From 46430483bac498e923f85ac4768040d32e72eff8 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=E6=8D=A1=E7=94=B0=E8=9E=BA=E7=9A=84=E5=B0=8F=E7=94=B7?=
=?UTF-8?q?=E5=AD=A9?= <327658337@qq.com>
Date: Sun, 10 Oct 2021 23:16:51 +0800
Subject: [PATCH 01/47] Add files via upload
---
...23\345\215\260\350\247\204\350\214\203.md" | 269 ++++++++++++++++++
1 file changed, 269 insertions(+)
create mode 100644 "\345\267\245\344\275\234\346\200\273\347\273\223/\346\227\245\345\277\227\346\211\223\345\215\260\350\247\204\350\214\203.md"
diff --git "a/\345\267\245\344\275\234\346\200\273\347\273\223/\346\227\245\345\277\227\346\211\223\345\215\260\350\247\204\350\214\203.md" "b/\345\267\245\344\275\234\346\200\273\347\273\223/\346\227\245\345\277\227\346\211\223\345\215\260\350\247\204\350\214\203.md"
new file mode 100644
index 0000000..4577332
--- /dev/null
+++ "b/\345\267\245\344\275\234\346\200\273\347\273\223/\346\227\245\345\277\227\346\211\223\345\215\260\350\247\204\350\214\203.md"
@@ -0,0 +1,269 @@
+## З°СФ
+
+ҙујТәГЈ¬ОТКЗ**јсМпВЭөДРЎДРәў**ЎЈИХЦҫКЗҝмЛЩ¶ЁО»ОКМвөДәГ°пКЦЈ¬КЗ**ЛәұЖәНЛҰ№ш**өДАыЖчЈЎҙтУЎәГИХЦҫ·ЗіЈЦШТӘЎЈҪсМмОТГЗАҙБДБД**ИХЦҫҙтУЎ**өД15ёцәГҪЁТй~
+
+- №«ЦЪәЕЈә**јсМпВЭөДРЎДРәў**
+
+
+## 1. СЎФсЗЎөұөДИХЦҫј¶ұр
+
+іЈјыөДИХЦҫј¶ұрУР5ЦЦЈ¬·ЦұрКЗerrorЎўwarnЎўinfoЎўdebugЎўtraceЎЈИХіЈҝӘ·ўЦРЈ¬ОТГЗРиТӘСЎФсЗЎөұөДИХЦҫј¶ұрЈ¬І»ТӘ·ҙКЦҫНКЗҙтУЎinfo№ю~
+
+
+
+- errorЈәҙнОуИХЦҫЈ¬ЦёұИҪПСПЦШөДҙнО󣬶ФХэіЈТөОсУРУ°ПмЈ¬РиТӘ**ФЛО¬ЕдЦГјаҝШөД**Ј»
+- warnЈәҫҜёжИХЦҫЈ¬Т»°гөДҙнО󣬶ФТөОсУ°ПмІ»ҙуЈ¬ө«КЗРиТӘ**ҝӘ·ў№ШЧў**Ј»
+- infoЈәРЕПўИХЦҫЈ¬јЗВјЕЕІйОКМвөД№ШјьРЕПўЈ¬ИзөчУГКұјдЎўіцІОИлІОөИөИЈ»
+- debugЈәУГУЪҝӘ·ўDEBUGөДЈ¬№ШјьВЯјӯАпГжөДФЛРРКұКэҫЭЈ»
+- traceЈәЧоПкПёөДРЕПўЈ¬Т»°гХвР©РЕПўЦ»јЗВјөҪИХЦҫОДјюЦРЎЈ
+
+
+## 2. ИХЦҫТӘҙтУЎіц·Ҫ·ЁөДИлІОЎўіцІО
+
+ОТГЗІўІ»РиТӘҙтУЎәЬ¶аәЬ¶аИХЦҫЈ¬Ц»РиТӘҙтУЎҝЙТФ**ҝмЛЩ¶ЁО»ОКМвөДУРР§ИХЦҫ**ЎЈУРР§өДИХЦҫЈ¬КЗЛҰ№шөДАыЖчЈЎ
+
+
+
+ДДР©ЛгөГөДЙП**УРР§№Шјь**өДИХЦҫДШЈҝұИИзЛөЈ¬·Ҫ·ЁҪшАҙөДКұәтЈ¬ҙтУЎ**ИлІО**ЎЈФЩИ»әуДШЈ¬ФЪ·Ҫ·Ё·ө»ШөДКұәтЈ¬ҫНКЗ**ҙтУЎіцІОЈ¬·ө»ШЦө**ЎЈИлІОөД»°Ј¬Т»°гҫНКЗ**userId»тХЯbizSeqХвР©№Шјь**РЕПўЎЈХэАэИзПВЈә
+
+```
+public String testLogMethod(Document doc, Mode mode){
+ log.debug(Ў°method enter paramЈә{}Ўұ,userId);
+ String id = "666";
+ log.debug(Ў°method exit paramЈә{}Ўұ,id);
+ return id;
+}
+```
+
+
+## 3. СЎФсәПККөДИХЦҫёсКҪ
+
+АнПлөДИХЦҫёсКҪЈ¬УҰөұ°ьАЁХвР©Чо»щұҫөДРЕПўЈәИзөұ**З°КұјдҙБ**ЈЁТ»°гәБГлҫ«И·¶ИЈ©Ўў**ИХЦҫј¶ұр**Ј¬**ПЯіМГыЧЦ**өИөИЎЈФЪlogbackИХЦҫАпҝЙТФХвГҙЕдЦГЈә
+
+```
+
+
+ %d{HH:mm:ss.SSS} %-5level [%thread][%logger{0}] %m%n
+
+
+```
+
+Из№ыОТГЗөДИХЦҫёсКҪЈ¬Б¬өұЗ°Кұјд¶јӣ]УРјЗВјЈ¬ДЗ**Б¬ЗлЗуөДКұјдөг¶јІ»ЦӘөАБЛ**Јҝ
+
+
+
+
+## 4. УцөҪif...else...өИМхјюКұЈ¬Гҝёц·ЦЦ§КЧРР¶јҫЎБҝҙтУЎИХЦҫ
+
+өұДгЕцөҪ**if...else...»тХЯswitch**ХвСщөДМхјюКұЈ¬ҝЙТФФЪ·ЦЦ§өДКЧРРҫНҙтУЎИХЦҫЈ¬ХвСщЕЕІйОКМвКұЈ¬ҫНҝЙТФНЁ№эИХЦҫЈ¬И·¶ЁҪшИлБЛДДёц·ЦЦ§Ј¬ҙъВлВЯјӯёьЗеОъЈ¬ТІёь·ҪұгЕЕІйОКМвБЛЎЈ
+
+
+
+
+ХэАэЈә
+```
+if(user.isVip()){
+ log.info("ёГУГ»§КЗ»бФұ,Id:{},ҝӘКјҙҰАн»бФұВЯјӯ",user,getUserId());
+ //»бФұВЯјӯ
+}else{
+ log.info("ёГУГ»§КЗ·З»бФұ,Id:{},ҝӘКјҙҰАн·З»бФұВЯјӯ",user,getUserId())
+ //·З»бФұВЯјӯ
+}
+```
+
+## 5.ИХЦҫј¶ұрұИҪПөНКұЈ¬ҪшРРИХЦҫҝӘ№ШЕР¶П
+
+¶ФУЪtrace/debugХвР©ұИҪПөНөДИХЦҫј¶ұрЈ¬ұШРлҪшРРИХЦҫј¶ұрөДҝӘ№ШЕР¶ПЎЈ
+
+ХэАэЈә
+```
+User user = new User(666L, "№«ЦЪәЕ", "јсМпВЭөДРЎДРәў");
+if (log.isDebugEnabled()) {
+ log.debug("userId is: {}", user.getId());
+}
+```
+
+ТтОӘөұЗ°УРИзПВөДИХЦҫҙъВлЈә
+```
+logger.debug("Processing trade with id: " + id + " and symbol: " + symbol);
+```
+
+Из№ы**ЕдЦГөДИХЦҫј¶ұрКЗwarn**өД»°Ј¬ЙПКцИХЦҫІ»»бҙтУЎЈ¬ө«КЗ»бЦҙРРЧЦ·ыҙ®ЖҙҪУІЩЧчЈ¬Из№ы```symbol```КЗ¶ФПуЈ¬
+»№»бЦҙРР```toString()```·Ҫ·ЁЈ¬АЛ·СБЛПөНіЧКФҙЈ¬ЦҙРРБЛЙПКцІЩЧчЈ¬ЧоЦХИХЦҫИҙГ»УРҙтУЎЈ¬ТтҙЛҪЁТй**јУИХЦҫҝӘ№ШЕР¶ПЎЈ**
+
+## 6. І»ДЬЦұҪУК№УГИХЦҫПөНіЈЁLog4jЎўLogbackЈ©ЦРөД APIЈ¬¶шКЗК№УГИХЦҫҝтјЬSLF4JЦРөДAPIЎЈ
+
+SLF4J КЗГЕГжДЈКҪөДИХЦҫҝтјЬЈ¬УРАыУЪО¬»ӨәНёчёцАаөДИХЦҫҙҰАн·ҪКҪНіТ»Ј¬ІўЗТҝЙТФФЪұЈЦӨІ»РЮёДҙъВлөДЗйҝцПВЈ¬әЬ·ҪұгөДКөПЦөЧІгИХЦҫҝтјЬөДёь»»ЎЈ
+
+
+
+ХэАэЈә
+```
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+private static final Logger logger = LoggerFactory.getLogger(TianLuoBoy.class);
+```
+
+## 7. ҪЁТйК№УГІОКэХјО»{}Ј¬¶шІ»КЗУГ+ЖҙҪУЎЈ
+
+·ҙАэЈә
+```
+logger.info("Processing trade with id: " + id + " and symbol: " + symbol);
+```
+
+ЙПГжөДАэЧУЦРЈ¬К№УГ```+```ІЩЧч·ыҪшРРЧЦ·ыҙ®өДЖҙҪУЈ¬УРТ»¶ЁөД**РФДЬЛрәД**ЎЈ
+
+ХэАэИзПВЈә
+```
+logger.info("Processing trade with id: {} and symbol : {} ", id, symbol);
+```
+ОТГЗК№УГБЛҙуАЁәЕ```{}```АҙЧчОӘИХЦҫЦРөДХјО»·ыЈ¬ұИУЪК№УГ```+```ІЩЧч·ыЈ¬ёьјУУЕСЕјтҪаЎЈІўЗТЈ¬**Па¶ФУЪ·ҙАэ**Ј¬К№УГХјО»·ыҪцКЗМж»»¶ҜЧчЈ¬ҝЙТФУРР§МбЙэРФДЬЎЈ
+
+## 8. ҪЁТйК№УГТмІҪөД·ҪКҪАҙКдіцИХЦҫЎЈ
+
+- ИХЦҫЧоЦХ»бКдіцөҪОДјю»тХЯЖдЛьКдіцБчЦРөДЈ¬IOРФДЬ»бУРТӘЗуөДЎЈИз№ыТмІҪЈ¬ҫНҝЙТФПФЦшМбЙэIOРФДЬЎЈ
+- іэ·ЗУРМШКвТӘЗуЈ¬ТӘІ»И»ҪЁТйК№УГТмІҪөД·ҪКҪАҙКдіцИХЦҫЎЈТФlogbackОӘАэ°ЙЈ¬ТӘЕдЦГТмІҪәЬјтөҘЈ¬К№УГAsyncAppenderҫНРР
+```
+
+
+
+```
+
+## 9. І»ТӘК№УГe.printStackTrace()
+
+
+
+
+
+·ҙАэЈә
+```
+try{
+ // ТөОсҙъВлҙҰАн
+}catch(Exception e){
+ e.printStackTrace();
+}
+```
+ХэАэЈә
+```
+try{
+ // ТөОсҙъВлҙҰАн
+}catch(Exception e){
+ log.error("ДгөДіМРтУРТміЈАІ",e);
+}
+```
+
+**АнУЙЈә**
+
+- e.printStackTrace()ҙтУЎіцөД¶СХ»ИХЦҫёъТөОсҙъВлИХЦҫКЗҪ»ҙн»мәПФЪТ»ЖрөДЈ¬НЁіЈЕЕІйТміЈИХЦҫІ»М«·ҪұгЎЈ
+- e.printStackTrace()УпҫдІъЙъөДЧЦ·ыҙ®јЗВјөДКЗ¶СХ»РЕПўЈ¬Из№ыРЕПўМ«іӨМ«¶аЈ¬ЧЦ·ыҙ®іЈБҝіШЛщФЪөДДЪҙжҝйГ»УРҝХјдБЛ,јҙДЪҙжВъБЛЈ¬ДЗГҙЈ¬УГ»§өДЗлЗуҫНҝЁЧЎАІ~
+
+## 10. ТміЈИХЦҫІ»ТӘЦ»ҙтТ»°лЈ¬ТӘКдіцИ«ІҝҙнОуРЕПў
+
+
+
+·ҙАэ1Јә
+
+```
+try {
+ //ТөОсҙъВлҙҰАн
+} catch (Exception e) {
+ // ҙнОу
+ LOG.error('ДгөДіМРтУРТміЈАІ');
+}
+
+```
+- ТміЈe¶јГ»УРҙтУЎіцАҙЈ¬ЛщТФС№ёщІ»ЦӘөАіцБЛКІГҙАаРНөДТміЈЎЈ
+
+·ҙАэ2Јә
+```
+try {
+ //ТөОсҙъВлҙҰАн
+} catch (Exception e) {
+ // ҙнОу
+ LOG.error('ДгөДіМРтУРТміЈАІ', e.getMessage());
+}
+```
+
+- ```e.getMessage()```І»»бјЗВјПкПёөД¶СХ»ТміЈРЕПўЈ¬Ц»»бјЗВјҙнОу»щұҫГиКцРЕПўЈ¬І»АыУЪЕЕІйОКМвЎЈ
+
+ХэАэЈә
+
+```
+try {
+ //ТөОсҙъВлҙҰАн
+} catch (Exception e) {
+ // ҙнОу
+ LOG.error('ДгөДіМРтУРТміЈАІ', e);
+}
+```
+
+## 11. ҪыЦ№ФЪПЯЙП»·ҫіҝӘЖф debug
+
+ҪыЦ№ФЪПЯЙП»·ҫіҝӘЖфdebugЈ¬ХвТ»өг·ЗіЈЦШТӘЎЈ
+
+
+ТтОӘТ»°гПөНіөДdebugИХЦҫ»бәЬ¶аЈ¬ІўЗТёчЦЦҝтјЬЦРТІҙуБҝК№УГ debugөДИХЦҫЈ¬ПЯЙПҝӘЖфdebugІ»ҫГҝЙДЬ»бҙтВъҙЕЕМЈ¬У°ПмТөОсПөНіөДХэіЈФЛРРЎЈ
+
+## 12.І»ТӘјЗВјБЛТміЈЈ¬УЦЕЧіцТміЈ
+
+
+
+
+
+·ҙАэИзПВЈә
+```
+log.error("IO exception", e);
+throw new MyException(e);
+```
+
+- ХвСщКөПЦөД»°Ј¬НЁіЈ»б°СХ»РЕПўҙтУЎБҪҙОЎЈХвКЗТтОӘІ¶»сБЛMyExceptionТміЈөДөШ·ҪЈ¬»№»бФЩҙтУЎТ»ҙОЎЈ
+- ХвСщөДИХЦҫјЗВјЈ¬»тХЯ°ьЧ°әуФЩЕЧіцИҘЈ¬І»ТӘН¬КұК№УГЈЎ·сФтДгөДИХЦҫҝҙЖрАҙ»бИГИЛәЬГФ»уЎЈ
+
+
+## 13.ұЬГвЦШёҙҙтУЎИХЦҫ
+
+ұЬГвЦШёҙҙтУЎИХЦҫЈ¬ҪҙЧП»бАЛ·СҙЕЕМҝХјдЎЈИз№ыДгТСҫӯУРТ»РРИХЦҫЗеіюұнҙпБЛТвЛјЈ¬**ұЬГвФЩИЯУаҙтУЎ**Ј¬·ҙАэИзПВЈә
+
+```
+if(user.isVip()){
+ log.info("ёГУГ»§КЗ»бФұ,Id:{}",user,getUserId());
+ //ИЯУаЈ¬ҝЙТФёъЗ°ГжөДИХЦҫәПІўТ»Жр
+ log.info("ҝӘКјҙҰАн»бФұВЯјӯ,id:{}",user,getUserId());
+ //»бФұВЯјӯ
+}else{
+ //·З»бФұВЯјӯ
+}
+```
+
+Из№ыДгКЗК№УГlog4jИХЦҫҝтјЬЈ¬ОсұШФЪ```log4j.xml```ЦРЙиЦГ additivity=falseЈ¬ТтОӘҝЙТФұЬГвЦШёҙҙтУЎИХЦҫ
+
+ХэАэЈә
+```
+
+```
+
+## 14.ИХЦҫОДјю·ЦАл
+
+
+
+
+
+- ОТГЗҝЙТФ°СІ»Н¬АаРНөДИХЦҫ·ЦАліцИҘЈ¬ұИИзaccess.logЈ¬»тХЯerrorј¶ұрerror.logЈ¬¶јҝЙТФөҘ¶АҙтУЎөҪТ»ёцОДјюАпГжЎЈ
+- өұИ»Ј¬ТІҝЙТФёщҫЭІ»Н¬өДТөОсДЈҝйЈ¬ҙтУЎөҪІ»Н¬өДИХЦҫОДјюАпЈ¬ХвСщОТГЗЕЕІйОКМвәНЧцКэҫЭНіјЖөДКұәтЈ¬¶ј»бұИҪП·ҪұгАІЎЈ
+
+
+## 15. әЛРД№ҰДЬДЈҝйЈ¬ҪЁТйҙтУЎҪПНкХыөДИХЦҫ
+
+
+
+
+
+- ОТГЗИХіЈҝӘ·ўЦРЈ¬Из№ыәЛРД»тХЯВЯјӯёҙФУөДҙъВлЈ¬ҪЁТйМнјУПкПёөДЧўКНЈ¬ТФј°ҪППкПёөДИХЦҫЎЈ
+- ИХЦҫТӘ¶аПкПёДШЈҝДФ¶ҙТ»ПВЈ¬Из№ыДгөДәЛРДіМРтДДТ»ІҪіцҙнБЛЈ¬НЁ№эИХЦҫҝЙТФ¶ЁО»өҪЈ¬ДЗҫНҝЙТФАІЎЈ
+
+
+
+
+
+
From 93194b68365941438a9d904fa1b3e9c258f7e28a Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=E6=8D=A1=E7=94=B0=E8=9E=BA=E7=9A=84=E5=B0=8F=E7=94=B7?=
=?UTF-8?q?=E5=AD=A9?= <327658337@qq.com>
Date: Sun, 10 Oct 2021 23:17:47 +0800
Subject: [PATCH 02/47] Update README.md
---
README.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/README.md b/README.md
index 6018cc3..214c8ab 100644
--- a/README.md
+++ b/README.md
@@ -2,7 +2,7 @@
## дёӘдәәе…¬дј—еҸ·
-
+еҫ®дҝЎжҗңпјҡжҚЎз”°иһәзҡ„е°Ҹз”·еӯ©
- еҰӮжһңдҪ жҳҜдёӘзҲұеӯҰд№ зҡ„еҘҪеӯ©еӯҗпјҢеҸҜд»Ҙе…іжіЁжҲ‘е…¬дј—еҸ·пјҢдёҖиө·еӯҰд№ и®Ёи®әе“Ҳ~~
From 6cd2682a3f262f88a9db736c5402df01c6aefc20 Mon Sep 17 00:00:00 2001
From: whx123 <327658337@qq.com>
Date: Mon, 6 Jun 2022 08:23:10 +0800
Subject: [PATCH 03/47] mhouduansiwei
---
...36\344\270\252\351\224\246\345\233\212.md" | 540 ++++++++++++++++
...03\347\224\250\346\250\241\346\235\277.md" | 599 ++++++++++++++++++
2 files changed, 1139 insertions(+)
create mode 100644 "\345\220\216\347\253\257\346\200\235\347\273\264\347\257\207/\345\220\216\347\253\257\346\200\235\347\273\264\344\270\200\357\274\232\350\256\276\350\256\241\346\216\245\345\217\243\347\232\20436\344\270\252\351\224\246\345\233\212.md"
create mode 100644 "\345\220\216\347\253\257\346\200\235\347\273\264\347\257\207/\345\220\216\347\253\257\346\200\235\347\273\264\347\257\207\344\272\214\357\274\232\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\345\256\236\347\216\260\344\270\200\344\270\252\345\271\266\350\241\214\350\260\203\347\224\250\346\250\241\346\235\277.md"
diff --git "a/\345\220\216\347\253\257\346\200\235\347\273\264\347\257\207/\345\220\216\347\253\257\346\200\235\347\273\264\344\270\200\357\274\232\350\256\276\350\256\241\346\216\245\345\217\243\347\232\20436\344\270\252\351\224\246\345\233\212.md" "b/\345\220\216\347\253\257\346\200\235\347\273\264\347\257\207/\345\220\216\347\253\257\346\200\235\347\273\264\344\270\200\357\274\232\350\256\276\350\256\241\346\216\245\345\217\243\347\232\20436\344\270\252\351\224\246\345\233\212.md"
new file mode 100644
index 0000000..f999d6b
--- /dev/null
+++ "b/\345\220\216\347\253\257\346\200\235\347\273\264\347\257\207/\345\220\216\347\253\257\346\200\235\347\273\264\344\270\200\357\274\232\350\256\276\350\256\241\346\216\245\345\217\243\347\232\20436\344\270\252\351\224\246\345\233\212.md"
@@ -0,0 +1,540 @@
+## З°СФ
+
+ҙујТәГЈ¬ОТКЗјсМпВЭөДРЎДРәўЎЈЧчОӘәу¶ЛҝӘ·ўЈ¬І»№ЬКЗКІГҙУпСФЈ¬```Java```Ўў```Go```»№КЗ```C++```Ј¬ЖдұіәуөДәу¶ЛЛјПл¶јКЗАаЛЖөДЎЈәуГжҙтЛгіцТ»ёцәу¶ЛЛјПлөДјјКхЧЁАёЈ¬ЦчТӘ°ьАЁәу¶ЛөДТ»Р©ЙијЖЎў»тХЯәу¶Л№ж·¶Па№ШөДЈ¬ПЈНы¶ФҙујТИХіЈ№ӨЧчУР°пЦъ№юЎЈ
+
+ОТГЗЧцәу¶ЛҝӘ·ў№ӨіМКҰЈ¬ЦчТӘ№ӨЧчҫНКЗЈә**ИзәО°СТ»ёцҪУҝЪЙијЖәГ**ЎЈЛщТФЈ¬ҪсМмҫНёшҙујТҪйЙЬЈ¬ЙијЖәГҪУҝЪөД36ёцҪхДТЎЈұҫОДҫНКЗәу¶ЛЛјПлЧЁАёөДөЪТ»ЖӘ№юЎЈ
+
+
+
+
+- №«ЦЪәЕЈәјсМпВЭөДРЎДРәў
+
+
+## 1. ҪУҝЪІОКэРЈСй
+
+ИлІОіцІОРЈСйКЗГҝёціМРтФұұШұёөД»щұҫЛШСшЎЈДгЙијЖөДҪУҝЪЈ¬ұШРлПИРЈСйІОКэЎЈұИИзИлІОКЗ·сФКРнОӘҝХЈ¬ИлІОіӨ¶ИКЗ·с·ыәПДгөДФӨЖЪіӨ¶ИЎЈХвёцТӘСшіЙП°№Я№юЈ¬ИХіЈҝӘ·ўЦРЈ¬әЬ¶аөНј¶bug¶јКЗІ»РЈСйІОКэөјЦВөДЎЈ
+
+> ұИИзДгөДКэҫЭҝвұнЧЦ¶ОЙиЦГОӘ```varchar(16)```,¶Ф·Ҫҙ«БЛТ»ёц32О»өДЧЦ·ыҙ®№эАҙЈ¬Из№ыДгІ»РЈСйІОКэЈ¬**ІеИлКэҫЭҝвЦұҪУТміЈБЛ**ЎЈ
+
+іцІОТІКЗЈ¬ұИИзДг¶ЁТеөДҪУҝЪұЁОДЈ¬ІОКэКЗІ»ОӘҝХөДЈ¬ө«КЗДгөДҪУҝЪ·ө»ШІОКэЈ¬Г»УРЧцРЈСйЈ¬ТтОӘіМРтДіР©ФӯТтЈ¬Цұ·ө»ШұрИЛТ»ёц```null```ЦөЎЈЎЈЎЈ
+
+
+
+## 2. РЮёДАПҪУҝЪКұЈ¬ЧўТвҪУҝЪөДјжИЭРФ
+
+әЬ¶аbug¶јКЗТтОӘРЮёДБЛ¶ФНвҫЙҪУҝЪЈ¬ө«КЗИҙ**І»ЧцјжИЭ**өјЦВөДЎЈ№ШјьХвёцОКМв¶аКэКЗұИҪПСПЦШөДЈ¬ҝЙДЬЦұҪУөјЦВПөНі·ў°жК§°ЬөДЎЈРВКЦіМРтФұәЬИЭТЧ·ёХвёцҙнОуЕ¶~
+
+
+
+ЛщТФЈ¬Из№ыДгөДРиЗуКЗФЪФӯАҙҪУҝЪЙПРЮёДЈ¬УИЖдХвёцҪУҝЪКЗ¶ФНвМṩ·юОсөД»°Ј¬Т»¶ЁТӘҝјВЗҪУҝЪјжИЭЎЈҫЩёцАэЧУ°ЙЈ¬ұИИзdubboҪУҝЪЈ¬ФӯұҫКЗЦ»ҪУКХAЈ¬BІОКэЈ¬ПЦФЪДгјУБЛТ»ёцІОКэCЈ¬ҫНҝЙТФҝјВЗХвСщҙҰАнЈә
+
+```
+//АПҪУҝЪ
+void oldService(A,B){
+ //јжИЭРВҪУҝЪЈ¬ҙ«ёцnullҙъМжC
+ newService(A,B,null);
+}
+
+//РВҪУҝЪЈ¬ФЭКұІ»ДЬЙҫөфАПҪУҝЪЈ¬РиТӘЧцјжИЭЎЈ
+void newService(A,B,C){
+ ...
+}
+```
+
+## 3. ЙијЖҪУҝЪКұЈ¬ід·ЦҝјВЗҪУҝЪөДҝЙА©Х№РФ
+
+ТӘёщҫЭКөјКТөОсіЎҫ°ЙијЖҪУҝЪЈ¬ід·ЦҝјВЗҪУҝЪөДҝЙА©Х№РФЎЈ
+
+ұИИзДгҪУөҪТ»ёцРиЗуЈәКЗУГ»§МнјУ»тХЯРЮёДФұ№ӨКұЈ¬РиТӘЛўБіЎЈДЗДгКЗ·ҙКЦМṩһёцФұ№Ө№ЬАнөДМбҪ»ЛўБіРЕПўҪУҝЪЈҝ»№КЗПИЛјҝјЈәМбҪ»ЛўБіКЗІ»КЗНЁУГБчіМДШЈҝұИИзЧӘХЛ»тХЯТ»јьМщПЦРиТӘҪУИлЛўБіөД»°Ј¬ДгКЗ·сРиТӘЦШРВКөПЦТ»ёцҪУҝЪДШЈҝ»№КЗөұЗ°°ҙТөОсАаРН»®·ЦДЈҝйЈ¬ёҙУГХвёцҪУҝЪҫНәГЈ¬ұЈБфҪУҝЪөДҝЙА©Х№РФЎЈ
+
+Из№ы°ҙДЈҝй»®·ЦөД»°Ј¬ОҙАҙИз№ыЖдЛыіЎҫ°ұИИзТ»јьМщПЦҪУИлЛўБіөД»°Ј¬І»УГФЩёгТ»МЧРВөДҪУҝЪЈ¬Ц»РиТӘРВФцГ¶ҫЩЈ¬И»әуёҙУГЛўБіНЁ№эБчіМҪУҝЪЈ¬КөПЦТ»јьМщПЦЛўБіөДІоТм»ҜјҙҝЙЎЈ
+
+
+
+
+## 4.ҪУҝЪҝјВЗКЗ·сРиТӘ·АЦШҙҰАн
+
+Из№ыЗ°¶ЛЦШёҙЗлЗуЈ¬ДгөДВЯјӯИзәОҙҰАнЈҝКЗІ»КЗҝјВЗҪУҝЪИҘЦШҙҰАнЎЈ
+
+өұИ»Ј¬Из№ыКЗІйСҜАаөДЗлЗуЈ¬ЖдКөІ»УГ·АЦШЎЈИз№ыКЗёьРВРЮёДАаөД»°Ј¬УИЖдҪрИЪЧӘХЛАаөДЈ¬ҫНТӘ№эВЛЦШёҙЗлЗуБЛЎЈјтөҘөгЈ¬ДгҝЙТФК№УГRedis·АЦШёҙЗлЗуЈ¬Н¬СщөДЗлЗу·ҪЈ¬Т»¶ЁКұјдјдёфДЪөДПаН¬ЗлЗуЈ¬ҝјВЗКЗ·с№эВЛЎЈөұИ»Ј¬ЧӘХЛАаҪУҝЪЈ¬Іў·ўІ»ёЯөД»°Ј¬**НЖјцК№УГКэҫЭҝв·АЦШұн**Ј¬ТФ**ОЁТ»БчЛ®әЕЧчОӘЦчјь»тХЯОЁТ»ЛчТэ**ЎЈ
+
+
+
+
+## 5. ЦШөгҪУҝЪЈ¬ҝјВЗПЯіМіШёфАлЎЈ
+
+Т»Р©өЗВҪЎўЧӘХЛҪ»ТЧЎўПВөҘөИЦШТӘҪУҝЪЈ¬ҝјВЗПЯіМіШёфАл№юЎЈИз№ыДгЛщУРТөОс¶ј№ІУГТ»ёцПЯіМіШЈ¬УРР©ТөОсіцbugөјЦВПЯіМіШЧиИыҙтВъөД»°Ј¬ДЗҫНұӯҫЯБЛЈ¬**ЛщУРТөОс¶јУ°ПмБЛ**ЎЈТтҙЛҪшРРПЯіМіШёфАлЈ¬ЦШТӘТөОс·ЦЕд¶аТ»өгөДәЛРДПЯіМЈ¬ҫНёьәГұЈ»ӨЦШТӘТөОсЎЈ
+
+
+
+
+## 6. өчУГөЪИэ·ҪҪУҝЪТӘҝјВЗТміЈәНі¬КұҙҰАн
+
+Из№ыДгөчУГөЪИэ·ҪҪУҝЪЈ¬»тХЯ·ЦІјКҪФ¶іМ·юОсөДөД»°Ј¬РиТӘҝјВЗЈә
+
+- ТміЈҙҰАн
+
+> ұИИзЈ¬ДгөчұрИЛөДҪУҝЪЈ¬Из№ыТміЈБЛЈ¬ФхГҙҙҰАнЈ¬КЗЦШКФ»№КЗөұЧцК§°Ь»№КЗёжҫҜҙҰАнЎЈ
+
+- ҪУҝЪі¬Кұ
+
+> Г»·ЁФӨ№А¶Ф·ҪҪУҝЪТ»°г¶аҫГ·ө»ШЈ¬Т»°гЙиЦГёці¬Кұ¶ПҝӘКұјдЈ¬ТФұЈ»ӨДгөДҪУҝЪЎЈ**Ц®З°јы№эТ»ёцЙъІъОКМв**Ј¬ҫНКЗhttpөчУГІ»ЙиЦГі¬КұКұјдЈ¬ЧоәуПмУҰ·ҪҪшіМјЩЛАЈ¬ЗлЗуТ»ЦұХјЧЕПЯіМІ»КН·ЕЈ¬НПҝеПЯіМіШЎЈ
+
+- ЦШКФҙОКэ
+> ДгөДҪУҝЪөчК§°ЬЈ¬РиІ»РиТӘЦШКФЈҝЦШКФјёҙОЈҝРиТӘХҫФЪТөОсЙПҪЗ¶ИЛјҝјХвёцОКМв
+
+
+
+
+## 7. ҪУҝЪКөПЦҝјВЗИЫ¶ПәНҪөј¶
+
+өұЗ°»ҘБӘНшПөНіТ»°г¶јКЗ·ЦІјКҪІҝКрөДЎЈ¶ш·ЦІјКҪПөНіЦРҫӯіЈ»біцПЦДіёц»щҙЎ·юОсІ»ҝЙУГЈ¬ЧоЦХөјЦВХыёцПөНіІ»ҝЙУГөДЗйҝц, ХвЦЦПЦПуұ»іЖОӘ**·юОсС©ұАР§УҰ**ЎЈ
+
+ұИИз·ЦІјКҪөчУГБҙВ·```A->B->C....```Ј¬ПВНјЛщКҫЈә
+
+
+
+> Из№ы·юОсCіцПЦОКМвЈ¬ұИИзКЗ**ТтОӘВэSQLөјЦВөчУГ»әВэ**Ј¬ДЗҪ«өјЦВBТІ»бСУіЩЈ¬ҙУ¶шAТІ»бСУіЩЎЈ¶ВЧЎөДAЗлЗу»бПыәДХјУГПөНіөДПЯіМЎўIOөИЧКФҙЎЈ өұЗлЗуAөД·юОсФҪАҙФҪ¶аЈ¬ХјУГјЖЛг»ъөДЧКФҙТІФҪАҙФҪ¶аЈ¬ЧоЦХ»бөјЦВПөНіЖҝҫұіцПЦЈ¬ФміЙЖдЛыөДЗлЗуН¬СщІ»ҝЙУГЈ¬ЧоәуөјЦВТөОсПөНіұААЈЎЈ
+
+ОӘБЛУҰ¶Ф·юОсС©ұА, іЈјыөДЧц·ЁКЗ**ИЫ¶ПәНҪөј¶**ЎЈЧојтөҘКЗјУҝӘ№ШҝШЦЖЈ¬өұПВУОПөНііцОКМвКұЈ¬ҝӘ№ШҪөј¶Ј¬І»ФЩөчУГПВУОПөНіЎЈ»№ҝЙТФСЎУГҝӘФҙЧйјю```Hystrix```ЎЈ
+
+## 8. ИХЦҫҙтУЎәГЈ¬ҪУҝЪөД№ШјьҙъВлЈ¬ТӘУРИХЦҫұЈјЭ»ӨәҪЎЈ
+
+№ШјьТөОсҙъВлОЮВЫЙнҙҰәОөШЈ¬¶јУҰёГУРЧг№»өДИХЦҫұЈјЭ»ӨәҪЎЈ
+ұИИзЈәДгКөПЦЧӘХЛТөОсЈ¬ЧӘёцјё°ЩНтЈ¬И»әуЧӘК§°ЬБЛЈ¬ҪУЧЕҝН»§Н¶ЛЯЈ¬И»әуДг»№Г»УРҙтУЎөҪИХЦҫЈ¬ПлПлДЗЦЦЛ®Йо»рИИөДА§ҫіПВЈ¬ДгИҙәБОЮ°м·ЁЎЈЎЈЎЈ
+
+ДЗГҙЈ¬ДгөДЧӘХЛТөОс¶јРиТӘДЗР©ИХЦҫРЕПўДШЈҝЦБЙЩЈ¬·Ҫ·ЁөчУГЗ°Ј¬ИлІОРиТӘҙтУЎРиТӘ°ЙЈ¬ҪУҝЪөчУГәуЈ¬РиТӘІ¶»сТ»ПВТміЈ°ЙЈ¬Н¬КұҙтУЎТміЈПа№ШИХЦҫ°ЙЈ¬ИзПВЈә
+```
+public void transfer(TransferDTO transferDTO){
+ log.info("invoke tranfer begin");
+ //ҙтУЎИлІО
+ log.info("invoke tranfer,paramters:{}",transferDTO);
+ try {
+ res= transferService.transfer(transferDTO);
+ }catch(Exception e){
+ log.error("transfer fail,accountЈә{}",
+ transferDTO.getAccountЈЁЈ©)
+ log.error("transfer fail,exception:{}",e);
+ }
+ log.info("invoke tranfer end");
+ }
+```
+
+Ц®З°Рҙ№эТ»ЖӘҙтУЎИХЦҫөД15ёцҪЁТйЈ¬ҙујТҝЙТФҝҙҝҙ№юЈә[№ӨЧчЧЬҪбЈЎИХЦҫҙтУЎөД15ёцҪЁТй](https://mp.weixin.qq.com/s?__biz=Mzg3NzU5NTIwNg==&mid=2247494838&idx=1&sn=cdb15fd346bddf3f8c1c99f0efbd67d8&chksm=cf22339ff855ba891616c79d4f4855e228e34a9fb45088d7acbe421ad511b8d090a90f5b019f&token=162724582&lang=zh_CN&scene=21#wechat_redirect)
+
+## 9. ҪУҝЪөД№ҰДЬ¶ЁТеТӘҫЯұёөҘТ»РФ
+
+өҘТ»РФКЗЦёҪУҝЪЧцөДКВЗйұИҪПөҘТ»ЎўЧЁТ»ЎЈұИИзТ»ёцөЗВҪҪУҝЪЈ¬ЛьЧцөДКВЗйҫНЦ»КЗРЈСйХЛ»§ГыГЬВлЈ¬И»әу·ө»ШөЗВҪіЙ№ҰТФј°```userId```јҙҝЙЎЈ**ө«КЗИз№ыДгОӘБЛјхЙЩҪУҝЪҪ»»ҘЈ¬°СТ»Р©ЧўІбЎўТ»Р©ЕдЦГІйСҜөИИ«·ЕөҪөЗВҪҪУҝЪЈ¬ҫНІ»М«НЧЎЈ**
+
+ЖдКөХвТІКЗОў·юОсТ»Р©ЛјПлЈ¬ҪУҝЪөД№ҰДЬөҘТ»ЎўГчИ·ЎЈұИИ綩өҘ·юОсЎў»э·ЦЎўЙМЖ·РЕПўПа№ШөДҪУҝЪ¶јКЗ»®·ЦҝӘөДЎЈҪ«АҙІр·ЦОў·юОсөД»°Ј¬КЗІ»КЗҫНұИҪПјтұгАІЎЈ
+
+
+## 10.ҪУҝЪУРР©іЎҫ°Ј¬К№УГТмІҪёьәПАн
+
+ҫЩёцјтөҘөДАэЧУЈ¬ұИИзДгКөПЦТ»ёцУГ»§ЧўІбөДҪУҝЪЎЈУГ»§ЧўІбіЙ№ҰКұЈ¬·ўёцУКјю»тХЯ¶МРЕИҘНЁЦӘУГ»§ЎЈХвёцУКјю»тХЯ·ў¶МРЕЈ¬ҫНёьККәПТмІҪҙҰАнЎЈТтОӘЧЬІ»ДЬТ»ёцНЁЦӘАаөДК§°ЬЈ¬өјЦВЧўІбК§°Ь°ЙЎЈ
+
+ЦБУЪЧцТмІҪөД·ҪКҪЈ¬јтөҘөДҫНКЗ**УГПЯіМіШ**ЎЈ»№ҝЙТФК№УГПыПў¶УБРЈ¬ҫНКЗУГ»§ЧўІбіЙ№ҰәуЈ¬ЙъІъХЯІъЙъТ»ёцЧўІбіЙ№ҰөДПыПўЈ¬Пы·СХЯАӯөҪЧўІбіЙ№ҰөДПыПўЈ¬ҫН·ўЛННЁЦӘЎЈ
+
+
+
+
+І»КЗЛщУРөДҪУҝЪ¶јККәПЙијЖОӘН¬ІҪҪУҝЪЎЈұИИзДгТӘЧцТ»ёцЧӘХЛөД№ҰДЬЈ¬Из№ыДгКЗөҘұКөДЧӘХЛЈ¬ДгКЗҝЙТФ°СҪУҝЪЙијЖН¬ІҪЎЈУГ»§·ўЖрЧӘХЛКұЈ¬ҝН»§¶ЛФЪҫІҫІөИҙэЧӘХЛҪб№ыҫНәГЎЈИз№ыДгКЗЕъБҝЧӘХЛЈ¬Т»ёцЕъҙОТ»З§ұКЈ¬ЙхЦБТ»НтұКөДЈ¬ДгФтҝЙТФ°СҪУҝЪЙијЖОӘТмІҪЎЈҫНКЗУГ»§·ўЖрЕъБҝЧӘХЛКұЈ¬іЦҫГ»ҜіЙ№ҰҫНПИ·ө»ШКЬАніЙ№ҰЎЈИ»әуУГ»§ёфК®·ЦЦУ»тХЯК®Ое·ЦЦУөИФЩАҙІйЧӘХЛҪб№ыҫНәГЎЈУЦ»тХЯЈ¬ЕъБҝЧӘХЛіЙ№ҰәуЈ¬ФЩ»ШөчЙПУОПөНіЎЈ
+
+
+
+
+
+## 11. УЕ»ҜҪУҝЪәДКұЈ¬Ф¶іМҙ®РРҝјВЗёДІўРРөчУГ
+
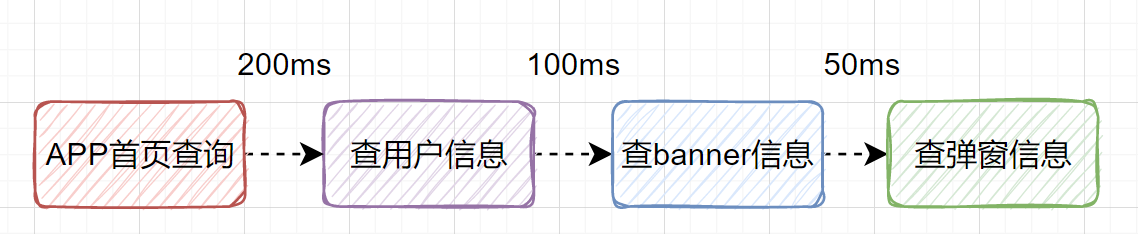
+јЩЙиОТГЗЙијЖТ»ёцAPPКЧТіөДҪУҝЪЈ¬ЛьРиТӘІйУГ»§РЕПўЎўРиТӘІйbannerРЕПўЎўРиТӘІйөҜҙ°РЕПўөИөИЎЈДЗДгКЗТ»ёцТ»ёцҪУҝЪҙ®РРөчЈ¬»№КЗІўРРөчУГДШЈҝ
+
+
+
+
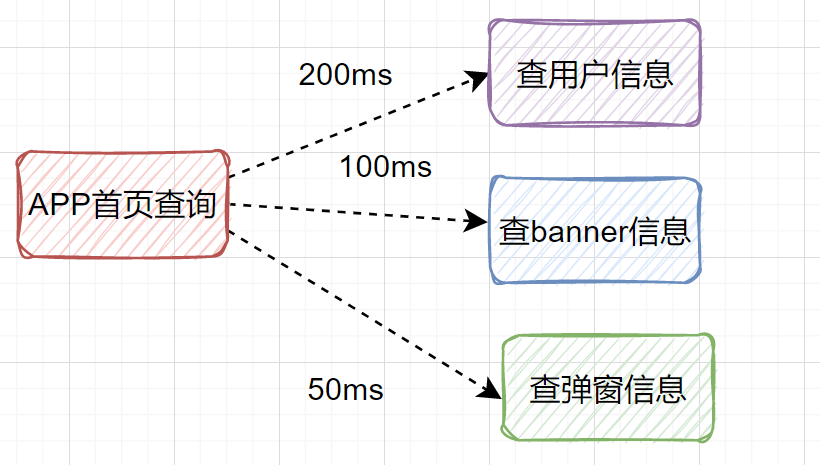
+Из№ыКЗҙ®РРТ»ёцТ»ёцІйЈ¬ұИИзІйУГ»§РЕПў200msЈ¬ІйbannerРЕПў100msЎўІйөҜҙ°РЕПў50msЈ¬ДЗТ»№ІҫНәДКұ```350ms```БЛЈ¬Из№ы»№ІйЖдЛыРЕПўЈ¬ДЗәДКұҫНёьҙуБЛЎЈХвЦЦіЎҫ°КЗҝЙТФёДОӘІўРРөчУГөДЎЈТІҫНКЗЛөІйУГ»§РЕПўЎўІйbannerРЕПўЎўІйөҜҙ°РЕПўЈ¬ҝЙТФН¬Кұ·ўЖрЎЈ
+
+
+
+
+ФЪJavaЦРУРёцТмІҪұаіМАыЖчЈә```CompletableFuture```Ј¬ҫНҝЙТФәЬәГКөПЦХвёц№ҰДЬЎЈУРРЛИӨөДРЎ»п°йҝЙТФҝҙОТЦ®З°ХвёцОДХВ№юЈә[CompletableFutureПкҪв](https://mp.weixin.qq.com/s?__biz=Mzg3NzU5NTIwNg==&mid=2247490456&idx=1&sn=95836324db57673a4d7aea4fb233c0d2&chksm=cf21c4b1f8564da72dc7b39279362bcf965b1374540f3b339413d138599f7de59a5f977e3b0e&token=1260947715&lang=zh_CN#rd)
+
+## 12. ҪУҝЪәПІў»тХЯЛөҝјВЗЕъБҝҙҰАнЛјПл
+
+КэҫЭҝвІЩЧч»т»тХЯКЗФ¶іМөчУГКұЈ¬ДЬЕъБҝІЩЧчҫНІ»ТӘforСӯ»·өчУГЎЈ
+
+
+Т»ёцјтөҘАэЧУЈ¬ОТГЗЖҪКұТ»ёцБРұнГчПёКэҫЭІеИлКэҫЭҝвКұЈ¬І»ТӘФЪforСӯ»·Т»МхТ»МхІеИлЈ¬ҪЁТйТ»ёцЕъҙОјё°ЩМхЈ¬ҪшРРЕъБҝІеИлЎЈН¬АнФ¶іМөчУГТІАаЛЖПл·ЁЈ¬ұИИзДгІйСҜУӘПъұкЗ©КЗ·сГьЦРЈ¬ҝЙТФТ»ёцұкЗ©Т»ёцұкЗ©ИҘІйЈ¬ТІҝЙТФЕъБҝұкЗ©ИҘІйЈ¬ДЗЕъБҝҪшРРЈ¬Р§ВКҫНёьёЯВпЎЈ
+
+```
+//·ҙАэ
+for(int i=0;i ұИИзТ»Р©ЖҪКұұд¶ҜәЬРЎ»тХЯЛөјёәхІ»»бұдөДЙМЖ·РЕПўЈ¬ҝЙТФ·ЕөҪ»әҙжЈ¬ЗлЗу№эАҙКұЈ¬ПИІйСҜ»әҙжЈ¬Из№ыГ»УРФЩІйКэҫЭҝвЈ¬ІўЗТ°СКэҫЭҝвөДКэҫЭёьРВөҪ»әҙжЎЈө«КЗЈ¬К№УГ»әҙжФцјУБЛРиТӘҝјВЗХвР©өгЈә»әҙжәНКэҫЭҝвТ»ЦВРФИзәОұЈЦӨЎўјҜИәЎў»әҙж»чҙ©Ўў»әҙжС©ұјЎў»әҙжҙ©НёөИОКМвЎЈ
+
+- ұЈЦӨКэҫЭҝвәН»әҙжТ»ЦВРФЈә**»әҙжСУКұЛ«ЙҫЎўЙҫіэ»әҙжЦШКФ»ъЦЖЎў¶БИЎbiglogТмІҪЙҫіэ»әҙж**
+- »әҙж»чҙ©ЈәЙиЦГКэҫЭУАІ»№эЖЪ
+- »әҙжС©ұјЈәRedisјҜИәёЯҝЙУГЎўҫщФИЙиЦГ№эЖЪКұјд
+- »әҙжҙ©НёЈәҪУҝЪІгРЈСйЎўІйСҜОӘҝХЙиЦГёцД¬ИПҝХЦөұкјЗЎўІјВЎ№эВЛЖчЎЈ
+
+Т»°гУГ```Redis```·ЦІјКҪ»әҙжЈ¬өұИ»УРР©КұәтТІҝЙТФҝјВЗК№УГұҫөШ»әҙжЈ¬Из```Guava CacheЎўCaffeine```өИЎЈК№УГұҫөШ»әҙжУРР©ИұөгЈ¬ҫНКЗОЮ·ЁҪшРРҙуКэҫЭҙжҙўЈ¬ІўЗТУҰУГҪшіМөДЦШЖфЈ¬»әҙж»бК§Р§ЎЈ
+
+## 14. ҪУҝЪҝјВЗИИөгКэҫЭёфАлРФ
+
+ЛІКұјдөДёЯІў·ўЈ¬ҝЙДЬ»бҙтҝеДгөДПөНіЎЈҝЙТФЧцТ»Р©ИИөгКэҫЭөДёфАлЎЈұИИз**ТөОсёфАлЎўПөНіёфАлЎўУГ»§ёфАлЎўКэҫЭёфАл**өИЎЈ
+
+- ТөОсёфАлРФЈ¬ұИИз12306өД·ЦКұ¶ОКЫЖұЈ¬Ҫ«ИИөгКэҫЭ·ЦЙўҙҰАнЈ¬ҪөөНПөНіёәФШС№БҰЎЈ
+- ПөНіёфАлЈәұИИз°СПөНі·ЦіЙБЛУГ»§ЎўЙМЖ·ЎўЙзЗшИэёц°еҝйЎЈХвИэёцҝй·ЦұрК№УГІ»Н¬өДУтГыЎў·юОсЖчәНКэҫЭҝвЈ¬ЧцөҪҙУҪУИлІгөҪУҰУГІгФЩөҪКэҫЭІгИэІгНкИ«ёфАлЎЈ
+- УГ»§ёфАлЈәЦШөгУГ»§ЗлЗуөҪЕдЦГёьәГөД»ъЖчЎЈ
+- КэҫЭёфАлЈәК№УГөҘ¶АөД»әҙжјҜИә»тХЯКэҫЭҝв·юОсИИөгКэҫЭЎЈ
+
+## 15. ҝЙұдІОКэЕдЦГ»ҜЈ¬ұИИзәм°ьЖӨ·фЗР»»өИ
+
+јЩИзІъЖ·ҫӯАнМбБЛёцәм°ьРиЗуЈ¬КҘө®ҪЪөДКұәтЈ¬әм°ьЖӨ·фОӘКҘө®ҪЪПа№ШөДЈ¬ҙәҪЪөДКұәтЈ¬ОӘҙәҪЪәм°ьЖӨ·фөИЎЈ
+
+Из№ыФЪҙъВлРҙЛАҝШЦЖЈ¬ҝЙУРАаЛЖТФПВҙъВлЈә
+```
+if(duringChristmas){
+ img = redPacketChristmasSkin;
+}else if(duringSpringFestival){
+ img = redSpringFestivalSkin;
+}
+```
+Из№ыөҪБЛФӘПьҪЪөДКұәтЈ¬ФЛУӘРЎҪгҪгН»И»УЦУРПл·ЁЈ¬әм°ьЖӨ·ф»»іЙөЖБэПа№ШөДЈ¬ХвКұәтЈ¬КЗІ»КЗТӘИҘРЮёДҙъВлБЛЈ¬ЦШРВ·ўІјБЛЈҝ
+
+ҙУТ»ҝӘКјҪУҝЪЙијЖКұЈ¬ҝЙТФКөПЦ**Т»ХЕәм°ьЖӨ·фөДЕдЦГұн**Ј¬Ҫ«әм°ьЖӨ·фЧціЙЕдЦГ»ҜДШЈҝёь»»әм°ьЖӨ·фЈ¬Ц»РиРЮёДТ»ПВұнКэҫЭҫНәГБЛЎЈ
+
+өұИ»Ј¬»№УРТ»Р©іЎҫ°ККәПТ»Р©ЕдЦГ»ҜөДІОКэЈәТ»ёц·ЦТі¶аЙЩКэБҝҝШЦЖЎўДіёцЗАәм°ь¶аҫГКұјд№эЖЪХвР©Ј¬¶јҝЙТФёгөҪІОКэЕдЦГ»ҜұнАпГжЎЈ**ХвТІКЗА©Х№РФЛјПлөДТ»ЦЦМеПЦЎЈ**
+
+## 16.ҪУҝЪҝјВЗГЭөИРФ
+
+ҪУҝЪКЗРиТӘҝјВЗГЭөИРФөДЈ¬УИЖдЗАәм°ьЎўЧӘХЛХвР©ЦШТӘҪУҝЪЎЈЧоЦұ№ЫөДТөОсіЎҫ°Ј¬ҫНКЗ**УГ»§Б¬ЧЕөг»чБҪҙО**Ј¬ДгөДҪУҝЪУРГ»УР**holdЧЎ**ЎЈ»тХЯПыПў¶УБРіцПЦЦШёҙПы·СөДЗйҝцЈ¬ДгөДТөОсВЯјӯФхГҙҝШЦЖЈҝ
+
+»ШТдПВЈ¬**КІГҙКЗГЭөИЈҝ**
+
+> јЖЛг»ъҝЖС§ЦРЈ¬ГЭөИұнКҫТ»ҙОәН¶аҙОЗлЗуДіТ»ёцЧКФҙУҰёГҫЯУРН¬СщөДёұЧчУГЈ¬»тХЯЛөЈ¬¶аҙОЗлЗуЛщІъЙъөДУ°ПмУлТ»ҙОЗлЗуЦҙРРөДУ°ПмР§№ыПаН¬ЎЈ
+
+ҙујТұрёг»м№юЈ¬**·АЦШәНГЭөИЙијЖЖдКөКЗУРЗшұрөД**ЎЈ·АЦШЦчТӘОӘБЛұЬГвІъЙъЦШёҙКэҫЭЈ¬°СЦШёҙЗлЗуА№ҪШПВАҙјҙҝЙЎЈ¶шГЭөИЙијЖіэБЛА№ҪШТСҫӯҙҰАнөДЗлЗ󣬻№ТӘЗуГҝҙОПаН¬өДЗлЗу¶ј·ө»ШТ»СщөДР§№ыЎЈІ»№эДШЈ¬әЬ¶аКұәтЈ¬ЛьГЗөДҙҰАнБчіМЎў·Ҫ°ёКЗАаЛЖөД№юЎЈ
+
+
+
+
+ҪУҝЪГЭөИКөПЦ·Ҫ°ёЦчТӘУР8ЦЦЈә
+
+- select+insert+Цчјь/ОЁТ»ЛчТэіеН»
+- ЦұҪУinsert + Цчјь/ОЁТ»ЛчТэіеН»
+- ЧҙМ¬»ъГЭөИ
+- ійИЎ·АЦШұн
+- tokenБоЕЖ
+- ұҜ№ЫЛш
+- АЦ№ЫЛш
+- ·ЦІјКҪЛш
+
+ҙујТҝЙТФҝҙОТХвЖӘОДХВ№юЈә[БДБДГЭөИЙијЖ](https://mp.weixin.qq.com/s?__biz=Mzg3NzU5NTIwNg==&mid=2247497427&idx=1&sn=2ed160c9917ad989eee1ac60d6122855&chksm=cf2229faf855a0ecf5eb34c7335acdf6420426490ee99fc2b602d54ff4ffcecfdab24eeab0a3&token=1260947715&lang=zh_CN#rd)
+
+## 17. ¶БРҙ·ЦАлЈ¬УЕПИҝјВЗ¶БҙУҝвЈ¬ЧўТвЦчҙУСУіЩОКМв
+
+ОТГЗөДКэҫЭҝв¶јКЗјҜИәІҝКрөДЈ¬УРЦчҝвТІУРҙУҝвЈ¬өұЗ°Т»°г¶јКЗ¶БРҙ·ЦАлөДЎЈұИИзДгРҙИлКэҫЭЈ¬ҝП¶ЁКЗРҙИлЦчҝвЈ¬ө«КЗ¶ФУЪ¶БИЎКөКұРФТӘЗуІ»ёЯөДКэҫЭЈ¬ФтУЕПИҝјВЗ¶БҙУҝвЈ¬ТтОӘҝЙТФ·ЦөЈЦчҝвөДС№БҰЎЈ
+
+Из№ы¶БИЎҙУҝвөД»°Ј¬РиТӘҝјВЗЦчҙУСУіЩөДОКМвЎЈ
+
+## 18.ҪУҝЪЧўТв·ө»ШөДКэҫЭБҝЈ¬Из№ыКэҫЭБҝҙуРиТӘ·ЦТі
+
+Т»ёцҪУҝЪ·ө»ШұЁОДЈ¬І»УҰёГ°ьә¬№э¶аөДКэҫЭБҝЎЈ№э¶аөДКэҫЭБҝІ»ҪцҙҰАнёҙФУЈ¬ІўЗТКэҫЭБҝҙ«КдөДС№БҰТІ·ЗіЈҙуЎЈТтҙЛКэБҝКөФЪКЗұИҪПҙуЈ¬ҝЙТФ·ЦТі·ө»ШЈ¬Из№ыКЗ№ҰДЬІ»Па№ШөДұЁОДЈ¬ДЗУҰёГҝјВЗҪУҝЪІр·ЦЎЈ
+
+## 19. әГөДҪУҝЪКөПЦЈ¬АлІ»ҝӘSQLУЕ»Ҝ
+
+ОТГЗЧцәу¶ЛөДЈ¬РҙәГТ»ёцҪУҝЪЈ¬АлІ»ҝӘSQLУЕ»ҜЎЈ
+
+SQLУЕ»ҜҙУХвјёёцО¬¶ИЛјҝјЈә
+
+- explain ·ЦОцSQLІйСҜјЖ»®ЈЁЦШөг№ШЧўtypeЎўextraЎўfilteredЧЦ¶ОЈ©
+- show profile·ЦОцЈ¬БЛҪвSQLЦҙРРөДПЯіМөДЧҙМ¬ТФј°ПыәДөДКұјд
+- ЛчТэУЕ»Ҝ ЈЁёІёЗЛчТэЎўЧоЧуЗ°ЧәФӯФтЎўТюКҪЧӘ»»Ўўorder byТФј°group byөДУЕ»ҜЎўjoinУЕ»ҜЈ©
+- ҙу·ЦТіОКМвУЕ»ҜЈЁСУіЩ№ШБӘЎўјЗВјЙПТ»ТіЧоҙуIDЈ©
+- КэҫЭБҝМ«ҙуЈЁ**·Цҝв·Цұн**ЎўН¬ІҪөҪesЈ¬УГesІйСҜЈ©
+
+## 20.ҙъВлЛшөДБЈ¶ИҝШЦЖәГ
+
+КІГҙКЗјУЛшБЈ¶ИДШЈҝ
+
+> ЖдКөҫНКЗҫНКЗДгТӘЛшЧЎөД·¶О§КЗ¶аҙуЎЈұИИзДгФЪјТЙПОАЙъјдЈ¬ДгЦ»ТӘЛшЧЎОАЙъјдҫНҝЙТФБЛ°ЙЈ¬І»РиТӘҪ«ХыёцјТ¶јЛшЖрАҙІ»ИГјТИЛҪшГЕ°ЙЈ¬ОАЙъјдҫНКЗДгөДјУЛшБЈ¶ИЎЈ
+
+ОТГЗРҙҙъВлКұЈ¬Из№ыІ»Йжј°өҪ№ІПнЧКФҙЈ¬ҫНГ»УРұШТӘЛшЧЎөДЎЈХвҫНәГПсДгЙПОАЙъјдЈ¬І»УГ°СХыёцјТ¶јЛшЧЎЈ¬ЛшЧЎОАЙъјдГЕҫНҝЙТФБЛЎЈ
+
+ұИИзЈ¬ФЪТөОсҙъВлЦРЈ¬УРТ»ёцArrayListТтОӘЙжј°өҪ¶аПЯіМІЩЧчЈ¬ЛщТФРиТӘјУЛшІЩЧчЈ¬јЩЙиёХәГУЦУРТ»¶ОұИҪПәДКұөДІЩЧчЈЁҙъВлЦРөД```slowNotShare```·Ҫ·ЁЈ©І»Йжј°ПЯіМ°ІИ«ОКМвЈ¬Дг»бИзәОјУЛшДШЈҝ
+
+·ҙАэЈә
+```
+//І»Йжј°№ІПнЧКФҙөДВэ·Ҫ·Ё
+private void slowNotShare() {
+ try {
+ TimeUnit.MILLISECONDS.sleep(100);
+ } catch (InterruptedException e) {
+ }
+}
+
+//ҙнОуөДјУЛш·Ҫ·Ё
+public int wrong() {
+ long beginTime = System.currentTimeMillis();
+ IntStream.rangeClosed(1, 10000).parallel().forEach(i -> {
+ //јУЛшБЈ¶ИМ«ҙЦБЛЈ¬slowNotShareЖдКөІ»Йжј°№ІПнЧКФҙ
+ synchronized (this) {
+ slowNotShare();
+ data.add(i);
+ }
+ });
+ log.info("cosume time:{}", System.currentTimeMillis() - beginTime);
+ return data.size();
+}
+```
+
+ХэАэЈә
+```
+public int right() {
+ long beginTime = System.currentTimeMillis();
+ IntStream.rangeClosed(1, 10000).parallel().forEach(i -> {
+ slowNotShare();//ҝЙТФІ»јУЛш
+ //Ц»¶ФListХвІҝ·ЦјУЛш
+ synchronized (data) {
+ data.add(i);
+ }
+ });
+ log.info("cosume time:{}", System.currentTimeMillis() - beginTime);
+ return data.size();
+}
+```
+
+## 21.ҪУҝЪЧҙМ¬әНҙнОуРиТӘНіТ»ГчИ·
+
+МṩұШТӘөДҪУҝЪөчУГЧҙМ¬РЕПўЎЈұИИзДгөДТ»ёцЧӘХЛҪУҝЪөчУГКЗіЙ№ҰЎўК§°ЬЎўҙҰАнЦР»№КЗКЬАніЙ№ҰөИЈ¬РиТӘГчИ·ёжЛЯҝН»§¶ЛЎЈИз№ыҪУҝЪК§°ЬЈ¬ДЗГҙҫЯМеК§°ЬөДФӯТтКЗКІГҙЎЈХвР©ұШТӘөДРЕПў¶јұШРлТӘёжЛЯёшҝН»§¶ЛЈ¬ТтҙЛРиТӘ¶ЁТеГчИ·өДҙнОуВләН¶ФУҰөДГиКцЎЈН¬КұЈ¬ҫЎБҝ¶ФұЁҙнРЕПў·вЧ°Т»ПВЈ¬І»ТӘ°Сәу¶ЛөДТміЈРЕПўНкИ«ЕЧіцөҪҝН»§¶ЛЎЈ
+
+
+
+
+## 22.ҪУҝЪТӘҝјВЗТміЈҙҰАн
+
+КөПЦТ»ёцәГөДҪУҝЪЈ¬АлІ»ҝӘУЕСЕөДТміЈҙҰАнЎЈ¶ФУЪТміЈҙҰАнЈ¬МбК®ёцРЎҪЁТй°ЙЈә
+
+- ҫЎБҝІ»ТӘК№УГ```e.printStackTrace()```,¶шКЗК№УГ```log```ҙтУЎЎЈТтОӘ```e.printStackTrace()```УпҫдҝЙДЬ»бөјЦВДЪҙжХјВъЎЈ
+- ```catch```ЧЎТміЈКұЈ¬ҪЁТйҙтУЎіцҫЯМеөД```exception```Ј¬АыУЪёьәГ¶ЁО»ОКМв
+- І»ТӘУГТ»ёц```Exception```І¶ЧҪЛщУРҝЙДЬөДТміЈ
+- јЗөГК№УГ```finally```№ШұХБчЧКФҙ»тХЯЦұҪУК№УГ```try-with-resource```
+- І¶»сТміЈУлЕЧіцТміЈұШРлКЗНкИ«ЖҘЕдЈ¬»тХЯІ¶»сТміЈКЗЕЧТміЈөДёёАа
+- І¶»сөҪөДТміЈЈ¬І»ДЬәцВФЛьЈ¬ЦБЙЩҙтөгИХЦҫ°Й
+- ЧўТвТміЈ¶ФДгөДҙъВлІгҙОҪб№№өДЗЦИҫ
+- ЧФ¶ЁТе·вЧ°ТміЈЈ¬І»ТӘ¶ӘЖъФӯКјТміЈөДРЕПў```Throwable cause```
+- ФЛРРКұТміЈ```RuntimeException``` Ј¬І»УҰёГНЁ№э```catch```өД·ҪКҪАҙҙҰАнЈ¬¶шКЗПИФӨјмІйЈ¬ұИИзЈә```NullPointerException```ҙҰАн
+- ЧўТвТміЈЖҘЕдөДЛіРтЈ¬УЕПИІ¶»сҫЯМеөДТміЈ
+
+РЎ»п°йГЗУРРЛИӨҝЙТФҝҙПВОТЦ®З°РҙөДХвЖӘОДХВ№юЈә[Java ТміЈҙҰАнөДК®ёцҪЁТй](https://mp.weixin.qq.com/s/3mqY77c8iXWvJFzkVQi9Og)
+
+## 23. УЕ»ҜіМРтВЯјӯ
+
+УЕ»ҜіМРтВЯјӯХвҝй»№КЗНҰЦШТӘөДЈ¬ТІҫНКЗЛөЈ¬ДгКөПЦөДТөОсҙъВлЈ¬**Из№ыКЗұИҪПёҙФУөД»°Ј¬ҪЁТй°СЧўКНРҙЗеію**ЎЈ»№УРЈ¬ҙъВлВЯјӯҫЎБҝЗеОъЈ¬ҙъВлҫЎБҝёЯР§ЎЈ
+
+> ұИИзЈ¬ДгТӘК№УГУГ»§РЕПўөДКфРФЈ¬ДгёщҫЭsessionТСҫӯ»сИЎөҪ```userId```БЛЈ¬И»әуҫН°СУГ»§РЕПўҙУКэҫЭҝвІйСҜіцАҙЈ¬К№УГНкәуЈ¬әуГжҝЙДЬУЦТӘУГөҪУГ»§РЕПўөДКфРФЈ¬УРЩС»п°йГ»ПлМ«¶аЈ¬·ҙКЦҫН°С```userId```ФЩҙ«ҪшИҘЈ¬ФЩІйТ»ҙОКэҫЭҝвЎЈЎЈЎЈОТФЪПоДҝЦРЈ¬јы№эХвЦЦҙъВлЎЈЎЈЎЈЦұҪУ°СУГ»§¶ФПуҙ«ПВАҙІ»әГВпЎЈЎЈ
+
+·ҙАэОұҙъВлЈә
+
+```
+public Response test(Session session){
+ UserInfo user = UserDao.queryByUserId(session.getUserId());
+
+ if(user==null){
+ reutrn new Response();
+ }
+
+ return do(session.getUserId());
+}
+
+public Response do(String UserId){
+ //¶аІйБЛТ»ҙОКэҫЭҝв
+ UserInfo user = UserDao.queryByUserId(session.getUserId());
+ ......
+ return new Response();
+}
+
+```
+
+ХэАэЈә
+
+```
+public Response test(Session session){
+ UserInfo user = UserDao.queryByUserId(session.getUserId());
+
+ if(user==null){
+ reutrn new Response();
+ }
+
+ return do(session.getUserId());
+}
+
+//ЦұҪУҙ«UserInfo¶ФПу№эАҙјҙҝЙЈ¬І»УГФЩ¶аІйТ»ҙОКэҫЭҝв
+public Response do(UserInfo user){
+ ......
+ return new Response();
+}
+```
+
+өұИ»Ј¬ХвЦ»КЗТ»Р©әЬРЎөДТ»ёцАэЧУЈ¬»№УРәЬ¶аАаЛЖөДАэЧУЈ¬РиТӘҙујТҝӘ·ў№эіМЦРЈ¬¶аөгЛјҝјөД№юЎЈ
+
+
+## 24. ҪУҝЪКөПЦ№эіМ»гЦРЈ¬ЧўТвҙуОДјюЎўҙуКВОсЎўҙу¶ФПу
+
+- ¶БИЎҙуОДјюКұЈ¬І»ТӘ```Files.readAllBytes```ЦұҪУ¶БИЎөҪДЪҙжЈ¬ХвСщ»бOOMөДЈ¬ҪЁТйК№УГ```BufferedReader```Т»РРТ»РРАҙЎЈ
+- ҙуКВОсҝЙДЬөјЦВЛАЛшЎў»Ш№цКұјдіӨЎўЦчҙУСУіЩөИОКМвЈ¬ҝӘ·ўЦРҫЎБҝұЬГвҙуКВОсЎЈ
+- ЧўТвТ»Р©ҙу¶ФПуөДК№УГЈ¬ТтОӘҙу¶ФПуКЗЦұҪУҪшИлАПДкҙъөДЈ¬»бҙҘ·ўfullGC
+
+## 25. ДгөДҪУҝЪЈ¬РиТӘҝјВЗПЮБч
+
+Из№ыДгөДПөНіГҝГлҝёЧЎөДЗлЗуКЗ1000Ј¬Из№ыТ»ГлЦУАҙБЛК®НтЗлЗуДШЈҝ»»ёцҪЗ¶ИҫНКЗЛөЈ¬ёЯІў·ўөДКұәтЈ¬БчБҝәй·еАҙБЛЈ¬і¬№эПөНіөДіРФШДЬБҰЈ¬ФхГҙ°мДШЈҝ
+
+Из№ыІ»ІЙИЎҙлК©Ј¬ЛщУРөДЗлЗуҙт№эАҙЈ¬ПөНіCPUЎўДЪҙжЎўLoadёәФШм®өДәЬёЯЈ¬ЧоәуЗлЗуҙҰАнІ»№эАҙЈ¬ЛщУРөДЗлЗуОЮ·ЁХэіЈПмУҰЎЈ
+
+Хл¶ФХвЦЦіЎҫ°Ј¬ОТГЗҝЙТФІЙУГПЮБч·Ҫ°ёЎЈҫНКЗОӘБЛұЈ»ӨПөНіЈ¬¶аУаөДЗлЗуЈ¬ЦұҪУ¶ӘЖъЎЈ
+
+ПЮБч¶ЁТеЈә
+> ФЪјЖЛг»ъНшВзЦРЈ¬ПЮБчҫНКЗҝШЦЖНшВзҪУҝЪ·ўЛН»тҪУКХЗлЗуөДЛЩВКЈ¬ЛьҝЙ·АЦ№DoS№Ҙ»чәНПЮЦЖWebЕАіжЎЈПЮБчЈ¬ТІіЖБчБҝҝШЦЖЎЈКЗЦёПөНіФЪГжБЩёЯІў·ўЈ¬»тХЯҙуБчБҝЗлЗуөДЗйҝцПВЈ¬ПЮЦЖРВөДЗлЗу¶ФПөНіөД·ГОКЈ¬ҙУ¶шұЈЦӨПөНіөДОИ¶ЁРФЎЈ
+
+ҝЙТФК№УГGuavaөД```RateLimiter```өҘ»ъ°жПЮБчЈ¬ТІҝЙТФК№УГ```Redis```·ЦІјКҪПЮБчЈ¬»№ҝЙТФК№УГ°ўАпҝӘФҙЧйјю```sentinel```ПЮБч
+
+ҙујТҝЙТФҝҙПВОТЦ®З°ХвЖӘОДХВ№юЈә[4ЦЦҫӯөдПЮБчЛг·ЁҪІҪв](https://mp.weixin.qq.com/s?__biz=Mzg3NzU5NTIwNg==&mid=2247490393&idx=1&sn=98189caa486406f8fa94d84ba0667604&chksm=cf21c470f8564d665ce04ccb9dc7502633246da87a0541b07ba4ac99423b28ce544cdd6c036b&token=162724582&lang=zh_CN&scene=21#wechat_redirect)
+
+
+## 26.ҙъВлКөПЦКұЈ¬ЧўТвФЛРРКұТміЈЈЁұИИзҝХЦёХлЎўПВұкФҪҪзөИЈ©
+
+ИХіЈҝӘ·ўЦРЈ¬ОТГЗРиТӘІЙИЎҙлК©**№жұЬКэЧйұЯҪзТзіцЈ¬ұ»БгХыіэЈ¬ҝХЦёХл**өИФЛРРКұҙнОуЎЈАаЛЖҙъВлұИҪПіЈјыЈә
+```
+String name = list.get(1).getName(); //listҝЙДЬФҪҪзЈ¬ТтОӘІ»Т»¶ЁУР2ёцФӘЛШ№ю
+```
+
+УҰёГІЙИЎҙлК©Ј¬ФӨ·АТ»ПВКэЧйұЯҪзТзіцЎЈХэАэИзПВЈә
+```
+if(CollectionsUtil.isNotEmpty(list)&& list.size()>1){
+ String name = list.get(1).getName();
+}
+```
+
+
+
+## 27.ұЈЦӨҪУҝЪ°ІИ«РФ
+
+Из№ыДгөДAPIҪУҝЪКЗ¶ФНвМṩөДЈ¬РиТӘұЈЦӨҪУҝЪөД°ІИ«РФЎЈұЈЦӨҪУҝЪөД°ІИ«РФУР**token»ъЦЖәНҪУҝЪЗ©Гы**ЎЈ
+
+**token»ъЦЖЙн·ЭСйЦӨ**·Ҫ°ё»№ұИҪПјтөҘөДЈ¬ҫНКЗ
+
+
+
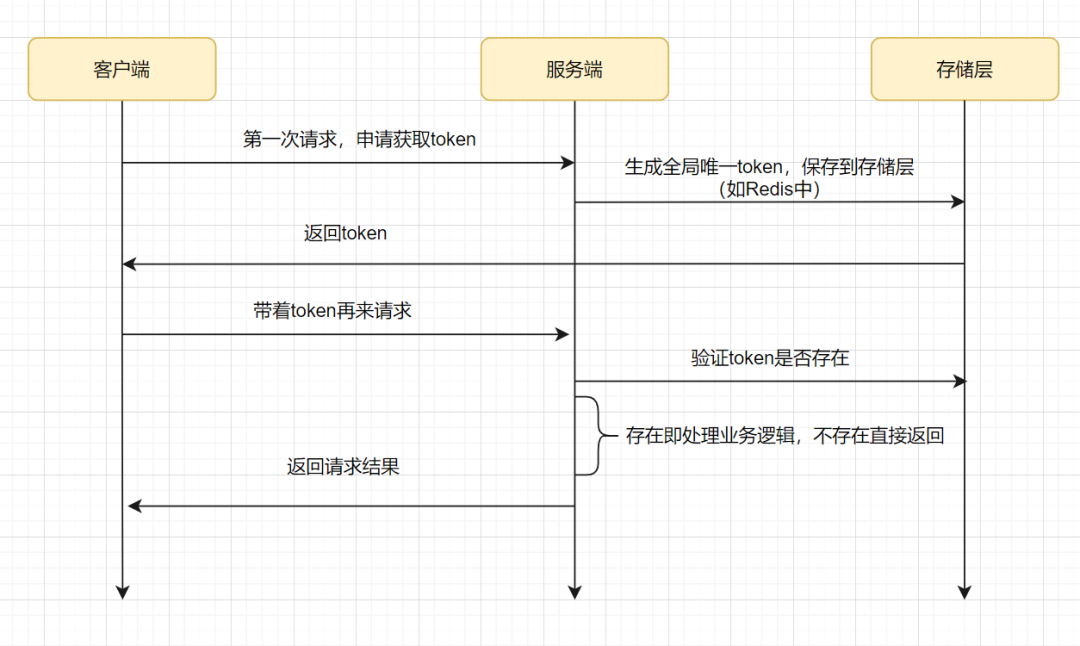
+1. ҝН»§¶Л·ўЖрЗлЗуЈ¬ЙкЗл»сИЎtokenЎЈ
+2. ·юОс¶ЛЙъіЙИ«ҫЦОЁТ»өДtokenЈ¬ұЈҙжөҪredisЦРЈЁТ»°г»бЙиЦГТ»ёц№эЖЪКұјдЈ©Ј¬И»әу·ө»ШёшҝН»§¶ЛЎЈ
+3. ҝН»§¶ЛҙшЧЕtokenЈ¬·ўЖрЗлЗуЎЈ
+4. ·юОс¶ЛИҘredisИ·ИПtokenКЗ·сҙжФЪЈ¬Т»°гУГ redis.del(token)өД·ҪКҪЈ¬Из№ыҙжФЪ»бЙҫіэіЙ№ҰЈ¬јҙҙҰАнТөОсВЯјӯЈ¬Из№ыЙҫіэК§°ЬІ»ҙҰАнТөОсВЯјӯЈ¬ЦұҪУ·ө»ШҪб№ыЎЈ
+
+**ҪУҝЪЗ©Гы**өД·ҪКҪЈ¬ҫНКЗ°СҪУҝЪЗлЗуПа№ШРЕПўЈЁЗлЗуұЁОДЈ¬°ьАЁЗлЗуКұјдҙБЎў°жұҫәЕЎўappidөИЈ©Ј¬ҝН»§¶ЛЛҪФҝјУЗ©Ј¬И»әу·юОс¶ЛУГ№«ФҝСйЗ©Ј¬СйЦӨНЁ№эІЕИПОӘКЗәП·ЁөДЎўГ»УРұ»ҙЫёД№эөДЗлЗуЎЈ
+
+УР№ШУЪјУЗ©СйЗ©өДЈ¬ҙујТҝЙТФҝҙПВОТХвЖӘОДХВ№юЈә[іМРтФұұШұё»щҙЎЈәјУЗ©СйЗ©](https://mp.weixin.qq.com/s?__biz=Mzg3NzU5NTIwNg==&mid=2247488022&idx=1&sn=70484a48173d36006c8db1dfb74ab64d&chksm=cf21cd3ff8564429a1205f6c1d78757faae543111c8461d16c71aaee092fe3e0fed870cc5e0e&token=162724582&lang=zh_CN&scene=21#wechat_redirect)
+
+ҙҰБЛ**јУЗ©СйЗ©әНtoken»ъЦЖЈ¬ҪУҝЪұЁОДТ»°гКЗТӘјУГЬөД**ЎЈөұИ»Ј¬УГhttpsРӯТйКЗ»б¶ФұЁОДјУГЬөДЎЈИз№ыКЗОТГЗ·юОсІгөД»°Ј¬ИзәОјУҪвГЬДШЈҝ
+> ҝЙТФІОҝјHTTPSөДФӯАнЈ¬ҫНКЗ·юОс¶Л°С№«ФҝёшҝН»§¶ЛЈ¬И»әуҝН»§¶ЛЙъіЙ¶ФіЖГЬФҝЈ¬ҪУЧЕҝН»§¶ЛУГ·юОс¶ЛөД№«ФҝјУГЬ¶ФіЖГЬФҝЈ¬ФЩ·ўөҪ·юОс¶ЛЈ¬·юОс¶ЛУГЧФјәөДЛҪФҝҪвГЬЈ¬өГөҪҝН»§¶ЛөД¶ФіЖГЬФҝЎЈХвКұәтҫНҝЙТФУдҝмҙ«КдұЁОДАІЈ¬ҝН»§¶ЛУГ**¶ФіЖГЬФҝјУГЬЗлЗуұЁОД**Ј¬**·юОс¶ЛУГ¶ФУҰөД¶ФіЖГЬФҝҪвГЬұЁОД**ЎЈ
+
+УРКұәтЈ¬ҪУҝЪөД°ІИ«РФЈ¬»№°ьАЁ**КЦ»ъәЕЎўЙн·ЭЦӨөИРЕПўөДНСГф**ЎЈҫНКЗЛөЈ¬**УГ»§өДТюЛҪКэҫЭЈ¬І»ДЬЛжұгұ©В¶**ЎЈ
+
+## 28.·ЦІјКҪКВОсЈ¬ИзәОұЈЦӨ
+
+> ·ЦІјКҪКВОсЈәҫНКЗЦёКВОсөДІОУлХЯЎўЦ§іЦКВОсөД·юОсЖчЎўЧКФҙ·юОсЖчТФј°КВОс№ЬАнЖч·ЦұрО»УЪІ»Н¬өД·ЦІјКҪПөНіөДІ»Н¬ҪЪөгЦ®ЙПЎЈјтөҘАҙЛөЈ¬·ЦІјКҪКВОсЦёөДҫНКЗ·ЦІјКҪПөНіЦРөДКВОсЈ¬ЛьөДҙжФЪҫНКЗОӘБЛұЈЦӨІ»Н¬КэҫЭҝвҪЪөгөДКэҫЭТ»ЦВРФЎЈ
+
+·ЦІјКҪКВОсөДјёЦЦҪвҫц·Ҫ°ёЈә
+- 2PC(¶юҪЧ¶ОМбҪ»)·Ҫ°ёЎў3PC
+- TCCЈЁTryЎўConfirmЎўCancelЈ©
+- ұҫөШПыПўұн
+- ЧоҙуЕ¬БҰНЁЦӘ
+- seata
+
+ҙујТҝЙТФҝҙПВХвЖӘОДХВ№юЈә[ҝҙТ»ұйҫНАнҪвЈә·ЦІјКҪКВОсПкҪв](https://mp.weixin.qq.com/s/3r9MfIz2RAtdFhYzwwZxjA)
+
+## 29. КВОсК§Р§өДТ»Р©ҫӯөдіЎҫ°
+
+ОТГЗөДҪУҝЪҝӘ·ў№эіМЦРЈ¬ҫӯіЈРиТӘК№УГөҪКВОсЎЈЛщТФРиТӘұЬҝӘКВОсК§Р§өДТ»Р©ҫӯөдіЎҫ°ЎЈ
+
+- ·Ҫ·ЁөД·ГОКИЁПЮұШРлКЗpublicЈ¬ЖдЛыprivateөИИЁПЮЈ¬КВОсК§Р§
+- ·Ҫ·Ёұ»¶ЁТеіЙБЛfinalөДЈ¬ХвСщ»бөјЦВКВОсК§Р§ЎЈ
+- ФЪН¬Т»ёцАаЦРөД·Ҫ·ЁЦұҪУДЪІҝөчУГЈ¬»бөјЦВКВОсК§Р§ЎЈ
+- Т»ёц·Ҫ·ЁИз№ыГ»Ҫ»ёшspring№ЬАнЈ¬ҫНІ»»бЙъіЙspringКВОсЎЈ
+- ¶аПЯіМөчУГЈ¬БҪёц·Ҫ·ЁІ»ФЪН¬Т»ёцПЯіМЦРЈ¬»сИЎөҪөДКэҫЭҝвБ¬ҪУІ»Т»СщөДЎЈ
+- ұнөДҙжҙўТэЗжІ»Ц§іЦКВОс
+- Из№ыЧФјәtry...catchОуНМБЛТміЈЈ¬КВОсК§Р§ЎЈ
+- ҙнОуөДҙ«ІҘМШРФ
+
+НЖјцҙујТҝҙПВХвЖӘОДХВЈә[БДБДspringКВОсК§Р§өД12ЦЦіЎҫ°Ј¬М«ҝУБЛ](https://mp.weixin.qq.com/s?__biz=Mzg3NzU5NTIwNg==&mid=2247494570&idx=2&sn=17357bcd328b2d1d83f4a72c47daac1b&chksm=cf223483f855bd95351a778d5f48ddd37917ce2790ebbbcd1d6ee4f27f7f4b147f0d41101dcc&token=2044040586&lang=zh_CN&scene=21#wechat_redirect)
+
+
+## 30. ХЖОХіЈУГөДЙијЖДЈКҪ
+
+°СҙъВлРҙәГЈ¬»№КЗРиТӘКмБ·іЈУГөДЙијЖДЈКҪЈ¬ұИИзІЯВФДЈКҪЎў№Өі§ДЈКҪЎўДЈ°е·Ҫ·ЁДЈКҪЎў№ЫІмХЯДЈКҪөИөИЎЈЙијЖДЈКҪЈ¬КЗҙъВлЙијЖҫӯСйөДЧЬҪбЎЈК№УГЙијЖДЈКҪҝЙТФҝЙЦШУГҙъВлЎўИГҙъВлёьИЭТЧұ»ЛыИЛАнҪвЎўұЈЦӨҙъВлҝЙҝҝРФЎЈ
+
+ОТЦ®З°Рҙ№эТ»ЖӘЧЬҪб№ӨЧчЦРіЈУГЙијЖДЈКҪөДОДХВЈ¬РҙөГНҰІ»ҙнөДЈ¬ҙујТҝЙТФҝҙПВЈә[КөХҪЈЎ№ӨЧчЦРіЈУГөҪДДР©ЙијЖДЈКҪ](https://mp.weixin.qq.com/s?__biz=Mzg3NzU5NTIwNg==&mid=2247495616&idx=1&sn=e74c733d26351eab22646e44ea74d233&chksm=cf2230e9f855b9ffe1ddb9fe15f72a273d5de02ed91cc97f3066d4162af027299718e2bf748e&token=1260947715&lang=zh_CN#rd)
+
+## 31. РҙҙъВлКұЈ¬ҝјВЗПЯРФ°ІИ«ОКМв
+
+ФЪ**ёЯІў·ў**ЗйҝцПВЈ¬```HashMap```ҝЙДЬ»біцПЦЛАСӯ»·ЎЈТтОӘЛьКЗ·ЗПЯРФ°ІИ«өДЈ¬ҝЙТФҝјВЗК№УГ```ConcurrentHashMap```ЎЈЛщТФХвёцТІҫЎБҝСшіЙП°№ЯЈ¬І»ТӘЙПАҙ·ҙКЦҫНКЗТ»ёц```new HashMap()```;
+
+> - HashmapЎўArraylistЎўLinkedListЎўTreeMapөИ¶јКЗПЯРФІ»°ІИ«өДЈ»
+> - VectorЎўHashtableЎўConcurrentHashMapөИ¶јКЗПЯРФ°ІИ«өД
+
+
+
+
+## 32.ҪУҝЪ¶ЁТеЗеОъТЧ¶®Ј¬ГьГы№ж·¶ЎЈ
+
+ОТГЗРҙҙъВлЈ¬І»ҪцҪцКЗОӘБЛКөПЦөұЗ°өД№ҰДЬЈ¬ТІТӘУРАыУЪәуГжөДО¬»ӨЎЈЛөөҪО¬»ӨЈ¬ҙъВлІ»ҪцҪцКЗРҙёшЧФјәҝҙөДЈ¬ТІКЗёшұрИЛҝҙөДЎЈЛщТФҪУҝЪ¶ЁТеТӘЗеОъТЧ¶®Ј¬ГьГы№ж·¶ЎЈ
+
+## 33. ҪУҝЪөД°жұҫҝШЦЖ
+
+ҪУҝЪТӘЧцәГ°жұҫҝШЦЖЎЈҫНКЗЛөЈ¬ЗлЗу»щҙЎұЁОДЈ¬УҰёГ°ьә¬```version```ҪУҝЪ°жұҫәЕЧЦ¶ОЈ¬·ҪұгОҙАҙЧцҪУҝЪјжИЭЎЈЖдКөХвёцөгТІЛгҪУҝЪА©Х№РФөДТ»ёцМеПЦөг°ЙЎЈ
+
+ұИИзҝН»§¶ЛAPPДіёц№ҰДЬУЕ»ҜБЛЈ¬РВАП°жұҫ»б№ІҙжЈ¬ХвКұәтОТГЗөД```version```°жұҫәЕҫНЕЙЙПУГіЎБЛЈ¬¶Ф```version```ЧцЙэј¶Ј¬ЧцәГ°жұҫҝШЦЖЎЈ
+
+## 34. ЧўТвҙъВл№ж·¶ОКМв
+
+ЧўТвТ»Р©іЈјыөДҙъВл»өО¶өАЈә
+- ҙуБҝЦШёҙҙъВлЈЁій№«УГ·Ҫ·ЁЈ¬ЙијЖДЈКҪЈ©
+- ·Ҫ·ЁІОКэ№э¶аЈЁҝЙ·вЧ°іЙТ»ёцDTO¶ФПуЈ©
+- ·Ҫ·Ё№эіӨЈЁійРЎәҜКэЈ©
+- ЕР¶ПМхјюМ«¶аЈЁУЕ»Ҝif...elseЈ©
+- І»ҙҰАнГ»УГөДҙъВл
+- І»ЧўЦШҙъВлёсКҪ
+- ұЬГв№э¶ИЙијЖ
+
+ҙъВлөД»өО¶өАЈ¬ХвАпОТ¶јРҙөҪАІЈә[25ЦЦҙъВл»өО¶өАЧЬҪб+УЕ»ҜКҫАэ](https://mp.weixin.qq.com/s?__biz=Mzg3NzU5NTIwNg==&mid=2247490148&idx=1&sn=00a181bf74313f751b3ea15ebc303545&chksm=cf21c54df8564c5bc5b4600fce46619f175f7ae557956f449629c470a08e20580feef4ea8d53&token=162724582&lang=zh_CN&scene=21#wechat_redirect)
+
+## 35.ұЈЦӨҪУҝЪХэИ·РФЈ¬ЖдКөҫНКЗұЈЦӨёьЙЩөДbug
+
+ұЈЦӨҪУҝЪөДХэИ·РФЈ¬»»ёцҪЗ¶ИҪІЈ¬ҫНКЗұЈЦӨёьЙЩөДbugЈ¬ЙхЦБКЗГ»УРbugЎЈЛщТФҪУҝЪҝӘ·ўНкәуЈ¬Т»°гРиТӘҝӘ·ў**ЧФІвТ»ПВ**ЎЈИ»әуөД»°Ј¬ҪУҝЪөДХэИ·»№МеПЦФЪЈ¬¶аПЯіМІў·ўөДКұәтЈ¬**ұЈЦӨКэҫЭөДХэИ·РФ**,өИөИЎЈұИИзДгЧцТ»ұКЧӘХЛҪ»ТЧЈ¬ҝЫјхУа¶оөДКұәтЈ¬ҝЙТФНЁ№эCASАЦ№ЫЛшөД·ҪКҪұЈЦӨУа¶оҝЫјхХэИ·°ЙЎЈ
+
+Из№ыДгКЗКөПЦГлЙұҪУҝЪЈ¬өГ·АЦ№і¬ВфОКМв°ЙЎЈДгҝЙТФК№УГRedis·ЦІјКҪЛш·АЦ№і¬ВфОКМвЎЈК№УГRedis·ЦІјКҪЛшЈ¬УРјёёцЧўТвТӘөгЈ¬ҙујТҝЙТФҝҙПВОТЦ®З°ХвЖӘОДХВ№юЈә[ЖЯЦЦ·Ҫ°ёЈЎМҪМЦRedis·ЦІјКҪЛшөДХэИ·К№УГЧЛКЖ](https://mp.weixin.qq.com/s?__biz=Mzg3NzU5NTIwNg==&mid=2247488142&idx=1&sn=79a304efae7a814b6f71bbbc53810c0c&chksm=cf21cda7f85644b11ff80323defb90193bc1780b45c1c6081f00da85d665fd9eb32cc934b5cf&token=162724582&lang=zh_CN&scene=21#wechat_redirect)
+
+## 36.С§»б№өНЁЈ¬ёъЗ°¶Л№өНЁЈ¬ёъІъЖ·№өНЁ
+
+ОТ°СХвТ»өг·ЕөҪЧоәуЈ¬С§»б№өНЁКЗ·ЗіЈ·ЗіЈЦШТӘөДЎЈұИИзДгҝӘ·ў¶ЁТеҪУҝЪКұЈ¬**Т»¶ЁІ»ДЬЙПАҙҫНЧФјәВсН·°СҪУҝЪ¶ЁТеНкБЛ**Ј¬**РиТӘёъҝН»§¶ЛПИ¶ФЖлҪУҝЪ**ЎЈУцөҪТ»Р©ДСөгКұЈ¬ёъјјКхleader¶ФЖл·Ҫ°ёЎЈКөПЦРиЗуөД№эіМЦРЈ¬УРКІГҙОКМвЈ¬ј°КұёъІъЖ·№өНЁЎЈ
+
+ЧЬЦ®ҫНКЗЈ¬ҝӘ·ўҪУҝЪ№эіМЦРЈ¬Т»¶ЁТӘ№өНЁәГ~
+
+
+## Чоәу(Зу№ШЧўЈ¬ұр°ЧжООТ)
+
+Из№ыХвЖӘОДХВ¶ФДъУРЛщ°пЦъЈ¬»тХЯУРЛщЖф·ўөД»°Ј¬»¶Уӯ№ШЧўОТөД№«ЦЪәЕЈәјсМпВЭөДРЎДРәў
+
+
diff --git "a/\345\220\216\347\253\257\346\200\235\347\273\264\347\257\207/\345\220\216\347\253\257\346\200\235\347\273\264\347\257\207\344\272\214\357\274\232\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\345\256\236\347\216\260\344\270\200\344\270\252\345\271\266\350\241\214\350\260\203\347\224\250\346\250\241\346\235\277.md" "b/\345\220\216\347\253\257\346\200\235\347\273\264\347\257\207/\345\220\216\347\253\257\346\200\235\347\273\264\347\257\207\344\272\214\357\274\232\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\345\256\236\347\216\260\344\270\200\344\270\252\345\271\266\350\241\214\350\260\203\347\224\250\346\250\241\346\235\277.md"
new file mode 100644
index 0000000..762cb1b
--- /dev/null
+++ "b/\345\220\216\347\253\257\346\200\235\347\273\264\347\257\207/\345\220\216\347\253\257\346\200\235\347\273\264\347\257\207\344\272\214\357\274\232\346\211\213\346\212\212\346\211\213\346\225\231\344\275\240\345\256\236\347\216\260\344\270\200\344\270\252\345\271\266\350\241\214\350\260\203\347\224\250\346\250\241\346\235\277.md"
@@ -0,0 +1,599 @@
+## З°СФ
+
+ҙујТәГЈ¬ОТКЗјсМпВЭөДРЎДРәўЎЈ
+
+ұҫОДКЗәу¶ЛЛјО¬ЧЁАёөДөЪ¶юЖӘ№юЎЈЙПТ»ЖӘ[36ёцЙијЖҪУҝЪөДҪхДТ](https://mp.weixin.qq.com/s?__biz=Mzg3NzU5NTIwNg==&mid=2247499388&idx=1&sn=49a22120a3238e13ad7c3d3b73d9e453&chksm=cf222155f855a8434026b2c460d963c406186578c2527ca8f2bb829bbe849d87a2392a525a9b&token=1380536362&lang=zh_CN#rd)Ј¬өГөҪ·ЗіЈ¶аРЎ»п°йөДИПҝЙЎЈ
+36ёцЙијЖҪУҝЪөДҪхДТЦРТІМбөҪТ»ёцөгЈәҫНКЗ**К№УГІўРРөчУГУЕ»ҜҪУҝЪ**ЎЈЛщТФҪУПВАҙҫНҝмВнјУұЮЈ¬РҙөЪ¶юЖӘЈәКЦ°СКЦҪМДгРҙТ»ёцІўРРөчУГДЈ°еЎЈ
+
+- Т»ёцҙ®РРөчУГөДАэЧУЈЁAppКЧТіРЕПўІйСҜЈ©
+- CompletionServiceКөПЦІўРРөчУГ
+- ійИЎНЁУГөДІўРРөчУГ·Ҫ·Ё
+- ҙъВлЛјҝјТФј°ЙијЖДЈКҪУҰУГ
+- ЛјҝјЧЬҪб
+- №«ЦЪәЕЈә**јсМпВЭөДРЎДРәў**
+
+
+## 1. Т»ёцҙ®РРөчУГөДАэЧУ
+
+Из№ыИГДгЙијЖТ»ёцAPPКЧТіІйСҜөДҪУҝЪЈ¬ЛьРиТӘІйУГ»§РЕПўЎўРиТӘІй```banner```РЕПўЎўРиТӘІйұкЗ©РЕПўөИөИЎЈТ»°гЗйҝцЈ¬РЎ»п°й»бКөПЦИзПВЈә
+
+```
+public AppHeadInfoResponse queryAppHeadInfo(AppInfoReq req) {
+ //ІйУГ»§РЕПў
+ UserInfoParam userInfoParam = buildUserParam(req);
+ UserInfoDTO userInfoDTO = userService.queryUserInfo(userInfoParam);
+ //ІйbannerРЕПў
+ BannerParam bannerParam = buildBannerParam(req);
+ BannerDTO bannerDTO = bannerService.queryBannerInfo(bannerParam);
+ //ІйұкЗ©РЕПў
+ LabelParam labelParam = buildLabelParam(req);
+ LabelDTO labelDTO = labelService.queryLabelInfo(labelParam);
+ //ЧйЧ°Ҫб№ы
+ return buildResponse(userInfoDTO,bannerDTO,labelDTO);
+}
+```
+
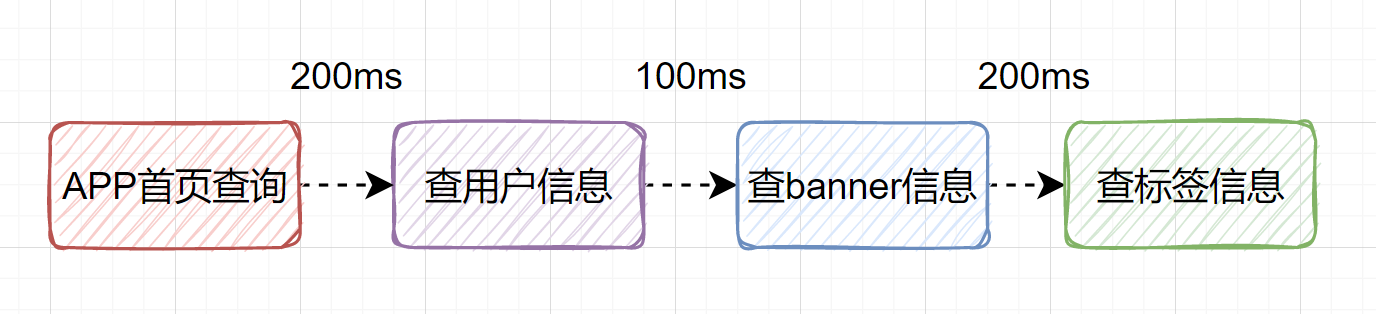
+Хв¶ОҙъВл»бУРКІГҙОКМвВпЈҝ ЖдКөХвКЗТ»¶ОНҰХэіЈөДҙъВлЈ¬ө«КЗХвёц·Ҫ·ЁКөПЦЦРЈ¬ІйСҜУГ»§ЎўbannerЎўұкЗ©РЕПўЈ¬**КЗҙ®РРөД**Ј¬Из№ыІйСҜУГ»§РЕПў```200ms```Ј¬ІйСҜbannerРЕПў```100ms```Ј¬ІйСҜұкЗ©РЕПў```200ms```өД»°Ј¬әДКұҫНКЗ```500ms```АІЎЈ
+
+
+
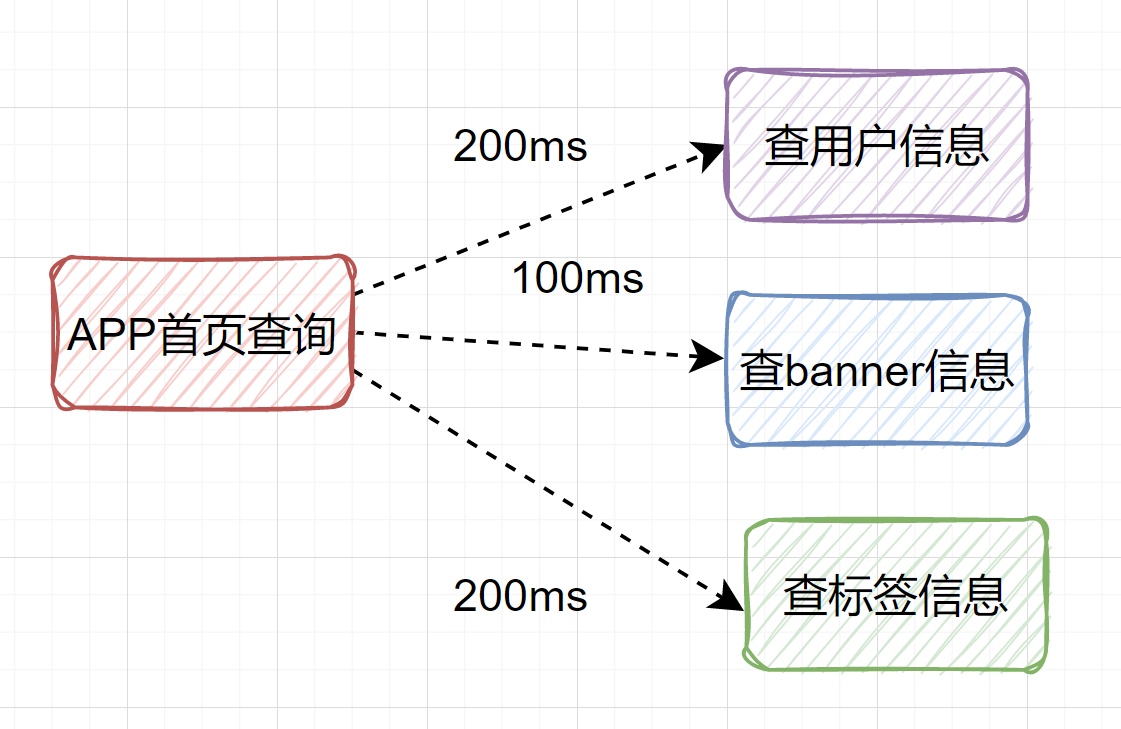
+ЖдКөОӘБЛУЕ»ҜРФДЬЈ¬ОТГЗҝЙТФРЮёДОӘ**ІўРРөчУГ**өД·ҪКҪЈ¬әДКұҝЙТФҪөОӘ```200ms```Ј¬ИзПВНјЛщКҫЈә
+
+
+
+
+
+## 2. CompletionServiceКөПЦІўРРөчУГ
+
+¶ФУЪЙПГжөДАэЧУЈ¬**ИзәОКөПЦІўРРөчУГДШЈҝ**
+
+УРРЎ»п°йЛөЈ¬ҝЙТФК№УГ```Future+Callable```КөПЦ¶аёцИООсөДІўРРөчУГЎЈө«КЗПЯіМіШЦҙРРЕъБҝИООсКұЈ¬·ө»ШЦөУГ```FutureөДget()```»сИЎКЗЧиИыөДЈ¬Из№ыЗ°Т»ёцИООсЦҙРРұИҪПәДКұөД»°Ј¬```getЈЁЈ©```·Ҫ·Ё»бЧиИыЈ¬РОіЙЕЕ¶УөИҙэөДЗйҝцЎЈ
+
+¶ш```CompletionService```КЗ¶Ф¶ЁТе```ExecutorService```ҪшРРБЛ°ьЧ°Ј¬ҝЙТФТ»ұЯЙъіЙИООс,Т»ұЯ»сИЎИООсөД·ө»ШЦөЎЈИГХвБҪјюКВ·ЦҝӘЦҙРР,ИООсЦ®јдІ»»б»ҘПаЧиИыЈ¬ҝЙТФ»сИЎЧоПИНкіЙөДИООсҪб№ыЎЈ
+
+
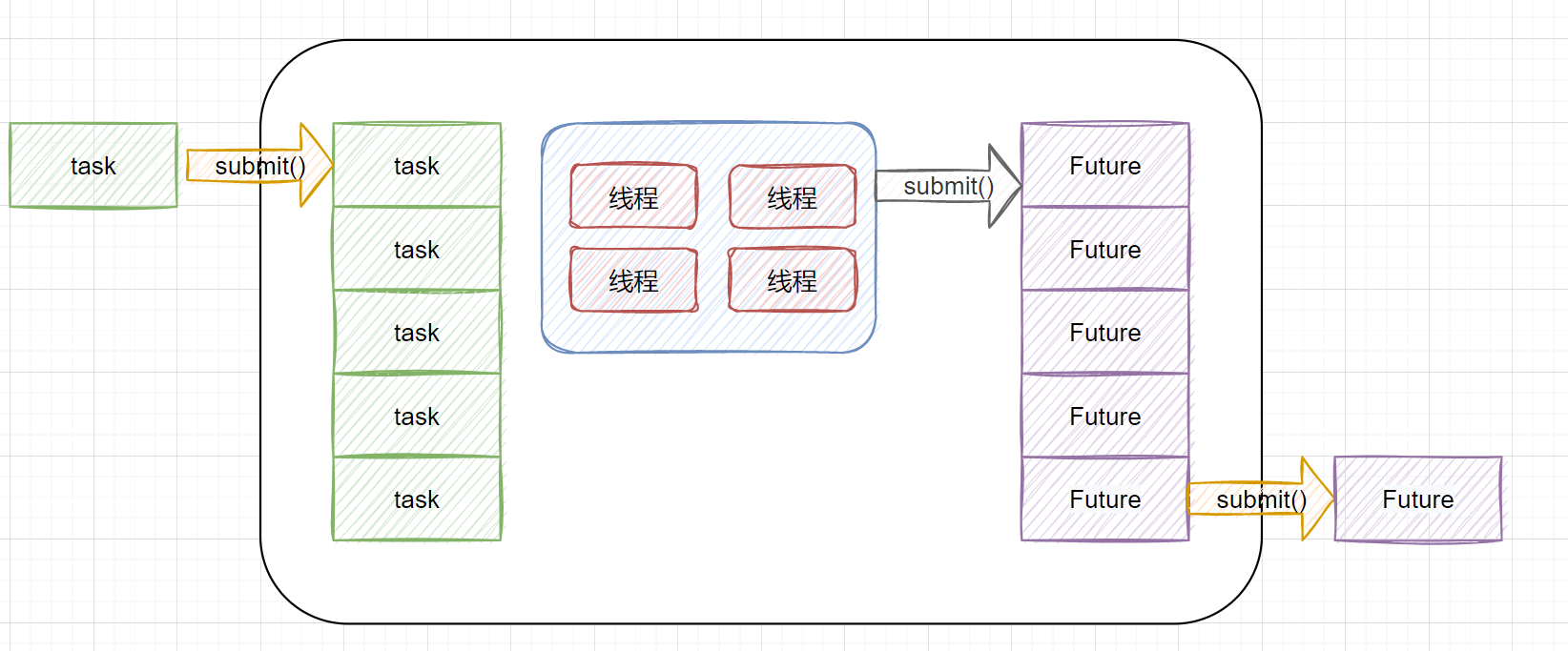
+> ```CompletionService```өДКөПЦФӯАнұИҪПјтөҘЈ¬өЧІгНЁ№эFutureTask+ЧиИы¶УБРЈ¬КөПЦБЛИООсПИНкіЙөД»°Ј¬ҝЙУЕПИ»сИЎөҪЎЈТІҫНКЗЛөИООсЦҙРРҪб№ы°ҙХХНкіЙөДПИәуЛіРтАҙЕЕРтЈ¬ПИНкіЙҝЙТФУЕ»Ҝ»сИЎөҪЎЈДЪІҝУРТ»ёцПИҪшПИіцөДЧиИы¶УБРЈ¬УГУЪұЈҙжТСҫӯЦҙРРНкіЙөДFutureЈ¬ДгөчУГ```CompletionService```өДpoll»тtake·Ҫ·ЁјҙҝЙ»сИЎөҪТ»ёцТСҫӯЦҙРРНкіЙөДFutureЈ¬Ҫш¶шНЁ№эөчУГFutureҪУҝЪКөПЦАаөД```get```·Ҫ·Ё»сИЎЧоЦХөДҪб№ыЎЈ
+
+
+
+
+ҪУПВАҙЈ¬ОТГЗАҙҝҙПВЈ¬ИзәОУГ```CompletionService```Ј¬КөПЦІўРРІйСҜAPPКЧТіРЕПў№юЎЈЛјҝјІҪЦиИзПВЈә
+
+1. ОТГЗПИ°СІйСҜУГ»§РЕПўөДИООсЈ¬·ЕөҪПЯіМіШЈ¬ИзПВЈә
+```
+ExecutorService executor = Executors.newFixedThreadPool(10);
+//ІйСҜУГ»§РЕПў
+CompletionService userDTOCompletionService = new ExecutorCompletionService(executor);
+Callable userInfoDTOCallableTask = () -> {
+ UserInfoParam userInfoParam = buildUserParam(req);
+ return userService.queryUserInfo(userInfoParam);
+ };
+userDTOCompletionService.submit(userInfoDTOCallableTask);
+```
+
+2. ө«КЗИз№ыПл°СІйСҜ```banner```РЕПўөДИООсЈ¬ТІ·ЕөҪХвёцПЯіМіШөД»°Ј¬·ўПЦІ»әГ·ЕБЛЈ¬ТтОӘ·ө»ШАаРНІ»Т»СщЈ¬Т»ёцКЗ```UserInfoDTO```Ј¬БнНвТ»ёцКЗ```BannerDTO```ЎЈДЗХвКұәтЈ¬ОТГЗКЗІ»КЗ°С·әРНЙщГчОӘObjectјҙҝЙЈ¬ТтОӘЛщУР¶ФПу¶јКЗјМіРУЪObjectөДЈҝИзПВЈә
+
+```
+ExecutorService executor = Executors.newFixedThreadPool(10);
+//ІйСҜУГ»§РЕПў
+CompletionService