
index cef6e51c6e5..fee06e512ea 100644
--- a/docs/high-quality-technical-articles/interview/how-to-examine-the-technical-ability-of-programmers-in-the-first-test-of-technology.md
+++ b/docs/high-quality-technical-articles/interview/how-to-examine-the-technical-ability-of-programmers-in-the-first-test-of-technology.md
@@ -1,24 +1,25 @@
---
title: 如何在技术初试中考察程序员的技术能力
+description: "如何在技术初试中考察程序员的技术能力:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
author: 琴水玉
tag:
- 面试
+head:
+ - - meta
+ - name: keywords
+ content: 技术面试,面试官技巧,技术考察,面试方法,技术基础,项目经历考察,面试题库,技术深度
---
> **推荐语**:从面试官和面试者两个角度探讨了技术面试!非常不错!
>
->
->
> **内容概览:**
>
> - 实战与理论结合。比如,候选人叙述 JVM 内存模型布局之后,可以接着问:有哪些原因可能会导致 OOM , 有哪些预防措施? 你是否遇到过内存泄露的问题? 如何排查和解决这类问题?
> - 项目经历考察不宜超过两个。因为要深入考察一个项目的详情,所占用的时间还是比较大的。一般来说,会让候选人挑选一个他或她觉得最有收获的/最有挑战的/印象最深刻的/自己觉得特有意思的项目。然后围绕这个项目进行发问。通常是从项目背景出发,考察项目的技术栈、项目模块及交互的整体理解、项目中遇到的有挑战性的技术问题及解决方案、排查和解决问题、代码可维护性问题、工程质量保障等。
> - 多问少说,让候选者多表现。根据候选者的回答适当地引导或递进或横向移动。
>
->
->
-> **原文地址**:https://www.cnblogs.com/lovesqcc/p/15169365.html
+> **原文地址**:
## 灵魂三连问
@@ -342,3 +343,5 @@ tag:
- [技术面试官的 9 大误区](https://zhuanlan.zhihu.com/p/51404304)
- [如何当一个好的面试官?](https://www.zhihu.com/question/26240321)
+
+
diff --git a/docs/high-quality-technical-articles/interview/my-personal-experience-in-2021.md b/docs/high-quality-technical-articles/interview/my-personal-experience-in-2021.md
index dba4a243ab6..b3f64e7d6c7 100644
--- a/docs/high-quality-technical-articles/interview/my-personal-experience-in-2021.md
+++ b/docs/high-quality-technical-articles/interview/my-personal-experience-in-2021.md
@@ -1,16 +1,19 @@
---
title: 校招进入飞书的个人经验
+description: "校招进入飞书的个人经验:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
author: 月色真美
tag:
- 面试
+head:
+ - - meta
+ - name: keywords
+ content: 字节跳动面试,飞书校招,C++面试,春招实习,日常实习,暑期实习,面试技巧,算法刷题
---
> **推荐语**:这篇文章的作者校招最终去了飞书做开发。在这篇文章中,他分享了自己的校招经历以及个人经验。
>
->
->
-> **原文地址**:https://www.ihewro.com/archives/1217/
+> **原文地址**:
## 基本情况
@@ -60,9 +63,9 @@ tag:
第一次投了钉钉,没想到因为行测做的不好,在简历筛选给拒绝了。
-第二次阿里妈妈的后端面试,一面电话面试,我感觉面的还可以,最后题目也做出来了。最后反问阶段问对我的面试有什么建议,面试官说投阿里最好还是 Java 的… 然后电话结束后就给我拒了…
+第二次阿里妈妈的后端面试,一面电话面试,我感觉面的还可以,最后题目也做出来了。最后反问阶段问对我的面试有什么建议,面试官说投阿里最好还是 Java 的…… 然后电话结束后就给我拒了……
-当时真的心态有点崩,问了这个晚上 7 点半的面试,一直看书晚上都没吃…
+当时真的心态有点崩,问了这个晚上 7 点半的面试,一直看书晚上都没吃……
所以春招和阿里就无缘了。
@@ -82,7 +85,7 @@ tag:
#### 字节飞书
-第一次一面就凉了,原因应该是笔试题目结果不对…
+第一次一面就凉了,原因应该是笔试题目结果不对……
第二次一面在 4 月底了,很顺利。二面在五一劳动节后,面试官还让学姐告诉我让我多看看智能指针,面试的时候让我手写 shared_ptr,我之前看了一些实现,但是没有自己写过,导致代码考虑的不够完善,leader 就一直提醒我要怎么改怎么改。
@@ -96,7 +99,7 @@ tag:
## 入职字节实习
-入职字节之前我本来觉得这个岗位可能是我面试的最适合我的了,因为我主 c++,而且飞书用 c++应该挺深的。来之后就觉得我可能不太喜欢做客户端相关,感觉好复杂…也许服务端好一些,现在我仍然不能确定。
+入职字节之前我本来觉得这个岗位可能是我面试的最适合我的了,因为我主 c++,而且飞书用 c++应该挺深的。来之后就觉得我可能不太喜欢做客户端相关,感觉好复杂……也许服务端好一些,现在我仍然不能确定。
字节的实习福利在这些公司中应该算是比较好的,小问题是工位比较窄,还是工作强度比其他的互联网公司大一些。字节食堂免费而且挺不错的。字节办公大厦很多,我所在的办公地点比较小。
@@ -199,3 +202,5 @@ tag:
- **对于自己不会的,尽量多的说!!!!** 实在不行,就往别的地方说!!!总之是引导面试官往自己会的地方上说。
- 面试中的笔试和前面的笔试风格不同,面试笔试题目不太难,但是考察是冷静思考,代码优雅,没有 bug,先思考清楚!!!在写!!!
- 在描述项目的难点的时候,不要去聊文档调研是难点,回答这部分问题更应该是技术上的难点,最后通过了什么技术解决了这个问题,这部分技术可以让面试官来更多提问以便知道自己的技术能力。
+
+
diff --git a/docs/high-quality-technical-articles/interview/screen-candidates-for-packaging.md b/docs/high-quality-technical-articles/interview/screen-candidates-for-packaging.md
index b2ed4c772b3..b39fa6520f4 100644
--- a/docs/high-quality-technical-articles/interview/screen-candidates-for-packaging.md
+++ b/docs/high-quality-technical-articles/interview/screen-candidates-for-packaging.md
@@ -1,16 +1,19 @@
---
title: 如何甄别应聘者的包装程度
+description: "如何甄别应聘者的包装程度:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
author: Coody
tag:
- 面试
+head:
+ - - meta
+ - name: keywords
+ content: 简历包装,面试官视角,简历甄别,技术面试,培训机构,项目经验,技术深度,面试技巧
---
> **推荐语**:经常听到培训班待过的朋友给我说他们的老师是怎么教他们“包装”自己的,不光是培训班,我认识的很多朋友也都会在面试之前“包装”一下自己,所以这个现象是普遍存在的。但是面试官也不都是傻子,通过下面这篇文章来看看面试官是如何甄别应聘者的包装程度。
>
->
->
-> **原文地址**:https://my.oschina.net/hooker/blog/3014656
+> **原文地址**:
## 前言
@@ -116,3 +119,5 @@ tag:
然而笔者碰到的问题是:使用 Git 两年却不知道 GitHub、使用 Redis 一年却不知道数据结构也不知道序列化、专业做爬虫却不懂 `content-type` 含义、使用搜索引擎技术却说不出两个分词插件、使用数据库读写分离却不知道同步延时等等。
写在最后,笔者认为在招聘途中,并不是不允许求职者包装,但是尽可能满足能筹平衡。虽然这篇文章没有完美的结尾,但是笔者提供了面试失败的各种经验。笔者最终招到了如意的小伙伴。也希望所有技术面试官早日找到符合自己产品发展的 IT 伙伴。
+
+
diff --git a/docs/high-quality-technical-articles/interview/some-secrets-about-alibaba-interview.md b/docs/high-quality-technical-articles/interview/some-secrets-about-alibaba-interview.md
index 32a33086c4e..82b3360ddf9 100644
--- a/docs/high-quality-technical-articles/interview/some-secrets-about-alibaba-interview.md
+++ b/docs/high-quality-technical-articles/interview/some-secrets-about-alibaba-interview.md
@@ -1,16 +1,19 @@
---
title: 阿里技术面试的一些秘密
+description: "阿里技术面试的一些秘密:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
author: 龙叔
tag:
- 面试
+head:
+ - - meta
+ - name: keywords
+ content: 阿里面试,技术面试,简历筛选,面试技巧,基础知识,动手能力,八股文,校招面试
---
> **推荐语**:详细介绍了求职者在面试中应该具备哪些能力才会有更大概率脱颖而出。
>
->
->
-> **原文地址:** https://mp.weixin.qq.com/s/M2M808PwQ2JcMqfLQfXQMw
+> **原文地址:**
最近我的工作稍微轻松些,就被安排去校招面试了
@@ -117,3 +120,5 @@ action,action,action ,重要的事情说三遍,做技术的不可能光
但是,面试时间有限,同学们一定要在有限的时间里展现出自己的**能力**和**无限的潜力** 。
最后,祝愿优秀的你能找到自己理想的工作!
+
+
diff --git a/docs/high-quality-technical-articles/interview/summary-of-spring-recruitment.md b/docs/high-quality-technical-articles/interview/summary-of-spring-recruitment.md
index 17644017cb3..4345532f3cc 100644
--- a/docs/high-quality-technical-articles/interview/summary-of-spring-recruitment.md
+++ b/docs/high-quality-technical-articles/interview/summary-of-spring-recruitment.md
@@ -1,18 +1,19 @@
---
title: 普通人的春招总结(阿里、腾讯offer)
+description: "普通人的春招总结(阿里、腾讯offer):围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
author: 钟期既遇
tag:
- 面试
+head:
+ - - meta
+ - name: keywords
+ content: 春招经验,阿里面试,腾讯面试,Java学习路线,面试准备,项目经验,算法刷题,双非本科
---
> **推荐语**:牛客网热帖,写的很全面!暑期实习,投了阿里、腾讯、字节,拿到了阿里和腾讯的 offer。
>
->
->
-> **原文地址:** https://www.nowcoder.com/discuss/640519
->
->
+> **原文地址:**
>
> **下篇**:[十年饮冰,难凉热血——秋招总结](https://www.nowcoder.com/discuss/804679)
@@ -57,7 +58,7 @@ tag:
更多书籍推荐建议大家看 [JavaGuide](https://javaguide.cn/books/) 这个网站上的书籍推荐,比较全面。
-
+
### 教程推荐
@@ -69,7 +70,7 @@ tag:
- [MySQL 实战 45 讲](https://time.geekbang.org/column/intro/100020801):前 27 讲多看几遍基本可以秒杀面试中遇到的 MySQL 问题了。
- [Redis 核心技术与实战](https://time.geekbang.org/column/intro/100056701):讲解了大量的 Redis 在生产上的使用场景,和《Redis 设计与实现》配合着看,也可以秒杀面试中遇到的 Redis 问题了。
- [JavaGuide](https://javaguide.cn/books/):「Java 学习+面试指南」一份涵盖大部分 Java 程序员所需要掌握的核心知识。
-- [《Java 面试指北》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247519384&idx=1&sn=bc7e71af75350b755f04ca4178395b1a&chksm=cea1c353f9d64a458f797696d4144b4d6e58639371a4612b8e4d106d83a66d2289e7b2cd7431&token=660789642&lang=zh_CN&scene=21#wechat_redirect):这是一份教你如何更高效地准备面试的小册,涵盖常见八股文(系统设计、常见框架、分布式、高并发 ......)、优质面经等内容。
+- [《Java 面试指北》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247519384&idx=1&sn=bc7e71af75350b755f04ca4178395b1a&chksm=cea1c353f9d64a458f797696d4144b4d6e58639371a4612b8e4d106d83a66d2289e7b2cd7431&token=660789642&lang=zh_CN&scene=21#wechat_redirect):这是一份教你如何更高效地准备面试的小册,涵盖常见八股文(系统设计、常见框架、分布式、高并发 ……)、优质面经等内容。
## 找工作
@@ -161,3 +162,5 @@ Java 卷吗?毫无疑问,很卷,我个人认为开发属于没有什么门
## 祝福
惟愿诸君,前程似锦!
+
+
diff --git a/docs/high-quality-technical-articles/interview/technical-preliminary-preparation.md b/docs/high-quality-technical-articles/interview/technical-preliminary-preparation.md
index 4a7a3de9239..60e4f0363d8 100644
--- a/docs/high-quality-technical-articles/interview/technical-preliminary-preparation.md
+++ b/docs/high-quality-technical-articles/interview/technical-preliminary-preparation.md
@@ -1,9 +1,14 @@
---
title: 从面试官和候选者的角度谈如何准备技术初试
+description: "从面试官和候选者的角度谈如何准备技术初试:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
author: 琴水玉
tag:
- 面试
+head:
+ - - meta
+ - name: keywords
+ content: 技术面试准备,面试官视角,候选人视角,技术基础,业务考察,面试技巧,技术深度广度,面试方法论
---
> **推荐语**:从面试官和面试者两个角度探讨了技术面试!非常不错!
@@ -15,7 +20,7 @@ tag:
> - 项目经历考察不宜超过两个。因为要深入考察一个项目的详情,所占用的时间还是比较大的。一般来说,会让候选人挑选一个他或她觉得最有收获的/最有挑战的/印象最深刻的/自己觉得特有意思的项目。然后围绕这个项目进行发问。通常是从项目背景出发,考察项目的技术栈、项目模块及交互的整体理解、项目中遇到的有挑战性的技术问题及解决方案、排查和解决问题、代码可维护性问题、工程质量保障等。
> - 多问少说,让候选者多表现。根据候选者的回答适当地引导或递进或横向移动。
>
-> **原文地址:** https://www.cnblogs.com/lovesqcc/p/15169365.html
+> **原文地址:**
## 考察目标和思路
@@ -212,3 +217,5 @@ tag:
重点是:有些问题你答得很有深度,也体现了你的深度思考能力。
这一点是我当了技术面试官才领会到的。当然,并不是每位技术面试官都是这么想的,但我觉得这应该是个更合适的方式。
+
+
diff --git a/docs/high-quality-technical-articles/interview/the-experience-and-thinking-of-an-interview-experienced-by-an-older-programmer.md b/docs/high-quality-technical-articles/interview/the-experience-and-thinking-of-an-interview-experienced-by-an-older-programmer.md
index 02ccd59a266..65ccd73d2aa 100644
--- a/docs/high-quality-technical-articles/interview/the-experience-and-thinking-of-an-interview-experienced-by-an-older-programmer.md
+++ b/docs/high-quality-technical-articles/interview/the-experience-and-thinking-of-an-interview-experienced-by-an-older-programmer.md
@@ -1,9 +1,14 @@
---
title: 一位大龄程序员所经历的面试的历炼和思考
+description: "一位大龄程序员所经历的面试的历炼和思考:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
author: 琴水玉
tag:
- 面试
+head:
+ - - meta
+ - name: keywords
+ content: 大龄程序员面试,面试准备,简历优化,技术面试,面试心态,职业规划,面试技巧,技术原理
---
> **推荐语**:本文的作者,今年 36 岁,已有 8 年 JAVA 开发经验。在阿里云三年半,有赞四年半,已是标准的大龄程序员了。在这篇文章中,作者给出了一些关于面试和个人能力提升的一些小建议,非常实用!
@@ -17,7 +22,7 @@ tag:
> 5. 要善于从失败中学习。正是在杭州四个月空档期的持续学习、思考、积累和提炼,以及面试失败的反思、不断调整对策、完善准备、改善原有的短板,采取更为合理的方式,才在回武汉的短短两个周内拿到比较满意的 offer 。
> 6. 面试是通过沟通来理解双方的过程。面试中的问题,千变万化,但有一些问题是需要提前准备好的。
>
-> **原文地址**:https://www.cnblogs.com/lovesqcc/p/14354921.html
+> **原文地址**:
从每一段经历中学习,在每一件事情中修行。善于从挫折中学习。
@@ -358,3 +363,5 @@ ZOOM 的一位面试官或许是我见过的所有面试官中最差劲的。共
经过这一段面试的历炼,我觉得现在相比离职时的自己,又有了不少进步的。不说脱胎换骨,至少也是蜕了一层皮吧。差距,差距还是有的。起码面试那些知名大厂企业的技术专家和架构师还有差距。这与我平时工作的挑战性、认知视野的局限性及总结不足有关。下一次,我希望积蓄足够实力做到更好,和内心热爱的有价值有意义的事情再近一些些。
面试,其实也是一段工作经历。
+
+
diff --git a/docs/high-quality-technical-articles/interview/the-experience-of-get-offer-from-over-20-big-companies.md b/docs/high-quality-technical-articles/interview/the-experience-of-get-offer-from-over-20-big-companies.md
index 16d8f9e4856..5b307bae671 100644
--- a/docs/high-quality-technical-articles/interview/the-experience-of-get-offer-from-over-20-big-companies.md
+++ b/docs/high-quality-technical-articles/interview/the-experience-of-get-offer-from-over-20-big-companies.md
@@ -1,16 +1,19 @@
---
title: 斩获 20+ 大厂 offer 的面试经验分享
+description: "斩获 20+ 大厂 offer 的面试经验分享:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
author: 业余码农
tag:
- 面试
+head:
+ - - meta
+ - name: keywords
+ content: 大厂面试,面试技巧,自我介绍,项目经历,技术面试,编码能力,HR面试,offer选择
---
> **推荐语**:很实用的面试经验分享!
>
->
->
-> **原文地址**:https://mp.weixin.qq.com/s/HXKg6-H0kGUU2OA1DS43Bw
+> **原文地址**:
突然回想起当年,我也在秋招时也斩获了 20+的互联网各大厂 offer。现在想起来也是有点唏嘘,毕竟拿得再多也只能选择一家。不过许多朋友想让我分享下互联网面试方法,今天就来给大家仔细讲讲打法!
@@ -76,7 +79,7 @@ tag:
- 明确的知道业务架构或技术方案选型以及决策逻辑
- 深入掌握项目中涉及的组件以及框架
- 熟悉项目中的疑难杂症或长期遗留 bug 的解决方案
-- ......
+- ……
## 专业知识考查
@@ -195,3 +198,5 @@ tag:
这篇文章其实算讲的是方法论,很多我们一看就明白的「道理」实施起来可能会很难。可能会遇到一个不按常理出牌的面试官,也可能也会遇到一个沟通困难的面试官,当然也可能会撞上一个不怎么匹配的岗位。
总而言之,为了自己想要争取的东西,做好足够的准备总是没有坏处的。祝愿大家能成为`π`型人才,获得想要的`offer`!
+
+
diff --git a/docs/high-quality-technical-articles/personal-experience/8-years-programmer-work-summary.md b/docs/high-quality-technical-articles/personal-experience/8-years-programmer-work-summary.md
index f6362c7fa05..9c44705ef3a 100644
--- a/docs/high-quality-technical-articles/personal-experience/8-years-programmer-work-summary.md
+++ b/docs/high-quality-technical-articles/personal-experience/8-years-programmer-work-summary.md
@@ -1,16 +1,19 @@
---
title: 一个中科大差生的 8 年程序员工作总结
+description: "一个中科大差生的 8 年程序员工作总结:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
author: 陈小房
tag:
- 个人经历
+head:
+ - - meta
+ - name: keywords
+ content: 中科大程序员,8年工作总结,航天研究所,华为工作,职业发展,买房经验,技术成长,人生复盘
---
> **推荐语**:这篇文章讲述了一位中科大的朋友 8 年的经历:从 2013 年毕业之后加入上海航天 x 院某卫星研究所,再到入职华为,从华为离职。除了丰富的经历之外,作者在文章还给出了很多自己对于工作/生活的思考。我觉得非常受用!我在这里,向这位作者表达一下衷心的感谢。
>
->
->
-> **原文地址**:https://www.cnblogs.com/scada/p/14259332.html
+> **原文地址**:
---
@@ -232,3 +235,5 @@ _PS:有几个问题先在这里解释一下,评论就不一一回复了_
## 总结
好了 7 年多,近 8 年的职场讲完了,不管过去如何,未来还是要继续努力,希望看到这篇文章觉得有帮助的朋友,可以帮忙点个推荐,这样可能更多的人看到,也许可以避免更多的人犯我犯的错误。另外欢迎私信或者其他方式交流(某 Xin 号,jingyewandeng),可以讨论职场经验,方向,我也可以帮忙改简历(免费啊),不用怕打扰,能帮助别人是一项很有成绩感的事,并且过程中也会有收获,程序员也不要太腼腆呵呵
+
+
diff --git a/docs/high-quality-technical-articles/personal-experience/four-year-work-in-tencent-summary.md b/docs/high-quality-technical-articles/personal-experience/four-year-work-in-tencent-summary.md
index c0d82be8417..0860b2be859 100644
--- a/docs/high-quality-technical-articles/personal-experience/four-year-work-in-tencent-summary.md
+++ b/docs/high-quality-technical-articles/personal-experience/four-year-work-in-tencent-summary.md
@@ -1,9 +1,14 @@
---
title: 从校招入职腾讯的四年工作总结
+description: "从校招入职腾讯的四年工作总结:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
author: pioneeryi
tag:
- 个人经历
+head:
+ - - meta
+ - name: keywords
+ content: 腾讯工作经验,四年总结,绩效考核,EPC度量,嫡系文化,职业发展,技术成长,互联网职场
---
程序员是一个流动性很大的职业,经常会有新面孔的到来,也经常会有老面孔的离开,有主动离开的,也有被动离职的。
@@ -20,7 +25,7 @@ tag:
**下文中的“我”,指这位作者本人。**
-> 原文地址:https://zhuanlan.zhihu.com/p/602517682
+> 原文地址:
研究生毕业后, 一直在腾讯工作,不知不觉就过了四年。个人本身没有刻意总结的习惯,以前只顾着往前奔跑了,忘了停下来思考总结。记得看过一个职业规划文档,说的三年一个阶段,五年一个阶段的说法,现在恰巧是四年,同时又从腾讯离开,该做一个总结了。
@@ -74,7 +79,7 @@ PS:还好以前有奖杯,不然一点念想都没了。(现在腾讯似乎
但另一方面,后来我负责了团队内很重要的事情,应该是中心内都算很重要的事,我独自负责一个方向,直接向总监汇报,似乎又有点像。
-网上也有其他说法,一针见血,是不是嫡系,就看钱到不到位,这么说也有道理。我在 7 级时,就发了股票,自我感觉,还是不错的。我当时以为不出意外的话,我以后的钱途和发展是不是就会一帆风顺。不出意外就出了意外,第二年,EPC 不达预期,部门总经理和总监都被换了,中心来了一个新的的总监。
+网上也有其他说法,一针见血,是不是嫡系,就看钱到不到位,这么说也有道理。我在 7 级时,就发了股票,自我感觉,还是不错的。我当时以为不出意外的话,我以后的钱途和发展是不是就会一帆风顺。不出意外就出了意外,第二年,EPC 不达预期,部门总经理和总监都被换了,中心来了一个新的总监。
好吧,又要重新建立信任了。再到后来,是不是嫡系已经不重要了,因为大环境不好,又加上裁员,大家主动的被动的差不多都走了。
@@ -105,3 +110,5 @@ PS:还好以前有奖杯,不然一点念想都没了。(现在腾讯似乎
- 深入一个技术方向,不断钻研底层技术知识,这样就有希望成为此技术专家。坦白来说,虽然我深入研究并实践过领域驱动设计,也用来建模和解决了一些复杂业务问题,但是发自内心的,我其实更喜欢钻研技术,同时,我又对大数据很感兴趣。因此,我决定了,以后的方向,就做数据相关的工作。
腾讯的四年,是我的第一份工作经历,认识了很多厉害的人,学到了很多。最后自己主动离开,也算走的体面(即使损失了大礼包),还是感谢腾讯。
+
+
diff --git a/docs/high-quality-technical-articles/personal-experience/huawei-od-275-days.md b/docs/high-quality-technical-articles/personal-experience/huawei-od-275-days.md
index 56b1c1299a1..e546e03a54d 100644
--- a/docs/high-quality-technical-articles/personal-experience/huawei-od-275-days.md
+++ b/docs/high-quality-technical-articles/personal-experience/huawei-od-275-days.md
@@ -1,15 +1,18 @@
---
title: 华为 OD 275 天后,我进了腾讯!
+description: "华为 OD 275 天后,我进了腾讯!:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
tag:
- 个人经历
+head:
+ - - meta
+ - name: keywords
+ content: 华为OD,腾讯面试,大数据开发,外包经历,面试经验,Java面试,职业发展,大厂面试
---
> **推荐语**:一位朋友的华为 OD 工作经历以及腾讯面试经历分享,内容很不错。
>
->
->
-> **原文地址**:https://www.cnblogs.com/shoufeng/p/14322931.html
+> **原文地址**:
## 时间线
@@ -64,7 +67,7 @@ tag:
还听到一些内部的说法:
- 没股票,没 TUP,年终奖少,只有工资可能比我司高一点点而已;
-- 不能借针对 HW 的消费贷,也不能买公司提供的优惠保险…
+- 不能借针对 HW 的消费贷,也不能买公司提供的优惠保险……
### 那,到底要不要去华为 OD?
@@ -94,7 +97,7 @@ d) 你的加班一定要提加班申请电子流换 Double 薪资,不然只能
**答案是:真的。**
-据各类非官方渠道(比如知乎上的一些分享),转华为自有是有条件的(https://www.zhihu.com/question/356592219/answer/1562692667):
+据各类非官方渠道(比如知乎上的一些分享),转华为自有是有条件的():
1)入职时间:一年以上
2)绩效要求:连续两次绩效 A
@@ -335,3 +338,5 @@ blabla 有少量的基础问题和一面有重复,还有几个和大数据相
**入职鹅厂已经 1 月有余。不同的岗位,不同的工作内容,也是不同的挑战。**
感受比较深的是,作为程序员,还是要自我驱动,努力提升个人技术能力,横向纵向都要扩充,这样才能走得长远。
+
+
diff --git a/docs/high-quality-technical-articles/personal-experience/two-years-of-back-end-develop--experience-in-didi-and-toutiao.md b/docs/high-quality-technical-articles/personal-experience/two-years-of-back-end-develop--experience-in-didi-and-toutiao.md
index b3609658d43..18e6bd6e05a 100644
--- a/docs/high-quality-technical-articles/personal-experience/two-years-of-back-end-develop--experience-in-didi-and-toutiao.md
+++ b/docs/high-quality-technical-articles/personal-experience/two-years-of-back-end-develop--experience-in-didi-and-toutiao.md
@@ -1,8 +1,13 @@
---
title: 滴滴和头条两年后端工作经验分享
+description: "滴滴和头条两年后端工作经验分享:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
tag:
- 个人经历
+head:
+ - - meta
+ - name: keywords
+ content: 滴滴工作经验,头条工作经验,后端开发,技术成长,职场经验,深入思考,总结沉淀,主动承担
---
> **推荐语**:很实用的工作经验分享,看完之后十分受用!
@@ -16,9 +21,9 @@ tag:
> - 想舔就舔,不想舔也没必要酸别人,Respect Greatness。
> - 时刻准备着,技术在手就没什么可怕的,哪天干得不爽了直接跳槽。
> - 平时积极总结沉淀,多跟别人交流,形成方法论。
-> - ......
+> - ……
>
-> **原文地址**:https://www.nowcoder.com/discuss/351805
+> **原文地址**:
先简单交代一下背景吧,某不知名 985 的本硕,17 年毕业加入滴滴,当时找工作时候也是在牛客这里跟大家一起奋战的。今年下半年跳槽到了头条,一直从事后端研发相关的工作。之前没有实习经历,算是两年半的工作经验吧。这两年半之间完成了一次晋升,换了一家公司,有过开心满足的时光,也有过迷茫挣扎的日子,不过还算顺利地从一只职场小菜鸟转变为了一名资深划水员。在这个过程中,总结出了一些还算实用的划水经验,有些是自己领悟到的,有些是跟别人交流学到的,在这里跟大家分享一下。
@@ -148,3 +153,5 @@ tag:
本来还想分享一些生活方面的故事,发现已经这么长了,那就先这样叭。上面写的一些总结和建议我自己做的也不是很好,还需要继续加油,和大家共勉。另外,其中某些观点,由于个人视角的局限性也不保证是普适和正确的,可能再工作几年这些观点也会发生改变,欢迎大家跟我交流~(甩锅成功)
最后祝大家都能找到心仪的工作,快乐工作,幸福生活,广阔天地,大有作为。
+
+
diff --git a/docs/high-quality-technical-articles/programmer/efficient-book-publishing-and-practice-guide.md b/docs/high-quality-technical-articles/programmer/efficient-book-publishing-and-practice-guide.md
index e7077a592a5..17d17c638cf 100644
--- a/docs/high-quality-technical-articles/programmer/efficient-book-publishing-and-practice-guide.md
+++ b/docs/high-quality-technical-articles/programmer/efficient-book-publishing-and-practice-guide.md
@@ -1,16 +1,19 @@
---
title: 程序员高效出书避坑和实践指南
+description: "程序员高效出书避坑和实践指南:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
author: hsm_computer
tag:
- 程序员
+head:
+ - - meta
+ - name: keywords
+ content: 程序员出书,出书避坑,稿酬收益,出版社编辑,图书公司,案例书写作,版权问题,技术写作
---
> **推荐语**:详细介绍了程序员出书的一些常见问题,强烈建议有出书想法的朋友看看这篇文章。
>
->
->
-> **原文地址**:https://www.cnblogs.com/JavaArchitect/p/14128202.html
+> **原文地址**:
古有三不朽, 所谓立德、立功、立言。程序员出一本属于自己的书,如果说是立言,可能过于高大上,但终究也算一件雅事。
@@ -138,3 +141,5 @@ tag:
可能当下,写公众号和录视频等的方式,挣钱收益要高于出书,不过话可以这样说,经营公众号和录制视频也是个长期的事情,在短时间里可能未必有收益,如果不是系统地发表内容的话,可能甚至不会有收益。所以出书可能是个非常好的前期准备工作,你靠出书系统积累了素材,靠出书整合了你的知识体系,那么在此基础上,靠公众号或者录视频挣钱可能就会事半功倍。
从上文里大家可以看到,在出书前期,联系出版社编辑和定选题并不难,如果要写案例书,那么在参考别人内容的基础上,要写完一般书可能也不是高不可攀的事情。甚至可以这样说,出书是个体力活,只要坚持,要出本书并不难,只是你愿不愿意坚持下去的问题。但一旦你有了属于自己的技术书,那么在找工作时,你就能自信地和面试官说你是这方面的专家,在你的视频、公众号和文字里,你也能正大光明地说,你是计算机图书的作者。更为重要的是,和名校、大厂经历一样,属于你的技术书同样是证明程序员能力的重要证据,当你通过出书有效整合了相关方面的知识体系后,那么在这方面,不管是找工作,或者是干私活,或者是接项目做,你都能理直气壮地和别人说:我能行!
+
+
diff --git a/docs/high-quality-technical-articles/programmer/high-value-certifications-for-programmers.md b/docs/high-quality-technical-articles/programmer/high-value-certifications-for-programmers.md
new file mode 100644
index 00000000000..b91b220e5f6
--- /dev/null
+++ b/docs/high-quality-technical-articles/programmer/high-value-certifications-for-programmers.md
@@ -0,0 +1,119 @@
+---
+title: 程序员最该拿的几种高含金量证书
+description: "程序员最该拿的几种高含金量证书:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
+category: 技术文章精选集
+tag:
+ - 程序员
+head:
+ - - meta
+ - name: keywords
+ content: 程序员证书,软考,PMP认证,AWS认证,阿里云认证,华为认证,OCP认证,Kubernetes认证,职业资格证书
+---
+
+证书是能有效证明自己能力的好东西,它就是你实力的象征。在短短的面试时间内,证书可以为你加不少分。通过考证来提升自己,是一种性价比很高的办法。不过,相比金融、建筑、医疗等行业,IT 行业的职业资格证书并没有那么多。
+
+下面我总结了一下程序员可以考的一些常见证书。
+
+## 软考
+
+全国计算机技术与软件专业技术资格(水平)考试,简称“软考”,是国内认可度较高的一项计算机技术资格认证。尽管一些人吐槽其实际价值,但在特定领域和情况下,它还是非常有用的,例如软考证书在国企和事业单位中具有较高的认可度、在某些城市软考证书可以用于积分落户、可用于个税补贴。
+
+软考有初、中、高三个级别,建议直接考高级。相比于 PMP(项目管理专业人士认证),软考高项的难度更大,特别是论文部分,绝大部分人都挂在了论文部分。过了软考高项,在一些单位可以内部挂证,每个月多拿几百。
+
+
+
+官网地址:。
+
+备考建议:[2024 年上半年,一次通过软考高级架构师考试的备考秘诀 - 阿里云开发者](https://mp.weixin.qq.com/s/9aUXHJ7dXgrHuT19jRhCnw)
+
+## PAT
+
+攀拓计算机能力测评(PAT)是一个专注于考察算法能力的测评体系,由浙江大学主办。该测评分为四个级别:基础级、乙级、甲级和顶级。
+
+通过 PAT 测评并达到联盟企业规定的相应评级和分数,可以跳过学历门槛,免除筛选简历和笔试环节,直接获得面试机会。具体有哪些公司可以去官网看看: 。
+
+对于考研浙江大学的同学来说,PAT(甲级)成绩在一年内可以作为硕士研究生招生考试上机复试成绩。
+
+
+
+## PMP
+
+PMP(Project Management Professional)认证由美国项目管理协会(PMI)提供,是全球范围内认可度最高的项目管理专业人士资格认证。PMP 认证旨在提升项目管理专业人士的知识和技能,确保项目顺利完成。
+
+
+
+PMP 是“一证在手,全球通用”的资格认证,对项目管理人士来说,PMP 证书含金量还是比较高的。放眼全球,很多成功企业都会将 PMP 认证作为项目经理的入职标准。
+
+但是!真正有价值的不是 PMP 证书,而是《PMBOK》 那套项目管理体系,在《PMBOK》(PMP 考试指定用书)中也包含了非常多商业活动、实业项目、组织规划、建筑行业等各个领域的项目案例。
+
+另外,PMP 证书不是一个高大上的证书,而是一个基础的证书。
+
+## ACP
+
+ACP(Agile Certified Practitioner)认证同样由美国项目管理协会(PMI)提供,是项目管理领域的另一个重要认证。与 PMP(Project Management Professional)注重传统的瀑布方法论不同,ACP 专注于敏捷项目管理方法论,如 Scrum、Kanban、Lean、Extreme Programming(XP)等。
+
+## OCP
+
+Oracle Certified Professional(OCP)是 Oracle 公司提供的一项专业认证,专注于 Oracle 数据库及相关技术。这个认证旨在验证和认证个人在使用和管理 Oracle 数据库方面的专业知识和技能。
+
+下图展示了 Oracle 认证的不同路径和相应的认证级别,分别是核心路径(Core Track)和专业路径(Speciality Track)。
+
+
+
+## 阿里云认证
+
+阿里云(Alibaba Cloud)提供的专业认证,认证方向包括云计算、大数据、人工智能、Devops 等。职业认证分为 ACA、ACP、ACE 三个等级,除了职业认证之外,还有一个开发者 Clouder 认证,这是专门为开发者设立的专项技能认证。
+
+
+
+官网地址:。
+
+## 华为认证
+
+华为认证是由华为技术有限公司提供的面向 ICT(信息与通信技术)领域的专业认证,认证方向包括网络、存储、云计算、大数据、人工智能等,非常庞大的认证体系。
+
+
+
+## AWS 认证
+
+AWS 云认证考试是 AWS 云计算服务的官方认证考试,旨在验证 IT 专业人士在设计、部署和管理 AWS 基础架构方面的技能。
+
+AWS 认证分为多个级别,包括基础级、从业者级、助理级、专业级和专家级(Specialty),涵盖多个角色和技能:
+
+- **基础级别**:AWS Certified Cloud Practitioner,适合初学者,验证对 AWS 基础知识的理解,是最简单的入门认证。
+- **助理级别**:包括 AWS Certified Solutions Architect – Associate、AWS Certified Developer – Associate 和 AWS Certified SysOps Administrator – Associate,适合中级专业人士,验证其设计、开发和管理 AWS 应用的能力。
+- **专业级别**:包括 AWS Certified Solutions Architect – Professional 和 AWS Certified DevOps Engineer – Professional,适合高级专业人士,验证其在复杂和大规模 AWS 环境中的能力。
+- **专家级别**:包括 AWS Certified Advanced Networking – Specialty、AWS Certified Big Data – Specialty 等,专注于特定技术领域的深度知识和技能。
+
+备考建议:[小白入门云计算的最佳方式,是去考一张 AWS 的证书(附备考经验)](https://mp.weixin.qq.com/s/xAqNOnfZ05GDRuUbAiMHIA)
+
+## Google Cloud 认证
+
+与 AWS 认证不同,Google Cloud 认证只有一门助理级认证(Associate Cloud Engineer),其他大部分为专业级(专家级)认证。
+
+备考建议:[如何备考谷歌云认证](https://mp.weixin.qq.com/s/Vw5LGPI_akA7TQl1FMygWw)
+
+官网地址:
+
+## 微软认证
+
+微软的认证体系主要针对其 Azure 云平台,分为基础级别、助理级别和专家级别,认证方向包括云计算、数据管理、开发、生产力工具等。
+
+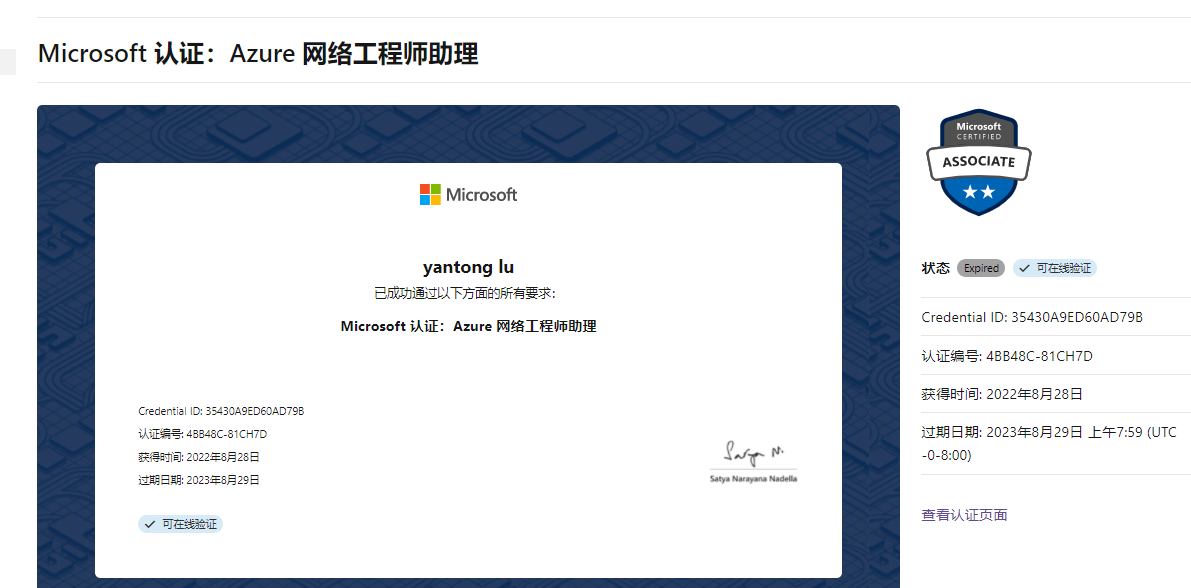
+
+## Elastic 认证
+
+Elastic 认证是由 Elastic 公司提供的一系列专业认证,旨在验证个人在使用 Elastic Stack(包括 Elasticsearch、Logstash、Kibana 、Beats 等)方面的技能和知识。
+
+如果你在日常开发核心工作是负责 ElasticSearch 相关业务的话,还是比较建议考的,含金量挺高。
+
+目前 Elastic 认证证书分为四类:Elastic Certified Engineer、Elastic Certified Analyst、Elastic Certified Observability Engineer、Elastic Certified SIEM Specialist。
+
+比较建议考 **Elastic Certified Engineer**,这个是 Elastic Stack 的基础认证,考察安装、配置、管理和维护 Elasticsearch 集群等核心技能。
+
+
+
+## 其他
+
+- PostgreSQL 认证:国内的 PostgreSQL 认证分为专员级(PCA)、专家级(PCP)和大师级(PCM),主要考查 PostgreSQL 数据库管理和优化,价格略贵,不是很推荐。
+- Kubernetes 认证:Cloud Native Computing Foundation (CNCF) 提供了几个官方认证,例如 Certified Kubernetes Administrator (CKA)、Certified Kubernetes Application Developer (CKAD),主要考察 Kubernetes 方面的技能和知识。
diff --git a/docs/high-quality-technical-articles/programmer/how-do-programmers-publish-a-technical-book.md b/docs/high-quality-technical-articles/programmer/how-do-programmers-publish-a-technical-book.md
index 1927c927127..3fcc17a191c 100644
--- a/docs/high-quality-technical-articles/programmer/how-do-programmers-publish-a-technical-book.md
+++ b/docs/high-quality-technical-articles/programmer/how-do-programmers-publish-a-technical-book.md
@@ -1,16 +1,19 @@
---
title: 程序员怎样出版一本技术书
+description: "程序员怎样出版一本技术书:围绕技术知识与面试总结梳理关键概念、常见问题与实践要点,帮助你高效学习与备战面试。"
category: 技术文章精选集
author: hsm_computer
tag:
- 程序员
+head:
+ - - meta
+ - name: keywords
+ content: 程序员出书,技术书籍出版,出版社合作,图书公司,写书技巧,稿酬收益,技术写作,畅销书
---
> **推荐语**:详细介绍了程序员应该如何从头开始出一本自己的书籍。
>
->  ](https://sourl.cn/e7ee87)
+- 推荐在线阅读(体验更好,速度更快):[javaguide.cn](https://javaguide.cn/)
+- 面试突击版本(只保留重点,附带精美 PDF 下载):[interview.javaguide.cn](https://interview.javaguide.cn/)
](https://sourl.cn/e7ee87)
+- 推荐在线阅读(体验更好,速度更快):[javaguide.cn](https://javaguide.cn/)
+- 面试突击版本(只保留重点,附带精美 PDF 下载):[interview.javaguide.cn](https://interview.javaguide.cn/)
 -
- diff --git a/README_EN.md b/README_EN.md
new file mode 100644
index 00000000000..ec1366de844
--- /dev/null
+++ b/README_EN.md
@@ -0,0 +1,452 @@
+Recommended to read through online reading platforms for better experience and faster speed! Link: [javaguide.cn](https://javaguide.cn/).
+
+
diff --git a/README_EN.md b/README_EN.md
new file mode 100644
index 00000000000..ec1366de844
--- /dev/null
+++ b/README_EN.md
@@ -0,0 +1,452 @@
+Recommended to read through online reading platforms for better experience and faster speed! Link: [javaguide.cn](https://javaguide.cn/).
+
+ +
+这句话表面上看似有道理,但实际上却暴露了一个人的**无知和偏执**。
+
+**知识越贫乏的人,相信的东西就越绝对**,因为他们从未认真了解过与自己观点相对立的角度,也缺乏对技术发展的全局认识。
+
+举个例子,我刚开始学习 Java 后端开发的时候,完全没什么经验,就随便买了一本书开始看。当时看的是 **《Java Web 整合开发王者归来》** 这本书(梦开始的地方)。
+
+在我上大学那会儿,这本书的很多内容其实已经过时了,比如它花了大量篇幅介绍 JSP、Struts、Hibernate、EJB 和 SVN 等技术。不过,直到现在,我依然非常感谢这本书,带我走进了 Java 后端开发的大门。
+
+
+
+这本书一共 **1010** 页,我当时可以说是废寝忘食地学,花了很长时间才把整本书完全“啃”下来。
+
+回头来看,我如果能有意识地避免学习这些已经淘汰的技术,真的可以节省大量时间去学习更加主流和实用的内容。
+
+那么,这些被淘汰的技术有用吗?说句实话,**屁用没有,纯粹浪费时间**。
+
+**既然都要花时间学习,为什么不去学那些更主流、更有实际价值的技术呢?**
+
+现在本身就很卷,不管是 Java 方向还是其他技术方向,要学习的技术都很多。
+
+想要理解所谓的“底层思想”,与其浪费时间在 JSP 这种已经不具备实际应用价值的技术上,不如深入学习一下 Servlet,研究 Spring 的 AOP 和 IoC 原理,从源码角度理解 Spring MVC 的工作机制。
+
+这些内容,不仅能帮助你掌握核心的思想,还能在实际开发中真正派上用场,这难道不比花大量时间在 JSP 上更有意义吗?
+
+## 还有公司在用的技术就要学吗?
+
+我把这篇文章的相关言论发表在我的[公众号](https://mp.weixin.qq.com/s/lf2dXHcrUSU1pn28Ercj0w)之后,又收到另外一类在我看来非常傻叉的言论:
+
+- “虽然 JSP 很老了,但还是得学学,会用就行,因为我们很多老项目还在用。”
+- “很多央企和国企的老项目还在用,肯定得学学啊!”
+
+这种观点完全是钻牛角尖!如果按这种逻辑,那你还需要去学 Struts2、SVN、JavaFX 等过时技术,因为它们也还有公司在用。我有一位大学同学毕业后去了武汉的一家国企,写了一年 JavaFX 就受不了跑了。他在之前从来没有接触过 JavaFX,招聘时也没被问过相关问题。
+
+一定不要假设自己要面对的是过时技术栈的项目。你要找工作肯定要用主流技术栈去找,还要尽量找能让自己技术有成长,干着也舒服点。真要是找不到合适的工作,去维护老项目,那都是后话,现学现卖就行了。
+
+**对于初学者来说别人劝了还非要学习淘汰的技术,多少脑子有点不够用,基本可以告别这一行了!**
diff --git a/docs/about-the-author/dog-that-copies-other-people-essay.md b/docs/about-the-author/dog-that-copies-other-people-essay.md
index cf849132759..2ae67150843 100644
--- a/docs/about-the-author/dog-that-copies-other-people-essay.md
+++ b/docs/about-the-author/dog-that-copies-other-people-essay.md
@@ -1,5 +1,6 @@
---
title: 抄袭狗,你冬天睡觉脚必冷!!!
+description: 原创文章被抄袭的无奈经历,知乎、CSDN多平台盗文现象吐槽,分享如何屏蔽低质量内容和维护原创权益。
category: 走近作者
tag:
- 杂谈
@@ -9,23 +10,23 @@ tag:
听朋友说我的文章在知乎又被盗了,原封不动地被别人用来引流。
-
+
而且!!!这还不是最气的。
这人还在文末注明的原出处还不是我的。。。
-
+
也就是说 CSDN 有另外一位抄袭狗盗了我的这篇文章并声明了原创,知乎抄袭狗又原封不动地搬运了这位 CSDN 抄袭狗的文章。
真可谓离谱他妈给离谱开门,离谱到家了。
-
+
我打开知乎抄袭狗注明的原出处链接,好家伙,一模一样的内容,还表明了原创。
-
+
看了一下 CSDN 这位抄袭狗的文章,好家伙,把我高赞回答搬运了一个遍。。。真是很勤奋了。。。
@@ -33,7 +34,7 @@ CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范
像我自己平时用 Google 搜索的时候,都是直接屏蔽掉 CSDN 这个站点的。只需要下载一个叫做 Personal Blocklist 的 Chrome 插件,然后将 blog.csdn.net 添加进黑名单就可以了。
-
+
我的文章基本被盗完了,关键是我自己发没有什么流量,反而是盗我文章的那些人比我这个原作者流量还大。
@@ -43,7 +44,7 @@ CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范
看看 CSDN 热榜上的文章都是一些什么垃圾,不是各种广告就是一些毫无质量的拼凑文。
-
+
当然了,也有极少部分的高质量文章,比如涛哥、二哥、冰河、微观技术等博主的文章。
@@ -51,6 +52,6 @@ CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范
今天提到的这篇被盗的文章曾经就被一个培训机构拿去做成了视频用来引流。
-
+
作为个体,咱也没啥办法,只能遇到一个举报一个。。。
diff --git a/docs/about-the-author/feelings-after-one-month-of-induction-training.md b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
index 8ecb6eac455..8ea32dd5c74 100644
--- a/docs/about-the-author/feelings-after-one-month-of-induction-training.md
+++ b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
@@ -1,5 +1,6 @@
---
title: 入职培训一个月后的感受
+description: ThoughtWorks入职培训一个月感受,从Windows切换到Mac的适应、TWU培训内容、Feedback反馈文化等新人入职体验分享。
category: 走近作者
tag:
- 个人经历
@@ -15,7 +16,7 @@ ThoughtWorks 非常提倡分享、提倡帮助他人成长,这一点在公司
另外,ThoughtWorks 也是一家非常提倡 Feedback (反馈) 文化的公司,反馈是告诉人们我们对他们的表现的看法以及他们应该如何更好地做到这一点。刚开始我并没有太在意,慢慢地自己确实感觉到正确的进行反馈对他人会有很大的帮助。因为人在做很多事情的时候,会很难发现别人很容易看到的一些小问题。就比如一个很有趣的现象一样,假如我们在做项目的时候没有测试这个角色,如果你完成了自己的模块,并且自己对这个模块测试了很多遍,你发现已经没啥问题了。但是,到了实际使用的时候会很大概率出现你之前从来没有注意的问题。解释这个问题的说法是:每个人的视野或多或少都是有盲点的,这与我们的关注点息息相关。对于自己做的东西,很多地方自己测试很多遍都不会发现,但是如果让其他人帮你进行测试的话,就很大可能会发现很多显而易见的问题。
-
+
工作之后,平时更新公众号、专栏还有维护 Github 的时间变少了。实际上,很多时候下班回来后,都有自己的时间来干自己的事情,但是自己也总是找工作太累或者时间比较零散的接口来推掉了。到了今天,翻看 Github 突然发现 14 天前别人在 Github 上给我提的 PR 我还没有处理。这一点确实是自己没有做好的地方,没有合理安排好自己的时间。实际上自己有很多想写的东西,后面会慢慢将他们提上日程。工作之后,更加发现下班后的几个小时如何度过确实很重要 ,如果你觉得自己没有完成好自己白天该做的工作的话,下班后你可以继续忙白天没有忙完的工作,如果白天的工作对于你游刃有余的话,下班回来之后,你大可去干自己感兴趣的事情,学习自己感兴趣的技术。做任何事情都要基于自身的基础,切不可好高骛远。
diff --git a/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md b/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
index 327715f2b73..d737f1a10b4 100644
--- a/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
+++ b/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
@@ -1,5 +1,6 @@
---
title: 从毕业到入职半年的感受
+description: 应届生入职半年的工作感受,CRUD业务代码的价值、技术积累靠工作之余、从学校到职场的转变心得分享。
category: 走近作者
tag:
- 个人经历
@@ -46,10 +47,8 @@ tag:
还没完成的:
1. Kafka 高级特性比如工作流程、Kafka 为什么快等等的分析;
-
2. 源码阅读分析;
-
-3. ......
+3. ……
**所以,我觉得技术的积累和沉淀很大程度在乎工作之外的时间(大佬和一些本身就特别厉害的除外)。**
diff --git a/docs/about-the-author/internet-addiction-teenager.md b/docs/about-the-author/internet-addiction-teenager.md
index d4a34b8fc27..82788023c3c 100644
--- a/docs/about-the-author/internet-addiction-teenager.md
+++ b/docs/about-the-author/internet-addiction-teenager.md
@@ -1,11 +1,12 @@
---
title: 我曾经也是网瘾少年
+description: 从网瘾少年到程序员的成长经历,初中沉迷游戏、高中觉醒奋起直追、高考失眠的真实故事,分享如何克服网瘾专注学习。
category: 走近作者
tag:
- 个人经历
---
-> 这篇文章写入 2021 年高考前夕。
+> 这篇文章写于 2021 年高考前夕。
聊到高考,无数人都似乎有很多话说。今天就假借高考的名义,简单来聊聊我的高中求学经历吧!
@@ -19,7 +20,11 @@ tag:
最开始接触电脑是在我刚上五年级的时候,那时候家里没电脑,刚开始上网都是在黑网吧玩的。
-在黑网吧上网的经历也是一波三折,经常会遇到警察来检查或者碰到大孩子骚扰。在黑网吧上网的一年多中,我一共两次碰到警察来检查,主要是看有没有未成年人(当时黑网吧里几乎全是未成年人),实际感觉像是要问黑网吧老板要点好处。碰到大孩子骚扰的次数就比较多,大孩子经常抢我电脑,还威胁我把身上所有的钱给他们。我当时一个人也比较怂,被打了几次之后,就尽量避开大孩子来玩的时间去黑网吧,身上也只带很少的钱。小时候的性格就比较独立,在外遇到事情我一般也不会给家里人说。
+黑网吧大概就是下面这样式儿的,一个没有窗户的房间里放了很多台老式电脑,非常拥挤。
+
+
+
+在黑网吧上网的经历也是一波三折,经常会遇到警察来检查或者碰到大孩子骚扰。在黑网吧上网的一年多中,我一共两次碰到警察来检查,主要是看有没有未成年人(当时黑网吧里几乎全是未成年人),实际感觉像是要问黑网吧老板要点好处。碰到大孩子骚扰的次数就比较多,大孩子经常抢我电脑,还威胁我把身上所有的钱给他们。我当时一个人也比较怂,被打了几次之后,就尽量避开大孩子来玩的时间去黑网吧,身上也只带很少的钱。小时候的性格就比较独立,在外遇到事情我一般也不会给家里人说(因为说了也没什么用,家人给我的安全感很少)。
我现在已经记不太清当时是被我哥还是我姐带进网吧的,好像是我姐。
@@ -57,6 +62,10 @@ QQ 飞车这款戏当时还挺火的,很多 90 后的小伙伴应该比较熟
我的最终军衔停留在了两个钻石,玩过的小伙伴应该清楚这在当时要玩多少把(现在升级比较简单)。
+
+
+ps: 回坑 CF 快一年了,目前的军衔是到了两颗星中校 3 了。
+
那时候成绩挺差的。这样说吧!我当时在很普通的一个县级市的高中,全年级有 500 来人,我基本都是在 280 名左右。而且,整个初二我都没有学物理,上物理课就睡觉,考试就交白卷。
为什么对物理这么抵触呢?这是因为开学不久的一次物理课,物理老师误会我在上课吃东西还狡辩,扇了我一巴掌。那时候心里一直记仇到大学,想着以后自己早晚有时间把这个物理老师暴打一顿。
@@ -81,6 +90,8 @@ QQ 飞车这款戏当时还挺火的,很多 90 后的小伙伴应该比较熟
## 高中从小班掉到平行班
+
+
由于参加了高中提前招生考试,我提前 4 个月就来到了高中,进入了小班,开始学习高中的课程。
上了高中的之后,我上课就偷偷看小说,神印王座、斗罗大陆、斗破苍穹很多小说都是当时看的。中午和晚上回家之后,就在家里玩几把 DNF。当时家里也买了电脑,姥爷给买的,是对自己顺利进入二中的奖励。到我卸载 DNF 的时候,已经练了 4 个满级的号,两个接近满级的号。
@@ -117,9 +128,11 @@ QQ 飞车这款戏当时还挺火的,很多 90 后的小伙伴应该比较熟

-高考那几天的失眠,我觉得可能和我喝了老师推荐的安神补脑液有关系,又或者是我自己太过于紧张了。因为那几天睡觉总会感觉有很多蚂蚁在身上爬一样,身上还起了一些小痘痘。
+高考那几天的失眠,我觉得可能和我喝了老师推荐的安神补脑液有关系,又或者是我自己太过于紧张了。因为那几天睡觉总会感觉有很多蚂蚁在身上爬一样,身上还起了一些小痘痘(有点像是过敏)。
+
+这里要格外说明一点,避免引起误导:**睡不着本身就是自身的问题,上述言论并没有责怪这个补脑液的意思。** 另外, 这款安神补脑液我去各个平台都查了一下,发现大家对他的评价都挺好,和我们老师当时推荐的理由差不多。如果大家需要改善睡眠的话,可以咨询相关医生之后尝试一下。
-然后,这里要格外说明一点,避免引起误导:**睡不着本身就是自身的问题,上述言论并没有责怪这个补脑液的意思。** 另外, 这款安神补脑液我去各个平台都查了一下,发现大家对他的评价都挺好,和我们老师当时推荐的理由差不多。如果大家需要改善睡眠的话,可以咨询相关医生之后尝试一下。
+高考也确实没发挥好,整个人在考场都是懵的状态。高考成绩出来之后,比我自己预估的还低了几十分,最后只上了一个双非一本。不过,好在专业选的好,吃了一些计算机专业的红利,大学期间也挺努力的。
## 大学生活
diff --git a/docs/about-the-author/javaguide-100k-star.md b/docs/about-the-author/javaguide-100k-star.md
index e89060dbe27..da851386ee9 100644
--- a/docs/about-the-author/javaguide-100k-star.md
+++ b/docs/about-the-author/javaguide-100k-star.md
@@ -1,5 +1,6 @@
---
title: JavaGuide 开源项目 100K Star 了!
+description: JavaGuide开源项目达成100K Star里程碑,从2018年创建到突破十万星标的复盘总结,分享开源维护心得与未来规划。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md b/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
index 91201ccec76..67306b969fa 100644
--- a/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
+++ b/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
@@ -1,5 +1,6 @@
---
title: 某培训机构盗我文章做成视频还上了B站热门
+description: 原创文章被培训机构盗用制作成B站视频的维权经历,揭露培训机构剽窃原创引流的套路,呼吁尊重原创内容。
category: 走近作者
tag:
- 杂谈
@@ -15,19 +16,19 @@ tag:
麻烦这个培训机构看到这篇文章之后可以考虑换一个人做类似恶心的事情哈!这人完全没脑子啊!
-
+
-
+
-
+
-
+
我随便找了一个视频看,发现也还是盗用别人的原创。
-
+
-
+
其他的视频就不用多看了,是否还是剽窃别人的原创,原封不动地做成视频,大家心里应该有数。
@@ -49,7 +50,7 @@ tag:
谁能想到,培训机构的人竟然找人来让我删文章了!讲真,这俩人是真的奇葩啊!
-
+

diff --git a/docs/about-the-author/my-college-life.md b/docs/about-the-author/my-college-life.md
index a24e899eea4..4df47ca785d 100644
--- a/docs/about-the-author/my-college-life.md
+++ b/docs/about-the-author/my-college-life.md
@@ -1,5 +1,6 @@
---
title: 害,毕业三年了!
+description: 双非一本程序员的大学四年,从参加社团活动到办补习班赚钱、确定Java后端方向、创建JavaGuide、最终拿到ThoughtWorks offer的真实经历。
category: 走近作者
star: 1
tag:
@@ -372,7 +373,7 @@ tag:
6. 管理自己的身材,没事去跑跑步,别当油腻男。
7. 别太看重绩点。我觉得绩点对于找工作还有考研实际的作用都可以忽略不计,不过不挂科还是比较重要的。但是,绩点确实在奖学金评选和保研名额选取上占有最大的分量。
8. 别太功利性。做事情以及学习知识都不要奢求它能立马带给你什么,坚持和功利往往是成反比的。
-9. ......
+9. ……
## 后记
diff --git a/docs/about-the-author/writing-technology-blog-six-years.md b/docs/about-the-author/writing-technology-blog-six-years.md
index 9e18a67d8c4..b03faf75e76 100644
--- a/docs/about-the-author/writing-technology-blog-six-years.md
+++ b/docs/about-the-author/writing-technology-blog-six-years.md
@@ -1,5 +1,6 @@
---
title: 坚持写技术博客六年了!
+description: 坚持写技术博客六年的心得分享,写博客的好处、如何坚持下去、写哪些方向的博客、实用写作技巧等经验总结。
category: 走近作者
tag:
- 杂谈
diff --git a/docs/about-the-author/zhishixingqiu-two-years.md b/docs/about-the-author/zhishixingqiu-two-years.md
index 9ca1fa7ddbd..f1f7885390a 100644
--- a/docs/about-the-author/zhishixingqiu-two-years.md
+++ b/docs/about-the-author/zhishixingqiu-two-years.md
@@ -1,58 +1,103 @@
---
-title: 我的知识星球快 3 岁了!
+title: 我的知识星球 6 岁了!
+description: JavaGuide知识星球介绍,提供Java面试指北专栏、简历修改、一对一答疑等服务,已帮助9000+球友提升求职竞争力。
category: 知识星球
star: 2
---
-
+在 **2019 年 12 月 29 号**,经过了大概一年左右的犹豫期,我正式确定要开始做一个自己的星球,帮助学习 Java 和准备 Java 面试的同学。一转眼,已经六年了。感谢大家一路陪伴,我会信守承诺,继续认真维护这个纯粹的 Java 知识星球,不让信任我的读者失望。
-时间过的真快,知识星球我已经平稳运行了 3 年有余了!
+
-在 2019 年 12 月 29 号,经过了大概一年左右的犹豫期,我正式确定要开始做一个自己的星球。
+我是比较早一批做星球的技术号主,也是坚持做下来的那一少部人(大部分博主割一波韭菜就不维护星球了)。最开始的一两年,纯粹靠爱发电。当初定价非常低(一顿饭钱),加上刚工作的时候比较忙,提供的服务也没有现在这么多。
-
-
-截止到今天,星球已经有 1.3w+ 的同学加入。虽然比不上很多大佬,但这于我来说也算是小有成就了,真的很满足了!我确信自己是一个普通人,能做成这些,也不过是在兴趣和运气的加持下赶上了时代而已。
+慢慢的价格提上来,星球的收入确实慢慢也上来了。不过,考虑到我的受众主要是学生,定价依然比同类星球低很多。另外,我也没有弄训练营的打算,虽然训练营对于我这个流量来说可以赚到更多钱。
**我有自己的原则,不割韭菜,用心做内容,真心希望帮助到他人!**
-## 什么是知识星球?
+## 我的知识星球评价如何?
+
+知识星球是一个私密、长期的知识社群,用来连接创作者和铁杆读者。相比微信群,它更适合沉淀内容、做系统化的学习和信息管理。
+
+下面是今年收到了部分好评,每一条都是真实存在的。我看到很多培训班或者机构通过虚构一些不存在的好评来欺骗他人购买高价服务(行业内非常常见),真的很难理解。
+
+
+
+在这里,不只有理论,更有具体、可落地的求职/转行指导:
-简单来说,知识星球就是一个私密交流圈子,主要用途是知识创作者连接铁杆读者/粉丝。相比于微信群,知识星球内容沉淀、信息管理更高效。
+- 有球友入球后,在多次一对一建议下,很快就收到了美国大模型应用开发的面试并通过;
+- 有球友在指导下顺利转行,拿到满意的中厂 Offer。
-
+不少球友评价我是“良心博主”:深夜 11 点多还在帮忙改简历、给建议;对非科班、大龄转行等焦虑问题,也会耐心一一解答,做到有问必回。
+
+口碑是最好的证明!这里有连续续费三年的老球友,也有因为信任而把星球推荐给弟弟妹妹的朋友。
+
+下面是部分球友今年的求职战绩分享(只是一小部分,有校招,也有社招),同样完全真实。每年面试季之后,星球就有大量的球友询问 offer 如何选择。
+
+
## 我的知识星球能为你提供什么?
-努力做一个最优质的 Java 面试交流星球!加入到我的星球之后,你将获得:
+致力于打造最优质的 Java 面试交流星球(后端面试通用)!加入我们,你将获得远超票价的一站式成长服务:
+
+💎 **核心面试求职服务**
+
+- **简历深度精修**:提供免费的一对一简历修改服务(已累计帮助 **9000+** 位球友,好评如潮)。
+- **6 大精品专栏**:永久阅读权限,内容涵盖高频面试题、源码解析、实战项目,构建完整知识体系。
+- **独家面试手册**:多本原创 PDF 后端面试手册免费领取,全网独家。
+- **有问必答**:一对一免费提问,提供专属求职指南,拒绝焦虑。
-1. 6 个高质量的专栏永久阅读,内容涵盖面试,源码解析,项目实战等内容!价值远超门票!
-2. 多本原创 PDF 版本面试手册。
-3. 免费的简历修改服务(已经累计帮助 4000+ 位球友修改简历)。
-4. 一对一免费提问交流(专属建议,走心回答)。
-5. 专属求职指南和建议,帮助你逆袭大厂!
-6. 海量 Java 优质面试资源分享!价值远超门票!
-7. 读书交流,学习交流,让我们一起努力创造一个纯粹的学习交流社区。
-8. 不定期福利:节日抽奖、送书送课、球友线下聚会等等。
-9. ......
+**🚀 实战项目**
-其中的任何一项服务单独拎出来价值都远超星球门票了。
+星球已经推出的实战项目如下:
+
+- [⭐AI 智能面试辅助平台 + RAG 知识库](https://javaguide.cn/zhuanlan/interview-guide.html):基于 Spring Boot 4.0 + Java 21 + Spring AI 2.0 开发。非常适合作为学习和简历项目,学习门槛低,帮助提升求职竞争力,是主打就业的实战项目。
+- [手写 RPC 框架](https://javaguide.cn/zhuanlan/handwritten-rpc-framework.html):从零开始基于 Netty+Kyro+Zookeeper 实现一个简易的 RPC 框架。麻雀虽小五脏俱全,项目代码注释详细,结构清晰。
+
+今年陆续还会推出更多企业级实战案例(预告一下,下一个是大家期待的:**企业智能客服**)!
+
+🔥 **氛围与福利**
+
+- **海量资源**:Java 优质面试资源持续更新分享。
+- **抱团成长**:打卡活动、读书交流、线下聚会,让学习之路不再孤单。
+- **惊喜福利**:不定期节日抽奖、送书送课,福利拿到手软。
+
+💡 **总结**:这里的任何一项服务(尤其是简历修改和面试资料),单独拎出来的价值都已远超星球门票。
+
+目前星球正在做活动,两本书的价格,就能让你拥有上万培训班的服务!
+
+这里再提供一张 **30**元的优惠卷(**价格马上上调,老用户扫码续费半价** ):
+
+
### 专属专栏
星球更新了 **《Java 面试指北》**、**《Java 必读源码系列》**(目前已经整理了 Dubbo 2.6.x、Netty 4.x、SpringBoot2.1 的源码)、 **《从零开始写一个 RPC 框架》**(已更新完)、**《Kafka 常见面试题/知识点总结》** 等多个优质专栏。
-
+
《Java 面试指北》内容概览:
-
+
+
+进入星球之后,这些专栏即可免费永久阅读,永久同步更新!
+
+### 实战项目
+
+星球已经推出的实战项目如下:
+
+- [⭐AI 智能面试辅助平台 + RAG 知识库](https://javaguide.cn/zhuanlan/interview-guide.html):基于 Spring Boot 4.0 + Java 21 + Spring AI 2.0 开发。非常适合作为学习和简历项目,学习门槛低,帮助提升求职竞争力,是主打就业的实战项目。
+- [手写 RPC 框架](https://javaguide.cn/zhuanlan/handwritten-rpc-framework.html):从零开始基于 Netty+Kyro+Zookeeper 实现一个简易的 RPC 框架。麻雀虽小五脏俱全,项目代码注释详细,结构清晰。
+
+今年陆续还会推出更多企业级实战案例!并且,星球还分享了很多高频项目经历的优化版介绍和面试准备(持续更新中)。
+
+
### PDF 面试手册
-免费赠送多本优质 PDF 面试手册。
+进入星球就免费赠送多本优质 PDF 面试手册。
-
+
### 优质精华主题沉淀
@@ -60,9 +105,15 @@ star: 2
-
+并且,每个月都会整理出当月优质的主题,方便大家阅读学习,避免错过优质的内容。毫不夸张,单纯这些优质主题就足够门票价值了。
-加入星球之后,记得抽时间把星球精华主题看看,相信你一定会有所收货!
+
+
+加入星球之后,一定要记得抽时间把星球精华主题看看,相信你一定会有所收货!
+
+JavaGuide 知识星球优质主题汇总传送门:
+
+这句话表面上看似有道理,但实际上却暴露了一个人的**无知和偏执**。
+
+**知识越贫乏的人,相信的东西就越绝对**,因为他们从未认真了解过与自己观点相对立的角度,也缺乏对技术发展的全局认识。
+
+举个例子,我刚开始学习 Java 后端开发的时候,完全没什么经验,就随便买了一本书开始看。当时看的是 **《Java Web 整合开发王者归来》** 这本书(梦开始的地方)。
+
+在我上大学那会儿,这本书的很多内容其实已经过时了,比如它花了大量篇幅介绍 JSP、Struts、Hibernate、EJB 和 SVN 等技术。不过,直到现在,我依然非常感谢这本书,带我走进了 Java 后端开发的大门。
+
+
+
+这本书一共 **1010** 页,我当时可以说是废寝忘食地学,花了很长时间才把整本书完全“啃”下来。
+
+回头来看,我如果能有意识地避免学习这些已经淘汰的技术,真的可以节省大量时间去学习更加主流和实用的内容。
+
+那么,这些被淘汰的技术有用吗?说句实话,**屁用没有,纯粹浪费时间**。
+
+**既然都要花时间学习,为什么不去学那些更主流、更有实际价值的技术呢?**
+
+现在本身就很卷,不管是 Java 方向还是其他技术方向,要学习的技术都很多。
+
+想要理解所谓的“底层思想”,与其浪费时间在 JSP 这种已经不具备实际应用价值的技术上,不如深入学习一下 Servlet,研究 Spring 的 AOP 和 IoC 原理,从源码角度理解 Spring MVC 的工作机制。
+
+这些内容,不仅能帮助你掌握核心的思想,还能在实际开发中真正派上用场,这难道不比花大量时间在 JSP 上更有意义吗?
+
+## 还有公司在用的技术就要学吗?
+
+我把这篇文章的相关言论发表在我的[公众号](https://mp.weixin.qq.com/s/lf2dXHcrUSU1pn28Ercj0w)之后,又收到另外一类在我看来非常傻叉的言论:
+
+- “虽然 JSP 很老了,但还是得学学,会用就行,因为我们很多老项目还在用。”
+- “很多央企和国企的老项目还在用,肯定得学学啊!”
+
+这种观点完全是钻牛角尖!如果按这种逻辑,那你还需要去学 Struts2、SVN、JavaFX 等过时技术,因为它们也还有公司在用。我有一位大学同学毕业后去了武汉的一家国企,写了一年 JavaFX 就受不了跑了。他在之前从来没有接触过 JavaFX,招聘时也没被问过相关问题。
+
+一定不要假设自己要面对的是过时技术栈的项目。你要找工作肯定要用主流技术栈去找,还要尽量找能让自己技术有成长,干着也舒服点。真要是找不到合适的工作,去维护老项目,那都是后话,现学现卖就行了。
+
+**对于初学者来说别人劝了还非要学习淘汰的技术,多少脑子有点不够用,基本可以告别这一行了!**
diff --git a/docs/about-the-author/dog-that-copies-other-people-essay.md b/docs/about-the-author/dog-that-copies-other-people-essay.md
index cf849132759..2ae67150843 100644
--- a/docs/about-the-author/dog-that-copies-other-people-essay.md
+++ b/docs/about-the-author/dog-that-copies-other-people-essay.md
@@ -1,5 +1,6 @@
---
title: 抄袭狗,你冬天睡觉脚必冷!!!
+description: 原创文章被抄袭的无奈经历,知乎、CSDN多平台盗文现象吐槽,分享如何屏蔽低质量内容和维护原创权益。
category: 走近作者
tag:
- 杂谈
@@ -9,23 +10,23 @@ tag:
听朋友说我的文章在知乎又被盗了,原封不动地被别人用来引流。
-
+
而且!!!这还不是最气的。
这人还在文末注明的原出处还不是我的。。。
-
+
也就是说 CSDN 有另外一位抄袭狗盗了我的这篇文章并声明了原创,知乎抄袭狗又原封不动地搬运了这位 CSDN 抄袭狗的文章。
真可谓离谱他妈给离谱开门,离谱到家了。
-
+
我打开知乎抄袭狗注明的原出处链接,好家伙,一模一样的内容,还表明了原创。
-
+
看了一下 CSDN 这位抄袭狗的文章,好家伙,把我高赞回答搬运了一个遍。。。真是很勤奋了。。。
@@ -33,7 +34,7 @@ CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范
像我自己平时用 Google 搜索的时候,都是直接屏蔽掉 CSDN 这个站点的。只需要下载一个叫做 Personal Blocklist 的 Chrome 插件,然后将 blog.csdn.net 添加进黑名单就可以了。
-
+
我的文章基本被盗完了,关键是我自己发没有什么流量,反而是盗我文章的那些人比我这个原作者流量还大。
@@ -43,7 +44,7 @@ CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范
看看 CSDN 热榜上的文章都是一些什么垃圾,不是各种广告就是一些毫无质量的拼凑文。
-
+
当然了,也有极少部分的高质量文章,比如涛哥、二哥、冰河、微观技术等博主的文章。
@@ -51,6 +52,6 @@ CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范
今天提到的这篇被盗的文章曾经就被一个培训机构拿去做成了视频用来引流。
-
+
作为个体,咱也没啥办法,只能遇到一个举报一个。。。
diff --git a/docs/about-the-author/feelings-after-one-month-of-induction-training.md b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
index 8ecb6eac455..8ea32dd5c74 100644
--- a/docs/about-the-author/feelings-after-one-month-of-induction-training.md
+++ b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
@@ -1,5 +1,6 @@
---
title: 入职培训一个月后的感受
+description: ThoughtWorks入职培训一个月感受,从Windows切换到Mac的适应、TWU培训内容、Feedback反馈文化等新人入职体验分享。
category: 走近作者
tag:
- 个人经历
@@ -15,7 +16,7 @@ ThoughtWorks 非常提倡分享、提倡帮助他人成长,这一点在公司
另外,ThoughtWorks 也是一家非常提倡 Feedback (反馈) 文化的公司,反馈是告诉人们我们对他们的表现的看法以及他们应该如何更好地做到这一点。刚开始我并没有太在意,慢慢地自己确实感觉到正确的进行反馈对他人会有很大的帮助。因为人在做很多事情的时候,会很难发现别人很容易看到的一些小问题。就比如一个很有趣的现象一样,假如我们在做项目的时候没有测试这个角色,如果你完成了自己的模块,并且自己对这个模块测试了很多遍,你发现已经没啥问题了。但是,到了实际使用的时候会很大概率出现你之前从来没有注意的问题。解释这个问题的说法是:每个人的视野或多或少都是有盲点的,这与我们的关注点息息相关。对于自己做的东西,很多地方自己测试很多遍都不会发现,但是如果让其他人帮你进行测试的话,就很大可能会发现很多显而易见的问题。
-
+
工作之后,平时更新公众号、专栏还有维护 Github 的时间变少了。实际上,很多时候下班回来后,都有自己的时间来干自己的事情,但是自己也总是找工作太累或者时间比较零散的接口来推掉了。到了今天,翻看 Github 突然发现 14 天前别人在 Github 上给我提的 PR 我还没有处理。这一点确实是自己没有做好的地方,没有合理安排好自己的时间。实际上自己有很多想写的东西,后面会慢慢将他们提上日程。工作之后,更加发现下班后的几个小时如何度过确实很重要 ,如果你觉得自己没有完成好自己白天该做的工作的话,下班后你可以继续忙白天没有忙完的工作,如果白天的工作对于你游刃有余的话,下班回来之后,你大可去干自己感兴趣的事情,学习自己感兴趣的技术。做任何事情都要基于自身的基础,切不可好高骛远。
diff --git a/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md b/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
index 327715f2b73..d737f1a10b4 100644
--- a/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
+++ b/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
@@ -1,5 +1,6 @@
---
title: 从毕业到入职半年的感受
+description: 应届生入职半年的工作感受,CRUD业务代码的价值、技术积累靠工作之余、从学校到职场的转变心得分享。
category: 走近作者
tag:
- 个人经历
@@ -46,10 +47,8 @@ tag:
还没完成的:
1. Kafka 高级特性比如工作流程、Kafka 为什么快等等的分析;
-
2. 源码阅读分析;
-
-3. ......
+3. ……
**所以,我觉得技术的积累和沉淀很大程度在乎工作之外的时间(大佬和一些本身就特别厉害的除外)。**
diff --git a/docs/about-the-author/internet-addiction-teenager.md b/docs/about-the-author/internet-addiction-teenager.md
index d4a34b8fc27..82788023c3c 100644
--- a/docs/about-the-author/internet-addiction-teenager.md
+++ b/docs/about-the-author/internet-addiction-teenager.md
@@ -1,11 +1,12 @@
---
title: 我曾经也是网瘾少年
+description: 从网瘾少年到程序员的成长经历,初中沉迷游戏、高中觉醒奋起直追、高考失眠的真实故事,分享如何克服网瘾专注学习。
category: 走近作者
tag:
- 个人经历
---
-> 这篇文章写入 2021 年高考前夕。
+> 这篇文章写于 2021 年高考前夕。
聊到高考,无数人都似乎有很多话说。今天就假借高考的名义,简单来聊聊我的高中求学经历吧!
@@ -19,7 +20,11 @@ tag:
最开始接触电脑是在我刚上五年级的时候,那时候家里没电脑,刚开始上网都是在黑网吧玩的。
-在黑网吧上网的经历也是一波三折,经常会遇到警察来检查或者碰到大孩子骚扰。在黑网吧上网的一年多中,我一共两次碰到警察来检查,主要是看有没有未成年人(当时黑网吧里几乎全是未成年人),实际感觉像是要问黑网吧老板要点好处。碰到大孩子骚扰的次数就比较多,大孩子经常抢我电脑,还威胁我把身上所有的钱给他们。我当时一个人也比较怂,被打了几次之后,就尽量避开大孩子来玩的时间去黑网吧,身上也只带很少的钱。小时候的性格就比较独立,在外遇到事情我一般也不会给家里人说。
+黑网吧大概就是下面这样式儿的,一个没有窗户的房间里放了很多台老式电脑,非常拥挤。
+
+
+
+在黑网吧上网的经历也是一波三折,经常会遇到警察来检查或者碰到大孩子骚扰。在黑网吧上网的一年多中,我一共两次碰到警察来检查,主要是看有没有未成年人(当时黑网吧里几乎全是未成年人),实际感觉像是要问黑网吧老板要点好处。碰到大孩子骚扰的次数就比较多,大孩子经常抢我电脑,还威胁我把身上所有的钱给他们。我当时一个人也比较怂,被打了几次之后,就尽量避开大孩子来玩的时间去黑网吧,身上也只带很少的钱。小时候的性格就比较独立,在外遇到事情我一般也不会给家里人说(因为说了也没什么用,家人给我的安全感很少)。
我现在已经记不太清当时是被我哥还是我姐带进网吧的,好像是我姐。
@@ -57,6 +62,10 @@ QQ 飞车这款戏当时还挺火的,很多 90 后的小伙伴应该比较熟
我的最终军衔停留在了两个钻石,玩过的小伙伴应该清楚这在当时要玩多少把(现在升级比较简单)。
+
+
+ps: 回坑 CF 快一年了,目前的军衔是到了两颗星中校 3 了。
+
那时候成绩挺差的。这样说吧!我当时在很普通的一个县级市的高中,全年级有 500 来人,我基本都是在 280 名左右。而且,整个初二我都没有学物理,上物理课就睡觉,考试就交白卷。
为什么对物理这么抵触呢?这是因为开学不久的一次物理课,物理老师误会我在上课吃东西还狡辩,扇了我一巴掌。那时候心里一直记仇到大学,想着以后自己早晚有时间把这个物理老师暴打一顿。
@@ -81,6 +90,8 @@ QQ 飞车这款戏当时还挺火的,很多 90 后的小伙伴应该比较熟
## 高中从小班掉到平行班
+
+
由于参加了高中提前招生考试,我提前 4 个月就来到了高中,进入了小班,开始学习高中的课程。
上了高中的之后,我上课就偷偷看小说,神印王座、斗罗大陆、斗破苍穹很多小说都是当时看的。中午和晚上回家之后,就在家里玩几把 DNF。当时家里也买了电脑,姥爷给买的,是对自己顺利进入二中的奖励。到我卸载 DNF 的时候,已经练了 4 个满级的号,两个接近满级的号。
@@ -117,9 +128,11 @@ QQ 飞车这款戏当时还挺火的,很多 90 后的小伙伴应该比较熟

-高考那几天的失眠,我觉得可能和我喝了老师推荐的安神补脑液有关系,又或者是我自己太过于紧张了。因为那几天睡觉总会感觉有很多蚂蚁在身上爬一样,身上还起了一些小痘痘。
+高考那几天的失眠,我觉得可能和我喝了老师推荐的安神补脑液有关系,又或者是我自己太过于紧张了。因为那几天睡觉总会感觉有很多蚂蚁在身上爬一样,身上还起了一些小痘痘(有点像是过敏)。
+
+这里要格外说明一点,避免引起误导:**睡不着本身就是自身的问题,上述言论并没有责怪这个补脑液的意思。** 另外, 这款安神补脑液我去各个平台都查了一下,发现大家对他的评价都挺好,和我们老师当时推荐的理由差不多。如果大家需要改善睡眠的话,可以咨询相关医生之后尝试一下。
-然后,这里要格外说明一点,避免引起误导:**睡不着本身就是自身的问题,上述言论并没有责怪这个补脑液的意思。** 另外, 这款安神补脑液我去各个平台都查了一下,发现大家对他的评价都挺好,和我们老师当时推荐的理由差不多。如果大家需要改善睡眠的话,可以咨询相关医生之后尝试一下。
+高考也确实没发挥好,整个人在考场都是懵的状态。高考成绩出来之后,比我自己预估的还低了几十分,最后只上了一个双非一本。不过,好在专业选的好,吃了一些计算机专业的红利,大学期间也挺努力的。
## 大学生活
diff --git a/docs/about-the-author/javaguide-100k-star.md b/docs/about-the-author/javaguide-100k-star.md
index e89060dbe27..da851386ee9 100644
--- a/docs/about-the-author/javaguide-100k-star.md
+++ b/docs/about-the-author/javaguide-100k-star.md
@@ -1,5 +1,6 @@
---
title: JavaGuide 开源项目 100K Star 了!
+description: JavaGuide开源项目达成100K Star里程碑,从2018年创建到突破十万星标的复盘总结,分享开源维护心得与未来规划。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md b/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
index 91201ccec76..67306b969fa 100644
--- a/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
+++ b/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
@@ -1,5 +1,6 @@
---
title: 某培训机构盗我文章做成视频还上了B站热门
+description: 原创文章被培训机构盗用制作成B站视频的维权经历,揭露培训机构剽窃原创引流的套路,呼吁尊重原创内容。
category: 走近作者
tag:
- 杂谈
@@ -15,19 +16,19 @@ tag:
麻烦这个培训机构看到这篇文章之后可以考虑换一个人做类似恶心的事情哈!这人完全没脑子啊!
-
+
-
+
-
+
-
+
我随便找了一个视频看,发现也还是盗用别人的原创。
-
+
-
+
其他的视频就不用多看了,是否还是剽窃别人的原创,原封不动地做成视频,大家心里应该有数。
@@ -49,7 +50,7 @@ tag:
谁能想到,培训机构的人竟然找人来让我删文章了!讲真,这俩人是真的奇葩啊!
-
+

diff --git a/docs/about-the-author/my-college-life.md b/docs/about-the-author/my-college-life.md
index a24e899eea4..4df47ca785d 100644
--- a/docs/about-the-author/my-college-life.md
+++ b/docs/about-the-author/my-college-life.md
@@ -1,5 +1,6 @@
---
title: 害,毕业三年了!
+description: 双非一本程序员的大学四年,从参加社团活动到办补习班赚钱、确定Java后端方向、创建JavaGuide、最终拿到ThoughtWorks offer的真实经历。
category: 走近作者
star: 1
tag:
@@ -372,7 +373,7 @@ tag:
6. 管理自己的身材,没事去跑跑步,别当油腻男。
7. 别太看重绩点。我觉得绩点对于找工作还有考研实际的作用都可以忽略不计,不过不挂科还是比较重要的。但是,绩点确实在奖学金评选和保研名额选取上占有最大的分量。
8. 别太功利性。做事情以及学习知识都不要奢求它能立马带给你什么,坚持和功利往往是成反比的。
-9. ......
+9. ……
## 后记
diff --git a/docs/about-the-author/writing-technology-blog-six-years.md b/docs/about-the-author/writing-technology-blog-six-years.md
index 9e18a67d8c4..b03faf75e76 100644
--- a/docs/about-the-author/writing-technology-blog-six-years.md
+++ b/docs/about-the-author/writing-technology-blog-six-years.md
@@ -1,5 +1,6 @@
---
title: 坚持写技术博客六年了!
+description: 坚持写技术博客六年的心得分享,写博客的好处、如何坚持下去、写哪些方向的博客、实用写作技巧等经验总结。
category: 走近作者
tag:
- 杂谈
diff --git a/docs/about-the-author/zhishixingqiu-two-years.md b/docs/about-the-author/zhishixingqiu-two-years.md
index 9ca1fa7ddbd..f1f7885390a 100644
--- a/docs/about-the-author/zhishixingqiu-two-years.md
+++ b/docs/about-the-author/zhishixingqiu-two-years.md
@@ -1,58 +1,103 @@
---
-title: 我的知识星球快 3 岁了!
+title: 我的知识星球 6 岁了!
+description: JavaGuide知识星球介绍,提供Java面试指北专栏、简历修改、一对一答疑等服务,已帮助9000+球友提升求职竞争力。
category: 知识星球
star: 2
---
-
+在 **2019 年 12 月 29 号**,经过了大概一年左右的犹豫期,我正式确定要开始做一个自己的星球,帮助学习 Java 和准备 Java 面试的同学。一转眼,已经六年了。感谢大家一路陪伴,我会信守承诺,继续认真维护这个纯粹的 Java 知识星球,不让信任我的读者失望。
-时间过的真快,知识星球我已经平稳运行了 3 年有余了!
+
-在 2019 年 12 月 29 号,经过了大概一年左右的犹豫期,我正式确定要开始做一个自己的星球。
+我是比较早一批做星球的技术号主,也是坚持做下来的那一少部人(大部分博主割一波韭菜就不维护星球了)。最开始的一两年,纯粹靠爱发电。当初定价非常低(一顿饭钱),加上刚工作的时候比较忙,提供的服务也没有现在这么多。
-
-
-截止到今天,星球已经有 1.3w+ 的同学加入。虽然比不上很多大佬,但这于我来说也算是小有成就了,真的很满足了!我确信自己是一个普通人,能做成这些,也不过是在兴趣和运气的加持下赶上了时代而已。
+慢慢的价格提上来,星球的收入确实慢慢也上来了。不过,考虑到我的受众主要是学生,定价依然比同类星球低很多。另外,我也没有弄训练营的打算,虽然训练营对于我这个流量来说可以赚到更多钱。
**我有自己的原则,不割韭菜,用心做内容,真心希望帮助到他人!**
-## 什么是知识星球?
+## 我的知识星球评价如何?
+
+知识星球是一个私密、长期的知识社群,用来连接创作者和铁杆读者。相比微信群,它更适合沉淀内容、做系统化的学习和信息管理。
+
+下面是今年收到了部分好评,每一条都是真实存在的。我看到很多培训班或者机构通过虚构一些不存在的好评来欺骗他人购买高价服务(行业内非常常见),真的很难理解。
+
+
+
+在这里,不只有理论,更有具体、可落地的求职/转行指导:
-简单来说,知识星球就是一个私密交流圈子,主要用途是知识创作者连接铁杆读者/粉丝。相比于微信群,知识星球内容沉淀、信息管理更高效。
+- 有球友入球后,在多次一对一建议下,很快就收到了美国大模型应用开发的面试并通过;
+- 有球友在指导下顺利转行,拿到满意的中厂 Offer。
-
+不少球友评价我是“良心博主”:深夜 11 点多还在帮忙改简历、给建议;对非科班、大龄转行等焦虑问题,也会耐心一一解答,做到有问必回。
+
+口碑是最好的证明!这里有连续续费三年的老球友,也有因为信任而把星球推荐给弟弟妹妹的朋友。
+
+下面是部分球友今年的求职战绩分享(只是一小部分,有校招,也有社招),同样完全真实。每年面试季之后,星球就有大量的球友询问 offer 如何选择。
+
+
## 我的知识星球能为你提供什么?
-努力做一个最优质的 Java 面试交流星球!加入到我的星球之后,你将获得:
+致力于打造最优质的 Java 面试交流星球(后端面试通用)!加入我们,你将获得远超票价的一站式成长服务:
+
+💎 **核心面试求职服务**
+
+- **简历深度精修**:提供免费的一对一简历修改服务(已累计帮助 **9000+** 位球友,好评如潮)。
+- **6 大精品专栏**:永久阅读权限,内容涵盖高频面试题、源码解析、实战项目,构建完整知识体系。
+- **独家面试手册**:多本原创 PDF 后端面试手册免费领取,全网独家。
+- **有问必答**:一对一免费提问,提供专属求职指南,拒绝焦虑。
-1. 6 个高质量的专栏永久阅读,内容涵盖面试,源码解析,项目实战等内容!价值远超门票!
-2. 多本原创 PDF 版本面试手册。
-3. 免费的简历修改服务(已经累计帮助 4000+ 位球友修改简历)。
-4. 一对一免费提问交流(专属建议,走心回答)。
-5. 专属求职指南和建议,帮助你逆袭大厂!
-6. 海量 Java 优质面试资源分享!价值远超门票!
-7. 读书交流,学习交流,让我们一起努力创造一个纯粹的学习交流社区。
-8. 不定期福利:节日抽奖、送书送课、球友线下聚会等等。
-9. ......
+**🚀 实战项目**
-其中的任何一项服务单独拎出来价值都远超星球门票了。
+星球已经推出的实战项目如下:
+
+- [⭐AI 智能面试辅助平台 + RAG 知识库](https://javaguide.cn/zhuanlan/interview-guide.html):基于 Spring Boot 4.0 + Java 21 + Spring AI 2.0 开发。非常适合作为学习和简历项目,学习门槛低,帮助提升求职竞争力,是主打就业的实战项目。
+- [手写 RPC 框架](https://javaguide.cn/zhuanlan/handwritten-rpc-framework.html):从零开始基于 Netty+Kyro+Zookeeper 实现一个简易的 RPC 框架。麻雀虽小五脏俱全,项目代码注释详细,结构清晰。
+
+今年陆续还会推出更多企业级实战案例(预告一下,下一个是大家期待的:**企业智能客服**)!
+
+🔥 **氛围与福利**
+
+- **海量资源**:Java 优质面试资源持续更新分享。
+- **抱团成长**:打卡活动、读书交流、线下聚会,让学习之路不再孤单。
+- **惊喜福利**:不定期节日抽奖、送书送课,福利拿到手软。
+
+💡 **总结**:这里的任何一项服务(尤其是简历修改和面试资料),单独拎出来的价值都已远超星球门票。
+
+目前星球正在做活动,两本书的价格,就能让你拥有上万培训班的服务!
+
+这里再提供一张 **30**元的优惠卷(**价格马上上调,老用户扫码续费半价** ):
+
+
### 专属专栏
星球更新了 **《Java 面试指北》**、**《Java 必读源码系列》**(目前已经整理了 Dubbo 2.6.x、Netty 4.x、SpringBoot2.1 的源码)、 **《从零开始写一个 RPC 框架》**(已更新完)、**《Kafka 常见面试题/知识点总结》** 等多个优质专栏。
-
+
《Java 面试指北》内容概览:
-
+
+
+进入星球之后,这些专栏即可免费永久阅读,永久同步更新!
+
+### 实战项目
+
+星球已经推出的实战项目如下:
+
+- [⭐AI 智能面试辅助平台 + RAG 知识库](https://javaguide.cn/zhuanlan/interview-guide.html):基于 Spring Boot 4.0 + Java 21 + Spring AI 2.0 开发。非常适合作为学习和简历项目,学习门槛低,帮助提升求职竞争力,是主打就业的实战项目。
+- [手写 RPC 框架](https://javaguide.cn/zhuanlan/handwritten-rpc-framework.html):从零开始基于 Netty+Kyro+Zookeeper 实现一个简易的 RPC 框架。麻雀虽小五脏俱全,项目代码注释详细,结构清晰。
+
+今年陆续还会推出更多企业级实战案例!并且,星球还分享了很多高频项目经历的优化版介绍和面试准备(持续更新中)。
+
+
### PDF 面试手册
-免费赠送多本优质 PDF 面试手册。
+进入星球就免费赠送多本优质 PDF 面试手册。
-
+
### 优质精华主题沉淀
@@ -60,9 +105,15 @@ star: 2

-
+并且,每个月都会整理出当月优质的主题,方便大家阅读学习,避免错过优质的内容。毫不夸张,单纯这些优质主题就足够门票价值了。
-加入星球之后,记得抽时间把星球精华主题看看,相信你一定会有所收货!
+
+
+加入星球之后,一定要记得抽时间把星球精华主题看看,相信你一定会有所收货!
+
+JavaGuide 知识星球优质主题汇总传送门: