diff --git a/doc/entrance.md b/doc/entrance.md
new file mode 100644
index 000000000..e3b670aad
--- /dev/null
+++ b/doc/entrance.md
@@ -0,0 +1,247 @@
+Java Enterprise Online Project
+===============================
+Разработка полнофункционального Spring/JPA Enterprise приложения c авторизацией и правами доступа на основе ролей с использованием наиболее популярных инструментов и технологий Java: Maven, Spring MVC, Security, JPA(Hibernate), REST(Jackson), Bootstrap (css,js), DataTables, jQuery + plugins, Java 8 Stream and Time API и хранением в базах данных Postgresql и HSQLDB.
+
+
+
+ Когда вы слышите что-то, вы забываете это.
+ Когда вы видите что-то, вы запоминаете это.
+ Но только когда вы начинаете делать это,
+ вы начинаете понимать это
+
+ Старинная китайская поговорка
+
+## Демо разрабатываемого приложения
+
+Обновленное вводное занятие (обязательно смотреть все видео)
+===============
+##  1. [Вступление, история, команда, источники](entrance/video1.md)
+
+## Обзор наиболее востребованных технологий, которые будут изучаться на курсе TopJava
+##  2.1. [Часть 1: инфраструктура](entrance/video2.1.md)
+
+##  2.2. [Часть 2: frameworks Spring, ORM](entrance/video2.2.md)
+
+##  2.3. [Часть 3: тренды](entrance/video2.3.md)
+
+##  2.3. [Часть 4: обзор разрабатываемого приложения](entrance/video2.4.md)
+
+##  3. [Рекомендуемые подходы к обучению на курсе](entrance/video3.md)
+
+##  4. [Структура приложения (многоуровневая архитектура)](entrance/video4.md)
+### [Демо приложения](http://javaops-demo.ru/topjava)
+
+##  5. [Системы управления версиями. Git](entrance/video5-vcs-git.md)
+
+##  6. Работа с проектом (выполнять инструкции)
+- Поправка: JetBrains больше не выдает ключей, вот [варианты после trial](https://github.com/JavaOPs/topjava/wiki/IDEA#licence)
+- **ВНИМАНИЕ: выбирайте для проекта простой пусть без пробелов и русских букв, например, `c:\projects\topjava\` (Windows). Иначе впоследствии будут проблемы**
+- **Плагин Git Intergation уже не требуется, а вкладку `Version control` в IDEA переименовали в `Git`**
+
+Для переключения режима отображения изменений из вкладки `Commit` в `Git: Local Changes` нужно переключить `Settings/Preferences | Version Control | Commit | Use non-modal commit interface` или в контекстном меню вкладки `Commit`:
+
+ 
+
+### Патч [prepare_to_HW0.patch](https://drive.google.com/file/d/1LNPpu9OkuCpfpD8ZJHO-o0vwu49p2i5M) (скачать и положить в каталог вашего проекта)
+
+> Проект постоянно улучшается, поэтому видео иногда отличается от кода проекта. Изменения указываю после видео:
+> - переименовал класс `UserMealWithExceed` и его поле `exceed` в `UserMealWithExcess.excess`
+> - в `UserMeals/UserMealWithExcess` поля изменились на `private`
+> - обновил данные `UserMealsUtil.meals` и переименовал некоторые переменные, поля и методы
+> - добавил `UserMealWithExcess.toString()` и метод для выполнения _Optional домашнего задания_
+> - метод фильтрации в `TimeUtil` переименовал в `isBetweenHalfOpen` (также изменилась логика сравнения: `startTime` включается в интервал, а `endTime` - не включается)
+
+### GitHub поменял политику: теперь пушить нужно через токен. IDEA предложит его сгенерировать при пуше, или можно [создать токен в настройках](https://www.jetbrains.com/help/idea/github.html#register-account)
+- [Способы авторизации в GitHub](https://topjava.ru/blog/vvedeniye-v-git-github-ustanovka-i-nastroyka#6)
+
+## Инструкция по шагам (из видео):
+- Установить ПО (Git, JDK8, IntelliJ IDEA, Maven)
+- Создать аккаунт на GitHub
+- Сделать Fork **ЭТОГО** проекта (https://github.com/JavaOPs/topjava)
+- Сделать локальный репозиторий проекта:
+
+
+> Вместо Fork можно сделать [клонирование проекта](https://github.com/JavaOPs/topjava/wiki/Git#user-content-Клонирование-проекта): он не будет привязан к исходному https://github.com/JavaOPs/topjava и у него не будет истории.
+
+- Открыть и настроить проект в IDEA
+ - Выставить кодировку UTF-8 в консоли
+ - Поставить кодировку UTF-8
+ - Опционально: поменять шрифт по умолчанию на DejaVu или на **новый [JetBrains Mono](https://habr.com/ru/company/jugru/news/t/484134/)**
+- По ходу видео сделать `Apply Patch...` скачанного патча [Prepare_ to_ HW0.patch](https://drive.google.com/file/d/1LNPpu9OkuCpfpD8ZJHO-o0vwu49p2i5M)
+- Закоммитить и запушить изменения (`commit` + `push`)
+- Сделать ветку домашнего задания
+- Выполнить задание и залить на GitHub (`commit` + `push`)
+- Переключиться в основную ветку проекта `master`.
+
+##  7. [Maven](https://drive.google.com/file/d/1qEJTwv9FNUQjx-y9MSydH01xaAne0-hu)
+- [Руководство по Maven](https://topjava.ru/blog/apache-maven-osnovy-1)
+- Wiki: [Apache Maven](https://ru.wikipedia.org/wiki/Apache_Maven)
+- [The Central Repository](http://search.maven.org)
+- Дополнительно:
+ - [Мой Wiki по Maven](https://github.com/JavaOPs/topjava/wiki/Maven)
+ - [Основы Maven](https://www.youtube.com/watch?v=0uwMKktzixU)
+ - JavaRush: [Основы Maven](https://javarush.ru/groups/posts/2523-chastjh-4osnovih-maven)
+ - Инструмент сборки проектов [Maven](https://www.examclouds.com/ru/java/java-core-russian/lesson20)
+ - [Maven Getting Started Guide](https://maven.apache.org/guides/getting-started/index.html)
+ - [Видео: Maven vs Gradle vs SBT (Архипов, Борисов, Садогурский)](https://www.youtube.com/watch?v=21qdRgFsTy0)
+ - [Build Lifecycle](http://maven.apache.org/guides/introduction/introduction-to-the-lifecycle.html)
+ - [Dependency Mechanism](http://maven.apache.org/guides/introduction/introduction-to-dependency-mechanism.html)
+
+##  8. [Как правильно относиться к техзаданию (ТЗ). Полуоткрытый интервал.](https://drive.google.com/file/d/1BpTzjNFjS0TSekCyt_xvt6YoLvuw5KTZ)
+- [Типы промежутков](https://ru.wikipedia.org/wiki/Промежуток_(математика))
+
+##  Домашнее задание HW0
+
+### ВНИМАНИЕ: НЕ НАДО в репозиторий делать Pull Request со своими решениями! См. видео выше ("Работа с проектом")
+Реализовать метод `UserMealsUtil.filteredByCycles` через циклы (`forEach`):
+- должны возвращаться только записи между `startTime` и `endTime`
+- поле `UserMealWithExcess.excess` должно показывать, превышает ли сумма калорий за весь день значение `caloriesPerDay`
+
+Т. е. `UserMealWithExcess` - это запись одной еды, но поле `excess` будет одинаково для всех записей за этот день.
+
+> - Проверьте результат выполнения ДЗ (можно проверить логику в [http://javaops-demo.ru/topjava](http://javaops-demo.ru/topjava), список еды)
+> - Оцените Time complexity алгоритма. Если она больше O(N), например O(N*N) или N*log(N), сделайте O(N).
+> **Внимание: внимательно прочитайте про O(N). O - это любой коэффициент, 2*N это тоже O(N).**
+
+- Java 8 Date and Time API
+- Алгоритмы и структуры данных для начинающих: сложность алгоритмов
+- [Сложность алгоритмов и Big O Notation](https://threadreaderapp.com/thread/1470666237286010881)
+- [Головач: сложность алгоритмов в теме коллекций](https://www.youtube.com/watch?v=Ek9ijOiplNE&feature=youtu.be&t=778)
+- Time complexity
+- Временная сложность алгоритма
+- Вычислительная сложность
+
+#### ВНИМАНИЕ: варианты Optional делайте в одной ветке в разных методах `UserMealsUtil`. Проще делать, проще проверять
+
+### Optional (Java 8 Stream API)
+```
+Реализовать метод `UserMealsUtil.filteredByStreams` через Java 8 Stream API.
+```
+- Видео: Доступно о Java 8 Lambda
+- Java 8: Lambda выражения
+- Java 8: Потоки
+- Pуководство по Java 8 Stream
+- [Полное руководство по Java 8 Stream API в картинках и примерах](https://annimon.com/article/2778)
+- [7 способов использовать groupingBy в Stream API](https://habrahabr.ru/post/348536)
+- Лямбда-выражения в Java 8
+- A Guide to Java 8
+- Шпаргалка Java Stream API
+- Алексей Владыкин: Элементы функционального программирования в Java
+- Yakov Fain о новом в Java 8
+- stream.map vs forEach`
+ - без циклов по другим коллекциям/массивам (к ним также относим методы коллекций `addAll()/removeAll()`)
+- через Stream API за 1 проход по исходному списку `meals.stream()`
+ - нельзя использовать внешние коллекции, не являющиеся частью коллектора
+ - возможно дополнительные проходы по частям списка, при этом превышение должно считаться один раз для всего подсписка. Те например нельзя разбить список на на 2 подсписка с четными и нечетными датами и затем их объединить, с подсчетом превышения для каждого элемента.
+
+Временная сложность реализации должна быть O(N) (обратите внимание на п. 13 замечаний)
+Решение должно быть рабочим в общем случае (должно работать в приложении с многими пользователями, не только при запуске `main`)
+Нельзя 2 раза проходить по исходному списку (в том числе по его отфильтрованной или преобразованной копии)
+
+Ресурсы:
+- [Baeldung: Custom Collectors](https://www.baeldung.com/java-8-collectors#Custom)
+- [Руководство по Java 8 Stream API: Collector](https://annimon.com/article/2778#collector)
+- [Хватит писать циклы! Топ-10 лучших методов для работы с коллекциями из Java 8](https://javarush.ru/groups/posts/524-khvatit-pisatjh-ciklih-top-10-luchshikh-metodov-dlja-rabotih-s-kollekcijami-iz-java8)
+- [Понять Java Stream API](https://vc.ru/u/604567-yerlan-akzhanov/194409-ponyat-java-stream-api)
+
+### Замечания по использованию Stream API:
+- Когда встречаешь что-то непривычное, приходится перестраивать мозги. Например, переход с процедурного на ООП-программирование дается непросто. Те, кто не знает шаблонов (и не хотят учить), также их встречают плохо. Хорошая новость в том, что если это принять и начать использовать, то начинаешь получать от этого удовольствие. И тут главное не впасть в другую крайность:
+ - [Используйте Stream API проще (или не используйте вообще)](https://habrahabr.ru/post/337350/)
+- Если вас беспокоит производительность стримов, обязательно прочитайте про оптимизацию
+ - ["Что? Где? Когда?"](http://optimization.guide/intro.html)
+ - [Перформанс: что в имени тебе моём?](https://habrahabr.ru/company/jugru/blog/338732/)
+ - [Performance это праздник](https://habrahabr.ru/post/326242/)
+
+При использовании Stream API производительность улучшится только на больших задачах, где возможно распараллеливание.
+Еще: просто так запустить и померить скорость JVM нельзя (как минимум надо дать прогреться и запустить очень большое число раз). Лучше использовать какие-нибудь бенчмарки, например [JMH](http://tutorials.jenkov.com/java-performance/jmh.html), который мы используем на другом проекте (Mastejava).
+
+##  Замечания к HW0
+- 1: Код проекта менять можно! Одна из распространенных ошибок как в тестовых заданиях на собеседовании, так и при работе на проекте, что ничего нельзя менять. Конечно, при правках в рабочем проекте обязательно нужно проконсультироваться/проревьюироваться у авторов кода (находятся по истории VCS)
+- 2: Наследовать `UserMealWithExcess` от `UserMeal` нельзя, т. к. это разные сущности: Transfer Object и Entity. Мы будем их проходить на 2-м уроке. Это относится и к их зависимости друг от друга.
+- 3: Правильная реализация должна быть простой и красивой, можно сделать 2-мя способами: через стримы и через циклы. Сложность должна быть O(N), т.е. без вложенных стримов и циклов.
+- 4: При реализации через циклы посмотрите в `Map` на методы `getOrDefault` или `merge`
+- 5: **При реализации через `Stream` заменяйте `forEach` оператором `stream.map(..)`**
+- 6: Объявляйте переменные непосредственно перед использованием (если возможно - сразу с инициализацией). При объявлении коллекций в качестве типа переменной используйте интерфейс (Map, List, ..)
+- 7: Если IDEA предлагает оптимизацию (желтым подчеркивает), например, заменить лямбду на ссылку на метод (method reference), соглашайтесь (Alt+Enter)
+- 8: Пользуйтесь форматированием кода в IDEA: `Alt+Ctrl+L`
+- 9: Перед check-in (отправкой изменений на GitHub) просматривайте внесенные изменения (Git -> [Log](https://www.jetbrains.com/help/idea/log-tab.html) -> курсор на файл и Ctrl+D): не оставляйте в коде ничего лишнего (закомментированный код, TODO и пр.). Если файл не меняется (например только пробелы или переводы строк), не надо его чекинить, делайте ему `revert` (Git -> Revert / `Ctrl+Alt+Z`).
+- 10: `System.out.println` нельзя использовать нигде, кроме как в `main`. Позже введем логирование.
+- 11: Результаты, возвращаемые `UserMealsUtil.filteredByStreams`, мы будем использовать [в нашем приложении](http://javaops-demo.ru/topjava) для фильтрации по времени и отображения еды правильным цветом.
+- 12: Обращайте внимание на комментарии к вашим коммитам в Git. Они должны быть короткие и информативные (лучше на english)
+- 13: Не полагайтесь в решении на то, что список еды будет подаваться отсортированным. Такого условия нет.
+-----
+
+> - ДЗ первого урока будет связано с созданием небольшого [CRUD](https://ru.wikipedia.org/wiki/CRUD)-приложения (в памяти, без базы данных) на JSP и сервлетах
+> - основы JavaScript необходимы для понимания проекта, начиная с 8-го занятия
+
+### Полезные ресурсы
+#### HTML
+- [Основы HTML от mozilla](https://developer.mozilla.org/ru/docs/Learn/Getting_started_with_the_web/HTML_basics)
+- [Основы HTML от webref](https://webref.ru/course/html-basics)
+- [Учебник HTML для начинающих](https://msiter.ru/tutorials/html-nachalnogo-urovnya)
+- [HTML для чайников](https://site-do.ru/html/)
+- [Основы HTML (видео от учеников JavaRush)](https://www.youtube.com/watch?v=BdsA7VCLRc8)
+
+#### Web, JavaScript, CSS
+- [Знакомство с HTML и CSS](https://htmlacademy.ru/courses/basic-html-css)
+- [Справочник по WEB](https://developer.mozilla.org/ru/)
+- [Видео по WEB-технологиям](https://www.youtube.com/user/WebMagistersRu/playlists)
+- [Изучение JavaScript в одном видео уроке за час](https://www.youtube.com/watch?v=QBWWplFkdzw)
+- HTML, CSS, JAVASCRIPT, SQL, JQUERY, BOOTSTRAP
+- Введение в программирование на JavaScript
+- Стандарты кодирования для HTML, CSS и JavaScript’a
+- Основы работы с HTML/CSS/JavaScript
+- JavaScript - Основы
+- Основы JavaScript
+- Bootstrap 3 - Основы
+- jQuery для начинающих
+
+#### Java (базовые вещи)
+- [Сборник видео "Изучаем Java"](https://www.youtube.com/playlist?list=PLyxk-1FCKqockmP-fXZmHQ7UlYP3qvZRa)
+- 1-й урок MasterJava: Многопоточность
+- [Основы Java garbage collection](http://web.archive.org/web/20180831013112/https://ggenikus.github.io/blog/2014/05/04/gc)
+- Размер Java объектов
+- Введение в Java Reflection API
+- Структуры данных в картинках
+- Обзор java.util.concurrent.*
+- Синхронизация потоков
+- String literal pool
+- Маленькие хитрости Java
+- A Guide to Java 8
+
+### Туториалы, разное
+- [Открытый курс: Spring Boot + HATEOAS](https://javaops.ru/view/bootjava)
+- [Что нужно знать о бэкенде новичку в веб-разработке](https://tproger.ru/translations/backend-web-development)
+- [Туториалы: Spring Framework, Hibernate, Java Core, JDBC](http://proselyte.net/tutorials/)
+
+#### Сервлеты
+- Как создать Servlet? Полное руководство.
+- [Сервлеты](https://metanit.com/java/javaee/4.1.php)
+
+#### JDBC, SQL
+- Основы SQL на примере задачи
+- Уроки по JDBC
+- Learn SQL
+- Интуит. Основы SQL
+- Try SQL
+- Курс "Введение в базы данных"
+
+#### Разное
+- Вопросы по собеседованию, ресурсы для подготовки
+- Эффективная работа с кодом в IntelliJ IDEA
+- Quizful- тесты онлайн
+- Введение в Linux
+
+#### Книги
+- Джошуа Блох: Java. Эффективное программирование. Второе издание
+- Гамма, Хелм, Джонсон: Приемы объектно-ориентированного проектирования. Паттерны проектирования
+- Редмонд Э.: Семь баз данных за семь недель. Введение в современные базы данных и идеологию NoSQL
+- Brian Goetz: Java Concurrency in Practice
+- G.L. McDowell: Cracking the Coding Interview
diff --git a/doc/entrance/video1.md b/doc/entrance/video1.md
new file mode 100644
index 000000000..3c62fc31b
--- /dev/null
+++ b/doc/entrance/video1.md
@@ -0,0 +1,124 @@
+## Вступление, история, команда, источники
+
+##  [Видео](https://drive.google.com/file/d/1ZPW2MizaVw3PzoQmedDPOlgy9RmOajCK)
+
+Друзья, всем привет.
+Спасибо, что выбрали Java Online projects и курс TopJava.
+
+### Об авторе и истории TopJava
+Меня зовут [Григорий Кислин](http://gkislin.ru/), я являюсь создателем и автором курса TopJava.
+Программированием занимаюсь с 1989 года, а с 2005 года работаю на Java (это более 17 лет опыта в Java-мире).
+
+Курс TopJava имеет большую историю. Первая его версия была создана в 2014 году, и
+с тех пор его прошло более 3500 участников.
+У нас есть [множество положительных отзывов](https://vk.com/topic-74381644_30447246?offset=161)
+и историй успеха людей, которые нашли работу Java-разработчиками
+после окончания TopJava.
+
+В создании обновленного курса мне помогает [Александр Никифоров](https://alexnikiforov.com/about-me/), с которым вы познакомитесь в видеоуроках.
+Александр - наш выпускник, получил свой первый оффер в качестве Java-разработчика в 2021 году после прохождения курса "BaseJava".
+
+С 2014 года команда Java Online projects находится
+в контакте со студентами и выпускниками курса TopJava, поэтому в материале курса учитывается множество нюансов обучения
+и трудоустройства.
+
+Это говорит о том, что стать Java-разработчиком реально, и
+вы находитесь в правильном месте на этом пути.
+
+### Об обновленном курсе
+Текущая версия курса включает в себя обновление всего кода с использованием
+актуальных версий языка и фреймворков.
+Мы используем Java 17, Spring Framework 6 и Spring Boot 3.
+
+Программа курса осталась прежней, поскольку она уже проверена годами,
+ее эффективность подтверждена множеством студентов, нашедших работу.
+
+В обновленной версии, помимо перехода на актуальные версии технологий, мы
+также добавили ряд дополнительных материалов, которые призваны упростить
+усвоение материала.
+Также в обновленных видеолекциях мы улучшили качество видео и звука.
+
+### О вхождении в профессию Java-разработчика
+Частым вопросом является вопрос о высоких требованиях для вхождения
+в специальность Java-разработчика.
+
+Действительно, число вакансий небольшое, требования высокие,
+поскольку и зарплаты разработчиков довольно высокие. Естественно, что компании хотят
+минимизировать срок от трудоустройства человека до того момента,
+когда он начинает приносить выгоду.
+
+Даже опытному разработчику при вхождении в новый проект требуется
+помощь и консультации коллег, которые могут познакомить нового
+члена команды с нюансами проекта.
+Если же речь идет о разработчике без опыта или с минимальным опытом,
+то время, которое уделяется его "онбордингу" более опытными
+разработчиками, увеличивается, что, безусловно, сказывается на их
+продуктивности и на показателях компании.
+
+Проекты, над которыми работают компании, в большинстве случаев довольно сложные.
+
+Опыт показывает, что это зачастую большие бэкенд-системы,
+включающие десятки микросервисов.
+Отдельные микросервисы могут быть написаны на разных
+языках программирования и использовать различные протоколы передачи данных.
+
+Помимо известного всем Hibernate, можно столкнуться
+с использованием JOOQ или чистого JDBC.
+Зачастую на проектах используются готовые решения
+для хеширования данных (Redis), поисковые движки (ElasticSearch),
+различные брокеры сообщений (RabbitMQ, ActiveMQ, Kafka).
+
+Инфраструктура проектов также может быть довольно сложной.
+На проектах часто используются инструменты для CI/CD (Continuous Integration and
+Continuous Delivery), специальные решения для генерации и
+хранения логинов и паролей и т. д.
+
+Взаимодействие микросервисов значительно сложнее одиночного приложения,
+каким бы непростым для изучения оно вам ни показалось.
+Продолжением TopJava планируется
+[курс по микросервисам](https://javaops.ru/view/cloudjava).
+Первое занятие открытое, можно оценить возрастающую сложность.
+
+Поэтому уровень сотрудников должен быть соответствующий.
+
+От кандидата ожидают способности довольно быстро ознакомиться
+с проектом, разобраться в незнакомых технологиях и начать писать
+качественный код, покрытый тестами, написанный в соответствии
+с принципами clean code, чтобы код в дальнейшем можно было легко
+читать, поддерживать и расширять.
+
+### О поддержке со стороны JavaOps на стадии поиска работы
+
+После стажировки мы помогаем составить твое резюме Java-разработчика:
+Обязательно убери из резюме любое упоминание Junior.
+Количество обращений возрастет на порядок.
+После завершения проектов ты освоишь все заявленные в них
+технологии - вставь их в квалификацию.
+В резюме обязательно должен быть указан Spring Boot.
+
+В разделе "опыт работы" (если нет коммерческого опыта Java-разработчика)
+укажи 2 проекта, над которыми велась работа в ходе стажировки:
+
+1. Участие в разработке enterprise-приложения с использованием Spring 5 и JPA, c авторизацией и правами доступа на основе ролей, с использованием технологий: Maven, Spring MVC, Spring Security, REST (Jackson), Java Stream API:
+реализация сохранения в базы данных PostgreSQL и HSQLDB на основе Spring JDBC, JPA (Hibernate) и Spring Data JPA
+реализация и тестирование REST- и AJAX-контроллеров (более 130 JUnit-тестов)
+реализация клиента на Bootstrap (css/js), DataTables, jQuery + plugins.
+
+2. Реализация с нуля приложения голосования за рестораны с REST API.
+3. Миграция на Spring Boot 3.0 с использованием Lombok, H2, Swagger/OpenAPI 3.0
+
+Делай упор не на обучение, а на полученный практический опыт.
+Выполнение домашних заданий и собственный выпускной проект -
+это полноценный опыт по всем пройденным технологиям.
+
+На собеседовании смотрят не на то, что ты заканчивал,
+а на твои практические навыки.
+Постарайся рассказать как можно больше о своем выпускном проекте,
+использованных в нем технологиях.
+
+Вам не нужно игнорировать вакансии, в которых заявлены требования
+наличия опыта работы 1-2 года. Тот опыт, который вы получите
+в ходе курса, и те знания, которые вы приобретете, дают вам право
+говорить о том, что у вас есть опыт работы. Это даст
+вам возможность попасть на технические собеседования.
+Далее все зависит от вашей способности отвечать на технические вопросы на интервью.
diff --git a/doc/entrance/video2.1.md b/doc/entrance/video2.1.md
new file mode 100644
index 000000000..137e5e160
--- /dev/null
+++ b/doc/entrance/video2.1.md
@@ -0,0 +1,154 @@
+## Обзор наиболее востребованных технологий, которые будут изучаться на курсе TopJava. Инфраструктура
+
+##  [Видео](https://drive.google.com/file/d/1foI_YIiQWM3Q3h928Fj8eqykY4NSx7Yp)
+
+В курсе TopJava предпочтение отдается наиболее востребованным
+технологиям, используемым Java Enterprise разработчиками.
+В этом уроке мы приведем результаты некоторых популярных опросов,
+после чего у вас появится общая картина того, инструменты каких
+типов используются в Java-мире и какие из них наиболее востребованы.
+
+---
+
+Ссылки на отчеты, которые будут использоваться в этом уроке:
+
+- [JVM Ecosystem Report 2021](https://snyk.io/jvm-ecosystem-report-2021/)
+- [Jetbrains Java Dev Ecosystem Report 2021](https://www.jetbrains.com/lp/devecosystem-2021/java/)
+- [JRebel 2021 Java Technology Repost](https://www.jrebel.com/blog/2021-java-technology-report)
+- [Top 5 Java ORM tools - 2022](https://www.knowledgefactory.net/2021/09/top-java-orm-tools-20XX.html)
+
+---
+
+### Языки программирования
+
+#### 1. Java
+Java по-прежнему является абсолютным лидером как среди языков,
+работающих на Java Virtual Machine, так и в целом среди
+строго типизированных backend-языков, что показывают нам все рейтинги.
+
+#### 2. Kotlin
+Kotlin показывает впечатляющий рост, но Java по-прежнему
+существенно опережает его. JVM ecosystem report за 2021 показывает,
+что 91% опрошенных разработчиков используют Java и 17.7% используют Kotlin.
+
+#### 3. Groovy
+Groovy занимает третье место в рейтинге.
+Groovy - это дополнение к Java. Его особенность заключается
+в том, что он поддерживает не только статическую,
+но и динамическую типизацию. Он отлично подходит для
+написания скриптов. Например, на нем пишут скрипты для
+сборки проектов на Gradle. Но также для него разработан
+ряд фреймворков, что позволяет использовать его для
+самых разнообразных задач.
+
+#### 4. Scala
+Scala - это статически типизированный язык с поддержкой
+функционального программирования, разработанный с целью
+решить ряд проблем, за который Java подвергается критике.
+Однако на сегодняшний день Scala сильно отстает от Java
+и занимает всего 10%.
+Очевидно, что для максимизации шансов на трудоустройство мы учим Java.
+---
+Если речь идет о бэкенд разработке, то Kotlin обычно изучается
+после освоения Java. Иначе может обстоять дело с мобильной разработкой,
+где Kotlin выходит на первое место.
+
+Кстати, у нас готовится курс [TopKotlin](https://javaops.ru/view/topkotlin),
+который будет являться продолжением курса TopJava.
+
+Scala существенно сложнее Java, для ее полного освоения
+требуется 2-3 года, и ей на замену идет Kotlin.
+
+### Среда разработки
+IntelliJ Idea является абсолютным лидером среди IDE
+и используется более, чем в 70% случаев. При этом более 50% опрошенных используют
+платную версию IntelliJ IDEA Ultimate.
+Безусловно, полезно познакомиться с функциями, которые
+предоставляет платная версия. Например, в платной версии есть
+встроенный модуль для того, чтобы вручную взаимодействовать
+с базой данных.
+Однако бесплатная (Community) версия также используется компаниями.
+На ней можно полноценно работать со Spring и другими фреймворками,
+но некоторые полезные интеграции (например, клиент для
+баз данных) приходится заменять отдельными программами
+(например, можно использовать DBeaver).
+
+### Инструменты для сборки (building tools)
+Для того, чтобы быстро и эффективно работать с библиотеками
+и фреймворками, которые мы используем в проекте (а это
+часто десятки или даже сотни java-архивов, которые нужно
+скачать из интернета и подключить к проекту),
+используются средства сборки (building tools).
+Они позволяют быстро собрать все используемые
+нами файлы в один java-архив (jar-файл) или веб-архив (war-файл),
+готовый для запуска.
+
+Помимо упомянутых функций, средства сборки позволяют
+запускать тесты перед сборкой, проверять покрытие кода тестами.
+Также существуют различные плагины, которые могут
+генерировать отчеты, документацию и выполнять множество других полезных функций.
+Наиболее популярными средствами сборки для Java являются Maven и Gradle.
+
+Несмотря на то, что Gradle является более гибким инструментом,
+Maven по-прежнему опережает его почти вдвое, занимая 76%.
+В курсе мы отдаем предпочтение ему.
+
+Для общего понимания. Различия между Maven и Gradle заключаются
+в том, что в Maven используются XML-файлы, в которых прописывается
+вся конфигурация для сборки.
+XML - это структурированный документ, в котором мы можем писать элементы
+в соответствии с ранее заданной схемой.
+Существует проект Maven Polyglot, где конфигурация сборки
+прописывается в формате json, но на продакшене мы его не
+встречали, видимо, проект "не взлетел". Поэтому в случае с
+Maven обычно используется традиционный XML-формат.
+
+В случае с Gradle вместо XML-файлов используются скрипты
+для сборки, написанные на языках программирования Groovy DSL
+или Kotlin DSL. Это позволяет писать более сложные и гибкие алгоритмы сборки.
+
+На наш взгляд, Maven более понятен и последователен,
+чем Gradle, IntelliJ IDEA с ним лучше интегрирована, и
+он подходит для подавляющего большинства проектов.
+
+### Application server
+Мы переходим к секции с наиболее популярными серверами приложений (application server)
+и видим, что первое место занимает Tomcat.
+Технически Tomcat - это не сервер приложений, а контейнер
+сервлетов - Java-программа, реализующая Java Servlet API
+и обеспечивающая взаимодействие с внешним миром с помощью протокола HTTP.
+
+Контейнер сервлетов принимает HTTP-запросы, возвращает ответы.
+Работает непрерывно, за исключением каких-то технических работ,
+что дает возможность обращаться к приложению через сеть в любое время.
+Application server расширяет функциональность контейнера сервлетов.
+
+Tomcat имеет наибольший вес среди контейнеров сервлетов
+(TomEE - application server на его основе).
+Он может быть установлен на компьютер, после чего
+в нем может быть развернут (или задеплоен) файл web archive
+с вашим приложением.
+Также Spring Boot предоставляет Tomcat в качестве
+встроенного (embedded) сервера, что позволяет запускать
+приложение как обычный java-процесс - локально, на сервере или в облаке.
+
+### Обзор пройденных тем
+Давайте подведем промежуточные итоги по результатам этого урока.
+
+В этом уроке мы:
+
+* познакомились с текущими позициями Java и
+других языков программирования - Java уверенно сохраняет лидерство;
+* поговорили о средах разработки, где IntelliJ Idea занимает
+лидирующие позиции;
+* обсудили, что такое средства для сборки (Build tools), и
+подтвердили статистикой популярности наш выбор в пользу Maven;
+* поговорили о серверах приложений и контейнерах сервлетов,
+среди которых Tomcat выглядит как очевидный выбор.
+
+
+
+
+
+
+
diff --git a/doc/entrance/video2.2.md b/doc/entrance/video2.2.md
new file mode 100644
index 000000000..2f05c4aa6
--- /dev/null
+++ b/doc/entrance/video2.2.md
@@ -0,0 +1,161 @@
+## Обзор наиболее востребованных технологий, которые будут изучаться на курсе TopJava. Frameworks Spring, ORM
+
+##  [Видео](https://drive.google.com/file/d/1JLIieojERPJQuqJXxJSC5tc4mzb_4JuU)
+
+### Frameworks
+Мы переходим к фреймворкам. Фреймворки нам нужны, чтобы использовать
+готовое решение для стандартной задачи и дописать только нужную
+для нас бизнес-логику. В чем-то есть сходство с паттерном
+"шаблонный метод", где определяют скелет алгоритма, перекладывая
+ответственность за некоторые его шаги на подклассы. Здесь же
+определяется скелет архитектуры, ее базовые классы, и даются
+различные реализации. Мы можем выбрать любую из них или написать собственную.
+
+Например, если мы создаем обычное web-приложение, чтобы
+принимать HTTP-запросы и отдавать HTTP-ответы, нам не
+нужно создавать все web-компоненты с нуля, мы берем
+готовый web-фреймворк (например, Spring MVC) и дописываем
+специфичную для нашего конкретного случая бизнес-логику.
+Значительная часть кода за нас уже написана и протестирована.
+Веб-приложение - это, безусловно, не единственный пример.
+Могут быть приложения, которые занимаются запуском каких-то
+периодических задач и не принимают HTTP-запросов.
+Это может быть приложение, которое только общается с
+брокером сообщений (например, RabbitMQ или Kafka): принимает
+сообщения и отправляет в него сообщения.
+Для множества подобных задач существуют специальные фреймворки
+с готовыми решениями.
+
+Одна бэкенд-система может иметь в себе множество компонентов,
+включающих разные виды упомянутых приложений. Подавляющее
+большинство современных приложений работают с HTTP
+(это взаимодействие с UI в браузере или между сервисами по REST).
+Поэтому на этом курсе мы создаем как веб-приложение, работающее с UI,
+так и REST API, готовое для интеграции с любыми другими сервисами
+(например, с мобильным приложением).
+
+>[JVM Ecosystem Report 2021](https://snyk.io/jvm-ecosystem-report-2021/)
+>показывает, что Spring является абсолютным
+>лидером среди фреймворков.
+
+На первом месте упоминается **Spring Boot**, а на втором - **Spring MVC**.
+
+Здесь хотелось бы внести некоторую ясность.
+"Сердцем" Spring является Spring Core, который реализует Dependency
+Injection.
+Этот компонент, как правило, используется во всех остальных
+проектах Spring Framework.
+
+Spring Boot - это надстройка над Spring Framework,
+которая позволяет быстро создавать приложения разных типов,
+использовать автоматическую конфигурацию для некоторых
+компонентов и использовать некоторые удобные встроенные
+инструменты, например, готовые инструменты для мониторинга
+работы приложения (Spring Actuator).
+
+Если мы создаем web-приложение, то мы можем создавать его с
+помощью Spring Boot, но Spring MVC, который является именно
+web-фреймворком, также будет присутствовать в таком приложении
+и играть ключевую роль.
+
+Spring Boot позволяет создавать очень простые приложения без
+единой строчки конфигурации. Но как только мы пытаемся
+создать что-то более сложное, нам все равно приходится
+создавать конфигурационные файлы и классы и настраивать все вручную
+точно так же, как в традиционном Spring-приложении.
+По своему опыту могу сказать, что на реальных проектах
+такая ситуация возникает в большинстве случаев.
+Например, как только нужно настроить подключение
+к нескольким базам данных, а не к одной, мы вынуждены
+создавать конфигурационные классы вручную.
+
+В этом случае Spring Boot в какой-то степени может даже
+навредить вашей продуктивности, потому что вам придется
+разбираться, какие автоконфигурационные классы отключить, и т. д.
+
+Мы изучаем Spring довольно глубоко.
+Традиционно хорошо показал себя подход, при котором
+вначале изучается чистый Spring Framework, после чего
+мы переходим к использованию Spring Boot. Такой подход
+сохраняется и в этой версии курса. Без этого Spring Boot
+будет для вас "черным ящиком", который вам будет очень
+сложно понять, настраивать и отлаживать.
+
+### ORM frameworks
+Отчеты, которые мы использовали, обычно не включают информацию
+о самых популярных ORM-фреймворках.
+
+>Известно,
+>что **Hibernate** является достаточно популярным фреймворком
+>и наиболее часто упоминается в вакансиях, если сравнивать
+>его с другими ORM-фреймворками и инструментами для работы Java-приложения
+>с базами данных.
+
+Вот одна из статей, которая также говорит о
+популярности Hibernate: [Top 5 Java ORM tools - 2022](https://www.knowledgefactory.net/2021/09/top-java-orm-tools-20XX.html)
+
+**ORM** или **Object-relational-mapping** можно перевести как
+"объектно-реляционное отображение (преобразование)".
+Это техника, которая позволяет создать виртуальную базу
+данных с помощью объектно ориентированного языка
+программирования и взаимодействовать с ней, в то время
+как взаимодействие уже с реальной базой данных выполняется
+фреймворком незаметно для нас.
+Это облегчает работу, позволяет работать с привычными
+и удобными для использования Java-объектами, вызывая
+их методы, вместо того, чтобы писать SQL-запросы к базе данных и код для интерпретации полученных данных.
+
+>Hibernate является реализацией спецификации JPA,
+>так же, как и менее популярный EclipseLink.
+
+Говоря простым языком, JPA (Java Persistence API) - это
+набор интерфейсов без реализации для работы с ORM,
+который включен в стандарт Java EE. Отдельные провайдеры
+могут предоставлять свои реализации этого интерфейса.
+
+Недостатками JPA и его реализации Hibernate являются удар по производительности
+и недостаточная гибкость. Вопрос производительности частично
+может быть решен с помощью различных техник оптимизации кода,
+написанного с использованием JPA, однако для некоторых
+приложений тот оверхед, который несет в себе JPA, является
+недопустимым, и вы можете увидеть на некоторых проектах
+использование других подходов, от использования
+чистого JDBC до использования MyBatis, JOOQ или каких-то
+альтернативных решений.
+
+В реальных приложениях те запросы к базе данных,
+которые создают наибольшую нагрузку на систему,
+могут быть оптимизированы для улучшения производительности: для
+них могут быть применены JDBC, альтернативные
+JPA-фреймворки, также запросы могут быть написаны
+с помощью нативных SQL-запросов в JPA.
+Для остальных запросов, которые не приводят к
+большой нагрузке на систему, в том же приложении может
+быть применен Hibernate.
+Таким образом, в одном приложении могут быть применены одновременно разные технологии.
+
+
+На курсе вы изучите, как работать с БД с помощью нескольких
+технологий: JDBC (а точнее, Spring JDBC template),
+а также JPA и Spring DataJPA.
+Вы сами не только увидите, но и почувствуете
+при написании кода в ваших домашних заданиях плюсы и минусы каждого подхода.
+
+### Обзор пройденных тем
+Давайте подведем промежуточные итоги по результатам этого урока.
+
+В этом уроке мы:
+
+* познакомились с тем, что такое фреймворки
+и для чего они нужны;
+* посмотрели статистику, которая определяет
+Spring Framework как самый популярный фреймворк на рынке;
+* познакомились с ORM - подходом для упрощения работы
+с базами данных с использованием объектно-ориентированного подхода;
+* узнали про JPA (Java Persistence API) - протокол для работы с
+ORM - и про реализации JPA, среди которых Hibernate является самой популярной;
+* обсудили недостатки подхода ORM и познакомились с инструментами,
+которые могут быть использованы в качестве альтернативы.
+
+В следующем коротком уроке мы завершим обзор используемых технологий.
+Увидимся в следующем видео.
diff --git a/doc/entrance/video2.3.md b/doc/entrance/video2.3.md
new file mode 100644
index 000000000..153e2ddfa
--- /dev/null
+++ b/doc/entrance/video2.3.md
@@ -0,0 +1,113 @@
+## Обзор наиболее востребованных технологий. Тренды
+
+##  [Видео](https://drive.google.com/file/d/1XcTRkArj2guek9OiPuFEq_U1V4Dg0N-j)
+
+### Тренд на отказ от reflection
+
+Говоря о трендах, хотелось бы сказать, что в настоящее
+время развиваются фреймворки, построенные на отказе
+от использования Reflection API.
+Dependency injection в Spring, сериализация с помощью
+Jackson построены на использовании Reflection, что
+сильно бьет по производительности, но было достаточно
+удобным решение до недавнего времени.
+Фреймворк Micronaut полностью построен на отказе от
+Reflection, и это дает существенный прирост
+производительности при измерении ряда параметров.
+Micronaut использует продвинутый компилятор и
+генерацию байткода, что позволяет создать все
+бины (управляемые фреймворком объекты) в ходе компиляции.
+
+Пока доля Micronaut очень мала, но он используется
+в продакшене. Я предполагаю, что в какой-то момент
+Spring может также внедрить подобный подход.
+
+### Тренд на развитие реактивного программирования
+
+Продолжает развиваться реактивное программирование,
+которое является в какой-то степени новой парадигмой
+в программировании.
+
+Spring развивает свой реактивный фреймворк Spring WebFlux,
+который поддерживает библиотеку Reactor.
+
+
+Ряд современных задач не решается традиционными
+методами, такими как блокирующий Input/Output,
+HTTP-протокол. Одним из решений данных вопросов
+является применение подходов реактивного
+программирования (Reactor, RxJava), использование
+новых протоколов передачи данных (RSocket).
+У нас также готовится курс [ReactJava](https://javaops.ru/#inprogress) как
+продолжение TopJava на реактивном стеке.
+
+### Тренд на микросервисы, тезисы
+
+ПО становиться большим и сложным. Очень большое приложение
+сложно поддерживать одной командой, управлять его жизненным
+циклом - разработкой, релизами.
+
+Если в большое монолитное приложение добавляется новая
+функциональность приходиться выполнять повторного тестирование
+всей большой системы, в результате срок выхода новых фич увеличивается.
+
+Микросервисная архитектура позволяет решить эту проблему - она
+предполагает разделение большого приложения на отдельные
+приложения-модули, которые взаимодействуют друг с другом.
+Над одним модулем-сервисом может работать один человек или
+небольшая команда. У такого модуля-сервиса будет отдельный
+Git-репозиторий, он может быть задеплоен (развернут) независимо
+от остальной системы. При таком подходе, команды могут вести работу
+над различными сервисами параллельно, параллельно деплоить
+их на серверах. При внесении изменений в микросервис “А”,
+вероятность вызывать проблемы в микросервисе “B” снижается.
+У разных микросервисов могут быть собственные базы данных.
+Это также повышает надежность и гибкость. Например, если по каким то причинам после обновления банковского микросервиса, ответственного за выдачу кредитов возникли сбои и база данных оказалась недоступна, другие компоненты системы, имеющие отдельные базы данных, продолжат свою работу без сбоев.
+
+Это существенно упрощает доработку, тестирование и деплой таких систем.
+
+Использование микросервисов дает большую гибкость в выборе
+технологий. Нам не нужно ограничивать себя в использовании
+технологий для того, чтобы все стандартизировать внутри
+одной большой системы. Работая с отдельными микросервисами,
+мы можем выбрать идеально подходящие технологии для отдельных задач.
+Например, один микросервис может использовать реляционные
+базы данных, а второй эффективнее решает свою задачу
+используя NoSQL базу данных или in memory базу данных.
+
+Еще одно важное преимущество, которое дает микросервисная
+архитектура это возможность легко масштабировать систему горизонтально.
+
+Предположим, что банк испытывает быстрый рост обращений
+об открытии новых счетов.
+
+Если банк использует монолитную архитектуру,
+то есть одно большое приложение, ему может потребоваться
+запускать отдельный экземпляр всего своего приложения
+и направлять часть обращений от клиентов на этот экземпляр (instance).
+
+Если же банк использует микросервисную архитектуру,
+он может запустить несколько экземпляров только сервиса,
+ответственного за открытие новых счетов и распределять
+нагрузку между этими экземплярами.
+При этом микросервис, ответственный за выдачу кредитов,
+который не испытывает повышенной нагрузки, может остаться
+в одном экземпляре. При этом увеличение числа микросервисов,
+ответственных за открытие счетов может происходить автоматически
+с помощью инструментов DevOps и Kubernetes.
+
+Однако использование микросервисов также создает сложности.
+Разработка систем, построенных на микросервисной архитектуре
+на порядок сложнее. Обслуживание таких систем также
+существенно сложнее.
+
+Компания должна обслуживать множество серверов,
+обеспечивать мониторинг каждого микросервиса и так далее.
+Также security таких систем существенно сложнее,
+поскольку мы имеем дело с множеством приложений,
+коммуницирующих друг с другом и все эти коммуникации
+должны быть безопасными.
+
+
+Следующий, готовый стать самым популярным
+после TopJava курс - **[Микросервисы](https://javaops.ru/view/cloudjava) ([Первые занятие открытые](https://javaops.ru/view/cloudjava#program))**
diff --git a/doc/entrance/video2.4.md b/doc/entrance/video2.4.md
new file mode 100644
index 000000000..14041e795
--- /dev/null
+++ b/doc/entrance/video2.4.md
@@ -0,0 +1,24 @@
+## 2.4 Обзор наиболее востребованных технологий. Обзор разрабатываемого приложения
+
+##  [Видео](https://drive.google.com/file/d/1LHI18LZK1MRIEBpVe3WjCE890EydN5Gz)
+
+### О работе с фронтендом и JavaScript
+Курс включает себя минимальную практику работы с JavaScript.
+Почему это нужно?
+В вакансиях backend разработчиков, как правило, отсутствуют
+требования глубокого знания JavaScript, но каждый разработчик
+должен уметь пользовать DevTools - инструментами разработчика
+в браузере, чтобы при работе над рабочими задачами по меньшей
+мере иметь возможность понять, происходит ли ошибка на стороне
+фронтенда или на стороне бэкенда, увидеть, какие данные уходят
+на сервер с фронтенда и так далее.
+
+Также, конечно, минимальные знания JavaScript приятны, поскольку
+они дают вам возможность написать свой несложный проект хотя
+бы с минимальным фронтендом.
+
+Существуют также fullstack-разработчики, от которых требуется
+способность полноценно решать задачи фронтенда на продакшене.
+Это требует довольно глубокого знания фронтенд-технологий и
+таких фреймворков, как Angular или React. Это требует много
+времени, и такая подготовка не входит в курс TopJava.
\ No newline at end of file
diff --git a/doc/entrance/video3.md b/doc/entrance/video3.md
new file mode 100644
index 000000000..1821aac3f
--- /dev/null
+++ b/doc/entrance/video3.md
@@ -0,0 +1,168 @@
+## Рекомендуемые подходы обучения на курсе
+
+##  [Видео](https://drive.google.com/file/d/1v5sVL8ivNvSXEPVlrYibFLD5byywRkmT)
+
+В предыдущих уроках мы сделали обзор технологий,
+которые будут использоваться в нашем курсе и создаваемом проекте.
+Теперь давайте поговорим о том, как начать
+изучать эти технологии и практиковаться в их использовании.
+
+---
+В 1980 году National Training Laboratories в
+США провели исследования эффективности разных
+способов обучения.
+Выяснилось, что у лекций и чтения книг крайне
+низкая эффективность — всего 5-10%.
+Дальше идет просмотр видео лекций и прослушивание аудио.
+
+Максимальная эффективность в 90% — это обучение
+людьми других людей — менторинг и немедленное
+применение полученных знаний на практике.
+
+
+
+
+
+Я хочу подчеркнуть этот момент.
+
+>Когда вы смотрите видео, вам может казаться, что вы все понимаете, но, поверьте, когда вы попытаетесь повторить это самостоятельно, у вас возникнет множество вопросов и сложностей. Практика - это важнейшая часть обучения, не пропускайте ее.
+
+На нашем курсе мы:
+- обсуждаем занятия с коллегами и преподавателями в Slack - эффективность 50%
+- выполняем практические домашние задания по каждой пройденной теме - 75%
+- помогаем коллегам и разрабатываем собственный выпускной проект - 90%
+
+### О проверке домашних заданий
+Также очень важная часть обучения - проверка
+ваших домашних заданий и ревью выпускного
+проекта нашими кураторами.
+
+>**Это самый эффективный способ научиться программировать!**
+
+При устройстве на работу, на собеседовании обязательно
+задавай вопрос про ревью кода.
+Если его нет, фирма занимается разработкой
+непрофессионально? и рост там будет достаточно
+медленным и ограниченным.
+
+В ревью укажут именно твои ошибки
+в стиле, структурах данных, алгоритмах и кодировании.
+До вечера вторника участники шлют ссылку
+на свой GitHub-репозиторий с домашним
+заданием занятия, проверка делается
+ассистентами, результат пишется в Slack.
+Получается эффективно и оперативно.
+
+После проверки можно исправить замечания
+и пройти ее еще раз.
+
+В конце стажировки делается ревью вашего выпускного проекта.
+
+
+### Участие на стажировке: ожидания и реальность
+
+Давайте кратко обсудим, чем курс TopJava является
+и чем он не является, что следует от него ожидать
+и чего не следует.
+
+#### 1-й тип ложного представления о стажировке:
+
+>Я увижу, как с нуля строится web-приложение A с использованием технологий B, просмотрю видео по темам, этого будет достаточно
+
+
+
+Почему такой подход не верный:
+TopJava - это стажировка, поэтому НЕ рассчитывайте
+пройти ее на диване с пакетом поп-корна.
+Тебе придется на ней РАБОТАТЬ (выполнять ДЗ,
+самостоятельно решать какие-то задачи, читать логи,
+дебажить, ходить на StackOverflow и даже думать
+об этом, засыпая)
+
+#### 2-й тип ложного представления о стажировке:
+>Меня научат шаблонам работы с технологией А, и я
+> смогу их применять в любой ситуации
+
+Почему это тоже не вполне верный подход:
+Используемые на стажировке технологии представляют
+собой инструменты, которые позволяет сделать
+что-то проще. Мы поделимся практикой их использования,
+неочевидными особенностями и т. п., покажем
+"грабли", на которые вы рано или поздно наступите.
+Нет гарантии, что, устроившись на работу, вы
+увидите точно такие же подходы.
+Все проекты и команды индивидуальны: используются
+различные инструменты и различные решения.
+Столкновение с технологиями, с которыми
+ты ранее не был знаком, - это нормальная
+часть жизни любого программиста. Нужно быть к этому готовым.
+
+Хорошее представление о решении проблем
+дает поиск на StackOverflow, где почти
+на любую проблему дается большое количество
+вариантов решения. Поиск решений и выбор
+лучшего - это основная работа Java-разработчика,
+и мы максимально постараемся этому научить:
+каждый раз в конкретной ситуации вы должны
+будете САМИ думать, что применять и как.
+Выполняя домашние задания, вы должны приложить
+все усилия, чтобы самостоятельно найти решение.
+Далее в начале следующего занятия вы также
+посмотрите разбор решения, подготовленного
+Григорием Кислиным.
+
+#### 3-й вариант ошибочного представления о стажировке TopJava связан с неверным представлением о том зачем нужна проверка домашних заданий. Например, человек может ошибочно рассуждать так:
+
+>я хочу проходить стажировку с проверкой ДЗ,
+> чтобы мне рассказали, как нужно правильно выполнять задания
+
+Задача проверки не в том, чтобы общими усилиями
+написать код, который ты и так увидишь в разборе.
+Если у тебя что-то не получается, наша
+задача - не найти ошибку/подебажить за тебя/почитать
+логи и т. п., а подсказать способ самостоятельно
+найти решение (хотя для этого мы сначала сами
+ищем/дебажим/читаем)
+Вторая важная задача, которую решает
+проверяющий, - увидеть то, что не увидел ты.
+Когда ты сдаешь задание на ревью, тебе
+может казаться, что все почти идеально. Проверяющий
+подскажет тебе, где ты что-то пропустил из-за
+недостатка опыта, что позволит тебе улучшить код.
+
+---
+
+>Любое знание стоит воспринимать как подобие семантического дерева: убедитесь в том, что понимаете фундаментальные принципы, то есть ствол и крупные ветки, прежде чем лезть в мелкие листья-детали. Иначе последним не на чем будет держаться
+— Илон Маск
+
+Обычно в занятии дается много дополнительного
+материала и ссылок. Не стоит стремиться прочитать
+все ссылки урока, их можно использовать как
+справочник. Гораздо важнее пройти основной
+материал урока и сделать домашнее
+задание - этого достаточно для усвоения
+материала и получения той самой
+основы - ствола и крупных веток, на
+которых впоследствии можно наращивать листву.
+
+
+Как правило, подбираются участники разного
+уровня. Поэтому главное – не стеснятся
+задавать вопросы (после самостоятельного
+гугления и поиска решения). Всегда есть
+поддержка группы (в том числе от пришедших
+на бесплатный повтор участников), моя и ассистентов.
+
+---
+### Основные навыки программиста, которые необходимо развить на курсе
+Давайте перечислим набор навыков, которые
+вам необходимо развивать в ходе курса
+и которые необходимы любому программисту:
+
+- умение и привычка искать
+информацию, чтобы иметь больший выбор из
+доступных вариантов технологий и подходов
+к решению задачи, умение пользоваться StackOverflow;
+- умение пользоваться дебаггером в Intellij Idea;
+- умение пользоваться DevTools в браузере;
+- определенный кругозор и опыт для того, чтобы придумывать поисковые запросы.
diff --git a/doc/entrance/video4.md b/doc/entrance/video4.md
new file mode 100644
index 000000000..7d9b00716
--- /dev/null
+++ b/doc/entrance/video4.md
@@ -0,0 +1,110 @@
+## Структура приложения (многоуровневая архитектура)
+##  [Видео](https://drive.google.com/file/d/1UHzSy9i-uonmTMFoR5v69Y-vyWLCLQWd)
+
+Приложение, которое мы будем разрабатывать, это [программа для подсчета калорий](http://javaops-demo.ru/topjava).
+
+В этом видео обсудим структуру этого приложения.
+
+---
+Ссылки на отчеты, которые будут использоваться в этом уроке:
+
+- [Многоуровневая архитектура (русскоязыная статья в Wikipedia)](https://ru.wikipedia.org/wiki/%D0%9C%D0%BD%D0%BE%D0%B3%D0%BE%D1%83%D1%80%D0%BE%D0%B2%D0%BD%D0%B5%D0%B2%D0%B0%D1%8F_%D0%B0%D1%80%D1%85%D0%B8%D1%82%D0%B5%D0%BA%D1%82%D1%83%D1%80%D0%B0)
+- [Multitier architecture (англоязычная статья в Wikipedia)](https://en.wikipedia.org/wiki/Multitier_architecture)
+
+---
+
+
+
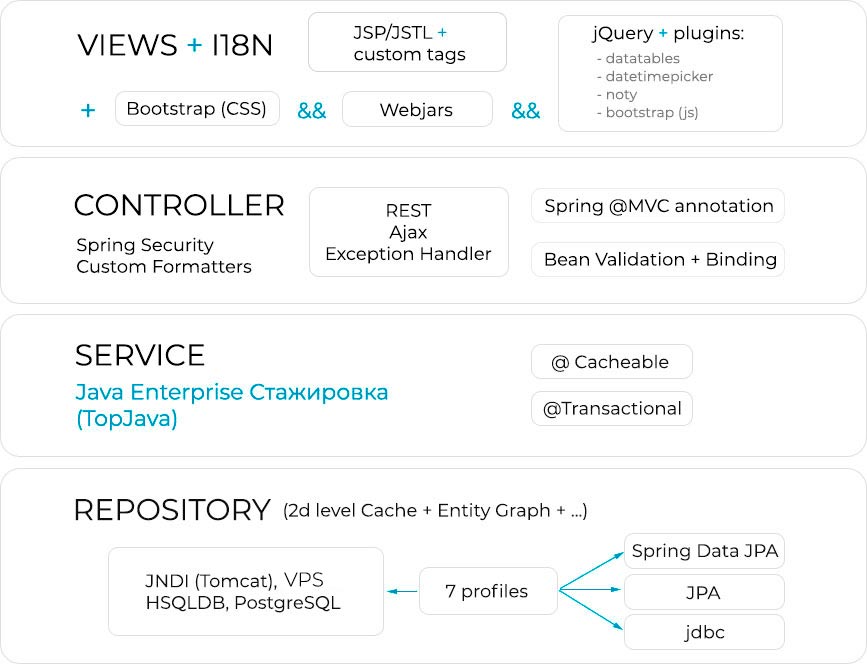
+На структурной схеме приложения вы видите, что оно условно разделено на 4 части: **Views**,
+**Controller**, **Service** и **Repository**.
+
+Такой подход является реализацией многоуровневой архитектуры в программировании.
+По-английски этот подход называется **_Multitier architecture_**.
+
+Его суть заключается в разделении приложения на несколько слоев,
+каждый из которых ответственен за конкретную задачу.
+
+### Слой отображения (View)
+Views соответствует слою отображения (или presentation layer). Это user interface (UI) или
+фронтенд - все то, что мы видим и с чем взаимодействуем в браузере.
+В качестве View могут быть HTML-страницы, созданные с использованием специальных
+движков шаблонов, например, JSP (встроен в Tomcat), или
+Thymeleaf (шаблоны по умолчанию в Spring Boot), или отдельное frontend-приложение,
+написанное на одном из JavaScript-фреймворков.
+
+В случае с движками шаблонов HTML-страницы будут располагаться в одном проекте
+с основным кодом приложения. Для приложений с "небогатым" UI используются именно шаблоны.
+Этот подход отличается от так называемых RIA - rich internet application - приложений со сложным UI.
+
+Главное отличие rich internet application от приложений с фронтендом
+на движках шаблонов заключается в том, что фронтенд, созданный на движке
+шаблонов, работает на сервере, и это что-то простое.
+В случае с rich internet application фронтенд-приложение загружается
+через Интернет к вам на компьютер и запускается в браузере.
+Оно может быть максимально сложным и выполнять функции традиционных
+десктоп-приложений.
+Иногда в одном приложении смешиваются оба способа: например, страница
+логина-пароля в RIA делаются на шаблонах.
+
+Создание простого фронтенда на движке шаблонов проще, поэтому
+в курсе мы будем использовать этот способ.
+
+### Слой контроллеров (Controller)
+Следующий слой, который мы видим - это **Controller**.
+
+В многоуровневой архитектуре он соответствует слою, который
+называется "**_Слой приложения_**" или "**_Application layer_**").
+В GRASP (General Responsibility Assignment Software Patterns)
+он так и называется - Controller layer.
+
+Это слой приложения, который ответственен за обработку HTTP-запросов и проверку корректности входных данных. Если мы открываем главную страницу на сайте или отправляем заполненную на сайте форму, фронтенд-приложение отправляет HTTP-запрос серверу (в нашем случае контейнеру сервлетов), который принимает запрос и перенаправляет его в контроллер, соответствующий введенному в браузере URL или адресу, который вызывается при отправке формы через сайт.
+Также контроллеры могут принимать запросы не только от фронтенда, но и от других приложений.
+
+Слой контроллеров не имеет доступа к базе данных. Контроллеры общаются только с сервисами.
+
+### Слой сервисов (Service layer)
+Слой **Service** на схеме приложения соответствует слою
+бизнес-логики (или **_Business layer_**) в многоуровневой архитектуре.
+В слое Service инкапсулирована вся бизнес-логика нашего приложения.
+Если коммуникация с фронтендом или другими приложениями - это ответственность контроллеров,
+то обработка данных - это ответственность сервисов.
+
+### Слой доступа к данным (Data layer)
+Слой сервисов общается со слоем, ответственным за работу с базами данных.
+Этот слой называют **Data layer** (также можно встретить
+названия **Persistence Layer** или **Data access layer**), и он
+представлен в виде **_Data Access Object_** классов
+(коротко - **_DAO-классы_**) или классов, реализующих паттерн "репозиторий".
+С обоими видами классов вы попрактикуетесь в ходе курса.
+[Репозиторий - это также один из архитектурных паттернов](https://martinfowler.com/eaaCatalog/repository.html)
+
+Подобное разделение приложения на слои дает гибкость
+и существенно упрощает доработку и переиспользование приложения.
+Например, создав по такому принципу приложение,
+содержащее слои репозиториев, сервисов и контроллеров,
+мы в дальнейшем можем легко использовать это приложение
+с различными фронтенд-приложениями или мобильными приложениями.
+Если мы решим перейти на другую базу данных, мы можем
+переписать только слой репозиториев, и нам не требуется
+вносить изменения в слои сервисов и контроллеров.
+
+>Для маленького приложение такой подход может показаться
+>избыточно сложным, но по мере расширения это является спасением.
+
+Подавляющее большинство реальных приложений построено с использованием именно этой архитектуры.
+
+### Краткие итоги
+В этом видео мы познакомились с концепцией многоуровневой архитектуры,
+которую мы применим при создании приложения на курсе.
+Многоуровневая архитектура предполагает разделение приложения на слои:
+- Views - слой отображения является фронтендом;
+- Controller - слой приложения ответственен за прием и валидацию входных данных;
+- слой Service включает в себя весь код, отражающий бизнес логику;
+- Repository или Data layer отвечает за взаимодействие с базой данных.
+
+Также мы обсудили какие преимущества дает такой подход.
+Среди преимуществ в первую очередь возможность повторного
+использования различных слоев и упрощение их доработки и изменения.
+
+
+
diff --git a/doc/entrance/video5-vcs-git.md b/doc/entrance/video5-vcs-git.md
new file mode 100644
index 000000000..7a172e517
--- /dev/null
+++ b/doc/entrance/video5-vcs-git.md
@@ -0,0 +1,180 @@
+## Системы управления версиями, Git
+##  [Видео](https://drive.google.com/file/d/1uFjIsxsaSAXxFSwSpjJIGK7Ug2VXf6yH)
+
+video5-vcs-git.md
+
+В этом уроке мы рассмотрим системы управления версиями
+и самую популярную из них - Git.
+
+---
+* [StackOverflow 2021 survey](https://insights.stackoverflow.com/survey/2021#technology-most-popular-technologies)
+* [Введение в Git и GitHub: установка и настройка](https://topjava.ru/blog/vvedeniye-v-git-github-ustanovka-i-nastroyka)
+* [Введение в Git и GitHub: базовые команды](https://topjava.ru/blog/vvedeniye-v-git-github-bazovyye-komandy)
+* [Введение в Git и GitHub: ошибки использования](https://topjava.ru/blog/vvedeniye-v-git-oshibki-ispolzovaniya-ch-9)
+* [Бесплатная русскоязычная книга Pro Git](https://git-scm.com/book/ru/v2/)
+---
+
+Git является де-факто стандартом среди систем управления версиями.
+Опрос, проведенный StackOverflow в 2021 году показывает,
+что Git используют почти 95% опрошенных разработчиков.
+
+Когда-то популярная централизованная система контроля
+версий SVN (Subversion) практически полностью заменена Git.
+Но некоторые большие проекты все еще используют SVN.
+Примером такого проекта является WordPress.
+Я также все еще иногда встречаю SVN в вакансиях российских компаний.
+
+### Что такое Git и GitHub
+В ходе курса мы будем использовать Git.
+Git - это распределенная система управления версиями.
+Это означает, что код, над которым работает команда,
+и ранее сохраненные (закоммиченные) версии проекта
+хранится на компьютерах каждого члена команды,
+а также в удаленном репозитории, который можно
+сравнить с облачным хранилищем.
+
+Некоторые путают Git и GitHub, но это не одно и то же.
+
+**Git** — это утилита, которую
+программист устанавливает у себя на компьютере для
+сохранения состояний проектов и контроля версий проекта.
+
+**GitHub** — это провайдер удаленных репозиториев,
+сайт (хостинг) для хранения кода проекта и его изменений,
+для обмена файлами с членами команды проекта.
+Программисты могут создавать на GitHub публичные репозитории,
+в которых код доступен всем. Компании могут приобрести платный
+аккаунт на GitHub и вести свои проекты в закрытых репозиториях,
+доступ к которым имеют только члены команды проекта.
+Существуют и другие подобные сайты - провайдеры удаленных
+репозиториев, например, BitBucket, SourceForge, GitLab и т. д.
+
+
+### Как работают Git и GitHub
+
+
+Говоря кратко, работа с Git и удаленным репозиторием
+(в нашем случае это Github) выглядит следующим образом.
+
+Первый разработчик, который начинал работу над проектом,
+использовал команду **_git init_** в корневой директории
+проекта для того, чтобы инициализировать пустой Git-репозиторий.
+В этот момент Git создает в директории с проектом скрытую
+директорию, содержащую файлы, необходимые для его работы.
+Теперь первый разработчик может с помощью команды **_git add_**
+добавлять файлы проекта в индекс - то есть в зону,
+отслеживаемую git, а также может фиксировать изменения,
+создавая коммиты (**_git commit_**), и загружать их в
+удаленный репозиторий (например, на GitHub) с помощью
+команды **_git push_**.
+
+Спустя некоторое время к работе над проектом подключается второй разработчик.
+
+Поскольку первый разработчик пушил изменения файлов проекта
+на удаленный репозиторий, второй разработчик может скачать
+их себе на компьютер с помощью команды **_git pull_**
+и продолжить работу с учетом этих изменений.
+
+Давайте повторим.
+В описанной работе использовались команды:
+
+* **_git init_** - эта команда инициализирует работу Git
+для конкретного проекта. В папке с проектом создается
+скрытая папка, хранящая все файлы, необходимые Git
+для работы. Папка с этими файлами впоследствии будет
+загружена в удаленный репозиторий, и второй программист,
+скачавший проект, увидит у себя на компьютере все ранее
+созданные с помощью Git версии.
+* **_git add_** - это команда, которая добавляет файлы
+проекта в индекс (или отслеживаемую зону), чтобы их можно
+было в какой-то момент закоммитить (то есть сохранить, зафиксировать).
+* **_git commit_** - сохраняет все файлы проекта в
+текущем состоянии так, что мы в любой момент сможем
+вернуться к этому состоянию - посмотреть, как изменились
+файлы, или даже полностью вернуть проект к состоянию
+данного коммита.
+* **_git push_** - загружает файлы в удаленный Git-репозиторий,
+чтобы их могли скачать другие программисты.
+* **_git pull_** используют для того, чтобы скачать
+файлы из удаленного репозитория себе на компьютер.
+
+Также Git позволяет создавать ветки. Это означает,
+что вы можете создать копию стабильного кода и
+продолжить работу в этой копии, не подвергая риску
+стабильную версию. Когда код с новой функциональностью
+готов, отлажен и протестирован, он может быть
+слит ("смержен", от слова "merge") в основную ветку со стабильным кодом.
+
+С помощью этих функций Git позволяет команде разработчиков
+работать одновременно над разными задачами и поддерживать
+код в стабильном состоянии.
+
+Также Git позволяет в любой момент понять, кто и когда внес
+изменения в определенный код, что существенно упрощает взаимодействия
+с коллегами. Например, в случае, если вы видите новые
+строки кода, которые вызывают у вас вопросы, с помощью
+Git вы можете разобраться, кто внес изменения именно
+в эти строки, и связаться с этим человеком
+для уточнения деталей.
+
+Если произошла ситуация, при которой два разработчика
+изменили один и тот же файл, Git потребует от вас вручную
+отрегулировать такой конфликт.
+
+Также благодаря Git у вас всегда под рукой детальная
+история изменений. С помощью комментариев к коммитам
+вы можете детально документировать ход работы над
+проектом и в случае необходимости разобраться, в
+какой момент что-то пошло не так, и откатиться
+к той версии, где ошибка еще не была сделана.
+Или просто выяснить, как выглядел код определенного
+класса или метода в определенной версии и внести правки
+в текущую версию, если это необходимо.
+
+### Дополнительные материалы
+
+Для изучения Git рекомендуем в первую очередь ознакомиться со статьями на сайте [topjava.ru](https://topjava.ru):
+
+* [Введение в Git и GitHub: установка и настройка](https://topjava.ru/blog/vvedeniye-v-git-github-ustanovka-i-nastroyka)
+* [Введение в Git и GitHub: базовые команды](https://topjava.ru/blog/vvedeniye-v-git-github-bazovyye-komandy)
+* [Введение в Git и GitHub: ошибки использования](https://topjava.ru/blog/vvedeniye-v-git-oshibki-ispolzovaniya-ch-9)
+
+В них дается детальная инструкция по первоначальной настройке
+Git, GitHub, в том числе инструкция по настройке
+Access token в GitHub, что вам обязательно нужно будет сделать.
+
+Также можно упомянуть официальную русскоязычную книгу Pro Git,
+которая доступна [бесплатно в электронном виде](https://git-scm.com/book/ru/v2/).
+
+### Как мы будем использовать Git на курсе
+В Git очень много команд, но в ходе курса мы будем использовать
+только самые необходимые из них.
+С git можно работать как через терминал с помощью команд,
+так и с помощью различных программ с графическим интерфейсом.
+Мы будем преимущественно использовать интеграцию
+IntelliJ Idea с Git, поскольку она очень удобна
+и существенно упрощает работу.
+Однако знать, как выполнять аналогичные операции
+в терминале, очень полезно.
+
+### Резюме
+В этом уроке мы сделали краткий обзор систем управления
+версиями и самой популярной из них - Git:
+
+* разобрались в различиях Git и GitHub.
+Git - это система контроля версий, а
+GitHub - провайдер удаленных репозиториев, один из многих, доступных на рынке.
+* кратко познакомились с тем, как Git работает.
+Узнали о командах git init, git add, git commit, git push и git pull.
+* Также мы обсудили, что такое ветки и какие возможности они дают.
+
+---
+
+Если вы не работали раньше с Git, не беспокойтесь.
+В последующих уроках работа с Git будет изучаться
+на практике в ходе работы над проектом. Но дополнительно
+почитать о Git все же стоит.
+
+
+
+
diff --git a/doc/graduation.md b/doc/graduation.md
new file mode 100644
index 000000000..123238d4e
--- /dev/null
+++ b/doc/graduation.md
@@ -0,0 +1,185 @@
+## Выпускной проект
+
+- **Дедлайн на заполнение [формы по выпускному проекту](https://javaops.ru/auth/graduate) - 12 января 2026, 23.59 МСК**
+- Ревью проекта входит в участие с проверкой домашних заданий. Проверяется два раза: один раз ассистентами и после ваших правок - финальная проверка, Кислиным Григорием.
+- Ревью выпускного делается только у участников с проверкой ДЗ. У кого оплачен Диплом, но нет проверки - даю краткие итоги.
+- **Ревью выпускного можно оплатить отдельно как [техническое собеседование](https://javaops.ru/auth/payonline?payId=I)**
+- Участникам проекта [Многомодульный maven. Многопоточность. XML (JAXB/StAX). Веб сервисы (JAX-RS/SOAP). Удаленное взаимодействие (JMS/AKKA) (Masterjava)](http://javaops.ru/reg/masterjava) срок ревью выпускного до
+ 12 апреля 2026 г.
+
+## Technical requirement:
+Design and implement a REST API using Hibernate/Spring/SpringMVC (Spring-Boot preferred!) **without frontend**.
+
+The task is:
+
+Build a voting system for deciding where to have lunch.
+
+* 2 types of users: admin and regular users
+* Admin can input a restaurant and it's lunch menu of the day (2-5 items usually, just a dish name and price)
+* Menu changes each day (admins do the updates)
+* Users can vote for a restaurant they want to have lunch at today
+* Only one vote counted per user
+* If user votes again the same day:
+ - If it is before 11:00 we assume that he changed his mind.
+ - If it is after 11:00 then it is too late, vote can't be changed
+
+Each restaurant provides a new menu each day.
+
+As a result, provide a link to github repository. It should contain the code, README.md with API documentation and couple curl commands to test it (**better - link to Swagger**).
+
+-----------------------------
+P.S.: Make sure everything works with latest version that is on github :)
+P.P.S.: Assume that your API will be used by a frontend developer to build frontend on top of that.
+
+-----------------------------
+
+##  Рекомендации
+
+**Пишем выпускной проект как тестовое задание на работу**
+
+- **Не списывай с коллег!** Выпускные проекты пишут только наши выпускники, их репозитории есть в нашей базе. Поэтому при подозрениях на списывание оригинал вычисляется легко. Лучше написать свое -
+ как можете, как поняли материал - и получить ревью (которое вами же оплачено) своего проекта, а не чужого. Даже если времени мало - сделайте основное. Если с Дипломом - это с очень большой
+ вероятностью 4, вместо отчисления
+- **Не изобретай велосипедов!** Грубая ошибка - пытаться сделать стандартные вещи по-своему, чаще всего криво. На проекте все должно быть единообразно! Ваш проект TopJava - сделай все МАКСИМАЛЬНО в
+ этом стиле. Если тебе кажется, что есть лучшее решение, чем в TopJava - пишите мне в личку, я всегда открыт для улучшений.
+- **Делай проект на востребованном на рынке стеке**: Spring Boot + Spring Data JPA (работа с БД) + Swagger/OpenAPI 3.0 (REST документация). Для старта оптимально подойдет финальный код **открытого курса [Spring Boot 3.x + HATEOAS](https://javaops.ru/view/bootjava)**:
+```
+git clone --branch patched https://github.com/JavaOPs/bootjava.git
+```
+
+*Представьте себе, что ПМ (лид, архитектор) дал вам ТЗ и некоторое время недоступен. У вас, конечно, есть много мыслей, для чего нужно приложение, как исправить ТЗ, дополнить его и сделать правильно.
+НО НЕ НАДО ИХ РЕАЛИЗОВЫВАТЬ В КОДЕ. Нужно сделать все строго по ТЗ, максимально просто, удобно для доработок и для использования со стороны клиента.*
+
+> Совершенство достигнуто не тогда, когда нечего добавить, а тогда, когда нечего отнять
+
+_Антуан де Сент-Экзюпери_
+
+### 1: ТЗ (Тех.задание)
+
+- 1.1: Читай ТЗ ОЧЕНЬ внимательно, НЕ надо ничего своего туда домысливать и творчески изменять
+- 1.2: Учитывай, что пользователей может быть ОООЧЕНЬ много, а админов - МАЛО
+- 1.3: Сначала сделай основные сценарии по ТЗ. Все остальное (если очень хочется, 3 раза подумай) - потом.
+
+### 2. API
+
+- 2.1: API продумывай с точки зрения не программиста и объектов, а с точки зрения того, кто им будет пользоваться (клиента, UI)
+- 2.1: Тщательно считайте количество запросов в вашем API для отображения нужной информации
+- 2.3: Из потребностей приложения (клиента) реализуй только очевидные сценарии. Необходимо и достаточно: ВСЕ НЕОБХОДИМОЕ для клиента и НИЧЕГО ЛИШНЕГО. Процесс творческий, приходит с опытом.
+- 2.4: Делаем REST API в соответствии с концепцией REST (url в общем имеют вид`{ресурс}/{id_ресурсa}[/{подресурс}/{id_подресурсa}][параметры]`, см. ниже ссылки про REST и иерархию). Имена ресурсов во множественном числе!
+ Самая распространенная и грубая ошибка - не придерживаться этих простых правил.
+ - **[15 тривиальных фактов о правильной работе с протоколом HTTP](https://habrahabr.ru/company/yandex/blog/265569/)**
+ - **[10 Best Practices for Better RESTful API](https://medium.com/@mwaysolutions/10-best-practices-for-better-restful-api-cbe81b06f291)**
+ - **[REST resource hierarchy](https://stackoverflow.com/questions/20951419/what-are-best-practices-for-rest-nested-resources)**
+ - [Лучшие практики разработки REST API: правила 1-7,15-17](https://tproger.ru/translations/luchshie-praktiki-razrabotki-rest-api-20-sovetov/)
+- 2.5: Разделение на роли я предпочитаю на уровне URL. Сразу и однозначно видно, какой API у админа, какое у пользователя (API админа начинается, например, с */admin/...*).
+- 2.6: На управление (CRUD) ресторанами и едой должны быть ОТДЕЛЬНЫЕ контроллеры. Не надо все, что может админ, сваливать в одну кучу! Смотрите на результат операции - помещаете в этот контроллер!
+- 2.7: Проверьте в Swagger, что в POST и PUT нет ничего лишнего, а в GET есть все необходимые данные. Например, при запросе голоса должен в ответе отображаться `id` ресторана, а не весь объект, при создании-редактировании ресторана в примерах swagger не должно быть меню и еды.
+- 2.8: `Profile` означает, что данные принадлежат профилю пользователя. Все остальное называйте по-другому.
+- 2.9: Отсутствие данных часто бывает "бизнес кейсом", те НЕ ошибкой в запросе или приложении. Исключение - это ошибка, например неверный `id`. Запрос на данные, которые могут быть, могут нет, не должен приводить к исключениям. Посмотрите в сторону `ResponseEntity.of()`
+- 2.10: По REST URL должно быть однозначно понятно, какие будут параметры на входе и что ждать на выходе. Без сюрпризов!
+
+### 3: Код:
+- 3.1: Строго соблюдайте соглашения Java по именованию: пакеты ТОЛЬКО маленькими буквами, методы начинаются с маленькой буквы, классы с большой. Незнания Java Core - тестовое задание сразу в корзину.
+- 3.2 В проекте (и тестовом задании на работу), в отличие от нашего учебного topjava, оставляйте только необходимый для работы по ТЗ приложения код, ничего лишнего
+ - 3.2.1: НЕ надо делать разные профили базы и работы с ней
+ - 3.2.2: НЕ надо делать абстрактных контроллеров на всякий случай
+ - 3.2.3: НЕ надо делать сервисов, если там нет ничего, кроме делегирования
+ - 3.2.4: НЕ нужны локализация, UI, типы ошибок, Json View
+- 3.3: Название пакетов, имен классов для `model/to/web` стандартные (например `model/domain`). НЕ надо придумывать своих собственных правил
+- 3.4: Проверьте, не торчат ли из кода учебные уши TopJava, типа `ProfileRestController.testUTF()`, `AbstractServiceTest.printResult()` или закомментированные `JdbcTemplate`. Назначение выпускного
+ совсем другое
+- 3.5: Вместо `return ResponseEntity.ok(object)` в контроллерах пишите `return object`. Проще!
+
+### 4: Модель
+
+- 4.1: В БД обычно хранятся все введенные пользователем и админом данные c возможность их редактирования. Это означает, что мы не удаляем прошлые меню, а храним их в базе, как и историю голосования. Есть базовые вещи, которые закладываются в архитектуру приложения, и есть неочевидные доработки к ТЗ, делать не надо.
+- 4.2: Не делайте в модели объектов, которые не будут использоваться в коде (например, не надо двунаправленных связей, если достаточно однонаправленных)
+- 4.3: еще раз про [hashCode/equals в Entity](https://stackoverflow.com/questions/5031614/the-jpa-hashcode-equals-dilemma): не делайте в модели сравнение по полям!
+- 4.4: ORM работает с объектами. [Иногда, для упрощения логики, fk_id как поля допустимы](https://stackoverflow.com/questions/6311776/hibernate-foreign-keys-instead-of-entities)
+
+### 5: Архитектура / pom
+- 5.1: Можно:
+ - или подключить DATA-REST (см.курс [Spring Boot 2.x + HATEOAS](https://javaops.ru/view/bootjava)). Контроллеры генерируются автоматически по репозиториям, требуется настройка ресурсов в кастомных контроллерах
+ - или делать на основе миграции TopJava / кода [TopJava-2](https://github.com/JavaOPs/topjava2)
+
+Нельзя смешивать эти подходы вместе! Я рекомендую 2-й вариант, без data-rest. Обязательно посмотрите в Swagger, какие контроллеры получились в результате.
+- 5.2: Не размещайте бизнес-логику приложения и преобразования в TO в слое доступа к DB
+- 5.3: Не смешивайте TO и Entity вместе. Они должны быть независимыми друг от друга. На TopJava мы смотрели разные варианты [c использованием TO и без](https://stackoverflow.com/a/21569720/548473).
+ Делаем максимально просто.
+- 5.4: [Use for money in java app](http://stackoverflow.com/a/43051227/548473)
+- 5.5 Не надо явно указывать версии зависимостей в `pom`, если они наследуются от `spring-boot-starter-parent`
+
+### 6: Доступ к БД
+
+- 6.1: Используйте Spring Data JPA (без лишней делегации). Методы Repository можно вызывать напрямую из сервиса или из контроллера.
+- 6.2: В DATA-JPA 2.x используются `Optional`. Попробуйте работать с ними, это безопасный способ работать с null-значениями (используйте `orElseThrow`)
+- 6.3: Не делайте при обновлении записи ради экономии пары строчек кода так:
+```
+if(updateCondition)
+ repository.delete(entity)
+}
+repository.save(entity)
+```
+Обновление записи базы должно быть через `UPDATE`.
+
+### 7: База Данных
+
+- 7.1: Берите без установки (H2 или HSQLDB). Одну и **в памяти**! Ваше приложение должно сразу запуститься, без всяких настроек и переменных окружения
+- 7.2: Тщательно считайте количество обращений в базу на каждый запрос. Особенно при запросах от юзеров, которых очень много! Также на сложность запросов от них, чтобы не положить базу
+- 7.3: Сделайте [индексы к таблицам](https://ru.wikipedia.org/wiki/Индекс_(базы_данных)). Попробуйте обеспечить UNIQUE (один голос пользователя в день, один уникальный пункт меню в день).
+Следите за **порядком полей в индексе**, от этого зависит индексирование запросов.
+- 7.4: При популировании добавь записи за сегодняшний день - `now()`, чтобы всегда были актуальные исходные данные
+- 7.5: Поля базы case insensitive, не пишите camelStyle (для которых нужны кавычки)
+- 7.6: Таблицы обычно именуются в единственном числе. Исключение - `users`, `orders` и другие зарезервированные слова
+- 7.7: `date`/`timestamp` - зарезервированное слово, лучше избегать их при именовании полей
+
+### 8: Security
+
+- 8.1: Проверьте, станет ли код проще с `@AuthenticationPrincipal` (урок 11, доступ к AuthorizedUser).
+- 8.2: Я предпочитаю четкое разделение ролей на основе URL. Для админа URL содержит `/admin`
+- 8.3: Еще раз - призываю не менять код TopJava
+
+### 9: Кэширование
+
+- 9.1: Кэширование желательно для частых и редко меняющихся запросов от пользователей.
+Тщательно продумайте, что надо кэшировать (самые частые запросы), а что нет (большие или редко запрашиваемые данные)
+- 9.2: Проверьте соответствие ключей к кэшу (параметры кэшируемого метода) с конфигурацией (например в singleNonExpiryCache, heap=1 в кэше может содержаться только ОДНО значение).
+
+### 10: Валидация
+
+- 10.1: Одних аннотаций валидации на полях недостаточно. Должны быть `@Valid/@Validation` в контроллере
+- 10.2: Прячте `id` при `create/update` в примерах Swagger. Если их передали - проверяйте на соответствие (в TopJava это `ValidationUtil.checkNew()/assureIdConsistent()`)
+
+### 11: Дополнительно
+
+- 11.1: По возможности сделать JUnit-тесты. Можно не делать 100% покрытие, только основные сценарии
+- 11.2: Уделяйте внимание обработке ошибок.
+
+### 12: `readme.md`:
+
+- 12.1: Поместите вначале `readme` ТЗ или **ссылку на него** - будет понятно о чем твой проект
+- 12.2: Если задание на English, описание пиши также на English (то же самое относится к языку резюме: вакансия на English предполагает резюме на English)
+- 12.3: Требуемые примеры `curl` не прячьте, а пишите здесь! Оптимально сделать **ссылку на `Swagger UI` с креденшелами для выполнения запросов**
+- 12.4: Проверяют люди с опытом в Java: не надо писать инструкций, как устанавливать Java и Maven
+
+### 13: Git
+
+- 13.1: Должна быть история ваших комитов с внятными комментариями. Это смотрят.
+> Эйчар обращает внимание на дату создания аккаунта и то, как в него заливались коммиты (элементы проекта), постепенно или в один день, насколько технологии в аккаунте коррелируют с технологиями в резюме
+- 13.2: Не комить служенбые файлы: логи, DB, настройки IDEA и пр., это сразу - уровень Junior.
+- 13.3: Все служебные файлы должны быть в `.gitignore`
+
+## Проверка
+
+- Попробуй подергать свое API по всем типичным сценариям ТЗ!
+ - Удобно использовать? Можно сделать проще? Например, чтобы проголосовать за ресторан залогиненному юзеру, достаточно `restorauntId`.
+ - Сколько раз пришлось его вызвать API для типичного сценария (например посмотреть рестораны с едой на сегодня)?
+ - Сколько запросов к базе было сделано? Можно ли сократить (например с `FETCH/Graph` или через кэширование)?
+ - **Еще раз - проверь все запросы в Sawgger, смотри на формат запросов и данные в ответе. Все должно работать, есть все данные и нет ничего лишнего**
+- 13.2: API ДОЛЖЕН соответствовать принципам REST (см. ссылки выше)
+- 13.3: ОБЯЗАТЕЛЬНО: запустите `mvn test` - ошибок быть не должно
+- 13.4: ОБЯЗАТЕЛЬНО: запустите приложение без всяких предварительных настроек (базы, переменных окружения, ..), лучше на другом компьютере. Приложение должно запускаться и работать!
+
+## Оценка
+ТЗ очень скромное, не дает понимания, что хочет получить заказчик, именно поэтому моих комментариев к этому ТЗ больше на 2 порядка. Это реальное тестовое задание на работу. При оценке учитывается отсутствие грубых ляпов, простота и красота решения + его расширяемость, если понадобится дорабатывать приложение. Если практический опыт небольшой, еще раз очень рекомендую держаться как можно ближе к нашему коду на Spring Boot.
+Тестовое задание дается для того, чтобы оценить вас, как программиста. Нужны ли вы компании или нет. Это умение спроектировать грамотную модель и API, придерживаясь принципов REST и без своих велосипедов, и ваш чистый красивый код.
diff --git a/doc/lesson01.md b/doc/lesson01.md
new file mode 100644
index 000000000..9468d02ec
--- /dev/null
+++ b/doc/lesson01.md
@@ -0,0 +1,262 @@
+# Стажировка Topjava
+
+### Правила похождения стажировки
+- Не стоит стремиться прочитать все ссылки урока, их можно использовать позднее как справочник. Гораздо важнее **пройти основной материал урока и сделать Домашнее Задание**
+- Обязательно посмотри правила работы с патчами на проекте
+ - Делать Apply Patch лучше по одному, непосредственно перед видео на эту тему, а при просмотре видео сразу отслеживать все изменения кода проекта по изменению в патче (`Git-> Local Changes-> Ctrl+D`)
+ - **При первом Apply удобнее выбрать имя локального ченджлиста Name: Change**. Далее все остальные патчи также будут в него попадать.
+- **Код проекта обновляется и не всегда совпадает с видео (можно увидеть как развивался проект). Изменения в проекте указываю после соответствующего патча.**
+- Если ссылка не открывается, попробуй [включить VPN](https://github.com/JavaOPs/topjava/wiki/VPN)
+- **ОСНОВНОЕ, чему мы учимся на проекте: мыслить и работать как Java разработчики уже сейчас**, потом это будет гораздо сложнее и стоить дороже. Вот на мой взгляд [хорошие советы новичкам](http://blog.csssr.ru/2016/09/19/how-to-be-a-beginner-developer). От себя я добавлю:
+ - Учись **грамотно формулировать проблему**. Проблема "у меня не работает" может иметь тысячи причин. В процессе формулирования очень часто приходит ее решение.
+ - что я делаю (подробно, чтобы понял человек, который не был занят этой проблемой несколько часов)
+ - что получаю (обычно верх самого последнего эксепшена)
+ - что я сделал для решения, какие результаты получил
+ - Учись исследовать проблему. Внимательное чтение логов и [умение дебажить](http://info.javarush.ru/idea_help/2014/01/22/Руководство-пользователя-IntelliJ-IDEA-Отладчик-.html) - основные навыки разработчика. Обычно самый верх самого нижнего эксепшена- причина ошибки, туда нужно ставить брекпойнт.
+ - Грамотно **уделяй время каждой проблеме**. Две крайности - сразу бросаться за помощью и биться над ней часами. Пробуй решить ее сам и в зависимости от проблемы выделяй на это разумное время.
+ - Наконец, уровень участников у всех разный. Бывают синьоры, бывают начинающие. Не стесняйтесь задавать вопросы, иначе стажировка пройдет впустую! **Глупых вопросов не бывает**.
+----------------------------------------------------
+- **Обязательно и как можно чаще пользуйтесь `Ctrl+Alt+L` - отформатировать код класса**
+- **При изменениях на UI не забываетй сбрасывать кэш браузера - `Ctrl+F5`**
+- **При удалении классов не забывате чистить target - в окошке Maven -> clean или `mvn clean`**
+- **При проблемах с IDEA пользуйтесь `Refresh` в окошке Maven**
+- **При проблемах с выполнением проверьте (и удалите) лишние java процессы (например в Task Manager)**
+
+
+## Материалы занятия (скачать все патчи можно через `Download/Скачать` папки patch)
+
+
+###  Рефакторинг проекта
+
+#### Apply 1_0_fix_rename.patch
+- переименовал классы `UserMeal*` в более красивые `Meal*`
+- преименовал `MealWithExceed` transfer object класс ([что это такое](https://ru.wikipedia.org/wiki/DTO) пройдем позже) в `MealTo` ([data transfer object naming convention](https://stackoverflow.com/questions/1724774/java-data-transfer-object-naming-convention))
+- IDEA предложила рефакторинг `TimeUtil.isBetweenHalfOpen` с использованием `isBefore`.
+
+##  Разбор домашнего задания HW0:
+###  1. Optional: реализация getFilteredMealsWithExcess через Stream API
+- В патче `prepare_to_HW0.patch` вступительного задания метод фильтрации в `TimeUtil` переименовали в `isBetweenHalfOpen` (также изменилась логика сравнения - `startTime` включается в интервал)
+
+#### Apply 1_1_HW0_streams.patch
+
+- [Презентация Java 8](https://docs.google.com/presentation/d/1oltLkHK60FqIdsXjUdm4pPLSeC6KpNYjDsM0ips-qBw)
+
+###  2. Работа с git в IDEA. Реализация через цикл.
+### ВНИМАНИЕ! Патчей `1_opt_2_HW0_cycles` и `1_opt_3_HW0_opt2` не будет в проекте!
+Делаем в отдельной ветке (у меня `MealsUtil_opt`). Это варианты решений, которые не идут в `master`
+
+
+
+#### Apply 1_opt_2_HW0_cycles.patch
+
+###  Вопросы по HW0
+
+> Почему не использовать в `TimeUtil` методы `isBefore/isAfter` ?
+
+это строгие (excluded) сравнения, а нам также нужно краевые значения
+
+> В `MealsUtil` у нас где-то есть ключевое слово `final`, где-то нет. В чем разница?
+
+Я участвовал в одном проекте, где `final` был обязательным (в сеттингах IDEA галочка стояла). Но это скорее исключение, чем правило в проектах java (в Java 8 вообще ввели эффективный final, те по факту). Во всех новомодных языках переменные final по умолчанию, а в java нужно помнить и везде добавлять, утомительно. Но если приучитесь - хуже не будет. Я обычно ставлю там, где важно по смыслу (если не забываю).
+
+###  3. [HW0 Optional 2: реализация в один проход циклами и Stream API](https://drive.google.com/file/d/1dSt3axySxu4V9dMnuR1wczerlI_WzCep)
+
+#### Apply 1_opt_3_HW0_opt2.patch
+- Дополнительно:
+ - [Первое занятие MasterJava: многопоточность](https://github.com/JavaOPs/masterjava)
+ - [Обзор java.util.concurrent.*](https://web.archive.org/web/20220427140138/https://habr.com/ru/company/luxoft/blog/157273/)
+
+## Занятие 1:
+
+###  4. [Интервью: Java разработка. Обучение. Трудоустройство](https://javaops.ru/view/news/javaInterview)
+- [JetBrains devecosystem 2022](https://www.jetbrains.com/lp/devecosystem-2022/java/)
+- [Сontinuum Java Ecosystem 2022 – Survey results](https://www.continuum.be/en/blog/the-java-ecosystem-2022-survey-results/)
+- [JRebel 2022 Java Developer Productivity Report](https://drive.google.com/file/d/1txLeRsNNR7EqYEeIvYmuyQi9hknBeR9G)
+
+###  5. [Servlet API. Apache Tomcat. JSP](lesson01/tomcat_servlet_war.md)
+
+###  6. [Логирование](https://www.youtube.com/watch?v=mo8z3zRVV1E)
+#### Последние версии _logback / slf4j_ не работают с JDK 8, понизил версии до совместимых с ней. Поднимем на 5м занятии при миграции на JDK 17+
+
+#### Apply 1_5_simple_logging.patch
+
+- [Зачем нужно логирование](https://javarush.ru/groups/posts/2293-zachem-nuzhno-logirovanie)
+- [Logback Project](https://logback.qos.ch/)
+
+> А зачем мы использовали logback? Почему SLF4J нас не устроило? Почему реализация логирования не log4j?
+
+`SLF4J-API` это API. В нее включена только пустая реализация `org.slf4j.helpers.NOPLogger` (можно посмотреть в исходниках). Logback для новых проектов стал стандарт, *Spring Boot* используют его по умолчанию.
+[Reasons to prefer logback over log4j](http://logback.qos.ch/reasonsToSwitch.html)
+
+> Почему `private static final Logger log` а не `LOG/LOGGER` ?
+
+Это [правило именования констант, которые не "deeply immutable"](https://google.github.io/styleguide/javaguide.html#s5.2.4-constant-names), те если их содержимое можно изменить.
+
+#### Apply 1_6_logging_config.patch
+
+- [Java Logging: история кошмара](http://habrahabr.ru/post/113145/)
+- [Project dependencies for logging](https://www.slf4j.org/manual.html#projectDep)
+- [Добавление зависимостей логирования](http://www.slf4j.org/legacy.html) в проект
+- Не делать конкатенацию строк: [форматирование в логах через {}](https://www.slf4j.org/faq.html#logging_performance)
+- Дополнительно:
+ - [Logback configuration](https://logback.qos.ch/manual/configuration.html)
+ - [Ведение лога приложения](http://www.skipy.ru/useful/logging.html)
+ - [Владимир Красильщик – Что надо знать о логировании прагматичному Java‑программисту](https://www.youtube.com/watch?v=qzqAUUgB3v8)
+
+**Установите переменную окружения на TOPJAVA_ROOT на корень проекта и перезапустите IDEA. Слеши в пути должны быть в стиле unix (/)**
+
+Проверить, видит ли Java вашу переменную можно через `System.getenv("TOPJAVA_ROOT")`
+
+- [Set environment for Win/Mac/Unix](https://chlee.co/how-to-setup-environment-variables-for-windows-mac-and-linux/)
+- [Set environment for UNIX (advanced)](https://askubuntu.com/a/849954)
+ - [Определить, какой Login или Non-Login Shell](https://tecadmin.net/difference-between-login-and-non-login-shell)
+ - [Порядок запуска скриптов при старте](https://www.baeldung.com/linux/bashrc-vs-bash-profile-vs-profile)
+- Или простой вариант (не забудте добавить и в Run, и в Debug)
+
+
+
+**Иногда антивирусы блокируют логирование (например Comodo). Если не работает и стоит антивирус- добавьте исключение.**
+
+> Изменения в проекте, которым могут встретиться в других видео:
+> - убрал `LoggerWrapper` и логирую напрямую в логгер SLF4J.
+> - удалил зависимости `jul-to-slf4j` и `jcl-over-slf4j`. Spring 5 напрямую использует `slf4j` без `common-logging`
+
+---------
+
+##  Домашнее задание HW01 (делаем ветку HW01 от последнего патча в master)
+--------------------------------------------
+#### 1. Реализовать сервлет с отображением в таблице списка еды (в памяти и БЕЗ учета пользователя)
+
+> Деплоиться в Tomcat лучше как `war exploded`: нет упаковки в war и при нажатой кнопке `Update Resources on Frame Deactivation` можно обновляться css, html, jsp без передеплоя. При изменении `web.xml`, добавлении методов, классов необходим redeploy.
+
+- 1.1 По аналогии с `UserServlet` добавить `MealServlet` и `meals.jsp`
+ - Задеплоить приложение (war) в Tomcat c `applicationContext=topjava` (приложение должно быть доступно по http://localhost:8080/topjava)
+ - Попробовать деплои в Tomcat как WAR в запушенный вручную Tomcat и через IDEA.
+- 1.2 Сделать отображения списка еды в JSP [в таблице](http://htmlbook.ru/html/table), цвет записи в таблице зависит от параметра `excess` (красный/зеленый).
+ - 1.2.1 Список еды захардкодить (те проинициализировать в коде, желательно чтобы в проекте инициализация была только в одном месте). Норму калорий (caloriesPerDay) сделать в коде константой
+ - 1.2.2 Время выводить без 'T'
+ - 1.2.3 Список выводим БЕЗ фильтрации по `startTime/endTime`
+ - 1.2.4 С обработкой исключений пока можно не заморачиваться, мы будем красиво обрабатывать в конце стажировки
+ - 1.2.5 Вариант реализации:
+ - из сервлета преобразуете еду в `List`;
+ - кладете список в запрос (`request.setAttribute`);
+ - делаете `forward` на jsp для отрисовки таблицы (при `redirect` атрибуты теряются).
+ - **JSP работает через геттеры: `meal.dateTime` в JSP вызывает `meal.getDateTime()`**
+ - в `JSP` для цикла можно использовать `JSTL tag forEach`. Для подключения `JSTL` в `pom.xml` и шапку JSP нужно добавить:
+```
+
+ javax.servlet
+ jstl
+ 1.2
+
+
+ <%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
+ ...
+```
+
+ - Интернет-приложения на JAVA
+ - JSP
+ - [Как создать Servlet? Полное руководство](https://devcolibri.com/как-создать-servlet-полное-руководство)
+ - [JSTL для написания JSP страниц](https://devcolibri.com/jstl-для-написания-jsp-страниц/)
+ - JSTL: Шаблоны для разработки веб-приложений в java
+ - JSTL LocalDateTime format
+
+### Optional
+#### 2. Реализуем в ПАМЯТИ (любая коллекция) CRUD (create/read/update/delete) для еды
+**Пример: [Simple CRUD using Servlet/JSP](https://web.archive.org/web/20230529120950/https://danielniko.dev/2012/04/17/simple-crud-using-jsp-servlet-and-mysql/)**
+> - Пример нужно САМОСТОЯТЕЛЬНО переделать: вместо хранения в MySql нужно хранить в коллекции ПАМЯТИ (задание упрощается).
+> - Классы: сервлет, **интерфейс хранения**, его реализация для хранения в памяти
+- 2.1 Хранение в памяти будет одна из наших CRUD реализаций (позже будет JDBC, JPA и DATA-JPA).
+- 2.2 Работать с реализацией CRUD через интерфейс, который не должен ничего знать о деталях реализации (Map, DB или что-то еще).
+- 2.3 Добавить поле `id` в `Meal/ MealTo`. Реализовать генерацию счетчика, УЧЕСТЬ МНОГОПОТОЧНОСТЬ СЕРВЛЕТОВ. В качестве первичного ключа используют UUID, Long, Integer. На нашем проекте будем использовать **Integer**.
+ - [обзор java.util.concurrent](https://web.archive.org/web/20220427140138/https://habr.com/ru/company/luxoft/blog/157273/)
+- 2.4 Предлагаю сейчас делать максимально просто (без защиты от CSRF, JavaScript и пр., это будет позже): где можно через [ссылки GET, метод сервлета doGet()](http://htmlbook.ru/html/a/href), редактирование через [форму POST, метод doPost()](http://htmlbook.ru/html/form/method)
+- 2.5 Для ввода дат и времени можно использовать html5 типы, хотя они поддерживаются не всеми браузерами (протестировать свой браузер). В конце курса мы добавим DateTimePicker jQuery plugin, который будет работать на всех браузерах.
+- 2.6 Форму на create-update предлагаю не дублировать, сделать одну (хотя это не ошибка сделать разные).
+
+## После выполнения ДЗ обязательно проверьте решение на ошибки
+
+###  Вопросы по HW1
+
+> Не попадаю на брекпойнт в сервлете или на страничку JSP.
+
+- внимательно проверь url и applicationContext (Application Context должен быть тот же, что и url приложения: wiki IDEA)
+- посмотрите в task manager: возможно запущено несколько JVM и они мешают друг другу. Лишние java приложения убить.
+- предлагаю пока размещать JSP в корне `webapp` и делать по аналогии с моим кодом для `user`, иначе придется бороться с путями Application context и Servlet context. Мы будем работать с ними позже. Пути бывают:
+ - относительными: от текущего положения, без '/' спереди. Если обращение к сервлету идет вложенное (нарпимер `/meals/....`), то `Servlet context=meals` и относительные пути формируются от него (в результате в браузере можно увидеть в браузере `/meals/meals/...`)
+ - абсолютными (от корня `localhost:8080`). Тогда [в путь необходимо добавлять Application context](https://stackoverflow.com/questions/4764405/548473).
+
+> Приложение не видит TOPJAVA_ROOT.
+
+**После выставления переменной окружения IDEA нужно рестартовать. Слеши в пути должны быть в стиле unix (/)**. Проверить, видит ли java переменную окружения можно так: `System.getenv("TOPJAVA_ROOT")`. Еще вариант: добавить `-DTOPJAVA_ROOT=...` в опции запуска приложения, тогда она доступна из java как `System.getProperty("TOPJAVA_ROOT")`.
+
+> Нужно ли разработчику знание HTML.
+
+Веб разработчику (а большинство Java приложений это веб-приложения) основы знать обязательно. Толстых книжек сейчас читать НЕ рекомендую (это общий совет по любой технологии на всю стажировку). Достаточно [посмотреть основы](https://github.com/JavaWebinar/topjava/blob/doc/doc/entrance.md#html) и того материала, что мы пройдем на курсе.
+
+> Проблемы с кодировкой в POST (кракозябры).
+
+Возможное решение - выставьте кодировку ДО первого чтения из request:
+```
+protected void doPost(HttpServletRequest request, ...) {
+ request.setCharacterEncoding("UTF-8");
+```
+
+> Если сервлет тыкают несколько пользователей / несколько браузеров, какого должно быть поведение? Нужно ли что-то делать с сессиями?
+
+В Optional нужно делать реализацию хранения потокобезопасной. Cессии пока НЕ используем (начнутся, когда будет прикручивать авторизацию).
+
+> Для чего нам нужна потокобезопасная реализация коллекции, если каждый пользователь видит только себя?
+
+Реализация хранения в памяти у нас одна на всех. Те коллекция шарится между пользователями, они в разных потоках ее дергают. Если несколько потоков одновременно будут изменять коллекцию без учета потокобезопасная (например один будет удалять, второй вставлять), без учета потокобезопасности мы получим `ConcurrentModificationException`
+
+> Предпочтительнее ли создавать новый объект `Meal` при каждом update?
+
+Если при обновлении не создавать копию, то сохраненный в памяти объект может кто-то попортить. Вопрос скорее доверия к коду- если проект большой и людей над ним трудится много, то вероятнее нужно копировать.
+
+> Почему теряются атрибуты при передаче на сервлет: `http://localhost:8080/topjava/meals?action=add&...` и `req.getAttribute("action")` = null ?
+
+См. Difference between getAttribute() and getParameter(). Отсюда также следует, что при редиректе атрибуты теряются.
+
+> Зачем нужен в jsp `` ?
+
+[jsp:useBean](http://java-online.ru/jsp-actions.xhtml#useBean) нужен IDEA для автодополнений - она понимает тип переменной, которая уже доступна в JSP (например через setAttribute). И еще эта переменная становится доступной в java вставках. Для вывода в JSP это тэг не обязателен. Если тип переменной JSP не совпадает с тем, что в `jsp:useBean`, будет ошибка.
+
+----------------------------
+### Итоги занятия после выполнения ДЗ:
+Мы создали CRUD веб-приложение для управления едой (создание-чтение-обновление-удаление) с использованием сервлетов и логированием. Пока в памяти, и пока еда никому не принадлежит.
+Пример выполнения ДЗ (не надо сложного интерфейса, Bootstrap css будем проходить на 8-м занятии):
+
+
+
+
+###  Типичные ошибки
+- 1 **Если в названии класса есть `Meal`, не нужно использовать слово meal в методах класса.**
+- 2 Привыкайте писать комментарии к чекину: одной фразой что вы сделали в нем. Например: *Meals CRUD implementation*. См.
+[Как писать сообщения коммитов](https://habr.com/ru/post/416887/)
+- 3 Хранение в памяти и операции с ней должны выполняться просто и эффективно
+- 4 Хранить нужно `Meal` и конвертировать ее в `MealTo` когда отдаем список на отображение в JSP.
+ - excess нужно пересчитывать каждый раз перед отображением
+ - форматирование должно находится в JSP! Именно он заведует отображением. Повторяем паттерн [MVC](https://ru.wikipedia.org/wiki/Model-View-Controller)
+- 5 Стили `color` можно применять ко всей строке таблицы `tr`, а не каждой ячейке.
+- 6 `DateTimeFormatter` можно сделать один заранее (он потокобезопасный в отличие от `SimpleDateFormatter`), а не создавать новый при каждом запросе.
+- 7 Работать с CRUD надо через интерфейс.
+- 8 Реализаций хранения будет несколько, нужно учитывать это в названии класса имплементации работы в памяти.
+- 9 В `web.xml` принято группировать сервлет со своим маппингом
+- 10 Не размещайте никакую логику (форматирование, счетчики) в бинах, где хранятся только данные (`Meal, MealTo`)
+- 11 Еще раз: детали реализации в памяти не должны быть никому видны. Те НЕ НАДО счетчик размещать в `Meal` или `MealServlet` или `MealsUtil`, в базе же он будет по другому генерится.
+- 12 `volatile` при ++ не помогает от многопоточности. Почему?
+- 13 Обратите также внимание на то, чтобы реализация вашей коллекции для хранения еды была также многопоточной.
+- 14 Попробуйте не делайть дублирование кода `MealsUtil`. Простой вариант - использовать то, что отсутствие фильтрации - это частный случай фильтрации (когда ничего не отсеивается).
+- 15 Не дублируйте строки в `jsp`. Посмотрите на тернарный оператор.
+- 16 После операции `delete` в браузере должен быть url `http:\\localhost:8080\topjava\meals`
+- 17 Перед чекином проверяйте свой ченджлист (`Ctrl+D` на файле из `Local Changes` - посмотреть что поменялось). Если там только пробелы/переводы строк, не надо его комитить - делайте файлу `Git->revert`.
+- 18 Учтите в названии реализации CRUD, что
+ - 18.1 у нас будет несколько реализаций (не только в памяти)
+ - 18.2 у нас будет 2 CRUD (для еды и пользователей). А в реальном проекте их намного больше.
+- 19 Сессии НЕ использовать! При редиректе все атрибуты (`req.getAttribute()`) теряются (см. вопрос выше). Сценарий редиректа:
+ - 1 из сервлета делаем редирект (снова на сервлет, не на JSP!)
+ - 2 снова заходим в сервлет
+ - 3 кладем нужные атрибуты и делаем forward на jsp
+ - 4 если очень хочется передать параметры из 1. в 2. можно сделать их через параметры запроса (например `meals?id=5`) и доставать через `reg.getParameter(id)`. В моей реализации такого не потребовалось.
+- 20 Для cancel в JSP можно использовать код: ``
diff --git a/doc/lesson01/tomcat_servlet_war.md b/doc/lesson01/tomcat_servlet_war.md
new file mode 100644
index 000000000..d6c099d3b
--- /dev/null
+++ b/doc/lesson01/tomcat_servlet_war.md
@@ -0,0 +1,149 @@
+## Servlet API. Apache Tomcat. JSP
+
+Большинство приложений, написанных на Java это [веб-приложения](https://ru.wikipedia.org/wiki/Веб-приложение): серверное приложение, в котором клиент взаимодействует с веб-сервером при помощи браузера.
+Браузер является универсальным клиентом, который уже есть практически у каждого пользователя. Общение между браузером и приложением идет по [протоколу HTTP/HTTPS](https://developer.mozilla.org/ru/docs/Web/HTTP).
+Открываем в браузере [демо нашего веб-приложения](http://javaops-demo.ru/topjava), затем _Delevoper Tools_ (в Chrome: _F12_ или _Ctrl+Shift+I_).
+Во вкладке _Network_ мы видим весь обмен данными между сервером и браузером по протоколу HTTP: в основном страницы передаются в формате [HTML](https://ru.wikipedia.org/wiki/HTML), JavaScript, CSS, изображения и просто данные в формате [JSON](https://ru.wikipedia.org/wiki/JSON).
+Вверху вкладки _Network_ можно поставить фильтр по типу данных или url, а также есть полезные галочки _Preserve log_ для сохранения истории запросов после редиректа и _Disable chache_ для предотвращения кэширования (запросы GET могут кэшироваться браузером, также _Ctrl+F5_ позволяет перегрузить страницу целиком).
+
+
+
+Для работы по HTTP в Java есть специальный фреймворк [Servlet API](https://ru.wikipedia.org/wiki/Сервлет_(Java)). Он не входит в Java SE(JDK), а является частью [Jakarta EE](https://wiki5.ru/wiki/Jakarta_EE) (бывшая Java Enterprise Edition/Java EE, об этом немного ниже).
+На Servlet API основаны подавляющее большинство Java веб-фреймворков, в том числе Spring MVC, который мы будем изучать позднее. Исключением являются фреймворки для асинхронной, неблокирующей работы по HTTP, например Spring WebFlux.
+Асинхронная разработка требует значительно больших усилий и неблокирующих взаимодействий на всей цепочке (например для работы с БД нужен асинхронный драйвер), поэтому оно в основном применяется при больших нагрузках.
+Стоит отметить, что сервлеты с версии 3.0 также поддерживают асинхронность (мы смотрим на них в 11 уроке курса [MasterJava](https://javaops.ru/view/masterjava#program)), но современные асинхронные фреймворки обычно его не используют (например Spring WebFlux по умолчанию использует [Netty](https://netty.io/),
+хотя его также можно [настроить на работу с Servlet non-blocking I/O](https://docs.spring.io/spring-framework/docs/current/reference/html/web-reactive.html#webflux-server-choice)).
+
+Реализуют Servlet API специальные Java приложения: серверы приложений Java (Application Server/AS) или их урезанный вариант - контейнеры сервлетов (Web Server), см [Web vs. Application Server](https://www.baeldung.com/java-servers).
+Мы будем работать на самом распространенном контейнере сервлетов/веб-сервере [Apache Tomcat](https://ru.wikipedia.org/wiki/Apache_Tomcat).
+
+При [передаче разработки](https://www.opennet.ru/opennews/art.shtml?num=51477) Java EE от Oracle проекту Eclipse она стала называться Jakarta и пакеты с реализацией спецификаций _javax_ были переименованы в _jakarta_.
+Поэтому при работе с сервлетами (равно как и с другими EE спецификациями) важно выбирать совместимые версии фреймворков. Мы начнем работать с реализацией Java EE (пакетом _javax_), это
+[9.x версия Tomcat](https://tomcat.apache.org/download-90.cgi), Spring 5.x, Hibernate 5.6.x, Hibernate Validator 6.x. При миграции в конце стажировки на Spring Boot 3.0 автоматически подтянутся новые зависимости Jakarta EE:
+встроенный Tomcat 10.x, Spring 6.x и [Hibernate Validator 8.x](https://hibernate.org/validator/releases/).
+
+Дополнительно:
+- [Категория Java Enterprise Edition](https://ru.wikipedia.org/wiki/Категория:Java_Enterprise_Edition)
+
+### Устанавливаем [Tomcat 9.x](https://tomcat.apache.org/download-90.cgi)
+Варианты: [как сервис в Windows](https://javarush.com/quests/lectures/questservlets.level11.lecture01), [вручную](https://javarush.com/quests/lectures/questservlets.level11.lecture02) или [как сервис в Unix](https://github.com/JavaOPs/startup/blob/main/tomcat.md)
+На мой взгляд самый простой способ - вручную: скачиванием Binary Distributions xxx.zip (например apache-tomcat-9.0.71.zip), разархивируем его и настраиваем [tomcat-users.xml, 3.3 Настройка Tomcat](https://javarush.com/quests/lectures/questservlets.level11.lecture02)
+**Установите Tomcat в каталог без пробелов и русских букв (пример С:\java\apache-tomcat-9.0.71), иначе в будущем возможны проблемы (например когда начнем работать с кэшем) на стандартный порт Tomcat 8080**
+Запускаем Tomcat и [смотрим стандартный список веб-приложений](https://javarush.com/quests/lectures/questservlets.level11.lecture03)
+- [Проверка, кто занял порт](https://stackoverflow.com/a/38953356/548473) в случае проблем с запуском на порту 8080
+
+-----------------------------
+### ВНИМАНИЕ! далее патчи идут в ветку `master` после `1_1_HW0_streams`
+
+#### Apply 1_2_war.patch (при изменении pom.xml на забывайте сделать [Reload All Maven Projects](https://github.com/JavaOPs/topjava/wiki/IDEA#maven_update) или сделайте авторелоад)
+Применяем патч и смотрим изменения в проекте (можно через _Ctrl+D_ в _Local Changes_):
+
+- Добавляем статический (не зависящий от состояния приложения) _index.html_
+- Добавляем пустой _web.xml_
+- Меняем _pom packaging_ на [WAR(Web archive)](https://ru.wikipedia.org/wiki/WAR_(тип_файла))
+- По умолчанию (_defaultGoal_) делаем сборку проекта _package_ (если запустить просто _mvn_)
+- Конфигурируем заранее WAR package через _maven-war-plugin_. Если у вас JDK выше 14, [сбока без этой правки не пройдет](https://stackoverflow.com/questions/66920567/548473)
+
+### Собираем и деплоим приложение в Tomcat
+- Собираем проект (_package_ в вкладке Maven) и смотрим в папке проекта на _target\topjava.war_ (это обычный архив, _Total Commander_ заходит в него по Enter или [еще варианты](https://filext.com/ru/rasshirenie-faila/WAR)) и его структуру
+ - [Устройство war-файла](https://javarush.com/quests/lectures/questservlets.level11.lecture05)
+- Деплоим наш _topjava.war_ в Tomcat ([4.2 Деплой тестового веб-приложения](https://javarush.com/quests/lectures/questservlets.level11.lecture03))
+- [Добавляем Tomcat в IDEA Ultimate, 5.1](https://javarush.com/quests/lectures/questservlets.level11.lecture04). После кнопки _Fix_ у меня IDEA предлагает такой выбор:
+
+
+
+
+Выбираем _war exploded_: то есть мы задеплоим его распакованным архивом. Это позволит нам его дебажить и менять в рантайме (без передеплоя).
+А в _Application Context_ пишем просто topjava:
+
+
+
+Если все сделали правильно, после запуска (Run или Debug) в браузере мы увидим отображение нашего _index.html_ (по умолчанию Tomcat открывает _index.html_ или _index.jsp_).
+
+`Application Context` должен быть тот же, что и url приложения, деплоить надо `war exploded`**
+
+
+
+### Динамическая перезагрузка
+Задеплойте приложение в IDEA через Debug и включите кнопку Update Resource On Frame Deactivation
+
+
+
+Попробуйте поменять _index.html_ (например поменяйте текст в _h3_) и проверьте, что по _F5_ в браузере также меняется его содержимое без передеплоя.
+
+### Маршрутизацию запросов, JSP шаблоны
+Все запросы по нашему _Application Context (topjava)_ Tomcat будет сверять с _web.xml_ нашего приложения.
+Файл web.xml [хранит информацию о конфигурации приложения]((https://javarush.com/quests/lectures/questservlets.level11.lecture06)) и, в частности, задает маппинг - какой сервлет какие запросы к нашему приложению будет обрабатывать.
+[Сервлет](https://javarush.com/quests/lectures/questservlets.level12.lecture00) принимает входящие запросы _HttpServletRequest_ и обрабатывает их, возвращая результат в _HttpServletResponse_, который затем отображается в браузере.
+
+Выводит ответ в сервлете через
+```
+ PrintWriter out = response.getWriter();
+ out.print(" ");
+ ....
+```
+неудобно для больших страниц, поэтому придумали технологию шаблонов, которые задают структуру страницы и места, куда нужно вставить данные приложения.
+В Tomcat по умолчанию включен [движок шаблонов JSP](https://javarush.com/quests/lectures/questservlets.level13.lecture00), в Spring Boot по умолчанию используются [шаблоны Thymeleaf](https://alexkosarev.name/2017/08/08/thymeleaf-template-engine/).
+Все они основаны на [паттерне MVC](https://javarush.com/quests/lectures/questcollections.level06.lecture01) - из приложения (Controller) мы отдаем шаблону (View) на отрисовку мапу с данными (Model).
+В нашем случае мы просто будем перенаправлять запрос (`request.getRequestDispatcher("/users.jsp").forward(request, response)`) на наш шаблон, в котором нет данных приложения, соответственно нет модели.
+
+#### Apply 1_3_servlet_api.patch
+> **Все зависимости в Maven проект подтягиваются ТОЛЬКО через Maven!** (см. [обновить зависимости в maven проекте](https://github.com/JavaOPs/topjava/wiki/IDEA#maven_update))
+
+- В _pom.xml_ добавляем зависимость на сервлеты (_javax.servlet-api_). [Scope _provided_](https://java-online.ru/maven-faq.xhtml#scope) означает, что зависимость используется при компиляции, но не пакуется в WAR (можете проверить). Эти классы уже есть в Tomcat и в WAR они будут мешать его правильной работе.
+- В _index.html_ мы делаем ссылку на url _users_ (она формируется от _Application Context_, который у нас задали _topjava_)
+- В _web.xml_ добавляем маппинг: запрос браузера _topjava/users_ Тоmcat направит на сервлет _UserServlet_
+- Сервлет _UserServlet_ принимает _HttpServletRequest_ запрос и перенаправляет его на _users.jsp_
+
+Перезапустите Tomcat и проверьте новый функционал приложения.
+Необходимо понимать [жизненный цикл сервлета](https://metanit.com/java/javaee/4.8.php): наш _UserServlet_ создается сразу при деплое приложения (параметр _load-on-startup_ в _web.xml_). При создании у него вызывается метод _init()_, а при выгрузке war метод _destroy()_. Внутри Tomcat находится пул HTTP запросов (_maxThreads_, 200 по умолчанию), его можно конфигурировать.
+Если нагрузка большая и мы не успели обработать 200 запросов за время, когда пришел 201-й, он встанет в очередь и будет ждать время timeout (60 секунд по умолчанию). Все _/topjava/user_ запросы будет обрабатывать один и тот же экземпляр _UserServlet_, то есть **поле сервлета будет общим для всех запросов** и это следует учитывать в логике.
+
+- Если проблема с Tomcat debug и работает Dr.Web- нужно его отключить, либо добавить в исключения путь к `.IntelliJIdeaXXX/`
+- Наше приложение: [http://localhost:8080/topjava](http://localhost:8080/topjava)
+- Наш сервлет: [http://localhost:8080/topjava/users](http://localhost:8080/topjava/users)
+
+#### Apply 1_4_forward_to_redirect.patch
+
+- Поменяем `Forward` на `Redirect`. Обратите внимание на изменение приложения во вкладке _Network_ браузера. Теперь при клике на _Users_ приложение возвращает браузеру ответ 302 и в заголовках (Headers) ответа _Location users.jsp_.
+
+
+
+Браузер по этому перенаправлению меняет свой url и выполняет новых запрос _/topjava/users.jsp_.
+
+### Попробуйте подебажить приложение: поставить брекпойнт в [IDEA в коде сервлета](http://info.javarush.ru/idea_help/2014/01/22/Руководство-пользователя-IntelliJ-IDEA-Отладчик-.html) и в JPS:
+
+
+
+> Alt+F8 - просмотр переменной в дебаге
+
+###  Ваши вопросы
+
+> Не устарели ли сервлеты, зачем их учить? Используются ли сервлеты на реальных проектах сегодня?
+
+1. Вопрос подобен подобным: "нужно ли знать JDBC, если работаешь исключительно с JPA/Hibernate" или "работу Spring MVC, если работаешь со Spring Boot".
+ Мой ответ - как минимум основы вы должны знать (совсем не обязательно учить их полную спецификацию и все методы). При написании учебных приложений часто можно обойтись без них,
+ но когда приходится решать проблемы (основная работа разработчика) или на большом коммерческом проекте, очень часто без этих основ вам будет очень тяжело справиться с задачей.
+2. Бывают легаси проекты, бывают современные, где не подтягивается сторонний web фреймворк. При этом, даже работая с фреймворком, приходится иметь дело с Servlet API (часто с `HttpServletRequest/HttpServletResponse`) - обработка ошибок, валидаторы, фильтры, пре/пост обработка зарпосов, получение ip, работа с сессией и пр.
+
+> Используются ли еще где-то в реальной разработке JSP, или это уже устаревшая технология? Заменит ли ее JSF [(форум)](https://web.archive.org/web/20170609064143/http://javatalks.ru/topics/38037)
+
+JSF и JSP- разные ниши и задачи.
+JSP- шаблонизатор, JSF - МVС фреймворк. Из моего опыта- с JSP сталкивался в 60% проектов. Его прямая замена: http://www.thymeleaf.org (в Spring-Boot по умолчанию), но в уже запущенных проектах встречается достаточно редко. JSP не умирает, потому что просто и дешево. Кроме того включается в большинство веб-контейнеров (в Tomcat его реализация Jasper)
+
+JSF- sun-овский еще фреймворк, с которым я ни разу не сталкивался и особого желания нет. Вот он как раз, по моему мнению, активно замещается хотя бы javascript фреймворками (Angular, React, Vue.js).
+
+> Какой метод сервлета вызвается из HTML/JSP: doGet/doDelete/doPut..?
+
+Методы можно посмотреть в вкладке браузера `Network`. По [сcылке](http://htmlbook.ru/html/a/href) вызывается `GET/doGet()`. Из [формы можно делать GET и POST](http://htmlbook.ru/html/form/method), обычно данные формы передаются через POST. **Для других методов нужен JavaScript, пока их не используем**
+
+### Краткие итоги
+- Мы посмотрели, как на Java работать с HTTP протоколом через Servlet API и JSP (части теперь уже Jakarta EE).
+- Установили самый популярный веб-сервер Tomcat и задеплоили в него наше приложение
+- Посмотрели на динамическую перезагрузку и поробовали IDEA дебаг
+
+### Дополнительно:
+- [Yakov Fain: Intro to Java EE. Glassfish. Servlets (по-русски)](https://www.youtube.com/watch?v=tN8K1y-HSws&list=PLkKunJj_bZefB1_hhS68092rbF4HFtKjW&index=14)
+- [Yakov Fain: HTTP Sessions, Cookies, WAR deployments, JSP (по-русски)](https://www.youtube.com/watch?v=Vumy_fbo-Qs&list=PLkKunJj_bZefB1_hhS68092rbF4HFtKjW&index=15)
+- [Golovach Courses: Junior.February2014.Servlets](https://www.youtube.com/playlist?list=PLoij6udfBncjHaO5s7Ln4w4BLj5FVc49P)
+- [Java объекты, доступные в JSP](http://stackoverflow.com/questions/1890438/how-to-get-parameters-from-the-url-with-jsp#1890462)
diff --git a/doc/lesson02.md b/doc/lesson02.md
new file mode 100644
index 000000000..9c4aa9f17
--- /dev/null
+++ b/doc/lesson02.md
@@ -0,0 +1,274 @@
+# Стажировка Topjava
+
+## [Материалы занятия](https://drive.google.com/drive/folders/0B9Ye2auQ_NsFfkpsWE1uX19zV19IVHd0bTlDclc5QmhMMm4xa0Npek9DT18tdkwyLTBZdXM) (скачать все патчи можно через Download папки patch)
+
+##  Разбор домашнего задания HW1:
+
+- **Перед сборкой проекта (или запуском Tomcat) откройте вкладку Maven Projects и сделайте `clean`**
+- **Если страничка в браузере работает неверно, очистите кэш (`Ctrl+F5` в хроме)**
+
+###  1. Отображения списка еды в JSP
+#### Apply 2_1_HW1.patch
+
+> - Переименовал `TimeUtil` в `DateTimeUtil`
+> - Переименовал `mealList.jsp` в `meals.jsp`
+> - Изменения в `MealsUtil`:
+> - Сделал константу `List meals`. [Правило именования констант, которые не "deeply immutable"](https://google.github.io/styleguide/javaguide.html#s5.2.4-constant-names)
+> - Для фильтрации по времени и без нее в метод `filterByPredicate` передаю реализацию `Predicate`, см. паттерн [Стратегия](https://refactoring.guru/ru/design-patterns/strategy) и, если непонятно, [картинку](https://user-images.githubusercontent.com/13649199/95467365-093a1080-0986-11eb-8177-0985456d857a.png)
+> - Форматирование даты сделал на основе Custom EL function
+> - [Create a custom Function for JSTL через tag library descriptor (TLD)](http://findnerd.com/list/view/How-to-create-a-custom-Function-for-JSTL/2869/)
+> - Добавил еще один способ вывести `dateTime` через стандартную JSTL функцию `replace` (префикс `fn` в шапке также надо поменять)
+
+- [jsp:useBean](http://java-online.ru/jsp-actions.xhtml#useBean)
+- [MVC - Model View Controller](http://design-pattern.ru/patterns/mvc.html)
+
+###  2. Optional: реализация CRUD
+#### Apply 2_2_HW1_optional.patch
+Про использование паттерна Repository будет подробно рассказано в видео "Слои приложения"
+> - Согласно ответам на [Java Interfaces/Implementation naming convention](https://stackoverflow.com/questions/2814805/java-interfaces-implementation-naming-convention)
+убрал `Impl` в `InMemory` (и всех последующих) реализациях репозиториев. Они не нужны.
+> - Поправил `InMemoryMealRepository.save()`. Если обновляется еда, которой нет в хранилище (c несуществующим id), вставка не происходит.
+> - В `MealServlet.doGet()` сделал выбор через `switch`
+> - В местах, где требуется `int`, заменил `Integer.valueOf()` на `Integer.parseInt()`
+> - В `mealForm.jsp` использую параметр запроса `param.action`, который не кладется в атрибуты.
+> - Переименовал `mealEdit.jsp` в `mealForm.jsp`. Поля ввода формы добавил `required`
+> - Пофиксил багу c `history.back()` в `mealForm.jsp` для **FireFox** (коммит формы при Cancel, сделал `type="button"`).
+
+Дополнительно:
+ - HTTP 1.0 vs 1.1
+
+###  Вопросы по HW1
+
+> Зачем в `InMemoryMealRepository` наполнять map с помощью нестатического блока инициализации, а не в конструкторе?
+
+В общем случае так делать не надо. Сделал, чтобы напомнить вам про эту конструкцию, см. [Малоизвестные особенности Java](https://habrahabr.ru/post/133237/)
+
+> Почему `InMemoryMealRepository` не singleton?
+
+Начиная с Servlet API 2.3 пул сервлетов не создается, [создается только один инстанс сервлетов](https://stackoverflow.com/questions/6298309). Те. `InMemoryMealRepository` в нашем случае создается тоже только один раз. Далее все наши классы слоев приложения будут создаваться через Spring, бины которого по умолчанию являются синглтонами (в его контексте).
+
+> `Objects.requireNonNull` в `MealServlet.getId(request)` если у нас нет `id` в запросе бросает NPE (`NullPointerException`). Но оно вылетит и без этого метода. Зачем он нужен и почему мы его не обрабатываем?
+
+`Objects.requireNonNull` - это проверка предусловия (будет подробно на 4-м занятии). Означает что в метод пришел неверный аргумент (должен быть не null) и приложение сообщает об ошибке сразу на входе (а не "может быть где-то потом"). См. [What is the purpose of Objects#requireNonNull](https://stackoverflow.com/a/27511204/548473). Если ее проглатывать или замазывать, то приложение возможно где-то работает неверно (приходят неверные аргументы), а мы об этом не узнаем. Красиво обрабатывать ошибки будем на последних занятиях (Spring Exception Handling).
+
+## Занятие 2:
+
+###  3. Многоуровневая(многослойная) архитектура
+
+- Многоуровневая(многослойная) архитектура
+- Data Access Object
+- Паттерн DTO
+- Should services always return DTOs, or can they also return domain models?
+- [Mapping Entity->DTO goes in which application layer: Controller or Service?](http://stackoverflow.com/questions/31644131/spring-dto-dao-resource-entity-mapping-goes-in-which-application-layer-cont/35798539#35798539)
+- Дополнительно:
+ - Value Object и Data Transfer Object
+ - Difference between Active Record and DAO
+
+###  4. Создание каркаса приложения для пользователей
+
+#### Apply 2_3_app_layers.patch
+> - Убрал интерфейсы к сервисам. Я всегда предпочитаю писать меньше кода и в случае с одной реализацией можно обходится без них.
+ По поводу инкапсуляции и отделения API от реализации - интерфейсы к сервисам это внутренняя часть приложения с одной реализацией. Меньше кода, проще поддерживать.
+> - Переименовал `ExceptionUtil` в `ValidationUtil`
+> - Поменял `LoggedUser` на `SecurityUtil`. Это класс, из которого приложение будет получать данные залогиненного пользователя (пока [аутентификации](https://ru.wikipedia.org/wiki/Аутентификация) нет, он реализован как заглушка). Находится в пакете `web`, т.к. аутентификация/[авторизация](https://ru.wikipedia.org/wiki/Авторизация) происходит на слое контроллеров и остальные слои приложения про нее знать не должны.
+> - Добавил проверку id пользователя, пришедшего в контроллер ([treat IDs in REST body](https://stackoverflow.com/a/32728226/548473), "If it is a public API you should be conservative when you reply, but accept liberally"). Считаю это важной частью проверки входных данных в контроллере, не забывайте это делать в ваших выпускных проектах.
+> - Удалил в `User` лишнюю инициализацию. Было немножко наперед, добавим при введении конструктора по умолчанию.
+
+
+##  Ваши вопросы
+
+> Почему у `User.registered` тип `Date`, а `Meal.dateTime` `LocalDateTime `?
+
+По логике приложения время регистрации - абсолютное (конкретный момент), а время еды по бизнес логике относительно (те не зависит от часового пояса, завтрак и в Африке должен быть завтраком)
+
+> Какова цель деления приложения на слои?
+
+Управляемость проекта (особенно большого) повышается на порядок:
+- Обеспечивается меньшая связываемость. Допустим если мы меняем что-то в контроллере, то сервис эти изменения не задевают.
+- Облегчается тестирование (мы будем тестировать слои сервисов и контроллеров отдельно)
+- Четко разделяется функционал - где писать, куда смотреть. Не создаются [God objects](https://ru.wikipedia.org/wiki/Божественный_объект)
+
+> DTO используются когда есть избыточность запросов, которую мы уменьшаем, собрав данные из разных бинов в один? Когда DTO необходимо использовать?
+
+(D)TO может быть как частью одного entity (набор полей) так и набором нескольких entities.
+В нашем проекте для данных, которые надо отдавать наружу и отличающихся от Entiy (хранимый бин), мы будем делать (Data) Transfer Object и класть в отдельный пакет to. Например `MealsTo` мы отдаем наружу и он является Transfer Object, его пернесем в пакет `to`.
+На многих проектах (и собеседованиях) практикуют разделение на уровне maven модулей entity слоя от логики и соответствующей конвертацией ВСЕХ Entity в TO, даже если у них те же самые поля.
+Хороший ответ когда TO обязательны есть на stackoverflow: When to Use.
+
+> Почему контроллеры положили в папку web, а не в controllers?
+
+То же самое что `domain/model` - просто разные названия, которые устоялись в Java. Не придумывайте своих!
+
+> Зачем мы наследуем `NotFoundException` от `RuntimeException`?
+
+Так с ним удобнее работать. И у нас нет никаких действий по восстановлению состояния приложения (no recoverable conditions): checked vs unchecked exception. По последним данным checked exception вообще depricated: Ignore Checked Exceptions
+
+> Что такое `ProfileRestController`?
+
+Контроллер, где залогиненный пользователь будет работать со своими данными
+
+> Зачем в `AdminRestController` переопределяются методы родителя с вызовом тех же родительских?
+
+Сделано на будущее, мы будем менять этот код.
+
+> Что лучше возвращать из API: `Collection` или `List`
+
+Вообще, как правило, возвращают `List`, если не просится по коду более общий случай (например возможный `Set` или `Collection`, возвращаемый `Map.values()`). Если возвращается отсортированный список, то `List` будет адекватнее.
+
+> **Вопрос вам (очень важный):** можно ли в `MealRestController` контроллере сделать член класса `private int userId = SecurityUtil.authUserId()` и использовать его в методах контроллера?
+
+###  5. [Что такое Spring Framework](https://www.youtube.com/watch?v=megjriLG35I).
+- [Wiki: Spring Framework](https://ru.wikipedia.org/wiki/Spring_Framework)
+- [JVM Ecosystem Report 2020: Spring](https://snyk.io/blog/spring-dominates-the-java-ecosystem-with-60-using-it-for-their-main-applications/)
+- [2020 Java Technology Report](https://www.jrebel.com/blog/2020-java-technology-report)
+- [Spring Framework Documentation](https://docs.spring.io/spring-framework/docs/current/spring-framework-reference/index.html)
+- [Что такое Spring Framework? Внедрение зависимостей](https://habr.com/ru/post/490586/)
+- [Евгений Борисов — Spring-построитель](https://www.youtube.com/watch?v=rd6wxPzXQvo)
+- [Инверсия управления] (https://ru.wikipedia.org/wiki/Инверсия_управления)
+
+#### Apply 2_4_add_spring.patch
+> Сделал рефакторинг конструктора User, чтобы была возможность создавать пользователя без ролей
+
+###  6. [Запуск Spring Application Context](https://drive.google.com/file/d/1y-3ok-6CzhjnR4Rmv3-z4EV4VsElIDn6)
+- [Container Overview](https://docs.spring.io/spring-framework/docs/current/spring-framework-reference/core.html#beans-basics)
+#### Apply 2_5_add_spring_context.patch
+
+###  7. [Dependency Injection, Annotation_processing](https://drive.google.com/file/d/1Z9cgULTrXxgeaqqnsh7rJtIaD2LSdzHT)
+#### Apply 2_6_dependency_injection.patch
+- [IoC, DI, IoC-контейнер. Просто о простом](http://habrahabr.ru/post/131993/)
+- [Что такое Spring Framework? Внедрение зависимостей](https://habr.com/ru/post/490586/)
+- [Перевод "Field Dependency Injection Considered Harmful"](https://habrahabr.ru/post/334636/)
+- [Field vs Constructor vs Setter DI](http://stackoverflow.com/questions/39890849/what-exactly-is-field-injection-and-how-to-avoid-it)
+
+#### Apply 2_7_annotation_processing.patch
+- [Spring Auto Scanning Components](http://www.mkyong.com/spring/spring-auto-scanning-components)
+- [Difference between @Component, @Repository & @Service annotations in Spring](http://stackoverflow.com/questions/6827752/whats-the-difference-between-component-repository-service-annotations-in)
+- [Использование аннотации @Autowired](http://www.seostella.com/ru/article/2012/02/12/ispolzovanie-annotacii-autowired-v-spring-3.html)
+- Дополнительное:
+ - [Подготовка к Spring Professional Certification. Контейнер, IoC, бины](https://habr.com/ru/post/470305/)
+ - [Spring на GitHub](https://github.com/spring-projects)
+ - [Spring Annotations](https://dzone.com/refcardz/spring-annotations)
+
+#### Дополнительно видео по Spring
+ - [Юрий Ткач: Spring Framework - The Basics](https://www.youtube.com/playlist?list=PL6jg6AGdCNaWF-sUH2QDudBRXo54zuN1t)
+ - [Java Brains: Spring Framework](https://www.youtube.com/playlist?list=PLC97BDEFDCDD169D7)
+ - [Тимур Батыршинов: Spring Core - основы фреймворка, ядро](https://www.youtube.com/watch?v=CfHDr-19WWY&list=PL8X2nqRlWfaYYP1-qXjdPKE7bXYkl6aL4)
+ - [alishev: Spring Framework](https://www.youtube.com/playlist?list=PLAma_mKffTOR5o0WNHnY0mTjKxnCgSXrZ)
+
+##  Ваши вопросы
+> Что такое схема в spring-app.xml xsi:schemaLocation и зачем она нужна
+
+XML схема нужна для валидации xml, IDEA делает по ней автозаполнение.
+
+> Что означает для Spring
+
+
+
+ ?
+
+Можно сказать так: создай и занеси в свой контекст экземпляр класса (бин) `UserService` и присвой его проперти `repository` бин `inmemoryUserRepository`, который возьми из своего контекста.
+
+> `SecurityUtil.authUserId()` и `user.id` это одно и то или это разные вещи?
+
+`User.id` это уникальный идентификатор юзера, которых в приложении много.
+`SecurityUtil.authUserId()` это идентификатор `id` залогиненного юзера. Мы можем, например, получить самого залогиненного юзера, выполнив запрос с `User.id==SecurityUtil.authUserId()`
+Когда вы логинитесь в свое почтовое приложение, оно отдает вам именно ваши письма на основе вашего `id`, который она определяет и запоминает во время аутентификации (логина).
+У нас пока этого нет и `id` задается константой (хардкодится). Но когда мы сделаем настоящую аутентификацию, все будет работать для любого залогиненного пользователя.
+
+> Как биндинг происходит для `@Autowired`? Как поступать, если у нас больше одной реализации `UserRepository`?
+
+`@Autowired` инжектит по типу (т.е. ижектит класс который реализует `UserRepository`). Обычно он один. Если у нас несколько реализаций, Spring не поднимится и поругается - `No unique bean`.
+ В этом случае можно уточнить имя бина через @Qualifier. `@Qualifier` обычно добавляют только в случае нескольких реализаций.
+См. [Inject 2 beans of same type](https://stackoverflow.com/a/2153680/548473)
+
+> Почему нельзя сервлет помещать в Spring контекст?
+
+Сервлеты- это исключительно классы `servlet-api` (веб контейнера), они инстанциируются Tomcat. Те технически можно (без `init/destroy`), но идеологически - неверно. Cоздастся два сервлета: один настоящий, Tomcat-ом, и второй - нерабочий, Spring-ом. НЕ надо включать сервлет в контекст Spring.
+
+--------------------
+- **Еще раз смотрим на [демо приложение](http://javaops-demo.ru/topjava) и вникаем, что такое пользователь и его еда и что он может с ней сделать.
+Когда пользователь логинится в приложении, его id и норма калорий "чудесным образом" попадают в `SecurityUtil.authUserId() / SecurityUtil.authUserCaloriesPerDay()`. Как они реально туда попадут будет в уроке 9 (Spring Security, сессия и куки)**
+- **Перед началом выполнения ДЗ (если есть хоть какие-то сомнения) прочитайте ВСЕ ДЗ. Если вопросы остаются - то ВСЕ подсказки**. Особенно этот пункт важный, когда будете делать реальное рабочее ТЗ.
+
+##  Домашнее задание HW02
+- 1: Имплементировать `InMemoryUserRepository` по аналогии с `InMemoryMealRepository` (список пользователей возвращать отсортированным по имени)
+- 2: сделать `Meal extends AbstractBaseEntity`, `MealTo` перенести в пакет `ru.javawebinar.topjava.to` (transfer objects)
+- 3: Изменить `MealRepository` и `InMemoryMealRepository` таким образом, чтобы вся еда всех пользователей находилась в одном общем хранилище, но при этом каждый конкретный аутентифицированный пользователь мог видеть и редактировать только свою еду.
+ - 3.1: реализовать хранение еды для каждого пользователя можно с добавлением поля `userId` в `Meal` ИЛИ без него (как нравится). Напомню, что репозиторий один и приложение может работать одновременно с многими пользователями.
+ - 3.2: если по запрошенному id еда отсутствует или чужая, возвращать `null/false` (см. комментарии в `MealRepository`)
+ - 3.3: список еды возвращать отсортированный в обратном порядке по датам
+ - 3.4: дополнительно: попробуйте сделать реализацию атомарной (те учесть коллизии при одновременном изменении еды одного пользователя)
+- 4: Реализовать слои приложения для функциональности "еда". API контроллера должна удовлетворять все потребности демо приложения и ничего лишнего (см. [демо](http://javaops-demo.ru/topjava)). Поиск и изменение порядка сортировки в таблице демо приложения реализованы на клиенте в браузере (плагин DataTables), сейчас делать не нужно.
+ - **Смотрите на реализацию слоя для user и делаете по аналогии! Если там что-то непонятно, не надо исправлять или делать по своему. Задавайте вопросы. Если действительно нужна правка - я сделаю и напишу всем.**
+ - 4.1: после авторизации (сделаем позднее), id авторизованного юзера можно получить из `SecurityUtil.authUserId()`. Запрос попадает в контроллер, методы которого будут доступны снаружи по http, т.е. запрос можно будет сделать с ЛЮБЫМ id для еды
+ (не принадлежащем авторизированному пользователю). Нельзя позволять модифицировать/смотреть чужую еду.
+ - 4.2: `SecurityUtil` может использоваться только на слое web (см. реализацию `ProfileRestController`). `MealService` можно тестировать без подмены логики авторизации, поэтому **в методы сервиса и репозитория мы передаем параметр `userId`: id авторизованного пользователя (предполагаемого владельца еды)**.
+ - 4.3: если еда не принадлежит авторизированному пользователю или отсутствует, в `MealService` бросать `NotFoundException`.
+ - 4.4: конвертацию в `MealTo` можно делать как в слое web, так и в service ([Mapping Entity->DTO: Controller or Service?](http://stackoverflow.com/questions/31644131))
+ - 4.5: в `MealService` постараться сделать в каждом методе только одни запрос к `MealRepository`
+ - 4.6 еще раз: не надо в названиях методов повторять названия класса (`Meal`).
+
+
+
+- 5: включить классы еды в контекст Spring (добавить аннотации) и вызвать из `SpringMain` любой метод `MealRestController` (проверить что Spring все корректно заинжектил)
+
+### Optional
+- 6: в `MealServlet` сделать инициализацию Spring, достать `MealRestController` из контекста и работать с едой через него (**как в `SpringMain`**). `pom.xml` НЕ менять, работаем со `spring-context`. Сервлет обращается к контролеру, контроллер вызывает сервис, сервис - репозиторий. Когда будем работать через Spring MVC, `MealServlet` удалим, останется только контроллер.
+
+
+
+- 7: добавить в `meals.jsp` и `MealServlet` фильтрацию еды по дате и по времени (см. [демо](http://javaops-demo.ru/topjava)). Сброс фильтра делать не надо (реализуем через ajax в HW8). ВНИМАНИЕ: в приложении фильтрация делается не по интервалу дата-время, а отдельно по датам и затем отдельно по времени.
+- 8: добавить выбор текущего залогиненного пользователя (имитация аутентификации, сделать [Select](http://htmlbook.ru/html/option) с двумя элементами со значениями 1 и 2 в `index.html` и `SecurityUtil.setAuthUserId(userId)` в `UserServlet`). От выбора user или admin будет зависеть отображение еды: user-а или admin-а.
+Настоящая аутентификация будет через Spring Security позже.
+
+----------------------------
+### Итоги занятия после выполнения ДЗ:
+Мы создали архитектуру нашего приложения с разделением на слои и внедрили в наш проект фреймворк Spring, который их связывает.
+Далее мы реализовали функционал нашего приложения для работы с едой, как он сделан в [демо приложении](http://javaops-demo.ru/topjava) (но с фиктивной аутентификацией)
+
+---------------------
+
+###  Типичные ошибки и подсказки по реализации
+
+- 1: **В реализации `InMemoryUserRepository`**
+ - 1.1: `getByEmail` попробуйте сделать через `stream`
+ - 1.2: `delete` попробуйте сделать за одно обращение к map (без `containsKey`). При удалении пользователя его еду можно оставить, при реализации в базе будет CASCADE.
+ - 1.3: при запросе списка юзеров предусмотрите случай одинаковых `User.name` (порядок должен быть зафиксированным). Поле `User.email`у нас уникально - в базе будет ограничение.
+- 2: **В реализации `InMemoryMealRepository`**
+ - 2.1: В `Meal`, которая приходит из браузера в контроллер, нет никакой информации о пользователе (еда приходит в контроллер **БЕЗ `user/userId`, она может быть только от авторизированного пользователя**). По id еды и авторизованному пользователю нужно проверить ее принадлежность (его это еда или чужая)
+ **Проверьте сценарий: авторизованный пользователь пробует изменить чужую еду (id еды ему не принадлежит).**
+ - 2.2: `get\update\delete` - следите, чтобы не было NPE (`NullPointException` может быть, если в хранилище отсутствует юзер или еда).
+ - 2.3: Фильтрацию по датам сделать в репозитории т.к. из базы будем брать сразу отфильтрованные по дням записи. Следите чтобы **первый и последний день не были обрезаны, иначе сумма калорий будет неверная**.
+ - 2.4: Если запрашивается список и он пустой, не возвращайте NULL! По пустому списку можно легко итерироваться без риска `NullPoinException`.
+ - 2.5: Не дублируйте код в `getAll` и метод с фильтрацией
+ - 2.6: попробуйте учесть, что следующая реализация (сортировка, фильтрация) будет делаться прямо в базе данных
+- 3: Проверьте, что удалили `Meal.id` и связанные с ним методы (он уже есть в базовом `BaseEntity`)
+- 4: Проверку `isBetweenHalfOpen` сделать в `DateTimeUtil`. Попробуйте использовать `LocalDateTime` вместо `LocalDate` с прицелом на то, что в DB будет тип даты `timestamp`. Тогда для `LocalTime` и `LocalDateTime` можно использовать один метод проверки полуоткрытого интервала и дженерики (см. [Generics Tutorials](https://docs.oracle.com/javase/tutorial/extra/generics/morefun.html) и [Погружаемся в Java Generics](https://habr.com/ru/company/sberbank/blog/416413/))
+- 5: **Реализация 'MealRestController' должен уметь обрабатывать запросы**:
+ - 5.1: Отдать свою еду (для отображения в таблице, формат `List`), запрос БЕЗ параметров
+ - 5.2: Отдать свою еду, отфильтрованную по startDate, startTime, endDate, endTime
+ - 5.3: Отдать/удалить свою еду по id, параметр запроса - id еды. Если еда с этим id чужая или отсутствует - `NotFoundException`
+ - 5.4: Сохранить/обновить еду, параметр запроса - Meal. Если обновляемая еда с этим id чужая или отсутствует - `NotFoundException`
+ - 5.5: Сервлет мы удалим, а контроллер останется, поэтому возвращать `List` надо из контроллера. И userId принимать в контроллере НЕЛЬЗЯ (иначе - для чего аторизация?).
+ - 5.6: В концепции REST при update дополнительно принято передавать id (см. `AdminRestController.update`)
+ - 5.7: Для получения всей своей еды сделайте отдельный `getAll` без применения фильтра
+- 6: Проверьте корректную обработку пустых значений date и time (в частности, если все значения пустые, должен выводится весь список)
+- 7: `id` авторизированного пользователя получаем так: `SecurityUtil.authUserId()`, cм. `ProfileRestController`
+- 8: В `MealServlet`
+ - 8.1: Закрывать springContext в сервлете грамотнее всего в `HttpServlet.destroy()`: если где-то в контексте Spring будет ленивая инициализация, метод-фабрика, не синглтон-scope, то контекст понадобится при работе приложения. У нас такого нет, но делать надо все грамотно.
+ - 8.2: Не храните параметры фильтра как члены класса сервлета, это не многопоточно! Один экземпляр сервлета используется всеми запросами на сервер, попробуйте дернуть его из 2х браузеров.
+ - 8.3: В сервлете нельзя использовать `@Autowired` и `@Component`. См вопрос выше- "Почему нельзя сервлет помещать в Spring контекст?"
+
+#### Если с ДЗ большие сложности, можно получить итоговые Meal интерфейсы для сверки в личке - пишите `@Katherine`.
+И напоследок история от Татьяны:
+> 2.1 По id еды и авторизованному пользователю нужно проверить ее принадлежность.
+
+На примере уточню:
+Вася Пупкин нашел неименную банковскую карточку, т.е. номер есть, но имени нет.
+Т.к. Вася не очень честный человек, то решил снять деньги с чужой карточки.
+Наклеил *стикер со своим именем* на карточку и пришел в банк. Дает свой паспорт и карточку операционисту и просит снять всю наличность.
+Варианты:
+1. операционист сверяет стикер на карточке и паспорт - все ок, Вася получает наличность
+2. операционист не обращает внимания на стикер, *а делает запрос в БД по номеру и сверяет ФИО в БД с паспортом* - ФИО не совпали, Вася в пролете
+
+Кто и так это понимает, тому небольшой спойлер. А кто не понимает, может, переспросят, пообсуждают.
diff --git a/doc/lesson03.md b/doc/lesson03.md
new file mode 100644
index 000000000..bae524b0d
--- /dev/null
+++ b/doc/lesson03.md
@@ -0,0 +1,394 @@
+# Стажировка Topjava
+
+## [Материалы занятия](https://drive.google.com/drive/u/0/folders/0B9Ye2auQ_NsFT1NxdTFOQ1dvVnM) (скачать все патчи можно через Download папки patch)
+> **ВНИМАНИЕ! При удалении класса из исходников, его скомпилированная версия все еще будет находиться в target (и classpath). В этом случае (или в любом другом, когда проект начинает глючить) сделайте `mvn clean`.**
+
+##  Разбор домашнего задания HW02
+###  1. [Реализация репозиториев](https://drive.google.com/file/d/1hZay5jV-mVEByMnDveZ36jUAY0I3WChT)
+
+#### Apply 3_01_HW2_repositories.patch
+
+###  2. [Фильтрация в репозитории](https://drive.google.com/file/d/1s1tAsopU60gRvMaL53TP9EjS1gap99s3)
+Метод `MealRepository.getBetweenHalfOpen` мы используем в следующем патче для фильтрации по целым дням.
+Используем `LocalDateTime` вместо `LocalDate` с прицелом на то, что в DB будем делать тип даты - `timestamp`.
+
+#### Apply 3_02_HW2_repo_filters.patch
+> - Исправил багу в `usersMealsMap.computeIfAbsent(userId, ConcurrentHashMap::new)` - в этом случае создается `new ConcurrentHashMap(userId)`, что неверно
+ - [Spring `@Nullable` аннотации](https://www.jetbrains.com/help/idea/nullable-and-notnull-annotations.html)
+
+###  3. [Meals Layers](https://drive.google.com/file/d/1jwd4Yhdy434fUAQyjpsZOO24XT-4lfp8)
+> - В `DateTimeUtil` переименовал методы. Название должно описывать, "что метод делает", а не "зачем его вызывают".
+> - Переименовал `getBetween` для дат. Для времени у нас полуоткрытый диапазон, для дат - закрытый.
+
+#### Apply 3_03_HW2_meal_layers.patch
+- [Should services always return DTOs, or can they also return domain models?](http://stackoverflow.com/questions/21554977/548473)
+- [Mapping Entity->DTO goes in which application layer: Controller or Service?](https://stackoverflow.com/a/35798539/548473)
+
+### Рефакторинг InMemory репозиториев
+#### Apply 3_04_refactor_repository.patch
+- сделал базовый `InMemoryBaseRepository`
+- наследую от него `InMemoryUserRepository`
+- использую его в `InMemoryMealRepository` вместо `Map`
+
+Обратите внимание на `InMemoryBaseRepository.counter` - счетчик один, общий для всех хранимых объектов
+
+###  4. [HW2 Optional](https://drive.google.com/file/d/1yzNvGBgjgtuKXDFo983OqtTNoHDbyn1z)
+#### Apply 3_05_HW2_optional_MealServlet.patch
+> - Заменил `@Depricated StringUtils.isEmpty` на `hasLength` (условие приходится инвертировать)
+> - Убрал логирование (уже есть в контроллере)
+> - `assureIdConsistent` позволяет в контроллере обновлять еду с `id=null`
+
+#### Apply 3_06_HW2_optional_filter.patch
+- [JSP Implicit Objects](https://stackoverflow.com/a/1890462/548473)
+- [Использование data-* атрибутов](https://developer.mozilla.org/ru/docs/Web/Guide/HTML/Using_data_attributes), имена сделал [low-case через дефисы](https://stackoverflow.com/questions/36176474/548473)
+
+#### Apply 3_07_HW2_optional_select_user.patch
+
+###  Вопросы по HW2
+
+> Что делает `repository.computeIfAbsent / computeIfPresent` ?
+
+Всегда пробуйте ответить на вопрос сами. Достаточно просто зайти по Ctrl+мышка в реализацию и посмотреть javadoc и **их дефолтную реализацию**
+
+> Почему выбрана реализация `Map>` а не `Meal.userId + Map` ?
+
+В данном случае двойная мапа (мультимапа) - способ хранения, который не требует итерирования (перебора всех значений) и он проще. С другой стороны затраты по памяти в этом решении больше.
+
+## Занятие 3:
+###  5. Коротко о жизненном цикле Spring контекста.
+#### Apply 3_08_bean_life_cycle.patch
+> ** Добавил в pom `javax.annotation-api` для JDK больше 8. Этот пакет [убрали из JDK начиная с версии 9](https://stackoverflow.com/a/46502132/548473).
+
+- Spring изнутри. Этапы инициализации контекста.
+- Ресурсы:
+ - Евгений Борисов. Spring, часть 1
+ - Евгений Борисов. Spring, часть 2
+
+###  6. [Тестирование через JUnit](https://www.youtube.com/watch?v=wSVg6_iK2Aw)
+### ВНИМАНИЕ!! Перед накаткой патча создайте каталог test (из корня проекта путь `\src\test` или `\src\test\java`), иначе часть файлов попадет в `src\main`.
+
+> - "Deeply mutable" константы `UserTestData.user/admin` [сделал lowercase](https://google.github.io/styleguide/javaguide.html#s5.2.4-constant-names).
+> - Добавил для тестирования в данные `User guest` без ролей и без еды.
+
+- все классы, которые не нужны при работе приложения переносятся в test (и не включаются в сборку)
+- в тестах очень частая ошибка - менять местами `expected` (ожидаемое) и `actual` (фактическое) значения.
+- [Регрессионное тестирование](https://ru.wikipedia.org/wiki/Регрессионное_тестирование)
+- [Разработка через тестирование](https://ru.wikipedia.org/wiki/Разработка_через_тестирование)
+- [Unit тестирование с JUnit](https://devcolibri.com/unit-тестирование-с-junit/)
+- [maven-surefire-plugin](https://maven.apache.org/surefire/maven-surefire-plugin/usage.html)
+- Дополнительно:
+ - [JUnit 4](http://junit.org/junit4)
+ - [Тестирование в Java. JUnit](http://habrahabr.ru/post/120101/)
+ - [Юнит-тестирование для чайников](https://habr.com/ru/post/169381/)
+ - [Тестирование кода Java с помощью фреймворка JUnit](https://www.youtube.com/watch?v=z9jEVLCF5_w) (youtube)
+
+#### Apply 3_09_add_junit.patch
+
+### После патча сделайте `clean` и [обновите зависимости Maven](https://github.com/JavaOPs/topjava/wiki/IDEA#maven_update), чтобы IDEA определила сорсы тестов
+####  Вопрос: почему проект упадет при попытке открыть страничку еды? (в логе смотреть самый верх самого нижнего исключения). Чинить приложение будем в HW03.
+
+###  7. Spring Test
+> - поменял `@RunWith`: `SpringRunner` is an alias for the `SpringJUnit4ClassRunner`
+#### Apply 3_10_add_spring_test.patch
+- [Spring Testing](https://docs.spring.io/spring/docs/current/spring-framework-reference/testing.html)
+
+###  8. Базы данных. Обзор NoSQL и Java persistence solution без ORM.
+### Postgres можно установить локально и/или через Docker - пригодиться!
+
+--------------
+### Установка локально:
+
+> **Рекомендуется PostgreSQL 13**
+- PostgreSQL.
+- [PostgreSQL JDBC Driver](https://github.com/pgjdbc/pgjdbc)
+- Установка PostgreSQL.
+- Чтобы избежать проблем с правами и именами каталогов, [**рекомендуют установить postgres в простой каталог, например `C:\Postgresql`**. И при проблемах создать каталог data на другом диске](https://stackoverflow.com/questions/43432713/548473). Если Unix, [проверить права доступа к папке (0700)](http://www.sql.ru/forum/765555/permissions-should-be-u-rwx-0700). Название ПК и имя пользователя должны быть латиницей (или можно устанавливать сервер [отсюда](https://postgrespro.ru/windows))
+ - [Установка PostgreSQL в UBUNTU](https://github.com/JavaOPs/startup/blob/main/postgres.md)
+
+> Создать в pgAdmin новую базу `topjava` и новую роль `user`, пароль `password`
+
+
+
+> Проверьте, что у user в Privileges есть возможность авторизации (особенно для pgAdmin4)
+
+или в UNIX командной строке:
+```
+sudo -u postgres psql
+CREATE DATABASE topjava;
+CREATE USER "user" WITH password 'password';
+GRANT ALL PRIVILEGES ON DATABASE topjava TO "user";
+```
+
+--------------
+### Установка через Docker (если у вас Windows, рекомендую этот вариант уже после выполнения ДЗ - с ним можно долго провозиться)
+Для работы современного ПО часто требуется большая настроенная инфраструктура: RDBMS, NoSQL, Kafka, RabbitMQ и др. Кроме того, концепция микросервисов подразумевает
+запуск каждого сервиса в изолированной среде, их быстрое поднятие и масштабирование.
+Инструмент [Docker](https://ru.wikipedia.org/wiki/Docker) позволяет «упаковать» приложение со всем его окружением и зависимостями в контейнер, который может быть развёрнут на любой Linux-системе, что делает его незаменимым инструментом разработчика.
+Аналогично GitHub, для контейнеров есть репозиторий [DockerHub](https://hub.docker.com/), куда можно публиковать свои контейнеры и откуда можно брать готовые контейнеры со стандартным ПО.
+Таким образом Docker служит для:
+- Ускорения процесса настройки окружения. Нет нужды в установке сторонних программ вроде PostgreSQL, Redis, Elasticsearch. Они могут быть запущены в контейнерах.
+- Удобной инкапсуляции приложений, которые можно представить как единый контейнер, а не набор файлов и инструкций развертывания.
+- Одинакового поведения приложений на локальном компьютере и тестовом/прод-сервере.
+- Простого и понятного мониторинга.
+- Легкого масштабирования. Если вы сделали свое приложение правильно, то оно будет готово к масштабированию не только в Docker.
+
+[**Основы и руководство по Docker**](https://tproger.ru/translations/how-to-start-using-docker/)
+[Docker - понятный туториал](https://badtry.net/docker-tutorial-dlia-novichkov-rassmatrivaiem-docker-tak-iesli-by-on-byl-ighrovoi-pristavkoi/)
+
+#### Для разных ОС установка Docker отличается. Для Windows часто это достаточно заморочно, возможно лучший вариант - [собственный UNIX хостинг](https://github.com/JavaOPs/startup). Он также пригодиться для практики с терминалом Linux и для деплоя приложения в конце стажировки.
+- для [Windows без поддержки Hyper-V](https://docs.microsoft.com/en-us/virtualization/hyper-v-on-windows/reference/hyper-v-requirements) требуется Docker Toolbox,
+для Windows 10 Pro and Enterprise - Docker Desktop. [Инструкция по проверке виртуализации и установке](https://devconnected.com/how-to-install-docker-on-windows-7-8-10-home-and-pro/)
+- На Windows Home можно поставить Docker Desktop, предварительно [установив WSL2 (Windows Subsystem for Linux)](https://docs.microsoft.com/ru-ru/windows/wsl/install)
+ - Убедитесь, что wsl версии 2: возможно понадобится включить в BIOS виртуализацию (гуглится по материнской плате) и [отключить в Windows гипервизор](https://sysadmintips.ru/kak-vykljuchit-virtualizaciju-hyper-v-windows-10.html#Otklucenie_Hyper-V_v_Windows_10_cerez_Programmy_i_komponenty)
+ - [Upgrade version from WSL 1 to WSL 2](https://docs.microsoft.com/en-us/windows/wsl/install#upgrade-version-from-wsl-1-to-wsl-2)
+ - [Обновление WSL до версии 2](https://docs.microsoft.com/en-us/windows/wsl/install-manual)
+ - Команды из cmd/PoswrShell:
+```
+wsl -l -v : проверить версию
+wsl --set-version Ubuntu-20.04 2 : поставить версию 2
+wsl : запустить Ubuntu
+
+sudo service docker status <- проверка статуса
+sudo service docker start <-старт
+sudo service docker restart <-рестарт
+```
+- [Установка на Mac](https://docs.docker.com/desktop/install/mac-install/)
+- [Установка на Linux](https://docs.docker.com/desktop/install/linux-install/)
+- Установка под Ubuntu: ` sudo apt install docker.io`
+ - [How can I use docker without sudo?](https://askubuntu.com/a/477554/1357134)
+
+#### Работе Docker могут мешать: DrWeb, firewall, анитивирусы
+
+#### Разворачиваем Postgres:
+- загружаем [контейнер с последним postgres](https://hub.docker.com/_/postgres): `docker pull postgres`
+- если на локальной машине уже запущен сервис postgres, надо его остановить: для Windows я запустил `C:\Windows\System32\cmd.exe as Admin` и остановил командой `net stop postgresql-x64-10`
+- **Запускаем контейнер с postgres:**
+```
+docker run -p 5432:5432 -d --name topjava_db -e POSTGRES_USER=user -e POSTGRES_PASSWORD=password -e POSTGRES_DB=topjava postgres
+```
+ -p: преобразование портов HOST PORT:CONTAINER PORT (или -P: все порты)
+ -d: флаг запускает контейнер в фоновом режиме (как демон)
+ -e: задание переменной окружения
+ --name [имя]: устанавливает имя демона для нового контейнера
+
+[Основные команды Docker](https://tproger.ru/translations/top-10-docker-commands):
+```
+docker ps -a : посмотреть все контейнеры
+docker stop topjava_db : остановить наш контейнер
+docker start topjava_db : запустить его
+docker rm topjava_db : удалить
+docker help : справка по командам
+```
+
+Если Docker установился через Docker Toolbox, он запускается в VirtualBox, необходимо настроить [проброс порта 5432 из VirtualBox на локальную машину](https://losst.ru/probros-portov-virtualbox). Порты можно делать одинаковые: Host Post: 5432, Guets Port: 5432
+Проверить postgres порт 5432 можно через
+- Unix: `netstat -an |grep 'LISTENING'`
+- Windows: `netstat -an |find /i "listening"`
+
+Если порт 5432 слушается, можно приконнектиться к нему из IDEA, следующее видео.
+
+------------
+
+- Обзор NoSQL систем. CAP
+- DB-Engines Ranking
+- JDBC
+- Обзор Java persistence solution без ORM: commons-dbutils,
+ Spring JdbcTemplate,
+ MyBatis, JDBI, jOOQ
+- Основы:
+ - Реляционная СУБД
+ - Реляционные базы
+ - [Руководство по проектированию реляционных баз данных](https://habr.com/ru/post/193136/)
+ - Уроки по JDBC
+ - Postgres Guide
+ - PostgreSQL Tutorial
+ - Базы данных на Java
+ - Возможности JDBC — второй этап
+- Дополнительно:
+ - [Документация к PostgreSQL](https://postgrespro.ru/docs/postgrespro)
+ - [Книги по PostgreSQL](https://postgrespro.ru/education/books)
+
+###  9. Настройка Database в IDEA.
+Heroku стал платным, вместо него предлагаю зарегистрировать [**собственный выделенный хостинг**](https://github.com/JavaOPs/startup).
+По цене от ~300р./мес имеем: собственный сайт, практика с Linux, деплой своих приложений, развертывание Docker.
+
+#### Apply 3_11_add_postgresql.patch
+- Настройка Database в IDEA и запуск SQL.
+
+###  10. Скрипты инициализации базы. Spring Jdbc Template.
+#### Apply 3_12_db_implementation.patch
+> - в `JdbcUserRepository`
+> - в `getByEmail()` заменил `queryForObject()` на `query()`. Загляните в код: `queryForObject` бросает `EmptyResultDataAccessException` вместо нужного нам `null`.
+> - в `save()` добавил проверку на несуществующей в базе `User.id`
+> - в классе `JdbcTemplate` есть настройки (`queryTimeout/ skipResultsProcessing/ skipUndeclaredResults`) уровня приложения (если они будут меняться, то, скорее всего, везде в приложении).
+ Мы можем дополнительно сконфигурировать его в `spring-db.xml` и использовать в конструкторах `NamedParameterJdbcTemplate` и в `SimpleJdbcInsert` вместо `dataSource`.
+
+Для запуска скриптов кликнуть правой мышкой на табе скрипта, выбрать Run и в диалоге добавть чз "+" базу
+
+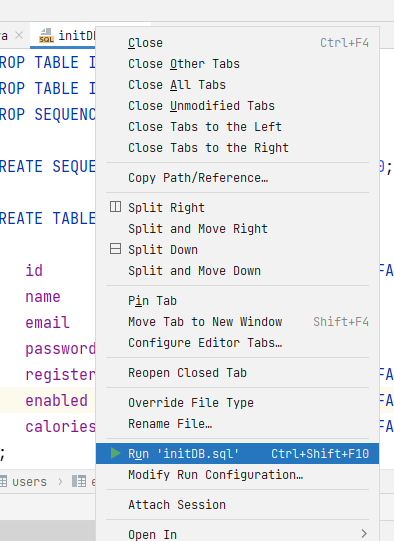
+
+
+- Дополнительно:
+ - [alishev: Spring Framework. Урок 27: JdbcTemplate](https://www.youtube.com/watch?v=YozbZQ7PxtQ&list=PLAma_mKffTOR5o0WNHnY0mTjKxnCgSXrZ&index=27&ab_channel=alishevalishev)
+
+ **Вопрос: почему отображение еды все еще не работает? (чинить приложение будете в HW03)**
+
+- Подключение Spring Jdbc.
+- Конфигурирование DataSource. Property Placeholder
+- Интеграция `JdbcUserRepository` с DB: [Добавить поддержку DB в JDBC](https://github.com/JavaOPs/topjava/wiki/IDEA#user-content-Добавить-поддержку-db-в-jdbc)
+
+> Проверьте, что в контекст Spring проекта включены оба файла конфигурации
+
+
+
+###  11. Тестирование UserService через AssertJ.
+#### Apply 3_13_test_UserService.patch
+> - В тестах `delete` и `create` проверяю результат напрямую (не через `getAll`)
+> - В `UserTestData` добавил вспомогательные `getNew()` и `getUpdated()`
+> - При выполнении функционала `create/update` объекты могут измениться, и мы не можем считать их эталонными. Поэтому при сравнении мы создаем эталон еще раз.
+> - Поставил `@Ignore` в inmomory тестах
+
+- [Tutorial: testing with AssertJ](http://www.vogella.com/tutorials/AssertJ/article.html)
+- [Spring Testing Annotations](https://docs.spring.io/spring/docs/4.3.x/spring-framework-reference/htmlsingle/#integration-testing-annotations-spring)
+- [The JPA hashCode() / equals() dilemma](https://stackoverflow.com/questions/5031614/548473)
+- [Hibernate: implementing equals() and hashCode()](https://docs.jboss.org/hibernate/orm/current/userguide/html_single/Hibernate_User_Guide.html#mapping-model-pojo-equalshashcode)
+- [Junit Matcher for comparators](https://stackoverflow.com/questions/17949752/548473)
+- [AssertJ custom comparison strategy](http://joel-costigliola.github.io/assertj/assertj-core-features-highlight.html#custom-comparison-strategy). [AssertJ field by field comparisons](http://joel-costigliola.github.io/assertj/assertj-core-features-highlight.html#field-by-field-comparison)
+
+###  12. Логирование тестов.
+#### Apply 3_14_test_logging.patch
+> - Новый PostgreSQL JDBC Driver [логирует через java.util.logging](https://github.com/pgjdbc/pgjdbc#changelog). [Направил логирование в SLF4J](http://stackoverflow.com/a/43242620/548473)
+> - Поменял формат вывода. См. [Logback Layouts](https://logback.qos.ch/manual/layouts.html)
+
+- Ресурсы, которые кладутся в classpath, maven при сборке берет из определенных каталогов `resources` ([Introduction to the Standard Directory Layout](https://maven.apache.org/guides/introduction/introduction-to-the-standard-directory-layout.html)). Их можно настраивать через [maven-resources-plugin](https://maven.apache.org/plugins/maven-resources-plugin/examples/resource-directory.html), меняем в проекте Masterjava.
+
+#### Apply 3_15_fix_servlet.patch
+**И снова вопрос: почему отображение еды все еще не работает? (чинить приложение будете в HW03)**
+
+##  Ваши вопросы
+> Что такое REST?
+
+Коротко посмотрите тут: [понимание REST](https://web.archive.org/web/20240919203427/http://spring-projects.ru/understanding/rest/). Более подробно мы будем разбирать этот архитектурный стиль API на 7-ом занятии.
+
+> Какая разница между @BeforeClass and @Before?
+
+`@BeforeClass` выполняется один раз после загрузки класса (поэтому метод может быть только статический), `@Before` перед каждым тестом.
+Также: для чистоты тестов экземпляр тестового класса [пересоздается перед каждым тестом](http://stackoverflow.com/questions/6094081/548473)
+
+> Тесты в классе в каком-то определенном порядке выполняются ("сверху вниз" например)?
+
+Порядок по умолчанию неопределен, каждый тест должен быть автономен и не зависеть от других. [См. также "How to run test methods in specific order in JUnit4?"](http://stackoverflow.com/questions/3693626/548473)
+
+> Обязательно ли разворачивать postgreSQL?
+
+Желательно: хорошая и надежная ДБ:) Если совсем не хочется - можно работать со своей любимой RDBMS (поправить `initDB.sql`) или, например,
+[развернуть на стороне, есть бесплатный тариф](https://neon.tech/pricing)
+
+. На следующем уроке добавим HSQLDB, она не требует установки.
+
+> Зачем начали индексацию с 100000?
+
+Так удобно вставлять в базу (если будет потребность) записи вручную не мешая счетчику. Но это не общий принцип, часто нумерация идет с 1.
+
+> Из 5-го видео - "Логика в базе - большое зло". Можно чуть поподробней об этом?
+
+- Есть успешные проекты с логикой в базе. Те все относительно.
+- Логика в базе - это процедуры и триггеры. Нет никакого ООП, переиспользовать код достаточно сложно, никагого рефакторинга, поиска по коду и других плюшек IDE. Нельзя делать всякие вещи типа кэширования, хранения в сессии - это все для логики на стороне java. Например json можно напрямую отдать в процедуру и там парсить и вставлять в таблицы или наоборот - собирать из таблиц и возвращать.
+А затем потребуется некоторая логика на стороне приложения и все равно придется этот json дополнительно парсить в java.
+Я на таком проекте делал специальную миграцию, чтобы процедуры мигрировать не как sql-скрипты, а каждую процедуру хранить как класс с историей изменений. Если логика: триггеры и простые процедуры записи-чтения, которые не требуют переиспользования кода или
+проект небольшой - это допустимо, иначе проект становится трудно поддерживать. Также иногда используют [View](http://postgresql.men/gruber/ch20.html) для разграничения доступа. Например, для финансовых систем, таблицы проводок доступны только для админ учеток, а View просто не дадут увидеть (тем более изменить) данные обычному оператору на уровне СУБД.
+
+> У JUnit есть ассерты и у спринга тоже. Можно ли обойтись без JUnit?
+
+Предусловия Spring `Assert` и JUnit-тесты совершенно разные вещи, один другого не заменит. У нас будут предусловия в следующем уроке.
+
+> Я так понял, что при работе с небольшими записями, VARCHAR быстрее, чем TEXT. Наши записи будут небольшими (255). Почему вы приняли решение перейти на TEXT?
+
+В отличие от MySql, в Postgres [VARCHAR и TEXT - тоже самое](https://stackoverflow.com/questions/4848964/548473)
+
+> Зачем при создании таблицы мы создаем `CREATE UNIQUE INDEX` и `CREATE INDEX`. При каких запросах он будет использоваться?
+
+UNIQUE индекс нужен для обеспечения уникальности, DB не даст сделать одинаковый индекс. Индексы используется для скорости выполнения запросов. Обычно они используются, когда в запросе есть условия, на которые сделан индекс. Узнать по конкретному запросу можно запросив план запроса: см. Оптимизация запросов. Основы EXPLAIN в PostgreSQL. На измерение производительности с индексами посмотрим в следующем уроке.
+
+> А это нормально, что у нас в базе у meals есть userId, а в классе - нет?
+
+Ненормально, когда в приложении есть "лишний" код, который не используется. Для ORM он нам понадобится - добавим `Meal.user`.
+
+> Почему мы делаем один sequence на разные таблицы?
+
+Мы будем использовать Hibernate. По умолчанию он делает глобальный sequence на все таблицы. В этом подходе есть [как плюсы, так и минусы](http://stackoverflow.com/questions/1536479/548473).
+
+> Каким образом попадают в тесты классы, расположенные в каталоге `test`, если в конфигурации спринга нет указание на ее сканирование?
+
+Сканируются не папки, а пакеты. Обычно тесты классов располагают в том же самом пакете каталога `test`. Таким образом тесты могут видеть поля классов `main` с видимостью по умолчанию (внутри пакета). При этом классы `test` видят `main`, а наоборот нет. Когда приложение деплоится, в коде тестов быть не должно!
+
+##  Домашнее задание HW03
+- 1 Понять, почему перестали работать `SpringMain, InMemoryAdminRestControllerTest, InMemoryAdminRestControllerSpringTest`. Чиним в Optional.
+- 2 Дополнить скрипты создания и инициализации базы таблицей `meals`. Запустить скрипты на вашу базу (через Run). Порядок таблиц при DROP и DELETE важен, если они связаны внешними ключами (foreign key, fk). Проверьте, что ваши скрипты работают.
+ - 2.1 Сделать индексы к таблице `meals`: запретить создавать у одного и того-же юзера еду с одинаковой dateTime.
+Индекс на pk (id) postgres создает автоматически: [Postgres and Indexes on Foreign Keys and Primary Keys](http://stackoverflow.com/questions/970562/548473)
+ - [Индекс_базы_данных](https://ru.wikipedia.org/wiki/Индекс_(базы_данных))
+ - [PostgreSQL: индексы](https://postgrespro.ru/docs/postgresql/10/indexes-intro)
+ - [Postgres Guide: Indexes](http://postgresguide.com/performance/indexes.html)
+ - [Оптимизация запросов. Основы EXPLAIN в PostgreSQL](https://habrahabr.ru/post/203320/)
+ - [Оптимизация запросов. Часть 2](https://habrahabr.ru/post/203386/)
+ - [Оптимизация запросов. Часть 3](https://habrahabr.ru/post/203484/)
+
+>  Как правильно придумать индекс для базы? Указать в нем все поля, комбинация которых создает по смыслу уникальную запись, или какие-то еще есть условия?
+
+Индекс нужно делать по тем полям, по которым будут искаться записи (участвуют в WHERE, ORDER BY). Уникальность - совсем необязательное условие. Индексы ускоряют поиск по определенным полям таблицы. Они не бесплатные (хранятся в памяти, замедляется вставка), поэтому на всякий случай их делать не надо. Также не строят индексы на колонки с малым процентом уникальности (например поле "М/Ж"). Поля индекса НЕ КОММУТАТИВНЫ и порядок полей в описании индекса НЕОБХОДИМО соблюдать (в силу использования B-деревьев и их производных как поисковый механизм индекса). При построении плана запроса EXPLAIN учитывается количество записей в базе, поэтому вместо индексного поиска (Index Scan) база может выбрать последовательный (Seq Scan). Проверить, работают ли индексы можно отключив Seq Scan. Также см. Queries on the first field of composite index
+
+- 3 Реализовать через Spring JDBC Template `JdbcMealRepository`
+ - 3.1. сделать каждый метод за один SQL запрос
+ - 3.2. `userId` в класс `Meal` вставлять НЕ надо, делаем _foreign key_ только в базе (для UI и REST это лишние данные, userId это id залогиненного пользователя)
+ - 3.3. `JbdcTemplate` работает через сеттеры. Вместе с конструктором по умолчанию их нужно добавить в `Meal`
+ - 3.4. Список еды должен быть отсортирован (тогда мы его сможем сравнивать с тестовыми данными). Кроме того это требуется для UI и API: последняя еда наверху.
+- 4 Проверить работу MealServlet, запустив приложение
+
+### Optional
+- 5 Сделать `MealServiceTest` из `MealService` и реализовать тесты для `JdbcMealRepository`.
+> По `Ctrl+Shift+T` (выбрать JUnit4) можно создать тест для конкретного класса, выбрав для него нужные методы. Тестовый класс создастся в папке `test` в том же пакете, что и тестируемый.
+ - 5.1 Сделать тестовые данные `MealTestData` (точно такие же, как вставляем в `populateDB.sql`).
+ - 5.2 Сделать тесты на чужую еду (delete, get, update) с тем, чтобы получить `NotFoundException` и `duplicateDateTimeCreate`, аналогичный `duplicateMailCreate`.
+- 6 Починить `SpringMain, InMemory*Test`. **InMemory тесты должны использовать реализацию в памяти**
+
+----------------------------
+### Итоги занятия после выполнения ДЗ:
+Наше приложение стало хранить данные в PostgreSQL.
+Добавили в приложение JUnit тесты.
+Разделили Spring контекст для работы с памятью и с БД.
+
+----------------------------
+
+###  Решение проблем
+
+> Из каталога `main` не видятся классы/ресурсы в `test`
+
+Все что находится в `test` используется только для тестов и недоступно в основном коде.
+
+> Из `IDEA` не видятся ресурсы в каталоге `test`
+
+- Сделайте Reimport All в Maven окне
+
+
+
+> В UserService и MealService подчеркнуты красным repository, ошибка: Could not autowire. There is more than one bean of 'MealRepository' type.
+
+- Spring test контекст не надо включать в Spring Facets проекта, там должны быть только `spring-app.xml` и `spring-db.xml`. Для тестовых контекстов поставьте чекбокс `Check test files` в Inspections.
+
+
+
+###  Типичные ошибки и подсказки по реализации
+
+- 1: В `MealTestData` еду делайте константами. Не надо `Map` конструкций!
+- 2: SQL case-insensitive, **не надо писать в стиле Camel**. В POSTGRES возможны case-sensitive значения, их надо в кавычки заключать (обычно не делают).
+- 3: ЕЩЕ РАЗ: `InMemory` тесты должны идти на `InMemory` репозитории
+- 4: **Проверьте, что возвращает `JdbcMealRepository` при обновлении чужой еды**
+- 5: В реализации `JdbcMealRepository` одним SQL запросом используйте возвращаемое `update` значение `the number of rows affected`
+- 6: При тестировании не портите эталонные тестовые объекты из `MealTestData`
+- 7: Проверьте, что все, что относится к тестам, находится в каталоге `test` (не попадает в сборку проекта)
+- 8: **Еще раз: в тестах нельзя сравнивать объекты через `JUnit Assert` и `assertThat().isEqualTo`, потому что в этом случае сравнение будет происходить через `AbstractBaseEntity.equals`, который сравнивает объекты только по `id`. Мы не можем переопределять `equals` для объектов модели, тк будем использовать JPA (см. [The JPA hashCode() / equals() dilemma](https://stackoverflow.com/questions/5031614/548473))**
+- 9: НЕ делайте склейку SQL запросов вручную из параметров, только через `jdbcTemplate` параметры! См. [Внедрение_SQL-кода](https://ru.wikipedia.org/wiki/Внедрение_SQL-кода)
+- 10: Напомню: `BeanPropertyRowMapper` работает через отражение. Ему нужны геттеры/сеттеры и имена полей должны "совпадать" с колонками `ResultSet` (Column values are mapped based on matching the column name as obtained from result set metadata to public setters for the corresponding properties. The names are matched either directly or by transforming a name separating the parts with underscores to the same name using "camel" case).
+- 11: Для разделения тестов InMemory и Jdbc можно использовать разные Spring context. В том числе переопределять контест для тестов в `src\test\resources`
+- 12: Обязательно протестируйте в `MealServiceTest` нормальное поведение методов (по аналогии с `UserServiceTest`)
diff --git a/doc/lesson04.md b/doc/lesson04.md
new file mode 100644
index 000000000..e17a3dd39
--- /dev/null
+++ b/doc/lesson04.md
@@ -0,0 +1,271 @@
+# Стажировка Topjava
+
+## Материалы занятия
+
+##  Разбор домашнего задания HW3
+
+###  1. [HW03: meals + JdbcMealRepository](https://drive.google.com/file/d/1_IIYBP5l2aHxHaY_j1bqFWj1maACvNpa)
+- [Последовательность столбцов в составном индексе](https://ru.wikipedia.org/wiki/Индекс_(базы_данных)#Последовательность_столбцов_в_составном_индексе)
+- Дополнительно: для `JdbcMealRepository.save` можно использовать [CombinedSqlParameterSource](https://stackoverflow.com/questions/13339171/548473)
+- В ответе на [Why is SELECT * considered harmful?](https://stackoverflow.com/questions/3639861) есть случаи, когда она допустима (наш случай): `when "*" means "a row"`
+
+#### `SpringMain, InMemoryAdminRestControllerTest, InMemoryAdminRestControllerSpringTest` починим в патче `4_7_create_inmemory_test_ctx` (видео 4)
+
+#### **Apply 4_1_HW3.patch**
+> Таблицы [принято именовать в единственном числе](https://stackoverflow.com/questions/338156/548473) (`users` - исключение, тк это ключевое слово).
+Переименовал таблицы в `user_role` и `meal`. Если у вас остались старая база с множественными именами - удалите их вручную.
+
+### [Сравнение времени выполнения для разных индексов](../doc/meals_index.md)
+- На id как на primary key индекс создается автоматически
+- Все запросы в таблицу meals у нас идут с `user_id`
+- По полю `date_time` не только есть запросы, но и сортируем результат. То есть это поле - хороший кандидат для индексирования
+- Следует иметь в виду, что индексы ускоряют операции чтения, но замедляют вставку и удаление. Поэтому необходим анализ в реальном приложении
+- [Оптимизация запросов. Основы EXPLAIN в PostgreSQL](https://habrahabr.ru/post/203320/)
+- [Оптимизация запросов. Часть 2](https://habrahabr.ru/post/203386/)
+- [Оптимизация запросов. Часть 3](https://habrahabr.ru/post/203484/)
+- [Документация Postgres: индексы](https://postgrespro.ru/docs/postgresql/9.6/indexes.html)
+
+##  Разбор домашнего задания HW3
+
+###  2. [HW03 Optional: Meals tests](https://drive.google.com/file/d/1RfO0Irz8ayw2ivnjffUol20BQrKpu-jg)
+
+#### **Apply 4_2_HW3_optional.patch**
+> Убрал `throws Exception` из тестов. IDEA по умолчанию перестала их добавлять.
+> В `MealServiceTest.updateNotOwn` добавил дополнительную проверку, что еда в тесте не модифицировалась.
+
+#### **Apply 4_3_tests_refactoring.patch**
+> - Переименовал класс генерации матчеров в `MatcherFactory`
+> - Переименовал статический метод генерации ([Блох Джошуа, "Java. Эффективное программирование."](http://javaops.ru/view/books)) на `usingIgnoringFieldsComparator`.
+ См. также [Java Constructors vs Static Factory Methods](https://www.baeldung.com/java-constructors-vs-static-factory-methods)
+
+
+#### **Apply 4_4_HW3_fix_logging.patch**
+- [Вызов статического метода из конфигурации спринга](https://stackoverflow.com/a/27296470/548473)
+
+## Занятие 4:
+###  3. Методы улучшения качества кода
+
+#### Поменяйте в `readme.md` сверху ссылку на свой `Codacy Badge` с сайта Codacy: `https://app.codacy.com/gh/[github_accaunt]/topjava/settings`
+
+> - Плагины проверки качества кода теперь объединены в один **QAPlug**
+> - Codacy Check code (проверка стиля и поиск багов в коде).
+> - добавил [Codacy configuration file](https://support.codacy.com/hc/en-us/articles/360005097654-Ignore-files-from-Codacy-analysis) для исключения из проверок содержимого `webapp` и `READ.me` (на нашем проекте он выдает на них кучу ошибок)
+> - после правок паттернов можно сделать [повторный анализ](https://support.codacy.com/hc/en-us/articles/213840489-How-do-I-reanalyze-my-project-), с результатами тормозит
+
+#### Сделайте `push` для отображения результатов текущего состояния проекта.
+
+#### **Apply 4_5_improve_code.patch**
+> - Добавил проверки предусловий `Assert.notNull` в сервисы
+> - Добавил конфигурацию `.codacy.yml`
+> - Ввел удобный метод `AbstractBaseEntity.id()`
+
+- Контрактное программирование, Программирование по контракту
+- Comparison Preconditions in Java
+- IDEA Settings -> Plugins -> Browse repositories... Add [QAPlug: PMD/FindBugs/Checkstyle/Hammurapi](https://qaplug.com/about/)
+ - Tools -> QAPlug -> Analyze Code...
+- IDEA [Analyze | Inspect Code](https://www.jetbrains.com/help/idea/running-inspections.html)
+
+###  4. Spring: инициализация и популирование DB
+#### **Apply 4_6_init_and_populate_db.patch**
+- [Инициализация базы при старте приложения](https://docs.spring.io/spring/docs/current/spring-framework-reference/data-access.html#jdbc-initializing-datasource-xml)
+
+###  5. Подмена контекста при тестировании
+#### **Apply 4_7_create_inmemory_test_ctx.patch**
+> Переименовал `mock.xml` в `inmemory.xml`
+
+###  6.1 [Основные определения ORM. Hibernate. JPA](https://drive.google.com/file/d/1S--FEm2R2LSgjN1ALAj7sN4AAFJ7rt4r)
+###  6.2 ORM. Hibernate. JPA.
+
+
+> Правка к видео: `Session` не потокобезопасный, `SessionFactory/EntityManager` - потокобезопасные
+
+Entity- класс (объект Java), который в ORM маппится в таблицу DB.
+> - Убрал дублирование объявления `unique` для `User.email`
+
+[EntityManager](https://jsehelper.blogspot.com/2016/04/java-persistence-api-jpa-2.html) - это по сути прокси-обертка над Hibernate Session, которая создается каждый раз при открытии транзакции.
+
+- ВНИМАНИЕ: патч меняет `postgres.properties`, в котором у вас, возможно, свои креденшелы к базе
+- `hibernate-core` с 5.2.x включает `hibernate-entitymanager` и `hibernate-java8`, то есть конверторы Time API уже не нужны
+> - JPA support for Java 8 new date and time API
+> - What's new in Hibernate 5?
+> - JPA support for Java 8 new date and time API
+- [EL implementation provided by the container. In a Java SE you have to add an implementation as dependency to your POM file](http://hibernate.org/validator/documentation/getting-started/#unified-expression-language-el): добавил `javax.el` зависимость со `scope=provided`
+
+#### **Apply 4_8_add_jpa.patch**
+> - **[Настройка JPA в IDEA](https://github.com/JavaOPs/topjava/wiki/IDEA#jpa).
+ПРОВЕРЬТЕ, что у вас не подтянулись Java EE libraries, все зависимости в проект попадают только через Maven! Перед настройкой сначала подтяните его зависимости**
+> - `indexes` и `uniqueConstraints` в Entities (у нас `User`) используются только при создании таблицы средствами JPA (автогенерации БД при запуске приложения).
+ В случае, если таблицы создаются скриптом, эти опции будут проигнорированы. У нас они дублируют ограничения в `initDB.sql` и будут использоваться, когда мы будем смотреть на автогенерацию DDL по модели на 7-м занятии.
+> - Тесты и приложение ломаются. Чиним в HW04 (`JpaMealRepository`)
+> - Если вы используете Java 9 и выше, то возникают проблемы с `JAXBException` (пакет `java.xml.bind`). [См. решение](https://www.concretepage.com/forum/thread?qid=531
+
+- [JPA - JPQL](https://www.tutorialspoint.com/ru/jpa/jpa_jpql.htm)
+- Дополнительно:
+ - [ORM](http://ru.wikipedia.org/wiki/ORM)
+ - [JPA и Hibernate в вопросах и ответах](http://habrahabr.ru/post/265061/)
+ - [Hibernate — о чем молчат туториалы](https://habr.com/ru/post/416851/)
+ - [Наследование в Hibernate: выбор стратегии](https://habrahabr.ru/post/337488/)
+ - [Entity Lifecycle Model in JPA & Hibernate](https://thorben-janssen.com/entity-lifecycle-model/)
+ - [Field vs property access](http://stackoverflow.com/a/6084701/548473)
+ - [Hibernate: введение и написания Hello world приложения](https://web.archive.org/web/20200810114404/http://www.quizful.net/post/Hibernate-3-introduction-and-writing-hello-world-application)
+ - [15 reasons why we need to choose Hibernate over JDBC](https://web.archive.org/web/20211201122631/https://habiletechnologies.com/blog/reasons-to-choose-hibernate-over-jdbc/#fin_form_pop)
+ - [Hibernate or JDBC](https://stackoverflow.com/questions/1353137/548473)
+ - [Mapping: описание модели Hibernate (hbm.xml/annotation)](http://en.wikibooks.org/wiki/Java_Persistence/Mapping).
+ - [used in Playframework](https://ru.wikipedia.org/wiki/Hibernate_(библиотека)">Hibernate). Другие ORM: [TopLink](http://en.wikipedia.org/wiki/TopLink), [EсlipseLink](http://en.wikipedia.org/wiki/EclipseLink)
+ - [Jakarta Persistence (JPA, english wiki)](https://en.wikipedia.org/wiki/Java_Persistence_API)
+ - [Стратегии генерации PK](http://en.wikibooks.org/wiki/Java_Persistence/Identity_and_Sequencing)
+ - [hibernate-validator](http://validator.hibernate.org).
+ - [Описание связей в модели. Ленивая загрузка объекта.](https://web.archive.org/web/20170514002949/http://java.devcolibri.com:80/post/15)
+ - [JPA definitions](http://docs.jboss.org/hibernate/entitymanager/3.6/reference/en/html/architecture.html#d0e61)
+ - [Spring expressions: выражения в конфигурации](https://docs.spring.io/spring/docs/current/spring-framework-reference/core.html#expressions)
+ - [HQL](https://proselyte.net/tutorials/hibernate-tutorial/hibernate-query-language), [JPQL](http://ru.wikipedia.org/wiki/Java_Persistence_Query_Language)
+ - Динамические запросы (которые формируются в коде): [Unified Queries for Java](http://www.querydsl.com/), [JPA Criteria API](http://www.objectdb.com/java/jpa/query/criteria)
+ - [Using the Java 8 Date Time Classes with JPA](https://web.archive.org/web/20170608194049/https://bitbucket.org/montanajava/jpaattributeconverters)
+
+#### **Apply 4_9_add_named_query_and_transaction.patch**
+> Чтобы посмотреть информацию о транзакциях (открытие/закрытие и пр.), можно выставить в конфигурации logback
+``
+
+- Транзакция. ACID. Уровни изоляции транзакций.
+- Spring Transaction Management
+- `@Transactional` в тестах. Настройка EntityManagerFactory
+- [Эффективное управление транзакциями в Spring](https://habr.com/ru/company/otus/blog/431508/)
+
+>  Зачем надо начинать транзакцию, если речь идет только о чтении данных? Начало транзакции при выполнении операции чтения всего лишь добавит лишних накладных расходов
+(см. [Стратегии работы с транзакциями, pаспространенные ошибки](http://web.archive.org/web/20170314073834/https://www.ibm.com/developerworks/ru/library/j-ts1/index.html))
+
+Вопрос сильно дискутируемый.
+1. Посмотрите в код Spring-Data-JPA и код [spring-petclinic](https://github.com/spring-projects/spring-petclinic/blob/main/src/main/java/org/springframework/samples/petclinic/vet/VetRepository.java) в открытием `@Transactional(readOnly = true)`
+```
+@Repository
+@Transactional(readOnly = true)
+public class SimpleJpaRepository implements JpaRepositoryImplementation {
+```
+Вот ответ от Oliver Drotbohm, автора Spring-Data на предложение работать без транзакций для операций чтения (`propagation=Propagation.SUPPORTS`): [Improve performance with Propagation.SUPPORTS for readOnly operation](https://github.com/spring-projects/spring-data-jpa/issues/987). Коротко:
+- Статья устаревшая и неверно упрощает многие вещи. Есть множество вещей, которые влияют на производительность
+- Без транзакции не будет оптимизации по флагу `readOnly` при выполнении JDBC и в управлении ресурсами Spring's JPA (в том числе выключение `flush`)
+См. [Non-transactional data access and the auto-commit mode](https://developer.jboss.org/docs/DOC-13953)
+
+С другой стороны есть такие статьи про перформансе:
+- [Опять транзакции…](https://habr.com/ru/articles/803395/ )
+- [Discuss about the optimization](https://github.com/spring-projects/spring-data-jpa/issues/1544)
+
+Так вижу: есть офоциальный путь и попытки его поменять...
+
+Справочник:
+ - Видео: Вячеслав Круглов — Как начинающему Java-разработчику подружиться со своей базой данных?
+ - Видео: Николай Алименков — Босиком по граблям Hibernate
+ - Видео: Николай Алименков — Сделаем Hibernate снова быстрым
+ - Стратегии работы с транзакциями
+ - Spring transaction propagation tutorial
+ - Getting Started with JPA
+ - Java Persistence
+ - Разделы по Java Persistence API
+ - Spring Framework transaction management
+ - Spring Persistence Tutorial
+ - Working with JPA Entity Objects
+ - Принципы работы СУБД. MVCC
+ - MVCC
+
+
+###  7. Добавляем поддержку HSQLDB
+
+#### **Apply 4_10_add_hsqldb.patch**
+> - Переделал `jdbc.initLocation`: IDEA не "тупит", если путь к скрипту полностью прописывать в пропертях.
+
+##  Ваши вопросы
+
+> Есть несколько аналогичных "встроенных" баз данных. H2, HSQLDB, Derby, SQLite. Почему был выбран HSQLDB?
+
+Просто с ней приходилось работать. HSQLDB и H2 наиболее популярны. В миграции на spring-boot будем использовать H2.
+Здесь интересное краткое описание встраиваемых баз данных в Java.
+В HSQLDB нет репликаций, кластеризации и объем данным ограничен несколькими TB. Для большого количества приложений она подходит и для продакшена. См.
+- What is HSQLDB limitations?
+- HSQLDB в режиме in-process
+
+> Чистого JPA не существует, т. е. это всего лишь интерфейс, спецификация? Говорим JPA, подразумеваем какой-то ORM фрэймворк? А что тогда используют чистый jdbc, Spring-jdbc, MyBatis? MyBatis не реализует JPA?
+
+ORM это технология связывания БД и объектов приложения, а JPA - это JavaEE спецификация (API) этой технологии.
+Реализации JPA - Hibernate, OpenJPA, EclipceLink, но, например, Hibernate может работать по собственному API (без JPA, которая появилась позже). Spring-JDBC, MyBatis, JDBI не реализуют JPA - это обертки к JDBC. Все ORM и JPA также реализованы поверх JDBC.
+
+> В зависимостях maven `hibernate-entitymanager` тянет за собой `jboss-logging`. Как будет происходить логирование?
+
+How do you configure logging in Hibernate 4 to use SLF4J: в нашем проекте автоматически подхватывается `logback-classic`.
+
+> В чем преимущество Hibernate?
+
+Hibernate (как любая ORM) реализует мапинг таблиц в объекты Java. Когда мы добавим роли пользователю, вы увидите, насколько код будет проще, чем в jdbc. Также см. 5 Reasons to Use JPA / Hibernate
+
+> Чем отличается `@Column(nullable = false)` от `@NotNull` и есть ли необходимость указывать обе аннотации ?
+
+`@Column(nullable = false)` - это атрибуты колонки таблицы базы. `@NotNull` - это валидация, которая происходит в приложении перед вставкой в базу. Если колонка ненулевая, то `NOT NULL` обязательна. Валидация опциональна. Также см.
+@NotNull vs @Column(nullable = false)
+
+> почему мы в бине `entityManagerFactory` не указали диалект базы данных?
+
+Он [автоматически определяется из `DataSource` драйвера](http://stackoverflow.com/a/39817822/548473)
+
+> В чем разница между `persist` и `merge`
+
+Подробный ответ со Stackoverflow с объяснением разницы. Упрощенно:
+ - `merge`, в отличие от `persist`, делает запрос в базу данных, если entity нет в текущей сессии
+ - entity, переданный в `merge`, не меняется. Нужно использовать возвращаемый результат
+
+> `em.merge` при отсутствии старой записи (несуществующий `id`) создает новую. Т. е. в `JpaUserRepository` нарушается логика
+
+В Hibernate есть такая бага: https://hibernate.atlassian.net/browse/HHH-1661, https://stackoverflow.com/questions/34249483
+- [Hibernate unexpectedly issues INSERT instead of throwing the javax.persistence.OptimisticLockException, when a nonexistent entity is passed to merge()](https://stackoverflow.com/questions/34249483)
+- [Should Hibernate Session#merge do an insert when receiving an entity with an ID?](https://stackoverflow.com/questions/21489300)
+
+Если это действительно наш критичный бизнес-кейс (например, с многопоточным удалением entity), то нужно искать варианты обходного решения.
+Если это не бизнес-кейс (попытка поломать или ошибка UI), то оставляем как есть (обычно на практике не парятся).
+
+> Почему в проекте транзакционность сделана в слое репозитория, а не сервиса? Транзакциями удобнее пользоваться на слое сервисов, так как здесь реализуется бизнес логика и бывает нужно делать несколько операций в одной транзакции.
+
+С классической точки зрения все транзакции действительно объявляются на уровне сервиса. Мы будем использовать в логике сервиса несколько запросов и тогда сделаем дополнительную транзакцию на методе сервисе. Новая транзакция при этом не создается (по умолчанию используется `Propagation.REQUIRED`, который поддерживают существующую), поэтому несколько `@Transactional` аннотаций ведут себя как одна. Я использую подход `spring-data-jpa` (будет на следующем занятии): в репозитории транзакции объявлять удобно, тк не надо думать о них в сервисах.
+
+--------------------
+
+##  Домашнее задание HW4
+
+- 1: Сделать из `Meal` Hibernate entity
+ - Hibernate Validator: @NotNull, @NotEmpty, @NotBlank
+ - Реализация ManyToOne
+- 2: Имплементировать и протестировать `JpaMealRepository`. Проверьте, нет ли в запросах ненужных данный (лишних `JOIN`)
+
+### Optional
+
+- 3: Добавить в тесты `MealServiceTest` функциональность `@Rule`:
+ - 3.1: вывод в лог времени выполнения каждого теста
+ - 3.2: вывод сводки в конце класса: имя теста - время выполнения
+- JUnit @Rules
+
+---------------------
+###  Типичные ошибки и подсказки по реализации
+- 1: Т.к. JPA работает с объектами, мы не можем использовать `userId` для сохранения. Можно сделать, например, так:
+
+ User ref = em.getReference(User.class, userId);
+ meal.setUser(ref);
+
+ При этом от `User` нам нужен только `id`. Над `id` создается lazy прокси, который обращается к базе при запросе любого поля. Т. е. у нас запроса в базу за юзером не будет: проверьте по логам Hibernate.
+
+**Внимание: проверять запросы Hibernate нужно через run. Если делаете debug и брекпойнт, то могут делаться лишние запросы к базе (дебаггер дергает `toString`)**
+
+- 2: В JPQL запросах можно писать: `m.user.id=:userId`
+- 3: При реализации `JpaMealRepository` предпочтительно не использовать `try-catch` в логике реализации. Но, если очень хочется, то ловить только специфические исключения (напр. `NoResultException`), чтобы, например, при отсутствии коннекта к базе приложение отвечало адекватно.
+- 4: Мы будем смотреть генерацию db-скриптов из модели. Для корректной генерации нужно в `Meal` добавить `uniqueConstraints`
+- 5: При записи в базу через `namedQuery` валидация энтити не работает, только валидация в БД.
+- 6: Результат `AssertionError` печатает результаты через `toString`, и поля в выводе могут не совпадать с полями сравнения (`toString` одинаковый, при этом сравнение идет по другим полям и вылетает ошибка)
+- 7: Если нашему приложению `Meal.user` не требуется, не следует включать его в тесты. В следующем уроке мы потренируемся разными способами доставать зависимости `Meal.user` и `User.meals`
+
+--------------------------------
+## [Выпускной проект](../doc/graduation.md)
+Чтобы все фреймворки и концепции стажировки стали "твоими", обязательно нужно сделать на нашем стеке СОБСТВЕННОЕ приложение. Домашнее задание на этом уроке небольшое, а полученных знаний уже достаточно для начала работы над выпускным проектом.
+Выпускной проект делайте параллельно с нашим: прошли тему занятия - сделали ее в выпускном. Не следует забегать вперед, но и не отставайте!
+На данном этапе уже можно делать модель приложения и репозитории-сервисы для работы с ними.
+- Для проекта я взял реальное тестовое задание, поэтому жалоб на неясность формулировок принимать не буду. Сделайте как поняли. Представьте, что это **ваше тестовое задание на работу**
+- Общение по выпускному в канале Slack *#graduation*
+- **Обязательно проверяйся [по рекомендациям в конце выпускного](../doc/graduation.md#-Рекомендации)**
+- По завершению вы сможете занести этот проект в свое портфолио и резюме как собственный без всяких оговорок
+
+### Успехов в выполнении!
diff --git a/doc/lesson05.md b/doc/lesson05.md
new file mode 100644
index 000000000..ad0a65a05
--- /dev/null
+++ b/doc/lesson05.md
@@ -0,0 +1,215 @@
+# Стажировка Topjava
+## Материалы занятия
+
+##  1. [Обзор JDK 9/11. Миграция Topjava с 1.8 на JDK 17+](http://javaops.ru/view/resources/jdk8+)
+### [OpenJDK JDK 21](https://jdk.java.net/21/). Обновите IDEA на 2023.x/2024.x и Tomcat на 9.x
+> - Перевел проект на JDK 21. Для запуска Maven или Tomcat переопредели переменную окружения `JAVA_HOME` и переменную `path` на `JAVA_HOME\bin`, чтобы `java -version` тоже было 21. Напомню, что IDEA это java процесс. Чтобы новые переменные окружения в ней увиделись, требуется ее перегрузить.
+> - Обновил версии логирования и плагина тестирования
+> - Добавил зависимость _findbugs_ для [удаления WARNING при компиляции](https://stackoverflow.com/questions/53326271/548473)
+
+- [API, ради которых наконец-то стоит обновиться с Java 8 (1)](https://habr.com/ru/post/485750)
+- [API, ради которых наконец-то стоит обновиться с Java 8 (2)](https://habr.com/ru/post/487636)
+- [Руководство по возможностям Java версий 8-19](https://habr.com/ru/post/719744/)
+
+#### Apply 5_1_jdk_21.patch
+- Сделал создание коллекций через фабричные методы `List.of`
+- Как пример в `InMemoryMealRepository` использовал *local variable type inference* `var`.
+ - [26 рекомендаций по использованию типа var в Java](https://habr.com/ru/post/438206/)
+- `switch` в `MealServlet` перевел на новый формат (IDEA сама переводит по Alt+Enter).
+ - [Новые switch выражения](https://habr.com/ru/post/443464/)
+- В `JdbcUserRepository.save` использовал [Text Blocks](https://www.infoq.com/articles/java-text-blocks/)
+- В JDK 17 вместо `.collect(Collectors.toList())` можно использовать `.toList()`. Посмотрите его реализацию.
+
+##  Разбор домашнего задания HW4
+
+###  2. [HW4: Meal / JpaMealRepository](https://drive.google.com/file/d/13JJRhLhkn8_C3-xpkyilRxGe_w9_xTF2)
+#### Apply 5_2_HW4.patch
+ - При сравнении еды тесты падают, т.к. Hibernate делает ленивую обертку к `user`, и если происходит обращение к любому его полю (кроме id) вне транзакции, бросается `LazyInitializationException`.
+По логике приложения поле `user` в еде не нужно, и мы не будем его отдавать наружу UI. Более того, включать `user` в запрос будет ошибкой: мы запрашиваем данные, которые приложению не требуются.
+В тестах исключаем `user` из сравнения.
+ - [SQL “between” not inclusive](https://stackoverflow.com/questions/16347649/sql-between-not-inclusive/16347680)
+
+###  3. [Hibernate issue / HW4 Optional](https://drive.google.com/file/d/1kbb2IO15L9ABJ0-2TFJm8XZU_QUXUdni)
+
+#### Apply 5_3_fix_hibernate_issue.patch
+ - Из-за [Hibernate bug with proxy initialization when using `AccessType.FIELD`](https://hibernate.atlassian.net/browse/HHH-3718)
+в `JpaMealRepository.get()` делался дополнительный запрос в базу для инициализации прокси `User`, и мы делали хак: доступ к полю `AbstractBaseEntity.id` через `AccessType.PROPERTY`.
+С версии `5.2.13.Final` загрузка прокси при обращении к `id` управляется флагом `JPA_PROXY_COMPLIANCE` (по умолчанию запрос не делается)
+ - [Call to id getter initializes proxy when using AccessType( "field" ): HHH-3718](https://hibernate.atlassian.net/browse/HHH-3718)
+ - [According to JPA, a Proxy should be loaded even when accessing the identifier: HHH-12034](https://hibernate.atlassian.net/browse/HHH-12034)
+ - Which is better, field or property access?
+ - Поправил [JPA equals_hashcode](https://stackoverflow.com/a/78077907/548473) с учетом НОВОЙ РЕДАКЦИИ рекомендаций и для исключения `LazyInitializationException` в прокси-сущностях вне транзакции
+ - Реализация `hashCode` возвращает константу для всех инстансов класса для случая, когда в hash-коллекцию добавляется новый объект с id=NULL, который после сохранения меняется на сгенерированный БД
+ ("Once the id is generated (on its first save) the hashCode gets changed. So the HashSet looks for the entity in a different bucket and cannot find it.
+ It wouldn’t be an issue if the id was set during the entity object creation (e.g. was a UUID set by the app), but DB-generated ids are more common.")
+ - Hibernate Proxy Pitfalls
+
+------------------------
+> Переопределять `equals()/hashCode()` необходимо, если
+> - использовать entity в `Set` (рекомендовано для Many-ассоциаций) либо как ключи в `HashMap`
+> - использовать _reattachment of detached instances_ (т.е. манипулировать одним Entity в нескольких транзакциях/сессиях).
+
+> [Implementing equals() and hashCode()](https://docs.jboss.org/hibernate/stable/core.old/reference/en/html/persistent-classes-equalshashcode.html)
+
+> Оптимально использовать уникальные бизнес-поля, но обычно таких нет, и чаще всего используются PK с ограничением, что он может быть `null` у новых объектов, и нельзя объекты сравнивать через `equals() and hashCode()` в бизнес-логике (например, тестах).
+
+------------------------
+
+>  Почему над `AbstractBaseEntity` стоит `@Access(AccessType.FIELD)` ? Почему при запросе `user.id` нам не нужно вытаскивать его из базы?
+
+`AccessType.FIELD` делает доступ в `AbstractBaseEntity` и всех классах-наследниках по полям. При загрузке `Meal` Hibernate на основе поля `meal.user_id` делает ленивую прокси к `User`, у которой нет ничего, кроме id.
+
+#### Apply 5_4_HW4_optional.patch
+- Stopwatch
+- [Logback layouts coloring](https://logback.qos.ch/manual/layouts.html#coloring)
+- Дополнительно: [use colored output only when logging to a real terminal](https://stackoverflow.com/questions/31046748)
+
+## Занятие 5:
+###  4. Транзакции
+- wiki Транзакция
+- readOnly и Propagation.SUPPORTS
+- [@Transactional In-Depth](https://www.marcobehler.com/guides/spring-transaction-management-transactional-in-depth)
+- Ресурсы:
+ - [Транзакции в Spring Framework](https://medium.com/@kirill.sereda/%D1%82%D1%80%D0%B0%D0%BD%D0%B7%D0%B0%D0%BA%D1%86%D0%B8%D0%B8-%D0%B2-spring-framework-a7ec509df6d2)
+ - How does Spring @Transactional Really Work
+ - Стратегии работы с транзакциями: распространенные ошибки
+ - Spring @Transactional - isolation, propagation
+
+###  5. Профили Maven и Spring
+#### Apply 5_5_profiles_connection_pool.patch
+> - `SLF4JBridgeHandler` перенес в профиль `postgres` (если логировать драйвер не нужно, то и он не нужен)
+> - **Галочка в XML-профиле влияет только на отображение в IDEA и никак не влияет на выполнение кода.**
+> - `Profiles.ACTIVE_DB` задает активный профиль базы (postgres/hsqldb)
+> - `Profiles.REPOSITORY_IMPLEMENTATION` определяет реализацию репозитория при запуске приложения (для тестов задаются через `@ActiveProfiles`).
+
+> Для переключения на HSQLDB необходимо:
+> - поменять в окне Maven Projects профиль (Profiles) - выключить `postgres`, включить `hsqldb` - и сделать `Reimport All Maven Projects` (1-я кнопка)
+> - поменять `Profiles.ACTIVE_DB = HSQLDB`
+> - почистить проект `mvn clean` (фаза `clean` не выполняется автоматически, чтобы каждый раз не перекомпилировать весь проект)
+
+Для корректного отображения неактивного профиля в IDEA проверьте флаг _Inactive profile highlighting_ и сделайте проекту clean
+
+
+
+> Вопрос: почему после этого патча не поднимается Spring при запуске приложения в Tomcat? (будем чинить в ДЗ, п.6)
+
+- Using Spring Profiles in XML Config
+- Spring Profiles example
+
+### Автоматический выбор профиля базы: [`ActiveProfilesResolver`](http://stackoverflow.com/questions/23871255/spring-profiles-simple-example-of-activeprofilesresolver)
+#### Apply 5_6_profile_resolver.patch
+> Сделал автоматический выбор профиля базы при запуске приложения (тестов) в зависимости от присутствия драйвера базы в classpath (`ActiveDbProfileResolver`)
+> В профили аттрибута `@ActiveProfiles(profiles=..)` добавляем `Profiles.getActiveDbProfile()`
+
+###  6. Пул коннектов
+ [Александр Колесников - JDBC Pools Battle](https://www.youtube.com/watch?v=J9GzE2qlNuM&feature=youtu.be&t=2895) (ссылка на выводы)
+
+> [BoneCP to be deprecated ](https://stackoverflow.com/a/1662916/548473)
+- Выбор реализации пула коннектов: Commons Database Connection Pooling, HikariCP
+- Самый быстрый пул соединений на java (читаем комменты)
+- Tomcat pool
+
+
+###  7. Spring Data JPA
+
+#### Apply 5_7_spring_data_jpa.patch
+> - Переименовал классы _Proxy_ на более адекватные _Crud_, убрал _Impl_
+> - В `spring-framework-bom` мы уже задали версию Spring. Убрал из остальных зависимостей.
+> - В spring-data-jpa 2.x поменялся интерфейс: `T CrudRepository.findOne(ID id)` -> `Optional CrudRepository findById(ID id)`
+> - [Java Optional — Отец холиваров](http://sboychenko.ru/java-optional)
+> - [Optonal от Oracle](https://stuartmarks.files.wordpress.com/2016/09/optionalmotherofallbikesheds3.pdf)
+> - [Java 8 Optional In Depth](https://www.mkyong.com/java8/java-8-optional-in-depth/)
+> - Не стал переопределять в `CrudUserRepository` методы `JpaRepository` (для явного указания всех используемых методов). Обычно этого не делают.
+
+### Внимание: при обновлении версий не забудьте обновить зависимости Maven и сделать `clean`.
+
+- Spring Data JPA
+- Замена AbstractDAO: JPA Repositories
+- Разрешение зависимостей: Maven BOM [Bill Of Materials] Dependency
+- Делегирование (в конце статьи)
+- Getting started with Spring Data JPA
+- Query methods
+- Spring Data – новый взгляд на persistence (JeeConf)
+- Евгений Борисов — Spring Data? Да, та!
+- Ресурсы:
+ - Github repositories
+ - Spring Data JPA Tutorial
+ - [Spring Data JPA with QueryDSL](https://dontpanic.42.nl/2011/06/spring-data-jpa-with-querydsl.html)
+ - [SpEL support in Spring Data JPA @Query](https://spring.io/blog/2014/07/15/spel-support-in-spring-data-jpa-query-definitions)
+
+##  Ваши вопросы
+> Какой паттерн проектирования применён в классе DataJpaUserRepository (декоратор/адаптер/прокси/другой)?:
+
+Вопрос интересный:) Ближе всего к адаптеру, но по логике композиция с делегированием. Мы просто используем для нашей реализации возможности `data-jpa: CrudUserRepository`.
+Делегат интерфейсов не меняет, а прокси похож на делегата, но служит для неявной подмены (часто прямо в рантайм). См. [ПАТТЕРНЫ
+ПРОЕКТИРОВАНИЯ](https://refactoring.guru/ru/design-patterns)
+
+> В spring-petclinic `DataJpa` реализована без дополнительных классов. В таком виде как у них, spring data смотрится, конечно, намного лаконичней других реализаций, но у нас получилось вдвое больше кода, чем с тем же jpa или jdbc. Плюс только пожалуй в том, что query находятся прямо в репозитории, а не где-то там в другом пакете. Так что получается, spring data лучше подходит для простейших crud без всяких "фишек"? или в чем его достоинство для больших и сложных проектов?
+
+Достоинства DATA-JPA по сравнению, например, с JPA: есть типизация, готовые реализации типовых методов CRUD, а также paging, data-common. Мы можем переключить реализацию JPA, например, на mongoDb (`PagingAndSortingRepository`, от которого наследуется `JpaRepository`, находится в `spring-data-common`).
+Соответственно, его методы будут поддерживаться всеми реализациями `spring-data-common` (JPA - одна из них) и пр. Подробнее о них есть в видео Spring Data – новый взгляд на persistence.
+Дополнительное проксирование в DATA-JPA - моя "фишка" для устранения минусов этого фреймворка: невозможность дебага, привязка к интерфейсу JpaRepository, перенос логики Repository в слой сервисов.
+Для большого приложения выигрыш этого стоит. Для небольших (тестовых) приложений (например выпускного) дополнительных классов делать не нужно.
+
+> Почему мы для InMemory не сделали отдельного профиля? Почему их не удалить вообще?
+
+Реализация InMemory является примером, как в test делать подмену контекста. Для них сделали отдельный `inmemory.xml`, и запускаемый проект ничего не должен о них знать. У нас учебный проект, в котором 4 реализации репозиториев, в реальном такого не будет.
+
+> А как делать транзакционность для реализации jdbc?
+
+Будем делать на следующем уроке.
+
+###  8. [Spring кэш](https://drive.google.com/file/d/1xpuL2YscL1ounS_qFRb1qzLciEOKn9I4/view?usp=sharing)
+#### Apply 5_8_spring_cache.patch
+- [Wiki Кэш](https://ru.wikipedia.org/wiki/Кэш)
+ - [Spring Cache Abstraction](https://docs.spring.io/spring-framework/docs/current/reference/html/integration.html#cache)
+ - [ECache](https://www.ehcache.org)
+ - [Configuring the Cache Storage](https://docs.spring.io/spring-framework/docs/current/reference/html/integration.html#cache-store-configuration)
+- [Spring 3.1 новый механизм кеширования](https://russianblogs.com/article/75981527090/)
+- [Spring 4+ with Ehcache 3 – how to](https://imhoratiu.wordpress.com/2017/01/26/spring-4-with-ehcache-3-how-to/)
+- [Evict Ehcache elements programmatically, using Spring](https://stackoverflow.com/questions/29557959/evict-ehcache-elements-programmatically-using-spring)
+- Дополнительно: [Оптимизация запросов с использованием Spring cache и Bean scope](https://habr.com/ru/companies/rosbank/articles/694768/)
+--------------------
+
+##  Домашнее задание HW05
+
+- 1: Имплементировать `DataJpaMealRepository` и протестировать через `MealServiceTest`.
+#### MealServlet не работает (почему?), чиним в _Optional п.5_
+- 2: Разделить реализации Repository по профилям Spring: `jdbc`, `jpa`, `datajpa` (общее в профилях можно объединять, например, ``).
+ - 2.1: Профили выбора DB (`postgres/hsqldb`) и реализации репозитория (`jdbc/datajpa/jpa`) независимы друг от друга, и при запуске приложения (тестов) нужно задать тот, и другой.
+ - 2.2: Удобно для интеграции с IDEA выставить в `spring-db.xml` справа вверху в `Change Profiles...` профили, например, `datajpa, postgres`. **Это влияет ТОЛЬКО на отображение в IDEA и НИКАК на работу приложения и тестов**
+ - 2.3: Общие части для всех в `spring-db.xml` можно оставить как есть без профилей вверху файла **(до первого `Java Persistence/OneToMany
+
+---------------------
+###  Типичные ошибки и подсказки по реализации
+- 1: Для того, чтобы не запускались родительские классы тестов, нужно сделать их `abstract`.
+- 2: В реализациях `JdbcMealRepository` **код не должен дублироваться**. Если вы возвращаете тип `Object`, посмотрите в сторону дженериков.
+- 3: В `MealServlet/SpringMain` в момент `setActiveProfiles` контекст спринга еще не должен быть инициализирован, иначе выставление профиля уже ни на что не повлияет.
+Уметь пользоваться гугл для разработчика, это умение №1. Если застряли, попробуйте, например, слова: `spring context set profile`
+- 4: Если у метода нет реализации, то стандартно бросается `UnsupportedOperationException`. Для уменьшения количества кода при реализации _Optional_ (п. 7, только `DataJpa`) попробуйте сделать `default` метод в интерфейсе.
+- 5: В Data-Jpa метод для ссылки на entity (аналог `em.getReference`) - `T getReferenceById(ID id)`
+- 6: Проверьте, что в `DataJpaMealRepository` все обращения к DB для одной операции выполняются в **одной транзакции**.
+(`` для логирования информации по транзакциям)
+- 7: Для 7.1 `достать по id пользователя вместе с его едой` - в `User` добавить `List meals`. Учесть, что у юзера может отсутствовать еда. [Ordering a join fetched collection in JPA using JPQL/HQL](http://stackoverflow.com/questions/5903774/ordering-a-join-fetched-collection-in-jpa-using-jpql-hql)
+- 8: Проверьте, что все тесты запускаются из Maven (имена классов тестов удовлетворяют соглашению) и итоги тестов класса выводятся корректно (не копятся). По умолчанию [maven-surefire-plugin](http://maven.apache.org/surefire/maven-surefire-plugin/examples/inclusion-exclusion.html) включает в тесты классы, заканчивающиеся на Test.
+- 9: В тестах можно вынести общие `@ActiveProfiles` наверх, в разных классах они суммируются
+- 10: `Topjava
+
+## Материалы занятия
+
+##  Разбор домашнего задания HW5
+
+###  1. [HW5: Spring Profiles. Spring Data JPA](https://drive.google.com/file/d/1dlhXeQr0fi0XymEFyBG-TXv5hpPgXtlT)
+
+
+ Краткое содержание
+
+Перед просмотром разбора домашнего задания еще раз ознакомьтесь с материалом по ссылке:
+
+- readOnly и Propagation.SUPPORTS (без транзакции не будет оптимизации по флагу `readOnly` при выполнении JDBC и в управлении ресурсами Spring's JPA, в том числе выключение `flush`).
+Однако, несмотря на ссылку выше и то, что в репозиториях Spring Data JPA (посмотрите `SimpleJpaRepository`) используются `@Transactional(readOnly = true)`, все не так просто в мире программирования.
+Вот еще несколько интересных ссылок: [Discuss about the optimization of read-only transactions](https://github.com/spring-projects/spring-data-jpa/issues/1544) и [Опять транзакции…](https://habr.com/ru/articles/803395/)
+В итоге все опять делается так, как это принято тимлидом на проекте.
+
+В нашем приложении над репозиториями **CrudMealRepository** и **CrudUserRepository** указана аннотация
+**@Transactional(readOnly = true)**, что предполагает выполнение всех операций в репозитории внутри транзакции на
+чтение. В таком случае, для операций, которые вносят изменения в базу данных, нам необходимо переопределить транзакцию и указать над модифицирующим методом аннотации:
+> @Transactional
+> @Modifying
+
+В реализации **SimpleJpaRepository**, которая используется Spring Data JPA, транзакционность описывается точно
+так же, как и в нашем приложении (все операции выполняются в транзакции на чтение, а для модифицирующих методов
+транзакции переопределяются).
+
+#### Для реализации репозитория для работы с Meal через Spring Data JPA:
+
+1. Создаем интерфейс `CrudMealRepository`, который должен быть унаследован от `JpaRepository`
+2. Этот интерфейс помечаем аннотацией `@Transactional(readonly = true)`
+3. Основная функциональность репозитория будет реализована прямо в интерфейсе (такой подход называется *интерфейсное
+ программирование*) - Spring Data JPA автоматически создаст прокси для нашего интерфейса с реализацией необходимой
+ функциональности.
+4. По аналогии с `DataJpaUserRepository` создаем класс `DataJpaMealRepository`, который имплементируют `MealRepository`. В
+ этот класс через конструктор спрингом будут внедрены `crudMealRepository` и `crudUserRepository`. Все методы
+ реализуются по аналогии с `DataJpaUserRepository`. Для сохранения еды в методе `save(Meal mea, int userId)` сначала
+ проверяем, что еда принадлежит аутентифицированному пользователю и после этого присваиваем еде ссылку на `User`,
+ которому она принадлежит. Чтобы не загружать этого user из базы, используем метод `getById(int id)`, который вернет
+ ссылку на прокси-объект user с указанным `id`.
+
+#### Разделение конфигурации на профили
+
+Spring позволяет настроить несколько профилей, которые позволяют переключать его функциональность.
+У нас уже настроено два профиля для переключения между базами данных:
+
+- `postgres` - для работы PostgreSQl
+- `hsqldb` - для работы с базой данных в памяти
+
+Для реализаций способа работы с базой данных настроим еще три профиля:
+
+- `jdbc`
+- `jpa`
+- `dataJpa`
+
+Общие для нескольких профилей свойства можно выносить в общий блок, перечислив в декларации профилей их наименования
+через запятую. Следует обратить особое внимание на то, что тег `` в котором объявляются профили и их
+конфигурация, может располагаться только в самом конце файла конфигурации после всех остальных настроек. Intellij Idea
+предоставляет интерфейс для переключения между профилями Spring, настроенными в конфигурации (такое переключение влияет
+только на отображение файла конфигурации, но не оказывает никакого влияния на запуск и работу приложения).
+
+#### Тесты для всех реализаций репозитория
+
+Все настройки логирования и определения времени выполнения тестов вынесем в общий абстрактный базовый класс
+`AbstractServiceTest`, от которого будут унаследованы остальные тестовые классы сервисов. Также над этим суперклассом
+указывается аннотация `@ActiveProfiles(resolver = ActiveDbProfileResolver.class)`, которая будет автоматически
+определять необходимый профиль базы данных при запуске тестов в зависимости от наличия драйвера БД в classpath.
+Его наследниками будут классы `AbstractMealServiceTest` и `AbstractUserServiceTest`, в которые мы переносим
+соответствующие тесты.
+Далее по цепочке наследования создадим тестовые классы для различных реализаций репозитория. Аннотация `@ActiveProfile`
+наследуется и может быть дополнена в классах — наследниках, поэтому в созданных тестовых классах `(Jpa | DataJpa |
+Jdbc) .. ServiceTest` с помощью этих аннотаций укажем конкретные профили Spring, соответствующие тестируемой
+функциональности.
+> При изменении профиля maven и изменении иерархии классов, удалении классов — обязательно нужно запускать `mvn clean`
+
+
+
+#### Apply 6_01_HW5_data_jpa.patch
+
+Транзакция начинается, когда встречается первая `@Transactional`. С default propagation `REQUIRED`
+остальные `@Transactional` просто участвуют в первой. Поэтому ставим аннотацию сверху `DataJpaMealRepository.save()`,
+чтобы все обращения к базе внутри метода были в одной транзакции. Аналогично, если из сервиса собирается несколько
+запросов к репозиториям, `@Transactional` ставится над методом сервиса.
+
+#### Apply 6_02_HW5_profile_test.patch
+
+**Для IDEA в `spring-db.xml` не забудьте выставить Spring Profiles. Например `datajpa, postgres`**
+
+> - Заменил `description.getMethodName()` на `getDisplayName()` в выводе результатов тестов. После `printResult()` буфер сбрасывается в 0, чтобы не накапливать изменения.
+
+#### Apply 6_03_extract_rules.patch
+
+> Вынес измерение времени и сводку в отдельный класс `TimingRules`
+
+[JUnit Rules External Resources](https://carlosbecker.com/posts/junit-rules/#external-resources)
+
+##  2. [HW5: Optional](https://drive.google.com/file/d/1S6gOOzLV9ndSbPiSuyEmqhEy3xZoUpXZ)
+
+
+ Краткое содержание
+
+#### Определим профиль Spring в SpringMain:
+
+При создании `XmlApplicationContext`, когда мы в конструктор передаем настройки в xml - Spring сразу считывает и
+применяет конфигурации и дальнейшее изменение профилей не оказывает на контекст никакого влияния, поэтому в данном
+классе сначала создаем `GenericXmlApplicationContext` без параметров, после чего указываем для него необходимые профили с
+помощью
+
+ ```java
+ appCtx.getEnviroment().setActiveProfiles(Profiles.POSTGRES,Profiles.DATAJPA)
+ ```
+
+Затем передаем контексту наши конфигурации и обновляем его. В данном случае Spring считает конфигурации, и настроит
+контекст в соответствии с указанными профилями.
+
+#### Для корректного запуска приложения определим профили Spring в MealServlet:
+
+Профиль Spring можно задать аналогичным способом. Также, вместо `GenericXmlApplicationContext` можно создать
+`ClassPathXmlApplicationContext`. Самый короткий способ задать профили — создать `ClassPathXmlApplicationContext`, передав
+ему в конструкторе конфигурации и установив флаг конструктора `refresh` в `false`. В данном случае спринг не будет
+парсить контекст сразу при инициализации и мы можем задать для него требуемые профили и вручную обновить контекст, после
+чего спринг поднимет и настроит контекст соответствующим образом:
+
+ ```java
+ springContext=new ClassPathXmlApplicationContext(new String[]{"spring/spring-app.xml","spring/spring-db.xml"}, false);
+ ```
+
+Так как HSQLDB (в данной версии) не работает с Java Time API, в отличие от PostgreSQL, необходимо разделить реализации репозитория для
+работы в двух различных профилях БД. Для данных профилей будет различаться только способ получения даты и времени
+употребления Meal. В соответствии с паттерном Template Method - создадим классы-наследники, где для
+соответствующих профилей будет реализовываться абстрактный `protected` метод суперкласса, который будет возвращать
+`LocalDateTime` - для PostgreSQL и `TimeStamp` для HSQLDB. Базовый класс `JdbcMealRepository` будет дженериком (типизированным классом),
+объект которого возвращается этим `protected` методом. Классы-наследники являются внутренними
+статическими классами, они помечены аннотациями `@Repository` и являтются бинами спринга. В `@Profile` над ними мы указываем
+соответствующий профиль спринга в зависимости от БД - Spring создаст бин только для тех классов, которые будут относиться к активным профилям.
+> последние версии драйвера HSQLDB поддерживает работу с Java Date Time Api, поэтому теперь можно просто обновить версию драйвера в `pom.xml`
+
+#### Получение Meal вместе с User
+
+1. В `MealService` внедряем `UserRepository` и в одной транзакции сначала
+ загружаем из БД `Meal`, затем загружаем соответствующего `User` и вручную устанавливаем для еды ее владельца. Так как
+ `@Transactional` объявлена на уровне сервиса — несмотря на то, что мы работаем с двумя разными репозиториями, операции
+ по получению из базы Meal и User выполнятся в одной транзакции благодаря тому, что аннотация имеет атрибут
+ `propagation`, который по умолчанию устанавливается как `required` - то есть, если внутри одной транзакции будет
+ исполняться другой транзакционный метод, то для его выполнения не будет открываться новая транзакция — он будет
+ выполняться во внешней транзакции.
+
+2. Способ: получение Meal с User в `MealRepository` через `FETCH JOIN`. Так как нам требуется реализовать получение еды с ее
+ владельцем только для `DataJpaMealRepository`, в интерфейсе `MealRepository` объявим `default UserMeal getWithUser(...)`,
+ который для всех реализаций этого интерфейса при вызове этого метода будет выбрасывать исключение
+ `UnsupportedOperationException()`. В `DataJpaMealRepository` переопределим этот дефолтный метод: этот метод пометим
+ аннотацией `@Query` и в скобках укажем HQL запрос получения Meal из базы. При этом, так как запрос содержит `JOIN
+ FETCH`, таблицы meals и users будут объединяться на уровне базы (обычный JOIN) и Spring Data за один запрос загрузит
+ из базы Meal вместе с ее User.
+
+#### Получение User вместе с Meals
+
+Для того чтобы получить из базы User вместе со всеми его Meals, для начала добавим `List meals` в класс `User`.
+Эта коллекция будет помечена аннотацией `@OneToMany`, которая говорит об отношении один-ко-многим. Мы видим, что
+у Meal есть ссылка на User, а у User есть ссылка на коллекцию его meal, и эти ссылки помечены соответствующими
+аннотациями — такое отношение называется BiDirectional. Пользователя с его едой получаем способом, аналогичным
+предыдущему шагу - с помощью HQL запроса с применением fetch join. JPA 2.0 позволяет использовать в таких случаях
+UniDirectional отношение со стороны
+@OneToMany [Unidirectional OneToMany](https://en.wikibooks.org/wiki/Java_Persistence/OneToMany#Unidirectional_OneToMany.2C_No_Inverse_ManyToOne.2C_No_Join_Table_.28JPA_2.x_ONLY.29).
+Обратите внимание на то, что нужно **объявлять поле только в том случае, когда ваше приложение их использует!**
+
+
+#### Проблема **N+1**
+
+Проблема **N + 1** возникает, когда выполняется N дополнительных SQL-запросов для получения тех же данных, которые можно
+получить при выполнении одного SQL-запроса. Чем больше значение N, тем больше запросов будет выполнено и тем больше
+влияние на производительность. Например, в нашем случае при получении списка пользователей сначала будут загружены все
+пользователи, и затем для каждого пользователя будет выполнен запрос в базу для получения его ролей. Таким образом, если
+бы у нас было 1000 пользователей, то будет выполнен 1 запрос для получения всех пользователей и дополнительно 1000
+запросов для получения ролей каждого пользователя, итого 1000 + 1 запрос.
+> Некоторые способы решения проблемы N+1:
+> 1. Получать сущность из базы данных через запрос с использованием `JOIN FETCH` - в таком случае таблицы будут объединяться на уровне БД и вся информация будет получена сразу.
+> 2. Пометить коллекцию сущности, для получения которой выполняются дополнительные запросы, аннотацией `@Fetch(FetchMode.SUBSELECT)`. В этом случае
+ > сначала будет загружена коллекция пользователей и затем будет выполнен один дополнительный запрос, который получит роли всех этих пользователей.
+> 3. Пометить коллекцию аннотацией `BatchSize(size = 200)` - в данном случае сначала будет выполнен запрос на получение всех пользователей, и затем дополнительными запросами будут загружаться
+ > роли этих пользователей — по 200 пользователей за запрос.
+> 4. JPA 2.1 предоставляет для решения этой проблемы функциональность `@EntityGraph` - на уровне сущности мы можем объявить граф полей, которые будут загружаться
+ > из базы данных совместно с сущностью. При определении последующих запросов мы можем указать наименование нужного нам Entity Graph, и JPA сформирует запрос в соответствии с этим графом и загрузит только описанные в нем поля.
+ `@EntityGraph` можно определять не только на уровне сущности, это можно сделать непосредственно в интерфейсе через параметр аннотации `attributePath`, например: `@EntityGraph(attributePaths = {"meals", "roles"})`
+>
+
+
+#### Apply 6_04_HW5_optional_fix_jdbc_profiles.patch
+
+- Spring Profiles. Spring 4 Conditional.
+- дополнительно:
+ - зайдите в исходники `@Profile` и посмотрите (подебажьте) его реализацию через `@Conditional(ProfileCondition.class)`.
+ - [реализация через Java Config и Profiles на уровне методов](http://stackoverflow.com/a/43645463/548473)
+
+#### Apply 6_05_update_hsqldb.patch
+
+В реальном проекте часто проблему можно решить простым обновлением версии: new HSQLDB version supports Java 8 time API
+
+#### Apply 6_06_HW5_optional_fetch_join.patch
+
+> - Добавил проверки и тесты на `NotFound` для `MealService.getWithUser` и `UserService.getWithMeals`
+> - Убрал `CascadeType.REMOVE`, в уроке далее будет про Cascade.
+
+- JPA JoinColumn vs mappedBy
+- Unidirectional OneToMany
+
+#### Apply 6_07_HW5_graph_batch_size.patch
+- **N+1 selects issue**
+
+- Using Named Entity Graphs
+ - [Entity Graph в Spring Data JPA](https://sysout.ru/entity-graph-v-spring-data-jpa/)
+ - [`EntityGraphType.FETCH` vs `LOAD`](http://stackoverflow.com/questions/31978011/what-is-the-diffenece-between-fetch-and-load-for-entity-graph-of-jpa)
+- Стратегии загрузки коллекций в JPA
+- Стратегии загрузки коллекций в Hibernate
+
+> Когда мы достаем всех юзеров с ролями без `@BatchSize`, делается запрос юзеров (1), и на каждого юзера идет в базу запрос ролей (+N). C `@BatchSize(size = 200)` делается запрос на юзеров (1), и затем роли достаются пачками для 200 юзеров (+ N/200).
+
+## Занятие 6:
+
+### Добавил тесты на валидацию
+
+> - К сожалению, в JUnit нет `ExpectedException.expectRootCause`. `AbstractServiceTest.validateRootCause()` сделал через [JUnit 4.13 assertThrows](https://stackoverflow.com/a/2935935/548473).
+
+>  Откуда у нас берется `ConstraintViolationException` в тестах на валидацию? Для каких наших исключений он является рутом?
+
+Прежде всего - пользуйтесь дебагом! Исключение легко увидеть в методе `getRootCause()`. Если подебажить выполение
+Hibernate валидации, то можно найти, где обрабатываются аннотации валидации и место
+в `org.hibernate.cfg.beanvalidation.BeanValidationEventListener.validate()`, где
+бросается `ConstraintViolationException`.
+Cамое простое - поставить брекпойнт в конструкторах `ConstraintViolationException` или в `ValidationException` и
+запустить тест `createWithException` в дебаге.
+
+#### Apply 6_08_add_test_validation.patch
+> Поменял реализацию `AbstractServiceTest.validateRootCause`. Вместо `ValidationUtil#getRootCause` [используем AssertJ](https://github.com/junit-team/junit-framework/issues/2129#issuecomment-565712630)
+
+**Тесты валидации для Jdbc не работают, нужно будет починить в HW6 (в реализация Jdbc валидация отсутствует, сделал `@Ignore`)**
+
+###  3. Кэш Hibernate
+
+> Кэш мигрировал на 3.x
+
+
+ Краткое содержание
+
+#### Уровни кэширования Hibernate
+
+Hibernate cache — это 3 уровня кеширования:
+
+- Кеш первого уровня (First-level cache) - включен по умолчанию всегда, его нельзя отключить, кэширует сущности на
+ уровне сессии;
+- Кеш второго уровня (Second-level cache) - используется на уровне фабрики сессий, по умолчанию всегда отключен и не
+ имеет реализации в Hibernate, для его использования нужно самостоятельно подключать сторонние реализации;
+- Кеш запросов (Query cache) - по умолчанию отключен, включается определением дополнительных параметров в
+ конфигурационном файле. В нем кэшируются идентификаторы объектов, которые соответствуют совокупности параметров
+ совершенного ранее запроса;
+
+Для кэширования определяются 4 стратегии, которые определяют его поведение в определенных ситуациях:
+
+- Read-only
+- Read-write
+- Nonstrict-read-write
+- Transactional
+
+#### Подключение кэш 2 уровня Hibernate
+
+Существует множество сторонних реализаций кэша, которые можно подключить к Hibernate. Мы будем использовать одну из
+самых распространенных - EhCache. Для того чтобы подключить к Hibernate EhCache, в файл `pom.xml` нужно добавить
+дополнительную зависимость:
+
+````
+
+ org.hibernate
+ hibernate-jcache
+ ${hibernate.version}
+
+````
+Теперь кэш подключен и его осталось лишь сконфигурировать в файле spring-db.xml для профилей
+"datajpa, jpa" :
+````
+
+
+
+
+
+
+
+
+
+
+````
+Сам кэш более тонко настраивается в отдельном файле `ehcache.xml`. В нем мы указываем какие
+таблицы будут кэшироваться, количество элементов, время и множество других параметров.
+
+Чтобы указать Hibernate какие сущности будут кэшироваться, их нужно пометить аннотацией `@Cache` и в скобках
+указать необходимую стратегию кэширования. Такая аннотация предоставляется как JPA, так и Hibernate, аннотация
+Hibernate позволяет определять дополнительные параметры кэширования.
+Так как мы пометили User `@Cache`, то сущности будут заноситься в кэш второго уровня, но не будет кэшироваться коллекция
+ролей. Чтобы роли тоже кэшировались нужно так же пометить это свойство пользователя аннотацией `@Cache`.
+Теперь, при запуске тестов мы столкнемся с частой проблемой — так как перед каждым тестом мы повторно заполняем базу
+тестовыми данными, и делаем мы это в обход Hibernate - содержимое кэша 2 уровня и базы данных будут различаться.
+Поэтому перед каждым тестом дополнительно нужно кэш инвалидировать — специально для этого мы создадим
+утильный класс `JpaUtil`, где определим метод, который будет получать текущую Session Factory и инвалидировать кэш Hibernate.
+Объект этого класса внедрили в тесты, и, так как в `spring-db.xml` мы определили, что этот бин будет создаваться только для профилей *jpa, datajpa*,
+тесты для JDBC реализации перестанут работать. `JpaUtil` отсутствует в профиле `jdbc` и не может быть разрезолвен при поднятии Spring контекста.
+
+
+#### Apply 6_09_hibernate_cache.patch
+
+**Теперь уже все `JdbcUserServiceTest` тесты поломались (в профиле `jdbc` отсутствует `JpaUtil`, сделал `@Ignore`). Требуется починить в HW6**
+
+- Уровни кэширования Hibernate
+- Hibernate Cache. Практика
+- Hibernate - Caching
+- Починка тестов: инвалидация кэша Hibernate
+- [Hibernate User Guide: Caching](http://docs.jboss.org/hibernate/orm/5.2/userguide/html_single/Hibernate_User_Guide.html#caching)
+- [Hibernate 5, Ehcache 3.x](https://www.boraji.com/index.php/hibernate-5-jcache-ehcache-3-configuration-example)
+- Ресурсы:
+ - **Hibernate performance tuning (Mikalai Alimenkou /Igor Dmitriev)**
+ - JPA2 @Cacheable vs Hibernate @Cache
+ - How does Hibernate Query Cache work
+ - Pitfalls of the Hibernate Second-Level / Query Caches
+
+###  4. Cascade. Auto generate DDL.
+
+
+Краткое содержание
+При создании таблиц `user_roles` и `meals` для внешнего ключа мы указывали свойство `ON DELETE CASCADE`. Это означает, что при удалении
+пользователя база данных автоматически будет удалять все записи, которые на него ссылались по внешнему ключу. Существует также
+свойство `ON UPDATE CASCADE`, определив которое, при обновлении первичного ключа пользователя этот ключ обновлялся бы во всех зависимых
+таблицах. При каскадных операциях на уровне базы данных могут возникнуть проблемы с консистентностью кэша второго уровня, так как все
+операции производятся в обход Hibernate.
+Hibernate тоже позволяет указывать `CascadeType` для управляемых сущностей (что не имеет абсолютно никакой связи с таким же свойством в базе данных).
+
+> Для Hibernate допускается указывать `CascadeType` только для сущности @OneToMany - со стороны родителя!
+> Для этой цели со стороны дочерней сущности можно указать аннотацию @OnDelete над ссылкой на родительскую сущность.
+> Для коллекций элементов сущности все действия всегда распространяются каскадно!
+
+Действие, указанное в `CascadeType` при манипулировании сущностью — будут распространяться на все ее дочерние объекты.
+
+> ALL - все возможные каскадные операции, выполняемые над исходной сущностью, применяются к дочерним сущностям.
+> MERGE - если исходная сущность объединяется, слияние каскадно передается на дочерние сущности.
+> PERSIST - если исходный объект сохраняется, сохранятся каскадно и дочерние объекты.
+> REFRESH - если исходная сущность обновляется, каскадно обновятся и дочерние объекты.
+> DELETE - при удалении исходной сущности удаляются и дочерние объекты.
+
+Также для аннотации `@OneToMany` существует параметр `orphanRemoval`. Если установить этот параметр в true, то при удалении исходной сущности
+все объекты, которые ранее на нее ссылались так же удалятся, если установить это значение в false, то в дочерних сущностях ссылка на
+исходную будет просто обнуляться.
+
+#### Генерация схемы базы данных по Java Entity
+JPA 2.1 предоставляет возможность генерировать базу данных по сущностям. Для этого в spring-db.xml
+укажем следующие параметры:
+```
+
+
+
+
+
+
+
+
+
+
+
+```
+> Автоматическую генерацию не рекомендуется использовать для реального приложения, так как генерируемые
+> команды часто некорректны. Чтобы они были более правильными — нужно указывать дополнительные условия и ограничения
+> в аннотациях при описании entity.
+
+
+#### Apply 6_10_cascade_ddl.patch
+
+#### Cascading
+
+> Есть SQL ON .. CASCADE, которая выполняется в базе данных, и есть аннотация в Hibernate, исполняемая в приложении
+
+- Do not use `CascadeType` for @ManyToOne
+- CascadeType meaning
+- No cascade option on an ElementCollection, the target objects are always persisted, merged, removed with their parent.
+- Create ON DELETE CASCADE: `@OnDelete`
+- [Сascade for `@ElementCollection`](https://stackoverflow.com/a/62848296/548473)
+- Hibernate second level cache and ON DELETE CASCADE in database schema
+- [`orphanRemoval=true` vs `CascadeType.REMOVE`](http://stackoverflow.com/a/19645397/548473)
+- [JPA `cascade/orphanRemoval` doesn't work with `NamedQuery`](http://stackoverflow.com/questions/7825484/jpa-delete-where-does-not-delete-children-and-throws-an-exception)
+
+#### Auto schema generation
+- JPA DATABASE SCHEMA GENERATION
+- hbm2ddl.auto and autoincrement
+- Hibernate/JPA DB Schema Generation Best Practices
+
+###  5. Spring Web
+
+
+ Краткое содержание
+Для работы с web с помощью Spring подключим к проекту следующие зависимости:
+
+```
+
+
+ org.apache.tomcat
+ tomcat-servlet-api
+ ${tomcat.version}
+ provided
+
+
+
+
+ javax.servlet
+ jstl
+ 1.2
+
+
+
+
+ org.springframework
+ spring-web
+ ${spring.version}
+
+```
+При старте web-приложения в контейнере сервлетов требуется инициализировать контекст спринга.
+Запустить Spring можно с помощью `ContextLoaderListener`, который будет отслеживать работу веб-приложения и при инициализации сервлета
+поднимать Spring context в методе `contextInitialized` и отключать контекст спринга при остановке
+приложения в методе `contextDestroyed`.
+Для этого нужно определить этот ContextListener в `web.xml`:
+
+```
+
+ org.springframework.web.context.ContextLoaderListener
+
+```
+Чтобы Listener смог поднять контекст спринга — ему нужно указать в `web.xml` путь к конфигурационным файлам и
+задать необходимые профили:
+
+```
+
+ spring.profiles.default
+ postgres,datajpa
+
+
+
+ contextConfigLocation
+
+ classpath:spring/spring-app.xml
+ classpath:spring/spring-db.xml
+
+
+```
+
+Для каждого сервлета, при инициализации, после создания запускается метод `init(ServletConfig config)`, где мы можем получить текущий контекст Spring.
+Для web приложений определяется свой собственный `WebApplicationContext`, который может работать с сервлетами.
+В `UserServlet` мы можем получить контекст с помощью метода `WebApplicationContextUtils.getRequiredWebApplicationContext(getServletContext())`.
+ Из полученного контекста мы можем получать бины Spring, например, объект `UserService`, и работать через него с пользователями.
+
+
+#### Apply 6_11_spring_web.patch
+
+> - Для сборки проекта в окне Maven отключите тесты (`Toggele 'Skip Tests' Mode`)
+> - В `web.xml` задаются профили запуска по умолчанию: `postgres,datajpa`. **Если запускаетесь под HSQLDB, надо поменять на `hsqldb,datajpa`**.
+
+- ServletContextListener.
+- Servlet Lifecycle
+
+###  6. JSP, JSTL, internationalization
+
+
+ Краткое содержание
+Ко всему, что находится в папке webapp, можно получить доступ из браузера.
+Для отображения пользователей создадим jsp страницу `userList`. Для работы со специализированными функциями и выражениями на
+странице импортируем некоторые библиотеки jstl(java standard tag library).
+
+#### Локализация
+ - для локализации **стандартными средствами java** можно использовать *Bundle* - это набор файлов properties,
+где определены ключ и значение. В зависимости от локали автоматически будет выбран нужный файл properties, из которого по
+ ключу страница будет получать текст на нужном языке и подставлять в места, где указаны соответствующие ключи.
+```html
+
+```
+ - Для локализации нашего приложения создадим в папке `resources/messages` два файла - `app.properties` и `app_ru.properties`, в которых
+мы и пропишем ключи и соответствующие им значения на русском и английском языках.
+При этом нужно иметь в виду, что локализация в jpa/jstl не работает с UTF8, поэтому для отображения текста на кириллице приходится записывать
+его в виде набора кодов unicode (intellij idea предоставляет нам удобный функционал для работы с этими кодами).
+
+> **Это было до Java 9. Теперь можно не парится и писать напрямую в UTF-8**
+
+ - На каждой странице будут дублироваться верхняя часть(header) и нижняя часть(footer), поэтому сделаем их в виде фрагментов, которые будут
+включаться в каждую страницу с помощью тега
+ ```< jsp:include page="fragments/bodyHeader.jsp"/ > ```
+ - Для того чтобы на странице JSP понимало, с каким объектом оно работает (а в IDEA работали автодополнения), мы можем явно указать с каким типом
+объекта мы будем работать. Для этого мы используем тег:
+```html
+
+```
+После этого на странице мы сможем работать с объектом в java-вставках *< % >* и с помощью expression language *${ }*.
+Без этого тэга приложение работать тоже будет, не будет IDEA интергации. Не забывайте про getter-ы, JSP обращается к объектам через них!
+
+> Локаль приложения определяется на основе локали операционной системы и свойств браузера. Чтобы проверить работу
+> локализации можно из браузера в заголовке запроса указать Content-Language:"en-US". Этот заголовок будет
+> считан в сервлете, и приложение определит требуемую локаль.
+
+
+
+**Убедитесь, что [в настройках IDEA](https://github.com/JavaOPs/topjava/wiki/IDEA#Поставить-кодировку-utf-8) кодировка везде UTF-8 до применения патча**
+#### Apply 6_12_jsp_jstl_i18n.patch
+
+> - Поменял `users/meals` в ключах локализации на `user/meal`. Понадобится при локализации ошибок (сделаем позже)
+> - [Since Java 9 default encoding in properties files is UTF-8](https://docs.oracle.com/javase/9/intl/internationalization-enhancements-jdk-9.htm). Галочка `Transparent` и ASCII кода уже не нужны.
+
+
+**Для работы с несколькими языками установите плагин `Resource Bundle Editor`**
+
+- Including Content in a JSP Page
+
+###  7. Динамическое изменение профиля при запуске.
+
+
+ Краткое содержание
+
+#### Динамическое изменение профиля при запуске
+Изначально мы определили профиль спринга в web.xml:
+```xml
+
+ spring.profiles.default
+ postgres,datajpa
+
+```
+При этом приложение будет деплоиться на сервер с указанными в конфигурации профилями.
+Чтобы определить профиль Spring при запуске без перекомпиляции проекта можно использовать системные опции, которые мы можем
+задать при запуске проекта, указав их в параметрах запуска (в командной строке, а для Intellij Idea: Edit Run/Debug Configurations - VM options).
+В этом случае конфигурации по умолчанию будут переопределены и будут использованы заданные при запуске системные переменные.
+
+
+
+ -Dspring.profiles.active="postgres,datajpa"
+
+- Set profiles in Spring 3.1
+
+###  8. Конфигурирование Tomcat через maven plugin. Jndi-lookup.
+
+
+ Краткое содержание
+Многие настройки сервера(web-контейнера) можно вынести в отдельный файл-конфигурацию.
+Настройки TomCat определим в отдельном файле `context.xml`
+
+#### Настройка пула TomCat для соединения с базой данных
+```xml
+
+```
+Для того чтобы TomCat при запуске создавал пул коннектов, требуется добавить maven плагин в
+секцию **buid**
+
+```xml
+
+
+
+ org.codehaus.cargo
+ cargo-maven3-plugin
+ 1.9.5
+
+
+ tomcat9x
+
+ UTF-8
+
+
+ tomcat,datajpa
+
+
+
+
+
+ org.postgresql
+ postgresql
+
+
+
+
+
+
+
+
+ src/main/resources/tomcat/context.xml
+ conf/Catalina/localhost/
+ ${project.build.finalName}.xml
+
+
+
+
+
+ ru.javawebinar
+ topjava
+ war
+
+ ${project.build.finalName}
+
+
+
+
+
+```
+В `spring-db.xml` создаем новый профиль "tomcat", для него будет создаваться бин `dataSource` с помощью соединения,
+которое будет получено из пула коннектов TomCat по JNDI. При этом в профиле мы можем указать расположение файла свойств,
+в котором будут описаны дополнительные параметры пула коннектов контейнера сервлетов - у нас это файл `tomcat.properties`.
+
+
+
+С плагином мы можем сконфигурировать Tomcat прямо в `pom.xml` и запустить его с задеплоенным туда нашим приложением WAR
+из командной строки без IDEA и без инсталляции Tomcat. По умолчанию он скачивает его из центрального maven-репозитория (
+можно также указать свой в `${container.home}`). При запуске Tomcat из IDEA
+запускается Tomcat, путь к которому мы прописали в конфигурации запуска (со своими настройками).
+
+#### Apply 6_13_tomcat_pool_jndi_cargo.patch
+
+> - для запуска в Tomcat 9 поменял `tomcat7-maven-plugin` на `cargo-maven3-plugin`.
+> - в `pom.xml` вместо `context.xml.default` можно делать [индивидуальный контекст приложения](https://stackoverflow.com/a/60797999/548473)
+> - Конфигурация сделана под postgres. Для HSQLDB нужно скорректировать `driverClassName` + `validationQuery="SELECT 1 FROM INFORMATION_SCHEMA.SYSTEM_USERS` в `context.xml` и `dependencies`.
+
+>  Томкат сам управляет пулом коннектов? На каждый запрос в браузере будет даваться свой коннект?
+
+Да, в Томкате есть реализация пула коннектов `tomcat-jdbc` (мы его подключаем со `scope=provided`). Если запускаемся с профилем `tomcat`, приложение на каждую транзакцию (или операцию не в транзакции) берет коннект к базе из пула, сконфигурированного в подкладываемом Tomcat `context.xml`.
+
+>  Для чего мы делаем профиль `tomcat`? Возможно два варианта запуска приложения: либо cargo, либо tomcat? И если мы запускаем через tomcat то в `spring-db.xml` через `jee:jndi-lookup` подтягивается конфигурация tomcata из `\src\main\resources\tomcat\context.xml`?
+
+1. Есть `cargo-maven3-plugin` который автоматически запускает Tomcat и деплоит туда наше приложение. Т.е. это тоже деплой
+ в Tomcat, но через Maven.
+2. В xml конфигурации Tomcat можно настраивать ресурсы (кроме пула коннектов к БД могут быть, например, JMS или
+ настройки Mail). Это никак не связано с `cargo` плагином. В Spring этот сконфигурированный ресурс контейнера
+ сервлетов подлючается через `jee:jndi-lookup`. Тк у нас несколько вариантов конфигурирования `DataSource`, мы этот
+ вариант сделали в `spring-db.xml` в профиле `tomcat`.
+3. Плагин cargo позволяет задавать xml конфигурацию запускаемого Tomcat (у нас `src/main/resources/tomcat/context.xml`).
+ И в параметрах запуска мы задаем активные профили Spring `tomcat,datajpa` через `spring.profiles.active`. Таким
+ образом мы в плагине конфигурируем Tomcat, деплоим в него приложение и задаем приложению активные профили Spring
+ для `DataSource` из конфигурации Tomcat.
+
+Еще раз: плагин `cargo` и JNDI - это две не связанные между собой вещи, просто мы добавили их в проект в одном патче.
+Плагин запускается **после сборки проекта**. Запуск из командной строки:
+
+ mvn clean package -DskipTests=true org.codehaus.cargo:cargo-maven3-plugin:1.9.5:run
+
+Приложение деплоится в application context topjava: [http://localhost:8080/topjava](http://localhost:8080/topjava)
+
+- Cargo Maven3 plugin
+- Кастомизация context.xml в cargo-maven2-plugin
+- Tomcat JNDI Resources
+- BasicDataSource Configuration
+
+###  9. Spring Web MVC
+
+
+ Краткое содержание
+
+Работа Spring MVC основана на паттерне Front Controller (Единая точка входа).
+Все запросы поступают в единый собственный сервлет Spring, в котором происходит его перенаправление на нужный сервлет приложения.
+Для работы со Spring MVC нужно заменить зависимость `spring-web` на `spring-webmvc`:
+```xml
+
+ org.springframework
+ spring-webmvc
+
+```
+После этого в `web.xml` необходимо сконфигурировать единую точку входа - Spring `DispatcherServlet`, в который будут поступать все запросы
+к приложению:
+```xml
+
+ mvc-dispatcher
+ org.springframework.web.servlet.DispatcherServlet
+
+
+ contextConfigLocation
+ classpath:spring/spring-mvc.xml
+
+ 1
+
+
+
+
+ mvc-dispatcher
+ /
+
+```
+> Различные контексты не имеют доступа к бинам друг друга (исключение - дочерние контексты могут получать доступ к бинам родителя, но не наоборот),
+> каждый контекст поднимает для себя свои собственные экземпляры, поэтому нужно следить за конфигурацией бинов и поднимать их в соответствующем контексте.
+
+Конфигурацию webmvc контекста и диспетчер-сервлета определим в файле `spring-mvc.xml`.
+
+#### Сценарий обработки запроса
+ 1. Запрос поступает в dispatcher-servlet, в нем определен набор Handler Mappings - классы, которые обрабатывают запросы в зависимости от их типа.
+- Соответствующий запросу Handler делегирует обработку запроса нужному контроллеру
+- Контроллер необходимым образом обрабатывает запрос и возвращает View
+- View отображает результат выполнения запроса
+
+В нашем приложении будет два вида контроллеров: одни — работают с User Interface и отображают результат работы приложения в браузере,
+другие — работают по REST-интерфейсу. Контроллеры помечаются аннотацией `@Controller`.
+Паттерн и тип HTTP метода, по которым мы можем получить доступ к методу контроллера конфигурируются
+с помощью аннотации `@RequestMapping(value = "/users", method = RequestMethod.GET)`.
+
+> **В последних версиях Spring можно сделать проще: `@GetMapping("/users")`**
+
+При этом Spring внедрит в метод объект `Model`, в который мы можем добавлять атрибуты и передавать их из слоя контроллера в слой представления.
+
+Чтобы Spring MVC контекст мог осуществлять роутинг запросов по этим аннотациям, в конфигурации `spring-mvc.xml` нужно
+вручную включить поддержку аннотаций:
+```xml
+
+```
+
+Методы контроллера, помеченные аннотацией `@RequestMapping` (а также `@GetMapping, @PostMapping, @PutMapping, ..`) после обработки запроса должны возвращать имя представления, в которое
+будет передана Model. Эта View отобразится как результат выполнения запроса. Чтобы в этих методах возвращать только название нужной View, в конфигурации нужно
+определить `ViewResolver`, который автоматически к этому названию добавит путь к view в приложении и суффикс — формат view:
+```xml
+
+```
+
+Для того чтобы приложение имело доступ к статическим ресурсам (например, стили) - нужно добавить дополнительную конфигурацию
+в `spring-mvc.xml`:
+```xml
+
+```
+> Spring MVC имеет конфигурацию по умолчанию. Если в `spring-mvc.xml` мы не укажем никаких Handlers, то их стандартный набор
+> будет создан автоматически и приложение будет работать. Как только мы добавляем собственные Handlers в конфигурацию — настройки
+> по умолчанию переопределяются и будут созданы только те бины, которые мы определили, стандартные Handlers созданы не будут.
+
+
+
+#### Apply 6_14_spring_webmvc.patch
+
+**Контроллеры переехали в _spring-mvc.xml_ и не резолвятся в тестах `InMemory`, сделал им `@Ignore`. Требуется починить в HW6**
+
+Обработка запросов переезжает в `RootController`, сервлеты уже не нужны
+> - Починил [путь к корню](http://stackoverflow.com/questions/10327390/how-should-i-get-root-folder-path-in-jsp-page)
+> - В Spring 4.3 ввели новые аннотации `@Get/Post/...Mapping` (сокращенный вариант `@RequestMapping`)
+
+- Spring Web MVC
+- [Spring MVC + Spring Data JPA + Hibernate - CRUD Example](https://www.codejava.net/frameworks/spring/spring-mvc-spring-data-jpa-hibernate-crud-example)
+- [ContextLoaderListener vs DispatcherServlet](https://howtodoinjava.com/spring-mvc/contextloaderlistener-vs-dispatcherservlet/)
+- Паттерн Front Controller
+- Иерархия контекстов в Spring Web MVC
+- Сценарий обработки запроса. HandlerMappings
+- View Resolution: прячем jsp под WEB-INF.
+- HandlerMapping: SimpleUrlHandlerMapping, BeanNameUrlHandlerMapping
+- Маппинг ресурсов.
+- Ресурсы:
+ - Spring MVC hello world
+ - Special bean types in the WebApplicationContext
+
+> Настройки `Project Structure->Modules->Spring`:
+
+
+
+>  В `web.xml` мы инициализируем `DispatcherServlet`, передавая ему параметром `spring-mvc.xml`. Получается, что `DispatcherServlet` парсит `spring-mvc.xml` и находит в нем context?
+
+Да, можно подебажить родителя (`FrameworkServlet.initWebApplicationContext()`). После инициализации
+сервлет `DispatcherServlet` раскидывает все запросы по контроллерам (бинам контекста Спринга).
+См. паттерн Front Controller.
+
+###  10. Spring Internationalization
+
+
+ Краткое содержание
+
+Spring нормально работает с кириллицей, замена русских символов на их коды уже не требуется (как и с JDK 9).
+Spring также автоматически может изменять локаль приложения, для этого в конфигурации `spring-mvc.xml` ему нужно
+определить `ReloadableResourceBundleMessageSource`, который будет отвечать за локализацию и указать для него путь к Bundles с локализованными данными.
+В страницах JSP мы также должны указать, что теперь будем работать не через JSTL, а через Spring локализацию.
+Для этого в страницах удаляем тег `fmt:setBundle`. Теперь Spring автоматически будет подставлять сообщения в зависимости от локали.
+ Но сейчас Spring работает на основании JDK `ResourceBundle` и он игнорирует свойство *p:cacheSeconds="5"*, так как ресурсы
+интернационализации будут кэшироваться Java. Чтобы ресурсы не кэшировались нужно использовать бин `ReloadableResourceBundleMessageSource` с путем к локализации, отличным от classpath приложения.
+
+```xml
+
+
+
+
+```
+Теперь ресурсы интернационализации не будут кэшироваться и их можно будет менять во время работы приложения "на ходу".
+
+
+#### Apply 6_15_spring_i18n.patch
+
+**Внимание: проверьте, что переменная окружения `TOPJAVA_ROOT` настроена!**
+> - В локализации поменял `fmt:message` на `spring:message`
+> - Выбор языка зависит от языка операционной системы и заголовка `Accept-Language`. Добавил в `spring-mvc.xml` `messageSource` параметр [`fallbackToSystemLocale`](http://stackoverflow.com/questions/4281504/spring-local-sensitive-data).
+Он управляет выбором, куда переключаться при выборе `en` и отсутствии `app_en.properties`: локаль операционной системы или `app.properties` (`fallbackToSystemLocale=false`). Переключение локалей будем реализовывать в конце проекта.
+
+#### Для тестирования локали [можно поменять `Accept-Language`](https://stackoverflow.com/questions/7769061/how-to-add-custom-accept-languages-to-chrome-for-pseudolocalization-testing). Для Хрома в `chrome://settings/languages` перетащить нужную локаль наверх или поставить [плагин Locale Switcher](https://chrome.google.com/webstore/detail/locale-switcher/kngfjpghaokedippaapkfihdlmmlafcc)
+
+- Reloadable MessageSources
+- nginx: Serving Static Content
+
+##  Ваши вопросы
+> Кэш hibernate надстраивается над ehcache или живет самостоятельно?
+
+- Как работает кэш в Hibernate:
+Hibernate подерживает следующие опенсорсные имлементации кэша: EHCache (Easy Hibernate Cache), OSCache (Open Symphony Cache), Swarm Cache, JBoss Tree Cache.
+
+> Где конфигурируется интернализация для jstl (т.е. файл, где задаются app, app_ru.properties)? Достаточно указать в страницах bundle и путь в ресурсы?
+
+`` означает, что ресурсы будут искаться в `classpath:messages/app(_xx)/properties`:
+Tag setBundle: fully-qualified resource name, which has the same form as a fully-qualified class name.
+После сборки проекта maven их можно найти в `target/classes` или `target/topjava/WEB-INF/classes`.
+
+> Отлично, что она все пишет на том языке, который пришел в заголовке запроса. А если я хочу выбрать?
+
+Выбор языка зависит от языка операционной системы и заголовка `Accept-Language`. Параметр `fallbackToSystemLocale`, который управляет выбором, когда с `Accept-Language: en,en-US;` не находится локализация `app_en.properties`. Для переключения локали используется JSTL Format Tag fmt:setLocale. Мы будем реализовывать переключение локалей в Spring i18n в конце проекта.
+
+> Мы создаем бин, где получаем dataSource по имени ``.
+Но там не указан класс, как в других dataSource. Получается, по имени jdbc/topjava нам уже отдается готовый объект dataSource, и мы как бы помещаем его в бин?
+
+Здесь используется namespace `jee:jndi-lookup`, который прячет под собой классы реализации. JNDI объект DataSource конфигурируется в `src/main/resources/tomcat/context.xml`
+
+> В плагине прописан профиль `tomcat,datajpa`, а в web.xml `postgres,datajpa`.
+Какой же реально отрабатывает?
+
+См. видео урока "Динамическое изменение профиля при запуске". В плагине мы задаем параметры JVM запуска Tomcat
+
+> A `@NamedQuery` или `@Query` подвержены кэшу запросов? Т.е. если мы поставим _USE_QUERY_CACHE_value_="true", будет ли Hibernate их кэшировать?
+
+Чтобы запрос кэшировался, кроме true в конфигурации [нужно еще явно выставить запросу _setCacheable_](http://vladmihalcea.com/2015/06/08/how-does-hibernate-query-cache-work/).
+По поводу кэширования `@NamedQuery` нашел [`@QueryHint`](https://docs.jboss.org/jbossas/docs/Clustering_Guide/5/html/ch04s02s03.html)
+
+> Почему messages мы кладем в config и используем system environment? Разве так делают в реальном проекте? Не будешь же вписывать на сервере эти переменные каждый раз, если проект куда-то будет переезжать. Можно по-другому, кроме systemEnvironment['TOPJAVA_ROOT'], задать путь от корня проекта?
+
+1. messages нам нужны в runtime (при работе приложения). Проект к собранному и задеплоенному в Tomcat war отношения никакого уже не имеет и на этом сервере он обычно не находится. Если ресурсы нужны только при сборке и тестировании, то путь к корню для одномодульного maven проекта можно задать как `${project.basedir}`, но для многомодульного проекта (а все реальные проекты многомодульные) это путь к корню своего модуля.
+2. В "реальном приложении" делается совершенно по-разному:
+ - нести с собой в classpath, но ресурсы нельзя будет динамически (без передеплоя) обновлять
+ - класть в war (не в classpath) и обновлять в развернутом TOMCAT_HOME/webapps/[appname]/...
+ - класть в зафиксированное определенное место (например, в home: `~` или в путь от корня `/app/config`). Можно задавать фиксированный пусть в пропертях профиля maven и фильтровать ресурсы (maven resources), чтобы они попали в проперти проекта.
+ - делать через переменную окружения, как у нас
+ - задавать в параметрах запуска JVM как системную переменную через -D..
+ - располагать в преференсах (для unix это home, для windows - registry): использование Preferences API
+ - держать настройки в DB
+
+ Часто в одном приложении используют несколько способов для разных видов конфигураций.
+
+> Не происходит ли дублирования при кэшировании пользователей чрез Hibernate и `@Cacheable`?
+
+`@Cacheable` кэширует результат запроса `getAll()`, т.е. список юзеров. Hibernate кэширует юзеров по отдельности, т.е., грубо говоря, делает мапу id->User. Можно назвать это дублированием. Нужно ли будет такое в реальном приложении? Все смотрится из логики запросов и их частоты, вполне вероятно, что нет. Как-то мы писали приложение для Дойчебанка (аналог skype на GWT, т.е. на экране небольшое окошко) - там было 5(!!!) уровней кэширования, первый вообще в базе.
+
+> У меня стоит Томкат 8-й версии, в помнике у нас 9-й прописан, но всё работает. Почему?
+
+В `pom.xml` мы подключаем `tomcat-servlet-api` со `scope=provided`, что означает, что он используется только для компиляции и не идет в war. Т.к. мы не используем никаких фич Tomcat 9.x, то наш код совместим с Tomcat 8.x. При запуске через `cargo-maven2-plugin` Tomcat 9 загружается из maven-репозитория.
+
+> Откуда `@Transactional` вытягивает класс для работы с транзакцией, в составе какого бина он идет?
+
+1. Если в контексте Spring есть ``, то подключается `BeanPostProcessors`, который проксирует классы (и методы), помеченные `@Transactional`.
+2. По умолчанию для TransactionManager используется бин с `id=transactionManager`
+
+---------------------------
+
+##  Домашнее задание HW06
+- 1.1 Починить тесты `InMemoryAdminRestControllerSpringTest/InMemoryAdminRestControllerTest` (добавлять `spring-mvc.xml` в контекст не стоит, т.к. в новой версии Spring для этого требуется `WebApplicationContext`. Можно просто поправить `inmemory.xml`).
+- 1.2 Починить тесты Jdbc (исключить валидацию в тестах Jdbc)
+ - org.junit.Assume
+ - [How to get active Profiles in Spring Application](https://stackoverflow.com/questions/9267799/548473)
+- 1.3 Перенести функциональность `MealServlet` в `JspMealController` контроллер (по аналогии с `RootController`).
+`MealRestController` у нас останется, с ним будем работать позже.
+ - 1.3.1 разнести запросы на update/delete/.. по разным методам (попробуйте вообще без параметра `action=`). Можно по аналогии с `RootController#setUser` принимать `HttpServletRequest request` (аннотации на параметры и адаптеры для `LocalDate/Time` мы введем позже).
+ - 1.3.2 в одном контроллере нельзя использовать другой. Чтобы не дублировать код, можно сделать наследование контроллеров от абстрактного класса.
+ - 1.3.3 добавить локализацию и `jsp:include` в `mealForm.jsp / meals.jsp`
+
+### Optional
+- 2.1 Добавить транзакционность (`DataSourceTransactionManager`) в Jdbc-реализации
+- 2.2 Добавить еще одну роль к юзеру Admin (будет 2 роли: `USER, ADMIN`).
+- 2.3 В `JdbcUserRepository` добавить реализацию ролей юзера (добавлять можно одним запросом с JOIN и `ResultSetExtractor/ RowCallbackHandler`, либо двумя запросами (отдельно `users` и отдельно `roles`). [Объяснение SQL JOIN](http://www.skillz.ru/dev/php/article-Obyasnenie_SQL_obedinenii_JOIN_INNER_OUTER.html)
+ - 2.3.1 В реализации `getAll` НЕ делать запрос ролей для каждого юзера (N+1 select)
+ - 2.3.2 При save посмотрите на batchUpdate()
+- 2.4 Добавить проверку ролей в `UserTestData.USER_MATCHER.assertMatch` и починить ВСЕ тесты (тесты должны проходить для юзера с несколькими ролями)
+- 2.5 Добавить валидацию для `Jdbc..Repository` через Bean Validation API (для JPA это делается автоматически при сохранении в базу, для Jdbc мы должны это делать вручную). Оптимизировать код.
+ - Валидацию `@NotNull` для `Meal.user` пока можно закомментировать. На 10-м уроке решим проблему через [Jackson JSON Views](http://www.baeldung.com/jackson-json-view-annotation)
+ - [Валидация данных при помощи Bean Validation API](https://web.archive.org/web/20231205131046/https://alexkosarev.name/2018/07/30/bean-validation-api/)
+
+### Optional 2 (повышенной сложности)
+- 3 Отключить Spring кэш в `UserService` в тестах через `NoOpCacheManager` и для кэша Hibernate 2-го уровня `hibernate.cache.use_second_level_cache=false`.
+ - [JPA 2.0 disable session cache for unit tests](https://stackoverflow.com/a/58963737/548473)
+ - [Example of PropertyOverrideConfigurer](https://www.concretepage.com/spring/example_propertyoverrideconfigurer_spring)
+ - [Spring util schema](https://docs.spring.io/spring/docs/current/spring-framework-reference/core.html#xsd-schemas-util)
+
+---------------------
+##  Подсказки по HW06
+- 1: Неверная кодировка UTF-8 с Spring обычно решается фильтром `CharacterEncodingFilter`:
+```
+
+ encodingFilter
+ org.springframework.web.filter.CharacterEncodingFilter
+
+ encoding
+ UTF-8
+
+
+ forceEncoding
+ true
+
+
+
+ encodingFilter
+ /*
+
+```
+- 2: **Если не поднимается контекст Spring, смотрим причину вверху самого нижнего исключения.** Все ошибки на отсутствия бина в контексте или его нескольких реализациях относятся к пониманию основ: Spring application context. Если нет понимания этих основ, двигаться дальше нельзя, нужно вернуться к видео Спринг, где объясняется, что это такое. Также пересмотрите видео [Тестирование UserService через AssertJ](https://drive.google.com/file/d/1SPMkWMYPvpk9i0TA7ioa-9Sn1EGBtClD). Начиная с 11.30 как раз разбираются подобные ошибки.
+- 3: Если неправильно формируется url относительно контекста приложения (например, `/topjava/meals/meals`), посмотрите на
+ - Relative paths in JSP
+ - Spring redirect: prefix
+- 4: При проблемах с запуском Томкат проверьте запущенные процессы `java`, нет ли в `TOMCAT_HOME\webapps` приложения каталога `topjava`, логи tomcat (нет ли проблем с доступом к каталогам или контекстом Spring)
+- 5: Если создаете неизменяемые List или Map, пользуйтесь `List.of()/ Map.of()`
+- 6: В MealController общую часть `@RequestMapping(value = "/meals")` лучше вынести на уровень класса
+- 7: Проверьте `@Transactional(readOnly = true)` сверху `Jdbc..Repository`
+- 8: Проверьте, что `config\messages\app_ru.properties` у вас в кодировке UTF-8 (в любом редакторе/вьюере или при отключенном [Transparent native-to-ascii conversion](https://github.com/JavaOPs/topjava/wiki/IDEA#%D0%9F%D0%BE%D1%81%D1%82%D0%B0%D0%B2%D0%B8%D1%82%D1%8C-%D0%BA%D0%BE%D0%B4%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D1%83-utf-8) в IDEA).
+- 9: Учтите, что роли у юзеров можно менять/добавлять/удалять
+- 10: Убедитесь, что все методы UserService корректно работают с юзерами, у которых несколько ролей (**запусти наши тесты для Admin с 2-мя ролями**)
diff --git a/doc/lesson07.md b/doc/lesson07.md
new file mode 100644
index 000000000..ed360a8d8
--- /dev/null
+++ b/doc/lesson07.md
@@ -0,0 +1,697 @@
+# Стажировка Topjava
+
+## Материалы занятия
+
+##  Разбор домашнего задания HW6
+
+###  1. HW6
+
+#### Apply 7_01_HW6_fix_tests.patch
+
+
+ Краткое содержание
+
+#### Починить InMemory и JDBC тесты
+
+InMemory-тесты перестали работать, т.к ранее мы перенесли сканирование каталога `web` из `spring-app.xml` в конфигурацию `spring-mvc.xml`, которой нет в тестах. В результате контроллеры перестали
+попадать в спринг-контекст тестов. Для восстановления добавим сканирование каталога `web` в конфигурацию `inmemory.xml`. Теперь в классах, которые работают с InMemory-реализацией, для создания
+контекста можно оставить импорт только конфигурации
+`spring/inmemory.xml`.
+
+JDBC-тесты перестали работать, т.к в конфигурации `spring-db.xml` мы объявили бин `JpaUtil` только для профилей jpa и dataJpa, для других профилей (jdbc) этот бин создаваться не будет.
+JDBC-тесты мы запускаем с профилем jdbc, но в абстрактном классе AbstractUserServiceTest (общем для всех тестов сервисного слоя User) для всех профилей мы указали необходимость создания переменной
+типа `JpaUtil`. Соответственно, для профиля jdbc в контексте спринга будет отсутствовать этот бин, и спринг не сможет запустить приложение из-за неразрешенной зависимости.
+
+Чтобы спринг смог поднять контекст в профиле JDBC, нужно указать над переменной `jpaUtil`
+аннотацию `@Autowired(required = false)` - мы указываем спрингу, что эта зависимость не является обязательной и можно ее проигнорировать.
+
+> В новой версии заменил аннотацию на ленивую инициализацию `@Lazy`
+
+И в `@Before` методе тестов используем этот бин только для JPA реализаций.
+Для этого создадим утильный метод `isJpaBased()`, который будет проверять, относится ли текущая реализация к jpa. Чтобы проверить, с какими профилями запущен Spring, нам придется внедрить
+в `AbstractServiceTest`
+бин класса `Environment`. Это класс спринга, который позволит получить доступ к информации о том, с какими параметрами он был запущен, с помощью
+```env.acceptsProfiles(org.springframework.core.env.Profiles.of(Profiles.JPA, Profiles.DATAJPA))```
+С помощью этого же утильного метода теперь мы можем проверить, что для `MealServiceTest` тесты на валидацию `validateRootCause()` будут выполняться только для jpa/dataJpa профилей (если этот тест
+запустить для профиля jdbc, то он упадет, т.к. пока в JDBC у нас нет валидации).
+
+#### Локализация, jsp:include для meal*.jsp
+
+1. В файлы интернационализации `app.properties` добавляем дополнительные пары ключ-значение для русского и английского языка. В JSP страницах вместо текста, по аналогии со страницами для User,
+ указываем ключи, вместо которых спринг должен подставить локализованные сообщения.
+2. Для каждой JSP страницы для включения фрагментов указываем теги:
+
+`` - в нем определены title страницы, ссылка на статические ресурсы и базовая ссылка на корень приложения.
+
+`` - верхняя часть страниц, в ней определены ссылки для навигации по приложению.
+И в самом низу страниц:
+``
+
+Так как мы локализуем приложение с помощью Spring, на страницах нужно удалить тег:
+`` - с ним работает только jstl.
+
+3. Для того, чтобы на страницах получить доступ к корню приложения, используется
+ `"${pageRequest.request.contextPath}"` - эту ссылку на root удобнее вынести в `headTag` в виде [`` элемента](https://stackoverflow.com/a/40228804/548473), чтобы она вместе с этим
+ фрагментом добавлялась к каждой странице, и не требовалось бы ее везде дублировать.
+
+4. Чтобы видеть, к каким URL были привязаны контроллеры во время работы приложения, в `logback.xml` настроим уровень логирования для Spring web:
+ ``
+
+#### Перенести функциональность из `MealServlet` в контроллеры
+
+Чтобы не дублировать одну и ту же функциональность для REST- и JSP-контроллеров, создадим абстрактный
+`AbstractMealController` (от него будут наследоваться остальные Meal-контроллеры), куда перенесем все методы из
+`MealRestController`. JSP-контроллер будет работать с jsp-страницами. Каждый метод этого контроллера будет делегировать основную функциональность в родительский абстрактный контроллер.
+
+> **Внимание!**. Не делайте без нужды абстрактных контроллеров в своих выпускных проектах!
+
+Так как каждый метод этого контроллера должен отвечать за единственное действие, разнесем функциональность по разным методам, а доступ к самим методам разделим с помощью
+аннотации `@RequestMapping (@GetMapping / @PostMapping)`, в их параметрах укажем путь к endpoint, по которому можно обратиться к методу.
+
+При этом для всего контроллера также зададим `@RequestMapping("/meals")` (`value=` - параметр по умолчанию, можно не указывать). Это префикс запроса для всех методов контроллера.
+
+> Один из признаков "хорошего" контроллера, где не смешивается разная функциональность, - этот общий url. Для каждой функциональности в выпускных создавайте свой собственный контроллер!
+
+Для доступа к определенному методу контроллера нужно будет указать уникальный для нашего приложения "путь + http-метод", который складывается из маппинга к контроллеру, маппинга к нужному методу и
+http-метода, например:
+`GET {корень приложения} + "/meals" + "/delete"`
+`GET {корень приложения} + "/meals"`
+`POST {корень приложения} + "/meals"`
+Для `mealList.jsp` теперь не нужно с запросом дополнительно передавать тип действия, которое мы хотим совершить с едой, мы можем просто обратиться к нужному методу по его уникальному пути (endpoint,
+url).
+
+Если на этом шаге запустить приложение, то мы столкнемся с проблемой: при выполнении манипуляций и переходе по ссылкам путь портится.
+
+- путь к ресурсу по этой ссылке строится не от корня приложения (application context - topjava), а от текущего контекста сервлета (servlet context), например:
+ `localhost:8080/topjava/meals'+'/meals`
+ Также перестали работать стили, так как путь к статическим ресурсам тоже определяется неверно (посмотрите вкладку *Network* браузера).
+ Чтобы это исправить, добавим базовый URL в `headTag`:
+ `base href = "${pageContext.request.contextPath}/"`. **Теперь это станет url, от которой будут строиться все относительные ссылки на страницах**.
+
+Также некоторые методы контроллера в результате работы должны не просто вернуть название view, который Spring MVC должен отобразить, а совершить *redirect*. Для этого при возврате имени view
+дополнительно укажем ключевое слово `redirect:`, например, `redirect: /meals`.
+
+Последняя проблема — некорректное отображение текста в кодировке UTF-8. Spring предоставляет для ее решения стандартный фильтр, который будет перехватывать все запросы и ответы сервера и устанавливать
+им нужную кодировку: в `web.xml` подключим `encodingFilter`.
+
+
+
+> Инжекцию в `AbstractUserServiceTest.jpaUtil` сделал [`@Lazy`: не иннициализировать бин до первого использования](https://www.logicbig.com/tutorials/spring-framework/spring-core/lazy-at-injection-point.html).
+
+#### Apply 7_02_HW6_meals.patch
+
+> сделал фильтрацию еды через `get`: операция идемпотентная, можно делать в браузере обновление по F5
+
+### Внимание: чиним пути в следующем патче
+
+При переходе на AJAX `JspMealController` удалим за ненадобностью, возвращение всей еды `meals()` останется в `RootController`.
+
+#### Apply 7_03_HW6_fix_relative_url_utf8.patch
+
+- [Relative paths in JSP](http://stackoverflow.com/questions/4764405/548473)
+- [Spring redirect: prefix](http://docs.spring.io/spring/docs/3.2.x/spring-framework-reference/html/mvc.html#mvc-redirecting-redirect-prefix)
+
+###  2. HW6 Optional
+
+
+ Краткое содержание
+
+#### Добавление еще одной роли для Admin
+
+1. В файле популирования базы данных `populateDB.sql` добавим для admin дополнительную роль `ROLE_USER`.
+
+2. В тестовых данных для него также добавим аналогичную роль.
+
+> После этого тесты, которые связаны с методом `getAll()`, перестали работать, потому что для получения
+> списка всех пользователей с их ролями в именованном запросе мы использовали **LEFT JOIN FETCH**.
+> Происходит объединение таблиц, в результирующей таблице вместо одной записи для админа появляются дублирующие записи для одного и того же пользователя.
+> - простой способ решения - исключить из запроса **LEFT JOIN FETCH**. Роли все равно будут загружены, так как они FetchType.EAGER.
+> - также можно добавить в запрос ключевое слово **DISTINCT(u)** - теперь в результирующей таблице будут содержаться только уникальные записи.
+
+#### Добавление транзакционности в JDBC реализацию репозитория
+
+Чтобы аннотация `@Transactional` стала работать во всех профилях Spring - в файле `spring-db.xml` вынесем из профиля jpa, dataJpa в общую конфигурацию для всех профилей тег:
+``````
+
+Для профиля jdbc настроим DatasourceTransactionManager, который будет управлять транзакциями:
+``
+
+
+
+``
+После этого в JDBC-репозитории мы можем расставить аннотации `@Transactional` аналогично jpa репозиториям, и действия станут выполняться транзакционно (
+напомню: `` для логирования информации по транзакциям)
+
+#### Чтобы JDBC репозиторий смог работать с множественными ролями пользователя:
+
+У пользователя добавим сеттер для его ролей. Для JDBC-репозитория создадим вспомогательные методы для записи ролей в базу и их считывания из базы и установления пользователю. Запись ролей в базу будем
+производить методом
+`JdbcTemplate#batchUpdate`, в таком случае не будет обращения в базу для записи каждой конкретной роли, команды для записи ролей будут накоплены в один пакет и выполнятся за одно обращение к БД. Для
+удобства работы с batch Spring предоставляет нам интерфейс `BatchPreparedStatementSetter`, с помощью которого мы определяем как будут устанавливаться параметры для запроса и количество запросов в
+одном пакете. Также создадим метод `deleteRoles`, в котором будем удалять роли пользователя из базы (для обновления ролей в базе мы делаем просто: сначала удалим старые из базы и запишем туда новые).
+
+> PS: в JPA с `@ElementCollection` и с параметром *cascade* в `@OneToMany` слияние (merge) изменений в связанных коллекциях происходит автоматически.
+
+Если мы будем получать всех пользователей вместе с их ролями из базы с помощью JOIN, мы столкнемся с проблемой Декартова произведения: для каждого уникального пользователя количество записей в
+результирующей таблице будет повторяться столько раз, сколько у него было ролей. Чтобы этого избежать, отдельным запросом получим из базы все роли, и сгруппируем их в `Map` по `userId`, где ключом
+будет являться `userId`, а значением — набор ролей пользователя. После чего пройдемся по всем пользователям, загруженным из базы, и установим каждому его роли.
+
+
+#### Apply 7_04_HW6_optional_add_role.patch
+
+> - Для доставания ролей у нас дублируется `fetch = EAGER` и `LEFT JOIN FETCH u.roles` (можно делать что-то одно). Запросы выполняются по-разному: проверьте.
+
+- Отключил `JdbcUserServiceTest` - роли не работают. Будем чинить в `7_06_HW6_jdbc_transaction_roles.patch`
+- `DataJpaUserServiceTest.getWithMeals` не работает для admin (у админа 2 роли, и еда при JOIN дублируется). Чиним в следующем патче.
+
+#### Apply 7_05_HW6_fix_hint_graph.patch
+
+- `@EntityGraph` в `DataJpaUserServiceTest.getWithMeals()` в последнем Hibernate работает только с `attributePaths = {"meals"}` и `type = EntityGraph.EntityGraphType.LOAD`
+- В `JpaUserRepositoryImpl.getByEmail` и `CrudUserRepository.getByEmail` DISTINCT попадает в запрос, хотя он там не нужен. Это просто указание Hibernate не дублировать данные. Для оптимизации можно
+ указать Hibernate делать запрос без distinct: [15.16.2. Using DISTINCT with entity queries](https://docs.jboss.org/hibernate/orm/5.2/userguide/html_single/Hibernate_User_Guide.html#hql-distinct)
+- Бага [HINT_PASS_DISTINCT_THROUGH does not work if 'hibernate.use_sql_comments=true'](https://hibernate.atlassian.net/browse/HHH-13280). При `hibernate.use_sql_comments=false` все работает - в SELECT
+ нет DISTINCT.
+
+Еще один вариант решения - в `User` сделать `Set`. Интересно, что в ее реализации `PersistentSet`порядок соблюдается и `@OrderBy` работает.
+
+#### Apply 7_06_HW6_jdbc_transaction_roles.patch
+
+> - в `JdbcUserRepositoryImpl.getAll()` собираю роли из `ResultSet` напрямую в `map`
+> - в `insertRoles` поменял метод `batchUpdate` и сделал проверку на empty
+> - в `setRoles` достаю роли через `queryForList`
+
+Еще интересные JDBC реализации:
+
+- в `getAll()/ get()/ getByEmail()` делать запросы с `LEFT JOIN` и сделать реализацию `ResultSetExtractor`
+- подключить зависимость `spring-data-jdbc-core`. Там есть готовый `OneToManyResultSetExtractor`. Можно посмотреть, как он реализован.
+- реализация, зависимая от БД: доставать агрегированные роли и делать им `split(",")`. В этой реализации есть ограничение - одно поле из зависимой таблицы.
+
+```
+SELECT u.*, string_agg(r.role, ',') AS roles
+FROM users u
+ JOIN user_roles r ON u.id=r.user_id
+GROUP BY u.id
+```
+
+### Валидация для `JdbcUserRepository` через Bean Validation API
+
+#### Apply 7_07_HW6_optional_jdbc_validation.patch
+
+- [Валидация данных при помощи Bean Validation API](https://alexkosarev.name/2018/07/30/bean-validation-api/).
+
+На данный момент у нас реализована валидация сущностей только для jpa- и dataJpa-репозиториев. При работе через JDBC-репозиторий может произойти попытка записи в БД некорректных данных, что приведет
+к `SQLException` из-за нарушения ограничений, наложенных на столбцы базы данных. Для того, чтобы перехватить невалидные данные еще до обращения в базу, воспользуемся API *javax.validation* (ее
+реализация `hibernate-validator` используется для проверки данных в Hibernate и будет использоваться в Spring Validation, которую подключим позже). В `ValidationUtil` создадим один потокобезопасный
+валидатор, который можно переиспользовать (см. *javadoc*).
+С его помощью в методах сохранения и обновления сущности в jdbc-репозиториях мы можем производить валидацию этой сущности: `ValidationUtil.validate(object);`
+Чтобы проверка не падала, `@NotNull Meal.user` пришлось пока закомментировать. Починим в 10-м занятии через `@JsonView`.
+
+В `AbstractServiceTest#validateRootCause` пришлось добавить проверку `isInstanceOf`, чтобы `ConstraintViolationException`, бросаемые в `ValidationUtil#validate` не ломали тест.
+`AbstractAssert.satisfiesAnyOf` проверяет, что хотя бы одно из условий выполняется.
+
+### Отключение кэша в тестах:
+
+Вместо наших приседаний с `JpaUtil` и проверкой профилей мы можем отключить Spring-кэш в тестах, подменив `spring-cache.xml` на тестовый (положив его в ресурсы тестов).
+Отключить кэширование можно через пустую реализацию `NoOpCacheManager` или, как сейчас, не включая `cache:annotation-driven`, который подключает обработку `@Cache`-аннотаций.
+Кэш Hibernate второго уровня отключаем через переопределение свойства `entityManagerFactory.jpaPropertyMap: hibernate.cache.use_second_level_cache=false` (кроме стандартного использования файла
+пропертей, можно задать их прямо в конфигурации, через автодополнение в xml можно смотреть все варианты). Подкладываем новый `spring-cache.xml` в ресурсы тестов, он перекроет настройки кэша в
+приложении. Остается удалить наши уже ненужные `JpaUtil` и `AbstractServiceTest.isJpaBased()`
+
+#### Apply 7_08_HW06_optional2_disable_tests_cache.patch
+
+- [Example of PropertyOverrideConfigurer](https://www.concretepage.com/spring/example_propertyoverrideconfigurer_spring)
+- [Spring util schema](https://docs.spring.io/spring/docs/current/spring-framework-reference/core.html#xsd-schemas-util)
+
+## Занятие 7:
+
+###  3. Тестирование Spring MVC
+
+
+ Краткое содержание
+
+#### Тестирование Spring MVC
+
+Для более удобного сравнения объектов в тестах мы будем использовать библиотеку *Harmcrest* с Matcher'ами, которая позволяет делать сложные проверки. С *Junit* по умолчанию подтягивается *Harmcrest
+core*, но нам потребуется расширенная версия:
+в `pom.xml` из зависимости Junit исключим дочернюю `hamcrest-core` и добавим `hamcrest-all`.
+
+Для тестирования web создадим вспомогательный класс `AbstractControllerTest`, от которого будут наследоваться все тесты контроллеров. Его особенностью будет наличие `MockMvc` - эмуляции Spring MVC для
+тестирования web-компонентов. Инициализируем ее в методе, отмеченном `@PostConstruct`:
+
+ ```
+mockMvc = MockMvcBuilders.webAppContextSetup(webApplicationContext).addFilter(CHARACTER_ENCODING_FILTER).build();
+ ```
+
+Для того, чтобы в тестах контроллеров не популировать базу перед каждым тестом, пометим этот базовый тестовый класс аннотацией `@Transactional`. Теперь каждый тестовый метод будет выполняться в
+транзакции, которая будет откатываться после окончания метода и возвращать базу данных в исходное состояние. Однако теперь в работе тестов могут возникнуть нюансы, связанные с пропагацией транзакций:
+все транзакции репозиториев станут вложенными во внешнюю транзакцию теста. При этом, например, кэш первого уровня станет работать не так, как ожидается. Т.е при таком подходе нужно быть готовыми к
+ошибкам: мы их увидим и поборем в тестах на обработку ошибок на последних занятиях TopJava.
+
+#### UserControllerTest
+
+Создадим тестовый класс для контроллера юзеров, он должен наследоваться от `AbstractControllerTest`. В `MockMvc`
+используется [паттерн проектирования Builder](https://refactoring.guru/ru/design-patterns/builder).
+
+ ```
+ mockMvc.perform(get("/users")) // выполнить HTTP метод GET к "/users"
+ .andDo(print()) // распечатать содержимое ответа
+ .andExpect(status().isOk()) // от контроллера ожидается ответ со статусом HTTP 200(ok)
+ .andExpect(view().name("users")) // контроллер должен вернуть view с именем "users"
+ .andExpect(forwardedUrl("/WEB-INF/jsp/users.jsp")) // ожидается, что клиент должен быть перенаправлен на "/WEB-INF/jsp/users.jsp"
+ .andExpect(model().attribute("users", hasSize(2))) // в модели должен быть атрибут "users" размером = 2
+ .andExpect(model().attribute("users", hasItem( // внутри которого есть элемент ...
+ allOf(
+ hasProperty("id", is(START_SEQ)), // ... с аттрибутом id = START_SEQ
+ hasProperty("name", is(USER.getName())) //... и name = user
+ )
+ )));
+}
+ ```
+
+В параметры метода `andExpect()` передается реализация `ResultMatcher`, в которой мы определяем как должен быть обработан ответ контроллера.
+
+
+
+#### Apply 7_09_controller_test.patch
+
+> - в `MockMvc` добавился `CharacterEncodingFilter`
+> - поменял реализацию `ActiveDbProfileResolver`: в профили аттрибута `@ActiveProfiles(profiles=..)` он добавляет `Profiles.getActiveDbProfile()`
+> - сделал вспомогательный метод `AbstractControllerTest.perform()`
+
+- Hamcrest
+- Unit Testing of Spring MVC Controllers
+
+###  4. [Миграция на JUnit 5](https://drive.google.com/open?id=16wi0AJLelso-dPuDj6xaGL7yJPmiO71e)
+
+
+ Краткое содержание
+
+Для миграции на 5-ю версию JUnit в файле `pom.xml` поменяем зависимость `junit`
+на `junit-jupiter-engine` ([No need `junit-platform-surefire-provider` dependency in `maven-surefire-plugin`](https://junit.org/junit5/docs/current/user-guide/#running-tests-build-maven)). Актуальную
+версию всегда можно посмотреть [в центральном maven репозитории](https://search.maven.org/search?q=junit-jupiter-engine), берем только релизы (..-Mx означают предварительные milestone версии)
+Изменять конфигурацию плагина `maven-sureface-plugin` в новых версиях JUnit уже не требуется. Junit5 не содержит в себе зависимости от *Harmcrest* (которую нам приходилось вручную отключать для JUnit4
+в предыдущих шагах), поэтому исключение `hamcrest-core` просто удаляем. В итоге у нас останутся зависимости JUnit5 и расширенный Harmcrest.
+Теперь мы можем применить все нововведения пятой версии в наших тестах:
+
+1. Для всех тестов теперь мы можем удалить `public`.
+2. Аннотацию `@Before` исправим на `@BeforeEach` - теперь метод, который будет выполняться перед каждым тестом, помечается именно так.
+3. В Junit5 работа с исключениями похожа на Junit4 версии 4.13: вместо ожидаемых исключений в параметрах аннотации `@Test(expected = Exception.class)` используется метод `assertThrows()`, в который
+ первым аргументом мы передаем ожидаемое исключение, а вторым аргументом — реализацию функционального интерфейса `Executable` (кода теста, в котором ожидается возникновение исключения).
+4. Метод `assertThrows()` возвращает исключение, которое было выброшено в переданном ему коде. Теперь мы можем получить это исключение, извлечь из него сообщение с помощью
+ `e.getMessage()` и сравнить с ожидаемым.
+5. Для теста на валидацию при проверке предусловия, только при выполнении которого будет выполняться следующий участок кода (например, в нашем случае тесты на валидацию выполнялись только в jpa
+ профиле), - теперь нужно пользоваться утильным методом `Assumptions` (нам уже не требуется).
+6. Проверку Root Cause - причины, из-за которой было выброшено пойманное исключение, мы будем делать позднее, при тестах на ошибки.
+7. Из JUnit5 исключена функциональность `@Rule`, вместо них теперь нужно использовать `Extensions`, которые могут встраиваться в любую фазу тестов. Чтобы добавить их в тесты, пометим базовый тестовый
+ класс аннотацией `@ExtendWith`.
+
+JUnit предоставляет нам набор коллбэков — интерфейсов, которые будут исполняться в определенный момент тестирования. Создадим класс `TimingExtension`, который будет засекать время выполнения тестовых
+методов.
+Этот класс будет имплементировать маркерные интерфейсы — коллбэки JUnit:
+
+- `BeforeTestExecutionCallback` - коллбэк, который будет вызывать методы этого интерфейса перед каждым тестовым методом.
+- `AfterTestExecutionCallback` - методы этого интерфейса будут вызываться после каждого тестового метода;
+- `BeforeAllCallback` - методы перед выполнением тестового класса;
+- `AfterAllCallback` - методы после выполнения тестового класса;
+
+Осталось реализовать соответствующие методы, которые описываются в каждом из этих интерфейсов, они и будут вызываться JUnit в нужный момент:
+
+- в методе `beforeAll` (который будет вызван перед запуском тестового класса) создадим спринговый утильный секундомер `StopWatch` для текущего тестового класса;
+- в методе `beforeTestExecution` (будет вызван перед тестовым методом) - запустим секундомер;
+- в методе `afterTestExecution` (будет вызван после тестового метода) - остановим секундомер.
+- в методе `afterAll` (который будет вызван по окончанию работы тестового класса) - выведем результат работы этого секундомера в консоль;
+
+8. Аннотации `@ContextConfiguration` и `@ExtendWith(SpringExtension.class)` (замена `@RunWith`) мы можем заменить одной `@SpringJUnitConfiguration` (в старых версиях IDEA ее не понимает)
+
+
+
+#### Apply 7_10_JUnit5.patch
+
+- [No need `junit-platform-surefire-provider` dependency in `maven-surefire-plugin`](https://junit.org/junit5/docs/current/user-guide/#running-tests-build-maven)
+- [Наконец пофиксили баг с `@SpringJUnitConfig`](https://youtrack.jetbrains.com/issue/IDEA-166549)
+- [JUnit 5 homepage](https://junit.org/junit5)
+- [Overview](https://junit.org/junit5/docs/snapshot/user-guide/#overview)
+- [Миграция с JUnit4 на JUnit5: важные отличия и преимущества](https://topjava.ru/blog/migratsiya-s-junit4-na-junit5)
+- [10 интересных нововведений](https://habr.com/post/337700)
+- Дополнительно:
+ - [Extension Model](https://junit.org/junit5/docs/current/user-guide/#extensions)
+ - [A Guide to JUnit 5](http://www.baeldung.com/junit-5)
+ - [Migrating from JUnit 4](http://www.baeldung.com/junit-5-migration)
+ - [Before and After Test Execution Callbacks](https://junit.org/junit5/docs/snapshot/user-guide/#extensions-lifecycle-callbacks-before-after-execution)
+ - [Conditional Test Execution](https://junit.org/junit5/docs/snapshot/user-guide/#writing-tests-conditional-execution)
+ - [Third party Extensions](https://github.com/junit-team/junit5/wiki/Third-party-Extensions)
+ - [Реализация assertThat](https://stackoverflow.com/questions/43280250)
+
+Последняя стабильная версия JUnit 6.0.1 не позволяет запускать единичные тесты из моей версии IDEA IDE (2025.1.1.1).
+При запуске из IDEA одного метода тестового класса, например `DataJpaUserServiceTest#getWithMeals()` я получаю эксепшен:
+```
+Exception in thread "main" java.lang.NoSuchMethodError: 'java.lang.String org.junit.platform.engine.discovery.MethodSelector.getMethodParameterTypes()'
+ at com.intellij.junit5.JUnit5TestRunnerUtil.loadMethodByReflection(JUnit5TestRunnerUtil.java:127)
+```
+В результате [понизил в `pom.xml` версию до 5.14.1](https://stackoverflow.com/questions/50323335/548473)
+
+###  5. [Принципы REST. REST контроллеры](https://drive.google.com/open?id=1e4ySjV15ZbswqzL29UkRSdGb4lcxXFm1)
+
+
+ Краткое содержание
+
+#### Принципы REST, REST-контроллеры
+
+> [REST](https://web.archive.org/web/20240919203427/http://spring-projects.ru/understanding/rest/) - архитектурный стиль проектирования распределенных систем (типа клиент-сервер).
+
+Чаще всего в REST сервер и клиент общаются посредством обмена JSON-объектами через HTTP-методы GET/POST/PUT/DELETE/PATCH.
+Особенностью REST является отсутствие состояния (контекста) взаимодействий клиента и сервера.
+
+В нашем приложении есть контроллеры для Admin и для User. Чтобы сделать их REST-контроллерами, заменим аннотацию `@Controller` на `@RestController`
+
+> Не поленитесь зайти чз Ctrl+Click в `@RestController`: к аннотации `@Controller` добавлена `@ResponseBody`. Т.е. ответ от нашего приложения будет не имя View, а данные в теле ответа.
+
+В `@RequestMapping`, кроме пути для методов контроллера (`value`) добавляем параметр `produces = MediaType.APPLICATION_JSON_VALUE`. Это означает, что в заголовки ответа будет добавлен
+тип `ContentType="application/json"` - в ответе от контроллера будет приходить JSON-объект.
+
+> Чтобы было удобно использовать путь к этому контроллеру в приложении и в тестах,
+> выделим путь к нему в константу REST_URL, к которой можно будет обращаться из других классов
+
+1. Метод `AdminRestController.getAll` пометим аннотацией `@GetMapping` - маршрутизация к методу по HTTP GET.
+
+2. Метод `AdminRestController.get` пометим аннотацией `@GetMapping("/{id}")`.
+ В скобках аннотации указано, что к основному URL контроллера будет добавляться `id` пользователя - переменная, которая передается в запросе непосредственно в URL.
+ Соответствующий параметр метода нужно пометить аннотацией `@PathVariable` (если имя в URL и имя аргумента метода не совпадают, в параметрах аннотации дополнительно нужно будет уточнить имя в URL.
+ Если они совпадают, [этого не требуется](https://habr.com/ru/post/440214/).
+
+3. Метод создания пользователя `create` отметим аннотацией `@PostMapping` - маршрутизация к методу по HTTP POST. В метод мы передаем объект `User` в теле запроса (аннотация `@RequestBody`) и в формате
+ JSON (`consumes = MediaType.APPLICATION_JSON_VALUE`). При создании нового ресурса правила хорошего тона - вернуть в заголовке ответа URL созданного ресурса. Для этого возвращем не `User`,
+ а `ResponseEntity`, который мы можем с помощью билдера `ServletUriComponentsBuilder` дополнить заголовком ответа `Location` и вернуть статус `CREATED(201)`
+ (если пойти в код `ResponseEntity.created` можно докопаться до сути, очень рекомендую смотреть в исходники кода).
+
+4. Метод `delete` помечаем `@DeleteMapping("/{id}")` - HTTP DELETE. Он ничего не возвращает, поэтому помечаем его аннотацией `@ResponseStatus(HttpStatus.NO_CONTENT)`. Статус ответа будет HTTP.204;
+
+5. Над методом обновления ставим `@PutMapping` (HTTP PUT). В аргументах метод принимает `@RequestBody User user` и `@PathVariable int id`.
+
+6. Метод поиска по `email` также помечаем `@GetMapping`, и, чтобы не было конфликта маршрутизации с методом `get()`, указываем в URL добавку "/by". В этот метод `email` передается как параметр
+ запроса, аннотация `@RequestParam`.
+
+> **Все это СТАНДАРТ архитектурного стиля REST. НЕ придумывайте ничего своего в своих выпускных проектах! Это очень большая ошибка - не придерживаться стандартов API.**
+
+7. `ProfileRestController` выполняем аналогичным способом с учетом того, что пользователь имеет доступ только к своим данным.
+
+Если на данном этапе попытаться запустить приложение и обратиться к какому-либо методу контроллера, сервер ответит нам ошибкой со статусом 406, так как Spring не знает, как преобразовать объект User в
+JSON...
+
+
+
+#### Apply 7_11_rest_controller.patch
+
+> - Переделал URL поиска по email на `/by-email`
+
+- Понимание REST
+- JSON (JavaScript Object Notation)
+- [15 тривиальных фактов о правильной работе с протоколом HTTP](https://habrahabr.ru/company/yandex/blog/265569/)
+- [10 Best Practices for Better RESTful](https://medium.com/@mwaysolutions/10-best-practices-for-better-restful-api-cbe81b06f291)
+- [Best practices for rest nested resources](https://stackoverflow.com/questions/20951419/what-are-best-practices-for-rest-nested-resources)
+-
+ Request mapping
+- [Лучшие практики разработки REST API: правила 1-7,15-17](https://tproger.ru/translations/luchshie-praktiki-razrabotki-rest-api-20-sovetov/)
+- Дополнительно:
+ - [Подборка практик REST](https://gist.github.com/Londeren/838c8a223b92aa4017d3734d663a0ba3)
+ - JAX-RS vs Spring MVC
+ - RESTful API для сервера – делаем правильно (Часть 1)
+ - RESTful API для сервера – делаем правильно (Часть 2)
+ - И. Головач. RestAPI
+ - [value/name в аннотациях @PathVariable и @RequestParam](https://habr.com/ru/post/440214/)
+
+###  6. [Тестирование REST контроллеров. Jackson.](https://drive.google.com/open?id=1aZm2qoMh4yL_-i3HhRoyZFjRAQx-15lO)
+
+
+ Краткое содержание
+
+Для работы с JSON добавляем в `pom.xml` зависимость `jackson-databind`.
+Актуальную версию библиотеки можно посмотреть в [центральном maven-репозитории](https://search.maven.org/artifact/com.fasterxml.jackson.core/jackson-databind).
+Теперь спринг будет автоматически использовать эту библиотеку для сериализации/десериализации объектов в JSON (найдя ее в *classpath*).
+Если сейчас запустить приложение и обратиться к методам REST-контроллера, то оно выбросит `LazyInitializationException`. Оно возникает из-за того, что у наших сущностей есть лениво загружаемые поля,
+отмеченные `FetchType.LAZY` - при загрузке сущности из базы, вместо этого поля подставится Proxy, который и должен вернуть реальный экземпляр этого поля при первом же обращении. Jackson при
+сериализации в JSON использует все поля сущности, и при обращении к *Lazy* полям возникает исключение, так как сессия работы с БД в этот момент уже закрыта, и нужный объект не может быть
+инициализирован. Чтобы Jackson игнорировал эти поля, пометим их аннотацией `@JsonIgnore`.
+
+Теперь при запуске приложения REST-контроллер будет работать. Но при получении JSON объектов мы можем увидеть, что Jackson сериализовал объект через геттеры (например в ответе есть поле `new` от
+метода `Persistable.isNew()`). Чтобы учитывались только поля объектов, добавим над `AbstractBaseEntity`:
+
+````java
+@JsonAutoDetect(fieldVisibility = ANY, // jackson видит все поля
+ getterVisibility = NONE, // ... но не видит геттеров
+ isGetterVisibility = NONE, //... не видит геттеров boolean полей
+ setterVisibility = NONE) // ... не видит сеттеров
+````
+
+Теперь все сущности, унаследованные от базового класса, будут сериализоваться/десериализоваться через поля.
+
+
+
+#### Apply 7_12_rest_test_jackson.patch (внимание: обновил патч 23.03 в 11.00)
+
+- [Jackson databind github](https://github.com/FasterXML/jackson-databind)
+- [Jackson Annotation Examples](https://www.baeldung.com/jackson-annotations)
+
+###  7. [Кастомизация Jackson Object Mapper](https://drive.google.com/open?id=1CM6y1JhKG_yeLQE_iCDONnI7Agi4pBks)
+
+
+ Краткое содержание
+
+Сейчас, чтобы не сериализовать *Lazy* поля, мы должны пройтись по каждой сущности и вручную пометить их аннотацией `@JsonIgnore`. Это неудобно, засоряет код и допускает возможные ошибки. К тому же,
+при некоторых условиях, нам иногда нужно загрузить и в ответе передать эти *Lazy* поля.
+Чтобы запретить сериализацию Lazy полей для всего проекта, подключим в `pom.xml` библиотеку `jackson-datatype-hibernate`.
+Также изменим сериализацию/десериализацию полей объектов в JSON: не через аннотацию `@JsonAutoDetect`, а в классе `JacksonObjectMapper`, который унаследуем от `ObjectMapper` (стандартный Mapper,
+который использует Jackson) и сделаем в нем другие настройки. В конструкторе:
+
+- регистрируем `Hibernate5Module` - модуль `jackson-datatype-hibernate`, который не делает сериализацию ленивых полей.
+- модуль для корректной сериализации `LocalDateTime` в поля JSON - `JavaTimeModule` модуль библиотеки `jackson-datatype-jsr310`
+- запрещаем доступ ко всем полям и методам класса и потом разрешаем доступ только к полям
+- не сериализуем null-поля (`setSerializationInclusion(JsonInclude.Include.NON_NULL)`)
+
+Чтобы подключить наш кастомный `JacksonObjectMapper` в проект, в конфигурации `spring-mvc.xml` к настройке `` добавим `MappingJackson2HttpMessageConverter`, который будет
+использовать наш маппер.
+
+
+
+#### Apply 7_13_jackson_object_mapper.patch
+
+- Сериализация hibernate lazy-loading с помощью
+ jackson-datatype-hibernate
+- Handle Java 8 dates with Jackson
+- Дополнительно:
+ - Jackson JSON Serializer & Deserializer
+
+###  8. [Тестирование REST контроллеров через JSONassert и Матчеры](https://drive.google.com/open?id=1oa3e0_tG57E71g6PW7_tfb3B61Qldctl)
+
+
+ Краткое содержание
+
+Сейчас в тестах REST-контроллера мы проводим проверку только на статус ответа и тип возвращаемого контента. Добавим проверку содержимого ответа.
+
+#### 7_14_json_assert_tests
+
+Чтобы сравнивать содержимое ответа контроллера в виде JSON и сущность, воспользуемся библиотекой
+`jsonassert`, которую подключим в `pom.xml` со scope *test*.
+
+Эта библиотека при сравнении в тестах в качестве ожидаемого значения ожидает от нас объект в виде JSON-строки. Чтобы вручную не преобразовывать объекты в JSON и не хардкодить их в виде строк в наши
+тесты, воспользуемся Jackson.
+Для преобразования объектов в JSON и обратно создадим утильный класс `JsonUtil`, в котором с помощью нашего `JacksonObjectMapper` и будет конвертировать объекты.
+И мы сталкиваемся с проблемой: `JsonUtil` - утильный класс и не является бином спринга, а для его работы требуется наш кастомный маппер, который находится под управлением спринга и расположен в
+контейнере зависимостей. Поэтому, чтобы была возможность получить наш маппер из других классов - сделаем его синглтоном и сделаем в нем статический метод, который будет возвращать его экземпляр.
+Теперь `JsonUtil` сможет его получить.
+И нам нужно указать спрингу, чтобы он не создавал второй экземпляр этого объекта, а клал в свой контекст существующий. Для этого в конфигурации `spring-mvc.xml` определим factory-метод, с помощью
+которого спринг должен получить экземпляр (instance) этого класса:
+
+```xml
+
+
+```
+
+а в конфигурации `message-converter` вместо создания бина просто сошлемся на сконфигурированный `objectMapper`.
+
+Метод `ContentResultMatchers.json()` из `spring-test` использует библиотеку `jsonassert` для сравнения 2-х JSON строк: одну из ответа контроллера и вторую - JSON-сериализация `admin` без
+поля `registered` (это поле инициализируется в момент создания и отличается). В методе `JsonUtil.writeIgnoreProps` мы преобразуем объект `admin` в мапу, удаляем из нее игнорируемые поля и снова
+сериализуем в JSON.
+
+Также сделаем тесты для утильного класса `JsonUtil`. В тестах мы записываем объект в JSON-строку, затем конвертируем эту строку обратно в объект и сравниваем с исходным. И то же самое делаем со
+списком объектов.
+
+#### 7_15_tests_refactoring
+
+**`RootControllerTest`**
+
+Сделаем рефакторинг `RootControllerTest`. Ранее мы в тесте получали модель, доставали из нее сущности и с помощью `hamcrest-all`
+производили по одному параметру их сравнение с ожидаемыми значениями. Метод `ResultActions.andExpect()` позволяет передавать реализацию интерфейса `Matcher`, в котором можно делать любые сравнения.
+Функциональность сравнения списка юзеров по ВСЕМ полям у нас уже есть - мы просто делегируем сравнение объектов в `UserTestData.MATCHER`. При этом нам больше не нужен `harmcrest-all`, нам достаточно
+только `harmcrest-core`.
+
+**`MatcherFactory`**
+
+Теперь вместо `jsonassert` и сравнения JSON-строк в тестах контроллеров сделаем сравнения JSON-объектов через `MatcherFactory`. Преобразуем ответ контроллера из JSON в объект и сравним с эталоном
+через уже имеющийся у нас матчер.
+Вместо сравнения JSON-строк в метод `andExpect()` мы будем передавать реализации интерфейса `ResultMatcher` из `MATCHER.contentJson(..)`.
+
+`MATCHER.contentJson(..)` принимают ожидаемый объект и возвращают для него `ResultMatcher` с реализацией единственного метода `match(MvcResult result)`, в котором делегируем сравнение уже существующим
+у нас матчерам. Мы берем JSON-тело ответа (`MatcherFactory.getContent`), десериализуем его в объект (`JsonUtil.readValue/readValues`) и сравниваем через имеющийся `MATCHER.assertMatch`
+десериализованный из тела контроллера объект и ожидаемое значение.
+
+> Методы из класса `TestUtil` перенес в `MatcherFactory`, лишние удалил.
+
+**`AdminRestControllerTest`**
+
+- `getByEmail()` - сделан по аналогии с тестом `get()`. Дополнительно нужно дополнить строку URL параметрами запроса.
+- `delete()` - выполняем HTTP.DELETE. Проверяем статус ответа 204. Проверяем, что пользователь удален.
+
+> Раньше я получал всех users из базы и проверял, что среди них нет удаленного. При этом тесты становятся чувствительными ко всем users в базе и ломаются при добавлении-удалении новых тестовых данных.
+
+- `update()` - выполняем HTTP.PUT. В тело запроса подаем сериализованный `JsonUtil.writeValue(updated)`. После выполнения проверяем, что объект в базе обновился.
+- `create()` - выполняем HTTP.POST аналогично `update()`. Но сравнить результат мы сразу не можем, т.к. при создании объекта ему присваивается `id`.
+ Поэтому мы извлекаем созданного пользователя из ответа (`MATCHER.readFromJson(action)`), получаем его `id`, и уже с этим `id` эталонный объект мы можем сравнить с объектом в ответе контроллера и со
+ значением в базе.
+- `getAll()` - аналогично get(). Список пользователей из ответа в формате JSON сравниваем с эталонным списком (`MATCHER.contentJson(admin, user)`).
+
+Тесты для `ProfileRestController` выполнены аналогично.
+
+
+
+#### Apply 7_14_json_assert_tests.patch
+
+> - В `JsonUtil.writeIgnoreProps` вместо цикла по мапе сделал `map.keySet().removeAll`
+
+- [JSONassert](https://github.com/skyscreamer/JSONassert)
+- [Java Code Examples for ObjectMapper](https://www.programcreek.com/java-api-examples/index.php?api=com.fasterxml.jackson.databind.ObjectMapper)
+
+#### Apply 7_15_tests_refactoring.patch
+
+> - Сделал внутренний класс `MatcherFactory.Matcher`, который возвращается из фабрики матчеров.
+> - Методы из класса `TestUtil` перенес в `MatcherFactory`, лишние удалил.
+> - Раньше в тестах я для проверок получал всех users из базы и сравнивал с эталонным списком. При этом тесты становятся чувствительными ко всем users в базе и ломаются при добавлении-удалении новых тестовых данных.
+
+- [Java @SafeVarargs Annotation](https://www.baeldung.com/java-safevarargs)
+
+###  9. [Тестирование через SoapUi. UTF-8](https://drive.google.com/open?id=0B9Ye2auQ_NsFVXNmOUdBbUxxWVU)
+
+
+ Краткое содержание
+
+SOAP UI - это один из инструментов для тестирования API приложений, которые работают по REST и по SOAP.
+Он позволяет нам по HTTP протоколу дернуть методы нашего API и увидеть ответ контроллеров.
+
+Если в контроллер мы добавим метод, который в теле ответа будет возвращать текст на кириллице, то увидим, что кодировка теряется. Для сохранения кодировки используем `StringHttpMessageConverter`,
+который конфигурируем в `spring-mvc.xml`. При этом мы должны явно указать, что конвертор будет работать только с текстом в кодировке *UTF-8*.
+
+
+
+#### Apply 7_16_soapui_utf8_converter.patch
+
+- Инструменты тестирования REST:
+ - SoapUi
+ - [Что такое Curl? Как работает эта команда?](https://highload.today/curl/)
+ - Написание HTTP-запросов с помощью Curl.
+ Для Windows 7 можно использовать Git Bash, с Windows 10 v1803 можно прямо из консоли. Возможны проблемы с UTF-8:
+ - [CURL doesn't encode UTF-8](https://stackoverflow.com/a/41384903/548473)
+ - [кириллица в теле POST-запроса](https://barbitoff.blogspot.com/2018/11/soapui-post-rest.html)
+ - [Нстройка кодировки в Windows](https://support.socialkit.ru/ru/knowledge-bases/4/articles/11110-preduprezhdenie-obnaruzhenyi-problemyi-svyazannyie-s-raspoznavaniem-russkih-simvolov)
+ - **[IDEA: Tools->HTTP Client->...](https://www.jetbrains.com/help/idea/rest-client-tool-window.html)**
+ - Postman
+ - [Insomnia REST client](https://insomnia.rest/)
+
+**Импортировать проект в SoapUi из `config\Topjava-soapui-project.xml`. Response смотреть в формате JSON.**
+
+> Проверка UTF-8: http://localhost:8080/topjava/rest/profile/text
+
+[ResponseBody and UTF-8](http://web.archive.org/web/20190102203042/http://forum.spring.io/forum/spring-projects/web/74209-responsebody-and-utf-8)
+
+##  Ваши вопросы
+
+> Зачем у нас и UIController'ы, и RestController'ы? То есть в общем случае backend-разработчику недостаточно предоставить REST-api и RestController?
+
+Часто используются и те и другие. REST обычно используют для отдельного UI например на React или Angular или для интеграции / мобильного приложения.
+У нас REST контроллеры используются только для тестирования. UI мы используем для нашего приложения на JSP шаблонах.
+Таких сайтов без богатой UI логики тоже немало. Например https://javaops.ru/ :)
+Разница в обработке запросов:
+
+- из UI контроллеров возвращаются как готовые HTML странички, так и данные в формате JSON (будет для AJAX запросов в следующих занятиях)
+- для UI мы используем только GET и POST запросы
+- при создании-обновлении в UI мы принимаем данные из формы `application/x-www-form-urlencoded` (посмотрите вкладку `Network`, не в формате JSON)
+- для REST запросы GET, POST, PUT, DELETE, PATCH и возвращают только данные (обычно JSON)
+
+И в способе авторизации:
+
+- для RESТ у нас будет базовая авторизация
+- для UI - через cookies
+
+Также часто бывают смешанные сайты - где есть и отдельное JS приложение и шаблоны.
+
+> При выполнении тестов через MockMvc никаких изменений на базе не видно, почему оно не сохраняет?
+
+`AbstractControllerTest` аннотируется `@Transactional` - это означает, что тесты идут в транзакции, и после каждого теста JUnit делает rollback базы.
+
+> Что получается в результате выполнения запроса `SELECT DISTINCT(u) FROM User u LEFT JOIN FETCH u.roles ORDER BY u.name, u.email`? В чем разница в SQL без `DISTINCT`.
+
+Запросы SQL можно посмотреть в логах. Т.е. `DISTINCT` в `JPQL` влияет на то, как Hibernate обрабатывает дублирующиеся записи (с `DISTINCT` их исключает). Результат можно посмотреть в тестах или
+приложении, поставив брекпойнт. По поводу `SQL DISTINCT` не стесняйтесь пользоваться google, например, [оператор SQL DISTINCT](http://2sql.ru/novosti/sql-distinct/)
+
+> В чем заключается расширение функциональности hamcrest в нашем тесте, что нам пришлось его отдельно от JUnit прописывать?
+
+`hamcrest-all` используется в проверках `RootControllerTest`: `org.hamcrest.Matchers.*`. JUnit 4 включает в себя `hamcrest-core`, в JUnit 5 его нужно подключать отдельно.
+
+> Jackson мы просто подключаем в помнике, и Spring будет с ним работать без любых других настроек?
+
+Да, Spring смотрит в classpath и если видит там Jackson, то подключает интеграцию с ним.
+
+> Где-то слышал, что любой ресурс по REST должен однозначно идентифицироваться через url без параметров. Правильно ли задавать URL для фильтрации в виде `http://localhost/topjava/rest/meals/filter/{startDate}/{startTime}/{endDate}/{endTime}` ?
+
+Так делают, только при отношении
+агрегация, например, если давать админу право смотреть еду любого юзера, URL мог бы быть похож на `http://localhost/topjava/rest/users/{userId}/meals/{mealId}` (не рекомендуется, см ссылку ниже).
+В случае критериев поиска или страничных данных они передаются как параметр. Смотри также:
+
+- [15 тривиальных фактов о правильной работе с протоколом HTTP](https://habrahabr.ru/company/yandex/blog/265569/)
+- 10 Best Practices for Better RESTful
+- [REST resource hierarchy (если кратко: не рекомендуется)](https://stackoverflow.com/questions/15259843/how-to-structure-rest-resource-hierarchy)
+
+> Что означает конструкция в `JsonUtil`: `reader.readValues(json)`;
+
+См. Generic Methods. Когда компилятор не может вывести тип, можно его уточнить при вызове generic метода. Неважно,
+static или нет.
+
+##  Домашнее задание HW07
+
+- 1: Добавить тесты контроллеров:
+ - 1.1 `RootControllerTest.getMeals` для `meals.jsp`
+ - 1.2 Сделать `ResourceControllerTest` для `style.css` (проверить `status` и `ContentType`)
+- 2: Реализовать `MealRestController` и протестировать его через `MealRestControllerTest`
+ - 2.1 следите, чтобы url в тестах совпадал с параметрами в методе контроллера. Можно добавить логирование `` для проверки маршрутизации.
+ - 2.2 в параметрах `getBetween` принимать `LocalDateTime` (конвертировать через @DateTimeFormat with Java 8
+ Date-Time API), пока без проверки на `null` (используя `toLocalDate()/toLocalTime()`, см. Optional п.3). В тестах передавать в формате `ISO_LOCAL_DATE_TIME` (
+ например `'2011-12-03T10:15:30'`).
+
+### Optional
+
+- 3: Переделать `MealRestController.getBetween` на параметры `LocalDate/LocalTime` c раздельной фильтрацией по времени/дате, работающий при `null` значениях (см. демо и `JspMealController.getBetween`)
+ . Заменить `@DateTimeFormat` на свои LocalDate/LocalTime конверторы или форматтеры.
+ - [Spring Type Conversion and Field Formatting — пишем первый конвертер или форматтер](https://habr.com/ru/post/703402/)
+- 4: Протестировать `MealRestController` (SoapUi, curl, IDEA Test RESTful Web Service, Postman). Запросы `curl` занести в отдельный `md` файл (или `README.md`)
+- 5: Добавить в `AdminRestController` и `ProfileRestController` методы получения пользователя вместе с едой (`getWithMeals`, `/with-meals`).
+ - [Jackson – Bidirectional Relationships](https://www.baeldung.com/jackson-bidirectional-relationships-and-infinite-recursion)
+
+### Optional 2
+
+- 6: Сделать тесты на методы контроллеров `getWithMeals()` (п.5)
+
+**На следующем занятии используется JavaScript/jQuery. Если у вас там пробелы, пройдите его основы**
+
+---------------------
+
+##  Типичные ошибки и подсказки по реализации
+
+- 1: Ошибка в тесте _Invalid read array from JSON_ обычно расшифровывается немного ниже: читайте внимательно.
+- 2: Jackson и неизменяемые объекты (для сериализации MealTo)
+- 3: Если у meal, приходящий в контроллер, поля `null`, проверьте `@RequestBody` перед параметром (данные приходят в формате JSON)
+- 4: При проблемах с собственным форматтером убедитесь, что в конфигурации `Topjava
+
+## Материалы занятия
+
+- **Браузер кэширует javascript и css. Если изменения не работают, обновите приложение в браузере (в хроме `Ctrl+F5`)**
+- **При удалении файлов не забывайте делать clean: `mvn clean`**
+
+##  Разбор домашнего задания HW7
+
+###  1. [HW7](https://drive.google.com/file/d/1h6wg2V9yZoNX7fA7mNA7w7Kxp8IACsIJ)
+
+
+ Краткое содержание
+
+#### Тесты ResourceController
+Прежде всего в настройках логирования для класса `ExceptionHandlerExceptionResolver`
+установим уровень "debug". Теперь в логах мы сможем увидеть запросы, у которых проблемы с маппингом.
+Чтобы протестировать доступ к ресурсам, создадим `ResourceControllerTest` с единственным тестовым методом.
+Класс `MediaType` позволяет указать требуемый тип с помощью фабричного метода `valueOf`.
+Начиная с [Spring 4.3 ожидаемый тип ответа нужно сравнивать с помощью `contentTypeCompatibleWith`](https://github.com/spring-projects/spring-framework/issues/19041), а не `contentType`
+(в этом случае кодировка UTF-8 в типе ответа не учитывается в сравнении).
+
+#### Тесты для RootController на еду
+Для `RootController` тесты на еду делаем точно так же, как и на `User`, с небольшим отличием.
+Так как `MealTo` - это транспортный объект, который не является Entity и не находится под управлением
+JPA, у него нет ограничений по методам `equals / hashCode`, и мы можем
+добавить свои (сгенерировать с помощью IDEA). Теперь в тестах объекты `MealTo` мы можем сравнивать
+через `equals()`.
+Чтобы убедиться, что два списка `MealTo` - ожидаемый и полученный от контроллера - сравниваются поэлементно
+через `equals`, мы можем установить в сравнении брейкпоинт и запустить тест в режиме дебага.
+
+#### Реализовать MealRestController
+`MealRestController` реализуем аналогично контроллерам пользователей.
+В метод `MealRestController#getBetween` с параметрами запроса нужно передать
+время и дату начала и конца диапазона, для которого будет найдена еда. Это можно сделать с помощью аннотации `@DateTimeFormat(iso = DateTimeFormat.ISO.DATE_TIME)`.
+Spring автоматически конвертирует параметры запроса в объекты типа `LocalDateTime`.
+
+В `MealRestControllerTest` нужно обратить внимание на тесты для методов `getAll` и `getBetween` контроллера, так как они возвращают список `MealTo`, а не `Meal`.
+Поэтому для сравнения списков еды создадим отдельный `TO_MATCHER` с помощью статического фабричного метода `usingEqualsComparator(MealTo.class)`:
+```
+public static MatcherFactory.Matcher TO_MATCHER = MatcherFactory.usingEqualsComparator(MealTo.class)
+```
+Он будет сравнивать `MealTo` уже не рекурсивно, а с помощью `MealTo#equals()` — сравнения в методах `assertMatch` переделал с использованием реализаций интерфейса `BiConsumer`:
+*assertion* и *iterableAssertion*. Получается очень гибко (привет, паттерн "стратегия"): для создания матчера мы можем использовать любые собственные реализации сравнений.
+
+Для того чтобы для тестов создать объекты `MealTo`, используем утилитный метод `MealsUtil#createTo`, изменив у него модификатор доступа на *public*.
+
+Для некоторых методов с переменным количеством аргументов IDEA сообщает о небезопасности типов. Чтобы подавить эти
+предупреждения, над методами у нас стоят аннотации `@SafeVarargs` (для использования этой аннотации метод должен быть `final`).
+
+Чтобы Jackson мог сериализовать/десериализовать объекты `MealTo`, нам нужно сделать для этого класса сеттеры или создать конструктор, помеченный специальной аннотацией `@ConstructorProperties`,
+в параметры которой передаем поля объекта json, соответствующие аргументам конструктора.
+
+
+
+
+
+#### Apply 8_01_HW07_controller_test.patch
+
+- [Persistent classes implementing equals and hashcode](https://docs.jboss.org/hibernate/orm/4.3/manual/en-US/html_single/#persistent-classes-equalshashcode): переопределять `equals()/hashCode()`
+ необходимо, если
+ - использовать Entity в `Set` (рекомендовано для many-ассоциаций) либо как ключи в `HashMap`
+ - использовать _reattachment of detached instances_ (т.е. манипулировать одним Entity в нескольких транзакциях/сессиях).
+- Оптимально использовать уникальные неизменяемые бизнес-поля, но обычно таких нет, и чаще всего используется суррогатный PK с ограничением, что он может быть `null` у новых объектов, и нельзя объекты сравнивать
+ через `equals` в бизнес-логике (например, в тестах).
+- [Equals() and hashcode() when using JPA and Hibernate](https://stackoverflow.com/questions/1638723)
+
+------------------------
+
+#### Apply 8_02_HW07_rest_controller.patch
+> - В `MealTo` вместо изменяемых полей и конструктора без параметров сделал [`@ConstructorProperties`](https://www.logicbig.com/tutorials/misc/jackson/constructor-properties.html). `Immutable` классы
+ всегда предпочтительнее для данных.
+- [Паттерн стратегия](https://refactoring.guru/ru/design-patterns/strategy).
+
+###  2. HW7 Optional
+
+
+ Краткое содержание
+
+#### Собственный Spring-конвертер (форматтер) для даты и времени
+Spring фреймворк с помощью встроенных конвертеров (реализующих интерфейс `org.springframework.core.convert.converter.Converter`) и форматтеров (интерфейс `org.springframework.format.Formatter`) делает автоматическое преобразование параметров запроса из одного типа в другой.
+В нашем случае параметры фильтрации еды - дата и время - по REST приходят в виде строки, и мы можем добавить свой конвертер или форматтер, чтобы он автоматически приводил их к нужному нам типу.
+> - Конвертер Spring преобразует объект одного типа в объект другого типа
+> - Форматер преобразует объект типа String в объект нужного типа (при этом может поддерживать локаль)
+
+Сделаем собственные форматтеры для преобразования строки в дату и время `DateTimeFormatters`, добавим в `spring-mvc.xml` бин `conversionService` с перечнем наших форматтеров и сделаем на него ссылку:
+```
+
+```
+`LocalTimeFormatter` и `LocalDateFormatter` - наши кастомные форматтеры, которые будут парсить строку параметра. Для этого они должны реализовывать
+интерфейс `Formatter<Целевой тип>` и переопределять его методы `#parse` и `#print`. Теперь мы можем убрать аннотации `@DateTimeFormat` из аргументов `MealRestController#getBetween`. `conversionService` будет
+искать среди форматеров или конвертеров те, которые смогли бы преобразовать параметр-строку в объект соответствующего типа, объявленный в методе контроллера, и в результате будут использованы наши кастомные форматеры.
+Для новой реализации метода `getBetween` теперь создадим несколько тестов - с различным набором параметров (в том числе и с пустыми параметрами).
+
+#### Протестировать сервисы с помощью SoapUI
+Помимо SoapUI, для тестирования REST можно использовать команду *curl* через *Git Bash* (этот способ имеет свои недостатки - не поддерживается UTF8).
+Для запросов требуется указывать Content-Type, иначе контроллер не сможет обработать запрос.
+Также популярными средствами тестирования REST являются *Postman* и в IDEA: *Tools->HTTP Client*.
+> Для тестирования REST у вас должен быть запущен Tomcat с вашим приложением!
+
+
+
+
+#### Apply 8_03_HW07_formatters.patch
+
+> - Перенес форматтеры в подпакет `web`, т.к. они используются Spring MVC
+> - Заменил `@RequestParam(required = false)` на `@RequestParam @Nullable`
+
+#### Apply 8_04_HW07_soapui_curl.patch
+
+> Добавил примеры запросов curl в `config/curl.md`
+
+- Написание HTTP-запросов с помощью Curl (для Windows можно использовать Git Bash)
+- В IDEA появился отличный инструмент тестирования запросов. Для конвертации
+ в [Tools->HTTP Client->Test RESTful Web Service](https://www.jetbrains.com/help/idea/http-client-in-product-code-editor.html) скопируйте curl без флага `-s`
+
+### Внимание! curl команды, требуемые в ТЗ к выпускному проекту, сделайте в `readme.md`, НЕ НАДО делать в выпускном проекте отдельный `curl.md`.
+
+###  3. [HW7 Optional: getWithMeals + тесты](https://drive.google.com/file/d/13cjenXzWDr52HTTzleomOd-yjPAEAbOA)
+
+
+ Краткое содержание
+
+В нашем приложении у `Meal` есть ссылка на `User`, а в `User` есть ссылка на коллекцию `Meal`.
+Таким образом, мы имеем дело с *BiDirectional* циклической зависимостью. При сериализации через Jackson у нас возникнут проблемы, так как он перейдет в
+бесконечный цикл при переходе по ссылкам сущностей друг на друга.
+Возможно следующее разрешение циклических зависимостей:
+
+- над полем `Meal.user` добавить аннотацию `@JsonBackReference`, теперь для еды это поле не будет сериализоваться в json;
+- над коллекцией `User.meals` добавить аннотацию `@JsonManagedReference`, поле будет сериализоваться.
+
+Теперь для получения пользователя с едой в методах контроллера можно просто вызвать соответствующий метод сервиса.
+
+Для новой функциональности создадим дополнительные тесты. В тестовых данных для пользователей заполним поля *meals*.
+Чтобы сразу проверять пользователя вместе с его едой, создадим дополнительный `UserTestData.WITH_MEALS_MATCHER`, который будет сравнивать сущности с помощью переданных ему интерфейсов сравнения.
+Коллекции пользователей с едой мы не реализуем, поэтому `iterableAssertion` также делать не нужно, бросаем `UnsupportedOperationException`.
+
+Так как метод получения пользователя с едой у нас реализован только в профиле `datajpa`, в тестах перед выполнением метода нужно проверить, что текущий профиль Spring - `dataJpa`, тесты будут пропускаться для других профилей.
+Такую функциональность мы ранее уже реализовывали - внедряем в тестовый класс `Environment` и проверяем активный профиль с помощью `Assumptions#assumeTrue`.
+
+
+
+#### Apply 8_05_HW07_with_meals.patch
+#### Apply 8_06_HW07_test_with_meals.patch
+> Изменения в AssertJ: `ignoringAllOverriddenEquals` для рекурсивных сравнений не нужен. См. [overridden equals used before 3.17.0](https://assertj.github.io/doc/#assertj-core-recursive-comparison-ignoring-equals)
+
+## Занятие 8:
+
+###  4. WebJars. jQuery and JavaScript frameworks
+
+
+ Краткое содержание
+
+**WebJars** — библиотеки на стороне клиента (JavaScript библиотека и/или CSS модуль), упакованные в JAR.
+
+Добавим в наш проект в `pom.xml` дополнительные зависимости - библиотеки JavaScript и css:
+- *jQuery* - самая распространенная утилитная JavaScript-библиотека;
+- *Bootstrap* - фреймворк CSS-стилей;
+- *Datatables* - плагин для отрисовки таблиц;
+- *datetimepicker* - плагин для работы с датой и временем;
+- *noty* - для работы с уведомлениями;
+
+
+
+#### Apply 8_07_webjars.patch
+
+> - Обновил jQuery до 3.x, Bootstrap до 4.x
+ > - Новое в jQuery 3
+> - УБРАЛ из проекта Dandelion обертку к Datatables
+ > - не встречал нигде, кроме Spring Pet Clinic;
+ > - поддержка работы с Datatables через Dandelion оказалось гораздо более трудоемкой, чем работа с плагином напрямую.
+> - Исключил ненужные зависимости
+
+- Подключение веб-ресурсов. WebJars.
+- Introducing WebJars
+- Document Object Model (DOM)
+- What is the DOM?
+- jQuery
+- Is jQuery a javascript library or framework
+- DataTables
+- Working with jQuery DataTables
+
+##  5. [Bootstrap](https://drive.google.com/file/d/1RHtzw8OQt6guCu6xe3apT7F9EfiX96tr)
+
+
+ Краткое содержание
+
+Front-end нашего приложения будет строиться на основе фреймворка Bootstrap.
+> В новой версии Bootstrap 5 из зависимостей исключена библиотека jQuery, и весь необходимый функционал Bootstrap делается на простом JavaScript. Однако JQuery нам нужна для *Datatables* и плагинов, поэтому не стал переходить на 5-ю версию.
+
+По ссылке [Bootstrap Examples](https://getbootstrap.com/docs/4.6/examples/) приведены примеры сайтов на Bootstrap. Из перечня уже готовых шаблонов можно выбрать
+подходящий шаблон, скопировать из его исходного кода стили, форматирование и использовать в своем проекте.
+- В `spring-mvc.xml` мы должны явно указать маппинг на *WebJars*-ресурсы, с которыми будет работать приложение:
+````xml
+
+````
+- В `headTag.jsp`, который у нас сейчас добавляется через `jsp:include` в начало каждой JSP страницы, подтягиваем из *WebJars* нужные нам *css*-ресурсы и иконку для нашего приложения.
+- Для отрисовывания стандартных иконок подключается ресурс ``.
+ В класс иконок `.fa` добавим `cursor: pointer` - это курсор-рука, который обычно используется для кнопок.
+- В стили добавим sticky-footer - это footer, который будет включаться в конце JSP-страниц и приклеиваться к нижней части экрана.
+- JSP-страницу со списком пользователей оформим с использованием элементов Bootstrap и добавим иконки на кнопки.
+- на странице `index.jsp` форму выбора пользователя поместим в класс Bootstrap *jumbotron* - крупный выносной элемент с большим текстом и большими отступами
+- таблицей пользователей в `users.jsp` поместим в аналогичный элемент *jumbotron*
+
+
+#### Apply 8_08_bootstrap4.patch
+
+> - [WIKI Bootstrap](https://ru.wikipedia.org/wiki/Bootstrap_(фреймворк))
+> - Добавил Font Awesome
+ > - [Map glyphicon icons to font-awesome](https://gist.github.com/blowsie/15f8fe303383e361958bd53ecb7294f9)
+> - В `headTag.jsp` в ссылку на `style.css` добавил `?v=2`. Стили изменились, изменяя версию в параметре мы заставляем браузер не брать их из кэша, а загружать заново.
+
+- [Bootstrap](https://getbootstrap.com/)
+ - [Navbar](https://getbootstrap.com/docs/4.1/components/navbar/)
+ - [Spacing](https://getbootstrap.com/docs/4.1/utilities/spacing/)
+ - [Forms](https://getbootstrap.com/docs/4.1/components/forms/)
+ - [Sticky footer](https://getbootstrap.com/docs/4.1/examples/sticky-footer/)
+- [Документация Bootstrap на русском](https://bootstrap-4.ru/)
+- Дополнительно
+ - Twitter Bootstrap Tutorial
+ - Видеоуроки Bootstrap 4
+ - [Bootstrap верстка современного сайта за 45 минут](https://www.youtube.com/watch?v=46q2eB7xvXA)
+
+##  Ваши вопросы
+
+> А где реально этот путь "classpath:/META-INF/resources/webjars"?
+
+Внутри подключаемых webjars ресурсы лежат по пути `/META-INF/resources/webjars/...` Не поленитесь посмотреть на них через `Ctrl+Shift+N`. Все подключаемые jar попадают в classpath, и ресурсы доступны
+по этому пути.
+
+> У меня webjars-зависимость лежит внутри ".m2\repository\org\webjars\". С чем это может быть связано?
+
+Maven скачивает все зависимости в local repository, который по умолчанию находится в `~/.m2`. Каталог по умолчанию можно переопределить в `APACHE-MAVEN-HOME\conf\settings.xml`,
+элемент `localRepository`.
+
+> WEBJARS лежат вообще в другом месте WEB-INF\lib\. Биндим mapping="/webjars/*" на реальное положение jar в war-e, откуда Spring знает, где искать наш jQuery?
+
+В war в `WEB-INF/lib/*` лежат все jar, которые попадают к classpath. Spring при обращении по url `/webjars/` ищет по пути
+биндинга ``
+по всему classpath (то же самое, как распаковать все jar в один каталог) в `META-INF/resources/webjars/`. В этом месте во всех jar, которые мы подключили из webjars, лежат наши ресурсы.
+
+> Оптимально ли делать доступ к статическим ресурсам (css, js, html) через webjars ?
+
+На продакшене под нагрузкой статические ресурсы лучше всего держать не в war, а снаружи. Доступ к ним делается либо
+через конфигурирование Tomcat.
+Но чаще всего для доступа к статике ставят прокси, например Nginx
+
+##  6. AJAX. Datatables. jQuery
+
+
+ Краткое содержание
+
+**AJAX** (асинхронный JavaScript и XML) — подход к построению интерактивных пользовательских интерфейсов веб-приложений, заключающийся в "фоновом" обмене данными браузера с веб-сервером.
+
+#### AdminUIController
+У нас будут отдельные от REST UI-контроллеры, так как в них будут отличаться обработка исключений, некоторая логика и авторизация.
+В `AdminUIController` метод `#create` будет использоваться как для создания, так и для обновления пользователя в зависимости от значения `id`.
+
+#### Список пользователей
+Оформляем таблицу пользователей с помощью js/css библиотеки `Datatables`. Таблица должна иметь id (в нашем случае "datatable"), чтобы к ней можно было обращаться.
+Также на страницу добавляем форму, с помощью которой будем редактировать и добавлять пользователей.
+Форма имеет скрытое поле `id`, которое будет использоваться в наших js-скриптах.
+
+#### topjava.users.js
+> Код по сравнению с видео изменился! Про изменения я говорю в конце видео и перечислил их после *Краткого содержания*
+
+Для работы AJAX объявляем переменные:
+- *ajaxUrl* - адрес нужного endpoint контроллера
+- *datatableApi* - объект таблицы `datatable`
+
+Страница html имеет определенный жизненный цикл, в процессе которого с ней совершаются какие-то действия.
+Одно из таких действий - загрузка, после которого мы можем производить какие-то манипуляции на странице.
+С помощью jQuery мы определяем коллбэк-метод, который будет вызываться после загрузки страницы:
+```
+$(function () {
+ ...
+```
+Строчка
+```
+datatableApi = $("#datatable").DataTable(
+```
+преобразует HTML-элемент c *id=datatable* в javaScript-объект с помощью метода `DataTable` библиотеки *Datatables*.
+Параметр этого метода - объект-конфигурация, который задает опции отображения таблицы и в "columns" задает соответствие колонок таблицы полям приходящего с сервера JSON-объекта пользователей.
+Внизу конфигурации добавляется сортировка таблицы по первому столбцу.
+После этого вызывается метод `makeEditable()` (он находится в `topjava.common.js`).
+
+#### topjava.common.js
+
+- В `makeEditable` к событию *click* всех объектов HTML c классом *delete* привязываем вызов метода `deleteRow`. Параметром берем аттрибут `id` текущего элемента `$(this)`.
+
+- Метод `add` вызывается из `users.jsp` по нажатию на кнопку "Добавить": `onclick="add()"`. В нем
+ - обнуляются все поля `input` формы `detailsForm`: `$("#detailsForm").find(":input").val("")`
+ - вызывается входящий в Bootstrap метод `modal()`, который преобразует HTML-элемент `id=editRow` в модальное окно. [Botstrap4 Modal](https://getbootstrap.com/docs/4.6/components/modal)
+
+- В методе `deleteRow` делаем AJAX-запросы к серверу и по после их успешного выполнения вызываем обновление таблицы.
+
+- В `updateTable` по AJAX запрашиваем с сервера массив пользователей, в случае успеха очищаем таблицу и заполняем ее данными, полученными с сервера.
+
+- В `save` средствами jQuery сериализуем форму `id=detailsForm` в JSON-объект и методом POST отдаем эти данные. После успешного выполнения запроса закрываем модальное окно и обновляем таблицу.
+
+Intellij IDEA предоставляет нам возможность дебага кода JavaScript. См. видео для примера.
+
+#### Загрузка HTML
+По умолчанию при стандартной загрузке страницы с js-скриптами браузер будет:
+- Парсить нужную HTML-страницу;
+- Как только браузер сталкивается с тегом `` и сохранить.**
+
+- XSS для новичков
+- XSS глазами злоумышленника
+
+Раньше я [реализовывал XSS защиту через `@SafeHtml`](https://stackoverflow.com/a/40644276/548473), пока его не [удалили из hibernate validator](https://hibernate.org/validator/documentation/migration-guide/).
+Пришлось сделать собственную аннотацию `@NoHtml` на основе [Sanitizing User Input](https://thoughtfulsoftware.wordpress.com/2013/05/26/sanitizing-user-input-part-ii-validation-with-spring-rest/)
+ и [jsoup - Sanitize HTML](https://www.tutorialspoint.com/jsoup/jsoup_sanitize_html.htm)
+Все классы, относящиеся к валидации перенес в пакет `ru.javawebinar.topjava.util.validation`
+- `password` проверять не надо, т.к. он не выводится в html, а [email надо](https://stackoverflow.com/questions/17480809)
+- Сделать общий интерфейс валидации `View.Web` и `@Validated(View.Web.class)` вместо `@Valid` для проверки содержимого только на входе UI/REST.
+При сохранении в базу проверка на безопасный html контент (XSS) повторно не делается.
+- [Validation groups in Spring MVC](https://blog.codeleak.pl/2014/08/validation-groups-in-spring-mvc.html)
+
+#### Apply 11_12_XSS.patch
+
+### Swagger2
+
+Swagger это фреймворк для автоматического создания REST-API документации по аннотациям контроллеров Spring MVC.
+Подключим зависимость `springfox-swagger2` и `springfox-swagger-ui` в `pom.xml`.
+Сразу же в проект подключается Swagger UI интерфейс, который позволяет отправлять запросы к эндпоинтам REST-API и просматривать документацию.
+
+Настройка swagger производится в конфигурации `spring-mvc.xml` подключением бина `Swagger2DocumentationConfiguration`.
+Чтобы смотреть REST-API документацию мог любой пользователь, в `spring-security.xml` доступ к эндпоинтам Swagger UI открываем всем:
+```xml
+
+
+
+```
+`AuthorizedUser authUser` не является реальным параметром методов контроллера, который передается клиентом.
+Это авторизированный пользователь, который резолвится Spring Security через `@AuthenticationPrincipal`.
+Убираем его из документации запросов через `@ApiIgnore`: Swagger будет игнорировать такие параметры при генерировании документации.
+UI контроллеры также исключаем из REST-API, пометив их `@ApiIgnore` на уровне класса.
+
+Создадим на `login.jsp` кнопку "Swagger REST Api Documentation".
+
+**Внимание: Swagger подключается в проект ОЧЕНЬ просто, а пользу от него для ревью трудно переоценить. Вместо примеров `curl` в выпускных проектах
+предлагаю вам подключить Swagger и в `readme.md` дать ссылку на сгенерированную REST API документацию.**
+
+- [Setting Up Swagger 2 with a Spring REST API](https://www.baeldung.com/swagger-2-documentation-for-spring-rest-api)
+- [Swagger 2 Configuration With Spring (XML)](https://medium.com/@andreymamontov/swagger-2-configuration-with-spring-xml-3cd643a12425)
+- [Hiding Endpoints From Swagger Documentation](https://www.baeldung.com/spring-swagger-hiding-endpoints)
+> В версиях выше 2.10 и 3.0 появились проблемы с маппингом. Вариант документации c OpenAPI 3.0 смотрите в [Spring Boot курсе](https://javaops.ru/view/bootjava)
+
+#### Apply 11_13_swagger2.patch
+
+---------------------
+### HW Optional 2
+
+Обратите внимание в Swagger UI на `Example Value` при
+- `POST /rest/admin/users (createWithLocation)` - здесь не должно быть поля `meals`. Пользователь создается без еды, еда управляется своими запросами.
+- `POST /rest/profile/meals (createWithLocation)` - здесь не должно быть поля `user`.
+Нужно поправит `Example Value`. При этом учтите, что в API у нас есть метод
+`GET /rest/admin/users/{id}/with-meals (getWithMeals)` - вернуть пользователя с едой.
+
+[Hide a Request Field in Swagger API](https://www.baeldung.com/spring-swagger-hide-field)
+
+-----------------------
+
+Платформа Heroku стала платной, вместо нее мы предлагаем зарегистрировать и задеплоиться на [собственный выделенный хостинг](https://github.com/JavaOPs/startup/blob/main/hosting.md).
+Тарифы хостингов самые демократичные: собственный Ubuntu сервер с доступом по SSH и 1ГБ памяти - оптимально для приложения Spring Boot - [тариф _Прогрев_ за 174 руб/мес](https://firstvds.ru/?from=1119260)
+
+### Ограничение модификации пользователей
+Наше [демо-приложение](http://javaops-demo.ru/topjava) доступно любому и нам нужно защитить стандартные учетные записи User и Admin от попыток их
+модификации. Сделаем новый профиль `VDS` и в `UserService` введем флаг `modificationRestriction` - нужна ли нам такая проверка.
+Через `Environment` проверяем активный профиль и для профиля `VDS` устанавливаем флаг в *true*.
+В методах, изменяющих пользователя, проверяем этот флаг и `id` изменяемой сущности, и, попытке несанкционированных изменений, бросаем `UpdateRestrictionException`.
+Отнаследовал это исключение от `ApplicationException` - универсального исключения нашего приложения, в котором можно задавать тип и код локализации ошибки.
+В `GlobalExceptionHandler` и `ExceptionInfoHandler` создаем обработчики `ApplicationException`.
+Для тестирования исключения при попытке изменение пользователя и админа для профиля `VDS` делаем `VdsRestControllerTest`:
+задаем профиль запуска `@ActiveProfiles(VDS)`, делаем модификацию и проверяем исключение.
+
+#### Apply 11_14_vds_restrict_modification.patch
+
+ - В `UserService` добавил защиту от изменения `Admin/User` для профиля `VDS` (в `UserService` заинжектил `Environment` и сделал проверку на наличие профиля `VDS`)
+ - **В выпускном проекте, если только не выставляете его в облако для показа, это НЕ требуется**.
+ - Чтобы тесты были рабочими, ввел профиль `VDS`, работающий так же, как и `POSTGRES`.
+ - Добавил универсальный `ApplicationException` для работы с ошибками с поддержкой i18n в приложении (от него отнаследовал `UpdateRestrictionException`)
+
+> Для тестирования с профилем vds добавьте в VM options: `-Dspring.profiles.active=datajpa,vds`
+
+### Деплой приложения на Выделенный сервер
+
+Наше [демо-приложение](http://javaops-demo.ru/topjava) теперь хостится на FirstVDS (SSD диск вместо NVMe)
+Первое открытое занятие [курса Startup](https://javaops.ru/view/startup) обучает регистрации хостинга, установке ПО и деплою приложения
+
+### [Открытое занятие курса Startup](https://github.com/JavaOPs/startup)
+
+#### Apply 11_15_vds.patch
+Файл пропертей с паролями не принято держать в репозитории (даже если репозиторий _private_).
+Поэтому вам необязательно комитить его, просто скопируйте на сервер по инструкции в разделе урока "_Деплой war на сервер_"
+
+### HW Optional 2 Solution:
+
+#### Apply [11_16_HW_fix_swagger.patch](https://drive.google.com/file/d/1qljW2tk8bI8GS5Tx43nO3stwlm5pLkEf)
+- Скрываем необязательные поле `id` при POST и PUT запросах через `@ApiModelProperty(hidden = true)` в примерах запроса Swagger, при этом передавать поле в запросе можно: [be conservative when you reply, but accept liberally](https://stackoverflow.com/a/28025008/548473)
+- `Meal.user` отсутствует в REST API, можно игнорировать: `@JsonIgnore`
+- `User.meals` можно было сделать `JsonProperty.Access.READ_ONLY`, но при этом не пройдут тесты `getWithMeals` (maels не будет сериализоваться из ответа сервера для сравнения). Скрыл также через `@ApiModelProperty(hidden = true)`
+- Также можно было скрыть нулевое поле `User.meals` при выводе через `@JsonInclude(JsonInclude.Include.NON_EMPTY)`. Но при этом поле исчезнет при запросе `getWithMeals` пользователя с пустым списком еды (например для Guest). Все зависит от бизнес-требований приложения (например насколько API публично и должно быть красивым). Можете попробовать самостоятельно скрыть это поле из вывода для запросов без еды через `View` (или отдельный TO).
+
+----------------------
+
+###  Собеседование. Разработка ПО
+- [Темы/ресурсы тестового собеседования](http://javaops.ru/interview/test.html)
+- [Составление резюме, подготовка к интервью, поиск работы](https://github.com/JavaOPs/topjava/blob/master/cv.md)
+- [Слайды](https://docs.google.com/presentation/d/18o__IGRqYadi4jx2wX2rX6AChHh-KrxktD8xI7bS33k), [Книги](http://javaops.ru/view/books)
+- [Jenkins/Hudson: что такое и для чего он нужен](https://habrahabr.ru/post/334730/)
+
+###  [Вебинар: Составление резюме и поиск работы в IT](https://www.facebook.com/watch/live/?v=2789025168007756)
+###  Разбор типовых собеседований (необработанный вебинар)
+###  Вебинар выпускников
+
+-----------------------
+
+##  Домашнее Задание:
+### **Опционально: [зарегистрировать хостинг и задеплоить в него свое приложение](https://github.com/JavaOPs/startup)**
+
+### **Пройдите основы Spring Boot по курсу [BootJava](https://javaops.ru/view/bootjava)**
+- **Занятие по миграция на Spring Boot будет в начале следующей недели**
+
+### **[Выполнить выпускной проект](https://github.com/JavaWebinar/topjava/blob/doc/doc/graduation.md)**
+ - Сроки сдачи и форма заполнения указаны в выпускном.
+ - Если проверки или Диплома нет, заполнять не нужно.
+ - **Возможно [доплатить за ревью выпускного отдельно из JavaOPs профиля](https://javaops.ru/auth/payonline?payId=OG)**
+
+### **Сделать / обновить резюме (отдать на ревью в канал #lesson11 группы slack)**
+- **Вставь ссылку на свой сертификат [из личного профиля](http://javaops.ru/auth/profile#finished), немного досрочно:)**
+ - [Загрузка сайта на GitHub. Бесплатный хостинг и домен.](https://www.youtube.com/watch?v=adaZZd73VGU)
+ - [CSS theme for hosting your personal site, blog, or portfolio](https://mademistakes.com/work/minimal-mistakes-jekyll-theme/)
+
+####  Замечания по резюме:
+ - **если нет опыта в IT, обязательно вставь [участие в стажировке Topjava](https://github.com/JavaOPs/topjava/blob/master/cv.md#Позиционирование-проекта-topjava). Весь не-IT опыт можно кратко.**
+ - варианты размещения: Pdf в любом облаке, [Google Doc](https://docs.google.com/), LinkedIn, HH, [еще варианты и рекомендации](https://github.com/JavaOPs/topjava/blob/master/cv.md#составление-резюме)
+Хорошо, если будет в html или pdf формате (например в https://pages.github.com/). [Например так](https://gkislin.github.io/), [на github](https://github.com/gkislin/gkislin.github.io/blob/master/index.html). Возраст и день рождения писать не обязательно
+ - [все упоминания Junior убрать!!](https://vk.com/javawebinar?w=wall-58538268_1589)
+ - линки делай кликабельными (если формат поддерживает)
+ - всю выгодную для себя информацию (и важную для HR) распологайте вверху. Название секций в резюме и их порядок относительно стандартный и важный
+ - **Резюме на hh или других ресурсах ДОЛЖНО БЫТЬ ОТКРЫТО ДЛЯ ПРОСМОТРА и иметь телефон для связи**
+ - Заполните контакты `skype/telegram/whatsapp`, HR ими пользуется! Почта как контакт очень медленная, телефон может быть не всегда удобен. Вообще `skype/telegram` для программиста - **Must have**.
+ - **Добавьте в резюме ссылки на свои проекты в `GitHub` и на задеплоенные на ваш сервер. Не забудьте про выпускной!**.
+ - Диплом РФ от Виакадемии о [профессиональной переподготовке](https://ru.wikipedia.org/wiki/Профессиональная_переподготовка) приравнивается ко второму высшему образованию. В резюме, полагаю, можно указать в высшем образовании
+ - Заполнить в [своем профиле Java Online Projects](http://javaops.ru/auth/profileER) ссылку на резюме и информацию по поиску работы (если конечно актуально): резюме, флаги рассматриваю работу, готов к релокации и информация для HR.
+ - **Рассылку обновления базы соискателей по HR буду делать в конце января, можно не спешить**
+
+### **После ревью резюме - опубликовать на ресурсах IT вакансий**
+ - [Основные сайты поиска работы](https://github.com/JavaOPs/topjava/blob/master/cv.md#основные-сайты-поиска-работы)
+
+### **Получить первое открытое занятие МНОГОПОТОЧНОСТЬ и пройти эту важную тему в [проекте Masterjava](http://javaops.ru/view/masterjava)**
+ - Обучение на MasterJava идет в индивидуальном режиме без проверки ДЗ: старт в любой момент, время прохождение ничем не ограничено
+ - Проект, патчи, группа Slack, занятия и видео, разбор ДЗ аналогичны проекту Topjava.
+ - **До середины января на курс MasterJava для выпускников специальная цена.**
+ - **Действует акция: при покупке MasterJava курс [Работа с документами в Java (DocJava)](https://javaops.ru/view/docjava) в подарок!**
+
+### **Моя реализация выпускного проекта [TopJava-2](http://javaops.ru/view/topjava2)**
+ - Так же, как и разбор домашних заданий, финальный разбор моей реализации выпускного проекта очень важен.
+ - Есть выгодные пакеты: TopJava-2 + полное ревью выпускного проекта + курс MasterJava
+ - **До середины мая курс TopJava2 и все пакеты по минимальной цене!**
+ - Оплатить TopJava-2 можно сейчас по специальной цене, а активировать доступ уже после ревью вашего выпускного
+
+### **[Полное ревью выпускного проекта](https://javaops.ru/auth/payonline?payId=OG)**
+- Ревью выпускного проекта входит в стоимость проверок. Если у вас их не было, вы много потеряли.
+- Но еще можно приобрести полное ревью выпускного проекта:
+ - Получить 1-е ревью от наших кураторов стажировки: стиль, архитектура, API, структура, кодирование
+ - Исправить замечания (срок - до нескольких недель)
+ - Получить финальное ревью проекта от Григория Кислина
+ - Получить [сертификат с отличием](https://javaops.ru/certificate/topjava?email=admin@javaops.ru) и попасть [на доску почета](https://javaops.ru/bestTopjava)
+**ВНИМАНИЕ: для отличников у нас скидка 30% на все проекты и пакеты (кроме проверки ДЗ) + валидация профиля у [партнера OfferHeap](https://offerheap.com/)**
+
+#### Возможные доработки приложения:
+- Разделить `Meal.dateTime` на `date` и `time` и выполнять запрос целиком в SQL
+- Для редактирования паролей сделать отдельный интерфейс с запросом старого пароля и кнопку сброса пароля для администратора.
+- Добавление и удаление ролей для пользователей в админке.
+- Перевести приложение на Spring Boot (а шаблоны с JSP на Thymeleaf)
+- Сделать авторизацию REST по JWT (см. открытый урок [CloudJava](https://javaops.ru/view/cloudjava))
+- Перевести UI на Angular / Vaadin elements /GWT /GXT /Vaadin / ZK/ [Ваш любимый фреймворк]..
+- Сделать авторизацию в приложение по OAuth 2.0 (Spring Security OAuth,
+VK auth, github oauth, ...)
+- Сделать отображение еды постранично, с поиском и сортировкой на стороне сервера.
+- Сделать desktop/mobile приложение, работающее по REST с нашим приложением.
+- Показ ошибок в модальном окне редактирования таблицы так же, как и в JSP профиля
+- Limit login attempts example
+
+#### Доработки участников прошлых выпусков:
+- [Авторизация в приложение по OAuth2 через GitHub, ветка oauth](https://github.com/rblik/topjava/tree/oauth)
+- [Авторизация в приложение по OAuth2 через GitHub/Facebook/Google](https://github.com/jacksn/topjava)
+- Angular 2 UI
+ - [tutorial по доработке](https://github.com/Gwulior/article/blob/master/article.md)
+ - [ветка angular2 в гитхабе](https://github.com/12ozCode/topjava08-to-angular2/tree/angular2)
+- Отдельный фронтэнд на Angular 2, который работает по REST с авторизацией по JWT
+ - [ветка development фронтэнда](https://github.com/evgeniycheban/topjava-frontend/tree/development)
+ - [ветка development бэкэнда](https://github.com/evgeniycheban/topjava/tree/development)
+ - в JWT токенен приложение topjava передает email, name и роль admin как boolean true/false,
+на клиенте он декодируется и из него получается auth-user, с которым уже работает фронтэнд
+
+### Жду твою доработку из списка!
+
+### Ресурсы по Проекту
+- Уроки Bootstrap 4
+- Spring at tutorialspoint
+- Articles in Spring
+- Learn Spring on Baeldung
+- Spring Framework
+ Reference Documentation
+- Hibernate Documentation
+- Java Course (книга 2)
+- Справочник «Паттерны проектирования»
+- Catalog of Patterns of Enterprise Application Architecture
diff --git a/doc/lesson12.md b/doc/lesson12.md
new file mode 100644
index 000000000..ca934dfbb
--- /dev/null
+++ b/doc/lesson12.md
@@ -0,0 +1,42 @@
+# Стажировка Topjava
+
+## [Патчи занятия](https://drive.google.com/drive/u/1/folders/1sizknxR29Yu7XXjaVIBdS88ffXiVuqiB)
+
+## Миграция на Spring Boot
+За основу кода взят **[финальный код BootJava, ветка patched](https://github.com/JavaOPs/bootjava/tree/patched/src/main/java/ru/javaops/bootjava)**
+Вычекайте в отдельную папку (как отдельный проект) ветку `spring_boot` нашего проекта (так удобнее, не придется постоянно переключаться между ветками):
+```
+git clone --branch spring_boot --single-branch https://github.com/JavaWebinar/topjava.git topjava_boot
+```
+Если будете его менять, [настройте `git remote`](https://javaops.ru/view/bootjava/lesson01#project)
+> Если захотите сами накатить патчи, сделайте ветку `spring_boot` от первого `init` и в корне **создайте каталог `src\test`**
+
+----
+
+#### Apply 12_1_init_boot_java
+- Для средних и больших проектов более удобна [организация пакетов по функционалу](https://stackoverflow.com/questions/6260302/548473): сначала крупными мазками функционал, внутри него слои.
+ Финальный код Spring Boot 3.x (BootJava) разбил по функционалу на `app`, `common` и `user`.
+ Процесс творческий, на одном из проектов я попробовал использовать [Spring Modulith](https://spring.io/projects/spring-modulith) и отказался от него, так как очень часто сущности делятся между разным функционалом и строгих границ не провести. "Суббота для человека, а не человек для субботы" в программировании звучит как: "Здравый смысл впереди строгой идеологии и архитектуры".
+ Именно поэтому еда, принадлежащая юзеру, попала в пакет `user`. Если будете соблюдать такую структуру в своем выпускном проекте - НЕ МЕЛЬЧИТЕ!
+- Для получения авторизованного пользователя из `AuthUser` выделил отдельный `AuthUtil` класс.
+
+#### Apply 12_2_migrate_spring_boot_4
+Мигрировал проект на [Spring Boot 4](https://javaops.ru/view/bootjava4/lesson01)
+
+#### Apply 12_3_add_calories_meals
+Добавил из TopJava:
+- Еду, калории
+- Таблицы назвал в единственном числе: `user_role, meal` (кроме `users`, _user_ зарезервированное слово)
+- Общие вещи (пусть небольшие) вынес в сервис : `MealService`
+- Проверку принадлежности еды делаю в `MealRepository.getBelonged`
+- Вместо своих конверторов использую `@DateTimeFormat`
+- Обратите внимание на `UserRepository.getWithMeals` - он [не работает с `@EntityGraph`. Зато работает с обычным `JOIN FETCH`](https://stackoverflow.com/a/46013654/548473) и `DISTINCT` больше не нужен:
+ - [forget about DISTINCT](https://vladmihalcea.com/spring-6-migration/#Auto-deduplication)
+ - [it is no longer necessary to use distinct in JPQL and HQL](https://docs.jboss.org/hibernate/orm/6.0/migration-guide/migration-guide.html#query-sqm-distinct)
+- Мигрировал все тесты контроллеров. В выпускном проекте столько тестов необязательно! Достаточно нескольких, на основные юзкейсы.
+- Кэширование в выпускном очень желательно. 7 раз подумайте, что будете кэшировать!
+- **Максимально просто, самые частые запросы, которые редко изменяются**.
+- **Добавьте в свой выпускной OpenApi/Swagger - это будет большим плюсом и избавит от необходимости писать документацию**.
+
+### За основу выпускного предлагаю взять этот код миграции, сделав свой выпускной МАКСИМАЛЬНО в этом стиле.
+### Успехов с выпускным проектом и в карьере!
diff --git a/doc/meals_index.md b/doc/meals_index.md
new file mode 100644
index 000000000..41f995577
--- /dev/null
+++ b/doc/meals_index.md
@@ -0,0 +1,144 @@
+## Запросы к таблице meal c разным index (1000 пользователей, у каждого за год по 3 записи в день):
+
+### Проверьте у себя, цифры у всех разные!
+
+### Скрипт по наполнению базы на PL/pgSQL:
+```
+drop function if exists populate_db();
+
+create function populate_db() returns void as $$
+declare
+ user_id integer;
+ meal_date timestamp;
+begin
+ DELETE FROM meal;
+ DELETE FROM users;
+ ALTER SEQUENCE global_seq RESTART WITH 100000;
+
+ for i in 1..1000 loop
+ INSERT INTO users (name, email, password)
+ VALUES ('User' || i, 'user' || i || '@yandex.ru', 'password');
+
+ user_id := currval('global_seq');
+
+ for j in 1..365 loop
+ meal_date := date '2014-12-31 10:00' + j;
+ INSERT INTO meal (date_time, description, calories, user_id) VALUES
+ (meal_date, 'Breakfast ' || j, 500, user_id);
+ meal_date := meal_date + interval '4';
+ INSERT INTO meal (date_time, description, calories, user_id) VALUES
+ (meal_date, 'Lunch ' || j, 1000, user_id);
+ meal_date := meal_date + interval '5';
+ INSERT INTO meal (date_time, description, calories, user_id) VALUES
+ (meal_date, 'Dinner ' || j, 500, user_id);
+ end loop;
+ end loop;
+end;
+$$ LANGUAGE plpgsql;
+
+select populate_db();
+```
+### Без индекса
+**время выполнения 200ms/150ms**
+
+> DROP INDEX IF EXISTS meal_unique_user_datetime_idx;
+
+> EXPLAIN ANALYZE
+ SELECT * FROM meal
+ WHERE user_id = 100000 AND date_time BETWEEN '2015-02-10' AND '2015-05-20'
+ ORDER BY date_time DESC;
+
+```
+Sort (cost=28292.17..28292.88 rows=286 width=31) (actual time=203.774..203.782 rows=298 loops=1)
+ Sort Key: date_time DESC
+ Sort Method: quicksort Memory: 48kB
+ -> Seq Scan on meal (cost=0.00..28280.50 rows=286 width=31) (actual time=0.023..203.714 rows=298 loops=1)
+ Filter: ((date_time >= '2015-02-10 00:00:00'::timestamp without time zone) AND (date_time <= '2015-05-20 00:00:00'::timestamp without time zone) AND (user_id = 100000))
+ Rows Removed by Filter: 1094702
+Planning time: 0.102 ms
+Execution time: 203.822 ms
+```
+
+> EXPLAIN ANALYZE
+ SELECT * FROM meal
+ WHERE user_id = 100003
+ ORDER BY date_time DESC;
+
+```
+Sort (cost=22858.59..22861.23 rows=1057 width=31) (actual time=147.481..147.481 rows=0 loops=1)
+ Sort Key: date_time DESC
+ Sort Method: quicksort Memory: 25kB
+ -> Seq Scan on meal (cost=0.00..22805.50 rows=1057 width=31) (actual time=147.474..147.474 rows=0 loops=1)
+ Filter: (user_id = 100003)
+ Rows Removed by Filter: 1095000
+Planning time: 0.097 ms
+Execution time: 147.514 ms
+```
+
+### Индекс по user_id;
+**время выполнения 0.415ms/0.05ms**
+
+> CREATE INDEX meal_idx ON meal (user_id);
+
+> EXPLAIN ANALYZE
+ SELECT * FROM meal
+ WHERE user_id = 100000 AND date_time BETWEEN '2015-02-10' AND '2015-05-20'
+ ORDER BY date_time DESC;
+
+```
+Sort (cost=59.88..60.59 rows=286 width=31) (actual time=0.372..0.378 rows=298 loops=1)
+ Sort Key: date_time DESC
+ Sort Method: quicksort Memory: 48kB
+ -> Index Scan using meal_user_id_idx on meal (cost=0.43..48.21 rows=286 width=31) (actual time=0.048..0.307 rows=298 loops=1)
+ Index Cond: (user_id = 100000)
+ Filter: ((date_time >= '2015-02-10 00:00:00'::timestamp without time zone) AND (date_time <= '2015-05-20 00:00:00'::timestamp without time zone))
+ Rows Removed by Filter: 797
+Planning time: 0.123 ms
+Execution time: 0.414 ms
+```
+
+> EXPLAIN ANALYZE
+ SELECT * FROM meal
+ WHERE user_id = 100003
+ ORDER BY date_time DESC;
+
+```
+Sort (cost=96.02..98.66 rows=1057 width=31) (actual time=0.020..0.020 rows=0 loops=1)
+ Sort Key: date_time DESC
+ Sort Method: quicksort Memory: 25kB
+ -> Index Scan using meal_user_id_idx on meal (cost=0.43..42.93 rows=1057 width=31) (actual time=0.013..0.013 rows=0 loops=1)
+ Index Cond: (user_id = 100003)
+Planning time: 0.095 ms
+Execution time: 0.047 ms
+```
+
+### Составной индекс по user_id и date_time (ЗАВИСИТ ОТ ПОРЯДКА ЗАДАНИЯ КОЛОНОК!)
+**время выполнения 0.110ms/0.035ms**
+
+> DROP INDEX meal_idx;
+
+> CREATE INDEX meal_idx ON meal (user_id, date_time);
+
+> EXPLAIN ANALYZE
+ SELECT * FROM meal
+ WHERE user_id = 100000 AND date_time BETWEEN '2015-02-10' AND '2015-05-20'
+ ORDER BY date_time DESC;
+
+```
+Index Scan Backward using meal_user_id_date_time_idx on meal (cost=0.43..511.74 rows=286 width=31) (actual time=0.026..0.081 rows=298 loops=1)
+ Index Cond: ((user_id = 100000) AND (date_time >= '2015-02-10 00:00:00'::timestamp without time zone) AND (date_time <= '2015-05-20 00:00:00'::timestamp without time zone))
+Planning time: 0.130 ms
+Execution time: 0.112 ms
+```
+
+> EXPLAIN ANALYZE
+ SELECT * FROM meal
+ WHERE user_id = 100003
+ ORDER BY date_time DESC;
+
+```
+Index Scan Backward using meal_user_id_date_time_idx on meal (cost=0.43..1795.68 rows=1057 width=31) (actual time=0.012..0.012 rows=0 loops=1)
+ Index Cond: (user_id = 100003)
+Planning time: 0.103 ms
+Execution time: 0.033 ms
+```
 +
+
+Я хочу подчеркнуть этот момент.
+
+>Когда вы смотрите видео, вам может казаться, что вы все понимаете, но, поверьте, когда вы попытаетесь повторить это самостоятельно, у вас возникнет множество вопросов и сложностей. Практика - это важнейшая часть обучения, не пропускайте ее.
+
+На нашем курсе мы:
+- обсуждаем занятия с коллегами и преподавателями в Slack - эффективность 50%
+- выполняем практические домашние задания по каждой пройденной теме - 75%
+- помогаем коллегам и разрабатываем собственный выпускной проект - 90%
+
+### О проверке домашних заданий
+Также очень важная часть обучения - проверка
+ваших домашних заданий и ревью выпускного
+проекта нашими кураторами.
+
+>**Это самый эффективный способ научиться программировать!**
+
+При устройстве на работу, на собеседовании обязательно
+задавай вопрос про ревью кода.
+Если его нет, фирма занимается разработкой
+непрофессионально? и рост там будет достаточно
+медленным и ограниченным.
+
+В ревью укажут именно твои ошибки
+в стиле, структурах данных, алгоритмах и кодировании.
+До вечера вторника участники шлют ссылку
+на свой GitHub-репозиторий с домашним
+заданием занятия, проверка делается
+ассистентами, результат пишется в Slack.
+Получается эффективно и оперативно.
+
+После проверки можно исправить замечания
+и пройти ее еще раз.
+
+В конце стажировки делается ревью вашего выпускного проекта.
+
+
+### Участие на стажировке: ожидания и реальность
+
+Давайте кратко обсудим, чем курс TopJava является
+и чем он не является, что следует от него ожидать
+и чего не следует.
+
+#### 1-й тип ложного представления о стажировке:
+
+>Я увижу, как с нуля строится web-приложение A с использованием технологий B, просмотрю видео по темам, этого будет достаточно
+
+
+
+Почему такой подход не верный:
+TopJava - это стажировка, поэтому НЕ рассчитывайте
+пройти ее на диване с пакетом поп-корна.
+Тебе придется на ней РАБОТАТЬ (выполнять ДЗ,
+самостоятельно решать какие-то задачи, читать логи,
+дебажить, ходить на StackOverflow и даже думать
+об этом, засыпая)
+
+#### 2-й тип ложного представления о стажировке:
+>Меня научат шаблонам работы с технологией А, и я
+> смогу их применять в любой ситуации
+
+Почему это тоже не вполне верный подход:
+Используемые на стажировке технологии представляют
+собой инструменты, которые позволяет сделать
+что-то проще. Мы поделимся практикой их использования,
+неочевидными особенностями и т. п., покажем
+"грабли", на которые вы рано или поздно наступите.
+Нет гарантии, что, устроившись на работу, вы
+увидите точно такие же подходы.
+Все проекты и команды индивидуальны: используются
+различные инструменты и различные решения.
+Столкновение с технологиями, с которыми
+ты ранее не был знаком, - это нормальная
+часть жизни любого программиста. Нужно быть к этому готовым.
+
+Хорошее представление о решении проблем
+дает поиск на StackOverflow, где почти
+на любую проблему дается большое количество
+вариантов решения. Поиск решений и выбор
+лучшего - это основная работа Java-разработчика,
+и мы максимально постараемся этому научить:
+каждый раз в конкретной ситуации вы должны
+будете САМИ думать, что применять и как.
+Выполняя домашние задания, вы должны приложить
+все усилия, чтобы самостоятельно найти решение.
+Далее в начале следующего занятия вы также
+посмотрите разбор решения, подготовленного
+Григорием Кислиным.
+
+#### 3-й вариант ошибочного представления о стажировке TopJava связан с неверным представлением о том зачем нужна проверка домашних заданий. Например, человек может ошибочно рассуждать так:
+
+>я хочу проходить стажировку с проверкой ДЗ,
+> чтобы мне рассказали, как нужно правильно выполнять задания
+
+Задача проверки не в том, чтобы общими усилиями
+написать код, который ты и так увидишь в разборе.
+Если у тебя что-то не получается, наша
+задача - не найти ошибку/подебажить за тебя/почитать
+логи и т. п., а подсказать способ самостоятельно
+найти решение (хотя для этого мы сначала сами
+ищем/дебажим/читаем)
+Вторая важная задача, которую решает
+проверяющий, - увидеть то, что не увидел ты.
+Когда ты сдаешь задание на ревью, тебе
+может казаться, что все почти идеально. Проверяющий
+подскажет тебе, где ты что-то пропустил из-за
+недостатка опыта, что позволит тебе улучшить код.
+
+---
+
+>Любое знание стоит воспринимать как подобие семантического дерева: убедитесь в том, что понимаете фундаментальные принципы, то есть ствол и крупные ветки, прежде чем лезть в мелкие листья-детали. Иначе последним не на чем будет держаться
+— Илон Маск
+
+Обычно в занятии дается много дополнительного
+материала и ссылок. Не стоит стремиться прочитать
+все ссылки урока, их можно использовать как
+справочник. Гораздо важнее пройти основной
+материал урока и сделать домашнее
+задание - этого достаточно для усвоения
+материала и получения той самой
+основы - ствола и крупных веток, на
+которых впоследствии можно наращивать листву.
+
+
+Как правило, подбираются участники разного
+уровня. Поэтому главное – не стеснятся
+задавать вопросы (после самостоятельного
+гугления и поиска решения). Всегда есть
+поддержка группы (в том числе от пришедших
+на бесплатный повтор участников), моя и ассистентов.
+
+---
+### Основные навыки программиста, которые необходимо развить на курсе
+Давайте перечислим набор навыков, которые
+вам необходимо развивать в ходе курса
+и которые необходимы любому программисту:
+
+- умение и привычка искать
+информацию, чтобы иметь больший выбор из
+доступных вариантов технологий и подходов
+к решению задачи, умение пользоваться StackOverflow;
+- умение пользоваться дебаггером в Intellij Idea;
+- умение пользоваться DevTools в браузере;
+- определенный кругозор и опыт для того, чтобы придумывать поисковые запросы.
diff --git a/doc/entrance/video4.md b/doc/entrance/video4.md
new file mode 100644
index 000000000..7d9b00716
--- /dev/null
+++ b/doc/entrance/video4.md
@@ -0,0 +1,110 @@
+## Структура приложения (многоуровневая архитектура)
+##  [Видео](https://drive.google.com/file/d/1UHzSy9i-uonmTMFoR5v69Y-vyWLCLQWd)
+
+Приложение, которое мы будем разрабатывать, это [программа для подсчета калорий](http://javaops-demo.ru/topjava).
+
+В этом видео обсудим структуру этого приложения.
+
+---
+Ссылки на отчеты, которые будут использоваться в этом уроке:
+
+- [Многоуровневая архитектура (русскоязыная статья в Wikipedia)](https://ru.wikipedia.org/wiki/%D0%9C%D0%BD%D0%BE%D0%B3%D0%BE%D1%83%D1%80%D0%BE%D0%B2%D0%BD%D0%B5%D0%B2%D0%B0%D1%8F_%D0%B0%D1%80%D1%85%D0%B8%D1%82%D0%B5%D0%BA%D1%82%D1%83%D1%80%D0%B0)
+- [Multitier architecture (англоязычная статья в Wikipedia)](https://en.wikipedia.org/wiki/Multitier_architecture)
+
+---
+
+
+
+
+Я хочу подчеркнуть этот момент.
+
+>Когда вы смотрите видео, вам может казаться, что вы все понимаете, но, поверьте, когда вы попытаетесь повторить это самостоятельно, у вас возникнет множество вопросов и сложностей. Практика - это важнейшая часть обучения, не пропускайте ее.
+
+На нашем курсе мы:
+- обсуждаем занятия с коллегами и преподавателями в Slack - эффективность 50%
+- выполняем практические домашние задания по каждой пройденной теме - 75%
+- помогаем коллегам и разрабатываем собственный выпускной проект - 90%
+
+### О проверке домашних заданий
+Также очень важная часть обучения - проверка
+ваших домашних заданий и ревью выпускного
+проекта нашими кураторами.
+
+>**Это самый эффективный способ научиться программировать!**
+
+При устройстве на работу, на собеседовании обязательно
+задавай вопрос про ревью кода.
+Если его нет, фирма занимается разработкой
+непрофессионально? и рост там будет достаточно
+медленным и ограниченным.
+
+В ревью укажут именно твои ошибки
+в стиле, структурах данных, алгоритмах и кодировании.
+До вечера вторника участники шлют ссылку
+на свой GitHub-репозиторий с домашним
+заданием занятия, проверка делается
+ассистентами, результат пишется в Slack.
+Получается эффективно и оперативно.
+
+После проверки можно исправить замечания
+и пройти ее еще раз.
+
+В конце стажировки делается ревью вашего выпускного проекта.
+
+
+### Участие на стажировке: ожидания и реальность
+
+Давайте кратко обсудим, чем курс TopJava является
+и чем он не является, что следует от него ожидать
+и чего не следует.
+
+#### 1-й тип ложного представления о стажировке:
+
+>Я увижу, как с нуля строится web-приложение A с использованием технологий B, просмотрю видео по темам, этого будет достаточно
+
+
+
+Почему такой подход не верный:
+TopJava - это стажировка, поэтому НЕ рассчитывайте
+пройти ее на диване с пакетом поп-корна.
+Тебе придется на ней РАБОТАТЬ (выполнять ДЗ,
+самостоятельно решать какие-то задачи, читать логи,
+дебажить, ходить на StackOverflow и даже думать
+об этом, засыпая)
+
+#### 2-й тип ложного представления о стажировке:
+>Меня научат шаблонам работы с технологией А, и я
+> смогу их применять в любой ситуации
+
+Почему это тоже не вполне верный подход:
+Используемые на стажировке технологии представляют
+собой инструменты, которые позволяет сделать
+что-то проще. Мы поделимся практикой их использования,
+неочевидными особенностями и т. п., покажем
+"грабли", на которые вы рано или поздно наступите.
+Нет гарантии, что, устроившись на работу, вы
+увидите точно такие же подходы.
+Все проекты и команды индивидуальны: используются
+различные инструменты и различные решения.
+Столкновение с технологиями, с которыми
+ты ранее не был знаком, - это нормальная
+часть жизни любого программиста. Нужно быть к этому готовым.
+
+Хорошее представление о решении проблем
+дает поиск на StackOverflow, где почти
+на любую проблему дается большое количество
+вариантов решения. Поиск решений и выбор
+лучшего - это основная работа Java-разработчика,
+и мы максимально постараемся этому научить:
+каждый раз в конкретной ситуации вы должны
+будете САМИ думать, что применять и как.
+Выполняя домашние задания, вы должны приложить
+все усилия, чтобы самостоятельно найти решение.
+Далее в начале следующего занятия вы также
+посмотрите разбор решения, подготовленного
+Григорием Кислиным.
+
+#### 3-й вариант ошибочного представления о стажировке TopJava связан с неверным представлением о том зачем нужна проверка домашних заданий. Например, человек может ошибочно рассуждать так:
+
+>я хочу проходить стажировку с проверкой ДЗ,
+> чтобы мне рассказали, как нужно правильно выполнять задания
+
+Задача проверки не в том, чтобы общими усилиями
+написать код, который ты и так увидишь в разборе.
+Если у тебя что-то не получается, наша
+задача - не найти ошибку/подебажить за тебя/почитать
+логи и т. п., а подсказать способ самостоятельно
+найти решение (хотя для этого мы сначала сами
+ищем/дебажим/читаем)
+Вторая важная задача, которую решает
+проверяющий, - увидеть то, что не увидел ты.
+Когда ты сдаешь задание на ревью, тебе
+может казаться, что все почти идеально. Проверяющий
+подскажет тебе, где ты что-то пропустил из-за
+недостатка опыта, что позволит тебе улучшить код.
+
+---
+
+>Любое знание стоит воспринимать как подобие семантического дерева: убедитесь в том, что понимаете фундаментальные принципы, то есть ствол и крупные ветки, прежде чем лезть в мелкие листья-детали. Иначе последним не на чем будет держаться
+— Илон Маск
+
+Обычно в занятии дается много дополнительного
+материала и ссылок. Не стоит стремиться прочитать
+все ссылки урока, их можно использовать как
+справочник. Гораздо важнее пройти основной
+материал урока и сделать домашнее
+задание - этого достаточно для усвоения
+материала и получения той самой
+основы - ствола и крупных веток, на
+которых впоследствии можно наращивать листву.
+
+
+Как правило, подбираются участники разного
+уровня. Поэтому главное – не стеснятся
+задавать вопросы (после самостоятельного
+гугления и поиска решения). Всегда есть
+поддержка группы (в том числе от пришедших
+на бесплатный повтор участников), моя и ассистентов.
+
+---
+### Основные навыки программиста, которые необходимо развить на курсе
+Давайте перечислим набор навыков, которые
+вам необходимо развивать в ходе курса
+и которые необходимы любому программисту:
+
+- умение и привычка искать
+информацию, чтобы иметь больший выбор из
+доступных вариантов технологий и подходов
+к решению задачи, умение пользоваться StackOverflow;
+- умение пользоваться дебаггером в Intellij Idea;
+- умение пользоваться DevTools в браузере;
+- определенный кругозор и опыт для того, чтобы придумывать поисковые запросы.
diff --git a/doc/entrance/video4.md b/doc/entrance/video4.md
new file mode 100644
index 000000000..7d9b00716
--- /dev/null
+++ b/doc/entrance/video4.md
@@ -0,0 +1,110 @@
+## Структура приложения (многоуровневая архитектура)
+##  [Видео](https://drive.google.com/file/d/1UHzSy9i-uonmTMFoR5v69Y-vyWLCLQWd)
+
+Приложение, которое мы будем разрабатывать, это [программа для подсчета калорий](http://javaops-demo.ru/topjava).
+
+В этом видео обсудим структуру этого приложения.
+
+---
+Ссылки на отчеты, которые будут использоваться в этом уроке:
+
+- [Многоуровневая архитектура (русскоязыная статья в Wikipedia)](https://ru.wikipedia.org/wiki/%D0%9C%D0%BD%D0%BE%D0%B3%D0%BE%D1%83%D1%80%D0%BE%D0%B2%D0%BD%D0%B5%D0%B2%D0%B0%D1%8F_%D0%B0%D1%80%D1%85%D0%B8%D1%82%D0%B5%D0%BA%D1%82%D1%83%D1%80%D0%B0)
+- [Multitier architecture (англоязычная статья в Wikipedia)](https://en.wikipedia.org/wiki/Multitier_architecture)
+
+---
+
+ +
+На структурной схеме приложения вы видите, что оно условно разделено на 4 части: **Views**,
+**Controller**, **Service** и **Repository**.
+
+Такой подход является реализацией многоуровневой архитектуры в программировании.
+По-английски этот подход называется **_Multitier architecture_**.
+
+Его суть заключается в разделении приложения на несколько слоев,
+каждый из которых ответственен за конкретную задачу.
+
+### Слой отображения (View)
+Views соответствует слою отображения (или presentation layer). Это user interface (UI) или
+фронтенд - все то, что мы видим и с чем взаимодействуем в браузере.
+В качестве View могут быть HTML-страницы, созданные с использованием специальных
+движков шаблонов, например, JSP (встроен в Tomcat), или
+Thymeleaf (шаблоны по умолчанию в Spring Boot), или отдельное frontend-приложение,
+написанное на одном из JavaScript-фреймворков.
+
+В случае с движками шаблонов HTML-страницы будут располагаться в одном проекте
+с основным кодом приложения. Для приложений с "небогатым" UI используются именно шаблоны.
+Этот подход отличается от так называемых RIA - rich internet application - приложений со сложным UI.
+
+Главное отличие rich internet application от приложений с фронтендом
+на движках шаблонов заключается в том, что фронтенд, созданный на движке
+шаблонов, работает на сервере, и это что-то простое.
+В случае с rich internet application фронтенд-приложение загружается
+через Интернет к вам на компьютер и запускается в браузере.
+Оно может быть максимально сложным и выполнять функции традиционных
+десктоп-приложений.
+Иногда в одном приложении смешиваются оба способа: например, страница
+логина-пароля в RIA делаются на шаблонах.
+
+Создание простого фронтенда на движке шаблонов проще, поэтому
+в курсе мы будем использовать этот способ.
+
+### Слой контроллеров (Controller)
+Следующий слой, который мы видим - это **Controller**.
+
+В многоуровневой архитектуре он соответствует слою, который
+называется "**_Слой приложения_**" или "**_Application layer_**").
+В GRASP (General Responsibility Assignment Software Patterns)
+он так и называется - Controller layer.
+
+Это слой приложения, который ответственен за обработку HTTP-запросов и проверку корректности входных данных. Если мы открываем главную страницу на сайте или отправляем заполненную на сайте форму, фронтенд-приложение отправляет HTTP-запрос серверу (в нашем случае контейнеру сервлетов), который принимает запрос и перенаправляет его в контроллер, соответствующий введенному в браузере URL или адресу, который вызывается при отправке формы через сайт.
+Также контроллеры могут принимать запросы не только от фронтенда, но и от других приложений.
+
+Слой контроллеров не имеет доступа к базе данных. Контроллеры общаются только с сервисами.
+
+### Слой сервисов (Service layer)
+Слой **Service** на схеме приложения соответствует слою
+бизнес-логики (или **_Business layer_**) в многоуровневой архитектуре.
+В слое Service инкапсулирована вся бизнес-логика нашего приложения.
+Если коммуникация с фронтендом или другими приложениями - это ответственность контроллеров,
+то обработка данных - это ответственность сервисов.
+
+### Слой доступа к данным (Data layer)
+Слой сервисов общается со слоем, ответственным за работу с базами данных.
+Этот слой называют **Data layer** (также можно встретить
+названия **Persistence Layer** или **Data access layer**), и он
+представлен в виде **_Data Access Object_** классов
+(коротко - **_DAO-классы_**) или классов, реализующих паттерн "репозиторий".
+С обоими видами классов вы попрактикуетесь в ходе курса.
+[Репозиторий - это также один из архитектурных паттернов](https://martinfowler.com/eaaCatalog/repository.html)
+
+Подобное разделение приложения на слои дает гибкость
+и существенно упрощает доработку и переиспользование приложения.
+Например, создав по такому принципу приложение,
+содержащее слои репозиториев, сервисов и контроллеров,
+мы в дальнейшем можем легко использовать это приложение
+с различными фронтенд-приложениями или мобильными приложениями.
+Если мы решим перейти на другую базу данных, мы можем
+переписать только слой репозиториев, и нам не требуется
+вносить изменения в слои сервисов и контроллеров.
+
+>Для маленького приложение такой подход может показаться
+>избыточно сложным, но по мере расширения это является спасением.
+
+Подавляющее большинство реальных приложений построено с использованием именно этой архитектуры.
+
+### Краткие итоги
+В этом видео мы познакомились с концепцией многоуровневой архитектуры,
+которую мы применим при создании приложения на курсе.
+Многоуровневая архитектура предполагает разделение приложения на слои:
+- Views - слой отображения является фронтендом;
+- Controller - слой приложения ответственен за прием и валидацию входных данных;
+- слой Service включает в себя весь код, отражающий бизнес логику;
+- Repository или Data layer отвечает за взаимодействие с базой данных.
+
+Также мы обсудили какие преимущества дает такой подход.
+Среди преимуществ в первую очередь возможность повторного
+использования различных слоев и упрощение их доработки и изменения.
+
+
+
diff --git a/doc/entrance/video5-vcs-git.md b/doc/entrance/video5-vcs-git.md
new file mode 100644
index 000000000..7a172e517
--- /dev/null
+++ b/doc/entrance/video5-vcs-git.md
@@ -0,0 +1,180 @@
+## Системы управления версиями, Git
+##  [Видео](https://drive.google.com/file/d/1uFjIsxsaSAXxFSwSpjJIGK7Ug2VXf6yH)
+
+video5-vcs-git.md
+
+В этом уроке мы рассмотрим системы управления версиями
+и самую популярную из них - Git.
+
+---
+* [StackOverflow 2021 survey](https://insights.stackoverflow.com/survey/2021#technology-most-popular-technologies)
+* [Введение в Git и GitHub: установка и настройка](https://topjava.ru/blog/vvedeniye-v-git-github-ustanovka-i-nastroyka)
+* [Введение в Git и GitHub: базовые команды](https://topjava.ru/blog/vvedeniye-v-git-github-bazovyye-komandy)
+* [Введение в Git и GitHub: ошибки использования](https://topjava.ru/blog/vvedeniye-v-git-oshibki-ispolzovaniya-ch-9)
+* [Бесплатная русскоязычная книга Pro Git](https://git-scm.com/book/ru/v2/)
+---
+
+Git является де-факто стандартом среди систем управления версиями.
+Опрос, проведенный StackOverflow в 2021 году показывает,
+что Git используют почти 95% опрошенных разработчиков.
+
+Когда-то популярная централизованная система контроля
+версий SVN (Subversion) практически полностью заменена Git.
+Но некоторые большие проекты все еще используют SVN.
+Примером такого проекта является WordPress.
+Я также все еще иногда встречаю SVN в вакансиях российских компаний.
+
+### Что такое Git и GitHub
+В ходе курса мы будем использовать Git.
+Git - это распределенная система управления версиями.
+Это означает, что код, над которым работает команда,
+и ранее сохраненные (закоммиченные) версии проекта
+хранится на компьютерах каждого члена команды,
+а также в удаленном репозитории, который можно
+сравнить с облачным хранилищем.
+
+Некоторые путают Git и GitHub, но это не одно и то же.
+
+**Git** — это утилита, которую
+программист устанавливает у себя на компьютере для
+сохранения состояний проектов и контроля версий проекта.
+
+**GitHub** — это провайдер удаленных репозиториев,
+сайт (хостинг) для хранения кода проекта и его изменений,
+для обмена файлами с членами команды проекта.
+Программисты могут создавать на GitHub публичные репозитории,
+в которых код доступен всем. Компании могут приобрести платный
+аккаунт на GitHub и вести свои проекты в закрытых репозиториях,
+доступ к которым имеют только члены команды проекта.
+Существуют и другие подобные сайты - провайдеры удаленных
+репозиториев, например, BitBucket, SourceForge, GitLab и т. д.
+
+
+### Как работают Git и GitHub
+
+
+На структурной схеме приложения вы видите, что оно условно разделено на 4 части: **Views**,
+**Controller**, **Service** и **Repository**.
+
+Такой подход является реализацией многоуровневой архитектуры в программировании.
+По-английски этот подход называется **_Multitier architecture_**.
+
+Его суть заключается в разделении приложения на несколько слоев,
+каждый из которых ответственен за конкретную задачу.
+
+### Слой отображения (View)
+Views соответствует слою отображения (или presentation layer). Это user interface (UI) или
+фронтенд - все то, что мы видим и с чем взаимодействуем в браузере.
+В качестве View могут быть HTML-страницы, созданные с использованием специальных
+движков шаблонов, например, JSP (встроен в Tomcat), или
+Thymeleaf (шаблоны по умолчанию в Spring Boot), или отдельное frontend-приложение,
+написанное на одном из JavaScript-фреймворков.
+
+В случае с движками шаблонов HTML-страницы будут располагаться в одном проекте
+с основным кодом приложения. Для приложений с "небогатым" UI используются именно шаблоны.
+Этот подход отличается от так называемых RIA - rich internet application - приложений со сложным UI.
+
+Главное отличие rich internet application от приложений с фронтендом
+на движках шаблонов заключается в том, что фронтенд, созданный на движке
+шаблонов, работает на сервере, и это что-то простое.
+В случае с rich internet application фронтенд-приложение загружается
+через Интернет к вам на компьютер и запускается в браузере.
+Оно может быть максимально сложным и выполнять функции традиционных
+десктоп-приложений.
+Иногда в одном приложении смешиваются оба способа: например, страница
+логина-пароля в RIA делаются на шаблонах.
+
+Создание простого фронтенда на движке шаблонов проще, поэтому
+в курсе мы будем использовать этот способ.
+
+### Слой контроллеров (Controller)
+Следующий слой, который мы видим - это **Controller**.
+
+В многоуровневой архитектуре он соответствует слою, который
+называется "**_Слой приложения_**" или "**_Application layer_**").
+В GRASP (General Responsibility Assignment Software Patterns)
+он так и называется - Controller layer.
+
+Это слой приложения, который ответственен за обработку HTTP-запросов и проверку корректности входных данных. Если мы открываем главную страницу на сайте или отправляем заполненную на сайте форму, фронтенд-приложение отправляет HTTP-запрос серверу (в нашем случае контейнеру сервлетов), который принимает запрос и перенаправляет его в контроллер, соответствующий введенному в браузере URL или адресу, который вызывается при отправке формы через сайт.
+Также контроллеры могут принимать запросы не только от фронтенда, но и от других приложений.
+
+Слой контроллеров не имеет доступа к базе данных. Контроллеры общаются только с сервисами.
+
+### Слой сервисов (Service layer)
+Слой **Service** на схеме приложения соответствует слою
+бизнес-логики (или **_Business layer_**) в многоуровневой архитектуре.
+В слое Service инкапсулирована вся бизнес-логика нашего приложения.
+Если коммуникация с фронтендом или другими приложениями - это ответственность контроллеров,
+то обработка данных - это ответственность сервисов.
+
+### Слой доступа к данным (Data layer)
+Слой сервисов общается со слоем, ответственным за работу с базами данных.
+Этот слой называют **Data layer** (также можно встретить
+названия **Persistence Layer** или **Data access layer**), и он
+представлен в виде **_Data Access Object_** классов
+(коротко - **_DAO-классы_**) или классов, реализующих паттерн "репозиторий".
+С обоими видами классов вы попрактикуетесь в ходе курса.
+[Репозиторий - это также один из архитектурных паттернов](https://martinfowler.com/eaaCatalog/repository.html)
+
+Подобное разделение приложения на слои дает гибкость
+и существенно упрощает доработку и переиспользование приложения.
+Например, создав по такому принципу приложение,
+содержащее слои репозиториев, сервисов и контроллеров,
+мы в дальнейшем можем легко использовать это приложение
+с различными фронтенд-приложениями или мобильными приложениями.
+Если мы решим перейти на другую базу данных, мы можем
+переписать только слой репозиториев, и нам не требуется
+вносить изменения в слои сервисов и контроллеров.
+
+>Для маленького приложение такой подход может показаться
+>избыточно сложным, но по мере расширения это является спасением.
+
+Подавляющее большинство реальных приложений построено с использованием именно этой архитектуры.
+
+### Краткие итоги
+В этом видео мы познакомились с концепцией многоуровневой архитектуры,
+которую мы применим при создании приложения на курсе.
+Многоуровневая архитектура предполагает разделение приложения на слои:
+- Views - слой отображения является фронтендом;
+- Controller - слой приложения ответственен за прием и валидацию входных данных;
+- слой Service включает в себя весь код, отражающий бизнес логику;
+- Repository или Data layer отвечает за взаимодействие с базой данных.
+
+Также мы обсудили какие преимущества дает такой подход.
+Среди преимуществ в первую очередь возможность повторного
+использования различных слоев и упрощение их доработки и изменения.
+
+
+
diff --git a/doc/entrance/video5-vcs-git.md b/doc/entrance/video5-vcs-git.md
new file mode 100644
index 000000000..7a172e517
--- /dev/null
+++ b/doc/entrance/video5-vcs-git.md
@@ -0,0 +1,180 @@
+## Системы управления версиями, Git
+##  [Видео](https://drive.google.com/file/d/1uFjIsxsaSAXxFSwSpjJIGK7Ug2VXf6yH)
+
+video5-vcs-git.md
+
+В этом уроке мы рассмотрим системы управления версиями
+и самую популярную из них - Git.
+
+---
+* [StackOverflow 2021 survey](https://insights.stackoverflow.com/survey/2021#technology-most-popular-technologies)
+* [Введение в Git и GitHub: установка и настройка](https://topjava.ru/blog/vvedeniye-v-git-github-ustanovka-i-nastroyka)
+* [Введение в Git и GitHub: базовые команды](https://topjava.ru/blog/vvedeniye-v-git-github-bazovyye-komandy)
+* [Введение в Git и GitHub: ошибки использования](https://topjava.ru/blog/vvedeniye-v-git-oshibki-ispolzovaniya-ch-9)
+* [Бесплатная русскоязычная книга Pro Git](https://git-scm.com/book/ru/v2/)
+---
+
+Git является де-факто стандартом среди систем управления версиями.
+Опрос, проведенный StackOverflow в 2021 году показывает,
+что Git используют почти 95% опрошенных разработчиков.
+
+Когда-то популярная централизованная система контроля
+версий SVN (Subversion) практически полностью заменена Git.
+Но некоторые большие проекты все еще используют SVN.
+Примером такого проекта является WordPress.
+Я также все еще иногда встречаю SVN в вакансиях российских компаний.
+
+### Что такое Git и GitHub
+В ходе курса мы будем использовать Git.
+Git - это распределенная система управления версиями.
+Это означает, что код, над которым работает команда,
+и ранее сохраненные (закоммиченные) версии проекта
+хранится на компьютерах каждого члена команды,
+а также в удаленном репозитории, который можно
+сравнить с облачным хранилищем.
+
+Некоторые путают Git и GitHub, но это не одно и то же.
+
+**Git** — это утилита, которую
+программист устанавливает у себя на компьютере для
+сохранения состояний проектов и контроля версий проекта.
+
+**GitHub** — это провайдер удаленных репозиториев,
+сайт (хостинг) для хранения кода проекта и его изменений,
+для обмена файлами с членами команды проекта.
+Программисты могут создавать на GitHub публичные репозитории,
+в которых код доступен всем. Компании могут приобрести платный
+аккаунт на GitHub и вести свои проекты в закрытых репозиториях,
+доступ к которым имеют только члены команды проекта.
+Существуют и другие подобные сайты - провайдеры удаленных
+репозиториев, например, BitBucket, SourceForge, GitLab и т. д.
+
+
+### Как работают Git и GitHub
+ +
+Говоря кратко, работа с Git и удаленным репозиторием
+(в нашем случае это Github) выглядит следующим образом.
+
+Первый разработчик, который начинал работу над проектом,
+использовал команду **_git init_** в корневой директории
+проекта для того, чтобы инициализировать пустой Git-репозиторий.
+В этот момент Git создает в директории с проектом скрытую
+директорию, содержащую файлы, необходимые для его работы.
+Теперь первый разработчик может с помощью команды **_git add_**
+добавлять файлы проекта в индекс - то есть в зону,
+отслеживаемую git, а также может фиксировать изменения,
+создавая коммиты (**_git commit_**), и загружать их в
+удаленный репозиторий (например, на GitHub) с помощью
+команды **_git push_**.
+
+Спустя некоторое время к работе над проектом подключается второй разработчик.
+
+Поскольку первый разработчик пушил изменения файлов проекта
+на удаленный репозиторий, второй разработчик может скачать
+их себе на компьютер с помощью команды **_git pull_**
+и продолжить работу с учетом этих изменений.
+
+Давайте повторим.
+В описанной работе использовались команды:
+
+* **_git init_** - эта команда инициализирует работу Git
+для конкретного проекта. В папке с проектом создается
+скрытая папка, хранящая все файлы, необходимые Git
+для работы. Папка с этими файлами впоследствии будет
+загружена в удаленный репозиторий, и второй программист,
+скачавший проект, увидит у себя на компьютере все ранее
+созданные с помощью Git версии.
+* **_git add_** - это команда, которая добавляет файлы
+проекта в индекс (или отслеживаемую зону), чтобы их можно
+было в какой-то момент закоммитить (то есть сохранить, зафиксировать).
+* **_git commit_** - сохраняет все файлы проекта в
+текущем состоянии так, что мы в любой момент сможем
+вернуться к этому состоянию - посмотреть, как изменились
+файлы, или даже полностью вернуть проект к состоянию
+данного коммита.
+* **_git push_** - загружает файлы в удаленный Git-репозиторий,
+чтобы их могли скачать другие программисты.
+* **_git pull_** используют для того, чтобы скачать
+файлы из удаленного репозитория себе на компьютер.
+
+Также Git позволяет создавать ветки. Это означает,
+что вы можете создать копию стабильного кода и
+продолжить работу в этой копии, не подвергая риску
+стабильную версию. Когда код с новой функциональностью
+готов, отлажен и протестирован, он может быть
+слит ("смержен", от слова "merge") в основную ветку со стабильным кодом.
+
+С помощью этих функций Git позволяет команде разработчиков
+работать одновременно над разными задачами и поддерживать
+код в стабильном состоянии.
+
+Также Git позволяет в любой момент понять, кто и когда внес
+изменения в определенный код, что существенно упрощает взаимодействия
+с коллегами. Например, в случае, если вы видите новые
+строки кода, которые вызывают у вас вопросы, с помощью
+Git вы можете разобраться, кто внес изменения именно
+в эти строки, и связаться с этим человеком
+для уточнения деталей.
+
+Если произошла ситуация, при которой два разработчика
+изменили один и тот же файл, Git потребует от вас вручную
+отрегулировать такой конфликт.
+
+Также благодаря Git у вас всегда под рукой детальная
+история изменений. С помощью комментариев к коммитам
+вы можете детально документировать ход работы над
+проектом и в случае необходимости разобраться, в
+какой момент что-то пошло не так, и откатиться
+к той версии, где ошибка еще не была сделана.
+Или просто выяснить, как выглядел код определенного
+класса или метода в определенной версии и внести правки
+в текущую версию, если это необходимо.
+
+### Дополнительные материалы
+
+Для изучения Git рекомендуем в первую очередь ознакомиться со статьями на сайте [topjava.ru](https://topjava.ru):
+
+* [Введение в Git и GitHub: установка и настройка](https://topjava.ru/blog/vvedeniye-v-git-github-ustanovka-i-nastroyka)
+* [Введение в Git и GitHub: базовые команды](https://topjava.ru/blog/vvedeniye-v-git-github-bazovyye-komandy)
+* [Введение в Git и GitHub: ошибки использования](https://topjava.ru/blog/vvedeniye-v-git-oshibki-ispolzovaniya-ch-9)
+
+В них дается детальная инструкция по первоначальной настройке
+Git, GitHub, в том числе инструкция по настройке
+Access token в GitHub, что вам обязательно нужно будет сделать.
+
+Также можно упомянуть официальную русскоязычную книгу Pro Git,
+которая доступна [бесплатно в электронном виде](https://git-scm.com/book/ru/v2/).
+
+### Как мы будем использовать Git на курсе
+В Git очень много команд, но в ходе курса мы будем использовать
+только самые необходимые из них.
+С git можно работать как через терминал с помощью команд,
+так и с помощью различных программ с графическим интерфейсом.
+Мы будем преимущественно использовать интеграцию
+IntelliJ Idea с Git, поскольку она очень удобна
+и существенно упрощает работу.
+Однако знать, как выполнять аналогичные операции
+в терминале, очень полезно.
+
+### Резюме
+В этом уроке мы сделали краткий обзор систем управления
+версиями и самой популярной из них - Git:
+
+* разобрались в различиях Git и GitHub.
+Git - это система контроля версий, а
+GitHub - провайдер удаленных репозиториев, один из многих, доступных на рынке.
+* кратко познакомились с тем, как Git работает.
+Узнали о командах git init, git add, git commit, git push и git pull.
+* Также мы обсудили, что такое ветки и какие возможности они дают.
+
+---
+
+Если вы не работали раньше с Git, не беспокойтесь.
+В последующих уроках работа с Git будет изучаться
+на практике в ходе работы над проектом. Но дополнительно
+почитать о Git все же стоит.
+
+
+
+
diff --git a/doc/graduation.md b/doc/graduation.md
new file mode 100644
index 000000000..123238d4e
--- /dev/null
+++ b/doc/graduation.md
@@ -0,0 +1,185 @@
+## Выпускной проект
+
+- **Дедлайн на заполнение [формы по выпускному проекту](https://javaops.ru/auth/graduate) - 12 января 2026, 23.59 МСК**
+- Ревью проекта входит в участие с проверкой домашних заданий. Проверяется два раза: один раз ассистентами и после ваших правок - финальная проверка, Кислиным Григорием.
+- Ревью выпускного делается только у участников с проверкой ДЗ. У кого оплачен Диплом, но нет проверки - даю краткие итоги.
+- **Ревью выпускного можно оплатить отдельно как [техническое собеседование](https://javaops.ru/auth/payonline?payId=I)**
+- Участникам проекта [Многомодульный maven. Многопоточность. XML (JAXB/StAX). Веб сервисы (JAX-RS/SOAP). Удаленное взаимодействие (JMS/AKKA) (Masterjava)](http://javaops.ru/reg/masterjava) срок ревью выпускного до
+ 12 апреля 2026 г.
+
+## Technical requirement:
+Design and implement a REST API using Hibernate/Spring/SpringMVC (Spring-Boot preferred!) **without frontend**.
+
+The task is:
+
+Build a voting system for deciding where to have lunch.
+
+* 2 types of users: admin and regular users
+* Admin can input a restaurant and it's lunch menu of the day (2-5 items usually, just a dish name and price)
+* Menu changes each day (admins do the updates)
+* Users can vote for a restaurant they want to have lunch at today
+* Only one vote counted per user
+* If user votes again the same day:
+ - If it is before 11:00 we assume that he changed his mind.
+ - If it is after 11:00 then it is too late, vote can't be changed
+
+Each restaurant provides a new menu each day.
+
+As a result, provide a link to github repository. It should contain the code, README.md with API documentation and couple curl commands to test it (**better - link to Swagger**).
+
+-----------------------------
+P.S.: Make sure everything works with latest version that is on github :)
+P.P.S.: Assume that your API will be used by a frontend developer to build frontend on top of that.
+
+-----------------------------
+
+##  Рекомендации
+
+**Пишем выпускной проект как тестовое задание на работу**
+
+- **Не списывай с коллег!** Выпускные проекты пишут только наши выпускники, их репозитории есть в нашей базе. Поэтому при подозрениях на списывание оригинал вычисляется легко. Лучше написать свое -
+ как можете, как поняли материал - и получить ревью (которое вами же оплачено) своего проекта, а не чужого. Даже если времени мало - сделайте основное. Если с Дипломом - это с очень большой
+ вероятностью 4, вместо отчисления
+- **Не изобретай велосипедов!** Грубая ошибка - пытаться сделать стандартные вещи по-своему, чаще всего криво. На проекте все должно быть единообразно! Ваш проект TopJava - сделай все МАКСИМАЛЬНО в
+ этом стиле. Если тебе кажется, что есть лучшее решение, чем в TopJava - пишите мне в личку, я всегда открыт для улучшений.
+- **Делай проект на востребованном на рынке стеке**: Spring Boot + Spring Data JPA (работа с БД) + Swagger/OpenAPI 3.0 (REST документация). Для старта оптимально подойдет финальный код **открытого курса [Spring Boot 3.x + HATEOAS](https://javaops.ru/view/bootjava)**:
+```
+git clone --branch patched https://github.com/JavaOPs/bootjava.git
+```
+
+*Представьте себе, что ПМ (лид, архитектор) дал вам ТЗ и некоторое время недоступен. У вас, конечно, есть много мыслей, для чего нужно приложение, как исправить ТЗ, дополнить его и сделать правильно.
+НО НЕ НАДО ИХ РЕАЛИЗОВЫВАТЬ В КОДЕ. Нужно сделать все строго по ТЗ, максимально просто, удобно для доработок и для использования со стороны клиента.*
+
+> Совершенство достигнуто не тогда, когда нечего добавить, а тогда, когда нечего отнять
+
+_Антуан де Сент-Экзюпери_
+
+### 1: ТЗ (Тех.задание)
+
+- 1.1: Читай ТЗ ОЧЕНЬ внимательно, НЕ надо ничего своего туда домысливать и творчески изменять
+- 1.2: Учитывай, что пользователей может быть ОООЧЕНЬ много, а админов - МАЛО
+- 1.3: Сначала сделай основные сценарии по ТЗ. Все остальное (если очень хочется, 3 раза подумай) - потом.
+
+### 2. API
+
+- 2.1: API продумывай с точки зрения не программиста и объектов, а с точки зрения того, кто им будет пользоваться (клиента, UI)
+- 2.1: Тщательно считайте количество запросов в вашем API для отображения нужной информации
+- 2.3: Из потребностей приложения (клиента) реализуй только очевидные сценарии. Необходимо и достаточно: ВСЕ НЕОБХОДИМОЕ для клиента и НИЧЕГО ЛИШНЕГО. Процесс творческий, приходит с опытом.
+- 2.4: Делаем REST API в соответствии с концепцией REST (url в общем имеют вид`{ресурс}/{id_ресурсa}[/{подресурс}/{id_подресурсa}][параметры]`, см. ниже ссылки про REST и иерархию). Имена ресурсов во множественном числе!
+ Самая распространенная и грубая ошибка - не придерживаться этих простых правил.
+ - **[15 тривиальных фактов о правильной работе с протоколом HTTP](https://habrahabr.ru/company/yandex/blog/265569/)**
+ - **[10 Best Practices for Better RESTful API](https://medium.com/@mwaysolutions/10-best-practices-for-better-restful-api-cbe81b06f291)**
+ - **[REST resource hierarchy](https://stackoverflow.com/questions/20951419/what-are-best-practices-for-rest-nested-resources)**
+ - [Лучшие практики разработки REST API: правила 1-7,15-17](https://tproger.ru/translations/luchshie-praktiki-razrabotki-rest-api-20-sovetov/)
+- 2.5: Разделение на роли я предпочитаю на уровне URL. Сразу и однозначно видно, какой API у админа, какое у пользователя (API админа начинается, например, с */admin/...*).
+- 2.6: На управление (CRUD) ресторанами и едой должны быть ОТДЕЛЬНЫЕ контроллеры. Не надо все, что может админ, сваливать в одну кучу! Смотрите на результат операции - помещаете в этот контроллер!
+- 2.7: Проверьте в Swagger, что в POST и PUT нет ничего лишнего, а в GET есть все необходимые данные. Например, при запросе голоса должен в ответе отображаться `id` ресторана, а не весь объект, при создании-редактировании ресторана в примерах swagger не должно быть меню и еды.
+- 2.8: `Profile` означает, что данные принадлежат профилю пользователя. Все остальное называйте по-другому.
+- 2.9: Отсутствие данных часто бывает "бизнес кейсом", те НЕ ошибкой в запросе или приложении. Исключение - это ошибка, например неверный `id`. Запрос на данные, которые могут быть, могут нет, не должен приводить к исключениям. Посмотрите в сторону `ResponseEntity.of()`
+- 2.10: По REST URL должно быть однозначно понятно, какие будут параметры на входе и что ждать на выходе. Без сюрпризов!
+
+### 3: Код:
+- 3.1: Строго соблюдайте соглашения Java по именованию: пакеты ТОЛЬКО маленькими буквами, методы начинаются с маленькой буквы, классы с большой. Незнания Java Core - тестовое задание сразу в корзину.
+- 3.2 В проекте (и тестовом задании на работу), в отличие от нашего учебного topjava, оставляйте только необходимый для работы по ТЗ приложения код, ничего лишнего
+ - 3.2.1: НЕ надо делать разные профили базы и работы с ней
+ - 3.2.2: НЕ надо делать абстрактных контроллеров на всякий случай
+ - 3.2.3: НЕ надо делать сервисов, если там нет ничего, кроме делегирования
+ - 3.2.4: НЕ нужны локализация, UI, типы ошибок, Json View
+- 3.3: Название пакетов, имен классов для `model/to/web` стандартные (например `model/domain`). НЕ надо придумывать своих собственных правил
+- 3.4: Проверьте, не торчат ли из кода учебные уши TopJava, типа `ProfileRestController.testUTF()`, `AbstractServiceTest.printResult()` или закомментированные `JdbcTemplate`. Назначение выпускного
+ совсем другое
+- 3.5: Вместо `return ResponseEntity.ok(object)` в контроллерах пишите `return object`. Проще!
+
+### 4: Модель
+
+- 4.1: В БД обычно хранятся все введенные пользователем и админом данные c возможность их редактирования. Это означает, что мы не удаляем прошлые меню, а храним их в базе, как и историю голосования. Есть базовые вещи, которые закладываются в архитектуру приложения, и есть неочевидные доработки к ТЗ, делать не надо.
+- 4.2: Не делайте в модели объектов, которые не будут использоваться в коде (например, не надо двунаправленных связей, если достаточно однонаправленных)
+- 4.3: еще раз про [hashCode/equals в Entity](https://stackoverflow.com/questions/5031614/the-jpa-hashcode-equals-dilemma): не делайте в модели сравнение по полям!
+- 4.4: ORM работает с объектами. [Иногда, для упрощения логики, fk_id как поля допустимы](https://stackoverflow.com/questions/6311776/hibernate-foreign-keys-instead-of-entities)
+
+### 5: Архитектура / pom
+- 5.1: Можно:
+ - или подключить DATA-REST (см.курс [Spring Boot 2.x + HATEOAS](https://javaops.ru/view/bootjava)). Контроллеры генерируются автоматически по репозиториям, требуется настройка ресурсов в кастомных контроллерах
+ - или делать на основе миграции TopJava / кода [TopJava-2](https://github.com/JavaOPs/topjava2)
+
+Нельзя смешивать эти подходы вместе! Я рекомендую 2-й вариант, без data-rest. Обязательно посмотрите в Swagger, какие контроллеры получились в результате.
+- 5.2: Не размещайте бизнес-логику приложения и преобразования в TO в слое доступа к DB
+- 5.3: Не смешивайте TO и Entity вместе. Они должны быть независимыми друг от друга. На TopJava мы смотрели разные варианты [c использованием TO и без](https://stackoverflow.com/a/21569720/548473).
+ Делаем максимально просто.
+- 5.4: [Use for money in java app](http://stackoverflow.com/a/43051227/548473)
+- 5.5 Не надо явно указывать версии зависимостей в `pom`, если они наследуются от `spring-boot-starter-parent`
+
+### 6: Доступ к БД
+
+- 6.1: Используйте Spring Data JPA (без лишней делегации). Методы Repository можно вызывать напрямую из сервиса или из контроллера.
+- 6.2: В DATA-JPA 2.x используются `Optional`. Попробуйте работать с ними, это безопасный способ работать с null-значениями (используйте `orElseThrow`)
+- 6.3: Не делайте при обновлении записи ради экономии пары строчек кода так:
+```
+if(updateCondition)
+ repository.delete(entity)
+}
+repository.save(entity)
+```
+Обновление записи базы должно быть через `UPDATE`.
+
+### 7: База Данных
+
+- 7.1: Берите без установки (H2 или HSQLDB). Одну и **в памяти**! Ваше приложение должно сразу запуститься, без всяких настроек и переменных окружения
+- 7.2: Тщательно считайте количество обращений в базу на каждый запрос. Особенно при запросах от юзеров, которых очень много! Также на сложность запросов от них, чтобы не положить базу
+- 7.3: Сделайте [индексы к таблицам](https://ru.wikipedia.org/wiki/Индекс_(базы_данных)). Попробуйте обеспечить UNIQUE (один голос пользователя в день, один уникальный пункт меню в день).
+Следите за **порядком полей в индексе**, от этого зависит индексирование запросов.
+- 7.4: При популировании добавь записи за сегодняшний день - `now()`, чтобы всегда были актуальные исходные данные
+- 7.5: Поля базы case insensitive, не пишите camelStyle (для которых нужны кавычки)
+- 7.6: Таблицы обычно именуются в единственном числе. Исключение - `users`, `orders` и другие зарезервированные слова
+- 7.7: `date`/`timestamp` - зарезервированное слово, лучше избегать их при именовании полей
+
+### 8: Security
+
+- 8.1: Проверьте, станет ли код проще с `@AuthenticationPrincipal` (урок 11, доступ к AuthorizedUser).
+- 8.2: Я предпочитаю четкое разделение ролей на основе URL. Для админа URL содержит `/admin`
+- 8.3: Еще раз - призываю не менять код TopJava
+
+### 9: Кэширование
+
+- 9.1: Кэширование желательно для частых и редко меняющихся запросов от пользователей.
+Тщательно продумайте, что надо кэшировать (самые частые запросы), а что нет (большие или редко запрашиваемые данные)
+- 9.2: Проверьте соответствие ключей к кэшу (параметры кэшируемого метода) с конфигурацией (например в singleNonExpiryCache, heap=1 в кэше может содержаться только ОДНО значение).
+
+### 10: Валидация
+
+- 10.1: Одних аннотаций валидации на полях недостаточно. Должны быть `@Valid/@Validation` в контроллере
+- 10.2: Прячте `id` при `create/update` в примерах Swagger. Если их передали - проверяйте на соответствие (в TopJava это `ValidationUtil.checkNew()/assureIdConsistent()`)
+
+### 11: Дополнительно
+
+- 11.1: По возможности сделать JUnit-тесты. Можно не делать 100% покрытие, только основные сценарии
+- 11.2: Уделяйте внимание обработке ошибок.
+
+### 12: `readme.md`:
+
+- 12.1: Поместите вначале `readme` ТЗ или **ссылку на него** - будет понятно о чем твой проект
+- 12.2: Если задание на English, описание пиши также на English (то же самое относится к языку резюме: вакансия на English предполагает резюме на English)
+- 12.3: Требуемые примеры `curl` не прячьте, а пишите здесь! Оптимально сделать **ссылку на `Swagger UI` с креденшелами для выполнения запросов**
+- 12.4: Проверяют люди с опытом в Java: не надо писать инструкций, как устанавливать Java и Maven
+
+### 13: Git
+
+- 13.1: Должна быть история ваших комитов с внятными комментариями. Это смотрят.
+> Эйчар обращает внимание на дату создания аккаунта и то, как в него заливались коммиты (элементы проекта), постепенно или в один день, насколько технологии в аккаунте коррелируют с технологиями в резюме
+- 13.2: Не комить служенбые файлы: логи, DB, настройки IDEA и пр., это сразу - уровень Junior.
+- 13.3: Все служебные файлы должны быть в `.gitignore`
+
+## Проверка
+
+- Попробуй подергать свое API по всем типичным сценариям ТЗ!
+ - Удобно использовать? Можно сделать проще? Например, чтобы проголосовать за ресторан залогиненному юзеру, достаточно `restorauntId`.
+ - Сколько раз пришлось его вызвать API для типичного сценария (например посмотреть рестораны с едой на сегодня)?
+ - Сколько запросов к базе было сделано? Можно ли сократить (например с `FETCH/Graph` или через кэширование)?
+ - **Еще раз - проверь все запросы в Sawgger, смотри на формат запросов и данные в ответе. Все должно работать, есть все данные и нет ничего лишнего**
+- 13.2: API ДОЛЖЕН соответствовать принципам REST (см. ссылки выше)
+- 13.3: ОБЯЗАТЕЛЬНО: запустите `mvn test` - ошибок быть не должно
+- 13.4: ОБЯЗАТЕЛЬНО: запустите приложение без всяких предварительных настроек (базы, переменных окружения, ..), лучше на другом компьютере. Приложение должно запускаться и работать!
+
+## Оценка
+ТЗ очень скромное, не дает понимания, что хочет получить заказчик, именно поэтому моих комментариев к этому ТЗ больше на 2 порядка. Это реальное тестовое задание на работу. При оценке учитывается отсутствие грубых ляпов, простота и красота решения + его расширяемость, если понадобится дорабатывать приложение. Если практический опыт небольшой, еще раз очень рекомендую держаться как можно ближе к нашему коду на Spring Boot.
+Тестовое задание дается для того, чтобы оценить вас, как программиста. Нужны ли вы компании или нет. Это умение спроектировать грамотную модель и API, придерживаясь принципов REST и без своих велосипедов, и ваш чистый красивый код.
diff --git a/doc/lesson01.md b/doc/lesson01.md
new file mode 100644
index 000000000..9468d02ec
--- /dev/null
+++ b/doc/lesson01.md
@@ -0,0 +1,262 @@
+# Стажировка Topjava
+
+### Правила похождения стажировки
+- Не стоит стремиться прочитать все ссылки урока, их можно использовать позднее как справочник. Гораздо важнее **пройти основной материал урока и сделать Домашнее Задание**
+- Обязательно посмотри правила работы с патчами на проекте
+ - Делать Apply Patch лучше по одному, непосредственно перед видео на эту тему, а при просмотре видео сразу отслеживать все изменения кода проекта по изменению в патче (`Git-> Local Changes-> Ctrl+D`)
+ - **При первом Apply удобнее выбрать имя локального ченджлиста Name: Change**. Далее все остальные патчи также будут в него попадать.
+- **Код проекта обновляется и не всегда совпадает с видео (можно увидеть как развивался проект). Изменения в проекте указываю после соответствующего патча.**
+- Если ссылка не открывается, попробуй [включить VPN](https://github.com/JavaOPs/topjava/wiki/VPN)
+- **ОСНОВНОЕ, чему мы учимся на проекте: мыслить и работать как Java разработчики уже сейчас**, потом это будет гораздо сложнее и стоить дороже. Вот на мой взгляд [хорошие советы новичкам](http://blog.csssr.ru/2016/09/19/how-to-be-a-beginner-developer). От себя я добавлю:
+ - Учись **грамотно формулировать проблему**. Проблема "у меня не работает" может иметь тысячи причин. В процессе формулирования очень часто приходит ее решение.
+ - что я делаю (подробно, чтобы понял человек, который не был занят этой проблемой несколько часов)
+ - что получаю (обычно верх самого последнего эксепшена)
+ - что я сделал для решения, какие результаты получил
+ - Учись исследовать проблему. Внимательное чтение логов и [умение дебажить](http://info.javarush.ru/idea_help/2014/01/22/Руководство-пользователя-IntelliJ-IDEA-Отладчик-.html) - основные навыки разработчика. Обычно самый верх самого нижнего эксепшена- причина ошибки, туда нужно ставить брекпойнт.
+ - Грамотно **уделяй время каждой проблеме**. Две крайности - сразу бросаться за помощью и биться над ней часами. Пробуй решить ее сам и в зависимости от проблемы выделяй на это разумное время.
+ - Наконец, уровень участников у всех разный. Бывают синьоры, бывают начинающие. Не стесняйтесь задавать вопросы, иначе стажировка пройдет впустую! **Глупых вопросов не бывает**.
+----------------------------------------------------
+- **Обязательно и как можно чаще пользуйтесь `Ctrl+Alt+L` - отформатировать код класса**
+- **При изменениях на UI не забываетй сбрасывать кэш браузера - `Ctrl+F5`**
+- **При удалении классов не забывате чистить target - в окошке Maven -> clean или `mvn clean`**
+- **При проблемах с IDEA пользуйтесь `Refresh` в окошке Maven**
+- **При проблемах с выполнением проверьте (и удалите) лишние java процессы (например в Task Manager)**
+
+
+## Материалы занятия (скачать все патчи можно через `Download/Скачать` папки patch)
+
+
+###  Рефакторинг проекта
+
+#### Apply 1_0_fix_rename.patch
+- переименовал классы `UserMeal*` в более красивые `Meal*`
+- преименовал `MealWithExceed` transfer object класс ([что это такое](https://ru.wikipedia.org/wiki/DTO) пройдем позже) в `MealTo` ([data transfer object naming convention](https://stackoverflow.com/questions/1724774/java-data-transfer-object-naming-convention))
+- IDEA предложила рефакторинг `TimeUtil.isBetweenHalfOpen` с использованием `isBefore`.
+
+##  Разбор домашнего задания HW0:
+###  1. Optional: реализация getFilteredMealsWithExcess через Stream API
+- В патче `prepare_to_HW0.patch` вступительного задания метод фильтрации в `TimeUtil` переименовали в `isBetweenHalfOpen` (также изменилась логика сравнения - `startTime` включается в интервал)
+
+#### Apply 1_1_HW0_streams.patch
+
+- [Презентация Java 8](https://docs.google.com/presentation/d/1oltLkHK60FqIdsXjUdm4pPLSeC6KpNYjDsM0ips-qBw)
+
+###  2. Работа с git в IDEA. Реализация через цикл.
+### ВНИМАНИЕ! Патчей `1_opt_2_HW0_cycles` и `1_opt_3_HW0_opt2` не будет в проекте!
+Делаем в отдельной ветке (у меня `MealsUtil_opt`). Это варианты решений, которые не идут в `master`
+
+
+
+#### Apply 1_opt_2_HW0_cycles.patch
+
+###  Вопросы по HW0
+
+> Почему не использовать в `TimeUtil` методы `isBefore/isAfter` ?
+
+это строгие (excluded) сравнения, а нам также нужно краевые значения
+
+> В `MealsUtil` у нас где-то есть ключевое слово `final`, где-то нет. В чем разница?
+
+Я участвовал в одном проекте, где `final` был обязательным (в сеттингах IDEA галочка стояла). Но это скорее исключение, чем правило в проектах java (в Java 8 вообще ввели эффективный final, те по факту). Во всех новомодных языках переменные final по умолчанию, а в java нужно помнить и везде добавлять, утомительно. Но если приучитесь - хуже не будет. Я обычно ставлю там, где важно по смыслу (если не забываю).
+
+###  3. [HW0 Optional 2: реализация в один проход циклами и Stream API](https://drive.google.com/file/d/1dSt3axySxu4V9dMnuR1wczerlI_WzCep)
+
+#### Apply 1_opt_3_HW0_opt2.patch
+- Дополнительно:
+ - [Первое занятие MasterJava: многопоточность](https://github.com/JavaOPs/masterjava)
+ - [Обзор java.util.concurrent.*](https://web.archive.org/web/20220427140138/https://habr.com/ru/company/luxoft/blog/157273/)
+
+## Занятие 1:
+
+###  4. [Интервью: Java разработка. Обучение. Трудоустройство](https://javaops.ru/view/news/javaInterview)
+- [JetBrains devecosystem 2022](https://www.jetbrains.com/lp/devecosystem-2022/java/)
+- [Сontinuum Java Ecosystem 2022 – Survey results](https://www.continuum.be/en/blog/the-java-ecosystem-2022-survey-results/)
+- [JRebel 2022 Java Developer Productivity Report](https://drive.google.com/file/d/1txLeRsNNR7EqYEeIvYmuyQi9hknBeR9G)
+
+###  5. [Servlet API. Apache Tomcat. JSP](lesson01/tomcat_servlet_war.md)
+
+###  6. [Логирование](https://www.youtube.com/watch?v=mo8z3zRVV1E)
+#### Последние версии _logback / slf4j_ не работают с JDK 8, понизил версии до совместимых с ней. Поднимем на 5м занятии при миграции на JDK 17+
+
+#### Apply 1_5_simple_logging.patch
+
+- [Зачем нужно логирование](https://javarush.ru/groups/posts/2293-zachem-nuzhno-logirovanie)
+- [Logback Project](https://logback.qos.ch/)
+
+> А зачем мы использовали logback? Почему SLF4J нас не устроило? Почему реализация логирования не log4j?
+
+`SLF4J-API` это API. В нее включена только пустая реализация `org.slf4j.helpers.NOPLogger` (можно посмотреть в исходниках). Logback для новых проектов стал стандарт, *Spring Boot* используют его по умолчанию.
+[Reasons to prefer logback over log4j](http://logback.qos.ch/reasonsToSwitch.html)
+
+> Почему `private static final Logger log` а не `LOG/LOGGER` ?
+
+Это [правило именования констант, которые не "deeply immutable"](https://google.github.io/styleguide/javaguide.html#s5.2.4-constant-names), те если их содержимое можно изменить.
+
+#### Apply 1_6_logging_config.patch
+
+- [Java Logging: история кошмара](http://habrahabr.ru/post/113145/)
+- [Project dependencies for logging](https://www.slf4j.org/manual.html#projectDep)
+- [Добавление зависимостей логирования](http://www.slf4j.org/legacy.html) в проект
+- Не делать конкатенацию строк: [форматирование в логах через {}](https://www.slf4j.org/faq.html#logging_performance)
+- Дополнительно:
+ - [Logback configuration](https://logback.qos.ch/manual/configuration.html)
+ - [Ведение лога приложения](http://www.skipy.ru/useful/logging.html)
+ - [Владимир Красильщик – Что надо знать о логировании прагматичному Java‑программисту](https://www.youtube.com/watch?v=qzqAUUgB3v8)
+
+**Установите переменную окружения на TOPJAVA_ROOT на корень проекта и перезапустите IDEA. Слеши в пути должны быть в стиле unix (/)**
+
+Проверить, видит ли Java вашу переменную можно через `System.getenv("TOPJAVA_ROOT")`
+
+- [Set environment for Win/Mac/Unix](https://chlee.co/how-to-setup-environment-variables-for-windows-mac-and-linux/)
+- [Set environment for UNIX (advanced)](https://askubuntu.com/a/849954)
+ - [Определить, какой Login или Non-Login Shell](https://tecadmin.net/difference-between-login-and-non-login-shell)
+ - [Порядок запуска скриптов при старте](https://www.baeldung.com/linux/bashrc-vs-bash-profile-vs-profile)
+- Или простой вариант (не забудте добавить и в Run, и в Debug)
+
+
+
+**Иногда антивирусы блокируют логирование (например Comodo). Если не работает и стоит антивирус- добавьте исключение.**
+
+> Изменения в проекте, которым могут встретиться в других видео:
+> - убрал `LoggerWrapper` и логирую напрямую в логгер SLF4J.
+> - удалил зависимости `jul-to-slf4j` и `jcl-over-slf4j`. Spring 5 напрямую использует `slf4j` без `common-logging`
+
+---------
+
+##  Домашнее задание HW01 (делаем ветку HW01 от последнего патча в master)
+--------------------------------------------
+#### 1. Реализовать сервлет с отображением в таблице списка еды (в памяти и БЕЗ учета пользователя)
+
+> Деплоиться в Tomcat лучше как `war exploded`: нет упаковки в war и при нажатой кнопке `Update Resources on Frame Deactivation` можно обновляться css, html, jsp без передеплоя. При изменении `web.xml`, добавлении методов, классов необходим redeploy.
+
+- 1.1 По аналогии с `UserServlet` добавить `MealServlet` и `meals.jsp`
+ - Задеплоить приложение (war) в Tomcat c `applicationContext=topjava` (приложение должно быть доступно по http://localhost:8080/topjava)
+ - Попробовать деплои в Tomcat как WAR в запушенный вручную Tomcat и через IDEA.
+- 1.2 Сделать отображения списка еды в JSP [в таблице](http://htmlbook.ru/html/table), цвет записи в таблице зависит от параметра `excess` (красный/зеленый).
+ - 1.2.1 Список еды захардкодить (те проинициализировать в коде, желательно чтобы в проекте инициализация была только в одном месте). Норму калорий (caloriesPerDay) сделать в коде константой
+ - 1.2.2 Время выводить без 'T'
+ - 1.2.3 Список выводим БЕЗ фильтрации по `startTime/endTime`
+ - 1.2.4 С обработкой исключений пока можно не заморачиваться, мы будем красиво обрабатывать в конце стажировки
+ - 1.2.5 Вариант реализации:
+ - из сервлета преобразуете еду в `List
+
+Говоря кратко, работа с Git и удаленным репозиторием
+(в нашем случае это Github) выглядит следующим образом.
+
+Первый разработчик, который начинал работу над проектом,
+использовал команду **_git init_** в корневой директории
+проекта для того, чтобы инициализировать пустой Git-репозиторий.
+В этот момент Git создает в директории с проектом скрытую
+директорию, содержащую файлы, необходимые для его работы.
+Теперь первый разработчик может с помощью команды **_git add_**
+добавлять файлы проекта в индекс - то есть в зону,
+отслеживаемую git, а также может фиксировать изменения,
+создавая коммиты (**_git commit_**), и загружать их в
+удаленный репозиторий (например, на GitHub) с помощью
+команды **_git push_**.
+
+Спустя некоторое время к работе над проектом подключается второй разработчик.
+
+Поскольку первый разработчик пушил изменения файлов проекта
+на удаленный репозиторий, второй разработчик может скачать
+их себе на компьютер с помощью команды **_git pull_**
+и продолжить работу с учетом этих изменений.
+
+Давайте повторим.
+В описанной работе использовались команды:
+
+* **_git init_** - эта команда инициализирует работу Git
+для конкретного проекта. В папке с проектом создается
+скрытая папка, хранящая все файлы, необходимые Git
+для работы. Папка с этими файлами впоследствии будет
+загружена в удаленный репозиторий, и второй программист,
+скачавший проект, увидит у себя на компьютере все ранее
+созданные с помощью Git версии.
+* **_git add_** - это команда, которая добавляет файлы
+проекта в индекс (или отслеживаемую зону), чтобы их можно
+было в какой-то момент закоммитить (то есть сохранить, зафиксировать).
+* **_git commit_** - сохраняет все файлы проекта в
+текущем состоянии так, что мы в любой момент сможем
+вернуться к этому состоянию - посмотреть, как изменились
+файлы, или даже полностью вернуть проект к состоянию
+данного коммита.
+* **_git push_** - загружает файлы в удаленный Git-репозиторий,
+чтобы их могли скачать другие программисты.
+* **_git pull_** используют для того, чтобы скачать
+файлы из удаленного репозитория себе на компьютер.
+
+Также Git позволяет создавать ветки. Это означает,
+что вы можете создать копию стабильного кода и
+продолжить работу в этой копии, не подвергая риску
+стабильную версию. Когда код с новой функциональностью
+готов, отлажен и протестирован, он может быть
+слит ("смержен", от слова "merge") в основную ветку со стабильным кодом.
+
+С помощью этих функций Git позволяет команде разработчиков
+работать одновременно над разными задачами и поддерживать
+код в стабильном состоянии.
+
+Также Git позволяет в любой момент понять, кто и когда внес
+изменения в определенный код, что существенно упрощает взаимодействия
+с коллегами. Например, в случае, если вы видите новые
+строки кода, которые вызывают у вас вопросы, с помощью
+Git вы можете разобраться, кто внес изменения именно
+в эти строки, и связаться с этим человеком
+для уточнения деталей.
+
+Если произошла ситуация, при которой два разработчика
+изменили один и тот же файл, Git потребует от вас вручную
+отрегулировать такой конфликт.
+
+Также благодаря Git у вас всегда под рукой детальная
+история изменений. С помощью комментариев к коммитам
+вы можете детально документировать ход работы над
+проектом и в случае необходимости разобраться, в
+какой момент что-то пошло не так, и откатиться
+к той версии, где ошибка еще не была сделана.
+Или просто выяснить, как выглядел код определенного
+класса или метода в определенной версии и внести правки
+в текущую версию, если это необходимо.
+
+### Дополнительные материалы
+
+Для изучения Git рекомендуем в первую очередь ознакомиться со статьями на сайте [topjava.ru](https://topjava.ru):
+
+* [Введение в Git и GitHub: установка и настройка](https://topjava.ru/blog/vvedeniye-v-git-github-ustanovka-i-nastroyka)
+* [Введение в Git и GitHub: базовые команды](https://topjava.ru/blog/vvedeniye-v-git-github-bazovyye-komandy)
+* [Введение в Git и GitHub: ошибки использования](https://topjava.ru/blog/vvedeniye-v-git-oshibki-ispolzovaniya-ch-9)
+
+В них дается детальная инструкция по первоначальной настройке
+Git, GitHub, в том числе инструкция по настройке
+Access token в GitHub, что вам обязательно нужно будет сделать.
+
+Также можно упомянуть официальную русскоязычную книгу Pro Git,
+которая доступна [бесплатно в электронном виде](https://git-scm.com/book/ru/v2/).
+
+### Как мы будем использовать Git на курсе
+В Git очень много команд, но в ходе курса мы будем использовать
+только самые необходимые из них.
+С git можно работать как через терминал с помощью команд,
+так и с помощью различных программ с графическим интерфейсом.
+Мы будем преимущественно использовать интеграцию
+IntelliJ Idea с Git, поскольку она очень удобна
+и существенно упрощает работу.
+Однако знать, как выполнять аналогичные операции
+в терминале, очень полезно.
+
+### Резюме
+В этом уроке мы сделали краткий обзор систем управления
+версиями и самой популярной из них - Git:
+
+* разобрались в различиях Git и GitHub.
+Git - это система контроля версий, а
+GitHub - провайдер удаленных репозиториев, один из многих, доступных на рынке.
+* кратко познакомились с тем, как Git работает.
+Узнали о командах git init, git add, git commit, git push и git pull.
+* Также мы обсудили, что такое ветки и какие возможности они дают.
+
+---
+
+Если вы не работали раньше с Git, не беспокойтесь.
+В последующих уроках работа с Git будет изучаться
+на практике в ходе работы над проектом. Но дополнительно
+почитать о Git все же стоит.
+
+
+
+
diff --git a/doc/graduation.md b/doc/graduation.md
new file mode 100644
index 000000000..123238d4e
--- /dev/null
+++ b/doc/graduation.md
@@ -0,0 +1,185 @@
+## Выпускной проект
+
+- **Дедлайн на заполнение [формы по выпускному проекту](https://javaops.ru/auth/graduate) - 12 января 2026, 23.59 МСК**
+- Ревью проекта входит в участие с проверкой домашних заданий. Проверяется два раза: один раз ассистентами и после ваших правок - финальная проверка, Кислиным Григорием.
+- Ревью выпускного делается только у участников с проверкой ДЗ. У кого оплачен Диплом, но нет проверки - даю краткие итоги.
+- **Ревью выпускного можно оплатить отдельно как [техническое собеседование](https://javaops.ru/auth/payonline?payId=I)**
+- Участникам проекта [Многомодульный maven. Многопоточность. XML (JAXB/StAX). Веб сервисы (JAX-RS/SOAP). Удаленное взаимодействие (JMS/AKKA) (Masterjava)](http://javaops.ru/reg/masterjava) срок ревью выпускного до
+ 12 апреля 2026 г.
+
+## Technical requirement:
+Design and implement a REST API using Hibernate/Spring/SpringMVC (Spring-Boot preferred!) **without frontend**.
+
+The task is:
+
+Build a voting system for deciding where to have lunch.
+
+* 2 types of users: admin and regular users
+* Admin can input a restaurant and it's lunch menu of the day (2-5 items usually, just a dish name and price)
+* Menu changes each day (admins do the updates)
+* Users can vote for a restaurant they want to have lunch at today
+* Only one vote counted per user
+* If user votes again the same day:
+ - If it is before 11:00 we assume that he changed his mind.
+ - If it is after 11:00 then it is too late, vote can't be changed
+
+Each restaurant provides a new menu each day.
+
+As a result, provide a link to github repository. It should contain the code, README.md with API documentation and couple curl commands to test it (**better - link to Swagger**).
+
+-----------------------------
+P.S.: Make sure everything works with latest version that is on github :)
+P.P.S.: Assume that your API will be used by a frontend developer to build frontend on top of that.
+
+-----------------------------
+
+##  Рекомендации
+
+**Пишем выпускной проект как тестовое задание на работу**
+
+- **Не списывай с коллег!** Выпускные проекты пишут только наши выпускники, их репозитории есть в нашей базе. Поэтому при подозрениях на списывание оригинал вычисляется легко. Лучше написать свое -
+ как можете, как поняли материал - и получить ревью (которое вами же оплачено) своего проекта, а не чужого. Даже если времени мало - сделайте основное. Если с Дипломом - это с очень большой
+ вероятностью 4, вместо отчисления
+- **Не изобретай велосипедов!** Грубая ошибка - пытаться сделать стандартные вещи по-своему, чаще всего криво. На проекте все должно быть единообразно! Ваш проект TopJava - сделай все МАКСИМАЛЬНО в
+ этом стиле. Если тебе кажется, что есть лучшее решение, чем в TopJava - пишите мне в личку, я всегда открыт для улучшений.
+- **Делай проект на востребованном на рынке стеке**: Spring Boot + Spring Data JPA (работа с БД) + Swagger/OpenAPI 3.0 (REST документация). Для старта оптимально подойдет финальный код **открытого курса [Spring Boot 3.x + HATEOAS](https://javaops.ru/view/bootjava)**:
+```
+git clone --branch patched https://github.com/JavaOPs/bootjava.git
+```
+
+*Представьте себе, что ПМ (лид, архитектор) дал вам ТЗ и некоторое время недоступен. У вас, конечно, есть много мыслей, для чего нужно приложение, как исправить ТЗ, дополнить его и сделать правильно.
+НО НЕ НАДО ИХ РЕАЛИЗОВЫВАТЬ В КОДЕ. Нужно сделать все строго по ТЗ, максимально просто, удобно для доработок и для использования со стороны клиента.*
+
+> Совершенство достигнуто не тогда, когда нечего добавить, а тогда, когда нечего отнять
+
+_Антуан де Сент-Экзюпери_
+
+### 1: ТЗ (Тех.задание)
+
+- 1.1: Читай ТЗ ОЧЕНЬ внимательно, НЕ надо ничего своего туда домысливать и творчески изменять
+- 1.2: Учитывай, что пользователей может быть ОООЧЕНЬ много, а админов - МАЛО
+- 1.3: Сначала сделай основные сценарии по ТЗ. Все остальное (если очень хочется, 3 раза подумай) - потом.
+
+### 2. API
+
+- 2.1: API продумывай с точки зрения не программиста и объектов, а с точки зрения того, кто им будет пользоваться (клиента, UI)
+- 2.1: Тщательно считайте количество запросов в вашем API для отображения нужной информации
+- 2.3: Из потребностей приложения (клиента) реализуй только очевидные сценарии. Необходимо и достаточно: ВСЕ НЕОБХОДИМОЕ для клиента и НИЧЕГО ЛИШНЕГО. Процесс творческий, приходит с опытом.
+- 2.4: Делаем REST API в соответствии с концепцией REST (url в общем имеют вид`{ресурс}/{id_ресурсa}[/{подресурс}/{id_подресурсa}][параметры]`, см. ниже ссылки про REST и иерархию). Имена ресурсов во множественном числе!
+ Самая распространенная и грубая ошибка - не придерживаться этих простых правил.
+ - **[15 тривиальных фактов о правильной работе с протоколом HTTP](https://habrahabr.ru/company/yandex/blog/265569/)**
+ - **[10 Best Practices for Better RESTful API](https://medium.com/@mwaysolutions/10-best-practices-for-better-restful-api-cbe81b06f291)**
+ - **[REST resource hierarchy](https://stackoverflow.com/questions/20951419/what-are-best-practices-for-rest-nested-resources)**
+ - [Лучшие практики разработки REST API: правила 1-7,15-17](https://tproger.ru/translations/luchshie-praktiki-razrabotki-rest-api-20-sovetov/)
+- 2.5: Разделение на роли я предпочитаю на уровне URL. Сразу и однозначно видно, какой API у админа, какое у пользователя (API админа начинается, например, с */admin/...*).
+- 2.6: На управление (CRUD) ресторанами и едой должны быть ОТДЕЛЬНЫЕ контроллеры. Не надо все, что может админ, сваливать в одну кучу! Смотрите на результат операции - помещаете в этот контроллер!
+- 2.7: Проверьте в Swagger, что в POST и PUT нет ничего лишнего, а в GET есть все необходимые данные. Например, при запросе голоса должен в ответе отображаться `id` ресторана, а не весь объект, при создании-редактировании ресторана в примерах swagger не должно быть меню и еды.
+- 2.8: `Profile` означает, что данные принадлежат профилю пользователя. Все остальное называйте по-другому.
+- 2.9: Отсутствие данных часто бывает "бизнес кейсом", те НЕ ошибкой в запросе или приложении. Исключение - это ошибка, например неверный `id`. Запрос на данные, которые могут быть, могут нет, не должен приводить к исключениям. Посмотрите в сторону `ResponseEntity.of()`
+- 2.10: По REST URL должно быть однозначно понятно, какие будут параметры на входе и что ждать на выходе. Без сюрпризов!
+
+### 3: Код:
+- 3.1: Строго соблюдайте соглашения Java по именованию: пакеты ТОЛЬКО маленькими буквами, методы начинаются с маленькой буквы, классы с большой. Незнания Java Core - тестовое задание сразу в корзину.
+- 3.2 В проекте (и тестовом задании на работу), в отличие от нашего учебного topjava, оставляйте только необходимый для работы по ТЗ приложения код, ничего лишнего
+ - 3.2.1: НЕ надо делать разные профили базы и работы с ней
+ - 3.2.2: НЕ надо делать абстрактных контроллеров на всякий случай
+ - 3.2.3: НЕ надо делать сервисов, если там нет ничего, кроме делегирования
+ - 3.2.4: НЕ нужны локализация, UI, типы ошибок, Json View
+- 3.3: Название пакетов, имен классов для `model/to/web` стандартные (например `model/domain`). НЕ надо придумывать своих собственных правил
+- 3.4: Проверьте, не торчат ли из кода учебные уши TopJava, типа `ProfileRestController.testUTF()`, `AbstractServiceTest.printResult()` или закомментированные `JdbcTemplate`. Назначение выпускного
+ совсем другое
+- 3.5: Вместо `return ResponseEntity.ok(object)` в контроллерах пишите `return object`. Проще!
+
+### 4: Модель
+
+- 4.1: В БД обычно хранятся все введенные пользователем и админом данные c возможность их редактирования. Это означает, что мы не удаляем прошлые меню, а храним их в базе, как и историю голосования. Есть базовые вещи, которые закладываются в архитектуру приложения, и есть неочевидные доработки к ТЗ, делать не надо.
+- 4.2: Не делайте в модели объектов, которые не будут использоваться в коде (например, не надо двунаправленных связей, если достаточно однонаправленных)
+- 4.3: еще раз про [hashCode/equals в Entity](https://stackoverflow.com/questions/5031614/the-jpa-hashcode-equals-dilemma): не делайте в модели сравнение по полям!
+- 4.4: ORM работает с объектами. [Иногда, для упрощения логики, fk_id как поля допустимы](https://stackoverflow.com/questions/6311776/hibernate-foreign-keys-instead-of-entities)
+
+### 5: Архитектура / pom
+- 5.1: Можно:
+ - или подключить DATA-REST (см.курс [Spring Boot 2.x + HATEOAS](https://javaops.ru/view/bootjava)). Контроллеры генерируются автоматически по репозиториям, требуется настройка ресурсов в кастомных контроллерах
+ - или делать на основе миграции TopJava / кода [TopJava-2](https://github.com/JavaOPs/topjava2)
+
+Нельзя смешивать эти подходы вместе! Я рекомендую 2-й вариант, без data-rest. Обязательно посмотрите в Swagger, какие контроллеры получились в результате.
+- 5.2: Не размещайте бизнес-логику приложения и преобразования в TO в слое доступа к DB
+- 5.3: Не смешивайте TO и Entity вместе. Они должны быть независимыми друг от друга. На TopJava мы смотрели разные варианты [c использованием TO и без](https://stackoverflow.com/a/21569720/548473).
+ Делаем максимально просто.
+- 5.4: [Use for money in java app](http://stackoverflow.com/a/43051227/548473)
+- 5.5 Не надо явно указывать версии зависимостей в `pom`, если они наследуются от `spring-boot-starter-parent`
+
+### 6: Доступ к БД
+
+- 6.1: Используйте Spring Data JPA (без лишней делегации). Методы Repository можно вызывать напрямую из сервиса или из контроллера.
+- 6.2: В DATA-JPA 2.x используются `Optional`. Попробуйте работать с ними, это безопасный способ работать с null-значениями (используйте `orElseThrow`)
+- 6.3: Не делайте при обновлении записи ради экономии пары строчек кода так:
+```
+if(updateCondition)
+ repository.delete(entity)
+}
+repository.save(entity)
+```
+Обновление записи базы должно быть через `UPDATE`.
+
+### 7: База Данных
+
+- 7.1: Берите без установки (H2 или HSQLDB). Одну и **в памяти**! Ваше приложение должно сразу запуститься, без всяких настроек и переменных окружения
+- 7.2: Тщательно считайте количество обращений в базу на каждый запрос. Особенно при запросах от юзеров, которых очень много! Также на сложность запросов от них, чтобы не положить базу
+- 7.3: Сделайте [индексы к таблицам](https://ru.wikipedia.org/wiki/Индекс_(базы_данных)). Попробуйте обеспечить UNIQUE (один голос пользователя в день, один уникальный пункт меню в день).
+Следите за **порядком полей в индексе**, от этого зависит индексирование запросов.
+- 7.4: При популировании добавь записи за сегодняшний день - `now()`, чтобы всегда были актуальные исходные данные
+- 7.5: Поля базы case insensitive, не пишите camelStyle (для которых нужны кавычки)
+- 7.6: Таблицы обычно именуются в единственном числе. Исключение - `users`, `orders` и другие зарезервированные слова
+- 7.7: `date`/`timestamp` - зарезервированное слово, лучше избегать их при именовании полей
+
+### 8: Security
+
+- 8.1: Проверьте, станет ли код проще с `@AuthenticationPrincipal` (урок 11, доступ к AuthorizedUser).
+- 8.2: Я предпочитаю четкое разделение ролей на основе URL. Для админа URL содержит `/admin`
+- 8.3: Еще раз - призываю не менять код TopJava
+
+### 9: Кэширование
+
+- 9.1: Кэширование желательно для частых и редко меняющихся запросов от пользователей.
+Тщательно продумайте, что надо кэшировать (самые частые запросы), а что нет (большие или редко запрашиваемые данные)
+- 9.2: Проверьте соответствие ключей к кэшу (параметры кэшируемого метода) с конфигурацией (например в singleNonExpiryCache, heap=1 в кэше может содержаться только ОДНО значение).
+
+### 10: Валидация
+
+- 10.1: Одних аннотаций валидации на полях недостаточно. Должны быть `@Valid/@Validation` в контроллере
+- 10.2: Прячте `id` при `create/update` в примерах Swagger. Если их передали - проверяйте на соответствие (в TopJava это `ValidationUtil.checkNew()/assureIdConsistent()`)
+
+### 11: Дополнительно
+
+- 11.1: По возможности сделать JUnit-тесты. Можно не делать 100% покрытие, только основные сценарии
+- 11.2: Уделяйте внимание обработке ошибок.
+
+### 12: `readme.md`:
+
+- 12.1: Поместите вначале `readme` ТЗ или **ссылку на него** - будет понятно о чем твой проект
+- 12.2: Если задание на English, описание пиши также на English (то же самое относится к языку резюме: вакансия на English предполагает резюме на English)
+- 12.3: Требуемые примеры `curl` не прячьте, а пишите здесь! Оптимально сделать **ссылку на `Swagger UI` с креденшелами для выполнения запросов**
+- 12.4: Проверяют люди с опытом в Java: не надо писать инструкций, как устанавливать Java и Maven
+
+### 13: Git
+
+- 13.1: Должна быть история ваших комитов с внятными комментариями. Это смотрят.
+> Эйчар обращает внимание на дату создания аккаунта и то, как в него заливались коммиты (элементы проекта), постепенно или в один день, насколько технологии в аккаунте коррелируют с технологиями в резюме
+- 13.2: Не комить служенбые файлы: логи, DB, настройки IDEA и пр., это сразу - уровень Junior.
+- 13.3: Все служебные файлы должны быть в `.gitignore`
+
+## Проверка
+
+- Попробуй подергать свое API по всем типичным сценариям ТЗ!
+ - Удобно использовать? Можно сделать проще? Например, чтобы проголосовать за ресторан залогиненному юзеру, достаточно `restorauntId`.
+ - Сколько раз пришлось его вызвать API для типичного сценария (например посмотреть рестораны с едой на сегодня)?
+ - Сколько запросов к базе было сделано? Можно ли сократить (например с `FETCH/Graph` или через кэширование)?
+ - **Еще раз - проверь все запросы в Sawgger, смотри на формат запросов и данные в ответе. Все должно работать, есть все данные и нет ничего лишнего**
+- 13.2: API ДОЛЖЕН соответствовать принципам REST (см. ссылки выше)
+- 13.3: ОБЯЗАТЕЛЬНО: запустите `mvn test` - ошибок быть не должно
+- 13.4: ОБЯЗАТЕЛЬНО: запустите приложение без всяких предварительных настроек (базы, переменных окружения, ..), лучше на другом компьютере. Приложение должно запускаться и работать!
+
+## Оценка
+ТЗ очень скромное, не дает понимания, что хочет получить заказчик, именно поэтому моих комментариев к этому ТЗ больше на 2 порядка. Это реальное тестовое задание на работу. При оценке учитывается отсутствие грубых ляпов, простота и красота решения + его расширяемость, если понадобится дорабатывать приложение. Если практический опыт небольшой, еще раз очень рекомендую держаться как можно ближе к нашему коду на Spring Boot.
+Тестовое задание дается для того, чтобы оценить вас, как программиста. Нужны ли вы компании или нет. Это умение спроектировать грамотную модель и API, придерживаясь принципов REST и без своих велосипедов, и ваш чистый красивый код.
diff --git a/doc/lesson01.md b/doc/lesson01.md
new file mode 100644
index 000000000..9468d02ec
--- /dev/null
+++ b/doc/lesson01.md
@@ -0,0 +1,262 @@
+# Стажировка Topjava
+
+### Правила похождения стажировки
+- Не стоит стремиться прочитать все ссылки урока, их можно использовать позднее как справочник. Гораздо важнее **пройти основной материал урока и сделать Домашнее Задание**
+- Обязательно посмотри правила работы с патчами на проекте
+ - Делать Apply Patch лучше по одному, непосредственно перед видео на эту тему, а при просмотре видео сразу отслеживать все изменения кода проекта по изменению в патче (`Git-> Local Changes-> Ctrl+D`)
+ - **При первом Apply удобнее выбрать имя локального ченджлиста Name: Change**. Далее все остальные патчи также будут в него попадать.
+- **Код проекта обновляется и не всегда совпадает с видео (можно увидеть как развивался проект). Изменения в проекте указываю после соответствующего патча.**
+- Если ссылка не открывается, попробуй [включить VPN](https://github.com/JavaOPs/topjava/wiki/VPN)
+- **ОСНОВНОЕ, чему мы учимся на проекте: мыслить и работать как Java разработчики уже сейчас**, потом это будет гораздо сложнее и стоить дороже. Вот на мой взгляд [хорошие советы новичкам](http://blog.csssr.ru/2016/09/19/how-to-be-a-beginner-developer). От себя я добавлю:
+ - Учись **грамотно формулировать проблему**. Проблема "у меня не работает" может иметь тысячи причин. В процессе формулирования очень часто приходит ее решение.
+ - что я делаю (подробно, чтобы понял человек, который не был занят этой проблемой несколько часов)
+ - что получаю (обычно верх самого последнего эксепшена)
+ - что я сделал для решения, какие результаты получил
+ - Учись исследовать проблему. Внимательное чтение логов и [умение дебажить](http://info.javarush.ru/idea_help/2014/01/22/Руководство-пользователя-IntelliJ-IDEA-Отладчик-.html) - основные навыки разработчика. Обычно самый верх самого нижнего эксепшена- причина ошибки, туда нужно ставить брекпойнт.
+ - Грамотно **уделяй время каждой проблеме**. Две крайности - сразу бросаться за помощью и биться над ней часами. Пробуй решить ее сам и в зависимости от проблемы выделяй на это разумное время.
+ - Наконец, уровень участников у всех разный. Бывают синьоры, бывают начинающие. Не стесняйтесь задавать вопросы, иначе стажировка пройдет впустую! **Глупых вопросов не бывает**.
+----------------------------------------------------
+- **Обязательно и как можно чаще пользуйтесь `Ctrl+Alt+L` - отформатировать код класса**
+- **При изменениях на UI не забываетй сбрасывать кэш браузера - `Ctrl+F5`**
+- **При удалении классов не забывате чистить target - в окошке Maven -> clean или `mvn clean`**
+- **При проблемах с IDEA пользуйтесь `Refresh` в окошке Maven**
+- **При проблемах с выполнением проверьте (и удалите) лишние java процессы (например в Task Manager)**
+
+
+## Материалы занятия (скачать все патчи можно через `Download/Скачать` папки patch)
+
+
+###  Рефакторинг проекта
+
+#### Apply 1_0_fix_rename.patch
+- переименовал классы `UserMeal*` в более красивые `Meal*`
+- преименовал `MealWithExceed` transfer object класс ([что это такое](https://ru.wikipedia.org/wiki/DTO) пройдем позже) в `MealTo` ([data transfer object naming convention](https://stackoverflow.com/questions/1724774/java-data-transfer-object-naming-convention))
+- IDEA предложила рефакторинг `TimeUtil.isBetweenHalfOpen` с использованием `isBefore`.
+
+##  Разбор домашнего задания HW0:
+###  1. Optional: реализация getFilteredMealsWithExcess через Stream API
+- В патче `prepare_to_HW0.patch` вступительного задания метод фильтрации в `TimeUtil` переименовали в `isBetweenHalfOpen` (также изменилась логика сравнения - `startTime` включается в интервал)
+
+#### Apply 1_1_HW0_streams.patch
+
+- [Презентация Java 8](https://docs.google.com/presentation/d/1oltLkHK60FqIdsXjUdm4pPLSeC6KpNYjDsM0ips-qBw)
+
+###  2. Работа с git в IDEA. Реализация через цикл.
+### ВНИМАНИЕ! Патчей `1_opt_2_HW0_cycles` и `1_opt_3_HW0_opt2` не будет в проекте!
+Делаем в отдельной ветке (у меня `MealsUtil_opt`). Это варианты решений, которые не идут в `master`
+
+
+
+#### Apply 1_opt_2_HW0_cycles.patch
+
+###  Вопросы по HW0
+
+> Почему не использовать в `TimeUtil` методы `isBefore/isAfter` ?
+
+это строгие (excluded) сравнения, а нам также нужно краевые значения
+
+> В `MealsUtil` у нас где-то есть ключевое слово `final`, где-то нет. В чем разница?
+
+Я участвовал в одном проекте, где `final` был обязательным (в сеттингах IDEA галочка стояла). Но это скорее исключение, чем правило в проектах java (в Java 8 вообще ввели эффективный final, те по факту). Во всех новомодных языках переменные final по умолчанию, а в java нужно помнить и везде добавлять, утомительно. Но если приучитесь - хуже не будет. Я обычно ставлю там, где важно по смыслу (если не забываю).
+
+###  3. [HW0 Optional 2: реализация в один проход циклами и Stream API](https://drive.google.com/file/d/1dSt3axySxu4V9dMnuR1wczerlI_WzCep)
+
+#### Apply 1_opt_3_HW0_opt2.patch
+- Дополнительно:
+ - [Первое занятие MasterJava: многопоточность](https://github.com/JavaOPs/masterjava)
+ - [Обзор java.util.concurrent.*](https://web.archive.org/web/20220427140138/https://habr.com/ru/company/luxoft/blog/157273/)
+
+## Занятие 1:
+
+###  4. [Интервью: Java разработка. Обучение. Трудоустройство](https://javaops.ru/view/news/javaInterview)
+- [JetBrains devecosystem 2022](https://www.jetbrains.com/lp/devecosystem-2022/java/)
+- [Сontinuum Java Ecosystem 2022 – Survey results](https://www.continuum.be/en/blog/the-java-ecosystem-2022-survey-results/)
+- [JRebel 2022 Java Developer Productivity Report](https://drive.google.com/file/d/1txLeRsNNR7EqYEeIvYmuyQi9hknBeR9G)
+
+###  5. [Servlet API. Apache Tomcat. JSP](lesson01/tomcat_servlet_war.md)
+
+###  6. [Логирование](https://www.youtube.com/watch?v=mo8z3zRVV1E)
+#### Последние версии _logback / slf4j_ не работают с JDK 8, понизил версии до совместимых с ней. Поднимем на 5м занятии при миграции на JDK 17+
+
+#### Apply 1_5_simple_logging.patch
+
+- [Зачем нужно логирование](https://javarush.ru/groups/posts/2293-zachem-nuzhno-logirovanie)
+- [Logback Project](https://logback.qos.ch/)
+
+> А зачем мы использовали logback? Почему SLF4J нас не устроило? Почему реализация логирования не log4j?
+
+`SLF4J-API` это API. В нее включена только пустая реализация `org.slf4j.helpers.NOPLogger` (можно посмотреть в исходниках). Logback для новых проектов стал стандарт, *Spring Boot* используют его по умолчанию.
+[Reasons to prefer logback over log4j](http://logback.qos.ch/reasonsToSwitch.html)
+
+> Почему `private static final Logger log` а не `LOG/LOGGER` ?
+
+Это [правило именования констант, которые не "deeply immutable"](https://google.github.io/styleguide/javaguide.html#s5.2.4-constant-names), те если их содержимое можно изменить.
+
+#### Apply 1_6_logging_config.patch
+
+- [Java Logging: история кошмара](http://habrahabr.ru/post/113145/)
+- [Project dependencies for logging](https://www.slf4j.org/manual.html#projectDep)
+- [Добавление зависимостей логирования](http://www.slf4j.org/legacy.html) в проект
+- Не делать конкатенацию строк: [форматирование в логах через {}](https://www.slf4j.org/faq.html#logging_performance)
+- Дополнительно:
+ - [Logback configuration](https://logback.qos.ch/manual/configuration.html)
+ - [Ведение лога приложения](http://www.skipy.ru/useful/logging.html)
+ - [Владимир Красильщик – Что надо знать о логировании прагматичному Java‑программисту](https://www.youtube.com/watch?v=qzqAUUgB3v8)
+
+**Установите переменную окружения на TOPJAVA_ROOT на корень проекта и перезапустите IDEA. Слеши в пути должны быть в стиле unix (/)**
+
+Проверить, видит ли Java вашу переменную можно через `System.getenv("TOPJAVA_ROOT")`
+
+- [Set environment for Win/Mac/Unix](https://chlee.co/how-to-setup-environment-variables-for-windows-mac-and-linux/)
+- [Set environment for UNIX (advanced)](https://askubuntu.com/a/849954)
+ - [Определить, какой Login или Non-Login Shell](https://tecadmin.net/difference-between-login-and-non-login-shell)
+ - [Порядок запуска скриптов при старте](https://www.baeldung.com/linux/bashrc-vs-bash-profile-vs-profile)
+- Или простой вариант (не забудте добавить и в Run, и в Debug)
+
+
+
+**Иногда антивирусы блокируют логирование (например Comodo). Если не работает и стоит антивирус- добавьте исключение.**
+
+> Изменения в проекте, которым могут встретиться в других видео:
+> - убрал `LoggerWrapper` и логирую напрямую в логгер SLF4J.
+> - удалил зависимости `jul-to-slf4j` и `jcl-over-slf4j`. Spring 5 напрямую использует `slf4j` без `common-logging`
+
+---------
+
+##  Домашнее задание HW01 (делаем ветку HW01 от последнего патча в master)
+--------------------------------------------
+#### 1. Реализовать сервлет с отображением в таблице списка еды (в памяти и БЕЗ учета пользователя)
+
+> Деплоиться в Tomcat лучше как `war exploded`: нет упаковки в war и при нажатой кнопке `Update Resources on Frame Deactivation` можно обновляться css, html, jsp без передеплоя. При изменении `web.xml`, добавлении методов, классов необходим redeploy.
+
+- 1.1 По аналогии с `UserServlet` добавить `MealServlet` и `meals.jsp`
+ - Задеплоить приложение (war) в Tomcat c `applicationContext=topjava` (приложение должно быть доступно по http://localhost:8080/topjava)
+ - Попробовать деплои в Tomcat как WAR в запушенный вручную Tomcat и через IDEA.
+- 1.2 Сделать отображения списка еды в JSP [в таблице](http://htmlbook.ru/html/table), цвет записи в таблице зависит от параметра `excess` (красный/зеленый).
+ - 1.2.1 Список еды захардкодить (те проинициализировать в коде, желательно чтобы в проекте инициализация была только в одном месте). Норму калорий (caloriesPerDay) сделать в коде константой
+ - 1.2.2 Время выводить без 'T'
+ - 1.2.3 Список выводим БЕЗ фильтрации по `startTime/endTime`
+ - 1.2.4 С обработкой исключений пока можно не заморачиваться, мы будем красиво обрабатывать в конце стажировки
+ - 1.2.5 Вариант реализации:
+ - из сервлета преобразуете еду в `List