|
| 1 | +# 队列是什么 |
| 2 | +与栈相似,队列也是一种特殊的线性表,与线性表的不同之处也是体现在对数据的增和删的操作上。 |
| 3 | + |
| 4 | +队列的特点是先进先出: |
| 5 | + |
| 6 | +* 先进,表示队列的数据新增操作只能在末端进行,不允许在队列的中间某个结点后新增数据; |
| 7 | +* 先出,队列的数据删除操作只能在始端进行,不允许在队列的中间某个结点后删除数据。也就是说队列的增和删的操作只能分别在这个队列的队尾和队头进行,如下图所示: |
| 8 | + |
| 9 | + |
| 10 | + |
| 11 | +与线性表、栈一样,队列也存在这两种存储方式,即顺序队列和链式队列: |
| 12 | + |
| 13 | +* 顺序队列,依赖数组来实现,其中的数据在内存中也是顺序存储。 |
| 14 | + |
| 15 | +* 链式队列,依赖链表来实现,其中的数据依赖每个结点的指针互联,在内存中并不是顺序存储。链式队列,实际上就是只能尾进头出的线性表的单链表。 |
| 16 | + |
| 17 | +如下图所示,我们将队头指针指向链队列的头结点,队尾指针指向终端结点。不管是哪种实现方式,一个队列都依赖队头(front)和队尾(rear)两个指针进行唯一确定。 |
| 18 | + |
| 19 | + |
| 20 | + |
| 21 | +当队列为空时,front 和 rear 都指向头结点,如下图所示: |
| 22 | + |
| 23 | + |
| 24 | + |
| 25 | +# 顺序队列的数据操作 |
| 26 | + |
| 27 | +## 增删查处理 |
| 28 | + |
| 29 | +**队列从队头(front)删除元素,从队尾(rear)插入元素**。对于一个顺序队列的数组来说,会设置一个 front 指针来指向队头,并设置另一个 rear 指针指向队尾。当我们不断进行插入删除操作时,头尾两个指针都会不断向后移动。 |
| 30 | + |
| 31 | +为了实现一个有 k 个元素的顺序存储的队列,我们需要建立一个长度比 k 大的数组,以便把所有的队列元素存储在数组中。队列新增数据的操作,就是利用 rear 指针在队尾新增一个数据元素。这个过程不会影响其他数据,时间复杂度为 O(1),状态如下图所示: |
| 32 | + |
| 33 | + |
| 34 | + |
| 35 | +队列删除数据的操作与栈不同。队列元素出口在队列头部,即下标为 0 的位置。当利用 front 指针删除一个数据时,队列中剩余的元素都需要向前移动一个位置,以保证队列头部下标为 0 的位置不为空,此时时间复杂度就变成 O(n) 了,状态如下图所示: |
| 36 | + |
| 37 | + |
| 38 | + |
| 39 | +我们看到,front 指针删除数据的操作引发了时间复杂度过高的问题,那么我们该如何解决呢?我们可以通过移动指针的方式来删除数据,这样就不需要移动剩余的数据了。但是,这样的操作,也可能会产生数组越界的问题。接下来,我们来详细讨论一下。 |
| 40 | + |
| 41 | +我们一起来看一个利用顺序队列,持续新增数据和删除数据的例子。 |
| 42 | + |
| 43 | +初始时,定义了长度为 5 的数组,front 指针和 rear 指针相等,且都指向下标为 0 的位置,队列为空队列。如下图所示: |
| 44 | + |
| 45 | + |
| 46 | + |
| 47 | +当 A、B、C、D 四条数据加入队列后,front 依然指向下标为 0 的位置,而 rear 则指向下标为 4 的位置。 |
| 48 | + |
| 49 | +当 A 出队列时,front 指针指向下标为 1 的位置,rear 保持不变。其后 E 加入队列,front 保持不变,rear 则移动到了数组以外,如下图所示: |
| 50 | + |
| 51 | + |
| 52 | + |
| 53 | +假设这个列队的总个数不超过 5 个,但是目前继续接着入队,因为数组末尾元素已经被占用,再向后加,就会产生我们前面提到的数组越界问题。而实际上,我们列队的下标 0 的地方还是空闲的,这就产生了一种 “假溢出” 的现象。 |
| 54 | + |
| 55 | +这种问题在采用顺序存储的队列时,是一定要小心注意的。两个简单粗暴的解决方法就是: |
| 56 | + |
| 57 | +* 不惜消耗 O(n) 的时间复杂度去移动数据; |
| 58 | + |
| 59 | +* 或者开辟足够大的内存空间确保数组不会越界。 |
| 60 | + |
| 61 | +## 循环队列的数据操作 |
| 62 | + |
| 63 | +很显然上面的两个方法都不太友好。其实,数组越界问题可以通过队列的一个特殊变种来解决,叫作循环队列。 |
| 64 | + |
| 65 | +循环队列进行新增数据元素操作时,首先判断队列是否为满。如果不满,则可以将新元素赋值给队尾,然后让 rear 指针向后移动一个位置。如果已经排到队列最后的位置,则 rea r指针重新指向头部。 |
| 66 | + |
| 67 | +循环队列进行删除操作时,即出队列操作,需要判断队列是否为空,然后将队头元素赋值给返回值,front 指针向后移一个位置。如果已经排到队列最后的位置,就把 front 指针重新指向到头部。这个过程就好像钟表的指针转到了表盘的尾部 12 点的位置后,又重新回到了表盘头部 1 点钟的位置。这样就能在不开辟大量存储空间的前提下,不采用 O(n) 的操作,也能通过移动数据来完成频繁的新增和删除数据。 |
| 68 | + |
| 69 | +我们继续回到前面提到的例子中,如果是循环队列,rear 指针就可以重新指向下标为 0 的位置,如下图所示: |
| 70 | + |
| 71 | + |
| 72 | + |
| 73 | +如果这时再新增了 F 进入队列,就可以放入在下标为 0 的位置,rear 指针指向下标为 1 的位置。这时的 rear 和 front 指针就会重合,指向下标为 1 的位置,如下图所示: |
| 74 | + |
| 75 | + |
| 76 | + |
| 77 | +此时,又会产生新的问题,即当队列为空时,有 front 指针和 rear 指针相等。而现在的队列是满的,同样有 front 指针和 rear 指针相等。那么怎样判断队列到底是空还是满呢?常用的方法是,设置一个标志变量 flag 来区别队列是空还是满。 |
| 78 | + |
| 79 | +# 链式队列的数据操作 |
| 80 | +链式队列就是一个单链表,同时增加了 front 指针和 rear 指针。链式队列和单链表一样,通常会增加一个头结点,并将 front 指针指向头结点。头结点不存储数据,只是用来辅助标识。 |
| 81 | + |
| 82 | +链式队列进行新增数据操作时,将拥有数值 X 的新结点 s 赋值给原队尾结点的后继,即 rear.next。然后把当前的 s 设置为队尾结点,指针 rear 指向 s。如下图所示: |
| 83 | + |
| 84 | + |
| 85 | + |
| 86 | +当链式队列进行删除数据操作时,实际删除的是头结点的后继结点。这是因为头结点仅仅用来标识队列,并不存储数据。因此,出队列的操作,就需要找到头结点的后继,这就是要删除的结点。接着,让头结点指向要删除结点的后继。 |
| 87 | + |
| 88 | +特别值得一提的是,如果这个链表除去头结点外只剩一个元素,那么删除仅剩的一个元素后,rear 指针就变成野指针了。这时候,需要让 rear 指针指向头结点。也许你前面会对头结点存在的意义产生怀疑,似乎没有它也不影响增删的操作。那么为何队列还特被强调要有头结点呢? |
| 89 | + |
| 90 | +这主要是为了防止删除最后一个有效数据结点后, front 指针和 rear 指针变成野指针,导致队列没有意义了。有了头结点后,哪怕队列为空,头结点依然存在,能让 front 指针和 rear 指针依然有意义。 |
| 91 | + |
| 92 | + |
| 93 | + |
| 94 | +对于队列的查找操作,不管是顺序还是链式,队列都没有额外的改变。跟线性表一样,它也需要遍历整个队列来完成基于某些条件的数值查找。因此时间复杂度也是 O(n)。 |
| 95 | + |
| 96 | +# 队列的案例 |
| 97 | + |
| 98 | +## 约瑟夫环问题 |
| 99 | + |
| 100 | +约瑟夫环是一个数学的应用问题,具体为,已知 n 个人(以编号 1,2,3...n 分别表示)围坐在一张圆桌周围。从编号为 k 的人开始报数,数到 m 的那个人出列;他的下一个人又从 1 开始报数,数到 m 的那个人又出列;依此规律重复下去,直到圆桌周围的人全部出列。这个问题的输入变量就是 n 和 m,即 n 个人和数到 m 的出列的人。输出的结果,就是 n 个人出列的顺序。 |
| 101 | + |
| 102 | +这个问题,用队列的方法实现是个不错的选择。它的结果就是出列的顺序,恰好满足队列对处理顺序敏感的前提。因此,求解方式也是基于队列的先进先出原则。解法如下: |
| 103 | + |
| 104 | +1. 先把所有人都放入循环队列中。注意这个循环队列的长度要大于或者等于 n。 |
| 105 | + |
| 106 | +2. 从第一个人开始依次出队列,出队列一次则计数变量 i 自增。如果 i 比 m 小,则还需要再入队列。 |
| 107 | + |
| 108 | +3. 直到i等于 m 的人出队列时,就不用再让这个人进队列了。而是放入一个用来记录出队列顺序的数组中。 |
| 109 | + |
| 110 | +4. 直到数完 n 个人为止。当队列为空时,则表示队列中的 n 个人都出队列了,这时结束队列循环,输出数组内记录的元素。 |
| 111 | + |
| 112 | +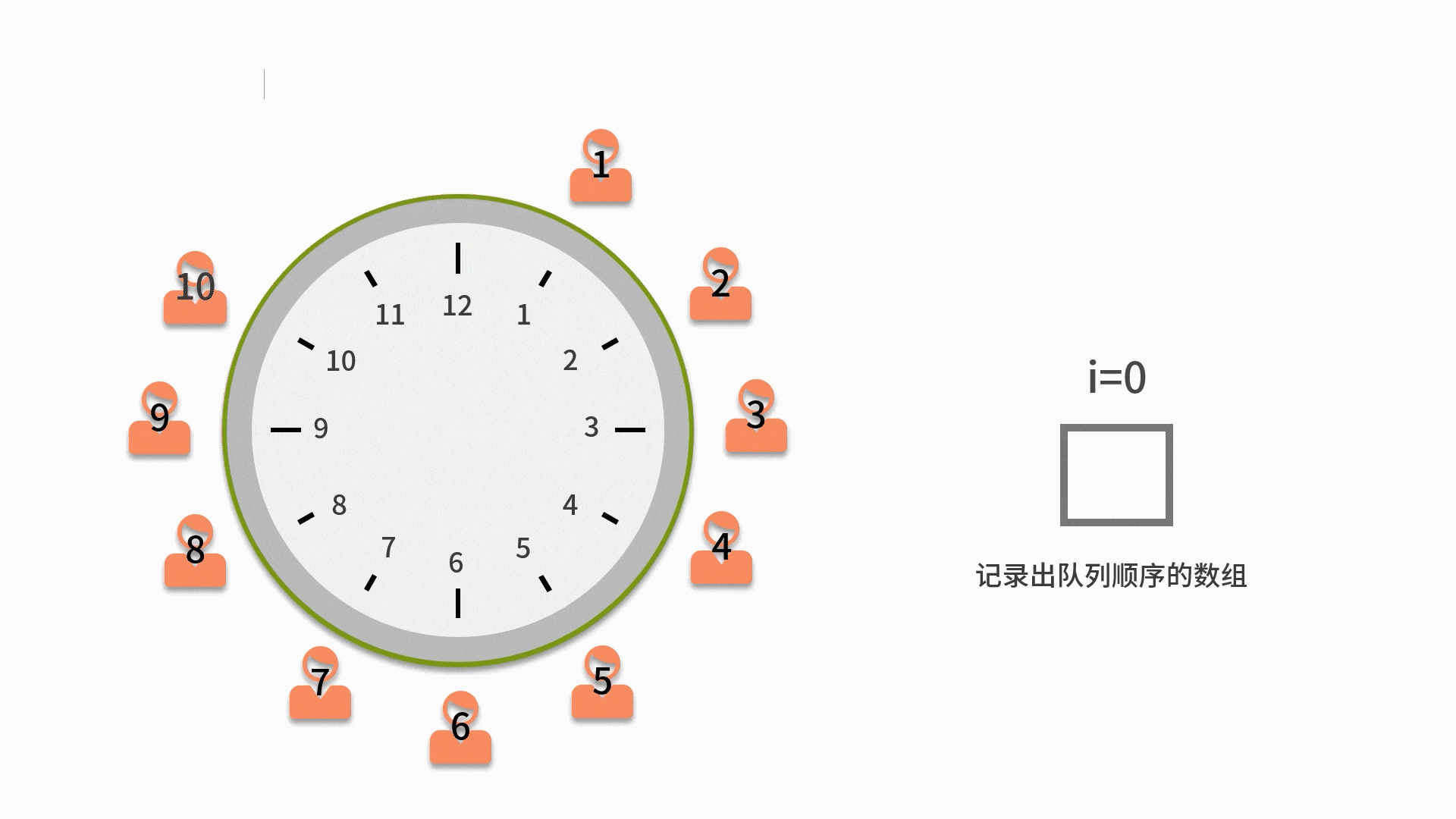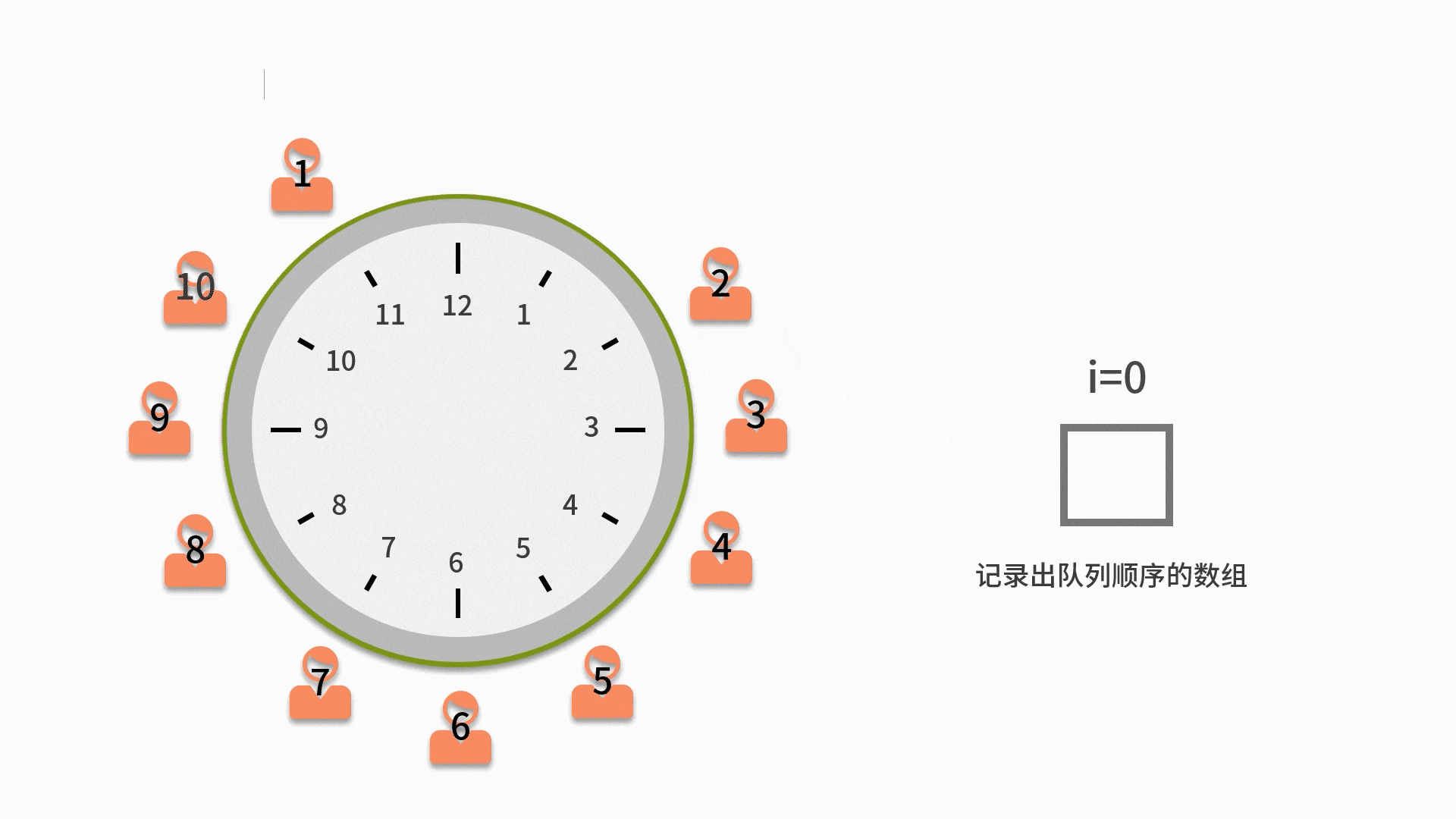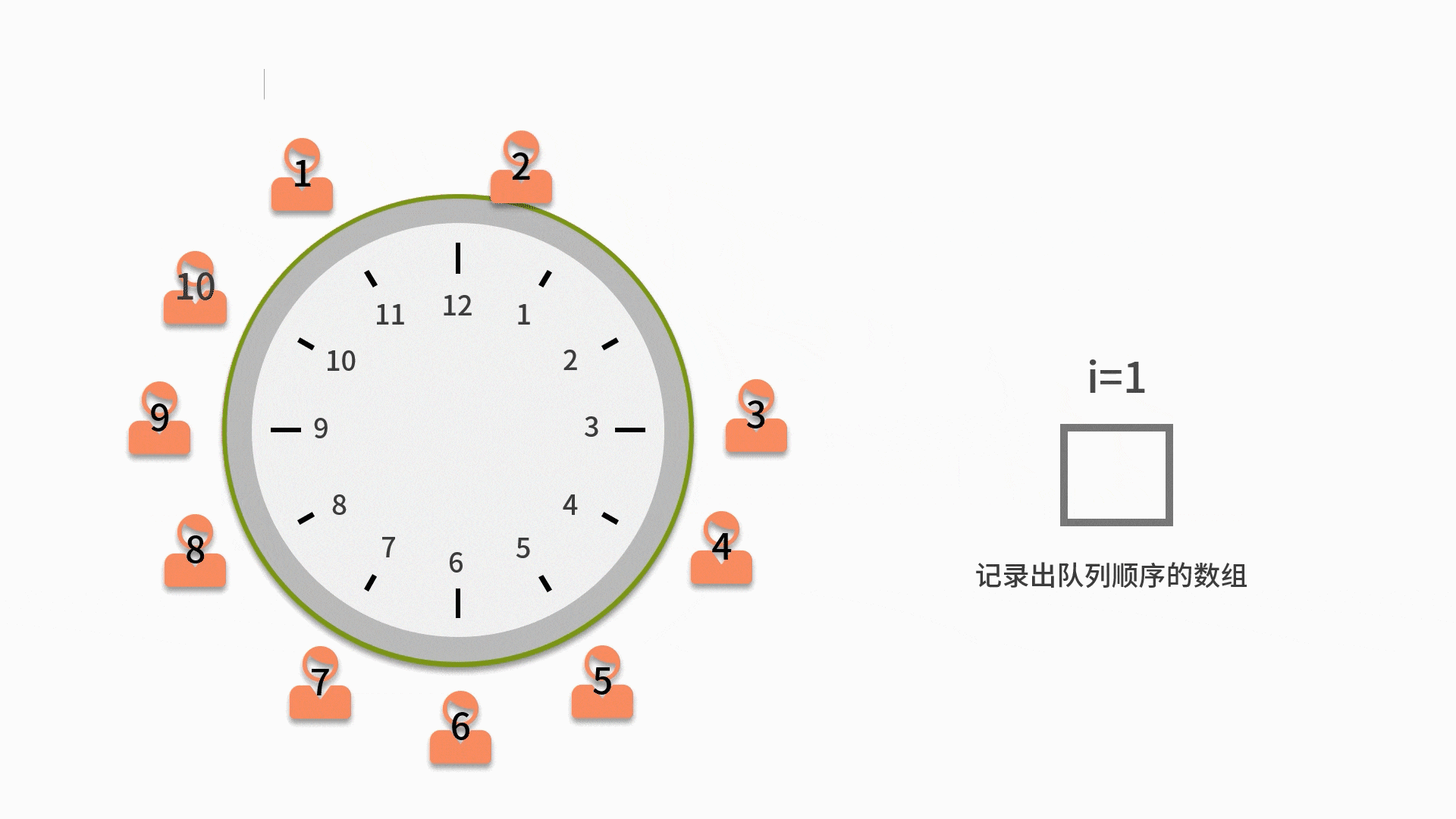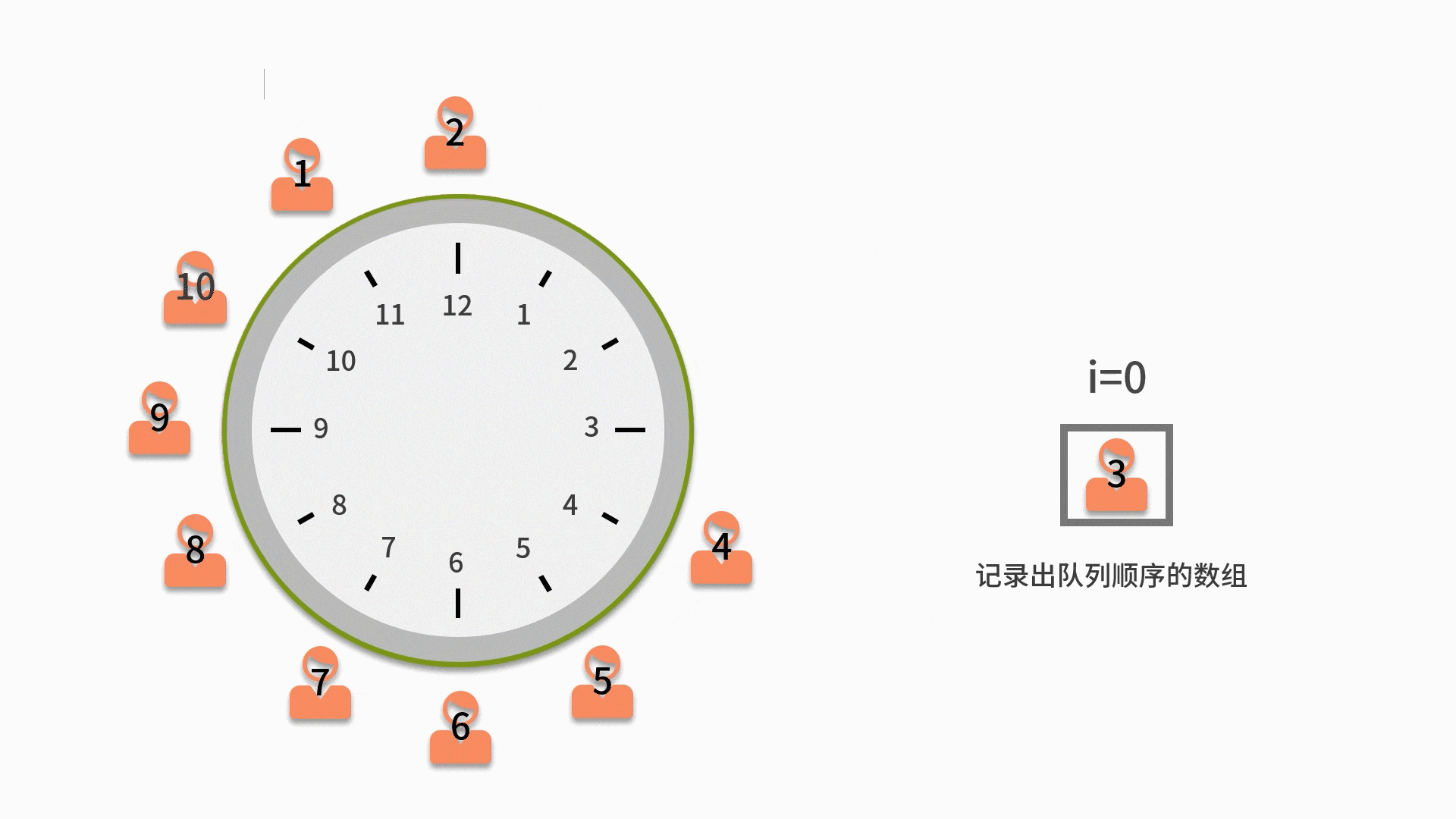 |
| 113 | + |
| 114 | +```java |
| 115 | +public class Josephus { |
| 116 | + public static void main(String[] args) { |
| 117 | + Josephus jp = new Josephus(); |
| 118 | + jp.josephus(10,3); |
| 119 | + } |
| 120 | + public void josephus(int length,int target){ |
| 121 | + LoopQueue<Integer> josephusCycle = new LoopQueue<Integer>(); |
| 122 | + int[] dequeueArray = new int[length]; |
| 123 | + int josephusIndex = 1; |
| 124 | + int arrayIndex = 0; |
| 125 | + //将每个序号压入栈中 |
| 126 | + for (int i=1; i<=length; i++){ |
| 127 | + josephusCycle.enqueue(i); |
| 128 | + } |
| 129 | + while (josephusCycle.size() != 1){ |
| 130 | + //将序号从队列弹出,如果刚好是目标序号,则只弹出而不压回队列中 |
| 131 | + if (josephusIndex == target){ |
| 132 | + Integer result = josephusCycle.dequeue(); |
| 133 | + dequeueArray[arrayIndex] = result; |
| 134 | + arrayIndex++; |
| 135 | + josephusIndex = 1; |
| 136 | + }else { |
| 137 | + Integer next = josephusCycle.dequeue(); |
| 138 | + josephusCycle.enqueue(next); |
| 139 | + josephusIndex++; |
| 140 | + } |
| 141 | + } |
| 142 | + dequeueArray[arrayIndex] = josephusCycle.dequeue(); |
| 143 | + for (int index:dequeueArray){ |
| 144 | + System.out.println(index); |
| 145 | + } |
| 146 | + } |
| 147 | +} |
| 148 | +``` |
| 149 | + |
| 150 | +**LoopQueue** |
| 151 | + |
| 152 | +```java |
| 153 | +package queue; |
| 154 | + |
| 155 | +import java.util.Arrays; |
| 156 | +import java.util.Collection; |
| 157 | +import java.util.Iterator; |
| 158 | +import java.util.Queue; |
| 159 | + |
| 160 | +/** |
| 161 | + * @Package queue |
| 162 | + * @ClassName LoopQueue |
| 163 | + * @Description TODO |
| 164 | + * @Date 20/6/28 10:34 |
| 165 | + * @Author krislin |
| 166 | + * @Version V1.0 |
| 167 | + */ |
| 168 | +public class LoopQueue<E> implements Queue<E> { |
| 169 | + /** |
| 170 | + * 承载队列元素的数组 |
| 171 | + */ |
| 172 | + private E[] data; |
| 173 | + /** |
| 174 | + * 队首的位置 |
| 175 | + */ |
| 176 | + private int front; |
| 177 | + /** |
| 178 | + * 队尾的位置 |
| 179 | + */ |
| 180 | + private int tail; |
| 181 | + /** |
| 182 | + * 队列中元素的个数 |
| 183 | + */ |
| 184 | + private int size; |
| 185 | + |
| 186 | + /** |
| 187 | + * 指定容量,初始化队列大小 |
| 188 | + * (由于循环队列需要浪费一个空间,所以我们初始化队列的时候,要将用户传入的容量加1) |
| 189 | + * |
| 190 | + * @param capacity |
| 191 | + */ |
| 192 | + public LoopQueue(int capacity) { |
| 193 | + data = (E[]) new Object[capacity + 1]; |
| 194 | + } |
| 195 | + |
| 196 | + /** |
| 197 | + * 模式容量,初始化队列大小 |
| 198 | + */ |
| 199 | + public LoopQueue() { |
| 200 | + this(10); |
| 201 | + } |
| 202 | + |
| 203 | + |
| 204 | + public void enqueue(E e) { |
| 205 | + // 检查队列为满 |
| 206 | + if ((tail + 1) % data.length == front) { |
| 207 | + // 队列扩容 |
| 208 | + resize(getCapacity() * 2); |
| 209 | + } |
| 210 | + data[tail] = e; |
| 211 | + tail = (tail + 1) % data.length; |
| 212 | + size++; |
| 213 | + } |
| 214 | + |
| 215 | + |
| 216 | + public E dequeue() { |
| 217 | + if (isEmpty()) { |
| 218 | + throw new IllegalArgumentException("队列为空"); |
| 219 | + } |
| 220 | + // 出队元素 |
| 221 | + E element = data[front]; |
| 222 | + // 元素出队后,将空间置为null |
| 223 | + data[front] = null; |
| 224 | + // 维护front的索引位置(循环队列) |
| 225 | + front = (front + 1) % data.length; |
| 226 | + // 维护size大小 |
| 227 | + size--; |
| 228 | + |
| 229 | + // 元素出队后,可以指定条件,进行缩容 |
| 230 | + if (size == getCapacity() / 2 && getCapacity() / 2 != 0) { |
| 231 | + resize(getCapacity() / 2); |
| 232 | + } |
| 233 | + return element; |
| 234 | + } |
| 235 | + |
| 236 | + public E getFront() { |
| 237 | + if (isEmpty()) { |
| 238 | + throw new IllegalArgumentException("队列为空"); |
| 239 | + } |
| 240 | + return data[front]; |
| 241 | + } |
| 242 | + |
| 243 | + public int getSize() { |
| 244 | + return size; |
| 245 | + } |
| 246 | + |
| 247 | + @Override |
| 248 | + public int size() { |
| 249 | + return size; |
| 250 | + } |
| 251 | + |
| 252 | + @Override |
| 253 | + public boolean isEmpty() { |
| 254 | + return front == tail; |
| 255 | + } |
| 256 | + |
| 257 | + @Override |
| 258 | + public boolean contains(Object o) { |
| 259 | + return false; |
| 260 | + } |
| 261 | + |
| 262 | + @Override |
| 263 | + public Iterator<E> iterator() { |
| 264 | + return null; |
| 265 | + } |
| 266 | + |
| 267 | + @Override |
| 268 | + public Object[] toArray() { |
| 269 | + return new Object[0]; |
| 270 | + } |
| 271 | + |
| 272 | + @Override |
| 273 | + public <T> T[] toArray(T[] a) { |
| 274 | + return null; |
| 275 | + } |
| 276 | + |
| 277 | + |
| 278 | + /** |
| 279 | + * 队列快满时,队列扩容;元素出队操作,指定条件可以进行缩容 |
| 280 | + * @param newCapacity |
| 281 | + */ |
| 282 | + private void resize(int newCapacity) { |
| 283 | + // 这里的加1还是因为循环队列我们在实际使用的过程中要浪费一个空间 |
| 284 | + E[] newData = (E[]) new Object[newCapacity + 1]; |
| 285 | + for (int i = 0; i < size; i++) { |
| 286 | + // 注意这里的写法:因为在数组中,front 可能不是在索引为0的位置,相对于i有一个偏移量 |
| 287 | + newData[i] = data[(i + front) % data.length]; |
| 288 | + } |
| 289 | + // 将新的数组引用赋予原数组的指向 |
| 290 | + data = newData; |
| 291 | + // 充值front的位置(front总是指向队列中第一个元素) |
| 292 | + front = 0; |
| 293 | + // size 的大小不变,因为在这过程中,没有元素入队和出队 |
| 294 | + tail = size; |
| 295 | + } |
| 296 | + |
| 297 | + |
| 298 | + private int getCapacity() { |
| 299 | + // 注意:在初始化队列的时候,我们有意识的为队列加了一个空间,那么它的实际容量自然要减1 |
| 300 | + return data.length - 1; |
| 301 | + } |
| 302 | + |
| 303 | + @Override |
| 304 | + public String toString() { |
| 305 | + return "LoopQueue{" + |
| 306 | + "【队首】data=" + Arrays.toString(data) + "【队尾】" + |
| 307 | + ", front=" + front + |
| 308 | + ", tail=" + tail + |
| 309 | + ", size=" + size + |
| 310 | + ", capacity=" + getCapacity() + |
| 311 | + '}'; |
| 312 | + } |
| 313 | + |
| 314 | + @Override |
| 315 | + public boolean add(E e) { |
| 316 | + return false; |
| 317 | + } |
| 318 | + |
| 319 | + @Override |
| 320 | + public boolean remove(Object o) { |
| 321 | + return false; |
| 322 | + } |
| 323 | + |
| 324 | + @Override |
| 325 | + public boolean containsAll(Collection<?> c) { |
| 326 | + return false; |
| 327 | + } |
| 328 | + |
| 329 | + @Override |
| 330 | + public boolean addAll(Collection<? extends E> c) { |
| 331 | + return false; |
| 332 | + } |
| 333 | + |
| 334 | + @Override |
| 335 | + public boolean removeAll(Collection<?> c) { |
| 336 | + return false; |
| 337 | + } |
| 338 | + |
| 339 | + @Override |
| 340 | + public boolean retainAll(Collection<?> c) { |
| 341 | + return false; |
| 342 | + } |
| 343 | + |
| 344 | + @Override |
| 345 | + public void clear() { |
| 346 | + |
| 347 | + } |
| 348 | + |
| 349 | + @Override |
| 350 | + public boolean offer(E e) { |
| 351 | + return false; |
| 352 | + } |
| 353 | + |
| 354 | + @Override |
| 355 | + public E remove() { |
| 356 | + return null; |
| 357 | + } |
| 358 | + |
| 359 | + @Override |
| 360 | + public E poll() { |
| 361 | + return null; |
| 362 | + } |
| 363 | + |
| 364 | + @Override |
| 365 | + public E element() { |
| 366 | + return null; |
| 367 | + } |
| 368 | + |
| 369 | + @Override |
| 370 | + public E peek() { |
| 371 | + return null; |
| 372 | + } |
| 373 | +} |
| 374 | +``` |
| 375 | + |
| 376 | + |
| 377 | + |
| 378 | +# 总结 |
| 379 | + |
| 380 | +了解了队列的基本原理和队列对于数据的增删查的操作。可以发现,队列与栈的特性非常相似,队列也继承了线性表的优点与不足,是加了限制的线性表,队列的增和删的操作只能在这个线性表的头和尾进行。 |
| 381 | + |
| 382 | +在时间复杂度上,循环队列和链式队列的新增、删除操作都为 O(1)。而在查找操作中,队列和线性表一样只能通过全局遍历的方式进行,也就是需要 O(n) 的时间复杂度。在空间性能方面,循环队列必须有一个固定的长度,因此存在存储元素数量和空间的浪费问题,而链式队列不存在这种问题,所以在空间上,链式队列更为灵活一些。 |
| 383 | + |
| 384 | +通常情况下,在可以确定队列长度最大值时,建议使用循环队列。无法确定队列长度时,应考虑使用链式队列。队列具有先进先出的特点,很像现实中人们排队买票的场景。在面对数据处理顺序非常敏感的问题时,队列一定是个不错的技术选型。 |
0 commit comments