From 01e6ab8ac9174d2e97da3c26ee3f7741c323f582 Mon Sep 17 00:00:00 2001
From: nathan lile <7707104+nlile@users.noreply.github.com>
Date: Tue, 2 Apr 2024 08:13:54 -0700
Subject: [PATCH 1/7] Update README.md
---
profile/README.md | 39 +++++++++++++++++++++++++++++----------
1 file changed, 29 insertions(+), 10 deletions(-)
diff --git a/profile/README.md b/profile/README.md
index f49c3e2..f258e47 100644
--- a/profile/README.md
+++ b/profile/README.md
@@ -1,6 +1,26 @@
-# Welcome to SynthLabs 👋
+SynthLabs
+Shaping an aligned and impactful AI future
+
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
-Welcome to the official GitHub for [SynthLabs.ai](https://www.synthlabs.ai/)
+Welcome to the official GitHub for [SynthLabs.ai](https://www.synthlabs.ai/) 👋
## 🔬 Featured Research
@@ -37,14 +57,13 @@ We're always looking for talented individuals to join our team. If you're passio
-
-[](https://twitter.com/intent/follow?screen_name=synth_labs)
-[](https://discord.gg/46uN42SE6x)
-[](https://www.linkedin.com/company/synthlabsai)
-[](https://www.synthlabs.ai/)
-[](https://github.com/SynthLabsAI)
-[](https://huggingface.co/SynthLabsAI)
-
+ +
+
+
+  +
+
+
+
+
Join us in shaping an aligned and impactful AI future! 🤝
From 4dc5d5f4dbec8cf18de803d9da18103728addc27 Mon Sep 17 00:00:00 2001
From: Alon Albalak
Date: Tue, 15 Oct 2024 16:16:00 -0700
Subject: [PATCH 2/7] WIP Update README.md
---
profile/README.md | 25 +++++++++++++++++++++++--
1 file changed, 23 insertions(+), 2 deletions(-)
diff --git a/profile/README.md b/profile/README.md
index f258e47..34a3dcf 100644
--- a/profile/README.md
+++ b/profile/README.md
@@ -1,5 +1,5 @@
SynthLabs
-Shaping an aligned and impactful AI future
+A post-training AI research lab advancing and scaling synthetic reasoning
@@ -24,11 +24,30 @@ Welcome to the official GitHub for [SynthLabs.ai](https://www.synthlabs.ai/)
## 🔬 Featured Research
+
+
### [Suppressing Pink Elephants with Direct Principle Feedback](https://arxiv.org/abs/2402.07896)

-Our most recent work represents a significant advancement in the field of controllable language models. This [research addresses](https://arxiv.org/pdf/2402.07896.pdf) the 'Pink Elephant Problem' - instructing language models to avoid certain topics ("Pink Elephants") and focus on preferred ones ("Grey Elephants"). Key highlights:
+This work represents a significant advancement in the field of controllable language models. This [research addresses](https://arxiv.org/pdf/2402.07896.pdf) the 'Pink Elephant Problem' - instructing language models to avoid certain topics ("Pink Elephants") and focus on preferred ones ("Grey Elephants"). Key highlights:
- **Controllable Generation**: Dynamically adjust language models at inference time for diverse needs across multiple contexts
@@ -43,11 +62,13 @@ Contributions from Louis Castricato, Nathan Lile, Suraj Anand, Hailey Schoelkopf
- [Interviewing Louis Castricato on RLHF, Synth Labs, and the Future of Alignment](https://www.interconnects.ai/p/rlhf-interview-1-louis)
- [New Microsoft-Backed Startup Wants to Make AI Work As Intended](https://archive.is/vczUI)
+
## 💼 Join Our Team
From 4650ef600c5d8ebfab1fa20d61f6a21ea0d08dad Mon Sep 17 00:00:00 2001
From: Alon Albalak
Date: Tue, 15 Oct 2024 20:49:17 -0700
Subject: [PATCH 3/7] Add PERSONA to README.md
---
profile/README.md | 6 +++---
1 file changed, 3 insertions(+), 3 deletions(-)
diff --git a/profile/README.md b/profile/README.md
index 34a3dcf..5a08363 100644
--- a/profile/README.md
+++ b/profile/README.md
@@ -32,16 +32,16 @@ Welcome to the official GitHub for [SynthLabs.ai](https://www.synthlabs.ai/)
Our latest work showcases
Contributions from Dakota Mahan*, Duy Van Phung*, Rafael Rafailov*, Chase Blagden, Nathan Lile, Louis Castricato, Jan-Philipp Fränken, Chelsea Finn, and Alon Albalak*. Check out the full paper on [our website](https://www.synthlabs.ai/pdf/Generative_Reward_Models.pdf).
-
+-->
### [PERSONA: A Reproducible Testbed for Pluralistic Alignment](https://www.synthlabs.ai/research/persona)
-
+This work introduces PERSONA, a framework for evaluating the ability of language models to align with a diverse set of user values, using 1,586 synthetic personas, 3,868 prompts, and 317,200 preference pairs. We focus on pluralistic alignment because we want langauge models that can reflect a diverse set of values, not just the majority opinion, and we don't prescribe to a one-size-fits-all approach. PERSONA is synthetically constructed from U.S. census data, allowing us to generate a large, diverse dataset while ensuring privacy and reproducibility. The dataset and evaluation framework can be used for a variety of purposes, inlcluding: (1) a test bed, (2) a development environment, (3) a reproducible evaluation for pluralistic alignment approaches, (4) the personalization of language models, (5) and for preference elicitation.
Contributions from Louis Castricato*, Nathan Lile*, Rafael Rafailov, Jan-Philipp Fränken, and Chelsea Finn. Read the full paper on [arXiv](https://arxiv.org/abs/2407.17387).
--->
+
### [Suppressing Pink Elephants with Direct Principle Feedback](https://arxiv.org/abs/2402.07896)
From 442daee90a242a6aaaa7eb7d5d9042da2d1366b8 Mon Sep 17 00:00:00 2001
From: Alon Albalak
Date: Tue, 15 Oct 2024 21:18:49 -0700
Subject: [PATCH 4/7] Add GenRM to README.md
---
profile/README.md | 12 ++++++++----
1 file changed, 8 insertions(+), 4 deletions(-)
diff --git a/profile/README.md b/profile/README.md
index 5a08363..4c55d92 100644
--- a/profile/README.md
+++ b/profile/README.md
@@ -24,15 +24,19 @@ Welcome to the official GitHub for [SynthLabs.ai](https://www.synthlabs.ai/)
## 🔬 Featured Research
-
+- **More Robust AI Systems**: Create AI systems that better generalize to new situations and maintain alignment with human values.
+- **Efficient Scaling**: Allow for more rapid iteration and refinement of AI behavior.
+- **Potential for Personalization**: Address the challenge of aligning AI with diverse and potentially conflicting human views.
+- **Improved Reasoning Capabilities**: Pave the way for AI systems that can continually improve their own reasoning and decision-making processes.
+
+Contributions from Dakota Mahan\*, Duy Van Phung\*, Rafael Rafailov\*, Chase Blagden, Nathan Lile, Louis Castricato, Jan-Philipp Fränken, Chelsea Finn, and Alon Albalak\*. Check out the full paper on [our website](https://www.synthlabs.ai/pdf/Generative_Reward_Models.pdf).
From 3a198a6fd854d8a8f2d28d587bb182507281f21c Mon Sep 17 00:00:00 2001
From: Alon Albalak
Date: Fri, 18 Oct 2024 12:21:55 -0700
Subject: [PATCH 5/7] Update README.md
---
profile/README.md | 7 ++++++-
1 file changed, 6 insertions(+), 1 deletion(-)
diff --git a/profile/README.md b/profile/README.md
index 4c55d92..1f0710a 100644
--- a/profile/README.md
+++ b/profile/README.md
@@ -22,6 +22,8 @@
Welcome to the official GitHub for [SynthLabs.ai](https://www.synthlabs.ai/) 👋
+---
+
## 🔬 Featured Research
@@ -38,7 +40,7 @@ Our latest work introduces Generative Reward Models (GenRM) and Chain-of-Thought
Contributions from Dakota Mahan\*, Duy Van Phung\*, Rafael Rafailov\*, Chase Blagden, Nathan Lile, Louis Castricato, Jan-Philipp Fränken, Chelsea Finn, and Alon Albalak\*. Check out the full paper on [our website](https://www.synthlabs.ai/pdf/Generative_Reward_Models.pdf).
-
+---
### [PERSONA: A Reproducible Testbed for Pluralistic Alignment](https://www.synthlabs.ai/research/persona)
@@ -46,6 +48,7 @@ This work introduces PERSONA, a framework for evaluating the ability of language
Contributions from Louis Castricato*, Nathan Lile*, Rafael Rafailov, Jan-Philipp Fränken, and Chelsea Finn. Read the full paper on [arXiv](https://arxiv.org/abs/2407.17387).
+---
### [Suppressing Pink Elephants with Direct Principle Feedback](https://arxiv.org/abs/2402.07896)
@@ -61,6 +64,8 @@ This work represents a significant advancement in the field of controllable lang
Contributions from Louis Castricato, Nathan Lile, Suraj Anand, Hailey Schoelkopf, Siddharth Verma, and Stella Biderman. Read the full paper on [arXiv](https://arxiv.org/abs/2402.07896).
+---
+
## 📰 Featured Media/Press
- [Interviewing Louis Castricato on RLHF, Synth Labs, and the Future of Alignment](https://www.interconnects.ai/p/rlhf-interview-1-louis)
From 5217eb21d6cdb27e96160221d8c45c1e27d1a07e Mon Sep 17 00:00:00 2001
From: Alon Albalak
Date: Mon, 21 Oct 2024 08:31:10 -0700
Subject: [PATCH 6/7] Update README.md
---
profile/README.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/profile/README.md b/profile/README.md
index 1f0710a..0db6d19 100644
--- a/profile/README.md
+++ b/profile/README.md
@@ -27,7 +27,7 @@ Welcome to the official GitHub for [SynthLabs.ai](https://www.synthlabs.ai/)
## 🔬 Featured Research
-### [Generative Reward Models](https://www.synthlabs.ai/research/genrm)
+### [Generative Reward Models](https://www.synthlabs.ai/research/generative-reward-models)
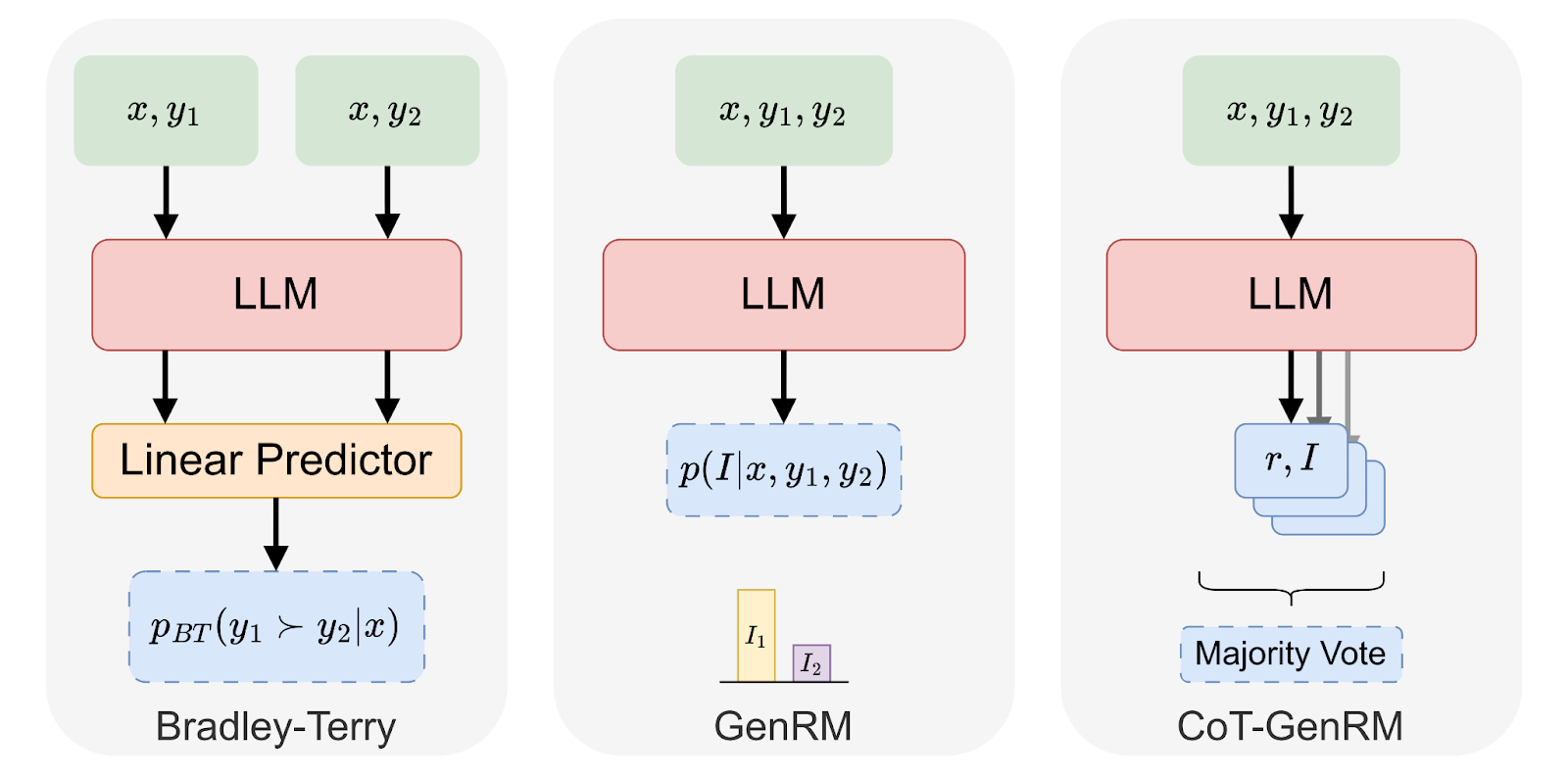
@@ -38,7 +38,7 @@ Our latest work introduces Generative Reward Models (GenRM) and Chain-of-Thought
- **Potential for Personalization**: Address the challenge of aligning AI with diverse and potentially conflicting human views.
- **Improved Reasoning Capabilities**: Pave the way for AI systems that can continually improve their own reasoning and decision-making processes.
-Contributions from Dakota Mahan\*, Duy Van Phung\*, Rafael Rafailov\*, Chase Blagden, Nathan Lile, Louis Castricato, Jan-Philipp Fränken, Chelsea Finn, and Alon Albalak\*. Check out the full paper on [our website](https://www.synthlabs.ai/pdf/Generative_Reward_Models.pdf).
+Contributions from Dakota Mahan\*, Duy Van Phung\*, Rafael Rafailov\*, Chase Blagden, Nathan Lile, Louis Castricato, Jan-Philipp Fränken, Chelsea Finn, and Alon Albalak\*. Check out the full paper on [arXiv](https://arxiv.org/abs/2410.12832).
---
From d7da1a9d4c11af1d0f2c7508b53aab940811cd30 Mon Sep 17 00:00:00 2001
From: Alon Albalak
Date: Mon, 21 Oct 2024 08:37:34 -0700
Subject: [PATCH 7/7] Update README.md
---
profile/README.md | 17 ++++++++++++++---
1 file changed, 14 insertions(+), 3 deletions(-)
diff --git a/profile/README.md b/profile/README.md
index 0db6d19..849574b 100644
--- a/profile/README.md
+++ b/profile/README.md
@@ -38,7 +38,11 @@ Our latest work introduces Generative Reward Models (GenRM) and Chain-of-Thought
- **Potential for Personalization**: Address the challenge of aligning AI with diverse and potentially conflicting human views.
- **Improved Reasoning Capabilities**: Pave the way for AI systems that can continually improve their own reasoning and decision-making processes.
-Contributions from Dakota Mahan\*, Duy Van Phung\*, Rafael Rafailov\*, Chase Blagden, Nathan Lile, Louis Castricato, Jan-Philipp Fränken, Chelsea Finn, and Alon Albalak\*. Check out the full paper on [arXiv](https://arxiv.org/abs/2410.12832).
+Contributions from Dakota Mahan\*, Duy Van Phung\*, Rafael Rafailov\*, Chase Blagden, Nathan Lile, Louis Castricato, Jan-Philipp Fränken, Chelsea Finn, and Alon Albalak\*.
+
+**Learn more:**
+- [Blog](https://www.synthlabs.ai/research/generative-reward-models)
+- [ArXiV](https://arxiv.org/abs/2410.12832)
---
@@ -46,7 +50,11 @@ Contributions from Dakota Mahan\*, Duy Van Phung\*, Rafael Rafailov\*, Chase Bla
This work introduces PERSONA, a framework for evaluating the ability of language models to align with a diverse set of user values, using 1,586 synthetic personas, 3,868 prompts, and 317,200 preference pairs. We focus on pluralistic alignment because we want langauge models that can reflect a diverse set of values, not just the majority opinion, and we don't prescribe to a one-size-fits-all approach. PERSONA is synthetically constructed from U.S. census data, allowing us to generate a large, diverse dataset while ensuring privacy and reproducibility. The dataset and evaluation framework can be used for a variety of purposes, inlcluding: (1) a test bed, (2) a development environment, (3) a reproducible evaluation for pluralistic alignment approaches, (4) the personalization of language models, (5) and for preference elicitation.
-Contributions from Louis Castricato*, Nathan Lile*, Rafael Rafailov, Jan-Philipp Fränken, and Chelsea Finn. Read the full paper on [arXiv](https://arxiv.org/abs/2407.17387).
+Contributions from Louis Castricato*, Nathan Lile*, Rafael Rafailov, Jan-Philipp Fränken, and Chelsea Finn.
+
+**Learn more:**
+- [Blog](https://www.synthlabs.ai/research/persona)
+- [ArXiv](https://arxiv.org/abs/2407.17387)
---
@@ -62,7 +70,10 @@ This work represents a significant advancement in the field of controllable lang
- **Significant Performance Improvements**: After fine-tuning with DPF on our synthetic Pink Elephants dataset, our 13B fine-tuned LLaMA 2 model outperformed existing models and matched the performance of GPT-4 on our curated test set for the Pink Elephant Problem.
-Contributions from Louis Castricato, Nathan Lile, Suraj Anand, Hailey Schoelkopf, Siddharth Verma, and Stella Biderman. Read the full paper on [arXiv](https://arxiv.org/abs/2402.07896).
+Contributions from Louis Castricato, Nathan Lile, Suraj Anand, Hailey Schoelkopf, Siddharth Verma, and Stella Biderman.
+
+**Learn more:**
+- [ArXiv](https://arxiv.org/abs/2402.07896)
---